

Page 1

User Guide
Version:8.5
Page 2

Page 3

User Guide
Version 8.5
Last Revision:4/12/2017
Objectif Lune, Inc.
2030 Pie-IX, Suite 500
Montréal, QC, Canada, H1V 2C8
+1 (514) 875-5863
www.objectiflune.com
All trademarks displayed are the property of their respective owners.
© Objectif Lune, Inc. 1994-2017. All rights reserved. No part of this documentation may be
reproduced, transmitted or distributed outside of Objectif Lune Inc. by any means whatsoever
without the express written permission of Objectif Lune Inc. Inc. Objectif Lune Inc. Inc. disclaims
responsibility for any errors and omissions in this documentation and accepts no responsibility
for damages arising from such inconsistencies or their further consequences of any kind.
Objectif Lune Inc. Inc reserves the right to alter the information contained in this documentation
without notice.
Page 4

Table of Contents
Table of Contents 4
Welcome to PReS Workflow 8.5 7
Icons used in this guide 7
System Requirements 9
Operating System (64-bit only) 9
Minimum Hardware Requirements 9
Basics 10
Setting Up the Working Environment 10
Setting Up Preferences 10
Create a New Process 10
Send your Configuration 11
Features 13
The Nature of PReS Workflow 13
About Branches and Conditions 13
Configuration Components 14
Connect Resources 14
About Data 16
Page 4
Page 5

About Documents 43
Debugging and Error Handling 44
The Plug-in Bar 55
About Printing 57
About Processes and Subprocesses 70
Using Scripts 79
Special Workflow Types 125
About Tasks 170
Task Properties 171
Variable Properties 172
Working With Variables 534
About Configurations 542
About Related Programs and Services 547
The Interface 551
Customizing the Workspace 552
PReS Workflow Button 561
The Configuration Components Pane 562
Other Dialogs 589
The Debug Information Pane 614
Page 5
Page 6

The Message Area Pane 615
The Object Inspector Pane 616
The Plug-in Bar 617
Preferences 619
The Process Area 659
The Quick Access Toolbar 670
The PReS Workflow Ribbon 671
The Task Comments Pane 673
Copyright Information 675
Legal Notices and Acknowledgements 676
Page 6
Page 7

Welcome to PReS Workflow 8.5
Note
Complementary information that is not critical, but may help you better use PReS Workflow.
Tip
Information that is useful or suggests an easier method.
This PDF documentation covers version 8.5. To view the documentation of previous versions
please refer to the PDF files available in the Downloads section of our website:
http://www.objectiflune.com/OL/Download/DownloadCenter.
Workflow is the heart of all of our solutions. Working in conjunction with PReS Connect, PReS
Capture, CaptureOnTheGO, PReS Imaging, PReS Fax, and a variety of plug-ins, it helps
improve your communications processes. Processes such as communication creation,
interaction, distribution and even maintenance.
Workflow is the "super dispatcher". It caters for inputs from a huge variety of sources, such as
email, web pages, databases, individual files (PDF, csv, XML, etc), print streams, FTP, Telnet
and even ERP systems! This data can then be analysed, modified, stored, verified, routed and
used as triggers for other processes from entirely within Workflow. Finally it is passed to one of
our other products (or not) to be outputted in multiple ways (printed, emailed, posted, archived,
sent to third party solutions, etc..).
Consider Workflow as a set of buildings blocks that enable you to build your own customised
automated processes which will fit your environment and not the other way around. Create
processes that will save you time and money!
Icons used in this guide
Icons are used throughout this guide to point your attention to certain information.
Page 7
Page 8

Technical
Information that may require specific knowledge to understand.
Warning
Information that is potentially critical to using PReS Workflow. Pay close attention.
Page 8
Page 9

System Requirements
Note
Windows XP, Windows 2003 and older versions of Windows are not supported by PReS
Workflow.
These are the system requirements for PReS Workflow 8.5.
Operating System (64-bit only)
l Microsoft Windows 2008/2008 R2 Server
l Microsoft Windows 2012/2012 R2 Server
l Microsoft Windows Vista
l Microsoft Windows 7
l Microsoft Windows 8.1
l Microsoft Windows 10
Minimum Hardware Requirements
l NTFS Filesystem (FAT32 is not supported)
l CPU Intel Core i7-4770 Haswell (4 Core)
l 8GB RAM (16GB Recommended)
l Disk Space: At least 10GB (20GB recommended)
Page 9
Page 10

Basics
PReS Workflow is a tool for the automation of the processing, the distribution and the printing of
your business documents. Once installed on the server, it can be set up to automate all tasks
related to document processing.
Setting Up the Working Environment
Setting up the working environment has to be done the first time you start PReS Workflow.
1. Defining the printer (see Activate Your Printers).
2. Configure PReS Workflow Services (see Workflow Services).
Setting Up Preferences
PReS Workflow Configuration program lets you configure a variety of options, from how the
application itself looks or behaves, to plugin specific options. For more information about
preferences accessible through the Preferences button in the PReS Workflow Button, please
refer to Preferences.
Create a New Process
You can create a new process in a two different ways:
l
In the Ribbon, go to the Home tab and click the Process button in the Processes group.
l
In the Configuration Components pane, right-click on any process or the Processes
folder and select Insert Process.
Regardless of the method, a new process is created with a default name (Process1, Process2,
etc), Input Task and Output Task. The defaults are configurable in the "Default Configuration
Behavior Preferences" on page623 screen. The same methods can be used to create a new
Startup process.
Page 10
Page 11

To add a PReS Workflow startup process:
Note
You can only have one Startup Process in any given configuration and cannot add more.
l
In the Ribbon, go to the Home tab and click the Startup Process button in the
Processes group.
l
In the Configuration Components pane, right-click on any process or the Processes
folder and select Insert Startup Process.
Considerations
l While your configuration is limited to a maximum of 512 processes, any given process
can have as many tasks as necessary.
l A given process may include output tasks that generate files used by input tasks from
other processes.
l When you send a configuration to your PReS Workflow service, all its active processes
are applied.
l Each process’ schedule determines when its initial input task can be performed.
l Other tasks included in the process are performed regardless of schedule, granted that
the previous task was performed.
Send your Configuration
PReS Workflow Configuration saves entire configurations in the form of a single file. Like any
other file, configuration files may be saved and reopened, as well as rename as desired. Simply
saving a configuration has no effect on the configuration actually used by the PReS Workflow
when it is started. To change any currently active configuration, you must use the Send
Configuration command.
When you use the Send command, the PReS Workflow Configuration program uses the
currently opened configuration (Any_name.pw7) to overwrite PReS Workflow service's current
configuration (ppwatch.cfg).
Page 11
Page 12

If PReS Workflow service is running when you send a new configuration, it stops and restarts
Note
If PReS Workflow service is paused when you send a new configuration, it will not stop
and restart. Since PReS Workflow service reads its configuration file when it starts up,
when you resume processing, PReS Workflow service will continue using the old
configuration.
automatically with the new configuration. If the service is stopped, it will not start automatically.
To send a Configuration to the local server:
1. Open the configuration you want to use as a new configuration.
2. Edit the configuration, if required.
3.
When the configuration is ready to be used, from the PReS Workflow button, choose
Send Configuration, then Send Local.
To send a Configuration to a remote server:
1. Open the configuration you want to use as a new configuration.
2. Edit the configuration, if required.
3.
When the configuration is ready to be used, from the PReS Workflow button, choose
Send Configuration, then Send Remote.
Alist of available servers on the local network appears.
4. Put a checkmark next to each server where the configuration should be sent.
5. Click OK.
If a server is grayed out, this may mean you do not have access to send a configuration
remotely to it. For more information, please see "Access Manager" on page597.
Page 12
Page 13

Features
PReS Workflow are input driven applications designed to output data in a variety of ways
through diverse means to various applications and devices. PReS Workflowcan be used as
simple go between, passing along input data to output devices, but it can also perform various
types of data processing. You can combine the various PReS Workflow services to set up
versatile automated processes to print jobs as well as generate other types of output.
The Nature of PReS Workflow
PReS Workflow act as sorts of dispatchers. On the one hand, they retrieves data and controls
plugins that retrieve data from watched locations, and on the other hand they send data and
controls plugins that send data to various devices, for printing or to generate documents that
can then be emailed or faxed. PReS Workflow can also perform a variety of operations on the
data using its action plugins.
In fact, the PReS Workflow plugin based architecture enables almost limitless customization.
You can create or purchase compatible plugins, drop them in any of PReS Workflow plugin
folder and use them to perform other operations. You can even find free unsupported plugins on
the Objectif Lune Web site.
PReS Workflow are service applications, or if you will, applications that continuously run on a
given computer and that perform actions automatically. Those actions are defined in a PReS
Workflow configuration. A given computer can only run one PReS Workflow configuration at a
time. The PReS Workflow Service Console may be used to monitor the services running on a
given computer.
About Branches and Conditions
While some processes can simply start with an input task, manipulate the data with a few action
tasks and finish with an output task, in some cases you may want to have more control over the
flow of your process. For example, you may want multiple outputs, such as printing to multiple
printers as well as generating a PDFand emailing it. To do this, you will need branches. You
may also want to detect certain criteria in your data and act differently depending on that data,
such as sending a fax only when a fax number is found, or printing to a different printer
depending on who send you a print job. To do this, conditions are used.
Page 13
Page 14
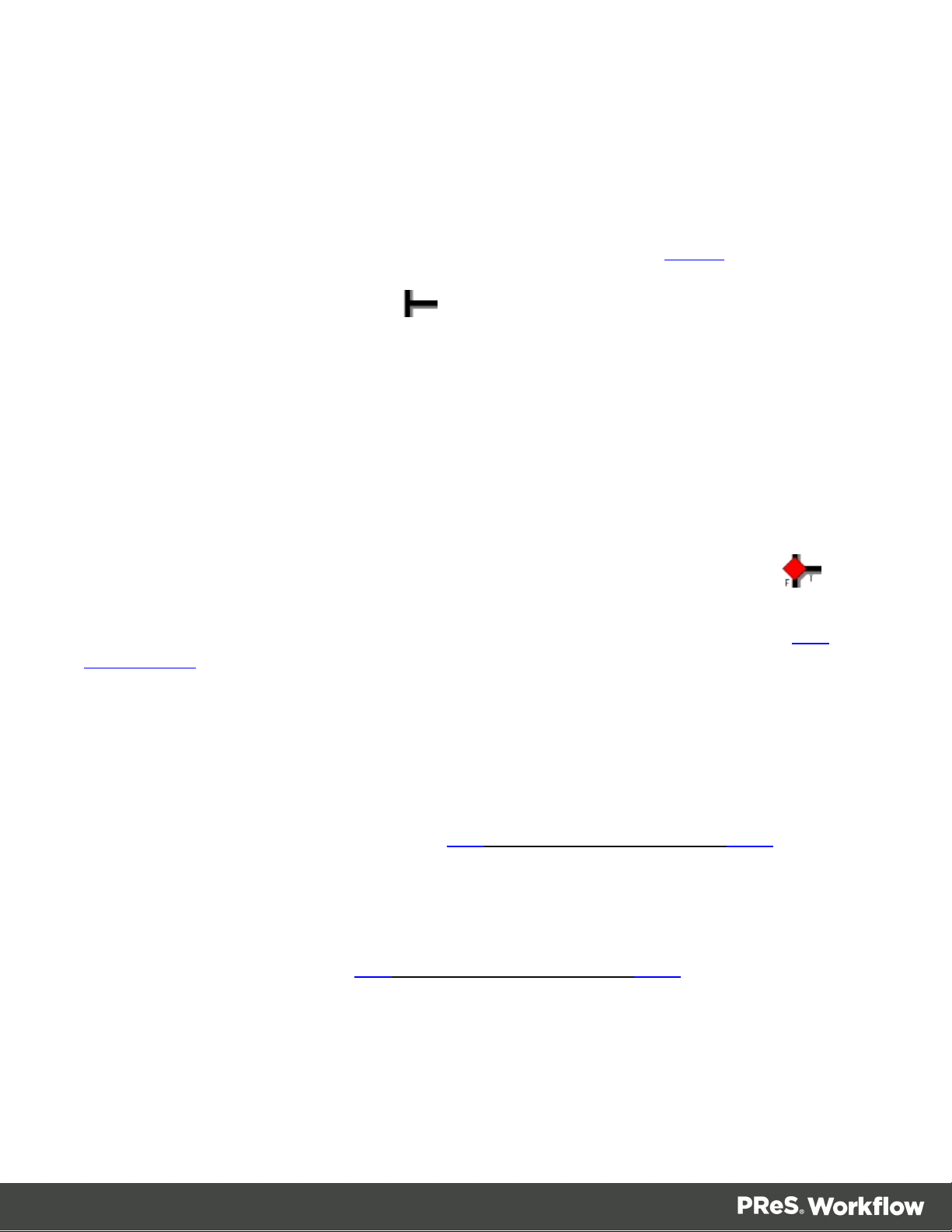
Branches
A branch is effectively a doubling of your job file. As your job file goes down the process, when
it encounters a branch it will go in that branch, process all tasks up to the output, and return to
the main trunk to continue processes. You can have branches within branches, and all
branches must have an output. For more information on branches, see Branch.
A branch is represented as a crossing .
Conditions
Acondition will either execute the branch it creates or the main trunk, but never both. As your
job file goes down the process, when it encounters a condition it will verify whether that
condition results in a "true"or "false"value. If the result is true, it goes in the branch, processes
all tasks up to the output, and the process finishes. If the result is false, it goes down the main
trunk and continues processing until the process finishes.
A conditional branch (or condition) is shown as a crossing with a red diamond over it .
For the list of operations you can perform on Branches and Conditions, please refer to The
Process Area.
Configuration Components
The Configuration Components items displayed in the pane are processes, subprocesses,
variables, documents and printer queues. For more information on operations that you can
perform on each component, please refer to The Configuration Components pane.
Connect Resources
Connect resources are visible in The Configuration Components pane and are added by
using the Send to Workflow option from the PReS 's File menu.
Page 14
Page 15

Available Resources
Note
Package Files are not saved anywhere. The individual resources contained within the
l Data Mapping Configurations:Displays a list of data mapping configurations used with
the Execute Data Mapping task. Each of the templates have been sent from PReS
Connect using the Send to Workflow tool. For each template in the list, the following two
items appear within them:
l Data Model:Displays the data model used in the data mapping configuration.
Double-click on the data model to view it in your default XMLviewer (generally,
Internet Explorer).
l Sample Data File(s):Displays a list of sample files that are included in the data
mapping configuration. Double-click on a file to use it as a sample data file for the
active process.
l Document Templates:Displays a list of templates that can be used in content creation
tasks:"Create Email Content Set" on page478, "Create Web Content" on page492 and
"Create Print Content" on page489.
l Job Presets:Displays a list of Job Presets that can be used in the "Create Job" on
page481 task.
l Output Presets:Displays a list of Output Presets that can be used in the "Create Output"
on page484 task.
Resource Save Location
Any resource sent to PReS Workflow from PReS Connect is saved locally at the following
location: %PROGRAMDATA%\Objectif Lune\PReS Workflow 8\PReS Watch\OLConnect
Resources are saved in their appropriate folder:
l DataMapper contains the data mapping configurations (.OL-datamapper)
l JobCreation contains the Job Presets(.OL-jobpreset)
l OutputCreation contains the Output Presets (.OL-outputpreset)
l Template contains the templates (.OL-template)
Page 15
Page 16
package are extracted and placed in the folders noted above.
Resource Archives
From version 8.2, PReS Workflow maintains an archive of previous versions of resources, in
the following location:%PROGRAMDATA%\Objectif Lune\PReS Workflow 8\PReS
Watch\OLConnect\Archive , each in their own folder:
l datamapper contains archives of the data mapping configurations (.OL-datamapper)
l jobcreation contains archives of the Job Presets(.OL-jobpreset)
l outputcreation contains archives of the Output Presets (.OL-outputpreset)
l template contains archives of the templates (.OL-template)
l workflow contains archives of Workflow configurations received by the server.
The archives are saved using the template named followed by a timestamp. A maximum of 30
of each instance of a resource is kept (meaning if you have 10 different templates, a maximum
of 300 files will be present in the archive\template folder). Older archives are deleted
automatically as new archives are created.
About Data
Data is what drives your business, and our software. We define data as anything that is
obtained through an Input Task and used within the process itself. Once the data is obtained, it
becomes the job file that is passed from one task to another and generally used to generate
output.
Data can be manipulated using the tasks in the process, used as comparison for conditions and
loops, complemented with data from other sources, and used to generate your output. It
originates from many different sources (as many as the input tasks support), parts of it can be
stored in variables, and is always accessible by the task that currently handles it.
Data is referred to using Data Selections either from PReS Workflow or a PlanetPress Design
Document that is being merged with the data (for example in a printed output).
For more information about Data, please refer to "Sample Data" on page28.
Page 16
Page 17

Note
Null characters present in the data may not be displayed properly when using PReS
Workflow Configuration program, and that they may also be printed differently by different
printers. To ensure consistency, you should consider filtering out such characters.
Data File and Job File
Whichever source it may come from, a serial port, an e-mail message, or an LPR request, for
instance, and whatever its format, data entering a PReS Workflow process via an input task is
always referred to as a data file. Job file is a more general term, that can refer to data files as
well as other types of files traveling through a process. Image files, for example, can be passed
from task to task in order to be downloaded to a printer. So files traveling within a process are
mostly referred to as job files.
By default, job file names are generated using the %f variable. You may change the wayPReS
Workflow names job files by using any combination of static characters, variables and Job info
variables. You could for instance enter Process_%w_Job_%f in the File name box to add the
process name in the name generated by the PReS Workflow Tools.
A single job file can be the source of multiple job files. This is the case, for example, when a
process includes multiple branches, as each branch is given a duplicate copy of the job file.
This is also the case when a job file is split into multiple smaller files by a Splitter action task,
for instance (See "Data Splitters" on page324).
It is important to note that job files may be used as a helpful debugging resource (See
"Debugging and Error Handling" on page44).
Actual Data and Sample Data
The actual data is the dynamic data captured by PReS Workflow at run-time. The sample data
file is a static sampling of the run-time data.
In the PReS Workflow Configuration program, you use sample data files to create and edit
PReS Workflow configurations.
Page 17
Page 18

Job File Names and Output File Names
When an input task sends a new data file down a process, it gives it an internal file name
referred to as the job file name (associated with the %f variable). The new job file typically
keeps the same name until the end of the process.
l If the job file comes to a branch in the process, PReS Workflow makes a copy of the job
file and give the new file a new job file name.
l If the job file is processed by a splitter action task, the task typically creates a number of
new files which are all given new job file names.
Since these files are generated and managed by PReS Workflow, you should not actually pay
too much attention to their names.
Many output tasks, on the other hand, let you determine exactly how you want the files they
generate to be named. In the case of Send to Folder output tasks, for example, output files are
saved under their job file names by default (using the variable %f), but you may use a static
(MyOutput.txt, for example) or variable name (%O_Invoices, for instance) of your choosing.
Variables such as %o (original file name) bring up the issue of file overwriting. If the process
receives two source files with the same name, the second output file may overwrite the first one.
This may be what you want, but otherwise you may consider using another variable, such as in
%u (unique 13-character string).
When choosing naming schemes for output files, consider the following:
l For the benefit of users who must identify files, be it in a folder or on a printer queue,
consider using names that are as meaningful and precise as possible.
l Some devices or applications may use file name extensions to know what to do with
incoming files.
Since variable properties can be entered in the boxes where you specify the folder and file
names, you can use variables, data selections and static text. You could, for example, use the
following: ClientID_@(1,1,1,1,14,KeepCase,Trim)_StatMonth_%m.
One last consideration regarding output file names has to do with standard JPEG and TIFF files
generated by PReS Image. When an output job contains multiple pages, multiple JPEG or TIFF
files are generated (one image per file), each one identified by a sequence number appended
to its name (this is managed by your PReS Workflow). A three page job to be called Invoice, for
Page 18
Page 19

example, will generate three JPEGs or TIFFs called Invoice0, Invoice1 and Invoice2. Note that
Note
You can change the name of a previously named file using a Rename action task (see "Rename"
on page296).
this does not apply to multiple TIFFs, which can include multiple images in a single file.
About Data Selections
A data selection could be compared to an address. It indicates a location within a data file
using coordinates. PReS Workflow includes a tool called the Data Selector that helps you
make data selections. The Data Selector does two things:
l It uses the current emulation (either the emulation chosen when the sample data file was
selected, or the one chosen in the last Change Emulation action task appearing above
the current task) to format the data.
l It displays the formatted data to let you make selections easily using the mouse pointer.
The Data Selector is essentially the same as the one used in PlanetPress Design.
Data Selections
A data selection is simply a reference to a given location within the job file or metadata file,
using the current emulation. Data selections are always evaluated at run-time so they are
always dynamic and depend on the job file that is currently being processed. When you make a
data selection, the PReS Workflow Configuration program converts it to text form, using
coordinates to reference the selected location.
There are three types of data selections you can use in PReS Workflow. The available type of
data selection depends on which emulation you are using and whether or not you have created
Metadata.
You can add data selections to variable properties of your tasks either automatically using the
data selector (See "The Data Selector" on page24) or manually by typing in the data selection.
Page 19
Page 20

Note
It is strongly recommended to use the automatic method, as it returns precisely the same
selections but is generally more reliable
Text-Based Data Selections
These selections are used for text data files such as Line Printer, ASCIIand Channel Skip
emulations. The selection refers to a rectangular selection that may contain multiple lines, rows,
columns on a given page.
Syntax
@(page number, from line, to line, from column, to column, case option, trim
option)
Here is a breakdown of the syntax (all options are mandatory):
l @():Always surrounds a data selection.
l Page Number:The data page number from which you want the data selection to grab the
data. If you want to get data from each page individually, this has to be done after a
splitter.
l From Line:The starting line of the data selection.
l To Line:the last line of the data selection.
l From Column:the leftmost character position of the data selection.
l To Column:the rightmost character position of the data selection.
l Case Options:This can be one of three options:
l
KeepCase:Keeps the current uppercase and lowercase letters as they are.
l
UpperCase:Converts all letters to their uppercase equivalent.
l
LowerCase:Converts all letters to their lowercase equivalent.
l Trim Option:Can either be "Trim"if you want to trim empty spaces before and after the
data selection or "NoTrim"if you want to retain the extra spaces.
Alternate Syntax
@(line number, from column, to column)
Page 20
Page 21

The alternate "quick"syntax lets you grab data from a single line from the first data page in the
file. Here is a breakdown of the syntax (all options are mandatory):
l @():Always surrounds a data selection.
l Line Number: The line from which to get the data.
l From Column: the leftmost character position of the data selection.
l To Column: the rightmost character position of the data selection.
Database Data Selections
These selections are used for database-driven data files such as Database and
CSVemulations. The selection refers to a specific field on any given data page.
Syntax
field(record set number, child number, field name, treatment of character case,
treatment of empty trailing cells)
Here is a breakdown of the syntax (all options are mandatory):
l field():Always surrounds database field selections.
l Record Set Number: The data page (or "record") of the data selection.
l Child Number:Line Number in the record (if there are multiple lines returned for one
single record).
l Field Name: The name of the field you want to retrieve.
l Case Option: This can be one of three options:
l KeepCase:Keeps the current uppercase and lowercase letters as they are.
l UpperCase:Converts all letters to their uppercase equivalent.
l LowerCase:Converts all letters to their lowercase equivalent.
l Trim Option:Can either be "Trim"if you want to trim empty spaces before and after the
data selection or "NoTrim"if you want to retain the extra spaces.
Data Repository Lookups
The Data Repository selections are made through the lookup function. Selections are done
from the data located in the "Data Repository Manager" on page610. The lookup function
returns the value of a single key, which is always a string.
Page 21
Page 22

Syntax
lookup(group, return key, lookup key, lookup value)
Here is a breakdown of the syntax (all arguments are mandatory):
l group:The name of the group in which to retrieve the value. Does not need to be
surrounded by quotes.
l return key:The name of the key where the information you want to retrieve is located.
Does not need to be surrounded by quotes.
l lookup key:The name of the key in the group with which to look up the value. The return
key of the KeySet in which the lookup key's value matches the lookup value will be
returned.
l lookup value: A string surrounded by quotes which will be used in the lookup.
PDF Data Selections
These selections are used for PDF data files. The selection refers to a specific area of any
given page of the PDF by using precise region coordinates (in inches).
Syntax
region(page, left, top, right, bottom, case option, trim option)
Here is a breakdown of the syntax (all options are mandatory):
l region():Always surrounds PDFdata selections.
l Page:The page of the PDFfrom which to retrieve the data.
l Left:Exact horizontal position (in inches)that defines the left of the selection region.
l Top:Exact vertical position (in inches)that defines the top of the selection region.
l Right:Exact horizontal position (in inches)that defines the right of the selection region.
l Bottom:Exact vertical position (in inches)that defines the bottom of the selection region.
l Case Option: This can be one of three options:
l KeepCase:Keeps the current uppercase and lowercase letters as they are.
l UpperCase:Converts all letters to their uppercase equivalent.
l LowerCase:Converts all letters to their lowercase equivalent.
Page 22
Page 23

l Trim Option:Can either be "Trim"if you want to trim empty spaces before and after the
data selection or "NoTrim"if you want to retain the extra spaces.
Metadata Selections
These selections are used with any type of file, as long as a metadata file was created by a
previous task.
Syntax
GetMeta(Field Name [, Option Flags, Metadata Path])
Here is a breakdown of the syntax:
l GetMeta():Always surrounds metadata selections.
l Field/Attribute Name:specifies the name of the field (or attribute, if the GetAttribute
option flag is set) to retrieve.
l Option Flag (optional):Sets the options for the selection (see table below)
l Metadata Path (optional):Defines the precise path where the Metadata Field is located.
Option Flags
Name Value Behavior
GetAttribute 1 Search for the name argument in the attribute collection
instead of the default field collection.
NoCascade 2 Search only the level specified by the path argument
(defaults to Page level when path argument is empty),
instead of default behavior, going from the Page level to
the Job level.
FailIfNotFound 4 Raise an error and crash the job is the specified name is
not found instead of returning an empty string.
SelectedNodesOnly 8 Returns values from the selected nodes only.
Page 23
Page 24
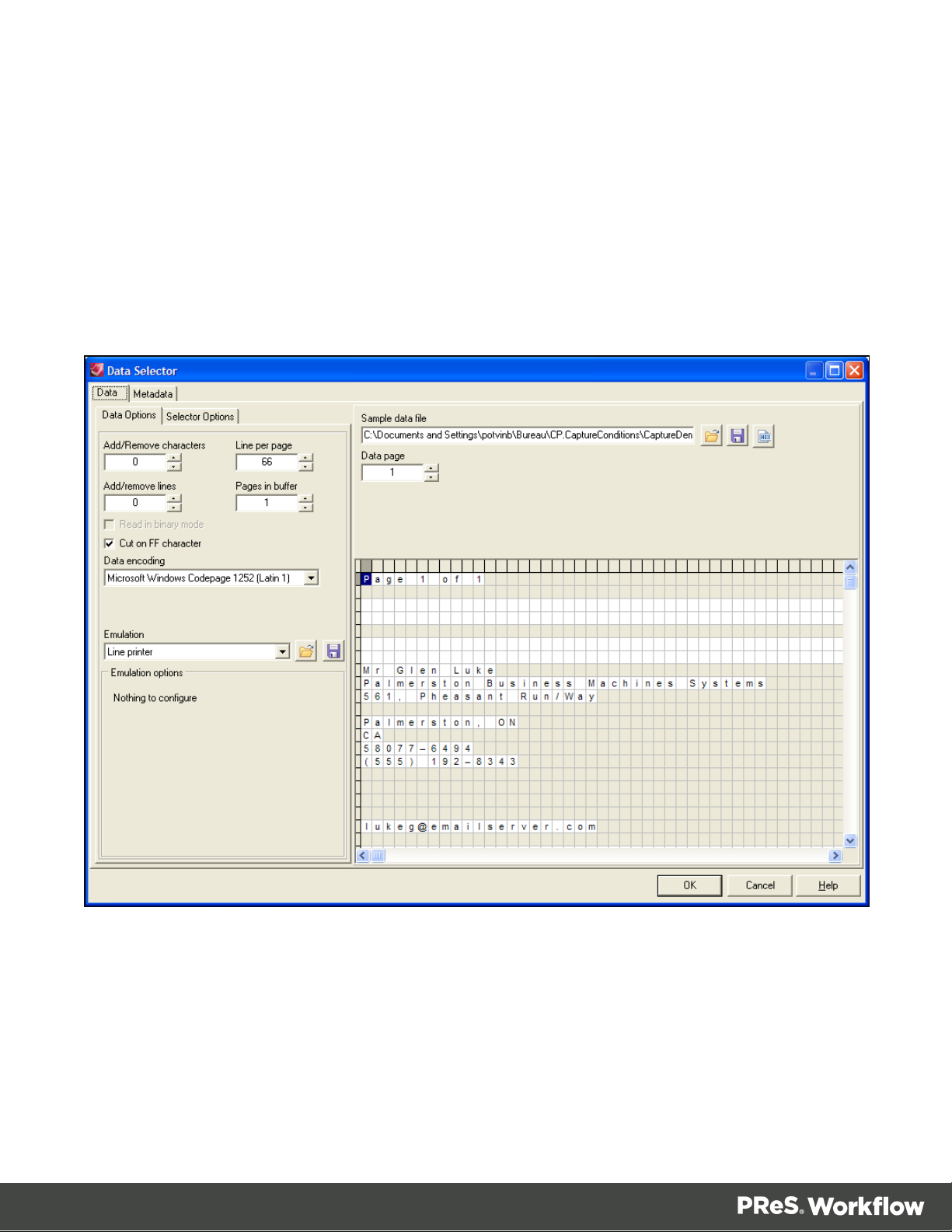
The Data Selector
The Data Selector is the tool you use to choose your sample data and metadata files, to select
the appropriate emulation, make data selections, and to stabilize your data.
The Data Selector is divided in two tabs:Data and Metadata. The Data tab contains the Data
Options, which let you select your emulation, and the Selector Options, which lets you
personalize the data selector's display options (see Data Selector Display Preferences)
Depending on the chosen emulation and data file, the options in the data selector, the Sample
data file section and the Data pane itself may change to accommodate your choice. The Line
Printer, Ascii, Channel Skip and User-Defined emulations will display the default options (see
the Emulation section)and a grid-like display of each character on each line. The following
emulations however, will be slightly different.
Page 24
Page 25

Database Emulation
l
The Database emulation changes the Browse button( ) for the Database Emulation
Configuration button ( ), which displays the Database Emulation Configuration (see
Database Emulation).
l
Once a database has been opened and query entered, the Data pane displays the results
of the SQLQuery in a grid format, which each line representing a single returned row from
the database. Each column represents a field returned by the query, with its field name as
a row header.
XMLEmulation
l XMLdata is represented in a tree structure which corresponds to the data in the XMLfile.
Each node of the XMLcan be expanded to see the nodes under it. See XML Data
Emulations.
PDF Emulation
l
If you use a PDF emulation, the Data pane displays the data as you would see it in any
PDFreader.
l A new zoom drop-down list is displayed to let you set the zoom in percentage or fit the
PDFto the window or the width of the window.
l A new status bar, displaying the (Left, Top) and (Right, Bottom) coordinate pairs, is shown
under the Data pane.
Page 25
Page 26

Metadata tab
The Metadata tab allows users to either generate the metadata file for their active sample data
file, or to associate an existing metadata file to their document.
The Sample Metadata file name is the path to the metadata file describing the current sample
data file. Buttons on the rightcan be usedto load metadata from a file or to save the current
metadata to a file.
The Generated PressTalk Expression is a PlanetPress Talk command corresponding to the
current attribute or field being selected. Its value is editable, which allows the user to customize
the string returned by the metadata selector.
Page 26
Page 27

The Search options defines how to retrieve the value of a given metadata element (attribute or
field) when it is not present at the current metadata level. The possible search options are:
l Search from a specific location only.
l Search from level X to Job, where X can be any metadata level (Job, Group, Document,
Datapage, Page). With this search option, if the selected metadata element does not exist
at the specified level, then it will be searched for, starting at the lowest metadata level as
specified in the search option, then one level up until the element is found.
The Raise an error if the field does not exist option allows to control what to do when a given
metadata element is not found, regardless of the search option.
The Data page box lets the user choose which data page metadata elements to be displayed.
The Metadata level is a tree view allowing users to select the metadata level from which to
display or select metadata elements.
TheAttributes list displays all metadata attributes describing the current metadatalevel,as
selected in the Metadata Level tree view, for the current data page, as selected in theData
Page control.
The Production information list displays all metadata fields describing the current
metadatalevel,as selected in the Metadata Level tree view, for the current data page, as
selected in theData page box.
AboutData Emulation
Emulations are like filters that can be used to read the data. When you create a document in
PlanetPress Design, you choose a sample data file and specify the emulation to use for the
chosen data. The emulation setting you choose will typically always be associated with that
document. If you choose a CSV (comma separated values) file and specify the corresponding
emulation, for instance, commas encountered in the data will typically be considered as value
separators.
Within PReS Workflow, the same emulation tools as PlanetPress Design are available
throughout your process, using the Data Selector. One notable exception however is that UserDefined Emulation is not available because it uses PReS Talk code, which is not available
within PReS Workflow Configuration Program.
Page 27
Page 28

The emulation that is used in your process can change during the process, and can be different
Warning
PDFEmulation, also called Document Input, is only available in PReS Workflow.
than the one used in any PlanetPress Design document used in your process. PlanetPress
Design documents use their own emulations, as defined in the document itself from
PlanetPress Design.
Emulations in PReS Workflow:
l Line Printer
l ASCII
l CSV
l Channel Skip
l Database
l XML
l PDF
For more information about each emulation and how to use them, please refer to PlanetPress
Design User Guide.
Using the File Viewer
The File Viewer is like a Data Selector without any data related options, such as emulation
settings. It is displayed when doing a data selection from the Generic Splitter task (see
"Generic Splitter" on page333) with the Use Emulation option unchecked. The only data
formatting codes to which the File Viewer responds are line breaks.
For more information on the selecting data, see "The Data Selector" on page24.
Sample Data
PReS Workflow is a versatile tool that can capture various types of data files and dispatch this
data to various PlanetPress Design documents. To fully understand PReS Workflow and how it
treats data, you must understand how it is integrated into PlanetPress Design.
Page 28
Page 29

This section covers issues relating to the sample data used to create your PReS Workflow
Note
You can also use the PReS Workflow Database action task to get data form a database,
and output in multiple different formats such as CSV. See "Database Query" on
page263.
configuration and to the actual data that PReS Workflow will send to PlanetPress Design
documents. It is an important section which you should fully understand before you start
creating your configuration. Also included in this section are procedures that let you make data
selections as well as get data from the sample data file.
Since many of the concepts and explanations included in this chapter are closely related to
concepts and explanations found in the PlanetPress Design User Guide, we suggest that you
review this document, especially the Selecting an Emulation section.
Choosing a Database Type Sample Data File
The procedure for selecting a sample data file that is in fact a database is the same as doing so
in PlanetPress Design. For more information, please see the relevant page in the PlanetPress
Design User Guide.
Choosing a Sample Data File
In order to create your PReS Workflow Process, the sample data you are going to use has to
correspond precisely to the job files that will be treated by that process, at least in terms of
structure.
The sample data file should have a relatively small number of pages (generally less than a
hundred)in order to be processed quickly, while your actual data may be much larger and take
more time to process. The sample data file should also contain at least one of every exception
you may want to detect, or data used for a specific condition. For example if you wanted to filter
out any data for clients in Canada, you would want to use a data file that has at least one user
from Canada, to test whether your condition removes it.
Page 29
Page 30

To choose a sample data file:
Note
Applications or plug-ins created in PlanetPress Suite 6 and using Metadata will need to
be updated for use in version 8.5. No backward compatibility mode is available.
Warning
When a user-defined emulation is used with metadata, results and behavior are unknown
and unsupported. For instance, refreshing the metadata file may cause the document to
crash and/or corrupt. For this reason, it is strongly advised to create backup copies of
1.
Click the Debug tab in the PReS Workflow Ribbon.
2. Click on Select in the Data group.
3. Use the Data Selector to choose your sample data file and emulation options.
4. Click OK on the Data Selector.
PReS Workflow also keeps the last 9 used data files in memory, which you can reopen to use
in the same process, or a different one.
To reopen a sample data file used previously:
1. Click the Debug tab in the PReS Workflow Ribbon.
2. Click on Reopen Data File in the Data group.
3. Click on one of the data files in the list.
4. Use the Data Selector to change the emulation options if necessary.
5.
Click OK on the Data Selector.
Metadata
Simply put, metadata is data about data or, in other words, information tagged to data. Metadata
includes information about the data file itself, the document, page properties, page counts and
custom user fields.
Page 30
Page 31

your documents beforehand.
Metadata structure
Metadata in PReS Workflow introduces the following concepts for adding information to a job:
l
Page: 1 side of a physical paper sheet.
l
Datapage: 1 atomic unit of content that produces zero, one or more pages.
l
Document: group of 1 or more ordered datapages intended to the same recipient from the
same source (ex: invoice).
l
Group: a logical and ordered group of documents (ex: all invoices for a specific customer
number; all documents going to the same address, etc.)
l
Job: file that contains 1 or more groups.
When Metadata is produced for a given job, a hierarchical (i.e. tree-like) structure is created,
composed of the above elements in the following order: Job->Group(s)->Document(s)>Datapage(s)->Page(s). Any operation that modifies the data with regards to this structure (ex:
remove pages, alter the data, etc.) makes the metadata obsolete and so it must be recreated or
refreshed.
As an example, consider the typical case of a PlanetPress Design document which uses a Line
Printer datafile of transactional data in order to generate PDF invoices for a series of clients. By
using the Metadata tools available in PReS Workflow, we can add the following information to
the datafile:
l The job contains only invoices for clients located in Montreal.
l Since more than one invoice can go to the same recipient, invoices are grouped by
customer.
l Each invoice is a document resulting from the execution of a PlanetPress Design
document over one or more datapages, which results in zero or more physical pages
being output.
Page 31
Page 32

A single JOB can be composed of GROUPS of DOCUMENTS, which themselves are
composed of physical PAGES produced by executing a PlanetPress Design document on one
or more DATAPAGES.
Metadata Elements
Each metadata node (i.e. Job, Group, Document, etc.) is described with a series of elements,
that is, system-defined attributes or user-defined fields holding static or dynamic information
about the node they are attached to. Each element has a name and a value. More specifically,
here is a definition of these 2 types of elements:
l
Attribute: A read-only, system-defined element which holds a certain information about a
certain node from the Metadata structure. This information can be static (e.g. the size of a
physical page) or evaluated on-the-fly (e.g. the number of documents in a group).
Attributes are non-repetitive (i.e. name is unique) and does not persist through metadata
recreation.
l
Field: A read-write, user-defined element which hold custom information about a certain
node from the metadata structure. Fields are repetitive (i.e. the same field may appear
multiple times) and persist through metadata recreation.
Page 32
Page 33

In addition to attributes and fields, each node of type group, document or datapage have a
Note
The presence of some finishing attributes depends on the PlanetPress Design document and target
device used when producing the job.
Boolean property called selected that indicates whether or not to produce the pages under that
node. By default, this property is set to true for all nodes.
Metadata Attributes Reference
Here is a description of the Metadata attributes. The attributes are categorized as either
Production, Finishing or Index/Count.
Production attributes describe the production of the job and/or metadata (e.g. path and name of
the datafile, date at which metadata was created, etc.)
Finishing attributes describe the finishing intent (e.g. page dimensions, page orientation,
duplex mode, etc.).
Index/Count attributes are not part of the original metadata file. They are evaluated live based
on the content of the metadata.
In the following table, the last 5 columns indicate at which level the corresponding attribute is
available.
Attribute Description CategoryJ
DataEncoding (optional)
Name of the
character
encoding.
DataFile (optional) Path
and name of
ProductionX X X
ProductionX X X
o
b
Gro
up
Docum
ent
Datap
age
Pa
ge
Page 33
Page 34

Attribute Description CategoryJ
Gro
Docum
Datap
Pa
the data file
used by the
PlanetPress
Design
Document.
Date Date the
metadata was
created in ISO
format.
Time Time the
metadata was
created in ISO
o
b
ProductionX X X
ProductionX X X
up
ent
age
ge
format.
Title Title of the
source
document.
Producer Name of the
software that
created the
metadata.
Creator Name of the
software that
created the
source of the
metadata.
ProductionX X X
ProductionX X X
ProductionX X X
TargetDevice Name of the Producti X X X
Page 34
Page 35

Attribute Description CategoryJ
Gro
Docum
Datap
Pa
device for
which the
metadata and
associated
data is
intended.
Dimension Two floats
separated by a
colon
indicating the
media size in
typographical
points (ex:
on
Finishin
g
o
b
X X X X X
up
ent
age
ge
612:792).
Orientation "Rotate0",
"Rotate90",
"Rotate180" or
"Rotate270",
indicating
respectively
portrait,
landscape,
rotated portrait
and rotated
landscape.
Side "Front" or
"Back";
indicate
Finishin
g
Finishin
g
X X X X X
X
whether the
Page 35
Page 36

Attribute Description CategoryJ
Gro
Docum
Datap
Pa
page is on the
front or the
back of the
paper sheet.
This attribute
is a "best
effort" and is
devicedependent.
Duplex "None",
"DuplexTumbl
e" or
"DuplexNoTu
Finishin
g
o
b
X X X X X
up
ent
age
ge
mble"; indicate
a change of
the duplex
status.
InputSlot Device-
dependent
identifier of the
media source.
OutputBin Device-
dependent
identifier of the
media
destination.
Weight Device-
Finishin
g
Finishin
g
Finishin
X X X X X
X X X X X
X X X X X
dependent
g
Page 36
Page 37

Attribute Description CategoryJ
Gro
Docum
Datap
Pa
weight of the
media.
MediaColor Device-
depedent
color of the
media.
MediaType Device-
dependent
type of the
media.
Index Index/C
Finishin
g
Finishin
g
o
b
X X X X X
X X X X X
up
X X X X
ent
age
ge
IndexInDocument Returns the
Absolute
index of the
node within all
the node
under the
parent
Document.
IndexInGroup Returns the
Absolute
index of the
node within all
the node
under the
ount
Index/C
ount
Index/C
ount
X X
X X X
parent Group.
Page 37
Page 38

Attribute Description CategoryJ
Gro
Docum
Datap
Pa
IndexInJob Returns the
Absolute
index of the
node within all
the node
under the
parent Job.
Count Index/C
DocumentCount Index/C
Index/C
ount
ount
ount
o
b
X X X X
X
up
X X X X
ent
age
ge
DatapageCount Index/C
ount
PageCount Index/C
ount
SelectedCount Index/C
ount
SelectedDocument
Count
SelectedDatapage
Count
SelectedPageCoun
t
Index/C
ount
Index/C
ount
Index/C
ount
X X
X X X
X X X X
X
X X
X X X
Page 38
Page 39

Attribute Description CategoryJ
Gro
Docum
Datap
Pa
SelectedIndexInDo
cument
SelectedIndexInGr
oup
Returns the
Absolute
index of the
node within all
the selected
node under
the parent
Document.
Returns the
Absolute
index of the
node within all
the selected
Index/C
ount
Index/C
ount
o
b
up
ent
X X X
age
X X
ge
node under
the parent
Group.
SelectedIndexInJo
b
NumCopies Indicates how
Returns the
Absolute
index of the
node within all
the selected
node under
the parent Job.
many times
the job is set
to execute, as
Index/C
ount
Index/C
ount
X X X X
X
set when
Page 39
Page 40

Attribute Description CategoryJ
Gro
Docum
Datap
Pa
printing using
a Windows
driver.
Author Name of the
user who
printed the job
initially, as
available in
the spool file,
and as the first
job info of the
Windows
capture input.
ProductionX
o
up
ent
age
ge
b
Metadata Tools
PReS Workflow includes a complete set of metadata-related functionality, which can be
referred to as Metadata Tools. These tools can be used to generate metadata, retrieve or define
metadata elements, and build the metadata structure.
Metadata Tools
Using PlanetPress Design, one can:
l Generate metadata for any given sample datafile.
l Graphically retrieve the value of a metadata attribute or field for use in any design object.
l Define documents and groups using any condition.
l Define custom metadata fields.
l Manipulate Metadata with PlanetPress Talk commands.
Following is a description of the Metadata tools which allows to perform the above tasks:
Page 40
Page 41

Metadata Generation using Data Capture with PReS Printer
The Objectif Lune Printer Driver (PS) allows end-users to print directly to PlanetPress Design
from any Windows application, by using the familiar File|Print option. At the other end,
PlanetPress Design can capture the incoming stream and convert it internally into a PDF file
along with its metadata. By default, capturing a document input using a PReS Printer will
generate a PDF along with its metadata.
Metadata Generation and Refresh without using PReSPrinter
It is possible to generate or refresh metadata for any given sample datafile by using the Refresh
Metadata option available when right-clicking on the Metadata Fields folder found in the
Document Structure Window. For example, metadata can be generated this way for a Line
Printer sample datafile captured using an LPD Queue Input.
Metadata Selector
PReS Workflow's Data Selector window is accessible by double clicking inside the Sample
Data window or by clicking on the Open Active Data button available in the ribbon. The Data
Selector is equipped with a new tab labeled Metadata.
Firstly, two buttons at the top right corner of this tab allows to load or save a metadata file
generated for the current sample datafile.
Secondly, the metadata tab graphically displays all elements (i.e. attributes and fields)
available at the current level (i.e. Page, Datapage, Document, etc.). More importantly, these
elements are graphically selectable, like any other part of the sample datafile when using the
'Select Data' option inside a Text object, for example.
Page 41
Page 42

The Metadata Selector allows to view and select metadata elements.
Metadata in Document Properties
Page 42
Page 43

Metadata tab in the properties of a PlanetPress Design document allows to easily define
documents or groups.
Metadata Fields
Metadata Fields in the properties of a PlanetPress Design document allows to easily define
documents or groups.
About Documents
A Document is a file sent to PReS Workflow by PlanetPress Design and is used to produce an
output when merged with data. ADocument can be an invoice, a report, a receipt or anything
else, but by itself it is empty and without any variable data.
Document are typically selected in Output Tasks, but can also appear in other tasks that
produce formatted data such as the Digital Action task and the Add Document task.
Documents contain static data such as logos, addresses and graphic formatting, as well as
placeholders for data. Documents can also contain conditions and programming logic. For
more information about PlanetPress Design documents, please see the PlanetPress Design
User Guide.
Page 43
Page 44

Import Documents
This procedure describes how to import variable content documents created in PlanetPress
Design. Importing documents can be useful when transferring configurations between PReS
Workflow installations.
To import documents into PReS Workflow:
1.
Choose File | Import Documents. The Import PlanetPress Design Document dialog
box appears.
2.
In the File type box, select the desired file type.
3.
Navigate to the document you want to import, select it and click Open.
The document is imported and displayed in the Configuration Components pane. This
physically installs the documents to the Documents folder relative to the install folder of PReS
Workflow.
Import PrintShop Mail Documents
This procedure describes how to import variable content documents created in PrintShop Mail.
Importing documents can be useful when transferring configurations between PReS Workflow
installations.
To import documents into PReS Workflow:
1.
Click the PReS Workflow button. The Import PrintShop Mail Document dialog box
appears.
2. Choose Import, then PrintShop Mail Documents.
3.
Navigate to the document you want to import, select it and click Open. The document is
imported and displayed in the Configuration Components pane. This physically installs
the documents to the Documents folder relative to the install folder of PReS Workflow.
Debugging and Error Handling
This chapter touches on two subjects that are intrinsically linked, though their use is different.
Debugging is the act of running through your process, either step by step or as a whole, directly
Page 44
Page 45

from the PReS Workflow Configuration Tool, in order to detect and resolve issues with your
process.
Error Handling, on the other hand, occurs when your configuration has been sent to PReS
Workflow services, and are running in "production"mode. On one hand the manual task is
critical when creating a process, on the other the automated handling of errors within your
processes will have a large impact on recovering from errors as they happen during production.
About Error Handling
When your process is running, or during debugging, it may happen that the task that is currently
running causes an error, and the task fails. For example, when trying to save to a folder that
does not exist, or printing to a printer that cannot be found.
When such an error occurs, in most cases you would want to be aware of it and to take certain
actions in order to correct or report the error. This is where our error handling features come in
handy.
Most of the tasks, branches and conditions included in your process can have their own error
handling behavior, with the exception of Comments, the Input Error bin task, and older legacy
tasks from previous versions of PReS Workflow that did not have error handling.
By default, when an error occurs, the task is skipped and the unmodified job file is passed on to
the next task. You can overwrite this behavior by changing the options of the On Error tab of
the task.
Using the On Error tab
Whenever an error is triggered either during debugging or when a process runs in production,
the settings specified in the On Error tab of the task that generated the error will be used to
determine a course of action.
On Error Tab
The On Error tab is common to all tasks. Details can be found in the" Task Properties Dialog"
on page663.
By default, any action task, branch, splitter or condition that generates an error will simply be
ignored, and the task just under it (not within a branch)will be given control of the job file
Page 45
Page 46

without any modification. Any initial input task that generates an error will stop the process from
running as a whole, and output tasks will not generate output. The On Error tab can be used to
overwrite the default behaviors.
l Send to Process: Check this option to send the job file to an error management process.
l
Error Process drop-down:Enabled only when the Send to Process option is checked.
Lists any process of which the initial input task is the Input Error Bin task.
l Action Group:This group is disabled in the initial input tasks and defaults to Stop
Process. In all other tasks where the On Error tab is present, the following options are
available:
l Ignore:The task is ignored as if it did not exist, and the job file is passed on to the
next task in the process.
l Stop Branch:If the task is in a branch of the process, the branch is stopped and the
job file is returned to the process after the branch. The branch will not produce any
output.
l Stop Process:The process is stopped and no more processing is done. No further
output is produced.
l
Log Message:Check this option to enable logging a custom error message in the PReS
Suite Workflow Tools' log file.
l
Message:Enabled only when the Log Message option is checked. Enter a message that
will be logged in the PReS Suite Workflow Tools' log file. You can use any variables
available in PReS Workflow to customize the message.
l
Store the message in variable:Select in which jobinfo, local or global variable you
want to store the message content.
l
ID:Enter an error ID. This IDwill be visible in the Windows Event Viewer. However, the
IDis not visible in the PReS Suite Workflow Tools' log file.
l
Store the IDin variable:Select in which jobinfo, local or global variable you want to
store the error ID.
l Reset to defaults:Resets all options in this tab to their default values.
If storing the message or ID, if they are store in a jobinfo they will be available in any error
handling process where errors are being forwarded. In all cases, if your process continues after
the error, the contents of the variables selected in this window will be available for the rest of
your process, or whenever they are overwritten.
Page 46
Page 47

Common Errors
Though some error messages are specific to a task in particular, others may apply to any and
all tasks because they are related more to the system than to PReS itself. Some examples
would be W3813, W3830, W3991, W4005. These correspond to issues such as not having any
space to write files, permission errors on folders or files, etc.
Creating and Using Error Processes
An Error Process is a special type of process that never runs on its own, and cannot be called
using the GoSub or Send to Process tasks. It can only be used in the On Error tab of a task in
your process, and will be triggered if the Send to Process option is checked in that tab and an
error process is selected in the drop-down list.
To create an error process, simply replace the initial input task by the InputErrorBin input task,
and that process automatically becomes able to handle error jobs sent to it. It is up to you,
however, to decide how that error job will be handled.
For example, you could place the job file in a specific folder, then send an email to a supervisor
indicating that a job has failed. Or you could update a database with an error status so that it
appears on a customer's online order. You could also zip the order up and send it to an
administrator, while simultaneously advising the person that sent the job that it failed.
You can have as many error processes as you can normal processes - that is, you are limited to
512 processes, subprocesses, startup processes and error processes combined.
The following information is available from within your information process when it is
triggered:
l Job Information variables (%1 to %9)
l The data file as it was before starting the task
l Global variables (which are, of course, available anywhere)
l Aseries of variables containing information about the error, the task that triggered it and
the process that contained it. See "Standard Variables" on page535
Page 47
Page 48

Note
Local variables in the process are not sent to error processes, even if the error process has a variable
of the same name.
Accessing the Logs
Note
The information that is displayed here is the same as in PReS Workflow logs and
depends on the logging level that you set in the "General Plug-In Preferences" on
If your process is running live in PReS Workflow service, you have two ways of seeing what is
happening, now or in the past.
To view what processes are running and processing data as it happens:
1.
In the PReS Workflow Ribbon, click on the Tools tab, then select Service Console in the
Services group. The PReS Workflow Service Console opens.
2. Click on the service you want to check, including:
l PReS Workflow
l LPDServer
l Telnet Capture
l Serial Capture
l HTTP/SOAP Server
l LPRClient
l FTPClient
l PReS Image
l PReS Fax
l PReS Messenger
3. When any job or file is processed by the selected service, the processing logs will be
displayed in the window on the right.
Page 48
Page 49

page638.
To view logs for jobs that have already processed
Note
The PReS Image and PReS Fax logs are available in different folders. From the Watch
folder, go up one level then go in either folders, under which you will find the Log folder
for that specific software within the suite.
By default, the logs are available in the following folder:
C:\Documents and Settings\All Users\Application Data\Objectif Lune\PlanetPress
7\PlanetPress Watch\Log
You can access this folder more quickly by using this procedure:
1. From PReS Workflow Configuration software, press CTRL+SHIFT+ALT+F4
simultaneously. The PReS Workflow working folders are opened.
2. Double-click on the folder called Log.
3. There are multiple logs displayed here, including:
l ppwYYYYMMDD.log - PReS Workflow logs, including the year, month and day of
the log (from midnight to midnight).
l FTP, LPD, LPR, ??? (to be verified)
Resubmit Backed Up Input Files to a Process
Each input task includes an option that lets you back up input files. This options is not selected
by default, since it has the potential to generate a very large number of back up files. To turn on
the backup option of an input task, simply open its properties, go to the Other tab and check the
Backup input files option, then type in a unique file name for the backup file (this should be
variable).
Page 49
Page 50

But if, for a given input task, you did select this option and something goes wrong and an
original input file is lost or corrupted, you will have the option to use the Resubmit Job
command to pull the backed up input file into the process.
Granted that you have back up copies of the files polled by an input task, you may resubmit
them as required. The PReS Workflow Configuration gives you the option to resubmit them as
they were submitted originally (polled by the initial input task) or to submit them to those tasks
located on the index you select.
The numbers on the left indicate the task index, the folder capture being level 1 and the Text
condition being on level 4.
To resubmit backed up input data files:
1.
In the PReS Workflow Ribbon, go to the Tools tab then click Resubmit Job in the
Services group. The File Resubmission dialog box is displayed.
2.
From the Process box, select the process for which you want to resubmit the backed up
input files.
3.
From the Task index box, select the index level to which you want the data to be sent.
The index is the position in the process where you want to submit the job file.
4. In the list of backed up input files, select the file you want to resubmit.
Page 50
Page 51

5.
Warning
The From page and To page boxes are only useful for printer queue (or printer
capture)inputs. They will not function for other types of inputs. In these cases, the
complete backup job is submitted.
Using the From page and To page boxes, select the data pages that you want to
resubmit. If you want to resubmit all the data pages from the selected input file, enter 0 in
both boxes.
6.
Click Send to resubmit the data.
7. To resubmit backed up input files for the same process or for a different one, repeat step 2
to step 6.
8.
To close the File Resubmission dialog box, click Close.
Knowing What to Resubmit
When something goes wrong with an output job, a print job for instance, and printouts are lost,
you usually need to know the following information in order to resubmit the input:
l The name of the job. This refers to the name used internally by PReS Workflow. This
name is generated by the input task using parameters defined within the task. To simplify
file identification, you should consider using names that include both the name of the
original input file (if any) plus some details such as the current date and time.
l The number of each failed page. If a job contains 1000 pages and if pages 1 to 950 were
printed correctly, you need not resubmit the entire job, but only the 50 last pages.
But finding this information often poses a problem. A good way to find this information easily is
to print it using small characters at the bottom of every page. To do this, you have to do the
following.
In PlanetPress Design:
1.
Use a Set Job Info action task and associate a variable with the job’s name.
2. In the output task, make sure to select the option that adds the job information to the
document.
Page 51
Page 52

In PReS Connect:
l Somewhere at the bottom of each document page, add a Data Selection object defined
as a custom data selection that contains a reference to the job info variable sent from
PReS Workflow and a current page marker.
You can use, for example, =&watch.jobinfos[6]+'-'+intostr(¤t.datapage)'
Debugging your PReS Workflow Process
Debugging a process is separated in two parts. The first part is designing the process, which is
to add the different tasks, branches and conditions to the process and configuring them. The
second step is testing whether or not the process and configuration actually work.
Before debugging begins, the following prerequisites must be completed:
l There must not be any Unknown Tasks in the process.
l Asample data file must be selected. To choose a sample data file, click the Select button
in the PReS Workflow Ribbon's Debug tab and browse to a valid sample data file.
Alternatively, if a document present in the configuration contains the necessary data file, it
can be attached to the process easily. See Use Data and Metadata Files Attached to
Documents.
When debugging your process, it is important to keep in mind that:
l
The Initial Input task is never executed. The sample data file is used instead of the initial
run. This is to prevent "live"data from being retrieved by the initial input task while
debugging is being done. If, however, the initial task is critical to the process, it can be
executed by copying the initial input task and pasting it as a secondary input task (the first
action task to actually run in the process). Do not forget, however, to remove this duplicate
task before saving the configuration!
l Since the initial input task is not performed, there is no actual job information to be added
at the beginning of a data file. Note that you can use the Object Inspector on your
process to enter sample job information as required.
l If any task makes an operation on the system (for example, capturing files, sending data,
printing, etc), it is actually executed, not simulated.
l
Any task is executed with the permissions of the user that is currently running the PReS
Workflow Configuration Tool. When running in service mode, the user configured in the
Page 52
Page 53

Configure Services dialog is used instead and this may lead to unexpected behaviors.
Note
The sample job file should generally be the exact same format as the data that you will
receive when PReS Workflow is processing the job at run-time. For more information on
how to capture your sample data file properly, please refer to the PReS Trigger and Data
Capture Guide.
Please See "Workflow Services" on page590 for more details.
Debugging can be run in different ways:
l
From the Debug tab, click on Step. This executes only the first task in the process and
waits for further action.
l
From the Debug tab, click on Run. This executes the complete process, step by step,
until it is completed.
l Right-click on any task in the process and click Run from Here or Step from Here.
These actions are the same as using the debug Step and Run buttons, but will execute
the process only starting from that task forward.
While stepping through a process (using Step, not Run):
l Double-click on any task to change its properties. If you change the properties of a task
before you step through it, those new properties will be used when the task is executed.
Note that you cannot modify the process itself while in debug mode (you cannot add,
delete or move tasks, change branches and conditions, etc).
l Click on Skip to ignore the next task or branch and go to the next one. The job file is not
modified in any way.
l Click on View as Text in the Data group of the Debug tab to view the current job file
using a text editor (Notepad by default).
l Click on View as PDFto view the current job file in Adobe Acrobat if it is present (this will
work only for PDFjob files).
l Click on View Metadata to open the data selector and see the current state of the
process' Metadata.
l Click on View as Hex to view the current job file in the internal Hex editor.
Page 53
Page 54

l Click on the Stop button to stop the debugging process. If you use Run, Step or Skip
after stopping the process, debugging starts over from the top.
l Use the Set Breakpoint button to tag the currently selected task, branch or condition as a
breakpoint. When you click Run in your process, the process will execute every task until
it reaches a breakpoint and will stop just before the task that is set as a breakpoint.
l Use the Ignore button to disable the task, branch or condition that is currently selected. If
you disable a branch or condition, all tasks inside that branch or condition are ignored
including the output. Note that if you set a task, branch or condition to be ignored, it will
also be ignored at run-time, providing you sent the configuration to the service.
l
Look at the Messages Area pane to see any message generated by the tasks that run
(See " The Message Area Pane" on page615).
l
Use the Debug Information pane to see the current value of any variable in your process
or globally, or to evaluate custom expression. See "The Debug Information Pane" on
page614.
Debugging and Emulation changes
One of the most useful case where debugging is crucial is whenever the job file is converted to
another type of emulation, or if a new data file of a different emulation is used within the
process. For example, if a process starts with a Line Printer data file and the converts it into a
PDF, it is not possible to do any data selection on the PDFbecause the Line Printer emulation
is active by default. The debugging features can easily resolve this limitation.
The first method is used if your process has all the required tasks, but data selections after an
emulation change are necessary.
l Step through the process until you have reached the point after the emulation or data
change.
l Any data selection used in task properties after this point will use the new emulation.
l Continue stepping through each task until the end of the process to debug it.
This method does not allow you to add, remove or move tasks, however. The second method
can be used when that is required.
l Step through the process in debug mode until you reach the emulation or data change.
l
Click on View as Text (or View as PDFif your data is PDF at this point) in the Data group
of the Debug tab.
l In the viewer that appears, save the file to a location on your hard drive.
Page 54
Page 55

l Stop the process, and select the file you saved as your process' data file.
l If you need to continue debugging your process after the emulation change, you can still
do it by using Skip on all the tasks until the emulation change, inclusively. Then use Step
or Run to continue debugging.
Lastly, PReS Workflow 7.4 and higher also has a new option that can be used in conjunction
with the previous to avoid skipping through large processes:
l Step through the process until the emulation or data change, as in the first method.
l Save the data file locally and then select it as your sample data file, as with the second
method.
l Instead of skipping through each task, use the Run from here or Step from here options,
either from the Debug tab or by right-clicking on the task where you want to start the
process.
Once you have created and fully debugged all your processes, you will be ready to send it to
PReS Workflow service. See "Saving and Sending" on page544.
The Plug-in Bar
PReS Workflow offer a constantly increasing number of plugins, while always allowing third
party plug-ins to be installed and set up to be used by PReS Workflow. The PReS Workflow
Plug-in Bar lists the available plugin in any of PReS Workflow, and is divided into categories,
which users can customize at will.
A"Plug-In"is normally something that is added to a software and, while most of the PReS
Plug-ins are installed by default, some may be added so the term is correct. However, because
the plug-ins are always expected to execute some sort of task, they are always referred to, in
this documentation, as "tasks", except in the specific case of importing a new plug-in or
customizing the Plug-in bar.
Categories
Page 55
Page 56

The default categories lists plug-ins according to what type of task each achieve. Therefore,
Note
An Uncategorized category is dynamically created if your PReS Workflow finds any plug-in that
would not be part of the existing Plug-in bar. User-defined plug-ins and third party application plugins falls into such a category.
when first starting your PReS Workflow Configuration program, the following categories are
used:
l Inputs
l Actions
l Outputs
l Data splitters
l Metadata Related
l Process logic
l Connectors
Settings & Customization
The Plug-in bar can be customized according to your needs and the plug-ins you most
frequently used.
You can use the horizontal dark blue bar separating the plug-in area and the list of categories
to change how many plug-in categories are displayed as the full-width bar with the title, and
how much are displayed as the icon only. Move the bar up to display more full-width categories,
down to display them more as icons.
Furthermore, the Plug-in bar can be customized using the Popup indicator control ( ).
Customizing the Plug-in bar is mostly for third party or legacy plug-ins.
Using the contextual menu displayed by the pop-up indicator, you can:
l Insert, delete and rename custom categories.
l Move categories up or down.
l Import third party or legacy plug-ins.
Page 56
Page 57

l Move plug-ins from one custom category to another (that you cannot move default plug-
ins from the default categories, you can only copy them)
l Copy plug-ins from one custom category to another by holding the CTRL key.
l
Delete plug-ins from any custom category by using the Delete key.
l
Revert to default Plug-in bar by selecting Reset to default.
To import a plugin:
1.
Click on the Popup control ( )
2. Click on Import Plugin
3. Browse to the location of the plugin DLLfile
4. Click on Open.
5. New plugins appear in the Uncategorized category.
About Printing
To print a document using PReS Workflow, you can either use the Print using a Windows
Driver output task, or use a combination of a printer queue and a Printer Queue output task.
These tasks are created and defined using PReS Workflow Configuration program.
The following types of printer outputs are available in PReS Workflow Configuration program:
l Local printing:
l Windows output queues let you send jobs to a local printer. See "Windows Output
Printer Queue" on page61.
l Send to Folder output queues let you save jobs to a local or network folder from
which they can be picked up and printed. See "Send to Folder Printer Queue" on
page65.
l Remote printing:
l FTP output queues let you upload jobs to an FTP site from which they can be
picked up and printed. See "FTP Output Printer Queue" on page63.
l LPR output queues let you send print jobs to remote printers via TCP/IP using the
LPR/LPD protocol. See "LPR Output Printer Queue" on page62.
Page 57
Page 58

l Windows Driver Printing:
Technical
In PReS Workflow Configuration, you may associate a single Printer Queue output task
with multiple Printer Queues. If you do so, you have the option of using load balancing or
not (See "Load Balancing" on page66).
l The Print using a Windows Driver output task lets you send a job to any printer
installed on the computer, using its own drivers. In this particular case, the printer
does not need to be a PostScript printer. See "Print Using a Windows Driver" on
page520.
PReS Workflow provides you with three main printing scenarios:
l Send output data to be printed as is: PReS Workflow sends a file containing only the
data to the selected queue.
l Send output data to be merged with a document on the printer: PReS Workflow
sends one of two things:
l A file that contains only the data to the selected printer queue. The document with
which the data must be merged must be present on the printer’s hard disk,
otherwise printing will fail.
l A file that contains the data and the document to the selected printer queue. Since
the data and the document with which it must be merged are both sent to the printer,
printing should never fail.
l In both cases, the document+data merging process takes place inside the printer.
l Send output data already merged with a document:PReS Workflow sends a file that
contains the document already merged with the data to the selected printer queue. The
document+data merging process therefore never takes place inside the printer.
PReS Workflow Printer Queues
The printer queues displayed in the Configuration Components pane of the PReS Workflow
Configuration program are not to be confused with Windows printer queues. When you start
building a PReS Workflow configuration it contains no printer queues so you have to create
queues and set each one’s properties.
The PReS Workflow Configuration program lets you create four types of printer queues:
Page 58
Page 59

l Windows Output printer queues are used to send print jobs to local or network printers.
See "Windows Output Printer Queue" on page61.
l LPR Output printer queues are used to send print jobs to printers via the LPR/LPD
protocol. See "LPR Output Printer Queue" on page62.
l FTP Output printer queues are typically used to send print jobs to FTP sites. See "FTP
Output Printer Queue" on page63.
l Send to Folder printer queues are typically used to send print jobs to local or network
folders. See "Send to Folder Printer Queue" on page65.
The properties associated with each queue will differ depending on the queue type. In the case
of an FTP Output printer queue, for example, the properties include the IP address of the FTP
server. In the case of a Windows Output printer queue, on the other hand, you will find the name
of a local or shared Windows printer queue.
To send print jobs to any of those PReS Workflow printer queues, you must use a Printer
Queue output task. Note that with a single task, you can send print jobs to multiple printer
queues, regardless queue types.
Shared Printer Queue Properties
A printer queue’s advanced properties includes the printer’s speed and any special pre- or
post-job commands required for printer specific reasons. Pre-job commands are added right
before the data in the data file, while post-job commands are placed at the end of the data file.
Properties
Advanced tab
l
Print speed: Enter the speed, in pages per minute (PPM), of the printer associated with
the printer queue. This value is used to determine how to divide jobs when you use the
Queue Balancing option for load balancing.
l
Commands: The list of available commands appears in this box. Select either Pre-job
commands or Post-job commands in the Selected box, and double-click a command
from this list to add it to the appropriate list.
l
Selected: Select either Pre-job commands or Post-job commands to add new
commands to the appropriate list and to see those commands that have already selected.
Double-click a command to remove it from the selected list.
Page 59
Page 60

l
Add: Click to add a new command to the list displayed in the Commands box. You must
then edit the new command’s description and value. Note that new commands are shared
by all printer queues.
l
Delete: Click to remove a command from the Commands box.
l
Command description: Use this box to edit the description of the command currently
selected in the Commands box.
l
Command value: Use this box to edit the code of the command currently selected in the
Commands box. Use the right-click menu for a list of standard printer control characters.
Frequently Used Printer Control Characters
Character name: Character
Typical use in printing context:
code:
End-Of-Job \004 Indicates the end of a print job
Backspace \b Moves a character space backwards
Horizontal Tab \t Adds a horizontal tab
Line Feed \012 Moves to the next line
Form Feed \f Moves to the next page
Carriage Return \r Moves to the beginning of the current line
DOS End-Of-File \032 Indicates the end of a print job in a DOS
environment
Escape \033 Adds an escape character
New Line
(CRLF)
\n Goes to a new line
Page 60
Page 61

Windows Output Printer Queue
Windows output printer queues send print jobs to local or network printer queues set up in the
Windows session in which PReS Workflow is running. The corresponding Windows printer
driver is used in the printing process.
This type of printer queue does not support the transparency and duo-tone features, so you
should not use it with PlanetPress Design documents that use those features.
Properties
General tab
l
Printer queue: Select the Windows printer queue to which you want to send print jobs.
l
Job name: Enter the job’s file name. By default, the variable %f (Job File Name) is used.
You may use a different variable, but you may not use a data selection. This information
may be used for the printer’s banner page.
l
Job owner name: Enter the job owner name. You may use a PReS Workflow
variable.The field is empty by default, which is equivalent to use the default print job
owner name, i.e. the current logged in user name.
Advanced tab
l
Print speed: Enter the speed, in pages per minute (PPM), of the printer associated with
the printer queue. This value is used to determine how to divide jobs when you use the
Queue Balancing option for load balancing.
l
Commands: The list of available commands appears in this box. Select either Pre-job
commands or Post-job commands in the Selected box, and double-click a command
from this list to add it to the appropriate list.
l
Selected: Select either Pre-job commands or Post-job commands to add new
commands to the appropriate list and to see those commands that have already selected.
Double-click a command to remove it from the selected list.
l
Add: Click to add a new command to the list displayed in the Commands box. You must
then edit the new command’s description and value. Note that new commands are shared
by all printer queues.
l
Delete: Click to remove a command from the Commands box.
Page 61
Page 62

l
Command description: Use this box to edit the description of the command currently
selected in the Commands box.
l
Command value: Use this box to edit the code of the command currently selected in the
Commands box. Use the right-click menu for a list of standard printer control characters.
LPR Output Printer Queue
LPR output printer queues send print jobs to LPD-compatible printers using the LPD/LPR
protocol. Note that most of the settings associated with LPR output are configured via the PReS
Workflow user options (See "LPR Output User Options" on page653).
Properties
General tab
l
Printer address: Enter the IP address or host name of the printer receiving LPR jobs.
l
Queue name: Enter the printer queue name. Based on printer and network requirements,
this property may not be required.
l
Data type: Select the proper data type. Select (l) Binary data if the job file is a standard
binary file. Select (f) Formatted text to interpret the first character of each line of text as a
standard FORTRAN carriage control character. Select (d) DVI file if the job file contains
data in the TeX DVI format. Select (o) PostScript file if the job file is a PostScript file.
Select (n) Ditroff format if the job file contains data in device independent troff. Select (t)
Troff format if the job file contains data in troff. Select (v) Sun raster file if the job file
contains raster images. This ensures that the printer uses the correct filter to interpret the
data.
l
Job name: Enter the job’s file name. By default, the variable %f (Job File Name) is used.
You may use a different variable, but you may not use a data selection. This information
may be used for the printer’s banner page.
l
Job owner name: Enter the job owner name. You may use a PReS Workflow variable.
Advanced tab
l
Print speed: Enter the speed, in pages per minute (PPM), of the printer associated with
the printer queue. This value is used to determine how to divide jobs when you use the
Queue Balancing option for load balancing.
Page 62
Page 63

l
Note
If you plan to use an LPR output printer queue to send PlanetPress Design documents generated
using the Optimized PostScript Stream option, you should not enter data selections in the Printer
address and Queue name variable property boxes. If you do need to use information stored in the
data to configure the LPR output printer queue, you should first use Job info variables to store the
information, and then use these variables in the Printer address and Queue name variable property
boxes.
Commands: The list of available commands appears in this box. Select either Pre-job
commands or Post-job commands in the Selected box, and double-click a command
from this list to add it to the appropriate list.
l
Selected: Select either Pre-job commands or Post-job commands to add new
commands to the appropriate list and to see those commands that have already selected.
Double-click a command to remove it from the selected list.
l
Add: Click to add a new command to the list displayed in the Commands box. You must
then edit the new command’s description and value. Note that new commands are shared
by all printer queues.
l
Delete: Click to remove a command from the Commands box.
l
Command description: Use this box to edit the description of the command currently
selected in the Commands box.
l
Command value: Use this box to edit the code of the command currently selected in the
Commands box. Use the right-click menu for a list of standard printer control characters.
FTP Output Printer Queue
Unlike FTP output tasks, which are typically used to send data files to FTP sites, FTP output
printer queues are mostly used to send print jobs to FTP sites.
FTP output printer queue properties are as follows:
General tab
l
FTP Server: Enter the IP address or host name of the FTP server.
l
User name: Enter an FTP server user name.
Page 63
Page 64

l
Password: Enter a password associated with the FTP server user name entered above.
l Use FTPClient default port number:Forces the FTPconnection on port 21, the default
FTPport.
l FTP Port:Enter the FTPport to use. This option is disabled if Use FTPClient default port
number is checked. The port should always correspond with the server's port number.
l
Directory: Enter the directory to which the print jobs are to be uploaded. If you leave this
box empty, the job files are sent to the root directory of the FTP server.
l
File name: Enter the name under which the print jobs will be saved. Consider using a
dynamic name, since if you use a static name every new file will overwrite the previous
one.
l Connection mode group
l Active: Select to prompt the ftp client to use the active mode when sending files to
the FTP server.
l Passive: Select to prompt the ftp client to use the passive mode when sending files
to the FTP server.
Advanced tab
l
Print speed: Enter the speed, in pages per minute (PPM), of the printer associated with
the printer queue. This value is used to determine how to divide jobs when you use the
Queue Balancing option for load balancing.
l
Commands: The list of available commands appears in this box. Select either Pre-job
commands or Post-job commands in the Selected box, and double-click a command
from this list to add it to the appropriate list.
l
Selected: Select either Pre-job commands or Post-job commands to add new
commands to the appropriate list and to see those commands that have already selected.
Double-click a command to remove it from the selected list.
l
Add: Click to add a new command to the list displayed in the Commands box. You must
then edit the new command’s description and value. Note that new commands are shared
by all printer queues.
l
Delete: Click to remove a command from the Commands box.
l
Command description: Use this box to edit the description of the command currently
selected in the Commands box.
l
Command value: Use this box to edit the code of the command currently selected in the
Commands box. Use the right-click menu for a list of standard printer control characters.
Page 64
Page 65

Send to Folder Printer Queue
Unlike Send to Folder output tasks, which are typically used to send data files to local or
network folders, Send to Folder output printer queues are mostly used to send print jobs. The
files generated will always be PostScript files.
Properties
General tab
l
Folder: Enter the path of the folder to which the print jobs are to be saved.
l
File name: Enter the name of the print jobs sent to this queue. To prevent each new file
from overwriting the previous one, you should use variable names. This variable property
box lets you use a combination of text, variables and data selections.
l
Concatenate files: If this option is selected, when PReS Workflow tries to save the print
job under an existing name, it appends the content of the new print job file to that of the
existing file, instead of overwriting it.
l
Separator string: This option is used to add a separator string between the content of
each file when the Concatenate files option is selected.
Advanced tab
l
Print speed: Enter the speed, in pages per minute (PPM), of the printer associated with
the printer queue. This value is used to determine how to divide jobs when you use the
Queue Balancing option for load balancing.
l
Commands: The list of available commands appears in this box. Select either Pre-job
commands or Post-job commands in the Selected box, and double-click a command
from this list to add it to the appropriate list.
l
Selected: Select either Pre-job commands or Post-job commands to add new
commands to the appropriate list and to see those commands that have already selected.
Double-click a command to remove it from the selected list.
l
Add: Click to add a new command to the list displayed in the Commands box. You must
then edit the new command’s description and value. Note that new commands are shared
by all printer queues.
l
Delete: Click to remove a command from the Commands box.
Page 65
Page 66

l
Command description: Use this box to edit the description of the command currently
selected in the Commands box.
l
Command value: Use this box to edit the code of the command currently selected in the
Commands box. Use the right-click menu for a list of standard printer control characters.
Triggers
In PReS Workflow, a trigger is typically a two line piece of PostScript code placed just before
the data. Triggers tell the printer to turn on PostScript mode and specify which document should
be used in the merging process (PlanetPress Design document+data).
Triggers are used in two situations:
l When the server running PReS Workflow sends a PlanetPress Design document along
with the data to the printer, it adds a trigger before the document (trigger+document+data).
l When the server running PReS Workflow only sends the data to the printer, because the
document is already present on the printer, it adds a trigger before the data (trigger+data).
PReS Workflow adds the trigger code automatically, but you may want to use custom triggers.
You would do this, for example, to use special printer functions. For more on custom triggers,
see the Data Capture and Trigger Implementation Guide as well as the PlanetPress Design
User Guide.
Load Balancing
PReS Workflow offers various load balancing options to distribute the printing load and to make
the process faster and more efficient. Print jobs may, for example, be split equally among
several printers, or they may be split according to each printer’s capacity and speed.
Load balancing can only be used for jobs sent to Printer Queue output tasks and it only
applies when multiple queues are selected.
In the General tab of the Printer Queue Output Properties dialog box, you may select multiple
printers, and in the Advanced tab, you can set the load balancing options for the selected
printers.
Page 66
Page 67

Objectif Lune Printer Driver (PS)
Introduction
The Objectif Lune Printer Driver (PS) allows end-users to print directly to PReS Workflow from
any Windows application, by using the familiar File|Print option. At the other end, PReS
Workflow specifically can capture the incoming stream and convert it internally into a PDF file
along with its metadata.
Although it is available with every PReS Workflow, this feature becomes even more useful in
environments where the Document Input emulation is available (with PReS Workflow).
Install a Objectif Lune Printer Driver (PS)
The Objectif Lune Printer Driver (PS) is automatically installed during the PReS Workflow
setup, along with a default Windows Printer Queue called PReS Printer.
Install a Windows Printer Queue using the Objectif Lune Printer Driver (PS)
A Windows Printer Queue using the Objectif Lune Printer Driver (PS) can be installed from
PReS Workflow WinQueue Input plugin properties.
Creating a new Windows printer queue from any PReS Workflow:
1. Start your PReS Workflow Configuration program.
2. Insert a WinQueue Input plugin.
3. In the WinQueue Input plugin properties, click New.
4. Enter a Name for the printer queue.
5. Click OK.
Every new Windows printer queue using the Objectif Lune Printer Driver (PS) is shared by
default. Once such a shared queue is created, end-users can install it on their own computer by
going through the same steps they would when installing a new remote printer in their
Operating System. By default, connecting to a shared printer will automatically result in the
Objectif Lune Printer Driver being downloaded to the connecting host.
Printer Properties setup
PReS Workflow WinQueue Input task can be configured to set a Windows printer queue using
Objectif Lune Printer Driver (PS) to produce one of 3 different types of data files: EMF,
Page 67
Page 68

PostScript, or PDF. Note that PReS Workflow can only produce EMF or PostScript files.
Possible printer properties settings, along with the data file type it will produce:
Spool Print Jobs in EMF Format:
l This will create an EMF data file.
l This format is usually reserved for use with the Windows Print Converter action plugin.
l This format can be obtained using PReS Workflow.
Spool Print Jobs in RAW Format:
l This will create a PostScript data file when the option Create Composed Document
Stream (with Medatada) is unchecked.
l This format can be obtained using PReS Workflow.
l This will create a PDF data file when the option Create Composed Document Stream
(with Medatada) is checked.
l This format can be obtained using PReS Workflow.
By default, the Create Composed Document Stream option is:
l Checked if the incoming stream has been produced with the Objectif Lune Printer Driver.
l Unchecked if the incoming stream comes from some other PostScript Driver.
l Grayed out and unchecked if the incoming stream is not PostScript.
Data Capture from PReS Workflow
Once a shared Windows printer queue using Objectif Lune Printer Driver (PS) is installed on
both the server and the client sides, data capture can be achieved the same way as with any
other Windows printer queues.
1. Open your PReS Workflow Configuration program.
2. Insert a new process.
3. Select WinQueue Input from the Plugin Bar and insert it in the new process.
4. In the WinQueue Input properties, select a Windows print queue using the Objectif Lune
Printer Driver (PS) from the drop-down list.
5. Click OK.
Page 68
Page 69

6. Send the configuration and start your PReS Workflow service.
Note
Steps 6-8 can be performed at any time, even if PReS Workflow is not yet started. This is because
every Windows printer queue using Objectif Lune Printer Driver (PS) is paused by default. Once
the service has started, it captures every queued job.
7. Start the windows application from which you want to capture data.
8. Open your selected document.
9. Click File | Print.
10. Choose the same Windows print queue as in step 4.
PDF Creation Parameters
PDF files retrieved from a Windows print queue using Objectif Lune Printer Driver (PS)
have the following properties:
l PDF 1.4
l Optimized PDF (subject to change)
l No down-sampling of images
These settings are pre-configured and cannot be changed by the user.
About Metadata
Metadata files are files containing information on the job itself rather than containing the job per
se. A job sent to the Objectif Lune Printer Driver (PS) creates its own metadata, allowing users
to retrieve relevant information, such as, for instance, the time and date the print request was
sent. For more on this, see the Metadata documentation pages.
Page 69
Page 70

About Processes and Subprocesses
Processes
Aprocess is a single workflow within the configuration. Aprocess begins with a single input
task, contains one or more tasks and/or branches, and terminates with one or more output
tasks. In its simplest form, a process can simply retrieve data from a given folder and save it in a
different folder. In most cases, though, processes are more elaborate and configurations, which
may include many processes, can be extremely complex.
The available processes in your PReS Workflow Configuration are listed in the "The
Configuration Components Pane" on page562. Processes in a configuration will always run
concurrently. You can schedule processes to run only at certain times or intervals (see "
Process Properties" on page592).
There are three types of processes available to you:
l A Normal process will run as soon as an input file is available through its input task or, if
it is scheduled not to run at that time, will start processing as soon as the schedule
permits it.
l Startup processes are processes that run only once before every other process in a
given configuration. They can be used to perform operations that need to be completed
once before the configuration can actually be run, such as to map network drives. You
may only have one single startup process in your configuration.
l Subprocesses are processes which can be called by any other process from any action
task. They can be used to perform and reuse redundant operations that may need to be
executed numerous times.
Regular and startup processes can be set to be Active (process runs normally)or Inactive
(process will not run at all). An inactive process will display in the Configuration components as
red and strike-through. Inactive processes can be useful for designing new processes in a live
configuration, since the process does not execute there is no danger is submitting it to a PReS
Workflow Service.
Subprocesses
Subprocesses are special processes that can be called by any other process. These act
exactly as subroutines in programming languages, allowing users to reuse existing processes
Page 70
Page 71

by sharing them to the whole configuration file. They can thus be used to perform redundant
Note
Subprocesses do not have the "General Tab" which is only used for scheduling, but they
do have the Information Tab.
operations that may need to be executed numerous times; for instance, archiving a copy of a
zipped file received as the input job file, then decompressing it before sending the unzipped
version of it back to the calling process .
Whenever a process calls a subprocess, the main process (the caller) will wait for the called
subprocess to finish its execution before carrying on with its own. This means the subprocess
feature is synchronous with the main process. This also means the calling process actually
appends the subprocess to its own workflow.
Process Properties
To have access to the properties of a process or subprocess:
l Right-Click on the Process in the Configuration Components Area.
l Select Properties.
You can also double-click on the process to show its options.
Options
General tab
l Active: Select to make the process active. Clear to prevent this process from running
when you send the configuration to PReS Workflow.
l Startup process: Select to make this process a startup process.
l Self-Replicating Process:Check this if you want the process to replicate itself in the
background when multiple input files are received simultaneously. When this is checked,
the input task polls its source once, determines the number of files to process, then
replicates itself up to the maximum allowed and treats the files simultaneously. The initial
process runs again once it has completed itself and replicates again as necessary, until
all files have been processed.
Page 71
Page 72

l Max percentage of threading (%):Determines how many processes you may have
running at the same time. This is a percentage of the maximum number of threads
specified in the "Messenger Plug-In Preferences" on page639. For example if the
maximum number of thread is 10 and you specify 50%here, a maximum of 5 replications
will occur (the original process +4 copies).
l As soon as possible: Select to have the process run continuously. Clear to enable the
Time Grid to fine-tune the schedule of the process.
l Day(s) to keep backup: Indicate the number of days to keep backups of jobs processed
by input tasks. Note that backups will only be kept for those input tasks that have the
Keep backup file option selected and that they are required to resubmit input files.
l Polling interval: Enter the frequency (in seconds)at which the process should verify if
there are new jobs to process. The polling interval also applies to scheduled tasks that
only run on certain times. For example, if your process polls every 30 seconds on a task
that's only scheduled to run one hour per week, it will capture the input 120 times during
that period. Note that the polling interval is ignored when multiple files are present in the
input and will be used only when there are no longer any files to process.
l Month: Select the month of the year when the process should be run or select All months
to have the process run all year long. This option is disabled when "As soon as
possible"is checked.
l Week of month / by date: Select the desired option for the time grid. Note that any
selection you make in this box will be interpreted based on the selection made in the
Month box. If you chose All months in the Month box and Last in the Week of month / by
date box, then the process will run on the last week of every month. If you chose January
in the Month box and First in the Week of month / by date box, then the process will run
only on the first week of January.
l Select Date to display dates on the grid’s top ruler.
l Select any of the other options to display days on the top ruler.
l Select All weeks to have the process run every week.
l Select First, Second, Third or Fourth to have the process run on the first, second,
third or fourth week.
l Select Last to have the process run only on the last week.
l Time division: Select the duration of each daily segment in the time grid. If you select
00:15, each segment will represent only 15 minutes and each day will be made up of 96
blocks (4 blocks per hour times 24 hours). If you select 24:00, each segment will
represent an entire day.
Page 72
Page 73

l Poll once per activity period: Select to perform this process’ initial input task no more
than once for each set of contiguous blocks (blocks that are on the top of one another).
Choosing this option overrides the polling interval option. By default since the Time Grid
blocks are divided by hours, this option will make your polling happen once every hour.
The Time Grid
The PReS Workflow Process Options dialog box includes a time grid that lets you set exactly
when you want a process to run. The grid is composed of blocks that represent time periods on
a given day. To activate the Time Grid, the "As soon as possible"option must be unchecked.
In the Time Grid, a blue block will indicate that the process is active within that time block.
While blocks mean the process will not be active.
Page 73
Page 74

l Click on any block to select / deselect it.
l Click and drag from one block to another to toggle all blocks between the two.
l Shift-click on any block to toggle all blocks from the top-left corner of the grid to the block
you click.
Page 74
Page 75

l To select all of the time segments for a given day or date, click the day or date on the top
Note
"Toggle" means turn on when it's off and vice-versa, when selecting multiple blocks in
one command. This means if you select a certain number of blocks in the Time Grid and
then use the shift+click or drag method, blocks that are on will turn off.
Technical
Changes made to the system time can have adverse effects on the processes managed
by PReS Workflow. When changing from daylight saving time to standard time, for
example, if PReS Workflow starts a given process at 2:00 AM, and if the system time is
then taken back to 1:00AM, the application will start a new instance of the same process
when the system time reaches 2:00 AM for a second time. So, when you manually
change the system time, be aware that it may have an effect on PReS Workflow and its
processes. And for those cases when you know the system time will change
automatically, you may consider creating special schedules.
grid ruler. To deselect all of the time segments for a given day or date, CTRL+click the
day or date on the top grid ruler.
l To select all the days or dates for a given time segment, click the time segment on the left
grid ruler. To deselect all the days or dates for a given time segment, CTRL+click the time
segment on the left grid ruler.
l To select the entire grid, use the Select All button located below the grid. To deselect the
entire grid, use the Clear All button located below the grid.
Information Tab
The Information tab lets you enter information that is not critical to your process but may help
others (or yourself in the future)to understand what the process does. It offers two boxes:
l Description: Aone-line box to give a title or short description to your process.
l Comments:A multi-line box to give more detailed information, for example the file format
expected, explanation of the system in general.
Page 75
Page 76

Activate or Deactivate a Process
Note
If you try to send a configuration that contains only inactive processes, the PReS
Workflow Configuration program will ask you to confirm the operation (this can be
changed in the Notification User Options).
Note
The Branch tasks options Backup job file, Backup job information and Backup emulation, are
also automatically passed to the subprocess, which means that, if the subprocess needs to use a
different emulation than the calling process, a Change Emulation task is required.
All processes are Active by default, but you may make any PReS Workflow process Inactive as
required. Because making a process active or inactive is a change in the configuration, to make
the change effective you will have to send the edited configuration to your PReS Workflow
service (See "Send your Configuration" on page11).
To activate or deactivate a process:
1.
Right-click the process in question in the Configuration Components pane
2. Click Active to disable or enable the process.
3. Send your configuration.
Convert a Branch to a Subprocess
To allow for maximum flexibility and backward compatibility with the subprocess feature, the
Convert to subprocess option lets users transform existing processes easily. This option is
available whenever a Branch task is selected; right-clicking on it will display the contextual
menu, which holds the Convert to subprocess option.
Selecting this option automatically creates a new subprocess, takes the branch and all of its
children tasks and inserts it in the new subprocess, including the branch task itself. In the main
process, the branch is removed and replaced with a GoSub action task referring to the newly
created subprocess.
Page 76
Page 77

If any task converted into a subprocess was previously using local variables, these variables
must be removed or transferred to global variables or job information to be usable in the newly
created subprocess.
Import Processes from Another Configuration File
You can import individual processes or groups of processes from a PReS Workflow
configuration file without having to import the contents of the entire configuration file. PReS
Workflow Configuration imports everything necessary to run the processes, including
configured tasks and configuration components.
To import components from another configuration file:
1.
From the PReS Workflow Button, choose Import | Configuration Components. The
Import dialog appears.
2. Navigate to the PReS Workflow configuration file containing the processes or groups of
processes you want to import.
3.
Select the file, then click Open. The Import Configuration dialog appears displaying all
the processes and/or process groups, as well as the Subprocesses, Global Variables,
PlanetPress Design documents and Printer Queues in the selected configuration file.
4. In the list, select the components you want to import. The PReS Workflow Configuration
program lets you open and import any of the following:
l Complete PlanetPress Watch 4 to 6 configurations, as well as PReS Workflow 7
configurations.
l Specific processes from Version 6 and 7 configurations, including their local
variables.
l Specific subprocesses from any PReS Workflow 7 Tools configurations.
l Specific global variables from PReS Workflow 7 Tools configurations.
l Specific PReS or PrintShop Mail documents.
l Specific Printer Queues.
5. Check "Overwrite existing components with same name" if you want processes with
existing names to be overwritten by those in the imported configuration, or uncheck it to
duplicate those processes under a new dynamic name.
6. Click OK to start the import.
PReS Workflow Configuration imports the selected objects and automatically renames
duplicate items in the imported configuration. If the current and imported configurations
Page 77
Page 78

both include a startup process, the one in the imported configuration will become a
Note
The term "Desktop"is defined as the desktop of the user logged on to the computer
where PReS Workflow is installed. These dialogs cannot be displayed on any other
computer.
standard process.
Important considerations
l When importing a PReS Workflow configuration file, your PlanetPress Design and
PrintShop Mail document are not physically imported as they are not part of the
configuration file itself. In order for the documents to be available, you will need to send
each document from PlanetPress Design and PrintShop Mail (see their respective
documentation for details).
l
If you import a PReS Workflow configuration that contains a PReS Fax output task, you
must update the task’s properties and refresh the host name. Otherwise, when PReS
Workflow will attempt to output the file, an error will be generated.
Toggle the Run on Desktop Property
Since PReS Workflow configurations are typically meant to run without user interaction, all of
their processes are set to run in the background by default. In some cases, such as when a
dialog box must appear or user input is required, you may make any process run on your
desktop instead of as a service.
Generally this will happen only when calling a third-party software using the Run External
Program plugin, but is also valid if using a Script that generates a dialog that someone must
click or interact with.
To toggle a process’ Run on Desktop property:
1.
Select an active process in the Configuration Components pane.
2.
In the Object Inspector Pane, change the Run on desktop property from False to True,
or vice versa.
Page 78
Page 79

Using Scripts
Warning
While this chapter provides some very useful and detailed information about scripting within PReS
Workflow, its focus is to inform you about the features, variables and functions unique to this
environment. This chapter assumes that you have a working knowledge of the scripting language you
wish to use and does not purport to teaching you anything about this language that you don't already
know. Learning any of these language is beyond the scope of this documentation.
Note
While JavaScript and VBScript are natively available on Windows operating systems. Python and Perl
require third-party tools to be functional. For Perl, ActivePerl can be installed. For Python
ActivePython (version 2.7.13 ) can be installed.
Scripts can be used to perform various operations, such as to manipulate data, for example. PReS Workflow
can perform scripts written in four different scripting languages and also provides an interface for editing
scripts.
There are four scripting languages available through the Run Script task: JavaScript, VBScript, Python and
Perl. Each language has its own strengths and weaknesses which we will not cover in this documentation.
While VBScript is the most used language at the moment, the examples provided in this chapter are
presented in all supported languages.
When using the Run Script as a condition, you need a way to tell your process whether the result is true or
false. The condition result is returned by the "Script.ReturnValue" on page106 variable. If the return value is
zero (the default), the condition is false. Otherwise, it is true.
When using the Run Script as an action task, the job file going out of the Run Script action task will be the
same as the one coming in, unless you have specifically changed it within your script by writing to the file
that is the target of the "Watch.GetJobFileName" on page97 function. The same goes for any job info, local
or global variables, unless you use the "Watch.SetJobInfo" on page101 or "Watch.SetVariable" on
page103 functions to modify them.
Page 80

Multiple APIs (methods of communicating with PReS Workflow scripting tools) are available through the
scripting engine, in all languages.
l The Watch object is used to communicate with your current process and configuration. See "The
Watch Object" on page93.
l You can manipulate PDFfiles using the PReS Alambic API. See AlambicEdit Library Reference. Note
that the PReS Alambic API is part of the PDFTools.
l You can manipulate the metadata in your process using the Metadata API. See Metadata API
Reference.
l You can communicate with a SOAPserver using the SOAPAPI. See "SOAP Server API Reference"
on page86.
l You can communicate with the PlanetPress Capture Database using the Capture API. See Capture
API Reference.
The Script Editor and XSLT Editor
How can I edit scripts and XSLT code?
Scripts can be edited in the Script Editor and the XSLT Editor. Both editors are visually identical and share
almost exactly the same commands. They let you import and export scripts, perform common editing
function, such as search and replace, and feature syntax highlighting and formatting.
You can use the Script Editor to edit scripts written in VBScript, JavaScript, Perl and Python (note that the
corresponding interpreter must be locally available). You can use the XSLT Editor to edit scripts written in
XSLT 1.0 and 2.0.
For information on how to use both editors, or for a complete description of the Script or XSLT Editor user
options, refer to the Reference Help (English only).
Use the Editor
The Script Editor and XSLT Editor share most of the same commands and functions. You can open the
Script Editor using the Open Editor button both from the Run Script Properties dialog box and from the
Open XSLT Properties dialog box. When you do so, the script currently displayed in the dialog box is
pasted to the editor’s scripting box.
For information on the available editor options, refer to "Editor Options" on page655.
Page 81

Import and Export Scripts
Note
When you import a script, it replaces any script currently displayed in the editor.
Both the Script Editor and XSLT Editor let you import and export scripts.
To import a script:
1.
In the editor, choose File | Import. The Open dialog box appears.
2. To import a script that uses a different scripting language or that was saved under a different file
format, make a selection in the Files of type drop-down list.
3. Navigate to the script you want to import and select it.
4.
Click OK. The script is imported, displayed and formatted according to the syntax of the language
selected in the editor. If the imported file had the extension of a recognized scripting language (.vbs or
.js, for example), the editor language is automatically changed.
To export a script:
1.
In the editor, choose File | Export. The Save As dialog box appears.
2. To save the script using a different scripting language or under a different file format, make a selection
in the Save as type drop-down list.
3. Navigate to the location where you want to save the exported script.
4.
Enter the name of the script in the File name box.
5. To save the script using a different scripting language or under a different file format, make a selection
in the Save as type drop-down list.
6.
Click OK.
Find Strings in a Script
The Find Text dialog box allows you to search for text strings in the editor. The available options help you
limit the search, making searches quicker and easier.
Page 82

To find strings in a script:
Note
If you only want to search a particular section of the script, you should select it before performing the following
procedure.
1.
Choose Search | Find, or press CTRL+F. The Find Text dialog box appears. The last used string is
displayed in the Text to find drop-down list box.
2. Set the search settings and options.
l
Text to find: Enter a new search string or select a previous search from the drop-down list.
l
Case sensitive: Select to limit the search to instances of text with the same case as the text in
the Text to find box.
l
Whole words only: Select to limit the search to complete words matching the text in the Text to
find box. Whole words are defined as strings that have a space or punctuation before and after
the word.
l
Regular expressions: Select to treat the regular expressions of the scripting language as text to
search. If you clear this option, the regular expressions of the language are not included in the
search.
l
Global: Select to search the entire content of the script.
l
Selected text: Select to find matching text within the text block you select. A portion of text must
be selected before you run the search.
l
Forward: Select to search the script forward, from the location of the cursor or from the beginning
of the script, depending on what you choose as the origin (From cursor begins where the cursor
is currently located in the script, Entire scope begins from the beginning of the script or beginning
of script selection). If you limit the scope to selected text, you move forward only within the
selection. When the search reaches the end of the script or script selection, the search finishes. It
does not loop back to the beginning.
l
Backward: Select to search the script backward, from the location of the cursor or from the end of
the script, depending on what you choose for the origin (From cursor begins where the cursor is
currently located in the script, Entire scope begins from the beginning of the script or beginning of
script selection). If you limit the scope to selected text, you move backward only within the script
Page 83

selection. When the search reaches the beginning of the script or script selection, the search
finishes. It does not loop back to the beginning.
l
From cursor: Select to start the search from the position of the cursor.
l
Entire scope: Select to search the entire script or a script selection. The scope croplands to a
script selection if you make a selection before executing the Find.
3.
Click OK. The first matching string is highlighted in the script.
4.
To find the next matching string, choose Search | Find Again or press F3.
Find and Replace Strings in a Script
The Replace With dialog box lets you search for and replace text strings in the editor. The available options
help you limit the search, making replacements quicker and easier.
To find and replace strings in a script:
1.
Choose Search | Replace, or press CTRL+R. The Replace With dialog box appears. The last used
strings are displayed in the Text to find and Replace with boxes.
2. Set the replacement settings and options.
l
Text to find: Enter a new search string or select a previous search from the drop-down list.
l
Replace with: Enter the string that will replace the string displayed in the Text to find box.
l
Case sensitive: Select to limit the search to instances of text with the same case as the text in
the Text to find box.
l
Whole words only: Select to limit the search to complete words that match the text in the Text to
find box. Whole words are defined as strings that have a space or punctuation before and after
the word.
l
Regular expressions: Select to treat the regular expressions of the scripting language as text. If
you clear this option, the regular expressions of the language are blocked from the search.
l
Prompt on replace: Select to have PReS Workflow display a prompt before it replaces text.
When you use the Replace All function, you are prompted each time matching text is found. The
prompt includes an All button for replacing all matching text. This suppresses any further
prompting.
l
Global: Select to search the entire content of the script.
Page 84

l
Selected text: Select to find matching text only within a text block you select. The text must be
selected before you run the search.
l
Forward: Select to search the script forward, from the location of the cursor or from the beginning
of the script, depending on what you choose as the origin (From cursor begins where the cursor
is currently located in the script, Entire scope begins from the beginning of the script or beginning
of script selection). If you limit the scope to selected text, you move forward only within the
selection. When the search reaches the end of the script or script selection, the search finishes. It
does not loop back to the beginning.
l
Backward: Select to search the script backward, from the location of the cursor or from the end of
the script, depending on what you choose for the origin (From cursor begins where the cursor is
currently located in the script, Entire scope begins from the beginning of the script or beginning of
script selection). If you limit the scope to selected text, you move backward only within the script
selection. When the search reaches the beginning of the script or script selection, the search
finishes. It does not loop back to the beginning.
l
From cursor: Select to start the search from the position of the cursor.
l
Entire scope: Select to search either the entire script, or a script selection. The scope
corresponds to a script selection if you make a selection before executing the Find.
3. Do one of the following:
l
Click OK to replace the first string encountered. If you selected Prompt on replace, a dialog box
opens to ask you whether to proceed with the replacement. You can OK to replace the first string
only, or you can click All to replace that string as well as every other string that matches the
replacement settings.
l
Click Replace All to replace all the strings that match the replacement settings.
4.
To find and replace the next matching string, choose Search | Find Again or press F3. Once again, if
you selected Prompt on replace, a dialog box opens to ask you whether to proceed with the
replacement. You can OK to replace that string only, or you can click All to replace that string as well
as every other string that matches the replacement settings.
Go to a Line in a Script
The Go To Line dialog box lets you jump to a specific line within your script. It works whether or not the line
number are displayed on the left side of the editor window (to know how to toggle the line number display
settings, See "Editor Options" on page655).
Page 85

To go to a line in a script:
Note
Bookmarks are not preserved when you close the editor.
1.
Click anywhere in the Script Editor, then choose Search | Go To Line, or press Alt+G. The Go To
Line dialog box appears. The last used line numbers are displayed in the Enter new line number
drop-down list box.
2.
Enter a new line number in the Enter new line number box or select one from drop-down list.
3.
Click OK.
Toggle Bookmarks
Bookmarks help you identify and jump to specific places within your script (see "Jump to Bookmarks"
below).
Bookmarks are displayed in the editor’s gutter, so you will not be able to see them unless the gutter is both
visible and sufficiently wide. If line numbers are also displayed in the gutter, bookmarks may be harder to
see. To control line number and gutter display, see "Editor Options" on page655.
To toggle bookmarks:
l
Place the cursor on a line in your script and, from the editor’s pop-up menu, choose Toggle
Bookmark and a given bookmark number.
If the bookmark you selected was not displayed on any line, it is added to the line where you placed the
cursor. If the bookmark you selected was displayed on the line where you placed the cursor, it is removed. If
the bookmark you selected was displayed on a different line, it is moved to the line where you placed the
cursor.
Jump to Bookmarks
Before you can jump to bookmarks, you must add bookmarks to specific lines in your script (See "Toggle
Bookmarks" above).
Page 86

To jump to a bookmark:
Note
PReS Workflow already come with a SOAP Client Plug-in, which can be used as an input, action or output;
this task was renamed Legacy SOAP Client.
l
From the editor’s pop-up menu, choose Go To Bookmark and a given bookmark number.
If the bookmark you selected was displayed on a line, the cursor jumps to that line.
SOAP Server API Reference
PReS Workflow offers a SOAP server API Reference allowing jobs to be submitted from third party
application using the SOAP protocol. Remember that SOAP stands for Simple Object Access Protocol.
While there are multiple possibilities for solutions using a SOAP server implementation, the SOAP Server
API Reference is specifically for submitting jobs from a SOAP client. It implements five methods that will
allow SOAP clients to submit jobs and get information from PReS Workflow executing them.
Since the SOAP Server API Reference is primarily targeted at programmers or systems engineers, it is
rather technical.
SOAP API - SubmitJob
Syntax
SubmitJob (File, SubmitJobInfStruc , ReturnJobFile, user name, Password) :
SubmitJobResult
Description
The SubmitJob method allows users to remotely submit files to their PReS Workflow from a SOAP client.
The SOAP client has the option to wait for a response file from PReS Workflow SOAP server.
Page 87

Arguments
Note
The SubmitJob method only returns a file if the PReS Workflow process contains a SOAP Input task.
Note
If ReturnJobFile is set to true, the schedule options of the process should be set to a pooling lower than four
seconds, so the client application gets a timely response.
l
File – base64Binary. This is an array of byte base64 encoded (see
http://en.wikipedia.org/wiki/Base64).
l
SubmitJobInfStruc – Structure containing any required information to prepare the file for a valid
insertion into a PReS Workflow process.
l
ReturnJobFile – Boolean value. When true, PReS Workflow SOAP server returns the job file. When
false, there no file is returned to the SOAP client. (For example: when submitting a job for print, there is
no need to return a file)
l
user name – String containing the user name.
l
Password – String containing the password. This value is case sensitive.
Return Value
l
SubmitJobResult - Structure containing the following information:
l
Success – Integer indicating the Success/Error level of the operation. A result of 0 means the
operation was successful.
l
Message – String containing text information about the Success/Failure status.
l
SubmitJobInfStruc – See point SubmitJobInfStruc for details.
l
ResultFile – base64Binary. If Success is different than 0 or the ReturnJobFile was set to False in the
initial call, no file is returned. Otherwise, ResultFile contains the job file, as it existed at the completion
of the PReS Workflow process (for instance, if the process creates a PDF and sets it as the current job
file, the PDF is the file that gets returned to the calling SOAP client).
Page 88

Note
To return the file, the process must be completed before the timeout of the server occurs. The Timeout option can
be set in your PReS Workflow preferences.
SOAP API - PostJob
Syntax
PostJob (File, PostJobInfStruc , user name, Password) : PostJobResult
Description
The PostJob method allows users to remotely submit files to PReS Workflow by using the Resubmit from
here feature. The main advantage of this feature is that it allows a user to specify a starting task index from
which the File is to be processed.
Parameters
l
File – base64Binary. This is an array of byte base64 encoded (see
http://en.wikipedia.org/wiki/Base64).
l
PostJobInfStruc – Structure containing any required information to prepare the file for resubmission
into a PReS Workflow process.
l
user name – String containing the user name.
l
Password – String containing the password. This value is case sensitive.
Return Value
l
PostjobResult - Structure containing the following information:
l
Success – Integer indicating the Success/Error level of the operation. A result of 0 means that the
operation was successful.
l
Message – String containing text information about the Success status.
l
PostjobInfStruc – See point PostJobInfoStruct for details.
Page 89

Note
The task index can be retrieved by using the GetProcessTaskList method. See point GetProcessTaskList for
details.
Note
The PostJob method can never return a file to the calling application.
SOAP API - GetProcessList
Syntax
GetProcessList (user name, Password) : GetProcessListResult
Description
The GetProcessList function allows SOAP clients to request the list of available PReS Workflow processes,
based on their authentication credentials.
Parameters
l user name – String containing the user name.
l Password – String containing the password. This value is case sensitive.
Return Value
l GetProcessListResult - Structure containing the following information:
l Success – Integer indicating the system-defined Success/Error level of the operation. A result of 0
means that the operation was successful.
l Message – String containing text information about the Success status.
l ProcessList – Structure containing the following information details.
l ProcessName – String containing the process name
l Active – Boolean value specifying whether the process is currently active.
Page 90

Note
To obtain access to the complete list of processes for all users, the end-user must have administrator privileges.
SOAP API - GetProcessTaskList
Syntax
GetProcessTaskList (ProcessName, user name, Password) :
GetProcessTaskListResult
Description
The GetProcessTaskList function will allow a user to remotely request the tasks list of a process. This will be
useful with the PostJob API since it needs a TaskIndex.
Parameters
l
ProcessName – The Name of the PReS Workflow process.
l
user name – String containing the user name.
l
Password – String containing the password. This is case sensitive.
Return Value
l
GetProcessTaskListResult – Structure containing the following information:
l
Success – Integer indicating the system-defined Success/Error level of the operation. A result of 0
means that the operation was successful.
l
Message – String containing text information about the Success status.
l
TaskNames – Structure containing the following information details.
l
TaskName – String containing the name of the task
l
TaskIndex – Integer : 1 based index of the task.
l
TaskDepth – Integer : 1 based depth of the task.
Page 91

Note
The TaskNames array will be sorted by the execution order of the process with the primary input of the process
having an index of 1.
SOAP API - GetSOAPProcessList
Syntax
GetSOAPProcessList (user name, Password) : GetSOAPProcessListResult
Description
The GetSOAPProcessList function will allow users to request the list of PReS Workflow processes that
contain a SOAP Input plug-in with the SOAP action name. This is useful when working with the SubmitJob
API since it requires a SOAPActionName.
Parameters
l
user name – String containing the user name.
l
Password – String containing the password. This is case sensitive.
Return Value
l
GetSOAPProcessListResult – Structure containing the following information:
l
Success – Integer indicating the system-defined Success/Error level of the operation. A result of 0
means that the operation was successful.
l
Message – String containing text information about the Success status.
l
ProcessList – Structure containing the following information details.
l
SOAPActionName – String containing the name of the process as seen in your PReS Workflow.
l
Active – Boolean value indicating if the process is active in your PReS Workflow.
Page 92

Note
If a user has administrator privilege, he will have access to all processes and therefore he will see all the processes.
SOAP API - PostJobInfoStruc
Note
If both FirstPage and LastPage are set to 0, the entire data file is used.
PostJobInfStruc
Structure containing any required information to prepare the file for resubmission into a PReS Workflow
process.
l
VariableList – Array of complex type, containing pairs of variable names and variables value. The list
also contains the JobInfo variables.
l VariableName – String
l VariableValue – String
l
ProcessName – String - Name of the PReS Workflow process.
l
TaskIndex – Integer - 1 based index of the task where the resubmission should start.
l
FirstPage – Integer - First page of data to process.
l
LastPage – Integer - Last page of data to process.
SOAP API - SubmitJobInfStruc
SubmitJobInfStruc
Structure containing any required information to prepare the file for a valid insertion into a PReS Workflow
process.
l
VariableList – Array of complex type, containing pairs of variable name and variable value. The list
also contains the JobInfo variables
Page 93

l
Note
While the functions here are in mixed case to simplify reading, it's important to note that some
languages (especially JavaScript)are case-sensitive and will require the proper case. Examples in
this chapter will always use the proper case when relevant.
VariableName – String
l
VariableValue – String
l
OAPActionName – String containing the name of the Input SOAP task’s action name.
The Watch Object
PReS Workflow scripting offers a number of methods of communicating with your process by means of
PReS Workflow automation object's methods and functions. The automation object is available in all 4
languages through their own syntax - the examples provided here are for VBScript.
Here is a list of the methods and functions that are available to you through the automation object (or
"Watch" object). While these examples are all in VBScript, you can click on any variable name to open a
page to see examples for each supported language.
Variable Name Description
Example Usage (VBScript)
"Watch.GetJobFileName" on
page97
Retrieves a string containing the job path and file name located in
the job spool folder.
Example Usage: str = Watch.getjobfilename
"Watch.GetOriginalFileName" on
page98
Retrieves a string containing the job's original path and filename.
Note: this filename is generally no longer available if it has been
captured by Watch.
Example Usage: str = Watch.getoriginalfilename
Page 94

Variable Name Description
Example Usage (VBScript)
"Watch.GetMetadataFilename"
on page99
Example Usage: str = Watch.getmetadatafilename
"Watch.GetJobInfo" on page100 Retrieves the content of a numbered job info (%1 to %9).
Example Usage: str = Watch.getjobinfo(9)
"Watch.GetVariable" on page102 Retrieves the content of a local or global variable by name.
Example Usage: str = Watch.getvariable("Varname")
"Watch.ExpandString" on
page103
Example Usage: watchDate = Watch.expandstring("%y-%m-%d")
Retrieves a string containing the job's metadata path and filename.
This is useful when using the Metadata API in your script.
Retrieves the content of any Workflow string, containing any
variable available to Watch, including data selections.
"Watch.Log" on page104 Writes to the Workflow log file, or the message window when in
debug - can accept multiple log levels from 1 (red) to 4 (gray).
Example Usage: Watch.log "Hello, World!",1
"Watch.ShowMessage" on the
next page
Example Usage: Watch.showmessage("Hello, World!")
"Watch.InputBox" on page99 Prompts the user for a string and returns the value(will not work
Displays a popup dialog box to the user (user has to be logged on).
when running as a service)
Page 95

Variable Name Description
Example Usage (VBScript)
Example Usage: str = Watch.inputbox("Caption","Message","default")
"Watch.SetJobInfo" on page101 Writes the value of a string to a numbered job info.
Example Usage: Watch.setjobinfo 9, "String"
"Watch.SetVariable" on page103 Writes the value of a string to a local or global variable by name.
Example Usage: Watch.setvariable "global.GlobalVar", "Hello World!"
"Watch.Sleep" on page106 Pauses all processing for X milliseconds.
Example Usage: Watch.sleep(1000)
"Watch.ExecuteExternalProgram"
on the next page
Example Usage: Watch.executeexternalprogram "del *.ps" "c:\" 0 true
"Script.ReturnValue" on
page106
Example Usage:
Watch.GetPDFEditObject Is used to manipulate PDF files using the AlambicEdit API.
Watch.ShowMessage
Displays a message to the user. This method is the same as PW_ShowMessage. Use this method to show
the current message displayed whether or not a user is logged in. Note that for this method to work, the "Run
Calls and executes an external program in the command line.
Returns a boolean True or False value to a Workflow scripted
condition
Script.returnvalue = 1
See the AlambicEdit API for more information.
Page 96

on Desktop"option must be enabled and you must be logged on as the same user as the PlanetPress
Watch Service.
Examples
In the following example, showmessage() displays a dialog box saying “test message”.
VBScript
Watch.ShowMessage("test message")
JavaScript
Watch.ShowMessage("test message");
Python
Watch.ShowMessage("test message")
Perl
$Watch->ShowMessage("test message");
Watch.ExecuteExternalProgram
Calls and executes an external program through a specified command line. The program's execution will be
directed by the appropriate flags specified as this method's parameters.
Syntax
Watch.ExecuteExternalProgram const CommandLine: WideString; const WorkingDir: WideString;
ShowFlags: Integer;
WaitForTerminate: WordBool: integer;
const CommandLine: The command line to execute as a widestring.
const WorkingDir: The working directory for the execution of the command line as a widestring.
ShowFlags: Integer value representing the flag to use during the execution of the command line. These
flags have an effect on the execution window opened by the ExecuteExternalProgram procedure.
Page 97

Flag
0 Hide the execution window.
1 Display the window normally.
2 Display the window minimized.
3 Display the window maximized.
4 Makes the window visible and brings it to the top, but does not make it the active window.
WaitForTerminate : A Boolean value that, if true, pauses the script until the command line has been fully
executed.
Examples
VBScript
Effect
Watch.ExecuteExternalProgram "lpr -S 192.168.100.001 -P auto c:\myfile.ps",
"c:\", 0, true
JavaScript
Watch.ExecuteExternalProgram("lpr -S 192.168.100.001 -P auto c:\\myfile.ps",
"c:\\", 0, true);
Python
Watch.ExecuteExternalProgram("lpr -S 192.168.100.001 -P auto c:\\myfile.ps",
"c:\\", 0, True)
Perl
$Watch->ExecuteExternalProgram("lpr -S 192.168.100.001 -P auto
c:\myfile.ps", "c:\", 0, true);
Watch.GetJobFileName
Returns the complete path and file name of the job. This method is the same as PW_GetJobFileName.
getjobfilename() obtains the file name of a PReS Workflow process. This is useful for manipulating the job
Page 98

file, for example to replace data within it. If your script writes to this file, the modified contents will be used by
the next plugin in your process.
Example
In the following example, GetJobFileName() retrieves the name of the job file, which is then logged using
"Watch.Log" on page104.
VBScript
Dim s
s = Watch.GetJobFileName
Watch.Log "The job filename is: " + s, 3
JavaScript
var s;
s = Watch.GetJobFilename();
Watch.Log("The job filename is: " + s, 3);
Python
s = Watch.GetJobFileName()
Watch.Log("The job filename is: " + s, 3)
Perl
$s = $Watch->GetJobFileName;
$Watch->Log("The job filename is: " + $s, 3);
Watch.GetOriginalFileName
Returns the original name of the file, when it was captured. This method is the same as PW_
GetOriginalFileName.
Example
VBScript
Watch.GetOriginalFileName
JavaScript
Watch.GetOriginalFileName();
Page 99

Python
Warning
Starting version 7.0, the Watch.InputBox function is deprecated and may no longer work due to
changes in the way in which the Watch Service functions. This function is completely disabled in
PReS Workflow 7.3 and higher.
Watch.GetOriginalFileName()
Perl
$Watch->GetOriginalFileName();
Watch.GetMetadataFilename
Returns the complete path and file name of the metadata file associated with the current job file.
Example
VBScript
Watch.GetMetadataFileName
JavaScript
Watch.GetMetadataFileName();
Python
Watch.GetMetadataFileName()
Perl
$Watch->GetMetadataFileName();
Watch.InputBox
Prompts the user to enter a string. The string is displayed as the window caption. You can specify a
message that is displayed above the text box. This method is the same as PW_InputBox.
Page 100

Clicking OK returns the value entered by the user. If no value was entered the default value is returned.
Clicking Cancel returns the default value.
You must enable the “Run on desktop” option for the PReS Workflow process whose script calls
Watch.InputBox. Otherwise PReS Workflow application may stop working and require a reboot.
Example
s = watch.inputbox("caption", "message", "default")
watch.showmessage(s)
Examples
In the following example,Watch.InputBoxrequires the user to enter a line of text. The script the displays a
pop-up of the message contents using "Watch.ShowMessage" on page95.
VBScript
s = Watch.InputBox("Your Name", "Please enter your name", "John Doe")
Watch.ShowMessage("Will the real " + s + " please stand up?")
JavaScript
s = Watch.InputBox("Your Name", "Please enter your name", "John Doe");
Watch.ShowMessage("Will the real " + s + " please stand up?");
Python
s = Watch.InputBox("Your Name", "Please enter your name", "John Doe")
Watch.ShowMessage("Will the real " + s + " please stand up?")
Perl
s = Watch->InputBox("Your Name", "Please enter your name", "John Doe");
Watch->ShowMessage("Will the real " + $s + " please stand up?");
Watch.GetJobInfo
Returns job information corresponding to the specified index. Index is an integer from 1 to 9.
 Loading...
Loading...