

Page 1

パフォーマンス&チューニング・ガイド
Sybase® IQ
12.7
Page 2

ドキュメント ID: DC00283-01-1270-01
改訂: 2006 年 6 月
Copyright © 1991-2006 by Sybase, Inc. All rights reserved.
このマニュアルは Sybase ソフトウェアの付属マニュアルであり、新しいマニュアルまたはテクニカル・ノートで特に示さ
れないかぎりは、後続のリリースにも付属します。このマニュアルの内容は、予告なく変更されることがありますが、
Sybase, Inc. およびその関連会社では内容の変更に関して一切の責任を負いません。このマニュアルに記載されているソフ
トウェアはライセンス契約に基づいて提供されるものであり、無断で使用することはできません。
マニュアルの注文
マニュアルの注文を承ります。ご希望の方は、サイベース株式会社営業部または代理店までご連絡ください。マニュアル
の変更は、弊社の定期的なソフトウェア・リリース時にのみ提供されます。このマニュアルの内容を弊社の書面による事
前許可を得ずに電子的、機械的、手作業、光学的、またはその他のいかなる手段によっても複製、転載、翻訳することを
禁じます。
Sybase、SYBASE ( ロゴ )、ADA Workbench、Adaptable Windowing Environment、Adaptive Component Architecture、Adaptive Server、Adaptive
Server Anywhere、Adaptive Server Enterprise、Adaptive Server Enterprise Monitor、Adaptive Server Enterprise Replication、Adaptive Server
Everywhere、Advantage Database Server、Afaria、Answers Anywhere、Applied Meta、Applied Metacomputing、AppModeler、APT Workbench、
APT-Build、APT-Edit、APT-Execute、APT-Translator、APT-Library、ASEP、Avak i、Avaki (Arrow Design)、Avaki Data Grid、Avan tG o、Backup
Server、BayCam、Beyond Connected、Bit-Wise、BizTracker、Certified PowerBuilder Developer、Certified SYBASE Professional、Certified SYBASE
Professional Logo、ClearConnect、Client-Library、Client Services、CodeBank、Column Design、ComponentPack、Connection Manager、Convoy/
DM、Copernicus、CSP、Data Pipeline、Data Workbench、DataArchitect、Database Analyzer、DataExpress、DataServer、DataWindow、
DataWindow .NET、DB-Library、dbQueue、Dejima、Dejima Direct、Developers Workbench、DirectConnect Anywhere、DirectConnect、Distribution
Director、Dynamic Mobility Model、e-ADK、E-Anywhere、e-Biz Integrator、E-Whatever、EC Gateway、ECMAP、ECRTP、eFulfillment
Accelerator、EII Plus、Electronic Case Management、Embedded SQL、EMS、Enterprise Application Studio、Enterprise Client/Server、Enterprise
Connect、Enterprise Data Studio、Enterprise Manager、Enterprise Portal ( ロゴ )、Enterprise SQL Server Manager、Enterprise Work Architecture、
Enterprise Work Designer、Enterprise Work Modeler、eProcurement Accelerator、eremote、Everything Works Better When Everything Works Together、
EWA、ExtendedAssist、Extended Systems、ExtendedView、Financial Fusion、Financial Fusion ( および設計 )、Financial Fusion Server、Formula
One、Fusion Powered e-Finance、Fusion Powered Financial Destinations、Fusion Powered STP、Gateway Manager、GeoPoint、GlobalFIX、
iAnywhere、iAnywhere Solutions、ImpactNow、Industry Warehouse Studio、InfoMaker、Information Anywhere、Information Everywhere、
InformationConnect、InstaHelp、Intelligent Self-Care、InternetBuilder、iremote、irLite、iScript、Jaguar CTS、jConnect for JDBC、KnowledgeBase、
Legion、Logical Memory Manager、M2M Anywhere、Mach Desktop、Mail Anywhere Studio、Mainframe Connect、Maintenance Express、Manage
Anywhere Studio、MAP、M-Business Anywhere、M-Business Channel、M-Business Network、M-Business Suite、MDI Access Server、MDI Database
Gateway、media.splash、Message Anywhere Server、MetaWorks、MethodSet、mFolio、Mirror Activator、ML Query、MobiCATS、MobileQ、
MySupport、Net-Gateway、Net-Library、New Era of Networks、Next Generation Learning、Next Generation Learning Studio、O DEVICE、OASiS、
OASiS logo、ObjectConnect、ObjectCycle、OmniConnect、OmniQ、OmniSQL Access Module、OmniSQL Toolkit、OneBridge、Open Biz、Open
Business Interchange、Open Client、Open ClientConnect、Open Client/Server、Open Client/Server Interfaces、Open Gateway、Open Server、Open
ServerConnect、Open Solutions、Optima++、Partnerships that Work、PB-Gen、PC APT Execute、PC DB-Net、PC Net Library、Pharma Anywhere、
PhysicalArchitect、Pocket PowerBuilder、PocketBuilder、Power++、Power Through Knowledge、power.stop、PowerAMC、PowerBuilder、
PowerBuilder Foundation Class Library、PowerDesigner、PowerDimensions、PowerDynamo、Powering the New Economy、PowerScript、PowerSite、
PowerSocket、Powersoft、PowerStage、PowerStudio、PowerTips、Powersoft Portfolio、Powersoft Professional、PowerWare Desktop、PowerWare
Enterprise、ProcessAnalyst、Pylon、Pylon Anywhere、Pylon Application Server、Pylon Conduit、Pylon PIM Server、Pylon Pro、QAnywhere、
Rapport、Relational Beans、RemoteWare、RepConnector、Report Workbench、Report-Execute、Replication Agent、Replication Driver、Replication
Server、Replication Server Manager、Replication Toolkit、Resource Manager、RFID Anywhere、RW-DisplayLib、RW-Library、SAFE、SAFE/PRO、
Sales Anywhere、Search Anywhere、SDF、Search Anywhere、Secure SQL Server、Secure SQL Toolset、Security Guardian、ShareSpool、ShareLink、
SKILS、smart.partners、smart.parts、smart.script、SOA Anywhere Trademark,SQL Advantage、SQL Anywhere、SQL Anywhere Studio、SQL Code
Checker、SQL Debug、SQL Edit、SQL Edit/TPU、SQL Everywhere、SQL Modeler、SQL Remote、SQL Server、SQL Server Manager、SQL
SMART、SQL Toolset、SQL Server/CFT、SQL Server/DBM、SQL Server SNMP SubAgent、SQL Station、SQLJ、Stage III Engineering、
Startup.Com、STEP、SupportNow、S.W.I.F.T. Message Format Libraries、Sybase Central、Sybase Client/Server Interfaces、Sybase Development
Framework、Sybase Financial Server、Sybase Gateways、Sybase IQ、Sybase Learning Connection、Sybase MPP、Sybase SQL Desktop、Sybase SQL
Lifecycle、Sybase SQL Workgroup、Sybase Synergy Program、Sybase Virtual Server Architecture、Sybase User Workbench、SybaseWare、Syber
Financial、SyberAssist、SybFlex、SybMD、SyBooks、System 10、System 11、System XI ( ロゴ )、SystemTools、Tabular Data Stream、The
Enterprise Client/Server Company、The Extensible Software Platform、The Future Is Wide Open、The Learning Connection、The Model For Client/Server
Solutions、The Online Information Center、The Power of One、TotalFix、Trade Force 、Transa ct-SQ L、Translation Toolkit、Turning Imagination Into
Reality、UltraLite、UltraLite.NET、UNIBOM、Unilib、Uninull、Unisep、Unistring、URK Runtime Kit for UniCode、Viafone、Viewer、
VisualWriter、VQL、WarehouseArchitect、Warehouse Control Center、Warehouse Studio、Warehouse WORKS、Wat com 、Watcom SQL、Watcom
SQL Server、Web Deployment Kit、Web.PB、Web.SQL、WebSights、WebViewer、WorkGroup SQL Server、XA-Library、XA-Server、XcelleNet、
XP Server、XTNDAccess、および XTNDConnect は、米国法人 Sybase, Inc. およびその子会社の商標です。
Unicode と Unicode のロゴは、Unicode, Inc. の登録商標です。
このマニュアルに記載されている上記以外の社名および製品名は、各社の商標または登録商標の場合があります。
Use, duplication, or disclosure by the government is subject to the restrictions set forth in subparagraph (c)(1)(ii) of DFARS 52.227-7013
for the DOD and as set forth in FAR 52.227-19(a)-(d) for civilian agencies.
Sybase, Inc., One Sybase Drive, Dublin, CA 94568.
Page 3

目次
はじめに .................................................................................................................................................. ix
第 1 章 データベース・テーブルからのデータの選択 ........................................ 1
前提条件 ................................................................................................. 2
テーブル情報の表示 ............................................................................... 3
クエリ結果の順序付け ........................................................................... 5
カラムとローの選択 ............................................................................... 6
探索条件の使用 ...................................................................................... 7
クエリでの日付の比較 .................................................................... 8
WHERE 句での複合探索条件 ......................................................... 8
探索条件でのパターン・マッチング............................................... 9
発音によるローのマッチング ....................................................... 10
探索条件を入力するためのショートカット.................................. 10
集約データの取得................................................................................. 11
集合関数の概要 ............................................................................. 11
集合関数によるグループ化されたデータの取得........................... 12
グループの制限 ............................................................................. 12
小計計算の活用 ............................................................................. 13
分析データの取得................................................................................. 17
重複したローの削除 ............................................................................. 18
第 2 章 テーブルのジョイン.............................................................................. 19
外積を使用したテーブルのジョイン.................................................... 19
ジョインの制限 .................................................................................... 20
テーブル間の関係................................................................................. 21
プライマリ・キーによるローの識別............................................. 21
外部キーによって関連付けられたテーブル.................................. 22
ジョイン演算子 .................................................................................... 22
キー・ジョインを使用したテーブルのジョイン........................... 22
ナチュラル・ジョインを使用したテーブルのジョイン................ 24
アドホック・ジョインとジョイン・インデックスの使用 ................... 25
ジョインとデータ型 ............................................................................. 25
ストアまたはデータベース間ジョインのサポート .............................. 26
リモート・データベースと異種データベースのクエリ ....................... 27
サブクエリによるジョインの置き換え ................................................ 28
パフォーマンス&チューニング・ガイド iii
Page 4

目次
第 3 章 クエリと削除の最適化 .......................................................................... 31
クエリ構築のヒント............................................................................. 31
UNION ALL での GROUP BY がクエリ・パフォーマンスに
与える影響............................................................................. 32
Adaptive Server Anywhere による処理を引き起こす条件............ 34
クエリ・プラン.................................................................................... 35
クエリ評価オプション.................................................................. 35
クエリ・ツリー............................................................................. 37
HTML クエリ・プランの使用 ....................................................... 37
クエリ処理の制御 ................................................................................ 37
クエリの時間制限の設定 .............................................................. 37
クエリの優先度の設定.................................................................. 38
クエリ最適化オプションの設定 ................................................... 38
述部ヒントの設定 ......................................................................... 39
削除オペレーションの最適化 .............................................................. 40
削除コスト.................................................................................... 41
削除パフォーマンス・オプションの使用 ..................................... 41
第 4 章 OLAP の使用......................................................................................... 43
OLAP について .................................................................................... 44
OLAP の利点................................................................................. 45
OLAP の評価について .................................................................. 45
GROUP BY 句の拡張機能.................................................................... 47
GROUP BY での ROLLUP と CUBE............................................ 48
統計関数............................................................................................... 61
単純な集合関数............................................................................. 61
ウィンドウ.................................................................................... 62
数値関数........................................................................................ 85
OLAP の規則と制限............................................................................. 88
その他の OLAP の例 ............................................................................ 89
例: クエリ内でのウィンドウ関数................................................ 89
例: 複数の関数で使用されるウィンドウ..................................... 91
例: 累積和の計算......................................................................... 92
例: 移動平均の計算 ..................................................................... 92
例: ORDER BY の結果................................................................ 93
例: 1 つのクエリ内で複数の集合関数を使用 .............................. 94
例: ウィンドウ・フレーム指定の ROWS と RANGE の比較 ..... 94
例: 現在のローを除外するウィンドウ・フレーム....................... 95
例: ROW のデフォルトのウィンドウ・フレーム........................ 96
例: UNBOUNDED PRECEDING と
UNBOUNDED FOLLOWING ................................................. 96
例: RANGE のデフォルトのウィンドウ・フレーム.................... 97
OLAP 関数の BNF 文法 ....................................................................... 98
iv Sybase IQ
Page 5

目次
第 5 章 システム・リソースの管理 ................................................................. 103
パフォーマンス用語の概要................................................................. 104
パフォーマンス向上のための設計...................................................... 104
メモリ使用の概要 ............................................................................... 105
ページングによる使用可能メモリの増加.................................... 105
スワッピングをモニタするためのユーティリティ ..................... 106
サーバ・メモリ ........................................................................... 106
バッファ・キャッシュの管理...................................................... 107
バッファ・キャッシュ・サイズの決定 ....................................... 107
バッファ・キャッシュ・サイズの設定 ....................................... 113
ページ・サイズの指定................................................................. 115
メモリの節約 ............................................................................... 116
ユーザが多数存在する場合の最適化........................................... 117
プラットフォーム固有のメモリ・オプション ............................ 119
メモリを増やすその他の方法...................................................... 122
プロセス・スレッド・モデル ............................................................. 123
スレッド不足エラー .................................................................... 124
スレッド使用を管理するための Sybase IQ オプション ............. 124
I/O の分散 ........................................................................................... 125
ロー I/O (UNIX オペレーティング・システム ) ........................... 125
ディスク・ストライピングの使用............................................... 125
内部ストライピング .................................................................... 127
複数の dbspace の使用 ............................................................... 128
戦略的なファイルの格納 ............................................................. 129
挿入、削除、同期のための作業領域........................................... 133
予約領域のオプションの設定...................................................... 133
リソース使用を調整するオプション .................................................. 133
同時クエリの制限........................................................................ 134
使用可能な CPU 数の設定........................................................... 134
クエリによるテンポラリ dbspace の使用の制限........................ 134
返されるローによるクエリの制限............................................... 135
カーソルのスクロールの禁止...................................................... 135
カーソル数の制限........................................................................ 135
文の数の制限 ............................................................................... 135
キャッシュ・ページのプリフェッチ........................................... 136
一般的な使用のための最適化...................................................... 136
プリフェッチされるローの数の制御........................................... 136
リソースを効率的に利用するための他の方法.................................... 137
マルチプレックス・データベースのディスク領域の管理 .......... 137
クエリ・サーバ間のロード・バランス ....................................... 137
データベース・アクセスの制限 .................................................. 137
ディスクのキャッシュ................................................................. 138
インデックスのヒント........................................................................ 138
正しいインデックス・タイプの選択........................................... 138
ジョイン・インデックスの使用 .................................................. 139
削除のための十分なディスク領域の確保.................................... 139
パフォーマンス&チューニング・ガイド v
Page 6

目次
データベース・サイズと構造の管理 ................................................. 140
データベース・サイズの管理 ..................................................... 140
インデックスの断片化の制御 ..................................................... 140
カタログ・ファイル増大の最小化.............................................. 141
パフォーマンス向上のための非正規化....................................... 141
非正規化のリスク ....................................................................... 141
非正規化の短所........................................................................... 142
非正規化のパフォーマンスの利点.............................................. 142
非正規化の決定........................................................................... 142
ロードを高速化するための UNION ALL ビューの使用 ..................... 143
UNION ALL ビューを参照するクエリの最適化.......................... 143
ネットワーク・パフォーマンス......................................................... 145
大量のデータ転送の向上 ............................................................ 145
ヘビー・ネットワーク・ユーザの分離....................................... 145
少量のデータを小さなパケットに入れる ................................... 146
大量のデータを大きなパケットに入れる ................................... 146
サーバ・レベルのプロセス......................................................... 146
第 6 章 パフォーマンスのモニタリングとチューニング................................. 147
Sybase IQ 環境の表示 ....................................................................... 147
ストアド・プロシージャを使用して情報を取得する ................. 148
Sybase Central パフォーマンス・モニタの使用........................ 148
データベース・プロシージャのプロファイリング..................... 149
バッファ・キャッシュのモニタリング.............................................. 157
バッファ・キャッシュ・モニタの起動....................................... 157
モニタ実行中の結果の確認......................................................... 163
バッファ・キャッシュ・モニタの停止....................................... 164
モニタリング結果の検査と保存 ................................................. 164
モニタリング結果の例................................................................ 165
バッファ・キャッシュの構造 ............................................................ 169
バッファ・マネージャのスラッシングの回避 ................................... 169
Windows システムでのページングのモニタリング ................... 171
UNIX システムでのページングのモニタリング ......................... 171
バッファ・キャッシュ・モニタリング・チェックリスト ................. 173
CPU 使用率をモニタリングするシステム・ユーティリティ ............ 176
第 7 章 Windows システムでのサーバのチューニング .................................. 177
パフォーマンスについての一般的なガイドライン............................ 177
スループットの最大化................................................................ 177
メモリの割り付け超過の防止 ..................................................... 178
物理メモリのモニタリング......................................................... 178
ファイル・システム ................................................................... 178
パフォーマンスのモニタリング......................................................... 179
仮想アドレス空間とワーキング・セットのモニタリング.......... 179
ページ・フォールトのモニタリング .......................................... 180
vi Sybase IQ
Page 7

目次
NTFS キャッシュの使用..................................................................... 180
挿入とクエリのチューニング ............................................................. 181
適切にチューニングされた挿入オペレーションの特性 .............. 181
クエリのチューニング................................................................. 182
バックアップ操作のチューニング...................................................... 182
索引....................................................................................................................................................... 185
パフォーマンス&チューニング・ガイド vii
Page 8

目次
viii Sybase IQ
Page 9

はじめに
このマニュアルの内容
対象読者
このマニュアルの使用方法
関連マニュアル
このマニュアルでは、パフォーマンスとチューニングの推奨事項について
説明します。
このマニュアルは、パフォーマンス上の問題を理解する必要があるシステ
ム管理者とデータベース管理者を対象としています。リレーショナル・
データベース・システムの基礎知識と、Sybase IQ のユーザ・レベルの基
本的な経験があることを前提にしています。このマニュアルは、他のマ
ニュアルとともに使用してください。
次のリストは、行う作業や必要性に応じてどの章を参照すべきかを示し
ます。
• SELECT 文の構築については、「第 1 章 データベース・テーブルから
のデータの選択」を参照してください。
• ジョイン条件については、「第 2 章 テーブルのジョイン」を参照して
ください。
• クエリの最適化については、「第 3 章 クエリと削除の最適化」を参照
してください。
• メモリ、ディスク I/O、CPU の調整については、「第 5 章 システム・
リソースの管理」を参照してください。
• パフォーマンスについては、「第 6 章 パフォーマンスのモニタリング
とチューニング」を参照してください。
• Windows パフォーマンスについては、「第 7 章 Windows システムでの
サーバのチューニング」を参照してください。
Sybase IQ には次のマニュアルが用意されています。
• 『Sybase IQ の概要』 - Sybase IQ と Sybase Central™ データベース管理
ツールに慣れていないユーザのための説明と練習が記載されています。
• 『Sybase IQ 12.7 の新機能』 - Sybase IQ の新機能の概略を説明してい
ます。
• 『Sybase IQ パフォーマンス&チューニング・ガイド』 - 巨大なデータ
ベースのクエリ最適化、設計、チューニングについて説明しています。
• 『Sybase IQ システム管理ガイド』 - Sybase IQ がサポートする、管理
面の概念と手順および最適なパフォーマンスのチューニングについ
て説明しています。IQ ストアの管理方法についても説明しています。
パフォーマンス&チューニング・ガイド ix
Page 10

• 『Sybase IQ トラブルシューティングおよびリカバリ・ガイド』 - 問題の解
決方法、システム・リカバリの実行方法、データベースの修復方法を紹介
しています。
• 『Sybase IQ エラー・メッセージ』 - Sybase IQ エラー・メッセージ (SQLCode、
SQLState、Sybase エラー・コードによって参照 )、お よ び SQL プリプロセッ
サのエラーと警告を示します。
• 『Sybase IQ ユーティリティ・ガイド』 - Sybase IQ ユーティリティ・プロ
グラムのリファレンス項目 ( 使用可能な構文、パラメータ、オプションな
ど ) について説明しています。
• 『Sybase IQ によるラージ・オブジェクト管理』 - Sybase IQ データ・リポ
ジトリ内での BLOB (Binary Large Object) および CLOB (Character Large
Object) の格納と取得について説明しています。このオプションの製品を
インストールするには、別のライセンスが必要です。
• 『Sybase IQ インストールおよび設定ガイド』 - プラットフォーム固有の
Sybase IQ のインストール手順、新バージョンの Sybase IQ へのマイグレー
ト、特定のプラットフォームでの Sybase IQ の設定について説明してい
ます。
• 『Sybase IQ リリース・ノート』 - 製品およびマニュアルに加えられた最新
の変更内容について説明しています。
• 『Sybase IQ の暗号化カラム』 - Sybase IQ データ・リポジトリ内でのユー
ザによるカラムの暗号化の使用について説明しています。このオプション
の製品をインストールするには、別のライセンスが必要です。
Sybase IQ と Adaptive Server Anywhere
Sybase IQ は、SQL Anywhere® Studio のコンポーネントである Adaptive Server®
Anywhere を拡張した製品のため、Adaptive Server Anywhere と同じ機能を数多
くサポートしています。Sybase IQ のマニュアル・セットは、SQL Anywhere
Studio のマニュアルの該当する箇所を参照しています。
Adaptive Server Anywhere には、次のマニュアルがあります。
• 『Adaptive Server Anywhere プログラミング・ガイド』 - ODBC、Embedded
SQL™、または Open Client™ インタフェースに直接アクセスするプログ
ラムを開発するアプリケーション開発者を対象にしています。このマニュ
アルでは、Adaptive Server Anywhere アプリケーションの開発方法につい
て説明しています。
• 『Adaptive Server Anywhere データベース管理ガイド』 - すべてのユーザを
対象に、データベースとデータベース・サーバの運用、管理、設定につい
て説明しています。
x Sybase IQ
Page 11

その他の情報ソース
はじめに
• 『Adaptive Server Anywhere SQL リファレンス・マニュアル』 - Adaptive
Server Anywhere で使用する SQL 言語のリファレンスです。さらに、
Adaptive Server Anywhere のシステム・テーブルとプロシージャについて
も説明します。
Sybase Product Manuals Web サイトでも、SQL Anywhere Studio 9.0.2 コレクショ
ンの Adaptive Server Anywhere マニュアルを参照できます。Product Manuals
(http://www.sybase.com/support/manuals/) にアクセスしてください。
Sybase Getting Started CD、Sybase CD、Sybase Product Manuals Web サイトを利
用すると、製品について詳しく知ることができます。
• Getting Started CD には、PDF 形式のリリース・ノートとインストール・ガイ
ド、および SyBooks CD に含まれていないその他のマニュアルや更新情報が
収録されています。この CD は製品のソフトウェアに同梱されています。
Getting Started CD に収録されているマニュアルを参照または印刷するには、
Adobe Acrobat Reader が必要です (CD 内のリンクを使用して Adobe の Web サ
イトから無料でダウンロードできます )。
• SyBooks CD には製品マニュアルが収録されています。この CD は製品の
ソフトウェアに同梱されています。Eclipse ベースの SyBooks ブラウザで
は、使いやすい HTML 形式のマニュアルにアクセスできます。
一部のマニュアルは PDF 形式で提供されています。それらのマニュアル
は SyBooks CD の PDF ディレクトリに収録されています。PDF ファイル
を開いたり印刷したりするには、Adobe Acrobat Reader が必要です。
SyBooks をインストールして起動するまでの手順については、Getting Started
CD の『SyBooks Installation Guide』または SyBooks CD の README.txt ファイ
ルを参照してください。
• Sybase Product Manuals Web サイトは、SyBooks CD のオンライン版であり、
標準の Web ブラウザを使ってアクセスできます。また、製品マニュアル
のほか、EBFs/Maintenance、Technical Documents、Case Management、Solved
Cases、ニュース・グループ、Sybase Developer Network へのリンクもあり
ます。
Sybase Product Manuals Web サイトにアクセスするには、Product Manuals
(http://www.sybase.com/support/manuals/) にアクセスしてください。
•Infocenter はオンライン・バージョンの SyBooks であり、標準の Web ブラ
ウザで表示できます。Infocenter Web サイトにアクセスするには、Sybooks
Online Help (http://infocenter.sybase.com/help/index.jsp) にアクセスして
ください。
パフォーマンス&チューニング・ガイド xi
Page 12

Web 上の Sybase 製品
の動作確認情報
Sybase Web サイトの技術的な資料は頻繁に更新されます。
❖ 製品動作確認の最新情報にアクセスする
1Web ブラウザで Technical Documents を指定します。
(http://www.sybase.com/support/techdocs/)
2 [Certification Report] をクリックします。
3 [Certification Report] フィルタで製品、プラットフォーム、時間枠を指定し
て [Go] をクリックします。
4 [Certification Report] のタイトルをクリックして、レポートを表示します。
❖ コンポーネント動作確認の最新情報にアクセスする
1Web ブラウザで Availability and Certification Reports を指定します。
(http://certification.sybase.com/)
2 [Search By Base Product] で製品ファミリとベース製品を選択するか、
[Search by Platform] でプラットフォームとベース製品を選択します。
3[Search] をクリックして、入手状況と動作確認レポートを表示します。
❖ Sybase Web サイト ( サポート・ページを含む ) の自分専用のビューを作成する
MySybase プロファイルを設定します。MySybase は無料サービスです。この
サービスを使用すると、Sybase Web ページの表示方法を自分専用にカスタマ
イズできます。
1Web ブラウザで Technical Documents を指定します。
(http://www.sybase.com/support/techdocs/)
2 [MySybase] をクリックし、MySybase プロファイルを作成します。
Sybase EBF とソフト
ウェア・メンテナンス
❖ EBF とソフトウェア・メンテナンスの最新情報にアクセスする
1Web ブラウザで Sybase Support Page (http://www.sybase.com/support)
を指定します。
2 [EBFs/Maintenance] を選択します。ユーザ名とパスワードの入力が求めら
れたら、MySybase のユーザ名とパスワードを入力します。
3 製品を選択します。
xii Sybase IQ
Page 13

SQL 構文の表記規則
はじめに
4 時間枠を指定して [Go] をクリックします。EBF/Maintenance リリースのリ
ストが表示されます。
鍵のアイコンは、自分が Technical Support Contact として登録されていな
いため、一部の EBF/Maintenance リリースをダウンロードする権限がない
ことを示しています。未登録ではあるが、Sybase 担当者またはサポート・
コンタクトから有効な情報を得ている場合は、[Edit Roles] をクリックし
て、「Technical Support Contact」役割を MySybase プロファイルに追加します。
5 EBF/Maintenance レポートを表示するには [Info] アイコンをクリックします。
ソフトウェアをダウンロードするには製品の説明をクリックします。
このマニュアルで、構文の説明に使用する表記規則は次のとおりです。
• キーワード SQL キーワードは大文字で示します。ただし、SQL キーワー
ドは大文字と小文字を区別しないので、入力するときはどちらで入力して
もかまいません。たとえば、SELECT は Select でも select でも同じです。
• プレースホルダ 適切な識別子または式で置き換えられる項目は、斜体で表
記します。
• 継続 省略記号 (…) で始まる行は、前の行から文が続いていることを表し
ます。
• 繰り返し項目 繰り返し項目のリストは、リストの要素の後ろに省略記号 ( ピ
リオド 3 つ ...) を付けて表します。複数の要素を指定できます。複数の要素
を指定する場合は、各要素間はカンマで区切る必要があります。
• オプション指定部分 文のオプション指定部分は、角カッコで囲みます。例:
RELEASE SAVEPOINT [ savepoint-name ]
この例では、savepoint-name がオプション部分です。角カッコは入力しな
いでください。
• オプション 項目リストから 1 つだけ選択しなければならない場合、また
何も選択する必要のない場合は、項目間を縦線で区切り、リスト全体を角
カッコで囲みます。例:
[ ASC | DESC ]
この例では、ASC、DESC のどちらか 1 つを選択しても、何も選択しなく
てもかまいません。角カッコは入力しないでください。
• 選択肢 オプションの中の 1 つを必ず選択しなければならない場合は、選
択肢を大カッコ { } で囲みます。例:
QUOTES { ON | OFF }
この例では、ON、OFF のどちらかを必ず入力しなければなりません。大
カッコ自体は入力しないでください。
パフォーマンス&チューニング・ガイド xiii
Page 14

書体の表記規則
サンプル・データベース
アクセシビリティ機能
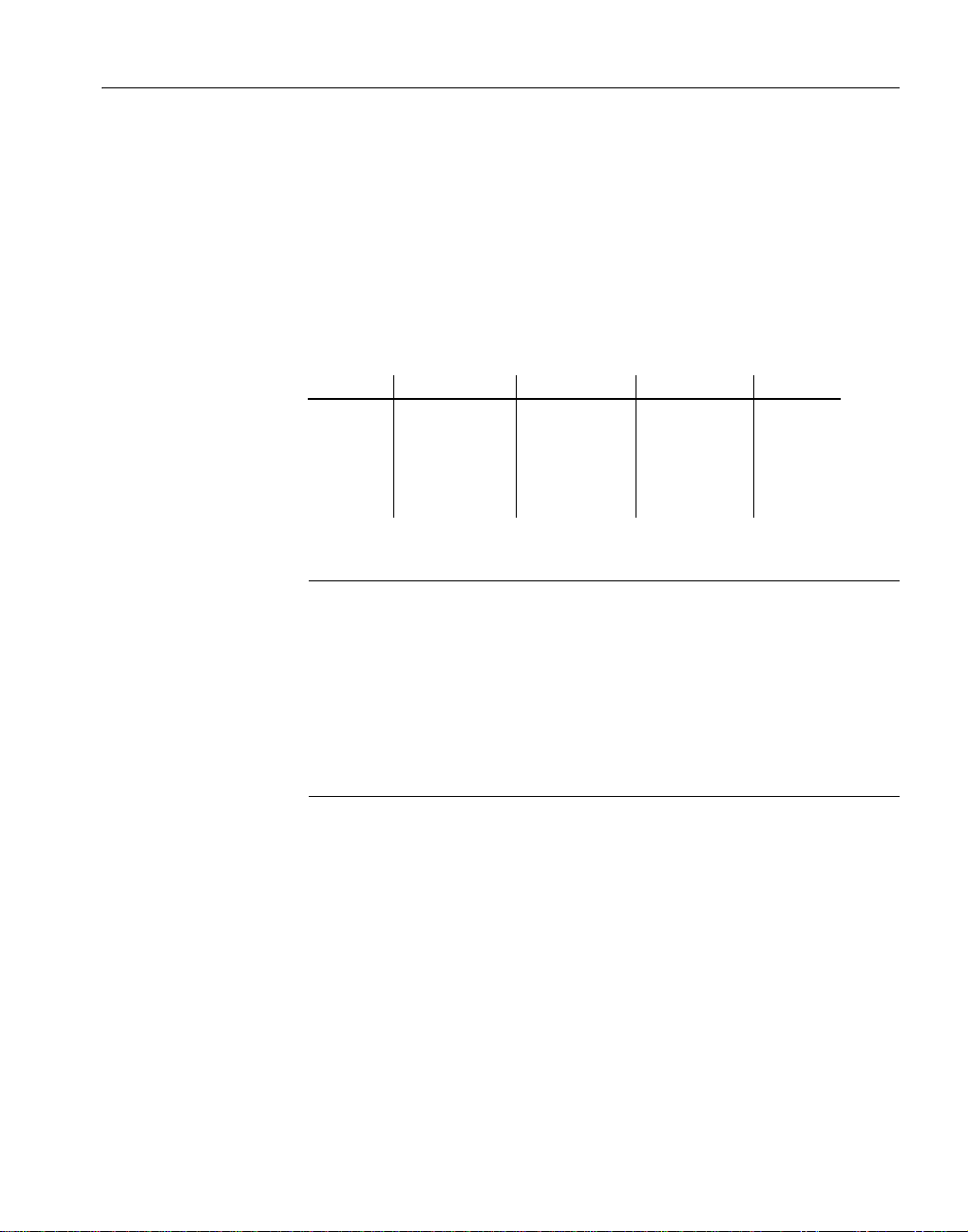
表 1 に、このマニュアルで使用している書体の表記規則を示します。
表 1: 書体の表記規則
項目 説明
Code
User entry
「強調」 強調する言葉は「 」で囲みます。
file names
database objects
SQL およびプログラム・コードは等幅 ( 固定幅 ) 文字フォントで
表記します。
ユーザが入力するテキストには等幅 ( 固定幅 ) 文字フォントを使
用します。
ファイル名は斜体で表記します。
テーブル、プロシージャなどのデータベース・オブジェクトの名
前は、印刷物ではゴシック体フォントで、オンラインでは斜体で
表記します。
Sybase IQ にはサンプル・データベースが用意されています。Sybase IQ マニュ
アルで紹介している例の多くは、このサンプル・データベースによるものです。
サンプル・データベースは小規模企業の例を示しています。データベースに
は、この企業の内部情報 (employee、department) とともに、製品情報 (product)、
販売情報 (sles_order、customer、contact)、財務情報 (fin_code、fin_data) が入っ
ています。
サンプル・データベース ( ファイル名 asiqdemo.db) は、UNIX システムでは
$ASDIR/demo ディレクトリに、Windows システムでは %ASDIR%¥demo ディ
レクトリにあります。
このマニュアルには、アクセシビリティを重視した HTML 版もあります。こ
の HTML 版マニュアルは、スクリーン・リーダーで読み上げる、または画面
を拡大表示するなどの方法により、その内容を理解できるよう配慮されてい
ます。
Sybase IQ 12.7 と HTML マニュアルは、連邦リハビリテーション法第 508 条の
アクセシビリティ規定に準拠していることがテストにより確認されています。
第 508 条に準拠しているマニュアルは通常、World Wide Web Consortium (W3C)
の Web サイト用ガイドラインなど、米国以外のアクセシビリティ・ガイドラ
インにも準拠しています。
Sybase Central 用 Sybase IQ プラグインのアクセシビリティへの対応について
は、『Sybase IQ の概要』の「アクセシビリティ機能の使用」を参照してくださ
い。この製品のオンライン・ヘルプは、スクリーン・リーダーの読み上げで内
容を理解でき、Sybase Central のキーボード・ショートカットなどのアクセシ
ビリティ機能についての説明もあります。
xiv Sybase IQ
Page 15

不明な点があるときは
はじめに
アクセシビリティ・ツールの設定
アクセシビリティ・ツールを効率的に使用するには、設定が必要な場合もありま
す。一部のスクリーン・リーダーは、テキストの大文字と小文字を区別して発音
します。たとえば、すべて大文字のテキスト (ALL UPPERCASE TEXT など ) はイ
ニシャルで発音し、大文字と小文字の混在したテキスト (MixedCase Text など ) は
単語として発音します。構文規則を発音するようにツールを設定すると便利かも
しれません。詳細については、ツールのマニュアルと『Sybase IQ の概要』の「ス
クリーン・リーダの使用」を参照してください。
Sybase のアクセシビリティに対する取り組みについては、Sybase Accessibility
(http://www.sybase.com/accessibility) を参照してください。Sybase Accessibility
サイトには、第 508 条と W3C 標準に関する情報へのリンクもあります。
Sybase IQ の第 508 条準拠の声明については、Sybase Accessibility
(http://www.sybase.com/accessibility) を参照してください。
サポート契約を購入済みの Sybase 製品のインストールには、定められた 1 人
以上のユーザに対して、Sybase 製品の保守契約を結んでいるサポート・センタ
を利用する権利が付属します。マニュアルだけでは解決できない問題があった
場合には、担当の方を通して Sybase のサポート・センタまでご連絡ください。
パフォーマンス&チューニング・ガイド xv
Page 16

xvi Sybase IQ
Page 17

第 1 章 データベース・テーブルからのデータの
選択
この章について
内容
この章では、基本的なクエリの構築と、製品設計を活用するための手法に
ついて説明します。ここではテーブルの内容の表示、クエリ結果の順序付
け、カラムとローの選択、探索条件を使ったクエリの絞り込みを行う
チュートリアル作業を実行します。
高度なクエリ・パフォーマンスの推奨事項については、「第 3 章 クエリと
削除の最適化」を参照してください。
トピック名 ページ
前提条件
テーブル情報の表示
クエリ結果の順序付け
カラムとローの選択
探索条件の使用
集約データの取得
分析データの取得
重複したローの削除
2
3
5
6
7
11
17
18
パフォーマンス&チューニング・ガイド 1
Page 18

前提条件
前提条件
DBISQL の代わりにグラフィカルなフロントエンド・ツールを使用してデータ
ベースへのクエリを実行すると、ツールが生成する SQL 構文を表示できる場
合があります。たとえば、InfoMaker では [ テーブル ] ペインタ・バーの [SQL
構文 ] ボタンを選択して SQL 文を表示できます。
このチュートリアルでは、データベースから情報を取得するときに使用する
SELECT 文について説明します。SELECT 文のことを一般にクエリと呼びます。
これは、SELECT 文がデータベース内の情報についてデータベース・サーバに
問い合わせるためです。
注意 SELECT 文は用途の広いコマンドです。大きなデータベースから非常に
具体的な情報を取得するアプリケーションでは、SELECT 文がきわめて複雑に
なる場合があります。このチュートリアルでは、単純な SELECT 文だけを使
用します。以降のチュートリアルで、より高度なクエリについて説明します。
SELECT 文の完全な構文については、『Sybase IQ リファレンス・マニュアル』
の「第 6 章 SQL 文」の「SELECT 文」を参照してください。
チュートリアルのレッスンを読んで実行している間は、コンピュータで Sybase
IQ ソフトウェアを実行しておくことが理想的です。
このチュートリアルでは、すでに DBISQL を起動し、サンプル・データベース
に接続していることを前提にしています。まだこれらを行っていない場合は、
『Sybase IQ ユーティリティ・ガイド』の「第 2 章 Interactive SQL (dbisql) の使
用」を参照してください。
2 Sybase IQ
Page 19
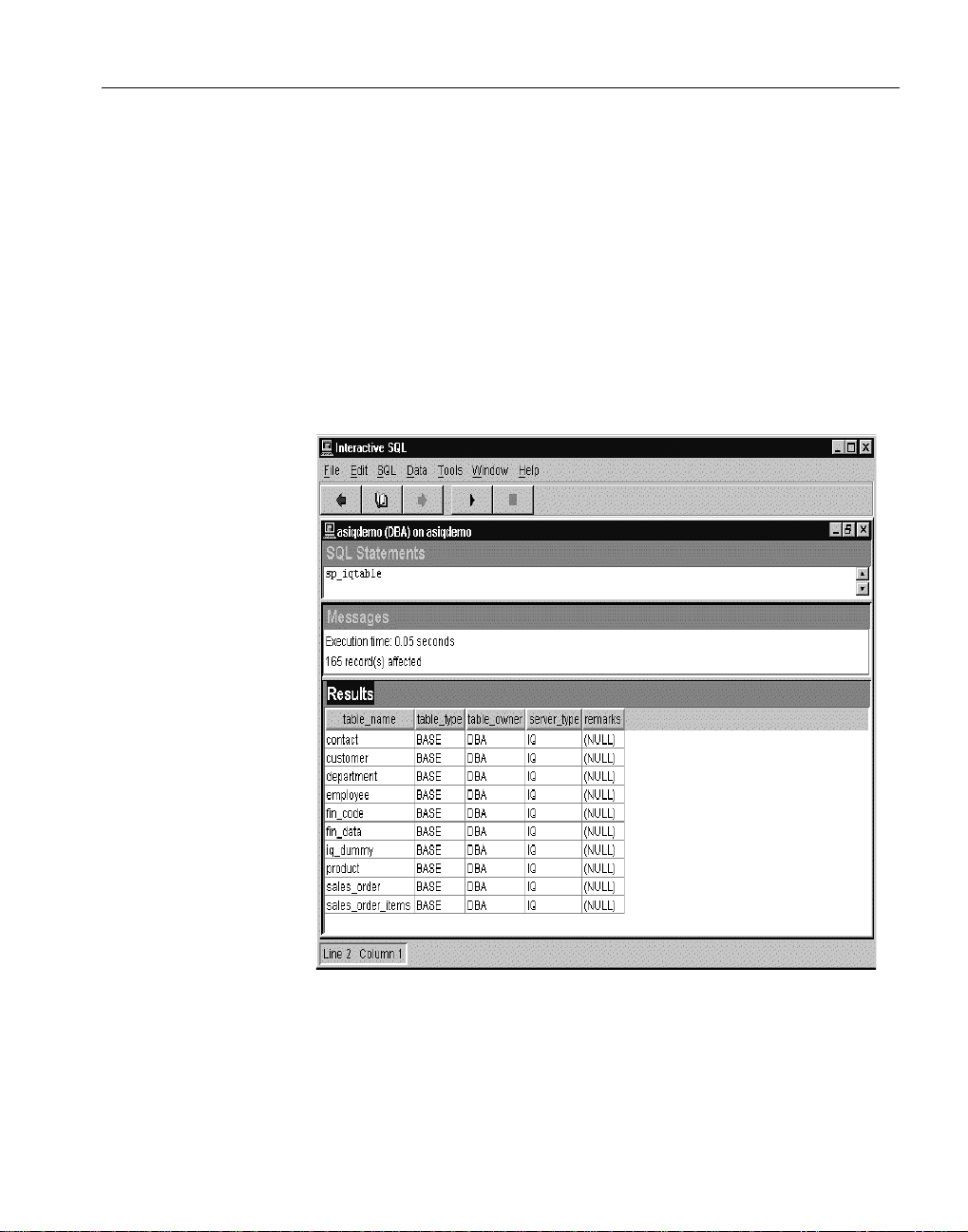
テーブル情報の表示
ここでは、employee テーブルのデータを表示します。
このチュートリアルで使用するサンプル・データベースは、架空の会社のもの
です。データベースには、従業員、部署、注文などについての情報が格納され
ています。すべての情報はテーブルに編成されています。
テーブルのリスト
『Sybase IQ の概要』では、Sybase Central で [ テーブル ] フォルダを開いてテー
ブルのリストを表示する方法について説明しました。システム・ストアド・プ
ロシージャの sp_iqtable を使用して、Interactive SQL からユーザ・テーブルを
リストすることもできます。システム・ストアド・プロシージャは、Sybase IQ
にストアド・プロシージャとして実装されているシステム関数です。
[SQL 文 ] ウィンドウで sp_iqtable と入力し、同じ名前のシステム・ストア
ド・プロシージャを実行します。
第 1 章 データベース・テーブルからのデータの選択
システム・ストアド・プロシージャの詳細については、『Sybase IQ リファレン
ス・マニュアル』の「第 10 章 システム・プロシージャ」を参照してください。
パフォーマンス&チューニング・ガイド 3
Page 20

テーブル情報の表示
SELECT 文の使用
大文字と小文字の区別
このレッスンでは、データベース内のテーブルの 1 つを表示します。使用する
コマンドは、employee という名前のテーブル全体を表示します。
次のコマンドを実行します。
SELECT * FROM employee
アスタリスクは、テーブル内のすべてのカラムを表す省略記号です。
SELECT 文は employee テーブルのすべてのローとカラムを取得し、DBISQL
[ 結果 ] ウィンドウに次の該当するものが表示されます。
emp_id manager_id emp_fname emp_lname dept_id
102 501 Fran Whitney 100
105 501 Matthew Cobb 100
129 902 Philip Chin 200
148 1293 Julie Jordan 300
160 501 Robert Breault 100
employee テーブルには、カラムに編成された複数のローが格納されています。
各カラムには、emp_lname や emp_id などの名前が付いています。会社の従業
員 1 人ずつに 1 つのローがあり、それぞれのローは各カラムに値を持ちます。
たとえば、従業員 ID が 102 の従業員は Fran Whitney であり、そのマネージャ
は従業員 ID 501 です。
DBISQL [ メッセージ ] ウィンドウにも一部の情報が表示されます。この情報
については後で説明します。
テーブル名 employee は、実際のテーブル名がすべて小文字の場合にも、先頭
は大文字の E で表示されます。Sybase IQ データベースは、文字列の比較で大
文字と小文字を区別するもの ( デフォルト ) と区別しないものを作成できます
が、その識別子では常に大文字と小文字は区別されません。
注意 このマニュアルの例は、CREATE DATABASE 修飾子の CASE IGNORE
を使用して、大文字と小文字を区別しないように作成されています。デフォル
トは CASE RESPECT であり、こちらの方がパフォーマンスが向上します。
データベースの作成方法については、『Sybase IQ システム管理ガイド』の「第
5 章 データベース・オブジェクトの使用」を参照してください。
SELECT の代わりに select または Select と入力することもできます。Sybase IQ
では、キーワードを大文字、小文字、またはその両方の組み合わせで入力でき
ます。このマニュアルでは、通常、SQL キーワードに大文字を使用しています。
DBISQL 環境の操作方法と DBISQL の使用法は、オペレーティング・システム
によって異なります。
データをスクロールして DBISQL 環境を操作する方法については、『Sybase IQ
ユーティリティ・ガイド』の「第 2 章 Interactive SQL (dbisql) の使用」を参照
してください。
4 Sybase IQ
Page 21
クエリ結果の順序付け
ここでは、SELECT 文に ORDER BY 句を追加して、結果をアルファベット順
または数値順に表示します。
特に指定しないかぎり、Sybase IQ ではテーブルのローが順不同で表示されます。
テーブルのローを意味のある順序で表示した方が便利なことがよくあります。
たとえば、従業員をアルファベット順で表示したいような場合です。
従業員をアルファベット
順にリストする
次の例は、SELECT 文に ORDER BY 句を追加して、結果をアルファベット順
に取得する方法を示します。
SELECT * FROM employee ORDER BY emp_lname
emp_id manager_id emp_fname emp_lname dept_id
1751 1576 Alex Ahmed 400
1013 703 Joseph Barker 500
591 1576 Irene Barletta 400
191 703 Jeannette Bertrand 500
1336 1293 Janet Bigelow 300
第 1 章 データベース・テーブルからのデータの選択
注意
句の順序は重要です。ORDER BY 句は FROM 句と SELECT 句の後に指定します。
注意 FROM 句を省略した場合、またはクエリ内のすべてのテーブルが SYSTEM
dbspace にある場合、クエリは Sybase IQ ではなく Adaptive Server Anywhere に
よって処理されます。これにより、特に構文上およびセマンティック上の制限
とオプション設定の効果に関して、クエリが異なる動作をする場合があります。
処理に適用されるルールについては Adaptive Server Anywhere のマニュアルを参
照してください。
FROM 句を必要としないクエリを実行する場合は、“FROM iq_dummy” 句を追
加して、クエリを強制的に Sybase IQ で処理できます。iq_dummy は、データ
ベースに作成される、ローが 1 つ、カラムが 1 つのテーブルです。
パフォーマンス&チューニング・ガイド 5
Page 22

カラムとローの選択
カラムとローの選択
多くの場合、表示する必要がある情報は、テーブル内の一部のカラムだけです。
たとえば、従業員への誕生日カードを作成するには、emp_lname、dept_id、
birth_date の各カラムを表示すれば十分です。
各従業員の姓、部署、
誕生日をリストする
ここでは、各従業員の誕生日、姓、部署 ID を選択します。次のコマンドを入
力します。
emp_lname dept_id birth_date ...
Whitney 100 1958-06-05 ...
Cobb 100 1960-12-04 ...
Chin 200 1966-10-30 ...
Jordan 300 1951-12-13 ...
Breault 100 1947-05-13 ...
SELECT emp_lname, dept_id, birth_date
FROM employee
カラムの並べ替え
ローの順序付け
この 3 つのカラムは、SELECT コマンドに入力した順序で表示されています。
カラムを並べ替えるには、コマンドで指定するカラム名の順序を変更します。
たとえば、birth_date カラムを左側に配置するには、次のコマンドを使用します。
SELECT birth_date, emp_lname, dept_id
FROM employee
次のように、特定のカラムだけを表示すると同時に、ローの順序を指定できます。
SELECT birth_date, emp_lname, dept_id
FROM employee
ORDER BY emp_lname
次のコマンドのアスタリスクは、テーブル内のすべてのカラムを表す省略記号
です。
SELECT * FROM employee
6 Sybase IQ
Page 23

探索条件の使用
❖ John という名前のすべての従業員をリストするには
第 1 章 データベース・テーブルからのデータの選択
ここでは、WHERE 句の複合探索条件、パターン・マッチング、探索条件ショー
トカットを使用して、日付を比較する手順について説明します。
employee テーブルにある一部の従業員の情報だけを表示したいことがあり
ます。SELECT 文に WHERE 句を追加すると、テーブルから一部のローだけ
を選択できます。
たとえば、John という名前の従業員だけを表示するとします。
• 次のコマンドを入力します。
SELECT *
FROM employee
WHERE emp_fname = 'John'
emp_id manager_id emp_fname emp_lname dept_id
318 1576 John Crow 400
862 501 John Sheffield 100
1483 1293 John Letiecq 300
アポストロフィおよび
大文字と小文字の区別
注意
• 名前 'John' はアポストロフィ ( 一重引用符 ) で囲む必要があります。アポ
ストロフィは、John が文字列であることを示します。引用符 ( 二重引用符 )
には別の意味があります。引用符を使用すると、無効な文字列を有効なカ
ラム名やその他の識別子として使用できるようになります。
• サンプル・データベースでは大文字と小文字が区別されないため、'JOHN'、
'john'、'John' のいずれで検索しても同じ結果が返ります。
次のように、これまで学習した句を組み合わせて実行できます。
SELECT emp_fname, emp_lname, birth_date
FROM employee
WHERE emp_fname = 'John'
ORDER BY birth_date
• 句を指定する順序は重要です。FROM 句を最初に指定し、その後に WHERE
句、ORDER BY 句の順に指定します。これ以外の順序で句を入力すると、
構文エラーが返されます。
• 文を複数の行に分ける必要はありません。[SQL 文 ] ウィンドウに自由な
フォーマットで文を入力できます。入力した文が画面の行数を超えると、
[SQL 文 ] ウィンドウのテキストがスクロールします。
パフォーマンス&チューニング・ガイド 7
Page 24

探索条件の使用
クエリでの日付の比較
1964 年 3 月 3 日より前に
生まれた従業員をリスト
する
検索対象の正確な値がわからない場合や、一連の値を表示したい場合があり
ます。WHERE 句で比較を使用すると、探索条件を満たす一連のローを選択で
きます。
次の例は、日付の不等号探索条件の使い方を示します。次のコマンドを入力し
ます。
SELECT emp_lname, birth_date
FROM employee
WHERE birth_date < 'March 3, 1964'
emp_lname birth_date
Whitney 1958-06-05 00:00:00.000
Cobb 1960-12-04 00:00:00.000
Jordan 1951-12-13 00:00:00.000
Breault 1947-05-13 00:00:00.000
Espinoza 1939-12-14 00:00:00.000
Dill 1963-07-19 00:00:00.000
Sybase IQ は、birth_date カラムに日付が格納されていることを認識し、自動的
に 'March 3, 1964' を日付に変換します。
WHERE 句での複合探索条件
これまでに、比較演算子の等号 (=) と未満 (<) を見てきました。Sybase IQ では、
より大きい (>)、以上 (>=)、以 下 (<=)、等しくない (<>) などのその他の比較演
算子もサポートされています。
これらの条件を AND や OR を使って組み合わせると、より複雑な探索条件を
作成できます。
リストの修飾
8 Sybase IQ
1964 年 3 月 3 日より前に生まれた従業員のうち、Whitney という名前の従業員
を除くすべての従業員をリストするには、次のコマンドを入力します。
SELECT emp_lname, birth_date
FROM employee
WHERE birth_date < '1964-3-3'
AND emp_lname <> 'Whitney'
emp_lname birth_date
Cobb 1960-12-04 00:00:00.000
Jordan 1951-12-13 00:00:00.000
Breault 1947-05-13 00:00:00.000
Espinoza 1939-12-14 00:00:00.000
Dill 1963-07-19 00:00:00.000
Francis 1954-09-12 00:00:00.000
Page 25

探索条件でのパターン・マッチング
もう 1 つの便利な検索方法が、パターンによる検索です。SQL では、LIKE と
いう語を使用してパターンを検索します。LIKE の使い方について、例を挙げ
て説明します。
姓が BR で始まる従業員
をリストする
姓検索の修飾
次のコマンドを入力します。
SELECT emp_lname, emp_fname
FROM employee
WHERE emp_lname LIKE 'br%'
emp_lname emp_fname
Breault Robert
Braun Jane
探索条件内の % は、BR という文字の後に別の文字が何文字続いてもかまわな
いことを示します。
姓が BR で始まり、その直後または数文字後に T という文字を含み、T で終わ
るかさらに別の文字が続くすべての従業員をリストするには、次のコマンドを
使用します。
SELECT emp_lname, emp_fname
FROM employee
WHERE emp_lname LIKE 'BR%T%'
emp_lname emp_fname
Breault Robert
第 1 章 データベース・テーブルからのデータの選択
最初の % 記号は文字列 “eaul” と一致し、2 番目の % 記号は空の文字列 ( 文字
なし ) と一致します。
LIKE で使用できるもう 1 つの特殊文字に _ ( アンダースコア) 文字があります。
これは 1 文字と一致します。
BR_U% というパターンは、BR で始まり、4 番目の文字が U であるすべての名
前と一致します。Braun では、_ が A という文字と一致し、% が N と一致します。
パフォーマンス&チューニング・ガイド 9
Page 26

探索条件の使用
発音によるローのマッチング
SOUNDEX 関数を使用すると、スペルだけでなく読みによってもローをマッチ
ングできます。たとえば、電話メッセージが残されていて、その宛先が “Ms.
Brown” のように発音されていたとします。社内で Brown のように発音される
名前を持つ従業員を見つける必要があります。
発音による姓の検索
Brown のように発音される姓を持つ従業員をリストするには、次のコマンドを
入力します。
SELECT emp_lname, emp_fname
FROM employee
WHERE SOUNDEX( emp_lname ) = SOUNDEX( 'Brown' )
emp_lname emp_fname
Braun Jane
この探索条件に一致する従業員は Jane Braun だけです。
探索条件を入力するためのショートカット
省略形 BETWEEN の
使用
省略形 IN の使用
SQL には、探索条件を入力するための省略形が 2 つあります。1 つは BETWEEN
であり、値を範囲で検索するときに使用します。この例を次に示します。
SELECT emp_lname, birth_date
FROM employee
WHERE birth_date BETWEEN '1964-1-1'
AND '1965-3-31'
これは次のコマンドに相当します。
SELECT emp_lname, birth_date
FROM employee
WHERE birth_date >= '1964-1-1'
AND birth_date <= '1965-3-31'
もう 1 つの省略形 IN は、複数のいずれかの値を検索するときに使用します。
次にコマンド例を示します。
SELECT emp_lname, emp_id
FROM employee
WHERE emp_lname IN ('Yeung','Bucceri','Charlton')
上記のコマンドは、次のコマンドと同じです。
SELECT emp_lname, emp_id
FROM employee
WHERE emp_lname = 'Yeung'
OR emp_lname = 'Bucceri'
OR emp_lname = 'Charlton'
10 Sybase IQ
Page 27

集約データの取得
集合関数の概要
第 1 章 データベース・テーブルからのデータの選択
ここでは、集約情報を返すクエリを構築する方法について説明します。集約情
報の例を次に示します。
• カラム内のすべての値の合計
• カラム内のエントリの数
• カラム内のエントリの平均値
従業員の人数を調べたいとします。次の文は、employee テーブルのローの数
を取得します。
SELECT count( * )
FROM employee
count(*)
75
このクエリによって、1 つのカラム (count(*) というタイトル ) と 1 つのロー
( 従業員数が格納されている ) だけで構成されるテーブルが返されます。
次のコマンドは、やや複雑な集約クエリです。
SELECT count( * ),
min( birth_date ),
max( birth_date )
FROM employee
count(*) min( birth_date ) max( birth_date )
75 1936-01-02 1973-01-18
このクエリの結果セットは、3 つのカラムと 1 つのローで構成されます。3 つ
のカラムには、従業員数、年齢が最も高い従業員の誕生日、年齢が最も低い従
業員の誕生日が格納されています。
COUNT、MIN、MAX を「集合関数」と呼びます。これらの各関数は、テーブ
ル全体の情報を要約します。集合関数は、MIN、MAX、COUNT、AV G 、SUM、
STDDEV、VA R I A N C E と全部で 7 個あります。すべての関数が、パラメータ
としてカラム名または式を使用します。前述のように、COUNT はアスタリス
クもパラメータとして使用します。
パフォーマンス&チューニング・ガイド 11
Page 28

集約データの取得
集合関数によるグループ化されたデータの取得
テーブル全体についての情報を取得することに加えて、集合関数をローのグ
ループに対して使うこともできます。
ローのグループに対する
集合関数の使用
各営業担当者が受け持つ注文数をリストするには、次のコマンドを入力します。
SELECT sales_rep, count( * )
FROM sales_order
GROUP BY sales_rep
sales_rep count(*)
129 57
195 50
299 114
467 56
667 54
このクエリの結果は、各営業担当者の ID 番号別に、営業担当者の ID が格納さ
れたローと、sales_order テーブル内でその ID 番号を持つローの数で構成され
ます。
GROUP BY 句を使用すると、結果のテーブルには、GROUP BY で指定したカ
ラムで見つかった値別のローが表示されます。
グループの制限
WHERE 句を使用して、クエリでローを制限する方法についてはすでに説明し
ました。GROUP BY 句の制限には、HAVING キーワードを使用します。
GROUP BY 句の制限
12 Sybase IQ
注文数が 55 を超えるすべての営業担当者をリストするには、次のコマンドを
入力します。
SELECT sales_rep, count( * )
FROM sales_order
GROUP BY sales_rep
HAVING count( * ) > 55
sales_rep count(*)
129 57
299 114
467 56
1142 57
注意 GROUP BY は常に HAVING の前に指定します。同様に、WHERE は GROUP
BY の前に指定します。
Page 29

第 1 章 データベース・テーブルからのデータの選択
WHERE と GROUP BY
の使用
小計計算の活用
ROLLUP の使用
注文数が 55 を超えており、ID が 1000 より大きいすべての営業担当者をリス
トするには、次のコマンドを入力します。
SELECT sales_rep, count( * )
FROM sales_order
WHERE sales_rep > 1000
GROUP BY sales_rep
HAVING count( * ) > 55
Sybase IQ クエリ・オプティマイザは、それによってパフォーマンスが向上す
る場合、述部を HAVING 句から WHERE 句に移動します。たとえば、上記の
例で WHERE 句の代わりに述部を次のように指定した場合、クエリ・オプティ
マイザは述部を WHERE 句に移動します。
GROUP BY sales_rep
HAVING count( *) > 55
AND sales_rep > 1000
Sybase IQ は、この最適化を (OR や IN を伴わない ) 単純な条件を使って実行し
ます。このため、WHERE 句と HAVING 句の両方を含むクエリを構築するとき
は、できるだけ多くの条件を WHERE 句で指定するようにします。
日付や場所などの次元によって異なるデータがある場合に、各次元でデータが
どのように異なるかを調べることが必要になる場合があります。ROLLUP 演
算子と CUBE 演算子を使用すると、グループ化カラムへの参照のリストから
複数レベルの小計と総計を作成できます。小計は、最も詳細なレベルから総計
まで「ロールアップ」します。たとえば、販売データを分析している場合は、
同じクエリを使用して全体の平均と年別の平均販売数を計算できます。
年別、モデル別、色別の合計自動車販売数を選択するには、次のコマンドを使
用します。
SELECT year, model, color, sum(sales)
FROM sales_tab
GROUP BY ROLLUP (year, model, color);
year model color sales
1990 Chevrolet red 5
1990 Chevrolet white 87
1990 Chevrolet blue 62
1990 Chevrolet NULL 154
1990 Ford blue 64
1990 Ford red 62
1990 Ford white 63
1990 Ford NULL 189
1990 NULL NULL 343
パフォーマンス&チューニング・ガイド 13
Page 30

集約データの取得
CUBE の使用
year model color sales
1991 Chevrolet blue 54
1991 Chevrolet red 95
1991 Chevrolet white 49
1991 Chevrolet NULL 198
1991 Ford blue 52
1991 Ford red 55
1991 Ford white 9
1991 Ford NULL 116
1991 NULL NULL 314
NULL NULL NULL 657
このクエリを処理するときに、Sybase IQ は最初に、指定された 3 つすべての
グループ化式 (year、model、color) によってデータをグループ化し、次に最後
の式 (color) を除くすべてのグループ化式によってデータをグループ化します。
5 番目のローの NULL は、color カラムの ROLLUP 値、つまり、そのモデルの
すべての色の合計販売数を示します。343 は、1990 年のすべてのモデルと色の
合計販売数を表し、314 は 1991 年の合計販売数を表します。最後のローは、す
べての年のすべてのモデルとすべての色の合計販売数を表します。
ROLLUP 演算子には、引数としてグループ化式の順番リストを指定する必要
があります。他のグループを含むグループをリストするときは、先に大きい方
のグループをリストします ( たとえば、state をリストしてから city をリスト
します )。
ROLLUP 演算子は、集合関数の SUM、COUNT、AV G 、MIN、MAX、STDDEV、
VA R I A N C E とともに使用できます。ただし、ROLLUP は COUNT DISTINCT と
SUM DISTINCT をサポートしていません。
次のクエリでは、人々の州 ( 地理的位置 )、性別、教育水準、所得を含む国勢調
査のデータを使用します。GROUP BY 句の CUBE 拡張を使用すると、census
テーブル内の国勢調査データを 1 回参照するだけで、州、性別、教育水準の国
勢調査全体の平均所得を計算し、state、gender、education の各カラムの可能な
すべての組み合わせの平均所得を計算できます。たとえば、すべての州のすべ
ての女性の平均所得を計算する場合や、教育水準と地理的位置を基準に国勢調
査のすべての人々の平均所得を計算する場合に、CUBE 演算子を使用します。
CUBE でグループを計算するときに、CUBE は計算されたグループのカラムに
NULL 値を挿入します。各ローが表すグループの種類と、その NULL がデータ
ベースに格納されている NULL なのか、CUBE が挿入した NULL なのかを区
別することは困難です。この問題を解決するのが GROUPING 関数です。指定
されたカラムが上位レベルのグループにマージされている場合、この関数は 1
を返します。
14 Sybase IQ
Page 31

第 1 章 データベース・テーブルからのデータの選択
次のクエリは、GROUPING 関数を GROUP BY CUBE と組み合わせた使用例
です。
SELECT
CASE GROUPING ( state ) WHEN 1 THEN 'ALL' ELSE state END
AS c_state,
CASE GROUPING ( gender ) WHEN 1 THEN 'ALL' ELSE gender
END AS c_gender,
CASE GROUPING ( education ) WHEN 1 THEN 'ALL' ELSE
education END AS c_education,
COUNT(*), CAST (ROUND ( AVG ( income ), 2 ) AS NUMERIC
(18,2)) AS average
FROM census
GROUP BY CUBE (state, gender, education);
このクエリの結果は次のとおりです。CUBE が生成した小計ローを示す NULL
値が、クエリ内の指定によって小計ローで ALL に置き換わっています。
c_state c_gender c_education count(*) average
MA f BA 3 48333.33
MA f HS 2 40000.00
MA f MS 1 45000.00
MA f ALL 6 45000.00
MA m BA 4 55000.00
MA m HS 1 55000.00
MA m MS 3 85000.00
MA m ALL 8 66250.00
MA ALL ALL 14 57142.86
NH f HS 2 50000.00
NH f MS 1 85000.00
NH f ALL 3 61666.67
NH m BA 3 55000.00
NH m MS 1 49000.00
NH m ALL 4 53500.00
NH ALL ALL 7 57000.00
ALL ALL ALL 21 57095.24
ALL ALL BA 10 53000.00
ALL ALL MS 6 72333.33
ALL ALL HS 5 47000.00
ALL f ALL 9 50555.56
パフォーマンス&チューニング・ガイド 15
Page 32

集約データの取得
c_state c_gender c_education count(*) average
ALL m ALL 12 62000.00
ALL f BA 3 48333.33
ALL m HS 1 55000.00
ALL m MS 4 76000.00
ALL m BA 7 55000.00
ALL f MS 2 65000.00
ALL f HS 4 45000.00
NH ALL HS 2 50000.00
NH ALL MS 2 67000.00
MA ALL MS 4 75000.00
MA ALL HS 3 45000.00
MA ALL BA 7 52142.86
NH ALL BA 3 55000.00
ROLLUP と CUBE は、データ・ウェアハウス管理者が次のような処理を行う
ときに特に役立ちます。
• 地理や時間などの階層的な次元での小計 ( たとえば、年/月/日や国/
州/市 )
• 要約テーブルへのデータの格納
ROLLUP と CUBE を使用すると、レベルごとに別々のクエリを使用する代わ
りに、1 つのクエリを使用して、複数レベルのグループ化を使ってデータを計
算できます。
ROLLUP 演算子と CUBE 演算子の詳細については、『Sybase IQ リファレンス・
マニュアル』の「第 6 章 SQL 文」の「SELECT 文」を参照してください。
16 Sybase IQ
Page 33

分析データの取得
第 1 章 データベース・テーブルからのデータの選択
ここでは、分析情報を返すクエリを構築する方法について説明します。統計関
数には、ランク付けと逆分散統計の 2 種類があります。ランク付け統計関数
は、グループ内の項目をランク付けしたり、分散統計を計算したり、結果セッ
トを複数のグループに分割したりします。逆分散統計関数は、K- 理論パーセ
ンタイル値を返します。これは、ひとまとまりのデータの値として許容し得る
しきい値を決定する際に使用します。
ランク分析関数には、RANK、DENSE_RANK、PERCENT_RANK、NTILE が
あります。逆分散統計関数には、PERCENTILE_CONT と PERCENTILE_DISC
があります。
たとえば、自動車販売店の販売状況を調べたいとします。NTILE 関数で、各販
売店が販売した車の台数に基づいて、販売店を 4 つのグループに分類します。
ntile = 1 になっているのは、車の販売台数で上位 25% までのディーラです。
SELECT dealer_name, sales,
NTILE(4) OVER ( ORDER BY sales DESC )
FROM carSales;
dealer_name sales ntile
Boston 1000 1
Worcester 950 1
Providence 950 1
SF 940 1
Lowell 900 2
Seattle 900 2
Natick 870 2
New Haven 850 2
Portland 800 3
Houston 780 3
Hartford 780 3
Dublin 750 3
Austin 650 4
Dallas 640 4
Dover 600 4
販売台数で上位 10% の販売店を調べるには、この例の SELECT 文で NTILE(10)
を指定します。同様に、販売台数で 50% の販売店を調べるには、NTILE(2) を指
定します。
NTILE はクエリ結果を指定された数のバケットに分割し、バケット内の各ロー
にバケット番号を割り当てるランク分析関数です。結果セットは 10 個 ( 十分
位数 )、4 個 ( 四分位数 )、その他の数のグループに分割できます。
ランク分析関数では、OVER (ORDER BY) 句を指定する必要があります。
ORDER BY 句は、ランク付けを実行するパラメータと、各グループ内でロー
をソートする順序を指定します。この ORDER BY 句は、OVER 句の中だけで
使用されるもので、SELECT の ORDER BY とは異なります。
パフォーマンス&チューニング・ガイド 17
Page 34

重複したローの削除
OVER 句は、関数がクエリの結果セットに対して処理を行うことを示します。
結果セットは、FROM、WHERE、GROUP BY、HAVING の各句がすべて評価
された後で返されるローです。OVER 句には、ランク付け統計関数の計算の対
象となるローのデータ・セットを定義します。
同様に、逆分布関数では WITHIN GROUP (ORDER BY) 句を指定する必要があ
ります。ORDER BY 句は、百分位関数を実行する式と、各グループでローを
ソートする順序を指定します。この ORDER BY 句は、WITHIN GROUP 句の
中でだけ使用されるもので、SELECT の ORDER BY とは異なります。WITHIN
GROUP 句は、クエリの結果を並べ替えて、関数が結果を計算するためのデー
タ・セットを形成します。
分析関数の詳細については、『Sybase IQ リファレンス・マニュアル』の「第 5
章 SQL 関数」の「統計関数」を参照してください。個別の分析関数について
は、「SQL 関数」の章の各関数の項を参照してください。
重複したローの削除
SELECT 文の結果テーブルに、重複したローが含まれることがあります。
DISTINCT キーワードを使用すると、重複したローを削除できます。たとえば、
次のコマンドを実行すると、多くの重複したローが返ります。
市と州のユニークな組み合わせだけをリストするには、次のコマンドを使用し
ます。
SELECT city, state FROM employee
SELECT DISTINCT city, state FROM employee
注意 ROLLUP 演算子と CUBE 演算子は、DISTINCT キーワードをサポートし
ていません。
この章では、単一テーブルの SELECT 文の概要について説明しました。単一
テーブルの SELECT 文の詳細については、『Sybase IQ システム管理ガイド』の
「第 5 章 データベース・オブジェクトの使用」、『Sybase IQ リファレンス・マ
ニュアル』の「第 3 章 SQL 言語の要素」、『Sybase IQ リファレンス・マニュア
ル』の「第 6 章 SQL 文」の「SELECT 文」を参照してください。
次の章では、SELECT 文の高度な使い方について説明します。
18 Sybase IQ
Page 35

第 2 章 テーブルのジョイン
この章について
この章では、複数のテーブルにある情報を参照する方法と、さまざまな種
類のジョインについて説明します。ここでは、テーブルをジョインする
チュートリアル作業を実行します。
内容
トピック名 ページ
外積を使用したテーブルのジョイン
ジョインの制限
テーブル間の関係
ジョイン演算子
アドホック・ジョインとジョイン・インデックスの使用
ジョインとデータ型
ストアまたはデータベース間ジョインのサポート
リモート・データベースと異種データベースのクエリ
サブクエリによるジョインの置き換え
外積を使用したテーブルのジョイン
サンプル・データベースに、会社の財務データをリストする fin_data とい
うテーブルがあります。各データ・レコードには、そのレコードの部署
と、それが支出レコードか収入レコードかを示す code カラムがあります。
fin_data テーブルには 84 のローがあります。
2 つのテーブルから同時に情報を取り出すには、SELECT クエリの FROM
句で、両方のテーブルをカンマで区切って指定します。
例
次の dbisql SELECT コマンドは、fin_code テーブルと fin_data テーブルの
すべてのデータをリストします。
SELECT *
FROM fin_code, fin_data
dbisql [ データ ] ウィンドウに表示されるこのクエリの結果は、fin_code テー
ブルのすべてのローと fin_data テーブルのすべてのローに一致します。この
ジョインを完全外積または直積と呼びます。各ローは、fin_code テーブルの
すべてのカラム、fin_data テーブルのすべてのカラムの順で構成されます。
19
20
21
22
25
25
26
27
28
パフォーマンス&チューニング・ガイド 19
Page 36

ジョインの制限
ジョインの制限
例 1
例 2
外積ジョインは、ジョインを理解するための単純な出発点にすぎず、それ自体
はあまり役に立ちません。これ以降の項で、より選択性の高いジョインを構築
する方法について説明します。このジョインは、外積テーブルへの制限の適用
と考えることができます。
外積ジョインを有効に利用するには、何らかの条件を満たすローだけを結果に
含める必要があります。ジョイン条件と呼ばれるこの条件では、比較演算子
(=、=>、< など ) を使用して、あるテーブルの 1 つのカラムを別のテーブルの
1 つのカラムと比較します。これにより、外積の結果から一部のローを除外し
ます。
たとえば、前の項のジョインを有効に利用するには、sales_order テーブルの
sales_rep と employee テーブルの従業員番号が一致するローだけを結果に含
めるように指定します。これにより、各ローには注文と、その注文を担当する
営業担当者の情報が格納されます。
これを実行するには、前のクエリに WHERE 句を追加し、従業員とその担当登
録のリストを表示します。
SELECT *
FROM sales_order, employee
WHERE sales_order.sales_rep = employee.emp_id
カラムを識別するために、テーブル名をプレフィクスとして指定します。この
例では必ずしも必要ありませんが、テーブル名のプレフィクスを使用すると文
が明確になります。2 つのテーブルに同じ名前のカラムがあるときは、このプ
レフィクスを指定する必要があります。このようなコンテキストで使用する
テーブル名を「修飾子」と呼びます。
このクエリの結果には 648 のローしかありません (sales_order テーブルの各
ローに 1 つずつ )。ジョインした元の 48,600 のローのうち、648 のローにだけ
2 つのテーブルで共通する従業員番号が含まれています。
次のクエリでは、一部のカラムだけをフェッチし、結果を順序付けするように
変更を加えています。
SELECT employee.emp_lname, sales_order.id,
sales_order.order_date
FROM sales_order, employee
WHERE sales_order.sales_rep = employee.emp_id
ORDER BY employee.emp_lname
SELECT コマンドに多くのテーブルがある場合は、修飾子名をいくつも入力し
なければならないことがあります。このようなときは、相関名を使用して入力
の手間を省くことができます。
20 Sybase IQ
Page 37

第 2 章 テーブルのジョイン
相関名
テーブル間の関係
相関名は、テーブルの特定のインスタンスのエイリアスです。このエイリアス
は、1 つの文中でのみ有効です。相関名を作成するには、テーブル名のすぐ後
ろに、テーブル名の省略形をキーワード AS で区切って指定します。それ以降
は、修飾子としてテーブル名の代わりにこの省略形を使用する必要があります。
SELECT E.emp_lname, S.id, S.order_date
FROM sales_order AS S, employee AS E
WHERE S.sales_rep = E.emp_id
ORDER BY E.emp_lname
この例では、sales_order テーブルと employee テーブルに対応する S と E と
いう 2 つの相関名を作成しています。
注意 テーブル名や相関名が必要になるのは、異なるテーブルに同じ名前のカ
ラムがあり、不明確になることを避ける場合だけです。相関名を作成した場合
は、テーブル名の代わりに必ず相関名を使用します。相関名を作成していない
場合は、テーブル名を使用します。
他の種類のジョインを構築するには、あるテーブルの情報が別のテーブルの情
報とどのように関係するかを先に理解する必要があります。
テーブルのプライマリ・キーは、そのテーブル内の各ローを識別します。各
テーブルは、外部キーを使って互いに関連付けられます。
ここでは、プライマリ・キーと外部キーを組み合わせて、複数のテーブルから
クエリを構築する方法について説明します。
プライマリ・キーによるローの識別
asiqdemo データベースのすべてのテーブルには、プライマリ・キーが設定さ
れています ( 各テーブルにプライマリ・キーを定義することをおすすめします )。
プライマリ・キーは、テーブル内のローをユニークに識別する 1 つまたは複数
のカラムです。たとえば、従業員番号は従業員をユニークに識別するため、
emp_id は employee テーブルのプライマリ・キーになります。
sales_order_items テーブルは、2 つのカラムでプライマリ・キーを構成して
いるテーブルの例です。注文 ID だけでは、sales_order_items テーブルのロー
がユニークに識別されません。注文には複数の項目が含まれる場合があるから
です。また、line_id 番号も sales_order_items テーブルのローをユニークに識
別しません。sales_order_items テーブルのローをユニークに識別するには、
注文 ID 名と line_id の両方が必要です。両方のカラムが一緒になってテーブル
のプライマリ・キーになります。
パフォーマンス&チューニング・ガイド 21
Page 38

ジョイン演算子
外部キーによって関連付けられたテーブル
asiqdemo データベースのいくつかのテーブルは、データベース内の他のテー
ブルを参照しています。たとえば、sales_order テーブルには、注文を担当す
る従業員を示す sales_rep カラムがあります。sales_order テーブルには、従業
員をユニークに識別するために必要な最小限の情報だけが格納されています。
sales_order テーブルの sales_rep カラムは、employee テーブルに対する外部
キーになっています。
外部キー
外部キーは、他のテーブルの候補キーの値を含む 1 つまたは複数のカラムです
( 候補キーの詳細については、『Sybase IQ システム管理ガイド』の「第 5 章 デー
タベース・オブジェクトの使用」を参照してください )。従業員データベース
内の各外部キーの関係は、2 つのテーブル間の矢印によって図示されます。
『Sybase IQ の概要』の図 1-1 (11 ページ ) のサンプル・データベースの図に、こ
れらの矢印が示されています。矢印は関係の外部キー側を起点とし、候補キー
側を指し示しています。
ジョイン演算子
多くの一般的なジョインは、外部キーで関連付けられた 2 つのテーブル間で行
われます。最も一般的なジョインでは、外部キーの値がプライマリ・キーの値
と等しいものに制限されます。すでに見てきた例では、sales_order テーブル
の外部キーの値が、employee テーブルの候補キーの値と等しいものに制限され
ています。
SELECT emp_lname, id, order_date
FROM sales_order, employee
WHERE sales_order.sales_rep = employee.emp_id
KEY JOIN を使用すると、クエリをより簡単に表現できます。
キー・ジョインを使用したテーブルのジョイン
キー・ジョインは、外部キーで関連付けられたテーブルを簡単にジョインする
方法です。例:
SELECT emp_lname, id, order_date
FROM sales_order
KEY JOIN employee
このコマンドは、次のように 2 つの従業員 ID 番号カラムを結び付ける WHERE
句を使ったクエリと同じ結果をもたらします。
SELECT emp_lname, id, order_date
FROM sales_order, employee
WHERE sales_order.sales_rep = employee.emp_id
22 Sybase IQ
Page 39

複数のテーブルの
ジョイン
第 2 章 テーブルのジョイン
ジョイン演算子 (KEY JOIN) は、単に WHERE 句の入力の手間を省くためのも
ので、2 つのクエリはまったく同じものです。
『Sybase IQ の概要』の asiqdemo データベースの図では、外部キーがテーブル
間の線で表されています。図中で 2 つのテーブルが線で結合されていれば、
KEY JOIN 演算子を使用できます。キー・ジョインによるクエリで期待どおり
の結果を得るには、アプリケーションで外部キーを強制的に適用する必要があ
ります。
ジョイン演算子を使用して、複数のテーブルをジョインできます。次のクエリ
では、4 つのテーブルを使用して、注文の合計額を顧客別にリストしています。
customer、sales_order、sales_order_items、product の 4 つのテーブルを、テー
ブルの各ペア間の 1 つの外部キー関係で接続しています。
SELECT company_name,
CAST( SUM(sales_order_items.quantity *
product.unit_price) AS INTEGER) AS value
FROM customer
KEY JOIN sales_order
KEY JOIN sales_order_items
KEY JOIN product
GROUP BY company_name
company_name value
McManus Inc. 3,156
Salt & Peppers. 4,980
The Real Deal 1,884
Totos Active Wear 2,496
The Ristuccia Center 4,596
...
このクエリで使用している CAST 関数は、式のデータ型を変換します。この例
では、整数として返される合計が値に変換されます。
パフォーマンス&チューニング・ガイド 23
Page 40

ジョイン演算子
ナチュラル・ジョインを使用したテーブルのジョイン
NATURAL JOIN 演算子は、共通のカラム名に基づいて 2 つのテーブルをジョ
インします。言い換えると、Sybase IQ が各テーブルに共通するカラムを結び
付ける WHERE 句を生成します。
例
NATURAL JOIN を使用
したときのエラー
たとえば、次のようなクエリがあるとします。
SELECT emp_lname, dept_name
FROM employee
NATURAL JOIN department
この例では、データベース・サーバが 2 つのテーブルを参照し、共通するカラ
ム名は dept_id だけであると判断します。次の ON フレーズが内部的に生成さ
れ、ジョインの実行に使用されます。
FROM employee JOIN department
...
ON employee.dept_id = department.dept_id
このジョイン演算子では、意図しないカラムを結び付けてしまう問題が起きる
可能性があります。たとえば、次のクエリは意図しなかった結果をもたらします。
SELECT *
FROM sales_order
NATURAL JOIN customer
このクエリの結果には、ローが 1 つもありません。
データベース・サーバは、内部的に次の ON フレーズを生成します。
FROM sales_order JOIN customer
ON sales_order.id = customer.id
sales_order テーブルの id カラムは、注文の ID 番号です。一方、customer テー
ブルの id カラムは、顧客の ID 番号です。これらの番号は 1 つも一致しません。
たとえ一致する番号があったとしても、当然それは意味を持ちません。
ジョイン演算子をむやみに使用しないように注意してください。ジョイン演算
子は、単に強制力のない外部キーや共通のカラム名で WHERE 句を入力する手
間を省くためのものであることを忘れないでください。WHERE 句を注意して
使用しないと、意図しない結果をもたらすクエリを作成してしまう可能性があ
ります。
24 Sybase IQ
Page 41

第 2 章 テーブルのジョイン
アドホック・ジョインとジョイン・インデックスの使用
クエリで参照されるジョイン・カラムにジョイン・インデックスを定義して
いる場合、Sybase IQ は自動的にそれらを使用してクエリ処理を高速化しま
す ( ジョイン・インデックスの定義については、『Sybase IQ システム管理ガ
イド』の「第 6 章 Sybase IQ インデックスの使用」を参照してください )。
ジョイン・インデックスを使用しないジョインを「アドホック・ジョイン」呼
びます。クエリでいくつものテーブルを参照しており、その中にジョイン・イ
ンデックスが定義されていないテーブルがある場合、Sybase IQ は定義されて
いるテーブルではジョイン・インデックスを、それ以外のテーブルではアド
ホック・ジョインを使用します。
可能なすべてのジョインに対してジョイン・インデックスを作成することはで
きないため、ときにはアドホック・ジョインが必要になることがあります。
Sybase IQ の最適化によって、クエリはジョイン・インデックスなしでも同等
かそれ以上のパフォーマンスで実行されます。
ジョイン・インデックスの作成には、次の制約があります。
• インデックス内では、完全な外部ジョインだけがサポートされます。クエ
リは、インデックス付けされている場合、内部、左外部、右外部のジョイ
ンになります。
完全な外部ジョインでは、指定された左右両方のテーブルのすべてのロー
が結果に含まれ、対応するカラムに一致する値がないカラムについては
NULL が返されます。
• ジョイン述部の ON 句で使用できる比較演算子は EQUALS だけです。
• ON 句の代わりに NATURAL キーワードを使用できますが、1 対のテーブ
ルしか指定できません。
• ジョイン・インデックス・カラムはいずれも同じデータ型、精度、位取り
でなければなりません。
ジョインとデータ型
最適なパフォーマンスを得るには、ジョイン・カラムを類似のデータ型にする
必要があります。Sybase IQ では、暗黙の変換が存在する任意のデータ型でア
ドホック・ジョインを行うことができます。ただし、ジョイン・カラムのデー
タ型が同じでない場合は、データ型とテーブルのサイズによって、パフォーマ
ンスがさまざまな範囲で低下する可能性があります。たとえば、INT を BIGINT
のカラムにジョインすることはできますが、このジョインによって特定の種類
の最適化ができなくなります。Sybase IQ インデックス・アドバイザは、データ
型が異なるジョイン・カラムにパフォーマンス上の問題があると見なします。
暗黙のデータ型変換のテーブルについては、『Sybase IQ システム管理ガイド』
の「第 7 章 データベースへのデータの入出力」を参照してください。
パフォーマンス&チューニング・ガイド 25
Page 42

ストアまたはデータベース間ジョインのサポート
ストアまたはデータベース間ジョインのサポート
この項では、ストア間またはデータベース間ジョインに対する現在のサポート
を明確にします。
Sybase IQ
ス内でのテーブルの
ジョイン
Adaptive Server
Enterprise テーブルと
Sybase IQ テーブルの
ジョイン
データベー
指定された Sybase IQ データベース内では、あらゆる種類のジョインがサポー
トされます。つまり、カタログ・ストアの任意のシステムまたはユーザ・テー
ブルを、IQ ストアの任意のテーブルに任意の順序でジョインできます。
Sybase IQ テーブルと Adaptive Server Enterprise データベースのテーブルのジョ
インは、次の条件下でサポートされます。
• Sybase IQ データベースは、ローカル・データベースとリモート・データ
ベースのどちらでもかまいません。
•ASE で Sybase IQ テーブルをプロキシ・テーブルとして使用する場合は、
テーブル名を 30 文字以内にしてください。
• ローカルの Adaptive Server Enterprise テーブルをリモートの Sybase IQ 12
テーブルにジョインするには、ASE のバージョンが 11.9.2 以降である必要
があります。また、次の適切なサーバ・クラスを使用してください。
• Adaptive Server Enterprise 12.5 以降のフロントエンドからリモートの
Sybase IQ 12.5 以降に接続するには、ASE 12.5 で追加された ASIQ サー
バ・クラスを使用します。
• Adaptive Server Enterprise 11.9.2 から 12.0 までのフロントエンドから
リモートの Sybase IQ 12.x ( または Adaptive Server Anywhere 6.x 以降 )
に接続するには、サーバ・クラス ASAnywhere を使用します。
• ローカルの Sybase IQ テーブルを任意のリモート・テーブルとジョインす
る場合は、ローカルのテーブルを FROM 句の最初に指定する必要があり
ます。つまり、ローカルのテーブルは、ジョインの最も外側のテーブルに
なります。
Sybase IQ と Adaptive Server Enterprise の間のジョインは、コンポーネント統合
サービス (CIS) に依存します。
Adaptive Server Enterprise データベースから Sybase IQ へのクエリの詳細につい
ては、Adaptive Server Enterprise 主要マニュアル・セットの『コンポーネント統
合サービス・ユーザーズ・ガイド』を参照してください。
Sybase IQ から他のデータベースへのクエリの詳細については、「リモート・
データベースと異種データベースのクエリ」を参照してください。
26 Sybase IQ
Page 43

第 2 章 テーブルのジョイン
Adaptive Server
Anywhere テーブルと
Sybase IQ テーブルの
ジョイン
データベースが BLANK PADDING OFF を指定して構築された場合、CHAR
データ型は Adaptive Server Anywhere と Sybase IQ の間で互換性がありません。
文字データをジョイン・キーとして使用して、Adaptive Server Anywhere テー
ブルと Sybase IQ テーブルの間でデータベースのジョインを実行する場合は、
BLANK PADDING ON を指定して CHAR データ型を使用します。
注意 Sybase IQ CREATE DATABASE は、新しいデータベースについては BLANK
PADDING OFF をサポートしなくなりました。この変更は、既存のデータベース
には影響しません。BlankPadding database プロパティを使用して、既存のデータ
ベースの状態をテストすることができます。
select db_property ( ‘BlankPadding’ )
Sybase では、ジョイン結果が正しくなるように、BLANK PADDING OFF によっ
て影響を受ける既存のカラムをすべて変更することを推奨しています。ジョイ
ン・カラムを VARCHAR ではなく CHAR データ型として再作成します。CHAR
カラムでは、常にブランクが埋め込まれます。
リモート・データベースと異種データベースのクエリ
ここでは、Sybase IQ をコンポーネント統合サービス (CIS) と組み合わせて使用
する方法について説明します。CIS を使用すると、Sybase IQ を通して Adaptive
Server Enterprise データベースとリモート・データベースまたは非リレーショ
ナル・データ・ソースにクエリを実行できます。CIS は Sybase IQ の一部とし
てインストールされます。
CIS を使用すると、リモート・サーバ上のテーブルに、ローカルのテーブルの
ようにアクセスできます。CIS は、複数のリモート異種サーバのテーブル間で
ジョインを実行し、1 つのテーブルの内容を、サポートされているリモート・
サーバへ転送します。
リモートのデータベースやデータ・ソースにクエリを実行するには、そのテー
ブルをローカル・プロキシ・テーブルにマッピングする必要があります。CIS
は、データがローカルに格納されているかのように、プロキシ・テーブルをク
ライアント・アプリケーションに示します。テーブルにクエリを実行すると、
CIS は実際のサーバ記憶位置を判別します。
❖ リモート・データベースをジョインするには
1 『Sybase IQ システム管理ガイド』の手順に従って、プロキシ・テーブルを
作成します。
2 リモート・テーブルをプロキシ・テーブルにマッピングします。
パフォーマンス&チューニング・ガイド 27
Page 44

サブクエリによるジョインの置き換え
3 プロキシ・データベース名を各リモート・テーブルの修飾名として使用
し、SELECT 文でプロキシ・テーブルを参照します。たとえば、次のよう
な文を発行します。
SELECT a.c_custkey, b.o_orderkey
FROM proxy_asiqdemo..cust2 a,
asiqdemo..orders b
WHERE a.c_custkey = b.o_custkey
詳細については、『Sybase IQ システム管理ガイド』の「第 16 章 リモート・デー
タへのアクセス」と「第 17 章 リモート・データ・アクセス用のサーバ・クラ
ス」を参照してください。
サブクエリによるジョインの置き換え
ジョインは、複数のテーブルのデータから構築される結果テーブルを返します。
サブクエリを使用して、同じ結果テーブルを取得することもできます。サブク
エリは、単に別の SELECT 文の中にある SELECT 文です。より複雑で多くの情
報を与えるクエリを構築するときに、このツールが役立ちます。
たとえば、注文とその発注先の会社を時系列にリストする必要があり、顧客
ID の代わりに会社名を使いたいとします。この結果を得るには、次のような
ジョインを使用します。
ジョインの使用
1994 年の年初以降の各注文の order_id、order_date、company_name をリス
トするには、次のコマンドを入力します。
SELECT sales_order.id,
sales_order.order_date,
customer.company_name
FROM sales_order
KEY JOIN customer
WHERE order_date > '1994/01/01'
ORDER BY order_date
id order_date company_name
2473 1994-01-04 Peachtree Active Wear
2474 1994-01-04 Sampson & Sons
2036 1994-01-05 Hermanns
2475 1994-01-05 Salt & Peppers
2106 1994-01-05 Cinnamon Rainbows
28 Sybase IQ
Page 45

第 2 章 テーブルのジョイン
外部ジョインの使用
サブクエリの使用
前項のチュートリアルのジョインは、より正確には「内部ジョイン」と呼ばれ
ます。
外部ジョインを明示的に指定します。この場合は、GROUP BY 句も必要です。
SELECT company_name,
MAX( sales_order.id ),state
FROM customer
KEY LEFT OUTER JOIN sales_order
WHERE state = 'WA'
GROUP BY company_name, state
company_name max(sales_order.id) state
Custom Designs 2547 WA
Its a Hit! (NULL) WA
在庫が少ない製品の注文項目をリストするには、次のコマンドを入力します。
SELECT *
FROM sales_order_items
WHERE prod_id IN
( SELECT id
FROM product
WHERE quantity < 20 )
ORDER BY ship_date DESC
id line_id prod_id quantity ship_date
2082 1 401 48 1994-07-09
2053 1 401 60 1994-06-30
2125 2 401 36 1994-06-28
2027 1 401 12 1994-06-17
2062 1 401 36 1994-06-17
カッコで囲まれたフレーズが、この文のサブクエリです。
( SELECT id
FROM product
WHERE quantity < 20 )
サブクエリを使用すると、検索を 1 回のクエリだけで実行できるようになり
ます。このため、在庫が少ない製品のリストをクエリで検索し、さらにその
製品の注文を別のクエリで検索する必要がなくなります。
このサブクエリは、製品テーブルの id カラムで WHERE 句の探索条件を満た
すすべての値をリストします。
パフォーマンス&チューニング・ガイド 29
Page 46

サブクエリによるジョインの置き換え
クエリの別の表現方法
受注した 10 枚のタンクトップが出荷され、タンクトップの数量カラムの値が
18 になった場合にどうなるかを考えてみます。サブクエリを使ったクエリは、
ウールの帽子とタンクトップの両方のすべての注文をリストします。これに対
して、最初に使用した文は次のように変更する必要があります。
SELECT *
FROM sales_order_items
WHERE prod_id IN ( 401, 300 )
ORDER BY ship_date DESC
サブクエリを使用するコマンドは、データベースのデータが変更されてもその
まま機能するように、改善されています。
サブクエリについては、次の点に注意してください。
• NOT EXISTS 述部を使用するクエリなど、ジョインの構築に問題がある場
合もサブクエリが役立つことがあります。
• サブクエリが返せるのは 1 つのカラムだけです。
• サブクエリは、比較の引数、IN、または EXISTS 句としてのみ使用でき
ます。
• 外部ジョインの ON 句の中に、サブクエリを使用することはできません。
30 Sybase IQ
Page 47

第 3 章 クエリと削除の最適化
この章について
内容
クエリ構築のヒント
この章では、次のようなクエリと削除のパフォーマンスに関する推奨事項
について説明します。
• 処理速度の速いクエリの構築
• クエリ・プランの使用
• クエリ処理オプションの設定
• 削除オペレーションの最適化
トピック名 ページ
クエリ構築のヒント
クエリ・プラン
クエリ処理の制御
削除オペレーションの最適化
31
35
37
40
ここでは、クエリ構造を改良するためのヒントを示します。
• サブクエリを含むコマンド文をジョインとして構成することによっ
て、実行速度を高めることができる場合があります。
• GROUP BY 句で複数のカラムをグループ化する場合、カラムに対応
するユニークな値をもとに降順にカラムをリストします。これによっ
て最適なクエリのパフォーマンスが実現されます。
• ジョイン・インデックスを使用すると、多くの場合、ジョイン・クエ
リはアドホック・ジョインより高速に実行されますが、より多くの
ディスク領域が必要となります。ただし、ジョイン・クエリがマルチ
テーブル・ジョイン・インデックスの最大のテーブルを参照しない場
合は、アドホック・ジョインの方がジョイン・インデックスよりパ
フォーマンスが高くなります。
• 追加のカラムを使用して、頻繁に行う計算の結果を格納すると、パ
フォーマンスを向上させることができます。
パフォーマンス&チューニング・ガイド 31
Page 48

クエリ構築のヒント
UNION ALL での GROUP BY がクエリ・パフォーマンスに与える影響
パフォーマンスを向上させるために、非常に大きなテーブルを複数の小さな
テーブルにセグメント化し、ビューで UNION ALL を使用してアクセスするこ
とがよくあります。このようなビューを GROUP BY とともに使用する特定の
非常に個別的なクエリでは、Sybase IQ オプティマイザがいくつかの GROUP
BY 処理を UNION ALL の各分岐に挿入して、処理を並列に実行し、結果を結
合することでパフォーマンスを向上させることができます。分割 GROUP BY
と呼ばれるこの方法では、最上位レベルの GROUP BY で処理されるデータの
量が減少し、その結果、クエリ処理時間が減少します。
パフォーマンスが向上するのは、UNION ALL で GROUP BY を使用する特定
のクエリだけです。たとえば、次の簡単なクエリは分割 GROUP BY によって
パフォーマンスが向上します。
CREATE VIEW vtable (v1 int, v2 char(4)) AS
SELECT a1, a2 FROM tableA
UNION ALL
SELECT b1, b2 FROM tableB;
SELECT COUNT(*), SUM(v1) FROM vtable GROUP BY v2;
このクエリを分析するときに、オプティマイザは先に tableA で COUNT(*)
GROUP BY を実行し、tableB で COUNT(*) GROUP BY を実行した後、結果を
最上位レベルの GROUP BY に渡します。最上位レベルの GROUP BY は、2 つ
の COUNT(*) の結果の SUM を実行し、最終的なクエリ結果を生成します。最
上位レベルの GROUP BY の役割が変化していることに注意してください。最
上位レベルの GROUP BY が使用している集合関数は COUNT ではなく SUM
です。
分割 GROUP BY の制限
分割 GROUP BY によってパフォーマンスが向上する状況とクエリには、いく
つかの制限があります。
• クエリで UNION ではなく UNION ALL を使用している場合に、分割 GROUP
BY によってクエリのパフォーマンスが向上する可能性があります。次のク
エリでは UNION で GROUP BY を使用しているため、分割 GROUP BY によ
るメリットはありません。
CREATE VIEW viewA (va1 int, va2 int, va3 int,
va4 int) AS
SELECT b1, b2, b3, b4 FROM tableB
UNION
SELECT c1, c2, c3, c4 FROM tableC;
SELECT SUM(va1) FROM viewA GROUP BY va3;
32 Sybase IQ
Page 49

第 3 章 クエリと削除の最適化
• クエリ内の集合関数で DISTINCT が指定されていない場合に、分割 GROUP
BY によってクエリのパフォーマンスが向上する可能性があります。次の
クエリでは SUM DISTINCT を使用しているため、分割 GROUP BY による
メリットはありません。
CREATE VIEW viewA (va1 int, va2 int, va3 int,
va4 int) AS
SELECT b1, b2, b3, b4 FROM tableB
UNION ALL
SELECT c1, c2, c3, c4 FROM tableC;
SELECT SUM(DISTINCT va1) FROM viewA GROUP BY va3;
• 分割 GROUP BY によってクエリのパフォーマンスを向上させるには、追
加の GROUP BY 演算子の処理に使われる集合情報とデータを格納するた
めに、テンポラリ共有バッファ・キャッシュに十分なメモリが必要です。
CREATE VIEW viewA (va1 int, va2 int, va3 int,
va4 int) AS
SELECT b1, b2, b3, b4 FROM tableB
UNION ALL
SELECT c1, c2, c3, c4 FROM tableC
UNION ALL
SELECT d1, d2, d3, d4 FROM tableD
UNION ALL
SELECT e1, e2, e3, e4 FROM tableE
UNION ALL
SELECT f1, f2, f3, f4 FROM tableF
UNION ALL
SELECT g1, g2, g3, g4 FROM tableG;
SELECT SUM(va1) FROM viewA GROUP BY va3;
この例では、Sybase IQ オプティマイザが GROUP BY を分割し、6 個の
GROUP BY 演算子をクエリ・プランに挿入しています。これにより、集
合情報とデータを格納するために、クエリにより多くのテンポラリ・
キャッシュが必要となります。システムが十分なキャッシュを割り付けら
れない場合、オプティマイザは GROUP BY を分割しません。
メモリに空きがある場合は、TEMP_CACHE_MEMORY_MB データベー
ス・オプションを使用してテンポラリ・キャッシュのサイズを増やす
ことができます。バッファ・キャッシュのサイズの設定方法について
は、『Sybase IQ リファレンス・マニュアル』の「データベース・オプショ
ン」の「バッファ・キャッシュ・サイズの決定」(107 ページ ) および
「TEMP_CACHE_MEMORY_MB オプション」を参照してください。
パフォーマンス&チューニング・ガイド 33
Page 50

クエリ構築のヒント
分割 GROUP BY の例
• 分割 GROUP BY によってクエリのパフォーマンスを向上させるには、
AGGREGATION_PREFERENCE データベース・オプションをデフォルト値
の 0 に設定します。これにより、Sybase IQ オプティマイザは GROUP BY に
適用する最善のアルゴリズムを判断できるようになります。Sybase IQ オプ
ティマイザが GROUP BY の処理にソート・アルゴリズムを選択するように
AGGREGATION_PREFERENCE の値が設定されている場合は、分割 GROUP
BY によるメリットはありません。AGGREGATION_PREFERENCE オプショ
ンを使用すると、オプティマイザが GROUP BY の処理に選択するアルゴリ
ズムを上書きできます。分割 GROUP BY では、この値を 1 または 2 に設定
しないでください。
次の例では、tableA という大きなテーブルを、tabA1、tabA2、tabA3、tabA4
という 4 つの小さなテーブルにセグメント化しています。この 4 つの小さな
テーブルと UNION ALL を使用して、unionTab ビューを作成します。
CREATE VIEW unionTab (v1 int, v2 int, v3 int, v4 int) AS
SELECT a, b, c, d FROM tabA1
UNION ALL
SELECT a, b, c, d FROM tabA2
UNION ALL
SELECT a, b, c, d FROM tabA3
UNION ALL
SELECT a, b, c, d FROM tabA4;
Sybase IQ オプティマイザは GROUP BY の処理を次のクエリに分割し、クエリ
のパフォーマンスを向上させます。
SELECT v1, v2, SUM(v3), COUNT(*) FROM unionTab
GROUP BY v1, v2;
SELECT v3, SUM(v1*v2) FROM unionTab
GROUP BY v3;
Adaptive Server Anywhere による処理を引き起こす条件
Sybase IQ アーキテクチャには、Adaptive Server Anywhere のルールに従ってク
エリを処理する製品の部分が含まれています。CIS ( 以前は OMNI) 機能補正と
呼ばれるこの機能を使用すると、Sybase IQ のセマンティックで直接サポート
されないクエリを処理できますが、パフォーマンスが大幅に低下します。
CIS は次のクエリを傍受します。
• ユーザ定義関数を参照するクエリ
• データベース間のジョインまたはプロキシ・テーブルを含むクエリ
• 特定のシステム関数を含むクエリ
• カタログ・ストア・テーブルまたは SYSTEM dbspace で作成されたテーブ
ルを参照するクエリ
34 Sybase IQ
Page 51

クエリ・プラン
第 3 章 クエリと削除の最適化
Sybase IQ と Adaptive Server Anywhere の違いの詳細については、『Sybase IQ リ
ファレンス・マニュアル』の「付録 A 他の Sybase データベースとの互換性」
を参照してください。
最も効果的な構文を使用していなくても、正しいインデックスを作成していれ
ば、通常は Sybase IQ クエリ・オプティマイザによって、最も効率的な方法で
クエリを実行できます。もちろん、クエリを正しく設計することは重要です。
クエリを計画する場合に、クエリの実行速度と得られる結果の正確さが主要な
問題点となります。
クエリを実行する前に、Sybase IQ クエリ・オプティマイザはクエリ・プラン
を作成します。Sybase IQ では、これ以降の項で説明するオプションを使用し
て、クエリ・プランを調査および変更し、クエリを評価できます。このオプ
ションを指定する方法の詳細については、『Sybase IQ リファレンス・マニュア
ル』を参照してください。
注意 整数値を指定できるデータベース・オプションでは、小数の option-value
の設定が常に整数値にトランケートされます。たとえば、3.8 という値は 3 に
トランケートされます。
クエリ評価オプション
次のオプションは、クエリ・プランの評価に役立ちます。これらのオプション
の詳細については、『Sybase IQ リファレンス・マニュアル』を参照してください。
• INDEX_ADVISOR - このオプションを ON に設定すると、インデックス・
アドバイザは、Sybase IQ クエリ・プランの一部として、またクエリ・プラ
ンが無効の場合には、Sybase IQ メッセージ・ログ・ファイル内の独立した
メッセージとして、インデックスの推奨を出力します。これらのメッセージ
は、“Index Advisor” という文字列で始まります。この文字列を検索すること
で、Sybase IQ メッセージ・ファイルからこれらのメッセージをフィルタで
きます。このオプションはメッセージを OWNER.TABLE.COLUMN 形式で出
力します。このオプションのデフォルト設定は OFF です。
『Sybase IQ リファレンス・マニュアル』の「sp_iqindexadvice プロシージャ」
も参照してください。
• INDEX_ADVISOR_MAX_ROWS - このオプションはインデックス・アド
バイザによって格納されるメッセージの数を制限します。指定された制限
値に達すると、INDEX_ADVISOR は新しいアドバイスの保存を停止しま
すが、既存のアドバイスのカウントとタイムスタンプの更新は続行します。
パフォーマンス&チューニング・ガイド 35
Page 52

クエリ・プラン
• NOEXEC - このオプションを ON に設定すると、Sybase IQ はクエ
リ・プランを生成しますが、クエリを実行しません。ただし、
EARLY_PREDICATE_EXECUTION オプションが ON の場合を除き
ます。
• QUERY_DETAIL - このオプションと、QUERY_PLAN または
QUERY_PLAN_AS_HTML の両方が ON の場合、Sybase IQ はクエ
リ・プランを生成するときに、クエリについての追加情報を表示し
ます。QUERY_PLAN と QUERY_PLAN_AS_HTML が OFF の場合、
このオプションは無視されます。
• QUERY_PLAN - このオプションが ON に設定されている場合 ( デフォル
ト )、Sybase IQ はクエリについてのメッセージを生成します。ジョイン・
インデックスの使用方法、ジョイン順序、クエリのジョイン・アルゴリズ
ムについてのメッセージなどが生成されます。
• QUERY_PLAN_AFTER_RUN - このオプションを ON に設定すると、ク
エリの実行が終了した後でクエリ・プランが出力されます。これにより、
クエリの各ノードから渡された実際のローの数など、追加情報をプランに
含めることができます。このオプションを使用するには、QUERY_PLAN
を ON にします。このオプションは、デフォルトでは OFF になっています。
• QUERY_PLAN_AS_HTML - このオプションは、We b ブラウザで表示で
きるように、HTML 形式のグラフィカルなクエリ・プランを生成します。
HTML 形式では、ノード間にハイパーリンクが設定されるため、.iqmsg
ファイルのテキスト形式よりはるかに使いやすくなります。クエリ・プラ
ンのファイル名にクエリ名を含めるには、QUERY_NAME オプションを
使用します。このオプションは、デフォルトでは OFF になっています。
• QUERY_PLAN_AS_HTML_DIRECTORY - このオプションを ON に設定
し、QUERY_PLAN_AS_HTML_DIRECTORY でディレクトリが指定され
ている場合、Sybase IQ は指定されたディレクトリに HTML クエリ・プラ
ンを書き込みます。
• QUERY_TIMING - このオプションは、サブクエリのタイミング統計の収
集などのクエリ・エンジンの反復的な機能を制御するのに使用します。非
常に短い相関サブクエリの場合、各サブクエリを実行するタイミングを合
わせる処理のために、全体のパフォーマンスが大幅に低下するため、この
オプションは、通常、OFF ( デフォルト ) にします。
注意 クエリ・プランを生成すると、.iqmsg ファイルに大量のテキストが追加
される場合があります。QUERY_PLAN が ON の場合で、特に QUERY_DETAIL
が ON の場合は、IQMSG_LENGTH_MB を正の値に設定し、メッセージ・ログ
の循環を有効にすることをおすすめします。
36 Sybase IQ
Page 53

クエリ・ツリー
オプティマイザは、クエリ内のデータの流れを表すクエリ「ツリー」を作成し
ます。クエリ・プランでは、クエリ・ツリーが .iqmsg ファイル内にテキスト
形式で表示されます。オプションで、グラフィカル形式のクエリ・ツリーも作
成できます。
クエリ・ツリーはノードで構成されます。それぞれのノードは処理の段階を表
します。ツリーの一番下のノードはリーフ・ノードです。各リーフ・ノード
は、クエリ内のテーブルまたはプリジョイン・インデックス・セットを表し
ます。
プランの最上部にあるのは、演算子ツリーのルートです。情報はテーブルから
上方向に、ジョイン、ソート、フィルタ、格納、集合、サブクエリを表す演算
子を通じて流れます。
HTML クエリ・プランの使用
クエリ・プランを初めて使用するときは、QUERY_PLAN_AS_HTML オプショ
ンを ON に設定することをおすすめします。このオプションを設定すると、
.iqmsg ファイルと同じディレクトリにグラフィカル版のクエリ・プランが作成
されます。このファイルは、ほとんどの Web ブラウザで表示できます。
HTML クエリ・プランでは、ツリーの各ノードが詳細へのハイパーリンクに
なっています。各ボックスが上位のツリーへハイパーリンクされています。任
意のノードをクリックし、プラン内をすばやく移動できます。
第 3 章 クエリと削除の最適化
クエリ処理の制御
すべてのユーザが、特定のクエリの処理にかかる時間に制限を設定できます。
DBA 権限を持つユーザは、特定のユーザのクエリに他のクエリより高い優先
度を与えることや、処理のアルゴリズムを変更し、クエリ処理の速度を操作す
ることができます。この項で説明するオプションの詳細については、『Sybase
IQ リファレンス・マニュアル』を参照してください。
クエリの時間制限の設定
MAX_QUERY_TIME オプションを設定すると、ユーザは長い時間がかかるク
エリを禁止できます。指定した時間よりクエリの実行時間が長くかかった場
合、Sybase IQ は適切なエラーを表示してクエリを停止します。
注意 Sybase IQ では、小数の option-value の設定がすべて整数値にトランケー
トされます。たとえば、3.8 という値は 3 にトランケートされます。
パフォーマンス&チューニング・ガイド 37
Page 54

クエリ処理の制御
クエリの優先度の設定
処理をキューで待機しているクエリは、そのクエリを送信したユーザの優先
度、そしてクエリが送信された順序の順に実行されます。優先度の高いクエリ
がすべて実行されるまで、優先度の低いキューのクエリは実行されません。
次のオプションは、クエリにユーザ別の処理の優先度を割り当てます。
• IQGOVERN_PRIORITY - 処理キューで待機しているクエリに数字の優
先度 (1、2、または 3 で、1 が最も高い ) を割り当てます。
• IQGOVERN_MAX_PRIORITY - DBA はユーザまたはグループの
IQGOVERN_PRIORITY に上限値を設定できます。
• IQ_GOVERN_PRIORITY_TIME - 優先度の高い ( 優先度 1 の ) クエリが、
指定した時間より長く -iqgovern キューで待機している場合に、優先度の
高いユーザを開始できます。
クエリの優先度を調べるには、sp_iqcontext ストアド・プロシージャによって
返される IQGovernPriority 属性を確認します。
クエリ最適化オプションの設定
次のオプションは、クエリの処理速度に影響を与えます。
• AGGREGATION_PREFERENCE - 集合 (GROUP BY、DISTINCT、SET
の各関数 ) を処理するためのアルゴリズムの選択を制御しますこのオプ
ションは、主に内部用として設計されているため、経験のあるデータベー
ス管理者のみが使用してください。
• DEFAULT_HAVING_SELECTIVITY - クエリ内のすべての HAVING 述部
の選択性を設定します。これが、HAVING 句によってフィルタされるロー
数についてのオプティマイザの見積もりに優先して使用されます。
• DEFAULT_LIKE_MATCH_SELECTIVITY - LIKE 'string%string'
(% はワイルドカード文字 ) などの、汎用 LIKE 述部のデフォルトの選択性
を設定します。他の選択性情報が利用できず、照合文字列が一連の定数文
字と 1 つのワイルドカードで始まっていない場合、オプティマイザはこの
オプションを利用します。
• DEFAULT_LIKE_RANGE_SELECTIVITY - 照合文字列が一連の定数文字
と 1 つのワイルドカード文字 (%) でできている LIKE 'string%' 形式の
先行定数 LIKE 述部のデフォルトの選択性を設定します。他の選択性情報
が利用できない場合、オプティマイザはこのオプションを利用します。
• EARLY_PREDICATE_EXECUTION - ジョインの最適化の前に簡単なロー
カル述部を実行するかどうかを制御します。通常は、このオプションを変
更しないでください。
38 Sybase IQ
Page 55

第 3 章 クエリと削除の最適化
• ENABLED_ORDERED_PUSHDOWN_INSERTION - クエリ・オプティ
マイザが、ジョイン・オプティマイザによって選択されたプッシュダウ
ン・ジョイン用のセミジョイン述部に追加する方法を制御します。それら
のセミジョインによって間接的に影響を受ける可能性のある中間のジョ
インを再分析します。通常は、このオプションを変更しないでください。
• IN_SUBQUERY_PREFERENCE - IN サブクエリを処理するためのアル
ゴリズムの選択を制御します。このオプションは、主に内部用として設計
されているため、経験のあるデータベース管理者のみが使用してください。
• INDEX_PREFERENCE - クエリ処理に使用するインデックスを設定し
ます。Sybase IQ オプティマイザは、通常最適なインデックスを使用して、
ローカルな WHERE 句 の述部など、1 つの IQ インデックスの範囲内で処
理できる操作を実行します。このオプションは、テスト目的にオプティマ
イザの選択を無効にするために使用します。通常の使用の際はこのオプ
ションの値を変更しないでください。
• JOIN_PREFERENCE - ジョインを処理するときのアルゴリズムの選択を
制御します。このオプションは、主に内部用として設計されているため、経
験のあるデータベース管理者のみが使用してください。
• JOIN_SIMPLIFICATION_THRESHOLD - ジョイン・オプティマイザの単
純化が適用される前にジョインされるテーブルの最小数を制御します。通
常は、この値を変更する必要はありません。
• MAX_HASH_ROWS - クエリ・オプティマイザがハッシュ・アルゴリズ
ムを使用するときに考慮する最大ロー数の推測値を設定します。デフォル
トは、1,250,000 のローです。たとえば、2 つのテーブル間にジョインがあ
り、両方のテーブルからジョインに入力されるロー数がこのオプションで
設定された値を超えると、オプティマイザはハッシュ・ジョインを選択肢
から外します。TEMP_CACHE_MEMORY_MB がユーザあたり 50 MB を
超えるシステムの場合は、このオプションにさらに大きな値を設定します。
• MAX_JOIN_ENUMERATION - オプティマイザの単純化が適用された後
で、ジョイン順のために最適化するテーブルの最大数を設定します。通常
は、このオプションを設定する必要はありません。
述部ヒントの設定
Sybase IQ は、選択性、有用性、インデックス設定、実行モードなどの述部単
位のヒントを指定できるヒント文字列をサポートします。
選択性は他の 3 つのクエリ最適化と組み合わせて設定できます。
• インデックス設定オプションに相当する機能の設定
• 有用性の設定 ( 述部の順序付け )
•1 つ以上の述部の遅延
パフォーマンス&チューニング・ガイド 39
Page 56

削除オペレーションの最適化
通常の状況では、評価を遅らせることにメリットはなく、クエリの処理が遅く
なるだけです。ただし、これによって次の 4 つの動作のいずれかをクエリ内の
もっと後ろに移動できます。
• 最適化の前
• 初回の「最初のフェッチ」時
•2 回目の「最初のフェッチ」時 ( 相関サブクエリの内部またはネストルー
プ・プッシュダウン・ジョインの左側のみ )
• インデックスの不使用 ( 水平処理 )
構文、パラメータ、使用例については、『Sybase IQ リファレンス・マニュアル』
の「第 3 章 SQL 言語の要素」の「ユーザ指定の条件ヒント文字列」を参照し
てください。
削除オペレーションの最適化
Sybase IQ は、削除オペレーションを処理するために次の 3 つのアルゴリズム
から 1 つを選択します。
• スモール・デリート
スモール・デリートでは、非常に少数のグループからローを削除するとき
に最適なパフォーマンスが得られます。通常は、削除するローが 1 つだけ
か、HG (High_Group) インデックスを持つカラムに等号述部がある場合に
選択されます。スモール・デリート・アルゴリズムは、HG にランダムに
アクセスできます。最悪の場合、I/O はアクセスされるグループの数に比
例します。
• ミッド・デリート
ミッド・デリートでは、いくつかのグループからローを削除するときに最
適なパフォーマンスが得られます。ただし、それらのグループが十分に分
散されているか、十分に少なくて、あまり多くの HG ページがアクセスさ
れないことが条件です。ミッド・デリート・アルゴリズムは、HG への順
序付けられたアクセスを提供します。最悪の場合、I/O はインデックス・
ページ数によって制限されます。ミッド・デリートは、削除するレコード
のソートという追加的なコストを伴います。
• ラージ・デリート
ラージ・デリートでは、多数のグループからローを削除するときに最適な
パフォーマンスが得られます。ラージ・デリートでは、すべてのローが削
除されるまで HG が順番にスキャンされます。最悪の場合、I/O はインデッ
クス・ページ数によって制限されます。ラージ・デリートは並列処理です
が、並列処理はインデックスの内部構造および削除対象のグループの分散
度によって制限されます。HG カラムの範囲述部を使用して、ラージ・デ
リートのスキャン範囲を狭めることができます。
40 Sybase IQ
Page 57

削除コスト
12.6 より前の HG 削除コスト・モデルでは、最悪の場合の I/O パフォーマンス
だけが考慮されていたため、たいていラージ・デリートが優先的に使用されて
いました。現在のコスト・モデルでは、I/O コスト、CPU コスト、使用可能な
リソース、インデックス・メタデータ、並列度、クエリから使用できる述部な
ど、多数の要素が考慮されます。
HG インデックスを持つカラムの述部を指定すると、コストが大幅に改善され
ます。HG コスト計算でラージ・デリート以外のアルゴリズムを選択するため
には、削除によって影響を受ける重複しない個別の値の数を判定できる必要が
あります。個別カウント数は、初めはインデックス・グループの数および削除
されるローの数より少ないものと見なされます。述部は個別カウント数の改善
された見積もりや、正確な見積もりでさえも提供できます。
現在のコスト計算では、ラージ・デリートにおける範囲述部の効果を考慮して
いません。そのため、ラージ・デリートのほうが速いケースでミッド・デリー
トが選択されることもあります。そうしたケースでは、必要に応じて強制的に
ラージ・デリート・アルゴリズムを適用できます。これについては、次の項で
説明します。
削除パフォーマンス・オプションの使用
HG_DELETE_METHOD オプションを使用すると、HG 削除パフォーマンスを
制御できます。
HG_DELETE_METHOD オプションでは、指定した削除アルゴリズムを強制的
に適用できます。
•1 = スモール・デリート
•2 = ラージ・デリート
第 3 章 クエリと削除の最適化
•3 = ミッド・デリート
パフォーマンス&チューニング・ガイド 41
Page 58

削除オペレーションの最適化
42 Sybase IQ
Page 59

第 4 章 OLAP の使用
この章について
内容
オンライン分析処理 (OLAP: Online Analytical Processing) は、リレーショナル・
データベースに格納されている情報を効率的に分析するための手法です。
OLAP を使用すると、データをさまざまな次元で分析し、小計ローを含んだ
結果セットを取得し、データを多次元キューブに編成するという処理をす
べて 1 つの SQL クエリで行うことができます。また、フィルタを使用して
データを絞り込み、結果セットを迅速に返すことができます。この章では、
Sybase IQ がサポートする SQL/OLAP 関数について説明します。
注意 以降で紹介する OLAP の例に出てくるテーブルは、asiqdemo データ
ベースに含まれています。
トピック名 ページ
OLAP について
GROUP BY 句の拡張機能
統計関数
単純な集合関数
ウィンドウ
ランク付け関数
ウィンドウ集合関数
統計集合関数
分散統計関数
数値関数
OLAP の規則と制限
その他の OLAP の例
OLAP 関数の BNF 文法
44
47
61
61
62
75
80
81
82
85
88
89
98
パフォーマンス&チューニング・ガイド 43
Page 60

OLAP について
OLAP について
1999 年の SQL 標準の改正によって、ANSI SQL 標準に複雑なデータ分析操作
を行うための拡張機能が導入されました。Sybase IQ では、以前のリリースで
これらの SQL 拡張機能の一部が取り入れられていますが、Sybase IQ 12.7 では、
これらの拡張機能が包括的にサポートされています。
この分析機能を使って複雑なデータ分析を 1 つの SQL 文で実行することがで
きますが、これはオンライン分析処理 (OLAP) と呼ばれるソフトウェア・テク
ノロジに基づいています。OLAP の関数には、GROUP BY 句の拡張機能や、
次のような統計関数が含まれています。
• GROUP BY 句の拡張機能 - CUBE、ROLLUP
• 統計関数
• 単純な集合 - AVG 、COUNT、MAX、 MIN、SUM、STDDEV、VARIANCE
注意 Grouping() 以外の単純な集合関数はすべて OLAP ウィンドウ関
数と併用できます。
• ウィンドウ関数
• ウィンドウでの集合 - AVG、COUNT、MAX, MIN、SUM
• ランク付け関数 - RANK、DENSE_RANK、PERCENT_RANK、
NTILE
• 統計関数 - STDDEV、STDDEV_SAMP、STDDEV_POP、
VARIANCE、VAR_SAMP、VA R_POP
• 分散統計関数 - PERCENTILE_CONT、PERCENTILE_DISC
• 数値関数 - WIDTH_BUCKET、CEIL、LN、EXP、POWER、SQRT、
FLOOR
データベース製品によっては、OLAP モジュールが独立しており、分析前に
データをデータベースから OLAP モジュールに移動しなければならないもの
もあります。一方、Sybase IQ では OLAP 機能がデータベースそのものに組み
込まれているため、ストアド・プロシージャなどのデータベース機能との配備
や統合を簡単かつシームレスに行うことができます。
44 Sybase IQ
Page 61

OLAP の利点
OLAP の評価について
第 4 章 OLAP の使用
OLAP 関数を GROUPING、CUBE、ROLLUP という拡張機能と組み合わせて
使用すると、2 つの大きな利点があります。第一に、多次元のデータ分析、デー
タ・マイニング、時系列分析、傾向分析、コストの割り当て、ゴール・シー
ク、一時的な多次元構造変更、非手続き型モデリング、例外の警告を多くの場
合 1 つの SQL 文で実行できます。第二に、OLAP のウィンドウおよびレポー
ト集合関数では、ウィンドウという関係演算子を使用することができ、これは
セルフジョインや相関サブクエリを使用するセマンティック的に等価なクエ
リよりも効率的に実行できます。OLAP を使用して取得した結果セットには小
計ローを含めることができ、この結果セットを多次元キューブに編成すること
もできます。詳細については、「ウィンドウ」(62 ページ ) を参照してください。
さまざまな期間での移動平均と移動和を計算したり、選択したカラムの値が変
化したときに集計とランクをリセットしたり、複雑な比率を単純な言葉で表現
したりできます。1 つのクエリ式のスコープ内で、それぞれ独自のパーティ
ショニング・ルールを持ついくつかの異なる OLAP 関数を定義することができ
ます。
OLAP の評価は、最終的な結果に影響を及ぼすクエリ実行のいくつかのフェー
ズとして概念化できます。OLAP の実行フェーズは、クエリ内の対応する句に
よって識別されます。たとえば、SQL クエリの指定にウィンドウ関数が含ま
れている場合は、WHERE、JOIN、GROUP BY、HAVING 句が先に処理され
ます。GROUP BY 句でグループが定義された後、クエリの ORDER BY 句に
含まれる最後の SELECT リストが評価される前に、パーティションが作成さ
れます。
グループ化の際には、NULL 値はすべて同じグループと見なされます ( それぞ
れの NULL 値が等しくない場合でも同様です )。
HAVING 句は、WHERE 句に似ており、GROUP BY 句の結果に対するフィル
タとして機能します。
ANSI SQL 標準に基づく SQL 文と SELECT、FROM、WHERE、GROUP BY、
HAVING 句を含んだ単純なクエリ仕様のセマンティックを考えてみます。
1 クエリにより、FROM 句のテーブル式を満たすロー・セットが取得され
ます。
2 WHERE 句の述部が、テーブルから取得したロー・セットに適用されます。
WHERE 句の条件を満たさない ( 条件が true にならない ) ローが除外され
ます。
3 残りの各ローについて、SELECT リストおよび GROUP BY 句に含まれて
いる式 ( 集合関数を除く ) が評価されます。
パフォーマンス&チューニング・ガイド 45
Page 62

OLAP について
4 GROUP BY 句の式の重複しない値に基づいて、結果のローがグループ化
されます (NULL はそれぞれのドメインで特殊な値として扱われます )。
PARTITION BY 句がある場合は、GROUP BY 句の式はパーティション・
キーとして使用されます。
5 各パーティションについて、SELECT リストまたは HAVING 句の集合関
数が評価されます。いったん集合関数を適用すると、中間の結果セットに
は個々のテーブル・ローが含まれなくなります。新しい結果セットには、
GROUP BY の式と、各パーティションについて計算した集合関数の値が
含まれます。
6 HAVING 句の条件が結果グループに適用されます。HAVING 句の条件を満
たさないグループが除外されます。
7 PARTITION BY 句で定義された境界に基づいて結果が分割されます。結果
ウィンドウについて、OLAP ウィンドウ関数 ( ランク付け関数および集合
関数 ) が計算されます。
図 4-1: 実行のセマンティック・フェーズ
詳細については、「文法規則 2」(98 ページ ) を参照してください。OLAP 構文の
詳細については、「OLAP 関数の BNF 文法」(98 ページ ) も参照してください。
46 Sybase IQ
Page 63

GROUP BY 句の拡張機能
GROUP BY 句の拡張機能により、次のような処理を行う複雑な SQL 文を書く
ことができます。
• 入力ローを複数の次元に分割し、結果グループの複数のサブセットを組み
合わせる。
•“データ・キューブ ” を作成し、データ・マイニング分析のための疎密度
の多次元結果セットを用意する。
• 元のグループを含んだ結果セットを作成する ( 必要に応じて、小計ローと
合計ローを含める場合もある )。
ROLLUP や CUBE などの OLAP の Grouping() ( グループ化 ) 操作は、プレフィ
クスや小計ローとして概念化できます。
プレフィクス
GROUP BY 句を含むクエリでは、プレフィクスのリストが作成されます。プ
レフィクスとは、GROUP BY 句の項目のサブセットであり、クエリの GROUP
BY 句の項目のうち最も右にある 1 つまたは複数の項目を除外することで作成
されます。残りのカラムはプレフィクス・カラムと呼ばれます。
ROLLUP 例 1 次に示す ROLLUP のクエリの例では、GROUP BY のリストに
2 つの変数 (Ye ar と Quarter) が含まれています。
SELECT year (order_date) Year, quarter(order_date)
Quarter, COUNT(*) Orders
FROM alt_sales_order
GROUP BY ROLLUP(Year, Quarter)
ORDER BY Year, Quarter
このクエリには次の 2 つのプレフィクスがあります。
• Quarter を除外するプレフィクス - プレフィクス・カラムには 1 つのカラ
ム (Yea r) が含まれます。
第 4 章 OLAP の使用
• Quarter と Ye a r の両方を除外するプレフィクス - プレフィクス・カラム
は存在しません。
注意 GROUP BY リストには、項目と同じ数のプレフィクスが含まれます。
パフォーマンス&チューニング・ガイド 47
Page 64

GROUP BY 句の拡張機能
GROUP BY での ROLLUP と CUBE
プレフィクスに関する一般的なグループ化を簡単に指定するために、2 つの重
要な構文簡略化パターンが用意されています。1 つ目のパターンは ROLLUP、
2 つ目のパターンは CUBE と呼ばれます。
GROUP BY ROLLUP
ROLLUP 演算子には、引数として適用するグループ化の式を、次の構文の中
で順序リストで指定します。
SELECT … [ GROUPING (column-name) … ] …
GROUP BY [ expression [, … ]
| ROLLUP ( expression [,
GROUPING は、カラム名をパラメータとして受け取り、表 4-1 に示すように
ブール値を返します。
表 4-1: ROLLUP 演算子が指定された GROUPING によって返される値
結果値の種類 GROUPING の戻り値
ROLLUP 演算子によって作成された NULL 1 ( 真 )
ローが小計であることを示す NULL 1 ( 真 )
ROLLUP 演算子によって作成された以外の NULL 0 ( 偽 )
格納されていた NULL 0 ( 偽 )
ROLLUP は、まず GROUP BY 句に指定された標準的な集合関数値を計算します。
次に、ROLLUP はグループ化を行うカラムのリストを右から左に移動し、より高
いレベルの小計を連続して作成します。最後に総計が作成されます。グループ化
するカラムの数が n 個の場合、ROLLUP は n+1 レベルの小計を作成します。
… ] ) ]
SQL 構文の例 定義されるセット
GROUP BY ROLLUP (A, B, C); (A, B, C)
(A, B)
(A)
( )
ROLLUP と小計ロー
ROLLUP は、GROUP BY のクエリ・セットに対して UNION を行うのと同じ
ことです。次の 2 つのクエリの結果セットは等しくなります。GROUP BY (A,
B) の結果セットは、A と B に定数が含まれているすべてのローについての小
計から成ります。UNION を可能にするために、カラム C には NULL が割り当
てられます。
48 Sybase IQ
Page 65
第 4 章 OLAP の使用
ROLLUP クエリの例 ROLLUP を使用せずに記述した同じ内容のクエリ
SELECT A, B, C,
SUM( D )
FROM T1
GROUP BY ROLLUP (A, B,
C);
SELECT *
FROM ( ( SELECT A, B, C, SUM( D )
GROUP BY A, B, C ) UNION ALL ( SELECT
A, B, NULL, SUM( D ) GROUP BY A,
B ) UNION ALL ( SELECT A, NULL,
NULL, SUM( D ) GROUP BY A )
UNION ALL ( SELECT NULL, NULL,
NULL, SUM( D ) ) )
小計ローはデータの分析に役立ちます。特に、データが大量にある場合、デー
タにさまざまな次元がある場合、データがさまざまなテーブルに含まれている
場合、あるいはまったく異なるデータベースに含まれている場合に威力を発揮
します。たとえば販売マネージャが、売上高についてのレポートを営業担当者
別、地域別、四半期別に整理して、売上パターンの理解に役立てることができ
ます。データの小計は、販売マネージャが売上高の全体像をさまざまな視点か
ら分析するのに役立ちます。販売マネージャが比較したいと考える基準に基づ
いて要約情報が提供されていれば、データの分析を容易に行うことができます。
OLAP を使用すると、ローおよびカラムの小計を分析、計算する処理をユーザ
の目から隠すことができます。図 4-2 に、Sybase IQ での小計の計算の概念を
示します。
図 4-2: 小計
1 このステップで、まだ ROLLUP とは見なされない中間の結果セットが生
成されます。
2 小計が評価され、結果セットに付加されます。
3 クエリ内の ORDER BY 句に従ってローが並べられます。
NULL 値と小計ロー
GROUP BY 操作に対する入力のローに NULL が含まれているときは、その中
に、ROLLUP または CUBE 操作によって追加された小計ローと、最初の入力
データの一部として NULL 値を含んでいるローが混在している可能性があり
ます。
Grouping() 関数は、小計ローをその他のローから区別します。具体的には、
GROUP BY リストのカラムを引数として受け取り、そのカラムが小計ローで
あるために NULL になっている場合は 1 を返し、それ以外の場合は 0 を返し
ます。
パフォーマンス&チューニング・ガイド 49
Page 66

GROUP BY 句の拡張機能
次の例では、結果セットの中に Grouping() カラムが含まれています。強調表示
されているローは、小計ローであるために NULL を含んでいるのではなく、入
力データの結果として NULL を含んでいるローです。Grouping() カラムは強調
表示されています。このクエリは、employee テーブルと sales_order テーブ
ルの間の外部ジョインです。このクエリでは、テキサス、ニューヨーク、また
はカリフォルニアに住んでいる女性従業員を選択しています。営業担当者でな
い ( したがって売上がない ) 女性従業員については、カラムに NULL が表示さ
れます。
SELECT employee.emp_id AS Employee, year(order_date) AS
Year, COUNT(*) AS Orders, GROUPING(Employee) AS
GE, GROUPING(Year) AS GY
FROM employee LEFT OUTER JOIN alt_sales_order ON
employee.emp_id = alt_sales_order.sales_rep
WHERE employee.sex IN ('F') AND employee.state
IN ('TX', 'CA', 'NY')
GROUP BY ROLLUP (Year, Employee)
ORDER BY Year, Employee
このクエリの結果セットを次に示します。
emp_id year Orders GY GE
------ ---- ------ -- -NULL NULL 1 1 0
NULL NULL 165 1 1
1090 NULL 1 0 0
NULL 2000 98 1 0
667 2000 34 0 0
949 2000 31 0 0
1142 2000 33 0 0
NULL 2001 66 1 0
667 2001 20 0 0
949 2001 22 0 0
1142 2001 24 0 0
個々のプレフィクスについて、プレフィクス・カラムに同じ値が含まれている
すべてのローに関する小計ローが作成されます。
ROLLUP の結果を具体的に説明するために、前述のクエリの例をもう一度詳
しく見ていきます。
SELECT year (order_date) AS Year, quarter
(order_date) AS Quarter, COUNT (*) Orders
FROM sales_order
GROUP BY ROLLUP (Year, Quarter)
ORDER BY Year, Quarter
このクエリでは、Year カラムを含んでいるプレフィクスにより、Year=2000 の
合計ローと Year=2001 の合計ローが作成されます。このプレフィクスに関する
1 つの合計ローはカラムを含んでいません。これは、中間の結果セットに含ま
れているすべてのローの小計です。
50 Sybase IQ
Page 67

第 4 章 OLAP の使用
小計ローの各カラムの値は、次のようになっています。
• プレフィクスに含まれているカラム - そのカラムの値です。たとえば前
述のクエリでは、Year=2000 のローに関する小計ローの Yea r カラムの値
は 2000 になります。
• プレフィクスから除外されたカラム - NULL です。たとえば、Year カラ
ムから成るプレフィクスにより生成された小計ローでは、Quarter カラム
の値は NULL になります。
• 集合関数 - 除外されているカラムの値を計算した結果です。
小計値は、集計されたローではなく基本データのローに対して計算され
ます。多くの場合、たとえば SUM や COUNT などでは結果は等しくなり
ますが、AVG 、STDDEV、VARIANCE などの統計関数では結果が異なっ
てくるため、この区別は重要です。
ROLLUP 演算子には次の制限があります。
• ROLLUP 演算子は、COUNT DISTINCT と SUM DISTINCT を除き、GROUP
BY 句で使用可能なすべての集合関数をサポートしています。
• ROLLUP は SELECT 文でのみ使用できます。サブクエリでは ROLLUP を
使用できません。
•1 つの GROUP BY 句の中で複数の ROLLUP、CUBE、および GROUP BY
カラムを組み合わせるグループ化の指定は、現時点ではサポートされてい
ません。
• GROUP BY のキーに定数式を指定することはできません。
式の一般的なフォーマットについては、『Sybase IQ リファレンス・マニュア
ル』の「式」と「SQL 言語の要素」を参照してください。
ROLLUP 例 2 次は、ROLLUP と GROUPING の使用例です。GROUPING によっ
て作成される一連のマスク・カラムを表示します。カラム S、N、C に表示され
ている数字 0 と 1 は、GROUPING からの戻り値で ROLLUP の結果の値を表現
しています。マスクが “011” であれば小計のローであり、“111” であれば総計の
ローであると特定できます。これを利用して、クエリの結果をプログラムで分
析することが可能です。
SELECT size, name, color, SUM(quantity),
GROUPING(size) AS S,
GROUPING(name) AS N,
GROUPING(color) AS C
FROM product
GROUP BY ROLLUP(size, name, color) HAVING (S=1 or N=1 or C=1)
ORDER BY size, name, color;
このクエリの結果セットを次に示します。
size name color SUMSNC
---- ----- ------ ------
(NULL) (NULL) (NULL) 496 1 1 1
パフォーマンス&チューニング・ガイド 51
Page 68

GROUP BY 句の拡張機能
Large (NULL) (NULL) 71 0 1 1
Large Sweatshirt (NULL) 71 0 0 1
Medium (NULL) (NULL) 134 0 1 1
Medium Shorts (NULL) 80 0 0 1
Medium Tee Shirt (NULL) 54 0 0 1
One size fits all (NULL) (NULL) 263 0 1 1
One size fits all Baseball Cap (NULL) 124 0 0 1
One size fits all Tee Shirt (NULL) 75 0 0 1
One size fits all Visor (NULL) 64 0 0 1
Small (NULL) (NULL) 28 0 1 1
Small Tee Shirt (NULL) 28 0 1 1
ROLLUP 例 3
次の例は、GROUPING を使用して、最初から格納されていた
NULL 値と ROLLUP 操作によって生成された “NULL” 値とを区別する方法を
示しています。このクエリで指定されているとおり、最初から格納されていた
NULL 値はカラム prod_id に [NULL] として表示され、ROLLUP によって生成
された “NULL” 値はカラム PROD_IDS で ALL に置き換えられます。
SELECT year(ship_date) AS Year, prod_id, SUM(quantity)
AS OSum, CASE WHEN GROUPING(Year) = 1 THEN 'ALL' ELSE
CAST(Year AS char(8)) END, CASE WHEN
GROUPING(prod_id) = 1 THEN 'ALL' ELSE CAST(prod_id
as char(8)) END
FROM alt_sales_order_items
GROUP BY ROLLUP(Year, prod_id) HAVING OSum > 36
ORDER BY Year, prod_id;
このクエリの結果セットを次に示します。
ship_date prod_id SUM SHIP_DATES PROD_IDS
--------- ------- --- ---------- --------
NULL NULL 28359 ALL ALL
2000 NULL 17642 2000 ALL
2000 300 1476 2000 300
2000 301 1440 2000 301
2000 302 1152 2000 302
2000 400 1946 2000 400
2000 401 1596 2000 401
2000 500 1704 2000 500
2000 501 1572 2000 501
2000 600 2124 2000 600
2000 601 1932 2000 601
2000 700 2700 2000 700
2001 NULL 10717 2001 ALL
2001 300 888 2001 300
2001 301 948 2001 301
2001 302 996 2001 302
2001 400 1332 2001 400
2001 401 1105 2001 401
2001 500 948 2001 500
52 Sybase IQ
Page 69

第 4 章 OLAP の使用
2001 501 936 2001 501
2001 600 936 2001 600
2001 601 792 2001 601
2001 700 1836 2001 700
ROLLUP 例 4
次のクエリ例は、注文数を年別および四半期別に集計したデー
タを返します。
SELECT year(order_date) AS Year, quarter(order_date)
AS Quarter, COUNT(*) AS Orders
FROM alt_sales_order
GROUP BY ROLLUP(Year, Quarter)
ORDER BY Year, Quarter
次の図は、このクエリの結果を示しています。結果セット内の小計ローは強調
表示されています。各小計ローでは、その小計の計算対象になったカラムに
NULL 値が格納されています。
ロー [1] は、両方の年 (2000 年および 2001 年 ) のすべての四半期の注文数の合
計を示しています。このローは、Ye ar カラムと Quarter カラムの両方が NULL
であり、すべてのカラムがプレフィクスから除外されています。
注意 ROLLUP 操作によって返される結果セットには、集合カラムを除くすべ
てのカラムが NULL であるローが必ず 1 つ含まれています。このローは、集
合関数に対する全カラムの要約を表しています。たとえば、集合関数として
SUM を使用している場合は、このローはすべての値の総計を表します。
ロー [2] は、2000 年および 2001 年の注文数の合計をそれぞれ示しています。
どちらのローも、Quarter カラムの値は NULL になっています。このカラムの
値を加算して、Year の小計を出しているためです。結果セットにこのような
ローがいくつ含まれるかは、ROLLUP クエリに登場する変数の数によって決
まります。
[3] としてマークされている残りのローは要約情報を示し、それぞれの年の各
四半期の注文数の合計を表しています。
パフォーマンス&チューニング・ガイド 53
Page 70

GROUP BY 句の拡張機能
ROLLUP 例 5 この ROLLUP 操作の例では、年別、四半期別、地域別の注文数
を集計するというやや複雑な結果セットを返します。この例では、第 1 および
第 2 四半期と 2 つの地域 ( カナダと東部地区 ) だけを分析します。
SELECT year(order_date) AS Year, quarter(order_date)
AS Quarter, region, COUNT(*) AS Orders
FROM alt_sales_order WHERE region IN ('Canada',
'Eastern') AND quarter IN (1, 2)
GROUP BY ROLLUP (Year, Quarter, Region)
ORDER BY Year, Quarter, Region
次の図は、このクエリの結果セットを示しています。各小計ローでは、その小
計の計算対象になったカラムに NULL が格納されています。
ロー [1] はすべてのローの集計結果であり、Year、Quarter、Region カラムに
NULL が含まれています。このローの Orders カラムの値は、カナダと東部地
区の 2000 年および 2001 年の第 1 および第 2 四半期の注文数の合計を示してい
ます。
[2] としてマークされているローは、それぞれの年 (2000 年と 2001 年 ) におけ
るカナダと東部地区の第 1 および第 2 四半期の注文数の合計を示しています。
ロー [2] の値を足すと、ロー [1] に示されている総計に等しくなります。
54 Sybase IQ
Page 71

第 4 章 OLAP の使用
[3] としてマークされているローは、特定の年および四半期の全地域の注文数
の合計を示しています。
[4] としてマークされているローは、結果セット内のそれぞれの年の各四半期
の各地域の注文の合計数を示しています。
パフォーマンス&チューニング・ガイド 55
Page 72

GROUP BY 句の拡張機能
GROUP BY CUBE
GROUP BY 句の CUBE 演算子は、データを複数の次元 ( グループ化の式 ) で
グループ化することでデータを分析します。CUBE に次元の順序リストを引数
として指定すると、SELECT 文の中で、そのクエリに指定した次元の考えら
れるすべての組み合わせの小計を計算し、選択した複数のカラムのすべての値
の組み合わせについての要約を示す結果セットを生成することができます。
CUBE の構文は次のとおりです。
SELECT … [ GROUPING (column-name) … ] …
GROUP BY [ expression [,… ]
| CUBE ( expression [,
… ] ) ]
GROUPING は、カラム名をパラメータとして受け取り、表 4-2 に示すように
ブール値を返します。
表 4-2: CUBE 演算子が指定された GROUPING によって返される値
結果値の種類 GROUPING の戻り値
CUBE 演算子によって作成された NULL 1 ( 真 )
ローが小計であることを示す NULL 1 ( 真 )
CUBE 演算子によって作成された以外の NULL 0 ( 偽 )
格納されていた NULL 0 ( 偽 )
CUBE は、同じ階層の一部ではない次元を扱うときに特に威力を発揮します。
SQL 構文の例 定義されるセット
GROUP BY CUBE (A, B, C); (A, B, C)
(A, B)
(A, C)
(A)
(B, C)
(B)
(C)
( )
CUBE 演算子には次の制限があります。
• CUBE 演算子は GROUP BY 句で使用可能なすべての集合関数をサポート
しますが、CUBE は現在 COUNT DISTINCT および SUM DISTINCT では
サポートされていません。
• CUBE は、現在、逆分散統計関数である PERCENTILE_CONT と
PERCENTILE_DISC ではサポートされていません。
• CUBE は SELECT 文でのみ使用できます。CUBE を SELECT のサブクエ
リで使用することはできません。
•1 つの GROUP BY 句の中で ROLLUP、CUBE、GROUP BY カラムを組み
合わせる GROUPING の指定は、現時点ではサポートされていません。
56 Sybase IQ
Page 73

第 4 章 OLAP の使用
• GROUP BY のキーに定数式を指定することはできません。
注意 キューブのサイズがテンポラリ・キャッシュのサイズを超えると、CUBE
のパフォーマンスが低下します。
GROUPING と CUBE 演算子を併用すると、格納されていた NULL 値と CUBE
によって作成されたクエリ結果の “NULL” 値を区別することができます。
GROUPING 関数を使用して結果を分析する方法については、ROLLUP 演算子
の説明で紹介した例を参照してください。
CUBE 操作が返す結果セットには、集計カラムを除くすべてのカラムの値が
NULL であるローが少なくとも 1 つは含まれています。このローは、集合関数
に対する全カラムの要約を表しています。
CUBE 例 1 次の例は、対象者の州 ( 地理的な位置 )、性別、教育レベル、およ
び収入などで構成される調査データを使用したクエリです。最初に紹介するク
エリには GROUP BY 句が指定されています。この句は、クエリの結果を
census テーブルの state、gender、education カラムの値に応じてロー・グルー
プに分類し、収入の平均とローの合計数をグループごとに計算します。このク
エリには GROUP BY 句だけを使用し、ローのグループ化に CUBE 演算子を使
用していません。
SELECT state, sex as gender, dept_id, COUNT(*),
CAST(ROUND(AVG(salary),2) AS NUMERIC(18,2))
AS average
FROM employee WHERE state IN ('MA' , 'CA')
GROUP BY state, sex, dept_id
ORDER BY 1,2;
このクエリの結果セットを次に示します。
state gender dept_id count(*) avg salary
----- ------ ------- -------- ---------CA F 200 2 58650.00
CA M 200 1 39300.00
MA F 500 4 29950.00
MA F 400 8 41959.88
MA F 300 7 59685.71
MA F 200 3 60451.00
MA F 100 6 58243.42
MA M 300 2 58850.00
MA M 500 5 36793.96
MA M 400 8 45321.47
MA M 100 13 58563.59
MA M 200 8 46810.63
パフォーマンス&チューニング・ガイド 57
Page 74

GROUP BY 句の拡張機能
GROUP BY 句の CUBE 拡張機能を使用すると、調査データを 1 回参照するだ
けで、調査データ全体における州別、性別、教育別の平均収入を計算し、state、
gender、education カラムの考えられるすべての組み合わせにおける平均収入
を計算することができます。CUBE 演算子を使用すると、たとえば、すべての
州における全女性の平均収入を計算したり、調査対象者全員の平均収入を、各
自の教育別および州別に計算したりすることができます。
CUBE でグループを計算するときには、計算されたグループのカラムに NULL
値が挿入されます。最初からデータベース内に格納されていた NULL なのか、
CUBE の結果として生成された NULL なのかを区別するためには、GROUPING
関数を使用する必要があります。GROUPING 関数は、指定されたカラムが上位
レベルのグループにマージされている場合は 1 を返します。
CUBE 例 2 次のクエリは、GROUP BY CUBE と GROUPING 関数を併用する
方法を示しています。
SELECT case grouping(state) WHEN 1 THEN 'ALL' ELSE state
END AS c_state, case grouping(sex) WHEN 1 THEN 'ALL'
ELSE sex end AS c_gender, case grouping(dept_id)
WHEN 1 THEN 'ALL' ELSE cast(dept_id as char(4)) end
AS c_dept, COUNT(*), CAST(ROUND(AVG(salary),2) AS
NUMERIC(18,2))AS AVERAGE
FROM employee WHERE state IN ('MA' , 'CA')
GROUP BY CUBE(state, sex, dept_id)
ORDER BY 1,2,3;
このクエリの結果は次のとおりです。クエリで指定されているとおり、小計
ローを示すために CUBE によって生成された NULL は、小計ロー内で ALL に
置き換えられています。
state sex dept_id count avg salary
----- --- ------- ----- ----------
ALL ALL 100 19 58462.48
ALL ALL 200 14 50888.43
ALL ALL 300 9 59500.00
ALL ALL 400 16 43640.67
ALL ALL 500 9 33752.20
ALL ALL ALL 67 50160.38
ALL F 100 6 58243.42
ALL F 200 5 59730.60
ALL F 300 7 59685.71
ALL F 400 8 41959.88
ALL F 500 4 29950.00
ALL F ALL 30 50713.08
ALL M 100 13 58563.59
ALL M 200 9 45976.11
ALL M 300 2 58850.00
ALL M 400 8 45321.47
ALL M 500 5 36793.96
ALL M ALL 37 49712.25
CA ALL 200 3 52200.00
58 Sybase IQ
Page 75

第 4 章 OLAP の使用
CA ALL ALL 3 52200.00
CA F 200 2 58650.00
CA F ALL 2 58650.00
CA M 200 1 39300.00
CA M ALL 1 39300.00
MA ALL 100 19 58462.48
MA ALL 200 11 50530.73
MA ALL 300 9 59500.00
MA ALL 400 16 43640.67
MA ALL 500 9 33752.20
MA ALL ALL 64 50064.78
MA F 100 6 58243.42
MA F 200 3 60451.00
MA F 300 7 59685.71
MA F 400 8 41959.88
MA F 500 4 29950.00
MA F ALL 28 50146.16
MA M 100 13 58563.59
MA M 200 8 46810.63
MA M 300 2 58850.00
MA M 400 8 45321.47
MA M 500 5 36793.96
MA M ALL 36 50001.48
CUBE 例 3
この例のクエリは、注文数の合計を要約する結果セットを返し、次
に、年別および四半期別の注文数の小計を計算します。
注意 比較する変数の数が増えると、キューブの計算のコストが急激に増大し
ます。
SELECT year(order_date) AS Year, quarter(order_date)
AS Quarter, COUNT(*) AS Orders
FROM alt_sales_order
GROUP BY CUBE(Year, Quarter)
ORDER BY Year, Quarter
パフォーマンス&チューニング・ガイド 59
Page 76

GROUP BY 句の拡張機能
次の図は、このクエリの結果セットを示しています。この結果セットでは、小
計ローが強調表示されています。各小計ローでは、その小計の計算対象になっ
たカラムに NULL が格納されています。
先頭のロー [1] は、両方の年のすべての四半期の注文数の合計を示しています。
Orders カラムの値は、[3] としてマークされている各ローの値の合計です。こ
れは、[2] としてマークされている 4 つのローの値の合計でもあります。
[2] としてマークされている一連のローは、両方の年の四半期別の注文数の合
計を示しています。[3] としてマークされている 2 つのローは、それぞれ 2000
年および 2001 年のすべての四半期の注文数の合計を示しています。
60 Sybase IQ
Page 77

統計関数
第 4 章 OLAP の使用
Sybase IQ では、1 つの SQL 文内で複雑なデータ分析を実行できる機能を備え
た単純な集合関数とウィンドウ集合関数の両方を提供しています。これらの関
数を使用して、たとえば “ ダウ工業株 30 種平均の四半期の移動平均はどうなっ
ているか ” または “ 各部署のすべての従業員とその累積給与を一覧表示せよ ”
というクエリに対する答えを計算することができます。さまざまな期間におけ
る移動平均と累積和を計算したり、パーティション値が変化したときに集合計
算がリセットされるような方法で集計とランクを分割したりできます。1 つの
クエリ式のスコープ内で、それぞれ独自のパーティショニング・ルールを持つ
いくつかの異なる OLAP 関数を定義することができます。統計関数は 2 つのカ
テゴリに分けられます。
• 単純な集合関数 (AVG、COUNT、MAX、 MIN、SUM など ) は、データベー
スに含まれるローのグループのデータを要約します。SELECT 文の
GROUP BY 句を使ってグループを形成します。
•1 つの引数を取る単項の統計集合関数には、STDDEV()、STDDEV_SAMP()、
STDDEV_POP()、VAR IANCE ()、VAR_SAMP()、および VA R_P OP() があり
ます。
単純な集合関数でも単項の集合関数でも、データベース内のローのグループに
関するデータを要約することができ、ウィンドウ指定と組み合わせて、処理の
際に結果セットに対する移動ウィンドウを計算することができます。
注意 集合関数 AVG、SUM、STDDEV、STDDEV_POP、STDDEV_SAMP、
VAR_POP、VAR_SAMP、VARIANCE は、バイナリ・データ型である BINARY
と VARBINARY をサポートしていません。
単純な集合関数
単純な集合関数 (AVG、COUNT、MAX、 MIN、SUM など ) は、データベース
に含まれるローのグループのデータを要約します。ローのグループを形成する
には SELECT 文の GROUP BY 句を使用します。集合関数は、select リストと、
SELECT 文の HAVING 句および ORDER BY 句の中だけで使用できます。
注意 Grouping() 関数を除き、単純な集合関数と単項の集合関数はどちらも、
SQL クエリの指定に「ウィンドウ句」( ウィンドウ ) を組み込むウィンドウ関
数として使用できます。これにより、処理時に結果セットに対して概念的に移
動ウィンドウを作成することができます。詳細については、「ウィンドウ」(62
ページ ) を参照してください。
詳細については、Sybase IQ リファレンス・マニュアルの「第 5 章 SQL 関数」
の「集合関数」を参照してください。
パフォーマンス&チューニング・ガイド 61
Page 78

統計関数
ウィンドウ
OLAP ウィンドウの 3 つ
の重要な側面
OLAP に関する ANSI SQL 拡張機能で導入された主な機能は、ウィンドウと呼
ぶ構造です。このウィンドウ拡張機能により、ユーザはクエリの結果セット
( または、クエリの論理パーティション ) をパーティションと呼ばれるローの
グループに分割し、現在のローについて集計するローのサブセットを決定する
ことができます。
1 つのウィンドウには 3 つのクラスのウィンドウ関数として、ランク付け関数、
ロー・ナンバリング関数、およびウィンドウ集合関数を使用できます。
<WINDOWED TABLE FUNCTION TYPE> ::=
<RANK FUNCTION TYPE> <LEFT PAREN> <RIGHT PAREN>
| ROW_NUMBER <LEFT PAREN> <RIGHT PAREN>
| <WINDOW AGGREGATE FUNCTION>
詳細については、「文法規則 6」(98 ページ ) を参照してください。
ウィンドウ拡張機能は、ウィンドウ名または指定に対するウィンドウ関数の種
類を指定し、1 つのクエリ式のスコープ内のパーティション化された結果セッ
トに適用されます。ウィンドウ・パーティションは、特殊な OVER 句の 1 つ
以上のカラムで定義されている、クエリから返されるローのサブセットです。
olap_function() OVER (PARTITION BY col1, col2...)
ウィンドウ操作では、パーティション内の各ローのランク付け、パーティショ
ン内のローの値の分布、および同様の操作などの情報を設定できます。また、
データの移動平均や合計を計算し、データおよび操作に対するそのデータの影
響を評価する機能を拡張することもできます。
ウィンドウ・パーティションは、特殊な OVER() 句の 1 つ以上のカラムで定義
されている、クエリから返されるローのサブセットです。
OLAP_FUNCTION() OVER (PARTITION BY col1, col2...)
OLAP ウィンドウは、ウィンドウ・パーティション、ウィンドウ順序、ウィン
ドウ・フレームという 3 つの重要な側面から成ります。それぞれの要素は、そ
の時点でウィンドウ内で可視となるデータ・ローに大きな影響を与えます。ま
た、OLAP の OVER 句は、次の 3 つの特徴的な機能により、OLAP 関数を他の
統計関数やレポート関数から区別します。
• ウィンドウ・パーティションの定義 (PARTITION BY 句 )。詳細について
は、「ウィンドウ・パーティション」(64 ページ ) を参照してください。
• パーティション内でのローの順序付け (ORDER BY 句 )。詳細については、
「ウィンドウ順序」(64 ページ ) を参照してください。
• ウィンドウ・フレームの定義 (ROWS/RANGE 指定 )。「ウィンドウ・フレー
ム」(65 ページ )。
62 Sybase IQ
Page 79

第 4 章 OLAP の使用
OLAP のウィンドウ指定に関して名前を指定することができます。冗長なウィ
ンドウ定義を避けるために、この名前を使用して複数のウィンドウ関数を指定
できます。その場合は、キーワード WINDOW の後に少なくとも 1 つのウィン
ドウ定義を指定します ( 複数指定する場合はカンマで区切ります )。ウィンド
ウ定義には、クエリ内でウィンドウを識別するための名前と、ウィンドウの
パーティション、順序、フレームを定義するためのウィンドウ指定の詳細を含
めます。
<WINDOW CLAUSE> ::= <WINDOW WINDOW DEFINITION LIST>
<WINDOW DEFINITION LIST> ::=
<WINDOW DEFINITION> [ { <COMMA> <WINDOW DEFINITION>
} . . . ]
<WINDOW DEFINITION> ::=
<NEW WINDOW NAME> AS <WINDOW SPECIFICATION>
<WINDOW SPECIFICATION DETAILS> ::=
[ <EXISTING WINDOW NAME> ]
[ <WINDOW PARTITION CLAUSE> ]
[ <WINDOW ORDER CLAUSE> ]
[ <WINDOW FRAME CLAUSE> ]
ウィンドウ・パーティション内の各ローについて、ウィンドウ・フレームを定
義することができます。ウィンドウ・フレームにより、パーティションの現在
のローに対して計算を実行するときに使われるローの範囲を変更することが
できます。現在のローは、ウィンドウ・フレームの開始ポイントと終了ポイン
トを決定するための参照ポイントとなります。
ウィンドウのサイズは、物理的なローの数 ( ウィンドウ・フレーム単位 ROWS
を定義するウィンドウ指定を使用 ) または論理的な数値の間隔 ( ウィンドウ・
フレーム単位 RANGE を定義するウィンドウ指定を使用 ) に基づきます。詳細
については、「ウィンドウ・フレーム」(65 ページ ) を参照してください。
OLAP のウィンドウ操作では、次のカテゴリの関数を使用できます。
• 「ランク付け関数」(75 ページ )
• 「ウィンドウ集合関数」(80 ページ )
• 「統計集合関数」(81 ページ )
• 「分散統計関数」(82 ページ )
パフォーマンス&チューニング・ガイド 63
Page 80

統計関数
ウィンドウ・パーティション
ウィンドウ・パーティションとは、 PARTITION BY 句を使用して、ユーザ指定
の結果セット ( 入力ロー ) を分割することです。パーティションは、カンマで
区切られた 1 つ以上の値の式によって定義されます。パーティションに分割さ
れたデータは暗黙的にソートされ、デフォルトのソート順序は昇順 (ASC) にな
ります。
ウィンドウ・パーティション句を指定しなかった場合は、入力が 1 つのパー
ティションとして扱われます。
注意 統計関数に対してパーティションという用語を使用した場合は、結果
セットのローを PARTITION BY 句に基づいて分割することだけを意味します。
ウィンドウ・パーティションは任意の式に基づいて定義できます。また、ウィ
ンドウ・パーティションの処理はグループ化の後に行われるので (GROUP BY
句が指定されている場合 )、SUM、AVG、VARIANCE などの集合関数の結果を
パーティションの式で使用することができます。したがって、パーティション
を使用すると、GROUP BY 句や ORDER BY 句とはまた別に、グループ化と
順序付けの操作を実行することができます。たとえば、ある数量の最大 SUM
を求めるなど、集合関数に対して集合関数を計算するクエリを記述できます。
GROUP BY 句がない場合でも、PAR TITION BY 句を指定できます。
<WINDOW PARTITION CLAUSE> ::=
PARTITION BY <WINDOW PARTITION EXPRESSION LIST>
ウィンドウ順序
ウィンドウ順序とは、ウィンドウ・パーティション内の結果 ( ロー ) をウィン
ドウ順序句に基づいて並べることです。ウィンドウ順序句には、1 つ以上の値
の式をカンマ区切りで指定します。ウィンドウ順序句を指定しなかった場合
は、入力ローが任意の順序で処理されることがあります。
<WINDOW ORDER CLAUSE> ::= <ORDER SPECIFICATION>
OLAP のウィンドウ順序句は、非ウィンドウ・クエリの式に指定できる ORDER
BY 句とは異なります。詳細については、「文法規則 31」(100 ページ ) を参照し
てください。
OLAP 関数で使用する ORDER BY 句は、通常はウィンドウ・パーティション
内のローをソートするための式を定義しますが、PA RTITION B Y 句がなくても
ORDER BY 句を使用することができます。その場合は、このソート指定によっ
て、確実に意味のある ( かつ意図どおりの ) 順序で並べられた中間の結果セッ
トに OLAP 関数を適用することができます。
64 Sybase IQ
Page 81

第 4 章 OLAP の使用
OLAP のランク付け関数には順序の指定が必須であり、ランキング値の基準は、
ランク付け関数の引数ではなく ORDER BY 句で指定します。OLAP の集合関
数では、通常は ORDER BY 句の指定は必須ではありませんが、ウィンドウ・
フレームを定義するときには必須とされています (「ウィンドウ・フレーム」
(65 ページ ) を参照してください )。これは、各フレームの適切な集合値を計算
する前に、パーティション内のローをソートしなければならないためです。
この ORDER BY 句には、昇順および降順のソートを定義するためのセマン
ティックと、NULL 値の取り扱いに関する規則を指定します。OLAP 関数は、
デフォルトでは昇順 (最も小さい値が 1 番目にランク付けされる) を使用します。
これは SELECT 文の最後に指定する ORDER BY 句のデフォルト動作と同じ
ですが、連続的な計算を行う場合にはわかりにくいかもしれません。OLAP の
計算では、降順 ( 最も大きい値が 1 番目にランク付けされる ) でのソートが必
要になることがよくあります。この要件を満たすには、ORDER BY 句に明示
的に DESC キーワードを指定する必要があります。
注意 ランク付け関数は、ソートされた入力のみを扱うように定義されている
ため、「ウィンドウ順序句」の指定を必要とします。「クエリ指定」の「order
by 句」と同様に、デフォルトのソート順序は昇順です。
「ウィンドウ・フレーム単位」で RANGE を使用する場合も、「ウィンドウ順序句」
を指定する必要があります。RANGE の場合は、「ウィンドウ順序句」に 1 つの式
のみを指定します。「ウィンドウ・フレーム」(65 ページ ) を参照してください。
ウィンドウ・フレーム
ランク付け関数を除く OLAP 集合関数では、ウィンドウ・フレーム句を使用し
てウィンドウ・フレームを定義することができます。ウィンドウ・フレーム句
には、現在のローを基準としてウィンドウの開始位置と終了位置を指定します。
<WINDOW FRAME CLAUSE> ::=
<WINDOW FRAME UNIT>
<WINDOW FRAME EXTENT>
これにより、パーティション全体の固定的な内容ではなく、移動するフレーム
の内容に対して OLAP 関数を計算できます。定義にもよりますが、パーティ
ションには開始ローと終了ローがあり、ウィンドウ・フレームは開始ポイント
からパーティションの終了位置に向けてスライドします。
パフォーマンス&チューニング・ガイド 65
Page 82

統計関数
図 4-3: 分割された入力と、3 ロー分の移動ウィンドウ
UNBOUNDED
PRECEEDING と
FOLLOWING
ウィンドウ・フレームは、パーティションの先頭 (UNBOUNDED PRECEDING)、
最後 (UNBOUNDED FOLLOWING)、または両方まで到達する無制限の集合グ
ループによって定義されます。
UNBOUNDED PRECEDING には、パーティション内の現在のロー以前にあるすべ
てのローが含まれており、ROWS または RANGE で指定できます。UNBOUNDED
FOLLOWING には、パーティション内の現在のロー以後にあるすべてのローが含
まれており、ROWS または RANGE で指定できます。詳細については、「ROWS」
(67 ページ ) と「RANGE」(70 ページ ) を参照してください。
FOLLOWING の値では、現在のロー以降にあるローの範囲または数を指定し
ます。ROWS を指定する場合、その値には、ローの数を表す正の数を指定し
ます。RANGE を指定する場合、そのウィンドウには、現在のローに指定の数
値を足した数よりも少ないローが含まれます。RANGE を指定する場合、その
ウィンドウ値のデータ型は、ORDER BY 句のソート・キー式の型に対応して
いる必要があります。指定できるソート・キー式は 1 つだけで、このソート・
キー式のデータ型は「加算」を許可していなければなりません。
PREDCEEDING の値では、現在のロー以前にあるローの範囲または数を指定し
ます。ROWS を指定する場合、その値には、ローの数を表す正の数を指定しま
す。RANGE を指定する場合、そのウィンドウには、現在のローから指定の数
値を引いた数よりも少ないローが含まれます。RANGE を指定する場合、その
ウィンドウ値のデータ型は、ORDER BY 句のソート・キー式の型に対応してい
る必要があります。指定できるソート・キー式は 1 つだけで、このソート・キー
式のデータ型は「減算」を許可していなければなりません。1 つ目のバインド
されたグループで CURRENT ROW または FOLLOWING の値を指定している場
合は、2 つ目のバインドされたグループにこの句を指定することはできません。
66 Sybase IQ
Page 83

CURRENT ROW の概念
第 4 章 OLAP の使用
BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING の組
み合わせを使用すると、グループ化したクエリとのジョインを構築しなくて
も、パーティション全体についての集合を計算できます。パーティション全体
についての集合は、レポート集合とも呼ばれます。
物理的な集合グループでは、現在のローに対する相対位置に基づき、隣接する
ローの数に応じて、ローを含めるか除外するかが判断されます。現在のロー
は、クエリの中間結果における次のローへの参照にすぎません。現在のローが
前に進むと、ウィンドウ内に含まれる新しいロー・セットに基づいてウィンド
ウが再評価されます。現在のローをウィンドウ内に含めるという要件はありま
せん。
ウィンドウ・フレーム句を指定しなかった場合のデフォルトのウィンドウ・フ
レームは、ウィンドウ順序句を指定しているかどうかによって異なります。
• ウィンドウ指定にウィンドウ順序句が含まれている場合は、ウィンドウの
開始ポイントは UNBOUNDED PRECEDING、終了ポイントは CURRENT
ROW になり、累積値の計算に適した可変サイズのウィンドウになります。
• ウィンドウ指定にウィンドウ順序句が含まれていない場合は、ウィンドウの
開始ポイントは UNBOUNDED PRECEDING、終了ポイントは UNBOUNDED
FOLLOWING になり、現在のローに関係なく固定サイズのウィンドウになり
ます。
注意 ウィンドウ・フレーム句はランク付け関数とは併用できません。
ローベース ( ロー指定 ) または値ベース ( 範囲指定 ) のウィンドウ・フレーム
単位を指定してウィンドウを定義することもできます。
<WINDOW FRAME UNIT> ::= ROWS | RANGE
<WINDOW FRAME EXTENT> ::= <WINDOW FRAME START> | <WINDOW
FRAME BETWEEN>
ウィンドウ・フレーム句で BETWEEN を使用するときは、ウィンドウ・フレー
ムの開始ポイントと終了ポイントを明示的に指定します。
ウィンドウ・フレーム句でこの 2 つの値のどちらか一方しか指定しなかった場
合は、他方の値がデフォルトで CURRENT ROW になります。
ROWS
ウィンドウ・フレーム単位 ROWS では、現在のローの前後に指定の数のロー
を含んでいるウィンドウを定義します ( 現在のローは、ウィンドウの開始ポイ
ントと終了ポイントを決定するための参照ポイントになります )。それぞれの
分析計算は、パーティション内の現在のローに基づいて行われます。ローで表
現されるウィンドウを使用して限定的な結果を生成するには、ユニークな順序
付けの式を指定する必要があります。
パフォーマンス&チューニング・ガイド 67
Page 84

統計関数
どのウィンドウ・フレームでも、現在のローが参照ポイントになります。
SQL/OLAP の構文には、ローベースのウィンドウ・フレームを、現在のローの
前または後にある任意の数のロー ( あるいは現在のローの前および後ろにある
任意の数のロー ) として定義するためのメカニズムが用意されています。
ウィンドウ・フレーム単位の代表的な例を次に示します。
• Rows Between Unbounded Preceding and Current Row - 各パーティションの
先頭を開始ポイントとし、現在のローを終了ポイントとするウィンドウを
指定します。累積和など、累積的な結果を計算するためのウィンドウを構
築するときによく使用されます。
• Rows Between Unbounded Preceding and Unbounded Following - 現在のローに
関係なく、パーティション全体についての固定ウィンドウを指定します。
そのため、ウィンドウ集合関数の値は、パーティションのすべてのローで
等しくなります。
• Rows Between 1 Preceding and 1 Following - 3 つの隣接するロー ( 現在の
ローとその前および後のロー) を含む固定サイズの移動ウィンドウを指定
します。このウィンドウ・フレーム単位を使用して、たとえば 3 日間また
は 3 か月間の移動平均を計算できます。詳細については、図 4-3 (66 ペー
ジ ) を参照してください。
ウィンドウ値にギャップがあると、ROWS を使用した場合に意味のない
結果が生成されることがあるので注意してください。値セットが連続して
いない場合は、ROWS の代わりに RANGE を使用することを検討してくだ
さい。RANGE に基づくウィンドウ定義では、重複する値を含んだ隣接
ローが自動的に処理され、範囲内にギャップがあるときに他のローが含ま
れません。
注意 移動ウィンドウでは、入力の最初のローの前、および入力の最後の
ローの後ろには、NULL 値を含むローが存在することが想定されます。つ
まり、3 つのローから成る移動ウィンドウの場合は、入力の最後のローを
現在のローとして計算するときに、直前のローと NULL 値が計算に含ま
れます。
• Rows Between Current Row and Current Row - ウィンドウを現在のローのみ
に制限します。
• Rows Between 1 Preceding and 1 Preceding - 現在のローの直前のローだけ
を含む単一ローのウィンドウを指定します。この指定を、現在のローのみ
に基づく値を計算する別のウィンドウ関数と組み合わせると、隣接する
ロー同士のデルタ ( 値の差分 ) を簡単に計算することができます。詳細につ
いては、「隣接ロー間のデルタの計算」(72 ページ ) を参照してください。
68 Sybase IQ
Page 85

第 4 章 OLAP の使用
ローベースのウィンドウ・フレーム 図 4-4 の例では、ロー [1] ~ [5] は 1 つのパー
ティションを表しています。それぞれのローは、OLAP のウィンドウ・フレー
ムが前にスライドするにつれて現在のローになります。このウィンドウ・フ
レームは Between Current Row And 2 Following として定義されているため、各
フレームには、最大で 3 つ、最小で 1 つのローが含まれます。フレームがパー
ティションの終わりに到達したときは、現在のローだけがフレームに含まれま
す。網掛けの部分は、図 4-4 の各ステップでフレームから除外されているロー
を表しています。
図 4-4: ローベースのウィンドウ・フレーム
図 4-4 のウィンドウ・フレームは、次のような規則で機能しています。
• ロー [1] が現在のローであるときは、ロー [4] および [5] が除外される。
• ロー [2] が現在のローであるときは、ロー [5] および [1] が除外される。
• ロー [3] が現在のローであるときは、ロー [1] および [2] が除外される。
• ロー [4] が現在のローであるときは、ロー [1]、[2]、[3] が除外される。
• ロー [5] が現在のローであるときは、ロー [1]、[2]、[3]、[4] が除外される。
次の図では、この規則を具体的な値セットに適用し、OLAP の AVG 関数を使
用して各ローの計算を行っています。スライド計算により、現在のローの位置
に応じて、3 つまたはそれ以下のローを範囲として移動平均を算出しています。
次のクエリは、移動ウィンドウの定義の例を示しています。
SELECT dimension, measure,
AVG(measure) OVER(partition BY dimension
ORDER BY measure
ROWS BETWEEN CURRENT ROW and 2 FOLLOWING)
AS olap_avg
FROM ...
パフォーマンス&チューニング・ガイド 69
Page 86

統計関数
RANGE
平均値は次のようにして計算されています。
• ロー [1] = (10 + 50 + 100)/3
• ロー [2] = (50+ 100 + 120)/3
• ロー [3] = (100 + 120 + 500)/3
• ロー [4] = (120 + 500 + NULL)/3
• ロー [5] = (500 + NULL + NULL)/3
結果セット内の以降のすべてのパーティション ( たとえば B、C など ) につい
ても、同様の計算が実行されます。
現在のウィンドウにローが含まれていない場合、COUNT 以外のケースでは、
結果は NULL になります。
範囲ベースのウィンドウ・フレーム 前述のローベースのウィンドウ・フレームの
例では、さまざまなローベースのウィンドウ・フレーム定義の中から 1 つを紹
介しました。SQL/OLAP 構文では、また別の種類のウィンドウ・フレームとし
て、物理的なローのシーケンスではなく、値ベース ( または範囲ベース ) の
ロー・セットに基づいて境界を定義する方法が用意されています。
値ベースのウィンドウ・フレームは、ウィンドウ・パーティション内で、特定
の範囲の数値を含んでいるローを定義します。OLAP 関数の ORDER BY 句で
は、範囲指定を適用する数値カラムを定義します。このカラムの現在のローの
値が、範囲指定の基準となります。範囲指定ではロー指定と同じ構文を使用し
ますが、構文の解釈の仕方は異なります。
ウィンドウ・フレーム単位 RANGE では、特定の順序付けカラムについて現在
のローを基準とする値範囲を指定し、その範囲内の値を持つローを検索して、
ウィンドウ・フレームに含めます。これは論理的なオフセットに基づくウィン
ドウ・フレームと呼ばれ、“3 preceding” などの定数を指定することも、評価結
果が数値定数となる任意の式を指定することもできます。RANGE に基づく
ウィンドウを使用するときは、ORDER BY 句に数値式を 1 つだけ指定します。
たとえば、次のように指定すると、year カラムに現在のローの前後数年に当た
る値を含んでいるロー・セットをフレームとして定義できます。
ORDER BY year ASC range BETWEEN CURRENT ROW and 1 PRECEDING
このクエリ例の 1 PRECEDING という部分は、現在のローの year 値から 1 を減
算することを意味しています。
70 Sybase IQ
Page 87

第 4 章 OLAP の使用
このような範囲指定は内包的です。現在のローの year 値が 2000 である場合は、
ウィンドウ・パーティション内で、year 値が 2000 および 1999 であるすべての
ローがこのフレームに含まれることになります。パーティション内での各ロー
の物理的な位置は問われません。値ベースのフレームでは、ローを含めたり
除外したりする規則が、ローベースのフレームの規則とは大きく異なります
( ローベースのフレームの規則は、ローの物理的なシーケンスに完全に依存し
ています )。
OLAP の AVG( ) 関数の例で考えてみます。次の部分的な結果セットは、値ベー
スのウィンドウ・フレームの概念を具体的に表しています。前述のように、こ
のフレームには次のローが含まれます。
• 現在のローと同じ year 値を持つロー
• 現在のローから 1 を減算したのと同じ year 値を持つロー
次のクエリは、範囲ベースのウィンドウ・フレーム定義の例を示しています。
SELECT dimension, year, measure,
AVG(measure) OVER(PARTITION BY dimension
ORDER BY year ASC
range BETWEEN CURRENT ROW and 1 PRECEDING)
FROM ...
as olap_avg
平均値は次のようにして計算されています。
• ロー [1] = 1999 のため、ロー [2] ~ [5] は除外。したがって AVG = 10,000/1
• ロー [2] = 2001 のため、ロー [1]、[4]、[5] は除外。したがって AVG = 6,000/2
• ロー [3] = 2001 のため、ロー [1]、[4]、[5] は除外。したがって AVG = 6,000/2
• ロー [4] = 2002 のため、ロー [1] は除外。したがって AVG = 21,000/4
• ロー [5] = 2002 のため、ロー [1] は除外。したがって AVG = 21,000/4
値ベースのフレームの昇順と降順 値ベースのウィンドウ・フレームを使用する
OLAP 関数の ORDER BY 句では、範囲指定の対象となる数値カラムを特定す
るだけではなく、ORDER BY 値のソート順序も宣言できます。次の指定によ
り、直前の部分のソート順序 (ASC または DESC) を設定できます。
RANGE BETWEEN CURRENT ROW AND n FOLLOWING
パフォーマンス&チューニング・ガイド 71
Page 88

統計関数
n FOLLOWING の指定には、次のような意味があります。
• パーティションがデフォルトの昇順 (ASC) でソートされている場合は、n
は正の値として解釈されます。
• パーティションが降順 (DESC) でソートされている場合は、n は負の値と
して解釈されます。
たとえば、year カラムに 1999 ~ 2002 の 4 種類の値が含まれているとします。
次のテーブルは、これらの値をデフォルトの昇順でソートした場合 ( 左側 ) と
降順でソートした場合 ( 右側 ) を示しています。
現在のローが 1999 で、フレームが次のように指定されている場合、このフレー
ムには値 1999 のローと値 1998 のロー ( このテーブルには存在しません ) が含
まれます。
ORDER BY year ASC range BETWEEN CURRENT ROW and 1 FOLLOWING
注意 ORDER BY 値のソート順序は、値ベースのフレームに含まれるローの条
件をテストするときに重要な要素です。フレームに含まれるか除外されるか
は、数値だけでは決まりません。
無制限ウィンドウの使用 次のクエリでは、すべての製品と全製品の総数から成
る結果セットが生成されます。
SELECT id, description, quantity,
SUM(quantity) OVER () AS total
FROM product;
隣接ロー間のデルタの計算
現在のローと前のローをそれぞれ 1 つのウィンドウ
として定義し、この 2 つのウィンドウを使用すると、隣接するロー間のデルタ
( つまり差分 ) を直接的に計算することができます。次のクエリ例と結果を確
認してください。
SELECT emp_id, emp_lname, SUM(salary) OVER (ORDER BY
birth_date rows between current row and current row)
AS curr, SUM(salary) OVER (ORDER BY birth_date rows
between 1 preceding and 1 preceding) AS prev, (curr
-prev) as delta
FROM employee WHERE state IN ('MA', 'AZ') AND dept_id
=100
ORDER BY emp_id, emp_lname;
72 Sybase IQ
Page 89

第 4 章 OLAP の使用
このクエリの結果セットを次に示します。
emp_id emp_lname curr prev delta
------ --------- --------- ---------- ---------102 Whitney 45700.000 64500.000 -18800.000
105 Cobb 62000.000 68400.000 -6400.000
160 Breault 57490.000 96300.000 -38810.000
243 Shishov 72995.000 59840.000 13155.000
247 Driscoll 48023.690 87900.000 -39876.310
249 Guevara 42998.000 48023.690 -5025.690
266 Gowda 59840.000 57490.000 2350.000
278 Melkisetian 48500.000 74500.000 -26000.000
316 Pastor 74500.000 62000.000 12500.000
445 Lull 87900.000 67890.000 20010.000
453 Rabkin 64500.000 42998.000 21502.000
479 Siperstein 39875.500 42500.000 -2624.500
501 Scott 96300.000 54900.000 41400.000
529 Sullivan 67890.000 72995.000 -5105.000
582 Samuels 37400.000 39875.500 -2475.500
604 Wang 68400.000 45700.000 22700.000
839 Marshall 42500.000 48500.000 -6000.000
1157 Soo 39075.000 37400.000 1675.000
1250 Diaz 54900.000
ここではウィンドウ関数 SUM() を使用していますが、ウィンドウの指定方法
により、この合計には現在のローまたは前のローの salary 値だけが含まれてい
ます。また、結果セットの最初のローには前のローが存在しないため、最初の
ローの prev 値は NULL になります。したがって、delta も NULL になります。
ここまでの例では、OVER() 句と一緒に SUM() 集合関数を使用しました。
明示的なウィンドウ句とインラインのウィンドウ句
SQL OLAP では、クエリ内でウィンドウを指定する方法が 2 とおり用意されて
います。
• 明示的なウィンドウ句。HAVING 句の後でウィンドウを定義します。OLAP
関数を呼び出すときには、このようなウィンドウ句で定義したウィンドウ
を、ウィンドウの名前を指定して参照します。たとえば次のようにします。
SUM ( ...) OVER w2
パフォーマンス&チューニング・ガイド 73
Page 90

統計関数
• インラインのウィンドウ指定。クエリ式の SELECT リスト内でウィンド
ウを定義します。これにより、HAVING 句の後のウィンドウ句でウィンド
ウを定義し、それをウィンドウ関数呼び出しから名前で参照するという方
法に加えて、関数呼び出しと一緒にウィンドウを定義するという方法が可
能になります。
注意 インラインのウィンドウ指定を使用する場合は、ウィンドウの名前
を指定できません。1 つの SELECT リスト内で複数のウィンドウ関数呼
び出しが同じウィンドウを使用する場合には、ウィンドウ句で定義した名
前付きウィンドウを参照するか、インラインのウィンドウ定義を繰り返す
必要があります。
ウィンドウ関数の例 ウィンドウ関数の例を次に示します。このクエリでは、デー
タを部署別のパーティションに分け、在社年数が最も長い従業員を基点とした従
業員の累積給与を計算して、結果セットを返します。この結果セットには、マサ
チューセッツ在住の従業員だけが含まれます。Sum_Salary カラムには、従業員
の給与の累積和が含まれます。
SELECT dept_id, emp_lname, start_date, salary,
SUM(salary) OVER (PARTITION BY dept_id ORDER BY
start_date rows between unbounded preceding and
current row) AS sum_salary
FROM employee
WHERE state IN ('MA') AND dept_id IN (100, 200)
ORDER BY dept_id;
次の結果セットは部署別に分割されています。
dept_id emp_lname start_date salary sum_salary
------- --------- ----------- ------ ----------100 Whitney 1984-08-28 45700.000 45700.000
100 Cobb 1985-01-01 62000.000 107700.000
100 Breault 1985-06-17 57490.000 165190.000
100 Shishov 1986-06-07 72995.000 238185.000
100 Driscoll 1986-07-01 48023.690 286208.690
100 Guevara 1986-10-14 42998.000 329206.690
100 Gowda 1986-11-30 59840.000 389046.690
100 Melkisetian 1986-12-06 48500.000 437546.690
100 Pastor 1987-04-26 74500.000 512046.690
100 Lull 1987-06-15 87900.000 599946.690
100 Rabkin 1987-06-15 64500.000 664446.690
100 Siperstein 1987-07-23 39875.500 704322.190
100 Scott 1987-08-04 96300.000 800622.190
100 Sullivan 1988-02-03 67890.000 868512.190
100 Samuels 1988-03-23 37400.000 905912.190
100 Wang 1988-09-29 68400.000 974312.190
100 Marshall 1989-04-20 42500.000 1016812.190
100 Soo 1990-07-31 39075.000 1055887.190
100 Diaz 1990-08-19 54900.000 1110787.190
74 Sybase IQ
Page 91

ランク付け関数
第 4 章 OLAP の使用
200 Dill 1985-12-06 54800.000 54800.000
200 Powell 1988-10-14 54600.000 109400.000
200 Poitras 1988-11-28 46200.000 155600.000
200 Singer 1989-06-01 34892.000 190492.000
200 Kelly 1989-10-01 87500.000 277992.000
200 Martel 1989-10-16 55700.000 333692.000
200 Sterling 1990-04-29 64900.000 398592.000
200 Chao 1990-05-13 33890.000 432482.000
200 Preston 1990-07-11 37803.000 470285.000
200 Goggin 1990-08-05 37900.000 508185.000
200 Pickett 1993-08-12 47653.000 555838.000
ランク付け関数を使用すると、データ・セットの値をランク付けされた順序
のリストにまとめ、“ 今年度出荷された製品の中で売上合計が上位 10 位の製
品名” または “15 社以上から受注した営業部員の上位 5%” といった質問に答え
るクエリを 1 つの SQL 文で作成することができます。ランク付け関数には
RANK()、DENSE_RANK()、PERCENT_RANK()、NTILE() などがあり、
PART I T I O N B Y 句と一緒に使用します。
SQL/OLAP では、次の 4 つの関数がランク付け関数として分類されています。
<RANK FUNCTION TYPE> ::=
RANK | DENSE RANK | PERCENT RANK | NTILE
ランク付け関数を使用すると、クエリで指定された順序に基づいて、結果セッ
ト内の各ローのランク値を計算することができます。たとえば販売マネージャ
が、営業成績が最高または最低の営業部員、販売成績が最高または最低の販売
地域、あるいは売上が最高または最低の製品を調べたい場合があります。この
情報はランク付け関数によって入手できます。
RANK() 関数
RANK 関数は、ORDER BY 句で指定されたカラムについて、ローのパーティ
ション内での現在のローのランクを表す数値を返します。パーティション内の
最初のローが 1 位となり、25 のローを含むパーティションでは、パーティショ
ン内の最後のローが 25 位となります。RANK は構文変換として指定されてお
り、実際に RANK を同等の構文に変換することも、変換を行った場合に返す
はずの値と同等の結果を返すこともできます。
次の例に出てくる ws1 は、w1 という名前のウィンドウを定義するウィンドウ
指定を表しています。
RANK() OVER ws
パフォーマンス&チューニング・ガイド 75
Page 92

統計関数
DENSE_RANK() 関数
これは次の指定に相当します。
( COUNT (*) OVER ( ws RANGE UNBOUNDED PRECEDING )
- COUNT (*) OVER ( ws RANGE CURRENT ROW ) + 1 )
この RANK 関数の変換では、論理的な集合 (RANGE) を使用しています。この
結果、同位のロー ( 順序付けカラムに同じ値が含まれているロー ) が複数ある
場合は、それらに同じランクが割り当てられます。パーティション内で異なる
値を持つ次のグループには、同位のローのランクよりも 1 以上大きいランクが
割り当てられます。たとえば、順序付けカラムに 10、20、20、20、30 という値
を含むローがある場合、1 つ目のローのランクは 1 になり、2 つ目のローのラン
クは 2 になります。3 つ目と 4 つ目のローのランクも 2 になりますが、5 つ目の
ローのランクは 5 になります。ランクが 3 または 4 のローは存在しません。こ
のアルゴリズムは非連続型ランキング (sparse ranking) とも呼ばれます。
『Sybase IQ リファレンス・マニュアル』の「第 5 章 SQL 関数」の「RANK 関
数 [ 統計 ]」も参照してください。
RANK 関数は同位のローがあるときに重複したランク値を割り当て非連続的
なランキングを返しますが、DENSE_RANK 関数は抜けのないランキングを返
します。同位のローに対しては同じように等しいランク値が割り当てられます
が、このローのランクは、個々のローの順位ではなく、順序付けカラムに等し
い値を含んでいるローの集まりの順位を表しています。RANK の例と同様に、
順序付けカラムに 10、20、20、20、30 という値を含むローがある場合、1 つ
目のローのランクは同じく 1 となり、2 つ目のローおよび 3 つ目、4 つ目のロー
のランクも同じく 2 となります。しかし、最後のローのランクは 5 ではなく 3
になります。
DENSE_RANK も、構文変換を通じて計算されます。
DENSE_RANK() OVER ws
これは次の指定に相当します。
COUNT ( DISTINCT ROW ( expr_1, . . ., expr_n ) )
OVER ( ws RANGE UNBOUNDED PRECEDING )
この例では、expr_1 から expr_n の部分が、ウィンドウ w1 のソート指定リスト
に含まれている値の式のリストを表しています。
『Sybase IQ リファレンス・マニュアル』の「第 5 章 SQL 関数」の「DENSE_RANK
関数 [ 統計 ]」も参照してください。
76 Sybase IQ
Page 93

PERCENT_RANK() 関数
第 4 章 OLAP の使用
PERCENT_RANK 関数は、個別の順位ではなく、パーセンテージでのランク
を計算して、0 ~ 1 の小数値を返します。つまり、PERCENT_RANK が返すの
はローの相対的なランクであり、この数値は、該当するウィンドウ・パーティ
ション内での現在のローの相対位置を表します。たとえば、順序付けカラムの
値がそれぞれ異なる 10 個のローがパーティションに含まれている場合、この
パーティションの 3 つ目のローに対する PERCENT_RANK の値は 0.222 ... と
なります。パーティションの 1 つ目のローに続く 2/9 (22.222...%) のローをカ
バーしているためです。次の例に示すとおり、ローの PERCENT_RANK は、
「ローの RANK - 1」を「パーティション内のローの数 - 1」で割ったものとし
て定義されています (“ANT” は、REAL や DOUBLE PRECISION などの概数値
の型を表します )。
PERCENT_RANK() OVER ws
これは次の指定に相当します。
CASE
WHEN COUNT (*) OVER ( ws RANGE BETWEEN UNBOUNDED
PRECEDING AND UNBOUNDED FOLLOWING ) = 1
THEN CAST (0 AS ANT)
ELSE
( CAST ( RANK () OVER ( ws ) AS ANT ) -1 /
( COUNT (*) OVER ( ws RANGE BETWEEN UNBOUNDED
PRECEDING AND UNBOUNDED FOLLOWING ) - 1 )
END
『Sybase IQ リファレンス・マニュアル』の「第 5 章 SQL 関数」の
「PERCENT_RANK 関数 [ 統計 ]」も参照してください。
ランク付けの例
ランク付けの例 1
次の SQL クエリでは、マサチューセッツ州在住の男性従業
員と女性従業員を取得し、給与を基準として降順にランク付けしています。
SELECT emp_lname, salary, sex, RANK() OVER (ORDER BY
salary DESC) AS Rank
FROM employee WHERE state IN ('MA') AND dept_id =100
ORDER BY salary DESC;
このクエリの結果セットを次に示します。
emp_lname salary sex rank
--------- -------- --- ----
Scott 96300.000 M 1
Lull 87900.000 M 2
Pastor 74500.000 F 3
Shishov 72995.000 F 4
Wang 68400.000 M 5
Sullivan 67890.000 F 6
Rabkin 64500.000 M 7
Cobb 62000.000 M 8
パフォーマンス&チューニング・ガイド 77
Page 94

統計関数
Gowda 59840.000 M 9
Breault 57490.000 M 10
Diaz 54900.000 M 11
Melkisetian 48500.000 F 12
Driscoll 48023.690 M 13
Whitney 45700.000 F 14
Guevara 42998.000 M 15
Marshall 42500.000 M 16
Siperstein 39875.500 F 17
Soo 39075.000 M 18
Samuels 37400.000 M 19
ランク付けの例 2
ランク付けの例 1 のクエリを基にして、データを性別のパー
ティションに分けることができます。次の例では、性別のパーティションに分
けて、従業員の給与を降順にランク付けしています。
SELECT emp_lname, salary, sex, RANK() OVER (PARTITION
BY sex ORDER BY salary DESC) AS RANK
FROM employee WHERE state IN ('MA', 'AZ') AND dept_id
IN (100, 200)
ORDER BY sex, salary DESC;
このクエリの結果セットを次に示します。
emp_lname salary sex rank
--------- --------- --- ----
Kelly 87500.000 F 1
Pastor 74500.000 F 2
Shishov 72995.000 F 3
Sullivan 67890.000 F 4
Melkisetian 48500.000 F 5
Pickett 47653.000 F 6
Poitras 46200.000 F 7
Whitney 45700.000 F 8
Siperstein 39875.500 F 9
Scott 96300.000 M 1
Lull 87900.000 M 2
Wang 68400.000 M 3
Sterling 64900.000 M 4
Rabkin 64500.000 M 5
Cobb 62000.000 M 6
Gowda 59840.000 M 7
Breault 57490.000 M 8
Martel 55700.000 M 9
Diaz 54900.000 M 10
Dill 54800.000 M 11
Powell 54600.000 M 12
Driscoll 48023.690 M 13
Guevara 42998.000 M 14
Marshall 42500.000 M 15
Soo 39075.000 M 16
Goggin 37900.000 M 17
Preston 37803.000 M 18
78 Sybase IQ
Page 95

第 4 章 OLAP の使用
Samuels 37400.000 M 19
Singer 34892.000 M 20
Chao 33890.000 M 21
ランク付けの例 3
この例では、カリフォルニアおよびテキサスの女性従業員を
取得し、給与を基準として降順にランク付けしています。累積和を降順で示す
ために、PERCENT_RANK 関数を使用しています。
SELECT emp_lname, salary, sex, CAST(PERCENT_RANK() OVER
(ORDER BY salary DESC) AS numeric (4, 2)) AS RANK
FROM employee WHERE state IN ('CA', 'TX') AND sex ='F'
ORDER BY salary DESC;
このクエリの結果セットを次に示します。
emp_lname salary sex percent
--------- --------- --- ----------
Savarino 72300.000 F 0.00
Smith 51411.000 F 0.33
Clark 45000.000 F 0.66
Garcia 39800.000 F 1.00
ランク付けの例 4
PERCENT_RANK 関数を使用して、データ・セットにおけ
る上位または下位のパーセンタイルを調べることができます。この例のクエリ
は、給与の額がデータ・セットの上位 5% に入る男性従業員を返します。
SELECT * FROM (SELECT emp_lname, salary, sex,
CAST(PERCENT_RANK() OVER (ORDER BY salary DESC) as numeric
(4, 2)) AS percent
FROM employee WHERE state IN ('MA') AND sex ='F' ) AS
DT where percent > 0.5
ORDER BY salary DESC;
このクエリの結果セットを次に示します。
emp_lname salary sex percent
--------- ---------- --- ---------
Whitney 45700.000 F 0.51
Barletta 45450.000 F 0.55
Higgins 43700.000 F 0.59
Siperstein 39875.500 F 0.62
Coe 36500.000 F 0.66
Espinoza 36490.000 F 0.70
Wetherby 35745.000 F 0.74
Braun 34300.000 F 0.77
Butterfield 34011.000 F 0.81
Bigelow 31200.000 F 0.85
Bertrand 29800.000 F 0.88
Lambert 29384.000 F 0.92
Kuo 28200.000 F 0.96
Romero 27500.000 F 1.00
パフォーマンス&チューニング・ガイド 79
Page 96

統計関数
ウィンドウ集合関数
ウィンドウ集合関数を使用すると、複数のレベルの集合を 1 つのクエリで計算
できます。たとえば、支出が平均より少ない四半期をすべて列挙することがで
きます。集合関数 (単純な集合関数 AV G、COUNT、MAX、MIN、SUM を含む )
を使用すると、1 つの文の中でさまざまなレベルで計算した結果を 1 つのローに
書き出すことができます。これにより、ジョインや相関サブクエリを使用しな
くても、集合値をグループ内のディテール・ローと比較することができます。
これらの関数を使用して、非集合値と集合値を比較することも可能です。たと
えば、営業部員が特定の年にある製品に対して平均以上の注文を出した顧客の
一覧を作成したり、販売マネージャが従業員の給与をその部署の平均給与と比
較したりすることが考えられます。
SELECT 文の中で DISTINCT が指定されている場合は、ウィンドウ演算子の
後に DISTINCT 操作が適用されます ( ウィンドウ演算子は、GROUP BY 句が
処理された後、SELECT リストの項目やクエリの ORDER BY 句が評価される
前に計算されます )。
ウィンドウ集合関数の例 1 この例のクエリは、平均販売数よりも多く売れた製
品の一覧を年別に示す結果セットを返します。
SELECT * FROM (SELECT year(order_date) AS Y, prod_id,
SUM(quantity) AS Q, CAST(AVG(SUM(quantity)) OVER
(PARTITION BY Y) AS numeric (8, 2)) AS Average
FROM alt_sales_order S, alt_sales_order_items O
WHERE S.id = O.id
GROUP BY Y, O.prod_id ) AS derived_table
WHERE Q > Average
ORDER BY Y, prod_id;
このクエリの結果セットを次に示します。
Year prod_id Q Average
---- ------- ---- ------2000 400 2030 1787.00
2000 600 2124 1787.00
2000 601 1932 1787.00
2000 700 2700 1787.00
2001 400 1248 1048.90
2001 401 1057 1048.90
2001 700 1836 1048.90
2000 年の平均注文数は 1,787 であり、4 つの製品 (700、601、600、400) が平均
を上回っています。2001 年の平均注文数は 1,048 であり、3 つの製品が平均を
上回っています。
80 Sybase IQ
Page 97

第 4 章 OLAP の使用
ウィンドウ集合関数の例 2 この例のクエリは、給与の額がそれぞれの部署の平
均給与よりも 1 標準偏差以上高い従業員を表す結果セットを返します。標準偏
差とは、そのデータが平均からどのぐらい離れているかを示す尺度です。
SELECT * FROM (SELECT emp_lname AS E_name, dept_id AS
Dept, CAST(salary AS numeric(10,2) ) AS Sal,
CAST(AVG(Sal) OVER(PARTITION BY dept_id) AS
numeric(10, 2)) AS Average, CAST(STDDEV_POP(Sal)
OVER(PARTITION BY dept_id) AS numeric(10,2)) AS
STD_DEV
FROM employee
GROUP BY Dept, E_name, Sal) AS derived_table WHERE
Sal> (Average+STD_DEV )
ORDER BY Dept, Sal, E_name;
このクエリの結果セットを次に示します。どの部署にも、給与の額が平均を大
きく上回っている従業員が 1 人以上いることがわかります。
Employee Dept Salary Average Std_Dev
-------- ---- -------- -------- --------
Lull 100 87900.00 58736.28 16829.59
Sheffield 100 87900.00 58736.28 16829.59
Scott 100 96300.00 58736.28 16829.59
Sterling 200 64900.00 48390.94 13869.59
Savarino 200 72300.00 48390.94 13869.59
Kelly 200 87500.00 48390.94 13869.59
Shea 300 138948.00 59500.00 30752.39
Blaikie 400 54900.00 43640.67 11194.02
Morris 400 61300.00 43640.67 11194.02
Evans 400 68940.00 43640.67 11194.02
Martinez 500 55500.80 33752.20 9084.49
従業員 Scott の給与は 96,300.00 ドルで、所属部署の平均給与は 58,736.28 ドル
です。この部署の標準偏差は 16,829.00 なので、給与の額が 75,565.88 ドル
(58736.28 + 16829.60 = 75565.88) 未満ならば、平均の 1 標準偏差以内の範囲に
収まります。Scott の給与 96,300.00 ドルは、この数字を大きく超えています。
統計集合関数
ANSI SQL/OLAP 拡張機能には、数値データの統計的分析を行うための集合関
数がこの他にも数多く用意されています。これには、分散、標準偏差、相関、
直線回帰を計算するための関数も含まれます。
標準偏差と分散 SQL/OLAP の一般的な関数の中には、STDDEV、STDDEV_POP、
STDDEV_SAMP、VARIANCE、VAR _POP、VAR_SAMP のように、
1 つの引数を取る関数があります。
<SIMPLE WINDOW AGGREGATE FUNCTION TYPE> ::=
<BASIC AGGREGATE FUNCTION TYPE>
| STDDEV | STDDEV_POP | STDDEV_SAMP
| VARIANCE | VARIANCE_POP | VARIANCE_SAMP
パフォーマンス&チューニング・ガイド 81
Page 98

統計関数
• STDDEV_POP - グループまたはパーティションの各ロー (DISTINCT が
指定されている場合は、重複が削除された後に残る各ロー ) に対して評価
される「値の式」についての母標準偏差を計算します。これは、母分散の
平方根として定義されます。
• STDDEV_SAMP - グループまたはパーティションの各ロー (DISTINCT
が指定されている場合は、重複が削除された後に残る各ロー ) に対して評
価される「値の式」についての母標準偏差を計算します。これは、標本分
散の平方根として定義されます。
• VAR_ POP - グループまたはパーティションの各ロー (DISTINCT が指定
されている場合は、重複が削除された後に残る各ロー ) に対して評価され
る「値の式」についての母分散を計算します。これは、「値の式」と「値
の式の平均」との差の 2 乗和をグループまたはパーティション内の残りの
ローの数で割った値として定義されます。
• VAR_ SAMP - グループまたはパーティションの各ロー (DISTINCT が指
定されている場合は、重複が削除された後に残る各ロー ) に対して評価さ
れる「値の式」の標本分散を計算します。これは、「値の式」の差の 2 乗
和を、グループまたはパーティション内の残りのローの数より 1 少ない数
で割った値として定義されます。
これらの関数と STDDEV および VARIANCE 関数は、クエリの ORDER BY 句の
指定に従ってローのパーティションについての値を計算できる集合関数です。
MAX や MIN などのその他の基本的な集合関数と同様に、これらの関数は入力
データ内の NULL 値を無視します。また、分析される式のドメインに関係なく、
分散と標準偏差の計算では必ず IEEE の倍精度浮動小数点数が使用されます。分
散関数または標準偏差関数への入力が空のデータ・セットである場合、これら
の関数は結果として NULL を返します。VAR_SAMP 関数は 1 つのローに対して
計算を行うと NULL を返しますが、VAR_P OP は値 0 を返します。
分散統計関数
SQL/OLAP には、順序付きセットを取り扱う関数がいくつか定義されています。
PERCENTILE_CONT と PERCENTILE_DISC という 2 つの逆分散統計関数があ
ります。これらの統計関数は、パーセンタイル値を引数として受け取り、WITHIN
GROUP 句で指定されたデータのグループまたはデータ・セット全体に対して処
理を行います。
これらの関数は、グループごとに 1 つの値を返します PERCENTILE_DISC
( 不連続 ) の場合、結果のデータ型は、WITHIN GROUP 句に指定した ORDER
BY の項目のデータ型と同じになります。PERCENTILE_CONT ( 連続 ) では、
結果のデータ型は、numeric (WITHIN GROUP 句の ORDER BY 項目が numeric
の場合 ) または double (ORDER BY 項目が整数または浮動小数点の場合 ) とな
ります。
82 Sybase IQ
Page 99

第 4 章 OLAP の使用
逆分散統計関数では、WITHIN GROUP (ORDER BY) 句を指定する必要があり
ます。次に例を示します。
PERCENTILE_CONT ( expression1 )
WITHIN GROUP ( ORDER BY expression2 [ ASC | DESC ] )
expression1 の値には、numeric データ型の定数を、0 以上 1 以下の範囲で指定し
ます。引数が NULL であれば、“wrong argument for percentile” エラーが返りま
す。引数の値が 0 よりも小さいか、1 よりも大きい場合は、“data value out of
range” エラーが返ります。
必須の ORDER BY には、パーセンタイル関数の実行の対象となる式と、各グ
ループ内でのローのソート順を指定します。この ORDER BY 句は、WITHIN
GROUP 句の内部でのみ使用するものであり、SELECT 文の ORDER BY とは
異なります。
WITHIN GROUP 句は、クエリの結果を並べ替えて、関数が結果を計算するた
めのデータ・セットを形成します。
expression2 には、カラム参照を含む 1 つの式でソートを指定します。このソー
ト式に、複数の式やランク付け統計関数、set 関数、またはサブクエリを指定
することはできません。
ASC と DESC のパラメータでは、昇順または降順の順序付けシーケンスを指
定します。昇順がデフォルトです。
逆分散統計関数は、サブクエリ、HAVING 句、ビュー、union で使用すること
が可能です。逆分散統計関数は、分析を行わない単純な集合関数が使用される
ところであれば、どこでも使用できます。逆分散統計関数は、データ・セット
内の NULL 値を無視します。
PERCENTILE_CONT 例 この例では、PERCENTILE_CONT 関数を使用して、
各地域の自動車販売の 10 番目のパーセンタイル値を求めます。次のような
データ・セットを使用します。
sales region dealer_name
----- --------- -----------
900 Northeast Boston
800 Northeast Worcester
800 Northeast Providence
700 Northeast Lowell
540 Northeast Natick
500 Northeast New Haven
450 Northeast Hartford
800 Northwest SF
600 Northwest Seattle
500 Northwest Portland
400 Northwest Dublin
500 South Houston
400 South Austin
300 South Dallas
200 South Dover
パフォーマンス&チューニング・ガイド 83
Page 100

統計関数
次のクエリ例では、SELECT 文に PERCENTILE_CONT 関数を含めています。
SELECT region, PERCENTILE_CONT(0.1)
WITHIN GROUP ( ORDER BY sales DESC )
FROM carSales GROUP BY region;
この SELECT 文の結果には、各地域の自動車販売の 10 番目のパーセンタイル
値が一覧表示されます。
region percentile_cont
--------- --------------Northeast 840
Northwest 740
South 470
PERCENTILE_DISC 例
この例では、PERCENTILE_DISC 関数を使用して、各
地域の自動車販売の 10 番目のパーセンタイル値を求めます。次のようなデー
タ・セットを使用します。
sales region dealer_name
----- --------- -----------
900 Northeast Boston
800 Northeast Worcester
800 Northeast Providence
700 Northeast Lowell
540 Northeast Natick
500 Northeast New Haven
450 Northeast Hartford
800 Northwest SF
600 Northwest Seattle
500 Northwest Portland
400 Northwest Dublin
500 South Houston
400 South Austin
300 South Dallas
200 South Dover
次のクエリ例では、SELECT 文に PERCENTILE_DISC 関数を含めています。
SELECT region, PERCENTILE_DISC(0.1) WITHIN GROUP
(ORDER BY sales DESC )
FROM carSales GROUP BY region;
この SELECT 文の結果には、各地域の自動車販売の 10 番目のパーセンタイル
値が一覧表示されます。
region percentile_cont
--------- ---------------
Northeast 900
Northwest 800
South 500
84 Sybase IQ
 Loading...
Loading...