

Dell DL4000 User Manual [de]

Dell DL4000-Gerät
Benutzerhandbuch

Anmerkungen, Vorsichtshinweise und
Warnungen
ANMERKUNG: Eine ANMERKUNG liefert wichtige Informationen, mit denen Sie den Computer
besser einsetzen können.
VORSICHT: Ein VORSICHTSHINWEIS macht darauf aufmerksam, dass bei Nichtbefolgung von
Anweisungen eine Beschädigung der Hardware oder ein Verlust von Daten droht, und zeigt auf,
wie derartige Probleme vermieden werden können.
WARNUNG: Durch eine WARNUNG werden Sie auf Gefahrenquellen hingewiesen, die materielle
Schäden, Verletzungen oder sogar den Tod von Personen zur Folge haben können.
Copyright © 2015 Dell Inc. Alle Rechte vorbehalten. Dieses Produkt ist durch US-amerikanische und internationale
Urheberrechtsgesetze und nach sonstigen Rechten an geistigem Eigentum geschützt. Dell™ und das Dell Logo sind
Marken von Dell Inc. in den Vereinigten Staaten und/oder anderen Geltungsbereichen. Alle anderen in diesem
Dokument genannten Marken und Handelsbezeichnungen sind möglicherweise Marken der entsprechenden
Unternehmen.
2015 - 12
Rev. A01

Inhaltsverzeichnis
1 Einführung in das Dell DL4000-Gerät............................................................ 10
Kerntechnologien................................................................................................................................10
Live Recovery................................................................................................................................. 11
Verified Recovery........................................................................................................................... 11
Universal Recovery.........................................................................................................................11
True Global Deduplication.............................................................................................................11
True Scale-Architektur........................................................................................................................ 12
Bereitstellungsarchitektur....................................................................................................................12
Smart Agent................................................................................................................................... 14
DL4000-Kern.................................................................................................................................14
Snapshot-Prozess..........................................................................................................................15
Replikation des Notfallwiederherstellungsstandorts oder Dienstanbieters................................ 15
Wiederherstellung..........................................................................................................................16
Produktmerkmale ...............................................................................................................................16
Repository...................................................................................................................................... 16
True Global Deduplication ........................................................................................................... 17
Verschlüsselung.............................................................................................................................18
Replikation..................................................................................................................................... 18
Recovery-as-a-Service (RaaS).......................................................................................................19
Aufbewahrung und Archivierung..................................................................................................20
Virtualisierung und Cloud..............................................................................................................21
Benachrichtigungs- und Ereignisverwaltung............................................................................... 21
Lizenzportal....................................................................................................................................21
Webkonsole...................................................................................................................................22
Serviceverwaltungs-APIs...............................................................................................................22
2 Arbeiten mit dem DL4000-Kern...................................................................... 23
Zugreifen auf die DL4000 Core Console...........................................................................................23
Aktualisieren von vertrauenswürdigen Seiten im Internet Explorer............................................ 23
Konfigurieren von Browsern für den Remotezugriff auf die Core Console............................... 23
Ablaufplan für die Konfiguration des Kerns .......................................................................................25
Lizenzverwaltung ............................................................................................................................... 25
Ändern eines Lizenzschlüssels .....................................................................................................25
Kontaktieren des Lizenzportalservers ..........................................................................................26
Manuelles Ändern der AppAssure-Sprache..................................................................................26
Ändern der BS-Sprache während der Installation........................................................................27
Verwalten von Kerneinstellungen ......................................................................................................27
Ändern des Anzeigenamens des Kerns ........................................................................................27
3

Anpassen der Uhrzeit für eine nächtliche Aufgabe .................................................................... 28
Ändern der Einstellungen für die Übertragungswarteschlange ................................................. 28
Anpassen der Client-Zeitüberschreitungseinstellungen ............................................................ 29
Konfigurieren von Deduplizierungs-Cache-Einstellungen ........................................................ 29
Ändern von Moduleinstellungen ................................................................................................. 30
Ändern der Datenbankverbindungseinstellungen .......................................................................31
Wissenswertes über Repositories .......................................................................................................31
Ablaufplan für die Verwaltung eines Repositorys ............................................................................. 32
Erstellen eines Repositorys .......................................................................................................... 33
Anzeigen von Details zu einem Repository..................................................................................36
Ändern von Repository-Einstellungen ........................................................................................ 36
Erweitern eines vorhandenen Repositorys...................................................................................37
Hinzufügen eines Speicherorts zu einem vorhandenen Repository ..........................................37
Überprüfen eines Repositorys ..................................................................................................... 39
Löschen eines Repositorys .......................................................................................................... 39
Erneutes Bereitstellen von Volumes............................................................................................ 40
Wiederherstellen eines Repositorys............................................................................................. 40
Verwalten von Sicherheit ................................................................................................................... 41
Hinzufügen eines Verschlüsselungscodes .................................................................................. 41
Bearbeiten eines Verschlüsselungscodes ................................................................................... 42
Ändern einer Verschlüsselungscode-Passphrase .......................................................................42
Importieren eines Verschlüsselungscodes ..................................................................................42
Exportieren eines Verschlüsselungscodes .................................................................................. 43
Entfernen eines Verschlüsselungsschlüssels .............................................................................. 43
Verwalten von Cloud-Konten ............................................................................................................43
Hinzufügen eines Cloud-Kontos..................................................................................................43
Bearbeiten eines Cloud-Kontos................................................................................................... 45
Konfigurieren von Cloud-Konto-Einstellungen...........................................................................45
Grundlegendes zur Replikation .........................................................................................................46
Wissenswertes über den Schutz von Workstations und Servern ............................................... 46
Wissenswertes über die Replikation ............................................................................................46
Wissenswertes über Seed-Routing ............................................................................................. 48
Wissenswertes über Failover und Failback ..................................................................................49
Wissenswertes über die Replikation und verschlüsselte Wiederherstellungspunkte ................49
Wissenswertes über Aufbewahrungsrichtlinien für die Replikation ...........................................49
Überlegungen zur Leistung bei der replizierten Datenübertragung ..........................................50
Ablaufplan zur Durchführung von Replikationen ..............................................................................51
Replizieren auf einen selbstverwalteten Kern...............................................................................51
Replizieren auf einen von einem Drittanbieter verwalteten Kern............................................... 56
Überwachen der Replikation ....................................................................................................... 58
Verwalten der Replikationseinstellungen ....................................................................................60
Entfernen der Replikation ...................................................................................................................61
4

Entfernen einer geschützten Maschine aus der Replikation auf dem Quellkern........................61
Entfernen einer geschützten Maschine aus dem Zielkern...........................................................61
Einen Zielkern aus der Replikation entfernen...............................................................................61
Einen Quellkern aus der Replikation entfernen........................................................................... 62
Wiederherstellen von replizierten Daten .....................................................................................62
Ablaufplan für Failover und Failback ................................................................................................. 62
Einrichten einer Failover-Umgebung ..........................................................................................63
Durchführen eines Failovers auf dem Zielkern ........................................................................... 63
Durchführen eines Failbacks ....................................................................................................... 64
Verwalten von Ereignissen .................................................................................................................65
Konfigurieren von Benachrichtigungsgruppen ...........................................................................65
Konfigurieren eines E-Mail-Servers und einer E-Mail-Benachrichtigungsvorlage ....................67
Konfigurieren der Wiederholungsreduzierung ........................................................................... 68
Konfigurieren der Ereignisaufbewahrung ................................................................................... 69
Verwalten der Wiederherstellung ......................................................................................................69
Wissenswertes über Systeminformationen .......................................................................................69
Anzeigen von Systeminformationen ........................................................................................... 69
Herunterladen von Installationsprogrammen ...................................................................................70
Informationen zum Agenten-Installationsprogramm ...................................................................... 70
Herunterladen und Installieren des Agenteninstallationsprogramms ........................................70
Wissenswertes über Local Mount Utility ........................................................................................... 70
Herunterladen und Installieren von Local Mount Utility ............................................................. 71
Hinzufügen eines Kerns zu Local Mount Utility ...........................................................................71
Bereitstellen eines Wiederherstellungspunkts mithilfe von Local Mount Utility ........................73
Aufheben der Bereitstellung eines Wiederherstellungspunkts mithilfe von Local Mount
Utility ............................................................................................................................................. 74
Informationen zum Taskleistenmenü von Local Mount Utility .................................................. 74
Verwenden von Kern- und Agentenoptionen..............................................................................75
Verwalten von Aufbewahrungsrichtlinien ......................................................................................... 76
Archivierung in eine Cloud................................................................................................................. 76
Wissenswertes über die Archivierung ................................................................................................76
Erstellen eines Archivs ..................................................................................................................76
Festlegen einer geplanten Archivierung ...................................................................................... 77
Anhalten und Wiederaufnehmen einer geplanten Archivierung ................................................79
Bearbeiten einer geplanten Archivierung ....................................................................................79
Überprüfen eines Archivs .............................................................................................................80
Importieren eines Archivs .............................................................................................................81
Verwalten der SQL-Anfügbarkeit .......................................................................................................81
Konfigurieren der SQL-Anfügbarkeitseinstellungen ...................................................................82
Konfigurieren von nächtlichen SQL-Anfügbarkeitsprüfungen und Abschneiden des
Protokolls ......................................................................................................................................83
5

Verwalten von Überprüfungen der Bereitstellungsfähigkeit und Abschneiden des Protokolls
bei Exchange-Datenbanken .............................................................................................................. 83
Konfigurieren von Bereitstellungsfähigkeit und Abschneiden des Protokolls von
Exchange-Datenbanken .............................................................................................................. 83
Erzwingen einer Überprüfung der Bereitstellungsfähigkeit ....................................................... 84
Erzwingen von Prüfsummen-Überprüfungen ............................................................................ 84
Erzwingen des Abschneidens des Protokolls ..............................................................................85
Statusanzeigen eines Wiederherstellungspunkts ........................................................................85
3 Verwalten des Geräts......................................................................................... 87
Überwachung des Gerätestatus......................................................................................................... 87
Speicherbereitstellung........................................................................................................................ 87
Breitstellung von ausgewählten Speichern........................................................................................88
Löschen der Speicherplatzzuweisung für ein virtuelles Laufwerk....................................................89
Auflösen fehlgeschlagener Aufgaben................................................................................................ 90
Upgrade des Geräts............................................................................................................................ 90
Reparieren des Geräts.........................................................................................................................90
4 Schutz von Arbeitsstationen und Servern..................................................... 92
Wissenswertes über den Schutz von Workstations und Servern ..................................................... 92
Konfigurieren von Maschineneinstellungen ..................................................................................... 92
Anzeigen und Ändern von Konfigurationseinstellungen ............................................................92
Anzeigen von Systeminformationen für eine Maschine .............................................................93
Konfigurieren von Benachrichtigungsgruppen für Systemereignisse ........................................94
Bearbeiten von Benachrichtigungsgruppen für Systemereignisse ............................................ 96
Anpassen der Einstellungen von Aufbewahrungsrichtlinien ...................................................... 97
Anzeigen von Lizenzinformationen .......................................................................................... 100
Ändern von Schutzzeitplänen ................................................................................................... 100
Ändern von Übertragungseinstellungen ....................................................................................101
Neustarten eines Services ..........................................................................................................104
Anzeigen von Maschinenprotokollen ........................................................................................104
Schützen einer Maschine .................................................................................................................105
Bereitstellen der Agentensoftware beim Schutz eines Agenten............................................... 107
Erstellen von benutzerdefinierten Zeitplänen für Volumes ......................................................108
Ändern von Exchange-Server-Einstellungen ............................................................................109
Ändern von SQL-Server-Einstellungen .....................................................................................109
Bereitstellen eines Agenten (Push-Installation) ...............................................................................110
Replizieren eines neuen Agenten .....................................................................................................111
Verwalten von Maschinen ................................................................................................................ 112
Entfernen einer Maschine ...........................................................................................................112
Replizieren von Agentendaten auf einer Maschine ...................................................................113
Replikationspriorität für einen Agenten einstellen .....................................................................113
6

Abbrechen von Vorgängen auf einer Maschine ........................................................................114
Anzeigen des Maschinenstatus und anderer Details .................................................................114
Verwalten von mehreren Maschinen ...............................................................................................115
Bereitstellen auf mehreren Maschinen ...................................................................................... 115
Überwachen der Bereitstellung von mehreren Maschinen ......................................................120
Schützen mehrerer Maschinen .................................................................................................. 121
Überwachen des Schutzes von mehreren Maschinen ............................................................. 122
Verwalten von Snapshots und Wiederherstellungspunkten ...........................................................123
Anzeigen von Wiederherstellungspunkten ................................................................................123
Anzeigen eines bestimmten Wiederherstellungspunkts............................................................124
Bereitstellen eines Wiederherstellungspunkts für eine Windows-Maschine ........................... 125
Entfernen der Bereitstellung ausgewählter Wiederherstellungspunkte....................................126
Entfernen der Bereitstellung aller Wiederherstellungspunkte...................................................126
Bereitstellen eines Wiederherstellungspunkts für eine Linux-Maschine ................................. 126
Entfernen von Wiederherstellungspunkten ...............................................................................127
Löschen einer verwaisten Wiederherstellungspunkt-Kette.......................................................128
Erzwingen eines Snapshots ....................................................................................................... 129
Anhalten und Wiederaufnehmen des Schutzes ........................................................................129
Wiederherstellen von Daten ............................................................................................................ 129
Backup......................................................................................................................................... 130
Über das Exportieren geschützter Daten von Windows-Maschinen auf virtuelle
Maschinen....................................................................................................................................132
Exportieren von Backupinformationen von der Microsoft Windows-Maschine auf eine
virtuelle Maschine .......................................................................................................................133
Exportieren von Windows-Daten über die Option „ESXi Export“ (ESXi-Export) ...................... 133
Exportieren von Windows-Daten über die Option „VMware Workstation Export“ (VMware
Workstation-Export) ................................................................................................................... 135
Exportieren von Windows-Daten mit Hyper-V-Export ............................................................ 138
Exportieren von Microsoft Windows-Daten mit Oracle VirtualBox-Export ............................ 142
Verwaltung der virtuellen Maschine........................................................................................... 145
Durchführen eines Rollbacks .....................................................................................................149
Durchführen eines Rollbacks für eine Linux-Maschine unter Verwendung der Befehlszeile..150
Wissenswertes über die Bare-Metal-Wiederherstellung für Windows-Maschinen .......................151
Voraussetzungen für eine Bare-Metal-Wiederherstellung für eine Windows-Maschine ....... 152
Voraussetzungen für eine Bare-Metal-Wiederherstellung für eine Windows-Maschine ............. 152
Erstellen eines startfähigen CD/ISO-Abbildes............................................................................152
Laden einer Start-CD.................................................................................................................. 154
Starten eines Wiederherstellungsvorgangs vom Kern aus ........................................................155
Zuweisen von Volumes ..............................................................................................................156
Anzeigen des Fortschritts der Wiederherstellung ..................................................................... 157
Starten des wiederhergestellten Zielservers ..............................................................................157
Beheben von Problemen beim Systemstart............................................................................... 157
7

Durchführen einer Bare-Metal-Wiederherstellung für eine Linux-Maschine ............................... 158
Installieren des Bildschirm-Dienstprogramms...........................................................................159
Erstellen von startbaren Partitionen auf einer Linux-Maschine................................................ 160
Anzeigen von Ereignissen und Benachrichtigungen ......................................................................160
5 Schützen von Server-Clustern....................................................................... 161
Wissenswertes über den Schutz von Server-Clustern ....................................................................161
Unterstützte Anwendungen und Cluster-Typen .......................................................................161
Schützen eines Clusters ...................................................................................................................162
Schützen von Knoten in einem Cluster ...........................................................................................163
Vorgang des Änderns der Einstellungen für Cluster-Knoten .........................................................165
Ablaufplan für das Konfigurieren von Cluster-Einstellungen .........................................................165
Ändern von Cluster-Einstellungen ............................................................................................ 165
Konfigurieren von Benachrichtigungen für Cluster-Ereignisse ............................................... 166
Bearbeiten der Cluster-Aufbewahrungsrichtlinie ..................................................................... 168
Bearbeiten von Cluster-Schutzzeitplänen ................................................................................ 168
Ändern von Cluster-Übertragungseinstellungen ......................................................................169
Konvertieren eines geschützten Cluster-Knotens in einen Agenten .............................................169
Anzeigen von Informationen über Server-Cluster ..........................................................................170
Anzeigen von Cluster-Systeminformationen ............................................................................170
Anzeigen von zusammenfassenden Informationen ................................................................. 170
Arbeiten mit Cluster-Wiederherstellungspunkten ...........................................................................171
Verwalten von Snapshots für einen Cluster .....................................................................................171
Erzwingen eines Snapshots für einen Cluster ........................................................................... 172
Anhalten und Wiederaufnehmen von Snapshots ......................................................................172
Entfernen der Bereitstellung lokaler Wiederherstellungspunkte ....................................................172
Durchführen eines Rollbacks für Cluster und Cluster-Knoten .......................................................173
Durchführen eines Rollbacks für CCR- (Exchange-) und DAG-Cluster .................................. 173
Durchführen eines Rollbacks für SCC- (Exchange-, SQL-) Cluster.......................................... 173
Replizieren von Cluster-Daten .........................................................................................................173
Entfernen eines Clusters aus dem Schutz .......................................................................................174
Entfernen von Cluster-Knoten aus dem Schutz ............................................................................. 174
Entfernen aller Knoten eines Clusters aus dem Schutz ............................................................ 175
Anzeigen eines Cluster- oder Knotenberichts ................................................................................ 175
6 Berichterstellung.............................................................................................. 177
Informationen über Berichte ............................................................................................................177
Informationen über die Symbolleiste „Reports“ (Berichte) ............................................................. 177
Informationen über Übereinstimmungsberichte ............................................................................ 177
Informationen über Fehlerberichte ................................................................................................. 178
Informationen über den Kern-Zusammenfassungsbericht ............................................................178
Repository-Zusammenfassung ..................................................................................................178
8

Agentenzusammenfassung ........................................................................................................179
Erstellen eines Berichts für einen Kern oder Agenten .................................................................... 179
Informationen über Berichte zu Kernen von zentralen Verwaltungskonsolen .............................180
Erstellen eines Berichts von der Central Management Console ................................................... 180
7 Durchführen einer vollständigen Wiederherstellung des DL4000-
Geräts..................................................................................................................... 181
Erstellen einer RAID 1-Partition für das Betriebssystem.................................................................. 181
Installieren des Betriebssystems.......................................................................................................182
Ausführung des Dienstprogramms zur Wiederherstellung und Aktualisierung............................. 183
8 Manuelles Ändern des Host-Namens........................................................... 184
Stoppen des Kerndienstes................................................................................................................ 184
Löschen von Serverzertifikaten........................................................................................................ 184
Löschen von Kernserver und Registrierungsschlüsseln.................................................................. 184
Starten des Kerns mit dem neuen Host-Namen..............................................................................185
Ändern des Anzeigenamens ............................................................................................................ 185
Aktualisieren von vertrauenswürdigen Seiten im Internet Explorer................................................185
9 Anhang A – Scripting.......................................................................................186
Wissenswertes über PowerShell Scripting ...................................................................................... 186
PowerShell Scripting-Voraussetzungen ....................................................................................186
Testen von Skripten ....................................................................................................................186
Eingabeparameter ............................................................................................................................ 187
VolumeNameCollection (namespace Replay.Common.Contracts.Metadata.Storage) .......... 192
Pretransferscript.ps1 ...................................................................................................................193
Posttransferscript.ps1 ................................................................................................................. 193
Preexportscript.ps1 .....................................................................................................................194
Postexportscript.ps1 ...................................................................................................................194
Prenightlyjobscript.ps1 ............................................................................................................... 195
Postnightlyjobscript.ps1.............................................................................................................. 197
Beispielskripte ...................................................................................................................................199
10 Wie Sie Hilfe bekommen.............................................................................. 200
Ausfindig machen der Dokumentation und Software-Aktualisierungen.......................................200
Kontaktaufnahme mit Dell............................................................................................................... 200
Feedback zur Dokumentation......................................................................................................... 200
9

1
Einführung in das Dell DL4000-Gerät
Dieses Kapitel ist eine Einführung in DL4000 und bietet außerdem eine Übersicht über das Gerät. Es
beschreibt Merkmale, Funktionen und die Architektur und enthält die folgenden Themen:
• Kerntechnologien
• True Scale-Architektur
• Bereitstellungsarchitektur
• Produktmerkmale
Ihr Gerät setzt neue Standards beim einheitlichen Datenschutz, indem es Backup, Replikation und
Wiederherstellung in einer Lösung kombiniert, die als schnellste und zuverlässigste Backuplösung zum
Schutz virtueller Maschinen (VM) sowie physischer Maschinen und Cloud-Umgebungen konzipiert wurde.
Ihr Gerät kann Datengrößen bis Petabyte verarbeiten und verfügt über integrierte globale Deduplizierung,
Komprimierung, Verschlüsselung sowie Replikation in jede beliebige private oder öffentliche CloudInfrastruktur. Server-Anwendungen und Daten können innerhalb von Minuten zur Datenaufbewahrung
(Data Retention, DR) und Datenkonformität wiederhergestellt werden.
Ihr Gerät unterstützt Multi-Hypervisor-Umgebungen auf VMware vSphere und Microsoft Hyper-V für
private und öffentliche Clouds.
Ihr Gerät kombiniert die folgenden Technologien:
• Live Recovery
• Verified Recovery
• Universal Recovery
• True Global Deduplication
Diese Technologien sind mit sicherer Integration für die Cloud-Notfallwiederherstellung ausgerüstet und
bieten schnelle sowie zuverlässige Wiederherstellung. Mit seinem skalierbaren Objektspeicher ist Ihr Gerät
das Einzige, welches Datengrößen bis Petabytes sehr schnell für integrierte globale Deduplizierung,
Komprimierung, Verschlüsselung sowie Replikation in privaten oder öffentlichen Cloud-Infrastrukturen
verarbeiten kann.
AppAssure befasst sich mit der Komplexität und Ineffizienz von Legacy-Tools mittels seiner
Kerntechnologie und der Unterstützung von Hypervisor-Umgebungen, einschließlich Umgebungen auf
VMware vSphere und Microsoft Hyper-V, die sowohl private als auch öffentliche Clouds umfassen. Mit
AppAssure können Sie jedoch nicht nur diese technologischen Fortschritte nutzen, sondern auch die
Kosten der IT-Verwaltung und Speicherung drastisch senken.
Kerntechnologien
Im Folgenden werden die Kerntechnologien von AppAssure ausführlich beschrieben.
10

Live Recovery
Live Recovery ist eine Technologie zur Sofortwiederherstellung für VMs oder Server, die nahezu
ununterbrochenen Zugang zu Datenträgern auf virtuellen oder physischen Servern gewährt. Mit dieser
Technologie können Sie einen kompletten Datenträger in gegen Null tendierenden RTO- und RPOZeiten wiederherstellen.
Die Backup- und Replikationstechnologie erstellt simultane Snapshots von mehreren VMs oder Servern
und liefert dadurch nahezu sofortigen Daten- und Systemschutz. Sie können den Server direkt aus der
Backupdatei wiederverwenden, ohne eine vollständige Wiederherstellung auf dem Produktionsspeicher
abwarten zu müssen. Dadurch bleibt die Produktivität der Benutzer erhalten und die IT-Abteilungen
können die Zahl der Wiederherstellungsfenster reduzieren, um die immer strengeren Leistungsverträge
hinsichtlich Recovery Time Objective (RTO) und Recovery Point Objective (RPO) erfüllen zu können.
Verified Recovery
Verified Recovery ermöglicht Ihnen die Durchführung automatisierter Wiederherstellungstests und die
Überprüfung von Backups. Die Technologie umfasst unter anderem Dateisysteme, Microsoft Exchange
2007, 2010 und 2013 sowie verschiedene Versionen von Microsoft SQL Server 2005, 2008, 2008 R2,
2012 und 2014. Verified Recovery ermöglicht die Wiederherstellbarkeit von Anwendungen und Backups
in virtuellen und physischen Umgebungen und verfügt über einen umfassenden Algorithmus zur
Integritätsprüfung, der auf 256-Bit SHA-Schlüsseln basiert. Diese Schlüssel prüfen während der
Archivierungs-, Replikations- und Daten-Seeding-Vorgänge die Richtigkeit jedes Datenträgerblocks im
Backup. Dadurch kann die Beschädigung von Daten rechtzeitig erkannt werden und es wird verhindert,
dass beschädigte Datenblöcke erhalten oder während des Backups übertragen werden.
Universal Recovery
Dank der Universal Recovery-Technologie erhalten Sie uneingeschränkte Flexibilität bei der
Maschinenwiederherstellung. Sie können Ihre Sicherungen auf folgenden Umgebungen wiederherstellen:
von physischen Systeme auf virtuelle Maschinen, von virtuellen Maschinen auf virtuelle Maschinen, von
virtuellen Maschinen auf physische Systeme oder von physischen Systemen auf physische Systeme.
Darüber hinaus können Sie Bare-Metal-Wiederherstellungen auf unterschiedlicher Hardware, z. B. P2V,
V2V, V2P, P2P, P2C, V2C, C2P und C2V, durchführen.
Die Universal Recovery-Technologie beschleunigt auch plattformübergreifende Verschiebungen
zwischen virtuellen Maschinen, zum Beispiel von VMware zu Hyper-V bzw. von Hyper-V zu VMware. Sie
umfasst die Wiederherstellung auf Anwendungs-, Element- und Objektebene von einzelnen Dateien,
Ordnern, E-Mails, Kalenderelementen, Datenbanken und Anwendungen. Mit AppAssure können Sie
außerdem von einer physischen oder einer virtuellen Umgebung auf eine Cloud-Umgebung
wiederherstellen oder exportieren.
True Global Deduplication
Das Gerät bietet echte globale Deduplizierung, die die Anforderungen an die Kapazitäten des physischen
Festplattenlaufwerks, dank Platzeinsparungsraten von über 50:1 bei gleichzeitiger Einhaltung der
Datenspeicherungsanforderungen, reduziert. Die Inline-Komprimierung und Deduplizierung von
AppAssure TrueScale auf Blockebene bei Verbindungsgeschwindigkeit und die vordefinierte
Integritätsprüfung verhindern, dass die Backup- und Archivierungsvorgänge durch Datenbeschädigungen
beeinträchtigt werden.
11
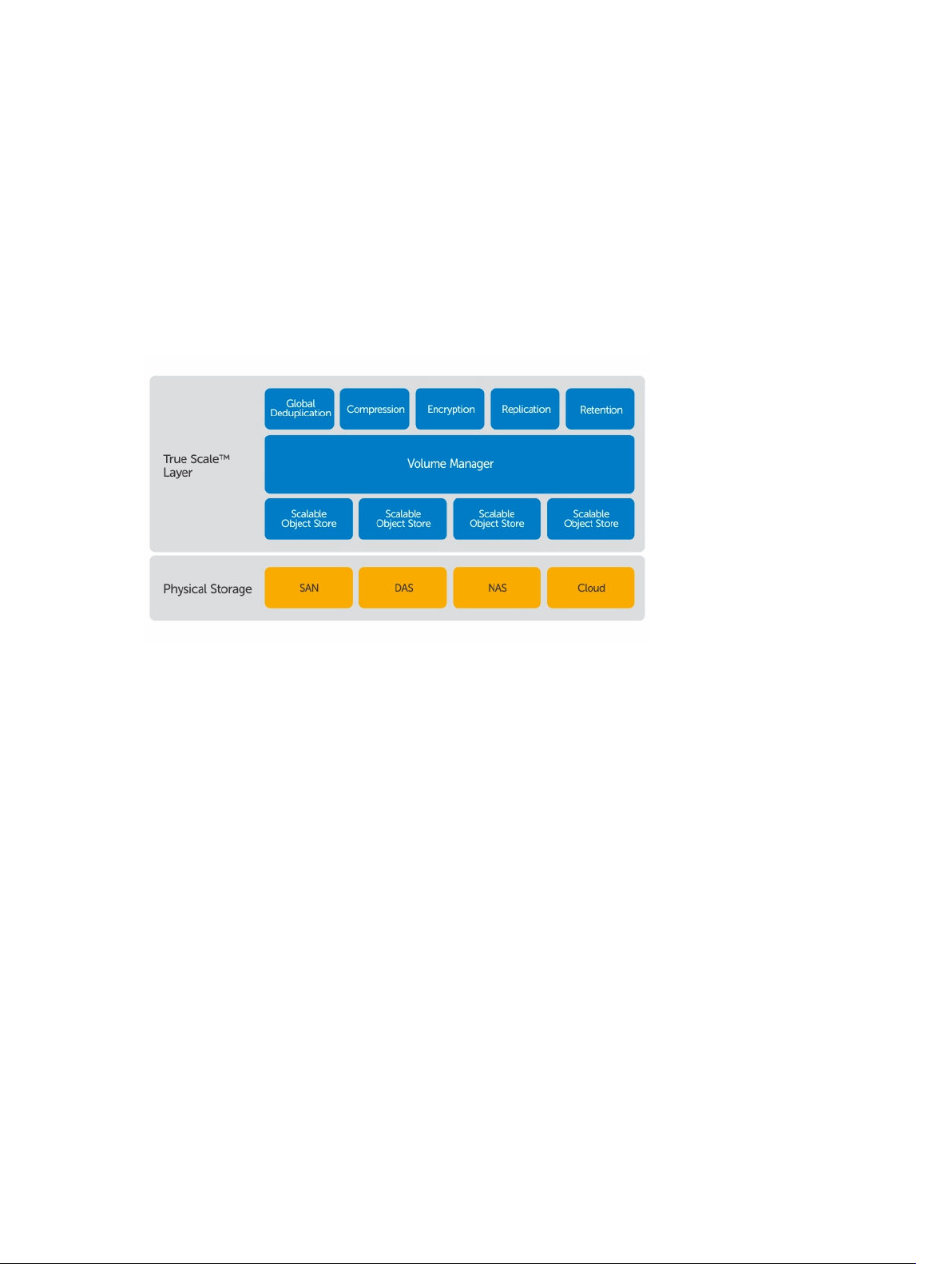
True Scale-Architektur
Ihr Gerät ist auf der AppAssure True Scale-Architektur aufgebaut. Es nutzt eine dynamische, aus mehreren
Kernen bestehende Pipeline-Architektur, die so optimiert wurde, dass sie Ihren
Unternehmensumgebungen eine solide Verbindungsgeschwindigkeit bereitstellt. True Scale wurde von
Grund auf für lineare Skalierbarkeit, effiziente Speicherung und Verwaltung großer Datenmengen sowie
für kurze RTOs und RPOs ohne Leistungseinbußen konzipiert. Die Technologie umfasst einen speziell
erstellten Objekt- und Datenträger-Manager mit integrierter globaler Deduplizierung, Komprimierung,
Verschlüsselung, Replikation und Aufbewahrung. Im folgenden Diagramm wird die AppAssure True ScaleArchitektur beschrieben.
Abbildung 1. AppAssure True Scale-Architektur
Der AppAssure Volume-Manager und der skalierbare Objektspeicher bilden die Basis der AppAssure True
Scale-Architektur. In den einzelnen skalierbaren Objektspeichern werden Blockebenen-Snapshots der
virtuellen und physischen Server gespeichert. Der Volume-Manager verwaltet die zahlreichen
Objektspeicher durch Bereitstellung eines gemeinsamen Repositorys oder durch bedarfsorientierte
Speicherung der notwendigen Elemente. Der Objektspeicher unterstützt simultane Vorgänge mit
asynchroner E/A, die hohen Durchsatz mit minimaler Latenz liefern und die Systemauslastung
maximieren. Das Repository beruht auf unterschiedlichen Speichertechnologien wie Storage Area
Network (SAN), Direct Attached Storage (DAS) oder Network Attached Storage (NAS).
Die Rolle des AppAssure Volume-Managers ähnelt der des Volume-Managers in einem Betriebssystem:
Unter Verwendung der Stripeset- oder sequenziellen Zuweisungsrichtlinien fasst er verschiedene
Speichergeräte mit unterschiedlicher Größe und unterschiedlichem Typ zu logischen Volumes
zusammen. Der Objektspeicher kümmert sich um Speicherung, Abfrage, Verwaltung und anschließende
Replizierung von Objekten, die von anwendungsbezogenen Snapshots abgeleitet wurden. Der VolumeManager bietet eine skalierbare E/A-Leistung zusammen mit globaler Datendeduplizierung,
Verschlüsslung sowie Aufbewahrungsverwaltung.
Bereitstellungsarchitektur
Das Gerät ist ein skalierbares Backup- und Wiederherstellungsprodukt, das flexibel im Unternehmen oder
als von einem Anbieter verwalteter Dienst bereitgestellt wird. Der Typ der Bereitstellung hängt von der
12
Größe und den Anforderungen des Kunden ab. Bei der Planung einer Bereitstellung des Geräts sind die
Planung des Netzwerks, die Speichertopologie, die Hardware- und Notfallwiederherstellungsinfrastruktur
des Kerns sowie die Sicherheit einzubeziehen.
Die Bereitstellungsarchitektur besteht aus lokalen Komponenten und Remote-Komponenten. Die
Remote-Komponenten sind möglicherweise für solche Umgebungen optional, die keinen
Notfallwiederherstellungsstandort oder keinen Anbieter verwalteter Dienste für eine externe
Wiederherstellung erfordern. Eine einfache lokale Bereitstellung besteht aus einem Backupserver, der als
Kern bezeichnet wird, und mindestens einer geschützten Maschine. Die externe Komponente wird
mithilfe einer Replikation aktiviert, die vollständige Wiederherstellungsfähigkeiten am
Notfallwiederherstellungsstandort bietet. Der Kern verwendet Basisabbilder und inkrementelle Snapshots,
um die Wiederherstellungspunkte der geschützten Maschinen zu kompilieren.
Darüber hinaus ist das Gerät mit Anwendungserkennung ausgestattet, da es die Fähigkeit besitzt,
vorhandene Microsoft Exchange- und SQL-Anwendungen und ihre entsprechenden Datenbanken und
Protokolldateien zu erkennen. Diese Datenträger werden anschließend nach Abhängigkeiten für
umfassenden Schutz und effektive Wiederherstellung automatisch gruppiert. Damit wird sichergestellt,
dass die Backups bei der Durchführung von Wiederherstellungen niemals unvollständig sind. Backups
werden mithilfe anwendungsspezifischer Snapshots auf Blockebene durchgeführt. Das Gerät kann auch
Vorgänge zum Abschneiden des Protokolls der geschützten Microsoft Exchange- und SQL-Server
durchführen.
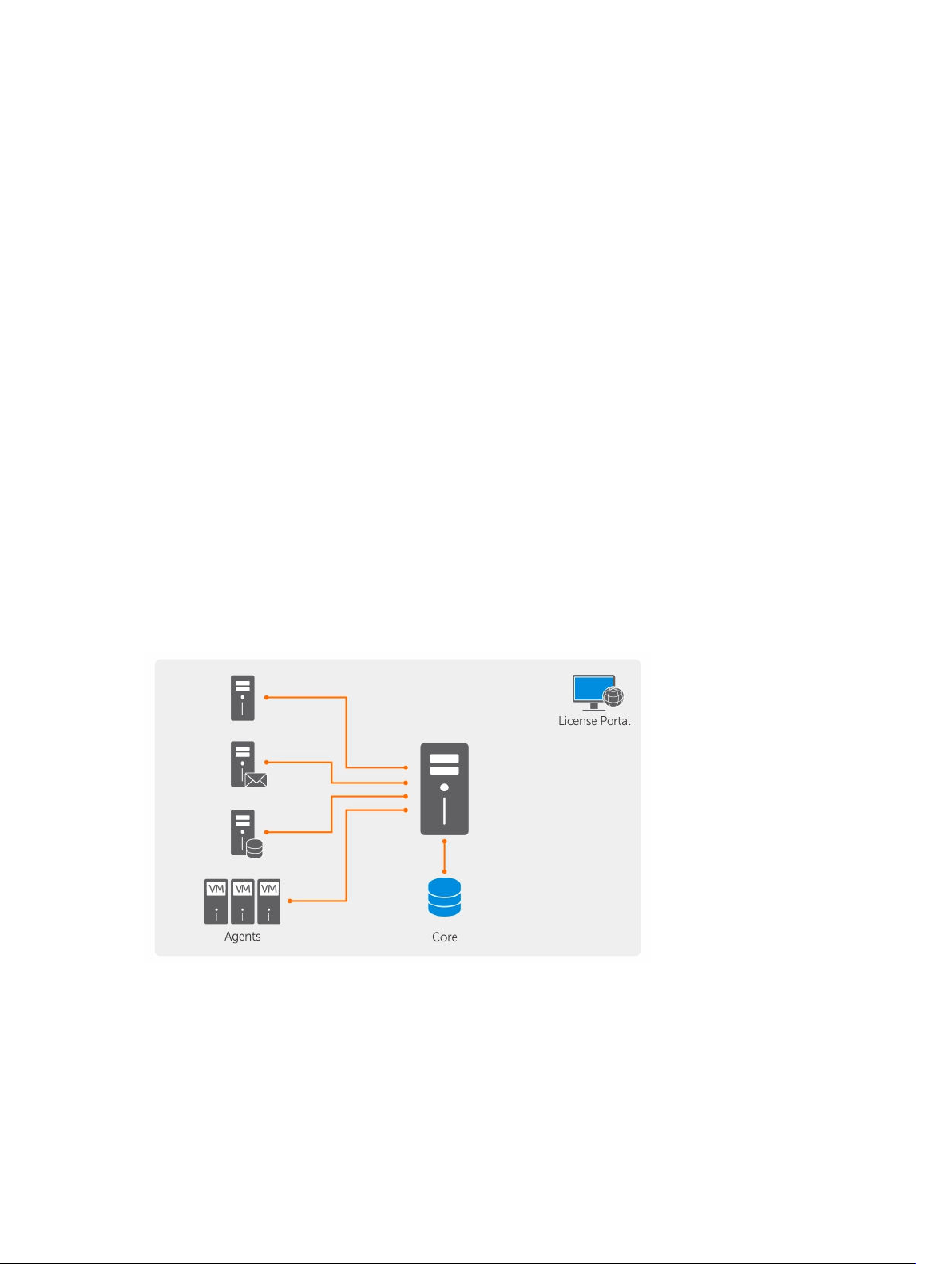
Das folgende Diagramm zeigt eine einfache Bereitstellung. In diesem Diagramm ist die AppAssureAgentsoftware auf Maschinen wie Dateiserver, E-Mail-Server, Datenbankserver oder virtuelle Maschinen
installiert. Sie sind mit einem einzigen Kern, der auch aus dem zentralen Repository besteht, verbunden
und werden von ihm geschützt. Das Lizenzportal verwaltet Lizenzabonnements, Gruppen und Benutzer
der geschützten Maschinen und Kerne in Ihrer Umgebung. Das Lizenzportal ermöglicht Benutzern, sich
anzumelden, Kontos zu aktivieren, Software herunterzuladen und geschützte Maschinen und Kerne je
nach Lizenz für Ihre Umgebung bereitzustellen.
Abbildung 2. Grundlegende Bereitstellungsarchitektur
Sie können auch mehrere Kerne bereitstellen, wie im folgenden Diagramm gezeigt. Eine zentrale Konsole
verwaltet mehrere Kerne.
13
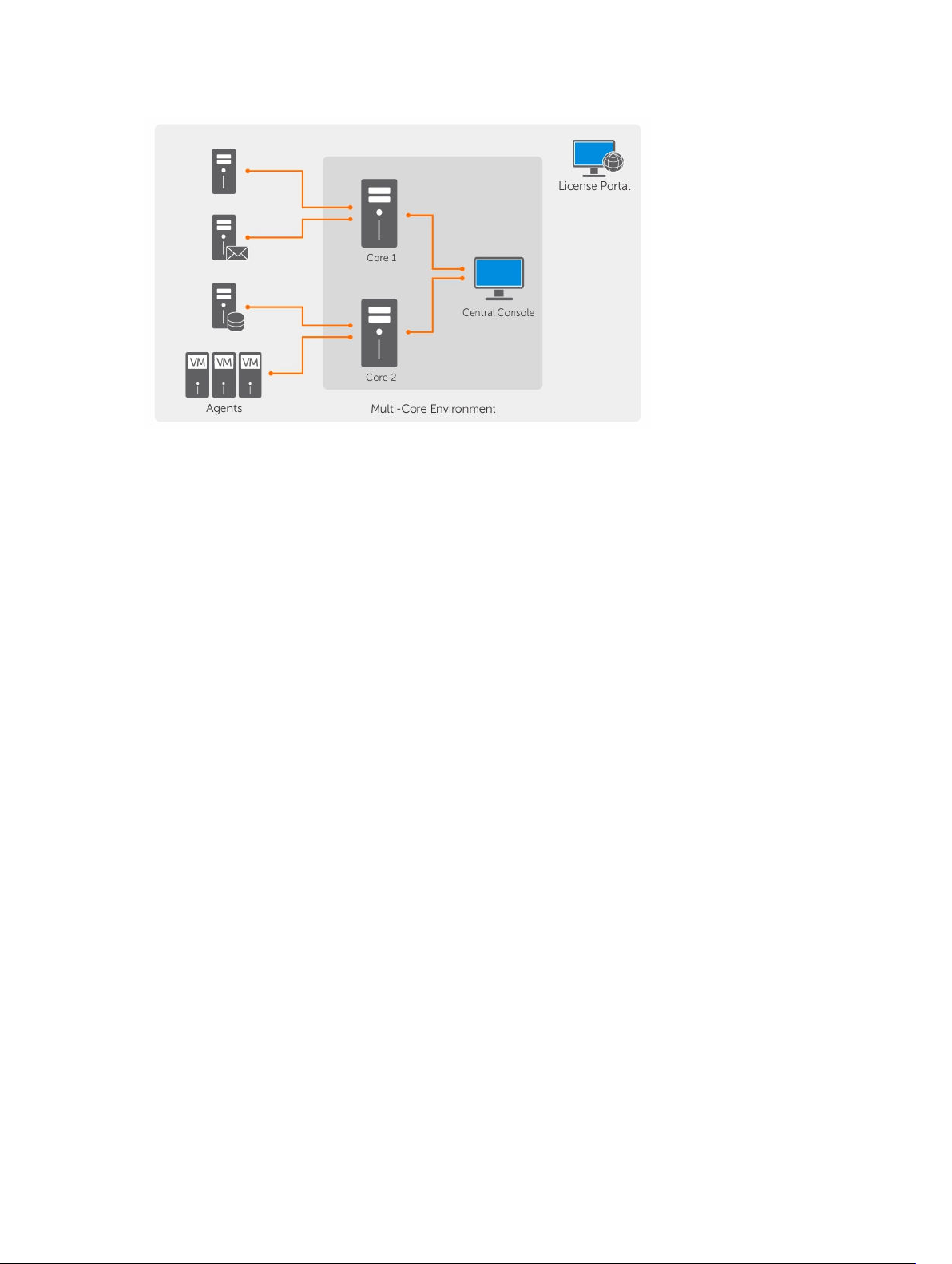
Abbildung 3. Multi-Kern-Bereitstellungsarchitektur
Smart Agent
Smart Agent überwacht die geänderten Blöcke auf dem Datenträger und erstellt ein Abbild der
geänderten Blöcke in einem vordefiniertem Schutzintervall. Der Ansatz eines fortlaufenden
inkrementellen Snapshots auf Blockebene verhindert das wiederholte Kopieren der gleichen Daten von
der geschützten Maschine auf den Kern. Der Smart Agent ist auf den Maschinen installiert, die durch den
Kern geschützt werden.
Der Smart Agent ist anwendungsbezogen und wechselt, wenn er nicht verwendet wird, in den
Ruhezustand, mit nahezu null (0) Prozent CPU-Auslastung und weniger als 20 MB Speicheraufwand. Im
aktiven Zustand nutzt der Smart Agent bis zu 2 bis 4 Prozent der Prozessor-Auslastung und weniger als
150 MB Speicher, worin bereits die Übertragung der Snapshots auf den Kern enthalten ist.
Der Smart Agent ist anwendungsbezogen und erkennt nicht nur den Typ der installierten Anwendung,
sondern auch den Speicherort der Daten. Er gruppiert Datenträger automatisch nach Abhängigkeiten wie
beispielsweise Datenbanken und protokolliert sie dann mit Blick auf einen effektiven Schutz und eine
schnelle Wiederherstellung zusammen. Nachdem die AppAssure-Agentsoftware konfiguriert ist,
verwendet er Smart-Technologie, um geänderte Blöcke auf geschützten Datenträgern nachzuverfolgen.
Wenn der Snapshot bereit ist, wird er schnell mithilfe mehrinstanzenfähiger, socketbasierter
Verbindungen auf den Kern übertragen. Um CPU-Bandbreite und Speicher auf den geschützten
Maschinen einzusparen, verschlüsselt oder dedupliziert der Smart Agent die Daten an der Quelle nicht.
Geschützte Maschinen werden zum Schutz mit einem Kern gepaart.
DL4000-Kern
Der Kern ist die zentrale Komponente der Bereitstellungsarchitektur. Der Kern speichert und verwaltet alle
Maschinenbackups und bietet Kern-Services für Backup, Wiederherstellung und Aufbewahrung,
Replikation, Archivierung sowie Verwaltung. Der Kern ist ein eigenständiger, über das Netzwerk
adressierbarer Computer, der eine 64-Bit- des Microsoft Windows-Betriebssystems ausführt. Das Gerät
führt die zielbasierte Inline-Komprimierung, Verschlüsselung und Deduplizierung der von der
geschützten Maschine empfangenen Daten aus. Der Kern speichert dann die Snapshot-Backups in
Repositorys wie Storage Area Network (SAN, Speicherbereichsnetzwerk), Direct Attached Storage (DAS,
Direktverbundener Speicher).
14

Das Repository kann auch auf interner Speicherung im Kern beruhen. Der Kern wird durch den Zugriff auf
die folgende URL von einem Webbrowser verwaltet: https://CORENAME:8006/apprecovery/admin.
Intern sind alle Kern-Services über REST-APIs zugänglich. Auf die Kern-Services kann innerhalb des Kerns
zugegriffen werden oder direkt über das Internet von jeder Anwendung aus, die eine HTTP/HTTPSAnforderung senden und eine HTTP/HTTPS-Antwort empfangen kann. Alle API-Vorgänge werden über
SSL durchgeführt und werden gegenseitig mithilfe von X.509 v3-Zertifikaten authentifiziert.
Kerne werden für die Replikation mit anderen Kernen gepaart.
Snapshot-Prozess
Als Snapshot wird der Vorgang bezeichnet, bei dem ein Basisabbild von einer geschützten Maschine auf
den Kern übertragen wird. Dies ist der einzige Zeitpunkt, zu dem eine vollständige Kopie der Maschine bei
Normalbetrieb über das Netzwerk transportiert wird, gefolgt von fortlaufenden inkrementellen Snapshots.
Die AppAssure Agentsoftware für Windows verwendet den Microsoft Volume Shadow Copy Service (VSS)
für das Einfrieren und Stilllegen von Anwendungsdaten auf Datenträgern, um ein dateisystemkonsistentes
und anwendungskonsistentes Backup zu erfassen. Wenn ein Snapshot erstellt wird, verhindern VSS und
der Generator auf dem Zielserver das Schreiben von Daten auf den Datenträger. Wenn das Schreiben von
Inhalten auf den Datenträger angehalten wird, kommen alle E/A-Vorgänge des Datenträgers in eine
Warteschlange und werden erst wieder fortgesetzt, nachdem der Snapshot fertiggestellt ist, alle derzeit
ausgeführten Vorgänge abgeschlossen und alle geöffneten Dateien geschlossen worden sind. Der
Prozess zum Erstellen einer Schattenkopie beeinträchtigt die Leistung des Produktionssystems nicht
wesentlich.
AppAssure verwendet Microsoft VSS, da der Service über eine integrierte Unterstützung für alle Windowsinternen Technologien wie NTFS, Registrierung, Active Directory usw. besitzt, um Daten vor dem Erstellen
des Snapshots auf den Datenträger abzulegen. Zusätzlich verwenden andere
Unternehmensanwendungen wie Microsoft Exchange und SQL die VSS-Generator-Plugins, um
benachrichtigt zu werden, wenn ein Snapshot vorbereitet wird und wenn sie ihre geänderten
Datenbankseiten auf dem Datenträger ablegen müssen, um die Datenbank in einen konsistenten
Transaktionsstatus zu versetzen. Es muss unbedingt beachtet werden, dass VSS zur Stilllegung von
System- und Anwendungsdaten auf dem Datenträger und nicht zum Erstellen des Snapshots verwendet
wird. Die erfassten Daten werden umgehend auf den Kern übertragen und dort gespeichert. Wenn VSS
für das Backup verwendet wird, wird der Anwendungsserver nicht für einen längeren Zeitraum in den
Backupmodus versetzt, da die benötigte Zeit für eine Snapshot-Erstellung Sekunden und nicht Stunden
beträgt. Ein weiterer Vorteil der Verwendung von VSS für Backups ist, dass es die AppAssureAgentsoftware einen Snapshot großer Datenmengen aufzeichnen lässt, da der Snapshot auf
Datenträgerebene funktioniert.
Replikation des Notfallwiederherstellungsstandorts oder Dienstanbieters
Für den Replikationsprozess benötigen Sie eine gekoppelte Quell-Ziel-Beziehung zwischen zwei Kernen.
Der Quellkern kopiert die Wiederherstellungspunkte der geschützten Maschinen und überträgt diese
asynchron und fortlaufend auf den Zielkern an einem Remote-Notfallwiederherstellungsstandort. Der
Remote-Standort kann ein unternehmenseigenes Rechenzentrum (selbstverwalteter Kern) oder ein MSPStandort (Managed Service Provider) eines Drittanbieters oder eine Cloud-Umgebung sein. Bei der
Replikation auf einem MSP können Sie integrierte Workflows verwenden, über die Sie Verbindungen
anfordern und automatische Rückmeldungen erhalten können. Für die erstmalige Übertragung der Daten
können Sie Daten-Seeding mithilfe von externen Datenträgern durchführen. Dieses Verfahren eignet sich
insbesondere für umfassende Datensätze oder Standorte mit langsamen Links.
15

Bei einem schwerwiegenden Ausfall unterstützt das Gerät Failover und Failback in replizierten
Umgebungen. Im Fall eines globalen Ausfalls kann der Zielkern am sekundären Standort Instanzen aus
replizierten geschützten Maschinen wiederherstellen und sofort den Schutz auf den Failed-overMaschinen starten. Nachdem der primäre Standort wiederhergestellt ist, kann der replizierte Kern ein
Failback der Daten aus den wiederhergestellten Instanzen zurück auf geschützte Maschinen am primären
Standort ausführen.
Wiederherstellung
Eine Wiederherstellung kann am lokalen Standort oder dem replizierten Remote-Standort durchgeführt
werden. Nachdem sich die Bereitstellung in einem stabilen Zustand mit lokalem Schutz und optionaler
Replikation befindet, ermöglicht Ihnen der Kern Wiederherstellungsvorgänge mithilfe von Verified
Recovery, Universal Recovery oder Live Recovery.
Produktmerkmale
Sie können den Schutz und die Wiederherstellung von kritischen Daten über folgende Funktionen und
Funktionalitäten sicherstellen:
• Repository
• True Global Deduplication (Funktionen)
• Verschlüsselung
• Replikation
• Recovery-as-a-Service (RaaS)
• Aufbewahrung und Archivierung
• Virtualisieurng und die Cloud
• Benachrichtigungs- und Ereignisverwaltung
• Lizenzportal
• Webkonsole
• Serviceverwaltungs-APIs
Repository
Das Repository verwendet einen Deduplizierungs-Volume-Manager (DVM, Deduplication Volume
Manager), um einen Volume-Manager zu implementieren, der Unterstützung für mehrere Volumes bietet.
Jedes dieser Volumes kann auf einer anderen Speichertechnologie wie Speicherbereichsnetzwerk (SAN,
Storage Area Network), direkt angeschlossener Speicherung (DAS, Direct Attached Storage),
netzgebundener Speicherung (NAS, Network Attached Storage) oder Cloud-Speicherung beruhen. Jedes
Volume besteht aus einem skalierbaren Objektspeicher mit Deduplizierung. Der skalierbare
Objektspeicher verhält sich wie ein datensatzbasiertes Dateisystem, bei dem die Einheit der
Speicherzuweisung ein Datenblock mit fester Größe ist, der Datensatz genannt wird. Mit dieser
Architektur können Sie Unterstützung in Blockgröße zur Komprimierung und Deduplizierung
konfigurieren. Rollup-Vorgänge werden von datenträgerintensiven Vorgängen zu Metadaten-Vorgängen
reduziert, da beim Rollup keine Daten mehr verschoben werden, sondern nur noch die Datensätze.
Der DVM kann eine Reihe von Objektspeichern in einem Datenträger zusammenfassen. Diese können
durch Erstellen zusätzlicher Dateisysteme erweitert werden. Die Objektspeicherdateien werden vorab
zugewiesen und können bei Bedarf hinzugefügt werden, falls sich die Speicheranforderungen ändern. Auf
einem einzigen Kern können bis zu 255 unabhängige Repositorys erstellt werden. Zusätzlich lässt sich ein
Repository durch Hinzufügen neuer Dateierweiterungen weiter vergrößern. Ein erweitertes Repository
16

kann bis zu 4.096 Erweiterungen enthalten, die verschiedene Speichertechnologien umfassen. Die
Maximalgröße eines Repositorys beträgt 32 Exabyte. Auf einem Kern können sich mehrere Repositorys
befinden.
True Global Deduplication
True Global Deduplication (echte globale Deduplizierung) ist ein wirksames Verfahren zur Verringerung
der Sicherungsspeicheranforderungen durch das Entfernen überflüssiger oder doppelter Daten.
Deduplizierung ist wirksam, weil nur eine eindeutige Instanz der Daten über mehrere Sicherungen im
Repository gespeichert wird. Die redundanten Daten werden zwar gespeichert, jedoch nicht physisch
abgelegt, sondern einfach durch einen Verweis auf die eindeutige Dateninstanz im Repository ersetzt.
Bei herkömmlichen Backupanwendungen wurden jede Woche iterative Komplettbackups durchgeführt,
Ihr Gerät hingegen führt inkrementelle Backups der Maschine auf Blockebene durch. Zusammen mit der
Datendeduplizierung hilft dieser Ansatz eines fortlaufenden inkrementellen Backups (Incremental forever)
dabei, die Gesamtmenge der an den Datenträger übergebenen Daten erheblich zu reduzieren.
Das typische Datenträgerlayout eines Servers besteht aus dem Betriebssystem, der Anwendung und den
Daten. In den meisten Umgebungen nutzen die Administratoren für eine effektive Bereitstellung und
Verwaltung oftmals eine allgemeine Konfiguration des Servers und Desktops, der bzw. die auf mehreren
Systemen ausgeführt werden. Wenn die Sicherung auf Blockebene für mehrere Maschinen gleichzeitig
durchgeführt wird, erhalten Sie einen genaueren Überblick darüber, welche Inhalte in die Sicherung
aufgenommen wurden und welche nicht, unabhängig von der Quelle. Zu diesen Daten gehören das
Betriebssystem, die Anwendungen und die Anwendungsdaten in der Umgebung.
Abbildung 4. Diagramm der Deduplizierung
Ihr Gerät führt zielbasierte Inline-Datendeduplizierungen durch. Das bedeutet, dass die Snapshot-Daten
vor ihrer Deduplizierung auf den Kern übertragen werden. Bei der Inline-Datendeduplizierung werden die
Daten dedupliziert, bevor sie an den Datenträger übergeben werden. Dieses Verfahren unterscheidet sich
von der At-Source-Deduplizierung, bei der die Daten an der Quelle dedupliziert werden, bevor sie zur
Speicherung auf das Ziel übertragen werden, und auch von der Postprocess-Deduplizierung, bei der die
Daten als Rohdaten an das Ziel gesendet werden, wo sie nach der Übergabe an den Datenträger
analysiert und dedupliziert werden. Bei der At-Source-Deduplizierung werden wertvolle
Systemressourcen auf der Maschine gebunden, wohingegen sich für die Postprocess-
17

Datendeduplizierung alle notwendigen Daten auf dem Datenträger befinden müssen (d. h. ein höherer
anfänglicher Kapazitätsaufwand), damit der Deduplizierungsprozess starten kann. Die InlineDatendeduplizierung benötigt andererseits für den Deduplizierungsprozess keine zusätzlichen
Datenträgerkapazitäten und CPU-Zyklen auf der Quelle oder auf dem Kern. Herkömmliche
Backupanwendungen führen jede Woche iterative Komplettbackups durch, Ihr Gerät hingegen führt
fortlaufende inkrementelle Backups der Maschine auf Blockebene durch. Zusammen mit der
Datendeduplizierung trägt dieser Ansatz des fortlaufenden inkrementellen Backups (Incremental forever)
dazu dabei, die Gesamtmenge der an den Datenträger übergebenen Daten erheblich zu reduzieren, und
zwar in einem Verhältnis von bis zu 50:1.
Verschlüsselung
Das Gerät bietet eine integrierte Verschlüsselung, um Backups sowie gespeicherte Daten vor nicht
autorisiertem Zugriff und unbefugter Nutzung zu schützen und gewährleistet damit Ihren Datenschutz.
Nur ein Benutzer mit dem entsprechenden Verschlüsselungscode kann auf diese Daten zugreifen und sie
entschlüsseln. Auf einem System können unbegrenzt viele Verschlüsselungscodes erstellt und
gespeichert werden. Der DVM verwendet 256-Bit-AES-Verschlüsselung im CBC-Modus (Cipher Block
Chaining) mit 256-Bit-Schlüsseln. Die Verschlüsselung wird inline auf Snapshot-Daten durchgeführt, bei
Verbindungsgeschwindigkeiten und ohne die Leistung zu beeinträchtigen. Dies liegt daran, dass die
DVM-Implementierung Multithread-fähig ist und Hardwarebeschleunigung verwendet, die für den
Prozessor, auf dem sie bereitgestellt wird, spezifisch ist.
Die Verschlüsselung ist mehrinstanzenfähig. Die Deduplizierung wurde speziell auf Datensätze
beschränkt, die mit dem gleichen Schlüssel verschlüsselt wurden. Zwei identische Datensätze, die mit
unterschiedlichen Schlüsseln verschlüsselt wurden, werden nicht gegeneinander dedupliziert. Dank
dieses Konzepts wird sichergestellt, dass mithilfe der Deduplizierung keine Daten zwischen
unterschiedlichen Verschlüsselungsdomains weitergegeben werden können. Dies ist von Vorteil für
Anbieter verwalteter Dienste, da replizierte Backups für mehrere Instanzen (Kunden) auf einem Kern
gespeichert werden können, ohne dass eine der Instanzen die Daten einer der anderen Instanzen
anzeigen oder darauf zugreifen kann. Jeder Verschlüsselungscode einer aktiven Instanz erstellt eine
Verschlüsselungsdomain im Repository, in dem nur der Besitzer des Schlüssels die Daten anzeigen,
darauf zugreifen oder sie verwenden kann. In einem Mehrinstanzenszenario werden Daten in den
Verschlüsselungsdomains partitioniert und dedupliziert.
In Replikationsszenarien sichert das Gerät die Verbindung zwischen den zwei Kernen in einer
Replikationstopologie mithilfe von SSL 3.0, um Abhören und Manipulation zu verhindern.
Replikation
Bei der Replikation handelt es sich um einen Prozess des Kopierens der Wiederherstellungspunkte von
einem AppAssure-Kern und des Übertragens dieser Punkte auf einen anderen AppAssure-Kern auf einem
separaten Speicherort zwecks der Notfall-Wiederherstellung. Für diesen Prozess benötigen Sie eine
gekoppelte Quell-Ziel-Beziehung zwischen zwei oder mehr Kernen.
Der Quellkern kopiert die Wiederherstellungspunkte der ausgewählten geschützten Maschinen und
überträgt die inkrementellen Snapshot-Daten asynchron und dauerhaft auf den Zielkern an einem
Remote-Notfallwiederherstellungsstandort. Sie können eine ausgehende Replikation auf ein
unternehmenseigenes Rechenzentrum oder auf einen Remote-Notfallwiederherstellungsstandort
(selbstverwalteter Zielkern) konfigurieren. Außerdem können Sie eine ausgehende Replikation auch auf
einen MSP-Standort (Managed Service Provider) eines Drittanbieters oder auf eine Cloud, die externe
18
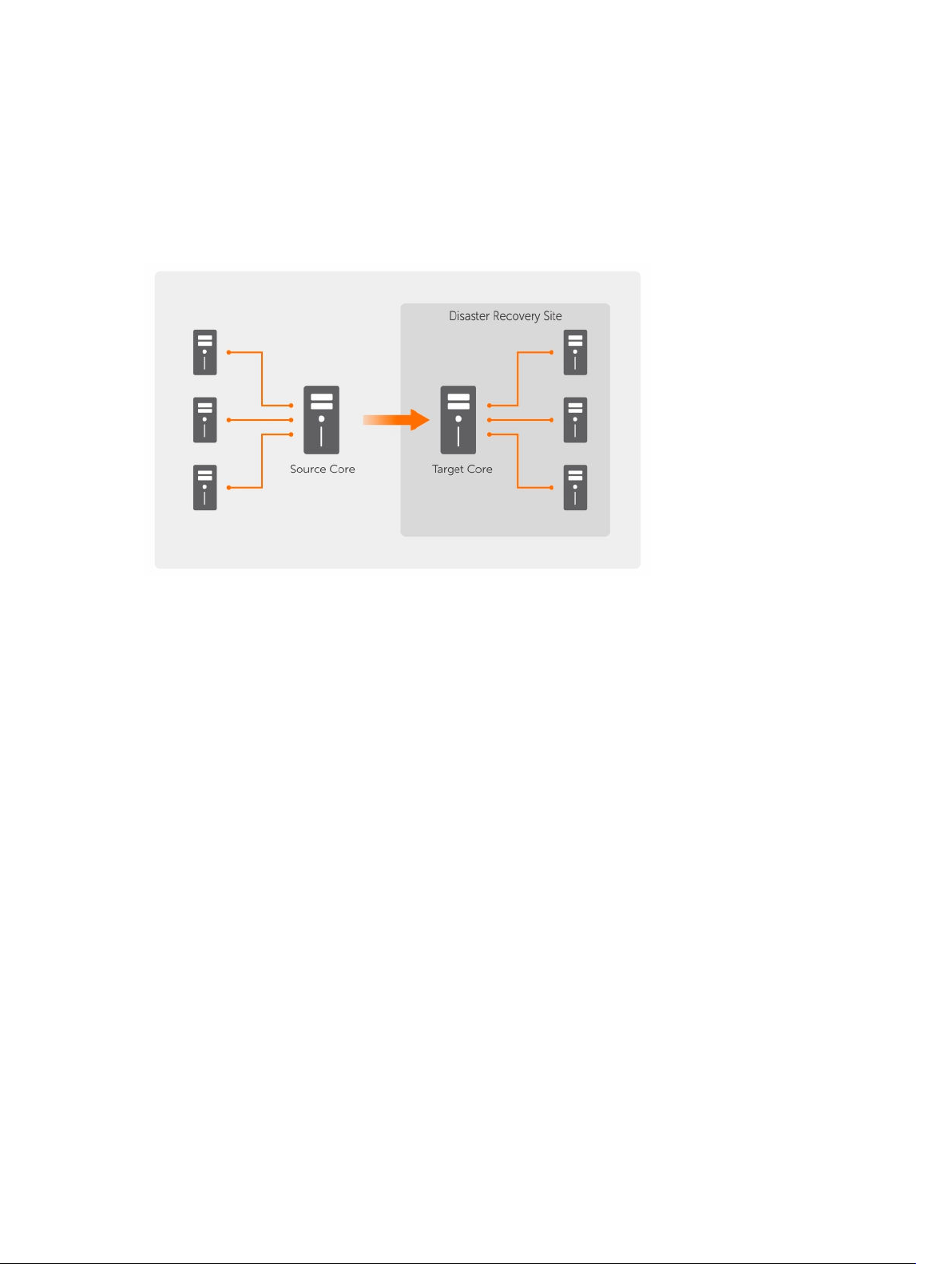
Backups und einen Notfall-Wiederherstellungs-Service bereitstellt, konfigurieren. Bei der Replikation auf
einen Zielkern eines Drittanbieters können Sie integrierte Arbeitsabläufe verwenden, über die Sie
Verbindungen anfordern und automatische Rückmeldungen erhalten können.
Replikation wird auf Basis jeder geschützten Maschine verwaltet. Jede Maschine (oder alle Maschinen),
die auf einem Quellkern geschützt oder repliziert sind, können für die Replikation auf einen Zielkern
konfiguriert werden.
Abbildung 5. Grundlegende Replikationsarchitektur
Die Replikation ist selbstoptimierend mit einem einzigartigen Read-Match-Write (RMW)-Algorithmus, der
eng mit der Deduplizierung verknüpft ist. Bei der RMW-Replikation gleicht der Quell- und ZielreplikationService die Schlüssel vor der Datenübertragung ab und repliziert dann nur die komprimierten –
verschlüsselten – deduplizierten Daten über das WAN, was eine 10-fache Reduzierung der
Bandbreitenanforderungen bedeutet.
Die Replikation beginnt mit dem Seeding. „Seeding“ ist die erste Übertragung deduplizierter Basisabbilder
und inkrementeller Snapshots von geschützten Maschinen. Die Daten können sich auf Hunderte oder
Tausende Gigabytes summieren. Die erste Replikation kann mithilfe externer Medien auf dem Zielkern
platziert werden. Dies ist bei großen Datensätzen oder Standorten mit langsamer Verbindung nützlich.
Die Daten im Seeding-Archiv sind komprimiert, verschlüsselt und dedupliziert. Wenn die Gesamtgröße
des Archivs auf dem externen Datenträger den verfügbaren Speicherplatz überschreitet, kann sich das
Archiv über mehrere Geräte erstrecken. Während des Seeding-Vorgangs werden die inkrementellen
Wiederherstellungspunkte auf den Zielstandort repliziert. Nachdem die Daten auf den Zielkern übertragen
wurden, werden die neu replizierten inkrementellen Wiederherstellungspunkte automatisch
synchronisiert.
Recovery-as-a-Service (RaaS)
Anbieter von verwalteten Diensten (Managed Service Providers, MSPs) können das Gerät vollständig als
Plattform für die Bereitstellung von Wiederherstellung als Service (RaaS, Recovery-as-a-Service) nutzen.
RaaS ermöglicht eine vollständige Wiederherstellung in der Cloud (Recovery-in-the-Cloud), indem die
physischen und virtuellen Server des Kunden zusammen mit deren Daten als virtuelle Maschinen zur
Cloud des Dienstanbieters repliziert werden, um Wiederherstellungstests oder tatsächliche
Wiederherstellungsvorgänge zu unterstützen. Kunden, die eine Wiederherstellung in der Cloud
19

durchführen möchten, können die Replikation auf ihren geschützten Maschinen auf den lokalen Kernen
zu einem AppAssure-Dienstanbieter konfigurieren. In einem Notfall können die Anbieter verwalteter
Dienste unverzüglich virtuelle Maschinen für den Kunden bereitstellen.
MSPs können eine mehrinstanzenfähige AppAssure-basierte RaaS-Infrastruktur bereitstellen, die mehrere
und eigenständige Organisationen oder Geschäftseinheiten (die Instanzen) hosten kann, die
üblicherweise keine Sicherheit oder Daten auf einem einzelnen Server oder einer Gruppe von Servern
gemeinsam nutzen. Die Daten jeder Instanz sind isoliert und vor anderen Instanzen und dem
Dienstanbieter geschützt.
Aufbewahrung und Archivierung
In dem Gerät sind Backup- sowie Aufbewahrungsrichtlinien flexibel und können daher einfach
konfiguriert werden. Die Möglichkeit zur Anpassung der Aufbewahrungsrichtlinien an die Bedürfnisse
einer Organisation unterstützt Sie nicht nur bei der Einhaltung von Konformitätsanforderungen, sondern
ermöglicht dies auch ohne Beeinträchtigung der RTO.
Aufbewahrungsrichtlinien erzwingen die Zeitdauer, für die Backups auf (schnellen und teuren)
Datenträgern gespeichert werden. Mitunter machen geschäftliche und technische Anforderungen eine
längere Aufbewahrung dieser Backups erforderlich, schnelle Speicherung ist jedoch unerschwinglich
teuer. Deshalb wird durch diese Anforderung (langsame und kostengünstige) Langzeitspeicherung
notwendig. Unternehmen verwenden Langzeitspeicherung oftmals zur Archivierung von konformen
sowie nicht-konformen Daten. Die Archivierungsfunktion unterstützt die längere Aufbewahrung von
konformen und nicht-konformen Daten, und kann auch für das Seeding von Replikationsdaten auf einem
Zielkern verwendet werden.
Abbildung 6. Benutzerdefinierte Aufbewahrungsrichtlinie
Aufbewahrungsrichtlinien können im Gerät benutzerdefiniert werden, um die Zeitspanne festzulegen,
über die ein Backup-Wiederherstellungspunkt aufrecht erhalten wird. Wenn das Alter der
Wiederherstellungspunkte das Ende der Aufbewahrungszeitspanne erreicht, läuft ihre Lebensdauer ab
und die Backups werden aus dem Aufbewahrungspool entfernt. Normalerweise wird dieser Prozess
ineffizient und schlägt schließlich fehl, da die Datenmenge und die Aufbewahrungsfrist schnell zu
wachsen beginnen. Das Gerät löst dieses große Datenproblem, indem es die Aufbewahrung großer
Datenmengen mithilfe komplexer Aufbewahrungsrichtlinien verwaltet und Rollup-Vorgänge für die
Alterung von Daten mithilfe effizienter Metadatenvorgänge durchführt.
20

Backups können im Intervall weniger Minuten ausgeführt werden. Während diese Backups über Tage,
Monate und Jahre altern, verwalten Aufbewahrungsrichtlinien die Alterung und das Löschen alter
Backups. Der Alterungsprozess wird durch eine einfache Wasserfallmethode definiert. Die Stufen im
Wasserfall werden in Minuten, Stunden und Tagen sowie Wochen, Monaten und Jahren definiert. Die
Aufbewahrungsrichtlinie wird durch den nächtlichen Rollup-Prozess erzwungen.
Für Langzeitspeicherung ermöglicht das Gerät die Fähigkeit ein Archiv der Quelle oder des Zielkerns zu
beliebigen Wechseldatenträgern zu erstellen. Das Archiv wird intern optimiert und alle Daten im Archiv
sind komprimiert, verschlüsselt und dedupliziert. Wenn die Gesamtgröße des Archivs den auf dem
Wechseldatenträger verfügbaren Speicherplatz überschreitet, kann sich das Archiv, je nach verfügbarem
Speicherplatz auf dem Datenträger, über mehrere Geräte erstrecken. Außerdem kann das Archiv mit einer
Passphrase gesperrt werden. Für die Wiederherstellung aus einem Archiv ist kein neuer Kern erforderlich.
Jeder Kern kann das Archiv aufnehmen und Daten wiederherstellen, wenn der Administrator die
Passphrase und den Verschlüsselungscode besitzt.
Virtualisierung und Cloud
Der Kern ist Cloud-fähig und ermöglicht es Ihnen, die Rechenkapazität der Cloud für die
Wiederherstellung zu nutzen.
Das Gerät kann beliebige geschützte oder replizierte Maschinen auf eine virtuelle Maschine exportieren,
z. B. lizenzierte Versionen von VMware oder Hyper-V. Sie können einen einmaligen virtuellen Export
durchführen, oder Sie können eine virtuelle Standby-VM festlegen, indem Sie einen kontinuierlichen
virtuellen Export einrichten. Bei einem kontinuierlichen Export wird die virtuelle Maschine inkrementell
nach jedem Snapshot aktualisiert. Die inkrementellen Aktualisierungen erfolgen sehr schnell und liefern
Ihnen Standby-Klone, die mit einem Mausklick eingeschaltet werden können. Die unterstützten
Exporttypen für virtuelle Maschinen sind VMware Workstation/Server in einen Ordner, direkter Export auf
einen vSphere/VMware ESX(i)-Host, Export zu Oracle VirtualBox und Export in Microsoft Hyper-V-Server
auf Windows Server 2008 (x64), 2008 R2, 2012 (x64) und 2012 R2 (mit Unterstützung für Hyper-V-VMs
der 2. Generation).
Sie haben jetzt außerdem die Möglichkeit, Ihre Repository-Daten in der Cloud zu archivieren. Verwenden
Sie dazu Microsoft Azure, Amazon S3, Rackspace Cloud Block Storage oder einen anderen OpenStackbasierten Cloud-Dienst.
Benachrichtigungs- und Ereignisverwaltung
Neben der HTTP-REST-API umfasst das Gerät auch einen umfangreichen Satz an Funktionen für die
Ereignisprotokollierung und Benachrichtigung mithilfe von E-Mails, Syslog oder WindowsEreignisprotokollen. Über E-Mail-Benachrichtigungen können Benutzer oder Gruppen über
Funktionszustand und Status unterschiedlicher Ereignisse als Reaktion auf eine Warnung benachrichtigt
werden. Die Syslog- und Windows-Ereignisprotokoll-Methoden werden für die zentrale Protokollierung
in ein Repository in Umgebungen mit mehreren Betriebssystemen verwendet. In reinen WindowsUmgebungen wird nur das Windows-Ereignisprotokoll verwendet.
Lizenzportal
Das Lizenzportal stellt einfach zu verwendende Tools für die Verwaltung der Lizenzberechtigungen
bereit. Sie können Lizenzschlüssel herunterladen, aktivieren, anzeigen und verwalten sowie ein
Unternehmensprofil zur Nachverfolgung Ihrer Lizenzbestände erstellen. Zusätzlich ermöglicht das Portal
den Dienstanbietern und Wiederverkäufern, ihre Kundenlizenzen nachzuverfolgen und zu verwalten.
21

Webkonsole
Das Gerät beinhaltet eine neue webbasierte zentrale Konsole, die verteilte Kerne von einem zentralen
Speicherort aus verwaltet. MSPs und Unternehmenskunden mit mehreren verteilten Kernen können die
zentrale Konsole bereitstellen und so eine vereinheitlichte Ansicht für die zentrale Verwaltung erhalten.
Die zentrale Konsole ermöglicht die Organisation der verwalteten Kerne in hierarchischen
Organisationseinheiten. Diese Organisationseinheiten können Geschäftseinheiten, -standorte oder kunden für MSPs mit rollenbasiertem Zugang darstellen. Außerdem kann die zentrale Konsole Berichte
auf verwalteten Kernen ausführen.
Serviceverwaltungs-APIs
Das Gerät wird zusammen mit einer Serviceverwaltungs-API geliefert und bietet programmgesteuerten
Zugriff auf alle Funktionen, die über die Central Management Console verfügbar sind. Die
Serviceverwaltungs-API ist eine REST-API. Alle API-Vorgänge werden über SSL durchgeführt und werden
gegenseitig mithilfe von X.509 v3-Zertifikaten authentifiziert. Auf den Verwaltungsservice kann innerhalb
der Umgebung oder direkt über das Internet von jeder Anwendung aus zugegriffen werden, die HTTPSAnforderungen und -Antworten senden und empfangen kann. Dieser Ansatz unterstützt eine einfache
Integration in jede beliebige Webanwendung wie etwa RMM-Tools (Relationship Management
Methodology) oder Abrechnungssysteme. Darüber hinaus ist ein SDK-Client für die PowerShellSkripterstellung enthalten.
22

2
Arbeiten mit dem DL4000-Kern
Zugreifen auf die DL4000 Core Console
So erhalten Sie Zugang zur Core Console:
1. Aktualisieren Sie die vertrauenswürdigen Seiten in Ihrem Browser. Weitere Informationen finden Sie
unter Aktualisieren von vertrauenswürdigen Seiten in Internet Explorer.
2. Konfigurieren Sie Ihre Browser für den Remotezugriff auf die Core Console. Weitere Informationen
finden Sie unter Konfigurieren von Browsern für den Remotezugriff auf die Core Console.
3. Führen Sie für den Zugang zur Core Console einen der folgenden Schritte aus:
• Melden Sie sich lokal bei Ihrem DL4000-Kernserver an, und doppelklicken Sie dann auf das
Symbol der Core Console.
• Geben Sie eine der folgenden URLs in den Webbrowser ein:
– https://<yourCoreServerName>:8006/apprecovery/admin/core oder
– https://<yourCoreServerIPaddress>:8006/apprecovery/admin/core
Aktualisieren von vertrauenswürdigen Seiten im Internet Explorer
So aktualisieren Sie vertrauenswürdige Seiten in Microsoft Internet Explorer:
1. Öffnen Sie Internet Explorer.
2. Wenn die File (Datei) Edit View (Anzeige bearbeiten) und andere Menüs nicht angezeigt werden,
drücken Sie auf <F10>.
3. Klicken Sie auf das Menü Tools (Extras) und wählen Sie Internet Options (Internetoptionen) aus.
4. Klicken Sie im Fenster Internet Options (Internetoptionen) auf die Registerkarte Security
(Datenschutz).
5. Klicken Sie auf Trusted Sites (Vertrauenswürdige Seiten) und klicken Sie dann auf Sites (Seiten).
6. Geben Sie in Add this website to the zone (Diese Website zur Zone hinzufügen) unter Verwendung
des Namens, den Sie als Anzeigenamen bereitgestellt haben, Folgendes ein:
(https://[Anzeigenamen]).
7. Klicken Sie auf Add (Hinzufügen).
8. Geben Sie in Add this website to the zone, (Diese Website zur Zone hinzufügen) Folgendes ein:
about:blank.
9. Klicken Sie auf Add (Hinzufügen).
10. Klicken Sie auf Close (Schließen) und dann auf OK.
https://[Display Name]
Konfigurieren von Browsern für den Remotezugriff auf die Core Console
Für den Zugriff auf die Core Console von einer Remote-Maschine müssen Sie Ihre Browser-Einstellungen
anpassen.
ANMERKUNG: Melden Sie sich zum Ändern der Browser-Einstellungen als Administrator am System
an.
23

ANMERKUNG: Google Chrome verwendet Microsoft Internet Explorer-Einstellungen, ändern Sie die
Einstellungen für den Chrome-Browser über den Internet Explorer.
ANMERKUNG: Stellen Sie sicher, dass die Option Internet Explorer Enhanced Security
Configuration (Verstärkte Sicherheitskonfiguration für Internet Explorer) eingeschaltet ist, wenn Sie
entweder lokal oder remote auf die Core-Web-Konsole zugreifen. So schalten Sie die Option
Internet Explorer Enhanced Security Configuration (Verstärkte Sicherheitskonfiguration für Internet
Explorer) ein:
1. Öffnen Sie den Server-Manager.
2. Wählen Sie die Option Local Server IE Enhanced Security Configuration (Verstärkte
Sicherheitskonfiguration für Internet Explorer für lokale Server) auf der rechten Seite aus.
Stellen Sie sicher, dass sich die Option in der Position On (Ein) befindet.
Konfiguration der Browser-Einstellungen für Internet Explorer und Chrome:
So ändern Sie Browser-Einstellungen für Internet Explorer und Chrome:
1. Öffnen Sie Internet Explorer.
2. Wählen Sie im Menü Tools (Extras) die Option Internet Options (Internetoptionen) auf der
Registerkarte Security (Sicherheit) aus.
3. Klicken Sie auf Trusted Sites (Vertrauenswürdige Seiten) und klicken Sie dann auf Sites (Seiten).
4. Deaktivieren Sie die Option Require server verification (https:) for all sites in the zone
(Serverüberprüfung erforderlich (https:) für alle Websites in der Zone), und fügen Sie dann http://
<Host-Name oder IP-Adresse des Geräteservers, der den AppAssure-Kern hostet> zu Trusted Sites
(Vertrauenswürdige Sites) hinzu.
5. Klicken sie auf Close (Schließen), wählen Sie Trusted Sites (Vertrauenswürdige Sites) aus und klicken
Sie dann auf Custom Level (Benutzerdefinierte Stufe).
6. Scrollen Sie zu Miscellaneous → Display Mixed Content (Verschiedenes → Gemischten Inhalt
anzeigen) und klicken Sie auf
7. Scrollen Sie auf dem Bildschirm nach unten zu User Authentication → Logon
(Benutzerauthentifizierung → Anmelden) und wählen Sie dann Automatic logon with current user
name and password (Automatische Anmeldung mit aktuellem Benutzernamen und Kennwort).
8. Klicken Sie auf OK und wählen Sie dann die Registerkarte Advanced (Erweitert).
9. Scrollen Sie zu Multimedia und wählen Sie Play animations in webpages (Auf Webseiten
Animationen abspielen) aus.
10. Scrollen Sie zu Security (Sicherheit), markieren Sie Enable Integrated Windows Authentication
(Integrierte Windows-Authentifizierung ) und klicken Sie dann auf OK.
Enable (Aktivieren).
Konfiguration von Mozilla Firefox-Browser-Einstellungen
ANMERKUNG: Um die Mozilla Firefox-Browser-Einstellungen in den neuesten Versionen von Firefox
zu ändern, muss der Schutz deaktiviert werden. Klicken Sie mit der rechten Maustaste auf die
Schaltfläche „Site Identify“ (Site identifizieren) (auf der linken Seite der URL), klicken Sie auf Options
(Optionen) und dann auf Disable protection for now (Schutz vorübergehend deaktivieren).
So ändern Sie die Mozilla Firefox-Browser-Einstellungen:
1. Geben Sie in die Firefox-Adresszeile about:config ein und klicken Sie dann, wenn aufgefordert, auf
I’ll be careful, I promise (Ich verspreche, ich werde vorsichtig sein).
2. Suchen Sie nach dem Begriff ntlm.
Die Suche sollte mindestens drei Ergebnisse aufzeigen.
3. Doppelklicken Sie auf network.automatic-ntlm-auth.trusted-uris und geben Sie die folgende
Einstellung entsprechend Ihrer Maschine ein:
24

• Geben Sie für lokale Maschinen den Hostnamen ein.
• Geben Sie für Remote-Maschinen den Hostnamen oder die IP-Adresse des Gerätessystems, das
den AppAssure-Kern hostet, durch ein Komma getrennt ein, zum Beispiel IP-Adresse, Hostname.
4. Starten Sie Firefox neu.
Ablaufplan für die Konfiguration des Kerns
Die Konfiguration umfasst verschiedene Aufgaben, wie etwa das Erstellen und Konfigurieren des
Repositorys für die Speicherung von Sicherungs-Snapshots, das Definieren von
Verschlüsselungsschlüsseln für die Sicherung geschützter Daten sowie das Einrichten von Warnungen
und Benachrichtigungen. Sobald Sie die Konfiguration des Kerns abgeschlossen haben, können Sie
Agenten schützen und Wiederherstellungen durchführen.
Für die Konfiguration des Kerns müssen Sie bestimmte Konzepte verstehen und zuerst die folgenden
Vorgänge durchführen:
• Erstellen eines Repositorys
• Konfigurieren von Verschlüsselungsschlüsseln
• Konfigurieren von Ereignisbenachrichtigungen
• Konfigurieren von Aufbewahrungsrichtlinien
• Konfigurieren der SQL-Anfügbarkeit
ANMERKUNG: Wenn Sie ein Gerät verwenden, sollten Sie die Konfiguration des Kerns über die
Registerkarte Appliance (Gerät) durchführen. Weitere Informationen zur Konfiguration des Kerns
nach der anfänglichen Installation finden Sie im Dell DL4000 Appliance Deployment Guide
(Bereitstellungshandbuch für das Dell DL4000-Gerät) unter dell.com/support/home.
Lizenzverwaltung
Sie können Ihre Lizenzen direkt über die Core Console verwalten. Über diese Konsole können Sie den
Lizenzschlüssel ändern und den Lizenzserver kontaktieren. Sie können auch über die Seite „Lizenzierung“
der Core Console auf das Lizenzportal zugreifen.
Die Lizenzierungsseite enthält folgende Informationen:
• Lizenztyp
• Lizenzstatus
• Lizenzbeschränkungen
• Anzahl von geschützten Maschinen
• Status der letzten Antwort vom Lizenzserver
• Zeitpunkt des letzten Kontaktes mit dem Lizenzserver
• Nächster geplanter Kontaktversuch mit dem Lizenzserver
Ändern eines Lizenzschlüssels
So ändern Sie einen Lizenzschlüssel:
1. Navigieren Sie zur Core Console.
2. Wählen Sie Konfiguration → Lizenzierung aus.
Die Seite Lizenzierung wird angezeigt.
25

3. Klicken Sie im Abschnitt Lizenzdetails auf Lizenz ändern.
Das Dialogfeld Lizenz ändern wird angezeigt.
4. Geben Sie im Dialogfeld Lizenz ändern den neuen Lizenzschlüssel ein, und klicken Sie auf
Fortfahren.
Kontaktieren des Lizenzportalservers
Die Core Console kontaktiert regelmäßig den Portalserver, um bezüglich aller Änderungen, die im
Lizenzportal durchgeführt wurden, auf dem neuesten Stand zu sein. In der Regel erfolgt die
Kommunikation mit dem Portalserver automatisch in bestimmten Intervallen. Sie können die
Kommunikation jedoch auch bei Bedarf initiieren.
So kontaktieren Sie den Portalserver:
1. Navigieren Sie zur Core Console.
2. Klicken Sie auf Konfiguration → Lizenzierung.
3. Klicken Sie in der Option Lizenzserver auf etzt kontaktieren.
Manuelles Ändern der AppAssure-Sprache
AppAssure ermöglicht Ihnen das Ändern der Sprache, die Sie bei der Ausführung des AppAssureGerätekonfigurationsassistenten ausgewählt haben, in eine andere unterstützte Sprache.
So ändern Sie die vorhandene AppAssure-Sprache in die gewünschte Sprache:
1. Starten Sie den Registrierungseditor mit dem Befehl regdit.
2. Navigieren Sie zu HKEY_LOCAL_MACHINE → SOFTWARE → AppRecovery → Core (Kern) →
Localization (Lokalisierung).
3. Öffnen Sie Lcid.
4. Wählen Sie decimal (dezimal) aus.
5. Geben Sie den gewünschten Sprachwert in das Datenfeld Value (Wert) ein. Folgende Sprachwerte
werden unterstützt:
a. Englisch: 1033
b. Portugiesisch (Brasilien): 1046
c. Spanisch: 1034
d. Französisch: 1036
e. Deutsch: 1031
f. Vereinfachtes Chinesisch: 2052
g. Japanisch: 1041
h. Koreanisch: 1042
6. Klicken Sie mit der rechten Maustaste, und starten Sie die Dienste in der angegebenen Reihenfolge
neu:
a. Windows-Verwaltungsinstrumentierung
b. SRM-Webdienst
c. App Assure-Kern
7. Löschen Sie den Browser-Cache.
8. Schließen Sie den Browser, und starten Sie die Core Console über das Desktop-Symbol neu.
26

Ändern der BS-Sprache während der Installation
Bei einer laufenden Windows-Installation können Sie über die Systemsteuerung Sprachpakete auswählen
und zusätzliche internationale Einstellungen konfigurieren.
So ändern Sie die BS-Sprache:
ANMERKUNG: Es wird empfohlen, die gleiche Sprache für das Betriebssystem und AppAssure
auszuwählen, da anderenfalls bestimmte Meldungen gemischt in zwei unterschiedlichen Sprachen
angezeigt werden.
ANMERKUNG: Es wird empfohlen, zuerst die Sprache für das Betriebssystem und dann die für
AppAssure zu ändern.
1. Geben Sie auf der Seite Start den Eintrag language (Sprache) ein, und stellen Sie sicher, dass der
Suchumfang auf „Settings“ (Einstellungen) gesetzt ist.
2. Wählen Sie im Bereich Results (Ergebnisse) den Wert Language (Sprache) aus.
3. Wählen Sie im Bereich Change your language preferences (Spracheinstellungen ändern) die Option
Add a language (Sprache hinzufügen) aus.
4. Navigieren Sie zu der Sprache, die Sie installieren möchten, oder suchen Sie nach ihr.
Wählen Sie z. B. „Catalan“ (Katalanisch) aus und dann „Add“ (Hinzufügen). Katalanisch wird daraufhin
als eine Ihrer Sprachen angezeigt.
5. Wählen Sie im Bereich „Change your language preferences“ (Spracheinstellungen andern) die Option
Options (Optionen) neben der Sprache aus, die Sie hinzugefügt haben.
6. Wenn ein Sprachpaket für Ihre Sprache verfügbar ist, wählen Sie Download and install
language pack (Sprachpaket herunterladen und installieren) aus.
7. Wenn das Sprachpaket installiert ist, wird die Sprache als verfügbare Anzeigesprache für Windows
angezeigt.
8. Um diese Sprache als Anzeigesprache festzulegen, verschieben Sie sie an die erste Stelle der
Sprachenliste.
9. Melden Sie sich bei Windows ab und wieder an, damit die Änderung wirksam wird.
Verwalten von Kerneinstellungen
Mit den Kerneinstellungen werden verschiedene Einstellungen für Konfiguration und Leistung definiert.
Die meisten Einstellungen werden für die optimale Nutzung konfiguriert. Sie können die folgenden
Einstellungen aber auch nach Bedarf ändern:
• Allgemein
• Nightly Jobs (Nächtliche Aufgaben)
• Transfer Queue (Übertragungswarteschlange)
• Client Timeout Settings (Einstellungen für Client-Zeitüberschreitung)
• Deduplication Cache Configuration (Konfiguration des Deduplizierungscache)
• Database Connection Settings (Einstellungen für Datenbankverbindung)
Ändern des Anzeigenamens des Kerns
ANMERKUNG: Es wird empfohlen, dass Sie gleich bei der anfänglichen Konfiguration des Geräts
einen permanenten Anzeigenamen auswählen. Wenn Sie ihn zu einem späteren Zeitpunkt ändern,
müssen Sie mehrere Schritte manuell ausführen, um sicherzustellen, dass der neue Host-Name in
Kraft tritt und das System richtig funktioniert. Weitere Informationen siehe Changing The Host
Name Manually (Manuelles Ändern des Host-Namens).
27

So ändern Sie den Anzeigenamen des Kerns
1. Navigieren Sie zur Core Console.
2. Klicken Sie auf Konfiguration → Einstellungen.
3. Klicken Sie im Bereich Allgemein auf Ändern.
Das Dialogfeld Allgemeine Einstellungen wird angezeigt.
4. Geben Sie im Textfeld Display Name (Anzeigename) einen neuen Anzeigenamen für den Kern ein.
Dies ist der Name, der in der Core Console angezeigt wird. Sie können bis zu 64 Zeichen eingeben.
5. Geben Sie in das Textfeld Web Server-Port eine Portnummer für den Web Server ein. Die
Standardeinstellung ist 8006.
6. Geben Sie in das Feld Service-Port eine Portnummer für den Dienst ein. Die Standardeinstellung ist
8006.
7. Klicken Sie auf OK.
Anpassen der Uhrzeit für eine nächtliche Aufgabe
So passen Sie die Zeit für eine nächtliche Aufgabe an:
1. Navigieren Sie zur Core Console.
2. Klicken Sie auf Konfiguration → Einstellungen.
3. Klicken Sie im Bereich Nightly Jobs (Nächtliche Aufgaben) auf Change (Ändern).
Das Dialogfeld Nächtliche Aufgaben wird angezeigt.
4. Geben Sie in das Textfeld Nightly Jobs Time (Uhrzeit für nächtliche Jobs) eine neue Uhrzeit zur
Ausführung der nächtlichen Jobs ein.
5. Klicken Sie auf OK.
Ändern der Einstellungen für die Übertragungswarteschlange
Die Einstellungen für die Übertragungswarteschlange sind Einstellungen der Kernebene, die die maximale
Anzahl gleichzeitiger Übertragungen und die maximale Anzahl der Wiederholungen für die Übertragung
der Daten einrichtet.
So ändern Sie die Einstellungen für die Übertragungswarteschlange:
1. Navigieren Sie zur Core Console.
2. Klicken Sie auf Konfiguration → Einstellungen.
3. Klicken Sie im Bereich Übertragungswarteschlange auf Ändern.
Das Dialogfeld Übertragungswarteschlange wird angezeigt.
4. Geben Sie im Textfeld Maximum Concurrent Transfers (Maximale Anzahl gleichzeitiger
Übertragungen) einen Wert ein, um die Anzahl gleichzeitiger Übertragungen zu aktualisieren.
Stellen Sie eine Nummer von 1 bis 60 ein. Je kleiner die Zahl, desto geringer ist die Last auf dem
Netzwerk und auf anderen System-Ressourcen. Wenn sich die verarbeitete Kapazität erhöht, nimmt
auch die Belastung des Systems zu.
5. Geben Sie im Textfeld Maximum Retries (Maximale Anzahl erneuter Versuche) einen Wert ein, um
die maximale Anzahl an Wiederholungsversuchen zu aktualisieren.
6. Klicken Sie auf OK.
28

Anpassen der Client-Zeitüberschreitungseinstellungen
So stellen Sie die Client-Zeitüberschreitungseinstellungen ein:
1. Navigieren Sie zur Core Console.
2. Klicken Sie auf Konfiguration → Einstellungen.
3. Klicken Sie im Bereich Client Timeout Settings Configuration (Konfiguration der Client-
Zeitüberschreitungseinstellungen) auf
Das Dialogfeld Client-Zeitüberschreitungseinstellungen wird angezeigt.
4. Geben Sie im Textfeld Connection Timeout (Verbindungszeitüberschreitung) die Anzahl an Minuten
und Sekunden ein, die vor einem Verbindungstimeout verstreichen müssen.
5. Geben Sie in das Textfeld Verbindungszeitüberschreitung Benutzeroberfläche die Anzahl der
Minuten und Sekunden ein, die vor einer Verbindungszeitüberschreitung auf der Benutzeroberfläche
verstreichen müssen.
6. Geben Sie im Textfeld Lese-/Schreibzeitüberschreitung die Anzahl an Minuten und Sekunden ein,
die vor einem Timeout während eines Lese-/Schreibereignisses verstreichen müssen.
7. Geben Sie in das Textfeld Lese-/Schreibzeitüberschreitung Benutzeroberfläche die Anzahl der
Minuten und Sekunden ein, die vor einer Zeitüberschreitung während eines Lese-/Schreibvorgangs
auf der Benutzeroberfläche verstreichen müssen.
8. Klicken Sie auf OK.
Change (Ändern).
Konfigurieren von Deduplizierungs-Cache-Einstellungen
So konfigurieren Sie Deduplizierungs-Cache-Einstellungen:
1. Navigieren Sie zur Core Console.
2. Klicken Sie auf Konfiguration → Einstellungen.
3. Klicken Sie im Bereich Deduplication Cache Configuration (Konfiguration der Deduplizierungs-
Cache) auf Change (Ändern).
Das Dialogfeld Konfiguration des Deduplizierungs-Cache wird angezeigt.
4. Geben Sie im Feld Primary Cache Location (Primärer Cache-Speicherort) einen aktualisierten Wert
ein, um den primären Cache-Speicherort zu ändern.
5. Geben Sie im Feld Secondary Cache Location (Sekundärer Cache-Speicherort) einen aktualisierten
Wert ein, um den sekundären Cache-Speicherort zu ändern.
6. Geben Sie im Feld Metadata Cache Location (Metadaten-Cache-Speicherort) einen aktualisierten
Wert ein, um den Metadaten-Cache-Speicherort zu ändern.
7. Geben Sie in das Textfeld Größe des Deduplizierungs-Cache einen Wert ein, der dem Speicherplatz
entspricht, den Sie für den Deduplizierungs-Cache zuweisen möchten.
Wählen Sie als Maßeinheit für den Wert im Textfeld „Größe des Deduplizierungs-Cache“ im DropDown-Menü die Option GB (Gigabyte) oder TB (Terabyte) aus.
8. Klicken Sie auf OK.
ANMERKUNG: Sie müssen den Kern-Service neu starten, damit die Änderungen wirksam
werden.
29

Ändern von Moduleinstellungen
So ändern Sie die Moduleinstellungen:
1. Navigieren Sie zur Core Console.
2. Klicken Sie auf Konfiguration → Einstellungen.
3. Klicken Sie im Bereich Replay-Modulkonfiguration auf Ändern.
Das Dialogfeld Replay-Modulkonfiguration wird angezeigt.
4. Geben Sie die nachfolgend beschriebenen Konfigurationsinformationen ein:
Textfeld Beschreibung
IP-Adresse
Preferable Port
(Bevorzugter Port)
Verwendeter Port Bezeichnet den Port, der für die Replay-Modulkonfiguration verwendet wird.
Automatische
Portzuweisung
zulassen
Admin Group
(Admin-Gruppe)
Minimum Async
I/O Length
(Minimale AsyncE/A-Länge)
Receive Buffer
Size (Größe
Empfangspuffersp
eicher)
• Um die bevorzugte IP-Adresse von Ihrem TCP/IP zu verwenden, klicken Sie
auf Automatisch bestimmt.
• Um eine IP-Adresse manuell einzugeben, klicken Sie auf Spezifische
Adresse verwenden.
Geben Sie eine Portnummer ein, oder akzeptieren Sie die
Standardeinstellungen. Der Standardport ist 8007. Der Port wird dazu
verwendet, den Kommunikationskanal für das Modul festzulegen.
Klicken Sie hier, um den TCP-Port automatisch zuzuweisen.
Geben Sie einen neuen Namen für die Verwaltungsgruppe ein. Der
Standardname ist BUILTIN\Administrators.
Geben Sie einen Wert ein oder wählen Sie die Standardeinstellung. Beschreibt
die minimale asynchrone Eingabe-/Ausgabelänge. Die Standardeinstellung ist
65536.
Geben Sie eine Puffergröße für eingehende Daten ein oder akzeptieren Sie die
Standardeinstellung. Die Standardeinstellung ist 8192.
Send Buffer Size
(Größe
Sendepufferspeic
her)
Read Timeout
(Zeitüberschreitun
g beim Lesen)
Write Timeout
(Zeitüberschreitun
g beim Schreiben)
30
Geben Sie eine Puffergröße für ausgehende Daten ein oder akzeptieren Sie die
Standardeinstellung. Die Standardeinstellung ist 8192.
Geben Sie einen Wert für die Zeitüberschreitung beim Lesen ein oder wählen
Sie die Standardeinstellung aus. Die Standardeinstellung ist 00:00:30.
Geben Sie einen Wert für die Zeitüberschreitung beim Schreiben ein oder
wählen Sie die Standardeinstellung aus. Die Standardeinstellung ist 00:00:30.
 Loading...
Loading...