

Page 1

NVIDIA CUDA 编程指南
NVIDIA
技术文档(全译文)
Jan. 2008
Version 1.1
Page 2

GPU
系列技术文档
.....................................................................................................................1
NVIDIA CUDA
Chapter1
1.1
作为一个并行数据计算设备的图形处理器单元
1.2 CUDA
Chapter2
2.1
一个超多线程协处理器
2.2
线程批处理
2.2.1
2.2.2
2.3
线程块
线程块栅格
内存模型
Chapter3
3.1
一组带有
3.2
执行模式
3.3
计算兼容性
3.4
多设备
3.5
模式切换
编程指南
介绍
CUDA…….....................................................................................................................11
: 一个在
编程模型
.........................................................................................................................1
GPU
上计算的新架构
............................................................................................................................... 15
.....................................................................................................................15
.......................................................................................................................................15
..........................................................................................................................................16
...................................................................................................................................16
...........................................................................................................................................17
硬件实现
on-chip
................................................................................................................................18
共享内存的
SIMD
多处理器
...........................................................................................................................................19
........................................................................................................................................20
...............................................................................................................................................20
...........................................................................................................................................20
………………………….............................................11
..............................................................................................12
....................................................................................18
Chapter4
4.1
一个C语言的扩展
4.2
语言扩展
4.2.1
应用程序编程接口(
API) ...................................................................................................21
..............................................................................................................................21
...........................................................................................................................................21
函数类型限定词
......................................................................................................................... 22
4.2.1.1 __device__..................................................................................................................22
4.2.1.2 __global__..........................................................................................................22
4.2.1.3 __host__............................................................................................................22
4.2.1.4
4.2.2
限定
....................................................................................................................22
变量类型限定词
........................................................................................................................23
4.2.2.1 __device__..................................................................................................23
4.2.2.2 __constant__ .......................................................................................................23
4.2.2.3 __shared__............................................................................................................23
4.2.2.4
4.2.3
4.2.4
限定
执行配置
内置变量
.............................................................................................................................24
...........................................................................................................................25
..............................................................................................................................26
4.2.4.1 gridDim.............................................................................................................................. 26
4.2.4.2 blockIdx...........................................................................................................................26
4.2.4.3 blockDim............................................................................................................................26
- 2 -
Page 3

4.2.4.4 threadIdx......................................................................................................................... 26
4.2.4.5
4.2.5 NVCC
限定
..................................................................................................................................... 26
编译
.................................................................................................................................. 26
4.2.5.1 __noinline__ ...................................................................................................................27
4.2.5.2 #pragmaunroll .................................................................................................................27
4.3
公共
4.3.1
Runtime
内置矢量类型
组件
........................................................................................................................... 28
............................................................................................................................. 28
4.3.1.1
char1,uchar1,char2,uchar2,char3,uchar3,char4,uchar4,short1,ushort1,short2,us
hort2,short3,ushort3,short4,ushort4,int1,uint1,int2,uint2,int3,uint3,int4,ui
nt4,long1,ulong1,long2,ulong2,long3,ulong3,long4,ulong4,float1,float2,float3
,float4.......................................................................................................................................... 28
4.3.1.2 dim3
4.3.2
数学函数
4.3.3
时间函数
4.3.4
纹理类型
4.3.4.1 Texture Reference
4.3.4.2 RuntimeTexture Reference
类型
........................................................................................................................... 28
..................................................................................................................................... 28
..................................................................................................................................... 28
..................................................................................................................................... 29
声明
.......................................................................................................29
属性
.........................................................................................30
4.3.4.3
4.4
设备
4.4.1
4.4.2
4.4.3
4.4.4 TypeCasting
4.4.5
4.4.5.1
4.4.5.2 CUDA
4.4.6
4.5
主机
4.5.1
4.5.1.1
4.5.1.2
线性内存纹理操作对比
Runtime
数学函数
同步函数
类型转换函数
组件
........................................................................................................................... 31
..................................................................................................................................... 31
..................................................................................................................................... 31
............................................................................................................................. 32
函数
纹理函数
..................................................................................................................................... 33
设备内存纹理操作
数组纹理操作
原子函数
Runtime
公共概念
...................................................................................................................................... 34
组件
........................................................................................................................... 34
..................................................................................................................................... 35
设备
..................................................................................................................................... 35
内存
..................................................................................................................................... 35
CUDA
数组
.......................................................................................31
........................................................................................................................32
................................................................................................................33
............................................................................................................33
4.5.1.3 OpenGL Interoperability ...................................................................................................... 36
4.5.1.4 Direct3D Interoperability ..................................................................................................... 36
4.5.1.5
异步的并发执行
...................................................................................................................37
- 3 -
Page 4

4.5.2 RuntimeAPI.................................................................................................................................... 38
4.5.2.1
4.5.2.2
4.5.2.3
4.5.2.4
4.5.2.5
4.5.2.6 Texture Reference
初始化
..................................................................................................................................... 38
设备管理
内存管理
流管理
..................................................................................................................................... 40
事件管理
.................................................................................................................................. 38
.................................................................................................................................. 39
.................................................................................................................................. 41
管理
...........................................................................................................42
4.5.2.7 OpenGL Interoperability .......................................................................................................... 44
4.5.2.8 Direct3D Interoperability ......................................................................................................... 44
4.5.2.9
4.5.3
4.5.3.1
4.5.3.2
4.5.3.3 Context
4.5.3.4
4.5.3.5
4.5.3.6
4.5.3.7
使用设备仿真方式调试
驱动
API ........................................................................................................................................ 47
初始化
设备管理
模块管理
执行控制
内存管理
流管理
..................................................................................................................................... 47
................................................................................................................................. 47
管理
............................................................................................................................. 47
................................................................................................................................. 48
................................................................................................................................. 49
................................................................................................................................. 49
..................................................................................................................................... 51
.............................................................................................................45
4.5.3.8
4.5.3.9 Texture Reference
事件管理
................................................................................................................................. 51
管理
..........................................................................................................52
4.5.3.10 OpenGL Interoperability ...................................................................................................... 53
4.5.3.11 Direct3D Interoperability ...................................................................................................... 53
Chapter5
5.1
指令性能
5.1.1
5.1.1.1
5.1.1.2
5.1.1.3
5.1.1.4
5.1.2
5.1.2.1
5.1.2.2
5.1.2.3
5.1.2.4
5.1.2.5
性能指导
................................................................................................................................ 54
........................................................................................................................................... 54
指令吞吐量
算术指令
控制流指令
内存指令
同步指令
内存带宽
全局内存
常量内存
纹理内存
共享内存
寄存器
................................................................................................................................. 54
............................................................................................................................. 54
.......................................................................................................................... 55
............................................................................................................................. 56
............................................................................................................................. 56
.................................................................................................................................... 56
............................................................................................................................. 57
............................................................................................................................. 62
............................................................................................................................. 63
............................................................................................................................. 63
................................................................................................................................. 70
- 4 -
Page 5

5.2
每个块的线程数量
5.3
主机与设备的数据传输
.......................................................................................................................... 70
....................................................................................................................71
5.4 Texture Fetch
5.5
性能优化策略总结
Chapter6
6.1
概要
6.2
源代码
6.3
源代码解释
矩阵乘法的例子
............................................................................................................................................... 74
........................................................................................................................................... 76
对比全局或常驻内存读取
.........................................................................................71
.......................................................................................................................... 72
....................................................................................................................74
.................................................................................................................................... 78
6.3.1 Mul().................................................................................................................................. 78
6.3.2 Muld()................................................................................................................................ 79
附录A 技术规格
A.1
通用规格
A.2
浮点数标准
附录B 数学函数
B.1
公共
runtime
B.2
设备
runtime
附录C 原子函数
C.1
算法函数
................................................................................................................................... 80
....................................................................................................................................... 81
.................................................................................................................................... 82
................................................................................................................................... 83
组件
............................................................................................................................. 83
组件
........................................................................................................................... 86
................................................................................................................................... 88
....................................................................................................................................... 88
C.1.1 atomicAdd() ................................................................................................................... 88
C.1.2 atomicSub() ................................................................................................................... 88
C.1.3 atomicExch() ................................................................................................................. 88
C.1.4 atomicMin() ................................................................................................................... 88
C.1.5 atomicMax() ................................................................................................................... 89
C.1.6 atomicInc() ....................................................................................................................89
C.1.7 atomicDec() ................................................................................................................... 89
C.1.8 atomicCAS() ................................................................................................................... 89
C.2
位操作函数
.................................................................................................................................... 90
C.2.1 atomicAnd() ................................................................................................................... 90
C.2.2 atomicOr()..................................................................................................................….. 90
C.2.3 atomicXor() ................................................................................................................... 90
附录
D Runtime API Reference ............................................................................................................ 91
D.1
设备管理
........................................................................................................................................ 91
D.1.1 cudaGetDeviceCount().......................................................................................................91
D.1.2 cudaSetDevice()..................................................................................................................91
D.1.3 cudaGetDevice()..................................................................................................................91
D.1.4 cudaGetDeviceProperties() .............................................................................91
D.1.5 cudaChooseDevice() .......................................................................................................93
- 5 -
Page 6

D.2
线程管理
...................................................................................................................................... 93
D.2.1 cudaThreadSynchronize()..................................................................................................93
D.2.2 cudaThreadExit()..................................................................................................................93
D.3
流管理
........................................................................................................................................... 93
D.3.1 cudaStreamCreate() ...........................................................................................................93
D.3.2 cudaStreamQuery()...............................................................................................................93
D.3.3 cudaStreamSyncronize().....................................................................................................93
D.3.4 cudaStreamDestroy() .........................................................................................................94
D.4
事件管理
....................................................................................................................................... 94
D.4.1 cudaEventCreate()...............................................................................................................94
D.4.2 cudaEventRecord()................................................................................................................94
D.4.3 cudaEventQuery()...................................................................................................................94
D.4.4 cudaEventSyncronize()........................................................................................................94
D.4.5 cudaEventDestroy() .............................................................................................................95
D.4.6 cudaEventElapsedTime()......................................................................................................95
D.5
内存管理
........................................................................................................................................ 95
D.5.1 cudaMalloc() ..........................................................................................................................95
D.5.2 cudaMallocPitch().................................................................................................................95
D.5.3 cudaFree()................................................................................................................................96
D.5.4 cudaMallocArray()................................................................................................................96
D.5.5 cudaFreeArray().....................................................................................................................96
D.5.6 cudaMallocHost()...................................................................................................................96
D.5.7 cudaFreeHost().......................................................................................................................96
D.5.8 cudaMemSet() ..........................................................................................................................97
D.5.9 cudaMemSet2D().......................................................................................................................97
D.5.10 cudaMemcpy() .........................................................................................................................97
D.5.11 cudaMemcpy2D() ...................................................................................................................98
D.5.12 cudaMemcpyToArray() .........................................................................................................98
D.5.13 cudaMemcpy2DToArray().....................................................................................................99
D.5.14 cudaMemcpyFromArray().....................................................................................................99
D.5.15 cudaMemcpy2DFromArray()................................................................................................100
D.5.16 cudaMemcpyArrayToArray()..............................................................................................100
D.5.17 cudaMemcpy2DArrayToArray() ........................................................................................101
D.5.18 cudaMemcpyToSymbol().....................................................................................................101
D.5.19 cudaMemcpyFromSymbol()..................................................................................................101
D.5.20 cudaGetSymbolAddress()..................................................................................................102
D.5.21 cudaGetSymbolSize() .......................................................................................................102
- 6 -
Page 7

D.6 Texture Reference
D.6.1
低级
API ................................................................................................................................... 102
管理
................................................................................................................102
D.6.1.1 cudaCreateChannelDesc() ............................................................................................102
D.6.1.2 cudaGetChannelDesc()...................................................................................................102
D.6.1.3 cudaGetTextureReference().........................................................................................103
D.6.1.4 cudaBindTexture().........................................................................................................103
D.6.1.5 cudaBindTextureToArray()..........................................................................................103
D.6.1.6 cudaUnBindTexture()......................................................................................................103
D.6.1.7 cudaGetTextureAlignmentOffset()............................................................................104
D.6.2
高级
API .....................................................................................................................................104
D.6.2.1 cudaCreateChannelDesc()...............................................................................................104
D.6.2.2 cudaBindTexture()............................................................................................................104
D.6.2.3 cudaBindTextureToArray().............................................................................................105
D.6.2.4 cudaUnBindTexture() ......................................................................................................105
D.7
执行控制
...................................................................................................................................... 105
D.7.1 cudaConfigureCall() .........................................................................................................105
D.7.2 cudaLaunch() ........................................................................................................................105
D.7.3 cudaSetupArgument() .........................................................................................................106
D.8 OpenGL Interoperability ............................................................................................................... 106
D.8.1 cudaGLRegisterBufferObject().......................................................................................106
D.8.2 cudaGLMapBufferObject()..................................................................................................106
D.8.3 cudaGLUnMapBufferObject() ............................................................................................106
D.8.4 cudaGLUnRegisterBufferObject()...................................................................................106
D.9 Direct3D Interoperability .............................................................................................................. 107
D.9.1 cudaD3D9Begin()...................................................................................................................107
D.9.2 cudaD3D9End().......................................................................................................................107
D.9.3 cudaD3D9RegisterVertexBuffer()...................................................................................107
D.9.4 cudaD3D9MapVertexBuffer() ............................................................................................107
D.9.5 cudaD3D9UnMapVertexBuffer().........................................................................................107
D.9.6 cudaD3D9UnRegisterVertexBuffer() ............................................................................107
D.9.7 cudaD3D9GetDevice() ........................................................................................................108
D.10
错误处理
......................................................................................................................................108
D.10.1 cudaGetLastError() .........................................................................................................108
D.10.2 cudaGetErrorString()......................................................................................................108
附录
E DriverAPIReference ................................................................................................................ 109
E.1
初始化
........................................................................................................................................... 109
E.1.1 cuInit()................................................................................................................................. 109
- 7 -
Page 8

E.2
设备管理
....................................................................................................................................... 109
E.2.1 cuGetDeviceCount().............................................................................................................109
E.2.2 cuDeviceGet() ......................................................................................................................109
E.2.3 cuDeviceGetName()...............................................................................................................109
E.2.4 cuDeviceTotalMem().............................................................................................................109
E.2.5 cuDeviceComputeCapability() .......................................................................................110
E.2.6 cuDeviceGetAttribute()....................................................................................................110
E.2.7 cuDeviceGetProperties()..................................................................................................111
E.3 Context
管理
...................................................................................................................................111
E.3.1 cuCtxCreate() .....................................................................................................................111
E.3.2 cuCtxAttach() .....................................................................................................................112
E.3.3 cuCtxDetach() .....................................................................................................................112
E.3.4 cuCtxGetDevice().................................................................................................................112
E.3.5 cuCtxSynchronize().............................................................................................................112
E.4
模块管理
.......................................................................................................................................112
E.4.1 cuModuleLoad().....................................................................................................................112
E.4.2 cuModuleLoadData()............................................................................................................113
E.4.3 cuModuleLoadFatBinary().................................................................................................113
E.4.4 cuModuleUnload()................................................................................................................113
E.4.5 cuModuleGetFunction().....................................................................................................113
E.4.6 cuModuleGetGlobal() .......................................................................................................113
E.4.7 cuModuleGetTexRef() .......................................................................................................114
E.5
流管理
.........................................................................................................................................114
E.5.1 cuStreamCreate()...............................................................................................................114
E.5.2 cuStreamQuery().................................................................................................................114
E.5.3 cuStreamSynchronize()....................................................................................................114
E.5.4 cuStreamDestroy().............................................................................................................114
E.6
事件管理
.....................................................................................................................................114
E.6.1 cuEventCreate().................................................................................................................114
E.6.2 cuEventRecord().................................................................................................................115
E.6.3 cuEventQuery()...................................................................................................................115
E.6.4 cuEventSynchronize() ....................................................................................................115
E.6.5 cuEventDestroy()...............................................................................................................115
E.6.6 cuEventElapsedTime() ....................................................................................................115
E.7
执行控制
.....................................................................................................................................116
E.7.1 cuFuncSetBlockShape()....................................................................................................116
E.7.2 cuFuncSetSharedSize().....................................................................................................116
- 8 -
Page 9

E.7.3 cuParamSetSize()................................................................................................................116
E.7.4 cuParamSeti() .....................................................................................................................116
E.7.5 cuParamSetf() .....................................................................................................................116
E.7.6 cuParamSetv() .....................................................................................................................116
E.7.7 cuParamSetTexRef()............................................................................................................117
E.7.8 cuLaunch().............................................................................................................................117
E.7.9 cuLaunchGrid().....................................................................................................................117
E.8 Memory
管理
..................................................................................................................................117
E.8.1 cuMemGetInfo().....................................................................................................................117
E.8.2 cuMemAlloc() .......................................................................................................................118
E.8.3 cuMemAllocPitch()...............................................................................................................118
E.8.4 cuMemFree()............................................................................................................................118
E.8.5 cuMemAllocHost().................................................................................................................118
E.8.6 cuMemFreeHost()...................................................................................................................119
E.8.7 cuMemGetAddressRange()....................................................................................................119
E.8.8 cuArrayCreate()...................................................................................................................119
E.8.9 cuArrayGetDescriptor()....................................................................................................120
E.8.10 cuArrayDestroy()...............................................................................................................121
E.8.11 cuMemset()........................................................................................................................... 121
E.8.12 cuMemset2D() .......................................................................................................................121
E.8.13 cuMemcpyHtoD()...................................................................................................................121
E.8.14 cuMemcpyDtoH()..................................................................................................................122
E.8.15 cuMemcpyDtoD()...................................................................................................................122
E.8.16 cuMemcpyDtoA()...................................................................................................................122
E.8.17 cuMemcpyAtoD()...................................................................................................................123
E.8.18 cuMemcpyAtoH()...................................................................................................................123
E.8.19 cuMemcpyHtoA()...................................................................................................................123
E.8.20 cuMemcpyAtoA()...................................................................................................................124
E.8.21 cuMemcpy2D() ......................................................................................................................124
E.9 Texture Reference
管理
.................................................................................................................126
E.9.1 cuTexRefCreate().................................................................................................................126
E.9.2 cuTexRefDestroy()...............................................................................................................127
E.9.3 cuTexRefSetArray().............................................................................................................127
E.9.4 cuTexRefSetAddress() .......................................................................................................127
E.9.5 cuTexRefSetFormat() ..........................................................................................................128
E.9.6 cuTexRefSetAddressMode()................................................................................................128
E.9.7 cuTexRefSetFilterMode()..................................................................................................128
- 9 -
Page 10

E.9.8 cuTexRefSetFlags().............................................................................................................129
E.9.9 cuTexRefGetAddress() ......................................................................................................129
E.9.10 cuTexRefGetArray()...........................................................................................................129
E.9.11 cuTexRefGetAddressMode()..............................................................................................129
E.9.12 cuTexRefGetFilterMode()................................................................................................129
E.9.13 cuTexRefGetFormat() .......................................................................................................130
E.9.14 cuTexRefGetFlags()...........................................................................................................130
E.10 OpenGLInteroperability .............................................................................................................. 130
E.10.1 cuGLInit()........................................................................................................................... 130
E.10.2 cuGLRegisterBufferObject() ........................................................................................130
E.10.3 cuGLMapBufferObject()....................................................................................................130
E.10.4 cuGLUnmapBufferObject()................................................................................................131
E.10.5 cuGLUnregisterBufferObject().....................................................................................131
E.11 Direct3DInteroperability ............................................................................................................. 131
E.11.1 cuD3D9Begin().....................................................................................................................131
E.11.2 cuD3D9End()..........................................................................................................................131
E.11.3 cuD3D9RegisterVertexBuffer() ...................................................................................131
E.11.4 cuD3D9MapVertexBuffer()................................................................................................131
E.11.5 cuD3D9UnmapVertexBuffer()...........................................................................................132
E.11.6 cuD3D9UnregisterVertexBuffer()................................................................................132
E.11.7 cuD3D9GetDevice()............................................................................................................132
附录
F TextureFetching .................................................................................................................... 133
F.1 Nearest-Point
F.2
线性过滤
F.3
查表法
........................................................................................................................................... 136
采样
..................................................................................................................... 134
..................................................................................................................................... 135
- 10 -
Page 11

Chapter 1 介绍CUDA
1.1
作为一个并行数据计算设备的图形处理器单元仅仅几年的时间,可编程的图形处理器单元演变成为了
一匹绝对的计算悍马,正如图
1-1
带宽驱动多核处理器时,当今的
所示。当极高的内存
GPU
为图型和非图型处理提供了难以置信的资源。
图
这个演变背后的主要原因是由于
1-1。CPU 和GPU
GPU
被设计用于高密度和并行计算,更确切地说是用于图形渲染。因此
的每秒浮点运算
更多的晶体管被投入到数据处理而不是数据缓存和流量控制,图
图
1-2。 GPU
投入更多晶体管进行数据处理
1-2
所示。
- 11 -
Page 12

更加具体地看,GPU 是特别适合于并行数据运算的问题-同一个程序在许多并行数据元素,
并带有高运算密度(算术运算与内存操作的比例)。由于同一个程序要执行每个数据元素,
降低了对复杂的流量控制要求; 并且,因为它执行许多数据元素并且据有高运算密度,内存
访问的延迟可以被忽略。
并行数据处理,意味着数据元素以并行线程处理。许多处理大量数据集,例如数组的应用程
序可以使用一个并行数据的编程模型来加速计算。在3D 渲染上,大的像素集和顶点被映射
到并行线程。同样,图像和媒体处理的应用程序例如着色的图像后处理,录像编码和解码,
图像缩放比例,立体视觉,以及图像识别也可以映射图像块和像素到并行处理线程。实际上,
在图像着色和处理领域外的许多算法同样可以通过并行数据处理得到加速,从一般信号处理
或物理模拟到金融计算或者生物计算。
然而直到今天,尽管强大的计算能力包装进了GPU,而它对非图形应用的有效支持依然有限:
GPU 只能通过图型API 来编程,导致新手很难学习和非图形API 上很不充分的应用。
GPU DRAM 可以用一般方式下读取,GPU 程序可以从任何DRAM 部分收集数据元素。
但不可写,在一般方式下的GPU 程序不能写入信息到DRAM 的任何部分,相比CPU 丧失
了很多编程的灵活性。
有些应用是由于DRAM 内存带宽而形成的瓶颈,未能充分利用GPU 的计算能力。
本文描述的是一个崭新的硬件和编程模型,它直接答复了这些问题并且展示了GPU 如何成
为一个真正的通用并行数据计算设备。
1.2 CUDA
备架构,在
构,它不需要映射到一个图型
都可以支持。操作系统的多任务机制通过几个
: 一个在
GPU
上发布的一个新的硬件和软件架
GPU
上计算的新架构
API
便可在
CUDA(Compute Unified Device Architecture
GPU
上管理和进行并行数据计算。从
CUDA
和图型应用程序协调运行来管理
G80
) 统一计算设
系列和以后的型号
访问
GPU
。
CUDA 软件堆栈由几层组成,如图1-3 所示:一个硬件驱动程序,一个应用程序编程接口(API)
和它的Runtime, 还有二个高级的通用数学库,CUFFT 和CUBLAS。硬件被设计成支持轻
量级的驱动和
Runtime 层面,因而提高性能。
- 12 -
Page 13
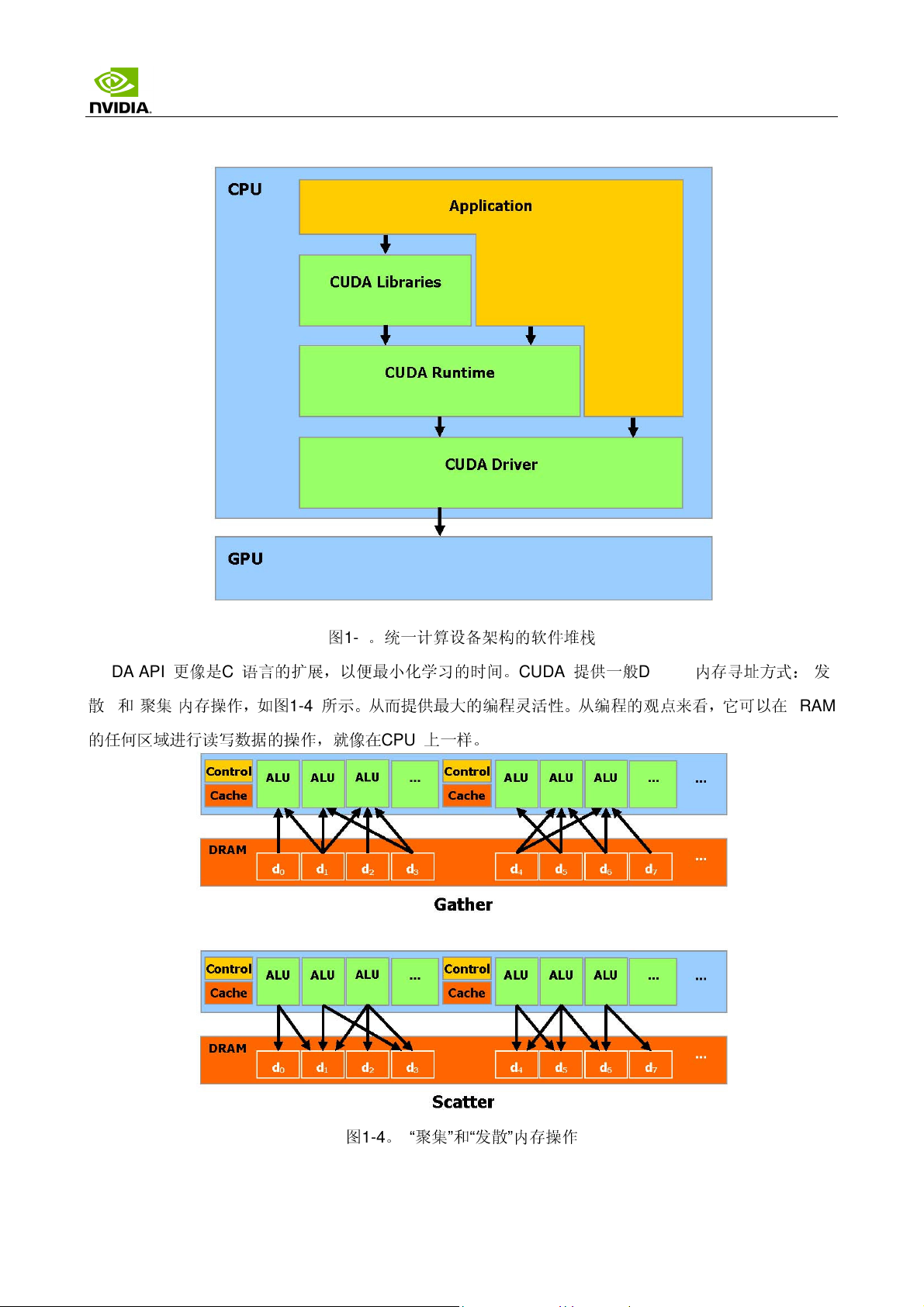
CUDA API
更像是C 语言的扩展,以便
散” 和“聚集”内存操作,如图
的任
何区域
进行读写数据的操作,
图
1-3
1-4
所示。从而提供
就像
。统一计算设备架构的软件
最小
化学习的时间。
在
CPU
上一样。
最大
的编程
CUDA
灵活
堆栈
提供一
般
DRAM
性。从编程的观点
内存
来看
,它可以在
寻址
方式:“发
DRAM
图
1-4。 “
聚集”和“发
散”内存操作
- 13 -
Page 14
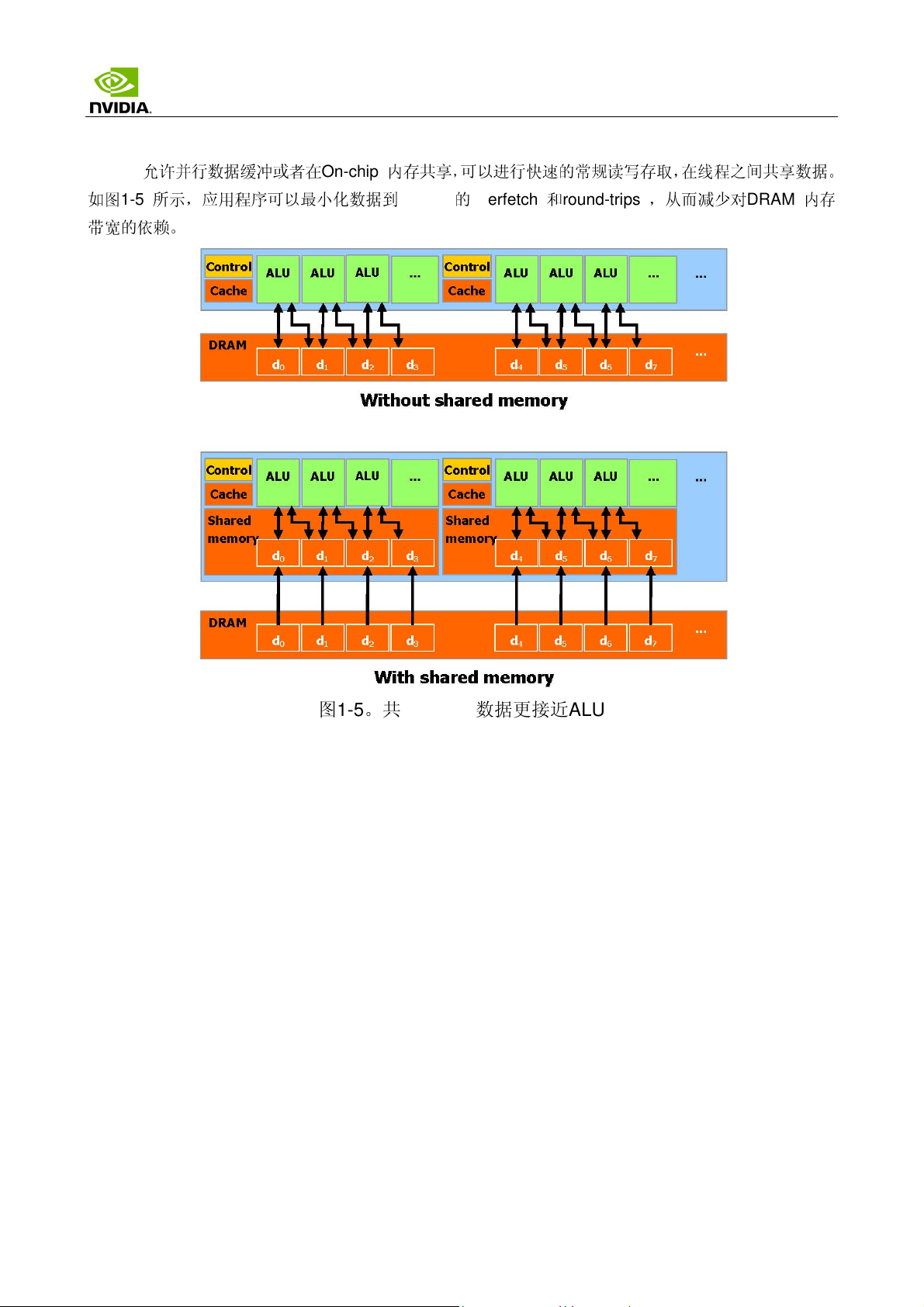
CUDA
如图
1-5
带宽的
允许
并行数据缓冲或者在
所示,应用程序可以
依赖
。
On-chip
最小
化数据到
内存共享,可以进行
快速
的常规读写存取,在线程之间共享数据。
DRAM 的overfetch 和round-trips
,从而
减少
对
DRAM
内存
图1-5。共享内存使数据更接近ALU
- 14 -
Page 15

Chapter 2 编程模型
2.1
一个超多线程协处理器
当通过
协处理器。换
CUDA
编译时,
句话
GPU
可以被视为能执行非常高数量并行线程的计算设备。它作为主
说,运行在主机上的并行数据和高密度计算应用程序
更准确地讲,一个被执行许多次不同数据的应用程序
执行的函数。达到这个
主机和设备使用它
的
引擎
(
API
)从一个
效果
们自己
DRAM
,这个函数被编译成设备的指令集(
的
DRAM
,主机内存和设备内存。并可以通过利用设备高性能直接内存存取
复
制数据到
其他
DRAM
2.2
线程批处理
线程批处理就是执行一个被组织成许多线程块的
kernel
部分
。
,如图
,可以被
kernel
2-1
CPU
部分
,被
卸载
到这个设备上。
分离
成为一个有很多不同线程在设备上
程序),被
下载
到设备上。
所示。
的一个
(DMA)
主机发送一个
连续
的
kernel
调用到设备。每个
图
2-1
kernel
作为一个由线程块组成的批处理线程来执行。
。线程批处理
- 15 -
Page 16

2.2.1
线程块
一个线程块是一个线程的批处理,它通过一
步它们的执行。更准确地说,它可以在
Kernel
同步点。
每条线程是由它的线程
一个应用程序可以指定一个块作为一个
指定每条线程。对于一个
一个
三维的大小
为
(
D
x
ID
,
大小
D
所确定,
为
(
D
y
,
D
z
)
的块,这个线程的
ID
是在块之内的线程编号。根据线程的
二维或三维
x
,
D
y
)
2.2.2
线程块栅格
些快速
二维
的共享内存有效地分享数据并且在制定的内存
中
指定同步点,一个块里的线程被
数组的任
块,线程的
索引
意大小,并且
索引
是
是
(
x,y,z
(x, y)
通过一个
,这个线程
)
, 线程的
挂起直
ID
可以
ID 是(x +
ID 是(x +
到它们所有都到
帮助
进行
2 -或3-
组件
y D
y D
访问中
复杂寻址
索引代替来
x
)
。而对于
x
+
z DxD
y
,
)
同
达
。
一个块可以
此通过单一
自
同一个栅格的不同线程块中的线程彼此之不间能通讯和同步。这个模式
效
地运行在
性,或者并行地运行,如果它有很多的并行的特性,或者通常是
包含
的线程
kernel
各种
设备上而不用再编译:一个设备可以序列地运行栅格的所有块,如果它有非常少的并行
最大
发送的
数量是有限的。然而,执行同一个
请求
的线程总数可以是非常
巨大
kernel
的块可以合成一批线程块的栅格,因
的。线程协作的
二者
的组合。
减少会造
允许
kernel
成性能的
损失
用不同的并行能力有
,因为
来
特
.
每个块是由它的块ID 确定的,块的ID 是在栅格之内的块编号。根据块ID 可以帮助进行
ٛ
复杂寻址,一个应用程序可也以指定一个栅格作为任意大小的一个二维数组,并且通过一个
2-组件索引替换来制定每个块。对于一个大小为 (
块的
ID 是(x +
y D
x
)
。
D
x
,
D
y
)
二维
块,这个块的索引是(x,y),
- 16 -
Page 17
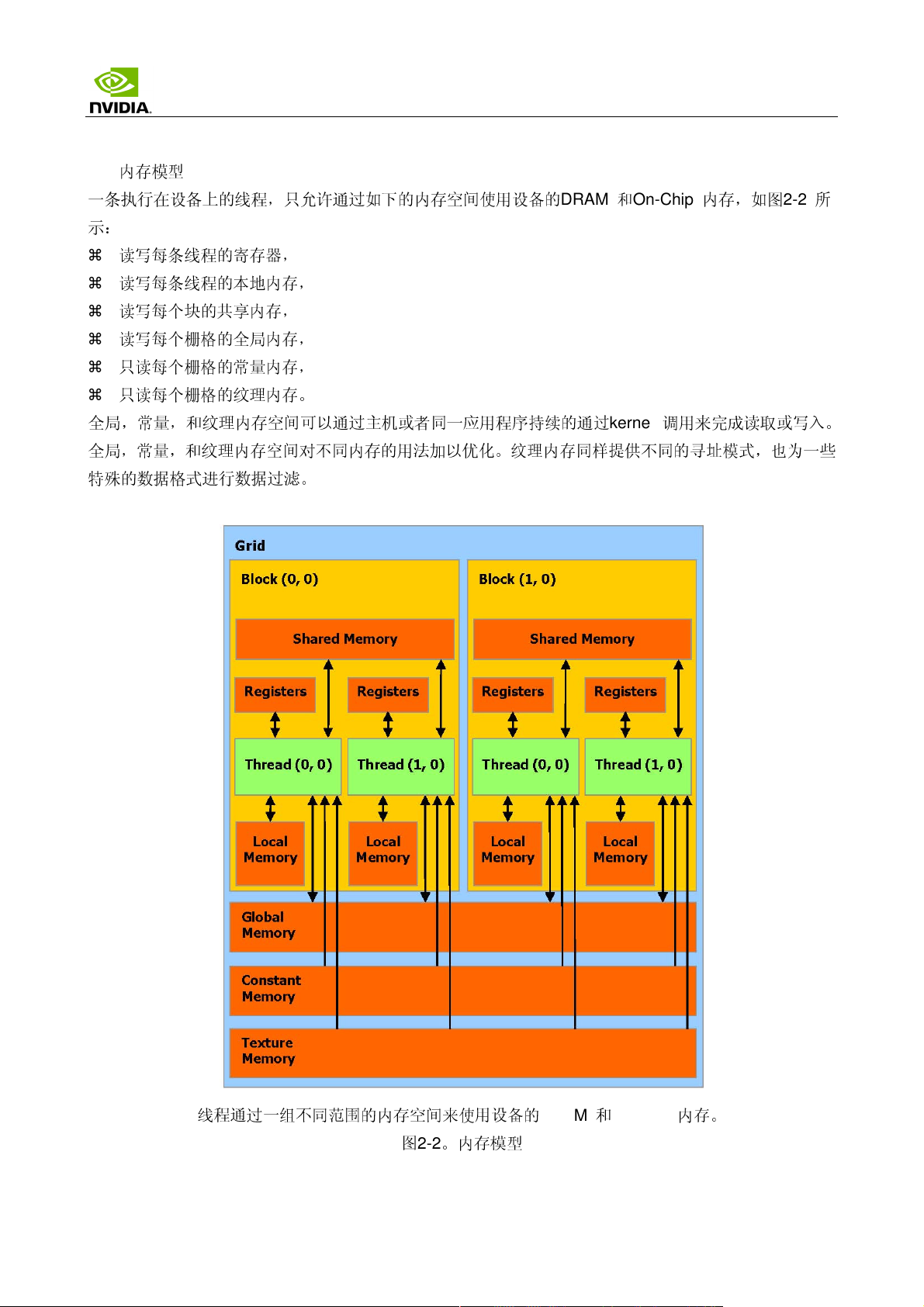
2.3
内存模型
一条执行在设备上的线程,
只允许
通过如下的内存空间使用设备的
DRAM 和On-Chip
示:
读写每条线程的寄存器,
读写每条线程的本地内存,
读写每个块的共享内存,
读写每个栅格的全局内存,
只
读每个栅格的常量内存,
只
读每个栅格的纹理内存。
全局,常量,和纹理内存空间可以通过主机或者同一应用程序持续的通过
kernel
调用
全局,常量,和纹理内存空间对不同内存的用法加以优化。纹理内存同样提供不同的
特殊
的数据格式进行数据过滤。
内存,如图
来完
成读取或写入。
寻址
模式,也为一
2-2
所
些
线程通过一组不同
范围
的内存空间来使用设备的
图
2-2
。内存模型
DRAM 和On-chip
内存。
- 17 -
Page 18

Chapter 3 硬件实现
3.1
一组带有
on-chip
共享内存的
SIMD
多处理器
设备可以被看作一组多处理器,如图
何给
定的时
钟周期
内,多处理器的每个处理器执行同一指令,但操作不同的数据。
每个多处理器使用四个以下类型的
每个处理器一组本地
并行数据缓存或共享内存,被所有处理器共享实现内存空间共享,
通过设备内存的一个只读
通过设备内存的一个只读
本
地和全局内存空间作为设备内存的读
每个多处理器通过纹理单元
32
位寄存器,
区域
区域
访问
3-1
所示。每个多处理器使用单一指令,多数据架构
on-chip
内存:
,一个只读常量缓冲器被所有处理器共享,
,一个只读纹理缓冲器被所有处理器共享,
写区域
纹理缓冲器,它执行
,而不被缓冲。
各种各
样的
寻址
模式和数据过滤。
(SIMD)
:在任
图
3-1
。硬件模型
- 18 -
Page 19

3.2
执行模式
一个线程块栅格是通过多处理器规划执行的。每个多处理器一个接一个的处理块批处理。一个块只被一个
多处理器处理,因此可以对驻留在
一个批处理中每一个多处理器可以处理多少个块,取决于每个线程
on-chip
共享内存中的共享内存空间形成非常
中分
配了多少个寄存器和
个时钟需要多少的共享内存,因为多处理器的寄存器和内存在所有的线程中是
中
,每个多处理器没有
足够
的寄存器或共享内存可用,
那么
内核
将无法启
动。
线程块在一个批处理中被一个多处理器执行,被称作
为
warps;
执行; 线程调度程序
每一条这样的
周期
warp
包含
性地从一
数量相同的线程,
条
warp
切换到另一
active
叫做
条
warp
。每个
warp
active
大小
块被
,并且在
,以达到多处理器计算资源使用的
块被
划分
成为
warp
程0 开始递增
的方式总是相同的; 每
。
条
warp
包含连续
的线程,线程
索引从第
快速的访问
分开
的。如果在
划分
成为
SIMD
一个
。
已知
内核中每
至少
一个块
SIMD
线程组,
称
方式下通过多处理器
最大
化。
warp
包含着
的线
一个多处理器可以处理并发地几个块,通过
划分
在它
们之中
的寄存器和共享内存。更准确地说,每条线程
可使用的寄存器数量,等于每个多处理器寄存器总数除以并发的线程数量,并发线程的数量等于并发块的
数量乘以每块线程的数量
。
在一个块内的warp 次序是未定义的,但通过协调全局或者共享内存的存取,它们可以同步
的执行。如果一个通过warp 线程执行的指令写入全局或共享内存的同一位置,写的次序是
未定义的。
在一个线程块栅格内的块次序是未定义的,并且在块之间不存在同步机制,因此
同块的线程不能通过全局内存彼此安全地通讯。
来自
同一个栅格的二个不
- 19 -
Page 20

3.3
计算兼容性
设备的计算兼容性由两个参数定义,主要
心
架构。在附录A 中列出
次要版本
3.4
号代表一
多设备
些改
的设备全部是
进的核心架构,比如新的特性。不同计算兼容性的技术规格见附录A。
版本
号和次要
1.x
(它们的主要
版本
号。设备拥有相同的主要
版本
号是1)。
版本
号代表相同的核
为一个应用程序使用多GPU 作为CUDA 设备,必须保证这些GPU 是一样的类型。如果系
统工作在SLI 模式下,那么只有一个GPU 可以作为CUDA 设备,由于所有的GPU 在驱动
堆栈中被底层的融合了。SLI 模式需要在控制面板中关闭,这样才能事多个GPU 作为CUDA
设备。
3.5
模式切换
GPU 指定一些DRAM 来存储被称作primary surface 的内容,这些内容被用于显示输出。如果
用户改变显示的分辨率或者色深,那么primary surface 的存储需求量将改变。比如,如果
用户将显示分辨率从1280x1024x32bit 到1600x1200x32bit ,系统必须指定7.68MB 的
primary surface 而不在是5.24MB。(使全屏抗锯齿的应用程序需要更多的primary surface
空间)。另外,比如在Windows 中使用Alt+Tab 的切换,或者Ctrl+Alt+Del 的操作同样需要
额外的primary surface 空间。
如果模式切换增加了primary surface 的内存空间,系统将占用CUDA 指定的内存空间,导
致程序崩溃。
- 20 -
Page 21

Chapter 4 应用程序编程接口(API)
4.1
一个C 语言的扩展
CUDA
它
编程接口的目标是为
包括
:
一个小的C 语言扩展集,在
熟悉C 语言的用户提供一个相对简单的
第
4.2
部分描述,允许
程序
员专注
途径来编写
于在设备执行的原代码的
设备执行程序。
部分
;
一个runtime 库分成:
一个主机组件,在第4.5 部分描述,它在主机上运行并且提供函数来控制和访问一个
或多个计算设备;
一个设备组件,在第4.4 部分描述,它在设备运行并且提供特定设备的函数;
一个公共的组件,在第4.3 部分描述,它提供内置矢量类型和主机与设备编码都支持
的C 标准库的一个子集。
应该强调的是,只有来自C 标准库的函数支持在设备上运行,是由公共Runtime 的组件提供
的函数。
4.2 语言扩展
C 语言的扩展是四重的:
函数类型限定句指定一个函数是否执行在主机或者执行在设备,和是否从主机或者从设
备上调用(第4.2.1 部分);
变量类型限定句指定设备上一个变量的内存位置(第4.2.2 部分);
一个新的指令指定一个来自主机的kernel 如何在设备上执行 (第4.2.3 部分);
四个内置的变量指定栅格和块的维数,还有块和线程的指标 (第4.2.4 部分)。
每个包含CUDA 语言扩展的源文件必须通过CUDA 编译器nvcc 编译,在第4.2.5 部分简要
地加以描述。 nvcc 的一个详细的描述可以在一单独的文件中找到。
每一个扩展
一个
警告,但有些违反无
伴随
的一些限定在每一
节下面给予描述
法被查出。
。
nvcc
将
提供在一
些违反这些
限制时的一个错误或
者
- 21 -
Page 22

4.2.1
函数类型限定词
4.2.1.1 __device__
__device__限定词声明一个函数是:
在设备上执行的,
仅可从设备调用。
4.2.1.2 __global__
__global__
在设备上执行的,
仅可从主机调用。
4.2.1.3 __host__
__host__
__host__限定词声明的函数是:
__host____host__
限定词声明一个函数作为一个存在的
__host__
__host____host__
kernel
。这样的一个函数是:
在主机上执行的,
仅可从主机调用。
它等于声明一个函数仅带有__host__
__global__
__global__限定词; 在其他情况下这个函数仅为主机编译。
__global____global__
然而,__host__
__host__ 限定词也可以用于与__device__
__host__ __host__
__host__限定词或者声明它没有任何__ho
__host____host__
__device__限定词的组合,这种的情况下,这个函数是
__device____device__
为主机和设备双方编译。
__host__
st__, __device__
__ho__ho
st__st__
__device__,或
__device____device__
4.2.1.4
__device__和__global__
__device__和__global__
__device__和__global__
__device__
的。
不能一起使用__global__和__host__限定词。
限定
函数不可能取得它们的地
函数不支持
函数不能声明
函数不能有自变量的一个变量数字。
递归
静态
址; 另
。
变量在它们体内。
一方面,函数指
- 22 -
向
__global__
函数是支持
Page 23

__global__
在
第
4.2.3
__global__
4.2.2
变量类型限定词
4.2.2.1 __device__
__device__
最
多的一个其它类型限定词被定义在
属在
哪些
驻留在全局内存空间,
具
有应用的生存期,
从栅格内所有线程和从主机通过
函数
必须
有
void
的
部分所描述
函数参数
限定词声明驻留在设备上的一个变量。
内存空间。如果它们都不存在,这个变量:
。对一个
目前
是通过共享内存到设备的,并且被限制在
返回
类型。任何调用到一个
__global__
下面的三项里
runtime
函数的调用是同步的,
库
,可以与
是可
访问
__global__
__device__
的。
函数
必须
指定它的执行配置,如
意味着
在设备执行完成
256
个
字节
。
一起共同用于进一步指定变量
前返回
。
归
4.2.2.2 __constant__
__constant__
驻留在常量内存空间,
具
有应用的生存期,
从栅格内所有线程和从主机通过
4.2.2.3 __shared__
__shared__
__shared__限定词,与__device__
__shared____shared__
__shared__
__shared__ __shared__
限定词,与
__device__一起选择使用,声明一个变量:
__device____device__
__device__
runtime
一
起随
机使用,声明一变量:
库
的是可
访问
的。
驻留在线程块的共享内存空间中,
具有块的生存期,
只有块之内的所有线程是可访问的。
在线程中共享的变量有完全的顺序一致性。只有执行过一个__syncthreads
__syncthreads()函数,从其他
__syncthreads__syncthreads
线程的写才保证可见。除非变量被定义为可挥发的,否则只要前一个状态到达,编译器将自
由的优化共享内存中的读写。
- 23 -
Page 24

当声明一个在共享内存的变量作为一个外部数组时,例如
extern_shared_float shared[];
数组的
地址,因此在数组的变量布局
大小
是由发送时间(参见第
必须
4.2.3
通过
部分)决
offset(
定的。所有变量用这种方式声明的,开始于内存的同一个
位移量)明确地加以控制。例如,如
short array0[128];
float array1[64];
int array2[256];
在动
态分
配的共享内存,你可以用以下方式定义数组
extern __shared__ short array[];
__device__ void func() //__device__or__global__function
{
Short* array0 = (short*)array;
float* array1 = (float*)&array0[128];
int* array2 = (int*)&array1[64];
}
果你想要等
于
4.2.2.4
这些限定词不允许的一个函数之内的
这些限定词不允许的一个函数之内的
这些限定词不允许的一个函数之内的这些限定词不允许的一个函数之内的
__shared__和__constant__
__device__,__shared__和__constant__
__device__和__constant__
__constant__
限定
限定
限定限定
变量不能从设备上
struct 和union
变量
隐含了静态存储
变量
只允许
赋值
,仅可以通过主机
。
变 量 不 能 被 用
在文件
范围
成员,形式参数和局部变量在主机上执行。
。
extern
runtime
关 键 字定义为外 部
函数从主机上
4.5.3.6)。
__shared__
变量不能作为它们声明的一
部分得
到初始化。
一个不用任何限定词在设备码中声明的自变量通常驻留在一个寄存器中。尽管在
择
在局部内存
确定数组用常量数量
如果变量在第一个编译
ld.local 和st.local
器空间,随后编译
报告
(
lmem)。
里安
置它。通常在这个
建立了索引
阶段期
阶段仍然
情况下,大
。
ptx
汇
型结构或者数组
编代码的检查(通过
将消耗许
- ptx 或-keep
间被安置在局部内存,因此它将声明是使用
助记符访问
可以
做出另外的决
的。假如它没有这样做,即使它们发现它为目标架构
定。可以使用
--ptxas-option=-v
多寄存器空间,并且编译器不能
赋值(参见
某些情况下
选项
编译
.local
生
成局部内存使用量
使 用 。
4.5.2.3
编译器可以
获得
的)将指出
助记符或者
消耗太
多寄存
和
选
,
使用
- 24 -
Page 25

执行在设备上的指针代码支持,当编译器可以解析它们是否指向全局内存空间或者局部内存空间。
们将
被限制只指
解除一个指针在主机上执行的全局或共享内存中的代码,或
一个未定义的行为,从而
向寻址
的内存或在全局内存中声明的空间。
产生片断
错误或者应用
终止
。
者载
设备上执行的主机内存代码,其结
否则
果产生
只能通过设备代码中的__device__,__shared__或__constant__变量来获取地址。
__device__或__constant__变量的地址只能通过主机代码获得,cudaGetSymbolAddress()
参见4.5.2.3 部分。
4.2.3
执行配置
所有
__global__
执行配置定义了通常在设备执行的函数的栅格和块的维数,同样
函数的调用
必须
指定执行配置。
相关
的
stream
(
参见
4.5.1.5
部分
对
它
streams
S>>>
Dg
的
描述
)。它通过在函数
来
指定,如:
Dg 是类型dim3
Dg Dg
dim3 (参见4.3.1.2 部分)并且指定栅格的维数和大小,这样Dg.x * Dg.y
dim3dim3
名称
和用
括弧括起来的参
被发送的块的数量;
Db
Db 是类型dim3
Db Db
Db.z
Db.z 等于每个块的线程数量;
Db.z Db.z
Ns
S
作为例子,函数被声明为
__global__ void Func(float* parameter);
必须象
是类型
分
配每个块的内存; 这个动
分会被涉及
是类型
这样调用:
dim3 (参见4.3.1.2 部分)并且指定每个块的维数和大小,这样Db.x * Db.y *
dim3 dim3
size_t
到
cudaStream_t
并且指定在共享内存中的
态分
; Ns
是一个
默认
并且指定
字节
数量,这个共享内存是
配的内存是被任何一个声明为
为0 的可
相关
选参
数。
的
stream;S
数表之间插入表达式的形式
是一个
静态分
外部
数组的变量使用的,在
默认
为0 的可选数。
配的内存
<<< Dg, Db, Ns,
Dg.x * Dg.y 等于
Dg.x * Dg.y Dg.x * Dg.y
Db.x * Db.y *
Db.x * Db.y * Db.x * Db.y *
之外
的动
态
4.2.2.3
部
Func<<< Dg, Db, Ns >>>(parameter);
- 25 -
Page 26

执行配置的函数参数在调用
如
果
Dg 或Db
减去
(共享内存中的
大
于设备
允许的最大值(参见
静态分
4.2.4
内置变量
4.2.4.1 gridDim
这个变量是类型
dim3 (
参见
4.2.4.2 blockIdx
这变量是类型
uint3 (
参见
4.2.4.3 blockDim
这变量是类型
dim3 (
参见
4.2.4.4 threadIdx
这变量是类型
uint3 (
参见
前将被评估,且
通过共享内存传至设备。
附录
A.1
),或
者
Ns
的
值大
于((设备共享内存的
配的内存,函数参数,和执行配置))的值,函数
4.3.1.2
4.3.1.1
4.3.1.2
4.3.1.1
部分)并
部分)并
部分)并
部分)并
且包含
且包含
且包含
栅格的维数。
栅格之内的块
在块的维数。
且包含块之
内的线程
索引
索引
。
。
将无
法被调用。
最大值
)
4.2.4.5
限定
内置变量不
不
允许赋值
允许取得任何地址
到任何内置变量。
。
4.2.5 NVCC
nvcc
实施不同编译
是编译
编译
CUDA
代码过程的编译器驱动程序的
阶段汇集的工具来
执行它们。
nvcc
的
cubin
基本工
对象。生成的主机代码输出,作为使用
作流程在于从主机代码
中分离出
间直接调用主机编译器的对象代码。
应用程序可以直接忽略生成的主机代码并使用
简称
:它提供简单和
熟悉的命
令行
选项
,并且通过调用
设备代码,并且编译设备代码成为一个二进制格式的或
其他工具提交
CUDA
驱动程序
编译的C 代码,或者作为在最后编译
API
加载
在设备上的
cubin
对
象(参见第
阶段期
- 26 -
Page 27

4.5.3
部分),或
包含
一个执行配置语法的转换,和进入必要的
者链接生
成的主机代码,代码
包括
作为一个全局初始化的数据数组的
CUDA Runtime
的起始码(
第
4.2.3
部分
cubin
),
来加载
对象,并
和发
且
送
每个编译了的
Kernel(
参见第
4.5.2
部分)。
编译器处理
C++
中
作为使用
配
给
non-void
CUDA
的C 子
C++
源文件的
集;在基本块中
语法的结果,
void
的指针。
前端部分完全遵照
的
C++
的特性,比如:
指针(例如,通过
nvcc
的一个
详细
描述
可在一个单独的文件中找
4.2.5.1 __noinline__
默认下
,
__device__
函数总是
inline
的。
本身必须放在调用的文件中,编译器不能
C++
的语法。主机代码完全支持
malloc()
到。
下面
__noinline__
保证
函数带有指
classes, inheritance
返回
)在没有使用
介绍
NVCC
两
函数可以作为一个非
针参
数和函数带有大量参数表的
C++
。但是设备代码只支持
, 或者变量的声明是不支持的。
个编译器
typecast
侦测
inline
的
情况下
不能
。
函数的提示。函数
__noinline__
分
的限定词正常工作。
4.2.5.2 #pragma unroll
默认下
它
例如
,编译器为
必须放在这个
:
已知
循环
的行程计数展
之前
,并只作用于这个
开小型循环
循环
。
#pragma unroll
可以
侦测
。同时,可以通过一个参数指定
和控制任何展开的
循环
可以展开多
少次
循环
。
#pragma unroll 5
For (int i = 0; i < n; ++i)
循环将展开5 次。请自行确定展开动作不会影响到程序的正确性。
如果#pragma unroll 后面没有附值,当行程计数为常数时,循环完全展开,否则不会展
开。
。
- 27 -
Page 28

4.3
公共
Runtime
组件
公共的
4.3.1
Runtime
的组件可同时被主机和设备函数使用。
内置矢量类型
4.3.1.1 char1, uchar1, char2, uchar2, char3, uchar3, char4, uchar4, short1, ushort1,
short2, ushort2, short3, ushort3, short4, ushort4, int1, uint1, int2, uint2, int3,
uint3, int4, uint4, long1, ulong1, long2, ulong2, long3, ulong3, long4, ulong4,
float1, float2, float3, float4
这些矢量类型是源于
y, z, 和 w
分别访问
基本的整
型和浮点类型。它们是结构和
。它们全都带有一个
来自
第1,
格式
make_<type name>
第2,
第3,还有
第4 个组件可通过
的构造器函数; 例如,
域
x,
int2 make_int2(int x, int y);
通过
赋值(x,y)创建一个类型
int2
的矢量。
4.3.1.2 dim3
这个类型是基于
类型
uint3
的用于指定维数的整型矢量类型。当定义一个类型
dim3
的变量时,所有
剩余
的
非特指的组件初始化为1。
4.3.2
数学函数
在附录中的表
备上执行时
在主机上执行时,一个给定的函数使用
B-1
各自
中包含
的错误
了一张当前支持的
范围
。
C/C++
C runtime
标准库数学函数的全面清
执行。
4.3.3
时间函数
clock_t clock();
每个时
在
钟周期递增下
kernel
开
的计数器的
返回值
。
始和的结束时采样这个计数器,取得这个二个采样的差,并
设备完全地执行线程取得的结果,而不是设备执行线程指令时实
后者更大是因为线程是被切成时间段的。
际花费
单,随同它们一起的是在设
且记录着
的时
钟周期
每线程每时
数量。
前着
钟周期
通过
的数字是比
- 28 -
Page 29

4.3.4
纹理类型
CUDA
内存有很多性能上的优势(
纹理内存通过一个
个参数指定一个
Texture reference
函数(
下或者
Texture reference
址,或者
的缩写
支持硬件纹理渲染的一个子集,通过
叫
texture fetches
叫
texture referece
定义纹理内存的哪一个
参见部分
纹理映射的内存中。
通过两个纹理坐标指定纹理是否使用
。
4.5.2.6 和4.5.3.9
有一些属性。
参见
5.4
部分
) 绑定到一些内存
其中
的一个就是,它可以通过一个纹理坐标指定纹理是否使用一维数组
GPU
为图形使用纹理内存。通过纹理内存读取数据相比全局
)。
的设备函数从
的对象。
部分
被
fetch
二维
数组
kernel
。在被
区域
。一
寻址
。数组的元素被
读取(
kernel
些
参加
4.4.5
使用
之前,它必须
texture reference
简称
)。
Texture fetch
通过主机的
也许绑定在同一个纹理
为
texels,texture elements
的第一
runtime
寻
另
一个属性是,为纹理的
4.3.4.1 Texture Reference
一
些
texture reference
在文件
范围
作为类型
fetch
定义输入输出数据类型。
声明
的属性是固定的,它们在声明
texture
的一个变量被声明:
texture reference
Texrure<Type, Dim, ReadMode> texRef;
此时:
Type
Type 指定的数据类型是在拾取纹理时返回的; Type
Type Type
在4.3.1.1 部分定义的所有的矢量类型;
DDDDim
im 指定texture reference 的维数,它等于1 或2; Dim
im im
ReadMode
ReadMode 等于cudaReadModeNormalizedFloat
ReadMode ReadMode
cudaReadModeNormalizedFloat
cudaReadModeNormalizedFloat 或cudaReadModeElementType
cudaReadModeNormalizedFloat cudaReadModeNormalizedFloat
而
且
Type
是一个
时被指定。一个
Type 被限定在基本的整型和浮点类型和
Type Type
Dim 的是默认为1 的一个可选自变量;
Dim Dim
cudaReadModeElementType; 如果它是
cudaReadModeElementTypecudaReadModeElementType
16-bit 或8-bit
的整型类型,实际上
texture reference
返回的值
- 29 -
Page 30

将被看
[-1.0,1.0]
作浮点类型,
;
例如,一个带有
unsigned
的整型类型被映射到
值
cudaReadModeElementType
ReadMode
是一个
默认
到
cudaReadModeElementType
4.3.4.2 Runtime Texture Reference
另外一些
runtime API 和4.5.3.9 driver API
texture reference
的属性是不固定的,它们可以通过主机的
)
。它们可以指定纹理坐标是否是
滤。
默认下
的纹理拥有坐标
[0,N)
,纹理通过浮点数坐标
范围x 轴[0,63]和y 轴[0,31]
。因此,同样的
64x32
[0,N)引用,N 是关于坐标在空间上纹理的
纹理将被指
0xff
的
无符
号的
,将不执行转换;
属性
。
Normalized
向
normalized
[0.0,1.0],signed
8-bit
纹理元素读作1;如果
的可
选自
runtime
normalized
的纹理通过坐标
的坐标x 轴[
0.0,1.0
的整型类型被映射到
它是
变量。
改变(
参见部分
,
寻址
模式,和纹理过
大小
。例如,一个
[
0.0,1.0
)和坐
标y 轴[
4.5.2.6
64x32
大小
)引用,而不是
0.0,1.0
)
。
Normalized
的纹理坐标天生适合一些
寻址
模式定义了,当纹理坐标超
围
[0, N)
坐标范围
用于,当纹理
将被看
时,小于0 的值被设成0,大于N 的值被设成N-1。。当使用
被限制在
作
0.75
包含
。
[
0.0,1.0
一个
周期
出范围后会怎样。当使用
)
。对于
性的信号时。它只作用于纹理坐标的分数
线性纹理过滤只能用在纹理被设置为
texel
周边的纹理拾取地
行在一维纹理中,
址将
bilinear
被读取,并基于
插值
执行在
附录F 有关于纹理拾取的更多细节
。
应用程序,例如纹理坐标独立
unnormalized
normalized
返回
浮点数据的
二维
的纹理坐标,同样指定了
情况下
texel
所在的纹理坐标
。它在
纹理中。
于纹理
normalized
部分;
邻近
的
返回插值
大小
。
的纹理坐标时,纹理坐标超
的纹理坐标时,纹理
"
warp
"
寻址
。
Warp
例如,
1.25
将被看
texel
中
执行一个低精度的
的纹理拾取值。简单的
作
寻址
0.25
通常被
,
插值
出范
-
1.25
插值
。
执
- 30 -
Page 31

4.3.4.3
线性内存纹理操作对比
CUDA
数组
一个纹理可以被划在线性的内存中或者一个CUDA 数组中(参见部分4.5.1.2)。
纹理分配在线性内存中:
只有维数为1 时;
不支持纹理过滤;
只能使用non-normalized 纹理坐标寻址;
不能支持不同的寻址模式:超出范围的纹理访问返回0。
4.4
设备
Runtime
设备
runtime
4.4.1
数学函数
对于表B-1 中的某些
组件
的组件只能用于设备函数。
的函数,它们在设备
Runtime
的组件中有低准确性而更
快速的版本; 它有相同的
加
__
前缀(例如
编译器有一个
4.4.2
同步函数
void __syncthreads();
在一个块内同步所有线程。一旦所有线程到达了这点,恢复
__syncthreads()
全局内存时,对于有些内存
这些数据
__syncthreads()
能被
挂起
__sin(x)
选项
危险
可以通过同步线程之间的
或导致没想
)
。这些函数在表
(
-use_fast_math
通常用于调整在相同块之间的线程通信。当在一个块内的有些线程
访问潜在
允许放在条件代码中,
到的副作用。
B-2
里列出
)来强
制每个函数编译到它的不太准确的副本
着
read-after-write, write-after-read,
访问得以避免
但只
。
。
有当整个线程块有相同的条件
正常执行。
。
或
者
write-after-write
贯穿
访问相
时,
同的共享或
否则
代码执行可
的
危险
。
- 31 -
Page 32

4.4.3
类型转换函数
下面
函数的后缀指定
rn
是
求最近的偶数,
rz
是
逼近零
ru
是向上舍入(到正无穷
rd
是
向下舍入(到负无穷)。
,
IEEE-754
),
的舍入模式:
int __float2int_[rn,rz,ru,rd](float);
用指定的舍入模式转换浮点参数到整型。
Unsignde int __float2unit_[rn,rz,ru,zd](float);
用指定的舍入模式转换浮点参数到
无符号整
型。
float __int2float_[rn,rz,ru,rd](int);
用指定的舍入模式转换整型参数到浮点数。
float __int2float_[rn,rz,ru,rd](unsigned int);
用指定的舍入模式转换无符号整型参数到浮点数。
4.4.4 Type Casting
函数
float __int_as_float(int);
在整型自变量上执行一个浮点数的
type cast
,保持值不变。例如,
于-2。
__int_as_float(0xC0000000)
等
int __float_as_int(float);
在浮点自变量上执行的一个整型的
等
于
0x3f800000
。
type cast
,保持值不变。例如,
__float_as_int (1.0f)
- 32 -
Page 33

4.4.5
纹理函数
4.4.5.1
设备内存中的纹理通过
设备内存纹理操作
tex1Dfetch()
函数
访问
,例如:
template<class Type>
Type tex1Dfetch(
texture<Type, 1, cudaReadModeElementType> texRef,
int x);
float tex1Dfetch(
texture<unsigned char, 1, cudaReadModeNormalizedFloat> texRef,
int x);
float tex1Dfetch(
texture<signed char, 1, cudaReadModeNormalizedFloat> texRef,
int x);
float tex1Dfetch(
texture<unsigned short, 1, cudaReadModeNormalizedFloat> texRef,
int x);
float tex1Dfetch(
texture<signed short, 1, cudaReadModeNormalizedFloat> texRef,
int x);
这些函数通过纹理坐标x 拾
许
纹理过滤和
下面
的函数展示了2-和4-元组的支持:
选择寻址
取线性内存中绑
定到
texture reference texRef
模式。对于这些函数,可能需要将整
型数升级到
的
32-bit
区域
。对于整型来说,不
浮点数。
float4 tex1Dfetch(
texture<uchar4, 1, cudaReadModeNormalizedFloat> texRef,
int x);
通过纹理坐标x 拾
取线性内存中绑
定到
texture reference texRef
的
区域
。
4.4.5.2 CUDA
从
CUDA
数组纹理操作
数组中的纹理通过
tex1D()或tex2D()
函数
访问
:
template<class Type, enum cudaTextureReadMode readMode>
Type tex1D(texture<Type, 1, readMode> texRef, float x);
template<class Type, enum cudaTextureReadMode readMode>
允
Type tex2D(texture<Type, 2, readMode> texRef, float x, float y);
这些函数通过纹理坐标x 和y 拾
取
CUDA
数组中绑
定到
texture reference texRef
的
区域
。
Texture
reference
的编译时(固定的)和运行时(可变的)的属性决定了,坐标如何被解释,纹理拾取时将有
哪些处理发生,和纹理拾取返回的值(参见部分4.3.4.1 和4.3.4.2)。
- 33 -
Page 34

4.4.6
原子函数
只
有计算兼容性为
1.1
的设备才可以使用原子函数。它们在附录C 中列出
。
原子函数在全局内存中的一个
内存中的同一个地址读取一个
证
操作不会干扰其它线程。在操作完成
32-bit
32-bit
原子操作只能用于
32-bit
有符号和
4.5
主机
主机
Runtime
Runtime
组件
的组件只能被主机函数使用。
它提供函数来处理:
设备管理,
Context
内存管理,
编码模块管理,
管理,
字中
执行一个读-修改-写
字,加
之前,其
无符
号的整型数。
一个整型进去,并
它线程
也无法访问
的原子操作。例如,
写回结果
到同一个地址。所
这个地址。
atomicAdd()
谓“原子”就是保
在全局
执行控制,
Texture reference
OpenGL 和Direct3D
它由二个
API
API
一个低级的
一个高级的
。
组成:
API
API
管理,
的互用性。
调用
CUDA
调用的
驱动程序
API
CUDA runtime API
,在
CUDA
驱动程序
API
这些API 是互相排斥:一个应用程序应该选择其中之一来使用。
CUDA runtime
C
主机代码基于
API
。
通过提供固有的初始化,
CUDA runtime(
参见第
context
4.2.5
管理,和模块管理减轻
部分),因此应用程序连接这个代码
了设备代码的管理。
之
上运行的
必须
Nvcc
使用
CUDA runtime
生
成的
- 34 -
Page 35

相反
,
CUDA
驱动程序
API
要求更多的代码,使编程和调试更加困
难,但它提供更好的控制,并且是语
言独立
Kernel
4.2.3
的,因为它只处理
更加困
部分
难,因为执行配置和
)。同样的,设备仿真(参见
CUDA
驱动程序
API
CUDA runtime API
cuda
。
4.5.1
公共概念
4.5.1.1
两
kernel
个
设备
API
都提供了函数来枚举
(
参见第
4.5.2.2
通过
通过
cubin
cudart
cuda
对
象(参见第
kernel
动
态库
动
态库
4.2.5
参数必须
4.5.2.9
部分)。尤其
指定外在的函数调用,
部分)不能与
是使用
CUDA
提供,所有它的进入点带有前缀cu。
提供,所有它的进入点带有前缀
在系统上可使用的设备,查询它们的属性,并
部分和第
4.5.3.2
部分
)。
CUDA
驱动程序
驱动程序
来替
换执行配置语法(
API
一
API
起工
选择它们中
配置和启动
参见第
作。
的一个来执行
一些主机线程可以在同一设备上执行设备代码,但从设计角度上看,一个主机线程只能在一个设备上执行
设备代码。因此,多主机线程需要在多个设备上执行设备代码。
创建的
CUDA
源文件不能被其它主机线程使用。
另外
,任何在一个主机线程中通过
runtime
4.5.1.2
设备内存可被分配到线性内存或者是
在设备上的线性内存使用
二
CUDA
个或
程序
内存
32-bit
地
CUDA
址空
数组。
间,因此单独分
配的实体可以通过指针的互相引
元的树结构中。
数组是针对纹理拾取优化的不透明的内存布局。它们是一维或
者4 个组件,每个组件可以是有符号或
API
支持),或
32
位浮点。
CUDA
无符
号8-,
数组只能通过
16- 或32-bit
kernel
二维
的元素组成的,每个有1 个,
整
型,
16-
纹理拾取读取。
用,例如,在一个
位浮点(仅通过
CUDA
驱动
通过主机的内存复制函,数线性内存和
CUDA
数组都是可读和可写的,
参见
4.5.2.3 和4.5.3.6
部分的描
2
述
。
- 35 -
Page 36

不同于由
主机内存的函数(
使用
page-locked
4.5.1.3 OpenGL Interoperability
malloc()
page-locked
内存
函数分配的
参见
附录
内存的优势是,主机内存和设备内存之间的带宽将非常高。但是,分配过多的
将减少
pageable
D.5.6 和D.5.7,E.8.5 和E.8.6
系统可用物理内存的
主机内存,主机
大小
,从而降低系统整体的性能。
runtime
部分
同样提供可以分配和释
)。如果主机内存被分配为
放
page-locked
page-locked
OpenGL 缓冲器对象可以被映射到CUDA 地址空间,使CUDA 能够读取被OpenGL 写入的数据,
或者使CUDA 能够写入被OpenGL 消耗的数据。 4.5.2.7 部分描述了在runtime API 下如何使
用,4.5.3.10 部分描述了驱动API 下如何使用。
4.5.1.4 Direct3D Interoperability
Direct3D 9.0
顶
点缓冲器可以被映射到
CUDA
地
址空
间,使
CUDA
能够读取被
Direct3D
写
入的数据,或
,
者
使
CUDA
部分描述
能
了驱动
够写
API
入被
下如何
Direct3D
使用。
消耗
的数据。
4.5.2.8
部分描述
了在
runtime API
下如何
使用,
4.5.3.11
一个CUDA context 每次只可以互用一个Direct3D 设备,通过把begin/end 函数括起来调用。
参见4.5.2.8 和4.5.3.11 部分的描述。
CUDA context 和Direct3D
Direct3D
动
API
的适配器来确保。对于
使用
cuD3D9GetDevice()
设备
必须建立
runtime API
(
参见
在同一个
使用
附录
E.11.7
GPU
上。可以通过查询与
cudaD3D9GetDevice()
)。
CUDA
(
参见
设备是
附录
D.9.7
否关联使用
),对于驱
Direct3D
设备
必须
使用
D3DCREATE_HARDWARE_VERTEXPROCESSING
标
志创建。
CUDA 尚不支持:
除Direct3D 9.0 之外的版本,
除顶点缓冲器之外的
Direct3D 对象。
- 36 -
Page 37

cudaD3D9GetDevice()和cuD3D9GetDevice()
不同的设备上,比如
Direct3D 的loading balance 和CUDA 的over interoperability
4.5.1.5
为了促使主机和设备之间的并发执行,一
将交还给
Kernel
一些设备也可以执行
CU_DEVICE_ATTRIBUTE_GPU_OVERLAP
有这个功能。这个功能
异步的并发执行
应用程序。
通过
__global__
执行内存
拷贝
的函数需要后
执行设备到设备内存
设置内存的函数。
page-locked
目前只
拷贝
些
runtime
函数或
cuGridLaunch()和cuGridLaunchAsync()
缀
Async
;
的函数;
主机内存和设备内存之间并发的
(
参见
E.2.6
支持内存
拷贝,且
是通过
同样可以确
保
Direct3D
设备和
函数是异步的:在设备完成
拷贝
。应用程序可以与
)一起通过
cuDeviceGetAttribute()
cudaMallocPitch()
CUDA context
。
请求
的任务
启动;
(
参见
4.5.2.3
之前
部分
建立
,控制
查询是
)或
在
权
否
cuMemAllocPitch()
(
参见
4.5.3.6
部分)分
应用程序通过流(
其
它或并行的乱序执行。
stream
) 管理并发。一个流是有序执行的操作序列。另一方面,不同的流
一个流被定义为,通过
4.5.2.4
部分描述
建立
了在
runtime API
流对
象且
指定它的流参数到
下如何
使用,
只
有当全部的操作
有零参
数的流才开
已完
成的
情况下:包括
始,例如:任
何
kernel
操作本事是流的一
的启动,内存的设置或内存的
cudaStreamQuery()和cuStreamQuery()
成了(分别
参见
D.3.2 和E.5.2
部分
)。
cudaStreamSynchronize() 和cuStreamSynchronize()
配的不
包括
CUDA
数组或
2D
数组的。
也许会遵
kernel
4.5.3.7
的启动序列和主机到设备的内存
部分描述
部分
,和在完成
了驱动
API
下如何
之前没有随之
拷贝
。
拷贝
使用。
的操作。一个带
提供一个方法使应用程序查询一个流中的全部操作是
循
。
否完
提供一个方法强制应用程序等待,直
到流中的全部操作完成(分别
参见
E.5.2 和E.5.3
部分
)。
- 37 -
Page 38

同样的,
直
到全部设备任务完成(分别
的的,孤立启
cudaThreadSynchronize()和cuThreadSynchronize()
参见
D.2.1 和E.3.5
动的或内存
拷贝失败的情况
。
runtime
意
一点的事件,并可查询这些事件是何时被纪录的。
4.5.3.8
同样提供一个方法更近的监控设备的进程。在精确的时间下,让应用程序异步的纪录程序中任
部分描述
了驱动
API
下如何
使用。
不同流中的两个操作不能并发的执行,无论
设置,设备到设备的内存
拷贝
,或它
们之
是
page-locked
间的事件纪录。
程序员可以通过设置
上的
CUDA
应用程序。这个功能仅限
CUDA_LAUNCH_BLOCKING
debug
用途,不要用于
部分
)。为了
4.5.2.5
避免速度下降
部分描述
主机内存分配,设备内存的分配,设备内存的
环境
变量为1,来全局的关闭
增加
软件产品
应用程序可以强制
,这些函数最好
了在
runtime API
异步执行,对于所有系统
的可靠性。
runtime
下如何
等待,
用于时间
使用,
目
4.5.2 Runtime API
4.5.2 Runtime API
4.5.2 Runtime API 4.5.2 Runtime API
4.5.2.1
没
适
初始化
有明确针对
时的调用
Runtime
RuntimeAPI
的初始化函数; 它在第一
次
Runtime
函数,和何时说明从第一次调用进入
函数调用时初始化。需要
Runtime
的错误代码。
4.5.2.2
附录
cudaGetDeviceCount()和cudaGetDeviceProperties()
们
设备管理
D.1
的函数用来管理系统中的设备。
的属性:
提供一个方法来枚举这些
int deviceCount;
cudaGetDeviceCount(&deviceCount);
Int device;
for (device = 0; device < deviceCount; ++device) {
cudaDeviceProp deviceProp;
注意
的是,何时
设备和
获得
它
cudaGetDeviceProperties(&deviceProp,device);
}
- 38 -
Page 39

cudaSetDevice()
cudaSetDevice(device);
用
来选择相关
于主机线程的设备:
一个设备必须在任何__global__函数或者所有来自附录D 的任何函数调用之前选择; 否
则,device 0 自动地被选择,并且所有随后的设备选择将是无效的。
4.5.2.3
内存管理
附录D.5 的函数用来分配和释放设备内存,访问在全局内存中任意声明的变量分配的内存,
和从主机内存到设备内存之间的数据传输。
线性内存通过
下面
的代码演示,在线性内存
float* devPtr;
cudaMalloc((void**)&devPtr, 256 * sizeof(float));
分
配
2D
区域的最佳性能。
cudaMalloc()或cudaMallocPitch()
中分
数组建议
配一个
使用
cudaMallocPitch()
返回
的
pitch
必须用来访问
256
分
配,通过
个浮点元素的数组:
, 从而
数组元素。
保证
访问
行地址,或
下面
的代码演示,分配一个宽x 高带有浮点数的
cudaFree()
拷贝
2D
释放。
数组到设备内存的其它
2D
数组,和在设备代码中如何循环
// host code
float* devPtr;
int pitch;
cudaMallocPitch((void**)&devPtr, &pitch,
数组元素:
width*sizeof(float),height);
myKernel<<<100,512>>>(devPtr,pitch);
// device code
__global__ void myKernel(float* devPtr, int pitch)
{
for (int r = 0; r < height; ++r) {
float* row = (float*)((char*)devPtr + r * pitch);
for (int c = 0; c < width; ++c) {
float element = row[c];
}
}
}
CUDA
要一
个格式的解释,通过
数组通过
cudaMallocArray()
cudaCreateChannelDesc()
分
配,通过
cudaFreeArray()
建立
。
- 39 -
释放。
cudaMallocArray()
需
Page 40

下面
的代码演示,分配一个宽x 高带有一个
cudaChannelFormatDescchannelDesc=
cudaCreateChannelDesc<float>();
cudaArray* cuArray;
cudaMallocArray(&cuArray, &channelDesc, width, height);
32-bit
浮点数的
2D
数组:
cudaGetSymbolAddress()用来获得指向全局内存中一个声明的变量分配的内存地址。分配内
存的大小用cudaGetSymbolSize()取得。
附录D.5 列出了不同的函数用来拷贝内存,包括用cudaMalloc()分配的线性内存,用
cudaMallocPitch() 分配的线性内存,CUDA 数组,全局变量分配的内存或常驻内存。
下面
的代码演示,
cudaMemcpy2DToArray(cuArray, 0, 0, devPtr, pitch,
拷贝
一个
2D
数组到
之前
例子
中分
配的
CUDA
数组:
width * sizeof(float),height,
cudaMemcpyDeviceToDevice);
下面
的代码演示,
float data[256];
int size = sizeof(data);
float* devPtr;
cudaMalloc((void**)&devPtr, size);
cudaMemcpy(devPtr, data, size, cudaMemcpyHostToDevice);
拷贝一些
主机内存数组到设备内存:
下面
的代码演示,
__constant__ float constData[256];
float data[256];
cudaMemcpyToSymbol(constData, data, sizeof(data));
拷贝一些
主机内存数组到常驻内存:
4.5.2.4
附录
流管理
D.3
的函数用来创建和
销毁
流,并且判
定一个流中的所有操作是
否完
成。
下面
的代码演示,创建两
cudaStream_t stream[2];
for(inti=0;i<2;++i)
cudaStreamCreate(&stream[i]);
个流:
- 40 -
Page 41

下面
的代码演示,每一个流被
的内存
for (int i = 0; i < 2; ++i)
for (int i = 0; i < 2; ++i)
for (int i = 0; i < 2; ++i)
cudaThreadSynchronize();
每个流
设备上处理
hostPtr
机内存:
float*hostPtr;
cudaMallocHost((void**)&hostPtr,2*size;
cudaThreadSynchronize()
4.5.2.5
附录
下面
cudaEvent_tstart,sto;
cudaEventCreate(&stat);
cudaEventCreate(&stop);
这些事件可以用来计算
cudaEventRecord(start, 0);
for (int i = 0; i < 2; ++i)
for (int i = 0; i < 2; ++i)
for (int i = 0; i < 2; ++i)
拷贝
。
cudaMemcpyAsync(inputDevPtr+i*size,hostPtr+i*size,
myKernel<<<100, 512, 0, stream[i]>>>
(outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
拷贝
部分
输入数组
inputDevPtr
允许
内存
拷贝
事件管理
D.4
的函数用来创建,纪录和
的代码演示,
cudaMemcpyAsync(inputDev + i * size, inputHost + i * size,
myKernel<<<100, 512, 0, stream[i]>>>
建立两
之前
(outputDev + i * size, inputDev + i * size, size);
依次定义
size,cudaMemcpyHostToDevice,stream[i]);
hostPtr
, 并
从一个流
在最后被调用,以确保在继续
个事件:
代码的时间:
size, cudaMemcpyHostToDevice, stream[i]);
执行一次:从主机到设备的内存
到设备内存中的输入数组
拷贝结果
覆盖到另
销毁
outputDevPtr 到hostPtr
一个流。对于任何覆盖
事件,并可查询两
inputDevPtr
,
处理
之前全部
个事件之间
拷贝
,
, 通过调用
的同一个
hostPtr
的流已经完成。
花费
的时间。
cudaMemcpyAsync(outputHost + i * size, outputDev + i * size,,,,
size, cudaMemcpyDeviceToHost, stream[i]);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
kernel
部分
必须指向
启
动,从设备到主机
myKernel()
。使用两个流处理
page-locked
在
的主
- 41 -
Page 42

4.5.2.6 Texture Reference
附录
D.6
的函数用来管理
纹理类型是由高级
API
管理
texture reference
定义的公开的结构,
。
texture Reference
struct textureReference
{
int normalized;
enum cudaTextureFilterMode filterMode;
enum cudaTextureAddressMode addressMode[2];
struct cudaChannelFormatDesc channelDesc;
}
normalized
[0,1]
, 而不是
指定纹理坐标是否是
normalized
[0,width-1]或[0,height-1]
; 如果
,
它不是零,纹理中的全部元素拥
其中
filterMode
指定过滤模式:基于输入的纹理坐标,计算纹理拾取的值是如
类型是由低级
API
width 和height
何返回的;
定义的,例如:
有纹理坐标
是纹理的
大小;
过滤模式等于
cudaFilterModePoint 或cudaFilterModeLinear
值等于最接近
入纹理坐标的,两个
cudaFilterModeLinear
于输入纹理坐标的
texel
(对于一维纹理)或四个
需要
texel
返回值
;如果
是
cudaFilterModeLinear
是浮点类型;
addressMode
的数组,分别
指定
寻址
模式:如果控制超
指定第一个纹理坐标的
寻址
出范围
模式和
cudaAddressModeClamp 或cudaAddressModeWrap
出范围
覆盖到合
cudaAddressModeWrap
channelDesc
的纹理坐标被钳制到合法的
法的
范围;
仅支持
定义了,当拾取纹理时
范围;如果
normalized
返回值
是
的格式
struct cudaChannelFormatDesc {
int x, y, z, w;
;如果
是
cudaFilterModePoint
texel
(对于
的纹理坐标
第二
个纹理坐标的
二维
;
; 如果
纹理)的线性
addressMode
寻址
是
cudaAddressModeClamp
cudaAddressModeWrap
的纹理坐标;
;参见下面
代码:
,
返回的值等于最接近
插值
的结
是一个拥有两个元
模式
;寻址
,超
模式等于
出范围
,
返回
于输
果;
,超
的纹理坐标被
的
素
enum cudaChannelFormatKind f;
};
- 42 -
Page 43

其中
,
x,y,z,和w
是
返回值
每个
部分
的位数,f 是:
cudaChannelFormatKindSigned
cudaChannelFormatKindUnsigned
cudaChannelFormatKindFloat
normalized
normalized,addressMode
normalizednormalized
addressMode,和filterMode
addressModeaddressMode
filterMode 可以在主机代码中直接修改。它们只应用在绑定
filterMode filterMode
如
果
这
些 部 分
如
果
它
如果它们是浮点数。
到CUDA 数组的texture reference。
在一个
cudaBindTexture()或cudaBindTextureToArray()
下面
kernel
的代码演示,绑定一个
使用低级
texture<float, 1, cudaReadModeElementType> texRef;
textureReference* texRefPtr;
cudaGetTextureReference(&texRefPtr, “texRef”);
cudaChannelFormatDesc channelDesc =
通过
texture reference
API
:
读取纹理内存
texture reference
之前
到通过
,
texture reference
的纹理中。
devPtr
指向的线性内存中:
们
是
是 有
无 符
符
号 的
必须绑定到一个使用
号 的
整
整
型 ,
型 ,
cudaCreateChannelDesc<float>();
cudaBindTexture(0, texRefPtr, devPtr, &channelDesc, size);
使用高级
texture<float, 1, cudaReadModeElementType> texRef;
cudaBindTexture(0, texRef, devPtr, size);
下面
的代码演示,绑定一个
使用低级
texture<float, 2, cudaReadModeElementType> texRef;
textureReference* texRefPtr;
cudaGetTextureReference(&texRefPtr, “texRef”);
cudaChannelFormatDesc channelDesc;
cudaGetChannelDesc(&channelDesc, cuArray);
cudaBindTextureToArray(texRef, cuArray, &channelDesc);
使用高级
texture<float, 2, cudaReadModeElementType> texRef;
API
API
API
:
:
:
texture reference 到CUDA
数组
cuArray
中
:
cudaBindTextureToArray(texRef, cuArray);
- 43 -
Page 44

绑
定一个纹理到
texture reference
的格式
必须
匹配声明
texture reference
时的参数
;否则
,纹理拾取的结
果将是未定义
cudaUnbindTexture()
4.5.2.7 OpenGL Interoperability
附录
D.8
一个缓冲对象在被映射
GLuint bufferObj;
cudaGLRegisterBufferObject(bufferObj);
的。
的函数用来控制
之前必须注册到
用
来卸载
OpenGL
texture reference
的互用性。
CUDA
。使用
的绑定。
cudaGLRegisterBufferObject()
:
注册以后,缓冲对象可以通过kenrel 使用设备内存读取或写入,内存设备的地址通过
cudaGLMapBufferObject()返回:
GLuint bufferObj;
float* devPtr;
cudaGLMapBufferObject((void**)&devPtr, bufferObj);
卸载
映射和注册
4.5.2.8 Direct3D Interoperability
附录
D.9
的函数用来控制
Direct3D
一个顶点对象在被映射
LPDIRECT3DVERTEXBUFFER9 vertexBuffer;
cudaD3D9RegisterVertexBuffer(vertexBuffer);
注册以后,缓冲对象可以通过
cudaD3D9MapVertexBuffer()
LPDIRECT3DVERTEXBUFFER9 vertexBuffer;
float* devPtr;
cudaD3D9MapVertexBuffer((void**)&devPtr, vertexBuffer);
卸载
映射和注册
通过,
的互用性
通过,
cudaGLUnmapBufferObject()和cudaGLUnregisterBufferObject()
Direct3D
必须
通过
cudaD3D9Begin()
之前必须注册到
cudaD3D9UnmapVertexBuffer()
kenrel
返回
的互用性。
来
初始化,
CUDA
使用设备内存读取或写入,内存设备的地址通过
:
。使用
cudaD3D9RegisterVertexBuffer()
cudaD3D9End()
和
来终止
。
。
:
cudaD3D9UnregisterVertexBuffer()
。
- 44 -
Page 45

4.5.2.9
编程
这个方式(使用
人员使用主机原生的调试支持来调试应用程序。预处理器
义
连
返回
当在设备仿真模式下运行应用程序时,编程模型通过
在主机生成一条线程。开发人员
通过设备仿真模式提供的许多特点使它成为一套非常有效的调试
使用设备仿真方式调试
环境
不支持任何原生的调试运行在设备上的代码,
-deviceemu
。对于当前应用程序的所有代码,
接设备仿真或设备执行的代码所
。
主机能够运行每个块线程的
足够
的内存可用于运行所有线程,每条线程需要
选项)下
产生
需要确定:
最大
但伴随而来
编译应用程序时,设备代码被编译成针对运行在主机上的,
宏
__DEVICE_EMULATION__
包括任何
的运行时错误,可以通过
数量,加上一条主线程。
被使用的库,
runtime
256 KB
必须
被仿真。对于在线程块中的每条线程,
堆栈
一个针对调试目的的设备仿真模式。在
允许开
在这个模式下被定
被编译,无论
cudaErrorMixedDeviceExxcution
。
工具
:
对于设备仿真或设备执行。
发
runtime
通过使用主机原生的调试支持,开发人员
由于设备代码被编译到主机上运行,这个代码可以把在设备不能运行的代码补充进来,
可以使用调试器的所有特性,像设置断点和数据检查。
像是对文件或者屏幕(printf(),等)的输入和输出操作。
因为所有数据驻留在主机上,任何设备的或者主机特定的数据可以从设备或者主机代码读取;同样的,
任何设备或主机的函数可以从设备或主机代码中调用。
为防止
同步的错误使用,
runtime
监测死锁
情况
。
开发人
有用的,
员必须牢记
但某些
设备仿真模式是模仿设备,不是模拟它。因此,设备仿真模式在发现算法错误上是非常
错误是很难发现
当内存单元在同一时间被栅格之内的多条线程访问时,运行在设备仿真方式下时的结果
与运行在设备上时的结果截然不同,因为在仿真模式下线程是顺序的执行。
当解除一个指向主机上的全局内存或者指向设备上的主机内存的引用时,设备执行几乎
肯定在一些未定义的方式上失败,反之,设备仿真可以产生正确的结果。
- 45 -
Page 46

在大多数
情况下
,在设备上执行和在主机上通过设备仿真模式执行,同一浮点计算将不
会产生完全相
同的结果。这在通常
项
形成的,更不用说不同的编译器,不同的指令组,或者不同的架构了。
情况下
是能
预料
到的,对于同一浮点计算,取得的不同结果是由不同的编译器
选
特别是,一些主机平台在扩展精度的寄存器里存贮了单精确度浮点计算的中间结果,往往造
成设备仿真模式下,精度上的很大不同。当出现这些情况时,开发人员可尝试以下方法,但
任何一种方法都不能完全保证工作:
声明一些浮点变量因为不稳定而强制单一精确度存贮;
使用gcc 编译器的–ffloat-storegcc 选项;
使用Visual C++编译器的/Op 或/fp 选项;
对于Linux 使用_FPU_GETCW()和_FPU_SETCW(),对于Windows 使用_controlfp()
函数来强制一部分代码单一精度浮点计算
unsigned int originalCW;
_FPU_GETCW(originalCW);
unsigned int cw = (originalCW & ~0x300) | 0x000;
_FPU_SETCW(cw);
或
unsigned int originalCW = _controlfp(0, 0);
_controlfp(_PC_24, _MCW_PC);
在一开始,存储控制字的当
_FPU_SETCW(originalCW);
或
_controlfp(originalCW, 0xfffff);
在最后,恢复
原是的控制字。
前值
,并强制尾数以
24
位存储
不同于计算设备(参见
模式之间明显不同的结果,因为
附录A),主机
某些
平台
通常也支持规格化的数字。这样可以导致在设备仿真和设备执行
计算在一
种情况下
可能
产生
一个有限结果而在
另外
一个
情况下
可能
产生
一个无限结果。
- 46 -
Page 47

4.5.3
驱动
API
驱动程序
可用于
表
4-1
Object Handle Description
Device CUdevice CUDA-capable device
Context N/A Roughly equivalent to a CPU process
Module CUmodule Roughly equivalent to a dynamic library
Function CUfunction Kernel
Heap memory CUdeviceptr Pointer to device memory
CUDA Array CUarray Opaque container for 1D or 2D data on the device, readable via
Texture reference CUtexref Object that describes how to interpret texture memory data
4.5.3.1
API
CUDA
。在
初始化
是基于句柄
的对象在表
CUDA
驱动
的,命令式的
4-1
加
API
上可用的对象
API
:多数对象通过不透明地句柄引用。
以概述。
texture references
在其他的函数(附录E)被调用之前,需要使用cuInit()函数初始化。
4.5.3.2 设备管理
附录E.2 的函数用来管理当前系统中的设备。
cuDeviceGetCount()和cuDeviceGet()用来枚举这些设备,E.2 中的其他函数用来获得
它们的属性:
int deviceCount;
cuDeviceGetCount(&deviceCount);
int device;
for (int device = 0; device < deviceCount; ++device) {
CUdevice cuDevice;
cuDeviceGet(&cuDevice, device)
int major, minor;
cuDeviceComputeCapability(&major, &minor, cuDevice);
}
4.5.3.3 Context管理
附录E.3 的函数用来创建,捆绑和分离CUDA context 。
一个CUDA context 是类似于一个CPU 处理。在计算API 之内执行的所有资源和行为被压缩
在
CUDA context
里,并且当context 被销毁时系统自动地清理这些资源。除了对象例如模块和纹理引用以外,
- 47 -
Page 48

每个context 有它自己的独立的32bit 地址空间。因此,来自不同的CUDA context 的
CUdeviceptr 值引用不同的内存单元。
Context 在主机线程中有一个一一对应的机制。一个主机线程当前一次只可以有一个设备
context。当一个context 被创建时cuCtxCreate(),它成为了当前调用的主机线程。
以一个context 操作的CUDA 函数(大多数函数不包括设备枚举或者
context 管理) 将返回CUDA_ERROR_INVALID_CONTEXT,如果当前的线
程不是一个合法的context。
为了促进运行在同一个context 中的第三方授权的代码之间的互用性,驱动API 提供一个由
每个确定客户给定的context 的使用量计数器。例如,如果三个库被加载使用同一个CUDA
context ,每个库必须调用cuCtxAttach()来增加使用量计数器,而且当库已经完成context
使用时,调用cuCtxDetach()减少使用量计数器。当使用量计数器为0 时context 就被销毁
了。对大多数库来说,应用程序应该在加载或初始化库之前创建一个CUDA context; 那样,
应用程序可以创建一个用于它自己的context,并且库仅简单的操作context 交给它的任务。
4.5.3.4 模块管理
附录E.4 的函数用来加载和卸载模块,并获得模块中的句柄,变量的指针或函数的定义。
模块是动态地可加载的包括设备代码和数据的压缩包,如同Windows 中的DLL, 它们通过
nvcc 输出。名称对于所有标志,包括函数,全局变量和纹理引用,在模块范围内提供,以
便被独立第三方编写的模块在同一CUDA context 可以互用。
下面的代码演示,加载一个模块并为kernel 取得一个句柄:
CUmodule cuModule;
cuModuleLoad(&cuModule, "myModule.cubin");
CUfunction cuFunction;
cuModuleGetFunction(&cuFunction, cuModule, “myKernel”);
- 48 -
Page 49

4.5.3.5
附录
个块中线程的数量,和线程
cuParam*()
cuLanuch()
执行控制
E.7
的函数用来管理在设备上一个
ID
函数集提供用于
。
如
何分
kernel
kernel
配。
的参数,当
的执行。
cuFuncSetSharedSize()
cuFuncSetBlockShape()
下次
kernel
启
动时
用来设置给定函数每
指定函数共享内存的
包含
culanuchGrid()
cuFuncSetBlockShape(cuFunction, blockWidth, blockHeight, 1);
int offset = 0; int i;
cuParamSeti(cuFunction, offset, i);
Offset += sizeof(i);
float f;
cuParamSetf(cuFunction, offset, f);
offset += sizeof(f);
char data[32];
cuParamSetv(cuFunction, offset, (void*)data, sizeof(data));
offset += sizeof(data);
cuParamSetSize(cuFunction, offset);
cuFuncSetSharedSize(cuFunction, numElements * sizeof(float));
cuLaunchGrid(cuFuntion, gridWidth, gridHeight);
4.5.3.6 内存管理
附录E.8 的函数用来分配和释放设备内存,并从主机和设备内存之前传输数据。
大小
或
。
线性内存通过cuMemAlloc()或cuMemAllocPitch()来分配,cuMemFree()来释放。
下面的代码演示,在线性内存中分配一个256 个浮点元素的数组:
CUdeviceptr devPtr;
cuMemAlloc(&devPtr, 256 * sizeof(float));
分配2D 数组建议使用cuMemMallocPitch(),从而保证访问行地址,或拷贝2D 数组到设
备内存的其它区域的最佳性能。返回的pitch 必须用来访问数组元素。下面的代码演示,分配
一个宽x 高带有浮点数的2D 数组,和在设备代码中如何循环数组元素:
// host code
CUdeviceptr devPtr;
int pitch;
cuMemAllocPitch(&devPtr, &pitch,
width * sizeof(float), height, 4);
cuModuleGetFunction(&cuFunction,cuModule,"myKernel");
cuFuncSetBlockShape(cuFunction, 512, 1, 1);
cuParamSeti(cuFunction, 0, devPtr);
cuParamSetSize(cuFunction, sizeof(devPtr));
cuLaunchGrid(cuFunction, 100, 1);
- 49 -
Page 50

// device code
__global__ void myKernel(float* devPtr)
{
for (int r = 0; r < height; ++r) {
float* row = (float*)((char*)devPtr + r * pitch);
for (int c = 0; c < width; ++c) {
float element = row[c];
}
}
}
CUDA 数组通过cuArrayCreate()分配,通过cuArrayDestroy()释放。
下面的代码演示,分配一个宽x 高带有一个32-bit 浮点数的CUDA 数组:
CUDA_ARRAY_DESCRIPTOR desc;
desc.Format = CU_AD_T_FLOAT;
desc.NumChannels = 1;
1; desc.Width = width;
desc.Height = height;
CUarray cuArray;
cuArrayCreate(&cuArray, &desc);
附录E.8 列出了不同的函数用来拷贝内存,包括用cuMemMalloc()分配的线性内存,用
cuMemMallocPitch()分配的线性内存,CUDA 数组。
下面的代码演示,拷贝一个2D 数组到之前例子中分配的CUDA 数组:
CUDA_MEMCPY2D copyParam;
memset(©Param, 0, sizeof(copyParam));
copyParam.dstMemoryType = CU_MEMORYTYPE_ARRAY;
copyParam.dstArray = cuArray;
copyParam.srcMemoryType = CU_MEMORYTYPE_DEVICE;
copyParam.srcDevice = devPtr;
copyParam.srcPitch = pitch;
copyParam.WidthInBytes = width * sizeof(float);
copyParam.Height = height;
cuMemcpy2D(©Param);
下面的代码演示,拷贝一些主机内存数组到设备内存:
float data[256];
int size = sizeof(data);
CUdeviceptr devPtr;
cuMemMalloc(&devPtr, size);
cuMemcpyHtoD(devPtr, data, size);
- 50 -
Page 51

4.5.3.7 流管理
附录E.5 的函数用来创建和销毁流,并且判定一个流中的所有操作是否完成。
下面的代码演示,创建两个流:
CUStream stream[2];
for (int i = 0; i < 2; ++i)
cuStreamCreate(&stream[i], 0);
下面的代码演示,每一个流被依次定义执行一次:从主机到设备的内存拷贝,kernel 启动,
从设备到主机的内存拷贝。
for (int i = 0; i < 2; ++i)
cuMemcpyHtoDAsync(inputDevPtr + i * size, hostPtr + i * size,
size, stream[i]);
for (int i = 0; i < 2; ++i) {
cuFuncSetBlockShape(cuFunction, 512, 1, 1);
int offset = 0;
cuParamSeti(cuFunction, offset, outputDevPtr);
offset += sizeof(int);
cuParamSeti(cuFunction, offset, inputDevPtr);
offset += sizeof(int);
cuParamSeti(cuFunction, offset, size);
offset += sizeof(int);
cuParamSetSize(cuFunction, offset);
cuLaunchGridAsync(cuFunction, 100, 1, stream[i]
}
for (int i = 0; i < 2; ++i)
cuMemcpyDtoHAsync(hostPtr + i * size, outputDevPtr + i * size,
size, stream[i]);
cuCtxSynchronize();
每个流
设备上处理
hostPtr
机内存:
float* hostPtr;
cuMemMallocHost((void**)&hostPtr, 2 * size);
cuCtxSynchronize()
4.5.3.8
附录
下面
CUEvent start,
stop;cuEventCreate(&start);
cuEventCreate(&stop);
拷贝
部分
输入数组
inputDevPtr
允许
内存
拷贝
事件管理
E.6
的函数用来创建,纪录和
的代码演示,
建立两
hostPtr
, 并
从一个流
在最后被调用,以确保在继续
个事件:
到设备内存中的输入数组
拷贝结果
覆盖到另
销毁
outputDevPtr 到hostPtr
一个流。对于任何覆盖
事件,并可查询两
inputDevPtr
处理
之前全部
个事件之间
,通过调用
的同一个
,
hostPtr
的流已经完成。
花费
的时间。
部分
必须指向
cuFunction
。使用两个流处理
page-locked
的主
在
- 51 -
Page 52

这些事件可以用来计算
之前
代码的时间:
cuEventRecord(start, 0);
for (int i = 0; i < 2; ++i)
cuMemcpyHtoDAsync(inputDevPtr + i * size, hostPtr + i * size,
size, stream[i]);
for (int i = 0; i < 2; ++i) {
cuFuncSetBlockShape(cuFunction, 512, 1, 1);
int offset = 0;
cuParamSeti(cuFunction, offset, outputDevPtr);
offset += sizeof(int);
cuParamSeti(cuFunction, offset, inputDevPtr);
offset += sizeof(int);
cuParamSeti(cuFunction, offset, size);
offset += sizeof(int);
cuParamSetSize(cuFunction, offset);
cuLaunchGridAsync(cuFunction, 100, 1, stream[i]
}
for (int i = 0; i < 2; ++i)
cuMemcpyDtoHAsync(hostPtr + i * size, outputDevPtr + i * size,
size, stream[i]);
cuEventRecord(stop, 0);
cuEventSynchronize(stop);
float elapsedTime;
cuEventElapsedTime(&elapsedTime, start, stop);
4.5.3.9 Texture Reference
附录
E.9
的函数用来管理
在一个
kernel
通过
texture reference
cuTexRefSetAddress()或cuTexRefSetArray()
如果一个模块
cuModule
管理
texture reference
读取纹理内存
中包含一些
texture reference texRef
。
之前
,
texture reference
的纹理中。
必须绑定到一个使用
定义为
texture<float, 2, cudaReadModeElementType> texRef;
下面
的代码演示,
获得
texRef
的句柄
:
CUtexref cuTexRef;
cuModuleGetTexRef(&cuTexRef, cuModule, “texRef”);
下面
的代码演示,绑定一个
texture reference
到通过
devPtr
指向的线性内存中:
cuTexRefSetAddress(Null, cuTexRef, devPtr, size);
下面
的代码演示,绑定一个
texture reference 到CUDA
数组
cuArray
中
:
cuTexRefSetArray(cuTexRef, cuArrary, CU_TRSA_OVERRIDE_FORMAT);
附录E.9 列出了各种函数用于,设定texture reference 的寻址模式,过滤模式,格式,和其
他标志。绑定一个纹理到texture reference 的格式必须匹配声明texture reference 时的参数;
否则,纹理拾取的结果将是未定义的。
- 52 -
Page 53

4.5.3.10 OpenGL Interoperability
附录
E.10
的函数用来控制
OpenGL
的互用性。
OpenGL
一个缓冲对象在被映射
的互用性
必须
通过
cuGLInit()
之前必须注册到
来
CUDA
初始化。
。使用
cuGLRegisterBufferObject():
GLuint bufferObj;
cuGLRegisterBufferObject(bufferObj);
注册以后,缓冲对象可以通过
cuGLMapBufferObject()
kenrel
返回
使用设备内存读取或写入,内存设备的地址通过
:
GLuint bufferObj;
CUdeviceptr devPtr;
Int size;
cuGLMapBufferObject(&devPtr, &size, bufferObj);
卸载
映射和注册
通过,
cuGLUnmapBufferObject()和cuGLUnregisterBufferObject()
4.5.3.11 Direct3D Interoperability
。
附录
E.11
的函数用来控制
Direct3D
的互用性
必须
一个顶点对象在被映射
Direct3D
通过
cuD3D9Begin()
的互用性。
之前必须注册到
CUDA
来
初始化,
。使用
cuD3D9End()
cuD3D9RegisterVertexBuffer()
LPDIRECT3DVERTEXBUFFER9 vertexBuffer;
cuD3D9RegisterVertexBuffer(vertexBuffer);
注册以后,缓冲对象可以通过
cuD3D9MapVertexBuffer()
kenrel
返回
使用设备内存读取或写入,内存设备的地址通过
:
LPDIRECT3DVERTEXBUFFER9 vertexBuffer;
CUdeviceptr devPtr;
Int size;
cuD3D9MapVertexBuffer(&devPtr, &size, vertexBuffer);
卸载
映射和注册
通过,
cuD3D9UnmapVertexBuffer()和cuD3D9UnregisterVertexBuffer()
来终止
。
:
。
- 53 -
Page 54

Chapter 5 性能指导
5.1
指令性能
处理一个
因此,有效的指令吞吐量取决于内存
5.1.1
warp
线程指令,一个多处理器
读取每
执行指令,
为每
将
最大
允许
条
warp
线程的指令运算域,
条
warp
线程
写出结果
低吞吐量的指令使用减到
化的使用每个内存类别可用的内存带宽(参见第
线程调度程序尽量把内存处理与数学计算交叠
线程执行的程序是高运算密度的,即每个内存操作有大量的算术运算;
很
多线程可以并行地运行,详述
指令吞吐量
。
最小(参见第
5.1.1.1 算术指令
必须
:
延迟
时间和带宽:
5.1.1
的在
第
5.2
部分),
5.1.2
起来
部分
。
部分),
,因此要求:
发布一个warp 指令,一个多处理器需要:
4 个时钟周期执行浮点相加,浮点相乘,浮点乘加,整数相加,逐字节操作,比较,最小,
最大,类型变换指令;
16 个时钟周期执行倒数,倒数平方根,__log(x)(参见表B-2)。
32 位整数乘法需要16 个时钟周期,但__mul24 和__umul24 (参见附录B)提供在4 个时钟
周期内做有符号的和没有符号的24 位整数乘法。对于将来的架构,__[u]mul24 将会比32
位整数乘法慢,因此我们建议保留32 位整数乘法以便以后使用。
整数除
(i/n)
他
法和模数操作是非常
等
于
(i>>log2(n))和(i%n)
函数占有更多时
消耗
钟周期,他们
资源的,应
作为几个指令的组
该避免或者只
等
于
(i&(n-1))
要可能就用逐位替换操作:如
;如果n 是字母
合加
以执行。
果n 是2 的指数,
的,编译器将执行这些转换。
其
- 54 -
Page 55

浮点平方根是作为一个倒数平方根跟随一个倒数被执行的,取代一个倒数平方根跟随一个乘法。因此一个
warp
操作需要
32
个时
钟周期
。
浮点除法需要
__sin(x),__cos(x),__exp(x)
有时,编译器
对于
双精
单精确度浮点变量是作为用于输入参数到在表
36
个时
必须插
char
入转换指令,引进额外
或
者
short
度浮点常量(没
钟周期,但
__fdividef(x,y)
需要
32
时
钟周期
的执行
周期
函数操作,操作数通常需要被转换成
有任何类型后缀的
情况下)是作为输入到单精确度浮点计算使用的。
B-1
最后两个情况可以通过使用下面方法避免,:
单精确度浮点常量,用f 后缀定义,例如
数学函数的单精确度
对于单精度代码,我们特
兼容性
精
1.x
的产品,双精
度的设备,这些函数将映射到
版本
,用f 后缀定义,例如
别推荐
使用单精度数学函数。在为设备编译而没有原生双精
度数学函数在
双精
默认情况下
度执行。
3.141592653589793f, 1.0f, 0.5f
被映射到
可以在
20
个时
钟周期完
成(参见
。
。这个
里定义的双精度版本
情况
是为:
int
,
的数学函数使用的。
sinf(), logf(), expf()
他们等值
的单精度。然而,在
附录B)。
,
。
度支持时,比如计算
那些未来
支持
双
5.1.1.2
任何流控制指令
量极
增加
控制流指令
(if,switch, do, for, while)
大冲击,
那就是允许
不同的执行路径。如果
了执行指令总数。当所有的执行路径完
为了在流控制
这是可能的,因为
条件只依赖
warp
完
依赖
线程
ID
的
warp
分
于
(threadIdx / WSIZE)
全结合而没有
warp
情况下得到最佳性能,控制条件应该被写为使分流的
流的
跨越
分
流。
它发生了,不同的执行路径必须
成,线程
块是确定的(如在
,这
里
WSIZE 是warp
- 55 -
可以通过同一
聚集回
同一个执行路径
第
3.2
部分提及
的
warp
分
流的线程促成对有效指令吞吐
是序列的,并且为这个
。
warp
数量减到
的)。一个普通的例子是,当控制
大小
。在这
种情况下
,因为控制条件与
warp
最小
。
Page 56

有时,编译器可能展开循环或者
些情况下
4.2.5.2
,
)。
warp
不可能分流。开发人员
它可以通过改用分支断言优化
同样可以通过
#pragma unroll
出
if
或
者
switch
指令控制
语句,详述如下
循环
的展开(
。在这
参见
当使用分支断言时没有一个
件代码或
者断言联
系在一起,根据控制条件
有真断言的指令实际上被执行。带有一个
依赖
控制条件执行的指令得以省略。
建立
了真或
假断
言的指令不写结果,并且同样不计算地
相反
,它
们之中
的每一个指令与每线程
者假,虽然每一个指令得到执行的确定时间,仅带
址值也
不读操作数。
只
有当分支条件控制的指令数少于或等于某一确定的门限值时,编译器用断言指令替换一个分支指令:如
果
编译器确定这个条件可能
生产很多分
流的
warp
,这个门限值是7,
否则
它是4。
5.1.1.3
内存指令
内存指令
包括
所有读入或
写出
到共享或者全局内存的指令。一个多处理器需要4 个时
钟周期发出一条
条
warp
内存指令。
另外
,当
访问
的全局内存时,内存延时时间需要
作为例子,用以下样本代码演示运算符:
__shared__ float shared[32];
__device__ float device[32];
shared[threadIdx.x] = device[threadIdx.x];
用4 个时
全局内存读取一个浮点要
钟周期
从全局内存发布一个读操作,用4 个时
400 到600
个时
钟周期
。
钟周期
在等待
线程调度程序隐藏
全局内存存取完成时,如果有
起来
。
足够的独立算术指令可以发布,很多这样的全局内存延时时间可以被
5.1.1.4
如果线程不
同步指令
必等待任
何其他
线程,
__syncthreads
可以用4 个时
400
个到
600
个时
钟周期
。
发布一个写操作共享内存,而最重
钟周期
发布
warp
。
要的是从
5.1.2
内存带宽
每个内存空间的有效带宽极大的取决于内存存取模式,在以下分项详述。
- 56 -
Page 57

由于设备内存比片上内存有更高的反应延时和更低的带宽,因此设备内存的存取应该减到最小
的编程模式是安排
从设备内存
与块的所有
在共享内存中处理数据,
如果需要
把结果写回
来自
设备内存的数据进入共享内存;换
加载
数据到共享内存,
其他
线程同步,以便每条线程可以安全地读取由不同线程写入的共享内存的存储单元,
再次
同步确认共享内存已被结果更新,
到设备内存。
句话
说,进入一个块的每条线程:
5.1.2.1
全局内存空间没有被缓存,因此使用正确的存取模式
贵
全局内存
的设备内存。
来获得最大
的内存带宽更为重要,尤其
是如何存取
首先
,设备有能力在一个单一指令下从全局内存读取
32-bit,64-bit 或128-bit
字
进入寄存器。分配如下:
__device__ type device[32];
type data = device[tid];
。一个典型
昂
编译一个单一
type
必须排列成
加载
指令,
字节
(
type
即它们
队
列要
求
4.3.1.1
部分
的内置类型
对于结构,
大小和队
列要求可以通过编译器强制使用队列指定的
如
struct __align(8)__ {
float a;
float b;
};
或
struct __align(16)__ {
float a;
float b;
必须
是
sizeof(type)
的地
址等
于
sizeof(type)
像
float2 或float4
等
于4,
8,
或
者
16
的倍数)。
一样的自动完成的。
__align__(8)或__align__(16)
是这样的,而且变量的类型
,例
float c;
};
- 57 -
Page 58

对于结构大于
用
__align__ (16)
16
字节
的,编译器生成几个
定义,例如
加载
指令。来保证它生成最
struct __align(16)__ {
float a;
float b;
float c
float d
float e;
};
被编译成为二个
128-bit
加载
指令而不是五个
32-bit
加载
指令。
其次
,全局内存地址同时被每线程的一个
half-warp
访问
(执行读和写指令)时,应
的存取可以结合进入一个接近单一的,排列好的内存存取。它
的
第N 个线程应该访问地址
HalfWarpBaseAddress + N
意味着
低数量的指令,这样的结构应
该排列好
在每一个
half-warp
中
,在
该
,以便内存
half-warp
中
这里,
HalfWarpBaseAddress
是类型
type*
HalfWarpBaseAddress
何
一个驻留在全局内存
地址,总是被排列成
至少
应
该排
列成
BaseAddress
256
个
字节
,以此来满足内存队列的
16*sizeof(type)
的变量的地址,或者一个
HalfWarpBaseAddress-BaseAddress
注意
,如果一个
线程实际上没有
half-warp
访问
内存。
满足了上面的所有需求,每线程的内存
我
们建议对于整个
求
。
warp
满足这些需求,而不是
图
5-1
展示了一些联合的内存
访问
的例子,图
,而
应该是
分开
5-2
type
应该符合之前
字节
,例如
来自
D.5 或E.8
约束
,
16*sizeof(type)
访问被联合了,即使
的,半个半个的。因为
和图
5-3
展示了一
些未联合
讨论
过的
大小和队
16*sizeof(type)
部分
内存分配规
的倍数。
half-warp
未来
的设备
的内存
将默认为必
访问
的例子。
列的要求。
的倍数。任
则返回
的一
些
要的要
的
联合的
64-bit
访问会比联合的
32-bit
访问
内存带宽低一点,联合
的
128-bit
访问会比联合的
32-bit
访问
内
存带宽低很多。
- 58 -
Page 59

图
5-1
联合的全局内存
- 59 -
访问
模式
Page 60

图
5-2
未联合
的全局内存
访问
模式
- 60 -
Page 61

图
5-3
未联合
的全局内存
- 61 -
访问
模式
Page 62

一个公共的全局内存
的地址位于类型
访问
样式是,当每个带有线程
type* 的BaseAddress
BaseAddress + tid
为了
获得
内存的联合
它应该被分成几个满足要求
个类型
type*
的单一数组。
,
type
必须符合之前
的结构,并且数据应该在内存中被
另
一个公共的全局内存
的
BaseAddress
访问
和宽度
样式是,当带有
width 的2D
BaseAddress + width * ty + tx
在这样的
情况下,获得
块线程的宽度是一
half-warp
半
warp
的所有块线程的内存结合,只有当:
大小的倍
ID tid
的线程
访问
位于一个数组的一个元素时,元
,使用以下地址:
讨论
过的
索引
大小和队
(tx,ty)
列的要求。如
划分成关
的每条线程
于这些结构的几个数组,而不是一
访问地址
数组的一个元素时使用以下地址:
数
;
果
type
的结构大于
位于类型
type*
16
素
字节
,
width 是16
特别是,这
近
16
E.8
部分描述的相关
意味着
的倍数而且它的列因此被
的倍数。
宽度不是
内存
拷贝
16
的倍数的数组将被更高效地
填充
了。
cudaMAllocPitch()和cuMemAllocPitch()
的函数,使开发人员能够编写
访问
,如果它实际上分配是宽度被舍入到最接
非硬件独立
的代码,
组。
5.1.2.2
常量内存
常量内存空间被缓存了,因此,当缓存被错过时,一个常量内存的读操作
否则
它的开销
不过是常量缓存的一个读操作。
对于一个
有线程读取不同地址时的开销
half-warp
的所有线程,只要所有线程读同一地址,常量缓存读操作和寄存器读操作一样快。所
量成线性。我们建议对于整个
warp
中
的所有线程读取同一地址,而不是
函数和在
来分配遵循这些约束
消耗
一个从设备内存的读操作,
D.5
和
的数
只
对每个
half-warp
的所有线程,因为
未来
的设备将需要它做全速读取。
- 62 -
Page 63

5.1.2.3
纹理内存空间被缓存了,因此,当缓存被错过时,一个纹理拾取操作
它的开销
程
纹理内存
不过是纹理缓存的一个读操作。纹理缓存优化了
靠拢
在一起以便达到最佳
性能。
2D
空
消耗
一个从设备内存的读操作,
间位置,同一
条
warp
通过纹理拾取读取设备内存相对于从全局或常驻内存读取设备内存有很多优势。
5.1.2.4
共享内存
由于它是在片上的,共享内存空间比局部和全局内存空间更快。实际上,对于一个
问
共享内存和
访问
寄存器一样快,只要在线程之间没有
bank
冲突,详述如下
。
为达到高内存带宽,共享内存空间被
所有内存读或
写请求
形成的n 个地址,它
划分成大小相等
们集合
在n 个不同的内存
的内存模块,
称之
bank
为
bank
中
,它可以被同时
可以被同时
读取纹理地址的线
warp
的所有线程,
访问
访问
,形成一个
否则
访
。因此,
像
单一模块带宽一样高的n 次有效
然
而,如果内存
硬件将一个带有
量。如果被分割
请求
bank
的内存
的2 个地
冲突的内存
请求
址集合
的数量是n,初始的内存
为了
获得最
bank
高性能,最重
冲突最小
要的是了解内存地址是如何映射到内存
化。
在共享内存空间
宽每个2 时
情况下
钟周期
。
,
bank
对于计算兼容性
1.x
的设备,
warp
带宽。
在同一个内存
bank
请求分成许多无冲突的
被组织成,比如
的
大小
连续
是32,
bank
中,这里就
请求
请求应该
的
32-bit
的数量是
存在
bank
,有效带宽的
有n 种
字分
bank
bank
的,并有
配到
连续的库,并且
16 (
参见第
冲突而
减少等
冲突。
效安排内存
5.1
且访问必须
于被分割
每个库有
被序列化。
的内存
请求
,从而使
32 bits
请求
数
带
部分)。所以,对于一个
warp
的共享内存请求被分成:一个请求于warp 的前半部分,而另一个请求于同warp 的后半部分。
- 63 -
Page 64

因此,在属于warp 前半部分的一个线程和属于同一个warp 的后半部的线程之间分不存在
bank 的冲突。
一个典型
__shared__ float shared[32];
float data = shared[BaseIndex + s * tid];
情况
,每个线程
访问
一个
32-bit
字
,从一个带有线程
索引
ID tid
和带有一
些字
长s 的数组:
在这种情况下,每当s*n 是bank m 数量的倍数或着相等,每当n 是m/d 的倍数,这里d 是
m 和s 的最大公因子,线程tid 和tid+n 将访问同一个库。因此,只有当warp 大小的一
半是小于或等于m/d 时,这里没有bank 冲突。对于计算兼容性1.x 的设备,只有当d 等于1
时,换句话说,只有当s 是奇数时,因为m 是二的次方,这个转换没有bank 冲突。
图
5-4
和图
5-5
其他
需要说明的
展示了一
情况
些没有冲突的内存
是,当每条线程
访问
访问
的一个元素小
,图
5-6
展示了一些有
于或大于
32 bits
bank
冲突的内存
时。例如,如果一个
访问
。
char
的数组
以下列方式被
__shared__ char shared[32];
char data = shared[BaseIndex + tid];
因为
shared[0], shared[1], shared[2], 和shared[3]
下
方式
访问
char data = shared[BaseIndex + 4 * tid];
一个结构任务被编译成,内存
__shared__ struct type shared[32];
struct type data = shared[BaseIndex + tid];
不同的结果:
三
个单独的内存读操作没有
struct type {
};
访问,将
,所有
float x, y, z;
库将
存在
bank
不存在冲突
bank
冲突:
:
请求
数量和结构中成员数量一样多,例如:
冲突,如
果
type
被定义为
属于同一个库。然而如果同一个数组用以
因为每名成员被一个长度为三个
32-bit
字访问;
- 64 -
Page 65

二个单独的内存读操作带有bank 冲突,如果type 被定义成为,
struct type {
float x, y;
};
因为每名成员被一个长度为二个32-bit 字访问。
二个单独的内存读操作带有bank 冲突,如果typ
type
typtyp
struct type {
float f;
char c;
};
因为每名成员被一个长度为五个
共享内存也有
线程。当一个
数量。更恰当地讲,一个内存
划分成若干没有冲突
选择
广播
机制的特性,当响应一个内存读
half-warp
一个指向剩余地址的字
的几条线程从同一个
的子
寻址
字访问
请求被分
操作,直到整个
作为
。
为几个地址和几个步骤操作,每一步需要2 个时
广播字,
32-bit
请求完
请求
字之
成,使用以下步骤:
e 被定义成为,
e e
时,一个
内的一个地址读取时,有效地
32-bit
字
可以被读取并且同时
减少
了
钟周期完
广播
bank
成一个被
到几个
冲突的
在子
集中包括
所有地址在
剩余
的地址指出的每个
哪个字被选择为广播字和哪个地址是被拾取对于每个
一个典型的
图
5-7
无冲突的
展示一些带有
:
广播
情况
广播
字之
内,
bank
是,一个
机制的内存读取
half-warp
的一个地址。
的所有线程从同一个
访问
的例子
bank
- 65 -
在每个
周期
是不确定的。
32-bit
字之
内读取一个地址。
Page 66

图
5-4
没
有
bank
冲突的共享内存
- 66 -
访问
模式
Page 67

图
5-5
没
有
bank
冲突的共享内存
访问
模式
- 67 -
Page 68

图
5-6
带有
bank
冲突的共享内存
访问
模式
- 68 -
Page 69

图5-7 带有广播机制的共享内存访问模式
- 69 -
Page 70

5.1.2.5
通常,每个指令
器内存
寄存器
bank
访问
一个寄存器是零附加时
冲突上。
钟周期
被
read-after-write
引
入的
延迟
可以被忽略,一旦每台多处理器存在
编译器和线程的调度程序
倍
数是达到最佳
或
者
int4
效果。另外
类型。
会尽
可能的优化指令时间,
,应用程序不直接控制这
5.2
每个块的线程数量
确定每个栅格的线程总数,每个块的线程数量,或
着
,在设备上的多处理器数量
至少应该
和块的数量一样多。
的,但延迟
避免
寄存器内存
些
bank
等效
的块数量,从而
也许发生
至少
bank
冲突。特别
在寄存器
192
read-after-write
条
并发线程。
冲突。当每个块线程数是
是,不需要把数据包装
最大化利
用可用计算资源。这
和寄存
64
成
float4
的
意味
此外,如果每个多处理器只执行一个块,在线程同步时,或设备内存读取时,将迫
在一个多处理器在建议
的处理器,而且每个块分配的共享内存的总量应该最
同时运行两个或两个以上的块。并且,在设备上不仅要有
多是用于每个多处理器共享内存总量的一半。
至少两倍的块数量
如果块的数量
倍
数,
参见部分
每条线程可用的寄存器越少。如果
随
后的调用。寄存器被
足够
多,每个块线程的数量应该选择
5.1.2.5
。为每个块分配更多的线程对于时间分割
kernel
kernel
编译的数量可以通过
成
warp
大小的倍
更有效,但是为每个块分配越多的线程,
编译的寄存器比执行配置
--ptxas-options=-v
数以
避免浪费
允许
的更多,这样
报告
对于计算兼容性
1.x
的设备,每个线程
允许
的寄存器数量等于
使多处理器闲置。因此
那么
计算资源,最好
也许
可以防止
是
64
kernel
。
多
的
- 70 -
Page 71

其中R 是附录A 中
程数,
每个块
较理想
如果要将代码用在
每个多处理器
到
的软件开发
5.3
ceil(T,32) 是T
最少应该
的,通常也有
最大
的
occupancy
主机与设备的数据传输
有
中活
工具包
每个多处理器中寄存器的总数,B 是每个多处理器
舍入最近的
64
条
线程并且每个多处理器应该有成倍的并发的块。每个块
足够
的寄存器进行编译。
未来
的设备中,每个栅格的块的数量
动的
warp
, 编译器试图
提供一个表格,辅助开发人
32
数量与
的倍数。
至少应该
最大允许活
减小
寄存器的使用量,同时开发人员也
动的
warp
数量的比值被称作多处理器
员基
于共享内存和寄存器的需
是
中活
动的块数,T 是每个块中的线
100 个; 1000
需要
谨慎
求来选择
192
条
或
256
个块将用在
occupancy
的使用执行配置。
线程块的
未来
条
线程是比
几代。
。为了
CUDA
大小
。
达
在设备到设备之间的内存带宽要比在设备到主机内存之间的带宽高很多。所以,应该力争使主机和设备
间数据传输减到
结构可以创建
同样,批处理许多小的传输成为一个大传输
最
后,使用
最小
。例如,移动更多的代码从主机到设备,即使这将导致更低的并行计算性。中间数据
在设备中,并在设备中执行,最后在设备中销毁
永远比分开地逐
page-locked
内存将使主机到设备的内存带宽达到
。
个传输好很
最大
。
多。
之
5.4 Texture Fetch 对比全局或常驻内存读取
通过Texture fetch 的内存读取相比从全局或常驻内存读取有几个优势:
它们是被缓存的,如果它们在texture fetch 中将提供更高的带宽;
它们不会像全局或常驻内存读取时受内存访问模式的约束(参见部分5.1.2.1 和5.1.2.2),
从而获得更高的性能;
寻址计算时的延迟更低,从而提高随机访问数据时的性能;
- 71 -
Page 72

在一个操作中,包装的数据可以通过广播到不同的变量中;
8-bit 和16-bit 的整型输入数据可以被转换成在范围[0.0, 1.0]或[-1.0, 1.0]的浮点数(参见
部分4.3.4.1)。
如果纹理是一个CUDA 数组(参见4.3.4.2),硬件提供其它有用的能力对于不同的应用程序,
特别是图像处理:
但
是,在同一个
将返回未定义
安
全的读取纹理。但是,被同一个
kernel
5.5
性能优化
最大
无法写
性能优化策略总结
最大
化并行执行;
优化内存使用,以达到
优化指令使用,以达到
化并行执行通过构建有效的算法到达数据的
kernel
的数据。换
入到一个
包括三个基本
调用中,纹理缓存在全局内存
句话
说,只有当内存地址被
kernel
CUDA
策略:
数组,因此,这
最大
内存带宽
最大
指令吞吐。
写无法保
之前
的
调用中的同一个或
只会发生
;
最大
在从线性内存拾取的
并行。为了彼此共享数据,一些线程需要同步,从而
持一致性,因此,任何纹理拾取到一个地址,
kernel
其他
调用或内存
的线程更新过,是不安全的。当然,一个
拷贝
更新过,一个线程才能
情况下
。
打破
了数据并行的机制。有
__syncthreads()
在这
种情况下
一个用来从全局内存读。
,它
, 并且通过同一
们必须
两种情况
通过全局内存使用两个
:这些线程在同一个块中,在这
kernel
调用中的共享内存共享数据;或者这些线程在不同的块中,
分开
- 72 -
的
kernel
请求来
种情况下
共享数据,一个用来从全局内存写,
,它们应该使用
Page 73

并行的算法同样需要尽可能有效的映射到硬件,这通过
应用程序同样需要在高层最大
化并行执行,这通过流在设备上的并发执行,
优化内存的使用通过尽量减低数据的传输。在
到全局内存的带宽更低。在
之
间的数据传输。有时,最佳
部分
5.1.2
中描述
的优化是通过简单的重新计算来避免任何
部分
5.3
的,通过
谨慎
的执行配置达到(
中描述
最大
的,
减小
主机到设备的数据传输,由于设备
化设备的共享内存,从而
的数据传输。
详细
内容
参见部分
最大
化主机到设备的并发执行。
减小
设备和全局内存
5.2
)。
在
部分
5.1.2.1,5.1.2.2,5.1.2.3 和5.1.2.4
效
的组合内存的
钟周期的延迟更重
访问
方式,从而优化内存的使用。对于全局内存的
要。对于共享内存的
对于指令的优化,
包括当最终结果不受影响
代替常规函数,或使用单精度代替双精
中描述
访问
,优化更针对于当它们有很高的
时,如何权衡精
的,依据不同的内存类型
度和速度。比如,使用本体(在表
度。控制流的指令需要特别
选择
不同的
访问
,优化全局内存的低带宽和上百时
bank
访问
冲突时。
方式。通过有
B-2
注意
,由于设备是
SIMD
的特性。
中列出
)
- 73 -
Page 74

Chapter 6 矩阵乘法的例子
6.1
概要
计算二个维度
每个线程块
在块之内的每条线程
C
维
度
sub
的昀大
线程数(附录A)。
(wA,hA)和(wB,wA)
负责
计算一个正方形的C的子矩阵
block_size
的矩阵A和B的乘
C
sub
负责
计算一个
等
于16, 因此每个块线程的数量是
C
的元素。
sub
积C,分以下几步完成:
warp
如图6-1 所示,
C
等于二个矩形矩阵的乘积:维度(wA,block_size)的子矩阵A具有指向
sub
相同的行,维度(block_size,wA)的子矩阵B具有指向
大小(第
C
5.2
部分)的倍数而且低于每个块
相同的列。为了适应设备的资源,
sub
C
sub
需要把这二个矩形矩阵划分成维度block_size 的许多个正方形矩阵,并且
C
是计算出来的
sub
这些方矩阵乘积的总和。每一个乘积是通过,加载二个对应的正方形矩阵从全局内存到共享
内存,一条线程每次加载每个矩阵的一个元素,然后通过每个线程计算乘积的一个元素获得
的。每条线程收集这些乘积的每个结果进入一个寄存器,最后把这些结果写到全局内存完成。
通过模块化计算这样的方式,我们利
局内存读取仅
(wA / block_size)
用了
次
快速
的共享内存而
。
且节省了很多全局内存带宽,因为A和B从全
- 74 -
Page 75

图
6-1
每个线程块计算一个子矩阵C 的
。矩阵乘法
C
。每条在块之内线程计算
sub
C
的一个元素。
sub
- 75 -
Page 76

6.2
源代码
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the device multiplication function
__global__ void Muld(float*, float*, int, int, float*);
// Host multiplication function
// Compute C = A * B
// hA is the height of A
// wA is the width of A
// wB is the width of B
void Mul(const float* A, const float* B, int hA, int wA, int wB, float* C)
{
int size;
// Load A and B to the device
float* Ad;
size = hA * wA * sizeof(float);
cudaMalloc((void**)&Ad, size);
cudaMemcpy(Ad, A, size, cudaMemcpyHostToDevice);
float* Bd;
size = wA * wB * sizeof(float);
cudaMalloc((void**)&Bd, size);
cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice);
// Allocate C on the device
float* Cd;
size = hA * wB * sizeof(float);
cudaMalloc((void**)&Cd, size);
// Compute the execution configuration
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(wB / dimBlock.x, hA / dimBlock.y);
// Launch the device computation
Muld<<<dimGrid, dimBlock>>>(Ad, Bd, wA, wB, Cd);
// Read C from the device
cudaMemcpy(C, Cd, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(Ad);
cudaFree(Bd);
cudaFree(Cd);
}
- 76 -
Page 77

// Device multiplication function called by Mul()
// Compute C = A * B
// wA is the width of A
// wB is the width of B
__global__ void Muld(float* A, float* B, int wA, int wB, float* C)
{
// Block index
int bx = blockIdx.x;
int by = blockIdx.y;
// Thread index
int tx = threadIdx.x;
int ty = threadIdx.y;
// Index of the first sub-matrix of A processed by the block
int aBegin = wA * BLOCK_SIZE * by;
// Index of the last sub-matrix of A processed by the block
int aEnd = aBegin + wA - 1;
// Step size used to iterate through the sub-matrices of A
int aStep = BLOCK_SIZE;
// Index of the first sub-matrix of B processed by the block
int bBegin = BLOCK_SIZE * bx;
// Step size used to iterate through the sub-matrices of B
int bStep = BLOCK_SIZE * wB;
// The element of the block sub-matrix that is computed
// by the thread
float Csub = 0;
// Loop over all the sub-matrices of A and B required
// to compute the block sub-matrix
for (int a = aBegin, b = bBegin;
a < aEnd;
a += aStep, b += bStep) {
// Shared memory for the sub-matrix of A
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
// Shared memory for the sub-matrix of B
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
// Load the matrices from global memory to shared memory;
// each thread loads one element of each matrix
As[ty][tx] = A[a + wA * ty + tx];
Bs[ty][tx] = B[b + wB * ty + tx];
// Synchronize to make sure the matrices are loaded
__syncthreads();
- 77 -
Page 78

// Multiply the two matrices together;
// each thread computes one element of the block sub-matrix
for (int k = 0; k < BLOCK_SIZE; ++k)
Csub += As[ty][k] * Bs[k][tx];
// Synchronize to make sure that the preceding
// computation is done before loading two new
// sub-matrices of A and B in the next iteration
__syncthreads();
}
// Write the block sub-matrix to global memory;
// each thread writes one element
int c = wB * BLOCK_SIZE * by + BLOCK_SIZE * bx;
C[c + wB * ty + tx] = Csub;
}
6.3
源代码解释
源代码
Mul()
Muld()
6.3.1 Mul()
Mul()
A
Mul()
包含二
, 一个主机函数作为一个
用作输入:
指向主机内存A 和B 元素的二个指
的高度和宽度,B 的宽度;
指向主机内存应该写
执行以下操作:
使用
个函数:
warpper
, 在设备上执行矩阵乘法的一个
入C 的一个指针。
cudaMalloc()
来分配足够
的全局内存存
kernel
针;
服
务于
Muld()
。
储A,B,和C;
;
使用
cudaMemcpy()
调用
Muld()
使用
cudaMemcpy()
使用
cudaFree()
来
从主机内存复制A和B到全局内存;
计算在设备上的C;
从全局内存复制C到主机内存;
释放分
配的全局内存A,B,和C。
- 78 -
Page 79

6.3.2 Muld()
Muld()和Mul()
对于每个块,
从全局内存
使用同步确认通过块之内的所有线程两个子矩阵得到完全地
计算二个子矩阵的乘积并且把它加到早先迭代获得
再次
同步,确认在开始下一个迭代
一旦所有子矩阵得到处理,
有一样的输入,除了指针指向设备内存而不是主机内存。
Muld()
迭
代A和B的全部子矩阵来计算
加载
一个A的子矩阵和一个B的子矩阵到共享内存;
C
sub
得到完
之前二
全地计算并
个子矩阵的乘积完
且
Muld()
C
,每次迭
sub
的乘积里;
把它写
代时:
加载;
成了。
到全局内存中。
根
据
5.1.2.1 和5.1.2.4
部分
,
Muld()
用
来达到最大
的内存性能。
如在5.1.2.1 部分建议的,假设wA和wB是16 的倍数,全局内存确定是聚集的,因为a,b,
和c 是BLOCK_SIZE的倍数,BLOCK_SIZE等于16。
对于每个
15
不同的
half-warp
之
间变化,因此,对于内存
bank
,而对于内存
,共享内存也不存在
访问
访问
As[ty][k]
bank
冲突,因为
As[ty][tx],Bs[ty][tx]和Bs[k][tx]
,每条线程
访问
ty 和k
的是同一个
对于所有线程是相同的,并
,每条线程
bank
。
且
tx 在0
访问
的是一个
和
- 79 -
Page 80

附录A 技术规格
这个附录介绍所有拥有计算兼容性(
原子函数只能应用于计算能
力
1.1
的设备(
下
表列出,所有支持
CUDA
的设备,以
参见部分
参见部分
及相
3.3)1.x
的设备技术规格。
4.4.6
)。
对于该设备的多处理器数量和计算兼容性数值:
设备的时钟频率和显存大小
可以通过
runtime
查询(
- 80 -
参见部分
4.5.2.2 和4.5.3.2
)。
Page 81

A.1
通用规格
一个块
一个线程块在x-,y-,和z-空
一个线程块栅格的每个
最大
线程数是
512
;
间的
最大空间大小
最大大小分别是
是
65535
;
512,512
,和64;
Warp
的
大小
是
32
个线程;
每个多处理器的寄存器数量是
每个多处理
常驻内存
允许
大小
的共享内存
是
64KB
;
每个多处理器常驻内存可用的缓存是
每个多处理器纹理内存可用的缓存是
每个多处理器
每个多处理器
每个多处理器
对于绑定到一
最大
可用的块数量是8;
最大
可用的
最大
可用的线程数是
维
CUDA
warp
数组的
8192
;
大小
是
16KB
8KB
8KB
数量是24;
768
;
texture reference
,被分为
;
;
16 个bank
,
最大
宽度是
;
13
2
15
16
对于绑定到
对于绑定到线性内存的
Kernel
每个多处理器由8 个处理器构成,因此每个多处理器可以在四个时
warp
。
二维
大小
限制为2 百万
CUDA
数组的
texture reference
texture reference
个原生指令
集;
,
最大
,
最大
宽度是
宽度是
2
27
2
,
最大
高度是
2
钟周期
- 81 -
内处理一个
32
个线程的
Page 82

A.2 浮点数标准
计算设备遵循单精度的二进制浮点数IEEE-754 标准,不同的是:
加法和乘法通常被合并成一个乘-加指令(FMAD);
除法通过非标准兼容的倒数实现;
平方根通过非标准兼容的平方根倒数实现;
对于加法和乘法,只支持通过静态舍入模式实现的输入到最近偶数和输入到零;不支持
直接舍入到正/负无穷;
没有动态配置的舍入模式;
不支持未归一化的数字;浮点算法和比较指令转换带有零优先级的未归一化操作数到浮
点操作;
Underflow 的结果被冲为零;
没有浮点异常的监测机制,浮点异常总是被mask 的;
不支持signaling NaN;
一个操作的结果包含一个或多个NaN,NaN 的位模式是0x7fffffff 。根据IEEE-754R 标
准,一个输入到
fminf(),fmin(),fmaxf()
当浮点数值超
围
。这点不
像
出
x86
IEEE-754
未定义的整
结构的习惯
。
,或
fmax()
型格式,浮点数转换成整型数。对于计算设备,仅钳制到支持的
的参数是
NaN
, 而不是其它,结果是一个非
NaN
参
数。
范
- 82 -
Page 83

附录B 数学函数
B.1
中
的函数可以被用作主机和设备函数,
B.1
公共
runtime
组件表
B-1
中列出
B.2
中
了
CUDA runtime
的函数只能被用作设备函数。
库中
支持的标准数学函数。同时
也报含
每个函数的
误差限,它们经
加
法和乘法为
IEEE
我
们建议求
而
rintf()
浮点数运算到整型时,使用
只
映射一个指令。
CUDA runtime
过了密集的测试,但不
兼容的,所以拥有
truncf(),ceilf()
库也
支持整型的
min()和max()
保证
所有的限都是绝对正确的。
最大误差
rintf()
0.5 ulp
,而不是
,和
。它们通常被合并成一个乘-加
roundf()
floorf()
,同样映射一个指令。
。因为
同样
roundf()
也只
映射一个指令。
指令(
FMAD
)。
映射8 个指令序列,
- 83 -
Page 84

- 84 -
Page 85

- 85 -
Page 86

B.2
表
B-2
设备
runtime
组件
列出了设备支持的固有函数。它们的误差限是
GPU
特
定的。虽然这些
函数的精度更低,但是它
们
的速度比表
B-1
中
的一些函数
快很多;它们拥
有同样的前缀__(比如
__sinf(x)
)。
__fadd_rz(x,y)
使用舍入零的方式计算浮点参数x 和y 和。
__fmul_rz(x,y)
使用舍入零的方式计算浮点参数x 和y 乘积。
常规的浮点除法和__fdividef(x,y)拥有同样的精度,但对于
126
2
< y < 2
__fdividef(x,y) 的结果为零,而常规的除法可以得到正确的结果。同样的,对于
128
2
,如果x 是无穷大,__fdividef(x,y) 的结果是NaN(结果是无穷大乘于零),常规的
128
,
126
2
< y <
除法返回无穷大。
__[u]mul24(x,y)计算24 位最低有效位的整型参数x 和y 的乘积,并且给出32 位最低有
效位的结果。x 和y 的8 位最高有效位被忽略。
__[u]mulhi(x,y)
计算整型参数x 和y 的乘积,并
且给出
64
位结
__[u]mul64hi(x,y)
计算
64
位整型参数x 和y 的乘积,并
且给出
__saturate(x)
如
果x 小
于0,
返回0;如果x 大
于1 返回1;如果x 在[0,1]之
__[u]sad(x,y,z)(Sum of Absolute Difference
)求整型参
数z 与整型参数x 和y 差
__clz(x)
计算
32
位整型参数x 的前导零。
__clzll(x)
计算
64
回整型参数x 的第一个为1 位的位置。最低有效位的位置是1,如
这里和
linux
函数
ffs
是一样的。
__ffsll(x)
__ffsll()
返回
64
位整型参数x 的第一个为1 位的位置。最低有效位的位置是1,如
返回0。这里和
Linux
函数
ffsll
是一样的。
果中
的
32
位最高有效位。
128
位结
果中
的
64
间,
返回x。
位整型参数x 的前导零。
果x 是0,
__ffs()
返回0。
果x 是0,
位最高有效位。
的绝对值的和。
__ffs(x)
返
- 86 -
Page 87

- 87 -
Page 88

附录C 原子函数
原子函数只能被设备函数使用。
C.1
算法函数
C.1.1 atomicAdd()
int atomicAdd(int* address, int val);
unsigned int atomicAdd(unsigned int* address,
unsigned int val);
从全局内存中读取地址为address 的32-bit 字old,计算(old + val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old。
C.1.2 atomicSub()
int atomicSub(int* address, int val);
unsigned int atomicSub(unsigned int* address,
unsigned int val);
从全局内存中读取地址为address 的32-bit 字old,计算(old - val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old。
C.1.3 atomicExch()
int atomicExch(int* address, int val);
unsigned int atomicExch(unsigned int* address,
unsigned int val);
float atomicExch(float* address, float val);
从全局内存中读取地址为address 的32-bit 字old,存储val 返回全局内存中的同一地址。
这二个操作由一个原子操作执行。函数返回old。
C.1.4 atomicMin()
int atomicMin(int* address, int val);
unsigned int atomicMin(unsigned int* address,
unsigned int val);
从全局内存中读取地址为address 的32-bit 字old,计算old 和val 的最小值,将结果返
回全局内存中的同一地址。这三个操作由一个原子操作执行。函数返回
- 88 -
old。
Page 89

C.1.5 atomicMax()
int atomicMax(int* address, int val);
unsigned int atomicMax(unsigned int* address,
unsigned int val);
从全局内存中读取地址为address 的32-bit 字old,计算old 和val 的最大值,将结果返
回全局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old。
C.1.6 atomicInc()
unsigned int atomicInc(unsigned int* address,
unsigned int val);
从全局内存中读取地址为address 的32-bit 字old,计算((old >= val) ? 0 :
(old+1)),将结果返回全局内存中的同一地址。这三个操作由一个原子操作执行。函数返
回old。
C.1.7 atomicDec()
unsigned int atomicDec(unsigned int* address,
unsigned int val);
从全局内存中读取地址为address的32-bit 字old,计算(((old ==0)| (old > val)) ?
val : (old-1)), 将结果返回全局内存中的同一地址。这三个操作由一个原子操作执行。
函数返回old。
C.1.8 atomicCAS()
int atomicCAS(int* address, int compare, int val);
unsigned int atomicCAS(unsignedint*address,
unsigned int compare,
unsigned int val);
从全局内存中读取地址为address 的32-bit 字old,计算(old == compare ? val :
old),将结果返回全局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old
(比较和置换)。
- 89 -
Page 90

C.2
位操作函数
C.2.1 atomicAnd()
int atomicAnd(int* address, int val);
unsigned int atomicAnd(unsigned int* address,
unsigned int val);
从全局内存中读取地址为address 的32-bit 字old,计算(old & val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old。
C.2.2 atomicOr()
int atomicOr(int* address, int val);
unsigned int atomicOr(unsigned int* address,
unsigned int val);
从全局内存中读取地址为address 的32-bit 字old,计算(old | val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old。
C.2.3 atomicXor()
int atomicXor(int* address, int val);
unsigned int atomicXor(unsigned int* address,
unsigned int val);
从全局内存中读取地址为address 的32-bit 字old,计算(old ^ val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回
- 90 -
old。
Page 91

附录D Runtime API Reference
Runtime API
低级
API(cuda_runtime_api.h
高级
API(cuda_runtime.h
何
的
C++
编译器编译。高级
D.1
设备管理
有两个级别。
API
)是C 接口类型的,不需要
)是
C++
接口类型的,基于低级
还
有一
些
CUDA
特
定的包,它们需要
nvcc
API
nvcc
编译。
之
上的,可直接使用
编译。
C++
代码,并被任
D.1.1 cudaGetDeviceCount()
cudaError_t cudaGetDeviceCount(int* count);
返 回 计 算 兼 容 性 大 于 等 于 1.0 的 设 备 数 量 到 指 针 *count 。 如 果 没 有 相 关 设 备 ,
cudaGetDeviceCount()返回1,device 0 仅支持设备仿真模式。
D.1.2 cudaSetDevice()
cudaError_t cudaSetDevice(int dev);
记
录
dev
作为设备在哪个活动的主机线程中执行设备代码。
D.1.3 cudaGetDevice()
cudaError_t cudaGetDevice(int* dev);
返回
设备在哪个活动的主机线程中执行设备代码到指
针
*dev
。
D.1.4 cudaGetDeviceProperties()
cudaError_t cudaGetDeviceProperties(struct cudaDeviceProp*
prop, int dev);
返回
设备
dev
的属性到指
针
*prop
。
- 91 -
Page 92

cudaGetDeviceProp
struct cudaDeviceProp {
char name[256];
size_t totalGlobalMem;
size_t sharedMemPerBlock;
int regsPerBlock;
int warpSize;
size_t memPitch;
int maxThreadsPerBlock;
int maxThreadsDim[3];
int maxGridSize[3];
size_t totalConstMem;
int major;
int minor;
int clockRate;
的结构被定义为:
size_t textureAlignment;
};
其中
:
name
totalGlobalMem
sharedMemPerBlock
regsPerBlock
warpSize 是warp
memPitch
maxThreadsPerBlock
maxThreadsDim[3]
maxGridSize[3]
totalConstMem
major 和minor
clockRate
是
识别
设备的
是通过
是时钟频率
字符串;
是设备上全局内存的总
是每个块中共享内存的总
是每个块中寄存器的总数;
的
大小
cudaMallocPitch()
是每个块
是一个块中每个空间的
是一个栅格中每个空间的
是设备上常住内存的总
是设备计算兼容性的主要次要
KHz
;
中最大
byte
数;
byte
数;
分
配的内存空间中,
的线程数;
最大大小;
最大大小;
byte
数;
版本;
允许
内存
拷贝
函数的
最大
pitch
;
textureAlignment
textureAlignment 是对齐需求;纹理地址对齐到textureAlignment
textureAlignment textureAlignment
texture fetch 中应用offset 。
D.1.5 cudaChooseDevice()
- 92 -
textureAlignment 字节的,不需要在
textureAlignment textureAlignment
Page 93

cudaError_t cudaChooseDevice(int* dev,
const struct cudaDeviceProp* prop);
返回
设备的
哪些
属性最匹配
*prop
到指
针
*dev
。
D.2
线程管理
D.2.1 cudaThreadSynchronize()
cudaError_t cudaThreadSynchronize(void);
阻止直到设备上所有请求的任务执行完毕。cudaThreadSynchronize()返回一个错误,
如果其中的一个任务失败。
D.2.2 cudaThreadExit()
cudaError_t cudaThreadExit(void);
清楚
主机调用的线程中所有
runtime
相关
的资源。任何后来的
API
将重新初始化
D.3
流管理
D.3.1 cudaStreamCreate()
cudaError_t cudaStreamCreate(cudaStream_t* stream);
创建一个流。
D.3.2 cudaStreamQuery()
cudaError_t cudaStreamQuery(cudaStream_t stream);
runtime
。
返回
cudasuccess
,如果所有流中的操作完成。
返回
cudaErrorNotReady
,如果不是。
D.3.3 cudaStreamSyncronize()
cudaError_t cudaStreamSyncronize(cudaStream_t stream);
阻
止直
到设备上完成流中的所有操作。
- 93 -
Page 94

D.3.4 cudaStreamDestroy()
cudaError_t cudaStreamDestroy(cudaStream_t stream);
销毁
一个流。
D.4
事件管理
D.4.1 cudaEventCreate()
cudaError_t cudaEventCreate(cudaEvent_t* event);
创建一个事件。
D.4.2 cudaEventRecord()
cudaError_t cudaEventRecord(cudaEvent_t event, CUstream stream);
记录一个事件。如果stream 是非零的,当流中所有的操作完毕,事件被记录;否则,当CUDA
context 中所有的操作完毕,事件被记录。由于这个操作是异步的,必须使用
cudaEventQuery 和/或cudaEventSyncronize 来决定何时事件被真的记录了。如果
cudaEventRecord 之前被调用了,并且事件还没有被记录,函数返回
cudaErrorInvalidValue。
D.4.3 cudaEventQuery()
cudaError_t cudaEventQuery(cudaEvent_t event);
返回
cudasuccess
果
cudaEventQuery()
,如果事件被真的记录了。
在这个事件
中没
有被调用,函数
返回
cudaErrorNotReady
返回
cudaErrorInvalidValue
,如果不是。如
。
D.4.4 cudaEventSyncronize()
cudaError_t cudaEventSyncronize(cudaEvent_t event);
阻
止直
到事件被真的记录了。如
返回
cudaErrorInvalidValue
果
cudaEventRecord()
。
- 94 -
在这个事件
中没
有被调用,函数
Page 95

D.4.5 cudaEventDestroy()
cudaError_t cudaEventDestroy(cudaEvent_t event);
销毁
一个事件。
D.4.6 cudaEventElapsedTime()
cudaError_t cudaEventElapsedTime(float* time,
cudaEvent_t start,
cudaEvent_t end);
计算两个事件之间
如果带有一个非零的
D.5
内存管理
D.5.1 cudaMalloc()
cudaError_t cudaMalloc(void** devPtr, size_t count);
花费
stream
的时间(
millisecond
事件被记录,结果是未定义的。
)。如果事件未被记录,函数
返回
cudaErrorInvalidValue
在设备上分配count 字节的线性内存,并返回分配内存的指针*devPtr。分配的内存适合
任何类型的变量。如果分配失败,cudaMalloc()返回cudaErrorAlloction。
D.5.2 cudaMallocPitch()
cudaError_t cudaMallocPitch(void** devPtr,
size_t* pitch,
size_t widthInBytes,
。
size_t height);
在设备上分配
在任
何给出
配的一个
T* pElement = (T*)((char*)BaseAddress + Row * pitch) + Column;
widthInBytes*height
的行中对应的指针是
分开的参
数,用来计算
字节
的线性内存,并
连续
的。
pitch
返回
的指
2D
数组中的地址。一个给定行和列的类型T 的数组元素,地
返回分
针
*pitch
配内存的指
的是分配的宽度。
针
*devPtr
Pitch
。函数将确
作为内存
址等
于:
保
分
对于2D 数组的分配,建议使用cudaMallocPitch()分配内存。由于pitch 对列限制受限于
硬件,特别是当应用程序从设备内存的不同区域执行一个2D 的内存拷贝(无论是线性内存
还是
CUDA 数组)。
- 95 -
Page 96

D.5.3 cudaFree()
cudaError_t cudaFree(void* devPtr);
释放被devPtr 指向的内存空间,devPtr 必须带有cudaMalloc()或cudaMallocPitch()的返回
值。否则将返回一个错误,或者cudaFree(devPtr)已经在之前被使用过。如果devPtr 是0,
不执行任何操作。如果cudaFree()调用失败,函数将返回cudaErrorInvalidDevicePointer。
D.5.4 cudaMallocArray()
cudaError_t cudaMallocArray(struct cudaArray** array,
const struct cudaChannelFormatDesc* desc,
size_t width, size_t height);
根据cudaChannelFormatDesc
cudaChannelFormatDesc 结构desc
cudaChannelFormatDesc cudaChannelFormatDesc
CUDA 数组的句柄。
D.5.5 cudaFreeArray()
cudaError_t cudaFreeArray(struct cudaArray* array);
释放一个
CUDA
数组
array
。如
果
desc 分配一个CUDA 数组,并返回一个在*array
desc desc
array 是0
,不执行任何操作。
*array 的新
*array *array
D.5.6 cudaMallocHost()
cudaError_t cudaMallocHost(void** hostPtr, size_t size);
分配一个size 字节可用于设备访问的page-locked 的主机内存。驱动程序追踪由这个函数
分配的虚拟内存的范围,并自动加速函数的调用,例如cudaMemcpy*()。由于内存可以被
设备直接访问,相比由例如函数malloc()分配的pagable 内存,拥有快很多的读写速度。
但是,分配过多的page-locked 内存将减少系统可用物理内存的大小,从而降低系统整体的
性能。
D.5.7 cudaFreeHost()
cudaError_t cudaFreeHost(void* hostPtr);
释放被
hostPtr
指向的内存空间,
hostPtr
必须
带有
cudaMallocHost()
- 96 -
的
返回值
。
Page 97

D.5.8 cudaMemSet()
cudaError_t cudaMemset(void* devPtr, int value, size_t count);
使用常数
D.5.9 cudaMemSet2D()
cudaError_t cudaMemset2D(void* dstPtr, size_t pitch,
值
value
字节
填充
由
devPtr
int value, size_t width, size_t height);
指向的内存空间内的
前
count
字节
。
设定由dstPtr 指向的一个矩阵中的值为vaule,pitch 是由dstPtr 指向的2D 数组中的
内存宽度字节,2D 数组中每行的最后包含自动填充的数值(为保证效率的队列需求)。当
pitch 是由cudaMallocPitch() 返回的值时,执行速度最快。
D.5.10 cudaMemcpy()
cudaError_t cudaMemcpy(void* dst, const void* src,
size_t count,
enum cudaMemcpyKind kind);
cudaError_t cudaMemcpyAsync(void* dst,constvoid*src,
size_t count,
enum cudaMemcpyKind kind,
cudaStream_t stream);
拷贝count 字节,从src 指向的内存区域到dst 指向的内存区域,kind 可以是
cudaMemcpyHostToHost, cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,或
cudaMemcpyDeviceToDevice 的拷贝方向。内存区域可能不会重叠。调用cudaMemcpy() 使用
不匹配拷贝方向的指针src 和dst 将导致结果是未定义的。
cudaMemcpyAsync()是异步的,并且可以作为一个可选参数通过流使用。它只能应用于
page-locked 的主机内存。如果使用一个指向pagable 的内存指针作为输入,函数将返回一
个错误。
- 97 -
Page 98

D.5.11 cudaMemcpy2D()
cudaError_t cudaMemcpy2D(void* dst, size_t dpitch,
const void* src, size_t spitch,
size_t width, size_t height,
enum cudaMemcpyKind kind);
cudaError_t cudaMemcpy2DAsync(void* dst, size_t dpitch,
const void* src, size_t spitch,
size_t width, size_t height,
enum cudaMemcpyKind kind,
cudaStream_t stream);
拷贝一个矩阵,从src 指向的内存区域到dst 指向的内存区域,kind 可以是
cudaMemcpyHostToHost, cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,或
cudaMemcpyDeviceToDevice 的拷贝方向。dpitch 和spitch 是由dst 和src 指向的2D 数组
中的内存宽度字节。内存区域可能不会重叠。调用cudaMemcpy2D()使用不匹配拷贝方向的指
针src 和dst 将导致结果是未定义的。如果dpitch 和spitch 大于允许的最大值(参见附录
D.1.4 中的memPitch),cudaMemcpy2D()将返回一个错误。
cudaMemcpy2DAsync()
的主机内存。如果使用一个指
D.5.12 cudaMemcpyToArray()
cudaError_t cudaMemcpyToArray(struct cudaArray* dstArray,
cudaError_t cudaMemcpyToArrayAsync(struct cudaArray* dstArray,
是异步的,并且可以作为一个可
向
pagable
的内存指针作为输入,函数
size_t dstX, size_t dstY,
const void* src, size_t count,
enum cudaMemcpyKind kind);
size_t dstX, size_t dstY,
const void* src, size_t count,
enum cudaMemcpyKind kind,
cudaStream_t stream);
选参
数通过流使用。它只能应用于
将返回
一个错误。
page-locked
拷贝count 字节,从src 指向的内存区域到dstArray 指向的CUDA 数组,从数组的左上角
(dstX, dstY) 开始,kind 可以是cudaMemcpyHostToHost, cudaMemcpyHostToDevice,
cudaMemcpyDeviceToHost,或cudaMemcpyDeviceToDevice 的拷贝方向。
cudaMemcpyToArrayAsync()
page-locked
的主机内存。如果使用一个指
是异步的,并且可以作为一个可
向
pagable
的内存指针作为输入,函数
- 98 -
选参
数通过流使用。它只能应用于
将返回
一个错误。
Page 99

D.5.13 cudaMemcpy2DToArray()
cudaError_t cudaMemcpy2DToArray(struct cudaArray* dstArray,
size_t dstX, size_t dstY,
const void* src, size_t spitch,
size_t width, size_t height,
enum cudaMemcpyKind kind);
cudaError_t cudaMemcpy2DToArrayAsync(struct cudaArray* dstArray,
size_t dstX, size_t dstY,
const void* src, size_t spitch,
size_t width, size_t height,
enum cudaMemcpyKind kind,
cudaStream_t stream);
拷贝一个矩阵,从src 指向的内存区域到dstArray 指向的CUDA 数组,从数组的左上角
(dstX, dstY) 开始,kind 可以是cudaMemcpyHostToHost, cudaMemcpyHostToDevice,
cudaMemcpyDeviceToHost,或cudaMemcpyDeviceToDevice 的拷贝方向。spitch 是由src 指
向的2D 数组中的内存宽度字节,2D 数组中每行的最后包含自动填充的数值( 为保证效率
的队列需求)。如果spitch 大于允许的最大值(参见附录D.1.4 中的memPitch),
cudaMemcpy2DToArray()将返回一个错误。
cudaMemcpy2DToArrayAsync()是异步的,并且可以作为一个可选参数通过流使用。它只
能应用于page-locked 的主机内存。如果使用一个指向pagable 的内存指针作为输入,函数
将返回一个错误。
D.5.14 cudaMemcpyFromArray()
cudaError_t cudaMemcpyFromArray(void* dst,
cudaError_t cudaMemcpyFromArrayAsync(void* dst,
const struct cudaArray* srcArray,
size_t srcX, size_t srcY,
size_t count,
enum cudaMemcpyKind kind);
const struct cudaArray* srcArray,
size_t srcX, size_t srcY,
size_t count,
enum cudaMemcpyKind kind,
cudaStream_t stream);
拷贝count 字节,从srcArray 指向的CUDA 数组,从数组的左上角(srcX, srcY)开始,
到dst 指向的内存区域,kind 可以是cudaMemcpyHostToHost, cudaMemcpyHostToDevice,
cudaMemcpyDeviceToHost,或cudaMemcpyDeviceToDevice 的拷贝方向。
- 99 -
Page 100

cudaMemcpy2DToArrayAsync()
page-locked
D.5.15 cudaMemcpy2DFromArray()
cudaError_t cudaMemcpy2DFromArray(void* dst, size_t dpitch,
cudaError_t cudaMemcpy2DFromArrayAsync(void* dst, size_t dpitch,
的主机内存。如果使用一个指
是异步的,并且可以作为一个可
向
pagable
const struct cudaArray* srcArray,
size_t srcX, size_t srcY,
size_t width, size_t height,
enum cudaMemcpyKind kind);
的内存指针作为输入,函数
const struct cudaArray* srcArray,
size_t srcX, size_t srcY,
size_t width, size_t height,
enum cudaMemcpyKind kind,
cudaStream_t stream);
选参
数通过流使用。它只能应用于
将返回
一个错误。
拷贝一个矩阵,从srcArray 指向的CUDA 数组,从数组的左上角(srcX, srcY)开始,到
dst 指向的内存区域,kind 可以是cudaMemcpyHostToHost, cudaMemcpyHostToDevice,
cudaMemcpyDeviceToHost,或cudaMemcpyDeviceToDevice 的拷贝方向。dpitch 是由dst 指
向的2D 数组中的内存宽度字节,2D 数组中每行的最后包含自动填充的数值( 为保证效率
的队列需求)。如果dpitch 大于允许的最大值(参见附录D.1.4 中的memPitch),
cudaMemcpy2DFromArray()将返回一个错误。
cudaMemcpy2DFromArrayAsync()
page-locked
D.5.16 cudaMemcpyArrayToArray()
cudaError_t cudaMemcpyArrayToArray(struct cudaArray* dstArray,
拷贝count
count 字节,从srcArray
count count
到dstArray
dstArray 指向的CUDA 数组,从数组的左上角(dstX, dstY),kind 可以是
dstArray dstArray
的主机内存。如果使用一个指
srcArray 指向的CUDA 数组,从数组的左上角(srcX
srcArray srcArray
是异步的,并且可以作为一个可
向
pagable
size_t dstX, size_t dstY,
const struct cudaArray* srcArray,
size_t srcX, size_t srcY,
size_t count,
enum cudaMemcpyKind kind);
的内存指针作为输入,函数
选参
数通过流使用。它只能应用于
将返回
srcX, srcY
srcXsrcX
一个错误。
srcY) 开始,
srcYsrcY
cudaMemcpyHostToHost,
cudaMemcpyDeviceToDevice
cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost
的
拷贝方向
。
,或
- 100 -
 Loading...
Loading...