



查询TMS320C80供应商
TMS320C80
Digital Signal Processor
Data Sheet
1997 Digital Signal Processing Solutions

Printed in U.S.A., October 1997 SPRS023B

Data Sheet
Type
Book
TMS320C80 DSP
1997
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
D
Single-Chip Parallel Multiple
Instruction/Multiple Data (MIMD) DSP
D
More Than Two Billion RISC-Equivalent
Operations per Second
D
Master Processor (MP)
– 32-Bit Reduced Instruction Set
Computing (RISC) Processor
– IEEE-754 Floating-Point Capability
– 4K-Byte Instruction Cache
– 4K-Byte Data Cache
D
Four Parallel Processors (PP)
– 32-Bit Advanced DSPs
– 64-Bit Opcode Provides Many Parallel
Operations per Cycle
– 2K-Byte Instruction Cache and 8K-Byte
Data RAM per PP
D
Transfer Controller (TC)
– 64-Bit Data Transfers
– Up to 480M-Byte/s Transfer Rate
– 32-Bit Addressing
– Direct DRAM / VRAM Interface With
Dynamic Bus Sizing
– Intelligent Queuing and Cycle
Prioritization
D
Video Controller (VC)
– Provides Video Timing and VRAM
Control
– Dual-Frame Timers for Two Simultaneous
Image-Capture and / or Display Systems
D
Big- or Little-Endian Operation
D
50K-Byte On-Chip RAM
D
4G-Byte Address Space
D
16.6-ns Cycle Time
D
3.3-V Operation
D
IEEE Standard 1149.1† Test Access Port
(JTAG)
AP
AM
AK
AH
AF
AD
AB
GF PACKAGE
(BOTTOM VIEW)
2
AR
AN
AL
AJ
AG
AE
AC
AA
Y
W
V
U
T
R
P
N
M
L
K
J
H
G
F
E
D
C
B
A
26
25
A
B
C
D
E
F
G
H
J
K
L
M
N
P
R
T
U
V
W
Y
AA
AB
AC
AD
AE
AF
10
98765431
GGP PACKAGE
(BOTTOM VIEW)
16 14
24
19
2123
17
18
22 20
12
15
64
10
9871113
35343332313029282726252423222120191817161514131211
2
5
13
Please be aware that an important notice concerning availability, standard warranty, and use in critical applications of
Texas Instruments semiconductor products and disclaimers thereto appears at the end of this data sheet.
†
IEEE Standard 1149.1–1990, IEEE Standard Test Access Port and Boundary-Scan Architecture
PRODUCTION DATA information is current as of publication date.
Products conform to specifications per the terms of Texas Instruments
standard warranty. Production processing does not necessarily include
testing of all parameters.
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
Copyright 1997, Texas Instruments Incorporated
1

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
description
The TMS320C80 is a single chip, MIMD parallel processor capable of performing over two billion operations
per second. It consists of a 32-bit RISC master processor with a 120-MFLOP IEEE floating-point unit, four 32-bit
parallel processing digital signal processors (DSPs), a transfer controller with up to 480M-byte/s off-chip
transfer rate, and a video controller. All the processors are coupled tightly through an on-chip crossbar that
provides shared access to on-chip RAM. This performance and programmability make the ’C80 ideally suited
for video, imaging, and high-speed telecommunications applications.
2
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
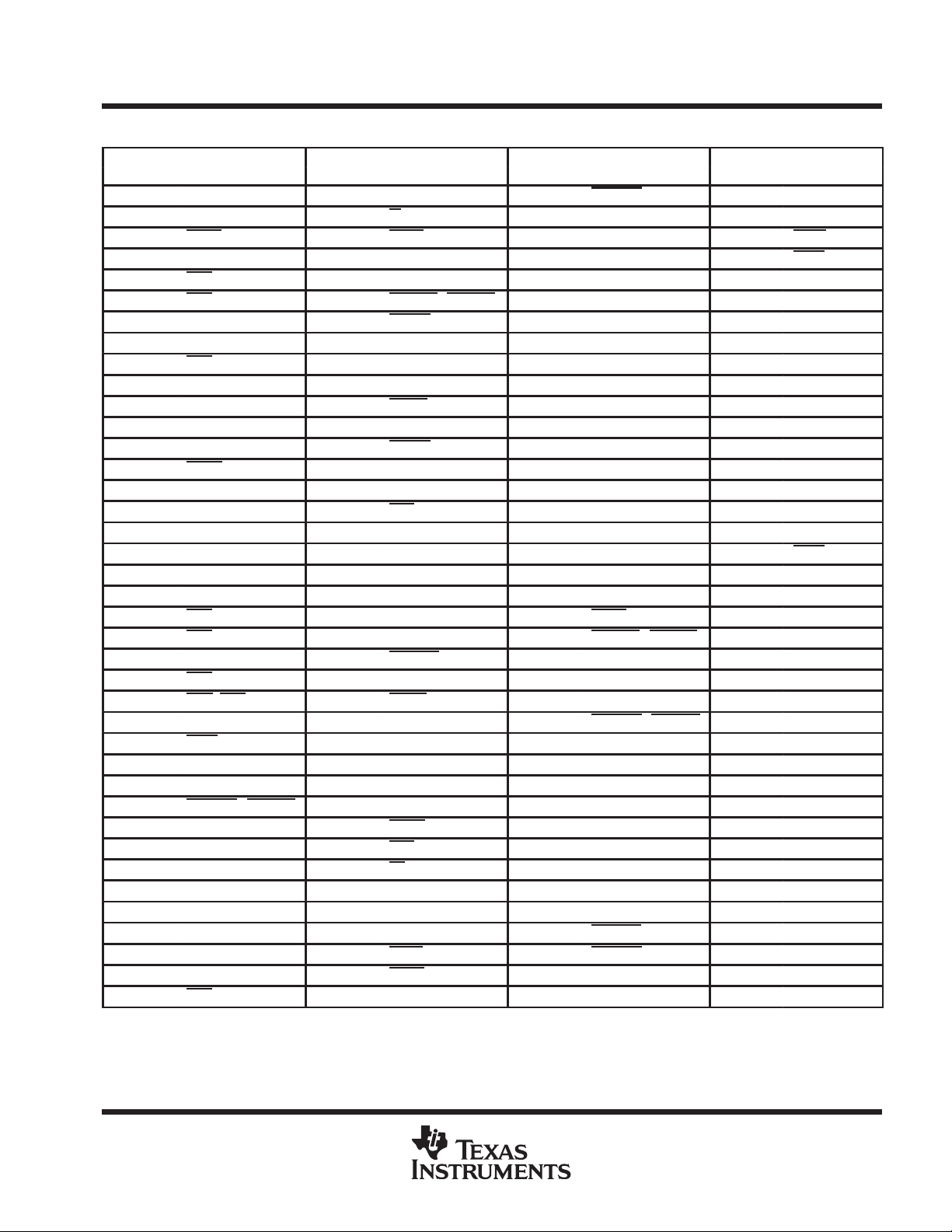
GF Terminal Assignments – Numerical Listing
TERMINAL TERMINAL TERMINAL TERMINAL
NO. NAME NO. NAME NO. NAME NO. NAME
A5 CT1 C21 V
A7 V
A9 HACK C25 DBEN F2 V
A11 V
A13 CAS/DQM7 C29 CAREA0 F8 V
A15 CAS/DQM5 C31 CBLNK0 / VBLNK0 F10 V
A17 V
A19 V
A21 RAS D6 V
A23 DSF D8 AS0 F18 CT2 N3 A8
A25 V
A27 SCLK1 D12 V
A29 V
A31 EINT1 D16 REQ0 F26 V
B2 No Connect D18 V
B4 BS1 D20 CAS/DQM0 F32 V
B6 V
B8 PS1 D24 V
B10 REQ1 D26 CAREA1 G3 A2 R1 V
B12 V
B14 CAS/DQM6 D30 V
B16 CAS/DQM3 D32 V
B18 V
B20 CAS/DQM1 E1 AS1 H2 STATUS0 R35 V
B22 TRG/CAS E3 FAULT H4 A3 T2 A5
B24 V
B26 DDIN E7 STATUS2 H34 TDI T32 D62
B28 FCLK0 E9 READY J1 STATUS1 T34 EMU0
B30 V
B32 CSYNC0 / HBLNK0 E13 V
C3 V
C5 STATUS3 E17 CAS/DQM4 J33 V
C7 AS2 E19 RL J35 EMU1 U33 D61
C9 V
C11 CT0 E23 V
C13 PS2 E25 CLKOUT K32 VSYNC1 V4 V
C15 V
C17 CLKIN E29 EINT3 L1 A0 V34 V
C19 CAS/DQM2 E31 V
DD
SS
DD
SS
SS
DD
DD
DD
DD
DD
DD
SS
SS
DD
C23 W E35 TCK L31 V
C27 V
D2 RETRY F12 V
D4 V
D10 UTIME F20 V
D14 RESET F24 V
D22 FCLK1 F34 V
D28 SCLK0 G5 A1 R3 V
D34 VSYNC0 G35 V
E5 V
E11 BS0 J3 V
E15 HREQ J31 V
E21 STATUS5 K2 STATUS4 U35 V
E27 LINT4 K34 HSYNC1 V32 V
DD
SS
DD
SS
SS
SS
SS
SS
DD
SS
SS
SS
SS
E33 HSYNC0 L5 V
DD
F4 V
F14 PS0 M34 V
F16 V
F22 V
F28 V
G1 V
G31 EINT2 R5 V
G33 CBLNK1 / VBLNK1 R31 V
H32 CSYNC1 / HBLNK1 T4 A13
J5 V
K4 A6 V2 V
L3 A7 W1 A11
SS
DD
SS
DD
SS
DD
SS
DD
SS
DD
SS
DD
DD
DD
SS
DD
DD
SS
L33 TRST
L35 XPT1
M2 V
M4 V
M32 V
N1 V
N5 V
N31 V
N33 TMS
N35 V
P2 A4
P4 A9
P32 TDO
P34 XPT0
R33 V
U1 V
U3 A10
U5 PS3
U31 FF1
SS
SS
DD
SS
SS
DD
DD
SS
SS
DD
SS
DD
DD
DD
DD
SS
DD
DD
DD
SS
SS
DD
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
3
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
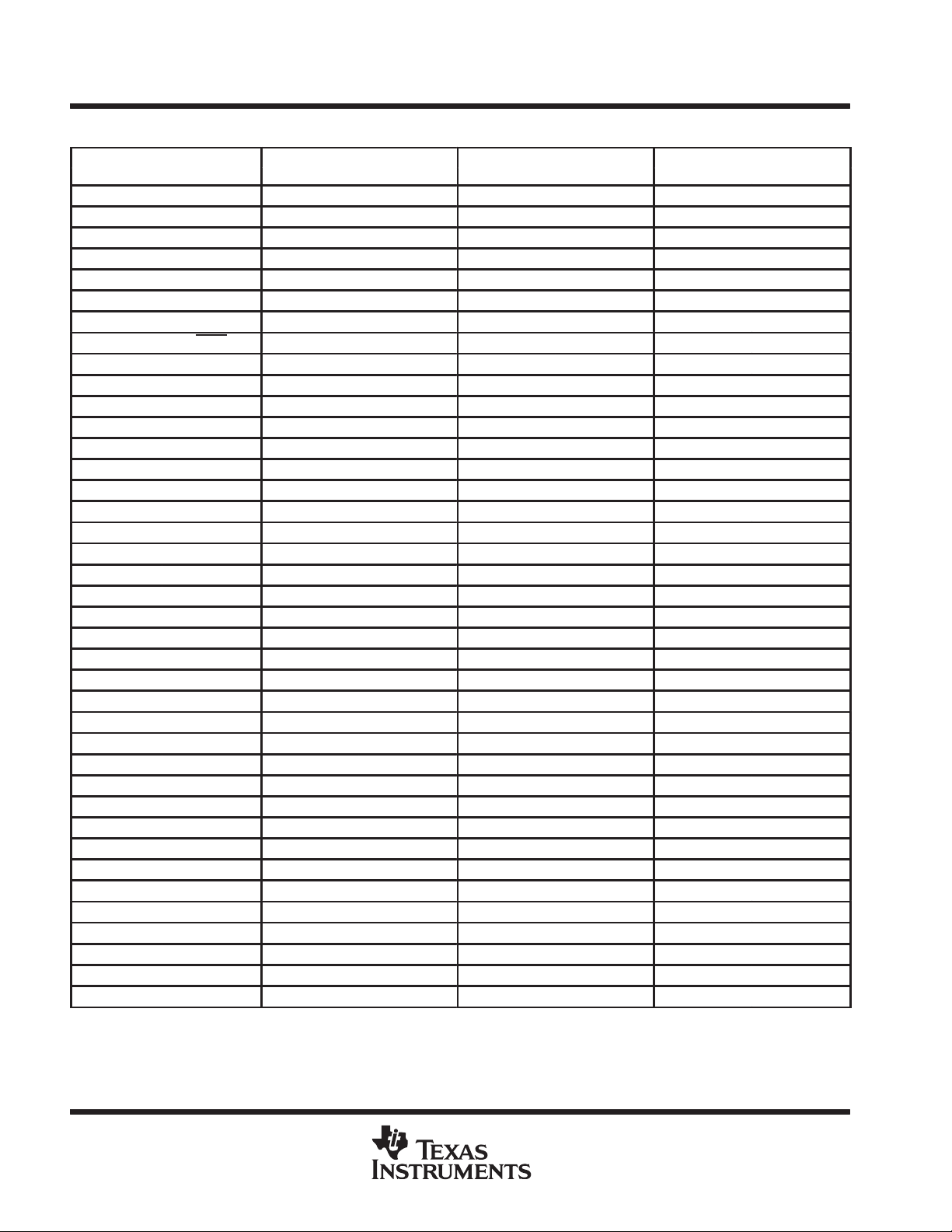
GF Terminal Assignments – Numerical Listing (Continued)
TERMINAL TERMINAL TERMINAL TERMINAL
NO. NAME NO. NAME NO. NAME NO. NAME
W3 A18 AG1 A16 AL17 D20 AN29 D35
W5 V
W31 V
W33 D59 AG31 V
W35 D63 AG33 V
Y2 A12 AG35 D57 AL27 D32 AP8 D5
Y4 A19 AH2 A20 AL29 D38 AP10 D8
Y32 XPT2 AH4 A30 AL31 V
Y34 D56 AH32 D44 AL33 D48 AP14 D13
AA1 V
AA3 V
AA5 V
AA31 V
AA33 V
AA35 V
AB2 A14 AJ35 V
AB4 A21 AK2 V
AB32 D55 AK4 V
AB34 D60 AK8 V
AC1 V
AC3 A22 AK12 V
AC5 V
AC31 V
AC33 D52 AK18 FF2 AM28 D33 AR15 D15
AC35 V
AD2 V
AD4 V
AD32 V
AD34 V
AE1 A15 AK32 V
AE3 A26 AK34 V
AE5 V
AE31 V
AE33 D51 AL5 V
AE35 D58 AL7 D3 AN19 D22
AF2 A17 AL9 D4 AN21 V
AF4 A28 AL11 D10 AN23 D28
AF32 D46 AL13 V
AF34 D49 AL15 D16 AN27 V
SS
SS
SS
DD
DD
DD
DD
SS
DD
SS
SS
DD
DD
SS
SS
DD
SS
SS
AG3 V
AG5 V
AH34 D54 AL35 D53 AP16 D17
AJ1 V
AJ3 A31 AM4 V
AJ5 V
AJ31 V
AJ33 D42 AM10 D6 AP26 D39
AK10 V
AK14 V
AK16 V
AK20 V
AK22 D27 AM32 V
AK24 V
AK26 V
AK28 V
AL1 A23 AN13 D12 AR31 D43
AL3 A25 AN15 V
SS
DD
DD
SS
DD
SS
SS
DD
DD
SS
DD
SS
DD
SS
DD
SS
DD
SS
DD
SS
DD
SS
SS
AL19 D21 AN31 D45
AL21 D24 AN33 V
AL23 V
AL25 D29 AP6 V
AM2 A24 AP18 V
AM6 V
AM8 D2 AP24 V
AM12 V
AM14 D14 AP30 V
AM16 D19 AP32 D47
AM18 V
AM20 D23 AR7 V
AM22 D25 AR9 D7
AM24 V
AM26 D31 AR13 D11
AM30 V
AM34 D50 AR21 D30
AN5 A29 AR23 D36
AN7 D1 AR25 V
AN9 V
AN11 D9 AR29 V
AN17 D18
AN25 D37
SS
SS
DD
SS
SS
SS
SS
SS
DD
SS
DD
DD
SS
AP4 A27
AP12 V
AP20 D26
AP22 D34
AP28 D41
AR5 D0
AR11 V
AR17 V
AR19 V
AR27 D40
DD
DD
DD
DD
DD
DD
DD
SS
SS
DD
SS
DD
4
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
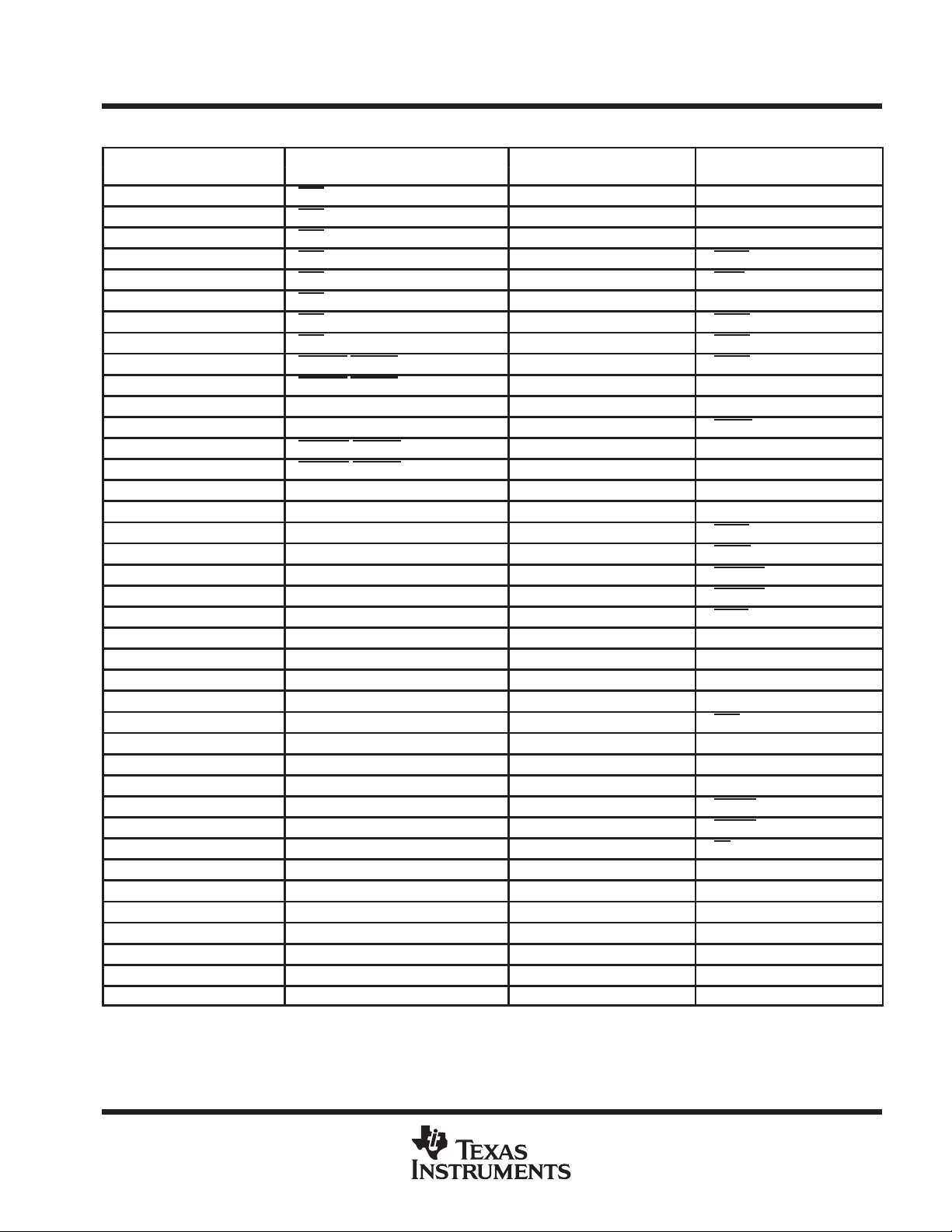
GF Terminal Assignments – Alphabetical Listing
TERMINAL TERMINAL TERMINAL TERMINAL
NAME NO. NAME NO. NAME NO. NAME NO.
A0 L1 CAS/DQM0 D20 D22 AN19 D61 U33
A1 G5 CAS/DQM1 B20 D23 AM20 D62 T32
A2 G3 CAS/DQM2 C19 D24 AL21 D63 W35
A3 H4 CAS/DQM3 B16 D25 AM22 DBEN C25
A4 P2 CAS/DQM4 E17 D26 AP20 DDIN B26
A5 T2 CAS/DQM5 A15 D27 AK22 DSF A23
A6 K4 CAS/DQM6 B14 D28 AN23 EINT1 A31
A7 L3 CAS/DQM7 A13 D29 AL25 EINT2 G31
A8 N3 CBLNK0/VBLNK0 C31 D30 AR21 EINT3 E29
A9 P4 CBLNK1/VBLNK1 G33 D31 AM26 EMU0 T34
A10 U3 CLKIN C17 D32 AL27 EMU1 J35
A11 W1 CLKOUT E25 D33 AM28 FAULT E3
A12 Y2 CSYNC0/HBLNK0 B32 D34 AP22 FCLK0 B28
A13 T4 CSYNC1/HBLNK1 H32 D35 AN29 FCLK1 D22
A14 AB2 CT0 C11 D36 AR23 FF1 U31
A15 AE1 CT1 A5 D37 AN25 FF2 AK18
A16 AG1 CT2 F18 D38 AL29 HACK A9
A17 AF2 D0 AR5 D39 AP26 HREQ E15
A18 W3 D1 AN7 D40 AR27 HSYNC0 E33
A19 Y4 D2 AM8 D41 AP28 HSYNC1 K34
A20 AH2 D3 AL7 D42 AJ33 LINT4 E27
A21 AB4 D4 AL9 D43 AR31 PS0 F14
A22 AC3 D5 AP8 D44 AH32 PS1 B8
A23 AL1 D6 AM10 D45 AN31 PS2 C13
A24 AM2 D7 AR9 D46 AF32 PS3 U5
A25 AL3 D8 AP10 D47 AP32 RAS A21
A26 AE3 D9 AN11 D48 AL33 READY E9
A27 AP4 D10 AL11 D49 AF34 REQ0 D16
A28 AF4 D11 AR13 D50 AM34 REQ1 B10
A29 AN5 D12 AN13 D51 AE33 RESET D14
A30 AH4 D13 AP14 D52 AC33 RETRY D2
A31 AJ3 D14 AM14 D53 AL35 RL E19
AS0 D8 D15 AR15 D54 AH34 SCLK0 D28
AS1 E1 D16 AL15 D55 AB32 SCLK1 A27
AS2 C7 D17 AP16 D56 Y34 STATUS0 H2
BS0 E11 D18 AN17 D57 AG35 STATUS1 J1
BS1 B4 D19 AM16 D58 AE35 STATUS2 E7
CAREA0 C29 D20 AL17 D59 W33 STATUS3 C5
CAREA1 D26 D21 AL19 D60 AB34 STATUS4 K2
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
5
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
GF Terminal Assignments – Alphabetical Listing (Continued)
TERMINAL TERMINAL TERMINAL TERMINAL
NAME NO. NAME NO. NAME NO. NAME NO.
STATUS5 E21 V
TCK E35 V
TDI H34 V
TDO P32 V
TMS N33 V
TRG/CAS B22 V
TRST L33 V
UTIME D10 V
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
A7 V
A17 V
A29 V
B6 V
B12 V
B18 V
B24 V
B30 V
C15 V
C21 V
D4 V
D32 V
F2 V
F8 V
F12 V
F20 V
F24 V
F28 V
F34 V
G1 V
G35 V
J5 V
J31 V
M2 V
M34 V
N1 V
N35 V
R3 V
R5 V
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
R31 V
R33 V
U1 V
U35 V
V2 V
V34 V
AA3 V
AA5 V
AA31 V
AA33 V
AC1 V
AC35 V
AD2 V
AD34 V
AG5 V
AG31 V
AJ1 V
AJ35 V
AK2 V
AK8 V
AK12 V
AK16 V
AK24 V
AK28 V
AK34 V
AM4 V
AM32 V
AN15 V
AN21 V
AN33 V
AP6 V
AP12 V
AP18 V
AP24 V
AP30 V
AR7 V
AR19 V
DD
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
AR29 V
A11 V
A19 V
A25 V
C3 V
C9 V
C27 V
D6 V
D12 V
D18 V
D24 V
D30 V
E5 V
E13 V
E23 V
E31 V
F4 V
F10 V
F16 V
F22 V
F26 V
F32 V
J3 V
J33 V
L5 V
L31 V
M4 V
M32 V
N5 V
N31 V
R1 V
R35 VSYNC0 D34
V4 VSYNC1 K32
V32 W C23
W5 XPT0 P34
W31 XPT1 L35
AA1 XPT2 Y32
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
AA35
AC5
AC31
AD4
AD32
AE5
AE31
AG3
AG33
AJ5
AJ31
AK4
AK10
AK14
AK20
AK26
AK32
AL5
AL13
AL23
AL31
AM6
AM12
AM18
AM24
AM30
AN9
AN27
AR11
AR17
AR25
6
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
GGP Terminal Assignments – Numerical Listing
TERMINAL TERMINAL TERMINAL TERMINAL
NO. NAME NO. NAME NO. NAME NO. NAME
A1 No Connect B1 No Connect C1 No Connect D1 A0
A2 No Connect B2 No Connect C2 No Connect D2 V
A3 No Connect B3 No Connect C3 No Connect D3 STATUS4
A4 STATUS1 B4 STATUS2 C4 V
A5 AS1 B5 AS2 C5 STATUS0 D5 V
A6 RETRY B6 READY C6 FAULT D6 AS0
A7 CT1 B7 BS0 C7 BS1 D7 UTIME
A8 PS0 B8 PS1 C8 PS2 D8 CT0
A9 V
A10 V
A11 V
A12 V
A13 No Connect B13
A14 No Connect B14 V
A15 V
A16 CAS/DQM2 B16 V
A17 CAS/DQM0 B17 RL C17 V
A18 V
A19 FCLK1 B19 V
A20 V
A21 V
A22 V
A23 V
A24 No Connect B24 No Connect C24 No Connect D24 LINT4
A25 No Connect B25 No Connect C25 No Connect D25 EINT3
A26 No Connect B26 No Connect C26 No Connect D26 EINT2
DD
SS
SS
DD
DD
SS
DD
DD
SS
SS
B9 HACK C9 HREQ D9 RESET
B10 V
B11 V
B12 CAS/DQM7 C12 CLKIN D12 V
B15 CAS/DQM4 C15 CAS/DQM3 D15 CT2
B18 RAS C18 V
B20 DSF C20 V
B21 DDIN C21 CLKOUT D21 CAREA1
B22 SCLK1 C22 V
B23 SCLK0 C23 V
SS
DD
No Connect
SS
SS
DD
C10 V
C11 V
C13 V
C14 CAS/DQM5 D14 V
C16 CAS/DQM1 D16 V
C19 W D19 STATUS5
SS
SS
DD
SS
SS
DD
SS
DD
DD
D4 STATUS3
D10 REQ1
D11 REQ0
D13 CAS/DQM6
D17 V
D18 TRG/CAS
D20 DBEN
D22 FCLK0
D23 CAREA0
DD
DD
DD
DD
DD
SS
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
7
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
GGP Terminal Assignments – Numerical Listing (Continued)
TERMINAL TERMINALTERMINALTERMINAL
NO. NAMENO.NAMENO.NAMENO.NAME
E1 A3 J23 HSYNC0 P1 No Connect V23 D52
E2 A2 J24 TRST P2 No Connect V24 V
E3 V
E4 A1 J26 TMS P4 V
E23 EINT1 K1 A12 P23 V
E24 CBLNK1/VBLNK1 K2 V
E25 CBLNK0/VBLNK0 K3 A11 P25 V
E26 V
F1 A4 K23 TDI R1 V
F2 V
F3 V
F4 V
F23 V
F24 CSYNC1/HBLNK1 L2 A13 R24 D57 Y2 A26
F25 V
F26 CSYNC0/HBLNK0 L4 V
G1 V
G2 V
G3 A5 L25 V
G4 V
G23 VSYNC1 M1 V
G24 VSYNC0 M2 A15 T24 V
G25 V
G26 V
H1 A8 M23 V
H2 V
H3 A7 M25 D62 U3 A21 AA25 D47
H4 A6 M26 D61 U4 V
H23 HSYNC1 N1 No Connect U23 V
H24 V
H25 V
H26 V
J1 A10 N23 V
J2 V
J3 A9 N25 No Connect V3 V
J4 V
SS
SS
DD
DD
DD
SS
DD
SS
SS
SS
SS
SS
DD
DD
DD
DD
DD
SS
J25 TCK P3 V
DD
K4 V
K24 TDO R2 A17 W24 D50
K25 EMU1 R3 A18 W25 D51
K26 XPT0 R4 V
L1 V
L3 V
L23 XPT1 T1 A19 Y23 V
L24 V
L26 EMU0 T4 A20 Y26 V
M3 PS3 T25 D56 AA3 A28
M4 A14 T26 V
M24 D63 U2 V
N2 A16 U24 D54 AB2 A29
N3 V
N4 V
N24 D60 V2 A23 AB24 D44
N26 No Connect V4 V
SS
DD
SS
SS
SS
SS
DD
DD
DD
DD
SS
P24 D59 W2 V
P26 No Connect W4 V
R23 XPT2 Y1 A25
R25 V
R26 D58 Y4 V
T2 V
T3 V
T23 V
U1 V
U25 V
U26 D55 AB4 V
V1 A22 AB23 V
SS
SS
SS
DD
SS
SS
DD
DD
DD
DD
DD
SS
SS
SS
DD
DD
SS
DD
DD
V25 V
V26 D53
W1 A24
W3 V
W23 D49
W26 V
Y3 A27
Y24 D48
Y25 V
AA1 V
AA2 V
AA4 V
AA23 D45
AA24 D46
AA26 V
AB1 V
AB3 A30
AB25 V
AB26 V
SS
SS
SS
SS
SS
DD
DD
DD
SS
SS
DD
DD
SS
DD
SS
SS
DD
SS
SS
8
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
GGP Terminal Assignments – Numerical Listing (Continued)
TERMINAL TERMINALTERMINALTERMINAL
NO. NAMENO.NAMENO.NAMENO.NAME
AC1 A31 AD1 No Connect AE1 No Connect AF1 No Connect
AC2 V
AC3 V
AC4 D0 AD4 V
AC5 D3 AD5 V
AC6 V
AC7 V
AC8 D9 AD8 D10 AE8 D11 AF8 V
AC9 D12 AD9 V
AC10 V
AC11 D16 AD11 V
AC12 D18 AD12 D19 AE12 V
AC13 D20 AD13 V
AC14 V
AC15 D24 AD15 V
AC16 D27 AD16 D26 AE16 D25 AF16 V
AC17 V
AC18 D31 AD18 D30 AE18 V
AC19 V
AC20 D35 AD20 D34 AE20 D33 AF20 V
AC21 D37 AD21 V
AC22 D40 AD22 V
AC23 D42 AD23 D41 AE23 V
AC24 D43 AD24 No Connect AE24 No Connect AF24 No Connect
AC25 V
AC26 V
DD
DD
SS
DD
DD
DD
SS
DD
DD
DD
AD2 No Connect AE2 No Connect AF2 No Connect
AD3 No Connect AE3 No Connect AF3 No Connect
SS
DD
AD6 D5 AE6 D6 AF6 D7
AD7 V
AD10 V
AD14 D21 AE14 No Connect AF14 No Connect
AD17 V
AD19 V
AD25 No Connect AE25 No Connect AF25 No Connect
AD26 No Connect AE26 No Connect AF26 No Connect
DD
SS
DD
SS
SS
DD
SS
DD
SS
DD
AE4 D1 AF4 D2
AE5 D4 AF5 V
AE7 D8 AF7 V
AE9 D13 AF9 D14
AE10 D15 AF10 V
AE11 V
AE13 V
AE15 D23 AF15 D22
AE17 D28 AF17 V
AE19 D32 AF19 V
AE21 D36 AF21 V
AE22 D39 AF22 D38
SS
DD
SS
DD
SS
AF11 D17
AF12 V
AF13 No Connect
AF18 D29
AF23 V
SS
SS
DD
SS
DD
SS
DD
SS
SS
DD
SS
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
9
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
GGP Terminal Assignments – Alphabetical Listing
TERMINAL TERMINAL TERMINAL TERMINAL
NAME NO. NAME NO. NAME NO. NAME NO.
A0 D1 CAS/DQM0 A17 D22 AF15 D61 M26
A1 E4 CAS/DQM1 C16 D23 AE15 D62 M25
A2 E2 CAS/DQM2 A16 D24 AC15 D63 M24
A3 E1 CAS/DQM3 C15 D25 AE16 DBEN D20
A4 F1 CAS/DQM4 B15 D26 AD16 DDIN B21
A5 G3 CAS/DQM5 C14 D27 AC16 DSF B20
A6 H4 CAS/DQM6 D13 D28 AE17 EINT1 E23
A7 H3 CAS/DQM7 B12 D29 AF18 EINT2 D26
A8 H1 CBLNK0/VBLNK0 E25 D30 AD18 EINT3 D25
A9 J3 CBLNK1/VBLNK1 E24 D31 AC18 EMU0 L26
A10 J1 CLKIN C12 D32 AE19 EMU1 K25
A11 K3 CLKOUT C21 D33 AE20 FAULT C6
A12 K1 CSYNC0/HBLNK0 F26 D34 AD20 FCLK0 D22
A13 L2 CSYNC1/HBLNK1 F24 D35 AC20 FCLK1 A19
A14 M4 CT0 D8 D36 AE21 HACK B9
A15 M2 CT1 A7 D37 AC21 HREQ C9
A16 N2 CT2 D15 D38 AF22 HSYNC0 J23
A17 R2 D0 AC4 D39 AE22 HSYNC1 H23
A18 R3 D1 AE4 D40 AC22 LINT4 D24
A19 T1 D2 AF4 D41 AD23 PS0 A8
A20 T4 D3 AC5 D42 AC23 PS1 B8
A21 U3 D4 AE5 D43 AC24 PS2 C8
A22 V1 D5 AD6 D44 AB24 PS3 M3
A23 V2 D6 AE6 D45 AA23 RAS B18
A24 W1 D7 AF6 D46 AA24 READY B6
A25 Y1 D8 AE7 D47 AA25 REQ0 D11
A26 Y2 D9 AC8 D48 Y24 REQ1 D10
A27 Y3 D10 AD8 D49 W23 RESET D9
A28 AA3 D11 AE8 D50 W24 RETRY A6
A29 AB2 D12 AC9 D51 W25 RL B17
A30 AB3 D13 AE9 D52 V23 SCLK0 B23
A31 AC1 D14 AF9 D53 V26 SCLK1 B22
AS0 D6 D15 AE10 D54 U24 STATUS0 C5
AS1 A5 D16 AC11 D55 U26 STATUS1 A4
AS2 B5 D17 AF11 D56 T25 STATUS2 B4
BS0 B7 D18 AC12 D57 R24 STATUS3 D4
BS1 C7 D19 AD12 D58 R26 STATUS4 D3
CAREA0 D23 D20 AC13 D59 P24 STATUS5 D19
CAREA1 D21 D21 AD14 D60 N24
10
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
GGP Terminal Assignments – Alphabetical Listing (Continued)
TERMINAL TERMINAL TERMINAL TERMINAL
NAME NO. NAME NO. NAME NO. NAME NO.
TCK J25 V
TDI K23 V
TDO K24 V
TMS J26 V
TRG/CAS D18 V
TRST J24 V
UTIME D7 V
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
A9 V
A12 V
A15 V
A20 V
A21 V
B11 V
B19 V
C11 V
C18 V
C22 V
C23 V
D2 V
D5 V
D12 V
D14 V
D16 V
F2 V
F3 V
F4 V
F25 V
H2 V
H24 V
H25 V
H26 V
J2 V
K2 V
L1 V
M1 V
M23 V
N3 V
N4
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
P25 V
R25 V
T2 V
T3 V
T23 V
T24 V
U4 V
U23 V
V3 V
V4 V
W26 V
Y4 V
Y23 V
AA1 V
AA2 V
AA26 V
AB23 V
AC2 V
AC3 V
AC7 V
AC10 V
AC14 V
AC19 V
AC25 V
AC26 V
AD5 V
AD7 V
AD10 V
AD15 V
AD19 V
AD22 V
AE12 V
AE18 V
AF8 V
AF12 V
AF17 V
AF21 V
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
A10 V
A11 V
A18 V
A22 V
A23 V
B10 V
B14 V
B16 V
C4 V
C10 V
C13 V
C17 V
C20 V
D17 V
E3 V
E26 V
F23 V
G1 V
G2 V
G4 V
G25 V
G26 V
J4 V
K4 V
L3 V
L4 V
L24 V
L25 V
N23 V
P3 V
P4 V
P23 VSYNC0 G24
R1 VSYNC1 G23
R4 W C19
T26 XPT0 K26
U1 XPT1 L23
U2 XPT2 R23
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
TMS320C80
U25
V24
V25
W2
W3
W4
Y25
Y26
AA4
AB1
AB4
AB25
AB26
AC6
AC17
AD4
AD9
AD11
AD13
AD17
AD21
AE11
AE13
AE23
AF5
AF7
AF10
AF16
AF19
AF20
AF23
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
11

TMS320C80
DESCRIPTION
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
Terminal Functions
TERMINAL
NAME TYPE
A31–A0 O
AS2–AS0 I
BS1–BS0 I
CT2–CT0 I Cycle-timing selection. CT2–CT0 signals determine the timing of the current memory access.
D63–D0 I/O Data bus. D63–D0 transfer up to 64 bits of data per memory cycle into or out of the ’C80.
DBEN O
DDIN O
FAULT I
PS3–PS0 I
READY I
RL O
RETRY I
STATUS5–STATUS0 O
UTIME I
CAS/DQM7–
CAS
/DQM0
DSF O
RAS O Row-address strobe. RAS drives the RAS inputs of DRAMs, VRAMs, and SDRAMs.
TRG/CAS O
W O
†
I = input, O = output, Z = high impedance
†
LOCAL MEMORY INTERFACE
Address bus. A31– A0 output the 32-bit byte address of the external memory cycle. The address can be
multiplexed for DRAM accesses.
Address-shift selection. AS2–AS0 determine how the column address appears on the address bus. Eight
shift values are supported, including zero.
Bus-size selection. BS1–BS0 indicate the bus size of the memory or other device being accessed, allowing
dynamic bus sizing for data buses less than 64-bits wide.
Data-buffer enable. DBEN drives the active-low output-enables of bi-directional transceivers that can be
used to buffer input and output data on D63–D0.
Data-direction indicator. DDIN indicates the direction of the data that passes through the transceivers. When
is low, the transfer is from external memory into the ’C80.
DDIN
Fault. FAULT is driven low by external circuitry to inform the ’C80 that a fault has occurred on the current
memory row-access.
Page-size indication. PS3 – PS0 indicate the page size of the memory device(s) being accessed by the
current cycle. The ’C80 uses this information to determine when to begin a new row-access.
Ready. READY indicates that the external device is ready to complete the memory cycle. READY is driven
low by external circuitry to insert wait states into a memory cycle.
Row latch. The high-to-low transition of RL can be used to latch the valid 32-bit byte address that is present
on A31–A0.
Retry. RETRY is driven low by external circuitry to indicate that the addressed memory is busy. The ’C80
memory cycle is rescheduled.
Status code. At row time, STATUS5–STA TUS0 indicate the type of cycle being performed. At column time,
they identify the processor and type of request that initiated the cycle.
User-timing selection. UTIME causes the timing of RAS and CAS/DQM7–CAS/DQM0 to be modified so
that custom memory timings can be generated. During reset, UTIME
’C80 operates.
DRAM, VRAM, AND SDRAM CONTROL
Column-address strobes. CAS/DQM7–CAS/DQM0 drive the CAS inputs of DRAMs and VRAMs, or the
O
DQM input of SDRAMs. The eight strobes provide byte-write access to memory.
Special function. DSF selects special VRAM functions such as block-write, load color register, split-register
transfer, and SGRAM block write.
Transfer/output enable or column-address strobe. TRG/CAS is used as an output-enable for DRAMs and
VRAMs, and also as a transfer-enable for VRAMs. TRG
Write enable. W is driven low before CAS during write cycles. W controls the direction of the transfer during
VRAM transfer cycles.
/CAS also drives the CAS inputs of SDRAMs.
selects the endian mode in which the
12
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

DESCRIPTION
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
Terminal Functions (Continued)
TERMINAL
NAME TYPE
HACK O
HREQ I
REQ1, REQ0 O
CLKIN I
CLKOUT O
EINT1, EINT2, EINT3 I
LINT4 I
RESET I
XPT2–XPT0 I External packet transfer. XPT2–XPT0 are used by external devices to request a high-priority XPT by the TC.
EMU0, EMU1
‡
TCK
‡
TDI
TDO O Test data output. TDO provides output data for all IEEE-1149.1 instructions and data scans of the ’C80.
‡
TMS
TRST
†
I = input, O = output, Z = high impedance
‡
This pin has an internal pullup and can be left unconnnected during normal operation.
§
This pin has an internal pulldown and can be left unconnnected during normal operation.
‡
§
†
HOST INTERFACE
Host acknowledge. The ’C80 drives HACK output low following an active HREQ to indicate that it has driven
the local-memory-bus signals to the high-impedance state and is relinquishing the bus. HACK
asynchronously following HREQ
Host request. An external device drives HREQ low to request ownership of the local-memory bus. When
HREQ
is high, the ’C80 owns and drives the bus. HREQ is synchronized internally to the ’C80’s internal clock.
Also, HREQ
of RESET
occurrence on EINT3
Internal cycle request. REQ1 and REQ0 provide a two-bit code indicating the highest-priority memory-cycle
request that is being received by the TC. External logic can monitor REQ1 and REQ0 to determine if it is
necessary to relinquish the local-memory bus to the ’C80.
Input clock. CLKIN generates the internal ’C80 clocks to which all processor functions (except the frame
timers) are synchronous.
Local output clock. CLKOUT provides a way to synchronize external circuitry to internal timings. All ’C80
output signals (except the VC signals) are synchronous to this clock.
Edge-triggered interrupts. EINT1, EINT2 and EINT3 allow external devices to interrupt the master processor
(MP) on one of three interrupt levels (EINT1
EINT3
the MP to unhalt and fetch its reset vector (the EINT3
Level-triggered interrupt. LINT4 provides an active-low level-triggered interrupt to the MP. Its priority falls
below that of the edge-triggered interrupts. Any interrupt request should remain low until it is recognized by
the ’C80.
Reset. RESET is driven low to reset the ’C80 (all processors). During reset, all internal registers are set to
their initial state and all outputs are driven to their inactive or high-impedance levels. During the rising edge
of RESET
and UTIME pins, respectively.
Emulation pins. EMU0 and EMU1 are used to support emulation host interrupts, special functions targeted
I/O
at a single processor, and multiprocessor halt-event communications.
Test clock. TCK provides the clock for the ’C80 IEEE-1149.1 logic, allowing it to be compatible with other
I
IEEE-1149.1 devices, controllers, and test equipment designed for different clock rates.
I T est data input. TDI provides input data for all IEEE-1149.1 instructions and data scans of the ’C80.
I T est-mode select. TMS controls the IEEE-1149.1 state machine.
Test reset. TRST resets the ’C80 IEEE-1149.1 module. When low, all boundary-scan logic is disabled,
I
allowing normal ’C80 operation.
is used at reset to determine the power-up state of the MP. If HREQ is low at the rising edge
, the MP comes up running. If HREQ is high, the MP remains halted until the first interrupt
.
also serves as an unhalt signal. If the MP is powered-up halted, the first rising edge on EINT3 causes
, the MP reset mode and the ’C80’s operating endian mode are determined by the levels of HREQ
EMULATION CONTROL
being detected inactive, and then the ’C80 resumes driving the bus.
SYSTEM CONTROL
is the highest priority). The interrupts are rising-edge triggered.
interrupt-pending bit is not set in this case).
is driven high
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
13

TMS320C80
DESCRIPTION
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
Terminal Functions (Continued)
TERMINAL
NAME TYPE
CAREA0, CAREA1 O
CBLNK0 / VBLNK0,
CBLNK1
CSYNC0 / HBLNK0,
CSYNC1
FCLK0, FCLK1 I
HSYNC0,
HSYNC1
SCLK0, SCLK1 I
VSYNC0,
VSYNC1
V
V
No Connect No connect serves as an alignment key and must be left unconnected.
FF2–FF1 FF2–FF1 (GF package only) are reserved for factory use and should be left unconnected.
†
I = input, O = output, Z = high-impedance
‡
For proper operation, all VDD and VSS pins must be connected externally.
SS
DD
/ VBLNK1
/ HBLNK1
‡
‡
†
VIDEO INTERFACE
Composite area. CAREA0 and CAREA1 define a special area such as an overscan boundary . This area
represents the logical OR of the internal horizontal and vertical area signals.
Composite blanking / vertical blanking. Each of CBLNK0 / VBLNK0 and VBLNK1 provides one of two
blanking functions, depending on the configuration of the CSYNC
Composite blanking disables pixel display/capture during both horizontal and vertical retrace periods
O
I/O/Z
I/O/Z
I/O/Z
I Ground. Electrical ground inputs
I Power. Nominal 3.3-V power supply inputs
and is enabled when CSYNC
Vertical blanking disables pixel display/capture during vertical retrace periods and is enabled when
HBLNK
is selected for separate-sync video systems.
Following reset, CBLNK0
respectively.
Composite sync/horizontal blanking. CSYNC0 / HBLNK0 and CSYNC1 / HBLNK1 can be programmed
for one of two functions:
Composite sync is for use on composite-sync video systems and can be programmed as an input,
output, or high-impedance signal
information from externally generated active-low sync pulses. As an output, the active-low composite
sync pulses are generated from either external HSYNC
video timers. In the high-impedance state, the pin is neither driven nor allowed to drive circuitry.
Horizontal blank disables pixel display /capture during horizontal retrace periods in separate-sync
video systems and can be used as an output only.
Immediately following reset, CSYNC0
high-impedance CSYNC0
Frame clock. FCLK0 and FCLK1 are derived from the external video system’s dotclock and are used to
drive the ’C80 video logic for frame timer 0 and frame timer 1.
Horizontal sync. HSYNC0 and HSYNC1 control the video system. They can be programmed as input,
output, or high impedance signals. As an input, HSYNC
generated horizontal sync pulses. As an output, HSYNC
by the ’C80 on-chip frame timer. In the high-impedance state, the pin is not driven, and no internal
synchronization is allowed to occur. Immediately following reset, HSYNC0
high-impedance state.
Serial-data clock. SCLK0 and SCLK1 are used by the ’C80 SRT controller to track the VRAM tap point
when using midline reload. SCLK0 and SCLK1 should be the same signals that clock the serial register
on the VRAMs controlled by frame timer 0 and frame timer 1, respectively.
Vertical sync. VSYNC0 and VSYNC1 control the video system. They can be programmed as inputs,
outputs, or high-impedance signals. As inputs, VSYNCx
generated vertical-sync pulses. As outputs, VSYNCx
’C80 on-chip frame timer. In the high-impedance state, the pin is not driven and no internal synchronization
is allowed to occur. Immediately following reset, VSYNCx
MISCELLANEOUS
is selected for composite sync video systems.
/ VBLNK0 and CBLNK1 / VBLNK1 are configured as CBLNK0 and CBLNK1,
and CSYNC1, respectively.
POWER
/HBLNK pin:
. As an input, the ’C80 extracts horizontal and vertical sync
and VSYNC signals or the ’C80’s internal
/ HBLNK0 and CSYNC1 / HBLNK1 are configured as
synchronizes the video timer to externally
is an active-low horizontal sync pulse generated
and HSYNC1 are in the
synchronizes the frame timer to externally
are active-low vertical-sync pulses generated by the
is in the high-impedance state.
14
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
architecture
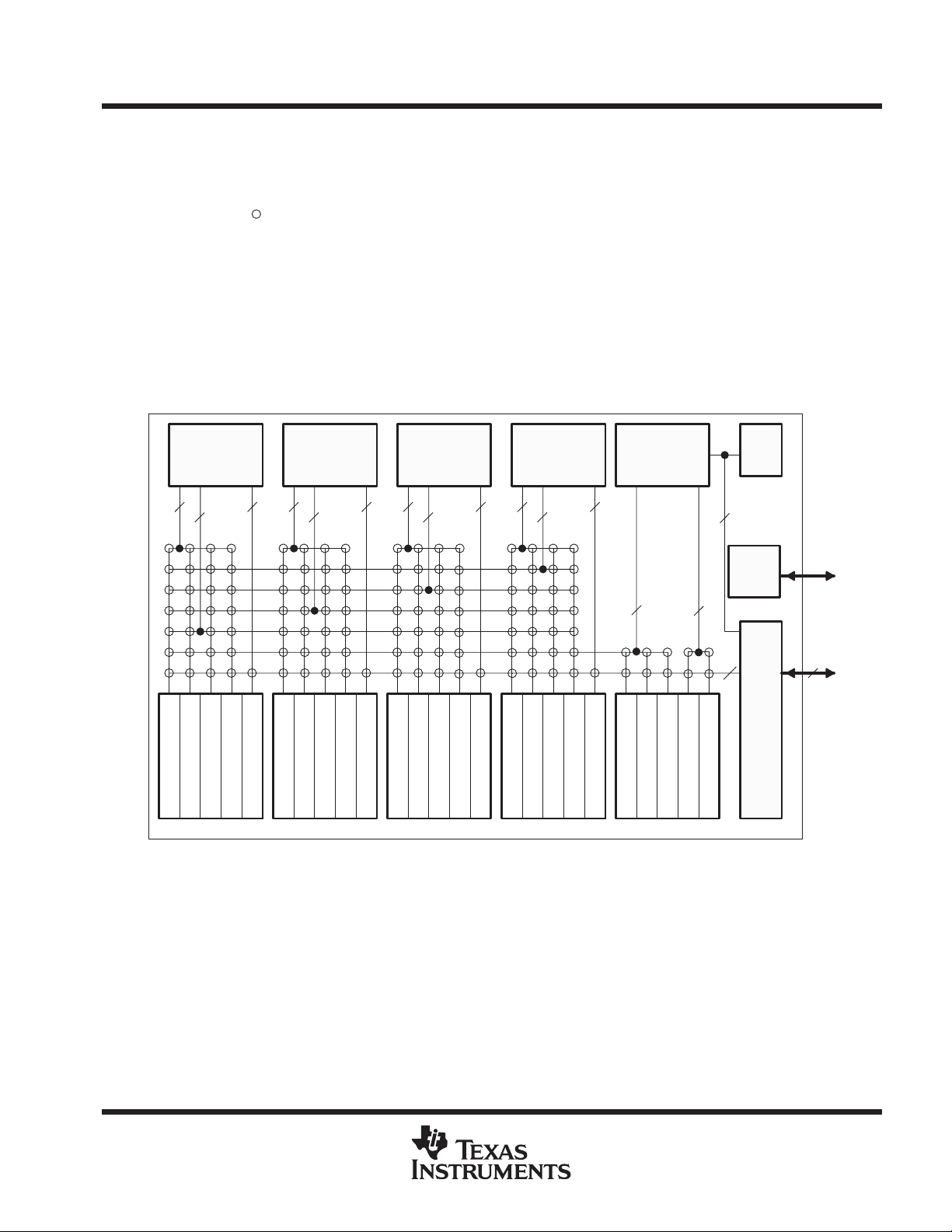
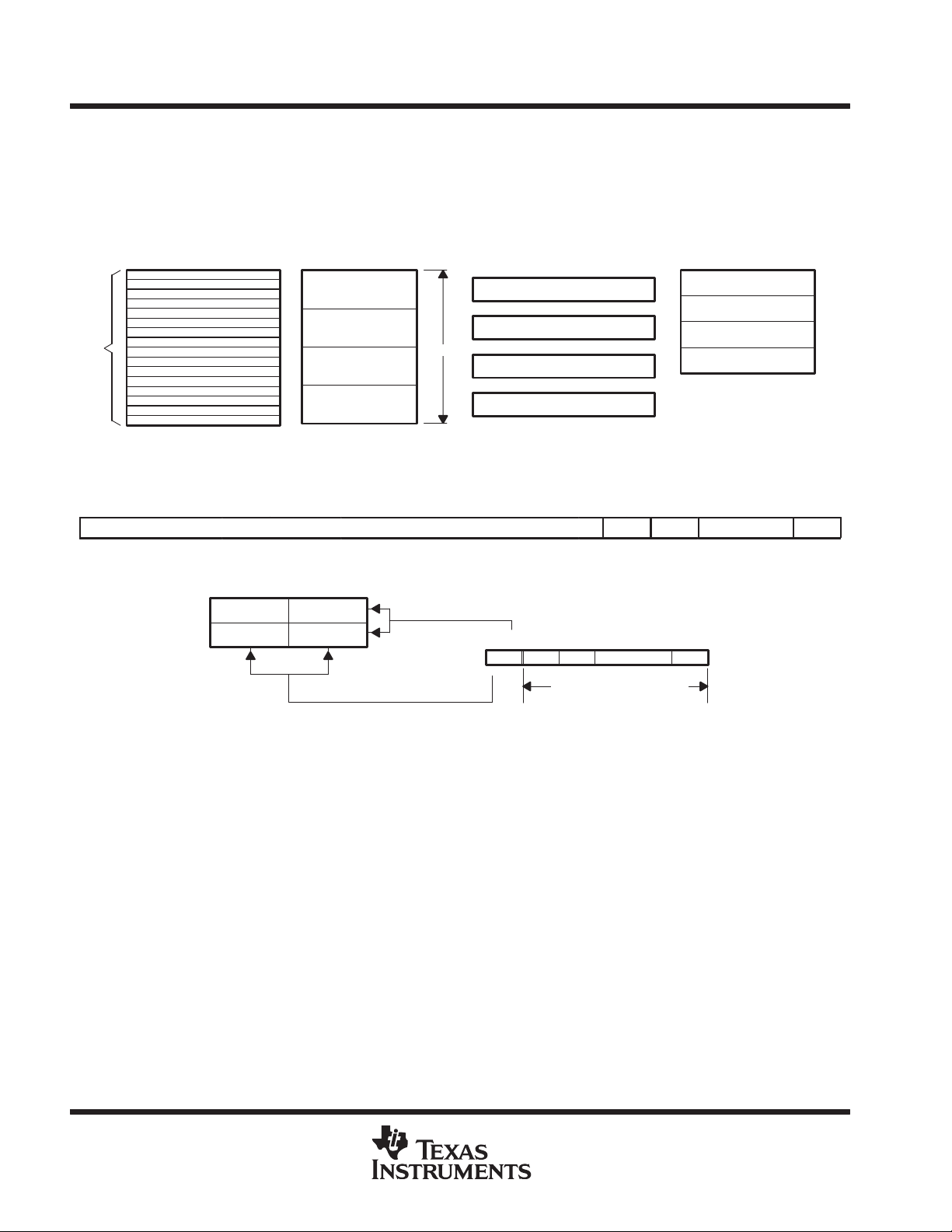
Figure 1 shows the major components of the ’C80: the master processor (MP), the parallel digital signal
processors (PPs), the transfer controller ( TC), the video controller (VC), and the IEEE-1149.1 emulation
interface. Shared access to on-chip RAM is achieved through the crossbar. Crossbar connections are
represented by
instruction (I) ports. The MP can access two RAMs per cycle through its crossbar/data (C/D) and instruction
(I) ports, and the TC can access one RAM through its crossbar interface. Up to 15 simultaneous accesses are
supported in each cycle. Addresses can be changed every cycle, allowing the crossbar matrix to be changed
on a cycle-by-cycle basis. Contention between processors for the same RAM in the same cycle is resolved by
a round-robin priority scheme. In addition to the crossbar, a 32-bit datapath exists between the MP and the TC
and VC. This allows the MP to access TC and VC on-chip registers that are memory mapped into the MP
memory space.
The ’C80 has a 4G-byte address space as shown in Figure 2. The lower 32M bytes are used to address internal
RAM and memory-mapped registers.
. Each PP can perform three accesses per cycle through its local ( L), global ( G ), and
PP3
LG I
32 64
32
Data RAM2
Data RAM1
Parameter RAM
LG I
32 64
Data RAM0
Parameter RAM
Instruction Cache
PP2
32
Data RAM2
Data RAM1
Data RAM0
Instruction Cache
PP1
LG I
32 64
32
Data RAM2
Data RAM1
Parameter RAM
LG I
32 64
Data RAM0
Parameter RAM
Instruction Cache
PP0
32
Data RAM2
Data RAM1
Data RAM0
Instruction Cache
Figure 1. Block Diagram Showing Datapaths
MP
OCR
C/D I
64
Parameter RAM
32
Data RAM2
Data RAM1
VC
32
IEEE-
1149.1
(JTAG)
64
64
TC
Data RAM0
Instruction Cache
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
15

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
architecture (continued)
PP0 Data RAM0
(2K Bytes)
PP0 Data RAM1
(2K Bytes)
PP1 Data RAM0
(2K Bytes)
PP1 Data RAM1
(2K Bytes)
PP2 Data RAM0
(2K Bytes)
PP2 Data RAM1
(2K Bytes)
PP3 Data RAM0
(2K Bytes)
PP3 Data RAM1
(2K Bytes)
Reserved
(16K Bytes)
PP0 Data RAM2
(2K Bytes)
Reserved
(2K Bytes)
PP1 Data RAM2
(2K Bytes)
Reserved
(2K Bytes)
PP2 Data RAM2
(2K Bytes)
Reserved
(2K Bytes)
PP3 Data RAM2
(2K Bytes)
Reserved
(16730112 Bytes)
PP0 Parameter RAM
(2K Bytes)
Reserved
(2K Bytes)
PP1 Parameter RAM
(2K Bytes)
Reserved
(2K Bytes)
PP2 Parameter RAM
(2K Bytes)
Reserved
(2K Bytes)
PP3 Parameter RAM
(2K Bytes)
0x00000000
0x000007FF
0x00000800
0x00000FFF
0x00001000
0x000017FF
0x00001800
0x00001FFF
0x00002000
0x000027FF
0x00002800
0x00002FFF
0x00003000
0x000037FF
0x00003800
0x00003FFF
0x00004000
0x00007FFF
0x00008000
0x000087FF
0x00008800
0x00008FFF
0x00009000
0x000097FF
0x00009800
0x00009FFF
0x0000A000
0x0000A7FF
0x0000A800
0x0000AFFF
0x0000B000
0x0000B7FF
0x0000B800
0x00FFFFFF
0x01000000
0x010007FF
0x01000800
0x01000FFF
0x01001000
0x010017FF
0x01001800
0x01001FFF
0x01002000
0x010027FF
0x01002800
0x01002FFF
0x01003000
0x010037FF
Reserved
(51200 Bytes)
MP Parameter RAM
(2K Bytes)
Reserved
(8327168 Bytes)
PP0 Instruction Cache
(2K Bytes)
Reserved
(6K Bytes)
PP1 Instruction Cache
(2K Bytes)
Reserved
(6K Bytes)
PP2 Instruction Cache
(2K Bytes)
Reserved
(6K Bytes)
PP3 Instruction Cache
(2K Bytes)
Reserved
(32K Bytes)
MP Data Cache
(4K Bytes)
Reserved
(28K Bytes)
MP Instruction Cache
(4K Bytes)
Reserved
(28K Bytes)
Memory-Mapped TC Registers
(512 Bytes)
Memory-Mapped VC Registers
(512 Bytes)
Reserved
(8327168 Bytes)
External Memory
(4064M Bytes)
0x01003800
0x0100FFFF
0x01010000
0x010107FF
0x01010800
0x018017FF
0x01801800
0x01801FFF
0x01802000
0x018037FF
0x01803800
0x01803FFF
0x01804000
0x018057FF
0x01805800
0x01805FFF
0x01806000
0x018077FF
0x01807800
0x01807FFF
0x01808000
0x0180FFFF
0x01810000
0x01810FFF
0x01811000
0x01817FFF
0x01818000
0x01818FFF
0x01819000
0x0181FFFF
0x01820000
0x018201FF
0x01820200
0x018203FF
0x01820400
0x01FFFFFF
0x02000000
0xFFFFFFFF
16
Figure 2. Memory Map
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
master processor (MP) architecture
The master processor (MP) is a 32-bit RISC processor with an integral IEEE-754 floating-point unit. The MP
is designed for effective execution of C code and is capable of performing at well over 130K dhrystones/s. Major
tasks which the MP typically performs are:
D
Task control and user interface
D
Information processing and analysis
D
IEEE-754 floating point (including graphics transforms)
MP functional block diagram
Figure 3 shows a block diagram of the master processor. Key features of the MP include:
D
32-bit RISC processor
– Load/store architecture
– Three operand arithmetic and logical instructions
D
4K-byte instruction cache and 4K-byte data cache
– Four-way set associative
– LRU replacement
– Data writeback
D
2K-byte non-cached parameter RAM
D
Thirty-one 32-bit general-purpose registers
D
Register and accumulator scoreboard
D
15-bit or 32-bit immediate constants
D
32-bit byte addressing
D
Scalable timer
D
Leftmost-one and rightmost-one logic
D
IEEE-754 floating-point hardware
– Four double-precision floating-point vector accumulators
– Vector floating-point instructions
Floating-point operation and parallel load or store
Multiply and accumulate
D
High performance
– 60 million instructions per second (MIPS)
– 120 million floating-point operations per second (MFLOPS)
– Over 130K dhrystones/s
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
17

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP functional block diagram (continued)
(Thirty-One 32-Bit Registers)
Register File
Barrel Rotator
Mask Generator
Zero Comparator
Integer ALU
Leftmost/Rightmost One
Timer
Control Registers
Instruction Register
Program Counters
PC Incrementer
Scoreboard
Double-Precision
Floating-Point Multiplier
(Single-Precision Core)
Double-Precision Floating-Point
Accumulators
Double-Precision
Floating-Point Adder
Emulation Logic
Instruction Cache
Controller
Crossbar Interface
Endian Multiplexers
Data/Cache
Controller
Figure 3. MP Block Diagram
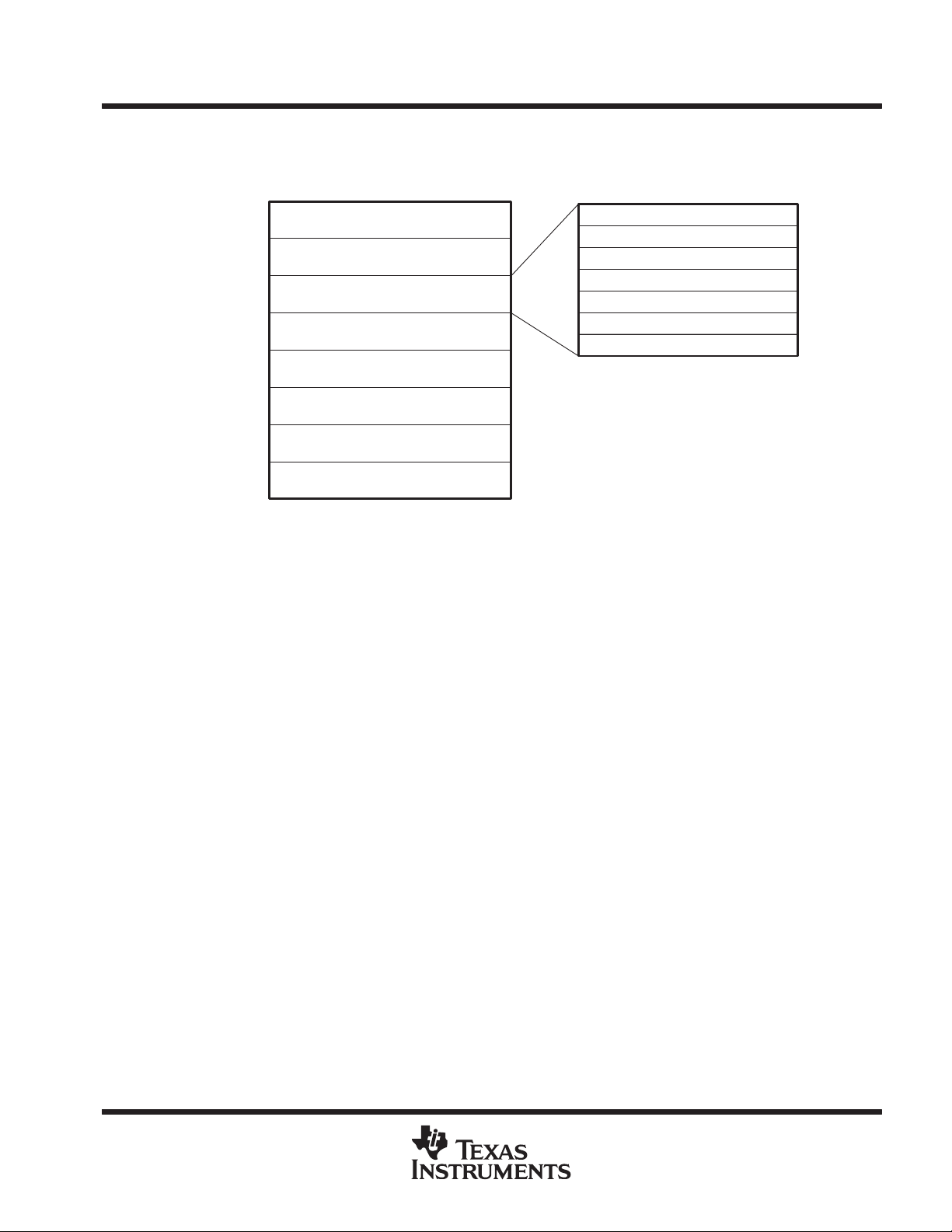
MP general-purpose registers
The MP contains 31 32-bit general-purpose registers, R1–R31. Register R0 always reads as zero and writes
to it are discarded. Double precision values are always stored in an even-odd register pair with the higher
numbered register always holding the sign bit and exponent. The R0/R1 pair is not available for this use. A
scoreboard keeps track of which registers are awaiting loads or the result of a previous instruction and stalls
the instruction pipeline until the register contains valid data. As a recommended software convention, typically
R1 is used as a stack pointer and R31 as a return-address link register.
Figure 4 shows the MP general-purpose registers.
18
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

Not Available
R2, R3
R4, R5
R30, R31
Floating Point
Integer
Unsi
Bit
Integer
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP general-purpose registers (continued)
Zero/Discard
R1
R2
R3
R4
R5
• • • • • •
R30
R31
32-Bit Registers 64-Bit Register Pairs
Figure 4. MP General-Purpose Registers
The 32-bit registers can contain signed-integer, unsigned-integer, or single precision floating-point values.
Signed and unsigned bytes and halfwords are sign extended or zero-filled. Doublewords may be stored in a
64-bit even/odd register pair. Double-precision floating-point values are referenced using the even register
number or the register pair. Figure 5 through Figure 7 show the register data formats.
Single Precision
Signed 32-bit
gned 32-
31 22 0
S E E E E E E E E M M M M M M M M M M M M M M M M M M M M M M M
MS LS
31 0
S I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
MS LS
31 0
U U U U U U U U U U U U U U U U U U U U U U U U U U U U U U U U
MS LS
Figure 5. MP Register 32-Bit Data Formats
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
19

TMS320C80
Unsi
d
Halfword
Double Precision
Double Precision
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP general-purpose registers (continued)
31 70
Signed Byte
Unsigned Byte
Signed Halfword
S S S S S S S S S S S S S S S S S S S S S S S S I I I I I I I
S
31 70
0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 U U U U U U U U
31 15 0
S S S S S S S S S S S S S S S S S I I I I I I I I I I I I I I I
MS LS
MS LS
MS LS
gne
31 15 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 U U U U U U U U U U U U U U U U
MS LS
Figure 6. MP Register 8-Bit and 16-Bit Data
31 0
Odd Register
MS
31 0
Even Register Least Significant 32-Bit Word
-
Floating-Point
Odd Register
Floating-Point
Even Register
31 19 0
S E E E E E E E E E E E M M M M M M M M M M M M M M M M M M M M
31 0
M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M M
M
Most Significant 32-Bit Word
MS
Figure 7. MP Register 64-Bit Data
MP double-precision floating-point accumulators
LS
LS
a0
a1 Accumulator 1
a2 Accumulator 2
a3 Accumulator 3
20
There are four double-precision floating-point registers (see Figure 8) to accumulate intermediate floating-point
results.
64 0
Accumulator 0
MSB LSB
Figure 8. Double-Precision Floating-Point Accumulators
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP control registers
In addition to the general-purpose registers, there are a number of control registers that are used to represent
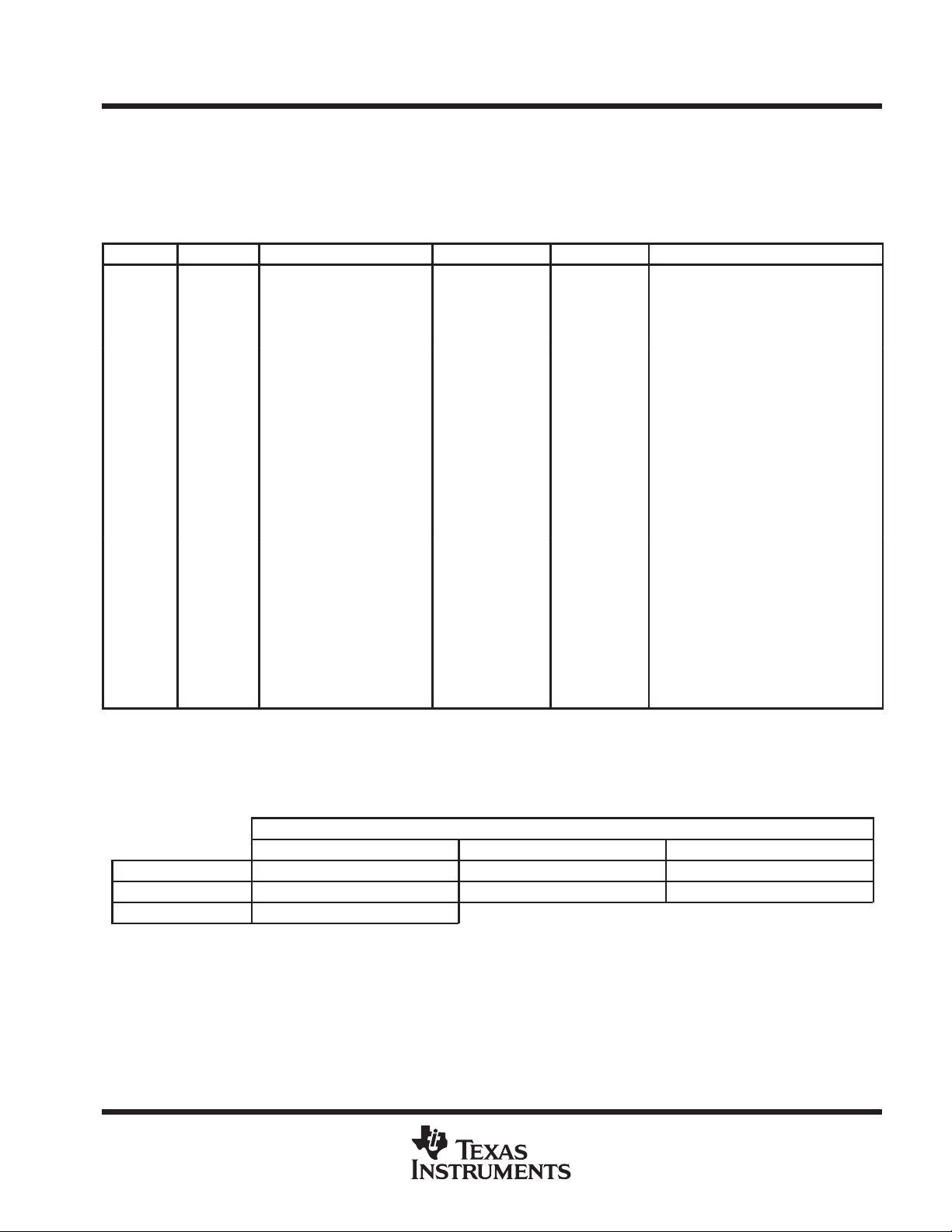
the state of the processor. Table 1 shows the control register numbers of the accessible registers.
Table 1. Control Register Numbers
NO. NAME DESCRIPTION NO. NAME DESCRIPTION
0x0000 EPC Exception Program Counter 0x0015–0x001F — Reserved
0x0001 EIP Exception Instruction Pointer 0x0020 SYSSTK System Stack Pointer
0x0002 CONFIG Configuration 0x0021 SYSTMP System Temporary Register
0x0003 — Reserved 0x0022–0x002F — Reserved
0x0004 INTPEN Interrupt Pending 0x0030 MPC Emulator Exception Program Cntr
0x0005 — Reserved 0x0031 MIP Emulator Exception Instruction Ptr
0x0006 IE Interrupt Enable 0x0032 — Reserved
0x0007 — Reserved 0x0033 ECOMCNTL Emulator Communication Control
0x0008 FPST Floating-Point Status 0x0034 ANASTA T Emulation Analysis Status Reg
0x0009 — Reserved 0x0035–0x0038 — Reserved
0x000A PPERROR PP Error Indicators 0x0039 BRK1 Emulation Breakpoint 1 Reg.
0x000B — Reserved 0x003A BRK2 Emulation Breakpoint 2 Reg.
0x000C — Reserved 0x003B–0x01FF — Reserved
0x000D PKTREQ Packet Request Register 0x0200 – 0x020F ITAG0–15 Instruction Cache Tags 0 to 15
0x000E TCOUNT Current Counter Value 0x0300 ILRU Instruction Cache LRU Register
0x000F TSCALE Counter Reload Value 0x0400–0x040F DT AG0–15 Data Cache Tags 0 to 15
0x0010 FLTOP Faulting Operation 0x0500 DLRU Data Cache LRU Register
0x0011 FLTADR Faulting Address 0x4000 IN0P Vector Load Pointer 0
0x0012 FLTTAG Faulting Tag 0x4001 IN1P Vector Load Pointer 1
0x0013 FLTDTL Faulting Data (low) 0x4002 OUTP V ector Store Pointer
0x0014 FLTDTH Faulting Date (high)
MP pipeline registers
The MP uses a three-stage fetch, execute, access (FEA) pipeline. The primary pipeline registers are
manipulated implicitly by branch and trap instructions and are not accessible by the user. The exception and
emulation pipeline registers are user accessible as control registers. All pipeline registers are 32 bits.
Program Execution Mode
Normal Exception Emulation
Program Counter PC EPC MPC
Instruction Pointer IP EIP MIP
Instruction Register IR
• Instruction register (IR) contains the instruction being
executed.
• Instruction pointer (IP) points to the instruction being
executed.
• Program counter (PC) points to the instruction being
fetched.
• Exception/emulator instruction pointer (EIP/MIP) points to the
instruction that would have been executed had the exception /
emulation trap not occurred.
• Exception/emulator program counter (EPC/MPC) points to the
instruction to be fetched on returning from the exception/emulation
trap.
Figure 9. MP FEA Pipeline Registers
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
21
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
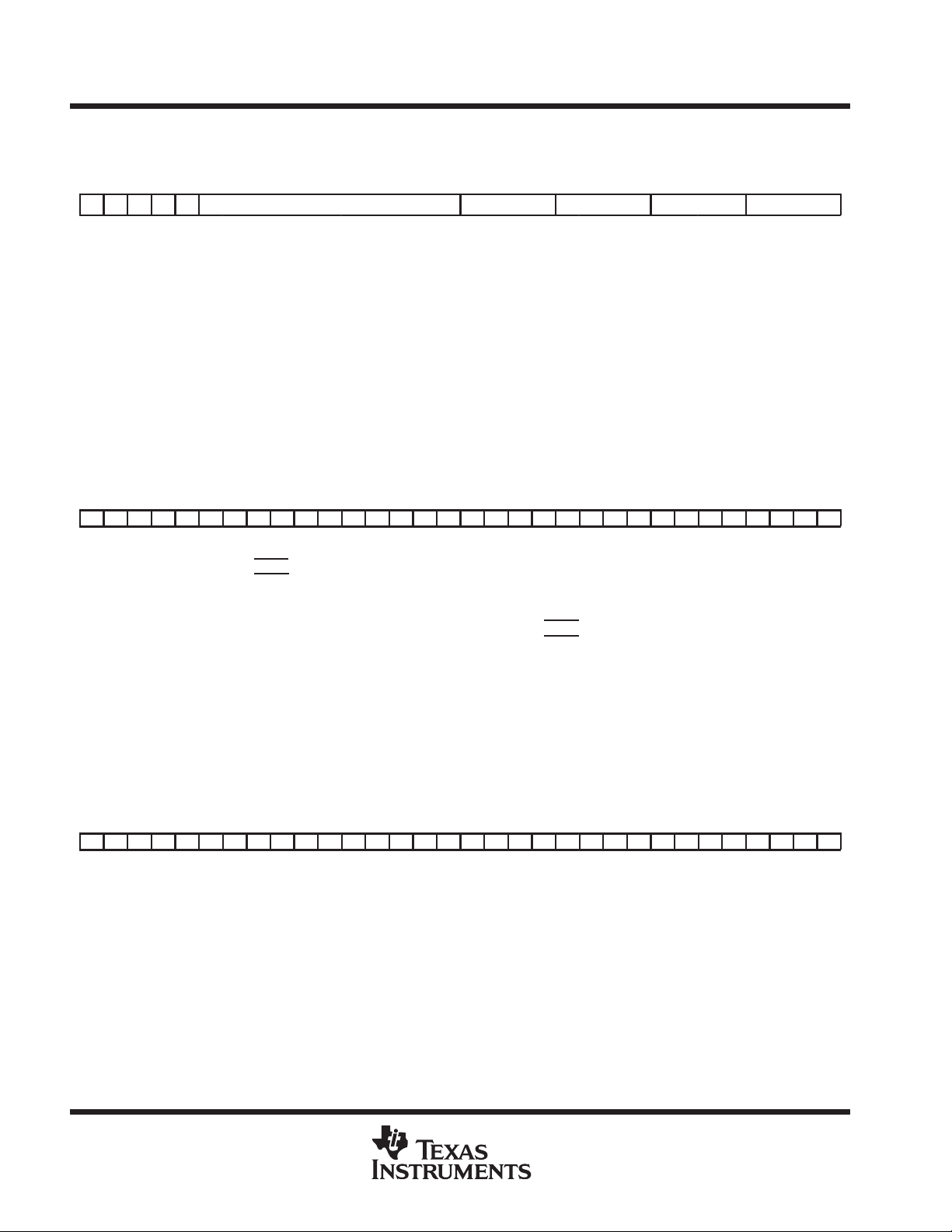
configuration (CONFIG) register (0x0002)
The CONFIG register controls or reflects the state of certain options as shown in Figure 10.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
E R T H X Reserved Type Reserved Release Reserved
Endian mode; 0 = big-endian, 1 = little-endian, read only
E
PPData RAM round robin; 0 = fixed, 1 = variable, read/write
R
TC PT round robin; 0 = variable, 1 = fixed, read/write.
T
High priority MP events; 0 = disabled, 1 = enabled, read/write
H
Externally initiated packet transfers; 0 = disabled, 1 = enabled, read/write
X
Number of PPs in device, read only
Type
Release
interrupt-enable (IE) register (0x0006)
The IE register contains enable bits for each of the interrupts/traps as shown in Figure 11. The
global-interrupt-enable (ie) bit and the appropriate individual interrupt-enable bit must be set in order for an
interrupt to occur.
TMS320C80 version number
Figure 10. CONFIG Register
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
pe x4 x3 bp pb pc mi p3 p2 p1 p0 io mf x2 x1 ti f1 f0 fx fu fo fz fi ie
PP2 message interrupt
PP error
pe
External interrupt 4 (LINT4
x4
x3
External interrupt 3 (EINT3
Bad packet transfer
bp
Packet transfer busy
pb
Packet transfer complete
pc
Message (MP self) interrupt
mi
PP3 message interrupt
p3
p2
PP1message interrupt
)
)
p1
PP0 message interrupt
p0
Integer overflow
io
Memory fault
mf
External interrupt 2 (EINT2
x2
x1
External interrupt 1 (EINT1
ti
MP timer interrupt
)
)
Frame-timer 1 interrupt
f1
Frame-timer 0 interrupt
f0
Floating-point inexact
fx
Floating-point underflow
fu
Floating-point overflow
fo
Floating-point divide-by-zero
fz
Floating-point invalid
fi
Global-interrupt enable
ie
Figure 11. IE Register
interrupt-pending (INTPEN) register (0x0004)
The bits in INTPEN register show the current state of each interrupt/trap. Pending interrupts do not occur unless
the ie bit and corresponding interrupt-enable bit are set. Software must write a 1 to the appropriate INTPEN bit
to clear an interrupt. Figure 12 shows the INTPEN register locations.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
pe x4 x3 bp pb pc mi p3 p2 p1 p0 io mf x2 x1 ti f1 f0 fx fu fo fz fi
Figure 12. INTPEN Register
22
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
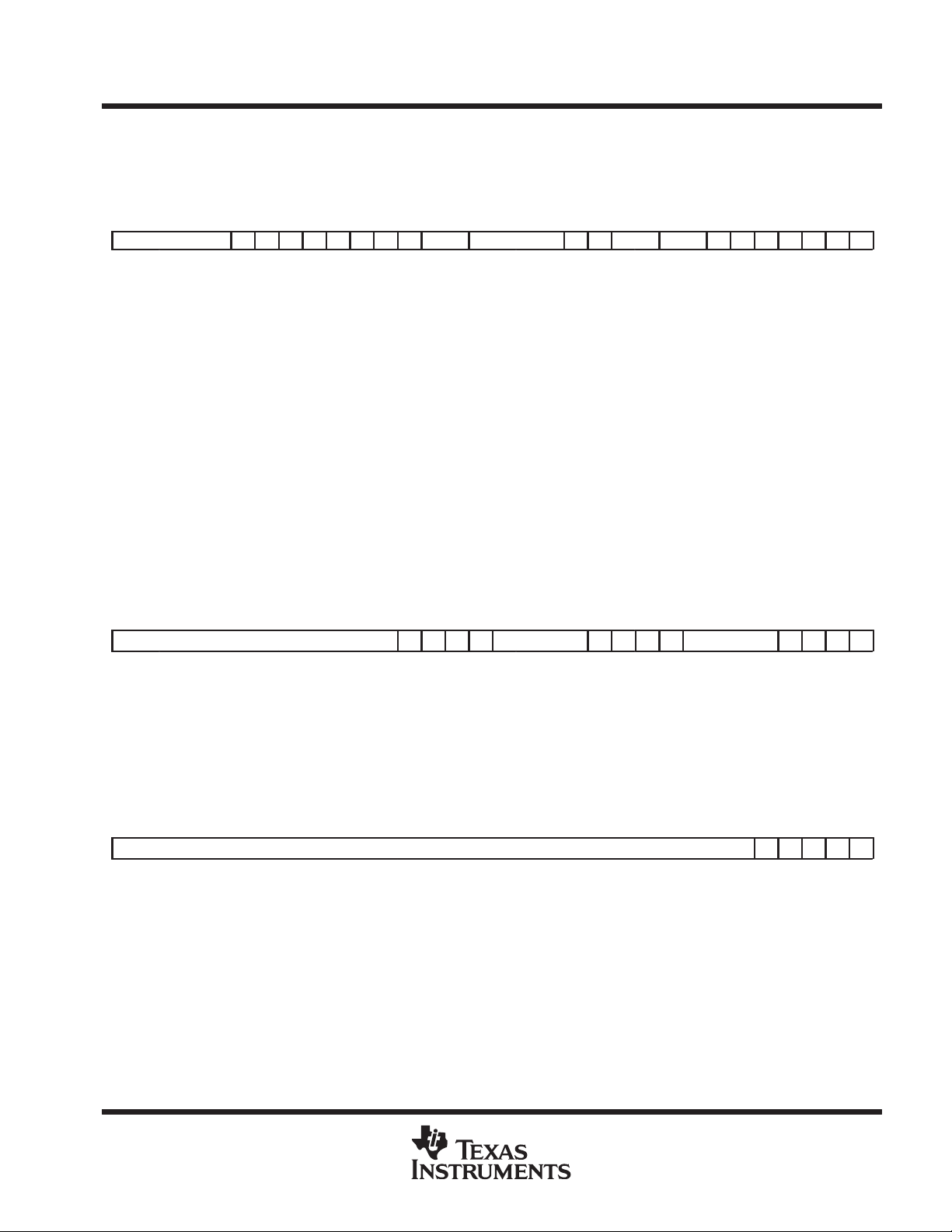
floating-point status register (FPST) (0x0008)
FPST contains status and control information for the FPU as shown in Figure 13. Bits 17–21 are read/write
floating-point unit (FPU) control bits. Bits 22–26 are read/write accumulated status bits. All other bits show the
status of the last FPU instruction to complete and are read only.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
destination
dest
ai
az
ao
au
ax
sm
fs
vm
drm
opcode
e1
ai az ao au ax sm fs vm drm opcode e1 e0 pd rm mo i z o u x
The ninth MSB of exponent
Destination register value
Accumulated value invalid
Accumulated divide-by-zero
Accumulated overflow
Accumulated underflow
Accumulated inexact
Sequential mode select
Floating-point stall
Vector fast mode
Rounding mode
00 – nearest 10 – positive ∞
01 – zero 11 – negative ∞
Last opcode
The tenth MSB of exponent
e0
Destination precision
pd
Rounding mode
rm
Int multiply overflow
mo
Invalid
i
Divide-by-zero
z
Overflow
o
Underflow
u
Inexact
x
00 – single float 10 – signed int
01 – double float 11 – unsigned int
00 – nearest 10 – positive ∞
01 – zero 11 – negative ∞
Figure 13. FPSTS Register
PP error register (PPERROR) (0x000A)
The bits in the PPERROR register reflect parallel processor errors (see Figure 14). The MP can use these when
a PP error interrupt occurs to determine the cause of the error.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Reserved h h h h Reserved i i i i Reserved f f f f
PP# 3 2 1 0 PP# 3 2 1 0 PP# 3 2 1 0
h – PP halted i – PP illegal instruction f – PP fault type; 0 = icache, 1 = DEA
Figure 14. PPERROR Register
packet-transfer request register (PKTREQ) (0x000D)
PKTREQ controls the submission and priority of packet-transfer requests as shown in Figure 15. It also
indicates that a packet transfer is currently active.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Reserved I F S Q P
I – Immediate (urgent) priority selected
F – High (foreground) priority selected
S – Suspend packet transfer
Q – Packet transfer queued; read only
P – Submit packet-transfer
request
Figure 15. PKTREQ Register
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
23
TMS320C80
FLTOP
(
)
(0x0010)
FLTTAG
(
)
(0x0012)
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
memory-fault registers
The five read-only memory-fault registers contain information about memory address exceptions, as shown in
Figure 16.
313029282726252423222120191817161514131211109876543210
0x0010
0x0012
FLTADR
(0x0011)
FLTDTH
(0x0013)
FLTDTL
(0x0014)
Dest Reserved K SZ i d x R Reserved Block
313029282726252423222120191817161514131211109876543210
22-Bit Cache Tag Address P D P D P D P D
3 2 1 0
Sub-Block
31 0
Faulting Address Accessed by the Instruction
Faulting Write Most-Significant-Data Word
Faulting Write Least-Significant-Data Word
Destination Register Number
Dest
Kind of Operation:
K
00 – load
01 – unsigned load
10 – store
11 – cache flush/clean
Size of Data:
SZ
00 – 8-bit
01 – 16-bit
10 – 32-bit
11 – 64-bit
MP icache fault
i
MP dcache fault
d
DEA Fault
x
Modified return sequence
R
Block
Faulting block number
Sub-block is present.
P
Dirty bit set
D
Figure 16. Memory-Fault Registers
24
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP cache registers
The ILRU and DLRU registers track least-recently-used (LRU) information for the sixteen instruction-cache and
sixteen data-cache blocks. The ITAGxx registers contain block addresses and the present flags for each
sub-block. DT AGxx registers are identical to IT AGxx registers but include dirty bits for each sub-block. Figure 17
shows the cache registers.
ILRU (0x0300)
DLRU (0x0500)
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
mru nmru nlru lru mru nmru nlru lru mru nmru nlru lru mru nmru nlru lru
Set 3
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
22-Bit Cache Tag Address P P P P
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
22-Bit Cache Tag Address P D P D P D P D
Set 2 Set 1 Set 0
ITAG0–ITAG15 (0x0200–0x020F)
3 2 1 0
Sub-Block
DTAG0–DTAG15 (0x0400–0x040F)
3 2 1 0
Sub-Block
mru
Most-recently-used block
nmru
Next most-recently-used block
nlru
Next least-recently-used block
mru, nmru, nlru, and lru have the value 0, 1, 2, or 3 representing the block number and are mutually exclusive for each set.
lru
Least-recently-used block
P
Sub-block present
D
Sub-block dirty
Figure 17. Cache Registers
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
25
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP cache architecture
The MP contains two four-way set-associative, 4K caches for instructions and data. Each cache is divided into
four sets with four blocks in each set. Each block represents 256 bytes of contiguous instructions or data and
is aligned to a 256-byte address boundary. Each block is partitioned into four sub-blocks that each contain
sixteen 32-bit words and are aligned to 64-byte boundaries within the block. Cache misses cause one sub-block
to be loaded into cache. Figure 18 shows the cache architecture for one of the four sets in each cache. Figure 19
shows how addresses map into the cache using the cache tags and address bits.
LRU in SET 0
NLRU in SET 0
NMRU in SET 0
MRU in SET 0
LRU Stack for SET 0
Sub-Blocks
Block 0
Block 1
Block 2
Block 3
Tag Reg 0 (Block 0)
Tag Reg 1 (Block 1)
Set 0
Tag Reg 2 (Block 2)
Tag Reg 3 (Block 3)
Figure 18. MP Cache Architecture (x4 Sets)
32-Bit Logical Address
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
T T T T T T T T T T T T T T T T T T T T T T S S s s W W W W B B
On-Chip MP 2K Cache RAMS
Bank 0
Set 0
Set 1 Set 3
T – Tag Address Bits s – Sub-Block (within block) Select (0–3) B – Byte (within word) Select (0–3)
S – Set Select Bits (0–3) W – Word (within sub-block) Select (0–15) A – Block Select (which tag matched) (0–3)
Bank 1
Set 2
11109876
SSAAss
Address in On-Chip
Cache Bank
543210
WWWWBB
26
Figure 19. MP Cache Addressing
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP parameter RAM
The parameter RAM is a noncachable, 2K-byte, on-chip RAM which contains MP-interrupt vectors,
MP-requested TC task buffers, and a general-purpose area. Figure 20 shows the parameter RAM address map.
0x01010000–0x0101007F
0x01010080–0x010100DF
0x010100E0–0x010100FB
0x010100FC–0x010100FF
0x01010100–0x0101017F
0x01010180–0x0101021F
0x01010220–0x0101029F
0x010102A0–0x010107FF
Suspended PT Parameters
(128 Bytes)
Reserved
(96 Bytes)
XPT Linked List Start Addresses
(28 Bytes)
MP Linked List Start Address
Off-Chip to Off-Chip PT Buffer
(128 Bytes)
Interrupt and Trap Vectors
(160 Bytes)
XPT Off-Chip to Off-Chip PT Buffer
(128 Bytes)
General-Purpose RAM
(1376 Bytes)
Figure 20. MP Parameter RAM
XPT7/SOF0 Linked List Start Add. 0x010100E0
XPT6/SAM0 Linked List Start Add. 0x010100E4
XPT5/SOF1 Linked List Start Add. 0x010100E8
XPT4/SAM1 Linked List Start Add. 0x010100EC
XPT3 Linked List Start Add. 0x010100F0
XPT2 Linked List Start Add. 0x010100F4
XPT1 Linked List Start Add. 0x010100F8
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
27

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP interrupt vectors
Table 2 and Table 3 show the MP interrupts and traps and their vector addresses.
Table 2. Maskable Interrupts
IE BIT
(TRAP#)
0 ie 0x01010180
2 fi 0x01010188 Floating-point invalid
3 fz 0x0101018C Floating-point divide-by-zero
5 fo 0x01010194 Floating-point overflow
6 fu 0x01010198 Floating-point underflow
7 fx 0x0101019C Floating-point inexact
8 f0 0x010101A0 Frame timer 0
9 f1 0x010101A4 Frame timer 1
10 ti 0x010101A8 MP timer
11 x1 0x010101AC External interrupt 1 (EINT1)
12 x2 0x010101B0 External interrupt 2 (EINT2)
14 mf 0x010101B8 Memory fault
15 io 0x010101BC Integer overflow
16 p0 0x010101C0 PP0 message
17 p1 0x010101C4 PP1 message
18 p2 0x010101C8 PP2 message
19 p3 0x010101CC PP3 message
25 mi 0x010101E4 MP message
26 pc 0x010101E8 Packet transfer complete
27 pb 0x010101EC Packet transfer busy
28 bp 0x010101F0 Bad packet transfer
29 x3 0x010101F4 External interrupt 3 (EINT3)
30 x4 0x010101F8 External interrupt 4 (LINT4)
31 pe 0x010101FC PP error
NAME
VECTOR
ADDRESS
MASKABLE INTERRUPT
28
Table 3. Nonmaskable Traps
TRAP
NO.
32 e1 0x01010200 Emulator trap1 (reserved)
33 e2 0x01010204 Emulator trap2 (reserved)
34 e3 0x01010208 Emulator trap3 (reserved)
35 e4 0x0101020C Emulator trap4 (reserved)
36 fe 0x01010210 Floating-point error
37 0x01010214 Reserved
38 er 0x01010218 Illegal MP instruction
39 0x0101021C Reserved
72
to
415
NAME
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
VECTOR
ADDRESS
0x010102A0 to
0x010107FC
NONMASKABLE TRAP
System or user defined

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP opcode formats
The three basic classes of MP instruction opcodes are; short immediate, three register, and long immediate.
Figure 21 shows the opcode structure for each class of instruction.
31 27 26 22 21 15 14 0
Short
Immediate
Three
Register
Long
immediate
Dest
31 27 26 22 21 20 19 13 12 11 5 4 0
Dest
31 27 26 22 21 20 19 13 12 11 5 4 0
Dest
Source 2 Opcode 15-Bit Immediate
Source 2 1 1 Opcode 0 Options Source 1
Source 2 1 1 Opcode 1 Options Source 1
32-Bit Long Immediate
Figure 21. MP Opcode Formats
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
29

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP opcode summary
Table 4 through Table 6 show the opcode formats for the MP. Table 7 summarizes the master processor
instruction set.
Table 4. Short-Immediate Opcodes
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
illop0
trap – – – – E – – – – – 0 0 0 0 0 0 1 Unsigned Trap Number
cmnd – – – – – – – – – – 0 0 0 0 0 1 0 Unsigned Immediate
rdcr Dest – – – – – 0 0 0 0 1 0 0 Unsigned Control Register Number
swcr Dest Source 0 000101 Unsigned Control Register Number
brcr – – – – – – – – – – 0 0 0 0 1 1 0 Unsigned Control Register Number
shift.dz Dest Source 0 0 0 1 0 0 0 – – – i n Endmask Rotate
shift.dm Dest Source 0 001001–––in Endmask Rotate
shift.ds Dest Source 0 001010–––in Endmask Rotate
shift.ez Dest Source 0 001011–––in Endmask Rotate
shift.em Dest Source 0 001100–––in Endmask Rotate
shift.es Dest Source 0 001101–––in Endmask Rotate
shift.iz Dest Source 0 001110–––in Endmask Rotate
shift.im Dest Source 0 001111–––in Endmask Rotate
and.tt Dest Source2 0 0 1 0 0 0 1 Unsigned Immediate
and.tf Dest Source2 0 010010 Unsigned Immediate
and.ft Dest Source2 0 010100 Unsigned Immediate
xor Dest Source2 0 010110 Unsigned Immediate
or.tt Dest Source2 0 010111 Unsigned Immediate
and.ff Dest Source2 0 011000 Unsigned Immediate
xnor Dest Source2 0 011001 Unsigned Immediate
or.tf Dest Source2 0 011011 Unsigned Immediate
or.ft Dest Source2 0 011101 Unsigned Immediate
or.f f Dest Source2 0 011110 Unsigned Immediate
ld Dest Base 0 1 0 0 M SZ Signed Offset
ld.u Dest Base 0 101M SZ Signed Offset
st Source Base 0 110M SZ Signed Offset
dcache – – – – F Source2 0 1 1 1 M 0 0 Signed Of fset
bsr Link – – – – – 1 0 0 0 0 0 A Signed Offset
jsr Link Base 1 00010A Signed Offset
bbz BITNUM Source 1 0 0 1 0 0 A Signed Offset
bbo BITNUM Source 1 00101A Signed Offset
bcnd Cond Source 1 00110A Signed Offset
cmp Dest Source2 1 0 1 0 0 0 0 Signed Immediate
add Dest Source2 1 0 1 1 0 0 U Signed Immediate
sub Dest Source2 1 01101U Signed Immediate
– Reserved bit (code as 0) M Modify, write modified address back to register
A Annul delay slot instruction if branch taken n Rotate sense for shifting
E Emulation trap bit SZ Size (0 = byte, 1 = halfword, 2 = word, 3 = doubleword)
F Clear present flags U Unsigned form
i Invert endmask
Dest
Source 0 0 0 0 0 0 0 Unsigned Immediate
30
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP opcode summary (continued)
Table 5. Long-Immediate and Three-Register Opcodes
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
trap
cmnd – – – – – – – – – – 1 1 0 0 0 0 0 1 0 I – – – – – – – Source1
rdcr Dest – – – – – 1 1 0 0 0 0 1 0 0 I – – – – – – – IND CR
swcr Dest Source 1 10000101I– – – – – – – IND CR
brcr – – – – – – – – – – 1 1 0 0 0 0 1 1 0 I – – – – – – – IND CR
shift.dz Dest Source 1 1 0 0 0 1 0 0 0 0 i n Endmask Rotate
shift.dm Dest Source 1 100010010i n Endmask Rotate
shift.ds Dest Source 1 100010100i n Endmask Rotate
shift.ez Dest Source 1 100010110i n Endmask Rotate
shift.em Dest Source 1 100011000i n Endmask Rotate
shift.es Dest Source 1 100011010i n Endmask Rotate
shift.iz Dest Source 1 100011100i n Endmask Rotate
shift.im Dest Source 1 100011110i n Endmask Rotate
and.tt Dest Source2 1 1 0 0 1 0 0 0 1 I – – – – – – – Source1
and.tf Dest Source2 1 10010010I– – – – – – – Source1
and.ft Dest Source2 1 10010100I– – – – – – – Source1
xor Dest Source2 1 10010110I– – – – – – – Source1
or.tt Dest Source2 1 10010111I– – – – – – – Source1
and.ff Dest Source2 1 10011000I– – – – – – – Source1
xnor Dest Source2 1 10011001I– – – – – – – Source1
or.tf Dest Source2 1 10011011I– – – – – – – Source1
or.ft Dest Source2 1 10011101I– – – – – – – Source1
or.ff Dest Source2 1 10011110I– – – – – – – Source1
ld.u Dest Base 1 10101M SZ I S D – – – – – Offset
dcache – – – – F Source2 1 1 0 1 1 1 M 0 0 I 0 0 – – – – – Source1
bsr Link – – – – – 1 1 1 0 0 0 0 0 A I – – – – – – – Offset
jsr Link Base 1 1100010AI – – – – – – – Offset
bbz BITNUM Source 1 1 1 0 0 1 0 0 A I – – – – – – – Target
bbo BITNUM Source 1 1100101AI – – – – – – – Target
bcnd Cond Source 1 1100110AI – – – – – – – Target
cmp Dest Source2 1 1 1 0 1 0 0 0 0 I – – – – – – – Source1
add Dest Source2 1 1 1 0 1 1 0 0 U I – – – – – – – Source1
sub Dest Source2 1 1101101UI – – – – – – – Source1
– Reserved bit (code as 0) l Long immediate
D Direct external access bit M Modify, write modified address back to register
E Emulation trap bit n Rotate sense for shifting
F Clear present flags S Scale offset by data size
i Invert endmask SZ Size (0 = byte, 1 = halfword, 2 = word, 3 = doubleword
– – – E – – – – – 1 1 0 0 0 0 0 0 1 I – – – – – – – IND TR
–
ld Dest Base 1 1 0 1 0 0 M SZ I S D – – – – – Offset
st Source Base 1 10110M SZ I S D – – – – – Offset
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
31

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP opcode summary (continued)
Table 6. Miscellaneous Instruction Opcodes
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
vadd
vsub Mem Src/Dst Source2/Dest 1 1110–001I– m P – d m s Source1
vmpy Mem Src/Dst Source2/Dest 1 1110–010I– m P – d m s Source1
vmsub Mem Src/Dst Dest 1 1110a011Ia m P Z – m – Source1
vrnd(F P) Mem Src/Dst Dest 1 1110a100Ia m P PD m s Source1
vrnd(Int) Mem Src/Dst Dest 1 1110–101I– m P – d m s Source1
vmac Mem Src/Dst Source2 1 1 1 1 0 a 1 1 0 I a m P Z – m – Source1
vmsc Mem Src/Dst Source2 1 1110a111Ia m P Z – m – Source1
fadd Dest Source2 1 1 1 1 1 0 0 0 0 I – PD P2 P1 Source1
fsub Dest Source2 1 11110001I– PD P2 P1 Source1
fmpy Dest Source2 1 11110010I– PD P2 P1 Source1
frndx Dest – ––––111110100I – PD RM P1 Source1
fcmp Dest Source2 1 11110101I– – –P2 P1 Source1
fsqrt Dest – ––––111110111I – PD – –P1 Source1
estop – – – – – – – – – – 1 1 1 1 1 1 1 1 0 – – – – – – – – – – – – –
illopF – –––––––––111111111C– –––––––––––
Mem Src/Dst Vector store or load source/dst register Z Use 0 rather than accumulator
Mem Src/Dst
fdiv Dest Source2 1 11110011I– PD P2 P1 Source1
lmo Dest Source 1 1 1 1 1 1 0 0 0 – – – – – – – – – – – – –
rmo Dest Source 1 11111001–– –––––––––––
– Reserved bit (code as 0) P Dest precision for parallel load/store (0 = single, 1 = double)
a Floating-point accumulator select P1 Precision of source1 operand
C Constant operands rather than register P2 Precision of source2 operand
d Destination precision for vector (0 = sp, 1 = dp) PD Precision of destination result
l Long immediate 32-bit data RM Rounding Mode (0 = N, 1 = Z, 2 = P , 3 = M)
m Parallel memory operation specifier s Scale offset by data size
Dest Destination register
Source2/Dest 1 1 1 1 0 – 0 0 0 I – m P – d m s Source1
32
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
MP opcode summary (continued)
Table 7. Summary of MP Opcodes
INSTRUCTION DESCRIPTION INSTRUCTION DESCRIPTION
add Signed integer add or.ff Bitwise OR with 1s complement
and.tt Bitwise AND or.ft Bitwise OR with 1s complement
and.ff Bitwise AND with 1s complement or.tf Bitwise OR with 1s complement
and.ft Bitwise AND with 1s complement rdcr Read control register
and.tf Bitwise AND with 1s complement rmo Rightmost one
bbo Branch bit one shift.dz Shift, disable mask, zero extend
bbz Branch bit zero shift.dm Shift, disable mask, merge
bcnd Branch conditional shift.ds Shift, disable mask, sign extend
br Branch always shift.ez Shift, enable mask, zero extend
brcr Branch control register shift.em Shift, enable mask, merge
bsr Branch and save return shift.es Shift, enable mask, sign extend
cmnd Send command shift.iz Shift, invert mask, zero extend
cmp Integer compare shift.im Shift, invert mask, merge
dcache Flush data cache sub-block st Store register into memory
estop Emulation stop sub Signed integer subtract
fadd Floating-point add swcr Swap control register
fcmp Floating-point compare trap Trap
fdiv Floating-point divide vadd Vector floating-point add
fmpy Floating-point multiply vmac Vector floating-point multiply and add to ac-
cumulator
frndx Floating-point convert/round vmpy Vector floating-point multiply
fsqrt Floating-point square root vmsc Vector floating-point multiply and subtract
from accumulator
fsub FLoating-point subtract vmsub Vector floating-point subtract accumulator
from source
illop Illegal operation vrnd(FP) Vector round with floating-point input
jsr Jump and save return vrnd(Int) Vector round with integer input
ld Load signed into register vsub Vector floating-point subtract
ld.u Load unsigned into register xnor Bitwise exclusive NOR
lmo Leftmost one xor Bitwise exclusive OR
or.tt Bitwise OR
TMS320C80
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
33

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP architecture
The parallel processor (PP) is a 32-bit integer DSP optimized for imaging and graphics applications. Each PP
can execute in parallel; a multiply, ALU operation, and two memory accesses within a single instruction. This
internal parallelism allows a single PP to achieve over 500 million operations per second for certain algorithms.
The PP has a three-input ALU that supports all 256 three input Boolean combinations and many combinations
of arithmetic and Boolean functions. Data-merging and bit-to-byte, bit-to-word, and bit-to-halfword translations
are supported by hardware in the input data path to the ALU. Typical tasks performed by a PP include:
D
Pixel-intensive processing
– Motion estimation
– Convolution
– PixBLTs
– Warp
– Histogram
– Mean square error
D
Domain transforms
– DCT
– FFT
– Hough
D
Core graphics functions
– Line
– Circle
– Shaded fills
– Fonts
D
Image Analysis
– Segmentation
– Feature extraction
D
Bit-stream encoding/decoding
– Data merging
– Table look-ups
34
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP functional block diagram
Figure 22 shows a block diagram of a parallel processor. Key features of the PP include:
D
64-bit instruction word (supports multiple parallel operations)
D
Three-stage pipeline for fast instruction cycle
D
Numerous registers
– 8 data, 10 address, 6 index registers
– 20 other user-visible registers
D
Data Unit
– 16x16 integer multiplier (optional dual 8x8)
– Splittable 3-input ALU
– 32-bit barrel rotator
– Mask generator
– Multiple-status flag expander for translations to/from 1 bit-per-pixel space.
– Conditional assignment of data unit results
TMS320C80
– Conditional source selection
– Special processing hardware
Leftmost one / rightmost one
Leftmost bit change / rightmost bit change
D
Memory addressing
– Two address units (global & local) provide up to two 32-bit accesses in parallel with data unit operation.
– 12 addressing modes (immediate and indexed)
– Byte, halfword, and word addressability
– Scaled indexed addressing
– Conditional assignment for loads
– Conditional source selection for stores
D
Program flow
– Three hardware loop controllers
Zero overhead looping / branching
Nested loops
Multiple loop endpoints
– Instruction cache management
– PC mapped to register file
– Interrupts for messages and context switching
D
Algebraic assembly language
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
35

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP functional block diagram (continued)
Data Unit
Local Destination/Source
Global Source
Global Destination
d0–d7
mf & sr
Registers
Local Address Unit Global Address Unit
a0–a4, a7
Local Data Path Global Data Path
x0–x2
Multiplier
Data Path
sp = a6 = a14
Program Flow Control Unit
ALU Data Path
Expander
Mask Generator Barrel
Rotator
Three-Input ALU
a8–a12,
a15
x8–x10
36
Repl
Local
Data Port
A/S
Repl
Global
Data Port
Three Zero-Overhead
Loop/Branch Controllers
A/S
Repl Replicate hardware
A/S Align/sign extend hardware
Figure 22. PP Block Diagram
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
Instruction and Cache Control
64 32
Instruction
Port
IAP Instruction address port
LAP Local address port
GAP Global address port
32
IAP LAP GAP

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP registers
The PP contains many general-purpose registers, status registers, and configuration registers. All PP registers
are 32-bit registers. Figure 23 shows the accessible registers of the PP blocks.
Data-Unit Registers
Data Registers
Multiple Flags
Status
Address-Unit Registers
Address Registers
a8
a9
a10
a11
a12
a14/sp
a15 = 0
d0/EALU Operation
d1
d2
d3
d4
d5
d6
d7
Global-address Unit Local-Address Unit
Index Flags
x8
x9
x10
Stack Pointer
Same Physical
Register
mf
Address Registers
sr
a0
a1
a2
a3
a4
a6/sp
a7 = 0
Index Flags
x0
x1
x2
PFC-Unit Registers
PC-Related Registers
pc (br, call)
iprs
ipa (read only)
ipe (read only)
Cache Tags
tag0 (read only)
tag1 (read only)
tag2 (read only)
tag3 (read only)
Loop Addresses
ls0
ls1
ls2
le0
le1
le2
Loop Control
lctl
Loop Counts
lr0
lr1
lr2
lc0
lc1
lc2
Figure 23. PP Registers
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
Communications
comm
Interrupts
lntflg
inten
37

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP data-unit registers
The data unit contains eight 32-bit general-purpose data registers (d0–d7) referred to as the D registers. The
d0 register also acts as the control register for EALU operations.
d0 register
Figure 24 shows the format when d0 is used as the EALU control register.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
FMOD A EALU Function Code C I S N E F – – – DMS M R – DBR
Explicit multiple carry-In
DMS
DBR
E
Expanded mf
F
Default multiply shift amount
Split multiply
M
Rounded multiply
R
Default barrel rotate amount
FMOD
Function modifiers
Arithmetic enable
A
EALU carry-In
C
Invert-carry-In
I
Sign extend
S
Nonmultiple mask
N
Figure 24. d0 Format for EALU Operations
multiple flags (mf) register
The mf register records status information from each split ALU segment for multiple arithmetic operations. The
mf register may be expanded to generate a mask for the ALU. Figure 25 shows the mf register format.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Figure 25. mf Register Format
status register (sr)
The sr contains status and control bits for the PP ALU. Figure 26 shows the sr register format.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
N C V Z LV – – – – – – – – – – – – – – – – – – MSS R Msize Asize
Negative status bit
N
Carry status bit
C
Overflow status bit
V
Zero status bit
Z
Latched overflow
LV
Rotation bit
R
MSS
Msize
Asize
mf Status selection
00 – set by zero 10 – set by extended result
01 – set by sign 11 – reserved
Expander data size
Split ALU data size
Figure 26. sr Format
PP address-unit registers
address registers
The address unit contains ten 32-bit address registers which contain the base address for address
computations or which can be used for general-purpose data. The registers a0 – a4 are used for local address
computations and registers a8–a12 are used for global-address computations.
38
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
index registers
The six 32-bit index registers contain index values for use with the address registers in address computations
or they can be used for general-purpose data. Registers x0–x2 are used by the local-address unit and registers
x8–x10 are used by the global-address unit.
stack pointer (sp)
The sp contains the address of the bottom of the PP’s system stack. The stack pointer is addressed as a6 by
the local-address unit and as a14 by the global-address unit. Figure 27 shows the sp register format.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Word-Aligned Address 0 0
Figure 27. sp Register Format
zero register
The zero registers are read-as-zero address registers for the local address unit (a7) and global-address unit
(a15). Writes to the registers are ignored and can be specified when operational results are to be discarded.
Figure 28 shows the zero register format.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Figure 28. zero Registers
PP program flow control (PFC) unit registers
loop registers
The loop registers control three levels of zero-overhead loops. The 32-bit loop start registers (ls0 – ls2) and
loop-end registers (le0 – le2) contain the starting and ending addresses for the loops. The loop-counter registers
(lc0 – lc2) contain the number of repetitions remaining in their associated loops. The lr0 – lr2 registers are loop
reload registers used to support nested loops. The format for the loop-control (lctl) register is shown in Figure 29.
There are also six special write-only mappings of the loop-reload registers. The lrs0 – lrs2 codes are used for
fast initialization of lsn, lrn, and lcn registers for multi-instruction loops while the lrse0 – lrse2 codes are used
for single instruction-loop fast initialization.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
– – – – – – – – – – – – – – – – – – – – E LCD2 E LCD1 E LCD0
E
Loop End Enable
LCDn
pipeline registers
The PFC unit contains a pointer to each stage of the PP pipeline. The pc contains the program counter which
points to the instruction being fetched. The ipa points to the instruction in the address stage of the pipeline and
the ipe points to the instruction in the execute stage of the pipeline. The instruction pointer
return-from-subroutine (iprs) register contains the return address for a subroutine call. Figure 30 shows the
variable pipeline register format.
Loop Counter Designator
000 – None 010 – lc1
001 – lc0 011 – lc2
1xx – reserved
le2 le1 le0
Figure 29. lctl Register
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
39

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
pipeline registers (continued)
313029282726252423222120191817161514131211109876543210
pc
G – Global Interrupt Enable L – Loop Inhibit
313029282726252423222120191817161514131211109876543210
ipa
313029282726252423222120191817161514131211109876543210
ipe
313029282726252423222120191817161514131211109876543210
iprs
PC (29-Bit Doubleword Address) – G L
32-Bit Copy of the Previous pc Register Value
32-Bit Copy of the Previous ipa Register V alue
29-Bit Doubleword Return Address – – –
Figure 30. Pipeline Registers
interrupt registers
The interrupt-enable (inten) register allows individual interrupts to be enabled and configures the interrupt flag
(intflg) register operation. The intflg register contains the interrupt flag bits. Interrupt priority increases moving
from left to right on intflg. Figure 31 shows the PP-interrupt register format.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
inten
r r r r E E E E – – – E E E E – – E – – – – – – – – – – – – – W
P
P
P
P
3
M
S
G
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
intflg
r r r r I I I I – – – I I I I – – I – – – – – – – – – – – – – –
r
Reserved (write as 0)
E
Enable Interrupt
W
Write Mode
P
P
P
P
2
1
0
M
M
M
S
S
S
G
G
G
0 – writing 1 clears intflg
1 – writing 1 sets intflg
PPnMSG
PPn message Interrupt
M
P
P
P
M
S
G
P
T
T
E
N
D
T
E
Q
R
R
T
A
S
K
MPMSG
PTEND
PTERR
PTQ
TASK
MP Message Interrupt
Packet Transfer Complete
Packet-Transfer Error
Packet Transfer Queued
MP Task Interrupt
Figure 31. PP-Interrupt Registers
40
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
communication (comm) register
The comm register contains the packet-transfer handshake bits and PP indicator bits. Figure 32 shows the
comm register format.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
H S Q P – – – – – – – – – – – – – – – – – – – – – – – – – PP#
MAREV MIREV DEV
High-priority packet transfer
H
Packet-transfer suspend
S
Packet transfer queued
Q
Submit packet transfer request
P
MAREV
MIREV
DEV Device
Major revision #
Minor revision #
00–320C80
10–320C82
Figure 32. comm Register
cache-tag registers
The tag0 – tag3 registers contain the tag address and sub-block present bits for each cache block. Figure 33
shows the cache tag registers.
PP# pp Number (read only)
000 – pp0 010 – pp2
001 – pp1 011 – pp3
1xx – not implemented
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
23-Bit Tag Address P P P P – – – LRU
P
Present bit
LRU
Least-recently-used code
00 – mru 10 – next lru
01 – next mru 11 – lru
Sub-Block # 3 2 1 0
Figure 33. Cache Tag Registers
PP cache architecture
Each PP has its own 2K-byte instruction cache. Each cache is divided into four blocks and each block is divided
into four sub-blocks containing 16 64-bit instructions each. Cache misses cause one sub-block to be loaded
into cache. Figure 34 shows the cache architecture for one of the four sets in each cache. Figure 35 shows how
addresses map into the cache using the cache tags and address bits.
LRU
NLRU
NMRU
MRU
LRU Stack
Sub-Blocks
Block 0
Block 1
Block 2
Block 3
tag 0 (Block 0)
tag 1 (Block 1)
tag 2 (Block 2)
tag 3 (Block 3)
Figure 34. PP Cache Architecture
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
23-Bit Tag Value sub instruction ignored
sub – sub-block
Figure 35. pc Register Cache-Address Mapping
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
41

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP parameter RAM
The parameter RAM is a, 2K-byte, on-chip RAM which contains PP-interrupt vectors, PP-requested TC task
buffers, and a general-purpose area. The parameter RAM does not use the cache memory. Figure 36 shows
the parameter RAM address map.
Suspended PT Parameters
(128 Bytes)
Reserved
(96 Bytes)
Restricted for Operating System Use
(24 Bytes)
Cache Fault Address
PP-Linked List Start Address
Off-Chip to Off-Chip PT Buffer
(128 Bytes)
Interrupt Vectors
(128 Bytes)
General-Purpose RAM
(1524 Bytes Less Stack Size)
Stack
Stack State Information After Reset
(12 Bytes)
Figure 36. PP Parameter RAM
0x0100#000–0x0100#07F
0x0100#080–0x0100#0DF
0x0100#0E0–0x0100#0F7
0x0100#0F8–0x0100#0FB
0x0100#0FC–0x0100#0FF
0x0100#100–0x0100#17F
0x0100#180–0x0100#1FF
0x0100#200
Application-Dependent Boundary
0x0100#7F0
0x0100#7F4–0x0100#7FF
# – PP Number
Stack Pointer After Reset
PP interrupt vectors
The PP interrupts and their vector addresses are shown in Table 8.
Table 8. PP-Interrupt Vectors
NAME
TASK
PTQ
PTERR
PTEND
MPMSG
PP0MSG
PP1MSG
PP2MSG
PP3MSG
VECTOR
ADDRESS
0x0100#1B8
0x0100#1C4
0x0100#1C8
0x0100#1CC
0x0100#1D0
0x0100#1E0
0x0100#1E4
0x0100#1E8
0x0100#1EC
Task Interrupt
Packet Transfer Queued
Packet-Transfer Error
Packet-Transfer End
MP Message
PP0 Message
PP1 Message
PP2 Message
PP3 Message
INTERRUPT
42
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP data-unit architecture
The data unit has independent data paths for the ALU and the multiplier, each with its own set of hardware
functions. The multiplier data path includes a 16 × 16 multiplier, a halfword swapper, and rounding hardware.
The ALU data path includes a 32-bit three-input ALU, a barrel rotator, mask generator, mf expander,
left/rightmost one and left/rightmost bit-change logic, and several multiplexers. Figure 37 shows the data-unit
block diagram.
src1/src2/ dstc/0
dst2 src3 src4
src4/src2 0 src1/0x1 d0 mf dst /dst1
Rotate Amount
Multiplexer
LMO, RMO,
Barrel Rotator
Multiplier
(Splittable)
Scale
Round
Swap/Merge
Legend:
src1 Any register, D reg only for l/rmo, l/rmbc hardware dst2 D reg only
scr2 D reg or sometimes 15/32-bit immediate dstc D reg only (destination companion reg source)
scr3 D reg only 0x1 Constant
scr4 D reg only 0 Constant
dst/dst1 Any register d0 5 LSBs of d0
A
N, C, V, Z, LV mf
LMBC, RMBC
B
Three-Input ALU (Splittable)
Mask Generator
Multiplexer
Mask
Generator
C Port
Multiplexer
C
Expander
Rotator Input
Function
Code Logic
Barrel
Sign Bit
ALU
Figure 37. Data Unit Block Diagram
The PP’s ALU can be split into one 32-bit ALU, two 16-bit ALUs, or four 8-bit ALUs. Figure 38 shows the multiple
arithmetic data flow for the case of a four 8-bit split of the ALU (called multiple-byte arithmetic). The ALU
operates as independent parallel ALUs where each ALU receives the same function code.
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
43

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP data-unit architecture (continued)
32
ABC
C-Out C-IN
C, Z, S,
or E
PP multiplier
mf Register
4
Expander (Replicate)
ABC
C-IN
8888
Logic
C-Out C-IN
C, Z, S,
or E
C-IN
Logic
ABC
C-Out C-IN
C, Z, S,
or E
C-IN
Logic
ABC
C-Out C-IN
C, Z, S,
or E
Rotate
Clear
8888
C-IN
Logic
sr(C)
Figure 38. Multiple-Byte Arithmetic Data Flow
The PP’s hardware multiplier can perform one 16x16 multiply with a 32-bit result or two 8x8 multiplies with two
16-bit results in a single cycle. A 16x16 multiply can use signed or unsigned operands as shown in Figure 39.
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
X X X X X X X X X X X X X X X X S Signed Input
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
S S Signed × Signed Result
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
X X X X X X X X X X X X X X X X Unsigned Input
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Unsigned × Unsigned Result
Figure 39. 16 x 16 Multiplier Data Formats
When performing two simultaneous 8x8 split multiplies, the first input word contains unsigned byte operands
and the second input word contains signed or unsigned byte operands. These formats are shown in Figure 40
and Figure 41.
44
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP multiplier (continued)
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
X X X X X X X X X X X X X X X X Unsigned Input 1b Unsigned Input 1a
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
X X X X X X X X X X X X X X X X S Signed Input 2b S Signed Input 2a
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
S 1b × 2b Signed Result S 1a × 2a Signed Result
Figure 40. Signed Split Multiply Data Formats
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
X X X X X X X X X X X X X X X X Unsigned Input 1b Unsigned Input 1a
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
X X X X X X X X X X X X X X X X Unsigned Input 2b Unsigned Input 2a
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
1b × 2b Unsigned Result 1a × 2a Unsigned Result
Figure 41. Unsigned Split Multiply Data Formats
PP program-flow-control unit architecture
The PP has a three-stage fetch, address, execute (FAE) pipeline as shown in Figure 42. The pc, ipa, and ipe
registers point to the address of the instruction in each stage of the pipeline. On each cycle in which the pipeline
advances, ipa is copied into ipe, pc is copied into ipa, and the pc is incremented by one instruction (8 bytes).
The program-flow-control (pfc) unit performs instruction fetching and decoding, loop control, and handshaking
with the transfer controller. The pfc unit architecture is shown in Figure 43.
pc
Instruction
One
Two
Three
T1 T2 T4T3 T5
Fetch Address Execute
Fetch Address Execute
ExecuteFetch Address
Figure 42. FAE-Instruction Pipeline
ipa
ipe
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
45

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP program-flow-control unit architecture (continued)
pc
incrementer
lprs
Cache Controller
ipa
ipe
Loop Controller 0
ls0
le0
Comparator
lr0
lc0
decr.
zero
Tag Comparators
Tag Registers Present Bits LRU Stack
lctl
Loop Control
Instruction Decode
FAE Pipeline Control
Control Signal Generation
Loop Controller 1
Instruction Control
Loop Controller 2
Signal
Figure 43. Program-Flow-Control Unit Block Diagram
PP address-unit architecture
The PP has both a local- and global-address unit which operate independently of each other. The address units
support twelve different addressing modes. In place of performing a memory access, either or both of the
address units can perform an address computation that is written directly to a PP register instead of being used
for a memory access. This address-unit arithmetic provides additional arithmetic operation to supplement the
data unit during compute-intensive algorithms. Figure 44 shows the address-out architecture.
46
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
Instruction
Address

PP address-unit architecture (continued)
TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
From Global
Destination Bus
a0–a4
(a7 = 0)
pba dba
PP-Relative
Multiplexer
Preindex/Postindex
Multiplexer
To Global
Offset
Index Scaler
32-Bit Adder/Subtracter Unit
Source Bus
Index Multiplexer
Preindex/Postindex
x0–x2
sp = a6 (local)
sp = a14 (global)
Scale
Data Size
From Global
Destination Bus
a8–a12
(a15 = 0)
PP-Relative
Multiplexer
Preindex/Postindex
Multiplexer
Offset
pba, dba
Index Scaler
32-Bit Adder/Subtracter Unit
Source Bus
Index Multiplexer
Preindex/Postindex
To Global
x8–x10
Scale
Data Size
Local-Address Port
Global-Address Port
Figure 44. Address-Unit Architecture
PP instruction set
PP instructions are represented by algebraic expressions for the operations performed in parallel by the
multiplier, ALU, global-address unit, and local-address unit. The expressions use the || symbol to indicate
operations that are to be performed in parallel. The PP ALU operator syntax is shown in Table 9. The data unit
operations (multiplier and ALU) are summarized in Table 10 and the parallel transfers (global and local) are
summarized in Table 11.
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443
47

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP instruction set (continued)
OPERATOR FUNCTION
src1 [n] src1–1
( ) Subexpression delimiters
@mf Expander operator
% Mask generator
%% Nonmultiple mask generator (EALU only)
%! Modified mask generator (0xFFFFFFFF output for 0 input)
%%! Nonmultiple shift right mask generator (EALU only)
\\ Rotate left
<< Shift left (pseudo-op for rotate and mask)
>>u Unsigned shift right
>> or >>s Signed shift right
& Bitwise AND
^ Bitwise XOR
| Bitwise OR
+ Addition
– Subtraction
=[cond] Conditional assignment
=[cond.pro] Conditional assignment with status protection
= Equate
Table 9. PP Operators by Precedence
Select odd (n=true) or even (n=false) register of D register pair
based on negative condition code
48
POST OFFICE BOX 1443 • HOUSTON, TEXAS 77251–1443

TMS320C80
DIGITAL SIGNAL PROCESSOR
SPRS023B – JULY 1994 – REVISED OCT OBER 1997
PP instruction set (continued)
Table 10. Summary of Data-Unit Operations
Operation Base set ALUs
Description Perform an ALU operation specifying ALU function, 2 src and 1 dest operand, and operand routing. ALU function is one of
Syntax dst = [fmod] [ [[cond [.pro] ]] ] ALU_EXPRESSION
Examples d6 = (d6 ^ d4) & d2
Operation EALU || ROTATE
Description Perform an extended ALU (EALU) operation (specified in d0) with one of two data routings to the ALU and optionally write
Syntax dst1 = [ [[cond [.pro] ]] ] ealu (src2, [dst2 = ] [