

Page 1

Parallels Cloud Storage
Administrator's Guide
Copyright © 1999-2012 Parallels IP Holdings GmbH and its affiliates. All rights reserved.
Page 2

Parallels IP Holdings GmbH.
Vordergasse 59
CH8200 Schaffhausen
Switzerland
Tel: + 41 526320 411
Fax: + 41 52672 2010
www.parallels.com
Copyright © 1999-2012 Parallels IP Holdings GmbH and its affiliates. All rights reserved.
This product is protected by United States and international copyright laws. The product’s underlying technology,
patents, and trademarks are listed at http://www.parallels.com/trademarks.
Microsoft, Windows, Windows Server, Windows NT, Windows Vista, and MS-DOS are registered trademarks of Microsoft
Corporation.
Apple, Mac, the Mac logo, Mac OS, iPad, iPhone, iPod touch, FaceTime HD camera and iSight are trademarks of Apple
Inc., registered in the US and other countries.
Linux is a registered trademark of Linus Torvalds.
All other marks and names mentioned herein may be trademarks of their respective owners.
Page 3

Contents
Introduction ............................................................................................................... 6
About This Guide ............................................................................................................ 6
About Parallels Cloud Storage ......................................................................................... 6
Parallels Cloud Storage Architecture ................................................................................ 7
Parallels Cloud Storage Configurations ............................................................................ 9
Minimum Configuration .............................................................................................................9
Recommended Configuration ................................................................................................ 11
System Requirements ................................................................................................... 13
Network Requirements .................................................................................................. 15
Setting Up a Parallels Cloud Storage Cluster ........................................................ 17
Setup Process Overview ............................................................................................... 18
Configuring Cluster Discovery ........................................................................................ 19
Using DNS Records .............................................................................................................. 20
Setting Up Avahi .................................................................................................................... 22
Specifying MDS Servers Manually ......................................................................................... 23
Setting Up the First Metadata Server ............................................................................. 24
Stage 1: Preparing for Creating the MDS Server ................................................................... 24
Stage 2: Creating the MDS Server ......................................................................................... 25
Setting Up Chunk Servers ............................................................................................. 26
Stage 1: Preparing for Creating the Chunk Server ................................................................. 27
Stage 2: Creating the Chunk Server ...................................................................................... 28
Setting Up Clients ......................................................................................................... 29
Stage 1: Preparing for Mounting the Cluster .......................................................................... 29
Stage 2: Mounting the Cluster ............................................................................................... 30
Stage 3: Configuring Virtual Machines and Containers .......................................................... 30
Configuring Parallels Cloud Storage Clusters ........................................................ 31
Configuring MDS Servers .............................................................................................. 32
Adding MDS Servers ............................................................................................................. 33
Removing MDS Servers ........................................................................................................ 34
Configuring Chunk Servers ............................................................................................ 35
Page 4

Contents
Adding New Chunk Servers to Increase Disk Space.............................................................. 35
Removing Chunk Servers ...................................................................................................... 36
Configuring Clients ........................................................................................................ 37
Adding Clients ....................................................................................................................... 37
Updating Clients .................................................................................................................... 37
Removing Clients .................................................................................................................. 37
Managing Cluster Parameters ........................................................................................ 38
Cluster Parameters Overview ................................................................................................ 38
Configuring Replication Parameters ....................................................................................... 39
Configuring Location Parameters .......................................................................................... 41
Accessing Parallels Cloud Storage Clusters via iSCSI ..................................................... 43
Managing Parallels Cloud Storage Licenses ................................................................... 44
Installing a License ................................................................................................................ 44
Updating a License ................................................................................................................ 45
Viewing the License Contents ................................................................................................ 46
Checking the License Status ................................................................................................. 47
Shutting Down Parallels Cloud Storage Clusters ............................................................ 48
Monitoring Parallels Cloud Storage Clusters ......................................................... 49
Monitoring General Cluster Parameters .......................................................................... 50
Monitoring Metadata Servers ......................................................................................... 52
Monitoring Chunk Servers ............................................................................................. 54
Understanding Disk Space Usage ......................................................................................... 56
Exploring Chunk States ......................................................................................................... 59
Monitoring Clients ......................................................................................................... 60
Monitoring Event Logs ................................................................................................... 62
Monitoring the Status of Replication Parameters ............................................................ 65
Managing Cluster Security ...................................................................................... 66
Security Considerations ................................................................................................. 66
Securing Server Communication in Clusters ................................................................... 67
Cluster Discovery Methods ............................................................................................ 69
Parallels Cloud Storage Ports ........................................................................................ 70
Password-Based Authentication .................................................................................... 73
Installations via PXE Servers .......................................................................................... 74
Page 5

Contents
Maximizing Cluster Performance ............................................................................ 75
Exploring Possible Disk Drive Configurations .................................................................. 76
Carrying Out Performance Benchmarking ...................................................................... 77
Using 1 Gb and 10 Gb Networks ................................................................................... 77
Using SSD Drives .......................................................................................................... 78
Configuring SSD Drives for Write Journaling .......................................................................... 79
Configuring SSD Drives for Data Caching .............................................................................. 81
Appendices .............................................................................................................. 84
Appendix A - Troubleshooting ....................................................................................... 85
Submitting a Problem Report to Technical Support ............................................................... 85
Out of Disk Space ................................................................................................................. 86
Poor Write Performance ........................................................................................................ 86
Poor Disk I/O Performance .................................................................................................... 86
Hardware RAID Controller and Disk Write Caches ................................................................. 87
SSD Drives Ignore Disk Flushes ............................................................................................. 87
Avahi-Daemon Is not Running ............................................................................................... 88
Appendix B - Frequently Asked Questions ..................................................................... 89
General .................................................................................................................................. 89
Scalability and Performance .................................................................................................. 90
Availability .............................................................................................................................. 91
Cluster Operation .................................................................................................................. 92
Glossary ................................................................................................................... 94
Index ........................................................................................................................ 95
Page 6

Network Requirements ........................................................................................... 15
C
HAPTER
1
Introduction
This chapter provides basic information about the Parallels Cloud Storage solution and this guide.
In This Chapter
About This Guide ................................................................................................... 6
About Parallels Cloud Storage ................................................................................ 6
Parallels Cloud Storage Architecture ....................................................................... 7
Parallels Cloud Storage Configurations ................................................................... 9
System Requirements ............................................................................................ 13
About This Guide
The guide is intended for system administrators interested in deploying Parallels Cloud Storage in
their networks.
The document assumes that you have good knowledge of the Linux command-line interface and
extensive experience working with local networks.
About Parallels Cloud Storage
Parallels Cloud Storage is a solution allowing you to quickly and easily transform low-cost
commodity storage hardware and network equipment into a protected enterprise-level storage, like
SAN (Storage Area Network) and NAS (Network Attached Storage).
Parallels Cloud Storage is optimized for storing large amounts of data and provides replication,
high-availability, and self-healing features for your data. Using Parallels Cloud Storage, you can
safely store and run Parallels virtual machines and Containers, migrate them with zero downtime
across physical hosts, provide high availability for your Parallels Cloud Server installations, and
much more.
Page 7
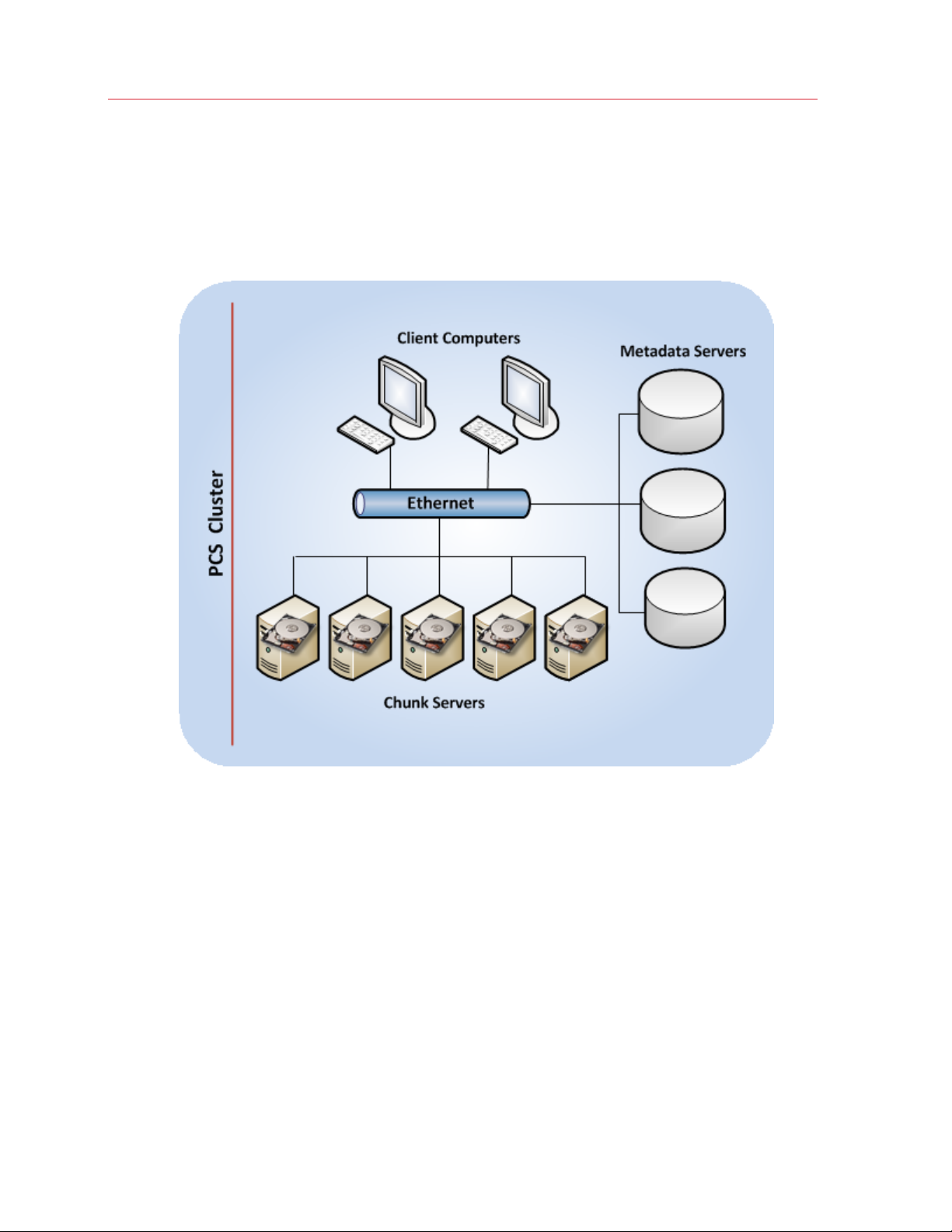
Introduction
Parallels Cloud Storage Architecture
Before starting the deployment process, you should have a clear idea of the Parallels Cloud
Storage infrastructure. A typical Parallels Cloud Storage is shown below.
The basic component of Parallels Cloud Storage is a cluster. The cluster is a group of physical
computers connected to the same Ethernet network and performing the following roles:
• chunk servers
• metadata servers
• client computers (or clients)
Brief Overview
All data in a Parallels Cloud Storage cluster, including Parallels virtual machine and Container disk
images, is stored in the form of fixed-size chunks on chunk servers. The cluster automatically
replicates the chunks and distributes them across the available chunk servers to provide high
availability of data.
7
Page 8

Introduction
To keep track of data chunks and their replicas, the cluster stores metadata about them on
metadata (MDS) servers. The central MDS server, called the master MDS server, monitors all
cluster activity and keeps metadata current.
Clients manipulate data stored in the cluster by sending different types of file requests, such as
modifying an existing file or creating a new one.
Chunk Servers
Chunk servers store all the data, including the contents of virtual machines and Containers, in the
form of fixed-size chunks and provide access to these chunks. All data chunks are replicated and
the replicas are kept on different chunk servers to achieve high availability. If one of the chunk
servers goes down, the other chunk servers will continue providing the data chunks that were
stored on the failed server.
Metadata Servers
Metadata (MDS) servers store metadata about chunk servers and control how files keeping the
contents of virtual machines and Containers are split into chunks and where these chunks are
located. MDS servers also ensure that a cluster has enough chunk replicas and store a global log
of all important events that happen in the cluster.
To provide high availability of a Parallels Cloud Storage cluster, you need to set up several MDS
servers in the cluster. In this case, if one MDS server goes offline, another MDS server will continue
keeping control over the cluster.
Note: MDS servers deal with processing metadata only and do not normally participate in any read/write
operations related to data chunks.
Clients
Clients are computers with Parallels Cloud Server 6.0 from where you run virtual machines and
Containers stored in a Parallels Cloud Storage cluster.
Notes:
1. You can set up any computer in the cluster to perform the role of a metadata server, chunk server, or
client. You can also assign two or all three roles to one and the same computer. For example, you can
configure a computer to act as a client by installing Parallels Cloud Server 6.0 on it and running virtual
machines and Containers from the computer. At the same time, if you want this computer to allocate its
local disk space to the cluster, you can set it up as a chunk server.
2. Though Parallels Cloud Storage can be mounted as a file system, it is not a POSIX-compliant file
system and lacks some POSIX features like ACL, user and group credentials, hardlinks, and some others.
8
Page 9
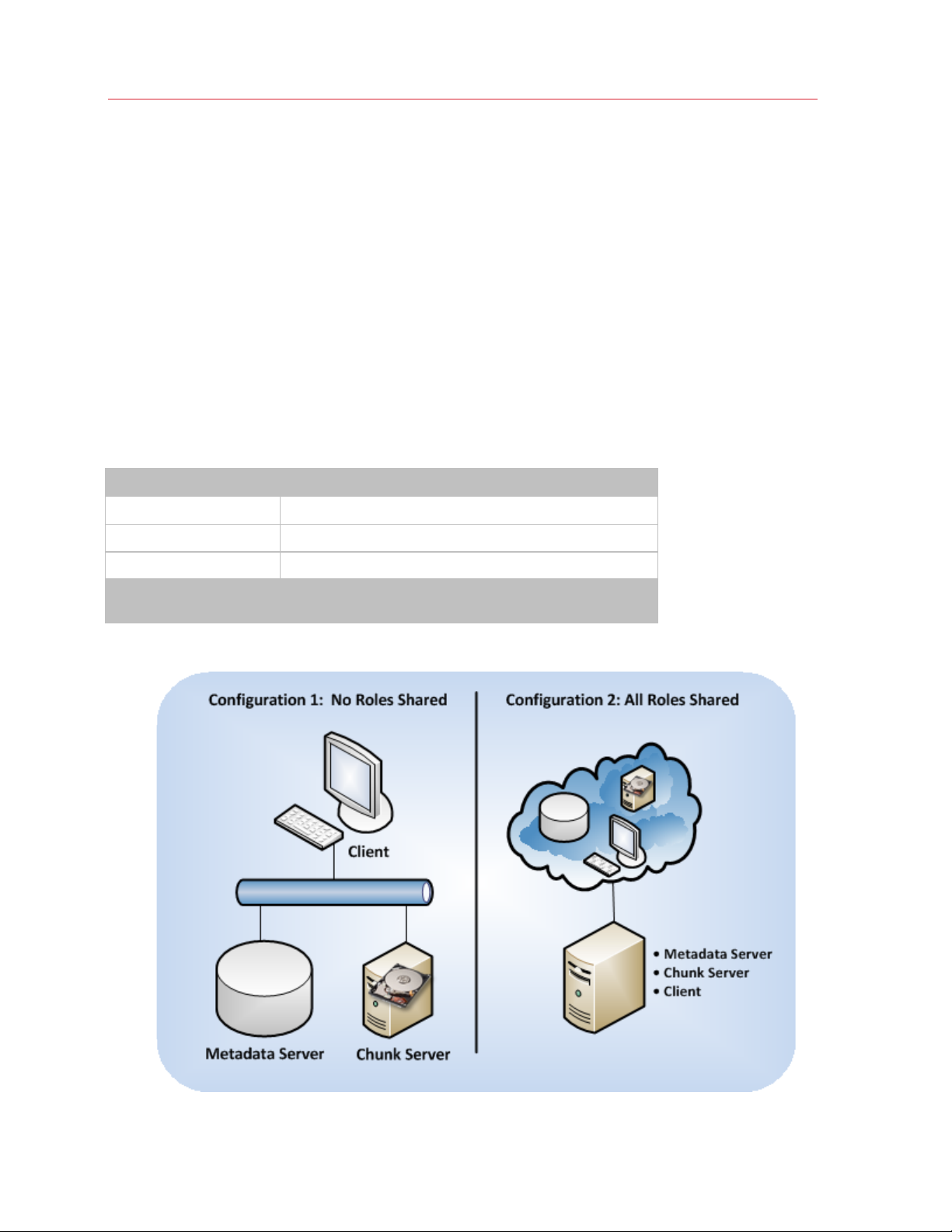
Introduction
Parallels Cloud Storage Configurations
This section provides information on two Parallels Cloud Storage configurations:
• Minimum configuration (p. 9). You can create the minimum configuration for evaluating the
Parallels Cloud Storage functionality. This configuration, however, is not recommended for use
in production environments.
• Recommended configuration (p. 11). You can use the recommended Parallels Cloud Storage
configuration in a production environment "as is" or adopt it to meet your needs.
Minimum Configuration
The minimum hardware configuration for deploying a Parallels Cloud Storage cluster is given below:
Server Role Number of Servers
Metadata Server
Chunk Server
Client
Total number of servers
1 (can be shared with chunk servers and clients)
1 (can be shared with metadata servers and clients)
1 (can be shared with chunk and metadata servers)
with sharing roles: 1
without sharing roles: 3
Graphically, the minimum configuration can be represented as follows:
9
Page 10

Introduction
For a Parallels Cloud Storage cluster to function, it must have at least one MDS server, one chunk
server, and one client. The minimum configuration has two main limitations:
1 The cluster has one metadata server, which presents a single point of failure. If the metadata
server fails, the entire Parallels Cloud Storage cluster will become non-operational.
2 The cluster has one chunk server that can store only one chunk replica. If the chunk server fails,
the cluster will suspend all operations with chunks until a new chunk server is added to the
cluster.
10
Page 11
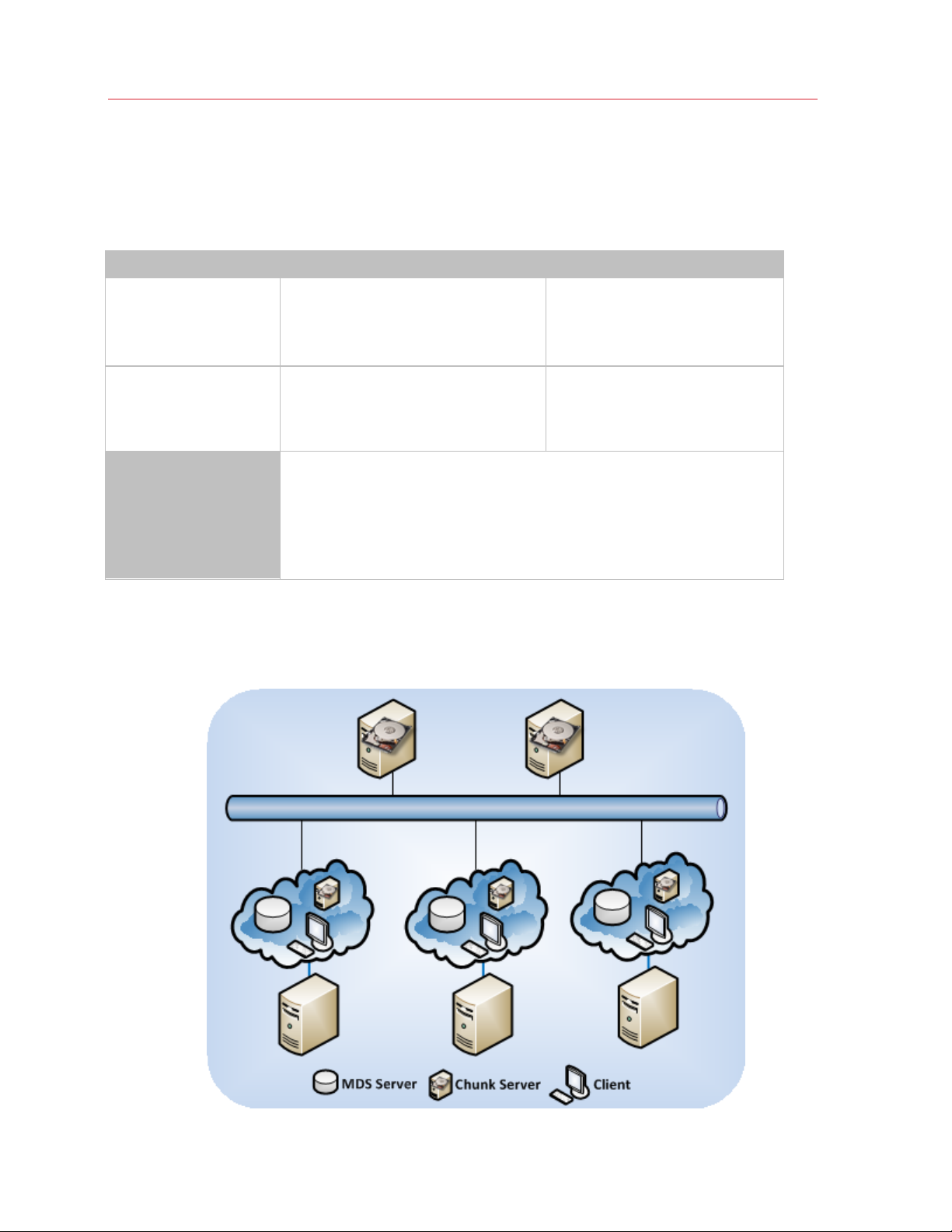
Introduction
Recommended Configuration
The table below lists two of the recommended configurations for deploying Parallels Cloud Storage
clusters.
Metadata Server Chunk Server Total Number of Servers
3
(can be shared with chunk
servers and clients)
5
(can be shared with
metadata servers and
clients)
Clients
3-9
(can be shared with chunk servers and
clients)
10 or more
(can be shared with chunk servers and
clients)
1 or more
You can include any number of clients in the cluster. For example, if you have 5
servers with Parallels Cloud Server, you can configure them all to act as clients.
You can share servers acting as clients with chunk and metadata servers. For
example, you can have 5 physical servers and configure each of them to
simultaneously act as an MDS server, a chunk server, and a client.
3 or more
(depending on the number of clients
and chunk severs and whether they
share roles)
5 or more
(depending on the number of clients
and chunk severs and whether they
share roles)
A recommended configuration should ensure that your cluster can continue operating even if one
or more MDS and chunk servers fail. For example, the figure below shows a configuration with 3
MDS servers, 5 chunk servers, and 3 clients. 3 physical servers share the server roles while two
physical servers act as chunk servers only.
11
Page 12

Introduction
If you deploy this configuration, you will be able to survive the loss of:
• 1 MDS server. In a setup with 3 MDS servers, the majority of MDS servers are achieved when
at least 2 of 3 servers are online, so your cluster will continue operating if 1 MDS server goes
offline.
• 2 chunk servers. A setup with 5 chunk servers assumes that you set the chunk replication
parameter to 3 replicas per each data chunk. Initially, this parameter is set to 1 replica, which is
sufficient to evaluate the Parallels Cloud Storage functionality using one server only. In
production, however, to provide high availability for your data, you need to configure each data
chunk to have at least three replicas. This requires at least three chunk servers to be set up in
the cluster. By configuring 5 chunk servers, you ensure that the cluster will still be operational
even if 2 chunk servers fail.
For information on configuring the chunk replication parameter, see Configuring Replication
Parameters (p. 39).
12
Page 13

Introduction
System Requirements
Before setting up a Parallels Cloud Storage cluster, make sure you have all the necessary
equipment at hand. You are also recommended to:
• Read Exploring Possible Disk Drive Configurations (p. 76) to ensure that your RAID
configuration is optimized for best performance.
• Consult Using SSD Drives (p. 78) to learn how you can increase the cluster performance by
configuring SSD drivers for write journaling and data caching.
• Check Troubleshooting (p. 85) for common hardware issues and misconfigurations that may
affect your cluster performance and lead to data inconsistency and corruption.
Metadata Servers
A metadata server must meet the following requirements:
• Software: Parallels Cloud Server 6.0
• RAM: 2 GB per each 512 TB of storage
• Disk space: 10 GB or more
• Network:
• 1 or more Ethernet adapters (1 Gb or faster)
• a static IP address for each Ethernet adapter
Chunk Servers
A chunk server must run Parallels Cloud Server 6.0 and have at least one Ethernet adapter (1 Gb or
faster) installed. Chunk servers can allocate any amount of available local disk space to a Parallels
Cloud Storage cluster and do not require more than 1 GB of RAM.
Clients
A client computer must run Parallels Cloud Server 6.0 and have at least one Ethernet adapter (1 Gb
or faster) installed. There are no special requirements to the amount of RAM and disk space that
must be available on a client, except for the general recommendations for running the Parallels
Cloud Server software.
13
Page 14

Introduction
Notes:
1. You can set up any computer in the cluster to perform the role of a metadata server, chunk server, or
client. You can also assign two or all three roles to one and the same computer. For example, you can
configure a computer to act as a client by installing Parallels Cloud Server 6.0 on it and running virtual
machines and Containers from the computer. At the same time, if you want this computer to allocate its
local disk space to the cluster, you can set it up as a chunk server.
2. For hard disk requirements and the recommended partitioning scheme for servers that run Parallels
Cloud Server and participate in clusters, see the Hardware Compatibility section in the Parallels Cloud
Server 6.0 Installation Guide.
14
Page 15
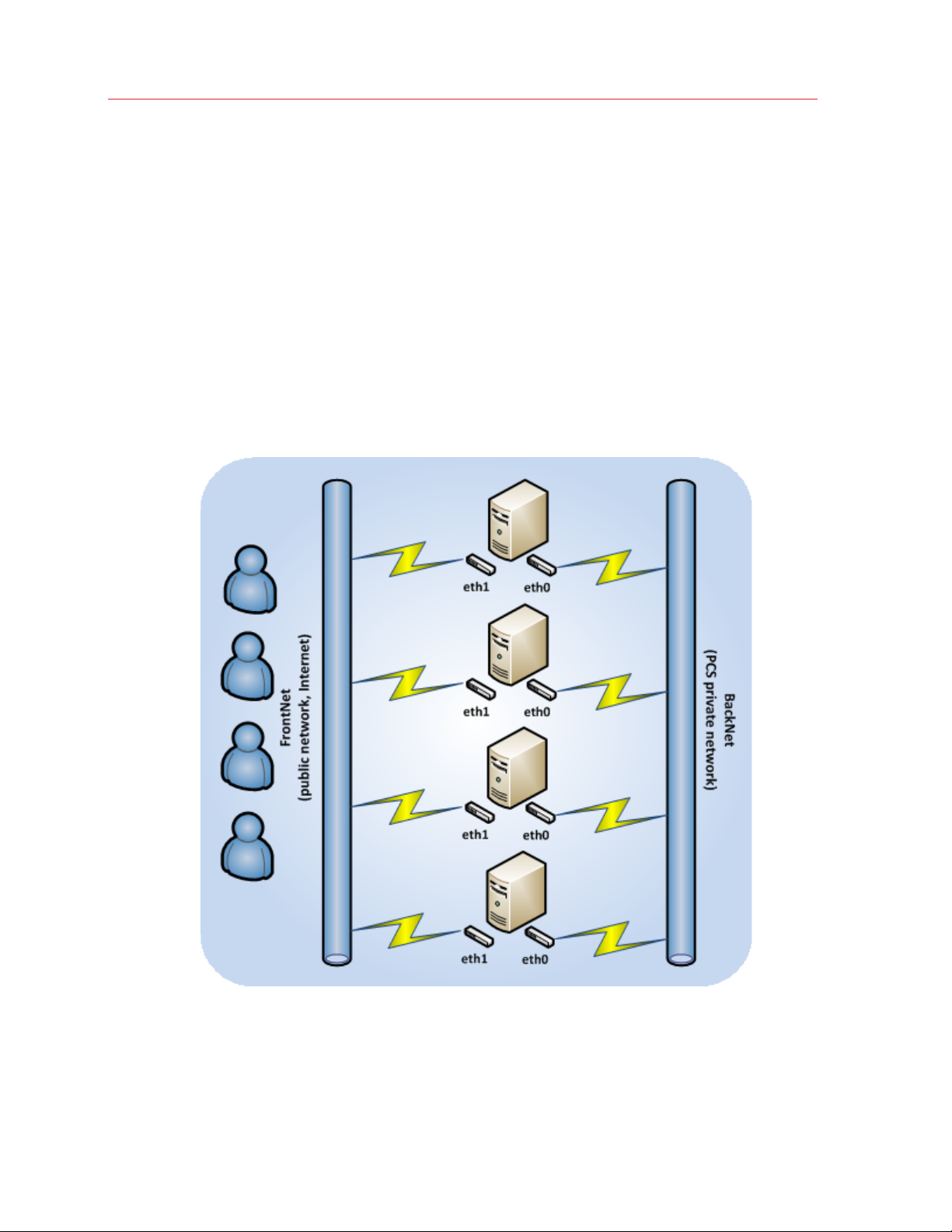
Introduction
Network Requirements
When planning your network, make sure that it
• operates at 1 Gb/s or higher
• has non-blocking Ethernet switches
You should use separate networks and Ethernet adapters for user and cluster traffic. This will
prevent possible I/O performance degradation in your cluster by external traffic. Besides, if a cluster
is accessible from public networks (e.g., from the Internet), it may become the target of Denial-ofService attacks, and the entire cluster I/O subsystem may get stuck.
The figure below shows a sample network configuration for Parallels Cloud Storage.
15
Page 16

Introduction
In this network configuration:
• BackNet is a private network used solely for interconnection and intercommunication of servers
in the cluster and is not available from the public network. All servers in the cluster are
connected to this network via one of their network cards.
• FrontNet is a public network customers use to access their virtual machines and Containers in
the Parallels Cloud Storage cluster.
Note: To learn more about Parallels Cloud Storage networks (in particular, how to bind chunk servers to
specific IP addresses), see Securing Server Communication in Clusters (p. 67).
16
Page 17

Setting Up Clients .................................................................................................. 29
C
HAPTER
2
Setting Up a Parallels Cloud Storage Cluster
This chapter provides information on setting up a Parallels Cloud Storage cluster. It starts with an
overview of the Parallels Cloud Storage setup process and then describes each setup step in
detail.
In This Chapter
Setup Process Overview ......................................................................................... 18
Configuring Cluster Discovery ................................................................................. 19
Setting Up the First Metadata Server....................................................................... 24
Setting Up Chunk Servers ...................................................................................... 26
Page 18

Setting Up a Parallels Cloud Storage Cluster
Setup Process Overview
The process of setting up a Parallels Cloud Storage cluster includes these steps:
1 Configuring Parallels Cloud Storage cluster discovery.
In this step, you define the way of detecting a cluster name and resolving the detected name
into the IP address of an MDS server. For more on this step, see Configuring Parallels Cloud
Storage Discovery (p. 19).
2 Setting up metadata servers.
In this step, you create and configure metadata servers for storing metadata about chunk
servers and data chunks. For more on this step, see Setting Up the First Metadata Server (p.
24).
3 Setting up chunk servers.
In this step, you create and configure chunk servers for storing the actual content of virtual
machines and Containers in data chunks. For more on this step, see Setting Up Chunk
Servers (p. 26).
4 Setting up clients.
In this step, you create and configure clients from where you will access the Parallels Cloud
Storage cluster and run virtual machines and Containers. For more on this step, see Setting Up
Clients (p. 29).
Note: You can also set up a Parallels Cloud Storage using the Parallels Cloud Server 6.0 installer. It
automatically configures your system as a metadata server, chunk server, or client. For detailed
information on this, see the Parallels Cloud Server 6.0 Installation Guide.
18
Page 19

Setting Up a Parallels Cloud Storage Cluster
Configuring Cluster Discovery
Parallels Cloud Storage discovery is the process of:
1 Detecting all available cluster names on the network. Each Parallels Cloud Storage cluster is
identified by a unique name. All cluster tools use this name when performing specific operations
on the cluster or monitoring its health and status.
2 Resolving the detected cluster names into the network addresses of MDS servers. MDS servers
are the central components of any cluster, so all cluster tools must be able to discover their IP
addresses.
To set up cluster discovery in your network, you can use one of the following techniques:
• (recommended) DNS records (p. 20)
• Avahi (p. 22)
You can also manually specify the information about metadata servers (p. 23) when setting up or
configuring the cluster.
19
Page 20

Setting Up a Parallels Cloud Storage Cluster
Using DNS Records
The recommended way of configuring cluster discovery is to use special DNS records. The process
of setting up this type of cluster discovery includes two steps:
1 Defining DNS TXT records or enabling DNS zone transfers to discover the unique names of
available clusters.
2 Resolving the detected cluster names into the IP addresses of MDS servers using DNS SRV
records.
Discovering Cluster Names
The easiest and most efficient way of discovering the names of clusters in your network is to
specify all cluster names in pstorage_clusters TXT records of DNS zone files. The following
example provides a sample of valid TXT record formats for Parallels Cloud Storage clusters:
pstorage_clusters 300 IN TXT "cluster1,cluster2" "cluster3,cluster4"
pstorage_clusters 300 IN TXT "cluster5"
pstorage_clusters 300 IN TXT "cluster6" "cluster7"
Another way of discovering cluster names in your network is to use DNS zone transfers. Once DNS
zone transfers are enabled, cluster tools will be able to retrieve all DNS SRV records (see
Resolving MDS Addresses below) from DNS zone files and extract cluster names from these
records.
After you set up cluster discovery via DNS TXT records or DNS zone transfers, you can run the
pstorage discover command on any of the cluster servers to discover the names of all
clusters in your network:
# pstorage discover
02-10-12 13:16:46.233 Discovering using DNS TXT records: OK
02-10-12 13:16:46.308 Discovering using DNS zone transfer: FAIL
02-10-12 13:16:47.313 Discovering using Avahi: FAIL
pcs1
pcs2
pcs3
The example pstorage output shows that:
• Clusters names are discovered via the DNS TXT records.
• Three clusters with the names of pcs1, pcs2, and pcs3 are currently set up on the network.
Resolving MDS Addresses
To resolve the detected cluster names into the IP addresses of MDS servers, you use DNS Service
(SRV) records. An SRV record pointing to an MDS server must have the following format:
_pstorage._tcp.CLUSTER_NAME
where
• _pstorage is a symbolic name reserved for Parallels Cloud Storage.
20
Page 21

Setting Up a Parallels Cloud Storage Cluster
• _tcp denotes the TCP protocol used for communication in the cluster.
• CLUSTER_NAME is the name of the Parallels Cloud Storage cluster for which the record is valid.
The following example shows a DNS zone file that contains records for three MDS servers listening
on the default port 2510 and configured for the pcs1 cluster:
$TTL 1H
@ IN SOA ns rname.invalid. (1995032001 5H 10M 1D 3H)
NS @
A 192.168.100.1
s1 A 192.168.100.1
s2 A 192.168.100.2
s3 A 192.168.100.3
; SERVICE SECTION
; MDS for the 'pcs1' cluster runs on s1.pcs.test and listens on port 2510
_pstorage._tcp.pcs1 SRV 0 1 2510 s1
; MDS for the 'pcs1' cluster runs on s2.pcs.test and listens on port 2510
_pstorage._tcp.pcs1 SRV 0 1 2510 s2
; MDS for the 'pcs1' cluster runs on s3.pcs.test and listens on port 2510
_pstorage._tcp.pcs1 SRV 0 1 2510 s3
; eof
Once you configure DNS SRV records for the pcs1 cluster, you can list them by issuing the
following SRV query:
# host -t SRV _pstorage._tcp.pcs1
_pstorage._tcp.pcs1.pcs.test has SRV record 0 1 2510 s1.pcs.test.
_pstorage._tcp.pcs1.pcs.test has SRV record 0 1 2510 s2.pcs.test.
_pstorage._tcp.pcs1.pcs.test has SRV record 0 1 2510 s3.pcs.test.
21
Page 22

Setting Up a Parallels Cloud Storage Cluster
Setting Up Avahi
Avahi (a free zeroconf implementation, http://avahi.org) is another method of discovering cluster
names and resolving the discovered names into the IP addresses of running MDS servers. This
method does not require any special configuration efforts on your part, except for the following:
• Making sure that the avahi-daemon service is running on all servers in your cluster. You can
use the following command to check that the service is up and running:
# service avahi-daemon status
• Ensuring that multicasts are supported and enabled on your network.
To enhance cluster security in a cluster setup with Avahi, you are strongly recommended to allow
only the use of network interface cards that belong to the cluster BackNet. To do this, configure the
allow-interfaces parameter in the /etc/avahi/avahi-daemon.conf file by setting its
value to the names of the allowed network cards. Configure this file on all servers in the cluster.
Warnings:
1. Avahi auto-discovery can be used for testing and evaluating the Parallels Cloud Storage functionality,
but this cluster discovery method is not recommended for use in production due to security reasons.
Malicious users can potentially perform DoS attacks on the Avahi service even if you use security
certificates for authentication in your network.
2. Avahi discovery does not work if services are running in Containers.
3. If you plan to use Avahi auto-discovery, make sure that all servers you plan to include in the cluster
have unique hostnames.
22
Page 23

Setting Up a Parallels Cloud Storage Cluster
Specifying MDS Servers Manually
If you cannot configure the DNS records and Avahi discovery methods in your network, you need
to manually specify IP addresses of running MDS servers in the cluster each time you do the
following:
• Add a new MDS server to a cluster. For details, see Adding and Removing MDS Servers (p.
32).
• Add a new chunk server to a cluster. For details, see Setting Up Chunk Servers (p. 26).
• Set up a new client for a cluster. For details, see Setting Up Clients (p. 29).
To specify an IP address of an MDS server manually, create the bs.list file in the
/etc/pstorage/clusters/Cluster_Name directory (make this directory if it does not exist)
and specify in it the IP address and port to use for connecting to the MDS server. For example:
# echo "10.10.100.101:2510" >> /etc/pstorage/clusters/pcs1/bs.list
# echo "10.10.100.102:2510" >> /etc/pstorage/clusters/pcs1/bs.list
This command:
1 Assumes that you are configuring discovery for the pcs1 cluster (thus, the directory name of
/etc/pstorage/clusters/pcs1).
2 Creates the /etc/pstorage/clusters/pcs1/bs.list file on the server.
3 Adds the information on two MDS servers with IP addresses 10.10.100.101 and
10.10.100.102 to the bs.list file.
23
Page 24

Setting Up a Parallels Cloud Storage Cluster
Setting Up the First Metadata Server
Setting up an MDS server is the first step in creating a Parallels Cloud Storage cluster. You can add
more MDS servers later to provide better availability of your cluster, as described in Adding and
Removing MDS Servers (p. 32).
The process of setting up the first MDS server (called master MDS server) and, thus, of creating a
cluster includes two stages:
1 Preparing for creating the MDS server (p. 24).
2 Creating the MDS server (p. 25).
Stage 1: Preparing for Creating the MDS Server
To prepare for making the MDS server, do the following:
1 Choose a name for the cluster that will uniquely identify it among other clusters in your network.
A name may contain the characters a-z, A-Z, 0-9, dash (-), and underscore (_). The examples
used throughout this guide assume that the cluster name is pcs1.
Note: When choosing a name for the cluster, make sure it is unique on your network. Also, do not use
names that were once assigned to other clusters in your network, even if these clusters do not exist any
more. This will help you avoid possible problems with services from previous cluster setups that might
still be running and trying to operate on the new cluster. Though such operations will not succeed, they
can make your work as a cluster administrator more difficult.
2 Log in to the computer you want to configure as a metadata server as root or as a user with
root privileges.
3 Download and install the following RPM packages on the computer: pstorage-ctl,
pstorage-libs-shared, and pstorage-metadata-server.
The packages are available in the Parallels Cloud Server remote repository (this repository is
automatically configured for your system when you install Parallels Cloud Server) and can be
installed with this command:
# yum install pstorage-metadata-server
4 Make sure that cluster discovery is configured in your network. For details, see Configuring
Cluster Discovery (p. 19).
For example, if you are evaluating Parallels Cloud Storage functionality and using Avahi to
discover clusters, you need to (1) start the avahi-daemon service, if it is not running on the
server, and (2) configure it to start automatically when the MDS server boots:
# service avahi-daemon start
# chkconfig avahi-daemon on
After you complete the steps above, you are ready to create the MDS server.
24
Page 25

Setting Up a Parallels Cloud Storage Cluster
Stage 2: Creating the MDS Server
To create the MDS server, you use the pstorage make-mds command, for example:
# pstorage -c pcs1 make-mds -I -a 10.30.100.101 -r /pstorage/pcs1-mds -p
This command does the following:
1 Asks you for a password to use for password-based authentication in your cluster. Password-
based authentication enhances security, requiring each server to be authenticated before it can
be included in the cluster. The password you specify is encrypted and saved into the
/etc/pstorage/clusters/pcs1/auth_digest.key file on the MDS server.
2 Creates the Parallels Cloud Storage cluster with the name of pcs1.
3 Creates the metadata server and configures the IP address of 10.10.100.101 for
communication with this server. By default, Parallels Cloud Storage uses ports 2510 and 2511
to communicate with MDS servers. If necessary, you can replace the default ports with your
own ones by reserving two unoccupied consecutive ports and specifying the first one after the
IP address of your MDS server (e.g., -a 10.30.100.101:4110 if your custom ports are
4110 and 4111).
Replace 10.10.100.101 in the example above with the IP address of your own MDS server. The
specified IP address must be (1) static (or in the case of using DHCP, mapped to the MAC
address of the MDS server) and (2) chosen from the range of IP addresses on the BackNet
network dedicated to your Parallels Cloud Storage cluster. See Network Requirements (p. 15)
for details.
4 Creates a journal in the /pstorage/pcs1-mds directory on the MDS server and adds the
information about the pcs1 cluster to it. When choosing a directory for storing the journal,
make sure that the partition where the directory is located has at least 10 GB of free disk
space.
After you have created the MDS server, start the MDS management service (pstorage-mdsd)
and configure it to start automatically when the server boots:
# service pstorage-mdsd start
# chkconfig pstorage-mdsd on
For information on including additional MDS servers in a Parallels Cloud Storage cluster, see
Adding and Removing MDS Servers (p. 32).
25
Page 26

Setting Up a Parallels Cloud Storage Cluster
Setting Up Chunk Servers
A chunk server stores actual data of virtual machines and Containers and services requests to it. All
data is split into chunks and can be stored in a Parallels Cloud Storage cluster in multiple copies
called replicas.
Initially, any cluster is configured to have only one replica per each data chunk, which is sufficient to
evaluate the Parallels Cloud Storage functionality using one server only. In production, however, to
provide high availability for your data, you need to configure each data chunk to have at least three
replicas. This requires at least three chunk servers to be set up in the cluster. You can modify the
default replication parameter using the pstorage utility. For details, see Configuring Replication
Parameters (p. 39).
The process of setting up a chunk server includes two stages:
1 Preparing for creating the chunk server (p. 27).
2 Creating the chunk server (p. 28).
26
Page 27

Setting Up a Parallels Cloud Storage Cluster
Stage 1: Preparing for Creating the Chunk Server
To prepare for creating the chunk server, do the following:
1 Log in to the computer you want to act as a chunk server as root or as a user with root
privileges.
2 Download and install the following RPM packages: pstorage-ctl, pstorage-libs-
shared, and pstorage-chunk-server.
These packages are available in the Parallels Cloud Server remote repository (this repository is
automatically configured for your system when you install Parallels Cloud Server) and can be
installed with this command:
# yum install pstorage-chunk-server
3 Make sure that cluster discovery is configured for the server. For details, see Configuring
Cluster Discovery (p. 19).
For example, if you are evaluating Parallels Cloud Storage functionality and using Avahi to
discover clusters, you need to (1) start the avahi-daemon service, if it is not running on the
server, and (2) configure it to start automatically when the chunk server boots:
# service avahi-daemon start
# chkconfig avahi-daemon on
4 Authenticate the server in the cluster. This step is required only if the server where you are
setting up the chunk server has never been authenticated in the cluster before.
For example, you can skip this step if this is the same server where you set up the first MDS
server. Otherwise, run the following command to authenticate the server in the cluster:
# pstorage -c pcs1 auth-node
Please enter password for cluster:
During its execution, the command asks you for the password to validate the server. Type the
password you specified when setting up the first MDS server and press Enter. pstorage then
compares the provided password with the one stored on the MDS server, and if the passwords
match, successfully authenticates the server.
Once the authentication is complete, you can create the chunk server.
27
Page 28

Setting Up a Parallels Cloud Storage Cluster
Stage 2: Creating the Chunk Server
To create the chunk server, you use the pstorage make-cs command, for example:
# pstorage -c pcs1 make-cs -r /pstorage/pcs1-cs -t 1
This command
1 Makes the /pstorage/pcs1-cs directory on your computer and configures it for storing
data chunks.
2 Configures your computer as a chunk server and joins it to the pcs1 cluster.
3 Assigns the chunk server to storage tier 1. If you omit the -t option, Parallels Cloud Storage
will assign the chunk server to the default storage tier 0.
Storage tiers allow you to keep different kinds of data on different chunk servers. For details,
see Configuring Location Parameters (p. 41).
After you have created the chunk server, start the MDS management service (pstorage-csd)
and configure it to start automatically when the chunk server boots:
# service pstorage-csd start
# chkconfig pstorage-csd on
Once you set up the first chunk server, proceed with creating other chunk servers.
28
Page 29

Setting Up a Parallels Cloud Storage Cluster
Setting Up Clients
The process of setting up a client includes three stages:
1 Preparing for mounting the Parallels Cloud Storage cluster to the client (p. 29).
2 Mounting the cluster (p. 30).
3 Configuring virtual machines and Containers to be stored in the cluster (p. 30).
Stage 1: Preparing for Mounting the Cluster
To prepare for mounting the Parallels Cloud Storage cluster to the client:
1 Log in to the server you want to act as a client as root or as a user with root privileges.
2 Download and install the pstorage-libs-shared and pstorage-client RPM
packages.
These packages are available in the Parallels Cloud Server remote repository (this repository is
automatically configured for your system when you install Parallels Cloud Server) and can be
installed with this command:
# yum install pstorage-client
3 Create the directory to mount the Parallels Cloud Storage cluster to, for example:
# mkdir -p /pstorage/pcs1
4 Make sure that cluster discovery is configured in your network. For details, see Configuring
Cluster Discovery (p. 19).
For example, if you are evaluating Parallels Cloud Storage functionality and using Avahi to
discover clusters, you need to (1) start the avahi-daemon service, if it is not running on the
server, and (2) configure it to start automatically on the client boot:
# service avahi-daemon start
# chkconfig avahi-daemon on
5 Authenticate the server in the cluster. This step is required only if the server where you are
setting up the client has never been authenticated in the cluster before.
For example, you can skip this step if this is the same server where you set up the first MDS
server or some of the chunk servers. Otherwise, run the following command to authenticate the
server in the cluster:
# pstorage -c pcs1 auth-node
Please enter password for cluster:
During its execution, the command asks you for the password to validate the server. Type the
password you specified when setting up the first MDS server and press Enter. pstorage then
compares the provided password with the one stored on the MDS server, and if the passwords
match, successfully authenticates the server.
29
Page 30

Setting Up a Parallels Cloud Storage Cluster
Stage 2: Mounting the Cluster
Next, you need to mount the cluster to make it accessible to the client. To mount clusters, you use
the pstorage-mount command. For example, if your Parallels Cloud Storage cluster has the
name of pcs1, you can run this command to mount it to the /pstorage/pcs1 directory on the
client:
# pstorage-mount -c pcs1 /pstorage/pcs1
You can also configure the client to automatically mount the cluster to the /pstorage/pcs1
directory when the client boots. To do this, add a line like the following to the /etc/fstab file:
pstorage://pcs1 /pstorage/pcs1 fuse.pstorage rw,nosuid,nodev 0 0
Stage 3: Configuring Virtual Machines and Containers
To configure a server with Parallels Cloud Server to store its virtual machines and Containers in the
cluster, do the following:
1 Log in to the server as root.
2 Configure Containers for use in the cluster:
a Check the path to the Container private area in the /etc/vz/vz.conf file. By default, the
path is set to the following:
VE_PRIVATE=/vz/private/$VEID
b Make a symbolic link from the Container private area to the directory in the Parallels Cloud
Storage cluster that will store Containers. Assuming that this directory is
/pstorage/pcs1/private, you can run the following command:
# ln -s /pstorage/pcs1/private/ /vz/private
3 Configure virtual machines for use in the cluster:
a Check the default location of virtual machine files:
# prlsrvctl info | grep "VM home"
VM home: /var/parallels
b Make a symbolic link from the default location to the directory in the Parallels Cloud Storage
cluster that will store virtual machines. For example, to make a link to the
/pstorage/pcs1/vmprivate directory, you can execute the following command:
# ln -s /pstorage/pcs1/vmprivate/ /var/parallels
30
Page 31

Shutting Down Parallels Cloud Storage Clusters ...................................................... 48
C
HAPTER
3
Configuring Parallels Cloud Storage Clusters
This chapter describes the ways to configure a Parallels Cloud Storage cluster once you create it.
You will learn to perform the following tasks:
• Adding MDS servers to and remove them from clusters (p. 32).
• Adding chunk severs to and remove them from clusters (p. 35).
• Adding clients to clusters (p. 37).
• Managing cluster parameters (p. 38).
• Accessing clusters via iSCSI (p. 43).
• Managing Parallels Cloud Storage licenses (p. 44).
• Shutting down clusters (p. 48).
All these operations are described in the following sections in detail.
In This Chapter
Configuring MDS Servers ....................................................................................... 32
Configuring Chunk Servers ..................................................................................... 35
Configuring Clients ................................................................................................. 37
Managing Cluster Parameters ................................................................................. 38
Accessing Parallels Cloud Storage Clusters via iSCSI .............................................. 43
Managing Parallels Cloud Storage Licenses ............................................................ 44
Page 32

Configuring Parallels Cloud Storage Clusters
Configuring MDS Servers
For a Parallels Cloud Storage cluster to function, the majority of MDS servers must be up and
running in the cluster. So to ensure high availability of a cluster, you need to set up at least three
MDS servers for it. This will allow you to survive the loss of one MDS server. By configuring five
MDS servers for a cluster, you can ensure that your cluster will continue operating even if two MDS
servers go offline.
Notes:
1. When adding and removing MDS servers, make sure that the majority of up and running MDS servers
in the cluster is never lost.
2. Remove non-functioning MDS servers from the cluster as soon as possible (e.g., right after you replace
a broken server with a new one) to ensure that all MDS servers are up and running and the majority is not
lost if one more MDS server fails. Let us assume that 3 MDS servers are running in your cluster. 1 MDS
server fails so you add a new MDS server to the cluster. Now the total number of MDS servers in the
cluster is 4, with one server offline. If one more MDS server fails, the cluster will have only 2 running MDS
servers and become unavailable because the majority (3 running MDS servers) cannot be achieved any
more.
This section explains how to
• add new MDS servers to a cluster (p. 33)
• remove existing MDS servers from a cluster (p. 34)
32
Page 33

Configuring Parallels Cloud Storage Clusters
Adding MDS Servers
The procedure of setting up the first MDS server is described in Setting Up the First Metadata
Server (p. 24). To configure the second and all subsequent MDS servers for a cluster, follow the
steps below:
1 Make sure that you remember the exact name of the Parallels Cloud Storage cluster you want
to add the MDS server to. The example below uses pcs1 as the cluster name.
2 Log in to the computer you want to configure as an MDS server and add to the cluster as root
or as a user with root privileges.
3 Download and install the following RPM packages on the computer: pstorage-ctl,
pstorage-libs-shared, and pstorage-metadata-server.
These packages can be installed with this command:
# yum install pstorage-metadata-server
4 Make sure that cluster discovery is configured for the server. For details, see Configuring
Cluster Discovery (p. 19).
5 Authenticate the server in the cluster.
This step is required only if the physical server where you are setting up the MDS server has
never been authenticated in the cluster before. For example, you can skip this step if you have
already configured the server as a chunk server or a client. Otherwise, run the following
command to authenticate the server in the cluster:
# pstorage -c pcs1 auth-node
Please enter password for cluster:
During its execution, the command asks you for the password to validate the server. Enter the
password you specified when setting up the first MDS server and press Enter. pstorage then
compares the provided password with the one stored on the MDS server, and if the passwords
match, successfully authenticates the server.
6 Create the MDS server and add it to the cluster:
# pstorage -c pcs1 make-mds -a 10.10.100.102:2510 -r /pstorage/pcs1-mds
In the command above:
• pcs1 is the name of the cluster you are adding the MDS server to.
• 10.10.100.102:2510 is the IP address and port of the new MDS server.
Replace 10.10.100.102 in the example above with the IP address of your own MDS server.
The specified IP address must be (1) static (or in the case of using DHCP, mapped to the
MAC address of the MDS server) and (2) chosen from the range of IP addresses on the
BackNet network dedicated to your Parallels Cloud Storage cluster. See Network
Requirements (p. 15) for details.
• /pstorage/pcs1-mds is the path to a journal that will store the information about the
pcs1 cluster. When choosing a directory for storing the journal, make sure that the partition
where the directory is located has at least 10 GB of free disk space.
33
Page 34

Configuring Parallels Cloud Storage Clusters
If the DNS records or Avahi discovery is not configured in your network, you need to additionally
use the -b option and specify the IP addresses of the first MDS server (and all other MDS
servers, if you have more than one in your cluster) when running the command:
# pstorage -c pcs1 make-mds -a 10.10.100.102:2510 -r /pstorage/pcs1-mds -b
10.10.100.101
7 Start the MDS management service (pstorage-mdsd) and configure it to start automatically
on the MDS server boot:
# service pstorage-mdsd start
# chkconfig pstorage-mdsd on
For instructions on how to check that the MDS server has been successfully configured for your
cluster, see Monitoring Parallels Cloud Storage Clusters (p. 49).
Removing MDS Servers
Sometimes, you may need to remove an MDS server from a Parallels Cloud Storage cluster, for
example, to upgrade the server or to perform some maintenance tasks on it. To do this:
1 Configure a new MDS server to replace the one you plan to remove from the cluster. For
instructions, see Adding MDS Servers (p. 33).
2 Find out the index number of the MDS server to remove by running the following command on
some of your MDS servers or clients:
# pstorage -c pcs1 top
This will display detailed information about the cluster. Locate the section with the information
about MDS servers, for example:
...
MDSID STATUS %CTIME COMMITS %CPU MEM UPTIME HOST
M 1 avail 0.0% 0/s 0.0% 64m 17d 6h 10.30.17.38
2 avail 0.0% 0/s 0.0% 50m 12d 3h 10.30.45.12
3 avail 0.0% 0/s 0.0% 57m 7d 1h 10.30.10.15
...
The index number is displayed in the MDSID column. In the output above, three MDS servers
are configured for the pcs1 cluster. They have index numbers of 1, 2, and 3.
3 Remove the MDS server from the cluster. For example, to remove the MDS server with index
number 3, run this command:
# pstorage -c pcs1 rm-mds 3
34
Page 35

Configuring Parallels Cloud Storage Clusters
Configuring Chunk Servers
This section explains how to complete the following tasks:
• Increase disk space in a cluster by adding new chunk servers to it (p. 35).
• Remove chunk servers from a cluster for performing maintenance tasks on them (p. 36).
Adding New Chunk Servers to Increase Disk Space
You can increase the amount of disk space in a Parallels Cloud Storage cluster simply by adding
new chunk servers to it. For details, see Setting Up Chunk Servers (p. 26).
Note: Parallels Cloud Storage can scale to support up to 1 PB of effective available disk space, which
means up to 3 PB of physical disk space in the case of mirroring with 3 copies.
35
Page 36

Configuring Parallels Cloud Storage Clusters
Removing Chunk Servers
CSID STATUS SPACE FREE REPLICAS IOWAIT IOLAT(ms) HOST
If you need to remove a chunk server from the cluster, for example, to perform some maintenance
tasks on it, do the following:
1 Make sure that
• The number of chunk servers configured for your cluster is enough to store the required
number of data chunks (that is, equals or exceeds the current replication value).
• The chunk servers have enough disk space to store the chunks.
For instructions on obtaining this information, see Monitoring Chunk Servers (p. 54). If you
need to add a new chunk server to the cluster before removing an active one, see Setting Up
Chunk Servers (p. 26).
2 Find out the index number of the chunk server you want to remove by running the following
command on some of your cluster servers:
# pstorage -c pcs1 top
This will display detailed information about the pcs1 cluster. Locate the section with the
information about chunk servers, for example:
...
1025 active 105GB 88GB 40 0% 0/0 10.30.17.38
1026 active 105GB 88GB 40 0% 0/0 10.30.18.40
1027 active 105GB 99GB 40 0% 0/0 10.30.21.30
1028 active 107GB 101GB 40 0% 0/0 10.30.16.38
...
The CSID column displays the index number of chunk servers. In the output above, four chunk
servers are configured for the pcs1 cluster. They have index numbers of 1025, 1026, 1027,
and 1028.
3 Remove the chunk server from the cluster. For example, to delete the chunk server with index
number 1028 from the pcs1 cluster, run this command:
# pstorage -c pcs1 rm-cs --wait 1028
Once you initiate the delete operation, the cluster starts replicating data chunks that were stored on
the removed server and placing them on the remaining chunk servers in the cluster. The --wait
option, when specified, tells the command to wait until the operation is complete.
Note: When the delete operation is in progress, you can cancel it using this command: # pstorage -
c pcs1 rm-cs --cancel 1028. This might be useful, for example, if you specified a wrong ID of the
chunk server to remove.
To add a removed chunk server back to the pcs1 cluster, set it up from scratch by following the
steps in Setting Up Chunk Servers (p. 26).
36
Page 37

Configuring Parallels Cloud Storage Clusters
Configuring Clients
This section explains how to complete the following tasks:
• Add new clients to clusters (p. 37).
• Remove clients from clusters (p. 37).
Adding Clients
The process of including additional clients in a Parallels Cloud Storage cluster does not differ from
that of setting up the first client and is described in Setting Up Clients (p. 29) in detail.
Once you configure the client, you can run different commands on it to administer the cluster. For
example, you can monitor the cluster health and status using the pstorage top command. For
more details on monitoring Parallels Cloud Storage clusters, see Monitoring Parallels Cloud
Storage Clusters (p. 49).
Updating Clients
The process of updating software on clients that participate in clusters does not differ from that of
updating software on standalone servers, except for updating the pstorage-client package.
When updating this package, pay attention to the following.
• If no cluster is mounted to the client, the client starts using the updated package right away.
• If at least one cluster is mounted to the client, the updated package is installed, but the client
starts using it only after you remount the cluster or reboot the client.
Removing Clients
Removing a client from a Parallels Cloud Storage cluster simply means unmounting the directory
under which the cluster is mounted on the client. Assuming that the cluster is mounted under
/pstorage/pcs1, you can unmount it as follows:
1 Make sure that all virtual machines and Containers in the cluster are stopped.
2 Unmount the cluster:
# umount /pstorage/pcs1
3 If your cluster is configured to be automatically mounted when the client boots, comment out
the cluster entry in the /etc/fstab file on the client:
# pstorage://pcs1 /pstorage/pcs1 fuse.pstorage rw,nosuid,nodev 0 0
37
Page 38

Configuring Parallels Cloud Storage Clusters
Managing Cluster Parameters
This section explains what cluster parameters are and how you can configure them with the
pstorage utility.
Cluster Parameters Overview
The cluster parameters control the process of creating, locating, and managing replicas for data
chunks in a Parallels Cloud Storage cluster. All parameters can be divided into two main groups:
• replication parameters
• location parameters
The table below briefly describes each of the cluster parameters. For more information on
parameters, including the way to configure them, see the subsequent sections.
Parameter Description
Replication Parameters
Default Replicas
Min Replicas
Location Parameters
Location
Max Local Replicas
Tier
Number of replicas to create for a data chunk, from 1 to 15 (1 by default).
Minimum number of replicas for a data chunk, from 1 to 15 (1 by default).
Placement policy for replicas, from 0 to 4 (3 by default).
Maximum number of replicas for a data chunk that can be stored on the same
physical server, from 1 to 15 (1 by default).
Storage tiers, from 0 to 3 (0 by default).
38
Page 39

Configuring Parallels Cloud Storage Clusters
Configuring Replication Parameters
The cluster replication parameters define
• Default number of replicas of a data chunk. When a new data chunk is created, Parallels Cloud
Storage automatically replicates it until the default number of replicas is reached.
• Minimum number of replicas of a data chunk. During the life cycle of a data chunk, the number
of its replicas may change, sometimes falling below the limit defined by the minimum number of
replicas. Once the limit is exceeded, all write operations to the affected replicas are suspended
until their number reaches the value set by the default number replicas.
To check the current replication parameters applied to a cluster, you can use the pstorage get-
attr command. For example, if your cluster is mounted under the /pstorage/pcs1 directory,
you can run the following command to see what replication parameters are set for the cluster:
# pstorage get-attr /pstorage/pcs1
connected to MDS#1
File: '/pstorage/pcs1'
Attributes:
replicas=1:1
...
As you can see, the default and minimum numbers of chunk replicas are set to 1
(replicas=1:1).
Initially, any cluster is configured to have only one replica per each data chunk, which is sufficient to
evaluate the Parallels Cloud Storage functionality using one server only. In production, however, to
provide high availability for your data, you are recommended to
• configure each data chunk to have at least three replicas
• set the minimum number of replicas to two
Such a configuration requires at least three chunk servers to be set up in the cluster.
To configure the current replication parameters so that they apply to all virtual machines and
Containers in your cluster, you run the pstorage set-attr command against the directory
under which the cluster is mounted. For example, to set the recommended replication values to the
pcs1 cluster mounted under /pstorage/pcs1, run this command:
# pstorage set-attr -R /pstorage/pcs1 replicas=3:2
The -R option applies the new settings recursively to all existing subdirectories in the
/pstorage/pcs1 directory. So when you create new files and subdirectories in this directory,
they inherit the replication parameters from their parent directories.
Along with applying replication parameters to the entire contents of your cluster, you can also
configure them for specific directories and files. Let us assume the following:
• The default and minimum numbers of replicas in the cluster are set to 3 and 2, respectively.
• Container 101 is running some mission-critical service.
39
Page 40

Configuring Parallels Cloud Storage Clusters
• The contents of Container 101 are stored in the /pstorage/pcs1/private/101 directory.
Now you want to configure the default and minimum numbers of replicas for Container 101 by
setting them to 4 and 3, respectively, to provide higher availability for the mission-critical service. To
do this, you can run the following command:
# pstorage set-attr -R /pstorage/pcs1/private/101 replicas=4:3
40
Page 41

Configuring Parallels Cloud Storage Clusters
Configuring Location Parameters
Parallels Cloud Storage uses three parameters to define the location of data chunks and their
replicas in the cluster: Location, Max Local Replicas, and Tier.
Location (0-4, 3 by default)
This parameter controls how replicas are distributed across chunk servers in the cluster. 0 creates
the maximum separation and 4 allows replicas to be stored on the same physical server.
Max Local Replicas (1-15, 1 by default)
This parameter sets the maximum number of replicas for a data chunk that can be stored on the
same physical server. You can use this parameter if a server has several disk drives and each drive
is configured as a separate chunk server. In this case, you can specify the maximum number of
replicas that can be stored on disk drives of the same physical server.
Assume the following:
• A server has 3 disk drives.
• Each disk drive is configured as a separate chunk server.
• Data chunks are configured to have 3 replicas.
By setting the maximum number of replicas to 2, you can prevent situations when all 3 replicas of a
chunk reside on the 3 disks of the server and can be lost when the server breaks down.
Note: The Max Local Replica parameter is ignored if the Location parameter is set to 4, allowing
replicas to be stored on the same physical server
Tier (0-3, 0 by default)
This parameter defines the types of storage to use for storing data chunks. You can use storage
tiers to keep different categories of data on different chunk servers.
For example, you can store frequently accessed data on high-speed SSD drives while keeping the
least active data on slow conventional drives. To do this:
1 Assign all chunk servers with SSD drives to tier 1. You do this when setting up a chunk server;
see Stage 2: Creating the Chunk Server (p. 28) for details.
2 Assign the directories and files that store frequently accessed data to tier 1. You do this with
pstorage get-attr command; see below for details.
41
Page 42

Configuring Parallels Cloud Storage Clusters
Working with Location Parameters
To check the current location parameters applied to a cluster, you can use the pstorage getattr command. For example, if your cluster is mounted under the /pstorage/pcs1 directory,
you can run the following command to see what replication parameters are set for the cluster:
# pstorage get-attr /pstorage/pcs1
connected to MDS#1
File: '/pstorage/pcs1'
Attributes:
...
locality=3
tier=0
max-host-replicas=1
You can configure any of the location parameters so that they apply to
• All data in the cluster. In this case, you run the pstorage get-attr command against the
directory under which the cluster is mounted, for example:
# pstorage set-attr -R /pstorage/pcs1 locality=4 max-local-replicas=2
This command assumes that the cluster is mounted under /pstorage/pcs1. The -R option
applies the new settings recursively to all existing subdirectories in the /pstorage/pcs1
directory. When you create new files and subdirectories in this directory, they inherit the
replication parameters from their parent directories.
• Specific directories and files. In this case, you specify the path to the directory or file you want
to modify the location parameters for.
# pstorage set-attr -R /pstorage/pcs1/private/101 locality=4 tier=1
This command applies the new location parameters to the contents of Container 101 only, by
allowing data chunks to be stored on the same server and keeping Container data on servers
from tier 1.
42
Page 43

Configuring Parallels Cloud Storage Clusters
Accessing Parallels Cloud Storage Clusters via iSCSI
Usually, you access Parallels virtual machines and Containers natively from clients running the
Parallels Cloud Server software. To do this, you use standard Parallels command-line utilities, like
prlctl or pbackup.
Along with running virtual machines and Containers natively, you can export them as block devices
using the iSCSI protocol. This process includes the following basic steps:
1 Configuring the client (that is, the server with Parallels Cloud Server where you create virtual
machines and Containers) as the iSCSI target.
2 Adding virtual machine and Container images as logical units to the iSCSI target.
3 Connecting to the iSCSI target from an iSCSI client.
For detailed information on using iSCSI to access virtual machines and Containers, consult the
pstorage-iscsi man page.
43
Page 44

Configuring Parallels Cloud Storage Clusters
Managing Parallels Cloud Storage Licenses
This section describes the process of managing Parallels Cloud Storage licenses. You will learn to
do the following:
• Install a new license for a Parallels Cloud Storage cluster (p. 44).
• Update an installed license (p. 45).
• View the contents of an installed license (p. 46).
• Check the current status of a license (p. 47).
Installing a License
Along with installing a Parallels Cloud Server license on all clients in a cluster, you need to load a
separate license to start using the Parallels Cloud Storage functionality. One license is required per
cluster. You can install the license from any server participating in the cluster: an MDS server, a
chunk server, or a client.
To install a license, use the pstorage load-license command:
# pstorage -c pcs1 load-license -p XXXXXX-XXXXXX-XXXXXX-XXXXXX-XXXXXX
If you have obtained a license in the form of a file, you can install it by using the -f option instead of
-p and specifying the full path to the license file:
# pstorage -c pcs1 load-license -f /etc/pcsLicense
44
Page 45

Configuring Parallels Cloud Storage Clusters
Updating a License
In Parallels Cloud Server, you can use the pstorage update-license command to update the
license currently installed on your server. When executed, the utility connects to the Parallels Key
Authentication (KA) server, retrieves a new license, downloads it to the server, and installs it there.
To update a license, do the following:
1 Make sure that the server where you want to update the license is connected to the Internet.
2 Run the pstorage update-license command to update the license.
For example, to update a license installed in the pcs1 cluster, execute this command:
# pstorage -c pcs1 update-license
By default, pstorage obtains a new license from the default KA server. However, you can
explicitly specify what KA server to use by passing the --server option to the command:
# pstorage -c pcs1 update-license --server ka.server.com
Once you run the command, pstorage will connect to the KA server with the hostname of
ka.server.com, download a new license, and install it on your server.
45
Page 46

Configuring Parallels Cloud Storage Clusters
Viewing the License Contents
You can use the pstorage view-license command to view the information on the license
currently installed in your cluster. When executed, the utility processes the license and shows its
contents on the screen. A sample output of pstorage is given below:
# pstorage -c pcs1 view-license
PCSSTOR
status="ACTIVE"
version=1.0
expiration="08/24/2012 19:59:59"
graceperiod=3600
key_number="PCSS.XXXXXXXX.XXXX"
platform="Linux"
product="PCSS"
gracecapacity=5
autorecovery=0
autorebalance=0
snapshots=1
capacity=500
replicas=5
The main license parameters are explained in the table below.
Name Description
status
version
expiration
graceperiod
key_number
platform
product
gracecapacity
capacity
replicas
autorecovery
autorebalance
License status. For details, see Checking the License Status (p. 47).
Version of Parallels Cloud Storage for which the license was issued.
License expiration date and time.
Period, in seconds, during which Parallels Cloud Storage continues functioning
after the license has expired.
Key number under which the license is registered on the Parallels Key
Authentication server.
Operating system with which the license is compatible.
Product for which the license has been issued.
Amount of disk space that data chunks may occupy in the cluster, in per cent
to the capacity limit value.
For example, if the capacity limit is set to 1 TB, and the grace capacity is 5%,
data chunks may use 50 GB above the capacity limit.
Total amount of disk space, in GB, data chunks may occupy in the cluster.
To view the disk space currently used by chunks, run the pstorage top
command, press the V key on your keyboard, and check the FS field. For
details, see Understanding Disk Space Usage (p. 56).
Maximum number of replicas a data chunk may have.
Denotes whether the auto-recovery feature is enabled (1) or disabled (0).
Denotes whether the auto-rebalance feature is enabled (1) or disabled (0).
snapshots
Denotes whether the snapshots feature is enabled (1) or disabled (0).
46
Page 47

Configuring Parallels Cloud Storage Clusters
Checking the License Status
You can check the status of your license in one of the following ways:
• Using the pstorage view-license, for example:
# pstorage -c pcs1 view-license | grep status
status="ACTIVE"
• Using the pstorage stat or pstorage top command, for example:
# pstorage -c pcs1 stat | grep License
connected to MDS#1
License: PCSS.XXXXXXXX.XXXX is ACTIVE
The table below lists all statuses a license can have.
Status Description
ACTIVE License is valid and active.
VALID License the utility is analyzing is valid and can be installed in the cluster.
EXPIRED License has expired.
GRACED License is currently on the grace period or data chunks in the cluster use disk space from
the grace capacity.
INVALID License is invalid (for example, because its start date is in the future).
47
Page 48

Configuring Parallels Cloud Storage Clusters
Shutting Down Parallels Cloud Storage Clusters
Sometimes, you may need to shut down a Parallels Cloud Storage cluster completely:
1 Stop all clients in the cluster. To do this, on each client:
a Shut down all running Containers and virtual machines.
b Unmount the cluster file system using the umount command. For example, if the cluster is
mounted to the /pstorage/pcs1 directory on a client, you can unmount it as follows:
# umount /pstorage/pcs1
c Disable the automatic mounting of the cluster by removing the cluster entry from the
/etc/fstat file:
2 Stop all MDS servers and disable their automatic start:
# service pstorage-mdsd stop
# chkconfig pstorage-mdsd off
3 Stop all chunk servers and disable their automatic start:
# service pstorage-csd stop
# chkconfig pstorage-csd off
48
Page 49

Monitoring the Status of Replication Parameters ...................................................... 65
C
HAPTER
4
Monitoring Parallels Cloud Storage Clusters
Monitoring a Parallels Cloud Storage cluster is a very important process because it allows you to
check the status and health of all computers in the cluster and react as necessary. This chapter
explains how to complete the following tasks:
• monitor general cluster parameters (p. 50)
• monitor MDS servers (p. 52)
• monitor chunk servers (p. 54)
• monitor clients (p. 60)
• monitor messages in the cluster event log (p. 62)
• monitor the status of replication parameters (p. 65)
In This Chapter
Monitoring General Cluster Parameters ................................................................... 50
Monitoring Metadata Servers................................................................................... 52
Monitoring Chunk Servers ....................................................................................... 54
Monitoring Clients ................................................................................................... 60
Monitoring Event Logs ............................................................................................ 62
Page 50

Monitoring Parallels Cloud Storage Clusters
Monitoring General Cluster Parameters
. There is not enough information about the cluster state (e.g.,
•
By monitoring general parameters, you can get detailed information about all components of a
Parallels Cloud Storage cluster, its overall status and health. To display this information, use the
pstorage -c ClusterName top command, for example:
The command above shows detailed information about the pcs1 cluster. The general parameters
(highlighted in red) are explained in the table below.
Parameter Description
Overall status of the cluster:
• healthy. All chunk servers in the cluster are active.
• unknown
Cluster
Space
50
because the master MDS server was elected a while ago).
• degraded. Some of the chunk servers in the cluster are inactive.
• failure. The cluster has too many inactive chunk servers; the automatic
replication is disabled.
Amount of disk space in the cluster:
• total. Total amount of physical disk space in the cluster.
free. Free physical disk space in the cluster.
Page 51

Monitoring Parallels Cloud Storage Clusters
• allocatable. Amount of logical disk space available to clients.
Allocatable disk space is calculated on the basis of the current
replication parameters and free disk space on chunk servers.
Note: For more information on monitoring and understanding disk
space usage in clusters, see Monitoring Disk Space Usage (p. 56).
MDS nodes
epoch time
CS nodes
License
IO
Number of active MDS servers as compared to the total number of MDS servers
configured for the cluster.
Time elapsed since the MDS master server election.
Number of active chunk servers as compared to the total number of chunk servers
configured for the cluster.
The information in parentheses informs you of the number of
• Active chunk servers (avail.) that are currently up and running in the
cluster.
• Inactive chunk servers (inactive) that are temporarily unavailable. A
chunk server is marked as inactive during its first 5 minutes of inactivity.
• Offline chunk servers (offline) that have been inactive for more than 5
minutes. A chunk server changes its state to offline after 5 minutes of
inactivity. Once the state is changed to offline, the cluster starts
replicating data to restore the chunks that were stored on the offline
chunk server.
Key number under which the license is registered on the Parallels Key
Authentication server and license state.
For more information on licenses, see Managing Parallels Cloud Storage
Licenses (p. 44).
Disks IO activity in the cluster:
• Speed of read and write I/O operations, in bytes per second.
• Number of read and write I/O operations per second.
51
Page 52

Monitoring Parallels Cloud Storage Clusters
Monitoring Metadata Servers
MDS servers are a critical component of any Parallels Cloud Storage cluster, and monitoring the
health and state of MDS servers is a very critical task. To monitor MDS servers, use the pstorage
-c ClusterName top command, for example:
The command above shows detailed information about the pcs1 cluster. The monitoring
parameters for MDS servers (highlighted in red) are explained in the table below:
Parameter Description
MDS server identifier (ID).
MDSID
STATUS
%CTIME
COMMITS
%CPU
MEM
UPTIME
The letter "M" before ID, if present, means that the given server is the master MDS
server.
MDS server status.
Total time the MDS server spent writing to the local journal.
Local journal commit rate.
MDS server activity time.
Amount of physical memory the MDS server uses.
Time elapsed since the last MDS server start.
52
Page 53

Monitoring Parallels Cloud Storage Clusters
HOST
MDS server hostname or IP address.
53
Page 54

Monitoring Parallels Cloud Storage Clusters
Monitoring Chunk Servers
•
By monitoring chunk servers, you can keep track of the disk space available in a Parallels Cloud
Storage cluster. To monitor chunk servers, use the pstorage -c ClusterName top
command, for example:
The command above shows detailed information about the pcs1 cluster. The monitoring
parameters for chunk servers (highlighted in red) are explained in the table below:
Parameter Description
CSID
STATUS
SPACE
Chunk server identifier (ID).
Chunk server status:
• active. The chunk server is up and running.
• Inactive. The chunk server is temporarily unavailable. A chunk server is
marked as inactive during its first 5 minutes of inactivity.
• offline. The chunk server is inactive for more than 5 minutes. After the
chunk server goes offline, the cluster starts replicating data to restore
the chunks that were stored on the affected chunk server.
dropped. The chunk serve was removed by the administrator.
Total amount of disk space on the chunk server.
54
Page 55

Monitoring Parallels Cloud Storage Clusters
FREE
Free disk space on the chunk server.
REPLICAS
IOWAIT
IOLAT
HOST
Number of replicas stored on the chunk server.
Percentage of time spent waiting for I/O operations being served.
Average/maximum time, in milliseconds, the client needed to complete a single IO
operation during the last 20 seconds.
Chunk server hostname or IP address.
55
Page 56

Monitoring Parallels Cloud Storage Clusters
Understanding Disk Space Usage
Usually, you get the information on how disk space is used in your cluster with the pstorage top
command. This command displays the following disk-related information: total space, free space,
and allocatable space. For example:
# pstorage -c pcs1 top
connected to MDS#1
Cluster 'pcs1': healthy
Space: [OK] allocatable 180GB of 200GB, 1.7TB total, 1.6TB free
...
In this command output:
• 1.7TB total is the total disk space in the pcs1 cluster. The total disk space is calculated on
the basis of used and free disk space on all partitions in the cluster. Used disk space includes
the space occupied by all data chunks and their replicas plus the space occupied by any other
files stored on the cluster partitions.
Let us assume that you have a 100 GB partition and 20 GB on this partition are occupied by
some files. Now if you set up a chunk server on this partition, this will add 100 GB to the total
disk space of the cluster, though only 80 GB of this disk space will be free and available for
storing data chunks.
• 1.6TB free is the free disk space in the pcs1 cluster. Free disk space is calculated by
subtracting the disk space occupied by data chunks and any other files on the cluster partitions
from the total disk space.
For example, if the amount of free disk space is 1.6 TB and the total disk space is 1.7 TB, this
means that about 100 GB on the cluster partitions are already occupied by some files.
• allocatable 180GB of 200GB is the amount of free disk space that can used for storing
data chunks. See Understanding allocatable disk space below for details.
56
Page 57

Monitoring Parallels Cloud Storage Clusters
Understanding allocatable disk space
When monitoring disk space information in the cluster, you also need to pay attention to the space
reported by the pstorage top utility as allocatable. Allocatable space is the amount of disk
space that is free and can be used for storing user data. Once this space runs out, no data can be
written to the cluster.
To better understand how allocatable disk space is calculated, let us consider the following
example:
• The cluster has 3 chunk servers. The first chunk server has 200 GB of disk space, the second
one — 500 GB, and the third one — 1 TB.
• The default replication factor of 3 is used in the cluster, meaning that each data chunk must
have 3 replicas stored on three different chunk servers.
In this example, the available disk space will equal 200 GB — that is, set to the amount of disk
space on the smallest chunk server:
# pstorage -c pcs1 top
connected to MDS#1
Cluster 'pcs1': healthy
Space: [OK] allocatable 180GB of 200GB, 1.7TB total, 1.6TB free
...
This is explained by the fact that in this cluster configuration each server is set to store one replica
for each data chunk. So once the disk space on the smallest chunk server (200 GB) runs out, no
more chunks in the cluster can be created until a new chunk server is added or the replication
factor is decreased.
57
Page 58

Monitoring Parallels Cloud Storage Clusters
If you now change the replication factor to 2, the pstorage top command will report the
available disk space as 700 GB:
# pstorage set-attr -R /pstorage/pcs1 replicas=2:2
# pstorage -c pcs1 top
connected to MDS#1
Cluster 'pcs1': healthy
Space: [OK] allocatable 680GB of 700GB, 1.7TB total, 1.6TB free
...
The available disk space has increased because now only 2 replicas are created for each data
chunk and new chunks can be made even if the smallest chunk server runs out of space (in this
case, replicas will be stored on a bigger chunk server).
Viewing space occupied by data chunks
To view the total amount of disk space occupied by all user data in the cluster, run the pstorage
top command and press the V key on your keyboard. Once you do this, your command output
should look like the following:
# pstorage -c pcs1 top
Cluster 'pcs1': healthy
Space: [OK] allocatable 180GB of 200GB, 1.7TB total, 1.6TB free
MDS nodes: 1 of 1, epoch uptime: 2d 4h
CS nodes: 3 of 3 (3 avail, 0 inactive, 0 offline)
Replication: 2 norm, 2 limit, 4 max
Chunks: [OK] 38 (100%) healthy, 0 (0%) degraded, 0 (0%) urgent,
0 (0%) blocked, 0 (0%) offline, 0 (0%) replicating,
0 (0%) overcommitted, 0 (0%) deleting, 0 (0%) void
FS: 1GB in 51 files, 51 inodes, 23 file maps, 38 chunks, 76 chunk replicas
...
The FS field shows how much disk space is used by all user data in the cluster and in how many
files these data are stored.
58
Page 59

Monitoring Parallels Cloud Storage Clusters
Exploring Chunk States
The table below lists all possible states a chunk can have.
Status Description
healthy
replicating
offline
void
pending
blocked
urgent
degraded
standby
overcommitted
Percentage of chunks that have enough active replicas.
Percentage of chunks whose replicas are being replicated.
Percentage of chunks that have no active replicas.
Percentage of chunks that have one or more replicas whose state cannot be
parsed.
Percentage of chunks that must be replicated in the first place because all
operations with these chunks are suspended and the client is waiting for the
replication to complete.
Percentage of chunks whose number of replicas is equal or below the minimum
replicas limit. No write operations to these chunks are allowed.
Percentage of chunks that are nearing the minimum replicas limit.
Percentage of chunks that do not have enough active replicas.
Percentage of chunks that have one or more replicas in the standby state. A
replica is marked standby if it is inactive no more than 5 minutes.
Percentage of chunks that have an excessive amount of replicas.
59
Page 60

Monitoring Parallels Cloud Storage Clusters
Monitoring Clients
By monitoring clients, you can check the status and health of servers that you use to access
Parallels virtual machines and Containers. To monitor clients, use the pstorage -c
ClusterName top command, for example:
The command above shows detailed information about the pcs1 cluster. The monitoring
parameters for clients (highlighted in red) are explained in the table below:
Parameter Description
CLID
LEASES
READ
WRITE
RD_OPS
WR_OPS
Client identifier (ID).
Average number of files opened for reading/writing by the client and not yet closed,
for the last 20 seconds.
Average rate, in bytes per second, at which the client reads data, for the last 20
seconds.
Average rate, in bytes per second, at which the client writes data, for the last 20
seconds.
Average number of read operations per second the client made, for the last 20
seconds.
Average number of write operations per second the client made, for the last 20
seconds.
60
Page 61

Monitoring Parallels Cloud Storage Clusters
FSYNCS
Average number of sync operations per second the client made, for the last 20
seconds.
IOLAT
HOST
Average/maximum time, in milliseconds, the client needed to complete a single IO
operation, for the last 20 seconds.
Client hostname or IP address.
61
Page 62

Monitoring Parallels Cloud Storage Clusters
Monitoring Event Logs
MDS#N (
)
You can use the pstorage -c ClusterName top utility to monitor significant events
happening in a Parallels Cloud Storage cluster, for example:
The command above shows the latest events in the pcs1 cluster. The information on events
(highlighted in red) is given in the table with the following columns:
Column Description
TIME
SYS
SEV
MESSAGE
Time when the event happened.
Component of the cluster where the event happened (e.g., MDS for an MDS server
or JRN for local journal).
Event severity.
Event description.
Exploring Basic Events
The table below describes the basic events displayed when you run the pstorage top utility.
Event Severity Description
addr:port
62
JRN err
Generated by the MDS master server when it detects that MDS#N is
Page 63

Monitoring Parallels Cloud Storage Clusters
lags behind for
more than 1000
stale.
mds.wd.offline_tout = 5min
are queued
completed
rounds
MDS#N (addr:port)
didn't accept
commits for M sec
MDS#N (addr:port)
state is outdated
and will do a full
resync
JRN err
JRN err
This message may indicate that some MDS server is very slow and
lags behind.
Generated by the MDS master server if MDS#N did not accept
commits for M seconds. MDS#N gets marked as stale.
This message may indicate that the MDS service on MDS#N is
experiencing a problem. The problem may be critical and should be
resolved as soon as possible.
Generated by the MDS master server when MDS#N will do a full
resync. MDS#N gets marked as stale.
This message may indicate that some MDS server was too slow or
disconnected for such a long time that it is not really managing the
state of metadata and has to be resynchronized. The problem may
be critical and should be resolved as soon as possible.
MDS#N at
<addr:port> became
master
The cluster is
healthy with N
active CS
The cluster is
degraded with N
active, M
inactive, K
offline CS
The cluster failed
with N active, M
inactive, K
offline CS
(mds.wd.max_offlin
e_cs=n)
JRN info
MDS info
MDS warn
MDS err
Generated every time a new MDS master server is elected in the
cluster.
Frequent changes of MDS masters may indicate poor network
connectivity and may affect the cluster operation.
Generated when the cluster status changes to healthy or when a
new MDS master server is elected.
This message indicates that all chunk servers in the cluster are active
and the number of replicas meets the set cluster requirements.
Generated when the cluster status changes to degraded or when a
new MDS master server is elected.
This message indicates that some chunk servers in the cluster are
• inactive (do not send any registration messages) or
• offline (are inactive for a period longer than
(by default)).
Generated when the cluster status changes to failed or when a new
MDS master server is elected.
This message indicates that the number of offline chunk servers
exceeds mds.wd.max_offline_cs (2 by default). When the
cluster fails, the automatic replication is not scheduled any more. So
the cluster administrator must take some actions to either repair
failed chunk servers or increase the mds.wd.max_offline_cs
parameter. Setting the value of this parameter to 0 disables the failed
mode completely.
The cluster is
filled up to N%
Replication
started, N chunks
Replication
Shows the current space usage in the cluster. A warning is
MDS
info/warn
MDS info
MDS info Generated when the cluster finishes the automatic data replication.
generated if the disk space consumption equals or exceeds 80%.
It is important to have spare disk space for data replicas if one of the
chunk servers fails.
Generated when the cluster starts the automatic data replication to
recover the missing replicas.
63
Page 64

Monitoring Parallels Cloud Storage Clusters
CS#N has reported
available
registered
hard error on
'path'
MDS warn
Generated when the chunk server CS#N detects disk data
corruption.
You are recommended to replace chunk servers with corrupted
disks as soon as possible with new ones and to check the hardware
for errors.
CS#N has not
registered during
the last T sec and
is marked as
inactive/offline
Failed to allocate
N replicas for
'path' by request
from <addr:port> K out of M chunks
servers are
Failed to allocate
N replicas for
'path' by request
from <addr:port>
since only K chunk
servers are
MDS warn
MDS warn
MDS warn
Generated when the chunk server CS#N has been unavailable for a
while. In this case, the chunk server first gets marked as inactive.
After 5 minutes, the state is changed to offline, which starts the
automatic replication of data to restore the replicas that were stored
on the offline chunk server.
Generated when the cluster cannot allocate chunk replicas, for
example, when it runs out of disk space.
Generated when the cluster cannot allocate chunk replicas because
not enough chunk servers are registered in the cluster.
64
Page 65

Monitoring Parallels Cloud Storage Clusters
Monitoring the Status of Replication Parameters
When you configure replication parameters, keep in mind that the new settings do not come into
effect immediately. For example, increasing the default replication parameter for data chunks may
take some time to complete, depending on the new value of this parameter and the number of data
chunks in the cluster.
To check that the new replication parameters have been successfully applied to your cluster:
1 Run the pstorage -c ClusterName top command.
2 Press the V key on your keyboard to display additional information about the cluster. Your
command output should look similar to the following:
# pstorage -c pcs1 top
connected to MDS#1
Cluster 'pcs1': healthy
Space: [OK] allocatable 15GB of 17GB, 144GB total, 131GB free
MDS nodes: 1 of 1, epoch uptime: 5d 4h
CS nodes: 3 of 3 (3 avail, 0 inactive, 0 offline)
Replication: 3 norm, 2 limit, 4 max
Chunks: [OK] 431 (100%) healthy, 0 (0%) degraded, 0 (0%) urgent,
0 (0%) blocked, 0 (0%) offline, 0 (0%) replicating,
0 (0%) overcommitted, 0 (0%) deleting, 0 (0%) void
...
3 Check the Chunks field for the following:
• When decreasing the replication parameters, look for chunks that are in the overcommitted
or deleting state. If the replication process is complete, no chunks with these states should
be present in the output.
• When increasing the replication parameters, look for chunks that are in the blocked or
urgent state. If the replication process is complete, no chunks with these states should be
present in the output. Besides, when the process is still in progress, the value of the healthy
parameter is less than 100%.
Note: For more information on available chunk statutes, see Exploring Chunk States (p. 59).
65
Page 66

Installations via PXE Servers ................................................................................... 74
C
HAPTER
5
Managing Cluster Security
This chapter describes some situations that may affect your cluster security.
In This Chapter
Security Considerations .......................................................................................... 66
Securing Server Communication in Clusters ............................................................ 67
Cluster Discovery Methods ..................................................................................... 69
Parallels Cloud Storage Ports ................................................................................. 70
Password-Based Authentication ............................................................................. 73
Security Considerations
This section describes the security limitations you should keep in mind when deploying a Parallels
Cloud Storage cluster.
Traffic sniffing
Parallels Cloud Storage does not protect you from traffic sniffing. Anyone who has access to your
network can capture and analyze the data being sent and received through your network.
To learn how to keep your data secure, see Securing Server Communication in Clusters (p. 67).
Absence of users and groups
Parallels Cloud Storage does not use the concept of users and groups, providing specific users
and groups with access to specific parts of a cluster. Anyone authorized to access a cluster can
access all its data.
Non-encrypted data on disks
Parallels Cloud Storage does not encrypt data stored in a cluster. Attackers can immediately see
the data once they gain access to a physical disk drive.
Page 67

Managing Cluster Security
Securing Server Communication in Clusters
A Parallels Cloud Storage cluster can contain three types of servers:
• MDS servers
• chunk servers
• clients
During cluster operation, the servers communicate with each other. To secure their communication,
you should keep all servers on an isolated private network—BackNet. The figure below shows an
example of a cluster configuration where all servers are set up on the BackNet.
The process of deploying such a configuration can be described as follows:
1 You create the cluster by making the MDS server and specifying one of its IP addresses:
# pstorage -c Cluster-Name make-mds -I -a MDS-IP-Address -r Journal-Directory -p
The specified address will then be used for MDS interconnection and intercommunication with
the other servers in the cluster.
2 You set up a chunk server:
67
Page 68

Managing Cluster Security
# pstorage -c Cluster-Name make-cs -r CS-Directory
Once it is created, the chunk server connects to the MDS server and binds to the IP address it
uses to establish the connection. If the chunk server has several networks cards, you can
explicitly assign the chunk server to the IP address of a specific network card so that all
communication between the chunk and MDS servers is carried out via this IP address.
To bind a chunk server to a custom IP address, you pass the -a option to the pstorage
make-cs command when you create the chunk server:
# pstorage make-cs -r CS-Directory -a Custom-IP-Address
Note: A custom IP address must belong to the BackNet not to compromise your cluster security.
3 You mount the cluster on the client:
# pstorage-mount -c Cluster-Name Mount-Directory
Once the cluster is mounted, the client connects to the MDS and chunk server IP addresses.
This example configuration provides a high level of security for server communication because the
MDS server, the chunk server, and the client are located on the isolated BackNet and cannot be
compromised.
68
Page 69

Managing Cluster Security
Cluster Discovery Methods
When choosing a cluster discovery method for your cluster, pay attention to the following:
• The recommended way of configuring auto-discovery for a Parallels Cloud Storage cluster is to
use DNS records. For more details on this discovery method, see Creating DNS SRV Records
(p. 20).
• Avahi auto-discovery can be used for testing and evaluating the Parallels Cloud Storage
functionality. This discovery method is not recommended for use in production due to security
reasons. Malicious users can potentially perform DoS attacks on the Avahi service even if you
use security certificates for authentication in your network.
• If you plan to use the Avahi discovery (though it is not recommended), consider enhancing your
cluster security by allowing the use only of network interface cards that belong to the cluster
BackNet. To do this, configure the allow-interfaces parameter in the
/etc/avahi/avahi-daemon.conf file by setting its value to the names of the allowed
network cards. Configure this file on all servers in the cluster.
69
Page 70

Managing Cluster Security
Parallels Cloud Storage Ports
This section lists the ports that must be open on servers that participate in a Parallels Cloud
Storage cluster, in addition to the ports used by Parallels Cloud Server and Parallels Virtual
Automation.
MDS Servers
The following ports must be open on an MDS server:
• Listening ports: 2510 for incoming connections from other MDS serves and 2511 for incoming
connections from chunk servers and clients
• Outbound ports: 2510 for outgoing connections to other MDS servers
By default, Parallels Cloud Storage uses port 2510 for communication between MDS servers and
port 2511 for incoming connections from both chunk servers and clients. You can override the
default ports when creating MDS servers:
1 Reserve two unoccupied consecutive ports.
The ports must be the same on all MDS servers you plan to set up in the cluster.
2 Execute the pstorage make-mds command to create the MDS server and specify the lower
port after the server IP address.
For example, to set up ports 4110 and 4111 for MDS communication in the pcs1 cluster, you can
run this command:
# pstorage -c pcs1 make-mds -I -a 10.30.100.101:4110 -r /pstorage/pcs1-mds -p
70
Page 71

Managing Cluster Security
If you choose to use custom ports 4110 and 4111, do the following:
• On each MDS server with custom ports, open ports 4110 and 4111 for inbound traffic and port
4110 for outbound traffic.
• On all chunk servers and clients in the cluster, open port 4111 for outbound traffic.
Chunk Servers
The following ports must be open on a chunk server:
• Listening ports: a randomly chosen port for incoming connections from clients and other
chunk servers
• Outbound ports: 2511 for outgoing connections to MDS servers and a randomly chosen port
for outgoing connections to other chunk servers
The chunk server management service requires
• A port to communicate with MDS servers (either the default port 2511 or your custom port).
• A port to communicate with chunk servers and clients.
By default, the service binds to any available port. You can manually redefine the port by
passing the -a option to the pstorage make-cs command when creating a chunk server.
For example, to configure the management service to use port 3000, run this command:
# pstorage make-cs -r /pstorage/pcs1-cs -a 132.132.1.101:3000
Once you set a custom port, open this port for outbound traffic on all clients and other chunk
servers in the cluster.
71
Page 72

Managing Cluster Security
Clients
The following ports must be open on a client:
• Listening ports: no
• Outbound ports: 2511 for outgoing connections to MDS servers and a port configured as the
listening one on chunk servers
By default, Parallels Cloud Storage automatically opens on a client the following outbound ports:
• For communication with MDS servers, the default port 2511.
• For communication with chunk servers, the port that was configured as the listening one on
your chunk servers.
If you specify custom ports for MDS and chunk server communication, open these ports on the
client for outgoing traffic. For example, if you configure port 4111 on MDS servers and port 3000
on chunk servers for communication with clients, open outbound ports 2511 and 3000 on the
client.
72
Page 73

Managing Cluster Security
Password-Based Authentication
Parallels Cloud Storage uses password-based authentication to enhance security in clusters.
Password authentication is mandatory meaning that you have to pass the authentication phase
before you can add a new server to the cluster.
Password-based authentication works as follows:
1 You set the authentication password when you create the first MDS server in the cluster. The
password you specify is encrypted and saved into the
/etc/pstorage/clusters/pcs1/auth_digest.key file on the server.
2 You add new MDS servers, chunk servers, or clients to the cluster and use the pstorage
auth-node command to authenticate them. During authentication, you use the password you
set when creating the first MDS server.
3 Parallels Cloud Storage compares the provided password with the one stored on the first MDS
server, and if the passwords match, successfully authenticates the server.
For each physical server, authentication is a one-time process. Once a server is authenticated in
the cluster (for example, when you configure it as an MDS server), the
/etc/pstorage/clusters/pcs1/auth_digest.key file is created on the authenticated
server. When you set up this server as another cluster component (e.g., as a chunk server), the
cluster checks that the auth_digest.key file is present and does not require you to authenticate
the server again.
73
Page 74

Managing Cluster Security
Installations via PXE Servers
Kickstart files you use to perform an unattended installation of Parallels Cloud Server 6.0 and
Parallels Cloud Storage over a network contain a cluster authentication password in plain text.
Attackers may intercept the password and gain access to your cluster. To secure your system, do
one of the following:
• Physically isolate the network where the PXE server is located from all other (potentially
insecure) networks.
• Install Parallels Cloud Server 6.0 via the PXE server but do not set up a Parallels Cloud Storage
cluster. Once the installation is complete, manually deploy the cluster in your network using the
Parallels Cloud Storage password-based authentication mechanism.
74
Page 75

Using SSD Drives ................................................................................................... 78
C
HAPTER
6
Maximizing Cluster Performance
This chapter describes recommended configurations for Parallels Cloud Storage clusters and ways
to tune them for maximum performance.
Note: Please also see Troubleshooting (p. 85) for common issues that might affect your cluster
performance.
In This Chapter
Exploring Possible Disk Drive Configurations ........................................................... 76
Carrying Out Performance Benchmarking ................................................................ 77
Using 1 Gb and 10 Gb Networks ............................................................................ 77
Page 76

Maximizing Cluster Performance
Exploring Possible Disk Drive Configurations
If the servers you plan to include in a Parallels Cloud Storage cluster have several disk drives, you
can choose one of the following configurations for the cluster:
1 No local RAIDs
A chunk server is set up per each hard drive and each data chunk has two or more replicas.
This configuration provides independence of disk failures, and the cluster replication adds
reliability close to RAID 1 (mirroring without parity or striping). However, the next configuration is
better optimized for performance.
2 (Recommended) Local striping RAID 0, data chunks with two or more replicas
The configuration is very well optimized for performance as a striping RAID improves a lot of
common I/O patterns and is similar to some extent to RAID 10.
This configuration is better optimized for performance than the one with no local RAIDs (see
item 1), but the cluster reliability degrades a bit because a single drive failure will result in the
whole RAID 0 failure, causing the cluster to replicate more data each time such a failure occurs.
However, this can be considered as a minor issue as the Parallels Cloud Storage cluster
performs parallel recovery from multiple servers, which is much faster than a traditional RAID 1
rebuild.
3 (Highly recommended) Local striping RAID 0, SSD drive, data chunks with two or
more replicas
This configuration is similar to the configuration with local striping RAID 0 (see item 2).
Additionally, it assumes using small SSD drives for caching and journaling to improve the overall
cluster performance and adds data checksumming and data scrubbing to improve the cluster
reliability. For more information on using SSD drives, see SSD Caching.
4 Local mirror RAID 1, data chunks with one or more replicas
When deployed with one replica per each data chunk, this configuration does not provide high
availability of your cluster if some of your servers fail. Besides, such configurations do no bring
any disk space savings as they are equivalent to cluster mirroring, and a local RAID just doubles
the data replication factor and saves cluster network traffic.
5 Local RAID 5, data chunks with two replicas
This configuration is quite reliable because it can effectively survive the loss of any two disks
and/or of a single server. However, the configuration uses about the same amount of disk
space as a cluster with three replicas and no local RAIDs. The only difference is that a local
RAID 5 may require less network traffic, which can be a bottleneck on 1 Gb networks. On the
other hand, RAID 5 is quite slow on disk writes. In general, this configuration is not
recommended if the cluster performance is important.
76
Page 77

Maximizing Cluster Performance
Carrying Out Performance Benchmarking
When testing the performance of a Parallels Cloud Storage cluster and comparing it with nonParallels Cloud Storage setups:
• Compare configurations with similar redundancy levels. For example, it is incorrect to compare
the performance of a cluster with two or three replicas per data chunk with a standalone server
that does not use any data redundancy, like RAID 1, 10, or 5.
• Take into account the usage of file system interfaces. Keep in mind that mounting a Parallels
Cloud Storage cluster using the FUSE interface provides a convenient view into the cluster but
is not optimal for performance. Therefore, do benchmarks from inside Containers and virtual
machines.
• Keep in mind that the data replication factor affects the cluster performance: clusters with two
replicas are slightly faster than those with three replicas.
Using 1 Gb and 10 Gb Networks
1 Gb Ethernet networks can deliver 110-120 MB/s, which is close to a single drive performance on
sequential I/O. It is obvious that several drives on a single sever can deliver higher throughput than
1 Gb Ethernet network, so networking may become a bottleneck.
However, in real-life applications and virtualized environments, sequential I/O is not common
(mainly on backups) and most of the I/O is random. Thus, a typical HDD throughput is much lower
and is close to 10-20 MB/s. This is proved by statistics from a number of big hosting companies
and hundreds of servers.
So if you need a high sequential I/O throughput, use 10-Gb networks; otherwise, you can deploy 1
Gb networks.
77
Page 78

Maximizing Cluster Performance
Using SSD Drives
Along with using SSD drives for storing data chunks, Parallels Cloud Storage also supports the use
of such drives for special purposes:
• write journaling (p. 79). You can attach an SSD drive to a chunk server and configure the drive
to store a write journal. By doing so, you can boost the performance of write operations in the
cluster by up to 2 and more times.
• data caching (p. 81). You can attach an SSD drive to a client and configure the drive to store a
local cache of frequently accessed data. By having a local cache on a client's SSD drive, you
can increase the overall cluster performance by up to 10 and more times.
The following sections provide detailed information on configuring SSD drives for write journaling
and data caching.
78
Page 79

Maximizing Cluster Performance
Configuring SSD Drives for Write Journaling
Note: To simplify the cluster configuration and be able to use a single SSD journal per chunk server, you
are recommended to use the configuration with local striping RAID 0; see configuration 2 in Possible
Disk Drive Configurations (p. 76). In this case, each server will run a single chunk server instance with a
single SSD journal and a logical RAID volume.
Using SSD drives for write journaling can help you reduce write latencies, thus improving the overall
cluster performance.
To set up a chunk server that stores a journal on an SSD drive, do the following:
1 Log in to the computer you want to act as a chunk server as root or as a user with root
privileges. The computer must have at least one hard disk drive (HDD) and one solid state drive
(SSD).
2 Download and install the following RPM packages: pstorage-ctl, pstorage-libs-
shared, and pstorage-chunk-server.
These packages are available in the Parallels Cloud Server remote repository (this repository is
automatically configured for your system when you install Parallels Cloud Server) and can be
installed with this command:
# yum install pstorage-chunk-server
3 Make sure that cluster discovery is configured for the server. For details, see Configuring
Cluster Discovery (p. 19).
4 Authenticate the server in the cluster, if it is not yet authenticated:
# pstorage -c pcs1 auth-node
5 Create the chunk server configuration, repository, and the journal, for example:
# pstorage -c pcs1 make-cs -r /pstorage/pcs1-cs -j /ssd/pcs1/cs1 -s 30720
This command
• Makes the /pstorage/pcs1-cs directory on your computer's hard disk drive and
configures it for storing data chunks.
• Configures your computer as a chunk server and joins it to the pcs1 Parallels Cloud
Storage cluster.
• Creates the journal in the /ssd/pcs1/cs1 directory on the SSD drive and allocates 30 GB
of disk space to this journal.
Note: When choosing a directory for keeping the journal and deciding on its size, allocate one
half of the SSD drive to the journal and leave the other half for checksumming.
6 Start the chunk server management service (pstorage-csd) and configure it to start
automatically on the chunk server boot:
# service pstorage-csd start
# chkconfig pstorage-csd on
79
Page 80

Maximizing Cluster Performance
Disabling Checksumming
Using checksumming, you can provide better reliability and integrity of all data in the cluster. When
checksumming is enabled, Parallels Cloud Storage generates checksums each time some data in
the cluster is modified. When this data is then read, the checksum is computed once more and
compared with the already existing value.
By default, data checksumming is automatically enabled for all newly created chunk servers. If
necessary, you can disable this functionality using the -S option when you set up a chunk server,
for example:
# pstorage -c pcs1 make-cs -r /pstorage/pcs1-cs -j /ssd/pcs1/cs1 -s 30720 -S
Configuring Data Scrubbing
Data scrubbing is the process of checking data chunks for durability and verifying their contents for
readability and correctness. By default, Parallels Cloud Storage is set to examine two data chunks
per minute on each chunk server in the cluster. If necessary, you can configure this number using
the pstorage utility, for example:
# pstorage -c pcs1 set-config mds.wd.verify_chunks=3
This command sets the number of chunks to be examined on each chunk server in the pcs1
cluster to 3.
80
Page 81

Maximizing Cluster Performance
Configuring SSD Drives for Data Caching
Another way of improving the overall cluster performance is to create a local cache on a client's
SSD drive. Once you create the cache, all cluster data accessed two or more times is put to that
cache.
The table below lists the main features specific to a local cache:
Feature Description
Quick access time
No network bandwidth
consumption
Special boot cache
Cache survivability
Sequential access filtering
Data in the local cache can be accessed much faster (up to 10
times and more) as compared to accessing the same data
stored on chunk servers in the cluster.
Cluster network bandwidth is not consumed because the data
is accessed locally.
Local cache uses a special boot cache to store small amounts
of data on file openings. This significantly speeds up the
process of starting virtual machines and Containers.
Local cache is persistent and can survive a graceful system
shutdown; however, it is dropped when the system crashes.
Only randomly accessed data is cached.
Data backup applications may generate a huge amount of
sequential IO. Preventing such IO from being cached helps to
avoid stressing the cache.
81
Page 82

Maximizing Cluster Performance
Creating a Local Cache
You create a local cache when mounting a Parallels Cloud Storage cluster to a client. This process
includes two steps:
1 Making sure that the SSD drive where you plan to store the local cache is mounted to the
client.
2 Using the pstorage-mount command to mount the cluster and create the cache.
For example, to make a 64 GB local cache for the pcs1 cluster and store it in the file
/mnt/ssd/pstorage-cache-for-cluster-pcs1, you can execute the following command:
# pstorage-mount -c pcs1 /pstorage/pcs1 -C /mnt/ssd/pstorage-cache-for-cluster-pcs1 -R
64000
If you do not specify the cluster size, pstorage-mount will automatically calculate it using the
following formula:
SSD_free_space - 10 GB - SSD_total_space/10
So if the total size of your SSD drive is 100 GB and it has 80 GB of free space, the command will
create the local cache with the size of 60 GB.
Notes:
1. The local cache is not created if the resulting cache size is less than 1 GB.
2. If you also plan to configure the SSD drive for write journaling, first create the journal to reserve disk
space for it and then create a local cache. For more information, see Configuring SSD Drives for Write
Journaling (p. 79).
Configuring Automatic Cache Creation
You can automate the procedure of creating a local cache so that it is automatically created each
time you start the client. To do this, add the information about the cache to the /etc/fstab file
on the client.
For example, to (1) have an automatically created cache with the name of pstorage-cache-
for-cluster-pcs1 and size of 64 GB, (2) store it in the /mnt/ssd directory on the client, and
(3) disable checksumming for data in the local cache, specify the following parameters in
/etc/fstab and separate them by commas:
• cache=N. Sets the full path to the local cache file.
• cachesize=N. Specifies the size of the local cache, in megabytes.
• cachechksum=n. Disables checksumming for your data; by default, data checksumming is
enabled.
Once you set these parameters, your fstab file should look like the following:
pstorage://pcs1 /pstorage/pcs1 fuse.pstorage cache=/mnt/ssd/pstorage-cache-for-clusterpcs1,cachesize=64000,cachechksum=n 0 0
82
Page 83

Maximizing Cluster Performance
For more information on options you can use to set up and configure a local cache, see the
pstorage-mount man pages.
Disabling Checksumming
To provide better reliability and integrity of your data, the pstorage-mount command
automatically enables checksumming for the data in the local cache. If necessary, you can disable
data checksumming by passing the -S option to pstorage-mount:
# pstorage-mount -c pcs1 /pstorage -C /mnt/ssd/pstorage-cache-for-cluster-pcs1 -R 64000
-S
Querying Cache Information
To check whether the cache for a mounted cluster is active and view its current parameters, you
can use this command:
# cat /pstorage/pcs1/.pstorage.info/read_cache_info
path : /mnt/ssd/pstorage-cache-for-cluster-pcs1
main size (Mb) : 56000
boot size (Mb) : 8000
block size (Kb) : 64
checksum : enabled
If the cache does not exist, the command output is empty. Otherwise, the command prints:
• path to the cache file
• size of the main and boot caches
• block size
• checksum status
83
Page 84

Appendix B - Frequently Asked Questions ............................................................... 89
C
HAPTER
7
Appendices
This chapter contains two appendices:
• Appendix A (p. 85) provides troubleshooting for most common problems in Parallels Cloud
Storage clusters.
• Appendix B (p. 89) gives answers to most frequently asked questions.
In This Chapter
Appendix A - Troubleshooting ................................................................................. 85
Page 85

Appendices
Appendix A - Troubleshooting
This chapter describes common issues you may encounter when working with Parallels Cloud
Storage clusters and ways to resolve them. The main tool you use to solve cluster problems and
detect hardware failures is pstorage top.
Submitting a Problem Report to Technical Support
If your cluster is experiencing a problem that you cannot solve on your own, you can use the
pstorage make-report command to compile a detailed report about the cluster. You can then
send the report to the Parallels support team who will closely examine your problem and make their
best to solve it as quickly as possible.
To generate a report:
1 Configure passwordless SSH access for the root user on all servers that participate in the
cluster.
For example, you can do this by providing each server with authorized public SSH RSA keys.
2 Run the pstorage make-report command to compile the report:
# pstorage -c pcs1 make-report
The report is created and saved to pstorage-report-20121023-90630.tgz
Please send the report to the Parallels support.
The command collects cluster-related information on all servers participating in the cluster and
saves it to a file in your current working directory. You can find the exact file name by checking
the pstorage output (pstorage-report-20121023-90630.tgz in the example above).
If necessary, you can save the report to a file with a custom name and put it to a custom
location. To do this, pass the -f option to the command and specify the desired file name (with
the .tgz extension) and location, for example:
# pstorage -c pcs1 make-report -f /home/reportPCS1.tgz
Once it is ready, submit the report to the Parallels support team. For example, you can do this
using the Parallels Support Request Tracker tool. For more information on using this tool, consult
the Parallels Cloud Server User's Guide.
Note: The report contains only information related to your cluster settings and configuration. It does not
contain any private information.
85
Page 86

Appendices
Out of Disk Space
When a Parallels Cloud Storage cluster runs out of free disk space, clients do not typically return
any errors, but rather freeze the application performing the I/O. In this case, applications running in
Containers may get stuck in the D state while applications in virtual machines just switch to the
"frozen" state to avoid guest OS I/O stack timeouts and unrecoverable issues. This behavior was
implemented to avoid file system corruptions and to seamlessly resolve situations when additional
disk space is added to the cluster.
To resolve out-of-disk-space problems, just add additional chunk servers to the cluster or decrease
the current replication parameters to remove some replicas from existing chunk servers.
Poor Write Performance
Some network adapters, like RTL8111/8168B, are known to fail to deliver full-bandwidth, fullduplex network traffic. This can result in poor write performance.
So before deploying a Parallels Cloud Storage cluster, you are highly recommended to test
networks for full-duplex support. You can use the netperf utility to simultaneously generate in
and out traffic. For example, in 1 Gb networks, it should constantly deliver about 2 Gb of total traffic
(1 Gb for in and 1 Gb for out traffic).
Poor Disk I/O Performance
In most BIOS setups, AHCI mode is configured to work by default with the Legacy option enabled.
With this option, your servers work with SATA devices via the legacy IDE mode, which may affect
the cluster performance, making it up to 2 times slower than expected. You can check that the
option is currently enabled by running the hdparm command, for example:
# hdparm -i /dev/sda
...
PIO modes: pio0 pio1 pio2 pio3 *pio4
DMA modes: mdma0 mdma1 mdma2
UDMA modes: udma0 udma1 udma2 udma3 udma4 udma5 udma6
The asterisk before pio4 in the PIO modes field indicates that your hard drive /dev/sda is
currently operating in the legacy mode.
To solve this problem and maximize the cluster performance, always enable the AHCI option in
your BIOS settings.
86
Page 87

Appendices
Hardware RAID Controller and Disk Write Caches
It is important that all hard disk drives obey the "flush" command and write their caches before the
command completes. Unfortunately, not all hardware RAID controllers and drives do this, which
may lead to data inconsistencies and file system corruptions on a power failure.
Some 3ware RAID controllers do not disable disk write caches and do not send "flush" commands
to disk drives. As a result, the file system may sometimes become corrupted even though the RAID
controller itself has a battery. To solve this problem, disable writes caches on all disk drives in the
RAID.
Also, make sure that your configuration is thoroughly tested for consistency before deploying a
Parallels Cloud Storage cluster. For information on how you can do this, see SSD Drives Ignore
Disk Flushes (p. 87).
SSD Drives Ignore Disk Flushes
A lot of desktop-grade SSD drives can ignore disk flushes and fool operating systems by reporting
that data was written while it was actually not. Examples of such drives are OCZ Vertex 3 and Intel
X25-E, X-25-M G2 that are known to be unsafe on data commits. Such disk drives should not be
used with databases and may easily corrupt the file system on a power failure.
The 3rd generation Intel SSD drives (320 and 710 series) do not have these problems, having a
capacitor to provide a battery backup for flushing the drive cache when the power goes out. For
more information, read http://newsroom.intel.com/servlet/JiveServlet/download/384324/Intel_SSD_320_Series_Enhance_Power_Loss_Technology_Brief.pdf.
Use SSD drives with care and only when you are sure that drives are server-grade drives and obey
"flush" rules. For more information on this issue, read the following article about PostreSQL:
http://www.postgresql.org/docs/current/static/wal-reliability.html.
87
Page 88

Appendices
Avahi-Daemon Is not Running
Sometimes, you can get messages like the following when running the pstorage top command
on a server in the cluster:
"Could not create avahi client: Daemon not running"
Such messages mean that the avahi-daemon service is not running on the server. This may be
the case if you did not start the service when setting up your cluster, or the daemon terminated
itself for some reason. For example, on a server obtaining its network settings via DHCP, the
avahi-daemon service is known to terminate itself when changing a lease on an IP address.
To solve the problem:
1 Restart the avahi-daemon service on all computers in the cluster:
# service avahi-daemon restart
2 Restart all MDS servers in the cluster:
# service pstorage-mdsd restart
88
Page 89

Appendices
Appendix B - Frequently Asked Questions
This Appendix lists most frequently asked questions about Parallels Cloud Storage clusters.
General
Do I need to buy additional storage hardware for Parallels Cloud Storage?
No, Parallels Cloud Storage eliminates the need for external storage devices typically used in SANs
by converting locally attached storage from multiple nodes into a shared storage.
What are the hardware requirements for Parallels Cloud Storage?
Parallels Cloud Storage does not require any special hardware and can run on commodity
computers with traditional SATA drives and 1 Gb Ethernet networks. Some hard drives and RAID
controllers, however, ignore the FLUSH command to imitate better performance and must not be
used in clusters as this may lead to file system or journal corruptions. This is especially true for
RAID controllers and SSD drives. Please consult with your hard drive's manual to make sure you
use reliable hardware.
For more information, see System Requirements (p. 13), Network Requirements (p. 15),
Hardware RAID Controller and Disk Write Caches (p. 87).
How many servers do I need to run a Parallels Cloud Storage cluster?
You need only one physical server to start using Parallels Cloud Storage. However, to provide high
availability for your data, you are recommended to configure your cluster to have at least 3 replicas
per each data chunk. This requires at least 3 servers to be set up in the cluster. For details, see
Parallels Cloud Storage Configurations (p. 9) and Configuring Replication Parameters (p. 39).
89
Page 90

Appendices
Scalability and Performance
How many servers can I join to a Parallels Cloud Storage cluster?
There is no strict limit on the number of servers you can include in a Parallels Cloud Storage cluster.
However, you are recommended to limit the servers in the cluster to a single rack to avoid any
possible performance degradation due to inter-rack communications.
How much disk space can a Parallels Cloud Storage cluster have?
A Parallels Cloud Storage cluster can support up to 1 PB of effective available disk space, which
totals to 3 PB of physical disk space when 3 replicas are kept for each data chunk.
Can I add nodes to an existing Parallels Cloud Storage cluster?
Yes, you can dynamically add and remove nodes from a Parallels Cloud Storage cluster to increase
its capacity or to take nodes offline for maintenance. For more information, see Adding and
Replacing Chunk Servers (p. 35).
What is the expected performance of a Parallels Cloud Storage cluster?
The performance depends on the network speed and the hard disks used in the cluster. In general,
the performance should be similar to locally attached storage or better. You can also use SSD
caching to increase the performance of commodity hardware by adding SSD drives to the cluster
for caching purposes. For more information on SSD, see Using SSD Drives (p. 78).
What performance should I expect on 1 Gb Ethernet?
The maximum speed of a 1 Gb Ethernet network is close to that of a single rotational drive. In
most workloads, however, random I/O access is prevalent and the network is usually not a
bottleneck. Research with large service providers has proved that average I/O performance rarely
exceeds 20 MB/sec due to randomization. Virtualization itself introduces additional randomization
as multiple independent environments perform I/O access simultaneously. Nevertheless, 10 Gb
Ethernet will often result in better performance and is recommended for use in production.
Will the overall cluster performance improve if I add new chunk servers to the
cluster?
Yes. Since data is distributed among all hard drives in the cluster, applications performing random
I/O experience an increase in IOPS when more drives are added to the cluster. Even a single
client machine may get noticeable benefits by increasing the number of chunk servers and
achieve performance far beyond traditional, locally attached storage.
Does performance depend on the number of chunk replicas?
Each additional replica degrades write performance by about 10%, but at the same time it may also
improve read performance because the Parallels Cloud Storage cluster has more options to select
a faster server.
90
Page 91

Appendices
Availability
How does Parallels Cloud Storage protect my data?
Parallels Cloud Storage protects against data loss and temporary unavailability by creating data
copies (replicas) and storing them on different servers. To provide additional reliability, you can
configure Parallels Cloud Storage to maintain user data checksums and verify them when
necessary.
What happens when a disk is lost or a server becomes unavailable?
Parallels Cloud Storage automatically recovers from a degraded state to the specified redundancy
level by replicating data on live servers. Users can still access their data during the recovery
process.
How fast does Parallels Cloud Storage recover from a degraded state?
Since Parallels Cloud Storage recovers from a degraded state using all the available hard disks in
the cluster, the recovery process is much faster than for traditional, locally attached RAIDs. This
makes the reliability of the storage system significantly better as the probability of losing the only
remaining copy of data during the recovery period is very small.
Can I change redundancy settings on the fly?
Yes, at any point you can change the number of data copies, and Parallels Cloud Storage will apply
the new settings by creating new copies or removing unneeded ones. For more details on
configuring replication parameters, see Configuring Replication Parameters (p. 39).
Do I still need to use local RAIDs?
No, Parallels Cloud Storage provides the same built-in data redundancy as a mirror RAID1 array
with multiple copies. However, for better sequential performance, you can use local stripping RAID0
exported to your Parallels Cloud Storage cluster. For more information on using RAIDs, see
Possible Disk Drive Configurations (p. 76).
Does Parallels Cloud Storage have redundancy levels similar to RAID5?
No. To build a reliable software-based RAID5 system, you also need to use special hardware
capabilities like backup power batteries. In the future, Parallels Cloud Storage may be enhanced to
provide RAID5-level redundancy for read-only data such as backups.
What is the recommended number of data copies?
It is recommended to configure Parallels Cloud Storage to maintain 2 or 3 copies, which allows
your cluster to survive the simultaneous loss of 1 or 2 hard drives.
91
Page 92

Appendices
Cluster Operation
How do I know that the new replication parameters have been successfully applied
to the cluster?
To check whether the replication process is complete, run the pstorage top command, press
the V key on your keyboard, and check information in the Chunks field:
• When decreasing the replication parameters, no chunks in the overcommitted or deleting
state should be present in the output.
• When increasing the replication parameters, no chunks in the blocked or urgent state should
be present in the output. Besides, the overall cluster health should equal 100%.
For details, see Monitoring the Status of Replication Parameters (p. 65).
How do I shut down a cluster?
To shut down a Parallels Cloud Storage cluster:
1 Stop all clients.
2 Stop all MDS servers.
3 Stop all chunk servers.
For details, see Shutting Down Parallels Cloud Storage Clusters (p. 48).
What tool do I use to monitor the status and health of a cluster?
You can monitor the status and health of your cluster using the pstorage top command. For
details, see Monitoring Parallels Cloud Storage Clusters (p. 49).
What does "allocatable disk space" mean?
Allocatable space is the amount of disk space in the cluster that is free and can be used for storing
user data. Once this space runs out, no data can be written to the cluster. For more information on
what allocatable disk space is and how it is calculated, see Understanding Disk Space Usage (p.
56).
To view the total amount of disk space occupied by all user data in the cluster, run the pstorage
top command, press the V key on your keyboard, and look for the FS field in the output. The FS
field shows how much disk space is used by all user data in the cluster and in how many files these
data are stored. For details, see Understanding Disk Space Usage (p. 56).
How do I configure a Parallels Cloud Server server for a cluster?
To prepare a server with Parallels Cloud Server for work in a cluster, you simply tell the server to
store its Containers and virtual machines in the cluster rather than on its local disk. For details, see
Configuring virtual machines and Containers (p. 30).
92
Page 93

Appendices
Why vmstat/top and pstorage stat show different IO times?
The pstorage and vmstat/top utilities use different methods to compute the percentage of
CPU time spent waiting for disk IO (wa% in top, wa in vmstat, and IOWAIT in pstorage). The
vmstat and top utilities mark an idle CPU as waiting only if an outstanding IO request is started
on that CPU, while the pstorage utility marks all idle CPUs as waiting, regardless of the number
of IO requests waiting for IO. As a result, pstorage can report much higher IO values. For
example, on a system with 4 CPUs and one thread doing IO, pstorage will report over 90%
IOWAIT time, while vmstat and top will show no more than 25% IO time.
93
Page 94

C
HAPTER
8
Glossary
Client computer (or client). A computer from where you access a Parallels Cloud Storage cluster
and run Parallels virtual machines and Containers.
Chunk replicas (or replicas). Copies of data chunks stored on different chunk servers in a Parallels
Cloud Storage cluster.
Chunk server. A computer storing the contents of real data, such as virtual machine and Container
disk images, in the form of fixed-size chunks and providing access to these data chunks.
Data chunk (or chunk). A fixed-size (e.g., 64 MB) piece of data residing in a Parallels Cloud
Storage cluster. For example, each Parallels virtual machine or Container disk image is split into
such chunks, and the chunks are distributed across servers in the cluster.
Master metadata server (or master MDS server). The central MDS server responsible for
monitoring all cluster activity and keeping all metadata current, along with acting as a regular MDS
server. Any MDS server can become the master one if the current master MDS server fails.
Parallels Cloud Storage cluster. A set of computers in a network where Parallels Cloud Storage is
deployed.
Replication. The process of storing data chunks on multiple storage devices to improve reliability,
fault-tolerance, or accessibility of Parallels virtual machines and Containers.
Regular metadata server (or regular metadata server or MDS server). A computer storing
metadata about Parallels Cloud Storage chunks, their replicas and locations. Regular MDS servers
periodically communicate with the master MDS server to get metadata updates.
Page 95

Index
Index
A
About Parallels Cloud Storage - 6
About This Guide - 6
Accessing Parallels Cloud Storage Clusters
via iSCSI - 43
Adding Clients - 37
Adding MDS Servers - 33
Adding New Chunk Servers to Increase Disk
Space - 35
Appendices - 84
Appendix A - Troubleshooting - 85
Appendix B - Frequently Asked Questions -
89
Avahi-Daemon Is not Running - 88
Availability - 91
C
Carrying Out Performance Benchmarking -
77
Checking the License Status - 47
Cluster Discovery Methods - 69
Cluster Operation - 92
Cluster Parameters Overview - 38
Configuring Chunk Servers - 35
Configuring Clients - 37
Configuring Cluster Discovery - 19
Configuring Data Scrubbing - 80
Configuring Location Parameters - 41
Configuring MDS Servers - 32
Configuring Parallels Cloud Storage Clusters -
31
Configuring Replication Parameters - 39
Configuring SSD Drives for Data Caching - 81
Configuring SSD Drives for Write Journaling -
79
Creating a Local Cache - 82
D
Disabling Checksumming - 80
E
Exploring Chunk States - 59
Exploring Possible Disk Drive Configurations -
76
G
General - 89
Glossary - 94
H
Hardware RAID Controller and Disk Write
Caches - 87
I
Installations via PXE Servers - 74
Installing a License - 44
Introduction - 6
M
Managing Cluster Parameters - 38
Managing Cluster Security - 66
Managing Parallels Cloud Storage Licenses -
44
Maximizing Cluster Performance - 75
Minimum Configuration - 9
Monitoring Chunk Servers - 54
Monitoring Clients - 60
Monitoring Event Logs - 62
Monitoring General Cluster Parameters - 50
Monitoring Metadata Servers - 52
Monitoring Parallels Cloud Storage Clusters -
49
Monitoring the Status of Replication
Parameters - 65
N
Network Requirements - 15
O
Out of Disk Space - 86
Page 96

Index
P
U
Parallels Cloud Storage Architecture - 7
Parallels Cloud Storage Configurations - 9
Parallels Cloud Storage Ports - 70
Password-Based Authentication - 73
Poor Disk I/O Performance - 86
Poor Write Performance - 86
R
Recommended Configuration - 11
Removing Chunk Servers - 36
Removing Clients - 37
Removing MDS Servers - 34
S
Scalability and Performance - 90
Securing Server Communication in Clusters -
67
Security Considerations - 66
Setting Up a Parallels Cloud Storage Cluster -
17
Setting Up Avahi - 22
Setting Up Chunk Servers - 26
Setting Up Clients - 29
Setting Up the First Metadata Server - 24
Setup Process Overview - 18
Shutting Down Parallels Cloud Storage
Clusters - 48
Specifying MDS Servers Manually - 23
SSD Drives Ignore Disk Flushes - 87
Stage 1
Preparing for Creating the Chunk Server -
27
Preparing for Creating the MDS Server -
24
Preparing for Mounting the Cluster - 29
Stage 2
Creating the Chunk Server - 28
Creating the MDS Server - 25
Mounting the Cluster - 30
Stage 3
Configuring Virtual Machines and
Containers - 30
Submitting a Problem Report to Technical
Support - 85
System Requirements - 13
Understanding Disk Space Usage - 56
Updating a License - 45
Updating Clients - 37
Using 1 Gb and 10 Gb Networks - 77
Using DNS Records - 20
Using SSD Drives - 78
V
Viewing the License Contents - 46
 Loading...
Loading...