

Hp COMPAQ PROLIANT CL380, PROLIANT BL35P, PROLIANT BL30P, PROLIANT BL25P, PROLIANT DL145 G3 The Intel® processor roadmap for industrystandard servers technology brief, 8th edition
...Page 1

The Intel® processor roadmap for industrystandard servers
technology brief, 8th edition
Abstract.............................................................................................................................................. 2
Introduction......................................................................................................................................... 2
Intel processor architecture and microarchitectures................................................................................... 2
NetBurst
Intel Core™ microarchitecture ............................................................................................................. 12
®
microarchitecture................................................................................................................... 5
Hyper-pipeline and clock frequency ................................................................................................... 5
Hyper-Threading Technology............................................................................................................. 7
NetBurst microarchitecture on 90nm silicon process technology............................................................. 9
Extended hyper-pipeline.............................................................................................................. 10
SSE3 instructions ........................................................................................................................ 10
64-bit extensions — Intel 64 ........................................................................................................ 10
Dual-core technology...................................................................................................................... 11
Processors ..................................................................................................................................... 12
Xeon dual-core processors............................................................................................................... 12
Xeon quad-core processors ............................................................................................................. 13
Enhanced SpeedStep® Technology .............................................................................................. 14
Intel Virtualization® Technology................................................................................................... 15
Performance comparisons................................................................................................................... 15
TPC-C performance ........................................................................................................................ 15
SPEC performance ......................................................................................................................... 16
Intel Nahalem microarchitecture .......................................................................................................... 17
Conclusion........................................................................................................................................ 17
For more information.......................................................................................................................... 18
Call to action .................................................................................................................................... 18
Page 2
Abstract
Intel® continues to introduce processor technologies that boost the performance of x86 processors in
multi-threaded environments. This paper describes these processors and some of the more important
innovations as they affect HP industry-standard enterprise servers.
Introduction
As standards-based computing has pushed into the enterprise server market, the demand for
increased performance and greater variety in processor solutions has grown with it. To meet this
demand, Intel continues to introduce processor innovations and new speeds. This paper summarizes
the recent history and near-term plans for Intel processors as they relate to the industry-standard
enterprise server market.
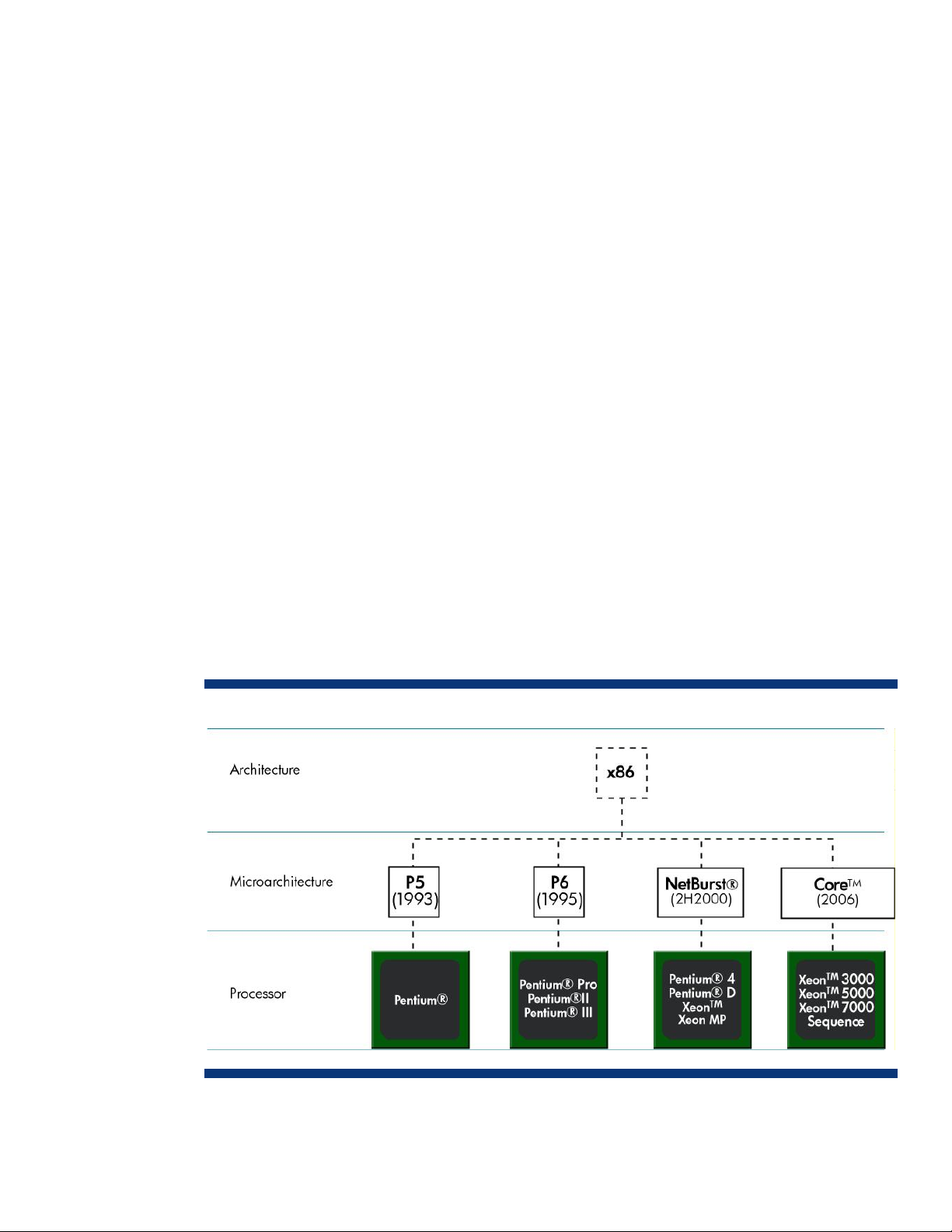
Intel processor architecture and microarchitectures
The Intel processor architecture refers to its x86 instruction set and registers that are exposed to
programmers. The x86 instruction set is the list of all instructions and their variations that can be
executed by processors derived from the original 16-bit 8086 processor architecture. Processor
manufacturers, such as Intel and AMD, use a common processor architecture to maintain backward
and forward compatibility of the instruction set among generations of their processors. Intel refers to
its 32-bit and 64-bit versions of the x86 processor architecture as Intel Architecture (IA)-32 and IA-64.
In comparison, the term “microarchitecture” refers to each processor’s physical design that implements
the instruction set. Processors with different microarchitectures, Intel and AMD x86 processors for
example, can still use a common instruction set.
Figure 1 shows the relationship between the x86 processor architecture and Intel’s evolving
microarchitectures, as well as processors based on these microarchitectures.
Figure 1. Intel processor architecture and microarchitectures for industry-standard enterprise servers
Page 3
Intel processor sequences are intended to help developers select the best processor for a particular
platform design. Intel offers three processor number sequences for server applications (see Table 1).
Intel processor series numbers within a sequence (for example, 5100 series) help differentiate
processor features such as number of cores, architecture, cache, power dissipation, and embedded
Intel technologies.
Table 1. Intel processor sequences
Processor sequence Platform
Dual-Core Intel® Xeon™ processor 3000 sequence Uni-processor servers
Dual-Core and Quad-Core Intel® Xeon™ processor
5000 sequence
Dual-Core and Quad-Core Intel® Xeon™ processor
7000 sequence
Dual-processor high-volume servers and
workstations
Enterprise servers with 4 to 32-processors
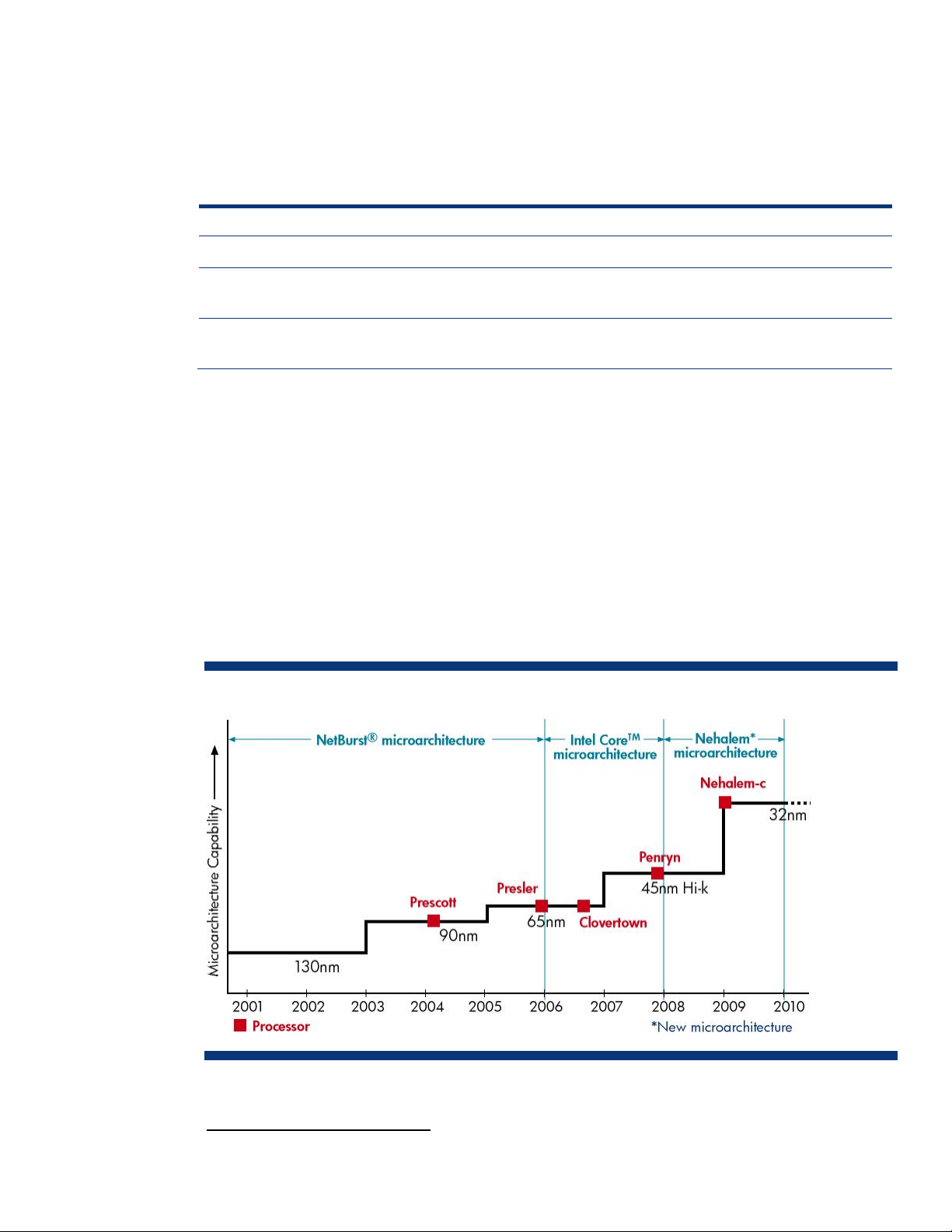
Intel enhances the microarchitecture of a family of processors over time to improve performance and
capability while maintaining compatibility with the processor architecture. One method to enhance
the microarchitectures involves changing the silicon process technology. For example, Figure 2 shows
that Intel enhanced NetBurst-based processors in 2004 by changing the manufacturing process from
130nm to 90nm silicon process technology.
In the second half of 2006, Intel launched the Core® microarchitecture, which is the basis for the
multi-core Xeon 5000 Sequence processors, including the first quad-core Xeon processor
(Clovertown). Beginning with the Penryn family of processors, Intel plans to enhance the performance
and energy efficiency of Intel Core microarchitecture-based processors by switching from 65nm to
45nm Hi-k
1
process technology with the hafnium-based high-K + metal gate transistor design. In
2008, Intel plans initial production of processors based on the “next generation” Nehalem
microarchitecture.
Figure 2. Intel microarchitecture introductions and associated silicon process technologies for industry-standard
servers
1
Hi-k, or High-k, stands for high dielectric constant, a measure of how much charge a material can hold. For
more information, refer to http://www.intel.com/technology/silicon/high-k.htm?iid=tech_arch_45nm+body_hik.
Page 4

Table 2 includes more details about the release dates and features of previously released Intel x86
processors as well as processors projected to be available through 2007.
Table 2. Release dates and features of Intel x86 processors
Code
Name
Smithfield Pentium D 90 Dual-core uni-
Irwindale Xeon 90 2MB L2 version of
Cranford Xeon MP 90 Xeon MP 1Q2005 1MB L2 667
Prescott 2M Xeon 90 2MB L2 version of
Potomac Xeon MP 90 Xeon MP 1Q2005 8MB L3 667
Paxville Xeon MP 90 Dual-core Xeon MP 4Q2005 2x1MB
Paxville Xeon MP 90 Dual-core Xeon MP 4Q2005 2x2MB
Presler Pentium D 65 Dual-core uni-
Dempsey Xeon
Market
name
5000
Feature
size
(nm)
65 Dual-core Xeon 1H2006 2MB L2
Description Date available/
Projected
availability
2H2005 1MB L2
processor
1Q2005 2MB L2 800
Nocona
1Q2005 2MB L2 800
Prescott
Q12006 2MB L2
processor
Cache Max. Bus
800
per
core
800
L2
800
L2
>800
per core
1066
per core
speed
(MT/s)
1
Woodcrest Xeon
5100
Conroe Core 2
Duo
Conroe Xeon 65 Dual-core,
Tulsa Xeon MP 65 Dual-core Xeon MP 4Q2006 16MB
Clovertown Xeon 65 Quad-core Xeon 4Q2006 2x4MB
Tigerton Xeon 65 Quad-core Xeon 2H2007 8MB L2 1066 MHz
Wolfdale Xeon 45 Dual-core 1Q2008 1x6MB
Harpertown Xeon 45 Quad-core Xeon 4Q2007 2x6MB
1
MT/s is an abbreviation for Mega-Transfers per second. A bus operating at 200 MHz and
65 Dual-core Xeon 1H2006 4MB L2
shared
65 Dual-core,
uni-processor
uni-processor
Mid-2006 4MB L2
shared
3Q2006 4MB L2
shared
L3
L2
L2
L2
1333
1333 MHz
1333 MHz
800 MHz
1333 MHz
1600 MHz*
1333/1600
MHz*
transferring four data packets on each clock (referred to as quad-pumped) would have 800 MT/s.
* Selected chipsets only
4
Page 5

NetBurst® microarchitecture
The NetBurst-based processor for low-cost, single-processor servers is the Pentium® 4 processor. The
original 180nm version of the Pentium 4 was known as Willamette, and the subsequent 130nm
version was known as Northwood. NetBurst-based processors intended for multi-processor
environments are referred to as Intel® Xeon™ (for dual-processor systems) and Xeon MP (for systems
using more than two processors).
The NetBurst microarchitecture included the following enhancements:
• Higher bandwidth for instruction fetches
• 256-KB Level 2 (L2) cache with 64-byte cache lines
• NetBurst system bus: a 64-bit, 100-MHz bus capable of providing 3.2 GB/s of bandwidth by
double pumping the address and quad pumping the data. The 100-MHz quad pumped data bus is
also referred to as a 400-MHz data bus. To provide higher levels of performance, Intel added
support for a 533-MHz front side bus to the Pentium 4 and Xeon processors and later added
support for 800 MHz to the Pentium 4.
• Integer arithmetic logic unit (ALU) running at twice the clock speed (double data rate)
• Modified floating point unit (FPU)
• Streaming SIMD extension 2 (SSE2): New instructions bring the total to 144 SIMD instructions to
manage floating point, application, and multimedia performance.
• Advanced dynamic execution
• Deeper instruction window for out-of-order, speculative execution and improved branch prediction
over the P6 dynamic execution core
• Execution trace cache (stores pre-decoded micro-operations)
• Enhanced floating point/multimedia engine
• Hyper-threading (HT) in Xeon processors and Pentium 4 processors (described below)
Hyper-pipeline and clock frequency
One performance-enhancing feature of the NetBurst microarchitecture was its hyper-pipeline, a 20stage branch-prediction pipeline. Previous 32-bit processors had a 10-stage pipeline. The hyperpipeline can contain more than 100 instructions at once and can handle up to 48 loads and stores
concurrently. The pipeline in a processor is analogous to a factory assembly line where production is
split into multiple stages to keep all factory workers busy and to complete multiple stages in parallel.
Likewise, the work to execute program code is split into stages to keep the processor busy and allow
it to execute more code during each clock cycle. In this case, the processor must complete the
operation for each stage within a single clock cycle. The processor can achieve this by splitting the
task into smaller tasks and using more (shorter) stages to execute the instructions (Figure 3). Thus,
each stage can be completed quicker, allowing the processor to have a higher clock frequency.
However, it is important to understand that splitting each stage into smaller stage to achieve a higher
clock frequency does not mean that more work is being done in the pipeline per clock cycle.
5
Page 6
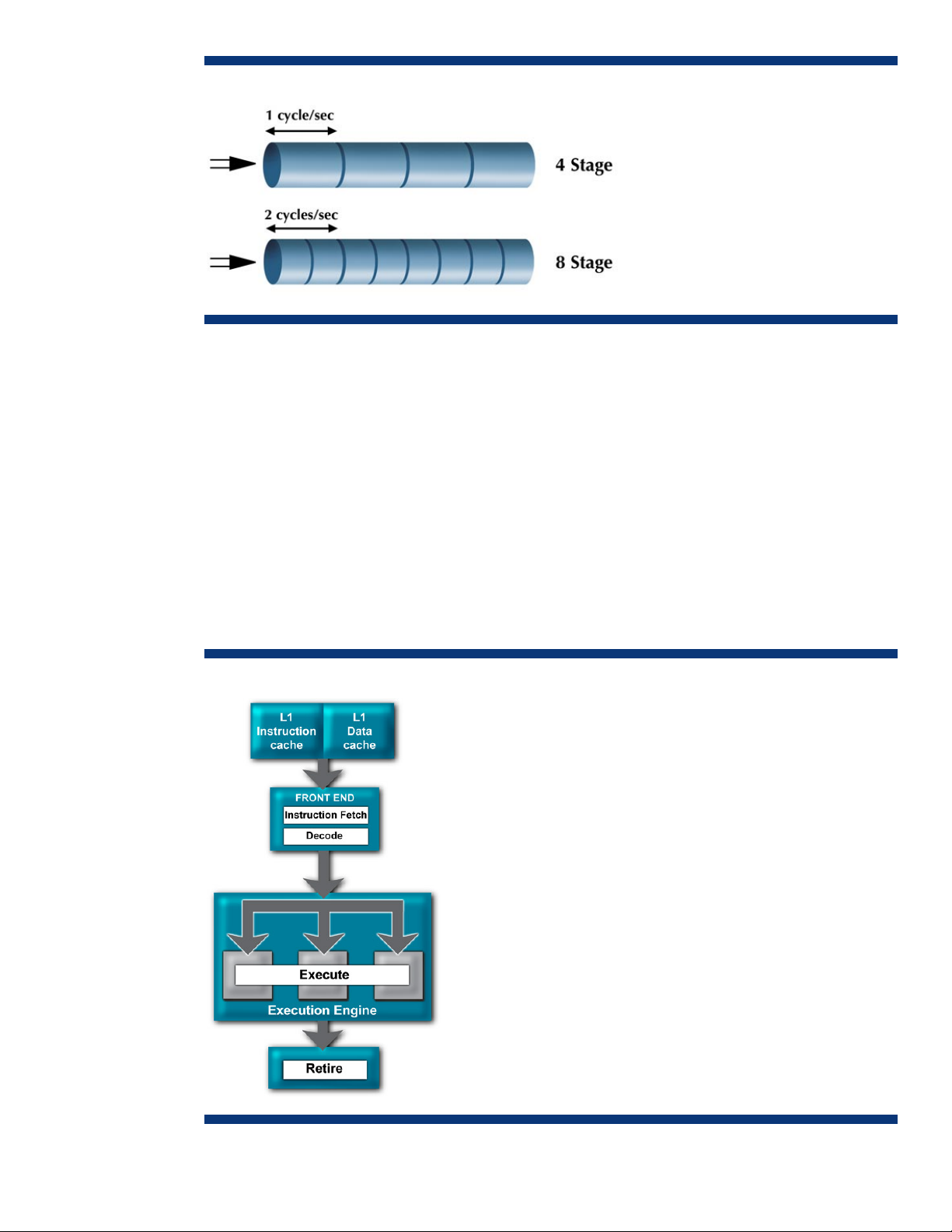
Figure 3. Decreasing the amount of work done in each stage allows the clock frequency to increase
A basic structure for a computer pipeline consists of the following four steps, which are performed
repeatedly to execute a program:
1. Fetch the next instruction from the address stored in the program counter.
2. Store that instruction in the instruction register and decode it, and increment the address in the
program counter.
3. Execute the instruction currently in the instruction register.
4. Write the results of that instruction from the execution unit back into the destination register.
Typical processor architectures split the pipeline into segments that perform those basic steps: the
“front end” of the microprocessor, the execution engine, and the retire unit, as shown in Figure 4. The
front end fetches the instruction and decodes it into smaller instructions (commonly referred to as
micro-ops). These decoded instructions are sent to one of the three types of execution units (integer,
load/store, or floating point) to be executed. Finally, the instruction is retired and the result is written
back to its destination register.
Figure 4. Basic 4-stage pipeline schematic
6
Page 7

Keeping the pipeline busy requires that the processor begin executing a second instruction before the
first has traveled completely through the pipeline. However, suppose a program has an instruction
that requires summing three numbers:
X = A + B + C
If the processor already has A and B stored in registers but needs to get C from memory, this causes a
“bubble,” or stall, in the pipeline in which the processor cannot execute the instruction until it obtains
the value for C from memory. This bubble must propagate all the way through the pipeline, forcing
each stage that contains the bubble to sit idle, wasting execution resources during that clock cycle.
Clearly, the longer the pipeline, the more significant this problem becomes.
Processor stalls often occur as a result of one instruction being dependent on another. If the program
has a branch, such as an IF… THEN loop, the processor has two options. The processor either waits
for the critical instruction to finish (stalling the pipeline) before deciding which program branch to
take, or it predicts which branch the program will follow.
If the processor predicts the wrong code branch, it must flush the pipeline and start over again with
the IF… THEN statement using the correct branch. The longer the pipeline, the higher the performance
cost for branch mispredicts. For example, the longer the pipeline, the more the processor must execute
speculative instructions that must be discarded when a mispredict occurs. Specific to the NetBurst
design was an improved branch-prediction algorithm aided by a large branch target array that stored
branch predictions.
Hyper-Threading Technology
Intel Hyper-Threading (HT) Technology is a design enhancement for server environments. It takes
advantage of the fact that, according to Intel estimates, the utilization rate for the execution units in a
NetBurst processor is typically only about 35 percent. To improve the utilization rate, HT Technology
adds Multi-Thread-Level Parallelism (MTLP) to the design. In essence, MTLP means that the core
receives two instruction streams from the operating system (OS) to take advantage of idle cycles on
the execution units of the processor. For one physical processor to appear as two distinct processors
to the OS, the new design replicates the pieces of the processor with which the OS interacts to create
two logical processors in one package. These replicated components include the instruction pointer,
the interrupt controller, and other general-purpose registers―all of which are collectively referred to
as the Architectural State, or AS (see Figure 5).
Figure 5. Hyper-Threading technology enables one physical processor to appear as two distinct, logical
processors to the OS so that the OS sends two instruction streams to the processor core.
IA-32 Processor with
Hyper-thread Technology
AS1
AS2
Processor
Core
Traditional Dual-processor
(D) System
AS AS
Processor
Core
Processor
Core
Logical
processor
System Bus
Logical
processor
System Bus
Since multi-processing operating systems such as Microsoft Windows and Linux are designed to
7
Page 8

divide their workload into threads that can be independently scheduled, these operating systems can
send two distinct threads to work their way through execution in the same device. This provides the
opportunity for a higher abstraction level of parallelism at the thread level rather than simply at the
instruction level, as in the Pentium 4 design. To illustrate this concept, refer to Table 3, where it can be
seen that instruction-level parallelism can take advantage of opportunities in the instruction stream to
execute independent instructions at the same time. Thread-level parallelism, shown in Table 4, takes
this a step further since two independent instruction streams are available for simultaneous execution
opportunities.
It should be noted that the performance gain from adding HT Technology does not equal the expected
gain from adding a second physical processor. The overhead to maintain the threads and the
requirement to share processor resources will necessarily limit the HT performance. Nevertheless, HT
Technology is a valuable and cost-effective addition to the Pentium 4 design.
Table 3. Instruction-level parallelism enables simultaneous execution of independent instructions.
Instruction
number
1 Read register A
2 Write register B
3 Read register C
4
5 Inc A This operation needs to wait for the completion of instruction 4 before
Table 4. Thread-level parallelism supports two independent instruction streams for simultaneous execution.
Instruction
number
1a Read
2a Write
3a Read
4a
5a Inc A
Instruction
thread
Add A + B
Instruction
thread
register A
register B
register C
Add A + B 4b
Instruction
number
1b
2b
3b
5b
Instruction execution
Operations 1, 2, and 3 are independent and can execute simultaneously if
resources permit.
This operation must wait for instructions 1 and 2 to complete, but it can
execute in parallel with operation 3.
executing.
Instruction
thread
Add D + E
Inc E
Read F
Add E+F
Write E
Instruction execution
None of the instructions in Thread
2 depend on those in Thread 1;
therefore, to the extent that
execution units are available, any
of them can execute in parallel
with those in Thread 1.
As an example, instruction 2b
must wait for instruction 1b, but
does not need to wait for 1a.
Similarly, if two arithmetic units
are available, 4a and 4b can
execute at the same time.
According to Intel’s internal simulations, HT Technology achieves its objective of improving the
microarchitecture utilization rate significantly. Improved performance is the real goal though, and Intel
reports that the performance gain can be as high as 30 percent.
The performance gained by these design changes is limited by the fact that two threads now share
and compete for processor resources, such as the execution pipeline and L1 and L2 caches. There is
some risk that data needed by one thread can be replaced in a cache by data that the other is using,
resulting in a higher turnover of cache data (referred to as thrashing) and a reduced hit rate. HT
Technology also puts a heavier load on the OS to allocate threads and switch contexts on the device.
8
Page 9

The evaluation of the threads for parallelism and context switching are OS tasks and increase the
operating overhead.
Currently, HT Technology presents little in the way of software licensing issues. Intel asserts that the HT
design is still only a single-processor unit, so customers should not have to purchase two software
licenses for each processor. This is true for Microsoft SQL Server 2000 and Windows Server 2003,
which only require one license for each physical processor, regardless of how many logical
processors it contains. However, Windows 2000 Server does not make this distinction between
physical and logical processors and fills the licensing limit based on the number of processors the
BIOS discovers at boot time.
2
According to Intel, the system requirements for HT Technology are as follows:
3
• A processor that supports HT Technology
• HT Technology-enabled chipset
• HT Technology-enabled system BIOS
• HT Technology-enabled/optimized operating system
For more information, refer to
http://www.intel.com/products/ht/hyperthreading_more.htm.
NetBurst microarchitecture on 90nm silicon process technology
In 2004, Intel introduced major improvement to the Pentium 4 and Xeon processor lines by changing
the manufacturing process from 130nm to 90nm silicon process technology. Enhancements for
NetBurst on 90nm technology included:
• Larger, more effective caches (1MB or 2-MB L2 Advanced Transfer Cache compared to 512-KB on
the 0.13 micron Pentium 4 processor)
• Faster processor bus: a 64-bit, 200-MHz bus capable of providing 6.4 GB/s of bandwidth by
double pumping the address and quad pumping the data. The 200-MHz Quad-pumped data bus is
also referred to as an 800-MHz data bus.
• Extended hyper-pipeline (31 stages versus 20 stages) to enable high CPU core frequencies
(described below)
• Enhanced execution units including the addition of a dedicated integer multiplier, and support for
shift and rotate instruction execution on a fast ALU
• Improved branch prediction to help compensate for longer pipeline
• Streaming SIMD Extensions 3 (SSE3) instructions (described below)
• Larger execution schedulers and execution queues
• Improved hardware memory prefetcher
• Improved Hyper-Threading
• 64-bit extensions (described below)
• Dual-core (for Smithfield, Dempsey, and Paxville)
2
For more information on Hyper-Threading technology, visit
www.microsoft.com/windows2000/docs/hyperthreading.doc
3
Hyper-Threading Technology supported in dual-core Intel Xeon processor 5000 series only.
9
Page 10

Extended hyper-pipeline
In keeping with its history of regularly increasing processor frequencies, Intel has extended the hyperpipeline queue from 20 (in the earlier Pentium 4 design) to 31 stages. The biggest drawback to this
approach is that, as the pipe gets longer, interruptions (stalls) to the regular flow of instructions in the
pipe become progressively more costly in terms of performance. To mitigate such stalls, Intel improved
the branch-prediction algorithm sufficiently to prevent this deeper pipeline from causing performance
degradation.
SSE3 instructions
The Prescott design added Streaming Single-Instruction-Multiple-Data (SIMD) Extensions 3, or Prescott
New Instructions. As they did in earlier processors, SIMD instructions provide the potential for
improved performance because each instruction permits operation on multiple data items at the same
time. For Prescott processors, there are newer versions of arithmetic, graphics, and HT
synchronization instructions.
The arithmetic group consists of one new instruction for converting x87 data into integer format, and
five instructions that simplify the process of performing complex arithmetic. Complex numbers actually
consist of two numbers, a real and an imaginary component. The additional instructions facilitate
complex operations because they are designed to operate on both parts of these complex pairs of
numbers at the same time. Using these instructions also simplifies coding complex arithmetic
operations because fewer instructions are needed to accomplish the goal.
The graphics group contains one instruction for video encoding and four that are specific to graphics
operations. Finally, two instructions facilitate HT operation, for example, by allowing one operational
thread to be moved to a higher priority than another.
64-bit extensions — Intel 64
In response to market demands, Intel added 64-bit extensions to the x86 architecture of the Xeon,
Xeon MP, and Pentium 4 processors. The key advantage of 64-bit processing is that the system can
address a much larger flat memory space (up to 16 exabytes). Even though the 32-bit architecture
can actually access up to 64 GB of memory, access above the standard 4 GB limit must go through a
slow and cumbersome windowing facility. Due to the complexities of this process, most 32-bit
applications have not made use of the higher address space. Today, few applications require more
than 1 or 2 GB of memory; however, this will eventually change. By adding 64-bit extensions to its
x86 processors, Intel has provided users with the same 64-bit addressing benefit at a much lower cost
than if users were forced to replace both the hardware and software.
AMD was first to release 64-bit extensions―called AMD64―with its Opteron processor in early
2003. Within the year, Intel responded with its own plans to deliver a similar solution called
Extended Memory 64 Technology, or EM64T, which is broadly compatible with AMD64. In late
2006, Intel began using the name Intel 64 for its implementation. Intel 64 and AMD64 use the same
register sets and definitions, and the 64-bit instructions are nearly identical. HP expects that any minor
differences will be handled by the OS and compiler, so that the average application writer or
customer should see no differences. New operating systems are required to make use of 64-bit
extensions. Red Hat, SuSE, and Microsoft provide AMD64 support and Intel 64 support.
Even though the larger memory addressing capability is the primary advantage of 64-bit extensions, it
is not the only one. 64-bit extensions also provide a larger register set with eight additional general
purpose registers (GPR) and 64-bit versions of the existing registers. With a total of 16 GPRs, 64-bit
extensions provide additional resources that compilers can use to increase performance. The 16register limit was a tradeoff AMD chose as a good compromise between performance and cost.
10
Page 11

Dual-core technology
Single-core processors that run multi-threaded applications become less cost effective with each
increase in frequency. This is because the multiple threads compete for available compute resources,
which limits the increase in performance at higher frequencies. Increasing the CPU core frequency not
only delivers lower incremental performance gains, but also increases power requirements and heat
generation. These factors create significant barriers for single-core architectures to keep pace with the
growing needs of data centers.
To address the performance, power, and heat issues, Intel announced its first dual-core processor
architecture in 2005. A dual-core processor is a single physical package that contains two, full
processor cores per socket. The two cores share the same functional execution units and cache
hierarchy; however, the OS recognizes each execution core as an independent processor.
Figure 6 illustrates the difference between single-core and dual-core processors with HT Technology.
In the case of the single-core processor, HT Technology allows the OS to schedule two threads on the
core by treating it as two separate "logical" processors with a shared 2-MB L2 cache. The dual-core
processor builds on HT Technology with two execution cores. Each core has its own 2-MB L2 cache
and separate interface to an 800-MHz front side bus. The dual-core architecture runs two threads on
each execution core, allowing the processor to run up to four threads simultaneously. The additional
capacity of the second core reduces competition for processor resources and increases processor
utilization. Thus, the performance improvement of a dual-core processor is in addition to the
improvement due to HT Technology.
A dual-core processor has better performance-per-watt than a single-core processor running at a
higher frequency. This is analogous to the way a wide pipe, by virtue of its volume, can carry more
water than a smaller pipe with a higher flow rate. Likewise, the dual-core architecture is designed to
make processors perform more efficiently at lower frequencies (and power). The dual-core processor
allows a better balance between performance and power requirements, and it is the first step in multicore processor technology.
Figure 6. Implementation of Hyper-Threading Technology on single processor core (left) supports two threads
through a shared L2 cache. Implementation of Hyper-Threading Technology on dual-core processors (right)
supports four threads running simultaneously.
11
Page 12

Intel Core™ microarchitecture
In 2006, Intel introduced the Core microarchitecture, which extends the NetBurst microarchitecture
features as well as adds the energy efficient features of Intel’s mobile microarchitecture. The Core
microarchitecture uses less power and produces less heat than previous generation Intel processors.
The Core microarchitecture features the following new technologies that improve per-watt
performance and energy efficiency
• Intel® Wide Dynamic Execution enables delivery of more instructions per clock cycle to improve
execution time and energy efficiency.
• Intel® Intelligent Power Capability reduces power consumption and design requirements.
• Intel® Smart Memory Access improves system performance by optimizing the use of the available
data bandwidth from the memory subsystem.
• Intel® Advanced Smart Cache is optimized for multi-core and dual-core processors to reduce
latency to frequently used data, providing a higher-performance, more efficient cache subsystem.
• Intel® Advanced Digital Media Boost improves performance when executing SSE, SSE2, and SSE3
instructions, accelerating a broad range of applications, including encryption, financial,
engineering, and scientific applications.
• Streaming SIMD Extensions 4 (SSE4) instructions
4
:
Processors
The dual-core Intel Xeon 3000 and 5000 Sequence and the 7300 series processors are based on the
Core microarchitecture.
of the Xeon 3000 Sequence processors) can simultaneously execute four software threads, thereby
increasing processor utilization. To avoid saturation of the Front Side Bus (FSB), the Intel 5000 chipset
widens the interface by providing dual independent buses. The Xeon 7300 series processors
introduce an independent point-to-point interface between the chipset and each processor that allows
full front-side-bus bandwidth.
Using Hyper-Threading technology, dual-core processors (with the exception
Xeon dual-core processors
The 64-bit Intel Xeon 3000 Sequence processors combine performance and power efficiency to
enable smaller, quieter systems. Xeon 3000 Sequence processors run at a maximum frequency of
2.66 gigahertz (GHz), with 4 megabytes (MB) of shared L2 cache (Figure 7 left) and a maximum
front-side bus speed of 1333 megahertz. These processors are compatible with IA-32 software and
support single-processor operation. Xeon 3000 Sequence processors use the Intel 3000 or 3010
chipsets, which support Error Correction Code (ECC) memory for a high level of data integrity,
reliability, and system uptime. ECC can detect multiple-bit memory errors and locate and correct
single-bit errors to keep business applications running smoothly.
64-bit Intel Xeon 5000 Sequence processors have two complete processor cores, including
The
caches, buses, and execution states. The Xeon 5000 Sequence processors run at a maximum
frequency of 3.73 GHz, with 2 MB of L2 cache per core. The processor supports maximum front-side
bus speeds of 1066 megahertz (Figure 7 center).
4
For more information, read the white paper “Introducing the 45nm next-generation Intel® Core™
microarchitecture at Intel® 45nm Hi-k silicon technology.
12
Page 13

The 64-bit Xeon 5100 series dual-core processor runs at a maximum frequency of 3.0 GHz with 4
MB of shared L2 cache and a maximum front-side bus speed of 1333 megahertz (Figure 7 right).
The Xeon 5000 Sequence and 5100 series processors use the Intel 5000 series chipsets. These
chipsets contains two main components: the Memory Controller Hub (MCH) and the I/O controller
hub. The new Northbridge MCH supports DDR2 Fully-Buffered DIMMs (dual in-line memory modules).
Figure 7. Diagram representing the major components of dual-core Intel Xeon 3000, 5000, and 5100
Sequence processors
Xeon quad-core processors
The quad-core Intel Xeon 5300 series processor (Clovertown) is the first quad-core processor for dualsocket platforms (Figure 8). The Xeon 5300 series processor has two dual-cores. Each pair of cores
shares a L2 cache; up to 4 MB of L2 cache can be allocated to one core. The processor runs at a
maximum frequency of 3.0 GHz, with 2 MB of L2 cache per core. This configuration delivers a
significant increase in processing capacity utilizing the Intel 5000 series chipsets. ProLiant 300 series
servers use the Intel 5000P and 5000Z chipsets. These chipsets support 1066-MHz and 1333-MHz
Dual Independent Buses, DDR2 FB-DIMMs, and PCI Express I/O slots.
The quad-core Xeon 5400 series processor (Harpertown) has two dual-cores, with each pair sharing
a 6-MB L2 cache. The Xeon 5400 series processor runs at a maximum frequency of 3.0 MHz with a
1333 MZ or 1600 MHz FSB.
Figure 8. Quad-core Intel Xeon 5300 sequence processor
13
Page 14

The quad-core Intel Xeon 7300 series processor (Tigerton) consists of two dual-core silicon chips on a
single ceramic module, similar to the Xeon 5300 series processors. Each pair of cores shares a L2
cache; up to 4 MB of L2 cache can be allocated to one core. Intel states the Xeon 7300 series
processors offer more than twice the performance and more than three times the performance-per-watt
of the previous generation 7100 series, which is based on the NetBurst microarchitecture. The Xeon
7300 series processors are empowered by the Intel® 7300 Chipset, which features Dedicated HighSpeed Interconnects (DHSI). DHSI is an independent a point-to-point interface between the chipset and
each processor that allows full front side bus bandwidth to each processor (Figure 9). The point-topoint interface significantly reduces data traffic on the DHSI, providing lower latencies and greater
available bandwidth. The chipset also features a 64 MB snoop filter that manages data coherency
across processors, eliminating unnecessary snoops and boosting available bandwidth.
Figure 9. The Xeon 7300 series processors and Intel 7300 Chipset enable 4-socket server architectures with up to
16 processor cores. It provides fast memory access through Dedicated High-Speed Interconnects.
Enhanced SpeedStep® Technology
Quad-core Intel Xeon 5300 and 7300 series processors support Enhanced Intel SpeedStep
Technology. These processors have power state hardware registers that are available (exposed) to
allow IT organizations to control the performance and power consumption of the processor. These
capabilities are implemented through Intel’s Enhanced Intel SpeedStep® Technology and demandbased switching. With the appropriate ROM firmware or operating system interface, programmers
can use the exposed hardware registers to switch a processor between different performance states,
also called P-states
5
, which have different power consumption levels. For example, HP developed a
power management feature called HP Power Regulator that utilizes P-state registers to control
processor power use and performance. These capabilities have become increasingly important for
power and heat management in high-density data centers. When combined with data-center
management tools like Insight Power Manager, IT organizations have more control over the power
consumption of all the servers in the data center.
5
The ACPI body defines P-states as processor performance states. For Intel and AMD processors, a P-state is
defined by a fixed operating frequency and voltage.
14
Page 15

Intel Virtualization® Technology
Virtualization techniques that are completely enabled in software perform many complex translations
between the guest operating systems and the hardware. With software virtualization, the processor
overhead increases (performance decreases) as each guest OS and application vies for the host
machine’s physical resources, such as memory space and I/O devices. Also, memory latency
increases as the virtual machine monitor, or hypervisor, dynamically translates the memory addresses
sent to and received from the memory controller. The hypervisor does this so that each guest
application does not realize that it is being virtualized.
Quad-core Intel Xeon 5300 and 7300 series processors support Intel Virtualization Technology (VT-x),
a processor hardware enhancement designed to reduce this software overhead. Intel VT-x is a group
of extensions to the x86 instruction set that affect the processor, memory, and local I/O address
translations. The new instructions enable guest operating systems to run in the standard Ring-0
architectural layer
The Xeon 7300 series processors also include APIC Task Programmable Register, a new Intel® VT
extension that improves interrupt handling to further optimize virtualization software efficiency.
6
.
Performance comparisons
TPC-C performance
The Transaction Processing Performance Council benchmark TPC-C results for Woodcrest,
Clovertown, Tulsa, and Tigerton processors are compared in Figure 10. TPC-C is measured in
transactions per minute (tpmC). The TPC-C results confirm the superior performance of multi-processor
dual-core and quad-core processors.
Figure 10. TPC-C performance comparisons for dual-processor (DP) and multi-processor (MP) Intel CPUs
6
For more information, refer to the technology brief “Server virtualization technologies for x86-based HP
BladeSystem and HP ProLiant servers” at
http://h20000.www2.hp.com/bc/docs/support/SupportManual/c01067846/c01067846.pdf
15
Page 16

SPEC performance
The Standard Performance Evaluation Corporation (SPEC) CPU2006 benchmark is provides
performance measurements that can be used to compare compute-intensive workloads on different
computer systems. SPEC results for Woodcrest, Clovertown, Tulsa, and Tigerton processors are
compared in Figure 10. SPEC CPU2006 contains two benchmark suites: CINT2006 for measuring
and comparing compute-intensive integer performance, and CFP2006 for measuring and comparing
compute-intensive floating point performance. The performance result show that the quad-core
processors, Clovertown and Tigerton, performed better in the SPEC tests.
Figure 11. SPEC CPU2006 performance comparisons for Intel processors show that the quad-core Clovertown
and Tigerton processors performed better than the dual-core Woodcrest and Tulsa processors.
16
Page 17

Intel Nahalem microarchitecture
Beginning in 2008, new Intel processors will incorporate Intel’s next-generation microarchitecture
codenamed Nehalem. Nehalem will provide on-demand performance and feature a design-scalable
architecture for optimal price-performance and energy efficiency. The Nahalem microarchitecture will
offer scalable performance for one-to-sixteen (or more) threads and from one-to-eight (or more) cores,
scalable and configurable system interconnects, and integrated memory controllers. The introduction
of Nahalem will be followed by Intel’s 32nm silicon process technology.
7
Conclusion
Intel processors continue to provide dramatic increases in the processing capability of HP industrystandard servers. In addition to improved system performance, multi-core Intel processors offer greater
energy efficiency to help HP customers manage power costs. HP ProLiant servers continue to offer
both AMD Opteron™ and Intel® Xeon™ processor architectures to deliver the best possible choice to
customers.
7
For more information, refer to http://www.intel.com/technology/architecture-
silicon/32nm/index.htm?iid=tech_arch_45nm+rhc_32nm.
17
Page 18

For more information
For additional information, refer to the resources listed below.
Resource description Web address
ProLiant servers home page www.hp.com/servers/proliant
Power Regulator for ProLiant
Servers
ISS Technology Papers
http://h20000.www2.hp.com/bc/docs/support/Su
pportManual/c00593374/c00593374.pdf
www.hp.com/servers/technology
Call to action
Send comments about this paper to TechCom@HP.com.
© 2002, 2005, 2006, 2007 Hewlett-Packard Development Company, L.P. The
information contained herein is subject to change without notice. The only
warranties for HP products and services are set forth in the express warranty
statements accompanying such products and services. Nothing herein should be
construed as constituting an additional warranty. HP shall not be liable for technical
or editorial errors or omissions contained herein.
Intel, Intel Xeon, Pentium and Itanium are trademarks or registered trademarks of
Intel Corporation or its subsidiaries in the United States and other countries
AMD and AMD Opteron are trademarks of Advanced Micro Devices, Inc.
Linux is a U.S. registered trademark of Linus Torvalds.
Microsoft and Windows are U.S. registered trademarks of Microsoft Corporation.
TC071201TB, December 2007
 Loading...
Loading...