


CAS
Referenzhandbuch
Dieser Leitfaden îst gültig für die TI-Nspire Software-Version 1.4.
Die aktuellste Version der Dokumentation finden Sie unter
education.ti.com/guides.

Wichtige Informationen
Außer im Fall anderslautender Bestimmungen der Lizenz für das
Programm gewährt Texas Instruments keine ausdrückliche oder implizite
Garantie, inklusive aber nicht ausschließlich sämtlicher impliziter
Garantien der Handelsfähigkeit und Eignung für einen bestimmten
Zweck, bezüglich der Programme und der schriftlichen
Dokumentationen, und stellt dieses Material nur im „Ist-Zustand“ zur
Verfügung. Unter keinen Umständen kann Texas Instruments für
besondere, direkte, indirekte oder zufällige Schäden bzw. Folgeschäden
haftbar gemacht werden, die durch Erwerb oder Benutzung dieses
Materials verursacht werden, und die einzige und exklusive Haftung von
Texas Instruments, ungeachtet der Form der Beanstandung, kann den in
der Programmlizenz festgesetzten Betrag nicht überschreiten. Zudem
haftet Texas Instruments nicht für Forderungen anderer Parteien
jeglicher Art gegen die Anwendung dieses Materials.
Lizenz
Bitte lesen Sie die vollständige Lizenz im Verzeichnis C:\Programme\TI
Education\TI-Nspire CAS
© 2008 Texas Instruments Incorporated
Macintosh®, Windows®, Excel®, Vernier EasyLink®, EasyTemp®,
Go!®Link, Go!®Motion, und Go!®Temp sind Warenzeichen und
Eigentum der jeweiligen Besitzer.
.
ii

Inhaltsverzeichnis
Wichtige Informationen
Vorlagen für Ausdrücke
Vorlage Bruch ..............................................1
Vorlage Exponent ........................................ 1
Vorlage Quadratwurzel ...............................1
Vorlage n-te Wurzel ....................................1
Vorlage e Exponent .....................................2
Vorlage Logarithmus ................................... 2
Vorlage Stückweise (2 Teile) .......................2
Vorlage Stückweise (n Teile) .......................2
Vorlage System von 2 Gleichungen ............3
Vorlage System von n Gleichungen ............ 3
Vorlage Absolutwert ...................................3
Vorlage dd°mm’ss.ss’’ ..................................3
Vorlage Matrix (2 x 2) .................................. 3
Vorlage Matrix (1 x 2) .................................. 3
Vorlage Matrix (2 x 1) .................................. 4
Vorlage Matrix (m x n) ................................ 4
Vorlage Summe (G) ......................................4
Vorlage Produkt (Π) .....................................4
Vorlage Erste Ableitung .............................. 4
Vorlage n-te Ableitung ............................... 5
Vorlage Bestimmtes Integral .......................5
Vorlage Unbestimmtes Integral .................. 5
Vorlage Limes ............................................... 5
Alphabetische Auflistung
A
abs() (Absolutwert) ...................................... 6
amortTbl() .................................................... 6
and (und) ......................................................6
angle() (Winkel) ...........................................7
ANOVA .........................................................7
ANOVA2way (ANOVA 2fach) ......................8
Ans (Antwort) ............................................ 10
approx() (Approximieren) .........................10
approxRational() ........................................ 10
arcLen() (Bogenlänge) ............................... 10
augment() (Erweitern) ............................... 11
avgRC() (Durchschnittliche Änderungsrate) .
11
B
bal() .............................................................12
4Base2 .........................................................12
4Base10 .......................................................13
4Base16 .......................................................13
binomCdf() ................................................. 13
binomPdf() ................................................. 13
C
ceiling() (Obergrenze) ............................... 14
cFactor() (Komplexer Faktor) .................... 14
char() (Zeichenstring) .................................14
charPoly() ....................................................15
2
2way ........................................................15
c
2
Cdf() .........................................................15
c
2
GOF ......................................................... 15
c
2
Pdf() ........................................................ 16
c
ClearAZ (LöschAZ) ...................................... 16
ClrErr (LöFehler) ......................................... 16
colAugment() (Spaltenerweiterung) ........17
colDim() (Spaltendimension) ..................... 17
colNorm() (Spaltennorm) .......................... 17
comDenom() (Gemeinsamer Nenner) .......17
conj() (Komplex Konjugierte) ................... 18
constructMat() ........................................... 18
CopyVar ...................................................... 18
corrMat() (Korrelationsmatrix) ................. 19
4cos ............................................................. 19
cos() (Kosinus) ............................................ 20
cosê() (Arkuskosinus) ................................. 21
cosh() (Cosinus hyperbolicus) .................... 21
coshê() (Arkuskosinus hyperbolicus) ........ 21
cot() (Kotangens) ....................................... 22
cotê() (Arkuskotangens) ............................ 22
coth() (Kotangens hyperbolicus) ............... 22
cothê() (Arkuskotangens hyperbolicus) ...23
count() (zähle) ............................................ 23
countIf() ..................................................... 23
crossP() (Kreuzprodukt) ............................. 24
csc() (Kosekans) .......................................... 24
cscê() (Inverser Kosekans) .......................... 24
csch() (Kosekans hyperbolicus) .................. 24
cschê() (Inverser Kosekans hyperbolicus) . 25
cSolve() (Komplexe Lösung) ...................... 25
CubicReg (Kubische Regression) ............... 27
cumSum() (Kumulierte Summe) ................ 27
Cycle (Zyklus) ............................................. 28
4Cylind (Zylindervektor) ............................ 28
cZeros() (Komplexe Nullstellen) ................ 28
D
dbd() ........................................................... 30
4DD (Dezimalwinkel) ................................. 30
4Decimal (Dezimal) .................................... 30
Definiere .................................................... 31
Definiere LibPriv (Define LibPriv) ............. 32
Definiere LibPub (Define LibPub) ............. 32
DelVar ........................................................ 32
deSolve() (Lösung) ..................................... 33
det() (Matrixdeterminante) ....................... 34
diag() (Matrixdiagonale) ........................... 34
dim() (Dimension) ...................................... 34
Disp (Zeige) ................................................ 35
4DMS (GMS) ................................................ 35
dominanterTerm (), dominantTerm() ....... 36
dotP() (Skalarprodukt) ............................... 36
E
e^() ............................................................. 37
eff() ............................................................. 37
eigVc() (Eigenvektor) ................................. 37
eigVl() (Eigenwert) .................................... 38
Else ............................................................. 38
ElseIf ........................................................... 38
EndFor ........................................................ 38
iii

EndFunc ......................................................38
EndIf ............................................................38
EndLoop ......................................................38
EndWhile ....................................................38
EndPrgm .....................................................38
EndTry .........................................................39
exact() (Exakt) .............................................39
Exit (Abbruch) ............................................39
4exp .............................................................39
exp() (e hoch x) ...........................................39
exp4list() (Ausdruck in Liste) ......................40
expand() (Entwickle) ..................................40
expr() (String in Ausdruck) ........................41
ExpReg (Exponentielle Regression) ...........41
F
factor() (Faktorisiere) .................................42
FCdf() ..........................................................43
Fill (Füllen) ..................................................43
FiveNumSummary ......................................44
floor() (Untergrenze) .................................44
fMax() (Funktionsmaximum) .....................44
fMin() (Funktionsminimum) ......................45
For ...............................................................45
format() (Format) .......................................46
fPart() (Funktionsteil) .................................46
FPdf() ..........................................................46
freqTable4list() ............................................46
frequency() (Häufigkeit) ............................47
FTest_2Samp (Zwei-Stichproben F-Test) ...47
Func .............................................................48
G
gcd() (Größter gemeinsamer Teiler) .........48
geomCdf() ...................................................48
geomPdf() ...................................................49
getDenom() (Nenner holen) ......................49
getLangInfo() .............................................49
getMode() ...................................................49
getNum() (Zähler holen) ............................50
getVarInfo() ................................................50
Goto (Gehe zu) ...........................................51
4Grad (Neugrad) .........................................51
I
identity() (Einheitsmatrix) ..........................52
If ..................................................................52
ifFn() ............................................................53
imag() (Imaginärteil) ..................................53
impDif() (Implizite Ableitung) ...................54
Umleitung ...................................................54
inString() (In String) ...................................54
int() (Ganze Zahl) .......................................54
intDiv() (Ganzzahl teilen) ..........................54
integrate (Integral) ....................................54
2
() .........................................................55
invc
invF() ...........................................................55
invNorm() ....................................................55
invt() ............................................................55
iPart() (Ganzzahliger Teil) ..........................55
irr() ..............................................................55
isPrime() (Primzahltest) ..............................56
L
Lbl (Marke) ................................................. 56
lcm() (Kleinstes gemeinsames Vielfaches) 56
left() (Links) ................................................ 57
libShortcut() ............................................... 57
limit() oder lim() (Limes) ............................ 57
LinRegBx ..................................................... 58
LinRegMx ................................................... 59
LinRegtIntervals (Lineare Regressions-t-In-
tervalle) ...................................................... 59
LinRegtTest (t-Test bei linearer Regression) .
61
@list() (Listendifferenz) .............................. 61
list4mat() (Liste in Matrix) .......................... 62
4ln (Natürlicher Logarithmus) ................... 62
ln() (Natürlicher Logarithmus) .................. 62
LnReg .......................................................... 63
Local (Lokale Variable) .............................. 64
log() (Logarithmus) .................................... 64
4logbase ...................................................... 65
Logistic ....................................................... 65
LogisticD ..................................................... 66
Loop (Schleife) ........................................... 67
LU (Untere/obere Matrixzerlegung) .........67
M
mat4list() (Matrix in Liste) .......................... 68
max() (Maximum) ...................................... 68
mean() (Mittelwert) ................................... 68
median() (Median) ..................................... 68
MedMed ..................................................... 69
mid() (Teil-String) ....................................... 69
min() (Minimum) ........................................ 70
mirr() ........................................................... 70
mod() (Modulo) ......................................... 71
mRow() (Matrixzeilenoperation) .............. 71
mRowAdd() (Matrixzeilenaddition) .......... 71
MultReg ...................................................... 71
MultRegIntervals ....................................... 72
MultRegTests ............................................. 72
N
nCr() (Kombinationen) .............................. 73
nDeriv() (Numerische Ableitung) .............. 74
newList() (Neue Liste) ................................ 74
newMat() (Neue Matrix) ........................... 74
nfMax() (Numerisches Funktionsmaximum) .
74
nfMin() (Numerisches Funktionsminimum) ..
74
nInt() (Numerisches Integral) .................... 75
nom() .......................................................... 75
norm() ......................................................... 75
normalLine() ............................................... 76
normCdf() (Normalverteilungswahrscheinli-
chkeit) ......................................................... 76
normPdf() (Wahrscheinlichkeitsdichte) ....76
not .............................................................. 76
nPr() (Permutationen) ............................... 77
npv() ........................................................... 78
nSolve() (Numerische Lösung) ................... 78
iv

O
OneVar (Eine Variable) ..............................79
or .................................................................80
ord() (Numerischer Zeichencode) ..............80
P
P4Rx() (Kartesische x-Koordinate) ............. 80
P4Ry() (Kartesische y-Koordinate) ............. 81
PassErr (ÜbgebFeh) ....................................81
piecewise() (Stückweise) ............................81
poissCdf() .................................................... 81
poissPdf() ....................................................82
4Polar ..........................................................82
polyCoeffs() ................................................ 83
polyDegree() .............................................. 83
polyEval() (Polynom auswerten) ............... 83
polyGcd() ....................................................84
polyQuotient() ........................................... 84
polyRemainder() ........................................ 84
PowerReg ...................................................85
Prgm ...........................................................86
Product (PI) (Produkt) ................................ 86
product() (Produkt) ....................................86
propFrac() (Echter Bruch) ...........................86
Q
QR ...............................................................87
QuadReg .....................................................88
QuartReg ....................................................88
R
R4Pq() (Polarkoordinate) ............................89
R4Pr() (Polarkoordinate) ............................89
4Rad (Bogenmaß) .......................................90
rand() (Zufallszahl) .....................................90
randBin() (Zufallszahl aus Binomialvertei-
lung) ...........................................................90
randInt() (Ganzzahlige Zufallszahl) ..........90
randMat() (Zufallsmatrix) .......................... 90
randNorm() (Zufallsnorm) ......................... 91
randPoly() (Zufallspolynom) ...................... 91
randSamp() (Zufallsstichprobe) .................91
RandSeed (Zufallszahl) ..............................91
real() (Reell) ................................................91
4Rect (Kartesisch) ........................................92
ref() (Diagonalform) ..................................92
remain() (Rest) ............................................ 92
Return (Rückgabe) ..................................... 93
right() (Rechts) ...........................................93
root() (Wurzel) ...........................................93
rotate() (Rotieren) ......................................94
round() (Runden) ....................................... 94
rowAdd() (Zeilenaddition) ........................95
rowDim() (Zeilendimension) .....................95
rowNorm() (Zeilennorm) ...........................95
rowSwap() (Zeilentausch) ..........................95
rref() (Reduzierte Diagonalform) .............. 95
S
sec() (Sekans) .............................................. 96
sec/() (Arkussekans) ................................... 96
sech() (Sekans hyperbolicus) ......................96
sechê() (Arkussekans hyperbolicus) .......... 97
seq() (Folge) ............................................... 97
series() ........................................................ 98
setMode ..................................................... 99
shift() (Verschieben) ................................ 100
sign() (Zeichen) ........................................ 100
simult() (Gleichungssystem) .................... 101
4sin ............................................................ 101
sin() (Sinus) ............................................... 102
sinê() (Arkussinus) .................................... 102
sinh() (Sinus hyperbolicus) ....................... 103
sinhê() (Arkussinus hyperbolicus) ........... 103
SinReg ...................................................... 104
solve() (Löse) ............................................ 104
SortA (In aufsteigender Reihenfolge sortier-
en) ............................................................ 107
SortD (In absteigender Reihenfolge sortier-
en) ............................................................ 107
4Sphere (Kugelkoordinaten) ................... 108
sqrt() (Quadratwurzel) ............................ 108
stat.results ................................................ 109
stDevPop() (Populations-Standardabwei-
chung) ...................................................... 110
stDevSamp() (Stichproben-Standardabwei-
chung) ...................................................... 110
stat.values ................................................ 110
Stop (Stopp) ............................................. 111
Store (Speichern) ..................................... 111
string() (String) ......................................... 111
subMat() (Untermatrix) ........................... 111
Summe (Sigma) ........................................ 111
sum() (Summe) ......................................... 112
sumIf() ...................................................... 112
system() (System) ..................................... 112
T
T (Transponierte) ..................................... 113
tan() (Tangens) ........................................ 113
tanê() (Arkustangens) ............................. 114
tangentLine() ........................................... 114
tanh() (Tangens hyperbolicus) ................ 114
tanhê() (Arkustangens hyperbolicus) ..... 115
taylor() (Taylor-Polynom) ........................ 115
tCdf() ........................................................ 116
tCollect() (Trigonometrische Zusammenfas-
sung) ......................................................... 116
tExpand() (Trigonometrische Entwicklung) .
116
Then ......................................................... 116
tInterval .................................................... 117
tInterval_2Samp (Zwei-Stichproben-t-Konfi-
denzintervall) ........................................... 117
tmpCnv() (Konvertierung von Temperaturw-
erten) ........................................................ 118
@tmpCnv() (Konvertierung von Temper-
aturbereichen) ......................................... 118
tPdf() ........................................................ 118
trace() ....................................................... 119
Try (Versuche) ......................................... 119
tTest .......................................................... 120
tTest_2Samp (t-Test für zwei Stichproben) ..
120
tvmFV() ..................................................... 121
v

tvmI() .........................................................121
tvmN() .......................................................121
tvmPmt() ...................................................121
tvmPV() .....................................................121
TwoVar (Zwei Variable) ...........................122
U
unitV() (Einheitsvektor) ...........................123
V
varPop() (Populationsvarianz) .................124
varSamp() (Stichproben-Varianz) ............124
W
when() (Wenn) .........................................124
While .........................................................125
“With” ......................................................125
X
xor (Boolesches exklusives oder) .............125
Z
zeros() (Nullstellen) ..................................126
zInterval (z-Konfidenzintervall) ..............127
zInterval_1Prop (z-Konfidenzintervall für
eine Proportion) .......................................128
zInterval_2Prop (z-Konfidenzintervall für
zwei Proportionen) ..................................128
zInterval_2Samp (z-Konfidenzintervall für
zwei Stichproben) ....................................129
zTest ..........................................................129
zTest_1Prop (z-Test für eine Proportion) 130
zTest_2Prop (z-Test für zwei Proportionen) .
130
zTest_2Samp (z-Test für zwei Stichproben) ..
131
Sonderzeichen
+ (addieren) ..............................................132
N(subtrahieren) .........................................132
·(multiplizieren) ......................................133
à (dividieren) ............................................134
^ (Potenz) .................................................134
2
(Quadrat) ..............................................135
x
.+ (Punkt-Addition) ..................................135
.. (Punkt-Subt.) .........................................135
·(Punkt-Mult.) ........................................ 136
.
. / (Punkt-Division) ................................... 136
.^ (Punkt-Potenz) ..................................... 136
ë(Negation) .............................................. 136
% (Prozent) .............................................. 137
= (gleich) ................................................... 137
ƒ (ungleich) .............................................. 138
< (kleiner als) ............................................ 138
{ (kleiner oder gleich) ............................. 138
> (größer als) ............................................ 138
| (größer oder gleich) .............................. 139
! (Fakultät) ............................................... 139
& (anfügen) .............................................. 139
d() (Ableitung) ......................................... 139
‰() (Integral) .............................................. 140
‡() (Quadratwurzel) ................................ 141
Π() (Produkt) ............................................ 141
G() (Summe) .............................................. 142
GInt() ......................................................... 143
GPrn() ........................................................ 143
# (Umleitung) ........................................... 144
í (Wissenschaftliche Schreibweise) .........144
g (Neugrad) .............................................. 144
ô(Bogenmaß) ........................................... 144
¡ (Grad) ..................................................... 145
¡, ', '' (Grad/Minute/Sekunde) ................. 145
(Winkel) ................................................ 145
' (Ableitungsstrich) .................................. 146
_ (Unterstrich) .......................................... 146
4 (konvertieren) ........................................ 147
10^() .......................................................... 147
^ê (Kehrwert) ........................................... 147
| (“with”) .................................................. 148
& (speichern) ............................................ 148
:= (zuweisen) ............................................ 149
© (Kommentar) ........................................ 149
0b, 0h ........................................................ 149
Fehlercodes und -meldungen
Hinweise zu TI Produktservice
und Garantieleistungen
vi
TI-Nspire™
In diesem Handbuch sind die Vorlagen, Funktionen, Befehle und Operatoren aufgelistet, die
zur Auswertung mathematischer Ausdrücke verfügbar sind.
CAS Referenzhandbuch
Vorlagen für Ausdrücke
Vorlagen für Ausdrücke bieten Ihnen eine einfache Möglichkeit, mathematische Ausdrücke in
der mathematischen Standardschreibweise einzugeben. Wenn Sie eine Vorlage eingeben, wird
sie in der Eingabezeile mit kleinen Blöcken an den Positionen angezeigt, an denen Sie
Elemente eingeben können. Der Cursor zeigt, welches Element eingegeben werden kann.
Verwenden Sie die Pfeiltasten oder drücken Sie
der Elemente zu bewegen, und geben Sie für jedes Element einen Wert oder Ausdruck ein.
Drücken Sie
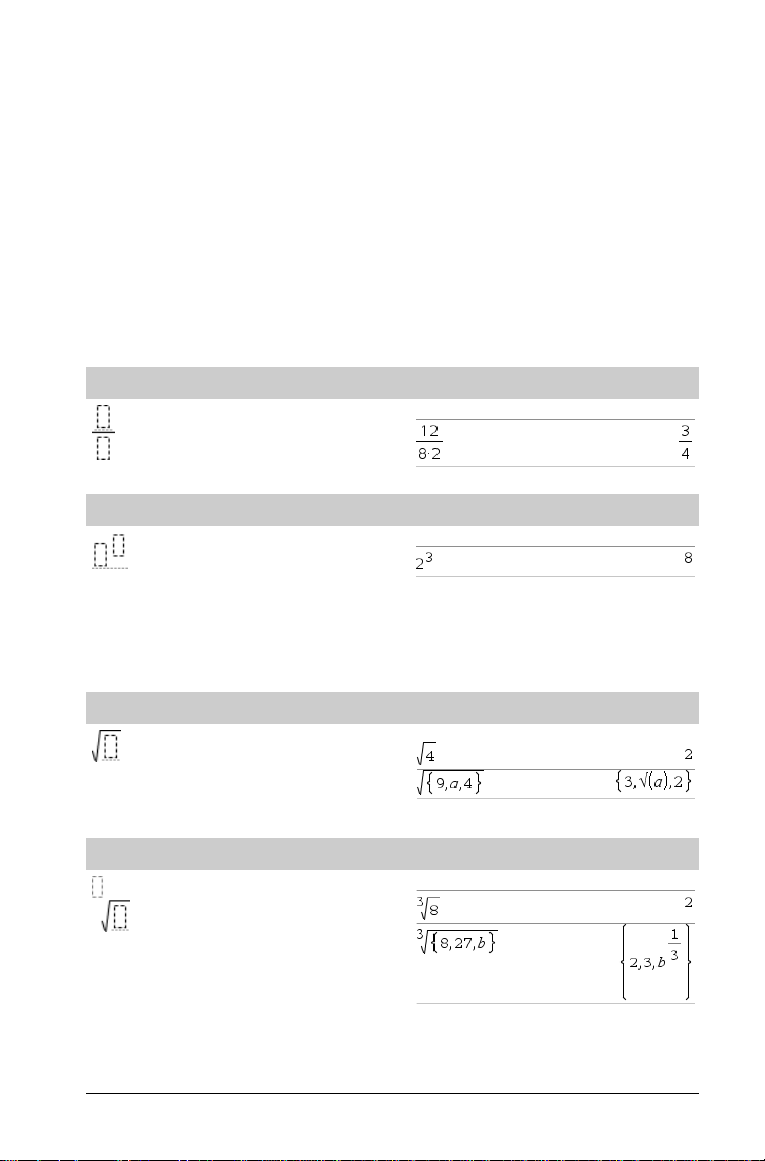
Vorlage Bruch
· oder /·, um den Ausdruck auszuwerten.
Hinweis: Siehe auch / (Dividieren), Seite 134.
e, um den Cursor zur jeweiligen Position
/p Tasten
Beispiel:
Vorlage Exponent
Hinweis: Geben Sie den ersten Wert ein, drücken Sie l und
geben Sie dann den Exponenten ein. Um den Cursor auf die
Grundlinie zurückzusetzen, drücken Sie die rechte Pfeiltaste (¢).
Hinweis: Siehe auch ^ (Potenz), Seite 134.
Vorlage Quadratwurzel
Hinweis: Siehe auch
Vorlage n-te Wurzel
Hinweis: Siehe auch root(), Seite 93.
‡
() (Quadratwurzel), Seite 141.
l Taste
Beispiel:
/q Tasten
Beispiel:
/l Tasten
Beispiel:
TI-Nspire™ CAS Referenzhandbuch 1
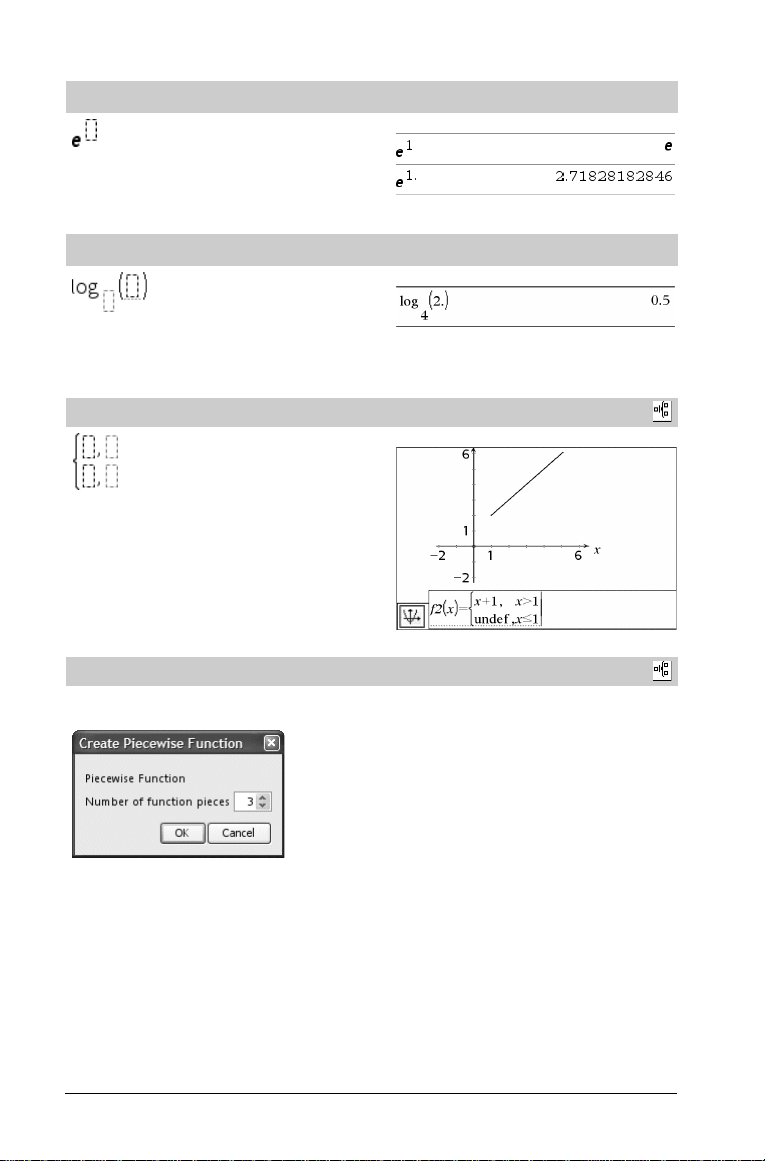
Vorlage e Exponent
Potenz zur natürlichen Basis e
Hinweis: Siehe auch e^(), Seite 37.
u Tasten
Example:
Vorlage Logarithmus
Berechnet den Logarithmus zu einer bestimmten Basis. Bei der
Standardbasis 10 wird die Basis weggelassen.
Hinweis: Siehe auch log(), Seite 64.
Vorlage Stückweise (2 Teile)
Ermöglicht es, Ausdrücke und Bedingungen für eine stückweise
definierte Funktion aus zwei-Stücken zu erstellen. Um ein Stück
hinzuzufügen, klicken Sie in die Vorlage und wiederholen die Vorlage.
Hinweis: Siehe auch piecewise(), Seite 81.
Vorlage Stückweise (n Teile)
Ermöglicht es, Ausdrücke und Bedingungen für eine stückweise
definierte Funktion aus n-Teilen zu erstellen. Fragt nach n.
/s Taste
Beispiel:
Katalog >
Beispiel:
Katalog >
Beispiel:
Siehe Beispiel für die Vorlage Stückweise (2 Teile).
Hinweis: Siehe auch piecewise(), Seite 81.
2 TI-Nspire™ CAS Referenzhandbuch
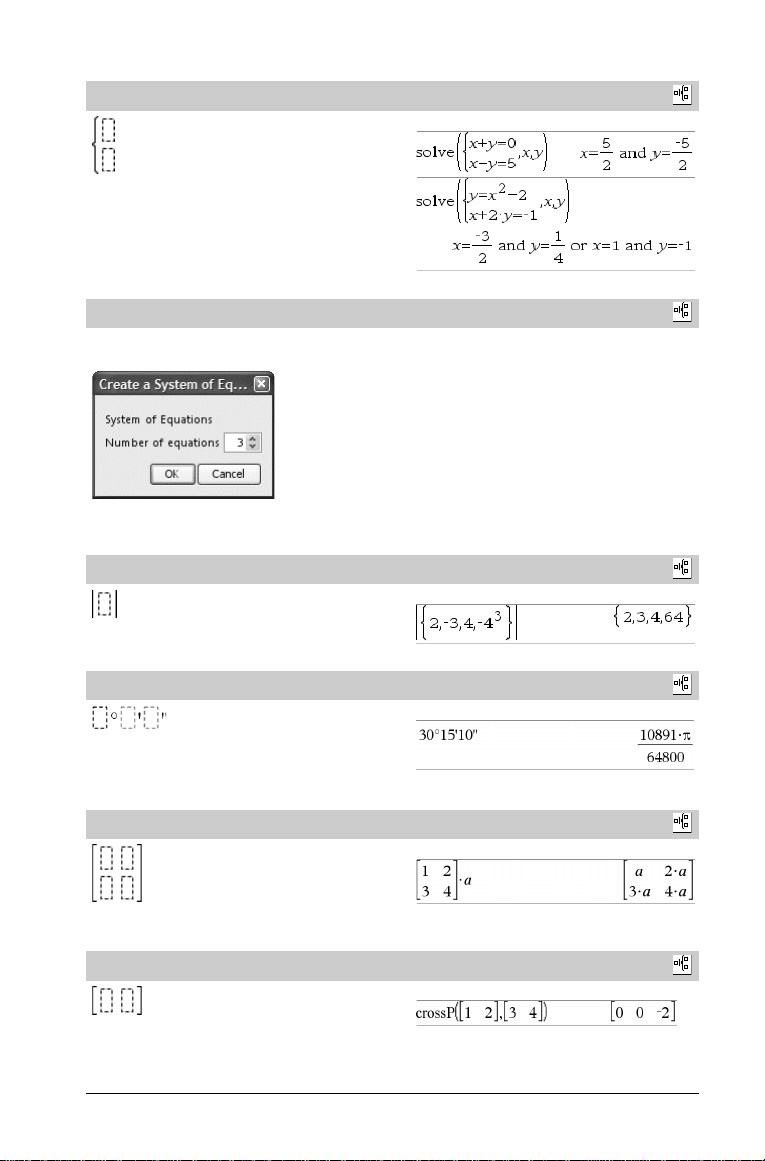
Vorlage System von 2 Gleichungen
Erstellt ein System von zwei Gleichungen. Um einem vorhandenen
System eine Zeile hinzuzufügen, klicken Sie in die Vorlage und
wiederholen die Vorlage.
Hinweis: Siehe auch system(), Seite 112.
Katalog >
Beispiel:
Vorlage System von n Gleichungen
Ermöglicht es, ein System von n Gleichungen zu erstellen. Fragt
nach n.
Hinweis: Siehe auch system(), Seite 112.
Vorlage Absolutwert
Hinweis: Siehe auch abs(), Seite 6.
Vorlage dd°mm’ss.ss’’
Ermöglicht es, Winkel im Format dd°mm’ss.ss’’ einzugeben, wobei
dd für den Dezimalgrad, mm die Minuten und ss.ss die Sekunden
steht.
Vorlage Matrix (2 x 2)
Katalog >
Beispiel:
Siehe Beispiel für die Vorlage Gleichungssystem (2 Gleichungen).
Katalog >
Beispiel:
Katalog >
Beispiel:
Katalog >
Beispiel:
Erzeugt eine 2 x 2 Matrix.
Vorlage Matrix (1 x 2)
Beispiel:
.
Katalog >
TI-Nspire™ CAS Referenzhandbuch 3
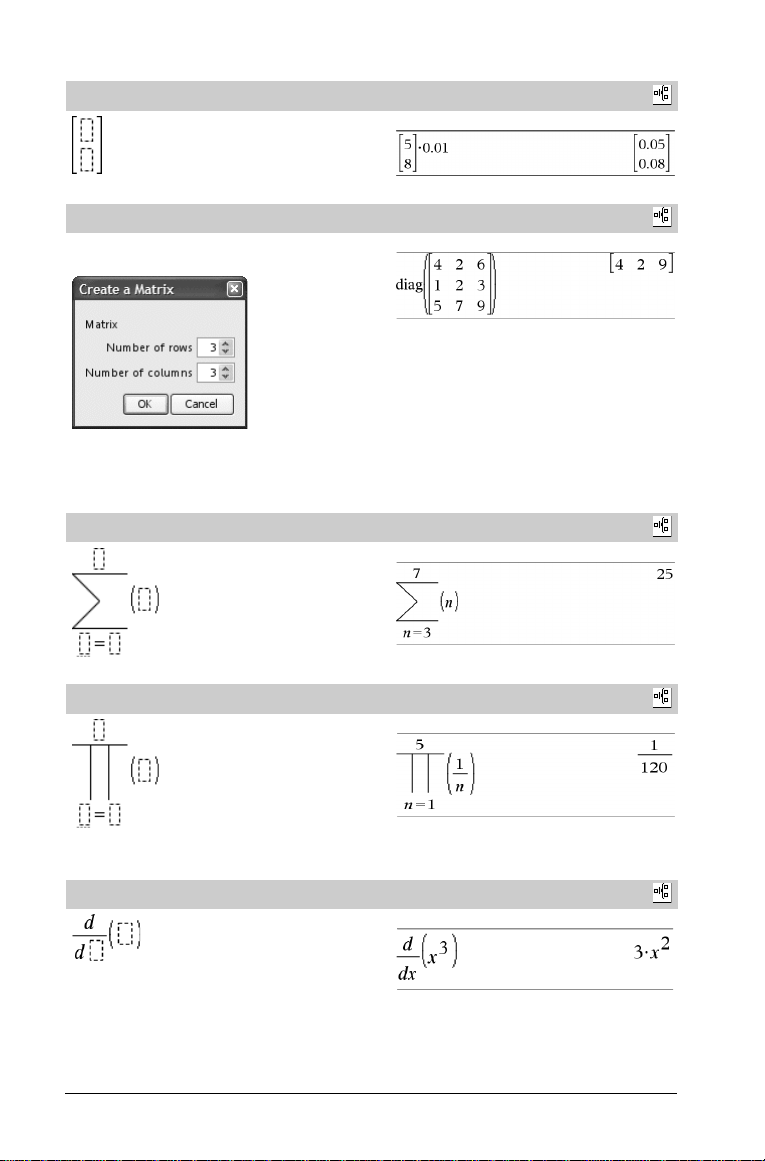
Vorlage Matrix (2 x 1)
Katalog >
Beispiel:
Vorlage Matrix (m x n)
Die Vorlage wird angezeigt, nachdem Sie aufgefordert wurden, die
Anzahl der Zeilen und Spalten anzugeben.
Hinweis: Wenn Sie eine Matrix mit einer großen Zeilen- oder
Spaltenanzahl erstellen, dauert es möglicherweise einen Augenblick,
bis sie angezeigt wird.
Vorlage Summe (G)
Vorlage Produkt (Π)
Katalog >
Beispiel:
Katalog >
Beispiel:
Katalog >
Beispiel:
Hinweis: Siehe auch Π() (Produkt), Seite 141.
Vorlage Erste Ableitung
Hinweis: Siehe auch
d() (Ableitung)
Beispiel:
, Seite 139.
Katalog >
4 TI-Nspire™ CAS Referenzhandbuch
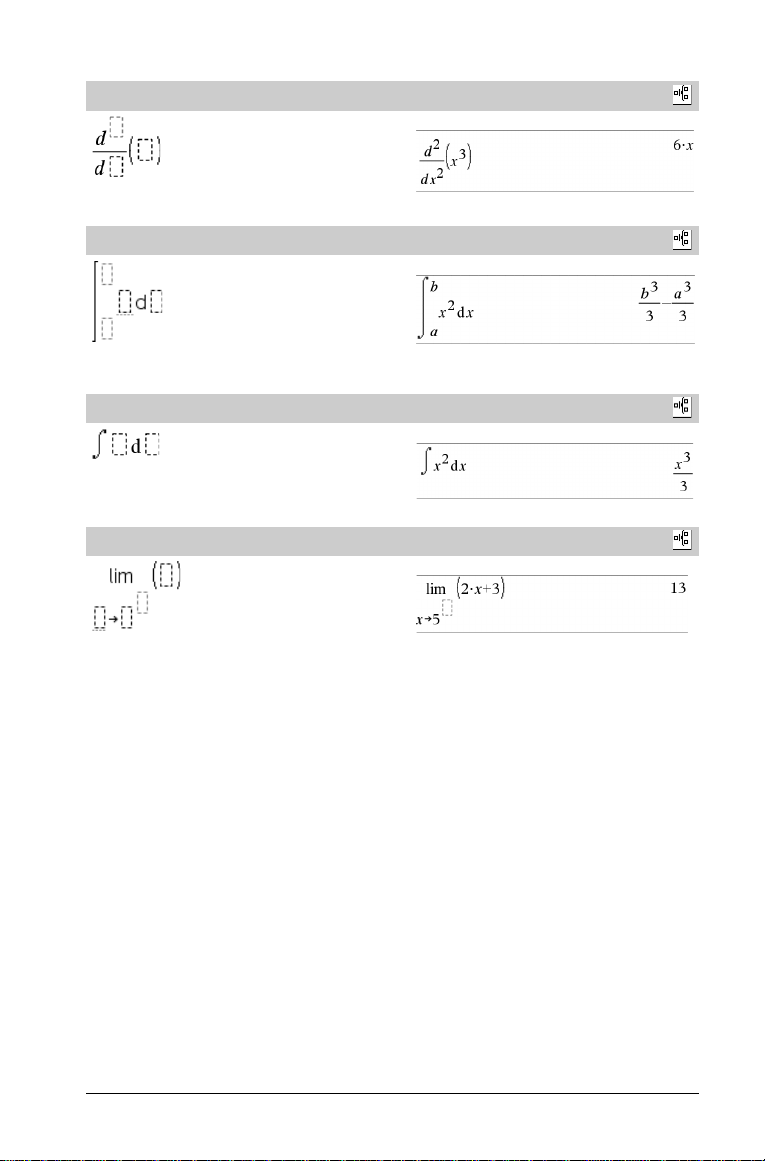
Vorlage n-te Ableitung
Katalog >
Beispiel:
Hinweis: Siehe auch
d() (Ableitung)
, Seite 139.
Vorlage Bestimmtes Integral
Hinweis: Siehe auch ‰() integrate(), Seite 140.
Vorlage Unbestimmtes Integral
Hinweis: Siehe auch ‰() integrate(), Seite 140.
Vorlage Limes
Verwenden Sie N oder (N) für den linksseitigen Grenzwert.
Verwenden Sie + für den rechtsseitigen Grenzwert.
Hinweis: Siehe auch limit(), Seite 57.
Katalog >
Beispiel:
Katalog >
Beispiel:
Katalog >
Beispiel:
TI-Nspire™ CAS Referenzhandbuch 5

Alphabetische Auflistung
Elemente, deren Namen nicht alphabetisch sind (wie +, !, und >) finden Sie am Ende dieses
Abschnitts ab Seite 132. Wenn nicht anders angegeben, wurden sämtliche Beispiele im
standardmäßigen Reset-Modus ausgeführt, wobei alle Variablen als nicht definiert
angenommen wurden.
A
abs() (Absolutwert)
abs(Ausdr1) ⇒ Ausdruck
abs(
Liste1) ⇒ Liste
abs(Matrix1) ⇒ Matrix
Gibt den Absolutwert des Arguments zurück.
Hinweis: Siehe auch Vorlage Absolutwert, Seite 3.
Ist das Argument eine komplexe Zahl, wird der Betrag der Zahl
zurückgegeben.
Hinweis: Alle undefinierten Variablen werden als reelle Variablen
behandelt.
amortTbl()
amortTbl(NPmt,N,I,PV, [Pmt], [FV], [PpY], [CpY], [PmtAt],
[
WertRunden]) ⇒ Matrix
Amortisationsfunktion, die eine Matrix als Amortisationstabelle für
eine Reihe von TVM-Argumenten zurückgibt.
NPmt ist die Anzahl der Zahlungen, die in der Tabelle enthalten sein
müssen. Die Tabelle beginnt mit der ersten Zahlung.
N, I, PV, Pmt, FV, PpY, CpY und PmtAt werden in der TVMArgumentetabelle auf Seite 122 beschrieben.
• Wenn Sie Pmt nicht angeben, wird standardmäßig
Pmt=tvmPmt(N,I,PV,FV,PpY,CpY,PmtAt) eingesetzt.
• Wenn Sie FV nicht angeben, wird standardmäßig FV=0
eingesetzt.
• Die Standardwerte für PpY, CpY und PmtAt sind dieselben wie
bei den TVM-Funktionen.
WertRunden (roundValue) legt die Anzahl der Dezimalstellen für das
Runden fest. Standard=2.
Die Spalten werden in der Ergebnismatrix in der folgenden
Reihenfolge ausgegeben: Zahlungsnummer, Zinsanteil,
Tilgungsanteil, Saldo.
Der in Zeile n angezeigte Saldo ist der Saldo nach Zahlung n.
Sie können die ausgegebene Matrix als Eingabe für die anderen
Amortisationsfunktionen GInt() und GPrn(), Seite 143, und bal(),
Seite 12, verwenden.
Katalog
Katalog
>
>
and (und)
Boolescher Ausdr1 and Boolescher Ausdr2
⇒ Boolescher Ausdruck
Boolesche Liste1 and Boolesche Liste2
⇒ Boolesche Liste
Boolesche Matrix1 and Boolesche Matrix2
⇒ Boolesche Matrix
Gibt „wahr“ oder „falsch“ oder eine vereinfachte Form des
ursprünglichen Terms zurück.
Katalog
>
6 TI-Nspire™ CAS Referenzhandbuch

and (und)
Ganzzahl1 and Ganzzahl2 ⇒ Ganzzahl
Vergleicht zwei reelle ganze Zahlen mit Hilfe einer
für Bit. Intern werden beide ganzen Zahlen in binäre 32-Bit-Zahlen
mit Vorzeichen konvertiert. Beim Vergleich der sich entsprechenden
Bits ist das Ergebnis dann 1, wenn beide Bits 1 sind; anderenfalls ist
das Ergebnis 0. Der zurückgegebene Wert stellt die Bit-Ergebnisse dar
und wird im jeweiligen Basis-Modus angezeigt.
Sie können die ganzen Zahlen in jeder Basis eingeben. F ür eine binäre
oder hexadezimale Eingabe ist das Präfix 0b bzw. 0h zu verwenden.
Ohne Präfix werden ganze Zahlen als dezimal behandelt (Basis 10).
Geben Sie eine dezimale ganze Zahl ein, die für eine 32-Bit-Dualform
mit Vorzeichen zu groß ist, dann wird eine symmetrische ModuloOperation ausgeführt, um den Wert in den erforderlichen Bereich zu
bringen.
and-Operation Bit
Katalog
>
Im Hex-Modus:
Wichtig: Null, nicht Buchstabe O.
Im Bin-Modus:
Im Dec-Modus:
Hinweis: Eine binäre Eingabe kann bis zu 64 Stellen haben
(das Präfix 0b wird nicht mitgezählt). Eine hexadezimale Eingabe
kann bis zu 16 Stellen aufweisen.
angle() (Winkel)
angle(Ausdr1) ⇒ Ausdruck
Gibt den Winkel des Arguments zurück, wobei das Argument als
komplexe Zahl interpretiert wird.
Hinweis: Alle undefinierten Variablen werden als reelle Variablen
behandelt.
angle(Liste1) ⇒ Liste
angle(Matrix1) ⇒ Matrix
Gibt als Liste oder Matrix die Winkel der Elemente aus Liste1 oder
Matrix1 zurück, wobei jedes Element als komplexe Zahl interpretiert
wird, die einen zweidimensionalen kartesischen Koordinatenpunkt
darstellt.
ANOVA
ANOVA Liste1,Liste2[,Liste3,...,Liste20][,Flag]
Führt eine einfache Varianzanalyse durch, um die Mittelwerte von
zwei bis maximal 20 Grundgesamtheiten zu vergleichen. Eine
Zusammenfassung der Ergebnisse wird in der Variable stat.results
gespeichert. (Siehe Seite 109.)
Flag=0 für Daten, Flag=1 für Statistik
Im Grad-Modus:
Im Neugrad-Modus:
Im Bogenmaß-Modus:
Katalog
Katalog
>
>
Ausgabevariable Beschreibung
stat.F Wert der F Statistik
stat.PVal Kleinste Signifikanzebene, bei der die Nullhypothese verworfen werden kann
TI-Nspire™ CAS Referenzhandbuch 7

Ausgabevariable Beschreibung
stat.df Gruppen-Freiheitsgrade
stat.SS Summe der Fehlerquadrate zwischen den Gruppen
stat.MS Mittlere Quadrate der Gruppen
stat.dfError Fehler-Freiheitsgrade
stat.SSError Summe der Fehlerquadrate
stat.MSError Mittleres Quadrat für die Fehler
stat.sp Verteilte Standardabweichung
stat.xbarlist Mittelwerte der Eingabelisten
stat.CLowerList 95 % Konfidenzintervalle für den Mittelwert jeder Eingabeliste
stat.CUpperList 95 % Konfidenzintervalle für den Mittelwert jeder Eingabeliste
ANOVA2way (ANOVA 2fach)
ANOVA2way Liste1,Liste2[,Liste3,…,Liste10][,LevZei]
Berechnet eine zweifache Varianzanalyse, um die Mittelwerte von
zwei bis maximal 10 Grundgesamtheiten zu vergleichen. Eine
Zusammenfassung der Ergebnisse wird in der Variable stat.results
gespeichert. (Siehe Seite 109.)
LevZei=0 für Block
LevZei=2,3,...,Len-1, für Faktor zwei, wobei
Len=length(Liste1)=length(Liste2) = … = length(Liste10) und
Len / LevZei ∈ {2,3,…}
Ausgaben: Block-Design
Ausgabevariable Beschreibung
stat.FF Statistik des Spaltenfaktors
stat.PVal Kleinste Signifikanzebene, bei der die Nullhypothese verworfen werden kann
stat.df Freiheitsgrade des Spaltenfaktors
stat.SS Summe der Fehlerquadrate des Spaltenfaktors
stat.MS Mittlere Quadrate für Spaltenfaktor
stat.FBlock F Statistik für Faktor
stat.PValBlock Kleinste Wahrscheinlichkeit, bei der die Nullhypothese verworfen werden kann
stat.dfBlock Freiheitsgrade für Faktor
stat.SSBlock Summe der Fehlerquadrate für Faktor
stat.MSBlock Mittlere Quadrate für Faktor
stat.dfError Fehler-Freiheitsgrade
stat.SSError Summe der Fehlerquadrate
stat.MSError Mittlere Quadrate für die Fehler
stat.s Standardabweichung des Fehlers
Katalog
>
8 TI-Nspire™ CAS Referenzhandbuch

Ausgaben des SPALTENFAKTORS
Ausgabevariable Beschreibung
stat.Fcol F Statistik des Spaltenfaktors
stat.PValCol Wahrscheinlichkeitswert des Spaltenfaktors
stat.dfCol Freiheitsgrade des Spaltenfaktors
stat.SSCol Summe der Fehlerquadrate des Spaltenfaktors
stat.MSCol Mittlere Quadrate für Spaltenfaktor
Ausgaben des ZEILENFAKTORS
Ausgabevariable Beschreibung
stat.Frow F Statistik des Zeilenfaktors
stat.PValRow Wahrscheinlichkeitswert des Zeilenfaktors
stat.dfRow Freiheitsgrade des Zeilenfaktors
stat.SSRow Summe der Fehlerquadrate des Zeilenfaktors
stat.MSRow Mittlere Quadrate für Zeilenfaktor
INTERAKTIONS-Ausgaben
Ausgabevariable Beschreibung
stat.FInteract F Statistik der Interaktion
stat.PValInteract Wahrscheinlichkeitswert der Interaktion
stat.dfInteract Freiheitsgrade der Interaktion
stat.SSInteract Summe der Fehlerquadrate der Interaktion
stat.MSInteract Mittlere Quadrate für Interaktion
FEHLER-Ausgaben
Ausgabevariable Beschreibung
stat.dfError Fehler-Freiheitsgrade
stat.SSError Summe der Fehlerquadrate
stat.MSError Mittlere Quadrate für die Fehler
s Standardabweichung des Fehlers
TI-Nspire™ CAS Referenzhandbuch 9

Ans (Antwort)
Ans ⇒ We r t
Gibt das Ergebnis des zuletzt ausgewerteten Ausdrucks zurück.
/v
Taste
approx() (Approximieren)
approx(Ausdr1) ⇒ Ausdruck
Gibt die Auswertung des Arguments ungeachtet der aktuellen
Einstellung des Modus Auto oder Näherung als Dezimalwert
zurück, sofern möglich.
Gleichwertig damit ist die Eingabe des Arguments und Drücken von
/
·.
approx(Liste1) ⇒ Liste
approx(Matrix1) ⇒ Matrix
Gibt, sofern möglich, eine Liste oder Matrix zurück, in der jedes
Element dezimal ausgewertet wurde.
approxRational()
approxRational(Expr[, tol]) ⇒ expression
approxRational(List[, tol]) ⇒ list
approxRational(Matrix[, tol]) ⇒ matrix
Gibt das Argument mit der Toleranz tol als Bruch zurück. Wird tol
weggelassen, so wird die Toleranz 5.E-14 verwendet.
arcLen() (Bogenlänge)
arcLen(Ausdr1,Var ,Start,Ende) ⇒ Ausdruck
Gibt die Bogenlänge von Ausdr1 von Start bis Ende bezüglich der
Variablen Va r zurück.
Die Bogenlänge wird als Integral unter Annahme einer Definition im
Modus Funktion berechnet.
Katalog
Katalog
Katalog
>
>
>
arcLen(Liste1,Var ,Start,Ende) ⇒ Liste
Gibt eine Liste der Bogenlängen für jedes Element von Liste1
zwischen Start und Ende bezüglich der Variablen Var zurück.
10 TI-Nspire™ CAS Referenzhandbuch

augment() (Erweitern)
augment(Liste1, Liste2) ⇒ Liste
Gibt eine neue Liste zurück, die durch Anfügen von Liste2 ans Ende
von Liste1 erzeugt wurde.
augment(Matrix1, Matrix2) ⇒ Matrix
Gibt eine neue Matrix zurück, die durch Anfügen von Matrix2 an
Matrix1 erzeugt wurde. Wenn das Zeichen “,” verwendet wird,
müssen die Matrizen gleiche Zeilendimensionen besitzen, und
Matrix2 wird spaltenweise an Matrix1 angefügt. Verändert weder
Matrix1 noch Matrix2.
Katalog
>
avgRC() (Durchschnittliche Änderungsrate)
avgRC(Ausdr1, Var [=Wert] [, H]) ⇒ Ausdruck
avgRC(Ausdr1, Var [=Wert] [, Liste1]) ⇒ Liste
avgRC(Liste1, Va r [=Wert] [, H]) ⇒ Liste
avgRC(Matrix1, Var [=Wert] [, H]) ⇒ Matrix
Gibt den rechtsseitigen Differenzenquotienten zurück
(durchschnittliche Änderungsrate).
Ausdr1 kann eine benutzerdefinierte Funktion sein (siehe Func).
Wenn Wer t angegeben wird, setzt er jede vorausgegangene
Variablenzuweisung oder jede aktuelle Ersetzung für die Variable
außer Kraft.
H ist der Schrittwert. Wird H nicht angegeben, wird als Vorgabewert
0,001 benutzt.
Beachten Sie, dass die ähnliche Funktion nDeriv() den zentralen
Differenzenquotienten benutzt.
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 11

B
bal()
bal(NPmt,N,I,PV,[Pmt], [FV], [PpY], [CpY], [PmtAt],
[
WertRunden]) ⇒ We rt
bal(NPmt,AmortTabelle) ⇒ We r t
Amortisationsfunktion, die den Saldo nach einer angegebenen
Zahlung berechnet.
N, I, PV, Pmt, FV, PpY, CpY und PmtAt werden in der TVMArgumentetabelle auf Seite 122 beschrieben.
NPmt bezeichnet die Zahlungsnummer, nach der die Daten berechnet
werden sollen.
N, I, PV, Pmt, FV, PpY, CpY und PmtAt werden in der TVMArgumentetabelle auf Seite 122 beschrieben.
• Wenn Sie Pmt nicht angeben, wird standardmäßig
Pmt=tvmPmt(N,I,PV,FV,PpY,CpY,PmtAt) eingesetzt.
• Wenn Sie FV nicht angeben, wird standardmäßig FV=0
eingesetzt.
• Die Standardwerte für PpY, CpY und PmtAt sind dieselben wie
bei den TVM-Funktionen.
WertRunden (roundValue) legt die Anzahl der Dezimalstellen für das
Runden fest. Standard=2.
bal(NPmt,AmortTabelle) berechnet den Saldo nach jeder
Zahlungsnummer NPmt auf der Grundlage der Amortisationstabelle
AmortTabelle. Das Argument AmortTabelle (amortTable) muss eine
Matrix in der unter amortTbl(), Seite 6, beschriebenen Form sein.
Hinweis: Siehe auch GInt() und GPrn(), Seite 143.
Base2
4
Ganzzahl1 4Base2 ⇒ Ganzzahl
Konvertiert Ganzzahl1 in eine Dualzahl. Dual- oder
Hexadezimalzahlen weisen stets das Präfix 0b bzw. 0h auf.
0b binäre_Zahl
0h hexadezimale_Zahl
Null (nicht Buchstabe O) und b oder h.
Eine Dualzahl kann bis zu 64 Stellen haben, eine Hexadezimalzah l bis
zu 16.
Ohne Präfix wird Ganzzahl1 als Dezimalzahl behandelt (Basis 10).
Das Ergebnis wird unabhängig vom Basis-Modus binär angezeigt.
Geben Sie eine dezimale ganze Zahl ein, die für eine 64-Bit-Dualform
mit Vorzeichen zu groß ist, dann wird eine symmetrische ModuloOperation ausgeführt, um den Wert in den erforderlichen Bereich zu
bringen.
Katalog
Katalog
>
>
12 TI-Nspire™ CAS Referenzhandbuch

Base10
4
4Base10 ⇒ Ganzzahl
Ganzzahl1
Konvertiert Ganzzahl1 in eine Dezimalzahl (Basis 10). Ein binärer
oder hexadezimaler Eintrag muss stets das Präfix 0b bzw. 0h
aufweisen.
0b binäre_Zahl
0h hexadezimale_Zahl
Null (nicht Buchstabe O) und b oder h.
Eine Dualzahl kann bis zu 64 Stellen haben, eine Hexadezimalzah l bis
zu 16.
Ohne Präfix wird Ganzzahl1 als Dezimalzahl behandelt. Das Ergebnis
wird unabhängig vom Basis-Modus dezimal angezeigt.
Base16
4
Ganzzahl1 4Base16 ⇒ Ganzzahl
Wandelt Ganzzahl1 in eine Hexadezimalzahl um. Dual- oder
Hexadezimalzahlen weisen stets das Präfix 0b bzw. 0h auf.
0b binäre_Zahl
0h hexadezimale_Zahl
Null (nicht Buchstabe O) und b oder h.
Eine Dualzahl kann bis zu 64 Stellen haben, eine Hexadezimalzah l bis
zu 16.
Ohne Präfix wird Ganzzahl1 als Dezimalzahl behandelt (Basis 10).
Das Ergebnis wird unabhängig vom Basis-Modus hexadezimal
angezeigt.
Geben Sie eine dezimale ganze Zahl ein, die für eine 64-Bit-Dualform
mit Vorzeichen zu groß ist, dann wird eine symmetrische ModuloOperation ausgeführt, um den Wert in den erforderlichen Bereich zu
bringen.
Katalog
Katalog
>
>
binomCdf()
binomCdf(n,p,untereGrenze,obereGrenze) ⇒ Zahl, wenn
untereGrenze und obereGrenze Zahlen sind, Liste, wenn
untereGrenze und obereGrenze Listen sind
binomCdf(
Zahl ist,
Berechnet die kumulative Wahrscheinlichkeit für die diskrete
Binomialverteilung mit n Versuchen und der Wahrscheinlichkeit p für
einen Erfolg in jedem Einzelversuch.
Für P(X obereGrenze) setzen Sie untereGrenze=0
binomPdf()
binomPdf(n,p) ⇒ Zahl
binomPdf(n,p,XWert) ⇒ Zahl, wenn XWert eine Zahl ist,
Liste, wenn XWert eine Liste ist
Berechnet die Wahrscheinlichkeit an einem XWert für die diskrete
Binomialverteilung mit n Versuchen und der Wahrscheinlichkeit p für
den Erfolg in jedem Einzelversuch.
n,p,obereGrenze) ⇒ Zahl, wenn obereGrenze eine
Liste, wenn obereGrenze eine Liste ist
Katalog
Katalog
>
>
TI-Nspire™ CAS Referenzhandbuch 13

C
ceiling() (Obergrenze)
ceiling(Ausdr1) ⇒ Ganzzahl
Gibt die erste ganze Zahl zurück, die ‚ dem Argument ist.
Das Argument kann eine reelle oder eine komplexe Zahl sein.
Hinweis: Siehe auch floor().
ceiling(Liste1) ⇒ Liste
ceiling(Matrix1) ⇒ Matrix
Für jedes Element einer Liste oder Matrix wird die kleinste ganze Zahl,
die größer oder gleich dem Element ist, zurückgegeben.
cFactor() (Komplexer Faktor)
cFactor(Ausdr1[,Var ]) ⇒ Ausdruck
cFactor(Liste1[,Va r]) ⇒ Liste
cFactor(Matrix1[,Var ]) ⇒ Matrix
cFactor(Ausdr1) gibt Ausdr1 nach allen seinen Variablen über
einem gemeinsamen Nenner faktorisiert zurück.
Ausdr1 wird soweit wie möglich in lineare rationale Faktoren zerlegt,
selbst wenn dies die Einführung neuer nicht-reeller Zahlen bedeutet.
Diese Alternative ist angemessen, wenn Sie die Faktorisierung
bezüglich mehr als einer Variablen vornehmen möchten.
cFactor(Ausdr1,Var ) gibt Ausdr1 nach der Variablen Va r
faktorisiert zurück.
Ausdr1 wird soweit wie möglich in Faktoren zerlegt, die linear in Var
sind, mit möglicherweise nicht-reellen Konstanten, selbst wenn
irrationale Konstanten oder Unterausdrücke, die in ander en Variablen
irrational sind, eingeführt werden.
Die Faktoren und ihre Terme werden mit Va r als Hauptvariable
sortiert. Gleichartige Potenzen von Var werden in jedem Faktor
zusammengefasst. Beziehen Sie Va r ein, wenn die Faktorisierung nur
bezüglich dieser Variablen benötigt wird und Sie irrationale
Ausdrücke in anderen Variablen akzeptieren möchten, um die
Faktorisierung bezüglich Va r so weit wie möglich vorzunehmen.
Es kann sein, dass als Nebeneffekt in gewissem Umfang eine
Faktorisierung nach anderen Variablen auftritt.
Bei der Einstellung Auto für den Modus Auto oder Näherung
ermöglicht die Einbeziehung von Va r auch eine Näherung mit
Gleitkommakoeffizienten in Fällen, wo irrationale Koeffizienten nicht
explizit bezüglich der integrierten Funktionen ausgedrückt werden
können. Selbst wenn es nur eine Variable gibt, kann das Einbeziehen
von Va r eine vollständigere Faktorisierung ermöglichen.
Hinweis: Siehe auch factor().
Katalog
Katalog
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
>
>
char() (Zeichenstring)
char(Ganzzahl) ⇒ Zeichen
Gibt ein Zeichenstring zurück, das das Zeichen mit der Nummer
Ganzzahl aus dem Zeichensatz des Handhelds enthält. Der gültige
Wertebereich für Ganzzahl ist 0–65535.
Katalog
>
14 TI-Nspire™ CAS Referenzhandbuch

charPoly()
charPoly(Quadratmatrix,Var) ⇒ Polynomausdruck
charPoly(Quadratmatrix, Ausdr) ⇒ Polynomausdruck
charPoly(Quadratmatrix1,Matrix2) ⇒ Polynomausdruck
Gibt das charakteristische Polynom von Quadratmatrix zurück.
Das charakteristische Polynom einer n×n Matrix A, gekennzeichnet
durch pA(l), ist das durch
pA(l) = det(l• I NA)
definierte Polynom, wobei I die n×n-Einheitsmatrix kennzeichnet.
Quadratmatrix1 und Quadratmatrix2 müssen dieselbe Dimension
haben.
2
c
2way
2
c
2way BeobMatrix
chi22way BeobMatrix
Berechnet eine c2 Testgröße auf Grundlage einer beobachteten
Matrix BeobMatrix. Eine Zusammenfassung der Ergebnisse wird in
der Variable stat.results gespeichert. (Siehe Seite 109.)
Ausgabevariable Beschreibung
stat.c2 Chi-Quadrat-Testgröße: sum(beobachtet - erwartet)2/erwartet
stat.PVal Kleinste Signifikanzebene, bei der die Nullhypothese verworfen werden kann
stat.df Freiheitsgrade der Chi-Quadrat-Testgröße
stat.ExpMat Berechnete Kontingenztafel der erwarteten Häufigkeiten bei Annahme der Nullhypothese
stat.CompMat Berechnete Matrix der Chi-Quadrat-Summanden in der Testgröße
Katalog
Katalog
>
>
2
c
Cdf()
2
c
Cdf(untereGrenze,obereGrenze,Freigrad) ⇒ Zahl, wenn
untereGrenze und obereGrenze Zahlen sind, Liste, wenn
untereGrenze und obereGrenze Listen sind
chi2Cdf(
untereGrenze,obereGrenze,Freiheitsgrad) ⇒ Zahl,
untereGrenze und obereGrenze Zahlen sind, Liste, wenn
wenn
untereGrenze und obereGrenze Listen sind
Berechnet die Verteilungswahrscheinlichkeit c2 zwischen
untereGrenze und obereGrenze für die angegebenen Freiheitsgrade
FreiGrad.
Katalog
>
Für P(X obereGrenze) setzen Sie untereGrenze= 0.
2
c
GOF
2
c
GOF BeobListe,expListe,FreiGrad
chi2GOF BeobListe,expListe,FreiGrad
Berechnet eine Testgröße, um zu überprüfen, ob die
Stichprobendaten aus einer Grundgesamtheit stammen, die einer
bestimmten Verteilung genügt. obsList ist eine Liste von Zählern und
muss Ganzzahlen enthalten. Eine Zusammenfassung der Ergebnisse
wird in der Variablen stat.results gespeichert. (Siehe Seite 109.)
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 15

Ausgabevariable Beschreibung
stat.c2 Chi-Quadrat-Testgröße: sum((beobachtet - erwartet)2/erwartet
stat.PVal Kleinste Signifikanzebene, bei der die Nullhypothese verworfen werden kann
stat.df Freiheitsgrade der Chi-Quadrat-Testgröße
stat.CompList Liste der Chi-Quadrat-Summanden in der Testgröße
2
c
Pdf()
2
c
Pdf(XWert,FreiGrad) ⇒ Zahl, wenn Xwert eine Zahl ist,
Liste, wenn XWert eine Liste ist
chi2Pdf(
XWert,FreiGrad) ⇒ Zahl, wenn XWert eine Zahl ist,
Liste, wenn XWert eine Liste ist
Berechnet die Wahrscheinlichkeitsdichtefunktion (Pdf) einer c2Verteilung an einem bestimmten XWert für die vorgegebenen
Freiheitsgrade FreiGrad.
Katalog
>
ClearAZ (LöschAZ)
ClearAZ
Löscht alle Variablen mit einem Zeichen im aktuellen Problembereich.
ClrErr (LöFehler)
ClrErr
Löscht den Fehlerstatus und setzt die Systemvariable FehlerCode
(errCode) auf Null.
Das Else im Block Try...Else...EndTry muss ClrErr oder PassErr
(ÜbgebFehler) verwenden. Wenn der Fehler verarbeitet oder
ignoriert werden soll, verwenden Sie ClrErr. Wenn nicht bekannt ist,
was mit dem Fehler zu tun ist, verwenden Sie PassErr, um ihn an
den nächsten Error Handler zu übergeben. Wenn keine weiteren
Try...Else...EndTry Error Handler unerledigt sind, wird das
Fehlerdialogfeld als normal angezeigt.
Hinweis: Siehe auch PassErr, Seite 81, und Try , Seite 119.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
Katalog
>
Katalog
>
Ein Beispiel für ClrErr finden Sie als Beispiel 2 im Abschnitt
zum Befehl Versuche (Try), Seite 119.
16 TI-Nspire™ CAS Referenzhandbuch

colAugment() (Spaltenerweiterung)
colAugment(Matrix1, Matrix2) ⇒ Matrix
Gibt eine neue Matrix zurück, die durch Anfügen von Matrix2 an
Matrix1 erzeugt wurde. Die Matrizen müssen gleiche
Spaltendimensionen haben, und Matrix2 wird zeilenweise an
Matrix1 angefügt. Verändert weder Matrix1 noch Matrix2.
Katalog
>
colDim() (Spaltendimension)
colDim(Matrix) ⇒ Ausdruck
Gibt die Anzahl der Spalten von Matrix zurück.
Hinweis: Siehe auch rowDim().
colNorm() (Spaltennorm)
colNorm(Matrix) ⇒ Ausdruck
Gibt das Maximum der Summen der absoluten Elementwerte der
Spalten von Matrix zurück.
Hinweis: Undefinierte Matrixelemente sind nicht zulässig. Siehe
auch rowNorm().
comDenom() (Gemeinsamer Nenner)
comDenom(Ausdr1[,Va r]) ⇒ Ausdruck
comDenom(Liste1[,Var ]) ⇒ Liste
comDenom(Matrix1[,Var ]) ⇒ Matrix
comDenom(Ausdr1) gibt den gekürzten Quotienten aus einem
vollständig entwickelten Zähler und einem vollständig entwickelten
Nenner zurück.
comDenom(Ausdr1,Va r) gibt einen gekürzten Quotienten von
Zähler und Nenner zurück, der bezüglich Va r entwickelt wurde.
Die Terme und Faktoren werden mit Va r als der Hauptvariablen
sortiert. Gleichartige Potenzen von Var werden zusammengefasst.
Es kann sein, dass als Nebeneffekt eine Faktorisierung der
zusammengefassten Koeffizienten auftritt. Verglichen mit dem
Weglassen von Va r spart dies häufig Zeit, Speicherplatz und Platz auf
dem Bildschirm und macht den Ausdruck verständlicher. Außerdem
werden anschließende Operationen an diesem Ergebnis schneller,
und es wird weniger wahrscheinlich, dass der Speicherplatz ausgeht.
Katalog
Katalog
Katalog
>
>
>
Wenn Va r nicht in Ausdr1 vorkommt, gibt
comDenom(Ausdr1,Va r) einen gekürzten Quotienten eines nicht
entwickelten Zählers und eines nicht entwickelten Nenners zurück.
Solche Ergebnisse sparen meist sogar noch mehr Zeit, Speicherplatz
und Platz auf dem Bildschirm. Solche partiell faktorisierten Ergebnisse
machen ebenfalls anschließende Operationen mit dem Ergebnis
schneller und das Erschöpfen des Speicherplatzes weniger
wahrscheinlich.
TI-Nspire™ CAS Referenzhandbuch 17

comDenom() (Gemeinsamer Nenner)
Sogar wenn kein Nenner vorhanden ist, ist die Funktion comden
häufig ein gutes Mittel für das partielle Faktorisieren, wenn factor()
zu langsam ist oder den Speicherplatz erschöpft.
Tipp: Geben Sie diese Funktionsdefinition comden() ein, und
verwenden Sie sie regelmäßig als Alternative zu
factor().
comDenom() und
Katalog
>
conj() (Komplex Konjugierte)
conj(Ausdr1) ⇒ Ausdruck
conj(Liste1) ⇒ Liste
conj(Matrix1) ⇒ Matrix
Gibt das komplex Konjugierte des Arguments zurück.
Hinweis: Alle undefinierten Variablen werden als reelle Variablen
behandelt.
constructMat()
constructMat(Ausdr,Var 1 ,Var 2 ,AnzZeilen,AnzSpalten)
⇒ Matrix
Gibt eine Matrix auf der Basis der Argumente zurück.
Ausdr ist ein Ausdruck in Variablen Va r 1 und Va r 2 . Die Elemente in
der resultierenden Matrix ergeben sich durch Berechnung von Ausdr
für jeden inkrementierten Wert von Va r 1 und Var 2 .
Var 1 wird automatisch von 1 bis AnzZeilen inkrementiert. In jeder
Zeile wird Va r2 inkrementiert von 1 bis AnzSpalten.
CopyVar
CopyVar Var 1 , Va r 2
CopyVar Var 1 ., Va r2 .
CopyVar Var 1 , Var 2 kopiert den Wert der Variablen Va r 1 auf die
Variable Var 2 und erstellt ggf. Va r 2. Variable Var 1 muss einen Wert
haben.
Wenn Va r1 der Name einer vorhandenen benutzerdefinierten
Funktion ist, wird die Definition dieser Funktion nach Funktion Va r 2
kopiert. Funktion Va r 1 muss definiert sein.
Var 1 muss die Benennungsregeln für Variablen e rfüllen oder muss ein
indirekter Ausdruck sein, der sich zu einem Variablennamen
vereinfachen lässt, der den Regeln entspricht.
Katalog
Katalog
Katalog
>
>
>
18 TI-Nspire™ CAS Referenzhandbuch

CopyVar
CopyVar Var 1 ., Va r2 . kopiert alle Mitglieder der Var 1 . -
Variablengruppe auf die Va r2
Var 1 . muss der Name einer bestehenden Variablengruppe sein, wie
die Statistikergebnisse stat.nn oder Variablen, die mit der Funktion
LibShortcut() erstellt wurden. Wenn Var 2 . schon vorhanden ist,
ersetzt dieser Befehl alle Mitglieder, die zu beiden Gruppen gehören,
und fügt die Mitglieder hinzu, die noch nicht vorhanden sind.
Wenn eine einfache (Nichtgruppen-) Variable namens Va r 2 existiert,
tritt ein Fehler auf.
. -Gruppe und erstellt ggf. Var 2 ..
Katalog
>
corrMat() (Korrelationsmatrix)
corrMat(Liste1,Liste2[,…[,Liste20]])
Berechnet die Korrelationsmatrix für die erweiterte Matrix [Liste1
Liste2 . . . Liste20].
4
cos
4
Ausdr
cos
Drückt Ausdr durch Kosinus aus. Dies ist ein
Anzeigeumwandlungsoperator. Er kann nur am Ende der Eingabezeile
verwendet werden.
4
cos reduziert alle Potenzen von
sin(...) modulo 1Ncos(...)^2,
so dass alle verbleibenden Potenzen von cos(...) Exponenten im
Bereich (0, 2) haben. Deshalb enthält das Ergebnis dann und nur dann
kein sin(...), wenn sin(...) im gegebenen Ausdruck nur bei geraden
Potenzen auftritt.
Hinweis: Dieser Umrechnungsoperator wird im Winkelmodus Grad
oder Neugrad (Gon) nicht unterstützt. Bevor Sie ihn verwenden,
müssen Sie sicherstellen, dass der Winkelmodus auf Radian
eingestellt ist und Ausdr keine expliziten Verweise auf W inkel in Grad
oder Neugrad enthält.
Katalog
Katalog
>
>
TI-Nspire™ CAS Referenzhandbuch 19

cos() (Kosinus)
cos(Ausdr1) ⇒ Ausdruck
cos(Liste1) ⇒ Liste
cos(Ausdr1) gibt den Kosinus des Arguments als Ausdruck zurück.
cos(Liste1) gibt in Form einer Liste für jedes Element in Liste1 den
Kosinus zurück.
Hinweis: Der als Argument angegebene Winkel wird gemäß der
aktuellen Winkelmoduseinstellung als Grad, Neugrad oder Bogenmaß
interpretiert. Sie können ó,G oderôbenutzen, um den Winkelmodus
vorübergend aufzuheben.
n Taste
Im Grad-Modus:
Im Neugrad-Modus:
Im Bogenmaß-Modus:
cos(Quadratmatrix1) ⇒ Quadratmatrix
Gibt den Matrix-Kosinus von Quadratmatrix1 zurück. Dies ist nicht
gleichbedeutend mit der Berechnung des Kosinus jedes einzelnen
Elements.
Wenn eine skalare Funktion f(A) auf Quadratmatrix1 (A)
angewendet wird, erfolgt die Berechnung des Ergebnisses durch den
Algorithmus:
Berechnung der Eigenwerte (li) und Eigenvektoren (Vi) von A.
Quadratmatrix1 muss diagonalisierbar sein. Sie darf auch keine
symbolischen Variablen ohne zugewiesene Werte enthalten.
Bildung der Matrizen:
Dann ist A = X B Xêund f(A) = X f(B) Xê. Beispiel: cos(A) = X cos(B)
Xê, wobei:
cos (B) =
Alle Berechnungen werden unter Verwendung von FließkommaOperationen ausgeführt.
Im Bogenmaß-Modus:
20 TI-Nspire™ CAS Referenzhandbuch

cosê() (Arkuskosinus)
cosê(Ausdr1) ⇒ Ausdruck
cosê(Liste1) ⇒ Liste
/n Tasten
Im Grad-Modus:
cosê(Ausdr1) gibt den Winkel, dessen Kosinus Ausdr1 ist, als
Ausdruck zurück.
cosê(Liste1) gibt in Form einer Liste für jedes Element aus Liste1
den inversen Kosinus zurück.
Hinweis: Das Ergebnis wird gemäß der aktuellen
Winkelmoduseinstellung in Grad, in Neugrad oder im Bogenmaß
zurückgegeben.
cosê(Quadratmatrix1) ⇒ Quadratmatrix
Gibt den inversen Matrix-Kosinus von Quadratmatrix1 zurück. Dies
ist nicht gleichbedeutend mit der Berechnung des inversen Kosinus
jedes einzelnen Elements. Näheres zur Berechnungsmethode finden
Sie im Abschnitt cos().
Quadratmatrix1 muss diagonalisierbar sein. Das Ergebnis enthält
immer Fließkommazahlen.
cosh() (Cosinus hyperbolicus)
cosh(Ausdr1) ⇒ Ausdruck
cosh(Liste1) ⇒ Liste
cosh(Ausdr1) gibt den Cosinus hyperbolicus des Arguments als
Ausdruck zurück.
cosh(Liste1) gibt in Form einer Liste für jedes Element aus Liste1
den Cosinus hyperbolicus zurück.
cosh(Quadratmatrix1) ⇒ Quadratmatrix
Gibt den Matrix-Cosinus hyperbolicus von Quadratmatrix1 zurück.
Dies ist nicht gleichbedeutend mit der Berechnung des Cosinus
hyperbolicus jedes einzelnen Elements. Näheres zur
Berechnungsmethode finden Sie im Abschnitt cos().
Quadratmatrix1 muss diagonalisierbar sein. Das Ergebnis enthält
immer Fließkommazahlen.
Im Neugrad-Modus:
Im Bogenmaß-Modus:
Im Winkelmodus Bogenmaß und Komplex-Formatmodus
“kartesisch”:
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
Katalog
Im Bogenmaß-Modus:
>
coshê() (Arkuskosinus hyperbolicus)
coshê(Ausdr1) ⇒ Ausdruck
coshê(Liste1) ⇒ Liste
ê
cosh
(Ausdr1) gibt den inversen Cosinus hyperbolicus des
Arguments als Ausdruck zurück.
ê
cosh
(Liste1) gibt in Form einer Liste für jedes Element aus Liste1
den inversen Cosinus hyperbolicus zurück.
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 21

coshê() (Arkuskosinus hyperbolicus)
coshê(Quadratmatrix1) ⇒ Quadratmatrix
Gibt den inversen Matrix-Cosinus hyperbolicus von Quadratmatrix1
zurück. Dies ist nicht gleichbedeutend mit der Berechnung des
inversen Cosinus hyperbolicus jedes einzelnen Elements. Näheres zur
Berechnungsmethode finden Sie im Abschnitt cos().
Quadratmatrix1 muss diagonalisierbar sein. Das Ergebnis enthält
immer Fließkommazahlen.
Katalog
Im Winkelmodus Bogenmaß und Komplex-Formatmodus
“kartesisch”:
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
>
cot() (Kotangens)
cot(Ausdr1) ⇒ Ausdruck
cot(Liste1) ⇒ Liste
Gibt den Kotangens von Ausdr1 oder eine Liste der Kotangens aller
Elemente in Liste1 zurück.
Hinweis: Der als Argument angegebene Winkel wird gemäß der
aktuellen Winkelmoduseinstellung als Grad, Neugrad oder Bogenmaß
interpretiert. Sie können ó,G oderôbenutzen, um den Winkelmodus
vorübergend aufzuheben.
cotê() (Arkuskotangens)
cotê(Ausdr1) ⇒ Ausdruck
cotê(Liste1) ⇒ Liste
Gibt entweder den Winkel, dessen Kotangens Ausdr1 ist, oder eine
Liste der inversen Kotangens aller Elemente in Liste1 zurück.
Hinweis: Das Ergebnis wird gemäß der aktuellen
Winkelmoduseinstellung in Grad, in Neugrad oder im Bogenmaß
zurückgegeben.
coth() (Kotangens hyperbolicus)
coth(Ausdr1) ⇒ Ausdruck
coth(Liste1) ⇒ Liste
Gibt den hyperbolischen Kotangens von Ausdr1 oder eine Liste der
hyperbolischen Kotangens aller Elemente in Liste1 zurück.
Im Grad-Modus:
Im Neugrad-Modus:
Im Bogenmaß-Modus:
Im Grad-Modus:
Im Neugrad-Modus:
Im Bogenmaß-Modus:
Katalog
Katalog
Katalog
>
>
>
22 TI-Nspire™ CAS Referenzhandbuch

cothê() (Arkuskotangens hyperbolicus)
cothê(Ausdr1) ⇒ Ausdruck
cothê(Liste1) ⇒ Liste
Gibt den inversen hyperbolischen Kotangens von Ausdr1 oder eine
Liste der inversen hyperbolischen Kotangens aller Elemente in Liste1
zurück.
Katalog
>
count() (zähle)
count(Wert1oderListe1 [,Wert2oderListe2 [,...]]) ⇒ We r t
Gibt die kumulierte Anzahl aller Elemente in de n Argumenten zurück,
deren Auswertungsergebnisse numerische Werte sind.
Jedes Argument kann ein Ausdruck, ein Wert, eine Liste oder eine
Matrix sein. Sie können Datenarten mischen und Argumente
unterschiedlicher Dimensionen verwenden.
Für eine Liste, eine Matrix oder einen Zellenbereich wird jedes
Element daraufhin ausgewertet, ob es in die Zählung eingeschlossen
werden soll.
Innerhalb der Lists & Spreadsheet Applikation können Sie anstelle
eines beliebigen Arguments auch einen Zellenbereich verwenden.
countIf()
countIf(Liste,Kriterien) ⇒ We r t
Gibt die kumulierte Anzahl aller Elemente in der Liste zurück, die die
festgelegten Kriterien erfüllen.
Kriterien können sein:
• Ein Wert, ein Ausdruck oder eine Zeichenfolge. So zählt zum
Beispiel 3 nur Elemente in der Liste, die vereinfacht den Wert 3
ergeben.
• Ein Boolescher Ausdruck, der das Sonderzeichen ? als Platzhalter
für jedes Element verwendet. Beispielsweise zählt ?<5 nur die
Elemente in der Liste, die kleiner als 5 sind.
Innerhalb der Lists & Spreadsheet Applikation können Sie anstelle der
Liste auch einen Zellenbereich verwenden.
Hinweis: Siehe auch sumIf(), Seite 112, und frequency(), Seite
47.
Katalog
>
Im letzten Beispiel werden nur 1/2 und 3+4*i gezählt. Die
übrigen Argumente ergeben unter der Annahme, dass x nicht
definiert ist, keine numerischen Werte.
Katalog
>
Zählt die Anzahl der Elemente, die 3 entsprechen.
Zählt die Anzahl der Elemente, die “def.” entsprechen
Zählt die Anzahl der Elemente, die x entsprechen; die ses Beispiel
nimmt an, dass die Variable x nicht definiert ist.
Zählt 1 und 3.
Zählt 3, 5 und 7.
Zählt 1, 3, 7 und 9.
TI-Nspire™ CAS Referenzhandbuch 23

crossP() (Kreuzprodukt)
crossP(Liste1, Liste2) ⇒ Liste
Gibt das Kreuzprodukt von Liste1 und Liste2 als Liste zurück.
Liste1 und Liste2 müssen die gleiche Dimension besitzen, die
entweder 2 oder 3 sein muss.
crossP(Vektor1, Vektor2) ⇒ Vektor
Gibt einen Zeilen- oder Spaltenvektor zurück (je nach den
Argumenten), der das Kreuzprodukt von Vektor1 und Vektor2 ist.
Entweder müssen Vektor1 und Vektor2 beide Zeilenvektoren oder
beide Spaltenvektoren sein. Beide Vektoren müssen die gleiche
Dimension besitzen, die entweder 2 oder 3 sein muss.
Katalog
>
csc() (Kosekans)
csc(Ausdr1) ⇒ Ausdruck
csc(Liste1) ⇒ Liste
Gibt den Kosekans von Ausdr1 oder eine Liste der Konsekans aller
Elemente in Liste1 zurück.
cscê() (Inverser Kosekans)
cscê(Ausdr1) ⇒ Ausdruck
cscê(Liste1) ⇒ Liste
Gibt entweder den Winkel, dessen Kosekans Ausdr1 entspricht, oder
eine Liste der inversen Kosekans aller Elemente in Liste1 zurück.
Hinweis: Das Ergebnis wird gemäß der aktuellen
Winkelmoduseinstellung in Grad, in Neugrad oder im Bogenmaß
zurückgegeben.
csch() (Kosekans hyperbolicus)
csch(Ausdr1) ⇒ Ausdruck
csch(Liste1) ⇒ Liste
Gibt den hyperbolischen Kosekans von Ausdr1 oder eine Liste der
hyperbolischen Kosekans aller Elemente in Liste1 zurück.
Im Grad-Modus:
Im Neugrad-Modus:
Im Bogenmaß-Modus:
Im Grad-Modus:
Im Neugrad-Modus:
Im Bogenmaß-Modus:
Katalog
Katalog
Katalog
>
>
>
24 TI-Nspire™ CAS Referenzhandbuch

cschê() (Inverser Kosekans hyperbolicus)
cschê(Ausdr1) ⇒ Ausdruck
cschê(Liste1) ⇒ Liste
Gibt den inversen hyperbolischen Kosekans von Ausdr1 oder eine
Liste der inversen hyperbolischen Kosekans aller Elemente in Liste1
zurück.
Katalog
>
cSolve() (Komplexe Lösung)
cSolve(Gleichung, Va r ) ⇒ Boolescher Ausdruck
cSolve(Gleichung, Var=Schätzwert) ⇒ Boolescher Ausdruck
cSolve(Ungleichung, Va r ) ⇒ Boolescher Ausdruck
Gibt mögliche komplexe Lösungen einer Gleichung oder Ungleichung
für Var zurück. Das Ziel ist, Kandidaten für alle reellen und nichtreellen Lösungen zu erhalten. Selbst wenn Gleichung reel ist, erlaubt
cSolve() nicht-reelle Lösungen im reellen Modus.
Obwohl alle undefinierten Variablen, die mit einem Unterstrich (_)
enden, so verarbeitet werden, als wären sie reell, kann cSolve()
Polynomgleichungen für komplexe Lösungen lösen.
cSolve() setzt den Bereich während der Berechnung zeitweise auf
komplex, auch wenn der aktuelle Bereich reell ist. Im Komplexen
benutzen Bruchexponenten mit ungeradem Nenner den Hauptzweig
und sind nicht reell. Demzufolge sind Lösungen mit solve() für
Gleichungen, die solche Bruchexponenten besitzen, nicht unbedingt
eine Teilmenge der mit cSolve() erzielten Lösungen.
cSolve() beginnt mit exakten symbolischen Verfahren. Außer im
Modus Exakt benutzt cSolve() bei Bedarf auch die iterative
näherungsweise polynomische Faktorisierung.
Hinweis: Siehe auch cZeros(), solve() und zeros().
Hinweis: Enthält Gleichung Funktionen wie beispielsweise abs(),
angle(), conj(), real() oder imag(), ist sie also kein Polynom,
sollten Sie einen Unterstrich (/_ drücken) hinter Va r
setzen. Standardmäßig wird eine Variable als reeller Wert behandelt.
Bei Verwendung von var_ wird die Variable als komplex behandelt.
Sie sollten var_ auch für alle anderen Variablen in Gleichung
verwenden, die nicht-reelle Werte haben könnten. Anderenfalls
erhalten Sie möglicherweise unerwartete Ergebnisse.
Katalog
Im Modus Angezeigte Ziffern auf Fix 2:
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
z wird als reell behandelt:
z_ wird als komplex behandelt:
>
TI-Nspire™ CAS Referenzhandbuch 25

cSolve() (Komplexe Lösung)
cSolve(Glch1 and Glch2 [and …],
VarOderSchätzwert1, VarOderSchätzwert2 [, … ])
⇒ Boolescher Ausdruck
cSolve(Gleichungssystem, VarOderSchätzwert1,
VarOderSchätzwert2 [, …]) ⇒ Boolescher Ausdruck
Gibt mögliche komplexe Lösungen eines algebraischen
Gleichungssystems zurück, in dem jede VarOderSchätzwert eine
Variable darstellt, nach der Sie die Gleichungen auflösen möchten.
Sie haben die Option, eine Ausgangsschätzung für eine Variable
anzugeben. VarOderSchätzwert muss immer die folgende Form
haben:
Variable
– oder –
Variable = reelle oder nicht-reelle Zahl
Beispiel: x ist gültig und x=3+i ebenfalls.
Wenn alle Gleichungen Polynome sind und Sie KEINE
Anfangsschätzwerte angeben, dann verwendet
lexikalischeGröbner/Buchbergersche Eliminationsverfahren bei m
Versuch, alle komplexen Lösungen zu bestimmen.
Komplexe Lösungen können, wie aus nebenstehendem Beispiel
hervorgeht, sowohl reelle als auch nicht-reelle Lösungen enthalten.
Gleichungssysteme, die aus Polynomen bestehen, können zusätzliche
Variablen ohne Wert aufweisen, die aber für numerische Werte
stehen, welche später eingesetzt werden können.
cSolve() das
Katalog
>
Hinweis: In folgenden Beispielen wird ein Unterstrich
(/_ drücken) verwendet, damit die Variablen als
komplex behandelt werden.
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
Sie können auch Lösungsvariablen angeben, die in der Gleichung
nicht erscheinen. Diese Lösungen verdeutlichen, dass Lösungsfamilien
willkürliche Konstanten der Form ck enthalten können, wobei k ein
ganzzahliger Index im Bereich 1 bis 255 ist.
Bei Gleichungssystemen aus Polynomen kann die Berechnungsdauer
oder Speicherbelastung stark von der Reihenfolge abhängen, in
welcher Sie die Lösungsvariablen angeben. Übersteigt Ihre erste Wahl
die Speicherkapazität oder Ihre Geduld, versuchen Sie, die Variablen
in der Gleichung und/oder VarOderSchätzwert-Liste umzuordnen.
Wenn Sie keine Schätzwerte angeben und eine Gleichung in einer
Variablen nicht-polynomisch ist, aber alle Gleichungen in allen
Lösungsvariablen linear sind, so verwendet cSolve() das Gaußsche
Eliminationsverfahren beim Versuch, alle Lösungen zu bestimmen.
Wenn ein System weder in all seinen Variablen polynomial noch in
seinen Lösungsvariablen linear ist, dann bestimmt cSolve()
mindestens eine Lösung anhand eines iterativen näherungsweisen
Verfahrens. Hierzu muss die Anzahl der Lösungsvariablen gleich der
Gleichungsanzahl sein, und alle anderen Variablen in den
Gleichungen müssen zu Zahlen vereinfachbar sein.
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
26 TI-Nspire™ CAS Referenzhandbuch

cSolve() (Komplexe Lösung)
Zur Bestimmung einer nicht-reellen Lösung ist häufig ein nicht-reeller
Schätzwert erforderlich. Für Konvergenz sollte ein Schätzwert
ziemlich nahe bei einer Lösung liegen.
Katalog
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
>
CubicReg (Kubische Regression)
CubicReg X, Y[, [Häuf] [, Kategorie, Mit]]
Berechnet die kubische polynomiale Regression y = a·x3+b·
x2+c·x+d auf Listen X und Y mit der Häufigkeit Häuf. Eine
Zusammenfassung der Ergebnisse wird in der Variablen stat.results
gespeichert. (Siehe Seite 109.)
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element
in Häuf gibt die Häufigkeit für jeden entsprechenden Datenpunkt X
und Y an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen
| 0 sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes.
Nur solche Datenelemente, deren Kategoriecode in dieser
Liste enthalten ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
stat.a, stat.b, stat.c,
stat.d
2
stat.R
stat.Resid Residuen von der Regression
stat.XReg Liste der Datenpunkte in der modifizierten X List, die schließlich in der Regression mit den
stat.YReg Liste der Datenpunkte in der modifizierten Y List, die schließlich in der Regression mit den
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
Regressionsgleichung: a·x3+b·x2+c·x+d
Regressionskoeffizienten
Bestimmungskoeffizient
Beschränkungen für Häufigkeit, Kategorieliste und Mit Kategorien verwendet wurde
Beschränkungen für Häufigkeit, Kategorieliste und Mit Kategorien verwendet wurde
Katalog
>
cumSum() (Kumulierte Summe)
cumSum(Liste1) ⇒ Liste
Gibt eine Liste der kumulierten Summen der Elemente aus Liste1
zurück, wobei bei Element 1 begonnen wird.
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 27

cumSum() (Kumulierte Summe)
cumSum(Matrix1) ⇒ Matrix
Gibt eine Matrix der kumulierten Summen der Elemente aus Matrix1
zurück. Jedes Element ist die kumulierte Summe der Spalte von oben
nach unten.
Katalog
>
Cycle (Zyklus)
Cycle (Zyklus)
Übergibt die Programmsteuerung sofort an die nächste Wiederholung
der aktuellen Schleife (For, While oder Loop).
Cycle ist außerhalb dieser drei Schleifenstrukturen (For, While
oder Loop) nicht zulässig.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
Cylind (Zylindervektor)
4
Vek t o r 4Cylind
Zeigt den Zeilen- oder Spaltenvektor in Zylinderkoordin aten [r,q, z]
an.
Vek t o r muss genau drei Elemente besitzen. Er kann entweder ein
Zeilen- oder Spaltenvektor sein.
cZeros() (Komplexe Nullstellen)
cZeros(Ausdr, Va r ) ⇒ Liste
Gibt eine Liste möglicher reeller und nicht-reeller Werte für Va r
zurück, die Ausdr=0 ergeben. cZeros() tut dies durch Berechnung
von
exp4list(cSolve(Ausdr=0,Var ),Va r ). Ansonsten ist cZeros()
ähnlich wie zeros().
Hinweis: Siehe auch cSolve(), solve() und zeros().
Hinweis: Ist Ausdr nicht-polynomial mit Funktionen wie
beispielsweise abs(), angle(), conj(), real() oder imag(), sollten
Sie einen Unterstrich (/_ drücken) hinter Va r setzen.
Standardmäßig wird eine Variable als reeller Wert behandelt. Bei
Verwendung von var_ wird die Variable als komplex behandelt.
Sie sollten var_ auch für alle anderen Variablen in Ausdr verwenden,
die nicht-reelle Werte haben könnten. Anderenfalls erhalten Sie
möglicherweise unerwartete Ergebnisse.
Katalog
>
Funktionslisting, das die ganzen Zahlen von 1 bis 100 summiert
und dabei 50 überspringt.
Katalog
>
Katalog
>
Im Modus Angezeigte Ziffern auf Fix 3:
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
z wird als reell behandelt:
z_ wird als komplex behandelt:
28 TI-Nspire™ CAS Referenzhandbuch

cZeros() (Komplexe Nullstellen)
cZeros({Ausdr1, Ausdr2 [, … ] },
{
VarOderSchätzwert1,VarOderSchätzwert2 [, … ] }) ⇒ Matrix
Gibt mögliche Positionen zurück, in welchen die Ausdrücke
gleichzeitig Null sind. Jeder VarOderSchätzwert steht für eine
Unbekannte, deren Wert Sie suchen.
Sie haben die Option, eine Ausgangsschätzung für eine Variable
anzugeben. VarOderSchätzwert muss immer die folgende Form
haben:
Variable
– oder –
Variable = reelle oder nicht-reelle Zahl
Beispiel: x ist gültig und x=3+i ebenfalls.
Wenn alle Ausdrücke Polynome sind und Sie KEINE
Anfangsschätzwerte angeben, dann verwendet cZeros() das
lexikalische Gröbner/Buchbergersche Eliminationsverfahren beim
Versuch, alle komplexen Nullstellen zu bestimmen.
Komplexe Nullstellen können, wie aus nebenstehendem Beispiel
hervorgeht, sowohl reelle als auch nicht-reelle Nullstellen enthalten.
Jede Zeile der sich ergebenden Matrix stellt eine alternativ e Nullstelle
dar, wobei die Komponenten in derselben Reihenfolge wie in der
VarOderSchätzwert-Liste angeordnet sind. Um eine Zeile zu erhalt en
ist die Matrix nach [Zeile] zu indizieren.
Gleichungssysteme, die aus Polynomen bestehen, können zusätzliche
Variablen haben, die zwar ohne Werte sind, aber gegebene
numerische Werte darstellen, die später eingesetzt werden können.
Katalog
>
Hinweis: In folgenden Beispielen wird ein Unterstrich _
(/_ drücken) verwendet, damit die Variablen als
komplex behandelt werden.
Zeile 2 extrahieren:
Sie können auch unbekannte Variablen angeben, die nicht in den
Ausdrücken erscheinen. Diese Nullstellen verdeutlichen, dass
Nullstellenfamilien willkürliche Konstanten der Form ck enthalten
können, wobei k ein ganzzahliger Index im Bereich 1 bis 255 ist.
Bei polynomialen Gleichungssystemen kann die Berechnungsdauer
oder Speicherbelastung stark von der Reihenfolge abhängen, in der
Sie die Unbekannten angeben. Übersteigt Ihre erste Wahl die
Speicherkapazität oder Ihre Geduld, versuchen Sie, die Variablen in
den Ausdrücken und/oder der VarOderSchätzwert-Liste
umzuordnen.
Wenn Sie keine Schätzwerte angeben und ein Ausdruck in einer
Variablen nicht-polynomial ist, aber alle Ausdrücke in allen
Unbekannten linear sind, so verwendet cZeros() das Gaußsche
Eliminationsverfahren beim Versuch, alle Nullstellen zu bestimmen.
TI-Nspire™ CAS Referenzhandbuch 29

cZeros() (Komplexe Nullstellen)
Wenn ein System weder in all seinen Variablen polynomial noch in
seinen Unbekannten linear ist, dann bestimmt cZeros() mindestens
eine Nullstelle anhand eines iterativen Näherungsverfahrens. Hierzu
muss die Anzahl der Unbekannten gleich der Ausdruckanzahl sein,
und alle anderen Variablen in den Ausdrücken müssen zu Zahlen
vereinfachbar sein.
Zur Bestimmung einer nicht-reellen Nullstelle ist häufig ein nichtreeller Schätzwert erforderlich. Für Konvergenz muss ein Schätzwert
ziemlich nahe bei der Nullstelle liegen.
D
Katalog
>
dbd()
dbd(Datum1,Datum2) ⇒ We r t
Zählt die tatsächlichen Tage und gibt die Anzahl der Tage zwischen
Datum1 und Datum2 zurück.
Datum1 und Datum2 können Zahlen oder Zahlenlisten innerhalb des
Datumsbereichs des Standardkalenders sein. Wenn sowohl Datum1
als auch Datum2 Listen sind, müssen sie dieselbe Länge haben.
Datum1 und Datum2 müssen innerhalb der Jahre 1950 und 2049
liegen.
Sie können Datumseingaben in zwei Formaten vornehmen. Die
Datumsformate unterscheiden sich in der Anordnung der
Dezimalstellen.
MM.TTJJ (üblicherweise in den USA verwendetes Format)
TTMM.JJ (üblicherweise in Europa verwendetes Format)
DD (Dezimalwinkel)
4
Zahl 4DD ⇒ We rt
Liste1 4DD ⇒ Liste
Matrix1 4DD ⇒ Matrix
Gibt das Dezimaläquivalent des Arguments zurück. Das Argument ist
eine Zahl, eine Liste oder eine Matrix, die gemäß der
Moduseinstellung als Neugrad, Bogenmaß oder Grad interpretiert
wird.
Im Grad-Modus:
Im Neugrad-Modus:
Im Bogenmaß-Modus:
Katalog
Katalog
>
>
4Decimal (Dezimal)
4Decimal
Ausdr1
4Decimal
Liste1
Matrix1
Zeigt das Argument in Dezimalform an. Dieser Operator kann nur am
Ende der Eingabezeile verwendet werden.
4
Decimal
⇒ Ausdruck
⇒ Ausdruck
⇒ Ausdruck
Katalog
>
30 TI-Nspire™ CAS Referenzhandbuch

Definiere
Define Var = Expression
Define Function(Param1, Param2, ...) = Expression
Definiert die Variable Va r oder die benutzerdefinierte Funktion
Function.
Parameter wie z.B. Param1 enthalten Platzhalter zur Übergabe von
Argumenten an die Funktion. Beim Aufrufen benutzerdefinierter
Funktionen müssen Sie Argumente angeben (z.B. Werte oder
Variablen), die zu den Parametern passen. Beim Aufruf wertet die
Funktion Ausdruck (Expression) unter Verwendung der
übergebenen Parameter aus.
Var und Funktion (Function) dürfen nicht der Name einer
Systemvariablen oder einer integrierten Funktion / eines integrierten
Befehls sein.
Hinweis: Diese Form von Definiere (Define) ist gleichwertig mit
der Ausführung folgenden Ausdrucks: expression &
Function(Param1,Param2).
Define Function(Param1, Param2, ...) = Func
Block
EndFunc
Program(Param1, Param2, ...) = Prgm
Define
Block
EndPrgm
In dieser Form kann die benutzerdefinierte Funktion bzw. das
benutzerdefinierte Programm einen Block mit mehr eren Anweisungen
ausführen.
Block kann eine einzelne Anweisung oder eine Serie von
Anweisungen in separaten Zeilen sein. Block kann auch Ausdrücke
und Anweisungen enthalten (wie If, Then, Else und For).
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
Hinweis: Siehe auch Definiere LibPriv (Define LibPriv),
Seite 32, und Definiere LibPub (Define LibPub), Seite 32.
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 31

Definiere LibPriv (Define LibPriv)
Define LibPriv Var = Expression
Define LibPriv Function(Param1, Param2, ...) = Expression
Define LibPriv Function(Param1, Param2, ...) = Func
Block
EndFunc
Define LibPriv
Block
EndPrgm
Funktioniert wie Define, definiert jedoch eine Variable, eine
Funktion oder ein Programm für eine private Bibliothek. Private
Funktionen und Programme werden im Katalog nicht angezeigt.
Hinweis: Siehe auch Definiere (Define), Seite 31, und
Definiere LibPub (Define LibPub), Seite 32.
Program(Param1, Param2, ...) = Prgm
Katalog
>
Definiere LibPub (Define LibPub)
Define LibPub Var = Expression
Define LibPub Function(Param1, Param2, ...) = Expression
Define LibPub Function(Param1, Param2, ...) = Func
Block
EndFunc
Define LibPub
Block
EndPrgm
Funktioniert wie Definiere (Define), definiert jedoch eine
Variable, eine Funktion oder ein Programm für eine öffentliche
Bibliothek. Öffentliche Funktionen und Programme werden im
Katalog angezeigt, nachdem die Bibliothek gespeichert und
aktualisiert wurde.
Hinweis: Siehe auch Definiere (Define), Seite 31, und
Definiere LibPriv (Define LibPriv), Seite 32.
Program(Param1, Param2, ...) = Prgm
DelVar
DelVar Var 1 [, Va r 2] [, Va r 3 ] ...
DelVar
Var .
Löscht die angegebene Variable oder Variablengruppe im Speicher.
DelVar Var . löscht alle Mitglieder der Variablengruppe Va r. (wie
die Statistikergebnisse stat.nn oder Variablen, die mit der Funktion
LibShortcut() erstellt wurden). Der Punkt (.) in dieser Form des
Befehls DelVar begrenzt ihn auf das Löschen einer Variablengruppe;
die einfache Variable Va r ist nicht davon betroffen.
Katalog
Katalog
>
>
32 TI-Nspire™ CAS Referenzhandbuch

deSolve() (Lösung)
deSolve(ODE1.Oder2.Ordnung, Var , abhängigeVar)
⇒ eine allgemeine Lösung
Ergibt eine Gleichung, die explizit oder implizit eine allgemeine
Lösung für die gewöhnliche Differentialgleichung erster oder zweiter
Ordnung (ODE) angibt. In der ODE:
• Verwenden Sie einen Strich (drücken Sie '), um die erste
Ableitung der abhängigen Variablen gegenüber der
unabhängigen Variablen zu kennzeichnen.
• Kennzeichnen Sie die entsprechende zweite Ableitung mit zwei
Strichen.
Das Zeichen ' wird nur für Ableitungen innerhalb von deSolve()
verwendet. Verwenden Sie für andere Fälle
Die allgemeine Lösung einer Gleichung erster Ordnung enthält eine
willkürliche Konstante der Form ck, wobei k ein ganzzahliger Index im
Bereich 1 bis 255 ist. Die Lösung einer Gleichung zweiter Ordnung
enthält zwei derartige Konstanten.
Wenden Sie solve() auf eine implizite Lösung an, wenn Sie
versuchen möchten, diese in eine oder mehrere äquivalente explizite
Lösungen zu konvertieren.
Beachten Sie beim Vergleich Ihrer Ergebnisse mit Lehrbuch- oder
Handbuchlösungen bitte, dass die willkürlichen Konstanten in den
verschiedenen Verfahren an unterschiedlichen Stellen in der
Rechnung eingeführt werden, was zu unterschiedlichen allgemeinen
Lösungen führen kann.
deSolve(ODE1.Ordnung and Anfangsbedingung, Var ,
abhängigeVar)
⇒ eine spezielle Lösung
Ergibt eine spezielle Lösung, die ODE1.Ordnung und
Anfangsbedingung erfüllt. Dies ist in der Regel einfacher, als eine
allgemeine Lösung zu bestimmen, Anfangswerte einzusetzen, nach
der willkürlichen Konstanten aufzulösen und dann diesen Wert in die
allgemeine Lösung einzusetzen.
Anfangsbedingung ist eine Gleichung der Form
abhängigeVar (unabhängigerAnfangswert) =
abhängigerAnfangswert
Der unabhängigeAnfangswert und abhängigeAnfangswert können
Variablen wie beispielsweise x0 und y0 ohne gespeicherte Werte sein.
Die implizite Differentiation kann bei der Prüfung impliziter Lösungen
behilflich sein.
deSolve(ODE2.Ordnung and Anfangsbedingung1 and
Anfangsbedingung2,
Var , abhängigeVar) ⇒ eine spezielle Lösung
Ergibt eine spezielle Lösung, die ODE2.Ordnung erfüllt und in einem
Punkt einen bestimmten Wert der abhängigen Variablen und deren
erster Ableitung aufweist.
Verwenden Sie für Anfangsbedingung1 die Form
abhängigeVar (unabhängigerAnfangswert) =
abhängigerAnfangswert
Verwenden Sie für Anfangsbedingung2 die Form
abhängigeVar (unabhängigerAnfangswert) =
anfänglicher1.Ableitungswert
d().
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 33

deSolve() (Lösung)
deSolve(ODE2.Ordnung and Randbedingung1 and
Randbedingung2, Var , abhängigeVar) ⇒ eine spezielle Lösung
Ergibt eine spezielle Lösung, die ODE2.Ordnung erfüllt und in zwei
verschiedenen Punkten angegebene Werte aufweist.
Katalog
>
det() (Matrixdeterminante)
det(Quadratmatrix[, Toleranz]) ⇒ Ausdruck
Gibt die Determinante von Quadratmatrix zurück.
Jedes Matrixelement wird wahlweise als 0 behandelt, wenn sein
Absolutwert kleiner als Toleranz ist. Diese Toleranz wird nur dann
verwendet, wenn die Matrix Fließkommaelemente aufweist und
keinerlei symbolische Variablen ohne zugewiesene Werte enthält.
Anderenfalls wird Toleranz ignoriert.
• Wenn Sie
•Wird Toleranz weggelassen oder nicht verwendet, so wird die
diag() (Matrixdiagonale)
diag(Liste) ⇒ Matrix
diag(Zeilenmatrix) ⇒ Matrix
diag(Spaltenmatrix) ⇒ Matrix
Gibt eine Matrix mit den Werten der Argumentliste oder der Matrix in
der Hauptdiagonalen zurück.
diag(Quadratmatrix) ⇒ Zeilenmatrix
Gibt eine Zeilenmatrix zurück, die die Elemente der Hauptdiagonalen
von Quadratmatrix enthält.
Quadratmatrix muss eine quadratische Matrix sein.
/
verwenden oder den Modus Autom.
·
oder Näherung
Berechnungen in Fließkomma-Arithmetik durchgeführt.
Standardtoleranz folgendermaßen berechnet:
5EM14 ·max(dim(Quadratmatrix))·
rowNorm(Quadratmatrix)
auf 'Approximiert' einstellen, werden
Katalog
Katalog
>
>
dim() (Dimension)
dim(Liste) ⇒ Ganzzahl
Gibt die Dimension von Liste zurück.
dim(Matrix) ⇒ Liste
Gibt die Dimensionen von Matrix als Liste mit zwei Elementen zurück
{Zeilen, Spalten}.
dim(Strin g) ⇒ Ganzzahl
Gibt die Anzahl der in der Zeichenkette Str ing enthaltenen Zeichen
zurück.
Katalog
>
34 TI-Nspire™ CAS Referenzhandbuch

Disp (Zeige)
Disp [AusdruckOderString1] [, AusdruckOderString2] ...
Zeigt die Argumente im Calculator Protokoll an. Die Argumente
werden hintereinander angezeigt, dabei werden Leerzeichen zur
Trennung verwendet.
Dies ist vor allem bei Programmen und Funktionen nützlich, um die
Anzeige von Zwischenberechnungen zu gewährleisten.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
DMS (GMS)
4
Ausdr 4DMS
Liste 4DMS
Matrix 4DMS
Interpretiert den Parameter als Winkel und zeigt die entsprechenden
GMS-Werte (engl. DMS) an (GGGGGG¡MM'SS.ss''). Siehe ¡, ', ''
auf Seite 145 zur Erläuterung des DMS-Formats (Grad, Minuten,
Sekunden).
Hinweis: 4DMS wandelt Bogenmaß in Grad um, wenn es im
Bogenmaß-Modus benutzt wird. Folgt auf die Eingabe das GradSymbol ¡, wird keine Umwandlung vorgenommen. Sie können 4DMS
nur am Ende einer Eingabezeile benutzen.
@ statt · drücken.
Im Grad-Modus:
Katalog
Katalog
>
>
TI-Nspire™ CAS Referenzhandbuch 35

dominanterTerm (), dominantTerm()
dominantTerm(Expr1, Va r [, Point]) ⇒ expression
dominantTerm(Expr1, Va r [, Point]) | Va r >Point
⇒ expression
dominantTerm(Expr1, Va r [, Point]) | Va r <Point
⇒ expression
Gibt den dominanten Term einer Potenzreihendarstellung von Expr1
entwickelt um Point zurück. Der dominante Term ist derjenige,
dessen Betrag nahe Va r = Point am schnellsten anwächst. Die
resultierende Potenz von (Va r N Point) kann einen negativen und/
oder Bruchexponenten haben. Der Koeffizient dieser Potenz kann
Logarithmen von (Va r N Point) und andere Funktionen von Va r
enthalten, die von allen Potenzen von (Va r N Point) dominiert
werden, die dasselbe Exponentenzeichen haben.
Point ist vorgegeben als 0. Point kann ˆ oder Nˆ sein; in diesen
Fällen ist der dominante Term eher derjenige mit dem größten
Exponenten von Va r als der mit dem kleinsten Exponenten von Va r .
dominantTerm(…) gibt “dominantTerm(…)” zurück, wenn es
keine Darstellung bestimmen kann wie für wesentliche Singu laritäten
wie z.B. sin(1/z) bei z=0, e
Wenn die Folge oder eine ihrer Ableitungen eine Sprungstelle bei
Point hat, enthält das Ergebnis wahrscheinlich Unterausdrücke der
Form sign(…) oder abs(…) für eine reelle Expansionsvariable oder (-
floor(…angle(…)…)
1)
endet. Wenn Sie beabsichtigen, den dominanten Term nur für Werte
auf einer Seite von Point zu verwenden, hängen Sie an
dominantTerm(...) je nach Bedarf "| Var > Point", "| Var <
Point", "| "Va r ‚ Point" oder "Va r Point" an, um ein einfacheres
Ergebnis zu erhalten.
dominantTerm() wird über Listen und Matrizen mit erstem
Argument verteilt.
dominantTerm() können Sie verwenden, wenn Sie den
einfachsten möglichen Ausdruck wissen möchten, der asymptotisch
zu einem anderen Ausdruck wie Va r " Point ist. dominantTerm()
ist ebenfalls hilfreich, wenn nicht klar ersichtlich ist, welchen Grad de r
erste Term einer Folge haben wird, der nicht Null ist und Sie nicht
iterativ interaktiv oder mit einer Programmschleife schätzen möchten.
Hinweis: Siehe auch series(), Seite 98.
N1/z
bei z=0 oder ez bei z = ˆ oder Nˆ.
für eine komplexe Expansionsvariable, die mit "_"
Katalog
>
dotP() (Skalarprodukt)
dotP(Liste1, Liste2) ⇒ Ausdruck
Katalog
>
Gibt das Skalarprodukt zweier Listen zurück.
dotP(Vektor1, Vektor2) ⇒ Ausdruck
Gibt das Skalarprodukt zweier Vektoren zurück.
Es müssen beide Zeilenvektoren oder beide Spaltenvektoren sein.
36 TI-Nspire™ CAS Referenzhandbuch

E
e^()
e^(Ausdr1) ⇒ Ausdruck
Gibt e hoch Ausdr1 zurück.
Hinweis: Siehe auch Vorlage e Exponent, Seite 2.
Hinweis: Das Drücken von u zum Anzeigen von
das gleiche wie das Drücken von E auf der Tastatur.
Sie können eine komplexe Zahl in der polaren Form re
Verwenden Sie diese aber nur im Winkelmodus Bogenmaß, da die
Form im Grad- oder Neugrad-Modus einen Bereichsfehler verursacht.
e^(Liste1) ⇒ Liste
Gibt e hoch jedes Element der Liste1 zurück.
e^(Quadratmatrix1) ⇒ Quadratmatrix
Ergibt den Matrix-Exponenten von Quadratmatrix1. Dies ist nicht
gleichbedeutend mit der Berechnung von e hoch jedes Element.
Näheres zur Berechnungsmethode finden Sie im Abschnitt cos().
Quadratmatrix1 muss diagonalisierbar sein. Das Ergebnis enthält
immer Fließkommazahlen.
eff()
eff(Nominalzinssatz, CpY) ⇒ We rt
Finanzfunktion, die den Nominalzinssatz Nominalzinssatz in einen
jährlichen Effektivsatz konvertiert, wobei CpY als die Anzahl der
Verzinsungsperioden pro Jahr gegeben ist.
Nominalzinssatz muss eine reelle Zahl sein und CpY muss eine reelle
Zahl > 0 sein.
Hinweis: Siehe auch nom(), Seite 75.
eigVc() (Eigenvektor)
eigVc(Quadratmatrix) ⇒ Matrix
Ergibt eine Matrix, welche die Eigenvektoren für eine reelle oder
komplexe Quadratmatrix enthält, wobei jede Spalte des Ergebnisses
zu einem Eigenwert gehört. Beachten Sie, dass ein Eigenvektor nicht
eindeutig ist; er kann durch einen konstanten Faktor skaliert werden.
Die Eigenvektoren sind normiert, d. h. wenn V = [x1, x2, …, xn],
dann:
2
2
+ … + x
2
= 1
n
x
+x
1
2
Quadratmatrix wird zunächst mit Ähnlichkeitstransformationen
bearbeitet, bis die Zeilen- und Spaltennormen so nahe wie möglich
bei demselben Wert liegen. Die Quadratmatrix wird dann auf die
obere Hessenberg-Form reduziert, und die Eigenvektoren werden mit
einer Schur-Faktorisierung berechnet.
e
^( ist nicht
i
q
eingeben.
u Taste
Katalog
Katalog
Im Komplex-Formatmodus “kartesisch”:
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
>
>
TI-Nspire™ CAS Referenzhandbuch 37

eigVl() (Eigenwert)
eigVl(Quadratmatrix) ⇒ Liste
Ergibt eine Liste von Eigenwerten einer reellen oder komplexen
Quadratmatrix.
Quadratmatrix wird zunächst mit Ähnlichkeitstransformationen
bearbeitet, bis die Zeilen- und Spaltennormen so nahe wie möglich
bei demselben Wert liegen. Die Quadratmatrix wird dann auf die
obere Hessenberg-Form reduziert, und die Eigenwerte werden aus der
oberen Hessenberg-Matrix berechnet.
Else Siehe If, Seite 52.
Im Komplex-Formatmodus “kartesisch”:
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
Katalog
>
ElseIf
If Boolescher Ausdr1 Then
Block1
ElseIf Boolescher Ausdr2 Then
Block2
©
ElseIf Boolescher AusdrN Then
BlockN
EndIf
©
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
EndFor
EndFunc Siehe Func, Seite 48.
EndIf Siehe If, Seite 52.
EndLoop Siehe Loop, Seite 67.
EndWhile Siehe While, Seite 125.
Katalog
>
Siehe For, Seite 45.
EndPrgm Siehe Prgm, Seite 86.
38 TI-Nspire™ CAS Referenzhandbuch

EndTry Siehe Try, Seite 119.
exact() (Exakt)
exact(Ausdr1 [, Toleranz]) ⇒ Ausdruck
exact(Liste1 [, Toleranz]) ⇒ Liste
exact(Matrix1 [, Toleranz]) ⇒ Matrix
Benutzt den Rechenmodus 'Exakt' und gibt nach Möglichkeit die
rationale Zahl zurück, die dem Argument äquivalent ist.
Tol e ra n z legt die Toleranz für die Umwandlung fest, wobei die
Vorgabe 0 (null) ist.
Exit (Abbruch)
Exit (Abbruch)
Beendet den aktuellen For, While, oder Loop Block.
Exit ist außerhalb dieser drei Schleifenstrukturen (For, While oder
Loop) nicht zulässig.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
Funktionslisting:
Katalog
Katalog
>
>
4
exp
4
Ausdr
exp
Drückt Ausdr durch die natürliche Exponentialfunktion e aus. Dies ist
ein Anzeigeumwandlungsoperator. Er kann nur am Ende der
Eingabezeile verwendet werden.
exp() (e hoch x)
exp(Ausdr1) ⇒ Ausdruck
Gibt e hoch Ausdr1 zurück.
Hinweis: Siehe auch Vorlage e Exponent, Seite 2.
i
Sie können eine komplexe Zahl in der polaren Form re
Verwenden Sie diese aber nur im Winkelmodus Bogenmaß, da die
Form im Grad- oder Neugrad-Modus einen Bereichsfehler verursacht.
q eingeben.
Katalog
u Taste
>
TI-Nspire™ CAS Referenzhandbuch 39

exp() (e hoch x)
exp(Liste1) ⇒ Liste
Gibt e hoch jedes Element der Liste1 zurück.
exp(Quadratmatrix1) ⇒ Quadratmatrix
Ergibt den Matrix-Exponenten von Quadratmatrix1. Dies ist nicht
gleichbedeutend mit der Berechnung von e hoch jedes Element.
Näheres zur Berechnungsmethode finden Sie im Abschnitt
Quadratmatrix1 muss diagonalisierbar sein. Das Ergebnis enthält
immer Fließkommazahlen.
cos().
u Taste
exp4list() (Ausdruck in Liste)
exp4list(Ausdr,Va r ) ⇒ Liste
Untersucht Ausdr auf Gleichungen, die durch das Wort “or” getrennt
sind und gibt eine Liste der rechten Seiten der Gleichungen in der
Form Var = A us d r zurück. Dies erlaubt Ihnen auf einfache Weise das
Extrahieren mancher Lösungswerte, die in den Ergebnissen der
Funktionen solve(), cSolve(), fMin() und fMax() enthalten sind.
Hinweis: exp4list() ist für die Funktionen zeros und cZeros()
unnötig, da diese direkt eine Liste von Lösungswerten zurückgeben.
expand() (Entwickle)
expand(Ausdr1 [, Va r ]) ⇒ Ausdruck
expand(Liste1 [,Va r ]) ⇒ Liste
expand(Matrix1 [,Var ]) ⇒ Matrix
expand(Ausdr1) gibt Ausdr1 bezüglich sämtlicher Variablen
entwickelt zurück. Die Entwicklung ist eine Polynomentwicklung für
Polynome und eine Partialbruchentwicklung für rationale Ausdrücke.
expand() versucht Ausdr1 in eine Summe und/oder eine Differenz
einfacher Ausdrücke umzuformen. Dagegen versucht factor()
Ausdr1 in ein Produkt und/oder einen Quotienten einfacher Faktoren
umzuformen.
expand(Ausdr1,Var ) entwickelt Ausdr1 bezüglich Va r.
Gleichartige Potenzen von Va r werden zusammengefasst. Die Terme
und Faktoren werden mit Va r als der Hauptvariablen sortiert. Es kann
sein, dass als Nebeneffekt in gewissem Umfang eine Faktorisierung
oder Entwicklung der zusammengefassten Koeffizienten auftritt.
Verglichen mit dem Weglassen von Va r spart dies häufig Zeit,
Speicherplatz und Platz auf dem Bildschirm und macht den Ausdruck
verständlicher.
Katalog
Katalog
>
>
Selbst wenn es nur eine Variable gibt, kann das Einbeziehen von Va r
eine vollständigere Faktorisierung des Nenners, die für die
Partialbruchentwicklung benutzt wird, ermöglichen.
Tipp: Für rationale Ausdrücke ist propFrac() eine schnellere, aber
weniger weitgehende Alternative zu expand().
Hinweis: Siehe auch comDenom() zu einem Quotienten aus
einem entwickelten Zähler und entwickeltem Nenner.
40 TI-Nspire™ CAS Referenzhandbuch

expand() (Entwickle)
expand(Ausdr1,[Va r]) vereinfacht auch Logarithmen und
Bruchpotenzen ungeachtet von Va r . Für weitere Zerlegungen von
Logarithmen und Bruchpotenzen können Einschränkungen notwendig
werden, um sicherzustellen, dass manche Faktoren nicht n egativ sind.
expand(Ausdr1, [Va r]) vereinfacht auch Absolutwerte, sign()
und Exponenten ungeachtet von Va r .
Hinweis: Siehe auch tExpand() zur trigonometrischen
Entwicklung von Winkelsummen und -produkten.
Katalog
>
expr() (String in Ausdruck)
expr(Stri ng) ⇒ Ausdruck
Gibt die in Strin g enthaltene Zeichenkette als Ausdruck zurück und
führt diesen sofort aus.
ExpReg (Exponentielle Regression)
ExpReg X, Y [, [Häuf] [, Kategorie, Mit]]
Berechnet die exponentielle Regression y = a·(b)xauf Listen X und
Y mit der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse
wird in der Variablen stat.results gespeichert. (Siehe Seite 109.)
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden Datenpunkt X und
Y an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0
sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
Regressionsgleichung: a·(b)
x
stat.a, stat.b Regressionskoeffizienten
stat.r
2
Koeffizient der linearen Bestimmtheit für transformierte Daten
stat.r Korrelationskoeffizient für transformierte Daten (x, ln(y))
Katalog
Katalog
>
>
TI-Nspire™ CAS Referenzhandbuch 41

Ausgabevariable Beschreibung
stat.Resid Mit dem exponentiellen Modell verknüpfte Residuen
stat.ResidTrans Residuum für die lineare Anpassung der transformierten Daten.
stat.XReg Liste der Datenpunkte in der modifizierten X List, die schließlich in der Regression mit den
stat.YReg Liste der Datenpunkte in der modifizierten Y List, die schließlich in der Regression mit den
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
Beschränkungen für Häufigkeit, Kategorieliste und Mit Kategorien verwendet wurde
Beschränkungen für Häufigkeit, Kategorieliste und Mit Kategorien verwendet wurde
F
factor() (Faktorisiere)
factor(Ausdr1[, Va r ]) ⇒ Ausdruck
factor(Liste1[,Va r ]) ⇒ Liste
factor(Matrix1[,Var ]) ⇒ Matrix
factor(Ausdr1) gibt Ausdr1 nach allen seinen Variablen bezüglich
eines gemeinsamen Nenners faktorisiert zurück.
Ausdr1 wird soweit wie möglich in lineare rationale Faktoren
aufgelöst, selbst wenn dies die Einführung neuer nicht-reeller
Unterausdrücke bedeutet. Diese Alternative i st angemessen, wenn Sie
die Faktorisierung bezüglich mehr als einer Variablen vornehmen
möchten.
factor(Ausdr1,Var ) gibt Ausdr1 nach der Variablen Var faktorisiert
zurück.
Ausdr1 wird soweit wie möglich in reelle Faktoren aufgelöst, die
linear in Va r sind, selbst wenn dadurch irrationale Konstanten oder
Unterausdrücke, die in anderen Variablen irrational sind, eingeführt
werden.
Die Faktoren und ihre Terme werden mit Va r als Hauptvariable
sortiert. Gleichartige Potenzen von Var werden in jedem Faktor
zusammengefasst. Beziehen Sie Va r ein, wenn die Faktorisierung nur
bezüglich dieser Variablen benötigt wird und Sie irrationale
Ausdrücke in anderen Variablen akzeptieren möchten, um die
Faktorisierung bezüglich Va r so weit wie möglich vorzunehmen. Es
kann sein, dass als Nebeneffekt in gewissem Umfang eine
Faktorisierung nach anderen Variablen auftritt.
Bei der Einstellung Auto für den Modus Auto oder Näherung
ermöglicht die Einbeziehung von Va r auch eine Näherung mit
Gleitkommakoeffizienten in Fällen, wo irrationale Koeffizienten nicht
explizit bezüglich der integrierten Funktionen ausgedrückt werden
können. Selbst wenn es nur eine Variable gibt, kann das Einbeziehen
von Va r eine vollständigere Faktorisierung ermöglichen.
Hinweis: Siehe auch comDenom() zu einer schnellen partiellen
Faktorisierung, wenn factor() zu langsam ist oder den Speicherplatz
erschöpft.
Hinweis: Siehe auch cFactor() zur kompletten Faktorisierung bis
zu komplexen Koeffizienten, um lineare Faktoren zu erhalten.
Katalog
>
42 TI-Nspire™ CAS Referenzhandbuch

factor() (Faktorisiere)
factor(RationaleZahl) ergibt die rationale Zahl in Primfaktoren
zerlegt. Bei zusammengesetzten Zahlen nimmt di e Berechnungsdauer
exponentiell mit der Anzahl an Stellen im zweitgrößten Faktor zu. Das
Faktorisieren einer 30-stelligen ganzen Zahl kann beispielsweise
länger als einen Tag dauern und das Faktorisieren einer 100-stelligen
Zahl mehr als ein Jahrhundert.
Hinweis: Um eine Berechnung anzuhalten (abzubrechen), drücken
Sie auf w.
Möchten Sie hingegen lediglich feststellen, ob es sich bei einer Zahl
um eine Primzahl handelt, verwenden Sie isPrime(). Dieser Vorgang
ist wesentlich schneller, insbesondere dann, wenn RationaleZahl
keine Primzahl ist und der zweitgrößte Faktor mehr als fünf Stellen
aufweist.
Katalog
>
FCdf()
FCdf(UntGrenze,ObGrenze,FreiGradZähler,FreiGradNenner)
⇒ Zahl, wenn UntGrenze und ObGrenze Zahlen sind, Liste,
UntGrenze und ObGrenze Listen sind
wenn
FCdf(
UntGrenze,ObGrenze,FreiGradZähler,FreiGradNenner)
⇒ Zahl, wenn UntGrenze und ObGrenze Zahlen sind, Liste,
UntGrenze und ObGrenze Listen sind
wenn
Berechnet die F Verteilungswahrscheinlichkeit zwischen UntGrenze
und ObGrenze für die angegebenen FreiGradZähler
(Freiheitsgrade) und FreiGradNenner.
Für P(X obereGrenze) setzen Sie untereGrenze = 0.
Fill (Füllen)
Fill Ausdr, MatrixVar ⇒ Matrix
Ersetzt jedes Element in der Variablen MatrixVar durch Ausdr.
MatrixVar muss bereits vorhanden sein.
Fill Ausdr, ListeVar ⇒ Liste
Ersetzt jedes Element in der Variablen ListeVar durch Ausdr.
ListeVar muss bereits vorhanden sein.
Katalog
Katalog
>
>
TI-Nspire™ CAS Referenzhandbuch 43

FiveNumSummary
FiveNumSummary X[,[Häuf][,Kategorie,Mit]]
Bietet eine gekürzte Version der Statistik mit 1 Variablen auf Liste X.
Eine Zusammenfassung der Ergebnisse wird in der Variablen
stat.results gespeichert. (Siehe Seite 109.)
X stellt eine Liste mit den Daten dar.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden X-Wert an. Der
Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0 sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden X-Werte.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.MinX Minimum der x-Werte
stat.Q1X 1. Quartil von x
stat.MedianX Median von x
stat.Q3X 3. Quartil von x
stat.MaxX Maximum der x-Werte
Katalog
>
floor() (Untergrenze)
floor(Ausdr1) ⇒ Ganzzahl
Gibt die größte ganze Zahl zurück, die { dem Argument ist. Diese
Funktion ist identisch mit int().
Katalog
>
Das Argument kann eine reelle oder eine komplexe Zahl sein.
floor(Liste1) ⇒ Liste
floor(Matrix1) ⇒ Matrix
Für jedes Element einer Liste oder Matrix wird die größte ganze Zahl,
die kleiner oder gleich dem Element ist, zurückgegeben.
Hinweis: Siehe auch ceiling() und int().
fMax() (Funktionsmaximum)
fMax(Ausdr, Var) ⇒ Boolescher Ausdruck
fMax(Ausdr, Var ,UntereGrenze)
fMax(
Ausdr, Va r,UntereGrenze,ObereGrenze)
fMax(
Ausdr, Va r) | UntereGrenze<Var <ObereGrenze
Gibt einen Booleschen Ausdruck zurück, der mögliche Werte von Va r
angibt, welche Ausdr maximieren oder seine kleinste obere Grenze
angeben.
Katalog
>
44 TI-Nspire™ CAS Referenzhandbuch

fMax() (Funktionsmaximum)
Sie können den Operator “|” zur Einschränkung des Lösungsintervalls
und/oder zur Angabe anderer Einschränkungen verwenden.
Ist der Modus Auto oder Näherung auf Approximiert eingestellt,
sucht fMax() iterativ nach einem annähernden lokalen Maximum.
Dies ist oft schneller, insbesondere, wenn Sie den Operator “|”
benutzen, um die Suche auf ein relativ kleines Intervall zu
beschränken, das genau ein lokales Maximum enthält.
Hinweis: Siehe auch fMin() und max().
Katalog
>
fMin() (Funktionsminimum)
fMin(Ausdr, Var) ⇒ Boolescher Ausdruck
fMin(Ausdr, Var ,UntereGrenze)
fMin(
Ausdr, Var ,UntereGrenze,ObereGrenze)
fMin(
Ausdr, Var ) | UntereGrenze<Va r<ObereGrenze
Gibt einen Booleschen Ausdruck zurück, der mögliche Werte von Va r
angibt, welche Ausdr minimieren oder seine kleinste untere Grenze
angeben.
Sie können den Operator “|” zur Einschränkung des Lösungsintervalls
und/oder zur Angabe anderer Einschränkungen verwenden.
Ist der Modus Auto oder Näherung auf Approximiert eingestellt,
sucht fMin() iterativ nach einem annähernden lokalen Minimum.
Dies ist oft schneller, insbesondere, wenn Sie den Operator “|”
benutzen, um die Suche auf ein relativ kleinesIntervall zu
beschränken, das genau ein lokales Minimum enthält.
Hinweis: Siehe auch fMax() und min().
For
For Var , Vo n , Bis [, Schritt]
Block
EndFor
Führt die in Block befindlichen Anweisungen für jeden Wert von Va r
zwischen Vo n und Bis aus, wobei der Wert bei jedem Durchlauf um
Schritt inkrementiert wird.
Var darf keine Systemvariable sein.
Schritt kann positiv oder negativ sein. Der Standardwert ist 1.
Block kann eine einzelne Anweisung oder eine Serie von
Anweisungen sein, die durch “:” getrennt sind.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
Katalog
Katalog
>
>
TI-Nspire™ CAS Referenzhandbuch 45

format() (Format)
format(Ausdr[, FormatString]) ⇒ Stri ng
Gibt Ausdr als Zeichenkette im Format der Formatvorlage zurück.
Ausdr muss zu einer Zahl vereinfachbar sein.
FormatString ist eine Zeichenkette und muss diese Form besitzen:
“F[n]”, “S[n]”, “E[n]”, “G[n][c]”, wobei [ ] optionale Teile bedeutet.
F[n]: Festes Format. n ist die Anzahl der angezeigten
Nachkommastellen (nach dem Dezimalpunkt).
S[n]: Wissenschaftliches Format. n ist die Anzahl der angezeigten
Nachkommastellen (nach dem Dezimalpunkt).
E[n]: Technisches Format. n ist die Anzahl der Stellen, die auf die erste
signifikante Ziffer folgen. Der Exponent wird auf ein Vielfaches von 3
gesetzt, und der Dezimalpunkt wird um null, eine oder zwei Stellen
nach rechts verschoben.
G[n][c]: Wie Festes Format, unterteilt jedoch auch die Stellen links des
Dezimaltrennzeichens in Dreiergruppen. c ist das
Gruppentrennzeichen und ist auf "Komma" voreingestellt. Wenn c
auf "Punkt" gesetzt wird, wird das Dezimaltrennzeichen zum
Komma.
[Rc]: Jeder der vorstehenden Formateinstellungen kann als Suffix das
Flag Rc nachgestellt werden, wobei c ein einzelnes Zeichen ist, das
den Dezimalpunkt ersetzt.
Katalog
>
fPart() (Funktionsteil)
fPart(Ausdr1) ⇒ Ausdruck
fPart(Liste1) ⇒ Liste
fPart(Matrix1) ⇒ Matrix
Gibt den Bruchanteil des Arguments zurück.
Bei einer Liste bzw. Matrix werden die Bruchanteile aller Elemente
zurückgegeben.
Das Argument kann eine reelle oder eine komplexe Zahl sein.
FPdf()
FPdf(XWert,FreiGradZähler,FreiGradNenner) ⇒ Zahl, wenn
XWert eine Zahl ist, Liste, wenn XWert eine Liste ist
FPdf(
XWert,FreiGradZähler,FreiGradNenner) ⇒ Zahl, wenn
XWert eine Zahl ist, Liste, wenn XWert eine Liste ist
Berechnet die F Verteilungswahrscheinlichkeit bei XWert für
die angegebenen FreiGradZähler (Freiheitsgrade) und
FreiGradNenner.
freqTable4list()
freqTable4list(Liste1,HäufGanzzahlListe) ⇒ Liste
Gibt eine Liste zurück, die die Elemente von Liste1 erweitert gemäß
den Häufigkeiten in HäufGanzzahlListe enthält. Diese Funktion kann
zum Erstellen einer Häufigkeitstabelle für die Applikation 'Data &
Statistics' verwendet werden.
Liste1 kann eine beliebige gültige Liste sein.
HäufGanzzahlListe muss die gleiche Dimension wie Liste1 haben
und darf nur nicht-negative Ganzzahlelemente enthalten. Jedes
Element gibt an, wie oft das entsprechende Liste1-Element in der
Ergebnisliste wiederholt wird. Der Wert 0 schließt das entsprechende
Liste1-Element aus.
Katalog
Katalog
Katalog
>
>
>
46 TI-Nspire™ CAS Referenzhandbuch

frequency() (Häufigkeit)
frequency(Liste1,binsListe) ⇒ Liste
Gibt eine Liste zurück, die die Zähler der Elemente in Liste1 enthält.
Die Zähler basieren auf Bereichen (bins), die Sie in binsListe
definieren.
Wenn binsListe {b(1), b(2), …, b(n)} ist, sind die festgelegten
Bereiche {?{b(1), b(1)<?{b(2),…,b(n-1)<?{b(n), b(n)>?}. Die
Ergebnisliste enthält ein Element mehr als die binsListe.
Jedes Element des Ergebnisses entspricht der Anzahl der Elemente
aus Liste1, die im Bereich dieser bins liegen. Ausgedrückt in Form der
countIf() Funktion ist das Ergebnis { countIf(Liste, ?{b(1)),
countIf(Liste, b(1)<?{b(2)), …, countIf(Liste, b(n-1)<?{b(n)),
countIf(Liste, b(n)>?)}.
Elemente von Liste1, die nicht “in einem bin platziert” werden
können, werden ignoriert.
Innerhalb der Lists & Spreadsheet Applikation können Sie für beide
Argumente Zellenbereiche verwenden.
Hinweis: Siehe auch countIf(), Seite 23.
Katalog
>
Erklärung des Ergebnisses:
2 Elemente aus Datenliste (Datalist) sind {2.5
4 Elemente aus Datenliste sind >2.5 und {4.5
3 Elemente aus Datenliste sind >4.5
Das Element "Hallo" ist eine Zeichenfolge und kann nicht in
einem der definierten bins platziert werden.
FTest_2Samp (Zwei-Stichproben F-Test)
FTest_2Samp
Liste1,Liste2[,Häufigkeit1[,Häufigkeit2[,Hypoth]]]
FTest_2Samp
Liste1,Liste2[,Häufigkeit1[,Häufigkeit2[,Hypoth]]]
(Datenlisteneingabe)
FTest_2Samp sx1,n1,sx2,n2[,Hypoth]
FTest_2Samp
(Zusammenfassende statistische Eingabe)
Führt einen F -Test mit zwei Stichproben durch. Eine
Zusammenfassung der Ergebnisse wird in der Variable stat.results
gespeichert. (Siehe Seite 109.)
Für Ha: s1 > s2 setzen Sie Hypoth>0
Für Ha: s1 ƒ s2 (Standard) setzen Sie Hypoth =0
Für Ha: s1 < s2 setzen Sie Hypoth<0
Ausgabevariable Beschreibung
Statistik.F
stat.PVal Kleinste Signifikanzebene, bei der die Nullhypothese verworfen werden kann
stat.dfNumer Freiheitsgrade des Zählers = n1-1
stat.dfDenom Freiheitsgrade des Nenners = n2-1
stat.sx1, stat.sx2 Stichproben-Standardabweichungen der Datenfolgen in Liste 1 und Liste 2
stat.x1_bar
stat.x2_bar
stat.n1, stat.n2 Stichprobenumfang
sx1,n1,sx2,n2[,Hypoth]
Berechnete ó Statistik für die Datenfolge
Stichprobenmittelwerte der Datenfolgen in Liste 1 und Liste 2
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 47

Func
Func
Block
EndFunc
Vorlage zur Erstellung einer benutzerdefinierten Funktion.
Block kann eine einzelne Anweisung, eine Reihe von durch das
Zeichen “:” voneinander getrennten Anweisungen oder eine Reihe
von Anweisungen in separaten Zeilen sein. Die Funktion kann die
Zurückgeben (Return) verwenden, um ein
Anweisung
bestimmtes Ergebnis zurückzugeben.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
G
Katalog
Definieren Sie eine stückweise definierte Funktion:
Ergebnis der graphischen Darstellung g(x)
>
gcd() (Größter gemeinsamer Teiler)
gcd(Zahl1, Zahl2) ⇒ Ausdruck
Gibt den größten gemeinsamen Teiler der beiden Argumente zurück.
Der gcd zweier Brüche ist der gcd ihrer Zähler dividiert durch das
kleinste gemeinsame Vielfache (lcm) ihrer Nenner.
In den Modi Auto oder Approximiert ist der gcd von
Fließkommabrüchen 1,0.
gcd(Liste1, Liste2) ⇒ Liste
Gibt die größten gemeinsamen Teiler der einander entsprechenden
Elemente von Liste1 und Liste2 zurück.
gcd(Matrix1, Matrix2) ⇒ Matrix
Gibt die größten gemeinsamen Teiler der einander entsprechenden
Elemente von Matrix1 und Matrix2 zurück.
geomCdf()
geomCdf(p,untereGrenze,obereGrenze) ⇒ Zahl, wenn
untereGrenze und obereGrenze Zahlen sind, Liste, wenn
untereGrenze und obereGrenze Listen sind
geomCdf(
p,obereGrenze) ⇒ Zahl, wenn obereGrenze eine
Liste, wenn obereGrenze eine Liste ist
Zahl ist,
Berechnet die kumulative geometrische Wahrscheinlichkeit von
UntereGrenze bis ObereGrenze mit der angegebenen
Erfolgswahrscheinlichkeit p.
Für P(X obereGrenze) setzen Sie untereGrenze = 1.
Katalog
Katalog
>
>
48 TI-Nspire™ CAS Referenzhandbuch

geomPdf()
geomPdf(p,XWert) ⇒ Zahl, wenn XWert eine Zahl ist, Liste,
XWert eine Liste ist
wenn
Berechnet die Wahrscheinlichkeit an einem XWert, die Anzahl der
Einzelversuche, bis der erste Erfolg eingetreten ist, für die diskrete
geometrische Verteilung mit der vorgegebenen
Erfolgswahrscheinlichkeit p.
Katalog
>
getDenom() (Nenner holen)
getDenom(Ausdr1) ⇒ Ausdruck
Transformiert das Argument in einen Ausdruck mit gekürztem
gemeinsamem Nenner und gibt dann den Nenner zurück.
getLangInfo( )
getLangInfo() ⇒ Zeichenkette
Gibt eine Zeichenkette zurück, die der Abkürzung der gegenwärtig
aktiven Sprache entspricht. Sie können den Befehl zum Beispiel in
einem Programm oder einer Funktion zum Bestimmen der aktuellen
Sprache verwenden.
Englisch = "en"
Dänisch = "da"
Deutsch = "de"
Finnisch = "fi"
Französisch = "fr"
Italienisch = "it"
Holländisch = "nl"
Holländisch (Belgien) = "nl_BE"
Norwegisch = "no"
Portugiesisch = "pt"
Spanisch = "es"
Schwedisch = "sv"
getMode()
getMode(ModusNameGanzzahl) ⇒ We r t
getMode(0) ⇒ Liste
getMode(ModusNameGanzzahl) gibt einen Wert zurück, der die
aktuelle Einstellung des Modus ModusNameGanzzahl darstellt.
getMode(0) gibt eine Liste mit Zahlenpaaren zurück. Jedes Paar
enthält eine Modus-Ganzzahl und eine Einstellungs-Ganzzahl.
Eine Auflistung der Modi und ihrer Einstellungen finden Sie in der
nachstehenden Tabelle.
Wenn Sie die Einstellungen mit getMode(0) & var speichern,
können Sie setMode(var) in einer Funktion oder in einem
Programm verwenden, um die Einstellungen nur innerhalb der
Ausführung dieser Funktion bzw. dieses Programms vorübergehend
wiederherzustellen. Siehe setMode(), Seite 99.
Katalog
Katalog
Katalog
>
>
>
TI-Nspire™ CAS Referenzhandbuch 49

Modus
Name
Angezeigte Ziffern
Winkel
Exponentialformat
Reell oder komplex
Auto oder Approx.
Vektorformat
Basis
Einheitensystem
Modus
Ganzzahl Einstellen von Ganzzahlen
1
2
3
4
5
6
7
8
1
=Fließ, 2=Fließ 1, 3=Fließ 2, 4=Fließ 3, 5=Fließ 4, 6=Fließ 5, 7=Fließ 6, 8=Fließ 7,
9=Fließ 8, 10=Fließ 9, 11=Fließ 10, 12=Fließ 11, 13=Fließ 12, 14=Fix 0, 15=Fix 1,
16=Fix 2, 17=Fix 3, 18=Fix 4, 19=Fix 5, 20=Fix 6, 21=Fix 7, 22=Fix 8, 23=Fix 9,
24=Fix 10, 25=Fix 11, 26=Fix 12
1
=Bogenmaß, 2=Grad, 3=Neugrad
1
=Normal, 2=Wissenschaftlich, 3=Technisch
1
=Reell, 2=Kartesisch, 3=Polar
1
=Auto, 2=Approximiert, 3=Exakt
1
=Kartesisch, 2=Zylindrisch, 3=Sphärisch
1
=Dezimal, 2=Hex, 3=Binär
1
=SI, 2=Eng/US
getNum() (Zähler holen)
getNum(Ausdr1) ⇒ Ausdruck
Transformiert das Argument in einen Ausdruck mit gekürztem
gemeinsamem Nenner und gibt dann den Zähler zurück.
getVarInfo()
getVarInfo() ⇒ Matrix oder St ring
getVarInfo(BiblioNameString) ⇒ Matrix oder Stri ng
getVarInfo() gibt eine Informationsmatrix (Name, Typ und
Erreichbarkeit einer Variablen in der Bibliothek) für a lle Variablen und
Bibliotheksobjekte zurück, die im aktuellen Problem definiert sind.
Wenn keine Variablen definiert sind, gibt getVarInfo() die
Zeichenfolge "KEINE" (NONE) zurück.
getVarInfo(BiblioNameString) gibt eine Matrix zurück, die
Informationen zu allen Bibliotheksobjekten enthält, die in der
Bibliothek BiblioNameString definiert sind. BiblioNameString muss
eine Zeichenfolge (in Anführungszeichen eingeschlossener Text) oder
eine Zeichenfolgenvariable sein.
Wenn die Bibliothek BiblioNameString nicht existiert, wird ein
Fehler angezeigt.
Katalog
Katalog
>
>
50 TI-Nspire™ CAS Referenzhandbuch

getVarInfo()
Beachten Sie das Beispiel links, in dem das Ergebnis von
getVarInfo() der Variablen vs zugewiesen wird. Beim Versuch,
Zeile 2 oder Zeile 3 von vs anzuzeigen, wird der Fehler "Liste oder
Matrix ungültig" zurückgegeben, weil mindestens eines der Elemente
in diesen Zeilen (Variable b zum Beispiel) eine Matrix ergibt.
Dieser Fehler kann auch auftreten, wenn Ans zum Neuberechnen
eines getVarInfo()-Ergebnisses verwendet wird.
Das System liefert den obigen Fehler, weil die aktuelle Version der
Software keine verallgemeinerte Matrixstruktur unterstützt, bei der
ein Element einer Matrix eine Matrix oder Liste sein kann.
Katalog
>
Goto (Gehe zu)
Goto MarkeName
Setzt die Programmausführung bei der Marke MarkeName fort.
MarkeName muss im selben Programm mit der Anweisung Lbl
definiert worden sein.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
Grad (Neugrad)
4
Ausdr1 4 Grad ⇒ Ausdruck
Wandelt Ausdr1 ins Winkelmaß Neugrad um.
Im Grad-Modus:
Im Bogenmaß-Modus:
Katalog
Katalog
>
>
TI-Nspire™ CAS Referenzhandbuch 51

I
identity() (Einheitsmatrix)
identity(Ganzzahl) ⇒ Matrix
Gibt die Einheitsmatrix mit der Dimension Ganzzahl zurück.
Ganzzahl muss eine positive ganze Zahl sein.
If
If Boolescher Ausdr Anweisung
If Boolescher Ausdr Then
Block
EndIf
Wenn Boolescher Ausdr wahr ergibt, wird die Einzelanweisung
Anweisung oder der Anweisungsblock Block ausgeführt und danach
mit EndIf fortgefahren.
Wenn Boolescher Ausdr falsch ergibt, wird das Programm
fortgesetzt, ohne dass die Einzelanweisung bzw. der
Anweisungsblock ausgeführt werden.
Block kann eine einzelne Anweisung oder eine Serie von
Anweisungen sein, die durch “:” getrennt sind.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
If Boolescher Ausdr Then
Block1
Else
Block2
EndIf
Wenn Boolescher Ausdr wahr ergibt, wird Block1 ausgeführt und
dann Block2 übersprungen.
Wenn Boolescher Ausdr falsch ergibt, wird Block1 übersprungen,
aber Block2 ausgeführt.
Block1 und Block2 können einzelne Anweisungen sein.
Katalog
Katalog
>
>
52 TI-Nspire™ CAS Referenzhandbuch

If
If Boolescher Ausdr1 Then
Block1
ElseIf
Boolescher Ausdr2 Then
Block2
©
ElseIf
Boolescher AusdrN Then
BlockN
EndIf
Gestattet Programmverzweigungen. Wenn Boolescher Ausdr1 wahr
ergibt, wird Block1 ausgeführt. Wenn Boolescher Ausdr1 falsch
ergibt, wird Boolescher Ausdr2 ausgewertet usw.
Katalog
>
ifFn()
ifFn(BoolescherAusdruck,Wert_wenn_wahr [,Wert_wenn_falsch
[,
Wert_wenn_unbekannt]]) ⇒ Ausdruck, Liste oder Matrix
Wertet den Booleschen Ausdruck BoolescherAusdruck (oder jedes
einzelne Element von BoolescherAusdruck) aus und erstellt ein
Ergebnis auf der Grundlage folgender Regeln:
• BoolescherAusdruck kann einen Einzelwert, eine Liste oder eine
Matrix testen.
• Wenn ein Element von BoolescherAusdruck als wahr bewertet
wird, wird das entsprechende Element aus Wert_wenn_wahr
zurückgegeben.
• Wenn ein Element von BoolescherAusdruck als falsch bewertet
wird, wird das entsprechende Element aus Wert_wenn_falsch
zurückgegeben. Wenn Sie Wert_wenn_falsch weglassen, wird
Undef zurückgegeben.
• Wenn ein Element von BoolescherAusdruck weder wahr noch
falsch ist, wird das entsprechende Element aus
Wert_wenn_unbekannt zurückgegeben. Wenn Sie
Wert_wenn_unbekannt weglassen, wird Undef zurückgegeben.
• Wenn das zweite, dritte oder vierte Argument der Funktion
ifFn() ein einzelnen Ausdruck ist, wird der Boolesche Test für
jede Position in BoolescherAusdruck durchgeführt.
Hinweis: Wenn die vereinfachte Anweisung BoolescherAusdruck
eine Liste oder Matrix einbezieht, müssen alle anderen Listen- oder
Matrixanweisungen dieselbe(n) Dimension(en) haben, und auch das
Ergebnis wird dieselben(n) Dimension(en) haben.
imag() (Imaginärteil)
imag(Ausdr1) ⇒ Ausdruck
Gibt den Imaginärteil des Arguments zurück.
Hinweis: Alle undefinierten Variablen werden als reelle Variablen
behandelt. Siehe auch real(), Seite 91
Katalog
>
Testwert von 1 ist kleiner als 2.5, somit wird das entsprechende
Wert_wenn_wahr-Element von 5 in die Ergebnisliste kopiert.
Testwert von 2 ist kleiner als 2.5, somit wird das entsprechende
Wert_wenn_wahr-Element von 6 in die Ergebnisliste kopiert.
Testwert von 3 ist nicht kleiner als 2.5, somit wird das
entsprechende Wert_wenn_falsch-Element von 10 in die
Ergebnisliste kopiert.
Wert_wenn_wahr ist ein einzelner Wert und entspricht einer
beliebigen ausgewählten Position.
Wert_wenn_falsch ist nicht spezifiziert. Undef wird verwendet.
Ein aus Wert_wenn_wahr ausgewähltes Element. Ein aus
Wert_wenn_unbekannt ausgewähltes Element.
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 53

imag() (Imaginärteil)
imag(Liste1) ⇒ Liste
Gibt eine Liste der Imaginärteile der Elemente zurück.
imag(Matrix1) ⇒ Matrix
Gibt eine Matrix der Imaginärteile der Elemente zurück.
Katalog
>
impDif() (Implizite Ableitung)
impDif(Gleichung, Va r, abhängigeVar[,Ord])
⇒ Ausdruck
wobei der Vorgabewert für die Ordnung Ord 1 ist.
Berechnet die implizite Ableitung für Gleichungen, in denen eine
Variable implizit durch eine andere definiert ist.
Umleitung Siehe
inString() (In String)
inString(Quellstring, Teilstring[, Start]) ⇒ Ganzzahl
Gibt die Position des Zeichens von Quellstring zurück, an der das
erste Vorkommen von Teilstring beginnt.
Start legt fest (sofern angegeben), an welcher Zeichenposition
innerhalb von Quellstring die Suche beginnt. Vorgabe = 1 (das erste
Zeichen von Quellstring).
Enthält Quellstring die Zeichenkette Teilstring nicht oder ist Start >
Länge von Quellstring, wird Null zurückgegeben.
int() (Ganze Zahl)
int(Ausdr) ⇒ Ganzzahl
int(Liste1) ⇒ Liste
int(Matrix1) ⇒ Matrix
Gibt die größte ganze Zahl zurück, die kleiner oder gleich dem
Argument ist. Diese Funktion ist identisch mit floor().
Das Argument kann eine reelle oder eine komplexe Zahl sein.
Für eine Liste oder Matrix wird für jedes Element die größte ganze
Zahl zurückgegeben, die kleiner oder gleich dem Element ist.
Katalog
, Seite 144.
#()
Katalog
Katalog
>
>
>
intDiv() (Ganzzahl teilen)
intDiv(Zahl1, Zahl2) ⇒ Ganzzahl
intDiv(Liste1, Liste2) ⇒ Liste
intDiv(Matrix1, Matrix2) ⇒ Matrix
Gibt den mit Vorzeichen versehenen ganzzahligen Teil von
(Zahl1 ÷ Zahl2) zurück.
Für eine Liste oder Matrix wird für jedes Elementpaar der mit
Vorzeichen versehene ganzzahlige Teil von
(Argument 1 ÷ Argument 2) zurückgegeben.
integrate (Integral)
Siehe
Katalog
, Seite 140.
‰()
>
54 TI-Nspire™ CAS Referenzhandbuch

invc2()
invc2(Fläche,FreiGrad)
Fläche,FreiGrad)
invChi2(
Berechnet die inverse kumulative c2 (Chi-Quadrat)
Wahrscheinlichkeitsfunktion, die durch Freiheitsgrade FreiGrad für
eine bestimmte Fläche unter der Kurve festgelegt ist.
Katalog
>
invF()
invF(Fläche,FreiGradZähler,FreiGradNenner)
Fläche,FreiGradZähler,FreiGradNenner)
invF(
Berechnet die inverse kumulative F Verteilungsfunktion, die durch
FreiGradZähler und FreiGradNenner für eine bestimmte Fläche
unter der Kurve festgelegt ist.
invNorm()
invNorm(Fläche[,m,s])
Berechnet die inverse kumulative Normalverteilungsfunktion für eine
bestimmte Fläche unter der Normalverteilungskurve, die durch m
und s festgelegt ist.
invt()
invt(Fläche,FreiGrad)
Berechnet die inverse kumulative Student-tWahrscheinlichkeitsfunktion, die durch Freiheitsgrade, FreiGrad, für
eine bestimmte Fläche unter der Kurve festgelegt ist.
iPart() (Ganzzahliger Teil)
iPart(Zahl) ⇒ Ganzzahl
iPart(Liste1) ⇒ Liste
iPart(Matrix1) ⇒ Matrix
Gibt den ganzzahligen Teil des Arguments zurück.
Für eine Liste oder Matrix wird der ganzzahlige Teil jedes Elements
zurückgegeben.
Das Argument kann eine reelle oder eine komplexe Zahl sein.
irr()
irr(CF0,CFListe [,CFFreq]) ⇒ We r t
Finanzfunktion, die den internen Zinsfluss einer Investition berechnet.
CF0 ist der Anfangs-Cash-Flow zum Zeitpunkt 0; dies muss eine
reelle Zahl sein.
CFListe ist eine Liste von Cash-Flow-Beträgen nach dem Anfangs-
Cash-Flow CF0.
CFFreq ist eine optionale Liste, in der jedes Element die Häufigkeit
des Auftretens für einen gruppierten (fortlaufenden) Cash-FlowBetrag angibt, der das entsprechende Element von CFListe ist.
Der Standardwert ist 1; wenn Sie Werte eingeben, müssen diese
positive Ganzzahlen < 10.000 sein.
Hinweis: Siehe auch mirr(), Seite 70.
Katalog
Katalog
Katalog
Katalog
Katalog
>
>
>
>
>
TI-Nspire™ CAS Referenzhandbuch 55

isPrime() (Primzahltest)
isPrime(Zahl) ⇒ Boolescher konstanter Ausdruck
Gibt “wahr” oder “falsch” zurück, um anzuzeigen, ob es sich bei
Zahl um eine ganze Zahl
ganzzahlig teilbar ist.
Übersteigt Zahl ca. 306 Stellen und hat sie keine Faktoren
dann zeigt isPrime(Zahl) eine Fehlermeldung an.
Möchten Sie lediglich feststellen, ob es sich bei Zahl um eine
Primzahl handelt, verwenden Sie isPrime() anstelle von factor().
Dieser Vorgang ist wesentlich schneller, insbesondere dann, wenn
Zahl keine Primzahl ist und ihr zweitgrößter Faktor ca. fünf Stellen
übersteigt.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
‚ 2 handelt, die nur durch sich selbst oder 1
{1021,
L
Katalog
Funktion zum Auffinden der nächsten Primzahl nach einer
angegebenen Zahl:
>
Lbl (Marke)
Lbl MarkeName
Definiert in einer Funktion eine Marke mit dem Namen MarkeName.
Mit der Anweisung Goto MarkeName können Sie die Ausführung
an der Anweisung fortsetzen, die unmittelbar auf die Marke folgt.
Für MarkeName gelten die gleichen Benennungsregeln wie für
einen Variablennamen.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
lcm() (Kleinstes gemeinsames Vielfaches)
lcm(Zahl1, Zahl2) ⇒ Ausdruck
lcm(Liste1, Liste2) ⇒ Liste
lcm(Matrix1, Matrix2) ⇒ Matrix
Gibt das kleinste gemeinsame Vielfache der beiden Argumente
zurück. Das lcm zweier Brüche ist das lcm ihrer Zähler dividiert
durch den größten gemeinsamen Teiler (gcd) ihrer Nenner. Das lcm
von Dezimalbruchzahlen ist ihr Produkt.
Für zwei Listen oder Matrizen wird das kleinste gemeinsame
Vielfache der entsprechenden Elemente zurückgegeben.
Katalog
Katalog
>
>
56 TI-Nspire™ CAS Referenzhandbuch

left() (Links)
left(Quellstring[, Anz]) ⇒ Stri ng
Gibt Anz Zeichen zurück, die links in der Zeichenkette Quellstring
enthalten sind.
Wenn Sie Anz weglassen, wird der gesamte Quellstring
zurückgegeben.
left(Liste1[, Anz]) ⇒ Liste
Gibt Anz Elemente zurück, die links in Liste1 enthalten sind.
Wenn Sie Anz weglassen, wird die gesamte Liste1 zurückgegeben.
left(Vergleich) ⇒ Ausdruck
Gibt die linke Seite einer Gleichung oder Ungleichung zurück.
Katalog
>
libShortcut()
libShortcut(BiblioNameString, VerknNameString
[, BiblioPrivMerker]) ⇒ Liste von Variablen
Erstellt eine Variablengruppe im aktuellen Problem, die Verweise auf
alle Objekte im angegebenen Bibliotheksdokument
BiblioNameString enthält. Fügt außerdem die Gruppenmitglieder
dem Variablenmenü hinzu. Sie können dann auf jedes Objekt mit
VerknNameString verweisen.
Setzen Sie BiblioPrivMerker=0, um private Bibliotheksobjekte
auszuschließen (Standard)
Setzen Sie BiblioPrivMerker=1, um private Bibliotheksobjekte
einzubeziehen
Informationen zum Kopieren einer Variablengruppe finden Sie unter
CopyVar auf Seite 18.
Informationen zum Löschen einer Variablengruppe finden Sie unter
DelVar auf Seite 32.
limit() oder lim() (Limes)
limit(Ausdr1, Va r, St elle [,Richtung]) ⇒ Ausdruck
limit(Liste1, Var , Stelle [, Richtung]) ⇒ Liste
limit(Matrix1, Var , Stelle [, Richtung]) ⇒ Matrix
Gibt den angeforderten Grenzwert zurück.
Hinweis: Siehe auch Vorlage Limes, Seite 5.
Richtung: negativ=von links, positiv=von rechts, ansonsten=beide.
(Wird keine Angabe gemacht, gilt für Richtung die Vorgabe beide.)
Katalog
>
Dieses Beispiel setzt ein richtig gespeichertes und aktualisiertes
Bibliotheksdokument namens linalg2 voraus, das als
clearmat, gauss1 und gauss2 definierte Objekte enthält.
Katalog
>
Grenzen bei positiv ˆ und negativ ˆ werden stets zu einseitigen
Grenzen von der endlichen Seite aus umgewandelt.
Je nach den Umständen gibt limit() sich selbst oder undef zurück,
wenn kein eindeutiger Grenzwert ermittelt werden kann. Das heißt
nicht unbedingt, dass es keinen eindeutigen Grenzwert gibt. undef
bedeutet lediglich, dass das Ergebnis entweder eine unbekannte Zahl
endlicher oder unendlicher Größenordnung ist, oder es ist die
Gesamtmenge dieser Zahlen.
TI-Nspire™ CAS Referenzhandbuch 57

limit() oder lim() (Limes)
limit() arbeitet mit Verfahren wie der Regel von L’Hospital; es gibt
daher eindeutige Grenzwerte, die es nicht ermitteln kann. Wenn
Ausdr1 über Va r hinaus weitere undefinierte Variablen enthält,
müssen Sie möglicherweise Einschränkungen dafür verwenden, um
ein brauchbareres Ergebnis zu erhalten.
Grenzwerte können sehr anfällig für Rundungsfehler sein. Vermeiden
Sie nach Möglichkeit die Einstellung Approximiert für den Modus
Auto oder Näherung sowie Näherungszahlen beim Berechnen
von Grenzwerten. Andernfalls kann es sein, dass Grenzen, die Null
oder unendlich sein müssten, dies nicht sind und umgekehrt endliche
Grenzwerte ungleich Null nicht erkannt werden.
Katalog
>
LinRegBx
LinRegBx X,Y[,[Häuf][,Kategorie,Mit]]
Berechnet die lineare Regression y = a+b·x auf Listen X und Y mit
der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird in
der Variablen stat.results gespeichert. (Siehe Seite 109.)
Katalog
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden Datenpunkt X und
Y an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0
sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
Regressionsgleichung: a+b·x
stat.a, stat.b Regressionskoeffizienten
stat.r
2
Bestimmungskoeffizient
stat.r Korrelationskoeffizient
stat.Resid Residuen von der Regression
stat.XReg Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für
stat.YReg Liste der Datenpunkte in der modifizierten Y- Li st e, die schließlich in der Regression mit den
Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
stat.FreqReg Liste der Häufigkeiten für stat.FreqReg und stat.YReg
>
58 TI-Nspire™ CAS Referenzhandbuch

LinRegMx
LinRegMx X,Y[,[Häuf][,Kategorie,Mit]]
Berechnet die lineare Regression y = m·x+b auf Liste X und Y mit
der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird in
der Variablen stat.results gespeichert. (Siehe Seite 109.)
Katalog
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden Datenpunkt X und
Y an. Der Standardwert ist 1. Alle Elemente müssen Ganzzahlen | 0
sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
Regressionsgleichung: m·x+b
stat.m, stat.b Regressionskoeffizienten
stat.r
2
Bestimmungskoeffizient
stat.r Korrelationskoeffizient
stat.Resid Residuen von der Regression
stat.XReg Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für
stat.YReg Liste der Datenpunkte in der modifizierten Y- Li st e, die schließlich in der Regression mit den
Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
>
LinRegtIntervals (Lineare Regressions-t-Intervalle)
LinRegtIntervals X,Y[,Häuf[,0[,KNiv]]]
Für Steigung. Berechnet ein Konfidenzintervall des Niveaus K für die
Steigung.
LinRegtIntervals X,Y[,Häuf[,1,XWert[,KNiv]]]
Für Antwort. Berechnet einen vorhergesagten y-Wert, ein Niveau-KVorhersageintervall für eine einzelne Beobachtung und ein Niveau-KKonfidenzintervall für die mittlere Antwort.
Eine Zusammenfassung der Ergebnisse wird in der Variablen
stat.results gespeichert. (Siehe Seite 109.)
Katalog
>
Alle Listen müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-
Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen
Ganzzahlen | 0 sein.
TI-Nspire™ CAS Referenzhandbuch 59
Ausgabevariable Beschreibung
stat.RegEqn
stat.a, stat.b Regressionskoeffizienten
stat.df Freiheitsgrade
2
stat.r
stat.r Korrelationskoeffizient
stat.Resid Residuen von der Regression
Nur für Steigung
Ausgabevariable Beschreibung
[stat.CLower,
stat.CUpper]
stat.ME Konfidenzintervall-Fehlertoleranz
stat.SESlope Standardfehler der Steigung
stat.s Standardfehler an der Linie
Nur für Antwort
Ausgabevariable Beschreibung
[stat.CLower,
stat.CUpper]
stat.ME Konfidenzintervall-Fehlertoleranz
stat.SE Standardfehler der mittleren Antwort
[stat.LowerPred ,
stat.UpperPred]
stat.MEPred Vorhersageintervall-Fehlertoleranz
stat.SEPred Standardfehler für Vorhersage
stat.y
Regressionsgleichung: a+b·x
Bestimmungskoeffizient
Konfidenzintervall für die Steigung
Konfidenzintervall für die mittlere Antwort
Vorhersageintervall für eine einzelne Beobachtung
a + b·XWert
60 TI-Nspire™ CAS Referenzhandbuch

LinRegtTest (t-Test bei linearer Regression)
LinRegtTest X,Y[,Häuf[,Hypoth]]
Berechnet eine lineare Regression auf den X- und Y-Listen und einen
t-Test auf dem Wert der Steigung b und den Korrelationskoeffizienten
r für die Gleichung y=a+bx. Er berechnet die Null-Hypothese
H
:b=0 (gleichwertig, r=0) in Bezug auf eine von drei alternativen
0
Hypothesen.
Alle Listen müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-
Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen
| 0 sein.
Ganzzahlen
Hypoth ist ein optionaler Wert, der eine von drei alternativen
Hypothesen angibt, in Bezug auf die die Nullhypothese (H0:b=r=0)
untersucht wird.
Für Ha: bƒ0 und rƒ0 (Standard) setzen Sie Hypoth=0
Für Ha: b<0 und r<0 setzen Sie Hypoth<0
Für Ha: b>0 und r>0 setzen Sie Hypoth>0
Eine Zusammenfassung der Ergebnisse wird in der Variablen
stat.results gespeichert. (Siehe Seite 109.)
Ausgabevariable Beschreibung
stat.RegEqn
stat.t t-Statistik für Signifikanztest
stat.PVal Kleinste Signifikanzebene, bei der die Nullhypothese verworfen werden kann
stat.df Freiheitsgrade
stat.a, stat.b Regressionskoeffizienten
stat.s Standardfehler an der Linie
stat.SESlope Standardfehler der Steigung
2
stat.r
stat.r Korrelationskoeffizient
stat.Resid Residuen von der Regression
Regressionsgleichung: a + b·x
Bestimmungskoeffizient
Katalog
>
list() (Listendifferenz)
@
Katalog
>
@list(Liste1) ⇒ Liste
Ergibt eine Liste mit den Differenzen der aufeinander folgenden
Elemente in Liste1. Jedes Element in Liste1 wird vom folgenden
Element in Liste1 subtrahiert. Die Ergebnisliste enthält stets ein
Element weniger als die ursprüngliche Liste1.
TI-Nspire™ CAS Referenzhandbuch 61

list4mat() (Liste in Matrix)
list4mat(Liste [, ElementeProZeile]) ⇒ Matrix
Gibt eine Matrix zurück, die Zeile für Zeile mit den Elementen aus
Liste aufgefüllt wurde.
ElementeProZeile gibt (sofern angegeben) die Anzahl der Elemente
pro Zeile an. Vorgabe ist die Anzahl der Ele mente in Liste (eine Zeile).
Wenn Liste die resultierende Matrix nicht vollständig auffüllt, werden
Nullen hinzugefügt.
ln
4
(Natürlicher Logarithmus)
Ausdr 4ln ⇒ Ausdruck
Führt dazu, dass der eingegebene Ausdr in einen Ausdruck
umgewandelt wird, der nur natürliche Logarithmen (ln) enthält.
Katalog
Katalog
>
>
ln() (Natürlicher Logarithmus)
ln(Ausdr1) ⇒ Ausdruck
ln(Liste1) ⇒ Liste
Gibt den natürlichen Logarithmus des Arguments zurück.
Gibt für eine Liste die natürlichen Logarithmen der einzelnen
Elemente zurück.
ln(Quadratmatrix1) ⇒ Quadratmatrix
Ergibt den natürlichen Matrix-Logarithmus von Quadratmatrix1.
Dies ist nicht gleichbedeutend mit der Berechnung des natürlichen
Logarithmus jedes einzelnen Elements. Näheres zum
Berechnungsverfahren finden Sie im Abschnitt cos().
Quadratmatrix1 muss diagonalisierbar sein. Das Ergebnis enthält
immer Fließkommazahlen.
/u
Bei Komplex-Formatmodus reell:
Bei Komplex-Formatmodus kartesisch:
Im Winkelmodus Bogenmaß und Komplex-Formatmodus
“kartesisch”:
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
Tasten
62 TI-Nspire™ CAS Referenzhandbuch

LnReg
LnReg X, Y[, [Häuf] [, Kategorie, Mit]]
Berechnet die logarithmische Regression y = a+b·ln(x) auf Listen X
und Y mit der Häufigkeit Häuf. Eine Zusammenfassung der
Ergebnisse wird in der Variablen stat.results gespeichert.
(Siehe Seite 109.)
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element
in Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-
Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen
Ganzzahlen | 0 sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
stat.a, stat.b Regressionskoeffizienten
2
stat.r
stat.r Korrelationskoeffizient für transformierte Daten (ln(x), y)
stat.Resid Mit dem logarithmischen Modell verknüpfte Residuen
stat.ResidTrans Residuen für die lineare Anpassung transformierter Daten
stat.XReg Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für
stat.YReg Liste der Datenpunkte in der modifizierten Y- Li st e, die schließlich in der Regression mit den
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
Regressionsgleichung: a+b·ln(x)
Koeffizient der linearen Bestimmtheit für transformierte Daten
Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 63

Local (Lokale Variable)
Local Var 1 [, Va r 2] [, Va r 3 ] ...
Deklariert die angegebenen Variablen Variable als lokale Variablen.
Diese Variablen existieren nur während der Auswertung einer
Funktion und werden gelöscht, wenn die Funktion beendet wird.
Hinweis: Lokale Variablen sparen Speicherplatz, da sie nur
temporär existieren. Außerdem stören sie keine vorhandenen
globalen Variablenwerte. Lokale Variablen müssen für
und für das temporäre Speichern von Werten in mehrzeiligen
Funktionen verwendet werden, da Änderungen globaler Variablen in
einer Funktion unzulässig sind.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
For-Schleifen
Katalog
>
log() (Logarithmus)
log(Ausdr1[,Ausdr2]) ⇒ Ausdruck
log(Liste1[,Ausdr2]) ⇒ Liste
Gibt für den Logarithmus des Arguments zur Basis Ausdr2 zurück.
Hinweis: Siehe auch Vorlage Logarithmus, Seite 2.
Gibt bei einer Liste den Logarithmus der Elemente zur Basis Ausdr2
zurück.
Wenn Ausdr2 weggelassen wird, wird 10 als Basis verwendet.
log(Quadratmatrix1[,Ausdr2]) ⇒ Quadratmatrix
Gibt den Matrix-Logarithmus von Quadratmatrix1 zur Basis Ausdr2
zurück. Dies ist nicht gleichbedeutend mit der Berechnung des
Logarithmus jedes Elements zur Basis Ausdr2. Näheres zur
Berechnungsmethode finden Sie im Abschnitt cos().
Quadratmatrix1 muss diagonalisierbar sein. Das Ergebnis enthält
immer Fließkommazahlen.
Wenn das Basisargument weggelassen wird, wird 10 als Basis
verwendet.
s
/
Bei Komplex-Formatmodus reell:
Bei Komplex-Formatmodus kartesisch:
Im Winkelmodus Bogenmaß und Komplex-Formatmodus
“kartesisch”:
Um das ganze Ergebnis zu sehen, drücken Sie £ und
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
Tasten
64 TI-Nspire™ CAS Referenzhandbuch

logbase
4
4logbase(Ausdr1) ⇒ Ausdruck
Ausdr
Führt dazu, dass der eingegebene Ausdruck zu einem Ausdruck mit
der Basis Ausdr1 vereinfacht wird.
Katalog
>
Logistic
Logistic X, Y[, [Häuf] [, Kategorie, Mit]]
Berechnet die logistische Regression y = (c/(1+a·e
und Y mit der Häufigkeit Häuf. Eine Zusammenfassung der
Ergebnisse wird in der Variablen stat.results gespeichert.
(Siehe Seite 109.)
-bx
)) auf Listen X
Katalog
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-
Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen
Ganzzahlen | 0 sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
Regressionsgleichung: c/(1+a·e
-bx
)
stat.a, stat.b, stat.c Regressionskoeffizienten
stat.Resid Residuen von der Regression
stat.XReg Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für
stat.YReg Liste der Datenpunkte in der modifizierten Y- Li st e, die schließlich in der Regression mit den
Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
>
TI-Nspire™ CAS Referenzhandbuch 65

LogisticD
LogisticD X, Y [, [Iterationen], [Häuf] [, Kategorie, Mit] ]
Berechnet die logistische Regression y = (c/(1+a·e
X und Y mit der Häufigkeit Häuf unter Verwendung einer bestimmten
Anzahl von Iterationen. Eine Zusammenfassung der Ergebnisse wird
in der Variablen stat.results gespeichert. (Siehe Seite 109.)
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Iterationen ist ein optionaler Wert, der angibt, wie viele
Lösungsversuche maximal stattfinden. Bei Auslassung wird 64
verwendet. Größere Werte führen in der Regel zu höherer
Genauigkeit, aber auch zu längeren Ausführungszeiten, und
umgekehrt.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-
Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen
| 0 sein.
Ganzzahlen
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
stat.a, stat.b, stat.c,
stat.d
stat.Resid Residuen von der Regression
stat.XReg Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für
stat.YReg Liste der Datenpunkte in der modifizierten Y- Li st e, die schließlich in der Regression mit den
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
Regressionsgleichung: c/(1+a·e
Regressionskoeffizienten
Häuf, Kategorieliste und Mit -Kategorien verwendet wurde
Beschränkungen für Häuf, Kategorieliste und Mit -Kategorien verwendet wurde
-bx
)+d) auf Listen
-bx
)+d)
Katalog
>
66 TI-Nspire™ CAS Referenzhandbuch

Loop (Schleife)
Loop
Block
EndLoop
Führt die in Block enthaltenen Anweisungen wiederholt aus.
Beachten Sie, dass dies eine Endlosschleife ist. Beenden Sie sie, indem
Sie die Anweisung
Block ist eine Folge von Anweisungen, die durch das Zeichen “:”
voneinander getrennt sind.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
Goto oder Exit in Block ausführen.
Katalog
>
LU (Untere/obere Matrixzerlegung)
LU Matrix, lMatName, uMatName, pMatName[, Tol ]
Berechnet die Doolittle LU-Zerlegung einer reellen oder komplexen
Matrix. Die untere Dreiecksmatrix ist in lMatName gespeichert, die
obere Dreiecksmatrix in uMatName und die Permutationsmatrix (in
welcher der bei der Berechnung vorgenommene Zeilentausch
dokumentiert ist) in pMatName.
lMatName · uMatName = pMatName · Matrix
Sie haben die Option, dass jedes Matrixelement als Null behandelt
wird, wenn dessen absoluter Wert geringer als To l ist. Diese Toleranz
wird nur dann verwendet, wenn die Matrix Fließkommaelemente
aufweist und keinerlei symbolische Variablen ohne zugewiesene
Werte enthält. Anderenfalls wird Tol ignoriert.
• Wenn Sie
•Wird Tol weggelassen oder nicht verwendet, so wird die
Der LU-Faktorisierungsalgorithmus verwendet partielle Pivotisierung
mit Zeilentausch.
/
oder Näherung
Berechnungen in Fließkomma-Arithmetik durchgeführt.
Standardtoleranz folgendermaßen berechnet:
5EM14 ·max(dim(Matrix)) ·rowNorm(Matrix)
· verwenden oder den Modus Auto
auf Approximiert einstellen, werden
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 67

M
mat4list() (Matrix in Liste)
mat4list(Matrix) ⇒ Liste
Gibt eine Liste zurück, die mit den Elementen aus Matrix gefüllt
wurde. Die Elemente werden Zeile für Zeile aus Matrix kopiert.
max() (Maximum)
max(Ausdr1, Ausdr2) ⇒ Ausdruck
max(Liste1, Liste2) ⇒ Liste
max(Matrix1, Matrix2) ⇒ Matrix
Gibt das Maximum der beiden Argumente zurück. Wenn die
Argumente zwei Listen oder Matrizen sind, wird eine Liste bzw.
Matrix zurückgegeben, die den Maximalwert für jedes entsprechende
Elementpaar enthält.
max(Liste) ⇒ Ausdruck
Gibt das größte Element von Liste zurück.
max(Matrix1) ⇒ Matrix
Gibt einen Zeilenvektor zurück, der das größte Element jeder Spalte
von Matrix1 enthält.
Hinweis: Siehe auch fMax() und min().
mean() (Mittelwert)
mean(Liste[, Häufigkeitsliste]) ⇒ Ausdruck
Gibt den Mittelwert der Elemente in Liste zurück.
Jedes Häufigkeitsliste-Element gewichtet die Elemente von Liste in
der gegebenen Reihenfolge entsprechend.
mean(Matrix1[, Häufigkeitsmatrix])
⇒ Matrix
Ergibt einen Zeilenvektor aus den Mittelwerten aller Spalten in
Matrix1.
Jedes Häufigkeitsmatrix-Element gewichtet die Elemente von
Matrix1 in der gegebenen Reihenfolge entsprechend.
Im Vektorformat kartesisch:
Katalog
Katalog
Katalog
>
>
>
median() (Median)
median(Liste) ⇒ Ausdruck
Gibt den Medianwert der Elemente in Liste zurück.
Katalog
>
68 TI-Nspire™ CAS Referenzhandbuch

median() (Median)
median(Matrix1) ⇒ Matrix
Gibt einen Zeilenvektor zurück, der die Medianwerte der einzelnen
Spalten von Matrix1 enthält.
Hinweis: Alle Elemente der Liste bzw. der Matrix müssen zu Zahlen
vereinfachbar sein.
Katalog
>
MedMed
MedMed X,Y [, Häuf] [, Kategorie, Mit]]
Berechnet die Median-Median-Linie y = (m·x+b) auf Listen X und Y
mit der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird
in der Variablen stat.results gespeichert. (Siehe Seite 109.)
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-
Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen
Ganzzahlen | 0 sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
stat.m, stat.b Modellkoeffizienten
stat.Resid Residuen von der Median-Median-Linie
stat.XReg Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für
stat.YReg Liste der Datenpunkte in der modifizierten Y- Li st e, die schließlich in der Regression mit den
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
Median-Median-Linien-Gleichung: m·x+b
Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Katalog
>
mid() (Teil-String)
mid(Quellstring, Start[, Anzahl]) ⇒ St ring
Gibt Anzahl Zeichen aus der Zeichenkette Quellstring ab dem
Zeichen mit der Nummer Start zurück.
Wird Anzahl weggelassen oder ist sie größer als die Länge von
Quellstring, werden alle Zeichen vonQuellstring ab dem Zeichen mit
der Nummer Start zurückgegeben.
Anzahl muss ‚ 0 sein. Bei Anzahl = 0 wird eine leere Zeichenkette
zurückgegeben.
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 69

mid() (Teil-String)
mid(Quellliste, Start [, Anzahl]) ⇒ Liste
Gibt Anzahl Elemente aus Quellliste ab dem Element mit der
Nummer Start zurück.
Wird Anzahl weggelassen oder ist sie größer als die Dimension von
Quellliste, werden alle Elemente von Quellliste ab dem Element mit
der Nummer Start zurückgegeben.
Anzahl muss
zurückgegeben.
mid(QuellstringListe, Start[, Anzahl]) ⇒ Liste
Gibt Anzahl Strings aus der Stringliste QuellstringListe ab dem
Element mit der Nummer Start zurück.
‚ 0 sein. Bei Anzahl = 0 wird eine leere Liste
min() (Minimum)
min(Ausdr1, Ausdr2) ⇒ Ausdruck
min(Liste1, Liste2) ⇒ Liste
min(Matrix1, Matrix2) ⇒ Matrix
Gibt das Minimum der beiden Argumente zurück. Wenn die
Argumente zwei Listen oder Matrizen sind, wird eine Liste bzw.
Matrix zurückgegeben, die den Minimalwert für jedes entsprechende
Elementpaar enthält.
min(Liste) ⇒ Ausdruck
Gibt das kleinste Element von Liste zurück.
min(Matrix1) ⇒ Matrix
Gibt einen Zeilenvektor zurück, der das kleinste Element jeder Spalte
von Matrix1 enthält.
Hinweis: Siehe auch fMin() und max().
Katalog
Katalog
>
>
mirr()
mirr(Finanzierungsrate,Reinvestitionsrate,CF0,CFListe[,CFFre
q])
Finanzfunktion, die den modifizierten internen Zinsfluss einer
Investition zurückgibt.
Finanzierungsrate ist der Zinssatz, den Sie für die Cash-FlowBeträge zahlen.
Reinvestitionsrate ist der Zinssatz, zu dem die Cash-Flows
reinvestiert werden.
CF0 ist der Anfangs-Cash-Flow zum Zeitpunkt 0; dies muss eine
reelle Zahl sein.
CFListe ist eine Liste von Cash-Flow-Beträgen nach dem AnfangsCash-Flow CF0.
CFFreq ist eine optionale Liste, in der jedes Element die Häufigkeit
des Auftretens für einen gruppierten (fortlaufenden) Cash-FlowBetrag angibt, der das entsprechende Element von CFListe ist. Der
Standardwert ist 1; wenn Sie Werte eingeben, müssen diese positive
Ganzzahlen < 10.000 sein.
Hinweis: Siehe auch irr(), Seite 55.
Katalog
>
70 TI-Nspire™ CAS Referenzhandbuch

mod() (Modulo)
mod(Ausdr1, Ausdr2) ⇒ Ausdruck
mod(Liste1, Liste2) ⇒ Liste
mod(Matrix1, Matrix2) ⇒ Matrix
Gibt das erste Argument modulo das zweite Argument gemäß der
folgenden Identitäten zurück:
mod(x,0) = x
mod(x,y) = x
Ist das zweite Argument ungleich Null, ist das Ergebnis in diesem
Argument periodisch. Das Ergebnis ist entweder Null oder besitzt das
gleiche Vorzeichen wie das zweite Argument.
Sind die Argumente zwei Listen bzw. zwei Matrizen, wird eine Liste
bzw. Matrix zurückgegeben, die den Modulus jedes Elementpaars
enthält.
Hinweis: Siehe auch remain(), Seite 92
-ìy floor(x/y)
Katalog
>
mRow() (Matrixzeilenoperation)
mRow(Ausdr, Matrix1, Index) ⇒ Matrix
Gibt eine Kopie von Matrix1 zurück, in der jedes Element der Zeile
Index von Matrix1 mit Ausdr multipliziert ist.
mRowAdd() (Matrixzeilenaddition)
mRowAdd(Ausdr, Matrix1, Index1, Index2) ⇒ Matrix
Gibt eine Kopie von Matrix1 zurück, wobei jedes Element in Zeile
Index2 von Matrix1 ersetzt wird durch:
Ausdr × Zeile Index1 + Zeile Index2
MultReg
MultReg Y, X1[,X2[,X3,…[,X10]]]
Berechnet die lineare Mehrfachregression der Liste Y für die Listen
X1, X2, …, X10. Eine Zusammenfassung der Ergebnisse wird in der
Variablen stat.results gespeichert. (Siehe Seite 109.)
Alle Listen müssen die gleiche Dimension besitzen.
Ausgabevariable Beschreibung
stat.RegEqn
Regressionsgleichung: b0+b1·x1+b2·x2+ ...
stat.b0, stat.b1, ... Regressionskoeffizienten
stat.R
2
Multiples Bestimmtheitsmaß
stat.yList yList = b0+b1·x1+ ...
stat.Resid Residuen von der Regression
Katalog
Katalog
Katalog
>
>
>
TI-Nspire™ CAS Referenzhandbuch 71

MultRegIntervals
MultRegIntervals Y,
X1[,X2[,X3,…[,X10]]],XWertListe[,KNiveau]
Berechnet einen vorhergesagten y-Wert, ein Niveau-KVorhersageintervall für eine einzelne Beobachtung und ein Niveau-KKonfidenzintervall für die mittlere Antwort.
Eine Zusammenfassung der Ergebnisse wird in der Variablen
stat.results gespeichert. (Siehe Seite 109.)
Alle Listen müssen die gleiche Dimension besitzen.
Ausgabevariable Beschreibung
stat.RegEqn
Regressionsgleichung: b0+b1·x1+b2·x2+ ...
stat.y Eine Punktschätzung: y = b0 + b1 · xl + ... für XWertListe
stat.dfError Fehler-Freiheitsgrade
stat.CLower, stat.CUpper Konfidenzintervall für eine mittlere Antwort
stat.ME Konfidenzintervall-Fehlertoleranz
stat.SE Standardfehler der mittleren Antwort
stat.LowerPred,
stat.UpperrPred
Vorhersageintervall für eine einzelne Beobachtung
stat.MEPred Vorhersageintervall-Fehlertoleranz
stat.SEPred Standardfehler für Vorhersage
stat.bList Liste der Regressionskoeffizienten, {b0,b1,b2,...}
stat.Resid Residuen von der Regression
Katalog
>
MultRegTests
MultRegTests Y, X1[,X2[,X3,…[,X10]]]
Der lineare Mehrfachregressionstest berechnet eine lineare
Mehrfachregression für die gegebenen Daten sowie die globale F-
Teststatistik und t-Teststatistik für die Koeffizienten.
Eine Zusammenfassung der Ergebnisse wird in der Variablen
stat.results gespeichert. (Siehe Seite 109.)
Katalog
>
Ausgaben
Ausgabevariable Beschreibung
stat.RegEqn
Regressionsgleichung: b0+b1·x1+b2·x2+ ...
stat.F Globale F-Testgröße
stat.PVal Mit globaler F-Statistik verknüpfter P-Wert
stat.R
stat.AdjR
2
2
Multiples Bestimmtheitsmaß
Angepasster Koeffizient des multiplen Bestimmtheitsmaßes
stat.s Standardabweichung des Fehlers
72 TI-Nspire™ CAS Referenzhandbuch

Ausgabevariable Beschreibung
stat.DW Durbin-Watson-Statistik; bestimmt, ob in dem Modell eine Autokorrelation erster Ordnung vorhanden ist
stat.dfReg Regressions-Freiheitsgrade
stat.SSReg Summe der Regressionsquadrate
stat.MSReg Mittlere Regressionsstreuung
stat.dfError Fehler-Freiheitsgrade
stat.SSError Summe der Fehlerquadrate
stat.MSError Mittleres Fehlerquadrat
stat.bList {b0,b1,...} Liste der Koeffizienten
stat.tList Liste der t-Testgrößen, eine für jeden Koeffizienten in b-Liste
stat.PList Liste der P-Werte für jede t-Testgröße
stat.SEList Liste der Standardfehler für Koeffizienten in b-Liste
stat.yList yList = b0+b1·x1+...
stat.Resid Residuen von der Regression
stat.sResid Standardisierte Residuen; wird durch Division eines Residuums durch die Standardabweichung ermittelt
stat.CookDist Cookscher Abstand; Maß für den Einfluss einer Beobachtung auf der Basis von Residuum und Hebelwert
stat.Leverage Maß für den Abstand der Werte der unabhängigen Variable von den Mittelwerten (Hebelwerte)
N
nCr() (Kombinationen)
nCr(Ausdr1, Ausdr2) ⇒ Ausdruck
Für ganzzahlige Ausdr1 und Ausdr2 mit Ausdr1 ‚ Ausdr2 ‚ 0 ist
nCr() die Anzahl der Möglichkeiten, Ausdr1 Elemente aus Ausdr2
Elementen auszuwählen (auch als Binomialkoeffizient bekannt).
Beide Argumente können ganze Zahlen oder symbolische Ausdrücke
sein.
nCr(Ausdr, 0) ⇒ 1
Ausdr, negGanzzahl) ⇒ 0
nCr(
Ausdr, posGanzzahl) ⇒ Ausdr·(AusdrN1)...
nCr(
(AusdrNposGanzzahl+1)/ posGanzzahl!
Ausdr, keineGanzzahl) ⇒ Ausdr!/
nCr(
((AusdrNkeineGanzzahl)!·keineGanzzahl!)
Liste1, Liste2) ⇒ Liste
nCr(
Gibt eine Liste von Binomialkoeffizienten auf der Basis der
entsprechenden Elementpaare der beiden Listen zurück. Die
Argumente müssen Listen gleicher Größe sein.
nCr(Matrix1, Matrix2) ⇒ Matrix
Gibt eine Matrix von Binomialkoeffizienten auf der Basis der
entsprechenden Elementpaare der beiden Matrizen zurück. Die
Argumente müssen Matrizen gleicher Größe sein.
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 73

nDeriv() (Numerische Ableitung)
nDeriv(Ausdr1, Va r [=Wert] [, H]) ⇒ Ausdruck
nDeriv(Ausdr1, Va r [, H] | Var = We r t ) ⇒ Ausdruck
nDeriv(Ausdr1, Va r [=Wert], Liste) ⇒ Liste
nDeriv(Liste1, Va r [=Wert] [, H]) ⇒ Liste
nDeriv(Matrix1, Va r [=Wert] [, H]) ⇒ Matrix
Gibt die numerische Ableitung als Ausdruck zurück. Benutzt die
Zentraldifferenzenquotientenformel.
Wenn Wer t angegeben wird, setzt er jede vorausgegangene
Variablenzuweisung oder jede aktuelle Ersetzung für die Variable
außer Kraft.
H ist der Schrittwert. Wird H nicht angegeben, wird als Vorgabewert
0,001 benutzt.
Wenn Sie Liste1 oder Matrix1 verwenden, wird die Operation über
die Werte in der Liste oder die Matrixelemente abgebildet.
Hinweis: Siehe auch avgRC() und d().
Katalog
>
newList() (Neue Liste)
newList(AnzElemente) ⇒ Liste
Gibt eine Liste der Dimension AnzElemente zurück. Jedes Element ist
Null.
newMat() (Neue Matrix)
newMat(AnzZeil, AnzSpalt) ⇒ Matrix
Gibt eine Matrix der Dimension AnzZeil mal AnzSpalt zurück, wobei
die Elemente Null sind.
nfMax() (Numerisches Funktionsmaximum)
nfMax(Ausdr, Var ) ⇒ We rt
nfMax(Ausdr, Var , UntereGrenze) ⇒ We r t
nfMax(Ausdr, Var , UntereGrenze, ObereGrenze) ⇒ We rt
nfMax(Ausdr, Var) | UntereGrenze<Var <ObereGrenze ⇒ We rt
Gibt einen möglichen numerischen Wert der Variablen Va r zurück,
wobei das lokale Maximum von Ausdr auftritt.
Wenn Sie UntereGrenze und ObereGrenze angeben, sucht die
Funktion zwischen diesen Werten nach dem lokalen Maximum.
Hinweis: Siehe auch fMax() und d().
nfMin() (Numerisches Funktionsminimum)
nfMin(Ausdr, Var ) ⇒ We rt
nfMin(
Ausdr, Va r, UntereGrenze) ⇒ We r t
Ausdr, Va r, UntereGrenze, ObereGrenze) ⇒ We rt
nfMin(
nfMin(
Ausdr, Var) | UntereGrenze<Var <ObereGrenze ⇒ We rt
Gibt einen möglichen numerischen Wert der Variablen Va r zurück,
wobei das lokale Minimum von Ausdr auftritt.
Wenn Sie UntereGrenze und ObereGrenze angeben, sucht die
Funktion zwischen diesen Werten nach dem lokalen Minimum.
Hinweis: Siehe auch fMin() und d().
Katalog
Katalog
Katalog
Katalog
>
>
>
>
74 TI-Nspire™ CAS Referenzhandbuch

nInt() (Numerisches Integral)
nInt(Ausdr1, Var, Untere, Obere) ⇒ Ausdruck
Wenn der Integrand Ausdr1 außer Va r keine anderen Variablen
enthält und wenn Untere und Obere Konstanten oder positiv
negativ ˆ sind, gibt nInt() eine Näherung für ‰(Ausdr1, Va r ,
Untere, Obere) zurück. Diese Näherung ist der gewichtete
Durchschnitt von Stichprobenwerten des Integranden im Intervall
Untere<Var <Obere.
Das Berechnungsziel sind sechs signifikante Stellen. Der angewendete
Algorithmus beendet die Weiterberechnung, wenn das Ziel
hinreichend erreicht ist oder wenn weitere Stichproben
wahrscheinlich zu keiner sinnvollen Verbesserung führen.
Wenn es scheint, dass das Berechnungsziel nicht erreicht wurde, wird
die Meldung “Zweifelhafte Genauigkeit” angezeigt.
Sie können nInt() verschachteln, um mehrere numerische
Integrationen durchzuführen. Die Integrationsgrenzen können von
außerhalb liegenden Integrationsvariablen abhängen.
Hinweis: Siehe auch ‰(), Seite 140.
ˆ oder
Katalog
>
nom()
nom(Effektivzins,CpY) ⇒ We rt
Finanzfunktion zur Umrechnung des jährlichen Effektivzinssatzes
Effektivzins in einen Nominalzinssatz, wobei CpY als Anzahl der
Verzinsungsperioden pro Jahr gegeben ist.
Effektivzins muss eine reelle Zahl sein und CpY muss eine re elle Zahl
> 0 sein.
Hinweis: Siehe auch eff(), Seite 37.
norm()
norm(Matrix) ⇒ Ausdruck
norm(Ve k to r ) ⇒ Ausdruck
Gibt die Frobeniusnorm zurück.
Katalog
Katalog
>
>
TI-Nspire™ CAS Referenzhandbuch 75

normalLine()
normalLi ne (Ausdr1,Va r ,Punkt) ⇒ Ausdruck
normalLine(Ausdr1,Va r =Punkt) ⇒ Ausdruck
Gibt die Normale zu der durch Ausdr1 dargestellten Kurve an dem in
Var =Punkt angegebenen Punkt zurück.
Stellen Sie sicher, dass die unabhängige Variable nicht definiert ist.
Wenn zum Beispiel f1(x):=5 und x:=3 ist, gibt
normalLine(f1(x),x,2) "false" zurück.
Katalog
>
normCdf() (Normalverteilungswahrscheinlichkeit)
normCdf(untereGrenze,obereGrenze[,m[,s]]) ⇒ Zahl, wenn
untereGrenze und obereGrenze Zahlen sind, Liste, wenn
untereGrenze und obereGrenze Listen sind
Berechnet die Normalverteilungswahrscheinlichkeit zwischen
untereGrenze und obereGrenze für die angegebenen m
(Standard = 0) und s (Standard = 1).
Für P(X obereGrenze) setzen Sie untereGrenze = .ˆ.
normPdf() (Wahrscheinlichkeitsdichte)
normPdf(XWert[,m[,s]]) ⇒ Zahl, wenn XWert eine Zahl ist,
Liste, wenn XWert eine Liste ist
Berechnet die Wahrscheinlichkeitsdichtefunktion für die
Normalverteilung an einem bestimmten XWert für die vorgegebenen
m und s.
not
not BoolescherAusdr1 ⇒ BoolescherAusdruck
Gibt „wahr“ oder „falsch“ oder eine vereinfachte Form des
Arguments zurück.
Katalog
Katalog
Katalog
>
>
>
76 TI-Nspire™ CAS Referenzhandbuch

not
not Ganzzahl1 ⇒ Ganzzahl
Gibt das Einerkomplement einer reellen ganzen Zahl zurück. Intern
wird Ganzzahl1 in eine 32-Bit-Dualzahl mit Vorzeichen
umgewandelt. Für das Einerkomplement werden die Werte aller Bits
umgekehrt (so dass 0 zu 1 wird und umgekehrt). Die Ergebnisse
werden im jeweiligen Basis-Modus angezeigt.
Sie können die ganzen Zahlen mit jeder Basis eingeben. Für eine
binäre oder hexadezimale Eingabe ist das Präfix 0b bzw. 0h zu
verwenden. Ohne Präfix wird die ganze Zahl als dezimal behandelt
(Basis 10).
Geben Sie eine dezimale ganze Zahl ein, die für eine 32-Bit-Dualform
mit Vorzeichen zu groß ist, dann wird eine symmetrische ModuloOperation ausgeführt, um den Wert in den erforderlichen Bereich zu
bringen.
Katalog
>
Im Hex-Modus:
Wichtig: Null, nicht Buchstabe O.
Im Bin-Modus:
Um das ganze Ergebnis zu sehen, drücken Sie
verwenden dann ¡ und ¢, um den Cursor zu bewegen.
Hinweis: Eine binäre Eingabe kann bis zu 64 Stellen haben
(das Präfix 0b wird nicht mitgezählt). Eine hexadezimale Eingabe
kann bis zu 16 Stellen aufweisen.
£ und
nPr() (Permutationen)
nPr(Ausdr1, Ausdr2) ⇒ Ausdruck
Für ganzzahlige Ausdr1 und Ausdr2 mit Ausdr1 ‚ Ausdr2 ‚ 0 ist
nPr() die Anzahl der Möglichkeiten, Ausdr1 Elemente unter
Berücksichtigung der Reihenfolge aus Ausdr2 Elementen
auszuwählen. Beide Argumente können ganze Zahlen oder
symbolische Ausdrücke sein.
nPr(Ausdr, 0) ⇒ 1
Ausdr, negGanzzahl) ⇒ 1/((Ausdr+1)·(Ausdr+2)...
nPr(
(
AusdrNnegGanzzahl))
nPr(
Ausdr, posGanzzahl) ⇒ Ausdr·(AusdrN1)...
AusdrNposGanzzahl+1)
(
Ausdr, keineGanzzahl)
nPr(
⇒ Ausdr! / (AusdrNkeineGanzzahl)!
nPr(
Liste1, Liste2) ⇒ Liste
Gibt eine Liste der Permutationen auf der Basis der entsprechenden
Elementpaare der beiden Listen zurück. D ie Argumente müssen Listen
gleicher Größe sein.
nPr(Matrix1, Matrix2) ⇒ Matrix
Gibt eine Matrix der Permutationen auf der Basis der entsprechenden
Elementpaare der beiden Matrizen zurück. Die Argumente müssen
Matrizen gleicher Größe sein.
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 77

npv()
npv(Zinssatz,CFO,CFListe[,CFFreq])
Finanzfunktion zur Berechnung des Nettobarwerts; die Summe der
Barwerte für die Bar-Zuflüsse und -Abflüsse. Ein positives Ergebnis für
npv zeigt eine rentable Investition an.
Zinssatz ist der Satz, zu dem die Cash-Flows (der Geldpreis) für einen
Zeitraum.
CF0 ist der Anfangs-Cash-Flow zum Zeitpunkt 0; dies muss eine
reelle Zahl sein.
CFListe ist eine Liste der Cash-Flow-Beträge nach dem anfänglichen
Cash-Flow CF0.
CFFreq ist eine Liste, in der jedes Element die Häufigkeit des
Auftretens für einen gruppierten (fortlaufenden) Cash-Flow-Betrag
angibt, der das entsprechende Element von CFListeist. Der
Standardwert ist 1; wenn Sie Werte eingeben, müssen diese positive
Ganzzahlen < 10.000 sein.
Katalog
>
nSolve() (Numerische Lösung)
nSolve(Gleichung,Var [=Schätzwert]) ⇒ Zahl oder
Fehler_String
nSolve(Gleichung,Var [=Schätzwert],UntereGrenze)
⇒ Zahl oder Fehler_String
nSolve(Gleichung,Var [=Schätzwert],UntereGrenze,ObereGrenz
e) ⇒ Zahl oder Fehler_String
nSolve(Gleichung,Var [=Schätzwert]) |
UntereGrenze<Var <ObereGrenze
⇒ Zahl oder Fehler_String
Ermittelt iterativ eine reelle numerische Näherungslösung von
Gleichung für deren eine Variable. Geben Sie die Variable an als:
Variable
– oder –
Variable = reelle Zahl
Beispiel: x ist gültig und x=3 ebenfalls.
nSolve() ist häufig sehr viel schneller als solve() oder zeros(),
insbesondere, wenn zusätzlich der Operator “|” benutzt wird, um die
Suche auf ein relativ kleines Intervall zu beschränken, das genau eine
einzige Lösung enthält.
nSolve() versucht entweder einen Punkt zu ermitteln, wo der
Unterschied zwischen tatsächlichem und erwartetem Wert Null ist
oder zwei relativ nahe Punkte, wo der Restfehler entgegengesetzte
Vorzeichen besitzt und nicht zu groß ist. Wenn nSolve() dies nicht mit
einer kleinen Anzahl von Versuchen erreichen kann, wird die
Zeichenkette “Keine Lösung gefunden” zurückgegeben.
Hinweis: Siehe auch cSolve(), cZeros(), solve() und zeros().
Katalog
>
Hinweis: Existieren mehrere Lösungen, können Sie mit Hilfe
einer Schätzung eine bestimmte Lösung suchen.
78 TI-Nspire™ CAS Referenzhandbuch

O
OneVar (Eine Variable)
OneVar [1,]X[,[Häufigkeit][,Kategorie,Mit]]
OneVar [
n,]X1,X2[X3[,…[,X20]]]
Berechnet die 1-Variablenstatistik für bis zu 20 Listen.
Eine Zusammenfassung der Ergebnisse wird in der Variable
stat.results gespeichert. (Siehe Seite 109.)
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
Die X-Argumente sind Datenlisten.
Häufigkeit ist eine optionale Liste von Häufigkeitswerten.
Jedes Element in Häufigkeit gibt die Häufigkeit für jeden
entsprechenden X-Wert an. Der Standardwert ist 1.
Alle Elemente müssen Ganzzahlen | 0 sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden X-Werte.
Mit ist eine Liste von einem oder mehreren Kategoriecodes.
Nur solche Datenelemente, deren Kategoriecode in dieser Liste
enthalten ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.v
stat.Gx
2
stat.Gx
stat.sx Stichproben-Standardabweichung von x
stat.ssssx Populations-Standardabweichung von x
stat.n Anzahl der Datenpunkte
stat.MinX Minimum der x-Werte
stat.Q1X 1. Quartil von x
stat.MedianX Median von x
stat.Q3X 3. Quartil von x
stat.MaxX Maximum der x-Werte
stat.SSX Summe der Quadrate der Abweichungen der x-Werte vom Mittelwert
Mittelwert der x-Werte
Summe der x-Werte
Summe der x2-Werte
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 79

or
Boolescher Ausdr1 or Boolescher Ausdr2
⇒ Boolescher Ausdruck
Gibt „wahr“ oder „falsch“ oder eine vereinfachte Form des
ursprünglichen Terms zurück.
Gibt “wahr” zurück, wenn ein Ausdruck oder beide Ausdrücke zu
”wahr” ausgewertet werden. Gibt nur dann “falsch” zurück, wenn
beide Ausdrücke “falsch” ergeben.
Hinweis: Siehe xor.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
Ganzzahl1 or Ganzzahl2 ⇒ Ganzzahl
Vergleicht zwei reelle ganze Zahlen mit Hilfe einer or-Operation Bit
für Bit. Intern werden beide ganzen Zahlen in binäre 32-Bit-Zahlen
mit Vorzeichen konvertiert. Beim Vergleich der sich entsprechenden
Bits ist das Ergebnis dann 1, wenn eines der Bits 1 ist; das Ergebnis ist
nur dann 0, wenn beide Bits 0 sind. Der zurückgegebene Wert stellt
die Bit-Ergebnisse dar und wird im jeweiligen Basis-Modus angezeigt.
Sie können die ganzen Zahlen in jeder Basis eingeben. F ür eine binäre
oder hexadezimale Eingabe ist das Präfix 0b bzw. 0h zu verwenden.
Ohne Präfix werden ganze Zahlen als dezimal behandelt (Basis 10).
Geben Sie eine dezimale ganze Zahl ein, die für eine 32-Bit-Dualform
mit Vorzeichen zu groß ist, dann wird eine symmetrische ModuloOperation ausgeführt, um den Wert in den erforderlichen Bereich zu
bringen.
Hinweis: Siehe xor.
Katalog
>
Im Hex-Modus:
Wichtig: Null, nicht Buchstabe O.
Im Bin-Modus:
Hinweis: Eine binäre Eingabe kann bis zu 64 Stellen haben
(das Präfix 0b wird nicht mitgezählt). Eine hexadezimale Eingabe
kann bis zu 16 Stellen aufweisen.
ord() (Numerischer Zeichencode)
ord(Str ing) ⇒ Ganzzahl
ord(Liste1) ⇒ Liste
Gibt den Zahlenwert (Code) des ersten Zeichens der Zeichenkette
Strin g zurück. Handelt es sich um eine Liste, wird der Code des ersten
Zeichens jedes Listenelements zurückgegeben.
Katalog
>
P
P4Rx() (Kartesische x-Koordinate)
P4Rx(rAusdr, qAusdr) ⇒ Ausdruck
P4Rx(rListe, qListe) ⇒ Liste
P4Rx(rMatrix, qMatrix) ⇒ Matrix
Gibt die äquivalente x-Koordinate des Paars
(r, q) zurück.
Hinweis: Das q-Argument wird gemäß deraktuellen
Winkelmoduseinstellung als Grad, Neugrad oder Bogenmaß
interpretiert. Ist das Argument ein Ausdruck, können Sie ó,G oder
ôbenutzen, um die Winkelmoduseinstellung temporär zu ändern.
Im Bogenmaß-Modus:
80 TI-Nspire™ CAS Referenzhandbuch
Katalog
>

P4Ry() (Kartesische y-Koordinate)
P4Ry(rAusdr, qAusdr) ⇒ Ausdruck
P4Ry(rListe, qListe) ⇒ Liste
P4Ry(rMatrix, qMatrix) ⇒ Matrix
Gibt die äquivalente y-Koordinate des Paars (r, q) zurück.
Hinweis: Das q-Argument wird gemäß deraktuellen
Winkelmoduseinstellung als Grad, Neugrad oder Bogenmaß
interpretiert. Ist das Argument ein Ausdruck, können Sie
G
ó,
oder
ôbenutzen, um die Winkelmoduseinstellung temporär zu ändern.
Im Bogenmaß-Modus:
Katalog
>
PassErr (ÜbgebFeh)
PassErr
Übergibt einen Fehler an die nächste Stufe.
Wenn die Systemvariable Fehlercode (errCode) Null ist, tut
PassErr nichts.
Das Else im Block Try...Else...EndTry muss ClrErr oder PassErr
verwenden. Wenn der Fehler verarbeitet oder ignoriert werden soll,
verwenden Sie ClrErr. Wenn nicht bekannt ist, was mit dem Fehler
zu tun ist, verwenden Sie PassErr, um ihn an den nächsten Error
Handler zu übergeben. Wenn keine weiteren Try...Else...EndTry
Error Handler unerledigt sind, wird das Fehlerdialogfeld als normal
angezeigt.
Hinweis: Siehe auch ClrfErr, Seite 16, und Try, Seite 119.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
piecewise() (Stückweise)
piecewise(Ausdr1 [, Bedingung1 [, Ausdr2 [, Bedingung2 [, …
]]]])
Gibt Definitionen für eine stückweise definierte Funktion in Form
einer Liste zurück. Sie können auch mit Hilfe einer Vorlage stückweise
Definitionen erstellen.
Hinweis: Siehe auch Vorlage Stückweise, Seite 2.
poissCdf()
poissCdf(l,untereGrenze,obereGrenze) ⇒ Zahl, wenn
untereGrenze und obereGrenze Zahlen sind, Liste, wenn
untereGrenze und obereGrenze Listen sind
poissCdf(
l,obereGrenze) (für P(0XobereGrenze) ⇒ Zahl,
obereGrenze eine Zahl ist, Liste, wenn obereGrenze eine
wenn
Liste ist
Berechnet die kumulative Wahrscheinlichkeit für die diskrete PoissonVerteilung mit dem vorgegebenen Mittelwert l.
Für P(X obereGrenze) setzen Sie untereGrenze = 0
Katalog
>
Ein Beispiel zu PassErr finden Sie im Beispiel 2 unter Befehl
Versuche (Try), Seite 119.
Katalog
>
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 81

poissPdf()
poissPdf(l,XWert) ⇒ Zahl, wenn XWert eine Zahl ist, Liste,
XWert eine Liste ist
wenn
Berechnet die Wahrscheinlichkeit für die diskrete Poisson-Verteilung
mit dem vorgegebenen Mittelwert l.
Polar
4
4Polar
Vek t o r
Zeigt Vektor in Polarform [r q] an. Der Vektor muss die Dimension
2 besitzen und kann eine Zeile oder eine Spalte sein.
Hinweis: 4Polar ist eine Anzeigeformatanweisung, keine
Konvertierungsfunktion. Sie können sie nur am Ende einer
Eingabezeile benutzen, und sie nimmt keine Aktualisierung von ans
vor.
Hinweis: Siehe auch 4Rect, Seite 92.
komplexerWert 4Polar
Zeigt komplexerVektor in Polarform an.
• Der Grad-Modus für Winkel gibt (rq) zurück.
• Der Bogenmaß-Modus für Winkel gibt re
komplexerWert kann jede komplexe Form haben. Eine re
verursacht jedoch im Winkelmodus Grad einen Fehler.
Hinweis: Für eine Eingabe in Polarform müssen Klammern (rq)
verwendet werden.
i
q zurück.
i
q-Eingabe
Im Bogenmaß-Modus:
Im Neugrad-Modus:
Im Grad-Modus:
Katalog
Katalog
>
>
82 TI-Nspire™ CAS Referenzhandbuch

polyCoeffs()
polyCoeffs(Poly [,Var ]) ⇒ Liste
Gibt eine Liste der Koeffizienten des Polynoms Poly mit Bezug auf die
Variable Var zurück.
Poly muss ein Polynomausdruck in Va r sein. Wir empfehlen, Va r
nicht wegzulassen, außer wenn Poly ein Ausdruck in einer einzelnen
Variablen ist.
Katalog
Entwickelt das Polynom und wählt x für die weggelassene
Variable Var .
>
polyDegree()
polyDegree(Poly [,Var ]) ⇒ Wer t
Gibt den Grad eines Polynomausdrucks Poly in Bezug auf die
Variable Var zurück. Wenn Sie Var weglassen, wählt die Funktion
polyDegree() einen Standardwert aus den im Polynom Poly
enthaltenen Variablen aus.
Poly muss ein Polynomausdruck in Va r sein. Wir empfehlen, Va r
nicht wegzulassen, außer wenn Poly ein Ausdruck in einer einzelnen
Variablen ist.
polyEval() (Polynom auswerten)
polyEval(Liste1, Ausdr1) ⇒ Ausdruck
polyEval(Liste1, Liste2) ⇒ Ausdruck
Interpretiert das erste Argument als Koeffizienten eines nach
fallenden Potenzen geordneten Polynoms und gibt das Polynom
bezüglich des zweiten Arguments zurück.
Katalog
>
Konstante Polynome
Der Grad kann auch extrahiert werden, wenn dies für die
Koeffizienten nicht möglich ist. Dies liegt daran, dass der Grad
extrahiert werden kann, ohne das Polynom zu entwickeln.
Katalog
>
TI-Nspire™ CAS Referenzhandbuch 83

polyGcd()
polyGcd(Ausdr1,Ausdr2) ⇒ Ausdruck
Gibt den größten gemeinsamen Teiler der beiden Argumente zurück.
Ausdr1 und Ausdr2 müssen Polynomausdrücke sein.
Listen-, Matrix- und Boolesche Argumente sind nicht zulässig.
Katalog
>
polyQuotient()
polyQuotient(Poly1,Poly2 [,Var ]) ⇒ Ausdruck
Gibt den Polynomquotienten von Poly1 geteilt durch Polynom Poly2
bezüglich der angegebenen Variable Va r zurück.
Poly1 und Poly2 müssen Polynomausdrücke in Va r sein. Wir
empfehlen, Va r nicht wegzulassen, außer wenn Poly1 und Poly2
Ausdrücke in derselben einzelnen Variablen sind.
polyRemainder()
polyRemainder(Poly1,Poly2 [,Var ]) ⇒ Ausdruck
Gibt den Rest des Polynoms Poly1 geteilt durch Polynom Poly2
bezüglich der angegebenen Variablen Va r zurück.
Poly1 und Poly2 müssen Polynomausdrücke in Va r sein. Wir
empfehlen, Va r nicht wegzulassen, außer wenn Poly1 und Poly2
Ausdrücke in derselben einzelnen Variablen sind.
Katalog
Katalog
>
>
84 TI-Nspire™ CAS Referenzhandbuch

PowerReg
PowerReg X,Y [, Häuf] [, Kategorie, Mit]]
Berechnet die Potenzregression y = (a·(x)b) auf Listen X und Y mit
der Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird in
der Variablen stat.results gespeichert. (Siehe Seite 109.)
Katalog
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-
Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen
Ganzzahlen | 0 sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
Regressionsgleichung: a·(x)
b
stat.a, stat.b Regressionskoeffizienten
stat.r
2
Koeffizient der linearen Bestimmtheit für transformierte Daten
stat.r Korrelationskoeffizient für transformierte Daten (ln(x), ln(y))
stat.Resid Mit dem Potenzmodell verknüpfte Residuen
stat.ResidTrans Residuen für die lineare Anpassung transformierter Daten
stat.XReg Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für
stat.YReg Liste der Datenpunkte in der modifizierten Y- Li st e, die schließlich in der Regression mit den
Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
>
TI-Nspire™ CAS Referenzhandbuch 85

Prgm
Prgm
Block
EndPrgm
Vorlage zum Erstellen eines benutzerdefinierten Programms. Muss
mit dem Befehl
(Define LibPub)
verwendet werden.
Block kann eine einzelne Anweisung, eine Reihe von durch das
Zeichen “:” voneinander getrennten Anweisungen oder eine Reihe
von Anweisungen in separaten Zeilen sein.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
Definiere (Define), Definiere LibPub
oder Definiere LibPriv (Define LibPriv)
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
Katalog
GCD berechnen und Zwischenergebnisse anzeigen.
>
Product (PI) (Produkt)
product() (Produkt)
product(Liste[, Start[, Ende]]) ⇒ Ausdruck
Gibt das Produkt der Elemente von Liste zurück. Start und Ende sind
optional. Sie geben einen Elementebereich an.
product(Matrix1[, Start[, Ende]]) ⇒ Matrix
Gibt einen Zeilenvektor zurück, der die Produkte der Elemente aus
den Spalten von Matrix1 enthält. Start und Ende sind optional.
Sie geben einen Zeilenbereich an.
propFrac() (Echter Bruch)
propFrac(Ausdr1[, Va r ]) ⇒ Ausdruck
propFrac(rationale_Wert) gibt rationale_Wert als Summe einer
ganzen Zahl und eines Bruchs zurück, der das gleiche Vorzeichen
besitzt und dessen Nenner größer ist als der Zähler.
Siehe Π(), Seite 141.
Katalog
>
Katalog
>
86 TI-Nspire™ CAS Referenzhandbuch

propFrac() (Echter Bruch)
propFrac(rationaler_Ausdruck,Var ) gibt die Summe der echten
Brüche und ein Polynom bezüglich Va r zurück. Der Grad von Va r im
Nenner übersteigt in jedem echten Bruch den Grad von Va r im Zähler.
Gleichartige Potenzen von Va r werden zusammengefasst. Die Terme
und Faktoren werden mit Va r als der Hauptvariablen sortiert.
Wird Var weggelassen, wird eine Entwicklung des echten Bruchs
bezüglich der wichtigsten Hauptvariablen vorgenommen.
Die Koeffizienten des Polynomteils werden dann zuerst bezüglich
der wichtigsten Hauptvariablen entwickelt usw.
Für rationale Ausdrücke ist propFrac() eine schnellere, aber
weniger weitgehende Alternative zu expand().
Q
Katalog
>
QR
QR Matrix, qMatrix, rMatrix[, Tol ]
Berechnet die Householdersche QR-Faktorisierung einer reellen oder
komplexen Matrix. Die sich ergebenden Q- und R-Matrzen werden in
den angegebenen Matrix gespeichert. Die Q-Matrix ist unitär. Bei der
R-Matrix handelt es sich um eine obere Dreiecksmatrix.
Sie haben die Option, dass jedes Matrixelement als Null behandelt
wird, wenn dessen absoluter Wert geringer als To l ist. Diese Toleranz
wird nur dann verwendet, wenn die Matrix Fließkommaelemente
aufweist und keinerlei symbolische Variablen ohne zugewiesene
Werte enthält. Anderenfalls wird Tol ignoriert.
• Wenn Sie
•Wird Tol weggelassen oder nicht verwendet, so wird die
Die QR-Faktorisierung wird anhand von Householderschen
Transformationen numerisch berechnet. Die symbolische Lösung
wird mit dem Gram-Schmidt-Verfahren berechnet. Die Spalten in
qMatName sind die orthonormalen Basisvektoren, die den durch
Matrix definierten Raum aufspannen.
/
oder Näherung
Berechnungen in Fließkomma-Arithmetik durchgeführt.
Standardtoleranz folgendermaßen berechnet:
5Eë14 ·max(dim(Matrix)) ·rowNorm(Matrix)
· verwenden oder den Modus Auto
auf Approximiert einstellen, werden
Katalog
>
Die Fließkommazahl (9,) in m1 bewirkt, dass das Ergebnis in
Fließkommaform berechnet wird.
TI-Nspire™ CAS Referenzhandbuch 87

QuadReg
QuadReg X,Y [, Häuf] [, Kategorie, Mit]]
Berechnet die quadratische polynomiale Regression y =
2
a
·x
+b·x+c auf Listen X und Y mit der Häufigkeit Häuf. Eine
Zusammenfassung der Ergebnisse wird in der Variablen stat.results
gespeichert. (Siehe Seite 109.)
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-
Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen
| 0 sein.
Ganzzahlen
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Ausgabevariable Beschreibung
stat.RegEqn
stat.a, stat.b, stat.c Regressionskoeffizienten
2
stat.R
stat.Resid Residuen von der Regression
stat.XReg Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für
stat.YReg Liste der Datenpunkte in der modifizierten Y- Li st e, die schließlich in der Regression mit den
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
Regressionsgleichung: a·x2+b·x+c
Bestimmungskoeffizient
Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Katalog
>
QuartReg
QuartReg X,Y [, Häuf] [, Kategorie, Mit]]
Berechnet die polynomiale Regression vierter Ordnung
y = a·x4+b·x3+c· x2+d·x+e auf Listen X und Y mit der
Häufigkeit Häuf. Eine Zusammenfassung der Ergebnisse wird in der
Variablen stat.results gespeichert. (Siehe Seite 109.)
Alle Listen außer Mit müssen die gleiche Dimension besitzen.
X und Y sind Listen von unabhängigen und abhängigen Variablen.
Häuf ist eine optionale Liste von Häufigkeitswerten. Jedes Element in
Häuf gibt die Häufigkeit für jeden entsprechenden X- und Y-
Datenpunkt an. Der Standardwert ist 1. Alle Elemente müssen
Ganzzahlen | 0 sein.
Kategorie ist eine Liste numerischer Kategoriecodes für die
entsprechenden Daten X und Y.
Mit ist eine Liste von einem oder mehreren Kategoriecodes. Nur
solche Datenelemente, deren Kategoriecode in dieser Liste enthalten
ist, sind in der Berechnung enthalten.
Katalog
>
88 TI-Nspire™ CAS Referenzhandbuch

Ausgabevariable Beschreibung
stat.RegEqn
stat.a, stat.b, stat.c,
stat.d, stat.e
2
stat.R
stat.Resid Residuen von der Regression
stat.XReg Liste der Datenpunkte in der modifizierten X-Liste, die in der Regression mit den Beschränkungen für
stat.YReg Liste der Datenpunkte in der modifizierten Y- Li st e, die schließlich in der Regression mit den
stat.FreqReg Liste der Häufigkeiten für stat.XReg und stat.YReg
Regressionsgleichung: a·x4+b·x3+c· x2+d·x+e
Regressionskoeffizienten
Bestimmungskoeffizient
Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
Beschränkungen für Häuf, Kategorieliste und Mit-Kategorien verwendet wurde
R
R4Pq() (Polarkoordinate)
R4Pq (xAusdr, yAusdr) ⇒ Ausdruck
R4Pq (xListe, yListe) ⇒ Liste
R4Pq (xMatrix, yMatrix) ⇒ Matrix
Gibt die äquivalente q-Koordinate des Paars
(x,y) zurück.
Hinweis: Das Ergebnis wird gemäß der aktuellen
Winkelmoduseinstellung in Grad, in Neugrad oder im Bogenmaß
zurückgegeben.
R4Pr() (Polarkoordinate)
R4Pr (xAusdr, yAusdr) ⇒ Ausdruck
R4Pr (xListe, yListe) ⇒ Liste
R4Pr (xMatrix, yMatrix) ⇒ Matrix
Gibt die äquivalente r-Koordinate des Paars (x,y) zurück.
Im Grad-Modus:
Im Neugrad-Modus:
Im Bogenmaß-Modus:
Im Bogenmaß-Modus:
Katalog
Katalog
>
>
TI-Nspire™ CAS Referenzhandbuch 89

4Rad (Bogenmaß)
4Rad ⇒ Ausdruck
Ausdr1
Wandelt das Argument ins Winkelmaß Bogenmaß um.
Im Grad-Modus:
Im Neugrad-Modus:
Katalog
>
rand() (Zufallszahl)
rand() ⇒ Ausdruck
rand(#Trials) ⇒ Liste
rand() gibt einen Zufallswert zwischen 0 und 1 zurück.
rand(#Trials) gibt eine Liste zurück, die #Trials Zufallswerte
zwischen 0 und 1 enthält.
randBin() (Zufallszahl aus Binomialverteilung)
randBin(n, p) ⇒ Ausdruck
randBin(n, p, #Trials) ⇒ Liste
randBin(n, p) gibt eine reelle Zufallszahl aus einer angegebenen
Binomialverteilung zurück.
randBin(n, p, #Trials) gibt eine Liste mit #Trials reellen
Zufallszahlen aus einer angegebenen Binomialverteilung zurück.
randInt() (Ganzzahlige Zufallszahl)
randInt(lowBound,upBound) ⇒ Ausdruck
randInt(lowBound,upBound,#Trials) ⇒ Liste
randInt(lowBound,upBound) gibt eine ganzzahlige Zufallszahl
innerhalb der durch UntereGrenze (lowBound) und ObereGrenze
(upBound) festgelegten Grenzen zurück.
randInt(lowBound,upBound,#Trials) gibt eine Liste mit #Trials
ganzzahligen Zufallszahlen innerhalb des festgelegten Bereichs
zurück.
randMat() (Zufallsmatrix)
randMat(AnzZeil, AnzSpalt) ⇒ Matrix
Gibt eine Matrix der angegebenen Dimension mit ganzzahligen
Werten zwischen -9 und 9 zurück.
Beide Argumente müssen zu ganzen Zahlen vereinfachbar sein.
Katalog
>
Setzt Ausgangsbasis für Zufallszahlengenerierung.
Katalog
>
Katalog
>
Katalog
>
Hinweis: Die Werte in dieser Matrix ändern sich mit jedem
Drücken von ·.
90 TI-Nspire™ CAS Referenzhandbuch

randNorm() (Zufal lsnorm)
randNorm(m, s [,AnzVersuche]) ⇒ Ausdruck
Gibt eine Dezimalzahl aus der Gaußschen Normalverteilung zurück.
Dies könnte eine beliebige reelle Zahl sein, die Werte konzentrieren
sich jedoch stark in dem Intervall [mN3·s, m+3·s].
Katalog
>
randPoly() (Zufallspolynom)
randPoly(Va r , Ordnung) ⇒ Ausdruck
Gibt ein Polynom in Va r der angegebenen Ordnung zurück. Die
Koeffizienten sind zufällige ganze Zahlen im Bereich ë9 bis 9. Der
führende Koeffizient ist nie Null.
Ordnung muss zwischen 0 und 99 betragen.
randSamp() (Zufallsstichprobe)
randSamp(List,#Trials[,noRepl]) ⇒ Liste
Gibt eine Liste mit einer Zufallsstichprobe von #Trials Versuchen aus
Liste (List) zurück mit der Möglichkeiten, Stichproben zu ersetzen
(noRepl=0) oder nicht zu ersetzen (noRepl=1). Die Vorgabe ist mit
Stichprobenersatz.
RandSeed (Zufallszahl)
RandSeed Zahl
Zahl = 0 setzt die Ausgangsbasis (“seed”) für den
Zufallszahlengenerator auf die Werkseinstellung zurück. Bei Zahl ƒ 0
werden zwei Basen erzeugt, die in den Systemvariablen seed1
und seed2 gespeichert werden.
real() (Reell)
real(Ausdr1) ⇒ Ausdruck
Gibt den Realteil des Arguments zurück.
Hinweis: Alle undefinierten Variablen werden als reelle Variablen
behandelt. Siehe auch imag(), Seite 53.
real(Liste1) ⇒ Liste
Gibt für jedes Element den Realteil zurück.
real(Matrix1) ⇒ Matrix
Gibt für jedes Element den Realteil zurück.
Katalog
Katalog
Katalog
Katalog
>
>
>
>
TI-Nspire™ CAS Referenzhandbuch 91

Rect (Kartesisch)
4
4Rect
Vek t o r
Zeigt Vek t o r in der kartesischen Form [x, y, z] an. Der Vektor muss die
Dimension 2 oder 3 besitzen und kann eine Zeile oder eine Spalte
sein.
Hinweis: 4Rect ist eine Anzeigeformatanweisung, keine
Konvertierungsfunktion. Sie können sie nur am Ende einer
Eingabezeile benutzen, und sie nimmt keine Aktualisierung von ans
vor.
Hinweis: Siehe auch 4Polar, Seite 82.
komplexerWert 4Rect
Zeigt komplexerWert in der kartesischen Form a+bi an.
KomplexerWert kann jede komplexe Form haben. Eine re
verursacht jedoch im Winkelmodus Grad einen Fehler.
Hinweis: Für eine Eingabe in Polarform müssen Klammern (rq)
verwendet werden.
i
q-Eingabe
Katalog
>
Im Bogenmaß-Modus:
Im Neugrad-Modus:
Im Grad-Modus:
Hinweis: Wählen Sie zur Eingabe von das Symbol aus der
Sonderzeichenpalette des Katalogs aus.
ref() (Diagonalform)
ref(Matrix1[, To l]) ⇒ Matrix
Gibt die Diagonalform von Matrix1 zurück.
Sie haben die Option, dass jedes Matrixelement als Null behandelt
wird, wenn dessen absoluter Wert geringer als To l ist. Diese Toleranz
wird nur dann verwendet, wenn die Matrix Fließkommaelemente
aufweist und keinerlei symbolische Variablen ohne zugewiesene
Werte enthält. Anderenfalls wird Tol ignoriert.
• Wenn Sie
•Wird Tol weggelassen oder nicht verwendet, so wird die
Hinweis: Siehe auch rref(), Seite 95.
remain() (Rest)
remain(Ausdr1, Ausdr2) ⇒ Ausdruck
remain(Liste1, Liste2) ⇒ Liste
remain(Matrix1, Matrix2) ⇒ Matrix
Gibt den Rest des ersten Arguments bezüglich des zweiten
Arguments gemäß folgender Definitionen zurück:
remain(x,0) x
remain(x,y) xNy·iPart(x/y)
/
oder Näherung
Berechnungen in Fließkomma-Arithmetik durchgeführt.
Standardtoleranz folgendermaßen berechnet:
5Eë14 ·max(dim(Matrix1)) ·rowNorm(Matrix1)
· verwenden oder den Modus Auto
auf Approximiert einstellen, werden
Katalog
Katalog
>
>
92 TI-Nspire™ CAS Referenzhandbuch

remain() (Rest)
Als Folge daraus ist zu beachten, dass remain(Nx,y)
Nremain(x,y ). Das Ergebnis ist entweder Null oder besitzt das
gleiche Vorzeichen wie das erste Argument.
Hinweis: Siehe auch mod(), Seite 71.
Katalog
>
Return (Rückgabe)
Return [Ausdr]
Gibt Ausdr als Ergebnis der Funktion zurück. Verwendbar in einem
Block Func...EndFunc.
Hinweis: Verwenden Sie Zurück (Return) ohne Argument
innerhalb eines Prgm...EndPrgm Blocks, um ein Programm zu
beenden.
Hinweis zur Eingabe des Beispiels: In der Calculator-
Applikation des Handheld können Sie mehrzeilige Definitionen
eingeben, indem Sie am Ende jeder Zeile @ statt · drücken.
Auf der Computertastatur halten Sie Alt gedrückt und drücken die
Eingabetaste.
right() (Rechts)
right(Liste1[, Anz]) ⇒ Liste
Gibt Anz Elemente zurück, die rechts in Liste1 enthalten sind.
Wenn Sie Anz weglassen, wird die gesamte Liste1 zurückgegeben.
right(Quellstring[, Anz]) ⇒ St ring
Gibt Anz Zeichen zurück, die rechts in der Zeichenkette Quellstring
enthalten sind.
Wenn Sie Anz weglassen, wird der gesamte Quellstring
zurückgegeben.
right(Ver g le i c h ) ⇒ Ausdruck
Gibt die rechte Seite einer Gleichung oder Ungleichung zurück.
root() (Wurzel)
root(Ausdr) ⇒ root
root(Ausdr1, Ausdr2) ⇒ Wurzel
root(Ausdr) gibt die Quadratwurzel von Ausdr zurück.
root(Ausdr1, Ausdr2) gibt die Ausdr2. Wurzel von Ausdr1 zurück.
Ausdr1 kann eine reelle oder eine komplexe Gleitkommakonstante,
eine ganze Zahl oder eine komplexe rationale Konstante oder ein
allgemeiner symbolischer Ausdruck sein.
Hinweis: Siehe auch Vorlage n-te Wurzel, Seite 1.
Katalog
Katalog
Katalog
>
>
>
TI-Nspire™ CAS Referenzhandbuch 93

rotate() (Rotieren)
rotate(Ganzzahl1[,#Rotationen]) ⇒ Ganzzahl
Rotiert die Bits in einer binären ganzen Zahl. Ganzzahl1 kann mit
jeder Basis eingegeben werden und wird automatisch in eine 32-BitDualform konvertiert. Ist der Absolutwert von Ganzzahl1 für diese
Form zu groß, wird eine symmetrische Modulo-Operation ausgeführt,
um sie in den erforderlichen Bereich zu bringen.
Ist #Rotationen positiv, erfolgt eine Rotation nach links. ist
#Rotationen negativ, erfolgt eine Rotation nach rechts. Vorgabe ist
ë1 (ein Bit nach rechts rotieren).
Beispielsweise in einer Rechtsrotation:
Im Bin-Modus:
Um das ganze Ergebnis zu sehen, drücken Sie
verwenden dann
Im Hex-Modus:
¡ und ¢, um den Cursor zu bewegen.
Katalog
£ und
>
Jedes Bit rotiert nach rechts.
0b00000000000001111010110000110101
Bit ganz rechts rotiert nach ganz links.
Es ergibt sich:
0b10000000000000111101011000011010
Das Ergebnis wird gemäß dem jeweiligen Basis-Modus angezeigt.
rotate(Liste1[,#Rotationen]) ⇒ Liste
Gibt eine um #Rotationen Elemente nach rechts oder links rotierte
Kopie von Liste1 zurück. Verändert Liste1 nicht.
Ist #Rotationen positiv, erfolgt eine Rotation nach links. ist
#Rotationen negativ, erfolgt eine Rotation nach rechts. Vorgabe ist
ë1 (ein Element nach rechts rotieren).
rotate(String1[,#Rotationen]) ⇒ Stri ng
Gibt eine um #Rotationen Zeichen nach rechts oder links rotierte
Kopie von String1 zurück. Verändert String1 nicht.
Ist #Rotationen positiv, erfolgt eine Rotation nach links. ist
#Rotationen negativ, erfolgt eine Rotation nach rechts. Vorgabe ist
ë1 (ein Zeichen nach rechts rotieren).
round() (Runden)
round(Ausdr1[, Ste llen]) ⇒ Ausdruck
Gibt das Argument gerundet auf die angegebene Anzahl von Stellen
nach dem Dezimaltrennzeichen zurück.
Stell en muss eine ganze Zahl im Bereich 0–12 sein. Wird Stellen
weggelassen, wird das Argument auf 12 signifikante Stellen
gerundet.
Hinweis: Die Anzeige des Ergebnisses kann von der Einstellung
"Angezeigte Ziffern" beeinflusst werden.
round(Liste1[, Stellen]) ⇒ Liste
Gibt eine Liste von Elementen zurück, die auf die angegebene
Stellenzahl gerundet wurden.
round(Matrix1[, Stel len]) ⇒ Matrix
Gibt eine Matrix von Elementen zurück, die auf die angegebene
Stellenzahl gerundet wurden.
Wichtig: Geben Sie eine Dual- oder Hexadezimalzahl stets mit
dem Präfix 0b bzw. 0h ein (Null, nicht der Buchstabe O).
Im Dec-Modus:
Katalog
>
94 TI-Nspire™ CAS Referenzhandbuch
 Loading...
Loading...