

Page 1

Using
ADOBE® LIVECYCLE® DATA SERVICES ES2
Version 3.1
Page 2

Copyright
© 2010 Adobe Systems Incorporated. All rights reserved.
Using Adobe® LiveCycle® Data Services ES2 version 3.1.
This user guide is protected under copyright law, furnished for informational use only, is subject to change without notice, and should not be construed as a
commitment by Adobe Systems Incorporated. Adobe Systems Incorporated assumes no responsibility or liability for any errors or inaccuracies that may appear
in the informational content contained in this guide.
This user guide is licensed for use under the terms of the Creative Commons Attribution Non-Commercial 3.0 License. This License allows users to copy,
distribute, and transmit the user guide for noncommercial purposes only so long as (1) proper attribution to Adobe is given as the owner of the user guide; and
(2) any reuse or distribution of the user guide contains a notice that use of the user guide is governed by these terms. The best way to provide notice is to include
the following link. To view a copy of this license, visit
http://creativecommons.org/licenses/by-nc-sa/3.0/
Adobe, the Adobe logo, ActionScript, Adobe AIR, AIR, Dreamweaver, Flash, Flash Builder, Flex, JRun, and LiveCycle are either registered trademarks or
trademarks of Adobe Systems Incorporated in the United States and/or other countries.
Microsoft and Windows are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Apple, Macintosh, and Mac OS are trademarks of Apple Inc., registered in the United States and other countries. IBM is a trademark of International Business
Machines Corporation in the United States, other countries, or both. Java is a trademark or registered trademark of Sun Microsystems, Inc. in the United States
and other countries. Linux is the registered trademark of Linus Torvalds in the U.S. and other countries. Solaris is a trademark or registered trademark of Sun
Microsystems, Inc. in the United States and other countries. UNIX is a registered trademark of The Open Group in the US and other countries. All other
trademarks are the property of their respective owners.
Updated Information/Additional Third Party Code Information available at http://www.adobe.com/go/thirdparty.
Portions include software under the following terms:
This product includes software developed by the Apache Software Foundation (http://www.apache.org/)
This product includes software developed by the OpenSymphony Group (http://www.opensymphony.com/)
This product contains either BSAFE and/or TIPEM software by RSA Security, Inc.
This software is based in part on the work of the Independent JPEG Group.
Adobe Systems Incorporated, 345 Park Avenue, San Jose, California 95110, USA.
Notice to U.S. Government End Users. The Software and Documentation are “Commercial Items,” as that term is defined at 48 C.F.R. §2.101, consisting of
“Commercial Computer Software” and “Commercial Computer Software Documentation,” as such terms are used in 48 C.F.R. §12.212 or 48 C.F.R. §227.7202,
as applicable. Consistent with 48 C.F.R. §12.212 or 48 C.F.R. §§227.7202-1 through 227.7202-4, as applicable, the Commercial Computer Software and
Commercial Computer Software Documentation are being licensed to U.S. Government end users (a) only as Commercial Items and (b) with only those rights
as are granted to all other end users pursuant to the terms and conditions herein. Unpublished-rights reserved under the copyright laws of the United States.
Adobe Systems Incorporated, 345 Park Avenue, San Jose, CA 95110-2704, USA. For U.S. Government End Users, Adobe agrees to comply with all applicable
equal opportunity laws including, if appropriate, the provisions of Executive Order 11246, as amended, Section 402 of the Vietnam Era Veterans Readjustment
Assistance Act of 1974 (38 USC 4212), and Section 503 of the Rehabilitation Act of 1973, as amended, and the regulations at 41 CFR Parts 60-1 through 60-60,
60-250, and 60-741. The affirmative action clause and regulations contained in the preceding sentence shall be incorporated by reference.
Last updated 3/10/2011
Page 3

Contents
Chapter 1: Getting started with LiveCycle Data Services
Introducing LiveCycle Data Services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
Building and deploying LiveCycle Data Services applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Chapter 2: System architecture
Client and server architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
Channels and endpoints . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
Managing session data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
Data serialization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
Chapter 3: Controlling data traffic
Data throttling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
Deserialization validators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
Advanced data tuning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
Message delivery with adaptive polling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
Measuring message processing performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
iii
Chapter 4: RPC services
Using RPC services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
Chapter 5: Message Service
Using the Message Service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
Connecting to the Java Message Service (JMS) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
Chapter 6: Data Management Service
Introducing the Data Management Service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
Data Management Service clients . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226
Data Management Service configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244
Custom assemblers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254
Standard assemblers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 268
Hierarchical data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293
Data paging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303
Occasionally connected clients . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 310
Server push . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323
Chapter 7: Model-driven applications
Building your first model-driven application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 326
Building an offline-enabled application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333
Customizing client-side functionality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341
Customizing server-side functionality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348
Generating database tables from a model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 364
Creating a client for an existing service destination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 366
Configuring a data source . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 371
Configuring RDS on the server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 371
Last updated 3/10/2011
Page 4

USING ADOBE LIVECYCLE DATA SERVICES
Contents
Building the client application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372
Using server-side logging with the Model Assembler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383
Setting Hibernate properties for a model in a Hibernate configuration file . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383
Configuring the model deployment service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383
Entity utility . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384
Chapter 8: Edge Server
Connecting an Edge Server to a server in the application tier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391
Example application configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394
Creating a merged configuration for client compilation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 398
Edge Server authentication and authorization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 400
Restricting access from the Edge Server with white lists and black lists . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 401
Connecting Flex clients to an Edge Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 401
Handling missing Java types at the edge tier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403
JMX management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403
Chapter 9: Generating PDF documents
About the PDF generation feature . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404
Using the PDF generation feature . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404
iv
Chapter 10: Run-time configuration
About run-time configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 411
Configuring components with a bootstrap service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 411
Configuring components with a remote object . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414
Using assemblers with run-time configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 416
Accessing dynamic components with a Flex client application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 417
Chapter 11: Administering LiveCycle Data Services applications
Logging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 420
Security . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 429
Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442
Integrating Flex applications with portal servers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 451
Chapter 12: Additional programming topics
The Ajax client library . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 460
Extending applications with factories . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 476
Last updated 3/10/2011
Page 5
Chapter 1: Getting started with LiveCycle Data Services
Introducing LiveCycle Data Services
Adobe® LiveCycle® Data Services provides highly scalable remote access, messaging, and data management services for
use with client-side applications built in Adobe® Flex® or Adobe® AIR™.
LiveCycle Data Services overview
LiveCycle Data Services provides a set of services that lets you connect a client-side application to server-side data, and
pass data among multiple clients connected to the server. LiveCycle Data Services synchronizes data sharing among
clients, performs data push and data conflict management, and implements real-time messaging between clients.
A LiveCycle Data Services application consists of two parts: a client-side application and a server-side J2EE web
application. The following figure shows this architecture:
1
Web Ser ve r
Client
Client
Client
J2EE Server
LiveCycle Data Services ES
The client-side application
A LiveCycle Data Services client application is typically an Flex or AIR application. Flex and AIR applications use Flex
components to communicate with the LiveCycle Data Services server, including the RemoteObject, HTTPService,
WebService, Producer, Consumer, and DataService components. The HTTPService, WebService, Producer, and
Consumer components are part of the Flex Software Development Kit (SDK). To use the DataService component,
configure your development environment to use the LiveCycle Data Services SWC files. For more information, see
“Building and deploying LiveCycle Data Services applications” on page 9.
Although you typically use Flex or AIR to develop the client-side application, you can develop the client as a
combination of Flex, HTML, and JavaScript. Or, you can develop it in HTML and JavaScript by using the Ajax client
library to communicate with LiveCycle Data Services. For more information on using the Ajax client library, see
Ajax client library” on page 460.
“The
The LiveCycle Data Services server
The LiveCycle Data Services server consists of a J2EE web application and a highly scalable socket server running on
a J2EE application server. The LiveCycle Data Services installer creates three web applications that you can use as the
basis of your application development. For more information on using these web applications, see
deploying LiveCycle Data Services applications” on page 9.
“Building and
Configure an existing J2EE web application to support LiveCycle Data Services by performing the following steps:
1 Add the LiveCycle Data Services JAR files and dependent JAR files to the WEB-INF/lib directory.
Last updated 3/10/2011
Page 6

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
2 Edit the LiveCycle Data Services configuration files in the WEB-INF/flex directory.
3 Define MessageBrokerServlet and a session listener in WEB-INF/web.xml.
Versions of LiveCycle Data Services
You can download a free developer version of LiveCycle Data Services with certain restrictions on its use. For more
information, see the LiveCycle Enterprise Suite page on
www.adobe.com.
LiveCycle Data Services features
The following figure shows the main features of LiveCycle Data Services:
LiveCycle Data Services ES
RPC Services
Web S er vi ce
HTTP Service
Remoting Service
Messaging Service
Publish & Subscribe
Collaboration
Real Time Data push
Data Management Service
Data Synchronization
O-line Applications
Data Paging
Proxy Service
Portal Deployment
RIA-PDF Generation
Service Adapters
LiveCycle
SQL
Hibernate
ColdFusion
JMS
Java
Custom
2
LiveCycle Data Services core features
The LiveCycle Data Services core features include the RPC services, Message Service, and Data Management Service.
RPC services
The Remote Procedure Call (RPC) services are designed for applications in which a call and response model is a good
choice for accessing external data. RPC services let a client application make asynchronous requests to remote services
that process the requests and then return data directly to the client. You can access data through client-side RPC
components that include HTTP GET or POST (HTTP services), SOAP (web services), or Java objects (remote object
services).
Use RPC components when you want to provide enterprise functionality, such as proxying of service traffic from
different domains, client authentication, whitelists of permitted RPC service URLs, server-side logging, localization
support, and centralized management of RPC services. LiveCycle Data Services lets you use RemoteObject
components to access remote Java objects without configuring them as SOAP-compliant web services.
A client-side RPC component calls a remote service. The component then stores the response data from the service in
an ActionScript object from which you can easily obtain the data. The client-side RPC components are the
HTTPService, WebService, and RemoteObject components.
Note: You can use Flex SDK without the LiveCycle Data Services proxy service to call HTTP services or web services
directly. You cannot use RemoteObject components without LiveCycle Data Services or Adobe® ColdFusion®.
For more information, see “Using RPC services” on page 135.
Last updated 3/10/2011
Page 7

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
Message Service
The Message Service lets client applications communicate asynchronously by passing messages back and forth through
the server. A message defines properties such as a unique identifier, LiveCycle Data Services headers, any custom
headers, and a message body.
Client applications that send messages are called message producers. You define a producer in a Flex application by
using the Producer component. Client applications that receive messages are called message consumers. You define a
consumer in a Flex application by using the Consumer component. A Consumer component subscribes to a serverside destination and receives messages that a Producer component sends to that destination. For more information on
messaging, see
“Using the Message Service” on page 190.
The Message Service also supports bridging to JMS topics and queues on an embedded or external JMS server by using
the JMSAdapter. Bridging lets Flex client applications exchange messages with Java client applications. For more
information, see
“Connecting to the Java Message Service (JMS)” on page 214.
Data Management Service
The Data Management Service lets you create applications that work with distributed data. By using the Data
Management Service, you build applications that provide real-time data synchronization, data replication, on-demand
data paging, and occasionally connected application services. You can manage large collections of data and nested data
relationships, such as one-to-one and one-to-many relationships. You can also use data adapters to integrate with data
resources, such as a database.
3
Note: The Data Management Service is not available in BlazeDS.
A client-side DataService component calls methods on a server-side Data Management Service destination. Use this
component to perform activities such as filling client-side data collections with data from remote data sources and
synchronizing the client and server versions of data. Changes made to the data at the client side are tracked
automatically using property change events.
When the user is ready to submit their changes, the changes are sent to a service running on the server. This service
then passes the changes to a server-side adapter, which checks for conflicts and commits the changes. The adapter can
be an interface you write, or one of the supplied adapters that work with a standard persistence layer such as SQL or
Hibernate. After the changes are committed, the Data Management Service pushes these changes to any other clients
looking at the same data.
For more information, see “Introducing the Data Management Service” on page 221.
Service adapters
LiveCycle Data Services lets you access many different persistent data stores and databases including Hibernate, SQL,
JMS, and other data persistence mechanisms. A Service Adapter is responsible for updating the persistent data store
on the server in a manner appropriate to the specific data store type. The adapter architecture is customizable to let
you integrate with any type of messaging or back-end persistence system.
The message-based framework
LiveCycle Data Services uses a message-based framework to send data back and forth between the client and server.
LiveCycle Data Services uses two primary exchange patterns between server and client. In the first pattern, the requestresponse pattern, the client sends a request to the server to be processed. The server returns a response to the client
containing the processing outcome. The RPC services use this pattern.
Last updated 3/10/2011
Page 8
USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
The second pattern is the publish-subscribe pattern where the server routes published messages to the set of clients
that have subscribed to receive them. The Message Service and Data Management Service use this pattern to push data
to interested clients. The Message Service and Data Management Service also use the request-response pattern to issue
commands, publish messages, and interact with data on the server.
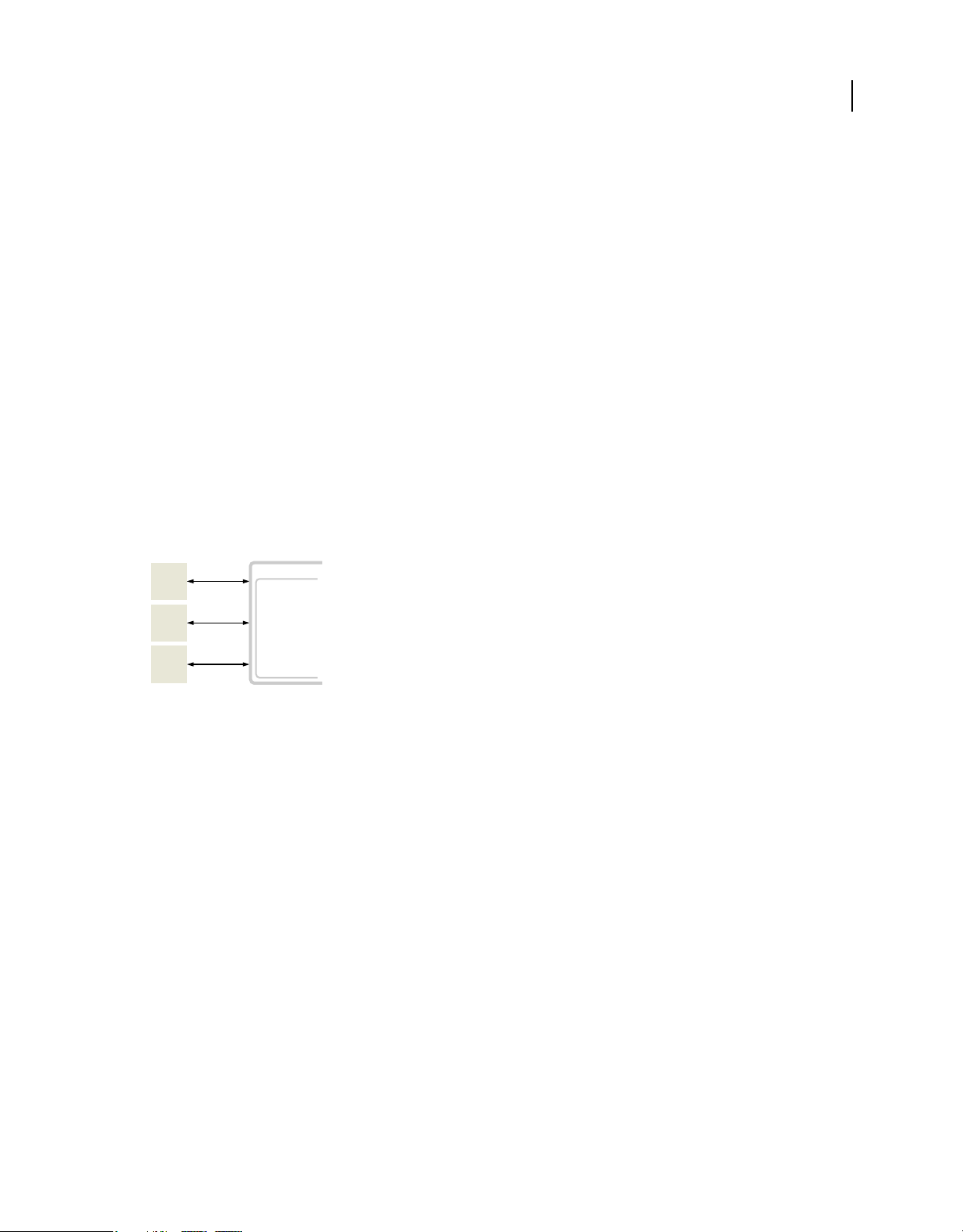
Channels and endpoints
To send messages across the network, the client uses channels. A channel encapsulates message formats, network
protocols, and network behaviors to decouple them from services, destinations, and application code. A channel
formats and translates messages into a network-specific form and delivers them to an endpoint on the server.
Channels also impose an order to the flow of messages sent to the server and the order of corresponding responses.
Order is important to ensure that interactions between the client and server occur in a consistent, predictable fashion.
Channels communicate with Java-based endpoints on the server. An endpoint unmarshals messages in a protocolspecific manner and then passes the messages in generic Java form to the message broker. The message broker
determines where to send messages, and routes them to the appropriate service destination.
LiveCycle Data Services ES
Client
4
Channel
Endpoint
For more information on channels and endpoints, see “Client and server architecture” on page 27.
Channel types
LiveCycle Data Services includes several types of channels, including standard and secure Real Time Messaging
Protocol (RTMP) channels and channels that support binary Action Message Format (AMF) and its text-based XML
representation called AMFX. AMF and HTTP channels support non-polling request-response patterns and client
polling patterns to simulate real-time messaging. The RTMP channels and streaming AMF and HTTP channels
provide true data streaming for real-time messaging.
LiveCycle Data Services summary of features
The following table summarizes some of the main features of LiveCycle Data Services:
Feature Description
Client-server
synchronization
Automatic and manual synchronization of a common set of data on multiple clients
and server-side data resources. Also supports offline client-side data persistence for
occasionally connected clients.
Removes the complexity and potential for error by providing a robust, highperformance data synchronization engine between client and server. It also can
easily integrate with existing persistence solutions to provide an end-to-end
solution.
Collaboration Enables a client application to concurrently share data with other clients or servers.
Data paging Facilitates the paging of large data sets, enabling developers to focus on core
This model enables new application concepts like "co-browsing" and synchronous
collaboration, which allow users to share experiences and work together in real time.
application business logic instead of worrying about basic data management
infrastructure.
Last updated 3/10/2011
Page 9

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
Feature Description
5
Data push Enables data to automatically be pushed to the client application without polling.
Data traffic control Provides a set of features for managing data traffic, such as data throttling,
Model-driven development Use Adobe application modeling technology to facilitate the development of data-
Occasionally connected
client
Portal service integration Configure a Flex client applications as local portlets hosted on JBoss Portal, Oracle
Proxy service Enables communication between clients and domains that they cannot access
Publish and subscribe
messaging
This highly scalable capability can push data to thousands of concurrent users to
provide up-to-the-second views of critical data. Examples include stock trader
applications, live resource monitoring, shop floor automation, and more.
deserialization validation, reliable messaging, message prioritization, message
filtering, and measuring message processing performance.
centric applications.
Handles temporary disconnects, ensuring reliable delivery of data to and from the
client application. Provides support for the development of offline and occasionally
connected applications that run in the browser or on the desktop. LiveCycle Data
Services takes advantage of the scalable local SQLite database in AIR to store data,
synchronize it back to the server, and rationalize any changes or conflicts.
WebLogic Portal, or IBM WebSphere Portal.
directly, due to security restrictions, allowing you to integrate multiple services with
a single application. By using the Proxy Service, you do not have to configure a
separate web application to work with web services or HTTP services.
Provides a messaging infrastructure that integrates with existing messaging
systems such as JMS. This service enables messages to be exchanged in real time
between browser clients and the server. It allows Flex clients to publish and
subscribe to message topics with the same reliability, scalability, and overall quality
of service as traditional thick client applications.
RIA-to-PDF generation Users can generate template-driven PDF documents that include graphical assets
Software clustering Handles failover when using stateful services and non-HTTP channels, such as RTMP,
from Flex applications, such as graphs and charts. The generated PDF documents
can be orchestrated with other LiveCycle services and policy-protected to ensure
only authorized access.
to ensure that Flex applications continue running in the event of server failure. The
more common form of clustering using load balancers, usually in the form of
hardware, is supported without any feature implementation.
Example LiveCycle Data Services applications
The following example applications show client-side and server-side code that you can compile and deploy to get
started with LiveCycle Data Services. You typically use the following steps to build an application:
1 Configure a destination in the LiveCycle Data Services server used by the client application to communicate with
the server. A destination is the server-side code that you connect to from the client. Configure a destination in one
of the configuration files in the WEB-INF/flex directory of your web application.
2 Configure a channel used by the destination to send messages across the network. The channel encapsulates
message formats, network protocols, and network behaviors and decouples them from services, destinations, and
application code. Configure a channel in one of the configuration files in the WEB-INF/flex directory of your web
application.
3 Write the Flex client application in MXML or ActionScript.
4 Compile the client application into a SWF file by using Adobe® Flash® Builder™ or the mxmlc compiler.
5 Deploy the SWF file to your LiveCycle Data Services web application.
Last updated 3/10/2011
Page 10

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
Running the examples
The LiveCycle Data Services installer creates a directory structure on your computer that contains all of the resources
necessary to build applications. As part of the installation, the installer creates three web applications that you can use
as the basis of your development environment. The lcds-samples web application contains many LiveCycle Data
Services examples.
You can run the following examples if you compile them for the lcds-samples web application and deploy them to the
lcds-samples directory structure. For more information on building and running the examples, see
“Building and
deploying LiveCycle Data Services applications” on page 9.
RPC service example
The Remoting Service is one of the RPC services included with LiveCycle Data Services. The Remoting Service lets
clients access methods of Plain Old Java Objects (POJOs) on the server.
In this example, you deploy a Java class, EchoService.java, on the server that echoes back a String passed to it from the
client. The following code shows the definition of EchoService.java:
package remoting;
public class EchoService
{
public String echo(String text) {
return "Server says: I received '" + text + "' from you";
}
}
6
The echo() method takes a String argument and returns it with additional text. After compiling EchoService.java,
place EchoService.class in the WEB-INF/classes/remoting directory. Notice that the Java class does not have to import
or reference any LiveCycle Data Services resources.
Define a destination, and reference one or more channels that transport the data. Configure EchoService.class as a
remoting destination by editing the WEB-INF/flex/remoting-config.xml file and adding the following code:
<destination id="echoServiceDestination" channels="my-amf">
<properties>
<source>remoting.EchoService</source>
</properties>
</destination>
The source element references the Java class, and the channels attribute references a channel called my-amf.
Define the my-amf channel in WEB-INF/flex/services-config.xml, as the following example shows:
<channel-definition id="my-amf" class="mx.messaging.channels.AMFChannel">
<endpoint url="http://{server.name}:{server.port}/{context.root}/messagebroker/amf"
class="flex.messaging.endpoints.AMFEndpoint"/>
<properties>
<polling-enabled>false</polling-enabled>
</properties>
</channel-definition>
The channel definition specifies that the Flex client uses a non-polling AMFChannel to communicate with the
AMFEndpoint on the server. Restart the LiveCycle Data Services server after making this change.
Note: If you deploy this application on the lcds-samples web application installed with LiveCycle Data Services, servicesconfig.xml already contains a definition for the my-amf channel.
Last updated 3/10/2011
Page 11

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
The Flex client application uses the RemoteObject component to access EchoService. The RemoteObject component
uses the
echo() method:
<?xml version="1.0"?>
<!-- intro\intro_remoting.mxml -->
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml"
width="100%" height="100%">
<mx:Script>
<![CDATA[
import mx.rpc.events.FaultEvent;
import mx.rpc.events.ResultEvent;
// Send the message in response to a Button click.
private function echo():void {
var text:String = ti.text;
remoteObject.echo(text);
}
// Handle the recevied message.
private function resultHandler(event:ResultEvent):void {
ta.text += "Server responded: "+ event.result + "\n";
}
// Handle a message fault.
private function faultHandler(event:FaultEvent):void {
ta.text += "Received fault: " + event.fault + "\n";
}
]]>
</mx:Script>
<mx:RemoteObject id="remoteObject"
destination="echoServiceDestination"
result="resultHandler(event);"
fault="faultHandler(event);"/>
<mx:Label text="Enter a text for the server to echo"/>
<mx:TextInput id="ti" text="Hello World!"/>
<mx:Button label="Send" click="echo();"/>
<mx:TextArea id="ta" width="100%" height="100%"/>
</mx:Application>
destination property to specify the destination. The user clicks the Button control to invoke the remote
7
Compile the client application into a SWF file by using Flash Builder or the mxmlc compiler, and then deploy it to your
web application.
Message Service example
The Message Service lets client applications send and receive messages from other clients. In this example, create a Flex
application that sends and receives messages from the same LiveCycle Data Services destination.
Define the messaging destination in WEB-INF/flex/messaging-config.xml, as the following example shows:
<destination id="MessagingDestination" channels="my-amf-poll"/>
Define the my-amf-poll channel in WEB-INF/flex/services-config.xml, as the following example shows:
Last updated 3/10/2011
Page 12

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
<channel-definition id="my-amf-poll" class="mx.messaging.channels.AMFChannel">
<endpoint
url="http://{server.name}:{server.port}/{context.root}/messagebroker/amfpoll"
class="flex.messaging.endpoints.AMFEndpoint"/>
<properties>
<polling-enabled>true</polling-enabled>
<polling-interval-seconds>1</polling-interval-seconds>
</properties>
</channel-definition>
This channel definition creates a polling channel with a polling interval of 1 second. Therefore, the client sends a poll
message to the server every second to request new messages. Use a polling channel because it is the easiest way for the
client to receive updates. Other options include polling with piggybacking, long-polling, and streaming. Restart the
LiveCycle Data Services server after making this change.
The following Flex client application uses the Producer component to send a message to the destination, and the
Consumer component to receive messages sent to the destination. To send the message, the Producer first creates an
instance of the AsyncMessage class and then sets its
method to send it. To receive messages, the Consumer first calls the
body property to the message. Then, it calls the Producer.send()
Consumer.subscribe() method to subscribe to
messages sent to a specific destination.
<?xml version="1.0"?>
<!-- intro\intro_messaging.mxml -->
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml"
width="100%" height="100%"
creationComplete="consumer.subscribe();">
<mx:Script>
<
USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
// Handle a message fault.
private function faultHandler(event:MessageFaultEvent):void {
ta.text += "Received fault: " + event.faultString + "\n";
}
]]>
</mx:Script>
<mx:Producer id="producer"
destination="MessagingDestination"
fault="faultHandler(event);"/>
<mx:Consumer id="consumer"
destination="MessagingDestination"
fault="faultHandler(event);"
message="messageHandler(event);"/>
<mx:Button label="Send" click="sendMessage();"/>
<mx:TextArea id="ta" width="100%" height="100%"/>
</mx:Application>
Compile the client application into a SWF file by using Flash Builder or the mxmlc compiler, and then deploy it to your
web application.
9
Building and deploying LiveCycle Data Services applications
Adobe LiveCycle Data Services applications consist of client-side code and server-side code. Client-side code is
typically is built with Flex in MXML and ActionScript and deployed as a SWF file. Server-side code is written in Java
and deployed as Java class files or Java Archive (JAR) files. Every LiveCycle Data Services application has client-side
code; however, you can implement an entire application without writing any server-side code.
For more information on the general application and deployment process for Flex applications, see the Flex
documentation.
Setting up your development environment
LiveCycle Data Services applications consist of two parts: client-side code and server-side code. Before you start
developing your application, configure your development environment, including the directory structure for your
client-side source code and for your server-side source code.
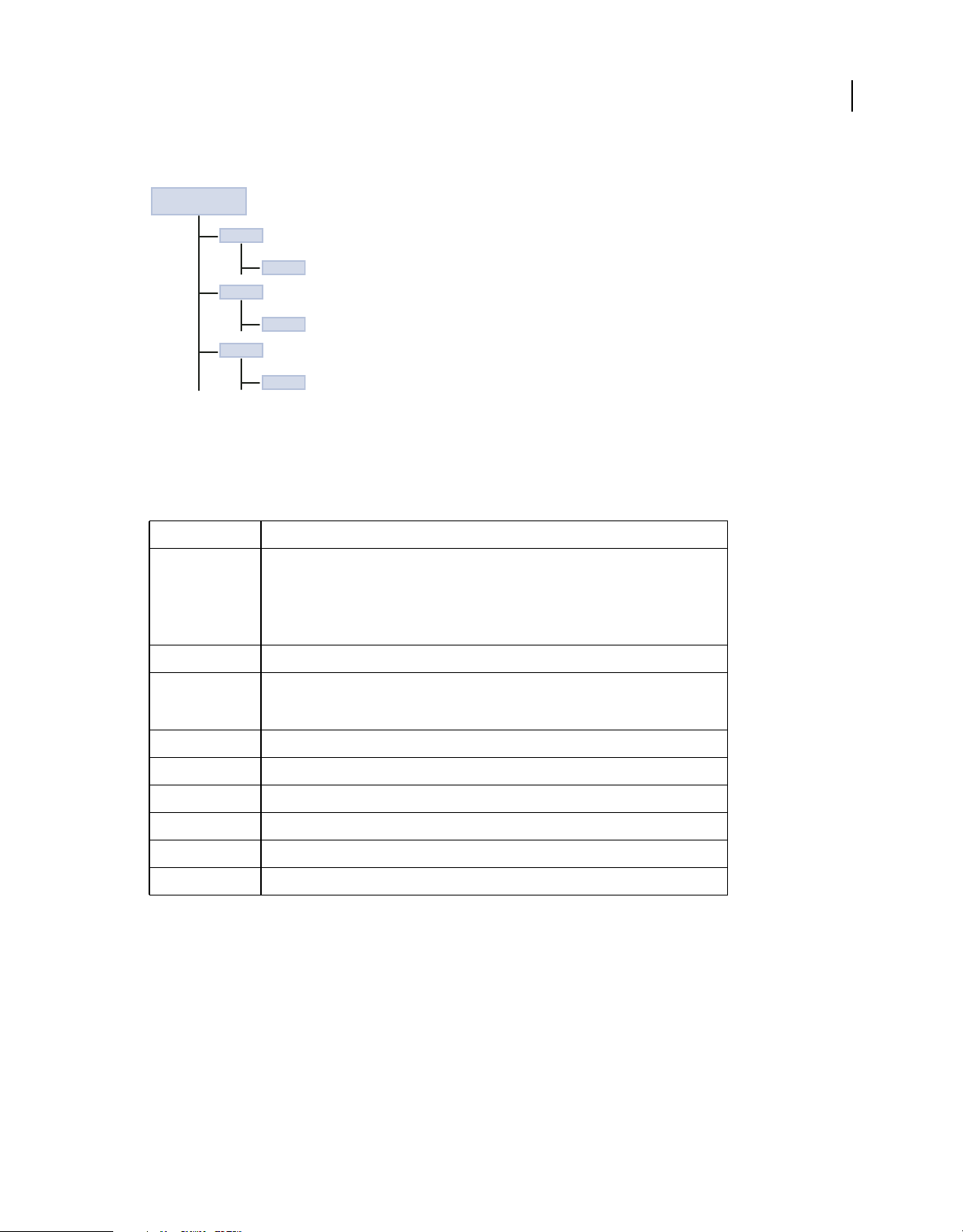
Installation directory structure
The LiveCycle Data Services installer creates a directory structure on your computer that contains all of the resources
necessary to build your application. As part of the installation, the installer creates three web applications that you can
use as the basis of your development environment.
Last updated 3/10/2011
Page 14
USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
The following example shows the directory structure of the web applications installed with LiveCycle Data Services:
J2EE appplication server
root directory
lcds
WEB-INF
lcds-samples
WEB-INF
ds-console
WEB-INF
The installer gives you the option of installing the integrated Tomcat application server to host these web applications.
Alternatively, you can install LiveCycle Data Services without installing Tomcat. Instead, you deploy the LiveCycle
Data Services web application on your J2EE application server or servlet container.
The following table describes the directory structure of each web application:
Directory Description
10
/lcds
/lcds-samples
/ds-console
/META-INF Contains package and extension configuration data.
/WEB-INF Contains the standard web application deployment descriptor (web.xml) that configures the
/WEB-INF/classes Contains Java class files and configuration files.
/WEB-INF/flex Contains LiveCycle Data Services configuration files.
/WEB-INF/flex/libs Contains SWC library files used when compiling a LiveCycle Data Services application.
/WEB-INF/flex/locale Contains localization resource files used when compiling a LiveCycle Data Services application.
/WEB-INF/lib Contains LiveCycle Data Services JAR files.
/WEB-INF/src (Optional) Contains Java source code used by the web application.
The root directory of a web application. Contains the WEB-INF directory.
This directory also includes all files that must be accessible by the user’s web browser, such as
SWF files, JSP pages, HTML pages, Cascading Style Sheets, images, and JavaScript files. You can
place these files directly in the web application root directory or in arbitrary subdirectories that
do not use the reserved name WEB-INF.
LiveCycle Data Services web application. This directory can also contain a vendor-specific web
application deployment descriptor.
Accessing a web application
To access a web application and the services provided by LiveCycle Data Services, you need the URL and port number
associated with the web application. The following table describes how to access each web application assuming that
you install LiveCycle Data Services with the integrated Tomcat application server.
Note: If you install LiveCycle Data Services into the directory structure of your J2EE application server or servlet
container, modify the context root URL based on your development environment.
Last updated 3/10/2011
Page 15

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
Application Context root URL for Tomcat Description
11
Sample application http://localhost:8400/lcds-samples/ A sample web application that includes many LiveCycle
Template
application
Console application http://localhost:8400/ds-console/ A console application that lets you view information about
http://localhost:8400/lcds/ A fully configured LiveCycle Data Services web application
Data Services examples. To start building your own
applications, start by editing these samples.
that contains no application code. You can use this
application as a template to create your own web
application.
LiveCycle Data Services web applications.
If you install LiveCycle Data Services with the integrated Tomcat application server, you can also access the ROOT web
application by using the following URL:
http://localhost:8400/.
Creating a web application
To get started writing LiveCycle Data Services applications, you can edit the samples in the lcds-samples web
application, add your application code to the lcds-samples web application, or add your application code to the empty
lcds web application.
However, Adobe recommends leaving the lcds web application alone, and instead copying its contents to a new web
application. That leaves the lcds web application empty so that you can use it as the template for creating web
applications.
If you base a new web application on the lcds web application, make sure you change the port numbers of the RTMP
and NIO channel definitions in the services-config.xml file of the new web application. Otherwise, the ports in the new
web application with conflict with those in the lcds web application. Make sure the new port numbers you use aren’t
already used in other web applications, such as the lcds-samples web application.
Defining the directory structure for client-side code
You develop LiveCycle Data Services client-side applications, and compile them in the same way that you compile
applications that use the Flex Software Development Kit (SDK). That means you can use the compiler built in to Flash
Builder, or the command line compiler, mxmlc, supplied with the Flex SDK.
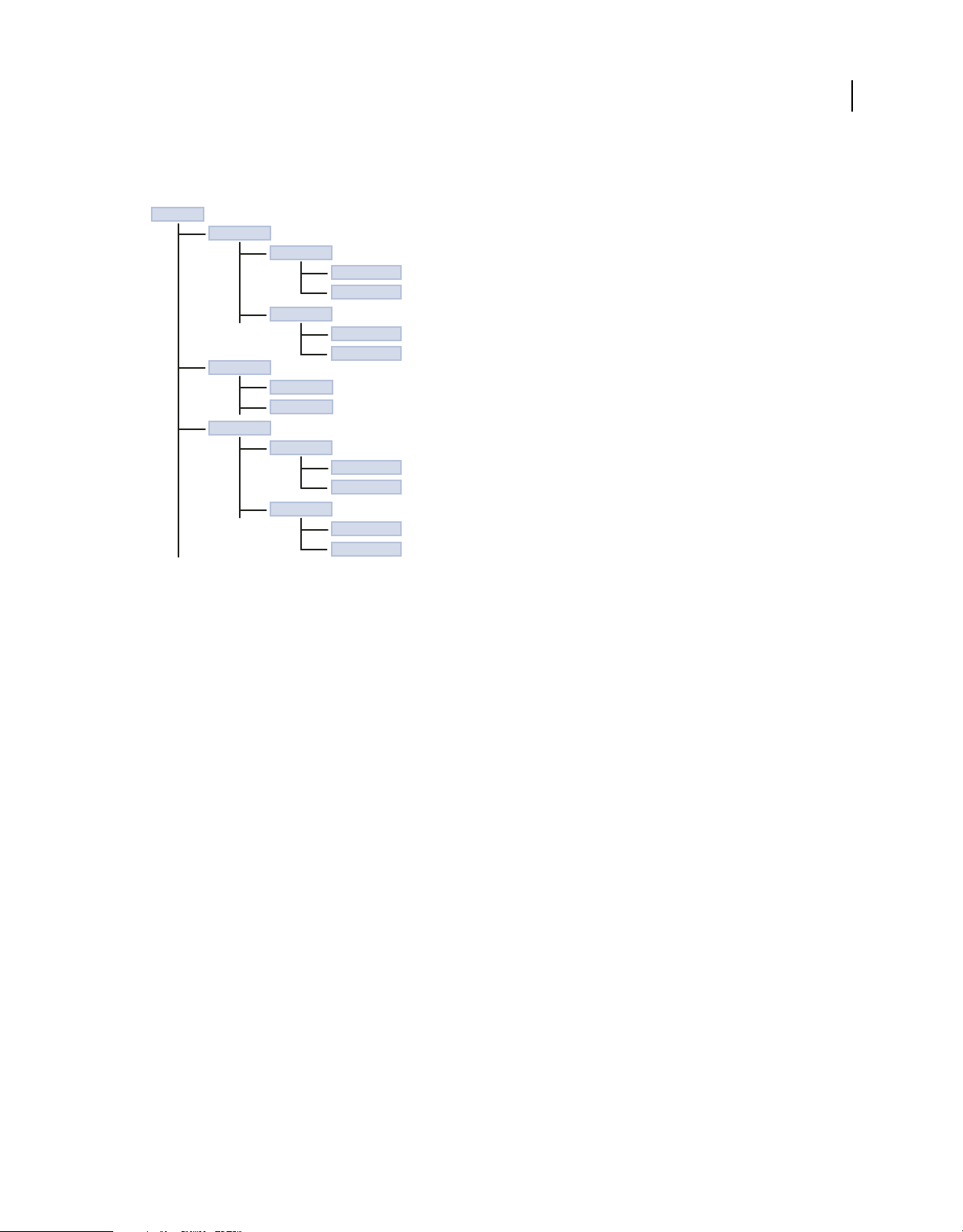
When you develop applications, you have two choices for how you arrange the directory structure of your application:
• Define a directory structure on your computer outside any LiveCycle Data Services web application. Compile the
application into a SWF file, and then deploy it, along with any run-time assets, to a LiveCycle Data Services web
application.
• Define a directory structure in a LiveCycle Data Services web application. In this scenario, all of your source code
and assets are stored in the web application. When you deploy the application, make sure to deploy only the
application SWF file and run-time assets. Otherwise, you run the risk of deploying your source code on a
production server.
You define each application in its own directory structure, with the local assets for the application under the root
directory. For assets shared across applications, such as image files, you can define a directory that is accessible by all
applications.
Last updated 3/10/2011
Page 16
USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
The following example shows two applications, appRoot1 and appRoot2. Each application has a subdirectory for local
MXML and ActionScript components, and can also reference a library of shared components:
base dir
appRoot1
myValidators
PriceValidator.mxml
AddressValidator.as
myFormatters
PriceFormatter.mxml
StringFormatter.as
appRoot2
myValidators
myFormatters
sharedLibrary
sharedValidators
SharedVal1.mxml
SharedVal2.as
sharedFormatters
SharedFormatter1.mxml
SharedFormatter2.as
12
Defining the directory structure for server-side code
You develop the server-side part of a LiveCycle Data Services application in Java. For example, the client-side
RemoteObject component lets you access the methods of server-side Java objects to return data to the client.
You also write Java classes to extend the functionality of the LiveCycle Data Services server. For example, a Data
Management Service destination references one or more message channels that transport messages, and contains
network- and server-related properties. The destination can also reference a data adapter, server-side code that lets the
destination work with data through a particular type of interface such as a Java object. An assembler class is a Java class
that interacts indirectly or directly with a data resource. For more information on assemblers, see
assemblers” on page 268.
When you develop server-side code, you have several choices for how you arrange the directory structure of your
application:
• Define a directory structure that corresponds to the package hierarchy of your Java source code outside any
LiveCycle Data Services web application. Compile the Java code, and then deploy the corresponding class files and
JAR files, along with any run-time assets, to a LiveCycle Data Services web application.
• Define a directory structure in a LiveCycle Data Services web application. In this scenario, all of your source code
and assets are stored in the web application. When you deploy the application, make sure to deploy only the class
and JAR files. Otherwise, you risk deploying source code on a production server.
The WEB-INF/classes and WEB-INF/lib directories are automatically included in the classpath of the web application.
When you deploy your server-side code, place the compiled Java class files in the WEB-INF/classes directory. Place
JAR files in the WEB-INF/lib directory.
“Standard
Running the LiveCycle Data Services sample applications
When you install LiveCycle Data Services, the installer creates the lcds-samples web application that contains sample
applications, including the 30 Minute Test Drive application. The sample applications demonstrate basic capabilities
and best practices for developing LiveCycle Data Services applications.
Last updated 3/10/2011
Page 17

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
The samples use an HSQLDB database that is installed in the install_root/sampledb directory. You must start the
LiveCycle Data Services server and the samples database before you can run the LiveCycle Data Services samples. After
starting the server and database, access the main sample application page by opening the following URL in a browser:
http://localhost:8400/lcds-samples/
The objective of the 30 Minute Test Drive is to give you, in a very short time, an understanding of how the LiveCycle
Data Services works. Access the 30 Minute Test Drive application by opening the following URL in a browser:
http://localhost:8400/lcds-samples/testdrive.htm
The client-side source code for the samples is shipped in the lcds-samples/WEB-INF/flex-src/flex-src.zip file. To
modify the client-side code, extract the flex-src.zip file into the lcds-samples directory, and then edit, compile, and
deploy the modified examples. Editing the samples makes it easier to get started developing applications because you
only have to modify existing code, rather than creating it from scratch.
Extract the client-side source code
1 Open lcds-samples/WEB-INF/flex-src/flex-src.zip file.
2 Extract the ZIP file into the lcds-samples directory.
Expanding the ZIP file adds a src directory to each sample in the lcds-samples directory. For example, the source
code for the chat example, Chat.mxml, is written to the directory lcds-samples/testdrive-chat/src.
13
The server-side source code for these examples is shipped in the lcds-samples/WEB-INF/src/flex/samples directory.
These source files are not zipped, but shipped in an expanded directory structure. To modify the server-side code you
can edit and compile it in that directory structure, and then copy it to the lcds-samples directory to deploy it.
Run the sample applications
1 Change directory to install_root/sampledb.
2 Start the samples database by using the following command:
startdb
You can stop the database by using the command:
stopdb
3 Start LiveCycle Data Services.
How you start LiveCycle Data Services depends on your system.
4 Open the following URL in a browser:
http://localhost:8400/lcds-samples/
Building your client-side application
You write the client-side part of a LiveCycle Data Services application in Flex, and then use Flash Builder or the mxmlc
command line compiler to compile it.
Before you begin
Before you begin to develop your client-side code, determine the files required to perform the compilation. Ensure that
you configured your Flex installation to compile SWF files for LiveCycle Data Services applications.
Last updated 3/10/2011
Page 18

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
Add the LiveCycle Data Services SWC files to the Flex SDK
To compile an application, Flash Builder and mxmlc reference the SWC library files that ship with the Flex SDK in
subdirectories of the frameworks directory. In Flash Builder, the frameworks directories for different Flex SDK
versions are in the install_root/sdks/sdkversion directory.
LiveCycle Data Services ships the following additional sets of SWC files. You must reference the set of SWC files that
matches the Flex SDK you compile against.
• Flex 4 compatible SWC files in subdirectories of the install_root/resources/lcds_swcs/FlexSDK4/frameworks
directory.
• Flex 3 compatible SWC files in subdirectories of the install_root/resources/lcds_swcs/FlexSDK3/frameworks
directory.
Copy the files in the LiveCycle Data Services frameworks directory (including its subdirectories) to the corresponding
Flex SDK frameworks directory.
Note: Flex 3 compatible SWC files are also available in the WEB-INF/flex/libs directory of a LiveCycle Data Services web
application. By default, Flash Builder adds these files to the library-path of a project that uses LiveCycle Data Services.
However, the Flex 4 compatible versions of these files are not available in that location. You must add them manually
from the install_root/resources/lcds_swcs/FlexSDK4/frameworks directory.
LiveCycle Data Services provides the following SWC files:
14
• fds.swc and fiber.swc
The SWC library files that define LiveCycle Data Services. These SWC files must be included in the library path of
the compiler.
• airfds.swc and playerfds.swc
The SWC files required to build LiveCycle Data Services applications for Flash Player (playerfds.swc) or AIR
(airfds.swc). One of these SWC files must be included in the library path of the compiler.
For the default Flex SDK installation, playerfds.swc must be in the libs/player directory, and airfds.swc must be in
the libs/air directory. The airfds.swc and playerfds.swc files must not both be available at the time of compilation.
When you compile your application in Flash Builder, it automatically references the correct SWC file based on your
project settings.
When you compile an application using mxmlc, by default the compiler references the flex-config.xml
configuration file, which specifies to include the libs/player directory in the library path for Flash Player. When you
compile an application for AIR, use the
load-config option to the mxmlc compiler to specify the air-config.xml
file, which specifies to include the libs/air directory in the library path.
• fds_rb.swc and fiber_rb.swc
The localized SWC files for LiveCycle Data Services. These SWC files must be in the library path of the compilation.
Specifying the services-config.xml file in a compilation
When you compile your Flex application, you typically specify the services-config.xml configuration file to the
compiler. This file defines the channel URLs that the client-side Flex application uses to communicate with the
LiveCycle Data Services server. Then the channel URLs are compiled into the resultant SWF file.
Both client-side and server-side code use the services-config.xml configuration file. If you change anything in servicesconfig.xml, you usually have to recompile your client-side applications and restart your server-side application for the
changes to take effect.
Last updated 3/10/2011
Page 19

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
In Flash Builder, the appropriate services-config.xml file is included automatically based on the LiveCycle Data
Services web application that you specified in the configuration of your Flash Builder project. When you use the mxmlc
compiler, use the
services option to specify the location of the file.
Note: You can also create channel definitions on the client in ActionScript or MXML. In that case, you might be able to
omit the reference to the services-config.xml configuration file from the compiler. For more information, see
“About
channels and endpoints” on page 38.
Specifying the context root in a compilation
The services-config.xml configuration file typically uses the context.root token to specify the context root of a web
application. At compile time, you use the compiler
context-root option to specify that information.
During a compilation, Flash Builder automatically sets the value of the context.root token based on the LiveCycle
Data Services web application that you specified in the configuration of your project. When you use the mxmlc
compiler, use the
context-root option to set it.
Using Flash Builder to compile client-side code
Flash Builder is an integrated development environment (IDE) for developing applications that use the Flex
framework, MXML, Adobe Flash Player, AIR, ActionScript, LiveCycle Data Services, and the Flex charting
components.
15
Flash Builder is built on top of Eclipse, an open-source IDE. It runs on Microsoft Windows, Apple Mac OS X, and
Linux, and is available in several versions. Installation configuration options let you install Flash Builder as a plug-in
to an existing Eclipse workbench installation, or to install it as a stand-alone application.
Using the stand-alone or plug-in configuration of Flash Builder
The Flash Builder installer provides the following two configuration options:
Plug-in configuration This configuration is for users who already use the Eclipse workbench, who already develop in
Java, or who want to add the Flash Builder plug-ins to their toolkit of Eclipse plug-ins. Because Eclipse is an open,
extensible platform, hundreds of plug-ins are available for many different development purposes. When you use the
plug-in configuration, you can create a combined Java and Flex Eclipse project; for more information, see
“Creating a
combined Java and Flex project in Eclipse” on page 22.
Stand-alone configuration This configuration is a customized packaging of Eclipse and the Flash Builder plug-in
created specifically for developing Flex and ActionScript applications. The stand-alone configuration is ideal for new
users and users who intend to develop only Flex and ActionScript applications.
Both configurations provide the same functionality. You select the configuration when you install Flash Builder.
Most LiveCycle Data Services developers choose to use the Eclipse plug-in configuration. Then they develop the Java
code that runs on the server in the same IDE that they use to develop the MXML and ActionScript code for the client
Flex application.
Note: The stand-alone configuration of Flash Builder does not contain tools to edit Java code, however, you can install
them. Select Help > Software Updates > Find and Install menu command to open the Install/Update dialog box. Then
select Search For New Features To Install. In the results, select Europa Discovery Site, and then select the Java
Development package to install.
If you aren’t sure which configuration to use, follow these guidelines:
• If you already use and have Eclipse 3.11 (or later) installed, select the plug-in configuration. On Macintosh, Eclipse
3.2 is the earliest version.
Last updated 3/10/2011
Page 20

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
• If you don’t have Eclipse installed and your primary focus is on developing Flex and ActionScript applications,
select the stand-alone configuration. This configuration also lets you install other Eclipse plug-ins, so you can
expand the scope of your development work in the future.
Create a Flash Builder project
Use this procedure to create a Flash Builder project to edit one of the samples shipped with the Test Drive application.
The procedure for creating and configuring a new project is almost the same as the following procedure.
Note: When you use the plug-in configuration of Flash Builder, you can create a combined Java and Flex Eclipse project;
for more information, see
“Creating a combined Java and Flex project in Eclipse” on page 22.
For more information on the Test Drive application, see “Running the LiveCycle Data Services sample applications”
on page 12.
1 Start Flash Builder.
2 Select File > New > Flex Project.
3
Enter a project name. You are editing an existing application, so use the exact name of the sample folder: testdrive-chat.
Note: If you are creating an empty project, you can name it anything that you want.
4 If you unzipped flex-src.zip in the lcds-samples directory, deselect the Use Default Location option, and specify the
directory as install_root/tomcat/webapps/lcds-samples/testdrive-chat, or wherever you unzipped the file on your
computer.
Note: By default, Flash Builder creates the project directory based on the project name and operating system. For
example, if you are using the plug-in configuration of Flash Builder on Microsoft Windows, the default project
directory is C:/Documents and Settings/USER_NAME/workspace/PROJECT_NAME.
16
5 Select the application type as Web (runs in Adobe® Flash® Player) to configure the application to run in the browser
as a Flash Player application.
If you are creating an AIR application, select Desktop (runs In Adobe AIR). However, make sure that you do not
have any server tokens in URLs in the configuration files. In the web application that ships with LiveCycle Data
Services, server tokens are used in the channel endpoint URLs in the WEB-INF/flex/services-config.xml file, as the
following example shows:
<endpoint
url="https://{server.name}:{server.port}/{context.root}/messagebroker/streamingamf"
class="flex.messaging.endpoints.StreamingAMFEndpoint"/>
You would change that line to the following:
<endpoint url="http://your_server_name:8400/lcds/messagebroker/streamingamf"
class="flex.messaging.endpoints.StreamingAMFEndpoint"/>
6 Select J2EE as the Application server type.
7 Select Use Remote Object Access.
8 Select LiveCycle Data Services.
9 Click Next.
10 Deselect Use Default Location For Local LiveCycle Data Services Server.
11 Set the root folder, root URL, and context root of your web application.
The root folder specifies the top-level directory of the web application (the directory that contains the WEB-INF
directory). The root URL specifies the URL of the web application, and the context root specifies the root of the web
application.
Last updated 3/10/2011
Page 21

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
If you are using the integrated Tomcat application server, set the properties as follows:
Root folder: C:\lcds\tomcat\webapps\lcds-samples\
Root URL: http://localhost:8400/lcds-samples/
Context root: /lcds-samples/
Modify these settings as appropriate if you are not using the Tomcat application server.
12 Make sure that your LiveCycle Data Services server is running, and click Validate Configuration to ensure that your
project is valid.
13 Clear the Output Folder field to set the directory of the compiled SWF file to the main project directory.
By default, Flash Builder writes the compiled SWF file to the bin-debug directory under the main project directory.
To use a different output directory, specify it in the Output Folder field.
14 Click Next.
15 Set the name of the main application file to Chat.mxml, and click Finish.
Edit, compile, and deploy a LiveCycle Data Services application in Flash Builder
1 Open src/Chat.mxml in your Flash Builder project.
2 Edit Chat.mxml to change the definition of the TextArea control so that it displays an initial text string when the
application starts:
<mx:TextArea id="log" width="100%" height="100%" text="My edited file!"/>
17
3 Save the file.
When you save the file, Flash Builder automatically compiles it. By default, the resultant SWF file is written to the
C:/lcds/tomcat/webapps/lcds-samples/testdrive-chat/bin-debug directory, or the location you set for the Output
directory for the project. You should have set the Output directory to the main project directory in the previous
procedure.
Note: If you write the Chat.SWF file to any directory other than lcds-samples\testdrive-chat, deploy the SWF file by
copying it to the lcds-samples\testdrive-chat directory.
4 Make sure that you have started the samples database and LiveCycle Data Services, as described in “Running the
LiveCycle Data Services sample applications” on page 12.
5 Select Run > Run Chat to run the application.
You can also request the application in a browser by using the URL http://localhost:8400/lcds-samples/testdrivechat/index.html.
Note: By default, Flash Builder creates a SWF file that contains debug information. When you are ready to deploy
your final application, meaning one that does not contain debug information, select File > Export > Release Build. For
more information, see Using Adobe Flash Builder 4.
6 Verify that your new text appears in the TextArea control.
Create a linked resource to the LiveCycle Data Services configuration files
While working on the client-side of your applications, you often look at or change the LiveCycle Data Services
configuration files. You can create a linked resource inside a Flash Builder project to make the LiveCycle Data Services
configuration files easily accessible.
1 Right-click the project name in the project navigation view.
Last updated 3/10/2011
Page 22

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
2 Select New > Folder in the pop-up menu.
3 Specify the name of the folder as it will appear in the navigation view. This name can be different from the name of
the folder in the file system. For example, type server-config.
4 Click the Advanced button.
5 Select the Link To Folder In The File System option.
6 Click the Browse button and select the flex folder under the WEB-INF directory of your web application. For
example, on a typical Windows installation that uses the Tomcat integrated server, select:
install_root/tomcat/webapps/lcds-samples/WEB-INF/flex.
7 Click Finish. The LiveCycle Data Services configuration files are now available in your Flash Builder project under
the server-config folder.
Note: If you change anything in the services-config.xml file, you usually have to recompile your client-side applications
and restart your server-side application for the changes to take effect.
Using mxmlc to compile client-side code
You use the mxmlc command line compiler to create SWF files from MXML, ActionScript, and other source files.
Typically, you pass the name of the MXML application file to the compiler. The output is a SWF file. The mxmlc
compiler ships in the bin directory of the Flex SDK. You run the mxmlc compiler as a shell script and executable file
on Windows and UNIX systems. For more information, see the Flex documentation set.
18
The basic syntax of the mxmlc utility is as follows:
mxmlc [options] target_file
The target file of the compile is required. If you use a space-separated list as part of the options, you can terminate the
list with a double hyphen before adding the target file.
mxmlc -option arg1 arg2 arg3 -- target_file.mxml
To see a list of options for mxmlc, use the helplist option, as the following example shows:
mxmlc -help list
To see a list of all options available for mxmlc, including advanced options, use the following command:
mxmlc -help list advanced
The default output of mxmlc is filename.swf, where filename is the name of the target file. The default output location
is in the same directory as the target, unless you specify an output file and location with the
output option.
The mxmlc command line compiler does not generate an HTML wrapper. Create your own wrapper to deploy a SWF
file that the mxmlc compiler produced. The wrapper embeds the SWF object in the HTML tag. The wrapper includes
<object> and <embed> tags, and scripts that support Flash Player version detection and history management. For
the
information about creating an HTML wrapper, see the Flex Help Resource Center.
Note: Flash Builder automatically generates an HTML wrapper when you compile your application.
Compiling LiveCycle Data Services applications
Along with the standard options that you use with the mxmlc compiler, use the following options to specify
information about your LiveCycle Data Services application.
• services filename
Specifies the location of the services-config.xml file.
• library-path context-path
Last updated 3/10/2011
Page 23

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
Sets the library path of the LiveCycle Data Services SWC files. Use the += syntax with the library-path option to add
the WEB-INF/flex/libs directory to the library path.
• context-root context-path
Sets the value of the context root of the application. This value corresponds to the {context.root} token in the
services-config.xml file, which is often used in channel definitions. The default value is null.
Edit, compile, and deploy the Chat.mxml file
1 Unzip flex-src.zip in the lcds/tomcat/webapps/lcds-samples directory, as described in “Running the LiveCycle Data
Services sample applications” on page 12.
2 Open the file install_root/tomcat/webapps/lcds-samples/testdrive-chat/src/Chat.mxml in an editor. Modify this
path as necessary based on where you unzipped flex-src.zip.
3 Change the definition of the TextArea control so that it displays an initial text string when the application starts:
<mx:TextArea id="log" width="100%" height="100%" text="My edited file!"/>
4 Change the directory to install_root/tomcat/webapps/lcds-samples.
5 Use the following command to compile Chat.mxml:
Note: This command assumes that you added the mxmlc directory to your system path. The default location is
install_root/resources/flex_sdk/bin.
19
mxmlc -strict=true
-show-actionscript-warnings=true
-use-network=true
-services=WEB-INF/flex/services-config.xml
-library-path+=WEB-INF/flex/libs
-context-root=lcds-samples
-output=testdrive-chat/Chat.swf
testdrive-chat/src/Chat.mxml
The compiler writes the Chat.swf file to the lcds-samples/testdrive-chat directory.
6 Start the samples database and LiveCycle Data Services as described in “Running the LiveCycle Data Services
sample applications” on page 12.
7 Request the application by using the URL http://localhost:8400/lcds-samples/testdrive-chat/index.html.
8 Verify that your new text appears in the TextArea control.
Rather than keep your source code in your deployment directory, you can set up a separate directory, and then copy
Chat.swf to lcds-samples/testdrive-chat to deploy it.
Loading LiveCycle Data Services client applications as sub-applications
You can load sub-applications that use RPC services, the Message Service, or the Data Management Service into a
parent client application. For general information about sub-applications, see Creating and loading sub-applications
in the Flex documentation.
To load LiveCycle Data Services sub-applications into a parent application when using Flash Player 10.1 or later, use
the SWFLoader control with its
domain; setting the
loadForCompatibility property to true lets you avoid class registration conflicts between sub-
applications by ensuring that each application has its own class table and its own security domain.
loadForCompatibility property to true. There is a single class table per security
Last updated 3/10/2011
Page 24

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
There is a bug in Flash Player versions prior to version 10.1 where applications in a single physical domain also run in
the same security domain and therefore only have one class table even when SWFLoader
true. For this reason, Adobe recommends that you use Flash Player 10.1 or later if your application is loading
set to
loadForCompatibility is
more than one sub-application that uses LiveCycle Data Services functionality.
If you must support Flash Player versions prior to version 10.1, there are a couple of workarounds to this issue. One
workaround is to use the SWFLoader control with the
loadForCompatibility property set to true, but load each
sub-application from a different domain. You can accomplish this in a production system by using different
subdomains for each SWF file, such as app1.domain.com/mylcdsapp.swf and app2.domain.com/mylcdsapp.swf,
where each subdomain resolves to the same server or host. Because each sub-application is loaded from a different
physical domain, Flash Player gives it a separate security domain.
The other workaround is to use the ModuleLoader control to load the sub-applications or use the SWFLoader control
with the
loadForCompatibility property set to false. In either case, in the parent application you define all data
services and RPC classes as well as any strongly typed objects that your application uses. The following example shows
this workaround with the SWFLoader control. FDSClasses and RPCClasses are the class definitions required for data
services and RPC classes.
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" xmlns="*"
backgroundColor="#FFFFFF">
<mx:SWFLoader loadForCompatibility="false" id="s1"
source="SampleDataService.swf"/>
<mx:SWFLoader loadForCompatibility="false" id="s2"
source="SampleDataService2.swf"/>
<mx:Script>
<![CDATA[
FDSClasses;
RPCClasses;
]]>
</mx:Script>
</mx:Application>
20
Building your server-side application
You write the server-side part of a LiveCycle Data Services application in Java, and then use the javac compiler to
compile it.
Creating a simple Java class to return data to the client
A common reason to create a server-side Java class is to represent data returned to the client. For example, the clientside RemoteObject component lets you access the methods of server-side Java objects to return data to the client.
The Test Drive sample application contains the Accessing Data Using Remoting sample where the client-side code
uses the RemoteObject component to access product data on the server. The Product.java class represents that data.
After starting the LiveCycle Data Services server and the samples database, view this example by opening the following
URL in a browser: http://localhost:8400/lcds-samples/testdrive-remoteobject/index.html.
The source code for Product.java is in the install_root/lcds-samples/WEB-INF/src/flex/samples/product directory.
For example, if you installed LiveCycle Data Services with the integrated Tomcat server on Microsoft Windows, the
directory is install_root/tomcat/webapps/lcds-samples/WEB-INF/src/flex/samples/product.
Modify, compile, and deploy Product.java on the lcds-sample server
1 Start the samples database.
Last updated 3/10/2011
Page 25

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
2 Start LiveCycle Data Services.
3 View the running example by opening the following URL in a browser:
http://localhost:8400/lcds-samples/testdrive-remoteobject/index.html
4 Click the Get Data button to download data from the server. Notice that the description column contains product
descriptions.
5 In an editor, open the file install_root/tomcat/webapps/lcds-samples/WEB-
INF/src//flex/samples/product/Product.java. Modify this path as necessary for your installation.
6 Modify the following getDescription() method definition so that it always returns the String "My description"
rather than the value from the database:
public String getDescription() {
return description;
}
The modified method definition appears as the following:
public String getDescription() {
return "My description.";
}
7 Change the directory to lcds-samples.
8 Compile Product.java by using the following javac command line:
javac -d WEB-INF/classes/ WEB-INF/src/flex/samples/product/Product.java
21
This command creates the file Product.class, and deploys it to the WEB-INF/classes/flex/samples/product
directory.
9 View the running example by opening the following URL in a browser:
http://localhost:8400/lcds-samples/testdrive-remoteobject/index.html
10 Click the Get Data button.
Notice that the description column now contains the String "My description" for each product.
Creating a Java class that extends a LiveCycle Data Services class
As part of developing your server-side code, you can create a custom assembler class, factory class, or other type of Java
class that extends the LiveCycle Data Services Java class library. For example, a data adapter is responsible for updating
the persistent data store on the server in a manner appropriate to the specific data store type.
You perform many of the same steps to compile a Java class that extends the LiveCycle Data Services Java class library
as you do for compiling a simple class. The major difference is to ensure that you include the appropriate LiveCycle
Data Services JAR files in the classpath of your compilation so that the compiler can locate the appropriate files.
The Test Drive sample application contains the Data Management Service sample, in which the server-side code uses
a custom assembler represented by the ProductAssembler.java class. To view the sample, start the LiveCycle Data
Services server and the samples database. Then open the following URL in a browser: http://localhost:8400/lcdssamples/testdrive-dataservice/index.html.
The source code for ProductAssembler.java is in the directory install_root/lcds-samples/WEBINF/src/flex/samples/product. For example, if you installed LiveCycle Data Services with the integrated Tomcat server
on Microsoft Windows, the directory is install_root/tomcat/webapps/lcds-samples/WEBINF/src/flex/samples/product.
Last updated 3/10/2011
Page 26

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
Compile and deploy ProductAssembler.java on the lcds-sample server
1 View the running example by opening the following URL in a browser:
http://localhost:8400/lcds-samples/testdrive-dataservice/index.html
2 Click the Get Data button to download data from the server.
3 In an editor, open the file install_root/tomcat/webapps/lcds-samples/WEB-
INF/src/flex/samples/product/ProductAssembler.java. Modify this path as necessary for your installation.
For more information on assemblers, see “Standard assemblers” on page 268.
4 Change the directory to install_root/tomcat/webapps/lcds-samples/WEB-INF/src.
5 Compile ProductAssembler.java by using the following javac command line:
javac
-sourcepath .
-d ..\classes
-classpath ..\lib\flex-messaging-common.jar;
..\lib\flex-messaging-core.jar;
..\lib\flex-messaging-data-req.jar;
..\lib\flex-messaging-data.jar;
..\lib\flex-messaging-opt.jar;
..\lib\flex-messaging-proxy.jar;
..\lib\flex-messaging-remoting.jar
flex\samples\product\ProductAssembler.java
22
Notice that the classpath contains many, but not all, of the JAR files in WEB-INF/lib. If you are compiling other
types of classes, you include additional JAR files in the classpath. These JAR files are also shipped in the
install_root/resources/lib directory.
This command creates the file ProductAssembler.class, and deploys it to the WEBINF/classes/flex/samples/product directory.
6 View the running example by opening the following URL in a browser:
http://localhost:8400/lcds-samples/testdrive-dataservice/index.html
7 Click the Get Data button to make sure that your code is working correctly.
Creating a combined Java and Flex project in Eclipse
If you use Eclipse for Java development, you can develop Java code in the same Eclipse project in which you develop
Flex client code. You toggle between the Java and Flash perspectives to work on Java or Flex code. This procedure
describes how to create a combined project. Another alternative is to use separate Eclipse projects for Java and Flex
development.
Note: To create a combined Java and Flex project, use a plug-in configuration of Flash Builder. You must have the Eclipse
Java perspective available in your installation.
1 Create a Java project in Eclipse.
2 When you create a Java project, you can optionally set the output location to be a linked directory in your LiveCycle
Data Services web application. For example, you can save compiled POJO classes to the WEB-INF/classes directory
of your web application.
Complete these steps to set the output location to a linked directory:
a When configuringa project in the New Java Project dialog, select the Allow Output Folders For Source Folders
option.
Last updated 3/10/2011
Page 27

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
b Click Browse to the right of the Default Output Folder field.
c Select the project directory in the Folder Selection dialog.
d Click Create New Folder.
e Select Advanced > Link To Folder In File System.
f Browse to the directory where you want to save output and click OK.
g Click OK on the New Folder dialog.
h Click OK on the Folder Selection dialog.
i Click Finish on the New Java Project dialog.
Similarly, if you plan to export your output to a JAR file, you can save the JAR file to the WEB-INF/lib directory of
your LiveCycle Data Services web application.
3 In the Package Explorer, right-click your new Java project and select Add/Change Project Type > Add Flex Project.
4 Set up your Flex project as described in “Using Flash Builder to compile client-side code” on page 15.
Debugging your application
If you encounter errors in your applications, you can use the debugging tools to perform the following:
23
• Set and manage breakpoints in your code
• Control application execution by suspending, resuming, and terminating the application
• Step into and over the code statements
• Select critical variables to watch
• Evaluate watch expressions while the application is running
Debugging Flex applications can be as simple as enabling trace() statements or as complex as stepping into a
source files and running the code, one line at a time. The Flash Builder debugger and the command line debugger,
fdb, let you step through and debug ActionScript files used by your Flex applications. For information on how to
use the Flash Builder debugger, see Using Adobe Flash Builder 4. For more information on the command line
debugger, fdb, see the Flex documentation set.
Using Flash Debug Player
To use the fdb command line debugger or the Flash Builder debugger, install and configure Flash Debug Player. To
determine whether you are running the Flash Debug Player or the standard version of Flash Player, open any Flex
application in Flash Player and right-click. If you see the Show Redraw Regions option, you are running Flash Debug
Player. For more information about installing Flash Debug Player, see the LiveCycle Data Services installation
instructions.
Flash Debug Player comes in ActiveX, Plug-in, and stand-alone versions for Microsoft Internet Explorer, Netscapebased browsers, and desktop applications. You can find Flash Debug Player installers in the following locations:
• Flash Builder: install_dir/Player/os_version
• Flex SDK: install_dir/runtimes/player/os_version/
Like the standard version of Adobe Flash Player 9, Flash Debug Player runs SWF files in a browser or on the desktop
in a stand-alone player. Unlike Flash Player, the Flash Debug Player enables you to do the following:
• Output statements and application errors to the local log file of Flash Debug Player by using the trace() method.
• Write data services log messages to the local log file of Flash Debug Player.
Last updated 3/10/2011
Page 28

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
• View run-time errors (RTEs).
• Use the fdb command line debugger.
• Use the Flash Builder debugging tool.
• Use the Flash Builder profiling tool.
Note: ADL logs trace() output from AIR applications.
Using logging to debug your application
One tool that can help in debugging is the logging mechanism. You can perform server-side and client-side logging of
requests and responses.
Client-side logging
For client-side logging, you directly write messages to the log file, or configure the application to write messages
generated by Flex to the log file. Flash Debug Player has two primary methods of writing messages to a log file:
• The global trace() method. The global trace() method prints a String to the log file. Messages can contain
checkpoint information to signal that your application reached a specific line of code, or the value of a variable.
• Logging API. The logging API, implemented by the TraceTarget class, provides a layer of functionality on top of
trace() method. For example, you can use the logging API to log debug, error, and warning messages
the
generated by Flex while applications execute.
Flash Debug Player sends logging information to the flashlog.txt file. The operating system determines the location of
this file, as the following table shows:
24
Operating system Location of log file
Windows 95/98/ME/2000/XP C:/Documents and Settings/username/Application
Windows Vista C:/Users/username/AppData/Roaming/Macromedia/Flash
Mac OS X /Users/username/Library/Preferences/Macromedia/Flash
Linux /home/username/.macromedia/Flash_Player/Logs/
Data/Macromedia/Flash Player/Logs
Player/Logs
Player/Logs/
Use settings in the mm.cfg text file to configure Flash Debug Player for logging. If this file does not exist, you can create
it when you first configure Flash Debug Player. The location of this file depends on your operating system. The
following table shows where to create the mm.cfg file for several operating systems:
Operating system Location of mm.cfg file
Mac OS X /Library/Application Support/Macromedia
Windows 95/98/ME %HOMEDRIVE%/%HOMEPATH%
Windows 2000/XP C:/Documents and Settings/username
Windows Vista C:/Users/username
Linux /home/username
The mm.cfg file contains many settings that you can use to control logging. The following sample mm.cfg file enables
error reporting and trace logging:
Last updated 3/10/2011
Page 29

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
ErrorReportingEnable=1
TraceOutputFileEnable=1
After you enable reporting and logging, call the trace() method to write a String to the flashlog.txt file, as the
following example shows:
trace("Got to checkpoint 1.");
Insert the following MXML line to enable the logging of all Flex-generated debug messages to flashlog.txt:
<mx:TraceTarget loglevel="2"/>
For information about client-side logging, see the Flex documentation set.
Server-side logging
You configure server-side logging in the logging section of the services configuration file, services-config.xml. By
default, output is sent to System.out.
You set the logging level to one of the following available levels:
• All
• Debug
• Info
• Warn
• Error
• None
You typically set the server-side logging level to Debug to log all debug messages, and also all info, warning, and error
messages. The following example shows a logging configuration that uses the
Debug logging level:
25
<logging>
<!-- You may also use flex.messaging.log.ServletLogTarget. -->
<target class="flex.messaging.log.ConsoleTarget" level="Debug">
<properties>
<prefix>[Flex]</prefix>
<includeDate>false</includeDate>
<includeTime>false</includeTime>
<includeLevel>false</includeLevel>
<includeCategory>false</includeCategory>
</properties>
<filters>
<pattern>Endpoint</pattern>
<!--<pattern>Service.*</pattern>-->
<!--<pattern>Message.*</pattern>-->
</filters>
</target>
</logging>
For more information, see “Logging” on page 420.
Measuring application performance
As part of preparing your application for final deployment, you can test its performance to look for ways to optimize
it. One place to examine performance is in the message processing part of the application. To help you gather this
performance information, enable the gathering of message timing and sizing data.
Last updated 3/10/2011
Page 30

USING ADOBE LIVECYCLE DATA SERVICES
Getting started with LiveCycle Data Services
The mechanism for measuring the performance of message processing is disabled by default. When enabled,
information regarding message size, server processing time, and network travel time is captured. This information is
available to the client that pushed a message to the server, to a client that received a pushed message from the server,
or to a client that received an acknowledge message from the server in response a pushed message. A subset of this
information is also available for access on the server.
You can use this mechanism across all channel types, including polling and streaming channels, that communicate
with the server. However, this mechanism does not work when you make a direct connection to an external server by
setting the
useProxy property to false for the HTTPService and WebService tags because it bypasses the LiveCycle
Data Services Proxy Server.
You use two parameters in a channel definition to enable message processing metrics:
• <record-message-times>
• <record-message-sizes>
Set these parameters to true or false; the default value is false. You can set the parameters to different values to
capture only one type of metric. For example, the following channel definition specifies to capture message timing
information, but not message sizing information:
<channel-definition id="my-streaming-amf"
class="mx.messaging.channels.StreamingAMFChannel">
<endpoint
url="http://{server.name}:{server.port}/{context.root}/messagebroker/streamingamf"
class="flex.messaging.endpoints.StreamingAMFEndpoint"/>
<properties>
<record-message-times>true</record-message-times>
<record-message-sizes>false</record-message-sizes>
</properties>
</channel-definition>
26
For more information, see “Measuring message processing performance” on page 121.
Deploying your application
Your production environment determines how you deploy your application. One option is to package your
application and assets in a LiveCycle Data Services web application, and then create a single WAR file that contains
the entire web application. You can then deploy the single WAR file on your production server.
Alternatively, you can deploy multiple LiveCycle Data Services applications on a single web application. In this case,
your production server has an expanded LiveCycle Data Services web application to which you add the directories that
are required to run your new application.
When you deploy your LiveCycle Data Services application in a production environment, ensure that you deploy all
the necessary parts of the application, including the following:
• The compiled SWF file that contains your client-side application
• The HTML wrapper generated by Flash Builder or created manually if you use the mxmlc compiler
• The compiled Java class and JAR files that represent your server-side application
• Any run-time assets required by your application
• A LiveCycle Data Services web application
• Updated LiveCycle Data Services configuration files that contain the necessary information to support your
application
Last updated 3/10/2011
Page 31

Chapter 2: System architecture
Client and server architecture
A LiveCycle Data Services application consists of a client application running in a web browser or Adobe AIR and a
J2EE web application on the server that the client application communicates with. The client application can be a Flex
application or it can be a combination of Flex, HTML, and JavaScript. When you use JavaScript, communication with
the LiveCycle Data Services server is accomplished using the JavaScript proxy objects provided in the Ajax Client
Library. For information about the Ajax Client Library, see
LiveCycle Data Services client architecture
LiveCycle Data Services clients use a message-based framework provided by LiveCycle Data Services to interact with
the server. On the client side of the message-based framework are channels that encapsulate the connection behavior
between the Flex client and the LiveCycle Data Services server. Channels are grouped together into channel sets that
are responsible for channel hunting and channel failover. For information about client class APIs, see the Adobe
LiveCycle ActionScript Reference.
“The Ajax client library” on page 460.
27
The following illustration shows the LiveCycle Data Services client architecture:
Flex Client
SWF from MXML
User Interface using Flex SDK
LiveCycle Data Services ES components
RemoteObject component
HTTPService/WebService components
Producer/Consumer components
DataService component
LiveCycle Data Services ES Client Architecture
HTTP/RTMP protocol
AMF/AMFX encoding
Channel Set
AMFChannel
HTTPChannel
RTMPChannel
Web Ser ve r
J2EE Server
LiveCycle Data
Services ES
Flex components
The following Flex components interact with a LiveCycle Data Services server:
• RemoteObject
• HTTPService
• WebService
• Producer
• Consumer
• DataService
All of these components, except for the DataService component, are included in the Flex SDK in the rpc.swc
component library. The DataService component is included in the fds.swc component library provided in the
LiveCycle Data Services installation.
Last updated 3/10/2011
Page 32

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Although the RemoteObject, Producer, and Consumer components are included with the Flex SDK, they require a
server that can interpret the messages that they send. The BlazeDS and LiveCycle Data Services servers are two
examples of such servers. A Flex application can also make direct HTTP service or web service calls to remote servers
without LiveCycle Data Services in the middle tier. However, going through the LiveCycle Data Services Proxy Service
is beneficial for several reasons; for more information, see
“Using RPC services” on page 135.
Client-side components communicate with services on the LiveCycle Data Services server by sending and receiving
messages of the correct type. For more information about messages, see
“Messages” on page 28.
Channels and channel sets
A Flex component uses a channel to communicate with a LiveCycle Data Services server. A channel set contains
channels; its primary function is to provide connectivity between the Flex client and the LiveCycle Data Services server.
A channel set contains channels ordered by preference. The Flex component tries to connect to the first channel in the
channel set and in the case where a connection cannot be established falls back to the next channel in the list. The Flex
component continues to go through the list of channels in the order in which they are specified until a connection can
be established over one of the channels or the list of channels is exhausted.
Channels encapsulate the connection behavior between the Flex components and the LiveCycle Data Services server.
Conceptually, channels are a level below the Flex components and they handle the communication between the Flex
client and the LiveCycle Data Services server. They communicate with their corresponding endpoints on the LiveCycle
Data Services server; for more information about endpoints, see
“Endpoints” on page 29.
28
Flex clients can use several different channel types, such as the AMFChannel, HTTPChannel, and RTMPChannel.
Channel selection depends on a number of factors, including the type of application you are building. For example, if
HTTP is the only protocol allowed in your environment, you would use the AMFChannel or HTTPChannel; you
would not use the RTMPChannel, which uses the RTMP protocol. If non-binary data transfer is required, you would
use the HTTPChannel, which uses a non-binary format called AMFX (AMF in XML). For more information about
channels, see
“Channels and endpoints” on page 38.
Messages
All communication between Flex client components and LiveCycle Data Services is performed with messages. Flex
components use several message types to communicate with their corresponding services in LiveCycle Data Services.
All messages have client-side (ActionScript) implementations and server-side (Java) implementations because the
messages are serialized and deserialized on both the client and the server. You can also create messages directly in Java
and have those messages delivered to clients using the server push API.
Some message types, such as AcknowledgeMessage and CommandMessage, are used across different Flex components
and LiveCycle Data Services services. For example, to have a Producer component send a message to subscribed
Consumer components, you create a message of type AsyncMessage and pass it to the
component.
In other situations, you do not write code for constructing and sending messages. For example, you simply use a
RemoteObject component to call the remote method from the Flex application. The RemoteObject component creates
a RemotingMessage to encapsulate the RemoteObject call. In response it receives an AcknowledgeMessage from the
server. The AcknowledgeMessage is encapsulated in a ResultEvent in the Flex application.
Sometimes you must create a message to send to the server. For example, you could send a message by creating an
AsyncMessage and passing it to a Producer.
send() method of the Producer
Last updated 3/10/2011
Page 33

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
LiveCycle Data Services uses two patterns for sending and receiving messages: the request/reply pattern and the
publish/subscribe pattern. RemoteObject, HTTPService, and WebService components use the request/reply message
pattern, in which the Flex component makes a request and receives a reply to that request. Producer and Consumer
components use the publish/subscribe message pattern. In this pattern, the Producer publishes a message to a
destination defined on the LiveCycle Data Services server. All Consumers subscribed to that destination receive the
message.
LiveCycle Data Services server architecture
The LiveCycle Data Services server is a combination of a J2EE web application and a highly scalable network socket
server. A Flex client makes a request over a channel and the request is routed to an endpoint on the LiveCycle Data
Services server. From the endpoint, the request is routed through a chain of Java objects that includes the
MessageBroker object, a service object, a destination object, and finally an adapter object. The adapter fulfills the
request either locally, or by contacting a backend system or a remote server such as Java Message Service (JMS) server.
The following illustration shows the LiveCycle Data Services server architecture:
LiveCycle Data Services Server Architecture
Destination AdapterServiceMessage
RemotingDestination
JavaAdapter
HTTPProxyDestination
HTTPProxyAdapter
SOAPAdapter
MessageDestination
ActionSc riptAda pter
JMSAdapter
DataDestination
ActionScriptObjectAdapter
JavaAdapter
Hibernate Assembler
SQLAssembler
Flex client
MessageBrokerServlet
Servlet- based endpoint s
AMFEndpoint
HTTPEndpoint
StreamingAMFEndpoint
...
Socket server
NIO-based endpoints
NIOAMFEndpoint
NIOHTTPEndpoint
RTMPEndpoint
...
Broker
RemotingService
HTTPProxyService
MessageService
DataService
29
Endpoints
LiveCycle Data Services has two types of endpoints: servlet-based endpoints and NIO-based endpoints.
Note: NIO-based endpoints are not available in BlazeDS.
NIO stands for Java New Input/Output. Servlet-based endpoints are inside the J2EE servlet container, which means
that the servlet handles the I/O and HTTP sessions for the endpoints. Servlet-based endpoints are bootstrapped by the
MessageBrokerServlet, which is configured in the web.xml file of the web application. In addition to the
MessageBrokerServlet, an HTTP session listener is registered with the J2EE server in the web application’s web.xml
file so that LiveCycle Data Services has HTTP session attribute and binding listener support.
NIO-based endpoints run in an NIO-based socket server. These endpoints can offer significant scalability gains
because they are not limited to one thread per connection and a single thread can manage multiple I/Os.
Flex client applications use channels to communicate with LiveCycle Data Services endpoints. There is a mapping
between the channels on the client and the endpoints on the server. It is important that the channel and the endpoint
use the same message format. A channel that uses the AMF message format, such as the AMFChannel, must be paired
with an endpoint that also uses the AMF message format, such as the AMFEndpoint or the NIOAMFEndpoint. A
channel that uses the AMFX message format such as the HTTPChannel cannot be paired with an endpoint that uses
the AMF message format. Also, a channel that uses streaming must be paired with an endpoint that uses streaming.
Last updated 3/10/2011
Page 34

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
You configure endpoints in the services-config.xml file in the WEB-INF/flex directory of your LiveCycle Data Services
web application. For more information on servlet-based and NIO-based endpoints, see
page 38.
“Channels and endpoints” on
MessageBroker
The MessageBroker is responsible for routing messages to services and is at the core of f LiveCycle Data Services on
the server. After an endpoint initially processes the request, it extracts the message from the request and passes it to
the MessageBroker. The MessageBroker inspects the message's destination and passes the message to its intended
service. If the destination is protected by a security constraint, the MessageBroker runs the authentication and
authorization checks before passing the message along (see
MessageBroker in the services-config.xml file in he WEB-INF/flex directory of your LiveCycle Data Services web
application.
“Configuring security” on page 432). You configure the
Services and destinations
Services and destinations are the next links in the message processing chain in the LiveCycle Data Services server. The
system includes four services and their corresponding destinations:
• RemotingService and RemotingDestination
• HTTPProxyService and HTTPProxyDestination
• MessageService and MessageDestination
• DataService and DataDestination
Note: DataService and DataDestination are not available in BlazeDS.
30
Services are the targets of messages from client-side Flex components. Think of destinations as instances of a service
configured in a certain way. For example, a RemoteObject component is used on the Flex client to communicate with
the RemotingService. In the RemoteObject component, you must specify a destination
remoting destination with certain properties, such as the class you want to invoke methods on. The mapping between
client-side Flex components and LiveCycle Data Services services is as follows:
id property that refers to a
• HTTPService and WebService communicate with HTTPProxyService/HTTPProxyDestination
• RemoteObject communicates with RemotingService/RemotingDestination
• Producer and Consumer communicate with MessageService/MessageDestination
• DataService communicates with DataService/DataDestination
You can configure services and their destinations in the services-config.xml file, but it is best practice to put them in
separate files as follows:
• RemotingService configured in the remoting-config.xml file
• HTTPProxyService configured in the proxy-config.xml file
• MessageService configured in the messaging-config.xml file
• DataService configured in the data-management-config.xml file
More Help topics
“Using RPC services” on page 135
“Using the Message Service” on page 190
“Introducing the Data Management Service” on page 221
Last updated 3/10/2011
Page 35

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Adapters and assemblers
Adapters, and optionally assemblers, are the last link in the message processing chain. When a message arrives at the
correct destination, it is passed to an adapter that fulfills the request either locally or by contacting a backend system
or a remote server such as a JMS server. Some adapters use yet another layer, called assemblers, to further break down
the processing. For example, a DataDestination can use JavaAdapter, and JavaAdapter could use HibernateAssembler
to communicate with Hibernate. LiveCycle Data Services uses the following mappings between destinations and
adapters/assemblers:
• RemotingDestination uses JavaAdapter
• HTTPProxyDestination uses HTTPProxyAdapter or SOAPAdapter
• MessageDestination uses ActionScriptAdapter or JMSAdapter
• DataDestination uses ASObjectAdapter or JavaAdapter
• JavaAdapter uses HibernateAssembler, SQLAssembler, or a custom assembler
Adapters and assemblers are configured along with their corresponding destinations in the same configuration files.
Although the LiveCycle Data Services server comes with a rich set of adapters and assemblers to communicate with
different systems, custom adapters and assemblers can be plugged into the server. Similarly, you do not have to create
all destinations in configuration files, but instead you can create them dynamically at server startup or when the server
is running; for more information, see
“Run-time configuration” on page 411.
31
For information about the LiveCycle Data Services server-side classes, see the Javadoc API documentation.
About configuration files
You configure LiveCycle Data Services in the services-config.xml file. The default location of this file is the WEBINF/flex directory of your LiveCycle Data Services web application. You can set this location in the configuration for
the MessageBrokerServlet in the WEB-INF/web.xml file.
You can include files that contain service definitions by reference in the services-config.xml file. Your LiveCycle Data
Services installation includes the Remoting Service, Proxy Service, Message Service, and Data Management Service by
reference.
The following table describes the typical setup of the configuration files. Commented versions of these files are
available in the resources/config directory of the LiveCycle Data Services installation.
Filename Description
services-config.xml The top-level LiveCycle Data Services configuration file. This file usually contains
remoting-config.xml The Remoting Service configuration file, which defines Remoting Service
security constraint definitions, channel definitions, and logging settings that each
of the services can use. It can contain service definitions inline or include them by
reference. Generally, the services are defined in the remoting-config.xml, proxyconfig.xml, messaging-config.xml, and data-management-config.xml files.
destinations for working with remote objects.
For information about configuring the Remoting Service, see “Using RPC services”
on page 135.
Last updated 3/10/2011
Page 36

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Filename Description
32
proxy-config.xml The Proxy Service configuration file, which defines Proxy Service destinations for
messaging-config.xml The Message Service configuration file, which defines Message Service
data-management-config.xml The Data Management Service configuration file, which defines Data
working with web services and HTTP services (REST services).
For information about configuring the Proxy Service, see “Using RPC services” on
page 135.
destinations for performing publish subscribe messaging.
For information about configuring the Message Service, see “Using the Message
Service” on page 190.
Management Service destinations.
For information about configuring the Data Management Service, see “Data
Management Service configuration” on page 244.
When you include a file by reference, the content of the referenced file must conform to the appropriate XML structure
for the service. The file-path value is relative to the location of the services-config.xml file. The following example
shows service definitions included by reference:
<services>
<!-- REMOTING SERVICE -->
<service-include file-path="remoting-config.xml"/>
<!-- PROXY SERVICE -->
<service-include file-path="proxy-config.xml"/>
<!-- MESSAGE SERVICE -->
<service-include file-path="messaging-config.xml"/>
<!-- DATA MANAGEMENT SERVICE -->
<service-include file-path="data-management-config.xml"/>
</services>
Configuration tokens
The configuration files sometimes contain special {server.name} and {server.port} tokens. These tokens are
replaced with server name and port values based on the URL from which the SWF file is served when it is accessed
through a web browser from a web server. Similarly, a special
context root of a web application.
Note: If you use server tokens in a configuration file for an Adobe AIR application and you compile using that file, the
application will not be able to connect to the server. You can avoid this issue by configuring channels in ActionScript
rather than in a configuration file (see
“Channels and endpoints” on page 38).
You can also use custom run-time tokens in service configuration files; for example, {messaging-channel} and
{my.token}. You specify values for these tokens in Java Virtual Machine (JVM) options. The server reads these JVM
options to determine what values are defined for them, and replaces the tokens with the specified values. If you have a
custom token for which a value cannot be found, an error is thrown. Because {server.name}, {server.port}, and
{context.root} are special tokens, no errors occur when these tokens are not specified in JVM options.
How you define JVM options depends on the application server you use. For example, in Apache Tomcat, you can
define an environment variable JAVA_OPTS that contains tokens and their values, as this code snippet shows:
JAVA_OPTS=-Dmessaging.channel=my-amf -Dmy.token=myValue
Last updated 3/10/2011
{context.root} token is replaced with the actual
Page 37

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Configuration elements
The following table describes the XML elements of the services-config.xml file. The root element is the services-
config element.
33
XML
element
services Contains definitions of individual data services or references to
Description
other XML files that contain service definitions. It is a best practice
to use a separate configuration file for each type of standard service.
These services include the Proxy Service, Remoting Service,
Message Service, and Data Management Service.
The services element is declared at the top level of the
configuration as a child of the root element,
For information about configuring specific types of services, see the
following topics:
services-config.
• “Using RPC services” on page 135
• “Using the Message Service” on page 190
• “Data Management Service configuration” on page 244
default-
channels
Sets the application-level default channels to use for all services. The
default channels are used when a channel is not explicitly
referenced in a destination definition. The channels are tried in the
order in which they are included in the file. When one is unavailable,
the next is tried.
Default channels can also be defined individually for each service, in
which case the application-level default channels are overwritten
by the service level default channels. Application-level default
channels are necessary when a dynamic component is created
using the run-time configuration feature and no channel set has
been defined for the component. In that case, application-level
default channels are used to contact the destination.
For more information about channels and endpoints, see “Channels
and endpoints” on page 38.
service-
include
Specifies the full path to an XML file that contains the configuration
elements for a service definition.
Attributes:
• file-path Path to the XML file that contains a service definition.
service
properties Contains service properties.
adapters Contains service adapter definitions that are referenced in a
Contains a service definition.
(Optional) You can use the service-include element to include
a file that contains a service definition by reference instead of inline
in the services-config.xml file.
In addition to standard data services, you can define custom
bootstrap services here for use with the run-time configuration
feature; bootstrap services dynamically create services,
destinations, and adapters at server startup. For more information,
“Run-time configuration” on page 411.
see
destination to provide specific types of functionality.
Last updated 3/10/2011
Page 38

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
34
XML
element
adapter-definition
Description
Contains a service adapter definition. Each type of service has its
own set of adapters that are relevant to that type of service. For
example, Data Management Service destinations can use the Java
adapter or the ActionScript object adapter. An
definition
has the following attributes:
• id Identifier of an adapter, which you use to reference the
adapter inside a destination definition.
• class Fully qualified name of the Java class that provides the
adapter functionality.
• default Boolean value that indicates whether this adapter is the
default adapter for service destinations. The default adapter is
used when you do not explicitly reference an adapter in a
destination definition.
default-
channels
channel
Contains references to default channels. The default channels are
used when a channel is not explicitly referenced in a destination
definition. The channels are tried in the order in which they are
included in the file. When one is unavailable, the next is tried.
Contains a reference to the id of a channel definition. A channel
element contains the following attribute:
• ref The id value of a channel definition
For more information about channels and endpoints, see “Channels
and endpoints” on page 38.
adapter-
destinationContains a destination definition.
adapter
Contains a reference to a service adapter. If this element is omitted,
the destination uses the default adapter.
properties
Contains destination properties.
The properties available depend on the type of service, which the
specified service class determines.
channels
Contains references to the channels that the service can use for data
transport. The channels are tried in the order in which they are
included in the file. When one is unavailable, the next is tried.
The channel child element contains references to the id value of a
channel. Channels are defined in the
level of the configuration as a child of the root element,
config
.
channels element at the top
services-
Last updated 3/10/2011
Page 39

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
35
XML
element
security
Description
Contains a reference to a security constraint definition and login
command definitions that are used for authentication and
authorization.
This element can also contain complete security constraint
definitions instead of references to security constraints that are
defined globally in the top-level
For more information, see “Security” on page 429.
The security-constraint child element contains references to
id value of a security constraint definition or contains a security
the
constraint definition.
Attributes:
• ref The id value of a security-constraint element defined
in the
configuration.
• id Identifier of a security constraint when you define the actual
security constraint in this element.
The login-command child element contains a reference to the id
value of a login command definition that is used for performing
authentication.
Attributes:
security element.
security element at the top level of the services
• ref The id value of a login command definition.
security Contains security constraint definitions and login command
security-
constraint
login-
command
definitions for authentication and authorization.
For more information, see “Security” on page 429.
Defines a security constraint.
Defines a login command that is used for custom authentication.
Attributes:
• class Fully qualified class name of a login command class.
• server Application server on which custom authentication is
performed.
• per-client-authentication You can only set this attribute
to
true for a custom login command and not an appication-
server-based login command. Setting it to
clients sharing the same session to have distinct authentication
states. For example, two windows of the same web browser could
authenticate users independently. This attribute is set to
by default.
channels Contains the definitions of message channels that are used to
transport data between the server and clients.
For more information about channels and endpoints, see “Channels
and endpoints” on page 38.
true allows multiple
false
Last updated 3/10/2011
Page 40

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
36
XML
element
channel-
Description
definition
Defines a message channel that can be used to transport data.
Attributes:
• id Identifier of the channel definition.
• class Fully qualified class name of a channel class.
endpoint Specifies the endpoint URI and the endpoint class of the channel
definition.
Attributes:
• uri Endpoint URI
• class Fully qualified name of the channel class used on the
client.
properties Contains the properties of a channel definition. The properties
clusters Contains cluster definitions, which configure software clustering
flexclient
reliablereconnectdurationmillis
available depend on the type of channel specified.
across multiple hosts.
For more information, see “Clustering” on page 442.
Idle timeout for FlexClient state at the server, including reliable
messaging sequences. To support reliable reconnects consistently
across all supported channels and endpoints, this value must be
defined and greater than 0.
Any active sessions/connections keep idle FlexClient instances
alive. This timeout only applies to instances that have no currently
active associated sessions/connections.
heartbeatintervalmillis
Optional setting that controls whether the client application issues
periodic heartbeat requests to the server to keep an idle connection
alive and to detect loss of connectivity. Use this setting to keep
sessions alive.
The default value of 0 disables this functionality. If the application
sets this value, it should use a longer rather than shorter interval to
avoid placing unnecessary load on the remote host.
As an illustrative example, low-level TCP socket keep-alives
generally default to an interval of 2 hours. That is a longer interval
than most applications that enable heartbeats would likely want to
use, but it serves as a clear precedent to prefer a longer interval over
a shorter interval.
Last updated 3/10/2011
Page 41

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
37
XML
element
timeout-
logging Contains server-side logging configuration. For more information,
target Specifies the logging target class and the logging level.
Description
minutes
Each Flex application that connects to the server triggers the
creation of a FlexClient instance that represents the remote client
application. I the value of the
undefined or set to 0 (zero), FlexClient instances on the server are
shut down when all associated FlexSessions (corresponding to
connections between the client and server) are shut down. If this
value is defined, FlexClient instances are kept alive for this amount
of idle time.
FlexClient instances that have an associated RTMP
connection/session open, are kept alive even if they are idle
because the open connection indicates the remote client
application is still running.
For HTTP connections/sessions, if the remote client application is
polling, the FlexClient is kept alive.
If the remote client is not polling and a FlexClient instance is idle for
this amount of time. it is shut down even if an associated
HttpSession is still valid. This is because multiple Flex client
applications can share a single HttpSession. A valid HttpSession
does not indicate that a specific client application instance is still
running.
“Logging” on page 420.
see
Attributes:
timeout-minutes element is left
• class Fully qualified logging target class name.
• level The logging level.
system System-wide settings that do not fall into a previous category. In
enforceendpointvalidation
locale (Optional) Locale string; for example, "en", "de", "fr", and "es"
default-
locale
redeploy Support for web application redeployment when configuration files
The default locale string.
addition to locale information, it also contains redeployment and
watch file settings.
(Optional) Default value is false. When a destination is accessed
over a channel, the message broker validates that the destination
accepts requests over that channel. However, the client can disable
this validation if the client has a null
this setting is
validation even if the client channel has a null
are valid locale strings.
If no default-locale element is provided, a base set of English
error messages is used.
are updated. This feature works with J2EE application server web
application redeployment.
The touch-file value is the file used by your application server to
force web redeployment.
Check the application server to confirm what the touch-file
value should be.
true, the message broker performs the endpoint
id value for its channel. When
id value.
enabled Boolean value that indicates whether redeployment is enabled.
Last updated 3/10/2011
Page 42
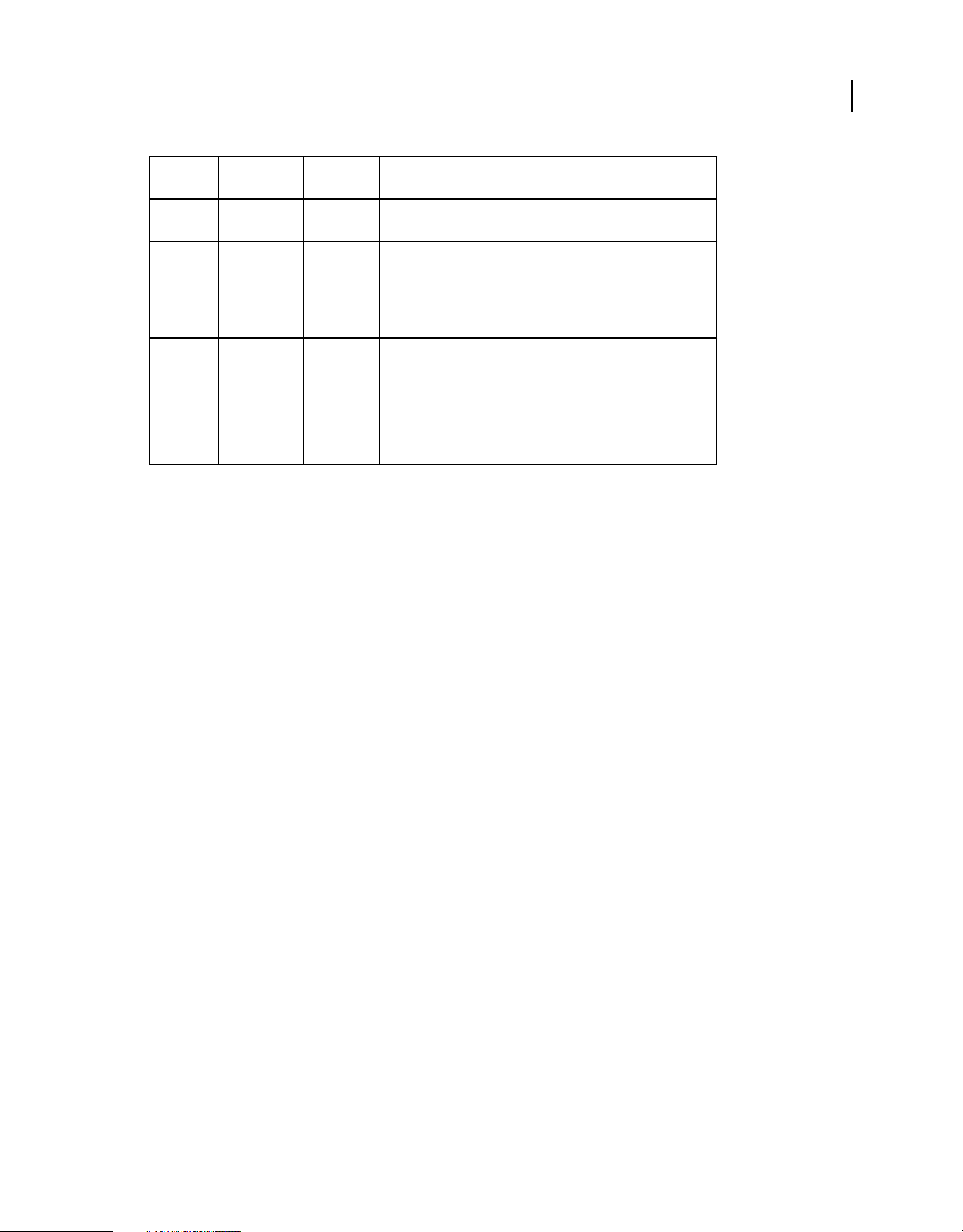
USING ADOBE LIVECYCLE DATA SERVICES
System architecture
38
XML
element
watch-
watch-file A data services configuration file watched for changes. The watch-
touch-file The file that the application server uses to force redeployment of a
Description
interval
Number of seconds to wait before checking for changes to
configuration files.
file
value must start with {context.root} or be an absolute
path. The following example uses
{context.root}/WEB-INF/flex/data-managementconfig.xml
web application. The value of the
{context.root} or be an absolute path. Check the
with
application server documentation to determine the
value. For Tomcat, the
following example shows:
{context.root}/WEB-INF/web.xml
{context.root}:
touch-file element must start
touch-file
touch-file value is the web.xml file, as the
Channels and endpoints
Channels are the client-side representation of the connection to a service, while endpoints are the server-side
representation.
About channels and endpoints
Channels are client-side objects that encapsulate the connection behavior between Flex components and the LiveCycle
Data Services server or the Edge Server. Channels communicate with corresponding endpoints on the LiveCycle Data
Services server. You configure the properties of a channel and its corresponding endpoint in the services-config.xml
file.
For more information on the Edge Server, see “Edge Server” on page 391.
How channels are assigned to a Flex component
Flex components use channel sets, which contain one or more channels, to contact the server. You can automatically
or manually create and assign a channel set to a Flex component. The channel allows the component to contact the
endpoint, which forwards the request to the destination.
If you compile an MXML file using the MXML compiler option -services pointing to the services-config.xml file,
the component (RemoteObject, HTTPService, and so on) is automatically assigned a channel set that contains one or
more appropriately configured channel instances. The configuration is based on the channel definition assigned to a
destination in a configuration file. Alternatively, if you do not compile your application with the
or want to override the compiled-in behavior, you can create a channel set in MXML or ActionScript, populate it with
one or more channels, and then assign the channel set to the Flex component.
Application-level default channels are especially important when you want to use dynamically created destinations
and you do not want to create and assign channel sets to your Flex components that use the dynamic destination. In
that case, application-level default channels are used. For more information, see
“Assigning channels and endpoints
to a destination” on page 42.
-services option
When you compile a Flex client application with the MXML compiler-services option, it contains all of the
information from the configuration files that is needed for the client to connect to the server.
Last updated 3/10/2011
Page 43

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Configuring channels and endpoints
You can configure channels in channel definitions in the services-config.xml file or on the Flex client.
Configuring channels on the server
The channel definition in the following services-config.xml file snippet creates an AMFChannel that communicates
with an AMFEndpoint on the server:
<channels>
...
<channel-definition id="samples-amf"
type="mx.messaging.channels.AMFChannel">
<endpoint url="http://servername:8400/myapp/messagebroker/amf" port="8700"
type="flex.messaging.endpoints.AMFEndpoint"/>
</channel-definition>
</channels>
The channel-definition element specifies the following information:
• id and channel class type of the client-side channel that the Flex client uses to contact the server
• remote attribute that specifies that the endpoint as remote. In that case, the endpoint is not started on this server
and it is assumed that the client will connect to a remote endpoint on another server. This is useful when the client
is compiled against this configuration but some of the endpoints are on a remote server.
• endpoint element that contains the URL and endpoint class type of the server-side endpoint
• properties element that contains channel and endpoint properties
• server element, which when using an NIO-based channel and endpoint optionally refers to a shared NIO server
configuration
The endpoint URL is the specific network location that the endpoint is exposed at. The channel uses this value to
connect to the endpoint and interact with it. The URL must be unique across all endpoints exposed by the server. The
url attribute can point to the MessageBrokerServlet or an NIO server if you are using an NIO-based endpoint.
39
Configuring channels on the client
To create channels at runtime in Flex code, you create your own channel set in MXML or ActionScript, add channels
to it, and then assign the channel set to a component. This process is common in the following situations:
• You do not compile your MXML file using the -services MXML compiler option. This is useful when you do not
want to hard code endpoint URLs into your compiled SWF files on the client. It is also useful when you want to use
a remote server when developing an application in Flash Builder.
• You want to use a dynamically created destination (the destination is not in the services-config.xml file) with the
run-time configuration feature. For more information, see
“Run-time configuration” on page 411.
• You want to control in your client code the order of channels that a Flex component uses to connect to the server.
When you create and assign a channel set on the client, the client requires the correct channel type and endpoint URL
to contact the server. The client does not specify the endpoint class that handles that request, but there must be a channel
definition in the services-config.xml file that specifies the endpoint class to use with the specified endpoint URL.
The following example shows a RemoteObject component that defines a channel set and channel inline in MXML:
Last updated 3/10/2011
Page 44

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
...
<RemoteObject id="ro" destination="Dest">
<mx:channelSet>
<mx:ChannelSet>
<mx:channels>
<mx:AMFChannel id="myAmf"
uri="http://myserver:2000/myapp/messagebroker/amf"/>
</mx:channels>
</mx:ChannelSet>
</mx:channelSet>
</RemoteObject>
...
The following example shows ActionScript code that is equivalent to the MXML code in the previous example:
...
private function run():void {
ro = new RemoteObject();
var cs:ChannelSet = new ChannelSet();
cs.addChannel(new AMFChannel("myAmf",
"http://myserver:2000/eqa/messagebroker/amf"));
ro.destination = "Dest";
ro.channelSet = cs;
}
...
40
Important: When you create a channel on the client, you still must include a channel definition that specifies an endpoint
class in the services-config.xml file. Otherwise, the message broker cannot pass a Flex client request to an endpoint.
To further externalize configuration, you can pass the endpoint URL value to the client at runtime. One way to do this
is by reading a configuration file with an HTTPService component at application startup. The configuration file
includes the information to programmatically create a channel set at runtime. You can use E4X syntax to get
information from the configuration file.
The following MXML application shows this configuration file technique:
Last updated 3/10/2011
Page 45

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml"
applicationComplete="configSrv.send()">
<mx:Script>
<![CDATA[
import mx.controls.Alert;
import mx.messaging.channels.AMFChannel;
import mx.messaging.ChannelSet;
import mx.rpc.events.ResultEvent;
private var channelSet:ChannelSet;
private function configResultHandler(event:ResultEvent):void
{
var xml:XML = event.result as XML;
var amfEndpoint:String = "" + xml..channel.(@id=="amf").@endpoint;
if (amfEndpoint == "")
{
Alert.show("amf channel not configured", "Error");
}
else
{
channelSet = new ChannelSet();
var channel:AMFChannel = new AMFChannel("my-amf", amfEndpoint);
channelSet.addChannel(channel);
ro.channelSet = channelSet;
ro.getProducts();
}
}
]]>
</mx:Script>
<mx:HTTPService id="configSrv" url="config.xml" resultFormat="e4x"
result="configResultHandler(event)"/>
<mx:RemoteObject id="ro" destination="product"/>
<mx:DataGrid dataProvider="{ro.getProducts.lastResult}" width="100%" height="100%"/>
</mx:Application>
41
The MXML application reads the following configuration file:
<?xml version="1.0" encoding="utf-8"?>
<config>
<channels>
<channel id="amf" endpoint="http://localhost:8400/lcds-samples/messagebroker/amf"/>
</channels>
</config>
Configuring a Flash Builder project with client-configured channels
When you create a new LiveCycle Data Services or BlazeDS project in Flash Builder, you typically select J2EE as the
Application Server Type and then check Use Remote Object Access Service. This adds an MXML compiler argument
that points to the services-config.xml file. If you check the Flex Compiler properties of your Flash Builder project, you
see something like this:
-services "c:\lcds\tomcat\webapps\samples\WEB-INF\flex\services-config.xml"
Last updated 3/10/2011
Page 46

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
When you compile the application, the required values of the services-config.xml are included in the SWF file. The
services-config.xml file is read at compile time and not at runtime as you might assume. You can use tokens such as
{server.name}, {server.port}, and {context.root} in the services-config.xml file. The {context.root} token is substituted
at compile time. The {server.name} and {server.port} are replaced at runtime with the server name and port number
of the server the SWF is loaded from; you can’t use these tokens for AIR applications.
When you configure channels on the client, you can avoid dependency on the services-config.xml file. You can create
a new Flex project with no Application Server Type settings because the channels are configured at runtime in the SWF
file. For existing LiveCycle Data Services or BlazeDS projects, you can remove the services-config.xml compiler
argument.
Assigning channels and endpoints to a destination
Settings in the LiveCycle Data Services configuration files determine the channels and endpoints from which a
destination can accept messages, invocations, or data, except when you use the run-time configuration feature. The
channels and endpoints are determined in one of the following ways:
• If most of the destinations across all services use the same channels, you can define application-level default
channels in the services-config.xml file, as the following example shows.
Note: Using application-level default channels is a best practice whenever possible.
<services-config ...>
...
<default-channels>
<channel ref="my-http"/>
<channel ref="my-amf"/>
</default-channels>
...
42
In this case, all destinations that do not define channels use a default channel. You can override the default channel
setting by specifying a channel at the destination level or service level.
• If most of the destinations in a service use the same channels, you can define service-level default channels, as the
following example shows:
<service ...>
...
<default-channels>
<channel ref="my-http"/>
<channel ref="my-amf"/>
</default-channels>
...
In this case, all destinations in the service that do not explicitly specify their own channels use the default channel.
• The destination definition can reference a channel inline, as the following example shows:
<destination id="sampleVerbose">
<channels>
<channel ref="my-secure-amf"/>
</channels>
...
</destination>
Last updated 3/10/2011
Page 47

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Fallback and failover behavior
The primary reason that channels are contained in a channel set is to provide a fallback mechanism from one channel
to the next listed in the channel set, and so on, in case the first choice is unable to establish a connection to the server.
For example, you could define a channel set that falls back from a StreamingAMFChannel to an AMFChannel with
polling enabled to work around network components such as web server connectors, HTTP proxies, or reverse proxies
that could buffer chunked responses incorrectly. You can also use this functionality to provide different protocol
options so that a client can first try to connect using RTMP and if that fails, can fall back to HTTP.
The connection process involves searching for the first channel and trying to connect to it. In addition to the fallback
behavior that the channel set provides, the channel defines a
a channel in ActionScript that causes failover across this array of endpoint URLs when it tries to connect to its
destination. If the channel defines failover URIs, each is attempted before the channel gives up and the channel set
searches for the next available channel. If no channel in the set can connect, any pending unsent messages generate
faults on the client.
If the channel was successfully connected before experiencing a fault or disconnection, it attempts a pinned
reconnection to the same endpoint URL once. If this immediate reconnection attempt fails, the channel falls back to
its previous failover strategy and attempts to fail over to other server nodes in the cluster or fall back to alternate
channel protocols.
failoverURIs property. This property lets you configure
43
Choosing an endpoint
The two types of endpoints in LiveCycle Data Services are servlet-based endpoints and NIO-based endpoints that use
Java New I/O APIs.
Note: NIO-based endpoints are not available in BlazeDS.
The J2EE servlet container manages networking, IO, and HTTP session maintenance for the servlet-based endpoints.
NIO-based endpoints are outside the servlet container and run inside an NIO-based socket server. NIO-based
endpoints can offer significant scalability gains. Because they are NIO-based, they are not limited to one thread per
connection. Far fewer threads can efficiently handle high numbers of connections and IO operations. If the web
application is not servicing general servlet requests, you can configure the servlet container to bind non-standard
HTTP and HTTPS ports. Ports 80 and 443 are then free for your NIO-based endpoints to use.
You can also deploy an Edge Server in your DMZ to forward client requests to a LiveCycle Data Services server in the
application tier. In this configuration, clients communicate with the Edge Server in the DMZ, and not directly with the
LiveCycle Data Services server inside the internal firewall. This configuration gives you more options for the endpoints
you can use and the ports those endpoints can listen over. For more information about the Edge Server, see
Server” on page 391.
The servlet-based endpoints are part of both BlazeDS and LiveCycle Data Services. Reasons to use servlet-based
endpoints when you have LiveCycle Data Services are that you must include third-party servlet filter processing of
requests and responses or you must access data structures in the application server HttpSession.
The NIO-based endpoints include RTMP endpoints as well as NIO-based AMF and HTTP endpoints that use the
same client-side channels as their servlet-based counterparts.
The following situations prevent the NIO socket server used with NIO-based endpoints from creating a real-time
connection between client and server in a typical deployment of a rich Internet application:
“Edge
• The only client access to the Internet is through a proxy server.
• The application server on which LiveCycle Data Services is installed can only be accessed from behind the web tier
in the IT infrastructure.
Last updated 3/10/2011
Page 48

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Servlet-based streaming endpoints and long polling are good alternatives when NIO-based streaming is not an
option. In the worst case, the client falls back to simple polling. The main disadvantages of polling are increased
overhead on client and server machines, and increased network latency.
Servlet-based channel and endpoint combinations
LiveCycle Data Services provides the following servlet-based channel and endpoint combinations. A secure version of
each of these channels/endpoints transports data over a secure HTTPS connection. The names of the secure channels
and endpoints all start with the text "Secure"; for example, SecureAMFChannel and SecureAMFEndpoint.
Servlet-based channel/endpoint classes Description
44
AMFChannel/AMFEndpoint A simple channel/endpoint that transports data over HTTP in the
HTTPChannel/HTTPEndpoint Provides the same behavior as the AMF channel/endpoint, but
StreamingAMFChannel/StreamingAMFEndp
oint
StreamingHTTPChannel/StreamingHTTPEnd
point
binary AMF format in an asynchronous call and response model. Use
for RPC requests/responses with RPC-style Flex components such as
RemoteObject, HTTPService, and WebService. You can also
configure a channel that uses this endpoint to repeatedly poll the
endpoint for new messages. You can combine polling with a long
wait interval for long polling, which handles near real-time
communication.
For more information, see “Simple channels and endpoints” on
page 47.
transports data in the AMFX format, which is the text-based XML
representation of AMF. Transport with this endpoint is not as fast as
with the AMFEndpoint because of the overhead of text-based XML.
Use when binary AMF is not an option in your environment.
For more information, see “Simple channels and endpoints” on
page 47.
Streams data in real time over the HTTP protocol in the binary AMF
format. Use for real-time data services, such as the Data
Management Service and the Message Service where streaming
data is critical to performance.
For more information, see “Streaming AMF and HTTP channels” on
page 52.
Provides the same behavior model as the streaming AMF
channel/endpoint, but transports data in the AMFX format, which is
the text-based XML representation of AMF. Transport with this
endpoint is not as fast as with the StreamingAMFEndpoint because
of the overhead of text-based XML. Use when binary AMF is not an
option in your environment.
For more information, see “Streaming AMF and HTTP channels” on
page 52.
NIO-based channel and endpoint combinations
The NIO-based endpoints include RTMP endpoints as well as NIO-based AMF and HTTP endpoints that use the
same client-side channels as their servlet-based counterparts.
Note: NIO-based endpoints are not available in BlazeDS.
LiveCycle Data Services provides the following NIO-based channels/endpoints. A secure version of the RTMP
channel/endpoint transports data over an RTMPS connection. A secure version of each of the HTTP and AMF
channels/endpoints transports data over an HTTPS connection. The names of the secure channels and endpoints all
start with the text "Secure"; for example, SecureAMFChannel and SecureNIOAMFEndpoint.
Last updated 3/10/2011
Page 49

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
NIO-based channel/endpoint classes Description
45
RTMPChannel/RTMPEndpoint Streams data in real time over the TCP-based RTMP protocol in
the binary AMF format. Use for real-time data services, such as
the Data Management Service and the Message Service where
streaming data is critical to performance.
The RTMP channel/endpoint uses an NIO server to support
scaling up to thousands of connections. It uses a single duplex
socket connection to the server and gives the server the best
notification of Flash Player being shut down. If the direct
connect attempt fails, Flash Player attempts a CONNECT tunnel
through an HTTP proxy if the browser defines one (resulting in a
direct, tunneled duplex socket connection to the server). In the
worst case, Flash Player falls back to adaptive polling of HTTP
requests that tunnel RTMP data back and forth between client
and server, or it fails to connect entirely.
When you define an RTMP endpoint with a URI that starts with
rtmp: and specifies no port, the endpoint automatically binds
ports 1935 and 80 when the server starts.
When you define an RTMP endpoint with a URI that starts with
rtmpt: and specifies no port, the endpoint will automatically
bind port 80 when the server starts.
When you define a secure RTMP endpoint that specifies no port,
the endpoint automatically binds port 443 when the server
starts.
A defined (hardcoded) port value in the channel/endpoint URI
overrides these defaults, and a
setting overrides these as well. When using a defined port in the
bind-port the endpoint binds just that single port at
URI or
startup.
For more information, see “Configuring channels with NIO-
based endpoints” on page 55.
bind-port configuration
AMFChannel/NIOAMFEndpoint NIO-based version of the AMF channel/endpoint. Uses an NIO
StreamingAMFChannel/
NIOStreamingAMFEndpoint
HTTPChannel/NIOHTTPEndpoint NIO-based version of HTTP channel/endpoint. Uses an NIO
StreamingHTTPChannel/StreamingNIOHTTPEnd
point
server and a minimal HTTP stack to support scaling up to
thousands of connections.
NIO-based version of streaming AMF channel/ endpoint. Uses
an NIO server and a minimal HTTP stack to support scaling up to
thousands of connections.
server and a minimal HTTP stack to support scaling up to
thousands of connections.
NIO-based version of streaming HTTP channel/endpoint. Uses
an NIO server and a minimal HTTP stack to support scaling up to
thousands of connections.
Choosing a channel
Depending on your application requirements, you can use simple AMF or HTTP channels without polling or with
piggybacking, polling, or long polling. You can also use streaming RTMP, AMF, or HTTP channels. The difference
between AMF and HTTP channels is that AMF channels transport data in the binary AMF format and HTTP channels
transport data in AMFX, the text-based XML representation of AMF. Because AMF channels provide better
performance, use an HTTP channel instead of an AMF channel only when you have auditing or compliance
requirements that preclude the use of binary data over your network or when you want the contents of messages to be
easily readable over the network (on the wire).
Last updated 3/10/2011
Page 50

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Non-polling AMF and HTTP channels
You can use AMF and HTTP channels without polling for remote procedure call (RPC) services, such as remoting
service calls, proxied HTTP service calls and web service requests, or Data Management Service requests without
automatic synchronization. These scenarios do not require the client to poll for messages or the server to push
messages to the client.
Piggybacking on AMF and HTTP channels
The piggybacking feature enables the transport of queued messages along with responses to any messages the client
sends to the server over the channel. By default, piggybacking is disabled. You can set it to
enabled property of a channel definition in the services-config.xml file or in the piggybackingEnabled property of
true in the piggybacking-
a Channel instance when you create a channel in ActionScript.
Piggybacking provides lightweight pseudo polling, where rather than the client channel polling the server on a fixed
or adaptive interval, when the client sends a non-command message to the server (using a Producer, RemoteObject,
or DataService object), the server sends any pending data for client messaging or data management subscriptions along
with the response to the client message.
Piggybacking can also be used on a channel that has polling enabled but on a wide interval like 5 seconds or 10 seconds
or more, in which case the application appears more responsive if the client is sending messages to the server. In this
mode, the client sends a poll request along with any messages it sends to the server between its regularly scheduled poll
requests. The channel piggybacks a poll request along with the message being sent, and the server piggybacks any
pending messages for the client along with the acknowledge response to the client message.
46
Polling AMF and HTTP channels
AMF and HTTP channels support simple polling mechanisms that clients can use to request messages from the server
at set intervals. A polling AMF or HTTP channel is useful when other options such as long polling or streaming
channels are not acceptable and also as a fallback channel when a first choice, such as a streaming channel, is
unavailable at run time.
Long polling AMF and HTTP channels
You can use AMF and HTTP channels in long polling mode to get pushed messages to the client when the other more
efficient and real-time mechanisms are not suitable. This mechanism uses the normal application server HTTP request
processing logic and works with typical J2EE deployment architectures.
You can establish long polling for any channel that uses a non-streaming AMF or HTTP endpoint by setting the
polling-enabled, polling-interval-millis, wait-interval-millis, and client-wait-interval-millis
properties in a channel definition; for more information, see
“Simple channels and endpoints” on page 47.
Streaming channels
For streaming, you can use RTMP channels, or streaming AMF or HTTP channels. Streaming channels must be paired
with corresponding streaming endpoints that are NIO-based or servlet-based. Streaming AMF and HTTP channels
work with servlet-based streaming AMF or HTTP endpoints or NIO-based streaming AMF or HTTP endpoints.
RTMP channels work with NIO-based RTMP endpoints.
For more information about endpoints, see “Choosing an endpoint” on page 43.
Configuring channels with servlet-based endpoints
The servlet-based endpoints are part of both BlazeDS and LiveCycle Data Services.
Last updated 3/10/2011
Page 51

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Simple channels and endpoints
The AMFEndpoint and HTTPEndpoint are simple servlet-based endpoints. You generally use channels with these
endpoints without client polling for RPC service components, which require simple call and response communication
with a destination. When working with the Message Service or Data Management Service, you can use these channels
with client polling to constantly poll the destination on the server for new messages, or with long polling to provide
near real-time messaging when using a streaming channel is not an option in your network environment.
Property Description
47
polling-enabled
polling-interval-millis
wait-interval-millis
client-wait-interval-millis
Optional channel property. Default value is false.
Optional channel property. Default value is 3000. This
parameter specifies the number of milliseconds the client
waits before polling the server again. When
interval-millis
a response from the server with no delay.
Optional endpoint property. Default value is 0. This
parameter specifies the number of milliseconds the server
poll response thread waits for new messages to arrive when
the server has no messages for the client at the time of poll
request handling. For this setting to take effect, you must use
a nonzero value for the
property.
A value of 0 means that server does not wait for new
messages for the client and returns an empty
acknowledgment as usual. A value of
waits indefinitely until new messages arrive for the client
before responding to the client poll request.
The recommended value is 60000 milliseconds (one
minute).
Optional channel property. Default value is 0. Specifies the
number of milliseconds the client will wait after it receives a
poll response from the server that involved a server wait
(wait-interval-millis is set to a non-zero value).
A value of 0 means the client uses its configured polling-
interval-millis
next poll. Otherwise, this value overrides the default polling
interval of the client.
Setting this value to 1 allows clients that poll the server with
wait (wait-interval-millis is set to a non-zero value) to poll
immediately upon receiving a poll response from the server,
providing a real-time message stream from the server to the
client.
Clients that poll the server and are not serviced with a server
wait (wait-interval-millis is not set to a non-zero value) use
polling-interval-millis value.
the
is 0, the client polls as soon as it receives
max-waiting-poll-requests
value to determine the wait until its
polling-
-1 means that server
max-waiting-poll-requests
piggybacking-enabled
Optional endpoint property. Default value is 0. Specifies the
maximum number of server poll response threads that can
be in wait state. When this limit is reached, the subsequent
poll requests are treated as having zero
millis
.
Optional endpoint property. Default value is false. Enable
to support piggybacking of queued messaging and data
management subscription data along with responses to any
messages the client sends to the server over this channel.
wait-interval-
Last updated 3/10/2011
Page 52

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Property Description
48
login-after-disconnect
flex-client-outbound-queue-processor
serialization
Optional channel property. Default value is false. Setting
true causes clients to automatically attempt to
to
reauthenticate themselves with the server when they send a
message that fails because credentials have been reset due
to server session timeout. The failed messages are resent
after reauthentication, making the session timeout
transparent to the client with respect to authentication.
login-after-disconnect functionality only works for
requests (messages) that fault due to an authentication error
for a client that was previously authenticated but is no
longer authenticated. The destination or service must be
protected with a security constraint. The
disconnect
other reason.
Optional channel property. Use to manage messaging
quality of service for subscribers. Every client that subscribes
to the server over this channel is assigned a unique instance
of the specified outbound queue processor implementation
that manages the flow of messages to the client. This can
include message conflation, filtering, scheduled delivery and
load shedding. You can define configuration properties, and
if so, they are used to configure each new queue processor
instance that is created. The following example shows how
to provide a configuration property:
<flex-client-outbound-queue-processor
class="my.company.QoSQueueProcessor">
<properties>
<custom-property>5000</custom-property>
</properties>
</flex-client-outbound-queue-processor>
Optional serialization properties on endpoint. For more
information, see
channel” on page 84.
setting is not used if a message faults for any
“Configuring AMF serialization on a
login-after-
connect-timeout-seconds
invalidate-session-on-disconnect
add-no-cache-headers
Optional channel property. Default value is 0. Use to limit the
client channel's connect attempt to the specified time
interval.
Optional endpoint property. Disabled by default. If enabled,
when a disconnect message is received from a client
channel, the corresponding server session is invalidated. If
the client is closed without first disconnecting its channel, no
disconnect message is sent, and the server session is
invalidated when its idle timeout elapses.
Optional endpoint property. Default value is true. HTTPS
requests on some browsers do not work when pragma nocache headers are set. By default, the server adds headers,
including pragma no-cache headers to HTTP responses to
stop caching by the browsers.
Non-polling AMF and HTTP channels
The simplest types of channels are AMF and HTTP channels in non-polling mode, which operate in a single requestreply pattern. The following example shows AMF and HTTP channel definitions configured for no polling:
Last updated 3/10/2011
Page 53

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<!-- Simple AMF -->
<channel-definition id="samples-amf"
type="mx.messaging.channels.AMFChannel">
<endpoint url="http://{server.name}:8100/myapp/messagebroker/amf"
type="flex.messaging.endpoints.AmfEndpoint"/>
</channel-definition>
<!-- Simple secure AMF -->
<channel-definition id="my-secure-amf"
class="mx.messaging.channels.SecureAMFChannel">
<endpoint url="https://{server.name}:9100/dev/messagebroker/
amfsecure" class="flex.messaging.endpoints.SecureAMFEndpoint"/>
</channel-definition>
<!-- Simple HTTP -->
<channel-definition id="my-http"
class="mx.messaging.channels.HTTPChannel">
<endpoint url="http://{server.name}:8100/dev/messagebroker/http"
class="flex.messaging.endpoints.HTTPEndpoint"/>
</channel-definition>
<!-- Simple secure HTTP -->
<channel-definition id="my-secure-http" class="mx.messaging.channels.SecureHTTPChannel">
<endpoint url=
"https://{server.name}:9100/dev/messagebroker/
httpsecure"
class="flex.messaging.endpoints.SecureHTTPEndpoint"/>
</channel-definition>
49
Polling AMF and HTTP channels
You can use an AMF or HTTP channel in polling mode to repeatedly poll the endpoint to create client-pull message
consumers. The interval at which the polling occurs is configurable on the channel. You can also manually poll by
calling the
a high number so that the channel does not automatically poll, and call the
poll() method of a channel for which polling is enabled; for example, you want set the polling interval to
poll() method to poll manually based on
an event, such as a button click.
When you use a polling AMF or HTTP channel, you set the polling property to true in the channel definition. You
can also configure the polling interval in the channel definition.
Note: You can also use AMF and HTTP channels in long polling mode to get pushed messages to the client when the other
more efficient and real-time mechanisms are not suitable. For information about long polling, see
“Long polling AMF
and HTTP channels” on page 50.
The following example shows AMF and HTTP channel definitions configured for polling:
Last updated 3/10/2011
Page 54

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<!-- AMF with polling -->
<channel-definition id="samples-polling-amf"
class="mx.messaging.channels.AMFChannel">
<endpoint url="http://{server.name}:8700/dev/messagebroker/amfpolling"
type="flex.messaging.endpoints.AMFEndpoint"/>
<properties>
<polling-enabled>true</polling-enabled>
<polling-interval-millis>8000</polling-interval-millis>
</properties>
</channel-definition>
<!-- HTTP with polling -->
<channel-definition id="samples-polling-http"
class="mx.messaging.channels.HTTPChannel">
<endpoint url="http://{server.name}:8700/dev/messagebroker/httppolling"
type="flex.messaging.endpoints.HTTPEndpoint"/>
<properties>
<polling-enabled>true</polling-enabled>
<polling-interval-millis>8000</polling-interval-millis>
</properties>
</channel-definition>
Note: You can also use secure AMF or HTTP channels in polling mode.
50
Long polling AMF and HTTP channels
In the default configuration for a polling AMF or HTTP channel, the endpoint does not wait for messages on the
server. When the poll request is received, it checks whether any messages are queued for the polling client and if so,
those messages are delivered in the response to the HTTP request. You configure long polling in the same way as
polling, but you also must set the
interval-millis properties.
wait-interval-millis, max-waiting-poll-requests, and client-wait-
To achieve long polling, you set the following properties in the properties section of a channel definition in the
services-config.xml file:
• polling-enabled
• polling-interval-millis
• wait-interval-millis
• max-waiting-poll-requests.
• client-wait-interval-millis
The following example shows AMF and HTTP channel definitions configured for long polling:
Last updated 3/10/2011
Page 55

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<!-- Long polling AMF -->
<channel-definition id="my-amf-longpoll" class="mx.messaging.channels.AMFChannel">
<endpoint
url="http://servername:8700/contextroot/messagebroker/myamflongpoll"
class="flex.messaging.endpoints.AMFEndpoint"/>
<properties>
<polling-enabled>true</polling-enabled>
<polling-interval-millis>0</polling-interval-millis>
<wait-interval-millis>60000</wait-interval-millis>
<client-wait-interval-millis>3000</client-wait-interval-millis>
<max-waiting-poll-requests>100</max-waiting-poll-requests>
</properties>
</channel-definition>
<!-- Long polling HTTP -->
<channel-definition id="my-http-longpoll" class="mx.messaging.channels.HTTPChannel">
<endpoint
url="http://servername:8700/contextroot/messagebroker/myhttplongpoll"
class="flex.messaging.endpoints.HTTPEndpoint"/>
<properties>
<polling-enabled>true</polling-enabled>
<polling-interval-millis>0</polling-interval-millis>
<wait-interval-millis>60000</wait-interval-millis>
<client-wait-interval-millis>3000</client-wait-interval-millis>
<max-waiting-poll-requests>100</max-waiting-poll-requests>
</properties>
</channel-definition>
51
Note: You can also use secure AMF or HTTP channels in polling mode.
The caveat for using the wait-interval-millis is the utilization of available application server threads. Because this
channel ties up one application server request handling thread for each parked poll request, this mechanism can have
an impact on server resources and performance. Modern JVMs can typically support about 200 threads comfortably
if given enough heap space. Check the maximum thread stack size (often 1 or 2 megabytes per thread) and make sure
that you have enough memory and heap space for the number of application server threads you configure. This
limitation does not apply to NIO-based endpoints.
To ensure that Flex clients using channels with wait-interval-millis do not lock up your application server,
LiveCycle Data Services requires that you set the
max-waiting-poll-requests property, which specifies the
maximum number of waiting connections that LiveCycle Data Services should manage. This number must be set to a
number smaller than the number of HTTP request threads your application server is configured to use. For example,
you configure the application server to have at most 200 threads and allow at most 170 waiting poll requests. This
setting would ensure that you have at least 30 application server threads to use for handling other HTTP requests. Your
free application server threads should be large enough to maximize parallel opportunities for computation.
Applications that are I/O heavy can require a large number of threads to ensure all I/O channels are utilized
completely. Multiple threads are useful for the following operations:
Using different settings for these properties results in different behavior. For example, setting the wait-interval-
millis property to 0 (zero) and setting the polling-interval-millis property to a nonzero positive value results
in normal polling. Setting the
wait-interval-millis property to a high value reduces the number of poll messages
that the server must process, but the number of request handling threads on the server limits the total number of
parked poll requests.
• Simultaneously writing responses to clients behind slow network connections
• Executing database queries or updates
Last updated 3/10/2011
Page 56

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
• Performing computation on behalf of user requests
Another consideration for using wait-interval-millis is that LiveCycle Data Services must avoid monopolizing
the available connections that the browser allocates for communicating with a server. The HTTP 1.1 specification
recommends that browsers allocate at most two connections to the same server when the server supports HTTP 1.1.
To avoid using more that one connection from a single browser, LiveCycle Data Services allows only one waiting
thread for a given application server session at a time. If more than one Flash Player instance within the same browser
process attempts to interact with the server using long polling, the server forces them to poll on the default interval
with no server wait to avoid busy polling.
Streaming AMF and HTTP channels
The streaming AMF and HTTP channels are HTTP-based streaming channels that the LiveCycle Data Services server
can use to push updates to clients using a technique called HTTP streaming. These channels give you the option of
using standard HTTP for real-time messaging. This capability is supported for HTTP 1.1, but is not available for HTTP
1.0. There are also a number of proxy servers still in use that are not compliant with HTTP 1.1. When using a streaming
channel, make sure that the channel has
back to, such as an AMF polling channel.
LiveCycle Data Services gives you the additional option of using NIO-based endpoints with streaming AMF and HTTP
channels. For more information about using NIO-based endpoints, see
endpoints” on page 55.
connect-timeout-seconds defined and the channel set has a channel to fall
“Configuring channels with NIO-based
52
Using streaming AMF or HTTP channels/endpoints is like setting a long polling interval on a standard AMF or HTTP
channel/endpoint, but the connection is never closed even after the server pushes the data to the client. By keeping a
dedicated connection for server updates open, network latency is greatly reduced because the client and the server do
not continuously open and close the connection. Unlike polling channels, because streaming channels keep a constant
connection open, they can be adversely affected by HTTP connectors, proxies, reverse proxies or other network
components that can buffer the response stream.
The following table describes the channel and endpoint configuration properties in the services-config.xml file that are
specific to streaming AMF and HTTP channels/endpoints. The table includes the default property values as well as
considerations for specific environments and applications.
Property Description
connect-timeout-seconds
idle-timeout-minutes
Using a streaming connection that passes through an HTTP 1.1 proxy server
that incorrectly buffers the response sent back to the client hangs the
connection. For this reason, you must set the
seconds
property to a relatively short timeout period and specify a
fallback channel such as an AMF polling channel.
Optional channel property. Default value is 0. Specifies the number of
minutes that a streaming channel is allowed to remain idle before it is
closed. Setting the
timeout completely, but it is a potential security concern.
idle-timeout-minutes property to 0 disables the
connect-timeout-
Last updated 3/10/2011
Page 57

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Property Description
53
max-streaming-clients
server-to-client-heartbeatmillis
Optional endpoint property. Default value is 10. Limits the number of Flex
clients that can open a streaming connection to the endpoint. To
determine an appropriate value, consider the number of threads available
on your application server because each streaming connection open
between a FlexClient and the streaming endpoints uses a thread on the
server. Use a value that is lower than the maximum number of threads
available on the application server.
This value is for the number of Flex client application instances, which can
each contain one or more MessageAgents (Producer or Consumer
components).
Optional endpoint property. Default value is 5000. Number of milliseconds
that the server waits before writing a single byte to the streaming
connection to make sure that the client is still available. This is important to
determine when a client is no longer available so that its resources
associated with the streaming connection can be cleaned up. A nonpositive value disables this functionality.
Note that this functionality does not keep the session alive. To keep a
session alive, add a
flex-client settings in the services-config.xml file. For more
information, see
heartbeat-interval-millis property to the
“Configuration elements” on page 33.
Last updated 3/10/2011
Page 58

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Property Description
54
user-agent-settings
Optional endpoint property. Use user agents to customize a long-polling or
streaming endpoints for specific browsers. Long-polling and streaming
endpoints require persistent HTTP connections which are limited
differently by different browsers per session. A single long-poll connection
requires two browser HTTP connections in order to send data in both
directions: one for the streamed response from the server to the client that
the channel hangs on to, and a second transient connection, drawn from
the browser pool only when data needs to be sent to the server and this
second transient connection is then immediately released back to the
browser's connection pool. For client applications to function properly, the
number of HTTP connections made by all clients running in the same
session must stay within the limit established by the browser.
The max-persistent-connections-per-session setting lets you
limit the number of long-polling or streaming connections that can be
made from clients in the same browser session. The
kickstart-bytes
setting indicates a certain number of bytes must be written before the
endpoint can reliably use a streaming connection.
There is a browser-specific limit to the number of connections allowed per
session. By default, LiveCycle Data Services uses
streaming-connections-per-session
specific limits by specifying
user-agent elements with a match-on value
1 as the value for max-
. You can add browser-
for specific browser user agents.
The special match string "*" defines a default to be used if no string
matches. The match strings
"MSIE" and "Firefox" are always defined
and must be specified explicitly to override the default settings. Specifying
"*" does not do so. If you are using streaming channels, you should
configure both the streaming and polling channels to the same values
The following example shows default user agent values:
<user-agent-settings>
<!-- MSIE 5, 6, 7 limit is 2.
<user-agent match-on="MSIE" max-persistent-connectionsper-session="1" kickstart-bytes="2048"/>
-->
<!-- MSIE 8 limit is 6.
<user-agent match-on="MSIE 8" max-persistentconnections-per-session="5" kickstart-bytes="2048"/>
-->
<!-- Firefox 1, 2 limit is 2.
<user-agent match-on="Firefox" max-persistentconnections-per-session="1"/>
-->
<!-- Firefox 3 limit is 6.
<user-agent match-on="Firefox/3" max-persistentconnections-per-session="5"/>
-->
<!-- Safari 3, 4 limit is 4.
<user-agent match-on="Safari" max-persistentconnections-per-session="3"/>
-->
<!-- Chrome 0, 1, 2 limit is 6.
<user-agent match-on="Chrome" max-persistentconnections-per-session="5"/>
-->
<!-- Opera 7, 9 limit is 4.
<user-agent match-on="Opera" max-persistentconnections-per-session="3"/>
-->
<!-- Opera 8 limit is 8.
<user-agent match-on="Opera 8" max-persistentconnections-per-session="7"/>
-->
<!-- Opera 10 limit is 8.
<user-agent match-on="Opera/9.8" max-persistentconnections-per-session="7"/>
-->
</user-agent-settings>
Last updated 3/10/2011
Page 59

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
The following example shows streaming AMF and HTTP channel definitions:
<!-- AMF with streaming -->
<channel-definition id="my-amf-stream"
class="mx.messaging.channels.StreamingAMFChannel">
<endpoint url="http://servername:2080/myapp/messagebroker/streamingamf"
class="flex.messaging.endpoints.StreamingAMFEndpoint"/>
</channel-definition>
<!-- Secure AMF with streaming -->
<channel-definition id="my-secure-amf-stream"
class="mx.messaging.channels.SecureStreamingAMFChannel">
<endpoint url="http://servername:2080/myapp/messagebroker/securestreamingamf"
class="flex.messaging.endpoints.SecureStreamingAMFEndpoint"/>
</channel-definition>
<!-- HTTP with streaming -->
<channel-definition id="my-http-stream"
class="mx.messaging.channels.StreamingHTTPChannel">
<endpoint url="http://servername:2080/myapp/messagebroker/streaminghttp"
class="flex.messaging.endpoints.StreamingHTTPEndpoint"/>
</channel-definition>
<!-- Secure HTTP with streaming -->
<channel-definition id="my-secure-http-stream"
class="mx.messaging.channels.SecureStreamingHTTPChannel">
<endpoint url="https://servername:2080/myapp/messagebroker/securestreaminghttp"
class="flex.messaging.endpoints.SecureStreamingHTTPEndpoint"/>
</channel-definition>
55
Configuring channels with NIO-based endpoints
Note: NIO-based endpoints are not available in BlazeDS.
AMF and HTTP (AMFX) channels offer long-polling and streaming channel support over HTTP. They are a good
alternative to simple polling and approximate real-time push. However, in LiveCycle Data Services 2.5 they relied on
servlet-based AMF and HTTP endpoints on the server. The servlet API requires a request-handler thread for each
long-polling or streaming connection. A thread is not available to service other requests while it is servicing a longpoll parked on the server, or while it is servicing a streaming HTTP response. Therefore, the servlet implementation
does not scale well for a large number of long-polling or streaming connections.
NIO-based AMF and HTTP endpoints address this scalability limitation by providing identical transport functionality
from the client perspective, while avoiding the requirement of using one thread for each long-polling or streaming
connection. NIO-based endpoints use the Java NIO API to service a large number of client connections in a nonblocking, asynchronous fashion.
Note: Like servlet-based endpoints, NIO-based AMF and HTTP endpoints return a session id to inject into the client
channel URL in the first response that is returned from the server. This allows client-server interaction to work when the
client has cookies disabled. NIO endpoints also return a stand-in representation of a javax.servlet.HttpServletRequest
object even though these endpoints do not use the Servlet API in any way. This stand-in object supports a subset of the
full HttpServletRequest API. For more information, see the flex.messaging.io.http.StandInHttpServletRequest class the
Javadoc API documentation.
Last updated 3/10/2011
Page 60

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Configuring a shared socket server for NIO-based endpoints
You can configure one or more socket servers for use with NIO-based endpoints. The only reason to define more than
one socket server is if you want to use both secure and insecure NIO endpoints. An underlying server either supports
secure (SSL or TLS) connections or insecure connections, not both.
Do not define more than one socket server unless you need both secure and insecure support in the same application.
When you do define more than one socket server, you can specify which server the endpoint of a channel definition
uses. You use the
can contain one or more
<servers>
<server id="my-nio-server" class="flex.messaging.socketserver.SocketServer">
</server>
<server id="secure-nio-server" class="flex.messaging.socketserver.SocketServer">
<properties>
<keystore-file>d:\keystores\localhoststore</keystore-file>
<keystore-file>{context.root}/WEB-INF/flex/localhost.keystore</keystore-file>
<keystore-password>changeit</keystore-password>
<alias>lh</alias>
</properties>
</server>
</servers>
server element in the services-config.xml file to create the server definition. The servers element
server elements, as the following example shows:
56
NIO-based endpoints within a channel definition reference a <server> definition by using the <server ref="..."/>
property, as the following example shows:
<channel-definition id="my-nio-amf" class="mx.messaging.channels.AMFChannel">
<endpoint url="http://localhost:2080/mynioamf"
class="flex.messaging.endpoints.NIOAMFEndpoint"/>
<server ref="my-nio-server"/>
</channel-definition>
Note: One reason to share a server definition among multiple endpoint definitions is that a single port cannot be bound
by more than one server definition. For example, if your application must define both a regular NIOAMFEndpoint as
well as a StreamingNIOAMFEndpoint, you want clients to be able to reach either endpoint over the same port so these
endpoints must reference a common server. If you do not require a shared server, you can configure socket server
properties inside channel definitions.
An NIO-based endpoint can implicitly define and use an internal server definition by omitting the <server ref="..."/>
property, and instead including any server configuration properties directly within its
<properties> element. For
example, if you define only a single NIO-based AMF or HTTP endpoint, omit the <server ref="…"/> element and
define any desired properties within the endpoint definition. However, if a <server ref="..."/> property is included in
the channel definition, any server-related configuration properties in the endpoint definition are ignored and must
instead be defined directly for the server itself.
If you configure more than one NIO-based AMF or HTTP endpoint that is not secure, they should all reference a
shared unsecured
should all reference a secured shared
server definition. If you define more than one secure NIO-based AMF or HTTP endpoint, they
<server> definition. This configuration lets all insecure endpoints share the
same insecure port, and lets all the secure endpoints share a separate, secure port.
Note: A server definition accepts either standard or secure connections based on whether it is configured to use a
keystore. A
server definition cannot service both standard and secure connections concurrently.
Last updated 3/10/2011
Page 61

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
The endpoint uses the class attribute to register the protocol-specific connection implementation classes with the
server. For information on the NIO HTTP implementation classes, see
“Defining channels and NIO-based endpoints”
on page 57.
Secure server definition
A secure server definition requires a digital certificate, and contains child elements for specifying a keystore filename
and password. You can create public and private key pairs and self-signed certificates with the Java keytool utility. The
common name (CN) of self-signed certificates must be set to
localhost or the IP address on which the RTMPS
endpoint is available. For information about key and certificate creation and management, see the Java keytool
documentation at
http://java.sun.com.
Optionally, you can store a keystore password in a separate file, possibly on removable media. Specify only one
keystore-password or keystore-password-file. The following example shows a
<keystore-password-file>a:\password</keystore-password-file>
keystore-password-file element:
Compatibility with previous versions of LiveCycle Data Services
The NIO-based AMF and HTTP endpoints are functionally equivalent to the existing servlet-based AMF and HTTP
endpoints as far as the client is concerned. You should be able to run your existing applications, using the existing
configuration files, when migrating your application to LiveCycle Data Services 2.6.
57
NIO-based endpoints do not support the following configuration options:
• max-waiting-poll-requests
NIO-based polling endpoints do not have the threading limitation that the servlet API imposes, so they do not
require nor support the
max-waiting-poll-requests property.
• max-streaming-clients
NIO-based streaming endpoints do not have the threading limitation that the servlet API imposes, so they do not
require nor support the
max-streaming-clients property.
Defining channels and NIO-based endpoints
When defining NIO-based endpoints, you specify one of the following classes to define the protocol-specific
connection implementation There is also a secure version of each of these endpoints that transports data over a secure
connection. The names of the secure endpoints all start with the text "Secure"; for example, SecureRTMPEndpoint.
• RTMPEndpoint
• NIOAMFEndpoint
• StreamingNIOAMFEndpoint
• NIOHTTPEndpoint
• StreamingNIOHTTPEndpoint
The NIO-based AMF and HTTP endpoints implement part of the HttpServletRequest interface to expose headers and
cookies in requests to custom LoginCommands or for other uses. You can access the HttpServletRequest instance by
using the
interface; therefore, the
FlexContext.getHttpRequest() method. These endpoints do not implement the HttpServletResponse
FlexContext.getHttpResponse() method returns null.
Supported methods from the HttpServletRequest interface include the following:
• getCookies()
• getDateHeader()
Last updated 3/10/2011
Page 62

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
• getHeader()
• getHeaderNames()
• getHeaders()
• getIntHeader()
Calling an unsupported method of the HttpServletRequest interface throws an UnsupportedOperationException
exception.
Configuring RTMP endpoints
You use RTMP channels to connect to an RTMP endpoint that supports real-time messaging and data. You can also
configure these channels for long polling.
RTMPT connections are HTTP connections from the client to the server over which RTMP data is tunneled. When a
direct RTMP connection is unavailable, the standard and secure channels automatically attempt to use RTMPT and
tunneled RTMPS connections, respectively, on the RTMP endpoint with no additional configuration required.
Note: You cannot use server.port tokens in an RTMP endpoint configuration. You can use the server.name token, but not
when using clustering. If you have a firewall in place, you must open the port that you assign to the RTMP endpoint to
allow RTMP traffic.
RTMP is a protocol that is primarily used to stream data, audio, and video over the Internet to Flash Player clients.
RTMP maintains a persistent connection with an endpoint and allows real-time communication. You can make an
RTMP connection in one of the following ways depending upon the network setup of the clients:
58
• Direct socket connection.
• Tunneled socket connection through an HTTP proxy server using the CONNECT method.
• Active, adaptive polling using the browser HTTP stack. This mechanism does place additional computational load
on the RTMP server and so reduces the scalability of the deployment.
RTMP direct socket connection
RTMP in its most direct form uses a simple TCP socket connection from the client machine directly to the RTMP
server.
RTMPT Tunnelling with HTTP Proxy Server Connect
This connection acts like a direct connection but uses the proxy server support for the CONNECT protocol if
supported. If this connection is not supported, the server falls back to using HTTP requests with polling.
RTMPT Tunnelling with HTTP requests
In this mode, the client uses an adaptive polling mechanism to implement two-way communication between the
browser and the server. This mechanism is not configurable and is designed to use at most one connection between
the client and server at a time to ensure that Flash Player does not consume all of the connections the browser allows
to one server.
Last updated 3/10/2011
Page 63

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Connecting RTMP from the web tier to the application server tier
Currently, all RTMP connections must be made from the browser, or an HTTP proxy server in the case of a
CONNECT-based tunnel connection, directly to the RTMP server. Because the NIO server is embedded in the
application server tier with access to the database, in some server environments it is not easy to expose it directly to
web clients. There are a few ways to address this problem in your configuration:
• You can expose a firewall and load balancer to web clients that can implement a TCP pass-through mode to the
LiveCycle Data Services server.
• You can place a proxy server on the web tier that supports the HTTP CONNECT protocol so it can proxy
connections from the client to the RTMP server. This provides real-time connection support by passing the web
tier. The proxy server configuration can provide control over which servers and ports can use this protocol so it is
more secure than opening up the RTMP server directly to clients. For an RTMP CONNECT tunnel to work, the
client browser must be configured to use a specific HTTP proxy server.
• You can place a reverse proxy server on the web tier which proxies simple HTTP requests to the NIO server. This
approach only works in RTMPT polling mode.
• You can deploy an Edge Server in your DMZ. Clients connect to the Edge Server over RTMP, and the Edge Server
then forwards the client requests to a LiveCycle Data Services server in the application tier. Because the Edge Server
is running in the DMZ, you are not exposing the secure application tier of your internal network.
59
Configuring a standard RTMPChannel/RTMPEndpoint
Use a standard RTMPChannel/RTMPEndpoint only when transmitting data that does not require security. The
following example shows an RTMP channel definition:
<channel-definition id="my-rtmp"
class="mx.messaging.channels.RTMPChannel">
<endpoint url="rtmp://{server.name}:2035"
class="flex.messaging.endpoints.RTMPEndpoint"/>
<properties>
<idle-timeout-minutes>20</idle-timeout-minutes>
</properties>
</channel-definition>
You can use the optional rtmpt-poll-wait-millis-on-client element when clients are connected over RTMPT
while performing adaptive polling. After receiving a server response, clients wait for an absolute time interval before
issuing the next poll request rather than using an exponential back-off up to a maximum poll wait time of 4 seconds.
Allowed values are integers in the range of 0 to 4000, for example:
<rtmpt-poll-wait-millis-on-client>0</rtmpt-poll-wait-millis-on-client>
You can set the optional block-rtmpt-polling-clients element to true to allow the server to be configured to
drop the inefficient polling connection. This action triggers the client to fall back to the next channel in its channel set.
The default value is
false.
When an RTMPChannel internally falls back to tunneling, it sends its HTTP requests to the same domain/port that is
used for regular RTMP connections and these requests must be sent over a standard HTTP port so that they make it
through external firewalls that some clients could be behind. For RTMP to work, you must bind your server-side
RTMP endpoint for both regular RTMP connections and tunneled connections to port 80. When the client channel
falls back to tunneling, it always goes to the domain/port specified in the channel endpoint URI.
If you have a switch or load balancer that supports virtual IPs, you can use a deployment as the following table shows,
using a virtual IP (and no additional NIC on the LiveCycle Data Services server) where client requests first hit a load
balancer that routes them back to a backing LiveCycle Data Services server:
Last updated 3/10/2011
Page 64

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Public Internet Load balancer LiveCycle Data Services
Browser client makes HTTP request my.domain.com:80 Servlet container bound to port 80
60
Browser client uses RTMP/T rtmp.domain.com:
80 (virtual IP
address)
RTMPEndpoint bound to any port; for example, 2037
The virtual IP/port in this example (rtmp.domain.com:80) is configured to route back to port 2037 or whatever port
the RTMPEndpoint is configured to use on the LiveCycle Data Services server. In this approach, the RTMPEndpoint
does not have to bind to a standard port because the load balancer publicly exposes the endpoint via a separate virtual
IP address on a standard port.
If you do not have a switch or load balancer that supports virtual IPs, you need a second NIC to allow the
RTMPEndpoint to bind port 80 on the same server as the servlet container that binds to port 80 on the primary NIC,
as the following table shows:
Public Internet LiveCycle Data Services
Browser client makes
HTTP request
Browser client uses
RTMP/T
NICs
my.domain.com:80 Servlet container bound to port 80 on primary NIC using
rtmp.domain.com:80 RTMPEndpoint bound to port 80 on a second NIC using a
LiveCycle Data Services
primary domain/IP address
separate domain/IP address
In this approach the physical LiveCycle Data Services server has two NICs, each with its own static IP address. The
servlet container binds port 80 on the primary NIC and the RTMPEndpoint binds port 80 on the secondary NIC. This
allows traffic to and from the server to happen over a standard port (80) regardless of the protocol (HTTP or RTMP).
The key take away is that for the RTMPT fallback to work smoothly, the RTMPEndpoint must be exposed to Flex
clients over port 80, which is the standard HTTP port that generally allows traffic (unlike nonstandard RTMP ports
like 2037, which are usually closed by IT departments).
To bind the RTMPEndpoint to port 80, one of the approaches above is required. For secure RTMPS (direct or
tunneled) connections, the information above is the same but you would use port 443. If an application requires both
secure and non-secure RTMP connections with tunneling fallback, you do not need three NICs; you need only two.
The first NIC services regular HTTP/HTTPS traffic on the primary IP address at ports 80 and 443, and the second NIC
services RTMP and RTMPS connections on the secondary IP at ports 80 and 443. If a load balancer is in use, it is the
same as the first option above where LiveCycle Data Services has a single NIC and the different IP/port combinations
are defined at the load balancer.
Configuring NIO-based AMF and HTTP endpoints
The NIO-based AMF and HTTP endpoint classes support simple polling, long-polling, and streaming requests. Like
the socket server configuration options, these endpoints support the existing configuration options defined for the
RTMPEndpoint, AMFEndpoint and HTTPEndpoint classes, and the following additional configuration options:
Last updated 3/10/2011
Page 65

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Option Description
61
session-cookie-name
session-timeoutminutes
max-request-line-size
max-request-body-size
(Optional) Default value is AMFSessionId. The name used for the session cookie
set by the endpoint.
If you define multiple NIO-based endpoints and specify a custom cookie name, it
must be the same for all NIO-based AMF and HTTP endpoints.
(Optional) Default value is 15 minutes. The session timeout for inactive NIO HTTP
sessions, in minutes. Long-poll requests or streaming connections that uses
server-to-client-heartbeat-millis keep the session alive, as will any
request from the client.
If you define multiple NIO-based endpoint and specify a custom session timeout,
it must be the same for all NIO-based AMF and HTTP endpoints.
(Optional) Default value is 8192 characters. Requests that contain request or
header lines that exceed this value are dropped and the connection is closed.
(Optional) Default is 5 MB. The maximum POST body size, in bytes, that the
endpoint accepts. Requests that exceed this limit are dropped and the connection
is closed.
Channels that use NIO-based endpoints
The following channel definition defines an RTMP channel for use with RTMP endpoints.
<!-- NIO RTMP -->
<channel-definition id="my-rtmp" class="mx.messaging.channels.RTMPChannel">
<endpoint url="rtmp://servername:2038"
class="flex.messaging.endpoints.RTMPEndpoint"/>
<properties>
<idle-timeout-minutes>0</idle-timeout-minutes>
<bind-address>10.132.64.63</bind-address>
<bind-port>2035</bind-port>
</properties>
</channel-definition>
The following channel definitions define AMF channels for use with NIO-based AMF endpoints.
<!-- NIO RTMP -->
<channel-definition id="my-rtmp" class="mx.messaging.channels.RTMPChannel">
<endpoint url="rtmp://servername:2038"
class="flex.messaging.endpoints.RTMPEndpoint"/>
<properties>
<idle-timeout-minutes>0</idle-timeout-minutes>
<bind-address>10.132.64.63</bind-address>
<bind-port>2035</bind-port>
</properties>
</channel-definition>
<!-- NIO AMF -->
<channel-definition id="my-nio-amf" class="mx.messaging.channels.AMFChannel">
<endpoint url="http://servername:2080/nioamf"
class="flex.messaging.endpoints.NIOAMFEndpoint"/>
<server ref="my-nio-server"/>
<properties>
<polling-enabled>false</polling-enabled>
</properties>
</channel-definition>
Last updated 3/10/2011
Page 66

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<!-- NIO AMF with polling -->
<channel-definition id="my-nio-amf-poll" class="mx.messaging.channels.AMFChannel">
<endpoint url="http://servername:2080/nioamfpoll"
class="flex.messaging.endpoints.NIOAMFEndpoint"/>
<server ref="my-nio-server"/>
<properties>
<polling-enabled>true</polling-enabled>
<polling-interval-millis>3000</polling-interval-millis>
</properties>
</channel-definition>
<!-- NIO AMF with long polling -->
<channel-definition id="my-nio-amf-longpoll" class="mx.messaging.channels.AMFChannel">
<endpoint url="http://servername:2080/nioamflongpoll"
class="flex.messaging.endpoints.NIOAMFEndpoint"/>
<server ref="my-nio-server"/>
<properties>
<polling-enabled>true</polling-enabled>
<polling-interval-millis>0</polling-interval-millis>
<wait-interval-millis>-1</wait-interval-millis>
</properties>
</channel-definition>
<!-- NIO AMF with streaming -->
<channel-definition id="my-nio-amf-stream"
class="mx.messaging.channels.StreamingAMFChannel">
<endpoint url="http://servername:2080/nioamfstream"
class="flex.messaging.endpoints.StreamingNIOAMFEndpoint"/>
<server ref="my-nio-server"/>
<properties>
<server-to-client-heartbeat-millis>10000</server-to-client-heartbeat-millis>
<user-agent-settings>
<user-agent match-on="MSIE"
kickstart-bytes="2048" max-streaming-connections-per-session="1"/>
<user-agent match-on="Firefox"
kickstart-bytes="0" max-streaming-connections-per-session="1"/>
</user-agent-settings>
</properties>
</channel-definition>
<!-- Secure NIO AMF -->
<channel-definition id="secure-nio-amf" class="mx.messaging.channels.SecureAMFChannel">
<endpoint url="https://servername:2443/securenioamf"
class="flex.messaging.endpoints.SecureNIOAMFEndpoint"/>
<server ref="secure-nio-server"/>
<properties>
<polling-enabled>false</polling-enabled>
</properties>
</channel-definition>
62
The following channel definitions define HTTP channels for use with NIO-based HTTP endpoints:
Last updated 3/10/2011
Page 67

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<!-- NIO HTTP -->
<channel-definition id="my-nio-http" class="mx.messaging.channels.HTTPChannel">
<endpoint url="http://servername:2080/niohttp"
class="flex.messaging.endpoints.NIOHTTPEndpoint"/>
<server ref="my-nio-server"/>
<properties>
<polling-enabled>false</polling-enabled>
</properties>
</channel-definition>
<!-- NIO HTTP with streaming -->
<channel-definition id="my-nio-http-stream"
class="mx.messaging.channels.StreamingHTTPChannel">
<endpoint url="http://servername:2080/niohttpstream"
class="flex.messaging.endpoints.StreamingNIOHTTPEndpoint"/>
<server ref="my-nio-server"/>
</channel-definition>
<!-- Secure NIO HTTP -->
<channel-definition id="secure-nio-http" class="mx.messaging.channels.SecureHTTPChannel">
<endpoint url="https://servername:2443/secureniohttp"
class="flex.messaging.endpoints.SecureNIOHTTPEndpoint"/>
<server ref="secure-nio-server"/>
<properties>
<polling-enabled>false</polling-enabled>
</properties>
</channel-definition>
63
Monitoring an NIO-based endpoint through a proxy service
You can use a proxy service to monitor traffic to and from an NIO-based endpoint. To do so, set the url property of
endpoint element in a channel definition to use the port on which you want the proxy service to listen. The client
the
uses the
url property of the endpoint element. Set the bind-port property of the NIO server to the port that the
server endpoint should listen on.
For the following channel definition, you would configure your proxy service to listen for requests on port 9999 and
forward requests to port 2081:
<channel-definition
class="mx.messaging.channels.StreamingAMFChannel" id="qa-nio-amf-stream-proxy">
<endpoint class="flex.messaging.endpoints.StreamingNIOAMFEndpoint"
url="http://yourserver:9999/nioamfstreamproxy"/>
<server ref="nio-server"/>
<properties>
<bind-port>2081</bind-port>
<server-to-client-heartbeat-millis>5000</server-to-client-heartbeat-millis>
</properties>
</channel-definition>
Configuring the socket server
You configure one or more socket server definitions in the services-config.xml file. Once defined, you can specify
which server a channel definition uses.
Note: You can optionally set any of the socket server properties directly in a channel definition for situations where you
are not sharing the same socket server for more than one endpoint.
Last updated 3/10/2011
Page 68

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Use a secure channel definition to connect to the endpoint over Transport Layer Security (TLS) for RTMP-based
endpoints or SSL for servlet-based endpoints. When using RTMP, the channel falls back to tunneled RTMPS when a
direct connection is unavailable.
The following table describes the configuration options for the socket server:
Option Description
Security Related Options
64
max-connection-count
connection-idle-timeout-minutes
idle-timeout-minutes
whitelist
blacklist
(Optional) The total number of open connections that the server
accepts. Clients that attempt to connect beyond this limit are
rejected. Setting
max-connection-count to 0, the default,
disables this limitation.
Note that this is a potential security concern.
(Optional) The number of minutes that a streaming channel is
allowed to remain idle before it is closed. Setting
minutes
to 0, the default value, disables the timeout.
idle-timeout-
Note that this is a potential security concern.
Supported but deprecated. See connection-idle-timeout-
minutes
above.
(Optional) Contains client IP addresses that are permitted to connect
to the server. When defined, client IPs must satisfy this filter to
connect. The
whitelist option if the client IP is a member of both sets.
blacklist option takes precedence over the
Define a whitelist by creating a list of ip-address and ip-
address-pattern
elements. The ipaddress- element supports
simple IP matching, allowing you to use a wildcard symbol, *, for
individual bytes in the address. The
ip-address-pattern element
supports regular-expression pattern matching of IP addresses to
support range-based IP filtering, as the following example shows:
<whitelist>
<ip-address>10.132.64.63</ip-address>
<ip-address-pattern>240.*</ip-address-pattern>
</whitelist>
(Optional) Contains client IPs that are restricted from accessing the
server. The
whitelist option if the client IP is a member of both sets.
blacklist option takes precedence over the
Blacklists take a list of ip-address and ip-address-pattern
elements, as the following example shows:
<blacklist>
<ip-address>10.132.64.63</ip-address>
<ip-address-pattern>240.63.*</ip-address-pattern>
</blacklist>
For more information on the ip-address and ip-address-
pattern
elements, see the whitelist option.
cross-domain-path
Path to a cross domain policy file. For more information, see “Using
cross domain policy files with the NIO server” on page 68.
Last updated 3/10/2011
Page 69

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Option Description
65
enabled-cipher-suites
General Server Options
bind-address
bind-port
reuse-address-enabled
A cipher suite is a set of encryption algorithms. Secure NIO socket
server definitions or secure NIO (RTMP, AMF, or HTTP) endpoint
definitions can define a restricted set of cipher suites to use with
secure connections, as the following examples shows:
<enabled-cipher-suites>
<cipher-suite>SSL_RSA_WITH_128_MD5</cipher-suite>
<ciphersuite>TLS_DHE_DSS_WITH_AES_128_CBC_SHA</ciphersuite>
</enabled-cipher-suites>
If left undefined, the default set of cipher suites for the security
provider implementation of the Java virtual machine (JVM) are used
for secure connection handshaking. If an unsupported cipher suite is
defined, an error occurs and a ConfigurationException exception is
thrown when the server starts.
(Optional) Binds the server to a specific network interface. If left
unspecified, the server binds to all local network interfaces on
startup.
(Optional) Binds the server to a port that differs from the public port
that clients connect to. This allows clients to connect to a public port
on a firewall or load balancer that forwards traffic to this internal port.
(Optional) When set to false disables address reuse by the socket
server. This causes the SocketServer to not start when it cannot bind
to a port because the port is in a TIME_WAIT state. The default value
is true, which allows the socket server to start if the port is in a
TIME_WAIT state.
Connection Configuration Options
connection-buffer-type
connection-read-buffer-size
connection-write-buffer-size
Control the threading behavior of the
server in the absence of a WorkManager.
websphere-workmanager-jndi-name
max-worker-threads
(Optional) Controls the type of byte buffers that connections use to
read and write from the network. Supported values include:
• heap (default) specifies to use heap-allocated ByteBuffers.
• direct specifies to use DirectByteBuffers.
Performance varies depending upon JRE and operating system.
(Optional) Default value is 8192 (8 KBytes). Size, in bytes, for the read
buffer for connections.
(Optional) Default value is 8192 (8 KBytes). Size, in bytes, for the write
buffer for connections.
(Optional) For IBM WebSphere deployment, the WorkManager
configured and referenced as the worker thread pool for the server.
A WorkManager must be referenced to support JTA, which the Data
Management Service uses.
(Optional) The upper bound on the number of worker threads that
the server uses to service connections. Defaults to unbounded with
idle threads being reaped based upon the
timeout-millis
value. Ignored if the server is using a
WorkManager.
idle-worker-thread-
Last updated 3/10/2011
Page 70

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Option Description
66
min-worker-threads
idle-worker-thread-timeoutmillis
worker-thread-priority
Accept or and Reactor Configuration
Options
accept-backlog
accept-thread-priority
reactor-count
(Optional) A nonzero, lower bound on the number of worker threads
that the server uses to service connections. Defaults to 0. If nonzero,
on server start up this number of worker threads is prestarted.
Ignored if the server is using a WorkManager.
(Optional) Time, in minutes, that a worker thread must be idle before
it is released. Defaults to 1. Ignored if the server is using a
WorkManager.
(Optional) Desired priority for the server threads. Defaults to
Thread.NORM_PRIORITY. Ignored if the server is using a
WorkManager.
(Optional) The suggested size of the accept queue for the server
socket to buffer new connect requests when the server is too busy to
handshake immediately. Default is the platform default value for a
server socket.
(Optional) Allows the priority for accepting new connections to be
adjusted either above or below the general server priority for
servicing existing connections. Default is the thread priority of the
worker thread pool or the WorkManager (whichever is used).
(Optional) Splits IO read/write readiness selection for all existing
connections to the server out across all available processors and
divides the total readiness selection set by the number of reactors to
avoid having a single Selector manage the state for all connections.
Default is the number of available physical processors on the
machine.
TLS/SSL Configuration Options
keystore-type
keystore-file
keystore-password
keystore-password-file
keystore-password-obfuscated
(Optional) Default value is JKS. Specifies the keystore type. The
supported values include:
JKS and PKCS12.
Points to the actual keystore file on the running server. The path to
the file may be specified as an absolute path, as in:
<keystore-file>C:\keystore.jks</keystore-file>
Or as a relative to the WEB-APP directory using the
{context.root} token, as in:
<keystore-file>{context.root}/WEBINF/certs/keystore.jks</keystore-file>
The keystore password.
Path to a text file on external or removable media that contains the
password value. Ignored if
keystore-password is specified.
(Optional) Default value is false. Set to true if an obfuscated value is
stored in the configuration file and a password deobfuscator has
been registered for use.
Last updated 3/10/2011
Page 71

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Option Description
67
password-deobfuscator
algorithm
(Optional) The class name of a password deobfuscator used to
handle obfuscated passwords safely at run time.
A password deobfuscator implements the
flex.messaging.util.PasswordDeobfuscator interface, which contains
deobfuscate() and a destroy() method. The
a
flex.messaging.util.AbstactPasswordDeobfuscator class is an
abstract class that implements the
deobfuscator class can extend this class, and just implement a
deobfuscate() method. The deobfuscate() method takes a
string that contains the obfuscated password and returns a
containing the deobfuscated password.
For more information, see the JavaDoc for the
flex.messaging.util.PasswordDeobfuscator interface and the
flex.messaging.util.AbstractPasswordDeobfuscator abstract base
class.
(Optional) Only configure this option when using a third-party
security provider implementation. Defaults to the current default
JVM algorithm. The default JVM algorithm can be controlled by
setting the
property.
Example usage:
ssl.KeyManagerFactory.algorithm security
destroy() method. Your
char[]
• <algorithm>Default</algorithm> - Explicitly uses the
default JVM algorithm.
• <algorithm>SunX509</algorithm> - Uses Sun algorithm;
requires the Sun secuity provider.
• <algorithm>IbmX509</algorithm> - Uses IBM algorithm;
requires the IBM security provider.
alias
protocol
Socket Configuration Options (for
accepted sockets)
socket-keepalive-enabled
socket-oobinline-enabled
socket-receive-buffer-size
socket-send-buffer-size
socket-linger-seconds
socket-tcp-no-delay-enabled
socket-traffic-class
(Optional) If a keystore is used that contains more than one server
certificate, use this property to define which certificate to use to
authenticate the server end of SSL/TLS connections.
(Optional) Default value is TLS. The preferred protocol for secure
connections.
(Optional) Enables/Disables SO_KEEPALIVE for sockets the server
uses.
(Optional) Enables/Disables OOBLINE (receipt of TCP urgent data).
Defaults to
(Optional) Sets the SO_RCVBUF option for sockets to this value,
which is a hint for the size of the underlying network I/O buffer to use.
(Optional) Sets the SO_SNDBUF option for sockets to this value,
which is a hint for the size of the underlying network I/O buffer to use.
(Optional) Enables/Disables SO_LINGER for sockets the server uses
where the value indicates the linger time for a closing socket in
seconds. A value of -1 disables socket linger.
(Optional) Enables/Disables TCP_NODELAY, which enables or
disables the use of the Nagle algorithm by the sockets.
(Optional) Defines the traffic class for the socket.
false, which is the JVM default.
Last updated 3/10/2011
Page 72

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Using cross domain policy files with the NIO server
By default, the Flash Player security sandbox only allows a SWF file to make requests back to the same domain that the
SWF file originated from. You use a cross domain policy file to deal with this security restriction. If a SWF file makes
a request to a domain that is different than the one from which it originated, Flash Player makes a request to the new
domain for a cross domain policy file that can provide the SWF file with additional permissions to communicate with
the domain.
For servlet-based endpoints, LiveCycle Data Services depends on the application server for cross domain policy file
handling. For NIO-based AMF and HTTP endpoints, LiveCycle Data Services must depend on the NIO server for
cross domain policy file handling and not the application server itself. This is because the NIO server listens for
requests on a different port than the application server.
If your application makes a request to an AMF or HTTP endpoint at the
http://domainA:8400/lcds/messagebroker/amfpolling and domainA is not the same domain the SWF file was
downloaded from, Flash Player makes a cross domain policy file request to http://domainA:8400. To allow the
application to make the request to the AMF endpoint, you must place a cross domain policy file in the root directory
of your application server. For example, with a typical installation of Tomcat, this would be the
TOMCAT_HOME\webapps\ROOT directory.
If your application makes a request to an NIO-based AMF or HTTP endpoint at the
http://domainA:1234/nioamfpolling and domainA is not the same domain the SWF file was downloaded from, Flash
Player makes a cross domain policy file request to http://domainA:1234. Since this request goes directly to the NIO
server and not to the application server, you must configure the NIO server to serve the cross domain policy file. To
do this, you add a cross-domain-path property to your NIO server settings in your services-config.xml file as the
following example shows:
68
<server id="my-nio-server" class="flex.messaging.socketserver.SocketServer">
<properties>
<http>
<cross-domain-path>crossdomain.xml</cross-domain-path>
</http>
</properties>
</server>
Because this setting only applies to NIO-based AMF and HTTP endpoints it goes in the http section of configuration
settings. The NIO server expects cross domain policy files to be under the WEB-INF/flex directory of the LiveCycle
Data Services web application. In the previous example, you would place a file called crossdomain.xml with your cross
domain policy settings in the WEB-INF/flex directory of your LiveCycle Data Services web application.
You can also place cross domain files in subdirectories under WEB-INF/flex. This lets you have cross domain policy
files for individual NIO-based endpoints. For example, if you want a cross domain policy file that only applies to your
NIO-based AMF endpoint at http://domainA:1234/nioamfpolling, you would configure your application as follows:
• Use a cross-domain-path of /nioamfpolling, which causes the NIO server to search for a cross domain policy file
under /WEB-INF/flex/nioamfpolling.
• The cross domain path must match the cross domain policy request. This means that to use the cross domain policy
file under /WEB-INF/flex/nioamfpolling, the request must be made to
http://domainA:1234/nioamfpolling/crossdomain.xml.
• By default, the cross domain policy request is made to the root of the application; for example,
http://domainA:1234/crossdomain.xml. To override this behavior in your application, you must use the
Security.loadPolicyFile() method; in your application, before you make the request to the endpoint, you would add
the following line of code.
Security.loadPolicyFile("http://domainA:1234/nioamfpolling/crossdomain.xml");
Last updated 3/10/2011
Page 73

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
This causes Flash Player to attempt to load a cross domain policy file with the supplied URL. In this case, the NIO
server returns a cross domain policy file from the WEB-INF/flex/nioamfpolling directory and the permissions in
the policy file are applied to requests to the http://domainA:1234/nioamfpolling endpoint only.
Channel and endpoint recommendations
The NIO-based AMF and HTTP endpoints use the same client-side channels as their servlet-based endpoint
counterparts. The main advantage that NIO-based endpoints have over servlet-based endpoints is that they scale
better. If a web application is not servicing general servlet requests, you can configure the servlet container to bind
non-standard HTTP and HTTPS ports, leaving ports 80 and 443 free for your NIO-based endpoints. You still have
access to the servlet-based endpoints if you want to use them instead.
Note: The LiveCycle Data Services installation includes an NIO load testing tool with sample test driver classes and a
readme file in the install_root/resources/load-testing-tool directory. You can use this tool in a Java client application to
load test LiveCycle Data Services NIO-based channels/endpoints running in a LiveCycle Data Services web application.
Use the servlet-based endpoints when you must include third-party servlet filter processing of requests and responses
or when you must access data structures in the application server HttpSession. NIO -based AMF and HTTP endpoints
are not part of the servlet pipeline, so, although they provide a FlexSession in the same manner that RTMP connections
do, these session instances are disjoint from the J2EE HttpSession.
If you are only using remote procedure calls or using the Data Management Service without auto synchronization, you
can use the AMFChannel.
69
Note: The HTTPChannel is the same as the AMFChannel behaviorally, but serializes data in an XML format called
AMFX. This channel only exists for customers who require all data sent over the wire to be non-binary for auditing
purposes. There is no other reason to use this channel instead of the AMFChannel for RPC-based applications.
The process for using real-time data push to web clients is not as simple as the RPC scenario. There are a variety of
trade-offs, and benefits and disadvantages to consider. Although the answer is not simple, it is prescriptive based on
the requirements of your application.
If your application uses both real-time data push as well as RPC, you do not need to use separate channels. All of the
channels listed can send RPC invocations to the server. Use a single channel set, possibly containing just a single
channel, for all of your RPC, messaging and data management components.
Servlet-based endpoints
Some servlet-based channel/endpoint combinations are preferred over others, depending on your application
environment. Each combination is listed here in order of preference. Although servlet-based channels/endpoints are
listed first, the equivalent NIO-based versions are preferred when NIO is available and acceptable in your application
environment.
1. AMFChannel/Endpoint configured for long polling (no fallback needed)
The channel issues polls to the server in the same way as simple polling, but if no data is available to return immediately
the server parks the poll request until data arrives for the client or the configured server wait interval elapses.
The client can be configured to issue its next poll immediately following a poll response making this channel
configuration feel like real-time communication.
A reasonable server wait time would be one minute. This eliminates the majority of busy polling from clients without
being so long that you’re keeping server sessions alive indefinitely or running the risk of a network component between
the client and server timing out the connection.
Last updated 3/10/2011
Page 74

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Benefits Disadvantages
70
Valid HTTP request/response
pattern over standard ports that
nothing in the network path will
have trouble with.
The Servlet API uses blocking IO, so you must define an upper bound for the
When many messages are being pushed to the client, this configuration has
the overhead of a poll round trip for every pushed message or small batch of
messages queued between polls. Most applications are not pushing data so
frequently for this to be a problem.
number of long poll requests parked on the server at any single instant. If your
number of clients exceeds this limit, the excess clients devolve to simple
polling on the default 3- second interval with no server wait. For example, if
you server request handler thread pool has a size of 500, you could set the
upper bound for waited polls to 250, 300, or 400 depending on the relative
amount of non-poll requests you expect to service concurrently.
2. StreamingAMFChannel/Endpoint (in a channel set followed by the polling AMFChannel for fallback)
Because HTTP connections are not duplex, this channel sends a request to open an HTTP connection between the
server and client, over which the server writes an infinite response of pushed messages. This channel uses a separate
transient connection from the browser connection pool for each send it issues to the server. The streaming connection
is used purely for messages pushed from the server down to the client. Each message is pushed as an HTTP response
chunk (HTTP 1.1 Transfer-Encoding: chunked).
Benefits Disadvantages
No polling overhead associated
with pushing messages to the
client.
Holding onto the open request on the server and writing an infinite response
is not typical HTTP behavior. HTTP proxies that buffer responses before
forwarding them can effectively consume the stream. Assign the channel’s
‘connect-timeout-seconds’ property a value of 2 or 3 to detect this and trigger
fallback to the next channel in your channel set.
Uses standard HTTP ports so
firewalls do not interfere and all
requests/responses are HTTP so
packet inspecting proxies won’t
drop the packets.
The Servlet API uses blocking IO so as with long polling above, you must set a
No support for HTTP 1.0 client. If the client is 1.0, the open request is faulted
and the client falls back to the next channel in its channel set.
configured upper bound on the number of streaming connections you allow.
Clients that exceed this limit are not able to open a streaming connection and
will fall back to the next channel in their channel set.
3. AMFChannel/Endpoint with simple polling and piggybacking enabled (no fallback needed)
This configuration is the same as simple polling support but with piggybacking enabled. When the client sends a
message to the server between its regularly scheduled poll requests, the channel piggybacks a poll request along with
the message being sent, and the server piggybacks any pending messages for the client along with the response.
Last updated 3/10/2011
Page 75

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Benefits Disadvantages
71
Valid HTTP request/response
pattern over standard ports that
nothing in the network path will
have trouble with.
User experience feels more realtime than with simple polling on
an interval.
Does not have thread resource
constraints like long polling and
streaming due to the blocking IO
of the Servlet API.
Less real-time behavior than long polling or streaming. Requires client
interaction with the server to receive pushed data faster than the channel's
configured polling interval.
NIO-based endpoints
Some NIO-based channel/endpoint combinations are preferred over others, depending on your application
environment. Each combination is listed here in order of preference.
1. RTMPChannel/Endpoint (in a channel set with fallback to NIO AMFChannel configured to long poll)
The RTMPChannel creates a single duplex socket connection to the server and gives the server the best notification of
Flash Player being shut down. If the direct connect attempt fails, the player attempts a CONNECT tunnel through an
HTTP proxy if one is defined by the browser, resulting in a direct, tunneled duplex socket connection to the server. In
the worst case, the channel falls back to adaptive HTTP requests that tunnel RTMP data back and forth between client
and server, or it fails to connect entirely.
Benefits Disadvantages
Single, stateful duplex socket that
gives clean, immediate
notification when a client is closed.
The NIO-based AMF and HTTP
channels/endpoints generally do
not receive notification of a client
going away until the HTTP session
on the server times out. That is not
optimal for a call center
application where you must know
whether representatives are
online or not.
The Flash Player internal fallback
to HTTP CONNECT to traverse an
HTTP proxy if one is configured in
the browser gives the same
benefit as above, and is a
technique that is not possible from
ActionScript or JavaScript.
RTMP generally uses a non-standard port so it is often blocked by client
firewalls. Network components that use stateful packet inspection might also
drop RTMP packets, killing the connection. Fallback to HTTP CONNECT
through a proxy or adaptive HTTP tunnel requests is difficult in deployment
scenarios within a Java servlet container which generally already has the
standard HTTP ports bound. This requires a non-trivial networking
configuration to route these requests to the RTMPEndpoint.
By using an Edge Server in the DMZ to forward requests to a LiveCycle Data
Services server in the application tier, you can avoid or work around some of
these issues. For more information about the Edge Server see
page 391.
“Edge Server” on
2. NIO AMFChannel/Endpoint configured for long polling (no fallback needed)
This configuration is behaviorally the same as the servlet-based AMFChannel/AMFEndpoint but uses an NIO server
and minimal HTTP stack to support scaling up to thousands of connections.
Last updated 3/10/2011
Page 76

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Benefits Disadvantages
72
The same benefits as mentioned
for RTMPChannel/Endpoint, along
with much better scalability and
no configured upper bound on the
number of parked poll requests.
Because the servlet pipeline is not used, this endpoint requires more network
configuration to route requests to it on a standard HTTP port if you must
concurrently service HTTP servlet requests. However, it can share the same
port as any other NIO- based AMF or HTTP endpoint for the application.
3. NIO StreamingAMFChannel/Endpoint (in a channel set followed by the polling AMFChannel for fallback)
This configuration is behaviorally the same as the servlet-based StreamingAMFChannel/Endpoint but uses an NIO
server and minimal HTTP stack to support scaling up to thousands of connections.
Benefits Disadvantages
The same benefits as mentioned
for NIO AMFChannel/Endpoint
configured for Long Polling, along
with much better scalability and
no configured upper bound on the
number of streaming connections.
Because the servlet pipeline is not being used, this endpoint requires more
network configuration to route requests to it on a standard HTTP port. It must
concurrently service HTTP servlet requests. However, it can share the same
port as any other NIO-based AMF or HTTP endpoint for the application.
Unlike RTMP, which provides a full duplex socket connection, this scenario
requires one connection for regular HTTP requests and responses, and another
connection for server-to-client updates.
4. NIO AMFChannel/Endpoint with simple polling enabled (no long polling) and piggybacking enabled (no
fallback needed)
Behaviorally the same as the equivalent servlet-based configuration, but uses an NIO server and minimal HTTP stack
to support scaling up to thousands of connections.
Benefits Disadvantages
Same benefits as the servlet-based
piggybacking configuration.
Shares the same FlexSession as
other NIO-based AMF and HTTP
endpoints
Same disadvantages as the servlet-based piggybacking configuration.
Because the servlet pipeline is not being used, this endpoint requires more
network configuration to route requests to it on a standard HTTP port if you
need to concurrently service HTTP servlet requests. However, it can share the
same port as any other NIO-based AMF or HTTP endpoint for the application.
Using LiveCycle Data Services clients and servers behind a firewall
Because servlet-based endpoints use standard HTTP requests, communicating with clients inside firewalls usually
works, as long as the client-side firewall has the necessary ports open. Using the standard HTTP port 80 and HTTPS
port 443 is recommended because many firewalls block outbound traffic over non-standard ports.
When working with NIO-based endpoints, using AMF and HTTP endpoints instead of RTMP endpoints when clients
are inside a firewall allows the clients to connect to the server through their client-side firewall without running into a
blocked port. This method also allows packets to traverse stateful proxies that drop packets that they do not recognize,
but this requires that you expose the NIO-based AMF and HTTP endpoints on the standard HTTP port 80 and the
standard HTTPS port 443.
You can use load balancers with the NIO-based AMF and HTTP endpoints. You must configure the load balancer to
do sticky sessions based on the session cookie
that match the format of J2EE-encoded URLs but use an
token. For RTMP endpoints, you should apply TCP round-robin connectivity to the load-balanced RTMP port.
AMFSessionId, or based upon the session id embedded in request URLs
AMFSessionId token rather than the J2EE jsessionid
Last updated 3/10/2011
Page 77

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
You must configure server-side firewalls the same way you would to allow access to servlet-based AMF and HTTP
endpoints. Be aware of the following potential issues when using web servers/connectors in front of NIO-based AMF
and HTTP endpoints:
• The web server/connector could buffer streamed chunks in the response, interfering with real-time streaming. This
is not an issue for polling or long-polling, where a complete HTTP response is returned whenever data is sent to
the client.
• The web server/connector may not use asynchronous IO, in which case a single webserver or connector most likely
will not scale up to thousands of persistent concurrent HTTP connections.
The protocols that the various client channels use are hard coded. For example, the AMFChannel always uses HTTP,
while the SecureAMFChannel always uses HTTPS. One thing to watch for when using a
SecureAMFChannel/SecureAMFEndpoint combination is an issue with Internet Explorer related to no-cache
response headers and HTTPS. By default, no-cache response headers are enabled on HTTP-based endpoints. This
causes problems for Internet Explorer browsers. You can suppress these response headers by adding the following
configuration property to your endpoint:
<add-no-cache-headers>false</add-no-cache-headers>
When you have a firewall/reverse HTTP proxy in your deployment that handles SSL for you, you must mix and match
your channel and endpoint. You need the client to use a secure channel and the server to use an insecure endpoint, as
the following example shows:
73
<channel-definition id="secure-amf" class="mx.messaging.channels.SecureAMFChannel">
<endpoint url="https://<<firewall ip:port>>/{context.root}/messagebroker/amf"
class="flex.messaging.endpoints.AMFEndpoint"/>
<properties>
<add-no-cache-headers>false</add-no-cache-headers>
...
The channel class uses HTTPS to hit the firewall/proxy, and the endpoint URL must point at the firewall/proxy.
Because SSL is handled in the middle, you want the endpoint class used by LiveCycle Data Services to be the insecure
AMFEndpoint and your firewall/proxy must hand back requests to the HTTP port of the LiveCycle Data Services
server, not the HTTPS port.
Testing channel and endpoint performance under load
Use the LiveCycle Data Services load testing tool in a Java client application to load test LiveCycle Data Services NIOand servlet-based channels/endpoints running in a LiveCycle Data Services web application.
The LiveCycle Data Services installation includes the load testing tool with sample test driver classes and a readme file
in the install_root/resources/load-testing-tool directory.
Managing session data
Instances of the FlexClient, MessageClient, and FlexSession classes on the LiveCycle Data Services server represent a
Flex application and its connections to the server. You can use these objects to manage synchronization between a Flex
application and the server.
Last updated 3/10/2011
Page 78

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
FlexClient, MessageClient, and FlexSession objects
The FlexClient object
Every Flex application, written in MXML or ActionScript, is eventually compiled into a SWF file. When the SWF file
connects to the LiveCycle Data Services server, a flex.messaging.client.FlexClient object is created to represent that
SWF file on the server. SWF files and FlexClient instances have a one-to-one mapping. In this mapping, every
FlexClient instance has a unique identifier named
ActionScript singleton class, mx.messaging.FlexClient, is also created for the Flex application to access its unique
FlexClient
id.
The MessageClient object
If a Flex application contains a Consumer component (flex.messaging.Consumer), the server creates a corresponding
flex.messaging.MessageClient instance that represents the subscription state of the Consumer component. Every
MessageClient has a unique identifier named
generate the
before calling the
clientId value, but the Flex application can also set the value in the Consumer.clientId property
Consumer.subscribe() method.
The FlexSession object
A FlexSession object represents the connection between the Flex application and the LiveCycle Data Services server.
Its life cycle depends on the underlying protocol, which is determined by the channels and endpoints used on the client
and server, respectively.
id, which the LiveCycle Data Services server generates. An
clientId. The LiveCycle Data Services server can automatically
74
If you use an RTMP channel in the Flex application, the FlexSession on the LiveCycle Data Services server is scoped to
the underlying RTMP connection from the single SWF file. The server is immediately notified when the underlying
SWF file is disconnected because RTMP provides a duplex socket connection between the SWF file and the LiveCycle
Data Services server. RTMP connections are created for individual SWF files, so when the connection is closed, the
associated FlexSession is invalidated.
If an HTTP-based channel, such as AMFChannel or HTTPChannel, is used in the Flex application, the FlexSession on
the LiveCycle Data Services server is scoped to the browser and wraps an HTTP session. If the HTTP-based channel
connects to a servlet-based endpoint, the underlying HTTP session is a J2EE HttpSession object. If the channel
connects to an NIO-based endpoint, the underlying HTTP session supports the FlexSession API, but it is disjointed
from the application server HttpSession object.
The relationship between FlexClient, MessageClient, and FlexSession classes
A FlexClient object can have one or more FlexSession instances associated with it depending on the channels that the
Flex application uses. For example, if the Flex application uses one HTTPChannel, one FlexSession represents the
HTTP session created for that HTTPChannel on the LiveCycle Data Services server. If the Flex application uses an
HTTPChannel and an RTMPChannel, two FlexSessions are created; one represents the HTTP session and the other
represents the RTMP session.
A FlexSession can also have one or more FlexClients associated with it. For example, when a SWF file that uses an
HTTPChannel is opened in two tabs, two FlexClient instances are created in the LCDS server (one for each SWF file),
but there is only one FlexSession because two tabs share the same underlying HTTP session.
In terms of hierarchy, FlexClient and FlexSession are peers whereas there is a parent-child relationship between
FlexClient/FlexSession and MessageClient. A MessageClient is created for every Consumer component in the Flex
application. A Consumer must be contained in a single SWF file and it must subscribe over a single channel. Therefore,
each MessageClient is associated with exactly one FlexClient and one FlexSession.
Last updated 3/10/2011
Page 79

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
If either the FlexClient or the FlexSession is invalidated on the server, it invalidates the MessageClient. This behavior
matches the behavior on the client. If you close the SWF file, the client subscription state is invalidated. If you
disconnect the channel or it loses connectivity, the Consumer component is unsubscribed.
Event listeners for FlexClient, MessageClient, and FlexSession
The LiveCycle Data Services server provides the following set of event listener interfaces that allow you to execute
custom business logic as FlexClient, FlexSession, and MessageClient instances are created and destroyed and as their
state changes:
Event listener Description
75
FlexClientListener FlexClientListener supports listening for life cycle events
FlexClientAttributeListener FlexClientAttributeListener supports notification when
FlexClientBindingListener FlexClientBindingListener supports notification when
FlexSessionListener FlexSessionListener supports listening for life cycle
FlexSessionAttributeListener FlexSessionAttributeListener supports notification when
FlexSessionBindingListener FlexSessionBindingListener supports notification when
MessageClientListener MessageClientListener supports listening for life cycle
for FlexClient instances.
attributes are added, replaced, or removed from
FlexClient instances.
the implementing class is bound or unbound as an
attribute to a FlexClient instance.
events for FlexSession instances.
attributes are added, replaced, or removed from
FlexSession instances.
the implementing class is bound or unbound as an
attribute to a FlexSession instance.
events for MessageClient instances representing
Consumer subscriptions.
For more information about these classes, see the Javadoc API documentation.
Log categories for FlexClient, MessageClient, and FlexSession classes
The following server-side log filter categories can be used to track creation, destruction, and other relevant information
for FlexClient, MessageClient, and FlexSession:
• Client.FlexClient
• Client.MessageClient
• Endpoint.FlexSession
Using the FlexContext class with FlexSession and FlexClient attributes
The flex.messaging.FlexContext class is a utility class that exposes the current execution context on the LiveCycle Data
Services server. It provides access to FlexSession and FlexClient instances associated with the current message being
processed. It also provides global context by accessing MessageBroker, ServletContext, and ServletConfig instances.
The following example shows a Java class that calls FlexContext.getHttpRequest() to get an HTTPServletRequest
object and calls
makes it accessible to a Flex client application. Place the compiled class in the WEB_INF/classes directory or your
LiveCycle Data Services web application.
FlexContext.getFlexSession() to get a FlexSession object. Exposing this class as a remote object
Last updated 3/10/2011
Page 80

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
package myROPackage;
import flex.messaging.*;
import java.io.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class SessionRO {
public HttpServletRequest request;
public FlexSession session;
public SessionRO() {
request = FlexContext.getHttpRequest();
session = FlexContext.getFlexSession();
}
public String getSessionId() throws Exception {
String s = new String();
s = (String) session.getId();
return s;
}
public String getHeader(String h) throws Exception {
String s = new String();
s = (String) request.getHeader(h);
return h + "=" + s;
}
}
76
The following example shows a Remoting Service destination definition that exposes the SessionRO class as a remote
object. You add this destination definition to your Remoting Service configuration file.
...
<destination id="myRODestination">
<properties>
<source>myROPackage.SessionRO</source>
</properties>
</destination>
...
The following example shows an ActionScript snippet for calling the remote object from a Flex client application. You
place this code inside a method declaration.
...
ro = new RemoteObject();
ro.destination = "myRODestination";
ro.getSessionId.addEventListener("result", getSessionIdResultHandler);
ro.getSessionId();
...
When you use an RTMP channel/endpoint, you can call the getClientInfo() method of the FlexSession instance to
get the IP address of the remote RTMP client and determine if the connection is an SSL connection, as the
getClientIp() method in the following example shows. You must cast the FlexSession instance to its
RTMPFlexSession subclass.
Last updated 3/10/2011
Page 81

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
package features.remoting;
import features.dataservice.paging.Employee;
import flex.messaging.FlexContext;
import flex.messaging.FlexSession;
import flex.messaging.MessageBroker;
import flex.messaging.endpoints.rtmp.ClientInfo;
import flex.messaging.endpoints.rtmp.RTMPFlexSession;
import flex.messaging.messages.AsyncMessage;
import flex.messaging.util.UUIDUtils;
import javax.servlet.http.HttpServletRequest;
public class EchoService
{
public String getClientIp()
{
FlexSession session = FlexContext.getFlexSession();
if (session instanceof RTMPFlexSession)
{
ClientInfo clientInfo = ((RTMPFlexSession)session).getClientInfo();
return "Client ip: " + clientInfo.getIp() + " isSecure? " + clientInfo.isSecure();
}
return null;
}
}
77
For more information about FlexContext, see the Javadoc API documentation.
Session life cycle
If you use an RTMP channel in the Flex application, the server is immediately notified when the SWF file is
disconnected because RTMP provides a duplex socket connection between the SWF file and the LiveCycle Data
Services server. RTMP channels connect to individual SWF files, so when the connection is closed, the associated
FlexSession is invalidated. This is not the case with HTTP-based channels because HTTP is a stateless protocol.
However, you can use certain techniques in your code to disconnect from HTTP-based channels and invalidate HTTP
sessions.
Disconnecting from an HTTP-based channel
Because HTTP is a stateless protocol, when a SWF file is disconnected, notification on the server depends on when the
HTTP session times out on the server. When you want a Flex application to notify the LiveCycle Data Services server
that it is closing, you call the
In your Flex application, expose a function for JavaScript to call, as the following example shows:
disconnectAll() method on the ChannelSet from JavaScript.
Last updated 3/10/2011
Page 82

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<mx:Application creationComplete="init();">
...
<mx:Script>
<
USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<channel-definition id="my-amf" class="mx.messaging.channels.AMFChannel">
<endpoint url="http://servername:port/contextroot/messagebroker/amf"
class="flex.messaging.endpoints.AMFEndpoint"/>
<properties>
<invalidate-session-on-disconnect>true</invalidate-session-on-disconnect>
</properties>
</channel>
Data serialization
LiveCycle Data Services and Flex provide functionality for serializing data to and from ActionScript objects on the
client and Java objects on the server, as well as serializing to and from ActionScript objects on the client and SOAP and
XML schema types. Basic types are automatically serialized and deserialized. When working with the Data
Management Service or Remoting Service, you can explicitly map custom ActionScript types to custom Java types.
Serialization between ActionScript and Java
LiveCycle Data Services and Flex let you serialize data between ActionScript (AMF 3) and Java in both directions.
79
Data conversion from ActionScript to Java
When method parameters send data from a Flex application to a Java object, the data is automatically converted from
an ActionScript data type to a Java data type. When LiveCycle Data Services searches for a suitable method on the Java
object, it uses further, more lenient conversions to find a match.
Simple data types on the client, such as Boolean and String values, typically exactly match a remote API. However, Flex
attempts some simple conversions when searching for a suitable method on a Java object.
An ActionScript Array can index entries in two ways. A strict Array is one in which all indices are Numbers. An
associative Array is one in which at least one index is based on a String. It is important to know which type of Array
you are sending to the server, because it changes the data type of parameters that are used to invoke a method on a Java
object. A dense Array is one in which all numeric indices are consecutive, with no gap, starting from 0 (zero). A sparse
Array is one in which there are gaps between the numeric indices; the Array is treated like an object and the numeric
indices become properties that are deserialized into a java.util.Map object to avoid sending many null entries.
The following table lists the supported ActionScript (AMF 3) to Java conversions for simple data types:
Last updated 3/10/2011
Page 84

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
ActionScript type (AMF 3) Deserialization to Java Supported Java type binding
Array (dense) java.util.List java.util.Collection, Object[ ] (native array)
If the type is an interface, it is mapped to the following
interface implementations
• List becomes ArrayList
• SortedSet becomes TreeSet
• Set becomes HashSet
• Collection becomes ArrayList
A new instance of a custom Collection implementation is
bound to that type.
Array (sparse) java.util.Map java.util.Map
80
Boolean
String of "true" or
"false"
flash.utils.ByteArray byte []
flash.utils.IExternalizable java.io.Externalizable
Date java.util.Date
int/uint java.lang.Integer java.lang.Double, java.lang.Long, java.lang.Float,
null null primitives
Number java.lang.Double java.lang.Double, java.lang.Long, java.lang.Float,
Object (generic) java.util.Map If a Map interface is specified, creates a new
String java.lang.String java.lang.String, java.lang.Boolean, java.lang.Number,
java.lang.Boolean Boolean, boolean, String
java.util.Date, java.util.Calendar, java.sql.Timestamp,
(formatted for
Coordinated Universal
Time (UTC))
java.sql.Time, java.sql.Date
java.lang.Integer, java.lang.Short, java.lang.Byte,
java.math.BigDecimal, java.math.BigInteger, String,
primitive types of double, long, float, int, short, byte
java.lang.Integer, java.lang.Short, java.lang.Byte,
java.math.BigDecimal, java.math.BigInteger, String, 0
(zero) if null is sent, primitive types of double, long, float,
int, short, byte
java.util.HashMap for java.util.Map and a new
java.util.TreeMap for java.util.SortedMap.
java.math.BigInteger, java.math.BigDecimal, char[],
enum, any primitive number type
typed Object typed Object
when you use
[RemoteClass]
metadata tag that
specifies remote class
name. Bean type must
have a public no args
constructor.
typed Object
Last updated 3/10/2011
Page 85

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
ActionScript type (AMF 3) Deserialization to Java Supported Java type binding
undefined null null for Object, default values for primitives
XML org.w3c.dom.Document org.w3c.dom.Document
81
XMLDocument
(legacy XML type)
org.w3c.dom.Document org.w3c.dom.Document
You can enable legacy XML support for the
XMLDocument type on any channel defined in the
services-config.xml file. This setting is only important for
sending data from the server back to the client; it controls
how org.w3c.dom.Document instances are sent to
ActionScript. For more information, see
serialization on a channel” on page 84.
“Configuring AMF
Primitive values cannot be set to null in Java. When passing Boolean and Number values from the client to a Java
object, Flex interprets null values as the default values for primitive types; for example, 0 for double, float, long, int,
short, byte, \u0000 for char, and
false for boolean. Only primitive Java types get default values.
LiveCycle Data Services handles java.lang.Throwable objects like any other typed object. They are processed with rules
that look for public fields and bean properties, and typed objects are returned to the client. The rules are like normal
bean rules except they look for getters for read-only properties. This lets you get more information from a Java
exception. If you require legacy behavior for Throwable objects, you can set the
on a channel; for more information, see
“Configuring AMF serialization on a channel” on page 84.
legacy-throwable property to true
You can pass strict Arrays as parameters to methods that expect an implementation of the java.util.Collection or native
Java Array APIs.
A Java Collection can contain any number of Object types, whereas a Java Array requires that entries are the same type
(for example, java.lang.Object[ ], and int[ ]).
LiveCycle Data Services also converts ActionScript strict Arrays to appropriate implementations for common
Collection API interfaces. For example, if an ActionScript strict Array is sent to the Java object method
addProducts(java.util.Set products), LiveCycle Data Services converts it to a java.util.HashSet instance before
public void
passing it as a parameter, because HashSet is a suitable implementation of the java.util.Set interface. Similarly,
LiveCycle Data Services passes an instance of java.util.TreeSet to parameters typed with the java.util.SortedSet
interface.
LiveCycle Data Services passes an instance of java.util.ArrayList to parameters typed with the java.util.List interface
and any other interface that extends java.util.Collection. Then these types are sent back to the client as
mx.collections.ArrayCollection instances. If you require normal ActionScript Arrays sent back to the client, you must
legacy-collection element to true in the serialization section of a channel-definition's properties; for
set the
more information, see
“Configuring AMF serialization on a channel” on page 84.
Explicitly mapping ActionScript and Java objects
For Java objects that LiveCycle Data Services does not handle implicitly, LiveCycle Data Services uses value objects,
also known as transfer objects, to send data between client and server. For Java objects on the server side, values found
in public bean properties with get/set methods and public variables are sent to the client as properties on an Object.
Private properties, constants, static properties, and read-only properties are not serialized. For ActionScript objects on
the client side, public properties defined with the get/set accessors and public variables are sent to the server.
LiveCycle Data Services uses the standard Java class, java.beans.Introspector, to get property descriptors for a Java bean
class. It also uses reflection to gather public fields on a class. It uses bean properties in preference to fields. The Java
and ActionScript property names should match. Native Flash Player code determines how ActionScript classes are
introspected on the client.
Last updated 3/10/2011
Page 86
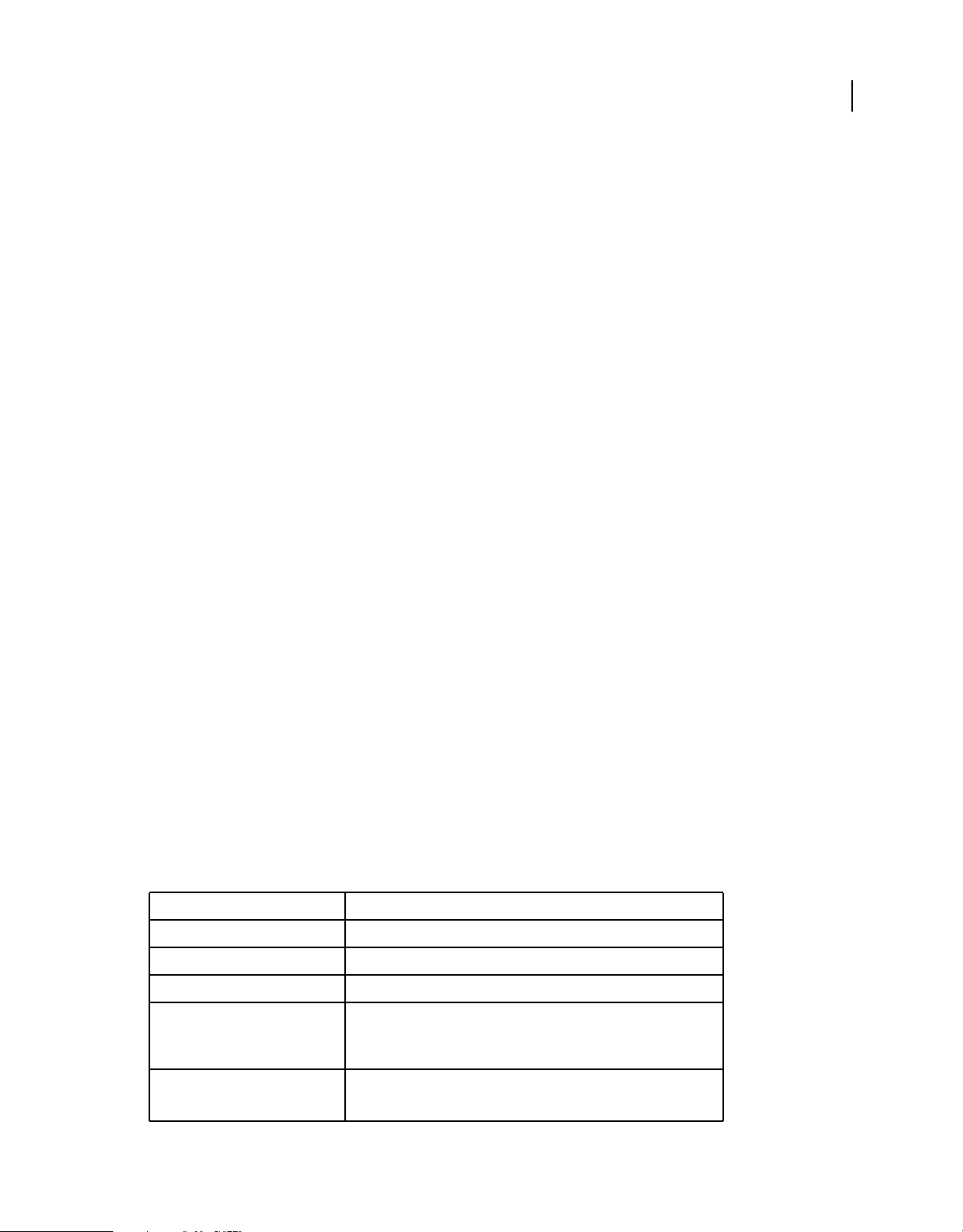
USING ADOBE LIVECYCLE DATA SERVICES
System architecture
In the ActionScript class, you use the [RemoteClass(alias=" ")] metadata tag to create an ActionScript object that
maps directly to the Java object. The ActionScript class to which data is converted must be used or referenced in the
MXML file for it to be linked into the SWF file and available at run time. A good way to do this is by casting the result
object, as the following example shows:
var result:MyClass = MyClass(event.result);
The class itself should use strongly typed references so that its dependencies are also linked.
The following example shows the source code for an ActionScript class that uses the [RemoteClass(alias=" ")]
metadata tag:
package samples.contact {
[Bindable]
[RemoteClass(alias="samples.contact.Contact")]
public class Contact {
public var contactId:int;
public var firstName:String;
public var lastName:String;
public var address:String;
public var city:String;
public var state:String;
public var zip:String;
}
}
82
You can use the [RemoteClass] metadata tag without an alias if you do not map to a Java object on the server, but
you do send back your object type from the server. Your ActionScript object is serialized to a special Map object when
it is sent to the server, but the object returned from the server to the clients is your original ActionScript type.
To restrict a specific property from being sent to the server from an ActionScript class, use the [Transient] metadata
tag above the declaration of that property in the ActionScript class.
Data conversion from Java to ActionScript
An object returned from a Java method is converted from Java to ActionScript. LiveCycle Data Services also handles
objects found within objects. LiveCycle Data Services implicitly handles the Java data types in the following table.
Java type ActionScript type (AMF 3)
enum (JDK 1.5) String
java.lang.String String
java.lang.Boolean, boolean Boolean
java.lang.Integer, int int
If value < 0xF0000000 || value > 0x0FFFFFFF, the value is promoted to
Number due to AMF encoding requirements.
java.lang.Short, short int
If i < 0xF0000000 || i > 0x0FFFFFFF, the value is promoted to Number.
Last updated 3/10/2011
Page 87

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Java type ActionScript type (AMF 3)
java.lang.Byte, byte[] int
If i < 0xF0000000 || i > 0x0FFFFFFF, the value is promoted to Number.
java.lang.Byte[] flash.utils.ByteArray
java.lang.Double, double Number
java.lang.Long, long Number
java.lang.Float, float Number
java.lang.Character, char String
java.lang.Character[], char[] String
java. math.BigInteger String
java.math.BigDecimal String
java.util.Calendar Date
Dates are sent in the Coordinated Universal Time (UTC) time zone. Clients
and servers must adjust time accordingly for time zones.
java.util.Date Date
Dates are sent in the UTC time zone. Clients and servers must adjust time
accordingly for time zones.
83
java.util.Collection (for example,
java.util.ArrayList)
java.lang.Object[] Array
java.util.Map Object (untyped). For example, a java.util.Map[] is converted to an Array (of
java.util.Dictionary Object (untyped)
org.w3c.dom.Document XML object
null null
java.lang.Object (other than
previously listed types)
mx.collections.ArrayCollection
Objects).
Typed Object
Objects are serialized using Java bean introspection rules and also include
public fields. Fields that are static, transient, or nonpublic, as well as bean
properties that are nonpublic or static, are excluded.
Note: You can enable legacy XML support for the flash.xml.XMLDocument type on any channel that is defined in the
services-config.xml file. In Flex 1.5, java.util.Map was sent as an associative or ECMA Array. This is no longer a
recommended practice. You can enable legacy Map support to associative Arrays, but Adobe recommends against doing this.
The following table contains type mappings between types that are specific to Apache Axis and ActionScript types for
RPC-encoded web services:
Apache Axis type ActionScript type
Map Object
Last updated 3/10/2011
Page 88

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Apache Axis type ActionScript type
RowSet Can only receive RowSets; can’t send them.
Document Can only receive Documents; can’t send them.
Element flash.xml.XMLNode
Configuring AMF serialization on a channel
You can support legacy AMF type serialization used in earlier versions of Flex and configure other serialization
properties in channel definitions in the services-config.xml file.
The following table describes the properties that you can set in the <serialization> element of a channel definition:
Property Description
84
enable-small-messages
ignore-property-errors
include-read-only Default value is false. Determines if read-only properties should be
log-property-errors
legacy-collection
legacy-map
legacy-xml
legacy-throwable
Default value is true. If enabled, messages are sent using an alternative
smaller form if one is available and the endpoint supports it. When you set
the value of this property to
messageId, timestamp, correlationId, and destination, which can be useful
for debugging. When you disable small messages, enable debug logging to
include messages in server logs. For information, see
on page 25.
Default value is true. Determines if the endpoint should throw an error
when an incoming client object has unexpected properties that cannot be
set on the server object.
serialized back to the client.
Default value is false. When true, unexpected property errors are logged.
Default value is false. When true, instances of java.util.Collection are
returned to the client as ActionScript Array objects instead of
mx.collections.ArrayCollection objects. When
deserialization, instances of ActionScript Array objects are deserialized into
Java List objects instead of Java Object arrays.
Default value is false. When true, java.util.Map instances are serialized as
an ECMA Array or associative array instead of an anonymous Object.
Default value is false. When true, org.w3c.dom.Document instances are
serialized as flash.xml.XMLDocument instances instead of intrinsic XML (E4X
capable) instances.
Default value is false. When true, java.lang.Throwable instances are
serialized as AMF status-info objects (instead of normal bean serialization,
including read-only properties).
false, messages include headers including
“Server-side logging”
true, during client to server
legacy-externalizable
Default value is false. When true, java.io.Externalizable types (that extend
standard Java classes like Date, Number, String) are not serialized as custom
objects (for example, MyDate is serialized as Date instead of MyDate). Note
that this setting overwrites any other legacy settings. For example, if
legacy-collection is true but the collection implements
java.io.Externalizable, the collection is returned as custom object without
taking the
legacy-collection value into account.
Last updated 3/10/2011
Page 89

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Property Description
85
type-marshaller
restore-references
instantiate-types
Specifies an implementation of flex.messaging.io.TypeMarshaller that
translates an object into an instance of a desired class. Used when invoking
a Java method or populating a Java instance and the type of the input object
from deserialization (for example, an ActionScript anonymous Object is
always deserialized as a java.util.HashMap) doesn't match the destination
API (for example, java.util.SortedMap). Thus, the type can be marshalled into
the desired type.
The flex.messaging.io.amf.translator.ASTranslator class is an
implementation of TypeMarshaller that you can use as an example for your
own TypeMarshaller implementations.
Default value is false. An advanced switch to make the deserializer keep
track of object references when a type translation has to be made; for
example, when an anonymous Object is sent for a property of type
java.util.SortedMap, the Object is first deserialized to a java.util.Map as
normal, and then translated to a suitable implementation of SortedMap
(such as java.util.TreeMap). If other objects pointed to the same anonymous
Object in an object graph, this setting restores those references instead of
creating SortedMap implementations everywhere. Notice that setting this
property to
amounts of data.
Default value is true. Advanced switch that when set to false stops the
deserializer from creating instances of strongly typed objects and instead
retains the type information and deserializes the raw properties in a Map
implementation, specifically flex.messaging.io.ASObject. Notice that any
classes under flex.* package are always instantiated.
true can slow down performance significantly for large
Using custom serialization between ActionScript and Java
If the standard mechanisms for serializing and deserializing data between ActionScript on the client and Java on the
server do not meet your needs, you can write your own serialization scheme. You implement the ActionScript-based
flash.utils.IExternalizable interface on the client and the corresponding Java-based java.io.Externalizable interface on
the server.
A typical reason to use custom serialization is to avoid passing all of the properties of either the client-side or serverside representation of an object across the network tier. When you implement custom serialization, you can code your
classes so that specific properties that are client-only or server-only are not passed over the wire. When you use the
standard serialization scheme, all public properties are passed back and forth between the client and the server.
On the client side, the identity of a class that implements the flash.utils.IExternalizable interface is written in the
serialization stream. The class serializes and reconstructs the state of its instances. The class implements the
writeExternal() and readExternal() methods of the IExternalizable interface to get control over the contents and
format of the serialization stream, but not the class name or type, for an object and its supertypes. These methods
supersede the native AMF serialization behavior. These methods must be symmetrical with their remote counterpart
to save the state of the class.
On the server side, a Java class that implements the java.io.Externalizable interface performs functionality that is
analogous to an ActionScript class that implements the flash.utils.IExternalizable interface.
Note: You should not use types that implement the IExternalizable interface with the HTTPChannel if precise byreference serialization is required. When you do this, references between recurring objects are lost and appear to be cloned
at the endpoint.
Last updated 3/10/2011
Page 90

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
Client-side Product class
The following example shows the complete source code for the client (ActionScript) version of a Product class that
maps to a Java-based Product class on the server. The client Product class implements the IExternalizable interface and
the server Product class implements the Externalizable interface.
// Product.as
package samples.externalizable {
import flash.utils.IExternalizable;
import flash.utils.IDataInput;
import flash.utils.IDataOutput;
[RemoteClass(alias="samples.externalizable.Product")]
public class Product implements IExternalizable {
public function Product(name:String=null) {
this.name = name;
}
public var id:int;
public var name:String;
public var properties:Object;
public var price:Number;
public function readExternal(input:IDataInput):void {
name = input.readObject() as String;
properties = input.readObject();
price = input.readFloat();
}
public function writeExternal(output:IDataOutput):void {
output.writeObject(name);
output.writeObject(properties);
output.writeFloat(price);
}
}
}
86
The client Product class uses two kinds of serialization. It uses the standard serialization that is compatible with the
java.io.Externalizable interface and AMF 3 serialization. The following example shows the
writeExternal() method
of the client Product class, which uses both types of serialization:
public function writeExternal(output:IDataOutput):void {
output.writeObject(name);
output.writeObject(properties);
output.writeFloat(price);
}
As the following example shows, the writeExternal() method of the server Product class is almost identical to the
client version of this method:
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(name);
out.writeObject(properties);
out.writeFloat(price);
}
Last updated 3/10/2011
Page 91

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
In the writeExternal() method of the client Product class, the flash.utils.IDataOutput.writeFloat()
method is an example of standard serialization methods that meet the specifications for the Java
java.io.DataInput.readFloat() methods for working with primitive types. This method sends the price
property, which is a Float, to the server Product.
The examples of AMF 3 serialization in the writeExternal() method of the client Product class is the call to the
flash.utils.IDataOutput.writeObject() method, which maps to the java.io.ObjectInput.readObject()
method call in the server Product class
method sends the
properties property, which is an Object, and the name property, which is a String, to the server
readExternal() method. The flash.utils.IDataOutput.writeObject()
Product. This is possible because the AMFChannel endpoint has an implementation of the java.io.ObjectInput
interface that expects data sent from the
writeObject() method to be formatted as AMF 3.
In turn, when the readObject() method is called in the server Product's readExternal() method, it uses AMF 3
deserialization; this is why the ActionScript version of the
properties value is assumed to be of type Map and name
is assumed to be of type String.
Server-side Product class
The following example shows the complete source code of the server Product class:
// Product.java
package samples.externalizable;
import java.io.Externalizable;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
import java.util.Map;
/**
* This Externalizable class requires that clients sending and
* receiving instances of this type adhere to the data format
* required for serialization.
*/
public class Product implements Externalizable {
private String inventoryId;
public String name;
public Map properties;
public float price;
public Product()
{
}
/**
* Local identity used to track third party inventory. This property is
* not sent to the client because it is server-specific.
* The identity must start with an 'X'.
*/
public String getInventoryId() {
return inventoryId;
}
public void setInventoryId(String inventoryId) {
if (inventoryId != null && inventoryId.startsWith("X"))
{
87
Last updated 3/10/2011
Page 92

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
this.inventoryId = inventoryId;
}
else
{
throw new IllegalArgumentException("3rd party product
inventory identities must start with 'X'");
}
}
/**
* Deserializes the client state of an instance of ThirdPartyProxy
* by reading in String for the name, a Map of properties
* for the description, and
* a floating point integer (single precision) for the price.
*/
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
// Read in the server properties from the client representation.
name = (String)in.readObject();
properties = (Map)in.readObject();
price = in.readFloat();
setInventoryId(lookupInventoryId(name, price));
}
/**
* Serializes the server state of an instance of ThirdPartyProxy
* by sending a String for the name, a Map of properties
* String for the description, and a floating point
* integer (single precision) for the price. Notice that the inventory
* identifier is not sent to external clients.
*/
public void writeExternal(ObjectOutput out) throws IOException {
// Write out the client properties from the server representation
out.writeObject(name);
out.writeObject(properties);
out.writeFloat(price);
}
private static String lookupInventoryId(String name, float price) {
String inventoryId = "X" + name + Math.rint(price);
return inventoryId;
}
}
88
The following example shows the readExternal() method of the server Product class:
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
// Read in the server properties from the client representation.
name = (String)in.readObject();
properties = (Map)in.readObject();
price = in.readFloat();
setInventoryId(lookupInventoryId(name, price));
}
Last updated 3/10/2011
Page 93

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
The writeExternal() method of the client Product class does not send the id property to the server during
serialization because it is not useful to the server version of the Product object. Similarly, the
method of the server Product class does not send the
inventoryId property to the client because it is a server-specific
writeExternal()
property.
Notice that the names of a Product properties are not sent during serialization in either direction. Because the state of
the class is fixed and manageable, the properties are sent in a well-defined order without their names, and the
readExternal() method reads them in the appropriate order.
Remote object class
The following example shows the source code of the Java class, ProductRegistry, which is called with the RemoteObject
component on the client:
package example.externalizable;
import java.util.Collection;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
/**
* A simple registry to manage instances of Product for an example of the
* Externalizable API for custom serialization.
*/
public class ProductRegistry
{
public ProductRegistry()
{
registry = Collections.synchronizedMap(new HashMap());
Product p = new Product();
p.name = "Example Widget";
p.description = "The right widget for any problem.";
p.price = 350;
registerProduct(p);
p = new Product();
p.name = "Example Gift";
p.description = "The perfect gift for any occasion.";
p.price = 225;
registerProduct(p);
}
public void registerProduct(Product product)
{
registry.put(product.getId(), product);
}
public Collection getProducts()
{
return registry.values();
}
private Map registry;
}
89
Destination configuration
The following XML snippet shows the ProductRegistry destination in the remoting-config.xml file:
Last updated 3/10/2011
Page 94

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<destination id="ProductRegistry">
<properties>
<source>example.externalizable.ProductRegistry</source>
<scope>application</scope>
</properties>
</destination>
MXML application code
The following example shows the MXML application that calls the ProductRegistry destination on the server:
<?xml version="1.0"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml">
<mx:Script>
<![CDATA[
import mx.collections.ArrayCollection;
import mx.controls.Alert;
import mx.rpc.events.FaultEvent;
import mx.rpc.events.ResultEvent;
import example.externalizable.Product;
[Bindable]
public var products:ArrayCollection
// Create a compile time dependency on Product class.
private static var dep:Product;
public function resultHandler(event:ResultEvent):void
{
products = event.result as ArrayCollection;
}
public function faultHandler(event:FaultEvent):void
{
Alert.show("Fault", event.fault.toString());
}
]]>
</mx:Script>
<mx:RemoteObject id="remoteObject" destination="ProductRegistry"
fault="faultHandler(event)"
result="resultHandler(event)" />
<mx:Panel title="Externalizable Example" height="400" width="600"
paddingTop="10" paddingLeft="10" paddingRight="10">
90
Last updated 3/10/2011
Page 95

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
<mx:DataGrid id="grid" width="100%" rowCount="5" dataProvider="{products}">
<mx:columns>
<mx:DataGridColumn dataField="name" headerText="Name"/>
<mx:DataGridColumn dataField="price" headerText="Price"/>
</mx:columns>
</mx:DataGrid>
<mx:Form width="100%">
<mx:FormItem label="Name">
<mx:Label text="{grid.selectedItem.name}"/>
</mx:FormItem>
<mx:FormItem label="Price">
<mx:Label text="{grid.selectedItem.price}"/>
</mx:FormItem>
<mx:FormItem label="Description">
<mx:TextArea text="{grid.selectedItem.description}"/>
</mx:FormItem>
</mx:Form>
<mx:Button label="Get Products" click="remoteObject.getProducts()" />
</mx:Panel>
</mx:Application>
Serialization between ActionScript and web services
91
Default encoding of ActionScript data
The following table shows the default encoding mappings from ActionScript 3 types to XML schema complex types.
XML schema definition Supported ActionScript 3
Top-level elements
xsd:element
nillable == true
xsd:element
fixed != null
xsd:element
default != null
Local elements
xsd:element
maxOccurs == 0
types
Object If input value is null, encoded output is set with
Object Input value is ignored and fixed value is used
Object If input value is null, this default value is used
Object Input value is ignored and omitted from encoded
Notes
xsi:nil attribute.
the
instead.
instead.
output.
Last updated 3/10/2011
Page 96

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
92
xsd:element
maxOccurs == 1
Object Input value is processed as a single entity. If the
associated type is a SOAP-encoded array, then
arrays and
mx.collection.IList
implementations pass through intact and are
handled as a special case by the SOAP encoder for
that type.
xsd:element
maxOccurs > 1
Object Input value should be iterable (such as an array or
mx.collections.IList implementation),
although noniterable values are wrapped before
processing. Individual items are encoded as
separate entities according to the definition.
xsd:element
minOccurs == 0
Object If input value is undefined or null, encoded
output is omitted.
The following table shows the default encoding mappings from ActionScript 3 types to XML schema built-in types.
XML schema type Supported ActionScript 3
types
xsd:anyType
xsd:anySimpleType
Object Boolean -> xsd:boolean
Notes
ByteArray -> xsd:base64Binary
Date -> xsd:dateTime
int -> xsd:int
Number -> xsd:double
String -> xsd:string
uint -> xsd:unsignedInt
xsd:base64Binary flash.utils.ByteArray mx.utils.Base64Encoder is used (without
line wrapping).
xsd:boolean Boolean
Number
Object
xsd:byte
xsd:unsignedByte
xsd:date Date
Number
String
Number
String
Always encoded as true or false.
Number == 1 then true, otherwise false.
Object.toString() == "true" or "1" then
true, otherwise false.
String first converted to Number.
Date UTC accessor methods are used.
Number used to set Date.time.
String assumed to be preformatted and encoded
as is.
xsd:dateTime Date
Number
String
Date UTC accessor methods are used.
Number used to set Date.time.
String assumed to be preformatted and encoded
as is.
xsd:decimal Number
String
Number.toString() is used. Note that Infinity,
-Infinity, and NaN are invalid for this type.
String first converted to Number.
Last updated 3/10/2011
Page 97

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
93
XML schema type Supported ActionScript 3
Notes
types
xsd:double Number
String
xsd:duration Object Object.toString() is called.
xsd:float Number
String
xsd:gDay Date
Number
String
xsd:gMonth Date
Number
String
xsd:gMonthDay Date
String
Limited to range of Number.
String first converted to Number.
Limited to range of Number.
String first converted to Number.
Date.getUTCDate() is used.
Number used directly for day.
String parsed as Number for day.
Date.getUTCMonth() is used.
Number used directly for month.
String parsed as Number for month.
Date.getUTCMonth() and
Date.getUTCDate() are used.
String parsed for month and day portions.
xsd:gYear Date
Number
String
Date.getUTCFullYear() is used.
Number used directly for year.
String parsed as Number for year.
xsd:gYearMonth Date
String
Date.getUTCFullYear() and
Date.getUTCMonth() are used.
String parsed for year and month portions.
xsd:hexBinary flash.utils.ByteArray mx.utils.HexEncoder is used.
xsd:integer
and derivatives:
xsd:negativeInteger
xsd:nonNegativeInteger
xsd:positiveInteger
xsd:nonPositiveInteger
xsd:int
xsd:unsignedInt
xsd:long
xsd:unsignedLong
xsd:short
xsd:unsignedShort
Number
String
Number
String
Number
String
Number
String
Limited to range of Number.
String first converted to Number.
String first converted to Number.
String first converted to Number.
String first converted to Number.
Last updated 3/10/2011
Page 98

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
94
XML schema type Supported ActionScript 3
xsd:string
and derivatives:
xsd:ID
xsd:IDREF
xsd:IDREFS
xsd:ENTITY
xsd:ENTITIES
xsd:language
xsd:Name
xsd:NCName
xsd:NMTOKEN
xsd:NMTOKENS
xsd:normalizedString
xsd:token
xsd:time Date
types
Object Object.toString() is invoked.
Number
String
Notes
Date UTC accessor methods are used.
Number used to set Date.time.
String assumed to be preformatted and encoded
as is.
xsi:nil null If the corresponding XML schema element
definition has minOccurs > 0, a
encoded by using xsi:nil; otherwise the element is
omitted entirely.
null value is
The following table shows the default mapping from ActionScript 3 types to SOAP-encoded types.
SOAPENC type Supported ActionScript 3
types
soapenc:Array Array
mx.collections.IList
soapenc:base64 flash.utils.ByteArray Encoded in the same manner as xsd:base64Binary.
soapenc:* Object Any other SOAP-encoded type is processed as if it were in the
Notes
SOAP-encoded arrays are special cases and are supported only
with RPC-encoded web services.
XSD namespace based on the
localName of the type's QName.
Default decoding of XML schema and SOAP to ActionScript 3
The following table shows the default decoding mappings from XML schema built-in types to ActionScript 3 types.
Last updated 3/10/2011
Page 99

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
95
XML schema type Decoded ActionScript 3
Notes
types
xsd:anyType
xsd:anySimpleType
String
Boolean
Number
If content is empty -> xsd:string.
If content cast to Number and value is NaN; or
if content starts with "0" or "-0", or
if content ends with "E":
then, if content is "true" or "false" -> xsd:boolean
otherwise -> xsd:string.
Otherwise content is a valid Number and thus ->
xsd:double.
xsd:base64Binary flash.utils.ByteArray mx.utils.Base64Decoder is used.
xsd:boolean Boolean If content is "true" or "1" then true, otherwise
xsd:date Date If no time zone information is present, local time is
false.
assumed.
xsd:dateTime Date If no time zone information is present, local time is
assumed.
xsd:decimal Number Content is created via Number(content) and is
thus limited to the range of Number.
Number.NaN, Number.POSITIVE_INFINITY and
Number.NEGATIVE_INFINITY are not allowed.
xsd:double Number Content is created via Number(content) and is
thus limited to the range of Number.
xsd:duration String Content is returned with whitespace collapsed.
xsd:float Number Content is converted through Number(content)
and is thus limited to the range of Number.
xsd:gDay uint Content is converted through uint(content).
xsd:gMonth uint Content is converted through uint(content).
xsd:gMonthDay String Content is returned with whitespace collapsed.
xsd:gYear uint Content is converted through uint(content).
xsd:gYearMonth String Content is returned with whitespace collapsed.
xsd:hexBinary flash.utils.ByteArray mx.utils.HexDecoder is used.
Last updated 3/10/2011
Page 100

USING ADOBE LIVECYCLE DATA SERVICES
System architecture
96
XML schema type Decoded ActionScript 3
types
xsd:integer
and derivatives:
xsd:byte
xsd:int
xsd:long
xsd:negativeInteger
xsd:nonNegativeInteger
xsd:nonPositiveInteger
xsd:positiveInteger
xsd:short
xsd:unsignedByte
xsd:unsignedInt
xsd:unsignedLong
xsd:unsignedShort
xsd:string
Number Content is decoded via parseInt().
String The raw content is simply returned as a string.
and derivatives:
xsd:ID
xsd:IDREF
xsd:IDREFS
xsd:ENTITY
xsd:ENTITIES
xsd:language
xsd:Name
xsd:NCName
xsd:NMTOKEN
xsd:NMTOKENS
xsd:normalizedString
xsd:token
Notes
Number.NaN, Number.POSITIVE_INFINITY and
Number.NEGATIVE_INFINITY are not allowed.
xsd:time Date If no time zone information is present, local time is
assumed.
xsi:nil null
The following table shows the default decoding mappings from SOAP-encoded types to ActionScript 3 types.
Last updated 3/10/2011
 Loading...
Loading...