

Page 1

查询MPC604D供应商
SA14-2053-00
(IBM Order Number)
(Motorola Order Number)
MPC604E/D
1/96
REV 1
Advance Information
PowerPC 604e
RISC Microprocessor
Technical Summary
This document provides an overview of the PowerPC 604e microprocessor features,
including a block diagram showing the major functional components. It provides
information about how the 604e implementation complies with the PowerPC
architecture definition. This document is divided into two parts:
• Part 1,“PowerPC 604e Microprocessor Overview,” provides an overview of the
604e features, including a block diagram showing the major functional
components.
• Part 2, “PowerPC 604e Microprocessor: Implementation,” gives specific details
about the implementation of the 604e as a 32-bit member of the PowerPC
processor family.
In this document, the term “604e” is used as an abbreviation for the phrase “PowerPC 604e
microprocessor” and “604” is an abbreviation for the phrase “PowerPC 604
microprocessor.” The PowerPC 604e microprocessors are available from IBM as PPC604e
and from Motorola as MPC604e.
The PowerPC name, the PowerPC logotype, PowerPC 604, and PowerPC 604e, are trademarks
Machines Corporation, used by Motorola under license from International Business Machines Corporation.
This document contains information on a new product under development by Motorola and IBM. Motorola and IBM reserve
the right to change or discontinue this product without notice.
Motorola Inc., 1996. All rights reserved.
Portions hereof
International Business Machines Corporation, 1991–1996. All rights reserved.
of International Business
604e Technical Summary
Page 2

2
Part 1 PowerPC 604e Microprocessor Overview
This section describes the features of the 604e, provides a block diagram showing the major functional units,
and describes briefly how those units interact.
The 604e is an implementation of the PowerPC family of reduced instruction set computer (RISC)
microprocessors. The 604e implements the PowerPC architecture as it is specified for 32-bit addressing,
which provides 32-bit effective (logical) addresses, integer data types of 8, 16, and 32 bits, and floatingpoint data types of 32 and 64 bits (single-precision and double-precision). For 64-bit PowerPC
implementations, the PowerPC architecture provides additional 64-bit integer data types, 64-bit addressing,
and related features.
The 604e is a superscalar processor capable of issuing four instructions simultaneously. As many as seven
instructions can finish execution in parallel. The 604e has seven execution units that can operate in parallel:
• Floating-point unit (FPU)
• Branch processing unit (BPU)
• Condition register unit (CRU)
• Load/store unit (LSU)
• Three integer units (IUs):
— Two single-cycle integer units (SCIUs)
— One multiple-cycle integer unit (MCIU)
This parallel design, combined with the PowerPC architecture’s specification of uniform instructions that
allows for rapid execution times, yields high efficiency and throughput. The 604e’s rename buffers,
reservation stations, dynamic branch prediction, and completion unit increase instruction throughput,
guarantee in-order completion, and ensure a precise exception model. (Note that the PowerPC architecture
specification refers to all exceptions as interrupts.)
The 604e has separate memory management units (MMUs) and separate 32-Kbyte on-chip caches for
instructions and data. The 604e implements two 128-entry, two-way set associative translation lookaside
buffers (TLBs), one for instructions and one for data, and provides support for demand-paged virtual
memory address translation and variable-sized block translation. The TLBs and the cache use least-recently
used (LRU) replacement algorithms.
The 604e has a 64-bit external data bus and a 32-bit address bus. The 604e interface protocol allows multiple
masters to compete for system resources through a central external arbiter. Additionally, on-chip snooping
logic maintains data cache coherency for multiprocessor applications. The 604e supports single-beat and
burst data transfers for memory accesses and memory-mapped I/O accesses.
The 604e uses an advanced, 2.5-V CMOS process technology and is fully compatible with TTL devices.
1.1 PowerPC 604e Microprocessor Features
This section summarizes features of the 604e’s implementation of the PowerPC architecture.
Figure 1 provides a block diagram showing features of the 604e. Note that this is a conceptual block
diagram intended to show the basic features rather than an attempt to show how these features are physically
implemented on the chip.
PowerPC 604e RISC Microprocessor Technical Summary
Page 3
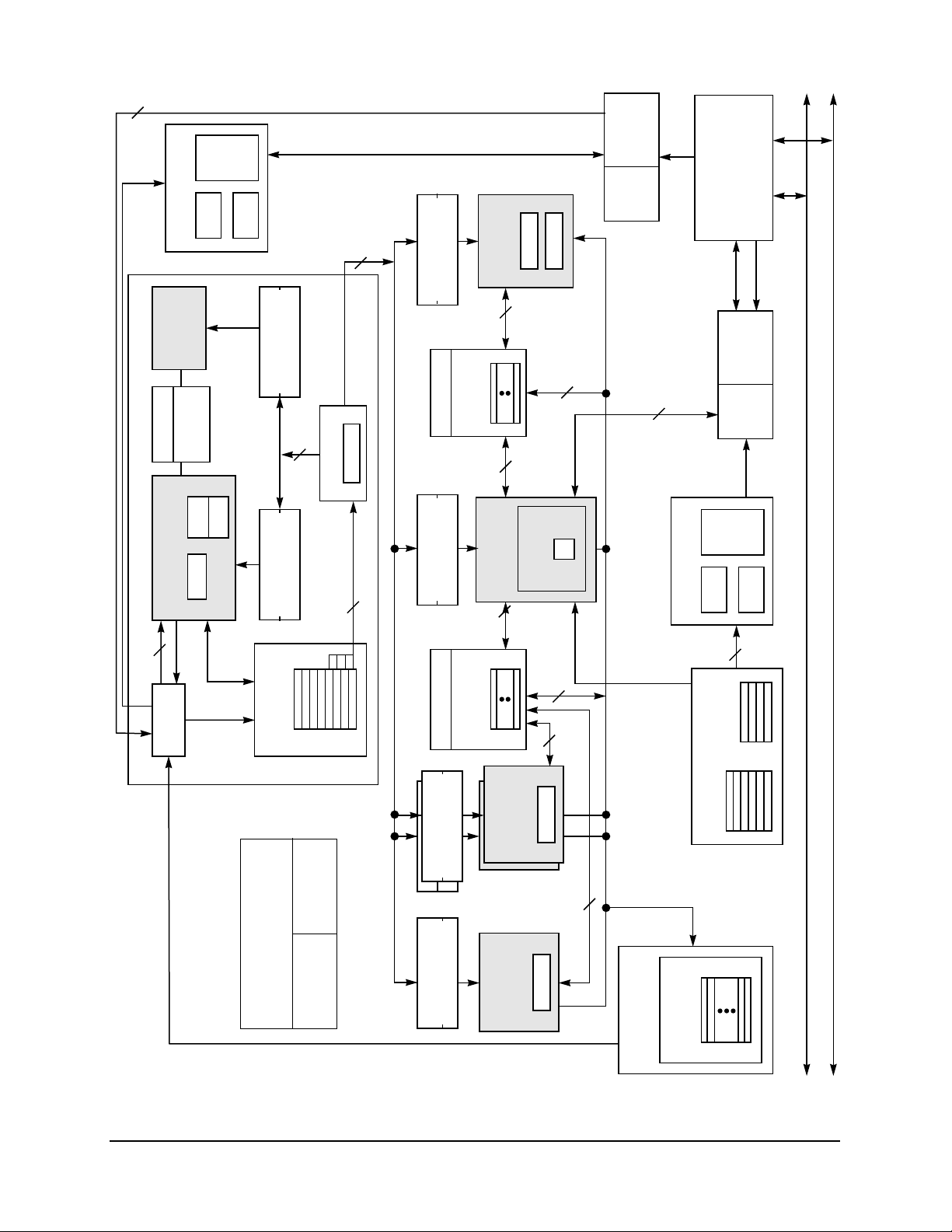
3
128 Bit
I MMU
SRs
IBAT
Array
ITLB
128 Bit
Reservation
Station (2 Entry)
Floating-
Point Unit
+
/
*
FPSCR
I Cache
32-Kbyte
Tags
UNIT
BUS INTERFACE
Register
Condition
Logical Unit
CR File
Rename
Buffers (8)
LR
CTR
INSTRUCTION UNIT
Unit
BTAC
Branch Processing
64 Bit
Fetcher
Reservation
Station (2 Entry)
32 Bit
Dispatch Unit
Reservation
Station (2 Entry)
128 Bit
(8 word)
Instruction Queue
BHT
FPR File
Rename
Buffers (8)
Reservation
Station (2 Entry)
GPR File
Rename
Buffers (12)
64 Bit
64 Bit
EA
Unit
Load/Store
32 Bit
64 Bit
+
Calculation
32 Bit
32 Bit
64 Bit
D MMU
D Cache
32-Kbyte
Tags
Array
DBAT
SRs
DTLB
32 Bit
Queue
Finish Load
Single-Cycle
Integer Units
Multiple-
Cycle Integer
Interface
JTAG/COP
Time Base
Counter/Decrementer
Clock
Multiplier
Reservation
Station (2 Entry)
Reservation
Station (2 Entry)
Figure 1. Block Diagram
PowerPC 604e RISC Microprocessor Technical Summary
Unit
+
*
+
/
32 Bit
Store Queue
32-BIT ADDRESS BUS
64-BIT DATA BUS
*
/
UNIT
16-Entry
COMPLETION
Reorder Buffer
Page 4
4
1.1.1 New Features of the PowerPC 604e Processor
Features of the 604e that are not implemented in the 604 are as follows:
• Additional special-purpose registers
— HID1 provides four read-only PLL_CFG bits for indicating the processor/bus clock ratio.
— Three additional registers to support the performance monitor—MMCR1 is a second control
register that includes bits to support the use of two additional counter registers, PMC3 and
PMC4.
• Instruction execution
— Separate units for branch and condition register (CR) instructions. The BPU is now split into a
CR logical unit and a branch unit, which makes it possible for branch instructions to execute
and resolve before preceding CR logical instructions. The 604e can still only dispatch one CR
logical or branch instruction per cycle, but it can execute both branch and CR logical
instructions at the same time.
— Branch correction in decode stage. Branch correction in the decode stage can now predict
branches whose target is taken from the count or link registers if no updates of the count and
link register are pending. This saves at least one cycle on branch correction when the Move to
Special-Purpose Register ( mtspr ) instruction can be sufficiently separated from the branch that
uses the special-purpose register (SPR) as a target address.
— Ability to disable the branch target address cache (BTAC)—HID0[30] has been defined to
allow the BTAC to be disabled. When HID0[30] is set, the BT AC contents are invalidated and
the BT AC behaves as if it were empty. New entries cannot be added until the BT AC is enabled.
• Improvements to cache implementation
— 32-Kbyte split data and instruction caches. Like the 604, both caches are four-way set
associative; however, each cache has twice as many sets, logically separated into 128 sets of
odd lines and 128 sets of even lines.
— Data cache line-fill buffer forwarding. In the 604 only the critical double word of a burst
operation was made available to the requesting unit at the time it was burst into the line-fill
buffer. Subsequent data was unavailable until the cache block was filled. On the 604e,
subsequent data is also made available as it arrives in the line-fill buffer.
— Additional cache copyback buffers. The 604e implements three copyback write buffers (as
opposed to one in the 604). Having multiple copyback buffers provides the ability for certain
instructions to take fuller advantage of the pipelined system bus to provide more efficient
handling of cache copyback, block invalidate operations caused by the Data Cache Block Flush
( dcbf ) instruction, and cache block clean operations resulting from the Data Cache Block Store
( dcbst ) instruction.
— Coherency support for instruction fetching. Instruction fetching coherency is controlled by
HID0[23]. In the default mode, HID0[23] is 0, GBL
is the case with the 604. If the bit is set, and instruction translation is enabled (MSR[IR] = 1),
the GBL
disabled (MSR[IR] = 0), the GBL
signal is set to reflect the M bit for this page or block. If instruction translation is
signal is asserted.
is not asserted for instruction accesses, as
• System interface operation
— The 604e has the same pin configuration as the 604; however, on the 604e Vdd and AVdd must
be tied to 2.5 Vdc and OVdd must be tied to 3.3 Vdc. The 604e uses split voltage planes, and
for replacement compatibility, 604/604e designs should provide both 2.5-V and 3.3-V planes
and the ability to tie those two planes together and disable the 2.5-V plane for operation with a
604.
PowerPC 604e RISC Microprocessor Technical Summary
Page 5

— Support for additional processor/bus clock ratios (5:2 and 4:1). Configuration of the processor/
bus clock ratios is displayed through a new 604e-specific register, HID1.
— T o support the changes in the clocking configuration, dif ferent precharge timings for the ABB
DBB
, ARTR Y, and SHD signals are implemented internally by the processor. The precharge
timings for AR
— No-DRTRY mode. In addition to the normal and fast L2 modes implemented on the 604, a no-
DRTRY mode is implemented on the 604e that improves performance on read operations for
systems that do not use the DR
processor one bus clock cycle sooner than in normal mode . In no-DRTRY mode, the DR
signal is no longer sampled as part of a qualified bus grant.
• Full hardware support for little-endian accesses. Little-endian accesses take alignment exceptions
for only the same set of causes as big-endian accesses. Accesses that cross a word boundary require
two accesses with the lower-addressed word accessed first.
• Additional enhancements to the performance monitor.
TRY and SHD can be disabled by setting HID0[7].
TRY signal. No-DRTRY mode makes read data available to the
1.1.2 Overview of the PowerPC 604e Microprocessor Features
Major features of the 604e are as follows:
• High-performance, superscalar microprocessor
— As many as four instructions can be issued per clock
— As many as seven instructions can start executing per clock (including three integer
instructions)
— Single-clock-cycle execution for most instructions
,
TRY
• Seven independent execution units and two register files
— BPU featuring dynamic branch prediction
– Two-entry reservation station
– Out-of-order execution through two branches
– Shares dispatch bus with CRU
– 64-entry fully-associative branch target address cache (BTAC). In the 604e, the BTAC can
be disabled and invalidated.
– 512-entry branch history table (BHT) with two bits per entry for four levels of prediction—
not-taken, strongly not-taken, taken, strongly taken
— Condition register logical unit
– Two-entry reservation station
– Shares dispatch bus with BPU
— Two single-cycle IUs (SCIUs) and one multiple-cycle IU (MCIU)
– Instructions that execute in the SCIU take one cycle to execute; most instructions that
execute in the MCIU take multiple cycles to execute.
– Each SCIU has a two-entry reservation station to minimize stalls
– The MCIU has a single-entry reservation station and provides early exit (three cycles)
for 16- x 32-bit and overflow operations.
– Thirty-two GPRs for integer operands
PowerPC 604e RISC Microprocessor Technical Summary
5
Page 6

6
— Three-stage floating-point unit (FPU)
– Fully IEEE 754-1985-compliant FPU for both single- and double-precision operations
– Supports non-IEEE mode for time-critical operations
– Fully pipelined, single-pass double-precision design
– Hardware support for denormalized numbers
– Two-entry reservation station to minimize stalls
– Thirty-two 64-bit FPRs for single- or double-precision operands
— Load/store unit (LSU)
– Two-entry reservation station to minimize stalls
– Single-cycle, pipelined cache access
– Dedicated adder performs EA calculations
– Performs alignment and precision conversion for floating-point data
– Performs alignment and sign extension for integer data
– Four-entry finish load queue (FLQ) provides load miss buffering
– Six-entry store queue
– Supports both big- and little-endian modes
• Rename buffers
— Twelve GPR rename buffers
— Eight FPR rename buffers
— Eight condition register (CR) rename buffers
The 604e rename buffers are described in Section 1.2.7, “Rename Buffers.”
• Completion unit
— The completion unit retires an instruction from the 16-entry reorder buffer when all instructions
ahead of it have been completed and the instruction has finished execution.
— Guarantees sequential programming model (precise exception model)
— Monitors all dispatched instructions and retires them in order
— Tracks unresolved branches and flushes executed, dispatched, and fetched instructions if branch
is mispredicted
— Retires as many as four instructions per clock
• Separate on-chip instruction and data caches (Harvard architecture)
— 32-Kbyte, four-way set-associative instruction and data caches
— LRU replacement algorithm
— 32-byte (eight-word) cache block size
— Physically indexed/physical tags. (Note that the PowerPC architecture refers to physical
address space as real address space.)
— Cache write-back or write-through operation programmable on a per page or per block basis
— Instruction cache can provide four instructions per clock; data cache can provide two words per
clock
— Caches can be disabled in software
PowerPC 604e RISC Microprocessor Technical Summary
Page 7

— Caches can be locked
— Parity checking performed on both caches
— Data cache coherency (MESI) maintained in hardware
— Secondary data cache support provided
— Instruction cache coherency maintained in hardware
— Data cache line-fill buffer forwarding. In the 604 only the critical double word of the cache
block was made available to the requesting unit at the time it was burst into the line-fill buffer .
Subsequent data was unavailable until the cache block was filled. On the 604e, subsequent data
is also made available as it arrives in the line-fill buffer.
• Separate memory management units (MMUs) for instructions and data
— Address translation facilities for 4-Kbyte page size, variable block size, and 256-Mbyte
segment size
— Both TLBs are 128-entry and two-way set associative
— TLBs are hardware reloadable (that is, the page table search is performed in hardware)
— Separate IBATs and DBATs (four each) also defined as SPRs
— Separate instruction and data translation lookaside buffers (TLBs)
— LRU replacement algorithm
— 52-bit virtual address; 32-bit physical address
• Bus interface features include the following:
— Selectable processor-to-bus clock frequency ratios (1:1, 3:2, 2:1, 5:2, 3:1, and 4:1)
— A 64-bit split-transaction external data bus with burst transfers
— Support for address pipelining and limited out-of-order bus transactions
— Four burst write queues—three for cache copyback operations and one for snoop push
operations
— Two single-beat write queues
— Additional signals and signal redefinition for direct-store operations
— Provides a data streaming mode that allows consecutive burst read data transfers to occur
without intervening dead cycles. This mode also disables data retry operations.
— No-DRTRY mode eliminates the DRTRY signal from the qualified bus grant and allows read
operations. This improves performance on read operations for systems that do not use the
DR
TRY signal. No-DRTRY mode makes read data available to the processor one bus clock
cycle sooner than if normal mode is used.
• Multiprocessing support features include the following:
— Hardware enforced, four-state cache coherency protocol (MESI) for data cache. Bits are
provided in the instruction cache to indicate only whether a cache block is valid or invalid.
— Separate port into data cache tags for bus snooping
— Load/store with reservation instruction pair for atomic memory references, semaphores, and
other multiprocessor operations
• Power management
— NAP mode supports full shut down and snooping
— Operating voltage of 2.5 ± 0.3 V
PowerPC 604e RISC Microprocessor Technical Summary
7
Page 8
8
• Performance monitor can be used to help in debugging system designs and improving software
efficiency, especially in multiprocessor systems.
• In-system testability and debugging features through JTAG boundary-scan capability
1.2 PowerPC 604e Microprocessor Hardware
Implementation
This section provides an overview of the 604e’s hardware implementation, including descriptions of the
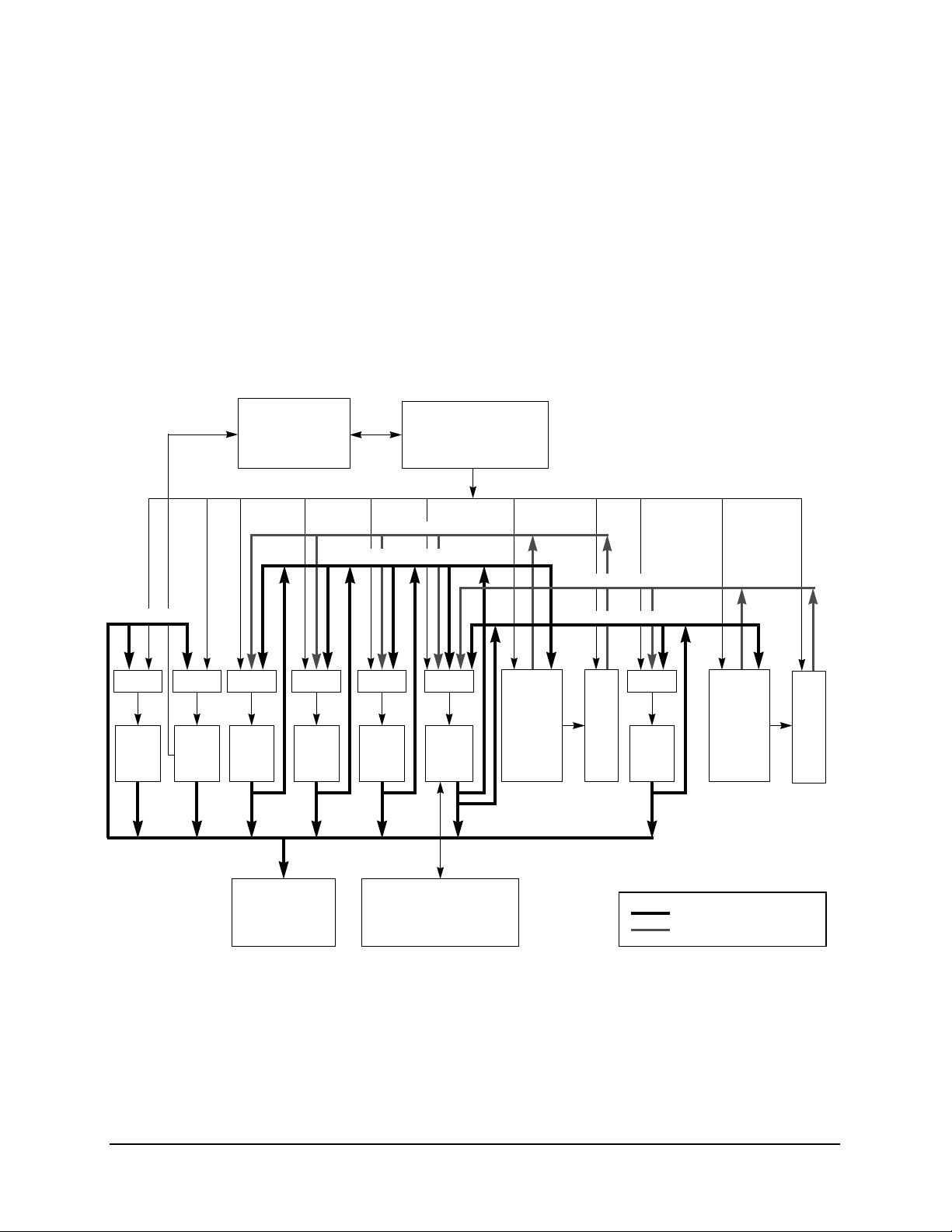
functional units, shown in Figure 2, the cache implementation, MMU, and the system interface.
Note that Figure 2 provides a more detailed block diagram than that presented in Figure 1—showing the
additional data paths that contribute to the improved efficiency in instruction execution and more clearly
shows the relationships between execution units and their associated register files.
Branch
correction
Fetch Unit
Dispatch Unit
(Four-instruction
dispatch)
CR result bus
RS(2)
CRU
BPU
Completion
Unit
Instruction dispatch buses
GPR operand buses
GPR result buses
RS(2)RS(1)RS(2)RS(2)RS(2)
LSUMCIUSCIUSCIU FPU
32-Kbyte data cache
4-way, 8 words/block
FPR result buses
GPR
Buffers
Rename
Result status buses
FPR operand buses
RS(2)
32 GPRs
FPR
Buffers
Rename
Result buses
Operand buses
32 FPRs
Figure 2. Block Diagram—Internal Data Paths
PowerPC 604e RISC Microprocessor Technical Summary
Page 9

1.2.1 Instruction Flow
Several units on the 604e ensure the proper flow of instructions and operands and guarantee the correct
update of the architectural machine state. These units include the following:
• Fetch unit—Using the next sequential address or the address supplied by the BPU when a branch
is predicted or resolved, the fetch unit supplies instructions to the eight-word instruction buffer.
• Dispatch unit—The decode/dispatch unit decodes instructions and dispatches them to the
appropriate execution unit. During dispatch, operands are provided to the execution unit (or
reservation station) from the register files, rename buffers, and result buses.
• Branch processing unit (BPU)—Provides the fetcher with predicted target instructions when a
branch is predicted (and a mispredict recovery address if a branch is incorrectly predicted).
• Condition register unit (CRU)—The CRU executes all condition register logical and flow control
instructions. The CRU shares the dispatch bus with the BPU only one condition register or branch
instruction can be issued per clock cycle.
• Completion unit—The completion unit retires executed instructions in program order and controls
the updating of the architectural machine state.
1.2.2 Fetch Unit
The fetch unit provides instructions to the eight-entry instruction queue by accessing the on-chip instruction
cache. Typically, the fetch unit continues fetching sequentially as many as four instructions at a time.
The address of the next instruction to be fetched is determined by several conditions, which are prioritized
as follows:
1. Detection of an exception. Instruction fetching begins at the exception vector.
2. The BPU recovers from an incorrect prediction when a branch instruction is in the execute stage.
Undispatched instructions are flushed and fetching begins at the correct target address.
3. The BPU recovers from an incorrect prediction when a branch instruction is in the dispatch stage.
Subsequent instructions are flushed and fetching begins at the correct target address.
4. The BPU recovers from an incorrect prediction when a branch instruction is in the decode stage.
Subsequent instructions are flushed and fetching begins at the correct target address.
5. A fetch address is found in the BTAC. As a cache block is fetched, the branch target address cache
(BT AC) and the branch history table (BHT) are searched with the fetch address. If it is found in the
BTAC, the target address from the BTAC is the first candidate for being the next fetch address.
6. If none of the previous conditions exists, the instruction is fetched from the next sequential address.
1.2.3 Decode/Dispatch Unit
The decode/dispatch unit provides the logic for decoding instructions and issuing them to the appropriate
execution unit. The eight-entry instruction queue consists of two four-entry queues—a decode queue (DEQ)
and a dispatch queue (DISQ).
The decode logic decodes the four instructions in the decode queue. For many branch instructions, these
decoded instructions along with the bits in the BHT , are used during the decode stage for branch correction.
The dispatch logic decodes the instructions in the DISQ for possible dispatch. The dispatch logic resolves
unconditional branch instructions and predicts conditional branch instructions using the branch decode
logic, the BHT, and values in the CTR.
PowerPC 604e RISC Microprocessor Technical Summary
9
Page 10

10
The 512-entry BHT provides two bits per entry , indicating four levels of dynamic prediction—strongly nottaken, not-taken, taken, and strongly taken. The history of a branch’s direction is maintained in these two
bits. Each time a branch is taken the value is incremented (with a maximum value of three meaning stronglytaken); when it is not taken, the bit value is decremented (with a minimum value of zero meaning strongly
not-taken). If the current value predicts taken and the next branch is taken again, the BHT entry then predicts
strongly taken. If the next branch is not taken, the BHT then predicts taken.
The dispatch logic also allocates each instruction to the appropriate execution unit. A reorder buffer (ROB)
entry is allocated for each instruction, and dependency checking is done between the instructions in the
dispatch queue. The rename buffers are searched for the operands as the operands are fetched from the
register file. Operands that are written by other instructions ahead of this one in the dispatch queue are given
the tag of that instruction’s rename buffer; otherwise, the rename buffer or register file supplies either the
operand or a tag. As instructions are dispatched, the fetch unit is notified that the dispatch queue can be
updated with more instructions.
1.2.4 Branch Processing Unit (BPU)
The BPU handles prediction and recovery for branch instructions. All branches, including unconditional
branches, are placed in a two-entry reservation station until conditions are resolved and they can be
executed. At that point, branch instructions are executed in order and the completion unit is notified whether
the prediction was correct.
Unlike the 604, the 604e has a separate unit for executing condition register logical instructions, which
makes it possible for branch instructions to execute and resolve before a preceding CR logical instruction.
The 604e can still only dispatch one CR logical or branch instruction per cycle, but it can execute both
branch and CR logical instructions at the same time.
Branch correction in the decode stage in the 604e can predict branches whose target is taken from the count
or link registers if no updates of the count and link register are pending. This saves at least one cycle on
branch correction when the mtspr instruction can be sufficiently separated from the branch that uses the
SPR as a target address.
HID0[30] has been defined to allow the BTAC to be disabled. When HID0[30] is set, the BTAC contents
are invalidated and that BTAC behaves as if it were empty. New entries cannot be added until the BTAC is
enabled.
The BPU shares a dispatch bus with the condition register.
1.2.5 Condition Register Unit (CRU)
Condition register logical instructions are executed by the CRU, which shares the dispatch bus with the
BPU. The CRU has its own two-entry reservation station. The 604e can still only dispatch one CR logical
or branch instruction per cycle, but it can execute both branch and CR logical instructions at the same time.
1.2.6 Completion Unit
The completion unit retires executed instructions from the reorder buffer (ROB) in the completion unit and
updates register files and control registers. The completion unit recognizes exception conditions and
discards any operations being performed on subsequent instructions in program order. The completion unit
can quickly remove instructions from a mispredicted branch, and the decode/dispatch unit begins
dispatching from the correct path.
PowerPC 604e RISC Microprocessor Technical Summary
Page 11

The instruction is retired from the reorder buffer when it has finished execution and all instructions ahead
of it have been completed. The instruction’ s result is written into the appropriate register file and is removed
from the rename buffers at or after completion. At completion, the 604e also updates any other resource
affected by this instruction. Several instructions can complete simultaneously. Most exception conditions
are recognized at completion time.
1.2.7 Rename Buffers
T o avoid contention for a given register location, the 604e provides rename registers for storing instruction
results before the completion unit commits them to the architected register. Twelve rename registers are
provided for the GPRs, eight for the FPRs, and eight for the condition register. GPRs are described in
Section 2.1.1.1, “General-Purpose Registers (GPRs),” FPRs are described in Section 2.1.1.2, “FloatingPoint Registers (FPRs),” and the condition register is described in Section 2.1.1.3, “Condition Register
(CR).”
When the dispatch unit dispatches an instruction to its execution unit, it allocates a rename register for the
results of that instruction. The dispatch unit also provides a tag to the execution unit identifying the result
that should be used as the operand. When the proper result is returned to the rename buffer it is latched into
the reservation station. When all operands are available in the reservation station, the execution can begin.
The completion unit does not transfer instruction results from the rename registers to the registers until any
branch conditions preceding it in the completion queue are resolved and the instruction itself is retired from
the completion queue without exceptions. If a branch is found to have been incorrectly predicted, all
instructions following the branch are flushed from the completion queue and any results of those
instructions are flushed from the rename registers.
1.2.8 Execution Units
The following sections describe the 604e’s arithmetic execution units—the two single-cycle integer units
(SCIUs), the multiple cycle integer unit (MCIU), and the FPU. When the reservation station sees the proper
result being written back, it will grab it directly from one of the result buses. Once all operands are in the
reservation station for an instruction, it is eligible to be executed. Reservation stations temporarily store
dispatched instructions that cannot be executed until all of the source operands are valid.
1.2.8.1 Integer Units (IUs)
The two SCIUs and one MCIU execute all integer instructions. These are shown in Figure 1 and Figure 2.
Each IU has a dedicated result bus that connects to rename buffers and to all reservation stations. Each SCIU
has a two-entry reservation station and the MCIU has a single-entry reservation station to reduce stalls. A
reservation station can receive instructions from the decode/dispatch unit and operands from the GPRs, the
rename buffers, or the result buses.
Each SCIU consists of three single-cycle subunits—a fast adder/comparator, a subunit for logical
operations, and a subunit for performing rotates, shifts, and count-leading-zero operations. These subunits
handle all one-cycle arithmetic instructions; only one subunit can execute an instruction at a time.
The MCIU consists of a 32-bit integer multiplier/divider. The multiplier supports early exit on 16- x 32-bit
operations, and is responsible for executing the Move from Special-Purpose Register ( mfspr) and Move to
Special-Purpose Register ( mtspr) instructions, which are used to read and write special-purpose registers.
Note that the load and store instructions that update their address base register (specified by the r A operand)
pass the update results on the MCIU’s result bus. Otherwise, the MCIU’s result bus is dedicated to MCIU
operations.
PowerPC 604e RISC Microprocessor Technical Summary
11
Page 12

12
1.2.8.2 Floating-Point Unit (FPU)
The FPU, shown in Figure 1 and Figure 2, is a single-pass, double-precision execution unit; that is, most
single- and double-precision operations require only a single pass, with a latency of three cycles.
As the decode/dispatch unit issues instructions to the FPU’s two reservation stations, source operand data
may be accessed from the FPRs, the floating-point rename buffers, or the result buses. Results in turn are
written to the floating-point rename buffers and to the reservation stations and are made available to
subsequent instructions. Instructions are executed from the reservation station in dispatch order.
1.2.8.3 Load/Store Unit (LSU)
The LSU, shown in Figure 1 and Figure 2, transfers data between the data cache and the result buses, which
route data to other execution units. The LSU supports the address generation and handles any alignment for
transfers to and from system memory. Note that the 604e provides additional hardware support for
misaligned little-endian accesses over previous versions of the 604. In the 604e, the conditions that cause
an alignment exception to be taken are the same regardless of whether the processor is in big- or little-endian
mode. When two accesses are required, the lower addressed word (in the current addressing mode) is
accessed first.
The LSU also supports cache control instructions and load/store multiple/string instructions. As noted
above, load and store instructions that update the base address register pass their results on the MCIU’s
result bus. This is the only exception to the dedicated use of result buses.
The LSU includes a 32-bit adder dedicated for EA calculation. Data alignment logic manipulates data to
support aligned or misaligned transfers with the data cache. The LSU’s load and store queues are used to
buffer instructions that have been executed and are waiting to be completed. The queues are used to monitor
data dependencies generated by data forwarding and out-of-order instruction execution ensuring a
sequential model.
The LSU allows load operations to precede pending store operations and resolves any dependencies
incurred when a pending store is to the same address as the load. If such a dependency exists, the LSU delays
the load operation until the correct data can be forwarded. If only the low-order 12 bits of the EAs match,
both addresses may be aliases for the same physical address, in which case, the load operation is delayed
until the store has been written back to the cache, ensuring that the load operation retrieves the correct data.
The LSU does not allow the following operations to be performed on unresolved branches:
• Store operations
• Loading of noncacheable data or cache miss operations
1.2.9 Memory Management Units (MMUs)
The primary functions of the MMUs are to translate logical (effective) addresses to physical addresses for
memory accesses, I/O accesses (most I/O accesses are assumed to be memory-mapped), and direct-store
accesses, and to provide access protection on blocks and pages of memory.
The PowerPC MMUs and exception model support demand-paged virtual memory. Virtual memory
management permits execution of programs larger than the size of physical memory; demand-paged implies
that individual pages are loaded into physical memory from system memory only when they are first
accessed by an executing program.
The hashed page table is a variable-sized data structure that defines the mapping between virtual page
numbers and physical page numbers. The page table size is a power of 2, and its starting address is a multiple
of its size.
PowerPC 604e RISC Microprocessor Technical Summary
Page 13

Address translations are enabled by setting bits in the MSR—MSR[IR] enables instruction address
translations and MSR[DR] enables data address translations.
The 604e’s MMUs support up to 4 Petabytes (252) of virtual memory and 4 Gigabytes (232) of physical
memory. The MMUs support block address translations, direct-store segments, and page translation of
memory segments. Referenced and changed status are maintained by the processor for each page to assist
implementation of a demand-paged virtual memory system.
Separate but identical translation logic is implemented for data accesses and for instruction accesses. The
604e implements two 128-entry, two-way set-associative translation lookaside buffers (TLBs), one for
instructions and one for data. These TLBs can be accessed simultaneously.
1.2.10 Cache Implementation
The PowerPC architecture does not define hardware aspects of cache implementations. For example,
whereas the 604e implements separate data and instruction caches (Harvard architecture), other processors
may use a unified cache, or no cache at all. The PowerPC architecture defines the unit of coherency as a
cache block, which for the 604e is a 32-byte (eight-word) line.
PowerPC implementations can control the following memory access modes on a page or block basis:
• Write-back/write-through mode
• Caching-inhibited mode
• Memory coherency
• Guarded memory (prevents access for out-of-order execution)
1.2.10.1 Instruction Cache
The 604e’s 32-Kbyte, four-way set-associative instruction cache is physically indexed. Within a single
cycle, the instruction cache provides up to four instructions.
The 604e provides coherency checking for instruction fetches. Instruction fetching coherency is controlled
by a HID0[23]. In the default mode, HID0[23] is 0, the GBL
on the bus, as is the case with the 604. If the bit is set and instruction translation is enabled (MSR[IR] = 1),
the GBL
is disabled (MSR[IR] = 0), the GBL
The PowerPC architecture defines a special set of instructions for managing the instruction cache. The
instruction cache can be invalidated entirely or on a cache-block basis. The instruction cache can be disabled
and invalidated by setting the HID0[16] and HID0[20] bits, respectively. The instruction cache can be
locked by setting HID0[18].
signal is set to reflect the M bit for this page or block. If HID0[23] is set and instruction translation
signal is asserted and coherency is maintained in the instruction cache.
signal is not asserted for instruction accesses
1.2.10.2 Data Cache
The 604e’s data cache is a 32-Kbyte, four-way set associative cache. It is a physically-indexed,
nonblocking, write-back cache with hardware support for reloading on cache misses. Within one cycle, the
data cache provides double-word access to the LSU.
Note that the 604e provides additional support for data cache line-fill buffer forwarding. In the 604 only the
critical double word of a burst operation was made available to the requesting unit at the time it was burst
into the line-fill buffer. Subsequent data was unavailable until the cache block was filled. On the 604e,
subsequent data is also made available as it arrives in the line-fill buffer.
The 604e implements three copyback write buffers (as opposed to one in the 604). Having multiple
copyback buffers provides the ability for certain instructions to take fuller advantage of the pipelined system
bus to provide more efficient handling of cache copyback, block invalidate operations caused by the data
PowerPC 604e RISC Microprocessor Technical Summary
13
Page 14

14
cache block flush ( dcbf ) instruction, and cache block clean operations resulting from the data cache block
store ( dcbst ) instruction.
To ensure cache coherency, the 604e data cache supports the four-state MESI (modified/exclusive/shared/
invalid) protocol. The data cache tags are dual-ported, so the process of snooping does not affect other
transactions on the system interface. If a snoop hit occurs, the LSU is blocked internally for one cycle to
allow the eight-word block of data to be copied to the writeback buffer.
Like the instruction cache, the data cache can be invalidated all at once or on a per cache block basis. The
data cache can be disabled and invalidated by setting the HID0[17] and HID0[21] bits, respectively. The
data cache can be locked by setting HID0[19].
Each cache line contains eight contiguous words from memory that are loaded from an eight-word boundary
(that is, bits A27–A31 of the physical addresses are zero); thus, a cache line never crosses a page boundary.
Accesses that cross a page boundary can incur a performance penalty.
To ensure coherency among caches in a multiprocessor (or multiple caching-device) implementation, the
604e implements the MESI protocol on a per cache-block basis. MESI stands for modified/exclusive/
shared/invalid. These four states indicate the state of the cache block as follows:
• Modified (M)—The cache block is modified with respect to system memory; that is, data for this
address is valid only in the cache and not in system memory.
• Exclusive (E)—This cache block holds valid data that is identical to the data at this address in
system memory. No other cache has this data.
• Shared (S)—This cache block holds valid data that is identical to this address in system memory
and at least one other caching device.
• Invalid (I)—This cache block does not hold valid data.
Figure 3 describes the cache unit organization on the 604e.
256 Sets
Block 0
Block 1
Block 2
Block 3
Address Tag 0
Address Tag 1
Address Tag 2
Address Tag 3
State
State
State
State
Words 0–7
Words 0–7
Words 0–7
Words 0–7
8 Words/Block
Figure 3. Cache Unit Organization
PowerPC 604e RISC Microprocessor Technical Summary
Page 15

1.2.11 System Interface/Bus Interface Unit (BIU)
The 604e provides a versatile bus interface that allows a wide variety of system design options. The
interface includes a 72-bit data bus (64 bits of data and 8 bits of parity), a 36-bit address bus (32 bits of
address and 4 bits of parity), and sufficient control signals to allow for a variety of system-level
optimizations. The 604e uses one-beat and four-beat data transactions, although it is possible for other bus
participants to perform longer data transfers. The 604e clocking structure supports processor-to-bus clock
ratios of 1:1, 3:2, 2:1, 5:2, 3:1, and 4:1, as described in Section 1.2.12, “Clocking.” Note that support for
processor/bus clock ratios 5:2 and 4:1 is specific to the 604e and is not supported in the 604.
To support the changes in the clocking configuration, different precharge timings for the ABB
TRY, and SHD signals are implemented internally by the processor. The precharge timings for ARTRY
AR
, DBB,
and SHD can be disabled by setting HID0[7].
The 604e has the same pin configuration as the 604; however, on the 604e Vdd and AVdd must be tied to
2.5 Vdc and OVdd must be tied to 3.3 Vdc. The 604e uses split voltage planes, and for replacement
compatibility , 604/604e designs should provide both 2.5-V and 3.3-V planes and the ability to tie those two
planes together and disable the 2.5-V plane for operation with a 604.
In addition to the normal and data-streaming modes implemented on the 604, a no-DRTRY mode is
implemented on the 604e that improves performance on read operations for systems that do not use the
TRY signal. No-DRTRY mode makes read data available to the processor one bus clock cycle sooner
DR
than in normal mode . In no-DRTRY mode, the DR
TRY signal is no longer sampled as part of a qualified
bus grant.
The system interface is specific for each PowerPC processor implementation. The 604e system interface is
shown in Figure 4.
ADDRESS
ADDRESS ARBITRATION
ADDRESS START
ADDRESS TRANSFER
TRANSFER ATTRIBUTE
PowerPC
604e
Processor
DATA
DATA ARBITRA TION
DATA TRANSFER
DATA TERMINATION
PROCESSOR STATE
ADDRESS TERMINATION
CLOCKS
+2.5 V+3.3 V
Figure 4. System Interface
TEST AND CONTROL
Four-beat burst-read memory operations that load an eight-word cache block into one of the on-chip caches
are the most common bus transactions in typical systems, followed by burst-write memory operations,
direct-store operations, and single-beat (noncacheable or write-through) memory read and write operations.
Additionally, there can be address-only operations, variants of the burst and single-beat operations (global
memory operations that are snooped and atomic memory operations, for example), and address retry
activity (for example, when a snooped read access hits a modified line in the data cache).
Memory accesses can occur in single-beat or four-beat burst data transfers. The address and data buses are
independent for memory accesses to support pipelining and split transactions. The 604e supports bus
pipelining and out-of-order split-bus transactions. In general, the bus-pipelining mechanism allows as many
PowerPC 604e RISC Microprocessor Technical Summary
15
Page 16

16
as three address tenures to be outstanding before a data tenure is initiated. Address tenures for address-only
transactions can exceed this limit.
Typically, memory accesses are weakly-ordered. Sequences of operations, including load/store string/
multiple instructions, do not necessarily complete in the same order in which they began—maximizing the
efficiency of the bus without sacrificing coherency of the data. The 604e allows load operations to precede
store operations (except when a dependency exists, of course). In addition, the 604e provides a separate
queue for snoop push operations so these operations can access the bus ahead of previously queued
operations. The 604e dynamically optimizes run-time ordering of load/store traffic to improve overall
performance.
In addition, the 604e implements a data bus write-only signal (DBWO
operations. Asserting DBWO
processor. Although this may be used with any write operations, it can also be used to reorder a snoop push
operation.
Access to the system interface is granted through an external arbitration mechanism that allows devices to
compete for bus mastership. This arbitration mechanism is flexible, allowing the 604e to be integrated into
systems that use various fairness and bus-parking procedures to avoid arbitration overhead. Additional
multiprocessor support is provided through coherency mechanisms that provide snooping, external control
of the on-chip caches and TLBs, and support for a secondary cache. The PowerPC architecture provides the
load/store with reservation instruction pair ( lwarx / stwcx. ) for atomic memory references and other
operations useful in multiprocessor implementations.
The following sections describe the 604e bus support for memory and direct-store operations. Note that
some signals perform different functions depending upon the addressing protocol used.
causes the first write operation to occur before any read operations on a given
) that can be used for reordering write
1.2.11.1 Memory Accesses
Memory accesses allow transfer sizes of 8, 16, 24, 32, 40, 48, 56, or 64 bits in one bus clock cycle. Data
transfers occur in either single-beat transactions or four-beat burst transactions. A single-beat transaction
transfers as much as 64 bits. Single-beat transactions are caused by noncached accesses that access memory
directly (that is, reads and writes when caching is disabled, caching-inhibited accesses, and stores in writethrough mode). Burst transactions, which always transfer an entire cache block (32 bytes), are initiated
when a block in the cache is read from or written to memory. Additionally, the 604e supports address-only
transactions used to invalidate entries in other processors’ TLBs and caches.
Typically I/O accesses are performed using the same protocol as memory accesses.
1.2.11.2 Signals
The 604e’s signals are grouped as follows:
• Address arbitration signals—The 604e uses these signals to arbitrate for address bus mastership.
• Address start signals—These signals indicate that a bus master has begun a transaction on the
address bus.
• Address transfer signals—These signals, which consist of the address bus, address parity, and
address parity error signals, are used to transfer the address and to ensure the integrity of the
transfer.
• Transfer attribute signals—These signals provide information about the type of transfer , such as the
transfer size and whether the transaction is bursted, write-through, or caching-inhibited.
• Address termination signals—These signals are used to acknowledge the end of the address phase
of the transaction. They also indicate whether a condition exists that requires the address phase to
be repeated.
PowerPC 604e RISC Microprocessor Technical Summary
Page 17

• Data arbitration signals—The 604e uses these signals to arbitrate for data bus mastership.
• Data transfer signals—These signals, which consist of the data bus, data parity , and data parity error
signals, are used to transfer the data and to ensure the integrity of the transfer.
• Data termination signals—Data termination signals are required after each data beat in a data
transfer. In a single-beat transaction, the data termination signals also indicate the end of the tenure,
while in burst accesses, the data termination signals apply to individual beats and indicate the end
of the tenure only after the final data beat. They also indicate whether a condition exists that requires
the data phase to be repeated.
• Interrupt signals—These signals include the interrupt signal, checkstop signals, and both soft- and
hard-reset signals. These signals are used to interrupt and, under various conditions, to reset the
processor.
• Processor state signals—These two signals are used to set the reservation coherency bit and set the
size of the 604e’s output buffers.
• Miscellaneous signals—These signals are used in conjunction with such resources as secondary
caches and the time base facility.
• COP interface signals—The common on-chip processor (COP) unit is the master clock control unit
and it provides a serial interface to the system for performing built-in self test (BIST).
• Clock signals—These signals determine the system clock frequency . These signals can also be used
to synchronize multiprocessor systems.
NOTE
A bar over a signal name indicates that the signal is active low—for
example, AR
TRY (address retry) and TS (transfer start). Active-low
signals are referred to as asserted (active) when they are low and negated
when they are high. Signals that are not active-low, such as AP0–AP3
(address bus parity signals) and TT0–TT4 (transfer type signals) are
referred to as asserted when they are high and negated when they are low.
1.2.11.3 Signal Configuration
Figure 5 illustrates the logical pin configuration of the 604e, showing how the signals are grouped.
PowerPC 604e RISC Microprocessor Technical Summary
17
Page 18

18
ADDRESS
ARBITRATION
ADDRESS
START
ADDRESS
TRANSFER
TRANSFER
ATTRIBUTE
ADDRESS
TERMINATION
BUS REQUEST
BUS GRANT
ADDRESS BUS BUSY
TRANSFER START
EXTENDED TRANSFER START
ADDRESS
ADDRESS PARITY
ADDRESS PARITY ERROR
TRANSFER TYPE
TRANSFER CODE
TRANSFER SIZE
TRANSFER BURST
CACHE INHIBIT
WRITE THROUGH
GLOBAL
CACHE SET MEMBER
ADDRESS ACKNOWLEDGE
ADDRESS RETRY
SHARED
5
3
3
1
1
1
1
2
1
1
1
1
1
1
1
1
32
4
1
DATA BUS GRANT
1
DATA BUS WRITE ONLY
1
DATA BUS BUSY
1
DATA
64
DATA PARITY
8
DATA PARITY ERROR
1
DATA BUS DISABLE
1
TRANSFER ACKNOWLEDGE
1
DATA RETRY
1
TRANSFER ERROR ACK
1
INTERRUPT
1
SYSTEM RESET
1
MACHINE CHECK_
1
SYSTEM MANAGEMENT
1
CHECKSTOP INPUT_
1
CHECKSTOP_OUTPUT_
1
RESERVATION
1
HARD RESET
1
SYSTEM CLOCK
1
CLOCK OUT
1
TEST ACCESS PORT
4
TEST DATA OUT
1
DATA
ARBITRATION
DATA
TRANSFER
DATA
TERMINATION
INTERRUPT
SIGNALS
PROCESSOR
STATE
CLOCK
JTAG / COP
ENABLE TIMEBASE
1
DRIVER MODE
2
L2_INT
1
1
1
4
1
RUN
HALTED
PLL CONFIG
ANALOG VDD
MISC
TOTAL: 171
Figure 5. PowerPC 604e Microprocessor Signal Groups
1.2.12 Clocking
The 604e has a phase-locked loop (PLL) that generates the internal processor clock. The input, or reference
signal, to the PLL is the bus clock. The feedback in the PLL guarantees that the processor clock is phase
locked to the bus clock, regardless of process variations, temperature changes, or parasitic capacitances. The
PLL also ensures a 50% duty cycle for the processor clock.
PowerPC 604e RISC Microprocessor Technical Summary
Page 19

The 604e supports the following processor-to-bus clock frequency ratios—1:1, 3:2, 2:1, 5:2, 3:1, and 4:1,
although not all ratios are available for all frequencies. Configuration of the processor/bus clock ratios is
displayed through a 604e-specific register, HID1.
Part 2 PowerPC 604e Microprocessor:
Implementation
The PowerPC architecture is derived from the IBM POWER architecture (Performance Optimized with
Enhanced RISC architecture). The PowerPC architecture shares the benefits of the POWER architecture
optimized for single-chip implementations. The PowerPC architecture design facilitates parallel instruction
execution and is scalable to take advantage of future technological gains.
This section describes the PowerPC architecture in general, and specific details about the implementation
of the 604e as a low-power, 32-bit member of the PowerPC processor family.
• Features—Section 2.1, “Features,” describes general features that the 604e shares with the
PowerPC microprocessor family.
• Registers and programming model—Section 2.1.1, “Registers and Programming Model,” describes
the registers for the operating environment architecture common among PowerPC processors and
describes the programming model. It also describes the additional registers that are unique to the
604e.
• Instruction set and addressing modes—Section 2.1.2, “Instruction Set and Addressing Modes,”
describes the PowerPC instruction set and addressing modes for the PowerPC operating
environment architecture, and defines and describes the PowerPC instructions implemented in the
604e.
• Exception model—Section 2.1.3, “Exception Model,” describes the exception model of the
PowerPC operating environment architecture and the differences in the 604e exception model.
• Instruction timing—Section 2.1.4, “Instruction Timing,” provides a general description of the
instruction timing provided by the parallel execution supported by the PowerPC architecture and
the 604e.
2.1 Features
The 604e is a high-performance, superscalar PowerPC implementation of the PowerPC architecture. Like
other PowerPC processors, it adheres to the PowerPC architecture specifications but also has additional
features not defined by the architecture. These features do not affect software compatibility. The PowerPC
architecture allows optimizing compilers to schedule instructions to maximize performance through
efficient use of the PowerPC instruction set and register model. The multiple, independent execution units
in the 604e allow compilers to maximize parallelism and instruction throughput. Compilers that take
advantage of the flexibility of the PowerPC architecture can additionally optimize instruction processing of
the PowerPC processors.
The following sections summarize the features of the 604e, including both those that are defined by the
architecture and those that are unique to the 604e implementation.
PowerPC 604e RISC Microprocessor Technical Summary 19
Page 20

The PowerPC architecture consists of the following layers, and adherence to the PowerPC architecture can
be measured in terms of which of the following levels of the architecture is implemented:
• PowerPC user instruction set architecture (UISA)—Defines the base user-level instruction set, userlevel registers, data types, floating-point exception model, memory models for a uniprocessor
environment, and programming model for a uniprocessor environment.
• PowerPC virtual environment architecture (VEA)—Describes the memory model for a
multiprocessor environment, defines cache control instructions, and describes other aspects of
virtual environments. Implementations that conform to the VEA also adhere to the UISA, but may
not necessarily adhere to the OEA.
• PowerPC operating environment architecture (OEA)—Defines the memory management model,
supervisor-level registers, synchronization requirements, and the exception model.
Implementations that conform to the OEA also adhere to the UISA and the VEA.
For more information, refer to the PowerPC RISC Microprocessor Family: The Programming
Environments user’s manual.
The 604e complies to all three levels of the PowerPC architecture. Note that the PowerPC architecture
defines additional instructions for 64-bit data types. These instructions cause an illegal instruction exception
on the 604e. PowerPC processors are allowed to have features that are implementation-specific features that
fall outside, but do not conflict with, the PowerPC architecture specification. Examples of features that are
specific to the 604e include the performance monitor and nap mode.
2.1.1 Registers and Programming Model
The PowerPC architecture defines register-to-register operations for most computational instructions.
Source operands for these instructions are accessed from the registers or are provided as immediate values
embedded in the instruction opcode. The three-register instruction format allows specification of a target
register distinct from the two source operands. Load and store instructions transfer data between registers
and memory.
During normal execution, a program can access the registers, shown in Figure 6, depending on the
program’s access privilege (supervisor or user, determined by the privilege-level (PR) bit in the machine
state register (MSR)). Note that registers such as the general-purpose registers (GPRs) and floating-point
registers (FPRs) are accessed through operands that are part of the instructions. Access to registers can be
explicit (that is, through the use of specific instructions for that purpose such as Move to Special-Purpose
Register (mtspr) and Move from Special-Purpose Register (mfspr) instructions) or implicitly as the part of
the execution of an instruction. Some registers are accessed both explicitly and implicitly.
The numbers to the left of the SPRs indicate the number that is used in the syntax of the instruction operands
to access the register.
Figure 6 shows the registers implemented in the 604e, indicating those that are defined by the PowerPC
architecture and those that are 604e-specific. Note that these are all of these registers except the FPRs are
32-bits wide.
20 PowerPC 604e RISC Microprocessor Technical Summary
Page 21

SUPERVISOR MODEL
USER MODEL
UISA
General-Purpose
Registers
Floating-Point
Registers
Condition Register
Floating-Point Status
and Control Register
XER
Link Register
Count Register
GPR0
GPR1
GPR31
FPR0
FPR1
FPR31
CR
FPSCR
XER
LR
CTR
SPR 1
SPR 8
SPR 9
Machine State
Register
MSR
Processor Version
Register
Instruction BAT
Registers
IBAT2U
Performance
Monitor Counters
PMC3
Data Address Register
DAR
SPRGs
SPRG2
USER MODEL
VEA
Time Base Facility
(For Reading)
TBL
TBU
1
604e-specific—not defined by the PowerPC architecture
TBR 268
TBR 269
Time Base Facility
(For Writing)
TBU
Instruction Address
Breakpoint Register
IABR
OEA
Configuration Registers
Hardware Implementation
Dependent Register
SPR 287PVR
1
SPR 1008HID0
Memory Management Registers
Data BAT Registers
SPR 528IBAT0U
SPR 529IBAT0L
SPR 530IBAT1U
SPR 531IBAT1L
SPR 532
SPR 533IBAT2L
SPR 534IBAT3U
SPR 535IBAT3L
DBAT2U
SPR 536DBAT0U
SPR 537DBAT0L
SPR 538DBAT1U
SPR 539DBAT1L
SPR 540
SPR 541DBAT2L
SPR 542DBAT3U
SPR 543DBAT3L
Performance Monitor
1
SPR 952MMCR0
SPR 956
SPR 953PMC1
SPR 954PMC2
SPR 957
SPR 958PMC4
1
Monitor Control
MMCR1
Exception Handling Registers
SPR 19
SPR 272SPRG0
SPR 273SPRG1
SPR 274
SPR 275SPRG3
Miscellaneous Registers
SPR 284TBL
SPR 285
1
SPR 1010
PLL Configuration
Register
1
Segment Registers
SR0
SR1
SR15
SDR1
Sampled Data/
Instruction Address
DSISR
SPR 18DSISR
Save and Restore
Registers
SPR 26SRR0
SRR1
SPR 27
Decrementer
DEC
SPR 22
External Access
Register (Optional)
EAR
SPR 282
SPR 1009HID1
SPR 25SDR1
1
SPR959SDA
SPR 955SIA
Figure 6. Programming Model—PowerPC 604e Microprocessor Registers
PowerPC 604e RISC Microprocessor Technical Summary 21
Page 22

PowerPC processors have two levels of privilege—supervisor mode of operation (typically used by the
operating environment) and one that corresponds to the user mode of operation (used by application
software). As shown in Figure 6, the programming model incorporates 32 GPRs, 32 FPRs, special-purpose
registers (SPRs), and several miscellaneous registers. Note that each PowerPC implementation has its own
unique set of implementation-dependent registers that are typically used for debugging, configuration, and
other implementation-specific operations.
Some registers are accessible only by supervisor-level software. This division allows the operating system
to control the application environment (providing virtual memory and protecting operating-system and
critical machine resources). Instructions that control the state of the processor, the address translation
mechanism, and supervisor registers can be executed only when the processor is in supervisor mode.
The following sections summarize the PowerPC registers that are implemented in the 604e.
2.1.1.1 General-Purpose Registers (GPRs)
The PowerPC architecture defines 32 user-level, general-purpose registers (GPRs). These registers are
either 32 bits wide in 32-bit PowerPC implementations and 64 bits wide in 64-bit PowerPC
implementations. The 604e also has 12 GPR rename buffers, which provide a way to buffer data intended
for the GPRs, reducing stalls when the results of one instruction are required by a subsequent instruction.
The use of rename buffers is not defined by the PowerPC architecture, and they are transparent to the user
with respect to the architecture. The GPRs and their associated rename buffers serve as the data source or
destination for instructions executed in the IUs.
2.1.1.2 Floating-Point Registers (FPRs)
The PowerPC architecture also defines 32 floating-point registers (FPRs). These 64-bit registers typically
are used to provide source and target operands for user-level, floating-point instructions. As with the GPRs,
the 604e also has eight FPR rename buffers, which provide a way to buffer data intended for the FPRs,
reducing stalls when the results of one instruction are required by a subsequent instruction. The rename
buffers are not defined by the PowerPC architecture. The FPRs and their associated rename buffers can
contain data objects of either single- or double-precision floating-point formats.
2.1.1.3 Condition Register (CR)
The CR is a 32-bit user-level register that consists of eight four-bit fields that reflect the results of certain
operations, such as move, integer and floating-point compare, arithmetic, and logical instructions, and
provide a mechanism for testing and branching. The 604e also has eight CR rename buffers, which provide
a way to buffer data intended for the CR. The rename buffers are not defined by the PowerPC architecture.
2.1.1.4 Floating-Point Status and Control Register (FPSCR)
The floating-point status and control register (FPSCR) is a user-level register that contains all exception
signal bits, exception summary bits, exception enable bits, and rounding control bits needed for compliance
with the IEEE 754 standard.
2.1.1.5 Machine State Register (MSR)
The machine state register (MSR) is a supervisor-level register that defines the state of the processor. The
contents of this register are saved when an exception is taken and restored when the exception handling
completes. The 604e implements the MSR as a 32-bit register; 64-bit PowerPC processors use a 64-bit MSR
that provide a superset of the 32-bit functionality.
22 PowerPC 604e RISC Microprocessor Technical Summary
Page 23

2.1.1.6 Segment Registers (SRs)
For memory management, 32-bit PowerPC implementations use sixteen 32-bit segment registers (SRs).
2.1.1.7 Special-Purpose Registers (SPRs)
The PowerPC operating environment architecture defines numerous special-purpose registers that serve a
variety of functions, such as providing controls, indicating status, configuring the processor, and performing
special operations. Some SPRs are accessed implicitly as part of executing certain instructions. All SPRs
can be accessed by using the move to/from special purpose register instructions, mtspr and mfspr.
In the 604e, all SPRs are 32 bits wide.
2.1.1.8 User-Level SPRs
The following SPRs are accessible by user-level software:
• Link register (LR)—The link register can be used to provide the branch target address and to hold
the return address after branch and link instructions. The LR is 32 bits wide.
• Count register (CTR)—The CTR is decremented and tested automatically as a result of branch and
count instructions. The CTR is 32 bits wide.
• XER—The 32-bit XER contains the integer carry and overflow bits.
• The time base registers (TBL and TBU) can be read by user-level software, but can be written to
only by supervisor-level software.
2.1.1.9 Supervisor-Level SPRs
The 604e also contains SPRs that can be accessed only by supervisor-level software. These registers consist
of the following:
• The 32-bit DSISR defines the cause of data access and alignment exceptions.
• The data address register (DAR) is a 32-bit register that holds the address of an access after an
alignment or DSI exception.
• Decrementer register (DEC) is a 32-bit decrementing counter that provides a mechanism for
causing a decrementer exception after a programmable delay. In the 604e, the decrementer
frequency is 1/4th of the bus clock frequency (as is the time base frequency).
• The 32-bit SDR1 register specifies the page table format used in logical-to-physical address
translation for pages.
• The machine status save/restore register 0 (SRR0) is a 32-bit register that is used by the 604e for
saving the address of the instruction that caused the exception, and the address to return to when a
Return from Interrupt (rfi) instruction is executed.
• The machine status save/restore register 1 (SRR1) is a 32-bit register used to save machine status
on exceptions and to restore machine status when an rfi instruction is executed.
• SPRG0–SPRG3 registers are 32-bit registers provided for operating system use.
• The external access register (EAR) is a 32-bit register that controls access to the external control
facility through the External Control In Word Indexed (eciwx) and External Control Out Word
Indexed (ecowx) instructions.
• The processor version register (PVR) is a 32-bit, read-only register that identifies the version
(model) and revision level of the PowerPC processor.
• The time base registers (TBL and TBU) together provide a 64-bit time base register. The registers
are implemented as a 64-bit counter, with the least-significant bit being the most frequently
incremented. The PowerPC architecture defines that the time base frequency be provided as a
PowerPC 604e RISC Microprocessor Technical Summary 23
Page 24

subdivision of the processor clock frequency. In the 604e. the time base frequency is 1/4th of the
bus clock frequency (as is the decrementer frequency). Counting is enabled by the Time Base
Enable (TBE
• Block address translation (BAT) registers—The PowerPC architecture defines 16 BAT registers,
divided into four pairs of data BATs (DBATs) and four pairs of instruction BATs (IBATs).
• Data address breakpoint register (DABR)—This register, defined as optional by the PowerPC
architecture, can be used to cause a breakpoint exception to occur if a specified data address is
encountered.
The 604e includes the following registers not defined by the PowerPC architecture:
• Instruction address breakpoint register (IABR)—This register can be used to cause a breakpoint
exception to occur if a specified instruction address is encountered.
• Hardware implementation-dependent register 0 (HID0)—This register is used to control various
functions within the 604e, such as enabling checkstop conditions, and locking, enabling, and
invalidating the instruction and data caches. Additional bits defined in the HID0 register disable the
BTAC, control whether coherency is maintained for instruction fetches, and for disabling the
default precharge values for the shared (SHD
• Hardware implementation-dependent register 1 (HID1)—This register, which is not implemented
in the 604, is used to display the PLL configuration.
• Processor identification register (PIR)—The PIR is a supervisor-level register that has a rightjustified, four-bit field that holds a processor identification tag used to identify a particular 604e.
This tag is used to identify the processor in multiple-master implementations.
) signal.
) and address retry (ARTRY) signals.
• Performance monitor counter registers (PMC1–PMC4). The counters are used to record the number
of times a certain event has occurred. PMC3 and PMC4 are not implemented in the 604.
• Performance monitor control registers (MMCR0 and MMCR1)—These registers are used for
enabling various performance monitoring interrupt conditions and establishes the function of the
counters. MMCR1 is not implemented in the 604.
• Sampled instruction address and sampled data address registers (SIA and SDA)—These registers
hold the addresses for instruction and data used by the performance monitoring interrupt.
Note that while it is not guaranteed that the implementation of HID registers is consistent among PowerPC
processors, other processors may be implemented with similar or identical HID registers.
2.1.2 Instruction Set and Addressing Modes
The following subsections describe the PowerPC instruction set and addressing modes in general.
2.1.2.1 PowerPC Instruction Set and Addressing Modes
All PowerPC instructions are encoded as single-word (32-bit) opcodes. Instruction formats are consistent
among all instruction types, permitting efficient decoding to occur in parallel with operand accesses. This
fixed instruction length and consistent format greatly simplifies instruction pipelining.
2.1.2.1.1 Instruction Set
The 604e implements the entire PowerPC instruction set (for 32-bit implementations) and most optional
PowerPC instructions. The PowerPC instructions can be grouped into the following general categories:
• Integer instructions—These include computational and logical instructions.
— Integer arithmetic instructions
— Integer compare instructions
24 PowerPC 604e RISC Microprocessor Technical Summary
Page 25

— Logical instructions
— Integer rotate and shift instructions
• Floating-point instructions—These include floating-point computational instructions, as well as
instructions that affect the FPSCR. Floating-point instructions include the following:
— Floating-point arithmetic instructions
— Floating-point multiply/add instructions
— Floating-point rounding and conversion instructions
— Floating-point compare instructions
— Floating-point move instructions
— Floating-point status and control instructions
— Optional floating-point instructions (listed with the optional instructions below)
The 604e supports all IEEE 754-1985 floating-point data types (normalized, denormalized, NaN,
zero, and infinity) in hardware, eliminating the latency incurred by software exception routines.
The PowerPC architecture also supports a non-IEEE mode, controlled by a bit in the FPSCR. In this
mode, denormalized numbers, NaNs, and some IEEE invalid operations are not required to conform
to IEEE standards and can execute faster. Note that all single-precision arithmetic instructions are
performed using a double-precision format. The floating-point pipeline is a single-pass
implementation for double-precision products. Except for divide instructions, a single-precision
instruction using only single-precision operands in double-precision format performs the same as
its double-precision equivalent.
• Load/store instructions—These include integer and floating-point load and store instructions.
— Integer load and store instructions
— Integer load and store multiple instructions
— Integer load and store string instructions
— Floating-point load and store
• Flow control instructions—These include branching instructions, condition register logical
instructions, trap instructions, and other instructions that affect the instruction flow.
— Branch and trap instructions
— System call and rfi instructions
— Condition register logical instructions
• Synchronization instructions—The PowerPC architecture defines instructions for memory
synchronizing, especially useful for multiprocessing:
— Load and store with reservation instructions—These UISA-defined instructions provide
primitives for synchronization operations such as test and set, compare and swap, and compare
memory .
— The Synchronize (sync) instruction—This UISA-defined instruction is useful for
synchronizing load and store operations on a memory bus that is shared by multiple devices.
— The Enforce In-Order Execution of I/O (eieio) instruction—The eieio instruction, defined by
the VEA, can be used instead of the sync instruction when only memory references seen by
I/O devices need to be ordered.
— The Instruction Synchronize (isync) instruction waits until all previous instructions have
completed and discards and then refetches any subsequent instructions to ensure that those
instructions complete in the context established by the previous instructions.
PowerPC 604e RISC Microprocessor Technical Summary 25
Page 26

— The TLB Synchronize (tlbsync) instruction ensures that all tlbie instructions previously
executed by the processor that issued the tlbsync instruction have completed.
• Processor control instructions—These instructions are used for synchronizing memory accesses
and managing caches, TLBs, and segment registers. These instructions include Move to/from
Special-Purpose Register instructions (mtspr and mfspr).
• Memory/cache control instructions—These instructions provide control of caches, TLBs, and
segment registers.
— User- and supervisor-level cache instructions
— Segment register manipulation instructions
— Translation lookaside buffer management instructions
• Optional instructions—the 604e implements the following optional instructions:
— The eciwx/ecowx instruction pair
— The TLB Synchronize (tlbsync) instruction
— Optional graphics instructions:
– Store Floating-Point as Integer Word Indexed (stfiwx)
– Floating Reciprocal Estimate Single (fres)
– Floating Reciprocal Square Root Estimate (frsqrte)
– Floating Select (fsel)
Note that this grouping of the instructions does not indicate which execution unit executes a particular
instruction or group of instructions.
Integer instructions operate on byte, half-word, and word operands. Floating-point instructions operate on
single-precision (one word) and double-precision (one double word) floating-point operands. The PowerPC
architecture uses instructions that are four bytes long and word-aligned. It provides for byte, half-word, and
word operand loads and stores between memory and a set of 32 GPRs. It also provides for word and doubleword operand loads and stores between memory and a set of 32 FPRs.
Computational instructions do not modify memory. To use a memory operand in a computation and then
modify the same or another memory location, the memory contents must be loaded into a register, modified,
and then written back to the target location with specific store instructions.
PowerPC processors follow the program flow when they are in the normal execution state. However, the
flow of instructions can be interrupted directly by the execution of an instruction or by an asynchronous
event. Either kind of exception may cause one of several components of the system software to be invoked.
2.1.2.1.2 Calculating Effective Addresses
The effective address (EA) is the 32-bit address computed by the processor when executing a memory
access or branch instruction or when fetching the next sequential instruction.
The PowerPC architecture supports two simple memory addressing modes:
• EA = (rA|0) + offset (including offset = 0) (register indirect with immediate index)
• EA = (rA|0) + rB (register indirect with index)
These simple addressing modes allow efficient address generation for memory accesses. Calculation of the
effective address for aligned transfers occurs in a single clock cycle.
For a memory access instruction, if the sum of the effective address and the operand length exceeds the
maximum effective address, the storage operand is considered to wrap around from the maximum effective
address to effective address 0.
26 PowerPC 604e RISC Microprocessor Technical Summary
Page 27

Effective address computations for both data and instruction accesses use 32-bit unsigned binary arithmetic.
A carry from bit 0 is ignored in the 604e.
2.1.3 Exception Model
The following subsections describe the PowerPC exception model and the 604e implementation,
respectively.
The PowerPC exception mechanism allows the processor to change to supervisor state as a result of external
signals, errors, or unusual conditions arising in the execution of instructions. When exceptions occur,
information about the state of the processor is saved to various registers and the processor begins execution
at an address (exception vector) predetermined for each exception and the processor changes to supervisor
mode.
Although multiple exception conditions can map to a single exception vector, a more specific condition may
be determined by examining a register associated with the exception—for example, the DSISR and the
FPSCR. Additionally, specific exception conditions can be explicitly enabled or disabled by software.
The PowerPC architecture requires that exceptions be handled in program order; therefore, although a
particular PowerPC processor may recognize exception conditions out of order, exceptions are handled
strictly in order. When an instruction-caused exception is recognized, any unexecuted instructions that
appear earlier in the instruction stream, including any that have not yet entered the execute state, are
required to complete before the exception is taken. Any exceptions caused by those instructions must be
handled first. Likewise, exceptions that are asynchronous and precise are recognized when they occur
(unless they are masked) and the reorder buffer is drained. The address of the next sequential instruction is
saved in SRR0 so execution can resume in the correct context when the exception handler returns control
to the interrupted process.
Unless a catastrophic condition causes a system reset or machine check exception, only one exception is
handled at a time. If, for example, a single instruction encounters multiple exception conditions, those
conditions are encountered sequentially. After the exception handler handles an exception, the instruction
execution continues until the next exception condition is encountered. This method of recognizing and
handling exception conditions sequentially guarantees that exceptions are recoverable.
Exception handlers should save the information stored in SRR0 and SRR1 early to prevent the program state
from being lost due to a system reset or machine check exception or to an instruction-caused exception in
the exception handler.
The PowerPC architecture supports four types of exceptions:
• Synchronous, precise—These are caused by instructions. All instruction-caused exceptions are
handled precisely; that is, the machine state at the time the exception occurs is known and can be
completely restored.
• Synchronous, imprecise—The PowerPC architecture defines two imprecise floating-point
exception modes, recoverable and nonrecoverable. The 604e implements only the imprecise,
nonrecoverable mode. The imprecise, recoverable mode is treated as the precise mode in the 604e.
PowerPC 604e RISC Microprocessor Technical Summary 27
Page 28

• Asynchronous—The OEA portion of the PowerPC architecture defines two types of asynchronous
exceptions:
— Asynchronous, maskable—The PowerPC architecture defines the external interrupt and
decrementer interrupt which are maskable and asynchronous exceptions. In the 604e, and in
many PowerPC processors, the hardware interrupt is generated by the assertion of the Interrupt
(INT
) signal, which is not defined by the architecture. In addition, the 604e implements one
additional interrupt, the system management interrupt, which performs similarly to the external
interrupt, and is generated by the assertion of the System Management Interrupt (SMI
) signal.
When these exceptions occur, their handling is postponed until all instructions, and any
exceptions associated with those instructions, complete execution.
— Asynchronous, nonmaskable—There are two nonmaskable asynchronous exceptions that are
imprecise: system reset and machine check exceptions. Note that the OEA portion of the
PowerPC architecture, which defines how these exceptions work, does not define the causes or
the signals used to cause these exceptions. These exceptions may not be recoverable, or may
provide a limited degree of recoverability for diagnostic purpose.
The PowerPC architecture defines two bits in the machine state register (MSR)—FE0 and FE1—that
determine how floating-point exceptions are handled. There are four combinations of bit settings, of which
the 604e implements three. These are as follows:
• Ignore exceptions mode (FE0 = FE1 = 0). In this mode, the instruction dispatch logic feeds the FPU
as fast as possible and the FPU uses an internal pipeline to allow overlapped execution of
instructions. In this mode, floating-point exception conditions return a predefined value instead of
causing an exception.
• Precise interrupt mode (FE0 = 1; FE1 = x). This mode includes both the precise mode and imprecise
recoverable mode defined in the PowerPC architecture. In this mode, a floating-point instruction
that causes a floating-point exception brings the machine to a precise state. In doing so, the 604e
takes floating-point exceptions as defined by the PowerPC architecture.
• Imprecise nonrecoverable mode (FE0 = 0; FE1 = 1). In this mode, when a floating-point instruction
causes a floating point exception, the save restore register 0 (SRR0) may point to an instruction
following the instruction that caused the exception.
The 604e exception classes are shown in Table 1.
Table 1. Exception Classifications
Type Exception
Asynchronous/nonmaskable Machine check
System reset
Asynchronous/maskable External interrupt
Decrementer
System management interrupt (not defined by the PowerPC architecture)
Synchronous/precise Instruction-caused exceptions
Synchronous/imprecise Floating-point exceptions (imprecise nonrecoverable mode)
28 PowerPC 604e RISC Microprocessor Technical Summary
Page 29

The 604e’s exceptions, and conditions that cause them, are listed in Table 2.
Table 2. Exceptions and Conditions
Exception
Type
Reserved 00000 —
System reset 00100 A system reset is caused by the assertion of either the soft or hard reset signal.
Machine
check
DSI 00300 The cause of a DSI exception can be determined by the bit settings in the
Vector Offset
(hex)
00200 A machine check exception is signaled by the assertion of a qualified TEA
indication on the 604e bus, or the machine check input (MCP
MSR[ME] is cleared, the processor enters the checkstop state when one of
these signals is asserted. Note that MSR[ME] is cleared when an exception is
taken. The machine check exception is also caused by parity errors on the
address or data bus or in the instruction or data caches.
The assertion of the TEA
initiated by the processor; however, it is expected that the TEA
used by a memory controller to indicate that a memory parity error or an
uncorrectable memory ECC error has occurred.
Note that the machine check exception is imprecise with respect to the
instruction that originated the bus operation.
DSISR, listed as follows:
0 Set if a load or store instruction results in a direct-store exception;
otherwise cleared.
1 Set if the translation of an attempted access is not found in the primary
table entry group (PTEG), or in the rehashed secondary PTEG, or in the
range of a BAT register; otherwise cleared.
4 Set if a memory access is not permitted by the page or DBAT protection
mechanism; otherwise cleared.
5 If SR[T] = 1, set by an eciwx, ecowx, lwarx, or stwcx. instruction;
otherwise cleared. Set by an eciwx or ecowx instruction if the access is to
an address that is marked as write-through.
6 Set for a store operation and cleared for a load operation.
9 Set if an EA matches the address in the DABR while in one of the three
compare modes.
10 Set if the segment table search fails to find a translation for the effective
address; otherwise cleared.
11 Set if eciwx or ecowx is used and EAR[E] is cleared.
Causing Conditions
) signal. If the
signal is determined by load and store operations
signal would be
ISI 00400 An ISI exception is caused when an instruction fetch cannot be performed for
any of the following reasons:
• The effective address cannot be translated. That is, a page fault occurred for
this part of the translation, so an ISI exception must be taken to retrieve the
translation from a storage device such as a hard disk drive.
• The fetch access is to a direct-store segment.
• The fetch access violates memory protection. If the key bits (Ks and Kp) in
the segment register and the PP bits in the PTE or IBAT are set to prohibit
read access, instructions cannot be fetched from this location.
• An attempt is made to fetch an instruction from a segment configured as no-
execute; that is, SR[N] = 1.
• An attempt is made to fetch an instruction from a block or page configured
as guarded, that is the G bit is set and translation is enabled, MSR[IR] = 1.
PowerPC 604e RISC Microprocessor Technical Summary 29
Page 30

Table 2. Exceptions and Conditions (Continued)
Exception
Type
External
interrupt
Alignment 00600 An alignment exception is caused when the processor cannot perform a
Program 00700 A program exception is caused by one of the following exception conditions,
Vector Offset
(hex)
00500 An external interrupt occurs when the external interrupt signal, INT, is asserted.
This signal is expected to remain asserted until the exception handler begins
execution. Once the signal is detected, the 604e stops dispatching instructions
and waits for all dispatched instructions to complete. Any exceptions associated
with dispatched instructions are taken before the interrupt is taken.
memory access for the following reasons:
• A floating-point load, store, lmw, stmw, lwarx, or stwcx. instruction is not
word-aligned.
•A dcbz instruction refers to a page that is marked either caching-inhibited or
write-through.
•A dcbz instruction has executed when the 604e data cache is locked or
disabled.
• An ecowx or eciwx is not word-aligned.
which correspond to bit settings in SRR1 and arise during execution of an
instruction:
• Floating-point exceptions—A floating-point enabled exception condition
causes an exception when FPSCR[FEX] is set and depends on the values in
MSR[FE0] and MSR[FE1].
FPSCR[FEX] is set by the execution of a floating-point instruction that
causes an enabled exception or by the execution of a “move to FPSCR”
instruction that results in both an exception condition bit and its
corresponding enable bit being set in the FPSCR.
• Illegal instruction—An illegal instruction program exception is generated
when execution of an instruction is attempted with an illegal opcode or illegal
combination of opcode and extended opcode fields or when execution of an
optional instruction not provided in the specific implementation is attempted
(these do not include those optional instructions that are treated as no-ops).
• Privileged instruction—A privileged instruction type program exception is
generated when the execution of a privileged instruction is attempted and
the MSR register user privilege bit, MSR[PR], is set. This exception is also
generated for mtspr or mfspr with an invalid SPR field if SPR[0] = 1 and
MSR[PR] = 1.
• Trap—A trap type program exception is generated when any of the
conditions specified in a trap instruction is met.
Causing Conditions
Floating-point
unavailable
Decrementer 00900 The decrementer exception occurs when the most significant bit of the
Reserved 00A00–00BFF Not implemented on the 604e.
System call 00C00 A system call exception occurs when a System Call (sc) instruction is executed.
Trace 00D00 Either the MSR[SE] = 1 and any instruction (except rfi) successfully completed
Floating-point
assist
00800 A floating-point unavailable exception is caused by an attempt to execute a
floating-point instruction (including floating-point load, store, and move
instructions) when the floating-point available bit is disabled (MSR[FP] = 0).
decrementer (DEC) register transitions from 0 to 1.
or MSR[BE] = 1 and a branch instruction is completed.
00E00 Defined by the PowerPC architecture, but not implemented on the 604e.
30 PowerPC 604e RISC Microprocessor Technical Summary
Page 31

Table 2. Exceptions and Conditions (Continued)
Exception
Type
Reserved 00E10–00EFF Not implemented on the 604e.
Performance
monitoring
interrupt
Reserved 01000–012FF —
Instruction
address
breakpoint
System
management
interrupt
Reserved 01500-02FFF —
Vector Offset
(hex)
00F00 The performance monitoring interrupt is a 604e-specific exception and is used
with the 604e performance monitor, described in Section 2.3, “Performance
Monitor.”
The performance monitoring facility can be enabled to signal an exception
when the value in one of the performance monitor counter registers (PMC1–
PMC4) goes negative. The conditions that can cause this exception can be
enabled or disabled in the monitor mode control registers (MMCR0 or MMCR1).
Although the exception condition may occur when the MSR EE bit is cleared,
the actual interrupt is masked by the EE bit and cannot be taken until the EE bit
is set.
01300 An instruction address breakpoint exception occurs when the address (bits 0 to
29) in the IABR matches the next instruction to complete in the completion unit,
and the IABR enable bit (bit 30) is set to 1.
01400 A system management interrupt is caused when MSR[EE] = 1 and the SMI
input signal is asserted. This exception is provided for use with the nap mode,
which is described in Section 2.2, “Power Management—Nap Mode.”
Causing Conditions
Reserved 01000–02FFF Reserved, implementation-specific exceptions. These are not implemented in
the 604e.
2.1.4 Instruction Timing
As shown in Figure 7, the common pipeline of the 604e has six stages through which all instructions must
pass. Some instructions occupy multiple stages simultaneously and some individual execution units have
additional stages. For example, the floating-point pipeline consists of three stages through which all
floating-point instructions must pass.
PowerPC 604e RISC Microprocessor Technical Summary 31
Page 32

Fetch (IF)
Decode (ID)
(Four-instruction dispatch per clock in
any combination)
SCIU1
SCIU2 FPU
Figure 7. Pipeline Diagram
Dispatch (DS)
Execute Stage
Complete (C)
Writeback (W)
The common pipeline stages are as follows:
• Instruction fetch (IF)—During the IF stage, the fetch unit loads the decode queue (DEQ) with
instructions from the instruction cache and determines from what address the next instruction
should be fetched.
LSUMCIU BPUCPU
• Instruction decode (ID)—During the ID stage, all time-critical decoding is performed on
instructions in the dispatch queue (DISQ). The remaining decode operations are performed during
the instruction dispatch stage.
• Instruction dispatch (DS)—During the dispatch stage, the decoding that is not time-critical is
performed on the instructions provided by the previous ID stage. Logic associated with this stage
determines when an instruction can be dispatched to the appropriate execution unit. At the end of
the DS stage, instructions and their operands are latched into the execution input latches or into the
unit’s reservation station. Logic in this stage allocates resources such as the rename registers and
reorder buffer entries.
• Execute (E)—While the execution stage is viewed as a common stage in the 604e instruction
pipeline, the instruction flow is split among the seven execution units, some of which consist of
multiple pipelines. An instruction may enter the execute stage from either the dispatch stage or the
execution unit’s dedicated reservation station.
At the end of the execute stage, the execution unit writes the results into the appropriate rename
buffer entry and notifies the completion stage that the instruction has finished execution.
32 PowerPC 604e RISC Microprocessor Technical Summary
Page 33

The execution unit reports any internal exceptions to the completion stage and continues execution,
regardless of the exception. Under some circumstances, results can be written directly to the target
registers, bypassing the rename buffers.
• Complete (C)—The completion stage ensures that the correct machine state is maintained by
monitoring instructions in the completion buffer and the status of instruction in the execute stage.
When instructions complete, they are removed from the reorder buffer (ROB). Results may be
written back from the rename buffers to the register as early as the complete stage. If the completion
logic detects an instruction containing exception status or if a branch has been mispredicted, all
subsequent instructions are cancelled, any results in rename buffers are discarded, and instructions
are fetched from the correct instruction stream.
The CR, CTR, and LR are also updated during the complete stage.
• Writeback (W)—The writeback stage is used to write back any information from the rename buffers
that was not written back during the complete stage.
All instructions are fully pipelined except for divide operations and some integer multiply operations. The
integer multiplier is a three-stage pipeline. Integer divide instructions iterate in stage two of the multiplier.
SPR operations can execute in the MCIU in parallel with multiply and divide operations.
The floating-point pipeline has three stages. Floating-point divide operations iterate in the first stage.
2.2 Power Management—Nap Mode
The 604e provides a power-saving mode, called nap mode, in which all internal processing and bus
operation is suspended. Software initiates nap mode by setting the MSR[POW] bit. After this bit is set, the
604e suspends instruction dispatch and waits for all activity in progress, including active and pending bus
transactions, to complete. It then powers down the internal clocks, and indicates nap mode by asserting the
HALTED output signal.
When the 604e is in nap mode, all internal activity stops except for decrementer, time base, and interrupt
logic, and the 604e does not snoop bus activity unless the system asserts the RUN input signal. Asserting
the RUN signal causes the HALTED signal to be negated.
Nap mode is exited (clocks resume and MSR[POW] cleared) when any asynchronous exception is detected.
2.3 Performance Monitor
The 604e incorporates a performance monitor facility that system designers can use to help bring up, debug,
and optimize software performance, especially in multiprocessing systems. The performance monitor is a
software-accessible mechanism that provides detailed information concerning the dispatch, execution,
completion, and memory access of PowerPC instructions.
A performance monitor control register (MMCR0 or MMCR1) can be used to specify the conditions for
which a performance monitoring interrupt is taken. For example, one such condition is associated with one
of the counter registers (PMC1–PMC4) incrementing until the most significant bit indicates a negative
value. Additionally, the sampled instruction address and sampled data address registers (SIA and SDA) are
used to hold addresses for instruction and data related to the performance monitoring interrupt.
PowerPC 604e RISC Microprocessor Technical Summary 33
Page 34

Information in this document is provided solely to enable system and software implementers to use PowerPC microprocessors. There are no express or
implied copyright or patent licenses granted hereunder by Motorola or IBM to design, modify the design of, or fabricate circuits based on the information in
this document.
The PowerPC 604e microprocessor embodies the intellectual property of Motorola and of IBM. However, neither Motorola nor IBM assumes any responsibility
or liability as to any aspects of the performance, operation, or other attributes of the microprocessor as marketed by the other party or by any third party. Neither
Motorola nor IBM is to be considered an agent or representative of the other, and neither has assumed, created, or granted hereby any right or authority to the
other, or to any third party, to assume or create any express or implied obligations on its behalf. Information such as data sheets, as well as sales terms and
conditions such as prices, schedules, and support, for the product may vary as between parties selling the product. Accordingly, customers wishing to learn more
information about the products as marketed by a given party should contact that party.
Both Motorola and IBM reserve the right to modify this document and/or any of the products as described herein without further notice. NOTHING IN THIS
DOCUMENT , NOR IN ANY OF THE ERRATA SHEETS, DATA SHEETS, AND OTHER SUPPORTING DOCUMENTATION, SHALL BE INTERPRETED AS THE
CONVEYANCE BY MOTOROLA OR IBM OF AN EXPRESS WARRANTY OF ANY KIND OR IMPLIED WARRANTY, REPRESENTATION, OR GUARANTEE
REGARDING THE MERCHANTABILITY OR FITNESS OF THE PRODUCTS FOR ANY PARTICULAR PURPOSE. Neither Motorola nor IBM assumes any
liability or obligation for damages of any kind arising out of the application or use of these materials. Any warranty or other obligations as to the products described
herein shall be undertaken solely by the marketing party to the customer, under a separate sale agreement between the marketing party and the customer . In the
absence of such an agreement, no liability is assumed by Motorola, IBM, or the marketing party for any damages, actual or otherwise.
“Typical” parameters can and do vary in different applications. All operating parameters, including “Typicals,” must be validated for each customer application
by customer’s technical experts. Neither Motorola nor IBM convey any license under their respective intellectual property rights nor the rights of others. Neither
Motorola nor IBM makes any claim, warranty, or representation, express or implied, that the products described in this document are designed, intended, or
authorized for use as components in systems intended for surgical implant into the body, or other applications intended to support or sustain life, or for any other
application in which the failure of the product could create a situation where personal injury or death may occur. Should customer purchase or use the products
for any such unintended or unauthorized application, customer shall indemnify and hold Motorola and IBM and their respective officers, employees, subsidiaries,
affiliates, and distributors harmless against all claims, costs, damages, and expenses, and reasonable attorney fees arising out of, directly or indirectly, any claim
of personal injury or death associated with such unintended or unauthorized use, even if such claim alleges that Motorola or IBM was negligent regarding the
design or manufacture of the part.
Motorola and are registered trademarks of Motorola, Inc. Motorola, Inc. is an Equal Opportunity/Affirmative Action Employer.
IBM, the IBM logo, and IBM Microelectronics are registered trademarks of International Business Machines Corporation.
The PowerPC name, the PowerPC logotype, PowerPC 604, and PowerPC 604e are trademarks of International Business Machines Corporation, used by
Motorola under license from International Business Machines Corporation. International Business Machines Corporation is an Equal Opportunity/Affirmative
Action Employer.
International Business Machines Corporation:
IBM Microelectronics Division, 1580 Route 52, Bldg. 504, Hopewell
Junction, NY 12533-6531; Tel. (800) PowerPC
World Wide Web Address: http://www.chips.ibm.com/products/ppc
http://www.ibm.com
Motorola Literature Distribution Centers:
USA/EUROPE: Motorola Literature Distribution; P.O. Box 20912; Phoenix, Arizona 85036;
Tel.: 1-800-441-2447
JAPAN: Nippon Motorola Ltd.; Tatsumi-SPD-JLDC, Toshikatsu Otsuki, 6F SeibuButsuryu-Center, 3-14-2 Tatsumi Koto-Ku, Tokyo 135, Japan; Tel.: 03-3521-8315
HONG KONG: Motorola Semiconductors H.K. Ltd.; 8B Tai Ping Industrial Park, 51 Ting
Kok Road, Tai Po, N.T., Hong Kong; Tel.: 852-26629298
MFAX: RMFAX0@email.sps.mot.com; TOUCHTONE (602) 244-6609
INTERNET: http://Design-NET.com
Technical Information: Motorola Inc. SPS Customer Support Center; (800) 521-6274.
Document Comments: FAX (512) 891-2638, Attn: RISC Applications Engineering.
World Wide Web Address: http://www.mot.com/powerpc/
 Loading...
Loading...