

Page 1
Match/Consolidate
Extended Matching Reference
Match/Consolidate 8.00c
April 2009
Page 2

Copyright information © 2009 SAP® BusinessObjects™. All rights reserved. SAP BusinessObjects and its logos,
BusinessObjects, Crystal Reports®, SAP BusinessObjects Rapid Mart™, SAP BusinessObjects Data Insight™, SAP BusinessObjects Desktop Intelligence™, SAP BusinessObjects
Rapid Marts®, SAP BusinessObjects Watchlist Security™, SAP BusinessObjects Web Intelligence®, and Xcelsius® are trademarks or registered trademarks of Business Objects, an SAP
company and/or affiliated companies in the United States and/or other countries. SAP® is a
registered trademark of SAP AG in Germany and/or other countries. All other names mentioned herein may be trademarks of their respective owners.
2
Match/Consolidate Extended Matching Reference
Page 3

Contents
Preface .............................................................................................................5
Chapter 1:
Introducing extended matching ................................................................... 7
Extended matching files.................................................................................10
The Match Results report ...............................................................................11
Enable extended matching ............................................................................13
Weighted scoring in rule matching ................................................................15
Chapter 2:
Extended matching blocks and parameters.............................................. 17
General ...........................................................................................................18
Parsing and Key Field Options.......................................................................19
Form Break Groups........................................................................................26
Break Field Definition....................................................................................28
Auto Field Option...........................................................................................29
Auto Match Spec............................................................................................36
Rule Definition...............................................................................................41
Rule Match Spec ............................................................................................51
Prioritize Matches ..........................................................................................54
Extended Match Criteria ................................................................................56
Appendix A:
Extended matching file (extmatch.mpg) ....................................................57
Index ..............................................................................................................63
Contents
3
Page 4

4
Match/Consolidate Extended Matching Reference
Page 5

Preface
About this manual
Conventions
This manual provides detailed information about Match/Consolidate (MCD)
extended matching. Use this guide as you set up and run extended-matching
jobs.
For conceptual information about matching records, refer to the User’s Guide
to Record Matching. You should read this guide first because it will acquaint
you with the concepts of matching records and all the options that are
available to you.
This document follows these conventions:
Convention Description
Bold We use bold type for file names, paths, emphasis, and text that you
should type exactly as shown. For example, “Type
Italics We use italics for emphasis and text for which you should substitute
your own data or values. For example, “Type a name for your file,
Menu
commands
!
and the
We indicate commands that you choose from menus in the following format: Menu Name > Command Name. For example, “Choose
File > New.”
We use this symbol to alert you to important information and potential problems.
.txt
extension (
testfile
.txt
).”
cd\dirs
.”
We use this symbol to point out special cases that you should know
about.
We use this symbol to draw your attention to tips that may be useful
to you.
Preface
5
Page 6

Documentation
Other documentation Documents related to this manual include the following:
Document Description
Access the latest
documentation
System Administrator’s
Explains how to install your software.
Guide
Database Prep
Explains how to prepare input files for processing, including how to create DEF, FMT, and DMT files.
Match/Consolidate
User’s Guide to Record
Matching
Explains the concepts behind name and address matching
software and provides examples of how to implement,
analyze, and fine-tune match detection strategies for the
best results.
Match/Consolidate
Job-File Reference
Quick Reference
Contains the operational how-to instructions for setting
up the Match/Consolidate job file.
Contains descriptions of the input and output fields, and
the command line for the Match/Consolidate job file.
You can access documentation in several places:
On your computer. Release notes, manuals, and other documents for
each product that you’ve installed are available in the Documentation
folder. Choose Start > Programs > Business Objects Applications >
Documentation.
On the SAP Service Market Place. Go to http://help.sap.com, and then
click the Business Objects tab. Here, you can search for your products’
documentation.
6
Match/Consolidate Extended Matching Reference
Page 7

Chapter 1:
Introducing extended matching
Match/Consolidate (MCD) extended matching lets you customize your MCD job
much more than you can with Match Consolidate’s standard matching. You can
specify matching criteria to the extent that you want. In other words, your setup
may be very simple, or very complex.
There are two kinds of extended matching: automatic matching and rulebased matching:
With automatic matching, you choose the type of matching you want to
perform, such as individual or firm, as described in “Match types” on page 8.
Then, MCD compares records based on the match type and other options you
selected.
With rule-based matching, you set up rules that MCD uses to compare
records. Each rule contains details about a particular field that you want to
compare and how you want the field compared.
Chapter 1: Introducing extended matching
7
Page 8

Match types Match types are a starting point for defining the kind of matching you want to
perform.
When you perform automatic extended matching, you choose a match
type at the Match Type parameter in the Auto Match Specification block. When
you perform rule-based extended matching, you start with the extended matching
template file that corresponds with the match type you want to use (for example,
firm.mpg).
When using match types, consider the following questions:
What fields do I want to compare? (Last name, firm, and so on.)
What end result do I want when the MCD job is complete? (One record per
family, per firm, and so on.)
You can use the following match types with MCD extended matching:
Match type Description
Family The purpose of the family match type is to determine whether two people should be considered mem-
bers of the same family, as reflected by their record data. Match/Consolidate compares the last name
and the address data. A match means that the two records reflect members of the same family.
The result of the match is one record per family.
Individual The purpose of the individual match type is to determine whether two records are for the same person,
as reflected by their record data. Match/Consolidate compares the first name, last name, and address
data. A match means that the two records reflect the same person.
The result of the match is one record per individual.
Resident The purpose of the resident match type is to determine whether two records should be considered mem-
bers of the same residence, as reflected by their record data. Match/Consolidate compares the address
data. A match means that the two records are members of the same household. Contrast this match type
with the family match type, which also compares last-name data.
The result of the match is one record per residence.
Firm The purpose of the firm match type is to determine whether two records reflect the same firm. This
match type involves comparisons of firm and address data. A match means that the two records represent the same firm.
The result of the match is one record per firm.
Firm-Individual The purpose of the firm-individual match type is to determine whether two records are for the same
person at the same firm, as reflected by their record data. With this match type, MCD compares the first
name, last name, firm name, and address data. A match means that the two records reflect the same person at the same firm.
The result of the match is one record per individual per firm.
8
Match/Consolidate Extended Matching Reference
Page 9

Rule-based matching With rule-based extended matching, you can define precisely which fields MCD
should compare and how MCD should compare them. You control what qualifies
as a match by setting up rules.
First, you choose
Required blocks Optional blocks
your match type by
choosing the
appropriate
extended matching
file (refer to
Parsing and Key Options
Rule Definition
Rule Match Spec
Prioritize Matches
Form Break Groups
Break Field Definition
Additional Rule Definition blocks
Extended Match Criteria
“Extended
matching files” on page 10). Then, if you want, you can adjust the settings to
further customize your matching criteria. You can leave the default settings if
they meet your needs.
Automatic matching Automatic matching requires you to select a match threshold and a match type
(refer to “Match types” on page 8). You can also edit various parameters to finetune the process, if you so choose. However, it’s not necessary to perform a fieldby-field setup.
Automatic matching
looks at the types of data
fields in your keys and
then selects the
appropriate fields to use
for performing
Required blocks Optional blocks
General
Parsing and Key Field Options
Auto Match Spec
Prioritize Matches
Break Field Definition
Form Break Groups
Auto Field option
comparisons. For
example, MCD would compare name fields if you selected a family or individual
match type, but not if you selected a firm match type.
Match/Consolidate uses four thresholds: exact, tight, medium, and loose. Each
threshold uses percentages to determine how similar fields must be for MCD to
consider them duplicates.
For two fields to match using an exact threshold, the fields compared must be 100
percent alike. The percentages decrease as we move from exact to loose.
Chapter 1: Introducing extended matching
9
Page 10

Extended matching files
Extended matching files defined
Extended matching files contain job-file blocks and parameters for extended
matching. We provides you with six extended matching file templates—one for
automatic matching and five for rule-based matching. You can use a rule-based
extended matching file template as-is, or save a copy of the file with a different
name and edit it as needed. Note that extended matching files must use the .mpg
extension.
File name Description
Auto.mpg
Family.mpg
Indiv.mpg
Hhold.mpg
Extended matching file for automatic matching. This file contains
settings for each kind of match type (family, individual, firm, firmindividual, and resident). You must copy the desired match-type
section from the
extended matching file.
Extended matching file for rule-based matching, using the family
match type. Refer to “Match types” on page 8 for details about
match types.
Extended matching file for rule-based matching, using the individual match type. Refer to “Match types” on page 8 for details about
match types.
Extended matching file for rule-based matching, using the household, or resident, match type. Refer to “Match types” on page 8 for
details about match types.
auto.mpg
file to create your own automatic
Extended matching files location
Firm.mpg
Firmindv.mpg
Extended matching file for rule-based matching, using the firm
match type. Refer to “Match types” on page 8 for details about
match types.
Extended matching file for rule-based matching, using the firmindividual match type. Refer to “Match types” on page 8 for details
about match types.
Refer to “Extended matching blocks and parameters” on page 17 for detailed
descriptions of the extended matching files blocks and parameters.
When you install MCD, it installs the extended matching file templates in the
template subdirectory (pw\mpg\template, or postware\merge\template). The
extmatch.mpg file contains all of the extended matching blocks, which is
installed in pw\mpg or postware\merge.
You can set up your extended matching job in one of two ways.
1. Set up extended matching in an extended matching file and refer to that file
from your job file at the Ext Match Blocks parameter in the Auxiliary Files
block (refer to “Enter the name and path of the extended matching file” on
page 14).
2. Copy the blocks from one of the extended matching templates directly into
your MCD job.
10
Match/Consolidate Extended Matching Reference
Page 11
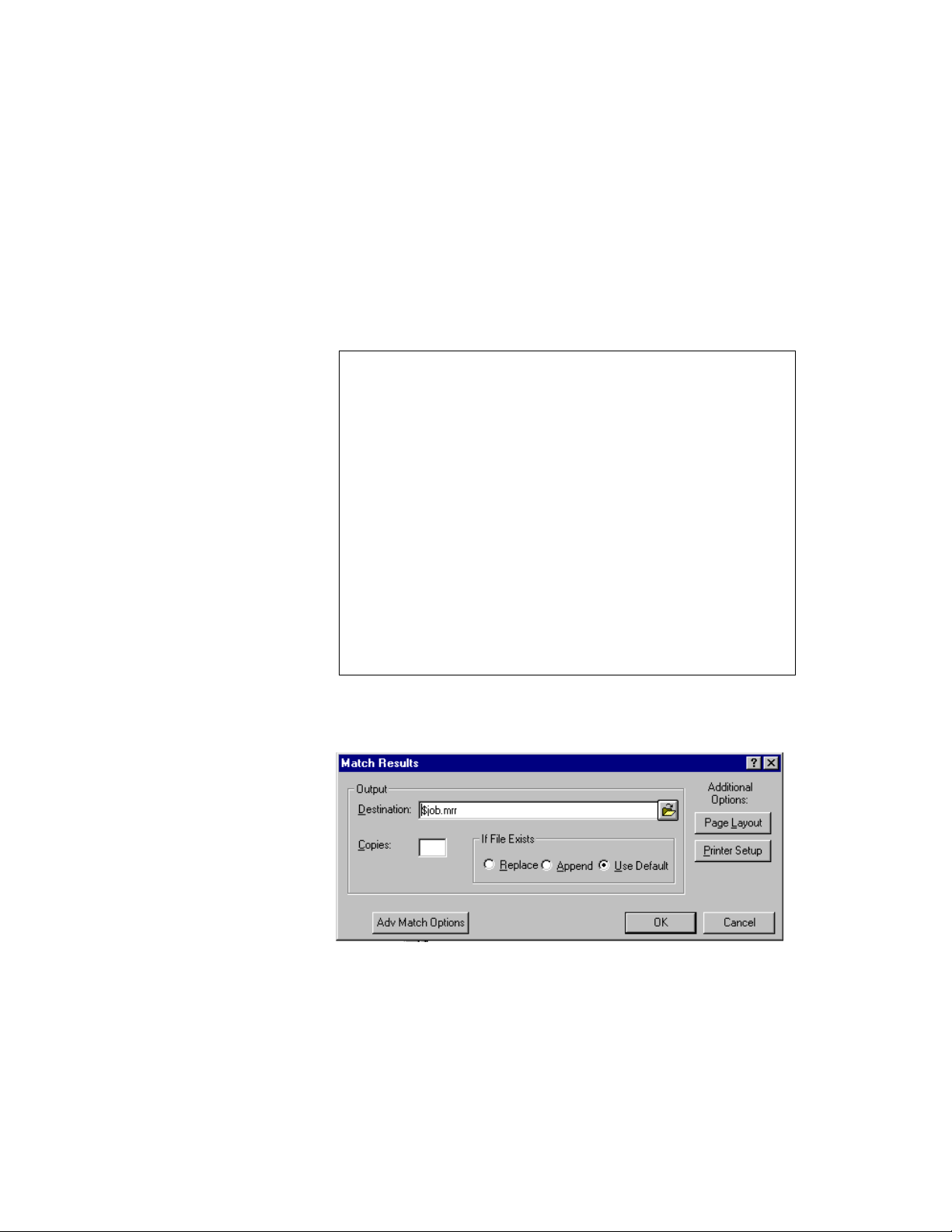
The Match Results report
The Match Results report shows the results of your extended matching. This may
help you if you get matching results that you did not expect or desire. Based on
information given in this report, you might decide to change settings in your
extended matching file.
Produce the report To produce the Match Results report (shown below), you must include and
complete the Report: Match Results block in your MCD job (not in the extended
matching file). Refer to the Match/Consolidate Job-File Reference or Views help
file for details about setting up this block.
BEGIN Report: Match Results ===================================
Location and File Name/Printer Device =
Existing File (APPEND/REPLACE)....... =
Number of Copies (1 to 10)........... =
Case (UPPER/Upper and Lower)......... =
Page Header Line 1 (to 80 chars)..... =
Page Header Line 2 (to 80 chars)..... =
Page Header Line 3 (to 80 chars)..... =
Page Header Line 4 (to 80 chars)..... =
Printer Init, For Reports (see NOTE). =
Printer Reset, For Reports (see NOTE) =
Page Length (in lines)............... =
Page Width (in chars)................ =
Top Margin (in lines)................ =
Bottom Margin (in lines)............. =
Left Margin (in chars)............... =
Right Margin (in chars).............. =
Adv Match Set to Report (ALL/SELECT). =
Adv Select Match Set(s) (name[,...]). =
Adv Match Level (FINEST/ALL/SELECT).. =
Adv Select Match Level to Report..... =
END
The following shows the Views Match Results window.
Chapter 1: Introducing extended matching
11
Page 12

Example report The following is an example of a match results report.
Match Results Report & job Match/Consolidate X.XX Page 1
-----------------------------------------------------------------------
Match Set Name: Keyset1
Match Level: level2
Total Comparisons: 22663
Non Match Spec Results
Not Compared - Forced No Match: 1674
Not Compared - Already a Match: 5240
Not Compared - Compares Disabled: 0
Pre-compare Exit Match Decisions: 0
Pre-compare Exit No Match Decisions: 0
Match Post-compare Exit No Match Decisions: 0
No Match Post-compare Exit Match Decisions: 0
Match Spec Results
Match Spec Name: R_Hhold
Match Spec Type: rule
Match Attempts: 15749
Match Decisions: 2587
No Match Decisions: 13162
Undecided: 0
Rule Match Results Summary
Rule Rule Attempts Match No Match Percent
Number Field Type Made Decision Decision Decision
1 Last_Name 15749 0 12725 56.15
2 Prim_Range 3024 0 351 1.55
3 PO_Box 2673 0 1 0.00
4 RR_Box 2672 0 14 0.06
5 Prim_Name 2658 0 29 0.13
6 RR_Number 2629 0 0 0.00
7 Address 2629 0 42 0.19
WEIGHTED 2587 2587 0 11.42
12
Match/Consolidate Extended Matching Reference
Page 13

Enable extended matching
As shown in the following job file application, to enable extended matching, you
must either set the Matching Method parameter in the MCD job’s Execution
Options block to Ext or Adv. As shown in the MCD Execution Options window,
set the Matching Method parameter to Extended or Advanced.
BEGIN Execution ===============================================
Read Records & Create Match Sets(Y/N) = Y
Find Duplicates (Y/N/PREDICT)........ = N
Matching Method (STD/EXT/ADV)........ = EXT
Create Match/Consolidate File (Y/N).. = N
Create Multi-Occurrence File (Y/N)... = N
Create All-Duplicates File (Y/N)..... = N
Create Custom M/C File (Y/N)......... = N
Post to Input File (Y/N)............. = N
Group Post to Purged Files (Y/N)..... = N
Purge (Y/N/PREDICT).................. = N
Custom Purge (Y/N/PREDICT)........... = N
Create Reports (Y/N)................. = Y
Create Report Statistics Files (Y/N). = N
Save Work Files (Y/N)................ = Y
Warn Before File Overwrite (Y/N)..... = Y
Work File Directory (path)........... =
Sort Work File Directory (path)...... =
Create Backup File(s) (Y/N).......... = Y
Backup Directory (path).............. =
Maximum Work Buffer Size (kilobytes) = 4096
Sort Optimization (SPACE/SPEED)...... = SPEED
Virtual Machine (NONE/CREATE)........ = NONE
END
Chapter 1: Introducing extended matching
13
Page 14
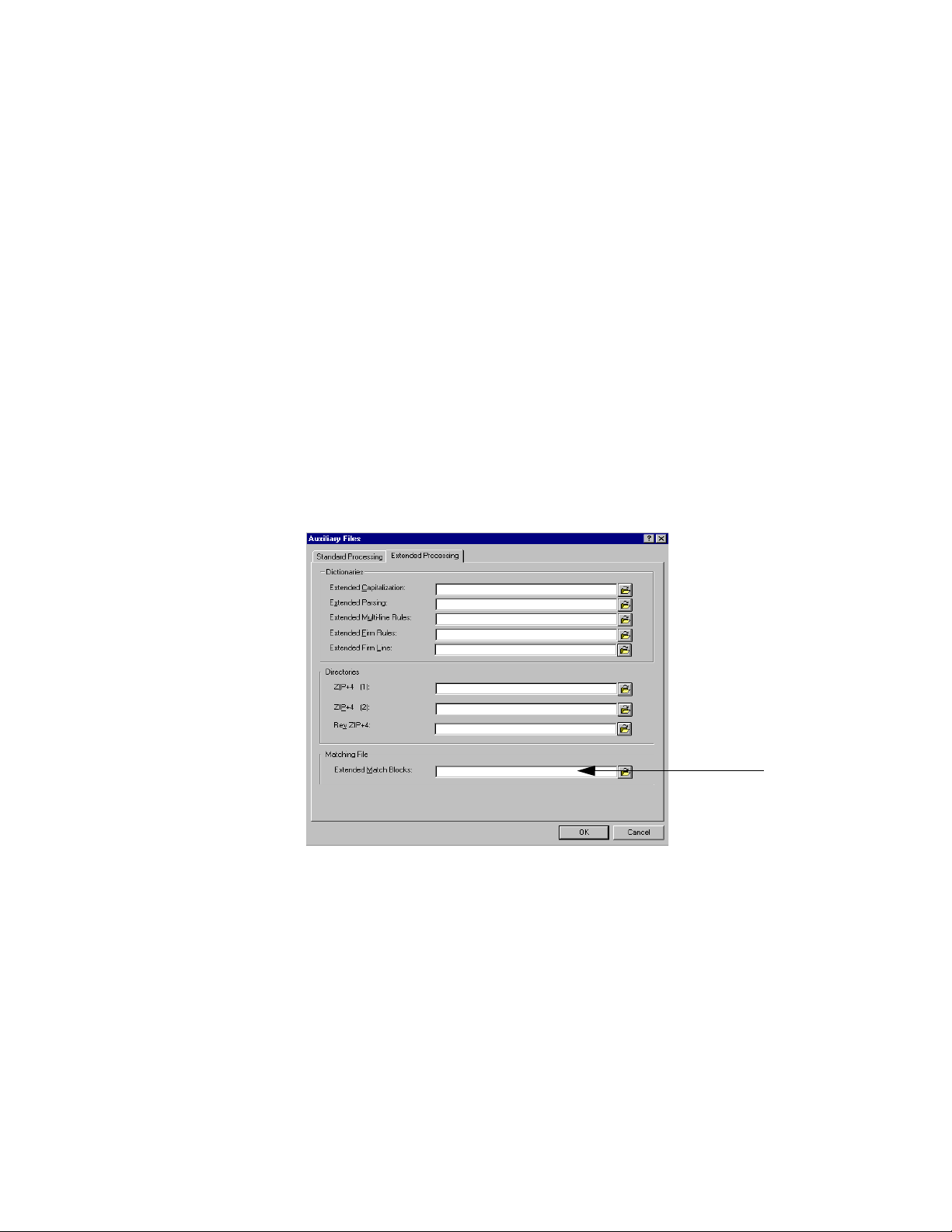
Enter the name and path of the extended matching file
If you choose to keep your extended match block in a separate file, you can also
enter the name and path of the extended matching file in the MCD job’s Auxiliary
Files block. For details about extended matching files, refer to “Extended
matching files” on page 10.
BEGIN Auxiliary Files =========================================
Address Line Dct (path & addrln.dct).. = *INSERT PATH HERE* addrln.dct
Last Line Dct (path & lastln.dct)..... = *INSERT PATH HERE* lastln.dct
City Directory (path & city08.dir).... = *INSERT PATH HERE* city08.dir
ZCF Directory (path & zcf08.dir)...... = *INSERT PATH HERE* zcf08.dir
Ext ZIP+4 Dir 1 (path & zip4??.dir)... = *INSERT PATH HERE* zip4??.dir
Ext ZIP+4 Dir 2 (path & zip4??.dir)... = *INSERT PATH HERE* zip4??.dir
Ext Rev ZIP+4 Dir (path & revzip4.dir).= *INSERT PATH HERE* revzip4.di
Ext Firm Line Dct (path & firmln.dct). = *INSERT PATH HERE* firmln.dct
Ext Cap Dct (path & pwcas.dct)........ = *INSERT PATH HERE* pwcas.dct
Std Prename Dct (path & prename.dct).. = *INSERT PATH HERE* prename.dc
Std Name Dct (path & name.dct)........ = *INSERT PATH HERE* name.dct
Std Pre-lastname (path & prelname.dct).= *INSERT PATH HERE* prelname.d
Std Postname (path & postname.dct).... = *INSERT PATH HERE* postname.d
Ext Multi-line Rules (mlrules.gcf).... = *INSERT PATH HERE* mlrules.gc
Ext Firm Rules (path & fprules.gcf)... = *INSERT PATH HERE* fprules.gc
Ext Parsing Dct (path & parsing.dct).. = *INSERT PATH HERE* parsing.dc
Std Match Percent Dct(path & file.dct).= *INSERT PATH HERE* matchpct.d
Ext Match Blocks (path & file name)... =
Default ASCII FMT (path & file.fmt)... =
Default DEF (path & file.def)......... =
END
Edit the extended matching file
14
Match/Consolidate Extended Matching Reference
You can use one of the rule-based extended matching templates that we provide
for you, as we provide it to you. Or you can create your own extended matching
file by copying blocks from one of the templates or extmatch.mpg.
Do not edit the parameter settings in the template files or extmatch.mpg. Instead,
you can save a copy of the original file with a different name, or copy the
extended matching blocks into your MCD job. You can then edit the parameter
settings as necessary. Installing software updates overwrites the extended
matching files.
Refer to “Extended matching blocks and parameters” on page 17 for detailed
descriptions of the extended matching blocks and parameters.
Page 15

Weighted scoring in rule matching
Weighted scoring adjusts the similarity score for each match rule that is used by
multiplying the similarity score times a weight. For example, if you match on two
fields, the sum of these weighted values is the similarity of the two fields. With
this, you can fail on one rule, but still get a match on the two fields. For example,
a spelling error in a street name will not prevent a match.
Similarity score times weight
When a rule is used to compare two key fields, the Match engine generates a
similarity score from 0 to 100. That score is then multiplied by the weight percent
that you set. For example, if the weight percent is set to 20 and two first names
have a similarity score of 90, then the first name comparison would contribute 18
(20 percent of 90) to the overall weighted score. For a perfect match, the sum of
all key field comparisons would normally be 100.
Force no-match For each match rule, you can set a maximum no dupe score, below which you’ll
never consider the keys a match, even if the overall weighted score is above the
threshold that has been set for a match. This allows you to “force no-match”—for
example, you could decide that if the last name similarity score is less than or
equal to 50, then the keys should be called a no-match.
Force a match For each match rule, you can set a minimum dupe similarity score, above which
you’ll always consider the keys a match, even if the overall weighted score is
below the threshold that has been set for a match. This allows you to force a
match. For example, you might decide that if the social security similarity score is
100, then the keys should be called a match.
The following example illustrates how weighting works—assume the minimum
overall weighted score required is 85.
field weight (in percent) force no-match force a match
street number 20 percent
street name 20 percent
secondary number 15 percent
first name 20 percent 25
last name 20 percent 50
post name 5 percent
If the first name similarity score is 25 or less, or if the last name score is 50 or
less, the keys will not match, even if the weighted score is 85 or greater.
But if the last name similarity score was 60, then the similarity score would be
multiplied by the weight percent, so that the last name comparison would
contribute 12 (20 percent of 60) to the overall weighted score.
Chapter 1: Introducing extended matching
15
Page 16

16
Match/Consolidate Extended Matching Reference
Page 17

Chapter 2:
Extended matching blocks and parameters
This chapter describes the extended matching blocks and parameters. You have
an option of placing extended matching reference blocks within your job file, or
you can set up extended matching in an external extended matching file. You can
then refer to that file from your job file at the Ext Match Blocks parameter in the
Auxiliary Files block (refer to “Enter the name and path of the extended matching
file” on page 14).
Chapter 2: Extended matching blocks and parameters
17
Page 18

General
The extended matching file that you use must contain a General block. This
allows us to update the extended matching files in the future.
Job Description (to 80 chars)
Job Owner (to 20 chars)
Do not enter any values at these two parameters in your extended matching file.
Match/Consolidate (MCD) takes the values entered in the MCD job-file
parameters instead. This block is only used for updating extended matching files
with the Edjob utility.
18
Match/Consolidate Extended Matching Reference
Page 19

Parsing and Key Field Options
In the Parsing and Key Field Options block, you specify the layout of keys and
the standardization to perform on the data stored in keys. The Parsing and Key
Field Options block is required if you perform extended matching. The Parsing
and Key Field Options block is required for both automatic and rule-based
extended matching.
Parsing and Key Options Name (to 20 chars)
This is an optional parameter that assigns a logical name for the block. The
Parsing and Key Options parameter in the Extended Matching Criteria block
references this name. Do not use the name in any other Parsing and Key Options
block.
Automatically Generate Key
This parameter controls whether MCD should automatically generate the length
of each key. Valid options for this parameter are listed below.
Option Description
None If you set this parameter to None, then the only key fields defined will
be the ones listed in the Key Length parameters, which appear at the
end of the Parsing and Key Options block.
Individual MCD designs keys so that the results will yield one record per person
(first and last name) at an address.
Family MCD designs keys so that the results will yield one record per family
(last name) at an address.
Firm MCD designs keys so that the results will yield one record per firm.
Firm_Individual MCD designs keys so that the results will yield one record per person
at a firm.
Resident MCD designs keys so that the results will yield one record per resi-
dence.
Name, Title, and Firm Parsing (Standard/Extended/None)
This parameter controls whether MCD uses its standard parsing routine or uses its
extended parsing routine for name, title, and firm data. You can expect better
matching results from the extended parsing routine, with an increase in
processing time.
Option Description
Standard If you set this parameter to Std (standard), MCD uses the name-related dic-
tionaries listed in the four Std parameters in the Auxiliary Files block.
Those four parameters must be filled out when this parameter is set to Std.
Extended If you set this parameter to Ext (extended), MCD uses the extended multi-
line, firm, and parsing dictionaries listed in the Auxiliary Files block.
None Select this option to disable parsing.
Chapter 2: Extended matching blocks and parameters
19
Page 20

Standard Number of Names to Store (1-2)
This parameter applies to standard parsing. You can enter the number of people’s
names that you want to store in the key. For example, if a name line was Bill and
Mary Smith, you could keep both names or just one name (in this case, the first
name, Bill Smith).
Match/Consolidate will store one or two (depending on your choice) of each of
the following name fields in the key: Pre_Name, First_Name, Mid_Name. The
more names, name components, and name standards that you store, the more disk
space and processing time you will need.
Standard Number of First_Name Stds (0-1)
This parameter applies to standard parsing. You can choose to store the
standardized first name (such as Robert) along with the original first name (such
as Bob) in the key. If you enter 0 (zero), only the original first name data will be
stored in the key.
Note that this applies to the name which appears first. For example, for Billy and
Mary Smith, MCD stores only the standards for Billy.
Standard Number of Mid_Name Stds (0-1)
This parameter applies to standard parsing. You can choose to store the
standardized middle name (such as Robert) along with the original name (such as
Bob) in the key. If you enter 0 (zero), only the original middle name data is stored
in the key.
This applies to the name that appears first. For example, for Billy Bob and Mary
Sue Smith, MCD stores the standards for only the Mid_Name Bob.
Extended Number of Names to Store (1-3)
This parameter applies to extended parsing. You can enter the number of people’s
names that you want to store in the key. For example, if a name line was Bill and
Mary Smith, you could keep both names or just one name (in this case, the first
name, Bill Smith).
Depending on your choice at this parameter, MCD will store one, two, or three of
each of the following fields in the key:
Pre_Name Oth_Post
First_Name Gender
Mid_Name SSN
Last_Name Birthdate
Mat_Post Title
20
Match/Consolidate Extended Matching Reference
Page 21

Extended Number of First_Name Stds (0-3)
This parameter applies to extended parsing. You can control the number of first
name standards to store in the key. If you enter 0 (zero), only the original first
name data will be stored in the key.
The results for this parameter depend also on how you set the Ext Number of
N a m e s t o S t o r e p a r a m e t e r . C o n s i d e r t h e f o l l o w i n g e x a m p l e f o r A l a n d L i z J o n e s .
Ext Number of
Names to Store
Ext Number of
First_Name Stds
11Alan
2 2 Alan, Albert, Elizabeth, Liza
1 2 Alan, Albert
2 1 Alan, Elizabeth
Extended Number of Mid_Name Stds (0-3)
This parameter applies to extended parsing. You can control the number of
middle name standards to store in the key. If you enter 0 (zero), only the original
middle name data will be stored in the key.
The results for this parameter depend also on how you set the Ext Number of
Names to Store parameter. See the Ext Number of First_Name Stds parameter
above for similar examples.
Extended Store Pre/Post Name (ORIG/STD/BOTH)
This parameter applies to extended parsing. This parameter controls what preand post-name data is stored in the following key fields:
Pre_Name
Results
Mat_Post
Oth_Post
Option Description
Orig The original pre- and post-name data is stored in the key.
Std Only standardized pre- and post-name data is stored in the key.
Both Both the original and standardized pre- and post-name data are stored in
the key.
Extended Store Title (ORIG/STD/BOTH)
This parameter applies to extended parsing. This parameter controls what title
data is stored in the title key field.
Option Description
Orig The original title data is stored in the key.
Std Only standardized title data is stored in the key.
Both Both the original and standardized title data are stored in the key.
Chapter 2: Extended matching blocks and parameters
21
Page 22

Extended Number of Firms to Store (1-2)
This parameter applies to extended parsing. You can control the number of firm
names to store in the key. For example, if a firm line were Tiny Tots Inc., Totsco
Company, you could store both firm names or just one.
Store Firm (ORIG/STD/BOTH)
This parameter controls what firm data is stored in the key.
Option Description
Orig The original firm data is stored in the key.
Std The standardized firm data is stored in the key.
Both The key holds both the original and standardized firm data.
Extended Number of Firm_Locs to Store (1-3)
This parameter applies to extended parsing. You can control the number of firm
locations to store in the key. For example, if the firm location was Mailstop 15,
Engineering Dept., you could store both locations or just one.
Extended Store Firm_Loc (ORIG/STD/BOTH)
This parameter applies to extended parsing. This parameter controls what firm
location data is stored in the key.
Option Description
Orig The original firm location data is stored in the key.
Std The standardized firm location data is stored in the key.
Both The key holds both the original and standardized firm location data.
Address and Last Line Parsing (Standard/Extended/None)
This parameter controls whether MCD uses its standard address parsing routine
or uses its extended address parsing routine. If you haven’t already standardized
your address data, you can expect better matching results from the extended
address parsing routine, with an increase in processing time.
Option Description
Standard MCD uses a smaller and faster process to parse address information. With
standard parsing, MCD standardizes only the suffix and directionals of the
address key data.
Extended MCD uses extended address parsing. MCD standardizes the address key
data to be consistent with the National Directory (
address parsing significantly increases processing time, but produces better
results.
None Select this option to disable parsing.
zip4us.dir
). Extended
22
Match/Consolidate Extended Matching Reference
Page 23

Standardize Last Line Keys (Y/N)
This parameter controls whether MCD will standardize last-line data (city, state,
ZIP Code) when copying it to the key file. You don’t need to standardize last-line
data with this parameter if you have already standardized it using ACE, for
example.
Option Description
Y MCD standardizes the last line data when copying it from the input file to
the key file. MCD compares the city, state, and ZIP Code data with the
USPS directories. If any one of the three elements is missing or wrong,
MCD assigns it based on the other two.
The ZIP Code alone is enough to assign city and state. More importantly,
MCD converts place names (unincorporated towns and vanity address, for
example) to USPS-preferred names to improve matching.
If this job uses extended address parsing (see the Address Parsing parameter on the previous page), any ZIP Code data may be affected. For example,
the extended parsing process can generate the ZIP+4 code for the address,
even if your record does not include it.
In addition, the extended parsing process might substitute a more accurate
ZIP Code, based on the comprehensive information in the national ZIP+4
directory file used by the extended process.
This standardization affects only the data used for breaking and matching; it
does not affect your input or output file.
N MCD uses last line data as it appears in the database.
Upper Case M/P & UserDef Fields (Y/N)
This parameter lets you control the capitalization of special user key fields
(Merg_Purg1, Merg_Purg2, and so on, plus user-defined fields). Match/
Consolidate handles casing of special user key fields differently than it does
casing of other fields. For example, it does not automatically convert special key
fields to uppercase as it does with other fields.
Option Description
Y MCD stores special key fields in uppercase letters. Choose Yes if you want
MCD to match on words even if their case is different in your input data.
N MCD stores special key fields as they appear in your input file. Choose No
if case differences in your input data should cause fields to be considered
unique.
Standardize Diacritical Chars (Y/N)
This parameter controls whether MCD standardizes diacritical characters.
Option Description
Y MCD standardizes diacritical characters.
N MCD does not standardize diacritical characters.
The following table shows some extended ASCII characters that MCD converts if
you select this option. As shown, the first character of a pair is the original value;
the second character in the pair is the replacement value.
Chapter 2: Extended matching blocks and parameters
23
Page 24

Store Priority Field (Y/N)
For example, the following table shows that the character À is converted to A.
Similarly, the table shows that the character Ä is converted to A.
Š S Œ O Ž Z š s œ o ž z Ÿ Y À A Á A  A Ä A Å A Æ A
Ç CÈ EÉ EÊ EË EÌ IÍ IÎ IÏ IÐ DÑ NÒ OÓ O
Ô OÕ OÖ OØ OÙ UÚ UÛ UÜ UÝ YÞ Pß Sà aá a
â aã aä aå aæ aç cè eé eê eë eì Ií Ií I
î Iï ið dñ nò oó oô oõ oö oø où uú uû u
ü uý yþ pÿ y
This parameter controls whether MCD stores the Priority field in the key.
Option Description
Y If you set this parameter to Yes, MCD stores the Priority field (as defined in
your DEF file) in they key. Choose Yes if you want MCD to prioritize
matching records based on the contents of a Priority field.
N If you set this parameter to No, MCD does not store a Priority field in the
key and does not prioritize matching records based on the contents of a
Priority field.
Key Length (fldname,length)
If you set the Auto Generate Key Lengths parameter to None, then you must enter
the key fields that you want to include and their lengths, in the format fieldname,
length. This parameter is repeatable: For every key field that you want to include,
there must be a Key Length parameter.
You can enter the following key fields at this parameter:
Pre_Name Phone State Merg_Purg1
First_Name Prim_Range ZIP Merg_Purg2
Mid_Name Predir ZIP4 Merg_Purg3
Last_Name Prim_Name Country Merg_Purg4
Mat_Post Suffix Unp_Addr Merg_Purg5
Oth_Post Postdir Unp_LLine Merg_Purg6
Birthdate Sec_Range Rec_Type Merg_Purg7
Gender PMB Error_Code Merg_Purg8
SSN PO_Box Merg_Purg9
Title RR_Box Merg_Purg0
Firm RR_Number
FirmLoc City
24
If you set the Auto Generate Key Lengths parameter to Individual, Family,
Resident, Firm_Individual, or Firm, then you don’t need to enter any key fields at
the Key Lengths parameter. Any values that you enter in a Key Length parameter
will override the automatic values.
Match/Consolidate Extended Matching Reference
Page 25

You can enter a value from 0 to 255 for a field’s key length. Some fields may
have a smaller maximum value. For example, as shown in the following
illustration, the ZIP field would have a maximum of five characters. For a list of
maximum field values, refer to the Match Criteria block in the Job-File Reference
manual. Consider the following example data:
Key Length (fldname,length).......... = FIRST_NAME, 13
Key Length (fldname,length).......... = LAST_NAME, 16
Key Length (fldname,length).......... = PRIM_RANGE, 8
Key Length (fldname,length).......... = PREDIR, 2
Key Length (fldname,length).......... = PRIM_NAME, 12
Key Length (fldname,length).......... = SUFFIX, 4
Key Length (fldname,length).......... = POSTDIR, 2
Key Length (fldname,length).......... = SEC_RANGE, 4
Key Length (fldname,length).......... = PO_BOX, 8
Key Length (fldname,length).......... = RR_NUMBER, 4
Key Length (fldname,length).......... = RR_BOX, 8
Key Length (fldname,length).......... = ZIP, 5
Chapter 2: Extended matching blocks and parameters
25
Page 26

Form Break Groups
This block controls how MCD performs break-grouping.
Form Break Groups Name (to 20 chars)
This is an optional parameter that assigns a logical name for this block. The Form
Break Groups Name parameter in the Extended Match Criteria block references
this name. Do not use the name in any other Form Break Groups block.
Combine Small Break Groups (Y/N)
Use this parameter to combine small break groups into a larger break group. A
small break group is a break group that is smaller than the work buffer used to
compare records. (You can set the maximum work buffer size in the MCD jobfile’s Execution block.)
Option Description
Y MCD combines small break groups into a larger break group. The advan-
tage of combining small break groups is that you can break more finely
without missing too many duplicates.
For example, if you broke on last name and some other field(s), the following three records would go into two separate break groups. The third record
would never be compared to the first two:
Peterson
Peterson
Petersno (typographical error)
When you combine small break groups, MCD would place the two smaller
break groups together and would view these three records
as duplicates.
N MCD will not combine small break groups.
To see how many keys will fit in the work buffer, you can run a MCD job, setting
the Execution block’s Find Duplicates parameter to Predict. Produce a Job
Summary to see work buffer and other breaking information.
Max Combined Keys in a Break Group
If you set the Combine Small Break Groups parameter to Yes, then at this
parameter you can specify the maximum number of keys you would like
combined.
You may want to specify a maximum so that the combined break group doesn’t
become too large. If you don’t set a maximum or you set one very high, MCD
will have to make so many comparisons that the time-saving potential of forming
break groups could be lost.
26
Match/Consolidate Extended Matching Reference
Page 27

The formula n2 - n divided by 2 (where n is the number of records to be searched)
predicts the maximum number of comparisons needed.
Option Description
numeric value MCD uses the value you enter here as the maximum number of keys
blank If you leave this parameter blank and you entered Yes at the Combine
Auto Generate Break Fields
This parameter controls how MCD will form break groups. Valid settings for this
parameter are listed below.
Option Description
None If you set this parameter to None, then you must specify the break
Individual MCD designs break fields so that the results will yield one record per
Family MCD designs break fields so that the results will yield one record per
in the combined break group.
Small Break Groups parameter, then MCD assumes that the whole
buffer is available for combining small break groups.
field at the Break Field Definition Name parameter(s) and the Break
Field Definition block(s).
person (first and last name) at an address.
family (last name) at an address.
Firm MCD designs break fields so that the results will yield one record
Firm_Individual MCD designs break fields so that the results will yield one record per
Resident MCD designs break fields so that the results will yield one record per
Break Field Definition Name
This parameter names a Break Field Definition block, which appears in this file
and specifies the characteristics of a break field. You repeat this parameter for
every Break Field Definition block.
If you set the Auto Generate Break Fields parameter to None, then you must enter
the name of a Break Field Definition block at this parameter.
per firm.
person at a firm.
residence.
This parameter does not exist in Views because Views does not have a Break
Field Definition block. Use the Form Break Groups block to define the Field
Name, Break Start, and Break Length.
Chapter 2: Extended matching blocks and parameters
27
Page 28

Break Field Definition
At the Break Field Definition block, you specify characteristics of a break field.
You can repeat this block for every field you want to use as a break field. Note
that this block does not exist in Views, so use the Form Break Groups block to
define the break fields.
Block Name (to 20 chars)
Enter a name for this break field definition. Use a name that will be easily
recognizable to you, such as ZIP. You will enter this block name at the Break
Field Definition parameter in the Form Break Groups block.
Field Name
Enter the name of the field on which you want to break. The following list shows
the available fields.
Pre_Name Phone State Merg_Purg1
First_Name Prim_Range ZIP Merg_Purg2
Mid_Name Predir ZIP4 Merg_Purg3
Last_Name Prim_Name Country Merg_Purg4
Mat_Post Suffix Unp_Addr Merg_Purg5
Oth_Post Postdir Unp_LLine Merg_Purg6
Gender Sec_Range Rec_Type Merg_Purg7
SSN PMB Error_Code Merg_Purg8
Birthdate PO_Box Merg_Purg9
Title RR_Box Merg_Purg0
Firm RR_Number User-defined
FirmLoc City
Break Starting Position (1-fieldlen)
Enter the starting position where you want to begin breaking on a field. For
example, to start breaking at the beginning of the field, enter 1.
Break Length (1-fieldlen,ALL)
Enter the number of characters to break on or enter All. For example, to break on
the 5-digit ZIP Code
1. Enter 1 at the Break Starting Position parameter.
2. Enter 5 or All at the Break Length parameter.
28
Match/Consolidate Extended Matching Reference
Page 29

Auto Field Option
Block Name (to 20 chars)
Field Name
In the Auto Field Option block, you can define matching criteria for one field,
when using automatic extended matching. You specify the field to compare and
how to compare it.
Note that this block is not required. When you perform automatic extended
matching, MCD compares fields according to predetermined factors. You can use
this block to override Match Consolidate’s automatic settings.
Enter a name for this Auto Field Option block. Use a name that will be easily
recognizable to you, such as firm or family.
To use this block, the block name that you enter here must appear at an Auto Field
Option Name parameter in the Auto Match Spec block.
Enter a name of the key field or match field that you want to compare. The
following are valid choices. For detailed information about these fields, refer to
the Quick Reference.
Key fields Match fields
Pre_Name Phone State Merg_Purg1 Name_Line
First_Name Prim_Range ZIP Merg_Purg2 FirmLine
Mid_Name Predir ZIP4 Merg_Purg3 Address
Last_Name Prim_Name Country Merg_Purg4 Last_Line
Mat_Post Suffix Unp_Addr Merg_Purg5
Oth_Post Postdir Unp_LLine Merg_Purg6
Birthdate Sec_Range Rec_Type Merg_Purg7
Gender PMB Error_Code Merg_Purg8
SSN PO_Box Merg_Purg9
Title RR_Box Merg_Purg0
Firm RR_Number User-defined
FirmLoc City
Chapter 2: Extended matching blocks and parameters
29
Page 30

One Field Blank Op (EVAL/IGNORE/AUTO)
Both Fields Blank Op (EVAL/IGNORE/AUTO)
These parameters control how MCD handles field comparisons when one or both
of the fields compared is blank.
For example, the First_Name field is blank in the second record shown below.
Would you want MCD to consider these records duplicates or not duplicates?
What if the First_Name field were blank in both records?
John Doe ____ Doe
204 Main St 204 Main St
La Crosse WI La Crosse WI
54601 54601
Option Description
Eval MCD scores the comparison using the score you enter at the One Field
Blank Score or Both Fields Blank Score parameter.
Ignore The score for this field’s rule will not contribute to the overall weighted
score for the record comparison. In other words, the two records shown
above could still be considered duplicates, despite the blank field.
Auto MCD scores the comparison using the selected match type and match
One Field Blank Score
Both Fields Blank Score
These parameters control how MCD will evaluate field comparisons when the
field is blank in one or both records. For this parameter to take effect, you must
have entered Eval at the corresponding One Field Blank Op or Both Fields Blank
Op parameter.
Option Description
Exact MCD considers the two fields an exact match.
Tight MCD considers the two fields a tight match.
Medium MCD considers the two fields a medium match.
Loose MCD considers the two fields a loose match.
Poor MCD considers the two fields a poor match.
NoMatch MCD considers the two records unique (not matching at all).
Note that an exact match means that two fields are 100 percent alike. The
percentage alike decreases from exact to poor. If you would like to control the
specific percentages, use rule-based extended matching.
threshold to determine how to treat blank fields.
30
Match/Consolidate Extended Matching Reference
Page 31

One Field Blank Extra Cmp
Both Fields Blank Extra Cmp
These parameters control the extra comparison MCD will perform if the field is
blank in one or both records.
For example, if you set the One Field Blank Extra Cmp parameter to Individual
for the Sec_Range field, and MCD encountered a field comparison in which one
of the Sec_Range fields was blank, then MCD would perform an extra
comparison: It would compare name data in addition to the other fields you had
set up to compare. This is useful if you are performing a resident type of
matching, which doesn’t look at name fields.
Option Description
Auto MCD uses the selected match type and match threshold to determine
Off MCD does not perform an extra comparison.
Individual MCD compares name data if one or both of the fields are blank.
Family MCD compares last-name data if one or both of the fields are blank.
Firm_Individual MCD compares name and firm data if one or both of the fields
whether to perform an extra comparison and, if necessary, which
data to compare.
are blank.
Firm MCD compares firm data if one or both of the fields are blank.
Fields Different Extra Cmp
This parameter controls the extra comparison MCD performs if two fields are not
exactly the same. Valid choices are shown below:
Option Description
Auto MCD uses the selected match type and match threshold to determine
Off MCD does not perform an extra comparison.
Individual MCD performs an extra comparison of name data.
Family MCD performs an extra comparison of last-name data.
Firm_Individual MCD performs an extra comparison of name and firm data.
Firm MCD performs an extra comparison of firm data.
No Match Score
At the No Match Score parameter for automatic matching, you set a threshold for
this key field’s comparison. Match/Consolidate uses this when evaluating the
fields to determine if they are not duplicates.
whether to perform an extra comparison and, if so, which data to
compare.
Option Description
Auto MCD uses the selected match type and match threshold to determine what
the no-match threshold is for this field.
Chapter 2: Extended matching blocks and parameters
31
Page 32

Option Description
Exact Unless the two fields match exactly, the two records will be considered not
duplicates.
Tight Unless the two fields meet a tight match criteria, the two records will be
considered not duplicates.
Medium Unless the two fields meet a medium match criteria, the two records will be
considered not duplicates.
Loose Unless the two fields meet a loose match criteria, the two records will be
considered not duplicates.
Poor Unless the two fields meet a poor match criteria, the two records will be
considered not duplicates.
WtOnly MCD will use this field’s score for weighting only. No minimum threshold
applies. MCD will consider other fields compared to determine if two
records are not duplicates.
Off MCD will not compare this field.
Note that an exact match means that two fields are 100 percent alike. The
percentage alike decreases from exact to poor. If you would like to control the
specific percentages, use rule-based extended matching.
Compare Algorithm (FIELD/WORD/AUTO)
The Compare Algorithm parameter controls the comparison algorithm for this
key field’s data.
Option Description
Field If you type Field at this parameter, MCD compares the entire field’s data as
a single string. This algorithm is the most efficient and should be used in
fields that typically have just one word, like the first name field.
Word If you type Word at this parameter, MCD first parses the data into words
and then compares the words. This algorithm is less efficient than the Field
algorithm, but will do a better job comparing data that typically has more
than one word in it, such as firm data.
Auto MCD will use the selected match type, match threshold, and field type to
determine which comparison algorithm to use.
Check for Transposed Letters (Y/N/A)
Transposed characters are two consecutive characters that are switched in a word.
Consider the example
shown. If you select this
option, MCD deducts
only half as much from
the match score for
transposed characters as
is deducted for an
Comparison Finding Percentage
alike
Smith → Simth characters 2 and 3
are transposed
→
Smith
Smeth character 3 is invalid 80%
90%
32
Match/Consolidate Extended Matching Reference
Page 33

invalid character. The transposition check enables MCD to detect more matching
records, but the transposition check takes additional processing time.
Option Description
Yes MCD deducts half as many points for transposed characters as it deducts
No MCD handles transposed characters the same way it handles any non-
Auto MCD uses the selected match type and match threshold to determine
Adjust Score for Initials (Y/N/A)
With this parameter, you can allow matching whole words to initials for the
selected field. For example, the firm name International Health Providers could
match IHP.
If there are other words in the field that are not shortened, they are scored as
whole words. For example, New York Police Department may be shortened to
New York PD and still match.
Option Description
Yes MCD allows matching of whole words to initials.
for other non-matching characters.
matching characters.
whether to adjust the score for transposed characters.
No MCD handles non-matching characters the same as any others. For exam-
Auto MCD uses the selected match type and match threshold to determine
Adjust Score for Substring (Y/N/A)
With this parameter, you can allow matching longer strings of words to shorter
strings for the selected field. For example, long firm names are often shortened to
just the first few words of the name. Mayfield Painting and Sand Blasting might
be shortened to Mayfield Painting.
To qualify as a substring match, the shorter string must exactly match the first
part of the longer string; refer to the table below for examples. Note that if you set
the Compare Algorithm parameter to String, MCD ignores this parameter.
Matching substrings Substrings that do not match
Mayfield
Mayfield Painting
Mayfield Painting and
Mayfield Painting and Sand
ple, the underlined characters below would be scored as unmatching
characters: IHP
whether to adjust the score for matching whole words to initials.
vs.
International Health Providers
Mayfield Sand Blasting
Painting and Sand Blasting
Alternate spellings in any of the words also disqualify
the substrings as a match. For example, “Murphy Painting and Sand Blasting” does not match.
Chapter 2: Extended matching blocks and parameters
33
Page 34

The following are valid options at this parameter:
Option Description
Yes MCD allows for matching long strings to shorter strings.
No MCD handles these unmatching characters the same as any others. For exam-
ple, the underlined characters below would be scored as unmatching characters: Tiny Tots Toys
Auto MCD uses the selected match type and match threshold to determine whether
to adjust the score for matching long strings to shorter strings.
Adjust Score for Abbreviation (Y/N/A)
With this parameter, you control matching whole words to abbreviations for the
selected field. For example, long firm names are often abbreviated by removing
letters. International Health Providers might be abbreviated to
Intl Health Providers.
vs.
Tiny Tots ____
Here, abbreviation means that the
first letter of the shorter word
matches the first letter of the longer
word. As shown in the examples at
right, all remaining letters of the
shorter word appear in the longer word in the same order as in the shorter word.
Note that if you set the Compare Algorithm parameter to String, MCD ignores
this parameter.
The following options are valid at this parameter:
Option Description
Yes MCD allows for matching words to abbreviations.
No MCD handles these unmatching characters the same as any other unmatching
characters. For example, the underlined characters below would be scored as
unmatching characters:
International
Auto MCD uses the selected match type and match threshold to determine whether
to adjust the score for words to abbreviations.
Qualify Record with Numeric Match (Y/N/A)
Health Providers
Use this parameter if you want MCD to score non-exact numeric data as zero
percent alike for the selected field. This ensures that fields with dissimilar
numeric data will not be considered duplicates. Note that if you set this parameter
to Yes, you must also set the Compare Algorithm parameter to Word.
Full word Possible abbreviations
Business Bus, Bsnss, Bss
Database Dat, Db, Dse
vs.
Intl Health Providers
34
Option Description
Yes Numeric data must match exactly, regardless of other match criteria.
No MCD will not handle numeric data any differently than it handles
alphabetic data.
Auto MCD uses the selected match type and match threshold to determine
whether to require exact matching on numeric data.
Match/Consolidate Extended Matching Reference
Page 35

If you set this parameter to Yes, use the Numeric Words Match Type parameter to
determine the way that the application matches on numeric words.
Numeric Words Match Type
This option affects how numeric data is matched when the Qualify Record with
Numeric Match parameter is set to a value other than No. If this parameter is set
to No, then this option will be ignored.
This option allows you to configure the type of matching to be used with numeric
data. For example, you might require exact matching on a telephone number,
SSN, street ranges, and so on.
This parameter allows you to choose from the following value options to match
on non-address data.
Option Description
POSITION_INDEPENDENT Set the value to this option if the position of the match-
ing numeric data is not important for the match to be
assessed. For example: 100 Main St Apt 103 will match
Apt 103 100 Main St.
POSITION_DEPENDENT Set the value to this option if the position of the match-
ing numeric data is important (the numeric data in both
the records needs to be equal and in the exact same
sequence).
For example: 608-782-5000 will match 608-782-5000,
but it will not match 782-608-5000.
DECIMAL Set the value to this option if the position of the match-
ing numeric data is not important for the match to be
assessed; however, the decimal separators (comma or
period) do impact matching.
For example: Accu 1.4L 29Bar will match Accu 29Bar
1.4L. It will not match Accu 1,4L 29Bar because there
is a comma between the 1 and the 4.
DECIMAL_IGNORE_
SEPARATOR
Set the value to this option if the position of the matching numeric data is not important for the match to be
assessed, and the decimal separators (comma or period)
do not impact matching.
For example: Accu 1.4L 29Bar will match Accu 29Bar
1.4L. It will also match Accu 1,4L 29Bar even though
there is a comma between the 1 and the 4.
Chapter 2: Extended matching blocks and parameters
35
Page 36

Auto Match Spec
At the Auto Match Spec block, you define the criteria MCD will use to find
matching records, based on criteria set up in this block and in the Auto Field
Option block(s).
This block is required if all of the following are true:
You enabled Find Duplicates in your MCD job’s Execution block.
You set Matching Method to Ext in your MCD job’s Execution block.
You’re performing automatic extended matching, as opposed to rule-based
extended matching. (If you use rule-based matching, you must use the Rule
Match Spec and Rule Definition blocks instead of the Auto Match Spec
block.)
Match Spec Name (to 20 chars)
Type a name for this match specification. Use a name that will be easily
recognizable to you because MCD uses this name in the Match
Results report.
Match Type
At this parameter, you choose the type of matching that you want to perform.
Option Description Fields compared
Family The purpose of the family match type is to determine whether two peo-
ple should be considered members of the same family, as reflected by
their record data. Match/Consolidate compares last name and address
data. A match means that the two records reflect members of the same
family.
The result of your match/consolidate is one record per family.
Individual The purpose of the individual match type is to determine whether two
records are for the same person, as reflected by their record data. MCD
compares the first name, last name, and address data. A match means
that the two records reflect the same person.
The result of your match/consolidate is one record per individual.
Resident The purpose of the resident match type is to determine whether two
records should be considered members of the same household, as
reflected by their record data. MCD compares the address data. A
match means that the two records are members of the same household.
Contrast this match type with the family match type, which also com-
merg_purg1-0
all address fields
last_name
For extra comparison:
other name fields
firm fields
merg_purg1-0
all address fields
all name fields
For extra comparison:
firm fields
merg_purg1-0
all address fields
For extra comparison:
name fields
firm fields
pares last name data.
The result of your match/consolidate is one record per residence.
* All fields to be compared must be defined in the DEF file and in the Parsing and Key Options block.
Firm The purpose of the firm match type is to determine whether two
records reflect the same firm. This match type involves comparisons of
firm and address data. A match means that the two records represent
the same firm.
The result of your match/consolidate is one record per firm.
merg_purg1-0
all address fields
all firm fields
For extra comparison:
name fields
*
36
Match/Consolidate Extended Matching Reference
Page 37

Option Description Fields compared
*
Firm-Individual The purpose of the firm-individual match type is to determine whether
two records are for the same person at the same firm, as reflected by
their record data. With this match type, MCD compares the first name,
last name, firm name, and address data. A match means that the two
records reflect the same person at the same firm.
The result of your match/consolidate is one record per individual
per firm.
* All fields to be compared must be defined in the DEF file and in the Parsing and Key Options block.
Once you choose your Match Type option, and depending on the fields being
compared, consider the following points:
merg_purg fields can only drive a non-match decision
blank address or name fields may drive a non-match decision
For example, assume that two records have the same address, but the last name
field is empty. If you choose the Family Match Type option, the records will not
match because the record is missing last name data; MCD considers these to be
unique records.
Match Threshold
At this parameter, you control how tight matching must be. An exact match
means that the record data compared are 100 percent alike. The percentage alike
decreases from exact to loose.
merg_purg1-0
all address fields
all firm fields
all name fields
Option Description
Exact Record data compared must match exactly for MCD to consider the records
duplicates.
Tight Record data compared must meet MCD’s tight match criteria (at least 90
percent alike) for two records to be considered duplicates.
Medium Record data compared must meet MCD’s medium match criteria (at least
84 percent alike) for two records to be considered duplicates.
Loose Record data compared must meet MCD’s loose match criteria (at least 78
percent alike) for two records to be considered duplicates.
# of Names That Must Match (ONE/ALL)
This parameter controls how MCD performs matching for keys with more than
one name. MCD compares each name in the respective keys.
Option Description
One If you set this parameter to One, then a match on any one of the names in
the keys results in a match.
All If you set this parameter to All, then all the names of multi-name records
must match to have a match.
Chapter 2: Extended matching blocks and parameters
37
Page 38

For example, if Jack/Jill is compared with Jock/Jill, setting this parameter to One
will generate a score of 100; setting this parameter to All would generate a score
of 75 (Jack and Jock are 75 percent alike).
Compare First to Middle Name
You can control whether MCD compares a first
name to a middle name.
For example, the two records shown at right could
be considered duplicate records if this parameter
is enabled.
Option Description
Yes MCD compares first names to middle names.
No MCD will not compare first names to middle names.
Auto MCD uses the selected match type and match threshold to determine
First Middle Last
John Smith
R. John Smith
Note that MCD will not make this comparison if either the first or middle
name is only an initial. For example, MCD would not compare “John T
Smith” with “Tom Smith.”
whether to compare first names to middle names.
Match on Hyphenated Last Name (Y/N/A)
This parameter controls whether MCD will match on hyphenated
last names.
Option Description
Yes MCD will match on hyphenated last names. For example,
match
Jones-Smith
No MCD will not match on hyphenated last names.
Auto MCD will use the selected match type and match threshold to determine
whether to match on hyphenated last names.
Turn on Maiden Name Adjustment (Y/N/A)
This parameter controls whether MCD will allow for differences in last names in
names for which the assigned gender is strong or weak female.
Option Description
Yes If you set this parameter to Yes, then the last name comparison of two
female names will not cause the comparison to fail. Any two last names
could match for female records. For example, Angie Smith could match
Angie Jones.
No If you set this parameter to No, then the last name comparison of two
female names could cause the comparison to fail.
Jones
would
.
38
Auto MCD will use the selected match type and match threshold to determine
whether to adjust the score for maiden names.
Match/Consolidate Extended Matching Reference
Page 39

Ambig Name Data
Ambig Firm Data
Ambig Address Data
Ambig Lastline Data
These parameters control how MCD will treat ambiguous data in name, firm,
address, and last-line fields. Ambiguous data means that, for two fields compared,
one or both of them are bla nk, o r that t he tw o fields have no da ta in co mmon .
Name data is ambiguous
because it’s blank
in one of the records.
Lastline data is
ambiguous because some
fields are blank.
Cindy Smith
Firstlogic Jenkens Auto
100 Harborview Plz PO Box 2523
La Crosse WI 54601-
4071
Option Description
No_Match When MCD encounters ambiguity, it will consider the two fields unique
(not a match).
Poor When MCD encounters ambiguity, it will consider the two fields a match if
they meet a poor match criteria.
Firm data is ambiguous
54601
because there is no
ambiguous because there
is no similarity: one is a
street address, the other
similarity.
Address data is
a post office box.
Loose When MCD encounters ambiguity, it will consider the two fields a match if
they meet a loose match criteria.
Auto MCD will use the selected match type and match threshold to determine
how to handle the ambiguity.
Ignore Firm if Names Match (Y/N/A)
This parameter controls whether MCD should ignore firm data if name
data matches.
Option Description
Yes MCD ignores firm data if the name data matches sufficiently. For example,
the following records could be considered a match:
Jane Doe Jane Doe
Widget Corp. Nuts-n-Bolts Inc.
No MCD treats firm data normally, in accordance with your settings.
Auto MCD will use the selected match type and match threshold to determine
whether to ignore firm data if the name data matches.
Chapter 2: Extended matching blocks and parameters
39
Page 40

Extra Compare If Firm Blank
Extra Compare If Srange Blank
Extra Compare If Addr Blank
These parameters control whether MCD should perform an extra comparison if
the Firm, Prim_Range, or Address fields are blank.
Option Description
Individual MCD performs an extra comparison of name data.
Family MCD performs an extra comparison of last-name data.
Firm_Individual MCD performs an extra comparison of name and firm data.
Firm MCD performs an extra comparison of firm data.
Off MCD does not perform an extra comparison.
Auto MCD will use the selected match type and match threshold to deter-
Auto Field Option Name
This parameter names an Auto Field Option block, which must also appear in the
extended matching file. Note that this parameter is repeatable. For every Auto
Field Option block you want to use, you must name it at an Auto Field Option
Name parameter.
mine whether to perform an extra comparison and, if so, which data
to compare.
40
BEGIN Auto Match Spec =========================================
Match Spec Name (to 20 chars)........ = FIRM MATCHING
Match Type (see NOTE)................ = FIRM
Match Threshold (see NOTE)........... = TIGHT
# of Names That Must Match (ONE/ALL). = ONE
Compare First to Middle Name (Y/N/A). = N
Match on Hyphenated Last Name (Y/N/A) = N
Turn on Maiden Name Adjustment (Y/N/A)= N
Ambig Name Data (see NOTE)........... = AUTO
Ambig Firm Data (see NOTE)........... = AUTO
Ignore Firm if Names Match (Y/N/A)... = N
Extra Compare If Firm Blank (see NOTE)= FIRM
Extra Compare If Srange Blank (NOTE). = FIRM
Extra Compare If Addr Blank (see NOTE)= FIRM
Ambig Address Data (see NOTE)........ = AUTO
Ambig Lastline Data (see NOTE)....... = AUTO
Auto Field Option Name............... = FIRM
Auto Field Option Name............... = PREDIR
BEGIN Auto Field Option =======================================
Block Name (to chars)................ = FIRM
…
BEGIN Auto Field Option =======================================
Block Name (to chars)................ = PREDIR
…
Match/Consolidate Extended Matching Reference
Page 41

Rule Definition
Block Name (to 20 chars)
Field Name
In the Rule Definition block, you define one rule for MCD to use when
comparing records. The rule specifies a field to compare and how it is to
be compared.
You can define up to 64 rules per extended matching session. Each rule that you
define in a Rule Definition block must be named in a Rule Definition Name
parameter in the Rule Match Spec block.
Enter a name for this Rule Definition block. Use a name that will be easily
recognizable to you. To use this block for matching, the block name that you enter
here must appear at a Rule Definition Name parameter in the Rule Match Spec
block.
Enter the name of the key field or match field that you want to compare in this
rule. The following are valid choices:
Key fields Match fields
Pre_Name Phone State Merg_Purg1 Name_Line
First_Name Prim_Range ZIP Merg_Purg2 FirmLine
Mid_Name Predir ZIP4 Merg_Purg3 Address
Last_Name Prim_Name Country Merg_Purg4 Last_Line
Mat_Post Suffix Unp_Addr Merg_Purg5 User-defined
Oth_Post Postdir Unp_LLine Merg_Purg6
Birthdate Sec_Range Rec_Type Merg_Purg7
Gender PMB Error_Code Merg_Purg8
SSN PO_Box Merg_Purg9
Title RR_Box Merg_Purg0
Firm RR_Number
FirmLoc City
Chapter 2: Extended matching blocks and parameters
41
Page 42

One Field Blank Op (EVAL/IGNORE)
Both Fields Blank Op (EVAL/IGNORE)
These parameters control how MCD will treat field comparisons when one or
both of the fields compared are blank.
For example, the First_Name field is blank in second record shown below. Would
you want MCD to consider these records duplicates or not duplicates? What if the
First_Name field were blank in both records?
John Doe ____ Doe
204 Main St 204 Main St
La Crosse WI La Crosse WI
54601 54601
Option Description
Eval If you enter Eval at this parameter, MCD will score the comparison using
the score you enter at the One Field Blank Score or Both Fields Blank
Score parameter.
Ignore If you enter Ignore at this parameter, the score for this field rule will not
contribute to the overall weighted score for the record comparison. In
other words, the two records shown above could still be considered duplicates, despite the blank field.
One Field Blank Score (0-100)
Both Fields Blank Score (0-100)
These parameters control how MCD will score field comparisons when the field
is blank in one or both records. You can enter any value from 0 to 100.
For these parameters to take effect, you must have entered Eval at the
corresponding One Field Blank Op or Both Fields Blank Op parameter.
To help you decide how to fill out these parameters, determine if you want MCD
to consider a blank field 0 percent similar to a filled field or another blank field,
100 percent similar, or somewhere in between.
Your answer will probably depend on what field you’re comparing. Giving a
blank field a high score might be appropriate if you’re matching on a first or
middle name or a company name, for example.
The examples on the next page may help you understand how your settings of the
blank matching options can affect the overall scoring of records.
One Field Blank Op
parameter for First_Name
field set to Ignore
Fields compared Record A Record B % alike Contribution* Score (per field)
ZIP 54601 54601 100 20 ( 22) 22
Note that when you set the blank options to Ignore, MCD recalculates the
contributions for the other fields.
Address 100 Water St 100 Water St 100 40 (
Last_Name Hamilton Hammilton 94 30 (
42
Match/Consolidate Extended Matching Reference
44) 44
33) 31
Page 43

Fields compared Record A Record B % alike Contribution* Score (per field)
First_Name Mary — 10 ( 0) —
* See Contribution to Weighted Score in the Rule Definition block
One Field Blank Op
parameter for First_Name
field set to Eval; One Field
Blank Score parameter
set
to 0
Fields compared Record A Record B % alike Contribution* Score (per field)
Weighted score:
ZIP 54601 54601 100 20 20
Address 100 Water St 100 Water St 100 40 40
Last_Name Hamilton Hammilton 94 30 28
First_Name Mary 0 10 0
* See Contribution to Weighted Score in the Rule Definition block
One Field Blank Op
parameter for First_Name
field set to Eval; One Field
Blank Score parameter set
to 100
Weighted score:
97
88
Fields compared Record A Record B % alike Contribution* Score (per field)
ZIP 54601 54601 100 20 20
Address 100 Water St 100 Water St 100 40 40
Last_Name Hamilton Hammilton 94 30 28
First_Name Mary 100 10 10
* See Contribution to Weighted Score in the Rule Definition block
Weighted score:
Match Score (0-101)
No Match Score (-1-100)
To determine if one record matches
another record, MCD compares selected
fields in those records and calculates what
percentage alike they are. A percentage of
0 means that MCD found no similarity
between the two fields. A percentage of
100 means that MCD considers the two
fields to be an exact match.
Comparison Percentage alike
Smith → Smith 100 percent
Smith
→
Smitt 80 percent
Smith
→
Smythe 72 percent
Smith
→
Jones 20 percent
98
Chapter 2: Extended matching blocks and parameters
43
Page 44

By setting the Match Score and No Match Score parameters, you’re determining
how similar fields must be for MCD to call the records duplicates. For some
fields, perhaps 80 percent is good enough for the records to be considered
duplicates. For other fields, maybe you’ll require a 100 percent match.
Match Score Match Score determines the
lowest percentage that will
cause MCD to consider two
records a match.
You can set the Match Score
to 101 if you want to turn off
this parameter. A value of 101 here means that a match on this field will never
cause a whole-record match. Instead MCD will consider the other fields
compared.
No Match Score No Match Score determines the highest percentage that will cause MCD to
consider two records unique (or not duplicates).
You can set the No Match Score to -1 if you want to turn off this parameter. A
value of -1 here means that if the two fields compared do not match, MCD will
consider the other fields compared to determine if the records are duplicates or
not.
Fields compared Record A Record B Percentage alike
ZIP 54601 54601 100 percent
Address 100 Water St 100 Water St 100 percent
Last_Name Hamilton Hammilton
First_Name Mary Marilyn
Usually, you wouldn’t want to judge records as duplicates based on just one field.
For example, records that match on last name are not necessarily duplicates.
That’s why, in most cases, it’s a good idea to force MCD to compare more than
one field.
Prevent over-matching In this example, the last names
match 100 percent, so MCD
doesn’t even compare the street
addresses or the last names. We
call this over-matching because
MCD judges these records to be duplicates, and they obviously are not.
With the bad setup shown above, these two records
would be judged as duplicates because their last
names match 100 percent, even though other fields
in the records don’t match.
Bad
94
percent
72
percent
Field Name......... = Last_Name
…
Match Score (0-101) = 100
Jim Brown Sue Brown
100 Main St 409 Water St
La Crosse WI La Crosse WI
54601 54601
44
To prevent over-matching, set
the Match Score to 101. Then
MCD will never judge records to
be duplicates based on just that
Match/Consolidate Extended Matching Reference
Good
Field Name......... = Last_Name
…
Match Score (0-101) = 101
Page 45

field. This ensures that MCD will compare other fields before determining if
records are duplicates.
Prevent under-matching Under-matching means that
MCD judges a pair of records
to be unique (not duplicates)
when, to your eye, they are
duplicates.
With the No Match Score parameter set
to 99, these two records would be
judged as unique because MCD
considers the two phone numbers to be
only 50 percent alike.
To prevent under-matching,
set the No Match Score
parameter to -1. Then MCD
has to consider the similarity
of other fields compared and
cannot judge the whole record as unique based on just that field.
To provide a medium level match on
Last_Name, use the setting shown at right
to ensure that MCD compares other fields
before determining if records are
duplicates.
Bad
Good
Field Name............. = Phone
…
No Match Score (-1-100) = 99
Jim Brown Jim Brown
100 Main St 100 Main St
La Crosse WI 54601 La Crosse WI 54601
608-555-1212 608-507-4985
Field Name............. = Phone
…
No Match Score (-1-100) = -1
Field Name......... = Last_Name
…
Match Score (0-101) = 101
No Match Score (-1–100) = 75
Contribution to Weighted Score (0-100)
To understand the Contribution to Weighted Score parameter, let’s look at the
steps MCD takes when comparing fields and records:
1. MCD compares the first field, using the first rule listed at the Rule Definition
Name parameter.
2. If the first rule does not cause MCD to judge the record pair as duplicates or
unique, then MCD looks at the next field (using the next rule listed at the
Rule Definition Name parameter), and so on.
3. If no single rule causes MCD to judge the record pair as duplicates or unique,
then MCD calculates an overall weighted score, using the percentages alike
for each field compared and the Contribution to Weighted Score values that
you enter at this parameter.
By setting the contribution amount for each field compared, you decide how
important each field is in determining if records match. Typically, the street
address is very important, while the first name is not as important. The
importance of other fields may be somewhere in between.
Chapter 2: Extended matching blocks and parameters
45
Page 46

If you set the contribution amount for the Last_Name field to 30 percent, and two
names are 80 percent alike, then the Last_Name field comparison contributes 24
(30 percent of 80) to the overall weighted score.
Note that if the sum of all contributions is greater than or less than 100, MCD
readjusts the percentages so that they equal 100.
For example, assume that you have a job that contains two rules, and you set
the contribution score for each rule to 25. On a scale of 100, MCD internally
adjusts each rule to a contribution score of 50.
Fields compared Record A Record B % alike Contribution Score (per field)
ZIP 54601 54601 100 20 20
Address 100 Water St 100 Water St 100 40 40
Last_Name Smith Smitt 80 30 24
First_Name Mary Marlene 54 10 5
Weighted score:
Use in Weighted Score if .GT. (-1-100)
Here, you can set a minimum score needed to qualify this rule to contribute to the
overall weighted score. For example, you could decide that if the First_Name
fields are not at least 60 percent alike, then you don’t want the First_Name score
to contribute to the overall weighted score.
If a field fails to qualify, based on your entry at this parameter, then MCD adjusts
that field’s contribution amount to 0 (zero), and adjusts the other fields’
contributions proportionally. Note that GT refers to greater than.
Field Name........................... = First_Name
…
Use in Weighted Score if .GT. (-1-100) = 60
Fields compared Record A Record B % alike Contribution* Score (per field)
ZIP 54601 54601 100
20 ( 22)
89
22
Address 100 Water St 100 Water St 100
Last_Name Smith Smitt 80
First_Name Mary Marlene 54
In this example, the first names were only 54 percent alike, less than the required
60 percent (according to the setting in the Use In Weighted Score If .GE.
parameter). So, MCD adjusted the contribution to 0 percent; the first-name
comparison did not contribute to the overall weighted score.
46
Match/Consolidate Extended Matching Reference
40 ( 44)
30 ( 33)
10 ( 0) —
Weighted score:
44
26
92
Page 47

Zero Weighted Score if .LE. (0-100)
You can set a maximum score that will cause this field to contribute 0 (zero) to
the overall weighted score. For example, you could decide that if the First_Name
fields are 59 percent alike or less, then you want the First_Name score to
contribute 0 (zero) points to the overall weighted score. Note that .LE. stands for
less than or equal to.
Field Name........................... = First_Name
…
Zero Weighted Score if .LE. (O-100).. = 59
Fields compared Record A Record B % alike Contribution* Score (per field)
ZIP 54601 54601 100 20 20
Address 100 Water St 100 Water St 100 40 40
Last_Name Smith Smitt 80 30 24
First_Name Mary Marlene 54 10 0
In this example, the first names are 54 percent alike, which falls under the 59
setting at Zero Weighted Score if .LE. This means that the first name will
contribute 0 points to the overall weighted score.
Compare Algorithm (FIELD/WORD)
The Compare Algorithm parameter controls the comparison algorithm for
this field’s data.
Option Description
Field If you enter Field at this parameter, MCD compares the entire field’s data as
Word If you enter Word at this parameter, MCD first parses the data into words
Weighted score:
84
a single string. This algorithm is the most efficient and should be used in
fields that typically have just one word, like the first name field.
and then compares the words. This algorithm is less efficient than the Field
algorithm, but will do a better job comparing data that typically has more
than one word in it, such as firm data.
Chapter 2: Extended matching blocks and parameters
47
Page 48

Check for Transposed Letters (Y/N/A)
As shown at right,
transposed characters are
two consecutive
characters that are
switched within a word.
If you select this option,
MCD deducts only half as much from the match score for transposed characters
as is deducted for an invalid character.
The transposition check enables MCD to detect more matching records, but the
transposition check takes additional processing time.
Option Description
Yes MCD will deduct half as many points for transposed characters as it
deducts for other non-matching characters.
No MCD will treat transposed characters the same way it treats any non-match-
ing characters.
Initials Adjustment Score (0-100)
With this parameter, you can allow matching whole words to initials. For
example, the firm name International Health Providers could match IHP.
Comparison Finding Percentage
alike
Smith → Simth characters 2 and 3
are transposed
90%
You can set this parameter to 0 (zero) for this field if you never want whole words
to match initials. Or you can set it to 100 if you want whole words and
corresponding initials to be considered a perfect match. You can set this
parameter to any number from 0 to 100, depending on your needs.
If there are other words in the field that are not shortened, they are scored the
usual way. For example, New York Police Department may be shortened to New
York P D and still match.
Substring Adjustment Score (0-100)
With this parameter, you can allow matching longer strings of words to shorter
strings. For example, long firm names are often shortened to just the first few
words of the name. Mayfield Painting and Sand Blasting might be shortened to
Mayfield Painting.
You can set this parameter to 0 (zero) for a particular field if you never want
substrings to match longer strings. Or you can set it to 100 if you want substrings
and longer strings to be considered a perfect match. You can set this parameter to
any number from 0 to 100, depending on your needs.
To qualify as a substring match, the shorter string must exactly match the first
part of the longer string. See the table below.
Note that if you set the Compare Algorithm parameter to String, MCD ignores
this parameter.
48
Match/Consolidate Extended Matching Reference
Page 49

Consider the following example for a fictitious company: Mayfield Painting and
Sandblasting.
Matching substrings Substrings that do not match
Mayfield
Mayfield Painting
Mayfield Painting and
Mayfield Painting and Sand
Abbreviation Adjustment Score (0-100)
With this parameter, you control matching whole words to abbreviations. For
example, long firm names are often abbreviated by removing letters. Inter-
national Health Providers might be abbreviated to Intl Health Providers. Note
that if you set the Compare Algorithm parameter to String, MCD ignores this
parameter.
You can set this option to 0 (zero)
for a particular field if you never
want abbreviations to match longer
words. Or you can set it to 100 if
you want abbreviations and longer
words to be considered a perfect
match. You can set this parameter to any number from 0 to 100, depending on
your needs.
As shown in the example above, abbreviation means that the first letter of the
shorter word matches the first letter of the longer word. And all remaining letters
of the shorter word appear in the longer word in the same order as in the shorter
word.
Mayfield Sand Blasting
Painting and Sand Blasting
Alternate spellings in any of the words also disqualify
the substrings as a match. For example, “Murphy Painting and Sand Blasting” does not match.
Full word Possible abbreviations
Business Bus, Bsnss, Bss
Database Dat, Db, Dse
Qualify Record with Numeric Match (Y/N)
Use this parameter if you want MCD to score non-exact numeric data as zero
percent alike for the selected field. This ensures that fields with dissimilar
numeric data will not be considered duplicates. Note that if you set this parameter
to Yes, you must also set the Compare Algorithm parameter to Word.
If you set this parameter to Yes, use the Numeric Words Match Type parameter to
determine the way that the application matches on numeric words.
Numeric Words Match Type
This option affects how numeric data is matched when the Qualify Record with
Numeric Match parameter is set to a value other than No. If this parameter is set
to No, then this option will be ignored.
This option allows you to configure the type of matching to be used with numeric
data. For example, you might require exact matching on a telephone number,
SSN, street ranges, and so on.
Chapter 2: Extended matching blocks and parameters
49
Page 50

This parameter allows you to choose from the following value options to match
on non-address data.
Option Description
POSITION_INDEPENDENT Set the value to this option if the position of the match-
ing numeric data is not important for the match to be
assessed. For example: 100 Main St Apt 103 will match
Apt 103 100 Main St.
POSITION_DEPENDENT Set the value to this option if the position of the match-
ing numeric data is important (the numeric data in both
the records needs to be equal and in the exact same
sequence).
For example: 608-782-5000 will match 608-782-5000,
but it will not match 782-608-5000.
DECIMAL Set the value to this option if the position of the match-
ing numeric data is not important for the match to be
assessed; however, the decimal separators (comma or
period) do impact matching.
For example: Accu 1.4L 29Bar will match Accu 29Bar
1.4L. It will not match Accu 1,4L 29Bar because there
is a comma between the 1 and the 4.
DECIMAL_IGNORE_
SEPARATOR
Set the value to this option if the position of the matching numeric data is not important for the match to be
assessed, and the decimal separators (comma or period)
do not impact matching.
For example: Accu 1.4L 29Bar will match Accu 29Bar
1.4L. It will also match Accu 1,4L 29Bar even though
there is a comma between the 1 and the 4.
50
Match/Consolidate Extended Matching Reference
Page 51

Rule Match Spec
At the Rule Match Spec block, you define the criteria MCD will use to find
matching records, based on rules you define in the Rule Definition block(s). This
block is required if:
You enabled Find Duplicates in your MCD job’s Execution block, and …
You set Matching Method to Ext or Adv in your MCD job’s Execution block,
and …
You’re performing rule-based extended matching, as opposed to automatic
extended matching. If you use automatic matching, you must use the Auto
Match Spec block instead of the Rule Match Spec and Rule Definition
blocks.
Match Spec Name (to 20 chars)
Enter a name for this match specification. Use a name that will be easily
recognizable to you. MCD uses this name in the Match Results report.
Weighted Match Score (0-101)
Weighted No-Match Score (-1-100)
The weighted score takes into consideration the percentage alike of all fields
compared. The table below shows the resulting weighted score when Record A
and Record B are compared.
Fields compared Record A Record B % alike Contribution* Score (per field)
ZIP 54601 54601 100 20 20
Address 100 Water St 100 Water St 100 40 40
Last_Name Hamilton Hammilton 94 30 28
First_Name Mary Marilyn 72 10 7
* See Contribution to Weighted Score in the Rule Definition block
Weighted score:
95
Weighted Match Score determines the lowest weighted score that will cause
MCD to consider two records matches. Weighted No-Match Score determines the
highest weighted score that will cause MCD to consider two records unique (or
not duplicates).
Using the example in
the table above, the
comparison of Record
A and Record B
receives a weighted
score of 95. With
Weighted Match
Score set to 85, and
Weighted No-Match Score set to 80, MCD would consider Record A and Record
B to be a match.
Chapter 2: Extended matching blocks and parameters
51
Page 52

You can set the Weighted Match Score to 101 if you want to turn off this
parameter. A value of 101 here means that this session will never determine a
match based solely on the weighted match score.
You can set the Weighted No-Match Score to -1 if you want to turn off this
parameter. A value of -1 here means that this session will never determine a nonmatch based solely on the weighted match score.
# of Names That Must Match (ONE/ALL)
This parameter controls how MCD performs matching for keys with more than
o n e n a m e . M a t c h / C o n s o l i d a t e c o m p a r e s e a c h n a m e in t h e r e s p e c t i v e k e y s .
Option Description
One If you set this parameter to One, then a match on any one of the names in
the keys results in a match.
All If you set this parameter to All, then all the names of multi-name records
must match to have a match.
Compare First to Middle Name
You can control whether a first name is compared
to a middle name.
For example, the two records shown at right could
be considered duplicate records if this parameter
is enabled.
First Middle Last
John Smith
R. John Smith
Option Description
Yes MCD will compare first names to middle names.
Note that MCD will not make this comparison if either the first or middle
name is only an initial. For example, MCD would not compare “John T
Smith” with “Tom Smith.”
No MCD will not compare first names to middle names.
Match on Hyphenated Last Name (Y/N)
This parameter controls whether MCD will match on hyphenated
last names.
Option Description
Yes If you set this parameter to Yes, then MCD will match on hyphenated last
names. For example,
No If you set this parameter to No, then MCD will not match on hyphenated
last names.
Jones
would match
Jones-Smith
.
52
Match/Consolidate Extended Matching Reference
Page 53

Turn on Maiden Name Adjustment (Y/N)
This parameter controls whether MCD will allow for differences in last names in
names for which the assigned gender is strong or weak female.
Option Description
Yes If you set this parameter to Yes, then the last name comparison of two
female names will not cause the comparison to fail.
No If you set this parameter to No, then the last name comparison of two
female names could cause the comparison to fail.
Rule Definition Name
The Rule Definition Name parameter names a Rule Definition block, which must
appear later in the extended matching job file. Match/Consolidate follows the
rules in the order that they appear in this block.
This parameter is repeatable: For every Rule Definition block you want to use,
you must name it at a Rule Definition Name parameter.
BEGIN Rule Match Spec =========================================
Match Spec Name (to 20 chars)........ =
Weighted Match Score (0-101)......... =
Weighted No-Match Score (-1-100)..... =
# of Names That Must Match (ONE/ALL). =
Match on Hyphenated Last Name (Y/N).. =
Turn on Maiden Name Adjustment (Y/N). =
Rule Definition Name............... = FIRM
Rule Definition Name............... = PREDIR
End
BEGIN Rule Definition =======================================
Block Name (to 20 chars)................ = FIRM
…
BEGIN Rule Definition =======================================
Block Name (to 20 chars)................ = PREDIR
…
Chapter 2: Extended matching blocks and parameters
53
Page 54

Prioritize Matches
The Prioritize Matches block controls the order in which records appear in a dupe
group. This is a required block when MCD performs extended matching and if
you set Find Duplicates in your job’s Execution block.
Prioritize Matches Name (to 20 chars)
This is an optional parameter that assigns a logical name to the block. The
Prioritize Matches Name parameter in the Extended Matching Criteria block
references this name. Do not use this name in any other Prioritize Matches block.
Type (LIST/FLD/LIST_FLD/FLD_LIST)
This parameter controls the type of prioritization to perform.
Option Description
List The list or blank priority will determine the priority of records within a
dupe group.
Fld MCD will prioritize records within a dupe group according to the Priority
field set up in your DEF file.
List_Fld MCD will prioritize records within a dupe group using list and blank prior-
ity first, and then field priority.
Fld_List MCD will prioritize records within a dupe group using field priority first,
and then list and blank priority.
Priority Field Order (DESCEND/ASCEND)
This parameter controls the order in which the priority field is sorted.
Option Description
Descend The sort sequence is z–a, Z–A, 9–0. With a date field, priority is given to
the later date.
Ascend The sort sequence is a–z, A–Z, 0–9. With a date field, priority is given to
the earlier date.
Break Priority Ties Randomly (Y/N)
This parameter controls the final action MCD takes in attempting to break ties
in priority.
Option Description
Y MCD’s final action in sorting dupe groups is to use random sortation. This
means that if you run the same job twice, you may get a different set of surviving records each time.
54
N MCD breaks ties in favor of the input file and record number.
Match/Consolidate Extended Matching Reference
Page 55

Blank Priority (field,priority)
This is an optional, repeatable parameter where you can enter a key field name
and priority value (from -999 to 999) for fields found with no data.
Whenever you enable blank matching for a key field (refer to “Rule Definition”
on page 41 for a list of key fields), we recommend that you also set a value for its
blank priority. The value you set is added to the List Match Priority value (refer to
your MCD Job-File Reference) for the record that contains the blank field. The
lowest numeric score is the highest priority. Generally this means that the records
with more complete data will be more likely to be output or survive a purge.
For example, let’s assume the list priority value for the following records is equal,
and a blank priority value of 5 is set for the Mid_Name field. The record that
lacks middle name data would end up with a larger number, hence lower overall
priority.
first middle last range Street suffix ZIP list priority + blank priority = overall
John Q Smith 100 Main St 54601 10 + 0 = 10
John Smith 100 Main St 54601 10 + 5 = 15
Chapter 2: Extended matching blocks and parameters
55
Page 56

Extended Match Criteria
This block, which is used only when performing extended matching, logically
gathers into a unit the extended matching blocks that define key layout, breaking,
matching, and prioritizing. This block is the extended matching equivalent of the
standard matching Match Criteria block and is used in the Match Set block.
Match Criteria Name (to 20 chars)
This is a required parameter that assigns a logical name for the block. The Criteria
argument of the Match parameter of the Match Set block references this name.
Do not use the name in any other Extended Match Criteria blocks or Match
Criteria blocks.
Parsing and Key Options
This is a required parameter that specifies a name of a Parsing and Key Options
block to use for such things as key layout and parsing choices.
Form Break Groups
This is an optional parameter that specifies a name of a Form Break Groups block
to use for breaking. If you leave this parameter blank, no breaking occurs.
Match Spec
Prioritize Matches
This is a required parameter that specifies either a Rule Match Spec or an Auto
Match Spec to be used for matching. For example, for Extended Rule Matching,
the Match Spec name parameter in the Extended Match Criteria block must
correspond with the Match Spec Name parameter in the Rule Match Spec block.
For Extended Auto Matching, the Match Spec name parameter in the Extended
Match Criteria block must correspond with the Match Spec Name parameter in
the Auto Match Spec block.
This is an optional parameter that specifies a name of a Prioritize Matches block
in order to prioritize the matches. If you leave this parameter blank, no
prioritization of matches occurs.
56
Match/Consolidate Extended Matching Reference
Page 57

Appendix A:
Extended matching file (extmatch.mpg)
This appendix lists the contents of the extended matching file, extmatch.mpg.
You can copy blocks from this file into your extended matching file.
**********************************************************************
* MASTER FILE FOR EXTENDED MATCH/CONSOLIDATE MATCHING BEGINS HERE
*
* You can copy these blocks to a separate extended matching file (.mpg).
* Do not place these blocks in your job file.
**********************************************************************
* GENERAL BLOCK IS REQUIRED
BEGIN General Match/Consolidate 7.60c =========================
Job Description (to 80 chars)........ =
Job Owner (to 20 chars).............. =
END
* EXTENDED MATCH CRITERIA BLOCK IS REQUIRED WHEN PERFORMING ADV
MATCHING
BEGIN Extended Match Criteria =================================
Match Criteria Name (to 20 chars).... =
Parsing and Key Options.............. =
Form Break Groups.................... =
Match Spec........................... =
Prioritize Matches................... =
END
* PARSING AND KEY OPTIONS BLOCK IS REQUIRED
BEGIN Parsing and Key Options =================================
Key Definition Name (to 20 chars).... =
Auto Generate Key Lengths (see note). =
Name & Firm Parsing (EXT/STD/NONE)... =
Std Number of Names to Store (1-2)... =
Std Number of First_Name Stds (0-1).. =
Std Number of Mid_Name Stds (0-1).... =
Ext Number of Names to Store (1-3)... =
Ext Number of First_Name Stds (0-3).. =
Ext Number of Mid_Name Stds (0-3).... =
Ext Store Pre/Post Name(ORIG/STD/BOTH)=
Ext Store Title (ORIG/STD/BOTH)...... =
Ext Number of Firms to Store (1-2)... =
Store Firm (ORIG/STD/BOTH)........... =
Ext Number of Firm_Locs to Store (1-3)=
Ext Store Firm_Loc (ORIG/STD/BOTH)... =
Address Parsing (EXT/STD/NONE)....... =
Standardize Last Line Keys (Y/N)..... =
Upper Case M/P & UserDef Fields (Y/N) =
Standardize Diacritical Chars (Y/N).. =
Store Priority Field (Y/N)........... =
Key Length (fldname,length).......... =
END
Appendix A: Extended matching file (extmatch.mpg)
57
Page 58

****************************************************************
* Note: Valid options for Auto Generate Key Lengths: *
* NONE *
* INDIVIDUAL *
* FAMILY *
* RESIDENT *
* FIRM_INDIVIDUAL *
* FIRM *
****************************************************************
BEGIN Form Break Groups =======================================
Form Break Groups Name (to 20 chars). =
Combine Small Break Groups (Y/N)..... =
Max Combined Keys in a Break Group... =
Auto Generate Break Fields (see note) =
Break Field Definition Name.......... =
END
****************************************************************
* Note: Valid options for Auto Generate Break Fields *
* NONE *
* INDIVIDUAL *
* FAMILY *
* RESIDENT *
* FIRM_INDIVIDUAL *
* FIRM *
****************************************************************
BEGIN Break Field Definition ==================================
Block Name (to 20 chars)............. =
Field Name........................... =
Break Starting Position (1-fieldlen). =
Break Length (1-fieldlen,ALL)........ =
END
* AUTO MATCH SPEC BLOCK IS REQUIRED FOR AUTOMATIC EXTENDED MATCHING
BEGIN Auto Match Spec =========================================
Match Spec Name (to 20 chars)........ =
Match Type (see NOTE)................ =
Match Threshold (see NOTE)........... =
# of Names That Must Match (ONE/ALL). =
Compare First to Middle Name (Y/N/A). =
Match on Hyphenated Last Name (Y/N/A) =
Turn on Maiden Name Adjustment (Y/N/A)=
Ambig Name Data (see NOTE)........... =
Ambig Firm Data (see NOTE)........... =
Ignore Firm if Names Match (Y/N/A)... =
Extra Compare If Firm Blank (see NOTE)=
Extra Compare If Srange Blank (NOTE). =
Extra Compare If Addr Blank (see NOTE)=
Ambig Address Data (see NOTE)........ =
Ambig Lastline Data (see NOTE)....... =
Auto Field Option Name............... =
END
****************************************************************
* Note: Valid options for Match Type *
* INDIVIDUAL *
* FAMILY *
* RESIDENT *
* FIRM_INDIVIDUAL *
* FIRM *
* *
58
Match/Consolidate Extended Matching Reference
Page 59

* Note: Valid options for Match Threshold *
* EXACT *
* TIGHT *
* MEDIUM *
* LOOSE *
* *
* Note: Valid options for Ambig Name Data *
* NO_MATCH *
* POOR *
* LOOSE *
* AUTO *
* *
* Note: Valid options for Ambig Firm Data *
* NO_MATCH *
* POOR *
* LOOSE *
* AUTO *
* *
* Note: Valid options for Extra Compare If Firm Blank *
* INDIVIDUAL *
* FAMILY *
* FIRM_INDIVIDUAL *
* FIRM *
* OFF *
* AUTO *
* *
* Note: Valid options for Extra Compare If Srange Blank *
* INDIVIDUAL *
* FAMILY *
* FIRM_INDIVIDUAL *
* FIRM *
* OFF *
* AUTO *
* *
* Note: Valid options for Extra Compare If Addr Blank *
* INDIVIDUAL *
* FAMILY *
* FIRM_INDIVIDUAL *
* FIRM *
* OFF *
* AUTO *
* *
* Note: Valid options for Ambig Address Data *
* NO_MATCH *
* POOR *
* LOOSE *
* AUTO *
* *
* Note: Valid options for Ambig LastLine Data *
* NO_MATCH *
* POOR *
* LOOSE *
* AUTO *
****************************************************************
BEGIN Auto Field Option =======================================
Block Name (to 20 chars)............. =
Field Name........................... =
One Field Blank Op (EVAL/IGNORE/AUTO) =
One Field Blank Score (see NOTE)..... =
One Field Blank Extra Cmp (see NOTE). =
Both Fields Blank Op(EVAL/IGNORE/AUTO)=
Both Fields Blank Score (see NOTE)... =
Both Fields Blank Extra Cmp (see NOTE)=
Fields Different Extra Cmp (see NOTE) =
No Match Score (see NOTE)............ =
Compare Algorithm (FIELD/WORD/AUTO).. =
Check for Transposed Letters (Y/N/A). =
Appendix A: Extended matching file (extmatch.mpg)
59
Page 60

Adjust Score for Initials (Y/N/A).... =
Adjust Score for Substring (Y/N/A)... =
Adjust Score for Abbreviation (Y/N/A) =
Qualify Record With Numeric Match(Y/N)=
Numeric Words Match Type(see NOTE)... = POSITION_INDEPENDENT
END
****************************************************************
* Note: Valid options for One Field Blank Score *
* EXACT *
* TIGHT *
* MEDIUM *
* LOOSE *
* POOR *
* NO_MATCH *
* *
* Note: Valid options for One Field Blank Extra Cmp *
* AUTO *
* OFF *
* INDIVIDUAL *
* FAMILY *
* FIRM_INDIVIDUAL *
* FIRM *
* *
* Note: Valid options for Both Fields Blank Score *
* EXACT *
* TIGHT *
* MEDIUM *
* LOOSE *
* POOR *
* NO_MATCH *
* *
* Note: Valid options for Both Fields Blank Extra Cmp *
* AUTO *
* OFF *
* INDIVIDUAL *
* FAMILY *
* FIRM_INDIVIDUAL *
* FIRM *
* *
* Note: Valid options for Fields Different Extra Cmp *
* AUTO *
* OFF *
* INDIVIDUAL *
* FAMILY *
* FIRM_INDIVIDUAL *
* FIRM *
* *
* Note: Valid options for No Match Score *
* AUTO *
* EXACT *
* TIGHT *
* MEDIUM *
* LOOSE *
* POOR *
* WTONLY *
* OFF *
* *
* Note: Valid options for Numeric Words Match Type *
* POSITION_INDEPENDENT *
* POSITION_DEPENDENT *
* DECIMAL *
* DECIMAL_IGNORE_SEPARATOR *
****************************************************************
60
Match/Consolidate Extended Matching Reference
Page 61

* RULE MATCH SPEC BLOCK IS REQUIRED FOR RULE-BASED EXTENDED MATCHING
BEGIN Rule Match Spec =========================================
Match Spec Name (to 20 chars)........ =
Weighted Match Score (0-101)......... =
Weighted No-Match Score (-1-100)..... =
# of Names That Must Match (ONE/ALL). =
Compare First to Middle Name (Y/N)... =
Match on Hyphenated Last Name (Y/N).. =
Turn on Maiden Name Adjustment (Y/N). =
Rule Definition Name................. =
END
* RULE DEFINITION BLOCK IS REQUIRED FOR RULE-BASED EXTENDED MATCHING
BEGIN Rule Definition =========================================
Block Name (to 20 chars)............. =
Field Name........................... =
One Field Blank Op (EVAL/IGNORE)..... =
One Field Blank Score (0-100)........ =
Both Fields Blank Op (EVAL/IGNORE)... =
Both Fields Blank Score (0-100)...... =
Match Score (0-101).................. =
No Match Score (-1-100).............. =
Contribution to Weighted Score (0-100)=
Use in Weighted Score if .GT. (-1-100)=
Zero Weighted Score if .LE. (0-100).. =
Compare Algorithm (FIELD/WORD)....... =
Check for Transposed Letters (Y/N)... =
Initials Adjustment Score (0-100).... =
Substring Adjustment Score (0-100)... =
Abbreviation Adjustment Score (0-100) =
Qualify Record With Numeric Match(Y/N)=
Numeric Words Match Type(see NOTE)... = POSITION_INDEPENDENT
END
****************************************************************
* Note: Valid options for Numeric Words Match Type *
* POSITION_INDEPENDENT *
* POSITION_DEPENDENT *
* DECIMAL *
* DECIMAL_IGNORE_SEPARATOR *
****************************************************************
* PRIORITIZE MATCHES BLOCK IS REQUIRED
BEGIN Prioritize Matches ======================================
Prioritize Matches Name (to 20 chars) =
Type (LIST/FLD/LIST_FLD/FLD_LIST).... =
Priority Field Order (DESCEND/ASCEND) =
Break Priority Ties Randomly (Y/N)... =
Blank Priority (field,priority)...... =
END
* TO PRODUCE A MATCH RESULTS REPORT, WITH INFORMATION ABOUT YOUR
* EXTENDED MATCHING RESULTS, INCLUDE THE REPORT: MATCH RESULTS
* BLOCK IN YOUR JOB FILE (NOT IN YOUR EXTENDED MATCHING FILE).
**********************************************************************
* MASTER FILE FOR MATCH/CONSOLIDATE EXTENDED MATCHING ENDS HERE
**********************************************************************
Appendix A: Extended matching file (extmatch.mpg)
61
Page 62

62
Match/Consolidate Extended Matching Reference
Page 63

Index
Symbols
# of Names That Must Match parameter
Auto Match Spec block, 37
Rule Match Spec block, 52
A
Abbreviation Adjustment Score parameter
Rule Definition block, 49
abbreviation matching, 34, 49
Address & Last Line Parsing parameter
Parsing and Key Options block, 22
Adjust Score for Abbreviation parameter
Auto Field Option block, 34
Adjust Score for Initials parameter
Auto Field Option block
Adjust Score for Substring parameter
Auto Field Option block, 33
Adv parameters
Form Break Groups, 56
Form Break Groups Name, 26
Key Definition Name, 19
Match Criteria Name, 56
Match Spec, 56
Parsing and Key Options, 56
Prioritize Matches, 56
Prioritize Matches Name, 54
Ambig Address Data parameter
Auto Match Spec block, 39
Ambig Firm Data parameter
Auto Match Spec block
Ambig Lastline Data parameter
Auto Match Spec block
Ambig Name Data parameter
Auto Match Spec block
ambiguous data, 39
Auto Field Option block, 29
Auto Field Option Name parameter
Auto Match Spec block
Auto Generate Break Fields parameter
Form Break Groups block
Auto Generate Key Lengths parameter
Parsing and Key Options block
Auto Match Spec block, 36
auto.mpg, 10
automatic extended matching, 9
, 33
, 39
, 39
, 39
, 40
, 27
, 19
B
blank matching, 30, 42
Blank Priority parameter
Prioritize Matches block
Block Name parameter
Auto Field Option block
Break Field Definition block, 28
, 55
, 29
Rule Definition block, 41
blocks
Auto Field Option
Auto Match Spec, 36
Break Field Definition, 28
Extended Match Criteria, 29
Form Break Groups, 26
General, 18
Parsing and Key Options, 19
Prioritize Matches, 54
Rule Definition, 41
Rule Match Spec, 51
Both Fields Blank Extra Cmp parameter
Auto Field Option block, 31
Both Fields Blank Op parameter
Auto Field Option block, 30
Rule Definition block, 42
Both Fields Blank Score parameter
Auto Field Option block, 30
Rule Definition block, 42
Break Field Definition block, 28
Break Field Definition Name parameter
Form Break Groups block, 27
Break Length parameter
Break Field Definition block, 28
Break Priority Ties Randomly parameter
Prioritize Matches block
Break Starting Position parameter
Break Field Definition block, 28
, 29
, 54
C
Check for Transposed Letters parameter
Auto Field Option block, 32
Rule Definition block, 48
Combine Small Break Groups parameter
Form Break Groups block, 26
Compare Algorithm parameter
Auto Field Option block
Rule Definition block, 47
Compare First to Middle Name parameter
Auto Match Spec block
Rule Match Spec block, 52
Contribution to Weighted Score parameter
Rule Definition block
, 32
, 38
, 45
E
enabling extended matching, 13
Ext Number of Firm_Locs to Store parameter
Parsing and Key Options block
Ext Number of Firms to Store parameter
Parsing and Key Options block
Ext Number of First_Name Stds parameter
Parsing and Key Options block
, 22
, 22
, 21
Index
63
Page 64

Ext Number of Mid_Name Stds parameter
Parsing and Key Options block, 21
Ext Number of Names to Store parameter
Parsing and Key Options block
Ext Store Firm_Loc parameter
Parsing and Key Options block, 22
Ext Store Pre/Post Name parameter
Parsing and Key Options block, 21
Ext Store Title parameter, 21
Extended Match Criteria, 19
Extended Match Criteria block, 56
extended matching
automatic, 7, 9
enabling, 13
file locations, 10
files, 10
rule-based, 7, 9
extended parsing, 19, 22
Extra Compare If Addr Blank parameter
Auto Match Spec block, 40
Extra Compare If Firm Blank parameter
Auto Match Spec block, 40
Extra Compare If Srange Blank parameter
Auto Match Spec block
extra comparisons, 31
, 20
, 40
F
family match type, 8, 36
family.mpg, 10
Field Name parameter
Auto Field Option block
Break Field Definition block, 28
Rule Definition block, 41
Fields Different Extra Cmp parameter
Auto Field Option block, 31
firm match type, 8, 36
firm.mpg, 10
firm-individual match type, 8, 37
firmindv.mpg, 10
first-to-middle name comparison, 38, 52
force a match, 15
force no-match, 15
Form Break Groups block, 26
Form Break Groups Name parameter
Form Break Groups block
Form Break Groups parameter
Extended Match Criteria block
, 29
, 26
, 56
G
General block, 18
H
hhold.mpg, 10
hyphenated-names matching, 38, 52
I
Ignore Firm if Names Match parameter
Auto Match Spec block
indiv.mpg, 10
individual match type, 8, 36
, 39
Initials Adjustment Score parameter
Rule Definition block, 48
initials matching, 33, 48
J
Job Description parameter
General block, 18
Job Owner parameter
General block
, 18
K
Key Definition Name parameter
Parsing and Key Options block, 19
key fields, 29
Key Length parameter
Parsing and Key Options block, 24
M
maiden-name matching, 38, 53
Match Criteria Name parameter
Extended Match Criteria block
match fields, 29
Match on Hyphenated Last Name parameter
Auto Match Spec block
Rule Match Spec block, 52
Match Results report, 11
Match Score parameter
Rule Definition block, 43
Match Spec Name parameter
Auto Match Spec block
Rule Match Spec block, 51
Match Spec parameter
Extended Match Criteria block
Match Threshold parameter
Auto Match Spec block, 37
Match Type parameter
Auto Match Spec block, 36
match types, 8
matching
force a match
force no-match, 15
weighted scoring, 15
Max Combined Keys in a Break Group parameter
Form Break Groups block, 26
middle-to-first name comparison, 38, 52
, 15
, 56
, 38
, 36
, 56
N
Name, Title, & Firm Parsing parameter
Parsing and Key Options block
No Match Score parameter
Auto Field Option
Rule Definition block, 43
Numeric Words Match Exactly parameter
Auto Field Option block
Rule Definition block, 49
, 31
, 19
, 34
O
One Field Blank Extra Cmp parameter
Auto Field Option block
One Field Blank Op parameter
, 31
64
Match/Consolidate Extended Matching Reference
Page 65

Auto Field Option block, 30
Rule Definition block, 42
One Field Blank Score parameter
Auto Field Option block
Rule Definition block, 42
over-matching, 44
, 30
P
Parsing and Key Options block, 19
Parsing and Key Options parameter
Extended Match Criteria block, 56
Prioritize Matches block, 54
Prioritize Matches parameter
Extended Match Criteria block, 56
Prioritize Matches block, 54
Priority Field Order parameter
Prioritize Matches block, 54
R
reports
Match Results, 11
required blocks, 9
resident match type, 8, 36
Rule Definition block, 41
Rule Definition Name parameter
Rule Match Spec block
Rule Match Spec block, 51
rule-based extended matching, 9
, 53
S
similarity scores, 15
standard parsing, 19, 22
Standardize Last Line Keys parameter
Parsing and Key Options block, 23
Std Number of First_Name Stds parameter
Parsing and Key Options block
Std Number of Mid_Name Stds parameter
Parsing and Key Options block, 20
Std Number of Names to Store parameter
, 20
Parsing and Key Options block, 20
Store Firm parameter
Parsing and Key Options block, 22
Store Priority Field parameter
Parsing and Key Options block, 24
Substring Adjustment Score parameter
Rule Definition block
substring matching, 33, 48
, 48
T
thresholds, 9
transposed letters, 32, 48
Turn on Maiden Name Adjustment parameter
Auto Match Spec block, 38
Rule Match Spec block, 53
two kinds of extended matching, 7
Type parameter
Prioritize Matches block, 54
U
under-matching, 45
Upper Case Merg_Purg Fields parameter
Parsing and Key Options block
Use in Weighted Score if .GE. parameter
Rule Definition block, 46
, 23
W
Weighted Match Score parameter
Rule Match Spec block, 51
Weighted No-Match Score parameter
Rule Match Spec block, 51
weighted scoring in rule matching, 15
work buffer, 26
Z
Zero Weighted Score if .LE. parameter
Rule Definition block
, 47
Index
65
Page 66

66
Match/Consolidate Extended Matching Reference
 Loading...
Loading...