

Page 1

vFabric SQLFire User's Guide
VMware vFabric SQLFire 1.1
VMware vFabric Suite 5.3
This document supports the version of each product listed and
supports all subsequent versions until the document is replaced by
a new edition. To check for more recent editions of this document,
see http://www.vmware.com/support/pubs.
EN-001171-00
Page 2

You can find the most up-to-date technical documentation on the VMware Web site
at: http://www.vmware.com/support/
The VMware Web site also pro vides the latest product updates. If you hav e comments
about this documentation, submit your feedback to: docfeedback@vmware.com
Copyright © 2013 VMware, Inc. All rights reserved.This product is protected by U.S.
and international copyright and intellectual property laws.VMware products are
covered by one or more patents listed at http://www.vmware.com/go/patents
VMware is a registered trademark or trademark of VMw are , Inc. in the United States
and/or other jurisdictions. All other marks and names mentioned herein may be
trademarks of their respective companies.
VMware, Inc.
3401 Hillview Ave.
Palo Alto, CA 94304
Page 3

Contents
About the SQLFire User's Guide.................................................................................13
Supported Configurations and System Requirements.............................................15
Part I: Getting Started with vFabric SQLFire............................................1
vFabric SQLFire in 15 Minutes.....................................................................................................................2
Chapter 1: Overview of vFabric SQLFire..................................................7
Data Flow Diagram.......................................................................................................................................8
GemFire, Apache Derby, and SQL Components..........................................................................................8
Chapter 2: Understanding the SQLFire Distributed System.................11
vFabric SQLFire Members..........................................................................................................................11
Servers, Peer Clients, and Server Groups..................................................................................................12
Discovery Mechanisms...............................................................................................................................12
Group Membership Service........................................................................................................................12
Replicated Tables and Par titioned Tables...................................................................................................13
Parallel Execution of Data-Aware Stored Procedures.................................................................................13
Cache Plug-ins for External Data Connections..........................................................................................14
Chapter 3: Installing vFabric SQLFire.....................................................15
Installation Note for vFabr ic Suite Customers.............................................................................................15
RHEL Only: Install vFabric SQLFire from an RPM.....................................................................................15
Install vFabric SQLFire from a ZIP File.......................................................................................................19
Chapter 4: Activating vFabric SQLFire Licensing.................................21
Understand vFabric SQLFire License Options...........................................................................................21
Choose a License Option Based on Topology............................................................................................22
How vFabric SQLFire Manages Licensing..................................................................................................24
Install and Configure vFabric SQLFire Licenses.........................................................................................25
Ver ify Your License and Check Your License Usage...................................................................................26
Chapter 5: Upgrading vFabric SQLFire..................................................29
Before You Upgrade....................................................................................................................................29
RHEL: Upgrade vFabric SQLFire from RPM..............................................................................................30
Upgrade vFabric SQLFire from a ZIP File..................................................................................................31
Version Compatibility Rules........................................................................................................................32
Chapter 6: Connect to vFabric SQLFire with JDBC Tools.....................33
Chapter 7: Tutorials..................................................................................35
Main Steps..................................................................................................................................................35
iii
Page 4

Create a SQLFire Cluster...........................................................................................................................35
Connect to the Cluster Using SQLF...........................................................................................................37
Create Replicated Tables and Execute Quer ies.........................................................................................38
Implement a Partitioning Strategy...............................................................................................................39
Persist Tables to Disk..................................................................................................................................41
Add Servers to the Cluster and Stop Servers.............................................................................................43
Perfor m Additional Tasks............................................................................................................................44
Chapter 8: vFabric SQLFire Features and Benefits...............................45
Part II: Managing Your Data in vFabric SQLFire.....................................47
Chapter 9: Designing vFabric SQLFire Databases................................49
Design Principles of Scalable, Partition-Aware Databases.........................................................................49
Identify Entity Groups and Partitioning Keys...............................................................................................49
Replicate Code Tables................................................................................................................................50
Dealing with Many-to-Many Relationships..................................................................................................50
Example: Adapting a Database Schema for SQLFire.................................................................................51
Chapter 10: Using Server Groups to Manage Data................................55
Server Groups Overview.............................................................................................................................55
Adding Members to Server Groups............................................................................................................57
Assigning Tables to Server Groups.............................................................................................................58
Chapter 11: Partitioning Tables...............................................................59
How Table Par titioning Wor ks.....................................................................................................................59
Understanding Where Data Is Stored.........................................................................................................60
Failure and Redundancy.............................................................................................................................61
Creating Partitioned Tables.........................................................................................................................62
Rebalancing Partitioned Data on SQLFire Members..................................................................................66
Managing Replication Failures....................................................................................................................67
Chapter 12: Replicating Tables................................................................69
How SQLFire Replicates Tables.................................................................................................................69
Deciding When to Use Replicated Tables...................................................................................................69
Creating Replicated Tables.........................................................................................................................70
Chapter 13: Estimating Memory Requirements.....................................71
Estimating SQLFire Overhead....................................................................................................................71
Viewing Memory Usage in SYS.MEMORYANALYTICS..............................................................................72
Chapter 14: Using Disk Stores to Persist Data......................................77
Overview of Disk Stores..............................................................................................................................77
Guidelines for Designing Disk Stores.........................................................................................................83
Creating a Disk Store or Using the Default.................................................................................................84
vFabric SQLFire User's Guideiv
Page 5

Contents
Persist Table Data to a Disk Store...............................................................................................................84
Optimizing Availability and Performance.....................................................................................................85
Starting System with Disk Stores................................................................................................................85
Disk Store Management.............................................................................................................................87
Chapter 15: Expor ting and Importing Data with vFabric SQLFire.......97
Using SQLF Commands to Export and Impor t Data..................................................................................97
Using Apache DdlUtils to Import Data........................................................................................................99
Exporting and Importing Data from Text Files...........................................................................................102
Chapter 16:Using T able Functions to Import Data as a SQLFire T ables.103
Overview of SQLFire Table Functions.......................................................................................................103
Example Table Function............................................................................................................................105
Part III: Developing Applications with SQLFire....................................107
Chapter 17:Starting SQLFire Servers with the FabricServer Interface.109
Starting a Network Ser ver........................................................................................................................110
Chapter 18: Developing Java Clients and Peers..................................113
Connect to a SQLFire Server with the Thin Client JDBC Driver...............................................................113
Start a SQLFire Peer with the Peer Client JDBC Driver...........................................................................116
Chapter 19: Configuring SQLFire as a JDBC Datasource..................119
Chapter 20: Storing and Loading JAR Files in SQLFire......................121
Class Loading Overview...........................................................................................................................121
Alternate Methods for Managing JAR Files..............................................................................................123
Chapter 21: Developing ADO.NET Client Applications.......................127
About the ADO.NET Driver.......................................................................................................................127
ADO.NET Driver Classes..........................................................................................................................128
Installing and Using the ADO.NET driver..................................................................................................129
Connecting to SQLFire with the ADO.NET Driver....................................................................................129
Managing Connections.............................................................................................................................130
Executing SQL Commands.......................................................................................................................130
Working with Result Sets..........................................................................................................................131
Storing a Table..........................................................................................................................................132
Storing Multiple Tables..............................................................................................................................133
Specifying Command Parameters with SQLFParameter..........................................................................134
Updating Row Data...................................................................................................................................135
Adding Rows to a Table............................................................................................................................136
Managing SQLFire Transactions...............................................................................................................137
Perfor ming Batch Updates........................................................................................................................138
Generic Coding with the SQLFire ADO.NET Driver..................................................................................139
v
Page 6

Chapter 22: Using SQLFire.NET Designer...........................................143
Installing SQLFire.NET Designer..............................................................................................................143
Connecting to a SQLFire Distributed System...........................................................................................143
Editing Tables............................................................................................................................................144
Chapter 23: Understanding the Data Consistency Model...................145
Data Consistency Concepts.....................................................................................................................145
No Ordering Guarantee for DML in Separate Threads.............................................................................146
Updates on Any Row Are Atomic and Isolated.........................................................................................146
Atomicity for Bulk Updates........................................................................................................................146
Chapter 24: Using Distributed Transactions in Your Applications.....147
Overview of SQLFire Distributed Transactions.........................................................................................147
Sequence of Events for a Distributed Transaction....................................................................................150
SQLFire Transaction Design.....................................................................................................................151
Best Practices for Using Transactions.......................................................................................................151
Transaction Functionality and Limitations.................................................................................................152
Chapter 25: Using Data-Aware Stored Procedures.............................153
Configuring a Procedure...........................................................................................................................153
Configuring a Custom Result Processor...................................................................................................154
Invoking a Procedure................................................................................................................................155
Example JDBC Client...............................................................................................................................156
Chapter 26: Using the Procedure Provider API....................................159
Procedure Parameters..............................................................................................................................159
Populating OUT and INOUT Parameters..................................................................................................160
Populating Result Sets..............................................................................................................................160
Using the <local> and <global> Escape Syntax with Nested Queries......................................................162
Chapter 27: Using the Custom Result Processor API.........................163
Implementing the ProcedureResultProcessor Interface ..........................................................................163
Example Result Processor: MergeSort.....................................................................................................163
Chapter 28: Programming User-Defined Types....................................167
Chapter 29: Using Result Sets and Cursors........................................171
Non-updatable, Forward-Only Result Sets...............................................................................................171
Updatable Result Sets..............................................................................................................................172
Scrollable Insensitive Result Sets.............................................................................................................177
Result Sets and Autocommit.....................................................................................................................178
Part IV: Caching Data with vFabric SQLFire.........................................179
vFabric SQLFire User's Guidevi
Page 7

Contents
Chapter 30: SQLFire Cache Strategies.................................................181
Chapter 31: Using a RowLoader to Load Existing Data......................183
How SQLFire Invokes a RowLoader.........................................................................................................183
Implementing the RowLoader Interface....................................................................................................184
Using the JDBCRowLoader Example.......................................................................................................184
Chapter 32: Evicting Table Data from SQLFire.....................................187
How LRU Eviction Works..........................................................................................................................187
Limitations of Eviction...............................................................................................................................187
Eviction in Partitioned Tables....................................................................................................................188
Create a Table with Eviction Settings........................................................................................................188
Chapter 33: Handling DML Events Synchronously.............................191
Writer and Listener Cache Plug-ins..........................................................................................................191
Example Writer Implementation................................................................................................................192
Example Listener Implementation............................................................................................................192
Chapter 34: Handling DML Events Asynchronously..........................193
How the AsyncEventListener Works.........................................................................................................193
Implementation Requirements..................................................................................................................193
Implementing an AsyncEventListener.......................................................................................................194
Chapter 35: Using DBSynchronizer to Apply DML to an RDBMS......199
How DBSynchronizer Works.....................................................................................................................199
Restrictions and Limitations......................................................................................................................200
Configuring DBSynchronizer....................................................................................................................201
Chapter 36:Suppressing Event Callbacks for a vFabric SQLFire Connection.205
Part V: Deploying vFabric SQLFire........................................................207
Chapter 37: SQLFire Deployment Models............................................209
Embedded Peer-to-Peer Deployment.......................................................................................................210
Client-Server Deployment.........................................................................................................................212
Multi-site Deployment...............................................................................................................................213
Chapter 38: Steps to Plan and Configure a Deployment....................217
Chapter 39: Configuring Discovery Mechanisms................................219
Using Locators..........................................................................................................................................219
Configure Multicast Discovery..................................................................................................................221
vii
Page 8

Chapter 40: Star ting and Configuring SQLFire Servers.....................223
Start and Stop SQLFire Ser vers Using sqlf..............................................................................................223
Specify the Server Working Directory.......................................................................................................224
Specify Client Connection Information......................................................................................................224
Define Server Groups...............................................................................................................................224
Execute SQL When You Start a Server.....................................................................................................225
Using Additional Boot Properties..............................................................................................................225
Chapter 41: Configuring Multi-site (WAN) Deployments.....................227
About Gateways........................................................................................................................................227
About High Availability for WAN Deployments..........................................................................................229
Limitations of Multi-Site Replication..........................................................................................................230
Prerequisites for WAN Replication............................................................................................................231
Steps to Configure a Multi-site Deployment..............................................................................................231
Chapter 42: Configuring Authentication and Authorization...............237
Configuring User Authentication...............................................................................................................237
User Names in Authentication and Authorization ....................................................................................245
Configuring User Authorization.................................................................................................................246
Configuring Network Encryption and Authentication with SSL/TLS..........................................................250
Part VI: Managing and Monitoring vFabric SQLFire............................255
Chapter 43: Configuring and Using SQLFire Log Files.......................257
Log Message Format................................................................................................................................257
Severity Levels..........................................................................................................................................257
Using java.util.logging.Logger for Application Log Messages...................................................................258
Using Trace Flags for Advanced Debugging.............................................................................................258
Chapter 44: Querying SQLFire System Tables and Indexes...............261
Getting Information About SQLFire Members..........................................................................................261
Getting Information About User Tables.....................................................................................................262
Chapter 45: Evaluating Query Plans and Query Statistics.................267
Capture a Query Plan for an Individual Statement...................................................................................267
Capture Query Plans for All Statements...................................................................................................268
Example Query Plan Analysis..................................................................................................................268
Query Plan Codes....................................................................................................................................271
Chapter 46: Overriding Optimizer Choices..........................................275
Chapter 47: Evaluating System and Application Performance..........279
Collecting System Statistics......................................................................................................................279
Collecting Application Statistics................................................................................................................280
vFabric SQLFire User's Guideviii
Page 9

Contents
Using VSD to Analyze Statistics...............................................................................................................280
Chapter 48: Using Java Management Extensions (JMX)....................291
Using a JMX Manager Node.....................................................................................................................291
Using a vFabric SQLFire JMX Agent........................................................................................................294
Chapter 49: Best Practices for Tuning Performance...........................307
Tune Application Logic..............................................................................................................................307
Reduce Distribution Overhead..................................................................................................................307
Reduce Overhead of Eviction to Disk.......................................................................................................308
Minimize Update Latency for Replicated Tables.......................................................................................308
Tune FabricServers...................................................................................................................................308
Tuning Disk I/O.........................................................................................................................................309
Running SQLFire in Virtualized Environments..........................................................................................310
Chapter 50:Detecting and Handling Network Segmentation ("Split Brain").311
Part VII: vFabric SQLFire Reference......................................................313
Chapter 51: Configuration Properties..................................................315
Chapter 52: JDBC API............................................................................351
Mapping java.sql.Types to SQL Types......................................................................................................351
java.sql.BatchUpdateException Class......................................................................................................352
java.sql.Connection Interface....................................................................................................................352
java.sql.DatabaseMetaData Interface.......................................................................................................353
java.sql.Driver Interface............................................................................................................................355
java.sql.DriverManager.getConnection Method........................................................................................355
java.sql.PreparedStatement Interface.......................................................................................................355
java.sql.ResultSet Interface......................................................................................................................357
java.sql.SavePoint Class...........................................................................................................................357
java.sql.SQLException Class....................................................................................................................357
java.sql.Statement Class..........................................................................................................................357
javax.sql.XADataSource...........................................................................................................................357
Chapter 53: sqlf Launcher Commands................................................359
sqlf backup................................................................................................................................................360
sqlf compact-all-disk-stores......................................................................................................................363
sqlf compact-disk-store.............................................................................................................................364
sqlf encrypt-password...............................................................................................................................365
sqlf install-jar.............................................................................................................................................365
sqlf list-missing-disk-stores.......................................................................................................................368
sqlf locator................................................................................................................................................369
sqlf Logging Support.................................................................................................................................374
sqlf merge-logs.........................................................................................................................................374
ix
Page 10

sqlf remove-jar..........................................................................................................................................375
sqlf replace-jar..........................................................................................................................................377
sqlf revoke-missing-disk-store...................................................................................................................379
sqlf server.................................................................................................................................................380
sqlf show-disk-store-metadata..................................................................................................................391
sqlf shut-down-all......................................................................................................................................392
sqlf stats....................................................................................................................................................393
sqlf upgrade-disk-store.............................................................................................................................397
sqlf validate-disk-store..............................................................................................................................398
sqlf version................................................................................................................................................398
sqlf write-data-dtd-to-file...........................................................................................................................399
sqlf write-data-to-db..................................................................................................................................401
sqlf write-data-to-xml................................................................................................................................405
sqlf write-schema-to-db............................................................................................................................409
sqlf write-schema-to-sql............................................................................................................................413
sqlf write-schema-to-xml...........................................................................................................................417
Chapter 54: sqlf Interactive Commands...............................................423
absolute ...................................................................................................................................................423
after last ...................................................................................................................................................424
async .......................................................................................................................................................425
autocommit ..............................................................................................................................................425
before first ................................................................................................................................................426
close ........................................................................................................................................................426
commit .....................................................................................................................................................427
connect ....................................................................................................................................................427
connect client ...........................................................................................................................................428
connect peer ............................................................................................................................................429
describe ...................................................................................................................................................429
disconnect ................................................................................................................................................430
driver ........................................................................................................................................................430
elapsedtime .............................................................................................................................................431
execute ....................................................................................................................................................432
exit ...........................................................................................................................................................433
first............................................................................................................................................................433
get scroll insensitive cursor.......................................................................................................................434
GetCurrentRowNumber ...........................................................................................................................436
help ..........................................................................................................................................................436
last ...........................................................................................................................................................436
LocalizedDisplay.......................................................................................................................................437
MaximumDisplayWidth.............................................................................................................................438
next...........................................................................................................................................................438
prepare ....................................................................................................................................................439
previous....................................................................................................................................................440
protocol.....................................................................................................................................................441
relative......................................................................................................................................................441
vFabric SQLFire User's Guidex
Page 11

Contents
remove......................................................................................................................................................442
rollback......................................................................................................................................................443
run.............................................................................................................................................................444
set connection...........................................................................................................................................444
show..........................................................................................................................................................445
wait for......................................................................................................................................................448
Chapter 55: SQLFire API........................................................................449
CredentialInitializer...................................................................................................................................450
UserAuthenticator.....................................................................................................................................450
Procedure Implementation Interfaces.......................................................................................................450
Procedure Result Processor Interfaces....................................................................................................452
Chapter 56: SQL Language Reference.................................................457
Keywords and Identifiers...........................................................................................................................457
SQL Statements.......................................................................................................................................458
SQL Queries.............................................................................................................................................517
SQL Clauses.............................................................................................................................................518
SQL Expressions......................................................................................................................................523
JOIN Operations.......................................................................................................................................536
Built-in Functions......................................................................................................................................538
Built-in System Procedures......................................................................................................................580
Data Types................................................................................................................................................604
SQL Standards Conformance...................................................................................................................615
Chapter 57: System Tables.....................................................................635
ASYNCEVENTLISTENERS.....................................................................................................................635
GATEWAYRECEIVERS............................................................................................................................636
GATEWAYSENDERS...............................................................................................................................637
INDEXES..................................................................................................................................................639
JARS.........................................................................................................................................................639
MEMBERS................................................................................................................................................639
MEMORYANALYTICS...............................................................................................................................641
STATEMENTPLANS.................................................................................................................................641
SYSALIASES............................................................................................................................................643
SYSCHECKS............................................................................................................................................644
SYSCOLPERMS......................................................................................................................................644
SYSCOLUMNS.........................................................................................................................................645
SYSCONGLOMERATES..........................................................................................................................647
SYSCONSTRAINTS.................................................................................................................................647
SYSDEPENDS.........................................................................................................................................648
SYSDISKSTORES....................................................................................................................................649
SYSFILES.................................................................................................................................................650
SYSFOREIGNKEYS.................................................................................................................................650
SYSKEYS.................................................................................................................................................651
SYSROLES...............................................................................................................................................651
xi
Page 12

SYSROUTINEPERMS..............................................................................................................................652
SYSSCHEMAS.........................................................................................................................................653
SYSSTATEMENTS...................................................................................................................................654
SYSSTATISTICS.......................................................................................................................................654
SYSTABLEPERMS...................................................................................................................................655
SYSTABLES.............................................................................................................................................657
SYSTRIGGERS........................................................................................................................................658
SYSVIEWS...............................................................................................................................................660
Chapter 58: Exception Messages and SQL States..............................661
Chapter 59: ADO.NET Driver Reference...............................................665
SQLFire Data Types in ADO.NET.............................................................................................................665
VMware.Data.SQLFire.BatchUpdateException........................................................................................665
VMWare.Data.SQLFire.SQLFClientConnection.......................................................................................665
VMware.Data.SQLFire.SQLFCommand...................................................................................................670
VMware.Data.SQLFire.SQLFCommandBuilder........................................................................................676
VMware.Data.SQLFire.SQLFType............................................................................................................676
VMware.Data.SQLFire.SQLFDataAdapter...............................................................................................677
VMware.Data.SQLFire.SQLFDataReader................................................................................................679
VMware.Data.SQLFire.SQLFException....................................................................................................681
VMware.Data.SQLFire.SQLFParameter...................................................................................................682
VMware.Data.SQLFire.SQLFParameterCollection...................................................................................682
VMware.Data.SQLFire.SQLFTransaction.................................................................................................683
Chapter 60: vFabric SQLFire Limitations.............................................687
SQL Language Limitations.......................................................................................................................687
ADO.NET Driver Limitations.....................................................................................................................695
Troubleshooting Common Problems........................................................................697
vFabric SQLFire Glossary..........................................................................................699
vFabric SQLFire User's Guidexii
Page 13

About the SQLFire User's Guide
Revised April 30, 2013.
The SQLFire User's Guide provides step-by-step procedures for installing, configuring, managing, and developing
applications with VMware® vFabric™ SQLFire. The guide also provides a complete reference for the SQLFire
tools, supported SQL statements, and APIs.
Intended Audience
The SQLFire User's Guide is intended for anyone who wants to install or deploy SQLFire, and for developers
who want to program applications that access a SQLFire system and/or implement SQLFire APIs. The guide
assumes that you are familiar with SQL databases and database terminology, and that you have experience in
developing database applications using Java or .NET technologies.
13
Page 14

Page 15

Supported Configurations and System Requirements
Before installing vFabric SQLFire, make sure your system meets the minimum system requirements for installing
and running the product.
Before installing vFabric SQLFire, make sure your system meets the minimum system requirements for installing
and running the product.
• Supported Configurations on page 15
• Host Machine Requirements on page 16
• Increase Unicast Buffer Size on Linux Platforms on page 16
• Disable SYN Cookies on Linux Platforms on page 16
• Client Requirements on page 16
Supported Configurations
The following table shows all supported configurations for vFabric SQLFire. These include Supported
Configurations and System Requirements for vFabric Suite.
Note:
The tables indicate whether the supported configuration is for production or development. Generally,
production support means you can run your production application on the platform; developer support
means you can develop on the platform but you should not run your production application on it.
Operating System
Architecture
SP2 Professional or
Enterprise*
Standard*
Professional or
Enterprise*
Production or Developer SupportJVMProcessor
ProductionJava SE 6, update 0_26x86 (64bit and 32 bit)Red Hat EL 5
ProductionJava SE 6, update 0_26x86 (64bit and 32 bit)Red Hat EL 6
ProductionJava SE 6, update 0_26x86 (64bit and 32 bit)Windows Server 2003 R2
ProductionJava SE 6, update 0_26x8 (64bit and 32 bit)Windows Server 2008 R2
DeveloperJava SE 6, update 0_26x8 (64bit and 32 bit)Windows 7 SP1
DeveloperJava SE 6x86 (64 bit)Windows XP
DeveloperJava SE 6x86 (64 bit)Ubuntu 10.04
*The Microsoft Loopback Adapter is not supported.
Note: The SQLFire product download does not include Java; you must download and install a supported
JDK for your system.
15
Page 16

Host Machine Requirements
Requirements for each host:
• A supported Java SE installation.
• File system that supports long file names.
• Adequate per-user quota of file handles (ulimit for Linux)
• TCP/IP.
• System clock set to the correct time.
•
For each Linux host, the hostname and host files must be properly configured. See the system manpages
for hostname and hosts.
• Time synchronization service such as Network Time Protocol (NTP).
Note: For troubleshooting, you must run a time synchronization service on all hosts. Synchronized time
stamps allow you to merge log messages from different hosts, for an accurate chronological history of a
distributed run.
Increase Unicast Buffer Size on Linux Platforms
On Linux platforms, execute the following commands as the root user to increase the unicast buffer size:
1.
Edit the /etc/sysctl.conf file to include the following lines:
net.core.rmem_max=1048576
net.core.wmem_max=1048576
2.
Reload sysctl.conf:
sysctl -p
Disable SYN Cookies on Linux Platforms
Many default Linux installations use SYN cookies to protect the system against malicious attacks that flood
TCP SYN packets. The use of SYN cookies dramatically reduces network bandwidth, and can be triggered by
a running SQLFire distributed system.
If your SQLFire distributed system is otherwise protected against such attacks, disable SYN cookies to ensure
that SQLFire network throughput is not affected.
To disable SYN cookies permanently:
1.
Edit the /etc/sysctl.conf file to include the following line:
net.ipv4.tcp_syncookies = 0
Setting this value to zero disables SYN cookies.
2.
Reload sysctl.conf:
sysctl -p
Client Requirements
SQLFire supports two JDBC drivers: a thin client JDBC dri ver and a peer JDBC driv er . SQLFire server instances
and the peer driver are supported only with Java SE 6. You can download Java from
http://www.oracle.com/technetwork/java/javase/downloads/index.htm.
vFabric SQLFire User's Guide16
Page 17

SQLFire provides a managed ADO.NET driver that you can use for developing non-Java client applications.
The ADO.NET driver uses IKVM technology to translate SQLFire JDBC core libraries to .NET MSIL. The
ADO.NET driver is supported for applications built using the Microsoft .NET 2.0 SP1 or higher framework.
17
Page 18

Page 19

Part 1
Getting Started with vFabric SQLFire
Getting Started with vF abric SQLFir e provides step-by-step procedures for installing, configuring, and using VMw are
vFabric™ SQLFire. The guide also explains main concepts and provides tutorials to help you quickly begin using
SQLFire.
Topics:
• vFabric SQLFire in 15 Minutes
• Overview of vFabric SQLFire
• Understanding the SQLFire Distributed System
• Installing vFabric SQLFire
• Activating vFabric SQLFire Licensing
• Upgrading vFabric SQLFire
• Connect to vFabric SQLFire with JDBC Tools
• Tutorials
• vFabric SQLFire Features and Benefits
®
1
Page 20

vFabric SQLFire in 15 Minutes
Need a quick introduction to vFabric SQLFire? Take this 15-minute tour to try out the basic features and
functionality.
The vFabric SQLFire tutorials expand on these concepts, and demonstrate additional product features. See
Tutorials on page 35.
1. Download the latest SQLFire 1.1 ZIP file distribution from the download page:
https://my.vmware.com/web/vmware/info/slug/application_platform/vmware_vfabric_sqlfire/1_0. Save the
downloaded file in your home directory.
2. Install SQLFire 1.1 by uncompressing the ZIP file:
$ cd ~
$ unzip vFabric_SQLFire_11_bNNNNN.zip
Substitute the exact filename that you downloaded.
This installs SQLFire in a new vFabric_SQLFire_11_b NNNNN subdirectory in your home directory,
where NNNNN is the specific SQLFire build number that you downloaded.
3. If you have not already done so, download and install Java.
For a list of Java v ersions supported with this release of vFabric SQLFire, see Supported Configurations and
System Requirements on page 15.
4.
Set your PATH environment variable to include the bin subdirectory of the vFabric SQLFire directory . For
example:
$ export PATH=$PATH:/home/username/vFabric_SQLFire_11_bNNNNN/bin
5.
Change to the SQLFire installation quickstart directory, and create three new directories for the locator
and two servers that will make up the SQLFire distributed system:
$ cd ~/vFabric_SQLFire_11_bNNNNN/quickstart
$ mkdir locator1 server1 server2
6. Start the locator:
$ sqlf locator start -peer-discovery-address=localhost -dir=locator1
Starting network server for SQLFire Locator at address
localhost/127.0.0.1[1527]
SQLFire Locator pid: 8787 status: running
Logs generated in
/home/yozie/vFabric_SQLFire_11_bNNNNN/quickstart/locator1/sqlflocator.log
This command starts a default locator that accepts connections on the localhost address. The default port of
10334 is used for communication with other members of the distributed system. (You can double-check that
this port is used by examining the locator1/sqlflocator.log file.) All new members of the distributed
system must specify this locator's address and peer discovery port, localhost[10334], in order to join the
system.
The default port of 1527 is used for client connections to the distributed system.
7. Start both servers:
$ sqlf server start -locators=localhost[10334] -bind-address=localhost
-client-port=1528 -dir=server1
$ sqlf server start -locators=localhost[10334] -bind-address=localhost
-client-port=1529 -dir=server2
Starting SQLFire Server using locators for peer discovery: localhost[10334]
Starting network server for SQLFire Server at address
localhost/127.0.0.1[1528]
vFabric SQLFire User's Guide2
Page 21

SQLFire Server pid: 8897 status: running
Logs generated in
/home/yozie/vFabric_SQLFire_11_bNNNNN/quickstart/server1/sqlfserver.log
Starting SQLFire Server using locators for peer discovery: localhost[10334]
Starting network server for SQLFire Server at address
localhost/127.0.0.1[1529]
SQLFire Server pid: 9003 status: running
Logs generated in
/home/yozie/vFabric_SQLFire_11_bNNNNN/quickstart/server2/sqlfserver.log
Both servers also bind to the localhost address. They must specify unique client ports in order to avoid
conflicts with the locator's default client port. As an alternati ve, they could disable the netw ork server entirely
by specifying -run-netserver=false, and all clients would need to connect through the locator.
8.
Before going any further, check to make sure that you're in the SQLFire quickstart subdirectory. You'll
need to run the script files in this directory later in the tutorial, and you must execute those scripts from within
the quickstart directory:
$ cd ~/vFabric_SQLFire_11_bNNNNN/quickstart
9. Connect to the distributed system as a thin client, and display information about the system members:
$ sqlf
sqlf> connect client 'localhost:1527';
10. Now that you're connected to the system, run a simple query to display information about the SQLFire system
members:
sqlf> select id, kind, netservers from sys.members;
ID |KIND |NETSERVERS
-----------------------------------------------------------------------------localhost(17355):1374 |locator(normal) |localhost/127.0.0.1[1527]
localhost(17535)<v2>:52946 |datastore(normal)|localhost/127.0.0.1[1529]
localhost(17438)<v1>:1230 |datastore(normal)|localhost/127.0.0.1[1528]
3 rows selected
By default, SQLFire servers are started as datastores, so that they can host database schemas. In this cluster,
you can connect as a client to any member by specifying localhost with the unique port number of the member
(the one specified in the NETSERVERS column). However, connecting to the locator provides basic load
balancing by routing the connection request to an available server member.
11. Create a simple table and insert a few rows:
sqlf> create table quicktable (id int generated always as identity, item
char(25));
0 rows inserted/updated/deleted
sqlf> insert into quicktable values (default, 'widget');
1 row inserted/updated/deleted
sqlf> insert into quicktable values (default, 'gadget');
1 row inserted/updated/deleted
sqlf> select * from quicktable;
ID |ITEM
------------------------------------2 |gadget
1 |widget
2 rows selected
3
Page 22

12. By default, SQLFire replicates new tables that you create onto data store members. You can validate this
using the query:
sqlf> select tablename, datapolicy from sys.systables where
tablename='QUICKTABLE';
TABLENAME |DATAPOLICY
----------------------------------------------------------------------------QUICKTABLE |REPLICATE
1 row selected
13. Execute two SQL scripts to generate a schema that has both replicated and partitioned tables, and then load
the schema with data:
sqlf> run 'create_colocated_schema.sql';
sqlf> run 'loadTables.sql';
You see numerous messages as various SQL commands are executed. The first script creates both replicated
and partitioned tables, as you can see using the query:
sqlf> select tablename, datapolicy from sys.systables where
tableschemaname='APP';
TABLENAME |DATAPOLICY
-----------------------------------------------------------------------------FLIGHTS_HISTORY |PARTITION
FLIGHTAVAILABILITY |PARTITION
FLIGHTS |PARTITION
MAPS |REPLICATE
CITIES |REPLICATE
COUNTRIES |REPLICATE
AIRLINES |REPLICATE
QUICKTABLE |REPLICATE
8 rows selected
14. To observe a benefit of table partitioning, look at a query plan that involves one of the partitioned tables.
Use the EXPLAIN command with a query to generate a query execution plan:
sqlf> explain select * from flights;
The EXPLAIN command stores the query execution plan for the statement in STATEMENTPLANS system
table.
vFabric SQLFire User's Guide4
Page 23

15. T o view the details of the query plan, disconnect as a thin client from the distributed system, and then reconnect
as a peer client. A peer client participates as a member of the SQLFire distrib uted system and can coordinate
queries, but it does not host any actual data. Execute these commands:
sqlf> disconnect;
sqlf> connect peer 'host-data=false;locators=localhost[10334]';
You can see that your peer client connection introduces a new member to the distributed system:
sqlf> select id, kind, netservers from sys.members;
ID |KIND |NETSERVERS
-----------------------------------------------------------------------------localhost(17355):1374 |locator(normal) |localhost/127.0.0.1[1527]
localhost(17438)<v1>:1230 |datastore(normal)|localhost/127.0.0.1[1528]
localhost(17535)<v2>:52946 |datastore(normal)|localhost/127.0.0.1[1529]
10.0.1.18(17894)<v3>:22695 |accessor(normal) |
4 rows selected
The term accessor indicates that the member only accesses data, but does not store data for the distributed
system.
16. To view the query execution plan that you generated earlier, query the SYS.STATEMENTPLANS table to
view the statement ID (STMT_ID), then use EXPLAIN again with the ID to view the plan:
sqlf> select stmt_id, stmt_text from sys.statementplans;
STMT_ID |STMT_TEXT
------------------------------------------------------------------------------00000001-ffff-ffff-ffff-00020000004c| select * from flights
1 row selected
sqlf> explain '00000001-ffff-ffff-ffff-00020000004c';
member localhost(17438)<v1>:1230 begin_execution 2013-02-27 15:33:30.759
end_execution 2013-02-27 15:33:30.779
QUERY-RECEIVE execute_time 19.440818 ms member_node
localhost(17535)<v2>:52946
RESULT-SEND execute_time 0.130708 ms member_node
localhost(17535)<v2>:52946
RESULT-HOLDER execute_time 10.600616 ms returned_rows 275 no_opens
1
TABLESCAN (100.00%) execute_time 3.250588 ms returned_rows 275
no_opens 1 scan_qualifiers None scanned_object APP.FLIGHTS scan_type HEAP
member localhost(17535)<v2>:52946 begin_execution 2013-02-27
15:33:30.758 end_execution 2013-02-27 15:33:30.89
QUERY-SCATTER execute_time 13.358717 ms member_node
localhost(17438)<v1>:1230,localhost(17535)<v2>:52946
QUERY-SEND execute_time 3.345079 ms member_node
localhost(17438)<v1>:1230
QUERY-SEND execute_time 1.140207 ms member_node
localhost(17535)<v2>:52946
RESULT-RECEIVE execute_time 0.008155 ms member_node
localhost(17535)<v2>:52946
RESULT-RECEIVE execute_time 1.4887 ms member_node
localhost(17438)<v1>:1230
SEQUENTIAL-ITERATION (35.23%) execute_time 10.463731 ms
5
Page 24

returned_rows 542 no_opens 1
RESULT-HOLDER execute_time 0.490328 ms returned_rows 267
no_opens 1 member_node localhost(17535)<v2>:52946
RESULT-HOLDER execute_time 1.65846 ms returned_rows 275
no_opens 1 member_node localhost(17438)<v1>:1230
DISTRIBUTION-END (64.76%) execute_time 19.233818 ms
returned_rows 542
Local plan:
member localhost(17535)<v2>:52946 begin_execution 2013-02-27
15:33:30.762 end_execution 2013-02-27 15:33:30.842
TABLESCAN (100.00%) execute_time 3.297607 ms returned_rows 267 no_opens
1 scan_qualifiers None scanned_object APP.FLIGHTS scan_type HEAP
Note: The generated statement ID may be dif ferent on your system. Copy the exact ID from the output
of the SELECT statement and paste it into the second EXPLAIN statement.
The plan describes exactly how SQLFire performed the query. Note the two QUERY-SEND entries. These
entries indicate that the results for the query were obtained from each of the two data store members in the
distributed system. Because the FLIGHTS table was created as a partitioned table, new rows that are added
to the table are uniquely assigned to partitions based on the partitioning key (in this case, the key is the
FLIGHT_ID column). Partitions are then placed on data stores, which can process their portion of the data
independently when queries are performed against the table. Results from multiple data stores are then merged
on a single query coordinator member to provide the final result set.
17. Either continue executing queries against the sample database, or shut down the SQLFire distrib uted system.
To shut down all members of the system, first use the shut-down-all command to stop data stores and
accessors. Then shut down any remaining locators:
sqlf> quit;
$ sqlf shut-down-all -include-admins -locators=localhost[10334]
Connecting to distributed system: locators=localhost[10334]
Successfully shut down 2 members
$ sqlf locator stop -dir=locator1
The SQLFire Locator has stopped.
18. To continue learning about vFabric SQLFire, read or work through the remaining Tutorials on page 35.
vFabric SQLFire User's Guide6
Page 25

Chapter 1
Overview of vFabric SQLFire
vFabric SQLFire is a memory-optimized, distributed database management system designed for applications that hav e
demanding scalability and availability requirements. Applications can manage database tables entirely in memory, or
they can persist tables to disk to reload the data after restarting the system. A SQLFire distributed system can be easily
scaled out using commodity hardware.
7
Page 26

Getting Started with vFabric SQLFire
Data Flow Diagram
GemFire, Apache Derby, and SQL Components
vFabric SQLFire incorporates core vFabric GemFire technology and Apache Derby RDBMS components to
provide a high-performance, distributed database management system. SQLFire extends standard SQL statements
where necessary for creating and managing tables and configuring the SQLFire system.
The sections that follow document how SQLFire utilizes the GemFire and Derby component functionality.
vFabric GemFire Technology
vFabric SQLFire incorporates the following VMware vFabric GemFire technology:
• Reliable data distribution
• High performance replication and partitioning
• Caching framework
• Parallel 'data-aware' application behavior routing
vFabric SQLFire User's Guide8
Page 27

Overview of vFabric SQLFire
The SQLFire community site provides a comparison of SQLFire to other data management systems, such as
vFabric GemFire.
Apache Derby RDBMS Components
SQLFire integrates vFabric GemFire functionality with several components of the Apache Derby relational
database management system (RDBMS):
• JDBC driver. SQLFire supports a native, high performant JDBC driver (peer driver) and a thin JDBC driver.
The peer driver is based on the Derby embedded driver and JDBC 4.0 interfaces, but all communication with
SQLFire servers is implemented through the vFabric GemFire distribution layer.
• Query engine. SQLFire uses Derby to parse the SQL queries and generate parse trees. SQLFire injects its own
logic for intermediate plan creation and distributes the plan to data stores in the cluster . SQLFire also capitalizes
on some aspects of the built-in optimizer in Derby to generate query plans. The query execution itself uses
memory-based indexes and custom storage data structures. When query e xecution requires distribution, SQLFire
uses a custom algorithm to execute the query in parallel on multiple data stores.
• Network server. SQLFire servers embed the Derby network server for connectivity from thin JDBC and
ADO.NET clients. The communication protocol is based on the DRDA standard that is used by in IBM DB2
drivers.
SQL Extensions
vFabric SQLFire modifies and extends the query engine and SQL interface to provide support for partitioned
and replicated tables, data-aware procedures, data persistence, data eviction, and other features unique to the
distributed SQLFire architecture. SQLFire also adds SQL commands, stored procedures, system tables, and
functions to help easily manage features of the distributed system, such as persistent disk stores, listeners, and
locators.
9
Page 28

Page 29

Chapter 2
Understanding the SQLFire Distributed System
A SQLFire deployment consists of distributed member processes that connect to each other to form a peer-to-peer
network, also known as a distributed system or SQLFire cluster.
The sections that follow explain the interactions of main system components and processes. Tutorials on page 35 help
you get started configuring and using a SQLFire distributed system.
vFabric SQLFire Members
Member processes form a single, logical system, and each member has single-hop access to any other member,
with single-hop or no-hop access to data.
A SQLFire member is an instance of the SQLFire code that runs in a JVM. A SQLFire member can optionally
host data, provide network server functionality for client connections, and provide location services for the
distributed system.
A SQLFire distributed system is dynamic, and members can be added or removed at any time. The SQLFire
implementation guarantees a consistent view of the distributed system to ensure that data consistency and data
integrity are not compromised.
Most SQLFire members are configured to host data, and are referred to as data stores. Members that are configured
to not host data are referred to as accessors. Both data stores and accessors can execute the DDL and DML
commands that SQLFire supports. Data stores provide single-hop or no-hop access to data stored that is stored
on members of the distributed system. Accessors provide single-hop access to data stores in the distributed
system. Data stores and accessors are licensed separately.
A third type of member, the standalone locator, does not host data and does not support DDL and DML statements
on user-defined tables. You use locators to discover members of the SQLFire cluster.
A SQLFire agent is an optional distributed system member that provides access to JMX MBeans for monitoring
and managing SQLFire.
For more information, see:
• Starting and Configuring SQLFire Servers on page 223
• Using Locators on page 219
• Start a SQLFire Peer with the Peer Client JDBC Driver on page 116
• Using a vFabric SQLFire JMX Agent on page 294
11
Page 30

Getting Started with vFabric SQLFire
Servers, Peer Clients, and Server Groups
A SQLFire server is a process that hosts data and is a member of a peer-to-peer distributed system. SQLFire
servers run in Java Virtual Machines (JVMs).
You start a SQLFire server using the sqlf tool from a command prompt or terminal window. sqlf launches
servers as standalone processes that are akin to database servers. The servers can accept TCP connections from
thin clients, authenticate credentials, manage sessions, delegate work to a thread pool for SQL processing, and
so forth.
A peer client, also known as an embedded client, is a SQLFire-aware JDBC client that connects to the distrib uted
system using the JDBC peer driver. Peer clients are always connected to the distributed system, and they have
single-hop access to data. A peer client can be configured as a pure client (referred to as an accessor member)
or as a client that also hosts data (a data store).
Both JDBC peer client processes and server processes are peer members of the distributed system. The members
discover each other dynamically through a built-in multicast based discovery mechanism or by using a locator
service when TCP discovery is more desirable.
Note: In addition to peer client members that participate in a cluster, SQLFire servers support thin client
connections from JDBC and ADO.NET thin client drivers. See Developing Java Clients and Peers on
page 113 and Developing ADO.NET Client Applications on page 127.
SQLFire servers and peer clients that host data (when the host-data property is set to true) are automatically
part of the default server group. A server gr oup is a logical grouping of SQLFire serv er and peer client members
that defines the data stores that should host data for table. When any SQLFire object is created, such as a table,
in the CREATE TABLE statement you can specify the server group name where the table will be hosted. If no
group is specified, the table is hosted in the default server group. Using Server Groups to Manage Data on page
55 provides additional information.
For more information, see:
• Starting and Configuring SQLFire Servers on page 223
• Using Locators on page 219
• Start a SQLFire Peer with the Peer Client JDBC Driver on page 116
• Using Server Groups to Manage Data on page 55
Discovery Mechanisms
A peer member (a server or peer client process) announces itself to the distributed system using one of two
mechanisms.
SQLFire provides these discovery mechanisms:
• Locator (TCP/IP). A locator service maintains a registry of all peer members in the distrib uted system at an y
given moment. A locator is typically started as a separate process (with redundancy), but you can also embed
a locator in any peer member, such as a SQLFire server. The locator opens a TCP port through which all new
members connect to get initial membership information.
• UDP/IP Multicast. Members can optionally use a multicast address to broadcast their presence and receive
membership notification information.
Configuring Discovery Mechanisms on page 219 provides more information.
Group Membership Service
The Group Membership Service (GMS) uses self-defined system membership. Processes can join or leave the
distributed system at any time. The GMS communicates this information to every other member in the system,
vFabric SQLFire User's Guide12
Page 31

Understanding the SQLFire Distributed System
with certain consistency guarantees. Each member in the group participates in membership decisions, which
ensures that either all members see a new member or no members see it.
The membership coordinator, a key component of the GMS, handles "join" and "lea ve" requests, and also handles
members that are suspected of having left the system. The system automatically elects the oldest member of the
distributed system to act as the coordinator, and it elects a new one if the member fails or is unreachable. The
coordinator's basic purpose is to relay the current membership view to each member of the distributed system
and to ensure the consistency of the view at all times.
Because the SQLFire distributed system is dynamic, you can add or remove members in a very short time period.
This makes it easy to reconfigure the system to handle added demand (load).The GMS permits the distributed
system to progress under conditions in which a statically-defined membership system could not. A static model
defines members by host and identity, which mak es it difficult to add or remove members in an acti ve distributed
system. The system would have to shut do wn partially or completely to expand or contract the number of members
that participate in the system.
For more information, see:
• Start and Stop SQLFire Servers Using sqlf on page 223
• Connect to a Distributed System Using Locators on page 221
• Rebalancing Partitioned Data on SQLFire Members on page 66
Replicated Tables and Partitioned Tables
Tables in SQLFire can be partitioned or replicated. A replicated table keeps a copy of its entire data set locally
on every SQLFire server in its server group. A partitioned table manages large volumes of data by partitioning
it into manageable chunks and distributing those chunks across all members in the table's server group.
By default, all tables are replicated unless you specify partitioning in the CREATE TABLE statement. The
schema information for all SQLFire objects is visible at all times to all peer members of the distributed system
including peer clients, but excluding standalone locators.
Partitioning Tables on page 59 and Replicating Tables on page 69 provide more information.
Parallel Execution of Data-Aware Stored Procedures
In a traditional relational database, stored procedures are application routines that are stored as part of the data
dictionary and executed on the database system itself. Stored procedures generally offer high performance
because they execute in close proximity to data required by the application logic. SQLFire extends this basic
stored procedure capability to support parallel execution of application logic on table data that is partitioned
across many peers.
SQLFire applications can execute stored procedures on specific data hosts, in parallel on all the members of a
server group, or can target specific members based on the data requirements for the procedure. Essentially,
application behavior that is encapsulated in stored procedures is moved to the process that hosts the associated
data set, and it is executed there. If the required data set is spread across multiple partitions, the procedure is
executed in parallel on the partition members. Results are streamed to a coordinating member and aggregated
for the client invoking the procedure.
For example, consider an 'Order' table that is partitioned by its 'customer_id', and an application wanting to
execute an expensive 'credit check' for several customers. Assume the credit test requires iteration over all the
order history. You can parallelize the execution on all members that manage data for these customers and stream
the results to the client. All order history required by each execution is locally available in-process.
// typical procedure call
CallableStatement callableStmt = connection.prepareCall("{CALL
order_credit_check(?) ");
callableStmt.setArray(1, <list of customer IDs>);
13
Page 32

Getting Started with vFabric SQLFire
// SQLFire data-aware procedure invocation
CallableStatement callableStmt = connection.prepareCall("{CALL
order_credit_check() "
+ "ON TABLE Orders WHERE customerID IN (?)}");
callableStmt.setArray(1, <list of customer IDs>);
// order_credit_check will be executed in parallel on all members where the
orders
// corresponding to the customerIDs are managed
For more information, see:
• Using Data-Aware Stored Procedures on page 153
• Using the Procedure Provider API on page 159
• Using the Custom Result Processor API on page 163
Cache Plug-ins for External Data Connections
SQLFire is commonly used as a distributed SQL cache in an embedded (peer client) or client-server configuration.
It provides a plug-in framework to connect the cache to external data sources such as another relational database.
Several cache plug-ins are supported:
• Reading from Backend on a Miss ("read through")
When SQLFire is used as a cache, applications can configure a SQL RowLoader that is triggered to load the
data from a backend repository on a miss in SQLFire. When an incoming query request for a uniquely identified
row cannot be satisfied by the distributed cache, the loader is invoked to retrieve the data from an external
source. SQLFire locks the associated row and prevents concurrent readers trying to fetch the same row from
bombarding the backend database.
Note: When SQLFire is used as a "pure" cache (that is, some or all tables are configured with LRU
eviction, and only the actively used subset of data is cached in SQLFire), queries on these tables can be
based only on the primary key. Only primary key-based queries invoke a configured loader. Any other
query potentially could produce inconsistent results from the cache.
See Using a RowLoader to Load Existing Data on page 183.
• Synchronous Write Back to Backend ("write through")
When data is strictly managed in memory, even with replication, a failure of the entire cluster means loss of
data. With synchronous write-through, all changes can be synchronously written to the backend repository
before the cache is changed. If and only if the write-through succeeds, the data becomes visible in the cache.
You configure synchronous write-through with a SQLFire "cache writer". See Handling DML Events
Synchronously on page 191.
• Asynchronous Write Back to Backend ("write behind")
If synchronous writes to the backend are too costly, the application can configure the use of a "write behind
cache listener". SQLFire supports several options for how the events are queued, batched, and written to the
database of record. It is designed for very high reliability and handles many failure conditions. Persistent queues
ensure writes even when the backend database is temporarily unavailable. You can order event delivery or
batch it based on a time interval. You can also conflate a certain number of rows and continuous updates to a
single update, to reduce the load on the backend database of an 'update heavy' system. See Handling DML
Events Asynchronously on page 193.
vFabric SQLFire User's Guide14
Page 33

Chapter 3
Installing vFabric SQLFire
Y ou can install vF abric SQLFire from the VMware yum repository (RHEL only), from a downloaded RPM file (RHEL
only), or from a downloaded ZIP file. The installation procedure varies according to whether you obtained vFabric
SQLFire as a standalone product or as part of VMware® vFabric Suite™Advanced.
Installation Note for vFabric Suite Customers
vFabric SQLFire is available as a standalone product installation, and as part of vF abric Suite Advanced. vF abric
Suite is a set of runtime components that let you build, scale, and run modern, agile applications in virtual
environments.
If you obtain SQLFire standalone, you can install it on physical or virtual machines according to the procedures
in this document.
If you obtain SQLFire as part of vFabric Advanced, you install it exclusively on VMware virtual machines that
run on vSphere. The vFabric Suite install process adds the vFabric License Server to an e xisting vCenter serv er.
The vFabric License Server accepts a network license, actually a pool of licenses for vFabric components, which
makes it easy to manage the licensing of all components installed on the VMs.
If you obtain SQLFire as part of vFabric Suite Advanced, first complete the license activation and installation
procedures in Getting Started with vFabric Suite . Then follow procedures in this document to set up your
environment for SQLFire and complete any remaining SQLFire-specific installation and configuration tasks.
RHEL Only: Install vFabric SQLFire from an RPM
If your operating system is Red Hat Enterprise Linux (RHEL), you can install vFabric SQLFire from an RPM.
The RPM installation process can be used whether you have purchased the standalone vFabric SQLFire product
or vFabric Suite Advanced, which includes vFabric SQLFire. Use the installation procedure that matches the
product(s) that you purchased:
• Install SQLFire as a Component of vFabric Suite Advanced on page 16
• Install SQLFire as a Standalone Product on page 18
See Getting Started with vFabric Suite Suite for more information.
Prerequisites
• Confirm that your system meets the hardware and software requirements described in Supported Configurations
and System Requirements on page 15.
• If you have not already done so, download and install a compatible JDK or JRE on the RHEL computer or
VM.
15
Page 34

Getting Started with vFabric SQLFire
Install SQLFire as a Component of vFabric Suite Advanced
If you purchased vFabric Suite Advanced, VMware recommends that you install vFabric SQLFire by first
installing the VMware RPM repository and then using yum to perform the actual installation. Follow this
procedure:
1.
On the RHEL computer, start a terminal either as the root user or as an unprivileged user who has sudo
privileges.
Note: If you are not logged in as the root user, you must use the sudo command to run the commands
in the following steps.
2.
Install the vFabric repository RPM using the following wget command, passing it the appropriate URL.
The URL differs depending on the version of RHEL you are using.
Note: Y ou must run the entire wget command on a single line. Be sure you include | sh at the end,
or the RPM installation will not work.
For RHEL 5:
wget -q -O http://repo.vmware.com/pub/rhel5/vfabric/5.3/vfabric-5.3-suite-installer
| sh
For RHEL 6:
wget -q -O http://repo.vmware.com/pub/rhel6/vfabric/5.3/vfabric-5.3-suite-installer
| sh
The command performs the following tasks:
• Imports the vFabric GNU Privacy Guard (GPG) key.
• Installs the vFabric 5.3 repository RPM.
• Launches the VMware End User License Agreement (EULA) acceptance and repository configuration
script.
•
Outputs the EULA for you to read; you must answer yes to accept the terms and continue.
3.
Use the yum search vfabric or yum search vmware command to view the list of vFabric
components that you can install from the VMware repository. For example (output truncated for clarity):
yum search vfabric
...
============================= N/S Matched: vfabric
=============================
vfabric-5.3-qa-repo.noarch : vFabric 5.3 internal qa repository
configuration
vfabric-agent.x86_64 : VMware vFabric Agent
vfabric-gemfire.noarch : VMware vFabric GemFire
vfabric-hyperic-agent.noarch : VMware vFabric Hyperic Agent
vfabric-hyperic-server.x86_64 : VMware vFabric Hyperic Server
vfabric-insight-dashboard.noarch :
com.springsource.insight.dist.vfabric:dashboard-rpm
vfabric-license-server.noarch : VMware vFabric License Server
vfabric-sqlfire.noarch : VMware vFabric SQLFire
...
The vFabric SQLFire RPM is called vfabric-sqlfire.
4.
Execute the yum command to install vFabric SQLFire:
yum install vfabric-sqlfire
vFabric SQLFire User's Guide16
Page 35

Installing vFabric SQLFire
Note: The yum install command installs the most recent version of the vFabric SQLFire RPM
that it finds in all installed repository. If you want to install a different version, you must explicitly
specify that version with the yum install command. Use yum search vfabric-sqlfire
--showduplicates to find all versions that are available in the installed repositories.
The yum command begins the install process, resolves dependencies, and displays the packages it plans to
install and the required space.
5.
Enter y at the prompt to begin the actual installation.
The installer downloads and installs the package, andn displays Complete! when the installation process
is finished.
6.
(Optional.) Specify that the vfabric-sqlfire process should automatically start when the operating
system starts by running the following command:
chkconfig --level 35 vfabric-sqlfire on
7.
(Optional.) Specify the configuration of the vfabric-sqlfire process by editing the file
/etc/sysconfig/sqlfire, which is the file sourced by the script that you will later use to start the
SQLFire process (/etc/init.d/vfabric-sqlfire.)
The /etc/sysconfig/sqlfire file includes many comments to help you decide whether you need to
modify it. Here are additional pointers:
• If you do not modify the /etc/sysconfig/sqlfire file but simply use the one installed by default, the
vfabric-sqlfire process starts up a server instance in a multicast configuration.
• If you want the vfabric-sqlfire process to start up using a locator-based configuration, change the LOCATOR
property in the /etc/sysconfig/sqlfire file to local, as shown:
LOCATOR=local
This configuration allows a local locator process to start along with a local server instance. To add additional
remote locators, add their IP address and port to the LOCA T OR_IP_STRING as shown in the configuration
file as a commented-out example.
• If you want to start up only a local locator process and not a local server instance, set the LOCATOR
property to locator_only. This sets up a redundant locator configuration; be sure you add the locator IP
addresses and port numbers to the LOCATOR_IP_STRING; an example is shown in the configuration file.
• Finally, set the LOCATOR property to remote if you want to start a local server instance that relies on
having locator processes running on one or more remote hosts. Specify these remote hosts using the
LOCATOR_IP_STRING property.
8. Start the processes associated with SQLFire by running the following command:
/etc/init.d/vfabric-sqlfire start
By default, the process uses an evaluation license; if you ha ve purchased a production license, see Acti vating
vFabric SQLFire Licensing on page 21 for information about configuring it in the
/opt/vmware/vfabric-sqlfire/vFabric_SQLFire_11/sqlfire.properties file. The
RPM installation process creates a skeleton sqlfire.properties file to get you started.
T o stop, restart, and get status about the processes, pass the stop, restart, and status parameters, respectively,
to the /etc/init.d/vfabric-sqlfire script:
/etc/init.d/vfabric-sqlfire status
17
Page 36

Getting Started with vFabric SQLFire
Install SQLFire as a Standalone Product
If you purchased the standalone product (rather than as part of vFabric Suite Advanced), follow this procedure
to download and install only the SQLFire RPM:
1. From the VMware downloads page, select VMware vF abric SQLFire. On the SQLFire 1.1 do wnload page,
perform the following steps:
• If you are installing SQLFire for evaluation, click on the "Download Free Trial" link, register an account
with VMware (if you have not done so already) and download SQLFire.
• If you have already purchased SQLFire, locate the vFabric SQLFire licensed offering that you ha ve purchased
from the Product Downloads tab. Click on the View Download button.
• Download the vFabric SQLFire RPM appropriate for your RHEL operating system.
•
RHEL 5: vfabric-sqlfire-1.1-1.el5.noarch.rpm
•
RHEL 6: vfabric-sqlfire-1.1-1.el6.noarch.rpm
2.
On the RHEL computer, start a terminal either as the root user or as an unprivileged user who has sudo
privileges.
Note: If you are not logged in as the root user, you must use the sudo command to run the commands
in the following steps.
3. Run the appropriate command to install the vFabric repository RPMs:
RHEL 5:
sudo rpm -ivh vfabric-sqlfire-1.1-1.el5.noarch.rpm
RHEL 6:
sudo rpm -ivh vfabric-sqlfire-1.1-1.el6.noarch.rpm
The rpm command begins the install process, resolves dependencies, and displays the packages it plans to
install. The SQLFire software is installed into the /opt/vmware/vfabric-sqlfire directory.
If necessary, the install process creates a sqlfire non-interactive user in the vfabric group. This user
owns the installed SQLFire directories and files, including any disk store files that you create later.
Note: You cannot log in directly as the sqlfire user because interactive login has been disabled.
Rather, you must first log in as the root user or as a user with sudo privileges. You can then execute
commands as the sqlfire user by using sudo -u sqlfire command_name .
4.
If the installation is successful, you see a [100%] installation status message. For example:
Preparing... ###########################################
[100%]
1:vfabric-sqlfire ###########################################
[100%]
5. If you have not already done so, download and install a compatible JDK or JRE on the RHEL computer or
VM.
6.
(Optional.) Specify that the vfabric-sqlfire process should automatically start when the operating
system starts by running the following command:
chkconfig --level 35 vfabric-sqlfire on
vFabric SQLFire User's Guide18
Page 37

Installing vFabric SQLFire
7.
(Optional) Specify the configuration of the vfabric-sqlfire process by editing the file
/etc/sysconfig/sqlfire, which is the file sourced by the script that you will later use to start the
SQLFire process (/etc/init.d/vfabric-sqlfire.)
The /etc/sysconfig/sqlfire file includes many comments to help you decide whether you need to
modify it. Here are additional pointers:
• If you do not modify the /etc/sysconfig/sqlfire file but simply use the one installed by default, the
vfabric-sqlfire process starts up a server instance in a multicast configuration.
• If you want the vfabric-sqlfire process to start up using a locator-based configuration, change the LOCATOR
property in the /etc/sysconfig/sqlfire file to local, as shown:
LOCATOR=local
This configuration allows a local locator process to start along with a local server instance. To add additional
remote locators, add their IP address and port to the LOCA T OR_IP_STRING as shown in the configuration
file as a commented-out example.
• If you want to start up only a local locator process and not a local server instance, set the LOCATOR
property to locator_only. This sets up a redundant locator configuration; be sure you add the locator IP
addresses and port numbers to the LOCATOR_IP_STRING; an example is shown in the configuration file.
• Finally, set the LOCATOR property to remote if you want to start a local server instance that relies on
having locator processes running on one or more remote hosts. Specify these remote hosts using the
LOCATOR_IP_STRING property.
8. Start the processes associated with SQLFire by running the following command:
/etc/init.d/vfabric-sqlfire start
By default, the process uses an evaluation license; if you ha ve purchased a production license, see Acti vating
vFabric SQLFire Licensing on page 21 for information about configuring it in the
/opt/vmware/vfabric-sqlfire/vFabric_SQLFire_11/sqlfire.properties file. The
RPM installation process creates a skeleton sqlfire.properties file to get you started.
9. T o stop, restart, and get status about the processes, pass the stop, restart, and status parameters, respectively,
to the /etc/init.d/vfabric-sqlfire script:
/etc/init.d/vfabric-sqlfire status
Install vFabric SQLFire from a ZIP File
This procedure describes how to install the SQLFire software on a single computer or VM, for either a peer
client or client/server deployments. Repeat the procedure to install and license SQLFire on each physical or
virtual machine where you want to run a SQLFire member.
Prerequisites
1. Confirm that your system meets the hardware and software requirements described in Supported Configurations
and System Requirements on page 15.
2. From the VMware downloads page, select VMware vF abric SQLFire. From the Download VMware vF abric
SQLFire 1.1 page, perform the following steps:
• If you are installing SQLFire for evaluation, click on the "Download Free Trial" link, register an account
with VMware (if you have not done so already) and download SQLFire.
• If you have already purchased SQLFire, locate the vFabric SQLFire licensed offering that you ha ve purchased
from the Product Downloads tab. Click on the View Download button.
Note: You can also get SQLFire from your salesperson.
19
Page 38

Getting Started with vFabric SQLFire
• Download the ZIP file distribution of vFabric SQLFire.
Procedure
1. Change to the directory where you downloaded the SQLFire software, and unzip the ZIP file:
• UNIX and Linux (Bourne and Korn shells - sh, ksh, bash). If you are using the command line, type the
following command:
$ unzip vFabric_SQLFire_XX_bNNNNN.zip -d path_to_product
where XX corresponds to the product version of SQLFire that you are installing, bNNNNN corresponds to
the build number of the software, and path_to_pr oduct corresponds to the location where you want to install
SQLFire. For example:
$ unzip vFabric_SQLFire_11_b40332.zip -d /opt/vmware/vfabric-sqlfire
Alternatively, unzip the .zip file directly with any common ZIP extraction tool suitable for your operating
system.
• Windows: Open the .zip file, and extract the product files to the desired installation location on your
machine.
2. Configure your SQLFire license, if you have purchased a production license. Activating vFabric SQLFire
Licensing on page 21 provides more information.
3.
To begin using the sqlf utility to start servers or execute other commands, add the SQLFire bin directory
to your path. For example:
export PATH=$PATH:/opt/vmware/vfabric-sqlfire/bin
The sqlf script automatically sets the class path relative to the installation directory.
4. Repeat this procedure to install and license SQLFire on each different computer where you want to run a
SQLFire member.
Obtaining Modified Open Source Code Libraries
Many open source licenses require that vendors who use or modify their libraries make that code available.
To obtain the open source code libraries modified in SQLFire, visit the product download page, and select the
Open Source tab. Download the vFabric_SQLFire_XX_bNNNNN_OSS.zip file (where XX corresponds to the
product version of SQLFire that you are installing and bNNNNN corresponds to the build number of the software.)
Download and read the associated disclosure information (.txt) file from the same download page.
The .zip file contains both the original open source libraries and the modified source libraries.
vFabric SQLFire User's Guide20
Page 39

Chapter 4
Activating vFabric SQLFire Licensing
vFabric SQLFire includes a default evaluation license that enables you to run the product tutorial and perform simple
evaluation acti vities. You can obtain custom evaluation licensing and purchase production licensing from your VMware
account manager or the VMware license portal.
Understand vFabric SQLFire License Options
vFabric SQLFire has a number of licensing options. Read the following sections to understand the different
license types.
Default Evaluation License
The default evaluation license included with SQLFire allows you to run up to three non-production data stores
in the distributed system. SQLFire uses the default evaluation license upon startup if custom evaluation or
production licensing has not been installed. This license never expires. It is not allowed for production use.
Custom Evaluation and Production Licenses
T o get expanded configuration options and to move into production with SQLFire, contact your VMware account
manager. You can obtain custom evaluation licenses for your specific ev aluation requirements. Y ou can purchase
a production license when you are finished with your evaluation. Your VMware account manager will help you
determine the best topology and expiration options for your needs. For information on purchasing SQLFire
licensing, see http://www.vmware.com/products/datacenter-virtualization/vfabric-sqlfire/buy.html.
Custom evaluation licenses have an expiration date. Production licenses never expire.
vFabric SQLFire Professional and Enterprise Licenses
vFabric SQLFire uses these main license types for custom evaluation and production licensing:
• vFabric SQLFire Professional license. Enables you to deploy a SQLFire distributed system in a production
environment. A license is required for each SQLFire distributed system member that hosts data, whether or
not they also act as a server in client/server deployments.
• vFabric SQLFire Enterprise license. Standalone license that enables you to deploy a SQLFire distributed
system in a production environment. This license also enables you to loosely couple SQLFire distributed
systems that are at different geographical locations (WAN replication). A license is required for each SQLFire
distributed system member that hosts data, whether or not they also act as a server in client/server deplo yments.
Because the vFabric SQLFire Enterprise license is available only as a standalone license and not as part of
vFabric Suite, you must install the license in the sqlfire.properties file or as a boot property. You
cannot install a vFabric SQLFire Enterprise license in the vFabric License Server.
21
Page 40

Getting Started with vFabric SQLFire
SQLFire licenses do not restrict the number of clients that can connect to a distributed system. Any number of
thin clients and peer clients (SQLFire accessor members) are permitted.
vFabric SQLFire Local Licensing and vFabric Suite Licensing
If you obtained vFabric SQLFire as a standalone product, you install a license locally on each physical and
virtual machine that runs vFabric SQLFire.
If you obtained vFabric SQLFire as part of vFabric Suite, you can either use the vFabric License Server to install
your SQLFire licenses, or install the license locally in vSphere virtual machines. To use the vFabric License
Server for licensing, you must first install and configure the vFabric License Server. Then you install your
SQLFire serial numbers in the vFabric License Server. SQLFire will retrieve your licenses dynamically.
To set up the vFabric License Server, see Install vFabric License Server on Your vCenter Server in the vFabric
Suite documentation.
Note: You cannot use the vFabric License Server to manage licenses on physical machines, or with
standalone SQLFire licenses such as vFabric SQLFire Enterprise.
Choose a License Option Based on Topology
How you plan to use vFabric SQLFire determines which SQLFire license offerings are right for your system.
Licensing options are available for the following topologies:
• Single-Site System with Multiple Data Stores on page 22
• Multi-Site (WAN) System on page 23
For further information about SQLFire purchase options, refer to
http://www.vmware.com/products/datacenter-virtualization/vfabric-sqlfire/buy.html.
Single-Site System with Multiple Data Stores
Any client/server system or peer-to-peer system requires a vFabric SQLFire license for the SQLFire data stores
(SQLFire members that host data). You configure these licenses for each SQLFire member.
The vFabric SQLFire Professional license enables you to run multiple data stores in a single cluster, with unlimited
clients.
Figure 1: Example vFabric SQLFire Professional Deployment
If you need to replicate table data across multiple SQLFire clusters, you must purchase and install a standalone
vFabric SQLFire Enterprise license. See Multi-Site (WAN) System on page 23.
vFabric SQLFire User's Guide22
Page 41

Activating vFabric SQLFire Licensing
Installing a vFabric SQLFire Professional License
1. Obtain a product vFabric SQLFire Professional license from VMware.
2. Install the license in SQLFire. Choose one of the following options:
• On each SQLFire data store member, add the vFabric SQLFire license serial number directly to the
sqlfire.properties file. See Option 1: Install Licenses Using sqlfire.properties on page 25; or
• Create a file that contains the vFabric SQLFire license serial number, and copy the file to the vFabric serial
number directory on each SQLFire data store member. See Option 2: Install Licenses Using Serial Number
Files on page 26; or
• If you have purchased SQLFire as part of vFabric Suite, install the vFabric SQLFire license using vFabric
License Server. See vFabric Suite Only: Configure vFabric SQLFire for vFabric License Server on page
26.
Multi-Site (WAN) System
If you need to replicate table data across multiple SQLFire clusters (for example, over a WAN), you must
purchase and install a standalone vFabric SQLFire Enterprise license. Any number of thin clients and peer clients
(SQLFire accessor members) are permitted in each cluster. All systems that participate in the WAN installation
must be licensed. The license is configured in each data store member in the distributed system. Any number of
thin clients and peer clients (SQLFire accessor members) are permitted in each cluster.
Installing a vFabric SQLFire Enterprise License
1. Obtain a vFabric SQLFire Enterprise license. You can use the same serial number in each distributed system;
however, as a best practice you should obtain a unique serial number for each distributed system that
communicates over the WAN.
23
Page 42

Getting Started with vFabric SQLFire
2. Install the license in SQLFire. Choose one of the following options:
• On each data store member in the distributed system, add the vFabric SQLFire Enterprise serial number
directly to the sqlfire.properties file. See Option 1: Install Licenses Using sqlfire.properties on page 25; or
• Create a file that contains both the vFabric SQLFire Enterprise serial number, and copy the file to the
vFabric serial number directory on all SQLFire data store members. See Option 2: Install Licenses Using
Serial Number Files on page 26.
3. If you have obtained unique serial numbers for your other distributed systems, install the unique serial numbers
on the other distributed systems by using one of the options described in step 2.
How vFabric SQLFire Manages Licensing
Before you install vFabric SQLFire licenses, understand how SQLFire manages your licensing information.
• How vFabric SQLFire Finds and Verifies Your License on page 24
• License Working Directory on page 24
• Local VMware vFabric Directories on page 25
How vFabric SQLFire Finds and Verifies Your License
SQLFire has a default license that it uses if it cannot locate any other valid licensing.
Non-default licensing is verified using a combination of the product sqlfire.jar file and the serial numbers
you provide, or a license may be acquired dynamically from the vFabric License Server.
SQLFire uses the first valid licensing it finds in this list:
1.
Serial number specified by the license-serial-number boot property.
2. Dynamic licensing provided from a serial number file stored in the local VMware vFabric serial number
directory, configured by specifying license-serial-number=dynamic as a boot property.
3. Dynamic licensing provided by the vFabric License Server, configured by specifying
license-serial-number=dynamic as a boot property.
If SQLFire cannot validate any of the specified licensing in the above list, the member process does not start
and throws an exception.
If no licensing is specified, SQLFire uses the default evaluation licensing shipped with the product.
License Working Directory
SQLFire stores licensing information in a directory on your system. It writes to the first writable directory it
finds in this list:
1.
The value of the license-working-dir boot property, if specified for the member.
2. The SQLFire member's current working directory as determined by
System.getProperty("user.dir") at startup.
These are the files that SQLFire writes:
1.
License state files with names ending with -license.cfg. Example: vf.sf-license.cfg.
2.
License events files with names ending with -events.txt. Example: vf.sf-events.txt.
Note: Leave these files alone. Do not edit or delete these files, and do not alter the permissions on the
files or the directory where these files are located. These files are created using the default permissions
of the user who is starting up the SQLFire process. To stop or start the SQLFire process, a user needs
write permissions for this directory and the files in it. Make sure that the permissions for each user are
sufficient; otherwise SQLFire may throw an exception during stop or start.
vFabric SQLFire User's Guide24
Page 43

Activating vFabric SQLFire Licensing
Local VMware vFabric Directories
The location of the local VMware vFabric home directory, if it exists, varies by operating system:
Windows
Linux (or other OS)
%ALLUSERSPROFILE%\VMware\vFabric
/opt/vmware/vFabric
The location of the local VMware vFabric serial number directory, if it exists, varies by operating system:
Windows
Linux (or other OS)
%ALLUSERSPROFILE%\VMware\vFabric
/etc/opt/vmware/vfabric
Install and Configure vFabric SQLFire Licenses
Installation is required for all licensing except the default evaluation license, which is used automatically when
other licensing is not provided. You do not need to install or configure the default evaluation license.
When you obtain custom evaluation licenses or purchase production licenses, you receive one or more serial
numbers to use in your SQLFire member configurations. The number of serial numbers that you receive depends
on the type of licensing that you purchase. You install licensing in all members that you run as data stores. You
do not need to install licensing in your clients (thin client applications or SQLFire accessors). Choose a License
Option Based on Topology on page 22 describes the appropriate licensing for each topology.
Note: If you obtain SQLFire as part of vFabric Suite, refer first to the license activation procedure in
Getting Started with vFabric Suite in the vFabric Suite documentation. Then complete the tasks in this
procedure, as necessary, to configure SQLFire-specific licensing.
Where to Install Your License
If you obtained vFabric SQLFire as a standalone product, you install licenses locally to each SQLFire member
by modifying the sqlfire.properties file, or by supplying a boot property when you start the SQLFire
member. See Option 1: Install Licenses Using sqlfire.properties on page 25 and Option 2: Install Licenses Using
Serial Number Files on page 26.
If you are installing SQLFire in a vSphere virtual machine as part of vFabric Suite, you can use the vFabric
License Server to install your SQLFire licenses and then configure vFabric SQLFire to communicate with the
license server. See vFabric Suite Only: Configure vFabric SQLFire for vFabric License Server on page 26.
Note: You cannot use the vFabric License Server if you purchased a standalone SQLFire license, such
as vFabric SQLFire Enterprise. Install standalone licenses in sqlfire.properties or as a boot
property.
Option 1: Install Licenses Using sqlfire.properties
Add a license key to the sqlfire.properties file on each data store member in your deployment, or specify the
keys as a boot property when you start a SQLFire member using sqlf or the FabricServer interface.
This is the recommended way to install licensing for standalone SQLFire deployments. (For SQLFire deployments
installed on vSphere virtual machines as part of a vFabric Suite deployment, VMware recommends that you use
the vFabric License Server. See vFabric Suite Only: Configure vFabric SQLFire for vFabric License Server on
page 26.)
25
Page 44
Getting Started with vFabric SQLFire
For example:
# sqlfire.properties for data store or accessor member
license-serial-number=#####-#####-#####-#####-#####
If you need to specify multiple serial numbers, use a comma separated list:
# sqlfire.properties for data store or accessor member
license-serial-number=#####-#####-#####-#####-#####,#####-#####-#####-#####-#####
Option 2: Install Licenses Using Serial Number Files
Place serial numbers in serial number files in the VMware vFabric serial number directory.
To configure SQLFire to use these for licensing, you specify license-serial-number=dynamic as a
boot property. You can specify this property in sqlfire.properties, or when starting a SQLFire member
using sqlf or the FabricServer interface.
Use this procedure to install and configure serial number files for any standalone SQLFire license.
1.
Create a file named vf.sf-serial-numbers.txt and paste the serial number into it.
Note: If you have multiple serial numbers, enter each serial number on a new line.
2. Save the file to the appropriate serial numbers directory on each SQLFire member. See Local VMware
vFabric Directories on page 25 for the appropriate directory based on your operating system.
3.
On all SQLFire data store members, specify license-serial-number=dynamic in
sqlfire.properties, or as a boot property. For example:
# sqlfire.properties for dynamic licensing of data stores
license-serial-number=dynamic
vFabric Suite Only: Configure vFabric SQLFire for vFabric License Server
You can only use this configuration method if you are running SQLFire on a vSphere virtual machine as part of
vFabric Suite. This method is not applicable to installing a standalone vFabric SQLFire license, such as a vFabric
SQLFire Enterprise license.
To set up vFabric License Server licensing, refer first to the license activation procedure in Activate vFabric
Suite Licenses in the vFabric Suite documentation.
After you install SQLFire licenses on the vFabric License Server, configure dynamic licensing in SQLFire:
1.
Specify license-serial-number=dynamic in the sqlfire.properties file on each data store
or accessor member. For example:
# sqlfire.properties for dynamic licensing
license-serial-number=dynamic
2. (Optional) Change the default timeout value (10000) to indicate the maximum time in milliseconds that the
member should wait when obtaining a license dynamically from the vFabric License Server. For example,
in sqlfire.properties:
#timeout in milliseconds
license-server-timeout=20000
Verify Your License and Check Your License Usage
You can verify the validity of your license and monitor your license usage.
vFabric SQLFire User's Guide26
Page 45

Activating vFabric SQLFire Licensing
If you install an invalid serial number or if SQLFire cannot obtain a dynamic license from the vFabric License
Server, SQLFire fails to start and throws an exception. In Getting Started with vFabric Suite , see "Check the
Validity of an Existing License Key." to learn how to verify your license.
See Licensing Problems on page 697 for a list of common problems and their solutions.
If you obtained vFabric SQLFire as part of vFabric Suite and want to check your license usage, see Monitoring
vFabric License Usage in the vFabric Suite documentation.
27
Page 46

Page 47

Chapter 5
Upgrading vFabric SQLFire
SQLFire 1.1 is not compatible with persistence files (disk stores) that were created in earlier versions of SQLFire
(1.0.x). You must use the sqlf upgrade-disk-store command to upgrade disk stores to the SQLFire 1.1 format after
upgrading the SQLFire software to version 1.1.
Refer to the Release Notes to learn about changes that were introduced in the latest update.
Note: If you installed SQLFire using an RPM from the VMware YUM repository, see RHEL Only: Upgrade
vFabric SQLFire from the VMWare YUM RepositoryWhen VMware releases a new maintenance version of
SQLFire, the appropriate VMware YUM repository is updated to include the new RPM. You can use yum to
quickly upgrade SQLFire to the latest version. for upgrade instructions.
Before You Upgrade
This section provides information you need to know before you begin to upgrade vFabric SQLFire.
• If you obtained SQLFire as part of a vFabric Suite package, first complete the vFabric License Server installation
and license activation procedures in Getting Started with vFabric Suite.Then follow procedures in this document
to set up your environment for SQLFire and to complete any remaining SQLFire-specific installation and
configuration tasks.
• During an upgrade from one major SQLFire version to another, you cannot connect members in the same
distributed system to other members running a different major version. Therefore, you cannot perform a rolling
upgrade between major versions of vFabric SQLFire and will need to plan your system downtime accordingly.
See Version Compatibility Rules on page 32 for more information on SQLFire version interoperability.
• Read the vFabric SQLFire Release Notes to familiarize yourself with all feature changes.
• Know how to configure environment variables for your system.
• Confirm that your system meets the requirements to run SQLFire. See Supported Configurations and System
Requirements on page 15.
Note: To check your current Java version, type java -version at a command-line prompt. You
can download Sun/Oracle Java SE from the following location:
http://www.oracle.com/technetwork/java/javase/downloads/index.html.
•
If you are upgrading from SQLFire 1.0.x you will need to run the sqlf command upgrade-disk-store
to upgrade each disk store to a format that is compatible with vFabric SQLFire 1.1 See the upgrade instructions
for ZIP files or RPMs for more information.
29
Page 48

Getting Started with vFabric SQLFire
RHEL: Upgrade vFabric SQLFire from RPM
If your guest operating system is Red Hat Enterprise Linux (RHEL) and you have installed a previous version
of SQLFire using yum and RPM, VMware recommends that you use the RPM distribution to upgrade vFabric
SQLFire. You complete the upgrade procedure on every virtual and physical machine that runs SQLFire.
Note: Thoroughly test your development systems with the new version before moving into production.
When you upgrade vFabric SQLFire on RHEL from RPM, the new software is installed by default into
/opt/vmware/vfabric-sqlfire/vFabric_SQLFire_XX where XX corresponds to the version of
SQLFire (for example, vFabric_SQLFire_11) that you have installed. No files are o verwritten during the upgrade
process.
Prerequisites
• Confirm that your system meets the hardware and software requirements described in Supported Configurations
and System Requirements on page 15.
• Download the vFabric SQLFire RPM:
• From the VMware downloads page, select VMware vFabric SQLFire.
• If you are installing SQLFire for evaluation, click the Try Now button to download an evaluation RPM.
• If you have purchased SQLFire, download the vFabric SQLFire of fering you have purchased from the Product
Downloads tab. You can also get SQLFire from your salesperson.
• Download the vFabric SQLFire RPM appropriate for your RHEL operating system.
•
RHEL 5: vfabric-sqlfire-1.1-1.el5.noarch.rpm
•
RHEL 6: vfabric-sqlfire-1.1-1.el6.noarch.rpm
Procedure
Upgrade vFabric SQLFire using the RPM:
1. Review the items listed in Prerequisites on page 30 and make any appropriate preparations.
2.
Stop all members of the system running with the prior version. For example, use the shut-down-all
command:
sqlf shut-down-all -locators=localhost[10101]
In the sample command, substitute the address and port of a locator for your SQLFire distributed system. To
shut down only the local SQLFire process, use the command:
/etc/init.d/vfabric-sqlfire stop
3.
Execute the following rpm command to install the new SQLFire RPM. If necessary, use sudo to run the
command if you are not logged in as root:
RHEL 5:
sudo rpm -Uvh vfabric-sqlfire-1.1-1.el5.noarch.rpm
RHEL 6:
sudo rpm -Uvh vfabric-sqlfire-1.1-1.el6.noarch.rpm
The rpm command begins the install process, resolves dependencies, and displays the packages it plans to
install.
vFabric SQLFire User's Guide30
Page 49

Upgrading vFabric SQLFire
4.
If you are upgrading from SQLFire 1.0.x, run the sqlf command upgrade-disk-store to upgrade
each disk store to a format that is compatible with vFabric SQLFire 1.1. See sqlf upgrade-disk-store on page
397 for more information.
Note: You must update the default disk stores as well as any additional disk stores that were defined
through the CREATE DISKSTORE statement. Specify the full path to each disk store in multiple
invocations of the sqlf upgrade-disk-store command.
SQLFire creates default disk stores in each SQLFire server or locator directory, as well as in the
/datadictionary subdirectory of each SQLFire server or locator directory. The example below
shows how to upgrade these default disk stores on a single member; you must repeat the commands
on each machine that hosts a locator or server.
By default, SQLFire disk store files are owned by the user sqlfire, and you must preserve the o wnership
of these files when upgrading the disk store. Use the sudo command to perform the upgrade commands as
the sqlfire user, as in these example commands:
sudo -u sqlfire sqlf upgrade-disk-store SQLF-DEFAULT-DISKSTORE
/var/opt/vmware/sqlfire/server
sudo -u sqlfire sqlf upgrade-disk-store SQLF-DD-DISKSTORE
/var/opt/vmware/sqlfire/server/datadictionary
Replace /var/opt/vmware/sqlfire/server with the actual server or locator directory.
5. Repeat the previous step to upgrade each default and user-defined disk store on the local system.
6. Repeat all previous steps for e very virtual or physical machine on which you run a vFabric SQLFire member.
7. Restart all system members according to your usual procedures.
What to Do Next
After you have upgraded, perform the following tasks:
• Run the product tutorial and examples. See Tutorials on page 35.
• Test your development systems with the new version.
Upgrade vFabric SQLFire from a ZIP File
Upgrade vFabric SQLFire on every virtual and physical machine that will run SQLFire, using the downloaded
SQLFire ZIP file.
Procedure
Note: Thoroughly test your development systems with the new version before moving into production.
1. Review the items listed in Before You Upgrade on page 29 and make any appropriate preparations.
2. Stop all members of the system running the prior version of SQLFire. For example, in a SQLFire deployment
you can use the shut-down-all command to stop all members of the distributed system:
sqlf shut-down-all -locators=mylocator[10101]
3. Install the latest version of SQLFire in a different directory than the existing version. See Install vFabric
SQLFire from a ZIP File on page 19.
Note: SQLFire is installed as a complete product, rather than as a modification to a prior version. The
Java JRE runtime environment is not bundled with SQLFire, so you need to install and configure an
appropriate JDK or JRE to comply with SQLFire requirements and your unique system needs.
31
Page 50

Getting Started with vFabric SQLFire
4.
If you are upgrading from SQLFire 1.0.x, run the sqlf command upgrade-disk-store to upgrade
each disk store to a format that is compatible with vFabric SQLFire 1.1. See sqlf upgrade-disk-store on page
397 for more information.
Note: Update the default disk stores as well as any additional disk stores that were defined through
the CREATE DISKSTORE statement. Specify the full path to each disk store in multiple invocations
of the sqlf upgrade-disk-store command.
SQLFire creates default disk stores in each SQLFire server or locator directory, as well as in the
/datadictionary subdirectory of each SQLFire server or locator directory. The example below
shows how to upgrade these default disk stores on a single member; you must repeat the commands
on each machine that hosts a locator or server.
By default, SQLFire disk store files are owned by the user sqlfire, and you must preserve the o wnership
of these files when upgrading the disk store. Use the sudo command to perform the upgrade commands as
the sqlfire user, as in these example commands:
sudo -u sqlfire sqlf upgrade-disk-store SQLF-DEFAULT-DISKSTORE
/var/opt/vmware/sqlfire/server
sudo -u sqlfire sqlf upgrade-disk-store SQLF-DD-DISKSTORE
/var/opt/vmware/sqlfire/server/datadictionary
Replace /var/opt/vmware/sqlfire/server with the actual server or locator directory.
5. Repeat the previous step to upgrade each default and user-defined disk store on the local system.
6. Redeploy your environment's license or configuration files to the new version's installation. Copy and edit
the files as necessary to point to the new installation directory.
7. Restart all system members according to your usual procedures.
What to Do Next
After you have upgraded, perform the following tasks:
• Run the product tutorial and examples. See Tutorials on page 35.
• Test your development systems with the new version.
Version Compatibility Rules
Upgraded SQLFire members cannot participate in a distributed system that contains SQLFire members from an
earlier version. Shut down all existing cluster members before restarting the cluster with upgraded SQLFire
members.
Thin clients from earlier versions of SQLFire can operate against the latest version of SQLFire. However, thin
clients using the latest SQLFire JDBC drivers are not compatible with older versions of SQLFire.
Refer to the Release Notes to learn about changes that were introduced in the latest update.
vFabric SQLFire User's Guide32
Page 51

Chapter 6
Connect to vFabric SQLFire with JDBC Tools
Third-party JDBC tools can help you browse data in tables, issue SQL commands, design new tables, and so forth.
You can configure these tools to use the SQLFire JDBC thin client driver to connect to a SQLFire distributed system.
Although the instructions for setting up each tool vary, the general process for establishing a connection involves
configuring the JDBC client driver and setting JDBC connection URL properties. Follow these basic steps:
1.
In the third-party tool, choose to configure a new driver, and select the sqlfireclient.jar file that contains
the SQLFire JDBC client driver. This file is installed in the lib directory of your SQLFire installation.
2. If the tool does not automatically select a driver class, you will generally have the option of selecting a class from
within the JAR file. For SQLFire, select the com.vmware.sqlfire.jdbc.ClientDriver class.
3. In order to use the client driver, you must specify a JDBC connection URL for your SQLFire distributed system.
The basic URL format for the client driver is:
jdbc:sqlfire://hostname:port/
where hostname and port correspond to the -client-bind-address and -client-port value of a SQLFire
server or locator in your distributed system.
4. Y our tool may require that you specify a username and password to use for connecting to the system. If the SQLFire
server or locator enables authentication (using the -auth-provider boot property), then enter a valid username and
password combination to connect to the distributed system.
If authentication is disabled, specify "app" as both the username and password values, or any other temporary v alue.
Note: SQLFire uses the username specified in the JDBC connection as the schema name when you do not
provide the schema name for a database object. SQLFire uses "APP" as the default schema. If your system
does not enable authentication, you can specify "APP" for both the username and password to maintain
consistency with the default schema behavior.
For a full example of configuring SQLFire with a third-party JDBC tool, see Connecting to VMware vF abric SQLFire
using SQuirreL SQL on the SQLFire community site.
33
Page 52

Page 53

Chapter 7
Tutorials
Learn to configure and use SQLFire features such as table replication and partitioning, persisting data to disk, and
dynamically resizing the cluster.
Main Steps
The tutorial is divided into the following steps, which explain how to set up a cluster of SQLFire servers on
multiple Java VMs and then distribute data across the cluster. Perform the steps in the sequence shown.
DescriptionStep
Create a SQLFire Cluster on page 35Step 1
Connect to the Cluster Using SQLF on page 37Step 2
Create Replicated Tables and Execute Queries on page 38Step 3
Implement a Partitioning Strategy on page 39Step 4
Persist Tables to Disk on page 41Step 5
Add Servers to the Cluster and Stop Servers on page 43Step 6
Prerequisites
Install SQLFire on your local computer as described in Install vFabric SQLFire from a ZIP File on page 19.
Create a SQLFire Cluster
In this procedure you set up and start a cluster of two SQLFire servers.
Procedure
1. Begin by opening a command prompt or terminal window on the computer or VM where you installed
SQLFire.
2. Move to the directory in which you installed the SQLFire software. This tutorial uses the e xample directory
~/vFabric_SQLFire_11_b NNNNN, but you should substitute the actual path to your installation. For
example:
cd ~/vFabric_SQLFire_11_bNNNNN
3. The initial SQLFire cluster in this tutorial contains two standalone SQLFire server members. Create a new
directory for each server:
mkdir server1
mkdir server2
Each server will use its local directory to write log files, backup disk store files, a datadictionary
directory for persisting data, and a single status file, .sqlfserver.ser.
35
Page 54

Getting Started with vFabric SQLFire
4. To manage client connections to the available SQLFire server members, the cluster in this tutorial uses a
SQLFire locator member. Create a new directory for the locator member:
mkdir locator
A locator maintains a list of available servers in the cluster, and updates that list as servers join and leave the
cluster. Locators also load balance client connections across all available servers.
5.
To start or stop a SQLFire locator or a SQLFire server, you use the sqlf script (for Linux platforms) or
sqlf.bat script (for W indows platforms). In either case, you must first ensure that the path to the SQLFire
bin directory is part of your PATH environment variable. For example, on a Linux platform enter:
export PATH=$PATH:~/vFabric_SQLFire_11_bNNNNN/bin
On a Windows platform enter:
set Path=%Path%;c:\vFabric_SQLFire_11_bNNNNN\bin
6.
When you start a SQLFire distributed system, always begin by starting the locator member. Use the sqlf
locator command to start the locator in the specified directory:
sqlf locator start -dir=locator -peer-discovery-address=ip_address
-peer-discovery-port=10101 \
-client-bind-address=ip_address -client-port=1527
Note: In this step and in all subsequent steps, replace ip_address with the IP address of your local
system.
The -peer-discovery-address and -peer-discovery-port combination defines a unique
connection that all members of this SQLFire distributed system use for communicating with one another.
Note: Always use a unique -peer-discovery-port number to avoid joining a cluster that is
already running on your network. If other people might be evaluating SQLFire on your netw ork, choose
a port number other than 10101.
The -client-bind-address and -client-port combination defines the connection that client
applications use to connect to this locator. In this tutorial, all SQLFire members run on the local computer's
IP address and use different port numbers to define unique connections.
You can verify the peer and client connections in the locator startup messages, which are similar to:
Starting SQLFire Locator using peer discovery on: ip_address[10101]
Starting network server for SQLFire Locator at address
localhost/127.0.0.1[1527]
SQLFire Locator pid: 41149 status: running
Note: By starting the locator member first, the locator can manage cluster membership from the start
as new servers join and leav e the distributed system. The locator member should also be the last process
that you shut down when you want to stop a SQLFire distributed system.
Note: As an alternative, SQLFire members can discover each other using multicast messaging.
However, important SQLFire features such as WAN replication and user authentication require that
a SQLFire system use locators rather than multicast for discovery. See Configuring Discovery
Mechanisms on page 219.
7.
Now use the sqlf server command to start both SQLFire server members and join them to the distributed
system:
sqlf server start -dir=server1 -locators=ip_address[10101]
-client-bind-address=ip_address -client-port=1528
vFabric SQLFire User's Guide36
Page 55

sqlf server start -dir=server2 -locators=ip_address[10101]
-client-bind-address=ip_address -client-port=1529
In each command, the -locators option defines the peer discovery address to use for joining the SQLFire
distributed system. (Production deployments generally use multiple locator members, in which case you
would specify a comma-separated list of locator host[port] connections when starting a server.)
Again, the combination of -client-bind-address and -client-port indicates that each server
will listen for thin clients on a unique connection (ip_address:1528 and ip_address:1529, respectively).
However, in this distributed system all clients will connect using the locator instead of making direct
connections to servers.
8. Both SQLFire servers output messages similar to:
Starting SQLFire Server using locators for peer discovery:
ip_address[10101]
Starting network server for SQLFire Server at address /ip_address[1528]
SQLFire Server pid: 41502 status: running
Distributed system now has 2 members.
Other members: localhost(41149:locator)<v0>:32977/50114
Logs generated in
/Users/yozie/vFabric_SQLFire_11_bNNNNN/server1/sqlfserver.log
Starting SQLFire Server using locators for peer discovery:
ip_address[10101]
Starting network server for SQLFire Server at address /ip_address[1529]
SQLFire Server pid: 41533 status: running
Distributed system now has 3 members.
Other members: localhost(41149:locator)<v0>:32977/50114,
10.0.1.11(41502:datastore)<v1>:49915/50462
Logs generated in
/Users/yozie/vFabric_SQLFire_11_bNNNNN/server2/sqlfserver.log
Tutorials
Startup messages show the cluster membership details.
By default, new SQLFire servers host data as data stores, and are automatically added to a default server
group. You can optionally specify server group membership at startup using the server-groups boot property .
Connect to the Cluster Using SQLF
sqlf implements a command-line tool that is based on the Apache Derby ij tool. You can use sqlf to connect
to a SQLFire cluster and run scripts or interactive queries. You execute sqlf using the sqlf or sqlf.bat
script.
Procedure
1. In the same command prompt or terminal Window in which you started the SQLFire cluster, change to the
quickstart directory:
cd quickstart
The quickstart directory contains example SQL script files that you will use later in the tutorial.
2.
Start an interactive sqlf session:
sqlf
This command starts the interactive shell and displays the prompt: sqlf>.
3.
Print a brief list of the available sqlf commands:
help;
37
Page 56

Getting Started with vFabric SQLFire
4.
T o connect to the SQLFire cluster using the JDBC thin client driver, use the connect client command
and specify the host and port number of the SQLFire locator:
connect client 'ip_address:1527';
Notice that SQLFire does not have the concept of a "database". When you connect to a SQLFire cluster, the
distributed system that you connect to is defined by the locator (or alternately, the mcast-port) specified in
the JDBC or ADO.NET connection.
5. Use the following command to view tables in the "sys" schema:
show tables in sys;
You will use information from many of these tables to view information and statistics about a working
SQLFire cluster.
6. The sys.members table stores information about the SQLFire members. Execute the following query to see
the unique ID assigned to the two SQLFire servers and the locator that you started:
select id from sys.members;
You will see output similar to:
ID
-------------------------------
0.0.1.11(41533)<v2>:52614/50508
localhost(41149)<v0>:32977/50114
10.0.1.11(41502)<v1>:49915/50462
3 rows selected
The output displays the member process ID that is also logged when you start the members at the command
line (41149, 41502, and 41533 in the tutorial example).
Create Replicated Tables and Execute Queries
By default SQLFire replicates tables to members of the cluster. In this procedure you create new tables that are
replicated the SQLFire cluster.
Procedure
1.
In the same sqlf session, run the ToursDB_schema.sql script to create the tables associated with the
ToursDB sample database:
run 'ToursDB_schema.sql';
You see DDL output such as:
sqlf> CREATE TABLE AIRLINES
(
AIRLINE CHAR(2) NOT NULL CONSTRAINT AIRLINES_PK PRIMARY KEY,
AIRLINE_FULL VARCHAR(24),
BASIC_RATE DOUBLE PRECISION,
DISTANCE_DISCOUNT DOUBLE PRECISION,
BUSINESS_LEVEL_FACTOR DOUBLE PRECISION,
FIRSTCLASS_LEVEL_FACTOR DOUBLE PRECISION,
ECONOMY_SEATS INTEGER,
BUSINESS_SEATS INTEGER,
FIRSTCLASS_SEATS INTEGER
);
vFabric SQLFire User's Guide38
Page 57

Tutorials
0 rows inserted/updated/deleted
[...]
2.
Run the loadTables.sql script to populate the tables with data:
run 'loadTables.sql';
The script output completes with:
sqlf> insert into FLIGHTAVAILABILITY values
('US1357',2,'2004-04-18',0,0,3);
1 row inserted/updated/deleted
3. Enter the following command to show the table names that you created (tables in the APP schema):
show tables in APP;
4. The new tables that you create and the data that you load are replicated on the two SQLFire servers by default.
You can check whether tables are partitioned or replicated by querying information in sys.systables. Use the
following query to check the data policy that SQLFire has assigned to the tables you just created:
select tablename, datapolicy from sys.systables where
tableschemaname='APP';
The output shows that each of the ToursDB tables that you created are replicated. SQLFire replicates tables
by default if you do not use the PARTITION BY clause in the CREATE TABLE statement.
Partitioning Tables on page 59 and Replicating Tables on page 69 provide more information about creating
tables in SQLFire.
5. You can also use the sys.members table to determine which members host a particular table:
select id from sys.systables s, sys.members where s.tablename='FLIGHTS';
In the tutorial, both of the SQLFire servers store information for each replicated table.
6. SQLFire provides query features similar to those available in other data management products. F or example,
the following command executes a simple query:
SELECT city_name, country, language FROM cities WHERE language LIKE
'%ese';
The following query executes a join between tables:
SELECT city_name, countries.country, region, language
FROM cities, countries
WHERE cities.country_iso_code = countries.country_iso_code AND language
LIKE '%ese';
Implement a Partitioning Strategy
In this procedure you drop all tables in the ToursDB schema and then recreate them using a new partitioning
and replication strategy.
The ToursDB schema in this tutorial is similar to a 'STAR' schema, having only a few fact tables and several
dimension tables. Dimension tables are generally small and change infrequently, b ut are commonly used in join
queries. Dimension tables are good candidates for replicating across SQLFire members, because join queries
can execute in parallel.
The AIRLINES, CITIES, COUNTRIES, and MAPS tables are treated as dimension tables, and are replicated
across the SQLFire cluster. In the tutorial it is assumed that applications frequently join these related tables based
on the FLIGHT_ID column, which is chosen as the partitioning column.
39
Page 58

Getting Started with vFabric SQLFire
FLIGHTS, FLIGHTS_HISTORY, and FLIGHTAVAILABILITY are fact tables, and they will be partitioned.
You will co-locate these tables to ensure that all rows that are associated with FLIGHT_ID are maintained in a
single partition. This step ensures that frequent join queries based on a selected flight are pruned to a single
member and executed efficiently.
Procedure
1.
In a separate terminal window or GUI editor, open the create_colocated_schema.sql file in the
vFabric_SQLFire_11_bNNNNN/quickstart directory to examine the included DDL commands.
The SQL script begins by dropping the existing tables in the schema:
DROP TABLE AIRLINES;
DROP TABLE CITIES;
DROP TABLE COUNTRIES;
DROP TABLE FLIGHTAVAILABILITY;
DROP TABLE FLIGHTS;
DROP TABLE MAPS;
DROP TABLE FLIGHTS_HISTORY;
Dimension tables can be replicated using the same basic CREATE statement from the preceding section of
the tutorial. However, this script explicitly adds the REPLICATE keyword for clarity. For example:
CREATE TABLE AIRLINES
(
AIRLINE CHAR(2) NOT NULL CONSTRAINT AIRLINES_PK PRIMARY KEY,
AIRLINE_FULL VARCHAR(24),
BASIC_RATE DOUBLE PRECISION,
DISTANCE_DISCOUNT DOUBLE PRECISION,
BUSINESS_LEVEL_FACTOR DOUBLE PRECISION,
FIRSTCLASS_LEVEL_FACTOR DOUBLE PRECISION,
ECONOMY_SEATS INTEGER,
BUSINESS_SEATS INTEGER,
FIRSTCLASS_SEATS INTEGER
) REPLICATE;
The FLIGHTS table is partitioned based on the FLIGHT_ID column:
CREATE TABLE FLIGHTS
(
FLIGHT_ID CHAR(6) NOT NULL ,
SEGMENT_NUMBER INTEGER NOT NULL ,
ORIG_AIRPORT CHAR(3),
DEPART_TIME TIME,
DEST_AIRPORT CHAR(3),
ARRIVE_TIME TIME,
MEAL CHAR(1),
FLYING_TIME DOUBLE PRECISION,
MILES INTEGER,
AIRCRAFT VARCHAR(6),
CONSTRAINT FLIGHTS_PK PRIMARY KEY (
FLIGHT_ID,
SEGMENT_NUMBER),
CONSTRAINT MEAL_CONSTRAINT
CHECK (meal IN ('B', 'L', 'D', 'S'))
)
PARTITION BY COLUMN (FLIGHT_ID);
The remaining facts tables are also partitioned, and also colocated with the FLIGHTS table. For example:
CREATE TABLE FLIGHTAVAILABILITY
(
FLIGHT_ID CHAR(6) NOT NULL ,
vFabric SQLFire User's Guide40
Page 59

SEGMENT_NUMBER INTEGER NOT NULL ,
FLIGHT_DATE DATE NOT NULL ,
ECONOMY_SEATS_TAKEN INTEGER DEFAULT 0,
BUSINESS_SEATS_TAKEN INTEGER DEFAULT 0,
FIRSTCLASS_SEATS_TAKEN INTEGER DEFAULT 0,
CONSTRAINT FLIGHTAVAIL_PK PRIMARY KEY (
FLIGHT_ID,
SEGMENT_NUMBER,
FLIGHT_DATE),
CONSTRAINT FLIGHTS_FK2 Foreign Key (
FLIGHT_ID,
SEGMENT_NUMBER)
REFERENCES FLIGHTS (
FLIGHT_ID,
SEGMENT_NUMBER)
)
PARTITION BY COLUMN (FLIGHT_ID)
COLOCATE WITH (FLIGHTS);
2.
In the sqlf session, execute the create_colocated_schema.sql script to drop the existing tables
and recreate them with the new partitioning and replication strategy . Execute loadTables.sql to populate
the tables with data:
run 'create_colocated_schema.sql';
run 'loadTables.sql';
Tutorials
3. Confirm that the tables are created:
show tables in APP;
4. Verify whether individual tables are replicated or partitioned:
select tablename, datapolicy from sys.systables where
tableschemaname='APP';
5. The FLIGHTS table and others are now partitioned across the SQLFire cluster . Query the sys.members table
again to display the member IDs that host the table:
select id from sys.systables s, sys.members where s.tablename='FLIGHTS';
6. Now use the DSID Function to see how many rows of the partitioned FLIGHT table are stored on that
SQLFire server. For example:
select count(*) memberRowCount, dsid() from flights group by dsid();
7. Execute a join on both partition members in parallel.
select * from flights f, flightavailability fa
where f.flight_id = fa.flight_id and f.flight_id = 'AA1116';
The combined results are returned. Because the table is partitioned by FLIGHT_ID, the execution of the join
is pruned to the partition that stores the value 'AA1116.' You can verify that flight_id 'AA1116' is located
on only one data store using the query:
select count(*), dsid() from flights where flight_id = 'AA1116';
Persist Tables to Disk
At this point, the SQLFire cluster manages the ToursDB tables only in memory. In this procedure you persist
table data to disk.
Procedure
41
Page 60

Getting Started with vFabric SQLFire
1. In a separate terminal window or GUI editor, examine the contents of the
create_persistent_schema.sql script. Notice that this script uses the PERSISTENT keyword in
each CREATE TABLE statement. For example:
CREATE TABLE COUNTRIES
(
COUNTRY VARCHAR(26) NOT NULL CONSTRAINT COUNTRIES_UNQ_NM Unique,
COUNTRY_ISO_CODE CHAR(2) NOT NULL CONSTRAINT COUNTRIES_PK PRIMARY
KEY,
REGION VARCHAR(26),
CONSTRAINT COUNTRIES_UC
CHECK (country_ISO_code = upper(country_ISO_code) )
) REPLICATE PERSISTENT;
2.
In the sqlf session, execute the create_persistent_schema.sql script, then load table data:
run 'create_persistent_schema.sql';
run 'loadTables.sql';
3.
Exit the sqlf session:
exit;
4. Now list the contents of each SQLFire server directory:
ls -l ../server1 ../server2
Notice that each SQLFire directory now contains several disk store files to manage the table data on disk.
For example:
BACKUPSQLF-DEFAULT-DISKSTORE.if
BACKUPSQLF-DEFAULT-DISKSTORE_1.crf
BACKUPSQLF-DEFAULT-DISKSTORE_1.drf
5. Because the data is persisted to disk, SQLFire will recover data from disk even if you shut down the data
stores. Use the shut-down-all command to shut down all data stores in the cluster, and then restart the
servers:
cd ~/vFabric_SQLFire_11_bNNNNN
sqlf shut-down-all -locators=ip_address[10101]
Connecting to distributed system: locators=ip_address[10101]
Successfully shut down 2 members
sqlf server start -dir=server1 -locators=ip_address[10101]
-client-bind-address=ip_address -client-port=1528 -sync=false
sqlf server start -dir=server2 -locators=ip_address[10101]
-client-bind-address=ip_address -client-port=1529 -sync=false
Note: The -sync=false option starts a server to a "waiting" state if that serv er depends on another
server or locator for disk store synchronization. This option is helpful for starting multiple SQLFire
members on the same machine, or when starting servers using a shell script or batch file, as the start
command returns immediately after the member reaches the waiting state. The server automatically
continues booting after any dependent servers or locators start. (Locators automatically boot using the
-sync=false option, but servers do not.)
When you restart the servers, you may notice messages similar to:
[info 2012/07/24 10:18:11.949 PDT <main> tid=0x1] Region
/_DDL_STMTS_META_REGION initialized with data from
/10.118.33.206:/Users/yozie/vFabric_SQLFire_11_bNNNNN/server1/./datadictionary
created at timestamp 1343149012698 version 0 diskStoreId
vFabric SQLFire User's Guide42
Page 61

1fc6a853-69d6-4ffe-8029-218acf165c34 is waiting for the data previously
hosted at
[/10.118.33.206:/Users/yozie/vFabric_SQLFire_11_bNNNNN
/server2/./datadictionary created at timestamp 1343149035681 version 0
diskStoreId
49c1e827-4bb5-49cc-951b-221d47bbc92f] to be available
These are not error messages. They indicate that the SQLFire member you are starting is waiting for another
member to become available online.
6. Now verify that the persistent tables were reloaded:
sqlf
connect client 'ip_address:1527';
select id from sys.systables s, sys.members where s.tablename='FLIGHTS';
select count(*) memberRowCount, dsid() from flights group by dsid();
Add Servers to the Cluster and Stop Servers
SQLFire manages data in a flexible way that enables you to expand or contract your cluster at runtime to support
different loads. To dynamically add more capacity to a cluster, you add new server members and specify the
-rebalance option.
Procedure
Tutorials
1. Open a new terminal or command prompt window, and create a directory for the new server. Also set your
PATH in the new terminal if necessary:
cd ~/vFabric_SQLFire_11_bNNNNN
mkdir server3
export PATH=$PATH:~/vFabric_SQLFire_11_bNNNNN/bin
2.
Start the new server with a unique port number and specify the -rebalance option:
sqlf server start -dir=server3 -locators=ip_address[10101]
-client-bind-address=ip_address -client-port=1530 -rebalance
3. View the contents of the new SQLFire directory:
ls server3
Notice that the new SQLFire server also persists the available table data, and contains the same disk store
files as the other two servers.
4.
You can view all members of the distributed system using sqlf. In the available sqlf session, e x ecute the
query:
select id from sys.members;
5. Verify that all servers now host the data:
select id from sys.systables s, sys.members where s.tablename='FLIGHTS';
6. Examine the table data that each server hosts:
select count(*) memberRowCount, dsid() from flights group by dsid();
7.
Exit the sqlf session:
exit;
8.
You can stop an individual SQLFire server by using the sqlf server stop command and specifying
the server directory. To shut down all data stores at once, use the sqlf shut-down-all command:
sqlf shut-down-all -locators=ip_address[10101]
43
Page 62

Getting Started with vFabric SQLFire
Connecting to distributed system: locators=ip_address[10101]
Successfully shut down 3 members
9. After all data stores have stopped, shut down the locator as well:
sqlf locator stop -dir=locator1
Perform Additional Tasks
After you complete the SQLFire tutorial, you can perform related tutorial tasks to explore other areas of the
product.
Explore the toursDB Database
The example toursDB database manages information about air transportation for scheduling flights. If you need
quick access to a database to use when trying SQLFire features, toursDB DDL and data script sare available in
the quickstart directory. To view the toursDB schema, see ToursDB sample database
Explore SQLFire Language Extensions
The tutorial introduces the basics of partitioning, replication, and perisistence using simple modifications to the
toursDB DDL. See SQL Statements on page 458 to begin learning about other features that are implemented in
SQLFire DDL. Y ou can copy and modify the create_colocated_schema.sql as necessary to implement
new features.
vFabric SQLFire User's Guide44
Page 63

Chapter 8
vFabric SQLFire Features and Benefits
The sections that follow summarize main features. The SQLFire community site provides additional information about
the features and benefits of SQLFire and a comparison of SQLFire to other data management systems. See also the
SQLFire product page.
In-Memory Data Management with Optimized Disk Persistence
SQLFire enables applications to manage data entirely in memory by using partitioning and synchronous replication
to distribute the data across numerous SQLFire members. SQLFire also provides an optimized disk persistence
mechanism with a non-flushing algorithm to maintain high performance in applications that require stable, long-term
storage. Applications can also use SQLFire to actively cache table data from a traditional disk-based RDBMS.
Continuous Availability, Elastically Scaled, Low Latency
A flexible architecture enables SQLFire to pool memory and disk resources from hundreds of clustered members. This
clustered approach provides extremely high throughput, predictable latency, dynamic and linear scalability, and
continuous availability of data. By collocating application logic with data and executing application logic in parallel,
SQLFire substantially increases application throughput. It also transparently re-executes application logic if a server
fails.
Highly Adaptable to Existing Applications
SQLFire is implemented entirely in Java, and it can be embedded directly within a Java application. You can also
deploy SQLFire members as standalone servers that participate in a cluster . Jav a applications can connect to a SQLFire
cluster using the provided JDBC drivers. Microsoft .NET and Mono applications can connect using the provided
ADO.NET driver.
The use of JDBC, ADO.NET, and SQL means that many existing database applications can be easily adapted to use
a SQLFire cluster. SQLFire introduces se veral extensions to common SQL Data Definition Language (DDL) statements
to manage data partitioning, replication, synchronization with data sources, and other features. However , most common
queries and Data Manipulation Language (DML) statements are based on ANSI SQL-92, so experienced database
application developers can use their knowledge of SQL when working with SQLFire.
45
Page 64

Page 65

Part 2
Managing Your Data in vFabric SQLFire
Managing Your Data in vFabric SQLF ir e describes how to design your database schema to take adv antage of replication
and partitioning in a distributed SQLFire cluster. You can use this information to design new databases, or to adapt an
existing database for use with SQLFire. This guide also describes how to persist your data to disk store files, and it
provides a simple procedure for importing an existing database into SQLFire.
Topics:
• Designing vFabric SQLFire Databases
• Using Server Groups to Manage Data
• Partitioning Tables
• Replicating Tables
• Estimating Memory Requirements
• Using Disk Stores to Persist Data
• Exporting and Importing Data with vFabric SQLFire
• Using Table Functions to Import Data as a SQLFire Tables
47
Page 66

Page 67

Chapter 9
Designing vFabric SQLFire Databases
Unlike in traditional database design, SQLFire requires the designer to analyze the common access patterns and choose
a partitioning strategy that results in queries that are pruned to a single partition. In addition, fact tables may need to
be replicated in order to make data available for join operations against partitioned data. This chapter describes the
basic table design principles that you can use to achieve linear scaling with SQLFire.
Design Principles of Scalable, Partition-Aware Databases
A key design principle for linear scaling is a partitioning strategy that allows most data access (queries) to be
pruned to a single partition, thus avoiding expensive locking or latching across multiple partitions during query
execution.
In a highly concurrent system having thousands of connections, multiple queries are uniformly spread across
the entire data set (and therefore across all partitions), and increasing the number of data stores enables linear
scalability. Given sufficient network performance, more connections can be supported without degrading the
response time.
Note: SQLFire supports distributed queries by parallelizing the query execution across data stores.
However, each query instance on a partition can only join rows that are collocated with the partitioned
data. This means that queries can join rows between a partitioned table and any number of replicated
tables hosted on the data store with no restrictions. But queries that join multiple, partitioned tables have
to be filtered based on the partitioning key. Query examples are provided in this section and in Query
Capabilities and Limitations on page 690.
Identify Entity Groups and Partitioning Keys
In relational database terms, an entity group corresponds to rows that are related to one another through foreign
key relationships. Members of an entity group are typically related by parent-child relationships and can be
managed in a single partition. To design a SQLFire database for data partitioning, begin by identifying "entity
groups" and their associated partitioning keys.
For example:
• In a customer order management system, most transactions operate on data related to a single customer at a
time. Queries frequently join a customer's billing information with their orders and shipping information. For
this type of application, you partition related tables using the customer identity. Any customer row along with
their "order" and "shipping" rows forms a single entity group having the customer ID as the entity group identity
(partitioning key). Partitioning related tables using the customer identity enables you to scale the system linearly
as you add more members to support additional customers.
• In a system that manages a comprehensive product catalog (product categories, product specifications, customer
reviews, rebates, related products, and so forth) most data access focuses on a single product at a time. In such
a system, you would partition your data on the product key.
49
Page 68

Managing Your Data in vFabric SQLFire
• In an online auction application, you may need to stream incoming auction bids to hundreds of clients with
very low latency. To do so, you must manage selected "hot" auctions on a single partition so that they receive
sufficient processing power . As the processing demand increases, add more partitions and route the application
logic that matches bids to clients to the data store itself.
• In a financial trading engine that constantly matches bid prices to asking prices for thousands of securities,
partition data using ID of the security. When market data for a security changes, all of the related reference
data is co-located with the matching algorithm to ensure low-latency execution.
Life beyond Distributed Transactions provides additional background information about entity groups and
distributed systems.
Creating Partitioned Tables on page 62 describes other ways to partition a table in SQLFire.
Use Entity Groups Instead of "Sharding"
Sharding is a common strategy in traditional databases where database rows are horizontally partitioned into
multiple "database shards."
There are a number of differences between application-assisted or system-assisted sharding and SQLFire
partition-aware database design:
• Rebalancing: SQLFire rebalances the data automatically by making sure that related rows are migrated together
and without any integrity loss. This enables you to add capacity as needed.
• Distributed transactions: SQLFire transaction boundaries are not limited to a single partition. Atomicity and
isolation guarantees are provided across the entire distributed system.
• Parallel scatter-gather: Queries that cannot be pruned to a single partition are automatically executed in
parallel on data stores. Joins can be performed between tables with the restriction that the joined rows are in
fact collocated.
• Subqueries on remote partitions: Even when a query is pruned to a single partition, the query can execute
subqueries that operate on data that is stored on remote partitions.
Replicate Code Tables
The "star" schema is the most common relational design pattern. In a star schema, large "fact" tables have foreign
key relationships to one or more "code" or "dimension" tables. With SQLFire, you should denormalize code
tables into fact tables when possible. When this is not possible, determine whether code tables can be replicated
in the SQLFire cluster.
The main goal is to partition the entities in fact tables, but to replicate the rows in slow-changing code tables on
each member where the partitions are managed. In this way, a join between the fact table and any number of its
code tables can be executed concurrently on each partition, without requiring network hops to other members.
Replicating Tables on page 69 provides more information.
Dealing with Many-to-Many Relationships
Where tables have many-to-many relationships, you have a choice of strategies for handling queries that need
to join non-colocated data.
Note: Joins are permitted only on data that is colocated. Query execution can be distributed and ex ecuted
in parallel, but the joined rows in each partition member have to be restricted to other rows in the same
partition.
For tables have many-to-many relationships, choose one of the following strategies to handle queries that need
to join non-colocated data:
vFabric SQLFire User's Guide50
Page 69

Designing vFabric SQLFire Databases
• Use parallel, data-aware procedures to run the logic for the query on the member that stores some or all of the
data (to minimize data distribution hops). The procedure should execute multiple queries and then join the
results using application code. Using Data-Aware Stored Procedures on page 153 provides more information.
• Split the query into multiple queries, and perform the join in the application client code.
Example: Adapting a Database Schema for SQLFire
If you have an existing database design that you want to deploy to SQLFire, translate the entity-relationship
model into a physical design that is optimized for SQLFire design principles.
The goal is to identify tables to partition or replicate in the SQLFire cluster, and determine the partitioning key(s)
for partitioned tables. This generally requires an iterative process to produce the most optimal design.
Procedure
1. Read Guidelines for Adapting a Database to SQLFire on page 51and the preceding sections under Designing
vFabric SQLFire Databases on page 49.
2. Evaluate data access patterns to define entity groups that are candidates for partitioning. See Step 1: Determine
the entity groups on page 52.
3. Identify all tables in the entity groups. See Step 2: Identify the tables in each entity group on page 52.
4. Identify the "partitioning key" for each partitioned table. The partitioning ke y is the column or set of columns
that are common across a set of related tables. See Step 3: Define the partitioning key for each group on page
53.
5. Identify the tables that are candidates for replication. You can replicate table data for high availability, or to
co-locate table data that is necessary to execute joins. See Step 4: Identify replicated tables on page 53.
Guidelines for Adapting a Database to SQLFire
Follow these guidelines for designing a SQLFire database or adapting an existing database to SQLFire:
• Focus your efforts on commonly-joined entities. Remember that all join queries must be performed on data
that is co-located. In this release, SQLFire only supports joins where the data is co-located. Co-located data is
also important for transaction updates, because the transaction can execute without requiring distributed locks
in a multi-phase commit protocol.
• After you locate commonly-joined entities, look for parent-child relationships in the joined tables. The
primary key of a root entity is generally also the best choice for partitioning key.
• Understand the trade-offs associated with different partitioning and co-location strategies.The steps that
follow describe how to evaluate a customer order management system.
This example shows tables from the Microsoft Northwind Traders sample database.
51
Page 70

Managing Your Data in vFabric SQLFire
Step 1: Determine the entity groups
Entity groups are generally course-grained entities that have children, grand children, and so forth, and they are
commonly used in queries. This example chooses these entity groups:
DescriptionEntity group
Customer
Product
This group uses the customer identity along with orders and order
details as the children.
This group uses product details along with the associated supplier
information.
Step 2: Identify the tables in each entity group
Identify the tables that belong to each entity group. In this example, entity groups use the following tables.
TablesEntity group
Customer
Customers
Orders
Shippers
vFabric SQLFire User's Guide52
Page 71

TablesEntity group
Order Details
Designing vFabric SQLFire Databases
Product
Product
Suppliers
Category
Step 3: Define the partitioning key for each group
In this example, the partitioning keys are:
Partitioning keyEntity group
CustomerIDCustomer
ProductIDProduct
This example uses customerID as the partitioning key for the Customer group. The customer ro w and all associated
orders will be collocated into a single partition. To explicitly colocate Orders with its parent customer row, use
the colocate with clause in the create table statement:
create table orders (<column definitions, constraints>)
partition by (customerID)
colocate with (customers);
Create the OrderDetails table in a similar fashion. In this way, SQLFire supports any queries that join any of
Customer, Orders, and OrderDetails. This join query w ould be distributed to all partitions and executed in parallel,
with the results streamed back to the client:
select * from customer c , orders o where c.customerID = o.customerID;
A query such as this would be pruned to the single partition that stores "customer100" and executed only on that
SQLFire member:
select * from customer c, orders o where c.customerID = o.customerID
and c.customerID = 'customer100';
The optimization provided when queries are highly selective comes from engaging the query processor and
indexing on a single member rather than on all partitions. With all customer data managed in memory, query
response times are very fast. Consider how the above query would execute if the primary key was not used to
partition the table. In this case, the query would be routed to each partition member where an index lookup would
be performed, even though only a single member might have any data associated with the query.
Finally, consider a case where an application needs to access customer order data for several customers:
select * from customer c, orders o
where c.customerID = o.customerID and c.customerID IN ('cust1', 'cust2',
'cust3');
Here, SQLFire prunes the query execution to only those partitions that host 'cust1', 'cust2', and 'cust3'. The union
of the results is then returned to the caller.
Step 4: Identify replicated tables
If we assume that the number of categories and suppliers rarely changes, those tables can be replicated in the
SQLFire cluster (replicated to all of the SQLFire members that host the entity group). If we assume that the
Products table does change often and can be relatively large in size, then partitioning is a better strate gy for that
table.
53
Page 72

Managing Your Data in vFabric SQLFire
So for the product entity group, table Products is partitioned by ProductID, and the Suppliers and Categories
tables are replicated to all of the members where Products is partitioned.
Applications can now join Products, Suppliers and categories. For example:
select * from Products p , Suppliers s, Categories c
where c.categoryID = p.categoryID and p.supplierID = s.supplierID
and p.productID IN ('someProductKey1', ' someProductKey2', '
someProductKey3');
In the above query, SQLFire prunes the query execution to only those partitions that host 'someProductKey1', '
someProductKey2', and ' someProductKey3.'
vFabric SQLFire User's Guide54
Page 73

Chapter 10
Using Server Groups to Manage Data
Use server groups to control where table data is stored.
Server Groups Overview
A server group specifies the SQLFire members that will host data for a table. Y ou use a server group to logically
group SQLFire data stores for managing a table's data.
Any number of SQLFire members that host data can participate in one or more server groups. You specify named
server groups when you start a SQLFire data store.
55
Page 74

Managing Your Data in vFabric SQLFire
A SQLFire member that is booted with host-data=false is an accessor and does not host table data, even
if you specify one or more server groups. However, peer clients that host data can also participate in server
groups.
vFabric SQLFire User's Guide56
Page 75

Using Server Groups to Manage Data
By default, all servers that host data are added to the "default" server group.
Different logical database schema are often managed in different server groups. F or example, an order management
system might manage all customers and their orders in an "Orders" schema deployed to one server group. The
same system might manage shipping and logistics data in a different server group. A single peer or server can
participate in multiple server groups, typically as a way to colocate related data or to control the number of
redundant copies in replicated tables.
With support for dynamic group membership, the number of processes hosting data for a server group can change
dynamically. Ho we ver, this dynamic aspect of server group membership is abstracted away from the application
developer, who can look at a server group as a single logical server.
Server groups only determine those peers and servers where a table's data is being managed. Tables are always
accessible for any peer member of the distributed system, and from thin clients that connect to a single server.
When you invoke server side procedures, you can parallelize the execution of the procedure on all members in
the server group. These data-aware procedures also e x ecute on any peer clients that belong to the serv er groups.
Without associating tables to specific member IP addresses, the capacity of a server group can be dynamically
increased or decreased without any impact to existing servers or client applications. SQLFire can automatically
rebalance the tables in the server group to the newly added members.
Adding Members to Server Groups
You define server group membership and/or create a server group when you start a SQLFire member using the
server-groups boot property.
57
Page 76
Managing Your Data in vFabric SQLFire
For example, if you start a SQLFire server from the command line with sqlf, use the server-groups
property to specify the names of one or more server groups that the server should join:
sqlf server start
-server-groups=OrdersDB,OrdersReplicationGrp,DBProcessInstance1
In this example, the SQLFire server participates in three server groups: OrdersDB, OrdersReplicationGrp and
DBProcessInstance1. If this is the first SQLFire member to define a named server group, then SQLFire creates
the group and adds the new member after startup. If other SQLFire members in the cluster were booted using
the same server group, then SQLFire adds this new member to the existing group. If you specify no
-server-groups property, then SQLFire automatically adds the data store member to the default server
group.
If you start a SQLFire peer client from within a Java application, specify the server-groups property as
part of the JDBC peer client connection string. For example, use the connection URL:
jdbc:sqlfire:;mcast-port=33666;host-data=true;server-groups=OrdersDB,OrdersReplicationGrp,DBProcessInstance1
Starting and Configuring SQLFire Servers on page 223 and Starting SQLFire Servers with the FabricServer
Interface on page 109 provide more information about specifying boot properties.
Assigning Tables to Server Groups
When you create a new table, the CREATE TABLE statement can specify the server group to which the table
belongs.
A partitioned table is spread across all of the members of the specified server group. A replicated table is replicated
to all members of the server group. See Replicating Tables on page 69.
For example, the following command creates a replicated table on two server groups:
CREATE TABLE COUNTRIES
(
COUNTRY VARCHAR(26) NOT NULL,
COUNTRY_ISO_CODE CHAR(2) NOT PRIMARY KEY,
REGION VARCHAR(26),
) SERVER GROUPS (OrdersDB, OrdersReplicationGrp)
Tables in SQLFire are replicated by default if you do not specify partitioning.
If you do not specify one or more server group names, tables are partitioned or replicated across all members of
the default server group for that schema. This behavior may not be desirable in all situations. For example, if
the data in a replicated table changes frequently, the cost of maintaining a copy on each server in the default
group may be prohibitive. In this case, the application developer or system administrator can have several
members participate in a new, smaller server group to limit the number of replicas.
When two tables are partitioned and colocated, it forces partitions that have the same values for those columns
in the two tables to be located on the same member. Colocated tables must belong to at least one common serv er
group. As a best practice, you deploy colocated tables on e xactly the same server groups. See P artitioning Tables
on page 59.
vFabric SQLFire User's Guide58
Page 77

Chapter 11
Partitioning Tables
Horizontal partitioning involv es spreading a large data set (many ro ws in a table) across members in a cluster . SQLFire
uses a variant of the consistent hash algorithm to ensure that data is uniformly balanced across all members of the
target server group.
How Table Partitioning Works
Y ou specify the partitioning strate gy of a table in the PARTITION BY clause of the CREATE TABLE statement.
The available strategies include hash-partitioning on each ro w's primary k ey v alue, hash-partitioning on column
values other than the primary key, range-partitioning, and list-partitioning.
SQLFire maps each row of a partitioned table to a logical "bucket." The mapping of rows to buckets is based
on the partitioning strategy that you specify. For example, with hash-partitioning on the primary key, SQLFire
determines the logical bucket by hashing the primary key of the table. Each bucket is assigned to one or more
members, depending on the number of copies that you configure for the table. Configuring a partitioned table
with one or more redundant copies of data ensures that partitioned data remains available even if a member is
lost.
When members are lost or removed, the buckets are reassigned to ne w members based on load. Losing a member
in the cluster never results in re-assigning rows to buckets. You can specify the total number of buckets to use
with the BUCKETS Clause clause of the CREATE TABLE statement. The default number of buckets is 113.
In SQLFire, all peer servers in a distributed system know which peers host which b uckets, so they can efficiently
access a row with at most one network hop to the member that hosts the data. Reads or writes to a partitioned
table are transparently routed to the server that hosts the row that is the target of the operation. Each peer maintains
persistent communication channels to every peer in the cluster.
59
Page 78

Managing Your Data in vFabric SQLFire
Figure 2: Partitioned Table Data
Although each bucket is assigned to one or more specific servers, you can use a procedure to relocate buckets
in a running system, in order to improve the utilization of resources across the cluster . See Rebalancing Partitioned
Data on SQLFire Members on page 66.
Understanding Where Data Is Stored
SQLFire uses a table's partitioning column values and the partitioning strategy to calculate routing values
(typically integer values). It uses the routing values to determine the "bucket" in which to store the data.
Each bucket is then assigned to a server, or to multiple servers if the partitioned table is configured to have
redundancy . The b uckets are not assigned when the table is started up, b ut occurs lazily when the data is actually
put into a bucket. This allows you to start a number of members before populating the table.
vFabric SQLFire User's Guide60
Page 79

Partitioning Tables
Figure 3: Partitioned Data in Buckets
If you set the redundant-copies for the table to be greater than zero, SQLFire designates one of the copies of
each bucket as the primary copy. All writes to the bucket go through the primary copy. This ensures that all
copies of the bucket are consistent.
The Group Membership Service (GMS) and distributed locking service ensure that all distributed members hav e
a consistent view of primaries and secondaries at any moment in time across the distributed system, regardless
of membership changes initiated by the administrator or by failures.
Failure and Redundancy
If you have redundant copies of a partitioned table, you can lose servers without loss of data or interruption of
service. When a server fails, SQLFire automatically re-routes any operations that were trying to write to the
failed member to the surviving members.
SQLFire also attempts to re-route failed read operations to another server if possible. If a read operation returns
only a single row, then transparent failover is always possible. However, if an operation returns multiple rows
and the application has consumed one or more rows, then SQLFire cannot fail over if a server involved in the
query happens goes offline before all the results have been consumed; in this case the application receives a
SQLException with SQLState X0Z01. All applications should account for the possibility of receiving such an
exception, and should manually retry the query if such a failure occurs..
Read operations are also retried if a server is unavailable when a query is performed. In this figure, M1 is reading
table values W and Y. It reads W directly from its local copy and attempts to read Y from M3, which is currently
offline. In this case, the read is automatically retried in another available member that holds a redundant copy
of the table data.
61
Page 80

Managing Your Data in vFabric SQLFire
Creating Partitioned Tables
You create a partitioned table on a set of servers identified by named server groups (or on the default server
group if you do not specify a named server group). Clauses in the CREATE TABLE statement determine how
table data is partitioned, colocated, and replicated across the server group.
This topic focuses on the partitioning_clause in CREATE TABLE. The CREATE TABLE reference
page describes all of the options in more detail.
The partitioning_clause controls the location and distribution of data in server groups. Using server
groups and colocation is important for optimizing queries, and it is essential for cross-table joins. This version
of SQLFire does not support cross-table joins for non-colocated data, so you must choose the partitioning clause
carefully to enable the joins required by your application.
The partitioning clause can specify column partitioning, range partitioning, list partitioning, or expression
partitioning:
{
{
PARTITION BY { PRIMARY KEY | COLUMN ( column-name [ , column-name ]* )
}
|
vFabric SQLFire User's Guide62
Page 81

Partitioning Tables
PARTITION BY RANGE ( column-name )
(
VALUES BETWEEN value AND value
[ , VALUES BETWEEN value AND value ]*
)
|
PARTITION BY LIST ( column-name )
(
VALUES ( value [ , value ]* )
[ , VALUES ( value [ , value ]* ) ]*
)
|
PARTITION BY ( expression )
}
[ COLOCATE WITH ( table-name [ , table-name ] * ) ]
}
[ REDUNDANCY integer-constant ]
[ BUCKETS integer-constant ]
[ MAXPARTSIZE integer-constant ]
[ RECOVERYDELAY integer-constant ]
Note: If the table has no primary key , then SQLFire generates a unique row ID that is uses for partitioning
the data.
SQLFire supports the partitioning strategies described below.
DescriptionPartitioning strategy
Column partitioning
Range partitioning
List partitioning
Expression partitioning
The PARTITION BY COLUMN clause defines a set of column names to use as the basis for
partitioning. As a short-cut, you can use PARTITION BY PRIMAR Y KEY to refer to the table's primary
key column(s). SQLFire uses an internal hash function that typically uses the hashCode() method of
the underlying Java type for the specified column. For multiple columns, the internal hash function
uses the serialized bytes of the specified columns to compute the hash.
The PARTITION BY RANGE clause specifies the ranges of a field that should be colocated.
This ensures the locality of data for range queries and for cross-table joins. The lower limit of the range
is inclusive and the upper limit is exclusiv e. It is not necessary for the ranges to cover the whole spectrum
of possible values for the field. Values that are not covered by the range are automatically partitioned
in the server group, but with no guarantee of locality for those values.
The PARTITION BY LIST clause specifies the set of values of a field that should be colocated
to optimize queries and to support cross-table joins. It is not necessary to list all of the possible values
for the field. Any the v alues that are not part of the list are automatically partitioned in the server group,
but with no guarantee of locality for those values.
The PARTITION BY ( expression ) clause that includes an expression is a type of
hash partitioning that uses the expression to specify the value on which to hash. The expression must
only reference field names from the table. This allows rows to be colocated based on a function of their
values.
Partitioning Examples
You can partition tables by, for example, column (such as customer name), expression, priority ranges, and
status.
63
Page 82

Managing Your Data in vFabric SQLFire
Partition Based on Columns
This statement creates a table that is partitioned by the "CustomerName" column. All rows with the same
CustomerName are guaranteed to be colocated in the same process space. Here, the SERVER GROUPS clause
determines the peers and servers that host data for the partitioned table. A server group is a subset of all the peers
and servers that host data in the distributed system.
CREATE TABLE Orders
(
OrderId INT NOT NULL,
ItemId INT,
NumItems INT,
CustomerName VARCHAR(100),
OrderDate DATE,
Priority INT,
Status CHAR(10),
CONSTRAINT Pk_Orders PRIMARY KEY (OrderId)
)
PARTITION BY COLUMN ( CustomerName )
SERVER GROUPS ( OrdersDBServers);
Partition Based on Ranges
When you use the PARTITION BY RANGE clause, specify a column with multiple ranges of values to use for
partitioning. The following example specifies partitioning based on three ranges of values for the "Priority"
column:
CREATE TABLE Orders
(
OrderId INT NOT NULL,
ItemId INT,
NumItems INT,
CustomerName VARCHAR(100),
OrderDate DATE,
Priority INT,
Status CHAR(10),
CONSTRAINT Pk_Orders PRIMARY KEY (OrderId)
)
PARTITION BY RANGE ( Priority )
(
VALUES BETWEEN 1 AND 11,
VALUES BETWEEN 11 AND 31,
VALUES BETWEEN 31 AND 50
);
Partition Based on a List
When you use the P ARTITION BY LIST clause, specify a column name and one or more lists of column values
to use for partitioning. The following example partitions the table based on three different lists of values for the
"Status" column:
CREATE TABLE Orders
(
OrderId INT NOT NULL,
ItemId INT,
NumItems INT,
CustomerName VARCHAR(100),
OrderDate DATE,
Priority INT,
Status CHAR(10),
CONSTRAINT Pk_Orders PRIMARY KEY (OrderId)
vFabric SQLFire User's Guide64
Page 83

Partitioning Tables
)
PARTITION BY LIST ( Status )
(
VALUES ( 'pending', 'returned' ),
VALUES ( 'shipped', 'received' ),
VALUES ( 'hold' )
);
Partition Based on an Expression
Expression partitioning partitions a table by evaluating a SQL expression that you supply. For example, the
following statement partitions the table based on the month of the OrderDate column, using the MONTH function
as the SQL expression:
CREATE TABLE Orders
(
OrderId INT NOT NULL,
ItemId INT,
NumItems INT,
CustomerName VARCHAR(100),
OrderDate DATE,
Priority INT,
Status CHAR(10),
CONSTRAINT Pk_Orders PRIMARY KEY (OrderId)
)
PARTITION BY ( MONTH( OrderDate ) );
Colocating Related Rows from Multiple Tables
The COLOCATE WITH clause specifies the tables with which the partitioned table must be colocated.
Note: Tables that are referenced in the COLOCATE WITH clause must exist at the time you create the
partitioned table.
When two tables are partitioned on columns and colocated, it forces partitions having the same values for those
columns in both tables to be located on the same SQLFire member. F or e xample, with range or list partitioning,
any rows that satisfy the range or list are colocated on the same member for all the colocated tables.
When you specify the COLOCATE WITH clause, you must use the PARTITION BY clause to specify partition
columns in the target tables in the same order using the same partitioning strategy (for example, with identical
ranges). The columns must also be of the same type, not considering constraints. Any REDUNDANCY or BUCKETS
clause must also be the same as the tables with which it is colocated.
Note: In order for two partitioned tables to be colocated, the SER VER GR OUPS clauses in both CREA TE
TABLE statements must be identical. In order for two replicated tables to be colocated, both tables must
specify the same server groups or one table's server groups must be a subset of the other table's server
groups.
For example, if you create the partitioned table, "countries," as follows:
CREATE TABLE COUNTRIES
(
COUNTRY VARCHAR(26) NOT NULL CONSTRAINT COUNTRIES_UNQ_NM Unique,
COUNTRY_ISO_CODE CHAR(2) NOT NULL CONSTRAINT COUNTRIES_PK PRIMARY KEY,
REGION VARCHAR(26),
CONSTRAINT COUNTRIES_UC
CHECK (country_ISO_code = upper(country_ISO_code) )
) PARTITION BY PRIMARY KEY
65
Page 84

Managing Your Data in vFabric SQLFire
You can colocate another table, "cities," using the command:
CREATE TABLE CITIES
(
CITY_ID INTEGER NOT NULL CONSTRAINT CITIES_PK Primary key,
CITY_NAME VARCHAR(24) NOT NULL,
COUNTRY VARCHAR(26) NOT NULL,
AIRPORT VARCHAR(3),
LANGUAGE VARCHAR(16),
COUNTRY_ISO_CODE CHAR(2) CONSTRAINT COUNTRIES_FK
REFERENCES COUNTRIES (COUNTRY_ISO_CODE)
) PARTITION BY COLUMN (COUNTRY_ISO_CODE)
COLOCATE WITH (COUNTRIES)
In this example, both "countries" and "cities" are partitioned using the COUNTRY_ISO_CODE column. Rows
with the same COUNTRY_ISO_CODE value are colocated on the same SQLFire members.
See the CREATE TABLE reference page for more information.
Making a Partitioned Table Highly Available
Use the REDUNDANCY clause to specify a number of redundant copies of a table for each partition to maintain.
Because SQLFire is primarily a memory-based data management system, it is important to use redundancy when
necessary to enable fail-over if a member shuts down or fails. However, keep in mind that maintaining a large
number of redundant copies has an adverse impact on performance, network usage, and memory usage. A
REDUNDANCY value of 1 is recommended to maintain a secondary copy of the table data. For example:
CREATE TABLE COUNTRIES
(
COUNTRY VARCHAR(26) NOT NULL,
COUNTRY_ISO_CODE CHAR(2) NOT PRIMARY KEY,
REGION VARCHAR(26),
)
REDUNDANCY 1
SQLFire attempts to place copies of the same bucket onto hosts that have different IP addresses if possible, to
protect against machine failure. Howev er , if there is only one machine a v ailable SQLFire places multiple copies
on that machine. Setting the enforce-unique-host boot property prevents SQLFire from ever placing
multiple copies on the same machine.
Set the redundancy-zone boot property to ensure that SQLFire places redundant copies on specific zones
that you define. For example, to ensure that redundant copies are placed on different racks, set the redundanc y-zone
for each machine to the logical name of the rack on which the machine runs.
See Boot PropertiesY ou specify boot properties when starting a SQLFire serv er with the FabricServer API; when
you make the first connection to an embedded SQLFire member with the JDBC embedded driver; and when
you use the sqlf connect peer command. .
Limiting the Memory Consumption on a Member
Use the MAXPARTSIZE clause of the CREATE TABLE statement to load- balance partitioned data among the
available members.
The MAXPARTSIZE ClauseExample with BUCKETS, RECOVERYDELAY, and MAXPARTSIZE clause
specifies the maximum memory for any partition on a SQLFire member.
Rebalancing Partitioned Data on SQLFire Members
You can use rebalancing to dynamically increase or decrease your SQLFire cluster capacity, or to improve the
balance of data across the distributed system.
vFabric SQLFire User's Guide66
Page 85

Partitioning Tables
Rebalancing is a SQLFire member operation that affects partitioned tables created in the cluster. Rebalancing
performs two tasks:
• If the a partitioned table's redundancy setting is not satisfied, rebalancing does what it can to recover redundancy .
See Making a Partitioned Table Highly Available on page 66.
• Rebalancing moves the partitioned table's data buckets between host members as needed to establish the best
balance of data across the distributed system.
For efficiency, when starting multiple members, trigger the rebalance a single time, after you have added all
members.
Note: If you have transactions running in your system, be careful in planning your rebalancing operations.
Rebalancing may move data between members, which could cause a running transaction to fail with a
TransactionDataRebalancedException.
Start a rebalance operation using one of the following options:
• At the command line when you boot a SQLFire server:
sqlf server start -rebalance
• Eexecuting a system procedure in a running SQLFire member:
call sys.rebalance_all_buckets();
This procedure initiates rebalancing of buckets across the entire SQLFire cluster for all partitioned tables.
How Partitioned Table Rebalancing Works
The rebalancing operation runs asynchronously.
As a general rule, rebalancing takes place on one partitioned table at a time. For tables that have colocated data,
rebalancing works on the tables as a group, maintaining the data colocation between the tables.
You can continue to access partitioned tables while rebalancing is in progress. Queries, DML operations, and
procedure executions continue while data is moving. If a procedure executes on a local data set, you may see a
performance degradation if that data moves to another member during procedure execution. Future invocations
are routed to the correct member.
For tables that are configured with expiration based on idle time, the rebalancing operation resets the last accessed
time of the table entries on buckets that are moved.
When to Rebalance a Partitioned Table
Y ou typically w ant to trigger rebalancing when overall capacity is increased or reduced through member startup,
shut down or failure.
You may also need to rebalance when you use partitioned table redundancy for high availability, and you have
configured your table to not automatically recover redundancy after a SQLFire member fails (the default
RECOVERYDELAY setting). In this case, SQLFire only restores redundancy when you invoke a rebalance
operation. See Making a Partitioned Table Highly Available on page 66.
Managing Replication Failures
SQLFire uses multiple failure detection algorithms to detect replication problems quickly. SQLFire replication
design focuses on consistency, and does not allow suspect members or network-partitioned members to operate
in isolation.
67
Page 86

Managing Your Data in vFabric SQLFire
Configuring suspect-member Alerts
When any member of the distributed system fails, it is important for other services to detect the loss quickly and
transition application clients to other members. An y peer or server in the cluster can detect a problem with another
member of the cluster, which initiates "SUSPECT" processing with the membership coordinator . The membership
coordinator then determines whether the suspect member should remain in the distributed system or should be
removed.
Use the ack-wait-threshold property to configure how long a SQLFire peer or server waits to recei v e an
acknowledgment from other members that are replicating a table's data. The default value is 15 seconds; you
specify a value from 0 to 2147483647 seconds. After this period, the replicating peer sends a severe alert w arning
to other members in the distributed system, raising a "suspect_member" alert in the cluster.
To configure how long the cluster waits for this alert to be acknowledged, set the
ack-severe-alert-threshold property. The default value is zero, which disables the property.
How Replication Failure Occurs
Failures during replication can occur in the following ways:
• A replica fails before sending an acknowledgment.
The most common failure occurs when a member process is terminated during replication. When this occurs,
the TCP connection from all members is terminated, and the membership view is updated quickly to reflect
the change. The member who initiated replication continues replicating to other members.
If instead of terminating, the process stays alive (but f ails to respond) the initiating member waits for a period
of time and then raises an alert with the distributed system membership coordinator . The membership coordinator
evaluates the health of the suspect member based on heartbeats and health reports from other members in the
distributed system. The coordinator may decide to evict the member from the distrib uted system, in which case
it communicates this change in the membership view to all members. At this point, the member that initiated
replication proceeds and completes replication using available peers and servers. In addition, clients connected
to this member are automatically re-routed to other members.
• An "Owning" member fails.
If the designated owner of data for a certain key fails, the system automatically chooses another replica to
become the owner for the key range that the failed member managed. The updating thread is blocked while
this transfer takes place. If at least one replica is available, the operations alw ays succeeds from the application's
viewpoint.
vFabric SQLFire User's Guide68
Page 87

Chapter 12
Replicating Tables
SQLFire server groups control which SQLFire data store members replicate the table's data. SQLFire replicates table
data both when a new table is initialized in a cluster and when replicated tables are updated.
How SQLFire Replicates Tables
SQLFire replicates every single row of a replicated table synchronously to each table replica in the tar get serv er
group(s). W ith synchronous replication, table reads can be e v enly balanced to any replica in the cluster, with no
single member becoming a contention point.
SQLFire replicates data to all peers in the server groups where the table was created. Replication occurs in
parallel to other peers over a TCP channel.
SQLFire replicates table data both when a new table is initialized in a cluster and when replicated tables are
updated.
Replication at Initialization
When a non-persistent ("memory only") replicated table is created in a peer or server, it initializes itself using
data from another member of the server group that hosts the table. A single data store member in the server group
is chosen, and data for the table is streamed from that member to initialize the new replica. If the selected member
fails during the replication process, the initializing process selects a different member in the server group to
stream the data.
Replication During Updates
When an application updates a replicated table, SQLFire distributes the update to all replicas in parallel, utilizing
the network bandwidth between individual members of the cluster . The sending peer or server locks the updated
row locally, and then distributes the update to the replicas. After each of the replicas processes the update and
responds with an acknowledgment message, the originating SQLFire peer returns control to the application. The
update process is conservative in order to ensure that all copies of a replicated table contain consistent data. Each
receiver processes the update entirely, applying constraint checks if necessary and updating the local table data,
before responding with an acknowledgment. Each operation on a single row key is performed atomically per
replica, regardless of how many columns are being read or updated.
Deciding When to Use Replicated Tables
Code tables are often good candidates for replication.
Application data is frequently normalized to maintain "code" fields in "fact" tables, and to maintain the details
associated with each "code" in an associated "dimension" table. Code tables are often small and change
infrequently, but they are frequently joined with their parent "fact" table in queries. Code tables of this sort are
good candidates for using replicated tables.
69
Page 88

Managing Your Data in vFabric SQLFire
Also note that this version of SQLFire supports joins only on co-located data. Instead of using partitioning in
all cases, you should consider having applications replicate smaller tables that are joined with other partitioned
tables.
Note: If multiple applications update the same row of a replicated table at the same time outside of a
transaction, the table data can become out of sync when SQLFire replicates those updates. Keep this
limitation in mind when using replicated tables.
Creating Replicated Tables
You can create replicated tables explicitly or by default, using CREATE TABLE statement.
SQLFire creates a replicated table by default when you execute a CREATE TABLE on page 476 statement and
you do not include a PARTITIONING clause. You can also explicitly create a replicated table using the
REPLICATE clause in the CREATE TABLE statement. For example:
CREATE TABLE COUNTRIES
(
COUNTRY VARCHAR(26) NOT NULL CONSTRAINT COUNTRIES_UNQ_NM Unique,
COUNTRY_ISO_CODE CHAR(2) NOT NULL CONSTRAINT COUNTRIES_PK PRIMARY
KEY,
REGION VARCHAR(26),
CONSTRAINT COUNTRIES_UC
CHECK (country_ISO_code = upper(country_ISO_code) )
) REPLICATE;
Because this command omits the SERVER GROUPS clause, the example creates the 'countries' table and
replicates it on members of the cluster that host data (all peers and servers in the default server group that set
the host-data property to true).
vFabric SQLFire User's Guide70
Page 89

Chapter 13
Estimating Memory Requirements
Designing a SQLFire database also involves estimating the memory requirements for your data based on the size of
the actual table values and indexes, the o verhead that SQLFire requires for your data, and the o v erall usage pattern for
your data. You can estimate the memory requirements for tables using general guidelines for SQLFire overhead. Or,
you can load tables with representative data and then query the SQLFire SYS.MEMORYANAL YTICS table to obtain
details about the memory required for individual tables and indexes.
Estimating SQLFire Overhead
SQLFire requires different amounts of overhead per table and index entry depending on whether you persist
table data or configure tables for overflow to disk. Add these overhead figures to the estimated size of each table
or index entry to provide a rough estimate for your data memory requirements. If you already have representati ve
data, use the SQLFire Java agent to query the SYS.MEMORYANALYTICS table to obtain a more accurate
picture of the memory required to store your data.
Note: All o verhead values are approximate. Be sure to validate your estimates in a test environment with
representative data.
Table 1: Approximate Overhead for SQLFire Table Entries
Approximate overheadOverflow is configured?Table is persisted?
64 bytesNoNo
120 bytesNoYes
152 bytesYesYes
Table 2: Approximate Overhead for SQLFire Index Entries
Approximate overheadType of index entry
80 bytesNew index entry
24 bytesFirst non-unique index entry
8 bytes to 24 bytes*Subsequent non-unique index entry
*If there are more than 100 entries for a single index entry, the overhead per entry increases from 8 bytes to
approximately 24 bytes.
71
Page 90

Managing Your Data in vFabric SQLFire
Viewing Memory Usage in SYS.MEMORYANALYTICS
SQLFire includes instrumentation to display the memory used by individual tables and indexes in a SQLFire
member. You can view this memory usage information by starting a Java agent process when you boot SQLFire
members, and then querying the SYS.MEMORYANALYTICS virtual table from a client connection.
Enabling SYS.MEMORYANALYTICS
Follow this procedure to enable the SYS.MEMORYANALYTICS virtual table.
Prerequisites
• Create an evaluation SQLFire distributed system to determine the memory footprint for your data. Do not
enable memory analytics on a production system.
• Y ou must ha ve representati ve table data and inde x entries in order to accurately ev aluate the memory footprint.
Create the necessary SQL scripts to automate creating your schema and loading data into your tables.
• Consider using fewer SQLFire members in the evaluation system to simplify the evaluation process.
• If your SQLFire distributed system uses locators for member discovery, be sure to enable the Java agent on
the locator as well as the data store members. Although a locator does not generally host data, you can use the
locator data to compare data memory footprints with non-data memory footprints.
Procedure
Follow these steps to start a SQLFire member with the Java agent to provide memory analytics:
1.
Use the -javaagent: jar_path Jav a system property to specify the sqlfire.jar file in your installation
when you start each SQLFire member. For example, if you use sqlf to start a SQLFire server:
sqlf server start -client-address=1527
-J-javaagent:c:\vFabric_SQLFire_11_bNNNNN\lib\sqlfire.jar
Specify the complete path and filename of sqlfire.jar for your system.
If you use a locator for member discovery, also use the -javaagent: jar_path system property when
starting the locator.
2. If your schema and data are not already available in the SQLFire system (as persisted data), run any necessary
SQL scripts to create the schema and load table data. For example:
cd c:\vFabric_SQLFire_11_bNNNNN\quickstart
sqlf
sqlf> connect client 'localhost:1527';
sqlf> run 'create_colocated_schema.sql';
sqlf> run 'loadTables.sql';
3. Connect to SQLFire and query the SYS.MEMORYANAL YTICS table to view the memory usage information:
sqlf
sqlf> connect client 'localhost:1527';
sqlf> select * from sys.memoryanalytics;
SQLENTITY
|ID
|MEMORY
---------------------------------------------------------------APP.FLIGHTS (Entry Size, Value Size, Row Count)
|dyozie-e4310(6880)<v0>:3439/59731
|30352,31436,542
AAP.FLIGHTS.DESTINDEX (Index Entry Overhead, SkipList Size, Max&
|dyozie-e4310(6880)<v0>:3439/59731
|2104,696,3 (2803 = 2.74 kb)
vFabric SQLFire User's Guide72
Page 91

Estimating Memory Requirements
APP.FLIGHTS.DESTINDEX (Index Entry Size, Value Size, Row Count)
|dyozie-e4310(6880)<v0>:3439/59731
|4888,3784,87
[...]
Understanding Table and Index Values
Querying the SYS.MEMORYANALYTICS table provides run-time information about the tables and indexes
available in SQLFire.
Table Values
Each table has a single row in SYS.MEMORYANALYTICS identitfied with the SQLENTITY format:
schema_name.table_name (Entry Size, Value Size, Row Count). The ID column value displays the values
separated by commas.
DescriptionTable Value
Entry Size
Value Size
Row Count
The per-entry overhead, in bytes. (This excludes the Value Size
below.)
The total size of a table row, in bytes. (This includes the Entry Size
overhead.)
The total number of rows stored on the local SQLFire member. For
a partitioned table, this includes all buckets for the table, as well as
primary and secondary replicas.
For example, the following row from SYS.MEMORYANALYTICS shows that the APP.FLIGHTS table has
30352 bytes of overhead per row, with 542 total rows:
SQLENTITY
|ID
|MEMORY
---------------------------------------------------------------APP.FLIGHTS (Entry Size, Value Size, Row Count)
|dyozie-e4310(6880)<v0>:3439/59731
|30352,31436,542
Index Values
Each index has two rows in SYS.MEMORYANALYTICS. The first row uses the SQLENTITY format:
schema_name.table_name.index_name (Index Entry Overhead, SkipList Size, Max Level). This row provides
details about concurrent skip lists for the index. The ID column value displays these v alues separated by commas:
DescriptionIndex Value
Index Entry Overhead
SkipList Size
The number of linked list objects that the index uses for storing the
entry.
The number of linked list objects that the index uses for skipping
values to expedite searches.
The total number of skip lists that are currently available for lookups.Max Level
73
Page 92
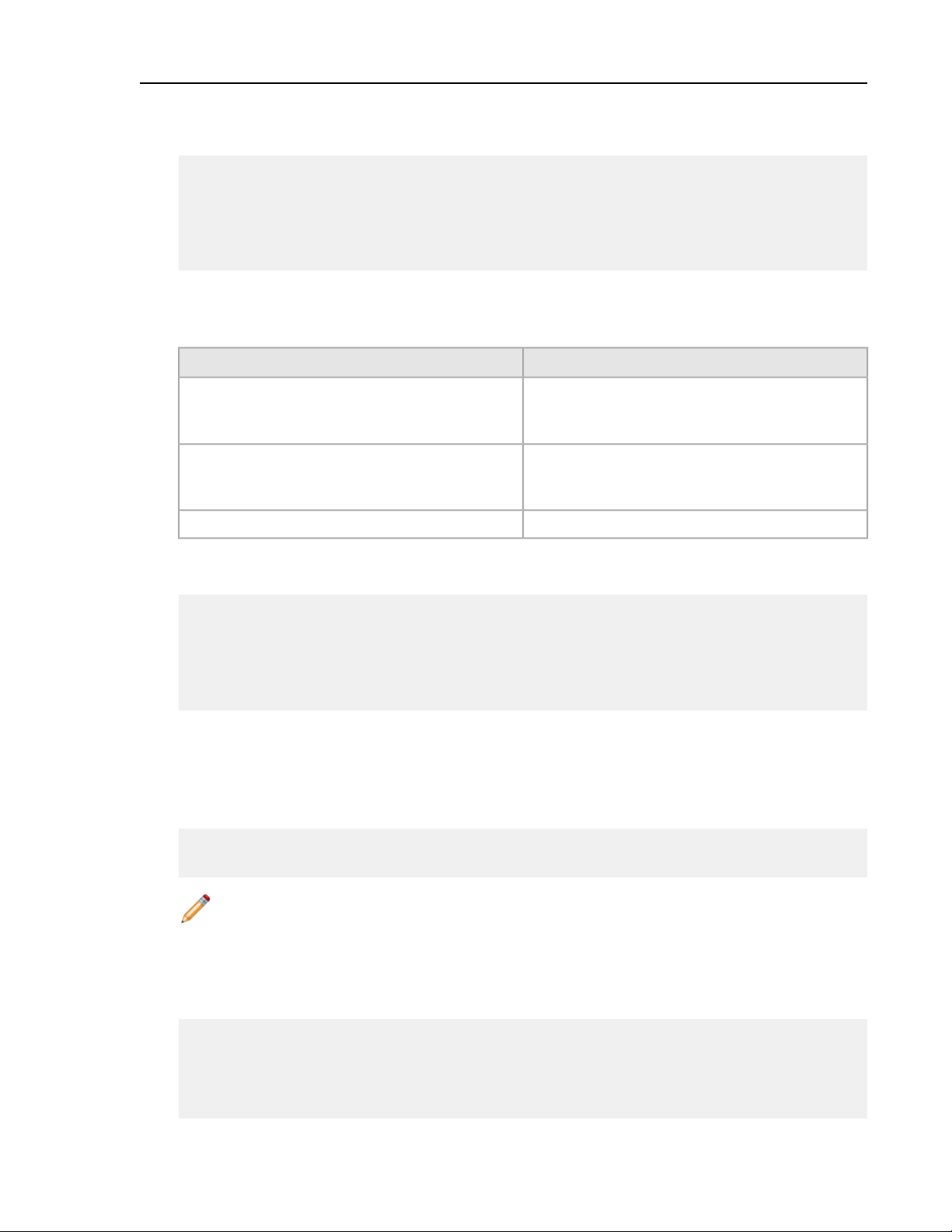
Managing Your Data in vFabric SQLFire
For example, the following row from SYS.MEMORYANALYTICS shows that APP.FLIGHTS.DESTINDEX
uses 2803 bytes for skip lists:
SQLENTITY
|ID
|MEMORY
----------------------------------------------------------------
APP.FLIGHTS.DESTINDEX (Index Entry Overhead, SkipList Size, Max&
|dyozie-e4310(6880)<v0>:3439/59731
|2104,696,3 (2803 = 2.74 kb)
The second row for an index uses the SQLENTITY format: schema_name.table_name.inde x_name (Index Entry
Size, Value Size, Row Count). This row provides information similar to the values for a table entry. The ID
column value displays these values separated by commas:
DescriptionIndex Value
Index Entry Size
Value Size
The per-index overhead, in bytes. (This includes the Index Entry
Overhead from the previous table, but excludes the Value Size
below.)
The size of the data structure used to point to the underlying region
entries, in bytes. For a unique index, this corresponds to the size of
a pointer reference.
The total number of entries in the index.Row Count
For example, the following row from SYS.MEMORYANALYTICS shows that APP.FLIGHTS.DESTINDEX
has 4888 bytes of overhead with 87 index entries:
SQLENTITY
|ID
|MEMORY
----------------------------------------------------------------
APP.FLIGHTS.DESTINDEX (Index Entry Size, Value Size, Row Count)
|dyozie-e4310(6880)<v0>:3439/59731
|4888,3784,87
Displaying the Total Memory Footprint
You can query SYS.MEMORYANALYTICS with an optmizer hint to display the complete memory footprint
of tables and indexes.
Use the sizerHints=withMemoryFootPrint hint with your query to display the memory footprint:
SELECT * FROM sys.memoryAnalytics -- SQLFIRE-PROPERTIES
sizerHints=withMemoryFootPrint
;
Note: When processing a SQL script file, SQLFire does not recognize the terminating semicolon character
if it appears at the end of a SQL comment line. For this reason, you must place the terminating semicolon
on a separate line by itself, if the optmizer hint extends to the end of the statement.
When you include this optimizer hint, the query displays an additional row for each table and index, summarizing
the memory footprint for the SQLFire, GemFire, and other components. For example:
SQLENTITY
|ID
|MEMORY
----------------------------------------------------------------
[...]
vFabric SQLFire User's Guide74
Page 93

Estimating Memory Requirements
APP.FLIGHTS (sqlfire,gemfire,others)
|dyozie-e4310(6880)<v0>:3439/59731
|12912,299736,680704 (993352 = 970.07 kb)
APP.FLIGHTS.DESTINDEX (sqlfire,gemfire,others)
|dyozie-e4310(6880)<v0>:3439/59731
|5072,0,3288 (8360 = 8.16 kb)
[...]
75
Page 94

Page 95

Chapter 14
Using Disk Stores to Persist Data
You can persist table data to disk as a backup to the in-memory copy, or ov erflo w table data to disk when memory use
gets too high.
Overview of Disk Stores
The two disk store options, overflow and persistence, can be used individually or together. Overflow uses disk
stores as an extension of in-memory table management for both partitioned and replicated tables. Persistence
stores a redundant copy of all table data managed in a peer.
See Evicting Table Data from SQLFire on page 187 for more information about configuring tables to overflow
to disk.
Data Types for Disk Storage
Disk storage is available for these data types:
• Table data. Persist and/or overflow table data managed in SQLFire peers.
• Gateway sender queues. Persist gateway sender queues for high availability in a WAN deployment. These
queues always overflow.
• AsyncEventListener and DBSynchronizer queues. Persist these queues for high availability. These queues
always overflow, and can be persistent.
You can store data from multiple tables and queues in a single disk store.
Creating Disk Stores and Using the Default Disk Store
Y ou create named disk stores in the data dictionary using the CREATE DISKSTORE DDL statement. Individual
tables can then specify named disk stores in their CREATE TABLE DDL statements to use the stores for
persistence and/or overflow. You can store data from multiple tables and queues in the same named disk store.
See Guidelines for Designing Disk Stores on page 83.
T ables that do not name a disk store b ut specify persistence or ov erflo w in their CREATE TABLE statement use
the default disk store. The location of the default diskstore is determined by the value of the sys-disk-dir
boot property. The default disk store is named SQLF-DEFAULT-DISKSTORE.
Gateway sender queues, AsyncEventListener queues, and DBSynchronizer queues can also be configured to use
a named disk store. The default disk store is used if you do not specify a named disk store when creating the
queue. See CREATE GATEWAYSENDER on page 469 or CREATE ASYNCEVENTLISTENER on page 462.
Peer Client Considerations for Persistent Data
Peer clients (clients started using the host-data=false property) do not use disk stores and can never persist
the SQLFire data dictionary. Instead, peer clients rely on other data stores or locators in the distributed system
77
Page 96
Managing Your Data in vFabric SQLFire
for persisting data. If you use a peer client to execute DDL statements that require persistence and there are no
data stores available in the distributed system, SQLFire throws a data store unavailable exception (SQLState:
X0Z08).
You must start locators and data stores before starting peer clients in your distributed system. If you start a peer
client as the first member of a distributed system, the client initializes an empty data dictionary for the distributed
system as a whole. Any subsequent datastore that attempts to join the system conflicts with the empty data
dictionary and fails to start with a ConflictingPersistentDataException.
Shared-Nothing Disk Store Design
Individual SQLFire peers that host table data manage their own disk store files, completely separate from the
disk stores files of any other member . When you create a disk store, you can define certain properties that specify
where and how each SQLFire peer should manages disk store files on their local filesystem.
SQLFire supports persistence for replicated and partitioned tables. The disk store mechanism is designed for
locally-attached disks. Each peer manages its own local disk store, and does not share any disk artifacts with
other members of the cluster. This shared nothing design eliminates the process-lev el contention that is normally
associated with traditional clustered databases. Disk stores use rolling, append-only log files to avoid disk seeks
completely. No comple x B-Tree data structures are stored on disk; instead SQLFire al ways assumes that complex
query navigation is performed using in-memory indexes.
Disk stores also support the SQLFire data rebalancing model. When you increase or decrease capacity by adding
or removing peers in a cluster, the disk data also relocates itself as necessary.
What SQLFire Writes to the Disk Store
For each disk store, SQLFire stores detailed information about related members and tables.
SQLFire stores these items in each disk store:
• List of members that host the store and information on their status, such as running or offline and time stamps.
• List of tables that use the disk store.
For each table in the disk store, SQLFire stores:
• Configuration attributes pertaining to loading and capacity management, used to load the data quickly on
startup.
• Table DML operations.
Disk Store State
Disk store access and management differs according to whether the store is online or offline.
When a member shuts down, its disk stores go offline. When the member starts up again, its disk stores come
back online in the SQLFire cluster.
• Online, a disk store is owned and managed by its member process.
• Offline, the disk store is simply a collection of files in your host file system. The files are open to access by
anyone with the right file system permissions. You can copy the files using your file system commands, for
backup or to move your member’s disk store location. You can also run maintenance operations on the offline
disk store, like file compaction and validation using the sqlf utility.
Note: The files for a disk store are used by SQLFire as a group. Treat them as a single entity. If you
copy them, copy them all together. Do not change the file names or permissions.
When a disk store is offline, its data is unavailable to the SQLFire distributed system. For partitioned tables,
the data is split between multiple members, so you can access the offline data only if you store replicas of the
partitioned table on other members of the cluster.
vFabric SQLFire User's Guide78
Page 97

Using Disk Stores to Persist Data
Disk Store Directories
When you create a disk store, optionally specify the location of directories where sqlf stores persistence-related
files.
sqlf generates disk store artifacts in a directory that it chooses in the following order:
1. If you provide absolute directory paths, sqlf uses the paths as-is. You must ensure that the proper directory
structure exists.
2. If you provide relative directory paths, or you do not specify an y directories, then the path resolution is done
in this order:
1.
If the sys-disk-dir boot property specifies a directory, the disk store path is resolv ed relati v e to that
directory or is used as the directory for persistence.
2.
If sys-disk-dir is not set, SQLFire uses the directory from which the system was started (the current
directory) for path resolution, or it uses that directory as the persistence directory.
Disk Store Persistence Attributes
SQLFire persists data on disk stores in synchronous or asynchronous mode.
You configure the persistence mode for a table in the CREATE TABLE statement, while attributes to control
asynchronous persistence are configured in the CREATE DISKSTOREstatement.
In synchronous mode, SQLFire writes each DML operation to the OS buffer as part of the statement ex ecution.
This mode provides greater reliability than asynchronous mode, but with lower performance.
In asynchronous mode, SQLFire batches DML statements before flushing them to the OS buffers. This is f aster
than synchronous mode, but batch operations may be lost if a failure occurs. (You can use redundancy to ensure
that updates are successfully logged on another machine.) In asynchronous mode, you can control the frequency
of flushing batches by setting the following attributes when you create a named disk store:
• QUEUESIZE sets the number of affected rows that can be asynchronously queued. After this number of
pending rows are queued, operations begin blocking until some of the modified, created, or deleted rows are
flushed to disk.
• TIMEINTERVAL sets the number of milliseconds that can elapse before queued data is flushed to disk.
See CREATE DISKSTORE on page 465
Note: Always start all SQLFire servers and peer processes that host data on disk in parallel. A SQLFire
process with persistent data may wait for other processes to startup first to guarantee consistency.
Always use the shutdown-all command to gracefully shut down a cluster. This allows each member to
reach a consistent replication state and record that state with other replicas in the cluster. When you restart
peers after a graceful shutdown, each member can recover in parallel without waiting for others to pro vide
consistent replication data.
Disk Store File Names and Extensions
Disk store files include store management and access control files and the operation log, or oplog, files, consisting
of one file for deletions and another for all other operations.
The next table describe file names and extensions; they are followed by example disk store files.
File Names
File names have three parts.
79
Page 98

Managing Your Data in vFabric SQLFire
First Part of File Name: Usage Identifier
ExamplesUsageUsage Identifier Values
OVERFLOW
only.
BACKUP
Oplog data from persistent and
persistent+overflow tables and queues.
Access control - locking the disk store.DRLK_IF
Second Part of File Name: Disk Store Name
Non-default disk stores.<disk store name>
SQLF-DEFAULT-DISKSTORE
Default disk store name, used when
persistence or overflow are specified on a
table or queue but no disk store is named.
OVERFLOWoverflowDS1_1.crfOplog data from overflow tables and queues
BACKUPoverflowDS1.if,
BACKUPSQLF-DEFAULT-DISKSTORE.if
DRLK_IFoverflowDS1.lk,
DRLK_IFSQLF-DEFAULT-DISKSTORE.lk
ExamplesUsageDisk Store Name Values
name=”OVERFLOWDS1”
DRLK_IFOVERFLOWDS1.lk,
name=”PERSISTDS1”
BACKUPPERSISTDS1_1.crf
Note: SQLFire internally converts
and uses disk store names in upper
case characters, even if you specify
lower case characters in the DDL
statement.
DRLK_IFSQLF-DEFAULT-DISKSTORE.lk,
BACKUPSQLF-DEFAUL T-DISKSTORE_1.crf
SQLF-DD-DISKSTORE
dictionary.
Third Part of File Name: oplog Sequence Number
Sequence number in the format _n
Oplog data files only. Numbering starts with
1.
File Extensions
Disk store metadataif
Disk store access controllk
crf
Oplog: create, update, and invalidate
operations
BACKUPSQLF-DD-DISKSTORE_1.crfDefault disk store for persisting the data
ExamplesUsageoplog Sequence Number
OVERFLOWoverflowDS1_1.crf,
BACKUPpersistDS1_2.crf,
BACKUPpersistDS1_3.crf
NotesUsageFile Extension Values
Stored in the first disk-dir listed for the store.
Negligible size - not considered in size
control.
Stored in the first disk-dir listed for the store.
Negligible size - not considered in size
control.
Pre-allocated 90% of the total max-oplog-size
at creation.
vFabric SQLFire User's Guide80
Page 99

Using Disk Stores to Persist Data
NotesUsageFile Extension Values
Oplog: delete operationsdrf
Oplog: key and crf offset informationkrf
Pre-allocated 10% of the total max-oplog-size
at creation.
Created after the oplog has reached the
max-oplog-size. Used to improve
performance at startup.
Disk Store Operation Logs
At creation, each operation log is initialized at the disk store's MAXLOGSIZE value, with the size divided
between the crf and drf files. SQLFire only truncates the unused space on a clean shutdown (for example,
sqlf server stop or sqlf shut-down-all).
After the oplog is closed, SQLFire also attempts to created a krf file, which contains the key names as well as
the offset for the value within the crf file. Although this file is not required for startup, if it is available, it will
improve startup performance by allowing SQLFire to load the entry values in the background after the entry
keys are loaded. See
When an operation log is full, SQLFire automatically closes it and creates a new log with the next sequence
number. This is called oplog rolling.
Note: Log compaction can change the names of the disk store files. File number sequencing is usually
altered, with some existing logs removed or replaced by newer logs with higher numbering. SQLFire
always starts a new log at a number higher than any existing number.
The system rotates through all available disk directories to write its logs. The next log is always started in a
directory that has not reached its configured capacity, if one exists.
When Disk Store oplogs Reach the Configured Disk Capacity
If no directory exists that is within its capacity limits, how SQLFire handles this depends on whether automatic
compaction is enabled.
• If A UT OCOMPACT is enabled (set to 'true), SQLFire creates a new oplog in one of the directories, going o ver
the limit, and logs a warning that reports:
Even though the configured directory size limit has been exceeded a
new oplog will be created. The current limit is of XXX. The current
space used in the directory is YYY.
Note: When auto-compaction is enabled, directory sizes do not limit how much disk space is used.
SQLFire performs auto-compaction, which should free space, but the system may go over the configured
disk limits.
• If auto-compaction is disabled, SQLFire does not create a new oplog. DML operations to tables block, and
SQLFire logs the error:
Disk is full and rolling is disabled. No space can be created
Factors Contributing to High Disk Throughput
SQLFire disk store design contains several factors that contribute to very high disk throughput. They include
pooling, avoiding seeks, and buffered logging.
81
Page 100

Managing Your Data in vFabric SQLFire
Pooling
Each SQLFire member manages its own disk store, and no disk contention exists between processes. Each
partition can manage its data on local disks.
If the application "write" load can be uniformly balanced across the cluster, the aggregate disk throughput is
equal to the disk transfer rate time the number of partitions, assuming a single disk per partition. Disk transfer
rates can be up to 100MB/sec on commodity machines today.
Avoiding Seeks
Random access on disk, which causes disk heads to seek for hundreds of concurrent thread, is probably the single
biggest reason why traditional databases do not scale. Average disk seek times today are still 2ms or higher.
SQLFire manages most (or all) of the data in cluster memory, and all reads are serv ed without navigating through
BTree-based indexes and data files on disk. This is the case when data is persistent. Note, however, that in
overflow-only mode, data files on disk are accessed as necessary.
Buffered Logging
When writes do occur, SQLFire simply logs the operations to disk in "append-only" oplog files. By appending,
SQLFire can continuously write to consecutive sectors on disk without requiring disk head mov ement. SQLFire
flushes writes to the OS buffer rather than 'fsync' all the way to disk. The writes are buf fered by the IO subsystem
in the kernel, which allows the IO scheduler to merge and sort disk writes to achieve the highest possible disk
throughput. Write requests need not initiate any disk I/O until some time in the future.
Thus, from the perspective of a user application, write requests stream at much higher speeds, unencumbered
by the performance of the disk. Risk of data loss due to sudden failures at a hardware level are mitigated by
having multiple members writing in parallel to disk. In fact, it is assumed that hardware will fail, especially in
large clusters and data centers, and that software needs to take these failures into account. The SQLFire system
is designed to recover in parallel from disk and to guarantee data consistency when data copies on disk do not
vFabric SQLFire User's Guide82
 Loading...
Loading...