


Content Router Setup
and Configuration Guide
Version 2.2

Content Router Setup and Configuration Guide: Version 2.2
Copyright © 2010 Caringo, Inc.
All Rights Reserved.
No part of this document may be reproduced, transmitted, or transcribed without the written consent of Caringo, Inc.

Table of Contents
1. Introduction to DX Content Router ........................................................................................ 1
1.1. Overview of DX Content Router ................................................................................. 1
1.2. About this Document ................................................................................................. 1
1.2.1. Audience ....................................................................................................... 1
1.2.2. Scope ............................................................................................................ 1
2. Replication Topologies ......................................................................................................... 2
2.1. Disaster Recovery ..................................................................................................... 2
2.2. Mirrored Clusters ...................................................................................................... 2
2.3. Multi-Site Disaster Recovery ...................................................................................... 2
2.4. Content Distribution ................................................................................................... 3
3. DX Content Router Services ................................................................................................ 4
3.1. Basic Architecture ..................................................................................................... 4
3.1.1. Structure of a DX Content Router Node ........................................................... 5
3.1.2. Publisher Service ........................................................................................... 7
3.1.3. Replicator Service ........................................................................................ 10
4. Installation ......................................................................................................................... 11
4.1. Requirements .......................................................................................................... 11
4.1.1. Operating System ......................................................................................... 11
4.1.2. 3rd Party Package Pre-requisites .................................................................. 11
4.1.3. Network ....................................................................................................... 11
4.2. Installing and Configuring DX Content Router Services .............................................. 13
4.2.1. Installing Services ......................................................................................... 13
4.2.2. Configuring Services and Rules .................................................................... 13
4.3. Upgrading DX Content Router ................................................................................. 14
4.3.1. Upgrading from 1.x ....................................................................................... 14
4.3.2. Upgrading from 2.x ....................................................................................... 14
4.4. Removing DX Content Router .................................................................................. 14
5. Running and Managing DX Content Router ......................................................................... 15
5.1. Starting DX Content Router Services ....................................................................... 15
5.2. Publisher and Replicator Shutdown .......................................................................... 15
5.3. Customizing the Standard Rule Sets ........................................................................ 15
5.3.1. Publish all streams on a single channel ......................................................... 15
5.3.2. Publish all streams on two separate channels ................................................ 16
5.3.3. Publish streams with header ‘someHeaderName’ on one channel and all
others except text files to a second ........................................................................ 16
5.3.4. Complex Content Metadata Analysis ............................................................. 16
5.4. Using the Publisher Console .................................................................................... 18
5.4.1. Publisher Console layout: ............................................................................. 19
5.5. HTTP Status Reporting for Publisher and Replicator ................................................. 21
5.5.1. Publisher Response ...................................................................................... 21
5.5.2. Replicator Response .................................................................................... 22
5.5.3. Request for Source Cluster IP Addresses ...................................................... 23
6. Support for Content Restoration and Fail-Over .................................................................... 24
6.1. Administrative Disaster Recovery ............................................................................. 24
6.2. Content Mirroring .................................................................................................... 24
6.3. Application-Assisted Fail-Over .................................................................................. 24
A. Content Metadata .............................................................................................................. 25
A.1. System Metadata .................................................................................................... 25
A.2. Content File Server Metadata .................................................................................. 25
A.2.1. Custom Metadata ......................................................................................... 25
B. DX Content Router Configuration ....................................................................................... 26
Copyright © 2010 Caringo, Inc.
All rights reserved iii
Version 2.2
December 2010

B.1. Publisher Configuration ........................................................................................... 26
B.2. Replicator Configuration .......................................................................................... 30
C. Enumerator API ................................................................................................................ 34
C.1. Enumerator Types .................................................................................................. 34
C.2. Enumerator Start .................................................................................................... 34
C.2.1. Enumerator Start Query Arguments .............................................................. 35
C.2.2. Enumerator Start Response ......................................................................... 35
C.3. Enumerator Next .................................................................................................... 36
C.3.1. Enumerator Next Query Arguments ............................................................... 36
C.3.2. Enumerator Next Response .......................................................................... 37
C.4. Enumerator End ..................................................................................................... 37
C.4.1. End Response ............................................................................................. 37
C.5. Enumerator Timeout ............................................................................................... 38
C.6. Configuration and Status Query Arguments .............................................................. 38
Copyright © 2010 Caringo, Inc.
All rights reserved iv
Version 2.2
December 2010

Chapter 1. Introduction to DX Content Router
1.1. Overview of DX Content Router
A DX Storage cluster routinely replicates content objects to other nodes in the same cluster in order
to improve fault tolerance and performance. For disaster recovery and other reasons, it may also be
desirable to automatically replicate content objects to another, remote cluster. The remote cluster
may typically have the following properties:
• A different multicast domain than the local cluster
• Connectivity to the local cluster via Transport Control Protocol (TCP)
• One or more firewalls separating it from the local cluster
• Unpredictable network latency that may prevent communication for long periods of time
The normal replication techniques used within a DX Storage cluster are not appropriate for remote
replication between clusters of this sort. DX Content Router (CR) supplies a more appropriate
mechanism for remote replication. It also supplies enumeration of DX Storage content for other
purposes like search indexing or virus scanning.
1.2. About this Document
1.2.1. Audience
This document is intended for people in the following roles.
1. Storage system administrators
2. Network administrators
3. Technical architects
4. Application integrators writing with the Enumeration API
Throughout this document, the storage system administrator and network administrator roles will be
referred to as the administrator. The administrators are normally responsible for allocating storage,
managing capacity, monitoring storage system health, replacing malfunctioning hardware, and
adding additional capacity when needed.
This document will be valuable to technical architects in designing scalable, highly redundant, cost
effective application storage solutions.
1.2.2. Scope
This document covers the steps needed to deploy DX Content Router and the administrative actions
necessary to monitor and run one or more DX Content Router nodes. The reader is expected to
have a background in TCP/IP networking, basic knowledge of server-class hardware, and optional
experience with regular expression languages.
Copyright © 2010 Caringo, Inc.
All rights reserved 1
Version 2.2
December 2010
Chapter 2. Replication Topologies
A replication topology is a defined arrangement between independent DX Storage clusters,
connected to one another via DX Content Router nodes. DX Content Router supports several
alternative replication topologies.
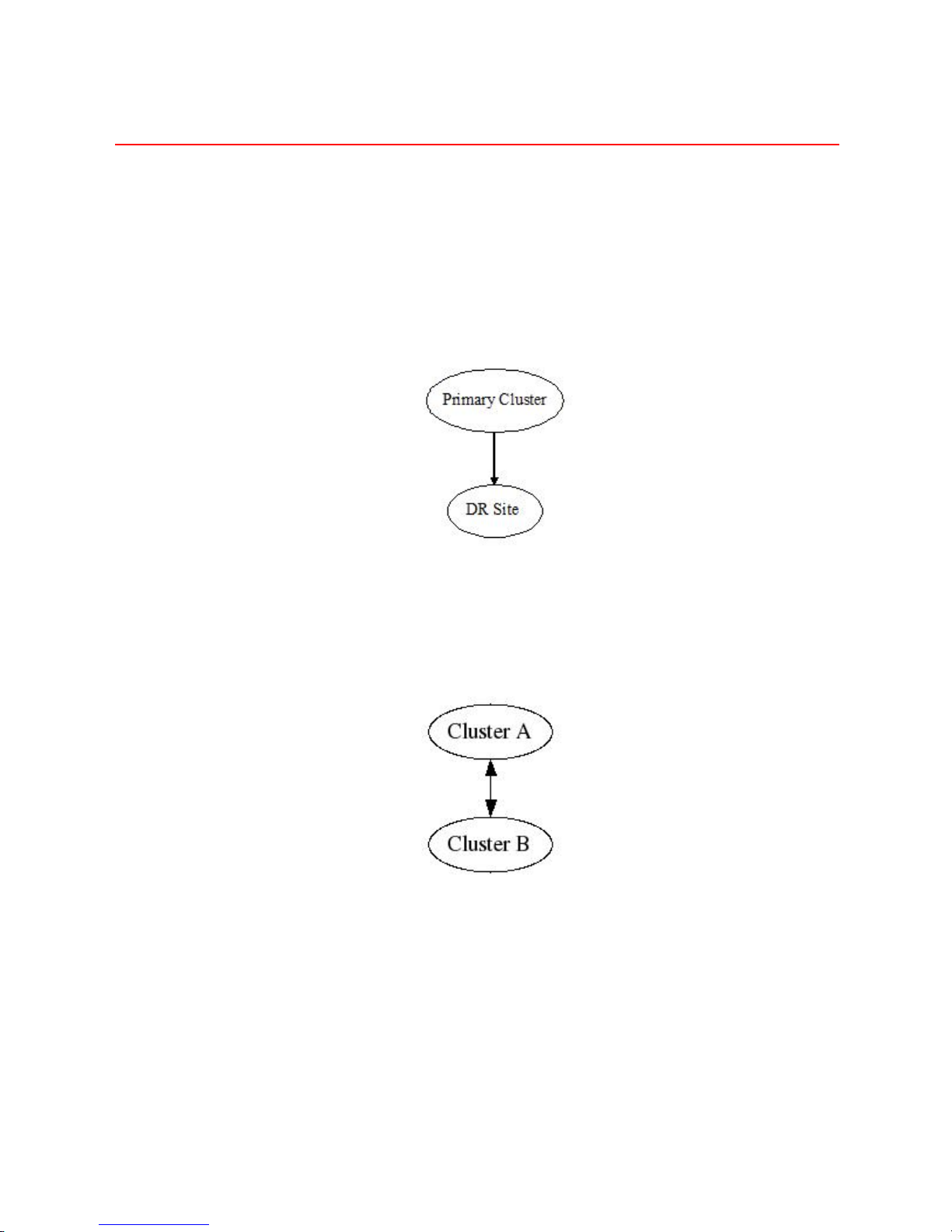
2.1. Disaster Recovery
DX Content Router allows an administrator to replicate some or all the streams stored in a primary
cluster to a disaster recovery site. In case of a complete failure or loss of the primary cluster, all
replicated streams can be recovered from the DR site. Hence, it is important that the administrator
carefully plan the type of content that should be replicated to the DR site.
2.2. Mirrored Clusters
DX Content Router allows mirroring between two or more primary clusters. All designated streams
stored in Cluster A will be replicated to Cluster B, and vice versa. The administrator of each cluster
can decide, based on stream metadata, which streams should be replicated to the other cluster. It is
possible that the two replication sets may identical, completely disjoint or have some overlap.
2.3. Multi-Site Disaster Recovery
Using a combination of one-way DR replication and mirrored clusters, more complex disaster
recovery topologies can be deployed. Such deployments rely upon a unique metadata identifier for
the origin of each object to ensure the correct subset of content is recovered from a pooled (manyto-one) DR cluster in the event of a disaster. See Appendix I for an overview of the various means
by which metadata can be associated with streams in DX Storage. Some or all the DR sites may be
shared with other independent primary clusters. In case of loss of the primary cluster, all replicated
streams can be recovered from one or more DR clusters. This requires modification of the rules set
in the DR cluster and you should seek the assistance of your designated support resource.
Copyright © 2010 Caringo, Inc.
All rights reserved 2
Version 2.2
December 2010
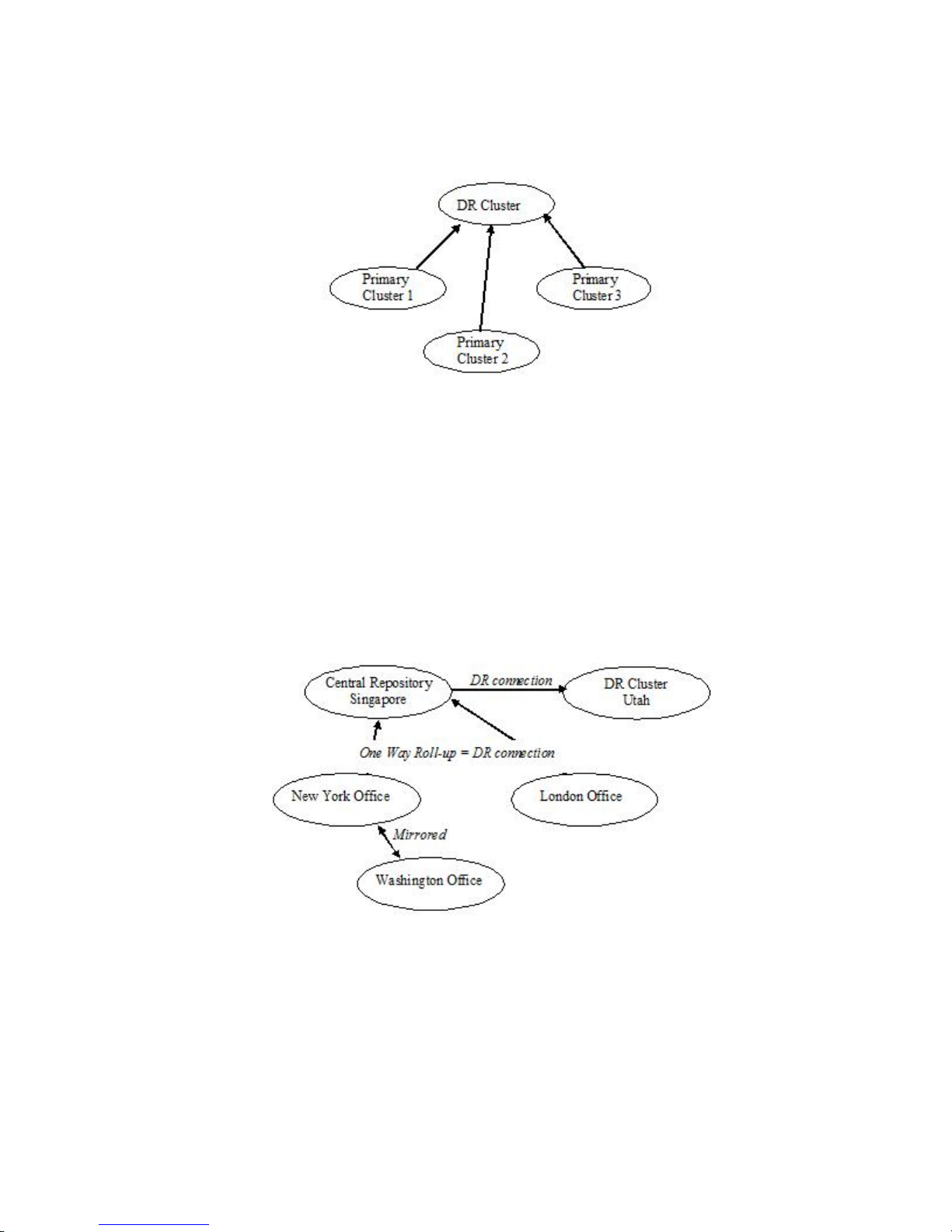
Below is a figure showing multiple primary clusters rolling up to one DR cluster. In order to
distinguish the streams in Primary Cluster 1 from those in Primary Cluster 2, metadata needs to be
stored with each stream identifying, at a minimum, the cluster of origin.
2.4. Content Distribution
An alternative use for DX Content Router replication infrastructure is to roll up or distribute content
within an organization or between cooperating organizations. With a little forethought and planning
when storing descriptive metadata with each stream, a very sophisticated data distribution and
storage infrastructure can be created. Because you have the ability to create your own rules, a
dynamic pool of data can be created and moved around with relative ease.
In the example below we use a combination of mirrored and one-way replication to create a
network of clusters with distinctly different data sets. The only two identical clusters are the Central
Repository in Singapore and the DR Cluster in Utah. This same model could be used for roll up of
major functional areas, such as Financial, Legal, Engineering, HR, etc.
Copyright © 2010 Caringo, Inc.
All rights reserved 3
Version 2.2
December 2010
Chapter 3. DX Content Router Services
3.1. Basic Architecture
A DX Content Router lives within a DX Storage cluster but is always visible to other clusters, and
perhaps to the external network at large. Consequently, it is assumed that all communication
between DX Content Router services occurs over a secure TCP connection.
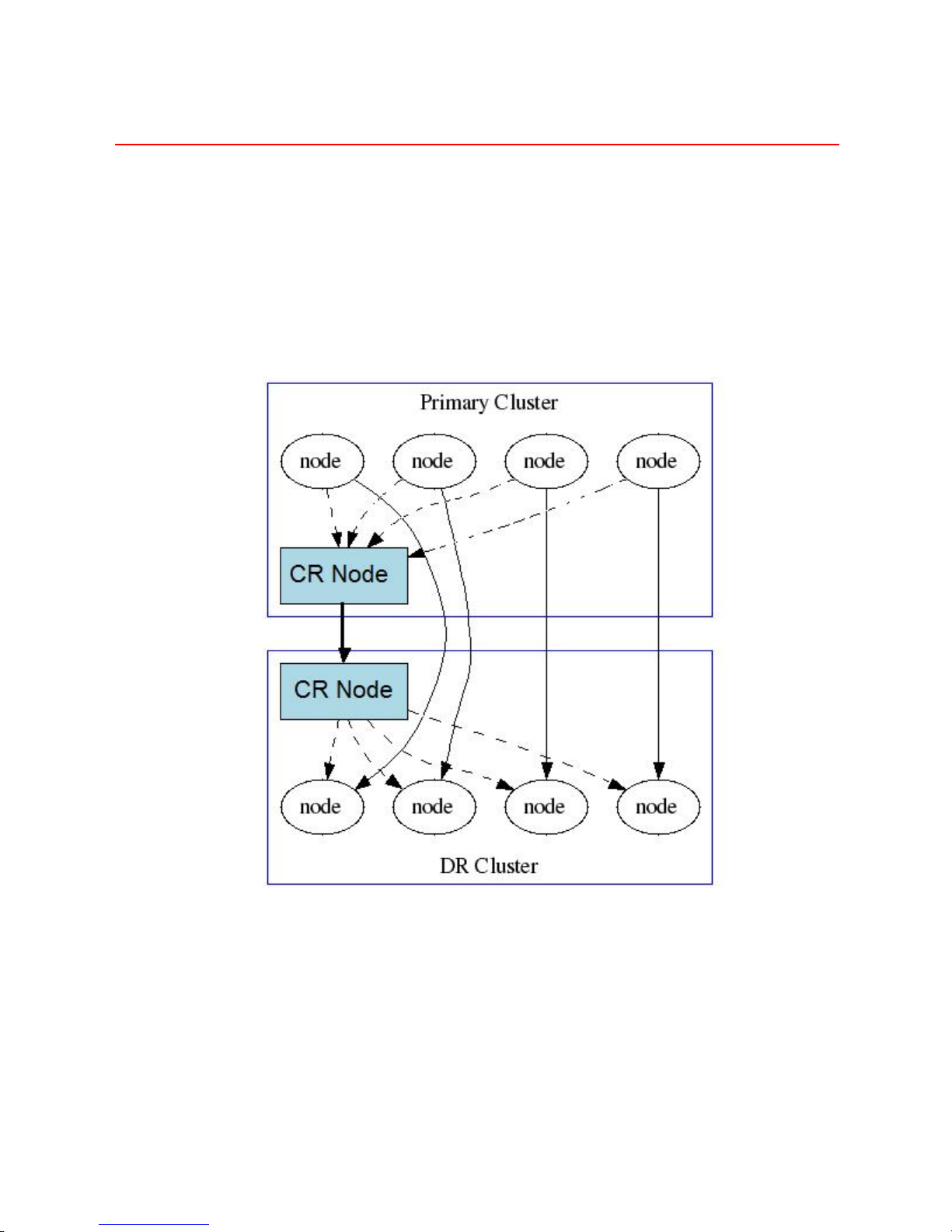
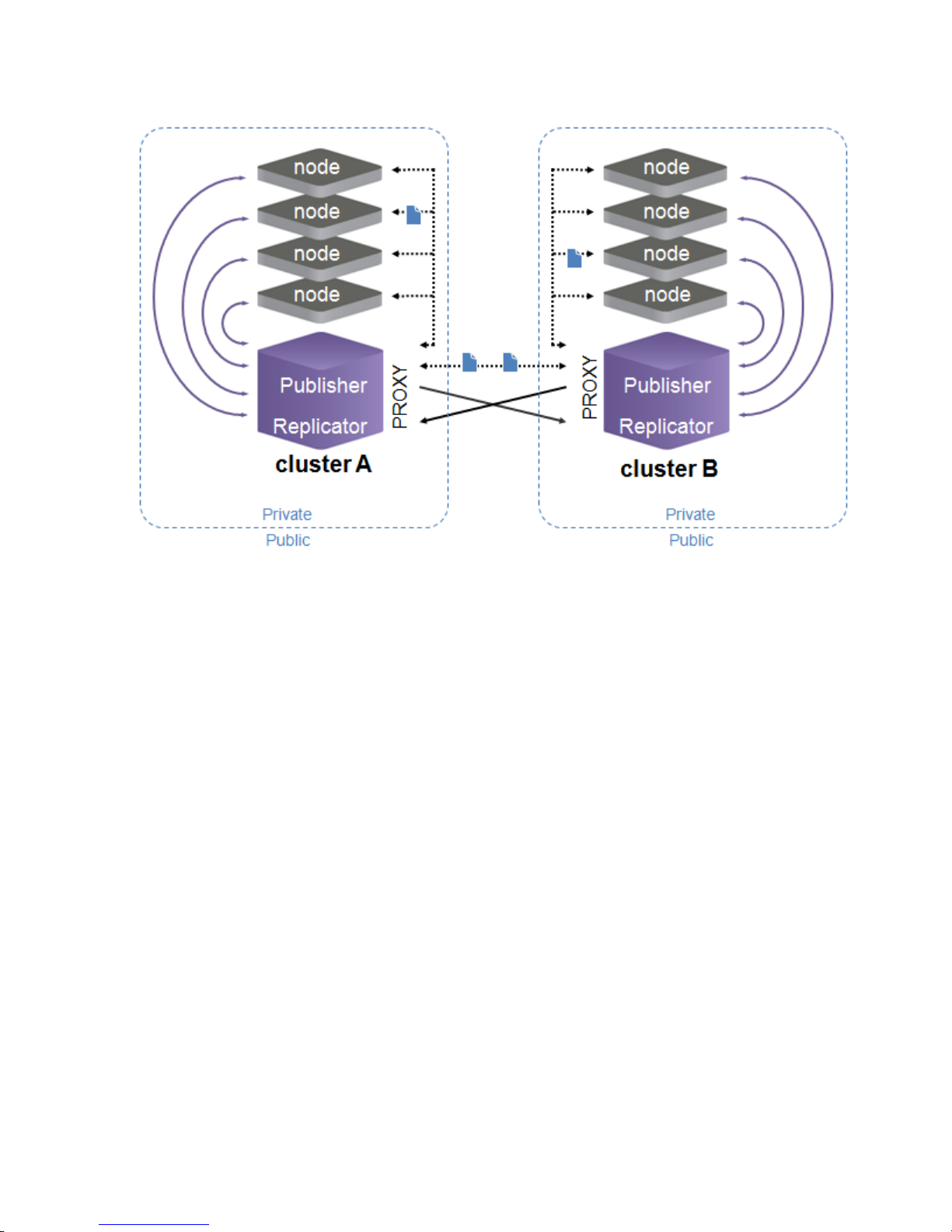
The following diagram illustrates, at a high level, the flow of messages that takes place between
two DX Storage clusters, one acting as the Primary Cluster and the other as a Disaster Recovery
Cluster. Dotted lines represent local cluster communication. Solid lines represent TCP traffic over
the HTTP protocol between DX Content Router services and also between storage nodes within the
two independent clusters.
Alternatively, if network configuration prevents direct communication between the storage nodes
(such as when DX Content Router installed on a CSN), communications can be configured to route
through an SCSP Proxy:
Copyright © 2010 Caringo, Inc.
All rights reserved 4
Version 2.2
December 2010
3.1.1. Structure of a DX Content Router Node
DX Content Router consists of a server machine running Linux and executes one or both of two
services:
1. Publisher - processes all streams stored in a cluster, filters them based on stream metadata, and
publishes UUIDs to remote Subscribers.
2. Subscriber - retrieves UUID publications from remote Publishers. A Replicator, the most
common subscriber, retrieves remote UUIDs and sends replication requests to local nodes
and must be installed on a server in the same subnet as its target storage cluster. A 3rd party
application, which may or may not be installed on a node with other DX Content Router services,
can also function as a subscriber by integrating with the Enumerator API defined in the Appendix.
DX Content Router service configuration parameters are used to enable one or both services,
depending on the intended network topology. For the simple example in the previous section, where
a primary cluster replicates in one direction to a single DR cluster and all nodes in both clusters are
mutually visible, the DX Content Router in the primary cluster would likely be configured to run only
the Publisher service and the DX Content Router in the DR cluster would run just the Subscriber. A
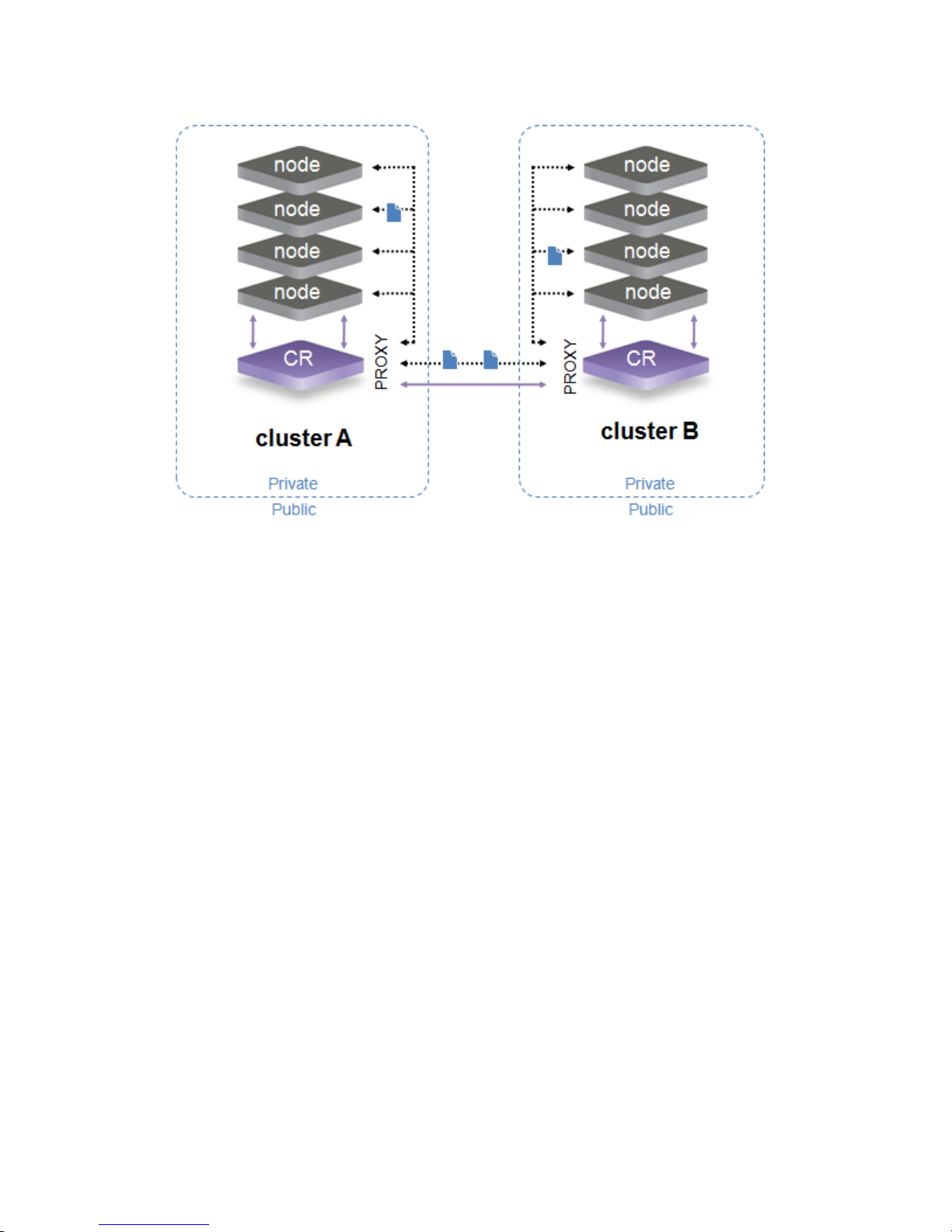
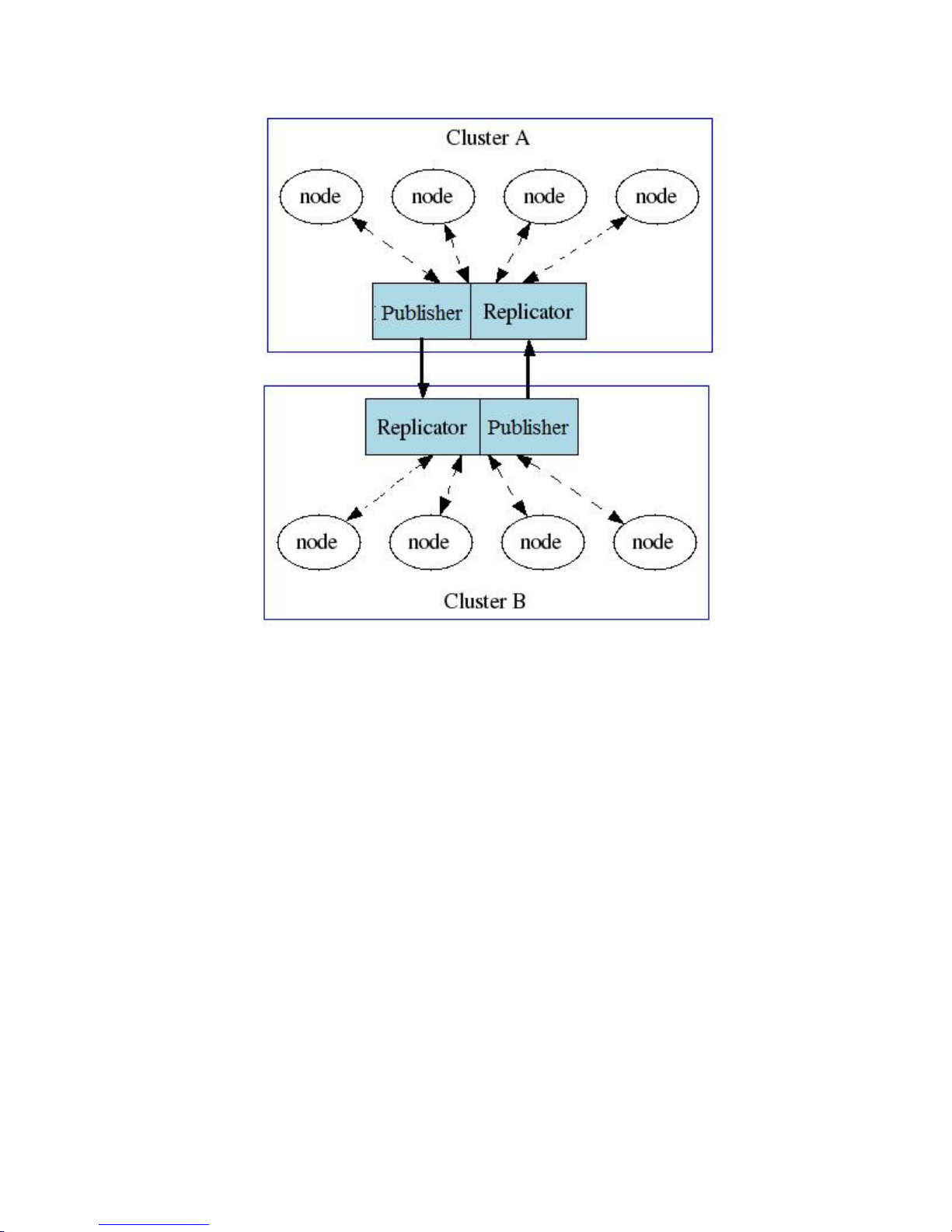
slightly more complex example would be a pair of mirrored clusters where all nodes in both clusters
still have mutual visibility. DX Content Router servers for this topology would look like the diagram
below. For clarity, the assumed direct connections between storage nodes in the two clusters as
shown and discussed in the previous example have been omitted.
Copyright © 2010 Caringo, Inc.
All rights reserved 5
Version 2.2
December 2010
Similar to the previous proxy-enabled example, if the storage nodes are not able to communicate
directly in the configured network topology, the Publisher can be configured to send responses via
an SCSP Proxy in a mirrored configuration as well:
Copyright © 2010 Caringo, Inc.
All rights reserved 6
Version 2.2
December 2010
The two optional DX Content Router services are designed and deployed as independent processes
running on a server. We discuss each of these services in more detail in the following sections.
3.1.2. Publisher Service
The Publisher service collects a comprehensive list of all the UUIDs stored in the cluster (as well as
those that have been deleted), filters those UUIDs, and publishes the resulting lists of UUIDs to one
or more remote Subscribers. The Publisher consists of several subcomponents:
1. Simple HTTP server
2. Attached data store
3. Filter Rules Engine
3.1.2.1. Filtering UUIDs for Publication
The Publisher traverses the list of UUIDs and evaluates one or more existence validations or simple
filter expressions against the values of certain headers in the metadata. A set of matching rules can
be configured by the administrator that will determine the topology of the intercluster network. These
rules are specified using an XML syntax, the full definition of which can be found below.
By way of an example, suppose we want to configure our local cluster to remotely replicate all
high and medium priority streams to a primary disaster recovery site, while all other streams get
replicated to a secondary DR site. The General XML rule structure to do this might look like this:
<rule-set>
<publish>
<select name="PrimaryDR"/>
<select name="SecondaryDR"/>
</publish>
Copyright © 2010 Caringo, Inc.
All rights reserved 7
Version 2.2
December 2010

</rule-set>
The example above is a good starting point, but it, alone, will not perform the filtering required for
this example. In order to select the PrimaryDR cluster as the destination of some of the locally
stored streams, we want to find all streams whose content metadata contains a header called
"DX Storage-priority" whose value starts with either a "1", a "2" or one of the words "high" or
"medium". Note that the header name is not case sensitive but the actual header value with a match
expression is case sensitive. Here is a select rule that uses a filter with a matches() expression that
would accomplish this:
<select name="PrimaryDR">
<filter header="<storageProduct/>-priority">
matches('\s*[12].*|\s*[Hh]igh.*|\s*[Mm]edium.*')
</filter>
</select>
A select clause specifies a pattern for a single set of data to be retrieved by the Subscriber process
by name. The select can contain zero or more filter clauses. If there are multiple filter clauses,
then all of them must match a stream’s metadata before the stream is published. As in HTTP, the
order of headers within the metadata is not significant. If there are multiple headers in the stream
metadata with the given header-name, then any of them can match the given pattern in order for the
select to execute. If there are no filter clauses, then the select matches any and every stream, as in
the following:
<select name="SecondaryDR">
</select>
The root tag for a set of DX Content Router rules is called rule-set, which can contain one or more
publish tags as shown above. The example rule set below will replicate all high and medium priority
streams to the PrimaryDR cluster and all others to the SecondaryDR cluster. It will also also send
all streams whose Content-Disposition header does not contain a file name ending with ".tmp" to the
Backup cluster.
<rule-set>
<publish>
<select name="PrimaryDR">
<filter header="<storageProduct/>-priority">
matches('\s*[12].*|\s*[Hh]igh.*|\s*[Mm]edium.*')
</filter>
</select>
<select name="SecondaryDR">
</select>
</publish>
<publish>
<select name="Backup">
<filter header="content-disposition">
not matches('.*filename\s*\=.*\.tmp.*')
</filter>
</select>
</publish>
</rule-set>
Notice that a rule-set can contain multiple publish clauses, and each publish clause can contain
multiple select clauses. The Filter Rules Engine evaluates all content elements for each publish
Copyright © 2010 Caringo, Inc.
All rights reserved 8
Version 2.2
December 2010

clause. In the example above, where there are two publish clauses, all content streams can be
queued for remote replication once for each publish. In addition, when there are two select clauses
in a given publish clause, the content metadata is evaluated against each select clause’s filter
set. The select clauses are evaluated in order from top to bottom. When the rules engine finds
a select whose filter clauses all evaluate to true, the content stream is placed in the appropriate
queue, (i.e. PrimaryDR or SecondaryDR), and awaits remote replication. Once the evaluation of that
publish clause is complete, the rules engine begins evaluation of the next publish clause. When all
publish clauses have been evaluated for a given content stream, then the Filter Rules Engine begins
evaluation for the next content stream.
3.1.2.2. Rules
The full syntax for the filter rules of a Publisher is presented in simplified RELAX-NG Compact
Syntax.
start = RuleSet
RuleSet = element rule-set {
Publish+
}
Publish = element publish {
Select+
}
Select = element select {
(Filter|Exists|NotExists)+,
attribute name { text }
}
Filter = element filter {
HeaderAttr,
# filter expression, using olderThan(), matches() etc.
text
}
Exists = element exists {
HeaderAttr
}
NotExists = element not-exists {
HeaderAttr
}
HeaderAttr = attribute header { text }
Exists and NotExists are tests to check if the header is present or not. An empty header will match
an exists query.
Filter expressions are built using a small set of functions. The set of functions available to a filter
are:
• matches(regexstr) or contains(regexstr) - matches any part of the header value to a given regular
expression
Copyright © 2010 Caringo, Inc.
All rights reserved 9
Version 2.2
December 2010

• olderThan(dateSpec) - matches if the header value is a date and that date is older than the date
given, which may be either an absolute date or a relative (to execution time) date.
• intValue(int) – matches if the header value is an integer and executes the specified comparison
against that integer (greater than, less than, equal to, etc).
Typical boolean and grouping operators are also available, so it is possible to easily construct more
sophisticated filters (e.g. (olderThan('365d') and not olderThan('730d')) or matches('^Mon\s.*') to
express "between one and two years old or on Mondays").
3.1.3. Replicator Service
A DX Content Router node’s Replicator service serves as a subscriber to one remote cluster’s
Publisher service. The Replicator’s purpose is to receive UUIDs from the Publisher service, and
then schedule those UUIDs for replication (or deletion) in its local cluster. The Replicator can
be configured to periodically poll, using an HTTP GET request, one or more remote Publishers
to obtain a list of UUIDs to be replicated or deleted. Upon receiving these lists, the Replicator
immediately writes the UUIDs to a queue on its local disk. The Replicator then attempts to process
each write or delete. Once completed the UUID is removed from the queue.
Copyright © 2010 Caringo, Inc.
All rights reserved 10
Version 2.2
December 2010

Chapter 4. Installation
DX Content Router installs as a service on a standard server, using standard Linux installation
and package management utilities as outlined in the sections below. Note, that if running DX
Content Router from a Cluster Services Node (CSN), the required infrastructure setup, installation
and configuration are performed automatically as part of CSN configuration so the steps below
are not necessary or even supported in some cases. Please reference the CSN Installation and
Configuration Guide for information on installing and configuring DX Content Router on the CSN.
4.1. Requirements
4.1.1. Operating System
DX Content Router has been developed and tested with 64-bit Red Hat Enterprise Linux (RHEL)
version 5.5. Other RHEL versions or Linux distributions are not currently supported. Subsequent
installation instructions will assume an existing RHEL installation.
4.1.2. 3rd Party Package Pre-requisites
DX Content Router has dependencies on Python 2.5, Python Setuptools 0.6c9, and Twisted 8.2.0,
which are not available as standard RPM packages under RHEL 5.5 but are included in the DX
Content Router installation package and will be unzipped into the same location as the DX Content
Router rpm (see the 'Installing Services' section below). If installing on a Cluster Services Node
(CSN), these RPMs will already be installed. If installing without a CSN, you may need to manually
install the packages using the commands shown below (in this order):
rpm -ivh caringo-3rdparty-Python-2.5.4-x86_64.rpm
rpm -ivh caringo-3rdparty-setuptools-0.6c9-x86_64.rpm
rpm -ivh caringo-3rdparty-Twisted-8.2.0-x86_64.rpm
4.1.3. Network
The DX Storage system has been designed to work within standard TCP/IP networking
environments. This is achieved through the use of widely supported network services and protocols.
4.1.3.1. Required Communications
A DX Content Router node must be able to initiate TCP connections with all nodes in a DX Storage
cluster through the designated access port. This is typically HTTP port 80, but it is configurable by
the administrator.
Internally, DX Content Router nodes must be able to communicate with each DX Storage node
via UDP on port 7000 and through IP multicasting. The multicast address must be unique for each
cluster and is configurable by the administrator. Multicast communication is only necessary between
the DX Content Router nodes and the DX Storage nodes.
All nodes in the DX Storage cluster, including DX Content Router nodes must reside within the
same IP subnet.
4.1.3.2. Bandwidth Requirements
The expected transfer rate for two clusters communicating over a wide area network can be roughly
calculated by dividing the minimum effective bandwidth available (ex: 512 kbps) by the number
of volumes in the target cluster. By default, DX Storage requires a minimum transfer rate of 1000
bytes/sec before timing out connections. The transfer rate is not checked for the initial 20 minutes to
provide some latitude for network variability. Administrators anticipating a transfer rate below 1000
Copyright © 2010 Caringo, Inc.
All rights reserved 11
Version 2.2
December 2010

bytes/sec between clusters based on the calculation above will need to modify the 'minBytesPerSec'
parameter in the DX Storage node.cfg or common.cfg file to account for a slower rate and avoid
timeouts. For example, to lower DX Storage's expectations for transfer rate to 512 bytes/sec, the
following parameter should be added to the node or cluster level configuration file to override the
default:
minBytesPerSec = 512
4.1.3.3. Recommended Infrastructure
The following networking services are recommended for the management of a DX Storage cluster
that includes DX Content Router nodes.
• Syslog server for receiving critical alerts
• NTP time server to provide clock synchronization.
Gigabit Ethernet is the recommended connection speed between DX Content Router servers and
DX Storage cluster nodes. A DX Content Router node should use the same speed connection as
the fastest DX Storage node it communicates with to prevent bottlenecks.
4.1.3.4. IP Address Configuration
DX Content Router Services expect a predictable communication pattern and therefore
configuration of one or more static IP addresses for each Content Router server is required. This
can be accomplished through either mapping MAC addresses via DHCP or by physically assigning
the IP addresses on the server. For mirrored environments, Publisher and Replicator each require
their own IP address to ensure communications for the two services do not intermingle. Please
reference the Red Hat documentation for materials on configuring static IPs. The following is an
example of the steps to configure additional alias interfaces in the '/etc/sysconfig/network-scripts'
directory:
1. cd /etc/sysconfig/network-scripts
2. Copy an existing interface file that has the same characteristics as the new alias interface:
cp ifcfg-eth1 ifcfg-eth1:1
3. Edit the new file to create the new alias. The essential fields to update are: DEVICE, IPADDR,
and VLAN. The following is an example of possible modifications to the file created above for a
new eth1:1 interface:
# Public ALIAS bonded interface
# the device value needs to be unique on the system, and should match the
# name specified in the file name.
DEVICE=eth1:1
# the static ip for the interface
IPADDR=192.168.99.110
NETMASK=255.255.0.0
GATEWAY=192.168.1.1
NETWORK=192.168.0.0
BROADCAST=192.168.255.255
BOOTPROTO=none
ONBOOT=yes
USERCTL=no
# set VLAN to yes for ALIAS network interfaces
Copyright © 2010 Caringo, Inc.
All rights reserved 12
Version 2.2
December 2010

VLAN=yes
4. Start the new interface:
ifup ifcfg-eth1:1
Note, that if the DX Content Router services are installed on a Cluster Services Node (CSN),
creation of the IP addresses is performed automatically when the services are configured.
4.2. Installing and Configuring DX Content Router Services
4.2.1. Installing Services
The DX Content Router distribution is available as a RHEL rpm package that is installed with a shell
script. The package and its dependencies must be installed as a 'root' user with the following steps:
1. Copy the distributed zip file to your RHEL server and unzip it. Unzipping the distribution on a
separate server and then transferring it to the DX Content Router server is not recommended
as the file may become corrupted during the transfer. The following commands will unzip the file
after it has been copied to the server:
$ sudo su # unzip contentrouter-install-2.2.0b1.zip -d contentrouter-install-2.2.0b1
2. Install DX Content Router by running the shell script from the directory location where the shell
script was unzipped. For instance, to install the 2.2 Beta 1 version of the software from the
contentrouter-install-2.2.0b1 directory created above you would run the following commands:
$ sudo su # cd contentrouter-install-2.2.0b1
# ./contentrouter-install.sh
Note
If the installation fails due to 'Missing Dependency', make sure you have installed the
packages mentioned above in the 3rd Party Package Pre-requisites section.
If DX Content Router is installed on a Cluster Services Node (CSN), the necessary software will be
installed automatically as part of the overall software bundle.
4.2.2. Configuring Services and Rules
After installing DX Content Router, you must configure the installed services by updating the
configuration files for each service, Replicator and Publisher, you plan to run as well as creating a
filter rules file for Publisher. The configuration files do not exist on the system after installation and
must be created prior to attempting either service. Failure to create and configure these files will
result in a 'Publisher/Replicator not configured' error when you attempt to start the service.
Both services would be utilized for a mirrored configuration where the server is both publishing
UUIDs from a local cluster and receiving incoming UUIDs to replicate from a remote cluster. For a
one-way Disaster Recovery scenario, you would likely only need to configure one of the services
on a single server. Both the Publisher and Replicator services can be configured from the CSN
management console. Please see the 'Configuration' appendix for a full list of all parameters and
best practice instructions for creating the configuration files and rules.xml file by copying the existing
sample configuration.
Copyright © 2010 Caringo, Inc.
All rights reserved 13
Version 2.2
December 2010

4.3. Upgrading DX Content Router
4.3.1. Upgrading from 1.x
Installations with a previously installed Ubuntu-based version of DX Content Router have two
upgrade options. Administrators with replication downtime tolerance may choose to stop all DX
Content Router processes, install Red Hat Enterprise Linux (RHEL) over Ubuntu on the existing DX
Content Router Publisher and Replicator servers and then install and start both DX Content Router
services again on both servers. For environments with no downtime tolerance, administrators may
wish to install Red Hat and DX Content Router on a second, parallel set of Publisher and Replicator
servers and then wait for the Publisher 'Stream Events Found' count on the Publisher console
to match the count on the Ubuntu installation. After the counts match, the Ubuntu Publisher and
Replicator servers can be decommissioned.
Regardless of the chosen upgrade path, administrators must upgrade DX Storage to 4.0 or later
prior to upgrading DX Content Router to ensure compatibility. Administrators should temporarily
raise the Multicast Frequency to 50% from the Setting popup on the DX Storage admin console
to support faster population of the Publisher data store. Depending on the size of the source DX
Storage cluster, it may take several days for the Publisher data store to fully populate. Please
contact your designated support resource if you have further questions about upgrading DX Content
Router.
4.3.2. Upgrading from 2.x
Prior to upgrading, users must upgrade their operating system to Red Hat 5.5. Installations with a
2.0 or 2.1.x RedHat-based version of DX Content Router may then install the new 2.2 rpm over the
previous version using the same process and script as above for initial installation. If DX Storage is
also being upgraded, it is recommended that DX Content Router be upgraded prior so it is prepared
to handle any new DX Storage features. It is also recommended that all Replicators be upgraded
prior to the Publisher being upgraded for similar reasons. Both services must be restarted after they
are upgraded. Any modifications to the data format used by either process will be automatically
transformed during the first Publisher process execution after upgrading.
Integrators wishing to use the new 'syncToken' functionality described in the Enumerator API
chapter with an existing enumeration may take advantage of this new feature by simply passing a
syncToken query argument with an empty string on the first Next request following the upgrade.
Replicator will automatically make use of the token after upgrade with no action required.
In the event of an upgrade error, customers should contact their designated support resource for
downgrade instructions.
4.4. Removing DX Content Router
If you need to remove DX Content Router from a server, you should first ensure there are no
subscribers actively querying the Publisher for streams. The following command will then remove
the configuration files and software for DX Content Router:
# sudo /opt/caringo/contentrouter/contentrouter-uninstall.sh
Copyright © 2010 Caringo, Inc.
All rights reserved 14
Version 2.2
December 2010

Chapter 5. Running and Managing DX Content Router
5.1. Starting DX Content Router Services
DX Content Router Publisher and Replicator will attempt to start every time the server on which they
are installed boots. Admins should be sure to update the config files for Publisher and/or Replicator
after installation to ensure DX Content Router has the necessary information to start correctly. If
a service was stopped for any reason it can be manually started with a standard init.d script. For
mirrored configurations with both services on the same server, Publisher and Replicator must be
started separately as follows:
$ sudo /etc/init.d/cr-publisher start
$ sudo /etc/init.d/cr-replicator start
5.2. Publisher and Replicator Shutdown
To stop a DX Content Router service, use one of the following commands:
$ sudo /etc/init.d/cr-publisher stop
$ sudo /etc/init.d/cr-replicator stop
5.3. Customizing the Standard Rule Sets
The standard rule set can easily be customized to control what content is published on a given
channel. Each Publish statement, or channel', will be evaluated against the full list of known UUIDs.
Multiple replicators may subscribe to the same channel when replicating the same content to more
than one remote cluster. Channel names are case sensitive. Modifications to rules files, both realtime and while Publisher is stopped, will delete all subscriber sessions as the list of previously
filtered events is no longer guaranteed to be accurate for the new rules. Subscriber clients that
receive a 404 on a request must restart their subscriber session(s).
The default channel in the sample rules file is a 'PublishAll' rule with no filter criteria that cannot be
modified. This channel name is reserved and the filter criteria associated with it cannot be modified
as the PublishAll case is optimized to speed performance by skipping the rule filtering process.
'PublishAll' is equivalent to the previous default of 'ReplicateAll'; customers using a 'ReplicateAll'
rule need not update their rule name to gain the same functionality. Legacy 'ReplicateAll' rules will
display on the Publisher console as 'PublishAll' (irrespective of the name displayed in the rules.xml
file) and will behave in all other ways as the 'PublishAll' rule. If there are any filter criteria associated
with either the 'PublishAll' or 'ReplicateAll' rule, Publisher will log an error and fail to start.
The examples below illustrate multiple alternate rule implementations.
Note
Delete events are considered to match all channels. They are sent to all subscribers. For
a Replicator subscriber, there is a configuration parameter, "ignoreDeleteEvents", which
tells Replicator to not propagate any deletes to the target cluster. Unless this parameter
is set, all object deletes are propagated independent of which channels streams matched
when they were written. This ensures content replicated to a remote cluster via a previous
rule version is still deleted. If a stream was never replicated to the target cluster, there will
be nothing to delete.
5.3.1. Publish all streams on a single channel
This is the same as the default "PublishAll" case.
Copyright © 2010 Caringo, Inc.
All rights reserved 15
Version 2.2
December 2010

<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE rule-set PUBLIC "-//CARINGO//DTD 1.0 PORTALRULES//EN"
"file:/tmp/caringo/rules.dtd">
<rule-set>
<publish>
<select name="subscriptionName">
</select>
</publish>
</rule-set>
5.3.2. Publish all streams on two separate channels
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE rule-set PUBLIC "-//CARINGO//DTD 1.0 PORTALRULES//EN"
"file:/tmp/caringo/rules.dtd">
<rule-set>
<publish>
<select name="subscriptionName1">
</select>
</publish>
<publish>
<select name="subscriptionName2">
</select>
</publish>
</rule-set>
5.3.3. Publish streams with header ‘someHeaderName’ on one channel and all others
except text files to a second
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE rule-set PUBLIC "-//CARINGO//DTD 1.0 PORTALRULES//EN"
"file:/tmp/caringo/rules.dtd">
<rule-set>
<publish>
<select name="subscriptionName1">
<exists header="someHeaderName"/>
</select>
<select name="subscriptionName2">
<filter header=”storage-filepath”>
(not contains('.txt'))
</filter>
</select>
</publish>
</rule-set>
5.3.4. Complex Content Metadata Analysis
When determining what content will be replicated, a variety of combinations of the filter, exists,
and notexists clauses may be utilized. In addition, the filter clause supports any combination of
olderThan(), matches(), intValue() and contains(). Below are some usage examples.
5.3.4.1. Filter Clause
<select name="subscriptionName1">
Copyright © 2010 Caringo, Inc.
All rights reserved 16
Version 2.2
December 2010

<filter header=”headerName”>
olderThan('Tue, 16 Oct 2007 00:00:00 GMT')
</filter>
</select>
<select name="subscriptionName1">
<filter header=”headerName”>
olderThan(‘365d’)
</filter>
</select>
<select name="subscriptionName1">
<filter header=”headerName”>
matches('.*filename\s*\=.*\.txt.*')
</filter>
</select>
<select name="subscriptionName1">
<filter header=”headerName”>
contains('.txt')
</filter>
</select>
<select name="subscriptionName1">
<filter header="headerName">
<![CDATA[
intValue() < 50000
]]>
</filter>
</select>
<select name="subscriptionName1">
<filter header="headerName">
intValue() != 0
</filter>
</select>
<select name="subscriptionName1">
<filter header=”headerName”>
(not contains('.txt')) and olderThan(‘365d’) and contains(‘caringo’)
</filter>
</select>
<select name="subscriptionName1">
<filter header=”headerNameXXX”>
(not contains('.txt')) and olderThan(‘365d’) and contains(‘caringo’)
</filter>
<filter header=”headerNameYYY”>
contains(‘someStringValue’)
</filter>
</select>
5.3.4.2. Exists Clause
<select name="subscriptionName1">
<exists header=”headerName”/>
</select>
<select name="subscriptionName1">
Copyright © 2010 Caringo, Inc.
All rights reserved 17
Version 2.2
December 2010

<exists header=”headerNameXXX”/>
<exists header=”headerNameYYY”/>
</select>
5.3.4.3. NotExists Clause
<select name="subscriptionName1">
<notexists header=”headerName”/>
</select>
<select name="subscriptionName1">
<notexists header=”headerNameXXX”/>
<notexists header=”headerNameYYY”/>
</select>
5.3.4.4. All Clauses
<select name="subscriptionName1">
<filter header=”headerName”>
olderThan(‘365d’)
</filter>
<exists header=”headerNameXXX”/>
<notexists header=”headerNameYYY”/>
</select>
5.4. Using the Publisher Console
The Publisher Console allows users to view progress made by the Publisher and the associated
subscribers. To better understand the data contained within this console page, a legend has been
provided below. To access the Publisher console, use the domain name or IP address of the DX
Content Router node and the configured console port number (by default, this is port 8090). In
the example below, we typed http://192.168.1.101:8090 into the address field of the browser. The
location of the console differs when the Publisher is installed on a Cluster Services Node (CSN).
Please reference the CSN Installation and Configuration Guide for related details.
Copyright © 2010 Caringo, Inc.
All rights reserved 18
Version 2.2
December 2010

5.4.1. Publisher Console layout:
• Version: the version of DX Content Router installed on the Publisher node
• Uptime: the amount of time elapsed since the DX Content Router Publisher service was last
started
• Source Cluster: the group multicast address of the DX Storage cluster from which the Publisher
is gathering UUIDs
• Stream Events Found: the total number of UUID write, update and delete events that the
Publisher has discovered from the DX Storage cluster from which it is gathering UUIDs. If the
Publisher already has upon start a lot of stream events in its data store, it may take a few hours
for the Stream Events Found counter to display a non-zero value.
• Filter Backlog: the number of UUIDs that have been discovered, but have not yet been
processed by the Filter Rules Engine.
• Space Available: the size and usage of the Hard Drive being utilized by the DX Content Router
Publisher Node
• Channels: This area contains information for each configured channel or subscription. To view
additional details for each channel, click the arrow next to the Channel name, which corresponds
to the subscription name in the rules.xml file.
• Subscriber UUID: the UUID for the subscriber instance of a particular channel. This UUID is
created by a Publisher whenever a new Subscriber subscribes to a channel. Because there can
be more than one Subscriber on the same Publisher channel, the Publisher must have a unique
ID to keep track of each separate subscription.
• Subscriber Status:
Copyright © 2010 Caringo, Inc.
All rights reserved 19
Version 2.2
December 2010

• Working: the subscriber is available and actively processing streams
• Offline: the subscriber has not contacted the DX Content Router Publisher node within the
expected configurable frequency
• Idle: the subscriber is available but is not currently processing any streams
• Busy: the subscriber is currently processing a republish action and is not available for
additional republish actions
• Paused: the subscriber is actively processing streams and is not taking additional input
• Context: the descriptive name for an subscriber instance of a particular channel. For Replicator
Subscribers this name is always the same but it is customizable for other types of Subscribers.
• Host: the subscriber client’s server IP address; Note if using an alias IP address the displayed
IP will be for the host server, not the alias on the server.
• Version: the DX Content Router software version for the enumerator client
• Uptime: the amount of time elapsed since the subscriber’s last reboot
• Stream Events Matched: the number of stream events (writes, updates, and deletes including
retries) that match the subscriber's specification, including channel and start/end interval if
applicable. This will be a subset of the Publisher's Stream Events Found, depending on which
of the stream events match the configured filter rules.
• Backlog: The total number of found streams events that a subscriber may be interested in but
has not completed processing yet. If there is a non-zero backlog, this is broken down further as
follows:
• Transmit Queue: the number of stream events (writes, updates, and deletes) that have been
identified but have not yet been retrieved by the subscriber
• Subscriber Queue: the number of stream events (writes, updates, and deletes) that have
been retrieved by the subscriber but not yet processed.
• Subscriber in Progress: the number of stream events (writes, updates, and deletes) that are
currently being processed by the subscriber.
• Dropped: the number of stream events that could not be processed by the subscriber. For
Replicator, events may end up with a Dropped status if:
• The source cluster is unavailable or unreachable due to configuration or network connectivity
issues and objects cannot be replicated
• An object has been deleted in the source cluster so it is no longer available for replication, but
the delete event has not yet been processed by the Publisher/Replicator
• A lifepoint has deleted the object in the source cluster so it is no longer available for
replication
In all these cases, Replicator will keep attempting to replicate streams for a configurable
amount of time (4 days by default) and only consider events dropped after that time. If there is
known delete activity that accounts for the Dropped events, no further action is necessary. If
Copyright © 2010 Caringo, Inc.
All rights reserved 20
Version 2.2
December 2010

the cause is unknown or a configuration or connectivity issue has been resolved, administrators
may wish to consider Republishing the subscription.
• Last Connection: the amount of time elapsed since the subscriber queried the Publisher for
stream events
• Last Transmit: the amount of time elapsed since the subscriber last retrieved at least one
stream event from the Publisher
• Republish buttons:
• Republish All: this button in the top right of the screen reruns all configured rules for all
subscribers, including any new or updated rules. It will then restart all existing subscribers.
• Subscriber Republish: this button next to each subscriber restarts the subscriber. Since the
Publisher has no way of knowing the Subscriber's status for each event, all stream events that
have been previously sent to the subscriber will be retransmitted as well as any new events.
Administrators may wish to republish a subscription if the Subscriber has failed and needs
a completely fresh list of events or, in the case of a Replicator, if there are a high number of
unexplained dropped events.
5.5. HTTP Status Reporting for Publisher and Replicator
Both the Publisher and the Replicator will provide basic status information in response to a GET
request from any HTTP client as follows:
For Publisher: GET http://<PublisherIP>:PublisherConsolePort/status
For Replicator: GET http://<ReplicatorIP>:ReplicatorConsolePort/status
The response to the request is a standard HTTP response but the response body differs slightly for
each service. All active enumerators will be included in the response in the same order with every
request. Enumerators may be deleted, however, so the index may change.
If either DX Content Router service is installed on a Cluster Services Node (CSN), the response
from the request is used to populate the SNMP MIB for the respective service on the CSN.
5.5.1. Publisher Response
The data in the Publisher response corresponds to the same fields available on the Publisher
console.
[settings]
hostip={publisher ip address or host name}
sourceCluster={source cluster multicast group}
[stats]
version={publisher software version}
upTime={seconds since Publisher started}
eventsFound={number of distinct stream events heard by Publisher}
filterBacklog={number of stream events remaining to be info-ed and filtered}
diskMBAvailable={total disk space available on Publisher data store file system}
diskMBCapacity={total disk space capacity on Publisher data store file system}
cycleTime={seconds elapsed for most recent completed data store merge cycle}
cycleStart={start of current data store merge cycle}
cycleNumber={data store merge cycle count during current Publisher run}
Copyright © 2010 Caringo, Inc.
All rights reserved 21
Version 2.2
December 2010

[enumerator1]
uuid=...
channel={rules file channel for which the enumerator was instantiated}
context={optional description for enumerator}
host=...
version=...
status=...
eventsMatched=...
backlogTotal=...
transmitQueue=...
subscriberQueue=...
subscriberInProgress=...
droppedEvents=...
lastConnection=...
lastTransmit=...
[enumerator2]
uuid=...
.
.
.
[enumerator3]
uuid=...
.
.
5.5.2. Replicator Response
[settings]
hostip={replicator ip address or host name}
targetCluster={target cluster multicast group}
[stats]
version={replicator software version}
upTime={seconds since Publisher started up}
[enumerator1]
uuid=...
publisherIP=...
channel=...
subscriberQueue=...
subscriberInProgress=...
droppedEvents=...
lastConnection=...
lastTransmit=...
[enumerator2]
uuid=...
.
.
[enumerator3]
Copyright © 2010 Caringo, Inc.
All rights reserved 22
Version 2.2
December 2010

uuid=...
.
.
.
5.5.3. Request for Source Cluster IP Addresses
Publisher clients such as Replicator may need to know IP addresses of nodes in the CAStor source
cluster that Publisher listens to (in order to make SCSP requests to this cluster). The Publisher
Channel Server will support a request for a list of source cluster IP addresses and SCSP port
numbers:
GET /sourceclusteripports.bin HTTP/1.1
You will want to provide the publisher's IP address & the Publication Server Port as part of the
request. For example:
http://publisherIp:publicationServerPort/sourceclusteripports.bin
A normal response to this request is:
HTTP/1.1 200
Date: ...
Server: Content Router Publisher
Content-Type: text/plain
Content-Length: ...
Each line of the response body will be of the form "<source cluster IP address>:<SCSP port
number>". Over time, new source cluster nodes may come online and others may go offline, so
it may become necessary for a client to update its list of IP addresses. This could be done, for
instance, whenever a previously accessible source cluster node is no longer accessible, or at
regular time intervals.
Copyright © 2010 Caringo, Inc.
All rights reserved 23
Version 2.2
December 2010

Chapter 6. Support for Content Restoration and FailOver
Some common uses of DX Content Router are disaster recovery, backup, and archiving. In all these
cases, it will sometimes be necessary to recover lost content data from a remote cluster. The exact
nature of such a recovery process, and the ease and speed with which it happens, will depend
somewhat on the topology of the cluster network.
6.1. Administrative Disaster Recovery
If the topology involves a one-way connection between the primary and DR clusters, then recovering
from a disaster that causes loss of data, perhaps because one or more nodes in the primary cluster
have been destroyed, must involve an administrative process to reverse the data flow. That's
because the primary cluster in such a topology is running only a Publisher service, which moves
data from the primary to the DR. In order to move data in the other direction for recovery purposes,
the primary cluster (and perhaps also the DR cluster) will need to be reconfigured to run one or
more Replicators, allowing the DR site to reconstitute lost data in the primary. Any lost data will be
unavailable until the loss is discovered and corrected by the two Content Router nodes.
Note
Administrators who temporarily install a Replicator or Publisher service on a DX Content
Router node as part of a DR event should plan to uninstall the temporary service when
all of the original objects have been replicated back to the source cluster. Failure to do so
may result in unintentional creation of a mirrored configuration when the cluster returns to
normal since both services will be installed on the same server.
6.2. Content Mirroring
In a mirrored architecture where the primary and DR clusters are both running paired Publishers
and Subscribers, the DX Content Router nodes will ensure that all appropriate data exists in both
clusters at all times. If there is a disaster in the primary cluster, the data can be repopulated using
the “Republish” function in the DR Publisher admin console.
6.3. Application-Assisted Fail-Over
In both the above scenarios, the loss of data can be corrected, but will be unavailable to applications
in the primary cluster until the DX Content Router nodes do their jobs and recover the data. If these
applications are made aware of the presence and address of the remote DR cluster, and if they
have visibility and access to the remote, then the applications can automatically fail-over to the
remote cluster in the event a stream is not currently accessible in the primary.
Copyright © 2010 Caringo, Inc.
All rights reserved 24
Version 2.2
December 2010

Appendix A. Content Metadata
In planning for replication of data from one location to another and/or disaster recovery scenarios
within DX Storage, it is advisable to ensure that you are both fully utilizing the system metadata
automatically stored with every stream as well as adding custom metadata that will allow you to
create dynamic rules for distributing your content. Metadata can be stored with a stream from one of
several sources outlined below.
A.1. System Metadata
As of the DX Storage 2.1 release, a ‘Castor-System-Cluster’ metadata attribute is automatically
stored with each stream in DX Storage based on the cluster name specified in your cluster
or node configuration files. This attribute ensures that a stream that is replicated to a disaster
recovery cluster can always be traced back to its cluster of origin in the event of a disaster.
This is particularly important in scenarios where multiple satellite clusters are replicated into a
centralized disaster recovery cluster. A naming scheme similar to the following is recommended:
uniquename_yourcompanydomainname (ex: cluster1_acme_com) for each cluster to ensure global
uniqueness. In addition to the cluster name, the date the stream was stored in DX Storage (Castorsystem-created) is also written with each stream and can be used for date-based rules.
A.2. Content File Server Metadata
If you are using a Content File Server (CFS) client, the following metadata is stored with CFS
streams automatically and can be used in content distribution or replication rules. For instance, an
admin may wish to replicate only those files written to a configured 'Legal' share and a rule based on
the CAStor-CFS-CFSID header could be used to isolate those files:
• Castor-CFS-Filepath: the full path to the file when it was originally stored
• Content-Disposition: the filename
• Castor-CFS-Server: the name of the server from which the file was originally stored
• Castor-CFS-Version: the version of the CFS software that originally stored the file
• Content-Type: the file's mimetype
• CAStor-CFS-CFSID: the name of the mountpoint id through which the file was originally stored
• Castor-CFS-FileId: the filesystem id for the file in the CFS namespace
• Castor-CFS-Uid: the file's user id at the time it was stored
• Castor-CFS-Gid: the file's group id at the time it was stored
• Castor-CFS-Mode: the file's permission mode in decimal at the time it was stored
A.2.1. Custom Metadata
If you are using a custom developed client to write to DX Storage, additional HTTP headers (ex:
Content-Language, Content-Type, etc) and optional custom metadata can also be stored with a
stream to aid in content distribution and processing with the new DX Content Router. CFS also
allows definition of custom metadata at the mountpoint level. See the Content Metadata section of
the DX Storage Application Guide or the Running and Managing CFS section of the CFS Setup and
Configuration Guide respectively for a complete overview of how to implement custom metadata.
Copyright © 2010 Caringo, Inc.
All rights reserved 25
Version 2.2
December 2010

Appendix B. DX Content Router Configuration
In order for DX Content Router to function correctly, each installed service has a separate
configuration file. Best practice is to copy the sample config files located in the /etc/caringo/
contentrouter directory with the name of each service:
$ sudo su -
cd /etc/caringo/contentrouter
cp publisher.cfg.sample publisher.cfg
cp rules.xml.sample rules.xml
cp replicator.cfg.sample replicator.cfg
The following command will create the necessary files if they do not already exist. The copied files
must be edited to properly configure the services within your network.
B.1. Publisher Configuration
A full explanation of all configuration options can be found below:
Option Name Default Mandatory Description
ipaddress none yes The Publisher's IP
address.
log /var/log/caringo/
contentrouterpublisher.log
loghost localhost no Syslog host name or
logbackups 8 no The number of older,
logsize 10 * 1024 * 1024 bytes no The number of bytes
no Local log file name
when not using a
syslog.
IP address. Content
Router services log
to the local 5 syslog
facility. The parameter
should not be set
if local file-based
logging will be used
instead of syslog.
rotated log files to
keep when file-based
logging is used.
allowed for all filebased log files. Each
log file is allocated 1/
n of the configured
logsize, where 'n' is
the configured number
of logbackups. A value
of 0 will prevent DX
Content Router from
rotating logs if an
alternate mechanism
Copyright © 2010 Caringo, Inc.
All rights reserved 26
Version 2.2
December 2010

Option Name Default Mandatory Description
like logrotate is
preferred.
loglevel 40 no The level of logging
verbosity with the
following supported
values: 50=critical,
40=error, 30=warning,
20=info, 10=debug,
0=no log
group 225.0.10.100 yes The multicast group
address for the DX
Storage cluster from
which UUIDs are
gathered. Must be a
Class D IP address in
the range 224.0.0.0 to
239.255.255.255.
scspport 80 no The SCSP connection
port for the DX
Storage cluster
listed in the group
parameter.
scsphosts none yes, if cluster is not
specified
A comma-separated
list of DX Storage
node IP addresses
used to validate
version compatibility
at boot time. Either
scsphosts or cluster
must be specified.
cluster none yes, if scsphosts is not
specified
The name of the
source DX Storage
cluster; used to
dynamically locate
a node and verify
version compatibility.
Either scsphosts
or cluster must be
specified.
castorProxyIp none no IP address for the
proxy that provides
external DX Content
Router subscribers
access to the DX
Storage cluster for
replication
castorProxyPort none no Port for the proxy
that provides external
DX Content Router
Copyright © 2010 Caringo, Inc.
All rights reserved 27
Version 2.2
December 2010

Option Name Default Mandatory Description
subscribers access to
the DX Storage cluster
for replication
rulesFile /etc/caringo/
contentrouter/
rules.xml
no The name and
location of the XML
rules file the Publisher
uses to filter UUIDs
consolePort 8090 no The port for the
Publisher web console
publicationServerPort 80 no The port Publisher
uses to publish UUID
data.
storageDir /var/opt/caringo/
contentrouter/
publisher
no A unique, writable
directory path for
use in storing in
process stream
information. The
specified location must
contain enough space
for the anticipated
size of the data store.
Approximate GB
required per 100
million streams =
16 + 0.07 (average
metadata size per
DX Storage object, in
bytes). For example,
if DX Storage objects
have 200 bytes of
metadata on average,
the requirement will
be: 16 + 14 = 30 GB.
subscriberOfflineAfter 180 no Time in seconds
before the Publisher
displays a Subscriber
as offline in the
Publisher console.
Applies only to
Subscribers that do
not send a offlineAfter
parameter at runtime.
subscriberErrOffline
After
3600 no Time in seconds
before the Publisher
logs a critical
error message if
a Subscriber has
not been heard
from. Applies only
to Subscribers
Copyright © 2010 Caringo, Inc.
All rights reserved 28
Version 2.2
December 2010

Option Name Default Mandatory Description
that do not send
an errOfflineAfter
parameter at runtime.
subscriberTimeout
Interval
90000 no Time in seconds
before the Publisher
terminates a
Subscriber if it has
not been heard
from. Applies only to
Subscribers that do
not send a Timeout
parameter at runtime.
Minimum of 9000.
maxActiveEvents 20 no The number of events
Publisher should
process at one time.
snmpCommunity ourpwdofchoicehere no The password used
to control access to
restricted capabilities
in the Publisher admin
console.
consoleReportStyleURL none no Provides the location
of an override
stylesheet for
overriding style types
in the admin console
style sheet.
consoleStyleURL none no Provides the location
of an override
stylesheet for
overriding style types
in the admin console
style sheet.
errorRetentionDays 4 no The number of days
the Publisher should
retry failed attempts to
read stream metadata
before the event is
dropped.
enumeratorDefault
MaxItems
5000 no Determines the
number of events that
are retrieved by an
enumerator from the
Publisher per request.
The configured
parameter can be
overridden by an
individual enumerator
using the maxItems
Copyright © 2010 Caringo, Inc.
All rights reserved 29
Version 2.2
December 2010

Option Name Default Mandatory Description
query argument on a
Start or Next request.
Replicator throughput
can be increased by
increasing the value of
this parameter.
publicationServerStrict
ArgsChecking
False no Determines whether
Enumerator API query
argument syntax
is strictly enforced
on requests to the
Publisher. By default,
invalid arguments and
values are tolerated
by dropping the
value and sending a
warning message to
the log. This enables
legacy applications to
continue to function.
If set to "True",
publication server
query argument
checking is strictly
enforced, with a 400
(error) returned on
the request if an
invalid argument
or value is given
on a request. This
checking is helpful
when developing
new subscribers as it
provides immediate
feedback on error
conditions.
B.2. Replicator Configuration
Option Name Default Mandatory Description
ipaddress none yes The Replicator's IP
log /var/log/caringo/
loghost localhost no Syslog host name or
Copyright © 2010 Caringo, Inc.
All rights reserved 30
contentrouterreplicator.log
address.
no Local log file name
when not using a
syslog.
IP address. Content
Router services log
to the local 5 syslog
facility. The parameter
should not be set
Version 2.2
December 2010

Option Name Default Mandatory Description
if local file-based
logging will be used
instead of syslog.
loglevel 20 no The level of logging
verbosity with the
following supported
values: 50=critical,
40=error, 30=warning,
20=info, 10=debug,
0=no log
logbackups 8 no The number of older,
rotated log files to
keep when file-based
logging is used.
logsize 10 * 1024 * 1024 bytes no The number of bytes
allowed for all filebased log files. Each
log file is allocated 1/
n of the configured
logsize, where 'n' is
the configured number
of logbackups. A value
of 0 will prevent DX
Content Router from
rotating logs if an
alternate mechanism
like logrotate is
preferred.
group 225.0.10.100 yes The multicast group
address for the DX
Storage cluster to
which UUIDs should
be replicated. Must be
a Class D IP address
in the range 224.0.0.0
to 239.255.255.255.
scsphosts none yes, if cluster is not
specified
A comma-separated
list of DX Storage
node IP addresses
used to validate
version compatibility
at boot time. Either
scsphosts or cluster
must be specified.
cluster none yes, if scsphosts is not
specified
The name of the
target DX Storage
cluster; used to
dynamically locate
a node and verify
version compatibility at
Copyright © 2010 Caringo, Inc.
All rights reserved 31
Version 2.2
December 2010

Option Name Default Mandatory Description
boot. Either scsphosts
or cluster must be
specified.
castorProxyIp none no IP address of a proxy
configured in front of
the target cluster
castorProxyPort none no Port of a proxy
configured in front of
the target cluster
subscribeTo none yes Specifies one or more
Publishers to query
for UUIDs. Syntax
of <channelName>
@<host>:<port>,
<channelName>
@<host>:<port>,etc
(one Name, host,
port group for
each Publisher the
Replicator subscribes
to)
subscriptionCheck
Interval
10 no Time in seconds
between checks for
new UUIDs; values
can be between 5 3600 seconds.
offlineAfter 120 no Time in seconds
before the Publisher
displays Replicator as
offline in the Publisher
console. Minimum of
60 seconds.
errOfflineAfter 1800 no Time in seconds
before the Publisher
logs a critical
error message if a
Subscriber has not
been heard from.
Minimum of 60
seconds.
timeoutInterval 86400 no Time in seconds
before the Publisher
will terminate a
Subscriber if it has
not been heard from.
Minimum of 9000
seconds.
consolePort 8088 no Replicator responds
to requests for its
Copyright © 2010 Caringo, Inc.
All rights reserved 32
Version 2.2
December 2010

Option Name Default Mandatory Description
state on this port.
There is not currently
a separate console for
Replicator.
storageDir /var/opt/caringo/
contentrouter/
replicator
no A unique, writable
directory path for use
in storing in process
stream information.
maxActiveEvents 20 no The number of events
Replicator should
process at one time.
ignoreDeleteEvents 0 no Determines whether
or not a Replicator
should process
delete events. By
default, delete events
are processed
(ignoreDeleteEvents=0)
Copyright © 2010 Caringo, Inc.
All rights reserved 33
Version 2.2
December 2010

Appendix C. Enumerator API
DX Content Router provides a public HTTP 1.1 server interface component as part of the DX
Content Router Publisher service. The purpose of the HTTP interface is to enable a simple
standards based approach for building "plug-in like" DX Storage internal and 3rd party applications
that require some form of object enumeration. The DX Content Router Replicator service utilizes
this interface extensively to provide reliable object replication across Wide Area Networks. Some
other applications might include 3rd party object replication and/or backup applications, object
index/search engines, metadata query engines and virus scan applications. The base URL for any
enumerator is:
http://<publisherHost>:<publicationServerPort>/
C.1. Enumerator Types
Enumerator types are defined based on the type of data that should be returned with the response.
The default type is a Metadata enumerator. The list of supported types is:
• Metadata Enumerator: Metadata enumerators return the UUIDs and all associated metadata
for objects that match the specified filters. In the 2.1 and later releases, Metadata enumeration
includes all creates and updates regardless of subsequent deletes. Every event associated
with a mutable object (POST, COPY, APPEND, PUT, DELETE, etc) is included as a separate
enumeration item. In DX Content Router 2.2, metadata enumerators include metadata for both
named and unnamed DX Storage objects.
• UUID Enumerator: UUID enumerators return the UUIDs for all objects that match the specified
filters.
UUID enumeration includes the UUIDs for create events of immutable objects unless a
subsequent delete event has been registered by the Publisher for the same object. For mutable
objects, the alias UUIDs for creates and updates are included regardless of subsequent deletes in
order to ensure proper processing of all object revisions across different nodes and clusters. This
will result in the same alias UUID being enumerated multiple times if there are update or delete
events.
Only unnamed DX Storage objects are returned by the UUID enumerator in DX Content Router
2.2.
• Event Enumerator: Event enumerators return the UUIDs for objects that match the specified
filters as well as the last event associated with the UUID (create, update or delete). Only unnamed
DX Storage objects are returned by the Event enumerator in DX Content Router 2.2.
Note
Delete events are considered to match all channels and are sent to all subscribers. This
ensures delete events transmitted via a previous rule version are known to be deleted
even if they no longer match the current rules.
For a complete discussion of different DX Storage object types, including named, unnamed and
alias objects, please refer to the DX Storage Application Guide.
C.2. Enumerator Start
The Enumeration Start command instantiates an object enumerator for a given channel in Publisher,
and returns a unique identifier for this enumerator. The format of the request is as follows:
Copyright © 2010 Caringo, Inc.
All rights reserved 34
Version 2.2
December 2010

POST /<channel>?type=<enumerator type>&start=<date-time1>&end=<date-time2>
HTTP/1.1
Host: <publisherhost>
Here channel is the "subscription name" as specified when configuring a DX Content Router
replicator service. It corresponds to one of the sets of filter rules identified by a select tag in the
publisher rules.xml file. The start and end parameters delimit the create dates of objects to be
enumerated for metadata and UUID enumerator types. Event type enumerators do not support
start and end dates. Both dates are ISO 8601 date-time values; RFC 1123 formatted date-time
values are not yet supported. The time-of-day specification may be omitted, in which case the time
00:00:00 is assumed. The start date-time is inclusive, the end date-time non-inclusive.
C.2.1. Enumerator Start Query Arguments
The following query arguments are supported for the Start command. The Publisher saves all
provided query arguments so arguments need not be supplied with every call after the initial one
unless a change is desired.
Argument Name Description
type The case-insensitive value for enumerator type:
Metadata, UUID or Event.
start An ISO 8601 formatted date-time string that
corresponds to the start of the time range
that should be enumerated. All time stamp
comparisons are based on file creation
timestamps.
end An ISO 8601 formatted date-time string that
corresponds to the end of the time range
that should be enumerated. All time stamp
comparisons are based on file creation
timestamps.
C.2.2. Enumerator Start Response
The normal response to an Enumerator Start command is:
HTTP/1.1 201
Date: ...
Server: Content Router Publisher
Content-UUID: 41a140b5271dc8d22ff8d027176a0821
Content-Sync-Token: <token value>
Content-Type: text/plain
Content-Length: <bytes in response body>
Object Enumerator created - channel: '<channel name>', type:
'<enumerator type>'[,start: '<date-time1>'][, end: '<date-time2>']
The Content-UUID header contains a generated UUID identifying the enumerator instance created.
The Content-Sync-Token is used by the Next command to indicate the previous request was
successfully received. The (optional) start/end date-times in the response body are displayed as
unix epoch time seconds. If for any reason the request is not successful, a 404 response code will
be returned with a descriptive message in the response body as to the encountered problem.
Copyright © 2010 Caringo, Inc.
All rights reserved 35
Version 2.2
December 2010

C.3. Enumerator Next
The Enumerator Next command is a request for the next objects in an enumeration which was
previously initiated with an Enumerator Start command. For performance reasons Publisher does
not attempt to retrieve elements in a specific order.
The format of the request is as follows:
GET /<Enumerator UUID>?maxItems=<max-objects-to-retrieve> HTTP/1.1
Host: <publisherhost>
Note the maxItems query argument is only supported for the UUID and Event enumerator types. A
maxItems argument supplied for a Metadata enumerator will be ignored.
C.3.1. Enumerator Next Query Arguments
The following optional query arguments are defined for the Next command only and used to convey
status information about the Enumerator to the Publisher. The Publisher will use some but not all of
this information to update Enumerator status on the Publisher console. See also the Configuration
and Status Query Arguments section below for additional optional arguments that are shared with
the Start method:
Argument Name Description
upTime Number of seconds since the subscriber was
started.
backLog Number of items the subscriber is holding that it
has not begun processing.
inProgress Number of items the subscriber is actively
processing.
dropped Number of items that the subscriber has failed
to process. The dropped query argument
provides the subscriber a way to report possible
trouble conditions to the Publisher. Subscribers
should take care to only "drop" events after
sufficient retries. Note: Dropped events will
not be resent by the Publisher without manual
intervention using the Republish or Republish
All commands from the Publisher Console.
syncToken The value of the Content-Sync-Token header
from the last successfully received Start or Next
response. The Content-Sync-Token is used to
confirm with the Publisher that a request was
successfully received and ensure UUIDs are
not missed due to a network or connectivity
issue. If the syncToken matches the one
expected by the Publisher from the previous
request, the next set of requested UUIDs will
be sent. If the syncToken does not match, the
Publisher will resend the previous set of UUIDs.
If the syncToken is not present on the request,
the Publisher will automatically send the next
set of requested UUIDs.
Copyright © 2010 Caringo, Inc.
All rights reserved 36
Version 2.2
December 2010

C.3.2. Enumerator Next Response
A typical normal response to an Enumerator Next command of type UUID or Event is:
HTTP/1.1 200
Date: ...
Server: Content Router Publisher
Content-Type: text/plain
Content-Length: <bytes in response body>
Content-Sync-Token: <token value>
For a Metadata Enumerator, the response has an additional "Content-UUID" header containing the
object's UUID.
HTTP/1.1 200
Date: ...
Server: Content Router Publisher
Content-UUID: <UUID of object>
Content-Type: text/plain
Content-Length: <bytes in response body>
Content-Sync-Token: <token value>
The content and format of each line of the response body varies by enumerator type as follows:
• UUID enumerators: "<object uuid>"
• Event enumerators: "UUID,<evType>" , where evType equals event types of 1 (deleted), 2
(created), or 4 (created/updated for anchor streams) (3 is not currently utilized)
• Metadata enumerators: "<header name>: <value>" (for each header present on the object)
Metadata enumerators will only contain metadata for a single object, but UUID and Event
enumerators support inclusion of data for multiple objects. If for any reason the request is not
successful, a 404 response code will be returned with a descriptive message in the response body
as to the encountered problem.
C.4. Enumerator End
The Enumerator End command is called to end an enumeration which was previously initiated with
an Enumerator Start command. The format of the request is as follows:
DELETE /<Enumerator UUID> HTTP/1.1
Host: <publisherhost>
C.4.1. End Response
The normal response to an Enumerator End command is:
HTTP/1.1 200
Date: ...
Server: Content Router Publisher
Content-Type: text/plain
Content-Length: ...
Object Enumerator deleted
Copyright © 2010 Caringo, Inc.
All rights reserved 37
Version 2.2
December 2010

If for any reason the request is not successful, a 404 response code will be returned with a
descriptive message in the response body as to the encountered problem.
C.5. Enumerator Timeout
The DX Content Router Publisher will repurpose the existing configuration parameter called
subscriberTimeout. If an enumerator is not accessed using GET for a time period equal to
subscriberTimeout seconds, it will be automatically terminated and removed. The timeout period
applies to enumerators created for any channel of a Publisher service. It is configurable in the
publisher.cfg file, with a default value of 90000 seconds (25 hrs).
An individual Enumerator may override the publisher timeout value. This is done by including a
timeout query arg on the POST request, as follows:
POST /<channel>?start=<date-time1>&end=<date-time2>&type=UUID&timeout=86400 HTTP/1.1
C.6. Configuration and Status Query Arguments
The following can be supplied on either an enumerator Start or Next command:
Argument Name Description
version Enumerator client's software version string.
When provided, this value will be displayed on
the Publisher console in association with the
channel/subscription rule set name.
context The descriptive name for an enumerator
instance of a particular channel. When
provided, this value will be displayed onthe
Publisher console in the expandable section
with enumerator details.
maxItems Maximum number of items to send in this
request response. Sending a value of 0 is a
logical pause that changes the enumerator's
state to "Paused" on the Publisher console.
The enumerator will remain paused until a nonzero maxItems value is received. If neither the
enumerator start or a next request specifies a
value for the maxItems parameter, Publisher
sets the maxItems value to 5000. A negative or
non-integer value is interpreted as a 0.
offlineAfter Number of seconds the Publisher should
wait after the last enumerator query before
declaring the enumerator as offline. When
used, this parameter should be some multiple
of the expected interval between enumerator
queries. When not specified, a default value for
offlineAfter will be derived from the Publisher's
"subscriberOfflineAfter" configuration value.
errOfflineAfter Number of seconds the Publisher should
wait after the last enumerator query before
showing an offline error. When used, this
parameter should be some multiple of the
Copyright © 2010 Caringo, Inc.
All rights reserved 38
Version 2.2
December 2010

Argument Name Description
expected interval between enumerator
queries. When not specified, a default value
for errOfflineAfter will be derived from the
Publisher's "subscriberErrOfflineAfter"
configuration value.
timeout Number of seconds before the Publisher will
terminate an enumerator if it has not been
heard from. The minimum supported value is
600 seconds.
Copyright © 2010 Caringo, Inc.
All rights reserved 39
Version 2.2
December 2010
 Loading...
Loading...