

Page 1
Novell®
www.novell.com
Developer Guide and Reference
PlateSpin® Orchestrate
novdocx (en) 13 May 2009
AUTHORIZED DOCUMENTATION
2.0.2
July 9, 2009
PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 2

Legal Notices
Novell, Inc. makes no representations or warranties with respect to the contents or use of this documentation, and
specifically disclaims any express or implied warranties of merchantability or fitness for any particular purpose.
Further, Novell, Inc. reserves the right to revise this publication and to make changes to its content, at any time,
without obligation to notify any person or entity of such revisions or changes.
Further, Novell, Inc. makes no representations or warranties with respect to any software, and specifically disclaims
any express or implied warranties of merchantability or fitness for any particular purpose. Further, Novell, Inc.
reserves the right to make changes to any and all parts of Novell software, at any time, without any obligation to
notify any person or entity of such changes.
Any products or technical information provided under this Agreement may be subject to U.S. export controls and the
trade laws of other countries. You agree to comply with all export control regulations and to obtain any required
licenses or classification to export, re-export or import deliverables. You agree not to export or re-export to entities on
the current U.S. export exclusion lists or to any embargoed or terrorist countries as specified in the U.S. export laws.
You agree to not use deliverables for prohibited nuclear, missile, or chemical biological weaponry end uses. See the
Novell International Trade Services Web page (http://www.novell.com/info/exports/) for more information on
exporting Novell software. Novell assumes no responsibility for your failure to obtain any necessary export
approvals.
novdocx (en) 13 May 2009
Copyright © 2008-2009 Novell, Inc. All rights reserved. No part of this publication may be reproduced, photocopied,
stored on a retrieval system, or transmitted without the express written consent of the publisher.
Novell, Inc. has intellectual property rights relating to technology embodied in the product that is described in this
document. In particular, and without limitation, these intellectual property rights may include one or more of the U.S.
patents listed on the Novell Legal Patents Web page (http://www.novell.com/company/legal/patents/) and one or
more additional patents or pending patent applications in the U.S. and in other countries.
Novell, Inc.
404 Wyman Street, Suite 500
Waltham, MA 02451
U.S.A.
www.novell.com
Online Documentation: To access the latest online documentation for this and other Novell products, see
the Novell Documentation Web page (http://www.novell.com/documentation).
Page 3

Novell Trademarks
For Novell trademarks, see the Novell Trademark and Service Mark list (http://www.novell.com/company/legal/
trademarks/tmlist.html).
Third-Party Materials
All third-party trademarks are the property of their respective owners.
novdocx (en) 13 May 2009
Page 4

novdocx (en) 13 May 2009
4 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 5

Contents
About This Guide 11
1 Getting Started With Development 15
1.1 What You Should Know . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.1.1 Prerequisite Knowledge. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.1.2 Setting Up Your Development Environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.2 Prerequisites for the Development Environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2 Advanced Job Development Concepts 19
2.1 JDL Job Scripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.1.1 Principles of Job Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2 Understanding TLS Encryption . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3 Understanding Job Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3.1 provisionBuildTestResource.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3.2 Workflow Job Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
novdocx (en) 13 May 2009
3 The PlateSpin Orchestrate Datagrid 25
3.1 Defining the Datagrid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.1.1 PlateSpin Orchestrate Datagrid Filepaths . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.1.2 Distributing Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.1.3 Simultaneous Multicasting to Multiple Receivers. . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.1.4 PlateSpin Orchestrate Datagrid Commands . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2 Datagrid Communications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2.1 Multicast Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.2 Grid Performance Factors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.3 Plan for Datagrid Expansion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3 datagrid.copy Example. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4 Using PlateSpin Orchestrate Jobs 31
4.1 Resource Discovery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1.1 Provisioning Jobs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1.2 Resource Discovery Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2 Resource Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3 Workload Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.4 Policy Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.5 Auditing and Accounting Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.6 BuildTest Job Examples. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.6.1 buildTest.policy Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.6.2 buildTest.jdl Example. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.6.3 Packaging Job Files. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.6.4 Deploying Packaged Job Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.6.5 Running Your Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.6.6 Monitoring Job Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.6.7 Debugging Jobs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
Contents 5
Page 6

5 Policy Elements 45
5.1 Constraints . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2 Facts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.3 Computed Facts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
6 Using the PlateSpin Orchestrate Client SDK 47
6.1 SDK Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
6.2 Creating an SDK Client . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
7 Job Architecture 49
7.1 Understanding JDL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
7.2 JDL Package . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
7.2.1 .sched Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
7.3 Job Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
7.3.1 Job State Transition Events. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
7.3.2 Handling Custom Events . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
7.4 Job Invocation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
7.5 Deploying Jobs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
7.5.1 Using the PlateSpin Orchestrate Development Client . . . . . . . . . . . . . . . . . . . . . . . . 54
7.5.2 Using the zosadmin Command Line Tool . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
7.6 Starting PlateSpin Orchestrate Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
7.7 Working with Facts and Constraints. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
7.7.1 Grid Objects and Facts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
7.7.2 Defining Job Elements. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
7.7.3 Job Arguments and Parameter Lists . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
7.8 Using Facts in Job Scripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
7.8.1 Fact Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
7.8.2 Fact Operations in the Joblet Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
7.8.3 Using the Policy Debugger to View Facts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
7.9 Using Other Grid Objects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
7.10 Communicating Through Job Events . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
7.10.1 Sending and Receiving Events . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
7.10.2 Synchronization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
7.11 Executing Local Programs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
7.11.1 Output Handling. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
7.11.2 Local Users . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
7.11.3 Safety and Failure Handling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
7.12 Logging and Debugging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
7.12.1 Creating a Job Memo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
7.12.2 Tracing. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
7.13 Improving Job and Joblet Robustness . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
7.14 Using an Event Notification in a Job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
7.14.1 Receiving Event Notifications in a Running Job . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
7.14.2 Event Types. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
novdocx (en) 13 May 2009
8 Job Scheduling 71
8.1 The PlateSpin Orchestrate Job Scheduler Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
8.2 Schedule and Trigger Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
8.2.1 Schedule File Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
8.2.2 Trigger File XML Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
8.3 Scheduling with Constraints. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
6 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 7

9 Virtual Machine Job Development 77
9.1 VM Job Best Practices. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
9.1.1 Plan Robust Application Starts and Stops . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
9.1.2 Managing VM Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
9.1.3 Managing VM Images . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
9.1.4 Managing VM Hypervisors. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
9.1.5 VM Job Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
9.2 Virtual Machine Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
9.3 VM Life Cycle Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
9.4 Manual Management of a VM Lifecycle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
9.4.1 Manually Using the zos Command Line . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
9.4.2 Automatically Using the Development Client Job Scheduler . . . . . . . . . . . . . . . . . . . 81
9.4.3 Provision Job JDL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
9.5 Provisioning Virtual Machines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
9.5.1 Provisioning VMs Using Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
9.5.2 VM Placement Policy. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
9.5.3 Provisioning Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
9.6 Automatically Provisioning a VM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
9.7 Defining Values for Grid Objects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
9.7.1 PlateSpin Orchestrate Grid Objects. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
9.7.2 Repository Objects and Facts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
9.7.3 VmHost Objects and Facts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
9.7.4 VM Resource Objects and Other Base Resource Facts . . . . . . . . . . . . . . . . . . . . . 101
9.7.5 Physical Resource Objects and Additional Facts . . . . . . . . . . . . . . . . . . . . . . . . . . 108
novdocx (en) 13 May 2009
10 Complete Job Examples 111
10.1 Accessing Job Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
10.2 Installation and Getting Started . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
10.3 PlateSpin Orchestrate Sample Job Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
10.4 Parallel Computing Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
demoIterator.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
quickie.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
10.5 General Purpose Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
dgtest.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
failover.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
instclients.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
notepad.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
sweeper.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
whoami.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
10.6 Miscellaneous Code-Only Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
factJunction.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
jobargs.job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
A PlateSpin Orchestrate Client SDK 187
A.1 Constraint Package . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
A.1.1 AndConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
A.1.2 BetweenConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
A.1.3 BinaryConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
A.1.4 Constraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
A.1.5 ContainerConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
A.1.6 ContainsConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
A.1.7 DefinedConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
A.1.8 EqConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
A.1.9 GeConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
Contents 7
Page 8

A.1.10 GtConstraint. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
A.1.11 IfConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
A.1.12 LeConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
A.1.13 LtConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
A.1.14 NeConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
A.1.15 NotConstraint. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
A.1.16 OperatorConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
A.1.17 OrConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
A.1.18 TypedConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
A.1.19 UndefinedConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
A.1.20 ConstraintException. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
A.2 Datagrid Package. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
A.2.1 GridFile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
A.2.2 GridFileFilter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
A.2.3 GridFileNameFilter. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
A.2.4 DGLogger . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
A.2.5 DataGridException. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
A.2.6 DataGridNotAvailableException . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
A.2.7 GridFile.CancelException . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
A.3 Grid Package . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
A.3.1 AgentListener. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
A.3.2 ClientAgent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
A.3.3 Credential . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
A.3.4 Fact . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
A.3.5 FactSet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
A.3.6 GridObjectInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
A.3.7 ID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
A.3.8 JobInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
A.3.9 Message . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
A.3.10 Message.Ack . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
A.3.11 Message.AuthFailure. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
A.3.12 Message.ClientResponseMessage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
A.3.13 Message.ConnectionID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
A.3.14 Message.Event . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
A.3.15 Message.GetGridObjects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
A.3.16 Message.GridObjects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
A.3.17 Message.JobAccepted . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
A.3.18 Message.JobError . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
A.3.19 Message.JobFinished . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
A.3.20 Message.JobIdEvent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
A.3.21 Message.JobInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
A.3.22 Message.Jobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
A.3.23 Message.JobStarted . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
A.3.24 Message.JobStatus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
A.3.25 Message.LoginFailed. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
A.3.26 Message.LoginSuccess. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
A.3.27 Message.LogoutAck . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
A.3.28 Message.RunningJobs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
A.3.29 Message.ServerStatus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
A.3.30 Node . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
A.3.31 Priority . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
A.3.32 WorkflowInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
A.3.33 ClientOutOfDateException. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
A.3.34 FactException . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
A.3.35 GridAuthenticationException . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
A.3.36 GridAuthorizationException . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
A.3.37 GridConfigurationException. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
A.3.38 GridDeploymentException . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
novdocx (en) 13 May 2009
8 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 9

A.3.39 GridException . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
A.3.40 GridObjectNotFoundException . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
A.4 TLS Package . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
A.4.1 TlsCallbacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
A.4.2 PemCertificate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
A.4.3 TlsConfiguration. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
A.5 Toolkit Package . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
A.5.1 ClientAgentFactory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
A.5.2 ConstraintFactory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
A.5.3 CredentialFactory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
B PlateSpin Orchestrate Job Classes and JDL Syntax 201
B.1 Job Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
B.2 Joblet Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
B.3 Utility Classes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
B.4 Built-in JDL Functions and Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
B.4.1 getMatrix() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
B.4.2 system(cmd) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
B.4.3 Grid Object TYPE_* Variables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
B.4.4 The __agent__ Variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
B.4.5 The __jobname__ Variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
B.4.6 The __mode__ Variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203
B.5 Job State Field Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203
B.6 Repository Information String Values. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
B.7 Joblet State Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
B.8 Resource Information Values. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
B.9 JDL Class Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
AndConstraint() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207
BinaryConstraint. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 208
BuildSpec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
CharRange. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
ComputedFact . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211
ComputedFactContext . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
Constraint. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213
ContainerConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
ContainsConstraint. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215
DataGrid. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 216
DefinedConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217
EqConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
Exec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219
ExecError . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220
FileRange. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
GeConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222
GridObjectInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223
GroupInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224
GtConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225
Job . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226
JobInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
Joblet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 228
JobletInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229
JobletParameterSpace. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
LeConstraint. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
LtConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232
MatchContext . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233
MatchResult . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234
MatrixInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235
novdocx (en) 13 May 2009
Contents 9
Page 10

MigrateSpec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236
NeConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237
NotConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238
OrConstraint. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239
ParameterSpace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240
PolicyInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241
ProvisionSpec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242
RepositoryInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243
ResourceInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244
RunJobSpec. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245
ScheduleSpec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246
Timer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 247
UndefinedConstraint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248
UserInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249
VMHostInfo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250
VmSpec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251
C Understanding Resource Metrics Facts 253
C.1 Resource Facts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253
C.2 Interpreting the Units of Metrics Fact Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254
novdocx (en) 13 May 2009
D Documentation Updates 257
D.1 July 9, 2009 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 257
D.2 June 17, 2009 (2.0.2 Release). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 257
10 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 11

About This Guide
novdocx (en) 13 May 2009
This Job Developer Guide and Reference is a component of the documentation library for
PlateSpin
and networking tools to manage complex virtual machines and high performance computing
resources in a datacenter, this guide explains how to develop grid application jobs and polices that
form the basis of PlateSpin Orchestrate functionality. This guide provides developer information to
create and run custom PlateSpin Orchestrate jobs. It also helps provides the basis to build, debug,
and maintain policies using PlateSpin Orchestrate.
This guide contains the following sections:
Chapter 1, “Getting Started With Development,” on page 15
Chapter 2, “Advanced Job Development Concepts,” on page 19
Chapter 3, “The PlateSpin Orchestrate Datagrid,” on page 25
Chapter 4, “Using PlateSpin Orchestrate Jobs,” on page 31
Chapter 5, “Policy Elements,” on page 45
Chapter 6, “Using the PlateSpin Orchestrate Client SDK,” on page 47
Chapter 7, “Job Architecture,” on page 49
Chapter 8, “Job Scheduling,” on page 71
Chapter 9, “Virtual Machine Job Development,” on page 77
Chapter 10, “Complete Job Examples,” on page 111
Appendix A, “PlateSpin Orchestrate Client SDK,” on page 187
®
Orchestrate from Novell®. While PlateSpin Orchestrate provides the broad framework
Appendix B, “PlateSpin Orchestrate Job Classes and JDL Syntax,” on page 201
Appendix C, “Understanding Resource Metrics Facts,” on page 253
Appendix D, “Documentation Updates,” on page 257
Audience
The developer has control of a self-contained development system where he or she creates jobs and
policies and tests them in a laboratory environment. When the jobs are tested and proven to function
as intended, the developer delivers them to the PlateSpin Orchestrate administrator.
Prerequisite Skills
As data center managers or IT or operations administrators, it is assumed that users of the product
have the following background:
General understanding of network operating environments and systems architecture.
Knowledge of basic Linux* shell commands and text editors.
Documentation Updates
For the most recent version of this Job Developer Guide and Reference, visit the PlateSpin
Orchestrate 2.0 Web site (http://www.novell.com/documentation/pso_orchestrate20/).
About This Guide 11
Page 12

Additional Product Documentation
In addition to this Job Developer Guide and Reference, PlateSpin Orchestrate 2.0 includes the
following additional guides that contain valuable information about the product:
PlateSpin Orchestrate 2.0 Getting Started Reference
PlateSpin Orchestrate 2.0 Upgrade Guide
PlateSpin Orchestrate 2.0 High Availability Configuration Guide
PlateSpin Orchestrate 2.0 Administrator Reference
PlateSpin Orchestrate 2.0 VM Client Guide and Reference
PlateSpin Orchestrate 2.0 Virtual Machine Management Guide
PlateSpin Orchestrate 2.0 Development Client Reference
PlateSpin Orchestrate 2.0 Command Line Reference
PlateSpin Orchestrate 2.0 Server Portal Reference
Documentation Conventions
novdocx (en) 13 May 2009
In Novell documentation, a greater-than symbol (>) is used to separate actions within a step and
items in a cross-reference path.
A trademark symbol (®, TM, etc.) denotes a Novell trademark. An asterisk (*) denotes a third-party
trademark.
When a single pathname can be written with a backslash for some platforms or a forward slash for
other platforms, the pathname is presented with a backslash. Users of platforms that require a
forward slash, such as Linux or UNIX, should use forward slashes as required by your software.
Other typographical conventions used in this guide include the following:
Convention Description
Italics Indicates variables, new terms and concepts, and book titles. For example, a job is
a piece of work that describes how an application can be run in Grid Management
on multiple computers.
Boldface Used for advisory terms such as Note, Tip, Important, Caution, and Warning.
Keycaps Used to indicate keys on the keyboard that you press to implement an action. If
you must press two or more keys simultaneously, keycaps are joined with a
hyphen. For example,
Ctrl-C. Indicates that you must press two or more keys to implement an action.
Simultaneous keystrokes (in which you press down the first key while you type the
second character) are joined with a hyphen; for example, press Stop-a.
Consecutive keystrokes (in which you press down the first key, then type the
second character) are joined with a plus sign; for example, press F4+q.
12 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 13

Convention Description
Fixed-width Used to indicate various types of items. These include:
Commands that you enter directly, code examples, user type-ins in body text, and
options. For example,
cd mydir
System.out.println("Hello World");
Enter abc123 in the Password box, then click Next.
-keep option
Jobs and policy keywords and identifiers. For example,
<run>
</run>
File and directory names. For example,
/usr/local/bin
novdocx (en) 13 May 2009
Note: UNIX path names are used throughout and are indicated with a forward
slash (/). If you are using the Windows platform, substitute backslashes (\) for the
forward slashes (/).
Fixed-width italic
and
<Fixed-width italic>
Indicates variables in commands and code. For example,
zos login <servername> [--user=] [--passwd=] [--port=]
Note: Angle brackets (< >) are used to indicate variables in directory paths and
command options.
| (pipe) Used as a separator in menu commands that you select in a graphical user
interface (GUI), and to separate choices in a syntax line. For example,
File|New
{a|b|c}
[a|b|c]
{ } (braces) Indicates a set of required choices in a syntax line. For example,
{a|b|c}
means you must choose a, b, or c.
[ ] (brackets) Indicates optional items in a syntax line. For example,
[a|b|c]
means you can choose a, b, c, or nothing.
< > (angle brackets) Used for XML content elements and tags, and to indicate variables in directory
paths and command options. For example,
<template>
<DIR>
-class <class>
About This Guide 13
Page 14

Convention Description
novdocx (en) 13 May 2009
. . . (horizontal
ellipses)
plain text Used for URLs, generic references to objects, and all items that do not require
ALL CAPS Used for SQL statements and HTML elements. For example,
lowercase Used for XML elements. For example,
PlateSpin
Orchestrate Server
root directory
Used to indicate that portions of a code example have been omitted to simplify the
discussion, and to indicate that an argument can be repeated several times in a
command line. For example,
zosadmin [options|optfile.xmlc ...] docfile
special typography. For example,
http://www.novell.com/documentation/index.html
The presentation object is in the presentation layer.
CREATE statement
<INPUT>
<onevent>
Note: XML is case-sensitive. If an existing XML element uses mixed-case or
uppercase, it is shown in that case. Otherwise, XML elements are in lowercase.
Where the PlateSpin Orchestrate Server is installed. The PlateSpin Orchestrate
executables and libraries are in a directory. This directory is referred to as the
PlateSpin Orchestrate Server root directory or <PlateSpin Orchestrate
Server_root>.
Paths UNIX path names are used throughout and are indicated with a forward slash (/). If
you are using the Windows platform, substitute backslashes (\) for the forward
slashes (/). For example,
UNIX: /usr/local/bin
Windows: \usr\local\bin
URLs URLs are indicated in plain text and are generally fully qualified. For example,
http://www.novell.com/documentation/index.html
Screen shots Most screen shots reflect the Microsoft Windows look and feel.
Feedback
We want to hear your comments and suggestions about this manual and the other documentation
included with this product. Please use the User Comments feature at the bottom of each page of the
online documentation, or go to www.novell.com/documentation/feedback.html (http://
www.novell.com/documentation/feedback.html) and enter your comments there.
Novell Support
Novell offers a support program designed to assist with technical support and consulting needs. The
Novell support team can help with installing and using the Novell product, developing and
debugging code, maintaining the deployed applications, providing onsite consulting services, and
delivering enterprise-level support.
14 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 15

1
Getting Started With Development
This Developer Guide for PlateSpin® Orchestrate from Novell® is intended for individuals acting as
PlateSpin Orchestrate job developers. This document discusses the tools and technology required to
create discrete programming scripts—called “jobs”—that control nearly every aspect of the
PlateSpin Orchestrate product.The guide also explains how to create, debug, and maintain policies
that can be associated with jobs running on the PlateSpin Orchestrate Server.
As a job developer, you need your own self-contained, standalone system with full access to your
network environment. As a job developer, you might eventually assume all system roles: job creator,
job deployer, system administrator, tester, etc. For more information about jobs, see “Jobs” in the
PlateSpin Orchestrate 2.0 Getting Started Reference.
This section includes the following information:
Section 1.1, “What You Should Know,” on page 15
Section 1.2, “Prerequisites for the Development Environment,” on page 16
novdocx (en) 13 May 2009
1
1.1 What You Should Know
This section includes the following information:
Section 1.1.1, “Prerequisite Knowledge,” on page 15
Section 1.1.2, “Setting Up Your Development Environment,” on page 16
1.1.1 Prerequisite Knowledge
This guide assumes you have the following background:
Sound understanding of networks, operating environments, and system architectures.
Familiarity with the Python development language. For more information, see the following
online references:
Python Development Environment (PyDEV): The PyDEV plug-in (http://
pydev.sourceforge.net/) enables developers to use Eclipse* for Python and Jython
development. The plug-in makes Eclipse a more robust Python IDE and comes with tools
for code completion, syntax highlighting, syntax analysis, refactoring, debugging, etc.
Python Reference Manual: This reference (http://python.org/doc/2.1/ref/ref.html)
describes the exact syntax and semantics but does not describe the Python Library
Reference, (http://python.org/doc/2.1/lib/lib.html) which is distributed with the language
and assists in development.
Python Tutorial: This online tutorial (http://python.org/doc/2.1/ref/ref.html)helps
developers get started with Python.
Sound understanding of the PlateSpin Orchestrate Job Development Language (JDL).
JDL incorporates compact Python scripts to create job definitions to manage nearly every
aspect of the PlateSpin Orchestrate grid. For more information, see Appendix B, “PlateSpin
Orchestrate Job Classes and JDL Syntax,” on page 201.
Knowledge of basic UNIX shell commands or the Windows command prompt, and text editors.
Getting Started With Development
15
Page 16

An understanding of parallel computing and how applications are run on PlateSpin Orchestrate
infrastructure.
Familiarity with on-line PlateSpin Orchestrate API Javadoc as you build custom client
applications. For more information see Appendix A, “PlateSpin Orchestrate Client SDK,” on
page 187.
Developer must assume both PlateSpin Orchestrate administrative and end-user roles while
testing and debugging jobs.
1.1.2 Setting Up Your Development Environment
To set up a development environment for creating, deploying, and testing jobs, we recommend the
following procedure:
1 Initially set up a simple, easy-to-manage server, agent, and client on a single machine. Even on
a single machine, you can simulate multiple servers by starting extra agents (see “Installing the
Orchestrate Agent Only” in the PlateSpin Orchestrate 2.0 Installation and Configuration
Guide.
2 As you get closer to a production environment, your setup might evolve to handle more
complex system demands, such as any of the following:
An Orchestrate Server instance deployed on one computer.
An Orchestrate Agent installed on every managed server.
novdocx (en) 13 May 2009
An Orchestrate Development Client installed on your desktop machine.
From your desktop machine, you can build jobs/policies, and then remotely deploy them
using zosadmin command line tool. You can then remotely modify the jobs and other grid
object through the PlateSpin Orchestrate Development Client.
3 Use a version control system, such as Subversion*, to organize and track development changes.
4 Put the job version number inside the deployed file. This will help you keep your job versions
organized.
5 Create make or Ant scripts for bundling and deploying your jobs.
By leveraging the flexibility of the PlateSpin Orchestrate environment, you should not have to write
jobs targeted specifically for one hypervisor technology (Xen*, VMware*, etc.).
1.2 Prerequisites for the Development Environment
Install the Java* Development Kit (https://sdlc3d.sun.com/ECom/
EComActionServlet;jsessionid=DCA955A842E56492B469230CC680B2E1), version 1.5 or
later, to create jobs and to compile a Java SDK client in the PlateSpin Orchestrate environment.
The PlateSpin Orchestrate installer ships with a Java Runtime Environment (JRE) suitable for
running PlateSpin Orchestrate jobs.
Components to write Python-based Job Description Language (JDL) scripts:
Eclipse version 3.2.1 or later. (http://www.eclipse.org/).
16 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 17

Development Environment: Set up your environment according to the guidelines outlined in
“Planning the Orchestrate Server Installation” in the PlateSpin Orchestrate 2.0 Installation and
Configuration Guide. In general, the installed PlateSpin Orchestrate Server requires 2
(minimum for 100 or fewer managed resources) to 4 gigabytes (recommended for more than
100 managed resources) of RAM.
Network Capabilities: For Virtual Machine Management, you need a high-speed Gigabit
Ethernet. For more information about network requirements, see “Orchestrate VM Client” and
“VM Hosts” in the PlateSpin Orchestrate 2.0 Installation and Configuration Guide.
Initial Configuration: After you install and configure PlateSpin Orchestrate, start in the agent
and user auto registration mode as described in “First Use of Basic PlateSpin Orchestrate
Components” in the PlateSpin Orchestrate 2.0 Installation and Configuration Guide. As a
first-time connection, the server creates an account for you as you set up a self-contained
system.
IMPORTANT: Because auto registration mode does not provide high security, make sure you
prevent unauthorized access to your network from your work station during development. As
you migrate to a production environment, make sure that this mode is deactivated.
novdocx (en) 13 May 2009
Getting Started With Development 17
Page 18

novdocx (en) 13 May 2009
18 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 19

2
Advanced Job Development
novdocx (en) 13 May 2009
Concepts
This section provides advanced conceptual information to help you create your own PlateSpin®
Orchestrate jobs:
Section 2.1, “JDL Job Scripts,” on page 19
Section 2.2, “Understanding TLS Encryption,” on page 21
Section 2.3, “Understanding Job Examples,” on page 21
2.1 JDL Job Scripts
The PlateSpin Orchestrate job definition language (JDL) is an extended and embedded
implementation of Python. The PlateSpin Orchestrate system provides additional constructs to
control and access the following:
Interaction with the infrastructure under management (requesting resources, querying load,
etc.)
Distributed variable space with job, user and system-wide scoping
Extensible event callbacks mechanism
Job logging
2
Datagrid for efficient movement of files across the infrastructure.
Automatic distribution of parallel operations
Failover logic
For more information about the PlateSpin Orchestrate JDL script editor, see Section 7.2, “JDL
Package,” on page 50.
The JDL language allows for the scripted construction of logic that can be modified by external
parameters and constraints (through one or more associated policies) at the time the job instance is
executed. Development of a job with the JDL (Python) language is very straightforward. For a
listing of the job, joblet, and utility classes, see Appendix B, “PlateSpin Orchestrate Job Classes and
JDL Syntax,” on page 201.
A simple “hello world” Python script example that runs a given number of times (numTests) in
parallel (subject to resource availability and policy) is shown below:
class exampleJob(Job):
def job_started_event(self):
print 'Hello world started: got job_started_event'
# Launch the joblets
numJoblets = self.getFact("jobargs.numTests")
pspace = ParameterSpace()
i = 1
while i <= numJoblets:
pspace.appendRow({'name':'test'+str(i)})
i += 1
Advanced Job Development Concepts
19
Page 20
self.schedule(exampleJoblet, pspace, {})
class exampleJoblet(Joblet):
def joblet_started_event(self):
print "Hello from resource%s" % self.getFact("resource.id")
This example script contains two sections:
The class that extends the job and runs on the server.
The class that extends the joblet that will run on any resource employed by this job.
Because the resources are not requested explicitly, they are allocated based on the resource
constraints associated with this job. If none are specified, all resources match. The
exampleJoblet
class would typically execute some process or test based on unique parameters.
2.1.1 Principles of Job Operation
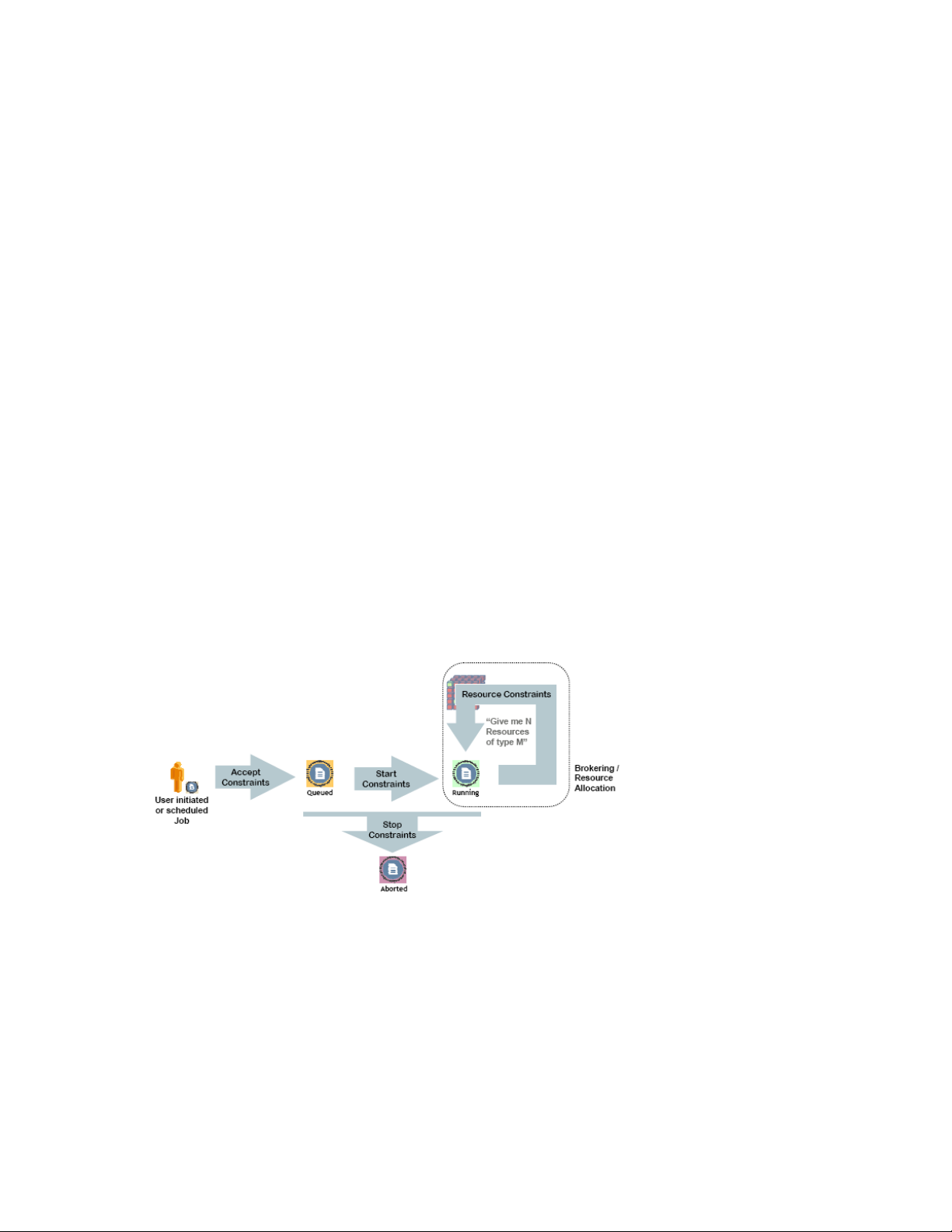
Whenever a job is run on the PlateSpin Orchestrate system it undergoes state transition, as illustrated
in Figure 2-1 on page 20. In all, there are 11 states. The following four states are important in
understanding how constraints are applied on a job’s life cycle through policies:
novdocx (en) 13 May 2009
Accept: Used to prevent work from starting; enforces a hard quota on the jobs.
Start: Used to queue up work requests; limits the quantity of jobs or the load on a resource.
Resource: Used to select specific resources.
Stop: Used to abort jobs; provides special timeout or overrun conditions.
Figure 2-1 Constraint-Based Job State Transition
For more information about job life cycle, see Section 7.3.1, “Job State Transition Events,” on
page 51.
20 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 21

2.2 Understanding TLS Encryption
Understanding Transport Layer Security (TLS) encryption is particularly important if you reinstall
the server and have an old server certificate in either your agent or client user profile similar to
shared keys. If you have an old certificate, you need to either manually replace it or delete it and
allow the client or agent to download the new one from the server using one of the following
procedures:
ssh
novdocx (en) 13 May 2009
For the Agent: The TLS certificate is in
<agentdir>/tls/server.pem
. Deleting this
certificate will cause the agent, by default, to log a minor warning message and download a
new one the next time it tries to connect to the server. This is technically not secure, since the
server could be an impersonator. If security is required for this small window of time, then the
real server’s
<serverdir>/<instancedir>/tls/cert.pem
can be copied to the above
server.pem file.
For the Client: The easiest way to update the certificate from the command line tools is to
simply answer “yes” both times when prompted about the out-of date certificate. This is, again,
not 100% secure, but is suitable for most situations. For absolute security, hand copy the
server’s cert.pem (see above) to
For Java SDK clients: Follow the manual copy technique above to replace the certificate. If
the local network is fairly trustworthy, you can also delete the above
~/.novell/zos/client/tls/<serverIPAddr:Port>.pem
~/.novell/.../*.pem
files, which will cause the client to auto-download a new certificate.
2.3 Understanding Job Examples
The following simple examples demonstrate how you can use JDL scripting to manage specific
functionality:
Section 2.3.1, “provisionBuildTestResource.job,” on page 21
Section 2.3.2, “Workflow Job Example,” on page 23
To learn about other job examples that are packaged with PlateSpin Orchestrate, see Chapter 10,
“Complete Job Examples,” on page 111.
.
2.3.1 provisionBuildTestResource.job
The following job example illustrates simple scripting to ensure that each of three desired OS
platforms might be available in the grid and, if not, it tries to provision them (provided that a VM
image matching the OS type exists). The resource Constraint object is created programmatically, so
there is no need for external policies.
1 class provisionBuildTestResource(Job):
2
3 def job_started_event(self):
4 oslist = ["Windows XP", "Windows 2000", "Windows 2003 Server"]
5 for os in oslist:
6 constraint = EqConstraint()
7 constraint.setFact("resource.os.name")
8 constraint.setValue(os)
9 resources = getMatrix().getGridObjects("resource",constraint)
10 if len(resources) == 0:
11 print "No resources were found to match constraint. \
12 os:%s" % (os)
Advanced Job Development Concepts 21
Page 22
13 else:
14 #
15 # Find an offline vm instance or template.
16 #
17 instance = None
18 for resource in resources:
19 if resource.getFact("resource.type") != "Fixed Physical"
and \
20 resource.getFact("resource.online") == False:
21 # Found a vm or template. provision it for job.
22 print "Submitting provisioning request for vm %s." %
(resource)
23 instance = resource.provision()
24 print "Provisioning successfully submitted."
25 break
26 if instance == None:
27 print "No offline vms or templates found for os: %s" %
(os)
It is not necessary to always script resource provisioning. Automatic resource provisioning (“on
demand”) is one of the built-in functions of the Orchestrate Server. For example, a job requiring a
Windows 2003 Server resource that cannot be satisfied with online resources only needs to have the
appropriate facts set in the Orchestrate Development Client; that is,
job.provision.maxcount
is
enabled.
novdocx (en) 13 May 2009
This fact could also be set through association with a policy. If it is set up this way, PlateSpin
Orchestrate detects that a job is in need of a resource and automatically takes the necessary
provisioning steps, including reservation of the provisioned resource.
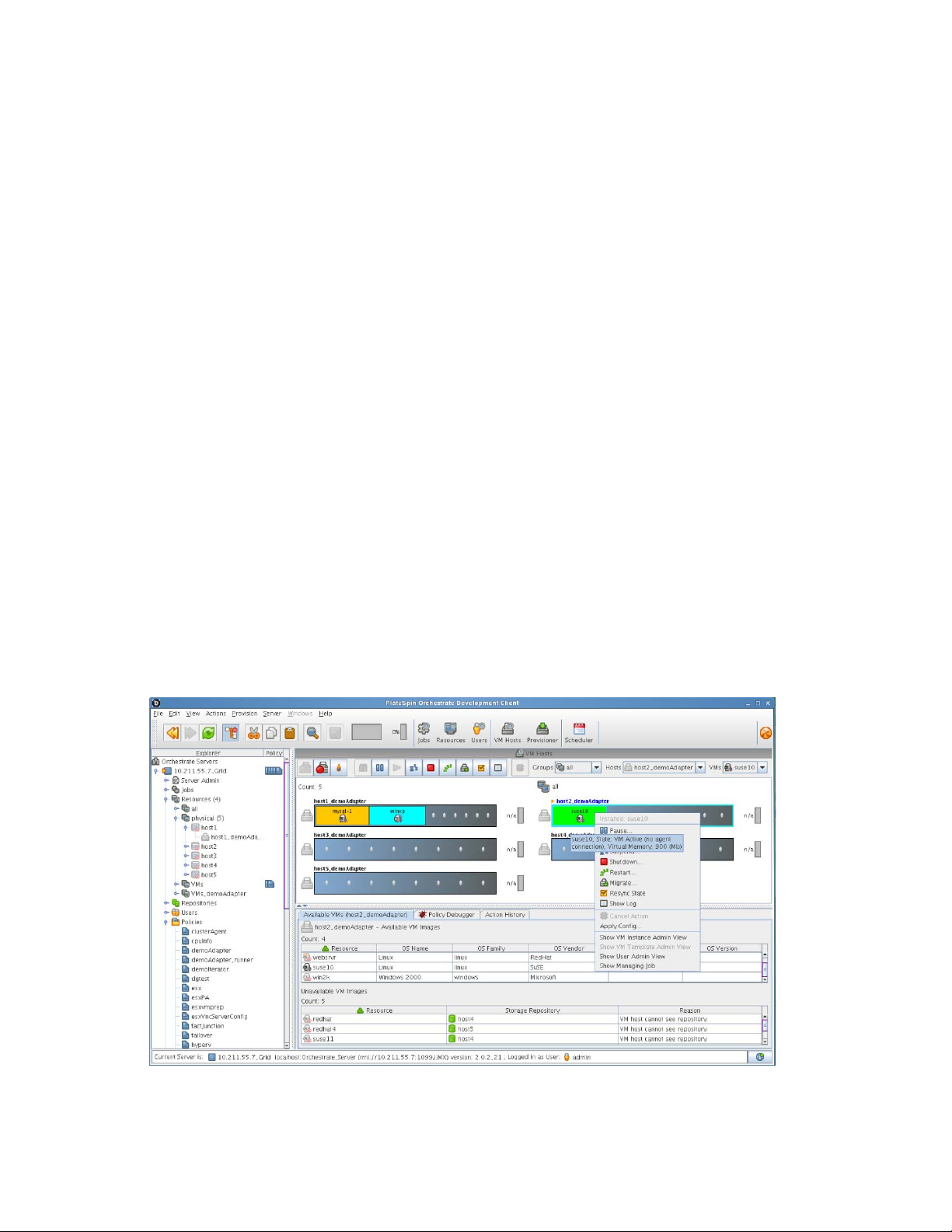
All provisioned virtual machines and the status of the various hosts are visible in the following view
of the Orchestrate Development Client.
Figure 2-2 The PlateSpin Orchestrate Development Client Showing Virtual Machine Management
22 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 23

2.3.2 Workflow Job Example
This brief example illustrates a job that does not require resources but simply acts as a coordinator
(workflow) for the buildTest and provision jobs discussed in Section 4.6, “BuildTest Job Examples,”
on page 35.
1 class Workflow(Job):
2 def job_started_event(self):
3 self.runJob("provisionBuildTestResource", {})
4 self.runJob("buildTest", { "testlist" : "/QA/testlists/production",
5 "buildId": "2006-updateQ1" } )
The job starts in line 1 with the job_started_event, which initiates provisionBuildTestResource.job
(page 21) to ensure all the necessary resources are available, and then starts the buildTest.jdl
Example (page 37). This workflow job does not complete until the two subjobs are complete, as
defined in lines 3 and 4.
If so desired, this workflow could monitor the progress of subjobs by simply defining new event
handler methods (by convention, using the
_event
events. Every message received by the job executes the corresponding event handler method and can
also contain a payload (a Python dictionary).
suffix). The system defines many standard
novdocx (en) 13 May 2009
Advanced Job Development Concepts 23
Page 24

novdocx (en) 13 May 2009
24 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 25
3
The PlateSpin Orchestrate
novdocx (en) 13 May 2009
Datagrid
This section explains concepts related to the datagrid of the PlateSpin® Orchestrate Server datagrid
and specifies many of the objects and facts that are managed in the grid environment:
Section 3.1, “Defining the Datagrid,” on page 25
Section 3.2, “Datagrid Communications,” on page 27
Section 3.3, “datagrid.copy Example,” on page 29
3.1 Defining the Datagrid
Within the PlateSpin Orchestrate environment, the datagrid has three primary functions:
Section 3.1.1, “PlateSpin Orchestrate Datagrid Filepaths,” on page 25
Section 3.1.2, “Distributing Files,” on page 26
Section 3.1.3, “Simultaneous Multicasting to Multiple Receivers,” on page 26
3.1.1 PlateSpin Orchestrate Datagrid Filepaths
The PlateSpin Orchestrate datagrid provides a file naming convention that is used in JDL code and
by the PlateSpin Orchestrate CLI for accessing files in the datagrid. The naming convention is in the
form of a URL. For more information, see “Jobs”in the PlateSpin Orchestrate 2.0 Administrator
Reference.
3
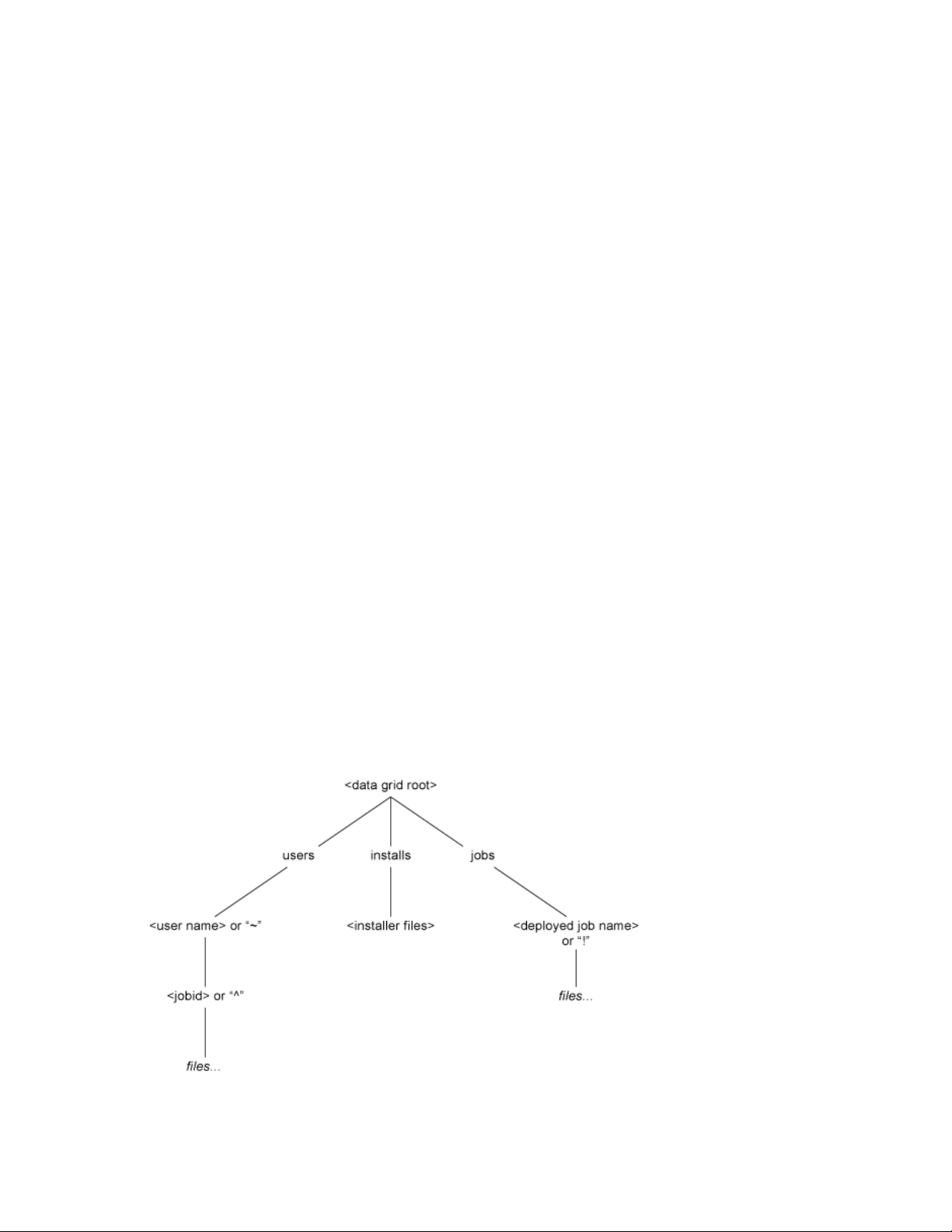
The datagrid defines the root of the namespace as
illustrated in the figure below:
Figure 3-1 File Structure of Data Nodes in a Datagrid
grid://
, with further divisions under the root as
The PlateSpin Orchestrate Datagrid
25
Page 26

novdocx (en) 13 May 2009
The grid URL naming convention is the form
grid://<gridID>/<file path>
. Including the
gridID is optional and its absence means the host default grid. When writing jobs and configuring a
datagrid, you can use the symbol ^ as a shortcut to the <jobid> directory either standalone,
indicating the current job, or followed by the jobid number to identify a particular job.Likewise, the
symbol ! can be used as a shortcut to the deployed jobs’ home directory either standalone, indicating
the current jobs’ type, or followed by the deployed jobs’ name. The symbol ~ is also a shortcut to the
user’s home directory in the datagrid, either by itself, indicating the current user, or followed by the
desired user ID to identify a particular user.
zos
The following examples show address locations in the datagrid using the
These examples assume you have logged in using
zos login
to the Orchestrate Server you are
command line tool.
using:
“Directory Listing of the Datagrid Root Example” on page 26
“Directory Listing of the Jobs Subdirectory Example” on page 26
Directory Listing of the Datagrid Root Example
$ zos dir grid:///
<DIR> Jun-26-2007 9:42 installs
<DIR> Jun-26-2007 9:42 jobs
<DIR> Jun-26-2007 14:26 users
<DIR> Jun-26-2007 9:42 vms
<DIR> Jun-26-2007 10:09 warehouse
Directory Listing of the Jobs Subdirectory Example
$ zos dir grid:///jobs
<DIR> Jun-26-2007 9:42 cpuInfo
<DIR> Jun-26-2007 9:42 findApps
<DIR> Jun-26-2007 9:42 osInfo
<DIR> Jun-26-2007 9:42 vcenter
<DIR> Jun-26-2007 9:42 vmHostVncConfig
<DIR> Jun-26-2007 9:42 vmprep
<DIR> Jun-26-2007 9:42 vmserver
<DIR> Jun-26-2007 9:42 vmserverDiscovery
<DIR> Jun-26-2007 9:42 xen30
<DIR> Jun-26-2007 9:42 xenDiscovery
<DIR> Jun-26-2007 9:42 xenVerifier
3.1.2 Distributing Files
The PlateSpin Orchestrate datagrid provides a way to distribute files in the absence of a distributed
file system. This is an integrated service of PlateSpin Orchestrate that performs system-wide file
delivery and management.
3.1.3 Simultaneous Multicasting to Multiple Receivers
The datagrid provides a multicast distribution mechanism that can efficiently distribute large files
simultaneously to multiple receivers. This is useful even when a distributed file system is present.
For more information, see Section 3.2, “Datagrid Communications,” on page 27.
26 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 27

3.1.4 PlateSpin Orchestrate Datagrid Commands
The following datagrid commands can be used when creating job files. To see where these
commands are applied in the PlateSpin Orchestrate Development Client, see “Typical Use of the
Grid”.
Command Description
novdocx (en) 13 May 2009
cat
copy
delete
dir
head
log
mkdir
move
tail
Displays the contents of a datagrid file.
Copies files and directories to and from the datagrid.
Deletes files and directories in the datagrid.
Lists files and directories in the datagrid.
Displays the first of a datagrid file.
Displays the log for the specified job.
Makes a new directory in the datagrid.
Moves files and directories in the datagrid.
Displays the end of a datagrid file.
3.2 Datagrid Communications
There is no set limit to the number of receivers (nodes) that can participate in the datagrid or in a
multicast operation. Indeed, multicast is rarely more efficient when the number of receivers is small.
Any type of file or file hierarchy can be distributed via the datagrid.
The datagrid uses both a TCP/IP and IP multicast protocols for file transfer. Unicast transfers (the
default) are reliable because of the use of the reliable TCP protocol. Unicast file transfers use the
same server/node communication socket that is used for other job coordination datagrid packets are
simply wrapped in a generic DataGrid message. Multicast transfers use the persistent socket
connection to setup a new multicast port for each transfer.
After the multicast port is opened, data packets are received directly. The socket communication is
then used to coordinate packet resends.Typically, a receiver will loose intermittent packets (because
of the use of IP multicast, data collisions, etc.). After the file is transferred, all receivers will respond
with a bit map of missed packets. The logically ANDing of this mask is used to initiate a resend of
commonly missed packets. This process will repeat a few times (with less data to resend on each
iteration). Finally, any receiver will still have incomplete data until all the missing pieces are sent in
a reliable unicast fashion.
The data transmission for a multicast datagrid transmission is always initiated by the Orchestrate
Server. Currently this is the same server that is running the grid.
With the exception of multicast file transfers, all datagrid traffic goes over the existing connection
between the agent/client and the server. This is done transparently to the end user or developer. As
long as the agent is connected and/or the user is logged in to the grid, the datagrid operations
function.
The PlateSpin Orchestrate Datagrid 27
Page 28

3.2.1 Multicast Example
Multicast transfers are currently only supported through JDL code on the agents. In JDL, after you
get the Datagrid object, you can enable and configure multicasting like this:
dg.setMulticast(true)
Additional multicast tuneables can be set on the object as well, such as the following example:
dg.setMulticastRate(20000000)
This would set the maximum data rate on the transfer to 20 million bytes/sec. There are a number of
other options as well. Refer to the JDL reference for complete information.
The actual multicast copy is initiated when a sufficient number of JDL joblets on different nodes
issue the JDL command:
dg.copy(...)
novdocx (en) 13 May 2009
to actually copy the requested file locally. See the
setMulticastMin
and
setMulticastQuorum
options to change the minimum receiver count and other thresholds for multicasting.
For example, to set up a multicast from a joblet, where the data rate is 30 million bytes/sec, and a
minimum of five receivers must request multicast within 30 seconds, but if 30 receivers connect,
then start right away, use the following JDL:
dg = DataGrid()
dg.setMulticast(true)
dg.setMulticastRate(30000000)
dg.setMulticastMin(5)
dg.setMulticastQuorum(30)
dg.setMulticastWait(30000)
dg.copy('grid:///vms/huge-image.dsk', 'image.dsk')
In the above example, if at least five agents running the joblet request the file within the same 30
second period, then a multicast is started to all agents that have requested multicast before the
transfer is started. Agents requesting after the cutoff have to wait for the next round. Also, if fewer
than 5 agents request the file, then each agent will simply fall back to plain old unicast file copy.
Furthermore, if more than 30 agents connect before 30 seconds is up, then the transfer begins
immediately after the 30th request. This is useful for situations where you know how many agents
will request the file and want to start as soon as all of them are ready.
3.2.2 Grid Performance Factors
The multicast system performance is dependent on the following factors:
Network Load: As the load increases, there is more packet loss, which results in more retries.
Number of Nodes: The more nodes (receivers) there are, the greater the efficiency of the
multicast system.
File Size: The larger the file size, the better. Unless there are a large number of nodes, files less
than 2 Mb are probably too small.
28 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 29

Tuning: The datagrid facility has the ability to throttle network bandwidth. Best performance
has been found at about maximum bandwidth divided by 2. Using more bandwidth leads to
more collisions. Also the number of simultaneous multicasts can be limited. Finally the
minimum receiver size, receiver wait time and quorum receiver size can all be tuned.
Access to the datagrid is typically performed via the CLI tool or JDL code within a job. There is also
a Java API in the Client SDK (on which the CLI is implemented). See “ClientAgent” on page 193.
3.2.3 Plan for Datagrid Expansion
When planning your datagrid, you need to consider where you want the Orchestrate Server to store
its data. Much of the server data is the contents of the datagrid, including ever-expanding job logs.
Every job log can become quite large and quickly exceed its storage constraints.
In addition, every deployed job with its job package—JDL scripts, policy information, and all other
associated executables and binary files—is stored in the datagrid. Consequently, if your datagrid is
/opt
going to grow very large, store it in a directory other than
.
3.3 datagrid.copy Example
novdocx (en) 13 May 2009
This example fetches the specified source file to the destination. A recursive copy is then attempted
setRecursive(True)
if
setMulticast(True)
is set. The default is a single file copy. A multicast also is attempted if
is set. The default is to do a unicast copy.The following example copies a
file from the datagrid to a resource, then read the lines of the file:
1 datagrid = DataGrid()
2 datagrid.copy("grid:///images/myFile","myLocalFile")
3 text = open("myLocalFile").readlines()
This is an example to recursively copy a directory and its sub directories from the datagrid to a
resource:
4 datagrid = DataGrid()
5 datagrid.setRecursive(True)
6 datagrid.copy("grid:///testStore/testFiles","/home/tester/
myLocalFiles")
Here’s an example to copy down a file from the job deployment area to a resource and then read the
lines of the file:
7 datagrid = DataGrid()
8 datagrid.copy("grid:///!myJob/myFile","myLocalFile")
9 text = open("myLocalFile").readlines()
Here are the same examples without using the shortcut characters. This shows the job “myJob” is
under the “jobs” directory under the Datagrid root:
10 datagrid = DataGrid()
11 datagrid.copy("grid:///jobs/myJob/myFile","myLocalFile")
12 text = open("myLocalFile").readlines()
The PlateSpin Orchestrate Datagrid 29
Page 30

novdocx (en) 13 May 2009
30 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 31

4
Using PlateSpin Orchestrate Jobs
This section discusses the core job types that can be run by the PlateSpin® Orchestrate Server on
grid objects. It also discusses the principles you need to know to run jobs.
Section 4.1, “Resource Discovery,” on page 31
Section 4.2, “Resource Selection,” on page 32
Section 4.3, “Workload Management,” on page 33
Section 4.4, “Policy Management,” on page 34
Section 4.5, “Auditing and Accounting Jobs,” on page 35
Section 4.6, “BuildTest Job Examples,” on page 35
4.1 Resource Discovery
Resource discovery jobs inspect a resource’s environment to set resource facts stored with the
resource grid object. These jobs automatically discover the resource attributes (fully extensible facts
relating to such things as CPU, memory, storage, bandwidth, load, software inventory) of the
resources being managed by the PlateSpin Orchestrate Server. These resource attributes are called
“facts.” These facts are used during PlateSpin Orchestrate runtime from within a policy or constraint
to select resources that have certain identifiable attributes.
novdocx (en) 13 May 2009
4
For more information, see “Walkthrough: Observing Discovery Jobs” in the PlateSpin Orchestrate
2.0 Installation and Configuration Guide, and “Discovering Registered VM Hosts” in the PlateSpin
Orchestrate 2.0 VM Client Guide and Reference.
4.1.1 Provisioning Jobs
The provisioning jobs included in PlateSpin Orchestrate are used for interacting with VM hosts and
repositories for VM life cycle management and for cloning, moving VMs, and other management
tasks. These jobs are called “Provisioning Adapters” and are members of the job group called
“provisionAdapters.”
With respect to resource discovery, the provisioning jobs are used to discover VM hosts (those
resources running a VM technology such as Xen or VmWare) and VM image repositories, as well as
VM images residing in those repositories.
For more information, see Section 9.2, “Virtual Machine Management,” on page 79 in this guide.
4.1.2 Resource Discovery Jobs
Some of the commonly used resource discovery jobs include:
“cpuInfo.job” on page 32
“demoInfo.job” on page 32
“findApps.job” on page 32
“osInfo.job” on page 32
Using PlateSpin Orchestrate Jobs
31
Page 32

cpuInfo.job
Gets CPU information of a resource.
demoInfo.job
Generates the CPU, operating system, and application information for testing.
findApps.job
Finds and reports what applications are installed on the datagrid.
osInfo.job
novdocx (en) 13 May 2009
Gets the operating system of a grid resource. On Linux, it reads the
uname
it reads the registry; on UNIX, it executes
resource.cpu.mhz (integer) e.g., "800" (in Mhz)
resource.cpy.vendor (string) e.g. "GenuineIntel"
resource.cpu.model (string) e.g. "Pentium III"
resource.cpu.family (string) e.g. "i686"
.
/proc/cpuinfo
; on Windows,
4.2 Resource Selection
PlateSpin Orchestrate lets you create jobs that meet the infrastructure scheduling and resource
management requirements of your data center, as illustrated in the following figure.
Figure 4-1 Multi-Dimensional Resource Scheduling Broker
There are many combinations of constraints and scheduling demands on the system that can be
managed by the highly flexible PlateSpin Orchestrate resource broker. As shown in the figure below,
many object types are managed by the resource broker. Resource objects are discovered (see
Section 4.1, “Resource Discovery,” on page 31). Other object types such as users and jobs can also
be managed. All of these object types have “facts” that define their specific attributes and
operational characteristics. PlateSpin Orchestrate compares these facts to requirements set by the
administrator for a specific data center task. These comparisons are called “constraints.”
A policy is an XML file that specifies (among other things) constraints and fact values. Policies
govern how jobs are dynamically scheduled based on various job constraints. These job constraints
are represented in the following figure.
32 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 33

Figure 4-2 Policy-Based Resource Management Relying on Various Constraints
Figure 4-3 Policy-Based Job Management
novdocx (en) 13 May 2009
See Chapter 8, “Job Scheduling,” on page 71 for examples of scheduling jobs. See also Section 7.7,
“Working with Facts and Constraints,” on page 55.
The Resource Broker function of the Orchestrate Server allocates or “dynamically schedules”
resources based on the runtime requirements of a job (for example, the necessary CPU type, OS
type, and so on) rather than allocating a specific machine in the data center to run a job. These
requirements are defined inside a job policy and are called “resource constraints.” In simpler terms,
in order to run a given job, the Resource Broker looks at the resource constraints defined in a job and
then allocates an available resource that can satisfy those constraints.
4.3 Workload Management
The Orchestrate Server uses a Provisioning Manager to allocate (assign) and preempt (reassign)
resources.
Using PlateSpin Orchestrate Jobs 33
Page 34

The Provisioning Manager preempts a resource by monitoring the job queue that is waiting for
allocation. The manager then compares the job’s relative priority to jobs already consuming
resources. Higher priority jobs can preempt lower priority jobs.
Figure 4-4 Workload Management
novdocx (en) 13 May 2009
Depending on the tasks that applications might require, the Orchestrate Server submits the required
jobs to one or more of the connected managed resources to perform specific tasks.
For more information about how job scheduling and provisioning works, see the following sections:
Chapter 8, “Job Scheduling,” on page 71
Section 9.6, “Automatically Provisioning a VM,” on page 87
Examples: dgtest.job (page 126) and factJunction.job (page 168).
4.4 Policy Management
Policies are XML-based files that aggregate the resource facts and constraints that are used to
control resources.
Policies are used to enforce quotas, job queuing, resource restrictions, permissions, etc. They can be
associated with various grid objects (jobs, users, resources, etc.). The policy example below shows a
constraint that limits the number of running jobs to a defined value, while exempting certain users
from this limit. Jobs started that exceed the limit are queued until the running jobs count decreases
and the constraint passes:
<policy>
<constraint type="start" reason="too busy">
<or>
<lt fact="job.instances.active" value="5" />
<eq fact="user.name" value="canary" />
</or>
</constraint>
</policy>
Policies can be based on goals, entitlements, quotas, and other factors, all of which are controlled by
jobs.
34 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 35

Figure 4-5 Policy Types and Examples
novdocx (en) 13 May 2009
For more information about policies, see Section 7.7, “Working with Facts and Constraints,” on
page 55.
4.5 Auditing and Accounting Jobs
You can create PlateSpin Orchestrate jobs that perform reporting, auditing, and costing functions
inside your data center. Your jobs can aggregate cost accounting for assigned resources and perform
resource audit trails.
4.6 BuildTest Job Examples
There are many available facts that you can use in creating your jobs. If you find that you need
specific kinds of information about a resource or a job, such as the load average of a user or the ID
of a job or joblet, chances are that it is already available.
If a fact is not listed, you can create your own facts by creating a
You can also create a fact directly in the JDL job code.
If you want to remember something from one loop to the next or make something available to other
objects in the grid, you can set a fact with your own self-defined name.
This section shows an example of a relatively simple working job that performs a set (100) of
regression tests on three different platform types. A number of assumptions have been made to
simplify this example:
<fact>
element in the job policy.
Each regression test is atomic and has no dependencies.
Every resource is preconfigured to run the tests. Typically, the configuration setup is included
as part of the job.
Using PlateSpin Orchestrate Jobs 35
Page 36

The tests are expressed as line entries in a file. PlateSpin Orchestrate has multiple methods to
specify parameters. This (
dir c:/windows
dir c:/windows/system32
dir c:/notexist
dir c:/tmp
dir c:/cygwin
/QA/testlists/nightly.dat
) is just one example:
To demonstrate the possible functionality for this example, here are some policies that might apply
to this example:
Only users running tests can use resources owned by their group.
To conserve resources, terminate the test after 50 failures.
Because the system under test requires a license, prevent more than three of these regression
tests from running at one time.
To prevent a job backlog, limit the number of queued jobs in the system.
To allow the regression test run to tolerate resource failures (for example, unexpected network
disconnections, unexpected reboots, and so on), enable automatic failover without affecting the
regression run.
novdocx (en) 13 May 2009
The section includes the following information:
Section 4.6.1, “buildTest.policy Example,” on page 36
Section 4.6.2, “buildTest.jdl Example,” on page 37
Section 4.6.3, “Packaging Job Files,” on page 40
Section 4.6.4, “Deploying Packaged Job Files,” on page 40
Section 4.6.5, “Running Your Jobs,” on page 41
Section 4.6.6, “Monitoring Job Results,” on page 41
Section 4.6.7, “Debugging Jobs,” on page 42
4.6.1 buildTest.policy Example
Policies are typically spread over different objects, entities, and groups on the system. However, to
simplify the concept, we have combined all policies into this one example that is directly associated
with the job.
The arguments available to the job are specified in the in the
<jobargs>
the job is run, job arguments are made available as facts to the job instance. The default values of
these arguments can be overridden when the job is invoked.
1 <policy>
2 <jobargs>
3 <fact name="buildId"
4 type="String"
5 value="02-24-06 1705"
6 description="Build Id to show in memo field" />
7 <fact name="testlist" type="String"
9 value="/QA/testlists/nightly.dat"
10 description="Path to testlist to use in tests" />
11 </jobargs>
section (lines 1-11). When
36 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 37

The
<job>
section (lines 12-25) defines facts that are associated with the job. These facts are used in
other policies or by the JDL logic itself. Typically, these facts are aggregated from inherited policies.
12 <job>
13 <fact name="max_queue_size"
14 type="Integer"
15 value="10"
16 description="Limit of queued jobs. Any above this limit are not
accepted." />
17 <fact name="max_licenses"
18 type="Integer"
19 value="5"
20 description="License count to limit number of jobs to run
simultaneously. Any above this limit are queued." />
21 <fact name="max_test_failures"
22 type="Integer"
23 value="50"
24 description="To decide to end the job if the number of failures
exceeds a limit" />
25 </job>
The
<accept>
(line 26),
<start>
(line 31), and
<continue>
(line 40) constraints control the job
life cycle and implement the policy outlined in the example. In addition, allowances are made for
“privileged users” (lines 28 and 33) to bypass the accept and start constraints.
novdocx (en) 13 May 2009
26 <constraint type="accept" reason="Maximum number of queued jobs has been
reached">
27 <or>
28 <defined fact="user.privileged_user" />
28 <lt fact="job.instances.queued" factvalue="job.max_queue_size" />
29 </or>
30 </constraint>
31 <constraint type="start">
32 <or>
33 <defined fact="user.privileged_user" />
34 <lt fact="job.instances.active" factvalue="job.max_licenses" />
35 </or>
36 </constraint>
The
<resource>
constraint (lines 37 and 38) ensures that only resources that are members of the
buildtest group are used by this job.
37 <constraint type="resource">
38 <contains fact="resource.groups" value="buildtest" reason="No
resources are in the buildtest group" />
39 </constraint>
40 <constraint type="continue" >
41 <lt fact="jobinstance.test_failures"
factvalue="job.max_test_failures" reason="Reached test failure limit" />
42 </constraint>
</policy>
4.6.2 buildTest.jdl Example
The following example shows how additional resource constraints representing the three test
platform types are specified in XML format. These also could have been specified in PlateSpin
Orchestrate Development Client.
Using PlateSpin Orchestrate Jobs 37
Page 38

Setting Resource Constraints
The annotated JDL code represents the job definition, consisting of base Python v2.1 (and libraries)
as well as a large number of added PlateSpin Orchestrate operations that allow interaction with the
Orchestrate Server:
1 import sys,os,time
2 winxp_platform = "<eq fact=\"resource.os.name\" value=\"Windows XP\" />"
3 win2k_platform = "<eq fact=\"resource.os.name\" value=\"Windows 2000\" />"
4 win2003_platform = "<eq fact=\"resource.os.name\" value=\"Windows 2003
Server\" />"
Lines 2-4 specify the resource constraints representing the three test platform types (Windows XP,
Windows 2000, and Windows 2003) in XML format.
novdocx (en) 13 May 2009
job_started_event
The
in line 6 is the first event delivered to the job on the server.The logic in
this method performs some setup and defines the parameter space used to iterate over the tests.
5 class BuildTest(Job):
6 def job_started_event(self):
7 self.total_counts = {"failed":0,"passed":0,"run":0}
8 self.setFact("jobinstance.test_failures",0)
9 self.testlist_fn = self.getFact("jobargs.testlist")
10 self.buildId = self.getFact("jobargs.buildId")
11 self.form_memo(self.total_counts)
12 # Form range of tests based on a testlist file
13 filerange = FileRange(self.testlist_fn)
Parameter spaces (lines 14-16) can be multidimensional but, in this example, they schedule three
units of work (joblets), one for each platform type, each with a parameter space of the range of lines
in the (optionally) supplied test file (lines 21, 24 and 27).
14 # Form ParameterSpace defining Joblet Splitting
15 pspace = ParameterSpace()
16 pspace.appendDimension("cmd",filerange)
17 # Form JobletSet defining execution on resources
18 jobletset = JobletSet()
19 jobletset.setCount(1)
20 jobletset.setJobletClass(BuildTestJoblet)
Within each platform test, a joblet is scheduled for each test line item on each different platform.
21 # Launch tests on Windows XP
22 jobletset.setConstraint(winxp_platform)
23 self.schedule(jobletset)
24 # Launch tests on Windows 2000
25 jobletset.setConstraint(win2k_platform)
26 self.schedule(jobletset)
27 # Launch tests on Windows 2003
28 jobletset.setConstraint(win2003_platform)
29 self.schedule(jobletset)
38 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 39

The
test_results_event
in line 32 is a message handler that is called whenever the joblets send
test results.
30 # Event invoked when a Joblet has completed running tests.
31 #
32 def test_results_event(self,params):
33 self.form_memo(params)
Creating a Memo Field
novdocx (en) 13 May 2009
In line 37, the
form_memo
method is called to form an informational string to display the running
totals for this test. These totals are displayed in the memo field for the job (visible in the Orchestrate
Development Client, and Web interface tools). The memo field is accessed through setting the String
jobinstance.memo
fact
34 #
35 # Update the totals and write totals to memo field.
36 #
37 def form_memo(self,params):
38 # total_counts will be empty at start
39 m = "Build Test BuildId %s " % (self.buildId)
40 i = 0
41 for key in self.total_counts.keys():
42 if params.has_key(key):
43 total = self.total_counts[key]
44 count = params[key]
45 total += count
46 printable_key = str(key).capitalize()
47 if i > 0:
48 m += ", "
48 else:
49 if len(m) > 0:
50 m+= ", "
51 m += printable_key + ": %d" % (total)
52 i += 1
53 self.total_counts[key] = total
54 self.setFact("jobinstance.test_failures",self.total_counts["failed"])
55 self.setFact("jobinstance.memo",m)
in line 55.
Joblet Definition
As previously discussed, a joblet is the logic that is executed on a remote resource employed by a
job, as defined in lines 56-80, below. The
job_started_event
(line 6) but runs on a different resource than the server.
joblet_started_event
in line 60 mirrors the
The portion of the parameter space allocated to this joblet in line 65-66 represents some portion of
the total test (parameter) space. The exact breakdown of this is under full control of the
administrator/job. Essentially, the size of the “work chunk” in line 67 is a compromise between
overhead and retry convenience.
In this example, each element of the parameter space (a test) in line 76 is executed and the exit code
is used to determine pass or failure. (The exit code is often insufficient and additional logic must be
added to analyze generated files, copy results, or to perform other tasks.) A message is then sent
back to the job prior to completion with the result counts.
Using PlateSpin Orchestrate Jobs 39
Page 40

56 #
57 # Define test execution on a resource.
58 #59 class BuildTestJoblet(Joblet):
60 def joblet_started_event(self):
61 passed = 0
62 failed = 0
63 run = 0
64 # Iterate over parameter space assigned to this Joblet
65 pspace = self.getParameterSpace()
66 while pspace.hasNext():
67 chunk = pspace.next()
68 cmd = chunk["cmd"].strip()
69 rslt = self.run_cmd(cmd)
70 print "rslt=%d cmd=%s" % (rslt,cmd)
71 if rslt == 0:
72 passed +=1
73 else:
74 failed +=1
75 run += 1
76
self.sendEvent("test_results_event",{"passed":passed,"failed":failed,"run":ru
n})
77 def run_cmd(self,cmd):
78 e = Exec()
79 e.setCommand(cmd)
80 return e.execute()
novdocx (en) 13 May 2009
4.6.3 Packaging Job Files
A job package might consist of the following elements:
Job description language (JDL) code (the Python-based script containing the bits to control
jobs).
One or more policy XML files, which apply constraints and other job facts to control jobs.
Constraints and facts are discussed Constraints (page 45) and Facts (page 45).
Any other associated executables or data files that the job requires. For example, the
cracker.jdl
sample job includes a set of Java code that discovers the user password in every
configured agent before the Java class is run.
Or, many discovery jobs that measure performance of Web servers or monitor any other
applications can include resource discovery utilities that enable resource discovery.
Section 7.2, “JDL Package,” on page 50 provides more information about job elements.
4.6.4 Deploying Packaged Job Files
After jobs are created, you deploy
using any of the following methods:
Copying job files into the “hot” Orchestrate Server deployment directory. See “Deploying a
Sample System Job” in the PlateSpin Orchestrate 2.0 Development Client Reference.
.jdl
or multi-element
.job
files to the Orchestrate Server by
40 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 41

Using the Orchestrate Development Client.
Using the PlateSpin Orchestrate command line (CLI) tools. This process is discussed in “The
zos Command Line Tool” in the PlateSpin Orchestrate 2.0 Command Line Reference and in
“The zosadmin Command Line Tool” in the PlateSpin Orchestrate 2.0 Command Line
Reference.
4.6.5 Running Your Jobs
After your jobs are deployed, you can execute them by using the following methods:
Command Line Interface: Nearly all PlateSpin Orchestrate functionality, including deploying
and running jobs, can be performed using the command line tool, as shown in the following
example:
zos run buildTest [testlist=mylist]
JobID: paul.buildTest.14
More detailed CLI information is available in the zos command line tool.
Server Portal: After PlateSpin Orchestrate is installed, you can use the PlateSpin Orchestrate
Server Portal to run jobs. This process is discussed in the PlateSpin Orchestrate 2.0 Server
Portal Reference.
Custom Client: The PlateSpin Orchestrate toolkit provides an SDK that provides a custom
client that can invoke your custom jobs. This process is discussed in Appendix A, “PlateSpin
Orchestrate Client SDK,” on page 187.
Built-in Job Scheduler: The Orchestrate Server uses a built-in Job Scheduler to run deployed
jobs. This tool is discussed in Chapter 8, “Job Scheduling,” on page 71 and in “The PlateSpin
Orchestrate Job Scheduler”in the PlateSpin Orchestrate 2.0 Development Client Reference.
From Other Jobs: As part of a job workflow, jobs can be invoked from within other jobs. You
integrate these processes within your job scripts as described in the Chapter 8, “Job
Scheduling,” on page 71.
novdocx (en) 13 May 2009
4.6.6 Monitoring Job Results
PlateSpin Orchestrate lets you monitor jobs by using the same methods outlined in Section 4.6.5,
“Running Your Jobs,” on page 41.
Monitoring Jobs from the Command Line
The following example shows the status of the job
interfaces:
zos status -e ray.buildtest.18
Job Status for ray.buildtest.18
------------------------------ State: Completed (0 this job)
Resource Count: 0
Percent Complete: 100%
Queue Pos: 1 of 1 (initial pos=1)
Child Job Count: 0 (0 this job)
ray.buildtest.18
using different monitoring
Using PlateSpin Orchestrate Jobs 41
Page 42

Instance Name: Buildtest
Job Type: buildtest
Memo: Build Test BuildID 02-02-09 1705 , failed: 1, Run: 5,
Passed: 4
Priority: medium
Arguments: <none>
Submit Time: 02/02/2009 01:46:12
Delayed Start: n/a
Start Time: 02/02/2009 01:46:12
End Time: 01/01/1009 01:46:14
Elapsed Time: 0:00:01
Queue Time: 0:00:00
Pause Time: 0:00:00
Total CPU Time: 0:00:00 (0:00:00 this job)
Total GCycles: 0:00:00 (0:00:00 this job)
Total Cost: $0.0002 ($0.0002 this job)
Burn Rate: $0.0003/hr (0.0003/hr this job)
The bottom section of the status report shows that you can also monitor job costing metrics, which
are quite minimal in this example. More sophisticated job monitoring is possible.
novdocx (en) 13 May 2009
Monitoring Jobs from the Server Portal
You can use the status page of the Server Portal to monitor jobs. In this example, the job memo field
is displayed.
Figure 4-6 Server Portal Job Monitoring Example
4.6.7 Debugging Jobs
The following view of the Development Client shows how you can determine that the
job was not able to find or match any resources because resources were not added to the buildtest
group as required by the policy.
42 PlateSpin Orchestrate 2.0 Developer Guide and Reference
buildTest
Page 43

Figure 4-7 Debugging Jobs Using the Orchestrate Development Client
novdocx (en) 13 May 2009
The policy debugger shows the blocking constraint, and the tooltip gives the reason. If you drag and
drop to add resources to the required group, the job continues quickly with no restart.
Using PlateSpin Orchestrate Jobs 43
Page 44

novdocx (en) 13 May 2009
44 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 45

5
Policy Elements
PlateSpin® Orchestrate policy elements are represented in XML. A policy can be deployed to the
server and associated with any grid object. The policy element is the root element for policies.
Policies contain constraints and fact definitions for grid objects:
Section 5.1, “Constraints,” on page 45
Section 5.2, “Facts,” on page 45
Section 5.3, “Computed Facts,” on page 45
5.1 Constraints
The constraint element defines the selection of grid objects such as resources. The required type
attribute defines the selection type. Supported types are:
resource
provision
allocation
novdocx (en) 13 May 2009
5
accept
start
continue
vmhost
repository
Constraints can also be constructed in JDL and in the Java Client SDK. A JDL constructed
constraint can be used for grid search and for scheduling. A Java Client SDK constructed constraint
can only be used for grid object search. See also Section 7.7, “Working with Facts and Constraints,”
on page 55.
5.2 Facts
The XML fact element defines a fact to be stored in the grid object’s fact namespace. The name,
type and value of the fact are specified as attributes. For list or array fact types, the element tag
defines list or array members. For dictionary fact types, the dict tag defines dictionary members.
See the example,
fact types.
Facts can also be created and modified in JDL and in the Java Client SDK.
/allTypes.policy
. This example policy has an XML representation for all the
5.3 Computed Facts
Computed facts are used when you want to calculate the value for a fact. Although computed facts
are not jobs, they use the same JDL syntax.
To create a new computed fact outside of the Orchestrate Development Client, you can create a file
with a
.cfact
extension with the JDL to compute the fact value.
Policy Elements
45
Page 46

After the new computed fact is created, you deploy it using the same procedures required for jobs
(using either the zosadmin command line tool or the Orchestrate Development Client).
The following example shows a computed fact that returns the number of active job instances for a
specific job for the current job instance. This fact can be used in an accept or start constraint to limit
how many jobs a user can run in the system. The constraint is added to the job policy in which to
have the limit. In this example, the start constraint uses this fact to limit the number of active jobs for
a user to one:
"""
<constraint type="start" >
<lt fact="cfact.activejobs"
value="1"
reason="You are only allowed to have 1 job running at a time" />
</constraint>
Change JOB_TO_CHECK to define which job is to be limited.
"""
JOB_TO_CHECK="quickie"
class activejobs(ComputedFact):
novdocx (en) 13 May 2009
def compute(self):
j = self.getContext()
if j == None:
# This means computed Fact is executed in a non running
# job context. e.g., the ZOC fact browser
print "no job instance"
return 0
else:
# Computed fact is executing in a job context
user = j.getFact("user.id")
activejobs = self.getMatrix().getActiveJobs()
count = 0
for j in activejobs:
jobname = j.getFact("job.id")
# Don't include queued in count !
state = j.getFact("jobinstance.state.string")
if jobname == JOB_TO_CHECK \
and j.getFact("user.id") == user \
and (state == "Running" or state == "Starting"):
count+=1
jobid = j.getFact("jobinstance.id")
print "jobid=%s count=%d" % (jobid,count)
return count
For another computed fact example, see activejobs.cfact (located in the
activejobs.cfact
directory).
46 PlateSpin Orchestrate 2.0 Developer Guide and Reference
examples/
Page 47

6
Using the PlateSpin Orchestrate
novdocx (en) 13 May 2009
Client SDK
PlateSpin® Orchestrate from Novell® includes a Java* Client SDK in which you can write Java
applications to remotely manage jobs. The zos command line tool is written using the Client SDK,
as described in Appendix A, “PlateSpin Orchestrate Client SDK,” on page 187. This SDK
application can perform the following operations:
Login and logout to an Orchestrate Server.
Manage the life cycle of a job (run/cancel).
Monitor running jobs (get job status).
Communicate to a running job using events.
Receive events from a running job.
Search for grid objects using constraints.
Retrieve and modify grid object facts.
Datagrid operations (such as copying files to the server and downloading files from the server).
6.1 SDK Requirements
Before you can run the PlateSpin Orchestrate Client SDK, you must perform the following tasks:
6
1. Install the PlateSpin Orchestrate Client package. For instructions, see “Installing and
Configuring All PlateSpin Orchestrate Components Together” and “Walkthrough: Launching
the PlateSpin Orchestrate Development Client” in the PlateSpin Orchestrate 2.0 Installation
and Configuration Guide.
2. Install JDK 1.4.x or 1.5.x.
3. Examine the two example PlateSpin Orchestrate SDK client applications that are included in
the examples directory:
extranetDemo: Provides a sophisticated example of launching multiple jobs and listening
and sending events to running jobs.
cracker: Demonstrates a simple example how to launch a job and listen for events sent
from the job to the client application..
6.2 Creating an SDK Client
Use the following procedure to create an SDK client in conjunction with the sample Java code (see
Section A.3.2, “ClientAgent,” on page 193):
1 Create ClientAgent instance:
// example zos server host is "myserver"
ClientAgent clientAgent = ClientAgentFactory.newClientAgent("myserver");
Using the PlateSpin Orchestrate Client SDK
47
Page 48

2 Use the following user and password example to log in to the Orchestrate Server (see
“Walkthrough: Logging In to the PlateSpin Orchestrate Server” in the PlateSpin Orchestrate
2.0 Installation and Configuration Guide):
Credential credential =
CredentialFactory.newPasswordCredential(username,password);
clientAgent.login(credential);
3 Run the server operations. In this case, it is the
quickie.jdl
example job (which must have
been previously deployed) with no job arguments:
String jobID = clientAgent.runJob("quickie",null)
4 (Optional) Listen for server events using the AgentListener interface:
clientAgent.addAgentListener(this);
4a Register with the PlateSpin Orchestrate Server to receive job events for the job you
started.
clientAgent.getMessages(jobID);
5 Log out of the server:
clientAgent.logout()
novdocx (en) 13 May 2009
48 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 49

7
Job Architecture
The PlateSpin® Orchestrate Job Scheduler is a sophisticated scheduling engine that maintains high
performance network efficiency and quality user service when running jobs on the grid. Such
efficiencies are managed through a set of grid component facts that operate in conjunction with job
constraints. Facts and constraints operate together like a filter system to maintain both the
administrator’s goal of high quality of service and the user’s goal to run fast, inexpensive jobs.
This section explains the following job architectural concepts:
Section 7.1, “Understanding JDL,” on page 49
Section 7.2, “JDL Package,” on page 50
Section 7.3, “Job Class,” on page 51
Section 7.4, “Job Invocation,” on page 53
Section 7.5, “Deploying Jobs,” on page 53
Section 7.6, “Starting PlateSpin Orchestrate Jobs,” on page 55
Section 7.7, “Working with Facts and Constraints,” on page 55
novdocx (en) 13 May 2009
7
Section 7.8, “Using Facts in Job Scripts,” on page 58
Section 7.9, “Using Other Grid Objects,” on page 59
Section 7.10, “Communicating Through Job Events,” on page 60
Section 7.11, “Executing Local Programs,” on page 61
Section 7.12, “Logging and Debugging,” on page 63
Section 7.13, “Improving Job and Joblet Robustness,” on page 65
Section 7.14, “Using an Event Notification in a Job,” on page 66
7.1 Understanding JDL
The PlateSpin Orchestrate Grid Management system uses an embedded Python-based language for
describing jobs (called the Job Definition Language or JDL). This scripting language is used to
control the job flow, request resources, handle events and generally interact with the Grid server as
jobs proceed.
Jobs run in an environment that expects facts (information) to exist about available resources. These
facts are either set up manually through configuration or automatically discovered via discovery
jobs. Both the end-user jobs and the discovery jobs have the same structure and language. The only
difference is in how they are scheduled.
The job JDL controls the complete life cycle of the job. JDL is a scripting language, so it does not
provide compile-time type checking. There are no checks for infinite loops, although various
precautions are available to protect against runaway jobs, including job and joblet timeouts,
maximum resource consumption, quotas, and limited low-priority JDL thread execution.
As noted, the JDL language is based on the industry standard Python language, which was chosen
because of its widespread use for test script writing in QA departments, its performance, its
readability of code, and ease to learn.
Job Architecture
49
Page 50

The Python language has all the familiar looping and conditional operations as well as some
powerful operations. There are various books on the language including O’Reilly’s Python in a
Nutshell and Learning Python. Online resources are available at http://www.python.org (http://
www.python.org)
Within the Orchestrate Server and grid jobs, JDL not only adds a suite of new commands but also
provides an event-oriented programming environment. A job is notified of every state change or
activity by calling an appropriately named event handler method.
A job only defines handlers for events it is interested in. In addition to built-in events (such as,
joblet_started_event, job_completed_event, job_cancelled_event
job_started_event
) it can define handlers for custom events caused by incoming messages. For
, and
example, if a job (Job (page 226) class) defines a method as follows:
def my_custom_event(self, job, params):
print \u201cGot a my_custom event carrying ", params)
And the joblet (Joblet (page 228) class) sends an event/message as follows:
self.sendEvent(“my_custom_evemt”, {“arg1”:”one”})
novdocx (en) 13 May 2009
NOTE: The event being sent has to be the same name as the defined method receiving the event.
The following line is added to the job log:
Got a my_custom event carrying arg1=”one”
JDL can also define timer events (periodic and one-time) with similar event handlers.
Each event handler can run in a separate thread for parallel execution or can be synchronized to a
single thread. A separate thread results in better performance, but also incurs the development
expense of ensuring that shared data structures are thread safe.
7.2 JDL Package
The job package consists of the following elements:
Job Description Language (JDL) code, consisting of a Python-based script containing the bits
to control jobs.
An optional policy XML file, which applies constraints and other job facts to control jobs.
Any other associated executables or data files that the job requires.
The
cracker.jdl
password in every configured agent before the Java class is run. Or, many discovery jobs, which
measure performance of Web servers or monitor any other applications, might include resource
discovery utilities that enable resource discovery.
sample job, for example, includes a set of Java code that discovers the user
Jobs include all of the code, policy, and data elements necessary to execute specific, predetermined
tasks administered either through the PlateSpin Orchestrate Development Client user interface or
from the command line. Because each job has specific, predefined elements, jobs can be scripted
and delivered to any agent, which ultimately can lead to automating almost any datacenter task.
50 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 51

7.2.1 .sched Files
novdocx (en) 13 May 2009
Job packages also can contain optional XML
.sched
files that describe the scheduling requirements
for any job. This file defines when the job is run.
For example, jobs might be run whenever an agent starts up, which is defined in the
.sched
file.
The discovery job “osInfo.job” on page 32 has a schedule XML file that specifies to always run a
specified job whenever a specific resource is started and becomes available.
7.3 Job Class
The Job class is a representation of a running job instance. This class defines functions for
interacting with the server, including handling notification of job state transitions, child job
submission, managing joblets and for receiving and sending events from resources and from clients.
A job writer defines a subclass of the job class and uses the methods available on the job class for
scheduling joblets and event processing.
For more information about the methods this class uses, see Section 7.3.1, “Job State Transition
Events,” on page 51.
The following example demonstrates a job that schedules a single joblet to run on one resource:
class Simple(Job):
def job_started_event(self):
self.schedule(SimpleJoblet)
class SimpleJoblet(Joblet):
def joblet_started_event(self):
print "Hello from Joblet"
For the above example, the class
Simple
is instantiated on the server when a job is run either by
client tools or by the job scheduler. When a job transitions to the started state, the method
job_started_event
schedule()
SimpleJoblet
to create a single joblet and schedule the joblet to run on a resource. The
is invoked. Here the
job_started_event
invokes the base class method
class is instantiated and run on a resource. A resource is a physical or virtual
machine on which the Orchestrator Agent is installed and running and where the Joblet code is
executed.
7.3.1 Job State Transition Events
Each job has a set of events that are invoked at the state transitions of a job. On the starting state of a
job, the
job_started_event
The following is a list of job events that are invoked upon job state transitions:
job_started_event
job_completed_event
job_cancelled_event
job_failed_event
job_paused_event
job_resumed_event
The following is a list of job events that are invoked upon child job state transitions:
is always invoked.
Job Architecture 51
Page 52

child_job_started_event
child_job_completed_event
child_job_cancelled_event
child_job_failed_event
The following is a list of provisioner events that are invoked upon provisioner state transitions:
provisioner_completed_event
provisioner_cancelled_event
provisioner_failed_event
The following is a list of joblet events that are invoked as the joblet state transitions:
joblet_started_event
joblet_completed_event
joblet_failed_event
joblet_cancelled_event
joblet_retry_event
novdocx (en) 13 May 2009
NOTE: Only the
job_started_event
is required; other events are optional.
7.3.2 Handling Custom Events
A job writer can also handle and invoke custom events within a job. Events can come from clients,
other jobs, and from joblets.
The following example defines an event handler named
class Simple(Job):
def job_started_event(self):
...
def mycustom_event(self,params):
dir = params["directory_to_list"]
self.schedule(MyJoblet,{ "dir" : dir } )
mycustom_event
In this example, the event retrieves a element from the params dictionary that is supplied to every
custom event. The dictionary is optionally filled by the caller of the event.
The following example invokes the custom event named
mycustom_event
Orchestrate client command line tool:
zos event <jobid_of_running_job> mycustom_event directory_to_list="/tmp"
In this example, a message is sent from the client tool to the job running on the server.The following
example invokes the same custom event from a joblet:
in a job:
from the PlateSpin
class SimpleJoblet(Joblet):
def joblet_started_event(self):
...
self.sendEvent("mycustom_event", {"directory_to_list":"/tmp"} )
In this example, a message is sent from the joblet running on a resource to the job running on the
server. The running job has access to a factset which is the aggregation of the job instance factset
(jobinstance.*), the deployed job factset (job.*, jobargs.*), the User factset (user.*), the Matrix
factset (matrix.*) and any jobargs or policy facts supplied at the time the job is started.
Fact values are retrieved using the GridObjectInfo (page 223) functions that the job class inherits.
52 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 53

The following example retrieves the value of the job instance fact state.string from the jobinstance
namespace:
class Simple(Job):
def job_started_event(self):
jobstate = self.getFact("jobinstance.state.string")
print "job state=%s" % (jobstate)
For further details about each of the events above, see Section B.1, “Job Class,” on page 201.
novdocx (en) 13 May 2009
The following example uses the
running on. If you implement the
joblet_started_event
joblet_started_event
to determine the resource a Joblet is
job method, your job is notified when a
Joblet has started execution:
1 class test(Job):
2 def job_started_event(self):
3 self.schedule(TestJoblet)
4
5 def joblet_started_event(self,jobletNum,resourceId):
6 print "joblet %d is running on %s" % (jobletNum, resourceId)
7
8 class TestJoblet(Joblet):
9 def joblet_started_event(self):
10 import time
11 time.sleep(10)
In lines 5 and 6, the
joblet_started_event
is notified when the instance of
TestJoblet
is
executing on a resource.
7.4 Job Invocation
Jobs can be started using either the zos command line tool, scheduling through a
manually through the PlateSpin Orchestrate Development Client. Internally, when a job is invoked,
an XML file is created. It can be deployed immediately or it can be scheduled for later deployment,
depending upon the requirements of the job.
.sched
file, or
Jobs also can be started within a job. For example, you might have a job that contains JDL code to
run a secondary job. Jobs also can be started through the Web portal.
Rather than running jobs immediately, there are many benefits to using the Job Scheduling Manager:
Higher priority jobs can be run first and jump ahead in the scheduling priority band.
Jobs can be run on the least costly node resources when accelerated performance is not as
critical.
Jobs can be run on specific types of hardware.
User classes can be defined to indicate different priority levels for running jobs.
7.5 Deploying Jobs
A job must be deployed to the Orchestrate Server before it can be run. Deployment to the server is
done in either of the following ways:
Section 7.5.1, “Using the PlateSpin Orchestrate Development Client,” on page 54
Section 7.5.2, “Using the zosadmin Command Line Tool,” on page 54
Job Architecture 53
Page 54

7.5.1 Using the PlateSpin Orchestrate Development Client
1 In the Actions menu, click Deploy Job.
2 For additional deployment details, see “Walkthrough: Deploying a Sample Job” in the
PlateSpin Orchestrate 2.0 Installation and Configuration Guide.
7.5.2 Using the zosadmin Command Line Tool
novdocx (en) 13 May 2009
From the CLI, you can deploy a component file (
.job, .jdl, .sar
) or refer to a directory
containing job components.
.job
files are Java jar archives containing
.sar
your job. A
1 To deploy a
>zosadmin deploy <myjob>.job
file is a Java jar archive for containing multiple jobs and policies.
.job
file from the command line, enter the following command:
2 To deploy a job from a directory where the directory
.sched
>zosadmin deploy /jobs/myjob
, and any other files required by your job, enter the following command:
Deploying from a directory is useful if you want to explode an existing job or
redeploy the job components without putting the job back together as a
.jdl, .policy, .sched
/jobs/myjob
and any other files required by
contains
.jdl, .policy
.sar
.job
or
.sar
file and
file.
,
3 Copy the job file into the “hot” deploy directory by entering the following command:
>cp <install dir>/examples/whoami.job <install dir>/deploy
As part of an iterative process, you can re-deploy a job from a file or a directory again after specified
local changes are made to the job file. You can also undeploy a job out of the system if you are done
with it. Use
zosadmin redeploy
and
zosadmin undeploy
to re-deploy and undeploy jobs,
respectively.
A typical approach to designing, deploying, and running a job is as follows:
1. Identify and outline the job tasks you want the Orchestrate Server to perform.
2. Use the preconfigured JDL files for specific tasks listed in Appendix B, “PlateSpin Orchestrate
Job Classes and JDL Syntax,” on page 201.
3. To configure jobs, edit the JDL file with an external text editor.
4. Repackage the job as a
.jar
file.
NOTE: The job could also be packaged and sent as an “exploded” file.
5. Run the zos CLI administration tool to redeploy the packaged job into the Orchestrate Server.
6. Run the job using the zos command line tool.
7. Monitor the results of the job in the PlateSpin Orchestrate Development Client.
Another method to deploy jobs is to edit JDL files through the Orchestrate Development Client.The
development client has a text editor that enables you to make changes directly in the JDL file as it is
stored on the server ready to deploy. After changes are made and the file is saved using the
Orchestrate Development Client, you simply re-run the job without redeploying it. The procedure is
useful when you need to fix typos in the JDL file or have minor changes to make in the job
functionality.
54 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 55

NOTE: Redeploying a job overwrites any job that has been previously saved on the Orchestrate
Server. The Orchestrate Development Client has a Save File menu option if you want to preserve
JDL modifications you made using the Orchestrate Development Client.
.jdl
There is no way “undo” a change to a
Client has saved the file, nor is there a method for rolling back to a previously deployed version. We
recommend that you use an external source code control system such as CVS or SVN for version
control.
file after the JDL editor in the Orchestrate Development
7.6 Starting PlateSpin Orchestrate Jobs
Jobs can be started by using any of the following options:
novdocx (en) 13 May 2009
Running jobs from the
Orchestrate 2.0 Command Line Reference).
Running jobs from the PlateSpin Orchestrate Job Scheduler (see “The PlateSpin Orchestrate
Job Scheduler” in the PlateSpin Orchestrate 2.0 Development Client Reference).
Running jobs from Web applications (see “Using the PlateSpin Orchestrate Server Portal” in
the PlateSpin Orchestrate 2.0 Server Portal Reference).
Running jobs from within jobs (see “Using Facts in Job Scripts” on page 58).
zos
command line (see “The zos Command Line Tool” in the PlateSpin
7.7 Working with Facts and Constraints
You can incorporate facts and constraints into the custom jobs you create to manage your data center
resources using PlateSpin Orchestrate. You should already be familiar with the concepts related to
controlling jobs using job facts and constraints. For more information, see the following JDL links:
Job (page 226)
Joblet (page 228)
This section contains the following topics:
Section 7.7.1, “Grid Objects and Facts,” on page 55
Section 7.7.2, “Defining Job Elements,” on page 56
Section 7.7.3, “Job Arguments and Parameter Lists,” on page 57
7.7.1 Grid Objects and Facts
Every resource and service discovered in an PlateSpin Orchestrate-enabled network is identified and
abstracted as an object. Within the PlateSpin Orchestrate management framework, objects are stored
within an addressable database called a grid. Every grid object has an associated set of facts and
constraints that define the properties and characteristics of either physical or virtual resources.
Essentially, by building, deploying, and running jobs on the Orchestrate Server, you can individually
change the functionality of any and all system resources by managing an object’s facts and
constraints.
The components that have facts include resources, users, jobs, repositories, and vmhosts. The grid
server assigns default values to each of the component facts, although they can be changed at
anytime by the administrator (unless they are read-only).
Job Architecture 55
Page 56

However, the developer wants certain constraints to be used for a job and might specify these in the
policy. These comprise a set of logical clauses and operators that are compared with the respective
component’s fact values when the job is run by the Job Scheduling Manager.
Remember, all properties appear in the job context, which is an environment where constraints are
evaluated. These constraints provide a multilevel filter for a job in order to ensure the best quality of
service the grid can provide.
7.7.2 Defining Job Elements
When you deploy a job, you can include an XML policy file that defines constraints and facts.
Because every job is a grid object with its own associated set of facts (
job.id
set of predefined facts, so jobs can also be controlled by changing job arguments at run time.
args
As a job writer, you define the set of job arguments in the job
fact space. Your goal in writing
a job is to define the specific elements a job user is permitted to change. These job argument facts
are defined in the job XML policy for every given job.
The job argument fact values are passed to a job when the job is run. Consequently, the Orchestrate
run
Server
command passes in the job arguments. Similarly, for the job scheduler, you can define
which job arguments you want to schedule or run a job. You can also specify job arguments when
using the Server Portal.
, etc.), it already has a
novdocx (en) 13 May 2009
For example, in the following
quickie.job
amount of sleep time between running joblets are set by the arguments
example, the number of joblets allowed to run and the
numJoblets
and
sleeptime
as defined in the policy file for the job. If no job arguments are defined, the client cannot affect the
job:
...
# Launch the joblets
numJoblets = self.getFact("jobargs.numJoblets")
print 'Launching ', numJoblets, ' joblets'
self.schedule(quickieJoblet, numJoblets)
class quickieJoblet(Joblet):
def joblet_started_event(self):
sleeptime = self.getFact("jobargs.sleeptime")
time.sleep(sleeptime)
To view the complete example, see quickie.job (page 121).
As noted, when running a job, you can pass in a policy file, which is another method the client can
use to control job behavior. Policy files can pass in additional constraints to the job, such as how a
resource might be selected or how the job runs. The policy file is an XML file defined with the
.policy
For example, as shown below, you can pass in a policy for the job named
extension.
quickie
, with an
additional constraint to limit the chosen resources to those with a Linux OS. Suppose a policy file
linux.policy
name
in the directory named
/mypolicies
with this content:
<constraint type="resource"> <eq fact="resource.os.family" value="linux" /
></constraint>
To start the
56 PlateSpin Orchestrate 2.0 Developer Guide and Reference
quickie
job using the additional policy, you would enter the following command:
Page 57

>zos run quickie --policyfile=/mypolicies/linux.policy
Creating Constraints Outside of the Constraint Evaluation
When you create constraints, it is sometimes useful to access facts on a Grid object that is not in the
context of the constraint evaluation. An example scenario would be to sequence the running of jobs
triggered by the Job Scheduler.
job2
In this example, you need to make
this, you could add the following start constraint to the
<constraint type="start">
<eq fact="job[job1].instances.active" value="0"/>
</constraint>
run only when all instances of
job2
definition:
job1
are complete. To do
novdocx (en) 13 May 2009
Here, the job in the context is
job2
, however the facts on
job1
(instances.active) can still be
accessed. The general form of the fact name is:
<grid_object_type>[<grid_object_name>].rest.of.fact.space
PlateSpin Orchestrate supports specific Grid object access for the following grid objects
Users
Jobs
Resources
VMHosts
Repositories
Currently, explicit group access is not supported.
7.7.3 Job Arguments and Parameter Lists
Part of a job’s static definition might include job arguments. A job argument defines what values can
be passed in when a job is invoked. This allows the developer to statically define and control how a
job behaves, while the administrator can modify policy values.
You define job arguments in an XML policy file named with the same base name as the job. The
example job
cracker.policy
cracker.jdl
file contains entries for the <jobargs> namespace, as shown in the following
partial example from
, for example, has an associated policy file named
cracker.policy
.
cracker.policy
. The
<jobargs>
<fact name="cryptpw"
type="String"
description="Password of abc"
value="4B3lzcNG/Yx7E"
/>
<fact name="joblets"
type="Integer"
description="joblets to run"
value="100"
/>
</jobargs>
Job Architecture 57
Page 58

novdocx (en) 13 May 2009
The above policy defines two facts in the
fact named
cryptpw
with a default value. The second
jobargs
namespace for the cracker job. One is a String
jobargs
fact is an integer named
joblets
.
Both of these facts have default values so they do not require been set on job invocation. If the
default value was omitted, then job would require that the two facts be set on job invocation. The job
will not start unless all required job argument facts are supplied at job invocation. The default values
of job argument facts can be overridden at job invocation. Job arguments are passed to a job when
the job is invoked. This is done in one of the following ways:
From the Orchestrate Server
>zos run cracker cryptpw="dkslsl"
From within a JDL job script when invoking a child job, as shown in the following job JDL
run
command from the CLI, as shown in the following example:
fragment:
self.runjob("cracker", { "cryptpw" : "asdfa" } )
From the Job Scheduler, either with the Orchestrate Development Client or by a
.sched
file.
7.8 Using Facts in Job Scripts
This section contains the following information:
Section 7.8.1, “Fact Values,” on page 58
Section 7.8.2, “Fact Operations in the Joblet Class,” on page 59
Section 7.8.3, “Using the Policy Debugger to View Facts,” on page 59
7.8.1 Fact Values
Facts can be retrieved, compared against, and written to (if not read-only) from within jobs. Every
grid object has a set of accessor and setter JDL functions. For example, to retrieve the
cryptpw
argument fact in the job example listed in “Job Arguments and Parameter Lists” on page 57, you
would write the following JDL code:
1 def job_started_event(self):
2 pw = self.getFact("jobargs.cryptpw")
In line 2, the function
getFact()
retrieves the value of the job argument fact.
getFact()
invoked on the job instance Grid object.
The following set of JDL grid object functions retrieve facts:
getFact()
factExists()
getFactLastModified()
getFactNames()
The following set of JDL grid object functions modify fact values (if they are not read-only) and
remove facts (if they are not deleteable):
setFact
setDateFact
setTimeFact
setArrayFact
setBooleanArrayFact
job
is
58 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 59

setDateArrayFact
setIntegerArrayFact
setTimeArrayFact
setStringArrayFact
deleteFact
For more complete information on these fact values, see GridObjectInfo (page 223).
7.8.2 Fact Operations in the Joblet Class
Each Joblet is also a Grid object with its own set of well known facts. These facts are listed in
Section B.2, “Joblet Class,” on page 201. An instance of the Joblet class runs on the resource. The
Joblet instance on the resource has access to the fact set of the resource where it is running. The
resource fact set has no meaning outside of this execution context, because the Joblet can be
scheduled to run on any of the resources that match the resource and allocation constraints.
novdocx (en) 13 May 2009
For example, using the
cracker
Parameter Lists,” on page 57, you would write the following JDL code to retrieve the
job example shown in Section 7.7.3, “Job Arguments and
cryptpw
job
argument fact, the OS family fact for the resource, the Job instanceID fact, and the joblet number:
1 class CrackerJoblet(Joblet):
2 def joblet_started_event(self):
3 pw = self.getFact("jobargs.cryptpw")
4 osfamily = self.getFact("resource.os.family")
5 jobid = self.getFact("jobinstance.id")
6 jobletnum = self.getFact("joblet.number")
In line 3, the function
invoked on the joblet instance grid object. In line 4, the
getFact()
retrieves the value of the job argument fact.
resource.os.family
getFact()
is
fact is retrieved for
the resource where the Joblet is being executed. This varies, depending on which resource the Joblet
is scheduled to run on. In line 5, the IDfact for the job instance is retrieved. This changes for every
job instance. In line 6, the joblet index number for this joblet instance is returned. The index is 0
based.
7.8.3 Using the Policy Debugger to View Facts
The Policy Debugger page of the PlateSpin Orchestrate Development Client provides a table view
of all facts in a running or completed job instance. This view includes the Job instance facts
jobinstance.*
(
Debugger tab in the Job Monitor view, the right side panel displays this fact table. For more
information, see “The Policy Debugger” in the PlateSpin Orchestrate 2.0 Development Client
Reference.
namespace) and the facts from the job context.After you select the Policy
7.9 Using Other Grid Objects
Grid objects can be created and retrieved using jobs. This is done when facts from other objects are
needed for job decision processing or when joblets are executed on a resource.
The MatrixInfo (page 235) Grid object represents the system and from the
MatrixInfo
can retrieve other grid objects in the system. For example, to retrieve the resource grid object named
webserver
and a fact named
resource.id
from this object, you would enter the following JDL
code:
object, you
Job Architecture 59
Page 60

webserver = getMatrix().getGridObject(TYPE_RESOURCE,"webserver")
id = webserver.getFact("resource.id")
novdocx (en) 13 May 2009
In Line 1, the
function retrieves the
MatrixInfo
The
MatrixInfo
ResourceInfo
MatrixInfo
class. In Line 2, the fact value for the resource fact
Grid object for
object instance.
webserver
is retrieved. The
getGridObject()
getMatrix()
is a method on the
resource.id
is retrieved.
Grid object also provides functions for creating other Grid objects. For more
built-in
complete information about these functions, see MatrixInfo (page 235).
MatrixInfo
The
MatrixInfo
MatrixInfo
use
object can be used in both
Job
and
Joblet
classes. In the
Joblet
class,
cannot create new Grid objects. If your job is required to create Grid objects, you must
in the Job class.
7.10 Communicating Through Job Events
JDL events are how the server communicates job state transitions to your job. The required
job_started_event
Likewise, all the other state transitions have JDL equivalents that can be optionally implemented in
your job. For example, the
completed. You could implement
send a custom event to a Client, another job, or another joblet.
You can also use your own custom events for communicating between Client, job, child jobs and
joblets.
Every partition of a job (client, job, joblet, child jobs) can communicate directly or indirectly with
any other partition of a job by using Events. Events are messages that are communicated to each of
the job partitions. For example, a joblet running on a resource can send an event to the job portion
running on the server to communicate the completion of a stage of operation.
is always invoked when the job transitions to the
joblet_completed_event
joblet_completed_event
is invoked when a joblet has transitioned to
to launch another job or joblet or
starting
state.
A job can send an event to a Java Client signalling a stage completion or just to send a log message
to display in a client GUI.
Every event carries a dictionary as a payload. You can put any key/values you want to fulfill the
requirements of your communication. The dictionary can be empty.
For more information about events are invoked at the state transitions of a job, see Job (page 226)
and Section B.7, “Joblet State Values,” on page 204.
7.10.1 Sending and Receiving Events
To send an event from a joblet to a job running on a server, you would input the following:
1 The portion in the joblet JDL to send the event:
self.sendEvent("myevent", { "message": "hello from joblet" } )
2 The portion in job JDL to receive the event:
def myevent(self,params):
print "hello from myevent. params=",params
To send an event from a job running on the server to a client, you would input the following:
60 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 61

self.sendClientEvent("notifyClient", { "log" : "Web server installation
completed" } )
In your Java client, you must implement AgentListener and check for an Event message.
novdocx (en) 13 May 2009
For testing, you can use the
additional details about the
zos run ... --listen
sendEvent()
and
sendClientEvent()
option to print events from the server.For
methods in the Job (page 226)
and Joblet (page 228) documentation.
7.10.2 Synchronization
By default, no synchronization occurs on job events. However, synchronization is necessary when
you update the same grid objects from multiple events.
In that case, you must put a synchronization wrapper around the critical section you want to protect.
The following JDL script is how this is done:
1 import synchronize
2 def objects_discovered_event(self, params):
3 print "hello"
4 objects_discovered_event =
synchronize.make_synchronized(objects_discovered_event)
Line 1 specifies to use the synchronization wrapper, which requires you to import the synchronize
package.
Lines 2 and 3 provide the normal definition to an event in your job, while line 4 wraps the function
definition with a synchronized wrapper.
7.11 Executing Local Programs
Running local programs is one of the main reasons for scheduling joblets on resources. Although
you are not allowed to run local programs on the server side job portion of JDL, there are two ways
to run local programs in a joblet:
1 Use the built-in
system()
function.
This function is used for simple executions requiring no output or process handling. It simply
runs the supplied string as a shell command on the resource and writes
stdout
and
stderr
to
the job log.
2 Use the
Exec
JDL class.
The Exec class provides flexibility in how to invoke executables, to process the output, and to
manage the process once running. There is provision for controlling
stderr
values.
stdout
and
stderr
can be redirected to a file, to the job log, or to a stream
stdin, stdout
, and
object.
Exec provides control of how the local program is run. You can choose to run as the agent user
or the job user. The default is to run as the job user, but fallback to agent user if the job user
does not exist on the resource.
For more information, see Exec (page 219).
Job Architecture 61
Page 62

7.11.1 Output Handling
novdocx (en) 13 May 2009
The Exec (page 219) function provides controls for specifying how to handle
stdout
out
stderr
.
By default, Exec discards the output.
The following example runs a program that directs
e = Exec()
e.setShellCommand(cmd)
e.writeStdoutToLog()
e.writeStderrToLog()
e.execute()
The following example runs a program that directs
stdout
e = Exec()
e.setCommand("ps -aef")
e.setStdoutFile("/tmp/ps.out")
e.setStderrFile("/tmp/ps.err")
result = e.execute()
if result == 0:
output = open("/tmp/ps.out").read()
print output
file if there is no error in execution:
stdout
stdout
and
and
stderr
stderr
to the job log:
to files and opens the
7.11.2 Local Users
You can choose to run local programs and have file operations done as the agent user or the job user.
The default is to run as the job user, but fallback to agent user if the job user does not exist on the
resource. These controls are specified on the job. The job.joblet.runtype fact specifies how file and
executable operations run in the joblet in behalf of the job user, or not.
The choices for
Table 7-1 Job Run Type Values
Option Description
RunAsJobUserFallingBackToNodeUser Default. This means if the job user exists as a user on the
RunOnlyAsJobUser This means resource can only run the executable or file
job.joblet.runtype
are defined in the following table:
resource, then executable and file operations is done on
behalf of that user. By falling back, this means that if the job
user does not exist, the agent will still execute the joblet
executable and file operation as the agent user. If the
executable or file operation still has a permission failure, then
the agent user is not allowed to run the local program or do
the file operation.
operation as the job user and will fail immediately if the job
user does not exist on the resource. You want to use this
mode of operation if you wish to strictly enforce execution and
file ownership. You must have your resource setup with NIS or
other naming scheme so that your users will exist on the
resource.
62 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 63

Option Description
RunOnlyAsNodeUser This means the resource will only run executables and do file
operations as the agent user.
novdocx (en) 13 May 2009
There is also a fact on the resource grid object that can override the
resource.agent.config.exec.asagentuseronly
fact
job.joblet.runtype
the
fact.
This ability to run as the job user is supported by the
on the resource grid object can overwrite
enhanced exec
job.joblet.runtype
feature of the Orchestrate
fact. The
Agent. A resource might not support PlateSpin Orchestrate enhanced execution of running as job
users. If the capability is not supported, the fact
resource.agent.config.exec.enhancedused
is
False. This fact is provided so you can create a resource or allocation constraint to exclude such a
resource if your grid mixes resource with/without the enhanced exec support and your job requires
enhanced exec capabilities.
7.11.3 Safety and Failure Handling
An exception in JDL will fail the job. By default, an exception in the joblet will fail the joblet. The
job.joblet.*
information, see Section 7.13, “Improving Job and Joblet Robustness,” on page 65.
try :
< JDL >
except:
exc_type, exc_value, exc_traceback = sys.exc_info()
print "Exception:", exc_type, exc_value
JDL also provides the
fail()
function takes an optional reason message.
facts provide controls on how many times a failure will fail the joblet. For more
fail()
function on the Job and Joblet class for failing a job and joblet. The
You would use
immediately. Usage of the joblet
failed
state of the joblet occurs when the maximum number of retries has been reached.
fail()
when you detect an error condition and wish to end the job or joblet
fail()
fails the currently running instance of the joblet. The actual
7.12 Logging and Debugging
The following sections show some examples how jobs can be logged and debugged:
Section 7.12.1, “Creating a Job Memo,” on page 63
Section 7.12.2, “Tracing,” on page 65
7.12.1 Creating a Job Memo
The following job example shows
Development Client.
logExample.jdl
output inthe JDL editor of the Orchestrate
Job Architecture 63
Page 64

Figure 7-1 Example Job Displayed in the JDL Editor of the Development Client
novdocx (en) 13 May 2009
In the job section of this example (lines 7-17), the fact
jobinstance.memo
(line 14) is set by the job
instance.The job log text is emitted on line 11. Both of those are visible in the following example.
Figure 7-2 Example Displaying the
Development Client
In the
joblet
section of this example (lines 24-29), the fact named
jobinstance.memo
Fact and Job Log Text in the Jobs Monitor View of the
joblet.memo
(line 27) is set by
the joblet instance and consists of a brief memo for each joblet. This is typically used for providing
detailed explanations, such as the name of the executable being run.
64 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 65
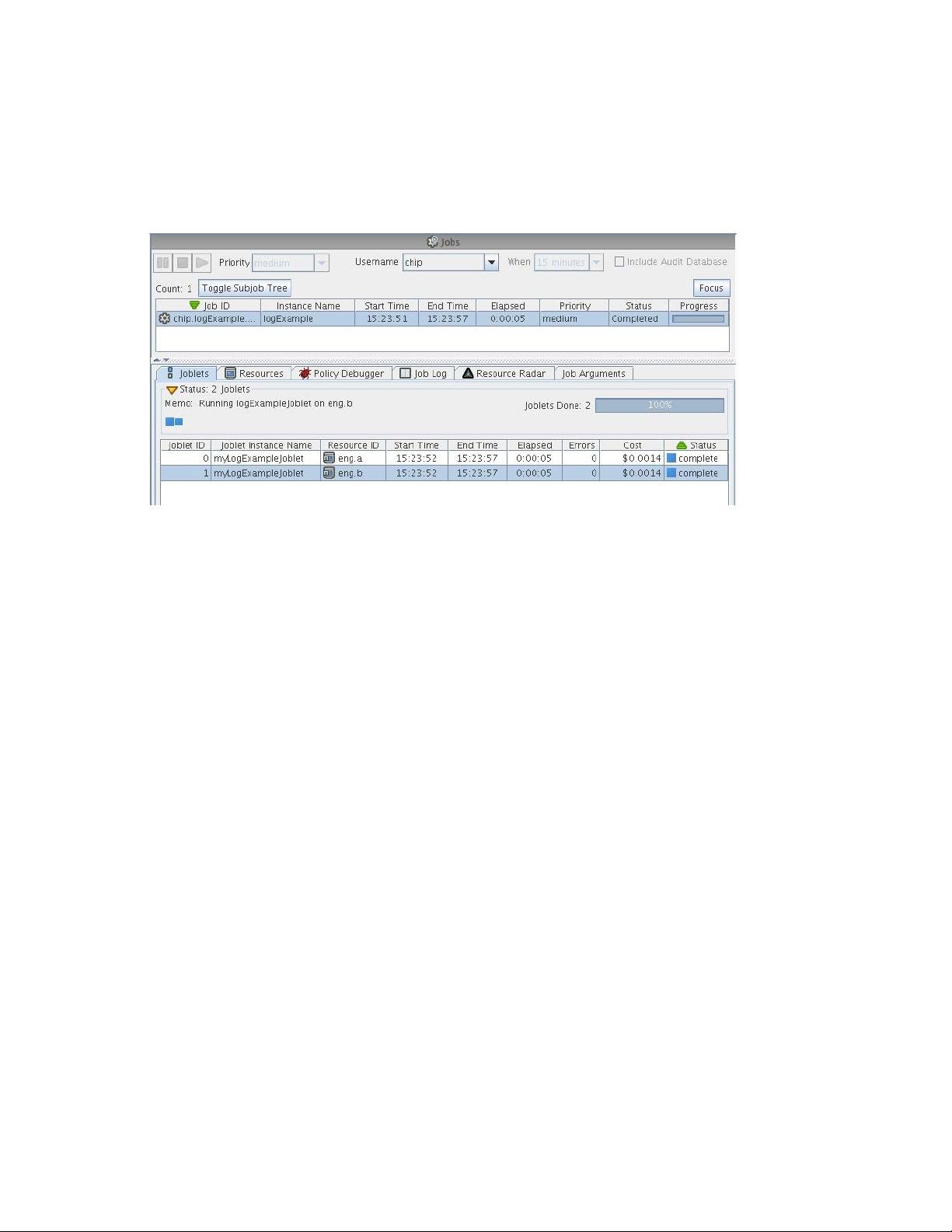
novdocx (en) 13 May 2009
The name of the joblet is specified by the fact named
joblet.instancename
(line 28). This is
typically a simple word displayed in the Development Client joblet column view. The following
example shows the joblet facts
joblet.memo
and
joblet.instancename
in the Development
Client.
Figure 7-3 Example of Joblet Facts Displayed in the Development Client
7.12.2 Tracing
There are two facts on the job grid object to turn tracing on or off. The tracing fact writes a message
to the job log when a job and/or joblet event is entered and exited.The facts are
job.joblet.tracing
use the
zos run
. You can turn these on using the Orchestrate Development Client or you can
command tool.
job.tracing
and
7.13 Improving Job and Joblet Robustness
The job and joblet grid objects provide several facts for controlling the robustness of job and joblet
operation.
The default setting of these facts is to fail the job on first error, since failures are typical during the
development phase. Depending on your job requirements, you adjust the retry maximum on the fact
to enable your joblets either to failover or to retry.
The fact
job.joblet.maxretry
the joblet is considered failed. This, in turn, fails the job. However, after you have written and tested
your job, you should introduce fault tolerance to the joblet.
For example, suppose you know that your resource application might occasionally timeout due to
network or other resource problems. Therefore, you might want to introduce the following behavior
by setting facts appropriately:
On timeout of 60 seconds, retry the joblet.
Retry a maximum of two times. This may cause a retry on another resource matching your
resource and allocation constraints.
defaults to 0, which means the joblet is not retried. On first failure,
On the third timeout, fail the joblet.
Job Architecture 65
Page 66

To configure this setup, you use the following facts in either the job policy (using the Orchestrate
Development Client to edit the facts directly) or within the job itself:
job.joblet.timeout set to 60 job.joblet.maxretry set to 2
In addition to timeout, there are different kinds of joblet failures for which you can set the maximum
retry. There are forced (job errors) and unforced connection errors. For example, an error condition
detected by the JDL code (forced) might require more retries than a network error, which might
cause resource disconnections. In the connection failure case, you might want to lower the retry
limit because you probably do not want a badly setup resource with connection problems to keep
retrying and getting work.
7.14 Using an Event Notification in a Job
Jobs can be notified of a PlateSpin Orchestrate event in two ways.
A running Job can subscribe to receive PlateSpin Orchestrate event notifications. (See
Section 7.14.1, “Receiving Event Notifications in a Running Job,” on page 66)
A Job can be scheduled to start upon an Event notification.
novdocx (en) 13 May 2009
For more information about job scheduling, see Chapter 8, “Job Scheduling,” on page 71 or
“The PlateSpin Orchestrate Job Scheduler” in the PlateSpin Orchestrate 2.0 Development
Client Reference.
7.14.1 Receiving Event Notifications in a Running Job
“Subscribe” on page 66
“Unsubscribe” on page 67
“Callback Method Signature” on page 67
“How an Event Notification Can Start a Job” on page 67
Subscribe
For a job to receive notifications, a job subscribes to an event and must remain running for the
notification to occur.
How to subscribe to an event is accomplished using the
below:
def subscribeToEvent( <event Name>, <Job callback method> )
In this method,
method>
<event name>
is the string name of the event being subscribed to;
is the reference to a Job method. Joblets and globals are not supported.
subscribeToEvent()
Job method, shown
<Job callback
Example: The following is an example of the
self.subscribeToEvent( "vmhost" ,self.eventHandler)
In this example,
vmhost
is the name of the event and
subscribeToEvent()
callback method.
66 PlateSpin Orchestrate 2.0 Developer Guide and Reference
method.
self.eventHandler
is a reference to the
Page 67

Unsubscribe
novdocx (en) 13 May 2009
To unsubscribe, use the
unscribeFromEvent()
Job method. For the subscribe example shown
above, the following is how to unsubscribe.
self.unsubscribeFromEvent("vmhost",self.eventHandler)
Callback Method Signature
def <Job callback method>( self, context):
The callback method must be a Job method. The context argument is a dictionary containing name/
value pairs. The dictionary contents passed to the callback vary depending on the event type.
Example: The following is an example of the callback method.
def eventHandler(self,context):
In this method,
context
is the required dictionary argument passed to every callback. The contents
of the dictionary vary depending on event type (for details, see Section 7.14.2, “Event Types,” on
page 68).
How an Event Notification Can Start a Job
You can create a schedule using the Job Scheduler or deploy a
.sched
file to start a job on an event
notification. For more information, see Chapter 8, “Job Scheduling,” on page 71 or “The PlateSpin
Orchestrate Job Scheduler” in the PlateSpin Orchestrate 2.0 Development Client Reference.
The job to be started must match a required job argument signature where the job must define at
least one job argument.
The required job argument must be called “context” and be of type Dictionary. The contents of the
dictionary vary depending on event type ( refer to "Event Types " below for details).
The contents of
EventResponse.jdl
is an example of a job and policy that can be scheduled on an
event notification:
1class EventResponse(Job):
2
3 def job_started_event(self):
4 context = self.getFact("jobargs.context")
5
6 print "Context:"
7 keys = context.keys()
8 keys.sort()
9 for k in keys:
10 v = context[k]
11 print " key(%s) type(%s) value(%s)" % (k,type(v),str(v))
Line 4: This line pulls out the job argument for the event context.
Lines 6-11: These lines print out the contents of the context dictionary.
The contents of
EventResponse.policy
are shown below:
Job Architecture 67
Page 68

1<policy>
2 <jobargs>
3 <fact name="context" type="Dictionary"
4 description="Dictionary containing the context for the event " />
5 </jobargs>
6</policy>
Lines 3-4: These lines define the required job argument containing the Event context. The running
job receives the job argument named
context
with the dictionary completed by the PlateSpin
Orchestrate Event Manager with the context that matches the trigger rules.
7.14.2 Event Types
“Event Objects” on page 68
“Built-in Events” on page 69
Event Objects
Event objects are defined in an XML document and deployed to a server and managed using the
Orchestrate Development Client. In the Development Client, these objects are shown in the tree
view.
novdocx (en) 13 May 2009
The callback method context argument dictionary contains every grid object type and a value or list
of values. The dictionary depends on the event XML definition and the matching grid objects of the
<trigger>
The following example event file (
rule.
vmhost.event
) shows the contents of the dictionary that will be
passed as either a jobarg to a job to be scheduled to start, or as a argument to an event callback for a
running job.
1<event>
2
3 <context>
4 <vmhost />
5 <user>zosSystem</user>
6 </context>
7
8 <trigger>
9 <gt fact="vmhost.resource.loadaverage" value="2" />
10 </trigger>
11
12</event>
Lines 3-6: Define the context for the Event object.
Line 4: Defines the match for the trigger rule that iterates over all vmhosts.
Line 5: Defines the context, and contains the user grid object named
zosSystem
.
Assuming that there are 10 vmhosts named "
vmhost1, vmhost2
three vmhosts match the trigger rule, the context includse a list of the matching vmhosts. In this
case, the context dictionary contains the following:
68 PlateSpin Orchestrate 2.0 Developer Guide and Reference
, ...
vmhost10
, but only the first
Page 69

{
1 "vmhost" : [ "vmhost1", "vmhost2", "vmhost3" ],
2 "user" : "zosSystem",
3 "repository" : "" ,
4 "resource" : "",
5 "job" : ""
}
novdocx (en) 13 May 2009
Line 1: List of the matching VM Hosts that passed the
Line 2: The user object that is defined in the
<context>
<trigger>
rule.
XML. In this case,
zosSystem
.
Lines 3-5: These grid objects are not defined in the context. Their value is empty.
In this example, the dictionary is passed as a job argument to a scheduled job that triggers on the
event or is passed to a callback method in a running job that has subscribed to the event.
Built-in Events
Built-in events occur when a managed object comes online or offline or when that object has a
health status change. For built-in events, the dictionary contains the name of the grid object type.
The value is the name of the grid object.
The PlateSpin Orchestrate built-in events are named as follows:
RESOURCE_ONLINE
RESOURCE_NEEDS_UPGRADE
USER_ONLINE
RESOURCE_HEALTH
USER_HEALTH
VMHOST_HEALTH
REPOSITORY_HEALTH
For example, when the resource
xen1
comes online, the built-in event called
RESOURCE_ONLINE
is
invoked. Any scheduled jobs are started and any running jobs that have subscribed are invoked. The
context dictionary contains the following:
{
"resource" : "xen1"
}
The dictionary shown above is passed as a job argument to a scheduled job that triggers on the event
or that is passed to a callback method in a running job that has subscribed to the event.
Job Architecture 69
Page 70

novdocx (en) 13 May 2009
70 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 71

8
Job Scheduling
PlateSpin® Orchestrate from Novell® schedules jobs either start manually using the Job Scheduler
or to start programatically using the Job Description Language (JDL). This section contains the
following topics:
Section 8.1, “The PlateSpin Orchestrate Job Scheduler Interface,” on page 71
Section 8.2, “Schedule and Trigger Files,” on page 72
Section 8.3, “Scheduling with Constraints,” on page 75
8.1 The PlateSpin Orchestrate Job Scheduler Interface
After PlateSpin Orchestrate is enabled with a license, users have access to a built-in job Scheduler.
This GUI interface allows jobs to be started periodically based upon user scheduling or when
various system or user-defined events occur.
novdocx (en) 13 May 2009
8
The following figure illustrates the Job Scheduler, with seven jobs staged in the main Scheduler
panel.
Figure 8-1 The PlateSpin Orchestrate Scheduler GUI
Jobs are individually submitted and managed using the Job Scheduler as discussed in “The
PlateSpin Orchestrate Job Scheduler” in the PlateSpin Orchestrate 2.0 Development Client
Reference and in “Using the PlateSpin Orchestrate Server Portal” in the PlateSpin Orchestrate 2.0
Server Portal Reference.
Job Scheduling
71
Page 72

8.2 Schedule and Trigger Files
In addition to using the Job Scheduler GUI, developers can also write XML files to schedule and
trigger jobs to run when triggered by specific events. These files are designated using the
.trig
and
extensions. and can be included as part of the job archive file (
.job
) or deployed
separately.
.sched
novdocx (en) 13 May 2009
Everything that you do manually in the Job Scheduler can be automated by creating a
.trig
XML script as part of a job. The XML files enable you to package system and job scheduling
.sched
or
logic without using the GUI. This includes setting up cron triggers (for example, running a job at
specified intervals) and other triggers that respond to built-in system events, such as resource
startup, user startup (that is, login), or user-defined events that trigger on a rule.
For example, the
osInfo
discovery job, which probes a resource for its operating system
information, is packaged with a schedule file, as shown in the “Schedule File Examples” on page 72.
See also Section 8.2.2, “Trigger File XML Examples,” on page 73.
This section includes the following information:
Section 8.2.1, “Schedule File Examples,” on page 72
Section 8.2.2, “Trigger File XML Examples,” on page 73
8.2.1 Schedule File Examples
A schedule file (
independently deployed using the zosadmin command line utility. Because the XML file defines the
job schedule programatically outside of the Orchestrate Development Client, packaging these scripts
into jobs is typically a developer task.
This section includes the following information:
“Schedule File Example: osInfo.sched” on page 72
“Schedule File Example: Multiple Triggers” on page 73
.sched
) can be packaged either within a
.job
archive alongside the
.jdl
file or
Schedule File Example: osInfo.sched
The
osinfo.sched
base server. Its purpose is to trigger a run of the
file is packaged with the
osInfo
osInfo
on line as it logs into the server.
The following shows the syntax of the schedule file that wraps the job:
1 <schedule name="osInfo" description="Discover OS info on resources."
active="true">
2 <runjob job="osInfo" user="zosSystem" priority="high" />
3 <triggers>
4 <trigger name="RESOURCE_ONLINE" />
5 </triggers>
6 </schedule>
Line 1: Defines a new schedule named
If the job (in this case,
osinfo
) is not deployed, the deployment returns a “Job is not deployed”
osinfo
, which is used to schedule a run of the job
error.
72 PlateSpin Orchestrate 2.0 Developer Guide and Reference
discovery job, which is deployed as part of the
job on a resource when the resource comes
osInfo
.
Page 73

novdocx (en) 13 May 2009
Line 2: Instructs the schedule to run the named job (
a defined priority (high). If the user (in this case,
osinfo
zosSystem
) by the named user (
zosSystem
) using
) does not exist, the deployment returns
a “...” error.
NOTE: Only the PlateSpin Orchestrate users belonging to the
priorities higher than
user.priority.max
medium
fact defaults to a priority equal to
. Assigning a higher priority than specified by the
Line 3-5: Defines the triggers (in this case only one trigger, an event,
administrator
user.priority.max
RESOURCE_ONLINE
group can assign
when the job runs.
) that
initiates the job.
Schedule File Example: Multiple Triggers
A schedule can include one or more triggers. The following example shows the syntax of a schedule
file that has two cron triggers for scheduling a job:
1 <schedule name="ReportTwice" active="true">
2 <runjob job="jobargs" user="JohnD" priority="medium" />
3 <triggers>
4 <trigger name="DailyReportTrigger" />
5 <trigger name="NightlyReportTrigger" />
6 </triggers>
7 </schedule>
Line 1: Defines the schedule name, deployed condition, and description (if any).
Line 2: Instructs the schedule to run the named job (
defined priority (
medium
).
jobargs
) by the named user (
JohnD
) using a
Lines 3-6: Defines the triggers (in this case two occurring time triggers) that initiate the job.
8.2.2 Trigger File XML Examples
Trigger files define when a job and how often schedule fires. This can happen when a defined event
occurs, when a defined amount of time passes, or when a given point in time is reached. so that one
or more triggers can be associated with a job schedule (
.sched
yourself in XML format and deploy them, or you can edit and choose them in the Job Scheduler,
which automatically deploys them. This section includes examples to show you the syntax of
different trigger files.
“XML Example: Event Trigger” on page 73
“XML Example: Interval Time Trigger” on page 74
“XML Example: Cron Expression Trigger” on page 74
XML Example: Event Trigger
An event trigger starts a job when a defined event occurs. Several built-in event triggers (such as
events that occur when a managed object comes online or offline or has a health status change) are
available in the Trigger chooser of the Job Scheduler along with any user-defined Events:
). You can create these triggers
RESOURCE_ONLINE
RESOURCE_OFFLINE
USER_ONLINE
Job Scheduling 73
Page 74

USER_OFFLINE
RESOURCE_HEALTH
USER_HEALTH
VMHOST_HEALTH
REPOSITORY_HEALTH
novdocx (en) 13 May 2009
When deployed as triggers in a schedule, built-in events do not generate a
.trig
file, as other
triggers do.
You can also associate an Event object with a job schedule (see “Event Triggers” in “The PlateSpin
Orchestrate Job Scheduler” in the PlateSpin Orchestrate 2.0 Development Client Reference). You
can define an Event object in an XML document, deploy it to a server, and then manage it with the
PlateSpin Orchestrate Development Client.
The following example,
PowerOutage.trig
shows the XML format for a trigger that references an
event object.
1 <trigger name="PowerOutage" description="Fires when UPS starts at power
outage">
2 <event value="UPS_interrupt"/>
3 </trigger>
Line 1: Defines the trigger name and description.
Line 2: Defines the event object chosen for the trigger.
For more information about events, see Section 7.14, “Using an Event Notification in a Job,” on
page 66.
XML Example: Interval Time Trigger
The following example,
EveryMin1Hr.trig
shows the XML format for a trigger that uses the
system clock to define (in seconds) how soon the schedule is to start, how often the schedule is to
repeat, and how many times the schedule is to be repeated:
1 <trigger name="EveryMin1Hr" description="Fires every minute for one hour">
2 <interval startin="600" interval="60" repeat="60"/>
3 </trigger>
Line 1: Defines the trigger name and description.
Lines 2-3: Defines how soon the schedule is to start, how often the schedule is to repeat, and how
many times the schedule is to be repeated
XML Example: Cron Expression Trigger
The following example,
NoonDaily.trig
shows the XML format for a trigger that uses a Quartz
Cron expression to precisely define when an event is to fire.
1 <trigger name="NoonDaily" description="Fires every day at noon">
2 <cron value="0 0 12 * * ?"/>
3 </trigger>
Line 1: Defines the trigger name and description.
74 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 75

Lines 2-3: Defines the cron expression to be used by the schedule. Cron expressions are used to
precisely define the future point in time when the schedule is to fires. For more information, see
“Understanding Cron Syntax in the Job Scheduler” in “The PlateSpin Orchestrate Job Scheduler” in
the PlateSpin Orchestrate 2.0 Development Client Reference.
8.3 Scheduling with Constraints
The constraint specification of the policies is comprised of a set of logical clauses and operators that
compare property names and values. The grid server defines most of these properties, but they can
also be arbitrarily extended by the user/developer.
All properties appear in the job context, which is an environment where constraints are evaluated.
Compound clauses can be created by logical concatenation of earlier clauses. A rich set of
constraints can thus be written in the policies to describe the needs of a particular job. However, this
is only part of the picture.
Constraints can also be set by an administrator via deployed policies, and additional constraints can
be specified by jobs to further restrict a particular job instance. The figure below shows the complete
process employed by the Orchestrate Server to constrain and schedule jobs.
novdocx (en) 13 May 2009
When a user issues a work request, the user facts (user.* facts) and job facts (job.* facts) are added
to the job context. The server also makes all available resource facts (resource.* facts) visible by
reference. This set of properties creates an environment in which constraints can be executed. The
scheduler applies a logic ANDing of job constraints (specified in the policies), grid policy
constraints (set on the server), optionally additional user defined constraints specified on job
submission, and optional constraints specified by the resources.
This procedure results in a list of matching resources. The PlateSpin Orchestrate solution returns
three lists:
Available resources
Pre-emptable resources (nodes running lower priority jobs that could be suspended)
Resources that could be “stolen” (nodes running lower-priority jobs that could be killed)
These lists are then passed to the resource allocation logic where, given the possible resources, the
ordered list of desired resources is returned together with information on the minimum acceptable
allocation. The scheduler uses this information to appropriate resources for all jobs within the same
priority group. Because the scheduler is continually re-evaluating the allocation of resources, the job
policies forms part of the schedulers real-time algorithm, thus providing an extremely versatile and
powerful scheduling mechanism.
Job Scheduling 75
Page 76

Figure 8-2 Job Scheduling Priority
Although job scheduling might appear complex, it is very easy to use for an end user. For example,
a job developer might write just a few lines of policy code to describe a job to require a node with a
x86 machine, greater than 512 MB of memory, and a resource allocation strategy of minimizing
execution time. Below is an example.
novdocx (en) 13 May 2009
<constraint type=”resource”>
<and>
<eq fact="cpu.architecture" value="x86" />
<gt fact="memory.physical.total" value="512" />
</and>
</constraint>
76 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 77

9
Virtual Machine Job Development
novdocx (en) 13 May 2009
9
This section explains the following concepts related to developing virtual machine (VM)
management jobs with PlateSpin
Section 9.1, “VM Job Best Practices,” on page 77
Section 9.2, “Virtual Machine Management,” on page 79
Section 9.3, “VM Life Cycle Management,” on page 80
Section 9.4, “Manual Management of a VM Lifecycle,” on page 80
Section 9.5, “Provisioning Virtual Machines,” on page 82
Section 9.6, “Automatically Provisioning a VM,” on page 87
Section 9.7, “Defining Values for Grid Objects,” on page 88
®
Orchestrate:
9.1 VM Job Best Practices
This section discusses some of VM job architecture best practices to help you understand and get
started developing VM jobs:
Section 9.1.1, “Plan Robust Application Starts and Stops,” on page 77
Section 9.1.2, “Managing VM Systems,” on page 78
Section 9.1.3, “Managing VM Images,” on page 78
Section 9.1.4, “Managing VM Hypervisors,” on page 78
Section 9.1.5, “VM Job Considerations,” on page 78
9.1.1 Plan Robust Application Starts and Stops
An application is required for a service, and a VM is provisioned on its behalf. As part of the
provisioning process, the VM’s OS typically must be prepared for specific work; for example, NAS
mounts, configuration, and other tasks. The application might also need customizing, such as
configuring file transfer profiles, client/server relationships, and other tasks.
Then, the application is started and its “identity” (IP address, instance name, and other identifying
characteristics) might need to be transferred to other application instances in the service, or a load
balancer).
If the Orchestrate Server loses the job/joblet communication state machine, such as when a server
failover or job timeout occurs, all of the state information must be able to be recovered from “facts”
that are associated with the server. This kind of job should also work in a disaster recovery mode, so
it should be implemented in jobs regularly when relevant services from Data Center A must be
started in Data Center B in a DR case. These jobs require special precautions.
Virtual Machine Job Development
77
Page 78

9.1.2 Managing VM Systems
A series of VMs must typically be provisioned in order to run system-wide maintenance tasks.
Because there might not be enough resources to bring up every VM simultaneously, you might
consider running discovery jobs to limit how many resources (RAM, cores, etc.) that can be used at
any given time. Then, you should consider running a task that writes a consolidated audit trail.
9.1.3 Managing VM Images
novdocx (en) 13 May 2009
Similar to how the job
Constraints and runs a VM operation (
Orchestrate image must be modified when the VM is not running. Preferably, this should occur
without having to provision the VM itself.
installagent
searches for virtual machine grid objects using specified
installAgent
) on the VMs that are returned, a PlateSpin
9.1.4 Managing VM Hypervisors
The management engine (“hypervisor”) underlying the host server must be “managed” while a VM
is running. For example, VM memory or CPU parameters must be adjusted on behalf of a
monitoring job or a Development Client action.
9.1.5 VM Job Considerations
In some instances, some managed resources might host VMs that do not contain an Orchestrate
Agent. Such VMs can only be controlled by administrators interacting directly with them.
Long-running VMs can be modified or migrated while the job managing the VM is not actively
interacting with it. If you have one joblet running on the container and one inside the VM, that
relationship might have to be re-established.
78 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 79
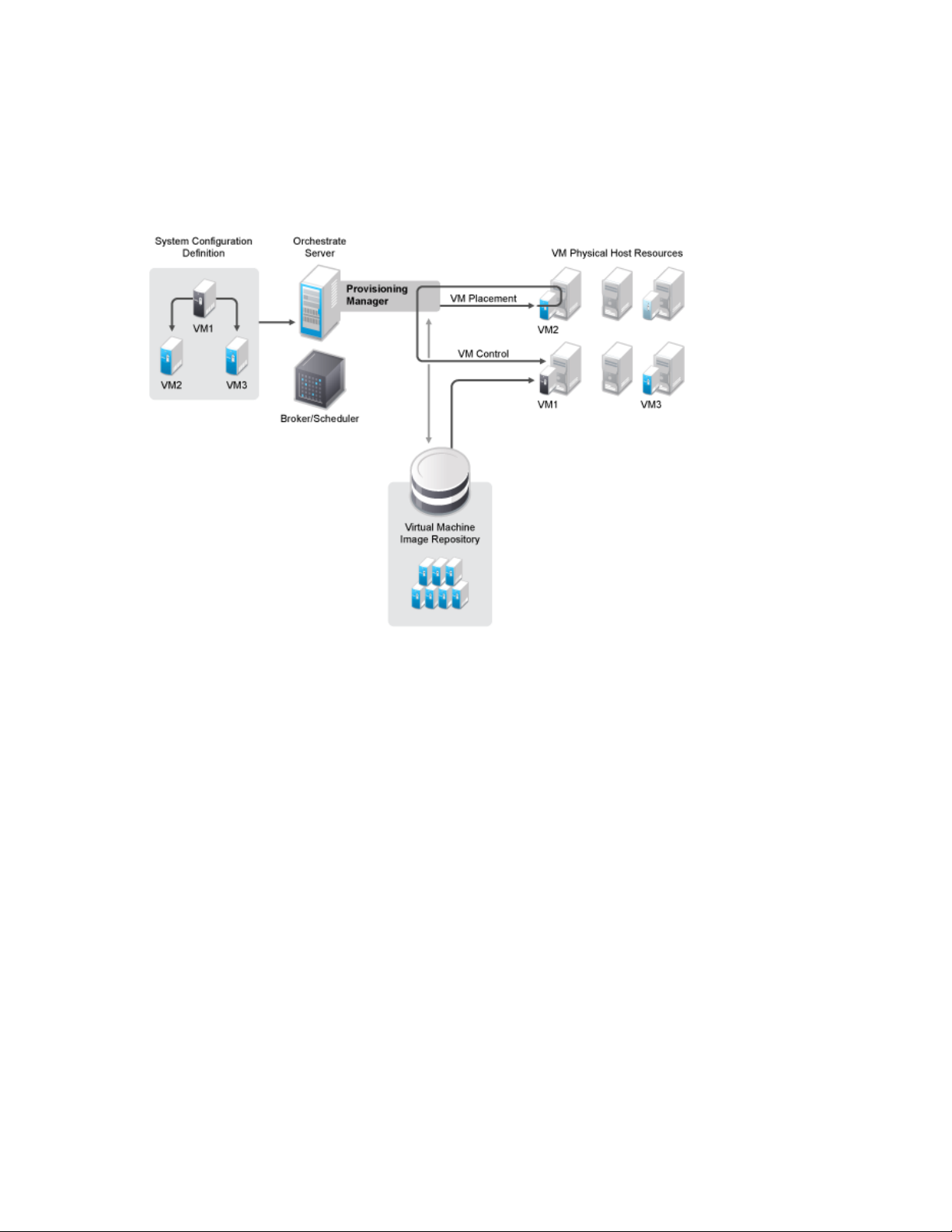
9.2 Virtual Machine Management
The PlateSpin Orchestrate provisioning manager provides the ability to manage the use of virtual
machines, as shown in the following figure:
Figure 9-1 VM Management
novdocx (en) 13 May 2009
For more information about managing virtual machines, see the PlateSpin Orchestrate 2.0 VM
Client Guide and Reference.
While PlateSpin Orchestrate enables you manage many aspects of your virtual environment, as a
developer, you can create custom jobs that do the following tasks:
Create and clone VMs: These jobs Creates virtual machine images to be stored or deployed.
They also create templates for building images to be stored or deployed (see “VM Instance:” on
page 83 and “VM Template:” on page 83).
Discover resources that can be used as VM hosts.
Provision, migrate, and move VMs: Virtual machine images can be moved from one physical
machine to another.
Provide checkpoints, restoration, and re-synchronization of VMs: Snapshots of the virtual
machine image can be taken and used to restore the environment if needed. For more
information, refer to the documentation for your hypervisor or contact technical support
organization for that hypervisor.
Monitor VM operations: Jobs can start, shut down, suspend and restart VMs.
Manage on, off, suspend, and restart operations.
Virtual Machine Job Development 79
Page 80

9.3 VM Life Cycle Management
The life cycle of a VM includes its creation, testing, modifications, use in your environment, and
removal when it's no longer needed.
For example, in setting up your VM environment, you might want to first create basic VMs from
which you can create templates. Then, to enable the most efficient use of your current hardware
capabilities, you can use those templates to create the many different specialized VMs that you need
to perform the various jobs. You can create and manage VM-related jobs through the Development
Client interface.
Life cycle functions are performed one at a time per given VM in order to prevent conflicts in using
the VM. Life cycle events include:
Creating a VM
Starting and stopping a VM
Pausing and resuming a VM
Suspending and provisioning a VM
Installing the Orchestrate Agent on a VM
Creating a template from a VM
novdocx (en) 13 May 2009
Using the VM (starting, stopping, pausing, suspending, restarting, and shutting down)
Running jobs for the VM
Editing a VM
Editing a template
Moving a stopped VM to another host server
Migrating a running VM to another host server
Resynchronizing a VM to ensure that the state of the VM displayed in the Development Client
is accurate
Cloning a VM
9.4 Manual Management of a VM Lifecycle
The example provided in this section is a general purpose job that only provisions a resource.
You might use a job like this, for example, each day at 5:00 p.m. when your accounting department
requires extra SAP servers to be available. As a developer, you would create a job that provisions the
required VMs, then use the PlateSpin Orchestrate Scheduler to schedule the job to run every day at
the time specified.
In this example, the
invokes the provision action on the VM objects. For an example of a provision job JDL, see
Section 9.4.3, “Provision Job JDL,” on page 81.
provision
job retrieves the members of a resource group (which are VMs) and
To setup to create the
1 Create your VMs and follow the discovery process in the Development Client so that the VMs
are contained in the PlateSpin Orchestrate inventory.
80 PlateSpin Orchestrate 2.0 Developer Guide and Reference
provision.job
, use the following procedure:
Page 81

novdocx (en) 13 May 2009
2 In the Development Client, create a Resource Group called
sap
and add the required VMs as
members of the group.
3 Given the
>jar cvf provision.job provision.jdl provision.policy
4 Deploy the
or the
.jdl
and
provision.job
zosadmin
command line.
.policy
below you would create a
.job
file (jar them):
file to the Orchestrate Server using either the Development Client
To run the job, use either of the following procedures:
Section 9.4.1, “Manually Using the zos Command Line,” on page 81
Section 9.4.2, “Automatically Using the Development Client Job Scheduler,” on page 81
9.4.1 Manually Using the zos Command Line
1 At the command line, enter:
>zos login <zos server>
>zos run provision VmGroup="sap"
For more complete details about entering CLI commands, see “The zos Command Line Tool” in the
PlateSpin Orchestrate 2.0 Command Line Reference.
9.4.2 Automatically Using the Development Client Job Scheduler
1 In the Development Client, create a New schedule.
2 Fill in the job name (
3 For the jobarg
provision
VmGroup
, enter
), user, priority.
sap
.
4 Create a Trigger for the time you want this job to run.
5 Save the Schedule and enable it by clicking Resume.
You can manually force scheduling by clicking Test Schedule Now.
For more complete details about using the Job Scheduler, see “The PlateSpin Orchestrate Job
Scheduler” in the PlateSpin Orchestrate 2.0 Development Client Reference. You can also refer to
Section 9.6, “Automatically Provisioning a VM,” on page 87 in this guide.
9.4.3 Provision Job JDL
"""Job that retrieves the members of a supplied resource group and invokes the
provision action on all members. For more details about this class, see Job
(page 226). See also ProvisionSpec (page 242).
The members must be VMs.
"""
class provision(Job):
def job_started_event(self):
# Retrieves the value of a job argument supplied in
Virtual Machine Job Development 81
Page 82

# the 'zos run' or scheduled run.
VmGroup = self.getFact("jobargs.VmGroup")
#
# Retrieves the resource group grid object of the supplied name.
# The job Fails if the group name does not exist.
#
group = getMatrix().getGroup(TYPE_RESOURCE,VmGroup)
if group == None:
self.fail("No such group '%s'." % (VmGroup))
#
# Gets a list of group members and invokes a provision action on each
one.
#
members = group.getMembers()
for vm in members:
vm.provision()
print "Provision action requested for VM '%s'" %
(vm.getFact("resource.id"))
novdocx (en) 13 May 2009
Job Policy:
<!- The policy definition for the provision example job.
This specifies the job argument VmGroup' which is required
-->
<policy>
<jobargs>
<fact name="VmGroup"
type="String"
description="Name of a VM resource group whose members will be
provisioned"
/>
</jobargs>
</policy>
9.5 Provisioning Virtual Machines
VM provisioning adapters run just like regular jobs on PlateSpin Orchestrate. The system can detect
a local store on each VM host and if a local disk might contain VM images. The provisioner puts in
a request for a VM host. However, before a VM is brought to life, the system pre-reserves that VM
for exclusive use.
That reservation prevents a VM from being stolen by any other job that’s waiting for a resource that
might match this particular VM. The constraints specified to find a suitable host evaluates machine
architectures, CPU, bit width, available virtual memory, or other administrator configured
constraints, such as the number of virtual machine slots.
82 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 83

This process provides heterogeneous virtual machine management using the following virtual
machine adapters (also called “provisioning adapters”):
Xen Adapter: For more information, see XenSource* (http://www.xensource.com/).
Virtual Center 1.3.x or later, and Virtual Center 2.0.1 or later: For more information, see
VMware (http://www.vmware.com).
Hyper-V: For more information, see Microsoft* Windows Server 2008 Virtualization with
Hyper-V (http://www.microsoft.com/windowsserver2008/en/us/hyperv.aspx).
VMware Server 1.x: For more information, see VMware (http://www.vmware.com).
ESX 3.0.x and 3.5.x: For more information, see VMware (http://www.vmware.com).
NOTE: Novell considers the PlateSpin Orchestrate provisioning technology used in conjunction
with VMware ESX or VMware Server as experimental because it has not yet been fully tested.
For more information, see PlateSpin Orchestrate 2.0 Virtual Machine Management
Guide“Provisioning a Virtual Machine” in the PlateSpin Orchestrate 2.0 Virtual Machine
Management Guide.
novdocx (en) 13 May 2009
There are two types of VMs that can be provisioned:
VM Instance: A VM instance is a VM that is “state-full.” This means there can only ever be
one VM that can be provisioned, moved around the infrastructure, and then shut down, yet
maintains its state.
VM Template: A VM template represents an image that can be cloned. After it is finished its
services, it is shut down and destroyed.
It can be thought of as a “golden master.” The number of times a golden master or template can
be provisioned or cloned is controlled though constraints that you specify when you create a
provisioning job.
Virtual Machine Job Development 83
Page 84

The following graphic is a representation of the provisioning adapters and the way they function to
communicate joblets to VMs:
Figure 9-2 VM Management Provisioning Communications
novdocx (en) 13 May 2009
NOTE: The Xen VM Monitor can support more than just SUSE Linux Enterprise (SLE) 10 (which
uses Xen 3.0.4) and Red Hat Enterprise Linux (RHEL) 5 (which uses Xen 3.0.3) VMs. For a
complete list of supported guest operating systems, see the Xen Web site (http://www.xen.org/).
NOTE: Novell considers the PlateSpin Orchestrate provisioning technology used in conjunction
with VMware ESX as experimental because it has not yet been fully tested.
The following sections provide more information on provision of VMs:
Section 9.5.1, “Provisioning VMs Using Jobs,” on page 84
Section 9.5.2, “VM Placement Policy,” on page 86
Section 9.5.3, “Provisioning Example,” on page 87
9.5.1 Provisioning VMs Using Jobs
The following actions can be performed by jobs:
Provision (schedule or manually provision a set of VMs at a certain time of day).
Move
Clone (clone a VM, an online VM, or a template)
Migrate
Destroy
84 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 85

Restart
Check status
Create a template to instance
Create an instance to template
Affiliate with a host
Make it a stand-alone VM
Create checkpoints
Restore
Delete
Cancel Action.
You might want to provision a set of VMs at a certain time of day before the need arises. You also
might create a job to shut down all VMs or a constrained group of VMs. You can perform these tasks
programatically (using a job), manually (through the Development Client), or automatically on
demand.
When performing tasks automatically, a job might make a request for an unavailable resource,
which triggers a job to look for a suitable VM image and host. If located, the image is provisioned
and the instance is initially reserved for calling a job to invoke the required logic to select, place, and
use the newly provisioned resource.
novdocx (en) 13 May 2009
For an example of this job, see sweeper.job (page 155).
VM operations are available on the ResourceInfo (page 244) grid object, and VmHost operations are
available on the VMHostInfo (page 250) grid object. In addition, as shown in Section 9.5.3,
“Provisioning Example,” on page 87, three provisioner events are fired when a provision action has
completed, failed, or cancelled.
The API is equivalent to the actions available within the Development Client. The selection and
placement of the VM host is governed by policies, priorities, queues, and ranking, similar to the
processes used selecting resources.
Provisioning adapters on the Orchestrate Server abstract the VM. These adapters are special
provisioning jobs that perform operations for each integration with different VM technologies. The
following figure shows the VM host management interface that is using the Development Client.
Virtual Machine Job Development 85
Page 86

Figure 9-3 VM Hosts Management
novdocx (en) 13 May 2009
9.5.2 VM Placement Policy
To provision virtual machines, a suitable host must be found. The following shows an example of a
VM placement policy:
<policy>
<constraint type="vmhost">
<and>
<eq fact="vmhost.enabled" value="true"
reason="VmHost is not enabled" />
<eq fact="vmhost.online" value="true"
reason="VmHost is not online" />
<eq fact="vmhost.shuttingdown" value="false"
reason="VmHost is shutting down" />
<lt fact="vmhost.vm.count" factvalue="vmhost.maxvmslots"
reason="VmHost has reached maximum vmslots" />
<ge fact="vmhost.virtualmemory.available"
factvalue="resource.vmimage.virtualmemory"
reason="VmHost has insufficient virtual memory for guest VM" />
<contains fact="vmhost.vm.availableids"
factvalue="resource.id"
reason="VmImage is not available on this VmHost" />
</and>
</constraint>
</policy>
86 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 87

9.5.3 Provisioning Example
This job example provisions a virtual machine and monitors whether provisioning completed
successfully. The VM name is “webserver” and the job requires a VM to be discovered before it is
run. After the provision has started, one of the three provisioner events is called.
1 class provision(Job):
2
3 def job_started_event(self):
4 vm = getMatrix().getGridObject(TYPE_RESOURCE,"webserver")
5 vm.provision()
6 self.setFact("job.autoterminate",False)
7
8 def provisioner_completed_event(self,params):
9 print "provision completed successfully"
10 self.setFact("job.autoterminate",True)
11
12 def provisioner_failed_event(self,params):
13 print "provision failed"
14 self.setFact("job.autoterminate",True)
15
16 def provisioner_cancelled_event(self,params):
17 print "provision cancelled"
18 self.setFact("job.autoterminate",True)
novdocx (en) 13 May 2009
See additional provisioning examples in Section 9.4, “Manual Management of a VM Lifecycle,” on
page 80 and Section 9.6, “Automatically Provisioning a VM,” on page 87.
9.6 Automatically Provisioning a VM
If you write jobs to automatically provision virtual machines, you set the following facts in the job
policy:
resoure.provision.maxcount
resource.provision.maxpending
resource.provision.hostselection
resource.provision.maxnodefailures
resource.provision.rankby
These are the job facts to enable and configure the usage of virtual machines for resource allocation.
These facts can be set in a job’s policy.
For example, setting the provision.maxcount to greater than 0 allows for virtual machines to be
included in resource allocation:
<job>
<fact name="provision.maxcount" type="Integer" value="1" />
<fact name="provision.maxpending" type="Integer" value="1" />
</job>
Virtual Machine Job Development 87
Page 88

The following figure shows the job’s Development Client settings to use VMs:
Figure 9-4 Job Settings for VM Provisioning
novdocx (en) 13 May 2009
When using automatic provisioning, the provisioned resource is reserved for the job requesting the
resource. This prevents another job requiring resources from obtaining the provisioned resource.
When the job that reserved the resource has finished its work (joblet has completed) on the
provisioned resource, then the reservation is relaxed allowing other jobs to use the provisioned
resource.
Using JDL, the reservation can be specified to reserve by JobID and also user. This is done using the
ProvisionSpec (page 242) class.
9.7 Defining Values for Grid Objects
The following sections describe the PlateSpin Orchestrate Server grid objects and facts that are
required for provisioning of PlateSpin Orchestrate resource objects. This section highlights the facts
that are expected to be set from a virtual machine discovery.
Section 9.7.1, “PlateSpin Orchestrate Grid Objects,” on page 89
Section 9.7.2, “Repository Objects and Facts,” on page 90
Section 9.7.3, “VmHost Objects and Facts,” on page 96
Section 9.7.4, “VM Resource Objects and Other Base Resource Facts,” on page 101
Section 9.7.5, “Physical Resource Objects and Additional Facts,” on page 108
88 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 89

9.7.1 PlateSpin Orchestrate Grid Objects
The following table explains the abbreviated codes used to define the PlateSpin Orchestrate grid
objects and facts listed in the following sections:
Table 9-1 PlateSpin Orchestrate Grid Object Definitions
Value Description
Automatic The fact should be automatically set after the successful discovery of virtual
resources (VmHosts and VMs).
Boolean The fact is a Boolean value.
Default The specified default value of the fact is set.
Dictionary The fact is selected from a specified dictionary listing.
Dynamic The fact is dynamically generated.
Enumerate The fact is a specified enumerated value.
novdocx (en) 13 May 2009
Example When available, provides an example how a fact might be applied to an object.
Integer The fact is an integer value.
Real The fact is a real number.
String The fact is a string value.
Datagrid Facts relate to datagrid object types.
Local Facts relate to local object types.
NAS Facts relate to Network Attached Storage (NAS) object types.
SAN Facts relate to Storage Area Network (SAN) object types.
Virtual Facts relate to virtual object types.
Virtual Machine Job Development 89
Page 90

9.7.2 Repository Objects and Facts
Facts marked with an X designate that they should be automatically set after the successful
discovery of virtual resources (VmHosts and VMs). Unless marked with the ° symbol, all of the
following repository objects and facts must be set for the particular provisioning adapter to function.
Facts marked with °° indicate the fact is required under certain conditions.
Table 9-2 Repository Objects and Facts
Typ e:
Fact Name Description
Fact
Type
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
novdocx (en) 13 May 2009
repository.capacity The maximum amount
of storage space
available to virtual
machines (in
megabytes). The value 1 means unlimited.
Integer Local: Note: Not auto discovered, but
set to a default value of -1 (unlimited
size). The Administrator should alter this
value.
This fact is not currently applicable to
SAN because you cannot move filebased disks into a SAN.
SAN: Note: Not auto discovered, but set
to a default value of -1 (unlimited size).
The Administrator should alter this
value.
nas: Note: Not auto discovered, but set
to a default value of -1 (unlimited size).
The Administrator should alter this
value.
datagrid: Note: Not auto discovered,
but set to a default value of -1 (unlimited
size). The Administrator should alter this
value.
virtual: Note: Not auto discovered, but
set to a default value of -1 (unlimited
size). The Administrator should alter this
value.
90 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 91

Fact Name Description
Fact
Type
novdocx (en) 13 May 2009
Typ e:
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
repository.searchpath The relative path from
the location to search for
VM configuration files,
which implicitly includes
repository.image.
preferredpath
.
repository.description The description of the
repository.
String [] Local: X. [etc/xen/vm, myimages]
NOTE: The path is relative to
repository.location or the leading '/' is
ignored.
o
SAN:
.
nas: X. [“my_vms”, “saved_vms”] or [""]
Specifiesto search the whole mount.
NOTE: The path is either relative to
repository.location; the leading '/'
ignored.
datagrid: N/A
virtual: N/A
o
String Local:
SAN:
nas:
datagrid:
virtual:
Default empty.
o
.
o
.
o
Default empty.
o
Default empty.
repository.efficency The efficiency coefficient
used to calculate the
cost of moving VM disk
images to and from the
repository. This value is
multiplied by the disk
image size in Mb to
determine a score.
Thus, thus 0 means no
cost and is very
efficient).
Real Local: Defaults to 1, which normalizes
the transfer efficiency for moving VM
disks.
o
SAN:
Defaults to 1, which normalizes
the transfer efficiency for moving VM
disks. Not currently applicable because
file-based disks cannot be moved into a
SAN.
nas: Defaults to 1, which normalizes the
transfer efficiency for moving VM disks.
datagrid: Defaults to 1, which
normalizes the transfer efficiency for
moving VM disks.
virtual: Defaults to 1, which normalizes
the transfer efficiency for moving VM
disks.
Virtual Machine Job Development 91
Page 92

Fact Name Description
Fact
Type
novdocx (en) 13 May 2009
Typ e:
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
repository.enabled True if the Repository is
enabled, meaning that
new VM instances can
be provisioned.
repository.freespace The amount of storage
space available to new
virtual machines (in
megabytes). The value 1 means unlimited.
repository.groups The groups this
Repository is a member
of.
Boolean Local: Defaults to true.
SAN: Defaults to true.
nas: Defaults to true.
datagrid: Defaults to true.
virtual: Defaults to true.
Integer Local: Dynamic: (capacity—used
space) or -1 if capacity is unlimited.
SAN: Dynamic: (capacity—used
space) or -1 if capacity is unlimited.
nas: Dynamic: (capacity—used space)
or -1 if capacity is unlimited.
datagrid: Dynamic: (capacity—used
space) or -1 if capacity is unlimited.
virtual: Dynamic: (capacity—used
space) or -1 if capacity is unlimited.
String[] Local: X
SAN: X
nas: X
repository.id The repository’s unique
name.
virtual: X
String Local: X
SAN: X
nas: X
datagrid: X. Currently one datagrid
repository is supported.
virtual: X
92 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 93

Fact Name Description
Fact
Type
novdocx (en) 13 May 2009
Typ e:
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
repository.preferredpath The relative path from
the location to search
and place VM files for
movement and cloning.
repository.location The Repository's
physical location.
String Local: X. "var/lib/xen/images"
NOTE: The path is relative to
repository.location; the leading '/' is
ignored.
SAN:
nas: X. "my_vms"
NOTE: The path is relative to
repository.location; the leading '/' is
ignored.
datagrid: N/A
virtual: N/A
String Local: X. "/" or /var/xen/images.
SAN: o.
nas: X. /u or /mnt/myshareddisk.
NOTE: This is the “mount point,” which
is assumed to be the same mount point
on every host that has a connection to
this NAS.
repository.provisioner.jobs The names of the
provisioning adapter
jobs that can manage
VMs on this repository.
repository.san.type The type of SAN
(Adapter specific, “iscsi”,
or “fibrechannel” or '' if
not applicable.
o
datagrid:
X. grid:///vms
virtual: N/A
String [] Local: X. ["xen30"]
SAN:
nas: X. ["xen30"]
datagrid: X. ["xen30"]
virtual: X. ["vcenter"]
String
Local: N/A, empty.
(enum)
SAN: Administrator must set to “iqn”,
“npiv“, or “emc.”
nas: N/A, empty.
datagrid: N/A, empty.
virtual: N/A, empty.
Virtual Machine Job Development 93
Page 94

Fact Name Description
Fact
Type
novdocx (en) 13 May 2009
Typ e:
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
repository.san.vendor The vendor of the SAN.
Controls which storage
bind logic to run (e.g.
LUN masking, etc.).
repository.type The type of repository:
Local; e.g. a local
disk.
nas; e.g. a NFS
mount.
san , datagrid: A
PlateSpin
Orchestrate built in
datagrid backed
store.
virtual: An
externally
managed VM; e.g.
VMWare Virtual
Center.
String Local: N/A, empty.
SAN: Administrator must set to “iscsi”
or “fibrechannel.”
nas: N/A, empty.
datagrid: N/A, empty.
virtual: N/A, empty.
String
(enum)
Local: X. Local
SAN:
nas:
datagrid: X. Datagrid
virtual: X. Virtual
94 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 95

Fact Name Description
Fact
Type
novdocx (en) 13 May 2009
Typ e:
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
repository.usedspace The amount of storage
space used for virtual
machines.
Integer Local: Dynamic: Sum of disk space
used by contained VMs. Only includes
disks that are stored as local files (not
partitions).
SAN: Dynamic: Sum of disk space
used by contained VMs. Only includes
disks that are stored as local files (not
partitions).
Not currently applicable to SAN
because you cannot move file-based
disks into SAN.
nas: Dynamic: Sum of disk space used
by contained VMs. Only includes disks
that are stored as local files (not
partitions).
datagrid: Dynamic: Sum of disk space
used by contained VMs. Only includes
disks that are stored as local files (not
partitions).
virtual: Dynamic: Sum of disk space
used by contained VMs. Only includes
disks that are stored as local files (not
partitions).
repository.vmhosts The list of VM hosts
capable of using this
repository (aggregated
from the individual VM
host fact).
repository.vmimages The list of VM images
stored in this repository
(aggregated from
individual VM fact).
String [] Local: X
SAN:
nas: X
datagrid: X
virtual: X
String [] Local: X
SAN:
nas: X
datagrid: X
virtual: X
Virtual Machine Job Development 95
Page 96

9.7.3 VmHost Objects and Facts
Unless marked with a “°” symbol, all of the following VmHost objects and facts must be set for the
particular provisioning adapter to function.The “X”mark designates that the fact should be
automatically set after the successful discovery of virtual resources (VmHosts and VMs).
Table 9-3 VmHost Objects and Facts
Provision Adapter
Fact Name Description
Fact
Typ e
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
novdocx (en) 13 May 2009
vmhost.accountinggroup The default vmhost
(resource) group
which is adjusted for
VM statistics.
vmhost.enabled True if the VM host is
enabled, which
enables new VM
instances to be
provisioned.
vmhost.groups The groups this VM
host is a member of.
Alias for
'vmhost.resource.grou
p.
vmhost.id The VM host's unique
name.
vmhost.loadindex.slots The loading index; the
ratio of active hosted
VMs to the specified
maximum.
String xen30: X. All.
vmserver: X. All.
vcenter: X. All.
Boolean xen30: X. True.
vmserver: X. True.
vcenter: X. True.
String [] xen30: X.
vmserver: X.
vcenter: X.
String xen30: X. <physical host id>_xen30
vmserver: X. <physical host
id>_vmserver
vcenter: X. <physical host
id>_vcenter
Dynamic
Real
xen30: X.
vmserver: X.
vcenter: X.
vmhost.loadindex.virtualmem
ory
The loading index; the
ratio of consumed
memory to the
specifed maximum.
vmhost.location The VM host's
physical location.
96 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Dynamic
Real
xen30: X.
vmserver: X.
vcenter: X.
String xen30:
vmserver:
vcenter: X. Virtual center's 'locator' to
the Vmhost; e.g., "/vcenter/eng/esx1".
o
Defaults to empty string.
o
Defaults to empty string.
Page 97

Fact Name Description
Fact
Typ e
novdocx (en) 13 May 2009
Provision Adapter
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
vmhost.maxvmslots The maximum
number of hosted VM
instances.
vmhost.memory.available The amount of
memory available to
new virtual machines.
vmhost.memory.max The maximum amount
of memory available
to virtual machines (in
megabytes).
vmhost.migration True if the VM host
can support VM
migration; also subject
to provision adapter
capabilities.
Integer xen30: Defaults to 3. Should be reset
by Administrator.
vmserver: Defaults to 3. Should be
reset by Administrator.
vcenter: Defaults to 3. Should be
reset by Administrator.
Dynamic
Integer
xen30: X. Calculated to be
'vmhost.memory.max; the memory
consumed by running VMs.
vmserver: X. Calculated to be
'vmhost.memory.max; the memory
consumed by running VMs.
vcenter: X. Calculated to be
'vmhost.memory.max; the memory
consumed by running VMs.
Integer xen30: X. Discovered.
vmserver: X. Discovered.
vcenter: X. Discovered.
Boolean xen30: X. Defaults to false. Not
discovered. Administrator should
enable as appropriate to indicate that
the VmHost supports migration.
vmserver: X. Defaults to false. Not
discovered. Should not be set to true
since vmserver/gsx does not support
migration.
vmhost.provisioner.job The name of the
provisioning adapter
job that manages VM
discovery on this host.
vmhost.provisioner.password The password
required for
provisioning on the
VM host. This fact is
used by the
provisioning adapter.
vcenter: X. Discovered.
String xen30: X. xen30.
vmserver: X. vmserver.
vcenter: X. vcenter.
o
String xen30:
vmserver:
.
o
. If set, this fact is passed
to the vmserver CLI tools to
authenticate. Not necessary if
Orchestrate Agent is run as root.
o
vcenter:
.
Virtual Machine Job Development 97
Page 98

Fact Name Description
Fact
Typ e
novdocx (en) 13 May 2009
Provision Adapter
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
vmhost.provisioner.username The username
required for
provisioning on the
VM host. This fact is
used by the
provisioning adapter.
vmhost.repositories This list of repositories
(VM disk stores) is
visible to this VM host.
o
String xen30:
.
vmserver: If set, is passed to
vmserver CLI tools to authenticate.
Not necessary if Orchestrate Agent is
run as root.
vcenter:
o
.
String [] xen30: X. Discovery only adds the
local repository and the datagrid on
the first creation of the vmhost.
Administrator is required to add SAN/
NAS repositories or remove local if
desired.
vmserver: X. Discovery only adds
the local repository and the datagrid
on the first creation of the vmhost.
Administrator is required to add SAN/
NAS repositories or remove local if
desired.
vcenter: X. Automatically set to
VirtualCenter
.
NOTE: This is the only sensible
setting.
vmhost.resource The name of the
resource that houses
this VM host
container.
vmhost.shuttingdown True if the VM host is
attempting to shut
down and does not
need to be
provisioned.
Dynamic
Boolean
o
xen30:
.
vmserver: X.
vcenter: X.
xen30: Initially False, then set to True
when the administrator specifies to
shut down a host.
vmserver: Initially False, then set to
True when the administrator specifies
to shut down a host.
vcenter: Initially False, then set to
True when the administrator specifies
to shut down a host.
98 PlateSpin Orchestrate 2.0 Developer Guide and Reference
Page 99

Fact Name Description
Fact
Typ e
novdocx (en) 13 May 2009
Provision Adapter
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
vmhost.vm.available.groups The list of resource
groups containing
VMs that are allowed
to run on this host.
String [] xen30: X. Automatically set to
VMs_<provisioning_adapter>; e.g.,
any VM of compatible type can be
provisioned. The
VMs_<provisioning_adapter> group
is automatically created by discovery.
The administrator can refine this by
creating new groups and editing if
further restrictions are required.
vmserver: X. Automatically set to
VMs_<provisioning_adapter>; e.g.,
any VM of compatible type can be
provisioned. The
VMs_<provisioning_adapter> group
is automatically created by discovery.
The administrator can refine this by
creating new groups and editing if
further restrictions are required.
vcenter: X. Discovery attempts to
map Virtual Center grouping to
PlateSpin Orchestrate resources
groups and sets this fact accordingly.
This also includes a special
"template_vcenter" group to map to
Virtual Center 1.3.x "templates".
vmhost.vm.count The current number of
active VM instances.
vmhost.vm.instanceids The list of active VM
instances.
vmhost.vm.templatecounts A dictionary of running
instance counts for
each running VM
template.
vmhost.xen.bits xen30 only. Legal
values are 32 and 64.
Dynamic
xen30: X.
Integer
vmserver: X.
vcenter: X.
Dynamic
xen30: X.
String[]
vmserver: X.
vcenter: X.
Dynamic
xen30: X.
Dictionar
y
vmserver: X.
vcenter: X.
Integer xen30: X. 64.
vmserver:
vcenter:
o
o
Not defined.
Not defined.
Virtual Machine Job Development 99
Page 100

Provision Adapter
Fact Name Description
Fact
Typ e
X = automatically set
° = Not necessary to be set
°° = Required under certain conditions
vmhost.xen.hvm xen30 only. Boolean xen30: X. True.
vmserver:
vcenter:
o
Not defined.
o
Not defined.
novdocx (en) 13 May 2009
vmhost.xen.version xen30 only:
Major.Minor version of
the Xen hypervisor.
vmhost.vcenter.hostname vcenter only. The
hostname of the
resource containing
this VM container.
NOTE: Deprecated.
Use
'vmhost.resource.host
name instead.
vmhost.vcenter.networks vcenter only. List of
network interfaces on
the physical host.
vmhost.vcenter.grouppath vcenter only: Part of
the Virtual Center
“locator” URL.
Real xen30: X. 3.00
vmserver: oNot defined.
vcenter:
String xen30:
vmserver:
o
Not defined.
o
Not defined.
o
Not defined.
vcenter: X. esx1.
List xen30:
vmserver:
o
Not defined.
o
Not defined.
vcenter: VM network.
List xen30: oNot defined.
vmserver:
o
Not defined.
vcenter: X. /vcenter/eng1.
100 PlateSpin Orchestrate 2.0 Developer Guide and Reference
 Loading...
Loading...