

Page 1

STAT 2
(Advanced Statistics Application)
Statistical Calculation (STAT) Software for the ALGEBRA FX2.0
1. Modifications Made to ALGEBRA 2.0 by STAT2
2. Tests
3. Confidence Interval
4. Distribution
Page 2
2
1.Modifications Made to ALGEBRA 2.0 by STAT2
uu
uu
uChanges to the Function Menu
Installing STAT2 changes the function menu of the STAT Mode list input screen (initial
screen) as shown below.
Pressing a function key that corresponds to the added item displays a menu that lets you
select one of the functions listed below.
• 3(TEST) ... Test (Chapter 2, page 6)
• 4(INTR) ... Confidence interval (Chapter 3, page 31)
• 5(DIST) ... Distribution (Chapter 4, page 42)
The SORT and JUMP functions available with ALGEBRA FX2.0 are moved to the TOOL
menu (6 and 1) by STAT2.
uu
uu
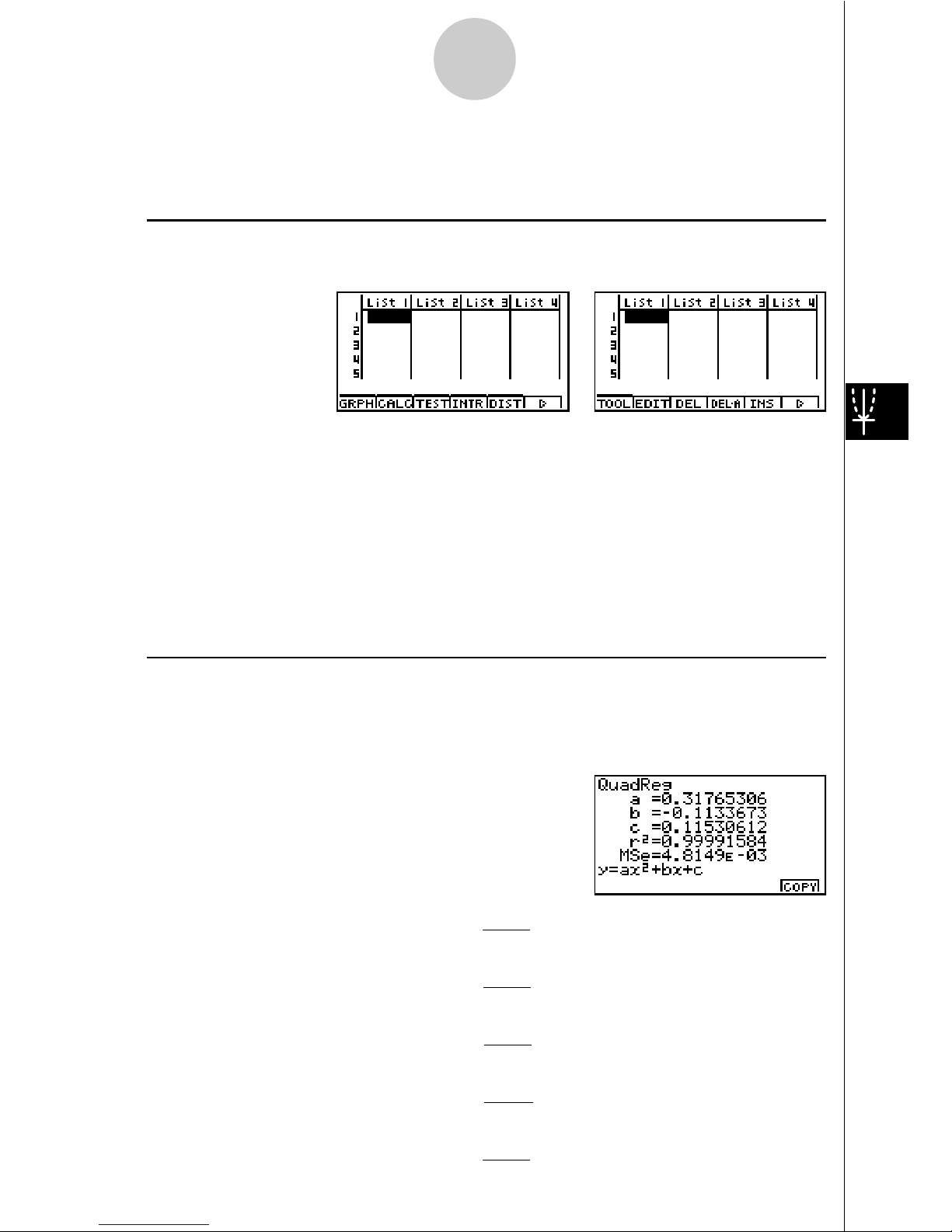
uCalculation of the Coefficient of Determination (r2) and MSE
STAT2 adds calculation of the coefficient of determination (r2) for quadratic regression, cubic
regression, and quartic regression. The following types of MSE calculations are also added
for each type of regression.
• Linear Regression ...
MSE =
!
1
n – 2
i=1
n
(yi – (axi+ b))
2
• Quadratic Regression ...
MSE =
!
1
n – 3
i=1
n
(yi – (ax
i
+ bxi+ c))
2
2
• Cubic Regression ...
MSE =
!
1
n – 4
i=1
n
(yi – (ax
i
3
+ bx
i
+ cx
i
+d ))
2
2
• Quartic Regression ...
MSE =
!
1
n – 5
i=1
n
(yi – (ax
i
4
+ bx
i3
+ cx
i
+ dx
i
+ e))
2
2
• Logarithmic Regression ...
MSE =
!
1
n – 2
i=1
n
(yi – (a + b ln xi ))
2
Page 3
3
• Exponential Repression ...
MSE =
!
1
n – 2
i=1
n
(ln yi – (ln a + bxi ))
2
• Power Regression ...
MSE =
!
1
n – 2
i=1
n
(ln yi – (ln a + b ln xi ))
2
• Sin Regression ...
MSE =
!
1
n – 2
i=1
n
(yi – (a sin (bxi + c) + d ))
2
• Logistic Regression ...
MSE =
!
1
n – 2 1 + ae
-bx
i
C
i=1
n
yi –
2
uu
uu
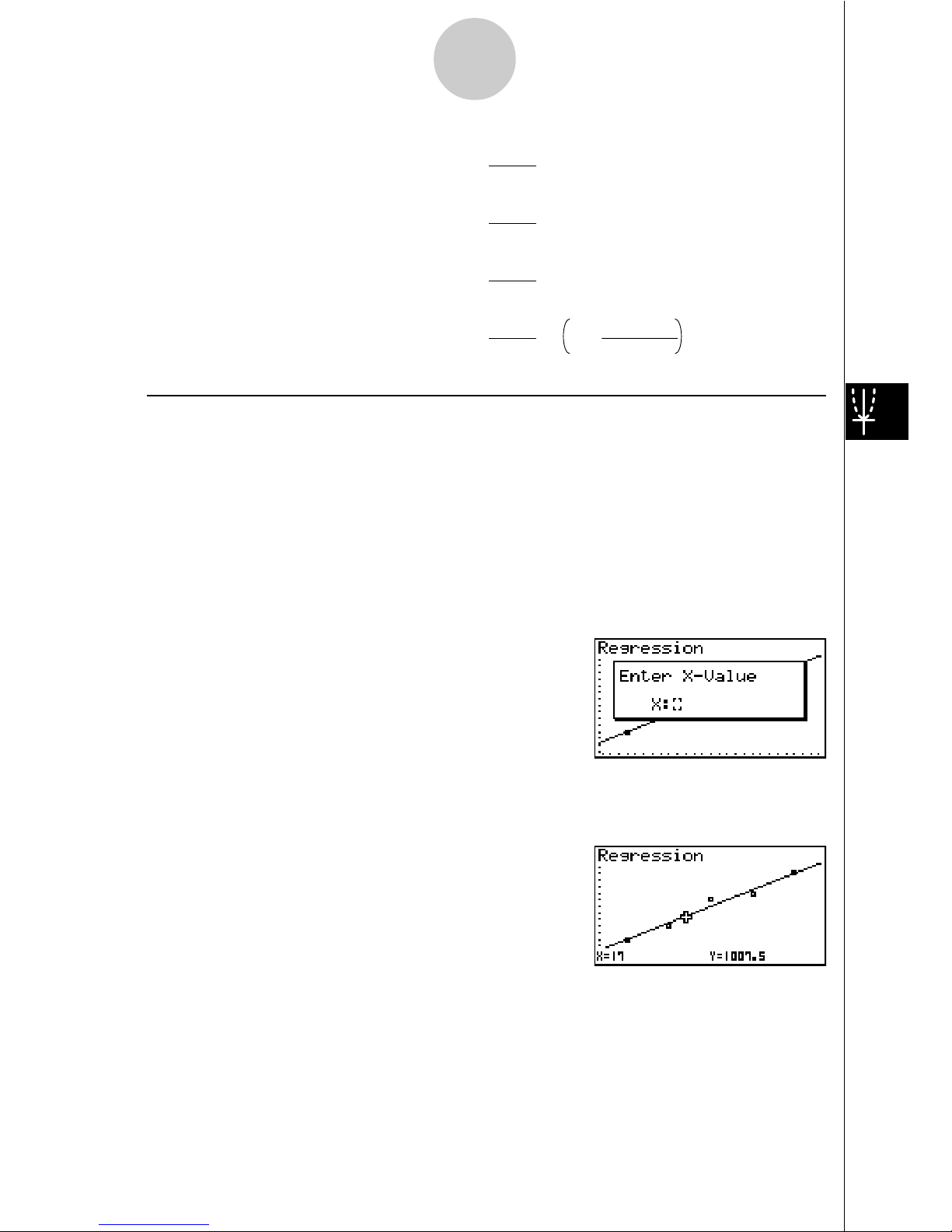
uEstimated Value Calculation for Regression Graphs
STAT2 adds a Y-CAL function that uses regression to calculate the estimated y-value for a
particular x-value after a paired-variable statistic regression graph is drawn.
The following is the general procedure for using the Y-CAL function.
1. After drawing a regression graph, press 62 (Y-CAL) to enter the graph selection mode,
and then press w.
If there are multiple graphs on the display, use f and c to select the graph you want, and
then press w.
• This causes an x-value input dialog box to appear.
2. Input the value you want for x and then press w.
• This causes the coordinates for x and y to appear at the bottom of the display, and moves
the pointer to the corresponding point on the graph.
3. Pressing v or a number key at this time causes the x-value input dialog box to reappear
so you can perform another estimated value calculation if you want.
4. After you are finished, press i to clear the coordinate values and the pointer from the
display.
· The pointer does not appear if the calculated coordinates are not within the display range.
Page 4

4
· The coordinates do not appear if [Off] is specified for the [Coord] item of the [SETUP] screen.
· The Y-CAL function can also be used with a graph drawn by using DefG feature.
uu
uu
uRegression Formula Copy Function from a Regression Calculation Result
Screen
In addition to the existing regression formula copy function that lets you copy the regression
calculation result screen after drawing a statistical graph (such as Scatter Plot), STAT2 also
adds a function that lets you copy the regression formula obtained as the result of a regression
calculation. This type of copy operation is performed by pressing 6(COPY).
kk
kk
k Tests, Confidence Interval, and Distribution Calculations
STAT2 adds functions for performing tests, confidence interval, and distribution calculations.
This manual fully describes each of these calculations in separate chapters: Chapter 2 Tests,
Chapter 3 Confidence Interval, and Chapter 4 Distribution.
uu
uu
uParameter Settings
The following describes the two methods you can use to make parameter settings for test,
confidence interval, and distribution calculations.
• Selection
With this method, you press the function key that corresponds to the setting you want to
select from the function menu.
• Value Input
With this method, you directly input the parameter value you want to input. In this case,
nothing appears in the function menu.
· Pressing i returns to the list input screen, with the cursor in the same position it was at
before you started the parameter setting procedure.
· Pressing ! i (QUIT) returns to the top of list input screen.
· Pressing w without pressing 1 (CALC) under “Execute” item advances to calculation ex-
ecution. To return to the parameter setting screen, press i, A, or w.
uu
uu
uCommon Functions
• The symbol “!” appears in the upper right corner of the screen while execution of a calcula-
tion is being performed and while a graph is being drawn. Pressing A during this time
terminates the ongoing calculation or draw operation (AC Break).
• Pressing i or w while a calculation result or graph is on the display returns to the param-
eter setting screen. Pressing ! i (QUIT) returns to the top of list input screen.
Page 5

5
· Pressing A while a calculation result is on the display returns to the parameter setting screen.
• Pressing u 5 (G"T) after drawing a graph switches to the parameter setting screen
(G"T function). Pressing u 5 (G"T) again returns to the graph screen.
· The G"T function is disabled whenever you change a setting on the parameter setting screen
, or when you perform a u 3 (SET UP) or ! K (V-Window) operation.
• You can perform the PICT menu's screen save or recall functions after drawing a graph.
· The ZOOM Function and SKETCH function are disabled.
The TRACE function is desabled, except for the geaph display of two-way ANOVA.
The graph screen cannot be scrolled.
• After drawing a graph, you can use a Save Result feature to save calculation results to a
specific list. Basically, all items are saved as they are displayed, except for the first line title.
· Each time you execute Save Result, any existing data in the list is replaced by the new
results.
Page 6

6
2.Tests (TEST)
The Z Test provides a variety of different standardization-based tests. They make it possible
to test whether or not a sample accurately represents the population when the standard
deviation of a population (such as the entire population of a country) is known from previous
tests. Z testing is used for market research and public opinion research that need to be
performed repeatedly.
1-Sample Z Test tests for unknown population mean when the population standard
deviation is known.
2-Sample Z Test tests the equality of the means of two populations based on independent
samples when both population standard deviations are known.
1-Prop Z Test tests for an unknown proportion of successes.
2-Prop Z Test tests to compare the propotion of successes from two populations.
The t Test tests the hypothesis when the population standard deviation is unknown. The
hypothesis that is the opposite of the hypothesis being proven is called the
null hypothesis
,
while the hypothesis being proved is called the
alternative hypothesis
. The t-test is normally
applied to test the null hypothesis. Then a determination is made whether the null hypothesis
or alternative hypothesis will be adopted.
1-Sample t Test tests the hypothesis for a single unknown population mean when the
population standard deviation is unknown.
2-Sample t Test compares the population means when standard deviations are unknown.
Linear Reg t Test calculates the strength of the linear association of paired data.
!
2
Test tests hypothesis concerning the proportion of samples included in each of a number
of independent groups. Mainly, it generates cross-tabulation of two categorical variables
(such as yes, no) and evaluates the independence of these variables. It could be used, for
example, to evaluate the relationship between whether or not a driver has ever been
involved in a traffic accident and that person’s knowledge of traffic regulations.
2-Sample F Test tests the hypothesis for the ratio of sample variances. It could be used, for
example, to test the carcinogenic effects of multiple suspected factors such as tobacco use,
alcohol, vitamin deficiency, high coffee intake, inactivity, poor living habits, etc.
ANOVA tests the hypothesis that the population means of the samples are equal when there
are multiple samples. It could be used, for example, to test whether or not different combinations of materials have an effect on the quality and life of a final product.
One-Way ANOVA is used when there is one independent variable and one dependent
variable.
Two-Way ANOVA is used when there here are two independent variables and one dependent variable.
The following pages explain various statistical calculation methods based on the principles
described above. Full details concerning statistical principles and terminology can be found
in any standard general statistics textbook.
Page 7

7
On the initial STAT2 Mode screen, press 3 (TEST) to display the test menu, which
contains the following items.
• 3(TEST)b(Z) ... Z Tests (p.7)
c(T) ... t Tests (p.15)
d(!2) ... !2 Test (p.23)
e(F) ... 2-Sample F Test (p.25)
f(ANOVA) ... ANOVA (p.27)
kk
kk
k Z Tests
uu
uu
uZ Test Common Functions
You can use the following graph analysis functions after drawing a graph.
• 1(Z) ... Displays z score.
Pressing 1 (Z) displays the z score at the bottom of the display, and displays the pointer at
the corresponding location in the graph (unless the location is off the graph screen).
Two points are displayed in the case of a two-tail test. Use d and e to move the pointer.
Press i to clear the z score.
• 2(P) ... Displays p-value.
Pressing 2 (P) displays the p-value at the bottom of the display without displaying the
pointer.
Press i to clear the p-value.
uu
uu
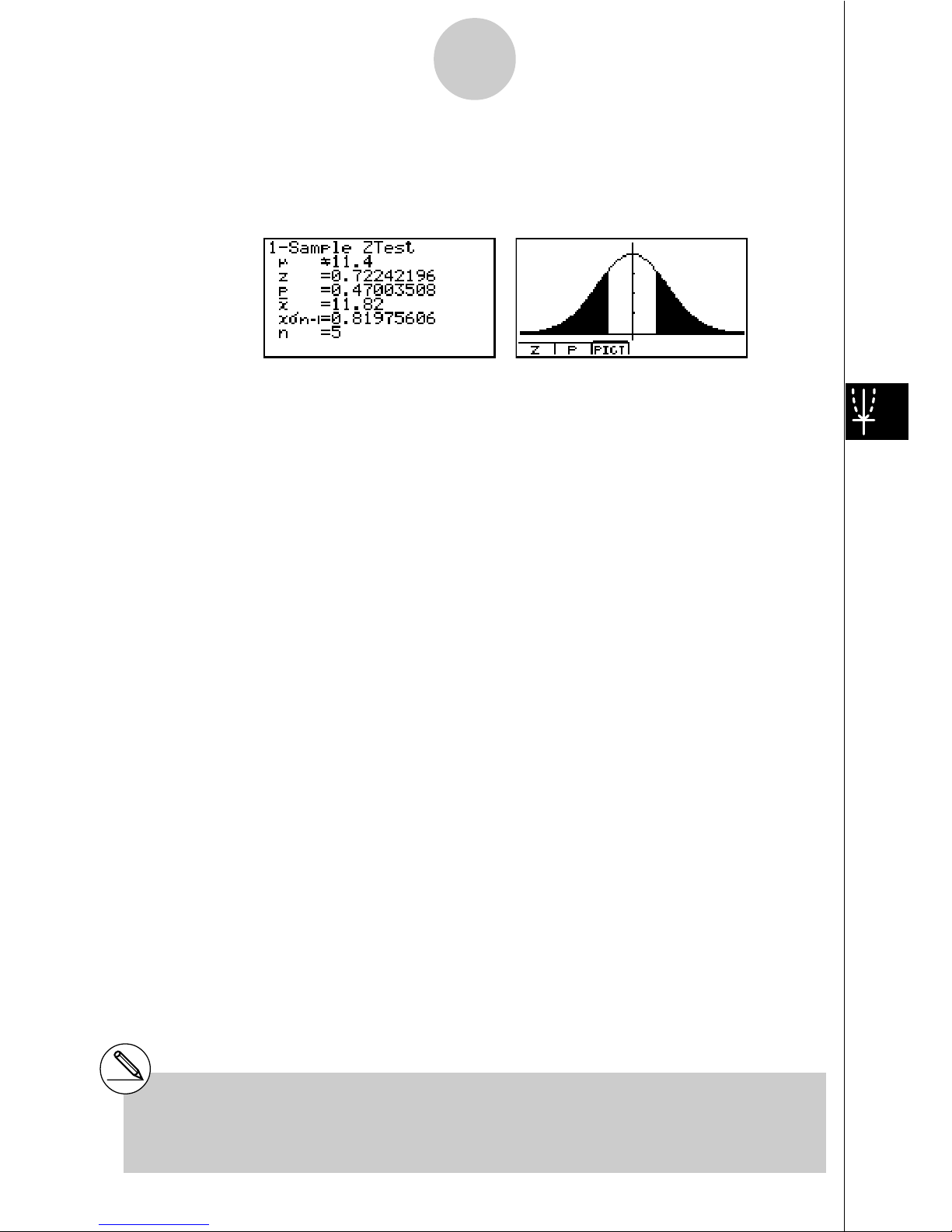
u1-Sample Z Test
This test is used when the sample standard deviation for a population is known to test the
hypothesis. The 1-Sample Z Test is applied to normal distribution.
Z =
o –
0
"
µ
n
o : mean of sample
µ
o : assumed population mean
"
: population standard deviation
n : size of sample
# The following V-Window settings are used for
drawing the graph. Xmin = –3.2, Xmax = 3.2,
Xscale = 1, Ymin = –0.1, Ymax = 0.45, Yscale
=0.1
# Executing an analysis function automatically
stores the z and p values in alpha variables Z
and P, respectively.
Page 8

8
Perform the following key operation from the statistical data list.
3(TEST)
b(Z)
b(1-Smpl)
The following shows the meaning of each item in the case of list data specification.
Data ............................ data type
µ
.................................. population mean value test conditions (“G
µ
0” specifies
two-tail test, “<
µ
0” specifies lower one-tail test, “> µ0”
specifies upper one-tail test.)
µ
0 ................................. assumed population mean
!
.................................. population standard deviation (! > 0)
List .............................. list whose contents you want to use as data (List 1 to 20)
Freq ............................. frequency (1 or List 1 to 20)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
The following shows the meaning of parameter data specification items that are different
from list data specification.
o .................................. mean of sample
n .................................. size of sample (positive integer)
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
Page 9
9
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Calculation Result Output Example
µ
G11.4
........................
direction of test
z .................................. Z score
p .................................. p-value
o .................................. mean of sample
x
"
n-1 ............................. sample standard deviation
(Displayed only for Data: List setting)
n .................................. size of sample
# [Save Res] does not save the µ condition in
line 2.
Page 10

10
uu
uu
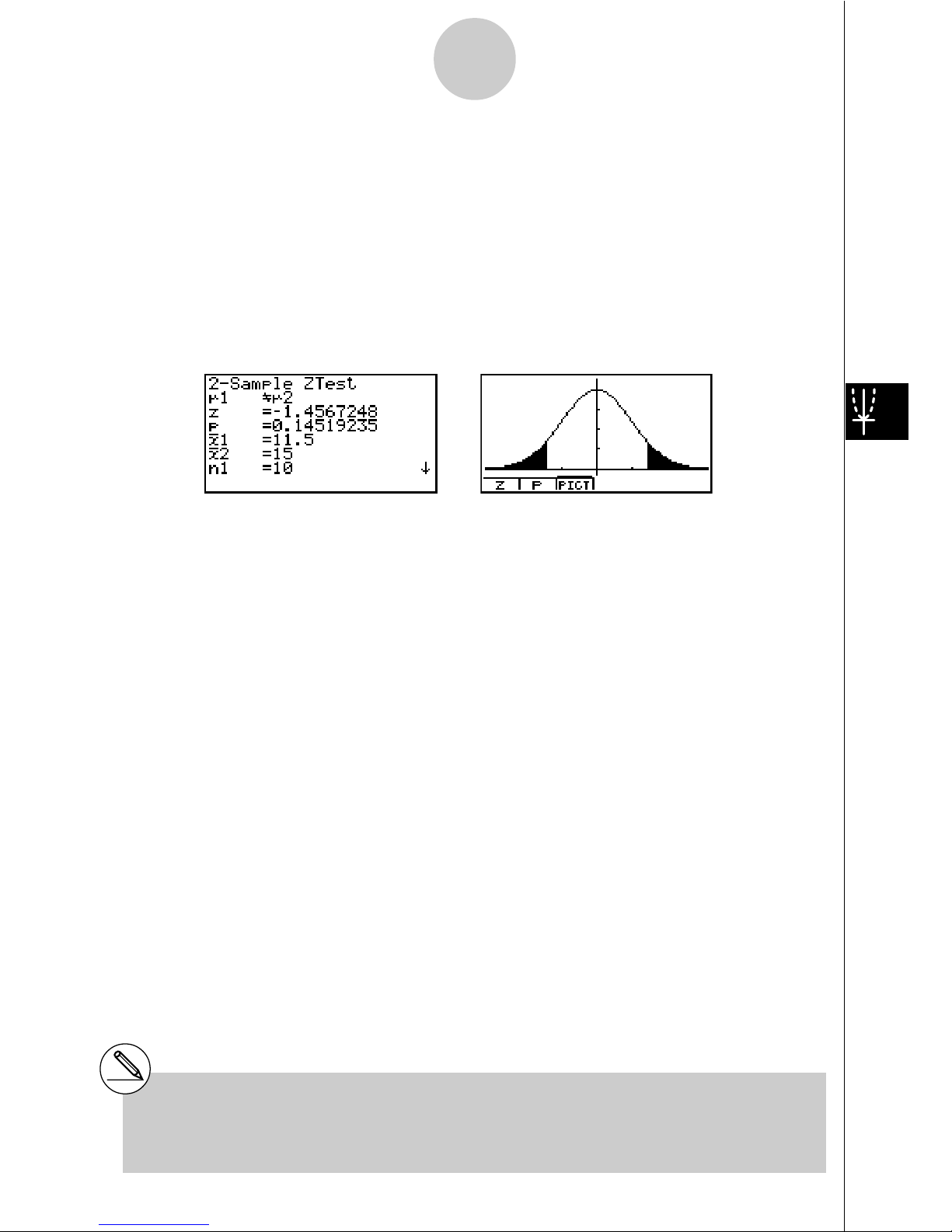
u2-Sample
Z Test
This test is used when the sample standard deviations for two populations are known to test
the hypothesis. The 2-Sample Z Test is applied to normal distribution.
Z =
o1 – o
2
"
n
1
1
2
"
n
2
2
2
+
o1 : mean of sample 1
o2 : mean of sample 2
"
1 : population standard deviation of sample 1
"
2 : population standard deviation of sample 2
n1 : size of sample 1
n2 : size of sample 2
Perform the following key operation from the statistical data list.
3(TEST)
b(Z)
c(2-Smpl)
The following shows the meaning of each item in the case of list data specification.
Data ............................ data type
µ
1 ................................. population mean value test conditions (“G µ2” specifies two-
tail test, “<
µ
2” specifies one-tail test where sample 1 is
smaller than sample 2, “>
µ
2” specifies one-tail test where
sample 1 is greater than sample 2.)
"
1 ................................. population standard deviation of sample 1 ("1 > 0)
"
2 ................................. population standard deviation of sample 2 ("2 > 0)
List(1) .......................... list whose contents you want to use as sample 1 data
List(2) .......................... list whose contents you want to use as sample 2 data
Freq(1) ........................ frequency of sample 1 (positive integer)
Freq(2) ........................ frequency of sample 2 (positive integer)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
The following shows the meaning of parameter data specification items that are different
from list data specification.
Page 11
11
o1 ................................. mean of sample 1
n1 ................................. size (positive integer) of sample 1
o2 ................................. mean of sample 2
n2 ................................. size (positive integer) of sample 2
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Calculation Result Output Example
µ
1
G
µ
2 ........................... direction of test
z ................................... Z score
p .................................. p-value
o1 ................................. mean of sample 1
o2 ................................. mean of sample 2
x1
"
n-1 ............................ standard deviation of sample 1
(Displayed only for Data: List Setting)
x2
"
n-1 ............................ standard deviation of sample 2
(Displayed only for Data: List Setting.)
n1 ................................. size of sample 1
n2 ................................. size of sample 2
# [Save Res] does not save the
µ
1 condition in
line 2.
Page 12

12
uu
uu
u1-Prop
Z Test
This test is used to test for an unknown proportion of successes. The 1-Prop Z Test is
applied to normal distribution.
Z =
n
x
n
p
0
(1– p0)
– p
0
p0 : expected sample proportion
n : size of sample
Perform the following key operation from the statistical data list.
3(TEST)
b(Z)
d(1-Prop)
Prop ............................ sample proportion test conditions (“G p0” specifies two-tail
test, “< p0” specifies lower one-tail test, “> p0” specifies upper
one-tail test.)
p0 ................................. expected sample proportion (0 < p0 < 1)
x .................................. sample value (x > 0 integer)
n .................................. size of sample (positive integer)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Calculation Result Output Example
PropG0.5 .................... direction of test
z ................................... Z score
p .................................. p-value
ˆp .................................. estimated sample proportion
n .................................. size of sample
# [Save Res] does not save the Prop condition
in line 2.
Page 13

13
uu
uu
u2-Prop Z Test
This test is used to compare the proportion of successes. The 2-Prop Z Test is applied to
normal distribution.
Z =
n
1
x
1
n
2
x
2
–
p(1 – p )
n
1
1
n
2
1
+
x1 : data value of sample 1
x2 : data value of sample 2
n1 : size of sample 1
n2 : size of sample 2
ˆp : estimated sample proportion
Perform the following key operation from the statistical data list.
3(TEST)
b(Z)
e(2-Prop)
p1 ................................. sample proportion test conditions (“G p2” specifies two-tail
test, “< p2” specifies one-tail test where sample 1 is less than
sample 2, “> p2” specifies upper one-tail test where sample 1
is greater than sample 2.)
x1 ................................. data value (x1 > 0 integer) of sample 1
n1 ................................. size (positive integer) of sample 2
x2 ................................. data value (x2 > 0 integer) of sample 1
n2 ................................. size (positive integer) of sample 2
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Calculation Result Output Example
Page 14

14
p1>p2 ............................ direction of test
z .................................. Z score
p .................................. p-value
ˆp 1 ................................. estimated proportion of sample 1
ˆp 2 ................................. estimated proportion of sample 2
ˆp .................................. estimated sample proportion
n1 ................................. size of sample 1
n2 ................................. size of sample 2
# [Save Res] does not save the p1 condition in
line 2.
Page 15

15
kk
kk
k t Tests
uu
uu
u t Test Common Functions
You can use the following graph analysis functions after drawing a graph.
• 1(T) ... Displays t score.
Pressing 1 (T) displays the t score at the bottom of the display, and displays the pointer at the
corresponding location in the graph (unless the location is off the graph screen).
Two points are displayed in the case of a two-tail test. Use d and e to move the pointer.
Press i to clear the t score.
• 2(P) ... Displays p-value.
Pressing 2 (P) displays the p-value at the bottom of the display without displaying the pointer.
Press i to clear the p-value.
# The following V-Window settings are used for
drawing the graph. Xmin = –3.2, Xmax = 3.2,
Xscale = 1, Ymin = –0.1, Ymax = 0.45, Yscale
=0.1
# Executing an analysis function automatically
stores the t and p values in alpha variables T
and P, respectively.
Page 16

16
uu
uu
u1-Sample t Test
This test uses the hypothesis test for a single unknown population mean when the population standard deviation is unknown. The 1-Sample t Test is applied to t-distribution.
t =
o –
0
µ
"
x
n–1
n
o : mean of sample
µ
0 : assumed population mean
x
"
n-1 : sample standard deviation
n : size of sample
Perform the following key operation from the statistical data list.
3(TEST)
c(T)
b(1-Smpl)
The following shows the meaning of each item in the case of list data specification.
Data ............................ data type
µ
.................................. population mean value test conditions (“G
µ
0” specifies two-
tail test, “<
µ
0” specifies lower one-tail test, “> µ0” specifies
upper one-tail test.)
µ
0 ................................. assumed population mean
List .............................. list whose contents you want to use as data
Freq ............................. frequency
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
The following shows the meaning of parameter data specification items that are different
from list data specification.
o .................................. mean of sample
x
"
n-1 ............................. sample standard deviation (x"n-1 > 0)
n .................................. size of sample (positive integer)
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Page 17
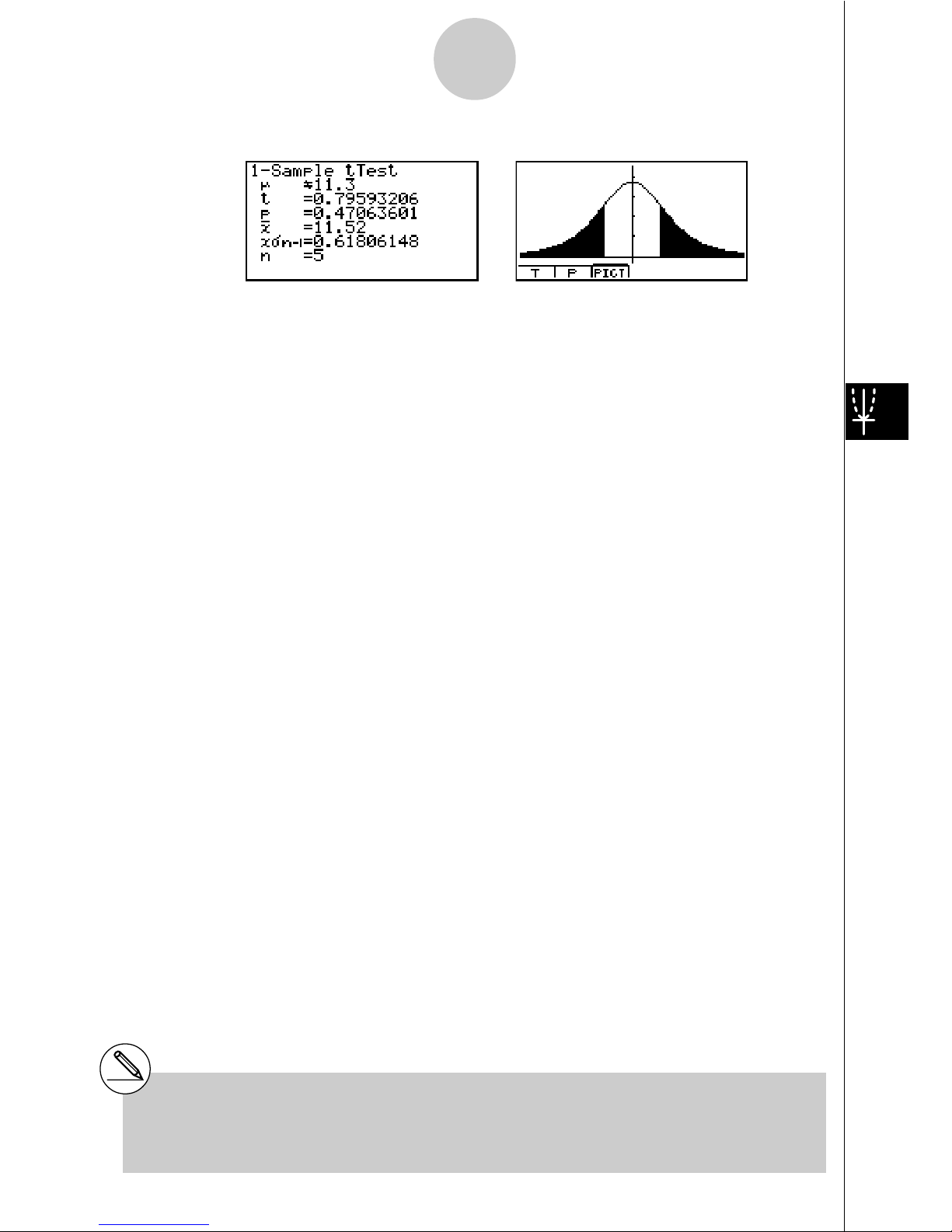
17
Calculation Result Output Example
µ
G 11.3 ...................... direction of test
t
...................................
t score
p .................................. p-value
o .................................. mean of sample
x
"
n-1 ............................. Sample standard deviation
n .................................. size of sample
# [Save Res] does not save the µ condition in
line 2.
Page 18

18
uu
uu
u2-Sample t Test
2-Sample t Test compares the population means when standard deviations are unknown.
The 2-Sample t Test is applied to t-distribution.
t =
o1 – o
2
x
1 n–1
2
"
n
1
+
x
2 n–1
2
"
n
2
o1 : mean of sample 1
o2 : mean of sample 2
x1
"
n-1 : standard deviation of sample 1
x2
"
n-1 : standard deviation of sample 2
n1 : size of sample 1
n2 : size of sample 2
This formula is applicable when the sample is not pooled, and the denominator is different
when the sample is pooled.
Degrees of freedom df and xp
"
n-1 differs according to whether or not pooling is in effect.
The following applies when pooling is in effect.
df
= n1 + n2 – 2
x
p n–1
=
"
n
1
+ n
2
– 2
(n
1
–1)x
1
n–1
2
+(n2–1)x
2
n–1
2
"
"
The following applies when pooling is not in effect.
df =
1
C
2
n1–1
+
(1–C )
2
n2–1
C =
x
1 n–1
2
"
n
1
+
x
2 n–1
2
"
n
2
x
1 n–1
2
"
n
1
Perform the following key operation from the statistical data list.
3(TEST)
c(T)
c(2-Smpl)
Page 19
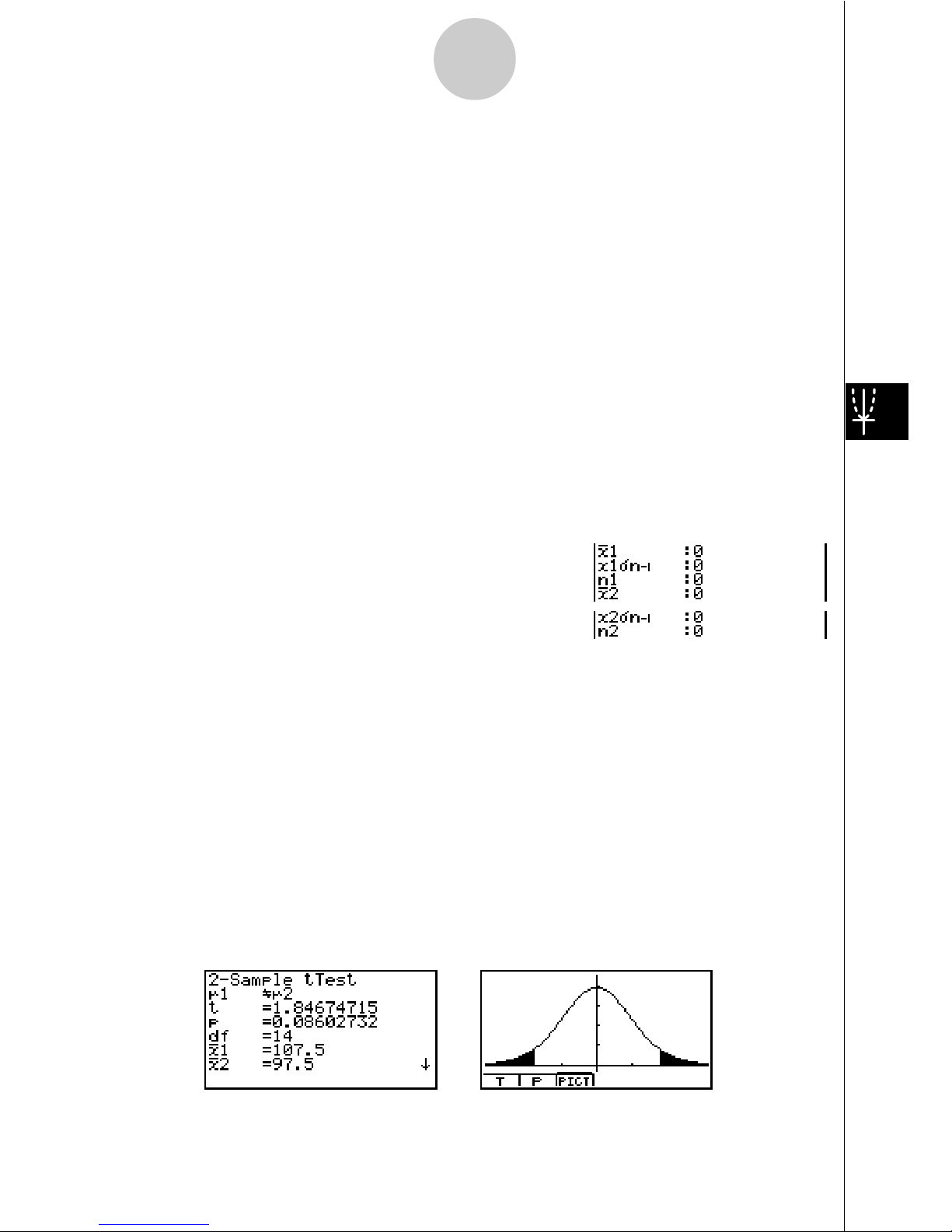
19
The following shows the meaning of each item in the case of list data specification.
Data ............................ data type
µ
1 ................................. sample mean value test conditions (“G µ2” specifies two-tail
test, “<
µ
2” specifies one-tail test where sample 1 is smaller
than sample 2, “>
µ
2” specifies one-tail test where sample 1 is
greater than sample 2.)
List(1) .......................... list whose contents you want to use as data of sample 1
List(2) .......................... list whose contents you want to use as data of sample 2
Freq(1) ........................ frequency of sample 1 (positive integer)
Freq(2) ........................ frequency of sample 2 (positive integer)
Pooled ......................... pooling On (in effect) or Off (not in effect)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
The following shows the meaning of parameter data specification items that are different
from list data specification.
o1 ................................. mean of sample 1
x1
"
n-1 ............................ standard deviation (x1"n-1 > 0) of sample 1
n1 ................................. size (positive integer) of sample 2
o2 ................................. mean of sample 2
x2
"
n-1 ............................ standard deviation (x2"n-1 > 0) of sample 2
n2 ................................. size (positive integer) of sample 2
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Calculation Result Output Example
µ1Gµ
2 ........................... direction of test
t
...................................
t score
Page 20

20
p .................................. p-value
df ................................. degrees of freedom
o1 ................................. mean of sample 1
o2 ................................. mean of sample 2
x1
"
n-1 ............................ standard deviation of sample 1
x2
"
n-1 ............................ standard deviation of sample 2
xp
"
n-1 ............................ pooled sample standard deviation (Displayed only when
Pooled: On Setting.)
n1 ................................. size of sample 1
n2 ................................. size of sample 2
# [Save Res] does not save the
µ1
condition in
line 2.
Page 21

21
uu
uu
uLinearReg
t Test
LinearReg t Test treats paired-variable data sets as (x, y) pairs and plots all data on a
graph. Next, a straight line (y = a + bx) is drawn through the area where the greatest number
of plots are located and the degree to which a relationship exists is calculated.
b =
#
( x – o)( y – p)
i=1
n
#
(x – o)
2
i=1
n
a = p – bo t = r
n – 2
1 – r
2
a : intercept
b : slope of the line
n : size of sample (n>3)
r : correlation coefficient
r
2
: c
oefficient of determination
Perform the following key operation from the statistical data list.
3(TEST)
c(T)
d(LinReg)
The following shows the meaning of each item in the case of list data specification.
$
& %............................ p-value test conditions (“G 0” specifies two-tail test, “< 0”
specifies lower one-tail test, “> 0” specifies upper one-tail
test.)
XList ............................ list for x-axis data
YList ............................ list for y-axis data
Freq ............................. frequency
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
After setting all the parameters, align the cursor with [Execute] and then press the function key
shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
# You cannot draw a graph for LinearReg t
Test.
Page 22

22
Calculation Result Output Example
$
G 0 &
%
G 0 .............. direction of test
t ................................... t score
p .................................. p-value
df ................................. degrees of freedom
a .................................. constant term
b .................................. coefficient
s .................................. standard error
r .................................. correlation coefficient
r
2
................................. coefficient of determination
Pressing 6 (COPY) while a calculation result is on the display copies the regression formula
to the graph formula editor.
When there is a list specified for the [Resid List] item on the SET UP screen, regression formula
residual data is automatically saved to the specified list after the calculation is finished.
# [Save Res] does not save the $ &
%
conditions in line 2.
# When the list specified by [Save Res] is the
same list specified by the [Resid List] item on
the SET UP screen, only[Resid List] data is
saved in the list.
Page 23

23
kk
kk
k !
2
Test
!2 Test sets up a number of independent groups and tests hypothesis related to the
proportion of the sample included in each group. The !2 Test is applied to dichotomous
variables (variable with two possible values, such as yes/no).
expected counts
Fij =
#
n
#
x
ij
i=1
k
&
#
x
ij
j=1
n : all data values
!2 =
##
F
ij
i=1
k
(xij – Fij)
2
j=1
Perform the following key operation from the statistical data list.
3(TEST)
d(!2)
Next, specify the matrix that contains the data. The following shows the meaning of the
above item.
Observed .................... name of matrix (A to Z) that contains observed counts (all cells
positive integers)
Expected ..................... name of matrix (A to Z) that is for saving expected frequency
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
# The matrix must be at least two lines by two
columns. An error occurs if the matrix has
only one line or one column.
# Pressing 2 ('MAT) while setting
parameters enters the MATRIX editor, which
you can use to edit and view the contents of
matrices.
Page 24
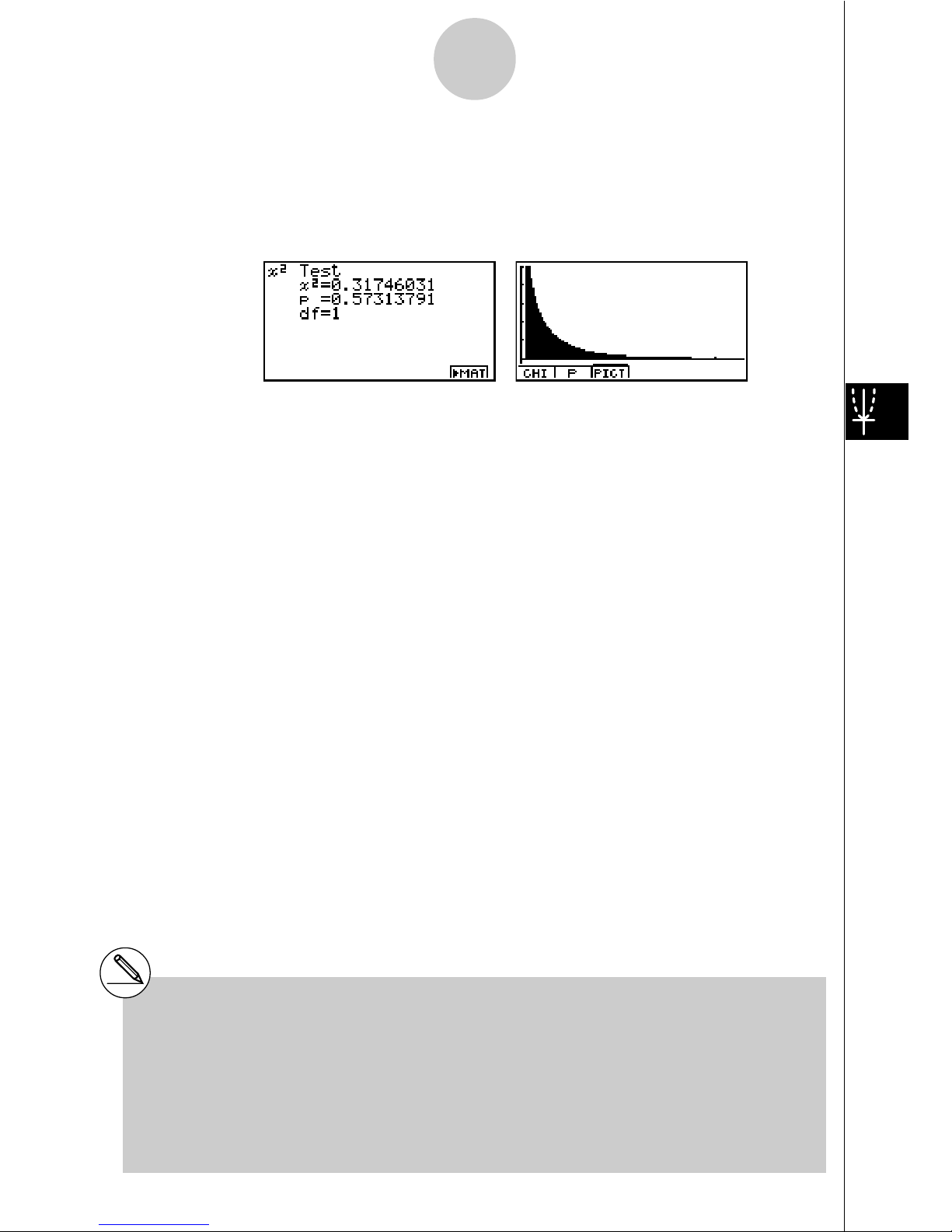
24
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Calculation Result Output Example
!
2
................................. !2 value
p .................................. p-value
df ................................. degrees of freedom
You can use the following graph analysis functions after drawing a graph.
• 1(CHI) ... Displays
!
2
value.
Pressing 1 (CHI) displays the
!
2
value at the bottom of the display, and displays the pointer at
the corresponding location in the graph (unless the location is off the graph screen).
Press i to clear the
!
2
value.
• 2(P) ... Displays p-value.
Pressing 2 (P) displays the p-value at the bottom of the display without displaying the pointer.
Press i to clear the p-value.
# Pressing 6 (('MAT) while a calculation
result is displayed enters the MATRIX editor,
which you can use to edit and view the
contents of matrices.
# The following V-Window settings are used for
drawing the graph.Xmin = 0, Xmax = 11.5,
Xscale = 2, Ymin = –0.1, Ymax = 0.5, Yscale
=0.1
# Executing an analysis function automatically
stores the
!
2
and p values in alpha variables
C and P, respectively.
Page 25

25
kk
kk
k 2-Sample F Test
2-Sample F Test tests the hypothesis for the ratio of sample variances. The F Test is
applied to F distribution.
F =
x
1 n–1
2
"
x
2 n–1
2
"
Perform the following key operation from the statistical data list.
3(TEST)
e(F)
The following is the meaning of each item in the case of list data specification.
Data ............................ data type
"
1 ................................. population standard deviation test conditions (“G "2”
specifies two-tail test, “<
"
2” specifies one-tail test where
sample 1 is smaller than sample 2, “>
"
2” specifies one-tail
test where sample 1 is greater than sample 2.)
List(1) .......................... list whose contents you want to use as data of sample 1
List(2) .......................... list whose contents you want to use as data of sample 2
Freq(1) ........................ frequency of sample 1
Freq(2) ........................ frequency of sample 2
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
The following shows the meaning of parameter data specification items that are different
from list data specification.
x1
"
n-1 ............................ standard deviation (x1
"
n-1
>
0) of sample 1
n1 ................................. size (positive integer) of sample 1
x2
"
n-1 ............................ standard deviation (x2
"
n-1
>
0) of sample 2
n2 ................................. size (positive integer) of sample 2
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Page 26

26
Calculation Result Output Example
"1G"
2 .......................... direction of test
F .................................. F value
p .................................. p-value
o1 ................................. mean of sample 1 (Displayed only for Data: List Setting)
o2 ................................. mean of sample 2 (Displayed only for Data: List Setting)
x1
"
n-1 ............................ standard deviation of sample 1
x2
"
n-1 ............................ standard deviation of sample 2
n1 ................................. size of sample 1
n2 ................................. size of sample 2
You can use the following graph analysis functions after drawing a graph.
• 1(F) ... Displays F value.
Pressing 1 (F) displays the F value at the bottom of the display, and displays the pointer at
the corresponding location in the graph (unless the location is off the graph screen).
Two points are displayed in the case of a two-tail test. Use d and e to move the pointer.
Press i to clear the F value.
• 2(P) ... Displays p-value.
Pressing 2 (P) displays the p-value at the bottom of the display without displaying the pointer.
Press i to clear the p-value.
# [Save Res] does not save the
"
1 condition in
line 2.
# V-Window settings are automatically
optimized for drawing the graph.
# Executing an analysis function automatically
stores the
F and p values in alpha variables
F and P, respectively
Page 27

27
kk
kk
k ANOVA
ANOVA tests the hypothesis that the population means of the samples are equal when there
are multiple samples.
One-Way ANOVA is used when there is one independent variable and one dependent
variable.
Two-Way ANOVA is used when there here are two independent variables and one dependent variable.
This Two-Way ANOVA calculation is available under the condition that is to prepare more
than two experimental data as each dependent data.
Perform the following key operation from the statistical data list.
3(TEST)
f(ANOVA)
The following is the meaning of each item in the case of list data specification.
How Many ................... selects One-Way ANOVA or Two-Way ANOVA (number of lev-
els).
Factor A....................... category list.
Dependnt .................... list to be used for sample data.
Save Res .................... first list for storage of calculation results.
Execute ....................... executes a calculation or draws a graph (Two-Way ANOVA only)
The following item appears in the case of Two-Way ANOVA only.
Factor B ...................... category list.
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph (Two-Way ANOVA only).
Calculation results are displayed in table form, just as they appear in science books.
# [Save Res] saves each vertical column of the
table into its own list. The leftmost column is
saved in the specified list, and each
subsequent column to the right is saved in
the next sequentially numbered list. Up to five
lists can be used for storing columns. You
can specify an first list number in the range of
1 to 16.
Page 28
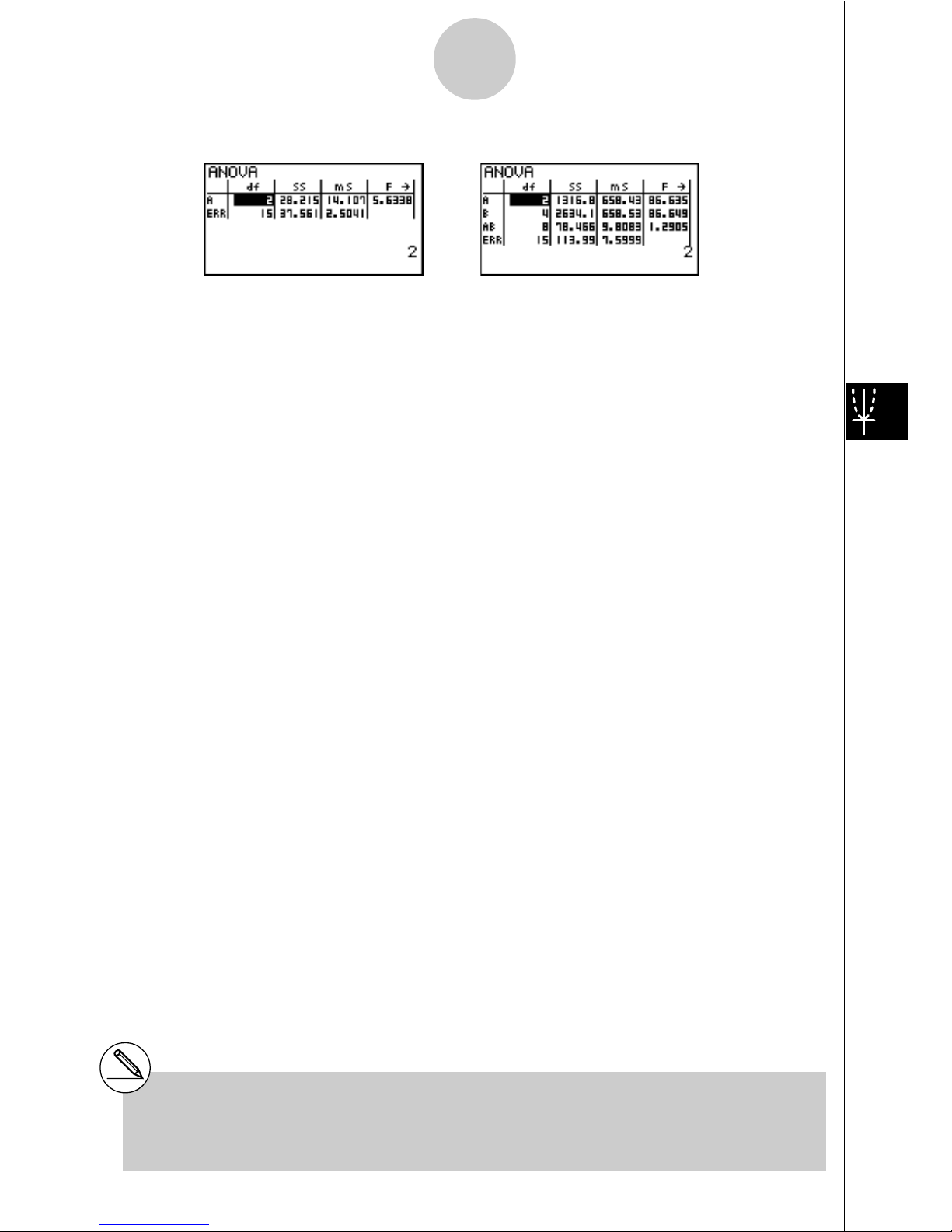
28
Calculation Result Output Example
One-Way ANOVA
Line 1 (A) .................... Factor A df value, SS value, MS value, F value, p-value
Line 2 (ERR) ............... Error df value, SS value, MS value
Two-Way ANOVA
Line 1 (A) .................... Factor A df value, SS value, MS value, F value, p-value
Line 2 (B) .................... Factor B df value, SS value, MS value, F value, p-value
Line 3 (AB) .................. Factor A x Factor B df value, SS value, MS value, F value,
p-value
Line 4 (ERR) ............... Error df value, SS value, MS value
F .................................. F value
p .................................. p-value
df ................................. degrees of freedom
SS ................................ sum of squares
MS ............................... mean squares
With Two-Way ANOVA, you can draw Interaction Plot graphs. The number of graphs depends
on Factor B, while the number of X-axis data depends on the Factor A. The Y-axis is the
average value of each category.
You can use the following graph analysis function after drawing a graph.
• 1(TRACE) ... Trace function
Pressing d or e moves the pointer on the graph in the corresponding direction. When there
are multiple graphs, you can move between graphs by pressing f and c.
Press i to clear the pointer from the display.
# Graphing is available with Two-Way ANOVA
only. V-Window settings are performed
automatically, regardless of SET UP screen
settings.
# Using the TRACE function automatically
stores the number of conditions to alpha
variable A and the mean value to variable M,
respectively.
Page 29

29
kk
kk
k ANOVA (Two-Way)
uu
uu
uDescription
The nearby table shows measurement results for a metal product produced by a heat
treatment process based on two treatment levels: time (A) and temperature (B). The
experiments were repeated twice each under identical conditions.
Perform analysis of variance on the following null hypothesis, using a significance level of
5%.
Ho : No change in strength due to time
Ho : No change in strength due to heat treatment temperature
Ho : No change in strength due to interaction of time and heat treatment temperature
uu
uu
uSolution
Use two-way ANOVA to test the above hypothesis.
Input the above data as shown below.
List1={1,1,1,1,2,2,2,2}
List2={1,1,2,2,1,1,2,2}
List3={113,116,139,132,133,131,126,122 }
Define List 3 (the data for each group) as Dependent. Define List 1 and List 2 (the factor
numbers for each data item in List 3) as Factor A and Factor B respectively.
Executing the test produces the following results.
• Time differential (A) level of significance P = 0.2458019517
The level of significance (p = 0.2458019517) is greater than the significance level (0.05),
so the hypothesis does not reject.
• Temperature differential (B) level of significance P = 0.04222398836
The level of significance (p = 0.04222398836) is less than the significance level (0.05), so
the hypothesis rejects.
• Interaction (A & B) level of significance P = 2.78169946e-3
The level of significance (p = 2.78169946e-3) is less than the significance level (0.05), so
the hypothesis rejects.
The above test indicates that the time differential is not significant, the temperature
differential is significant, and interaction is highly significant.
B (Heat Treatment Temperature) B1 B2
A1 113 , 116
133 , 131
139 , 132
126 , 122
A2
A (Time)
Page 30
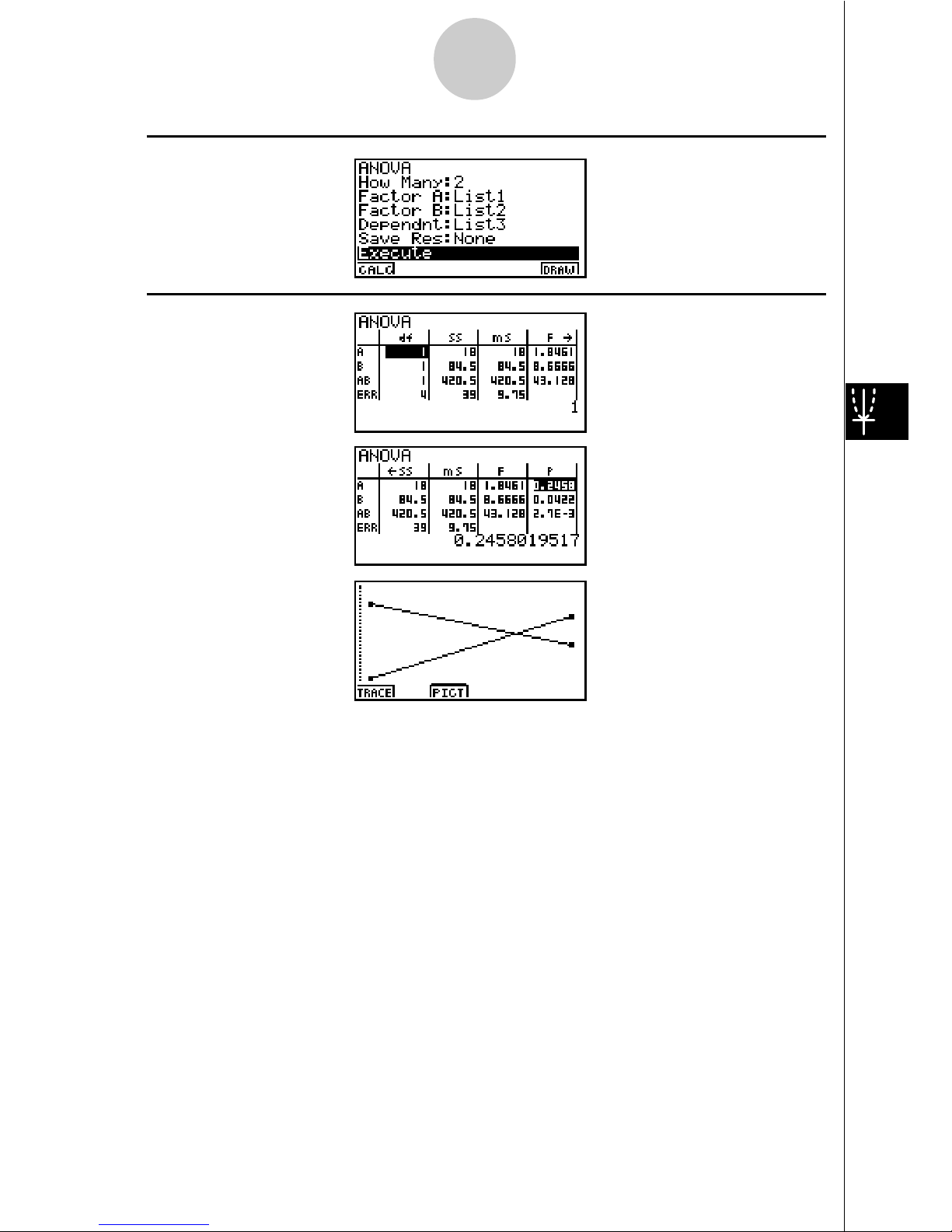
30
uu
uu
uInput Example
uu
uu
uResults
Page 31

31
3. Confidence Interval (INTR)
A confidence interval is a range (interval) that includes the population mean value.
A confidence interval that is too broad makes it difficult to get an idea of where the population
value (true value) is located. A narrow confidence interval, on the other hand, limits the
population value and makes it possible to obtain reliable results. The most commonly used
confidence levels are 95% and 99%. Raising the confidence level broadens the confidence
interval, while lowering the confidence level narrows the confidence level, but it also
increases the chance of accidently overlooking the population value. With a 95% confidence
interval, for example, the population value is not included within the resulting intervals 5% of
the time.
When you plan to conduct a survey and then
t test and Z test the data, you must also
consider the sample size, confidence interval width, and confidence level. The confidence
level changes in accordance with the application.
1-Sample Z Interval calculates the confidence interval for an unknown population mean
when standard deviation is known.
2-Sample Z Interval calculates the confidence interval for the difference between two
population means when the standard deviations of two samples are known.
1-Prop Z Interval uses the number of data to calculate the confidence interval for an
unknown proportion of successes .
2-Prop Z Interval uses the number of data items to calculate the confidence interval for the
difference between the propotion of successes in two populations .
1-Sample t Interval calculates the confidence interval for an unknown population mean
when the population standard deviation is unknown .
2-Sample t Interval calculates the confidence interval for the difference between two
population means when both population standard deviations are unknown.
On the initial STAT Mode screen, press 4 (INTR) to display the confidence interval menu,
which contains the following items.
• 4(INTR)b(Z) ... Z intervals (p.33)
c(T)... t intervals (p.38)
# There is no graphing for confidence interval
functions.
Page 32

32
uu
uu
uGeneral Confidence Interval Precautions
Inputting a value in the range of 0 < C-Level<1 for the C-Level setting sets you value you
input. Inputting a value in the range of 1 < C-Level<100 sets a value equivalent to your input
divided by 100.
# Inputting a value of 100 or greater, or a
negative value causes an error (Ma ERROR).
Page 33

33
kk
kk
k Z Interval
uu
uu
u1-Sample Z Interval
1-Sample Z Interval calculates the confidence interval for an unknown population mean
when standard deviation is known.
The following is the confidence interval.
Left = o – Z
!
2
"
n
Right = o + Z
!
2
"
n
However, ! is not the confidence level itself. The value 100 (1-!) % is the confidence level.
When the confidence level is 95%, for example, inputting 0.95 produces 1 – 0.95 = 0.05 = !.
Perform the following key operation from the statistical data list.
4(INTR)
b(Z)
b(1-Smpl)
The following shows the meaning of each item in the case of list data specification.
Data ............................ data type
C-Level ........................ confidence level (0 < C-Level < 1)
"
.................................. population standard deviation (" > 0)
List .............................. list whose contents you want to use as sample data
Freq ............................. sample frequency
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
The following shows the meaning of parameter data specification items that are different
from list data specification.
o .................................. mean of sample
n .................................. size of sample (positive integer)
Page 34

34
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
Left .............................. interval lower limit (left edge)
Right ............................ interval upper limit (right edge)
o .................................. mean of sample
x
"
n-1 ............................. sample standard deviation
(Displayed only for Data: List Setting)
n .................................. size of sample
uu
uu
u 2-Sample Z Interval
2-Sample Z Interval calculates the confidence interval for the difference between two
population means when the standard deviations of two samples are known.
The following is confidence interval. The value 100 (1-!) % is the confidence level.
Left = (o1 – o2) – Z
!
2
Right = (o
1
– o2) + Z
!
2
n
1
1
2
"
+
n
2
2
2
"
n
1
1
2
"
+
n
2
2
2
"
o1 : mean of sample 1
o2 : mean of sample 2
"
1 : population standard deviation
of sample 1
"
2 : population standard deviation
of sample 2
n1 : size of sample 1
n2 : size of sample 2
Perform the following key operation from the statistical data list.
4(INTR)
b(Z)
c(2-Smpl)
Page 35

35
The following shows the meaning of each item in the case of list data specification.
Data ............................ data type
C-Level ........................ confidence level (0 < C-Level < 1)
"
1 ................................. population standard deviation of sample 1 ("1 > 0)
"
2 ................................. population standard deviation of sample 2 ("2 > 0)
List(1) .......................... list whose contents you want to use as data of sample 1
List(2) .......................... list whose contents you want to use as data of sample 2
Freq(1) ........................ frequency of sample 1
Freq(2) ........................ frequency of sample 2
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
The following shows the meaning of parameter data specification items that are different
from list data specification.
o1 ................................. mean of sample 1
n1 ................................. size (positive integer) of sample 1
o2 ................................. mean of sample 2
n2 ................................. size (positive integer) of sample 2
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
Left .............................. interval lower limit (left edge)
Right ............................ interval upper limit (right edge)
o1 ................................. mean of sample 1
o2 ................................. mean of sample 2
x1
"
n-1 ............................ standard deviation of sample 1
(Displayed only for Data: List Setting)
x2
"
n-1 ............................ standard deviation of sample 2
(Displayed only for Data: List Setting)
n1 ................................. size of sample 1
n2 ................................. size of sample 2
Page 36

36
uu
uu
u1-Prop Z Interval
1-Prop Z Interval uses the number of data to calculate the confidence interval for an
unknown proportion of successes.
The following is the confidence interval. The value 100 (1-!) % is the confidence level.
Left = – Z
!
2
Right = + Z
x
n
n
1
n
x
n
x
1–
x
n
!
2
n1nxn
x
1–
n : size of sample
x : data
Perform the following key operation from the statistical data list.
4(INTR)
b(Z)
d(1-Prop)
Data is specified using parameter specification. The following shows the meaning of each
item.
C-Level ........................ confidence level (0 < C-Level < 1)
x .................................. data (0 or positive integer)
n .................................. size of sample (positive integer)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
Left .............................. interval lower limit (left edge)
Right ............................ interval upper limit (right edge)
ˆp .................................. estimated sample proportion
n .................................. size of sample
Page 37

37
uu
uu
u 2-Prop
Z Interval
2-Prop Z Interval uses the number of data items to calculate the confidence interval for the
defference between the proportion of successes in two populations.
The following is the confidence interval. The value 100 (1-!) % is the confidence level.
Left = – – Z
!
2
x
1
n
1
x
2
n
2
n
1
n
1
x
1
1–
n
1
x
1
+
n
2
n
2
x
2
1–
n
2
x
2
Right = – + Z
!
2
x
1
n
1
x
2
n
2
n
1
n
1
x
1
1–
n
1
x
1
+
n
2
n
2
x
2
1–
n
2
x
2
n1, n2 : size of sample
x1, x2 : data
Perform the following key operation from the statistical data list.
4(INTR)
b(Z)
e(2-Prop)
Data is specified using parameter specification. The following shows the meaning of each
item.
C-Level ........................ confidence level (0 < C-Level < 1)
x1 ................................. data value (x1 > 0) of sample 1
n1 ................................. size (positive integer) of sample 1
x2 ................................. data value (x2 > 0) of sample 2
n2 ................................. size (positive integer) of sample 2
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
Page 38

38
Left .............................. interval lower limit (left edge)
Right ............................ interval upper limit (right edge)
ˆp 1 ................................. estimated sample propotion for sample 1
ˆp 2 ................................. estimated sample propotion for sample 2
n1 ................................. size of sample 1
n2 ................................. size of sample 2
kk
kk
k t Interval
uu
uu
u 1-Sample t Interval
1-Sample t Interval calculates the confidence interval for an unknown population mean
when the population standard deviation is unknown.
The following is the confidence interval. The value 100 (1-!) % is the confidence level.
Left = o– t
n – 1
!
2
Right = o+ t
n – 1
!
2
x
n–1
"
n
x
n–1
"
n
Perform the following key operation from the statistical data list.
4(INTR)
c(T)
b(1-Smpl)
The following shows the meaning of each item in the case of list data specification.
Data ............................ data type
C-Level ........................ confidence level (0 < C-Level < 1)
List .............................. list whose contents you want to use as sample data
Freq ............................. sample frequency
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
The following shows the meaning of parameter data specification items that are different
from list data specification.
Page 39

39
o .................................. mean of sample
x
"
n-1 ............................. sample standard deviation (x"n-1 > 0)
n .................................. size of sample (positive integer)
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
Left .............................. interval lower limit (left edge)
Right ............................ interval upper limit (right edge)
o .................................. mean of sample
x
"
n-1 ............................. sample standard deviation
n .................................. size of sample
uu
uu
u 2-Sample t Interval
2-Sample t Interval calculates the confidence interval for the difference between two
population means when both population standard deviations are unknown. The t Interval is
applied to t distribution.
The following confidence interval applies when pooling is in effect. The value 100 (1-!) % is
the confidence level.
Left = (o1 – o2)– t
!
2
Right = (o1 – o2)+ t
!
2
n1+n
2
–2
n
1
1
+
n
2
1
xp
n–1
2
"
n1+n
2
–2
n
1
1
+
n
2
1
xp
n–1
2
"
Page 40

40
The following confidence interval applies when pooling is not in effect. The value 100 (1-!)
% is the confidence level.
Left = (o1 – o2)– t
df
!
2
Right = (o
1
– o2)+ t
df
!
2
+
n
1
x
1 n–1
2
"
n
2
x
2 n–1
2
"
+
n
1
x
1 n–1
2
"
n
2
x
2 n–1
2
"
C =
df =
1
C
2
n1–1
+
(1–C )
2
n2–1
+
n
1
x
1 n–1
2
"
n
1
x
1 n–1
2
"
n
2
x
2 n–1
2
"
Perform the following key operation from the statistical data list.
4(INTR)
c(T)
c(2-Smpl)
The following shows the meaning of each item in the case of list data specification.
Data ............................ data type
C-Level ........................ confidence level (0 < C-Level < 1)
List(1) .......................... list whose contents you want to use as data of sample 1
List(2) .......................... list whose contents you want to use as data of sample 2
Freq(1) ........................ frequency of sample 1
Freq(2) ........................ frequency of sample 2
Pooled ......................... pooling On (in effect) or Off (not in effect)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
The following shows the meaning of parameter data specification items that are different
from list data specification.
Page 41

41
o1 ................................. mean of sample 1
x1
"
n-1 ............................ standard deviation (x1"n-1 > 0) of sample 1
n1 ................................. size (positive integer) of sample 1
o2 ................................. mean of sample 2
x2
"
n-1 ............................ standard deviation (x2"n-1 > 0) of sample 2
n2 ................................. size (positive integer) of sample 2
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
Left .............................. interval lower limit (left edge)
Right ............................ interval upper limit (right edge)
df ................................. degrees of freedom
o1 ................................. mean of sample 1
o2 ................................. mean of sample 2
x1
"
n-1 ............................ standard deviation of sample 1
x2
"
n-1 ............................ standard deviation of sample 2
xp
"
n-1 ............................ pooled sample standard deviation
(Displayed only when Pooled: On Setting.)
n1 ................................. size of sample 1
n2 ................................. size of sample 2
Page 42

42
4. Distribution (DIST)
There is a variety of different types of distribution, but the most well-known is “normal
distribution,” which is essential for performing statistical calculations. Normal distribution is a
symmetrical distribution centered on the greatest occurrences of mean data (highest
frequency), with the frequency decreasing as you move away from the center. Poisson
distribution, geometric distribution, and various other distribution shapes are also used,
depending on the data type.
Certain trends can be determined once the distribution shape is determined. You can
calculate the probability of data taken from a distribution being less than a specific value.
For example, distribution can be used to calculate the yield rate when manufacturing some
product. Once a value is established as the criteria, you can calculate normal probability
when estimating what percent of the products meet the criteria. Conversely, a success rate
target (80% for example) is set up as the hypothesis, and normal distribution is used to
estimate the proportion of the products will reach this value.
Normal probability density calculates the probability density of normal distribution that data
taken from a specified x value.
Normal distribution probability calculates the probability of normal distribution data falling
between two specific values.
Inverse cumulative normal distribution calculates a value that represents the location
within a normal distribution for a specific cumulative probability.
Student-
t probability density calculates the probability density of t distribution that data
taken from a specified x value.
Student- t distribution probability calculates the probability of t distribution data falling
between two specific values.
Like t distribution, distribution probability can also be calculated for !2, F, Binomial,
Poisson, and Geometric distributions.
On the initial STAT2 Mode screen, press 5 (DIST) to display the distribution menu, which
contains the following items.
• 5(DIST)b(Norm) ... Normal distribution (p.44)
c(T) ... Student-t distribution (p.48)
d(!2) ... !2 distribution (p.50)
e(F) ... F distribution (p.53)
f(Binmal) ... Binomial distribution (p.57)
g(Poissn) ... Poisson distribution (p.60)
h(Geo) ... Geometric distribution (p.62)
Page 43

43
uu
uu
uCommon Distribution Functions
After drawing a graph, you can use the P-CAL function to calculate an estimated p-value for
a particular x value.
The following is the general procedure for using the P-CAL function.
1. After drawing a graph, press 1 (P-CAL) to display the x value input dialog box.
2. Input the value you want for x and then press w.
• This causes the x and p values to appear at the bottom of the display, and moves the pointer
to the corresponding point on the graph.
3. Pressing v or a number key at this time causes the x value input dialog box to reappear so
you can perform another estimated value calculation if you want.
4. After you are finished, press i to clear the coordinate values and the pointer from the
display.
# Executing an analysis function automatically
stores the x and p values in alpha variables
X
and P, respectively.
Page 44

44
kk
kk
k Normal Distribution
uu
uu
uNormal Probability Density
Normal probability density calculates the probability density of nomal distribution that data
taken from a specified x value. Normal probability density is applied to standard normal
distribution.
"#
2
f(x) =
1
e
–
2
2
#
(x – µ)
2
µ
(# > 0)
Perform the following key operation from the statistical data list.
5(DIST)
b(Norm)
b(P.D)
Data is specified using parameter specification. The following shows the meaning of each
item.
x .................................. data
#
.................................. population standard deviation (
#
> 0)
µ
.................................. population mean
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
• Specifying # = 1 and µ = 0 specifies standard normal distribution.
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Calculation Result Output Example
• p ... normal probability density
# V-Window settings for graph drawing are set
automatically when the SET UP screen's
[Stat Wind] setting is [Auto]. Current V-
Window settings are used for graph drawing
when the [Stat Wind] setting is [Manual].
Page 45

45
uu
uu
uNormal Distribution Probability
Normal distribution probability calculates the probability of normal distribution data falling
between two specific values.
"#
2
p =
1
e
–
dx
2
2
#
(x – µ)
2
µ
a
b
$
a : lower boundary
b : upper boundary
Perform the following key operation from the statistical data list.
5 (DIST)
b (Norm)
c (C.D)
Data is specified using parameter specification. The following shows the meaning of each
item.
Lower .......................... lower boundary
Upper .......................... upper boundary
#
.................................. population standard deviation (# > 0)
µ
.................................. population mean
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
# There is no graphing for normal distribution
probability.
Page 46

46
Calculation Result Output Example
p .................................. normal distribution probability
z:Low ........................... z:Low value (converted to standardize z score for lower
value)
z:Up ............................. z:Up value (converted to standardize z score for upper
value)
uu
uu
uInverse Cumulative Normal Distribution
Inverse cumulative normal distribution calculates a value that represents the location within a
normal distribution for a specific cumulative probability.
f (x)dx = p
%&
$
f (x)dx = p
+&
$
f (x)dx = p
$
Specify the probability and use this formula to obtain the integration interval.
Perform the following key operation from the statistical data list.
5(DIST)
b(Norm)
d(Invrse)
Data is specified using parameter specification. The following shows the meaning of each
item.
Tail ............................... probability value tail specification (Left, Right, Central)
Area ............................ probability value (0 < Area < 1)
#
.................................. population standard deviation (
#
> 0)
µ
.................................. population mean
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
Tail : Left
upper
boundary of
integration
interval
' = ?
Tail : Right
lower
boundary of
integration
interval
' = ?
Tail : Central
upper and
lower
boundaries
of integration
interval
' = ? ( = ?
Page 47

47
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Examples
x ....................................... inverse cumulative normal distribution
(Tail:Left upper boundary of integration interval)
(Tail:Right lower boundary of integration interval)
(Tail:Central upper and lower boundaries of integration
interval)
# There is no graphing for inverse cumulative
normal distribution.
Page 48

48
kk
kk
k Student-t Distribution
uu
uu
uStudent-t Probability Density
Student-t probability density calculates the probability density of t distribution that data taken
from a specified x value.
f
(x) =
)
)
df
"
–
df+1
2
2
df
2
df + 1
df
x
2
1+
Perform the following key operation from the statistical data list.
5(DIST)
c(T)
b(P.D)
Data is specified using parameter specification. The following shows the meaning of each
item.
x .................................. data
df ................................. degrees of freedom (df >0)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Calculation Result Output Example
p ... Student-t probability density
# Current V-Window settings are used for
graph drawing when the SET UP screen's
[Stat Wind] setting is [Manual]. The VWindow settings below are set automatically
when the [Stat Wind] setting is [Auto].
Xmin = –3.2, Xmax = 3.2, Xscale = 1,
Ymin = –0.1, Ymax = 0.45, Yscale =0.1
Page 49

49
uu
uu
uStudent-t Distribution Probability
Student-t distribution probability calculates the probability of t distribution data falling
between two specific values.
p =
)
)
df
"
2
df
2
df + 1
–
df+1
2
df
x
2
1+
dx
a
b
$
a : lower boundary
b : upper boundary
Perform the following key operation from the statistical data list.
5(DIST)
c(T)
c(C.D)
Data is specified using parameter specification. The following shows the meaning of each
item.
Lower .......................... lower boundary
Upper .......................... upper boundary
df ................................. degrees of freedom (df > 0)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
# There is no graphing for Student-t distribution
probability.
Page 50

50
Calculation Result Output Example
p ... Student-t distribution probability
t:Low ... t:Low value (input lower value)
t:Up ... t:Up value (input upper value)
kk
kk
k !2 Distribution
uu
uu
u!2 Probability Density
!2 probability density calculates the probabilitty density function for the !2 distribution at a
specified x value.
f
(x) =
)
1
2
df
df
2
x e
2
1
df
2
–1
x
2
–
Perform the following key operation from the statistical data list.
5(DIST)
d(!2)
b(P.D)
Data is specified using parameter specification. The following shows the meaning of each
item.
x .................................. data
df ................................. degrees of freedom (positive integer)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Page 51

51
Calculation Result Output Example
p ... !2 probability density
# Current V-Window settings are used for
graph drawing when the SET UP screen's
[Stat Wind] setting is [Manual]. The VWindow settings below are set automatically
when the [Stat Wind] setting is [Auto].
Xmin = 0, Xmax = 11.5, Xscale = 2, Ymin = -0.1,
Ymax = 0.5, Yscale =0.1
Page 52

52
uu
uu
u!
2
Distribution Probability
!2 distribution probability calculates the probability of !2 distribution data falling between two
specific values.
p =
)
1
2
df
df
2
x e dx
2
1
df
2
–1
x
2
–
a
b
$
a : lower boundary
b : upper boundary
Perform the following key operation from the statistical data list.
5(DIST)
d(!2)
c(C.D)
Data is specified using parameter specification. The following shows the meaning of each
item.
Lower .......................... lower boundary
Upper .......................... upper boundary
df ................................. degrees of freedom (positive integer)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
# There is no graphing for !2 distribution
probability.
Page 53

53
Calculation Result Output Example
p ... !2 distribution probability
kk
kk
k F Distribution
uu
uu
u F Probability Density
F
probability density calculates the probability density function for the F distribution at a
specified x value.
)
n
2
x
d
n
n
2
–1
2
n
)
2
n + d
)
2
d
d
nx
1 +
n + d
2
f
(x) =
–
Perform the following key operation from the statistical data list.
5(DIST)
e(F)
b(P.D)
Data is specified using parameter specification. The following shows the meaning of each
item.
x .................................. data
n:df .............................. numerator degrees of freedom (positive integer)
d:df .............................. denominator degrees of freedom (positive integer)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation or draws a graph
After setting all the parameters, align the cursor with [Execute] and then press one of the
function keys shown below to perform the calculation or draw the graph.
• 1(CALC) ... Performs the calculation.
• 6(DRAW) ... Draws the graph.
Page 54

54
Calculation Result Output Example
p ... F probability density
# V-Window settings for graph drawing are set
automatically when the SET UP screen's
[Stat Wind] setting is [Auto]. Current V-
Window settings are used for graph drawing
when the [Stat Wind] setting is [Manual].
Page 55

55
uu
uu
u F Distribution Probability
F distribution probability calculates the probability of F distribution data falling between two
specific values.
p =
)
n
2
dx
x
d
n
n
2
–1
2
n
)
2
n + d
)
2
d
d
nx
1 +
n + d
2
–
a
b
$
a : lower boundary
b : upper boundary
Perform the following key operation from the statistical data list.
5 (DIST)
e (F)
c (C.D)
Data is specified using parameter specification. The following shows the meaning of each
item.
Lower .......................... lower boundary
Upper .......................... upper boundary
n:df .............................. numerator degrees of freedom (positive integer)
d:df .............................. denominator degrees of freedom (positive integer)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
# There is no graphing for F distribution
probability.
Page 56

56
Calculation Result Output Example
p ... F distribution probability
Page 57

57
kk
kk
k Binomial Distribution
uu
uu
u Binomial Probability
Binomial probability calculates a probability at specified value for the discrete binomial
distribution with the specified numtrials and probability of success on each trial.
f
(x) = nCxpx(1–p)
n – x
(x = 0, 1, ·······, n) p : success probability
(0 < p < 1)
n : number of trials
Perform the following key operation from the statistical data list.
5(DIST)
f(Binmal)
b(P.D)
The following shows the meaning of each item when data is specified using list specification.
Data ............................ data type
List .............................. list whose contents you want to use as specified data
Numtrial ....................... number of trials
p .................................. success probability (0 < p < 1)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
The following shows the meaning of parameter data specification items that are different
from list data specification.
x .................................. integer from 0 to n
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
# There is no graphing for binomial distribution.
Page 58

58
Calculation Result Output Example
p ... Binomial probability
uu
uu
uBinomial Cumulative Density
Binomial cumulative density calculates a cumulative probability at specified value for the
discrete binomial distribution with the specified numtrials and probability of success on each
trial.
Perform the following key operation from the statistical data list.
5 (DIST)
f (Binmal)
c (C.D)
The following shows the meaning of each item when data is specified using list specification.
Data ............................ data type
List .............................. list whose contents you want to use as specified data
Numtrial ....................... number of trials
p .................................. success probability (0 < p < 1)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
The following shows the meaning of parameter data specification item that is different from
list data specification.
x .................................. integer from 0 to n
Page 59

59
After setting all the parameters, align the cursor with [Execute] and then press the
function key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
p ... Binomial cumulative density
Page 60

60
kk
kk
k Poisson Distribution
uu
uu
uPoisson Probability
Poisson probability calculates a probability at specified value for the discrete Poisson distribution with the specified mean.
f(x) =
x!
e
–
x
µ
µ
(x = 0, 1, 2, ···)
µ
: population mean (
µ
> 0)
Perform the following key operation from the statistical data list.
5 (DIST)
g (Poissn)
b (P.D)
The following shows the meaning of each item when data is specified using list specification.
Data ............................ data type
List .............................. list whose contents you want to use as specified data
µ
.................................. population mean (µ > 0)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
The following shows the meaning of parameter data specification item that is different from
list data specification.
x .................................. ( x
> 0)
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
p ... Poisson probability
# There is no graphing for Poisson distribution.
Page 61

61
uu
uu
u Poisson Cumulative Density
Poisson cumulative density calculates a cumulative probability at specified value for the
discrete Poisson distribution with the specified mean.
Perform the following key operation from the statistical data list.
5 (DIST)
g (Poissn)
c (C.D)
The following shows the meaning of each item when data is specified using list specification.
Data ............................ data type
List .............................. list whose contents you want to use as specified data
µ
.................................. population mean (µ > 0)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a caluculation
The following shows the meaning of parameter data specification item that is different from
list data specification.
x .................................. ( x
> 0)
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
p ... Poisson cumulative density
Page 62

62
kk
kk
k Geometric Distribution
uu
uu
uGeometric Probability
Geometric probability calculates a probability at specified value, the number of the trial on
which the first success occurs, for the discrete geometric distribution with the specified
probability of success.
f
(x) = p(1– p)
x – 1
(x = 1, 2, 3, ···)
Perform the following key operation from the statistical data list.
5(DIST)
h(Geo)
b(P.D)
The following shows the meaning of each item when data is specified using list specification.
Data ............................ data type
List .............................. list whose contents you want to use as specified data
p .................................. success probability (0 < p < 1)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
The following shows the meaning of parameter data specification item that is different from
list data specification.
x .................................. positive integer (x > 1)
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
p ... Geometric probability
# There is no graphing for geometric distribu-
tion.
# Positive integer number is calculated whether
list data (Data:List) or
x value (Data:variable)
is specified.
Page 63

63
uu
uu
uGeometric Cumulative Density
Geometric cumulative density calculates a cumulative probability at specified value, the
number of the trial on which the first success occurs, for the discrete geometric distribution
with the specified probability of success.
Perform the following key operation from the statistical data list.
5(DIST)
h(Geo)
c(C.D)
The following shows the meaning of each item when data is specified using list specification.
Data ............................ data type
List .............................. list whose contents you want to use as specified data
p .................................. success probability (0 < p < 1)
Save Res .................... list for storage of calculation results (None or List 1 to 20)
Execute ....................... executes a calculation
The following shows the meaning of parameter data specification item that is different from
list data specification.
x .................................. positive integer (x > 1)
After setting all the parameters, align the cursor with [Execute] and then press the function
key shown below to perform the calculation.
• 1(CALC) ... Performs the calculation.
Calculation Result Output Example
p ... Geometric cumulative density
# Positive integer number is calculated whether
list data (Data:List) or
x value (Data:variable)
is specified.
Page 64

Examples
Page 65

2
examples
kk
kk
k 1-Sample
Z Test
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as the Data parameter), be sure to input data into
the list first.
3. 3(TEST)b(Z)b(1-Smpl) ... 1-Sample Z Test
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph.
Page 66

3
examples
Example Five new members of a football team are timed for the 100-
meter dash, yielding the following times.
A: 12.5 B: 11.6 C: 10.8 D: 12.8 E: 11.4
The average time of current team members is 11.4 seconds,
with a standard deviation of 1.30. Test the null hypothesis that
the times of the five new members are at the same level as
current team members at the 0.05 level of significance.
Procedure
1 m STAT2
2 bc.fwbb.gwba.iw
bc.iwbb.ew
3 3(TEST) b(Z)b(1-Smpl)
4 1(LIST) c
1(!) c
bb.ew
b.dw
1(LIST) bwc
1(1)c
1(None)c
5 1(CALC)
6(DRAW)
Result Screen
Since P = 0.47003508 > 0.05 (level of significance), we can't reject the null hypothesis and
can conclude the times of the five new numbers is at the same level as current team
members.
Page 67

4
examples
kk
kk
k 2-Sample
Z Test
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as the Data parameter) , be sure to input data into
the list first.
3. 3(TEST)b(Z)c(2-Smpl) ... 2-Sample Z Test
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph.
Page 68

5
examples
Example A consumer group is testing camp stoves. To test the heating capacity
of a stove they measure the time required to bring 2 qt of water from
50
qq
qq
q
F to boiling (at sea level). Two competing models are under
consideration. 36 stoves of each model were tested and the following
results were obtained.
Model 1: mean time
oo
oo
o1 = 11.5min; standard deviation "1= 2.4min
Model 2: mean time
oo
oo
o2 = 10 min; standard deviation "2= 3 min
Is there any difference between the performances of these two
models? (Use a 5% level of significance.)
Procedure
1 m STAT2
2 3(TEST) b(Z)c(2-Smpl)
3 2(VAR) c
1(!) c
c.ew
dw
bb.fw
dgw
baw
dgw
1(None) c
4 1(CALC)
6(DRAW)
Result Screen
Since P = 0.01914957 < 0.05 (level of significance), we reject the null hypothesis µ1-µ2 =0
and conclude the performances of the two models are different.
Page 69

6
examples
kk
kk
k 1-Prop
Z Test
Set Up
1. On the icon menu, select STAT2.
Execution
2. 3(TEST)b(Z)d(1-Prop) ... 1-Prop Z Test
3. Set calculation parameters.
4. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph.
Page 70

7
examples
Example A team of eye surgeons has developed a new technique for a risky eye
operation to restore the sight of people blinded from a certain disease.
Under the old method it is known that only 30% of the patients who
undergo this operation recover their eyesight. Suppose that surgeons
in various hospitals have performed a total of 250 operations using
the new method and that 93 have been successful (the patients fully
recovered their sight). Can we justify the claim that the new method is
better than the old one?(Use a 1% level of significance.)
Procedure
1 m STAT2
2 3(TEST) b(Z)d(1-Prop)
3 3(>) c
.dw
jdw
cfaw
1(None) c
4 1(CALC)
6(DRAW)
Result Screen
Since P = 6.4915e-3 < 0.01 (level of significance), we can reject the null hypothesis that the
successful probability of new operation is 0.3 and conclude that it can be said the new
method obtains good results more than existing method. That is to say it is more effective by
new methods.
Page 71

kk
kk
k 2-Prop
Z Test
Set Up
1. On the icon menu, select STAT2.
Execution
2. 3(TEST)b(Z)e(2-Prop) ... 2-Prop Z Test
3. Set calculation parameters.
4. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph.
8
examples
Page 72

9
examples
Example The County Clerk wishes to improve voter registration. One method
under consideration is to send reminders in the mail to all citizens in
the county who are eligible to register. As a pilot study to determine if
this method will actually improve voter registration, a random sample
of 1224 potential voters was taken. Then this sample was randomly
divided into two groups.
Group A : There were 612 people in this group. No reminders to
register were sent to them. The number of potential
voters from this group who registered was 280.
Group B : This group also contained 612 people. Reminders were
sent in the mail to each member in the group, and the
number who registered to vote was 335.
The County Clerk claims that the proportion of people to register was
significantly greater in group B. On the basis of this claim the clerk
recommends that the project be funded for the entire population of
Macek County. Use 5% level of significance to test the claim that the
proportion of potential voters who registered was greater in group B,
the group that received reminders.
Procedure
1 m STAT2
2 3(TEST) b(Z)e(2-Prop)
3 2(<) c
ciaw
gbcw
ddfw
gbcw
1(None) c
4 1(CALC)
6(DRAW)
Result Screen
Since P = 8.3277e-4 < 0.05 (level of significance), we can reject the null hypothesis (P1>P2)
and conclude that the County Clerk‘s claim is valid at the 0.05 level of significance.
Page 73

kk
kk
k 1-Sample
t Test
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as the Data parameter), be sure to input data into
the list first.
3. 3(TEST)c(T)b(1-Smpl) ... 1-Sample t Test
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph.
10
examples
Page 74

Example A company manufactures large rocket engines used to project
satellites into space. The government buys the rockets, and the
contract specifies that these engines are to use an average of 5550 lb
of rocket fuel the first 15 sec operation. The company claims their
engines fit specifications. To test the claim an inspector randomly
selects six such engines from the warehouse. These 6 engines are
fired 15 sec each and the fuel consumption for each engine is measured. For all six engines, the mean fuel consumption is
oo
oo
o = 5750
pounds and the standard deviation is x
"
n-1 = 250 lb. Is the claim
justified at the 5% level of significance?
Procedure
1 m STAT2
2 3(TEST) c(T)b(1-Smpl)
3 2(VAR) c
1(!) c
fffaw
fhfaw
cfaw
gw
1(None) c
4 1(CALC)
6(DRAW)
Result Screen
11
examples
Since P = 0.107344401 > 0.05 (level of significance), we can’t reject the null hypothesis
µ=5550 and conclude that the data does not present sufficient evidence to indicate that the
average fuel consumption from the first 15 seconds of operation is different from µ =5550.
Page 75

kk
kk
k 2-Sample
t Test (Pooled On)
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as the Data parameter), be sure to input data into
the list first.
3. 3(TEST)c(T)c(2-Smpl) ... 2-Sample t Test
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph.
12
examples
Page 76

Example Two different processes (Type A and Type B) are used to produce
tinplate. The following values show the weights of samples produced
by each process.
Type A: 105 108 86 103 103 107 124 124
Type B: 89 92 84 97 103 107 111 97
Using the level of significance 0.05, test the null hypothesis that the
tinplate produced by the two processes are of the same level.
Procedure
1 m STAT2
2 bafwbaiwigwbadw
badwbahwbcewbcew
e
ijwjcwiewjhw
badwbahwbbbwjhw
3 3(TEST) c(T)c(2-Smpl)
4 1(LIST) c
1(!) c
1(LIST) bwc
1(LIST) cwc
1(1)c
1(1)c
1(On) c
1(None) c
5 1(CALC)
6(DRAW)
Result Screen
13
examples
Since P = 0.08602732 > 0.05 (level of significance), we can not reject the null hypothesis
and conclude that the tinplate produced by the two processes are of the same level.
Page 77

kk
kk
k 2-Sample
t Test (Pooled Off)
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as the Data parameter) , be sure to input data into
the list first.
3. 3(TEST)c(T)c(2-Smpl) ... 2-Sample t Test
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph.
14
examples
Page 78

15
examples
Example Two competing headache remedies claim to give fast-acting relief. An
experiment was performed to compare the mean lengths of time
required for bodily absorption of brand A and brand B headache
remedies. 12 people were randomly selected and given an oral dosage
of brand A. Another 12 were randomly selected and given an equal
dosage of brand B. The length of time in minutes for the drugs to
reach a specified level in the blood was recorded. The means, standard deviations, and sizes of the two samples follow;
Brand A:
oo
oo
o1 = 19.8; x1
"
n-1 = 8.6; n1 = 12
Brand B:
oo
oo
o2 = 19 ; x2
"
n-1 = 6 ; n2 = 12
Past experience with the drug composition of the two remedies
permits researchers to assume the standard deviations of the two time
distributions are approximately equal. Let us use a 5% level of
significance to test the null hypothesis that there is no difference in
the mean time required for bodily absortion.
Procedure
1 m STAT2
2 3(TEST) c(T)c(2-Smpl)
3 2(VAR) c
1(!) c
bj.iw
i.gw
bcw
bjw
gw
bcw
2(Off) c
1(None) c
4 1(CALC)
6(DRAW)
Result Screen
Since P = 0.79431564 > 0.05 (level of significance), the difference is in acceptance region.
We conclude that the data does not contain sufficient evidence to reject H0. Therefore, at the
5% level of significance we conclude that there is no difference in the mean times.
Page 79

16
examples
kk
kk
k LinearReg
t Test
Set Up
1. On the icon menu, select STAT2.
Execution
2. Input data into the list.
3. 3(TEST)c(T)d(LinReg) ... LinearReg t Test
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
Page 80

17
examples
Example A survey conducted by a city on its real estate investments revealed
the following data on the relationship between area and price.
Does the data indicate that the value
#
1, that is, the slope of the popula-
tion regression line, is not zero, which would mean that x (Area) can be
use as a predictor of y (Sales Price)? Use a 5% level of significance.
Procedure
1 m STAT2
2jwbfwbawbbwbaw
e
dgwiaweewffwdfw
3 3(TEST) c(T)d(LinReg)
4 1(!) c
1(LIST) bwc
1(LIST) cwc
1(1)c
1(None) c
5 1(CALC)
Result Screen
Since P = 6.4531e-3 < 0.05 (level of significance), we can reject the null hypothesis
#
1 ! 0
and conclude that there is a linear relationship y =
#
0 + #1x + $ between area(x) and price(y).
x Area (square feet) 9 15 10 11 10
y Sales Price (% $1000) 36 80 44 55 35
Page 81

18
examples
kk
kk
k
&
2
Test
Set Up
1. On the icon menu, select STAT2.
Execution
2. 3(TEST)d(
&
2
)...
&
2
Test
3. Input data into the Matrix.
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph.
Page 82

19
examples
Example A certain club collected data on the attendance at meetings by married
status, and obtained the data shown below.
Married Divorced Widowed Single Row Totals
Often Absent 34 16 14 36 100
Seldom Absent 64 34 20 82 200
Never Absent 52 50 16 82 200
Column Totals 150 100 50 200 500
Test the
null hypothesis that two phenomena are independent using
the level of significance of 0.05.
Procedure
1 m STAT2
2 3(TEST) d( &2)
3 2('MAT)
1(DIM)
dw
eww
dewbgwbewdgw
gewdewcawicw
fcwfawbgwicw
ii
4 1(MAT) v(A) wc
1(MAT) l(B) wc
1(None) c
5 1(CALC)
6(DRAW)
Result Screen
Since P = 0.17546141 > 0.05 (level of significance), we can not reject the null hypothesis
and conclude that there the two phenomena are independent of each other.
Page 83

kk
kk
k 2-Sample
F Test
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as the Data parameter), be sure to input data into
the list first.
3. 3(TEST)e(F)... 2-Sample F Test
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph.
20
examples
Page 84

Example There are two possible routes to get to the airport from a certain
company, and so manager wants to determine which route is the
fastest in order to make a plane that leaves at 7 o'clock. One route was
researched five times and then the other route was researched five
times, producing the data shown below.
mean of x1 = 33.8min mean of x2 = 34.2min
x1
"
n-1 = 16.4min x2"n-1 = 6.1min
Test the null hypothesis that the two routes have the same travel time
variance using the level of significance of 0.10.
Procedure
1 m STAT2
2 3(TEST) e( F)
3 2(VAR) c
1(!) c
bg.ew
fw
g.bw
fw
1(None) c
4 1(CALC)
6(DRAW)
Result Screen
21
examples
Since P = 0.08144232 < 0.1 (level of significance), we can reject the null hypothesis and
conclude that two routes don’t have same travel time variance.
Page 85

22
examples
kk
kk
k One-Way ANOVA
Set Up
1. On the icon menu, select STAT2.
Execution
2. Input data into the list.
3. 3(TEST)f(ANOVA) ... Analysis of Variance (ANOVA)
4. Set calculation parameters. Specify 1 for How Many setting.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
Page 86

23
examples
Example A psychologist is studying pattern recognition skills under four
laboratory settings. In each setting, a fourth-grade child is given a
pattern recognition test with ten patterns to identify. In setting A, the
child is given praise for each correct answer and no comment about
wrong answers. In setting B, the child is given criticism for each
wrong answer and no comment about correct answers. In setting C,
the child is given no praise or criticism but the observer expresses
interest in what the child is doing. In setting D, the observer remains
silent in an adjacent room watching the child through a one-way
mirror. A random sample of fourth-grade children was used, and each
child participated in the test only once. The test scores (number
correct) for each group follow. Find F
0.01, the critical values for an ' =
0.01 level of significance. Does the test indicate we should accept or
reject the null hypothesis?
Group A = {10, 8, 7, 9, 11}
Group B = { 2, 5, 3, 3, 4}
Group C = { 9, 3, 7, 8, 5, 6}
Group D = { 5, 7, 3, 6, 7}
Procedure
1 m STAT2
2bwbwbwbwbwcwcwcwcwcw
dwdwdwdwdwdwewewewewew
e
bawiwhwjwbbwcwfwdwdwew
jwdwhwiwfwgwfwhwdwgwhw
3 3(TEST) f(ANOVA)
4 1(1)c
1(LIST) bwc
1(LIST) cwc
1(None) c
5 1(CALC)
Result Screen
Since P = 7.992708666e-4 < 0.01 (level of significance), we can reject the null hypothesis
and conclude that the laboratory setting affects the mean score.
Page 87

24
examples
kk
kk
k Two-Way ANOVA
Set Up
1. On the icon menu, select STAT2.
Execution
2. Input data into the list.
3. 3(TEST)f(ANOVA) ... Analysis of Variance (ANOVA)
4. Set calculation parameters. Specify 2 for How Many setting.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
6(DRAW) ... Draws graph
Example The nearby table shows measurement results for a metal product
produced by a heat treatment process based on two treatment levels:
time (A) and temperature (B). The experiments were repeated twice
each under identical conditions.
Perform analysis of variance on the following null hypothesis, using a significance level of 5%.
H0 : No change in strength due to time
H0 : No change in strength due to heat treatment temperature
H0 : No change in strength due to interaction of time and heat treatment
temperature
B (Heat Treatment Temperature) B1 B2
A1 113 , 116
133 , 131
139 , 132
126 , 122
A2
A (Time)
Page 88

Procedure
1 m STAT2
2bwbwbwbwcwcwcwcwe
bwbwcwcwbwbwcwcwe
bbdwbbgwbdjwbdcwbddwbd
bwbcgwbccw
3 3(TEST) f(ANOVA)
4 2(2)c
1(LIST) bwc
1(LIST) cwc
1(LIST) dwc
1(None) c
5 1(CALC)
6(DRAW)
Result Screen
• Time differential (A) :
Since P=0.2458019517 > 0.05 (level of significance), we can not reject the null hypothesis.
• Temperature differential (B) :
Since P=0.04222398836 < 0.05 (level of significance), we can reject the null hypothesis.
• Interaction (A % B) :
Since P=2.78169946e-3 < 0.05 (level of significance), we can reject the null hypothesis.
The above test indicates that the time differential is not significant, the temperature differential is significant, and interaction is highly significant.
25
examples
Page 89

26
examples
kk
kk
k 1-Sample Z Interval
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as the Data parameter), be sure to input data into
the list first.
3. 4(INTR)b(Z)b(1-Smpl)... 1-Sample Z Interval
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
Page 90

27
examples
Example In a random sample of size n = 20 from a normal population
with the standard deviation ! = 15 and the mean
oo
oo
o = 64.3,
construct a 95% confidence interval for the population mean µ.
Procedure
1 m STAT2
2 4(INTR) b(Z)b(1-Smpl)
3 2(VAR) c
.jfw
bfw
ge.dw
caw
1(None)c
4 1(CALC)
Result Screen
Thus, the 95% confidence interval for µ becomes 57.7<µ<70.9 .
Page 91

28
examples
kk
kk
k 2-Sample Z Interval
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as Data parameter), be sure to input data into the
list first.
3. 4(INTR)b(Z)c(2-Smpl)... 2-Sample Z Interval
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
Page 92

29
examples
Example Construct a 94% confidence interval for the difference between the
mean lifetimes of two kinds of light bulbs(
µ1-µ
2), given that random
sample of 40 light bulbs of the first kind lasted on the average for 418
hours of continuous use and 50 light bulbs of the second kind lasted
on the average for 402 hours of continuous use. The population
standard deviations are known to be
!
1 = 26 and !2 = 22.
Procedure
1 m STAT2
2 4(INTR) b(Z)c(2-Smpl)
3 2(VAR) c
.jew
cgw
ccw
ebiw
eaw
eacw
faw
1(None)c
4 1(CALC)
Result Screen
Thus, the 94% confidence interval for
µ1-µ2
becomes 6.3<
µ1-µ
2<25.7.
Page 93

30
examples
kk
kk
k 1-Prop Z Interval
Set Up
1. On the icon menu, select STAT2.
Execution
2. 4(INTR)b(Z)d(1-Prop)... 1-Prop Z Interval
3. Set calculation parameters.
4. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
Page 94

31
examples
Example Suppose 800 students were selected at random from a student body
of 20,000 and given shots to prevent a certain type of flu. All 800
students were exposed to the flu and 600 of them did not get the flu.
Let p present the probability that the shot will be successful for any
single student selected at random from the entire population of
20,000. Let q be the probability that the shot is not successful.
a) What are the point estimates for p and q?
b) Find a 99% confidence interval for p.
Procedure
1 m STAT2
2 4(INTR) b(Z)d(1-Prop)
3 .jjw
gaaw
iaaw
1(None)c
4 1(CALC)
Result Screen
a) The point of estimates for p = 0.75, and the point of
estimates for q = 1-p = 0.25.
b) Thus, the 99% confidence interval for p becomes 0.71<p<0.79 .
Page 95

32
examples
kk
kk
k 2-Prop Z Interval
Set Up
1. On the icon menu, select STAT2.
Execution
2. 4(INTR)b(Z)e(2-Prop)... 2-Prop Z Interval
3. Set calculation parameters.
4. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
Page 96

33
examples
Example If 132 of 200 male voters and 90 of 150 female voters favor a certain
candidate running for governor of Texas, find a 99% confidence
interval for the difference between the actual proportions of male and
female voters who favor the candidate.
Procedure
1 m STAT2
2 4(INTR) b(Z)e(2-Prop)
3 .jjw
bdcw
caaw
jaw
bfaw
1(None)c
4 1(CALC)
Result Screen
Let p1 the actual propotion of male voters who favor the candidate.
Let p2 the actual propotion of female voters who favor the candidate.
Thus, the 99% confidence interval for (p1-p2) is -0.074<p1-p2<0.194.
Page 97

34
examples
kk
kk
k 1-Sample t Interval
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as Data parameter), be sure to input data into the
list first.
3. 4(INTR)c(T)b(1-Smpl)... 1-Sample t Interval
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
Page 98

35
examples
Example A paint manufacture wants to determine the average drying time of a
new interior wall paint. If for 12 test areas of equal size he obtained a
mean drying time of 66.3 minutes and a standard deviation of 8.4
minutes, construct a 95% confidence interval for the population mean
µ
.
Procedure
1 m STAT2
2 4(INTR) c(T)b(1-Smpl)
3 2(VAR) c
.jfw
gg.dw
i.ew
bcw
1(None)c
4 1(CALC)
Result Screen
Thus, the 95% confidence interval for µ becomes 61.0<µ<71.6 .
Page 99

36
examples
kk
kk
k 2-Sample t Interval (Pooled On)
Set Up
1. On the icon menu, select STAT2.
Execution
2. When using list data (List is selected as the Data parameter), be sure to input data into
the list first.
3. 4(INTR)c(T)c(2-Smpl) ... 2-Sample t Interval
4. Set calculation parameters.
5. Align the cursor with [Execute]
1(CALC) ... Performs calculation.
Page 100

37
examples
Example Factory A and Factory B both manufacture the same item. To compare
the productivity of the two factories, the production data shown below
was collected for 10 items at Factory A and nine items at Factory B.
Factory A: 78, 80, 79, 83, 82, 85, 78, 74, 76, 84 (kg/h)
Factory B: 81, 84, 82, 88, 86, 83, 78, 84, 89 (kg/h)
Construct a 95% confidence interval for the difference between
µ
1 and
µ
2 when the following is assumed: ! 1
2
=
!
2
2
, Factory A population
distribution is N(
µ
1,
!
1
2
), and Factory B population distribution is N(
µ
2,
!
2
2
).
Procedure
1 m STAT2
2 hiwiawhjwidwicw
ifwhiwhewhgwiew
e
ibwiewicwiiwigw
idwhiwiewijw
3 4(INTR) c(T)c(2-Smpl)
4 1(LIST) c
.jfw
1(LIST)bwc
1(LIST)cwc
1(1)c
1(1)c
1(On)c
1(None)c
5 1(CALC)
Result Screen
Thus, the 95% confidence interval for
µ1-µ2
becomes -7.4<
µ1-µ
2<-0.6.
 Loading...
Loading...