

Page 1

Guide de l'utilisateur et de
l'administrateur VMware vSphere Big
Data Extensions
vSphere Big Data Extensions 2.3
Ce document prend en charge la version de chacun des produits
répertoriés, ainsi que toutes les versions publiées par la suite
jusqu'au remplacement dudit document par une nouvelle
édition. Pour rechercher des éditions plus récentes de ce
document, rendez-vous sur :
http://www.vmware.com/fr/support/pubs.
FR-TBD-00
Page 2

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Vous trouverez la documentation technique la plus récente sur le site Web de VMware à l'adresse :
http://www.vmware.com/fr/support/
Le site Web de VMware propose également les dernières mises à jour des produits.
N’hésitez pas à nous transmettre tous vos commentaires concernant cette documentation à l’adresse suivante :
docfeedback@vmware.com
Copyright © 2013 – 2015 VMware, Inc. Tous droits réservés. Copyright et informations sur les marques.
Cet ouvrage est concédé sous la licence Creative Commons Attribution-NoDerivs 3.0 aux États-Unis
(http://creativecommons.org/licenses/by-nd/3.0/us/legalcode).
VMware, Inc.
3401 Hillview Ave.
Palo Alto, CA 94304
www.vmware.com
2 VMware, Inc.
VMware, Inc.
100-101 Quartier Boieldieu
92042 Paris La Défense
France
www.vmware.com/fr
Page 3

Table des matières
À propos de ce guide 7
À propos de VMware vSphere Big Data Extensions 9
1
Prise en main de Big Data Extensions 9
Big Data Extensions et Project Serengeti 10
À propos de l'architecture de Big Data Extensions 12
À propos des gestionnaires d'applications 13
Installation de Big Data Extensions 17
2
Configuration système requise pour Big Data Extensions 17
Prise en charge d'Unicode UTF-8 et des caractères spéciaux 20
Le programme d'amélioration du produit 22
Déployer le vApp Big Data Extensions dans vSphere Web Client 23
Installer des RPM dans le référentiel Yum du serveur de gestion Serengeti 26
Installer le plug-in Big Data Extensions 27
Configurer les paramètres vCenter Single Sign-On du serveur de gestion Serengeti 29
Se connecter à un serveur de gestion Serengeti 30
Installer le client d'interface de ligne de commande distant Serengeti 31
Accéder à l'interface de ligne de commande Serengeti à l'aide du client d'interface de ligne de
commande distant 31
Mise à niveau de Big Data Extensions 35
3
Préparer la mise à niveau de Big Data Extensions 35
Mettre à niveau le dispositif virtuel Big Data Extensions 36
Mettre à niveau le plug-in Big Data Extensions 37
Mettre à niveau des clusters Big Data Extensions à l'aide de l'interface de ligne de commande
Serengeti 38
Mettre à niveau l' Serengeti CLI 39
Ajouter un serveur Syslog distant 39
VMware, Inc.
Gestion des gestionnaires d'applications 41
4
Ajouter un gestionnaire d'applications à l'aide de vSphere Web Client 41
Modifier un gestionnaire d'applications à l'aide de vSphere Web Client 42
Supprimer un gestionnaire d'applications à l'aide de vSphere Web Client 42
Afficher les gestionnaires d'applications et les distributions à l'aide de vSphere Web Client 42
Afficher les rôles du gestionnaire d'applications et de la distribution à l'aide de vSphere Web
Client 43
Gestion de distributions Hadoop 45
5
Types de déploiement de distribution Hadoop 45
3
Page 4

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Configurer une distribution Hadoop déployée sur Tarball à l'aide de l'interface de ligne de
commande Serengeti 46
Configuration de Yum et de référentiels Yum 48
Gérer les modèles de nœud 65
6
Tenir à jour une machine virtuelle de modèle Hadoop personnalisée 65
Créer une machine virtuelle de modèle de nœud à l'aide de RHEL Server 6.7 et VMware Tools 66
Prendre en charge plusieurs modèles de machine virtuelle 70
Gérer l'environnement Big Data Extensions 71
7
Ajouter des noms d'utilisateur spécifiques pour la connexion au serveur de gestion Serengeti 71
Modifier le mot de passe du serveur de gestion Serengeti 72
Créer un nom d'utilisateur et un mot de passe pour l'interface de ligne de commande Serengeti 73
Autoriser et vérifier les commandes exécutées en tant qu'utilisateur racine 74
Spécifier un groupe d'utilisateurs dans Active Directory ou LDAP pour utiliser un cluster Hadoop 74
Arrêter et démarrer les services Serengeti 75
Ports utilisés pour la communication entre Big Data Extensions et vCenter Server 76
Vérifier l'état de fonctionnement de l'environnement Big Data Extensions 77
Passer en mode maintenance pour effectuer la sauvegarde et la restauration à l'aide du client
d'interface de ligne de commande Serengeti 86
Sauvegarder et restaurer l'environnement Big Data Extensions 87
Gestion de ressources vSphere pour les clusters 89
8
Ajouter un pool de ressources avec l'interface de ligne de commande Serengeti 89
Supprimer un pool de ressources avec l'interface de ligne de commande Serengeti 90
Mettre à jour les pools de ressources à l'aide de l'interface de ligne de commande Serengeti 90
Ajouter une banque de données dans vSphere Web Client 91
Supprimer une banque de données de vSphere Web Client 92
Mettre à jour les banques de données à l'aide de l'interface de ligne de commande Serengeti 93
Ajouter un contrôleur SCSI Paravirtual pour les disques système et de permutation 94
Ajouter un réseau dans vSphere Web Client 94
Modifier le type de DNS dans vSphere Web Client 95
Reconfigurer un réseau IP statique dans vSphere Web Client 96
Supprimer un réseau de vSphere Web Client 96
Création de clusters Hadoop et HBase 99
9
À propos des types de déploiement de clusters Hadoop et HBase 101
Distributions Hadoop prenant en charge MapReduce v1 et MapReduce v2 (YARN) 101
À propos de la topologie des clusters 102
À propos de l'accès à la base de données HBase 103
Créer un cluster Big Data dans vSphere Web Client 103
Créer un cluster uniquement HBase dans Big Data Extensions 107
Créer un cluster avec un gestionnaire d'applications à l'aide de vSphere Web Client 109
Créer un cluster de calcul uniquement avec un gestionnaire d'applications tiers en utilisant
vSphere Web Client 110
Créer un cluster de calcul du travailleur uniquement à l'aide de vSphere Web Client 110
4 VMware, Inc.
Page 5

Gestion des clusters Hadoop et HBase 113
10
Arrêter et démarrer un cluster dans vSphere Web Client 113
Supprimer un cluster dans vSphere Web Client 114
Agrandir ou réduire un cluster à l'aide de vSphere Web Client 114
Mettre à l'échelle le CPU et la RAM dans vSphere Web Client 115
Utiliser des partages de disque E/S pour fixer la priorité des machines virtuelles de cluster dans
vSphere Web Client 116
À propos de vSphere High Availability et de vSphere Fault Tolerance 117
Modifier le mot de passe utilisateur sur tous les nœuds d'un cluster 117
Reconfigurer un cluster avec l'interface de ligne de commande Serengeti 118
Configurer le nombre de disques de données par groupe de nœuds 120
Récupérer d'une défaillance disque avec le client d'interface de ligne de commande Serengeti 121
Se connecter aux nœuds Hadoop avec le client d'interface de ligne de commande Serengeti 122
Table des matières
Surveillance de l'environnement Big Data Extensions 123
11
Activer le collecteur de données Big Data Extensions 123
Désactiver le collecteur de données Big Data Extensions 124
Afficher l'état d'initialisation du serveur de gestion Serengeti 124
Afficher les clusters provisionnés dans vSphere Web Client 125
Afficher les informations des clusters dans vSphere Web Client 126
Surveiller l'état de HDFS dans vSphere Web Client 127
Surveiller le statut MapReduce dans vSphere Web Client 128
Surveiller l'état de HBase dans vSphere Web Client 129
Accès aux données Hive avec JDBC ou ODBC 131
12
Configurer Hive pour travailler avec JDBC 131
Configurer Hive pour travailler avec ODBC 133
Référence de sécurité Big Data Extensions 135
13
Services, ports réseau et interfaces externes 135
Fichiers de configuration de Big Data Extensions 138
Clé publique, certificat et KeyStore Big Data Extensions 138
Fichiers journaux Big Data Extensions 138
Comptes d'utilisateurs Big Data Extensions 139
Correctifs et mises à jour de sécurité 140
Dépannage 141
14
Fichiers journaux pour le dépannage 142
Configurer les niveaux de journalisation Serengeti 142
Collecter les fichiers journaux à des fins de dépannage 143
Résolution des échecs de création d'un cluster 144
La mise à niveau du dispositif virtuel de Big Data Extensions échoue. 150
Erreur de mise à niveau du cluster lors de l'utilisation du cluster créé dans une version antérieure
de Big Data Extensions 151
Impossible de connecter le plug-in Big Data Extensions au serveur Serengeti 152
Les connexions à vCenter Server échouent. 152
Le serveur de gestion ne peut pas se connecter à vCenter Server 153
VMware, Inc. 5
Page 6

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Erreur de certificat SSL lors de la connexion à un serveur autre que Serengeti avec la console
vSphere 153
Impossible de redémarrer ou de reconfigurer un cluster pour lequel l'heure n'est pas synchronisée 153
Impossible de redémarrer ou de reconfigurer un cluster après la modification de sa distribution 154
La machine virtuelle ne peut pas obtenir d'adresse IP et la commande échoue. 154
Impossible de modifier l'adresse IP du serveur Serengeti dans vSphere Web Client 155
Une nouvelle instance de plug-in avec un numéro de version identique ou antérieure à une
instance de plug-in précédente ne se charge pas. 155
Le nom d'hôte et le FQDN ne correspondent pas pour le serveur de gestion Serengeti. 156
Les opérations de Serengeti échouent après que vous ayez renommé une ressource dans vSphere. 157
Big Data Extensions Le serveur refuse les noms de ressource comptant au moins deux espaces
blancs à la suite. 157
Les caractères non ASCII ne s'affichent pas correctement. 157
L'exécution de la tâche MapReduce échoue et n'apparaît pas dans l'historique des tâches. 158
Impossible d'envoyer des tâches MapReduce pour les clusters de calcul uniquement avec l'HDFS
Isilon externe 158
La tâche MapReduce ne répond plus sur un cluster PHD ou CDH4 YARN. 159
Impossible de télécharger le paquet à l'aide du plug-in Downloadonly 159
Impossible de trouver des paquets avec la recherche Yum 159
Supprimer HBase Rootdir dans HDFS avant de supprimer le cluster uniquement HBase 160
Index 161
6 VMware, Inc.
Page 7

À propos de ce guide
Guide de l'administrateur et de l'utilisateur de VMware vSphere Big Data Extensions décrit comment installer
VMware vSphere Big Data Extensions™ au sein de votre environnement vSphere, puis comment gérer et
surveiller les clusters Hadoop et HBase à l'aide du plug-in Big Data Extensions pour vSphere Web Client.
Guide de l'administrateur et de l'utilisateur de VMware vSphere Big Data Extensions décrit également comment
effectuer des opérations Hadoop et HBase à l'aide du client d'interface de ligne de commande VMware
Serengeti™, qui permet un contrôle plus important de certaines tâches de gestion système et de création de
clusters Big Data.
Public ciblé
Le guide est destiné aux administrateurs système et aux développeurs qui veulent utiliser
Big Data Extensions pour déployer et gérer des clusters Hadoop. Pour utiliser correctement
Big Data Extensions, il est préférable de connaître VMware® vSphere® ainsi que le déploiement et le
fonctionnement de Hadoop et HBase.
Glossaire VMware Technical Publications
VMware Technical Publications fournit un glossaire des termes qui peuvent éventuellement ne pas vous
être familiers. Pour consulter la définition des termes utilisés dans la documentation technique VMware,
visitez le site Web http://www.vmware.com/support/pubs.
VMware, Inc.
7
Page 8

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
8 VMware, Inc.
Page 9

À propos de VMware vSphere Big
Data Extensions 1
VMware vSphere Big Data Extensions vous permet de déployer et d'utiliser de manière centralisée des
clusters Big Data exécutés sur VMware vSphere. Big Data Extensions simplifie le processus de déploiement
et de provisionnement Hadoop et HBase. Il vous permet aussi de voir en temps réel les services en cours
d'exécution et l'état de leurs hôtes virtuels. Il offre un point central à partir duquel vous pouvez gérer et
surveiller votre cluster Big Data, et incorpore un ensemble complet d'outils susceptibles de vous aider à
optimiser les performances et l'utilisation du cluster.
Ce chapitre aborde les rubriques suivantes :
« Prise en main de Big Data Extensions », page 9
n
« Big Data Extensions et Project Serengeti », page 10
n
« À propos de l'architecture de Big Data Extensions », page 12
n
« À propos des gestionnaires d'applications », page 13
n
Prise en main de Big Data Extensions
Big Data Extensions vous permet de déployer des clusters Big Data. Les tâches incluses dans cette section
décrivent la manière de configurer VMware vSphere® pour une utilisation avec Big Data Extensions, de
déployer le vApp Big Data Extensions, d'accéder aux consoles d'administration VMware vCenter Server® et
d'interface de ligne de commande (CLI), ainsi que de configurer une distribution Hadoop à utiliser avec
Big Data Extensions.
Prérequis
Une bonne compréhension de ce que sont Project Serengeti® et Big Data Extensions vous permet
n
d'appréhender la manière dont ils s'intègrent dans votre workflow Big Data et votre environnement
vSphere.
Vérifiez que les fonctionnalités Big Data Extensions que vous souhaitez utiliser, comme les clusters de
n
calcul uniquement ou les clusters données-calcul séparés, sont prises en charge par Big Data Extensions
pour la distribution Hadoop que vous souhaitez utiliser.
Examinez les fonctionnalités prises en charge par votre distribution Hadoop.
n
VMware, Inc.
9
Page 10

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Procédure
1 Effectuez l'une des opérations suivantes.
Effectuez la première installation de Big Data Extensions. Passez en revue la configuration système
n
requise, installez vSphere et installez les composants Big Data Extensions : vApp
Big Data Extensions, plug-in Big Data Extensions pour vCenter Server et Serengeti CLI Client.
Effectuez une mise à niveau de Big Data Extensions à partir d'une version précédente. Suivez les
n
étapes de mise à niveau.
2 (Facultatif) Installez et configurez une distribution autre qu'Apache Bigtop à utiliser avec
Big Data Extensions.
Apache Bigtop est inclus dans le serveur de gestion Serengeti, mais vous pouvez utiliser n'importe
quelle distribution Hadoop prise en charge par Big Data Extensions.
Suivant
Une fois que vous avez correctement installé et configuré votre environnement Big Data Extensions, vous
pouvez effectuer les tâches supplémentaires suivantes.
Arrêtez et démarrez les services Serengeti, créez des comptes d'utilisateurs, gérez des mots de passe et
n
connectez-vous à des nœuds de cluster pour résoudre les problèmes.
Gérez les pools de ressources vSphere, les banques de données et les réseaux que vous utilisez pour
n
créer des clusters Hadoop et HBase.
Créez, provisionnez et gérez des clusters Big Data.
n
Surveillez l'état des clusters que vous créez, notamment leurs banques de données, réseaux et pools de
n
ressources, via vSphere Web Client et l'interface de ligne de commande Serengeti.
Sur vos clusters Big Data, exécutez des commandes HDFS, des scripts Hive et Pig, ainsi que des travaux
n
MapReduce, et accédez aux données Hive.
Si vous rencontrez des problèmes en utilisant Big Data Extensions, consultez Chapitre 14,
n
« Dépannage », page 141.
Big Data Extensions et Project Serengeti
Big Data Extensions s'exécute sur Project Serengeti, projet open source lancé par VMware pour automatiser
le déploiement et la gestion des clusters Hadoop et HBase dans des environnements virtuels comme
vSphere.
Big Data Extensions et Project Serengeti fournissent les composants suivants.
Project Serengeti
Projet open source lancé par VMware, Project Serengeti permet aux
utilisateurs de déployer et gérer des clusters Big Data dans un
environnement géré vCenter Server. Les composants majeurs sont ceux de
Serengeti Management Server, qui permettent le provisionnement de cluster,
la configuration logicielle et les services de gestion, ainsi qu'une interface de
ligne de commande. Project Serengeti est disponible sous licence Apache 2.0,
laquelle permet à tout le monde de modifier et de redistribuer Project
Serengeti conformément à ses termes.
Serengeti Management
Server
Fournit l'infrastructure et les services permettant d'exécuter des clusters Big
Data sur vSphere. Serengeti Management Server assure la gestion des
ressources, le placement des machines virtuelles selon la stratégie, le
provisionnement du cluster, la gestion de la configuration logicielle et la
surveillance de l'environnement.
10 VMware, Inc.
Page 11

Chapitre 1 À propos de VMware vSphere Big Data Extensions
Client d'interface de
ligne de commande
Serengeti
Big Data Extensions
Le client d'interface de ligne de commande (CLI, Command-Line Interface)
offre un ensemble complet d'outils et d'utilitaires permettant de surveiller et
de gérer votre déploiement Big Data. Si vous utilisez la version open source
de Serengeti sans Big Data Extensions, l'interface de ligne de commande est
la seule interface par l'intermédiaire de laquelle vous pouvez effectuer des
tâches administratives. Pour plus d'informations sur l'interface de ligne de
commande, consultez le Guide de l'interface de ligne de commande VMware
vSphere Big Data Extensions.
La version commerciale de Project Serengeti, projet open source de VMware,
à savoir Big Data Extensions, est fournie en tant que
vCenter Server Appliance. Big Data Extensions inclut toutes les fonctions de
Project Serengeti, ainsi que les fonctionnalités et composants
supplémentaires suivants.
Support de niveau entreprise par VMware.
n
Distribution Bigtop par la communauté Apache.
n
REMARQUE VMware fournit la distribution Hadoop par souci pratique
mais n'en assure pas le support de niveau entreprise. La distribution
Apache Bigtop est prise en charge par la communauté open source.
Plug-in Big Data Extensions, interface graphique utilisateur intégrée
n
dans vSphere Web Client. Ce plug-in vous permet d'effectuer des tâches
administratives courantes de gestion de l'infrastructure et du cluster
Hadoop.
VMware, Inc. 11
Page 12
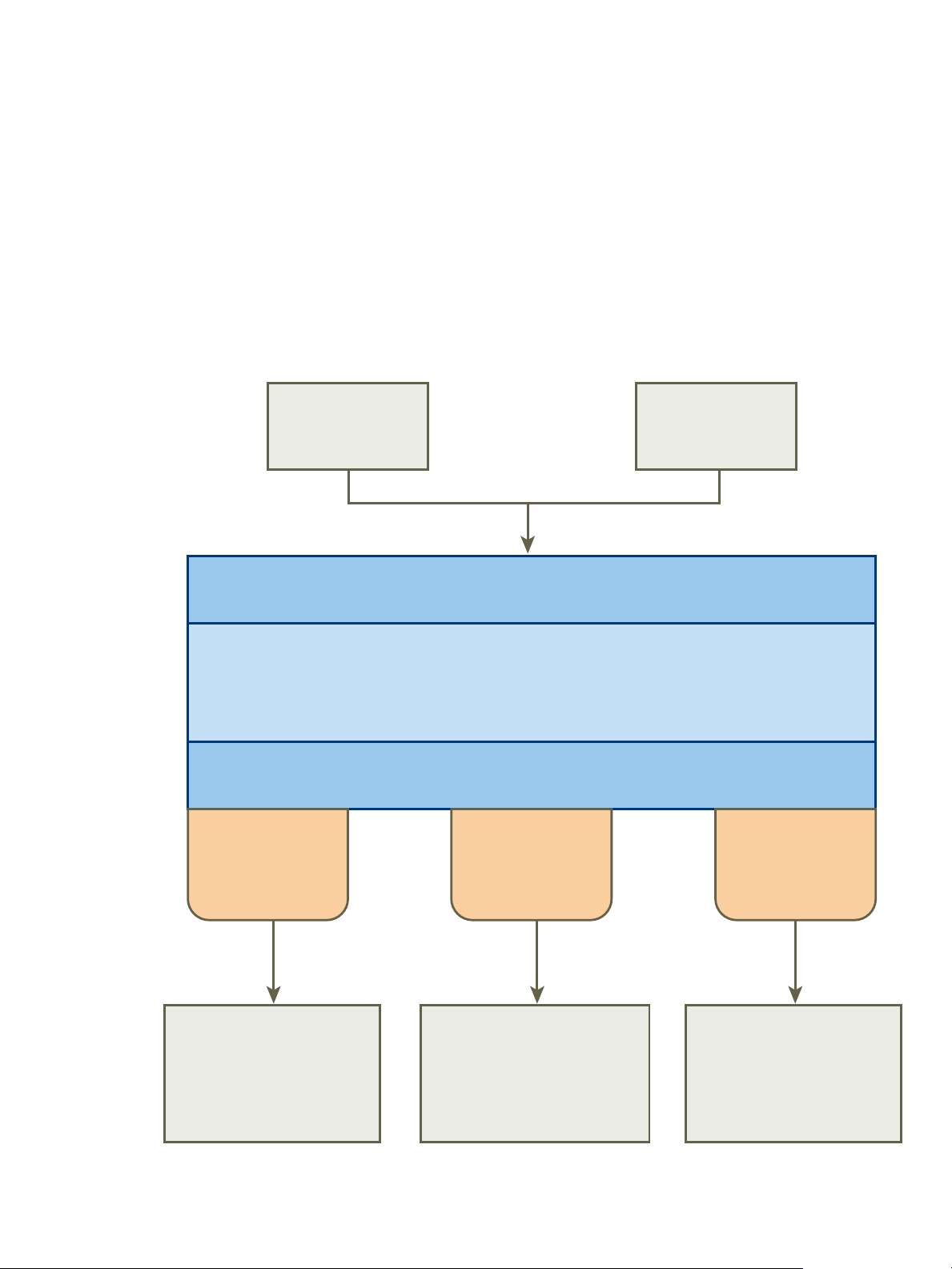
CLI GUI
API Rest
Infrastructure d'approvisionnement
de machines virtuelles et d'applications
Gestion de logiciels SPI
Adaptateur
par défaut
Adaptateur
Cloudera
Adaptateur
Ambari
Service Thrift
Gestionde
logiciels
Serveur
Cloudera
Manager
Serveur
Ambari
Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
À propos de l'architecture de Big Data Extensions
Serengeti Management Server et la machine virtuelle du modèle Hadoop fonctionnent ensemble pour
configurer et provisionner des clusters Big Data.
Figure 1‑1. Architecture de Big Data Extensions
12 VMware, Inc.
Page 13

Big Data Extensions effectue les étapes suivantes pour déployer un cluster Big Data.
1 Serengeti Management Server recherche les hôtes ESXi dotés de suffisamment de ressources pour faire
fonctionner le cluster avec les paramètres de configuration que vous spécifiez, puis sélectionne les hôtes
ESXi sur lesquels placer des machines virtuelles Hadoop.
2 Serengeti Management Server envoie une demande à vCenter Server pour cloner et configurer les
machines virtuelles à utiliser avec le cluster Big Data.
3 Serengeti Management Server configure le système d'exploitation et les paramètres réseau des
nouvelles machines virtuelles.
4 Chaque machine virtuelle télécharge les modules logiciels Hadoop et les installe conformément aux
informations d'installation et de distribution issues de Serengeti Management Server.
5 Serengeti Management Server configure les paramètres Hadoop pour les nouvelles machines virtuelles
en fonction des paramètres de configuration du cluster que vous spécifiez.
6 Les services Hadoop sont démarrés sur les nouvelles machines virtuelles. À ce stade, vous avez un
cluster en cours d'exécution selon vos paramètres de configuration.
À propos des gestionnaires d'applications
Vous pouvez utiliser Cloudera Manager, Apache Ambari et le gestionnaire d'applications par défaut pour
provisionner et gérer des clusters avec VMware vSphere Big Data Extensions.
Chapitre 1 À propos de VMware vSphere Big Data Extensions
Après avoir ajouté un nouveau gestionnaire d'applications Cloudera Manager ou Ambari à
Big Data Extensions, vous pouvez y rediriger vos tâches de gestion logicielle, notamment la surveillance et
la gestion des clusters.
Vous pouvez utiliser un gestionnaire d'applications pour effectuer les tâches suivantes :
Dresser la liste de toutes les instances de fournisseurs disponibles, des distributions prises en charge et
n
des configurations ou des rôles pour un gestionnaire d'applications et une distribution spécifiques.
Créer des clusters.
n
Surveiller et gérer des services à partir de la console du gestionnaire d'applications.
n
Consultez la documentation de votre gestionnaire d'applications pour identifier les exigences propres aux
outils.
Restrictions
Les restrictions suivantes s'appliquent aux gestionnaires d'applications Cloudera Manager et Ambari :
Pour ajouter un gestionnaire d'applications avec HTTPS, utilisez le nom de domaine complet (FQDN)
n
au lieu de l'URL.
Vous ne pouvez pas renommer un cluster créé avec le gestionnaire d'applications Cloudera Manager ou
n
Ambari.
Vous ne pouvez pas changer les services d'un cluster Big Data à partir de Big Data Extensions si le
n
cluster a été créé avec le gestionnaire d'applications Ambari ou Cloudera Manager.
Pour modifier les services, les configurations ou les deux, vous devez le faire à partir du gestionnaire
n
d'applications sur les nœuds.
Si vous installez de nouveaux services, Big Data Extensions les démarre et les arrête en même temps
que les anciens.
VMware, Inc. 13
Page 14

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Si vous utilisez un gestionnaire d'applications pour modifier les services et les configurations de
n
clusters Big Data, ces modifications ne peuvent pas être synchronisées à partir de Big Data Extensions.
Les nœuds que vous créez avec Big Data Extensions ne contiennent pas les nouveaux services ni les
nouvelles configurations.
Services et opérations pris en charge par les gestionnaires d'applications
Si vous utilisez Cloudera Manager ou Apache Ambari avec Big Data Extensions, il existe plusieurs services
supplémentaires à votre disposition.
Distributions et gestionnaires d'applications pris en charge
Big Data Extensions prend en charge certains gestionnaires d'applications et certaines distributions Hadoop.
Toutes les fonctionnalités et opérations ne sont pas prises en charge par certaines versions des gestionnaires
d'applications. Le tableau ci-dessous indique les fonctionnalités disponibles avec chacun des gestionnaires
d'applications listés.
Tableau 1‑1. Distributions Hadoop et gestionnaires d'applications pris en charge
Fonctionnalités et
opérations prises en
charge Cloudera Manager
Versions prises en
charge
Distributions prises en
charge
Déploiement
automatique
Liste de clusters,
Arrêter, Démarrer,
Exporter et Reprendre
vSphere High
Availability
vSphere Fault
Tolerance
Multiples réseaux Les multiples
Données-calcul
combinés
Séparation de calcul
de données
5.3-5.4 2.0-2.1 1.7 2.3
CDH 5.3-5.4, OneFS
7.1-7.2
X X X X
X X X X
X X X X
X X X X
réseaux ne sont pas
pris en charge.
X X X X
X X X X
Hortonworks
Ambari Pivotal Ambari
HDP 2.2-2.3, OneFS*
7.1-7.2
Les multiples
réseaux ne sont pas
pris en charge.
PHD 3.0, OneFS*
7.1-7.2
Les multiples
réseaux ne sont pas
pris en charge.
Gestionnaire
d'applications par
défaut
Bigtop 1.0, CDH
5.3-5.4, HDP 2.1, PHD
2.0-2.1, MapR 4.1-5.0
et OneFS 7.1-7.2
Non pris en charge
avec MapR.
14 VMware, Inc.
Page 15

Chapitre 1 À propos de VMware vSphere Big Data Extensions
Tableau 1‑1. Distributions Hadoop et gestionnaires d'applications pris en charge (suite)
Fonctionnalités et
opérations prises en
charge Cloudera Manager
Calcul uniquement X Ambari peut
Cluster HBase X X X X
HBase uniquement Non pris en charge
Topologie/HVE
Hadoop
Configuration Hadoop Pris en charge via
Composants de
l'écosystème Hadoop
X X X La topologie n'est pas
l'interface Web du
gestionnaire
d'applications.
Pile pleine via
Cloudera Manager.
Hortonworks
Ambari Pivotal Ambari
Ambari peut
provisionner des
clusters de calcul
uniquement avec
Isilon OneFS.
Reportez-vous à la
documentation EMC
Isilon Hadoop
Starter Kit for
Hortonworks pour
obtenir des
informations sur la
configuration de
Ambari et de
Isilon OneFS.
Pris en charge via
l'interface Web du
gestionnaire
d'applications.
Pile pleine via
Ambari.
provisionner des
clusters de calcul
uniquement avec
Isilon OneFS.
Reportez-vous à la
documentation EMC
Isilon Hadoop
Starter Kit for
Hortonworks pour
obtenir des
informations sur la
configuration de
Ambari et de
Isilon OneFS.
Pris en charge via
l'interface Web du
gestionnaire
d'applications.
Pile pleine via
Ambari.
Gestionnaire
d'applications par
défaut
Non pris en charge
avec MapR.
avec MapR.
prise en charge avec
MapR.
HVE n'est pris en
charge qu'avec PHD.
Non pris en charge
avec MapR.
Pig, Hive, Hive Server
et Zookeeper.
Prise en charge des distributions Hadoop dans Isilon OneFS
Si vous souhaitez utiliser Isilon OneFS, vérifiez d'abord si votre distribution Hadoop est compatible avec
OneFS. Reportez-vous à la section Distributions Hadoop prises en charge dans OneFS du site Internet
d'EMC.
REMARQUE Big Data Extensions ne prend pas nativement en charge le provisionnement des clusters de
calcul uniquement avec Ambari Manager. Cependant, Ambari peut provisionner des clusters de calcul
uniquement avec Isilon OneFS. Reportez-vous à la documentation EMC Isilon Hadoop Starter Kit for
Hortonworks pour obtenir des informations sur la configuration de Ambari et de Isilon OneFS.
Services pris en charge sur Cloudera Manager et Ambari
Tableau 1‑2. Services pris en charge sur Cloudera Manager et Ambari
Nom du service Cloudera Manager 5.3, 5.4 Ambari 1.6, 1.7
Falcon X
Flume X X
Ganglia X
HBase X X
HCatalog X
VMware, Inc. 15
Page 16

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Tableau 1‑2. Services pris en charge sur Cloudera Manager et Ambari (suite)
Nom du service Cloudera Manager 5.3, 5.4 Ambari 1.6, 1.7
HDFS X X
Hive X X
Hue X X
Impala X
MapReduce X X
Nagios X
Oozie X X
Pig X
Sentry
Solr X
Spark X
Sqoop X X
Storm X
TEZ X
WebHCAT X
YARN X X
Zookeeper X X
À propos du niveau de service vSphere High Availability pour Ambari
Ambari prend en charge la fonction NameNode HA. Toutefois, vous devez configurer cette fonction de
sorte qu'elle utilise votre déploiement Hadoop. Reportez-vous à la section Haute disponibilité NameNode
pour Hadoop de la documentation Hortonworks.
À propos du niveau de service vSphere High Availability pour Cloudera
Les distributions Cloudera offrent la prise en charge suivante de la haute disponibilité vSphere de niveau de
service.
Cloudera avec MapReduce v1 offre une prise en charge de la haute disponibilité vSphere de niveau de
n
service pour JobTracker.
Cloudera offre sa propre prise en charge de la haute disponibilité de niveau de service pour NameNode
n
via HDFS2.
Pour plus d'informations sur la manière d'utiliser un gestionnaire d'applications avec l'interface de ligne de
commande, consultez le Guide de l'interface de ligne de commande VMware vSphere Big Data Extensions.
16 VMware, Inc.
Page 17

Installation de Big Data Extensions 2
Pour installer Big Data Extensions afin de pouvoir créer et provisionner des clusters Big Data, vous devez
installer les composants Big Data Extensions dans l'ordre indiqué.
Suivant
Si vous voulez créer des clusters sur une distribution Hadoop autre qu'Apache Bigtop, incluse dans
Serengeti Management Server, installez et configurez la distribution afin de l'utiliser avec
Big Data Extensions.
Ce chapitre aborde les rubriques suivantes :
« Configuration système requise pour Big Data Extensions », page 17
n
« Prise en charge d'Unicode UTF-8 et des caractères spéciaux », page 20
n
« Le programme d'amélioration du produit », page 22
n
« Déployer le vApp Big Data Extensions dans vSphere Web Client », page 23
n
« Installer des RPM dans le référentiel Yum du serveur de gestion Serengeti », page 26
n
« Installer le plug-in Big Data Extensions », page 27
n
« Configurer les paramètres vCenter Single Sign-On du serveur de gestion Serengeti », page 29
n
« Se connecter à un serveur de gestion Serengeti », page 30
n
« Installer le client d'interface de ligne de commande distant Serengeti », page 31
n
« Accéder à l'interface de ligne de commande Serengeti à l'aide du client d'interface de ligne de
n
commande distant », page 31
Configuration système requise pour Big Data Extensions
Avant de commencer à déployer Big Data Extensions, votre système doit remplir toutes les conditions
préalables liées à vSphere, aux clusters, aux réseaux, au stockage, au matériel et aux licences.
Big Data Extensions requiert que vous installiez et configuriez vSphere et que votre environnement réponde
aux besoins en ressources minimaux. Assurez-vous de posséder des licences pour les composants VMware
de votre déploiement.
Exigences vSphere
VMware, Inc. 17
Avant d'installer Big Data Extensions, configurez les produits VMware
suivants.
Installez vSphere 5.5 (ou version ultérieure) Enterprise ou Enterprise
n
Plus.
Page 18

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Quand vous installez Big Data Extensions sur vSphere 5.5 ou version
n
ultérieure, utilisez VMware® vCenter™ Single Sign-On pour fournir
l'authentification utilisateur. Quand vous vous connectez à vSphere 5.5
ou version ultérieure, vous transmettez l'authentification au serveur
vCenter Single Sign-On, que vous pouvez configurer avec plusieurs
sources d'identité comme Active Directory et OpenLDAP. Quand
l'authentification réussit, votre nom d'utilisateur et votre mot de passe
sont échangés contre un jeton de sécurité qui est utilisé pour accéder aux
composants vSphere comme Big Data Extensions.
Si votre instance de vCenter Server utilise un FQDN, assurez-vous de le
n
configurer correctement à l'installation de vCenter Server.
Configurez tous les hôtes ESXi de sorte à utiliser le même serveur NTP
n
(Network Time Protocol).
Sur chaque hôte ESXi, ajoutez le serveur NTP à la configuration d'hôte,
n
puis, dans la liste Stratégie de démarrage de la configuration d'hôte,
sélectionnez Démarrer et arrêter avec l'hôte. Le démon NTP veille à ce
que les processus dépendant de l'heure se produisent de manière
synchronisée sur tous les hôtes.
Paramètres cluster
Paramètres réseau
Configurez votre cluster avec les paramètres suivants.
Activez la haute disponibilité vSphere et VMware vSphere® Distributed
n
Resource Scheduler™.
Activez la surveillance de l'hôte.
n
Activez le contrôle d'admission et définissez la stratégie souhaitée. La
n
stratégie par défaut consiste à tolérer une seule défaillance de l'hôte.
Définissez une priorité élevée pour le redémarrage de la machine
n
virtuelle.
Définissez la surveillance de la machine virtuelle sur une surveillance de
n
la machine virtuelle et de l'application.
Définissez une sensibilité élevée pour la surveillance.
n
Activez vMotion et la journalisation de la tolérance aux pannes.
n
Tous les hôtes du cluster ont le VT matériel activé dans le BIOS.
n
Pour le port VMkernel du réseau de gestion, vMotion et la journalisation
n
de la tolérance aux pannes sont activés.
Big Data Extensions peut déployer des clusters sur un seul réseau ou utiliser
plusieurs réseaux. L'environnement détermine la manière dont les groupes
de ports attachés aux cartes réseau sont configurés et quel réseau soutient
chaque groupe de ports.
Vous pouvez utiliser soit un vSwitch, soit un vDS (vSphere Distributed
Switch) pour assurer le soutien du groupe de ports par un cluster Serengeti.
Un vDS joue le rôle d'un commutateur virtuel unique sur tous les hôtes
attachés tandis qu'un vSwitch est individuel pour chaque port et requiert la
configuration manuelle du groupe de ports.
18 VMware, Inc.
Page 19

Chapitre 2 Installation de Big Data Extensions
Quand vous configurez vos réseaux à utiliser avec Big Data Extensions,
vérifiez que les ports suivants sont ouverts en tant que ports d'écoute.
Les ports 8080 et 8443 sont utilisés par l'interface utilisateur du plug-in
n
Big Data Extensions et le client d'interface de ligne de commande
Serengeti.
Le port 5480 est utilisé par vCenter Single Sign-On à des fins de
n
surveillance et de gestion.
Le port 22 est utilisé par les clients SSH.
n
Pour éviter d'avoir à ouvrir un port de pare-feu réseau pour accéder aux
n
services Hadoop, connectez-vous au nœud client Hadoop. À partir de ce
nœud, vous pouvez en effet accéder à votre cluster.
Pour vous connecter à Internet (par exemple, pour créer un référentiel
n
Yum interne à partir duquel installer des distributions Hadoop), vous
pouvez utiliser un proxy.
Pour permettre les communications, assurez-vous que les pare-feu et
n
filtres Web ne bloquent pas le serveur de gestion Serengeti ni d'autres
nœuds Serengeti.
Stockage en
attachement direct
Ne pas utiliser
Big Data Extensions en
conjonction avec
vSphere Storage DRS
La migration des
machines virtuelles
dans vCenter Server
peut perturber la
stratégie de placement
des machines virtuelles
Attachez et configurez un stockage en attachement direct sur le contrôleur
physique pour présenter chaque disque séparément au système
d'exploitation. Cette configuration est couramment désignée par l'acronyme
JBOD (Just A Bunch Of Disks, juste un paquet de disques). Créez des
banques de données VMFS sur le stockage en attachement direct en
respectant les recommandations suivantes liées aux lecteurs de disque.
Entre 8 et 12 lecteurs de disque par hôte. Plus le nombre de lecteurs de
n
disque par hôte est élevé, meilleures sont les performances.
Entre 1 et 1,5 lecteurs de disque par cœur de processeur.
n
Lecteurs de disques Serial ATA 7 200 tr/min.
n
Avant de les créer, Big Data Extensions place les machines virtuelles sur les
hôtes en fonction des ressources disponibles, des meilleures pratiques
Hadoop et des stratégies de placement définies par l'utilisateur. De ce fait,
évitez de déployer Big Data Extensions dans les environnements vSphere en
conjonction avec Storage DRS. Storage DRS équilibre en permanence
l'utilisation de l'espace de stockage et la charge d'E/S de stockage pour
respecter les niveaux de service applicatif dans les environnements
spécifiques. Si Storage DRS est utilisé avec Big Data Extensions, les stratégies
de placement du cluster Big Data de vos machines virtuelles ne seront pas
respectées.
Big Data Extensions place les machines virtuelles en fonction des ressources
disponibles, des meilleures pratiques Hadoop et des stratégies de placement
définies par l'utilisateur que vous spécifiez. De ce fait, DRS est désactivé sur
toutes les machines virtuelles créées dans l'environnement
Big Data Extensions. Cela empêche la migration automatique des machines
virtuelles par vSphere, mais ne vous empêche pas de déplacer
accidentellement les machines virtuelles avec l'interface utilisateur de
vCenter Server. Cela peut enfreindre la stratégie de placement définie dans
Big Data Extensions. Par exemple, le nombre d'instances par hôte et les
associations de groupes peuvent ne pas être respectés.
VMware, Inc. 19
Page 20

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Besoins en ressources
du serveur de gestion et
des modèles vSphere
Besoins en ressources
du cluster Hadoop
Configuration matérielle
requise pour
l'environnement
vSphere et
Big Data Extensions
Pool de ressources doté d'au moins 27,5 Go de RAM.
n
Espace disque de 40 Go ou plus (recommandé) pour les disques virtuels
n
du serveur de gestion et du modèle Hadoop.
L'espace libre de banque de données n'est pas inférieur à la taille totale
n
requise par le cluster Hadoop, outre les disques d'échange pour chaque
nœud Hadoop égal à la taille de mémoire demandée.
Le réseau est configuré sur tous les hôtes ESXi appropriés et une
n
connectivité existe avec le réseau utilisé par le serveur de gestion.
La haute disponibilité vSphere est activée pour le nœud master si la
n
protection de la haute disponibilité vSphere est nécessaire. Pour utiliser
la haute disponibilité ou la tolérance aux pannes vSphere afin de
protéger le nœud master Hadoop, vous devez utiliser le stockage
partagé.
Le matériel de l'hôte est répertorié dans le Guide de compatibilité VMware.
Pour obtenir des performances optimales à l'exécution, installez votre
environnement vSphere et Big Data Extensions sur le matériel suivant.
Double CPU quadricœurs ou plus avec Hyper-Threading activé. Si vous
n
pouvez estimer votre charge de travail de calcul, envisagez d'utiliser un
CPU plus puissant.
Utilisez la haute disponibilité et deux blocs d'alimentation pour la
n
machine hôte du nœud master.
Entre 4 et 8 Go de mémoire pour chaque cœur de processeur, avec 6 %
n
de traitement pour la virtualisation.
Utilisez une interface Ethernet de 1 Go ou plus pour fournir la bande
n
passante réseau adéquate.
Prise en charge de
l'hôte et de la machine
virtuelle testés
Licences vSphere
La prise en charge maximale de l'hôte et de la machine virtuelle qui a été
confirmée par une exécution correcte avec Big Data Extensions comprend
256 hôtes physiques exécutant un total de 512 machines virtuelles.
Vous devez disposer d'une licence vSphere Enterprise ou supérieure pour
utiliser la haute disponibilité VMware vSphere et vSphere DRS.
Prise en charge d'Unicode UTF-8 et des caractères spéciaux
Big Data Extensions prend en charge le niveau 3 de l'internationalisation (I18N). Cependant, il existe des
ressources que vous spécifiez qui n'offrent pas de prise en charge UTF-8. Vous pouvez uniquement utiliser
des noms d'attribut ASCII composés de caractères alphanumériques et de traits de soulignement (_) pour
ces ressources.
Big Data Extensions prend en charge Unicode UTF-8
Les ressources vCenter Server que vous spécifiez avec l'interface de ligne de commande et vSphere Web
Client peuvent être exprimées avec des traits de soulignement (_), des tirets (-), des espaces et la totalité des
lettres et chiffres de toute langue. Par exemple, vous pouvez spécifier des ressources comme les banques de
données étiquetées à l'aide de caractères étendus.
20 VMware, Inc.
Page 21

Chapitre 2 Installation de Big Data Extensions
Quand vous utilisez un système d'exploitation Linux, vous devez configurer le système de manière à utiliser
un codage UTF-8 propre à vos paramètres régionaux. Par exemple, pour utiliser le français de France,
spécifiez le codage de paramètres régionaux suivant : fr_FR.UTF-8. Reportez-vous à la documentation de
votre fournisseur pour plus d'informations sur la configuration du codage UTF-8 pour votre environnement
Linux.
Prise en charge des caractères spéciaux
Les ressources vCenter Server suivantes peuvent comporter un point (.) dans leur nom, ce qui vous permet
de les sélectionner à la fois avec l'interface de ligne de commande et vSphere Web Client.
nom de groupe de ports
n
nom de cluster
n
nom de pool de ressources
n
nom de banque de données
n
L'utilisation d'un point n'est pas autorisée dans le nom de la ressource Serengeti.
Ressources exclues de la prise en charge Unicode UTF-8
Le fichier de spécification de cluster Serengeti, le fichier de manifeste et le fichier de mappage racks-hôtes de
topologie n'offrent pas de prise en charge UTF-8. Quand vous créez ces fichiers pour définir les nœuds et
ressources que le cluster va utiliser, utilisez uniquement des noms d'attributs ASCII composés de caractères
alphanumériques et de traits de soulignement (_).
Les noms de ressources suivants sont exclus de la prise en charge UTF-8 :
nom de cluster
n
nom nodeGroup
n
nom de nœud
n
nom de machine virtuelle
n
Les attributs suivants inclus dans le fichier de spécification de cluster Serengeti sont exclus de la prise en
charge UTF-8 :
nom de distribution
n
rôle
n
configuration de cluster
n
type de stockage
n
haFlag
n
instanceType
n
groupAssociationsType
n
Le nom de rack dans le fichier de mappage racks-hôtes de topologie et le champ placementPolicies du
fichier de spécification de cluster Serengeti sont également exclus de la prise en charge UTF-8.
VMware, Inc. 21
Page 22

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Le programme d'amélioration du produit
Vous pouvez configurer Big Data Extensions de sorte qu'il collecte des données afin de nous aider à
améliorer votre expérience utilisateur des produits VMware. La section suivante contient des informations
importantes sur le programme d'amélioration du produit VMware.
Le programme d'amélioration du produit vise à identifier et à régler rapidement les problèmes qui peuvent
affecter votre expérience. Si vous choisissez de participer au programme d'amélioration du produit,
Big Data Extensions enverra régulièrement des données anonymes à VMware. Nous utiliserons ces données
à des fins de développement de produits et de résolution des problèmes.
Avant de collecter des données, VMware anonymise tous les champs contenant des informations propres à
votre entreprise. VMware rend ces champs neutres en hachant leur valeur réelle. Lorsqu'une valeur hachée
est collectée, VMware n'est pas en mesure d'identifier la valeur réelle, mais détecte les changements qu'elle
subit lorsque vous modifiez votre environnement.
Catégories d'information dans les données collectées
Lorsque vous choisissez de participer au programme d'amélioration du produit VMware (CEIP), VMware
obtient des données des catégories suivantes :
Données de
configuration
Données sur l'utilisation
des fonctions
Données performances
Données sur votre configuration des produits VMware et informations liées
à votre environnement informatique. Exemples de données de
configuration : informations sur la version des produits VMware, sur le
matériel et les logiciels utilisés dans votre environnement, paramètres de
configuration des produits et informations sur votre environnement réseau.
Les données de configuration peuvent inclure des versions hachées des ID et
des adresses MAC et IP de vos périphériques.
Données sur votre utilisation des produits et services VMware. Exemples de
données sur l'utilisation des fonctions : informations sur les fonctions
utilisées, indicateurs d'activité dans l'interface utilisateur et informations sur
vos appels API.
Données sur les performances des produits et services VMware. Exemples de
données sur les performances : indicateurs de performance et échelle des
produits et services VMware, temps de réponse des interfaces utilisateur et
informations sur vos appels d'API.
Activation et désactivation de la collecte des données
Par défaut, l'inscription au programme d'amélioration du produit est activée pendant l'installation. Vous
avez la possibilité de désactiver ce service à ce moment-là. Vous pouvez également mettre fin à votre
participation au programme à tout moment et ainsi arrêter d'envoyer des données à VMware. Reportezvous à « Désactiver le collecteur de données Big Data Extensions », page 124.
Pour toute question ou inquiétude concernant le programme d'amélioration du produit pour Log Insight,
contactez bde-info@vmware.com.
22 VMware, Inc.
Page 23

Chapitre 2 Installation de Big Data Extensions
Déployer le vApp Big Data Extensions dans vSphere Web Client
Le déploiement du vApp Big Data Extensions constitue la première étape pour rendre votre cluster
opérationnel avec Big Data Extensions.
Prérequis
Installez et configurez vSphere.
n
Configurez tous les hôtes ESXi pour utiliser le même serveur NTP.
n
Sur chaque hôte ESXi, ajoutez le serveur NTP à la configuration d'hôte, puis, dans la liste Stratégie
n
de démarrage de la configuration d'hôte, sélectionnez Démarrer et arrêter avec l'hôte. Le démon
NTP veille à ce que les processus dépendant de l'heure se produisent de manière synchronisée sur
tous les hôtes.
Lorsque vous installez Big Data Extensions sur vSphere 5.5 ou version ultérieure, utilisez vCenter
n
Single Sign-On pour fournir l'authentification utilisateur.
Vérifiez que vous possédez une licence vSphere Enterprise pour chaque hôte sur lequel vous déployez
n
des nœuds Hadoop virtuels. Vous gérez vos licences vSphere dans vSphere Web Client ou dans
vCenter Server.
Installez le plug-in Client Integration pour vSphere Web Client. Ce plug-in permet le déploiement OVF
n
sur votre système de fichiers local.
REMARQUE Selon les paramètres de sécurité de votre navigateur, vous devrez peut-être accepter le
plug-in lors de sa première utilisation.
Téléchargez Big Data Extensions OVA depuis le site de téléchargement VMware.
n
Vérifiez que vous avez au moins 40 Go d'espace disque disponible pour OVA. Vous avez besoin
n
d'autres ressources pour le cluster Hadoop.
Assurez-vous de connaître l'URL du service de recherche vCenter Single Sign-On pour votre service
n
vCenter Single Sign-On.
Si vous installez Big Data Extensions sur vSphere 5.5 ou version ultérieure, veillez à ce que votre
environnement inclue vCenter Single Sign-On. Utilisez vCenter Single Sign-On pour fournir
l'authentification utilisateur sur vSphere 5.5 ou version ultérieure.
Lisez la description du programme d'amélioration du produit et décidez si vous souhaitez collecter des
n
données et les envoyer à VMware afin de contribuer à améliorer l'expérience client dans
Big Data Extensions. Reportez-vous à « Le programme d'amélioration du produit », page 22.
Procédure
1 Dans vSphere Web Client, sélectionnez un pool de ressources de niveau supérieur, puis Actions >
Déployer le modèle OVF.
Sélectionnez un pool de ressources de niveau supérieur : Les pools de ressources enfants ne sont pas
pris en charge par Big Data Extensions même si vous pouvez en sélectionner un. Si vous en sélectionnez
un, vous ne pouvez pas créer de clusters Big Data avec Big Data Extensions.
2 Choisissez l'emplacement dans lequel Big Data Extensions OVA réside et cliquez sur Suivant.
Option Description
Déployez à partir du fichier
Déployez à partir d'une URL
Parcourez votre système de fichiers pour un modèle OVF ou OVA.
Tapez l'URL d'un modèle OVF ou OVA situé sur Internet. Par exemple :
http://vmware.com/VMTN/appliance.ovf.
VMware, Inc. 23
Page 24

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
3 Consultez la page des détails du modèle OVF et cliquez sur Suivant.
4 Acceptez le contrat de licence, puis cliquez sur Suivant.
5 Spécifiez un nom pour le vApp, sélectionnez un centre de données cible pour OVA, puis cliquez sur
Suivant.
Les seuls caractères valides dans les noms de vApp Big Data Extensions sont les caractères
alphanumériques et les traits de soulignement. Le nom de vApp doit comprendre moins de
60 caractères. Quand vous choisissez le nom de vApp, tenez également compte de la manière dont vous
allez nommer vos clusters. Ensemble, les noms de vApp et de cluster doivent comprendre moins de
80 caractères.
6 Sélectionnez un stockage partagé pour OVA et cliquez sur Suivant.
Si le stockage partagé n'est pas disponible, un stockage local est acceptable.
7 Pour chaque réseau spécifié dans le modèle OVF, sélectionnez un réseau dans la colonne Réseaux de
destination de votre infrastructure pour configurer le mappage réseau.
Le premier réseau permet au serveur de gestion de communiquer avec votre cluster Hadoop. Le second
réseau permet au serveur de gestion de communiquer avec vCenter Server. Si votre déploiement
vCenter Server n'utilise pas IPv6, vous pouvez spécifier le même réseau de destination IPv4 à utiliser
par les deux réseaux sources.
24 VMware, Inc.
Page 25

Chapitre 2 Installation de Big Data Extensions
8 Configurez les paramètres réseau de votre environnement, puis cliquez sur Suivant.
a Entrez les paramètres réseau qui permettent au serveur de gestion de communiquer avec votre
cluster Hadoop.
Utilisez un réseau IPv4 (IP) statique. Une adresse IPv4 correspond à quatre nombres séparés par
des points comme dans aaa.bbb.ccc.ddd, où chaque plage numérique est comprise entre 0 et 255.
Vous devez entrer un masque de réseau, comme 255.255.255.0, ainsi qu'une adresse de passerelle,
comme 192.168.1.253.
Si vCenter Server, tout hôte ESXi ou un référentiel de distribution Hadoop sont résolus à l'aide
d'un nom de domaine complet (FQDN, Fully Qualified Domain Name), vous devez entrer une
adresse DNS. Entrez l'adresse IP du serveur DNS dans Serveur DNS 1. S'il existe un serveur DNS
secondaire, entrez son adresse IP dans Serveur DNS 2.
REMARQUE Vous ne pouvez pas utiliser un pool IP partagé avec Big Data Extensions.
b (Facultatif) Si vous utilisez IPv6 entre le serveur de gestion et vCenter Server, cochez la case
Activer la connexion Ipv6.
Entrez l'adresse IPv6 ou le FQDN de vCenter Server. La taille de l'adresse IPv6 s'élève à 128 bits. La
représentation préférée de l'adresse IPv6 est : xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx où chaque
x est un chiffre hexadécimal qui représente 4 bits. Les adresses IPv6 vont de
0000:0000:0000:0000:0000:0000:0000:0000 à ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff. Par commodité, une
adresse IPv6 peut être abrégée sous la forme d'une notation plus courte en appliquant les règles ciaprès.
Supprimez le ou les zéros non significatifs de tous les groupes de chiffres hexadécimaux. Cette
n
suppression est généralement appliquée soit à tous les zéros non significatifs, soit à aucun. Par
exemple, le groupe 0042 est converti en 42.
Remplacez les sections consécutives de zéros par un double deux-points (::). Vous pouvez
n
utiliser le double deux-points une seule fois dans une adresse, car en utiliser plusieurs rendrait
l'adresse imprécise. La norme RFC 5952 recommande de ne pas utiliser de double deux-points
pour représenter une section unique de zéros omise.
L'exemple suivant montre comment ces règles sont appliquées à l'adresse
2001:0db8:0000:0000:0000:ff00:0042:8329.
La suppression de tous les zéros non significatifs permet d'obtenir l'adresse
n
2001:db8:0:0:0:ff00:42:8329.
L'omission des sections consécutives de zéros permet d'obtenir l'adresse
n
2001:db8::ff00:42:8329.
Consultez la norme RFC 4291 pour plus d'informations sur la notation des adresses IPv6.
9 Vérifiez que la case Initialiser les ressources est cochée et cliquez sur Suivant.
Si la case n'est pas cochée, le pool de ressources, la banque de données et la connexion réseau affectés à
vApp ne sont pas ajoutés à Big Data Extensions.
Si vous n'ajoutez pas le pool de ressources, la banque de données et le réseau quand vous déployez
vApp, utilisez vSphere Web Client ou Serengeti CLI Client pour spécifier des informations s'y
rapportant avant de créer un cluster Hadoop.
10 Exécutez l'URL du service de recherche vCenter Single Sign-On pour activer vCenter Single Sign-On.
Si vous utilisez vCenter 5.x, utilisez l'URL suivante : https://FQDN_ou_IP_de_SSO_SERVER:
n
7444/lookupservice/sdk
VMware, Inc. 25
Page 26

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Si vous utilisez vCenter 6.0, utilisez l'URL suivante : https://FQDN_de_SSO_SERVER:
n
443/lookupservice/sdk
Si vous ne renseignez pas l'URL, vCenter Single Sign-On est désactivé.
11 Pour désactiver la collecte de données Big Data Extensions, décochez la case Programme d'amélioration
du produit.
12 (Facultatif) Pour désactiver l'enregistrement automatique du plug-in Web Big Data Extensions,
décochez la case d'activation correspondante.
Par défaut, la case d'activation de l'enregistrement automatique du plug-in Web Big Data Extensions est
cochée. Lorsque vous vous connectez au client Web de Big Data Extensions pour la première fois, il se
connecte automatiquement au Serengeti management server.
13 Spécifiez un serveur Syslog distant, tel que VMware vRealize Log Insight, auquel Big Data Extensions
peut envoyer des informations de journalisation à travers le réseau.
Il s'agit du serveur Syslog recevant et gérant les journaux qui contrôle les paramètres de rétention, de
rotation et de division de ceux-ci. Big Data Extensions ne peut pas configurer ni contrôler la gestion des
journaux sur un serveur Syslog distant. Pour en savoir plus sur la gestion des journaux, reportez-vous à
la documentation relative au serveur Syslog.
Quelle que soit la configuration Syslog supplémentaire spécifiée avec cette option, les journaux
continuent d'être placés dans les emplacements par défaut de l'environnement Big Data Extensions.
14 Vérifiez les liaisons vService et cliquez sur Suivant.
15 Vérifiez les informations d'installation, puis cliquez sur Terminer.
vCenter Server déploie Big Data Extensions vApp. Quand le déploiement est terminé, deux machines
virtuelles sont disponibles dans vApp :
La machine virtuelle du serveur de gestion, management-server (également appelée
n
Serengeti Management Server), qui est démarrée dans le cadre du déploiement OVA.
La machine virtuelle de modèle de nœud, node-template, n'est pas allumée. Big Data Extensions
n
clone les nœuds Hadoop à partir de ce modèle lors du provisionnement d'un cluster. Ne démarrez
pas ou n'arrêtez pas cette machine virtuelle sans bonne raison. Le modèle n'inclut pas de
distribution Hadoop.
IMPORTANT Ne supprimez pas de fichiers dans le répertoire /opt/serengeti/.chef. Si vous supprimez
l'un de ces fichiers, comme serengeti.pem, les mises à niveau ultérieures de Big Data Extensions
risquent d'échouer sans afficher de notifications d'erreur.
Suivant
Installez le plug-in Big Data Extensions dans vSphere Web Client. Reportez-vous à « Installer le plug-in Big
Data Extensions », page 27.
Si la case Initialiser les ressources n'est pas cochée, ajoutez des ressources au serveur Big Data Extensions
avant de créer un cluster Hadoop.
Installer des RPM dans le référentiel Yum du serveur de gestion Serengeti
Installer les packages Red Hat Package Manager (RPM) wsdl4j et mailx dans le référentiel Yum interne de
Serengeti Management Server.
Les packages RPM wsdl4j et mailx ne sont pas intégrés dans Big Data Extensions en raison des contrats de
licence. De ce fait, vous devez les installer dans le référentiel Yum interne de Serengeti Management Server.
26 VMware, Inc.
Page 27

Chapitre 2 Installation de Big Data Extensions
Prérequis
Déployez le vApp Big Data Extensions.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Téléchargez et installez les packages RPM wsdl4j et mailx.
Si Serengeti Management Server peut se connecter à Internet, exécutez les commandes comme
n
indiqué dans l'exemple ci-dessous pour télécharger les RPM, copiez les fichiers dans le répertoire
requis, puis créez un référentiel.
umask 022
cd /opt/serengeti/www/yum/repos/centos/6/base/RPMS/
wget http://mirror.centos.org/centos/6/os/x86_64/Packages/mailx-12.4-8.el6_6.x86_64.rpm
wget http://mirror.centos.org/centos/6/os/x86_64/Packages/wsdl4j-1.5.2-7.8.el6.noarch.rpm
createrepo ..
Si Serengeti Management Server ne peut pas se connecter à Internet, vous devez exécuter les tâches
n
suivantes manuellement.
a Téléchargez les fichiers RPM comme indiqué dans l'exemple ci-dessous.
http://mirror.centos.org/centos/6/os/x86_64/Packages/mailx-12.4-8.el6_6.x86_64.rpm
http://mirror.centos.org/centos/6/os/x86_64/Packages/wsdl4j-1.5.2-7.8.el6.noarch.rpm
b Copiez les fichiers RPM dans /opt/serengeti/www/yum/repos/centos/6/base/RPMS/.
c Exécutez la commande createrepo pour créer un référentiel à partir des RPM que vous avez
téléchargés.
umask 022
chmod a+r /opt/serengeti/www/yum/repos/centos/6/base/*.rpm
createrepo /opt/serengeti/www/yum/repos/centos/6/base/
Installer le plug-in Big Data Extensions
Pour permettre à l'interface utilisateur Big Data Extensions d'être utilisée avec vCenter Server Web Client,
enregistrez le plug-in auprès de vSphere Web Client. L'interface utilisateur graphique Big Data Extensions
est uniquement prise en charge lorsque vous utilisez vSphere Web Client 5.5 et version ultérieure.
Le plug-in Big Data Extensions propose une interface graphique utilisateur qui s'intègre à
vSphere Web Client. À l'aide de l'interface du plug-in Big Data Extensions, vous pouvez effectuer des tâches
courantes de gestion de l'infrastructure Hadoop et de clusters.
REMARQUE Utilisez uniquement l'interface du plug-in Big Data Extensions dans vSphere Web Client ou le
client Serengeti CLI pour surveiller et gérer votre environnement Big Data Extensions. L'exécution
d'opérations de gestion dans vCenter Server risque d'entraîner une désynchronisation des outils de gestion
Big Data Extensions et leur incapacité à signaler correctement l'état de fonctionnement de votre
environnement Big Data Extensions.
Prérequis
Déployez le vApp Big Data Extensions. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23.
VMware, Inc. 27
Page 28

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Par défaut, le plug-in Web Big Data Extensions s'installe et s'enregistre automatiquement lors du
n
déploiement du vApp Big Data Extensions. Pour installer le plug-in Web Big Data Extensions après
avoir déployé le vApp Big Data Extensions, vous devez avoir choisi de ne pas activer l'enregistrement
automatique du plug-in Web pendant le déploiement. Reportez-vous à « Déployer le vApp Big Data
Extensions dans vSphere Web Client », page 23.
Assurez-vous de disposer d'informations d'identification de connexion avec des privilèges
n
d'administration pour le système vCenter Server pour lequel vous enregistrez Big Data Extensions.
REMARQUE Le nom d'utilisateur et le mot de passe que vous utilisez pour la connexion ne peuvent pas
contenir de caractères dont le codage UTF-8 est supérieur à 0x8000.
Si vous voulez utiliser l'adresse IP de vCenter Server pour accéder à vSphere Web Client et que votre
n
navigateur utilise un proxy, ajoutez l'adresse IP de vCenter Server à la liste des exceptions de proxy.
Procédure
1 Ouvrez un navigateur Web et accédez à l'URL de vSphere Web Client 5.5 ou version ultérieure.
https://hostname-or-ip-address:port/vsphere-client
La variable hostname-or-ip-address peut être le nom d'hôte DNS ou l'adresse IP de vCenter Server. Par
défaut, le port est 9443, mais il peut avoir changé au cours de l'installation de vSphere Web Client.
2 Entrez le nom d'utilisateur et le mot de passe avec des privilèges d'administration qui possèdent des
autorisations sur vCenter Server, puis cliquez sur Connexion.
3 À l'aide du volet de navigation vSphere Web Client, accédez au fichier ZIP sur
Serengeti Management Server qui contient le plug-in Big Data Extensions à enregistrer auprès de
vCenter Server.
Pour trouver Serengeti Management Server, recherchez sous le centre de données et le pool de
ressources dans lesquels il est déployé.
4 Dans l'arborescence de l'inventaire, sélectionnez management-server pour afficher des informations sur
Serengeti Management Server dans le volet central.
Cliquez sur l'onglet Résumé dans le volet central pour accéder à des informations supplémentaires.
5 Notez l'adresse IP de la machine virtuelle Serengeti Management Server.
6 Ouvrez un navigateur Web et accédez à l'URL de la machine virtuelle management-server.
https://management-server-ip-address:8443/register-plugin
La variable management-server-ip-address correspond à l'adresse IP que vous avez notée à l'étape Étape 5.
7 Entrez les informations pour enregistrer le plug-in.
Option Action
Enregistrer ou annuler
l'enregistrement
Nom d'hôte ou adresse IP de
vCenter Server
Nom utilisateur et Mot de passe
URL du package Big Data
Extensions
Cliquez sur Installer pour installer le plug-in. Sélectionnez Désinstaller
pour désinstaller le plug-in.
Entrez le nom d'hôte ou l'adresse IP de vCenter Server.
N'incluez pas http:// ni https:// quand vous entrez le nom d'hôte ou
l'adresse IP.
Entrez le nom d'utilisateur et le mot de passe avec des privilèges
d'administration que vous utilisez pour vous connecter à vCenter Server.
Le nom d'utilisateur et le mot de passe ne peuvent pas contenir de
caractères dont le codage UTF-8 est supérieur à 0x8000.
Entrez l'URL avec l'adresse IP de la machine virtuelle management-server
où se trouve le package du plug-in Big Data Extensions :
https://management-server-ip-address/vcplugin/serengetiplugin.zip
28 VMware, Inc.
Page 29

Chapitre 2 Installation de Big Data Extensions
8 Cliquez sur Soumettre.
Le plug-in Big Data Extensions s'enregistre auprès de vCenter Server et de vSphere Web Client.
9 Déconnectez-vous de vSphere Web Client, puis reconnectez-vous à l'aide de vos nom d'utilisateur et
mot de passe vCenter Server.
L'icône Big Data Extensions apparaît dans la liste des objets de l'inventaire.
10 Cliquez sur Big Data Extensions dans le volet Inventaire.
Suivant
Connectez le plug-in Big Data Extensions à l'instance Big Data Extensions que vous voulez gérer en vous
connectant au Serengeti Management Server correspondant. Reportez-vous à « Se connecter à un serveur de
gestion Serengeti », page 30.
Configurer les paramètres vCenter Single Sign-On du serveur de gestion Serengeti
Si les paramètres d'authentification Single Sign-On (SSO) Big Data Extensions ne sont pas configurés ou s'ils
ont changé suite à l'installation du plug-in Big Data Extensions, vous pouvez utiliser le portail
d'administration du serveur de gestion Serengeti pour activer SSO, mettre à jour le certificat et enregistrer le
plug-in pour pouvoir vous connecter au serveur de gestion Serengeti et continuer à gérer des clusters.
Le certificat SSL du plug-in Big Data Extensions peut changer pour de nombreuses raisons. Par exemple,
vous installez un certificat personnalisé ou remplacez un certificat qui a expiré.
Prérequis
Assurez-vous de connaître l'adresse IP du serveur de gestion Serengeti auquel vous voulez vous
n
connecter.
Assurez-vous de disposer des informations d'identification de connexion de l'utilisateur root du
n
serveur de gestion Serengeti.
Procédure
1 Ouvrez un navigateur Web et accédez à l'URL du portail d'administration du serveur de gestion
Serengeti.
https://management-server-ip-address:5480
2 Tapez root pour le nom d'utilisateur, tapez le mot de passe, puis cliquez sur Connexion.
3 Sélectionnez l'onglet SSO.
4 Effectuez l'une des opérations suivantes.
Option Description
Mettre à jour le certificat
Activer SSO pour la première fois
Cliquez sur Mettre à jour le certificat.
Tapez l'URL du service de recherche, puis cliquez sur Activer SSO.
Les certificats de serveur SSO Big Data Extensions et vCenter sont synchronisés.
Suivant
Enregistrez de nouveau le plug-in Big Data Extensions auprès du serveur de gestion Serengeti. Reportezvous à « Se connecter à un serveur de gestion Serengeti », page 30.
VMware, Inc. 29
Page 30

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Se connecter à un serveur de gestion Serengeti
Pour utiliser le plug-in Big Data Extensions pour gérer et surveiller des clusters Big Data et des distributions
Hadoop, vous devez connecter le plug-in Big Data Extensions au Serengeti Management Server dans votre
déploiement Big Data Extensions.
Vous pouvez déployer plusieurs instances du Serengeti Management Server dans votre environnement. En
revanche, vous ne pouvez connecter le plug-in Big Data Extensions qu'à une seule instance du serveur de
gestion Serengeti à la fois. Vous pouvez changer l'instance Serengeti Management Server à laquelle se
connecte le plug-in, puis utiliser l'interface du plug-in Big Data Extensions pour gérer et surveiller plusieurs
distributions Hadoop et HBase déployées dans votre environnement.
IMPORTANT Le Serengeti Management Server auquel vous vous connectez est partagé par tous les
utilisateurs de l'interface du plug-in Big Data Extensions dans vSphere Web Client. Si un utilisateur se
connecte à un autre Serengeti Management Server, tous les autres utilisateurs sont affectés par ce
changement.
Prérequis
Vérifiez que le déploiement du vApp Big Data Extensions s'est correctement déroulé et que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Vérifiez que la version du serveur de gestion Serengeti et du plug-in Big Data Extensions est la même.
n
Vérifiez que vCenter Single Sign-On est activé et configuré pour être utilisé par Big Data Extensions
n
pour vSphere 5.5 et versions ultérieures.
Installez le plug-in Big Data Extensions.
n
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Sélectionnez Big Data Extensions.
3 Cliquez sur l'onglet Résumé.
4 Dans le volet Serveur connecté, cliquez sur le lien Connecter le serveur.
5 Accédez à la machine virtuelle du Serengeti Management Server dans le vApp Big Data Extensions
auquel se connecter, sélectionnez-la, puis cliquez sur OK.
Le plug-in Big Data Extensions communique via le protocole SSL avec le Serengeti Management Server.
Quand vous vous connectez à une instance du serveur Serengeti, le plug-in vérifie que le certificat SSL
en cours d'utilisation par le serveur est installé, valide et approuvé.
L'instance du serveur Serengeti apparaît en tant que serveur connecté sous l'onglet Résumé de la page
d'accueil Big Data Extensions.
Suivant
Vous pouvez ajouter un pool de ressources, une banque de données et des ressources réseau à votre
déploiement Big Data Extensions, puis créer des clusters Big Data que vous pouvez provisionner à des fins
d'utilisation.
30 VMware, Inc.
Page 31

Chapitre 2 Installation de Big Data Extensions
Installer le client d'interface de ligne de commande distant Serengeti
Bien que le plug-in Big Data Extensions pour vSphere Web Client prenne en charge des tâches de gestion de
ressources et de clusters basiques, vous pouvez exécuter bien plus de tâches de gestion à l'aide du client
Serengeti CLI.
Prérequis
Vérifiez que le déploiement du vApp Big Data Extensions s'est correctement déroulé et que le serveur
n
de gestion est en cours d'exécution.
Vérifiez que vous disposez du nom d'utilisateur et du mot de passe corrects pour vous connecter au
n
client Serengeti CLI. Si vous effectuez le déploiement sur vSphere 5.5 ou version ultérieure, le client
Serengeti CLI utilise vos informations d'identification vCenter Single Sign-On.
Vérifiez que l'environnement d'exécution Java (JRE, Java Runtime Environment) est installé dans votre
n
environnement et que son emplacement se trouve dans votre variable d'environnement PATH.
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Sélectionnez Big Data Extensions.
3 Cliquez sur l'onglet Démarrage, puis sur le lien Télécharger la console d'interface de ligne de
commande Serengeti.
Un fichier ZIP contenant le client Serengeti CLI est téléchargé sur votre ordinateur.
4 Décompressez-le et examinez le téléchargement, qui inclut les composants suivants dans le répertoire
cli.
Fichier JAR serengeti-cli-version, qui inclut le client Serengeti CLI.
n
Répertoire samples, qui inclut des exemples de configurations de clusters.
n
Bibliothèques dans le répertoire lib.
n
5 Ouvrez une interface de commande, puis accédez au répertoire dans lequel vous avez décompressé le
package de téléchargement du client Serengeti CLI.
6 Accédez au répertoire cli, puis exécutez la commande suivante pour ouvrir le client Serengeti CLI :
java -jar serengeti-cli-version.jar
Suivant
Pour en savoir plus sur l'utilisation du client Serengeti CLI, consultez le Guide de l'interface de ligne de
commande VMware vSphere Big Data Extensions.
Accéder à l'interface de ligne de commande Serengeti à l'aide du client d'interface de ligne de commande distant
Vous pouvez accéder à l'interface de ligne de commande (CLI) Serengeti pour effectuer des tâches
administratives Serengeti à l'aide du client d'interface de ligne de commande distant Serengeti.
Prérequis
Utilisez VMware vSphere Web Client pour vous connecter au serveur VMware vCenter Server® sur
n
lequel vous avez déployé le vApp Serengeti.
Vérifiez que le déploiement de Serengeti vApp s'est correctement déroulé et que le serveur de gestion
n
est en cours d'exécution.
VMware, Inc. 31
Page 32

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Vérifiez que le mot de passe dont vous disposez pour vous connecter à la Serengeti CLI est exact.
n
Consultez le Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions.
La Serengeti CLI utilise ses informations d'identification vCenter Server.
Vérifiez que l'environnement d'exécution Java (JRE, Java Runtime Environment) est installé dans votre
n
environnement et que son emplacement se trouve dans votre variable d'environnement path.
Procédure
1 Téléchargez le package Serengeti CLI à partir du Serengeti Management Server.
Ouvrez un navigateur Web et naviguez jusqu'à l'URL suivante :
https://server_ip_address/cli/VMware-Serengeti-CLI.zip
2 Téléchargez le fichier ZIP.
Le nom de fichier est au format VMware-Serengeti-cli-numéro_version-numéro_build.ZIP.
3 Décompressez le fichier téléchargé.
Celui-ci inclut les composants suivants.
Le fichier JAR serengeti-cli-version_number, qui inclut le Serengeti Remote CLI Client.
n
Répertoire samples, qui inclut des exemples de configurations de clusters.
n
Bibliothèques dans le répertoire lib.
n
4 Ouvrez une interface de commande, puis accédez au répertoire dans lequel vous avez décompressé le
package.
5 Accédez au répertoire cli, puis exécutez la commande suivante pour entrer dans l'interface de ligne de
commande Serengeti.
Pour les langues autres que le français ou l'allemand, exécutez la commande suivante.
n
java -jar serengeti-cli-numéro_version.jar
Pour le français ou l'allemand, qui utilisent l'encodage linguistique de page de code 850 (CP 850)
n
exécuter l'interface de ligne de commande Serengeti à partir d'une console de commandes
Windows, exécutez la commande suivante.
java -Dfile.encoding=cp850 -jar serengeti-cli-numéro_version.jar
6 Connectez-vous au service Serengeti.
Vous devez exécuter la commande connect host chaque fois que vous commencez une session
d'interface de ligne de commande, puis une nouvelle fois à l'issue du délai d'expiration de session de
30 minutes. Si vous n'exécutez pas cette commande, vous ne pouvez pas en exécuter d'autres.
a Exécutez la commande connect.
connect --host xx.xx.xx.xx:8443
b À l'invite, tapez votre nom d'utilisateur, qui peut être différent des informations d'identification
que vous utilisez pour vous connecter au Serengeti Management Server.
REMARQUE Si vous ne créez pas de nom d'utilisateur et de mot de passe pour le
Serengeti Command-Line Interface Client, vous pouvez utiliser les informations d'identification
d'administrateur vCenter Server par défaut. Le Serengeti Command-Line Interface Client utilise les
informations d'identification de vCenter Server avec les autorisations de lecture sur le
Serengeti Management Server.
c À l'invite, tapez votre mot de passe.
32 VMware, Inc.
Page 33

Chapitre 2 Installation de Big Data Extensions
Une interface de commande s'ouvre, puis l'invite de la Serengeti CLI apparaît. Vous pouvez utiliser la
commande help pour obtenir de l'aide sur les commandes Serengeti et leur syntaxe.
Pour afficher la liste des commandes disponibles, tapez help.
n
Pour obtenir de l'aide sur une commande particulière, ajoutez son nom après la commande help.
n
help cluster create
Appuyez sur Tab exécuter une commande.
n
VMware, Inc. 33
Page 34

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
34 VMware, Inc.
Page 35

Mise à niveau de Big Data Extensions 3
Vous pouvez mettre à niveau Big Data Extensions à partir de versions antérieures.
Ce chapitre aborde les rubriques suivantes :
« Préparer la mise à niveau de Big Data Extensions », page 35
n
« Mettre à niveau le dispositif virtuel Big Data Extensions », page 36
n
« Mettre à niveau le plug-in Big Data Extensions », page 37
n
« Mettre à niveau des clusters Big Data Extensions à l'aide de l'interface de ligne de commande
n
Serengeti », page 38
« Mettre à niveau l'Serengeti CLI », page 39
n
« Ajouter un serveur Syslog distant », page 39
n
Préparer la mise à niveau de Big Data Extensions
Avant d'effectuer la mise à niveau Big Data Extensions, vous devez préparer votre système pour vous
assurer que tous les logiciels requis sont correctement installés et configurés et que l'état de tous les
composants est correct.
VMware, Inc.
Les données issues de déploiements Big Data Extensions qui ne fonctionnent pas ne sont pas migrées
pendant le processus de mise à niveau. Si Big Data Extensions ne fonctionne pas et que vous ne pouvez pas
effectuer une récupération conformément aux procédures de résolution des problèmes, n'essayez pas
d'effectuer la mise à niveau. Désinstallez plutôt les composants Big Data Extensions précédents et installez
la nouvelle version.
IMPORTANT Ne supprimez pas de fichiers dans le répertoire /opt/serengeti/.chef. Si vous supprimez l'un
de ces fichiers, comme serengeti.pem, les mises à niveau ultérieures de Big Data Extensions risquent
d'échouer sans afficher de notifications d'erreur.
Prérequis
Vérifiez que votre déploiement Big Data Extensions précédent fonctionne normalement.
n
Procédure
1 Connectez-vous à Serengeti Management Server.
2 Exécutez le script /opt/serengeti/sbin/serengeti-maintenance.sh pour placer Big Data Extensions en
mode Maintenance.
serengeti-maintenance.sh on
35
Page 36

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
3 Vérifiez que Big Data Extensions est en mode maintenance.
Lorsque Big Data Extensions a terminé toutes les tâches qui ont été envoyées, l'état de maintenance
entre en mode sécurisé. Exécutez le script serengeti-maintenance.sh avec le paramètre status de
manière répétée jusqu'à obtenir le message d'état du système sécurisé.
serengeti-maintenance.sh status
safe
Lorsque le système renvoie le message d'état système sécurisé, vous pouvez procédez aux tâches de
mise à niveau du système.
Suivant
Vous pouvez à présent effectuer la mise à niveau vers la nouvelle version de Big Data Extensions. Reportezvous à la section « Mettre à niveau le dispositif virtuel Big Data Extensions », page 36.
Mettre à niveau le dispositif virtuel Big Data Extensions
Vous devez effectuer plusieurs tâches pour accomplir la mise à niveau du dispositif virtuel
Big Data Extensions.
Prérequis
La nouvelle version de Big Data Extensions se déploie avec succès dans le même environnement
vCenter Server que la version à partir de laquelle vous effectuez la mise à niveau.
Procédure
1 Exécutez le script de mise à niveau de Big Data Extensions. page 36
Le script de mise à niveau importe la configuration de la version précédente de Big Data Extensions.
2 Mettre à niveau Serengeti Management Server à l'aide du Portail d'administration de Serengeti
Management Server page 37
Vous pouvez effectuer des mises à niveau de votre version antérieure de Big Data Extensions vers la
dernière version à l'aide du Portail d'administration de Serengeti Management Server.
Exécutez le script de mise à niveau de Big Data Extensions .
Le script de mise à niveau importe la configuration de la version précédente de Big Data Extensions.
Prérequis
Déployez la nouvelle version de Big Data Extensions sur la même instance vCenter Server que votre
n
ancienne version. Cela permet au script de mise à niveau d'importer les paramètres Big Data Extensions
de votre précédent déploiement dans la dernière version.
Vous ne pouvez utiliser cette méthode de mise à niveau que pour passer de la version 2.2 à la
n
version 2.3. Si vous effectuez une mise à niveau depuis une version antérieure de Big Data Extensions,
vous devez d'abord procéder à la mise à niveau vers la version 2.2.
Si vous utilisez un modèle Hadoop personnalisé, créez un modèle Hadoop pour votre environnement
n
avant de procéder à la mise à niveau vers la nouvelle version de Big Data Extensions. Reportez-vous à
la section « Créer une machine virtuelle de modèle de nœud à l'aide de RHEL Server 6.7 et VMware
Tools », page 66.
Veillez à avoir à disposition l'adresse IP de la version 2.2 de Serengeti Management Server.
n
Procédure
1 Ouvrez une interface de commande sur la version de Serengeti Management Server vers laquelle vous
effectuez la mise à niveau (version 2.3) et connectez-vous en tant qu'utilisateur serengeti.
36 VMware, Inc.
Page 37

Chapitre 3 Mise à niveau de Big Data Extensions
2 Exécutez le script /opt/serengeti/sbin/upgrade.py.
Indiquez l'adresse IP de la version 2.2 de Serengeti Management Server. Le script vous invite à entrer le
mot de passe d'utilisateur serengeti de la version 2.2 de Serengeti Management Server.
/opt/serengeti/sbin/upgrade.py ip_address_2.2
Le processus de mise à niveau prend quelques minutes. Des messages vous informent de la progression
de la mise à niveau au fil de celle-ci.
3 Ouvrez une interface de commande sur Serengeti Management Server pour la version 2.3 et connectez-
vous en tant qu'utilisateur serengeti.
Si la procédure de mise à niveau renvoie une erreur, consultez le
fichier /opt/serengeti/logs/serengeti-upgrade.log. Ce fichier journal assure le suivi et
l'enregistrement des événements pendant la mise à niveau de Big Data Extensions et peut servir à
diagnostiquer d'éventuels problèmes.
Suivant
Vous pouvez à présent procéder à la mise à niveau de Serengeti Management Server. Reportez-vous à
« Mettre à niveau Serengeti Management Server à l'aide du Portail d'administration de Serengeti
Management Server », page 37.
Mettre à niveau Serengeti Management Server à l'aide du Portail d'administration de Serengeti Management Server
Vous pouvez effectuer des mises à niveau de votre version antérieure de Big Data Extensions vers la
dernière version à l'aide du Portail d'administration de Serengeti Management Server.
Procédure
1 Ouvrez un navigateur Web et accédez à l'URL du Portail d'administration de
Serengeti Management Server pour Big Data Extensions 2.3.
https://management-server-ip-address:5480
2 Tapez root pour le nom d'utilisateur, tapez le mot de passe, puis cliquez sur Connexion.
3 Sélectionnez l'onglet Mettre à niveau.
4 Saisissez les adresses IP du serveur Big Data Extensions à partir duquel vous souhaitez effectuer la mise
à niveau, puis le mot de passe de l'utilisateur serengeti, et cliquez sur Mettre à niveau.
Mettre à niveau le plug-in Big Data Extensions
Vous devez utiliser la même version pour le Serengeti Management Server et le plug-in Big Data Extensions.
Par défaut, le plug-in Web Big Data Extensions s'installe et s'enregistre auprès du
Serengeti Management Server automatiquement lors du déploiement du vApp Big Data Extensions. Si vous
choisissez de ne pas installer ni enregistrer le plug-in Web Big Data Extensions lors de l'installation du vApp
Big Data Extensions, vous devez procéder comme suit pour mettre à niveau le plug-in.
Procédure
1 Ouvrez un navigateur Web et accédez à l'URL du service de gestion de plug-in
Serengeti Management Server.
https://management-server-ip-address:8443/register-plugin
2 Sélectionnez Désinstaller et cliquez sur Envoyer.
3 Sélectionnez Installer.
VMware, Inc. 37
Page 38

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
4 Entrez les informations pour enregistrer le nouveau plug-in, puis cliquez sur Envoyer.
Mettre à niveau des clusters Big Data Extensions à l'aide de l'interface de ligne de commande Serengeti
Pour permettre à Serengeti Management Server de gérer les clusters créés dans une version antérieure de
Big Data Extensions, vous devez mettre à niveau les composants des machines virtuelles de chaque cluster.
Serengeti Management Server utilise ces composants pour contrôler les nœuds de cluster.
Quand vous effectuez une mise à niveau à partir d'une version antérieure de Big Data Extensions, les
clusters que vous avez besoin de mettre à niveau apparaissent avec une icône d'alerte en regard de leur
nom. Lorsque vous cliquez sur l'icône d'alerte, le message d'erreur Mettre à niveau le cluster vers la
version la plus récente s'affiche sous la forme d'une info-bulle. Reportez-vous à « Afficher les clusters
provisionnés dans vSphere Web Client », page 125.
Vous pouvez également identifier les clusters qui ont besoin d'une mise à niveau avec la commande cluster
list. Quand vous exécutez la commande cluster list, une indication d'antériorité s'affiche là où se trouve
normalement la version du cluster.
Prérequis
Vous pouvez mettre à niveau tout cluster créé par Big Data Extensions 2.x vers la version 2.3. Vous
n
n'avez pas à mettre à niveau le cluster vers la version 2.2 avant de le mettre à niveau vers la version 2.3.
Procédure
1 Connectez-vous au vSphere Web Client qui est connecté à vCenter Server et accédez à Hôtes et
clusters.
2 Sélectionnez le pool de ressources du cluster, sélectionnez l'onglet Machines virtuelles, puis mettez
sous tension les machines virtuelles du cluster.
IMPORTANT L'affectation des adresses IP valides aux nœuds de cluster Big Data par vCenter Server peut
prendre jusqu'à cinq minutes. N'effectuez pas les étapes de mise à niveau restantes tant que les nœuds
n'ont pas reçu leurs adresses IP. Si un nœud ne possède pas d'adresse IP valide, il n'est pas possible de
le mettre à niveau vers la nouvelle version des outils de machine virtuelle Big Data Extensions.
3 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous à
Serengeti Management Server en tant qu'utilisateur serengeti.
4 Exécutez la commande cluster upgrade pour chaque cluster qui a été créé avec une version antérieure
de Big Data Extensions.
5 Si la mise à niveau échoue pour un nœud, assurez-vous que le nœud qui a échoué possède une adresse
IP valide, puis réexécutez la commande cluster upgrade.
Vous pouvez réexécuter la commande autant de fois que nécessaire pour mettre à niveau tous les
nœuds.
Suivant
Arrêtez et redémarrez vos clusters Big Data.
38 VMware, Inc.
Page 39

Mettre à niveau l' Serengeti CLI
La version de l'Serengeti CLI doit être la même que celle de votre déploiement Big Data Extensions. Si vous
exécutez l'interface de ligne de commande à distance pour vous connecter au serveur de gestion, vous devez
mettre à niveau l'Serengeti CLI.
Procédure
1 Connectez-vous à vSphere Web Client.
2 Sélectionnez Big Data Extensions dans le panneau de navigation.
3 Cliquez sur l'onglet Résumé.
4 Dans le panneau Serveur connecté, cliquez sur Connecter le serveur.
5 Sélectionnez la machine virtuelle Serengeti Management Server dans le vApp Big Data Extensions
auquel se connecter, puis cliquez sur OK.
6 Cliquez sur l'onglet Démarrage, puis sur Télécharger la console d'interface de ligne de commande
Serengeti.
Un fichier ZIP contenant le client Serengeti CLI est téléchargé sur votre ordinateur.
7 Décompressez et examinez le fichier ZIP, qui inclut les composants suivants dans le répertoire CLI :
Chapitre 3 Mise à niveau de Big Data Extensions
Fichier JAR serengeti-cli-version, qui inclut le client Serengeti CLI.
n
Répertoire samples, qui inclut des exemples de configurations de clusters.
n
Bibliothèques dans le répertoire lib.
n
8 Ouvrez une interface de commande, puis accédez au répertoire dans lequel vous avez décompressé le
package de téléchargement du client Serengeti CLI.
9 Accédez au répertoire CLI, puis exécutez la commande suivante pour ouvrir le client Serengeti CLI :
java -jar serengeti-cli-version.jar
Suivant
1 Si vos clusters sont déployés avec une machine virtuelle de modèle Hadopp dont la version du système
d'exploitation CentOS 6.x est personnalisée et inclut VMware Tools, vous devez personnaliser un
nouveau modèle CentOS 6.x à utiliser après la mise à niveau de Big Data Extensions.
2 Pour permettre à Serengeti Management Server de gérer les clusters que vous avez créés dans une
version précédente de Big Data Extensions, vous devez mettre à niveau chaque cluster.
Ajouter un serveur Syslog distant
Si vous souhaitez utiliser un serveur Syslog distant après une mise à niveau depuis des versions antérieures
de Big Data Extensions, vous devez spécifier manuellement le serveur Syslog distant que vous souhaitez
utiliser.
C'est le serveur Syslog recevant et gérant les journaux qui contrôle les paramètres de rétention, de rotation et
de division de ceux-ci. Big Data Extensions ne peut pas configurer ni contrôler la gestion des journaux sur
un serveur Syslog distant. Pour en savoir plus sur la gestion des journaux, reportez-vous à la documentation
relative à votre serveur Syslog.
Prérequis
Effectuer une mise à niveau vers la version actuelle de Big Data Extensions.
n
VMware, Inc. 39
Page 40

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Disposer dans votre environnement d'un serveur Syslog distant auquel Big Data Extensions peut
n
envoyer des informations de journalisation.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Ouvrez le fichier /etc/rsyslog.d/20-base.conf dans un éditeur de texte.
3 Modifiez le fichier pour inclure les informations sur le service Syslog distant.
*.* @syslog_ip_address:port_number
4 Redémarrez le service Syslog.
service rsyslog restart
Votre déploiement Big Data Extensions mis à niveau enverra des ifnormations de journalisation au service
Syslog distant que vous spécifiez.
REMARQUE Quelle que soit la configuration Syslog supplémentaire spécifiée avec cette procédure, les
journaux continuent d'être placés dans les emplacements par défaut de l'environnement
Big Data Extensions. Reportez-vous à « Fichiers journaux pour le dépannage », page 142.
40 VMware, Inc.
Page 41

Gestion des gestionnaires
d'applications 4
Pour bien gérer vos clusters Hadoop, il est essentiel de comprendre comment gérer les différents
gestionnaires d'applications que vous utilisez dans votre environnement Big Data Extensions.
Ce chapitre aborde les rubriques suivantes :
« Ajouter un gestionnaire d'applications à l'aide de vSphere Web Client », page 41
n
« Modifier un gestionnaire d'applications à l'aide de vSphere Web Client », page 42
n
« Supprimer un gestionnaire d'applications à l'aide de vSphere Web Client », page 42
n
« Afficher les gestionnaires d'applications et les distributions à l'aide de vSphere Web Client »,
n
page 42
« Afficher les rôles du gestionnaire d'applications et de la distribution à l'aide de vSphere Web
n
Client », page 43
Ajouter un gestionnaire d'applications à l'aide de vSphere Web Client
Pour utiliser un gestionnaire d'applications Cloudera Manager ou Ambari visant à gérer des clusters, vous
devez ajouter ce gestionnaire d'applications ainsi que des informations sur le serveur à Big Data Extensions.
Les noms des gestionnaires d'applications peuvent comporter uniquement des caractères alphanumériques
([0-9, a-z, A-Z]) et les caractères spéciaux suivants : trait de soulignement, tiret et espace.
Procédure
1 Dans le volet de navigation Big Data Extensions, cliquez sur Gestionnaires d'applications.
2 Cliquez sur l'icône Ajouter un gestionnaire d'applications (+) en haut de la page pour ouvrir
l'Assistant Nouveau gestionnaire d'applications.
3 Suivez les invites pour terminer l'installation du gestionnaire d'applications.
Vous pouvez utiliser soit http, soit https.
Option Action
Utiliser http
Utiliser https
L'interface utilisateur Web vSphere actualise la liste des gestionnaires d'applications et l'affiche en mode
Liste.
Entrez l'URL du serveur avec http. La zone de texte Certification SSL est
désactivée.
Entrez le FQDN au lieu de l'URL. La zone de texte Certification SSL est
activée.
VMware, Inc.
41
Page 42

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Modifier un gestionnaire d'applications à l'aide de vSphere Web Client
Vous pouvez modifier les informations d'un gestionnaire d'applications. Par exemple, vous pouvez modifier
l'adresse IP du serveur de gestion si elle n'est pas statique ou vous pouvez mettre à niveau le compte
d'administrateur.
Prérequis
Vérifiez que vous avez au moins un gestionnaire d'applications externe installé dans votre environnement
Big Data Extensions.
Procédure
1 Dans vSphere Web Client, cliquez sur Gestionnaires d'applications dans le menu de navigation.
2 Dans la liste Gestionnaires d'applications, cliquez avec le bouton droit sur le gestionnaire d'applications
à modifier et sélectionnez Modifier les paramètres.
3 Dans la boîte de dialogue Modifier le gestionnaire d'applications, apportez les modifications au
gestionnaire d'applications et cliquez sur OK.
Supprimer un gestionnaire d'applications à l'aide de vSphere Web Client
Vous pouvez supprimer un gestionnaire d'applications avec vSphere Web Client quand vous n'en avez plus
besoin.
Le processus échoue si le gestionnaire d'applications que vous voulez supprimer contient des clusters.
Prérequis
Vérifiez que vous avez au moins un gestionnaire d'applications externe installé dans votre environnement
Big Data Extensions.
Procédure
1 Dans vSphere Web Client, cliquez sur Gestionnaires d'applications dans le volet de navigation.
2 Cliquez avec le bouton droit sur le gestionnaire d'applications à supprimer et sélectionnez Supprimer.
Le gestionnaire d'applications est supprimé de la liste Gestionnaires d'applications.
Afficher les gestionnaires d'applications et les distributions à l'aide de vSphere Web Client
Vous pouvez afficher la liste des gestionnaires d'applications et des distributions en cours d'utilisation dans
votre environnement Big Data Extensions.
Procédure
À partir de Big Data Extensions, cliquez sur Gestionnaires d'applications depuis Listes d'inventaire.
u
La liste qui s'ouvre contient les distributions, les descriptions, les gestionnaires d'applications, ainsi que
le nombre de clusters gérés par votre environnement Big Data Extensions.
42 VMware, Inc.
Page 43

Chapitre 4 Gestion des gestionnaires d'applications
Afficher les rôles du gestionnaire d'applications et de la distribution à l'aide de vSphere Web Client
Vous pouvez utiliser le volet Gestionnaires d'applications pour afficher la liste et les détails des rôles
Hadoop pour un gestionnaire d'applications et une distribution spécifiques.
Procédure
1 À partir de Big Data Extensions, cliquez sur Listes d'inventaire > Gestionnaires d'applications.
2 Sélectionnez le gestionnaire d'applications pour lequel vous voulez afficher les détails.
Le volet de détails qui s'ouvre contient la liste des distributions prises en charge avec leur nom, leur
fournisseur, leur version et leurs rôles.
VMware, Inc. 43
Page 44

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
44 VMware, Inc.
Page 45

Gestion de distributions Hadoop 5
Le Serengeti Management Server inclut la distribution Apache Bigtop, mais vous pouvez ajouter n'importe
quelle distribution Hadoop prise en charge dans votre environnement Big Data Extensions.
Procédure
1 Types de déploiement de distribution Hadoop page 45
Vous pouvez choisir la distribution Hadoopà utiliser lorsque vous déployez un cluster. Le type de
distribution que vous choisissez détermine la manière de la configurer pour une utilisation avec
Big Data Extensions. Lorsque vous déployez l'application virtuelle Big Data Extensions, la distribution
Bigtop 1.0 est incluse dans le fichier OVA que vous téléchargez et déployez.
2 Configurer une distribution Hadoop déployée sur Tarball à l'aide de l'interface de ligne de commande
Serengeti page 46
Vous pouvez ajouter et configurer des distributions Hadoop différentes de celles incluses avec
l'application virtuelle Big Data Extensions à l'aide de la ligne de commande. Vous pouvez configurer
plusieurs distributions Hadoop de différents fournisseurs.
3 Configuration de Yum et de référentiels Yum page 48
Vous pouvez déployer les distributions Hadoop Cloudera CDH4 et CDH5, Apache Bigtop, MapR et
Pivotal PHD à l'aide de Yellowdog Updater, Modified (Yum). Yum permet la mise à jour automatique
et la gestion des paquets des distributions de logiciel basées sur RPM. Pour déployer une distribution
Hadoop à l'aide de Yum, vous devez créer et configurer un référentiel Yum.
Types de déploiement de distribution Hadoop
Vous pouvez choisir la distribution Hadoopà utiliser lorsque vous déployez un cluster. Le type de
distribution que vous choisissez détermine la manière de la configurer pour une utilisation avec
Big Data Extensions. Lorsque vous déployez l'application virtuelle Big Data Extensions, la distribution
Bigtop 1.0 est incluse dans le fichier OVA que vous téléchargez et déployez.
En fonction de la distribution Hadoopque vous souhaitez configurer pour une utilisation avec
Big Data Extensions, utilisez un référentiel tarball ou yum pour installer votre distribution. Le tableau
répertorie les distributions Hadoop prises en charge, ainsi que le nom, l'abréviation du fournisseur et le
numéro de version de la distribution à utiliser en tant que paramètres d'entrée lors de la configuration de la
distribution pour une utilisation avec Big Data Extensions.
Tableau 5‑1. Types de déploiement Hadoop dans le gestionnaire d'applications par défaut
Numéro de
Distribution Hadoop
Bigtop 1.0 BIGTOP Yum Non
Pivotal HD 2.0, 2.1 PHD Yum Oui
VMware, Inc. 45
version
Abréviation du
fournisseur
Type de
déploiement
Prise en charge
HVE ?
Page 46

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Tableau 5‑1. Types de déploiement Hadoop dans le gestionnaire d'applications par défaut (suite)
Numéro de
Distribution Hadoop
Hortonworks Data Platform 1.2, 2.1 HDP Yum Non
Cloudera 5.3, 5.4 CDH Yum Non
MapR 4.1, 5.0 MAPR Yum Non
À propos des
Extensions de
virtualisation Hadoop
version
Hadoop Virtualization Extensions (HVE), développé par VMware, optimise
les performances Hadoop dans les environnements virtuels en améliorant le
mécanisme de reconnaissance de topologie de Hadoop afin de tenir compte
Abréviation du
fournisseur
Type de
déploiement
Prise en charge
HVE ?
de la couche de virtualisation.
Configurer des
distributions
Hadoop 2.x et version
ultérieure avec
résolution des noms
DNS
Lorsque vous créez des clusters en utilisant des distributions Hadoopbasées
sur Hadoop 2.0 ou version ultérieure, le serveur DNS de votre réseau doit
assurer une résolution FQDN/IP dans les deux sens. Sans paramètres DNS et
FQDN valides, le processus de création du cluster risque d'échouer ou le
cluster est créé mais il ne fonctionne pas. Les distributions Hadoop basées
sur Hadoop 2.x et version ultérieure incluent Apache Bigtop,
Cloudera CDH4 et CDH5, Hortonworks HDP 2.x, et Pivotal PHD 1.1 et
versions ultérieures.
Configurer une distribution Hadoop déployée sur Tarball à l'aide de l'interface de ligne de commande Serengeti
Vous pouvez ajouter et configurer des distributions Hadoop différentes de celles incluses avec l'application
virtuelle Big Data Extensions à l'aide de la ligne de commande. Vous pouvez configurer plusieurs
distributions Hadoop de différents fournisseurs.
Reportez-vous au site Web de votre fournisseur de distribution Hadoop pour acquérir les URL de
téléchargement à utiliser pour les composants que vous souhaitez installer. Si vous utilisez un pare-feu,il se
peut que vous ayez à modifier les paramètres de votre proxy pour permettre le téléchargement. Avant
d'installer et de configurer des déploiements basés sur un tarball, vérifiez que vous disposez des URL du
fournisseur pour télécharger les différents composants Hadoop. Utilisez ces URL comme paramètres de
saisie dans l'utilitaire de configuration config-distro.rb.
Si vous possédez une distribution Hadoop locale et que votre serveur ne peut pas accéder à Internet, vous
pouvez télécharger la distribution manuellement.
Prérequis
Déployez Big Data Extensions vApp.
n
Vérifiez toutes les distributions Hadoop pour savoir quel nom de distribution, quelle abréviation de
n
fournisseur et quel numéro de version utiliser en paramètre de saisie et si la distribution prend en
charge Hadoop Virtualization Extension (HVE).
(Facultatif) Définissez le mot de passe du serveur de gestion Serengeti.
n
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au serveur de gestion
Serengeti en tant qu'utilisateur serengeti.
46 VMware, Inc.
Page 47

Chapitre 5 Gestion de distributions Hadoop
2 Exécutez le script Ruby /opt/serengeti/sbin/config-distro.rb.
config-distro.rb --name distro_name --vendor vendor_name --version version_number
--hadoop hadoop_package_url --pig pig_package_url --hive hive_package_url
--hbase hbase_package_url --zookeeper zookeeper_package_URL --hve {true | false} --yes
Option Description
--nom
-- fournisseur
--version
--hadoop
--pig
--hive
--hbase
--zookeeper
--hve {true | false}
--oui
Nommez la distribution Hadoop que vous téléchargez. Par exemple, hdp
pour Hortonworks. Ce nom peut comporte des caractères alphanumérique
([a-z], [A-Z], [0-9]) et des underscores (« _ »).
Nom du fournisseur de la distribution Hadoop que vous souhaitez utiliser.
Par exemple, HDP pour Hortonworks.
Version de la distribution Hadoop que vous souhaitez utiliser. Par
exemple, 1.3.
URL à partir de laquelle télécharger le package tarball de distribution
Hadoop sur le site Web du fournisseur d'Hadoop.
URL à partir de laquelle télécharger le package tarball de distribution Pig
sur le site Web du fournisseur d'Hadoop.
URL à partir de laquelle télécharger le package tarball de distribution Hive
sur le site Web du fournisseur d'Hadoop.
(Facultatif) URL à partir de laquelle télécharger le package tarball de
distribution HBase sur le site Web du fournisseur d'Hadoop.
(Facultatif) URL à partir de laquelle télécharger le package tarball de
distribution ZooKeeper sur le site Web du fournisseur d'Hadoop.
(Facultatif) Indique si la distribution Hadoop prend en charge HVE.
(Facultatif) Indique que toutes les invites de confirmation du script
config-distro.rb ont été confirmées.
Dans cet exemple, la version tarball d'Hortonworks Data Platform (HDP) est téléchargée. Elle se
compose des distributions Hortonworks Hadoop, Hive, HBase, Pig et ZooKeeper. Veuillez noter que
vous devez fournir l'URL de téléchargement de chacun des composants logiciels que vous souhaitez
configurer pour les utiliser avec Big Data Extensions.
config-distro.rb --name hdp --vendor HDP --version 1.3.2
--hadoop http://public-repo-1.hortonworks.com/HDP/centos6/1.x/updates/1.3.2.0/tars/
hadoop-1.2.0.1.3.2.0-111.tar.gz
--pig http://public-repo-1.hortonworks.com/HDP/centos6/1.x/updates/1.3.2.0/tars/
pig-0.11.1.1.3.2.0-111.tar.gz
--hive http://public-repo-1.hortonworks.com/HDP/centos6/1.x/updates/1.3.2.0/tars/
hive-0.11.0.1.3.2.0-111.tar.gz
--hbase http://public-repo-1.hortonworks.com/HDP/centos6/1.x/updates/1.3.2.0/tars/
hbase-0.94.6.1.3.2.0-111-security.tar.gz
--zookeeper http://public-repo-1.hortonworks.com/HDP/centos6/1.x/updates/1.3.2.0/tars/
zookeeper-3.4.5.1.3.2.0-111.tar.gz
--hve true
Le script télécharge les fichiers.
VMware, Inc. 47
Page 48

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
3 À la fin du téléchargement, explorez le répertoire /opt/serengeti/www/distros, qui inclue les
répertoires et les fichiers suivants.
Élément Description
nom
manifeste
manifeste.exemple
Répertoire nommé d'après la distribution. Par exemple, apache.
Fichier manifeste généré par config-distro.rb qui est utilisé pour le
téléchargement de la distribution Hadoop.
Fichier manifeste d'exemple. Ce fichier est disponible avant l'exécution
du téléchargement. Le fichier manifeste est un fichier JSON contenant trois
sections : le nom, la version et les packages.
4 Pour permettre à Big Data Extensions d'utiliser la distribution ajoutée, redémarrez le service Tomcat.
sudo /sbin/service tomcat restart
Serengeti Management Server lit le fichier manifeste modifié et ajoute la distribution à celles à partir
desquelles vous pouvez créer un cluster.
5 Revenez au plug-in Big Data Extensions de vSphere Web Client, puis cliquez sur Distributions Hadoop
afin de vérifier que la distribution Hadoop est disponible pour créer un cluster.
La distribution et le rôle correspondant apparaissent.
La distribution est ajoutée à Serengeti Management Server, mais n'est pas installée dans la machine virtuelle
du modèle Hadoop. L'agent est préinstallé sur chaque machine virtuelle qui copie dans les nœuds les
composants de la distribution que vous spécifiez à partir de Serengeti Management Server au cours du
processus de création d'un cluster Hadoop.
Suivant
Vous pouvez ajouter une banque de données et des ressources de réseau pour les clusters Hadoop que vous
créez.
Vous pouvez créer et déployer des clusters Big Data à l'aide de la distribution Hadoop de votre choix.
Configuration de Yum et de référentiels Yum
Vous pouvez déployer les distributions Hadoop Cloudera CDH4 et CDH5, Apache Bigtop, MapR et Pivotal
PHD à l'aide de Yellowdog Updater, Modified (Yum). Yum permet la mise à jour automatique et la gestion
des paquets des distributions de logiciel basées sur RPM. Pour déployer une distribution Hadoop à l'aide de
Yum, vous devez créer et configurer un référentiel Yum.
Valeurs de configuration de référentiels Yum page 49
n
Pour créer un référentiel Yum local, vous créez un fichier de configuration qui identifie les noms de
fichiers et de packages d'une distribution à télécharger et à déployer. Lorsque vous créez le fichier de
configuration, vous remplacez un ensemble de valeurs d'espaces réservés par des valeurs qui
correspondent à votre distribution Hadoop. Les référentiels Yum sont utilisés pour installer ou mettre
à jour des logiciels Hadoop sur CentOS et d'autres systèmes d'exploitation qui utilisent
Red Hat Package Manager (RPM).
Configurer un référentiel Yum local pour des distributions Hadoop Apache Bigtop, Cloudera,
n
Hortonworks et MapR page 52
Bien que des référentiels Yum publics existent pour les distributions Ambari, Apache Bigtop,
Cloudera, Hortonworks et MapReduce, le fait de créer votre propre référentiel Yum peut vous
permettre des téléchargements plus rapides et un meilleur contrôle du référentiel.
48 VMware, Inc.
Page 49

Chapitre 5 Gestion de distributions Hadoop
Configurer un référentiel Yum local pour la distribution Hadoop Pivotal page 54
n
Pivotal ne fournit pas de référentiel Yum public à partir duquel il est possible de déployer et de mettre
à jour la distribution de logiciel Hadoop Pivotal. Il vous est néanmoins possible de télécharger les
tarballs de logiciel Pivotal et de créer votre référentiel Yum pour Pivotal qui vous permettra d'accéder
plus facilement et de mieux contrôler l'installation et la mise à jour de votre logiciel de distribution HD
Pivotal.
Configurer une distribution Hadoop déployée sur Yum page 56
n
Vous pouvez installer les distributions Hadoop qui utilisent des référentiels Yum (contrairement aux
tarballs) à utiliser avec Big Data Extensions. Lorsque vous créez un cluster pour une distribution
Hadoop déployée sur Yum, les nœuds Hadoop téléchargent et installent les paquets Red Hat Package
Manager (RPM) depuis les référentiels Yum officiels pour une distribution donnée ou pour vos
référentiels Yum locaux.
Configurer un référentiel Yum local pour le gestionnaire d'applications Cloudera Manager page 57
n
Lorsque vous créez un nouveau cluster avec un gestionnaire d'applications externe, vous devez
installer les agents et les paquets de distribution sur chaque nœud de cluster. Si l'installation
télécharge les agents et les paquets sur Internet, le processus peut être lent. Si vous ne disposez pas de
connexion Internet, le processus de création du cluster n'est pas possible. Pour éviter ces problèmes,
vous pouvez créer un référentiel Yum local.
Configurer un référentiel Yum local pour le gestionnaire d'applications Ambari page 60
n
Lorsque vous créez un nouveau cluster avec un gestionnaire d'applications externe, vous devez
installer les agents et les paquets de distribution sur chaque nœud de cluster. Si l'installation
télécharge les agents et les paquets sur Internet, le processus peut être lent. Si vous ne disposez pas de
connexion Internet, le processus de création du cluster n'est pas possible. Pour éviter ces problèmes,
vous pouvez créer un référentiel Yum local.
Valeurs de configuration de référentiels Yum
Pour créer un référentiel Yum local, vous créez un fichier de configuration qui identifie les noms de fichiers
et de packages d'une distribution à télécharger et à déployer. Lorsque vous créez le fichier de configuration,
vous remplacez un ensemble de valeurs d'espaces réservés par des valeurs qui correspondent à votre
distribution Hadoop. Les référentiels Yum sont utilisés pour installer ou mettre à jour des logiciels Hadoop
sur CentOS et d'autres systèmes d'exploitation qui utilisent Red Hat Package Manager (RPM).
Les tableaux suivants répertorient les valeurs à utiliser pour les distributions Ambari, Apache Bigtop,
Cloudera, Hortonworks, MapR et Pivotal.
REMARQUE Si vous copiez et collez des valeurs dans ce tableau, veillez à inclure toutes les informations
requises. Certaines valeurs apparaissent sur deux lignes dans le tableau, par exemple, « maprtech
maprecosystem », alors que vous devez les combiner sur une seule ligne quand vous les utilisez.
Valeurs de configuration de référentiels Yum Apache Bigtop
VMware, Inc. 49
Page 50

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Tableau 5‑2. Valeurs d'espaces réservés de référentiels Yum Apache Bigtop
Espace réservé Valeur
repo_file_name bigtop.repo
package_info [bigtop]
name=Bigtop
enabled=1
gpgcheck=1
type=NONE
baseurl=http://bigtop-repos.s3.amazonaws.com/releases/1.0.0/centos/6/x86_64
gpgkey=https://dist.apache.org/repos/dist/release/bigtop/KEYS
REMARQUE Si vous utilisez une version autre que 1.0.0, utilisez le numéro de version exact de
votre distribution Apache Bigtop dans le nom du chemin.
mirror_cmds reposync -r bigtop
default_rpm_dir bigtop
target_rpm_dir bigtop
local_repo_info [bigtop]
name=Apache Bigtop
baseurl=http://ip_of_yum_repo_webserver/bigtop/
enabled=1
gpgcheck=0
Valeurs de configuration de référentiels Yum Cloudera
Tableau 5‑3. Valeurs d'espaces réservés de référentiels Yum Cloudera
Espace réservé Valeur
repo_file_name cloudera-cdh.repo
package_info Si vous utilisez CDH4, utilisez les valeurs ci-dessous.
[cloudera-cdh]
name=Cloudera's Distribution for Hadoop
http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/4/
gpkey=http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
gpgcheck=1
Si vous utilisez CDH5, utilisez les valeurs ci-dessous.
[cloudera-cdh]
name=Cloudera's Distribution for Hadoop
baseurl=http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/5/
gpgkey=http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
gpgcheck=1
mirror_cmds reposync -r cloudera-cdh4
default_rpm_dir cloudera-cdh/RPMS
target_rpm_dir cdh/version_number
local_repo_info [cloudera-cdh]
name=Cloudera's Distribution for Hadoop
baseurl=http://ip_of_yum_repo_webserver/cdh/version_number/
enabled=1
gpgcheck=0
50 VMware, Inc.
Page 51

Valeurs de configuration de référentiels Yum Hortonworks
Tableau 5‑4. Valeurs d'espaces réservés de référentiels Yum Hortonworks
Espace réservé Valeur
repo_file_name hdp.repo
package_info [hdp]
name=Hortonworks Data Platform Version - HDP-2.1.1.0
baseurl=http://public-repo-1.hortonworks.com/HDP/centos6/2.x/GA/2.1.1.0
gpgcheck=1
gpgkey=http://public-repo-1.hortonworks.com/HDP/centos6/2.x/GA/2.1.1.0/RPM-GPG-
KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
REMARQUE Si vous utilisez une version autre que HDP 2.1.1.0, utilisez le numéro de version
exact de votre distribution Hortonworks dans le nom du chemin.
mirror_cmds reposync -r hdp
default_rpm_dir hdp
target_rpm_dir hdp/2
local_repo_info [hdp]
name=Hortonworks Data Platform Version -HDP-2.1.1.0
baseurl=http://ip_of_yum_repo_webserver/hdp/2/
enabled=1
gpgcheck=0
Chapitre 5 Gestion de distributions Hadoop
Valeurs de configuration de référentiels Yum MapR
Tableau 5‑5. Valeurs d'espaces réservés de référentiels Yum MapR
Espace réservé Valeur
repo_file_name mapr.repo
package_info [maprtech]
name=MapR Technologies
baseurl=http://package.mapr.com/releases/3.1.0/redhat/
enabled=1
gpgcheck=0
protect=1
[maprecosystem]
name=MapR Technologies
baseurl=http://package.mapr.com/releases/ecosystem/redhat
enabled=1
gpgcheck=0
protect=1
REMARQUE Si vous utilisez une version autre que 3.1.0, utilisez le numéro de version exact de
votre distribution MapR dans le nom du chemin.
mirror_cmds reposync -r maprtech
reposync -r maprecosystem
default_rpm_dir maprtech maprecosystem
VMware, Inc. 51
Page 52

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Tableau 5‑5. Valeurs d'espaces réservés de référentiels Yum MapR (suite)
Espace réservé Valeur
target_rpm_dir mapr/3
local_repo_info [mapr]
name=MapR Version 3
baseurl=http://ip_of_yum_repo_webserver/mapr/3/
enabled=1
gpgcheck=0
protect=1
Valeurs de configuration de référentiels Yum Pivotal
Tableau 5‑6. Valeurs d'espaces réservés de référentiels Yum Pivotal
Espace réservé Valeur
repo_file_name phd.repo
package_info Non applicable
mirror_cmds Non applicable
default_rpm_dir pivotal
target_rpm_dir phd/1
local_repo_info [pivotalhd]
name=PHD Version 1.0
baseurl=http://ip_of_yum_repo_webserver/phd/1/
enabled=1
gpgcheck=0
Configurer un référentiel Yum local pour des distributions Hadoop Apache Bigtop, Cloudera , Hortonworks et MapR
Bien que des référentiels Yum publics existent pour les distributions Ambari, Apache Bigtop, Cloudera,
Hortonworks et MapReduce, le fait de créer votre propre référentiel Yum peut vous permettre des
téléchargements plus rapides et un meilleur contrôle du référentiel.
Prérequis
Connexion Internet haut débit.
n
CentOS 6.x 64 bits ou Red Hat Enterprise Linux (RHEL) 6.x 64 bits.
n
La machine virtuelle du modèle de nœud de l'application virtuelle Serengeti contient
CentOS 6.7 64 bits. Vous pouvez cloner la machine virtuelle du modèle de nœud vers une nouvelle
machine virtuelle et y créer le référentiel Yum.
Serveur HTTP sur lequel créer le référentiel Yum. Par exemple, serveur HTTP Apache.
n
Si votre système est doté d'un pare-feu, vérifiez que celui-ci ne bloque pas le numéro de port du réseau
n
utilisé par votre serveur proxy HTTP. Il s'agit généralement du port 80.
Reportez-vous aux valeurs du signet du référentiel Yum pour alimenter les variables nécessaires dans
n
les étapes. Reportez-vous à « Valeurs de configuration de référentiels Yum », page 49.
52 VMware, Inc.
Page 53

Chapitre 5 Gestion de distributions Hadoop
Procédure
1 Si votre serveur de référentiel Yum nécessite un serveur proxy HTTP, ouvrez une interface de
commande, comme Bash ou PuTTY, puis connectez-vous au serveur du référentiel Yum et exécutez les
commandes suivantes pour exporter la variable de l'environnement http_proxy.
# switch to root user
sudo su
umask 002
export http_proxy=http://hôte:port
Option Description
hôte
port
Nom d'hôte ou adresse IP du serveur proxy.
Numéro de port du réseau à utiliser avec le serveur proxy.
2 Installez le serveur HTTP que vous souhaitez utiliser comme serveur Yum.
Dans cet exemple, le serveur HTTP Apache est installé et le serveur httpd est activé pour démarrer dès
que la machine redémarre.
yum install -y httpd
/sbin/service httpd start
/sbin/chkconfig httpd on
3 Installez yum-utils et les paquets createrepo.
Le paquet yum-utils contient la commande reposync.
yum install -y yum-utils createrepo
4 Synchronisez le serveur Yum avec le référentiel Yum officiel de votre fournisseur Hadoop préféré.
a À l'aide d'un éditeur de texte, créez le fichier /etc/yum.repos.d/$repo_file_name.
b Ajoutez le contenu package_info au nouveau fichier.
c Mettez en miroir le référentiel Yum distant sur la machine locale en exécutant mirror_cmds pour les
paquets de votre distribution.
Le téléchargement des RPM à partir du référentiel distant peut vous prendre plusieurs minutes.
Les RPM sont placés dans les répertoires $default_rpm_dir.
5 Créez le référentiel Yum local.
a Déplacez les RPM dans un nouveau répertoire sous la racine de document du serveur HTTP
Apache.
La racine de document par défaut est /var/www/html/.
doc_root=/var/www/html
mkdir -p $doc_root/$target_rpm_dir
mv $default_rpm_dir $doc_root/$target_rpm_dir/
Par exemple, la commande mv de la distribution Hadoop MapR est la suivante :
mv maprtech maprecosystem $doc_root/mapr/3/
b Créez un référentiel Yum pour les RPM.
cd $doc_root/$target_rpm_dir
createrepo .
VMware, Inc. 53
Page 54

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
c Créez un nouveau fichier, $doc_root/$target_rpm_dir/$repo_file_name,et incluez
local_repo_info.
d Dans une autre machine, vérifiez que vous pouvez télécharger le fichier de référentiel à partir de
http://ip_of_webserver target_rpm_dir//repo_file_name.
6 (Facultatif) Configurez le proxy HTTP.
Si les machines virtuelles créées par Serengeti Management Server n'ont pas besoin de proxy HTTP
pour se connecter au référentiel Yum local, passez directement à l'étape suivante.
Sur le serveur de gestion Serengeti, modifiez le fichier /opt/serengeti/conf/serengeti.properties et
ajoutez le contenu suivant n'importe où dans le fichier ou remplacez les éléments existants :
# set http proxy server
serengeti.http_proxy = http://<proxy_server:port>
# set the FQDNs (or IPs if no FQDN) of the Serengeti Management Server and the
local yum repository servers for 'serengeti.no_proxy'.
The wildcard for matching multi IPs doesn't work.
serengeti.no_proxy = serengeti_server_fqdn_or_ip.
yourdomain.com, yum_server_fqdn_or_ip.
yourdomain.com
Suivant
Configurez votre déploiement Apache Bigtop, Cloudera, Hortonworks ou MapR à utiliser avec
Big Data Extensions. Reportez-vous à « Configurer une distribution Hadoop déployée sur Yum », page 56.
Configurer un référentiel Yum local pour la distribution Hadoop Pivotal
Pivotal ne fournit pas de référentiel Yum public à partir duquel il est possible de déployer et de mettre à
jour la distribution de logiciel Hadoop Pivotal. Il vous est néanmoins possible de télécharger les tarballs de
logiciel Pivotal et de créer votre référentiel Yum pour Pivotal qui vous permettra d'accéder plus facilement
et de mieux contrôler l'installation et la mise à jour de votre logiciel de distribution HD Pivotal.
Pivotal ne fournit pas de référentiel Yum public à partir duquel il est possible de déployer et de mettre à
jour la distribution de logiciel Hadoop Pivotal. Il est néanmoins possible de télécharger des tarballs de
logiciel Pivotal et de créer un référentiel Yum à partir duquel déployer et configurer le logiciel Hadoop
Pivotal.
Prérequis
Connexion Internet haut débit.
n
CentOS 6.x 64 bits ou Red Hat Enterprise Linux (RHEL) 6.x 64 bits.
n
La machine virtuelle du modèle de nœud de l'application virtuelle Big Data Extensions contient
CentOS 6.7 64 bits. Vous pouvez cloner la machine virtuelle du modèle de nœud vers une nouvelle
machine virtuelle et y créer le référentiel Yum.
REMARQUE La distribution Hadoop Pivotal nécessitant la version CentOS 6.2 64-bit ou 6.4 64-bit
(x86_64), le serveur Yum que vous créez pour déployer la distribution doit également utiliser un
système d'exploitation CentOS 6.x 64-bit.
Serveur HTTP sur lequel créer le référentiel Yum. Par exemple, serveur HTTP Apache.
n
Si votre système est doté d'un pare-feu, vérifiez que celui-ci ne bloque pas le numéro de port du réseau
n
utilisé par votre serveur proxy HTTP. Il s'agit généralement du port 80.
54 VMware, Inc.
Page 55

Chapitre 5 Gestion de distributions Hadoop
Procédure
1 Si votre serveur de référentiel Yum nécessite un serveur proxy HTTP, ouvrez une interface de
commande, comme Bash ou PuTTY, puis connectez-vous au serveur du référentiel Yum et exécutez les
commandes suivantes pour exporter la variable de l'environnement http_proxy.
# switch to root user
sudo su
umask 002
export http_proxy=http://hôte:port
Option Description
hôte
port
Nom d'hôte ou adresse IP du serveur proxy.
Numéro de port du réseau à utiliser avec le serveur proxy.
2 Installez le serveur HTTP que vous souhaitez utiliser avec un serveur Yum.
Dans cet exemple, le serveur HTTP Apache est installé et le serveur httpd est activé pour démarrer dès
que la machine redémarre.
yum install -y httpd
/sbin/service httpd start
/sbin/chkconfig httpd on
3 Installez yum-utils et les paquets createrepo.
Le paquet yum-utils contient la commande reposync.
yum install -y yum-utils createrepo
4 Téléchargez le tarball Pivotal HD 1.0 ou 2.0 sur le site Web de Pivotal.
5 Extrayez le tarball que vous avez téléchargé.
Le nom du tarball peut varier si vous téléchargez une autre version de Pivotal HD.
tar -xf phd_1.0.1.0-19_community.tar
6 Extrayez PHD_1.0.1_CE/PHD-1.0.1.0-19.tar dans le répertoire default_rpm_dir.
Pour Hadoop Pivotal, le répertoire default_rpm_dir est pivotal.
Les numéros de version du tar que vous extrayez peuvent être différents de ceux utilisés dans l'exemple
s'il y a eu une mise à jour.
tar -xf PHD_1.0.1_CE/PHD-1.0.1.0-19.tar -C pivotal
7 Créez et configurez le référentiel Yum local.
a Déplacez les RPM dans un nouveau répertoire sous la racine de document du serveur HTTP
Apache.
La racine de document par défaut est /var/www/html/.
doc_root=/var/www/html
mkdir -p $doc_root/$target_rpm_dir
mv $default_rpm_dir $doc_root/$target_rpm_dir/
Dans cet exemple, les RPM sont déplacés pour la distribution Hadoop Pivotal.
mv pivotal $doc_root/phd/1/
b Créez un référentiel Yum pour les RPM.
cd $doc_root/$target_rpm_dir
createrepo .
VMware, Inc. 55
Page 56

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
c Créez un fichier, $doc_root/$target_rpm_dir/$repo_file_name, et incluez local_repo_info.
d Dans une autre machine, vérifiez que vous pouvez télécharger le fichier de référentiel à partir de
http://ip_of_webserver/$target_rpm_dir/$repo_file_name.
8 (Facultatif) Configurez un proxy HTTP.
Si les machines virtuelles créées par Serengeti Management Server n'ont pas besoin de proxy HTTP
pour se connecter au référentiel Yum local, passez directement à l'étape suivante.
Sur Serengeti Management Server, modifiez le fichier /opt/serengeti/conf/serengeti.properties et
ajoutez le contenu suivant n'importe où dans le fichier ou remplacez les éléments existants :
# set http proxy server
serengeti.http_proxy = http://<proxy_server:port>
# set the FQDNs (or IPs if no FQDN) of the Serengeti Management Server and the
local yum repository servers for 'serengeti.no_proxy'.
The wildcard for matching multi IPs doesn't work.
serengeti.no_proxy = serengeti_server_fqdn_or_ip.
yourdomain.com, yum_server_fqdn_or_ip.yourdomain.com
Configurer une distribution Hadoop déployée sur Yum
Vous pouvez installer les distributions Hadoop qui utilisent des référentiels Yum (contrairement aux
tarballs) à utiliser avec Big Data Extensions. Lorsque vous créez un cluster pour une distribution Hadoop
déployée sur Yum, les nœuds Hadoop téléchargent et installent les paquets Red Hat Package Manager
(RPM) depuis les référentiels Yum officiels pour une distribution donnée ou pour vos référentiels Yum
locaux.
Prérequis
Vérifiez toutes les distributions Hadoop pour savoir quel nom de distribution, quelle abréviation de
n
fournisseur et quel numéro de version utiliser en paramètre de saisie et si la distribution prend en
charge Hadoop Virtualization Extensions.
Créez un référentiel Yum local pour votre distribution Hadoop. La création de votre référentiel peut
n
contribuer à améliorer l'accès et le contrôle du référentiel.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au serveur de gestion
Serengeti en tant qu'utilisateur serengeti.
2 Exécutez le script Ruby /opt/serengeti/sbin/config-distro.rb.
config-distro.rb --name distro_name --vendor vendor_abbreviation --version ver_number
--repos http://url_to_yum_repo/name.repo
Option Description
--nom
-- fournisseur
Nommez la distribution Hadoop que vous téléchargez. Par exemple, chd4
pour Cloudera CDH4. Ce nom peut comporte des caractères
alphanumérique ([a-z], [A-Z], [0-9]) et des underscores (« _ »).
Abréviation du nom du fournisseur de la distribution Hadoop que vous
souhaitez utiliser. Par exemple, CDH.
56 VMware, Inc.
Page 57

Chapitre 5 Gestion de distributions Hadoop
Option Description
--version
--référentiels
Version de la distribution Hadoop que vous souhaitez utiliser. Par
exemple, 4.6.0.
URL à partir de laquelle télécharger le paquet Yum de la distribution
Hadoop. Cette URL peut se trouver sur un référentiel Yum local que vous
créez ou sur un référentiel Yum public hébergé par le fournisseur de
logiciel.
Cet exemple ajoute la distribution Hadoop Apache Bigtop à Big Data Extensions.
config-distro.rb --name bigtop --vendor BIGTOP --version 0.8.0
--repos http://url_to_yum_repo/bigtop.repo
Cet exemple ajoute la distribution Hadoop Cloudera CDH4 à Big Data Extensions.
config-distro.rb --name cdh4 --vendor CDH --version 4.6.0 --repos
http://url_to_yum_repo/cloudera-cdh4.repo
REMARQUE Le script config-distro.rb ne télécharge que les fichiers pour les distributions déployées
sur tarball. Aucun fichier n'est téléchargé pour les distributions déployées sur Yum.
Cet exemple ajoute la distribution Hadoop Hortonworks à Big Data Extensions.
config-distro.rb --name hdp --vendor HDP --version 2.1.1
--repos http://url_to_yum_repo/hdp.repo
Cet exemple ajoute la distribution Hadoop MapR à Big Data Extensions.
config-distro.rb --name mapr --vendor MAPR --version 3.1.0 --repos
http://url_to_yum_repo/mapr.repo
Cet exemple ajoute la distribution Hadoop Pivotal à Big Data Extensions.
config-distro.rb --name phd --vendor PHD --version 2.0
--repos http://url_to_yum_repo/phd.repo
3 Pour permettre à Big Data Extensions d'utiliser la nouvelle distribution, redémarrez le service Tomcat.
sudo /sbin/service tomcat restart
Le serveur de gestion Serengeti lit le fichier manifeste modifié et ajoute la distribution à ceux à partir
desquels vous pouvez créer un cluster.
4 Revenez au plug-in Big Data Extensions de vSphere Web Client, puis cliquez sur Distributions Hadoop
pour vérifier que la distribution Hadoop est disponible.
Suivant
Vous pouvez créer des clusters Hadoop et HBase.
Configurer un référentiel Yum local pour le gestionnaire d'applications Cloudera Manager
Lorsque vous créez un nouveau cluster avec un gestionnaire d'applications externe, vous devez installer les
agents et les paquets de distribution sur chaque nœud de cluster. Si l'installation télécharge les agents et les
paquets sur Internet, le processus peut être lent. Si vous ne disposez pas de connexion Internet, le processus
de création du cluster n'est pas possible. Pour éviter ces problèmes, vous pouvez créer un référentiel Yum
local.
VMware, Inc. 57
Page 58

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Préparer l'environnement logiciel pour le référentiel local pour Cloudera Manager
Pour créer un référentiel Yum local pour Cloudera Manager, la première étape consiste à préparer
l'environnement logiciel en configurant les serveurs et les répertoires nécessaires.
Prérequis
Vérifiez que toutes les conditions suivantes sont réunies.
Connexion Internet haut débit.
n
CentOS 6.x 64 bits ou Red Hat Enterprise Linux (RHEL) 6.x 64 bits.
n
La machine virtuelle du modèle de nœud de l'application virtuelle Serengeti contient
CentOS 6.7 64 bits. Vous pouvez cloner la machine virtuelle du modèle de nœud vers une nouvelle
machine virtuelle et y créer le référentiel Yum.
Serveur HTTP sur lequel créer le référentiel Yum. Par exemple, serveur HTTP Apache.
n
Si votre système dispose d'un pare-feu, vérifiez que celui-ci ne bloque pas le numéro de port du réseau
n
que votre proxy de serveur HTTP utilise. Il s'agit généralement du port 80.
Pour plus d'informations sur les valeurs du signet du référentiel Yum, reportez-vous à « Valeurs de
n
configuration de référentiels Yum », page 49.
Procédure
1 Si votre serveur de référentiel Yum nécessite un serveur proxy HTTP, procédez comme suit :
a Ouvrez une interface de commande, comme Bash ou PuTTY.
b Connectez-vous au serveur de référentiel Yum.
c Exportez la variable de l'environnement http_proxy.
# switch to root user
sudo su
umask 002
export http_proxy=http://hôte:port
Option Description
hôte
port
Nom d'hôte ou adresse IP du serveur proxy.
Numéro de port du réseau à utiliser avec le serveur proxy.
2 Installez le serveur HTTP que vous souhaitez utiliser comme serveur Yum.
Dans cet exemple, le serveur HTTP Apache est installé et le serveur httpd est activé pour démarrer dès
que la machine redémarre.
yum install -y httpd
/sbin/service httpd start
/sbin/chkconfig httpd on
3 Créez le répertoire CentOS.
mkdir -p /var/www/html/yum/centos6
4 Créez le répertoire Cloudera Manager.
mkdir -p /var/www/html/yum/cm
5 Installez le RPM createrepo.
yum install -y createrepo
58 VMware, Inc.
Page 59

Chapitre 5 Gestion de distributions Hadoop
Configurer le référentiel Yum CentOS local
Vous devez copier tous les packages RPM des images CentOS 6 DVD ISO pour configurer le référentiel Yum
CentOS local.
Prérequis
Vérifiez que vous avez préparé l'environnement logiciel pour la création du référentiel Yum CentOS,
notamment les répertoires pour CentOS et le gestionnaire d'applications. Reportez-vous à la documentation
CentOS.
Procédure
1 Téléchargez les images CentOS 6 DVD ISO CentOS-6.7-x86_64-bin-DVD1.iso et CentOS-6.7-x86_64-
bin-DVD2.iso sur le site Internet officiel de CentOS.
2 Téléchargez les images ISO sur les serveurs de machine virtuelle.
3 Copiez tous les packages RPM CentOS vers /var/www/html/yum/centos6.
mkdir /mnt/centos6-1
mount -o loop CentOS-6.7-x86_64-bin-DVD1.iso /mnt/centos6-1
cp /mnt/centos6-1/Packages/* /var/www/html/yum/centos6
mkdir /mnt/centos6-2
mount -o loop CentOS-6.7-x86_64-bin-DVD2.iso /mnt/centos6-2
cp /mnt/centos6-2/Packages/* /var/www/html/yum/centos6
4 Créez le référentiel Yum CentOS 6.
createrepo /var/www/html/yum/centos6
Télécharger les packages pour Cloudera Manager
Après avoir configuré le référentiel Yum CentOS local, vous devez télécharger les packages de Cloudera
Manager.
Procédure
1 Téléchargez le fichier cm5.4.8-centos6.tar.gz.
wget http://archive-primary.cloudera.com/cm5/repo-as-tarball/5.4.8/cm5.4.8-centos6.tar.gz
Pour les autres versions de Cloudera Manager, les URL utilisées dans l'exemple peuvent varier.
2 Extrayez le tarball.
tar xzf cm5.4.8-centos6.tar.gz -C /var/www/html/yum/cm/
Pour les autres versions de Cloudera Manager, les URL utilisées dans l'exemple peuvent varier.
Configurer le serveur du référentiel Yum et le référentiel de paquet local
Vous devez configurer le serveur du référentiel Yum et le référentiel de paquet local avant de pouvoir
distribuer le fichier de paquets.
Procédure
1 Créez le référentiel Yum.
Le répertoire repodata est créé sous /var/www/html/yum/cm/5.4.8.
createrepo /var/www/html/yum/cm/5.4.8
2 Vérifiez que vous pouvez accéder à l'URL http://yum_repo_server_ip/yum à partir d'un navigateur.
VMware, Inc. 59
Page 60

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
3 Créez le répertoire Parcels (Paquets).
mkdir -p /var/www/html/parcels
4 Passez au répertoire Parcels (Paquets).
cd /var/www/html/parcels
5 Téléchargez le fichier Parcels (Paquets).
wget http://archive-primary.cloudera.com/cdh5/parcels/5.4.8/CDH-5.4.8-1.cdh5.4.8.p0.4el6.parcel
6 Téléchargez le fichier manifest.json.
wget http://archive-primary.cloudera.com/cdh5/parcels/5.4.8/manifest.json
7 Dans le fichier manifest.json, supprimez tous les éléments sauf CDH-5.4.8-1.cdh5.4.8.p0.4-
el6.parcel.
8 Ouvrez un navigateur, accédez à http://your_cloudera_manager_server:7180/cmf/parcel/status et cliquez
sur Edit Settings (Modifier les paramètres).
9 Dans la zone de texte Parcel Update Frequency (Fréquence de mise à jour des paquets), sélectionnez
une minute.
10 Supprimez l'URL du répertoire de paquet distant qui était remplacée par l'URL de paquet cible.
11 Ajoutez l'URL http://yum_repo_server_ip/parcels.
Vous pouvez maintenant créer des clusters pour Cloudera Manager à l'aide du référentiel Yum local.
Configurer un référentiel Yum local pour le gestionnaire d'applications Ambari
Lorsque vous créez un nouveau cluster avec un gestionnaire d'applications externe, vous devez installer les
agents et les paquets de distribution sur chaque nœud de cluster. Si l'installation télécharge les agents et les
paquets sur Internet, le processus peut être lent. Si vous ne disposez pas de connexion Internet, le processus
de création du cluster n'est pas possible. Pour éviter ces problèmes, vous pouvez créer un référentiel Yum
local.
Préparer l'environnement logiciel pour le référentiel local pour Ambari
Pour créer un référentiel Yum local pour Ambari, la première étape consiste à préparer l'environnement
logiciel.
Prérequis
Vérifiez que toutes les conditions suivantes sont réunies.
Connexion Internet haut débit.
n
CentOS 6.x 64 bits ou Red Hat Enterprise Linux (RHEL) 6.x 64 bits.
n
La machine virtuelle du modèle de nœud de l'application virtuelle Serengeti contient
CentOS 6.7 64 bits. Vous pouvez cloner la machine virtuelle du modèle Hadoop à une nouvelle machine
virtuelle et y créer le référentiel Yum.
Serveur HTTP sur lequel créer le référentiel Yum. Par exemple, serveur HTTP Apache.
n
Si votre système dispose d'un pare-feu, vérifiez que celui-ci ne bloque pas le numéro de port du réseau
n
que votre proxy de serveur HTTP utilise. Il s'agit généralement du port 80.
Pour plus d'informations sur les valeurs du signet du référentiel Yum, reportez-vous à « Valeurs de
n
configuration de référentiels Yum », page 49.
60 VMware, Inc.
Page 61

Chapitre 5 Gestion de distributions Hadoop
Procédure
1 Si votre serveur de référentiel Yum nécessite un serveur proxy HTTP, ouvrez une interface de
commande, comme Bash ou PuTTY, puis connectez-vous au serveur du référentiel Yum et exportez la
variable de l'environnement http_proxy.
# switch to root user
sudo su
umask 002
export http_proxy=http://hôte:port
Option Description
hôte
port
Nom d'hôte ou adresse IP du serveur proxy.
Numéro de port du réseau à utiliser avec le serveur proxy.
2 Installez le serveur HTTP que vous souhaitez utiliser comme serveur Yum.
Dans cet exemple, le serveur HTTP Apache est installé et le serveur httpd est activé pour démarrer dès
que la machine redémarre.
yum install -y httpd
/sbin/service httpd start
/sbin/chkconfig httpd on
3 Créez le répertoire CentOS.
mkdir -p /var/www/html/yum/centos6
4 Créez le répertoire Ambari.
mkdir -p /var/www/html/yum/ambari
5 Installez le RPM createrepo.
yum install -y createrepo
Configurer le référentiel Yum CentOS local
Vous devez copier tous les packages RPM des images CentOS 6 DVD ISO pour configurer le référentiel Yum
CentOS local.
Prérequis
Vérifiez que vous avez préparé l'environnement logiciel pour la création du référentiel Yum CentOS,
notamment les répertoires pour CentOS et le gestionnaire d'applications. Reportez-vous à la documentation
CentOS.
Procédure
1 Téléchargez les images CentOS 6 DVD ISO CentOS-6.7-x86_64-bin-DVD1.iso et CentOS-6.7-x86_64-
bin-DVD2.iso sur le site Internet officiel de CentOS.
2 Téléchargez les images ISO sur les serveurs de machine virtuelle.
3 Copiez tous les packages RPM CentOS vers /var/www/html/yum/centos6.
mkdir /mnt/centos6-1
mount -o loop CentOS-6.7-x86_64-bin-DVD1.iso /mnt/centos6-1
cp /mnt/centos6-1/Packages/* /var/www/html/yum/centos6
mkdir /mnt/centos6-2
mount -o loop CentOS-6.7-x86_64-bin-DVD2.iso /mnt/centos6-2
cp /mnt/centos6-2/Packages/* /var/www/html/yum/centos6
VMware, Inc. 61
Page 62

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
4 Créez le référentiel Yum CentOS 6.
createrepo /var/www/html/yum/centos6
Télécharger les packages pour Ambari
Après avoir configuré le référentiel Yum CentOS local, téléchargez les paquets du gestionnaire
d'applications Ambari.
Procédure
1 Faites de /var/www/html/yum/ambari votre répertoire de travail.
cd /var/www/html/yum/ambari
2 Téléchargez l'agent Ambari.
wget http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.1.2/AMBARI-2.1.2-377centos6.tar.gz
Si vous utilisez d'autres versions d'Ambari, par exemple Ambari 2.1.1, l'URL que vous utilisez peut
varier.
3 Téléchargez les paquets HDP.
Si vous utilisez d'autres versions de HDP, par exemple HDP 2.2 ou HDP 2.3, l'URL que vous utilisez
peut varier.
4 Téléchargez les paquets HDP-UTILS.
wget http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos6/HDPUTILS-1.1.0.20-centos6.tar.gz
5 Procédez à l'extraction de tous les fichiers tarball.
tar xzf AMBARI-2.1.2-377-centos6.tar.gz
tar xzf HDP-2.3.2.0-centos6-rpm.tar.gz
tar xzf HDP-UTILS-1.1.0.20-centos6.tar.gz
Configurer le fichier de référentiel Ambari sur le serveur Ambari
Pour configurer le référentiel Yum local, vous devez configurer le fichier de référentiel Ambari.
Procédure
1 Connectez-vous à Ambari via SSH.
ssh nom d'utilisateur@ambari_server_ip_address
2 Arrêtez le serveur Ambari.
ambari-server stop
3 Téléchargez le fichier ambari.repo.
cd /etc/yum.repos.d
wget http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.1.2/ambari.repo
4 Modifiez le fichier ambari.repo.
a Remplacez les URL par l'adresse du serveur de référentiel Yum.
b Supprimez la vérification de groupe.
c Ajoutez une nouvelle section pour CentOS.
62 VMware, Inc.
Page 63

Chapitre 5 Gestion de distributions Hadoop
Exemple : Configuration du fichier de référentiel Ambari sur le serveur Ambari
[centos]
name=centos6
baseurl=http://<yum_repo_server_ip>/yum/centos6/
gpgcheck=0
enabled=1
[Updates-ambari-2.1.2]
name=ambari-2.1.2 - Updates
baseurl=http://<yum_repo_server_ip>/yum/ambari/AMBARI-2.1.2/centos6/
gpgcheck=0
enabled=1
priority=1
Configurer le référentiel HDP sur le serveur Ambari
Après avoir configuré le référentiel Ambari sur le serveur Ambari, vous devez configurer le référentiel HDP
sur le serveur Ambari.
Prérequis
Vérifiez que vous avez configuré ambari.repository sur le serveur Ambari.
Procédure
1 Modifiez le fichier suivant :
/var/lib/ambari-server/resources/stacks/HDP/2.3/repos/repoinfo.xml
a Remplacez le numéro de version 2.3 par le vôtre.
b Remplacez l'url de base de os type="redhat6" par l'URL de votre référentiel HDP local, comme
indiqué dans l'exemple suivant :
<?xml version="1.0"?>
<!- License section(not displayed here).
-->
<reposinfo>
<os family="redhat6">
<repo>
<baseurl>http://yum_repo_server_ip/yum/ambari/HDP/centos6/2.x/updates/2.3.0.0</baseurl>
<repoid>HDP-2.3</repoid>
<reponame>HDP</reponame>
</repo>
<repo>
<baseurl>http://yum_repo_server_ip/yum/ambari/HDPUTILS-1.1.0.20/repos/centos6</baseurl>
<repoid>HDP-UTILS-1.1.0.20</repoid>
<reponame>HDP-UTILS</reponame>
</repo>
</os>
</reposinfo>
2 Démarrez le serveur Ambari.
ambari-server start
Vous pouvez désormais créer des clusters pour le serveur Ambari à l'aide du référentiel Yum local.
VMware, Inc. 63
Page 64

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
64 VMware, Inc.
Page 65

Gérer les modèles de nœud 6
Vous pouvez gérer les modèles.
Prérequis
Procédure
u
Exemple :
Suivant
Ce chapitre aborde les rubriques suivantes :
« Tenir à jour une machine virtuelle de modèle Hadoop personnalisée », page 65
n
« Créer une machine virtuelle de modèle de nœud à l'aide de RHEL Server 6.7 et VMware Tools »,
n
page 66
« Prendre en charge plusieurs modèles de machine virtuelle », page 70
n
Tenir à jour une machine virtuelle de modèle Hadoop personnalisée
Vous pouvez modifier ou mettre à jour le système d'exploitation d'une machine virtuelle du modèle
Hadoop. Si vous procédez à des mises à jour, vous devez supprimer l'instantané qui est créé par la machine
virtuelle.
Si vous créez une machine virtuelle du modèle Hadoop personnalisée qui utilise une version de RHEL 6.x,
ou si vous modifiez le système d'exploitation, vous devez supprimer l'instantané Serengeti que Big Data
Extensions crée. Si vous ne supprimez pas l'instantané Serengeti, les modifications que vous apportez à la
machine virtuelle du modèle Hadoop ne prendront pas effet.
Prérequis
Déployez Big Data Extensions vApp. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23.
Créez une machine virtuelle du modèle Hadoop personnalisée à l'aide de RHEL 6.x. Voir « Créer une
n
machine virtuelle de modèle de nœud à l'aide de RHEL Server 6.7 et VMware Tools », page 66
.
VMware, Inc.
65
Page 66

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Allumez la machine virtuelle du modèle Hadoop et appliquez les modifications ou les mises à jour.
3 Supprimez le fichier /etc/udev/rules.d/70-persistent-net.rules pour éviter d'augmenter le nombre
eth lors du clonage.
Si vous ne supprimez pas ce fichier, les machines virtuelles clonées à partir du modèle ne peuvent pas
obtenir d'adresses IP. Si vous mettez la machine virtuelle du modèle Hadoop sous tension pour
apporter des modifications, supprimez le fichier avant d'éteindre cette machine virtuelle.
4 Dans vSphere Web Client, éteignez la machine virtuelle du modèle Hadoop.
5 Supprimez l'instantané Serengenti étiqueté de la machine virtuelle du modèle Hadoop personnalisée.
a Dans vSphere Web Client, cliquez avec le bouton droit de la souris sur la machine virtuelle du
modèle Hadoop et sélectionnez Snapshot > Snapshot Manager (Instantané, Gestionnaire
d'instantanés).
b Sélectionnez l'instantané Serengeti et cliquez sur Supprimer.
L'instantané généré est supprimé.
6 Synchronisez l'heure sur la machine virtuelle du modèle Hadoop avec vCenter Server.
a Dans vSphere Web Client, cliquez avec le bouton droit sur la machine virtuelle du modèle Hadoop
et sélectionnez Modifier les paramètres.
b Dans l'onglet Options VM, cliquez sur VMware Tools > Synchroniser l'heure invité avec l'hôte.
Créer une machine virtuelle de modèle de nœud à l'aide de RHEL Server 6.7 et VMware Tools
Vous pouvez créer une machine virtuelle de modèle de nœud possédant une version personnalisée du
système d'exploitation Red Hat Enterprise Linux (RHEL) Server 6.x, qui inclut VMware Tools. Bien que peu
de distributions Hadoop nécessitent une version personnalisée de RHEL Server 6.7, vous pouvez le
personnaliser pour toute distribution Hadoop.
Avant de créer une machine virtuelle de modèle de nœud à l'aide de RHEL Server 6.7 et VMware Tools
Avant de créer une machine virtuelle de modèle de nœud à l'aide de RHEL Server 6.7 et de VMware Tools,
vous devez effectuer quelques tâches préalables et connaître certaines informations importantes sur RHEL
Server 6.1, les noms d'hôte, le partitionnement du disque et la création de machines virtuelles du modèle
Hadoop avec plusieurs cœurs par socket.
Vous pouvez créer une machine virtuelle de modèle de nœud qui utilise RHEL Server 6.7 ou version
ultérieure en tant que système d'exploitation invité sur lequel vous pouvez installer VMware Tools pour
RHEL 6.7 en association avec une distribution Hadoop prise en charge. Cela vous permet de créer une
machine virtuelle du modèle Hadoop qui utilise la configuration du système d'exploitation de votre
entreprise. Lorsque vous provisionnez des clusters Big Data à l'aide du modèle Hadoop personnalisé,
VMware Tools pour RHEL 6.7 sera installé sur les machines virtuelles créées à partir de la machine virtuelle
du modèle Hadoop.
66 VMware, Inc.
Page 67

Chapitre 6 Gérer les modèles de nœud
Si vous créez des machines virtuelles du modèle Hadoop dotées de plusieurs cœurs par socket, lorsque vous
spécifiez les paramètres de CPU pour la machine virtuelle, vous devez indiquer plusieurs cœurs par socket.
Par exemple, si la machine virtuelle utilise deux cœurs par socket, les paramètres du vCPU doivent être un
nombre pair. Par exemple 4, 8 ou 12. Si vous spécifiez un nombre impair, le provisionnement du cluster ou
le redimensionnement du CPU échouera.
IMPORTANT
Vous devez utiliser localhost.localdomain comme nom d'hôte lorsque vous installez le modèle RHEL,
n
sinon le FQDN de la machine virtuelle clonée à partir du modèle risque de ne pas être défini
correctement.
Si vous effectuez un partitionnement de disque, n'utilisez pas Linux Volume Manager (LVM).
n
Prérequis
Déployez le vApp Big Data Extensions. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23.
Obtenez l'adresse IP du serveur de gestion Serengeti.
n
Localisez la version de VMware Tools correspondant à la version ESXi de votre centre de données.
n
Créer un modèle de machine virtuelle avec un disque à provisionnement dynamique de 20 Go et installer RHEL 6.7
Vous créez un modèle de machine virtuelle et installez Red Hat Enterprise Linux 6.7.
Pour plus d'informations sur cette procédure, consultez le Guide d'installation de Red Hat Enterprise Linux,
disponible sur le site Web de Red Hat.
Procédure
1 Téléchargez l'ISO d'installation de RHEL Server 6.7 sur www.redhat.com dans une banque de données.
2 Dans vSphere Client, créez une nouvelle machine virtuelle avec un disque à provisionnement
dynamique de 20 Go et sélectionnez Red Hat Enterprise Linux 6.7 (64 bits) comme système
d'exploitation invité.
3 Cliquez avec le bouton droit sur la machine virtuelle et cliquez sur Modifier les paramètres.
4 Sélectionnez CD/DVD Device 0 (CD/DVD Appareil 0), puis sélectionnez le fichier ISO de la banque de
données pour le fichier ISO RHEL.
5 Sélectionnez SCSI controller 0 > Change Type > LSI Logic Parallel (Contrôleur SCSI 0, Changer Type,
Parallèle Logique LSI), puis cliquez sur OK.
6 Dans Device Status (État de l'appareil), sélectionnez Connecté et Connecté sous tension, puis cliquez
sur OK.
7 Dans la fenêtre de console de la machine virtuelle, installez le système d'exploitation RHEL Server 6.x à
l'aide des paramètres par défaut pour tous les paramètres, à l'exception des éléments suivants :
Vous pouvez sélectionner la langue et le fuseau horaire que vous souhaitez utiliser sur votre
n
système d'exploitation.
Vous pouvez indiquer que la partition de permutation utilise une plus petite taille pour enregistrer
n
l'espace disque (par exemple, 500 Mo).
Vous pouvez réduire la taille de la partition de permutation car elle n'est pas utilisée par
n
Big Data Extensions.
Sélectionnez Minimal dans l'écran Package Installation Defaults (Paramètres par défaut de
n
l'installation du paquet).
VMware, Inc. 67
Page 68

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Vérifier que la machine virtuelle possède une adresse IP valide et une connectivité Internet
La machine virtuelle du modèle Hadoop a besoin d'une adresse IP valide et d'une connexion à Internet.
Prérequis
n
Procédure
Exécutez la commande ifconfig pour vérifier que la machine virtuelle possède une adresse IP valide et
u
une connectivité Internet.
Cette tâche suppose que le protocole DHCP (Dynamic Host Configuration Protocol) est utilisé.
Si les informations sur l'adresse IP apparaissent dans la sortie de la commande ifconfig, reportez-
n
vous à « Configurer le réseau pour que la machine virtuelle du modèle Hadoop utilise DHCP »,
page 68.
Si aucune information sur l'adresse IP n'apparaît, reportez-vous à « Configurer le réseau pour que
n
la machine virtuelle du modèle Hadoop utilise DHCP », page 68.
Configurer le réseau pour que la machine virtuelle du modèle Hadoop utilise DHCP
Procédure
1 À l'aide d'un éditeur de texte, ouvrez le fichier /etc/sysconfig/network-scripts/ifcfg-eth0.
2 Localisez les paramètres suivants et spécifiez la configuration suivante.
ONBOOT=yes
DEVICE=eth0
BOOTPROTO=dhcp
3 Enregistrez les modifications et fermez le fichier.
4 Redémarrez le service réseau.
sudo /sbin/service network restart
5 Exécutez la commande ifconfig pour vérifier que la machine virtuelle possède une adresse IP valide et
une connectivité Internet.
Installer le RPM JDK 7
Procédure
1 À partir de la page des téléchargements Oracle® Java SE 7, téléchargez le dernier RPM JDK 7 Linux x64
et copiez-le dans le dossier racine du modèle de machine virtuelle.
2 Installez le RPM.
rpm -Uvh jdk-7u91-linux-x64.rpm
3 Supprimez le fichier RPM.
rm -f jdk-7u91-linux-x64.rpm
4 Modifiez /etc/environment et ajoutez la ligne suivante : JAVA_HOME=/usr/java/default
68 VMware, Inc.
Page 69

Chapitre 6 Gérer les modèles de nœud
Personnaliser la machine virtuelle
Exécutez les scripts d'installation pour personnaliser la machine virtuelle.
Procédure
1 Enregistrez le système d'exploitation RHEL pour activer les référentiels Yum RHEL. Cela permet au
script d'installation de télécharger des packages à partir du référentiel Yum. Reportez-vous à la section
« Registering from the Command Line » dans le document Red Hat Enterprise Linux 6 Deployment Guide,
disponible sur le site Web de Red Hat.
2 Téléchargez les scripts à l'adresse https://deployed_serengeti_server_IP/custos/custos.tar.gz.
3 Créez le répertoire /tmp/custos, faites-en votre répertoire de travail, et exécutez tar xf pour
décompresser le fichier .tar.
mkdir /tmp/custos
cd /tmp/custos
tar xf /tmp/custos/custos.tar.gz
4 Exécutez le script installer.sh en spécifiant le chemin du répertoire /usr/java/default.
./installer.sh /usr/java/default
Vous devez utiliser la même version du script installer.sh que votre déploiement
Big Data Extensions.
5 Supprimez le fichier /etc/udev/rules.d/70-persistent-net.rules pour éviter d'augmenter le nombre
eth lors du clonage.
Si vous ne supprimez pas ce fichier, les machines virtuelles clonées à partir du modèle ne peuvent pas
obtenir d'adresses IP. Si vous mettez la machine virtuelle du modèle Hadoop sous tension pour
apporter des modifications, supprimez le fichier avant d'éteindre cette machine virtuelle.
Installer VMware Tools pou RHEL 6.x
Procédure
1 Cliquez avec le bouton droit de la souris sur la machine virtuelle RHEL 6 de vSphere Client, puis
sélectionnez Guest > Install/Upgrade VMware Tools (Invité, Installer/Mettre à niveau VMware Tools).
2 Connectez-vous à la machine virtuelle et installez le CD-ROM pour accéder au paquet d'installation
VMware Tools.
mkdir /mnt/cdrom
mount /dev/cdrom /mnt/cdrom
mkdir /tmp/vmtools
cd /tmp/vmtools
3 Exécutez la commande tar xf pour extraire le fichier tar du paquet VMware Tools.
tar xf /mnt/cdrom/VMwareTools-*.tar.gz
4 Faites de vmware-tools-distrib votre répertoire de travail et exécutez le script vmware-install.pl.
cd vmware-tools-distrib
./vmware-install.pl
Appuyez sur Entrée pour terminer l'installation.
VMware, Inc. 69
Page 70

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
5 Supprimez le fichier temporaire (temp) vmtools qui est créé en guise d'artéfact du processus
d'installation.
rm -rf /tmp/vmtools
6 Arrêtez la machine virtuelle.
Synchroniser l'heure sur la machine virtuelle de modèle Hadoop
Synchronisez l'heure sur la machine virtuelle de modèle Hadoop avec vCenter Server.
Procédure
1 Dans vSphere Web Client, cliquez avec le bouton droit sur la machine virtuelle du modèle Hadoop et
sélectionnez Modifier les paramètres.
2 Dans l'onglet Options VM, cliquez sur VMware Tools > Synchroniser l'heure invité avec l'hôte.
Terminer le processus de création d'une machine virtuelle de modèle Hadoop
Pour utiliser la machine virtuelle du modèle Hadoop, vous devez remplacer la machine virtuelle du modèle
Hadoop d'origine et redémarrer le service Tomcat pour activer le modèle de machine virtuelle RHEL
personnalisé.
Procédure
1 Dans l'onglet Matériel virtuel de la boîte de dialogue Modifier les paramètres, décochez la case
Connecté. Si le lecteur CD/DVD est connecté au fichier ISO, le processus de clonage de la machine
virtuelle échoue.
2 Remplacez la machine virtuelle du modèle Hadoop d'origine par la machine virtuelle personnalisée que
vous avez créée. Pour ce faire, faites glisser la nouvelle machine virtuelle de modèle que vous avez
créée dans l'application virtuelle.
3 Connectez-vous à Serengeti Management Server en tant qu'utilisateur serengeti et redémarrez le
service Tomcat.
sudo /sbin/service tomcat restart
Le fait de redémarrer le service Tomcat active le modèle de machine virtuelle RHEL personnalisé pour
en faire votre machine virtuelle du modèle Hadoop.
Prendre en charge plusieurs modèles de machine virtuelle
Vous pouvez configurer plusieurs modèles de machines virtuelles et choisir celui que vous souhaitez utiliser
lorsque vous créez un cluster Big Data. Cela vous permet de satisfaire les besoins d'optimisation propres à
différents scénarios d'utilisation.
Big Data Extensions prend en charge l'utilisation de plusieurs modèles de machine virtuelle. Vous pouvez
spécifier le modèle de nœud à partir duquel créer un cluster dans Serengeti CLI ou vSphere Web Client.
Pour créer un modèle de nœud en utilisant un système d'exploitation autre que celui par défaut, reportezvous à la section « Tenir à jour une machine virtuelle de modèle Hadoop personnalisée », page 65.
70 VMware, Inc.
Page 71

Gérer l'environnement
Big Data Extensions 7
Après avoir installé Big Data Extensions, vous pouvez arrêter et démarrer les services Serengeti, créer des
comptes d'utilisateur, gérer les mots de passe, mettre à jour les certificats SSL et vous connecter aux nœuds
de cluster pour résoudre les problèmes.
Ce chapitre aborde les rubriques suivantes :
« Ajouter des noms d'utilisateur spécifiques pour la connexion au serveur de gestion Serengeti »,
n
page 71
« Modifier le mot de passe du serveur de gestion Serengeti », page 72
n
« Créer un nom d'utilisateur et un mot de passe pour l'interface de ligne de commande Serengeti »,
n
page 73
« Autoriser et vérifier les commandes exécutées en tant qu'utilisateur racine », page 74
n
« Spécifier un groupe d'utilisateurs dans Active Directory ou LDAP pour utiliser un cluster Hadoop »,
n
page 74
« Arrêter et démarrer les services Serengeti », page 75
n
« Ports utilisés pour la communication entre Big Data Extensions et vCenter Server », page 76
n
« Vérifier l'état de fonctionnement de l'environnement Big Data Extensions », page 77
n
« Passer en mode maintenance pour effectuer la sauvegarde et la restauration à l'aide du client
n
d'interface de ligne de commande Serengeti », page 86
« Sauvegarder et restaurer l'environnement Big Data Extensions », page 87
n
Ajouter des noms d'utilisateur spécifiques pour la connexion au serveur de gestion Serengeti
Vous pouvez ajouter des noms d'utilisateur spécifiques avec lesquels vous pouvez vous connecter au
Serengeti Management Server. Les noms d'utilisateur que vous ajoutez correspondent aux seuls utilisateurs
autorisés à se connecter au Serengeti Management Server à l'aide de la Serengeti CLI ou de l'interface
utilisateur de Big Data Extensions pour une utilisation avec vSphere Web Client.
Les mots de passe doivent contenir 8 à 20 caractères, utiliser uniquement des caractères ASCII inférieurs
visibles (pas d'espaces) et comporter au moins une lettre majuscule (A - Z), une lettre minuscule (a - z), un
chiffre (0 - 9) et l'un des caractères spéciaux suivants : _, @, #, $, %, ^, &, *
Prérequis
Déployez le vApp Serengeti.
n
VMware, Inc.
71
Page 72

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Procédure
1 Cliquez avec le bouton droit sur la machine virtuelle du Serengeti Management Server et sélectionnez
Ouvrir la console.
Le mot de passe du Serengeti Management Server s'affiche.
REMARQUE Si le mot de passe disparaît de l'écran de la console, appuyez sur Ctrl+D pour revenir à
l'invite de commande.
2 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
Utilisez l'adresse IP qui figure sur l'onglet Résumé et le mot de passe actuel.
3 Modifiez le fichier /opt/serengeti/conf/Users.xml pour ajouter des noms d'utilisateur.
vi /opt/serengeti/conf/Users.xml
4 Modifiez l'attribut <user name="*" /> en remplaçant le caractère générique astérisque (*) par le nom
d'utilisateur que vous souhaitez utiliser. Vous pouvez ajouter plusieurs noms d'utilisateur en ajoutant
un nouvel attribut <user name="nom" /> sur sa ligne. Le fichier User.xml prend en charge plusieurs
lignes.
<user name="jsmith" />
<user name="sjones" />
<user name="jlydon" />
5 Redémarrez le service Tomcat.
/sbin/service tomcat restart
Seuls les noms d'utilisateur que vous ajoutez au fichier User.xml peuvent être utilisés pour se connecter au
Serengeti Management Server à l'aide de la Serengeti CLI ou de l'interface utilisateur de Big Data Extensions
pour une utilisation avec vSphere Web Client.
Modifier le mot de passe du serveur de gestion Serengeti
Lorsque vous vous connectez pour la première fois sur le serveur de gestion Serengeti, celui-ci génère un
mot de passe aléatoire destiné aux utilisateurs root et serengeti. Si vous souhaitez utiliser un mot de passe
plus facile à retenir, vous pouvez modifier le mot de passe aléatoire destiné aux utilisateurs root et
serengeti à l'aide de la console de la machine virtuelle.
REMARQUE Vous pouvez modifier le mot de passe pour la machine virtuelle de n'importe quel nœud en
procédant comme suit.
Les mots de passe doivent contenir 8 à 20 caractères, utiliser uniquement des caractères ASCII inférieurs
visibles (pas d'espaces) et comporter au moins une lettre majuscule (A - Z), une lettre minuscule (a - z), un
chiffre (0 - 9) et l'un des caractères spéciaux suivants : _, @, #, $, %, ^, &, *
Prérequis
Déployez le vApp Serengeti.
n
Utilisez vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine virtuelle
n
du serveur de gestion Serengeti est en marche.
72 VMware, Inc.
Page 73

Chapitre 7 Gérer l'environnement Big Data Extensions
Procédure
1 Cliquez avec le bouton droit de la souris sur la machine virtuelle du serveur de gestion Serengeti et
sélectionnez Open Console (Ouvrir console).
Le mot de passe du serveur de gestion Serengeti s'affiche.
REMARQUE Si le mot de passe disparaît de l'écran de la console, appuyez sur Ctrl+D pour revenir à
l'invite de commande.
2 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au serveur de gestion
Serengeti en tant qu'utilisateur serengeti.
Utilisez l'adresse IP qui figure sur l'onglet Résumé et le mot de passe actuel.
3 Utilisez la commande /opt/serengeti/sbin/set-password pour modifier le mot de passe des
utilisateurs root et serengeti.
sudo /opt/serengeti/sbin/set-password -u
4 Saisissez le nouveau mot de passe deux fois pour le confirmer.
À votre prochaine connexion au serveur de gestion Serengeti, utilisez le nouveau mot de passe.
Suivant
Vous pouvez créer un nouvel identifiant et un nouveau mot de passe pour le client d'interface de ligne de
commande Serengeti.
Créer un nom d'utilisateur et un mot de passe pour l'interface de ligne de commande Serengeti
Le client d'interface de ligne de commande Serengeti utilise les informations d'identification de connexion
vCenter Server avec des autorisations de lecture sur le serveur de gestion Serengeti. Si vous ne créez pas de
nom d'utilisateur et de mot de passe pour le client d'interface de ligne de commande Serengeti, il utilisera
les informations d'identification d'administrateur vCenter Server. Néanmoins, pour des raisons de sécurité,
il est préférable de créer un compte utilisateur spécifique au client d'interface de ligne de commande
Serengeti.
Les mots de passe doivent contenir 8 à 20 caractères, utiliser uniquement des caractères ASCII inférieurs
visibles (pas d'espaces) et comporter au moins une lettre majuscule (A - Z), une lettre minuscule (a - z), un
chiffre (0 - 9) et l'un des caractères spéciaux suivants : _, @, #, $, %, ^, &, *
Prérequis
Déployez Big Data Extensions vApp. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23.
Installez le client d'interface de ligne de commande Serengeti. Reportez-vous à « Installer le client
n
d'interface de ligne de commande distant Serengeti », page 31.
Procédure
1 Ouvrez un navigateur Web et rendez-vous sur : https://vc-hostname:port/vsphere-client.
Le vc-hostname peut être soit le nom d'hôte DNS soit l'adresse IP de vCenter Server. Par défaut, le port
est 9443, mais il est possible de le changer au cours de l'installation de vSphere Web Client.
2 Saisissez le nom d'utilisateur et le mot de passe qui correspondent aux privilèges administratifs de
vCenter Server, puis cliquez sur Login (Connexion).
REMARQUE Les utilisateurs de vCenter Server 5.5 doivent utiliser un domaine local pour exécuter les
opérations relatives au SSO.
VMware, Inc. 73
Page 74

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
3 Dans le panneau Navigator (Navigateur) de vSphere Web Client, sélectionnez Administration, SSO
Users and Groups (Utilisateurs et groupes SSO).
4 Modifiez les informations de connexion.
Les informations de connexion sont mises à jour. Pour votre prochaine connexion à l'interface de ligne de
commande Serengeti, utilisez les nouvelles informations de connexion.
Suivant
Vous pouvez modifier le mot de passe du serveur de gestion Serengeti. Reportez-vous à « Modifier le mot
de passe du serveur de gestion Serengeti », page 72.
Autoriser et vérifier les commandes exécutées en tant qu'utilisateur racine
Vous pouvez personnaliser la commande sudo en utilisant pbrun. La commande pbrun vous permet
d'exécuter les commandes avec les privilèges d'un autre utilisateur, généralement l'utilisateur racine.
La commande pbrun utilise PowerBroker, une application de serveur centralisée, pour autoriser et vérifier
les commandes exécutées en tant qu'utilisateur racine. PowerBroker vous permet d'attribuer des privilèges
d'utilisateur racine à des utilisateurs spécifiques, puis d'autoriser et de vérifier leur utilisation de
l'environnement.
Prérequis
Pour utiliser PowerBroker ou des services d'identité similaires, vous devez d'abord configurer votre
environnement pour pouvoir l'utiliser avec eux.
Procédure
1 Connectez-vous à Serengeti Management Server.
2 Exportez la commande sudo personnalisée en utilisant pbrun dans votre environnement.
"export SUDO_CMD=pbrun" >> /opt/serengeti/sbin/env.sh
3 Connectez-vous au nœud de cluster, puis exécutez la séquence de commandes suivante.
sed -i 's|^serengeti.sudo.command.*|serengeti.sudo.command =
pbrun|' /opt/serengeti/conf/serengeti.properties
Spécifier un groupe d'utilisateurs dans Active Directory ou LDAP pour utiliser un cluster Hadoop
Vous pouvez spécifier un serveur Active Directory ou LDAP pour l'authentification utilisateur. Cela vous
permet de gérer les utilisateurs de manière centralisée.
Par défaut, l'authentification est configurée uniquement pour les comptes d'utilisateurs locaux dans
Big Data Extensions. Si vous voulez utiliser LDAP ou Active Directory pour authentifier les utilisateurs,
vous devez configurer Big Data Extensions pour utiliser votre service LDAP ou Active Directory.
Big Data Extensions vous permet d'authentifier les utilisateurs locaux, ceux gérés par le serveur LDAP ou
Active Directory, ou une combinaison de ces méthodes d'authentification.
Prérequis
Déployez le vApp Big Data Extensions. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23.
74 VMware, Inc.
Page 75

Chapitre 7 Gérer l'environnement Big Data Extensions
Utilisez le portail d'administration du Serengeti Management Server pour activer le SSO et mettre à jour
n
le certificat. Reportez-vous à « Configurer les paramètres vCenter Single Sign-On du serveur de gestion
Serengeti », page 29.
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Sélectionnez Big Data Extensions et cliquez sur l'onglet Gérer.
3 Sélectionnez Mode utilisateur et cliquez sur Modifier.
La boîte de dialogue Configurer utilisateur apparaît.
4 Choisissez le mode d'authentification utilisateur que vous souhaitez utiliser pour votre environnement
Big Data Extensions.
Tableau 7‑1. Modes d'authentification utilisateur
Mode utilisateur Description
Local Sélectionnez Local pour créer et gérer les utilisateurs et les groupes stockés localement
dans votre environnement Big Data Extensions. Il s'agit de la solution de gestion des
utilisateurs par défaut.
Utilisateur LDAP Sélectionnez Utilisateur LDAP pour créer et gérer les utilisateurs et les groupes stockés
dans la source d'identité de votre entreprise telle qu'Active Directory ou LDAP. Si vous
choisissez ce mode, vous devez configurer Big Data Extensions pour qu'il utilise un service
LDAP ou Active Directory.
Mode mixte Sélectionnez Mode mixte pour utiliser une combinaison des utilisateurs locaux et de ceux
stockés dans une source d'identité externe. Si vous choisissez ce mode, vous devez
configurer Big Data Extensions de sorte à utiliser le mode AD en tant que LDAP.
5 Si vous choisissez le mode LDAP ou le mode mixte, vous devez configurer Big Data Extensions pour
qu'il utilise un service LDAP ou Active Directory.
Tableau 7‑2. Informations de connexion LDAP
DN utilisateur de base Indiquez le DN utilisateur de base.
DN groupe de base Indiquez le DN groupe de base.
URL du serveur
principal
URL secondaire du
serveur
Nom d'utilisateur Saisissez le nom d'utilisateur du compte d'administrateur Active Directory ou LDAP.
Mot de passe Saisissez le mot de passe du compte d'administrateur Active Directory ou LDAP.
Indiquez l'URL du serveur principal de votre serveur Active Directory ou LDAP.
Indiquez l'URL du serveur secondaire de votre serveur Active Directory ou LDAP.
6 (Facultatif) Cliquez sur Tester pour vérifier que les comptes d'utilisateurs ne sont pas introuvables.
Arrêter et démarrer les services Serengeti
Vous pouvez arrêter et démarrer les services Serengeti pour appliquer une reconfiguration ou pour
récupérer suite à une anomalie d'opération.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au serveur de gestion
Serengeti en tant qu'utilisateur serengeti.
VMware, Inc. 75
Page 76

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
2 Exécutez le script serengeti-stop-services.sh pour arrêter les services Serengeti.
serengeti-stop-services.sh
3 Exécutez le script serengeti-start-services.sh pour démarrer les services Serengeti.
serengeti-start-services.sh
Ports utilisés pour la communication entre Big Data Extensions et vCenter Server
Big Data Extensions demande des informations à vCenter Server et utilise le service Single Sign-On de
vCenter Server.
Serveur de gestion Big Data Extensions
Le tableau ci-dessous indique le port publié pour le serveur de gestion.
VMware Port Commentaires
API Rest Serengeti 8080, 8443 Ouvert pour le client Serengeti et pour
l'enregistrement du plug-in BDE appelé par VC
SSHD 22 Ouvert pour la connexion au client Serengeti
Ports Hadoop
Serengeti déploie les clusters Hadoop et Hbase en utilisant tous les ports par défaut. Le tableau suivant
indique tous les ports utilisés par le service Hadoop ou HBase, le réseau de production.
Processus Port défini par défaut
HDFS Page Web NameNode 50070
RPC NameNode 8020
DataNode 50075
50010
50020
MapReduce Page Web JobTracker 50030
RPC JobTracker 8021
TaskTracker 50060
Yarn Page Web du gestionnaire de
ressources
RPC du gestionnaire de ressources 8030, 8031, 8032, 8033
Gestionnaire de nœuds 8040, 8042
Hive S/O 1000
8088
Ports HBase
Le tableau ci-dessous indique les ports utilisés par les clusters HBase ainsi que les numéros de port par
défaut.
VMware Nom de propriété Port
ZooKeeper hbase.zookeeper.property.clientPort 2181
Maître hbase.master.port 60000
76 VMware, Inc.
Page 77

Chapitre 7 Gérer l'environnement Big Data Extensions
VMware Nom de propriété Port
Maître hbase.master.info.port 60010
Serveur régional hbase.regionserver.port 60020
Serveur régional hbase.regionserver.info.port 60030
Serveur REST hbase.rest.port 8080
Serveur REST hbase.rest.info.port 8085
Serveur Thrift hbase.thrift.port 9090
Serveur Thrift hbase.thrift.info.port 9095
Ports MapR
Le tableau ci-dessous définit les ports utilisés par un cluster MapR ainsi que les numéros de port par défaut.
VMware Port
CLDB 7222
Port de surveillance JMX CLDB 7220
CLDB web port 7221
HBase Master 60000
HBase Master (pour l'interface graphique utilisateur) 60010
HBase RegionServer 60020
Hive Metastore 9083
Page Web JobTracker 50030
RPC JobTracker 8021
Serveur MFS 5660
MySQL 3306
NFS 2049
Contrôle NFS (pour la HA) 9997
Gestion NFS 9998
Dispositif de mappage des ports 111
TaskTracker 50060
HTTPS de l'UI Web 8443
ZooKeeper 5181
Vérifier l'état de fonctionnement de l'environnement Big Data Extensions
Pour que vous puissiez provisionner correctement un cluster Hadoop, votre environnement
Big Data Extensions doit remplir certains critères. Vous pouvez vérifier que votre environnement répond
bien à ces critères avant de créer des clusters Hadoop, et résoudre les éventuels problèmes de création de
clusters.
VMware, Inc. 77
Page 78

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
État de fonctionnement des services Big Data Extensions
Big Data Extensions se compose de plusieurs services dont vous pouvez vérifier l'exécution.
Big Data Extensions se compose des serveurs suivants : serveur Tomcat, serveur Yum, serveur Chef et
serveur PostgreSQL. Vous pouvez vérifier que ces services sont exécutés avant de créer des clusters
Hadoop.
Prérequis
Déployez le vApp Serengeti.
n
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Vérifiez que le service Tomcat est en cours d'exécution.
a Exécutez la commande pgrep -f org.apache.catalina.startup.Bootstrap -l.
pgrep -f org.apache.catalina.startup.Bootstrap -l
b Exécutez la commande wget https://bde_server_ip:8443 --no-check-certificate
wget https://bde_server_ip:8443 --no-check-certificate
3 Vérifiez que le serveur Yum est en cours d'exécution.
Exécutez la commande /sbin/service httpd status.
/sbin/service httpd status
Si le serveur Yum fonctionne correctement, il renvoie le message d'état en cours d'exécution.
4 Vérifiez que le serveur Chef est en cours d'exécution.
Exécutez la commande sudo /chef-server-ctl status. La sous-commande status affiche l'état de tous
les services disponibles pour le serveur Chef.
sudo /chef-server-ctl status
5 Vérifiez que le serveur PostgreSQL est en cours d'exécution.
a Exécutez la commande pgrep -f /opt/opscode/embedded/bin/postgres -l pour vérifier que le
processus postgresest en cours d'exécution. L'option -l indique les bases de données disponibles.
pgrep -f /opt/opscode/embedded/bin/postgres -l
b Exécutez la commande echo "\dt" | psql -U serengeti pour afficher les tables de bases de
données créées pour Big Data Extensions. L'option -dt indique le nom de la base de données à
laquelle se connecter et désactive l'affichage des noms des colonnes des bases de données dans la
sortie en résultant. L'option -U indique le nom d'utilisateur avec lequel se connecter à la base de
données.
echo "\dt" | psql -U serengeti
Si les bases de données disponibles pour PostgreSQL et les tables appartenant à l'utilisateur serengeti
s'affichent, votre serveur PostgreSQL fonctionne correctement.
78 VMware, Inc.
Page 79

Chapitre 7 Gérer l'environnement Big Data Extensions
Suivant
Si l'un des services ci-dessus ne s'exécute pas, vous pouvez consulter l'état d'initialisation des services
Serengeti Management Server, les messages d'erreur pour résoudre les problèmes et restaurer les services
qui ont pu rencontrer des problèmes de démarrage à l'aide du portail d'administration du serveur de
gestion Serengeti. Reportez-vous à « Afficher l'état d'initialisation du serveur de gestion Serengeti »,
page 124.
Vérifier la connectivité réseau avec vCenter Server
Vous pouvez vérifier si votre déploiement Big Data Extensions est en mesure de se connecter à
vCenter Server et identifier les causes possibles d'un échec de connexion réseau.
Prérequis
Déployez le vApp Serengeti.
n
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Exécutez la commande wget https://vcenter_server_ip:9443 --no-check-certificate.
wget https://vcenter_server_ip:9443 --no-check-certificate
Si cette commande récupère le fichier index.html intitulé vSphere Web Client, vCenter Server est en cours
d'exécution et il existe une connectivité entre Big Data Extensions et vCenter Server.
Si cette commande ne parvient pas à récupérer le fichier index.html, reportez-vous à l'étape 3.
3 Si la commande renvoie le message d'erreur Connecting to
vcenter_server_ip:vcenter_server_port... failed: Connection refused, l'adresse IP de vCenter
Server que vous avez indiquée est joignable, mais le numéro de port réseau de vCenter Server est
incorrect.
4 Si l'adresse IP et le numéro de port de vCenter Server sont corrects, vérifiez la configuration réseau de
votre déploiement Big Data Extensions. Par exemple, vérifiez que Big Data Extensions utilise une
adresse IP et une passerelle valides.
Suivant
Si vous n'êtes pas en mesure de vérifier une connexion réseau entre Big Data Extensions et vCenter Server,
et que vous ne parvenez pas à identifier l'origine du problème, les rubriques de dépannage fournissent des
solutions aux problèmes que vous pourriez rencontrer avec Big Data Extensions. Reportez-vous à Chapitre
14, « Dépannage », page 141
Vérifier l'authentification utilisateur de vCenter Server
Vous pouvez vérifier si l'authentification utilisateur de vCenter Server fonctionne correctement et identifier
les causes possibles des problèmes de création de clusters.
Prérequis
Déployez le vApp Serengeti.
n
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
VMware, Inc. 79
Page 80

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Saisissez serengeti pour lancer l'interface de ligne de commande Serengeti.
3 Exécutez la commande connect –host localhost:8443 et, lorsque vous y êtes invité, saisissez votre
nom d'utilisateur et votre mot de passe (ils peuvent être différents de ceux de
Serengeti Management Server). Si vous parvenez à vous connecter à Big Data Extensions,
l'authentification utilisateur de vCenter Server fonctionne correctement.
Suivant
Avant la création de nouvelles machines virtuelles sur des hôtes, l'heure sur les hôtes cibles est comparée à
celle sur le Serengeti Management Server. Si l'heure n'est pas synchronisée entre le
Serengeti Management Server et les hôtes, la création de la machine virtuelle échouera. Reportez-vous à
« Vérifier la synchronisation de l'heure entre le serveur de gestion Serengeti et les hôtes », page 80.
Vérifier la synchronisation de l'heure entre le serveur de gestion Serengeti et les hôtes
Lorsque vous exécutez la commande cluster create ou cluster create ... --resume, celle-ci peut
échouer s'il existe des différences d'heure dans l'environnement. Vous pouvez vérifier que l'heure se trouve
dans les limites de tolérance et synchroniser l'heure entre le Serengeti Management Server et les autres hôtes
de votre environnement.
Avant la création de nouvelles machines virtuelles sur des hôtes, l'heure sur les hôtes cibles est comparée à
celle sur le Serengeti Management Server. Si l'heure n'est pas synchronisée entre le
Serengeti Management Server et les hôtes, la création du cluster peut échouer.
Prérequis
Déployez le vApp Serengeti.
n
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Exécutez la commande date +%T pour afficher l'heure sur le Serengeti Management Server.
date +%T
3 Dans vSphere Web Client, notez l'heure de chaque hôte du centre de données.
4 Comparez la date et l'heure entre le Serengeti Management Server et chaque hôte pour voir si la
différence excède le seuil maximal. Si le service HBase est présent dans le cluster, le seuil maximal est
de 20 secondes. Autrement, le seuil maximal est de 4 minutes.
Si l'heure n'est pas synchronisée entre les hôtes, connectez-vous à chaque hôte et affichez le
fichier /etc/ntp.conf pour vérifier si la configuration NTP est correcte.
5 Dans vSphere Web Client, configurez tous les hôtes ESXi de sorte qu'ils synchronisent leurs horloges
avec le même serveur NTP.
Suivant
Une fois l'heure synchronisée entre le Serengeti Management Server et les autres hôtes ESXi dans votre
environnement, essayez de créer un cluster.
80 VMware, Inc.
Page 81

Chapitre 7 Gérer l'environnement Big Data Extensions
Vérifier la connectivité réseau entre des nœuds de calcul et Isilon HDFS
Si vous utilisez EMC Isilon OneFS pour votre HDFS, vous pouvez vérifier la connectivité réseau des nœuds
de calcul jusqu'au système de fichiers Isilon OneFS.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Pour chaque nœud de calcul (TaskTracker or NodeManager), connectez-vous et exécutez la commande
hadoop dfsadmin -report pour vérifier que le HDFS fonctionne correctement. Si la commande renvoie
la Capacité configurée et la Capacité présente, le nœud worker peut accéder au HDFS.
Si le HDFS ne répond pas, reportez-vous à l'étape 3.
3 Vérifiez que l'adresse IP et le numéro de port réseau du HDFS sont corrects. Connectez-vous au
NameNode Isilon (qui peut demander un nom d'utilisateur et un mot de passe différents) et vérifiez
que le service HDFS écoute le port 8020.
Si le HDFS écoute le bon port réseau, reportez-vous à l'étape 4.
4 Vérifiez l'entrée fs.defaultFS dans le fichier de configuration Hadoop core-site.xml. Assurez-vous
que l'adresse IP, le FQDN et le port réseau sont configurés pour utiliser le service HDFS approprié.
Vérifier les utilisateurs et les groupes d'utilisateurs existant dans Isilon OneFS
Si vous utilisez EMC Isilon OneFS en tant que cluster HDFS externe, vous devez créer et configurer des
utilisateurs et des groupes d'utilisateurs, et préparer votre environnement Isilon OneFS. Vous pouvez
vérifier que vous avez créé les bons utilisateurs et groupes d'utilisateurs, et savoir lesquels existent dans
votre environnement Isilon OneFS.
Prérequis
Préparez Isilon OneFS à être utilisé en tant que cluster HDFS externe. Reportez-vous à « Préparer EMC
Isilon OneFS en tant que cluster HDFS externe », page 108.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au nœud
Isilon OneFS via SSH.
2 Exécutez la commande isi auth users/groups list pour afficher la liste des utilisateurs et groupes
d'utilisateurs Isilon OneFS existants.
3 Exécutez la commande ls -al HDFS_ROOT_DIR pour vérifier les utilisateurs et les groupes d'utilisateurs
du HDFS.
Lorsque vous exécutez la commande ls dans le système de fichiers Isilon, l'option -al doit apparaître
avant le nom du répertoire HDFS_ROOT_DIR. Sinon, l'option -al sera considérée par la commande comme
un nom de répertoire ls.
ls -al HDFS_ROOT_DIR
REMARQUE Dans le sous-répertoire HDFS, les autorisations et droits de propriété de certains fichiers et
répertoires peuvent être attribués à des utilisateurs ou des groupes autres que ceux utilisant
Big Data Extensions.
VMware, Inc. 81
Page 82

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Vérifier la capacité de stockage
Pour déployer correctement un cluster, vous devez disposer d'une capacité de stockage suffisante dans
votre environnement Big Data Extensions.
Les banques de données que vous ajoutez à votre environnement Big Data Extensions sont disponibles pour
les clusters que vous créez dans Big Data Extensions. Si vous n'ajoutez pas une capacité de stockage
suffisante, la création du cluster échouera.
Outre la capacité de stockage globale, vous devez vous assurer de disposer d'un stockage partagé et local
suffisant. Le stockage partagé est recommandé pour les nœuds master et vous permet d'utiliser vMotion, la
haute disponibilité et la tolérance aux pannes. Le stockage local est recommandé pour les nœuds worker
Prérequis
Vous devez avoir ajouté une banque de données à votre environnement Big Data Extensions. Reportez-vous
à « Ajouter une banque de données dans vSphere Web Client », page 91
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Exécutez la commande datastore list --detail pour afficher les banques de données vCenter Server
utilisées par Big Data Extensions.
3 À l'aide des valeurs de configuration indiquées dans le fichier de spécification du cluster, calculez la
capacité de stockage requise par le cluster.
4 Utilisez vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que les banques de
données que vous avez identifiées comme appartenant à Big Data Extensions disposent d'une capacité
de stockage suffisante pour les clusters que vous souhaitez créer. Assurez-vous également que les
banques de données sont à l'état actif.
Suivant
Si votre environnement Big Data Extensions ne dispose pas d'une capacité de stockage adéquate pour créer
des clusters, ajoutez des banques de données. Reportez-vous à « Ajouter une banque de données dans
vSphere Web Client », page 91.
Vérifier l'installation du gestionnaire d'applications the Ambari
Si vous utilisez Apache Ambari pour gérer votre cluster Hadoop, vous pouvez vérifier que le service
Ambari est en cours d'exécution, dispose d'une connexion réseau et d'informations d'identification
utilisateur valides lui permettant de se connecter à votre cluster.
Prérequis
Déployez le vApp Big Data Extensions. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Ajoutez le gestionnaire d'applications Ambari à votre environnement Big Data Extensions. Reportez-
n
vous à « Ajouter un gestionnaire d'applications à l'aide de vSphere Web Client », page 41.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
82 VMware, Inc.
Page 83

Chapitre 7 Gérer l'environnement Big Data Extensions
2 Exécutez la commande curl avec l'option -u pour indiquer le nom d'utilisateur et le mot de passe utilisé
par le service Ambari, et l'option -G pour indiquer l'URL du service de vérification système Ambari :
http://ambari_server_ip:8080/api/v1/check
curl -u nom d'utilisateur:mot de passe -G http://ambari_server_ip:8080/api/v1/check
Si le système renvoie EN COURS D'EXÉCUTION, le serveur Ambari est en cours d'exécution. Si vous
n
recevez un message système indiquant que votre service Ambari n'est pas en cours d'exécution,
recherchez le problème et vérifiez que vous pouvez démarrer Ambari correctement avant de
continuer.
Si le système renvoie Informations d'identification erronées, le nom d'utilisateur et le mot de
n
passe sont incorrects. Procurez-vous le nom d'utilisateur et le mot de passe appropriés pour votre
installation Ambari.
Si la commande curl ne répond pas pendant 30 secondes ou plus et que le système renvoie le
n
message d'erreur curl: (7) Failed to connect to ambari_server_ip port port_number:
Connection refused, l'adresse IP, le FQDN ou le numéro de port est incorrect. Procurez-vous
l'adresse réseau appropriée pour votre installation Ambari.
Ce message d'erreur peut également indiquer que le serveur virtuel Ambari est hors tension.
Vérifiez que la machine virtuelle Ambari est sous tension et que le serveur Ambari est en cours
d'exécution.
Suivant
Si votre installation Ambari ne répond pas, vérifiez qu'elle est installée et configurée correctement.
Reportez-vous à « Modifier un gestionnaire d'applications à l'aide de vSphere Web Client », page 42.
Vérifier l'installation de Cloudera Manager
Si vous utilisez Cloudera Manager pour gérer votre cluster Hadoop, vous pouvez vérifier que
Cloudera Manager est en cours d'exécution, dispose d'une connexion réseau et d'informations
d'identification utilisateur valides lui permettant de se connecter à votre cluster.
Prérequis
Déployez le vApp Big Data Extensions. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Ajoutez l'application Cloudera Manager à votre environnement Big Data Extensions. Reportez-vous à
n
« Ajouter un gestionnaire d'applications à l'aide de vSphere Web Client », page 41.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Exécutez la commande curl avec l'option -u pour indiquer le nom d'utilisateur et le mot de passe
utilisés par Cloudera Manager, et l'option -G pour indiquer l'URL du numéro de version de l'API
Cloudera Manager : http://cloudera_manager_server_ip:7180/api/version
curl -u nom d'utilisateur:mot de passe -G http://cloudera_manager_server_ip:7180/api/version
Notez le numéro de version de l'API renvoyé par Cloudera Manager.
VMware, Inc. 83
Page 84

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
3 Exécutez la commande curl avec l'option -u pour indiquer le nom d'utilisateur et le mot de passe
utilisés par Cloudera Manager, et l'option -G pour indiquer l'URL de la requête
Cloudera Manager /tools/echo : http://cloudera_manager_server_ip:
7180/api/cloudera_manager_api_version/tools/echo
curl -u nom d'utilisateur:mot de passe -G http://cloudera_manager_server_ip:
7180/api/cloudera_manager_api_version/tools/echo
Cet exemple indique une installation Cloudera Manager dont l'adresse réseau est 192.168.1.1 à l'aide
du nom d'utilisateur et du mot de passe cloudera, avec la version v5 de l'API.
curl -u cloudera:cloudera -G http://192.168.1.1:7180/api/v5/tools/echo
Si le système renvoie Hello world!, Cloudera Manager est en cours d'exécution. Si vous recevez un
n
message système indiquant que votre Cloudera Manager n'est pas en cours d'exécution, recherchez
le problème et vérifiez que vous pouvez démarrer Cloudera Manager correctement avant de
continuer.
Si le système renvoie Error 401 Bad credentials, le nom d'utilisateur et le mot de passe sont
n
incorrects. Procurez-vous le nom d'utilisateur et le mot de passe appropriés pour votre installation
Cloudera Manager.
Si le système renvoie le message d'erreur curl: (7) Failed to connect to
n
cloudera_manager_server_ip port 7180: No route to host, l'adresse IP ou le FQDN est incorrect.
Procurez-vous l'adresse réseau appropriée pour votre installation Cloudera Manager.
Ce message d'erreur peut également indiquer que la machine virtuelle Cloudera Manager est hors
tension. Vérifiez que la machine virtuelle Cloudera Manager est sous tension et que
Cloudera Manager est en cours d'exécution.
Suivant
Si votre installation Cloudera Manager ne répond pas, vérifiez qu'elle est installée et configurée
correctement. Reportez-vous à « Modifier un gestionnaire d'applications à l'aide de vSphere Web Client »,
page 42.
Vérifier la recherche DNS normale et inverse
Big Data Extensions nécessite un environnement réseau correctement configuré. Vous pouvez vérifier que
votre recherche DNS normale et inverse est bien configurée.
La recherche DNS inverse détermine le nom d'hôte associé à une adresse IP donnée. La recherche DNS
normale détermine l'adresse IP associée à un nom d'hôte donné.
Prérequis
Déployez le vApp Big Data Extensions. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Exécutez la commande echo pour récupérer les adresses IP utilisées par le cluster.
echo ipv4_address_from_network_interface | psql
Notez les adresses IP de chaque carte d'interface réseau utilisée par le cluster.
84 VMware, Inc.
Page 85

Chapitre 7 Gérer l'environnement Big Data Extensions
3 Pour chaque adresse IP que vous avez notée à l'étape précédente, exécutez la commande host pour
vérifier que la recherche DNS inverse renvoie le nom de domaine complet (FQDN). Si le système
renvoie un FQDN pour chaque adresse IP, la recherche DNS inverse fonctionne.
host IP_address
Notez le FQDN pour chaque adresse réseau que vous vérifiez.
4 Pour chaque FQDN que vous avez noté à l'étape précédente, exécutez la commande host pour vérifier
que la recherche DNS normale renvoie l'adresse IP associée au FQDN. Si le système renvoie une
adresse IP pour chaque FQDN, la recherche DNS normale fonctionne.
5 (Facultatif) Si vous n'êtes pas en mesure de résoudre les adresses IP et les FQDN, ouvrez le
fichier /etc/resolv.conf et vérifiez qu'un serveur de noms DNS a été configuré pour être utilisé dans
votre environnement.
Si aucun serveur de noms n'a été configuré pour être utilisé dans votre environnement, demandez
n
à votre administrateur le nom du serveur DNS à utiliser.
Si un serveur de noms est configuré, mais que votre DNS ne fournit pas de recherche normale ou
n
inverse, recherchez la cause et configurez votre DNS selon les besoins. Les causes d'un
dysfonctionnement de votre DNS peuvent être les suivantes :
Le serveur de nom n'est pas joignable en raison d'une adresse IP incorrecte.
n
Le service DNS sur cette machine virtuelle peut être éteint ou ne pas répondre.
n
La machine virtuelle contenant le service DNS peut être éteinte.
n
Suivant
Si votre DNS ne fonctionne pas comme prévu, recherchez la cause et apportez les modifications nécessaires
à la configuration ou au fonctionnement jusqu'à ce que vous puissiez vérifier que la recherche d'adresse
normale et inverse de votre DNS est correctement configurée. Reportez-vous à « Modifier le type de DNS
dans vSphere Web Client », page 95.
Vérifier la connexion réseau entre Big Data Extensions et les nœuds de clusters
Le Serengeti Management Server doit être en mesure de se connecter à chacun des nœuds d'un cluster
Hadoop. Vous pouvez vérifier que le Serengeti Management Server est capable de contacter chaque nœud
du cluster.
Prérequis
Déployez le vApp Big Data Extensions. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Ajoutez un réseau à utiliser par Big Data Extensions. Reportez-vous à « Ajouter un réseau dans vSphere
n
Web Client », page 94.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Exécutez la commande echo pour récupérer les adresses IP utilisées par le cluster.
echo "select ipv4_address_from_network_interface" | psql
Notez les adresses IP de chaque carte d'interface réseau utilisée par le cluster.
VMware, Inc. 85
Page 86

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
3 Exécutez la commande ping pour contacter chaque adresse IP et vérifier que le
Serengeti Management Server est en mesure de contacter chacun des nœuds du cluster.
Suivant
Si vous ne parvenez pas à établir une connexion entre le Serengeti Management Server et les nœuds du
cluster Hadoop, recherchez la cause et apportez les modifications nécessaires jusqu'à ce que vous puissiez
vérifier que votre réseau est configuré correctement.
Vérifier le référentiel Yum local
Si vous avez créé un référentiel Yum local à partir duquel vous souhaitez déployer vos distributions
Hadoop, vous pouvez vérifier que le référentiel fonctionne correctement.
Prérequis
Déployez le vApp Big Data Extensions. Reportez-vous à « Déployer le vApp Big Data Extensions dans
n
vSphere Web Client », page 23
Utilisez le vSphere Web Client pour vous connecter à vCenter Server, et vérifiez que la machine
n
virtuelle Serengeti Management Server est en cours d'exécution.
Vous avez créé un référentiel Yum local à partir duquel vous souhaitez déployer vos distributions
n
Hadoop. Reportez-vous à « Configuration de Yum et de référentiels Yum », page 48.
Procédure
1 Ouvrez une interface de commande, comme Bash ou PuTTY, puis connectez-vous au
Serengeti Management Server en tant qu'utilisateur serengeti.
2 Exécutez la commande wget local_repository_url pour télécharger la page Web du référentiel local.
3 Vous pouvez ouvrir et afficher la page Web du référentiel local à l'aide d'un navigateur Web dans votre
réseau pour vérifier son fonctionnement.
Suivant
Vous pouvez créer des clusters Hadoop dans votre environnement Big Data Extensions. Reportez-vous à
Chapitre 9, « Création de clusters Hadoop et HBase », page 99
Passer en mode maintenance pour effectuer la sauvegarde et la restauration à l'aide du client d'interface de ligne de commande Serengeti
Avant d'effectuer les opérations de sauvegarde et de restauration, ou d'autres tâches de maintenance, vous
devez placer Big Data Extensions en mode maintenance.
Prérequis
Déployez le vApp Serengeti.
n
Assurez-vous d'avoir les ressources adéquates allouées exécuter le cluster Hadoop.
n
Pour utiliser une distribution Hadoop autre que la distribution par défaut, ajoutez une ou plusieurs
n
distributions Hadoop. Consultez le Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data
Extensions.
Procédure
1 Connectez-vous à Serengeti Management Server.
86 VMware, Inc.
Page 87

Chapitre 7 Gérer l'environnement Big Data Extensions
2 Exécutez le script /opt/serengeti/sbin/serengeti-maintenance.sh pour placer Big Data Extensions en
mode maintenance ou vérifier l'état de maintenance.
serengeti-maintenance.sh on | off | status
Option Description
activé
désactivé
Statut
Active le mode maintenance. Lorsque vous entrez en mode maintenance,
Big Data Extensions continue à exécuter les tâches déjà commencées, mais
ne répond pas aux nouvelles requêtes.
Désactive le mode maintenance et remet Big Data Extensions dans son état
de fonctionnement normal.
Affiche l'état de maintenance de Big Data Extensions.
n
L'état sécurisé indique que les opérations de sauvegarde et les autres
tâches de maintenance peuvent être effectuées en toute sécurité dans
votre déploiement Big Data Extensions.
n
L'état désactivé indique que le mode maintenance a été désactivé et
que les tâches de maintenance telles que la sauvegarde et la
restauration ne peuvent pas être effectuées en toute sécurité.
n
L'état activé signifie que Big Data Extensions est entré en mode
maintenance, mais que les opérations de sauvegarde et de restauration
ne peuvent pas encore être effectuées en toute sécurité. Vous devez
attendre que le système renvoie le message d'état sécurisé.
Pour placer votre déploiement Big Data Extensions en mode maintenance, exécutez le script serengeti-
maintenance.sh avec l'option on.
serengeti-maintenance.sh on
3 Vérifiez que Big Data Extensions est en mode maintenance.
Lorsque Big Data Extensions a terminé toutes les tâches qui ont été envoyées, l'état de maintenance
entre en mode sécurisé. Exécutez le script serengeti-maintenance.sh avec le paramètre status de
manière répétée jusqu'à obtenir le message d'état du système sécurisé.
serengeti-maintenance.sh status
safe
4 Effectuez les tâches de maintenance système souhaitées.
5 Une fois que vous avez terminé, faites repasser Big Data Extensions à son état de fonctionnement
normal en quittant manuellement le mode maintenance.
serengeti-maintenance.sh off
Sauvegarder et restaurer l'environnement Big Data Extensions
Vous pouvez récupérer Big Data Extensions depuis un état de fonctionnement anormal en effectuant une
opération de sauvegarde et de restauration.
Vous pouvez effectuer une opération de sauvegarde et de restauration sur la même instance
Big Data Extensions, ou sur deux serveurs Big Data Extensions différents déployés dans le même
environnement vCenter Server.
Prérequis
Avant d'effectuer une opération de sauvegarde et de restauration, placez Big Data Extensions en mode de
maintenance. Reportez-vous à « Passer en mode maintenance pour effectuer la sauvegarde et la restauration
à l'aide du client d'interface de ligne de commande Serengeti », page 86.
VMware, Inc. 87
Page 88

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Procédure
1 Sauvegardez vos données dans un fichier du serveur Big Data Extensions source en utilisant le
script /opt/serengeti/sbin/backup.sh.
/opt/serengeti/sbin/backup.sh nom de fichier
2 Copiez le fichier bde-backup-xxxx.tar.gz sur le serveur Big Data Extensions cible.
3 Sur le serveur Big Data Extensions cible, exécutez le fichier /opt/serengeti/sbin/restore.sh bde-
backup-xxxx.tar.gz pour restaurer les données du premier serveur Big Data Extensions.
Une fois le processus de restauration terminé, le serveur Big Data Extensions cible est prêt à l'utilisation.
88 VMware, Inc.
Page 89

Gestion de ressources vSphere pour
les clusters 8
Big Data Extensions vous permet de gérer les pools de ressources, banques de données et réseaux que vous
utilisez dans les clusters que vous créez.
Ce chapitre aborde les rubriques suivantes :
« Ajouter un pool de ressources avec l'interface de ligne de commande Serengeti », page 89
n
« Supprimer un pool de ressources avec l'interface de ligne de commande Serengeti », page 90
n
« Mettre à jour les pools de ressources à l'aide de l'interface de ligne de commande Serengeti »,
n
page 90
« Ajouter une banque de données dans vSphere Web Client », page 91
n
« Supprimer une banque de données de vSphere Web Client », page 92
n
« Mettre à jour les banques de données à l'aide de l'interface de ligne de commande Serengeti »,
n
page 93
« Ajouter un contrôleur SCSI Paravirtual pour les disques système et de permutation », page 94
n
« Ajouter un réseau dans vSphere Web Client », page 94
n
« Modifier le type de DNS dans vSphere Web Client », page 95
n
« Reconfigurer un réseau IP statique dans vSphere Web Client », page 96
n
« Supprimer un réseau de vSphere Web Client », page 96
n
Ajouter un pool de ressources avec l'interface de ligne de commande Serengeti
Vous pouvez ajouter des pools de ressources pour qu'ils puissent être utilisés par les clusters Hadoop. Les
pools de ressources doivent être situés au niveau supérieur du cluster. Les pools de ressources imbriqués ne
sont pas pris en charge.
Lorsque vous ajoutez un pool de ressources à Big Data Extensions, il représente symboliquement le pool de
ressources vSphere réel tel qu'il est identifié par vCenter Server. Cette représentation symbolique vous
permet d'utiliser le nom du pool de ressources Big Data Extensions au lieu du chemin d'accès complet du
pool de ressources dans vCenter Server, dans les fichiers de spécification de cluster.
REMARQUE Après avoir ajouté un pool de ressources à Big Data Extensions, ne renommez pas le pool de
ressources dans vSphere. Si vous le renommez, vous ne pourrez pas exécuter d'opérations Serengeti sur les
clusters qui utilisent ce pool de ressources.
VMware, Inc.
89
Page 90

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Procédure
1 Accédez au client d'interface de ligne de commande Serengeti.
2 Exécutez la commande resourcepool add.
Le paramètre --vcrp est facultatif.
Cet exemple ajoute un pool de ressources Serengeti nommé myRP au pool de ressources vSphere rp1
contenu dans le cluster vSphere cluster1.
resourcepool add --name myRP --vccluster cluster1 --vcrp rp1
Supprimer un pool de ressources avec l'interface de ligne de commande Serengeti
Vous pouvez supprimer de Serengeti les pools de ressources qui ne sont pas utilisés par un cluster Hadoop.
Vous supprimez des pools de ressources quand vous n'en avez plus besoin ou si vous voulez que les
clusters Hadoop que vous créez dans le serveur de gestion Serengeti soient déployés sous un autre pool de
ressources. La suppression d'un pool de ressources supprime sa référence dans vSphere. Le pool de
ressources n'est pas réellement supprimé.
Procédure
1 Accédez au client d'interface de ligne de commande Serengeti.
2 Exécutez la commande resourcepool delete.
Si la commande échoue parce que le pool de ressources est référencé par un cluster Hadoop, vous
pouvez utiliser la commande resourcepool list pour voir quel cluster référence ce pool de ressources.
Cet exemple supprime le pool de ressources nommé myRP.
resourcepool delete --name myRP
Mettre à jour les pools de ressources à l'aide de l'interface de ligne de commande Serengeti
Vous pouvez mettre à jour un cluster existant pour utiliser de nouveaux pools de ressources. Pour ce faire,
lorsque vous étendez votre environnement, ajoutez un nouveau cluster ESX avec les nouveaux pools de
ressources.
La commande cluster update vous permet d'ajouter de nouveaux pools de ressources à un cluster existant,
ainsi que de mettre à jour les pools de ressources déjà utilisés.
Vous pouvez également ajouter de nouveaux pools de ressources à ceux existants à l'aide du paramètre --
append. Cela vous permet d'ajouter de nouveaux pools de ressources sans mettre à jour ceux déjà utilisés par
le cluster. Si votre environnement contient de nombreux pools de ressources, le paramètre --append vous
permet d'ajouter de nouveaux pools de ressource sans avoir à lister explicitement chacun des pools de
ressources déjà utilisés.
Prérequis
Vous devez disposer d'un cluster Big Data que vous souhaitez mettre à jour avec des pools de
n
ressources nouveaux ou différents.
Exécutez la commande cluster export pour vérifier et noter quels pools de ressources sont
n
actuellement utilisés par le cluster que vous souhaitez mettre à jour avec des pools de ressources
nouveaux ou différents.
Procédure
1 Connectez-vous à Serengeti CLI.
90 VMware, Inc.
Page 91

Chapitre 8 Gestion de ressources vSphere pour les clusters
2 Ajoutez un nouveau pool de ressources à partir d'un cluster ESX à l'aide de la commande resourcepool
add.
Dans cet exemple, un pool de ressources étiqueté myRP2 est ajouté à partir du pool de ressources
vSphere rp1 contenu dans le cluster vSphere cluster1.
resourcepool add --name myRP2 --vccluster cluster1 --vcrp rp1
3 Exécutez la commande cluster export pour vérifier et noter quels pools de ressources sont
actuellement utilisés par le cluster.
cluster export --name cluster_name
4 Mettez à jour les pools de ressources du cluster à l'aide de la commande cluster update.
cluster update --name cluster1 –-rpNames myRP,myRP2
Le nouveau pool de ressources, myRP2, est à présent disponible pour une utilisation par le cluster
étiqueté cluster1.
5 Vous pouvez si vous le souhaitez ajouter le nouveau pool de ressources myRP2 à vos pools de ressources
existants à l'aide du paramètre --append. Cela vous permet d'ajouter de nouveaux pools de ressources
sans mettre à jour ceux déjà utilisés par le cluster.
cluster update --name cluster1 --rpNames myPR2 --append
Suivant
Vous pouvez si vous le souhaitez mettre à jour le cluster pour utiliser de nouvelles banques de données.
Reportez-vous à « Mettre à jour les banques de données à l'aide de l'interface de ligne de commande
Serengeti », page 93.
Ajouter une banque de données dans vSphere Web Client
Vous pouvez ajouter des banques de données à Big Data Extensions pour les mettre à la disposition des
clusters Big Data. Big Data Extensions prend en charge les banques de données partagées et les banques de
données locales.
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Sélectionnez Big Data Extensions.
3 Dans les listes d'inventaire, sélectionnez Ressources.
4 Développez les listes d'inventaire, puis sélectionnez Banques de données.
5 Cliquez sur l'icône Ajouter (+).
6 Dans la zone de texte Nom, tapez un nom servant à identifier la banque de données dans Big Data
Extensions.
Les mots de passe doivent contenir 8 à 20 caractères, utiliser uniquement des caractères ASCII inférieurs
visibles (pas d'espaces) et comporter au moins une lettre majuscule (A - Z), une lettre minuscule (a - z),
un chiffre (0 - 9) et l'un des caractères spéciaux suivants : _, @, #, $, %, ^, &, *
VMware, Inc. 91
Page 92

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
7 Dans la liste Type, sélectionnez le type de banque de données dans vSphere.
Type Description
Partagée
Local
Recommandé pour les nœuds master. Vous permet d'exploiter vMotion, la
haute disponibilité et la tolérance aux pannes.
REMARQUE Si vous ne spécifiez pas de stockage partagé et que vous
essayez de provisionner un cluster en utilisant vMotion, la haute
disponibilité ou la tolérance aux pannes, le provisionnement échoue.
Recommandé pour les nœuds worker. Le débit est évolutif et le coût de
stockage moindre.
8 Sélectionnez une ou plusieurs banques de données vSphere à mettre à la disposition de la banque de
données Big Data Extensions que vous ajoutez.
9 Cliquez sur OK pour enregistrer vos modifications.
Les banques de données vSphere peuvent être utilisées par les clusters Big Data déployés au sein de
Big Data Extensions.
Supprimer une banque de données de vSphere Web Client
Vous supprimez une banque de données de Big Data Extensions quand vous ne voulez plus que les clusters
Hadoop que vous créez l'utilise.
Prérequis
Supprimez tous les clusters Hadoop associés à la banque de données. Reportez-vous à « Supprimer un
cluster dans vSphere Web Client », page 114.
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Sélectionnez Big Data Extensions.
3 Dans les listes d'inventaire, sélectionnez Ressources.
4 Développez Ressources, sélectionnez Listes d'inventaire, puis Banques de données.
5 Sélectionnez la banque de données à supprimer, cliquez avec le bouton droit, puis sélectionnez
Supprimer.
6 Cliquez sur Oui pour confirmer.
Si vous n'avez pas supprimé le cluster qui utilise la banque de données, vous recevez un message
d'erreur indiquant que la banque de données ne peut pas être supprimée, car elle est actuellement
utilisée.
La banque de données est supprimée de Big Data Extensions.
92 VMware, Inc.
Page 93

Chapitre 8 Gestion de ressources vSphere pour les clusters
Mettre à jour les banques de données à l'aide de l'interface de ligne de commande Serengeti
Vous pouvez mettre à jour un cluster existant pour utiliser de nouvelles banques de données. Pour ce faire,
lorsque vous étendez votre environnement, ajoutez un nouvel hôte ESXi avec les nouvelles banques de
données.
Lorsque vous ajoutez des banques de données à un cluster existant, si les noms des nouvelles banques de
données correspondent à ceux des banques de données déjà utilisées par le cluster, elles seront
automatiquement disponibles pour une utilisation par le cluster. En revanche, si les noms des banques de
données existantes ne correspondent pas à ceux des banques de données des nouveaux hôtes ESXi, vous
devez utiliser les commandes datastore add et cluster update pour mettre à jour les banques de données
disponibles pour le cluster, en spécifiant les noms des banques de données existantes et nouvelles.
Prérequis
Vous devez disposer d'un cluster Big Data que vous souhaitez mettre à jour avec une banque de données
nouvelle ou différente. Par exemple si vous avez ajouté un nouvel hôte ESXi à votre environnement et que
vous souhaitez étendre les ressources disponibles à votre environnement Big Data Extensions.
Procédure
1 Connectez-vous à Serengeti CLI.
2 Ajoutez une nouvelle banque de données à partir d'un hôte ESXi à l'aide de la commande datastore
add ou de vSphere Web Client.
Dans cet exemple, Serengeti CLI est utilisée pour ajouter une nouvelle banque de données de stockage
local nommée newDS. La valeur du paramètre --spec, local*, est un caractère générique spécifiant un
ensemble de banques de données vSphere. Toutes les banques de données vSphere dont le nom
commence par « local » sont ajoutées et gérées comme un tout par Big Data Extensions.
datastore add --name newDS --spec local* --type LOCAL
3 Mettez à jour la liste des banques de données disponibles pour être utilisées par le cluster à l'aide de la
commande cluster update. Lorsque vous ajoutez des banques de données à un cluster existant, vous
devez également spécifier les banques de données actuellement utilisées par le cluster. Dans cette
exemple, les étiquettes currentDS et newDS sont utilisées pour différencier les banques de données en
cours d'ajout au cluster (newDS) et celles déjà utilisées par le cluster (currentDS).
Si vous n'indiquez pas les noms des banques de données déjà utilisées par le cluster avec le paramètre
--dsNames, un message d'avertissement vous prévient que le cluster utilise toutes les banques de
données disponibles, et que les banques de données en cours de mise à jour appartiennent à un sousensemble de ces banques de données. Dans ce cas, il se peut que certaines données ne soient pas
disponibles après la mise à jour, ce qui peut provoquer des erreurs. Serengeti CLI vous invitera à
confirmer que vous souhaitez poursuivre la mise à jour en tapant O (oui) ou à abandonner la mise à jour
en tapant N (non).
cluster update --name cluster1 –-dsNames currentDS,newDS
L'ancienne et la nouvelle banque de données sont à présent toutes deux disponibles pour une utilisation
par le cluster étiqueté cluster1.
4 Si vous souhaitez ajouter de nouvelles banques de données en plus de celles déjà utilisées par le cluster,
utilisez le paramètre --append. La commande --append vous permet d'omettre de lister les banques de
données déjà utilisées par le cluster avec le paramètre --dsNames.
cluster update --name cluster1 –-dsNames newDS --append
La nouvelle banque de données est à présent disponible pour une utilisation par le cluster étiqueté
cluster1. Aucune des banques de données déjà utilisées par le cluster auparavant n'est affectée.
VMware, Inc. 93
Page 94

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Suivant
Vous pouvez si vous le souhaitez mettre à jour le cluster pour utiliser de nouveaux pools de ressources.
Reportez-vous à « Mettre à jour les pools de ressources à l'aide de l'interface de ligne de commande
Serengeti », page 90.
Ajouter un contrôleur SCSI Paravirtual pour les disques système et de permutation
Vous pouvez ajouter un contrôleur de stockage haute performance VMware Paravirtual SCSI (PVSCSI) pour
optimiser le débit et minimiser l'utilisation du CPU.
Les contrôleurs PVSCSI sont mieux adaptés aux environnements d'exécution d'opérations intensives en E/S
tels que les disques système et de permutation. Le contrôleur PVSCSI optimise le débit et minimise
l'utilisation du CPU.
REMARQUE Par défaut, le type de contrôleur des disques de données est défini sur PVSCSI. Vous pouvez
faire en sorte que le disque de données utilise le contrôleur LSI Logic SAS en modifiant le paramètre
storage.data.disk.controller.type comme décrit dans cette procédure.
Prérequis
Avant d'ajouter le contrôleur PVSCSI, arrêtez la machine virtuelle du modèle Hadoop.
Procédure
1 À partir de vSphere Web Client, arrêtez la machine virtuelle du modèle Hadoop.
2 Connectez-vous à Serengeti Management Server en tant qu'utilisateur serengeti.
3 Ouvrez le fichier /opt/serengeti/conf/serengeti.properties dans un éditeur de texte.
4 Définissez la valeur de configuration du paramètre storage.system_swap.disk.controller.type= sur
ParaVirtualSCSIController.
storage.system_swap.disk.controller.type=ParaVirtualSCSIController
5 Dans l'arborescence des machines virtuelles et modèles, sélectionnez la machine virtuelle du modèle de
nœud dont vous souhaitez modifier le paramètre de contrôleur de disque.
6 Dans le panneau Matériel de la machine virtuelle, cliquez sur Modifier les paramètres.
7 Cliquez sur Matériel virtuel.
8 Cliquez sur le triangle à côté du périphérique SCSI pour développer les options de périphérique.
9 Dans le menu déroulant Modifier le type, sélectionnez Paravirtuel VMware.
10 Cliquez sur OK pour enregistrer les modifications et quitter la boîte de dialogue.
11 Supprimez tous les instantanés de la machine virtuelle du modèle de nœud.
Ajouter un réseau dans vSphere Web Client
Ajoutez des réseaux à Big Data Extensions pour que les adresses IP qu'ils contiennent soient disponibles
pour les clusters Big Data.
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Sélectionnez Big Data Extensions.
3 Dans les listes d'inventaire, sélectionnez Ressources.
94 VMware, Inc.
Page 95

Chapitre 8 Gestion de ressources vSphere pour les clusters
4 Développez Ressources, cliquez sur Listes d'inventaire > Listes d'inventaire et sélectionnez Réseaux.
5 Cliquez sur l'icône Ajouter (+).
6 Dans la zone de texte Nom, tapez un nom servant à identifier la ressource réseau dans Big Data
Extensions.
7 Dans la liste Nom du groupe de ports, sélectionnez le groupe de ports vSphere à ajouter à Big Data
Extensions.
8 Sélectionnez un type de DNS.
Option Description
Normale
Dynamique
Autres
Le serveur DNS fournit la résolution FQDN/IP dans les deux sens. Le DNS
inverse correspond au mappage de l'adresse IP au nom de domaine. Il
s'agit de l'inverse du DNS normal qui mappe les noms de domaine aux
adresses IP. Par défaut, le type de DNS est normal.
Dynamic DNS (DDNS ou DynDNS) est une méthode qui permet la mise à
jour automatique d'un nom de serveur du système DNS (Domain Name
System) avec la configuration DNS active de ses noms d'hôte configurés,
adresses ou autres informations. Big Data Extensions s'intègre à un serveur
Dynamic DNS de son réseau, au travers duquel il fournit des noms d'hôte
significatifs aux nœuds d'un cluster Hadoop. Le cluster s'enregistre ensuite
automatiquement auprès du serveur DNS.
Il n'y a pas de serveur DNS dans le VLAN ou le serveur DNS n'offre pas
de résolution DNS normale ou de services Dynamic DNS. Dans ce cas,
vous devez ajouter un mappage FQDN/IP pour tous les nœuds du
fichier /etc/hosts de chaque nœud du cluster. Grâce à ce mappage de
noms d'hôte vers des adresses IP, chaque nœud peut contacter un autre
nœud du cluster.
9 Choisissez le type d'adressage à utiliser pour le réseau : Utiliser DHCP pour obtenir les adresses IP ou
Utiliser des adresses IP statiques.
10 (Facultatif) Si vous avez choisi Utiliser des adresses IP statiques dans Étape 9, entrez une ou plusieurs
plages d'adresses IP.
11 Cliquez sur OK pour enregistrer vos modifications.
Les adresses IP du réseau sont disponibles pour les clusters Big Data que vous créez au sein de Big Data
Extensions.
Modifier le type de DNS dans vSphere Web Client
DHCP sélectionne l'adresse IP du pool IP de manière aléatoire. Le FQN et l'adresse IP des nœuds d'un
cluster sont aléatoires. L'utilisateur ou l'application Hadoop ne peut pas localiser les nœuds master à moins
qu'ils n'envoient une requête à Big Data Extensions. Même si l'utilisateur connaît l'adresse d'origine, elle
peut changer lors du redémarrage du cluster. De ce fait, il est difficile pour l'utilisateur ou l'application
Hadoop d'accéder au cluster.
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Sélectionnez Big Data Extensions.
3 Dans les listes d'inventaire, sélectionnez Ressources.
4 Développez l'option Ressources, sélectionnez Listes d'inventaire > Réseaux.
5 Sélectionnez un seul réseau à modifier, cliquez avec le bouton droit et sélectionnez Modifier le type de
DNS.
VMware, Inc. 95
Page 96

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
6 Sélectionnez un type de DNS.
Option Description
Normale
Dynamique
Autres
Le serveur DNS fournit la résolution FQDN/IP dans les deux sens. Le DNS
inverse correspond au mappage de l'adresse IP au nom de domaine. Il
s'agit de l'inverse du DNS normal qui mappe les noms de domaine aux
adresses IP. Par défaut, le type de DNS est normal.
Dynamic DNS (DDNS ou DynDNS) est une méthode qui permet la mise à
jour automatique d'un nom de serveur du système DNS (Domain Name
System) avec la configuration DNS active de ses noms d'hôte configurés,
adresses ou autres informations. Big Data Extensions s'intègre à un serveur
Dynamic DNS de son réseau, au travers duquel il fournit des noms d'hôte
significatifs aux nœuds d'un cluster Hadoop. Le cluster s'enregistre ensuite
automatiquement auprès du serveur DNS.
Il n'y a pas de serveur DNS dans le VLAN ou le serveur DNS n'offre pas
de résolution DNS normale ou de services Dynamic DNS. Dans ce cas,
vous devez ajouter un mappage FQDN/IP pour tous les nœuds du
fichier /etc/hosts de chaque nœud du cluster. Grâce à ce mappage de
noms d'hôte vers des adresses IP, chaque nœud peut contacter un autre
nœud du cluster.
7 Cliquez sur OK pour enregistrer vos modifications.
Reconfigurer un réseau IP statique dans vSphere Web Client
Vous pouvez reconfigurer un réseau IP statique Big Data Extensions en lui ajoutant des segments d'adresse
IP. Il se peut que vous ayez besoin d'ajouter des segments d'adresse IP de telle sorte qu'il y ait assez de
capacité pour le cluster que vous voulez créer.
Prérequis
Si votre réseau utilise des adresses IP statiques, assurez-vous que les adresses ne sont pas occupées avant
d'ajouter le réseau.
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Sélectionnez Big Data Extensions.
3 Dans les listes d'inventaire, sélectionnez Ressources.
4 Développez l'option Ressources, sélectionnez Listes d'inventaire > Réseaux.
5 Sélectionnez le réseau IP statique pour le reconfigurer, cliquez sur le bouton droit de la souris et
sélectionnez Ajouter une plage d'adresses IP.
6 Cliquez sur Ajouter une plage d'adresses IP, puis saisissez les informations de l'adresse IP.
7 Cliquez sur OK pour enregistrer vos modifications.
Les segments d'adresse IP sont ajoutés au réseau.
Supprimer un réseau de vSphere Web Client
Vous pouvez supprimer un réseau existant de Big Data Extensions si vous n'en avez plus besoin. La
suppression d'un réseau non utilisé libère les adresses IP pour qu'elles soient utilisées par d'autres services.
Prérequis
Supprimez les clusters attribués au réseau. Reportez-vous à « Supprimer un cluster dans vSphere Web
Client », page 114.
96 VMware, Inc.
Page 97

Chapitre 8 Gestion de ressources vSphere pour les clusters
Procédure
1 Utilisez vSphere Web Client pour vous connecter à vCenter Server.
2 Sélectionnez Big Data Extensions.
3 Dans les listes d'inventaire, sélectionnez Ressources.
4 Développez l'option Ressources, sélectionnez Listes d'inventaire > Réseaux.
5 Sélectionnez le réseau à supprimer, cliquez sur le bouton droit de la souris, puis cliquez sur Supprimer.
6 Cliquez sur Oui pour confirmer.
Si vous n'avez pas supprimé le cluster qui utilise le réseau, vous recevez un message d'erreur indiquant
que le réseau ne peut pas être supprimé, car il est actuellement utilisé.
Le réseau est supprimé et les adresses IP peuvent être utilisées.
VMware, Inc. 97
Page 98

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
98 VMware, Inc.
Page 99

Création de clusters Hadoop et
HBase 9
Dans Big Data Extensions, vous pouvez créer et déployer des clusters Hadoop et HBase. Un cluster Big Data
est un type de cluster de calcul conçu pour stocker et analyser de grandes quantités de données non
structurées dans un environnement informatique distribué.
Restrictions.
Lorsque vous créez un cluster uniquement HBase, vous devez utiliser le gestionnaire d'applications par
n
défaut, car les autres ne prennent pas en charge ce type de cluster.
Vous ne pouvez pas renommer un cluster créé avec le gestionnaire d'applications Cloudera Manager ou
n
Ambari.
La mise hors tension temporaire des hôtes provoque l'échec des clusters Big Data pendant la création
n
du cluster.
Lorsque vous créez des clusters Big Data, Big Data Extensions calcule le placement des machines
virtuelles en fonction des ressources disponibles, des meilleures pratiques Hadoop et des stratégies de
placement définies par l'utilisateur avant la création des machines virtuelles. Lors de ces calculs, si
certains hôtes sont mis hors tension ou en veille soit manuellement soit par VMware Distributed Power
Management (VMware DPM), ces hôtes ne sont pas considérés comme des ressources disponibles par
Big Data Extensions.
Si un hôte est mis hors tension ou en veille après que Big Data Extensions a calculé le placement des
machines virtuelles, mais avant leur création, la création du cluster échoue tant que vous ne remettez
pas ces hôtes sous tension. Les solutions de contournement suivantes peuvent vous aider à éviter ce
problème et à y remédier.
n
n
n
Conditions
Les besoins en ressources sont différents pour les clusters créés avec l'interface de ligne de commande de
Serengeti et le plug-in Big Data Extensions pour vSphere Web Client, car les clusters utilisent des modèles
par défaut différents. Les clusters par défaut créés à l'aide de la Serengeti CLI sont ciblés sur les utilisateurs
de Project Serengeti et les applications de validation technique. Ils sont plus petits que les modèles de plugin de Big Data Extensions, qui sont ciblés sur des déploiements de plus grande envergure à usage
commercial.
VMware, Inc.
Désactivez VMware DPM sur les clusters vSphere où vous déployez et exécutez
Big Data Extensions.
Mettez les hôtes en mode maintenance avant de les mettre hors tension.
Si la création d'un cluster Big Data échoue en raison de l'indisponibilité temporaire des hôtes qui
lui sont attribués, reprenez la création du cluster après avoir mis les hôtes sous tension.
99
Page 100

Guide de l'utilisateur et de l'administrateur VMware vSphere Big Data Extensions
Certaines configurations de déploiement nécessitent plus de ressources que d'autres. Par exemple, si vous
créez un cluster Greenplum HD 1.2, vous ne pouvez pas utiliser la machine virtuelle de petite taille. Si vous
créez un cluster MapR ou Greenplum HD par défaut à l'aide de la Serengeti CLI, il est recommandé de
disposer d'au moins 550 Go de stockage et de 55 Go de mémoire. Pour les autres distributions Hadoop, il est
recommandé de disposer d'au moins 350 Go de stockage et de 35 Go de mémoire.
AVERTISSEMENT Lorsque vous créez un cluster avec Big Data Extensions, Big Data Extensions désactive la
migration automatique des machines virtuelles sur le cluster. Cela empêche la migration automatique des
machines virtuelles par vSphere, mais ne vous empêche pas de déplacer accidentellement les nœuds du
cluster vers d'autres hôtes avec l'interface utilisateur de vCenter Server. N'utilisez pas l'interface utilisateur
de vCenter Server pour migrer des clusters. L'utilisation de ces fonctions de gestion en dehors de
l'environnement Big Data Extensions peut vous empêcher d'effectuer certaines opérations de Big Data
Extensions telles que la récupération de défaillances de disque.
Les mots de passe doivent contenir 8 à 20 caractères, utiliser uniquement des caractères ASCII inférieurs
visibles (pas d'espaces) et comporter au moins une lettre majuscule (A - Z), une lettre minuscule (a - z), un
chiffre (0 - 9) et l'un des caractères spéciaux suivants : _, @, #, $, %, ^, &, *
Ce chapitre aborde les rubriques suivantes :
« À propos des types de déploiement de clusters Hadoop et HBase », page 101
n
« Distributions Hadoop prenant en charge MapReduce v1 et MapReduce v2 (YARN) », page 101
n
« À propos de la topologie des clusters », page 102
n
« À propos de l'accès à la base de données HBase », page 103
n
« Créer un cluster Big Data dans vSphere Web Client », page 103
n
« Créer un cluster uniquement HBase dans Big Data Extensions », page 107
n
« Créer un cluster avec un gestionnaire d'applications à l'aide de vSphere Web Client », page 109
n
« Créer un cluster de calcul uniquement avec un gestionnaire d'applications tiers en utilisant vSphere
n
Web Client », page 110
« Créer un cluster de calcul du travailleur uniquement à l'aide de vSphere Web Client », page 110
n
100 VMware, Inc.
 Loading...
Loading...