

Integrated Device Technology Inc IDT79RV4650100MS, IDT79RV465080MS, IDT79RV4650133MS, IDT79R4650100MS, IDT79R465080MS Datasheet
...
EMBEDDED
Integrated Device Technology, Inc.
64-BIT ORION
™
RISC IDT79R4650
MICROPROCESSOR
IDT79RV4650
™
™
FEATURES
• High-performance embedded 64-bit microprocessor
- 64-bit integer operations
- 64-bit registers
- 80MHz, 100MHz, 133MHz operation frequency
• High-performance DSP capability
- 66.7 Million Integer Multiply-Accumulate Operations/
sec @ 133 MHz
- 44 MFlops floating point operations @133MHz
• High-performance microprocessor
- 133 MIPS at 133MHz
- 66.7 M Mul-Add/second at 133MHz
- 44 MFLOP/s at 133MHz
- >300,000 dhrystone (2.1)/sec capability at 133MHz
(175 dhrystone MIPS)
• High level of integration
- 64-bit, 133 MIPS integer CPU
- 44MFlops Single precision floating-point unit
- 8KB instruction cache; 8KB data cache
- Integer multiply unit with 66.7M Mul-Add/sec
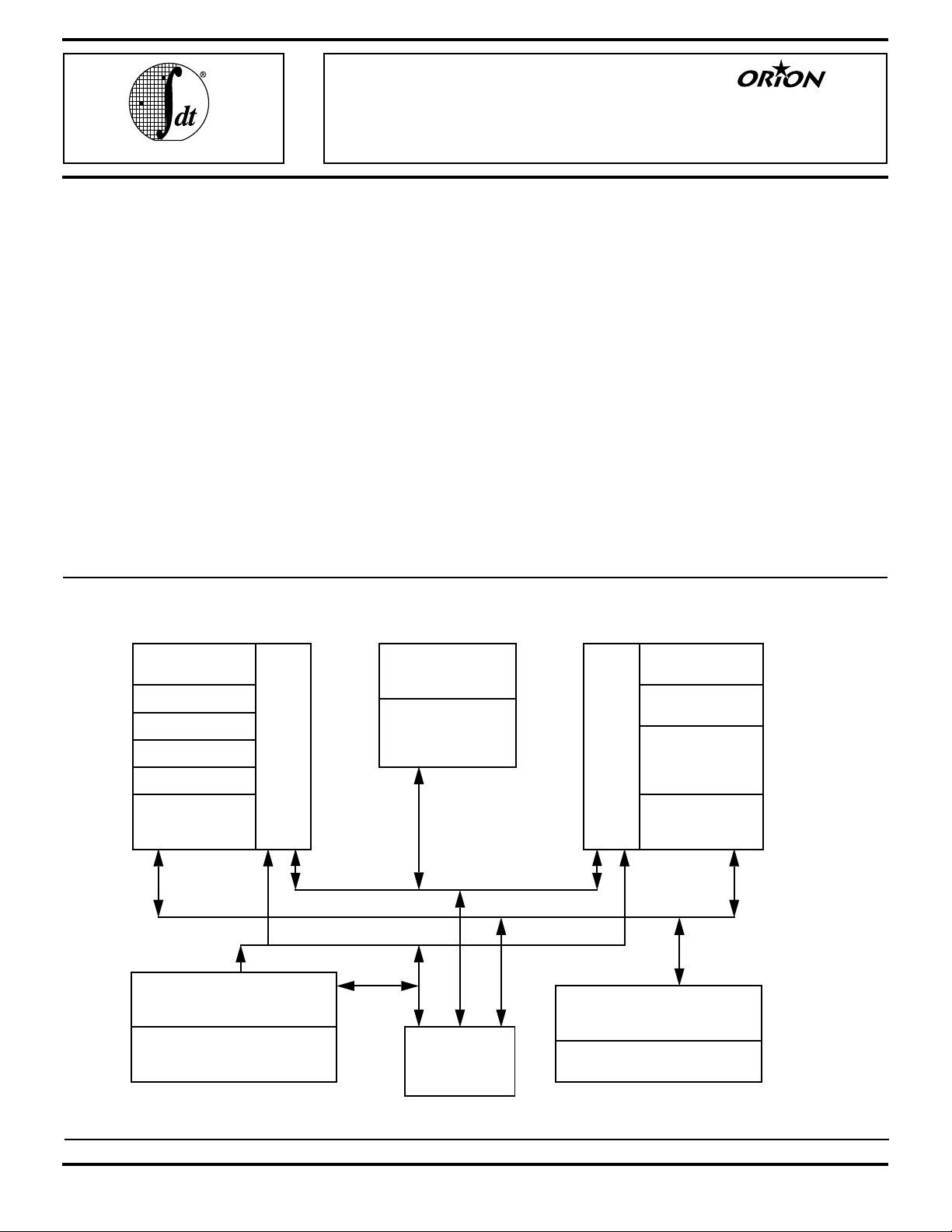
BLOCK DIAGRAM:
133 MIPS 64-bit ORION CPU
System Control Coprocessor
• Low-power operation
- Active power management powers-down inactive units
- Standby mode
• Upward software compatible with IDT RISController Family
• Large, efficient on-chip caches
- Separate 8kB Instruction and 8kB Data caches
- Over 1500MB/sec bandwidth from internal caches
- 2-set associative
- Write-back and write-through support
- Cache locking to facilitate deterministic response
• Bus compatible with
ORION
family
- System interfaces to 67 MHz, provides bandwidth up to
533 MB/S
- Direct interface to 32-bit wide or 64-bit wide systems
- Synchronized to external reference clock f or multi-master
operation
• Improved real-time support
- Fast interrupt decode
- Optional cache locking
44MFLOPS Single-Precision FPA
64-bit register file
64-bit adder
Load aligner
Store Aligner
Logic Unit
High-Performance
Integer Multiply
Instruction Cache
Set A
(Lockable)
Instruction Cache
Set B
Pipeline Control
Control Bus
Instruction Bus
Address Translation/
Cache Attribute Control
Exception Management
Functions
32-/64-bit
Synchronized
System Interface
Data Bus
FP register file
FP Add/Sub/Cvt/
Pipeline Control
Data Cache
Set A
(Lockable)
Data Cache
Set B
Pack/Unpack
Div/Sqrt
FP Multiply
The IDT logo is a registered trademark and ORION, R4650, RV4650, R4600, R3081, R3052, R3051, R3041, RISController, and RISCore are trademarks of Integrated Device Technology, Inc.
COMMERCIAL TEMPERA TURE RANGE
1996 Integrated Device Technology, Inc.
5.8
MARCH 1996
DSC3149/2
1

IDT79R4650 COMMERCIAL TEMPERATURE RANGE
DESCRIPTION
The IDT79R4650 is a low-cost member of the IDT
family, targeted to a variety of performance hungry
embedded applications. The R4650 continues the
tradition of high-performance through high-speed pipelines,
high-bandwidth caches and bus interface, 64-bit architecture, and careful attention to efficient control. The R4650
reduces the cost of this performance relative to the R4600,
by removing functional units that are frequently unneeded
for many embedded applications, such as double-precision
floating point arithmetic and a TLB.
The R4650 adds features relative to the R4600, reflective
of its target applications. These features enable system
cost reduction (e.g. optional 32-bit system interface) as well
as higher performance for certain types of systems (e.g.
cache locking, improved real-time support, integer DSP
capability).
The R4650 supports a wide variety of embedded
processor-based applications, such as consumer game
systems, multi-media functions, internetworking
equipment, switching equipment, and printing systems.
Upwardly software-compatible with the RISController
family, and bus- and upwardly software-compatible with the
ORION
IDT
family, the R4650 will serve in many of the same
applications, but, in addition supports other applications
such as those requiring integer DSP functions.
The R4650 brings
cost systems.
ORION
ORION
performance levels to lower
performance is preserved by retaining
large on-chip caches that are two-way set associative, a
streamlined high-speed pipeline, high-bandwidth, 64-bit
execution, and facilities such as early restart for data cache
misses. These techniques combine to allow the system
designer over 2GB/sec aggregate internal bandwidth, 533
MB/sec bus bandwidth, 175 Dhrystone MIPS, 44MFlops,
and 66.7 M Multiply-add/second.
The R4650 provides complete upward applicationsoftware compatibility with the IDT79R3000
IDT79R4700
™
families of microprocessors.An array of
ORION
ORION
™
and
development tools facilitates the rapid development of
R4650-based systems, enabling a wide variety of
customers to take advantage of the high-performance
capabilities of the processor while maintaining short time to
market goals.
The 64-bit computing capability of the R4650 enables a
wide variety of capabilities previously limited by the lower
bandwidth and bit-manipulation rates inherent in 32-bit
architectures. For example, the R4650 can perform loads
and stores from cached memory at the rates of 8-bytes
every clock cycle, doubling the bandwidth of an equivalent
32-bit processor. This capability, coupled with the high
clock rate for the R4650 pipeline, enables new levels of
performance to be obtained from embedded systems.
This data sheet provides an overview of the features and
architecture of the R4650 CPU. A more detailed description
of the processor is available in the
Hardware User’s Manual
,
available from IDT. Further infor-
IDT79R4650 Processor
mation on development support, applications notes, and
complementary products are also available from your local
IDT sales representative.
HARDWARE OVERVIEW
The R4650 family brings a high-level of integration
designed for high-performance computing. The key
elements of the R4650 are briefly described below. A more
detailed description of each of these subsystems is
available in the User’s Manual.
Pipeline
The R4650 uses a 5-stage pipeline similar to the
IDT79R3000 and the IDT79R4600. The simplicity of this
pipeline allows the R4650 to be lower cost and lower power
than super-scalar or super-pipelined processors. Unlike
superscalar processors, applications that have large data
dependencies or that require a great deal of load/stores
can still achieve performance close to the peak
General Purpose Registers
63 0
0630
r1 HI (Accumulate HI)
r2 63 0
• LO (Accumulate LO)
•
•
•63310
r29 PC
Multiply/Divide Registers
Program Counter
Figure 1: CPU Registers
5.8
2
IDT79R4650 COMMERCIAL TEMPERATURE RANGE
I
0
I
1
I
2
I
3
I
4
1I-1R Instruction cache access
2A-2D Data cache access and load align
1D-2D Virtual to physical address translation
1A-2A Integer add, logical, shift
1I 2I 1R 2R 1A 2A 1D 2D 1W 2W
1I 2I 1R 2R 1A 2A
1I 2I 1R 2R
1I 2I
2I Instruction virtual to physical address translation
1D Data virtual to physical address translation
2R Register file read
2R Bypass calculation
2R Instruction decode
2R Branch address calculation
1A Issue or slip decision
1A Data virtual address calculation
2A Store align
1A Branch decision
2W Register file write
Figure 2: R4650 Pipeline
1D 2D 1W 2W
1A 2A 1D 2D 1W •••
1R 2R 1A 2A 1D •••
1I
one cycle
2I 1R 2R 1A •••
performance of the processor. Figure 2 shows the R4650
pipeline.
Integer Execution Engine
The R4650 implements the MIPS-III Instruction Set
Architecture, and thus is fully upward compatible with applications running on the earlier generation parts. The R4650
includes the same additions to the instruction set found in
the R4600 family of microprocessors, targeted at improving
performance and capability while maintaining binary
compatibility with earlier R30xx processors. The extensions
result in better code density, greater multi-processing
support, improved performance for commonly used code
sequences in operating system kernels, and faster
execution of floating-point intensive applications. All
resource dependencies are made transparent to the
programmer, insuring transportability among implementations of the MIPS instruction set architecture. In addition,
MIPS-III specifies new instructions defined to take
advantage of the 64-bit architecture of the processor.
Finally, the R4650 also implements additional instructions, which are considered extensions to the MIPS-III
architecture. These instructions improve the multiply and
multiply-add throughput of the CPU, making it well suited to
a wide variety of imaging and DSP applications. These
extensions, which use opcodes allocated by MIPS
Technologies for this purpose, are supported by a wide
variety of development tools.
The MIPS integer unit implements a load/store architecture with single cycle ALU operations (logical, shift, add,
sub) and autonomous multiply/divide unit. The 64-bit
register resources include: 32 general-purpose orthogonal
integer registers, the HI/LO result registers for the integer
multiply/divide unit, and the program counter. In addition,
the on-chip floating-point co-processor adds 32 floatingpoint registers, and a floating-point control/status register.
Register File
The R4650 has thirty-two general-purpose 64-bit
registers. These registers are used for scalar integer
operations and address calculation. The register file
consists of two read ports and one write port, and is fully
bypassed to minimize operation latency in the pipeline.
Figure 1 illustrates the R4650 Register File.
ALU
The R4650 ALU consists of the integer adder and logic
unit. The adder performs address calculations in addition to
arithmetic operations, and the logic unit performs all logical
and shift operations. Each of these units is highly optimized
and can perform an operation in a single pipeline cycle.
5.8
3

IDT79R4650 COMMERCIAL TEMPERATURE RANGE
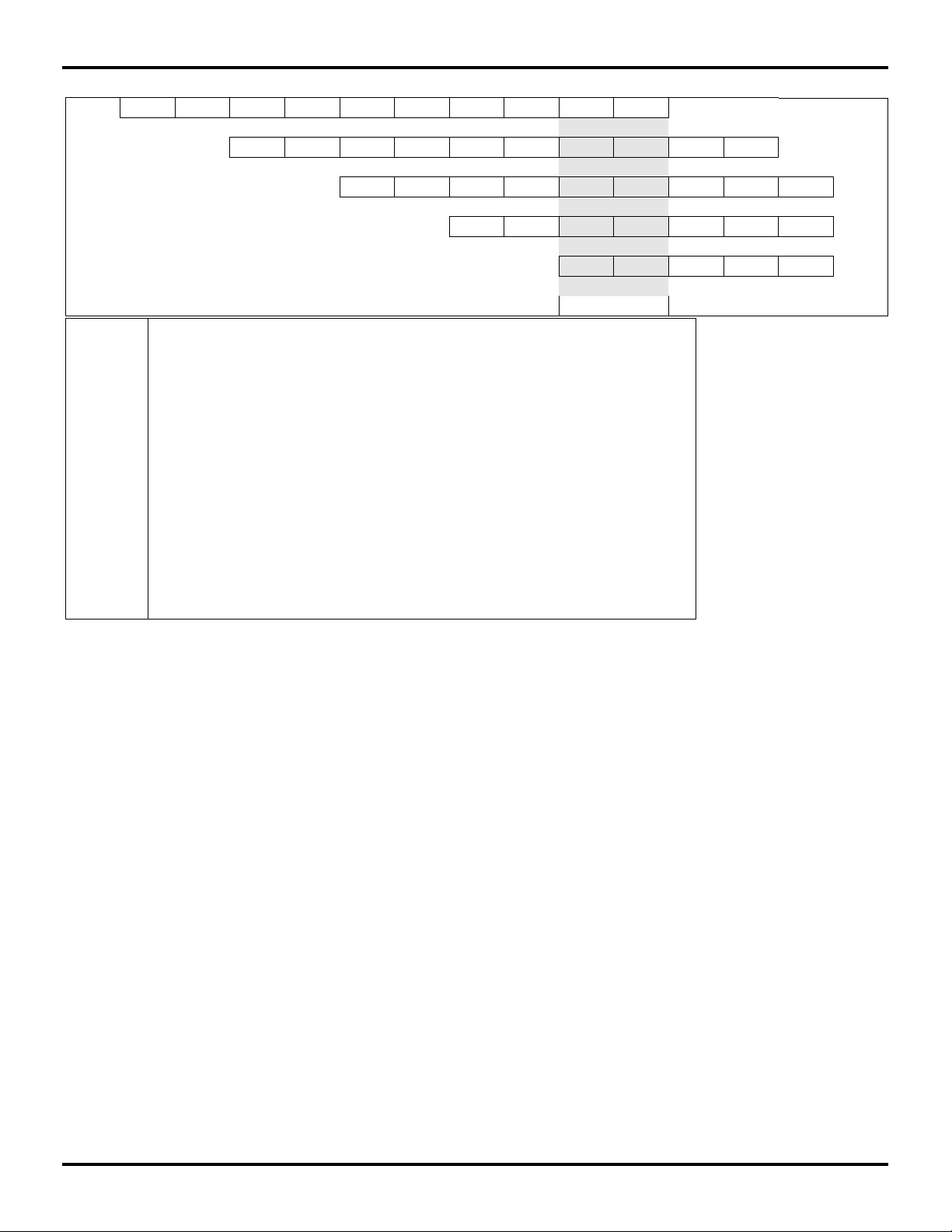
Integer Multiply/Divide
The R4650 uses a dedicated integer multiply/divide unit,
optimized for high-speed multiply and multiply-accumulate
operation. Table 1 shows the performance, expressed in
terms of pipeline clocks, achieved by the R4650 integer
multiply unit.
Opcode Operand
MULT/U,
MAD/U
MUL 16 bit 3 2 1
DMULT,
DMULTU
DIV, DIVU any 36 36 0
DDIV,
DDIVU
Table 1: R4650 Integer Multiply Operation
Size
16 bit 3 2 0
32 bit 4 3 0
32 bit 4 3 2
any 6 5 0
any 68 68 0
Latency Repeat Stall
The MIPS-III architecture defines that the results of a
multiply or divide operation are placed in the HI and LO
registers. The values can then be transferred to the general
purpose register file using the MFHI/MFLO instructions.
The R4650 adds a new multiply instruction, “MUL”, which
can specify that the multiply results bypass the “Lo” register
and are placed immediately in the primary register file. By
avoiding the explicit “Move-from-Lo” instruction required
when using “Lo”, throughput of multiply-intensive operations is increased.
An additional enhancement offered by the R4650 is an
atomic “multiply-add” operation, MAD, used to perform
multiply-accumulate operations. This instruction multiplies
two numbers and adds the product to the current contents
of the HI and LO registers. This operation is used in
numerous DSP algorithms, and allows the R4650 to cost
reduce systems requiring a mix of DSP and control
functions.
Finally, aggressive implementation techniques feature
low latency for these operations along with pipelining to
allow new operations to be issued before a previous one
has fully completed. Table 1 also shows the repeat rate
(peak issue rate), latency, and number of processor stalls
required for the various operations. The R4650 performs
automatic operand size detection to determine the size of
the operand, and implements hardware interlocks to
prevent overrun, allowing this high-performance to be
achieved with simple programming.
unit, decoding and executing instructions in parallel with
the integer unit.
The floating-point unit of the R4650 directly implements
single-precision floating point operations. This enables the
R4650 to perform functions such as graphics rendering,
without requiring extensive die area or power consumption.
The single-precision unit of the R4650 is directly
compatible with the single-precision operation of the
R4600, and features the same latencies and repeat rates.
The R4650 does not directly implement the doubleprecision operations found in the R4600. However, to
maintain software compatibility, the R4650 will signal a trap
when a double-precision operation is initiated, allowing the
requested function to be emulated in software. Alternatively, the system architect could use a software library
emulation of double-precision functions, selected at
compile time, to eliminate the overhead associated with
trap and emulation.
Floating-Point Units
The R4650 floating-point execution units perform single
precision arithmetic, as specified in the IEEE Standard 754.
The execution unit is broken into a separate multiply unit
and a combined add/convert/divide/square root unit.
Overlap of multiplies and add/subtract is supported. The
multiplier is partially pipelined, allowing a new multiply to
begin every 6 cycles.
As in the IDT79R4600, the R4650 maintains fully precise
floating-point exceptions while allowing both overlapped
and pipelined operations. Precise exceptions are extremely
important in mission-critical environments, such as ADA,
and highly desirable for debugging in any environment.
The floating-point unit’s operation set includes floatingpoint add, subtract, multiply, divide, square root,
conversion between fixed-point and floating-point format,
conversion among floating-point formats, and floating-point
compare. These operations comply with IEEE Standard
754. Double precision operations are not directly
supported; attempts to execute double-precision floating
point operations, or refer directly to double-precision
registers, result in the R4650 signalling a “trap” to the CPU,
enabling emulation of the requested function.
Floating-Point Co-Processor
The R4650 incorporates an entire single-precision
floating-point co-processor on chip, including a floatingpoint register file and execution units. The floating-point coprocessor forms a “seamless” interface with the integer
5.8
4

IDT79R4650 COMMERCIAL TEMPERATURE RANGE
Table 2 gives the latencies of some of the floating-point
instructions in internal processor cycles.
Instruction
Operation
ADD 4
SUB 4
MUL 8
DIV 32
SQRT 31
CMP 3
FIX 4
FLOAT 6
ABS 1
MOV 1
NEG 1
LWC1 2
SWC1 1
Table 2: Floating-Point Operation
Latency
Floating-Point General Register File
The floating-point register file is made up of thirty-two 32bit registers. These registers are used as source or target
registers for the single-precision operations.
References to these registers as 64-bit registers (as
supported in the R4600) will cause a trap to be signalled to
the integer unit.
The floating-point control register space contains two
registers; one for determining configuration and revision
information for the coprocessor and one for control and
status information. These are primarily involved with
diagnostic software, exception handling, state saving and
restoring, and control of rounding modes.
lation is controlled, exceptions are handled, and operating
modes are controlled (kernel vs. user mode, interrupts
enabled or disabled, cache features). In addition, the
R4650 includes registers to implement a real-time cycle
counting facility, which aids in cache diagnostic testing,
assists in data error detection, and facilitates software
debug. Alternatively, this timer can be used as the
operating system reference timer, and can signal a periodic
interrupt.
Table 3 shows the CP0 registers of the R4650.
Number Name Function
0 IBase Instruction address space base
(new in R4650)
1 IBound Instruction address space bound
(new in R4650)
2 DBase Data address space base (new in
R4650)
3 DBound Data address space bound (new in
R4650)
4-7, 10, 20-
25, 29, 31
8 BadVAddr Virtual address on address excep-
9 Count Counts every other cycle
11 Compare Generate interrupt when Count
12 Status Miscellaneous control/status
13 Cause Exception/Interrupt information
14 EPC Exception PC
15 PRId Processor ID
16 Config Cache and system attributes
17 CAlg Cache attributes for the eight
18 IWatch Instruction breakpoint virtual
19 DWatch Data breakpoint virtual address
— Not used
tions
= Compare
512MB regions of the virtual
address space — new register
address
System Control Co-processor (CP0)
The system control co-processor in the MIPS architecture is responsible for the virtual to physical address
translation and cache protocols, the exception control
system, and the diagnostics capability of the processor. In
the MIPS architecture, the system control co-processor
(and thus the kernel software) is implementation
dependent.
In the R4650, significant changes in CP0 relative to the
R4600 have been implemented. These changes are
designed to simplify memory management, facilitate
debug, and speed real-time processing.
System Control Co-Processor Registers
The R4650 incorporates all system control co-processor
(CP0) registers on-chip. These registers provide the path
through which the virtual memory system’s address trans-
26 ECC Used in cache diagnostics
27 CacheErr Cache diagnostics
28 TagLo Cache index
30 ErrorEPC CacheError exception PC
Table 3: R4650 CPO Registers
Operation modes
The R4650 supports two modes of operation: user mode
and kernel mode.
Kernel mode operation is typically used for exception
handling and operating system kernel functions, including
CP0 management and access to IO devices. In kernel
mode, software has access to the entire address space
and all of the co-processor 0 registers, and can select
whether to enable co-processor 1 accesses. The processor
5.8
5

IDT79R4650 COMMERCIAL TEMPERATURE RANGE
enters kernel mode at reset, and whenever an exception is
recognized.
User mode is typically used for applications programs.
User mode accesses are limited to a subset of the virtual
address space, and can be inhibited from accessing CP0
functions.
0xFFFFFFFF
Kernel virtual address space
(kseg2)
Unmapped, 1.0 GB
0xC0000000
0xBFFFFFFF
Uncached kernel physical address space
(kseg1)
Unmapped, 0.5GB
0xA0000000
0x9FFFFFFF
Cached kernel physical address space
(kseg0)
Unmapped, 0.5GB
0x80000000
0x7FFFFFF
User virtual address space
(useg)
Mapped, 2.0GB
0x00000000
Figure 3: Mode Virtual Addressing (32-bit mode)
Virtual to Physical Address Mapping
The 4GB virtual address space of the R4650 is shown in
figure 3. The 4 GB address space is divided into addresses
accessible in either kernel or user mode (kuseg), and
addresses only accessible in kernel mode (kseg2:0).
The R4650 supports the use of multiple user tasks
sharing common virtual addresses, but mapped to
separate physical addresses. This facility is implemented
via the “base-bounds” registers contained in CP0.
When a user virtual address is asserted (load, store, or
instruction fetch), the R4650 compares the virtual address
with the contents of the appropriate “bounds” register
(instruction or data). If the virtual address is “in bounds”,
the value of the corresponding “base” register is added to
the virtual address to form the physical address for that
reference. If the address is not within bounds, an exception
is signalled.
This facility enables multiple user processes in a single
physical memory without the use of a TLB. This type of
operation is further supported by a number of development
tools for the R4650, including real-time operating systems
and “position independent code”.
Kernel mode addresses do not use the base-bounds
registers, but rather undergo a fixed virtual to physical
address translation.
Debug Support
To facilitate software debug, the R4650 adds a pair of
“watch” registers to CP0. When enabled, these registers
will cause the CPU to take an exception when a “watched”
address is appropriately accessed.
Interrupt Vector
The R4650 also adds the capability to speed interrupt
exception decoding. Unlike the R4600, which utilizes a
single common exception vector for all exception types
(including interrupts), the R4650 allows kernel software to
enable a separate interrupt exception vector. When
enabled, this vector location speeds interrupt processing by
allowing software to avoid decoding interrupts from general
purpose exceptions.
Cache Memory
In order to keep the R4650’s high-performance pipeline
full and operating efficiently, the R4650 incorporates onchip instruction and data caches that can each be
accessed in a single processor cycle. Each cache has its
own 64-bit data path and can be accessed in parallel. The
cache subsystem provides the integer and floating-point
units with an aggregate bandwidth of over 1500 MB per
second at a pipeline clock frequency of 133MHz. The
cache subsystem is similar in construction to that found in
the R4600, although some changes have been implemented. Table 6 is an overview of the caches found on the
R4650.
Instruction Cache
The R4650 incorporates a two-way set associative onchip instruction cache. This virtually indexed, physically
tagged cache is 8KB in size and is parity protected.
Because the cache is virtually indexed, the virtual-tophysical address translation occurs in parallel with the
cache access, thus further increasing performance by
allowing these two operations to occur simultaneously. The
tag holds a 20-bit physical address and valid bit, and is
parity protected.
The instruction cache is 64-bits wide, and can be refilled
or accessed in a single processor cycle. Instruction fetches
require only 32 bits per cycle, for a peak instruction
bandwidth of 533MB/sec at 133MHz. Sequential accesses
take advantage of the 64-bit fetch to reduce power dissipation, and cache miss refill, can write 64 bits-per-cycle to
minimize the cache miss penalty. The line size is eight
instructions (32 bytes) to maximize performance.
In addition, the contents of one set of the instruction
cache (set “A”) can be “locked” by setting a bit in a CP0
register. Locking the set prevents its contents from being
overwritten by a subsequent cache miss; refill occurs then
only into “set B”.
This operation effectively “locks” time critical code into
one 4kB set, while allowing the other set to service other
instruction streams in a normal fashion. Thus, the benefits
5.8
6
IDT79R4650 COMMERCIAL TEMPERATURE RANGE
of cached performance are achieved, while deterministic
real-time response is preserved.
Data Cache
For fast, single cycle data access, the R4650 includes an
8KB on-chip data cache that is two-way set associative
with a fixed 32-byte (eight words) line size. Table 4 lists the
R4650 cache attributes.
Characteristics Instruction Data
Size
Organization
Line size
Index
Tag
Write policy
Line transfer order
Miss restart after
transfer of
Parity
Cache locking
Table 4: R4650 Cache Attributes
8KB 8KB
2-way set associa-
tive
32B 32B
vAddr
11..0
pAddr
31..12
n.a. writeback /writethru
read sub-block
order
write sequential write sequential
entire line first word
per-word per-byte
set A set A
2-way set associative
vAddr
11..0
pAddr
31..12
read sub-block
order
The data cache is protected with byte parity and its tag is
protected with a single parity bit. It is virtually indexed and
physically tagged to allow simultaneous address translation
and data cache access
The normal write policy is writeback, which means that a
store to a cache line does not immediately cause memory
to be updated. This increases system performance by
reducing bus traffic and eliminating the bottleneck of
waiting for each store operation to finish before issuing a
subsequent memory operation. Software can however
select write-through for certain address ranges, using the
CAlg register in CP0. Cache protocols supported for the
data cache are:
• Uncached . Addresses in a memory area indicated as
uncached will not be read from the cache. Stores to such
addresses will be written directly to main memory, without changing cache contents.
• Writeback . Loads and instruction f etches will first search
the cache, reading main memory only if the desired data
is not cache resident. On data store operations, the
cache is first searched to see if the target address is
cache resident. If it is resident, the cache contents will be
updated, and the cache line marked for later writeback. If
the cache lookup misses, the target line is first brought
into the cache before the cache is updated.
• Write-through with write allocate. Loads and instruction fetches will first search the cache, reading main
memory only if the desired data is not cache resident. On
data store operations, the cache is first searched to see if
the target address is cache resident. If it is resident, the
cache contents will be updated and main memory will
also be written; the state of the “writeback” bit of the
cache line will be unchanged. If the cache lookup misses ,
the target line is first brought into the cache before the
cache is updated.
• Write-through without write-allocate. Loads and
instruction fetches will first search the cache, reading
main memory only if the desired data is not cache resident. On data store operations, the cache is first
searched to see if the target address is cache resident. If
it is resident, the cache contents will be updated, and the
cache line marked for later writeback. If the cache lookup
misses, then only main memory is written.
Associated with the Data Cache is the store buffer. When
the R4650 executes a Store instruction, this single-entry
buffer gets written with the store data while the tag
comparison is performed. If the tag matches, then the data
is written into the Data Cache in the next cycle that the
Data Cache is not accessed (the next non-load cycle). The
store buffer allows the R4650 to execute a store every
processor cycle and to perform back-to-back stores without
penalty.
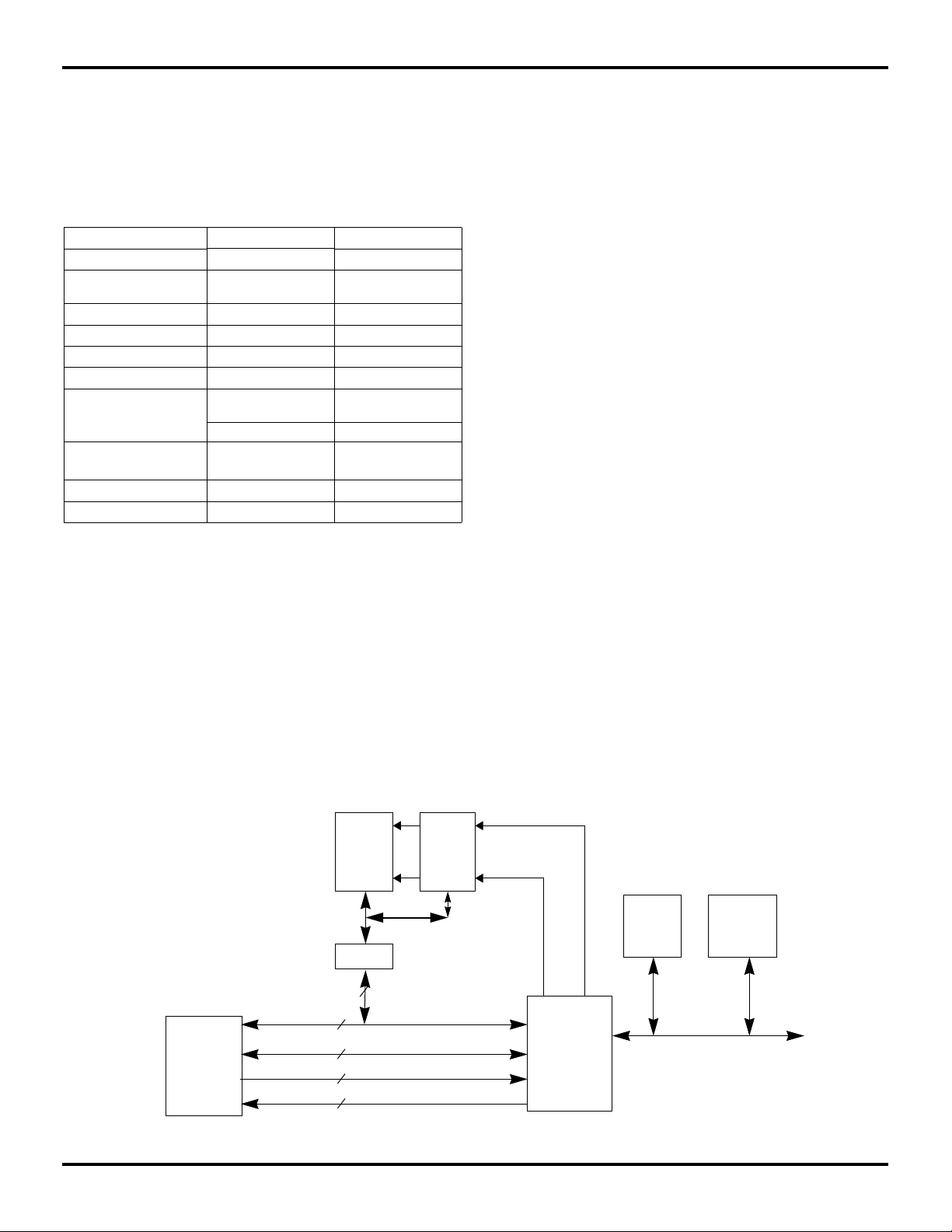
R4650
Address
Boot
ROM
DRAM
(80ns)
Control
32 or 64
32 or 64
9
2
11
Figure 4: Typical R4650 System Architecture
5.8
Memory I/O
Controller
SCSI
ENET
7
 Loading...
Loading...