

SGS Thomson Microelectronics ST20GP1X33S Datasheet
ST20-GP1
GPS PROCESSOR
FEATURES
■ Application specific features
• 12 channel GPS correlation DSP hardware
and ST20 CPU (for control and position caluculations) on one chip
• no TCXO required
• RTCA-SC159 / WAAS / EGNOS supported
■ GPS performance
• accuracy
- stand alone
with SA on <100m, SA off <30m
- differential <1m
- surveying <1cm
• time to first fix
- autonomous start 90s
- cold start 45s
- warm start 7s
- obscuration 1s
■ 32-bit ST20 CPU
• 16/33 MHz processor clock
• 25 MIPS at 33 MHz
• fast integer/bit operations
■ 4 Kbytes on-chip SRAM
• 130 Mbytes/s maximum bandwidth
■ Programmable memory interface
• 4 separately configurable regions
• 8/16-bits wide
• support for mixed memory
• 2 cycle external access
■ Serial communications
• Programmable UART (ASC)
• OS-Link
■ Vectored interrupt subsystem
• 2 dedicated interrupt pins
• 5 levels of interrupt
■ Power management
• low power operation
• power down modes
■ Professional toolset support
• ANSI C compiler and libraries
• INQUEST advanced debugging tools
■ Technology
• Static clocked 50 MHz design
• 3.3 V, sub micron technology
■ 100 pin PQFP package
ENGINEERING DATA
GPS
radio
ST20-GP1
12 channel GPS
hardware DSP
Low
power
controller
Real time
clock/calendar
4K
SRAM
Programmable
memory
interface
RAM
APPLICATIONS
■ Global Positioning System (GPS) receivers
■ Car navigation systems
■ Fleet management systems
■ Time reference for telecom systems
ROM/
FLASH
ST20
CPU
Interrupt
controller
Serial
communications
2 UART (ASC)
1 OS-Link
Parallel
input/output
Byte-wide
parallel port
.
.
6
.
.
.
8
.
October 1996
The information in this datasheet is subject to change
1/116
42 1672 02

Contents
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 ST20-GP1 architecture overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3 Digital signal processing module . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1 DSP module registers .......................................................................................................................... 13
4 Central processing unit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.1 Registers .............................................................................................................................................. 18
4.2 Processes and concurrency ................................................................................................................ 19
4.3 Priority .................................................................................................................................................. 21
4.4 Process communications ..................................................................................................................... 21
4.5 Timers .................................................................................................................................................. 22
4.6 Traps and exceptions .......................................................................................................................... 23
5 Interrupt controller . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.1 Interrupt vector table ............................................................................................................................ 29
5.2 Interrupt handlers ................................................................................................................................. 29
5.3 Interrupt latency ................................................................................................................................... 30
5.4 Pre-emption and interrupt priority ........................................................................................................30
5.5 Restrictions on interrupt handlers ........................................................................................................ 30
5.6 Interrupt configuration registers ........................................................................................................... 31
6 Instruction set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
6.1 Instruction cycles .................................................................................................................................34
6.2 Instruction characteristics ....................................................................................................................35
6.3 Instruction set tables ............................................................................................................................ 36
7 Memory map . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
7.1 System memory use ............................................................................................................................ 45
7.2 Boot ROM ............................................................................................................................................ 46
7.3 Internal peripheral space .....................................................................................................................46
8 Memory subsystem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
8.1 SRAM .................................................................................................................................................. 49
9 Programmable memory interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
9.1 EMI signal descriptions ........................................................................................................................ 51
9.2 Strobe allocation .................................................................................................................................. 52
9.3 External accesses ................................................................................................................................ 52
2/116

ST20-GP1
9.4 MemWait .............................................................................................................................................. 56
9.5 EMI configuration registers .................................................................................................................. 58
9.6 Reset and bootstrap behavior .............................................................................................................. 59
10 Clocks and low power controller . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
10.1 Clocks .................................................................................................................................................. 61
10.2 Low power control ................................................................................................................................ 61
10.3 Low power configuration registers ....................................................................................................... 63
10.4 Clocking sources ................................................................................................................................. 65
11 System services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
11.1 Reset, initialization and debug ............................................................................................................. 67
11.2 Bootstrap ............................................................................................................................................. 68
12 Serial link interface (OS-Link) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
12.1 OS-Link protocol .................................................................................................................................. 70
12.2 OS-Link speed ..................................................................................................................................... 70
12.3 OS-Link connections ............................................................................................................................ 71
13 UART interface (ASC) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
13.1 Asynchronous serial controller operation ............................................................................................. 73
13.2 Hardware error detection capabilities ..................................................................................................76
13.3 Baud rate generation ...........................................................................................................................76
13.4 Interrupt control .................................................................................................................................... 77
13.5 ASC configuration registers ................................................................................................................. 79
14 Parallel input/output . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
14.1 PIO Port ............................................................................................................................................... 85
15 Byte-wide parallel port . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
15.1 EMI mode operation ............................................................................................................................ 88
15.2 Parallel link (DMA) mode operation ..................................................................................................... 88
15.3 Configuration registers ......................................................................................................................... 88
15.4 External data transfer protocols ........................................................................................................... 89
16 Configuration register addresses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
17 Electrical specifications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
18 GPS Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
18.1 Accuracy ............................................................................................................................................ 100
18.2 Time to first fix ................................................................................................................................... 101
3/116

ST20-GP1
19 Timing specifications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
19.1 EMI timings ........................................................................................................................................ 102
19.2 Link timings ........................................................................................................................................ 104
19.3 Reset and Analyse timings ................................................................................................................105
19.4 ClockIn timings .................................................................................................................................. 106
19.5 Parallel port timings ...........................................................................................................................107
20 Pin list . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
21 Package specifications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
21.1 ST20-GP1 package pinout ................................................................................................................ 112
21.2 100 pin PQFP package dimensions .................................................................................................. 113
22 Device ID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
23 Ordering information . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
4/116
ST20-GP1
1 Introduction
The ST20-GP1 is an application-specific single chip micro using the ST20 CPU with
microprocessor style peripherals added on-chip. It incorporates DSP hardware for processing the
signals from GPS (Global Positioning System) satellites.
The twelve channel GPS correlation DSP hardware is designed to handle twelve satellites, two of
which can be initialized to support the RTCA-SC159 specification for WAAS (Wide Area
Augmentation Service) and EGNOS (European Geostationary Navigation Overlay System)
services.
The ST20-GP1 has been designed to minimize system costs and reduce the complexity of GPS
systems. It offers all hardware DSP and microprocessor functions on one chip. Whilst the entire
analogue section, RF and clock generation are available on a companion chip. Thus, with the
addition of a ROM and a RAM chip, a complete GPS system is possible using just four chips, see
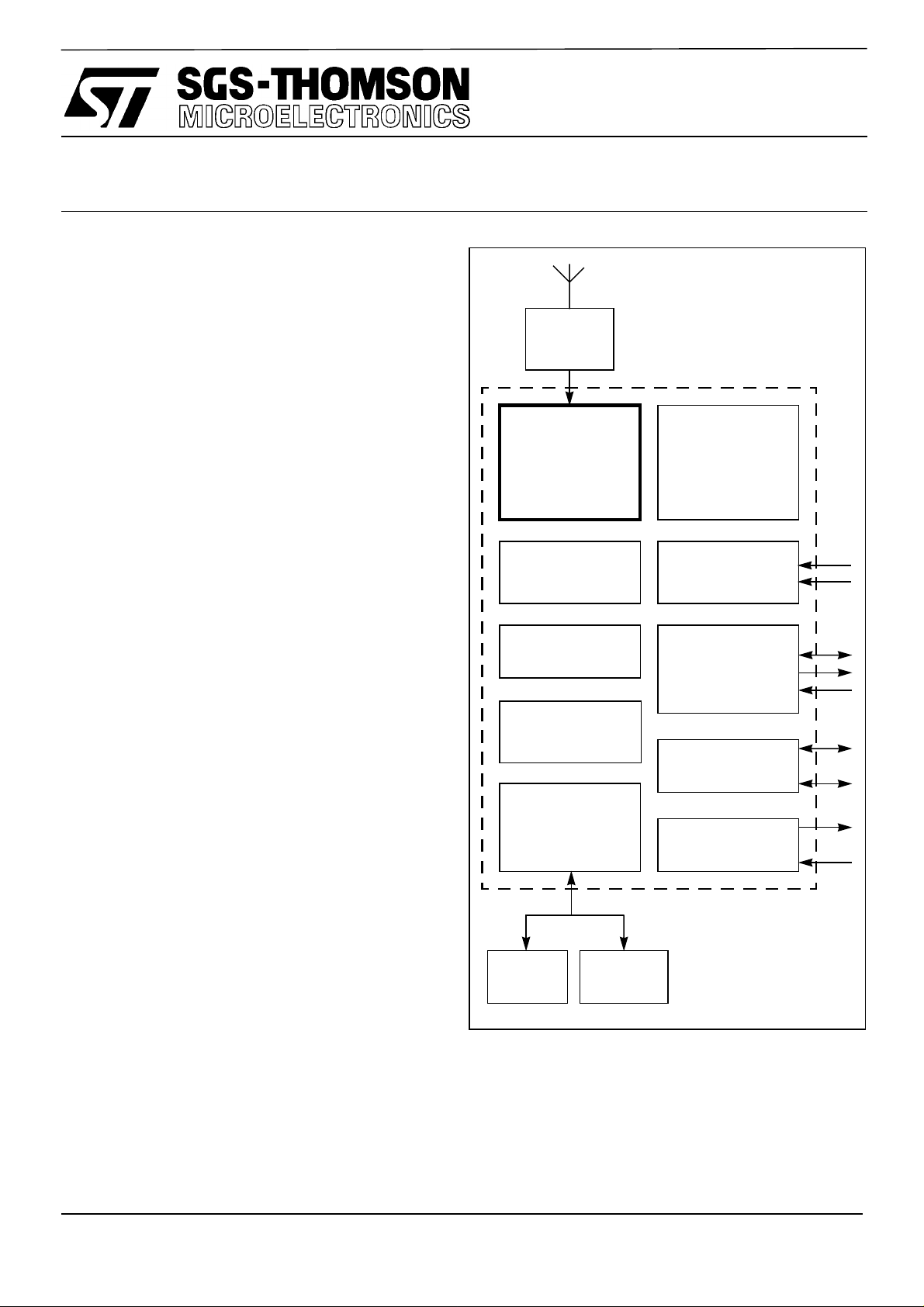
Figure 1.1.
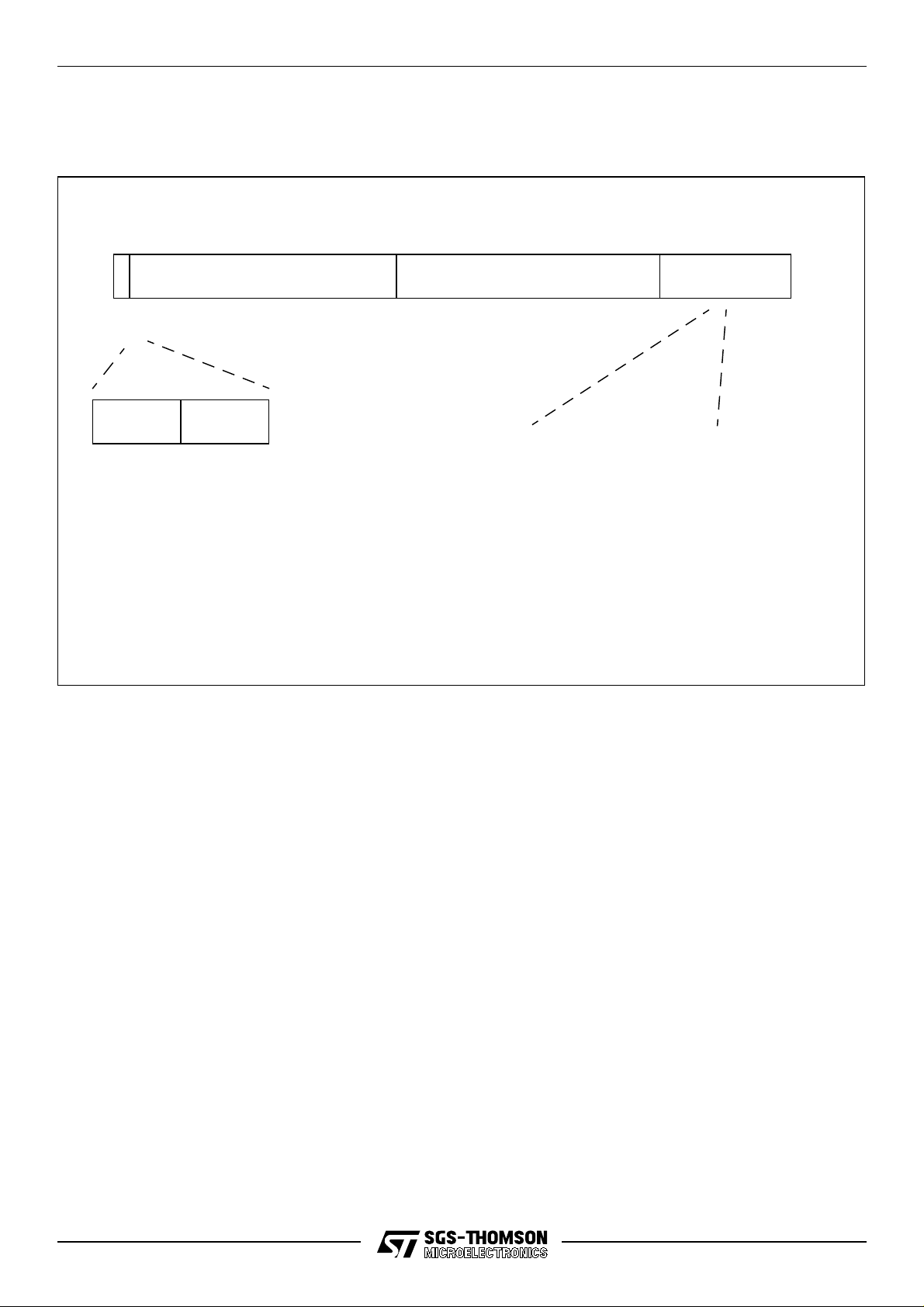
Antenna
Radio
Single chip
Low
cost
crystal
No TCXO
ST20-GP1
DSP
ASIC
CPU
Watchdog
timer
RAMROM
UART
Real
time
clock
Driver
(optional)
Parallel I/O
Figure 1.1 GPS system
The ST20-GP1 supports large values of frequency offset, allowing the use of a very low cost
oscillator, thus saving the cost of a Temperature Controlled Crystal Oscillator (TCXO).
The CPU and software have access to the part-processed signal to enable accelerated acquisition
time.
The ST20-GP1 can implement the GPS digital signal processing algorithms using less than 50% of
the available CPU processing power. This leaves the rest available for integrating OEM application
functions such as route-finding, map display and telemetry. A hardware microkernel in the ST20
5/116

ST20-GP1
CPU supports the sharing of CPU time between applications without an operating system or
executive overhead.
The architecture is based on the ST20 CPU core and supporting macrocells developed by SGSTHOMSON Microelectronics. The ST20 micro-core family provides the tools and building blocks to
enable the development of highly integrated application specific 32-bit devices at the lowest cost
and fastest time to market. The ST20 macrocell library includes the ST20Cx family of 32-bit VLRISC (variable length reduced instruction set computer) micro-cores, embedded memories,
standard peripherals, I/O, controllers and ASICs.
The ST20-GP1 uses the ST20 macrocell library to provide the hardware modules required in a
GPS system. These include:
• DSP hardware
• Dual channel UART for serial communications
• 6 bits of parallel I/O
• Interrupt controller
• Real time clock/calendar
• Watchdog timer
The ST20-GP1 is supported by a range of software and hardware development tools for PC and
UNIX hosts including an ANSI-C ST20 software toolset and the ST20 INQUEST window based
debugging toolkit.
6/116

ST20-GP1
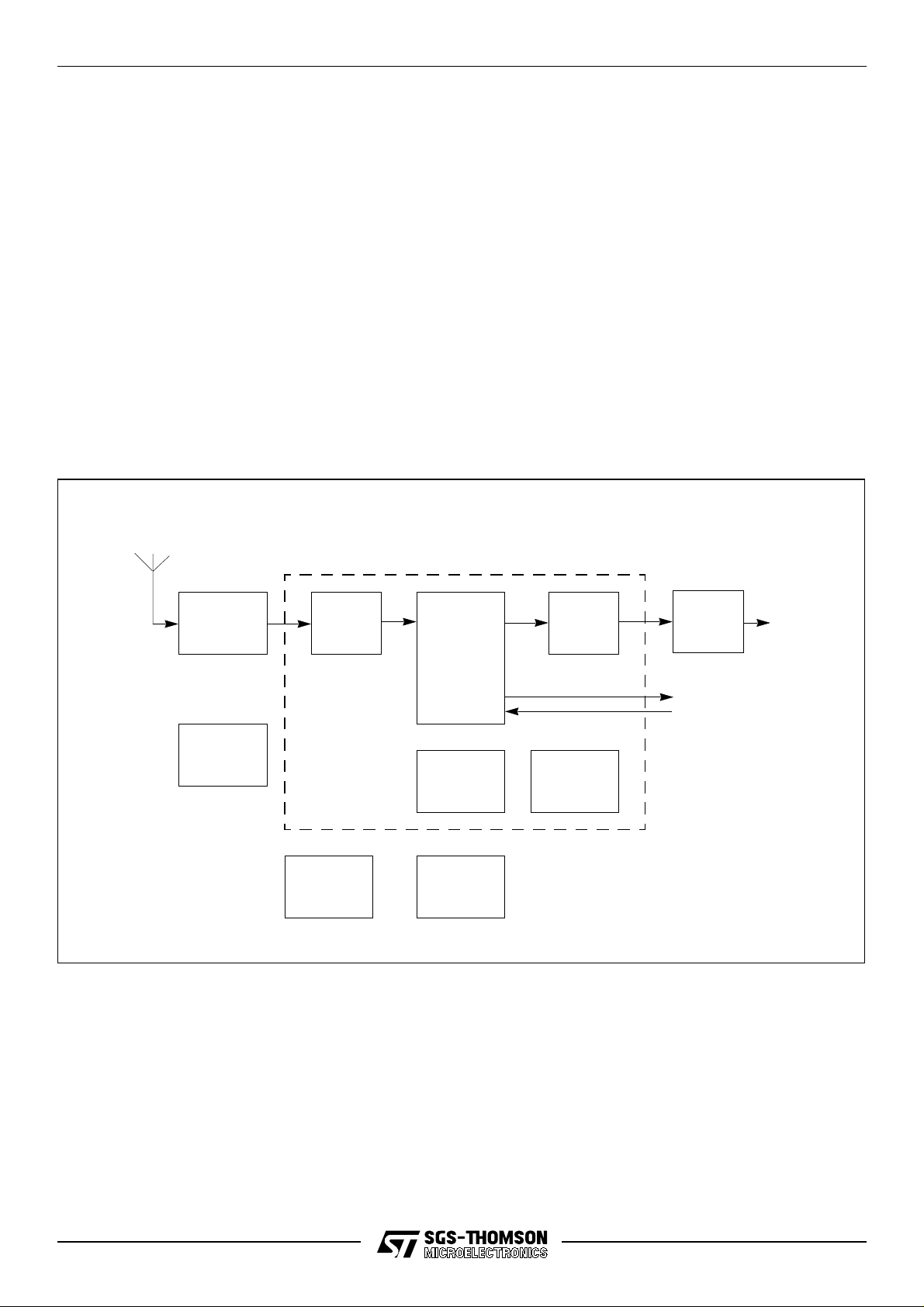
2 ST20-GP1 architecture overview
The ST20-GP1 consists of an ST20 CPU plus application specific DSP hardware for handling GPS
signals, plus a dual channel U AR T, 8-bit parallel half-duple x link interface, 6-bit parallel IO, real time
clock and watchdog functions.
Figure 2.1 shows the subsystem modules that comprise the ST20-GP1. These modules are
outlined below and more detailed information is given in the following chapters.
DSP
The ST20-GP1 includes DSP hardware for processing signals from the GPS satellites. The DSP
module generates the pseudo-random noise (prn) signals, and de-spreads the incoming signal.
It consists of a down conversion stage that takes the 4 MHz input signal down to nominally zero
frequency both in-phase and quadrature (I & Q). This is followed by 12 parallel hardware channels
for satellite tracking, whose output is passed to the CPU for further software processing at a
programmable interval, nominally every millisecond.
CPU
The Central Processing Unit (CPU) on the ST20-GP1 is the ST20 32-bit processor core. It contains
instruction processing logic, instruction and data pointers, and an operand register. It directly
accesses the high speed on-chip memory, which can store data or programs. The processor can
access up to 4 Mbytes of memory via the programmable memory interface.
7/116
ST20-GP1
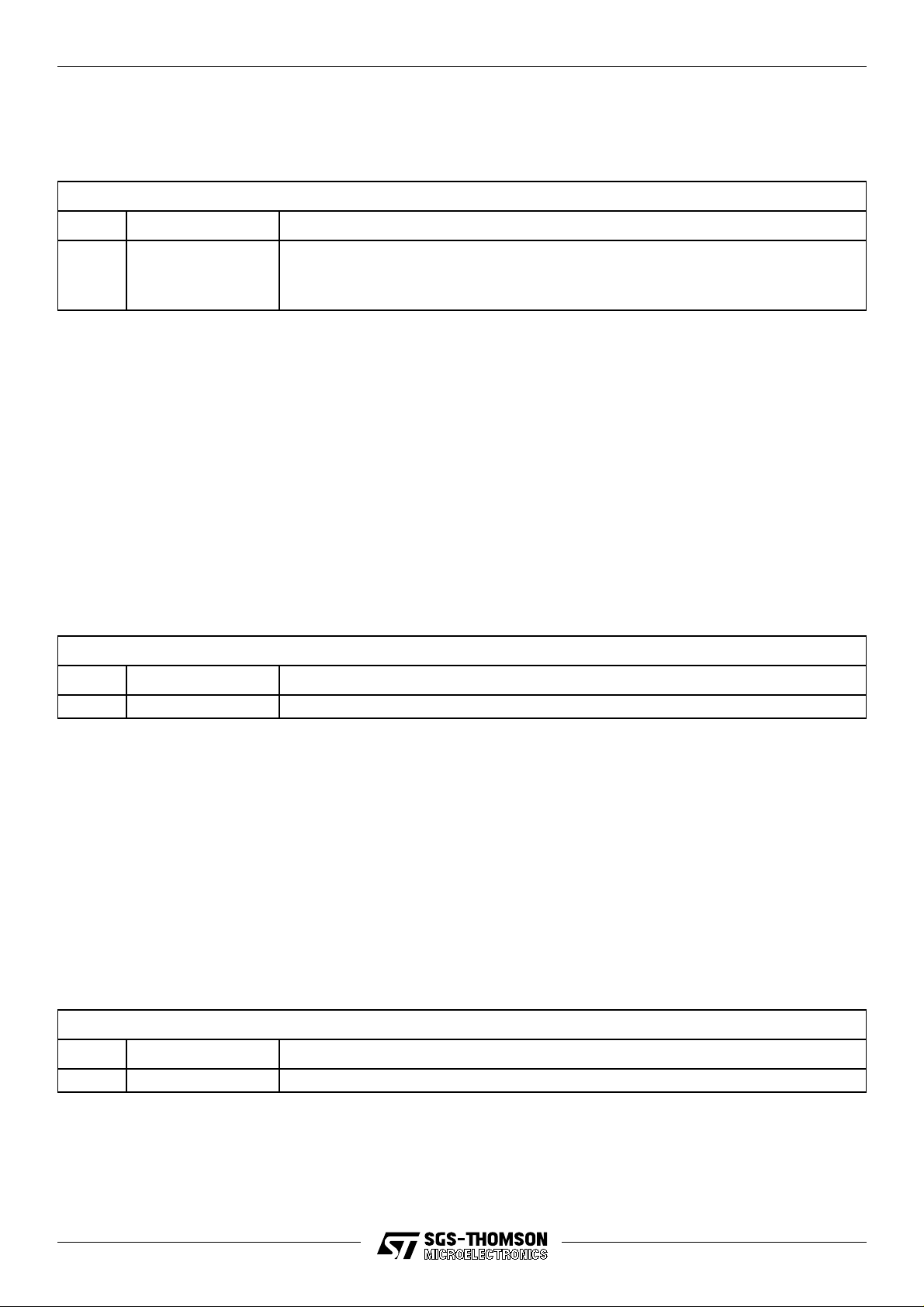
GPS
radio
ST20-GP1
Interrupts
12 channel GPS
hardware DSP
Interrupt
controller
Low
power
controller
Real time
clock
4K
SRAM
Programmable
memory
interface
ST20
CPU
Serial
communications
2 UART
1 OS-Link
Parallel
input/output
Byte-wide
parallel
port
System
services
.
.
6
.
.
.
8
.
OS-Link
Reset
Analyse
Error
Clock
User position
output in
ASCII
8/116
RAM
ROM/
FLASH
Figure 2.1 ST20-GP1 architectural block diagram

ST20-GP1
Memory subsystem
The ST20-GP1 on-chip memory system provides 130 Mbytes/s internal data bandwidth,
supporting pipelined 2-cycle internal memory access at 30 ns cycle times. The ST20-GP1 memory
system consists of SRAM and a programmable memory interface. The programmable memory
interface is also referred to as an external memory interface (EMI).
The ST20-GP1 uses 8 or 16-bit external RAM, 8 or 16-bit ROM, and supports an address width of
20 bits.
The ST20-GP1 product has 4 Kbytes of on-chip SRAM. The advantage of this is the ability to store
time critical code on chip, for instance interrupt routines, software kernels or device drivers, and
even frequently used data.
The ST20-GP1 memory interface controls the movement of data between the ST20-GP1 and offchip memory. It is designed to support memory subsystems without any external support logic and
is programmable to support a wide range of memory types. Memory is divided into 4 banks which
can each have different memory characteristics and each bank can access up to 1 Mbyte of
external memory.
The normal memory provision in a simple GPS receiv er is a single 128K x 8-bit SRAM (55 or 70 ns
access time), and a single 64K x 16-bit ROM or Flash ROM (70, 90 or 100 ns access time). The
ST20-GP1 can support up to 1 Mbyte of SRAM plus 1 Mbyte of ROM, enabling additional
applications to be loaded if required.
Low power controller, real time clock and watchdog timer
The ST20-GP1 has power-down capabilities configurable in software. When powered down, a
timer can be used as an alarm, re-activating the CPU after a programmed dela y. This is suitable f or
ultra low power or solar powered applications such as container tracking, railway truck tracking, or
marine navigation buoys that must check they are on station at intervals. The timer can also be
used to provide a watchdog function, resetting the system if it times out.
The real time clock/calendar function is provided by a 64-bit binary counter running continuously
from the low-power clock (nominally 32768 Hz).
The ST20-GP1 is designed for 0.5 micron, 3.3 V CMOS technology and runs at speeds of up to
33 MHz. 3.3 V operation provides reduced power consumption internally and allows the use of low
power peripherals. In addition, a power-down mode is available on the ST20-GP1.
The different power levels of the ST20-GP1 are listed below.
• Operating power — power consumed during functional operation.
• Stand-by power — power consumed during little or no activity. The CPU is idle but ready to
immediately respond to an interrupt/reschedule.
• Power-down — clocks are stopped and power consumption is significantly reduced. Functional operation is stalled. Normal functional operation can be resumed from previous state
as soon as the clocks are stable. No information is lost during power down as all internal
logic is static.
• Power to most of the chip removed — only the real time clock supply (RTCVDD) power on.
In power-down mode the processor and all peripherals are stopped, including the e xternal memory
controller and optionally the PLL. Effectively the internal clock is stopped and functional operation
is stalled. On restart the clock is restarted and the chip resumes normal functional operation.
9/116

ST20-GP1
Serial communications
The ST20-GP1 has two UARTs (Asynchronous Serial Controllers (ASCs)) for serial
communication. The UARTs provide an asynchronous serial interface and can be programmed to
support a range of baud rates and data formats, for example, data size, stop bits and parity.
There is one OS-Link on the ST20-GP1 which acts as a DMA engine independent of the CPU. The
OS-Link uses an asynchronous bit-serial (byte-stream) protocol, each bit received is sampled five
times, hence the term
oversampled link
(OS-Link). The OS-Link provides a pair of channels, one
input and one output channel. The link is used for:
• bootstrapping during development,
• debugging,
• communicating with OS-Link peripherals or other ST20 devices.
Interrupt subsystem
The ST20-GP1 interrupt subsystem supports five prioritized interrupts. Three interrupts are
connected to on-chip peripherals (2 for the UARTs, 1 for the programmable IO) and two are
available as external interrupt pins.
All interrupts are at a higher priority than the high priority process queue. Each interrupt lev el has a
higher priority than the previous and each level supports only one software handler process.
Note that interrupt handlers must not prevent the GPS DSP data tr affic from being handled. During
continuous operation this has 1 ms latency and is not a problem, but during initial acquisition it has
a 32 µs rate and thus all interrupts must be disabled except if used to stop GPS operation.
Byte-wide parallel port
The byte-wide parallel port is provided to communicate with an external device. It transfers a byte
at a time, operating half duplex in the program-selected direction.
Parallel IO module
Six bits of parallel IO are provided. Each bit is programmable as an output or an input. Edge
detection logic is provided which can generate an interrupt on any change of an input bit.
System services module
The ST20-GP1 system services module includes:
• reset, initialization and error port.
• phase locked loop (PLL) — accepts 16.368 MHz input and generates all the internal high
frequency clocks needed for the CPU and the OS-Link.
10/116
ST20-GP1
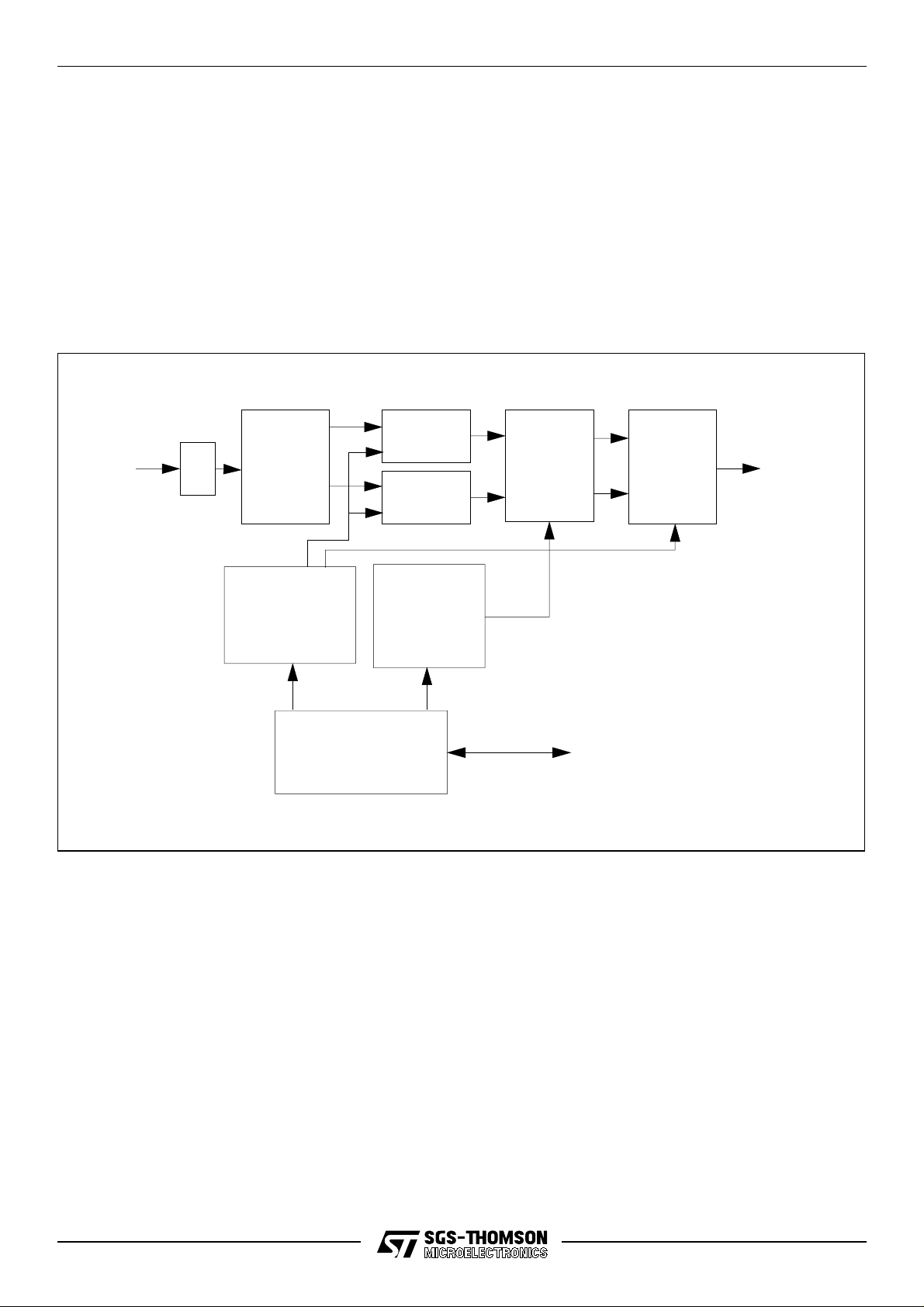
3 Digital signal processing module
The ST20-GP1 chip includes 12 channel GPS correlation DSP hardware. It is designed to handle
twelve satellites, two of which can be initialized to support the RTCA-SC159 specification.
The digital signal processing (DSP) module extracts GPS data from the incoming IF (Intermediate
Frequency) data. There are a number of stages of processing involved; these are summarized
below and in Figure 3.1. After the 12 pairs of hardware correlators, the data for all channels are
time division multiplexed onto the appropriate internal buses (i.e. values for each channel are
passed in sequence, for example: I
, Q1, I2, Q2 ... I12, Q12, I1, Q1).
1
4 MHz IF
input
data
sampler
frequency
converter A
Pseudo random
noise sequence
generator
(x 12)
ST20 CPU accessible
registers
I correlator
(x 12)
Q correlator
(x 12)
Numerically
controlled
oscillator
frequency
converter B
DMA
interface
accumulator
Figure 3.1 DSP module block diagram
The main stages of processing are as follows:
Data sampling
This stage removes any meta-stability caused by the asynchronous input data coming from an
analogue source (the radio receiver). The data at this point consists of a carrier of nominally
4.092 MHz with a bandwidth of approximately ±1 MHz.
This stage is common to all 12 channels.
Frequency conversion (A)
The first frequency converter mixes the sampled IF data with the (nominal) 4.092 MHz signal. This
is done twice with a quarter cycle offset to produce I and Q (In-phase and Quadrature) versions of
the data at nominal zero centre frequency (this can actually be up to ±132 KHz due to errors such
11/116

ST20-GP1
as doppler shift, crystal accuracy, etc.). The sum frequency (~8 MHz) is removed by low-pass
filtering in the correlator.
This stage is common to all 12 channels.
Correlation against pseudo-random sequence
The GPS data is transmitted as a spread-spectrum signal (with a bandwidth of about 2 MHz). In
order to recover the data it is necessary to correlate against the same Pseudo-Random Noise
(PRN) signal that was used to transmit the data. The output of the correlator accumulator is
sampled at 264 KHz. The PRN sequences come from the PRN generator.
There is a correlator for the I and Q signals for each of the 12 channels. The output signal is now
narrowband.
Frequency conversion (B)
The second stage of frequency conversion mixes the data with the local oscillator signal generated
by the Numerically Controlled Oscillator (NCO). This signal is locked, under softw are control, to the
Space Vehicle (SV) frequency and phase to remove the errors and take the frequency and
bandwidth of the data down to 0 and ±50 Hz respectively. Filtering to 500 Hz is achieved in
hardware, to 50 Hz in software.
This stage is shared by time division multiplexing between all 12 channels. This is loss-free as the
stage supports 12 channels x 264 KHz, approximately 3 MHz, well within its 16 MHz clock rate.
Result integration
The final stage sums the I and Q values for each channel over a user defined period. In normal
operation, the sampling period is slightly less than the 1ms length of the PRN sequence. This
ensures that no data is lost, although it may mean that some data samples are seen twice — this is
handled (mainly) in software.
The sampling period can also be programmed to be much shorter (i.e. a higher cut-off frequency
for the filter) when the system is trying to find new satellites (‘acquisition mode’).
There are two further stages of buffering for the accumulated 16-bit I and Q values for each
1
channel. These allow for the slightly different time domains involved
.
The results after hardware processing of the signal, using the parameters set in the DSP registers,
refer to Section 3.1, are delivered to the CPU via a DMA engine in packet format. The CPU should
in
perform an
(input) instruction on the appropriate channel (see address map, Figure 7.1 on
page 47) in order to read a packet.
The format of the 62-byte packets is given in Figure 3.2. These represent a two byte header,
followed b y the 16-bit I-v alues for 12 channels, then the 16-bit Q-values for 12 channels, then the 8bit timestamp values for the 12 channels. The I and Q values are sent least significant byte first.
The 2 byte header contains: a ‘sync’ byte with the value #1B, and a ‘sample rate’ byte which
contains the two SampleRate bits from the DSPControl register, see Table 3.1.
Packets are delivered at the rate selected by the DSPControl register, even if new data is not
availab le . In this case, the data v alue f or the field is set to #8000. This guar antees that synchronism
1. Data sampled in SV time, data transmitted to the CPU at fixed intervals.
12/116
ST20-GP1
is maintained between the satellite one-millisecond epochs and the receiver, despite time-ofreception variations due to the varying path length from the satellite.
62 byte packet every 840/970/31/62 µs
16-bit
header
sync
12 x 16-bit
I values
sample
rate
12 x 16-bit
Q values
Absent 16-bit values padded with #8000
Tracking mode
T[7:6] = 10
T[5:0] = time[5:0]
Figure 3.2 DSP packet format
12 x 8-bit
time values
Acquisition mode
First packet (in SV ms)
T[7:6] = 10
T[5:0] = time[5:0]
Remaining packets
T[7:6] = 00
T[5:0] = sequence number
(sequence numbers are 2 to
16 or 32)
3.1 DSP module registers
The GPS hardware channels of the ST20-GP1 are controlled by three sets of registers:
1 DSPControl register
2 PRNcode0-11 and PRNphase0-11 registers
3 NCOfrequency0-11 and NCOphase0-11 registers
The base addresses for the DSP registers are given in the Memory Map chapter.
DSPControl register
The DSPControl register determines whether the PRN generators are on (normal use) or disabled
(for built-in-self-test of a system), whether the system is in tracking mode (840/970 µs output rate)
or initial acquisition mode (31/62 µs), and selects which of the two rates for each mode. It also
determines whether the accumulated carrier phase in the NCO are reset to zero automatically or
continue from their existing value. The bit allocations are given in Table 3.1.
13/116

ST20-GP1
DSPControl DSP base address + #140 Write only
Bit Bit field Function
1:0 SampleRate These bits control the sampling rate (the rate at which data is sent to the DMA
controller). The encoding of these bits is as follows:
SampleRate[1:0] Transfer period
00 840 µs 256 Tracking
01 970 µs 256
10 31 µs 8 Acquisition
11 62 µs16
2NCOResetEnable When set to 1, the accumulated NCO phase for a channel is reset when the corre-
sponding PRN code register is written.
3 PRNDisable When set to 1, all PRN generators are disabled.
No. of samples
accumulated
Mode
Table 3.1 DSPControl register format
PRNcode0-11 registers
The PRNcode0-11 registers choose the code for the particular satellite, and writing these causes a
reset to the accumulated carrier phase in the NCO for the corresponding channel, if enabled by the
DSPControl register.
PRNcode0-11 DSP base address + #00 to #2C Write only
Bit Bit field Function
6:0 PRNcode Satellite code as a 7-bit value.
Table 3.2 PRNcode0-11 register format
The bit-fields for selecting particular GPS satellites are given in Table 3.3.
Satellite ID
1 #62 6 2
2 #73 7 3
3 #04 8 4
4 #15 9 5
5 #11 9 1
6 #22 10 2
7 #01 8 1
8 #12 9 2
9 #23 10 3
10 #32 3 2
11 #43 4 3
12 #65 6 5
13 #76 7 6
14 #07 8 7
15 #18 9 8
PRNcode0-11
register value
Taps selected from G2 shift register
by bits 6 to 4 by bits 3 to 0
a
14/116
Table 3.3 PRNcode0-11 register value

ST20-GP1
Satellite ID
16 #29 10 9
17 #41 4 1
18 #52 5 2
19 #63 6 3
20 #74 7 4
21 #05 8 5
22 #16 9 6
23 #31 3 1
24 #64 6 4
25 #75 7 5
26 #06 8 6
27 #17 9 7
28 #28 10 8
29 #61 6 1
30 #72 7 2
31 #03 8 3
32 #14 9 4
- #25 10 5
- #24 10 4
- #71 7 1
- #02 8 2
- #24 10 4
b
WAAS
PRNcode0-11
register value
#20 10 0
Taps selected from G2 shift register
by bits 6 to 4 by bits 3 to 0
a
Table 3.3 PRNcode0-11 register value
a. Refer to the US DoD document ICD-GPS-200.
b. It is the responsibility of the software to ensure that when this value is selected, a suitable value has
been written into the PRNinitialVal0-1 register. If this channel is later used for a standard GPS satellite, the PRNinitialVal0-1 must be set to all ones (#3FF).
For channels 0 and 1, RTCA-SC159 satellite codes can also be selected. This is achieved by
setting the PRNcode0-11 register appropriately and also writing the initial value for the satellite to
the PRNinitialVal0-1 register, see Table 3.8. If uninitialized by the software, the PRNinitialVal
register defaults to 11 1111 1111 (#3FF) as required for GPS satellites.
The PRNcode0-11 and PRNinitialVal0-1 registers are normally written only when the satellite is
first chosen.
PRNphase0-11 registers
The PRN0-11phase registers determine the relative delay between the receiver master clock, and
the start of the one millisecond repetitive code sequence. The code sequence starts when the
receiver clock counter (invisible to the software except through message timestamps) reaches the
value written to the PRNphase0-11 register. The PRNphase0-11 register must only be written
once per satellite milliseconds-epoch, which varies from the receiver epoch dynamically due to
satellite motion. Synchronism with the software is achieved by reading the register, when a wr ite
enable flag is returned. If not enabled, the write operation is abandoned by the software.
15/116
ST20-GP1
The 19-bit value comprises three fields. The 3 least significant bits represent the fractional-delay in
eighths of a code-chip. The middle 10 bits represent the integer delay in code-chips, 0-1022, with
the value 1023 illegal. The upper 6 most significant bits represent the dela y in integer milliseconds.
PRNphase0-11 DSP base address + #40 to #6C Write only
Bit Bit field Function
2:0 FractionalDelay Fractional delay in eighths of a code-chip.
12:3 IntegerDelay Integer delay in code-chips. Value 0-1022. Note, the value 1023 is illegal.
18:13 Delay Delay in integer milliseconds.
Table 3.4 PRNphase0-11 register format
Note also that the eighth-chip resolution of the code generator is not sufficient for positioning. At
125 ns it represents approximately 40 m of range, over 100 m of position. The software must
maintain the range measurements around the 1 ns resolution level in a 32-bit field, and send an
appropriate 19-bit sub-field to the register. Note, care m ust be taken when calculating this field from
a computed delay, or vice versa, to allow for the missing value 1023. The overall register bit-field
cannot be used mathematically as a single binary number.
PRNphase0-11WrEn registers
The PRNphase0-11WrEn flags are active low flags that record when the PRNphase0-11 register
can be updated. The PRNphaseWrEn flag for a channel is set high when the corresponding
PRNphase register is written. The flag is reset again when the value written is loaded into the PRN
generator. Note, the PRNphase0-11 register should only be updated when the PRNphase0-
11WrEn register has been cleared by the hardware.
PRNphase0-11WrEn DSP base address + #40 to #6C Read only
Bit Bit field Function
0 PRNphaseWrEn Set when the corresponding PRNphase0-11 register is set.
Table 3.5 PRNphase0-11WrEn register format
NCOfrequency0-11 registers
The NCOfrequency0-11 registers hold a signed 18-bit value that is added repetitively, ignoring
overflows, to the accumulated NCO phase from which the NCO sine and cosine waveforms are
generated. The addition is performed at a 264 KHz rate (16.368MHz/62). The accumulated NCO
phase is not accessible to the software, but can be cleared when initialising the channel if enabled
by the DSPControl register.
18
Each unit value in the NCOfrequency0-11 register represents 264KHz/(2
), i.e.
1.007080078125 Hz.
If the extreme values are written, #1FFFF and #20000, the sine wave generated will be at
approximately +132 KHz, and precisely -132 KHz respectively.
NCOfrequency0-11 DSP base address + #80 to #AC Write only
Bit Bit field Function
17:0 NCOfrequency NCO frequency as a signed 18-bit value.
Table 3.6 NCOfrequency0-11 register format
16/116

ST20-GP1
NCOphase0-11 registers
The NCOphase0-11 registers contents are added to the accumulated phase to correct the carrier
for the final 1 Hz that cannot be resolved by the NCO frequency. This addition is not cumulative,
and the value must be updated regularly by the software as a result of carrier phase errors
measured on the satellite signal. The register holds a signed 7-bit field representing +/-180
degrees total in steps of 2.8125 degrees (360/128).
NCOphase0-11 DSP base address + #C4 to #EC Write only
Bit Bit field Function
6:0 NCOphase NCO phase as a signed 7-bit value representing +/-180 degrees total in steps of
2.8125 degrees (360/128).
Table 3.7 NCOphase0-11 register format
PRNinitialVal0-1 registers
The initial value for the two RTCA-SC159 capable satellites channels should be written to the
PRNinitialVal0-1 registers. The value can be found in the
RTCA-SC159 Specification
.
Note: The value written to the register is the Initial Value defined by RTCA-SC159 for the PRN
required. The conversion from ‘big-endian’ as used in the specification to ‘little-endian’ as
conventionally used in ST20 architectures has been implemented in the hardware.
If uninitialized by the software, this register defaults to 11 1111 1111 (#3FF) as required for GPS
satellites.
PRNinitialVal0-1 DSP base address + #100, #104 Write only
Bit Bit field Function
9:0 InitialValue Initial value of the RTCA-SC159 satellite channel.
Table 3.8 PRNinitialVal0-1 register format
17/116

ST20-GP1
4 Central processing unit
The Central Processing Unit (CPU) is the ST20 32-bit processor core. It contains instruction
processing logic, instruction and data pointers, and an operand register. It can directly access the
high speed on-chip memory, which can store data or programs. Where larger amounts of memory
are required, the processor can access memory via the External Memory Interface (EMI).
The processor provides high performance:
• Fast integer multiply — 3 cycle multiply
• Fast bit shift — single cycle barrel shifter
• Byte and part-word handling
• Scheduling and interrupt support
• 64-bit integer arithmetic support
The scheduler provides a single level of pre-emption. In addition, multi-level pre-emption is
provided by the interrupt subsystem, see Chapter 5 for details. Additionally, there is a per-priority
trap handler to improve the support for arithmetic errors and illegal instructions, ref er to section 4.6.
4.1 Registers
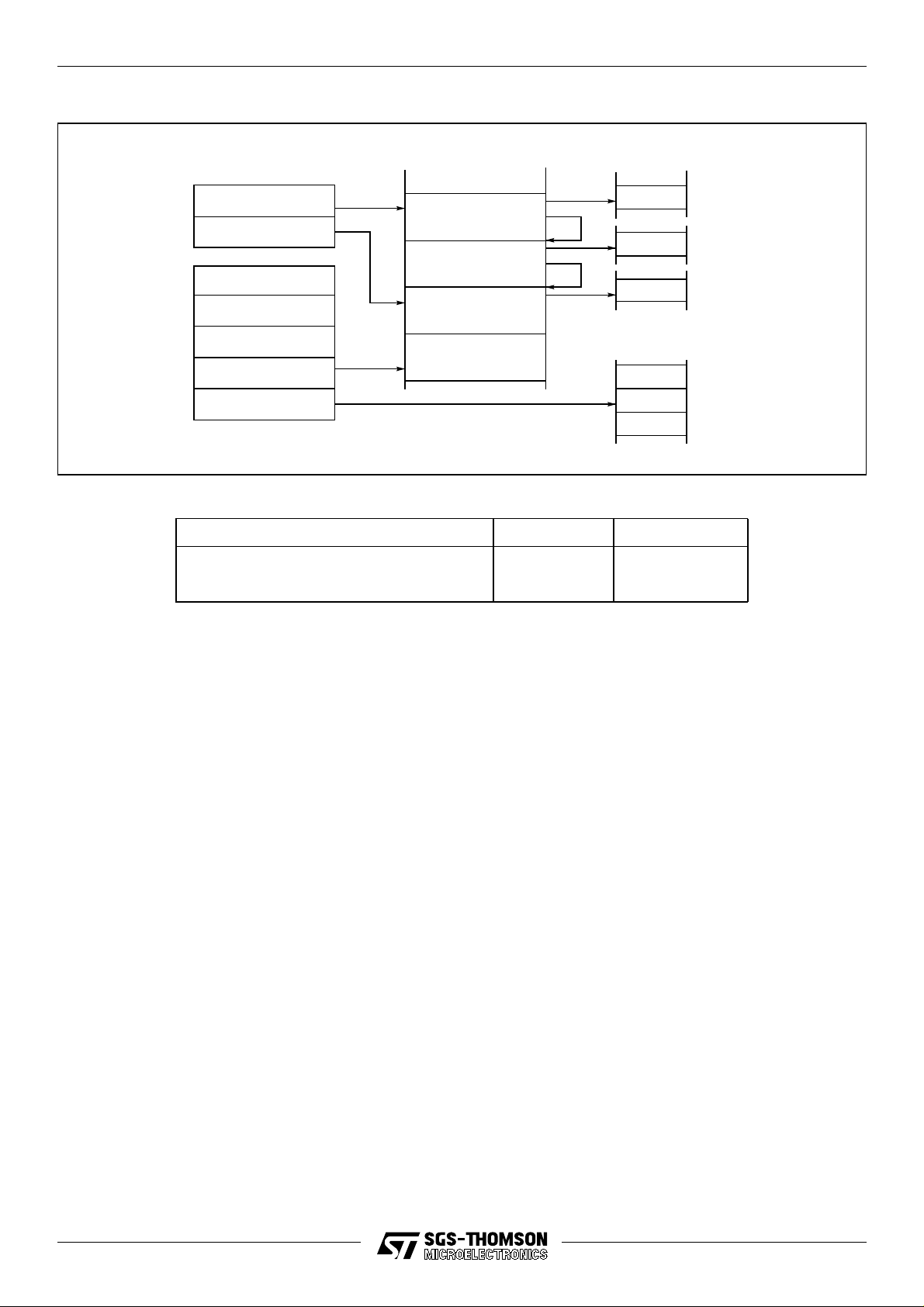
The CPU contains six registers which are used in the execution of a sequential integer process.
The six registers are:
• The workspace pointer (Wptr) which points to an area of store where local data is kept.
• The instruction pointer (IptrReg) which points to the next instruction to be executed.
• The status register (StatusReg).
• The Areg, Breg and Creg registers which form an evaluation stack.
The Areg, Breg and Creg registers are the sources and destinations for most arithmetic and
logical operations. Loading a value into the stack pushes Breg into Creg, and Areg into Breg,
before loading Areg. Storing a value from Areg, pops Breg into Areg and Creg into Breg. Creg is
left undefined.
Local data ProgramRegisters
Areg
Breg
Creg
18/116
Wptr
IptrReg
Figure 4.1 Registers used in sequential integer processes

ST20-GP1
Expressions are evaluated on the evaluation stack, and instructions refer to the stack implicitly. For
add
example, the
instruction adds the top two values in the stack and places the result on the top of
the stack. The use of a stack removes the need for instructions to explicitly specify the location of
their operands. No hardware mechanism is provided to detect that more than three values have
been loaded onto the stack; it is easy for the compiler to ensure that this never happens.
Note that a location in memory can be accessed relative to the workspace pointer, enabling the
workspace to be of any size.
The use of shadow registers provides fast, simple and clean context switching.
4.2 Processes and concurrency
The following section describes ‘default’ behavior of the CPU and it should be noted that the user
can alter this behavior, for example, by disabling timeslicing, installing a user scheduler, etc.
A process starts, performs a number of actions, and then either stops without completing or
terminates complete. Typically, a process is a sequence of instr uctions. The CPU can run several
processes in parallel (concurrently). Processes may be assigned either high or low priority, and
there may be any number of each.
The processor has a microcoded scheduler which enables any number of concurrent processes to
be executed together, sharing the processor time. This removes the need for a software kernel,
although kernels can still be written if desired.
At any time, a process may be
active
- being executed
- interrupted by a higher priority process
- on a list waiting to be executed
inactive
- waiting to input
- waiting to output
- waiting until a specified time
The scheduler operates in such a way that inactive processes do not consume any processor time.
Each active high priority process executes until it becomes inactive. The scheduler allocates a
portion of the processor’s time to each active low priority process in turn (see Section 4.3). Active
processes waiting to be executed are held in two linked lists of process workspaces, one of high
priority processes and one of low priority processes. Each list is implemented using two registers,
one of which points to the first process in the list, the other to the last. In the linked process list
S
shown in Figure 4.2, process
is ex ecuting andP,Q andR are active, a w aiting e xecution. Only the
low priority process queue registers are shown; the high priority process ones behave in a similar
manner.
19/116
ST20-GP1
Registers Program
FptrReg1
BptrReg1
Areg
Breg
Creg
Wptr
IptrReg
Local Data
pw.Iptr
P
pw.Link
pw.Iptr
Q
pw.Link
pw.Iptr
R
S
Figure 4.2 Linked process list
Function High priority Low priority
Pointer to front of active process list FptrReg0 FptrReg1
Pointer to back of active process list BptrReg0 BptrReg1
Table 4.1 Priority queue control registers
Each process runs until it has completed its action or is descheduled. In order for several
processes to operate in parallel, a low priority process is only permitted to execute for a maximum
of two timeslice periods. After this, the machine deschedules the current process at the next
timeslicing point, adds it to the end of the low priority scheduling list and instead executes the next
active process. The timeslice period is 1ms.
There are only certain instructions at which a process may be descheduled. These are known as
descheduling points. A process may only be timesliced at certain descheduling points. These are
known as timeslicing points and are defined in such a way that the operand stack is always empty.
This removes the need for saving the operand stack when timeslicing. As a result, an expression
evaluation can be guaranteed to execute without the process being timesliced part way through.
Whenever a process is unable to proceed, its instruction pointer is saved in the process w orkspace
and the next process taken from the list.
The processor core provides a number of special instructions to support the process model,
including
construct,
startp
(start process) and
startp
is used to create the necessary additional concurrent processes. A
endp
(end process). When a main process executes a parallel
startp
instruction creates a new process by adding a new workspace to the end of the scheduling list,
enabling the new concurrent process to be executed together with the ones already being
executed. When a process is made active it is always added to the end of the list, and thus cannot
pre-empt processes already on the same list.
endp
The correct termination of a parallel construct is assured by use of the
instruction. This uses
a data structure that includes a counter of the parallel construct components which have still to
terminate. The counter is initialized to the number of components before the processes are started.
endp
Each component ends with an
20/116
instruction which decrements and tests the counter. F or all but

ST20-GP1
the last component, the counter is non zero and the component is descheduled. For the last
component, the counter is zero and the main process continues.
4.3 Priority
The following section describes ‘default’ behavior of the CPU and it should be noted that the user
can alter this behavior, for example, by disabling timeslicing and priority interrupts.
The processor can execute processes at one of two priority levels, one level for urgent (high
priority) processes, one for less urgent (low priority) processes. A high priority process will always
execute in preference to a low priority process if both are able to do so.
High priority processes are expected to execute for a short time. If one or more high priority
processes are active, then the first on the queue is selected and executes until it has to wait for a
communication, a timer input, or until it completes processing.
If no process at high priority is active, but one or more processes at low priority are active , then one
is selected. Low priority processes are periodically timesliced to provide an even distribution of
processor time between computationally intensive tasks.
n
If there are
process becomes active to the time when it starts processing is the order of 2
is then able to execute for between one and two timeslice periods, less any time taken by high
priority processes. This assumes that no process monopolizes the CPU’s time; i.e. it has frequent
timeslicing points.
low priority processes, then the maximum latency from the time at which a low priority
n
timeslice periods. It
The specific condition for a high priority process to start execution is that the CPU is idle or running
at low priority and the high priority queue is non-empty.
If a high priority process becomes able to run whilst a low priority process is executing, the low
priority process is temporarily stopped and the high prior ity process is executed. The state of the
low priority process is saved into ‘shadow’ registers and the high priority process is executed.
When no further high priority processes are able to run, the state of the interrupted low priority
process is re-loaded from the shadow registers and the interrupted low priority process continues
executing. Instructions are provided on the processor core to allow a high priority process to store
the shadow registers to memory and to load them from memory. Instructions are also provided to
allow a process to exchange an alternative process queue for either priority process queue (see
Table 6.21 on page 43). These instructions allow extensions to be made to the scheduler for
custom runtime kernels.
A low priority process may be interrupted after it has completed execution of any instruction. In
addition, to minimize the time taken for an interrupting high priority process to star t executing, the
potentially time consuming instructions are interruptible. Also some instructions are abortable and
are restarted when the process next becomes active (refer to the Instruction Set chapter).
4.4 Process communications
Communication between processes takes place over channels, and is implemented in hardware.
Communication is point-to-point, synchronized and unbuffered. As a result, a channel needs no
process queue, no message queue and no message buffer.
A channel between two processes executing on the same CPU is implemented by a single word in
memory; a channel between processes executing on different processors is implemented by point-
21/116

ST20-GP1
to-point links. The processor provides a number of operations to support message passing, the
most important being
in
and
out
The
instructions use the address of the channel to determine whether the channel is
(input message) and
out
(output message).
in
internal or external. This means that the same instruction sequence can be used for both hard and
soft channels, allowing a process to be written and compiled without knowledge of where its
channels are implemented.
Communication takes place when both the inputting and outputting processes are ready.
Consequently, the process which first becomes ready must wait until the second one is also ready.
The inputting and outputting processes only become active when the communication has
completed.
A process performs an input or output by loading the e valuation stack with, a pointer to a message,
the address of a channel, and a count of the number of bytes to be transferred, and then executing
in
or
out
an
instruction.
4.5 Timers
There are two 32-bit hardware timer clocks which ‘tick’ periodically. These are independent of any
on-chip peripheral real time clock. The timers provide accurate process timing, allowing processes
to deschedule themselves until a specific time.
One timer is accessible only to high priority processes and is incremented every microsecond,
cycling completely in approximately 4295 seconds. The other is accessible only to low priority
processes and is incremented every 64 microseconds, giving 15625 ticks in one second. It has a
full period of approximately 76 hours. All times are approximate due to the clock rate.
Register Function
ClockReg0 Current value of high priority (level 0) process clock
ClockReg1 Current value of low priority (level 1) process clock
TnextReg0 Indicates time of earliest event on high priority (level 0) timer queue
TnextReg1 Indicates time of earliest event on low priority (level 1) timer queue
TptrReg0 High priority timer queue
TptrReg1 Low priority timer queue
Table 4.2 Timer registers
The current value of the processor clock can be read b y executing a
tin
A process can arrange to perform a
after a specified time has been reached. The
(timer input), in which case it will become ready to execute
tin
instruction requires a time to be specified. If this
ldtimer
(load timer) instruction.
time is in the ‘past’ then the instruction has no effect. If the time is in the ‘future’ then the process is
descheduled. When the specified time is reached the process becomes active. In addition, the
ldclock
clockenb
(load clock),
(clock enable),
stclock
(store clock) instructions allow total control ov er the cloc k v alue and the
clockdis
(clock disable) instructions allow each clock to be individually
stopped and re-started.
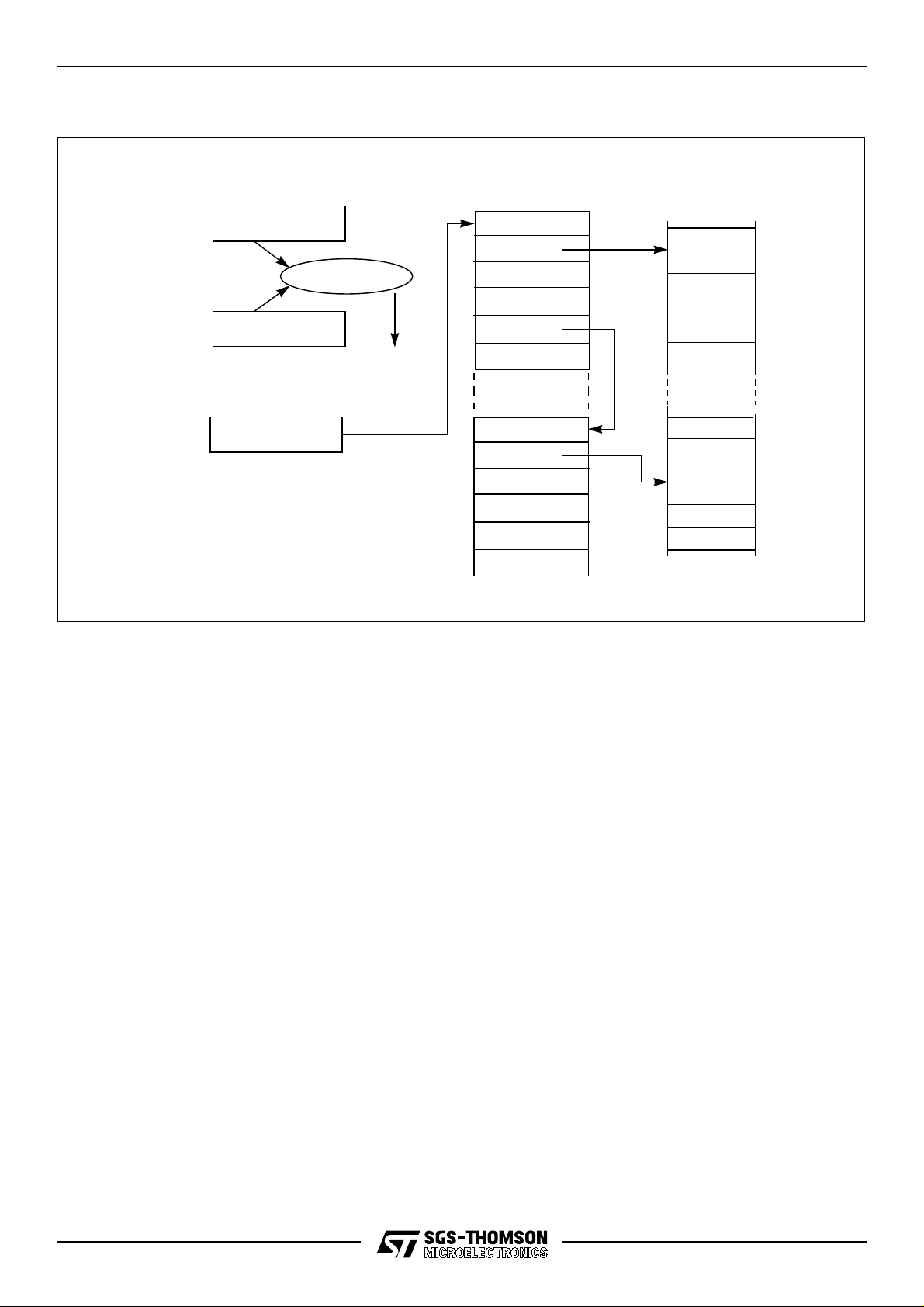
Figure 4.3 shows two processes waiting on the timer queue, one waiting for time 21, the other for
time 31.
Note, these timers stop counting when power-down mode (see Section 10.2 on page 61) is
invoked.
22/116
ClockReg0
ST20-GP1
Workspaces
Program
5
comparator
TnextReg0
TptrReg0
21
Alarm
21
Empty
31
Figure 4.3 Timer registers
4.6 Traps and exceptions
A software error, such as arithmetic overflow or array bounds violation, can cause an error flag to
be set in the CPU. The flag is directly connected to the ErrorOut pin. Both the flag and the pin can
be ignored, or the CPU stopped. Stopping the CPU on an error means that the error cannot cause
further corruption. As well as containing the error in this way it is possible to determine the state of
the CPU and its memory at the time the error occurred. This is par ticularly useful for postmortem
debugging where the debugger can be used to examine the state and history of the processor
leading up to and causing the error condition.
In addition, if a trap handler process is installed, a variety of traps/exceptions can be trapped and
handled by software. A user supplied trap handler routine can be provided for each high/low
process priority level. The handler is started when a trap occurs and is given the reason for the
trap. The trap handler is not re-entrant and must not cause a trap itself within the same group. All
traps are individually maskable.
4.6.1 Trap groups
The trap mechanism is arranged on a per priority basis. For each priority there is a handler for each
group of traps, as shown in Figure 4.4.
23/116
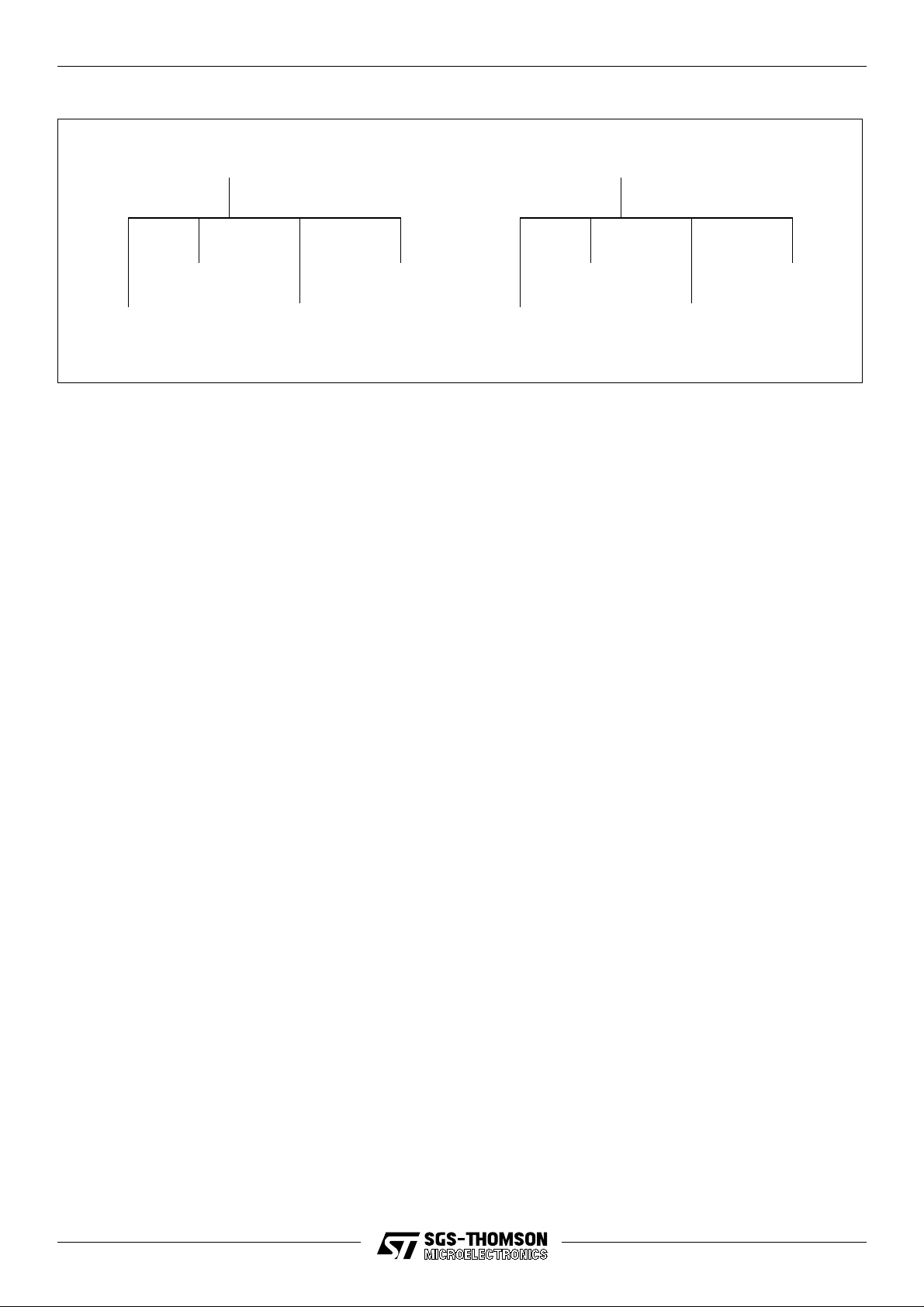
ST20-GP1
Low priority traps High priority traps
Scheduler
trap handler
Breakpoint
trap handler
CPU Error
trap handler
System operations
trap handler
Figure 4.4 Trap arrangement
There are four groups of traps, as detailed below.
• Breakpoint
This group consists of the
Breakpoint
trap. The breakpoint instruction (j0) calls the break-
point routine via the trap mechanism.
• Errors
The traps in this group are
IntegerError
and
flow, such as arithmetic results which do not fit in the result word.
errors caused when data is erroneous, for example when a range checking instruction finds
that data is out of range.
• System operations
This group consists of the
LoadTrap,StoreTrap
trap is signalled when an attempt is made to execute an illegal instruction. The
and
StoreTrap
traps allow a kernel to intercept attempts by a monitored process to change
or examine trap handlers or trapped process infor mation. It enables a user program to signal to a kernel that it wishes to install a new trap handler.
CPU Error
trap handler
Breakpoint
trap handler
Overflow.Overflow
and
IllegalOpcode
Scheduler
trap handler
System operations
trap handler
represents arithmetic over-
IntegerError
traps. The
represents
IllegalOpcode
LoadTrap
• Scheduler
The scheduler trap group consists of the
lice, Run, Signal, ProcessInterrupt
nals that the machine has performed a priority interrupt from low to high. The
trap indicates that there is no further executable work to perform. The other traps in this
group indicate that the hardware scheduler wants to schedule a process on a process
queue, with the different traps enabling the different sources of this to be monitored.
The scheduler traps enable a software scheduler kernel to use the hardware scheduler to
implement a multi-priority software scheduler.
Note that scheduler traps are different from other traps as they are caused by the microscheduler rather than by an executing process.
Note, when the scheduler trap is caused by a process that is ready to be scheduled, the
Wptr of that process is stored in the workspace of the scheduler trap handler, at address 0.
The trap handler can access this using a
24/116
ExternalChannel, InternalChannel, Timer, TimeS-
and
QueueEmpty
ldl 0
traps. The
instruction.
ProcessInterrupt
QueueEmpty
trap sig-
ST20-GP1
Trap groups encoding is shown in Table 4.4 below. These codes are used to identify trap groups to
various instructions.
Trap group Code
Breakpoint 0
CPU Errors 1
System operations 2
Scheduler 3
Table 4.3 Trap group codes
In addition to the trap groups mentioned above, the CauseError flag in the Status register is used
to signal when a trap condition has been activated by the
causeerror
instruction. It can be used to
indicate when trap conditions have occurred due to the user setting them, rather than by the
system.
4.6.2 Events that can cause traps
Table 4.4 summarizes the events that can cause traps and gives the encoding of bits in the trap
Status and Enable words.
Trap cause Status/Enable
codes
Breakpoint
IntegerError
Overflow
IllegalOpcode
LoadTrap
StoreTrap
InternalChannel
ExternalChannel
Timer
Timeslice
Run
0 0 When a process executes the breakpoint instruction (j0) then it traps
1 1 Integer error other than integer overflow – e.g. explicitly checked or
2 1 Integer overflow or integer division by zero.
3 2 Attempt to execute an illegal instruction. This is signalled when
4 2 When the trap descriptor is read with the
5 2 When the trap descriptor is written with the
6 3 Scheduler trap from internal channel.
7 3 Scheduler trap from external channel.
8 3 Scheduler trap from timer alarm.
9 3 Scheduler trap from timeslice.
10 3 Scheduler trap from
Trap
group
Comments
to its trap handler.
explicitly set error.
opr
(operate) is executed with an invalid operand.
ldtraph
instruction or when the trapped process status is read with the
ldtrapped
instruction or when the trapped process status is written with the
sttrapped
(load trapped) instruction.
(store trapped) instruction.
runp
(run process) or
sttraph
(load trap handler)
(store trap handler)
startp
(start process).
Signal
ProcessInterrupt
QueueEmpty
CauseError
11 3 Scheduler trap from
12 3 Start executing a process at a new priority level.
13 3 Caused by no process active at a priority level.
15 (Status only) Any ,
encoded
0-3
Signals that the
signal
causeerror
.
instruction set the trap flag.
Table 4.4 Trap causes and Status/Enable codes
25/116

ST20-GP1
4.6.3 Trap handlers
For each trap handler there is a trap handler structure and a trapped process structure. Both the
trap handler structure and the trapped process structure are in memory and can be accessed via
instructions, see Section 4.6.4.
The trap handler structure specifies what should happen when a trap condition is present, see
Table 4.6.
Comments
Iptr Iptr of trap handler process. Base + 3
Wptr Wptr of trap handler process. Base + 2
Status Contains the Status register that the trap handler starts with. Base + 1
Enables Contains a word which encodes the trap enable and global interrupt masks which will be
ANDed with the existing masks to allow the trap handler to disable various events while it
runs.
Base + 0
Table 4.5 Trap handler structure
The trapped process structure saves some of the state of the process that was running when the
trap was taken, see Table 4.7.
Comments
Iptr Points to the instruction after the one that caused the trap condition. Base + 3
Wptr Wptr of the process that was running when the trap was taken. Base + 2
Status The relevant trap bit is set, see Table 4.5 for trap codes. Base + 1
Enables Interrupt enables. Base + 0
Table 4.6 Trapped process structure
In addition, for each priority, there is an Enables register and a Status register. The Enables
register contains flags to enable each cause of trap. The Status register contains flags to indicate
which trap conditions have been detected. The Enables and Status register bit encodings are
given in Table 4.4.
A trap will be taken at an interruptible point if a trap is set and the corresponding trap enable bit is
set in the Enables register. If the trap is not enabled then nothing is done with the trap condition. If
the trap is enabled then the corresponding bit is set in the Status register to indicate the trap
condition has occurred.
When a process takes a trap the processor saves the existing Iptr, Wptr, Status and Enables in
the trapped process structure. It then loads Iptr, Wptr and Status from the equivalent trap handler
structure and ANDs the value in Enables with the value in the structure. This allows the user to
disable various events while in the handler, in particular a trap handler must disable all the traps of
its trap group to avoid the possibility of a handler trapping to itself.
The trap handler then executes. The values in the trapped process structure can be examined
using the
ldtrapped
operation it returns to the trapped process via the
instruction (see Section 4.6.4). When the trap handler has completed its
tret
(trap return) instruction. This reloads the
values saved in the trapped process structure and clears the trap flag in Status.
Note that when a trap handler is started, Areg, Breg and Creg are not saved. The trap handler
stl
must save the Areg, Breg, Creg registers using
26/116
(store local).

4.6.4 Trap instructions
ST20-GP1
Trap handlers and trapped processes can be set up and examined via the
ldtrapped
and
sttrapped
instructions. Table 4.8 describes the instructions that may be used when
ldtraph,sttraph
dealing with traps.
Instruction Meaning Use
ldtraph
sttraph
ldtrapped
sttrapped
trapenb
trapdis
tret
causeerror
load trap handler load the trap handler from memory to the trap handler descriptor
store trap handler store an existing trap handler descriptor to memory
load trapped load replacement trapped process status from memory
store trapped store trapped process status to memory
trap enable enable traps
trap disable disable traps
trap return used to return from a trap handler
cause error program can simulate the occurrence of an error
Table 4.7 Instructions which may be used when dealing with traps
The first four instructions transfer data to/from the trap handler structures or trapped process
structures from/to an area in memory. In these instructions Areg contains the trap group code (see
Table 4.4) and Breg points to the 4 word area of memor y used as the source or destination of the
transfer. In addition Creg contains the priority of the handler to be installed/examined in the case of
ldtraphor sttraph. ldtrapped
and
sttrapped
apply only to the current priority.
,
If the
LoadTrap
LoadTrap trap flag. If the
trap is enabled then
StoreTrap
ldtraph
and
ldtrapped
trap is enabled then
do not perform the transfer but set the
sttraph
and
sttrapped
do not perform the
transfer but set the StoreTrap trap flag.
The trap enable masks are encoded by an array of bits (see Table 4.5) which are set to indicate
which traps are enabled. This array of bits is stored in the lower half-word of the Enables register.
There is an Enables register for each priority. Traps are enabled or disabled by loading a mask into
Areg with bits set to indicate which traps are to be affected and the priority to affect in Breg.
Executing
trapenb
register for the priority in Breg. Executing
ORs the mask supplied in Areg with the trap enables mask in the Enables
trapdis
negates the mask supplied in Areg and ANDs it
with the trap enables mask in the Enables register for the priority in Breg. Both instructions return
the previous value of the trap enables mask in Areg.
4.6.5 Restrictions on trap handlers
There are various restrictions that must be placed on trap handlers to ensure that they work
correctly.
1 Trap handlers must not deschedule or timeslice. Trap handlers alter the Enables masks,
therefore they must not allow other processes to execute until they have completed.
2 Trap handlers must have their Enable masks set to mask all traps in their trap group to
avoid the possibility of a trap handler trapping to itself.
3 Trap handlers must terminate via the
is that a scheduler kernel may use
restart
tret
(trap return) instruction.The only exception to this
to return to a previously shadowed process.
27/116
ST20-GP1
5 Interrupt controller
The ST20-GP1 supports external interrupts, enabling an on-chip subsystem or external interrupt
pin to interrupt the currently running process in order to run an interrupt handling process.
The ST20-GP1 interrupt subsystem supports five prioritized interrupts. This allows nested preemptive interrupts for real-time system design. Three interrupts are connected to on-chip
peripherals (2 for the UARTs, 1 for the programmable IO) and two are available as external
interrupt pins.
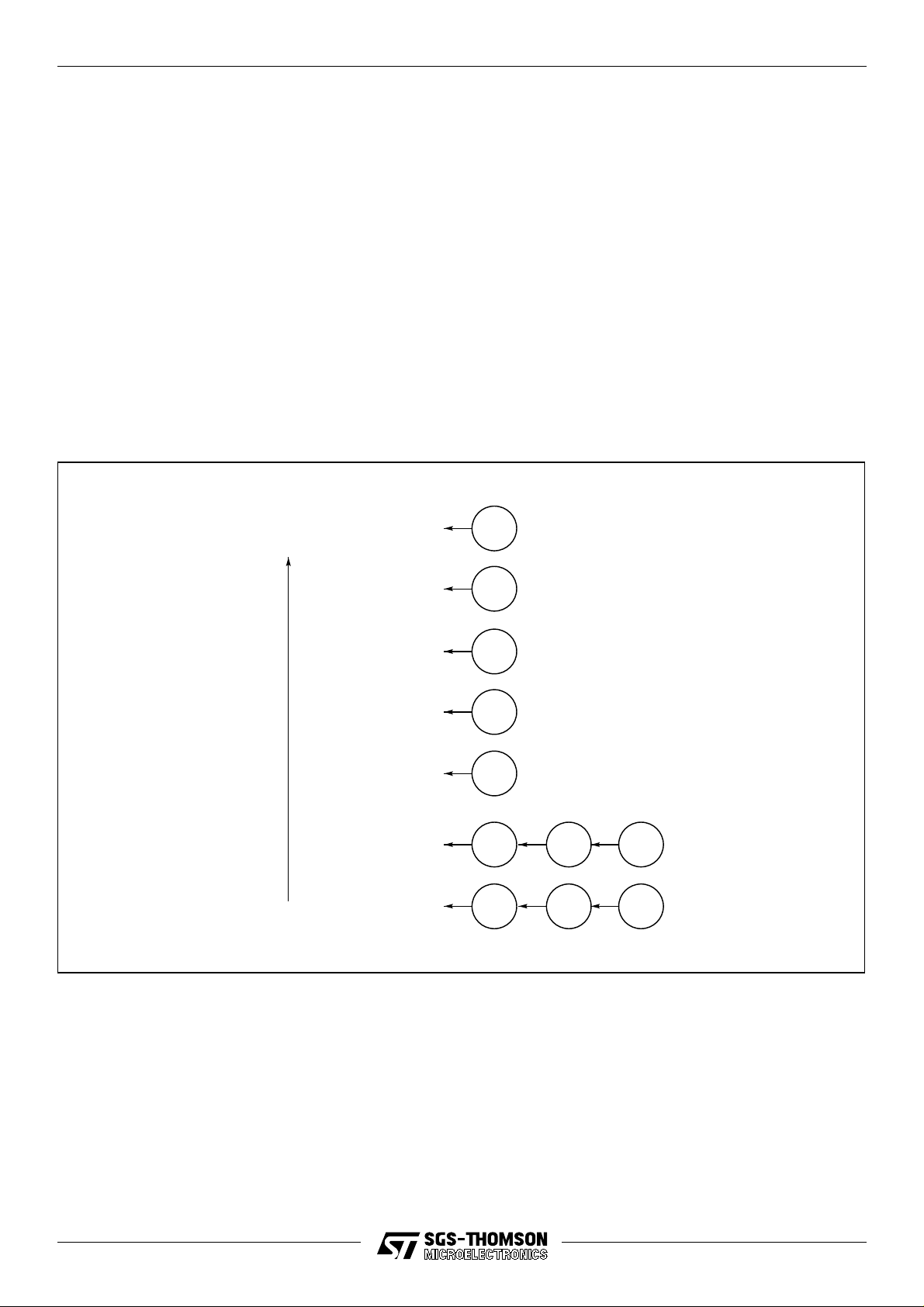
All interrupts are at a higher priority than the high priority process queue, see Figure 5.1. Each
interrupt level has a higher priority than the previous (interrupt 0 is lowest priority) and each level
supports only one software handler process.Note that interrupt handlers must not prevent the GPS
DSP data traffic from being handled. During continuous operation this has 1 ms latency and is not
a problem, but during initial acquisition it has a 32 µs rate and thus all interrupts must be disabled
except if used to stop GPS operation.
Increasing
pre-emption
Interrupt 4
Interrupt1 pin
Interrupt 3
Interrupt0 pin
Interrupt 2
UART1
Interrupt 1
UART0
Interrupt 0
Programmable IO
High priority
process
Low priority
process
Figure 5.1 Interrupt priority
Interrupts on the ST20-GP1 are implemented via an on-chip interrupt controller peripheral. An
interrupt can be signalled to the controller by one of the following:
• a signal on an external Interrupt pin
• a signal from an internal peripheral or subsystem
• software asserting an interrupt in a bit mask
28/116

ST20-GP1
5.1 Interrupt vector table
The interrupt controller contains a table of pointers to interrupt handlers. Each interrupt handler is
represented by its workspace pointer (Wptr). The table contains a workspace pointer f or each level
of interrupt.
The Wptr gives access to the code, data and interrupt save space of the interrupt handler. The
position of the Wptr in the interrupt table implies the priority of the interrupt.
Run-time library support is provided for setting and programming the vector table.
5.2 Interrupt handlers
At any interruptible point in its execution the CPU can receive an interrupt request from the
interrupt controller. The CPU immediately acknowledges the request.
In response to receiving an interrupt the CPU performs a procedure call to the process in the
vector table . The state of the interrupted process is stored in the workspace of the interrupt handler
as shown in Figure 5.2. Each interrupt level has its own workspace.
Wptr
Before interrupt
Handler Iptr
Handler Status
Wptr
Interrupting high priority
process
Handler Iptr
Handler Status
Creg
Breg
Areg
Iptr
Wptr
Status
Interrupting low priority
process or CPU idle
Wptr
Handler Iptr
Handler Status
Null Status
Figure 5.2 State of interrupted process
The interrupt routine is initialized with space below Wptr. The Iptr and Status word for the routine
are stored there permanently . This should be prog rammed bef ore theWptr is written into the vector
table. The behavior of the interrupt differs depending on the priority of the CPU when the interrupt
occurs.
When an interrupt occurs when the CPU was running at high priority, the CPU saves the current
process state (Areg, Breg, Creg, Wptr, Iptr and Status) into the workspace of the interrupt
handler. The value HandlerWptr, which is stored in the interrupt controller, points to the top of this
29/116

ST20-GP1
workspace. The values of Iptr and Status to be used by the interrupt handler are loaded from this
workspace and starts executing the handler. The value of Wptr is then set to the bottom of this
save area.
When an interrupt occurs when the CPU was idle or running at low priority, the Status is saved.
This indicates that no valid process is running (
Null Status
process) state is stored in shadow registers. This state can be accessed via the
shadow registers) and
stshadow
(store shadow registers) instructions. The interrupt handler is then
). The interrupted processes (low priority
ldshadow
(load
run at high priority.
When the interrupt routine has completed it must adjust Wptr to the value at the start of the
iret
handler code and then execute the
(interrupt return) instruction. This restores the interr upted
state from the interrupt handler structure and signals to the interrupt controller that the interrupt has
completed. The processor will then continue from where it was before being interrupted.
5.3 Interrupt latency
The interrupt latency is dependent on the data being accessed and the position of the interrupt
handler and the interrupted process. This allows systems to be designed with the best trade-off use
of fast internal memory and interrupt latency.
5.4 Pre-emption and interrupt priority
Each interrupt channel has an implied priority fixed by its place in the interrupt vector table. All
interrupts will cause scheduled processes of any priority to be suspended and the interrupt handler
started. Once an interrupt has been sent from the controller to the CPU the controller keeps a
record of the current executing interrupt priority. This is only cleared when the interrupt handler
iret
executes a return from interrupt (
) instruction. Interrupts of a lower priority arriving will be
blocked by the interrupt controller until the interrupt priority has descended to such a level that the
routine will execute. An interrupt of a higher priority than the currently executing handler will be
passed to the CPU and cause the current handler to be suspended until the higher priority interrupt
is serviced.
In this way interrupts can be nested and a higher priority interrupt will always pre-empt a lower
priority one. Deep nesting and placing frequent interrupts at high prior ity can result in a system
where low priority interrupts are never serviced or the controller and CPU time are consumed in
nesting interrupt priorities and not executing the interrupt handlers.
5.5 Restrictions on interrupt handlers
There are various restrictions that must be placed on interrupt handlers to ensure that they interact
correctly with the rest of the process model implemented in the CPU.
1 Interrupt handlers must not deschedule.
2 Interrupt handlers must not execute communication instructions. However they may com-
municate with other processes through shared variables using the semaphore
synchronize.
3 Interrupt handlers must not perform block move instructions.
4 Interrupt handlers must not cause program traps. However they may be trapped by a
scheduler trap.
30/116
signal
to
 Loading...
Loading...