

Page 1

Page 2

Page 3

SPARC®Enterprise T1000 Server
Service Manual
Manual Code : C120-E384-01EN
Part No. 875-4022-10
April 2007
Page 4

Copyright 2007 Sun Microsystems, Inc., 4150 Network Circle, Santa Clara, California 95054, U.S.A. All rights reserved.
FUJITSU LIMITED provided technical input and review on portions of this material.
Sun Microsystems,Inc. andFujitsu Limited eachown orcontrol intellectualproperty rights relating to products andtechnology described in
this document,and such products, technology andthis documentare protectedby copyright laws, patents andother intellectual property laws
and internationaltreaties. Theintellectual propertyrights of SunMicrosystems, Inc.and Fujitsu Limited in suchproducts, technologyand this
document include,without limitation, one or moreof theUnited States patents listed athttp://www.sun.com/patentsand one or more
additional patentsor patent applications in theUnited States or other countries.
This documentand the product and technologyto whichit pertains are distributed underlicenses restrictingtheir use, copying, distribution,
and decompilation.No part of such productor technology,or of this document, maybe reproducedin anyform by anymeans withoutprior
written authorizationof Fujitsu Limited and SunMicrosystems, Inc.,and their applicable licensors, ifany.The furnishingof this documentto
you doesnot give you any rightsor licenses, express or implied, with respectto theproduct or technology to whichit pertains,and this
document doesnot contain or representany commitment ofany kindon the partof FujitsuLimited or SunMicrosystems, Inc.,or anyaffiliate of
either ofthem.
This documentand the product and technologydescribed inthis document mayincorporate third-partyintellectual propertycopyrighted by
and/or licensedfrom suppliersto Fujitsu Limitedand/or SunMicrosystems, Inc.,including software and font technology.
Per theterms of the GPL orLGPL, a copy of thesource codegoverned by the GPL orLGPL, as applicable, is availableupon requestby the End
User.Please contactFujitsu Limited orSun Microsystems,Inc.
This distribution may include materials developed by third parties.
Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark
in the U.S. and in other countries, exclusively licensed through X/Open Company, Ltd.
Sun, Sun Microsystems, the Sun logo, Java, Netra, Solaris, Sun StorEdge, docs.sun.com, OpenBoot, SunVTS, Sun Fire, SunSolve, CoolThreads,
J2EE, and Sun are trademarks or registered trademarks of Sun Microsystems, Inc. in the U.S. and other countries.
Fujitsu and the Fujitsu logo are registered trademarks of Fujitsu Limited.
All SPARC trademarks are used under license and are registered trademarks of SPARC International, Inc. in the U.S. and other countries.
Products bearing SPARC trademarks are based upon architecture developed by Sun Microsystems, Inc.
SPARC64 is a trademark of SPARC International, Inc., used under license by Fujitsu Microelectronics, Inc. and Fujitsu Limited
The OPEN LOOK and Sun™ Graphical User Interfacewas developed by Sun Microsystems, Inc. for itsusers and licensees. Sun acknowledges
the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun
holds anon-exclusive license from Xeroxto the Xerox GraphicalUser Interface, whichlicense alsocovers Sun’s licensees who implementOPEN
LOOK GUIs and otherwise comply with Sun’s written license agreements.
United StatesGovernment Rights - Commercial use.U.S. Governmentusers aresubject to thestandard governmentuser license agreements of
Sun Microsystems,Inc. andFujitsu Limited andthe applicableprovisions ofthe FAR andits supplements.
Disclaimer: The only warranties granted by Fujitsu Limited, Sun Microsystems, Inc. or any affiliate of either of them in connection with this
document or any product or technology described herein are those expressly set forth in the license agreement pursuant to which the product
or technology is provided. EXCEPT AS EXPRESSLY SET FORTH IN SUCH AGREEMENT, FUJITSU LIMITED, SUN MICROSYSTEMS, INC.
AND THEIRAFFILIATES MAKENO REPRESENTATIONSOR WARRANTIES OFANY KIND (EXPRESSOR IMPLIED) REGARDING SUCH
PRODUCT OR TECHNOLOGY OR THIS DOCUMENT, WHICH ARE ALL PROVIDED AS IS, AND ALL EXPRESS OR IMPLIED
CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING WITHOUT LIMITATION ANY IMPLIED WARRANTY OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE
EXTENT THAT SUCH DISCLAIMERS AREHELD TO BE LEGALLY INVALID.Unless otherwise expressly set forth in such agreement, to the
extent allowed by applicable law, in no event shall Fujitsu Limited, Sun Microsystems, Inc. or any of their affiliates have any liability to any
third party under any legal theory for any loss of revenues or profits, loss of use or data, or business interruptions, or for any indirect, special,
incidental or consequential damages, even if advised of the possibility of such damages.
DOCUMENTATION IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES,
INCLUDING ANYIMPLIED WARRANTY OFMERCHANTABILITY, FITNESSFOR A PARTICULARPURPOSE OR NON-INFRINGEMENT,
ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID.
.
Page 5

Copyright 2007 Sun Microsystems, Inc., 4150 Network Circle, Santa Clara, California 95054, Etats-Unis. Tous droits réservés.
Entrée et revue tecnical fournies par FUJITSU LIMITED sur des parties de ce matériel.
Sun Microsystems, Inc. et Fujitsu Limited détiennent et contrôlent toutes deux des droits de propriété intellectuelle relatifs aux produits et
technologies décrits dans ce document. De même, ces produits, technologies et ce document sont protégés par des lois sur le copyright, des
brevets, d’autreslois sur la propriétéintellectuelle et des traités internationaux. Les droits de propriété intellectuelle de SunMicrosystems, Inc.
et Fujitsu Limited concernant ces produits, ces technologies et ce document comprennent, sans que cette liste soit exhaustive, un ou plusieurs
des brevets déposésaux États-Unis et indiqués à l’adresse http://www.sun.com/patents de mêmequ’un ou plusieurs brevetsou applications
brevetées supplémentaires aux États-Unis et dans d’autres pays.
Ce document, le produit et les technologies afférents sont exclusivement distribués avec des licences qui en restreignent l’utilisation, la copie,
la distribution et la décompilation. Aucune partie de ce produit, de ces technologies ou de ce document ne peut être reproduite sous quelque
forme quece soit, parquelque moyen quece soit, sansl’autorisation écrite préalablede Fujitsu Limitedet de SunMicrosystems, Inc., etde leurs
éventuels bailleurs de licence. Ce document, bien qu’il vous ait été fourni, ne vous confère aucun droit et aucune licence, expresses ou tacites,
concernant le produitou la technologie auxquelsil se rapporte. Par ailleurs, il ne contient nine représente aucun engagement,de quelque type
que ce soit, de la part de Fujitsu Limited ou de Sun Microsystems, Inc., ou des sociétés affiliées.
Ce document, et le produit et les technologies qu’il décrit, peuvent inclure des droits de propriété intellectuelle de parties tierces protégés par
copyright et/ou cédés sous licence par des fournisseurs à Fujitsu Limited et/ou Sun Microsystems, Inc., y compris des logiciels et des
technologies relatives aux polices de caractères.
Par limites du GPL ou du LGPL, une copie du code source régi par le GPL ou LGPL, comme applicable, est sur demande vers la fin utilsateur
disponible; veuillez contacter Fujitsu Limted ou Sun Microsystems, Inc.
Cette distribution peut comprendre des composants développés par des tierces parties.
Des parties de ce produit pourront être dérivées des systèmes Berkeley BSD licenciés par l’Université de Californie. UNIX est une marque
déposée aux Etats-Unis et dans d’autres pays et licenciée exclusivement par X/Open Company, Ltd.
Sun, Sun Microsystems, le logo Sun, Java, Netra, Solaris, Sun StorEdge, docs.sun.com, OpenBoot, SunVTS, Sun Fire, SunSolve, CoolThreads,
J2EE, et Sun sont des marques de fabrique ou des marques déposées de Sun Microsystems, Inc. aux Etats-Unis et dans d’autres pays.
Fujitsu et le logo Fujitsu sont des marques déposées de Fujitsu Limited.
Toutes les marques SPARC sont utilisées sous licence et sont des marques de fabrique ou des marques déposées de SPARC International, Inc.
aux Etats-Unis et dans d’autres pays. Les produits portant les marques SPARC sont basés sur une architecture développée par Sun
Microsystems, Inc.
SPARC64 est une marques déposée de SPARC International, Inc., utilisée sous le permis par Fujitsu Microelectronics, Inc. et Fujitsu Limited.
L’interface d’utilisation graphique OPEN LOOK et Sun™ a été développée par Sun Microsystems, Inc. pour ses utilisateurs et licenciés. Sun
reconnaît les effortsde pionniers de Xerox pour la recherche et le développementdu concept des interfaces d’utilisation visuelle ou graphique
pour l’industrie de l’informatique. Sun détient une license non exclusive de Xerox sur l’interface d’utilisation graphique Xerox, cette licence
couvrant également les licenciés de Sun qui mettent en place l’interface d’utilisation graphique OPEN LOOK et qui, en outre, se conforment
aux licences écrites de Sun.
Droits du gouvernement américain - logiciel commercial. Les utilisateurs du gouvernement américain sont soumis aux contrats de licence
standard de Sun Microsystems, Inc. et de Fujitsu Limited ainsi qu’aux clauses applicables stipulées dans le FAR et ses suppléments.
Avis de non-responsabilité: les seulesgaranties octroyéespar Fujitsu Limited,Sun Microsystems, Inc.ou toutesociété affiliée del’une ou l’autre
entité enrapport avec cedocument ou toutproduit ou toutetechnologie décrit(e) dansles présentes correspondent aux garantiesexpressément
stipulées dans le contrat de licence régissant le produit ou la technologie fourni(e). SAUF MENTION CONTRAIRE EXPRESSÉMENT
STIPULÉE DANS CE CONTRAT, FUJITSU LIMITED, SUN MICROSYSTEMS, INC. ET LES SOCIÉTÉS AFFILIÉES REJETTENT TOUTE
REPRÉSENTATION OU TOUTE GARANTIE, QUELLE QU’EN SOIT LA NATURE (EXPRESSE OU IMPLICITE) CONCERNANT CE
PRODUIT,CETTE TECHNOLOGIE OUCE DOCUMENT, LESQUELSSONT FOURNIS ENL’ÉTAT.EN OUTRE, TOUTESLES CONDITIONS,
REPRÉSENTATIONS ET GARANTIES EXPRESSES OUTACITES, YCOMPRIS NOTAMMENTTOUTE GARANTIE IMPLICITERELATIVE À
LA QUALITÉ MARCHANDE, À L’APTITUDE À UNE UTILISATION PARTICULIÈRE OU À L’ABSENCE DE CONTREFAÇON, SONT
EXCLUES, DANS LA MESURE AUTORISÉE PAR LA LOI APPLICABLE. Sauf mention contraire expressément stipulée dans ce contrat, dans
la mesure autoriséepar la loi applicable, en aucun cas Fujitsu Limited,Sun Microsystems, Inc. ou l’une de leurs filiales nesauraient être tenues
responsables envers une quelconque partie tierce, sous quelque théorie juridique que ce soit, de tout manque à gagner ou de perte de profit,
de problèmes d’utilisation ou de perte de données, ou d’interruptions d’activités, ou de tout dommage indirect, spécial, secondaire ou
consécutif, même si ces entités ont été préalablement informées d’une telle éventualité.
LA DOCUMENTATION EST FOURNIE “EN L’ETAT” ET TOUTES AUTRES CONDITIONS, DECLARATIONS ET GARANTIES EXPRESSES
OU TACITES SONT FORMELLEMENT EXCLUES,DANS LAMESURE AUTORISEEPARLA LOI APPLICABLE,Y COMPRISNOTAMMENT
TOUTE GARANTIE IMPLICITE RELATIVE A LA QUALITE MARCHANDE, A L’APTITUDE A UNE UTILISATION PARTICULIERE OU A
L’ABSENCE DE CONTREFACON.
Page 6

Page 7

Contents
Preface xv
1. Safety Information 1–1
1.1 Safety Information 1–1
1.2 Safety Symbols 1–1
1.3 Electrostatic Discharge Safety 1–2
1.3.1 Using an Antistatic Wrist Strap 1–2
1.3.2 Using an Antistatic Mat 1–2
2. Server Overview 2–1
2.1 Server Overview 2–1
2.2 Obtaining the Chassis Serial Number 2–3
3. Server Diagnostics 3–1
3.1 Overview of Server Diagnostics 3–1
3.1.1 Memory Configuration and Fault Handling 3–6
3.1.1.1 Memory Configuration 3–7
3.1.1.2 Memory Fault Handling 3–7
3.1.1.3 Troubleshooting Memory Faults 3–8
3.2 Using LEDs to Identify the State of Devices 3–8
3.2.1 Front and Rear Panel LEDs 3–10
v
Page 8

3.2.2 Power Supply LEDs 3–11
3.3 Using ALOM CMT for Diagnosis and Repair Verification 3–11
3.3.1 Running ALOM CMT Service-Related Commands 3–13
3.3.1.1 Connecting to ALOM 3–13
3.3.1.2 Switching Between the System Console and ALOM 3–
14
3.3.1.3 Service-Related ALOM CMT Commands 3–14
3.3.2 Running the showfaults Command 3–16
3.3.3 Running the showenvironment Command 3–17
3.3.4 Running the showfru Command 3–19
3.4 Running POST 3–22
3.4.1 Controlling How POST Runs 3–22
3.4.2 Changing POST Parameters 3–26
3.4.3 Reasons to Run POST 3–27
3.4.3.1 Verifying Hardware Functionality 3–27
3.4.3.2 Diagnosing the System Hardware 3–28
3.4.4 Running POST in Maximum Mode 3–28
3.4.5 Correctable Errors Detected by POST 3–35
3.4.5.1 Correctable Errors for Single DIMMs 3–36
3.4.5.2 Determining When to Replace Detected Devices 3–37
3.4.6 Clearing POST Detected Faults 3–38
3.5 Using the Solaris Predictive Self-Healing Feature 3–39
3.5.1 Identifying PSH Detected Faults 3–40
3.5.1.1 Using the fmdump Command to Identify Faults 3–41
3.5.2 Clearing PSH Detected Faults 3–43
3.6 Collecting Information From Solaris OS Files and Commands 3–44
3.6.1 Checking the Message Buffer 3–44
3.6.2 Viewing System Message Log Files 3–45
vi SPARC Enterprise T1000 Server Service Manual • April 2007
Page 9

3.7 Managing Components With Automatic System Recovery Commands 3–
45
3.7.1 Displaying System Components 3–46
3.7.2 Disabling Components 3–47
3.7.3 Enabling Disabled Components 3–48
3.8 Exercising the System With SunVTS 3–48
3.8.1 Checking Whether SunVTS Software Is Installed 3–48
3.8.2 Exercising the System Using SunVTS Software 3–49
3.8.3 Using SunVTS Software 3–50
4. Preparing for Servicing 4–1
4.1 Common Procedures for Parts Replacement 4–1
4.1.1 Required Tools 4–2
4.1.2 Shutting the System Down 4–2
4.1.3 Removing the Server From a Rack 4–3
4.1.4 Performing Electrostatic Discharge (ESD) Prevention Measures
4–5
4.1.5 Removing the Top Cover 4–5
5. Replacing Field-Replaceable Units 5–1
5.1 Replacing the Optional PCI-Express Card 5–2
5.1.1 Removing the Optional PCI-Express Card 5–2
5.1.2 Installing the Optional PCI-Express Card 5–3
5.2 Replacing the Fan Tray Assembly 5–4
5.2.1 Removing the Fan Tray Assembly 5–4
5.2.2 Installing the Fan Tray Assembly 5–5
5.3 Replacing the Power Supply 5–5
5.3.1 Removing the Power Supply 5–5
5.3.2 Installing the Power Supply 5–6
5.4 Replacing the Hard Drive Assembly 5–7
Contents vii
Page 10

5.4.1 Removing the Single-Drive Assembly 5–7
5.4.2 Installing the Dual-Drive Assembly 5–8
5.5 Replacing a Hard Drive 5–12
5.5.1 Replacing a Hard Drive in a Single-Drive Assembly 5–12
5.5.1.1 Removing the Hard Drive in a Single-Drive Assembly
5–12
5.5.1.2 Installing the Hard Drive in a Single-Drive Assembly
5–13
5.5.2 Replacing a Hard Drive in a Dual-Drive Assembly 5–15
5.5.2.1 Removing a Hard Drive in a Dual-Drive Assembly 5–
15
5.5.2.2 Installing the Hard Drive in a Dual-Drive Assembly 5–
17
5.6 Replacing DIMMs 5–19
5.6.1 Removing DIMMs 5–19
5.6.2 Installing DIMMs 5–21
5.7 Replacing the Motherboard and Chassis 5–25
5.7.1 Removing the Motherboard and Chassis 5–25
5.7.2 Installing the Motherboard and Chassis 5–25
5.8 Replacing the Clock Battery 5–27
5.8.1 Removing the Clock Battery on the Motherboard 5–27
5.8.2 Installing the Clock Battery on the Motherboard 5–27
6. Finishing Up Servicing 6–1
6.1 Final Service Procedures 6–1
6.1.1 Replacing the Top Cover 6–1
6.1.2 Reinstalling the Server Chassis in the Rack 6–1
6.1.3 Applying Power to the Server 6–2
A. Field-Replaceable Units A–1
viii SPARC Enterprise T1000 Server Service Manual • April 2007
Page 11

Index Index–1
Contents ix
Page 12

x SPARC Enterprise T1000 Server Service Manual • April 2007
Page 13

Figures
FIGURE 2-1 Server 2–1
FIGURE 2-2 Server Components 2–2
FIGURE 2-3 Server Front Panel 2–2
FIGURE 2-4 Server Rear Panel 2–3
FIGURE 3-1 Diagnostic Flow Chart 3–3
FIGURE 3-2 LEDs on the Server Front Panel 3–8
FIGURE 3-3 LEDs on the Server Rear Panel 3–9
FIGURE 3-4 ALOM CMT Fault Management 3–12
FIGURE 3-5 Flow Chart of ALOM CMT Variables for POST Configuration 3–25
FIGURE 3-6 SunVTS GUI 3–51
FIGURE 3-7 SunVTS Test Selection Panel 3–52
FIGURE 4-1 Unlocking a Mounting Bracket 4–4
FIGURE 4-2 Location of the Mounting Bracket Release Buttons 4–4
FIGURE 4-3 Location of Top Cover Release Button 4–6
FIGURE 5-1 Releasing the PCI-Express Card Release Lever 5–2
FIGURE 5-2 Removing and Installing the PCI-Express Card 5–3
FIGURE 5-3 Removing the Fan Tray Assembly 5–4
FIGURE 5-4 Removing the Power Supply 5–6
FIGURE 5-5 Installing the Power Supply 5–7
FIGURE 5-6 Removing the Single-Drive Assembly 5–8
xi
Page 14

FIGURE 5-7 Location of Drive Power and Data Connectors on the Motherboard 5–9
FIGURE 5-8 Installing the Drive Assembly 5–10
FIGURE 5-9 Removing the Single-Drive Assembly 5–13
FIGURE 5-10 Installing the Single-Drive Assembly 5–14
FIGURE 5-11 Location of Drive Power and Data Connectors on the Motherboard 5–15
FIGURE 5-12 Removing the Dual-Drive Assembly 5–16
FIGURE 5-13 Installing the Dual-Drive Assembly 5–18
FIGURE 5-14 DIMM Locations 5–20
FIGURE 5-15 Removing the Clock Battery From the Motherboard 5–27
FIGURE 5-16 Installing the Clock Battery on the Motherboard 5–28
FIGURE A-1 Field-Replaceable Units A–2
xii SPARC Enterprise T1000 Server Service Manual • April 2007
Page 15

Tables
TABLE 3-1 Diagnostic Flow Chart Actions 3–4
TABLE 3-2 Front and Rear Panel LEDs 3–10
TABLE 3-3 Power Supply LEDs 3–11
TABLE 3-4 Service-Related ALOM CMT Commands 3–14
TABLE 3-5 ALOM CMT Parameters Used for POST Configuration 3–23
TABLE 3-6 ALOM CMT Parameters and POST Modes 3–26
TABLE 3-7 ASR Commands 3–46
TABLE 3-8 Useful SunVTS Tests to Run on This Server 3–52
TABLE 5-1 DIMM Names and Socket Numbers 5–20
TABLE A-1 Server FRU List A–3
xiii
Page 16

xiv SPARC Enterprise T1000 Server Service Manual • April 2007
Page 17

Preface
The SPARC Enterprise T1000 Server Service Manual provides information to aid in
troubleshooting problems with and replacing components within SPARC Enterprise
T1000 servers.
This manual is written for technicians, service personnel, and system administrators
who service and repair computer systems. The person qualified to use this manual:
■ Can open a system chassis, identify, and replace internal components
■ Understands the Solaris Operating System and the command-line interface
■ Has superuser privileges for the system being serviced
■ Understands typical hardware troubleshooting tasks
FOR SAFE OPERATION
This manual contains important information regarding the use and handling of this
product. Read this manual thoroughly. Pay special attention to the section “Notes on
Safety” on page xx. Use the product according to the instructions and information
available in this manual. Keep this manual handy for further reference.
Fujitsu makes every effort to prevent users and bystanders from being injured or
from suffering damage to their property. Use the product according to this manual.
xv
Page 18

Structure and Contents of This Manual
This manual is organized as described below:
■ Chapter 1 Safety Information
Provides important safety information for servicing the server.
■ Chapter 2 Server Overview
Describes the main features of the server.
■ Chapter 3 Server Diagnostics
Describes the diagnostics that are available for monitoring and troubleshooting
the server.
■ Chapter 4 Preparing for Servicing
Describes how to prepare for servicing the server.
■ Chapter 5 Replacing Field-Replaceable Units
Describes how to remove and replace the FRUS within the server.
■ Chapter 6 Finishing Up Servicing
Describes how to finish up the servicing of the server.
■ Appendix A Field-Replaceable Units
Lists the field replaceable components in the server.
■ Index
Provides keywords and corresponding reference page numbers so that the reader
can easily search for items in this manual as necessary.
Related Documentation
The latest versions of all the SPARC Enterprise Series manuals are available at the
following Web sites:
Global Site
http://www.fujitsu.com/sparcenterprise/manual/
Japanese Site
http://primeserver.fujitsu.com/sparcenterprise/manual/
xvi SPARC Enterprise T1000 Server Service Manual • April 2007
Page 19

Title Description Manual Code
SPARC Enterprise T1000 Server Product
Notes
SPARC Enterprise T1000 Server Site
Planning Guide
SPARC Enterprise T1000 Server Getting
Started Guide
Information about the latest
product updates and issues
Server specifications for site
planning
Information about where to find
documentation to get your
C120-E381
C120-H018
C120-E379
system installed and running
quickly
SPARC Enterprise T1000 Server
Overview Guide
SPARC Enterprise T1000 Server
Installation Guide
Provides an overview of the
features of this server
Detailed rackmounting, cabling,
power on, and configuring
C120-E380
C120-E383
information
SPARC Enterprise T1000 Server
Administration Guide
How to perform administrative
tasks that are specific to this
C120-E385
server
Advanced Lights Out Management
(ALOM) CMT vx.x Guide
SPARC Enterprise T1000 Server Safety
and Compliance Guide
How to use the Advanced Lights
Out Manager (ALOM) software
Safety and compliance
information about this server
C120-E386
C120-E382
Note – The product notes document is available on the website only. Please check
for the recent update on your product.
■ Manuals included on the Enhanced Support Facility CD-ROM disk
■ Remote maintenance service
Title Manual Code
Enhanced Support Facility User's Guide for REMCS C112-B067
Preface xvii
Page 20

Using UNIX Commands
This document might not contain information about basic UNIX® commands and
procedures such as shutting down the system, booting the system, and configuring
devices. Refer to the following for this information:
■ Software documentation that you received with your system
■ Solaris™ Operating System documentation, which is at:
http://docs.sun.com
Text Conventions
This manual uses the following fonts and symbols to express specific types of
information.
Typeface* Meaning Example
AaBbCc123 The names of commands, files and
directories; on-screen computer
output
AaBbCc123 What you type, when contrasted
with on-screen computer output
AaBbCc123 Book titles, new words or terms,
words to be emphasized.
Replace command-line variables
with real names or values.
Edit your.login file.
Use ls -a to list all files.
% You have mail.
%su
Password:
Read Chapter 6 in the User’s
Guide.
These are called class options.
Yo u must be superuser to do this.
To delete a file, type rm filename.
* The settings on your browser might differ from these settings.
xviii SPARC Enterprise T1000 Server Service Manual • April 2007
Page 21

Prompt Notations
The following prompt notations are used in this manual.
Shell Prompt Notations
C shell machine-name%
C shell superuser machine-name#
Bourne shell and Korn shell $
Bourne shell and Korn shell and Korn shell superuser #
Conventions for Alert Messages
This manual uses the following conventions to show alert messages, which are
intended to prevent injury to the user or bystanders as well as property damage, and
important messages that are useful to the user.
Warning – This indicates a hazardous situation that could result in death or serious
personal injury (potential hazard) if the user does not perform the procedure
correctly.
Caution – This indicates a hazardous situation that could result in minor or
moderate personal injury if the user does not perform the procedure correctly. This
signal also indicates that damage to the product or other property may occur if the
user does not perform the procedure correctly.
Alert Messages in the Text
An alert message in the text consists of a signal indicating an alert level followed by an alert
statement. Alert messages are indented to distinguish them from regular text. Also, a space of
one line precedes and follows an alert statement.
Preface xix
Page 22

Caution – The following tasks regarding this product and the optional products
provided from Fujitsu should only be performed by a certified service engineer.
Users must not perform these tasks. Incorrect operation of these tasks may cause
malfunction.
■ Unpacking optional adapters and such packages delivered to the users
Also, important alert messages are shown in “Important Alert Messages” on
page xx.
Notes on Safety
Important Alert Messages
This manual provides the following important alert signals:
Caution – This indicates a hazardous situation could result in minor or moderate
personal injury if the user does not perform the procedure correctly. This signal also
indicates that damage to the product or other property may occur if the user does
not perform the procedure correctly.
Task Warning
Maintenance Electric shock
The system supplies 3.3 Vdc standby power to the circuit boards even
when the system is powered off if the AC power cord is plugged in.
xx SPARC Enterprise T1000 Server Service Manual • April 2007
Page 23

Product Handling
Maintenance
Warning – Certain tasks in this manual should only be performed by a certified
service engineer. User must not perform these tasks. Incorrect operation of these
tasks may cause electric shock, injury, or fire.
■ Installation and reinstallation of all components, and initial settings
■ Removal of front, rear, or side covers
■ Mounting/de-mounting of optional internal devices
■ Plugging or unplugging of external interface cards
■ Maintenance and inspections (repairing, and regular diagnosis and maintenance)
Caution – The following tasks regarding this product and the optional products
provided from Fujitsu should only be performed by a certified service engineer.
Users must not perform these tasks. Incorrect operation of these tasks may cause
malfunction.
■ Unpacking optional adapters and such packages delivered to the users
■ Plugging or unplugging of external interface cards
Remodeling/Rebuilding
Caution – Do not make mechanical or electrical modifications to the equipment.
Using this product after modifying or reproducing by overhaul may cause
unexpected injury or damage to the property of the user or bystanders.
Preface xxi
Page 24

Alert Labels
The followings are labels attached to this product:
■ Never peel off the labels.
■ The following labels provide information to the users of this product.
Sample of SPARC Enterprise T1000
Fujitsu Welcomes Your Comments
We would appreciate your comments and suggestions to improve this document.
You can submit your comments by using "Reader's Comment Form"
xxii SPARC Enterprise T1000 Server Service Manual • April 2007
Page 25

Reader's Comment Form
Preface xxiii
Page 26

FOLD AND TAPE
NO POSTAGE
NECESSARY
IF MAILED
IN THE
UNITED STATES
BUSINESS REPLY MAIL
FIRST-CLASS MAIL PERMIT NO 741 SUNNYVALE CA
POSTAGE WILL BE PAID BY ADDRESSEE
FUJITSU COMPUTER SYSTEMS
AT T E N TI ON ENGINEERING OPS M/S 249
1250 EAST ARQUES AVENUE
P O BOX 3470
SUNNYVALE CA 94088-3470
FOLD AND TAPE
xxiv SPARC Enterprise T1000 Server Service Manual • April 2007
Page 27

CHAPTER
1
Safety Information
This chapter provides important safety information for servicing the server.
The following topics are covered:
■ Section 1.1, “Safety Information” on page 1-1
■ Section 1.2, “Safety Symbols” on page 1-1
■ Section 1.3, “Electrostatic Discharge Safety” on page 1-2
1.1 Safety Information
This section describes safety information you need to know prior to removing or
installing parts in the server.
For your protection, observe the following safety precautions when setting up your
equipment:
■ Follow all standard cautions, warnings, and instructions marked on the
equipment and described in Important Safety Information for Hardware Systems,
C120-E391.
■ Ensure that the voltage and frequency of your power source match the voltage
and frequency inscribed on the equipment’s electrical rating label.
■ Follow the electrostatic discharge safety practices as described in this Section 1.3,
“Electrostatic Discharge Safety” on page 1-2.
1.2 Safety Symbols
The following symbols might appear in this document. Note their meanings:
1-1
Page 28

Caution – There is a risk of personal injury and equipment damage. To avoid
personal injury and equipment damage, follow the instructions.
Caution – Hot surface. Avoid contact. Surfaces are hot and might cause personal
injury if touched.
Caution – Hazardous voltages are present. To reduce the risk of electric shock and
danger to personal health, follow the instructions.
1.3 Electrostatic Discharge Safety
Electrostatic discharge (ESD) sensitive devices, such as the motherboard, PCI cards,
hard drives, and memory cards require special handling.
Caution – The boards and hard drives contain electronic components that are
extremely sensitive to static electricity. Ordinary amounts of static electricity from
clothing or the work environment can destroy components. Do not touch the
components along their connector edges.
1.3.1 Using an Antistatic Wrist Strap
Wear an antistatic wrist strap and use an antistatic mat when handling components
such as drive assemblies, boards, or cards. When servicing or removing server
components, attach an antistatic strap to your wrist and then to a metal area on the
chassis. Do this after you disconnect the power cords from the server. Following this
practice equalizes the electrical potentials between you and the server.
1.3.2 Using an Antistatic Mat
Place ESD-sensitive components such as the motherboard, memory, and other PCB
cards on an antistatic mat.
1-2 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 29

CHAPTER
2
Server Overview
This chapter provides an overview of the server. Topics include:
■ Section 2.1, “Server Overview” on page 2-1
■ Section 2.2, “Obtaining the Chassis Serial Number” on page 2-3
2.1 Server Overview
The server is a high-performance, entry-level server that is highly scalable and very
reliable (
FIGURE 2-1).
FIGURE 2-1 Server
2-1
Page 30
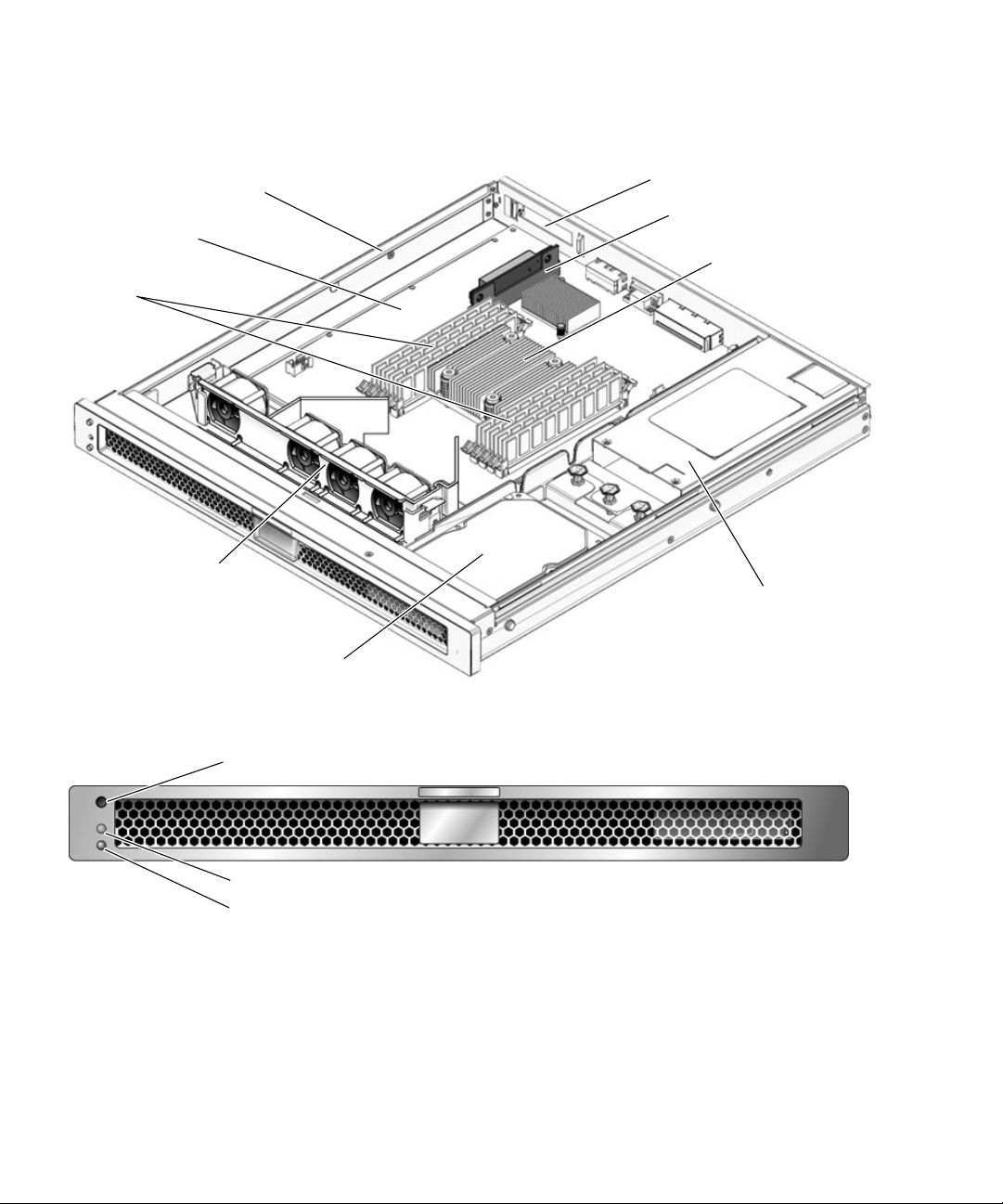
FIGURE 2-2 shows the major components in the server, and FIGURE 2-3 and FIGURE 2-4
show the front and rear panels of the server.
Chassis assembly
Motherboard
DIMMs
Fan tray assembly
PCI-E slot opening
PCI-E riser board
UltraSPARC T1
mullticore processor
Power supply
Hard drive
FIGURE 2-2 Server Components
Locator LED/button
Service Required LED
Power OK LED and Power On/Off button
FIGURE 2-3 Server Front Panel
2-2 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 31

Power supply LEDs
Ethernet ports
PCI-E slot
Locator LED/button
Service Required LED
FIGURE 2-4 Server Rear Panel
Power OK LED
SC network management port
SC serial management port
DB9 serial port
2.2 Obtaining the Chassis Serial Number
To obtain support for your system, you need your chassis serial number. On the
server, the chassis serial number is located on a sticker that is on the front of the
server and another sticker at the rear of the server, below the AC power connector.
You can also run the ALOM CMT showplatform command to obtain the chassis
serial number.
Example:
sc> showplatform
SUNW,SPARC-Enterprise-T1000
Chassis Serial Number: 0529AP000882
Domain Status
------ -----S0 OS Standby
sc>
Chapter 2 Server Overview 2-3
Page 32

2-4 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 33

CHAPTER
3
Server Diagnostics
This chapter describes the diagnostics that are available for monitoring and
troubleshooting the server. This chapter does not provide detailed troubleshooting
procedures, but instead describes the server diagnostics facilities and how to use
them.
This chapter is intended for technicians, service personnel, and system
administrators who service and repair computer systems.
The following topics are covered:
■ Section 3.1, “Overview of Server Diagnostics” on page 3-1
■ Section 3.2, “Using LEDs to Identify the State of Devices” on page 3-8
■ Section 3.3, “Using ALOM CMT for Diagnosis and Repair Verification” on
page 3-11
■ Section 3.4, “Running POST” on page 3-22
■ Section 3.5, “Using the Solaris Predictive Self-Healing Feature” on page 3-39
■ Section 3.6, “Collecting Information From Solaris OS Files and Commands” on
page 3-44
■ Section 3.7, “Managing Components With Automatic System Recovery
Commands” on page 3-45
■ Section 3.8, “Exercising the System With SunVTS” on page 3-48
3.1 Overview of Server Diagnostics
There are a variety of diagnostic tools, commands, and indicators you can use to
troubleshoot a server.
■ LEDs – Provide a quick visual notification of the status of the server and of some
of the FRUs.
3-1
Page 34

■ ALOM CMT firmware – Is the system firmware that runs on the system
controller. In addition to providing the interface between the hardware and OS,
ALOM CMT also tracks and reports the health of key server components. ALOM
CMT works closely with POST and Solaris Predictive Self-Healing technology to
keep the system up and running even when there is a faulty component.
■ Power-on self-test (POST) – Performs diagnostics on system components upon
system reset to ensure the integrity of those components. POST is configurable
and works with ALOM CMT to take faulty components offline if needed and
blacklist them in the asr-db.
■ Solaris OS Predictive Self-Healing (PSH) – This technology continuously
monitors the health of the CPU and memory, and works with ALOM CMT to take
a faulty component offline if needed. The Predictive Self-Healing technology
enables systems to accurately predict component failures and mitigate many
serious problems before they occur.
■ Log files and console messages – Provide the standard Solaris OS log files and
investigative commands that can be accessed and displayed on the device of your
choice.
■ SunVTS™ – An application that exercises the system, provides hardware
validation, and discloses possible faulty components with recommendations for
repair.
The LEDs, ALOM CMT, Solaris OS PSH, and many of the log files and console
messages are integrated. For example, a fault detected by the Solaris PSH software
displays the fault, logs it, passes information to ALOM CMT where it is logged, and
depending on the fault, might illuminate of one or more LEDs.
The flow chart in
FIGURE 3-1 and TABLE 3-1 describes an approach for using the server
diagnostics to identify a faulty field-replaceable unit (FRU). The diagnostics you use,
and the order in which you use them, depend on the nature of the problem you are
troubleshooting, so you might perform some actions and not others.
The flow chart assumes that you have already performed some troubleshooting such
as verification of proper installation and visual inspection of cables and power, and
possibly performed a reset of the server (refer to the SPARC Enterprise T1000 Server
Installation Guide and SPARC Enterprise T1000 Server Administration Guide for
details).
FIGURE 3-1 is a flow chart of the diagnostics available to troubleshoot faulty
hardware.
TABLE 3-1 has more information about each diagnostic in this chapter.
Note – POST is configured with ALOM CMT configuration variables (TABLE 3-6). If
diag_level is set to max (diag_level=max), POST reports all detected FRUs
including memory devices with errors correctable by Predictive Self-Healing (PSH).
Thus, not all memory devices detected by POST need to be replaced. See
Section 3.4.5, “Correctable Errors Detected by POST” on page 3-35.
3-2 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 35

flow chart
FIGURE 3-1 Diagnostic Flow Chart
Chapter 3 Server Diagnostics 3-3
Page 36

TABLE 3-1 Diagnostic Flow Chart Actions
Action
No. Diagnostic Action Resulting Action
1.
Check Power OK
and AC OK LEDs
on the server.
The Power OK LED is located on the front and rear
of the chassis.
The AC OK LED is located on the rear of the server
on each power supply.
If these LEDs are not on, check the power source
and power connections to the server.
2.
Run the ALOM
CMT
showfaults
command to
check for faults.
The showfaults command displays the following
kinds of faults:
• Environmental faults
• Solaris Predictive Self-Healing (PSH) detected
faults
• POST detected faults
Faulty FRUs are identified in fault messages using
the FRU name. For a list of FRU names, see
Appendix A.
3.
Check the Solaris
log files for fault
information.
The Solaris message buffer and log files record
system events and provide information about
faults.
• If system messages indicate a faulty device,
replace the FRU.
• To obtain more diagnostic information, go to
Action No.
4.
Run SunVTS. SunVTS is an application you can run to exercise
and diagnose FRUs. To run SunVTS, the server
must be running the Solaris OS.
• If SunVTS reports a faulty device replace the
FRU.
• If SunVTS does not report a faulty device, go to
Action No.
For more information, see
these sections
Section 3.2, “Using LEDs
to Identify the State of
Devices” on page 3-8
Section 3.3.2, “Running
the showfaults
Command” on page 3-16
Section 3.6, “Collecting
Information From Solaris
OS Files and Commands”
on page 3-44
Chapter 5
4.
Section 3.8, “Exercising
the System With SunVTS”
on page 3-48
Chapter 5
5.
3-4 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 37

TABLE 3-1 Diagnostic Flow Chart Actions (Continued)
Action
No. Diagnostic Action Resulting Action
5.
Run POST. POST performs basic tests of the server components
and reports faulty FRUs.
Note - diag_level=min is the default ALOM
CMT setting, which tests devices required to boot
the server. Use diag_level=max for
troubleshooting and hardware replacement.
• If POST indicates a faulty FRU while
diag_level=min, replace the FRU.
• If POST indicates a faulty memory device while
diag_level=max, the detected errors might be
correctable by PSH after the server boots.
• If POST does not indicate a faulty FRU, go to
Action No.
6.
Determine if the
fault is an
environmental
fault.
If the fault listed by the showfaults command
displays a temperature or voltage fault, then the
fault is an environmental fault. Environmental
faults can be caused by faulty FRUs (power supply
or fan tray) or by environmental conditions such as
when computer room ambient temperature is too
high, or the server airflow is blocked. When the
environmental condition is corrected, the fault will
automatically clear. You can also use the fault LEDs
on the server to identify the faulty FRU (fan tray or
power supply).
For more information, see
these sections
Section 3.4, “Running
POST” on page 3-22
TABLE 3-5, TABLE 3-6
Chapter 5
Section 3.4.5, “Correctable
Errors Detected by POST”
on page 3-35
9.
Section 3.3.2, “Running
the showfaults
Command” on page 3-16
Chapter 5, Section ,
“Replacing FieldReplaceable Units” on
page 5-1
Section 3.2, “Using LEDs
to Identify the State of
Devices” on page 3-8
Chapter 3 Server Diagnostics 3-5
Page 38

TABLE 3-1 Diagnostic Flow Chart Actions (Continued)
Action
No. Diagnostic Action Resulting Action
7.
8.
Determine if the
fault was detected
by PSH.
Determine if the
fault was detected
by POST.
If the fault message displays the following text, the
fault was detected by the Solaris Predictive SelfHealing software:
Host detected fault
If the fault is a PSH detected fault, identify the
faulty FRU from the fault message and replace the
faulty FRU.
After the FRU is replaced, perform the procedure to
clear PSH detected faults.
POST performs basic tests of the server components
and reports faulty FRUs. When POST detects a
faulty FRU, it logs the fault and if possible, takes
the FRU offline. POST detected FRUs display the
following text in the fault message:
FRU_name deemed faulty and disabled
In this case, replace the FRU and run the procedure
to clear POST detected faults.
9.
Contact technical
support.
The majority of hardware faults are detected by the
server’s diagnostics. In rare cases a problem might
require additional troubleshooting. If you are
unable to determine the cause of the problem,
contact technical support.
For more information, see
these sections
Section 3.5, “Using the
Solaris Predictive SelfHealing Feature” on
page 3-39
Chapter 5, Section ,
“Replacing FieldReplaceable Units” on
page 5-1
Section 3.5.2, “Clearing
PSH Detected Faults” on
page 3-43
Section 3.4, “Running
POST” on page 3-22
Chapter 5, Section ,
“Replacing FieldReplaceable Units” on
page 5-1
Section 3.4.6, “Clearing
POST Detected Faults” on
page 3-38
Section 2.2, “Obtainingthe
Chassis Serial Number”
on page 2-3
3.1.1 Memory Configuration and Fault Handling
A variety of features play a role in how the memory subsystem is configured and
how memory faults are handled. Understanding the underlying features helps you
identify and repair memory problems. This section describes how the memory is
configured and how the server deals with memory faults.
3-6 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 39

3.1.1.1 Memory Configuration
In the server memory, there are eight slots that hold DDR-2 memory DIMMs in the
following DIMM sizes:
■ 512 MB (maximum of 4 GB)
■ 1 GB (maximum of 8 GB)
■ 2 GB (maximum of 16 GB)
■ 4 GB (maximum of 32 GB)
All DIMMS installed must be the same size, and DIMMs must be added four at a
time. In addition, Rank 0 memory must be fully populated for the server to function.
See Section 5.6.2, “Installing DIMMs” on page 5-21, for instructions about adding
memory to the server.
3.1.1.2 Memory Fault Handling
The server uses advanced ECC technology, also called chipkill, that corrects up to 4bits in error on nibble boundaries, as long as the bits are all in the same DRAM. If a
DRAM fails, the DIMM continues to function.
The following server features independently manage memory faults:
■ POST – Based on ALOM CMT configuration variables, POST runs when the
server is powered on. In normal operation, the default configuration of POST
(diag_level=min), provides a check to ensure the server will boot. Normal
operation applies to any boot of the server not intended to test power-on errors,
hardware upgrades, or repairs. Once the Solaris OS is running, PSH provides runtime diagnosis of faults.
When a memory fault is detected, POST displays the fault with the device name
of the faulty DIMMS, logs the fault, and disables the faulty DIMMs by placing
them in the ASR blacklist. For a given memory fault, POST disables half of the
physical memory in the system. When this offlining process occurs in normal
operation, you must replace the faulty DIMMs based on the fault message and
enable the disabled DIMMs with the ALOM CMT enablecomponent command.
In other than normal operation, POST can be configured to run various levels of
testing (see
subsystem based on the purpose of the test. However, with thorough testing
enabled (diag_level=max), POST finds faults and offlines memory devices with
errors that could be correctable with PSH. Thus, not all memory devices detected
and offlined by POST need to be replaced. See Section 3.4.5, “Correctable Errors
Detected by POST” on page 3-35.
TABLE 3-5 and TABLE 3-6) and can thoroughly test the memory
Chapter 3 Server Diagnostics 3-7
Page 40

■ Solaris Predictive Self-Healing (PSH) technology – A feature of the Solaris OS,
uses the fault manager daemon (fmd) to watch for various kinds of faults. When
a fault occurs, the fault is assigned a unique fault ID (UUID), and logged. PSH
reports the fault and provides a recommended proactive replacement for the
DIMMs associated with the fault.
3.1.1.3 Troubleshooting Memory Faults
If you suspect that the server has a memory problem, follow the flow chart (see
TABLE 3-1). Run the ALOM CMT showfaults command. The showfaults
command lists memory faults and lists the specific DIMMS that are associated with
the fault. Once you identify which DIMMs to replace, see Chapter 5 for DIMM
removal and replacement instructions. It is important that you perform the
instructions in that chapter to clear the faults and enable the replaced DIMMs.
3.2 Using LEDs to Identify the State of Devices
The server provides the following groups of LEDs:
■ Front and rear panel LEDS (FIGURE 3-2, FIGURE 3-3, and TABLE 3-2)
■ Power supply LEDs (FIGURE 3-3 and TABLE 3-3)
These LEDs provide a quick visual check of the state of the system.
Locator LED/button
Service Required LED
Power OK LED and Power On/Off button
FIGURE 3-2 LEDs on the Server Front Panel
3-8 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 41

Fault LED
Activity LED
Link LED
Activity LED
Link LED
DC OK LED
AC OK LED
FIGURE 3-3 LEDs on the Server Rear Panel
Power OK LED
Service Required LED
Locator LED/button
Chapter 3 Server Diagnostics 3-9
Page 42

3.2.1 Front and Rear Panel LEDs
Two LEDs and one LED/button are located in the upper left corner of the front
panel (
TABLE 3-2). The LEDs are also provided on the rear panel.
TABLE 3-2 Front and Rear Panel LEDs
LED Location Color Description
Locator LED/button Front and
rear panels
Service Required LED Front and
rear panels
Power OK LED Front and
rear panels
Power On/Off button Front panel N/A Turns the server on and off.
Ethernet Link Activity LEDs Rear panel Green These LEDs indicate that there is activity on the
Ethernet Link LEDs Rear panel Yellow Indicates that the server is linked to the associated
SC Network Management
Activity LED
SC Network Management
Link LED
Rear panel Yellow Indicates that there is activity on the SC Network
Rear panel Green Indicates that the server is linked to the SC network
White Enables you to identify a particular server. Activate
the LED using one of the following methods:
• Issuing the setlocator on or off command.
• Pressing the button to toggle the indicator on or off.
This LED provides the following indications:
• Off – Normal operating state.
• Fast blink – The server received a signal as a result
of one of the preceding methods and is indicating
here I am— that it is operational.
Yellow If on, indicates that service is required. The ALOM
CMT showfaults command will indicate any
faults causing this indicator to light.
Green The LED provides the following indications:
• Off – Indicates that the system is unavailable.
Either it has no power or ALOM
running.
• Steady on – Indicates that the system is powered on
and is running in its normal operating state. No
service actions are required.
• Standby blink – Indicates the system is running at a
minimum level in standby and is ready to be
quickly returned to full function. The service
processor is running.
• Slow blink – Indicates that a normal transitory
activity is taking place. Server diagnostics could be
running, or the system might be powering on.
associated nets.
nets.
Management port.
management port.
CMT is not
3-10 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 43

3.2.2 Power Supply LEDs
The power supply LEDs (TABLE 3-3) are located on the back of the power supply.
TABLE 3-3 Power Supply LEDs
Name Color Description
Fault Amber • On – Power supply has detected a failure.
• Off – Normal operation.
DC OK Green • On – Normal operation. DC output voltage is within normal limits.
• Off – Power is off.
AC OK Green • On – Normal operation. Input power is within normal limits.
• Off – No input voltage, or input voltage is below limits.
3.3 Using ALOM CMT for Diagnosis and Repair Verification
The Advanced Lights Out Management (ALOM) CMT is a system controller in the
server that enables you to remotely manage and administer your server.
ALOM CMT enables you to remotely run diagnostics, such as power-on self-test
(POST), that would otherwise require physical proximity to the server’s serial port.
You can also configure ALOM CMT to send email alerts of hardware failures,
hardware warnings, and other events related to the server or to ALOM CMT.
The ALOM CMT circuitry runs independently of the server, using the server’s
standby power. Therefore, ALOM CMT firmware and software continue to function
when the server operating system goes offline or when the server is powered off.
Note – Refer to the Advanced Lights Out Management (ALOM) CMT Guide for
comprehensive ALOM CMT information.
Chapter 3 Server Diagnostics 3-11
Page 44

Faults detected by ALOM CMT, POST, and the Solaris Predictive Self-Healing (PSH)
technology are forwarded to ALOM CMT for fault handling (
FIGURE 3-4).
In the event of a system fault, ALOM CMT ensures that the Service Required LED is
lit, FRU ID PROMs are updated, the fault is logged, and alerts are displayed. Faulty
FRUs are identified in fault messages using the FRU name. For a list of FRU names,
see Appendix A.
Service Required LED
FRU LEDs
FRUID PROMs
Logs
Alerts
FIGURE 3-4 ALOM CMT Fault Management
ALOM CMT sends alerts to all ALOM CMT users that are logged in, sending the
alert through email to a configured email address, and writing the event to the
ALOM CMT event log.
ALOM CMT can detect when a fault is no longer present and clears the fault in
several ways:
■ Fault recovery – The system automatically detects that the fault condition is no
longer present. ALOM CMT extinguishes the Service Required LED and updates
the FRU’s PROM, indicating that the fault is no longer present.
■ Fault repair – The fault has been repaired by human intervention. In most cases,
ALOM CMT detects the repair and extinguishes the Service Required LED. If
ALOM CMT does not perform these actions, you must perform these tasks
manually using the clearfault or enablecomponent commands.
ALOM CMT can detect the removal of a FRU, in many cases even if the FRU is
removed while ALOM CMT is powered off. This enables ALOM CMT to know that
a fault, diagnosed to a specific FRU, has been repaired. The ALOM CMT
clearfault command enables you to manually clear certain types of faults without
a FRU replacement or if ALOM CMT was unable to automatically detect the FRU
replacement.
Note – ALOM CMT does not automatically detect hard drive replacement.
3-12 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 45

Many environmental faults can automatically recover. A temperature that is
exceeding a threshold might return to normal limits. An unplugged power supply
can be plugged in, and so on. Recovery of environmental faults is automatically
detected. Recovery events are reported using one of two forms:
■ fru at location is OK.
■ sensor at location is within normal range.
Environmental faults can be repaired through the removal of the faulty FRU. FRU
removal is automatically detected by the environmental monitoring and all faults
associated with the removed FRU are cleared. The message for that case, and the
alert sent for all FRU removals is:
fru at location has been removed.
There is no ALOM CMT command to manually repair an environmental fault.
The Solaris Predictive Self-Healing technology does not monitor the hard drive for
faults. As a result, ALOM CMT does not recognize hard drive faults, and will not
light the fault LEDs on either the chassis or the hard drive itself. Use the Solaris
message files to view hard drive faults. See Section 3.6, “Collecting Information
From Solaris OS Files and Commands” on page 3-44.
3.3.1 Running ALOM CMT Service-Related Commands
This section describes the ALOM CMT commands that are commonly used for
service-related activities.
3.3.1.1 Connecting to ALOM
Before you can run ALOM CMT commands, you must connect to the ALOM. There
are several ways to connect to the system controller:
■ Connect an ASCII terminal directly to the serial management port.
■ Use either the telnet or the ssh command to connect to ALOM CMT through
an Ethernet connection on the network management port. ALOM CMT can be
configured for either the telnet or the ssh command, but not both.
Note – Refer to the Advanced Lights Out Management (ALOM) CMT Guide for
instructions on configuring and connecting to ALOM.
Chapter 3 Server Diagnostics 3-13
Page 46

3.3.1.2 Switching Between the System Console and ALOM
■ To switch from the console output to the ALOM CMT sc> prompt, type #.
(Hash-Period). Note that this command is user-configureable. Refer to the
Advanced Lights Out Management (ALOM) CMT Guide for more information.
■ To switch from the sc> prompt to the console, type console.
3.3.1.3 Service-Related ALOM CMT Commands
TABLE 3-4 describes the typical ALOM CMT commands for servicing the server. For
descriptions of all ALOM CMT commands, issue the help command or refer to the
Advanced Lights Out Management (ALOM) CMT Guide.
TABLE 3-4 Service-Related ALOM CMT Commands
ALOM CMT Command Description
help [command] Displays a list of all ALOM CMT commands with syntax and descriptions.
Specifying a command name as an option displays help for that command.
break [-y][-c][-D] Takes the host server from the OS to either kmdb or OpenBoot PROM
(equivalent to a Stop-A), depending on the mode Solaris software was
booted.
• -y skips the confirmation question
• -c executes a console command after the break command completes
• -D forces a core dump of the Solaris OS
clearfault UUID Manually clears host-detected faults. The UUID is the unique fault ID of
the fault to be cleared.
console [-f] Connects you to the host system. The -f option forces the console to have
read and write capabilities.
consolehistory [-b lines|-e
lines|-v] [-g lines]
[boot|run]
bootmode
[normal|reset_nvram|
bootscript=string]
Displays the contents of the system’s console buffer. The following options
enable you to specify how the output is displayed:
• -g lines specifies the number of lines to display before pausing.
• -e lines displays n lines from the end of the buffer.
• -b lines displays n lines from beginning of buffer.
• -v displays entire buffer.
• boot|run specifies the log to display (run is the default log).
Enables control of the firmware during system initialization with the
following options:
• normal is the default boot mode.
• reset_nvram resets OpenBoot PROM parameters to their default
values.
• bootscript=string enables the passing of a string to the boot
command.
3-14 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 47

TABLE 3-4 Service-Related ALOM CMT Commands (Continued)
ALOM CMT Command Description
powercycle [-f] Performs a poweroff followed by poweron. The -f option forces an
immediate poweroff, otherwise the command attempts a graceful
shutdown.
poweroff [-y][-f] Powers off the host server. The -y option enables you to skip the
confirmation question. The -f option forces an immediate shutdown.
poweron [-c] Powers on the host server. Using the -c option executes a console
command after completion of the poweron command.
reset [-y] [-c] Generates a hardware reset on the host server. The -y option enables you
to skip the confirmation question. The -c option executes a console
command after completion of the reset command.
resetsc [-y] Reboots the system controller. The -y option enables you to skip the
confirmation question.
setkeyswitch [-y] normal |
stby | diag | locked
Sets the virtual keyswitch. The -y option enables you to skip the
confirmation question when setting the keyswitch to stby.
setlocator [on | off] Turns the Locator LED on the server on or off.
showenvironment Displays the environmental status of the host server. This information
includes system temperatures, power supply, front panel LED, hard drive,
fan, voltage, and current sensor status. See Section 3.3.3, “Running the
showenvironment Command” on page 3-17.
showfaults [-v] Displays current system faults. See Section 3.3.2, “Running the
showfaults Command” on page 3-16.
showfru [-g lines][-s | -d]
[FRU]
Displays information about the FRUs in the server.
• -g lines specifies the number of lines to display before pausing the
output to the screen.
• -s displays static information about system FRUs (defaults to all FRUs,
unless one is specified).
• -d displays dynamic information about system FRUs (defaults to all
FRUs, unless one is specified). See Section 3.3.4, “Running the showfru
Command” on page 3-19.
showkeyswitch Displays the status of the virtual keyswitch.
showlocator Displays the current state of the Locator LED as either on or off.
showlogs [-b lines | -e lines |v] [-g lines][-p
Displays the history of all events logged in the ALOM CMT event buffers
(in RAM or the persistent buffers).
logtype[r|p]]]
showplatform [-v] Displays information about the host system’s hardware configuration, the
system serial number, and whether the hardware is providing service.
Chapter 3 Server Diagnostics 3-15
Page 48

Note – See TABLE 3-7 for the ALOM CMT ASR commands.
3.3.2 Running the showfaults Command
The ALOM CMT showfaults command displays the following kinds of faults:
■ Environmental faults – temperature or voltage problems that might be caused by
faulty FRUs (a power supply or fan tray), or by room temperature or blocked air
flow to the server.
■ POST detected faults – faults on devices detected by the power-on self-test
diagnostics.
■ PSH detected faults – faults detected by the Solaris Predictive Self-Healing (PSH)
technology
Use the showfaults command for the following reasons:
■ To see if any faults have been passed to, or detected by ALOM.
■ To obtain the fault message ID (SUNW-MSG-ID) for PSH detected faults.
■ To verify that the replacement of a FRU has cleared the fault and not generated
any additional faults.
● At the sc> prompt, type the showfaults command.
The following showfaults command examples show the different kinds of output
from the showfaults command:
■ Example of the showfaults command when no faults are present:
sc> showfaults
Last POST run: THU MAR 09 16:52:44 2006
POST status: Passed all devices
No failures found in System
■ Example of the showfaults command displaying an environmental fault:
sc> showfaults -v
Last POST run: TUE FEB 07 18:51:02 2006
POST status: Passed all devices
ID FRU Fault
0 IOBD VOLTAGE_SENSOR at IOBD/V_+1V has exceeded
low warning threshold.
3-16 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 49

■ Example showing a fault that was detected by POST. These kinds of faults are
identified by the message deemed faulty and disabled and by a FRU name.
sc> showfaults -v
ID Time FRU Fault
1 OCT 13 12:47:27 MB/CMP0/CH0/R1/D0 MB/CMP0/CH0/R1/D0 deemed
faulty and disabled
■ Example showing a fault that was detected by the PSH technology. These kinds of
faults are identified by the text Host detected fault and by a UUID.
sc> showfaults -v
ID Time FRU Fault
0 SEP 09 11:09:26 MB/CMP0/CH0/R1/D0 Host detected fault, MSGID:
SUN4U-8000-2S UUID: 7ee0e46b-ea64-6565-e684-e996963f7b86
3.3.3 Running the showenvironment Command
The showenvironment command displays a snapshot of the server’s
environmental status. This command displays system temperatures, hard disk drive
status, power supply and fan status, front panel LED status, voltage and current
sensors. The output uses a format similar to the Solaris OS command prtdiag (1m).
● At the sc> prompt, type the showenvironment command.
The output differs according to your system’s model and configuration. Example:
sc> showenvironment
=============== Environmental Status ===============
-------------------------------------------------------------------------------System Temperatures (Temperatures in Celsius):
-------------------------------------------------------------------------------Sensor Status Temp LowHard LowSoft LowWarn HighWarn HighSoft HighHard
-------------------------------------------------------------------------------MB/T_AMB OK 28 -10 -5 0 45 50 55
MB/CMP0/T_TCORE OK 50 -10 -5 0 85 90 95
MB/CMP0/T_BCORE OK 51 -10 -5 0 85 90 95
MB/IOB/T_CORE OK 49 -10 -5 0 95 100 105
-------------------------------------------------------System Indicator Status:
--------------------------------------------------------
Chapter 3 Server Diagnostics 3-17
Page 50

SYS/LOCATE SYS/SERVICE SYS/ACT
OFF OFF ON
--------------------------------------------------------
---------------------------------------------------------Fans (Speeds Revolution Per Minute):
---------------------------------------------------------Sensor Status Speed Warn Low
---------------------------------------------------------FT0/F0 OK 6762 2240 1920
FT0/F1 OK 6762 2240 1920
FT0/F2 OK 6762 2240 1920
FT0/F3 OK 6653 2240 1920
-------------------------------------------------------------------------------Voltage sensors (in Volts):
-------------------------------------------------------------------------------Sensor Status Voltage LowSoft LowWarn HighWarn HighSoft
-------------------------------------------------------------------------------MB/V_VCORE OK 1.30 1.20 1.24 1.36 1.39
MB/V_VMEM OK 1.79 1.69 1.72 1.87 1.90
MB/V_VTT OK 0.89 0.84 0.86 0.93 0.95
MB/V_+1V2 OK 1.18 1.09 1.11 1.28 1.30
MB/V_+1V5 OK 1.49 1.36 1.39 1.60 1.63
MB/V_+2V5 OK 2.51 2.27 2.32 2.67 2.72
MB/V_+3V3 OK 3.29 3.06 3.10 3.49 3.53
MB/V_+5V OK 5.02 4.55 4.65 5.35 5.45
MB/V_+12V OK 12.25 10.92 11.16 12.84 13.08
MB/V_+3V3STBY OK 3.33 3.13 3.16 3.53 3.59
----------------------------------------------------------System Load (in amps):
----------------------------------------------------------Sensor Status Load Warn Shutdown
----------------------------------------------------------MB/I_VCORE OK 20.560 80.000 88.000
MB/I_VMEM OK 8.160 60.000 66.000
-----------------------------------------------------------
---------------------Current sensors:
---------------------Sensor Status
---------------------MB/BAT/V_BAT OK
-----------------------------------------------------------------------------Power Supplies:
-----------------------------------------------------------------------------Supply Status Underspeed Overtemp Overvolt Undervolt Overcurrent
------------------------------------------------------------------------------
3-18 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 51

PS0 OK OFF OFF OFF OFF OFF
sc>
Note – Some environmental information might not be available when the server is
in Standby mode.
3.3.4 Running the showfru Command
The showfru command displays information about the FRUs in the server. Use this
command to see information about an individual FRU, or for all the FRUs.
Note – By default, the output of the showfru command for all FRUs is very long.
● At the sc> prompt, enter the showfru command.
sc> showfru -s
FRU_PROM at MB/SEEPROM
SEGMENT: SD
/ManR
/ManR/UNIX_Timestamp32: TUE OCT 18 21:17:55 2005
/ManR/Description: ASSY,SPARC-Enterprise-T1000,Motherboard
/ManR/Manufacture Location: Sriracha,Chonburi,Thailand
/ManR/Sun Part No: 5017302
/ManR/Sun Serial No: 002989
/ManR/Vendor: Celestica
/ManR/Initial HW Dash Level: 03
/ManR/Initial HW Rev Level: 01
/ManR/Shortname: T1000_MB
/SpecPartNo: 885-0505-04
FRU_PROM at PS0/SEEPROM
SEGMENT: SD
/ManR
/ManR/UNIX_Timestamp32: SUN JUL 31 19:45:13 2005
/ManR/Description: PSU,300W,AC_INPUT,A207
/ManR/Manufacture Location: Matamoros, Tamps, Mexico
/ManR/Sun Part No: 3001799
/ManR/Sun Serial No: G00001
/ManR/Vendor: Tyco Electronics
/ManR/Initial HW Dash Level: 02
/ManR/Initial HW Rev Level: 01
Chapter 3 Server Diagnostics 3-19
Page 52

/ManR/Shortname: PS
/SpecPartNo: 885-0407-02
FRU_PROM at MB/CMP0/CH0/R0/D0/SEEPROM
/SPD/Timestamp: MON OCT 03 12:00:00 2005
/SPD/Description: DDR2 SDRAM, 2048 MB
/SPD/Manufacture Location:
/SPD/Vendor: Infineon (formerly Siemens)
/SPD/Vendor Part No: 72T256220HR3.7A
/SPD/Vendor Serial No: d03fe27
FRU_PROM at MB/CMP0/CH0/R0/D1/SEEPROM
/SPD/Timestamp: MON OCT 03 12:00:00 2005
/SPD/Description: DDR2 SDRAM, 2048 MB
/SPD/Manufacture Location:
/SPD/Vendor: Infineon (formerly Siemens)
/SPD/Vendor Part No: 72T256220HR3.7A
/SPD/Vendor Serial No: d03f623
FRU_PROM at MB/CMP0/CH0/R1/D0/SEEPROM
/SPD/Timestamp: MON OCT 03 12:00:00 2005
/SPD/Description: DDR2 SDRAM, 2048 MB
/SPD/Manufacture Location:
/SPD/Vendor: Infineon (formerly Siemens)
/SPD/Vendor Part No: 72T256220HR3.7A
/SPD/Vendor Serial No: d03fc26
FRU_PROM at MB/CMP0/CH0/R1/D1/SEEPROM
/SPD/Timestamp: MON OCT 03 12:00:00 2005
/SPD/Description: DDR2 SDRAM, 2048 MB
/SPD/Manufacture Location:
/SPD/Vendor: Infineon (formerly Siemens)
/SPD/Vendor Part No: 72T256220HR3.7A
/SPD/Vendor Serial No: d03eb26
FRU_PROM at MB/CMP0/CH3/R0/D0/SEEPROM
/SPD/Timestamp: MON OCT 03 12:00:00 2005
/SPD/Description: DDR2 SDRAM, 2048 MB
/SPD/Manufacture Location:
/SPD/Vendor: Infineon (formerly Siemens)
/SPD/Vendor Part No: 72T256220HR3.7A
/SPD/Vendor Serial No: d03e620
3-20 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 53

FRU_PROM at MB/CMP0/CH3/R0/D1/SEEPROM
/SPD/Timestamp: MON OCT 03 12:00:00 2005
/SPD/Description: DDR2 SDRAM, 2048 MB
/SPD/Manufacture Location:
/SPD/Vendor: Infineon (formerly Siemens)
/SPD/Vendor Part No: 72T256220HR3.7A
/SPD/Vendor Serial No: d040920
FRU_PROM at MB/CMP0/CH3/R1/D0/SEEPROM
/SPD/Timestamp: MON OCT 03 12:00:00 2005
/SPD/Description: DDR2 SDRAM, 2048 MB
/SPD/Manufacture Location:
/SPD/Vendor: Infineon (formerly Siemens)
/SPD/Vendor Part No: 72T256220HR3.7A
/SPD/Vendor Serial No: d03ec27
FRU_PROM at MB/CMP0/CH3/R1/D1/SEEPROM
/SPD/Timestamp: MON OCT 03 12:00:00 2005
/SPD/Description: DDR2 SDRAM, 2048 MB
/SPD/Manufacture Location:
/SPD/Vendor: Infineon (formerly Siemens)
/SPD/Vendor Part No: 72T256220HR3.7A
/SPD/Vendor Serial No: d040924
sc>
Chapter 3 Server Diagnostics 3-21
Page 54

3.4 Running POST
Power-on self-test (POST) is a group of PROM-based tests that run when the server
is powered on or reset. POST checks the basic integrity of the critical hardware
components in the server (CPU, memory, and I/O buses).
If POST detects a faulty component, the component is disabled automatically,
preventing faulty hardware from potentially harming any software. If the system is
capable of running without the disabled component, the system will boot when
POST is complete. For example, if one of the processor cores is deemed faulty by
POST, the core will be disabled, and the system will boot and run using the
remaining cores.
In normal operation*, the default configuration of POST (diag_level=min),
provides a sanity check to ensure the server will boot. Normal operation applies to
any power on of the server not intended to test power-on errors, hardware
upgrades, or repairs. Once the Solaris OS is running, PSH provides run time
diagnosis of faults.
*Note – Earlier versions of firmware have max as the default setting for the POST
diag_level variable. To set the default to min, use the ALOM CMT command,
setsc diag_level min
For validating hardware upgrades or repairs, configure POST to run in maximum
mode (diag_level=max). Note that with maximum testing enabled, POST detects
and offlines memory devices with errors that could be correctable by PSH. Thus, not
all memory devices detected by POST need to be replaced. See Section 3.4.5,
“Correctable Errors Detected by POST” on page 3-35.
Note – Devices can be manually enabled or disabled using ASR commands (see
Section 3.7, “Managing Components With Automatic System Recovery Commands”
on page 3-45).
3.4.1 Controlling How POST Runs
The server can be configured for normal, extensive, or no POST execution. You can
also control the level of tests that run, the amount of POST output that is displayed,
and which reset events trigger POST by using ALOM CMT variables.
3-22 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 55

TABLE 3-5 lists the ALOM CMT variables used to configure POST and FIGURE 3-5
shows how the variables work together.
Note – Use the ALOM CMT setsc command to set all the parameters in TABLE 3-5
except setkeyswitch.
TABLE 3-5 ALOM CMT Parameters Used for POST Configuration
Parameter Values Description
setkeyswitch normal The system can power on and run POST (based
on the other parameter settings). For details see
TABLE 3-6. This parameter overrides all other
commands.
diag The system runs POST based on predetermined
settings.
stby The system cannot power on.
locked The system can power on and run POST, but no
flash updates can be made.
diag_mode off POST does not run.
normal Runs POST according to diag_level value.
service Runs POST with preset values for diag_level
and diag_verbosity.
diag_level min If diag_mode = normal, runs minimum set of
tests.
max If diag_mode = normal, runs all the minimum
tests plus extensive CPU and memory tests.
diag_trigger none Does not run POST on reset.
user_reset Runs POST upon user initiated resets.
power_on_reset Only runs POST for the first power on. This
option is the default.
error_reset Runs POST if fatal errors are detected.
all_reset Runs POST after any reset.
diag_verbosity none No POST output is displayed.
Chapter 3 Server Diagnostics 3-23
Page 56

TABLE 3-5 ALOM CMT Parameters Used for POST Configuration (Continued)
Parameter Values Description
min POST output displays functional tests with a
banner and pinwheel.
normal POST output displays all test and informational
messages.
max POST displays all test, informational, and some
debugging messages.
3-24 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 57

FIGURE 3-5 Flow Chart of ALOM CMT Variables for POST Configuration
Chapter 3 Server Diagnostics 3-25
Page 58

TABLE 3-6 shows combinations of ALOM CMT variables and associated POST modes.
TABLE 3-6 ALOM CMT Parameters and POST Modes
Parameter Normal Diagnostic
Mode
(Default Settings)
diag_mode normal off service normal
*
setkeyswitch
diag_level
diag_trigger power-on-reset
diag_verbosity normal n/a max max
Description of POST
execution
* The setkeyswitch parameter, when set to diag, overrides all the other ALOM CMT POST variables.
\ Earlier versions of firmware have max as the default setting for the POST diag_level variable. To set the default to min, use the
ALOM CMT command, setsc diag_level min
\
normal normal normal diag
min n/a max max
error-reset
This is the default POST
configuration. This
configuration tests the
system thoroughly, and
suppresses some of the
detailed POST output.
No POST
Execution
none all-resets all-resets
POST does not
run, resulting in
quick system
initialization, but
this is not a
suggested
configuration.
Diagnostic
Service Mode
POST runs the
full spectrum of
tests with the
maximum output
displayed.
Keyswitch
Diagnostic Preset
Values
POST runs the
full spectrum of
tests with the
maximum output
displayed.
3.4.2 Changing POST Parameters
1. Access the ALOM CMT sc> prompt:
At the console, issue the #. key sequence:
#.
2. Use the ALOM CMT sc> prompt to change the POST parameters.
Refer to
TABLE 3-5 for a list of ALOM CMT POST parameters and their values.
The setkeyswitch parameter sets the virtual keyswitch, so it does not use the
setsc command. For example, to change the POST parameters using the
setkeyswitch command, enter the following:
sc> setkeyswitch diag
3-26 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 59

To change the POST parameters using the setsc command, you must first set the
setkeyswitch parameter to normal, then you can change the POST parameters
using the setsc command:
sc> setkeyswitch normal
sc> setsc value
Example:
sc> setkeyswitch normal
sc> setsc diag_mode service
3.4.3 Reasons to Run POST
You can use POST for basic hardware verification and diagnosis, and for
troubleshooting as described in the following sections.
3.4.3.1 Verifying Hardware Functionality
POST tests critical hardware components to verify functionality before the system
boots and accesses software. If POST detects an error, the faulty component is
disabled automatically, preventing faulty hardware from potentially harming
software.
In normal operation (diag_level=min), POST runs in mimimum mode by default
to test devices required to power on the server. Replace any devices POST detects as
faulty in minimum mode.
Run POST in maximum mode (diag_level=max) for all power-on or errorgenerated resets, and to validate hardware upgrades or repairs. With maximum
testing enabled, POST finds faults and offlines memory devices with errors that
could be correctable by PSH. Check the POST-generated errors with the
showfaults -v command to verify if memory devices detected by POST can be
corrected by PSH or need to be replaced. See Section 3.4.5, “Correctable Errors
Detected by POST” on page 3-35.
Chapter 3 Server Diagnostics 3-27
Page 60

3.4.3.2 Diagnosing the System Hardware
You can use POST as an initial diagnostic tool for the system hardware. In this case,
configure POST to run in maximum mode (diag_mode=service, setkeyswitch=
diag, diag_level=max) for thorough test coverage and verbose output.
3.4.4 Running POST in Maximum Mode
This procedure describes how to run POST when you want maximum testing, as in
the case when you are troubleshooting a server or verifying a hardware upgrade or
repair.
1. Switch from the system console prompt to the sc> prompt by issuing the #. escape
sequence.
ok #.
sc>
2. Set the virtual keyswitch to diag so that POST will run in Service mode.
sc> setkeyswitch diag
3. Reset the system so that POST runs.
There are several ways to initiate a reset. The following example uses the
powercycle command. For other methods, refer to the SPARC Enterprise T1000
Server Administration Guide.
sc> powercycle
Are you sure you want to powercycle the system [y/n]? y
Powering host off at MON JAN 10 02:52:02 2000
Waiting for host to Power Off; hit any key to abort.
SC Alert: SC Request to Power Off Host.
SC Alert: Host system has shut down.
Powering host on at MON JAN 10 02:52:13 2000
SC Alert: SC Request to Power On Host.
3-28 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 61

4. Switch to the system console to view the POST output:
sc> console
Example of POST output:
SC: Alert: Host system has reset1 Note: Some output omitted.
0:0>
0:0>@(#) ERIE Integrated POST 4.x.0.build_17 2005/08/30 11:25
/export/common-source/firmware_re/ontariofireball_fio/build_17/post/Niagara/erie/integrated (firmware_re)
0:0>Copyright © 2005 Sun Microsystems, Inc. All rights reserved
SUN PROPRIETARY/CONFIDENTIAL.
Use is subject to license terms.
0:0>VBSC selecting POST IO Testing.
0:0>VBSC enabling threads: 1
0:0>VBSC setting verbosity level 3
0:0>Start Selftest.....
0:0>Init CPU
0:0>Master CPU Tests Basic.....
0:0>CPU =: 0
0:0>DMMU Registers Access
0:0>IMMU Registers Access
0:0>Init mmu regs
0:0>D-Cache RAM
0:0>DMMU TLB DATA RAM Access
0:0>DMMU TLB TAGS Access
0:0>DMMU CAM
0:0>IMMU TLB DATA RAM Access
0:0>IMMU TLB TAGS Access
0:0>IMMU CAM
0:0>Setup and Enable DMMU
0:0>Setup DMMU Miss Handler
Chapter 3 Server Diagnostics 3-29
Page 62

0:0> Niagara, Version 2.0
0:0> Serial Number 00000098.00000820 = fffff238.6b4c60e9
0:0>Init JBUS Config Regs
0:0>IO-Bridge unit 1 init test
0:0>sys 200 MHz, CPU 1000 MHz, mem 200 MHz.
0:0>Integrated POST Testing
0:0>L2 Tests.....
0:0>Setup L2 Cache
0:0>L2 Cache Control = 00000000.00300000
0:0>Scrub and Setup L2 Cache
0:0>L2 Directory clear
0:0>L2 Scrub VD & UA
0:0>L2 Scrub Tags
0:0>Test Memory Basic.....
0:0>Probe and Setup Memory
0:0>INFO:4096MB at Memory Channel [0 3 ] Rank 0 Stack 0
0:0>INFO:4096MB at Memory Channel [0 3 ] Rank 0 Stack 1
0:0>INFO:No memory detected at Memory Channel [0 3 ] Rank 1 Stack 0
0:0>INFO:No memory detected at Memory Channel [0 3 ] Rank 1 Stack 1
0:0>
0:0>Data Bitwalk
0:0>L2 Scrub Data
0:0>L2 Enable
0:0> Testing Memory Channel 0 Rank 0 Stack 0
0:0> Testing Memory Channel 3 Rank 0 Stack 0
0:0> Testing Memory Channel 0 Rank 0 Stack 1
0:0> Testing Memory Channel 3 Rank 0 Stack 1
0:0>L2 Directory clear
0:0>L2 Scrub VD & UA
0:0>L2 Scrub Tags
0:0>L2 Disable
3-30 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 63

0:0>Address Bitwalk
0:0> Testing Memory Channel 0 Rank 0 Stack 0
0:0> Testing Memory Channel 3 Rank 0 Stack 0
0:0> Testing Memory Channel 0 Rank 0 Stack 1
0:0> Testing Memory Channel 3 Rank 0 Stack 1
0:0>Test Slave Threads Basic.....
0:0>Set Mailbox
0:0>Setup Final DMMU Entries
0:0>Post Image Region Scrub
0:0>Run POST from Memory
0:0>Verifying checksum on copied image.
0:0>The Memory’s CHECKSUM value is cc1e.
0:0>The Memory’s Content Size value is 7b192.
0:0>Success... Checksum on Memory Validated.
0:0>L2 Cache Ram Test
0:0>Enable L2 Cache
0:0>L2 Scrub Data
0:0>L2 Enable
0:0>CPU =: 0
0:0>CPU =: 0
0:0>Test slave strand registers...
0:0>Extended CPU Tests.....
0:0>Scrub Icache
0:0>Scrub Dcache
0:0>D-Cache Tags
0:0>I-Cache RAM Test
0:0>I-Cache Tag RAM
0:0>FPU Registers and Data Path
0:0>FPU Move Registers
0:0>FSR Read/Write
0:0>FPU Branch Instructions
Chapter 3 Server Diagnostics 3-31
Page 64

0:0>Enable Icache
0:0>Enable Dcache
0:0>Scrub Memory.....
0:0>Scrub Memory
0:0>Scrub 00000000.00600000->00000001.00000000 on Memory Channel [0 3 ] Rank 0
Stack 0
0:0>Scrub 00000001.00000000->00000002.00000000 on Memory Channel [0 3 ] Rank 0
Stack 1
0:0>IMMU Functional
0:0>DMMU Functional
0:0>Extended Memory Tests.....
0:0>Print Mem Config
0:0>Caches : Icache is ON, Dcache is ON.
0:0> Bank 0 4096MB : 00000000.00000000 -> 00000001.00000000.
0:0> Bank 1 4096MB : 00000001.00000000 -> 00000002.00000000.
0:0>Block Mem Test
0:0>Test 6291456 bytes at 00000000.00600000 Memory Channel [ 0 3 ] Rank 0 Stack 0
0:0>........
0:0>Test 6291456 bytes at 00000001.00000000 Memory Channel [ 0 3 ] Rank 0 Stack 1
0:0>........
0:0>IO-Bridge Tests.....
0:0>IO-Bridge Quick Read
0:0>
0:0>--------------------------------------------------------------
0:0>--------- IO-Bridge Quick Read Only of CSR and ID ---------------
0:0>--------------------------------------------------------------
0:0>fire 1 JBUSID 00000080.0f000000 =
0:0> fc000002.e03dda23
0:0>--------------------------------------------------------------
0:0>fire 1 JBUSCSR 00000080.0f410000 =
0:0> 00000ff5.13cb7000
0:0>--------------------------------------------------------------
3-32 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 65

0:0>IO-Bridge unit 1 jbus perf test
0:0>IO-Bridge unit 1 int init test
0:0>IO-Bridge unit 1 msi init test
0:0>IO-Bridge unit 1 ilu init test
0:0>IO-Bridge unit 1 tlu init test
0:0>IO-Bridge unit 1 lpu init test
0:0>IO-Bridge unit 1 link train port B
0:0>IO-Bridge unit 1 interrupt test
0:0>IO-Bridge unit 1 Config MB bridges
0:0>Config port B, bus 2 dev 0 func 0, tag 5714 BRIDGE
0:0>Config port B, bus 3 dev 8 func 0, tag PCIX BRIDGE
0:0>IO-Bridge unit 1 PCI id test
0:0> INFO:10 count read passed for MB/IOB_PCIEb/BRIDGE! Last read
VID:1166|DID:103
0:0> INFO:10 count read passed for MB/IOB_PCIEb/BRIDGE/GBE! Last read
VID:14e4|DID:1648
0:0> INFO:10 count read passed for MB/IOB_PCIEb/BRIDGE/HBA! Last read
VID:1000|DID:50
0:0>Quick JBI Loopback Block Mem Test
0:0>Quick jbus loopback Test 262144 bytes at 00000000.00600000
0:0>INFO:
0:0> POST Passed all devices.
0:0>POST:Return to VBSC.
0:0>Master set ACK for vbsc runpost command and spin...
5. Perform further investigation if needed.
■ If no faults were detected, the system will boot.
■ If POST detects a faulty device, the fault is displayed and the fault information is
passed to ALOM CMT for fault handling. Faulty FRUs are identified in fault
messages using the FRU name. For a list of FRU names, see Appendix A.
Chapter 3 Server Diagnostics 3-33
Page 66

a. Interpret the POST messages:
POST error messages use the following syntax:
c:s > ERROR: TEST = failing-test
c:s > H/W under test = FRU
c:s > Repair Instructions: Replace items in order listed by H/W
under test above
c:s > MSG = test-error-message
c:s > END_ERROR
In this syntax, c = the core number and s = the strand number.
Warning and informational messages use the following syntax:
INFO or WARNING: message
The following example shows a POST error message.
.
.
.
0:0>Data Bitwalk
0:0>L2 Scrub Data
0:0>L2 Enable
0:0>Testing Memory Channel 0 Rank 0 Stack 0
0:0>Testing Memory Channel 3 Rank 0 Stack 0
0:0>Testing Memory Channel 0 Rank 1 Stack 0
.
.
.
0:0>ERROR: TEST = Data Bitwalk
0:0>H/W under test = MB/CMP0/CH0/R1/D0/S0 (J0701)
0:0>Repair Instructions: Replace items in order listed by ’H/W
under test’ above.
0:0>MSG = Pin 3 failed on MB/CMP0/CH0/R1/D0/S0 (J0701)
0:0>END_ERROR
0:0>Testing Memory Channel 3 Rank 1 Stack 0
In this example, POST is reporting a memory error at DIMM location
MB/CMP0/CH0/R1/D0 (J0701).
3-34 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 67

b. Run the showfaults command to obtain additional fault information.
The fault is captured by ALOM, where the fault is logged, the Service Required
LED is lit, and the faulty component is disabled.
Example:
ok #.
sc> showfaults -v
ID Time FRU Fault
1 APR 24 12:47:27 MB/CMP0/CH0/R1/D0 MB/CMP0/CH0/R1/D0
deemed faulty and disabled
In this example,
memory that was not disabled until the faulty component is replaced.
MB/CMP0/CH0/R1/D0 is disabled. The system can boot using
Note – You can use ASR commands to display and control disabled components.
See Section 3.7, “Managing Components With Automatic System Recovery
Commands” on page 3-45.
3.4.5 Correctable Errors Detected by POST
In maximum mode, POST detects and offlines memory devices with errors that
could be correctable by PSH. Use the examples in this section to verify if the
detected memory devices are correctable.
Note – For servers powered on in maximum mode without the intention of
validating a hardware upgrade or repair, examine all faults detected by POST to
verify if the errors can be corrected by Solaris PSH. See Section 3.5, “Using the
Solaris Predictive Self-Healing Feature” on page 3-39.
When using maximum mode, if no faults are detected, return POST to minimum
mode.
sc> setkeyswitch normal
sc> setsc diag_mode normal
sc> setsc diag_level min
Chapter 3 Server Diagnostics 3-35
Page 68

3.4.5.1 Correctable Errors for Single DIMMs
If POST faults a single DIMM (CODE EXAMPLE 3-1) that was not part of a hardware
upgrade or repair, it is likely that POST encountered a correctable error that can be
handled by PSH.
CODE EXAMPLE 3-1 POST Fault for a Single DIMM
sc> showfaults -v
ID Time FRU Fault
1 OCT 13 12:47:27 MB/CMP0/CH0/R0/D0 MB/CMP0/CH0/R0/D0 deemed
faulty and disabled
In this case, reenable the DIMM and run POST in minimum mode as follows:
1. Reenable the DIMM.
sc> enablecomponent name-of-DIMM
2. Return POST to minimum mode.
sc> setkeyswitch normal
sc> setsc diag_mode normal
sc> setsc diag_level min
3. Reset the system so that POST runs.
There are several ways to initiate a reset. The following example uses the
powercycle command. For other methods, refer to the SPARC Enterprise T1000
Server Administration Guide.
sc> powercycle
Are you sure you want to powercycle the system [y/n]? y
Powering host off at MON JAN 10 02:52:02 2000
Waiting for host to Power Off; hit any key to abort.
SC Alert: SC Request to Power Off Host.
SC Alert: Host system has shut down.
Powering host on at MON JAN 10 02:52:13 2000
SC Alert: SC Request to Power On Host.
4. Replace the DIMM if POST continues to fault the device in minimum mode.
3-36 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 69

3.4.5.2 Determining When to Replace Detected Devices
Note – This section assumes faults are detected by POST in maximum mode.
If a detected device is part of a hardware upgrade or repair, or if POST detects
multiple DIMMs (
CODE EXAMPLE 3-2 POST Fault for Multiple DIMMs
sc> showfaults -v
ID Time FRU Fault
1 OCT 13 12:47:27 MB/CMP0/CH0/R0/D0 MB/CMP0/CH0/R0/D0 deemed
faulty and disabled
2 OCT 13 12:47:27 MB/CMP0/CH0/R0/D1 MB/CMP0/CH0/R0/D1 deemed
faulty and disabled
Note – The previous example shows two DIMMs on the same channel/rank, which
could be an uncorrectable error.
If the detected device is not a part of a hardware upgrade or repair, use the following
list to examine and repair the fault:
CODE EXAMPLE 3-2), replace the detected devices.
1. If a detected device is not a DIMM, or if more than a single DIMM is detected,
replace the detected devices.
2. If a detected device is a single DIMM and the same DIMM is also detected by
PSH, replace the DIMM (
CODE EXAMPLE 3-3 PSH and POST Faults on the Same DIMM
sc> showfaults -v
ID Time FRU Fault
0 SEP 09 11:09:26 MB/CMP0/CH0/R0/D0 Host detected fault,
MSGID:SUN4V-8000-DX UUID: 7ee0e46b-ea64-6565-e684-e996963f7b86
1 OCT 13 12:47:27 MB/CMP0/CH0/R0/D0 MB/CMP0/CH0/R0/D0 deemed
faulty and disabled
CODE EXAMPLE 3-3).
Note – The detected DIMM in the previous example must also be replaced because
it exceeds the PSH page retire threshold.
Chapter 3 Server Diagnostics 3-37
Page 70

3. If a device detected by POST is a single DIMM and the same DIMM is not
detected by PSH, follow the procedure in Section 3.4.5.1, “Correctable Errors for
Single DIMMs” on page 3-36.
After the detected devices are repaired or replaced, return POST to the default
minimum level.
sc> setkeyswitch normal
sc> setsc diag_mode normal
sc> setsc diag_level min
3.4.6 Clearing POST Detected Faults
In most cases, when POST detects a faulty component, POST logs the fault and
automatically takes the failed component out of operation by placing the component
in the ASR blacklist (see Section 3.7, “Managing Components With Automatic
System Recovery Commands” on page 3-45).
In most cases, after the faulty FRU is replaced, ALOM CMT detects the repair and
extinguishes the Service Required LED. If ALOM CMT does not perform these
actions, use the enablecomponent command to manually clear the fault and
remove the component from the ASR blacklist. This procedure describes how to do
this.
1. After replacing a faulty FRU, at the ALOM CMT prompt use the showfaults
command to identify POST detected faults.
POST detected faults are distinguished from other kinds of faults by the text:
deemed faulty and disabled, and no UUID number is reported.
Example:
sc> showfaults -v
ID Time FRU Fault
1 APR 24 12:47:27 MB/CMP0/CH0/R1/D0 MB/CMP0/CH0/R1/D0
deemed faulty and disabled
■ If no fault is reported, you do not need to do anything else. Do not perform the
subsequent steps.
■ If a fault is reported, perform Step 2 through Step 4.
3-38 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 71

2. Use the enablecomponent command to clear the fault and remove the component
from the ASR blacklist.
Use the FRU name that was reported in the fault in the previous step.
Example:
sc> enablecomponent MB/CMP0/CH0/R1/D0
The fault is cleared and should not appear when you run the showfaults
command. Additionally, if there are no other faults remaining, the Service Required
LED should be extinguished.
3. Power cycle the server.
You must reboot the server for the enablecomponent command to take effect.
4. At the ALOM CMT prompt, use the showfaults command to verify that no
faults are reported.
sc> showfaults
Last POST run: THU MAR 09 16:52:44 2006
POST status: Passed all devices
No failures found in System
3.5 Using the Solaris Predictive Self-Healing Feature
The Solaris Predictive Self-Healing (PSH) technology enables the server to diagnose
problems while the Solaris OS is running, and mitigate many problems before they
negatively affect operations.
The Solaris OS uses the fault manager daemon, fmd(1M), which starts at boot time
and runs in the background to monitor the system. If a component generates an
error, the daemon handles the error by correlating the error with data from previous
errors and other related information to diagnose the problem. Once diagnosed, the
fault manager daemon assigns the problem a Universal Unique Identifier (UUID)
that distinguishes the problem across any set of systems. When possible, the fault
manager daemon initiates steps to self-heal the failed component and take the
component offline. The daemon also logs the fault to the syslogd daemon and
Chapter 3 Server Diagnostics 3-39
Page 72

provides a fault notification with a message ID (MSGID). You can use the message
ID to get additional information about the problem from Sun’s knowledge article
database.
The Predictive Self-Healing technology covers the following server components:
■ UltraSPARC® T1 multicore processor
■ Memory
■ I/O bus
The PSH console message provides the following information:
■ Type
■ Severity
■ Description
■ Automated response
■ Impact
■ Suggested action for system administrator
If the Solaris PSH facility detects a faulty component, use the fmdump command to
identify the fault. Faulty FRUs are identified in fault messages using the FRU name.
For a list of FRU names, see Appendix A.
Note – Additional Predictive Self-Healing information is available at:
http://www.sun.com/msg
3.5.1 Identifying PSH Detected Faults
When a PSH fault is detected, a Solaris console message similar to the following is
displayed:
SUNW-MSG-ID: SUN4V-8000-DX, TYPE: Fault, VER: 1, SEVERITY: Minor
EVENT-TIME: Wed Sep 14 10:09:46 EDT 2005
PLATFORM: SPARC-Enterprise-T1000, CSN: -, HOSTNAME: wgs48-37
SOURCE: cpumem-diagnosis, REV: 1.5
EVENT-ID: f92e9fbe-735e-c218-cf87-9e1720a28004
DESC: The number of errors associated with this memory module has exceeded
acceptable levels. Refer to http://sun.com/msg/SUN4V-8000-DX for more
information.
AUTO-RESPONSE: Pages of memory associated with this memory module are being
removed from service as errors are reported.
IMPACT: Total system memory capacity will be reduced as pages are retired.
REC-ACTION: Schedule a repair procedure to replace the affected memory module.
Use fmdump -v -u <EVENT_ID> to identify the module.
3-40 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 73

The following is an example of the ALOM CMT alert for the same PSH diagnosed
fault:
SC Alert: Host detected fault, MSGID: SUN4V-8000-DX
Note – The Service Required LED is also turns on for PSH diagnosed faults.
3.5.1.1 Using the fmdump Command to Identify Faults
The fmdump command displays the list of faults detected by the Solaris PSH facility
and identifies the faulty FRU for a particular EVENT_ID (UUID). Do not use
fmdump to verify a FRU replacement has cleared a fault because the output of
fmdump is the same after the FRU has been replaced. Use the fmadm faulty
command to verify the fault has cleared.
Note – Faults detected by the Solaris PSH facility are also reported through ALOM
CMT alerts. In addition to the PSH fmdump command, the ALOM CMT
showfaults command provides information about faults and displays fault UUIDs.
See Section 3.3.2, “Running the showfaults Command” on page 3-16.
1. Check the event log using the fmdump command with -v for verbose output:
# fmdump -v
TIME UUID SUNW-MSG-ID
Sep 14 10:09:46.2234 f92e9fbe-735e-c218-cf87-9e1720a28004 SUN4V-8000-DX
95% fault.memory.dimm
FRU: mem:///component=MB/CMP0/CH0:R0/D0/J0601
rsrc: mem:///component=MB/CMP0/CH0:R0/D0/J0601
In this example, a fault is displayed, indicating the following details:
■ Date and time of the fault (Sep 14 10:09)
■ Universal Unique Identifier (UUID) that is unique for every fault (f92e9fbe-
735e-c218-cf87-9e1720a28004)
■ The message identifier (SUN4V-8000-DX) that can be used to obtain additional
fault information
■ Faulted FRU (FRU: mem:///component=MB/CMP0/CH0:R0/D0/J0601), that in
this example MB is identified as the DIMM at
R0/D0 (J0601)
Chapter 3 Server Diagnostics 3-41
Page 74

Note – fmdump displays the PSH event log. Entries remain in the log after the fault
has been repaired.
2. Use the message ID to obtain more information about this type of fault.
a. In a browser, go to the Predictive Self-Healing Knowledge Article web site:
http://www.sun.com/msg
b. Obtain the message ID from the console output or the ALOM CMT
showfaults command.
c. Enter the message ID in the SUNW-MSG-ID field, and click Lookup.
In this example, the message ID SUN4V-8000-DX returns the following
information for corrective action:
Article for Message ID: SUN4V-8000-DX
Correctable memory errors exceeded acceptable levels
Type
Fault
Severity
Major
Description
The number of correctable memory errors reported against a memory DIMM has
exceeded acceptable levels.
Automated Response
Pages of memory associated with this memory DIMM are being removed from
service as errors are reported.
Impact
Total system memory capacity will be reduced as pages are retired.
Suggested Action for System Administrator
Schedule a repair procedure to replace the affected memory DIMM, the identity
of which can be determined using the command fmdump -v -u EVENT_ID.
Details
The Message ID: SUN4V-8000-DX indicates diagnosis has determined that a
memory DIMM is faulty as a result of exceeding the threshold for correctable
memory errors. Memory pages associated with the correctable errors have been
retired and no data has been lost. However, the system is at increased risk
of incurring an uncorrectable error, which will cause a service
interruption, until the memory DIMM module is replaced.
Use the command fmdump -v -u EVENT_ID with the EVENT_ID from the console
message to locate the faulty DIMM. For example:
fmdump -v -u f92e9fbe-735e-c218-cf87-9e1720a28004
TIME UUID SUNW-MSG-ID
Sep 14 10:09:46.2234 f92e9fbe-735e-c218-cf87-9e1720a28004 SUN4V-8000-DX
95% fault.memory.dimm
FRU: mem:///component=MB/CMP0/CH0:R0/D0/J0601
3-42 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 75

rsrc: mem:///component=MB/CMP0/CH0:R0/D0/J0601
In this example, the DIMM location is:
MB/CMP0/CH0:R0/D0/J0601
Refer to the Service Manual or the Service Label attached to the server
chassis to find the physical location of the DIMM. Once the DIMM has been
replaced, use the Service Manual for instructions on clearing the fault
condition and validating the repair action.
NOTE - The server Product Notes may contain updated service procedures. The
latest version of the Service Manual and Product Notes are available at the
Sun Documentation Center.
3. Follow the suggested actions to repair the fault.
3.5.2 Clearing PSH Detected Faults
When the Solaris PSH facility detects faults, the faults are logged and displayed on
the console. After the fault condition is corrected, for example by replacing a faulty
FRU, you must clear the fault.
Note – If you are dealing with faulty DIMMs, do not follow this procedure. Instead,
perform the procedure in Section 5.6.2, “Installing DIMMs” on page 5-21.
1. After replacing a faulty FRU, power on the server.
2. At the ALOM CMT prompt, use the showfaults command to identify PSH
detected faults.
PSH detected faults are distinguished from other kinds of faults by the text:
Host detected fault.
Example:
sc> showfaults -v
ID Time FRU Fault
0 SEP 09 11:09:26 MB/CMP0/CH0/R1/D0 Host detected fault, MSGID:
SUN4U-8000-2S UUID: 7ee0e46b-ea64-6565-e684-e996963f7b86
■ If no fault is reported, you do not need to do anything else. Do not perform the
subsequent steps.
■ If a fault is reported, perform Step 2 through Step 4.
Chapter 3 Server Diagnostics 3-43
Page 76

3. Run the clearfault command with the UUID provided in the showfaults
output:
sc> clearfault 7ee0e46b-ea64-6565-e684-e996963f7b86
Clearing fault from all indicted FRUs...
Fault cleared.
4. Clear the fault from all persistent fault records.
In some cases, even though the fault is cleared, some persistent fault information
remains and results in erroneous fault messages at boot time. To ensure that these
messages are not displayed, perform the following command:
fmadm repair UUID
Example:
# fmadm repair 7ee0e46b-ea64-6565-e684-e996963f7b86
3.6 Collecting Information From Solaris OS Files and Commands
With the Solaris OS running on the server, you have the full compliment of Solaris
OS files and commands available for collecting information and for troubleshooting.
If POST, ALOM, or the Solaris PSH features do not indicate the source of a fault,
check the message buffer and log files for notifications for faults. Hard drive faults
are usually captured by the Solaris message files.
Use the dmesg command to view the most recent system message. To view the
system messages log file, view the contents of the /var/adm/messages file.
3.6.1 Checking the Message Buffer
1. Log in as superuser.
3-44 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 77

2. Issue the dmesg command:
# dmesg
The dmesg command displays the most recent messages generated by the system.
3.6.2 Viewing System Message Log Files
The error logging daemon, syslogd, automatically records various system
warnings, errors, and faults in message files. These messages can alert you to system
problems such as a device that is about to fail.
The /var/adm directory contains several message files. The most recent messages
are in the /var/adm/messages file. After a period of time (usually every ten days),
a new messages file is automatically created. The original contents of the
messages file are rotated to a file named messages.1. Over a period of time, the
messages are further rotated to messages.2 and messages.3, and then deleted.
1. Log in as superuser.
2. Issue the following command:
# more /var/adm/messages
3. If you want to view all logged messages, issue the following command:
# more /var/adm/messages*
3.7 Managing Components With Automatic System Recovery Commands
The Automatic System Recovery (ASR) feature enables the server to automatically
configure failed components out of operation until they can be replaced. In the
server, the following components are managed by the ASR feature:
■ UltraSPARC T1 processor strands
■ Memory DIMMS
■ I/O bus
Chapter 3 Server Diagnostics 3-45
Page 78

The database that contains the list of disabled components is called the ASR blacklist
(asr-db).
In most cases, POST automatically disables a faulty component. After the cause of
the fault is repaired (FRU replacement, loose connector reseated, and so on), you
must remove the component from the ASR blacklist.
The ASR commands (
TABLE 3-7) enable you to view, and manually add or remove
components from the ASR blacklist. These commands are run from the ALOM CMT
sc> prompt.
TABLE 3-7 ASR Commands
Command Description
showcomponent
enablecomponent asrkey Removes a component from the asr-db blacklist,
disablecomponent asrkey Adds a component to the asr-db blacklist, where
clearasrdb Removes all entries from the asr-db blacklist.
* The showcomponent command might not report all blacklisted DIMMS.
*
Displays system components and their current state.
where asrkey is the component to enable.
asrkey is the component to disable.
Note – The components (asrkeys) vary from system to system, depending on how
many cores and memory are present. Use the showcomponent command to see the
asrkeys on a given system.
Note – A reset or power cycle is required after disabling or enabling a component.
If the status of a component is changed with power on there is no effect to the
system until the next reset or power cycle.
3.7.1 Displaying System Components
The showcomponent command displays the system components (asrkeys) and
reports their status.
● At the sc> prompt, enter the showcomponent command.
3-46 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 79

Example with no disabled components:
sc> showcomponent
Keys:
.
.
.
ASR state: clean
Example showing a disabled component:
sc> showcomponent
Keys:
.
.
.
ASR state: Disabled Devices
MB/CMP0/CH3/R1/D1 : dimm8 deemed faulty
3.7.2 Disabling Components
The disablecomponent command disables a component by adding it to the ASR
blacklist.
1. At the sc> prompt, enter the disablecomponent command
sc> disablecomponent MB/CMP0/CH3/R1/D1
SC Alert:MB/CMP0/CH3/R1/D1 disabled
2. After receiving confirmation that the disablecomponent command is complete,
reset the server so that the ASR command takes effect.
sc> reset
.
Chapter 3 Server Diagnostics 3-47
Page 80

3.7.3 Enabling Disabled Components
The enablecomponent command enables a disabled component by removing it
from the ASR blacklist.
1. At the sc> prompt, enter the enablecomponent command.
sc> enablecomponent MB/CMP0/CH3/R1/D1
SC Alert:MB/CMP0/CH3/R1/D1 reenabled
2. After receiving confirmation that the enablecomponent command is complete,
reset the server so that the ASR command takes effect.
sc> reset
3.8 Exercising the System With SunVTS
Sometimes a server exhibits a problem that cannot be isolated definitively to a
particular hardware or software component. In such cases, it might be useful to run
a diagnostic tool that stresses the system by continuously running a comprehensive
battery of tests. Sun provides the SunVTS software for this purpose.
This section describes the tasks necessary to use SunVTS software to exercise your
server:
■ Section 3.8.1, “Checking Whether SunVTS Software Is Installed” on page 3-48
■ Section 3.8.2, “Exercising the System Using SunVTS Software” on page 3-49
3.8.1 Checking Whether SunVTS Software Is Installed
This procedure assumes that the Solaris OS is running on the server, and that you
have access to the Solaris command line.
1. Check for the presence of SunVTS packages using the pkginfo command.
% pkginfo -l SUNWvts SUNWvtsr SUNWvtsts SUNWvtsmn
■ If SunVTS software is installed, information about the packages is displayed.
3-48 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 81

■ If SunVTS software is not installed, you see an error message for each missing
package.
ERROR: information for "SUNWvts" was not found
ERROR: information for "SUNWvtsr" was not found
...
The following table lists the SunVTS packages:
Package Description
SUNWvts SunVTS framework
SUNWvtsr SunVTS framework (root)
SUNWvtsts SunVTS for tests
SUNWvtsmn SunVTS man pages
If SunVTS is not installed, you can obtain the installation packages from the Solaris
Operating System DVDs.
The SunVTS 6.1 software, and future compatible versions, are supported on the
server.
SunVTS installation instructions are described in the SunVTS User’s Guide.
3.8.2 Exercising the System Using SunVTS Software
Before you begin, the Solaris OS must be running. You also need to ensure that
SunVTS validation test software is installed on your system. See Section 3.8.1,
“Checking Whether SunVTS Software Is Installed” on page 3-48.
The SunVTS installation process requires that you specify one of two security
schemes to use when running SunVTS. The security scheme you choose must be
properly configured in the Solaris OS for you to run SunVTS. For details, refer to the
SunVTS User’s Guide.
SunVTS software features both character-based and graphics-based interfaces. This
procedure assumes that you are using the graphical user interface (GUI) on a system
running the Common Desktop Environment (CDE). For more information about the
character-based SunVTS TTY interface, and specifically for instructions on accessing
it by tip or telnet commands, refer to the SunVTS User’s Guide.
SunVTS software can be run in several modes. This procedure assumes that you are
using the default mode.
Chapter 3 Server Diagnostics 3-49
Page 82

This procedure also assumes that the server is headless, that is, it is not equipped
with a monitor capable of displaying bitmap graphics. In this case, you access the
SunVTS GUI by logging in remotely from a machine that has a graphics display.
Finally, this procedure describes how to run SunVTS tests in general. Individual tests
may presume the presence of specific hardware, or might require specific drivers,
cables, or loopback connectors. For information about test options and prerequisites,
refer to the following documentation:
■ SunVTS Test Reference Manual (SPARC)
■ SunVTS Doc Supplement (SPARC)
3.8.3 Using SunVTS Software
1. Log in as superuser to a system with a graphics display.
The display system should be one with a frame buffer and monitor capable of
displaying bitmap graphics such as those produced by the SunVTS GUI.
2. Enable the remote display.
On the display system, type:
# /usr/openwin/bin/xhost + test-system
where test-system is the name of the server you plan to test.
3. Remotely log in to the server as superuser.
Use a command such as rlogin or telnet.
4. Start SunVTS software.
If you have installed SunVTS software in a location other than the default /opt
directory, alter the path in the following command accordingly.
# /opt/SUNWvts/bin/sunvts -display display-system:0
where display-system is the name of the machine through which you are remotely
logged in to the server.
The SunVTS GUI is displayed (
3-50 SPARC Enterprise T1000 Server Service Manual • April 2007
FIGURE 3-6).
Page 83

FIGURE 3-6 SunVTS GUI
5. Expand the test lists to see the individual tests.
The test selection area lists tests in categories, such as Network, as shown in
FIGURE 3-7. To expand a category, left-click the icon (expand category icon) to the
+
left of the category name.
Chapter 3 Server Diagnostics 3-51
Page 84

Processor(s)
Memory
Cryptography
SCSI - Devices(mpt0)
Network
e1000g3(netlbtest)
e1000g1(netlbtest)
e1000g2(netlbtest)
e1000g0(nettest)
FIGURE 3-7 SunVTS Test Selection Panel
6. (Optional) Select the tests you want to run.
Certain tests are enabled by default, and you can choose to accept these.
Alternatively, you can enable and disable individual tests or blocks of tests by
clicking the checkbox next to the test name or test category name. Tests are enabled
when checked, and disabled when not checked.
TABLE 3-8 lists tests that are especially useful to run on this server.
TABLE 3-8 Useful SunVTS Tests to Run on This Server
SunVTS Tests FRUs Exercised by Tests
cmttest, cputest, fputest,
iutest, l1dcachetest, dtlbtest,
and l2sramtest—indirectly: mptest,
and systest
disktest Disks, cables, disk backplane
nettest, netlbtest Network interface, network cable, CPU
pmemtest, vmemtest, ramtest DIMMs, motherboard
serialtest I/O (serial port interface)
hsclbtest Motherboard, system controller
DIMMS, motherboard
motherboard
(Host to system controller interface)
7. (Optional) Customize individual tests.
You can customize individual tests by right-clicking on the name of the test. For
example, in
FIGURE 3-7, right-clicking on the text string ce0(nettest) brings up a
menu that enables you to configure this Ethernet test.
3-52 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 85

8. Start testing.
Click the Start button that is located at the top left of the SunVTS window. Status
and error messages appear in the test messages area located across the bottom of the
window. You can stop testing at any time by clicking the Stop button.
During testing, SunVTS software logs all status and error messages. To view these
messages, click the Log button or select Log Files from the Reports menu. This action
opens a log window from which you can choose to view the following logs:
■ Information – Detailed versions of all the status and error messages that appear
in the test messages area.
■ Test Error – Detailed error messages from individual tests.
■ VTS Kernel Error – Error messages pertaining to SunVTS software itself. You
should look here if SunVTS software appears to be acting strangely, especially
when it starts up.
■ Solaris OS Messages (/var/adm/messages) – A file containing messages
generated by the operating system and various applications.
■ Log Files (/var/opt/SUNWvts/logs) – A directory containing the log files.
Chapter 3 Server Diagnostics 3-53
Page 86

3-54 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 87

CHAPTER
4
Preparing for Servicing
This chapter describes how to prepare the server for servicing.
The following topics are covered:
■ Section 4.1, “Common Procedures for Parts Replacement” on page 4-1
For a list of FRUs, see Appendix A.
Note – Never attempt to run the system with the cover removed. The cover must be
in place for proper air flow. The cover interlock switch immediately shuts the system
down when the cover is removed.
4.1 Common Procedures for Parts Replacement
Before you can remove and replace parts that are inside the server, you must
perform the following procedures:
■ Section 4.1.2, “Shutting the System Down” on page 4-2
■ Section 4.1.3, “Removing the Server From a Rack” on page 4-3
■ Section 4.1.4, “Performing Electrostatic Discharge (ESD) Prevention Measures” on
page 4-5
■ Section 4.1.5, “Removing the Top Cover” on page 4-5
The corresponding procedures that you perform when maintenance is complete are
described in Chapter 6.
4-1
Page 88

4.1.1 Required Tools
The server can be serviced with the following tools:
■ Antistatic wrist strap
■ Antistatic mat
■ No. 2 Phillips screwdriver
4.1.2 Shutting the System Down
Performing a graceful shutdown ensures that all of your data is saved and the
system is ready for restart.
1. Log in as superuser or equivalent.
Depending on the nature of the problem, you might want to view the system status
or the log files, or run diagnostics before you shut down the system. Refer to the
SPARC Enterprise T1000 Server Administration Guide for log file information.
2. Notify affected users.
Refer to your Solaris system administration documentation for additional
information.
3. Save any open files and quit all running programs.
Refer to your application documentation for specific information on these processes.
4. Shut down the OS.
At the Solaris OS prompt, issue the uadmin command to halt the Solaris OS and to
return to the ok prompt.
# shutdown -g0 -i0 -y
WARNING: proc_exit: init exited
syncing file systems... done
Program terminated
ok
This command is described in the Solaris system administration documentation.
5. Switch from the system console prompt to the SC console prompt by issuing the
#. (Hash-Period) escape sequence.
ok #.
sc>
4-2 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 89

6. Using the SC console, issue the poweroff command.
sc> poweroff -fy
SC Alert: SC Request to Power Off Host Immediately.
Note – You can also use the Power On/Off button on the front of the server to
initiate a graceful system shutdown.
Refer to the SPARC Enterprise T1000 Server Administration Guide for more
information about the ALOM poweroff command.
4.1.3 Removing the Server From a Rack
If the server is installed in a rack with the extendable slide rails (outer and middle
section) that were supplied with the server, use this procedure to remove the server
chassis from the rack.
1. (Optional) Issue the following command from the ALOM sc> prompt to locate
the system that requires maintenance:
sc> setlocator on
Locator LED is on.
Once you have located the server, press the Locator button to turn it off.
2. Check to see that no cables will be damaged or interfere when the server chassis
is removed from the rack.
3. Disconnect the power cord from the power supply.
Note – After you have disconnected the power cord from the power supply, you
must wait about five seconds before reconnecting the power cord to the power
supply.
4. Disconnect all cables from the server and label them.
5. From the front of the server, unlock both mounting brackets and pull the server
chassis out until the brackets lock in the open position (
Chapter 4 Preparing for Servicing 4-3
FIGURE 4-1).
Page 90

FIGURE 4-1 Unlocking a Mounting Bracket
6. Press the gray release tab on both mounting brackets to release the right and left
mounting brackets, then pull the server chassis out of the rails (
FIGURE 4-2).
The mounting brackets slide approximately 4 in. (10 cm) farther before disengaging.
FIGURE 4-2 Location of the Mounting Bracket Release Buttons
7. Set the chassis on a sturdy work surface.
4-4 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 91

4.1.4 Performing Electrostatic Discharge (ESD) Prevention Measures
1. Prepare an antistatic surface to set parts on during removal and installation.
Place ESD-sensitive components, such as the printed circuit boards, on an antistatic
mat. The following items can be used as an antistatic mat:
■ Antistatic bag used to wrap a replacement part
■ ESD mat, part number 250-1088
■ Disposable ESD mat (shipped with some replacement parts or optional system
components)
2. Use an antistatic wrist strap.
4.1.5 Removing the Top Cover
Access to all field-replaceable units (FRUs) requires the removal of the top cover.
Note – Never run the system with the top cover removed. The top cover must be in
place for proper air flow. The cover interlock switch immediately shuts the system
down when the cover is removed.
Caution – The system supplies 3.3 Vdc standby power to the circuit boards even
when the system is powered off if the AC power cord is plugged in.
1. Press the cover release button (
2. While pressing the release button, grasp the rear of the cover and slide the cover
toward the rear of the server about one half inch (1.2 cm).
3. Lift the cover off the chassis.
FIGURE 4-3).
Chapter 4 Preparing for Servicing 4-5
Page 92

Cover release
button
FIGURE 4-3 Location of Top Cover Release Button
Top cover
4-6 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 93

CHAPTER
5
Replacing Field-Replaceable Units
This chapter describes how to remove and replace customer-replaceable fieldreplaceable units (FRUs) in the server.
The following topics are covered:
■ Section 5.1, “Replacing the Optional PCI-Express Card” on page 5-2
■ Section 5.2, “Replacing the Fan Tray Assembly” on page 5-4
■ Section 5.3, “Replacing the Power Supply” on page 5-5
■ Section 5.4, “Replacing the Hard Drive Assembly” on page 5-7
■ Section 5.5, “Replacing a Hard Drive” on page 5-12
■ Section 5.6, “Replacing DIMMs” on page 5-19
■ Section 5.7, “Replacing the Motherboard and Chassis” on page 5-25
■ Section 5.8, “Replacing the Clock Battery” on page 5-27
For a list of FRUs, see Appendix A.
Note – Never attempt to run the system with the cover removed. The cover must be
in place for proper air flow. The cover interlock switch immediately shuts the system
down when the cover is removed.
5-1
Page 94

5.1 Replacing the Optional PCI-Express Card
5.1.1 Removing the Optional PCI-Express Card
Use this procedure to remove the optional low-profile PCI-Express (PCI-E) card from
the server.
1. Perform the procedures described in Chapter 4.
2. Remove any cables that are attached to the card.
3. On the rear of the chassis, pull the release lever that secures the PCI-Express card
to the chassis (
FIGURE 5-1).
Release lever
PCI-E card
FIGURE 5-1 Releasing the PCI-Express Card Release Lever
5-2 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 95

4. Carefully pull the PCI-Express card out of the connector on the PCI-Express card
riser board and the note slot (
FIGURE 5-2).
Note slot
Connector
FIGURE 5-2 Removing and Installing the PCI-Express Card
PCI-E riser board
5. Place the PCI-Express card on an antistatic mat.
5.1.2 Installing the Optional PCI-Express Card
Use this procedure to replace the PCI-Express cards.
1. Unpack the replacement PCI-Express card and place it on an antistatic mat.
Note – Only low-profile PCI-Express cards with low brackets fit into the chassis.
There are a variety of PCI-Express cards on the market. Read the product
documentation for your device for additional installation requirements and
instructions that are not covered here.
2. Insert the PCI-Express card into the connector on the PCI-Express riser board and
the note slot (
FIGURE 5-2).
Chapter 5 Replacing Field-Replaceable Units 5-3
Page 96

3. On the rear of the chassis, engage the release lever to secure the card to the chassis
(
FIGURE 5-1).
4. Perform the procedures described in Chapter 6.
5.2 Replacing the Fan Tray Assembly
5.2.1 Removing the Fan Tray Assembly
1. Perform the procedures described in Chapter 4.
2. Disconnect the fan power cable from the motherboard.
3. Push in on the clasps on both sides of the fan assembly (
Fan tray
assembly
FIGURE 5-3 Removing the Fan Tray Assembly
4. Remove the fan assembly from the sheet metal mounting brackets.
FIGURE 5-3).
5-4 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 97

5.2.2 Installing the Fan Tray Assembly
1. Unpack the replacement fan tray assembly and place it on an antistatic mat.
2. Align the fan tray assembly with the sheet metal mounting brackets and slide it
into place until the clasps on each side lock it into place.
3. Reconnect the fan power cable to the motherboard.
4. Perform the procedures described in Chapter 6.
5.3 Replacing the Power Supply
5.3.1 Removing the Power Supply
1. Perform the procedures described in Chapter 4.
2. Disconnect the power cable from the motherboard and pull the cable through the
midwall.
3. Pull the fastener up on the front of the power supply and remove the power
supply from the chassis (
FIGURE 5-4).
Chapter 5 Replacing Field-Replaceable Units 5-5
Page 98

Fastener
Power supply
FIGURE 5-4 Removing the Power Supply
5.3.2 Installing the Power Supply
1. Unpack the replacement power supply.
2. Slide the power supply into the chassis and engage the two alignment pins in the
rear of the chassis that mate with the power supply.
3. Push the fastener down on the front of the power supply to lock it into place in
the chassis (
FIGURE 5-5).
5-6 SPARC Enterprise T1000 Server Service Manual • April 2007
Page 99

Fastener
FIGURE 5-5 Installing the Power Supply
4. Redress the power cable through the midwall in the chassis and connect the cable
to the motherboard.
5. Perform the procedures described in Chapter 6.
6. At the sc> prompt, issue the showenvironment command to verify the status of
the power supply.
Power supply
5.4 Replacing the Hard Drive Assembly
5.4.1 Removing the Single-Drive Assembly
1. Disconnect the drive cable from the data/power connector at the rear of the hard
drive (
FIGURE 5-6).
2. Pull the fasteners up on the rear of the single-drive assembly, and remove the
single-drive assembly from the chassis (
FIGURE 5-6).
Chapter 5 Replacing Field-Replaceable Units 5-7
Page 100

FIGURE 5-6 Removing the Single-Drive Assembly
5.4.2 Installing the Dual-Drive Assembly
1. Unpack the drive assembly and the dual-drive cable.
The drive assembly should be shipped to you with one or two drives already
installed in the assembly, depending on the type of drive assembly that you ordered.
2. Disconnect the drive cable from the data and power connectors on the
motherboard and remove the drive cable from your server (
5-8 SPARC Enterprise T1000 Server Service Manual • April 2007
FIGURE 5-7).
 Loading...
Loading...