

Page 1

Guide de l'utilisateur de vRealize
Operations Manager
vRealize Operations Manager 6.1
Ce document prend en charge la version de chacun des produits
répertoriés, ainsi que toutes les versions publiées par la suite
jusqu'au remplacement dudit document par une nouvelle
édition. Pour rechercher des éditions plus récentes de ce
document, rendez-vous sur :
http://www.vmware.com/fr/support/pubs.
FR-001858-00
Page 2

Guide de l'utilisateur de vRealize Operations Manager
Vous trouverez la documentation technique la plus récente sur le site Web de VMware à l'adresse :
http://www.vmware.com/fr/support/
Le site Web de VMware propose également les dernières mises à jour des produits.
N’hésitez pas à nous transmettre tous vos commentaires concernant cette documentation à l’adresse suivante :
docfeedback@vmware.com
Copyright © 2015 VMware, Inc. Tous droits réservés. Copyright et informations sur les marques.
VMware, Inc.
3401 Hillview Ave.
Palo Alto, CA 94304
www.vmware.com
2 VMware, Inc.
VMware, Inc.
100-101 Quartier Boieldieu
92042 Paris La Défense
France
www.vmware.com/fr
Page 3

Table des matières
À propos de ce Guide de l'utilisateur 5
Surveillance des objets dans votre environnement géré avec
1
vRealize Operations Manager 7
Que faire si... 7
Surveillance et résolution des alertes 34
Surveillance et résolution des problèmes 39
Exécution d'actions dans vRealize Operations Manager 70
Affichage de l'inventaire 85
Planification des ressources de votre environnement géré à l'aide de
2
vRealize Operations Manager 87
Scénario utilisateur : Vérifier l'impact des besoins en capacité future 88
Création de projets matériels 91
Création de projets de machines virtuelles 92
Index 95
VMware, Inc. 3
Page 4

Guide de l'utilisateur de vRealize Operations Manager
4 VMware, Inc.
Page 5

À propos de ce Guide de l'utilisateur
Le VMware® Guide de l'utilisateur de vRealize Operations Manager décrit ce qu'il faut faire lorsque des
utilisateurs rencontrent des problèmes de performance dans votre environnement géré.
En tant qu'administrateur système, vous pouvez détecter la présence d'un problème sur un objet de votre
environnement lorsque vRealize Operations Manager génère une alerte ou lorsqu'un utilisateur vous
contacte. Pour contribuer à garantir des performances optimales, ces informations vous indiquent comment
utiliser vRealize Operations Manager pour surveiller, dépanner et prendre des mesures afin d'éliminer les
problèmes. Il fournit également des informations sur les procédures permettant d'évaluer si les problèmes
sont dus à une demande excessive ou à un manque de capacité imposant une modification ou une mise à
niveau du système.
Public visé
Ces informations sont destinées aux administrateurs de vRealize Operations Manager, aux administrateurs
de l'infrastructure virtuelle et aux techniciens d'opérations qui suivent et maintiennent la performance des
objets de votre environnement géré.
Glossaire VMware Technical Publications
VMware Technical Publications fournit un glossaire des termes qui peuvent éventuellement ne pas vous
être familiers. Pour consulter la définition des termes utilisés dans la documentation technique VMware,
visitez le site Web http://www.vmware.com/support/pubs.
VMware, Inc.
5
Page 6

Guide de l'utilisateur de vRealize Operations Manager
6 VMware, Inc.
Page 7

Surveillance des objets dans votre
environnement géré avec
vRealize Operations Manager 1
Vous pouvez utiliser vRealize Operations Manager pour résoudre les problèmes soulevés par vos clients,
traiter les alertes détectant des problèmes avant que vos clients ne les signalent et rechercher plus
généralement des problèmes dans votre environnement.
Lorsque vos clients rencontrent des problèmes de performance et vous appellent pour les résoudre, les
données que vRealize Operations Manager collecte et analyse se présentent sous des formes graphiques, si
bien que vous pouvez comparer et opposer des objets, comprendre leurs relations et déterminer la cause
principale des problèmes.
Pour gérer votre environnement de façon proactive plutôt que réactive, il vous faut surveiller les alertes et
agir en conséquence. Une alerte générée vous avertit lorsque des objets de votre environnement connaissent
des problèmes. En résolvant le problème signalé par l'alerte avant que vos clients ne le remarquent, vous
évitez toute interruption de service.
Vous pouvez étudier les problèmes qui génèrent des alertes ou pour lesquels vous recevez des appels grâce
aux onglets Analyse, Dépannage, Détails et Environnement.
En déterminant la cause principale du problème, vous pourrez certainement le résoudre à l'aide de l'action
adaptée. Les actions apportent des modifications aux objets dans le système cible, par exemple
vCenter Server, à partir de vRealize Operations Manager.
Ce chapitre aborde les rubriques suivantes :
« Que faire si... », page 7
n
« Surveillance et résolution des alertes », page 34
n
« Surveillance et résolution des problèmes », page 39
n
« Exécution d'actions dans vRealize Operations Manager », page 70
n
« Affichage de l'inventaire », page 85
n
Que faire si...
En tant qu'administrateur d'infrastructure virtuelle, ingénieur des opérations réseau, ou autre professionnel
de l'informatique, vous utilisez vRealize Operations Manager pour surveiller des objets dans votre
environnement afin d'assurer les services fournis à vos clients et de résoudre les problèmes rencontrés.
Votre administrateur vRealize Operations Manager a configuré vRealize Operations Manager de manière à
gérer deux instances de vCenter Server gérant plusieurs hôtes et machines virtuelles. C'est la première fois
que vous utilisez vRealize Operations Manager pour gérer votre environnement.
VMware, Inc.
7
Page 8

Guide de l'utilisateur de vRealize Operations Manager
Scénario utilisateur : un utilisateur appelle pour faire part d'un problème page 8
n
La vice-présidente du service des ventes appelle le service d'assistance pour signaler que sa machine
virtuelle, VPSALES4632, fonctionne lentement. Elle travaille sur des rapports de ventes pour une
réunion à venir et est en retard en raison des faibles performances de sa machine virtuelle.
Scénario utilisateur : une alerte arrive dans votre boîte de réception page 12
n
À votre retour de la pause déjeuner, vous trouvez une notification d'alerte dans votre boîte de
réception. Vous pouvez utiliser vRealize Operations Manager pour examiner et résoudre l'alerte.
Scénario utilisateur : Vous détectez des problèmes en surveillant l'état de vos objets page 20
n
Lorsque vous analysez vos objets dans le cadre de ce scénario, vRealize Operations Manager fournit
des détails pour vous aider à résoudre les problèmes. Vous analysez l'état de votre environnement,
examinez les problèmes actuels, cherchez des solutions et prenez les mesures appropriées pour
résoudre les problèmes.
Scénario utilisateur : un utilisateur appelle pour faire part d'un problème
La vice-présidente du service des ventes appelle le service d'assistance pour signaler que sa machine
virtuelle, VPSALES4632, fonctionne lentement. Elle travaille sur des rapports de ventes pour une réunion à
venir et est en retard en raison des faibles performances de sa machine virtuelle.
En tant qu'ingénieur des opérations réseau, vous venez de passer en revue les alertes du matin et n'avez pas
constaté de problèmes avec sa machine virtuelle ; vous commencez donc le dépannage du problème.
Procédure
1 Scénario utilisateur : Rechercher un objet spécifique page 8
En tant qu'ingénieur des opérations réseau, vous devez trouver la machine virtuelle du client dans
vRealize Operations Manager afin de pouvoir commencer à résoudre le problème signalé.
2 Scénario utilisateur : vérifier les alertes liées aux problèmes signalés page 9
Pour déterminer si la machine virtuelle à propos de laquelle la vice-présidente des ventes a signalé des
problèmes présente des alertes indiquant la cause du problème, passez en revue les alertes dans
vRealize Operations Manager pour l'objet.
3 Scénario utilisateur : utiliser les options de l'onglet Dépannage pour examiner un problème signalé
page 10
Pour résoudre des problèmes sur la machine virtuelle VPSALES4632, évaluez les symptômes,
examinez les informations chronologiques, prenez en considération les événements et créez des
graphiques de mesures pour trouver la cause racine du problème.
Scénario utilisateur : Rechercher un objet spécifique
En tant qu'ingénieur des opérations réseau, vous devez trouver la machine virtuelle du client dans
vRealize Operations Manager afin de pouvoir commencer à résoudre le problème signalé.
Utilisez vRealize Operations Manager pour surveiller trois instances de vCenter Server avec un total de
360 hôtes et 18 000 machines virtuelles. La façon la plus simple de trouver une machine virtuelle spécifique
est de la rechercher.
Procédure
1 Dans la zone de texte Recherche, dans la barre de titre de vRealize Operations Manager, tapez le nom
de la machine virtuelle.
La zone de texte Recherche affiche tous les objets contenant la chaîne tapée dans la zone de texte. Si
votre client sait que le nom de sa machine virtuelle contient SALES, vous pouvez taper la chaîne pour
inclure la machine virtuelle dans la liste.
2 Sélectionnez l'objet dans la liste.
8 VMware, Inc.
Page 9

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Le volet de gauche affiche le nom de l'objet et les objets associés, y compris le système hôte et l'instance de
vCenter Server. Le volet principal affiche l'onglet Résumé.
Suivant
Recherchez des alertes correspondant au problème signalé pour l'objet. Reportez-vous à « Scénario
utilisateur : vérifier les alertes liées aux problèmes signalés », page 9.
Scénario utilisateur : vérifier les alertes liées aux problèmes signalés
Pour déterminer si la machine virtuelle à propos de laquelle la vice-présidente des ventes a signalé des
problèmes présente des alertes indiquant la cause du problème, passez en revue les alertes dans
vRealize Operations Manager pour l'objet.
Les alertes sur un objet fournissent des informations sur les problèmes autres que celui pour lequel
l'utilisateur signale un problème.
Prérequis
Identifiez la machine virtuelle du client pour pouvoir passer en revue les alertes la concernant. Reportezvous à « Scénario utilisateur : Rechercher un objet spécifique », page 8.
Procédure
1 Cliquez sur l'onglet Résumé pour l'objet problématique.
L'onglet Résumé affiche les alertes actives pour l'objet et tout objet descendant classé dans les alertes les
plus fréquentes.
2 Passez en revue les alertes les plus fréquentes pour la santé, le risque et l'efficacité.
Les alertes les plus fréquentes sont considérées comme les principaux contributeurs de l'état actuel des
badges d'alerte. Certaines d'entre elles semblent-elles être à la source du problème de lenteur ? Par
exemple, toute alerte de gonflage ou d'échange, qui indique que vous devez ajouter de la mémoire à la
machine virtuelle ? Une alerte liée à la contention de mémoire, qui indique que vous devez ajouter de la
mémoire à l'hôte.
3 Si l'onglet Résumé n'inclut aucun des problèmes fréquents semblant expliquer les problèmes signalés,
cliquez sur l'onglet Alertes.
L'onglet Alertes affiche toutes les alertes actives pour l'objet actif.
4 Passez en revue les alertes pour les problèmes similaires ou contribuant au problème signalé.
a Pour afficher les alertes actives et annulées, cliquez sur État : Actif pour effacer le filtre et afficher
les alertes actives et inactives.
Les alertes annulées peuvent fournir des informations sur le problème.
b Cliquez sur la colonne Créé le pour trier les alertes afin de pouvoir trouver les alertes générées
avant ou au moment où le client a signalé le problème.
c Pour afficher les alertes pour les objets ancêtres dans la même liste que celle contenant l'alerte pour
la machine virtuelle, cliquez sur la flèche vers la haut et sélectionnez Système hôte et Ressource de
calcul du cluster, si ces options sont configurées dans votre environnement.
Ajoutez ces types d'objets à la liste afin de pouvoir déterminer si les alertes des objets parents
contribuent au problème signalé.
5 Si vous trouvez une alerte qui semble expliquer le problème signalé, cliquez sur le nom de l'alerte dans
la liste des alertes.
6 Dans l'onglet Résumé des détails de l'alerte, passez en revue les symptômes déclenchés et les
recommandations pour déterminer si l'alerte indique la cause racine du problème signalé.
VMware, Inc. 9
Page 10

Guide de l'utilisateur de vRealize Operations Manager
Suivant
Si l'alerte semble indiquer la source du problème, suivez les recommandations et vérifiez la résolution
n
avec votre client. Pour obtenir un exemple, voir « Scénario utilisateur : Exécuter une recommandation
sur une banque de données pour résoudre une alerte », page 19.
Si vous ne trouvez pas la cause du problème signalé dans les alertes, commencez un dépannage plus
n
approfondi. Reportez-vous à « Scénario utilisateur : utiliser les options de l'onglet Dépannage pour
examiner un problème signalé », page 10.
Scénario utilisateur : utiliser les options de l'onglet Dépannage pour examiner un problème signalé
Pour résoudre des problèmes sur la machine virtuelle VPSALES4632, évaluez les symptômes, examinez les
informations chronologiques, prenez en considération les événements et créez des graphiques de mesures
pour trouver la cause racine du problème.
Si l'observation des alertes n'a pas permis d'identifier la cause du problème signalé pour la machine
virtuelle, utilisez les onglets Dépannage, Symptômes, Chronologie, Événements et Toutes les mesures, pour
dépanner l'historique et l'état actuel de la machine virtuelle.
Prérequis
Trouvez l'objet pour lequel le problème a été signalé. Reportez-vous à « Scénario utilisateur :
n
Rechercher un objet spécifique », page 8.
Passez en revue les alertes pour la machine virtuelle afin de déterminer si le problème a déjà été
n
identifié et des recommandations effectuées. Reportez-vous à « Scénario utilisateur : vérifier les alertes
liées aux problèmes signalés », page 9.
Procédure
1 Dans les onglets Détails de l'alerte, cliquez sur Machine virtuelle dans le volet de gauche et
sélectionnez VPSALES4632 dans la liste inférieure.
Le volet principal met à jour l'affichage de l'onglet Résumé de l'objet.
2 Cliquez sur l'onglet Dépannage, puis sur l'onglet Symptômes et passez en revue les symptômes pour
déterminer si l'un des symptômes est lié au problème signalé.
En fonction de la configuration des alertes, certains symptômes peuvent être déclenchés, mais pas
suffisants pour générer une alerte.
a Passez en revue les noms des symptômes pour déterminer si un ou plusieurs symptômes sont liés
au problème signalé.
La colonne Informations indique la condition du déclenchement, la tendance et la valeur actuelle.
Quels sont les symptômes les plus courants qui affectent le temps de réponse ? Voyez-vous des
symptômes liés à l'utilisation du CPU ou de la mémoire ?
b Triez les symptômes par date de création (Créé le) afin de tenir uniquement compte de la période
pour laquelle le client a signalé le problème.
c Cliquez sur le bouton de filtre État : Actif pour désactiver le filtre et pouvoir observer les
symptômes actifs et inactifs.
En raison des symptômes, vous pensez que le problème est lié à l'utilisation du CPU ou de la mémoire.
En revanche, vous ne savez pas si le problème provient de la machine virtuelle ou de l'hôte.
10 VMware, Inc.
Page 11

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
3 Cliquez sur l'onglet Chronologie et passez en revue les alertes, les symptômes et les événements de
modification dans le temps qui pourraient vous aider à identifier des tendances communes participant
au problème signalé.
a Pour déterminer si des symptômes ont été déclenchés et des alertes générées sur d'autres machines
virtuelles en même temps que le problème signalé, cliquez sur Afficher les événements
homologues.
Les alertes d'autres machines virtuelles sont ajoutées à la chronologie. Si vous voyez que plusieurs
machines virtuelles ont déclenché des symptômes pendant la même période, vous pouvez alors
examiner les objets ancêtres.
b Cliquez sur Afficher les événements des ancêtres et sélectionnez Système hôte.
Les alertes et symptômes associés à l'hôte sur lequel la machine virtuelle est déployée sont ajoutés à
la chronologie. Utilisez les informations pour déterminer si une corrélation existe entre le problème
signalé et les alertes sur l'hôte.
4 Cliquez sur l'onglet Événement pour afficher les modifications des mesures collectées pour la machine
virtuelle rencontrant le problème et qui pourraient vous indiquer la cause du problème signalé.
a Utilisez l'événement de vue de l'option Contrôles de date pour l'heure approximative du problème
signalé par le client.
b Cliquez sur les badges Charge de travail, Capacité et Contrainte pour déterminer si des
événements sont associés au problème.
c Cliquez sur Zoomer la vue et zoomez sur les événements et les clusters d'événements s'étant
produits avant ou au moment où le problème a été signalé.
d Cliquez sur Afficher les valeurs des données et placez le curseur sur un événement pour afficher
les détails relatifs à l'événement.
Les événements pour la période sélectionnée s'affichent également dans la grille de données en
dessous du graphique des événements.
e Dans le volet de gauche, cliquez sur Système hôte, cliquez sur le nom de l'hôte dans la liste du
volet de gauche inférieur, puis répétez l'analyse de l'hôte dans les badges Charge de travail,
Capacité et Contrainte.
La comparaison des événements sur la machine virtuelle et sur l'hôte et l'évaluation de ces résultats
indiquent que des problèmes de CPU ou de mémoire sont probablement la cause du problème.
5 Si vous pouvez identifier que le problème est lié, par exemple, à l'utilisation du CPU ou de la mémoire,
cliquez sur l'onglet Toutes les mesures pour créer vos propres graphiques de mesures, afin de
déterminer s'il s'agit de l'un ou de l'autre, ou des deux.
a Si l'hôte est encore sélectionné, commencez par travailler sur les mesures de l'hôte.
b Dans la liste des mesures, double-cliquez sur les mesures Utilisation du CPU (%) et Utilisation de
la mémoire (%) pour les ajouter à l'espace de travail de droite.
c Dans la carte, cliquez sur l'objet VPSALES4632.
La liste de mesures affiche à présent les mesures des machines virtuelles.
d Dans la liste des mesures, double-cliquez sur les mesures Utilisation du CPU (%) et Utilisation de
la mémoire (%) pour les ajouter à l'espace de travail de droite.
e Passez en revue les graphiques de l'hôte et de la machine virtuelle pour voir si vous pouvez
identifier une tendance indiquant la cause du problème signalé.
VMware, Inc. 11
Page 12

Guide de l'utilisateur de vRealize Operations Manager
Dans ce scénario, la comparaison des quatre graphiques révèle que l'utilisation du CPU est normale tant
sur l'hôte que sur la machine virtuelle, et que l'utilisation de la mémoire est normale sur la machine
virtuelle. Cependant, l'utilisation de la mémoire sur l'hôte a commencé à augmenter de manière
constante trois jours avant que le problème signalé sur la machine virtuelle VPSALES4632.
La mémoire de l'hôte s'exécute constamment à un niveau élevé, ce qui affecte le temps de réponse pour les
machines virtuelles. Le nombre de machines virtuelles qu'il exécute correspond aux quantités prises en
charge. Le problème peut être dû à un nombre trop élevé d'applications de processus élevé sur les machines
virtuelles. Vous pouvez déplacer certaines machines virtuelles vers d'autres hôtes, distribuer la charge de
travail ou mettre hors tension des machines virtuelles inactives.
Suivant
Dans cet exemple, vous pouvez utiliser vRealize Operations Manager pour mettre hors tension des
n
machines virtuelles sur l'hôte afin d'améliorer les performances des machines virtuelles utilisées.
Reportez-vous à « Exécuter des actions dans les barres d'outils de vRealize Operations Manager »,
page 75.
Si vous êtes susceptible de réutiliser la combinaison de graphiques que vous avez créés sur l'onglet
n
Toutes les mesures, cliquez sur Générer un tableau de bord.
Si vous n'avez pas résolu le problème, poursuivez votre investigation.
n
Scénario utilisateur : une alerte arrive dans votre boîte de réception
À votre retour de la pause déjeuner, vous trouvez une notification d'alerte dans votre boîte de réception.
Vous pouvez utiliser vRealize Operations Manager pour examiner et résoudre l'alerte.
En tant que technicien d'opérations réseau, vous êtes responsable de plusieurs hôtes et de leurs banques de
données et machines virtuelles, et vous recevez des e-mails lorsqu'une alerte est générée pour vos objets
surveillés. Les alertes vous signalent non seulement les problèmes de votre environnement, mais elles
fournissent aussi des recommandations utiles pour résoudre ces problèmes. Lors de l'examen de cette alerte,
vous évaluez les données pour déterminer si une ou plusieurs des recommandations peuvent résoudre le
problème.
Ce scénario part du principe que vous avez configuré des alertes sortantes de manière à envoyer un e-mail
standard à l'aide du protocole SMTP et que vous avez configuré des notifications pour vous envoyer des
notifications d'alerte à l'aide du plug-in d'e-mail standard. Lorsque des alertes et des notifications sortantes
sont configurées, vRealize Operations Manager vous envoie des messages lorsqu'une alerte est générée afin
que vous puissiez répondre aux problèmes le plus rapidement possible.
Prérequis
Vérifiez que les alertes sortantes sont configurées sous forme d'alertes par e-mail standard. Reportez-
n
vous à Guide d'administration et de personnalisation de vRealize Operations Manager.
Vérifiez que les alertes sortantes sont configurées sous forme d'alertes par e-mail standard. Reportez-
n
vous à Guide d'administration et de personnalisation de vRealize Operations Manager.
Procédure
1 Scénario utilisateur : répondre à une alerte dans votre messagerie électronique page 13
En tant que technicien d'opérations réseau, vous recevez un e-mail de vRealize Operations Manager
fournissant des informations sur l'une des banques de données dont vous êtes responsable. La
notification par e-mail vous informe du problème même lorsque vous ne travaillez pas à ce moment
précis dans vRealize Operations Manager.
12 VMware, Inc.
Page 13

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
2 Scénario utilisateur : évaluer d'autres symptômes déclenchés pour la banque de données affectée
page 14
Vous avez déterminé que vous avez besoin d'informations complémentaires sur la banque de données
avant de choisir la meilleure réponse. En tant que technicien d'opérations réseau, vous examinez
l'onglet Symptômes des objets affectés pour voir les autres symptômes déclenchés pour la banque de
données.
3 Scénario utilisateur : comparer des alertes et des événements dans le temps en réponse à une alerte de
banque de données page 15
Pour évaluer une alerte dans le temps, comparez l'alerte et les symptômes actuels pour la banque de
données à d'autres alertes et symptômes, d'autres événements, d'autres objets, dans le temps.
4 Scénario utilisateur : Afficher la banque de données affectée en relation à d'autres objets page 16
Pour voir l'objet pour lequel l'alerte a été générée en relation à d'autres objets, utilisez la carte
topologique dans l'onglet Relations de vRealize Operations Manager pour visualiser l'environnement.
5 Scénario utilisateur : Créer des graphiques de mesures pour rechercher la cause de l'alerte de banque
de données page 17
Pour analyser les mesures de capacité associée à l'alerte générée, vous créez des graphiques dans
vRealize Operations Manager qui comparent différentes mesures. Ces comparaisons vous aident à
identifier à quel moment une modification est survenue dans votre environnement et quel effet elle a
eu sur la banque de données.
6 Scénario utilisateur : Exécuter une recommandation sur une banque de données pour résoudre une
alerte page 19
En tant que technicien d'opérations réseau, vous avez examiné l'alerte concernant l'espace disque de la
banque de données et déterminé que les recommandations fournies résoudront le problème,
particulièrement la recommandation de supprimer les snapshots inutilisés. Vous utilisez
vRealize Operations Manager pour supprimer les snapshots.
Scénario utilisateur : répondre à une alerte dans votre messagerie électronique
En tant que technicien d'opérations réseau, vous recevez un e-mail de vRealize Operations Manager
fournissant des informations sur l'une des banques de données dont vous êtes responsable. La notification
par e-mail vous informe du problème même lorsque vous ne travaillez pas à ce moment précis dans
vRealize Operations Manager.
Dans votre client de messagerie, vous recevez une alerte similaire au message suivant.
L'alerte a été mise à jour le mardi 1er juillet 16:34:04 MDT : Info:datastore1 La banque de
données se comporte anormalement depuis Lun 30 Jun 10:21:07 MDT et a été mise à jour le Mar 01
Jui 16:34:04 MDT Nom de définition d'alerte : La banque de données n'a presque plus d'espace
disque Description de la définition d'alerte : La banque de données n'a presque plus d'espace
disque Nom de l'objet : datastore1 Type d'objet : Alerte de banque de données Impact : risque
État de l'alerte : critique Type d'alerte : Stockage Sous-type d'alerte : Capacité État de santé
de l'objet : info État de risque de l'objet : critique État d'efficacité de l'objet : info
Symptômes : JEU DE SYMPTÔMES - auto Nom de symptôme | ID d'objet | Mesure | Message Info
Utilisation de l'espace de banque de données atteignant la limite critique datastore1 | b0885859e0c5-4126-8eba-6a21c895fe1b | Capacité|Espace utilisé | HT au-dessus 99.20800922575977 > 95
Recommandations : - Avec Storage VMotion déplacer des machines virtuelles vers une autre banque
de données - Supprimer des snapshots inutilisés de machines virtuelles - Ajouter de la capacité
à la banque de données Notification Nom de la règle : Toutes les alertes -- Banque de données
Notification Description de la règle : ID De l'alerte : a9d6cf35-a332-4028-90f0-d1876459032b
Operations Manager Server - 192.0.2.0 Détails de l'alerte
VMware, Inc. 13
Page 14

Guide de l'utilisateur de vRealize Operations Manager
Prérequis
Vérifiez que les alertes sortantes sont configurées sous forme d'alertes par e-mail standard. Reportez-
n
vous à Guide d'administration et de personnalisation de vRealize Operations Manager.
Vérifiez que les notifications sont configurées pour envoyer des messages à vos utilisateurs pour la
n
définition d'alerte. Pour un exemple de création de notification d'alerte, reportez-vous à Guide
d'administration et de personnalisation de vRealize Operations Manager.
Procédure
1 Dans votre client de messagerie, examinez le message pour bien comprendre l'état des objets affectés et
déterminez si vous devez commencer l'investigation immédiatement.
Recherchez le nom de l'alerte, l'état de l'alerte pour déterminer le niveau actuel de criticité et les objets
affectés.
2 Dans l'e-mail, cliquez sur Détails de l'alerte.
vRealize Operations Manager s'ouvre dans l'onglet Résumé dans les détails de l'alerte générée et de
l'objet affecté.
3 Examinez les informations de l'onglet Résumé.
Option Processus d'évaluation
Nom et description de
l'alerte
Recommandations Vérifiez la première recommandation et, le cas échéant, les autres recommandations
Quelle est la cause du
problème ?
Vérifiez le nom et la description et assurez-vous que vous évaluez bien l'alerte pour
laquelle vous avez reçu un e-mail.
pour comprendre les mesures à prendre pour résoudre le problème. Si elles sont mises
en œuvre, les recommandations prioritaires résoudront-elles le problème ?
Quels symptômes ont été déclenchés ? Quels sont ceux qui n'ont pas été déclenchés ?
Quel sera l'effet de cette évaluation dans votre investigation ? Dans cet exemple, l'alerte
indiquant que la banque de données n'a presque plus d'espace est configurée de
manière à baser la criticité sur des symptômes. Si vous recevez une alerte critique, il est
probable que les symptômes sont déjà à un niveau critique, relevé à partir
d'Avertissement et Urgent. Examinez le graphique Sparkline ou le graphique de
mesures pour chaque symptôme pour déterminer à quel moment le problème a atteint
l'objet de banques de données.
Suivant
Si vous déterminez que les recommandations résoudront le problème, mettez-les en œuvre. Reportez-
n
vous à « Scénario utilisateur : Exécuter une recommandation sur une banque de données pour résoudre
une alerte », page 19.
S'il vous faut plus d'informations sur les objets affectés, poursuivez votre investigation. Commencez par
n
examiner d'autres symptômes déclenchés pour la banque de données. Reportez-vous à « Scénario
utilisateur : évaluer d'autres symptômes déclenchés pour la banque de données affectée », page 14.
Scénario utilisateur : évaluer d'autres symptômes déclenchés pour la banque de données affectée
Vous avez déterminé que vous avez besoin d'informations complémentaires sur la banque de données avant
de choisir la meilleure réponse. En tant que technicien d'opérations réseau, vous examinez l'onglet
Symptômes des objets affectés pour voir les autres symptômes déclenchés pour la banque de données.
Si d'autres symptômes sont déclenchés pour l'objet, en plus du symptôme inclus dans l'alerte, vous pouvez
les évaluer pour déterminer quel effet ces symptômes peuvent avoir sur l'alerte à laquelle vous répondez, et
si les recommandations peuvent résoudre le problème.
14 VMware, Inc.
Page 15

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Prérequis
Vérifiez que vous résolvez l'alerte pour laquelle vous avez reçu un message d'alerte dans votre messagerie.
Reportez-vous à « Scénario utilisateur : répondre à une alerte dans votre messagerie électronique », page 13.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Alertes.
2 Dans l'une des listes d'alertes, cliquez sur le nom de l'alerte.
Le volet du centre change pour afficher les onglets de détails de l'alerte.
3 Cliquez sur l'onglet Symptôme des objets affectés et examinez les symptômes actifs.
Option Processus d'évaluation
Criticité D'autres symptômes de criticité similaires affectent-ils l'objet ?
Symptôme Des symptômes déclenchés sont-ils associés aux symptômes ayant déclenché l'alerte courante ? Des
symptômes liés au temps restant, à la capacité ou à la contrainte peuvent-ils indiquer des problèmes
de stockage ?
Créé le Les horodatages des symptômes indiquent-ils qu'ils ont été déclenchés avant l'alerte que vous
examinez, indiquant qu'il pourrait s'agir d'un symptôme associé ? Les symptômes ont-ils été
déclenchés après la génération de l'alerte, indiquant que les symptômes de l'alerte ont contribué à ces
autres symptômes ?
Informations Pouvez-vous identifier une corrélation entre les symptômes de l'alerte et les autres symptômes sur la
base des valeurs de mesure de déclenchement ?
Suivant
Si votre examen des symptômes et des informations fournies indiquent clairement que les
n
recommandations résoudront le problème, mettez en œuvre une ou plusieurs des recommandations.
Pour un exemple de mise en œuvre des recommandations, reportez-vous à « Scénario utilisateur :
Exécuter une recommandation sur une banque de données pour résoudre une alerte », page 19.
Si votre examen des symptômes ne démontre pas que les recommandations résoudront le problème ou
n
vous fourniront suffisamment d'informations pour identifier la cause première, poursuivez vos
investigations en utilisant l'onglet Chronologie. Reportez-vous à « Scénario utilisateur : comparer des
alertes et des événements dans le temps en réponse à une alerte de banque de données », page 15.
Scénario utilisateur : comparer des alertes et des événements dans le temps en réponse à une alerte de banque de données
Pour évaluer une alerte dans le temps, comparez l'alerte et les symptômes actuels pour la banque de
données à d'autres alertes et symptômes, d'autres événements, d'autres objets, dans le temps.
En tant technicien des opérations réseau, vous utilisez l'onglet Chronologie pour comparer cette alerte à
d'autres alertes et événements dans votre environnement afin de déterminer si vous pouvez résoudre le
problème de manque d'espace disque de la banque de données en appliquant une ou plusieurs
recommandations d'alerte.
Prérequis
Vérifiez que vous résolvez l'alerte pour laquelle vous avez reçu un message d'alerte dans votre messagerie.
Reportez-vous à « Scénario utilisateur : répondre à une alerte dans votre messagerie électronique », page 13.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Alertes.
2 Cliquez sur le lien du nom de l'alerte.
Le volet du centre change pour afficher les onglets de détails de l'alerte.
VMware, Inc. 15
Page 16

Guide de l'utilisateur de vRealize Operations Manager
3 Cliquez sur l'onglet Chronologie.
L'onglet Chronologie affiche l'alerte générée et les symptômes déclenchés pour l'objet affecté dans un
format de chronologie déroulant, qui commence au moment où l'alerte a été générée.
4 Pour déterminer si d'autres alertes sont générées pour l'objet, cliquez sur les autres boutons d'alerte.
Dans cet exemple, l'alerte de banque de données a généré une alerte Risque, de telle sorte que les autres
alertes à ajouter à la chronologie sont Santé et Efficacité. Faites défiler la chronologie à l'aide de la
chronologie de semaine en bas de l'écran.
5 Pour afficher les événements pouvant contribuer à l'alerte, cliquez sur Sélectionner le type
d'événement et cliquez sur la coche de chaque type d'événement.
Les événements associés à l'objet sont ajoutés à la chronologie. Vous ajoutez les événements à votre
évaluation de l'état actuel de l'objet et indiquez si les recommandations peuvent résoudre le problème.
6 Cliquez sur Afficher les événements des ancêtres, puis sélectionnez Hôte.
Comme l'alerte est associée à l'espace disque, l'ajout de l'hôte à la chronologie vous permet de voir les
alertes et symptômes générés pour l'hôte. Lors du défilement de la chronologie, à quel moment
certaines des alertes associées ont-elles commencé ? À quel moment sont-elles disparues de la
chronologie ? Quelle a été l'effet sur l'état de l'objet de banque de données ?
7 Cliquez sur Afficher les événements homologues.
Si d'autres banques de données présentent des alertes associées à l'alerte que vous examinez
actuellement, la détermination du moment de génération des alertes concernant d'autres banques de
données peut vous aider à identifier les problèmes de ressources que vous rencontrez dans votre
environnement.
8 Pour supprimer des alertes annulées de votre chronologie, cliquez sur Sélectionner l'état, puis
décochez la case Annulé.
La suppression des alertes et des symptômes annulés de la chronologie efface la vue et vous permet de
vous concentrer sur les alertes actuelles.
Suivant
Si votre évaluation de l'alerte dans la chronologie a fourni suffisamment d'informations pour indiquer
n
si une ou plusieurs des recommandations de résolution de l'alerte sont valides, mettez en œuvre ces
recommandations. Reportez-vous à « Scénario utilisateur : Exécuter une recommandation sur une
banque de données pour résoudre une alerte », page 19.
Pour obtenir plus d'informations sur l'objet concerné, poursuivez votre investigation. Reportez-vous à
n
« Scénario utilisateur : Afficher la banque de données affectée en relation à d'autres objets », page 16.
Scénario utilisateur : Afficher la banque de données affectée en relation à d'autres objets
Pour voir l'objet pour lequel l'alerte a été générée en relation à d'autres objets, utilisez la carte topologique
dans l'onglet Relations de vRealize Operations Manager pour visualiser l'environnement.
En tant que technicien d'opérations réseau, vous affichez une banque de données et les objets associés dans
une carte pour mieux comprendre le problème, et pour déterminer si la mise en œuvre des
recommandations d'alerte résoudra le problème identifié par l'alerte.
Prérequis
Évaluez l'alerte dans le temps en comparaison à d'autres objets. Reportez-vous à « Scénario utilisateur :
comparer des alertes et des événements dans le temps en réponse à une alerte de banque de données »,
page 15.
16 VMware, Inc.
Page 17

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Alertes.
2 Cliquez sur le lien du nom de l'alerte.
Le volet du centre change pour afficher les onglets de détails de l'alerte.
3 Cliquez sur l'onglet Relations.
L'onglet Relations affiche la banque de données dans une carte avec les objets associés. Par défaut, le
badge affecté par cette alerte est sélectionné sur la barre d'outils et les objets dans l'arborescence
comportent un carré de couleur indiquant l'état actuel du badge.
4 Pour voir l'état d'alerte des objets pour les autres badges, cliquez sur le bouton Santé, puis sur le bouton
Efficacité.
Lorsque vous cliquez sur chaque bouton de badge, les carrés sur chaque objet indiquent si une alerte est
générée et la criticité de l'alerte.
5 Pour afficher les alertes d'un objet, sélectionnez l'objet et cliquez sur Afficher les alertes.
La boîte de dialogue Liste des alertes s'affiche, vous permettant de rechercher et de trier les alertes de
l'objet.
6 Pour afficher la liste des objets enfants d'un objet dans la carte, cliquez sur l'objet.
Une liste indiquant le nombre d'enfants par type d'objet s'affiche en bas du volet central.
7 Utilisez les options pour évaluer la banque de données.
Par exemple, quelles indications la carte vous fournit-t-elle quant au nombre de machines virtuelles
associées à la banque de données ? Si plusieurs machines virtuelles sont associées à une banque de
données, leur déplacement peut libérer de l'espace disque de banque de données.
Suivant
Si votre examen de la carte vous a fourni suffisamment d'informations pour indiquer qu'une ou
n
plusieurs des recommandations de résolution de l'alerte sont valides, mettez en œuvre les
recommandations. Reportez-vous à « Scénario utilisateur : Exécuter une recommandation sur une
banque de données pour résoudre une alerte », page 19.
Pour obtenir plus d'informations sur l'objet concerné, poursuivez votre investigation. Reportez-vous à
n
« Scénario utilisateur : Créer des graphiques de mesures pour rechercher la cause de l'alerte de banque
de données », page 17.
Scénario utilisateur : Créer des graphiques de mesures pour rechercher la cause de l'alerte de banque de données
Pour analyser les mesures de capacité associée à l'alerte générée, vous créez des graphiques dans
vRealize Operations Manager qui comparent différentes mesures. Ces comparaisons vous aident à identifier
à quel moment une modification est survenue dans votre environnement et quel effet elle a eu sur la banque
de données.
En tant que technicien des opérations réseau, vous créez des graphiques personnalisés vous permettant
d'analyser le problème et de déterminer si la mise en œuvre des recommandations d'alerte résoudra le
problème que l'alerte identifie.
Prérequis
Affichez la carte topologique de la banque de données pour déterminer si des objets associés contribuent à
l'alerte ou si des symptômes déclencheurs indiquent que la banque de données est responsable d'autres
problèmes dans votre environnement. Reportez-vous à « Scénario utilisateur : Afficher la banque de
données affectée en relation à d'autres objets », page 16.
VMware, Inc. 17
Page 18

Guide de l'utilisateur de vRealize Operations Manager
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Alertes.
2 Cliquez sur le lien du nom de l'alerte.
Le volet du centre change pour afficher les onglets de détails de l'alerte.
3 Cliquez sur l'onglet Graphiques de mesures.
L'onglet Graphiques de mesures n'inclut pas de graphiques. Vous devez ajouter les graphiques à
comparer.
4 Pour analyser la première recommandation, Ajouter de la capacité au stockage de banques de données,
ajoutez les graphiques associés à l'espace de travail.
a Entrez capacité dans la zone de texte de recherche de la liste de mesures.
La liste affiche les mesures contenant le terme recherché.
b Double-cliquez sur les mesures suivantes pour ajouter les graphiques suivants à l'espace de
travail :
Capacité | Espace utilisé (Go)
n
Espace disque | Capacité (Go)
n
Résumé | Nombre de consommateurs de capacité
n
c Comparez les graphiques.
Par exemple, si le graphique Capacité | Espace utilisé (%) montre une augmentation de l'espace
utilisé, alors que Espace disque | Capacité (Go) n'a pas augmenté et que Résumé | Nombre de
consommateurs de capacités n'a pas augmenté, l'ajout de capacité est une solution, mais ne résout
pas la cause première.
5 Pour analyser la seconde recommandation, Déplacer avec vMotion certaines machines virtuelles
vers une autre banque de données, ajoutez des graphiques associés à l'espace de travail.
a Entrez vm dans la zone de texte de recherche de la liste de mesures.
b Double-cliquez sur la mesure Résumé | Nombre total de VM pour l'ajouter à l'espace de travail
c Comparez les 4 graphiques.
Par exemple, si le graphique Résumé | Nombre total de VM indique que le nombre de machines
virtuelles n'a pas suffisamment augmenté pour affecter négativement la banque de données, le
déplacement de certaines machines virtuelles constitue une solution, mais ne résout pas la cause
première.
6 Pour analyser la troisième recommandation, Supprimer les snapshots inutilisés de machines virtuelles,
ajoutez des graphiques associés à l'espace de travail.
a Entrez snapshot dans la zone de texte de recherche de la liste de mesures.
b Double-cliquez sur les mesures suivantes pour ajouter les graphiques à l'espace de travail :
Espace disque | Espace de snapshot (Go)
n
Espace disque récupérable | Espace de snapshot | Valeur gaspillée (Go)
n
c Comparez les graphiques.
Par exemple, si la quantité de la mesure Espace disque | Espace de snapshot (Go) a augmenté et si
la mesure Espace disque récupérable | Espace de snapshot | Valeur gaspillée (Go) indique une
zone dans laquelle de l'espace peut être récupéré, la suppression des snapshots inutilisés affectera
positivement le problème d'espace disque de la banque de données et résoudra l'alerte.
18 VMware, Inc.
Page 19

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
7 S'il s'agit d'une banque de données problématique que vous devez continuer à surveiller, vous pouvez
créer un tableau de bord.
a Cliquez sur le bouton Générer un tableau de bord sur la barre d'outils de l'espace de travail.
b Entrez un nom pour le tableau de bord, puis cliquez sur OK.
Dans cet exemple, utilisez un nom tel que Espace disque de banque de données.
Le tableau de bord est ajouté à vos tableaux de bord disponibles.
Vous avez comparé les graphiques de mesure pour déterminer si les recommandations sont valides et quelle
recommandation mettre en œuvre en premier. Dans cet exemple, la recommandation Supprimer les
snapshots non utilisés des machines virtuelles semble constituer l'option la plus efficace pour résoudre
l'alerte.
Suivant
Mettez en œuvre les recommandations de l'alerte. Reportez-vous à « Scénario utilisateur : Exécuter une
recommandation sur une banque de données pour résoudre une alerte », page 19.
Scénario utilisateur : Exécuter une recommandation sur une banque de données pour résoudre une alerte
En tant que technicien d'opérations réseau, vous avez examiné l'alerte concernant l'espace disque de la
banque de données et déterminé que les recommandations fournies résoudront le problème,
particulièrement la recommandation de supprimer les snapshots inutilisés. Vous utilisez
vRealize Operations Manager pour supprimer les snapshots.
Si vous n'utilisez pas l'adaptateur d'action, vous pouvez manuellement supprimer les snapshots sur votre
instance de vCenter Server.
Prérequis
Comparez les graphiques de mesures pour identifier la cause première probable de l'alerte. Reportez-
n
vous à « Scénario utilisateur : comparer des alertes et des événements dans le temps en réponse à une
alerte de banque de données », page 15.
Vérifiez que l'adaptateur vCenter Python Actions est installé et configuré pour s'exécuter sur la même
n
instance de vCenter Server que celle qui inclut la banque de données pour laquelle l'alerte a été générée.
Reportez-vous à Guide d'administration et de personnalisation de vRealize Operations Manager.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Alertes.
2 Cliquez sur le lien du nom de l'alerte.
3 Cliquez sur l'onglet Résumé.
4 Cliquez sur la flèche Autres recommandations pour développer la liste.
Les autres recommandations incluent la recommandation Déplacer avec Storage vMotion des
machines virtuelles vers une autre banque de données et la recommandation Supprimer des
snapshots inutilisés pour les machines virtuelles. La recommandation de suppression de
snapshots inutilisés inclut un bouton d'action.
5 Cliquez sur Supprimer les snapshots inutilisés pour la banque de données.
6 Dans la zone de texte Jours d'ancienneté, sélectionnez ou entrez le nombre de jours d'ancienneté que
doit avoir le snapshot pour être récupéré pour suppression et cliquez sur OK.
Par exemple, entrez 30 pour récupérer tous les snapshots sur la banque de données remontant à au
moins 30 jours.
VMware, Inc. 19
Page 20

Guide de l'utilisateur de vRealize Operations Manager
7 Dans la boîte de dialogue Supprimer les snapshots inutilisés pour la banque de données, examinez
Espace de snapshot, Heure de création du snapshot et Nom de VM pour déterminer quels snapshots il
convient de supprimer et cochez la case en regard de chacun des snapshots à supprimer.
8 Cliquez sur OK.
La boîte de dialogue qui s'affiche fournit un lien vers les tâches récentes et un lien vers la tâche.
9 Pour vérifier que la tâche a abouti, cliquez sur Tâches récentes.
La page Tâches récentes s'affiche. L'action Supprimer les snapshots inutilisés inclut deux tâches, une
première pour récupérer les snapshots et une autre pour supprimer les snapshots.
10 Sélectionnez la tâche Supprimer les snapshots inutilisés présentant la date d'achèvement la plus récente.
Il s'agit de la tâche de suppression. L'état doit être Terminé.
Dans cet exemple, vous exécutez une action sur la banque de données dans vCenter Server. Les autres
recommandations peuvent également être valides.
Suivant
Vérifiez que les recommandations résolvent l'alerte. Laissez quelques cycles de collecte s'exécuter après
n
l'exécution de l'action, puis vérifiez que l'alerte est annulée. Les alertes sont annulées lorsque les
conditions les ayant générées n'ont plus la valeur true.
Mettez en œuvre les autres recommandations. Les autres recommandations pour cette alerte nécessitent
n
l'utilisation d'autres applications. Vous ne pouvez pas mettre en œuvre les recommandations à partir de
vRealize Operations Manager.
Utilisez d'autres options pour rechercher la cause première. Voir « Scénario utilisateur : Recherche de la
n
cause principale d'un problème à l'aide des options de l'onglet Dépannage », page 58 pour un autre
exemple de recherche de la cause première d'un problème.
Scénario utilisateur : Vous détectez des problèmes en surveillant l'état de vos objets
Lorsque vous analysez vos objets dans le cadre de ce scénario, vRealize Operations Manager fournit des
détails pour vous aider à résoudre les problèmes. Vous analysez l'état de votre environnement, examinez les
problèmes actuels, cherchez des solutions et prenez les mesures appropriées pour résoudre les problèmes.
En tant qu'administrateur de l'infrastructure virtuelle, vous parcourez régulièrement
vRealize Operations Manager à différents niveaux afin de connaître l'état général des objets de votre
environnement géré. Bien que vous n'ayez reçu aucun appel ni aucune plainte et que vous ne voyez aucune
nouvelle alerte, vous commencez à constater que votre cluster est à court de capacité.
Ce scénario se réfère à des objets associés à la solution VMware vSphere, qui relie
vRealize Operations Manager à une ou plusieurs instances de vCenter Server. Les objets de votre
environnement comprennent plusieurs instances de vCenter Server, des centres de données, des clusters
(ressources de calcul en cluster), des systèmes hôtes, des pools de ressources et des machines virtuelles.
À mesure que vous suivrez les étapes de ce scénario et avancerez dans la procédure de dépannage, vous
apprendrez à utiliser vRealize Operations Manager pour résoudre les problèmes. Vous analyserez l'état des
objets de votre environnement, examinerez les problèmes en cours, chercherez des solutions et prendrez les
mesures appropriées pour résoudre les problèmes.
Ce scénario montre comment évaluer les problèmes qui se produisent sur vos objets et prendre des mesures
appropriées pour les résoudre.
L'onglet Analyse vous permet d'afficher les paramètres des ressources d'objet, de cliquer sur les liens
n
fournis pour analyser le problème plus en détails et d'examiner les paramètres de stratégie et les seuils.
20 VMware, Inc.
Page 21

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
L'onglet Dépannage vous permet d'examiner les symptômes déclenchés sur les objets, de déterminer le
n
moment auquel les problèmes à l'origine de ces symptômes sont apparus, d'identifier les événements
associés à ces problèmes et d'examiner les mesures impliquées.
L'onglet Détails vous permet d'étudier l'activité des mesures sous forme de graphiques, de listes ou de
n
diagrammes de distribution et d'examiner les niveaux de gravité des problèmes survenant sur vos
objets à l'aide de cartes thermiques.
L'onglet Environnement vous permet d'évaluer l'état de santé, de risque et d'efficacité de divers objets
n
associés dans votre hiérarchie globale d'objets. Vous pouvez afficher les relations des objets pour
déterminer la façon dont un objet se trouvant dans un état critique peut affecter d'autres objets.
Pour faciliter les futures opérations de dépannage et celles de maintenance constante, vous pouvez créer une
définition d'alerte, ainsi qu'un tableau de bord et un ensemble de vues et de rapports. Pour planifier la
croissance et prendre en compte les projets récemment approuvés, vous pouvez créer et engager des projets
de capacité. Pour respecter les règles utilisées pour surveiller vos objets, vous pouvez créer et personnaliser
des stratégies opérationnelles.
Prérequis
Vérifiez que vous surveillez une ou plusieurs instances de vCenter Server. Reportez-vous au Guide
d'administration et de personnalisation de vRealize Operations Manager.
Procédure
1 Scénario utilisateur : Analyser l'état de votre environnement page 22
Les onglets d'analyse facilitent l'analyse de vos objets de plusieurs façons. En tant qu'administrateur
d'infrastructure virtuelle, vous utilisez les onglets d'analyse pour évaluer les détails sur l'état de vos
objets, afin de résoudre les problèmes plus facilement.
2 Scénario utilisateur : Résolution de problèmes sur un système hôte page 24
Utilisez les onglets de l'espace de dépannage afin d'identifier la cause principale de problèmes ne
pouvant être résolus par les recommandations des alertes ou par une analyse simple.
3 Scénario utilisateur : Examiner les détails de l'environnement page 26
Examinez l'état de vos objets dans les vues et dans les cartes thermiques pour identifier les tendances
et les pics présentés par les ressources de votre cluster et de vos objets. Pour déterminer si des écarts se
sont produits, vous pouvez afficher des résumés globaux sur un objet, comme la répartition de
l'utilisation de l'espace disque du cluster.
4 Scénario utilisateur : Examiner les relations de l'environnement page 28
Utilisez la présentation et la vue de liste de l'environnement pour examiner l'état des badges, qui
représentent des objets de votre hiérarchie d'environnement, et pour déterminer les objets se trouvant
dans un état critique pour un badge particulier. Pour afficher les relations entre vos objets et
déterminer si un problème critique touchant un objet ancêtre concerne également ses descendants,
utilisez la carte Environnement.
5 Scénario utilisateur : Résoudre le problème page 30
Utilisez les fonctionnalités d'analyse et de dépannage de vRealize Operations Manager pour examiner
les problèmes qui mettent vos objets dans un état critique et identifier des solutions. Pour résoudre les
problèmes lorsque des actions existent pour le type d'objet, sélectionnez un objet et une action
disponible propre à cet objet. Vous pouvez également ouvrir l'objet dans le système
vSphere Web Client et modifier ses paramètres pour résoudre le problème.
VMware, Inc. 21
Page 22

Guide de l'utilisateur de vRealize Operations Manager
6 Scénario utilisateur : Créer une définition d'alerte page 32
À partir de la cause principale du problème et des solutions que vous avez utilisées pour le résoudre,
vous pouvez créer une définition d'alerte pour que vRealize Operations Manager vous avertisse.
Lorsque l'alerte est déclenchée sur votre système hôte, vRealize Operations Manager vous avertit et
vous fournit des recommandations concernant la résolution du problème.
7 Scénario utilisateur : Créer des tableaux de bord et des vues page 33
Pour identifier et résoudre plus facilement les problèmes de cluster et de systèmes d'hôtes susceptibles
de se produire, vous pouvez créer des tableaux de bord et des vues qui appliquent les outils et les
solutions de dépannage que vous avez utilisés pour identifier et résoudre les problèmes de votre
système hôte. Ces outils et solutions de dépannage seront ainsi disponibles pour une utilisation future.
Scénario utilisateur : Analyser l'état de votre environnement
Les onglets d'analyse facilitent l'analyse de vos objets de plusieurs façons. En tant qu'administrateur
d'infrastructure virtuelle, vous utilisez les onglets d'analyse pour évaluer les détails sur l'état de vos objets,
afin de résoudre les problèmes plus facilement.
En parcourant l'arborescence d'inventaire, vous remarquez que l'un de vos groupes, nommé USA-Cluster,
connaît des problèmes de capacité. Vous utilisez les onglets d'analyse pour essayer de déterminer la cause
du problème sur USA-Cluster et vous voyez apparaître des problèmes concernant la capacité de l'un de vos
systèmes hôtes et d'autres objets.
Prérequis
Vérifiez que vous comprenez le contexte de ce scénario. Reportez-vous à « Scénario utilisateur : Vous
détectez des problèmes en surveillant l'état de vos objets », page 20.
Procédure
1 Cliquez sur Environnement > Hôtes et clusters vSphere > USA-Cluster.
2 Cliquez sur l'onglet Analyse.
Des icônes rouges apparaissent sur les onglets Capacité restante et Temps restant.
3 Cliquez sur l'onglet Temps restant.
Vous pouvez constater que l'allocation de mémoire est très limitée.
22 VMware, Inc.
Page 23

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
4 Examinez la répartition du temps restant pour le cluster.
Les icônes indiquent qu'il ne reste aucun jour, sans qu'aucun projet de capacité planifiée ne soit pris en
compte.
5 Faites défiler jusqu'à ce que le volet Temps restant dans les objets associés apparaisse.
L'objet parent est le centre de données et l'homologue représente un autre cluster. Les objets enfants
comprennent le pool de ressources et les systèmes hôtes. Le centre de données et l'un des systèmes
hôtes connaissent des problèmes de mémoire critiques.
6 Passez votre souris au-dessus des icônes rouges de parents et d'enfants.
La capacité de la mémoire est épuisée sur le centre de données et sur l'un des systèmes hôtes.
Le problème de capacité de mémoire du cluster affecte la capacité de mémoire des objets liés.
Suivant
Utilisez l'onglet Dépannage pour résoudre les problèmes de capacité sur votre cluster et sur le système hôte.
Reportez-vous à « Scénario utilisateur : Résolution de problèmes sur un système hôte », page 24.
VMware, Inc. 23
Page 24

Guide de l'utilisateur de vRealize Operations Manager
Scénario utilisateur : Résolution de problèmes sur un système hôte
Utilisez les onglets de l'espace de dépannage afin d'identifier la cause principale de problèmes ne pouvant
être résolus par les recommandations des alertes ou par une analyse simple.
Pour résoudre les symptômes des problèmes de capacité touchant le cluster et le système hôte, ainsi que
pour déterminer le moment auquel ces problèmes sont survenus, utilisez les onglets de dépannage afin
d'analyser le problème de mémoire plus en profondeur.
Prérequis
Utilisez les onglets de l'espace Analyse pour analyser votre environnement. Reportez-vous à « Scénario
utilisateur : Analyser l'état de votre environnement », page 22.
Procédure
1 Cliquez sur Environnement > Hôtes et clusters vSphere > USA-Cluster.
2 Cliquez sur l'onglet Dépannage et passez les symptômes en revue.
L'onglet Symptômes affiche les symptômes qui se sont déclenchés sur le cluster sélectionné. Vous
remarquez plusieurs symptômes critiques.
Le temps restant pour les ressources de calcul du cluster avec les projets validés est
n
dangereusement faible
Le temps restant pour les ressources de calcul du cluster est dangereusement faible
n
La capacité restante est dangereusement faible
n
3 Analysez les symptômes critiques.
a Passez votre souris sur chaque symptôme critique pour identifier la mesure utilisée.
b Pour afficher uniquement les symptômes qui touchent le cluster, entrez cluster dans la zone de
texte de filtre rapide.
Lorsque vous passez la souris sur Cluster Compute Resource Time Remaining is critically low,
la mesure Badge|Time Remaining with committed projects (%) apparaît. Vous remarquez que sa
valeur est inférieure ou égale à zéro, ce qui a déclenché le symptôme concernant la capacité et a
généré une alerte sur le cluster USA-Cluster.
4 Cliquez sur l'onglet Chronologie pour examiner les symptômes déclenchés, les alertes et les
événements qui se sont produits sur USA-Cluster au fil du temps, ainsi que pour déterminer le moment
où les problèmes sont survenus.
a Sur la barre d'outils, cliquez sur Sélectionner le type d'événement.
b Cliquez sur Contrôles de date et sélectionnez 7 derniers jours.
Plusieurs événements apparaissent en rouge.
c Passez votre souris sur chaque événement pour en afficher les détails.
d Pour afficher les événements survenus sur le centre de données du cluster, cliquez sur Afficher les
événements ancêtres et sélectionnez Centre de données.
Les événements de type Avertissement concernant le centre de données apparaissent en jaune.
24 VMware, Inc.
Page 25
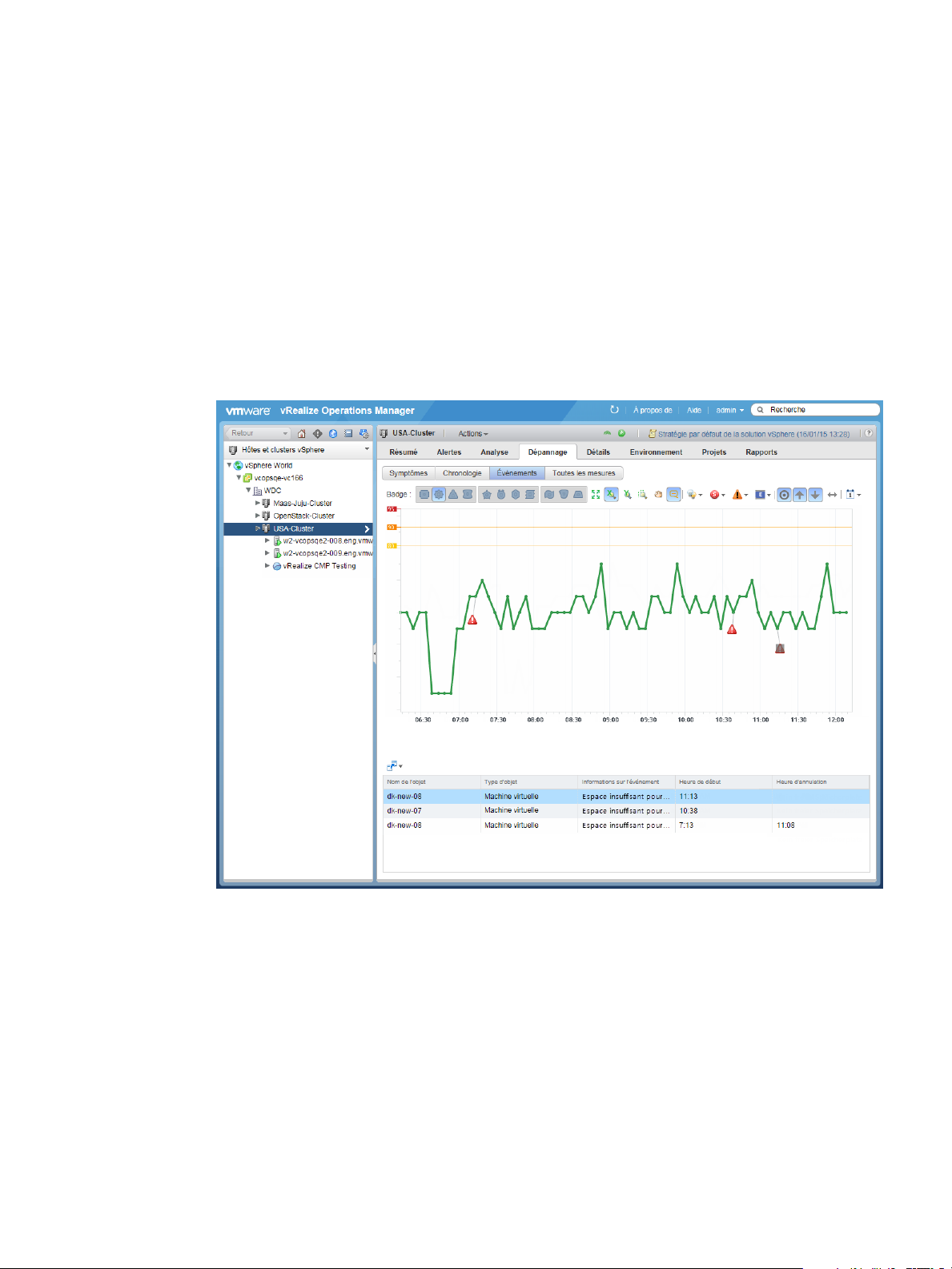
Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
e Passez votre souris sur les événements de type Avertissement.
Vous remarquez que la densité commence à être faible et qu'un seuil fixe a été dépassé sur le centre
de données en fin de soirée. La violation du seuil fixe indique que la valeur de la mesure Badge|
Densité était au-dessous de la valeur acceptable de 25 et que la violation a été déclenchée par une
valeur de 14.89.
f Pour voir les objets enfants touchés, cliquez sur Afficher les événements des descendants et
sélectionnez Système hôte.
5 Cliquez sur l'onglet Événements pour examiner les changements survenus sur USA-Cluster et pour
déterminer si l'un d'entre eux a contribué à la cause principale de l'alerte ou à d'autres problèmes sur le
cluster.
a Sur la barre d'outils, cliquez sur chaque badge et affichez les événements survenus.
Le badge Charge de travail affiche un graphique des événements survenus sur le cluster. Plusieurs
triangles rouges apparaissent à divers points du graphique.
b Passez votre souris sur chaque triangle rouge.
En examinant le graphique, vous pouvez déterminer si un événement récurrent est à l'origine des
erreurs. Chaque événement indique que le système de fichiers invité est à court d'espace disque.
Les objets touchés apparaissent dans le volet en dessous du graphique.
c Cliquez sur chaque triangle rouge pour identifier l'objet affecté et le mettre en surbrillance dans le
volet ci-dessous.
VMware, Inc. 25
Page 26

Guide de l'utilisateur de vRealize Operations Manager
6 Cliquez sur l'onglet Toutes les mesures pour évaluer les objets en contexte dans la topologie de
l'environnement afin de mieux identifier la cause possible d'un problème.
a Dans la vue supérieure, sélectionnez USA-Cluster.
b Dans le volet des mesures, développez Badge et cliquez deux fois sur Badge|Capacity Remaining
(%).
Le calcul Badge|Capacity Remaining (%) est ajouté au volet inférieur droit.
c Dans le volet des mesures, cliquez deux fois sur Densité.
d Dans le volet des mesures, cliquez deux fois sur Charge de travail.
e Sur la barre d'outils, cliquez sur Contrôles de date et sélectionnez 7 derniers jours.
Le diagramme des mesures indique que la capacité du cluster est restée stable au cours de la
semaine passée, mais que la densité du cluster a augmenté jusqu'à atteindre sa valeur maximale
dans les derniers jours. Le calcul Badge|Workload (%) affiche les valeurs extrêmes de charge de
travail qui correspondent au problème de densité.
Vous avez analysé les symptômes, la chronologie, les événements et les mesures liés aux problèmes sur
votre cluster. Vous avez ainsi déterminé que la lourde charge de travail sur le cluster a réduit la densité de
celui-ci au cours des derniers jours, ce qui indique que le cluster arrive à court de capacité.
Suivant
Examinez les vues et les cartes thermiques de l'espace Détails pour identifier des tendances et des pics
concernant les ressources de vos objets en interprétant les différentes propriétés, mesures et alertes. Vous
pouvez également y consulter la répartition des ressources sur tous vos objets et utiliser des cartes de
données pour examiner l'utilisation de divers types de ressources sur tous vos objets. Reportez-vous à
« Scénario utilisateur : Examiner les détails de l'environnement », page 26.
Scénario utilisateur : Examiner les détails de l'environnement
Examinez l'état de vos objets dans les vues et dans les cartes thermiques pour identifier les tendances et les
pics présentés par les ressources de votre cluster et de vos objets. Pour déterminer si des écarts se sont
produits, vous pouvez afficher des résumés globaux sur un objet, comme la répartition de l'utilisation de
l'espace disque du cluster.
Pour examiner plus en profondeur les problèmes avec votre cluster USA-Cluster, utilisez les vues Détails
pour afficher les mesures et les données de capacité collectées pour votre cluster. Chaque vue inclut des
données de mesure spécifiques collectées sur vos objets. Par exemple, les vues de tendance utilisent des
données collectées sur des objets au fil du temps pour calculer des tendances et des prévisions concernant
l'utilisation de ressources comme la mémoire, les CPU, l'espace disque, etc.
Les cartes thermiques permettent d'examiner les niveaux de capacité sur le cluster, les systèmes hôtes et les
machines virtuelles. La taille et la couleur des blocs dépendent des mesures sélectionnées dans la
configuration de la carte thermique. Par exemple, la taille de la carte thermique indiquant la plus forte
anomalie de charge de travail pour les machines virtuelles dépend de la mesure Badge|Workload (%), et sa
couleur de la mesure Badge|Anomaly.
Prérequis
Utilisez les onglets de dépannage pour rechercher les causes principales. Reportez-vous à « Scénario
utilisateur : Résolution de problèmes sur un système hôte », page 24
Procédure
1 Cliquez sur Environnement > Hôtes et clusters vSphere > USA-Cluster.
26 VMware, Inc.
Page 27

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
2 Examinez les informations détaillées sur le cluster USA-Cluster dans les vues.
a Cliquez sur l'onglet Options, puis sur Vues.
Les vues offrent plusieurs façons d'examiner différents types de données collectées, à l'aide de
tendances, de listes, de distributions et de résumés.
b Dans la zone de texte de recherche, saisissez capacité.
La liste filtre et affiche les vues de capacité pour les clusters et autres objets.
c Cliquez sur la vue nommée Prévision des risques de capacité des clusters et examinez le nombre
de machines virtuelles du cluster USA-Cluster dans le volet inférieur.
Même si le cluster USA-Cluster comporte deux systèmes hôtes et 30 machines virtuelles, il n'existe
aucune capacité.
3 Examinez les systèmes hôtes du cluster et récupérez de la capacité sur les machines virtuelles en aval.
a Cliquez sur l'onglet Analyse et sur Capacité restante.
b Dans l'arborescence de l'inventaire, développez USA-Cluster et cliquez sur chacun des systèmes
hôtes.
Le système hôte nommé w2-vcopsqe2-009 est dans un état critique et n'a plus de capacité restante.
c Dans le volet inférieur, développez Mémoire et Allocation.
La valeur sans contrainte est égale à zéro, de même que la quantité de mémoire disponible, ce qui
indique que la capacité du système hôte a été épuisée.
d Dans l'onglet Détails, cliquez sur Vues, puis sur la vue Capacité récupérable de la machine
virtuelle.
e Dans le volet inférieur, cliquez sur le titre de la colonne Mémoire récupérable pour trier la liste des
machines virtuelles de sorte à placer la plus grande quantité de capacité récupérable en haut.
f Pour récupérer de la capacité sur plusieurs machines virtuelles, vous devez les sélectionner :
cliquez à droite du nom de la première machine virtuelle, appuyez sur Maj , puis cliquez à droite
de la dernière machine virtuelle.
Les machines virtuelles sur laquelle de la capacité peut être récupérée sont mises en surbrillance.
g Cliquez sur l'icône en forme d'engrenage et sélectionnez l'option Définir le nombre de CPU et la
mémoire de la VM.
h Cliquez sur le titre de la colonne CPU actuel pour ordonner la liste en fonction du plus grand
nombre de CPU.
En se fondant sur l'utilisation effective des machines virtuelles énumérées, la colonne Nouvelle
CPU recommande un nombre réduit de CPU pour chaque machine virtuelle.
i Cochez la case située à côté de chaque machine virtuelle dont le nombre de CPU correspond à la
valeur recommandée, puis cliquez sur OK.
En réduisant le nombre de CPU pour chaque machine virtuelle, vous libérez de la capacité sur
votre système hôte et vous améliorez la capacité et la charge de travail du cluster USA-Cluster.
4 Examinez les cartes thermiques des objets de système hôte et de machine virtuelle dans le cluster USA-
Cluster.
a Dans l'arborescence de l'inventaire, cliquez sur USA-Cluster.
b Cliquez sur Détails, puis sur Cartes thermiques et plusieurs fois dans la liste des vues de cartes
thermiques.
VMware, Inc. 27
Page 28

Guide de l'utilisateur de vRealize Operations Manager
c Cliquez sur Quelles machines virtuelles ont actuellement les plus hautes valeurs de conflits et
de demande de CPU ?
La carte thermique affiche des blocs qui représentent les objets du cluster USA-Cluster. Le bloc
d'une machine virtuelle apparaît en rouge, ce qui indique la présence d'un problème critique.
d Passez la souris sur le bloc rouge et examinez les détails.
Les noms de cluster, de système hôte et de machines virtuelles apparaissent avec des liens
dirigeant vers des informations supplémentaires sur l'objet.
e Cliquez sur l'option Afficher les graphiques Sparkline pour afficher la tendance d'activité de la
machine virtuelle.
f Cliquez sur chacun des liens Détails pour afficher plus d'informations.
Pour vérifier si la libération de mémoire sur les machines virtuelles a amélioré la charge de travail du
système hôte et du cluster, vous pouvez maintenant examiner leur état.
Vous avez utilisé des vues et des cartes thermiques pour évaluer l'état de vos objets et identifier les
tendances et les pics, ainsi que pour libérer de la capacité pour votre système hôte et votre cluster USACluster. Pour étudier les problèmes de manière plus précise, vous pouvez examiner les autres vues et cartes
thermiques. Vous pouvez également créer vos propres vues et cartes thermiques.
Suivant
Examinez l'état des badges des objets de votre hiérarchie d'environnement pour identifier les objets qui sont
dans un état critique et étudiez les relations entre objets pour déterminer si un problème détecté sur un objet
en affecte d'autres. Reportez-vous à « Scénario utilisateur : Examiner les relations de l'environnement »,
page 28.
Scénario utilisateur : Examiner les relations de l'environnement
Utilisez la présentation et la vue de liste de l'environnement pour examiner l'état des badges, qui
représentent des objets de votre hiérarchie d'environnement, et pour déterminer les objets se trouvant dans
un état critique pour un badge particulier. Pour afficher les relations entre vos objets et déterminer si un
problème critique touchant un objet ancêtre concerne également ses descendants, utilisez la carte
Environnement.
En cliquant sur chacun des badges de la présentation de l'environnement, vous constatez que plusieurs
objets rencontrent des problèmes critiques de santé, de charge de travail et de pannes. D'autres présentent
un état critique en matière de risque et bon nombre présentent ce même état critique en matière de temps
restant et de capacité restante.
Plusieurs objets se trouvent sous contrainte. Vous remarquez que vous pouvez récupérer de la capacité sur
plusieurs machines virtuelles et sur un système hôte, mais que l'état global d'efficacité de votre
environnement ne présente aucun problème.
Prérequis
Examinez l'état de vos objets dans les vues et les cartes thermiques. Reportez-vous à « Scénario utilisateur :
Examiner les détails de l'environnement », page 26.
Procédure
1 Cliquez sur Environnement > Hôtes et clusters vSphere > USA-Cluster.
28 VMware, Inc.
Page 29

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
2 Examinez la présentation de l'environnement USA-Cluster pour consulter l'état des badges d'objets
dans une vue hiérarchique.
a Dans l'arborescence de l'inventaire, cliquez sur USA-Cluster et cliquez sur Environnement >
Présentation.
b Sur la barre d'outils Badge, cliquez sur les badges et recherchez les icônes rouges identifiant les
problèmes critiques.
Option Processus d'évaluation
Icônes d'état Lorsque l'état de mon objet est critique, que dois-je faire pour résoudre le
problème ?
Comment puis-je être averti avant que des problèmes graves ne se produisent ?
Badges : Santé, Charge de
travail, Anomalies et
Pannes
Badges : Risque, Temps
restant, Capacité restante,
Contrainte
Badges : Efficacité,
Capacité récupérable,
Densité
Comment l'état de santé et de charge de travail de mes systèmes hôtes peut-il
affecter mes machines virtuelles ?
Les anomalies et les pannes présentes sur mes systèmes hôtes et sur mes machines
virtuelles touchent-elles d'autres objets ?
Comment le niveau de contrainte de mon cluster et de mes systèmes hôtes affectet-il les descendants des machines virtuelles ?
Pour améliorer l'efficacité, comment puis-je récupérer de la capacité sur le cluster,
les systèmes hôtes, le pool de ressources et les machines virtuelles, et comment
appliquer la capacité récupérée à d'autres objets de mon environnement ?
En cliquant sur les badges, vous remarquez que votre objet vCenter Server et d'autres objets de
haut niveau semblent être en bonne santé, mais vous constatez qu'un système hôte et plusieurs
machines virtuelles sont dans un état critique concernant la santé, la charge de travail et les pannes.
Plusieurs objets présentent aussi des problèmes critiques relatifs au temps restant et à la capacité
restante.
c Passez votre souris sur l'icône rouge du système hôte pour en afficher l'adresse IP.
d Entrez l'adresse IP dans la zone de texte de recherche et cliquez sur le lien qui apparaît.
Le système hôte apparaît en surbrillance dans l'arborescence d'inventaire. Vous pouvez alors
rechercher des recommandations ou des alertes le concernant dans l'onglet Résumé.
3 Examinez la liste de l'environnement et affichez l'état des badges pour vos objets afin de déterminer
ceux qui sont dans un état critique.
a Cliquez sur Environnement > Liste.
b Examinez l'état des badges pour les objets du cluster USA-Cluster.
c Cliquez sur le nom de colonne du badge Capacité restante pour trier la liste des objets et afficher
ceux qui se trouvent dans un état critique.
Une grande partie des objets présentant un risque concernant la capacité restante affichent
également des états critiques en matière de temps restant, de risque et de santé. Vous remarquerez
que plusieurs machines virtuelles et un système hôte nommé w2-vropsqe2-009 sont touchés de
manière critique. Le système hôte étant l'objet qui rencontre les problèmes les plus critiques,
lesquels touchent probablement des objets, concentrez-vous sur la résolution des problèmes le
concernant.
d Cliquez sur le système hôte nommé w2-vropsqe2-009, qui se trouve dans un état critique, pour le
localiser dans l'arborescence d'inventaire.
e Cliquez sur w2-vropsqe2-009 dans l'arborescence de l'inventaire, puis cliquez sur l'onglet Résumé
pour rechercher des recommandations et des alertes afin de pouvoir prendre des mesures.
VMware, Inc. 29
Page 30

Guide de l'utilisateur de vRealize Operations Manager
4 Examinez la carte de l'environnement.
a Cliquez sur Environnement > Carte.
b Dans l'arborescence de l'inventaire, cliquez sur USA-Cluster et affichez la carte des objets associés.
Dans la carte des relations, vous pouvez constater que le cluster USA-Cluster dispose d'un centre
de données ancêtre, d'un pool de ressources descendant et de deux systèmes hôtes descendants.
c Cliquez sur le système hôte nommé w2-vropsqe2-009.
Le type et le nombre des objets descendants de ce système hôte apparaissent dans la liste cidessous. Utilisez la liste des objets descendants pour identifier tous les objets liés au système hôte,
lesquels rencontrent sans doute des problèmes.
Suivant
Prenez les mesures appropriées dans l'interface utilisateur pour résoudre les problèmes. Reportez-vous à
« Scénario utilisateur : Résoudre le problème », page 30.
Scénario utilisateur : Résoudre le problème
Utilisez les fonctionnalités d'analyse et de dépannage de vRealize Operations Manager pour examiner les
problèmes qui mettent vos objets dans un état critique et identifier des solutions. Pour résoudre les
problèmes lorsque des actions existent pour le type d'objet, sélectionnez un objet et une action disponible
propre à cet objet. Vous pouvez également ouvrir l'objet dans le système vSphere Web Client et modifier ses
paramètres pour résoudre le problème.
Vous avez utilisé les fonctionnalités Analyse, Dépannage, Détails et Environnement de l'interface utilisateur
pour examiner les problèmes critiques qui se produisent sur vos objets. Pour résoudre ces problèmes, vous
pouvez sélectionner des actions dans le menu Actions, qui apparaît dans les menus de listes et de vues, et
afficher différents widgets de tableau de bord.
Les actions que vous pouvez sélectionner sont propres à un type d'objet, comme une machine virtuelle. Bien
que plusieurs actions soient disponibles lorsque vous sélectionnez un système hôte qui rencontre des
problèmes critiques de capacité et de temps restant, toutes sauf une s'appliquent aux machines virtuelles.
L'action de suppression des snapshots inutilisés s'applique aux banques de données.
Prérequis
Examiner les relations de l'environnement. Reportez-vous à « Scénario utilisateur : Examiner les relations de
l'environnement », page 28.
Procédure
1 Cliquez sur Environnement > Hôtes et clusters vSphere > USA-Cluster.
2 Dans la vue Détails, sélectionnez le système hôte et prenez les mesures appropriées.
a Dans l'arborescence d'inventaire, cliquez sur le système hôte nommé w2-vropsqe2-009.
b Cliquez sur Détails > Vues et entrez mémoire dans la zone de texte de recherche.
30 VMware, Inc.
Page 31

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
c Cliquez sur la vue nommée Hôte Taille optimale de CPU, de mémoire espace disque.
Le système hôte nommé w2-vropsqe2-009 apparaît dans le volet inférieur. Vous constatez que les
CPU et la mémoire du système hôte gaspillent de la capacité. Vous remarquez également que vous
pouvez essayer de libérer de la capacité pour tenter de résoudre le problème de capacité sur le
système hôte.
Alloué Recommandation Récupérable
CPU 16 cœurs CPU 10 cœurs CPU 35 cœurs
127 Go de mémoire 35 Go de mémoire 68 Go de mémoire
Espace disque de 4 011 Go Espace disque de 11 158 Go Espace disque de 122 Go
d Dans le volet inférieur, cliquez à droite du système hôte nommé w2-vropsqe2-009.
e Sur la barre d'outils du volet inférieur, cliquez sur l'icône Ouvrir dans une application externe,
puis sur Ouvrir l'hôte dans vSphere Client.
f Connectez-vous au système vSphere Web Client et modifiez l'unité centrale et la mémoire
provisionnées pour le système hôte.
3 Dans la vue Environnement, sélectionnez le système hôte et prenez les mesures appropriées. (Facultatif)
a Dans l'arborescence de l'inventaire, cliquez sur USA-Cluster.
b Cliquez sur Environnement > Liste.
c Cliquez à droite du nom du système hôte w2-vropsqe2-009.
d Dans le volet inférieur, cliquez à droite du système hôte nommé w2-vropsqe2-009.
e Sur la barre d'outils du volet inférieur, cliquez sur l'icône Ouvrir dans une application externe,
puis sur Ouvrir l'hôte dans vSphere Client.
f Connectez-vous au système vSphere Web Client et modifiez l'unité centrale et la mémoire
provisionnées pour le système hôte.
4 Dans l'arborescence d'inventaire, sélectionnez le système hôte et prenez des mesures. (Facultatif)
a Dans l'arborescence d'inventaire, cliquez sur w2-vropsqe2-009.
b En haut de la barre d'outils du volet droit, cliquez sur Actions.
c Cliquez sur Ouvrir l'hôte dans vSphere Client.
d Connectez-vous au système vSphere Web Client et modifiez l'unité centrale et la mémoire
provisionnées pour le système hôte.
Vous avez utilisé les actions disponibles pour résoudre des problèmes critiques sur un système hôte.
L'action disponible apparaît dans Contenu > Actions.
Suivant
Pour détecter les problèmes critiques survenant sur vos objets avant qu'ils n'affectent les performances
d'autres objets et de votre environnement, créez une définition d'alerte et ajoutez éventuellement des actions
aux recommandations de la définition d'alerte. Reportez-vous à « Scénario utilisateur : Créer une définition
d'alerte », page 32.
VMware, Inc. 31
Page 32

Guide de l'utilisateur de vRealize Operations Manager
Scénario utilisateur : Créer une définition d'alerte
À partir de la cause principale du problème et des solutions que vous avez utilisées pour le résoudre, vous
pouvez créer une définition d'alerte pour que vRealize Operations Manager vous avertisse. Lorsque l'alerte
est déclenchée sur votre système hôte, vRealize Operations Manager vous avertit et vous fournit des
recommandations concernant la résolution du problème.
Pour être averti de problèmes de capacité sur vos systèmes hôtes avant qu'ils ne deviennent critiques et
pour que vRealize Operations Manager vous informe des problèmes à l'avance, vous pouvez créer des
définitions d'alerte et y ajouter des définitions de symptômes.
Prérequis
Résolvez le problème. Reportez-vous à « Scénario utilisateur : Résoudre le problème », page 30.
Procédure
1 Dans le volet de gauche, cliquez sur Contenu > Définitions d'alerte.
2 Entrez capacité dans la zone de texte de recherche.
Passez en revue la liste des définitions d'alerte de capacité disponible. Si aucune définition d'alerte de
capacité n'existe pour les systèmes hôtes, vous pouvez en créer une.
3 Cliquez sur le signe plus pour créer une définition d'alerte de capacité pour vos systèmes hôtes.
a Dans l'espace de travail de définition d'alerte, entrez Hôtes - Alerte de dépassement de capacité
comme nom et description.
b Pour le type d'objet Base, sélectionnez Adaptateur vCenter > Système hôte
c Pour Impact d'alerte, sélectionnez les options suivantes.
Option Sélection
Impact Sélectionnez Risque.
Criticité Sélectionnez Immédiat.
Type et sous-type de l'alerte Sélectionnez Application : Capacité.
Cycle d'attente Sélectionnez 1.
Cycle d'annulation Sélectionnez 1.
d Pour Ajouter des définitions de symptômes, sélectionnez les options suivantes.
Option Sélection
Défini activé Sélectionnez Auto.
Type de définition de symptôme Sélectionnez Mesures/super mesures.
Filtre rapide (nom)
Entrez capacité.
e Dans la liste de définitions de symptômes, cliquez sur le message La capacité restante du système
hôte est modérément faible et faites-le glisser vers le volet de droite.
Dans le volet Symptômes, assurez-vous que les critères d'exposition de l'objet de base sont définis
sur Tous par défaut.
32 VMware, Inc.
Page 33

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
f Pour ajouter des recommandations, entrez machine virtuelle dans la zone de texte de filtre rapide.
g Cliquez sur Passer en revue les symptômes énumérés et retirez le nombre de vCPU comme
recommandé par le système et faites-la glisser dans la zone des recommandations, dans le volet
droit.
Cette recommandation est définie sur le niveau de priorité 1.
4 Cliquez sur Enregistrer pour enregistrer la définition d'alerte.
Votre nouvelle alerte apparaît dans la liste des définitions d'alerte.
Vous avez ajouté une définition d'alerte pour que vRealize Operations Manager vous avertisse lorsque la
capacité de vos systèmes hôte commence à s'épuiser.
Suivant
Créez des tableaux de bord et des vues pour les recherches futures. Reportez-vous à « Scénario utilisateur :
Créer des tableaux de bord et des vues », page 33.
Scénario utilisateur : Créer des tableaux de bord et des vues
Pour identifier et résoudre plus facilement les problèmes de cluster et de systèmes d'hôtes susceptibles de se
produire, vous pouvez créer des tableaux de bord et des vues qui appliquent les outils et les solutions de
dépannage que vous avez utilisés pour identifier et résoudre les problèmes de votre système hôte. Ces outils
et solutions de dépannage seront ainsi disponibles pour une utilisation future.
Pour visualiser facilement l'état de vos clusters et systèmes hôtes lorsque votre responsable informatique
vous pose des questions sur leur santé, vous pouvez utiliser les tableaux de bord d'aide à la décision qui se
trouvent sur la page d'accueil de vRealize Operations Manager. Par exemple :
Utilisez le tableau de bord des clusters vSphere pour afficher l'indice d'utilisation, la demande de CPU
n
et l'utilisation de la mémoire pour vos clusters. Ce tableau de bord suit également l'utilisation du réseau
et les opérations d'E/S sur le disque.
Utilisez le tableau de bord de résumé de configuration de cluster vSphere pour analyser les états de
n
haute disponibilité et d'autres éléments de configuration.
Utilisez la présentation des hôtes vSphere pour examiner les niveaux de capacité du cluster, des
n
systèmes hôtes et des machines virtuelles.
Utilisez le tableau de bord de santé des systèmes hôtes pour afficher la liste des alertes active, le
n
graphique des mesures de capacité et la carte thermique de votre système hôte.
Si nécessaire, vous pouvez également créer vos propres tableaux de bord pour suivre l'état de vos clusters et
systèmes hôtes.
Si vous travaillez dans un environnement de type centre d'opérations réseau et que vous utilisez plusieurs
moniteurs, vous pouvez exécuter plusieurs instances de vRealize Operations Manager et affecter un
moniteur à chaque tableau de bord spécifique de manière à pouvoir suivre visuellement l'état de vos objets.
Prérequis
Créez une définition d'alerte pour vous avertir lorsque la capacité de votre système hôte est faible. Reportezvous à « Scénario utilisateur : Créer une définition d'alerte », page 32.
Procédure
1 Dans le volet de gauche, cliquez sur Accueil.
2 Cliquez sur Liste des tableaux de bord et parcourez la liste des tableaux de bord existants pour
déterminer si vous pouvez suivre vos clusters et vos systèmes hôtes à l'aide des tableaux de bords
dédiés.
VMware, Inc. 33
Page 34

Guide de l'utilisateur de vRealize Operations Manager
3 Cliquez sur le tableau de bord Santé des systèmes hôtes et examinez les widgets inclus.
L'inclusion des widgets Liste d'objets, Liste des alertes, du système de Sélecteur de mesures, Graphique
de mesures, Carte thermique et Analyse N meilleurs vous permet d'examiner facilement l'état des
systèmes hôtes que vous sélectionnez dans le widget Liste d'objets. L'interaction entre widgets est
configurée pour ce tableau de bord, si bien que l'objet que vous sélectionnez dans le widget Liste
d'objets est celui pour lequel les autres widgets affichent des données.
4 Créez et configurez un nouveau tableau de bord utilisant des widgets pour surveiller la santé de vos
systèmes hôtes et générer des alertes.
a Au-dessus de la vue du tableau de bord, cliquez sur Actions et sélectionnez Créer un tableau de
bord.
b Dans l'espace de travail Nouveau tableau de bord, entrez Santé des systèmes hôtes comme nom
du tableau de bord et conservez les autres paramètres par défaut.
c Dans l'espace de travail Liste des widgets, ajoutez le widget Liste d'objets et configurez-le de sorte
à afficher les objets de système hôte.
d Ajoutez le widget Liste des alertes au tableau de bord et configurez-le de sorte à afficher des alertes
lorsque la capacité de vos systèmes hôtes présente un risque immédiat.
e Dans l'espace de travail des interactions de widgets, pour chaque widget de la liste, sélectionnez le
widget Liste d'objets pour le définir en tant que fournisseur de données des autres widgets, puis
cliquez sur Appliquer les interactions.
f Dans l'espace de travail Navigation de tableau de bord, sélectionnez les tableaux de bord qui
reçoivent des données à partir des widgets sélectionnés et cliquez sur Appliquer les navigations.
Lorsque vRealize Operations Manager collecte des données, si un problème de capacité survient sur vos
systèmes hôtes, le widget Liste des alertes de votre nouveau tableau de bord affiche les alertes
configurées pour vos systèmes hôtes.
Suivant
Préparez-vous à partager des informations avec les autres utilisateurs, planifiez la croissance et les
nouveaux projets et utilisez des stratégies pour surveiller en permanence tous les objets de votre
environnement. Pour planifier la croissance et de nouveaux projets, reportez-vous à Chapitre 2,
« Planification des ressources de votre environnement géré à l'aide de vRealize Operations Manager »,
page 87. Pour générer des rapports, et créer et personnaliser des stratégies, consultez le
vRealize Operations Managerguide d'administration et de personnalisation.
Surveillance et résolution des alertes
Les alertes signalent un problème dans votre environnement. Les alertes sont générées lorsque les données
collectées pour un objet sont comparées aux définitions d'alertes de ce type d'objet et que les symptômes
définis sont vrais. Lorsqu'une alerte est générée, vous pouvez voir les symptômes déclencheurs afin
d'évaluer l'objet dans votre environnement, ainsi que des recommandations de résolution de l'alerte.
Les alertes vous informent lorsqu'un objet ou un groupe d'objets présente des symptômes qui ne sont pas
favorables à votre environnement. En surveillant et en traitant les alertes, vous êtes informé en permanence
des problèmes et pouvez y réagir en temps utile.
Les alertes générées régissent l'état des badges de premier niveau : Santé, Risque et Efficacité.
En plus de résoudre les alertes, vous pouvez également résoudre l'état des badges des objets de votre
environnement.
Vous ne pouvez pas attribuer des alertes aux utilisateurs de vRealize Operations Manager. Vos utilisateurs
doivent s'approprier une alerte.
34 VMware, Inc.
Page 35

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Surveillance des alertes dans vRealize Operations Manager
Vous pouvez surveiller votre environnement pour détecter des alertes générées dans plusieurs régions de
vRealize Operations Manager. Des alertes sont générées lorsque les symptômes de la définition d'alerte sont
déclenchés, vous permettant de savoir si des objets de votre environnement ne respectent pas les paramètres
que vous avez définis comme acceptables.
Les alertes générées apparaissent dans de nombreuses régions de vRealize Operations Manager, ce qui vous
permet de surveiller et de résoudre les problèmes de votre environnement.
Alertes
Les alertes sont classées dans les catégories Santé, Risque ou Efficacité. Les alertes de santé signalent des
problèmes requérant une attention immédiate. Les alertes de type Risque signalent des problèmes devant
être résolus dans de brefs délais, avant qu'ils ne deviennent des problèmes de santé immédiats. Les alertes
d'efficacité signalent des emplacements où il est possible de récupérer de l'espace inutilisé ou d'améliorer les
performances des objets de votre environnement.
Vous pouvez surveiller les alertes de votre environnement dans les emplacements suivants.
Alertes
n
Santé
n
Risque
n
Efficacité
n
Vous pouvez surveiller les alertes concernant un objet sélectionné dans les emplacements suivants.
Détails de l'alerte, comprenant les onglets Résumé, Symptômes de l'objet concerné, Chronologie,
n
Relations et Graphiques de mesures
Onglet Résumé
n
Onglet Alertes
n
Onglet Dépannage
n
Tableaux de bord personnalisés
n
Notifications d'alerte
n
Utilisation des alertes
Les alertes sont déclenchées par des problèmes devant être résolus pour que l'alerte soit annulée. Des
conseils de résolution sont fournis sous forme de recommandations, afin que vous disposiez de solutions
pour aborder le problème.
Vous pouvez vous approprier, suspendre ou annuler manuellement des alertes.
Lorsque vous annulez une alerte, celle-ci et tous les symptômes de type Panne, Événement de message ou
Événement de mesure sont annulés. Vous ne pouvez pas annuler manuellement d'autres types de
symptômes. Si l'alerte a été déclenchée par un symptôme de type Panne, Événement de message ou
Événement de mesure, l'alerte est définitivement annulée. Si l'alerte a été déclenchée par un symptôme de
mesure ou de propriété, une nouvelle alerte peut être déclenchée par les mêmes problèmes dans les minutes
qui suivent.
La façon correcte de supprimer une alerte est de corriger les problèmes sous-jacents qui ont déclenché les
symptômes et généré l'alerte.
VMware, Inc. 35
Page 36

Guide de l'utilisateur de vRealize Operations Manager
Alertes migrées
Si vous avez migré des alertes à partir d'une version précédente de vRealize Operations Manager, elles
apparaissent avec l'état Annulé dans la présentation, mais les détails d'alerte ne sont pas disponibles.
Scénario utilisateur : Surveiller et traiter les alertes dans
vRealize Operations Manager
Les alertes de vRealize Operations Manager vous avertissent lorsque des objets de votre environnement
rencontrent un problème. Ce scénario illustre une méthode de surveillance et de traitement des alertes pour
les objets dont vous êtes responsable.
Une alerte est générée lorsque l'un ou plusieurs des symptômes d'alerte sont déclenchés. En fonction de la
manière dont l'alerte est configurée, celle-ci est générée lorsqu'un symptôme se déclenche ou lorsque tous
les symptômes se déclenchent.
Lorsque les alertes sont générées, vous devez les traiter en fonction de leur effet négatif sur les objets de
votre environnement. Pour ce faire, commencez par les alertes de santé et traitez-les par niveau de gravité.
En tant qu'administrateur de l'infrastructure virtuelle, vous contrôlez les alertes au moins deux fois par jour.
Dans le cadre du processus d'évaluation que vous utilisez dans ce scénario, vous rencontrez les alertes
suivantes :
La machine virtuelle présente une charge de travail de CPU anormalement élevée
n
L'hôte présente un conflit de mémoire dû à quelques machines virtuelles
n
De nombreuses machines virtuelles du cluster présentent un conflit de mémoire en raison d'une
n
compression, d'un gonflage ou d'un échange de mémoire
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Alertes.
2 Dans le volet de gauche, cliquez sur les listes des alertes de santé.
Les alertes de santé requièrent une attention immédiate.
3 Placez votre curseur dans la colonne de criticité, cliquez sur la flèche du bas et sélectionnez Tri
descendant.
La liste est maintenant classée par ordre de gravité, avec en premier les alertes critiques, suivies par les
alertes immédiates, d'avertissement et d'information.
4 Passez en revue les alertes en regardant leur nom, l'objet sur lequel elles ont été déclenchées, le type des
objets et l'heure à laquelle elles ont été générées.
Par exemple, reconnaissez-vous des objets dont vous êtes responsable ? Savez-vous si le correctif que
vous mettrez en œuvre dans l'heure résoudra toutes les alertes qui concernent l'état de santé de l'objet ?
Savez-vous si certaines de vos alertes ne peuvent être résolues en l'état en raison de limitations de
ressources ?
5 Pour indiquer aux autres administrateurs ou ingénieurs que vous assumez la propriété des alertes de
type La machine virtuelle présente une charge de travail de CPU anormalement élevée, maintenez
la touche Ctrl enfoncée, cliquez sur les alertes sélectionnées, puis sur S'approprier.
Votre nom d'utilisateur apparaît dans la colonne Propriétaire. Cette action est possible s'il s'agit de
vous-même, mais vous ne pouvez pas attribuer la propriété d'une alerte à d'autres utilisateurs.
36 VMware, Inc.
Page 37

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
6 Pour vous approprier cette alerte et l'empêcher temporairement d'agir sur l'état de l'objet, sélectionnez
l'alerte L'hôte présente un conflit de mémoire dû à quelques machines virtuelles dans la liste et
cliquez sur Suspendre.
a Entrez 60 pour suspendre l'alerte pendant une heure.
b Cliquez sur OK.
L'alerte est suspendue pour 60 minutes et vous en apparaissez comme propriétaire dans la liste des
alertes. Si cette alerte n'est pas résolue au bout d'une heure, elle revient à l'état actif.
7 Sélectionnez la ligne qui contient l'alerte De nombreuses machines virtuelles du cluster présentent
un conflit de mémoire en raison d'une compression, d'un gonflage ou d'un échange de mémoire et
cliquez sur Annuler pour la retirer de la liste.
Cette alerte est un problème connu que vous ne pouvez pas résoudre avant l'arrivée de nouveau
matériel.
L'alerte est retirée de la liste des alertes, mais le problème sous-jacent n'est pas résolu par cette action.
Les symptômes de cette alerte sont fondés sur des mesures, de sorte que l'alerte sera générée de
nouveau lors du prochain cycle de collecte et d'analyse. La situation se répète jusqu'à ce que vous
parveniez à résoudre les problèmes de matériel et de répartition de charge de travail sous-jacents.
Vous avez traité les alertes de santé critiques et vous êtes approprié celles à résoudre ou requérant des
opérations de dépannage plus avancées.
Suivant
Répondez à une alerte. Reportez-vous à « Scénario utilisateur : Traiter une alerte vRealize Operations
Manager de la liste des alertes de santé », page 37.
Scénario utilisateur : Traiter une alerte vRealize Operations Manager de la liste
des alertes de santé
Les alertes générées dans vRealize Operations Manager apparaissent dans les listes des alertes. Les listes des
alertes permettent d'analyser, de résoudre et de commencer à corriger les problèmes rencontrés dans votre
environnement.
Dans ce scénario, vous étudiez et résolvez l'alerte La machine virtuelle présente une charge de travail
de CPU anormalement élevée. Cette alerte peut être générée pour plus d'une machine virtuelle.
Prérequis
Traiter et s'approprier les alertes à résoudre. Reportez-vous à « Scénario utilisateur : Surveiller et traiter
n
les alertes dans vRealize Operations Manager », page 36.
Examiner les informations sur le fonctionnement du paramètre Mise hors tension autorisée lorsque
n
vous exécutez des actions. Reportez-vous à « Actions qui utilisent l'option Mise hors tension
autorisée », page 71.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Alertes.
2 Dans le volet de gauche, cliquez sur les listes des alertes de santé.
3 Pour limiter la liste aux alertes de machine virtuelle, cliquez sur Tous les filtres sur la barre d'outils.
a Sélectionnez Type d'objet dans le menu déroulant.
b Entrez machine virtuelle dans la zone de texte.
c Cliquez sur OK.
La liste des alertes affiche uniquement les alertes issues de machines virtuelles.
VMware, Inc. 37
Page 38

Guide de l'utilisateur de vRealize Operations Manager
4 Pour localiser les alertes par nom, entrez charge de travail de CPU anormalement élevée dans la zone
de texte Filtre rapide (nom).
5 Dans la liste, cliquez sur le nom d'alerte La machine virtuelle présente une charge de travail de CPU
anormalement élevée.
L'onglet Résumé des détails de l'alerte apparaît pour l'alerte générée et l'objet concerné.
6 Examinez les informations de l'onglet Résumé.
Option Processus d'évaluation
Description de l'alerte
Recommandations
Quelle est la cause du problème ?
Symptômes non déclenchés
7 Pour résoudre l'alerte en suivant la recommandation de vérifier les applications invitées afin de
déterminer si une charge de travail de CPU élevée est un comportement attendu, cliquez sur le menu
Action de la barre d'outils du volet central et sélectionnez Ouvrir la machine virtuelle dans vSphere
Client.
Examinez la description pour mieux comprendre l'alerte.
Pensez-vous que la mise en œuvre d'une ou plusieurs des
recommandations permettra de résoudre l'alerte ?
Les symptômes déclenchés corroborent-ils les recommandations ? Les
autres symptômes déclenchés contredisent-ils les recommandations,
indiquant que vous devez faire des recherches supplémentaires ?
Dans cet exemple, les symptômes déclenchés indiquent que la demande de
CPU de la machine virtuelle est à un niveau critique et que l'anomalie sur
la machine virtuelle commence à prendre de l'ampleur.
Certaines alertes sont générées uniquement lorsque tous les symptômes
sont déclenchés. D'autres sont configurées pour générer une alerte dès que
l'un des symptômes est déclenché. Si des symptômes n'ont pas été
déclenchés, évaluez-les dans le contexte des alertes déclenchées.
Les symptômes non déclenchés corroborent-ils les recommandations ? Les
symptômes non déclenchés indiquent-ils que les recommandations ne sont
pas valides et que vous devez faire des recherches supplémentaires ?
a Connectez-vous à l'instance vCenter Server avec vos informations d'identification vSphere.
b Lancez la console de la machine virtuelle et identifiez les applications invitées qui consomment des
ressources de CPU.
38 VMware, Inc.
Page 39

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
8 Pour résoudre l'alerte sur la base de la recommandation indiquant d'accroître la capacité de CPU de
cette machine virtuelle, cliquez sur Définir le nombre de CPU de la machine virtuelle.
a Entrez une nouvelle valeur dans la zone de texte Nouveau CPU.
La valeur qui s'affiche correspond au résultat du calcul de taille recommandée. Si
vRealize Operations Manager a surveillé la machine virtuelle pendant six heures ou plus, selon
votre environnement, la valeur qui apparaît correspond à la mesure de taille de CPU
recommandée.
b Sélectionnez les options suivantes pour autoriser la mise hors tension ou créer un snapshot, selon la
configuration de vos machines virtuelles.
Option Description
Mise hors tension autorisée
Instantané
Arrête ou met hors tension la machine virtuelle avant de modifier la
valeur. Si VMware Tools est installé et en cours d'exécution, la machine
virtuelle est arrêtée. Si VMware Tools n'est ni installé ni en cours
d'exécution, la machine virtuelle est mise hors tension quel que soit
l'état du système d'exploitation.
En plus d'indiquer si l'action doit arrêter ou mettre hors tension une
machine virtuelle, vous devez déterminer si l'objet est sous tension et
quels sont les paramètres appliqués.
Crée un snapshot de la machine virtuelle avant l'ajout des CPU.
Si le CPU est modifié alors que l'option Connexion à chaud de CPU est
activée, le snapshot est pris pendant que la machine virtuelle est en
cours d'exécution, ce qui consomme davantage d'espace disque.
c Cliquez sur OK.
L'action ajoute le nombre recommandé de CPU à la machine virtuelle cible.
9 Autorisez l'exécution de plusieurs cycles de collecte de courir après la mise en œuvre des changements
recommandés et vérifiez la liste des alertes.
Suivant
Si l'alerte ne réapparaît pas après plusieurs cycles de collecte, elle est résolue. Si elle réapparaît, un
dépannage supplémentaire est nécessaire. Pour un autre scénario de dépannage d'alertes, reportez-vous à
« Scénario utilisateur : une alerte arrive dans votre boîte de réception », page 12.
Surveillance et résolution des problèmes
L'organisation des options et des onglets de vRealize Operations Manager fournit un workflow intégré que
vous pouvez utiliser lorsque vous travaillez avec des objets dans votre environnement.
Les onglets, Résumé, Alertes, Analyse, etc. fournissent un niveau progressif de détails sur l'objet
sélectionné. Lorsque vous utilisez les onglets l'un après l'autre, en commençant par les onglets de niveau
élevé Résumé et Alertes, vous pouvez consulter l'état général. Si vous détectez un problème, vous pouvez
utiliser les mesures agrégées dans les onglets Analyse pour afficher l'état de l'objet de manière plus
détaillée. Les données fournies dans les onglets Dépannage sont utiles lorsque vous recherchez la cause
principale d'un problème. Les onglets Détails sont des vues de données spécifiques, tandis que les onglets
Environnement indiquent les relations entre objets.
À mesure que vous surveillerez des objets dans votre environnement, vous déterminerez les onglets qui
fournissent les informations qui vous sont le plus utiles pour rechercher l'origine de problèmes.
VMware, Inc. 39
Page 40

Guide de l'utilisateur de vRealize Operations Manager
Évaluation des informations récapitulatives d'un objet
L'onglet Résumé associé aux autres onglets de l'objet répertorie les badges d'alerte de santé, de risque et
d'efficacité de l'objet sélectionné et affiche les alertes les plus fréquentes causant l'état actuel. Il affiche
également les alertes les plus fréquentes pour les descendants de l'objet sélectionné dans la hiérarchie de
navigation actuelle.
Cet onglet vous offre un aperçu des alertes pour un objet, un groupe d'objets ou une application. Vous
pouvez donc l'utiliser afin d'évaluer l'impact des alertes sur un objet et pour commencer à résoudre les
problèmes.
Types d'alertes de l'onglet Résumé
Les états des badges de santé, de risque et d'efficacité se basent sur le nombre et la criticité des alertes
générées pour l'objet sélectionné.
Les alertes de santé signalent les problèmes qui affectent la santé de votre environnement et nécessitent
n
une intervention urgente afin d'éviter toute répercussion sur le service auprès de vos clients.
Les alertes de risque indiquent les problèmes qui ne représentent pas des menaces immédiates, mais
n
qui doivent être résolus assez rapidement.
Les alertes d'efficacité vous indiquent à quel niveau vous pouvez améliorer vos performances ou
n
récupérer des ressources.
Onglet Résumé pour un objet ou un groupe d'objets
Lorsque vous travaillez avec un seul objet, les Alertes les plus fréquentes correspondent aux alertes générées
pour l'objet et les Alertes les plus fréquentes pour les descendants correspondent à celles générées pour les
objets enfants ou descendants dans la hiérarchie de navigation sélectionnée. Par exemple, si vous travaillez
avec un objet hôte dans la hiérarchie de navigation Hôtes et clusters vSphere, les descendants peuvent
inclure des machines virtuelles et des banques de données.
Lorsque vous travaillez avec des groupes d'objets, qui peuvent inclure un type d'objet (par exemple, des
hôtes) ou plusieurs types d'objets (par exemple, des hôtes, des machines virtuelles et des banques de
données), tous les objets du membre du groupe sont des descendants du conteneur du groupe. Les alertes
les plus critiques générées pour les objets du membre s'affichent en tant qu'Alertes les plus fréquentes des
descendants.
Les alertes de population d'un groupe prédéfini sont les seules Alertes les plus fréquentes qui peuvent être
générées pour un groupe d'objets. Une alerte de population d'un groupe prend en compte la santé de tous
les membres du groupe et se déclenche lorsque la santé moyenne dépasse le seuil Critique, Urgent ou
Avertissement. Lorsqu'une alerte de population d'un groupe est générée, elle affecte le score et la couleur du
badge. Si aucune alerte de population d'un groupe n'est générée, les badges restent verts. Cela est dû au fait
qu'un groupe d'objets contient d'autres objets.
Onglet résumé et Hiérarchies associées
Les alertes qui s'affichent pour un objet dans l'onglet Résumé varient en fonction de la hiérarchie
actuellement sélectionnée dans les Hiérarchies associées, dans le volet de gauche.
Différentes alertes et relations s'affichent pour un objet dans l'onglet Résumé en fonction de la hiérarchie
sélectionnée. Le nom de l'objet actuellement sélectionné s'affiche dans la barre de titre du volet central, mais
les alertes des descendants dépendent des relations définies par la hiérarchie sélectionnée dans les
Hiérarchies associées, dans le volet supérieur gauche. Par exemple, si vous travaillez avec un objet hôte
associé à des machines virtuelles dans la hiérarchie Hôtes et clusters vSphere, les descendants incluent à la
fois des machines virtuelles et des banques de données. En revanche, si vous travaillez avec le même hôte
40 VMware, Inc.
Page 41

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
qu'un membre d'un groupe d'objets, les alertes des machines virtuelles qui sont également membres du
groupe n'apparaissent pas, car l'hôte et les machines virtuelles sont considérées comme des enfants du
groupe, et sont donc des homologues. Dans cet exemple, le focus de l'onglet Résumé est l'hôte dans le
contexte du groupe, et non pas la hiérarchie Hôtes et clusters vSphere.
Techniques d'évaluation de l'onglet Résumé
Vous pouvez évaluer l'état des objets, en commençant par l'onglet Résumé, en suivant l'une ou plusieurs
des techniques suivantes.
Sélectionnez un objet ou un groupe d'objets, cliquez sur les alertes dans l'onglet Résumé, puis résolvez
n
les problèmes signalés par les alertes.
Sélectionnez un objet, puis examinez les informations le concernant disponibles dans les autres onglets.
n
Vous pouvez par exemple commencer par l'onglet Résumé de l'objet et comparer les alertes générées
aux informations analytiques sur l'objet dans l'onglet Analyse.
Sélectionnez un objet, examinez les alertes dans l'onglet Résumé, puis sélectionnez d'autres objets, afin
n
de comparer le volume et les types des alertes générées de chaque objet.
Scénario utilisateur : Évaluer les badges Alerte pour des objets d'un groupe
vRealize Operations Manager
Dans vRealize Operations Manager, vous utilisez les alertes sur un groupe pour vérifier les informations du
résumé de l'alerte pour des objets de descendant de machine virtuelle et d'hôte, afin d'afficher la manière
dont l'état d'un type d'objet peut affecter l'état d'un autre type.
En tant qu'ingénieur du centre des opérations réseau, vous êtes responsable de la surveillance d'un groupe
d'hôtes et de machines virtuelles pour le service commercial. Vos tâches quotidiennes incluent notamment
la vérification de l'état des objets du groupe, afin de déterminer s'il existe des problèmes immédiats ou si des
problèmes risquent de survenir, en fonction des alertes générées. Pour ce faire, commencez par votre groupe
d'objets, en particulier les systèmes hôtes du groupe et passez en revue les informations dans
l'ongletRésumé.
Dans le présent exemple, le groupe comprend les alertes d'objets ci-après.
L'hôte comprend de la contention de mémoire à cause de quelques machines virtuelles est une
n
alerte de santé.
La machine virtuelle présente une charge de travail pour la mémoire chronique élevée est une
n
alerte de risque
La machine virtuelle nécessite davantage de CPU que sa limite configurée est une alerte de risque
n
La machine virtuelle comprend des snapshots de disques volumineux est une alerte d'efficacité
n
La méthode ci-après servant à évaluer des alertes dans l'onglet Résumé est fournie à titre d'exemple
d'utilisation de vRealize Operations Manager et elle n'est pas définitive. Vos compétences en matière de
dépannage et votre connaissance des spécificités de votre environnement déterminent les méthodes qui
vous correspondent.
Prérequis
Créez un groupe incluant des machines virtuelles et les hôtes sur lesquels elles s'exécutent. Par
n
exemple, les machines virtuelles et les hôtes du service commercial. Pour consulter un exemple de
création de groupe similaire, reportez-vous à Guide d'administration et de personnalisation de vRealize
Operations Manager.
Passez en revue le fonctionnement de l'onglet Résumé avec des groupes d'objets et des hiérarchies
n
associées. Reportez-vous à « Évaluation des informations récapitulatives d'un objet », page 40.
VMware, Inc. 41
Page 42

Guide de l'utilisateur de vRealize Operations Manager
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Environnement.
2 Dans le volet central, cliquez sur l'onglet Groupes, puis sur le groupe Machines virtuelles et hôtes du
service commercial.
3 Pour afficher les alertes pour un hôte et les machines virtuelles enfants associées, dans le volet gauche,
cliquez sur Système hôte, puis sur le nom de l'hôte dans le volet gauche inférieur.
L'onglet Résumé affiche la santé, les risques et les badges d'efficacité, ainsi que les alertes les plus
fréquentes pour l'hôte. Le groupe demeurant l'épicentre, les alertes pour les machines virtuelles enfants
n'apparaissent pas dans les alertes les plus fréquentes pour les widgets de descendants.
4 Pour afficher l'onglet Résumé pour l'hôte et travailler également avec les machines virtuelles enfants,
cliquez sur la flèche droite située à droite du nom d'hôte, dans le volet gauche inférieur.
5 Sélectionnez les hôtes et les clusters vSphere, situés dans la partie supérieure du volet gauche.
Pour travailler avec des alertes pour des machines virtuelles enfants, l'hôte de la hiérarchie des hôtes et
des clusters vSphere doit être l'épicentre de l'onglet Résumé au lieu d'être l'hôte en tant que membre du
groupe d'objets.
6 Pour afficher les détails d'une alerte dans le volet de l'alerte de santé la plus fréquente, cliquez sur le
nom de l'alerte L'hôte comprend de la contention de mémoire à cause de quelques machines
virtuelles.
Lorsque plusieurs objets sont affectés, vous pouvez cliquer sur le lien de l'alerte pour afficher les détails,
la boîte de dialogue des problèmes de santé s'affiche. Si un objet seulement est affecté, l'onglet Résumé
des détails de l'alerte pour l'objet s'affiche.
7 Dans l'onglet Résumé des détails de l'alerte, commencez à évaluer les recommandations et les
symptômes engendrés.
Une recommandation pour l'alerte générée est de déplacer certaines machines virtuelles dotées d'une
charge de travail de la mémoire élevée vers un hôte ayant plus de mémoire disponible.
8 Pour revenir à l'onglet Résumé de l'objet et vérifier les alertes de n'importe quelle machine virtuelle de
descendant, cliquez sur le bouton Précédent situé à gauche des icônes de la barre d'outils dans le volet
gauche.
L'hôte est de nouveau l'épicentre de l'onglet Résumé de l'objet. Les alertes générées pour les machines
virtuelles enfants s'affichent dans une ou plusieurs des alertes les plus fréquentes des volets de
descendants.
42 VMware, Inc.
Page 43

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
9 Cliquez sur chaque alerte de machine virtuelle et évaluez les informations fournies dans l'onglet
Résumé des détails de l'alerte.
Alerte de machine
virtuelle Évaluation
La charge de travail
élevée de la mémoire
de la machine virtuelle
est chronique.
La machine virtuelle
nécessite davantage de
CPU que sa limite
configurée
Il est recommandé d'ajouter plus de mémoire à la machine virtuelle en question.
Si une ou plusieurs machines virtuelles subissent des charges de travail élevées, cela
engendre probablement l'alerte de contention de mémoire pour l'hôte. Les présentes
machines virtuelles sont aptes à être déplacées vers un hôte ayant plus de mémoire
disponible. Le déplacement des machines virtuelles peut résoudre l'alerte de contention de
mémoire de l'hôte et l'alerte de la machine virtuelle.
Il est recommandé d'augmenter ou de supprimer les limites du CPU sur la machine
virtuelle concernée.
Si une ou plusieurs machines virtuelles nécessitent plus de CPU que ce qui a été configuré
et que l'hôte est confronté à de la contention de mémoire, vous ne pouvez pas ajouter des
ressources de CPU à la machine virtuelle sans aggraver la contrainte de l'hôte. Les
présentes machines virtuelles sont aptes à être déplacées vers un hôte ayant plus de
mémoire disponible. Le déplacement des machines virtuelles permet d'augmenter le
nombre de CPU et de résoudre l'alerte de la machine virtuelle. Cela peut résoudre l'alerte
de contention de mémoire pour l'hôte.
10 En fonction de votre évaluation, réagissez selon les recommandations pour la machine virtuelle enfant.
Après l'exécution des actions, vous devez encore patienter pendant quelques cycles de collection pour
déterminer si ces actions ont permis de résoudre les alertes des hôtes et des machines virtuelles.
Suivant
Après quelques cycles de collection, vérifiez de nouveau votre groupe de machines virtuelles et d'hôtes du
service commercial pour déterminer si les alertes sont annulées et n'apparaissent plus dans l'onglet Résumé.
Si les alertes sont encore présentes, reportez-vous à « Scénario utilisateur : Recherche de la cause principale
d'un problème à l'aide des options de l'onglet Dépannage », page 58 pour obtenir un exemple de workflow
de dépannage.
Examen des alertes d'objets
L'onglet Alertes fournit une liste d'alertes générées pour l'objet actuellement sélectionné. Lorsque vous
utilisez des objets, l'examen des alertes générées sur l'onglet Alerte et la réponse à celle-ci vous aident à
gérer les problèmes survenant dans votre environnement.
Les alertes vous avertissent lorsqu'un problème survient dans votre environnement en fonction des
définitions d'alertes configurées. Les alertes d'objets vous sont utiles de deux manières comme outil
d'investigation. Elles peuvent vous fournir des notifications proactives sur les problèmes de votre
environnement avant qu'un utilisateur vous appelle pour s'en plaindre, et elles fournissent des informations
sur l'objet que vous pouvez utiliser lors du dépannage de problèmes généraux ou signalés.
Lors de l'examen de l'onglet Alertes, vous pouvez ajouter des ancêtres et des descendants à la liste pour
élargir votre vue des alertes. Vous pouvez voir si des alertes sur l'objet actuel affectent d'autres objets ou
comment l'objet actuel est affecté par les problèmes indiqués par les alertes sur d'autres objets.
Selon les meilleures pratiques et les workflows de votre équipe d'opérations d'infrastructure, vous pouvez
utiliser l'onglet Alertes d'un objet pour gérer les alertes générées sur des objets individuels.
Prenez possession des alertes afin que votre équipe sache que vous travaillez sur la résolution du
n
problème.
Suspendez une alerte afin qu'elle soit temporairement exclue et n'affecte plus l'état Santé, Risque ou
n
Efficacité de l'objet pendant que vous examinez le problème.
VMware, Inc. 43
Page 44

Guide de l'utilisateur de vRealize Operations Manager
Annulez les alertes qui résultent à l'évidence d'une action délibérée, par exemple, une carte réseau a été
n
retirée d'un hôte pour remplacement, ou qui correspondent à des problèmes que vous ne pouvez pas
résoudre pour le moment en raison de contraintes de ressources. L'annulation d'une alerte qui est
générée uniquement en raison d'une erreur, d'un événement de message ou de symptômes
d'événements de mesures annule l'alerte de façon permanente. L'annulation d'une alerte qui est causée
en raison d'une mesure, d'une super mesure ou de symptômes de propriétés peut entraîner la
régénération de l'alerte si la condition de mesure ou de propriété sous-jacente conserve la valeur true.
Seule l'annulation d'alertes générées en raison d'une erreur, d'un événement de message ou de
symptômes d'événements de mesures est efficace.
L'examen et la résolution d'alertes vous aident à fournir le meilleur environnement possible à vos clients.
Scénario utilisateur : Résoudre les alertes de l'onglet Alertes pour des machines virtuelles défectueuses
Vous résolvez les alertes d'objets, afin de pouvoir ramener les objets affectés au niveau de configuration ou
de performance requis. Selon les informations contenues dans l'alerte et à l'aide des autres informations
fournies dans vRealize Operations Manager, évaluez l'alerte, identifiez la solution la plus plausible et
résolvez le problème.
En tant qu'administrateur d'infrastructure ou gestionnaire des opérations, vous résolvez les problèmes liés
aux objets. La consultation des alertes générées pour les objets et leur résolution font partie du processus de
dépannage. Dans cet exemple, vous souhaitez résoudre des problèmes de charge de travail pour une
machine virtuelle. Dans le cadre de ce processus, vous consultez l'onglet Alertes pour déterminer celles qui
sont susceptibles d'indiquer le problème identifié ou d'aider à le résoudre.
La machine virtuelle défectueuse est db-01-kyoto, que vous utilisez en tant que serveur de base de données.
La méthode suivante, permettant de résoudre les alertes dans l'onglet Alertes, est fournie à titre d'exemple
d'utilisation de vRealize Operations Manager et n'est pas décisive. Vos compétences en matière de
dépannage et votre connaissance des spécificités de votre environnement déterminent les méthodes qui
vous correspondent.
Prérequis
Vérifiez que les adaptateurs Python Remediation vCenter sont configurés pour les actions de chaque
n
instance de vCenter Server. Reportez-vous à Guide d'administration et de personnalisation de vRealize
Operations Manager.
Vérifiez que vous comprenez le fonctionnement de l'option Mise hors tension autorisée si vous exécutez
n
les actions Définir le nombre de CPU, Définir la mémoire et Définir le nombre de CPU et la mémoire.
Reportez-vous à « Actions qui utilisent l'option Mise hors tension autorisée », page 71.
Procédure
1 Entrez le nom de l'objet, db-01-kyoto, dans la zone de texte Recherche et sélectionnez la machine
virtuelle dans la liste.
L'onglet Résumé de l'objet s'affiche. Les volets Alertes les plus fréquentes affichent d'importantes
alertes actives pour l'objet.
2 Cliquez sur l'onglet Analyse.
L'onglet Charge de travail est le premier onglet. Ce badge indique que la charge de travail est la plus
élevée par CPU, mais que la mémoire est également supérieure à la limite configurée.
3 Cliquez sur l'onglet Alertes.
Dans le présent exemple, la liste des alertes inclut les alertes suivantes qui peuvent être associées au
problème en cours d'investigation.
La machine virtuelle subit une charge de travail de processeur élevée inattendue.
n
44 VMware, Inc.
Page 45

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
La machine virtuelle subit une charge de travail de mémoire élevée inattendue.
n
4 Dans le volet supérieur gauche, sélectionnez la hiérarchie associée Hôtes et clusters vSphere, puis
sélectionnez les alertes des descendants ou des ancêtres à ajouter à la liste.
Vous souhaitez rechercher des alertes éventuelles liées à des objets ancêtres ou descendants dans le
contexte de la hiérarchie sélectionnée.
a Dans la barre d'outils, cliquez sur Afficher les alertes des ancêtres et cochez les cases Système
hôte et Pool de ressources.
Toutes les alertes du système hôte ou du pool de ressources liées à cette machine virtuelles sont
ajoutées à la liste.
b Cliquez sur Afficher les alertes des descendants et sélectionnezBanque de données.
Toutes les alertes de la banque de données sont ajoutées à la liste.
Dans cet exemple, étant donné qu'il n'existe pas d'alerte supplémentaire pour l'hôte, le pool de
ressources ou la banque de données, vous commencez par traiter les alertes de la machine virtuelle.
5 Cliquez sur le nom de l'alerte La machine virtuelle subit une charge de travail de processeur élevée
inattendue.
L'onglet Résumé des détails de l'alerte s'affiche.
6 Consultez les recommandations suggérées pour déterminer si une ou plusieurs d'entre elles permettent
de résoudre le problème.
Le présent exemple inclut les recommandations courantes suivantes :
Vérifiez les applications invitées pour déterminer si la charge de travail du processeur
n
correspond au comportement attendu.
Ajoutez de la capacité de CPU supplémentaire à cette machine virtuelle.
n
7 Pour suivre la recommandation Check the guest applications to determine whether high CPU
workload is expected behavior, cliquez sur Actions dans la barre de titre et sélectionnez Ouvrir la
machine virtuelle dans vSphere Client.
L'onglet Résumé de vSphere Web Client s'affiche pour vous permettre d'ouvrir la machine virtuelle
dans la console et de déterminer les applications affectées par la charge de travail de processeur élevée
signalée.
8 Pour suivre la Add more CPU Capacity for this virtual machine recommandation, cliquez sur Définir
le nombre de CPU de la machine virtuelle.
a Entrez une valeur dans la zone de texte Nouveau CPU.
La valeur par défaut qui s'affiche avant que vous ne fournissiez une valeur est une valeur
recommandée en fonction de l'analyse effectuée.
b Pour permettre la mise hors tension de la machine virtuelle avant d'exécuter l'action lorsque
l'option Ajouter à chaud pour le CPU n'est pas activée, cochez la case Mise hors tension autorisée.
c Pour créer un snapshot avant de modifier la configuration du CPU de la machine virtuelle, cochez
la case Snapshot.
d Cliquez sur OK.
e Cliquez sur le lien ID de tâche et vérifiez que la tâche s'est exécutée correctement.
Le nombre de CPU spécifié est ajouté à la machine virtuelle.
VMware, Inc. 45
Page 46

Guide de l'utilisateur de vRealize Operations Manager
Suivant
Après quelques cycles de collecte, revenez à l'onglet Alertes de l'objet. Si l'alerte ne s'affiche plus, cela
signifie que vos actions ont permis de résoudre l'alerte. Si le problème n'est pas résolu, reportez-vous à
« Scénario utilisateur : Recherche de la cause principale d'un problème à l'aide des options de l'onglet
Dépannage », page 58 pour obtenir un exemple de workflow de dépannage.
Scénario utilisateur : Résoudre les alertes sur un tableau de bord personnalisé
Vous pouvez utiliser un tableau de bord personnalisé incluant des widgets associés à des alertes, afin de
contrôler si les alertes existent dans votre environnement. Le tableau de bord personnalisé fournit une
interface unique dans laquelle vous pouvez surveiller l'état d'alerte général pour les objets et les groupes
d'objets, et commencer à traiter les alertes afin de les résoudre.
En tant qu'administrateur d'infrastructure virtuelle, vous êtes responsable des machines virtuelles et des
hôtes utilisés par le service comptable. Vous avez créé des alertes pour gérer les objets du service comptable.
Créez alors un tableau de bord sur lequel le widget principal affiche des objets du groupe d'objets
comptables. Vous voulez désormais utiliser le tableau de bord pour gérer les alertes pour le groupe en
question.
Prérequis
Créez des alertes pour gérer les objets de service de comptable. Reportez-vous à Guide d'administration
n
et de personnalisation de vRealize Operations Manager.
Créez un tableau de bord personnalisé pour y ajouter des widgets d'alertes, de liste d'alertes et des
n
alertes les plus fréquentes. Les widgets sont configurés pour surveiller des objets de votre
environnement. Reportez-vous à Guide d'administration et de personnalisation de vRealize Operations
Manager.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Page d'accueil.
2 Dans la barre d'outils du tableau de bord, cliquez sur Tableau de bord et sélectionnezVM et hôtes de la
comptabilité.
3 Dans la liste des alertes du service comptable, cliquez sur l'en-tête de la colonne État pour trier et placer
les alertes actives au début de la liste.
4 Dans la barre d'outils de la liste d'alertes, cliquez sur Colorer la ligne en fonction de la criticité de
l'alerte.
Les alertes sont désormais mises en surbrillance par couleur, afin de traiter en premier celles avec le
plus haut niveau de criticité.
5 Cliquez sur la ligne de l'objet doté de l'alerte la plus critique, afin de la traiter en premier.
Étant donné les interactions des widgets configurés, les widgets Santé, Risque, Efficacité, Volume des
symptômes, Alertes les plus fréquentes affichent les données pour l'objet sélectionné.
a Passez en revue les widgets Santé, Risque et Efficacité pour comprendre l'état d'alerte général de
l'objet.
b Passez en revue le widget Alertes les plus fréquentes pour déterminer le nombre d'alertes pour
l'objet.
46 VMware, Inc.
Page 47

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
c Cliquez sur le nom de l'alerte dans le widget.
Par exemple, cliquez sur l'alerte Avertissement préalable CPU VM compta. L'onglet Résumé des
détails de l'alerte s'affiche.
d Résolvez l'alerte à l'aide des recommandations.
Par exemple, pour utiliser la recommandation S'il s'agit d'un hôte autonome, ajoutez plus de
mémoire à l'hôte, cliquez sur le lien vers les instructions pour ajouter de la mémoire à un hôte.
6 Pour revenir au tableau de bord Machines virtuelles et hôtes comptables, afin de traiter plus d'alertes,
cliquez sur le bouton Précédent situé sur la barre d'outils du volet gauche.
7 Sélectionnez l'alerte suivante dans la liste et continuez à traiter les alertes.
Suivant
Après quelques cycles de collection, vérifiez de nouveau les alertes pour déterminer si elles ont été annulées
et n'apparaissent plus dans le tableau de bord. Si les alertes sont encore présentes, reportez-vous à
« Scénario utilisateur : Recherche de la cause principale d'un problème à l'aide des options de l'onglet
Dépannage », page 58 pour obtenir un exemple de workflow de dépannage.
Analyse des ressources de votre environnement
Outre la surveillance, vRealize Operations Manager vous offre des outils efficaces pour analyser les
ressources et les performances de votre environnement virtuel.
Vous pouvez utiliser l'onglet Analyse pour analyser l'état actuel de votre environnement virtuel.
Présentation de l'analyse de charge de travail
La charge de travail dans vRealize Operations Manager est la demande en ressources requises par un objet
par rapport à la capacité réelle à laquelle cet objet peut accéder. La valeur du badge Charge de travail est un
score calculant l'intensité avec laquelle un objet doit fonctionner pour accéder à des ressources. Utilisez la
valeur Charge de travail comme outil d'investigation lorsque vous faites des recherches sur des limitations
de capacité ou que vous évaluez l'état général d'objets de votre environnement.
Badge Charge de travail
Le badge d'analyse Charge de travail vRealize Operations Manager détermine jusqu'à quel point un objet
doit fonctionner pour les ressources. vRealize Operations Manager indique la charge de travail par une
icône de couleur basée sur les seuils de score de badge définis.
Le score Charge de travail est compris entre 0 (bon) et 100 (mauvais). Les seuils de score de badge peuvent
être modifiés par l'administrateur vRealize Operations Manager.
Tableau 1‑1. États de charge de travail des objets
Icône Badge Description Action utilisateur
La charge de travail sur l'objet
n'est pas excessive.
L'objet subit des charges de
travail élevées.
Aucune intervention n'est
requise.
Vérifiez les détails et prenez les
mesures appropriées.
La charge de travail sur l'objet
approche sa capacité maximale
dans au moins une zone.
VMware, Inc. 47
Vérifiez les détails et prenez les
mesures appropriées dès que
possible.
Page 48

Guide de l'utilisateur de vRealize Operations Manager
Tableau 1‑1. États de charge de travail des objets (suite)
Icône Badge Description Action utilisateur
Présentation des anomalies
vRealize Operations Manager calcule des seuils dynamiques pour chaque mesure collectée pour un objet.
vRealize Operations Manager analyse également le nombre de mesures qui enfreignent leurs seuils
dynamiques pour déterminer les tendances et les niveaux normaux de violation des seuils. En fonction de
ces tendances, le score d'analyse Anomalies est calculé en utilisant le nombre total de violations de seuil de
toutes les mesures de l'objet sélectionné et de ses objets enfants.
Badge Anomalies
Le score du badge Anomalies de vRealize Operations Manager représente le comportement anormal de
l'objet en fonction de ses données de mesure historiques. vRealize Operations Manager indique les
anomalies par une icône de couleur basée sur les seuils de score de badge définis.
La charge de travail sur l'objet
se situe à sa capacité maximale
ou au-delà dans une ou
plusieurs zones.
L'objet est hors ligne ou aucune
donnée n'est disponible.
Intervenez immédiatement pour
éviter les problèmes ou les
résoudre.
Lors de l'évaluation des scores des badges, un nombre élevé d'anomalies peut indiquer un problème
potentiel. Un score d'anomalies faible indique qu'un objet se comporte conformément à ses paramètres
d'historique établis. La plupart ou l'intégralité des mesures de l'objet, en particulier ses KPI, sont situées au
sein de leurs seuils. Sachant que les changements de comportement indiquent généralement des problèmes
en cours de développement, si les mesures d'un objet franchissent les seuils calculés, le score d'anomalies de
l'objet augmente. Plus le nombre de mesures franchissant les seuils augmente, plus les anomalies continuent
de croître.
Les dépassement des mesures KPI augmentent davantage le score d'anomalies que ceux des mesures non
KPI. Un nombre élevé d'anomalies indique généralement un problème ou, au moins, une situation qui
nécessite votre attention.
Les anomalies impliquent le nombre de statistiques dépassant les tendances comportementales attendues,
tandis que la charge de travail implique une mesure absolue de l'intensité d'exécution d'un objet pour les
ressources. Anomalies et Charge de travail sont utiles pour rechercher une cause probable et résoudre des
problèmes de performances.
Le score Anomalies est compris entre 0 (bien) et 100 (mauvais). Les seuils de score de badge peuvent être
modifiés par l'administrateur vRealize Operations Manager.
Tableau 1‑2. États des anomalies d'objets
Icône Badge Description Action utilisateur
Le score d'anomalies est
normal.
Le score d'anomalies dépasse la
plage de seuils normale.
Aucune intervention n'est
requise.
Vérifiez les détails et prenez les
mesures appropriées.
Le score d'anomalies est très
élevé.
48 VMware, Inc.
Vérifiez les détails et prenez les
mesures appropriées dès que
possible.
Page 49

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Tableau 1‑2. États des anomalies d'objets (suite)
Icône Badge Description Action utilisateur
La plupart des mesures se
situent au-delà de leurs seuils.
Il est possible que cet objet ne
fonctionne pas correctement ou
qu'il s'arrête de fonctionner
prochainement.
L'objet est hors ligne ou aucune
donnée n'est disponible.
Intervenez immédiatement pour
éviter les problèmes ou les
résoudre.
Présentation des pannes
Le badge Pannes mesure le niveau des problèmes que l'objet peut rencontrer en fonction des événements
récupérés à partir du système vCenter Server.
Le badge Pannes
Le score Pannes est calculé en fonction des événements publiés par le système vCenter Server. Ce score
inclut des événements tels que la perte de redondance des cartes réseau ou des HBA, des erreurs de total de
contrôle de mémoire, des problèmes de basculement HA, des événements CIM, etc. Les pannes sont incluses
dans le score de santé, car elles nécessitent une résolution urgente, tandis que les éléments qui contribuent
au score de risque ne sont pas nécessairement urgents, mais nécessitent tout de même votre attention. Les
événements susceptibles de générer des pannes incluent, notamment, la perte de redondance des cartes
réseau ou des HBA, des erreurs de total de contrôle de mémoire, des basculements HA ou des événements
CIM (Common Information Model) qui nécessitent une intervention urgente.
Chaque ressource de vRealize Operations Manager a un score de pannes compris entre 0 (aucune panne) et
100 (pannes critiques). Les scores sont calculés en fonction de la gravité des problèmes sous-jacents.
Lorsqu'il existe plusieurs problèmes associés à des pannes sur la ressource, le score de pannes est basé sur le
problème le plus grave.
Plus le score Pannes est élevé, plus la santé de la ressource est faible. La résolution du problème indiquée
par le badge Panne permettra de restaurer le score de santé de la ressource.
Contrairement aux autres badges de vRealize Operations Manager, aucune alerte n'est générée à partir du
score de seuil du badge Pannes. Chaque problème génère plutôt sa propre alerte de panne, et la résolution
du problème supprime ou annule l'alerte et diminue le score du badge.
Configurez les seuils de symptômes pour le score du badge de pannes.
Le score Pannes est compris entre 0 (bon) et 100 (mauvais). Les seuils de score de badge peuvent être
modifiés par l'administrateur vRealize Operations Manager.
Tableau 1‑3. États de pannes des objets
Icône Badge Description Action utilisateur
Aucune panne n'est enregistrée
sur l'objet sélectionné.
Les pannes de faible
importance sont enregistrées
sur l'objet sélectionné.
Les pannes de haute
importance sont enregistrées
sur l'objet sélectionné.
Aucune intervention n'est
requise.
Vérifiez les détails et prenez les
mesures appropriées.
Vérifiez les détails et prenez les
mesures appropriées dès que
possible.
VMware, Inc. 49
Page 50

Guide de l'utilisateur de vRealize Operations Manager
Tableau 1‑3. États de pannes des objets (suite)
Icône Badge Description Action utilisateur
Présentation de la capacité
Le badge Capacité représente la capacité restante de votre environnement virtuel à accueillir de nouvelles
machines virtuelles.
Le nombre de machines virtuelles restantes représente le nombre de machines virtuelles pouvant être
déployées sur l'objet sélectionné, en fonction de la quantité actuelle de ressources inutilisées et du profil
moyen de machines virtuelles des « n » dernières semaines. Le nombre de machines virtuelles restantes est
fonction des mêmes ressources de calcul de CPU, de mémoire, d'E/S disque et d'espace disque utilisées pour
calculer le score Temps restant.
Badge Capacité restante
Les pannes d'importance
critique sont enregistrées sur
l'objet sélectionné.
L'objet est hors ligne ou aucune
donnée n'est disponible.
Intervenez immédiatement pour
éviter les problèmes ou les
résoudre.
vRealize Operations Manager calcule le score Capacité restante comme le rapport (en pourcentages) de la
capacité restante sur la capacité totale pouvant être déployée sur l'objet sélectionné.
Le score Capacité est compris entre 0 (mauvais) et 100 (bon). Les seuils de score de badge peuvent être
modifiés par l'administrateur vRealize Operations Manager.
Tableau 1‑4. États de la capacité de l'objet
Icône Description Action utilisateur
La capacité restante de
l'objet est au niveau
normal.
La capacité restante de
l'objet est inférieure au
niveau normal.
La capacité restante de
l'objet est à un niveau
sérieusement faible.
La capacité de l'objet est
insuffisante ou épuisée.
L'objet est hors ligne ou
aucune donnée n'est
disponible pour les
mesures de la période
concernée.
Aucune intervention n'est requise.
Vérifiez les détails et prenez les mesures
appropriées.
Vérifiez les détails et prenez les mesures
appropriées dès que possible.
Intervenez immédiatement pour éviter les
problèmes ou les résoudre.
Présentation du temps restant
Le score Temps restant affiche le temps qu'il reste avant que les ressources de l'objet soient épuisées.
Le score Temps restant est calculé par type de ressource pour un objet. Par exemple, les valeurs d'utilisation
de CPU ou des opérations E/S du disque sont basées sur les données historiques du type d'objet. Le score
Temps restant représente le temps restant estimé par rapport à ces données historiques. Le score Temps
restant vous permet de planifier le provisionnement des ressources physiques ou virtuelles de l'objet
sélectionné, ou d'ajuster la charge de travail aux besoins des ressources de votre environnement virtuel.
50 VMware, Inc.
Page 51

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Badge Temps restant
vRealize Operations Manager calcule le score Temps restant sous forme de pourcentage du temps restant
pour chaque ressource calcul en comparaison de la marge de provisionnement que vous avez définie dans la
boîte de dialogue Configuration. Par défaut, la marge de provisionnement du score Temps restant est de
30 jours. Même si l'une des ressources de calcul dispose d'une capacité inférieure à la marge provisionnée, le
score Temps restant est de 0.
Par exemple, si la marge de provisionnement est définie sur 30 jours et si l'objet que vous avez sélectionné
dispose de ressources de CPU pendant 81 jours, de ressources mémoire pendant 5 jours, de ressources d'E/S
disque pendant 200 jours et de ressources d'E/S réseau pendant plus d'un an, le score Temps restant est de 0,
car l'une des ressources dispose d'une capacité inférieure à 30 jours.
Le score Temps reste compris entre 0 (mauvais) et 100 (bon). Les seuils de score de badge peuvent être
modifiés par l'administrateur vRealize Operations Manager.
Tableau 1‑5. États de Temps restant
Icône Badge Description Action utilisateur
Le nombre de jours restants est
bien supérieur à celui de la
marge de provisionnement que
vous avez spécifiée.
Le nombre de jours restants est
supérieur à celui de la marge de
provisionnement, mais deux
fois inférieur à la marge que
vous avez spécifiée.
Le nombre de jours restants est
supérieur à celui de la marge de
provisionnement, mais
s'approche de la marge que
vous avez spécifiée.
Le nombre de jours restants est
bien inférieur à celui de la
marge de provisionnement que
vous avez spécifiée. L'objet
sélectionné peut avoir épuisé
certaines de ses ressources ou
les épuisera bientôt.
L'objet est hors ligne ou aucune
donnée n'est disponible pour le
score Temps restant.
Aucune intervention n'est
requise.
Vérifiez les détails et prenez les
mesures appropriées.
Vérifiez les détails et prenez les
mesures appropriées dès que
possible.
Intervenez immédiatement pour
éviter les problèmes ou les
résoudre.
Badge Contrainte
L'analyse de contrainte indique le volume de demandes d'un objet sur une période donnée, tel que calculé
par vRealize Operations Manager. Cette analyse compare la charge de travail de l'objet à sa capacité. Cette
mesure facilite le dimensionnement de l'objet pour répondre aux demandes de ressources.
Badge Contrainte
Le score Contrainte indique la charge de travail historique de l'objet sélectionné. Alors que le score Charge
de travail montre un snapshot de l'utilisation actuelle des ressources, le score Contrainte analyse les données
d'utilisation des ressources sur une période plus longue.
Le score Contrainte est calculé comme le rapport entre la demande de ressources et la capacité utilisable
pour une certaine période.
VMware, Inc. 51
Page 52

Guide de l'utilisateur de vRealize Operations Manager
Le score Contrainte permet d'identifier les hôtes et les machines virtuelles auquel une quantité insuffisante
de ressources est allouée, ou les hôtes qui hébergent un trop grand nombre de machines virtuelles. Un score
Contrainte élevé n'indique pas un problème de performance immédiat, mais signale de possibles problèmes
de performance à l'avenir.
Le score Contrainte est compris entre 0 (bon) et 100 (mauvais). Les seuils de score de badge peuvent être
modifiés par l'administrateur vRealize Operations Manager.
Tableau 1‑6. États de contrainte
Icône Badge Description Action utilisateur
Le score Contrainte est normal. Aucune intervention n'est
requise.
Certaines des ressources de
l'objet sont en quantité
insuffisante pour répondre aux
exigences.
L'objet connaît une pénurie
régulière de ressources.
La plupart des ressources sur
l'objet sont constamment
insuffisantes. L'objet risque de
cesser de fonctionner
correctement.
L'objet est hors ligne ou aucune
donnée n'est disponible pour le
score Contrainte.
Vérifiez les détails et prenez les
mesures appropriées.
Vérifiez les détails et prenez les
mesures appropriées dès que
possible.
Intervenez immédiatement pour
éviter les problèmes ou les
résoudre.
Présentation de la capacité récupérable
La capacité récupérable est la quantité de capacité fournie qui peut être récupérée sans causer de contrainte
ou de dégradation des performances. La capacité récupérable est calculée pour chaque type de ressource, tel
que le CPU, la mémoire et le disque, pour chaque objet de l'environnement. Il identifie la quantité de
ressources pouvant être récupérée et provisionnée à d'autres objets de votre environnement.
Pour les groupes, la capacité récupérable correspond à la quantité d'espace disque pouvant être récupérée
sur les machines virtuelles du groupe qui sont considérées comme éléments de gaspillage selon les
paramètres de stratégie pour les états inactif et hors tension. Si la machine virtuelle est inactive, toutes ses
ressources sont considérées comme étant récupérables. Si un groupe ne contient aucune machine virtuelle,
mais des banques de données, la valeur de Gaspillage récupérable est 0, même si la banque de données
contient des machines virtuelles qui gaspillent des ressources selon les paramètres VM hors tension et
inactives.
Badge Capacité récupérable
Le score Capacité récupérable indique un surprovisionnement dans votre infrastructure virtuelle ou pour
un objet spécifique.
Le score de Gaspillage récupérable est compris entre 0 (bon) et 100 (mauvais). Les seuils de score de badge
peuvent être modifiés par l'administrateur vRealize Operations Manager.
52 VMware, Inc.
Page 53

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Tableau 1‑7. États du badge Gaspillage récupérable
Icône Badge Description Action utilisateur
Aucune ressource n'est
gaspillée sur l'objet sélectionné.
Aucune intervention n'est
requise.
L'utilisation de certaines
ressources peut être optimisée.
De nombreuses ressources sont
sous-utilisées.
La plupart des ressources sur
l'objet sélectionné sont
gaspillées.
L'objet est hors ligne ou aucune
donnée n'est disponible pour
les mesures de la période
concernée.
Vérifiez les détails et prenez les
mesures appropriées.
Vérifiez les détails et prenez les
mesures appropriées dès que
possible.
Intervenez immédiatement pour
éviter les problèmes ou les
résoudre.
Présentation de la densité
Le score Densité indique les taux de consolidation, tels que le nombre de machines virtuelles par hôte, de
CPU virtuelles par CPU physique, de mémoire virtuelle par mémoire physique, etc.
Badge Densité
Le score Densité vous permet d'optimiser les taux de consolidation et les économies de coût. Dès que vous
connaissez le comportement et les performances de vos machines virtuelles et applications, vous pouvez
optimiser la consolidation de votre environnement virtuel sans affecter les performances ni les contrats de
niveau de service.
Le score Densité est compris entre 0 (mauvais) et 100 (bon). Les seuils de score de badge peuvent être
modifiés par l'administrateur vRealize Operations Manager.
Tableau 1‑8. États de densité des objets
Icône Badge Description Action utilisateur
La consolidation des ressources
est bonne.
Certaines ressources ne sont
pas entièrement consolidées.
La consolidation de
nombreuses ressources est
faible.
La consolidation des ressources
est extrêmement faible.
L'objet est hors ligne ou aucune
donnée n'est disponible pour
les mesures de la période
concernée.
Aucune intervention n'est
requise.
Vérifiez les détails et prenez les
mesures appropriées.
Vérifiez les détails et prenez les
mesures appropriées dès que
possible.
Intervenez immédiatement pour
éviter les problèmes ou les
résoudre.
VMware, Inc. 53
Page 54

Guide de l'utilisateur de vRealize Operations Manager
Présentation de la conformité
La conformité consiste à vous assurer que les objets de votre environnement répondent à des normes
industrielles, gouvernementales, réglementaires ou internes. Ces normes sont constituées de règles sur la
façon dont les objets doivent être configurés pour être conformes aux meilleures pratiques et éviter toute
menace de sécurité.
Dans vRealize Operations Manager, vous pouvez utiliser les paramètres de conformité basée sur des alertes
fournis ou, si vous utilisez également vRealize Configuration Manager dans votre environnement, vous
pouvez utiliser l'adaptateur qui fournit les informations de conformité de vRealize Configuration Manager à
la place de la conformité basée sur des alertes.
Conformité basée sur des alertes dans vRealize Operations Manager
La valeur du badge Conformité est basée sur les résultats des alertes de conformité portant sur les données
collectées dans vRealize Operations Manager. La conformité sur la base des alertes vous permet de vous
assurer que les objets de votre environnement répondent aux normes définies.
Les alertes de conformité sont configurées avec le sous-type Conformité et comprennent un ou plusieurs
symptômes représentant les règles. Lorsqu'une alerte de conformité est générée, elle apparaît comme une
violation de norme dans l'onglet Conformité, tandis que les symptômes déclenchés apparaissent comme
règles violées. Les règles sont des symptômes d'alerte configurés pour identifier la valeur ou la
configuration indésirables. Si un symptôme de règle est déclenché pour une alerte associée aux normes, la
norme est considérée comme enfreinte, ce qui modifie le score du badge dans l'onglet Conformité.
La valeur de badge est un score défini par paliers sur la base de la gravité des symptômes déclenchés pour
différents types d'objets. Le badge affiche l'une des valeurs suivantes :
100 si aucune norme n'est déclenchée. Le badge est vert.
n
75 si la norme déclenchée la plus critique est de type Avertissement. Le badge est jaune.
n
25 si la norme déclenchée la plus critique est de type Immédiate. Le badge est orange.
n
0 si la norme déclenchée la plus critique est de type Critique. Le badge est rouge.
n
Vous devez personnaliser une stratégie pour activer la conformité basée sur les alertes. Si les alertes de
conformité ne sont pas activées, la valeur du badge Conformité est de 100, le badge est vert et la liste de
normes est vide.
Personnaliser une stratégie pour activer les alertes du guide de renforcement de vSphere
Les alertes du guide de renforcement Hardening Guide de vSphere vous avertissent lorsque des paramètres
ou des propriétés ne sont pas configurés conformément au guide sur vos hôtes ou vos machines virtuelles.
Pour utiliser ces alertes, remplacez le paramètre de stratégie afin que l'option Local soit activée.
La conformité basée sur des alertes ne fonctionne que lorsque vous activez au moins une des deux alertes du
guide de renforcement de vSphere. Une alerte concerne les hôtes ESXi et l'autre les machines virtuelles. Le
guide de renforcement vérifie les données collectées pour déterminer si les paramètres recommandés sont
configurés de sorte que vos hôtes ESXi et vos machines virtuelles fonctionnent de manière sécurisée.
Prérequis
Vérifiez que votre instance de vRealize Operations Manager inclut la stratégie par défaut ainsi qu'une ou
plusieurs autres stratégies. Reportez-vous à Guide d'administration et de personnalisation de vRealize Operations
Manager.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Administration.
2 Cliquez sur Stratégies et sur l'onglet Bibliothèque de stratégie.
54 VMware, Inc.
Page 55

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
3 Développez les paramètres de base, sélectionnez la stratégie que vous souhaitez personnaliser et
cliquez sur le crayon pour la modifier.
4 Dans la navigation de l'espace de travail, cliquez sur Remplacer les définitions d'alertes et de
symptômes.
5 Dans le volet Définitions d'alertes, entrez hardening dans la zone de texte Filtrer.
La liste affiche des alertes indiquant que l'hôte ESXi enfreint les règles du guide de renforcement
Hardening Guide de vSphere et que la machine virtuelle également.
6 Pour chaque alerte, cliquez sur le menu déroulant État, puis sur Local.
7 Cliquez sur Enregistrer.
Les alertes et les définitions de symptômes associées sont activées. Lorsque la stratégie de configuration est
active, les alertes du guide de renforcement sont générées lorsque les définitions de symptômes configurées
sont vérifiées pour des hôtes ou des machines virtuelles.
Suivant
Consultez l'onglet Conformité pour déterminer si un objet sélectionné est en conformité. Pour obtenir un
exemple, voir « Scénario utilisateur : Garantir que vos objets hôtes sont conformes à l'aide de la conformité
basée sur des alertes », page 55.
Scénario utilisateur : Garantir que vos objets hôtes sont conformes à l'aide de la conformité basée sur des alertes
En tant qu'administrateur de l'infrastructure virtuelle, vous utilisez vRealize Operations Manager pour
surveiller les objets de votre environnement, y compris les hôtes ESXi sur lesquels vous exécutez les
machines virtuelles de votre entreprise. Vous passez en revue l'onglet Conformité correspondant à un ou
plusieurs de vos hôtes et constatez que plusieurs d'entre eux enfreignent la norme du guide de renforcement
Hardening Guide de VMware vSphere. Vous devez donc détecter ces problèmes et les résoudre.
Les options de conformité basée sur des alertes d'une partie des règles du guide de renforcement de
VMware vSphere sont incluses dans vRealize Operations Manager.
Dans ce scénario, vous résolvez une seule violation de règle. Répétez le processus pour toute autre violation.
Prérequis
Vérifiez que vous pouvez ouvrir un fichier .XLSX sur le système que vous utilisez pour accéder à
n
vRealize Operations Manager.
Activez les alertes du guide de renforcement pour que la conformité basée sur des alertes soit active
n
dans votre environnement. Consultez le centre de documentation vRealize Operations Manager.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Environnement.
2 Accédez à un objet d'hôte.
Si vous avez créé un groupe d'objets pour gérer vos hôtes, sélectionnez un hôte du groupe.
3 placez la focale du volet central sur cet hôte et cliquez sur l'onglet Analyse, puis sur l'onglet
Conformité.
4 Si le badge Conformité affiche une valeur autre que 100 ou n'est pas de couleur verte, cliquez sur la
norme L'hôte ESXi enfreint le guide de renforcement de vSphere 5.5.
La zone de répartition de la conformité se développe et affiche toutes les règles enfreintes.
VMware, Inc. 55
Page 56

Guide de l'utilisateur de vRealize Operations Manager
5 Consultez la page pour déterminer le niveau de gravité et le nombre des normes non conformes pour
cet hôte et dans votre environnement.
Option Évaluation
Répartition de la conformité
Conformité des objets associés
Ressources du système hôte
6 Si la lecture de la page vous indique que vous devez résoudre la violation de la règle Service DCUI en
cours d'exécution, cliquez sur l'onglet Alertes.
Ces normes de conformité sont basées sur les alertes. Les alertes peuvent inclure des recommandations.
Dans l'exemple fourni pour les normes de type L'hôte ESXi enfreint le guide de renforcement de
vSphere 5.5, l'alerte également générée pour ce problème de conformité comprend une
recommandation avec un lien vers le guide de renforcement VMware vSphere.
7 Sur l'onglet Alertes, recherchez l'alerte L'hôte ESXi enfreint le guide de renforcement de vSphere 5.5
et cliquez dessus.
L'onglet Résumé des détails de l'alerte apparaît. Il indique les violations de règles sous forme de
symptômes et fournit des recommandations pour les résoudre.
Quels sont le nombre et la gravité des violations de règles détectées sur
l'hôte ? Combien de violations sont-elles critiques et doivent-elles être
traitées ?
D'autres hôtes sont-ils dans un état de conformité similaire ? Des objets
enfants sont-ils non conformes ?
L'hôte est-il configuré comme vous le souhaitez ?
8 Dans la zone des recommandations, cliquez sur le lien menant vers le guide de renforcement
vSphere 5.5.
Le guide de renforcement est téléchargé sur le système que vous utilisez pour accéder à
vRealize Operations Manager.
9 Dans le classeur du guide de renforcement, cliquez sur l'onglet ESXi et cherchez la règle Désactiver
DCUI pour empêcher le contrôle administratif local.
10 Consultez les informations de la ligne et appliquez la méthode de résolution appropriée.
Pour cette règle, vous pouvez utiliser les commandes ESXi Shell, les commandes PowerCLI, ou suivre la
procédure fournie dans le Centre de documentation VMware vSphere pour modifier le paramètre.
Vous avez identifié et résolu une règle non conforme pour votre objet d'hôte. Une fois que vous avez
modifié les paramètres de l'hôte, la règle cesse normalement d'apparaître dans la liste des règles enfreintes
pour l'hôte après quatre cycles de collecte ou plus.
Utilisation des outils de dépannage pour résoudre les problèmes
Les données fournies dans les onglets Symptômes, Chronologie, Événements et Toutes les mesures vous
aident à identifier la cause première d'un problème qui n'est pas résolu par les recommandations d'alertes
ou par une simple analyse.
Lors de la résolution de problèmes sur les objets dans votre environnement, vous pouvez utiliser les onglets
de dépannage de façon individuelle ou dans le cadre d'un workflow. Chacun des onglets affiche les données
collectées de manière différente. Lors de la résolution des problèmes, vous passez parfois directement d'un
onglet d'analyse à l'onglet Toutes les mesures. Dans d'autres circonstances, vous savez que l'onglet
Chronologie peut fournir les informations dont vous avez besoin.
56 VMware, Inc.
Page 57

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Présentation de l'onglet Symptômes
Vous pouvez afficher la liste des symptômes déclenchés pour l'objet sélectionné. Utilisez les symptômes
pour résoudre des problèmes sur un objet.
L'onglet Symptômes affiche tous les symptômes déclenchés pour l'objet sélectionné. L'examen des
symptômes déclenchés vous fournit la liste des problèmes rencontrés par l'objet sélectionné. Si vous
souhaitez voir plus clairement les symptômes associés aux alertes générées, accédez à l'onglet Alertes de
l'objet.
Lorsque vous évaluez les symptômes déclenchés, tenez compte de l'heure à laquelle ils ont été créés, ainsi
que des informations de configuration et des diagrammes de tendances, si disponibles.
Présentation de l'onglet Chronologie
La chronologie fournit une vue des symptômes déclenchés, des alertes générées et des événements d'un
objet pendant une période donnée. La chronologie vous permet d'identifier les tendances communes dans le
temps qui contribuent à l'état actuel des objets de votre environnement.
La chronologie est dotée d'un mécanisme de défilement à trois niveaux qui vous permet de passer
rapidement en revue de grandes périodes de temps, ou au contraire de la remonter plus lentement et plus
minutieusement, heure par heure, lorsque vous vous concentrez sur une période de temps donnée. Pour
vous assurer que vous disposez des données dont vous avez besoin, vous pouvez configurer les contrôles de
date de sorte à englober le problème que vous étudiez.
Il n'est pas toujours productif d'étudier un problème concernant un objet individuel en se focalisant
uniquement sur cet objet. Utilisez les options des ancêtres, des descendants et des homologues pour
examiner l'objet dans un contexte d'environnement plus large. Ce contexte révèle souvent des influences ou
des conséquences inattendues pour le problème.
La chronologie vous offre une vue graphique des modèles. Si un symptôme est déclenché et annulé par le
système à divers intervalles de temps, vous pouvez comparer cet événement à d'autres modifications
apportées à l'objet ou aux objets associés. Ces modifications peuvent être la cause principale du problème.
Présentation de l'onglet Événements
Les événements sont des modifications des mesures de vRealize Operations Manager qui reflètent les
modifications qui sont produites sur les objets gérés suite à des actions d'utilisateurs, des actions système,
des symptômes déclenchés ou des alertes générées sur un objet. Vous utilisez l'onglet Événements pour
comparer l'occurrence d'événements avec les alertes générées pour déterminer si une modification sur votre
objet géré a contribué à créer la cause première de l'alerte ou d'autres problèmes sur l'objet.
Les événements peuvent se produire sur n'importe quel objet, et non uniquement sur celui indiqué.
Les activités de vCenter Server suivantes sont quelques-unes des activités qui génèrent des événements
dans vRealize Operations Manager :
Démarrage ou arrêt d'une machine virtuelle
n
Création d'une machine virtuelle
n
Installation de VMware Tools sur le système d'exploitation invité d'une machine virtuelle
n
Ajout d'un système ESX/ESXi récemment configuré à un système vCenter Server
n
Selon les définitions d'alertes, ces événements peuvent générer des alertes.
Si vous surveillez les mêmes machines virtuelles avec d'autres applications qui fournissent des informations
à vRealize Operations Manager et que les adaptateurs de ces applications sont configurés pour fournir des
événements de modification, l'onglet Événements comprend certains événements de modification qui se
produisent sur les objets contrôlés. Ces événements de modification peuvent fournir d'autres
renseignements sur la cause des problèmes que vous étudiez.
VMware, Inc. 57
Page 58

Guide de l'utilisateur de vRealize Operations Manager
Présentation de l'onglet Toutes les mesures
L'onglet Toutes les mesures fournit une carte des relations et des graphiques des mesures définis par
l'utilisateur. La carte topologique vous permet d'évaluer les objets dans le contexte de leur emplacement au
sein de la topologie de votre environnement. Les graphiques de mesures sont basés sur les mesures de
l'objet sélectionné qui, selon vous, devraient vous aider à identifier la cause possible d'un problème dans
votre environnement.
Même si vous n'analysez les problèmes que d'un seul objet, un système hôte par exemple, la carte de
relation vous permet de voir l'hôte dans le contexte des objets parents et enfants. Il fonctionne également
comme système de navigation hiérarchique. Lorsque vous double-cliquez sur un objet de la carte, il en
devient le centre et les mesures disponibles pour cet objet sont actives dans le volet inférieur gauche.
Vous pouvez également créer votre propre ensemble de graphiques de mesures. Vous pouvez sélectionner
les objets et les mesures pour obtenir une vue plus détaillée des modifications apportées à différentes
mesures pour un seul objet ou pour des objets associés au fil du temps.
Scénario utilisateur : Recherche de la cause principale d'un problème à l'aide des options de l'onglet Dépannage
Un de vos clients signale de mauvaises performances de sa machine virtuelle, notamment des problèmes de
lenteur et de pannes. Ce scénario décrit une façon d'utiliser vRealize Operations Manager pour étudier les
causes du problème à partir des informations disponibles dans les onglets Dépannage.
En tant qu'administrateur de l'infrastructure virtuelle, vous répondez à un billet d'aide dans lequel l'un de
vos clients signale des problèmes avec sa machine virtuelle, sales-10-dk. Les problèmes signalés concernent
de mauvaises performances des applications, notamment des temps de chargement prolongés et un
démarrage lent, un chargement de plus en plus long de certains de ses programmes et un enregistrement
ralenti de ses fichiers. Aujourd'hui ses programmes ont commencé à rencontrer des pannes et l'installation
d'une mise à jour a échoué.
Lorsque vous consultez l'onglet Alertes de la machine virtuelle, une alerte indique qu'une charge de travail
élevée de la mémoire entraîne une contrainte. Les symptômes déclenchés indiquent une contrainte de
mémoire et la recommandation associée conseille un ajout de mémoire.
Suivant votre expérience, vous n'êtes pas convaincu que cette alerte indique la cause principale du
problème, si bien que vous examinez les onglets Analyse. Tous les badges associés sont verts sauf celui de
Capacité restante, qui signale des problèmes de mémoire et d'espace disque, et celui de Temps restant, qui
n'indique aucun jour restant pour la mémoire et l'espace disque.
Cet examen initial vous révèle que des problèmes autres que l'alerte de mémoire existent et vous utilisez
donc les onglets Dépannage pour effectuer une étude plus approfondie.
Procédure
1 Scénario utilisateur : Examen des symptômes déclenchés lors de la résolution d'un problème de
machine virtuelle page 59
Lorsque vous répondez aux plaintes des clients et aux alertes ou lorsque vous constatez des problèmes
dans votre environnement, les informations fournies dans l'onglet Symptômes de
vRealize Operations Manager vous aident à déterminer si les symptômes déclenchés indiquent des
états qui contribuent au problème signalé ou identifié.
2 Scénario utilisateur : Comparaison des symptômes d'une chronologie lors du dépannage d'une
machine virtuelle page 60
L'examen des symptômes déclenchés par un objet au fil du temps vous permet de comparer les
symptômes, les alertes et les événements déclenchés lorsque vous résolvez des problèmes sur des
objets dans votre environnement. L'onglet Chronologie de vRealize Operations Manager fournit un
graphique visuel sur lequel vous pouvez voir les symptômes déclenchés et qui permet d'étudier les
problèmes de votre environnement.
58 VMware, Inc.
Page 59

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
3 Scénario utilisateur : Identifier les événements influents lors de la résolution d'un problème de
machine virtuelle page 61
Les événements sont des modifications apportées aux objets dans votre environnement, qu'il s'agisse
de modifications de mesures, de propriétés ou d'informations sur l'objet. L'examen des événements de
la machine virtuelle problématique dans le contexte des badges d'analyse et des alertes peut fournir
des indices visuels quant à la cause principale d'un problème.
4 Scénario utilisateur : Créer des graphiques de mesures pour la résolution d'un problème de machine
virtuelle page 62
Lorsque vous résolvez un problème sur une machine virtuelle, vous pouvez créer un groupe
personnalisé de graphiques de mesures afin de comparer différentes mesures. Le niveau de détail
obtenu en utilisant l'onglet Toutes les mesures de vRealize Operations Manager peut contribuer de
manière significative à vos efforts pour trouver la cause principale d'un problème.
Scénario utilisateur : Examen des symptômes déclenchés lors de la résolution d'un problème de machine virtuelle
Lorsque vous répondez aux plaintes des clients et aux alertes ou lorsque vous constatez des problèmes dans
votre environnement, les informations fournies dans l'onglet Symptômes de vRealize Operations Manager
vous aident à déterminer si les symptômes déclenchés indiquent des états qui contribuent au problème
signalé ou identifié.
En tant qu'ingénieur d'exploitation de réseau, vous faites des recherches supplémentaires sur une machine
virtuelle pour laquelle l'un de vos clients signale de mauvaises performances. Lorsque vous consultez
l'onglet Alertes de la machine virtuelle, seule apparaît l'alerte indiquant que La machine virtuelle viole
la règle du guide de renforcement vSphere 5.5.
En examinant les onglets Analyse, vous avez repéré des problèmes de mémoire et d'espace disque et vous
focalisez donc l'étude des symptômes déclenchés sur ces éléments.
La méthode d'évaluation des problèmes via l'onglet Symptômes décrite ci-dessous n'est fournie que comme
exemple d'utilisation de vRealize Operations Manager et n'est pas forcément la meilleure. Vos compétences
en matière de dépannage et votre connaissance des spécificités de votre environnement déterminent les
méthodes qui vous correspondent.
Procédure
1 Entrez le nom de la machine virtuelle dans la zone de texte Recherche, située sur la barre de titre
principale.
Dans cet exemple, le nom de la machine virtuelle est sales-10-dk.
2 Cliquez sur l'onglet Dépannage, puis sur l'ongletSymptômes.
3 Passez en revue les symptômes déclenchés.
Option Processus d'évaluation
Symptôme Certains des symptômes déclenchés sont-ils liés aux états critiques qui apparaissent pour la mémoire
ou l'espace disque ?
Statut Les symptômes sont-ils actifs ou inactifs ? Même des symptômes inactifs peuvent fournir des
informations sur l'état passé de l'objet. Pour ajouter des symptômes inactifs, cliquez sur Statut : Actif
sur la barre d'outils, afin de retirer le filtre.
Créé sur Quand les symptômes ont-ils été déclenchés ? La comparaison avec l'heure de déclenchement
d'autres symptômes fournit-elle des informations intéressantes ?
Informations Pouvez-vous identifier une corrélation entre les symptômes déclenchés et l'état des badges Temps
restant et Capacité restante ?
VMware, Inc. 59
Page 60

Guide de l'utilisateur de vRealize Operations Manager
L'examen des symptômes vous révèle que la plupart des symptômes déclenchés sont associés à l'alerte
relative au guide de renforcement de la machine virtuelle, mais que certains des symptômes concernent
apparemment la mémoire et le temps restant, y compris les symptômes suivants :
L'utilisation globale de l'espace disque du système de fichiers invité atteint la limite critique
n
Le temps restant pour l'espace disque de la machine virtuelle est faible
n
Le temps restant pour le CPU de la machine virtuelle est faible
n
Utilisation de l'espace disque de la partition invitée
n
Le temps restant pour la mémoire de la machine virtuelle est faible
n
Suivant
Passez en revue les symptômes de l'objet sur une chronologie. Reportez-vous à « Scénario utilisateur :
Comparaison des symptômes d'une chronologie lors du dépannage d'une machine virtuelle », page 60.
Scénario utilisateur : Comparaison des symptômes d'une chronologie lors du dépannage d'une machine virtuelle
L'examen des symptômes déclenchés par un objet au fil du temps vous permet de comparer les symptômes,
les alertes et les événements déclenchés lorsque vous résolvez des problèmes sur des objets dans votre
environnement. L'onglet Chronologie de vRealize Operations Manager fournit un graphique visuel sur
lequel vous pouvez voir les symptômes déclenchés et qui permet d'étudier les problèmes de votre
environnement.
Après avoir identifié les symptômes suivants comme des indicateurs possibles de la cause principale des
problèmes de performances signalés sur la machine virtuelle sales-10-dk, vous les comparez les uns aux
autres au cours du temps pour essayer de dégager des tendances communes ou intéressantes.
L'utilisation globale de l'espace disque du système de fichiers invité atteint la limite critique
n
Le temps restant pour l'espace disque de la machine virtuelle est faible
n
Le temps restant pour le CPU de la machine virtuelle est faible
n
Utilisation de l'espace disque de la partition invitée
n
Le temps restant pour la mémoire de la machine virtuelle est faible
n
La méthode d'évaluation des problèmes via l'onglet Chronologie décrite ci-dessous n'est fournie que
comme exemple d'utilisation de vRealize Operations Manager et n'est pas forcément la meilleure. Vos
compétences en matière de dépannage et votre connaissance des spécificités de votre environnement
déterminent les méthodes qui vous correspondent.
Prérequis
Passez en revue les symptômes d'objets déclenchés. Reportez-vous à « Scénario utilisateur : Examen des
symptômes déclenchés lors de la résolution d'un problème de machine virtuelle », page 59.
Procédure
1 Entrez le nom de la machine virtuelle dans la zone de texte Recherche, située sur la barre de titre
principale.
Dans cet exemple, le nom de la machine virtuelle est sales-10-dk.
2 Cliquez sur l'onglet Dépannage, puis sur l'onglet Chronologie.
60 VMware, Inc.
Page 61

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
3 Sur la barre d'outils Chronologie, cliquez sur Contrôle de date et sélectionnez une heure antérieure ou
égale à l'heure de déclenchement des symptômes de référence.
La plage de temps par défaut correspond aux 6 dernières heures. Pour un aperçu plus large de la
machine virtuelle dans le temps, définissez une plage qui inclut les symptômes déclenchés et les alertes
générées.
4 Pour voir l'instant où les symptômes ont été déclenchés et identifier la courbe représentant tel ou tel
symptôme, faites glisser la section des semaines, des jours ou des heures de la chronologie vers la droite
et vers la gauche sur la page.
5 Cliquez sur Sélectionner le type d'événement et sélectionnez tous les types d'événements.
Déterminez si les événements correspondent à des symptômes déclenchés ou à des alertes générées.
6 Dans la liste des hiérarchies associées située dans le volet supérieur gauche, cliquez sur Hôtes et
clusters vSphere.
Les objets ancêtres et descendants disponibles dépendent de la hiérarchie sélectionnée.
7 Pour voir si l'hôte rencontre des problèmes ayant un impact sur des objets ancêtres, cliquez sur Afficher
les événements ancêtres.
Vérifiez si l'hôte présente des symptômes, des alertes ou des événements qui vous fournissent plus
d'informations sur les problèmes de mémoire ou d'espace disque.
La comparaison des symptômes de la machine virtuelle et de ceux de l'hôte, ainsi que l'examen des
symptômes au fil du temps révèlent les tendances suivantes :
Les symptômes d'utilisation des ressources, du disque et du CPU de l'hôte se sont déclenchés pendant
n
approximativement 10 minutes environ toutes les 4 heures.
Le symptôme indiquant que le système de fichiers invité de la machine virtuelle est à cours d'espace est
n
régulièrement déclenché puis annulé au cours du temps. Il est parfois actif pendant une heure avant
d'être annulé. Parfois, il est actif pendant deux heures. Cependant, il ne s'écoule jamais plus
de 30 minutes entre l'annulation et le déclenchement suivant du symptôme.
Suivant
Examinez les événements en utilisant le contexte fourni par les badges d'analyse et les alertes. Reportezvous à « Scénario utilisateur : Identifier les événements influents lors de la résolution d'un problème de
machine virtuelle », page 61.
Scénario utilisateur : Identifier les événements influents lors de la résolution d'un problème de machine virtuelle
Les événements sont des modifications apportées aux objets dans votre environnement, qu'il s'agisse de
modifications de mesures, de propriétés ou d'informations sur l'objet. L'examen des événements de la
machine virtuelle problématique dans le contexte des badges d'analyse et des alertes peut fournir des
indices visuels quant à la cause principale d'un problème.
En tant qu'administrateur de l'infrastructure virtuelle, vous recherchez les causes d'un problème de
performances signalé sur une machine virtuelle. Vous avez comparé les symptômes sur la chronologie et
détecté un comportement intéressant dans le système de fichiers invité ; vous souhaitez à présent examiner
celui-ci dans le contexte d'autres mesures de badges pour déterminer si vous trouvez la cause principale du
problème.
La méthode d'évaluation des problèmes via l'onglet Événements décrite ci-dessous n'est fournie que comme
exemple d'utilisation de vRealize Operations Manager et n'est pas forcément la meilleure. Vos compétences
en matière de dépannage et votre connaissance des spécificités de votre environnement déterminent les
méthodes qui vous correspondent.
VMware, Inc. 61
Page 62

Guide de l'utilisateur de vRealize Operations Manager
Prérequis
Examinez les symptômes, les alertes et les événements déclenchés au cours du temps. Reportez-vous à
« Scénario utilisateur : Comparaison des symptômes d'une chronologie lors du dépannage d'une machine
virtuelle », page 60
Procédure
1 Entrez le nom de la machine virtuelle dans la zone de texte Recherche, située sur la barre de titre
principale.
Dans cet exemple, le nom de la machine virtuelle est sales-10-dk.
2 Cliquez sur l'onglet Dépannage, puis cliquez sur l'onglet Événements.
3 Sur la barre d'outils Événements, cliquez sur Contrôle de date et sélectionnez une heure antérieure ou
égale à l'heure de déclenchement des symptômes.
4 Cliquez sur Sélectionner le type d'événement et sélectionnez tous les types d'événements.
Vérifiez si des modifications correspondent à d'autres événements.
5 Cliquez sur Afficher les événements parents, puis sur les badges de la barre d'outils pour examiner les
événements.
Déterminez si l'un des événements répertoriés dans la grille de données située sous le tableau
correspond à des problèmes sur l'hôte qui pourraient contribuer au problème signalé.
6 Cliquez sur Afficher les événements enfants, puis sur les badges de la barre d'outils pour examiner les
événements.
Déterminez si l'un des événements présente des problèmes sur la banque de données.
Votre examen ne montre aucune corrélation particulière entre la charge de travail ou les anomalies et l'heure
de déclenchement systématique du symptôme indiquant que le système de fichiers invité est à court
d'espace.
Suivant
Pour voir les détails de la machine virtuelle au niveau d'une mesure, vous pouvez créer vos propres
graphiques. Reportez-vous à « Scénario utilisateur : Créer des graphiques de mesures pour la résolution
d'un problème de machine virtuelle », page 62.
Scénario utilisateur : Créer des graphiques de mesures pour la résolution d'un problème de machine virtuelle
Lorsque vous résolvez un problème sur une machine virtuelle, vous pouvez créer un groupe personnalisé
de graphiques de mesures afin de comparer différentes mesures. Le niveau de détail obtenu en utilisant
l'onglet Toutes les mesures de vRealize Operations Manager peut contribuer de manière significative à vos
efforts pour trouver la cause principale d'un problème.
En tant qu'administrateur de l'infrastructure virtuelle, vous recherchez les causes d'un problème de
performances signalé sur une machine virtuelle. Vous avez déterminé que vous avez besoin de graphiques
détaillés sur les symptômes signalés suivants.
L'utilisation globale de l'espace disque du système de fichiers invité atteint la limite critique
n
Utilisation de l'espace disque de la partition invitée
n
La méthode d'évaluation des problèmes via l'onglet Toutes les mesures décrite ci-dessous n'est fournie que
comme exemple d'utilisation de vRealize Operations Manager et n'est pas forcément la meilleure. Vos
compétences en matière de dépannage et votre connaissance des spécificités de votre environnement
déterminent les méthodes qui vous correspondent.
62 VMware, Inc.
Page 63

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Prérequis
Comparez des mesures d'événements et de badges. Reportez-vous à « Scénario utilisateur : Identifier les
événements influents lors de la résolution d'un problème de machine virtuelle », page 61.
Procédure
1 Entrez le nom de la machine virtuelle dans la zone de texte Recherche, située sur la barre de titre
principale.
Dans cet exemple, le nom de la machine virtuelle est sales-10-dk.
2 Cliquez sur l'onglet Dépannage, puis sur l'onglet Toutes les mesures.
3 Dans la carte de topologie des relations, cliquez sur la machine virtuelle dk-new-10.
La liste des mesures, située dans le coin inférieur gauche du volet central, affiche les mesures de la
machine virtuelle.
4 Sur la barre d'outils du graphique, cliquez sur Contrôle de date et sélectionnez une heure antérieure ou
égale à l'heure de déclenchement des symptômes.
5 Ajoutez des graphiques de mesure à la zone d'affichage de la machine virtuelle.
a Dans la liste des mesures, sélectionnez Statistiques du système de fichiers invité > Espace total
disponible sur le système de fichiers invité (Go) et double-cliquez sur le nom de la mesure.
b Pour ajouter la partition invitée, par exemple C:\, sélectionnez Statistiques du système de fichier
invité > C:\ > Espace total disponible sur le système de fichiers invité (Go) et double-cliquez sur
le nom de la mesure.
c Pour ajouter de l'espace disque pour la comparaison, sélectionnez Espace disque > Capacité
restante (%) et double-cliquez sur le nom de la mesure.
6 Comparez les graphiques.
Une comparaison des graphiques montre une diminution similaire de l'espace libre sur le système de
fichiers et indique que la capacité d'espace disque restante sur la machine virtuelle diminue à un
rythme régulier. Vous déterminez qu'il est nécessaire d'ajouter de l'espace disque à la machine virtuelle,
mais vous ne savez pas si la banque de données autorise la modification de la machine virtuelle.
7 Ajoutez le graphique des capacités de banque de données aux autres graphiques.
a Dans la carte de topologie, double-cliquez sur l'hôte.
Celui-ci devient l'objet central de la carte de topologie.
b Cliquez sur la banque de données.
c Dans la liste de mesures, qui est mise à jour pour afficher les mesures de banques de données,
sélectionnez Capacité > Espace disponible (Go) et double-cliquez sur le nom de la mesure.
8 Consultez le graphique de la capacité de la banque de données pour déterminer si celle-ci dispose d'une
capacité suffisante pour augmenter l'espace disque sur la machine virtuelle.
Vous savez que vous devez augmenter la taille du disque virtuel sur la machine virtuelle.
Suivant
Développez le disque virtuel sur la machine virtuelle et affectez-le à des partitions sous contrainte. Sur la
barre de titre de l'objet, cliquez sur Actions et ouvrez la machine virtuelle dans vSphere Web Client.
VMware, Inc. 63
Page 64

Guide de l'utilisateur de vRealize Operations Manager
Création et utilisation des détails d'un objet
Les vues et les détails de la carte thermique vous fournissent des données spécifiques sur l'objet. Ces
informations vous permettent d'évaluer les problèmes plus en détail. Si les vues ou les cartes thermiques
actuelles ne fournissent pas les informations dont vous avez besoin, vous pouvez en créer une que vous
utiliserez lorsque vous étudierez un problème spécifique.
Utilisation de cartes thermiques
Avec la fonctionnalité de carte thermique de vRealize Operations Manager, vous pouvez localiser les zones
à problème sur la base de valeurs de mesure des objets de votre infrastructure virtuelle.
vRealize Operations Manager utilise des algorithmes d'analyse permettant de comparer les performances
des objets dans l'infrastructure virtuelle en temps réel à l'aide des cartes thermiques.
Vous pouvez utiliser des cartes thermiques prédéfinies ou créer vos propres cartes personnalisées pour
comparer les valeurs de mesures d'objets de votre environnement virtuel. vRealize Operations Manager
propose des cartes thermiques prédéfinies dans l'onglet Détails, qui permettent de comparer les mesures
couramment utilisées. Grâce à ces données, vous pouvez envisager de réduire le gaspillage de ressources et
d'augmenter la capacité de l'infrastructure virtuelle.
Indications fournies par la carte thermique
Une carte thermique contient des rectangles de différentes tailles et couleurs, et chaque rectangle représente
un objet dans votre environnement virtuel. La couleur du rectangle représente la valeur d'une mesure, sa
taille représente la valeur d'une autre mesure. Par exemple, une carte thermique montre la capacité de
mémoire totale et le pourcentage d'utilisation de la mémoire pour chaque machine virtuelle. Les rectangles
plus volumineux représentent les machines virtuelles dont la capacité totale de mémoire est plus
importante. Le vert indique une faible utilisation de la mémoire et le rouge une utilisation élevée.
vRealize Operations Manager met à jour les cartes thermiques en temps réel lors de la collecte de nouvelles
valeurs pour chaque objet et mesure. La barre de couleur sous la carte thermique représente la légende. La
légende identifie les valeurs représentées par les points de terminaison et le point médian de la gamme de
couleurs.
Les objets de carte thermique sont regroupés par parent. Par exemple, une carte thermique qui affiche les
performances des machines virtuelles, regroupe les machines virtuelles selon les hôtes ESX auxquels elles
appartiennent.
Créer une carte thermique personnalisée
Vous pouvez définir un nombre illimité de cartes thermiques personnalisées pour analyser précisément les
mesures dont vous avez besoin.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur Environnement.
2 Sélectionnez un objet à inspecter dans une arborescence d'inventaire.
3 Cliquez sur l'onglet Carte thermique sous l'onglet Détails.
4 Sélectionnez la balise à utiliser pour le regroupement de premier niveau des objets dans le menu
déroulant Grouper par.
Si un objet sélectionné ne dispose pas de valeur pour cette balise, il s'affiche dans un groupe appelé
Autres groupes.
5 Sélectionnez la balise à utiliser pour diviser les objets en sous-groupes dans le menu déroulant Puis par.
Si un objet sélectionné ne dispose pas de valeur pour cette balise, il s'affiche dans un sous-groupe
appelé Autres groupes.
64 VMware, Inc.
Page 65

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
6 Sélectionnez une option Mode.
Option Description
Instance
Général
Effectuez le suivi de toutes les instances d'une mesure d'objet avec un
rectangle distinct pour chaque mesure.
Choisissez une instance spécifique de mesure pour chaque objet et
effectuez le suivi de cette mesure.
7 Si vous avez sélectionné le mode Général, sélectionnez l'attribut à utiliser pour définir la taille du
rectangle de chaque ressource dans la liste Taille par et l'attribut à utiliser pour déterminer la couleur
du rectangle de chaque objet dans la liste Colorer par.
Les objets ayant des valeurs supérieures pour l'attribut Taille par disposent de zones plus grandes dans
l'affichage de la carte thermique. Vous pouvez également sélectionner des rectangles de taille fixe. Les
couleurs varient entre celles que vous avez définies en fonction de la valeur de l'attribut Colorer par.
Dans la plupart des cas, les listes d'attributs incluent uniquement les mesures générées par
vRealize Operations Manager. Si vous sélectionnez un type d'objet, la liste affiche tous les attributs
définis pour ce type d'objet.
a Pour effectuer le suivi des objets d'un type particulier, sélectionnez le type d'objet dans le menu
déroulant Types d'objet.
8 Si vous avez sélectionné le mode Instance, sélectionnez un type d'attribut dans la liste Type d'attribut.
Le type d'attribut détermine la couleur du rectangle de chaque objet.
9 Configurez les couleurs de la carte thermique.
a Cliquez sur chacun des petits blocs situés sous la barre de couleurs afin de définir la couleur des
valeurs faibles, moyennes et élevées.
La barre affiche la gamme de couleurs des valeurs intermédiaires. Vous pouvez également définir
les valeurs correspondant aux extrémités haute et basse de la gamme de couleurs.
b (Facultatif) Entrez les valeurs de couleurs minimales et maximales dans les zones de texte Valeur
minimale et Valeur maximale.
Si vous laissez les zones de texte vides, vRealize Operations Manager mappe les valeurs les plus
élevées et les plus faibles de la mesure Colorer par aux couleurs d'extrémités. Si vous définissez
une valeur minimale ou maximale, toute mesure égale ou au-delà de celle-ci s'affiche dans la
couleur d'extrémité.
10 Cliquez sur Enregistrer pour enregistrer la configuration.
La carte thermique personnalisée que vous avez créée s'affiche dans la liste des cartes thermiques sur
l'onglet Cartes thermiques.
Rechercher les objets les plus performants et les moins performants d'une mesure
Vous pouvez utiliser des cartes thermiques pour rechercher les objets avec les valeurs les plus élevées ou les
plus faibles pour une mesure spécifique.
Prérequis
Si la combinaison des mesures que vous souhaitez comparer n'est pas disponible dans la liste des cartes
thermiques définies, vous devez d'abord définir une carte thermique personnalisée. Reportez-vous à « Créer
une carte thermique personnalisée », page 64.
Procédure
1 Dans le volet de gauche, cliquez sur Environnement et sélectionnez un objet dans une arborescence
d'inventaire.
VMware, Inc. 65
Page 66

Guide de l'utilisateur de vRealize Operations Manager
2 Cliquez sur l'onglet Carte thermique sous l'onglet Détails.
Toutes les cartes thermiques de mesures associées à la ressource sélectionnée apparaissent dans la liste
des cartes thermiques prédéfinies.
3 Dans la liste des cartes thermiques, cliquez sur celle que vous souhaitez afficher.
Le nom et les valeurs de mesures de chaque objet présenté sur la carte thermique apparaissent dans la
liste sous la carte thermique.
4 Cliquez sur l'en-tête de la colonne de la mesure qui vous intéresse pour modifier l'ordre de tri, afin que
les objets les plus ou les moins performants apparaissent en haut de la colonne.
Comparer les ressources disponibles pour équilibrer la charge dans l'infrastructure
Une carte thermique permet de comparer les performances des mesures sélectionnées dans l'infrastructure
virtuelle. Vous pouvez utiliser ces informations pour équilibrer la charge entre des hôtes et des machines
virtuelles ESX.
Prérequis
Si la combinaison des mesures à comparer n'est pas disponible dans la liste des cartes thermiques définies,
vous devez d'abord définir une carte thermique personnalisée. Reportez-vous à « Créer une carte thermique
personnalisée », page 64.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur Environnement.
2 Sélectionnez un objet à inspecter dans une arborescence d'inventaire.
3 Cliquez sur l'onglet Carte thermique sous l'onglet Détails.
4 Dans la liste des cartes thermiques, cliquez sur celle que vous souhaitez afficher.
La carte thermique des mesures sélectionnées apparaît. Elle est dimensionnée et groupée en fonction de
votre sélection.
5 Utilisez la carte thermique pour comparer des objets et cliquez sur des ressources et des valeurs de
mesure pour tous les objets de votre environnement virtuel.
La liste des noms et des valeurs de mesure de tous les objets figurant sur la carte thermique apparaît en
dessous de celle-ci. Vous pouvez cliquer sur les en-têtes de colonne pour trier la liste par colonne. Si
vous triez la liste en fonction d'une colonne de mesures, les valeurs les plus élevées ou les plus basses
de cette mesure apparaissent en haut.
6 (Facultatif) Pour afficher plus d'informations sur un objet de la carte thermique, cliquez sur le rectangle
qui le représente ou sur la fenêtre contextuelle.
Suivant
Selon vos résultats, vous pouvez réorganiser les objets de votre environnement virtuel de sorte à équilibrer
la charge entre les clusters, les banques de données ou les hôtes ESX.
66 VMware, Inc.
Page 67

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Utilisation de cartes thermiques pour analyser les données sur les risques de capacités
La planification du risque des capacités consiste à analyser les données pour déterminer la capacité
disponible et vérifier si vous utilisez efficacement l'infrastructure.
Identifier les clusters contenant assez d'espace pour accueillir des machines virtuelles
Identifiez les clusters dans un centre de données qui ont suffisamment d'espace pour votre prochain
ensemble de machines virtuelles.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur Environnement.
2 Sélectionnez Univers vSphere.
3 Cliquez sur l'onglet Carte thermique sous l'onglet Détails.
4 Sélectionnez la carte thermique Quels clusters ont la capacité disponible la plus importante et le
moins de contraintes ?.
5 Dans la carte thermique, pointez vers chaque zone de cluster pour afficher le pourcentage de capacité
restante.
Une couleur autre que grise indique un problème potentiel.
6 Dans la fenêtre contextuelle, cliquez sur Détails pour examiner les ressources du cluster ou du centre
de données.
Suivant
Identifiez les clusters avec le plus de capacité pour stocker les machines virtuelles.
Examiner les problèmes de santé d'un hôte
Identifier la source d'un problème de performances au niveau d'un hôte implique d'examiner sa charge de
travail.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur Environnement.
2 Sélectionnez Univers vSphere.
3 Cliquez sur l'onglet Carte thermique sous l'onglet Détails.
4 Sélectionnez la carte thermique Quels hôtes ont actuellement la charge de travail la plus anormale ?.
5 Dans la carte thermique, pointez vers la zone de cluster pour afficher le pourcentage de capacité
restante.
Une couleur autre que grise indique un problème potentiel.
6 Dans la fenêtre contextuelle, cliquez sur Détails en regard de l'hôte ESX pour examiner les ressources
de l'hôte.
Suivant
Ajustez les charges de travail afin d'équilibrer les ressources selon les besoins.
Identifier les banques de données contenant assez d'espace pour accueillir des machines virtuelles
Identifiez les banques de données qui ont le plus d'espace pour votre prochain ensemble de machines
virtuelles.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur Environnement.
VMware, Inc. 67
Page 68

Guide de l'utilisateur de vRealize Operations Manager
2 Sélectionnez Univers vSphere.
3 Cliquez sur l'onglet Carte thermique sous l'onglet Détails.
4 Sélectionnez la carte thermique Quelles banques de données ont la plus grande surcharge d'espace
disque et le moins de temps restant ?.
5 Dans la carte thermique, pointez vers chaque zone de centre de données pour afficher les statistiques
sur l'espace.
6 Si une couleur autre que verte indique un problème potentiel, cliquez sur Détails dans la fenêtre
contextuelle pour vérifier l'espace disque et les ressources d'E/S de disque.
Suivant
Identifiez les banques de données avec la plus grande quantité d'espace disponible pour les machines
virtuelles.
Identifier les banques de données contenant de l'espace gaspillé
Pour améliorer l'efficacité de votre infrastructure virtuelle, identifiez les banques de données ayant la
quantité la plus élevée d'espace gaspillé que vous pouvez récupérer.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur Environnement.
2 Sélectionnez Univers vSphere.
3 Cliquez sur l'onglet Carte thermique sous l'onglet Détails.
4 Sélectionnez la carte thermique Quelles banques de données ont le plus d'espace disque inutilisé et
d'espace total utilisé ?.
5 Dans la carte thermique, pointez vers chaque zone de centre de données pour afficher les statistiques
sur le gaspillage.
6 Si une couleur autre que verte indique un problème potentiel, cliquez sur Détails dans la fenêtre
contextuelle pour vérifier l'espace disque et les ressources d'E/S de disque.
Suivant
Identifiez les banques de données rouges, oranges ou jaunes avec la plus grande quantité d'espace gaspillé.
Identifier les machines virtuelles contenant des ressources gaspillées parmi les banques de données
Identifiez les machines virtuelles contenant des ressources gaspillées en raison d'un état inactif,
surdimensionné ou hors tension, ou en raison de snapshots.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur Environnement.
2 Sélectionnez Univers vSphere.
3 Cliquez sur l'onglet Carte thermique sous l'onglet Détails.
4 Sélectionnez la carte thermique Pour chaque banque de données, quelles VM ont le plus d'espace
disque inutilisé ?.
5 Dans la carte thermique, pointez vers chaque machine virtuelle pour afficher les statistiques sur le
gaspillage.
6 Si une couleur autre que verte indique un problème potentiel, cliquez sur Détails dans la fenêtre
contextuelle pour vérifier l'espace disque et les ressources d'E/S.
68 VMware, Inc.
Page 69

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Suivant
Identifiez les machines virtuelles rouges, oranges ou jaunes avec la plus grande quantité d'espace gaspillé.
Examen des relations dans votre environnement
La plupart des objets d'un environnement y sont liés à d'autres objets. L'onglet Environnement affiche les
relations entre les objets de votre environnement. Utilisez cet écran pour résoudre des problèmes pouvant
ne pas concerner l'objet que vous examiniez initialement. Par exemple, une alerte signalant un problème sur
un hôte peut être due à un manque de capacité d'une machine virtuelle liée à l'hôte.
Sélections de l'onglet Environnement
Lorsque vous sélectionnez un objet dans l'inventaire de votre environnement, vous pouvez afficher les
objets liés dans un aperçu, une liste ou une carte.
L'aperçu montre tous les objets de votre environnement avec un badge d'état pour chaque objet. En
n
cliquant sur un badge, vous pouvez voir les objets liés.
La liste affiche uniquement les objets liés à l'objet sélectionné. Selon l'objet sélectionné, vous pouvez
n
effectuer une action ou lancer une application externe.
La carte montre les objets sous forme d'icônes selon un affichage hiérarchique. Vous pouvez afficher le
n
nombre d'objets connexes en sélectionnant une icône.
Utilisez l'aperçu pour identifier les objets de votre environnement présentant des problèmes d'intégrité, de
risque ou d'efficacité. Selon le type d'objet, vous pouvez prendre des mesures à partir de la vue de liste.
Utiliser la présentation de l'environnement pour détecter les problèmes
Si vous êtes un administrateur système et que vous recherchez la cause d'un ralentissement des
performances de votre environnement, vous pouvez sélectionner des objets clés tels que des systèmes hôtes
pour voir si des objets connexes, par exemple des machines virtuelles, présentent des problèmes.
Procédure
1 Sélectionnez Environnement > Hôtes et clusters vSphere et sélectionnez l'objet Univers vSphere.
2 Sélectionnez l'onglet Environnement.
vRealize Operations Manager affiche les badges d'intégrité pour tous les objets de l'univers vSphere.
3 Cliquez sur chacun des badges de système hôte.
Le badge d'intégrité des machines virtuelles qui appartiennent à l'hôte est mis en surbrillance. Un hôte
dont le badge indique un bon état d'intégrité peut contenir des machines virtuelles pour lesquelles il
existe un avertissement.
Suivant
Recherchez la cause du problème. Par exemple, une fois que vous avez déterminé si le problème est
chronique ou temporaire, vous pouvez décider de la façon de le corriger. Reportez-vous à « Utilisation des
outils de dépannage pour résoudre les problèmes », page 56.
VMware, Inc. 69
Page 70

Guide de l'utilisateur de vRealize Operations Manager
Exécution d'actions dans vRealize Operations Manager
Les actions disponibles dans vRealize Operations Manager vous permettent de modifier l'état ou la
configuration des objets sélectionnés dans vCenter Server à partir de vRealize Operations Manager. Par
exemple, vous pouvez avoir besoin de modifier la configuration d'un objet afin de traiter une ressource
problématique ou de redistribuer des ressources afin d'optimiser votre infrastructure virtuelle.
L'utilisation la plus courante des actions consiste à résoudre des problèmes. Vous pouvez les exécuter dans
le cadre de vos procédures de dépannage ou les ajouter en tant que recommandation de résolution en cas
d'alerte.
Utiliser des actions avec vRealize Operations Manager
(http://link.brightcove.com/services/player/bcpid2296383276001?bctid=ref:video_actions_vrom)
Lorsque vous résolvez des problèmes, vous pouvez exécuter les actions dans le menu Actions du volet
central ou dans la barre d'outils des affichages de listes contenant les objets pris en charge.
Lorsqu'une alerte se déclenche et que vous déterminez que l'action recommandée est le moyen le plus
efficace de résoudre le problème, vous pouvez exécuter l'action sur un ou plusieurs objets.
Liste des actions vRealize Operations Manager
La liste des actions comprend le nom de l'action, les objets que chaque option modifie et les niveaux d'objets
auxquels vous pouvez exécuter l'action. Vous utilisez ces informations pour vous assurer que vous
appliquez correctement les actions conformément aux recommandations d'alertes et au moment où ces
actions sont disponibles dans le menu Actions.
Actions et objets modifiés
Les actions de vRealize Operations Manager modifient les objets de vos instances gérées de vCenter Server.
Niveaux d'objets d'action
Les actions sont disponibles lorsque vous travaillez avec différents niveau d'objets, mais elles modifient
uniquement l'objet spécifié. Si vous travaillez au niveau du cluster et sélectionnez Mettre sous tension la
VM, toutes les machines virtuelles du cluster pour lequel vous avez une autorisation d'accès sont
disponibles pour exécuter l'action. Si vous travaillez au niveau d'une machine virtuelle, seule la machine
virtuelle sélectionnée est disponible.
Tableau 1‑9. Objets affectés par les actions vRealize Operations Manager
Action Objet modifié Niveaux d'objets
Rééquilibrer le conteneur Machines virtuelles
Déplacer la VM Machine virtuelle
Mettre hors tension la VM Machine virtuelle
Arrêter le SE invité de la VM Machine virtuelle
VMware Tools doit être installé et s'exécuter sur
les machines virtuelles pour exécuter cette action.
Mettre sous tension la VM Machine virtuelle
Centre de données
n
Centre de données
n
personnalisé
Cluster
n
Machines virtuelles
n
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
70 VMware, Inc.
Page 71

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Tableau 1‑9. Objets affectés par les actions vRealize Operations Manager (suite)
Action Objet modifié Niveaux d'objets
Supprimer la VM mise hors
tension
Définir la mémoire de la VM
et
Définir la mémoire pour la mise
hors tension autorisée des VM
Définir les ressources de
mémoire de la VM
Définir le nombre de CPU de la
VM
et
Définir le nombre de CPU pour
la mise hors tension autorisée
des VM
Définir les ressources de CPU de
la VM
Définir le nombre de CPU et la
mémoire de la VM
et
Définir le nombre de CPU et la
mémoire pour la mise hors
tension autorisée des VM
Supprimer les snapshots
inutilisés pour la VM
Supprimer les snapshots
inutilisés pour la banque de
données
Machine virtuelle
Machine virtuelle
Machine virtuelle
Machine virtuelle
Machine virtuelle
Machine virtuelle
Instantané
Instantané
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
des clusters
n
Systèmes hôtes
n
Machines virtuelles
n
des clusters
n
Banques de données
n
Systèmes hôtes
n
Actions qui utilisent l'option Mise hors tension autorisée
Certaines des actions fournies avec vRealize Operations Manager nécessitent l'arrêt ou la mise hors tension
des machines virtuelles, selon la configuration des machines cibles, afin d'exécuter les actions. Avant
d'exécuter les actions, vous devez comprendre les répercussions de l'option Mise hors tension autorisée afin
de pouvoir sélectionner les meilleures options pour vos machines virtuelles cibles.
Mettre hors tension et arrêter
Les actions que vous pouvez exécuter sur vos instances de vCenter Server comprennent des actions qui
arrêtent les machines virtuelles et d'autres qui mettent les machines virtuelles hors tension. Elles
comprennent également des actions dont l'exécution exige la mise hors tension de la machine virtuelle.
L'arrêt ou la mise hors tension de la machine virtuelle dépend de sa configuration et des options que vous
sélectionnez lorsque vous exécutez l'action.
L'action d'arrêt arrête le système d'exploitation invité, puis met la machine virtuelle hors tension. Pour
arrêter une machine virtuelle dans vRealize Operations Manager, la fonctionnalité VMware Tools doit être
installée et en cours d'exécution sur les objets cibles.
VMware, Inc. 71
Page 72

Guide de l'utilisateur de vRealize Operations Manager
L'action de mise hors tension désactive la machine virtuelle, quel que soit l'état du système d'exploitation
invité. Dans ce cas, si la machine virtuelle exécute des applications, votre utilisateur peut perdre des
données. Une fois l'action exécutée, par exemple, la modification du nombre de CPU, la machine virtuelle
reprend l'état d'alimentation dans lequel elle se trouvait lorsque l'action a commencé.
Mise hors tension autorisée et VMware Tools
Pour les actions qui consistent à augmenter le nombre de CPU ou la quantité de mémoire sur une machine
virtuelle, certains systèmes d'exploitation les prennent en charge si l'enfichage à chaud est configuré sur la
machine virtuelle. En revanche, pour d'autres systèmes d'exploitation, la machine virtuelle doit être hors
tension pour modifier la configuration. Pour répondre à ce besoin lorsque VMware Tools n'est pas en cours
d'exécution, les actions Définir le nombre de CPU, Définir la mémoire et Définir le nombre de CPU et la
mémoire incluent l'option Mise hors tension autorisée.
Si vous sélectionnez Mise hors tension autorisée alors que la machine est en cours d'exécution, l'action
vérifie si VMware Tools est installé et en cours d'exécution.
Si VMware Tools est installé et en cours d'exécution, la machine virtuelle est arrêtée avant de terminer
n
l'action.
Si VMware Tools n'est pas installé ou n'est pas en cours d'exécution, la machine virtuelle est mise hors
n
tension sans tenir compte de l'état du système d'exploitation.
Si vous ne sélectionnez pas Mise hors tension autorisée et que vous diminuez le nombre de CPU ou la
mémoire, ou si l'enfichage à chaud n'est pas activé pour augmenter le nombre de CPU ou la mémoire,
l'action ne s'exécute pas et l'échec est signalé dans Tâches récentes.
Mise hors tension autorisée lors de la modification du nombre de CPU ou de la
mémoire
Lorsque vous exécutez les actions qui modifient le nombre de CPU et la quantité de mémoire, vous devez
tenir compte de plusieurs facteurs pour déterminer si vous souhaitez utiliser l'option Mise hors tension
autorisée. Par exemple, si vous augmentez ou diminuez le nombre de CPU ou la quantité de mémoire, et si
les machines virtuelles cibles sont sous tensions. Si vous augmentez le nombre de CPU ou la quantité de
mémoire, l'activation ou non de l'enfichage à chaud affecte également la manière dont vous appliquez
l'option lorsque vous exécutez l'action.
Le mode d'utilisation de Mise hors tension autorisée lorsque vous diminuez le nombre de CPU ou la
capacité de mémoire varie selon l'état d'alimentation des machines virtuelles cibles.
Tableau 1‑10. Diminution du nombre de CPU et comportement de la mémoire basé sur des options
État d'alimentation d'une machine
virtuelle
Activé Oui Si VMware Tools est installé et en
Activé Non L'action ne s'exécute pas sur la
Désactivé Non applicable. La machine virtuelle
Mise hors tension autorisée
sélectionnée Résultats
cours d'exécution, l'action arrête la
machine virtuelle, diminue le nombre
de CPU ou la capacité de mémoire, et
remet la machine sous tension.
Si VMware Tools n'est pas installé,
l'action met la machine virtuelle hors
tension, diminue le nombre de CPU ou
la capacité de mémoire, et remet la
machine sous tension.
machine virtuelle.
L'action diminue la valeur et place la
est mise hors tension.
machine virtuelle dans un état hors
tension.
72 VMware, Inc.
Page 73

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Le mode d'utilisation de Mise hors tension autorisée lorsque vous augmentez le nombre de CPU ou la
capacité de mémoire dépend de plusieurs facteurs, notamment l'état de la machine virtuelle cible et si la
connexion à chaud est activée. Utilisez les informations suivantes pour déterminer le scénario qui s'applique
à vos objets cibles.
Si vous augmentez le nombre de CPU, vous devez tenir compte de l'état de l'alimentation de la machine
virtuelle et de l'éventuelle activation de Connexion CPU à chaud lorsque vous déterminez s'il convient
d'appliquer Mise hors tension autorisée.
Tableau 1‑11. Comportement de l'augmentation du nombre de CPU.
État d'alimentation d'une
machine virtuelle
Activé Oui Non Cette action augmente le
Activé Non Oui Si VMware Tools est installé
Désactivé Non applicable. La
Connexion CPU à chaud
activée
machine virtuelle est mise
hors tension.
Mise hors tension
autorisée sélectionnée Résultats
nombre de CPU à la quantité
spécifiée.
et en cours d'exécution,
l'action arrête la machine
virtuelle, augmente le
nombre de CPU et remet la
machine sous tension.
Si VMware Tools n'est pas
installé, l'action met la
machine virtuelle hors
tension, augmente le nombre
de CPU et remet la machine
sous tension.
Non requis. Cette action augmente le
nombre de CPU à la quantité
spécifiée.
Si vous augmentez la capacité de mémoire, vous devez tenir compte de l'état d'alimentation de la machine
virtuelle, de l'éventuelle activation de la connexion à chaud de la mémoire et de l'utilisation éventuelle d'une
limite de mémoire connectée à chaud lors de la détermination du mode d'application de Mise hors tension
autorisée.
VMware, Inc. 73
Page 74

Guide de l'utilisateur de vRealize Operations Manager
Tableau 1‑12. Comportement de l'augmentation de la capacité de mémoire
État d'alimentation
d'une machine
virtuelle
Activé Oui Nouvelle valeur de
Activé Oui Nouvelle valeur de
Activé Non Non applicable. La
Désactivé Non applicable. La
Connexion
mémoire à chaud
activée
machine virtuelle est
mise hors tension.
Mise hors tension
Limite de mémoire
connectée à chaud
mémoire ≤ limite de
mémoire connectée à
chaud
mémoire > limite de
mémoire connectée à
chaud
connexion à chaud
n'est pas activée.
Non applicable. Non requise L'action augmente la
autorisée
sélectionnée Résultats
Non L'action augmente la
capacité mémoire de la
valeur spécifiée.
Oui Si VMware Tools est
installé et en cours
d'exécution, l'action
arrête la machine
virtuelle, augmente la
capacité de mémoire
et remet la machine
sous tension.
Si VMware Tools n'est
pas installé, l'action
met la machine
virtuelle hors tension,
augmente la capacité
de mémoire et remet
la machine sous
tension.
Oui Si VMware Tools est
installé et en cours
d'exécution, l'action
arrête la machine
virtuelle, augmente la
capacité de mémoire
et remet la machine
sous tension.
Si VMware Tools n'est
pas installé, l'action
met la machine
virtuelle hors tension,
augmente la capacité
de mémoire et remet
la machine sous
tension.
capacité mémoire de la
valeur spécifiée.
Actions prises en charge pour l'automatisation
Les recommandations permettent de déterminer des façons de résoudre des problèmes signalés par une
alerte. Il est possible d'associer certaines de ces approches avec des actions définies dans votre instance de
vRealize Operations Manager. Vous pouvez automatiser plusieurs de ces actions de résolution d'une alerte
lorsque la recommandation concernée constitue la première priorité pour cette alerte.
Vous activez des alertes d'action dans vos stratégies. Par défaut, l'automatisation est désactivée dans les
stratégies. Pour configurer l'automatisation pour votre stratégie, sélectionnez Administration > Stratégies >
Bibliothèque de stratégies. Modifiez ensuite une stratégie, accédez à l'espace de travail Définitions d'alertes
et de symptômes et sélectionnez l'option Local pour le paramètre Automatiser dans le volet Définitions des
alertes.
74 VMware, Inc.
Page 75

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Lorsqu'une action est automatisée, vous pouvez utiliser les colonnes Automatisé et Alerte dans
Administration > Tâches récentes pour identifier l'action automatisée et visualiser les résultats de l'action.
vRealize Operations Manager utilise le compte automationAdmin pour déclencher des actions
n
automatisées. Pour les actions automatisées déclenchées par les alertes, la colonne Soumis par affiche
l'utilisateur automationAdmin.
La colonne Alerte affiche l'alerte qui a déclenché automatiquement l'action. Lorsqu'une alerte associée à
n
la recommandation est déclenchée, elle met en œuvre l'action sans aucune intervention de l'utilisateur.
Les actions suivantes sont recommandées pour l'automatisation :
Supprimer la VM mise hors tension
n
Déplacer la VM
n
Mettre hors tension la VM
n
Mettre sous tension la VM
n
Définir le nombre de CPU et la mémoire de la VM
n
Définir le nombre de CPU et la mémoire pour la mise hors tension autorisée des VM
n
Définir le nombre de CPU de la VM
n
Définir le nombre de CPU pour la mise hors tension autorisée des VM
n
Définir les ressources de CPU de la VM
n
Définir la mémoire de la VM
n
Définir la mémoire pour la mise hors tension autorisée des VM
n
Définir les ressources de mémoire de la VM
n
Arrêter le SE invité de la VM
n
IMPORTANT Tout utilisateur disposant d'un accès pour modifier les alertes peut automatiser l'action.
Exemple : Action prise en charge pour l'automatisation
Pour la définition d'alerte appelée Une machine virtuelle est soumise en permanence à une charge de
travail de CPU élevée, ce qui entraîne une contrainte de CPU, vous pouvez automatiser l'action
appelée Définir le nombre de CPU de la machine virtuelle.
Lorsque la contrainte de CPU appliquée à vos machines virtuelles dépasse un niveau critique et immédiat,
ou entraînant un avertissement, l'alerte déclenche l'action recommandée sans intervention de l'utilisateur.
Exécuter des actions dans les barres d'outils de vRealize Operations Manager
Lorsque vous exécutez des actions dans vRealize Operations Manager, vous modifiez l'état des objets
vCenter Server dans vRealize Operations Manager. Vous exécutez une ou plusieurs actions lorsque vous
rencontrez des objets dont la configuration ou l'état affecte votre environnement. Ces actions vous
permettent de récupérer de l'espace inutilisé, d'ajuster la mémoire ou de conserver des ressources.
Cette procédure d'exécution des actions, basée sur les menus Actions de vRealize Operations Manager, est
couramment utilisée pour résoudre des problèmes. Les actions disponibles dépendent du type d'objets avec
lequel vous travaillez. Vous pouvez également exécuter des actions en tant que recommandations d'alertes.
Prérequis
Vérifiez que les adaptateurs Python Remediation vCenter sont configurés pour les actions de chaque
n
instance de vCenter Server. Reportez-vous à Guide d'administration et de personnalisation de vRealize
Operations Manager.
VMware, Inc. 75
Page 76

Guide de l'utilisateur de vRealize Operations Manager
Assurez-vous de bien comprendre le fonctionnement de l'option Mise hors tension autorisée si vous
n
exécutez les actions Définir le nombre de CPU, Définir la mémoire et Définir le nombre de CPU et la
mémoire. Reportez-vous à « Actions qui utilisent l'option Mise hors tension autorisée », page 71.
Procédure
1 Dans vRealize Operations Manager, sélectionnez l'objet dans l'inventaire de l'environnement, ou
sélectionnez un ou plusieurs objets dans une vue de liste.
2 Cliquez sur Actions dans la barre d'outils principale ou dans une vue intégrée.
3 Sélectionnez l'une des actions.
Si vous travaillez avec une machine virtuelle, seule celle-ci est incluse dans la boîte de dialogue. Si vous
travaillez avec des clusters, des hôtes ou des banques de données, la boîte de dialogue qui s'affiche
inclut tous les objets.
4 Cochez la case pour exécuter l'action sur l'objet, puis cliquez sur OK.
L'action s'exécute et une boîte de dialogue s'affiche avec l'ID de tâche.
5 Pour afficher l'état de la tâche et vérifier que la tâche est terminée, cliquez sur Tâches récentes ou sur
OK pour fermer la boîte de dialogue.
La liste Tâches récentes s'affiche, qui inclut la tâche que vous venez de démarrer.
Suivant
Pour vérifier que la tâche est terminée, cliquez sur Administration dans le volet de gauche, puis sur Tâches
récentes. Recherchez le nom ou l'ID de la tâche dans la liste et vérifiez que l'état est Terminé. Reportez-vous
à « Surveiller l'état des tâches récentes », page 78.
Actions de dépannage de vRealize Operations Manager
S'il vous manque des données ou si vous ne pouvez pas exécuter des actions dans
vRealize Operations Manager, vérifiez les options de dépannage.
Vérifiez que votre adaptateur VMware est configuré pour se connecter aux instances de vCenter Server
appropriées. Reportez-vous à Guide d'administration et de personnalisation de vRealize Operations Manager.
Vérifiez que votre adaptateur Python Remediation vCenter est configuré pour se connecter aux instances de
vCenter Server appropriées. Reportez-vous à Guide d'administration et de personnalisation de vRealize
Operations Manager.
Données de colonne manquantes dans les boîtes de dialogue Actions page 77
n
Les données d'un ou plusieurs objets manquent dans la boîte de dialogue Action, compliquant la tâche
de déterminer si vous souhaitez exécuter l'action.
Données de colonne manquantes dans la boîte de dialogue Définir la mémoire de la VM page 77
n
Les colonnes de données en lecture seule n'affichant pas les valeurs actuelles, il est difficile de spécifier
correctement une nouvelle valeur de mémoire.
Le nom d'hôte ne s'affiche pas dans la boîte de dialogue Action page 77
n
Lors de l'exécution d'une action sur une machine virtuelle, le nom d'hôte est vide dans la boîte de
dialogue d'action.
76 VMware, Inc.
Page 77

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Données de colonne manquantes dans les boîtes de dialogue Actions
Les données d'un ou plusieurs objets manquent dans la boîte de dialogue Action, compliquant la tâche de
déterminer si vous souhaitez exécuter l'action.
Problème
Lorsque vous exécutez une ou plusieurs actions, certains champs sont vides.
Cause
L'adaptateur VMware vSphere n'a pas recueilli les données de l'instance vCenter Server qui gère l'objet, ou
l'utilisateur vRealize Operations Manager actuel ne dispose pas des privilèges pour afficher les données
recueillies pour l'objet.
Solution
1 Vérifiez que vRealize Operations Manager est configuré pour recueillir des données.
2 Vérifiez que vous disposez des privilèges nécessaires pour afficher les données.
Données de colonne manquantes dans la boîte de dialogue Définir la mémoire de la VM
Les colonnes de données en lecture seule n'affichant pas les valeurs actuelles, il est difficile de spécifier
correctement une nouvelle valeur de mémoire.
Problème
Les colonnes Actuelle (Mo) et État de l'alimentation n'affichent pas les valeurs actuelles qui sont collectées
pour l'objet géré.
Cause
L'adaptateur chargé de la collecte des données auprès de l'instance de vCenter Server sur laquelle la
machine virtuelle cible s'exécute n'a ni exécuté un cycle de collecte ni collecté les données. Cela peut se
produire lorsque vous venez de créer une instance d'adaptateur VMware pour l'instance de vCenter Server
cible et d'initier une action. L'adaptateur VMware vSphere utilise un cycle de collecte de 5 minutes.
Solution
1 Patientez 5 minutes après avoir créé une instance d'adaptateur VMware.
2 Relancez l'action Définir la mémoire de la VM.
La valeur de la mémoire et l'état d'alimentation actuels s'affichent dans la boîte de dialogue.
Le nom d'hôte ne s'affiche pas dans la boîte de dialogue Action
Lors de l'exécution d'une action sur une machine virtuelle, le nom d'hôte est vide dans la boîte de dialogue
d'action.
Problème
Lorsque vous sélectionnez une machine virtuelle sur laquelle exécuter une action, puis cliquez sur le bouton
Action, la boîte de dialogue s'affiche, mais la colonne hôte est vide.
VMware, Inc. 77
Page 78

Guide de l'utilisateur de vRealize Operations Manager
Cause
Bien que votre rôle d'utilisateur soit configuré pour exécuter une action sur les machines virtuelles, vous ne
disposez pas d'un rôle d'utilisateur qui vous donne accès à l'hôte. Vous pouvez afficher les machines
virtuelles et exécuter des actions sur celles-ci, mais vous ne pouvez pas afficher les données hôtes
correspondantes. vRealize Operations Manager ne peut pas récupérer les données pour lesquelles vous ne
disposez pas de l'autorisation d'accès.
Solution
Vous pouvez exécuter l'action, mais vous ne pouvez pas afficher le nom d'hôte dans la boîte de dialogue de
l'action.
Surveiller l'état des tâches récentes
L'état Tâches récentes inclut toutes les tâches initiées à partir de vRealize Operations Manager. Vous pouvez
utiliser les informations d'état des tâches pour vérifier que vos tâches ont abouti ou pour déterminer l'état
actuel des tâches.
Vous pouvez surveiller l'état des tâches qui sont démarrées lorsque vous exécutez des actions et déterminer
si une tâche a abouti.
Prérequis
Vous avez exécuté au moins une action préconisée par une recommandation d'alerte ou à partir d'une des
barres d'outils. Reportez-vous à « Exécuter des actions dans les barres d'outils de vRealize Operations
Manager », page 75.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Administration.
2 Cliquez sur Tâches récentes.
3 Pour déterminer si certaines de vos tâches ne sont pas terminées, cliquez sur la colonne État et triez les
résultats.
Option Description
En cours
Terminé
Échec
Heure maximale atteinte
Indique des tâches en cours d'exécution.
Indique des tâches terminées.
Indique des tâches non terminées sur au moins un objet lorsqu'elles sont
démarrées sur plusieurs objets.
Indique des tâches ayant expiré.
4 Pour évaluer le processus d'une tâche, sélectionnez la tâche dans la liste et vérifiez les informations du
volet Détails de la tâche sélectionnée.
Les détails s'affichent dans le volet Messages. Si le message d'information inclut Aucune mesure n'est
prise, la tâche s'est terminée, car l'objet se trouvait déjà dans l'état demandé.
5 Pour afficher les messages pour un objet lorsque la tâche comprend plusieurs objets, sélectionnez l'objet
dans la liste Objets associés.
Pour effacer la sélection de l'objet et afficher tous les messages, appuyez sur la barre d'espace.
Suivant
Dépannez les tâches présentant l'état Heure maximale atteinte ou Échec pour déterminer pourquoi une
tâche a échoué. Reportez-vous à « Dépannage des tâches ayant échoué », page 79.
78 VMware, Inc.
Page 79

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Dépannage des tâches ayant échoué
Si l'exécution des tâches échoue dans vRealize Operations Manager, consultez la page Tâches récentes et
dépannez la tâche afin de déterminer la raison de son échec.
Ces informations constituent la procédure générale pour utiliser les informations de la page Tâches récentes
afin de résoudre les problèmes identifiés dans les tâches.
Déterminer si une tâche récente a échoué page 80
n
Les tâches récentes fournissent l'état des tâches d'actions démarrées dans
vRealize Operations Manager. Si vous ne voyez pas les résultats attendus, passez en revue les tâches
afin de déterminer si votre tâche a échoué.
Dépannage de l'état de la tâche Heure maximale atteinte page 80
n
Une tâche d'action dispose d'un état Heure maximale atteinte et vous ne connaissez pas l'état actuel
de la tâche.
Dépannage des tâches de définition de CPU ou de mémoire ayant échoué page 81
n
Une tâche de l'action Définir le nombre de CPU ou Définir la mémoire de la VM a l'état Échec dans la
liste des tâches récentes du fait que la mise hors tension n'est pas autorisée.
Dépannage de la définition du nombre de CPU ou de la définition de la mémoire avec l'option Mise
n
hors tension autorisée page 81
Les tâches récentes indiquent qu'une action Définir le nombre de CPU, Définir la mémoire ou Définir
le nombre de CPU et la mémoire a échoué.
Dépannage de la définition du nombre de CPU et de la mémoire des valeurs ne sont pas prises en
n
charge page 82
Si vous exécutez l'action Définir le nombre de CPU ou Définir la mémoire avec une valeur non prise
en charge sur une machine virtuelle, cette dernière peut être laissée dans un état instable et vous
devrez alors résoudre le problème dans vCenter Server.
Dépannage des actions Définir les ressources de CPU ou Définir les ressources de mémoire lorsque la
n
valeur n'est pas prise en charge page 83
Si vous exécutez l'action Définir les ressources de CPU avec une valeur non prise en charge sur une
machine virtuelle, la tâche échoue et une erreur s'affiche dans les messages Tâches récentes.
Dépannage des options Définir les ressources de CPU ou Définir les ressources de mémoire lorsque la
n
valeur est trop élevée page 83
Si vous exécutez l'action Définir les ressources de CPU ou Définir les ressources de mémoire avec une
valeur supérieure à la valeur prise en charge par votre instance de vCenter Server, la tâche échoue et
une erreur apparaît dans les messages Tâches récentes.
Dépannage des options Définir les ressources de mémoire lorsque la valeur n'est pas un multiple
n
de 1024 page 84
Si vous exécutez l'action Définir les ressources de mémoire avec une valeur ne pouvant pas être
convertie de kilo-octets en mégaoctets, la tâche échoue et une erreur s'affiche dans les messages Tâches
récentes.
Dépannage de l'échec de l'arrêt de machine virtuelle page 84
n
Une tâche d'action d'arrêt de machine virtuelle a l'état Échec dans la liste Tâches récentes.
Dépannage de l'impossibilité d'exécuter VMware Tools pour arrêter une machine virtuelle page 85
n
Une tâche d'action Arrêter la VM a l'état Échec dans la liste Tâches récentes et le message indique que
VMware Tools était requis.
VMware, Inc. 79
Page 80

Guide de l'utilisateur de vRealize Operations Manager
Dépannage de l'état de suppression des snapshots inutilisés ayant échoué page 85
n
Une tâche d'action de suppression des snapshots inutilisés a un état Échec dans la liste Tâches
récentes.
Déterminer si une tâche récente a échoué
Les tâches récentes fournissent l'état des tâches d'actions démarrées dans vRealize Operations Manager. Si
vous ne voyez pas les résultats attendus, passez en revue les tâches afin de déterminer si votre tâche a
échoué.
Procédure
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Administration.
2 Cliquez sur Tâches récentes.
3 Sélectionnez la tâche échouée dans la liste de tâches.
4 Dans la liste Messages, trouvez les occurrences de Résultat renvoyé par le script : échec et passez
en revue les informations entre cette valeur et <-- Exécution : [nom du script] sur {type d'objet}.
Résultat renvoyé par le script constitue la fin de l'exécution de l'action et <-- Exécution indique le
début. Les informations fournies incluent les paramètres transmis, l'objet cible et les exceptions
inattendues qui vous permettent d'identifier le problème.
Dépannage de l'état de la tâche Heure maximale atteinte
Une tâche d'action dispose d'un état Heure maximale atteinte et vous ne connaissez pas l'état actuel de la
tâche.
Problème
La liste Tâches récentes indique qu'une tâche a l'état Heure maximale atteinte.
La durée d'exécution de la tâche dépasse la valeur par défaut ou configurée. Pour déterminer l'état actuel,
vous devez dépanner l'action initiée.
Cause
La durée d'exécution de la tâche dépasse la valeur par défaut ou configurée pour l'une des raisons
suivantes .
L'exécution de l'action est exceptionnellement longue et ne s'est pas terminée avant que la limite du
n
délai d'expiration ait été atteinte.
L'adaptateur de l'action n'a pas reçu de réponse du système cible avant d'atteindre le délai d'expiration.
n
L'action s'est peut-être correctement terminée, mais l'état d'achèvement n'a pas été renvoyé à
vRealize Operations Manager.
L'action n'a pas correctement démarré.
n
L'adaptateur de l'action peut comporter une erreur ou être dans l'impossibilité de signaler l'état.
n
Solution
Vérifiez l'état de l'objet cible afin de déterminer si l'action s'est correctement terminée. Si ce n'est pas le cas,
continuez à rechercher la cause première.
80 VMware, Inc.
Page 81

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Dépannage des tâches de définition de CPU ou de mémoire ayant échoué
Une tâche de l'action Définir le nombre de CPU ou Définir la mémoire de la VM a l'état Échec dans la liste
des tâches récentes du fait que la mise hors tension n'est pas autorisée.
Problème
La liste Tâches récentes indique qu'une tâche Définir le nombre de CPU, Définir la mémoire ou Définir le
nombre de CPU et la mémoire a l'état Échec. Lorsque vous consultez la liste des messages correspondant à la
tâche sélectionnée, vous voyez le message suivant s'afficher.
Impossible d'effectuer une action. Machine virtuelle trouvée mise sous tension, mise hors
tension non autorisée
Lorsque vous augmentez la mémoire ou le nombre de CPU, le message suivant s'affiche.
Machine virtuelle trouvée mise sous tension, mise hors tension non autorisée, et si l'ajout à
chaud est activé, la limite d'ajout à chaud est dépassée.
Cause
Vous avez envoyé l'action pour augmenter ou diminuer la valeur de CPU ou de mémoire sans sélectionner
l'option Autoriser la mise hors tension. Lorsque vous avez exécuté l'action dans laquelle un objet cible est
sous tension et l'option Connexion mémoire à chaud n'est pas activée dans vCenter Server, l'action échoue.
Solution
1 Activez Connexion mémoire à chaud sur vos machines virtuelles cibles dans vCenter Server ou
sélectionnez Autoriser la mise hors tension lorsque vous exécutez l'action Définir le nombre de CPU,
Définir la mémoire ou Définir le nombre de CPU et la mémoire.
2 Vérifiez votre limite de connexion à chaud dans vCenter Server.
Dépannage de la définition du nombre de CPU ou de la définition de la mémoire avec l'option Mise hors tension autorisée
Les tâches récentes indiquent qu'une action Définir le nombre de CPU, Définir la mémoire ou Définir le
nombre de CPU et la mémoire a échoué.
Problème
Lorsque vous exécutez une action qui modifie le nombre de CPU, la mémoire ou les deux, l'action échoue
même si vous savez que l'option Mise hors tension autorisée a été cochée, que la machine virtuelle est en
cours d'exécution et que VMware Tools est installé et en cours d'exécution.
Cause
La machine virtuelle devrait arrêter le système d'exploitation invité avant de mettre la machine virtuelle
hors tension afin d'effectuer les modifications demandées. Le processus d'arrêt attend une réponse de la
machine virtuelle cible pendant 120 secondes, puis échoue sans modifier la machine virtuelle.
Solution
1 Vérifiez la machine virtuelle cible dans vCenter Server pour déterminer si elle exécute des tâches qui
retardent la mise en œuvre de l'action.
2 Recommencez l'action dans vRealize Operations Manager.
VMware, Inc. 81
Page 82

Guide de l'utilisateur de vRealize Operations Manager
Dépannage de la définition du nombre de CPU et de la mémoire des valeurs ne sont pas prises en charge
Si vous exécutez l'action Définir le nombre de CPU ou Définir la mémoire avec une valeur non prise en
charge sur une machine virtuelle, cette dernière peut être laissée dans un état instable et vous devrez alors
résoudre le problème dans vCenter Server.
Problème
Vous ne pouvez pas mettre sous tension une machine virtuelle après avoir correctement exécuté l'action
Définir le nombre de CPU ou Définir la mémoire. Lorsque vous consultez les messages dans Tâches récentes
suite à l'échec de l'action Mettre sous tension la VM, des messages indiquent que l'hôte ne prend pas en
charge le nouveau nombre de CPU ou la nouvelle valeur de mémoire.
Cause
En raison du mode de validation des modifications des valeurs de CPU et de mémoire par vCenter Server,
vous pouvez utiliser les actions de vRealize Operations Manager pour remplacer la valeur par une quantité
non prise en charge si vous exécutez l'action lorsque la machine virtuelle est hors tension.
Si l'objet était sous tension, la tâche échoue, annule toute modification de valeur et remet la machine sous
tension. Si l'objet était hors tension, la tâche réussit, la valeur est modifiée dans vCenter Server, mais l'objet
cible est laissé dans un état dans lequel vous ne pouvez le mettre sous tension ni à l'aide des actions ni dans
vCenter Server sans remplacer manuellement la valeur de CPU ou de mémoire par une valeur prise en
charge.
Solution
1 Dans le volet gauche de vRealize Operations Manager, cliquez sur l'icône Administration.
2 Cliquez sur Tâches récentes.
3 Dans la liste des tâches, localisez l'action Mettre sous tension la VM ayant échoué et vérifiez les
messages associés à la tâche.
4 Recherchez un message qui indique la raison pour laquelle la tâche a échoué.
Par exemple, supposons que vous exécutez une action Définir le nombre de CPU sur une machine
virtuelle hors tension pour augmenter le nombre de CPU de 2 à 4 alors que l'utilisation de 4 CPU n'est
pas prise en charge par l'hôte. Les tâches Définir le nombre de CPU sont signalées comme ayant réussi
dans les tâches récentes. Cependant, lorsque vous tentez de mettre sous tension la machine virtuelle, les
tâches échouent. Dans cet exemple, le message est La machine virtuelle nécessite 4 CPU pour
fonctionner, mais le matériel de l'hôte n'en fournit que 2.
5 Cliquez sur le nom de l'objet dans la liste Tâches récentes.
Le volet principal est mis à jour pour afficher les détails de l'objet sélectionné.
6 Cliquez sur le menu Actions dans la barre d'outils, puis sur Ouvrir la machine virtuelle dans vSphere
Client.
vSphere Web Client s'ouvre et la machine virtuelle est l'objet actuel.
7 Dans vSphere Web Client, cliquez sur l'onglet Gérer, puis cliquez sur Matériel de la VM.
8 Cliquez sur Edit.
9 Dans la boîte de dialogue Modifier les paramètres, remplacez le nombre de CPU ou la valeur de la
mémoire par une valeur prise en charge et cliquez sur OK.
Vous pouvez maintenant mettre sous tension la machine virtuelle à partir de Web Client ou à partir de
vRealize Operations Manager.
82 VMware, Inc.
Page 83

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Dépannage des actions Définir les ressources de CPU ou Définir les ressources de mémoire lorsque la valeur n'est pas prise en charge
Si vous exécutez l'action Définir les ressources de CPU avec une valeur non prise en charge sur une machine
virtuelle, la tâche échoue et une erreur s'affiche dans les messages Tâches récentes.
Problème
La liste Tâches récentes indique qu'une action Définir les ressources de CPU ou Définir les ressources de
mémoire indique l'état Échec. Lorsque vous consultez la liste des messages correspondant à la tâche
sélectionnée, vous voyez un message similaire aux exemples suivants s'afficher.
Exception RuntimeFault, message : [Un paramètre spécifié est incorrect.
spec.cpuAllocation.reservation]
Exception RuntimeFault, message : [Un paramètre spécifié est incorrect.
spec.cpuAllocation.limits]
Cause
Vous avez envoyé l'action pour augmenter ou diminuer la valeur de réservation ou de limite de CPU ou de
mémoire avec une valeur non prise en charge. Par exemple, si vous avez fourni un entier négatif autre
que -1, qui définit la valeur sur Illimité, vCenter Server n'a pas pu apporter la modification et l'action a
échoué.
Solution
Exécutez l'action avec une valeur prise en charge.
u
Les valeurs prises en charge pour la réservation sont 0 et toute valeur supérieure à 0. Les valeurs prises
en charge pour la limite sont -1, 0 ou toute valeur supérieure à 0.
Dépannage des options Définir les ressources de CPU ou Définir les ressources de mémoire lorsque la valeur est trop élevée
Si vous exécutez l'action Définir les ressources de CPU ou Définir les ressources de mémoire avec une valeur
supérieure à la valeur prise en charge par votre instance de vCenter Server, la tâche échoue et une erreur
apparaît dans les messages Tâches récentes.
Problème
La liste Tâches récentes indique qu'une action Définir les ressources de CPU ou Définir les ressources de
mémoire indique l'état Échec. Lorsque vous consultez la liste des messages correspondant à la tâche
sélectionnée, vous voyez des messages similaires aux exemples suivants s'afficher.
Si vous exécutez l'action Définir les ressources de CPU, le message est similaire à l'exemple suivant, où
1000000000 est la valeur de réservation fournie.
Reconfiguration de la réservation de la machine virtuelle sur :[1000000000] MHz
Le message d'erreur pour cette action est similaire à cet exemple.
Exception RuntimeFault, message : [Un paramètre spécifié est incorrect. reservation]
Si vous exécutez l'action Définir les ressources de mémoire, le message est similaire à l'exemple suivant, où
1000000000 est la valeur de réservation fournie.
Reconfiguration de la réservation de la machine virtuelle sur :[1000000000] (Mo)
Le message d'erreur pour cette action est similaire à cet exemple.
Exception RuntimeFault, message : [Un paramètre spécifié est incorrect.
spec.memoryAllocation.reservation]
VMware, Inc. 83
Page 84

Guide de l'utilisateur de vRealize Operations Manager
Cause
Vous avez exécuté l'action pour remplacer la valeur de réservation ou de limite de CPU ou de mémoire par
une valeur supérieure à la valeur prise en charge par vCenter Server ou la valeur de réservation envoyée est
supérieure à la limite.
Solution
Exécutez l'action avec une valeur plus basse.
u
Dépannage des options Définir les ressources de mémoire lorsque la valeur n'est pas un multiple de 1024
Si vous exécutez l'action Définir les ressources de mémoire avec une valeur ne pouvant pas être convertie de
kilo-octets en mégaoctets, la tâche échoue et une erreur s'affiche dans les messages Tâches récentes.
Problème
La liste Tâches récentes indique qu'une action Définir les ressources de mémoire indique l'état Échec.
Lorsque vous consultez la liste des messages correspondant à la tâche sélectionnée, vous voyez un message
similaire à l'exemple suivant s'afficher.
Validation du paramètre ; échec de conversion de [nouvelle limite en Ko] en (Mo, (Ko)[2000]
n'est pas un multiple de 1024
Cause
Étant donné que vCenter Server gère les valeurs de réservation et de limite de mémoire en mégaoctets, mais
que vRealize Operations Manager calcule et indique la mémoire en kilo-octets, vous devez fournir une
valeur en kilo-octets directement convertible en mégaoctets. Pour ce faire, la valeur doit être un multiple
de 1024.
Solution
Exécutez l'action lorsque les valeurs de réservation et de limite sont configurées avec des valeurs prises
u
en charge.
Les valeurs prises en charge pour la réservation sont 0 ou toute valeur supérieure à 0 et multiple
de 1024. Les valeurs prises en charge pour la limite sont -1, 0 ou toute valeur supérieure à 0 et multiple
de 1024.
Dépannage de l'échec de l'arrêt de machine virtuelle
Une tâche d'action d'arrêt de machine virtuelle a l'état Échec dans la liste Tâches récentes.
Problème
L'action Arrêter la VM ne s'est pas correctement exécutée.
La liste Tâches récentes indique qu'une action Arrêter la VM a pour état de tâche Échec. Lorsque vous
consultez la liste des messages correspondant à la tâche sélectionnée, vous voyez le message suivant :
Échec : expiration de la confirmation de l'arrêt.
Cause
Le processus d'arrêt implique l'arrêt du système d'exploitation invité et la mise hors tension de la machine
virtuelle. Le délai d'attente pour arrêter le système d'exploitation invité est de 120 secondes. Si le système
d'exploitation invité ne s'arrête pas pendant ce délai, l'action échoue du fait que l'action d'arrêt n'est pas
confirmée.
Solution
Vérifiez l'état du système d'exploitation invité dans vCenter Server afin de déterminer la raison pour
u
laquelle il ne s'est pas arrêté pendant la durée impartie.
84 VMware, Inc.
Page 85

Chapitre 1 Surveillance des objets dans votre environnement géré avec vRealize Operations Manager
Dépannage de l'impossibilité d'exécuter VMware Tools pour arrêter une machine virtuelle
Une tâche d'action Arrêter la VM a l'état Échec dans la liste Tâches récentes et le message indique que
VMware Tools était requis.
Problème
L'action Arrêter la VM ne s'est pas correctement exécutée.
La liste Tâches récentes indique qu'une action Arrêter la VM a pour état de tâche Échec. Lorsque vous
consultez la liste des messages correspondant à la tâche sélectionnée, vous voyez le message suivant : VMware
Tools : non exécuté (non installé).
Cause
L'action Arrêter la VM nécessite que VMware Tools soit installé et en cours d'exécution sur les machines
virtuelles cibles. Si vous avez exécuté l'action sur plusieurs objets, VMware Tools n'était pas installé, ou était
installé mais pas en cours d'exécution, sur au moins l'une des machins virtuelles.
Solution
Dans l'instance de vCenter Server qui gère la machine virtuelle ayant échoué l'exécution de l'action,
u
installez et démarrez VMware Tools sur les machines virtuelles concernées.
Dépannage de l'état de suppression des snapshots inutilisés ayant échoué
Une tâche d'action de suppression des snapshots inutilisés a un état Échec dans la liste Tâches récentes.
Problème
L'action de suppression des snapshots inutilisés n'a pas abouti.
La liste Tâches récentes indique qu'une action de suppression des snapshots inutilisés a un état de tâche
Échec. Lorsque vous consultez la liste des messages correspondant au travail sélectionné, vous voyez le
message suivant.
Échec de suppression du snapshot, l'attente de la réponse a expiré après :[120] secondes,
impossible de confirmer la suppression
Cause
Le processus de suppression de snapshot implique l'attente de l'accès aux banques de données. Le temps
d'attente d'accès à la banque de données et de suppression du snapshot est de 600 secondes. Si la demande
de suppression n'est pas transmise à la banque de données avant l'expiration de ce délai d'attente, l'action de
suppression du snapshot n'aboutit pas.
Solution
1 Vérifiez l'état du snapshot dans vCenter Server pour déterminer s'il a été supprimé.
2 Dans la négative, envoyez la demande de suppression du snapshot ultérieurement.
Affichage de l'inventaire
vRealize Operations Manager collecte des données sur tous les objets de votre environnement et affiche
l'état de santé, de risque et d'efficacité de chaque objet.
Examinez l'ensemble de votre inventaire pour vous faire une idée rapide de l'état de tout objet ou cliquez
sur un nom d'objet pour plus d'informations. Reportez-vous à « Évaluation des informations récapitulatives
d'un objet », page 40.
VMware, Inc. 85
Page 86

Guide de l'utilisateur de vRealize Operations Manager
86 VMware, Inc.
Page 87

Planification des ressources de votre
environnement géré à l'aide de
vRealize Operations Manager 2
Vous pouvez utiliser la fonctionnalité de projets vRealize Operations Manager pour planifier des mises à
niveau de capacité ou une optimisation de votre environnement virtuel.
Fonctionnement des projets
Vous créez un projet pour planifier votre capacité. Vous pouvez inclure les changements à venir qui
influeront sur la capacité. Un projet comporte un ou plusieurs scénarios dans lesquels la capacité ou la
demande change à une date dans le futur. Vous pouvez visualiser un ou plusieurs projets dans le volet de
visualisation pour prévoir votre capacité et votre demande. Lorsque vous attendez qu'un projet se
concrétise, vous pouvez le valider et réserver la capacité requise.
Modélisation des modifications de ressources
Vous pouvez créer des projets et ajouter des scénarios avec des instances, des clusters, des hôtes, des
machines virtuelles et des banques de données vCenter Server.
Tableau 2‑1. Scénarios pour les objets sélectionnés
Objet sélectionné Scénarios applicables
vCenter Server Scénarios liés à la capacité.
Ajouter ou supprimer la capacité de l'hôte système, de
n
la banque de données ou le pourcentage de capacité.
Changer la capacité absolue.
n
Scénarios liés à la demande.
Ajouter ou supprimer la demande de machine virtuelle
n
ou le pourcentage de demande.
Modifier la demande absolue.
n
Cluster
Hôte Scénarios liés à la capacité.
Ajoutez, supprimez ou mettez à jour des hôtes.
n
Ajoutez, supprimez ou mettez à jour des banques de
n
données.
Ajoutez ou supprimez des machines virtuelles.
n
Ajouter ou supprimer la capacité de la banque de
n
données ou le pourcentage de capacité.
Changer la capacité absolue.
n
Scénarios liés à la demande.
Ajouter ou supprimer la demande de machine virtuelle
n
ou le pourcentage de demande.
Modifier la demande absolue.
n
VMware, Inc. 87
Page 88

Guide de l'utilisateur de vRealize Operations Manager
Tableau 2‑1. Scénarios pour les objets sélectionnés (suite)
Objet sélectionné Scénarios applicables
Banque de données Scénarios liés à la capacité.
Machine virtuelle
Liste de projets
Les projets énumérés sont filtrés et directement associés à l'objet que vous sélectionnez à partir de
l'inventaire. Utilisez la barre d'outils de la liste de projets pour créer un projet ou agir sur un projet,
notamment modifier ou supprimer un projet existant. À partir de la liste de projets, cliquez sur le titre d'une
colonne pour trier chaque colonne du tableau ou filtrer la liste. Chaque ligne de projet dans le tableau
contient une icône permettant d'ajouter le projet au volet de visualisation. Vous pouvez également faire
glisser un projet pour afficher son effet sur le graphique de visualisation.
Ajouter ou supprimer le pourcentage de capacité.
n
Changer la capacité absolue.
n
Scénarios liés à la demande.
Ajouter ou supprimer la demande de machine virtuelle
n
ou le pourcentage de demande.
Modifier la demande absolue.
n
Ajoutez, modifiez ou supprimez la capacité.
n
Ajoutez, modifiez ou supprimez la demande.
n
Graphique de visualisation
vRealize Operations Manager applique un ou plusieurs projets au graphique de visualisation. La vue est le
contexte pour la comparaison qui est modélisée dans le scénario. Le volet Projets s'actualise alors que vous
appliquez un nouveau projet dans le volet de visualisation. Les projets perdurent jusqu'à ce que vous les
supprimiez ou que vous actualisiez vRealize Operations Manager. vRealize Operations Manager attribue
des noms, tels que 1a et 2a aux projets dans le graphique de visualisation. L'info-bulle d'un projet apparaît
dans le graphique et affiche le nom, ainsi que la description du projet.
Ce chapitre aborde les rubriques suivantes :
« Scénario utilisateur : Vérifier l'impact des besoins en capacité future », page 88
n
« Création de projets matériels », page 91
n
« Création de projets de machines virtuelles », page 92
n
Scénario utilisateur : Vérifier l'impact des besoins en capacité future
En tant qu'administrateur système du centre de données, vous devez prévoir les exigences permettant de
prendre en charge une augmentation de la charge de travail au cours des mois à venir. La prévision des
données pour anticiper les risques de capacité dans vRealize Operations Manager implique la création de
projets de capacité afin d'examiner la demande et l'attribution de ressources dans une infrastructure
virtuelle. Créez un projet afin de contrôler l'impact des besoins de capacité à venir dans votre
environnement.
Un projet est une hypothèse permettant de déterminer le degré de modification de la capacité et de la charge
qu'entraînerait la modification de certaines conditions. Vous n'avez donc pas besoin de modifier votre
infrastructure virtuelle. Si vous mettez en œuvre le projet, vous savez d'avance quels sont vos besoins en
capacité.
Prérequis
Au moins deux ou trois semaines de collecte de données pour chaque vRealize Operations Manager.
Dans vRealize Operations Manager, vérifiez que l'onglet Projets est ouvert.
88 VMware, Inc.
Page 89

Chapitre 2 Planification des ressources de votre environnement géré à l'aide de vRealize Operations Manager
Scénario utilisateur : Créer un projet pour augmenter la charge de travail
Vous pouvez créer un projet en utilisant un cluster configuré à l'aide de machines virtuelles. Créez un
scénario pour augmenter votre charge de travail de 50 % en un mois.
Dans ce projet, vous allez découvrir ce qu'il se passe lorsque vous augmentez la demande sur un cluster.
Prérequis
Dans vRealize Operations Manager, vérifiez que l'onglet Projets est ouvert.
Procédure
1 Sélectionnez un cluster cible dans le volet d'inventaire.
L'hôte cible est l'emplacement dans lequel vous simulez les modifications apportées à l'environnement
afin d'examiner les conséquences possibles. Assurez-vous que le cluster cible comporte plusieurs
machines virtuelles.
2 Cliquez sur l'onglet Projets, puis sur l'icône Ajouter un nouveau projet.
3 Dans l'espace de travail Projets, entrez le nom et une description du project.
Nommez le projet (par exemple, « Augmentation de la charge du cluster »).
4 Sélectionnez l'état Planifié.
5 Cliquez sur Scénarios pour ajouter des scénarios au projet.
6 Sélectionnez le scénario Ajouter une demande : ajouter un pourcentage de demande et faites-le glisser
vers le volet Scénarios.
7 Dans le volet Configuration, définissez la date d'implémentation (un mois à partir de la date actuelle).
8 Définissez la valeur globale sur 50 %.
9 Cliquez sur Enregistrer pour ajouter le scénario au projet.
10 Cliquez sur Fermer pour fermer l'espace de travail du projet.
vRealize Operations Manager applique le scénario au projet.
Suivant
Créez un projet pour ajouter des machines virtuelles et des hôtes ESX au cluster. Reportez-vous à « Scénario
utilisateur : Créer un projet pour ajouter des machines virtuelles et des hôtes », page 89.
Scénario utilisateur : Créer un projet pour ajouter des machines virtuelles et des hôtes
Vous pouvez créer un autre projet pour le même cluster. Créez des scénarios pour ajouter des machines
virtuelles et des hôtes.
Dans ce projet, vous créez un autre projet planifié pour le même cluster. La visualisation montre l'effet
obtenu si vous ajoutez une nouvelle machine virtuelle et des hôtes au cluster.
Prérequis
vRealize Operations ManagerDans vRealize Operations Manager, vérifiez que l'onglet Projets est ouvert.
VMware, Inc. 89
Page 90

Guide de l'utilisateur de vRealize Operations Manager
Procédure
1 Sélectionnez l'hôte cible dans le panneau d'inventaire.
L'hôte cible est l'emplacement dans lequel vous simulez les modifications apportées à l'environnement
afin d'examiner les conséquences possibles.
2 Cliquez sur l'onglet Projet et cliquez sur l'icône Ajouter un nouveau projet.
3 Dans l'espace de travail Projets, entrez le nom et la description du projet.
Par exemple, Nouvelles machines virtuelles et nouveaux hôtes.
4 Sélectionnez l'état Planifié.
5 Cliquez sur Scénarios pour ajouter des scénarios à ce projet.
6 Sélectionnez le scénario Ajouter une demande : Ajouter une machine virtuelle et faites-le glisser vers
le volet Scénarios.
7 Dans le volet Configuration, ajoutez dix machines virtuelles avec 43 Go de mémoire et deux cœurs de
CPU.
8 Sélectionnez le scénario Ajouter de la capacité : Ajouter un système hôte et faites-le glisser vers le volet
Scénarios.
9 Ajouter deux hôtes ESX avec 8 Go de mémoire et quatre cœurs de CPU.
10 Cliquez sur Enregistrer pour ajouter le scénario au projet.
11 Cliquez sur Fermer pour fermer l'espace de travail du projet.
vRealize Operations Manager applique les scénarios au projet.
Suivant
Vous pouvez à présent visualiser l'effet de deux projets de planification de capacité en utilisant le graphique
de visualisation. « Scénario utilisateur : Visualiser l'effet de deux projets de planification de la capacité »,
page 90.
Scénario utilisateur : Visualiser l'effet de deux projets de planification de la capacité
Vous pouvez à présent ajouter le projet visant à augmenter les besoins de capacité au projet d'ajout de
machines virtuelles et d'hôtes.
Vérifiez que vous avez créé au moins deux projets.
Prérequis
Dans vRealize Operations Manager, vérifiez que l'onglet Projets est ouvert.
Procédure
1 Dans l'onglet Projets, sélectionnez le projet Augmentation de la charge du cluster et le projet Nouvelles
machines virtuelles et nouveaux hôtes dans la liste des projets. Ajoutez-les au diagramme de
visualisation.
2 Sélectionnez Combiner des projets dans cette visualisation.
Les valeurs combinées de tous les projets s'affichent sous forme de lignes pointillées dans le graphique de
visualisation.
90 VMware, Inc.
Page 91

Chapitre 2 Planification des ressources de votre environnement géré à l'aide de vRealize Operations Manager
Suivant
À partir des résultats du tableau de visualisation, déterminez si vous devez convertir les projets planifiés en
projets validés.
Création de projets matériels
La création d'un projet de capacité pour le matériel implique la modification du matériel de l'hôte, puis du
matériel de la banque de données. Avant d'acheter du nouveau matériel, créez des projets pour déterminer
si l'achat est nécessaire.
Si vous mettez en œuvre un projet de modification de matériel, vous connaissez d'avance vos besoins en
matière de capacité. Vous pouvez utiliser des projets pour planifier des modifications de matériel dans vos
environnements dans les circonstances suivantes.
Si vous mettez en œuvre une nouvelle application, disposez-vous de ressources suffisantes pour
n
prendre en charge l'espace disque requis pour le déploiement ?
Si vous ajoutez trois serveurs à un cluster existant, cela sera-t-il suffisant pour soutenir l'augmentation
n
de bande passante au quatrième trimestre ?
Quelles seraient les conséquences d'une modification de la configuration dans votre environnement ?
n
Avant d'agir sur une recommandation de vRealize Operations Manager, vérifiez ce qui se produirait si
n
vous mettiez en œuvre la modification recommandée dans votre environnement.
Créer un projet de changement de matériel
Avant d'acquérir du nouveau matériel, vous pouvez créer des projets de changement de matériel à l'aide de
scénarios afin de déterminer si l'achat est nécessaire. Pour déterminer les répercussions de l'ajout, de la
suppression ou de la mise à jour de la capacité matérielle sur un cluster, créez un projet qui modélise les
modifications apportées aux hôtes et aux banques de données.
Prérequis
Dans vRealize Operations Manager, vérifiez que l'onglet Projets est ouvert.
Procédure
1 Sélectionnez l'hôte cible dans le panneau d'inventaire.
L'hôte cible est l'emplacement dans lequel vous simulez les modifications apportées à l'environnement
afin d'examiner les conséquences possibles.
2 Cliquez sur l'onglet Projets, puis sur l'icône Ajouter un nouveau projet.
3 Dans l'espace de travail Projets, entrez le nom et une description du projet.
4 Sélectionnez l'état Planifié.
5 Cliquez sur Scénarios pour ajouter des scénarios à ce projet.
6 Sélectionnez le scénario Ajouter un magasin de données et faites-le glisser vers le volet Scénarios.
7 Dans le volet Configuration, entrez les paramètres généraux du scénario.
8 Cliquez sur les options de la banque de données pour modifier l'utilisation et l'allocation de l'espace
disque.
9 Cliquez sur Appliquer pour voir l'effet dans l'espace de travail de projet lorsque vos sélections de
configuration sont terminées.
10 Cliquez sur Enregistrer pour ajouter le scénario au projet.
11 Cliquez sur Fermer pour fermer l'espace de travail du projet.
VMware, Inc. 91
Page 92

Guide de l'utilisateur de vRealize Operations Manager
vRealize Operations Manager applique le scénario à la vue que vous avez sélectionnée. Le scénario
prévisionnel s'affiche dans le graphique sous la forme d'une ligne en pointillés grise. Vous pouvez comparer
la capacité réelle actuelle à la capacité attendue si vous appliquez les modifications que vous avez spécifiées
dans le scénario de changement de matériel.
Création de projets de machines virtuelles
Avant d'appliquer des modifications dans votre environnement virtuel, vous pouvez créer des projets de
machines virtuelles pour modéliser l'ajout ou la suppression de machines virtuelles à un hôte ou à un
cluster. Les projets de machines virtuelles vous aident à évaluer les conséquences de la modification des
ressources virtuelles sans appliquer de modifications réelles à votre environnement virtuel.
Créer des scénarios de capacité pour des machines virtuelles ayant des profils existants
Vous pouvez créer un scénario qui utilise des profils de machines virtuelles existantes comme modèles pour
simuler l'ajout d'une ou de plusieurs nouvelles machines virtuelles à un hôte ou à un cluster.
Pour vous aider à effectuer des sélections de configuration pour des machines virtuelles, l'espace de travail
scénarios contient des informations de population provenant de profils prédéfinis.
vRealize Operations Manager calcule des données de machines virtuelles en partitionnement la plage de
capacité de CPU, de mémoire et de dimensions de disque, et crée un profil à utiliser comme modèle existant.
Pour plus d'informations sur les valeurs maximales de CPU et de mémoire, reportez-vous à la
documentation de VMware vSphere.
Procédure
1 Sélectionnez l'objet de destination dans le volet d'inventaire.
L'objet de destination est un cluster ou un hôte dans lequel vous pouvez localiser les nouvelles
machines virtuelles si vous mettez en œuvre votre scénario.
2 Cliquez sur l'onglet Projets, puis sur l'icôneAjouter un nouveau projet.
3 Dans l'espace de travail Projets, entrez le nom du projet et une description.
4 Sélectionnez l'état Planifié.
5 Cliquez sur Scénarios pour ajouter des scénarios à ce projet.
6 Sélectionnez le scénario ajouter une machine virtuelle et faites-le glisser vers le volet Scénarios.
7 Sélectionnez Remplir les mesures à partir de.
8 Dans la liste, sélectionnez des machines virtuelles existantes à utiliser comme profils pour la nouvelle
machine virtuelle.
Option Description
Copiez les valeurs de mesure à
partir d'un profil prédéfini.
Copier les valeurs de mesure à
partir d'un objet existant.
Sélectionnez une liste de profils prédéfinis à utiliser comme profil pour la
nouvelle machine virtuelle.
Dans la liste, sélectionnez des machines virtuelles existantes à utiliser
comme profils pour la nouvelle machine virtuelle. La liste des machines
virtuelles existantes s'applique au centre de données de l'objet sélectionné.
Le Centre de données et les menus déroulants Cluster ou Hôte réduit
l'étendue de la liste de machines virtuelles.
9 Cliquez sur OK.
10 Pour dupliquer des machines virtuelles, augmentez le nombre de machines virtuelles et cliquez sur
Suivant.
92 VMware, Inc.
Page 93

Chapitre 2 Planification des ressources de votre environnement géré à l'aide de vRealize Operations Manager
11 Cliquez sur Appliquer pour voir l'effet sur le graphique de visualisation dès que les sélections de
configuration sont effectuées.
12 Cliquez sur Enregistrer pour ajouter le scénario au projet.
13 Cliquez sur Fermer pour fermer l'espace de travail du projet.
vRealize Operations Manager applique le scénario à la vue que vous avez sélectionnée et affiche la capacité
actuelle comparée à la capacité prévue si vous ajoutez des machines virtuelles à l'objet cible.
Créer des projets de capacité pour des machines virtuelles ayant de nouveaux profils
Les projets de machines virtuelles évaluent les conséquences de l'ajout d'une nouvelle machine virtuelle à
un cluster ou à un hôte sans appliquer de réelles modifications à votre environnement virtuel.
Pour plus d'informations sur les valeurs maximales de CPU et de mémoire, reportez-vous à la
documentation de VMware vSphere.
Procédure
1 Sélectionnez l'objet de destination dans le volet d'inventaire.
L'objet de destination est un cluster ou un hôte dans lequel vous pouvez localiser les nouvelles
machines virtuelles si vous mettez en œuvre votre scénario.
2 Cliquez sur l'onglet Projets, puis sur l'icône Ajouter un nouveau projet.
3 Dans l'espace de travail Projets, entrez le nom et une description du projet.
4 Sélectionnez l'état Planifié.
5 Cliquez sur Scénarios pour ajouter des scénarios à ce projet.
6 Sélectionnez le scénario ajouter une machine virtuelle et faites-le glisser vers le volet Scénarios.
7 Définissez le nombre de machines virtuelles et la configuration de la machine virtuelle.
vRealize Operations Manager ne vous oblige pas à spécifier l'utilisation d'E/S disque et d'E/S réseau des
nouvelles machines virtuelles. vRealize Operations Manager emploie l'utilisation moyenne d'E/S disque
et d'E/S réseau sur les machines virtuelles de l'hôte ou du cluster comme estimation de l'utilisation de la
nouvelle machine virtuelle.
8 Cliquez sur Appliquer pour voir l'effet sur le graphique de visualisation dès que les sélections de
configuration sont effectuées.
9 Cliquez sur Enregistrer pour ajouter le scénario au projet.
10 Cliquez sur Fermer pour fermer l'espace de travail du projet.
vRealize Operations Manager applique le projet à la vue que vous avez sélectionnée et montre la capacité
actuelle comparée à la capacité attendue si vous ajoutez les machines virtuelles à l'objet cible.
VMware, Inc. 93
Page 94

Guide de l'utilisateur de vRealize Operations Manager
Créer un projet pour simuler la suppression de machines virtuelles
Vous pouvez créer un projet qui simule la suppression d'une machine virtuelle ou d'un groupe de machines
virtuelles d'un hôte ou d'un cluster. Vous pouvez souhaiter supprimer des machines virtuelles si vous n'en
avez plus besoin ou si vous souhaitez les déplacer vers un autre hôte ou un autre cluster.
Procédure
1 Sélectionnez l'objet cible dans le panneau d'inventaire.
L'objet cible identifie l'hôte ou le cluster duquel les machines virtuelles sont supprimées si vous mettez
en œuvre votre scénario.
2 Cliquez sur l'onglet Projets, puis sur l'icône Ajouter un nouveau projet.
3 Dans l'espace de travail Projets, entrez le nom et une description du projet.
4 Sélectionnez l'état Planifié.
5 Cliquez sur Scénarios pour ajouter des scénarios au projet.
6 Sélectionnez le scénario objet sélectionné dans l'option Supprimer la demande et faites-le glisser vers le
volet Scénarios.
7 Dans le menu déroulant Objet à supprimer, sélectionnez Machine virtuelle.
8 Sélectionnez et double-cliquez sur l'élément Supprimer une machine virtuelle pour le supprimer.
9 Cliquez sur Appliquer pour voir l'effet dans la visualisation du projet.
10 Cliquez sur Enregistrer pour ajouter le scénario au projet.
11 Cliquez sur Fermer pour fermer l'espace de travail du projet.
vRealize Operations Manager applique le scénario au projet. Lorsque vous ajoutez le projet au graphique de
visualisation, la capacité prévue s'affiche dans le graphique sous la forme d'une ligne pointillée grise. Vous
pouvez comparer la capacité actuelle à la capacité attendue si vous supprimez les machines virtuelles de
l'objet cible.
Suivant
Si vous avez plusieurs projets, vous pouvez combiner ou comparer les résultats du projet dans le graphique
de visualisation.
94 VMware, Inc.
Page 95

Index
A
à l'ensemble de règles
basée sur des alertes 54, 55
personnaliser une stratégie 54
vRealize Configuration Manager 54
action
arrêter la machine virtuelle 70
arrêter le système d'exploitation invité 70
arrêter une machine virtuelle 75
mise hors tension autorisée 71
VMware Tools 71
actions
dépannage 76, 77, 79–85
exécutez 75
tâches récentes 78
vCenter Server 70
actions recommandées pour l'automatisation 74
ajouter des machines virtuelles et des hôtes,
nouveau projet 89
alerte
cancel 35, 36
Interrompre 36
propriété 36
recommandation 37
répondre 12–17, 19, 34
résoudre 37
surveillance 34–36
alerte par e-mail, répondre 12–17, 19
alertes
groupe d'objets 41
onglet Alertes d'objet 43
onglet résumé de l'objet 40
répondre 44
tableau de bord personnalisé 46
analyse de la charge de travail, défini 47
analyse des anomalies, défini 48
analyse des ressources 47
analyser les données de risque de capacité 67
arrêter la machine virtuelle, action 70
arrêter le système d'exploitation invité, action 70
augmenter la charge de travail, nouveau
projet 89
B
badge, Conformité 54
badge Anomalies, défini 48
Badge Capacité récupérable, défini 52
badge de conformité, basée sur des alertes 55
badge Pannes, défini 49
badges
anomalies 48
capacité 50
Capacité récupérable 52
capacité restante 50
charge de travail 47
contrainte 51
défaillances 49
densité 53
gaspillage récupérable 52
temps restant 50, 51
banques de données, espace gaspillé 68
Banques de données, espace pour les machines
virtuelles 67
C
cancel, alerte 35, 36
capacité
dans les banques de données pour les
machines virtuelles 67
défini 50
planification 88
restant(e) dans les clusters pour les machines
virtuelles 67
capacité restante, définie 50
cartes thermiques 64, 67
charge de travail
défini 47
hôte 67
chronologie, scénario utilisateur 60
clusters, capacité restante 67
comparaison des objets 66
comparaison des ressources 66
contrainte, définie 51
couleurs de cartes thermiques 64
création personnalisée, personnaliser 64
D
densité, définie 53
dépannage
actions 76, 77, 79–85
chronologie 56, 57
événements 56, 57
Scénario utilisateur
Résolution des problèmes 24
VMware, Inc. 95
Page 96

Guide de l'utilisateur de vRealize Operations Manager
Créer des tableaux de bord et des
vues 33
Résoudre le problème 30
Analyser l'état de votre
environnement 22
Créer une définition d'alerte 32
Examiner les détails de
l'environnement 26
Examiner les relations de
l'environnement 28
Vous détectez des problèmes en
surveillant l'état de vos
objets 20
symptômes 56, 57
tâches récentes 79–85
toutes les mesures 56, 58, 62
détails de cartes thermiques, meilleure
performance 65
E
environnement
inventaire 85
relations de l'objet 69
événements, scénario utilisateur 61
F
filter, liste des alertes 37
G
gaspillage
dans les machines virtuelles 68
parmi les banques de données 68
récupérer les banques de données 68
gaspillage récupérable, définition 52
glossaire 5
graphiques de mesures, scénario utilisateur 62
groupe d'objets, gérer des alertes 41
H
hôte, charge de travail 67
I
Interrompre, alerte 36
inventaire
affichage 85
présentation de l'environnement 85
L
lecture de cartes thermiques 64
liste de symptômes, scénario utilisateur 59
liste des alertes
filter 37
trier 36
M
machine virtuelle
action d'arrêt 75
action de mise hors tension 70
action de suppression de machine virtuelle
hors tension 70
action définir la CPU 70
action définir la mémoire 70
action mettre sous tension 70
exécuter l'action de définition de la CPU 75
exécuter l'action de définition de la
mémoire 75
exécuter l'action de mise hors tension 75
exécuter l'action de mise sous tension 75
exécuter l'action de suppression de la mise
hors tension 75
projets 93
machines virtuelles, gaspillage 68
meilleure performance 65
mémoire, mise hors tension autorisée 71
mise hors tension autorisée
action 71
mémoire 71
Nombre de CPU 71
moins bonne performance 65
N
Nombre de CPU, mise hors tension
autorisée 71
O
objet
recherche 8
surveillance 7
onglet alerte 43
onglet alertes
répondre 44
utilisation 9
onglet Alertes d'objet 43
onglet Chronologie
dépannage 57, 60
scénario utilisateur 15
utilisation 10
onglet dépannage, scénario utilisateur 58
onglet Dépannage
onglet Chronologie 10
onglet Événements 10
onglet Symptômes 10
onglet Toutes les mesures 10
utilisation 10
onglet Événements
dépannage 57
onglet dépannage 61
utilisation 10
96 VMware, Inc.
Page 97

Index
onglet graphiques de mesures, scénario
utilisateur 17
onglet relations, scénario utilisateur 16
onglet résumé, utilisation 9, 41
onglet Symptôme des objets, scénario
utilisateur 14
onglet Symptômes
dépannage 57, 59
utilisation 10
onglet Toutes les mesures
dépannage 58, 62
utilisation 10
onglets, à propos 39
P
planification, besoins de capacité futurs 88
présentation de l'environnement 69
problèmes
Scénario utilisateur :Analyser l'état de votre
environnement 22
Scénario utilisateur :Créer des tableaux de
bord et des vues 33
Scénario utilisateur :Créer une définition
d'alerte 32
Scénario utilisateur :Examiner les détails de
l'environnement 26
Scénario utilisateur :Examiner les relations de
l'environnement 28
Scénario utilisateur :Résoudre le problème 30
Scénario utilisateur :Résoudre les
problèmes 24
Scénario utilisateur :Vous détectez des
problèmes en surveillant l'état de vos
objets 20
projets
ajout de nouvelles machines virtuelles à partir
de machines existantes 92
combiner des résultats 90
matériel 91, 92
présentation 87
ressources de planification 87
suppression de machines virtuelles 94
projets de banque de données 91
projets de machine virtuelle, ajout de nouvelles
machines virtuelles à partir de
machines existantes 92
projets de matériel 91
propriété, alerte 36
Public ciblé 5
R
réagir aux problèmes
Scénario utilisateur :Analyser l'état de votre
environnement 22
Scénario utilisateur :Créer des tableaux de
bord et des vues 33
Scénario utilisateur :Créer une définition
d'alerte 32
Scénario utilisateur :Examiner les détails de
l'environnement 26
Scénario utilisateur :Examiner les relations de
l'environnement 28
Scénario utilisateur :Résoudre le problème 30
Scénario utilisateur :Résoudre les
problèmes 24
Scénario utilisateur :Vous détectez des
problèmes en surveillant l'état de vos
objets 20
recherche d'un objet 8
recommandation, alerte 37
recommandations, répondre à une alerte 19
règle, personnalisations de conformité 54
relations de l'objet, environnement 69
répondre
alerte 12–17, 19
alerte par e-mail 12–17, 19
alertes 44
répondre à une alerte, scénario
utilisateur 12–17, 19
résoudre, alerte 37
S
scénario hypothétiques, ajout de nouvelles
machines virtuelles 93
scénario utilisateur
chronologie 60
événements 61
graphiques de mesures 62
liste de symptômes 59
onglet dépannage 58
répondre à une alerte 12–17, 19
résolution des problèmes 7
Scénario utilisateur :Analyser l'état de votre
environnement 22
Scénario utilisateur :Créer des tableaux de
bord et des vues 33
Scénario utilisateur :Créer une définition
d'alerte 32
Scénario utilisateur :Examiner les détails de
l'environnement 26
Scénario utilisateur :Examiner les relations de
l'environnement 28
Scénario utilisateur :Résoudre le problème 30
Scénario utilisateur :Résoudre les
problèmes 24
Scénario utilisateur :Vous détectez des
problèmes en surveillant l'état de vos
objets 20
scénarios
matériel 91
un utilisateur appelle pour faire part d'un
problème 8–10
VMware, Inc. 97
Page 98

Guide de l'utilisateur de vRealize Operations Manager
vous parcourez l'environnement
Scénario utilisateur :Analyser l'état de
votre environnement 22
Scénario utilisateur :Créer des
tableaux de bord et des
vues 33
Scénario utilisateur :Créer une
définition d'alerte 32
Scénario utilisateur :Examiner les
détails de
l'environnement 26
Scénario utilisateur :Examiner les
relations de
l'environnement 28
Scénario utilisateur :Résoudre le
problème 30
Scénario utilisateur :Résoudre les
problèmes 24
Scénario utilisateur :Vous détectez
des problèmes en surveillant
l'état de vos objets 20
scénarios d'hôtes 91
scénarios de banques de données 91
scénarios de machines virtuelles, suppression
de machines virtuelles 94
scénarios de matériel 91
snapshots
exécuter l'action de suppression des
ressources inutilisées 75
supprimer une action inutilisée 70
surveillance
alerte 35, 36
tâches récentes 78
surveiller des objets 7
vue détaillée
comparaison des ressources 66
moins bonne performance 65
T
tableau de bord, personnalisé 46
tableau de bord personnalisé
alertes 46
utilisation 46
tâches, surveillance 78
tâches récentes
actions 78
dépannage 79–85
surveillance 78
temps restant, défini 50
trier, liste des alertes 36
U
utiliser 5
V
VMware Tools, action 71
vRealize Configuration Manager, à l'ensemble
de règles 54
98 VMware, Inc.
 Loading...
Loading...