

Page 1

ALGEBRA FX 2.0 PLUS
FX 1.0 PLUS
Bedienungsanleitung, Teil 2
G
http://world.casio.com/edu_e/
Page 2

CASIO ELECTRONICS CO., LTD.
Unit 6, 1000 North Circular Road,
London NW2 7JD, U.K.
Wichtig!
Bitte bewahren Sie Ihre Anleitung und alle Informationen
griffbereit für spätere Nachschlagzwecke auf.
Page 3

•••••••••••••••••••
•••••••••••••••••••
•••••••••••••••••••
•••••••••••••••••••
•••••••••••••••••••
• ••••••••••••••••••
ALGEBRA FX 2.0 PLUS
FX 1.0 PLUS
(Weitere Menüs und Funktionen)
• ••••••••••••••••••
•••••••••••••••••••
•••••••••••••••••••
•••••••••••••••••••
•••••••••••••••••••
• ••••••••••••••••••
•••••••••••••••••••
• ••••••••••••••••••
•••••••••••••••••••
•••••••••••••••••••
•••••••••••••••••••
•••••••••••••••••••
20010901
Page 4

1
Inhalt
Inhalt
Kapitel 1 Statistische Schätz-, Test- und Analyseverfahren (STAT)
1-1 Weitere Funktionen im STAT-Menü .................................................. 1-1-1
1-2 Statistische Testverfahren (TEST) .................................................... 1-2-1
1-3 Vertrauensintervalle (INTR).............................................................. 1-3-1
1-4 Wahrscheinlichkeitsverteilungen (DIST)........................................... 1-4-1
Kapitel 2 Finanzmathematik (TVM)
2-1 Vor dem Ausführen finanzmathematischer Berechnungen .............. 2-1-1
2-2 Einfache Kapitalverzinsung .............................................................. 2-2-1
2-3 Kapitalverzinsung mit Zinseszins ..................................................... 2-3-1
2-4 Geldflußberechnungen (Cash-Flow, Investitionsrechnung) ............. 2-4-1
2-5 Tigungsberechnungen (Amortisation) .............................................. 2-5-1
2-6 Zinssatz-Umrechnungen .................................................................. 2-6-1
2-7 Herstellungskosten, Verkaufspreis, Gewinnspanne ......................... 2-7-1
2-8 Berechnung von Zinstagen (Datumsberechnungen)........................ 2-8-1
2-9 Abschreibungsberechnungen (Amortisation) ................................... 2-9-1
2-10 Wertpapieranalyse (Zinsanleihen, Obligationen, ...) ...................... 2-10-1
2-11 TVM-Grafik (weitere grafische Darstellungen) ............................... 2-11-1
Kapitel 3 Differenzialgleichungen (DIFF EQ)
3-1 Zur Lösung von Aufgaben im DIFF EQ - Menü ................................ 3-1-1
3-2 Differenzialgleichungen 1. Ordnung ................................................. 3-2-1
3-3 Lineare Differenzialgleichungen 2. Ordnung .................................... 3-3-1
3-4 Differenzialgleichungen N-ter Ordnung ............................................ 3-4-1
3-5 Systeme von Differenzialgleichungen 1. Ordnung ........................... 3-5-1
Kapitel 4 EA-100 Controller (E-CON)
4-1 Überblick zum E-CON-Menü ............................................................ 4-1-1
4-2 Einrichten des EA-100 (SET UP) ..................................................... 4-2-1
4-3 SET UP - Speicher (Konfigurations-Speicher) ................................. 4-3-1
4-4 SET UP - Programm-File (Konfigurations-Programm) ..................... 4-4-1
4-5 Durchführung einer Datenerfassung ................................................ 4-5-1
Anhang
α-1 Allgemeiner Index ................................................................................α-1
20010901
Page 5

Kapitel
Statistische Schätz-, Testund Analyseverfahren (STAT)
In der Bedienungsanleitung zum ALGEBRA FX 2.0 PLUS /
FX 1.0 PLUS wurden vorrangig die beschreibende Statistik,
d.h. die elementare Datenauswertung, statistische Grafiken und
verschiedene Regressionsmodelle, behandelt und Wahrscheinlichkeiten mithilfe der Normalverteilung berechnet. In diesem
Kapitel werden ergänzend folgende Fragestellungen betrachtet:
1
•Mittlerer quadratischer Fehler in Regressionsmodellen
•Parametertests zur Überprüfung statistischer Hypothesen
•
Varianz- und Korrelationsanalyse, Tests in Kontingenztafeln
•Vertrauensintervalle für unbekannte Parameter
•Diskrete und stetige Wahrscheinlichkeitsverteilungen
1-1 Weitere Funktionen im STAT-Menü
1-2 Statistische Testverfahren (TEST)
1-3 Vertrauensintervalle (INTR)
1-4 Wahrscheinlichkeitsverteilungen (DIST)
20010901
Page 6
MSE =
Σ
1
n – 2
i=1
n
(yi – (axi+ b))
2
MSE =
Σ
1
n – 3
i=1
n
(yi – (ax
i
+ bxi+ c))
2
2
MSE =
Σ
1
n – 4
i=1
n
(yi – (ax
i
3
+ bx
i
+ cx
i
+d ))
2
2
MSE =
Σ
1
n – 5
i=1
n
(yi – (ax
i
4
+ bx
i3
+ cx
i
+ dx
i
+ e))
2
2
Weitere Funktionen im STAT-Menü
1-1-1
1-1 Weitere Funktionen im STAT-Menü
uu
u Funktionstasten im STAT-Eingangsbildschirm
uu
Nachfolgend sind weitere Funktionstasten zum Öffnen entsprechender Untermenüs aufgeführt,
die Sie im Eingangsbildschirm (Listeneditor) des STAT-Menüs vorfinden.
Sie können eine der folgenden Funktionstasten drücken, die einem neu hinzugekommenen
Untermenü zu weiterführenden statistischen Fragestellungen entspricht.
• 3(TEST) ... Statistische Testverfahren (ab Seite 1-2-1 beschrieben)
• 4(INTR) ... Vertrauensintervalle (ab Seite 1-3-1 beschrieben)
• 5(DIST) ... Wahrscheinlichkeitsverteilungen (ab Seite 1-4-1 beschrieben)
Die Funktionen SORT und JUMP finden Sie im TOOL-Untermenü (6(g)1(TOOL)).
uu
u Berechnung des Bestimmtheitsmaßes (r2) und der Reststreuung (MSE)
uu
Sie können das CALC-Untermenü im STAT-Menü verwenden, um zusätzlich zu den
Regressionsanalysen das Bestimmtheitsmaß (r2) in den linearen und quasilinearen
Regressionsmodellen (z.B. auch für die quadratische, kubische oder quartische Regression)
zu berechnen. Für diese Regressionsmodelle werden auch die Reststreuungen (MSE, mittlere
quadratische Fehler) auf Grundlage einer entsprechenden Streuungszerlegung gemäß den
folgenden Formeln berechnet.
• Lineare Regression ..............
•Quadratische Regression .....
•Kubische Regression ............
•Quartische Regression .........
20010901
Page 7
MSE =
Σ
1
n – 2
i=1
n
(yi – (a + b ln xi ))
2
MSE =
Σ
1
n – 2
i=1
n
(ln yi – (ln a + bxi ))
2
MSE =
Σ
1
n – 2
i=1
n
(ln yi – (ln a + b ln xi ))
2
MSE =
Σ
1
n – 2
i=1
n
(yi – (a sin (bxi + c) + d ))
2
MSE =
Σ
1
n – 2 1 + ae
-bx
i
C
i=1
n
yi –
2
Weitere Funktionen im STAT-Menü
1-1-2
• Logarithmische Regression ....
•Exponentielle Regression .......
•Potenz-Regression .................
•Sinus-Regression ...................
• Logistische Regression ...........
uu
u Berechnung eines Schätzwertes für y(x) in Regressionsgrafiken
uu
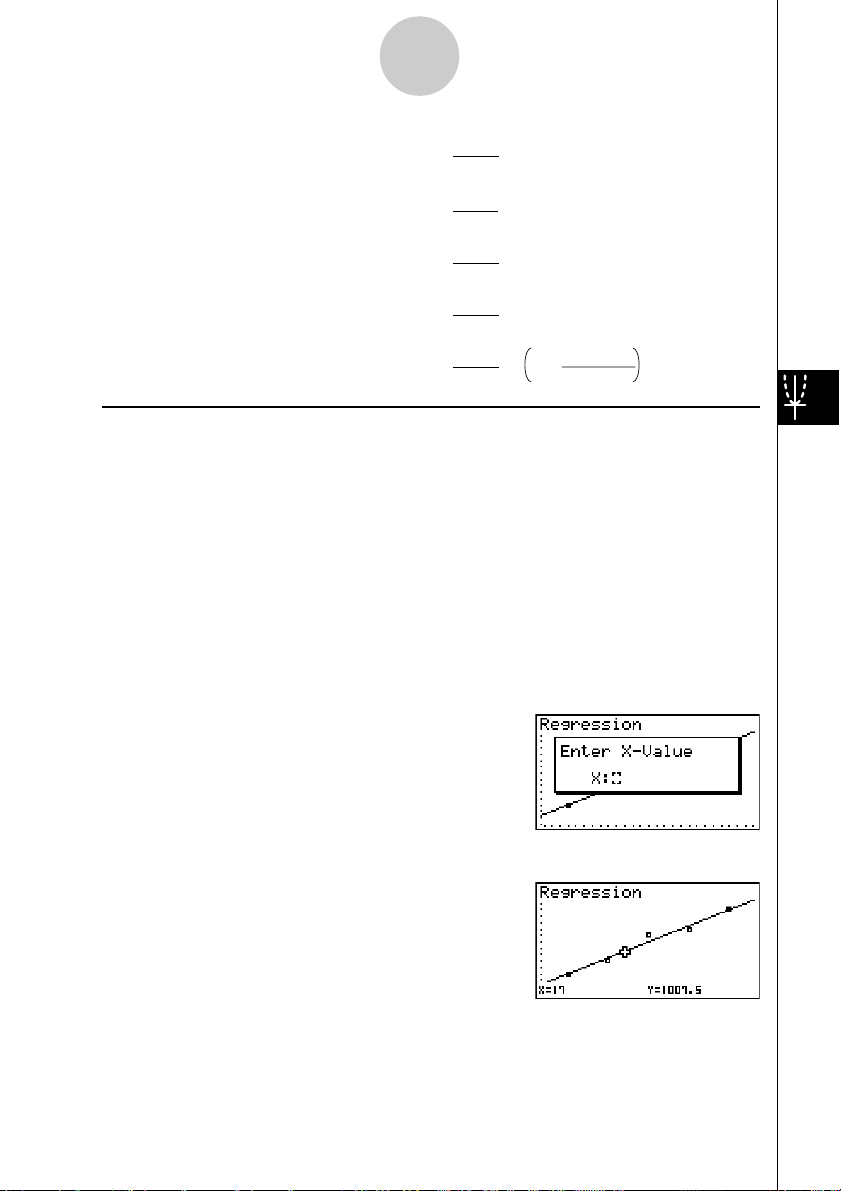
Wird im STAT-Menü eine Regressionsgrafik erzeugt, können Sie auch die Funktionstaste YCAL nutzen, die für die durchgeführte Regressionsanalyse die Berechnung des (geschätzten)
y-Wertes für einen bestimmten x-Wert mithilfe der ermittelten Regressionsgleichung ermöglicht.
Die Regressionsgrafik beinhaltet die grafische Darstellung der Regressionsfunktion auf Grundlage der zuvor geschätzten Kurvenparameter mithilfe einer zweidimensionalen Stichprobe (die
entsprechenden Datenpaare liegen in verbundenen Datenlisten vor).
Nachfolgend wird das allgemeine Vorgehen zur Verwendung der Y-CAL-Funktion beschrieben.
1. Nach dem Zeichnen einer Regressionsgrafik drücken Sie die Tasten 6(g)2(Y-CAL), um
die Y-CAL-Funktion aufzurufen. Danach drücken Sie die w-Taste.
Falls sich mehrere Grafiken im Display befinden, verwenden Sie die Cursor-Tasten f und
c, um die gewünschte Regressionskurve auszuwählen, danach drücken Sie die w-Taste.
•Es erscheint ein Dialogfenster für die Eingabe des x-Wertes.
2. Geben Sie den gewünschten x-Wert ein und drücken Sie danach die w-Taste.
•Nun erscheinen die Koordinaten für x und y in der Fußzeile des Displays, wobei der Cursor
an den entsprechenden Punkt der Regressionsgrafik verschoben wird. Im SET UP - Menü
ist dazu vorher Coord: On einzustellen!
3. Drücken Sie erneut die v-Taste oder eine Zifferntaste, um das Dialogfenster für die Eingabe
eines weiteren x-Wertes zu öffnen, falls Sie eine weitere Schätzwertberechnung für y
ausführen möchten.
20010901
Page 8

Weitere Funktionen im STAT-Menü
4. Nachdem Sie Ihre Schätzwertberechnungen beendet haben, drücken Sie die i-Taste, um
die Koordinatenanzeige und den Cursor vom Display zu löschen.
· Der Cursor erscheint nicht, wenn sich die berechneten Koordinaten nicht innerhalb des
Betrachtungsfensters (V-Window) befinden.
· Die Koordinaten erscheinen nicht, wenn [Off] in der Position [Coord] des [SETUP]-Menüs
voreingestellt ist.
· Die Y-CAL-Funktion ist auch in einer Kurvendarstellung aktiv, die durch Verwendung der
Funktionstaste [DefG] aktiviert wurde.
uu
u Regressionsformel-Kopierfunktion innerhalb der Regressionsrechnungs-
uu
1-1-3
Ergebnisanzeige
Zusätzlich zur normalen Kopierfunktion für Bilder (PICT), die Sie in der Ergebnisanzeige der
Regressionsberechnung oder nach dem Zeichnen einer statistischen Grafik (wie z.B. eines
Streudiagramms) vorfinden, besitzt das STAT-Menü auch eine COPY-Funktion für Formeln, so
dass Sie die im Ergebnis einer Regressionsberechnung erhaltene Regressionsformel auch in
den Grafik-Funktionsspeicher kopieren können. Um eine erhaltene Regressionsformel zu
kopieren, drücken Sie die Taste 6(COPY).
kk
k
Testverfahren, Vertrauensintervalle und Wahrscheinlichkeitsverteilungen
kk
Das STAT-Menü enthält Untermenüs für die Durchführung statistischer Tests und die Berechnung von Vertrauensintervallen sowie die Berechnung von Einzelwahrscheinlichkeiten oder Intervallwahrscheinlichkeiten. Sie finden die entsprechenden Erläuterungen dazu in den folgenden
Abschnitten: 1-2 Testverfahren, 1-3 Vertrauensintervalle, 1-4 Wahrscheinlichkeitsverteilungen.
uu
u Parametereinstellungen (Vorgabewerte für statistische Aufgabenstellungen)
uu
Nachfolgend sind die beiden Methoden beschrieben, die Sie für die Parametereinstellungen
(Vorgabewerte, z.B. Hypothesen für Testverfahren, Konfidenzniveau für Vertrauensintervalle)
verwenden können.
• Auswahl einer Variante
Bei dieser Methode drücken Sie im geöffneten Funktionsmenü die Funktionstaste, welche
der zu wählenden Fragestellung entspricht (Auswahl unter mehreren Möglichkeiten).
• Direkte Werteingabe von Daten oder Kennzahlen
Bei dieser Methode geben Sie den gewünschten Parameterwert (Vorgabewert) direkt ein. In
diesem Fall können Sie nicht über eine Funktionstaste Ihre Eingabe vornehmen.
· Drücken Sie die i-Taste, um zur Listeneingabeanzeige zurückzukehren. Dabei befindet
sich der Cursor an der gleichen Position wie vor dem Beginn der Parametereinstellung.
· Drücken Sie die Tasten ! i(QUIT), um an den Anfang des Listeneditors zurückzukehren.
· Drücken Sie im geöffneten Funktionsmenü in der Position “Execute” einfach die w-Taste ohne
Betätigung der Taste 1(CALC), um die Berechnung auszuführen. Um zur Anzeige der
Parametereinstellung zurückzukehren, drücken Sie einfach die i-, A-oder w-Taste.
20010901
Page 9

Weitere Funktionen im STAT-Menü
1-1-4
uu
u Gemeinsame Funktionen im STAT-Menü
uu
• Das Symbol “■” erscheint während der Ausführung einer Berechnung und während des
Zeichnens einer Grafik in der rechten oberen Ecke der Anzeige. Sie können innerhalb dieser
Zeitspanne die A-Taste drücken, um die Berechnungs- oder Zeichnungsoperation
abzubrechen (AC Break).
• Sie können die i- oder w-Taste drücken, während ein Berechnungsergebnis oder eine
Grafik im Display angezeigt wird, um in die Anzeige für die Parametereinstellung zurückzukehren. Wenn Sie die Tasten ! i(QUIT) drücken, können Sie an den Anfang des Listeneditors (Listeneingabeanzeige) zurückkehren.
• Sie können die A-Taste drücken, während ein Berechnungsergebnis im Display angezeigt
wird, um in die Anzeige für die Parametereinstellung zurückzukehren.
• Sie können die Tasten u 5(G↔T) nach dem Zeichnen einer Grafik drücken, um zur
Anzeige für die Parametereinstellung (G↔T Funktion) umzuschalten. Falls Sie erneut die
Tasten u 5(G↔T) drücken, können Sie zur Grafikanzeige zurückkehren.
• Die G↔T Funktion ist deaktiviert, wenn Sie in der Anzeige für die Parametereinstellung eine
Veränderung vornehmen oder wenn Sie eine u 3(SET UP) oder ! K(V-Window)
Operation ausführen.
• Sie können die Speicher- oder Rückruf-Funktion des PICT-Menüs nach dem Zeichnen einer
Grafik ausführen, indem hier ein entsprechendes Untermenü geöffnet wird.
• Die ZOOM-Funktion und die SKETCH-Funktion sind im STAT-Menü deaktiviert.
Die TRACE-Funktion ist deaktiviert, jedoch nicht im Grafikdisplay einer ZweiwegVarianzanalyse (ANOVA). Diese Grafikanzeige kann jedoch nicht gescrollt werden.
• Nach dem Zeichnen einer Grafik, können Sie die Ergebnisspeicherfunktion verwenden, um
die Berechnungsergebnisse in einer bestimmten Liste zu speichern. Grundsätzlich werden
alle Positionen (Zahlenwerte) hintereinander abgespeichert, so wie sie angezeigt werden,
ausgenommen die erste Zeile mit dem Titel (und ggf. die Alternativhypothese).
• Mit jeder Ausführung der Ergebnisspeicherung (Save Result), werden die in der Liste
vorhandenen Daten durch die neuen Ergebnisse ersetzt.
20010901
Page 10

Statistische Testverfahren (TEST)
1-2-1
1-2 Statistische Testverfahren (TEST)
Im Untermenü TEST können Sie zwischen 10 verschiedenen Testverfahren auswählen.
Das Z-Test-Menü bietet vier oft benutzte Parametertests an, die auf einer(näherungsweise)
N(0,1)-verteilten Testgröße ( Z ) zur Beurteilung der jeweiligen Nullhypothese beruhen. Diese
ermöglichen (mit einer vorher festzulegenden Irrtumswahrscheinlichkeit, Signifikanzniveau) die
Beurteilung, ob z. B. eine Stichprobe den vermuteten Mittelwert einer Grundgesamtheit genau
repräsentiert oder nicht, wobei die Streuung (oder Standardabweichung) der Grundgesamtheit
(zum Beispiel die Streuung für ein bestimmtes statistisches Merkmal innerhalb der gesamten
Bevölkerung eines Landes) von früheren Tests her bekannt sein muß. Der Z-Test wird z.B. in
der Marktforschung oder zur Auswertung von Meinungsumfragen verwendet, die immer wieder
durchgeführt werden.
Der 1-Stichproben Z-Test (1-Sample Z-Test) prüft für eine (normalverteilte) Grundgesamtheit
eine Mittelwerthypothese, wenn die Grundgesamtheits-Standardabweichung bekannt ist.
Der 2-Stichproben Z-Test (2-Sample Z-Test) prüft eine Gleichheitshypothese für zwei Mittelwerte
zweier (normalverteilter) Grundgesamtheiten mittels zweier unabhängiger Stichproben, wenn
beide Grundgesamtheits-Standardabweichungen bekannt sind.
Der 1-Prop Z-Test prüft eine Hypothese über einen unbekannten Anteilswert in einer dichotomen
Grundgesamtheit auf Grundlage der Trefferquote k/n in n Versuchen.
Der 2-Prop Z-Test prüft eine Gleichheitshypothese für zwei Anteilswerte zweier dichotomer
Grundgesamtheiten auf Grundlage der jeweiligen empirischen Trefferquoten in den betrachteten
Grundgesamtheiten.
Der t-Test bietet drei oft benutzte Testverfahren und prüft z.B. die entsprechenden Mittelwert-
Hypothesen, wenn die Grundgesamtheits-Standardabweichungen unbekannt sind. Die Testgröße ist (näherungsweise) t-verteilt. Die der vermuteten (und im Test vorausgesetzten) Hypothese (
Nullhypothese
Der t-Test wird oftmals zur Untersuchung einer Alternativhypothese verwendet. Eine Ablehnung
der Nullhypothese durch das Testverfahren spricht dann für die Alternativhypothese. Die Testentscheidung hängt dabei vom vorzugebenden Signifikanzniveau (Irrtumswahrscheinlichkeit) ab.
Der einfache t-Test (1-Sample t-Test) prüft für eine (normalverteilte) Grundgesamtheit eine
Mittelwerthypothese, wenn die Grundgesamtheits-Standardabweichung unbekannt ist.
Der doppelte t-Test (2-Sample t-Test) prüft eine Gleichheitshypothese für zwei Mittelwerte
zweier (normalverteilter) Grundgesamtheiten mittels zweier unabhängiger Stichproben, wenn
beide Grundgesamtheits-Standardabweichungen unbekannt sind.
Der t-Test zur linearen Regression (LinearReg t-Test) untersucht die Stärke des linearen
Zusammenhanges zweier Merkmale X und Y mithilfe verbundener Datenlisten (Datenpaare)
und beurteilt gleichzeitig zwei Hypothesen: Nullanstieg im linearen Regressionsmodell bzw.
Unkorreliertheit zwischen X und Y (Korrelationsanalyse).
2
Der
χ
-Test untersucht Hypothesen (Unabhängigkeits- oder Homogenitätshypothesen in Kontingenztafeln) auf Grundlage von zweidimensonalen Häufigkeitstafeln (Matrix der beobachteten
Häufigkeiten). Die Testgröße ist (näherungsweise)
für zwei kategoriale Variablen (z.B. Ja-Nein-Antworten auswerten) und beurteilt die
Unabhängigkeit dieser Variablen. Er könnte z.B. verwendet werden, um anhand der Befragung
von Kraftfahrern den Zusammenhang zwischen dem Verursachen von Verkehrsunfällen
(Merkmal X) und dem Beherrschen der Verkehrsregeln (Merkmal Y) zu untersuchen.
Der 2-Stichproben F-Test (2-Sample F-Test) prüft eine Hypothese zur Streuungsgleichheit
auf Grundlage von Stichproben zweier (normalverteilter) Grundgesamtheiten mithilfe einer F-
verteilten Testgröße. Er könnte z.B. verwendet werden, um die krebserregenden Effekte von
) entgegengesetzte Hypothese wird als
2
χ
-verteilt. Er untersucht z.B. Vierfeldertafeln
20010901
Alternativhypothese
bezeichnet.
Page 11

Statistische Testverfahren (TEST)
1-2-2
mehreren vermuteten Faktoren zu untersuchen, wie z.B. den Konsum von Tabak, Alkohol, den
Vitaminmangel, hohen Kaffeekonsum, Untätigkeit, schlechte Lebensgewohnheiten usw.
Die Varianzanalyse (ANOVA) prüft z.B. die Hypothese zur Mittelwertgleichheit mehrerer (nor-
malverteilter) Grundgesamtheiten auf Grundlage entsprechender Stichproben mithilfe einer
Streuungszerlegung und einer F-verteilten Prüfgröße. Dieser Test kann z.B. verwendet werden,
um zu untersuchen, ob die Kombination verschiedener Werkstoffe oder Herstellungsverfahren
eine Auswirkung auf die Qualität und die Lebensdauer eines Endproduktes hat.
Die Einweg-Varianzanalyse (One-Way ANOVA) wird verwendet, wenn nur ein unabhängiger
Einflußfaktor A in verschiedenen Abstufungen auf die (abhängige) Variable Y wirkt.
Die Zweiweg-Varianzanalyse (Two-Way ANOVA) wird verwendet, wenn zwei unabhängige
Einflußfaktoren A und B in bestimmten Abstufungen auf ein Meßergebnis Y wirken.
Auf den folgenden Seiten werden die oben genannten statistischen Testverfahren und deren
Ergebnisdarstellungen genauer erläutert. Weitere Einzelheiten dazu können in speziellen StatistikLehrbüchern nachgelesen werden.
In der Eingangsanzeige des STAT-Menüs drücken Sie die Taste 3(TEST), um das TestUntermenü zu öffnen, das die folgenden Positionen enthält.
• 3(TEST)b(Z) ... Z-Tests (vier Testvarianten, ab Seite 1-2-2)
c(T) ... t-Tests (drei Testvarianten, ab Seite 1-2-10)
d(χ2) ... χ2-Tests (ab Seite 1-2-18)
e(F) ... 2-Stichproben F-Test (ab Seite 1-2-20)
f(ANOVA) ... Varianzanalysen (ab Seite 1-2-22)
kk
k Z-Tests (Tests mit einer N(0,1)-verteilten Testgröße)
kk
uu
u Gemeinsame Funktionen der Z-Tests
uu
Sie können folgende Grafikanalysefunktion nach dem Zeichnen einer Test-Grafik verwenden.
• 1(Z) ... Zeigt den berechneten Wert der (N(0,1)-verteilten) Z-Testgröße an.
Drücken Sie die Taste 1(Z), um die berechnete Z-Testgröße z in der Fußzeile des Displays
anzuzeigen, wobei der Cursor an der entsprechenden Position der Grafik angezeigt wird (sofern
diese Stelle nicht außerhalb des Betrachtungsfensters liegt).
Im Fall eines zweiseitigen Tests werden zwei Punkte -z und z angezeigt. Verwenden Sie die
d- und e-Tasten, um den Cursor hin und her zu verschieben.
Drücken Sie die i-Taste, um die Anzeige der Z-Testgröße zu löschen.
• 2(P) ... Zeigt den zur berechneten Testgröße gehörenden p-Wert an. Es handelt
sich hierbei um die sogenannte kritische Irrtumswahrscheinlichkeit, die
der schraffierten Fläche unter der (Gaußschen) Glockenkurve entspricht.
Drücken Sie die Taste 2(P) , um den p-Wert in der Fußzeile des Displays anzuzeigen, ohne
dass der Cursor erscheint.
Drücken Sie die i-Taste, um die Anzeige des p-Wertes zu löschen.
#
Folgende Betrachtungsfenstereinstellungen
werden für das Zeichnen der Testgrafik
(Glockenkurve) verwendet.
Xmin –3,2, Xmax = 3,2, Xscale = 1,
Ymin = –0,1, Ymax = 0,45, Yscale = 0,1
# Durch die Ausführung einer Testfunktion werden
die
z- und p-Werte automatisch in den symboli-
schen Variablen Z bzw. P gespeichert.
20010901
Page 12

Statistische Testverfahren (TEST)
1-2-3
uu
u1-Stichproben Z-Test (1-Sample Z-Test)
uu
Der 1-Proben Z-Test wird verwendet, um die Mittelwerthypothese Ho: µ=
µ
o zu prüfen, wenn
die Standardabweichung σ der (normalverteilten) Grundgesamtheit bekannt ist.
Testgröße:
Z =
o –
σ
n
µ
0
o
: empirischer Stichprobenmittelwert
µ
o : hypothetischer Mittelwert
σ
: Grundgesamtheits-Standardabweichung
n : Stichprobenumfang
Führen Sie die folgende Tastenbetätigung im STAT-Eingangsmenü (Listeneditor) aus.
3(TEST)
b(Z)
b(1-Smpl)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der Stichprobendaten [List] oder
empirische Kennzahlen [Variable])
µ
.................................. Art der Alternativhypothese (“G
kritischen Bereich fest, “<
Bereich links fest, “>
µ
0” legt den einseitigen kritischen Bereich
µ
µ
0” legt den zweiseitigen
0” legt den einseitigen kritischen
rechts fest.)
µ
0 ................................ hypothetischer Mittelwert (Nullhypothese Ho:
σ
.................................. bekannte Grundgesamtheits-Standardabweichung (σ > 0)
µ=µ
o)
List .............................. Liste der Stichprobendaten (List 1 bis 20)
Freq ............................. einfache Häufigkeiten [1] oder Häufigkeitsliste (Liste 1 bis 20)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus oder zeichnet eine Test-Grafik
(N(0,1)-Glockenkurve)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Kennzahlenvorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
o .................................. empirischer Stichproben-Mittelwert
n .................................. Stichprobenumfang (positive ganze Zahl)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken danach eine der nachfolgend dargestellten Funktionstasten, um die
Berechnung auszuführen oder eine Test-Grafik (N(0,1)-Glockenkurve) zu zeichnen.
20010901
Page 13
Statistische Testverfahren (TEST)
• 1(CALC) ... Führt die Berechnung aus.
• 6(DRAW) ... Zeichnet die Test-Grafik zum Testergebnis.
1-2-4
u u u u u
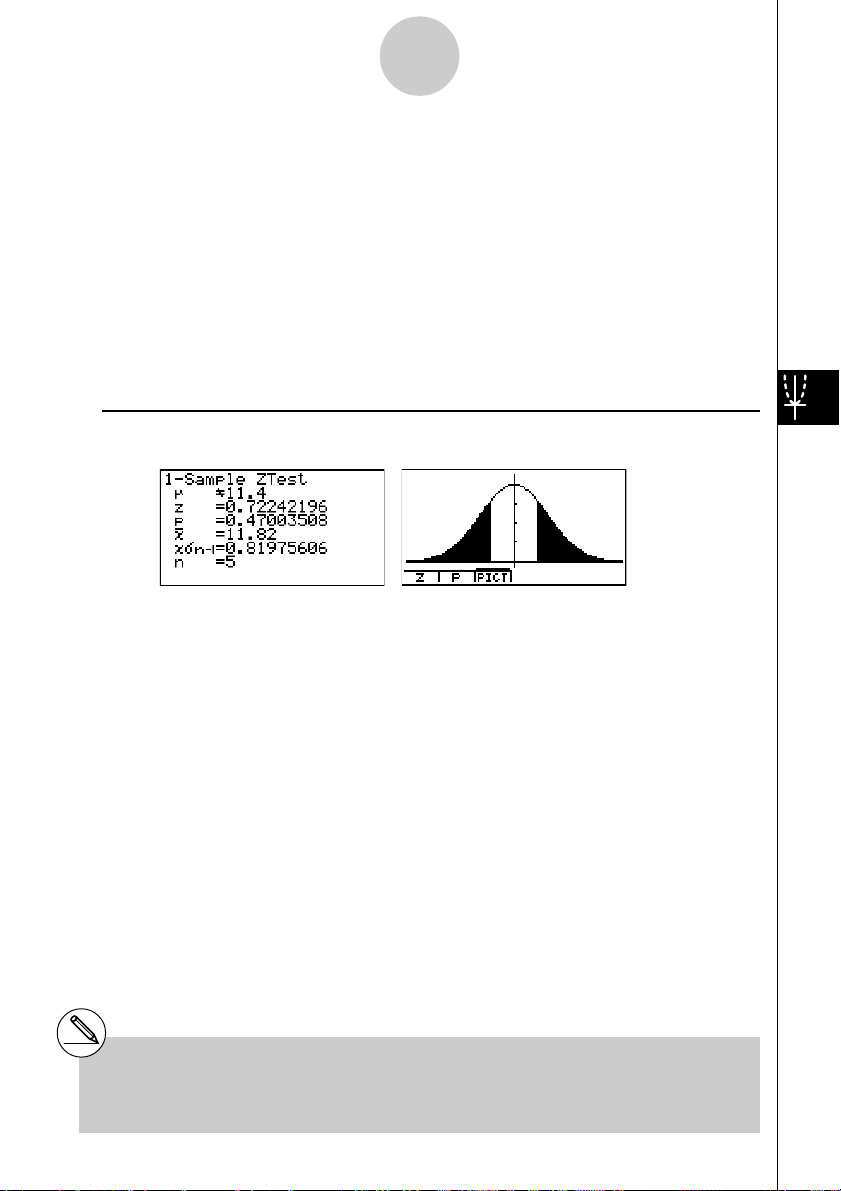
Beispiel Gegeben ist die Stichprobe {12.5, 11.6, 10.8, 12.8, 11.4} = List 1 (aus einer
Berechnungsergebnis-Ausgabebildschirm für 1(CALC) bzw. 6(DRAW)
normalverteilten Grundgesamtheit mit σ =1,30 ) vom Umfang
rechnen sind die statistischen Kennzahlen
z
(unter der Nullhypothese Ho: µ=
kritische Irrtumswahrscheinlichkeit p. Kann die Nullhypothese auf Grundlage
der vorliegenden Stichprobe abgelehnt werden (Irrtumswahrscheinlichkeit α =
0.05) ?
µ
G11.4
........................
Art der Alternativhypothese (zweiseitiger kritischer Bereich)
oo
o und x
σ
oo
µ
o
mit
µ
n -1 , sowie die Testgröße
o
=11.4, HA:
µ
z .................................. berechnete z-Testgröße
p .................................. p-Wert: p
vgl. Bedienungsanleitung zum Taschenrechner S. 6-4-5.
= P
(-|
z | ) + R (| z |
) (kritische Irrtumswahrscheinlichkeit),
o .................................. empirischer Stichproben-Mittelwert
x
σ
n-1 ............................. empirische Stichproben-Standardabweichung
(Angezeigt nur für Datenlistenvorgabe (Data: List)).
n .................................. Stichprobenumfang
n
GG
G
µ
GG
= 5. Zu be-
o
, ) und die
Entscheidungsregel zum durchgeführten Test:
Für eine vorgegebene Irrtumswahrscheinlichkeit α (Signifikanzniveau α) wird bei p<α die
Nullhypothese abgelehnt (Testgröße im kritischen Bereich) und bei p≥α kein Einwand gegen
die Nullhypothese erhoben (Testgröße nicht im kritischen Bereich). In diesem Beispiel gilt
d.h. es besteht kein Einwand gegen die Nullhypothese.
# [Save Res] speichert die µ-Bedingung in
Zeile 2 (Art der Alternativhypothese) nicht ab.
20010901
p≥
α
,
Page 14

Statistische Testverfahren (TEST)
1-2-5
uu
u 2-Stichproben
uu
Der 2-Stichproben Z-Test wird verwendet, um die Hypothese Ho:
Z-Test (2-Sample Z-Test)
µ
=
µ
zur Gleichheit zweier
1
2
Mittelwerte zu prüfen, wenn die Standardabweichungen der zwei (normalverteilten)
Grundgesamtheiten bekannt sind.
Testgröße:
Z =
o1 – o
2
σ
1
+
n
1
o1 : empirischer Mittelwert der Stichprobe 1
2
o2 : empirischer Mittelwert der Stichprobe 2
2
σ
2
σ
n
1 : Standardabweichung der Grundgesamtheit 1
2
σ
2 : Standardabweichung der Grundgesamtheit 2
n1 : Umfang der Stichprobe 1
n2 : Umfang der Stichprobe 2
Führen Sie die folgende Tastenbetätigung im STAT-Eingangsmenü (Listeneditor) aus.
3(TEST)
b(Z)
c(2-Smpl)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ...................... Art der Datenvorgabe (Liste der Stichprobendaten [List] oder
µ
1 .......................... Art der Alternativhypothese (“G
σ
1 ........................... bekannte Standardabweichung der Grundgesamtheit 1 (σ1 > 0)
σ
2 ........................... bekannte Standardabweichung der Grundgesamtheit 2 (σ2 > 0)
List(1) .................... Liste der Stichprobendaten 1
List(2) .................... Liste der Stichprobendaten 2
Freq(1) .................. einfache Häufigkeiten [1] oder Häufigkeitsliste 1
Freq(2) .................. einfache Häufigkeiten [1] oder Häufigkeitsliste 2
Save Res............... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ................. Führt die Berechnung aus oder zeichnet eine Test-Grafik
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Kennzahlenvorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
empirische Kennzahlen [Variable])
µ
2” legt den zweiseitigen
kritischen Bereich fest, “<
Bereich links fest, “>
µ
2” legt den einseitigen kritischen
µ
2” legt den einseitigen kritischen Bereich
rechts fest.)
nisse (Keine [None] oder Liste 1 bis 20)
(N(0,1)-Glockenkurve)
20010901
20011201
Page 15
Statistische Testverfahren (TEST)
1-2-6
o1 ................................. Mittelwert der Stichprobe 1
n1 ................................. Umfang (positive ganze Zahl) der Stichprobe 1
o2 ................................. Mittelwert der Stichprobe 2
n2 ................................. Umfang (positive ganze Zahl) der Stichprobe 2
Nachdem Sie alle Parameter eingestellt haben, stellen Sie den Cursor auf [Execute] und drücken
danach eine der folgenden Funktionstasten, um die Berechnung auszuführen oder eine TestGrafik (N(0,1)-Glockenkurve) zu zeichnen.
• 1(CALC) ... Führt die Berechnung aus.
• 6(DRAW) ... Zeichnet die Test-Grafik zum Testergebnis.
u u u u u
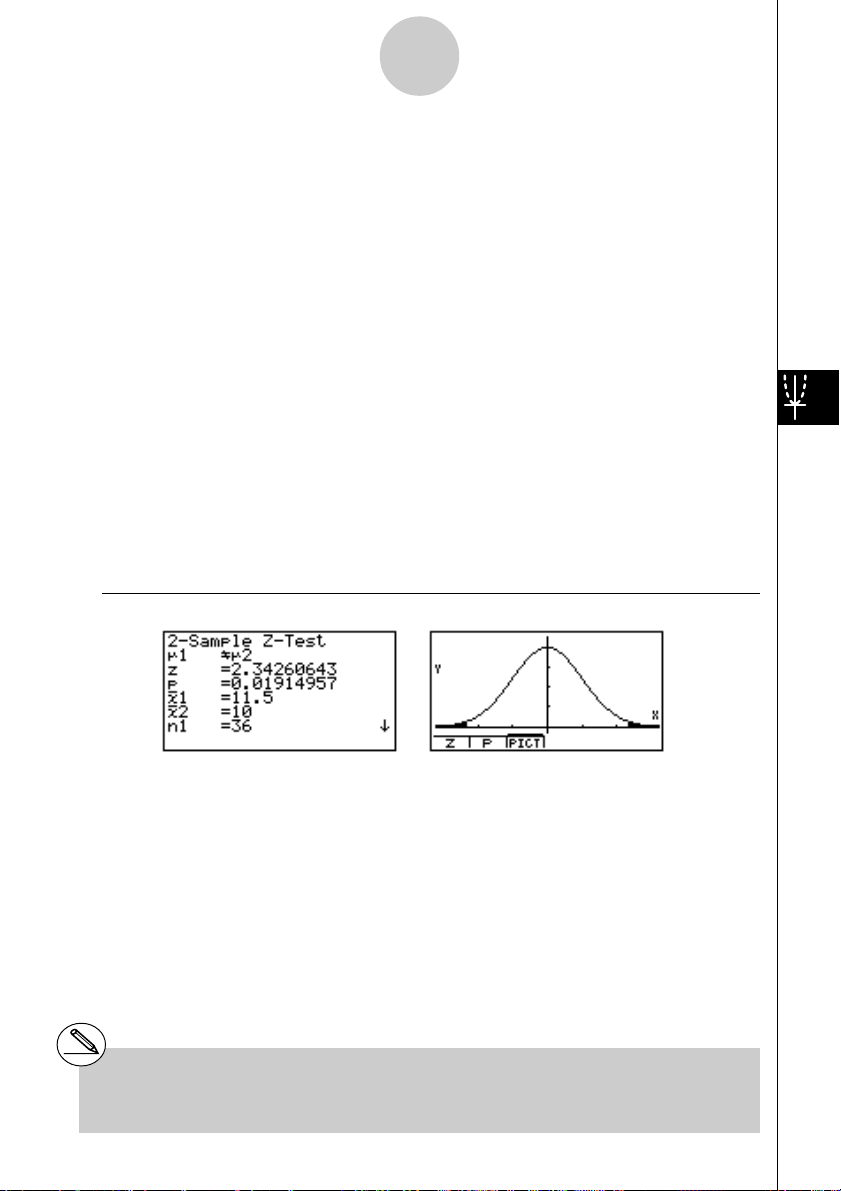
Beispiel
Gegeben sind die empirischen Stichprobenmittelwerte
oo
o
2
=10.0 (
n
2
oo
σ
=3.00 ). Zu be
2
µ
=
1
= 36) (aus normalverteilten Grundgesamtheiten mit
rechnen sind die Testgröße z (unter der Nullhypothese Ho:
, HA:
µ
GG
G
GG
1
µ
, ) und die
2
kritische Irrtumswahrscheinlichkeit p. Kann die
µ
2
Nullhypothese auf Grundlage der ausgewerteten Stichproben abgelehnt werden
(Irrtumswahrscheinlichkeit α = 0.05) ?
(Antwort: Ja, wegen p<α , vgl. Entscheidungsregel S. 1-2-4)
Berechnungsergebnis-Ausgabebildschirm für 1(CALC) bzw. 6(DRAW)
oo
o
1
=11.5 (
oo
n
1
= 36) und
σ
=2.40 und
1
µ
1
µ
2 ........................... Art der Alternativhypothese (zweiseitiger kritischer Bereich)
G
z .................................. berechnete z-Testgröße
p .................................. p-Wert: p
vgl. Bedienungsanleitung zum Taschenrechner S. 6-4-5.
= P
(-|
z | ) + R (| z |
o1 ................................. empirischer Mittelwert der Stichprobe 1
o2 ................................. empirischer Mittelwert der Stichprobe 2
x1
σ
n-1 ............................ empirische Stichproben-Standardabweichung 1
(Angezeigt nur für Datenlistenvorgabe (Data: List)).
x2
σ
n-1 ............................ empirische Stichproben-Standardabweichung 2
(Angezeigt nur für Datenlistenvorgabe (Data: List)).
n1
.................................
Umfang der Stichprobe 1
n2 ................................. Umfang der Stichprobe 2
# [Save Res] speichert die µ-Bedingung in
Zeile 2 (Art der Alternativhypothese) nicht ab.
20010901
) (kritische Irrtumswahrscheinlichkeit),
Page 16

Statistische Testverfahren (TEST)
1-2-7
uu
u 1-Prop
uu
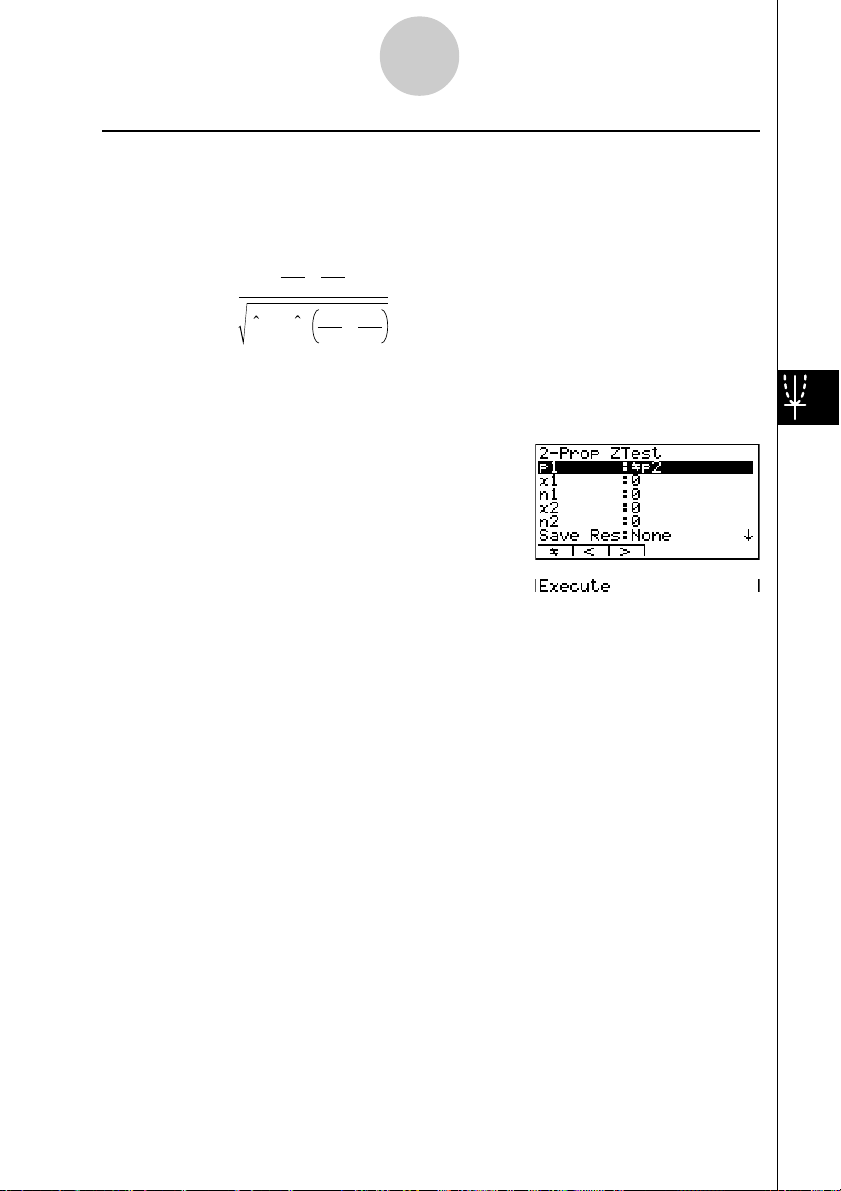
Der 1-Prop Z-Test wird für die Prüfung der Hypothese über einen unbekannten Anteilswert
(Prop) in einer dichotomen Grundgesamtheit benutzt (Ho: Prop = p0). Für den Test wird eine
näherungsweise N(0,1)-verteilte Testgröße Z verwendet:
Führen Sie die folgende Tastenbetätigung
im STAT-Eingangsmenü (Listeneditor) aus.
Nachdem Sie alle Parameter eingestellt haben, stellen Sie den Cursor auf [Execute] und drücken
danach eine der folgenden Funktionstasten, um die Berechnung auszuführen oder eine TestGrafik (N(0,1)-Glockenkurve) zu zeichnen.
Z-Test (Z-Test für einen unbekannten Anteilswert)
x
– p
0
n
Z =
p
(1– p0)
0
n
3(TEST)
b(Z)
d(1-Prop)
............................
Prop
.................................
p0
..................................
x
..................................
n
Save Res
Execute
• 1(CALC) ... Führt die Berechnung aus.
• 6(DRAW) ... Zeichnet die Test-Grafik zum Testergebnis.
....................
.......................
Art der Alternativhypothese
(“G p0” legt den zweiseitigen kritischen Bereich fest,
“< p0” legt den einseitigen kritischen Bereich links fest,
“> p0” legt den einseitigen kritischen Bereich rechts fest.)
hypothetischer Anteilswert (0 < p0 < 1)
Anzahl der Treffer in der Stichprobe (x > 0, ganze Zahl)
Stichprobenumfang (positive ganze Zahl)
Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Führt die Berechnung aus oder zeichnet eine Test-Grafik
(N(0,1)-Glockenkurve)
p0 : hypothetischer Anteilswert
n : Stichprobenumfang
x : Trefferanzahl
Beispiel: Ausgabebildschirm für 1(CALC) bzw. 6(DRAW), vgl. S.1-2-4
PropG0.5 ...................... Art der Alternativhypothese (zweiseitiger kritischer Bereich)
p ......... p-Wert (kritische Irrtumswahrscheinlichkeit), z ...... berechnete Z-Testgröße,
ˆp = x/n = 2048
# [Save Res] speichert die µ-Bedingung in
Zeile 2 (Art der Alternativhypothese) nicht ab.
/
4040 ....... Geschätzter Anteilswert, n ...... Stichprobenumfang.
20010901
Page 17
Statistische Testverfahren (TEST)
1-2-8
uu
u 2-Prop
uu
Der 2-Prop Z-Test wird für die Prüfung der Hypothese der Gleichheit zweier unbekannter
Anteilswerte zweier dichotomer Grundgesamtheiten benutzt (Ho: p1 = p2). Für den Test wird
eine näherungsweise N(0,1)-verteilte Testgröße Z verwendet:
Führen Sie die folgende Tastenbetätigung
Z-Test (Z-Test zum Vergleich zweier unbekannter Anteilswerte)
x1 : Anzahl der Treffer in der Stichprobe 1
x2 : Anzahl der Treffer in der Stichprobe 2
n1 : Umfang der Stichprobe 1
n2 : Umfang der Stichprobe 2
ˆp :
Geschätzter Anteilswert in der Gesamt
stichprobe
im STAT-Eingangsmenü (Listeneditor) aus.
Z =
3(TEST)
b(Z)
e(2-Prop)
x
1
n
p(1 – p )
x
2
–
n
2
1
1
1
+
n
n
2
1
p1 ................................. Art der Alternativhypothese
(“G p2” legt den zweiseitigen kritischen Bereich fest,
“< p2” legt den einseitigen kritischen Bereich links fest,
“> p2” legt den einseitigen kritischen Bereich rechts fest.)
x1 ................................. Anzahl der Treffer in der Stichprobe 1 (x1 > 0, ganze Zahl)
n1 ................................. Umfang der Stichprobe 1 (positive ganze Zahl)
x2 ................................. Anzahl der Treffer in der Stichprobe 2 (x2 > 0, ganze Zahl)
n2 ................................. Umfang der Stichprobe 2 (positive ganze Zahl)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus oder zeichnet eine Test-Grafik
nisse (Keine [None] oder Liste 1 bis 20)
(N(0,1)-Glockenkurve)
-
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken danach eine der nachfolgend dargestellten Funktionstasten, um die
Berechnung auszuführen oder eine Test-Grafik (N(0,1)-Glockenkurve) zu zeichnen.
1(CALC) ... Führt die Berechnung aus.
• 6(DRAW) ... Zeichnet die Test-Grafik zum Testergebnis.
20010901
Page 18
Statistische Testverfahren (TEST)
1-2-9
u u u u u
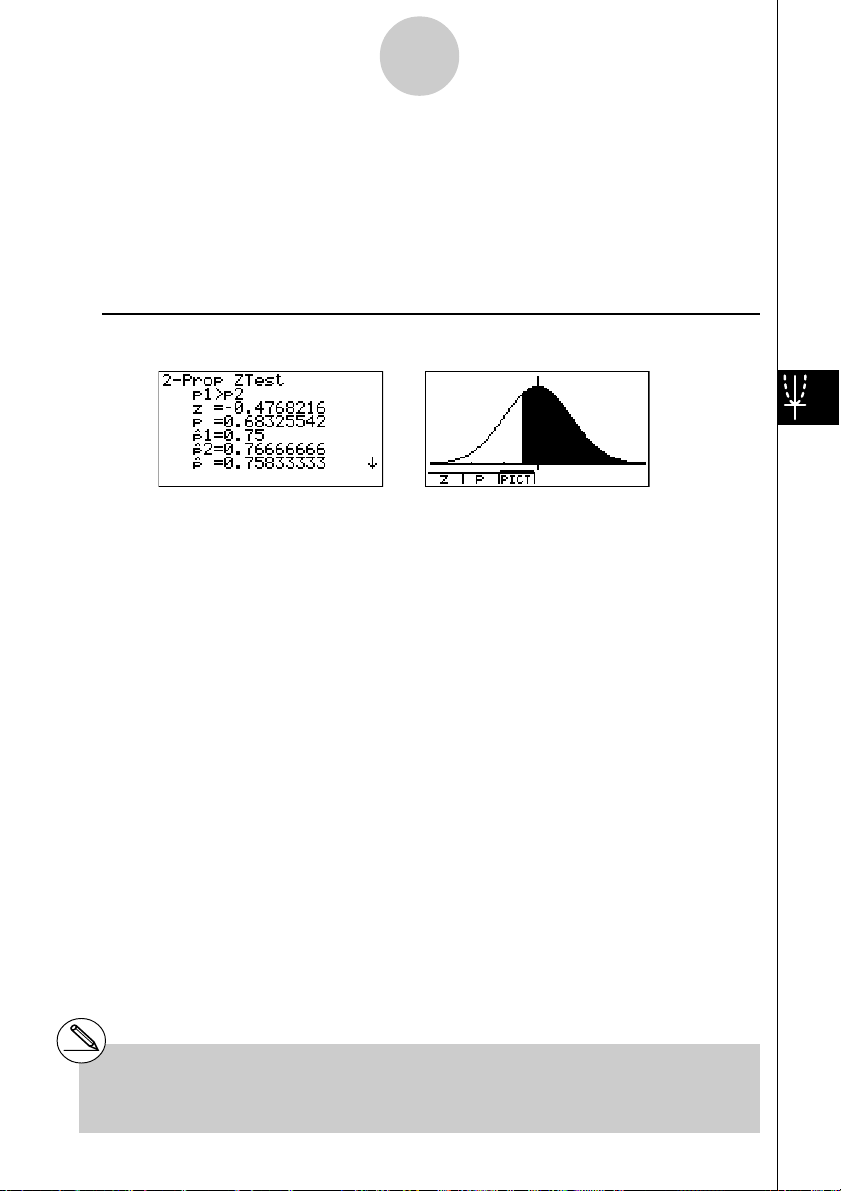
Beispiel In zwei dichotomen Grundgesamtheiten wurden die Trefferanzahlen x1 = 225
und x2 = 230 erzielt (Stichprobenumfang n1 = 300, n2 = 300)
sind die statistischen Kennzahlen ˆp 1 , ˆp 2 und ˆp , sowie die Testgröße z (unter
der Nullhypothese
scheinlichkeit p. Kann die Nullhypothese auf Grundlage der vorliegenden
Stichprobe abgelehnt werden (Irrtumswahrscheinlichkeit α = 0.05) ?
Ho: p1 = p2 und HA: p1 > p2
) und die
Berechnungsergebnis-Ausgabebildschirm für 1(CALC) bzw. 6(DRAW)
. Zu be
rechnen
kritische Irrtumswahr-
p1>p2 ............................ Art der Alternativhypothese (einseitiger kritischer Bereich,
rechtsseitig)
z .................................. berechnete z-Testgröße ( - 0.4768216 )
p .................................. p-Wert: p
lichkeit, , vgl. Bedienungsanleitung S. 6-4-5)
= R (z ) =
0.68325542 (kritische Irrtumswahrschein-
ˆp 1 ................................. Geschätzter Anteilswert der Grundgesamtheit 1
( 225 / 300 = 0.75 )
ˆp 2 ................................. Geschätzter Anteilswert der Grundgesamtheit 2
( 230 / 300 = 0.76666666... )
ˆp .................................. Geschätzter Anteilswert für die Gesamtstichprobe
( (225+230) / (300+300) = 0.75833333...)
n1 ................................. Umfang der Stichprobe 1 ( 300)
n2 ................................. Umfang der Stichprobe 2 ( 300)
Entscheidungsregel zum durchgeführten Test:
Für eine vorgegebene Irrtumswahrscheinlichkeit α (Signifikanzniveau α , hier α = 0.05 ) wird
bei p<α die Nullhypothese abgelehnt (Testgröße im kritischen Bereich) und bei p≥α kein
Einwand gegen die Nullhypothese erhoben (Testgröße nicht im kritischen Bereich).
In diesem Beispiel gilt
d.h. auf Grund des durchgeführten Tests besteht kein Anlaß, die Nullhypothese zu gunsten der
Alternativhypothese HA: p1 > p2 abzulehnen.
# [Save Res] speichert die µ-Bedingung in
Zeile 2 (Art der Alternativhypothese) nicht ab.
p≥
α
, d.h. es besteht kein Einwand gegen die Nullhypthese Ho: p1 = p2 ,
20010901
Page 19

Statistische Testverfahren (TEST)
1-2-10
kk
t-Tests (Tests mit einer t
k
kk
uu
u Gemeinsame Funktionen des t-Tests
uu
Sie können folgende Grafikanalysefunktion nach dem Zeichnen einer Test-Grafik verwenden.
• 1(T) ... Zeigt den berechneten Wert der (tm -verteilten) t-Testgröße an.
Drücken Sie die Taste 1(T), um die berechnete t-Testgröße t in der Fußzeile des Displays
anzuzeigen, wobei der Cursor an der entsprechenden Position der Grafik angezeigt wird (sofern
diese Stelle nicht außerhalb des Betrachtungsfensters liegt).
Im Fall eines zweiseitigen Tests werden zwei Punkte -t und t angezeigt. Verwenden Sie die
d- und e-Tasten, um den Cursor hin und her zu verschieben.
Drücken Sie die i-Taste, um die Anzeige der t-Testgröße zu löschen.
• 2(P) ... Zeigt den zur berechneten Testgröße gehörenden p-Wert an. Es handelt
sich hierbei um die sogenannte kritische Irrtumswahrscheinlichkeit, die
der schraffierten Fläche unter der Dichtefunktion einer t-Verteilung mit
m
Freiheitsgraden entspricht. Die Anzahl der Freiheitsgrade ist vom Stich-
probenumfang und dem verwendeten Testverfahren abhängig.
Drücken Sie die Taste 2(P) , um den p-Wert in der Fußzeile des Displays anzuzeigen, ohne
dass der Cursor erscheint.
Drücken Sie die i-Taste, um die Anzeige des p-Wertes zu löschen.
-verteilten Testgröße, m Freiheitsgrade)
m
#
Folgende Betrachtungsfenstereinstellungen
werden für das Zeichnen der Testgrafik
(Dichtefunktion einer t-Verteilung) verwendet.
Xmin = –3,2, Xmax = 3,2, Xscale = 1,
Ymin = –0,1, Ymax = 0,45, Yscale = 0,1
#Durch die Ausführung einer Testfunktion
werden die
symbolischen Variablen T bzw. P gespeichert.
20010901
t- und p-Werte automatisch in den
Page 20

Statistische Testverfahren (TEST)
1-2-11
uu
u Einfacher
uu
t-Test (1-Stichproben t-Test, 1-Sample t-Test)
Der einfache t-Test (1-Stichproben t-Test) wird verwendet, um die Mittelwerthypothese Ho:
µ=µ
o zu prüfen, wenn die Standardabweichung
σ
der (normalverteilten) Grundgesamtheit
unbekannt ist. Für den Test wird eine (näherungsweise) tm-verteilte Testgröße t verwendet:
t =
o –
σ
x
n
n–1
µ
0
o : empirischer Stichprobenmittelwert
µ
0 : hypothetischer Mittelwert
x
σ
n-1 : Stichproben-Standardabweichung
n : Stichprobenumfang (
m = n
-1)
Führen Sie die folgende Tastenbetätigung im STAT-Eingangsmenü (Listeneditor) aus.
3(TEST)
c(T)
b(1-Smpl)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der Stichprobendaten [List] oder
empirische Kennzahlen [Variable])
µ
.................................. Art der Alternativhypothese (“G
kritischen Bereich fest, “<
Bereich links fest, “>
µ
0” legt den einseitigen kritischen Bereich
µ
0” legt den zweiseitigen
µ
0” legt den einseitigen kritischen
rechts fest.)
µ
0 ................................ hypothetischer Mittelwert (Nullhypothese Ho:
µ=µ
o)
List .............................. Liste der Stichprobendaten (List 1 bis 20)
Freq ............................. einfache Häufigkeiten [1] oder Häufigkeitsliste (Liste 1 bis 20)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus oder zeichnet eine Test-Grafik
(Dichtefunktion einer tm -Verteilung, glockenförmige Kurve)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Kennzahlenvorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
o
..................................
x
σ
n-1
.............................
n
..................................
empirischer Stichproben-Mittelwert
empirische Stichproben-Standardabweichung (x
Stichprobenumfang (positive ganze Zahl)
σ
n-1 > 0)
Nachdem Sie alle Parameter eingestellt haben, stellen Sie den Cursor auf [Execute] und drücken
danach eine der nachfolgend dargestellten Funktionstasten, um die Berechnung auszuführen
oder eine Test-Grafik (Dichtefunktion einer t
-Verteilung, glockenförmige Kurve) zu zeichnen.
m
20010901
Page 21
Statistische Testverfahren (TEST)
1-2-12
• 1(CALC) ... Führt die Berechnung aus.
• 6(DRAW) ... Zeichnet die Test-Grafik zum Testergebnis.
u u u u u
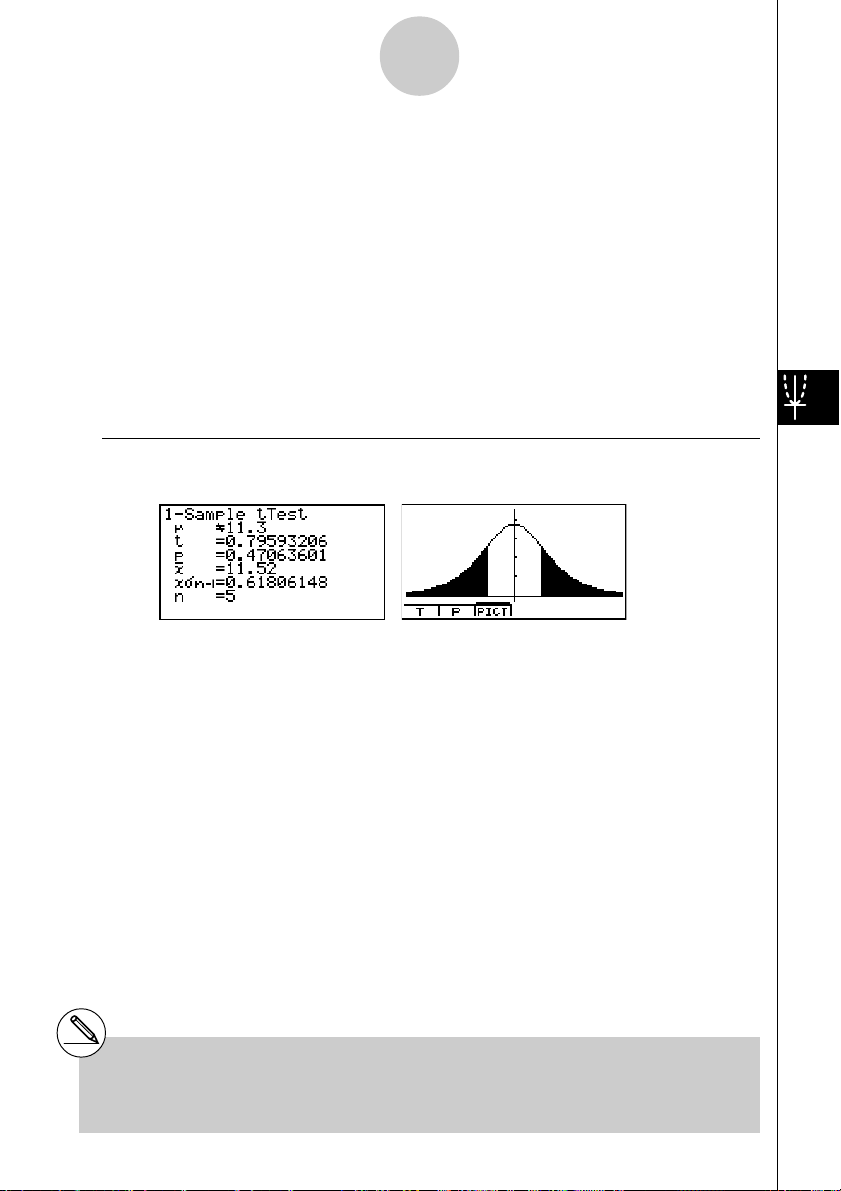
Beispiel Gegeben sind die empirischen Kennzahlen
einer normalverteilten Grundgesamtheit mit unbekannten Parametern). Der
Stichprobenumfang betrug dabei
(unter der Nullhypothese Ho: µ =
kritische Irrtumswahrscheinlichkeit p. Kann die Nullhypothese auf Grundlage
der ausgewerteten Stichprobe abgelehnt werden (Irrtumswahrscheinlichkeit
= 0.05) ?
Berechnungsergebnis-Ausgabebildschirm für 1(CALC) bzw. 6(DRAW)
µ
G 11.3 ...................... Art der Alternativhypothese (zweiseitiger kritischer Bereich)
t
...................................
berechnete t-Testgröße (m = n-1 Freiheitsgrade)
p .................................. p-Wert (kritische Irrtumswahrscheinlichkeit)
o .................................. empirischer Stichproben-Mittelwert
x
σ
n-1 ............................. empirische Stichproben-Standardabweichung
n .................................. Stichprobenumfang
n
µ
oo
o = 11.52 und x
oo
= 5. Zu be
o
mit
µ
o
σ
n-1 = 0.382
rechnen sind die Testgröße
=11.3, HA:
µ
GG
G
GG
µ
o
) und die
1/2
(aus
z
α
Entscheidungsregel zum durchgeführten Test:
Für eine vorgegebene Irrtumswahrscheinlichkeit α (Signifikanzniveau α) wird bei p<α die
Nullhypothese abgelehnt (Testgröße im kritischen Bereich) und bei p≥α kein Einwand gegen
die Nullhypothese erhoben (Testgröße nicht im kritischen Bereich). In diesem Beispiel gilt
d.h. es besteht kein Einwand gegen die Nullhypothese. (D.h. der empirische Mittelwert weicht
nicht wesentlich (also nicht signifikant, nur unwesentlich) vom hypothetischen Mittelwert ab.)
# [Save Res] speichert die µ-Bedingung in
Zeile 2 (Art der Alternativhypothese) nicht ab.
20010901
p≥
α
,
Page 22

Statistische Testverfahren (TEST)
1-2-13
uu
u Doppelter
uu
Der doppelte t-Test (2-Stichproben t-Test) wird verwendet, um die Hypothese Ho:
t-Test (2-Stichproben t-Test, 2-Sample t-Test)
µ
=
µ
zur
1
2
Gleichheit zweier Mittelwerte zu prüfen, wenn die Standardabweichungen der zwei
(normalverteilten) Grundgesamtheiten unbekannt sind. Für den Test wird eine (näherungsweise)
t
-verteilte Testgröße t verwendet (Anzahl der Freiheitsgrade: m = df ):
m
Unter der Voreinstellung [Pooled: On] gilt für die Anzahl der Freiheitsgrade:
t =
xp
o1 – o
σ
n–1
2
1
1
2
+
n
n
2
1
o1 :empirischer Mittelwert der
Stichprobe 1
o2 :empirischer Mittelwert der
Stichprobe 2
x1
σ
n-1 :Standardabweichung der
Grundgesamtheit 1
x2
σ
n-1 :Standardabweichung der
Grundgesamtheit 2
df
= n1 + n2 – 2
n1 : Umfang der Stichprobe 1
n2 : Umfang der Stichprobe 2
xp
σ
n-1 : gemeinsame
Standardabweichung der
Gesamtstichprobe (wird nur
angezeigt unter der
Voreinstellung [Pooled:On].)
df :Freiheitsgrade der
Prüfverteilung
Unter der Voreinstellung [Pooled: Off] gilt für die Anzahl der Freiheitsgrade:
o1 – o
t =
df =
σ
x
1 n–1
n
C
n1–1
2
2
2
σ
x
2 n–1
+
n
2
1
2
1
(1–C )
+
n2–1
mit
2
o1 :empirischer Mittelwert der
Stichprobe 1
o2 :empirischer Mittelwert der
Stichprobe 2
x1
σ
n-1 :Standardabweichung der
Grundgesamtheit 1
x2
σ
n-1 :Standardabweichung der
Grundgesamtheit 2
n1 : Umfang der Stichprobe 1
n2 : Umfang der Stichprobe 2
df :Freiheitsgrade der
Prüfverteilung
Führen Sie die folgende Tastenbetätigung im STAT-Eingangsmenü (Listeneditor) aus.
3(TEST)
c(T)
c(2-Smpl)
20010901
20011201
Page 23

Statistische Testverfahren (TEST)
1-2-14
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der Stichprobendaten [List] oder
empirische Kennzahlen [Variable])
µ
1 ................................. Art der Alternativhypothese (“G µ2” legt den zweiseitigen
kritischen Bereich fest, “<
Bereich links fest, “>
µ
2” legt den einseitigen kritischen
µ
2” legt den einseitigen kritischen
Bereich rechts fest.)
List(1) .......................... Liste der Stichprobendaten der 1. Stichprobe
List(2) .......................... Liste der Stichprobendaten der 2. Stichprobe
Freq(1) ........................ einfache Häufigkeiten [1] oder Häufigkeitsliste 1
Freq(2) ........................ einfache Häufigkeiten [1] oder Häufigkeitsliste 2
Pooled ......................... Streuungsgleichheit eingeschaltet ([Pooled: On]) oder
ausgeschaltet ([Pooled: Off])
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus oder zeichnet eine Test-Grafik
(Dichtefunktion einer t
-
Verteilung, glockenförmige Kurve)
df
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Kennzahlenvorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
o1 ................................. empirischer Stichproben-Mittelwert der Stichprobe 1
x1
σ
n-1 ............................ empirische Standardabweichung (x1σn-1 > 0) der Stichprobe 1
n1 ................................. Umfang der Stichprobe 1 (positive ganze Zahl)
o2 ................................. empirischer Stichproben-Mittelwert der Stichprobe 2
x2
σ
n-1 ............................ empirische Standardabweichung (x2σn-1 > 0) der Stichprobe 2
n2 ................................. Umfang der Stichprobe 2 (positive ganze Zahl)
Nachdem Sie alle Parameter eingestellt haben, stellen Sie den Cursor auf [Execute] und drücken
danach eine der nachfolgend dargestellten Funktionstasten, um die Berechnung auszuführen
oder eine Test-Grafik (Dichtefunktion einer t
• 1(CALC) ... Führt die Berechnung aus.
• 6(DRAW) ... Zeichnet die Test-Grafik zum Testergebnis.
-
Verteilung, glockenförmige Kurve) zu zeichnen.
df
20010901
20011201
Page 24
Statistische Testverfahren (TEST)
1-2-15
u u u u u
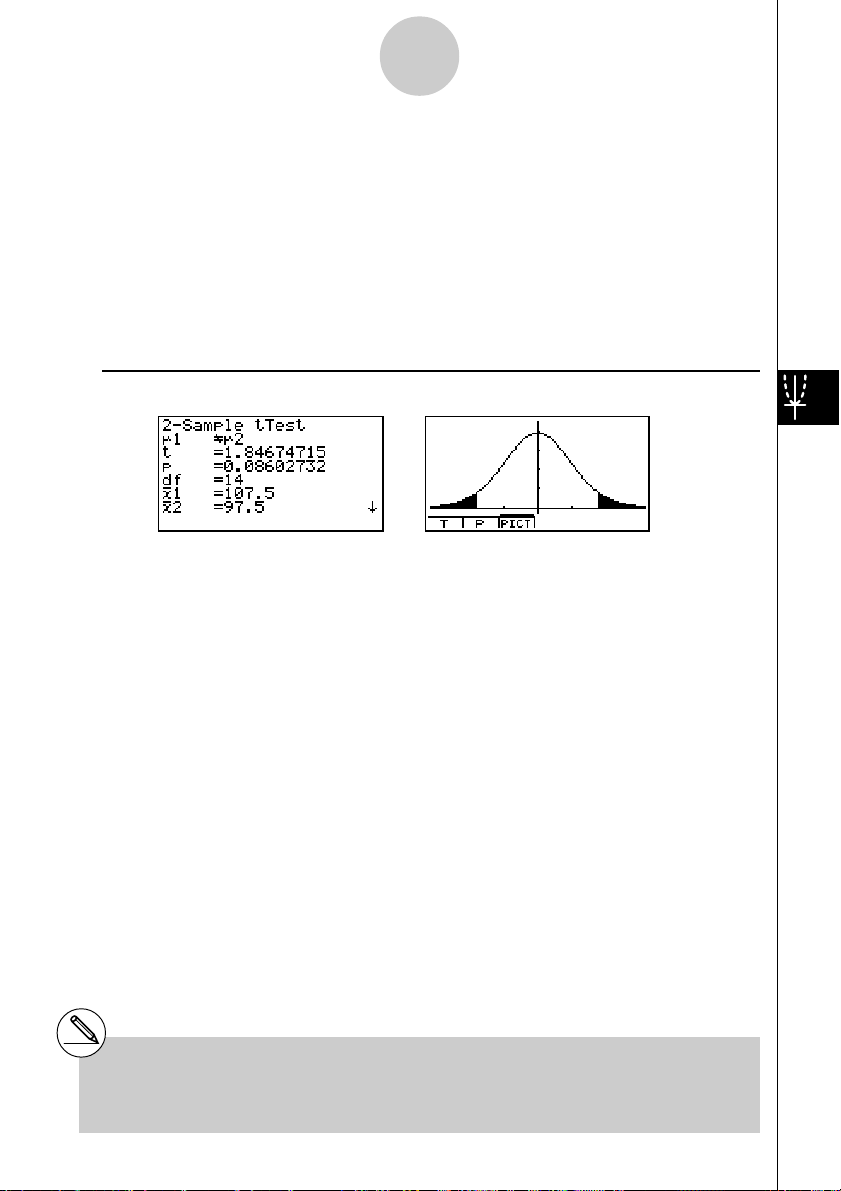
Beispiel Aus zwei (normalverteilten) Grundgesamtheiten, deren (unbekannte) Streu-
ungsparameter als gleich angesehen werden können, wurden die Stichproben
1 und 2 wie folgt entnommen: {105, 108, 86, 103, 103, 107, 124, 124} = List 1,
{89, 92, 84, 97, 103, 107, 111, 97} = List 2.
dabei jeweils
x1
σ
n-1, x2σn-1 und xpσn-1 sowie die Testgröße
µ
=
µ
1
, HA:
2
n
= 8. Zu be
GG
µ
G
GG
1
µ
, ) und die
2
rechnen sind die statistischen Kennzahlen o1, o2,
kritische Irrtumswahrscheinlichkeit p. Kann die
Nullhypothese auf Grundlage der ausgewerteten Stichprobe abgelehnt werden
(Irrtumswahrscheinlichkeit α = 0.05) ?
Berechnungsergebnis-Ausgabebildschirm für 1(CALC) bzw. 6(DRAW)
µ1Gµ
2 ........................... Art der Alternativhypothese (zweiseitiger kritischer Bereich)
t
...................................
berechnete t-Testgröße (df = n1+n2-1 Freiheitsgrade)
p .................................. p-Wert (kritische Irrtumswahrscheinlichkeit)
df ................................. Freiheitsgrade der Prüfverteilung
o1 ................................. empirischer Stichproben-Mittelwert der Stichprobe 1
o2 ................................. empirischer Stichproben-Mittelwert der Stichprobe 2
x1
σ
n-1 ............................ empirische Standardabweichung der Stichprobe 1
x2
σ
n-1 ............................ empirische Standardabweichung der Stichprobe 2
xp
σ
n-1 ............................ gemeinsame Standardabweichung der Gesamtstichprobe (wird
nur angezeigt unter der Voreinstellung [Pooled:On].)
n1 ................................. Umfang der Stichprobe 1
n2 ................................. Umfang der Stichprobe 2
Der Stichprobenumfang betrug
z
(unter der Nullhypothese Ho:
Entscheidungsregel zum durchgeführten Test:
Für eine vorgegebene Irrtumswahrscheinlichkeit α (Signifikanzniveau α) wird bei p<α die
Nullhypothese abgelehnt (Testgröße im kritischen Bereich) und bei p≥α kein Einwand gegen
die Nullhypothese erhoben (Testgröße nicht im kritischen Bereich). In diesem Beispiel gilt
d.h. es besteht kein Einwand gegen die Nullhypothese. (D.h. die empirischen Mittelwerte
unterscheiden sich noch nicht wesentlich (also nicht signifikant, nur unwesentlich). Bei α =
würde man jedoch die Nullhypothese wegen vermuteter Unterschiede bereits ablehnen! )
# [Save Res] speichert die
Zeile 2 (Art der Alternativhypothese) nicht ab.
µ
1-Bedingung in
20010901
p≥
α
0.10
,
Page 25

Statistische Testverfahren (TEST)
1-2-16
uu
t-Test zur linearer Regression (LinearReg t-Test) (Korrelationsanalyse)
u
uu
Der t-Test zur linearer Regression untersucht verbundene Datenlisten des Zufallsvektors (X,
Y) und plottet alle Datenpaare (x
) in einer statistischen Grafik. Danach wird eine
i,yi
Regressioinsgerade (y = a + bx) berechnet und durch die geplottete Punktwolke gelegt. Der
Anstieg  (geschätzt durch b) der Regressionsgeraden steht in unmittelbaren Zusammenhang
zum (Pearsonschen) Korrelationskoeffizienten (geschätzt durch r), so dass gleichzeitig die
Nulhypothesen "Nullanstieg" bzw. "Unkorreliertheit" untersucht werden können. Für a und b
sowie die t
-verteilte Testgröße t gelten die Formeln (Freiheitsgrade: df = n - 2):
df
a : Achsenabschnitt
b : Anstieg der Geraden
n : Stichprobenumfang
(n > 3)
r : Korrelationskoeffizient
2
r
: Bestimmtheitsmaß
Führen Sie die folgende Tastenbetätigung im STAT-Eingangsmenü (Listeneditor) aus.
3(TEST)
c(T)
d(LinReg)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe
beschrieben.
β
& ρ............................ Alternativhypothese für den Anstieg β bzw. den Korrelations-
koeffizienten ρ (“G 0” legt den zweiseitigen kritischen Bereich
fest, “< 0” legt den einseitigen kritischen Bereich links fest,
“> 0” legt den einseitigen kritischen Bereich rechts fest.)
XList ............................ Liste für die x-Werte der Datenpaare
YList ............................ Liste für die y-Werte der Datenpaare
Freq ............................. einfache Häufigkeiten [1] oder Häufigkeitsliste zu den Daten-
paaren
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus
Nachdem Sie alle Parameter eingestellt haben, stellen Sie den Cursor auf [Execute] und drücken
danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung aus.
# Sie können für den t-Test zur linearen
Regression keine Test-Grafik zeichnen.
20010901
20011201
Page 26

Statistische Testverfahren (TEST)
1-2-17
u u u u u
Beispiel Aus zwei (normalverteilten) Grundgesamtheiten X und Y wurden die Stichproben
1 und 2 wie folgt entnommen: {
Der Stichprobenumfang betrug dabei jeweils
Anstieg b und das Absolutglied a der Regressionsgeraden, der Korrelationskoeffizient r und das Bestimmtheitsmaß r2, sowie die Testgröße z (unter der
Nullhypothese Ho: β =
tumswahrscheinlichkeit p. Kann die Nullhypothese auf Grundlage der ausgewerteten Stichproben abgelehnt werden (Irrtumswahrscheinlichkeit α = 0.10)?
(Antwort: Ja, Ablehnung von
statistisch noch nicht gesichert!)
Berechnungsergebnis-Ausgabebildschirm für 1(CALC) und 6(COPY)
β
G 0 &
ρ
G 0 .............. Art der Alternativhypothese (zweiseitiger kritischer Bereich)
t ................................... berechnete t-Testgröße (df = n - 2 Freiheitsgrade)
p .................................. p-Wert (kritische Irrtumswahrscheinlichkeit)
df ................................. Freiheitsgrade (df = n - 2 Freiheitsgrade)
a .................................. Absolutglied der Regressionsgeraden (Schittpunkt mit der y-
Achse)
b .................................. Anstieg der Regressionsgeraden
s .................................. Anpassungsfehler, Wurzel aus der Reststreuung (Restvarianz
mit n - 2 normiert).
r .................................. Korrelationskoeffizient
2
r
................................. Bestimmtheitsmaß
x
1
,
x
2
,
x
3
,
x
4
,
x
5
0 &
ρ
=
0 , HA:
β
GG
G 0 &
GG
} = List 1, {
y
n
= 5. Zu be
GG
ρ
G 0 ,) und die
GG
1
,
y
2
,
y
3
,
y
4
,
rechnen sind der
kritische Irr-
Ho wegen p<α . Mit α = 0.05 wäre die Korrelation
y
5
} = List 2.
Drücken Sie die Taste 6(COPY), während das
Berechnungsergebnis im Display angezeigt wird,
um die Regressionsgleichung in den Grafik-Formelspeicher zu kopieren.
Wenn Sie eine Liste für die Position [Resid List] im SET UP-Menü vorgegeben haben, werden
die Residuen der linearen Regressionsanalyse automatisch in der vorgegebenen Liste
abgespeichert, nachdem die Berechnung abgeschlossen ist.
# [Save Res] speichert die β & ρ -Bedingungen
in Zeile 2 (Alternativhypothese) nicht.
#Wenn die durch [Save Res] benannte Liste die
gleiche Liste ist, wie sie in der Position [Resid
List] im SET UP-Menü festgelegt wurde, erfolgt
nur eine Speicherung der [Resid List] Daten.
20010901
Page 27

Statistische Testverfahren (TEST)
j
1-2-18
2
kk
-Test (χ2-Homogenitäts- und χ2-Unabhängigkeitstest)
k χ
kk
Der χ2-Test untersucht Homogenitäts- und Unabhängigkeitshypothesen mithilfe von Kontingenztafeln, die im Zusammenhang mit den festgestellten Häufigkeiten
x
bei k bzw. l Merkmals-
ij
ausprägungen bestehen. Der χ2-Test wird insbesondere für dichotome Variablen (Variable mit
zwei möglichen Werten, wie Ja / Nein) verwendet, d.h. k =
l
= 2 (Vierfeldertafel).
Erwartete Häufigkeiten n : Gesamthäufigkeit
(im Fall der Unabhängigkeit (Summe aller
bzw. Homogenität):
x
)
ij
Testgröße, χ2-verteilt mit
(k-1)(l-1) Freiheitsgraden:
χ2 =
k
ΣΣ
i=1
(xij – Fij)
=1
2
F
ij
die folgende Tastenbetätigung im
STAT-Eingangsmenü (Listeneditor) aus.
3(TEST)
d(χ2)
Danach bezeichnen Sie die Matrix [Observed], welche die Daten (empirische Häufigkeiten,
Kontingenztafel) enthält, und die Matrix [Expected] für die berechneten Häufigkeiten
F
Nachfolgend ist die Bedeutung der einzelnen Positionen im Eingabefenster aufgeführt.
Observed .................... Name der Matrix (A bis Z), welche die beobachteten Häufig-
keiten (alles positive ganze Zahlen) enthält.
Expected ..................... Name der Matrix (A bis Z), in welcher die erwarteten Häufig-
keiten (unter der Nullhypothese, z.B. Unabhängigkeit) durch
den Rechner abspeichert werden.
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus oder zeichnet eine Test-Grafik
(Dichtefunktion einer χ
2
-
Verteilung mit df = (k-1)(l-1) )
df
Nachdem Sie alle Parameter eingestellt haben, stellen Sie den Cursor auf [Execute] und drücken
danach eine der nachfolgend dargestellten Funktionstasten, um die Berechnung auszuführen
oder eine Test-Grafik (Dichtefunktion einer χ
2
-
Verteilung mit df = (k-1)(l-1) ) zu zeichnen.
df
.
ij
• 1(CALC) ... Führt die Berechnung aus.
• 6(DRAW) ... Zeichnet die Test-Grafik zum Testergebnis.
# Die Matrix muss mindestens zwei Zeilen mal
zwei Spalten aufweisen. Es kommt zu einem
Fehler, wenn die Matrix nur als Zeilen- oder nur
nur als Spaltenmatrix definiert ist.
#Drücken Sie die Taste 2 ('MAT), um die
bezeichneten Matrizen auch im MATRIX-Editor,
der für das Betrachten und die Bearbeitung des
Inhalts der Matrizen verwendet werden kann,
zu definieren.
20010901
Page 28
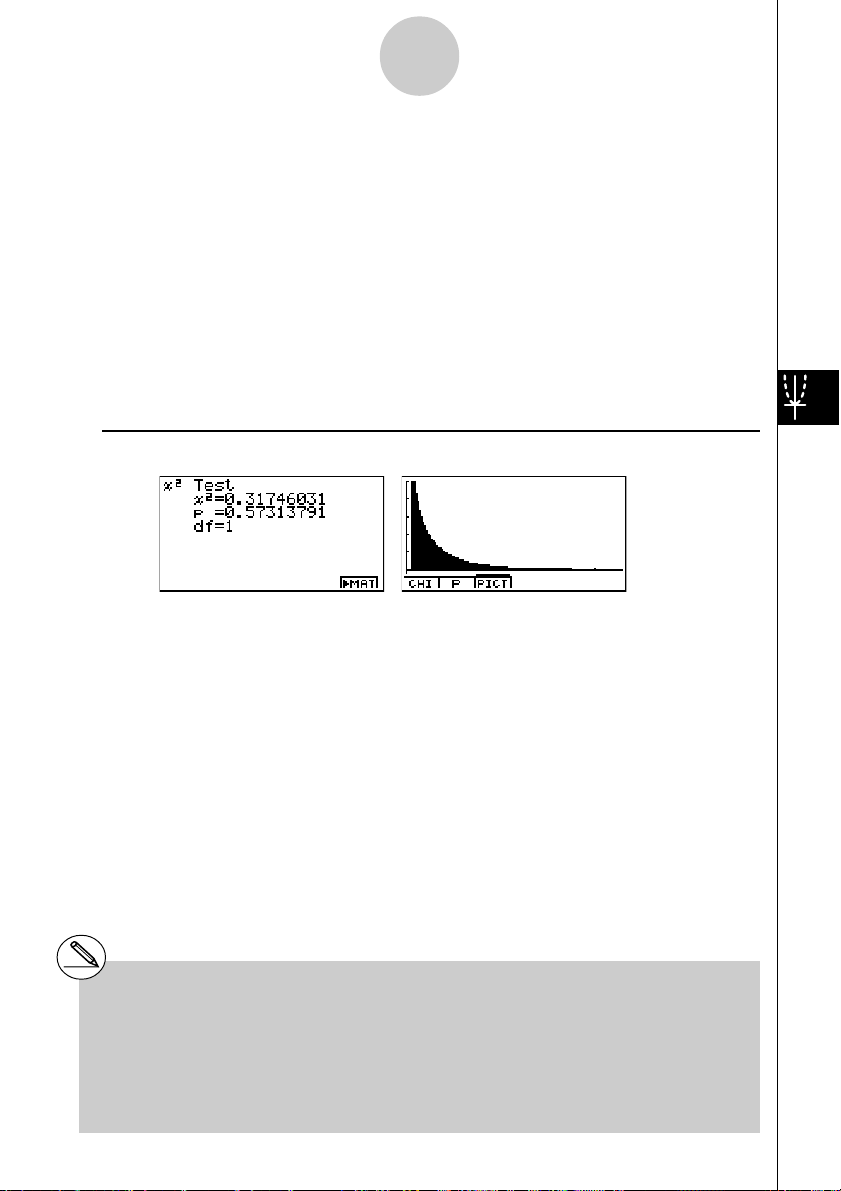
Statistische Testverfahren (TEST)
1-2-19
u u u u u
Beispiel Die Komponenten des Zufallsvektors (X,Y) entstammen aus zwei dichotomen
Grundgesamtheiten X und Y . Eine Stichprobenerhebung ergab die folgende
Kontingenztafel: Mat A = [ [
ist die Unabhängigkeit der beobachteten Merkmale X und Y. Zu berechnen
und unter Mat B abzuspeichern ist die Matrix [ [
hin sind
die Testgröße χ2 (unter der Nullhypothese Ho: P(
P(X=
x
) P(Y=
y
i
die
kritische Irrtumswahrscheinlichkeit p zu bestimmen. Kann die Nullhypothese
) für alle Indexpaare, HA: ... nicht für alle Indexpaare) und
j
auf Grundlage der vorliegenden Vierfeldertafel abgelehnt werden (Irrtumswahrscheinlichkeit α = 0.10) ?
(Antwort: Nein, keine Ablehnung von
ausgegangen werden, dass es sich um unabhängige Merkmale handeln könnte.)
Berechnungsergebnis-Ausgabebildschirm für 1(CALC) bzw. 6(DRAW)
h
11
,
h
1 2
] [
h
21
,
h
22
] ]
, d.h. k = 2, l = 2.
F
11
,
F
1 2
] [
F
Zu untersuchen
21
,
F
22
] ].
(X,Y) =(xi,yj)
Ho wegen p≥α . Es kann also davon
Weiter-
) =
2
χ
................................. berechnete
2
χ
-Testgröße (df = 1 Freiheitsgrad)
p .................................. p-Wert (kritische Irrtumswahrscheinlichkeit)
df ................................. Freiheitsgrad
Sie können die folgenden Grafikanalysefunktionen nach dem Zeichnen der Test-Grafik
verwenden.
• 1(CHI) ... Zeigt die berechnete
Drücken Sie die Taste 1(CHI), um den
wobei der Cursor an der entsprechenden Stelle in der Grafik erscheint (sofern diese Stelle
nicht außerhalb des Betrachtungsfensters liegt).
Drücken Sie die i-Taste, um die Anzeige des
• 2(P) ... Zeigt den zur berechneten Testgröße gehörenden p-Wert an.
Drücken Sie die Taste 2(P), um den p-Wert in der Fußzeile des Displays anzuzeigen, ohne
dass der Cursor erscheint. Drücken Sie die i-Taste, um die Anzeige des p-Wertes zu löschen.
# Drücken Sie die Taste 6('MAT), während ein
Berechnungsergebnis angezeigt wird, um den
MATRIX-Editor aufzurufen, den Sie für die
Bearbeitung und das Betrachten des Inhalts der
Matrizen verwenden können.
# Folgende Betrachtungsfenster-Einstellungen
werden für das Zeichnen der Grafik verwendet:
2
χ
-Testgröße an.
2
χ
-Wert in der Fußzeile des Display anzuzeigen,
2
χ
-Wertes zu löschen.
Xmin = 0, Xmax = 11,5, Xscale = 2,
Ymin = –0,1, Ymax = 0,5, Yscale = 0,1
# Bei der Ausführung des Testverfahrens werden
2
der
χ
-Wert und der p-Wert automatisch in den
alphabetischen Variablen C bzw. P abgespeichert.
20010901
Page 29

Statistische Testverfahren (TEST)
1-2-20
kk
k 2-Stichproben F-Test (2-Sample
kk
F-Test) zum Streuungsvergleich
Der 2-Stichproben F-Test prüft die Hypothese zur Gleichheit der Streuungen zweier (normal-
verteilter) Grundgesamtheiten mithilfe empirischer Stichprobenstreuungen. Der F-Test beruht
auf einer F-verteilten Testgröße mit den Freiheitsgraden n1-1 (Zähler-FG) und n2-1 (NennerFG).
F =
x
x
σ
1 n–1
σ
2 n–1
2
2
Führen Sie die folgende Tastenbetätigung im STAT-Eingangsmenü (Listeneditor) aus.
3(TEST)
e(F)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der Stichprobendaten [List] oder
empirische Kennzahlen [Variable])
σ
1 ................................. Art der Alternativhypothese (“G σ2” legt den zweiseitigen
kritischen Bereich fest, “<
Bereich links fest, “>
σ
2” legt den einseitigen kritischen Bereich
σ
2” legt den einseitigen kritischen
rechts fest.)
List(1) .......................... Liste der Stichprobendaten 1
List(2) .......................... Liste der Stichprobendaten 2
Freq(1) ........................ einfache Häufigkeiten [1] oder Häufigkeitsliste 1
Freq(2) ........................ einfache Häufigkeiten [1] oder Häufigkeitsliste 2
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus oder zeichnet eine Test-Grafik
(Dichtefunktion einer F
df1,df2
-
Verteilung)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Kennzahlenvorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
x1
σ
n-1 ............................ empirische Standardabweichung (x1σn-1
>
0) der Stichprobe 1
n1 ................................. Umfang der Stichprobe 1 (positive ganze Zahl)
x2
σ
n-1 ............................ empirische Standardabweichung (x2σn-1
>
0) der Stichprobe 2
n2 ................................. Umfang der Stichprobe 2 (positive ganze Zahl)
20010901
20011201
Page 30
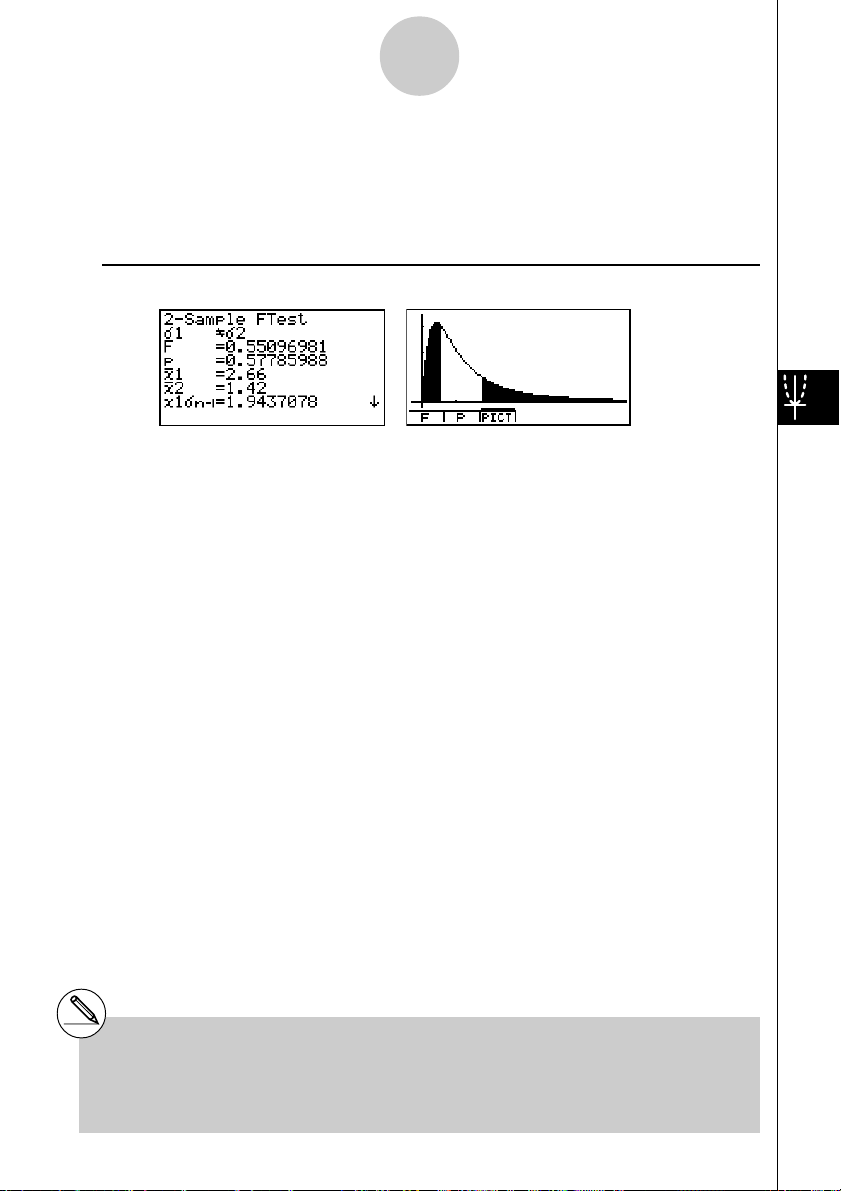
Statistische Testverfahren (TEST)
1-2-21
Nachdem Sie alle Parameter eingestellt haben, stellen Sie den Cursor auf [Execute] und drücken
danach eine der nachfolgend dargestellten Funktionstasten, um die Berechnung auszuführen
oder eine Test-Grafik (Dichtefunktion einer Fdf1,df2 - Verteilung) zu zeichnen.
• 1(CALC) ... Führt die Berechnung aus.
• 6(DRAW) ... Zeichnet die Test-Grafik zum Testergebnis.
Beispiel: Ausgabebildschirm für 1(CALC) bzw. 6(DRAW)
σ1Gσ
2 .......................... Art der Alternativhypothese (zweiseitiger kritischer Bereich)
F .................................. berechnete F-Testgröße (df 1 = 4, df 2 = 4 Freiheitsgrade)
p .................................. p-Wert (kritische Irrtumswahrscheinlichkeit) ( p≥
α
=0.10 z.B.)
o1 ................................. empirischer Stichproben-Mittelwert der Stichprobe 1
(Angezeigt nur für Datenlistenvorgabe [Data: List].)
o2 ................................. empirischer Stichproben-Mittelwert der Stichprobe 2
(Angezeigt nur für Datenlistenvorgabe [Data: List].)
x1
σ
n-1 ............................ emp. Standardabweichung der Stichprobe 1 (1.9437078)
x2
σ
n-1 ............................ emp. Standardabweichung der Stichprobe 2 (2.61858741)
n1 ................................. Umfang der Stichprobe 1 (n1 = 5)
n2 ................................. Umfang der Stichprobe 2 (n2 = 5)
Sie können die folgenden Grafikanalysefunktionen nach dem Zeichnen der Test-Grafik
verwenden.
• 1(F) ... Zeigt die berechnete F-Testgröße an.
Drücken Sie die Taste 1(F), um den F-Wert in der Fußzeile des Displays anzuzeigen, wobei
der Cursor an de entsprechenden Stelle in der Grafik erscheint (sofern diese Stelle nicht
außerhalb des Betrachtungsfensters liegt).
Im Falle eines Tests mit zweiseitigem kritischen Bereich werden zwei Punkte angezeigt.
Verwenden Sie die d- und e-Taste, um den Cursor zu verschieben.
Drücken Sie die i-Taste, um die Anzeige des F-Wertes zu löschen.
• 2(P) ... Zeigt den zur berechneten Testgröße gehörenden p-Wert an.
Drücken Sie die Taste 2(P), um den p-Wert in der Fußzeile des Displays anzuzeigen, ohne
dass der Cursor erscheint. Drücken Sie die i-Taste, um den p-Wert zu löschen.
# [Save Res] speichert die
2 (Alternativhypothese) nicht ab.
# Die Betrachtungsfenstereinstellungen werden
automatisch für das Zeichnen der Grafik
optimiert.
σ
1-Bedingung in Zeile
# Bei der Ausführung des Testverfahrens werden
der
F-Wert und der p-Wert automatisch in den
alphabetischen Variablen F bzw. P abgespeichert.
20010901
Page 31

Statistische Testverfahren (TEST)
1-2-22
kk
k Varianzanalyse (ANOVA)
kk
ANOVA prüft Hypothesen zur Gleichheit von Mittelwerten mehrerer (normalverteilter) Grundgesamtheiten auf Grundlage entsprechender Stichproben mithilfe einer Streuungszerlegung
("Varianzanalyse") und einer oder mehrerer F-verteilter Prüfgrößen.
Die Einweg-Varianzanalyse (One-Way ANOVA) wird verwendet, wenn nur ein unabhängiger
Einflußfaktor A in verschiedenen Abstufungen Ai auf eine abhängige Variable Yir wirkt.
Die Zweiweg-Varianzanalyse (Two-Way ANOVA) wird verwendet, wenn zwei unabhängige
Einflußfaktoren A und B in bestimmten Abstufungen Ai und Bj auf eine abhängige Variable
Y
wirken (Indexnotation: i-te Stufe von A, j-te Stufe von B, r=ri-te bzw. r=rij-te Wiederholung).
ijr
Führen Sie die folgende Tastenbetätigung im STAT-Eingangsmenü (Listeneditor) aus.
3(TEST)
f(ANOVA)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Einweg- bzw. ZweiwegVarianzanalyse beschrieben.
How Many ................... Wählt die Einweg-Varianzanalyse oder Zweiweg-Varianz-
analyse (Anzahl der Einflußfaktoren)
Factor A ....................... Kategorienliste der auf Y wirkenden Faktorstufen A
Dependnt .................... Liste der Stichprobendaten Y
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 16)*
bzw. Y
ir
ijr
1
Execute ....................... Führt die Berechnung aus oder zeichnet eine Test-Grafik
(letztes nur für die Zweiweg-Varianzanalyse)
Die folgende Position erscheint nur im Fall der Zweiweg-Varianzanalyse.
Factor B....................... Kategorienliste der auf Y wirkenden Faktorstufen B
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken Sie danach eine der nachfolgend dargestellten Funktionstasten, um die
Berechnung auszuführen oder im Fall einer Zweiweg-Varianzanlyse die Test-Grafik zu zeichnen.
• 1(CALC) ... Führt die Berechnung aus.
• 6(DRAW) ... Zeichnet die Test-Grafik (nur Zweiweg-Varianzanalyse)
i
j
Die Berechnungsergebnisse werden in Tabellenform angezeigt, genau wie sie in jedem StatistikLehrbuch zu finden ist.
*1 [Save Res] speichert jede vertikale Spalte der
Tabelle in einer eigenen Liste ab. Die Spalte
ganz links wird in der benannten Liste abgespeichert, jede rechts davon angeordnete
Spalte wird in der Liste mit der nächstfolgenden
Nummer abgespeichert. Bis zu fünf Listen
können für die Speicherung der Spalten verwendet werden. Sie können eine Nummer im
Bereich von 1 bis 16 für die erste Liste vorgeben.
20010901
20011201
Page 32

Statistische Testverfahren (TEST)
1-2-23
Die Einweg-Varianzanalyse benötigt für ihre Auswertung zwei verbundene Datenlisten mit den
Datenpaaren (
Datenlisten mit den Datentripeln (
Ai , Yir). Die Zweiweg-Varianzanalyse hingegen benötigt drei verbundene
Ai , Bj , Yijr).
Beispiel: Ausgabebildschirm für eine Einweg- bzw. Zweiweg-Varianzanalyse
Einweg-Varianzanalyse (One-Way ANOVA)
Zeile 1 (A) ................... zum Faktor A: df-Wert, SS-Wert, MS-Wert, F-Wert, p-Wert
Zeile 2 (ERR) .............. zum Fehler: df-Wert, SS-Wert, MS-Wert
Zweiweg-Varianzanalyse (Two-Way ANOVA)
Zeile 1 (A) ................... zum Faktor A: df-Wert, SS-Wert, MS-Wert, F-Wert, p-Wert
Zeile 2 (B) ................... zum Faktor B: df-Wert, SS-Wert, MS-Wert, F-Wert, p-Wert
Zeile 3 (AB) ................. zum Wechselwirkungseffekt (Faktor A × Faktor B):
df-Wert, SS-Wert, MS-Wert, F-Wert, p-Wert
*Die Zeile 3 erscheint nur, wenn für jede Stufen-Kombination
Ai , Bj gleichviele Mehrfach-Beobachtungen vorhanden sind.
Zeile 4 (ERR) .............. zum Fehler: df-Wert, SS-Wert, MS-Wert
F .................................. F-Wert(e) (F = MS / MS
p
.................................. p-Wert zum jeweiligen F-Wert ( p
df
................................. Freiheitsgrade
ERR
)
=
P( F > MS / MS
ERR
) )
SS ................................ Summe der Fehler-Quadrate
MS (= SS / df ) ............
gemittelte Fehler-Quadrat-Summen (gemittelte Streuungsanteile)
Bei der Zweiweg-Varianzanalyse können Sie Grafiken zum Wechselwirkungseffekt zeichnen.
Die Anzahl der Graphen ist durch die Anzahl der Stufen des Faktors B bestimmt, die Anzahl
der Datenpunkte auf der x-Achse ist durch die Anzahl der Stufen des Faktors A bestimmt. Auf
der y-Achse werden die Mittelwerte der Y
zur entsprechenden Kombination(Ai,Bj) abgetragen.
ijr
Sie können die folgende Grafikanalysefunktion nach dem Zeichnen einer Test-Grafik verwenden.
• 1(TRACE) ... Abtastfunktion (Trace) für die berechneten Einzelmittelwerte
Drücken Sie die d- oder e-Taste, um den Cursor auf der Grafik in die entsprechende Richtung
zu verschieben. Wenn mehrere Graphen vorhanden sind, können Sie zwischen den Graphen
wechseln, indem Sie die f- oder c-Taste drücken. Drücken Sie die i-Taste, um den
Zeiger vom Diplay zu löschen.
#
Die grafische Darstellung steht nur für die
Zweiweg-ANOVA zur Verfügung. Die Betrachtungsfenster-Einstellungen werden automatisch ausgeführt, unabhängig von den Vorgaben
im SET UP-Menü.
# Bei Verwendung der TRACE-Funktion werden
entsprechend der Cursorposition die Anzahl der
Wiederholungen automatisch in der alphabetischen Variablen A bzw. der angezeigte Mittelwert in der Variablen M gespeichert.
20010901
Page 33

Statistische Testverfahren (TEST)
1-2-24
kk
k ANOVA (Zweiweg)
kk
uu
u
Darstellung einer Aufgabensituation
uu
Die folgende Tabelle zeigt Messungsergebnisse für ein Merkmal Y (z. B. Festigkeit) eines
Metallerzeugnisses, das mittels eines Wärmebehandlungsverfahren unter dem Einfluß zweier
Faktoren hergestellt wurde: Zeit (A) und Temperatur (B). Die Messungen wurden zwei Mal
unter identischen Bedingungen wiederholt.
B (
Temperatur der Wärmebehandlung
A (Zeit)
A1 113 , 116
A2
Untersuchen Sie mithilfe der Varianzanalyse die folgenden Nullhypothesen, wobei eine
Irrtumswahrscheinlichkeit von α = 5% zu verwenden ist.
HA : Die Zeitabstufungen (
HB : Die Temperaturabstufungen (
HAB :
Die Stufenkombinationen (Ai,Bj) sind im Mittel ohne Einfluß auf die Festigkeit
uu
u Lösungsweg
uu
Verwenden Sie die Zweiweg-Varianzanalyse, um die obigen Null-Hypothesen zu prüfen. Geben Sie die obigen Stichprobenwerte (Y-Daten) z.B. wie folgt als verbundene Listen ein.
List 1 = { 1, 1, 1, 1, 2, 2, 2,
List 2 = { 1, 1, 2, 2, 1, 1, 2,
List 3 = {113, 116, 139, 132, 133, 131, 126, 122 }
Definieren Sie im Eingabemenü zum Testverfahren List 3 (die gemessenen Werte Y ) als
abhängig. Ordnen Sie List 1 und List 2 (die Faktorenstufenzuordnung für jeden Werte Y in
List 3) dem Faktor A bzw. Faktor B zu.
Durch Ausführung der Varianzanalyse werden die folgenden Ergebnisse erhalten.
•Kritische Irrtumswahrscheinlichkeit (Sicherheitsschwelle) p = 0,2458019517 für den Faktor
A (Zeitabstufungen):
Der p-Wert (p = 0,2458019517) ist größer als die Irrtumswahrscheinlichkeit (Sicherheitsschwelle α = 0,05), sodass die Null-Hypothese HA nicht verworfen werden kann.
•Kritische Irrtumswahrscheinlichkeit (Sicherheitsschwelle) p = 0,04222398836 für den Faktor
B (Temperaturabstufungen):
Der p-Wert (p = 0,04222398836) ist kleiner als die Irrtumswahrscheinlichkeit (Sicherheitsschwelle α = 0,05), sodass die Null-Hypothese HB verworfen werden muss.
•Kritische Irrtumswahrscheinlichkeit (Sicherheitsschwelle) p = 2,78169946E-3 der Interaktion
(Wechselwirkungseffekt) (A × B):
Die Sicherheitsschwelle (p = 2,78169946E-3) ist kleiner als die Sicherheitsschwelle (0,05),
sodass die Null-Hypothese HAB verworfen werden muss.
Der obige Test zeigt, dass für die Festigkeit des Metallerzeugnisses die Zeitdauer der Wärmebehandlung nicht von Bedeutung ist, wohl aber die Höhe der Temperatur maßgebend und
der Wechselwirkungseffekt sehr maßgebend sind.
Ai) sind im Mittel ohne Einfluß auf die Festigkeit Y
(Zweiwegklassifikation, Mehrfachbesetzung)
)B1 B2
139 , 132
133 , 131
Bj) sind im Mittel ohne Einfluß auf die Festigkeit Y
20010901
126 , 122
2}
2}
Y
Page 34

uu
u Eingabebeispiel
uu
uu
u Ergebnisse
uu
Statistische Testverfahren (TEST)
1-2-25
Hinweis:
Für die Streuungszerlegung (Varianzanalyse) werden folgende mathematische Modelle zur
Darstellung von Y mithilfe eines allgemeinen Mittelwertes µ, sowie der individuellen
Mittelwertanteile αi bzw. βj bzw. (αβ)ij und des stochastischen Fehlers E benutzt:
Einweg-Varianzanalyse:
SS = SS
+ SS
A
für Yir = µ + αi + Eir mit E
ERR
僆
N(0,σ
2
ir
).
Zweiweg-Varianzanalyse (ohne Wechselwirkungseffet):
SS = SS
+ SSB + SS
A
für Yir = µ + αi + βj + E
ERR
mit E
ijr
僆
N(0,σ
2
ijr
).
Zweiweg-Varianzanalyse (mit Wechselwirkungseffet):
SS = SS
+ SSB + SSAB + SS
A
ERR
für Y
= µ + αi + βj + (αβ)ij + E
ijr
mit E
ijr
僆
N(0,σ
ijr
2
Unter den oben genannten Nullhypothesen wurde praktisch stets von Y = µ + E ausgegangen,
d.h. HA : αi = 0 bzw. HB : βj = 0 bzw. HAB : (αβ)
20010901
= 0.
ij
).
Page 35

Vertrauensintervalle (INTR)
1-3-1
1-3 Vertrauensintervalle (INTR)
Ein Vertrauensintervall (Konfidenzintervall) ist ein Zahlenbereich (Intervall [Gu, Go]), das den
unbekannten Mittelwert einer untersuchten Grundgesamtheit mit hoher Wahrscheinlichkeit
einschließen soll. Die Intervallgrenzen Gu, Go werden dabei durch eine Zufallsstichprobe
geschätzt unter Berücksichtigung des vorgegebenen Konfidenzniveaus ε.
Bei einem zu breiten Vertrauensintervall ist es nur sehr schwer nachvollziehbar, wo der Mittelwert
(wahre Wert) der Grundgesamtheit liegt. Ein zu enges Vertrauensintervall schränkt dagegen
den möglichen Mittelwert zu sehr ein und macht es schwierig, zuverlässige Aussagen zu erhalten. Die am häufigsten verwendeten Vertrauenswahrscheinlichkeiten (Konfidenzniveaus,
Sicherheitswahrscheinlichkeiten) betragen ε=95% oder ε=99%. Durch das Anheben des
Konfidenzniveaus wird das Vertrauensintervall verbreitert, hingegen ein Absenken des
Konfidenzniveaus zu einem engeren Vertrauensintervall führt und gleichzeitig aber auch die
Gefahr eines ungewollten Ausklammerns des tatsächlichen Mittelwertes in sich birgt. Mit einem
Konfidenzniveau von ε=95% z.B. wird der unbekannte Parameter nur mit einer Irrtumswahrscheinlichkeit von α=1-ε= 5% außerhalb des Intervalls [Gu, Go] liegen.
Wenn Sie eine Untersuchung planen, um dann mit den erfaßten Daten ein t-Intervall oder ZIntervall zu bestimmen, müssen Sie auch den Stichprobenumfang, die Breite des Vertrauensintervalls und das Konfidenzniveau bedenken. Das Grenzen Gu, Go des Vertrauensintervalls
sind von den Anwendungsbedingungen (Vorgabewerten) abhängig.
Das 1-Stichproben Z-Intervall (1-Sample Z-Interval) beschreibt mithilfe einer Stichprobe das
Vertrauensintervall für den unbekannten Mittelwert einer (normalverteilten) Grundgesamtheit,
wenn die Standardabweichung der Grundgesamtheit bekannt ist.
Das 2-Stichproben Z-Intervall (2-Sample Z-Interval) beschreibt mithilfe zweier Stichproben
das Vertrauensintervall für die Differenz zweier unbekannter Mittelwerte zweier (normalverteilter)
Grundgesamtheiten, wenn die Standardabweichungen der zwei Grundgesamtheiten bekannt
sind.
Das 1-Prop Z-Intervall beschreibt mithilfe einer Stichprobe das Vertrauensintervall für die
Erfolgswahrscheinlichkeit [Prop] in einer dichotomen Grundgesamtheit, wobei die Berechnung
der Intervallgrenzen näherungsweise über eine N(0,1)-verteilte Zufallsgröße realisiert wird.
Das 2-Prop Z-Intervall beschreibt mithilfe zweier Stichproben das Vertrauensintervall für die
Differenz der Erfolgswahrscheinlichkeit p1 und p2 zweier dichotomer Grundgesamtheiten, wobei
die Berechnung der Intervallgrenzen wieder näherungsweise über eine N(0,1)-verteilte
Zufallsgröße realisiert wird.
Das 1-Stichproben t-Intervall (1-Sample t-Interval) beschreibt mithilfe einer Stichprobe das
Vertrauensintervall für den unbekannten Mittelwert einer (normalverteilten) Grundgesamtheit,
wenn die Standardabweichung der Grundgesamtheit unbekannt ist und geschätzt werden muß.
Das 2-Stichproben t-Intervall (2-Sample t-Interval) beschreibt mithilfe zweier Stichproben das
Vertrauensintervall für die Differenz zweier unbekannter Mittelwerte zweier (normalverteilter)
Grundgesamtheiten, wenn die Standardabweichungen der zwei Grundgesamtheiten unbekannt
sind und geschätzt werden müssen.
# Für die Vertrauensintervalle können keine
speziellen Grafiken erstellt werden.
20010901
20011201
Page 36

Vertrauensintervalle (INTR)
1-3-2
In der Eingangsanzeige (Listeneditor) des STAT-Menüs drücken Sie die Taste 4 (INTR), um
das Untermenü für die Vertrauensintervalle anzuzeigen, das die folgenden Positionen enthält.
• 4(INTR)b(Z) ... Z-Intervalle (vier Varianten mithilfe der N(0,1)-Verteilung,
ab S. 1-3-3)
c(T) ... t-Intervalle (zwei Varianten mithilfe der t-Verteilung,
ab S. 1-3-8)
uu
u Allgemeine Hinweise hinsichtlich des Konfidenzniveaus
uu
Durch die Eingabe eines C-Wertes (C-Level, Konfidenzniveau, Sicherheitswahrscheinlichkeit)
im Bereich von 0
Konfidenzniveau festgelegt. Durch die Eingabe eines C-Wertes (in %) im Bereich von 1
<<
< C < 1 für die Einstellung des C-Level wird das von Ihnen eingegebene
<<
<<
< C <
<<
100 wird ein C-Wert intern abgespeichert, der dem von Ihnen eingegebenen C-Wert, geteilt
durch 100, entspricht.
# Die Eingabe eines Wertes von 100 oder größer
bzw. die Eingabe eines negativen Wertes
erzeugt eine Fehlermeldung (Ma ERROR).
20010901
Page 37

Vertrauensintervalle (INTR)
kk
k Z-Intervalle (mit Quantilen der N(0,1)-Verteilung)
kk
uu
u 1-Stichproben Z-Intervall (1-Sample Z-Interval)
uu
Das 1-Stichproben Z-Intervall beschreibt mithilfe einer Stichprobe das Vertrauensintervall für
den unbekannten Mittelwert µ einer (normalverteilten) Grundgesamtheit, wenn die Standardabweichung der Grundgesamtheit bekannt ist.
Die nachfolgenden Formeln beschreiben die Intervallgrenzen Left = Gu , Right = Go .
1-3-3
Es gilt: 1-
α
ist jedoch das Signifikanzniveau. Der Wert 100 (1–α )
ε
% , d.h. ε = 1-α . Wenn zum Beispiel das Vertrauensniveau 95% beträgt, dann wird durch die
Eingabe von 0,95 die Irrtumswahrscheinlichkeit α = 1 – 0,95 = 0,05 erhalten. z
das Quantil der Ordnung 1-
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
4(INTR)
b(Z)
b(1-Smpl)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Fall der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der Stichprobendaten [List] oder
C-Level ........................ Konfidenzniveau C (0 < C < 1)
σ
.................................. bekannte Grundgesamtheits-Standardabweichung (σ > 0)
List .............................. Liste der Stichprobendaten
Freq ............................. einfache Häufigkeiten [1] oder Häufigkeitsliste
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung der Intervallgrenzen aus
α /
2 einer N(0,1)-Verteilung.
empirische Kennzahlen [Variable])
nisse (Keine [None] oder Liste 1 bis 20)
α /
2 = P( Z
≤ z
vgl. S. 1-4-5 oder
Bedienungsanleitung S. 6-4-5
% entspricht dem Konfidenzniveau 100
α /
1-
α /
1-
) ,
2
bezeichnet
2
Nachfolgend ist die Bedeutung der einzelnen Positionen im Fall der Kennzahlenvorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
o .................................. empirischer Mittelwert der Stichprobe
n .................................. Stichprobenumfang (positive ganze Zahl)
20010901
20011201
Page 38

Vertrauensintervalle (INTR)
1-3-4
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken Sie danach die folgende Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallgrenzen aus.
Beispiel:
Ausgabebildschirm (Vorgabewerte: Datenliste,sowie C = 0.95, σ = 15)
Left .............................. Untere Intervallgrenze (Gu) des Konfidenzintervalls für
Right ............................ Obere Intervallgrenze (Go) des Konfidenzintervalls für
µ
µ
o .................................. empirischer Mittelwert der Stichprobe
x
σ
n-1 ............................. empirische Stichproben-Standardabweichung
(Angezeigt nur für Datenlistenvorgabe [Data: List].)
n .................................. Stichprobenumfang
uu
u 2-Stichproben Z-Intervall (2-Sample Z-Interval)
uu
Das 2-Stichproben Z-Intervall beschreibt mithilfe zweier Stichproben das Vertrauensintervall
für die Differenz
heiten, wenn die Standardabweichungen der zwei Grundgesamtheiten bekannt sind. α = 1 - ε.
µ
-
µ
zweier unbekannter Mittelwerte zweier (normalverteilter) Grundgesamt-
1
2
Die nachfolgenden Formeln beschreiben die Intervallgrenzen Left = Gu , Right = Go .
o1 :Mittelwert der Stichprobe 1
o2 :Mittelwert der Stichprobe 2
σ
1 :
bekannte Standardabweichung
der Grundgesamtheit 1
σ
2 :
bekannte Standardabweichung
der Grundgesamtheit 2
n1 : Umfang der Stichprobe 1
n2 : Umfang der Stichprobe 2
Für das
z
1-
α
/ 2
-Quantil gilt:
1-
α
/ 2 = P( z
)
, vgl. S. 1-4-5 oder Bedienungsanleitung S. 6-4-5.
1-
α
/ 2
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
4(INTR)
b(Z)
c(2-Smpl)
20010901
Page 39

Vertrauensintervalle (INTR)
1-3-5
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der Stichprobendaten [List] oder
empirische Kennzahlen [Variable])
C-Level ........................ Konfidenzniveau C (0 < C < 1)
σ
1 .................................
σ
2 .................................
bekannte Grundgesamtheits-Standardabweichung 1 (
bekannte Grundgesamtheits-Standardabweichung 2 (
σ
σ
1
> 0)
2
> 0)
List(1) .......................... Liste der Stichprobendaten der 1. Stichprobe
List(2) .......................... Liste der Stichprobendaten der 2. Stichprobe
Freq(1) ........................ einfache Häufigkeiten [1] oder Häufigkeitsliste 1
Freq(2) ........................ einfache Häufigkeiten [1] oder Häufigkeitsliste 2
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung der Intervallgrenzen aus
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Kennzahlenvorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
o1 ................................. empirischer Mittelwert der Stichprobe 1
n1 ................................. Umfang der Stichprobe 1 (positive ganze Zahl)
o2 ................................. empirischer Mittelwert der Stichprobe 2
n2 ................................. Umfang der Stichprobe 2 (positive ganze Zahl)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken Sie danach die folgende Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallgrenzen aus.
Beispiel: Ausgabebildschirm (mit x
1σn-1
=26, x
=22, C=94%)
2σn-1
Left .............................. Untere Intervallgrenze des Konfidenzintervalls für
Right ............................ Obere Intervallgrenze des Konfidenzintervalls für
o1 ................................. empirischer Mittelwert der Stichprobe 1 (o1 = 418)
o2 ................................. empirischer Mittelwert der Stichprobe 2 (o2 = 402)
x1
σ
n-1 ............................ empirische Standardabweichung der Stichprobe 1
(Angezeigt nur für Datenlistenvorgabe [Data: List].)
x2
σ
n-1 ............................ empirische Standardabweichung der Stichprobe 2
(Angezeigt nur für Datenlistenvorgabe [Data: List].)
n1 ................................. Umfang der Stichprobe 1, n2 ..... Umfang der Stichprobe 2
20010901
20011201
µ
µ
-
µ
1
2
-
µ
1
2
Page 40

Vertrauensintervalle (INTR)
uu
u 1-Prop Z-Intervall, Vertrauensintervall für einen Anteilswert [Prop]
uu
Das 1-Prop Z-Intervall beschreibt mithilfe der Anzahl der Treffer x in einer Stichprobe das
Vertrauensintervall für den unbekannten Anteilswert (Prop) in einer dichotomen Grundgesamtheit. In den nachstehenden Berechnungsformeln für Left = Gu , Right = Go wird
ausgenutzt, dass die Trefferquote näherungsweise normalverteilt ist. α = 1 - ε.
Der Wert 100 (1–α) % entspricht dem Konfidenzniveau ε bzw. 100ε %
1-3-6
.
n :Stichprobenumfang
x :Anzahl der Treffer in einer
Stichprobe
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
4(INTR)
b(Z)
d(1-Prop)
Im Eingabefenster zum 1-Prop Z-Intervall sind folgende Positionen einzugeben:
C-Level ........................ Konfidenzniveau C (0 < C < 1)
x ..................................
Anzahl der Treffer in der Stichprobe (0 oder positive ganze Zahl)
n .................................. Stichprobenumfang (positive ganze Zahl)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung der Intervallgrenzen aus
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken Sie danach die folgende Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallgrenzen aus.
nisse (Keine [None] oder Liste 1 bis 20)
Beispiel: Ausgabebildschirm (mit x =600, C=99%)
Left .............................. Untere Intervallgrenze des Konfidenzintervalls für [Prop]
Right ............................ Obere Intervallgrenze des Konfidenzintervalls für [Prop]
ˆp .................................. mithilfe der Stichprobe geschätzter Anteilswert ( x
n .................................. Stichprobenumfang
20010901
/
n )
Page 41

Vertrauensintervalle (INTR)
1-3-7
uu
u 2-Prop
uu
Das 2-Prop Z-Intervall beschreibt mithilfe der Anzahl der Treffer x1, x2 zweier Stichproben das
Vertrauensintervall für die Differenz p1 - p2 zweier unbekannter Anteilswerte p1 , p2 zweier
dichotomer Grundgesamtheiten. In den nachstehenden Berechnungsformeln für Left = Gu ,
Right = Go wird ausgenutzt, dass die Trefferquotendifferenz näherungsweise normalverteilt
ist. α = 1 - ε. Der Wert 100 (1–α) % entspricht dem Konfidenzniveau ε bzw. 100ε %.
Z-Intervall, Vertrauensintervall für eine Anteilswertdifferenz p
- p
1
2
n1, n2 : Stichprobenumfänge
x1, x2 : Trefferanzahlen in
den einzelnen Stich proben
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
4(INTR)
b(Z)
e(2-Prop)
Im Eingabefenster zum 2-Prop Z-Intervall sind folgende Positionen einzugeben:
C-Level ........................ Konfidenzniveau C (0 < C < 1)
x1 .................................
Anzahl der Treffer in der Stichprobe 1
(x1 > 0)
n1 ................................. Umfang der Stichprobe 1 (positive ganze Zahl)
x2 .................................
Anzahl der Treffer in der Stichprobe 2
(x2 > 0)
n2 ................................. Umfang der Stichprobe 2 (positive ganze Zahl)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung der Intervallgrenzen aus
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken Sie danach die folgende Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallgrenzen aus.
nisse (Keine [None] oder Liste 1 bis 20)
Beispiel: Ausgabebildschirm (mit x1 =132, x2 =90, C=99%)
20010901
Page 42

Vertrauensintervalle (INTR)
1-3-8
Left .............................. Untere Intervallgrenze des Konfidenzintervalls für p1 -
Right ............................ Obere Intervallgrenze des Konfidenzintervalls für p1 -
ˆp 1 ................................. mithilfe der Stichprobe geschätzter Anteilswert 1 ( x1
ˆp 2 ................................. mithilfe der Stichprobe geschätzter Anteilswert 2 ( x2
n1 ................................. Umfang der Stichprobe 1
n2 ................................. Umfang der Stichprobe 2
kk
k t-Intervalle (mit Quantilen einer t-Verteilung)
kk
uu
u 1-Stichproben t-Intervall (1-Sample t-Interval)
uu
Das 1-Stichproben t-Intervall beschreibt mithilfe einer Stichprobe das Vertrauensintervall für
den unbekannten Mittelwert µ einer (normalverteilten) Grundgesamtheit, wenn die Standardabweichung der Grundgesamtheit unbekannt ist. In den nachstehenden Berechnungsformeln
für Left = Gu , Right = Go wird ausgenutzt, dass die standardisierte Mittelwertschätzung
näherungsweise tm-verteilt mit (m = n-1 Freiheitsgraden) ist. α = 1 - ε. Der Wert 100 (1–α) %
entspricht dem Konfidenzniveau ε
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
4(INTR)
c(T)
b(1-Smpl)
bzw. 100ε %.
t
n-1, 1-α/2
(mit m = n-1 Freiheitsgraden) der Ordnung 1- α/2,
d.h. 1- α/2 = F
Verteilungsfunktion der tm-Verteilung bezeichnet,
vgl. 1-4-8.
ist das Quantil einer tm-Verteilung
n-1(tn-1, 1-α/2
), wenn F
n-1
/
n1 )
/
n2 )
die
p2
p2
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der Stichprobendaten [List] oder
C-Level ........................ Konfidenzniveau C (0 < C < 1)
List .............................. Liste der Stichprobendaten
Freq ............................. einfache Häufigkeiten [1] oder Häufigkeitsliste
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung der Intervallgrenzen aus
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Kennzahlenvorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
empirische Kennzahlen [Variable])
nisse (Keine [None] oder Liste 1 bis 20)
20010901
20011201
Page 43

Vertrauensintervalle (INTR)
1-3-9
o .................................. empirischer Mittelwert der Stichprobe
x
σ
n-1 ............................. empirische Stichproben-Standardabweichung (xσn-1 > 0)
n .................................. Stichprobenumfang (positive ganze Zahl)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken Sie danach die folgende Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallgrenzen aus.
Beispiel:
Ausgabebildschirm (Vorgabewert: C = 0.95 )
Left .............................. Untere Intervallgrenze (Gu) des Konfidenzintervalls für
Right ............................ Obere Intervallgrenze (Go) des Konfidenzintervalls für
µ
µ
o .................................. empirischer Mittelwert der Stichprobe
x
σ
n-1 ............................. empirische Stichproben-Standardabweichung
n .................................. Stichprobenumfang
Hinweis: Ein beliebiges t
uu
u 2-Stichproben t-Intervall (2-Sample t-Interval)
uu
Das 2-Stichproben t-Intervall beschreibt mithilfe zweier Stichproben das Vertrauensintervall
für die Differenz
heiten, wenn die Standardabweichungen der zwei Grundgesamtheiten unbekannt sind.
Die nachfolgenden Formeln beschreiben die Intervallgrenzen Left = Gu , Right = G
Der Wert 100 (1–α) % entspricht dem Konfidenzniveau ε bzw. 100ε %.
folgende Vorgabewerte benutzt werden:
µ
-
µ
1
-Quantil kann formal als Intervallgrenze angezeigt werden, wenn
m, γ
zweier unbekannter Mittelwerte zweier (normalverteilter) Grundgesamt-
2
oo
o = 0, x
oo
σ
n-1 = (m+1)
1/2
und C = 2γ - 1 > 0.
.
α = 1 - ε.
o
Diese Formel wird verwendet, wenn die Grundgesamtheiten übereinstimmende (unbekannte)
Streuungsparameter besitzen ([Pooled: On]).
t
n1+n2-1, 1-α/2
1- α/2,
bezeichnet, vgl. S. 1-4-8.
ist das Quantil einer
d.h. 1- α/2 = F
t
m
n1+n2-1(tn1+n2-1
-Verteilung (mit m =
), wenn F
, 1-α/2
20010901
m
n1+n
-1 Freiheitsgraden) der Ordnung
2
die Verteilungsfunktion der tm-Verteilung
Page 44

Vertrauensintervalle (INTR)
1-3-10
Die folgende Formel wird verwendet, wenn die Grundgesamtheiten keine übereinstimmenden
Streuungsparameter besitzen ([Pooled: Off]).
Der Wert 100 (1–α) % entspricht dem Konfidenz-
niveau ε bzw. 100ε %.
C
n1–1
2
1
(1–C )
+
n2–1
2
mit
df =
Hinweis: Das Formelsymbol C für df darf nicht mit dem Konfidenzniveau C verwechselt werden!
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
4(INTR)
c(T)
c(2-Smpl)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der Stichprobendaten [List] oder
empirische Kennzahlen [Variable])
C-Level ........................ Konfidenzniveau C (0 < C < 1)
List(1) .......................... Liste der Stichprobendaten der 1. Stichprobe
List(2) .......................... Liste der Stichprobendaten der 2. Stichprobe
Freq(1) ........................ einfache Häufigkeiten [1] oder Häufigkeitsliste 1
Freq(2) ........................ einfache Häufigkeiten [1] oder Häufigkeitsliste 2
Pooled ......................... Streuungsgleichheit eingeschaltet ([Pooled: On]) oder
ausgeschaltet ([Pooled: Off])
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung der Intervallgrenzen aus
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Kennzahlenvorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
20010901
20011201
Page 45

Vertrauensintervalle (INTR)
1-3-11
o1 ................................. empirischer Mittelwert der Stichprobe 1
x1
σ
n-1 ............................ empirische Standardabweichung (x1σn-1 > 0) der Stichprobe 1,
jedoch x1
σ
n-1 + x2σn-1 > 0.
n1 ................................. Umfang der Stichprobe 1 (positive ganze Zahl)
o2 ................................. empirischer Mittelwert der Stichprobe 2
x2
σ
n-1 ............................ empirische Standardabweichung (x2σn-1 > 0) der Stichprobe 2,
jedoch x1
σ
n-1 + x2σn-1 > 0.
n2 ................................. Umfang der Stichprobe 2 (positive ganze Zahl)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken Sie danach die folgende Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallgrenzen aus.
Beispiel für einen
Ausgabebildschirm unter der Voreinstellung [Pooled: Off]
Left ..............................
Right ............................
Untere Intervallgrenze (Gu) des Konfidenzintervalls für
Obere Intervallgrenze (Go) des Konfidenzintervalls für
µ
-
µ
1
µ
-
µ
1
df ................................. Freiheitsgrade (hier: df = 7.29033011)
o1 ................................. empirischer Stichproben-Mittelwert der Stichprobe 1
o2 ................................. empirischer Stichproben-Mittelwert der Stichprobe 2
x1
σ
n-1 ............................ empirischer Standardabweichung der Stichprobe 1
x2
σ
n-1 ............................ empirischer Standardabweichung der Stichprobe 2
xp
σ
n-1 ............................ gemeinsame Standardabweichung der Gesamtstichprobe
(wird nur angezeigt unter der Voreinstellung [Pooled:On].)
n1 ................................. Umfang der Stichprobe 1
n2 ................................. Umfang der Stichprobe 2
Interpretation:
oo
Auf Grundlage der Stichprobenerhebungen unterscheiden sich die Mittelwerte
-3,8. Mit einer Wahrscheinlichkeit von C (Vertrauenswahrscheinlichkeit) liegt die tatsächliche
Differenz
[-7.5088264, -0.0911735].
µ
-
µ
der unbekannten Mittelwertparameter im (Vertrauens-)Intervall [Gu,
1
2
o
oo
und
1
oo
o
um
oo
2
Go] =
2
2
20010901
Page 46

Wahrscheinlichkeitsverteilungen (DIST)
1-4-1
1-4 Wahrscheinlichkeitsverteilungen (DIST)
Es gibt eine Vielzahl verschiedenartigster Wahrscheinlichkeitsverteilungen, unter denen die
wohl bekannteste die Normalverteilung ist, die für statistische und wahrscheinlichkeitstheoretische Berechnungen verwendet wird. Die Normalverteilung ist eine stetige und symmetrische Verteilung um den Mittelwertparameter µ, d.h. bei einer statistischen Datenerhebung in
einer normalverteilten Grundgesamtheit werden Daten in unmittelbarer Umgebung von
häufiger und weiter links oder rechts von µ liegende Zahlenwerte seltener in der Stichprobe
vorkommen. Dabei spielt als zweiter Parameter die Standardabweichung σ eine wichtige Rolle.
Die Poission-Verteilung, die geometrische Verteilung und andere diskrete Wahrscheinlich-
keitsverteilungen finden ebenfalls häufig Anwendung bei stochastischen Betrachtungen. Welche
Wahrscheinlichkeitsverteilung als wahrscheinlichkeitstheoretisches Datenmodell zur Anwendung
kommen wird, ist oftmals von der praktischen Fragestellung abhängig.
Ist das wahrscheinlichkeitstheoretische Datenmodell für X (die Wahrscheinlichkeitsverteilung
der Grundgesamtheit X oder der Zufallsgröße X ) bekannt, können Sie z.B. Intervallwahrscheinlichkeiten P(
= P(X
≥
a) usw. berechnen.
So kann zum Beispiel die Verteilungsfunktion verwendet werden, um den Qualitätsanteil bei
der (Massen-)Produktion eines bestimmten Erzeugnisses zu berechnen, indem ein Qualitätsmerkmal X betrachtet wird. Sobald ein x-Intervall (Wertebereich für X) als Kriterium vorgegeben
ist, können Sie die Normalverteilungswahrscheinlichkeit dafür berechnen, dass die
betrachtete Produktionskennziffer X genau in diesem x-Intervall liegen wird. D.h., Sie berechnen
den Prozentsatz dafür, dass ein vorgegebenes Kriterium erfüllt wird.
Andererseits kann z.B. eine unbekannte Ausschußrate q als Null-Hypothese (zum Beispiel q =
q
=10%) in einer dichotomen Grundgesamtheit Y angesetzt und dann mithilfe einer
o
normalverteilten Testgröße Z untersucht werden, um zu entscheiden, ob (mit einer gewissen
Irrtumswahrscheinlichkeit α) die Null-Hypothese zugunsten einer Alternativhypothese abgelehnt
werden muß.
Weiterhin spielt die Normalverteilung in Form ihrer Umkehrfunktion (Quantile der N(0,1)Verteilung) eine wichtige Rolle zur Berechnung der Intervallgrenzen von Vertrauensintervallen
z.B. für den Qualitätsanteil (Erfolgsquote
X苸[a, b]
) = P(a
≤ X ≤
b), P(
X苸(-
p) innerhalb einer dichotomen Grundgesamtheit Y.
∞
, b]
) = P(X
≤ b) oder P(
X苸[a,
∞
µ
)
)
Mithilfe der Normalverteilungsdichte(-funktion) kann für einen vorgegebenen x-Wert die
Wahrscheinlichkeitsdichte der Normalverteilung an der Stelle x berechnet werden.
Mithilfe der Verteilungsfunktion einer Normalverteilung können unkompliziert Intervallwahr-
scheinlichkeiten der Form P(
werden. Intervallwahrscheinlichkeiten können als schraffierte Fläche unter der (Gaußschen)
Glockenkurve grafisch veranschaulicht werden.
Mithilfe der Umkehrfunktion der (Normal-)Verteilungsfunktion kann schließlich für eine
vorgegebene Intervallwahrscheinlichkeit γ = P(
x
(Quantil der Ordnung γ) berechnet werden.
γ
Mithilfe der Studentschen t-Verteilungsdichte(-funktion) kann für einen vorgegebenen x-
Wert die Wahrscheinlichkeitsdichte der t-Verteilung an der Stelle x berechnet werden.
Mithilfe der Verteilungsfunktion einer Student-Verteilung (t-Verteilung) können unkompliziert
Intervallwahrscheinlichkeiten der Form P(
berechnet werden. Als Parameter der t-Verteilung sind deren Freiheitsgrade zu beachten.
X苸[a, b]
) = P(a
X苸[a, b]
20010901
≤ X ≤
b) für eine Normalverteilung berechnet
X苸(-
, xγ ]
∞
) = P(
) = P(
X ≤
a ≤ X ≤ b
x
) die Intervallgrenze
γ
) für eine t-Verteilung
Page 47

Wahrscheinlichkeitsverteilungen (DIST)
1-4-2
Die Umkehrfunktion der t-Verteilungsfunktion ist im DIST-Menü nicht vorhanden. Jedoch
können Sie für eine vorgegebene Intervallwahrscheinlichkeit γ = P(
t
) die Intervallgrenze t
m ,γ
(Quantil der Ordnung γ) im INTR-Menü (als fiktive Vertrauens-
m ,γ
X苸(-
∞
, t
m ,γ
]
) = P(
X
intervallgrenze) erhalten, vgl. Hinweis S. 1-3-9.
Analog zur t-Verteilung können auch Intervallwahrscheinlichkeiten für die χ2- , F-, Binomial-,
Poisson- oder geometrische Verteilung berechnet werden. Außerdem stehen für die genannten
stetigen Prüfverteilungen (χ
2
- und F
m
-Verteilung mit den Freiheitsgraden m bzw. m
m1, m2
, m2)
1
auch die Dichtefunktionen und für die genannten diskreten Verteilungen (Binomial-, Poisson-
oder geometrische Verteilung) auch die Einzelwahrscheinlichkeiten zum Abruf bereit.
In der Eingangsanzeige des STAT-Menüs (Listeneditor) drücken Sie die Taste 5(DIST), um
das Untermenü zu den Wahrscheinlichkeitsverteilungen zu öffnen, das die folgenden Positionen
enthält.
• 5(DIST)b(Norm) ... Normalverteilung (ab Seite 1-4-3)
c(T) .......... Studentsche t-Verteilung (ab Seite 1-4-7)
d(χ2) ......... χ2-Verteilung (ab Seite 1-4-9)
e(F) ........... F-Verteilung (ab Seite 1-4-12)
f(Binmal) ... Binomialverteilung (ab Seite 1-4-16)
g(Poissn) ... Poisson-Verteilung (ab Seite 1-4-19)
h(Geo) ....... Geometrische Verteilung (ab Seite 1-4-21)
≤
uu
u Gemeinsame Funktionen im DIST-Menü
uu
Nach dem Zeichnen einer Wahrscheinlichkeits-Grafik (Dichtefunktion) können Sie die P-CALFunktion verwenden, um für einen bestimmten x-Wert den zugehörigen p-Wert (Wert der
Dichtefunktion an der vorgegebenen Stelle x) zu berechnen.
Nachfolgend ist der allgemeine Vorgehen für die Verwendung der P-CAL-Funktion aufgeführt.
1. Nach dem Zeichnen einer Wahrscheinlichkeits-Grafik drücken Sie die Taste 1(P-CAL), um
das Eingabefenster für den x-Wert zu öffnen.
2. Geben Sie den gewünschten x-Wert ein und drücken Sie danach die w-Taste.
• Dadurch erscheinen die x- und p-Werte in der Fußzeile des Displays, wobei der Cursor an
den entsprechenden Punkt (x,p) in der Wahrscheinlichkeits-Grafik verschoben wird.
3. Falls Sie einen weiteren p-Wert berechnen möchten, drücken Sie nun die v- oder eine
Ziffern-Taste, wodurch erneut das Eingabefenster für den x-Wert erscheint.
4. Wenn Sie die p-Werte-Abfrage beenden möchten, drücken Sie die i-Taste, um die Anzeige
der Koordinatenwerte (x,p) und den Cursor vom Display zu löschen.
# Mit der Ausführung einer Wertberechnung
werden die
alphabetischen Variablen X bzw. P abgespeichert.
x- und p-Werte automatisch in den
20010901
Page 48

Wahrscheinlichkeitsverteilungen (DIST)
1-4-3
kk
k Normalverteilung (
kk
uu
u Dichtefunktion einer N(
uu
In diesem Untermenü kann mithilfe der Normalverteilungsdichte-(Funktion) die Wahrscheinlichkeitsdichte f (x) einer Normalverteilung an einer bestimmten Stelle x berechnet werden. f (x)
beschreibt näherungsweise die im Intervall [
häufigkeit in einer entsprechenden Stichprobe aus einer normalverteilten Grundgesamtheit.
Die Standard-Normalverteilung (N(0,1)-Verteilung) besitzt folgende Wahrscheinlichkeitsdichtefunktion f (x).
f(x) =
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
b(Norm) ... Normalverteilung
b(P.D)
Folgende Positionen erscheinen im Eingabefenster zur Festlegung der Parameter (Vorgabewerte, Einstellungen). Nachfolgend wird die Bedeutung der einzelnen Positionen beschrieben.
kurz: N(
µ
, σ
(x – µ)
–
1
2
σ
e
2
πσ
... Dichtefunktion
µ
2 ) -
2
µ
2
, σ
2 ) -
Verteilung
(σ > 0)
Verteilung )
x -
0.5, x + 0.5 ] zu erwartende relative Daten-
x .................................. x-Wert
σ
.................................. Standardabweichung der N(
µ
.................................. Mittelwert der N(
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus oder zeichnet eine Wahrscheinlich-
keits-Grafik (Dichtefunktion, Gaußsche Glockenkurve)
• Durch die Vorgabe von σ = 1 und µ = 0 ergibt sich die Standard-Normalverteilung .
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken danach eine der nachfolgend dargestellten Funktionstasten, um die
Berechnung auszuführen oder die Wahrscheinlichkeits-Grafik zu zeichnen.
• 1(CALC) ... Führt die Berechnung des p-Wertes ( p =
• 6(DRAW) ... Zeichnet die Wahrscheinlichkeits-Grafik.
Berechnungsergebnis-Ausgabebeispiel (für x = 36, σ = 2, µ = 35): p ... berechneter Wert
µ , σ 2
µ, σ 2
)-Verteilung
)-Verteilung (
f
(x) ) aus.
σ
> 0)
# Die Betrachtungsfenster-Einstellungen für das
Zeichnen der Grafik werden automatisch festgelegt, wenn im SET UP - Menü [Stat Wind]
auf [Auto] eingestellt ist.
Für das Zeichnen der Grafik werden die aktuellen Betrachtungsfenster-Einstellungen verwendet, wenn im SET UP - Menü [Stat Wind]
auf [Manual] eingestellt ist.
20010901
Page 49

Wahrscheinlichkeitsverteilungen (DIST)
1-4-4
uu
u Verteilungsfunktion einer N(
uu
µ
, σ
2 ) -
Verteilung
In diesem Untermenü kann mithilfe der Verteilungsfunktion einer Normalverteilung unkompliziert eine Intervallwahrscheinlichkeit der Form p = P(
X苸[a, b]
) = P(a
≤ X ≤
b) für eine
Normalverteilung berechnet werden.
2
µ
p =
1
2
πσ
2
2
σ
e
dx
a
(x – µ)
b
–
a : Untere Intervallgrenze
b : Obere Intervallgrenze
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
b(Norm) ... Normalverteilung
c(C.D) ... Verteilungsfunktion
Folgende Positionen erscheinen im Eingabefenster zur Festlegung der Parameter (Vorgabewerte, Einstellungen). Nachfolgend wird die Bedeutung der einzelnen Positionen beschrieben.
Lower .......................... Untere Intervallgrenze a
Upper .......................... Obere Intervallgrenze b
σ
.................................. Standardabweichung der N(
µ
.................................. Mittelwert der N(
µ , σ 2
µ, σ 2
)-Verteilung
)-Verteilung (
σ
> 0)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallwahrscheinlichkeit p aus.
Hinweis: Weitere Intervallwahrscheinlichkeiten können über die Funktionen P(t), Q(t) und R(t)
im RUN•MAT-Menü (Untermenü [OPTN], [PROB], [5:P( ] oder [6:Q( ] oder [7:R( ] )
berechnet werden, vgl. Bedienungsanleitung S. 6-4-5 bis 6-4-8:
# Für die Intervallwahrscheinlichkeit einer
Normalverteilung kann im STAT-Menü keine
Wahrscheinlichkeits-Grafik gezeichnet werden.
# Im GRPH•TBL-Menü kann die N(0,1) -Vertei-
lungsfunktion als Y=P(X) gezeichnet werden.
Intervallwahrscheinlichkeiten können dort als
Flächenanteil unter der Gaußschen Glockenkurve
schraffiert werden (Ungleichungsgrafik nutzen).
20010901
Page 50

Wahrscheinlichkeitsverteilungen (DIST)
1-4-5
Berechnungsergebnis-Ausgabebeispiel
im STAT- Menü
p .................................. Intervallwahrscheinlichkeit p = P(- 21
z:Low ........................... unterer z-Wert eines entsprechenden N(0,1)-Intervalles
z:Up ............................. oberer z-Wert eines entsprechenden N(0,1)-Intervalles
Wahrscheinlichkeitsgrafik-Ausgabebeispiel
(unterer z-Wert = 1, oberer z-Wert = 1.5)
: (im RUN•MAT-Menü)
(standardisierte untere Intervallgrenze a: z = (
(standardisierte obere Intervallgrenze b: z = (
(für a = - 21, b = -19, µ = - 25, σ = 4)
≤ X ≤
im GRPH•TBL-Menü (als Ungleichungsgrafik)
-19) = P(1
a - µ ) / σ )
b - µ ) / σ )
≤ Z ≤
1.5)
uu
u Umkehrfunktion der N(
uu
Die Umkehrfunktion der N(
rechten Intervallgrenze b =
lichkeit γ = P(
Hinweis: Der Index γ des betrachteten Quantils xγ beschreibt definitionsgemäß stets die links
von xγ (einschließlich xγ)
kurve (γ = Flächenanteil = Area).
Weiterhin können analog dazu auch eine linke Intervallgrenze a =
1-
γ) zur vorgegebenen Intervallwahrscheinlichkeit γ = P(
symmetrisch zum Mittelwert µ liegende Grenzen a =
Intervallwahrscheinlichkeit
werden. Hierbei gilt dann
X苸(-
∞
µ , σ 2
)-Verteilungsfunktion (Quantil-Berechnungen)
µ , σ 2
)-Verteilungsfunktion dient zunächst zur Berechnung der
x
(Quantil der Ordnung γ) zu einer vorgegebenen Intervallwahrschein-
γ
, xγ ]
) = P(
X ≤
x
µ
), wobei X eine N(
γ
liegende Wahrscheinlichkeit unter der Gaußschen Glocken-
x
γ
=
P(
-
a = b
X苸[ x
- µ
,
(1-γ )
/ 2
, d.h. a =
20010901
x
(1+γ ) /
µ
- ( b - µ )
(1-γ ) /
]
)
2
X苸[ x
und b =
2
= P(
.
µ , σ 2
)-verteilte Zufallsgröße ist.
x
(Quantil der Ordnung
γ
1-
, ∞)
) = P(
γ
1-
x
zur vorgegebenen
(1+γ ) /
2
x
≤ X ≤ x
(1-γ ) /
2
(1+γ ) /
X ≥
2
x
) oder
γ
1-
) berechnet
Page 51

Wahrscheinlichkeitsverteilungen (DIST)
1-4-6
Formeln:
LEFT: linkes Intervall RIGHT: rechtes Intervall CENTR: zu µ symmetrisches Intervall
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
b(Norm) ... Normalverteilung
d(Invrse) ... Umkehrfunktion
Folgende Positionen erscheinen im Eingabefenster zur Festlegung der Parameter (Vorgabewerte, Einstellungen). Nachfolgend wird die Bedeutung der einzelnen Positionen beschrieben.
Ta il...............................
Area ............................ vorgegebene Intervallwahrscheinlichkeit γ (0 < Area = γ < 1)
σ
.................................. Standardabweichung der N(
µ
.................................. Mittelwert der N(
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallwahrscheinlichkeit p aus.
Berechnungsergebnis-Ausgabebeispiele (Quantil x
95% und symmetrische Grenzen mit Intervallwahrscheinlichkeit γ = 5%)
x ....................................... Intervallgrenze (Quantil), hier: für eine N(0,1)-Verteilung.
Lage des betrachteten x-Intervalls (Left, Right, Central), dessen
rechte, linke oder symmetrische Grenzen (Quantile) gesucht sind.
µ, σ 2
)-Verteilung (
µ , σ 2
)-Verteilung
nisse (Keine [None] oder Liste 1 bis 20)
= z
mit α = 5% bzw. γ =
γ
α
1-
(LEFT: obere Intervallgrenze eines linksseitigen Intervalls)
(RIGHT: untere Intervallgrenze eines rechtsseitigen Intervalls)
(CENTR: untere und obere Intervallgrenze eines symmetri-
schen (zu µ) Intervalls [
a,
b] mit a = µ - ( b - µ ) = -
σ
> 0)
b)
# Für die Umkehrfunktion der Normalverteilungs-
funktion kann keine Grafik gezeichnet werden.
20010901
Page 52

f
Wahrscheinlichkeitsverteilungen (DIST)
1-4-7
kk
k Studentsche
kk
uu
u Dichtefunktion einer Studentschen t-Verteilung
uu
In diesem Untermenü kann mithilfe der Studentschen t-Verteilungsdichte(-Funktion) die Wahrscheinlichkeitsdichte f (x) einer Studentschen t-Verteilung an einer bestimmten Stelle x
berechnet werden. f (x) beschreibt näherungsweise die im Intervall [
Wahrscheinlichkeit z.B. für eine t-verteilte Testgröße.
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
Folgende Positionen erscheinen im Eingabefenster zur Festlegung der Parameter (Vorgabewerte, Einstellungen). Nachfolgend wird die Bedeutung der einzelnen Positionen beschrieben.
t-Verteilung (mit df Freiheitsgraden)
df+1
–
2
2
1+
x
df
df
π
df + 1
Γ
(x) =
5(DIST) ... Wahrscheinlichkeitsverteilung
c(T)
b(P.D) ... Dichtefunktion
2
df
Γ
2
... t-Verteilung
x -
0.5, x + 0.5 ] zu erwartende
x .................................. x-Wert
df ................................. Anzahl der Freiheitsgrade (df > 0)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus oder zeichnet eine Wahrscheinlich-
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken danach eine der nachfolgend dargestellten Funktionstasten, um die
Berechnung auszuführen oder die Wahrscheinlichkeits-Grafik zu zeichnen.
• 1(CALC) ... Führt die Berechnung des p-Wertes ( p =
• 6(DRAW) ... Zeichnet die Wahrscheinlichkeits-Grafik.
Berechnungsergebnis-Ausgabebeispiel (für x = 1, df = 2): p ... berechneter Wert
nisse (Keine [None] oder Liste 1 bis 20)
keits-Grafik (Dichtefunktion, glockenförmige Kurve)
f
(x) ) aus.
# Für das Zeichnen der Grafik werden die aktu-
ellen Betrachtungsfenster-Einstellungen verwendet, wenn im SET UP - Menü [Stat Wind]
auf [Manual] eingestellt ist. Die folgenden
Betrachtungsfenster-Einstellungen werden
automatisch eingestellt, wenn [Stat Wind] auf
[Auto] voreingestellt ist.
Xmin = –3.2 , Xmax = 3.2 , Xscale = 1,
Ymin = –0.1 , Ymax = 0.45 , Yscale = 0.1
20010901
Page 53

Wahrscheinlichkeitsverteilungen (DIST)
1-4-8
uu
u Verteilungsfunktion einer Studentschen t-Verteilung
uu
In diesem Untermenü kann mithilfe der Verteilungsfunktion einer Studentschen t-Verteilung
unkompliziert eine Intervallwahrscheinlichkeit der Form p = P(
eine Studentsche t-Verteilung berechnet werden.
df + 1
Γ
p =
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
c(T)
c(C.D) ... Verteilungsfunktion
Folgende Positionen erscheinen im Eingabefenster zur Festlegung der Parameter (Vorgabewerte, Einstellungen). Nachfolgend wird die Bedeutung der einzelnen Positionen beschrieben.
Lower .......................... Untere Intervallgrenze a
Upper .......................... Obere Intervallgrenze b
2
df
Γ
2
... t-Verteilung
b
1+
a
df
π
df+1
–
2
2
x
dx
df
T苸[a, b]
) = P(a
≤ T ≤
a :Untere Intervallgrenze
b :Obere Intervallgrenze
b) für
df ................................. Anzahl der Freiheitsgrade (df > 0)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus
nisse (Keine [None] oder Liste 1 bis 20)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallwahrscheinlichkeit p aus.
Berechnungsergebnis-Ausgabebeispiel ( p = P(1.7 ≤ T < ∞) bei df = 15)
p .................................. Intervallwahrscheinlichkeit einer Studentschen t-Verteilung
t:Low . ......................... unterer eingegebener t-Wert des betrachteten t-Intervalls
t:Up ............................. oberer eingegebener t-Wert des betrachteten t-Intervalls
# Für die Intervallwahrscheinlichkeit einer
Studentschen
keine Grafik gezeichnet werden.
t-Verteilung kann im STAT-Menü
20010901
Page 54

f
Wahrscheinlichkeitsverteilungen (DIST)
1-4-9
uu
u Quantile einer Studentschen
uu
Die Umkehrfunktion der t-Verteilungsfunktion ist im DIST-Menü nicht vorhanden. Jedoch
kann für eine vorgegebene Intervallwahrscheinlichkeit γ = P(
die Intervallgrenze t
intervallgrenze) erhalten werden, vgl. Hinweis S. 1-3-9.
Berechnungsergebnis-Ausgabebeispiel ( γ = P(
kk
k χ2 -Verteilung (mit df Freiheitsgraden)
kk
uu
u Dichtefunktion einer χ2 -Verteilung
uu
In diesem Untermenü kann mithilfe der χ2 -Verteilungsdichte(-Funktion) die Wahrscheinlichkeitsdichte f (x) einer χ2 -Verteilung an einer bestimmten Stelle x berechnet werden. f (x) beschreibt
näherungsweise die im Intervall [
eine χ2 -verteilte Testgröße, wobei x > 0 gelten muß. Die angegebene Formel gilt für x > 0.
(x) =
(Quantil der Ordnung γ) im INTR-Menü (als fiktive Vertrauens-
m ,γ
1
df
Γ
2
t-Verteilung
X苸(-
T ≤
t
) bei m = df = 15 und γ = 0.95)
m ,γ
x -
0.5, x + 0.5 ] zu erwartende Wahrscheinlichkeit z.B. für
df
df
x
–1
–
2
2
x e
2
Im Fall x ≤ 0 gilt f (x) = 0.
1
2
∞
, t
m ,γ
]
) = P(
X ≤
t
m ,γ
)
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
d(χ2)
... χ2 -Verteilung
b(P.D) ... Dichtefunktion
Folgende Positionen erscheinen im Eingabefenster zur Festlegung der Parameter (Vorgabewerte, Einstellungen). Nachfolgend wird die Bedeutung der einzelnen Positionen beschrieben.
x .................................. x-Wert
df ................................. Anzahl der Freiheitsgrade (df positive ganze Zahl)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus oder zeichnet eine Wahrscheinlich-
keits-Grafik (Dichtefunktion, Kurve über der positiven x-Achse)
20010901
Page 55

Wahrscheinlichkeitsverteilungen (DIST)
1-4-10
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken danach eine der nachfolgend dargestellten Funktionstasten, um die
Berechnung auszuführen oder die Wahrscheinlichkeits-Grafik zu zeichnen.
• 1(CALC) ... Führt die Berechnung des p-Wertes ( p =
f
(x) ) aus.
• 6(DRAW) ... Zeichnet die Wahrscheinlichkeits-Grafik.
Berechnungsergebnis-Ausgabebeispiel ( für x = 1 und df = 3 )
p .................................. berechneter p-Wert der χ2-Wahrscheinlichkeitsdichtefunktion
(hier mit df = 3)
# Für das Zeichnen der Grafik werden die aktu-
ellen Betrachtungsfenster-Einstellungen verwendet, wenn im SET UP - Menü [Stat Wind]
auf [Manual] eingestellt ist. Die folgenden
Betrachtungsfenster-Einstellungen werden
automatisch eingestellt, wenn [Stat Wind] auf
[Auto] voreingestellt ist.
Xmin = 0, Xmax = 11.5 , Xscale = 2,
Ymin = –0.1 , Ymax = 0.5 , Yscale = 0.1
20010901
Page 56

Wahrscheinlichkeitsverteilungen (DIST)
1-4-11
uu
u Verteilungsfunktion einer χ
uu
2
-Verteilung
In diesem Untermenü kann mithilfe der χ2-Verteilungsfunktion unkompliziert eine Intervallwahrscheinlichkeit der Form p = P(
werden.
1
p =
df
Γ
2
df
2
1
2
T苸[a, b]
b
df
2
x e dx
a
–1
) = P(a
x
–
2
≤ T ≤
b) für eine χ2-Verteilung berechnet
a :Untere Intervallgrenze (a ≥ 0)
b :Obere Intervallgrenze
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
d(χ2)
... χ2-Verteilung
c(C.D) ... Verteilungsfunktion
Folgende Positionen erscheinen im Eingabefenster zur Festlegung der Parameter (Vorgabewerte, Einstellungen). Nachfolgend wird die Bedeutung der einzelnen Positionen beschrieben.
Lower .......................... Untere Intervallgrenze a
Upper .......................... Obere Intervallgrenze b
df ................................. Anzahl der Freiheitsgrade (df positive ganze Zahl)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus
nisse (Keine [None] oder Liste 1 bis 20)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallwahrscheinlichkeit p aus.
# Für die Intervallwahrscheinlichkeit einer χ2-
Verteilung kann im STAT-Menü keine Grafik
gezeichnet werden.
20010901
Page 57

f
Wahrscheinlichkeitsverteilungen (DIST)
1-4-12
Berechnungsergebnis-Ausgabebeispiel ( a = 0, b = 2, df = 4 )
p .................................. berechnete Intervallwahrscheinlichkeit einer χ2-Verteilung
(für a = 0, b = 2, df = 4 )
kk
k F-Verteilung
kk
mit n: df (Zähler-Freiheitsgrade) und d: df (Nenner-Freiheitsgrade)
uu
u Dichtefunktion einer F-Verteilung
uu
In diesem Untermenü kann mithilfe der F-Verteilungsdichte(-Funktion) die Wahrscheinlichkeitsdichte f (x) einer F -Verteilung an einer bestimmten Stelle x berechnet werden. f (x) beschreibt
näherungsweise die im Intervall [
eine F -verteilte Testgröße, wobei x > 0 gelten muß. Die angegebene Formel gilt für x > 0.
Γ
(x) =
n
Γ
2
n + d
2
Γ
x -
0.5, x + 0.5 ] zu erwartende Wahrscheinlichkeit z.B. für
1 +
nx
n + d
–
2
d
Im Fall x ≤ 0 gilt f (x) = 0.
n
n
–1
2
2
n
d
x
d
2
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
e(F)
... F -Verteilung
b(P.D) ... Dichtefunktion
Folgende Positionen erscheinen im Eingabefenster zur Festlegung der Parameter (Vorgabewerte, Einstellungen). Nachfolgend wird die Bedeutung der einzelnen Positionen beschrieben.
x .................................. x-Wert
n:df .............................. Anzahl der Zähler-Freiheitsgrade (df positive ganze Zahl)
d:df .............................. Anzahl der Nenner-Freiheitsgrade (df positive ganze Zahl)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus oder zeichnet eine Wahrscheinlich-
nisse (Keine [None] oder Liste 1 bis 20)
keits-Grafik (Dichtefunktion, Kurve über der positiven x-Achse)
20010901
Page 58

Wahrscheinlichkeitsverteilungen (DIST)
1-4-13
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf
[Execute] und drücken danach eine der nachfolgend dargestellten Funktionstasten, um die
Berechnung auszuführen oder die Wahrscheinlichkeits-Grafik zu zeichnen.
• 1(CALC) ... Führt die Berechnung des p-Wertes ( p =
f
(x) ) aus.
• 6(DRAW) ... Zeichnet die Wahrscheinlichkeits-Grafik.
Berechnungsergebnis-Ausgabebeispiel ( für x = 1 und n:df = 24, d:df = 19 )
p .................................. berechneter p-Wert der F-Wahrscheinlichkeitsdichtefunktion
(hier mit n:df = 24, d:df = 19)
# Für das Zeichnen der Grafik werden die aktu-
ellen Betrachtungsfenster-Einstellungen verwendet, wenn im SET UP - Menü [Stat Wind]
auf [Manual] eingestellt ist.
Die Betrachtungsfenster-Einstellungen werden
automatisch eingestellt, wenn [Stat Wind] auf
[Auto] voreingestellt ist.
20010901
Page 59

Wahrscheinlichkeitsverteilungen (DIST)
1-4-14
uu
u Verteilungsfunktion einer F-Verteilung
uu
In diesem Untermenü kann mithilfe der F-Verteilungsfunktion unkompliziert eine Intervallwahr-
scheinlichkeit der Form p = P(
werden.
Γ
p =
n
Γ
2
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5 (DIST) ... Wahrscheinlichkeitsverteilung
e (F)
c (C.D) ... Verteilungsfunktion
Folgende Positionen erscheinen im Eingabefenster zur Festlegung der Parameter (Vorgabewerte, Einstellungen). Nachfolgend wird die Bedeutung der einzelnen Positionen beschrieben.
Lower .......................... Untere Intervallgrenze a
Upper .......................... Obere Intervallgrenze b
T苸[a, b]
n + d
2
Γ
... F-Verteilung
n
d
d
2
n
2
) = P(a
≤ T ≤
b) für eine F-Verteilung berechnet
b
n
–1
2
1 +
x
a
n + d
a: Untere Intervall-
–
2
nx
b: Obere Intervall-
dx
d
grenze (a ≥ 0)
grenze
n:df .............................. Anzahl der Zähler-Freiheitsgrade (df positive ganze Zahl)
d:df .............................. Anzahl der Nenner-Freiheitsgrade (df positive ganze Zahl)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus
nisse (Keine [None] oder Liste 1 bis 20)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Intervallwahrscheinlichkeit p aus.
# Für die Intervallwahrscheinlichkeit einer F-
Verteilung kann im STAT-Menü keine Grafik
gezeichnet werden.
20010901
Page 60

Wahrscheinlichkeitsverteilungen (DIST)
1-4-15
Berechnungsergebnis-Ausgabebeispiel
( a = 0, b = 1.9824 , n:df = 19, d:df = 16 )
p .................................. berechnete Intervallwahrscheinlichkeit einer F-Verteilung
(für a = 0, b = 1.9824 , n:df = 19, d:df = 16 )
20010901
Page 61

Wahrscheinlichkeitsverteilungen (DIST)
1-4-16
kk
k Binomialverteilung (
kk
uu
u Einzelwahrscheinlichkeit einer B(n,
uu
In diesem Untermenü können die Einzelwahrscheinlichkeiten einer B(n,
der Stelle x (x = 0, 1, ..., n) berechnet werden, wobei x die Anzahl der Treffer in n Versuchen
beschreibt und p die Erfolgswahrscheinlichkeit im Einzelversuch darstellt (Bernoulli-Schema).
f (x) = nC x px(1–p)
kurz: B(n,
n – x
p) -
Verteilung )
p) -
Verteilung
p) -
Verteilung an
(x = 0, 1, ..., n) p :Trefferwahrscheinlichkeit
(0 < p < 1)
n :Anzahl der Versuche
nCx bezeichnet hierbei den Binomialkoeffizienten "n über x". f
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
f(Binmal) ... Binomialverteilung
b(P.D) ... Einzelwahrscheinlichkeit
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der x-Werte [List] oder ein
einzelner x-Wert [Variable])
List .............................. Liste der x-Werte
Numtrial ....................... Anzahl n der Versuche
(x) = 0 für x ≠ 0, 1, ..., n.
p .................................. Trefferwahrscheinlichkeit im Einzelversuch (0 < p < 1)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
nisse (Keine [None] oder Liste 1 bis 20)
Execute ....................... Führt die Berechnung aus
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der x-Wert-Vorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
x .................................. einzelner x-Wert (ganze Zahl von 0 bis n)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Einzelwahrscheinlichkeit(en) aus.
# Für die Einzelwahrscheinlichkeit(en) einer
Binomialverteilung kann im STAT-Menü keine
Grafik gezeichnet werden.
20010901
20011201
Page 62

Wahrscheinlichkeitsverteilungen (DIST)
1-4-17
Berechnungsergebnis-Ausgabebeispiel (n=2, p=0.4, x=List={0,1,2} bzw. x=1)
p .................................. Liste der Einzelwahrscheinlichkeiten bzw. Einzelwahrschein-
uu
u Verteilungsfunktion einer B(n,
uu
Die Verteilungsfunktion einer B(n,
von der Stelle 0 bis einschließlich einer vorgegebenen Stelle x (x = 0, 1, ..., n), wobei x die
Maximalanzahl der Treffer in n Versuchen beschreibt und p die Erfolgswahrscheinlichkeit im
Einzelversuch darstellt (Bernoulli-Schema).
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5 (DIST) ... Wahrscheinlichkeitsverteilung
f (Binmal) ... Binomialverteilung
c (C.D) ... Verteilungsfunktion
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der x-Werte [List] oder ein
List .............................. Liste der x-Werte
Numtrial ....................... Anzahl n der Versuche
lichkeit p
p) -
Verteilung
p) -
Verteilung summiert die Einzelwahrscheinlichkeiten
einzelner x-Wert [Variable])
p .................................. Trefferwahrscheinlichkeit im Einzelversuch (0 < p < 1)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus
nisse (Keine [None] oder Liste 1 bis 20)
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der x-Wert-Vorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
x .................................. einzelner x-Wert (ganze Zahl von 0 bis n)
20010901
20011201
Page 63

Wahrscheinlichkeitsverteilungen (DIST)
1-4-18
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der summierten Einzelwahrscheinlichkeiten aus.
Berechnungsergebnis-Ausgabebeispiel
(n = 5, p = 0.25, x = List = {5, 4, 3, 2, 1, 0} bzw. x = 3)
p .................................. Liste der berechneten Werte der Verteilungsfunktion bzw.
Einzelwert p
# Der Ergebniswert p (berechnete Wahrschein-
lichkeit) darf nicht mit dem Eingabewert
(Parameter) verwechselt werden.
p
20010901
Page 64

Wahrscheinlichkeitsverteilungen (DIST)
1-4-19
kk
k Poisson-Verteilung (
kk
uu
u Einzelwahrscheinlichkeit einer Π (µ ) - Verteilung
uu
In diesem Untermenü können die Einzelwahrscheinlichkeiten einer Π (µ ) - Verteilung an
der Stelle x (x = 0, 1, ... ) berechnet werden, wobei µ den Mittelwert-Parameter der PoissonVerteilung bezeichnet.
f(x) =
Hinweis: f (x) = 0 für x ≠ 0, 1, ... .
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5 (DIST) ... Wahrscheinlichkeitsverteilung
g (Poissn) ... Poisson-Verteilung
b (P.D) ... Einzelwahrscheinlichkeit
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der x-Werte [List] oder ein
List .............................. Liste der x-Werte
µ
................................. Mittelwert-Parameter (
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der x-Wert-Vorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
kurz: Π (µ) - Verteilung )
µ
–
x
µ
e
x!
(x = 0, 1, ... )
einzelner x-Wert [Variable])
nisse (Keine [None] oder Liste 1 bis 20)
µ
:Mittelwert-Parameter (
µ
> 0)
µ
> 0)
x .................................. einzelner x-Wert (ganze nichtnegative Zahl)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Einzelwahrscheinlichkeit(en) aus.
Berechnungsergebnis-Ausgabebeispiel (µ=1.5, x=List={0,1,2} bzw. x=2): p ... berechneter Wert
# Für die Einzelwahrscheinlichkeit(en) einer
Poisson-Verteilung kann im STAT-Menü keine
Grafik gezeichnet werden.
20010901
20011201
Page 65

Wahrscheinlichkeitsverteilungen (DIST)
1-4-20
uu
u Verteilungsfunktion einer
uu
Die Verteilungsfunktion einer Π (
von der Stelle 0 bis einschließlich einer vorgegebenen Stelle x (x = 0, 1, ..., n), wobei µ den
Mittelwert-Parameter der Poisson-Verteilung bezeichnet.
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5 (DIST) ... Wahrscheinlichkeitsverteilung
g (Poissn) ... Poisson-Verteilung
c (C.D) ... Verteilungsfunktion
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der x-Werte [List] oder ein
List .............................. Liste der x-Werte
µ
.................................. Mittelwert-Parameter (
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der x-Wert-Vorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
Π
(
µ
) - Verteilung
µ
) - Verteilung summiert die Einzelwahrscheinlichkeiten
einzelner x-Wert [Variable])
µ
> 0)
nisse (Keine [None] oder Liste 1 bis 20)
x .................................. einzelner x-Wert (ganze nichtnegative Zahl)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ...
Führt die Berechnung der summierten Einzelwahrscheinlichkeiten aus.
Berechnungsergebnis-Ausgabebeispiel (µ=12, x=List={0,1,2,3,4} bzw. x=8)
p .................................. Liste der berechneten Werte der Verteilungsfunktion bzw.
Einzelwert p
20010901
20011201
Page 66

f
Wahrscheinlichkeitsverteilungen (DIST)
1-4-21
kk
k Geometrische Verteilung (mit dem Parameter
kk
uu
u Einzelwahrscheinlichkeit einer geometrischen Verteilung
uu
p)
In diesem Untermenü können die Einzelwahrscheinlichkeiten einer geometrischen
Verteilung an der Stelle x (x = 1, 2, ... ) berechnet werden, wobei x die Anzahl der Versuche
bedeutet, bis der erste Erfolg eingetreten ist, und p die Erfolgswahrscheinlichkeit im Einzelversuch darstellt. D.h., es gibt genau x-1 Mißerfolge und den erstmaligen Erfolg genau im x-
ten Versuch.
(x) = p(1– p)
x – 1
(x = 1, 2, 3, ...) oder f (x) = 0 sonst (x ≠ 1, 2, 3, ...)
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
h(Geo) ... geometrische Verteilung
b(P.D) ... Einzelwahrscheinlichkeit
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der x-Werte [List] oder ein
einzelner x-Wert [Variable])
List .............................. Liste der x-Werte
p .................................. Trefferwahrscheinlichkeit im Einzelversuch (0 < p < 1)
Save Res..................... Listenspeicherplatz zur Speicherung der Berechnungsergeb-
Execute ....................... Führt die Berechnung aus
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der x-Wert-Vorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
nisse (Keine [None] oder Liste 1 bis 20)
x .................................. einzelner x-Wert (positive ganze Zahl)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ... Führt die Berechnung der Einzelwahrscheinlichkeit(en) aus.
Berechnungsergebnis-Ausgabebeispiel ( p = 0.75, x = List = {0, 1, 2, 3, 4} bzw. x = 4 )
p ................... Liste der Einzelwahrscheinlichkeiten bzw. Einzelwahrscheinlichkeit p
# Für die Einzelwahrscheinlichkeit(en) einer
geometrischen Verteilung kann im STAT-Menü
keine Grafik gezeichnet werden.
# Unabhängig von der Art der Datenvorgabe
([Data: List] oder [Data: Variable]) sind für
nur ganze Zahlen zugelassen.
20010901
20011201
x
Page 67

Wahrscheinlichkeitsverteilungen (DIST)
1-4-22
uu
u Verteilungsfunktion einer geometrischen Verteilung
uu
Die Verteilungsfunktion einer geometrischen Verteilung summiert die Einzelwahrscheinlichkeiten von der Stelle 1 bis einschließlich einer vorgegebenen Stelle x (x = 1, 2, ..., n),
wobei x die Maximalanzahl der Versuche bedeutet, nach denen spätestens der erste Erfolg
eingetreten ist, und p die Erfolgswahrscheinlichkeit im Einzelversuch darstellt. D.h., das
erstmalige Eintreten eines Erfolges in einer Versuchsserie mit lauter Mißerfolgen soll sich
spätestens im x-ten Versuch ereignen.
Führen Sie die folgende Tastenbedienung im STAT-Eingangsmenü (Listeneditor) aus.
5(DIST) ... Wahrscheinlichkeitsverteilung
h(Geo) ... geometrische Verteilung
c(C.D) ... Verteilungsfunktion
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der Datenlistenvorgabe ([Data:
List] statt [Data: Variable] eingestellt) beschrieben.
Data ............................ Art der Datenvorgabe (Liste der x-Werte [List] oder ein
einzelner x-Wert [Variable])
List .............................. Liste der x-Werte
p .................................. Trefferwahrscheinlichkeit im Einzelversuch (0 < p < 1)
Save Res .................... Listenspeicherplatz zur Speicherung der Berechnungs-
Execute ....................... Führt die Berechnung aus
Nachfolgend ist die Bedeutung der einzelnen Positionen im Falle der x-Wert-Vorgabe [Data:
Variable] beschrieben, die sich von der Datenlistenvorgabe [Data: List] unterscheiden.
ergebnisse (Keine [None] oder Liste 1 bis 20)
x .................................. einzelner x-Wert (positive ganze Zahl)
Nachdem Sie alle Parameter (Vorgabewerte) eingestellt haben, stellen Sie den Cursor auf [Execute]
und drücken danach die nachfolgend dargestellte Funktionstaste, um die Berechnung auszuführen.
• 1(CALC) ...
Berechnungsergebnis-Ausgabeanzeige
p ................. Liste der berechneten Werte der Verteilungsfunktion bzw. Einzelwert p
# Unabhängig von der Art der Datenvorgabe
([Data: List] oder [Data: Variable]) sind für
nur ganze Zahlen zugelassen.
Führt die Berechnung der summierten Einzelwahrscheinlichkeiten aus.
( p = 0.5, x = List = { 2, 3, 4} bzw. x = 3)
# Der Ergebniswert p (berechnete Wahrschein-
x
lichkeit) darf nicht mit dem Eingabewert
(Parameter) verwechselt werden.
20010901
20011201
p
Page 68

Kapitel
Finanzmathematik (TVM)
In diesem Kapitel werden wichtige finanzmathematischen Berechnungsverfahren (von der einfachen Kapitalverzinsung über die
Investition, Tilgung und Abschreibung bis hin zur Wertpapieranalyse)
und auch die entsprechenden Berechnungsformeln erklärt. Sie
erhalten Erläuterungen zur Erzeugung von Abschreibungstabellen
und speziellen finanzmathematischen Grafiken.
2
2-1 Vor dem Ausführen finanzmathematischer Berechnungen
2-2 Einfache Kapitalverzinsung
2-3 Kapitalverzinsung mit Zinseszins
2-4
Geldfluß-Berechnungen (Cash-Flow, Investitionsrechnung)
2-5 Tilgungsberechnungen (Amortisation)
2-6 Zinssatz-Umrechnungen
2-7 Herstellungskosten, Verkaufspreis, Gewinnspanne
2-8 Berechnung der Zinstage (Datumsberechnungen)
2-9 Abschreibungsberechnungen (Amortisation)
2-10 Wertpapieranalyse (Zinsanleihen, Obligationen, ...)
2-11 TVM-Grafik (weitere grafische Darstellungen)
20010901
Page 69

Vor dem Ausführen finanzmathematischer Berechnungen
2-1-1
2-1 Vor dem Ausführen finanzmathematischer
Berechnungen
kk
k Das TVM - Menü (Zeitwert eines Geldbetrages, Time Value of Money)
kk
Wählen Sie im Hauptmenü das TVM-Icon aus.
* Hier ist das Hauptmenü des
ALGEBRA FX 2.0 PLUS
dargestellt.
Nach dem Öffnen des TVM-Menüs erscheint der Eingangsbildschirm zur Finanzmathematik.
TVM-Menü (Teil 1) TVM-Menü (Teil 2)
Bedeutung der Funktionstasten:
• 1(SMPL) .... Einfache Kapitalverzinsung (SiMPLe)
• 2(CMPD) ...Kapitalverzinsung mit Zinseszins (CoMPounD)
• 3(CASH).... Geldfluß-Berechnungen (CASH-Flow, Investitionsrechnung)
• 4(AMT) ......Tilgungsberechnungen (AMorTization)
• 5(CNVT) .... Zinssatz-Umrechnung (CoNVersion)
• 6(g)1(COST) ... Herstellungskosten, Verkaufspreis, Gewinnspanne
2(DAYS) ... Berechnung der Zinstage (Datumsberechnung)
3(DEPR) ... Abschreibungsberechnungen (DEPReciation, Amortisation)
4(BOND) ...
5(TVMG) ... TVM-Grafik (Simulation von Zinseszinseffekten u.a.)
Wertpapierberechnungen (Zinsanleihen, Obligationen, BONDs)
20010901
Page 70

Vor dem Ausführen finanzmathematischer Berechnungen
2-1-2
kk
k Spezielle SET UP-Positionen im TVM-Menü
kk
uu
u Payment
uu
•{BGN}/{END} ........ Festlegung der Fälligkeit {vorschüssig, zu Beginn} / {nachschüssig,
uu
u Date Mode
uu
•{365}/{360}
uu
u Periods/YR. (Wertpapierberechnungen)
uu
•{Annual}/{SEMI}
Für finanzmathematische Berechnungen im TVM-Menü sind folgende Hinweise zu beachten,
die das SET UP-Menü und dessen Voreinstellungen betreffen.
•Wenn die SET UP-Position Label: On voreingestellt ist, erscheinen in finanzmathematischen
Grafiken die Achsenbezeichnungen CASH (für die vertikale Achse, Ein- oder Auszahlungen)
und TIME (horizontale Achse, Zeitpunkte einer Kontobewegung).
Die Achsenbezeichnungen erscheinen nicht in einer TVM-Grafik, da hier die Variablenzuordnung zu den Achsen frei wählbar ist.
•
Im TVM-Menü kann die Anzahl der angezeigten Ziffern im Vergleich zur Voreinstellung und
den Berechnungen in andern Menüs anders ausfallen. Der Rechner geht automatisch zum
Anzeigeformat Norm 1 über, wenn Sie finanzmathematische Berechnungen durchführen und
ignoriert dabei andere Voreinstellungen wie Sci (Mantissenlänge bei Gleitkomma-Darstellung)
oder Eng (Technisches Anzeigeformat), die in einem anderen Menü getroffen wurden.
am Ende} der Zahlungsperiode
Festlegung des Jahresmodus mit {365-Tage} / {360-Tage} im Jahr
.........
Festlegung der Couponperiode als {Jahres-} / {Halbjahres-} Periode
...
kk
k Ergebnisanzeige als TVM-Grafik
kk
Nach Abschluß einer Berechnung können Sie
6 (GRPH) drücken, um die Ergebnisse grafisch
darzustellen, so wie es im rechten Bild angedeutet
ist.
•Während der grafischen Anzeige drücken Sie 1 (TRACE), um die Trace-Funktion zu
aktivieren. Im Fall z.B. der einfachen Kapitalverzinsung drücken Sie anschließend die
Cursortaste e zur Anzeige von PV, SI und SFV. Wenn Sie die Cursortaste d drücken,
werden die gleichen finanzmathematischen Größen in umgekehrter Reihenfolge angezeigt.
•Die Zoom-, Scroll- und Sketch-Funktionen sind im TVM-Menü nicht aktiv und nicht benutzbar.
•
Ob Sie für den aktuellen Geldbetrag (PV) einen positiven oder negativen Zahlenwert benutzen
oder ob z.B. der Stückpreis eines Wertpapiers (PRC) positiv oder negativ erscheint, ist durch
das finanzmathematische Modell bestimmt, mit dem Sie Ihre Berechnungen durchführen
wollen. In der Regel gehen Soll-Werte negativ und Haben-Werte positiv in die Berechnung ein.
•Hinweis: TVM-Grafiken sollten nur zur Veranschaulichung einer Berechnung aber nicht als
Berechnungsergebnis selbst verwendet werden. Sie sollten sich stets an den numerischen
Berechnungsergebnissen orientieren und diese, wenn erforderlich, weiterverwenden.
•Wenn Sie aktuelle Geldbewegungen oder Geldanlagen usw. berechnen wollen, müssen Sie
die Berechnungen besonders sorgfältig durchführen und die Ergebnisse prüfen, um sie dann
mit den Berechnungen Ihres Geldinstitutes vergleichen zu können.
20010901
Page 71

Einfache Kapitalverzinsung
2-2-1
2-2 Einfache Kapitalverzinsung
Im Rechner werden zur einfachen Kapitalverzinsung folgende Formeln verwendet.
uu
u Formeln
uu
365-Tage Modus PV :Grundkapital (Barwert)
I% : Jahreszinssatz [in %]
360-Tage Modus n :Anzahl der Zinstage
SI : Zinsen
SFV :Endkapital (Grundkapital +
Zinsen)
Drücken Sie 1(SMPL) im ersten Teil des TVM-Eingangsbildschirms, um das Eingabefenster
für die einfache Kapitalverzinsung zu öffnen.
1(SMPL)
n .................................. Anzahl der Zinstage
I% ............................... Jahreszinssatz [in %]
PV ............................... Grundkapital (Barwert)
Nachdem Sie die Vorgabewerte (Eingabegrößen: z.B. Anlagewert PV= -12000[ ] für n=180
Tage fest anlegen bei einem Jahreszinssatz von I%= 5[%]) eingegeben haben, drücken Sie
eine der unten beschriebenen Funktionstasten, um die entsprechende Berechnung auszuführen.
• 1(SI) ....... Zinsen (einfache Verzinsung
• 2(SFV) ... Endkapital (Grundkapital +
im Anlagezeitraum)
Zinsen)
20010901
Page 72

Einfache Kapitalverzinsung
2-2-2
• Falls Eingabewerte nicht korrekt sind, erscheint eine Fehlermeldung (Ma ERROR).
Verwenden Sie die folgenden Funktionstasten, um zwischen den Eingabe- und Ergebnisbildschirmen zu wechseln.
• 1(REPT) ... Bildschirm zur Dateneingabe
• 6(GRPH) ... Grafikbildschirm mit den
Berechnungsergebnissen:
Nachdem der Grafikbildschirm zur Ergebnisdarstellung geöffnet ist, können Sie die Funktionstaste 1(TRACE) drücken, um die Trace-Funktion zu aktivieren und die Berechnungsergebnisse
entlang des Graphen abzulesen.
Bei jedem Tastendruck der Cursortaste e werden, sofern die Trace-Funktion aktiv ist, die
Berechnungsergebnisse in folgender Reihenfolge hintereinander sichtbar:
Grundkapital (Barwert) (PV) → Jahreszinssatz (SI) → Endkapital (einschließlich Zinsen)
(SFV).
Bei jedem Tastendruck der Cursortaste d werden die Berechnungsergebnisse in umgekehrter
Reihenfolge angezeigt.
Mit dem Tastendruck i wird die Trace-Funktion ausgeschaltet.
Mit einem erneuten Tastendruck i kommt man in den Eingabebildschirm zurück.
20010901
Page 73

i =
100
I %
Kapitalverzinsung mit Zinseszins
2-3-1
2-3 Kapitalverzinsung mit Zinseszins
Im Rechner werden zur Kapitalverzinsung mit Zinseszins folgende Formeln verwendet.
uu
u Formel I (Barwertformel)
uu
( F(i) = )
Mit den Faktoren α und β folgt hieraus:
PV :Grundkapital (Kreditbetrag)
FV :Endkapital (Restschuld)
PMT :Rate (pro Zahlungsperiode)
n :Gesamtanzahl der Zahlungs-
perioden (z.B. Jahre)
I
%
:Zinssatz (als Jahreszinssatz)
(1+ i S ) PMT–FVi
log
{ }
n =
F'(i) = 1. Ableitung der linken Seite von Formel I nach der Variablen i, d.h.
F(i) = –
(1+ i S ) PMT+PVi
log(1+ i)
PMT
(1+ i S)[1– (1+ i)
[
S = 0: Indikator (Fälligkeit nachschüssig)
S = 1: Indikator (Fälligkeit vorschüssig)
α
: Faktor zur Abzinsung von PMT
β
: Faktor zur Abzinsung von FV
: mit dem Newton-Verfahren berech-
i
neter Zinssatz in Formel I
–n
]
ii
+ (1+ i S)[n(1+ i)
–n–1
]+S
–
+S [1–(1 + i)–n]
uu
u Formel II (I% = 0): Zahlungen ohne Kapitalverzinsung.
uu
PV + PMT × n + FV = 0
Hieraus ergibt sich:
nFV(1+ i)
]
20010901
20011201
–n–1
Page 74

Kapitalverzinsung mit Zinseszins
2-3-2
PMT = –
n = –
• Guthaben werden durch ein positives Vorzeichen (+) angegeben, während Sollbeträge mit
negativem Vorzeichen (–) versehen sind.
uu
u
Interne Umrechnung der Zinssätze (zwischen Nominalzins und Effektivzins)
uu
Der Nominalzinssatz (der dem Anwender bekannte I%-Wert, Jahreszinssatz) wird in den
relativen Zinssatz (I%') einer Ratenperiode (Effektivzins) umgerechnet, wenn die Anzahl der
jährlichen Ratenzahlungen (P/Y ) von der Anzahl der jährlichen Zinsperioden (C/Y ) abweicht.
Diese Umrechnung ist sinnvoll bei bestimmten Einzahlungsplänen, Kreditrückzahlungen usw.
P/Y: Anzahl der Raten-
I%' =
C/Y: Anzahl der Verzinsungs-
Zur Berechnung von n, PV, PMT, FV
Nach der Umrechnung des Nominalzinssatzes in den internen relativen Zinssatz (I%') wird die
folgende Darstellung für i dann auch in allen weiteren Berechnungen gemäß Formel I genutzt.
PV + FV
n
PV + FV
PMT
[C / Y ]
zahlungen pro Jahr
(1+ ) –1
{ }
I%
100 × [C / Y ]
[P / Y ]
×100
perioden pro Jahr
i = I%'÷100
Zur Berechnung des I%-Wertes
Wenn die I%-Berechnung mithilfe der anderen Vorgabegrößen ausgeführt worden ist, wurde
intern folgende Berechnung zur Darstellung von I%' als nomineller Jahreszinssatz vorgenommen.
[P / Y ]
[C / Y ]
I%' =
Der Wert für I%' wird dann als Ergebnis der I%-Berechnung (als Jahreszinssatz) angezeigt.
I%
(1+ ) –1
{ }
100
zahlungen pro Jahr
×[C / Y ]×100
perioden pro Jahr
einer Ratenperiode
20010901
P/Y: Anzahl der Raten-
C/Y: Anzahl der Verzinsungs-
I%:
interner relativer Zinssatz
Page 75

Kapitalverzinsung mit Zinseszins
Drücken Sie 2(CMPD) im ersten Teil des TVM-Eingangsbildschirms, um das Eingabefenster
für die Kapitalverzinsung mit Zinseszins zu öffnen.
2(CMPD)
2-3-3
n .................................. Gesamtanzahl der Ratenzahlungen (Gesamtanzahl der
Zahlungsperioden)
I% ............................... Jahreszinssatz (Nominalzins, wird intern umgerechnet in
den relativen Zinssatz (Effektivzins), basierend auf den
Werten von P/Y und C/Y)
PV ............................... Grundkapital (Barwert, Kreditbetrag im Fall eines Darlehens;
Einzahlungsbetrag im Fall einer Kapitalanlage usw.)
PMT ............................ Rate (Ratenzahlbetrag im Fall eines Darlehens; Sparrate im
Fall einer Kapitalanlage usw.)
FV ............................... Endkapital (Höhe der Restschuld im Fall eines Darlehens;
Einzahlungen zuzüglich Zinsen im Fall eines Sparvertrages
usw.)
P/Y .............................. Anzahl der Ratenzahlungen pro Jahr
C/Y .............................. Anzahl der Verzinsungsperioden pro Jahr
Wichtig!
Zu den Vorzeichen der Eingabewerte
Die Gesamtanzahl der Ratenzahlungen (n) und auch die Anzahl der Ratenzahlungen pro Jahr
(P/Y) werden durch einen positiven Wert dargestellt. Für die Geldbeträge gilt: Entweder der
Wert für das Grundkapital (PV) oder der Wert für das Endkapital (FV) ist als positiv anzunehmen,
während gleichzeitig der andere Wert (FV oder PV ) als negativ in die Berechnung eingeht.
Zur Rechengenauigkeit
Der Rechner ermittelt Zinssätze mithilfe des Newton-Verfahrens approximativ, d.h. die erhaltene
Genauigkeit ist durch rechnerinterne Bedingungen beeinflußt. Deshalb sollten Zinssatzberechnungen, die mit diesem Rechner ausgeführt werden, unter Beachtung des Approximationsverfahrens und dessen Genauigkeit besonders im Auge behalten und überprüft werden.
20010901
Page 76

Kapitalverzinsung mit Zinseszins
2-3-4
Nachdem die Vorgabewerte eingegeben sind (z.B. soll eine dreijährige (n=3[Jahre], P/Y=1)
Geldanlage (PV=-10000[ ], PMT=0[ ]) bei halbjährlicher (C/Y=2) Verzinsung hinsichtlich
des erforderlichen Zinssatzes (I%) untersucht werden, um ein gewünschtes Endkapital (FV=
12000[ ]) zu erzielen.), drücken Sie eine der folgenden Funktionstasten, um die entsprechende
Berechnung auszuführen.
• 1(n) ............ Gesamtanzahl der Ratenzahlungen (unter Beachtung von P/Y)
• 2(I%) .......... Zinssatz für C/Y Zinsperioden (als Jahreszinssatz betrachtet)
• 3(PV) ......... Grundkapital (Darlehen: Kreditbetrag; Geldanlage: Anfangsbetrag)
• 4(PMT) ....... Rate (Darlehen: Ratenzahlbetrag; Geldanlage: Sparrate)
• 5(FV) .......... Endkapital (Darlehen: Restschuld; Geldanlage: Einzahlungen
zuzüglich Zinsen)
• 6(AMT) ....... Bildschirm zur Armortisationsrechnung (z.B. Schuldentilgung)
• Falls Eingabewerte nicht korrekt sind, erscheint eine Fehlermeldung (Ma ERROR).
Verwenden Sie die folgenden Funktionstasten, um zwischen den Eingabe- und Ergebnis-
bildschirmen zu wechseln.
• 1(REPT) ..... Bildschirm zur Dateneingabe
• 4(AMT) ....... Bildschirm zur Armortisationsrechnung
• 6(GRPH) .... Grafikbildschirm mit den
Berechnungsergebnissen:
Nachdem der Grafikbildschirm zur Ergebnisdarstellung geöffnet ist, können Sie die Funktionstaste 1(TRACE) drücken, um die Trace-Funktion zu aktivieren und die Berechnungsergebnisse
entlang des Graphen abzulesen.
Mit dem Tastendruck i wird die Trace-Funktion ausgeschaltet.
Mit einem erneuten Tastendruck i kommt man in den Eingabebildschirm zurück.
20010901
Page 77

Geldfluß-Berechnungen (Cash-Flow, Investitionsrechnung)
2-4-1
2-4 Geldfluß-Berechnungen (Cash-Flow,
Investitionsrechnung)
Dieser Rechner benutzt die Barwertmethode, d.h. alle Kapitalbeträge werden auf den ersten
Zahlungszeitpunkt abgezinst (engl.: discounted cash flow (DCF) method), um eine Investition
unter Beachtung des gesamten Geldflusses in einem Zeitraum mit festen Zins- und
Zahlungsperioden zu bewerten und vergleichbar zu machen. Der Rechner ermittelt die folgenden
vier Größen zur Beurteilung einer Investition.
• NPV ... Nettobarwert (abgezinst, Summe aller Barwerte der Kapitalausgaben
und -rückflüsse)
• NFV ... Nettoendwert (aufgezinst)
• IRR
... interner Zinssatz in % zum Null-Nettobarwert
• PBP ... Anzahl der Zinsperioden
Ein Geldfluß-Diagramm der nachstehenden Art veranschaulicht die einzelnen vorzeichenbehafteten Kapitalflüsse (Pfeil nach unten: negativer Wert, Pfeil nach oben: positiver Wert).
CF
7
6
CF
CF
5
CF
3
2
CF
CF
4
CF
1
CF
0
Entsprechend dieser Grafik wird das eingesetzte Anfangskapital mit CF0 bezeichnet. CF1
bezeichnet z.B. den Kapitaleinsatz nach einem Jahr, CF2 den Kapitalrückfluß nach zwei Jahren
usw. Die Investitionsrechnung wird verwendet, um eine klare Aussage darüber zu finden, ob
eine Investition rentabel (gewinnbringend) ist, was ja die Zielstellung einer Investition ist.
u NPV (Abzinsung auf den Barwert der Investition, n: natürliche Zahl bis zu 254)
1
NPV = CF0 + + + + … +
CF
(1+ i )
CF2
(1+ i )
2
CF3
(1+ i )
3
(1+ i )
n
CFn
i =
I %
100
u NFV (Aufzinsung auf den Endwert der Investition)
NFV = NPV × (1 + i )
u IRR (Formel zur Ermittlung des internen Zinssatzes i
0 = CF0 + + + + … +
CF
(1+ i )
n
)
1
CF
2
CF
(1+ i )
2
20010901
20011201
(1+ i )
3
3
CF
(1+ i )
n
n
Page 78

Geldfluß-Berechnungen (Cash-Flow, Investitionsrechnung)
2-4-2
In der zuletzt genannten Formel gilt NPV = 0 und der Wert für IRR ist gleich i × 100. Es wird
jedoch darauf hingewiesen, dass sich unbedeutende Rundungsfehler in einzelnen Summanden
durch die Teilschritte der Berechnung aufsummieren können, so dass NPV mit dem berechneten
i niemals exakt Null sein wird. Je genauer IRR berechnet ist, desto genauer wird sich NPV
dem Wert Null annähern.
uu
u PBP
uu
Anzahl der (konstanten) Zinsperioden N, sofern NPV > 0 gilt.
• Drücken Sie 3(CASH) im ersten Teil des TVM-Eingangsbildschirms, um das Eingabefenster für die Geldfluß-Berechnungen zu öffnen.
3(CASH)
I% ............................... Zinssatz für eine Zahlungsperiode (in %)
Csh .............................. Liste der Cash-Flow-Werte CF0, CF1, ..., CFN.
Falls die vorzeichenbehafteten Kapitalbeträge (Cash-Flow-Werte) noch nicht in einer Datenliste
erfaßt sind, drücken Sie 5('LIST) und geben im Listeneditor die Werte in eine Liste ein.
Nachdem Sie alle Vorgabewerte (Eingabegrößen: z.B. Untersuchung einer Investition in Höhe
von CF0 und CF1 und anschließenden Kapitalrückflüssen CF2 bis CFN bei einem Zinssatz
I%=11%, Csh = List 1 = {CF0, CF1, ..., CFN} = {-86000[ ], -5000[ ], 42000[ ], 31000[ ],
24000[ ], 23000[ ], 26000[ ]}) eingegeben haben, drücken Sie eine der unten beschriebenen
Funktionstasten, um die entsprechende Berechnung auszuführen.
• 1(NPV) ......... Nettobarwert der Investition (ein positiver Barwert bedeutet: die
Investition ist für den Investor rentabel)
• 2(IRR) .......... interner Zinssatz zum Null-Nettobarwert
• 3(PBP) ......... Anzahl der Zahlungsperioden (entsprechend der Csh-Liste)
• 4(NFV) ......... Nettoendwert der Investition (aufgezinster Barwert)
• 5('LIST) ..... Zur Dateneingabe den Listeneditor öffnen
• 6(LIST) ......... Auswahl einer Liste mit den Cash-Flow-Werten
20010901
20011201
Page 79

Geldfluß-Berechnungen (Cash-Flow, Investitionsrechnung)
2-4-3
• Falls Eingabewerte nicht korrekt sind, erscheint eine Fehlermeldung (Ma ERROR).
Verwenden Sie die folgenden Funktionstasten, um zwischen den Eingabe- und Ergebnis-
bildschirmen zu wechseln.
• 1(REPT) ...... Bildschirm zur Dateneingabe
• 6(GRPH) ..... Grafikbildschirm mit den
Berechnungsergebnissen:
Nachdem der Grafikbildschirm zur Ergebnisdarstellung geöffnet ist, können Sie die Funktionstaste 1(TRACE) drücken, um die Trace-Funktion zu aktivieren und den Geldfluß entlang des
Graphen abzulesen.
Mit dem Tastendruck i wird die Trace-Funktion ausgeschaltet.
Mit einem erneuten Tastendruck i kommt man in den Eingabebildschirm zurück.
20010901
Page 80

;;;;;;;;;;;
;;;;;;;;;
;;;;;;;
;;;;;
;;;
;
;
;
;
;
;
;
;
;;;;;
;;;;;
;;;
;
Tilgungsberechnungen (Amortisation)
2-5-1
2-5 Tilgungsberechnungen (Amortisation)
Der Rechner kann dazu benutzt werden, um den jeweiligen Tilgungsanteil sowie Zinsanteil der
Zahlungsrate (z.B. Monatsrate) zu berechnen, damit Sie einen entsprechenden Tilgungsplan
mit der jeweiligen Restschuld aufzustellen können. Für einen beliebigen Zeitpunkt im Tilgungsverlauf können die genannten Einzelwerte abgerufen oder grafisch dargestellt werden.
uu
u Formeln
uu
Rate (Betrag einer einzelnen Zahlung im Tilgungsverlauf)
;;;
e
;;;
;;;
;;;
;;;
;;;
;;;
;;;
d
12 mn
(Zeitpunkte der Fälligkeit einer Rate)
a: Zinsanteil in der Rate zum Zeitpunkt PM1 (INT)
b: Tilgungsanteil in der Rate zum Zeitpunkt PM1 (PRN)
c: verbleibende Restschuld nach der Rate zum Zeitpunkt PM2 (BAL)
d: Gesamttilgungsanteil der Raten vom Zeitpunkt PM1 bis zum Zeitpunkt PM2 (ΣPRN)
e: Gesamtzinsanteil der Raten vom Zeitpunkt PM1 bis zum Zeitpunkt PM2 (ΣINT)
*a + b = Rate (Betrag einer einzelnen Zahlung, PMT)
a
b
c
sign(PMT) = Vorzeichen der Rate
BAL0 = PV (Restschuld = Gesamtdarlehen zu Beginn des Tilgungszeitraumes, INT1 = 0 und
PRN1 = PMT bei vorschüssiger Tilgung)
20010901
Page 81

Tilgungsberechnungen (Amortisation)
uu
u
Interne Umrechnung der Zinssätze (zwischen Nominalzins und Effektivzins)
uu
Der Nominalzinssatz (der dem Anwender bekannte I%-Wert, Jahreszinssatz) wird in den
relativen Zinssatz (I%') einer Ratenperiode (Effektivzins) umgerechnet, wenn die Anzahl der
jährlichen Ratenzahlungen (P/Y ) von der Anzahl der jährlichen Zinsperioden (C/Y ) abweicht.
I%' =
(1+ ) –1
{ }
Nach der Umrechnung des Nominalzinssatzes in den internen relativen Zinssatz (I%') wird
die folgende Darstellung für i dann auch in allen weiteren Berechnungen genutzt.
I%
100 × [C / Y ]
2-5-2
[C / Y ]
[P / Y ]
×100
i = I%'÷100
Drücken Sie 4(AMT) im ersten Teil des TVM-Eingangsbildschirms, um das Eingabefenster
für die Tilgungsberechnungen zu öffnen.
4(AMT)
PM1 ............................. Index1, erster Betrachtungszeitpunkt zwischen 1 und n
PM2 ............................. Index2, zweiter Betrachtungszeitpunkt zwischen 1 und n
.................................. Gesamtanzahl der Ratenperioden (Ratenzahlungen)
n
I% ............................... Zinssatz (Jahreszinssatz, wird intern in I%' umgerechnet)
PV ............................... Gesamtdarlehen (Anfangskapital, Gesamtschuld)
PMT ............................ Rate (Ratenzahlbetrag)
FV ............................... Restschuld nach der Schlußrate (Endkapital)
P/Y .............................. Anzahl der Ratenzahlungen pro Jahr
C/Y .............................. Anzahl der Verzinsungsperioden pro Jahr
20010901
Page 82

Tilgungsberechnungen (Amortisation)
2-5-3
Nachdem Sie alle Vorgabewerte (Eingabegrößen: z.B. Untersuchung des Tilgungsverlaufes
einer Hypothek in Höhe von PV= 140000[ ] mit 15 Jahren Laufzeit (n=15 ×12=180) und FV=
0[ ] bei einem Zinssatz I%=6,5%, halbjählicher Verzinsung (C/Y=2) und 12 Ratenzahlungen
pro Jahr (P/Y=12), speziell zum Zeitpunkt der 24.Rate (PM1=24) wird unten der Tilgungsanteil
(PRN) angezeigt.) eingegeben haben, drücken Sie eine der unten beschriebenen Funktionstasten, um die entsprechende Berechnung auszuführen.
• 1(BAL) ......... verbleibende Restschuld nach der Rate zum Zeitpunkt PM2
• 2(INT) .......... Zinsanteil in der Rate zum Zeitpunkt PM1
• 3(PRN) ......... Tilgungsanteil in der Rate zum Zeitpunkt PM1
• 4(Σ INT) ....... Gesamtzinssanteil der Raten vom Zeitpunkt PM1 bis zum
Zeitpunkt PM2
• 5(Σ PRN) ...... Gesamttilgungsanteil der Raten vom Zeitpunkt PM1 bis zum
Zeitpunkt PM2
• 6(CMPD) ...... Eingabebildschirm zur Zinseszinsrechnung
• Falls Eingabewerte nicht korrekt sind, erscheint eine Fehlermeldung (Ma ERROR).
Verwenden Sie die folgenden Funktionstasten, um zwischen den Eingabe- und Ergebnis-
bildschirmen zu wechseln.
• 1(REPT) ....... Bildschirm zur Dateneingabe (Amortisation)
• 4(CMPD) ...... Eingabebildschirm zur Zinseszinsrechnung
• 6(GRPH) ...... Grafikbildschirm mit den
Berechnungsergebnissen:
Nachdem der Grafikbildschirm zur Ergebnisdarstellung geöffnet ist, können Sie die Funktionstaste 1(TRACE) drücken, um die Trace-Funktion zu aktivieren und den Tilgungsverlauf entlang
des Graphen abzulesen. Nach dem Drücken von 1(TRACE) werden INT und PRN für n = 1
angezeigt. Beim Drücken der Cursortaste e werden INT und PRN für n = 2, n = 3 usw.
angezeigt.
Mit dem Tastendruck i wird die Trace-Funktion ausgeschaltet.
Mit einem erneuten Tastendruck i kommt man in den Eingabebildschirm zurück.
20010901
Page 83

2-6-1
Zinssatz-Umrechnung
2-6 Zinssatz-Umrechnung
Der Rechner verfügt über einen speziellen Eingangsbildschirm zur Zinssatz-Umrechnung. In
diesem Abschnitt wird die Umrechnung des Nominalzinssatzes (pro Jahr) in den jährlichen
Effektivzinssatz und umgekehrt beschrieben.
uu
u Formeln
uu
APR/100
1+
EFF =
1+
EFF
100
APR =
Drücken Sie 5(CNVT) im ersten Teil des TVM-Eingangsbildschirmes, um das Eingabefenster
für die Zinssatz-Umrechnung zu öffnen.
5(CNVT)
n
–1 × 100
n
1
n
–1 × n ×100
APR : Jahreszinssatz (in %)
EFF : jährlicher Effektivzinssatz
(in %)
n :Anzahl der Zinsperioden
pro Jahr
n ....................................... Anzahl der Zinsperioden pro Jahr
I% ............................... Zinssatz
Nachdem Sie die Vorgabewerte (Eingabegrößen: z.B. vierteljährliche Verzinsung n=4 bei einem
Jahreszinssatz von I%= 12[%]) eingegeben haben, drücken Sie eine der unten beschriebenen
Funktionstasten, um die entsprechende Berechnung auszuführen.
• 1('EFF) ... Umrechnung des Nominalzinssatzes in den jährlichen
• 2('APR) ... Umrechnung des jährlichen Effektivzinssatzes in den
• Falls Eingabewerte nicht korrekt sind, erscheint eine Fehlermeldung (Ma ERROR).
Verwenden Sie die folgende Funktionstaste, um in den Eingabebildschirm zu wechseln.
• 1(REPT) ... Bildschirm zur Dateneingabe
Effektivzinssatz
Nominalzinssatz
20010901
Page 84

M
Cost, Selling Price, Margin
2-7-1
2-7 Herstellungskosten, Verkaufspreis, Gewinn-
spanne
Herstellungskosten, Verkaufspreis oder Gewinnspanne (in %) können durch Vorgabe der jeweils
anderen zwei Größen mit dem Rechner ermittelt werden.
uu
u Formel
uu
CST
MRG
100
1–
1–
MRG
100
CST
SEL
× 100
CST = SEL
SEL =
1–
RG(%) =
Drücken Sie 1(COST) im zweiten Teil des TVM-Eingangsbildschirms, um das folgende
Eingabefenster zu öffnen. Zwei der drei Eingabegrößen sind vorzugeben.
6(g)1(COST)
CST :Herstellungskosten (Netto)
SEL :Verkaufspreis (Brutto)
MRG : Gewinnspanne (in %)
Cst ............................... Herstellungskosten
Sel ............................... Verkaufspreis
Mrg .............................. Gewinnspanne
Nachdem Sie die Vorgabewerte (Eingabegrößen: z.B. Verkaufspreis SEL=2000[ ] bei einer
Gewinnspanne von MRG=15%) eingegeben haben, drücken Sie eine der unten beschriebenen
Funktionstasten, um die entsprechende Berechnung auszuführen.
• 1(COST) .... Herstellungskosten
• 2(SEL) ....... Verkaufspreis
• 3(MRG) ...... Gewinnspanne
• Falls Eingabewerte nicht korrekt sind, erscheint eine Fehlermeldung (Ma ERROR).
Verwenden Sie die folgende Funktionstaste, um in den Eingabebildschirm zu wechseln.
• 1(REPT) ... Bildschirm zur Dateneingabe
20010901
Page 85

Berechnung der Zinstage (Datumsberechnungen)
2-8-1
2-8 Berechnung der Zinstage (Datums-
berechnungen)
Sie können die Anzahl der Tage zwischen zwei Datumsvorgaben berechnen (Anzahl der
Zinstage), oder Sie können eine zukünftige oder zurückliegende Datumsangabe in der Form
ermitteln, dass Sie ausgehend von einem vorgegebenen Datum eine bestimmte Anzahl von
(Zins-)Tagen vorwärts oder zurück rechnen.
Drücken Sie 2(DAYS) im zweiten Teil des TVM-Eingangsbildschirms, um das folgende
Eingabefenster zur Zinstage- oder Datumsberechnung zu öffnen.
6(g)2(DAYS)
d1 ................................ erstes Datum (Datum 1)
d2 ................................ zweites Datum (Datum 2)
D ................................. Anzahl der (Zins-)Tage (für Vorwärts- oder Rückwärtsrechnung)
Um ein Datum (Datums-Format: Monat-Tag-Jahr (Wochentag)) eingeben zu können, müssen
Sie zuerst die Zeile d1 oder d2 markieren. Mit der Eingabe der Monatszahl öffnet sich ein
kleineres Eingabefenster, so wie es im folgenden Screen-Shot abgebildet ist.
# Das SET UP-Eingabefenster kann dazu ver-
wendet werden, um entweder das 360-TageJahr oder das 365-Tage-Jahr für die weiteren
finanzmathematischen Berechnungen voreinzustellen. Die Zinstage- oder Datumsberechnungen werden in Übereinstimmung mit dem
voreingestellten 360- bzw. 365-Tage-Jahr
realisiert, jedoch kann im 360-Tage-Modus
20010901
keine Datumsberechnung ausgeführt werden:
(Datum) + (Anzahl der Zinstage)
(Datum) - (Anzahl der Zinstage)
In diesem Fall erscheint eine Fehlermeldung.
# Für die Berechnung zulässig ist folgender
Zeitbereich:
1. Januar 1901 bis 31. Dezember 2099.
Page 86

Berechnung der Zinstage (Datumsberechnungen)
2-8-2
Geben Sie den Monat, den Tag und das Jahr in dieser Reihenfolge ein und drücken Sie jedesmal
die w -Taste.
Nachdem Sie die Vorgabewerte eingegeben haben (z.B. d1=08M21D1970Y und
d2=10M04D1977Y), drücken Sie eine der folgenden Funktionstasten, um die Berechnung
auszuführen (z.B. Anzahl der Zinstage).
• 1(PRD) ........ Anzahl der Tage von d1 bis d2 (d2 – d1)
• 2(d1+D) ....... d1 plus eine Anzahl D von Tagen (d1 + D)
• 3(d1 – D) ..... d1 minus eine Anzahl D von Tagen (d1 – D)
• Falls Eingabewerte nicht korrekt sind, erscheint eine Fehlermeldung (Ma ERROR).
Verwenden Sie die folgende Funktionstaste, um in den Eingabebildschirm zu wechseln.
• 1(REPT) ...... Bildschirm zur Dateneingabe
Berechnungen im 360-Tage-Modus (30/360-Tage-Modus)
Nachstehend wird beschrieben, wie die Berechnungen ausgeführt werden, wenn der 360-TageModus im SET UP-Menü voreingestellt ist.
• Falls d1 der 31. Tag eines Monats ist, wird d1 als 30. Tag des Monats interpretiert.
• Falls d2 der 31. Tag eines Monats ist, wird d2 als der 1. Tag des nachfolgenden Monats
interpretiert, falls nicht d1 ein 30. Tag ist. (z.B. d1=05M31D2001Y oder d1=05M30D2001Y,
d2=08M31D2001Y ergibt PRD=90 Zinstage, jedoch d1=05M29D2001Y, d2=08M31D2001Y
ergibt dann bereits PRD=92 Zinstage usw.)
20010901
Page 87

Abschreibungsberechnungen (Amortisation)
2-9
Abschreibungsberechnungen (Amortisation)
Um Abschreibungen zu berechnen, stehen im Rechner die folgenden vier Abschreibungsverfahren zur Verfügung.
uu
u Methode der linearen Abschreibung (Straight-Line Method)
uu
Für eine gegebene Nutzungsdauer wird die lineare Abschreibung wie folgt berechnet und
tabelliert.
2-9-1
PV :Anschaffungswert (Kosten)
FV :Restwert (Schrottwert)
–
Y
1 :Anzahl der Abschreibungs-
monate im 1. Jahr
n :Nutzungsdauer (in Jahren)
j : Jahresindex ( j-tes Jahr)
SL j :Abschreibungsbetrag im j-ten
Jahr
Die Abschreibung für den Jahresanteil des ersten Jahres (Y–1 Monate) bzw. des letzten Jahres
(12 - Y–1 Monate) kann monatsweise berücksichtigt werden. (Die Schreibweise Y–1 erfolgt in
Anlehnung an die Taschenrechnernotation und ist eine symbolische Variable mit dem Wertebereich {1, 2, ..., 11, 12} und entspricht der Indexschreibweise Y1.)
uu
u Geometrisch-degressive Abschreibung I (Fixed Percentage Method)
uu
Für eine gegebene Nutzungsdauer wird die geometrisch-degressive Abschreibung berechnet
und tabelliert, oder es wird der Abschreibungssatz (in %) bestimmt.
FPj :Abschreibungsbetrag im j-ten
Jahr
RDVj :Restabschreibungswert am
Ende des j-ten Jahres
I
%
:Abschreibungsrate (in %,
Abschreibungsprozentsatz)
Die Abschreibung für den Jahresanteil des ersten Jahres (Y–1 Monate) bzw. des letzten Jahres
(12 - Y–1 Monate) kann monatsweise berücksichtigt werden. (Die Schreibweise Y–1 erfolgt in
Anlehnung an die Taschenrechnernotation und ist eine symbolische Variable mit dem Wertebereich {1, 2, ..., 11, 12} und entspricht der Indexschreibweise Y1.)
20011201
20010901
Page 88

Abschreibungsberechnungen (Amortisation)
uu
Arithmetisch-degressive Abschreibung (Digitale Abschreibung, Sum-of-the-Year's
u
uu
Digits Method)
Für eine gegebene Nutzungsdauer (in Jahren) wird die arithmetisch-degressive Abschreibung
(digitale Abschreibung) berechnet und tabelliert.
2-9-2
SYDj :Abschreibungsbetrag im j-ten Jahr
RDVj :Restabschreibungswert am Ende
des j-ten Jahres
Ganzteil(n' ) = ganzzahliger Anteil von n' , Bruchteil(2 ×
Die Abschreibung für den Jahresanteil des ersten Jahres (Y–1 Monate) bzw. des letzten Jahres
(12 - Y–1 Monate) kann monatsweise berücksichtigt werden. (Die Schreibweise Y–1 erfolgt in
Anlehnung an die Taschenrechnernotation und ist eine symbolische Variable mit dem Wertebereich {1, 2, ..., 11, 12} und entspricht der Indexschreibweise Y1.)
uu
u Geometrisch-degressive Abschreibung II (Declining Balance Method)
uu
Für eine gegebene Nutzungsdauer kann die geometrisch-degressive Abschreibung auch wie
folgt berechnet und tabelliert werden.
n'
) = gebrochener Anteil von 2 ×
n'.
DBj :Abschreibungsbetrag im j-
ten Jahr
RDVj :Restabschreibungswert
am Ende des j-ten Jahres
I
%
:Abschreibungsfaktor (in %)
für n Jahre
I
%
/
n :Abschreibungssatz (in %)
Die Abschreibung für den Jahresanteil des ersten Jahres (Y–1 Monate) bzw. des letzten Jahres
(12 - Y–1 Monate) kann monatsweise berücksichtigt werden. (Die Schreibweise Y–1 erfolgt in
20010901
20011201
Page 89

Abschreibungsberechnungen (Amortisation)
2-9-3
Anlehnung an die Taschenrechnernotation und ist eine symbolische Variable mit dem Wertebereich {1, 2, ..., 11, 12} und entspricht der Indexschreibweise Y1.)
Drücken Sie 3(DEPR) im zweiten Teil des TVM-Eingangsbildschirms, um das folgende
Eingabefenster für die Amortisationsberechnung zu öffnen.
6(g)3(DEPR)
n .................................. Nutzungsdauer (in vollen Jahren)
I% ............................... Abschreibungsrate/Abschreibungsfaktor (in %)
PV ............................... Anschaffungswert (Kosten)
FV ............................... Restwert (Schrottwert)
j ................................... Jahresindex für eine Einzelabfrage ( j-tes Jahr)
–
Y
1 .............................. Anzahl der anteiligen Abschreibungsmonate im 1. Jahr
• Eingabegrößen werden als ganze Zahl oder Dezimalzahl angezeigt, selbst wenn diese als
gemeine Brüche eingegeben wurden.
Nachdem Sie die Vorgabewerte eingegeben haben (z.B. lineare Abschreibung: PV=9500[ ],
FV=0[ ], n=5), drücken Sie eine der folgenden Funktionstasten, um die Berechnung
auszuführen (Das folgende Bild zeigt die Abschreibungsbeträge bei linearer Abschreibung.).
• 1(SL) ........... Lineare Abschreibung (Straight-Line Method)
• 2(FP) ........... Geometrisch-degressive Abschreibung I: 1. wahlweise Berechnung
• 3(SYD) ........ Arithmetisch-degressive Abschreibung (Digitale Abschreibung,
• 4(DB) .......... Geometrisch-degressive Abschreibung II (Declining Balance
einer Abschreibungsrate I% (Fixed Percentage Method)
........... Geometrisch-degressive Abschreibung I: 2. Abschreibungs-
berechnung (Fixed Percentage Method)
Sum-of-the-Year's Digits Method)
Method)
20011201
20010901
Page 90

Abschreibungsberechnungen (Amortisation)
2-9-4
• Falls Eingabewerte nicht korrekt sind, erscheint eine Fehlermeldung (Ma ERROR).
Verwenden Sie die folgende Funktionstaste, um in den Eingabebildschirm zu wechseln.
• 1(REPT) ...... Bildschirm zur Dateneingabe
• 6(TABL) ...... Abschreibungstabelle mit den berechneten Werten
Die folgenden Funktionstasten erscheinen als Fußzeile im Bildschirm der Abschreibungstabelle.
• 1(REPT) ...... Bildschirm zur Dateneingabe
• 6(GRPH) ..... Grafikbildschirm mit den
Berechnungsergebnissen:
Nachdem der Grafikbildschirm zur Ergebnisdarstellung geöffnet ist, können Sie die Funktionstaste 1(TRACE) drücken, um die Trace-Funktion zu aktivieren und den Tilgungsverlauf entlang
des Graphen abzulesen.
Mit dem Tastendruck i wird die Trace-Funktion ausgeschaltet.
Mit einem erneuten Tastendruck i kommt man in den Eingabebildschirm zurück.
Hinweis:
Ist im SET UP-Menü Label: On voreingestellt, erscheinen die Achsenbezeichnungen CASH und TIME.
20010901
Page 91

Wertpapieranalyse (Zinsanleihen, Obligationen, ...)
2-10-1
2-10 Wertpapieranalyse (Zinsanleihen,
Obligationen, ...)
Mithilfe der Wertpapieranalyse können der Kaufpreis eines festverzinslichen Wertpapiers, einer
Zinsanleihe, einer Obligation, von Schatzanweisungen und ähnlichem (Stückwert zum Kauftermin,
aktueller Kurs, Börsenkurs) und die Marktrendite berechnet werden. Die Berechnungsformel
(Kontoführungsmethode) beruht dabei auf der US-Methode, die sich bei unterjähriger Verzinsung
von der ISMA-Methode (International Securities Market Association) unterscheidet. Zur Ermittlung
der Renditen werden alle zukünftigen Zahlungen (Zinsen) auf den Valutatag (Kaufdatum) abgezinst.
Es werden dabei nicht nur volle Couponperioden diskontiert sondern auch die angebrochene
Periode (Teilperiode ab Valutatag). Damit setzt bereits ab dem Kauftermin die Verzinsung ein.
uu
u Formeln
uu
PRC : aktueller Kurs pro Stück (mit 100 Nennwert) ohne aufgelaufenen Stückzins
RDV :Rückkaufwert, Rückzahlungskurs pro Stück (mit 100 Nennwert)
CPN : jährlicher Stückzins (Jahreszins, Couponrate [in %] / 100 ×
vorausgesetzten Nennwertes gleichen sich die Werte von Zins und Zinssatz!)
100[ ] , wegen des
YLD : jährliche Rendite (Umlaufrendite), jährlicher Gewinn (Marktgewinn) (in %)
YLD/M :Rendite (in %) einer Couponperiode, bei unterjähriger Verzinsung: US-Methode
M :
Anzahl der Coupontermine pro Jahr (Jahrescoupon: M=1, Halbjahrescoupon: M=2),
Anzahl der jährlichen Zinsausschüttungen
A :Anzahl der bereits abgelaufenen Zinstage bis zum Valutatag seit dem letzten
Co
N : Anzahl der noch ausstehenden
N-1 :Anzahl der noch ausstehenden vollständigen
D :Gesamtanzahl der Tage derjenigen
B :Anzahl der Tage vom Valutatag an bis zum nächsten
INT : bereits aufgelaufene Stückzinsen bis zum Kaufdatum: (A
upontermin
datum (=Restlaufzeit in Jahren bzw. Halbjahren)
(D=360: Jahrescouponperiode, D=180: Halbjahrescouponperiode)
Co
upontermine ab Kaufdatum bis zum Fälligkeits-
Co
Co
uponperiode, in der der Valutatag liegt
uponperioden
Co
upontermin: B = D – A
/ D) ×
(CPN / M)
CST : aktueller Stückpreis einschließlich aufgelaufener Stückzinsen: CST = PRC + INT
• Falls weniger als eine Couponperiode bis zur Fälligkeit verbleibt (nur einfache Verzinsung):
20010901
Page 92

Wertpapieranalyse (Zinsanleihen, Obligationen, ...)
2-10-2
• Falls mindestens eine Couponperiode bis zur Fälligkeit verbleibt (Zinseszinsrechnung):
–
DA M
×
CPN
INT =
CST = PRC + INT
Drücken Sie 4(BOND) im zweiten Teil des TVM-Eingangsbildschirms, um das folgende
Eingabefenster für die Wertpapieranalyse zu öffnen.
6(g)4(BOND)
d1 ................ Kaufdatum (Valutatag)
d2 ................ Verkaufsdatum (Fälligkeit)
RDV ............ Rückkaufwert, Rückzahlungskurs pro Stück (mit 100 Nennwert)
CPN ............ jährlicher Stückzins (Jahreszins [in ] oder Couponrate [in %])
PRC ............ aktueller Kurs pro Stück (mit 100 Nennwert) ohne aufgelaufenen
Stückzins
YLD ............. jährliche Rendite, jährlicher Gewinn (in %)
Um ein Datum (Datums-Format: Monat-Tag-Jahr (Wochentag)) eingeben zu können, müssen
Sie zuerst die Zeile d1 oder d2 markieren. Mit der Eingabe der Monatszahl öffnet sich ein
kleineres Eingabefenster, so wie es im folgenden Screen-Shot abgebildet ist.
Geben Sie den Monat, den Tag und das Jahr in dieser Reihenfolge ein und drücken Sie jedesmal
die w -Taste.
20010901
Page 93

Wertpapieranalyse (Zinsanleihen, Obligationen, ...)
2-10-3
Nachdem Sie die Vorgabewerte eingegeben haben (z.B. 365-Tage-Modus und Jahrescoupon
(M=1) im SET UP-Menü einstellen, d1= 01M12D1998Y (Valutatag), d2= 04M04D1999Y
(Fälligkeit), RDV=100[ ], CPN= 5[%] = 5[ ] (Couponrate), YLD= 8[%] (Marktrendite)), drücken
Sie eine der folgenden Funktionstasten, um die Berechnung auszuführen (z.B. aktueller Kurs
der Anleihe: PRC).
• 1(PRC) ..... aktueller Kurs pro Stück
(mit 100 Nennwert)
• 2(YLD) ..... jährliche Rendite,
jährlicher Gewinn (in %)
• Falls Eingabewerte nicht korrekt sind, erscheint eine Fehlermeldung (Ma ERROR).
Verwenden Sie die folgende Funktionstaste, um in den Eingabebildschirm zu wechseln.
• 1(REPT) .......Bildschirm zur Dateneingabe
• 5(MEMO) ..... Bildschirm mit verschiedenen Zeit-Angaben der aktuellen Analyse*
• 6(GRPH) ......Grafikbildschirm mit den Berechnungsergebnissen
Indem Sie 5(MEMO) drücken, werden Ihnen verschiedene zeitbezogene Berechnungsgrößen, die
in die Wertpapieranalyse eingehen, wie rechts dargestellt angezeigt.
*Als Fälligkeitstermin wird in der Analyse vom Datum d2 ausgegangen, wenn im 365-Tage-
Modus gerechnet wird, der zuvor im SET UP-Menü (Date Mode) eingestellt wurde.
w~w
(CPD ... Coupontermin (Fälligkeitsdatum))
6(GRPH)
Nachdem der Grafikbildschirm zur Ergebnisdarstellung geöffnet ist, können Sie die Funktionstaste 1(TRACE) drücken, um die Trace-Funktion zu aktivieren und Angaben zur Wertpapieranalyse entlang des Graphen abzulesen PRC, CPN und RDV(=100 ).
Mit dem Tastendruck i wird die Trace-Funktion
ausgeschaltet.
Mit einem erneuten Tastendruck i kommt man
in den Eingabebildschirm zurück.
20010901
Page 94

TVM-Grafik (weitere grafische Darstellungen)
2-11
TVM-Grafik (weitere grafische Darstellungen)
In der TVM-Grafik können Sie zwei der fünf Berechnungsgrößen (n, I%, PV, PMT, FV) den
Koordinatenachsen (x-Achse und y-Achse der grafischen Darstellung) zuordnen und den
grafischen Verlauf der Veränderung der y -Variablen in Abhängigkeit von der Veränderung der
2-11-1
x -Variablen darstellen. Die drei anderen Größen sind dabei feste Parameter.
Drücken Sie 5(TVMG) im zweiten Teil des TVM-Eingangsbildschirms, um das folgende
Eingabefenster für die TVM-Grafik zu öffnen.
6(g)5(TVMG)
Nachdem Sie die Vorgabewerte eingegeben haben, drücken Sie eine der unten angegebenen
Funktionstasten, um die entsprechenden Berechnungsgrößen der x-Achse und der y-Achse
zuzuordnen.
• 1(X) ... Zuordnung der markierten Berechnungsgröße zur x-Achse
• 2(Y) ... Zuordnung der markierten Berechnungsgröße zur y-Achse
Nachdem Sie die geforderten Einstellungen vorgenommen haben, können Sie den Graphen
zeichnen.
• 6(GRPH) ... Darstellung des Graphen
Nachdem der Grafikbildschirm zur Ergebnisdarstellung geöffnet ist, können Sie die Funktionstaste 1(TRACE) drücken, um die Trace-Funktion zu aktivieren und die Zahlenpaare (x,y)
entlang des Graphen abzulesen.
Mit dem Tastendruck i wird die Trace-Funktion ausgeschaltet.
20010901
Page 95

TVM-Grafik (weitere grafische Darstellungen)
2-11-2
Indem Sie 6(Y-CAL) drücken, nachdem der Graph gezeichnet ist, öffnet sich das
nachfolgend dargestellte Eingabefenster zur Eingabe eines x-Wertes.
Nach der Eingabe eines x-Wertes in dieses Eingabefenster und dem Tastendruck w
wird der entsprechende y-Wert berechnet und angezeigt.
Drücken Sie i zur Rückkehr in den Eingabebildschirm der darzustellenden Größen.
•Die Berechnung kann etwas Zeit in Anspruch nehmen, falls Sie den I%-Wert als
abhängigen y-Wert festgelegt haben.
20010901
Page 96

Kapitel
Differenzialgleichungen
(DIFF EQ)
In diesem Kapitel werden numerische und grafische Lösungsmöglichkeiten für folgende Arten von Differenzialgleichungen
(Anfangswertaufgaben)
• Lineare und nichtlineare Differenzialgleichungen 1. Ordnung
• Lineare Differenzialgleichungen 2. Ordnung
•
Differenzialgleichungen N-ter Ordnung
•Systeme von Differenzialgleichungen 1. Ordnung
erklärt:
3
3-1 Zur Lösung von Aufgaben im DIFF EQ - Menü
3-2 Differenzialgleichungen 1. Ordnung
3-3 Lineare Differenzialgleichungen 2. Ordnung
3-4
Differenzialgleichungen N-ter Ordnung
3-5 Systeme von Differenzialgleichungen 1. Ordnung
20010901
Page 97

Zur Lösung von Aufgaben im DIFF EQ - Menü
3-1-1
3-1
Zur Lösung von Aufgaben im DIFF EQ - Menü
Sie können verschiedene Typen von Differenzialgleichungen (Anfangswertaufgaben) numerisch
lösen und die Lösungen grafisch darstellen (Integralkurven). Das allgemeine Vorgehen zur
Lösung einer Differenzialgleichung mithilfe des Rechners wird in diesem Abschnitt beschrieben.
Eingangsbildschirm des DIFF EQ - Menüs
1. Rufen Sie das DIFF EQ - Menü aus dem Hauptmenü
auf. Nach dem Öffnen des DIFF EQ - Menüs erscheint
der Eingangsbildschirm zu den Differenzialgleichungen.
Voreinstellungen, Eingabe und Lösung der Aufgabenstellung
2. Wählen Sie den zu Ihrer Aufgabenstellung passenden Differenzialgleichungstyp aus.
• 1(1st)........ Auswahlfenster mit vier Differenzialgleichungstypen 1. Ordnung
• 2(2nd) ...... Eingabefenster für eine lineare Differenzialgleichung 2. Ordnung
• 3(N-th) ...... Eingabefenster für eine Differenzialgleichung N-ter Ordnung (N⬉9)
• 4(SYS) ..... Eingabefenster für ein System von Differenzialgleichungen 1. Ordnung
• 5(RCL) ..... Anzeige des zuletzt benutzten Eingabefensters mit der zuletzt
•Mittels 1(1st) öffnen Sie ein weiteres Auswahlfenster, um Ihre Aufgabenstellung
genauer zuordnen zu können (z.B. Bernoullische Differenzialgleichung). Weitere
Informationen dazu finden Sie im Abschnitt 3-2 "Differenzialgleichungen 1. Ordnung".
•Mittels 3(N-th) öffnen Sie ein Eingabefenster zur Festlegung der Ordnung der zu
lösenden Differenzialgleichung. Die Ordnung kann maximal 9 betragen.
•Mittels 4 (SYS) öffnen Sie ein Eingabefenster zur Festlegung der Anzahl der
unbekannten Funktionen im Differenzialgleichungssystem, wobei das System bis zu 9
unbekannte Funktionen enthalten kann.
3.
Geben Sie entsprechend Ihrer Voreinstellung die erforderlichen Terme der Differenzialgleichung ein.
4. Geben Sie die Anfangswerte Ihrer Anfangswertaufgabe ein.
5. Drücken Sie 5(SET) und wählen Sie b(Param) aus, um ein Eingabefenster für weitere
erforderliche Daten (Parameter) zu öffnen. Legen Sie das x-Intervall für das RungeKutta-Verfahren fest und geben Sie weitere notwendige Parameter ein.
• h ...................Schrittweite für das klassische Runge-Kutta-Verfahren (4. Ordnung)
•Step ............. Punktschrittweite für die Grafik*1, Datenspeicherung möglich: LIST.
betrachteten Differenzialgleichung.
*1Wenn die Integralkurve erstmalig ermittelt wird,
werden die Kurvenpunkte eines jeden Iterationsschrittes für die Grafik ausgenutzt. Wird die
Integralkurve jedoch erneut gezeichnet, werden
entsprechend der Vorgabe von "Step" nur noch
ausgewählte Kurvenpunkte benutzt. Z.B. wird
bei "Step=2" nur jeder zweite Kurvenpunkt für
die grafische Darstellung genutzt.
20010901
Page 98

Zur Lösung von Aufgaben im DIFF EQ - Menü
3-1-2
Drücken Sie dazu 5(SET) und wählen Sie c(Output) aus, um ein
Eingabefenster für die Listenzuordnung zu öffnen: 2(LIST).
•SF................ Anzahl (0 – 100) der Spalten, in denen eine grafische Darstellung von
Linienelementen für das Richtungsfeld erfolgt. Richtungsfelder können
nur für Differenzialgleichungen 1. Ordnung gezeichnet werden.
6. Auswahl der darzustellenden und Zuordnung der abzuspeichernden Größen zu verbundenen Datenlisten: LIST. Drücken Sie 5(SET) und wählen Sie c(Output), um
das Listenzuordnungsmenü zu öffnen. Sie erkennen in der ersten Spalte die Variablen
aus der Aufgabenstellung:
(1)
(2)
x, y, y
, y
(8)
, ..., y
symbolisieren die unabhängige bzw. die abhängige Variable sowie
deren Ableitungen bis hin zur 8. Ordnung. Im Fall eines Differenzialgleichungssystems
stehen in der ersten Spalte die Systemvariablen x, y1, y2, ..., y9. In der Kopfzeile symbolisieren 1st, 2nd, 3rd, ..., 9th die bis zu 9 Datensätze mit vorgebbaren Anfangswerten.
Um die abhängigen Variablen für die Grafik auszuwählen, nutzen Sie die Cursottasten
(f, c) und drücken 1(SEL). Zur Abspeicherung einer Variablen in einer Liste LIST,
wählen Sie diese mit den Cursortasten aus (f, c) und drücken 2(LIST) und geben
anschließend die Listennummer ein.
7. Drücken Sie !K(V-Window), um das Eingabemenü für das Betrachtungsfenster zu
öffnen. Bevor Sie Lösungen (Integralkurven) einer Differenzialgleichung darstellen,
müssen Sie das Betrachtungsfenster (V-Window) einstellen .
Xmin … Minimalwert auf der x-Achse
max … Maximalwert auf der x-Achse
scale … Skalierung auf der x-Achse
dot … Intervallbreite, entsprechend
einem x-Achsen-Pixel
Ymin … Minimalwert auf der y-Achse
max … Maximalwert auf der y-Achse
scale … Skalierung auf der y-Achse
8. Drücken Sie 6(CALC), um die Differenzialgleichung numerisch zu lösen und die Integralkurve anzuzeigen.
• Jede berechnete (Näherungs-)Lösung kann entsprechend Ihrer Festlegung grafisch
dargestellt und in Listen abgespeichert werden.
#Es wird nur das Richtungsfeld angezeigt, wenn
Sie keine Anfangswerte eingeben oder wenn
Ihre Anfangswerte ungeeignet sind.
#Eine Fehlermeldung erscheint, wenn Sie den
SF-Parameter auf Null setzen und keine
Anfangswerte eingegeben haben oder dies
ungeeignet sind.
# Um Berechnungsfehlern vorzubeugen, wird
empfohlen, Terme in Klammern zu setzen und
für Faktoren das Multiplikationszeichen zu
benutzen.
#Verwechseln Sie nicht die Minustaste - und
die Vorzeichentaste -. Wenn Sie die Vorzeichentaste - als Subtraktionszeichen
verwenden, erscheint eine Fehlermeldung
(Syntaxfehler).
#Wenn Sie
erscheint eine Fehlermeldung. Die Variable
hier als Variable zu verwenden. Andere
Var iablen (A bis
können als Konstanten mit den zugeordneten
Zahlenwerten verwendet werden.
#Wenn Sie
erscheint eine Fehlermeldung. Die Variable
hier als Variable zu verwenden. Andere
Var iablen (A bis
können als Konstanten mit den zugeordneten
Zahlenwerten verwendet werden.
20010901
y in der Funktion f(x) verwenden,
Ζ, r,
θ
, jedoch nicht X und Y)
x in der Funktion g(y) verwenden,
Ζ, r,
θ
, jedoch nicht X und Y)
x ist
y ist
Page 99

Differenzialgleichungen 1. Ordnung
3-2-1
3-2 Differenzialgleichungen 1. Ordnung
k Differenzialgleichungen mit trennbaren Variablen
Beschreibung der Anfangswertaufgabe
Dieser Differenzialgleichungstyp hat folgende Formelstruktur:
y' = f(x)g(y), d.h. dy/dx = f(x)g(y) mit y0 = y(x0).
Um eine Differenzialgleichung mit trennbaren Variablen numerisch und grafisch lösen zu
können, sind die Differenzialgleichung und die Anfangswerte einzugeben. Für y0 kann auch
eine Werteliste y0 = {y01, y02, ...} eingegeben werden, um mehrere Integralkurven gleichzeitig
berechnen und grafisch darstellen zu können.
Eingangsbildschirm des DIFF EQ - Menüs
1. Rufen Sie das DIFF EQ - Menü aus dem Hauptmenü
DIFF EQ - Menüs erscheint der Eingangsbildschirm zu den Differenzialgleichungen.
Voreinstellungen, Eingabe und Lösung der Aufgabenstellung
2. Zur Auswahl des passenden Differenzialgleichungstyps drücken Sie 1(1st) und wählen
anschließend b(Separ) aus.
3. Geben Sie die Terme für f(x) und g(y) ein.
4. Geben Sie die Daten für x0, y0 ein (Anfangswerte an einer festen Stelle x0).
5.
Drücken Sie 5(SET)b(Param) zur Voreinstellung der Parameter für das Runge-Kutta-
Verfahren und die grafische Darstellung der Kurve (Step) und des Richtungsfeldes (SF).
6. Legen Sie das x-Intervall für das Runge-Kutta-Verfahren fest.
7. Legen Sie die Schrittweite h für das Runge-Kutta-Verfahren fest.
8. Drücken Sie 5(SET)c(Output), um das Listenzuordnungsmenü zu öffnen, wo Sie
auch die abhängige Variable y markieren müssen, die an der grafischen Darstellung der
Lösungskurven für y beteiligt sein wird.
9. Unabhängig von Punkt 6 müssen Sie das Betrachtungsfenster (V-Window) für die
grafische Darstellung festlegen, indem Sie das entsprechende Eingabefenster nutzen.
10. Drücken Sie schließlich 6(CALC), um entsprechend Ihrer Vorgaben die Anfangswertaufgabe numerisch und grafisch zu lösen.
heraus auf. Nach dem Öffnen des
20010901
Page 100

Differenzialgleichungen 1. Ordnung
3-2-2
○○○○○
Beispiel Lösen Sie die Anfangswertaufgabe y' = y2 –1 , x0 = 0, y0 = {0, 1}, grafisch,
indem Sie zunächst die Differenzialgleichung im DIFF EQ - Menü einem
bekannten Differenzialgleichungstyp zuordnen. Benutzen Sie für die
numerische Lösung (Runge-Kutta-Verfahren) folgende Vorgaben:
<<
<<
– 5
< x
< 5, h = 0.1,
<<
<<
und stellen Sie das Betrachtungsfenster (V-Window) wie folgt ein:
Xmin = –6.3, Xmax = 6.3, Xscale = 1
Ymin = –3.1, Ymax = 3.1, Yscale = 1 (INIT-Einstellungen)
Vorgang
1 m DIFF EQ
2 1(1st)b(Separ)
3bw
a-(Y)Mc-bw
4aw
!*( { )a,b!/( } )w
5 5(SET)b(Param)
6 -fw
fw
7 a.bwi
8 5(SET)c(Output)4(INIT)i
9 !K(V-Window)1(INIT)i
0 6(CALC)
Ergebnisanzeige
Sie erkennen zwei Integralkurven: y = 1 (für alle x) zur Anfangsbedingung (x0,
y = - tanh
x zur Anfangsbedingung (x0, y0)=(0,0)
(
x0, y0) = (0,1)
(x0, y0) = (0,0)
Hinweis: Berechnen Sie auf analytischem Weg die allgemeine Lösung der Differenzial-
gleichung, um die Funktionsgleichungen der Integralkurven zu überprüfen.
# Zur Darstellung einer Kurvenschar (Integral-
kurven zur gegebenen Differenzialgleichung)
Geben Sie eine Liste mit Anfangswerten
y ein.
20010901
20011201
y0)=(0,1)
 Loading...
Loading...