

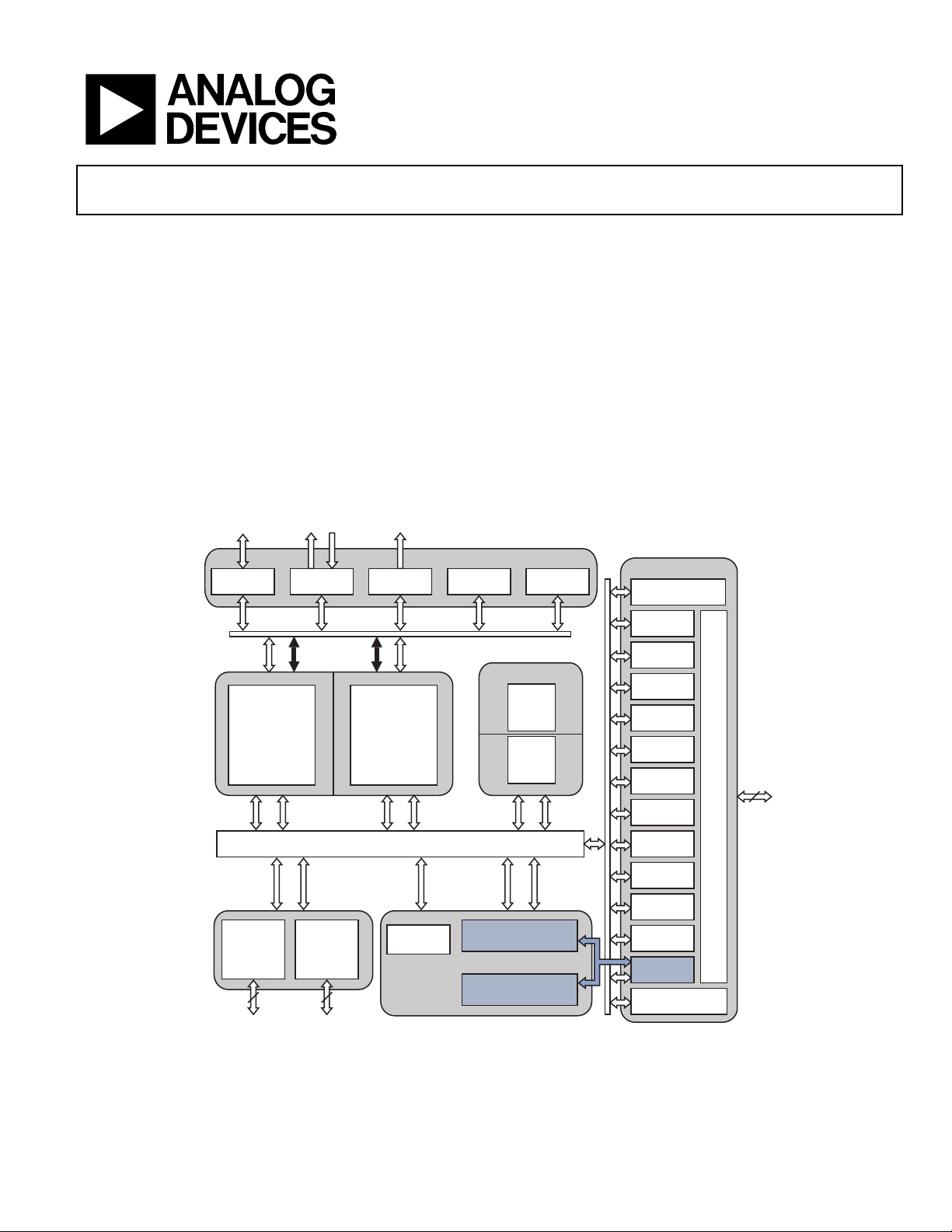
Blackfin Dual Core
SYSTEM CONTROL BLOCKS
PERIPHERALS
HARDWARE
FUNCTIONS
EXTERNAL
BUS
INTERFACES
LPDDR
DDR2
CRC
PIPELINED
VISION PROCESSOR
PIXEL
COMPOSITOR
DMA SYSTEM
3× PPI
4× LINK PORT
2× EMAC
WITH
2× IEEE 1588
EMMC/RSI
3× SPORT
2× SPI
2× UART
1× CAN
8× TIMER
2× PWM
1× COUNTER
2× TWI
USB 2.0 HS OTG
L2 MEMORY
256K BYTE
ECC-
PROTECTED
SRAM
32K BYTE
ROM
112
GP
I/O
FLASH
SRAM
EMULATOR
TEST & CONTROL
PLL & POWER
MANAGEMENT
FAULT
MANAGEMENT
EVENT
CONTROL
DUAL
WATCHDOG
CORE 1
148K BYTE
PARITY BIT PROTECTED
L1 SRAM
INSTRUCTION/DATA
B
1× ACM
16
16
DYNAMIC
MEMORY
CONTROLLER
STATIC
MEMORY
CONTROLLER
VIDEO
SUBSYSTEM
CORE 0
148K BYTE
PARITY BIT PROTECTED
L1 SRAM
INSTRUCTION/DATA
B
Embedded Processor
Preliminary Technical Data
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609
FEATURES
Dual-core symmetric high-performance Blackfin processor,
up to 500 MHz per core
Each core contains two 16-bit MACs, two 40-bit ALUs, and a
40-bit barrel shifter
RISC-like register and instruction model for ease of
programming and compiler-friendly support
Advanced debug, trace, and performance monitoring
Pipelined Vision Processor provides hardware to process sig-
nal and image algorithms used for pre- and co-processing
of video frames in ADAS or other video processing
applications
Accepts a range of supply voltages for I/O operation. See
Operating Conditions on Page 31
Off-chip voltage regulator interface
349-ball (19 mm × 19 mm) RoHS compliant BGA package
MEMORY
Each core contains 148K bytes of L1 SRAM memory (proces-
sor core-accessible) with multi-parity bit protection
Up to 256K bytes of L2 SRAM memory with ECC protection
Dynamic memory controller provides 16-bit interface to a
single bank of DDR2 or LPDDR DRAM devices
Static memory controller with asynchronous memory inter-
face that supports 8-bit and 16-bit memories
Flexible booting options from flash, eMMC and SPI memories
and from SPI, link port and UART hosts
Memory management unit provides memory protection
Blackfin and the Blackfin logo are registered trademarks of Analog Devices, Inc.
Rev. PrD
Information furnished by Analog Devices is believed to be accurate and reliable.
However, no responsibility is assumed by Analog Devices for its use, nor for any
infringements of patents or other rights of third parties that may result from its use.
Specifications subject to change without notice. No license is granted by implication
or otherwise under any patent or patent rights of Analog Devices. Trademarks and
registered trademarks are the property of their respective owners.
Figure 1. Processor Block Diagram
One Technology Way, P.O. Box 9106, Norwood, MA 02062-9106 U.S.A.
Tel: 781.329.4700 www.analog.com
Fax: 781.461.3113 © 2012 Analog Devices, Inc. All rights reserved.

ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609 Preliminary Technical Data
TABLE OF CONTENTS
Features ................................................................. 1
Memory ................................................................ 1
General Description ................................................. 3
Blackfin Processor Core .......................................... 3
Instruction Set Description ..................................... 4
Processor Infrastructure ......................................... 5
Memory Architecture ............................................ 6
Video Subsystem .................................................. 9
Processor Safety Features ...................................... 10
Additional Processor Peripherals ............................ 11
Power and Clock Management ............................... 14
System Debug .................................................... 17
EZ-KIT Lite® Evaluation Board .............................. 17
Designing an Emulator-Compatible
Processor Board (Target) ................................... 17
Related Documents ............................................. 18
REVISION HISTORY
3/12—Revision PrD: Initial public version
Related Signal Chains ........................................... 18
Signal Descriptions ................................................. 19
Pin Multiplexing ................................................. 20
Pin Termination and Drive Characteristics-Requirements 24
Specifications ........................................................ 31
Operating Conditions ........................................... 31
Electrical Characteristics ....................................... 33
Processor — Absolute Maximum Ratings .................. 34
ESD Sensitivity ................................................... 34
Processor — Package Information ........................... 34
Environmental Conditions .................................... 35
349-Ball CSP_BGA Ball Assignments .......................... 36
Outline Dimensions ................................................ 42
Surface-Mount Design .......................................... 42
Automotive Products .............................................. 43
Pre Release Products ............................................... 43
Rev. PrD | Page 2 of 44 | March 2012
Preliminary Technical Data
GENERAL DESCRIPTION
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609
The ADSP-BF609 processor is a member of the Blackfin
family of products, incorporating the Analog Devices/Intel
Micro Signal Architecture (MSA). Blackfin processors combine
a dual-MAC state-of-the-art signal processing engine, the
advantages of a clean, orthogonal RISC-like microprocessor
instruction set, and single-instruction, multiple-data (SIMD)
multimedia capabilities into a single instruction-set
architecture.
The processor offers performance up to 500 MHz, as well as low
static power consumption. Produced with a low-power and lowvoltage design methodology, they provide world-class power
management and performance.
By integrating a rich set of industry-leading system peripherals
and memory (shown in Table 1), Blackfin processors are the
platform of choice for next-generation applications that require
RISC-like programmability, multimedia support, and leadingedge signal processing in one integrated package. These applications span a wide array of markets, from automotive systems to
embedded industrial, instrumentation and power/motor control applications.
Table 1. Processor Comparison
Processor Feature
ADSP-BF606
Up/Down/Rotary Counters 1
Timer/Counters with PWM 8
3-Phase PWM Units (4-pair) 2
SPORTs 3
SPIs 2
USB OTG 1
Parallel Peripheral Interface 3
Removable Storage Interface 1
CAN 1
TWI 2
UART 2
ADC Control Module (ACM) 1
Link Ports 4
Ethernet MAC (IEEE 1588) 2
Pixel Compositor (PIXC) No 1 1
Pipelined Vision Processor
1
(PVP)
GPIOs 112
ADSP-BF607
No VGA HD
ADSP-BF608
ADSP-BF609
Table 1. Processor Comparison (Continued)
Processor Feature
ADSP-BF606
L1 Instruction SRAM 64K
L1 Instruction SRAM/Cache 16K
L1 Data SRAM 32K
L1 Data SRAM/Cache 32K
L1 Scratchpad 4K
L2 Data SRAM 128K 256K
L2 Boot ROM 32K
Memory (bytes, per core)
Maximum Speed Grade (MHz)
Maximum SYSCLK (MHz)
Package Options 349-Ball CSP_BGA
1
VGA is 640 x 480 pixels per frame, 30 frames per second. HD is 1280 x 960 pixels
per frame, 30 frames per second.
2
Maximum speed grade is not available with every possible SYSCLK selection.
2
400
ADSP-BF607
250
ADSP-BF608
500
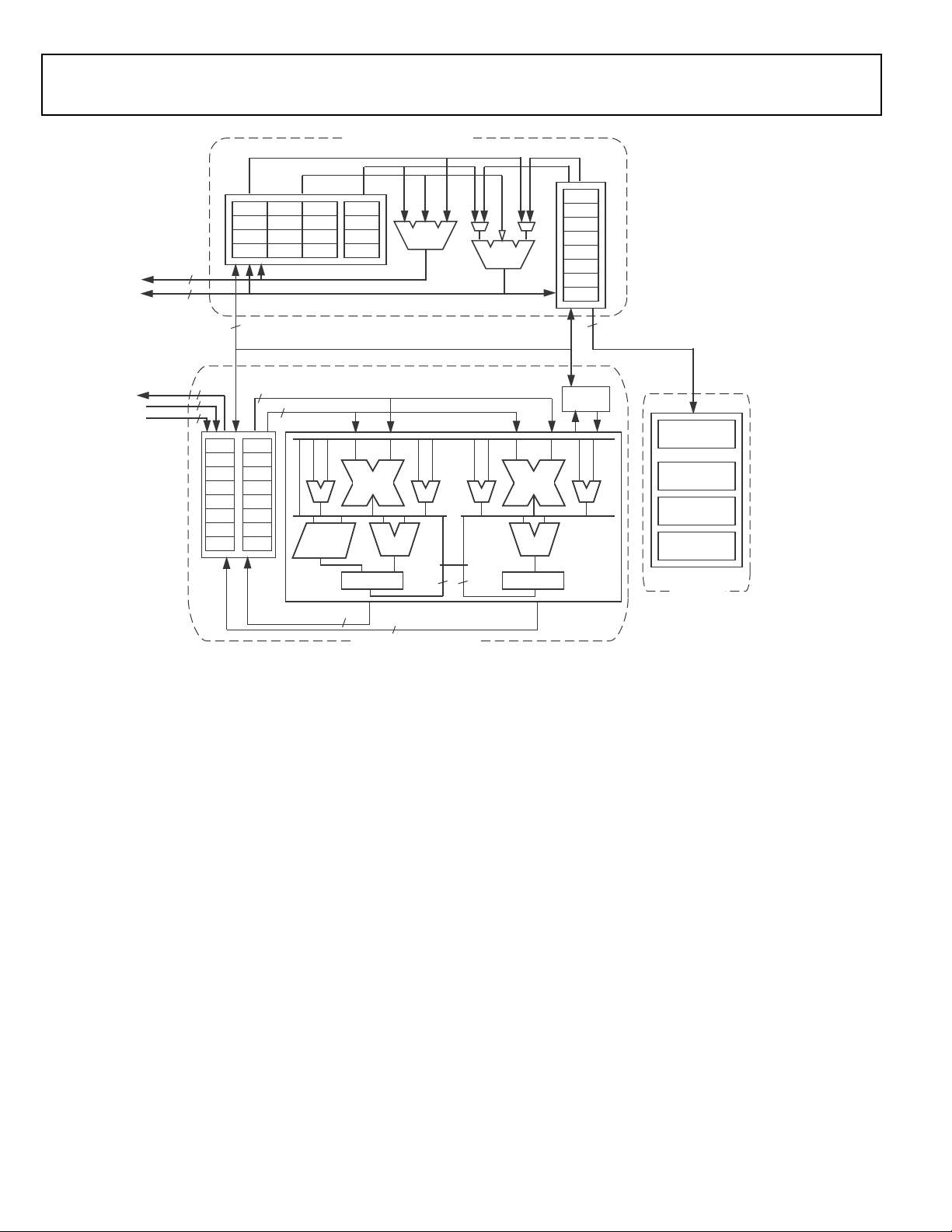
BLACKFIN PROCESSOR CORE
As shown in Figure 1, the processor integrates two Blackfin processor cores. Each core, shown in Figure 2, contains two 16-bit
multipliers, two 40-bit accumulators, two 40-bit ALUs, four
video ALUs, and a 40-bit shifter. The computation units process
8-, 16-, or 32-bit data from the register file.
The compute register file contains eight 32-bit registers. When
performing compute operations on 16-bit operand data, the
register file operates as 16 independent 16-bit registers. All
operands for compute operations come from the multiported
register file and instruction constant fields.
Each MAC can perform a 16-bit by 16-bit multiply in each
cycle, accumulating the results into the 40-bit accumulators.
Signed and unsigned formats, rounding, and saturation
are supported.
The ALUs perform a traditional set of arithmetic and logical
operations on 16-bit or 32-bit data. In addition, many special
instructions are included to accelerate various signal processing
tasks. These include bit operations such as field extract and population count, modulo 2
and rounding, and sign/exponent detection. The set of video
instructions include byte alignment and packing operations,
16-bit and 8-bit adds with clipping, 8-bit average operations,
and 8-bit subtract/absolute value/accumulate (SAA) operations.
Also provided are the compare/select and vector search
instructions.
For certain instructions, two 16-bit ALU operations can be performed simultaneously on register pairs (a 16-bit high half and
16-bit low half of a compute register). If the second ALU is used,
quad 16-bit operations are possible.
32
multiply, divide primitives, saturation
ADSP-BF609
Rev. PrD | Page 3 of 44 | March 2012
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609 Preliminary Technical Data
SEQUENCER
ALIGN
DECODE
LOOP BUFFER
16
16
8888
40 40
A0 A1
BARREL
SHIFTER
DATA ARITHMETIC UNIT
CONTROL
UNIT
R7.H
R6.H
R5.H
R4.H
R3.H
R2.H
R1.H
R0.H
R7.L
R6.L
R5.L
R4.L
R3.L
R2.L
R1.L
R0.L
AS TAT
40 40
32
32
32
32
32
32
32LD0
LD1
SD
DAG0
DAG1
ADDRESS ARITHMETIC UNIT
I3
I2
I1
I0
L3
L2
L1
L0
B3
B2
B1
B0
M3
M2
M1
M0
SP
FP
P5
P4
P3
P2
P1
P0
DA1
DA0
32
32
32
PREG
RAB
32
TO MEMORY
The 40-bit shifter can perform shifts and rotates and is used to
support normalization, field extract, and field deposit
instructions.
The program sequencer controls the flow of instruction execution, including instruction alignment and decoding. For
program flow control, the sequencer supports PC relative and
indirect conditional jumps (with static branch prediction), and
subroutine calls. Hardware supports zero-overhead looping.
The architecture is fully interlocked, meaning that the programmer need not manage the pipeline when executing instructions
with data dependencies.
The address arithmetic unit provides two addresses for simultaneous dual fetches from memory. It contains a multiported
register file consisting of four sets of 32-bit index, modify,
length, and base registers (for circular buffering), and eight
additional 32-bit pointer registers (for C-style indexed stack
manipulation).
Blackfin processors support a modified Harvard architecture in
combination with a hierarchical memory structure. Level 1 (L1)
memories are those that typically operate at the full processor
speed with little or no latency. At the L1 level, the instruction
memory holds instructions only. The data memory holds data,
and a dedicated scratchpad data memory stores stack and local
variable information.
Figure 2. Blackfin Processor Core
In addition, multiple L1 memory blocks are provided, offering a
configurable mix of SRAM and cache. The memory management unit (MMU) provides memory protection for individual
tasks that may be operating on the core and can protect system
registers from unintended access.
The architecture provides three modes of operation: user mode,
supervisor mode, and emulation mode. User mode has
restricted access to certain system resources, thus providing a
protected software environment, while supervisor mode has
unrestricted access to the system and core resources.
INSTRUCTION SET DESCRIPTION
The Blackfin processor instruction set has been optimized so
that 16-bit opcodes represent the most frequently used instructions, resulting in excellent compiled code density. Complex
DSP instructions are encoded into 32-bit opcodes, representing
fully featured multifunction instructions. Blackfin processors
support a limited multi-issue capability, where a 32-bit instruction can be issued in parallel with two 16-bit instructions,
allowing the programmer to use many of the core resources in a
single instruction cycle.
The Blackfin processor family assembly language instruction set
employs an algebraic syntax designed for ease of coding and
readability. The instructions have been specifically tuned to provide a flexible, densely encoded instruction set that compiles to
Rev. PrD | Page 4 of 44 | March 2012

Preliminary Technical Data
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609
a very small final memory size. The instruction set also provides
fully featured multifunction instructions that allow the programmer to use many of the processor core resources in a single
instruction. Coupled with many features more often seen on
microcontrollers, this instruction set is very efficient when compiling C and C++ source code. In addition, the architecture
supports both user (algorithm/application code) and supervisor
(O/S kernel, device drivers, debuggers, ISRs) modes of operation, allowing multiple levels of access to core
processor resources.
The assembly language, which takes advantage of the processor’s unique architecture, offers the following advantages:
• Seamlessly integrated DSP/MCU features are optimized for
both 8-bit and 16-bit operations.
• A multi-issue load/store modified-Harvard architecture,
which supports two 16-bit MAC or four 8-bit ALU + two
load/store + two pointer updates per cycle.
• All registers, I/O, and memory are mapped into a unified
4G byte memory space, providing a simplified programming model.
• Control of all asynchronous and synchronous events to the
processor is handled by two subsystems: the Core Event
Controller (CEC) and the System Event Controller (SEC).
• Microcontroller features, such as arbitrary bit and bit-field
manipulation, insertion, and extraction; integer operations
on 8-, 16-, and 32-bit data-types; and separate user and
supervisor stack pointers.
• Code density enhancements, which include intermixing of
16-bit and 32-bit instructions (no mode switching, no code
segregation). Frequently used instructions are encoded
in 16 bits.
PROCESSOR INFRASTRUCTURE
The following sections provide information on the primary
infrastructure components of the ADSP-BF609 processor.
DMA Controllers
The processor uses Direct Memory Access (DMA) to transfer
data within memory spaces or between a memory space and a
peripheral. The processor can specify data transfer operations
and return to normal processing while the fully integrated DMA
controller carries out the data transfers independent of processor activity.
DMA transfers can occur between memory and a peripheral or
between one memory and another memory. Two channels are
used for Memory-to-Memory DMA where one channel is the
source channel, and the second is the destination channel.
All DMAs can transport data to and from all on-chip and offchip memories. Programs can use two types of DMA transfers,
descriptor-based or register-based. Register-based DMA allows
the processor to directly program DMA control registers to initiate a DMA transfer. On completion, the control registers may
be automatically updated with their original setup values for
continuous transfer. Descriptor-based DMA transfers require a
set of parameters stored within memory to initiate a DMA
sequence. Descriptor-based DMA transfers allow multiple
DMA sequences to be chained together and a DMA channel can
be programmed to automatically set up and start another DMA
transfer after the current sequence completes.
The DMA controller supports the following DMA operations.
• A single linear buffer that stops on completion.
• A linear buffer with negative, positive or zero stride length.
• A circular, auto-refreshing buffer that interrupts when each
buffer becomes full.
• A similar buffer that interrupts on fractional buffers (for
example, 1/2, 1/4).
• 1D DMA – uses a set of identical ping-pong buffers defined
by a linked ring of two-word descriptor sets, each containing a link pointer and an address.
• 1D DMA – uses a linked list of 4 word descriptor sets containing a link pointer, an address, a length, and a
configuration.
• 2D DMA – uses an array of one-word descriptor sets, specifying only the base DMA address.
• 2D DMA – uses a linked list of multi-word descriptor sets,
specifying everything.
CRC Protection
The two CRC protection modules allow system software to periodically calculate the signature of code and/or data in memory,
the content of memory-mapped registers, or communication
message objects. Dedicated hardware circuitry compares the
signature with pre calculated values and triggers appropriate
fault events.
For example, every 100 ms the system software might initiate
the signature calculation of the entire memory contents and
compare these contents with expected, pre calculated values. If a
mismatch occurs, a fault condition can be generated (via the
processor core or the trigger routing unit).
The CRC is a hardware module based on a CRC32 engine that
computes the CRC value of the 32-bit data words presented to
it. Data is provided by the source channel of the memory-tomemory DMA (in memory scan mode) and is optionally forwarded to the destination channel (memory transfer mode).
The main features of the CRC peripheral are:
•Memory scan mode
•Memory transfer mode
•Data verify mode
• Data fill mode
• User-programmable CRC32 polynomial
• Bit/byte mirroring option (endianness)
• Fault/error interrupt mechanisms
• 1D and 2D fill block to initialize array with constants.
• 32-bit CRC signature of a block of a memory or MMR
block.
Rev. PrD | Page 5 of 44 | March 2012

ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609 Preliminary Technical Data
Event Handling
The processor provides event handling that supports both nesting and prioritization. Nesting allows multiple event service
routines to be active simultaneously. Prioritization ensures that
servicing of a higher-priority event takes precedence over servicing of a lower-priority event. The processor provides support
for five different types of events:
• Emulation – An emulation event causes the processor to
enter emulation mode, allowing command and control of
the processor via the JTAG interface.
• Reset – This event resets the processor.
• Nonmaskable Interrupt (NMI) – The NMI event can be
generated either by the software watchdog timer, by the
input signal to the processor, or by software. The
NMI
NMI event is frequently used as a power-down indicator to
initiate an orderly shutdown of the system.
• Exceptions – Events that occur synchronously to program
flow (in other words, the exception is taken before the
instruction is allowed to complete). Conditions such as
data alignment violations and undefined instructions cause
exceptions.
• Interrupts – Events that occur asynchronously to program
flow. They are caused by input signals, timers, and other
peripherals, as well as by an explicit software instruction.
Core Event Controller (CEC)
The CEC supports nine general-purpose interrupts (IVG15–7),
in addition to the dedicated interrupt and exception events. Of
these general-purpose interrupts, the two lowest-priority
interrupts (IVG15–14) are recommended to be reserved for
software interrupt handlers. For more information, see the
ADSP-BF60x Processor Programmer’s Reference.
System Event Controller (SEC)
The SEC manages the enabling, prioritization, and routing of
events from each system interrupt or fault source. Additionally,
it provides notification and identification of the highest priority
active system interrupt request to each core and routes system
fault sources to its integrated fault management unit.
Trigger Routing Unit (TRU)
The TRU provides system-level sequence control without core
intervention. The TRU maps trigger masters (generators of triggers) to trigger slaves (receivers of triggers). Slave endpoints can
be configured to respond to triggers in various ways. Common
applications enabled by the TRU include:
• Automatically triggering the start of a DMA sequence after
a sequence from another DMA channel completes
•Software triggering
• Synchronization of concurrent activities
Pin Interrupts
Every port pin on the processor can request interrupts in either
an edge-sensitive or a level-sensitive manner with programmable polarity. Interrupt functionality is decoupled from GPIO
operation. Six system-level interrupt channels (PINT0–5) are
reserved for this purpose. Each of these interrupt channels can
manage up to 32 interrupt pins. The assignment from pin to
interrupt is not performed on a pin-by-pin basis. Rather, groups
of eight pins (half ports) can be flexibly assigned to interrupt
channels.
Every pin interrupt channel features a special set of 32-bit memory-mapped registers that enable half-port assignment and
interrupt management. This includes masking, identification,
and clearing of requests. These registers also enable access to the
respective pin states and use of the interrupt latches, regardless
of whether the interrupt is masked or not. Most control registers
feature multiple MMR address entries to write-one-to-set or
write-one-to-clear them individually.
General-Purpose I/O (GPIO)
Each general-purpose port pin can be individually controlled by
manipulation of the port control, status, and interrupt registers:
• GPIO direction control register – Specifies the direction of
each individual GPIO pin as input or output.
• GPIO control and status registers – A “write one to modify” mechanism allows any combination of individual
GPIO pins to be modified in a single instruction, without
affecting the level of any other GPIO pins.
• GPIO interrupt mask registers – Allow each individual
GPIO pin to function as an interrupt to the processor.
GPIO pins defined as inputs can be configured to generate
hardware interrupts, while output pins can be triggered by
software interrupts.
• GPIO interrupt sensitivity registers – Specify whether individual pins are level- or edge-sensitive and specify—if
edge-sensitive—whether just the rising edge or both the rising and falling edges of the signal are significant.
Pin Multiplexing
The processor supports a flexible multiplexing scheme that multiplexes the GPIO pins with various peripherals. A maximum of
4 peripherals plus GPIO functionality is shared by each GPIO
pin. All GPIO pins have a bypass path feature – that is, when the
output enable and the input enable of a GPIO pin are both
active, the data signal before the pad driver is looped back to the
receive path for the same GPIO pin. For more information, see
Pin Multiplexing on Page 20.
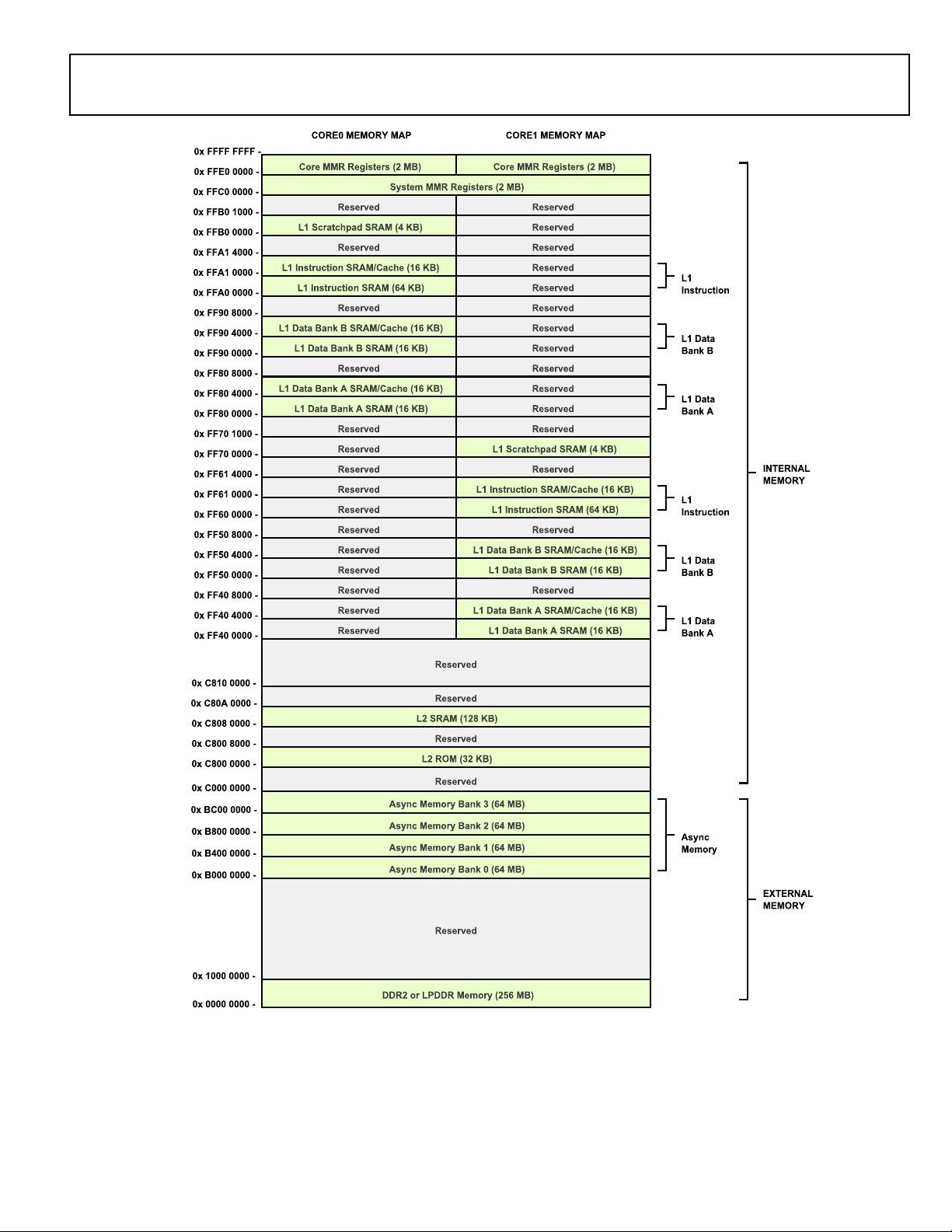
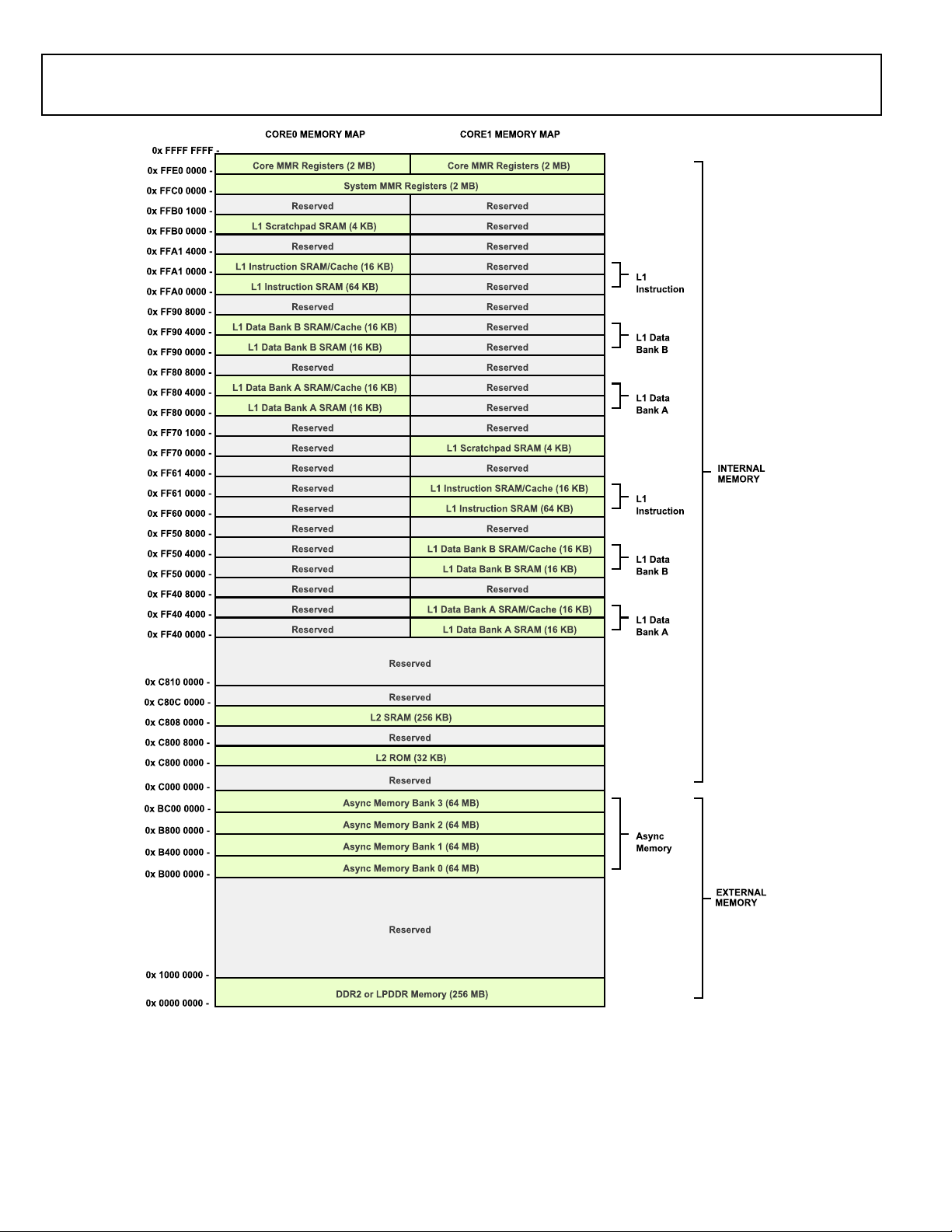
MEMORY ARCHITECTURE
The ADSP-BF609 processor views memory as a single unified
4G byte address space, using 32-bit addresses. All resources,
including internal memory, external memory, and I/O control
registers, occupy separate sections of this common address
space. The memory portions of this address space are arranged
in a hierarchical structure to provide a good cost/performance
balance of some very fast, low-latency core-accessible memory
as cache or SRAM, and larger, lower-cost and performance
interface-accessible memory systems. See Figure 3 and Figure 4.
Rev. PrD | Page 6 of 44 | March 2012
Preliminary Technical Data
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609
Figure 3. ADSP-BF606 Internal/External Memory Map
Rev. PrD | Page 7 of 44 | March 2012
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609 Preliminary Technical Data
Figure 4. ADSP-BF607/ADSP-BF608/ADSP-BF609 Internal/External Memory Map
Rev. PrD | Page 8 of 44 | March 2012

Preliminary Technical Data
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609
Internal (Core-Accessible) Memory
The L1 memory system is the highest-performance memory
available to the Blackfin processor cores.
Each core has its own private L1 memory. The modified Harvard architecture supports two concurrent 32-bit data accesses
along with an instruction fetch at full processor speed which
provides high bandwidth processor performance. Two separate
64K-byte of data memory blocks partner with an 80K-byte
memory block for instruction storage. Each block is multibanked for efficient data exchange through DMA and can be
configured as SRAM. Alternatively, 16K bytes of each block can
be configured in L1 cache mode. The four-way set-associative
instruction cache and the 2 two-way set-associative data caches
greatly accelerate memory access performance, especially when
accessing external memories.
The L1 memory domain also features a 4K-byte scratchpad
SRAM block which is ideal for storing local variables and the
software stack. All L1 memory is protected by a multi-parity bit
concept, regardless of whether the memory is operating in
SRAM or cache mode.
Outside of the L1 domain, L2 and L3 memories are arranged
using a Von Neumann topology. The L2 memory domain is a
unified instruction and data memory and can hold any mixture
of code and data required by the system design. The L2 memory
domain is accessible by both Blackfin cores through a dedicated
64-bit interface. It operates at half the frequency of the cores.
The processor features up to 256K bytes of L2 SRAM which is
ECC-protected and organized in eight banks. Individual banks
can be made private to any of the cores or the DMA subsystem.
There is also a 32K-byte single-bank ROM in the L2 domain. It
contains boot code and safety functions.
Static Memory Controller (SMC)
The SMC can be programmed to control up to four banks of
external memories or memory-mapped devices, with very flexible timing parameters. Each bank occupies a 64M byte segment
regardless of the size of the device used, so that these banks are
only contiguous if each is fully populated with 64M bytes of
memory.
Dynamic Memory Controller (DMC)
The DMC includes a controller that supports JESD79-2E compatible double data rate (DDR2) SDRAM and JESD209A low
power DDR (LPDDR) SDRAM devices.
I/O Memory Space
The processor does not define a separate I/O space. All
resources are mapped through the flat 32-bit address space. Onchip I/O devices have their control registers mapped into memory-mapped registers (MMRs) at addresses near the top of the
4G byte address space. These are separated into two smaller
blocks, one which contains the control MMRs for all core functions, and the other which contains the registers needed for
setup and control of the on-chip peripherals outside of the core.
The MMRs are accessible only in supervisor mode and appear
as reserved space to on-chip peripherals.
Booting
The processor has several mechanisms for automatically loading
internal and external memory after a reset. The boot mode is
defined by the SYS_BMODE input pins dedicated for this purpose. There are two categories of boot modes. In master boot
modes, the processor actively loads data from parallel or serial
memories. In slave boot modes, the processor receives data
from external host devices.
The boot modes are shown in Table 2. These modes are implemented by the SYS_BMODE bits of the reset configuration
register and are sampled during power-on resets and softwareinitiated resets.
Table 2. Boot Modes
SYS_BMODE Setting Boot Mode
000 No boot/Idle
001 Memory
010 RSI0 Master
011 SPI0 Master
100 SPI0 Slave
101 Reserved
110 LP0 Slave
111 UART0 Slave
VIDEO SUBSYSTEM
The following sections describe the components of the processor’s video subsystem. These blocks are shown with blue
shading in Figure 1 on Page 1.
Video Interconnect (VID)
The Video Interconnect provides a connectivity matrix that
interconnects the Video Subsystem: three PPIs, the PIXC, and
the PVP. The interconnect uses a protocol to manage data
transfer among these video peripherals.
Pipelined Vision Processor (PVP)
The PVP engine provides hardware implementation of signal
and image processing algorithms that are required for
co-processing and pre-processing of monochrome video frames
in ADAS applications, robotic systems, and other machine
applications.
The PVP works in conjunction with the Blackfin cores. It is
optimized for convolution and wavelet based object detection
and classification, and tracking and verification algorithms. The
PVP has the following processing blocks.
• Four 5x5 16-bit convolution blocks optionally followed by
down scaling
• A 16-bit cartesian-to-polar coordinate conversion block
• A pixel edge classifier that supports 1st and 2nd derivative
modes
• An arithmetic unit with 32-bit addition, multiply and
divide
Rev. PrD | Page 9 of 44 | March 2012

ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609 Preliminary Technical Data
• A 32-bit threshold block with 16 thresholds, a histogram,
and run-length encoding
• Two 32-bit integral blocks that support regular and diagonal integrals
• An up- and down-scaling unit with independent scaling
ratios for horizontal and vertical components
• Input and output formatters for compatibility with many
data formats, including Bayer input format
The PVP can form a pipe of all the constituent algorithmic
modules and is dynamically reconfigurable to form different
pipeline structures.
The PVP supports the simultaneous processing of up to four
data streams. The memory pipe stream operates on data
received by DMA from any L1, L2, or L3 memory. The three
camera pipe streams operate on a common input received
directly from any of the three PPI inputs. Optionally, the PIXC
can convert color data received by the PPI and forward luma
values to the PVP’s monochrome engine. Each stream has a
dedicated DMA output. This preprocessing concept ensures
careful use of available power and bandwidth budgets and frees
up the processor cores for other tasks.
The PVP provides for direct core MMR access to all control/status registers. Two hardware interrupts interface to the system
event controller. For optimal performance, the PVP allows register programming through its control DMA interface, as well as
outputting selected status registers through the status DMA
interface. This mechanism enables the PVP to automatically
process job lists completely independent of the Blackfin cores.
Pixel Compositor (PIXC)
The pixel compositor (PIXC) provides image overlays with
transparent-color support, alpha blending, and color space conversion capabilities for output to TFT LCDs and NTSC/PAL
video encoders. It provides all of the control to allow two data
streams from two separate data buffers to be combined,
blended, and converted into appropriate forms for both LCD
panels and digital video outputs. The main image buffer provides the basic background image, which is presented in the
data stream. The overlay image buffer allows the user to add
multiple foreground text, graphics, or video objects on top of
the main image or video data stream.
Parallel Peripheral Interface (PPI)
The processor provides up to three parallel peripheral interfaces
(PPIs), supporting data widths up to 24 bits. The PPI supports
direct connection to TFT LCD panels, parallel analog-to-digital
and digital-to-analog converters, video encoders and decoders,
image sensor modules and other general-purpose peripherals.
The following features are supported in the PPI module:
• Programmable data length: 8 bits, 10 bits, 12 bits, 14 bits,
16 bits, 18 bits, and 24 bits per clock.
• Various framed, non-framed, and general-purpose operating modes. Frame syncs can be generated internally or can
be supplied by an external device.
• ITU-656 status word error detection and correction for
ITU-656 receive modes and ITU-656 preamble and status
word decode.
• Optional packing and unpacking of data to/from 32 bits
from/to 8 bits, 16 bits and 24 bits. If packing/unpacking is
enabled, endianness can be configured to change the order
of packing/unpacking of bytes/words.
• RGB888 can be converted to RGB666 or RGB565 for transmit modes.
•Various de-interleaving/interleaving modes for receiving/transmitting 4:2:2 YCrCb data.
•Configurable LCD data enable (DEN) output available on
Frame Sync 3.
PROCESSOR SAFETY FEATURES
The ADSP-BF609 processor has been designed for functional
safety applications. While the level of safety is mainly dominated by the system concept, the following primitives are
provided by the devices to build a robust safety concept.
Dual Core Supervision
The processor has been implemented as dual-core devices to
separate critical tasks to large independency. Software models
support mutual supervision of the cores in symmetrical fashion.
Multi-Parity-Bit-Protected L1 Memories
In the processor’s L1 memory space, whether SRAM or cache,
each word is protected by multiple parity bits to detect the single
event upsets that occur in all RAMs. This applies both to L1
instruction and data memory spaces.
ECC-Protected L2 Memories
Error correcting codes (ECC) are used to correct single event
upsets. The L2 memory is protected with a Single Error CorrectDouble Error Detect (SEC-DED) code. By default ECC is
enabled, but it can be disabled on a per-bank basis. Single-bit
errors are transparently corrected. Dual-bit errors can issue a
system event or fault if enabled. ECC protection is fully transparent to the user, even if L2 memory is read or written by 8-bit
or 16-bit entities.
CRC-Protected Memories
While parity bit and ECC protection mainly protect against random soft errors in L1 and L2 memory cells, the CRC engines can
be used to protect against systematic errors (pointer errors) and
static content (instruction code) of L1, L2 and even L3 memories (DDR2, LPDDR). The processors feature two CRC engines
which are embedded in the memory-to-memory DMA controllers. CRC check sums can be calculated or compared on the fly
during memory transfers, or one or multiple memory regions
can be continuously scrubbed by single DMA work unit as per
DMA descriptor chain instructions. The CRC engine also protects data loaded during the boot process.
Rev. PrD | Page 10 of 44 | March 2012

Preliminary Technical Data
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609
Memory Protection
The Blackfin cores feature a memory protection concept, which
grants data and/or instruction accesses from enabled memory
regions only. A supervisor mode vs. user mode programming
model supports dynamically varying access rights. Increased
flexibility in memory page size options supports a simple
method of static memory partitioning.
System Protection
All system resources and L2 memory banks can be controlled by
either the processor cores, memory-to-memory DMA, or the
system debug unit (SDU). A system protection unit (SPU)
enables write accesses to specific resources that are locked to
any of four masters: Core 0, Core 1, Memory DMA, and the System Debug Unit. System protection is enabled in greater
granularity for some modules (L2, SEC and GPIO controllers)
through a global lock concept.
Watchpoint Protection
The primary purpose of watchpoints and hardware breakpoints
is to serve emulator needs. When enabled, they signal an emulator event whenever user-defined system resources are accessed
or a core executes from user-defined addresses. Watchdog
events can be configured such that they signal the events to the
other Blackfin core or to the fault management unit.
Dual Watchdog
The two on-chip watchdog timers each may supervise one
Blackfin core.
Bandwidth Monitor
All DMA channels that operate in memory-to-memory mode
(Memory DMA, PVP Memory Pipe DMA, PIXC DMA) are
equipped with a bandwidth monitor mechanism. They can signal a system event or fault when transactions tend to starve
because system buses are fully loaded with higher-priority
traffic.
Signal Watchdogs
The eight general-purpose timers feature two new modes to
monitor off-chip signals. The Watchdog Period mode monitors
whether external signals toggle with a period within an expected
range. The Watchdog Width mode monitors whether the pulse
widths of external signals are in an expected range. Both modes
help to detect incorrect undesired toggling (or lack thereof) of
system-level signals.
Up/Down Count Mismatch Detection
The up/down counter can monitor external signal pairs, such as
request/grant strobes. If the edge count mismatch exceeds the
expected range, the up/down counter can flag this to the processor or to the fault management unit.
Fault Management
The fault management unit is part of the system event controller
(SEC). Any system event, whether a dual-bit uncorrectable ECC
error, or any peripheral status interrupt, can be defined as being
a “fault”. Additionally, the system events can be defined as an
interrupt to the cores. If defined as such, the SEC forwards the
event to the fault management unit which may automatically
reset the entire device for reboot, or simply toggle the
SYS_FAULT output pins to signal off-chip hardware. Optionally, the fault management unit can delay the action taken via a
keyed sequence, to provide a final chance for the Blackfin cores
to resolve the crisis and to prevent the fault action from being
taken.
ADDITIONAL PROCESSOR PERIPHERALS
The processor contains a rich set of peripherals connected to the
core via several high-bandwidth buses, providing flexibility in
system configuration as well as excellent overall system performance (see the block diagram on Page 1). The processors
contain high-speed serial and parallel ports, an interrupt controller for flexible management of interrupts from the on-chip
peripherals or external sources, and power management control
functions to tailor the performance and power characteristics of
the processor and system to many application scenarios.
The following sections describe additional peripherals that were
not described in the previous sections.
Timers
The processor includes several timers which are described in the
following sections.
General-Purpose Timers
There is one GP timer unit and it provides eight general-purpose programmable timers. Each timer has an external pin that
can be configured either as a pulse width modulator (PWM) or
timer output, as an input to clock the timer, or as a mechanism
for measuring pulse widths and periods of external events.
These timers can be synchronized to an external clock input on
the TMRx pins, an external clock TMRCLK input pin, or to the
internal SCLK0.
The timer units can be used in conjunction with the UARTs and
the CAN controller to measure the width of the pulses in the
data stream to provide a software auto-baud detect function for
the respective serial channels.
The timers can generate interrupts to the processor core, providing periodic events for synchronization to either the system
clock or to external signals. Timer events can also trigger other
peripherals via the TRU (for instance, to signal a fault).
Core Timers
Each processor core also has its own dedicated timer. This extra
timer is clocked by the internal processor clock and is typically
used as a system tick clock for generating periodic operating
system interrupts.
Watchd o g Ti m er s
Each core includes a 32-bit timer, which may be used to implement a software watchdog function. A software watchdog can
improve system availability by forcing the processor to a known
state, via generation of a hardware reset, nonmaskable interrupt
(NMI), or general-purpose interrupt, if the timer expires before
Rev. PrD | Page 11 of 44 | March 2012
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609 Preliminary Technical Data
SPORTx
SPT_AD1
SPT_AD0
SPT_CLK
SPT_FS
ADC
D
OUT
B
D
OUT
A
ADSCLK
CS
RANGE
SGL/DIFF
A[2:0]
ACM
ACM_FS
ACM_CLK
ACM_A4
ACM_A3
ACM_A[2:0]
ADSP-BF60x
SPORT
SELECT
MUX
being reset by software. The programmer initializes the count
value of the timer, enables the appropriate interrupt, then
enables the timer. Thereafter, the software must reload the
counter before it counts to zero from the programmed value.
This protects the system from remaining in an unknown state
where software, which would normally reset the timer, has
stopped running due to an external noise condition or software
error.
After a reset, software can determine if the watchdog was the
source of the hardware reset by interrogating a status bit in the
timer control register, which is set only upon a watchdog generated reset.
3-Phase PWM Units
The two 3-phase PWM generation units each feature:
• 16-bit center-based PWM generation unit
•Programmable PWM pulse width
• Single/double update modes
• Programmable dead time and switching frequency
• Twos-complement implementation which permits smooth
transition to full ON and full OFF states
• Dedicated asynchronous PWM shutdown signal
Each PWM block integrates a flexible and programmable
3-phase PWM waveform generator that can be programmed to
generate the required switching patterns to drive a 3-phase voltage source inverter for ac induction motor (ACIM) or
permanent magnet synchronous motor (PMSM) control. In
addition, the PWM block contains special functions that considerably simplify the generation of the required PWM
switching patterns for control of the electronically commutated
motor (ECM) or brushless dc motor (BDCM). Software can
enable a special mode for switched reluctance motors (SRM).
The eight PWM output signals (per PWM unit) consist of four
high-side drive signals and four low-side drive signals. The
polarity of a generated PWM signal can be set with software, so
that either active HI or active LO PWM patterns can be
produced.
Pulses synchronous to the switching frequency can be generated
internally and output on the PWM_SYNC pin. The PWM unit
can also accept externally generated synchronization pulses
through PWM_SYNC.
Each PWM unit features a dedicated asynchronous shutdown
pin which (when brought low) instantaneously places all six
PWM outputs in the OFF state.
Link Ports
Four DMA-enabled, 8-bit-wide link ports can connect to the
link ports of other DSPs or processors. Link ports are bidirectional ports having eight data lines, an acknowledge line and a
clock line.
Serial Ports (SPORTs)
Three synchronous serial ports that provide an inexpensive
interface to a wide variety of digital and mixed-signal peripheral
devices such as Analog Devices’ AD183x family of audio codecs,
ADCs, and DACs. The serial ports are made up of two data
lines, a clock, and frame sync. The data lines can be programmed to either transmit or receive and each data line has a
dedicated DMA channel.
Serial port data can be automatically transferred to and from
on-chip memory/external memory via dedicated DMA channels. Each of the serial ports can work in conjunction with
another serial port to provide TDM support. In this configuration, one SPORT provides two transmit signals while the other
SPORT provides the two receive signals. The frame sync and
clock are shared.
Serial ports operate in five modes:
• Standard DSP serial mode
•Multichannel (TDM) mode
2
S mode
•I
•Packed I
• Left-justified mode
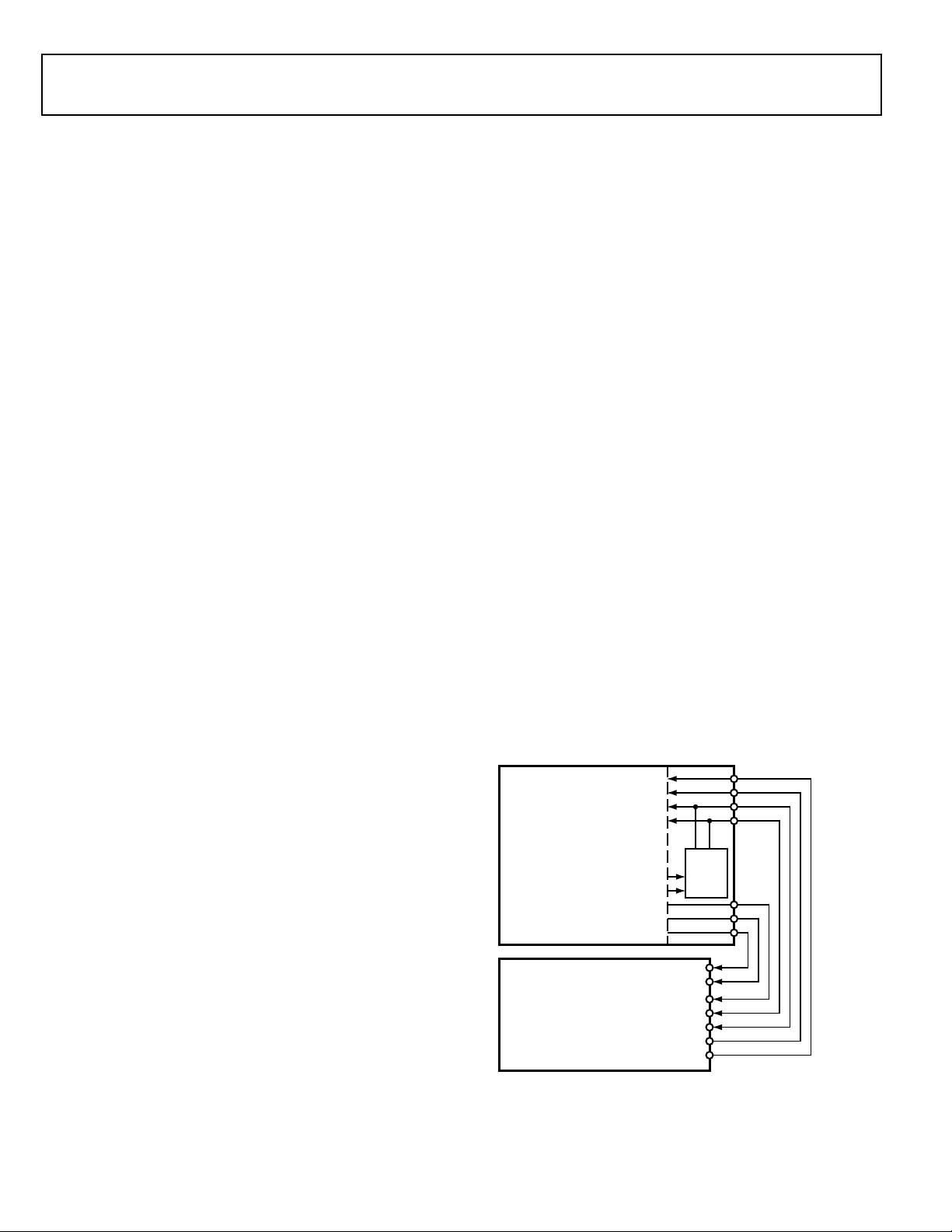
ACM Interface
The ADC control module (ACM) provides an interface that
synchronizes the controls between the processor and an analogto-digital converter (ADC). The analog-to-digital conversions
are initiated by the processor, based on external or internal
events.
The ACM allows for flexible scheduling of sampling instants
and provides precise sampling signals to the ADC.
Figure 5 shows how to connect an external ADC to the ACM
and one of the SPORTs.
Rev. PrD | Page 12 of 44 | March 2012
2
S mode
Figure 5. ADC, ACM, and SPORT Connections

Preliminary Technical Data
ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609
The ACM synchronizes the ADC conversion process, generating the ADC controls, the ADC conversion start signal, and
other signals. The actual data acquisition from the ADC is done
by a peripheral such as a SPORT or a SPI.
The processor interfaces directly to many ADCs without any
glue logic required.
General-Purpose Counters
A 32-bit counter is provided that can operate in general-purpose up/down count modes and can sense 2-bit quadrature or
binary codes as typically emitted by industrial drives or manual
thumbwheels. Count direction is either controlled by a levelsensitive input pin or by two edge detectors.
A third counter input can provide flexible zero marker support
and can alternatively be used to input the push-button signal of
thumb wheels. All three pins have a programmable debouncing
circuit.
Internal signals forwarded to each general-purpose timer enable
these timers to measure the intervals between count events.
Boundary registers enable auto-zero operation or simple system
warning by interrupts when programmable count values are
exceeded.
Serial Peripheral Interface (SPI) Ports
The processors have two SPI-compatible ports that allow the
processor to communicate with multiple SPI-compatible
devices.
In its simplest mode, the SPI interface uses three pins for transferring data: two data pins (Master Output-Slave Input, MOSI,
and Master Input-Slave Output, MISO) and a clock pin (serial
clock, SCK). An SPI chip select input pin (SPISS
devices select the processor, and seven SPI chip select output
pins (SPISEL7–1
SPI select pins are reconfigured general-purpose I/O pins. Using
these pins, the SPI port provides a full-duplex, synchronous
serial interface, which supports both master/slave modes and
multimaster environments.
The SPI port’s baud rate and clock phase/polarities are programmable, and it has integrated DMA channels for both
transmit and receive data streams.
) let the processor select other SPI devices. The
) lets other SPI
UART Ports
The processors provide two full-duplex universal asynchronous
receiver/transmitter (UART) ports, which are fully compatible
with PC-standard UARTs. Each UART port provides a simplified UART interface to other peripherals or hosts, supporting
full-duplex, DMA-supported, asynchronous transfers of serial
data. A UART port includes support for five to eight data bits,
and none, even, or odd parity. Optionally, an additional address
bit can be transferred to interrupt only addressed nodes in
multi-drop bus (MDB) systems. A frame is terminates by one,
one and a half, two or two and a half stop bits.
The UART ports support automatic hardware flow control
through the Clear To Send (CTS) input and Request To Send
(RTS) output with programmable assertion FIFO levels.
To help support the Local Interconnect Network (LIN) protocols, a special command causes the transmitter to queue a break
command of programmable bit length into the transmit buffer.
Similarly, the number of stop bits can be extended by a programmable inter-frame space.
The capabilities of the UARTs are further extended with support for the Infrared Data Association (IrDA®) serial infrared
physical layer link specification (SIR) protocol.
TWI Controller Interface
The processors include a 2-wire interface (TWI) module for
providing a simple exchange method of control data between
multiple devices. The TWI module is compatible with the
widely used I
capabilities of simultaneous master and slave operation and
support for both 7-bit addressing and multimedia data arbitration. The TWI interface utilizes two pins for transferring clock
(TWI_SCL) and data (TWI_SDA) and supports the protocol at
speeds up to 400k bits/sec. The TWI interface pins are compatible with 5 V logic levels.
Additionally, the TWI module is fully compatible with serial
camera control bus (SCCB) functionality for easier control of
various CMOS camera sensor devices.
2
C bus standard. The TWI module offers the
Removable Storage Interface (RSI)
The removable storage interface (RSI) controller acts as the host
interface for multimedia cards (MMC), secure digital memory
cards (SD), secure digital input/output cards (SDIO), and CEATA hard disk drives. The following list describes the main features of the RSI controller.
• Support for a single MMC, SD memory, SDIO card or CEATA hard disk drive
• Support for 1-bit and 4-bit SD modes
• Support for 1-bit, 4-bit, and 8-bit MMC modes
• Support for 4-bit and 8-bit CE-ATA hard disk drives
• Support for eMMC 4.3 embedded NAND flash devices
• A ten-signal external interface with clock, command, and
up to eight data lines
• Card interface clock generation from SCLK0
• SDIO interrupt and read wait features
• CE-ATA command completion signal recognition and
disable
Controller Area Network (CAN)
A CAN controller implements the CAN 2.0B (active) protocol.
This protocol is an asynchronous communications protocol
used in both industrial and automotive control systems. The
CAN protocol is well suited for control applications due to its
capability to communicate reliably over a network. This is
because the protocol incorporates CRC checking, message error
tracking, and fault node confinement.
Rev. PrD | Page 13 of 44 | March 2012

ADSP-BF606/ADSP-BF607/ADSP-BF608/ADSP-BF609 Preliminary Technical Data
The CAN controller offers the following features:
• 32 mailboxes (8 receive only, 8 transmit only, 16 configurable for receive or transmit).
• Dedicated acceptance masks for each mailbox.
• Additional data filtering on first two bytes.
• Support for both the standard (11-bit) and extended (29bit) identifier (ID) message formats.
• Support for remote frames.
• Active or passive network support.
• CAN wakeup from hibernation mode (lowest static power
consumption mode).
• Interrupts, including: TX complete, RX complete, error
and global.
An additional crystal is not required to supply the CAN clock, as
the CAN clock is derived from a system clock through a programmable divider.
10/100 Ethernet MAC
The processor can directly connect to a network by way of an
embedded fast Ethernet media access controller (MAC) that
supports both 10-BaseT (10M bits/sec) and 100-BaseT (100M
bits/sec) operation. The 10/100 Ethernet MAC peripheral on the
processor is fully compliant to the IEEE 802.3-2002 standard
and it provides programmable features designed to minimize
supervision, bus use, or message processing by the rest of the
processor system.
Some standard features are:
• Support and RMII protocols for external PHYs
• Full duplex and half duplex modes
• Media access management (in half-duplex operation)
• Flow control
• Station management: generation of MDC/MDIO frames
for read-write access to PHY registers
Some advanced features are:
• Automatic checksum computation of IP header and IP
payload fields of Rx frames
• Independent 32-bit descriptor-driven receive and transmit
DMA channels
• Frame status delivery to memory through DMA, including
frame completion semaphores for efficient buffer queue
management in software
• Tx DMA support for separate descriptors for MAC header
and payload to eliminate buffer copy operations
• Convenient frame alignment modes
• 47 MAC management statistics counters with selectable
clear-on-read behavior and programmable interrupts on
half maximum value
• Advanced power management
• Magic packet detection and wakeup frame filtering
• Support for 802.3Q tagged VLAN frames
• Programmable MDC clock rate and preamble suppression
IEEE 1588 Support
The IEEE 1588 standard is a precision clock synchronization
protocol for networked measurement and control systems. The
processor includes hardware support for IEEE 1588 with an
integrated precision time protocol synchronization engine
(PTP_TSYNC). This engine provides hardware assisted time
stamping to improve the accuracy of clock synchronization
between PTP nodes. The main features of the engine are:
• Support for both IEEE 1588-2002 and IEEE 1588-2008 protocol standards
• Hardware assisted time stamping capable of up to 12.5 ns
resolution
• Lock adjustment
• Automatic detection of IPv4 and IPv6 packets, as well as
PTP messages
• Multiple input clock sources (SCLK0, RMII clock, external
clock)
• Programmable pulse per second (PPS) output
• Auxiliary snapshot to time stamp external events
USB 2.0 On-the-Go Dual-Role Device Controller
The USB 2.0 OTG dual-role device controller provides a lowcost connectivity solution for the growing adoption of this bus
standard in industrial applications, as well as consumer mobile
devices such as cell phones, digital still cameras, and MP3 players. The USB 2.0 controller allows these devices to transfer data
using a point-to-point USB connection without the need for a
PC host. The module can operate in a traditional USB peripheral-only mode as well as the host mode presented in the Onthe-Go (OTG) supplement to the USB 2.0 specification.
The USB clock (USB_CLKIN) is provided through a dedicated
external crystal or crystal oscillator.
The USB On-the-Go dual-role device controller includes a
Phase Locked Loop with programmable multipliers to generate
the necessary internal clocking frequency for USB.
POWER AND CLOCK MANAGEMENT
The processor provides four operating modes, each with a different performance/power profile. When configured for a 0 volt
internal supply voltage (V
nate state. Control of clocking to each of the processor
peripherals also reduces power consumption. See Table 5 for a
summary of the power settings for each mode.
Crystal Oscillator (SYS_XTAL)
The processor can be clocked by an external crystal, (Figure 6) a
sine wave input, or a buffered, shaped clock derived from an
external clock oscillator. If an external clock is used, it should be
a TTL compatible signal and must not be halted, changed, or
operated below the specified frequency during normal operation. This signal is connected to the processor’s SYS_CLKIN
), the processor enters the hiber-
DD_INT
Rev. PrD | Page 14 of 44 | March 2012
 Loading...
Loading...