

Page 1

AN253
Optimizing Code Speed for the MaverickCrunch™
Coprocessor
Brett Davis
1. Introduction
This application note is intended to assist developers in optimizing their source code for use with the MaverickCrun ch co proc essor . This do cum ent begins with a brie f ove rview of the M ave rickC runc h cop roce ssor, followed by optimization guidelines and concludes with an example applying the guidelines
discussed.
Multiple facets of code optimization must be considered in order to realize the full benefit of the MaverickCrunch coprocessor. The guidelines in this document are categorized as algorithm, compiler, or hardware
optimizat ions . The dis cu ssion on alg ori thm op tim ization cent ers on high le vel pr ogr ammi ng detail s such
as compound expressions and loop unrolling. Next, the compiler optimization guidelines deal with the effects of co mpil er op timi zatio n on co de pe rfor mance - pri mari ly cod e siz e and ex ecut ion s peed. Fina lly , the
hardware optimiza tio n s ec t ion enume rat es optimization guideline s r ela te d t o th e M av erickCru nc h coprocessor im plementat ion such as IEEE-754 im plementat ion and pipeline stalls.
Note: Algorithm selection will not be discussed in this applications note. It is assumed that the
developer has selec t ed and imple m ented the co rrect algorit hm f or t heir applic at ion.
2. MaverickCrunch
This sectio n introduc es and sum marizes the features, instruction s et and arch itecture of the Maver ickCrunch coprocessor. For further in-depth information on these topics, please read Chapter 3 of the User's
Guide.
2.1 Features
The MaverickCrunch coprocessor accelerates IEEE-754 floating point arithmetic, and 32-bit and 64-bit
fixed poin t arithmetic . The Ma verickCru nch co process or is an exce llent cand idate fo r encodin g and decoding digital audio, digital signal processing (such as IIR, FIR, FFT) and numeric approximations. Key
features of t he M averickCrunch include:
- IEEE-754 based single and double pr ecisio n f l oating point sup port
- Full IEEE -754 rounding suppor t
- Inex ac t, Overflow, Underflow , and Invalid Operator IEEE-754 exceptions
- 32/64-bit fi xe d point integer operati ons
- Add, multiply, and compare functions for all data types
- Fixed point integer MAC 32-bit input with 72-bit accumulate
- Fixe d point int eger shifts
http://www.cirrus.com
Copyright Cirrus Logic, Inc. 2004
(All Rights Reserved)
JAN ‘04
AN253REV1
1
Page 2

AN253
- Conversion between floating point and in te ger data representatio ns
- Sixt een (16) 64 - bit general-pu rpose regi s ters
- Four (4) 72-bit accumulators
- Stat us and contr ol regist ers
2.2 Instruction Set
The MaverickCrunch coprocessor's i nstructio n set is robust and in cludes memory, control, a nd arithmetic
operations. MaverickCrunch mnemonics are translated by the compiler or assembler into ARM coprocessor instruc t ions. For ex ample, th e M averickCrunch mnemonic f or double p rec is ion floating-point m ult iply
is:
cfmuld c0, c1 , c2
The equivalent ARM coprocessor instruction is:
cdp p4, 1, c0 , c1 , c2 , 1
There are five categories of ARM coprocessor instructions: Data Path (CDP), Load (LDC), Store (STC),
Coprocessor to ARM Moves (MCR), and ARM to coproc essor moves (MRC). CDP instr uctions i nclude all
arithmetic operation s , an d any other operation internal to the c oprocesso r. LD C and STC instructions in clude the set of operations responsible for moving data between memory and the coprocessor. MCR and
MRC instructions ar e responsible for movin g data between ARM and c oprocess or registers .
Table 1, Table 2 and Table 3 summarize all of the MaverickCrunch's instruction mnemonics. For more
information on the MaverickCrunch inst ruction se t, please see t he table:
MaverickCrunch Instruction Set
in the User's Gui d e.
Table 1. MaverickCrunch Load/Store Mnemonics
cfldrs Cd, [ R n ] cfld r d Cd, [Rn ] cfld r 3 2 C d , [Rn]
cfldr64 Cd, [Rn] cfstrs Cd, [Rn] cfstrd Cd, [Rn]
cflstr32 Cd, [Rn] cfstr64 Cd, [Rn] cfmvsr Cn, Rd
cfmvdlr Cn, Rd cfmvdhr Cn, Rd cfmv64lr Cn, Rd
cfmv64hr Cn, Rd cfmvsr Rd, Cn cfmvrdl Rd, Cn
cfmvrdh Rd, Cn cfmvr64l Rd, Cn cfmvr64h Rd, Cn
cfmval32 Cd, Cn cfmvam32 Cd, Cn cfmv32a Cd, Cn
cfmv64a Cd, Cn cfmvsc32 Cd, Cn cfmv32sc Cd, Cn
cfcpys Cd, Cn cfcpyd Cd, Cn
2
Page 3

AN253
Table 2. MaverickCrunch Data Manipulation Mnemo nics
cfcvtsd Cd, Cn cfcvtds Cd, Cn cfcmp64 Rd, Cn, Cm
cfcvt32d Cd, Cn cfcvt64s Cd, Cn cfcvt32s Cd, Cn
cfcvts32 Cd, Cn cfcvtd32 Cd, Cn cfcvt64d Cd, Cn
cfrshl32 Cm, Cn, Rd cftruncs32 Cd, Cn cftruncd32 Cd, Cn
cfsh64 Cd, Cn, <imm> cfrshl64 Cm, Cn, Rd cfsh32 Cd, Cn, <imm>
cfcmp32 Rd, Cn, Cm cfcmps Rd, Cn, Cm cfcmpd Rd, Cn, Cm
Table 3. MaverickCrunch Arithmetic Mnemonics
cfabss Cd, Cn cfnegs Cd, Cn cfadds Cd, Cn, Cm
cfsubs Cd, Cn, Cm cfnegd Cd, Cn cfaddd Cd, Cn, Cm
cfsubd Cd, Cn, Cm cfmuld Cd, Cn, Cm cfabs32 Cd, Cn
cfadd64 Cd, Cn, Cm cfneg32 Cd, Cn cfadd32 Cd, Cn, Cm
cfsub32 Cd, Cn, Cm cfmul32 Cd, Cn, Cm cfmac32 Cd, Cn, Cm
cfmsc32 Cd, Cn, Cm cfabs64 Cd, Cn cfneg64 Cd, Cn
cfsub64 Cd, Cn, Cm cfmul64 Cd, Cn, Cm cfmadd32 Ca, Cd, Cn, Cm
cfmsub32 Ca, Cd, Cn, Cm cfmadda32 Ca, Cd, Cn, Cm cfmsuba32 Ca, Cd, Cn, Cm
cfmuls Cd, Cn, Cm cfabsd Cd, Cn
2.3 Architecture
The MaverickCrun c h c oprocess or uses the st andard AR M c oprocessor interface , sharing its m emory interface and instruction stream. The MaverickCrunch coprocessor is pipelined, has data forwarding capabilities, and can run sy nc hronousl y o r as y nc hronous ly wi th res pect to the AR M 920T pipe line.
There are two se parate pipelin es in the Mav erickCr unch cop roces sor (see Figure 1). Th e first p ipeline,
five stages long, is used for LDC, STC, MCR, and MRC instructions. Its stages are Fetch (F), Decode (D),
Execute (E), Memory Access (M), and Register Write-Back (W). The second pipeline, seven stages long,
is used for t he CDP instructions. I ts s t ages are Fet c h (F ), Decode (D ), Ex ecute/Op erand Fetc h (E), Execute (E1), Ex ecute (E2), Execute (E3), and Register Wr it e-Back (W) .
The MaverickCrunch LDC/STC/MCR/MRC pipeline is identical to, and 'follows' the ARM920T's pipeline.
That is, the c onten ts of the LD C/ST C/MCR /MRC pipeline ar e iden tical to the c onten ts of the AR M920 T
pipeline.
Note: The ARM pipeline is not shown in Figure 1, but is identical to the LDC/STC/MCR/MRC
pipeline.
The MaverickCru nc h C D P pipeline is near ly twice as deep and runs at half t he speed of the ARM920T's
pipe line. T he CDP pipel ine may r un asynchr onously w ith respect to t he ARM920 T ' s pipeline afte r t he initial execution stage. Specifically, the CDP pipeline may run asynchronously in the E1, E2, E3 and W stages. Runni ng Mave rickCrunch i n synchro nous mo de forces th e CDP p ipeline to se rialize th e instruction
stream resulting in an eight-cycl e stal l per data path inst ructi o n. Th e CDP pipeline's a synchr onous capable stages are shaded in Figure 1.
3
Page 4
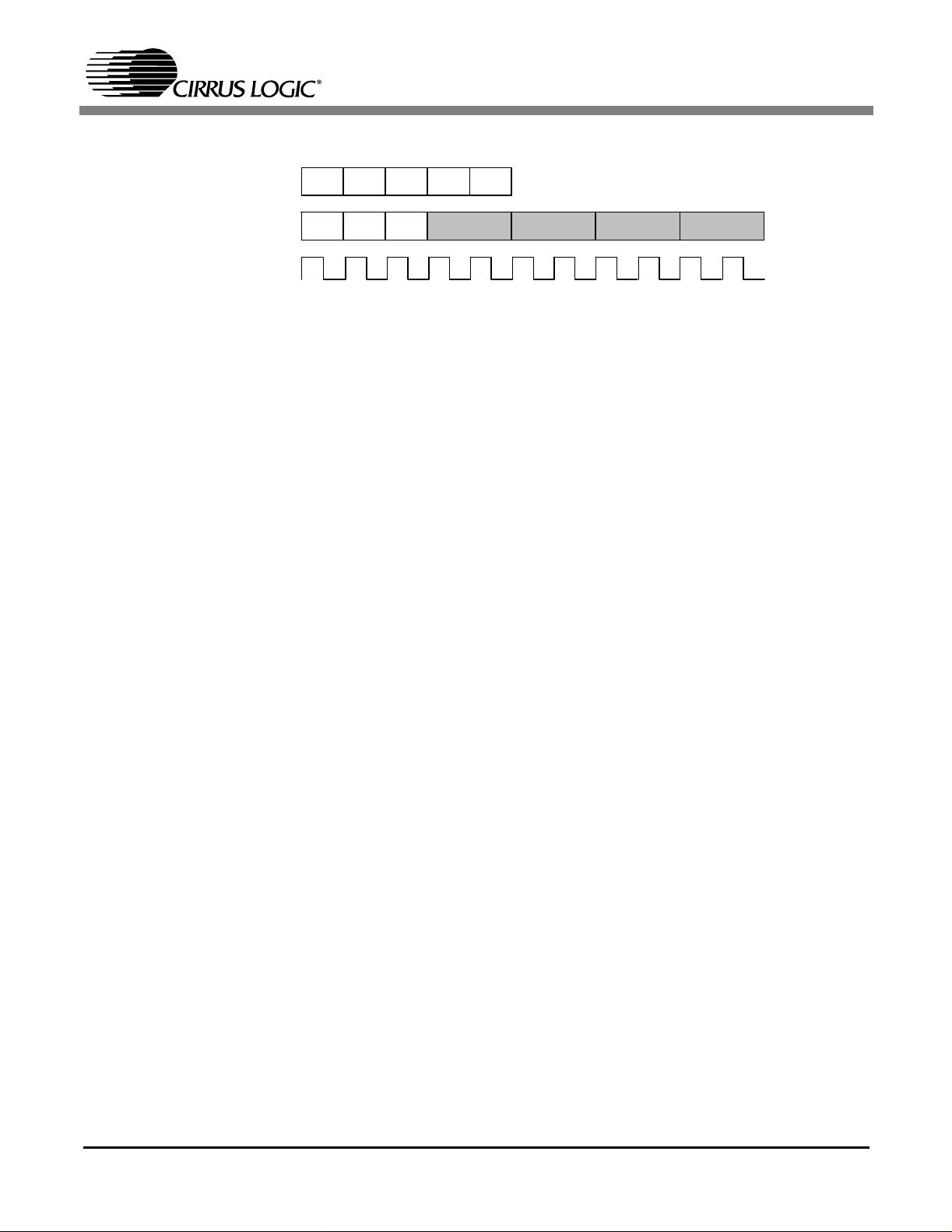
Figure 1. MaverickCrunch Pipelines
AN253
LDC/STC
MCR/MRC
CDP
ARM MCLK
F D E M W
F D E E1 E2 E3 W
3. Code Optimization for MaverickCrunch
This section describes guidelines for writing optimized code for the MaverickCrunch coprocessor. These
guidelin es are divided int o algorithm, compiler and ar chitectur e sections. It is as sumed that th e correct
algorithm has been chosen, and that all non-hardware specific optimizations have been completed. How-
ever, optimization should not begin until all of the code has been written and tested for functionality.
3.1 Algorithms
This section focuses on metho ds to r educe alg ori th m execut i on ti me. Afte r the co de's functionality is verified, profile and disa ssemble the objects. Look for and optimize the following:
- Sections of code that are executed most frequently
- Sections of code that take the most CPU cycles to execute
- Inefficiencie s in assembly code from the compilation
When opt im iz ing these se c ti ons keep in m ind the follow ing general c oncepts of c ode optimiz at ion:
- Avoid Redundancy - store computations rather than recomputing them
- Serialize C ode - code should be des igned with a mi nim um amount of branching. Code branching
is expensiv e. The ARM920T doe s
not
support b ranch predi c tio n
- Code Locality - code executed closely together in time should be placed closely together in
memory, increasing spatial locality of reference and reducing expensive cache misses
Unless your goal is to create small code, code density is not always an indicator of code optimization.
Loop Unrolling is an optimiza ti on te chni que that gener all y i ncre ases code siz e, but also incr eases code
speed. This is because unrolled loops iterate fewer times than their unoptimized versions resulting in fewer index ca lc ulations, com parisons and branc hes taken.
Note: Taken bra nches are expensive o perations, as th ey take th ree cycles to co mplete and cause
the pipeline to be flush ed. (There is no branch pr ediction in th e AR M 920T.)
Induction Variable Analysis is another speed optimization technique used in the case where a variable
in a loop is a funct ion of the loop index. This var iable can be up dat ed each time th e index is updated, reducing th e number of ca lc ulations in th e loop.
4
Page 5

AN253
Although not a loop optimization technique, Common Sub-Expression Elimination is a speed optimization technique that can be used in the case where a complex calculation has redundant sub-expressions.
In th is te chni que , thes e red und ant su b-e xpres sion s are calc ulat ed on ce, s tor ed and reu sed whe n ne eded.
Constant Folding is a speed o ptimiz ati on te chni que us ed in cas es wh ere const ant expr ess ions are re placed wi th th eir final value, rat her than calc ulating the se at run-time.
Various other algorithm techniques exist. Each optimization has trade-offs, and should be selected based
on the algorithm's application. For further information, please consult one of the many available books on
algorithm optimization.
3.2 Compilers
This section describes genera l opt im ization issues that ari s e w hen compilin g fo r t he ARM and M av erickCrunch coprocessor. Ev ery compiler i s diffe rent in how it imple ments and opti mizes co de. Most compil ers
conside r th e f ollowing typ es of optimizations:
- Peepho le - c om bining se ve ral instructions into one sim ple instruct ion
- Local - analyzing, reordering and optimizing instructions in a basic block (serial code) for faster
execution
- Loop - redu c es t im e s pent in loop s b y applying basic loop optimiz ations
- Intrapro ce dural - optimiz es the way c ontrol and da t a are passed between procedure s
The following guidelines will generally help the compiler produce optimal ARM and MaverickCrunch code.
Set the appropriate target processor for the compiler, linker and assembler. This would be the
ARM920T. Furthermore, set the correct floating-point support for the compilation. This may either be hardware floating-point support through the MaverickCrunch coprocessor, soft-float support through a floatingpoint library , or no floating-point support.
Turn off all debug options. Compiling source code with debugging enabled generates un-optimized objects. The se ob jects are typ ical ly la rger, and slo wer than th ose com pile d w ith out the debu gg ing o ptio ns
selected. The debugging option forces the compiler to not use all optimization techniques because some
intermed iat e debug dat a is los t in the process. Fu rt hermore, th e objects are blo at ed with symb ol data for
the debugging tool.
Set the compiler to optimize for code speed. Be sure to experiment with the optimization modes of the
compiler, because some optimizations may have negative unintended effects. For instance, some intermediate results may be optimized out of the code whether these results are needed or not. Please note
that some compilers will optimize code for speed or size better than other compilers.
3.3 Architecture The following guidelines are specific to the MaverickCrunch hardware. The MaverickCrunch should be
running in asynchronous mode with data forwarding enabled to obtain the highest pipeline
throughput. Additionally, the ARM920T's master clock should be set to run at the highest allowed fre-
quency. Please see the example of the initialization source code in the User’s Guide.
5
Page 6

AN253
Avoid single or double floati ng-point div ision. These operations are not implemented in the Maverick-
Crunch and will be carried out by a soft-float library routine. When possible, calculate the reciprocal during
compile-time and multiply instead. Be vigilant of compounding rounding errors from calculating the reciprocal, and repeated multiplication of the reciprocal.
Avoid creating data dependencies in algorithms when performing MaverickCrunch operations. A
data dependency occurs when an instruction takes the output of a previous instruction as its operand. This
depende ncy will stall the p ipeline if the outpu t of the p revious instruc tion is not availa ble for the c urrent
instructio n. The follow ing table co ntains the Ma verickCrunch 's instructio n stall time in cycle coun ts for
each type of coprocessor instruction.
Table 4. Instruction Stall Time
INSTRUCTION TYPE CYCLE COUNT
CDP 5
CDP (Multiply Double & 64) 1 1
LDC/MCR 2
STR/MRC 0
Conside r th e f ollowing Mav erickCru nc h c ode:
fmuls c 3, c1 , c2 // CD P ins tr uc ti on
fadds c0 , c0, c3 // CDP inst ru ct io n - sta ll s on c3
In this example, the addition operation stall s for 5 cycle s on the product (
c3
) of the multiplication. However,
if the first instruction had been a double precision multiplication the addition operation would have stalled
on the product (c3) for 11 cycles.
Conside ring the pipe line stall cycle s , the above sourc e c ode looks lik e:
fmuls
c3, c1, c2 // CD P ins tr uc ti on
<stall cycle>
<stall cycle>
<stall cycle>
<stall cycle>
<stall cycle>
fadds c0 , c0, c3 // CDP inst ru ct io n - sta ll s on c3
Optimize data-dependent pipeline stalls by interleaving the dependent instructions with independent instructions. This will have a positive eff ec t by increasing pipeline through put. Again, t his is espe-
cially impo rtant when e xecutin g a doub le pre cision m ultiply, and si gnificant ly impo rtant wh en exe cuting
adds, compares, or other data-path operations. These interleaved instructions may either be ARM or MaverickCrun ch operations an d should be plac ed just after th e stalling instruc tion. H owever, be judi cious
about which interleaved instructions are used s o th at new data depen dencies are not introduc ed into the
source code.
Finally, the optimized example source code looks like:
6
Page 7

AN253
fmuls c3, c1, c2
<Indep en den t AR M/ Ma ve ri ckC ru nc h In st ru cti on >
<Indep en den t AR M/ Ma ve ri ckC ru nc h In st ru cti on >
<Indep en den t AR M/ Ma ve ri ckC ru nc h In st ru cti on >
<Indep en den t AR M/ Ma ve ri ckC ru nc h In st ru cti on >
<Indep en den t AR M/ Ma ve ri ckC ru nc h In st ru cti on >
fadds c0, c0, c3
Note: Please be aware that some sequences of MaverickCrun ch inst ructi o ns are not supp orte d.
For an up-t o-date list of th es e instruction sequen c es , please see th e appropriat e Errata
Sheet. The Errata Sheets are available at www.cirrus.com. Furthermore, a parsing tool is
available t hat can ident if y illegal seque nc es of MaverickCrun ch ins t ructions. T his t ool is
also avail able from Cirrus Logic.
Attempt to maximize the throughput of the ARM920T, and MaverickCrunch CDP pipelines by interleaving independent ARM and CDP instructions. The maximum throughput of the CDP pipeline is
one CDP instruction every other ARM CLK. This is because the E1, E2, E3, and W pipeline stages of the
CDP pipeline take two ARM cycles to complete. Please note that MaverickCrunch must be operating in
asynchronous mode to realize this optimization.
Conside r th e f ollowing code sequen c e:
<Indep en den t Ma ve ri ck Cr unc h In st ru ct io n A>
<Indep en den t Ma ve ri ck Cr unc h In st ru ct io n B>
<Indep en den t Ma ve ri ck Cr unc h In st ru ct io n C>
<Indep en den t AR M In st ru cti on A>
<Indep en den t AR M In st ru cti on B>
<Indep en den t AR M In st ru cti on C>
The above code i s ineffi c ient bec ause Mave rickCrunch Ins t ructi ons A, B, an d C w ill st all the ARM ’s pipeline during their execution of the second cycle in the E1, E2, E3, and W stages. The following code interleaves the MaverickCrunch and ARM instructions, which removes the stalls and maximizes the
throughput of both pipel ines.
<Indep en den t Ma ve ri ck Cr unc h In st ru ct io n A>
<Indep en den t AR M In st ru cti on A>
<Indep en den t Ma ve ri ck Cr unc h In st ru ct io n B>
<Indep en den t AR M In st ru cti on B>
<Indep en den t Ma ve ri ck Cr unc h In st ru ct io n C>
<Indep en den t AR M In st ru cti on C>
Utilize both the ARM and co-processor registers, and the data caching capabilities of the ARM
core to reduce the latency of fetching data. For exam ple, FI R filters typ ically have many filter co effi-
cients - more coefficients than there are available registers. Many costly memory accesses will be executed to load the filter coefficients. One solution to this problem is to load and lock-in the filter coeffici ents
in a data cache at start-up. This will result in an increase in performance because of the reduction in pipeline stallin g w hile waiting f or data to tran s fe r f rom (s lower) ext ernal memory to the coprocessor.
7
Page 8
AN253
4. Examples
This example illustr at es the pr ocess o f opti mi zi ng code for the Mave ri ckCrun ch co pro cessor at t he arch itecture level. The following source code is part of a simple real-time implementation of an FIR filter (Figure
2). There is a data dependency in the accumulate portion of the basic source code (on the left). This data
dependency stalls the MaverickCrunch CDP pipeline for 11 cycles. To reduce this penalty, it is possible
to re-arrange the sourc e code to us e t he ARM cycl es in t he shadow of th e s t all.
Figure 2: FIR Op t imi z at io n Ex am pl e
// Unoptimized FIR // Optimized FIR
acc = 0; acc = 0;
add r0,pc,#0x80 ; #0x8544 add r0,pc,#0x80 ; #0x8544
cfldrd c4, [r0] cfldrd c4, [r0]
for (i = 0; i < n; i++){
mov r4,#0
b 0x8508 ; (fir + 0x6c)
acc += h[i] * z[i]; for (i = 0; i < n; i++){
add r1,r5,r4,lsl #3 // Ptr mov r4,#0
cfldrd c0, [r1] b 0x8508 ; (fir + 0x6c)
add r0,r7,r4,lsl #3 // Ptr
cfldrd c1, [r0] acc += h[i] * z[i];
cfmuld c0, c0, c1 // <-- 11-cycles cfldrd c0, [r1]
cfaddd c4, c4, c0 // <-- stalled cfldrd c1, [r0]
add r4,r4,#1
cmp r4,r6
blt 0x84d8 ; (fir + 0x3c)
}
1
// ** initialize array ptrs here **
mov r1, r5
mov r0, r7
cfmuld c0, c0, c1
// ** increment ptrs here **
add r1,r5,r4,lsl #3
add r0,r7,r4,lsl #3
cfaddd c4, c4, c0
add r4,r4,#1
cmp r4,r6
blt 0x84d8 ; (fir + 0x3c)
2
}
To acco mplis h t his opt imiza tion (se e Figu re 2 ): 1 .) M ov e t he in de x in itial ization /up date co de behi nd the
cfmuld opera tion; 2. ) Add inde x initial izati on code jus t above the loop cons t ruct. T his optim izatio n results
8
Page 9

AN253
in a 2-cycle incr ease i n perfo r mance pe r iteration of the loop constr u ct. Th i s i n creas e in per forma nce ca n
be significant for FIR filters with larg e numbers of c oef f ic ients.
In this nex t algo rithm an d a rchite ctu ral opt imiza tion e xam ple, a Biqu ad IIR filte r (Fig ure 3) is mod ified to
reduce the number of loads/stores in the inner loop. The Biquad IIR filter’s difference equation is:
y[n] = b[0]*x[n] + b[1]*x[n-1] + b[2]*x[n-2] - a[1]*y[n-1] - a[2]*y[n-2]
One C imp lem entation of t his IIR Biquad dif fe rence equa ti on, and the one used for th is ex ample is:
double inp, accumulator;
long i;
for (i=0; i<(long)nn; i++)
{
inp = data[ i] ;
accumulator = 0;
accumulator -= filtcoefs[0]*bqd1k_dCstates[0];
accumulator -= filtcoefs[0]*bqd1k_dCstates[1];
accumulator += filtcoefs[2]*inp;
accumulator += filtcoefs[3]*bqd1k_dCstates[2];
accumulator += filtcoefs[4]*bqd1k_dCstates[3];
// Update y[n] states (output history for feedback lines)
bqd1k_dCstates[1] = bqd1k_dCstates[0];
bqd1k_dCstates[0] = accumulator;
// Store the output
data[i] = accumulator;
// Update x[n] states (input history for delay lines)
bqd1k_dCstates[3] = bdq1k_dCstates[2];
bqd1k_dCstates[2] = inp;
}
In the assembly version of the original algorithm (on the left), the filter coefficients are loaded when needed. Consequently, they are loaded in each iteration of the loop. Additionally, the state variables are loaded
when need ed and then stored when updated. They are als o loaded and s tored in ea ch iteration o f the
loop.
9
Page 10

Figure 3: IIR Op timi z a tio n Ex a m pl e
// Floating-point Biquad IIR // Floating-point Biquad IIR
// (Basic: Non-optimized) // (Optimized)
AN253
main_loop
cfldrd temp2, [fcoef] cfldrd bqd1k_s2, [bdq1k, 16]
cfldrd bqd1k_s0, [bdq1k] cfldrd bqd1k_s3, [bdq1k, 24]
cfmuld acc, temp2, bqd1k_s0
cfnegd acc, acc
cfldrd temp2, [fcoef, 8] cfldrd temp2, [fcoef, 16]
cfldrd bqd1k_s1, [bdq1k, 8] cfldrd temp3, [fcoef, 24]
cfmuld temp, temp2, bqd1k_s1
cfsubd acc, acc, temp
cfldrd temp2, [fcoef, 16] cfnegd temp1, temp1
cfldrd temp4, [data]
cfmuld temp, temp2, temp4 main_loop
cfaddd acc, acc, temp
cfldrd temp2, [fcoef, 24] cfldrd inp, [data]
cfldrd bqd1k_s2, [bdq1k, 16] cfmuld acc, outp, bqd1k_s0
cfmuld temp, temp2, bqd1k_s2 cfmuld temp, temp1, bqd1k_s1
cfaddd acc, acc, temp
cfldrd temp2, [fcoef, 32] cfaddd acc, acc, temp
cfldrd bqd1k_s3, [bdq1k, 24] cfmuld temp, temp2, inp
cfmuld temp, temp2, bqd1k_s3 cfaddd acc, acc, temp
cfaddd acc, acc, temp cfmuld temp, temp3, bqd1k_s2
cfstrd acc, [data], 8 cfaddd acc, acc, temp
cfstrd acc, [bdq1k] cfmuld temp, temp4, bqd1k_s3
cfstrd bqd1k_s0, [bdq1k, 8] cfcpyd bqd1k_s3, bqd1k_s2
cfstrd temp4, [bdq1k, 16] cfcpyd bqd1k_s2, inp
cfstrd bqd1k_s2, [bdq1k, 24] cfaddd acc, acc, temp
subs nn, nn, 1
bgt main_loop subs nn, nn, 1
1
3
cfldrd bqd1k_s0, [bdq1k]
cfldrd bqd1k_s1, [bdq1k, 8]
cfldrd outp, [fcoef]
cfldrd temp1, [fcoef, 8]
cfldrd temp4, [fcoef, 32]
cfnegd outp, outp
cfcpyd bqd1k_s1, bqd1k_s0
cfcpyd bqd1k_s0, acc
bgt main_loop
2
ldr temp1, =bqd1k_dCrstates
cfstrd bqd1k_s0, [temp1]
cfstrd bqd1k_s1, [temp1, 8]
cfstrd bqd1k_s2, [temp1, 16]
cfstrd bqd1k_s3, [temp1, 24]
To accomplish this optimization (see Figure 3): 1.) Use the additional registers in the MaverickCrunch coprocessor to load the f ilter an d stat e var iables onc e befo re th e inner lo op ; 2.) Shu ffle the sta te varia bl es
around in registers during the inner loop; 3.) Store the state variables after the inner loop. This removes
nine loads and f our s tores fr om the i nne r loo p. Al so not e t hat th e cop y ins truc tio ns used to s huff le th e st ate
10
Page 11

AN253
variables have been interlea v ed with da t a dependa nt i ns tructions in order to reduce their respec tive st all
penalties.
5. Summary
The opt imizati on guide lines su ggested in t his document are:
- Write and test all source code before attempting any optimizations
- Focus optimizations on sections of code that are executed most frequently, and take the most CPU
cycles to execute
- Identify a nd resolve any im plementation ineff ic iencies generated by th e c ompiler
- Set the app ropriate target process or for the compiler, linker and assem bler
- Turn off all of th e c om pilers deb ug options
- Set the compiler to optimize the code for speed
- Set the Mav erickCrun c h c oprocess or t o run in async hronous mod e w it h data-forw arding enabled
- Avoid sing le or double f loating-po int div is ion
- Avoid creating data dependencies in algorithms w hen performing Mav erickCrunch oper ations
- Optimize data-dep endent pip eline stalls by interleaving the dependent instr uc t ions with
inde pendent instruc t ions
- Utilize both the ARM and MaverickCrunch's registers, and the data caching capabilities of the ARM
core to reduce the latency of fetching data from external memory
In summ ary , thi s d ocu men t has det ail e d ma ny op ti mi za ti on t ech niq ue s th at c an i mpr ov e th e per fo r manc e
of applica ti ons w ritten for the M averickCrunch coprocesso r.
11
Page 12

Revision Date Changes
1 23 January 2004 Initial Release
AN253
Contacting Cirrus Logic Support
For all product questions and inquiries contact a Cirr us Logic Sales Representative.
To find one nearest you go to http://www.cirrus.com/corporate/contacts/sales.cfm
IMPORTANT NOTICE
"Preliminary" product information describes products that are in production, but for which full characterization data is not yet available. Cirrus Logic, Inc. and its sub-
sidiaries ("Cirrus") believe that the information contained in this document is accurate and reliable. However, the information is subject to change without notice and
is provided "AS IS" without warranty of any kind (express or implied). Customers are advised to obtain the latest version of relevant information to verify, before placing
orders, that information being relied on is current and complete. All products are sold subject to the terms and conditions of sale supplied at the time of order acknowledgment, including those pertaining to warranty, patent infringement, and limitation of liability. No responsibility is assumed by Cirrus for the use of this information,
including use of this information as the basis for manufacture or sale of any items, or for infringement of patents or other rights of third parties. This document is the
property of Cirrus and by furnishing this information, Cirrus grants no license, express or implied under any patents, mask work rights, copyrights, trademarks, trade
secrets or other intellectual property rights. Cirrus owns the copyrights associated with the information contained herein and gives consent for copies to be made of
the information only for use within your organization with respect to Cirrus integrated circuits or other products of Cirrus. This consent does not extend to other copying
such as copying for general distribution, advertising or promotional purposes, or for creating any work for resale.
CERTAIN APPLICAT IONS USING SEMICONDUCTOR PRODUCTS MAY INVOLVE POTENTIAL RISKS OF DEATH, PERSONAL INJURY, OR SEVERE PROPERTY OR ENVIRONMENTAL DAMAGE ("CRITICAL APPLICATIONS"). CIRRUS PRODUCTS ARE NOT DESIGNED, AUTHORIZED OR WARRANTED FOR USE
IN AIRCRAFT SYSTEMS, MILITARY APPLICATIONS, PRODUCTS SURGICALLY IMPLANTED INTO THE BODY, LIFE SUPPORT PRODUCTS OR OTHER CRITICAL APPLICATIONS (INCLUDING MEDICAL DEVICES, AIRCRAFT SYSTEMS OR COMPONENTS AND PERSONAL OR AUTOM OTIVE SAFETY OR SECURITY DEVICES). INCLUSION OF CIRRUS PRODUCTS IN SUCH APPLICATIONS IS UNDERSTOOD TO BE FULLY AT THE CUSTOMER'S RISK AND CIRRUS
DISCLAIMS AND MAKES NO WA RRANTY, EXPRESS, STATUTORY OR IMPLIED, INCLUDING THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR PARTICULAR PURPOSE, WITH REGARD TO ANY CIRRUS PRODUCT THAT IS USED IN SUCH A MANNER. IF THE CUSTOMER OR CUSTOMER'S CUSTOMER USES OR PE RMITS THE USE OF CIRRUS PRODUCTS IN CRITICAL APPLICATIONS, CUSTOMER AGREES, BY SUCH USE, TO FULLY
INDEMNIFY CIRRUS, ITS OFFICERS, DIRECT ORS, EMPLOYEES, DISTRIBUTORS AND OTHER AGENTS FROM ANY AND ALL LIABIL ITY, INCLUDING ATTORNEYS' FEES AND COSTS, THAT MAY RESULT FROM OR ARISE IN CONNECTION WITH THESE USES.
Cirrus Logic, Cirrus, MaverickCrunch, MaverickKey, and the Cirrus Logic logo designs are trademarks of Cirrus Logic, Inc. All other brand and product names in this
document may be trademarks or service marks of their respective owners.
Microsoft and Windows are registered trademarks of Microsoft Corporation.
MicrowireTM is a trademark of National Semiconductor Corp. National Semiconductor is a registered trademark of National Semiconductor C o rp.
Texas Instruments is a registered trademark of Texas Instruments, Inc.
Motorola is a reigistered trademark of Motorola, Inc.
LINUX is a registered trademark of Linus Torvalds.
12
 Loading...
Loading...