

Page 1
Match/Consolidate
User’s Guide to Record Matching
Match/Consolidate 8.00c
April 2009
Page 2

Copyright information © 2009 SAP® BusinessObjects™. All rights reserved. SAP BusinessObjects and its logos,
BusinessObjects, Crystal Reports®, SAP BusinessObjects Rapid Mart™, SAP
BusinessObjects Data Insight™, SAP BusinessObjects Desktop Intelligence™, SAP
BusinessObjects Rapid Marts®, SAP BusinessObjects Watchlist Security™, SAP
BusinessObjects Web Intelligence®, and Xcelsius® are trademarks or registered trademarks of
Business Objects, an SAP company and/or affiliated companies in the United States and/or
other countries. SAP® is a registered trademark of SAP AG in Germany and/or other countries.
All other names mentioned herein may be trademarks of their respective owners.
2
Match/Consolidate User’s Guide
Page 3

Contents
Preface .............................................................................................................7
Chapter 1:
Fundamentals of record matching............................................................... 9
Terms..............................................................................................................10
Benefits of Match/Consolidate.......................................................................11
Data, rules, and results ...................................................................................13
Chapter 2:
Record matching overview ......................................................................... 15
Summary of the record matching process ......................................................16
About your first job........................................................................................18
Prepare your files for Match/Consolidate ......................................................19
Set up your Match/Consolidate job................................................................20
Read records and create Match Sets...............................................................21
Find matching records....................................................................................23
Process the match results................................................................................24
Match/Consolidate features............................................................................25
Chapter 3:
Define your input files and lists.................................................................. 27
Input files and lists .........................................................................................28
Input files........................................................................................................29
Re-use processed input (key data) with reference files..................................30
Group your records with lists .........................................................................31
Use lists to control the matching process.......................................................32
List types ........................................................................................................33
Dupe search within this list ............................................................................35
List Break Priority..........................................................................................36
Three approaches to defining lists..................................................................37
When a record doesn’t fit into any list ...........................................................40
Create groups of lists (super lists)..................................................................41
Reports on your lists.......................................................................................42
Chapter 4:
Prioritize and suppress records ................................................................. 47
Record priorities and types.............................................................................48
Record priority and suppression.....................................................................50
Prioritize or suppress records based on list membership ...............................52
Penalize records that contain blank fields ......................................................54
Prioritize records based on the contents of one field .....................................56
Reports about record ranking and priorities...................................................58
Chapter 5:
Purge input files or create output files ...................................................... 61
Match/Consolidate results ..............................................................................62
Purge bad records or post good records .........................................................64
Contents
3
Page 4

Purge the input file......................................................................................... 65
Create an output file or post data to the input file ......................................... 67
Data that you can post.................................................................................... 68
Choose the best records for your output file.................................................. 69
Custom sort your output records....................................................................72
Create a multi-buyer file................................................................................74
Create a multi-occurrence file........................................................................ 76
Select a sample of records .............................................................................77
Reports about your purging or output process............................................... 78
Chapter 6:
Reports and statistics files.......................................................................... 81
Introduction to reports and report files .......................................................... 82
Statistics files ................................................................................................. 84
How statistics files relate to Match/Consolidate reports ............................... 86
How Match/Consolidate counts intra-list and inter-list matches................... 88
Use super lists for report data ........................................................................91
Print reports....................................................................................................92
Duplicate Records Report (.dup) ................................................................... 93
Executive Summary Report (.exs) ................................................................. 95
Input File Summary Report (.ifs)................................................................... 96
Input List Summary Report (.ils)................................................................... 97
Job Summary Report (.mjs) ........................................................................... 98
List-by-List Match Report (.llm) ................................................................. 104
List Duplicates Reports (.ldr)....................................................................... 106
List Match Reports (.lm).............................................................................. 109
List Quality Report (.lqr) .............................................................................113
Match Results Report (.mrr) ........................................................................115
Multi-List Report (.mlr)............................................................................... 117
Output File Reports (.ofr) ............................................................................ 119
Posted Dupe Groups Report (.pdg).............................................................. 124
Purge by List Reports (.prl) ......................................................................... 125
Sorted Records Report (.sor) .......................................................................127
Unparsed Records Report (.unp) ................................................................. 133
Job statistics file...........................................................................................135
Input statistics file........................................................................................ 137
List match statistics file ............................................................................... 138
List statistics file .......................................................................................... 139
Output statistics file .....................................................................................140
Purge statistics file.......................................................................................141
Super list match statistics file ...................................................................... 142
Multi-buyer statistics file .............................................................................143
List subordinates statistics file..................................................................... 144
Chapter 7:
Use group posting to consolidate data..................................................... 145
The basics of group posting.........................................................................146
Introduction to group posting ......................................................................147
Post data sources and destinations ............................................................... 148
Group posting depends on your fields .........................................................149
Group posting more than once per destination record................................. 150
Example: post a new phone number............................................................ 151
Example: additive information .................................................................... 154
4
Match/Consolidate User’s Guide
Page 5

Examples of group posting strategies...........................................................155
When group posting is all you want to do....................................................159
Group post with an input purge....................................................................160
Reports on group posting .............................................................................162
Chapter 8:
Record matching ....................................................................................... 163
Introduction ..................................................................................................164
Choose between standard and extended matching.......................................165
Factors that affect comparison time .............................................................167
Matching strategies ......................................................................................168
Implement a matching strategy ....................................................................169
Rule matching ..............................................................................................170
Automatic matching .....................................................................................171
Advanced matching......................................................................................173
Use reports to examine the matching process ..............................................174
Chapter 9:
Engineer key data...................................................................................... 175
Key files .......................................................................................................176
Include record keys only as needed..............................................................178
Define key fields ..........................................................................................180
Standardize key data for lastline information ..............................................181
Standardize key data for peoples’ names .....................................................183
Standardize key data for firm (company) names .........................................185
Chapter 10:
Engineer break groups.............................................................................. 187
Form break groups .......................................................................................188
Break strategies ............................................................................................190
Prioritize your break group records..............................................................192
Break-group analysis....................................................................................194
Chapter 11:
Engineer your match setup....................................................................... 195
Compare record keys: the driver record.......................................................196
What makes records match ..........................................................................198
Simscore .......................................................................................................199
How close is close enough ...........................................................................202
How record order affects comparisons.........................................................204
Control record comparisons .........................................................................206
Match with unparsed addresses, last lines, names, and firms ......................208
Matching options..........................................................................................210
How blank fields affect matching ................................................................216
Fine-tune your matching process .................................................................218
Chapter 12:
Advanced matching................................................................................... 219
Terms............................................................................................................220
Match Sets....................................................................................................222
Multi level matching ....................................................................................224
Combine match set.......................................................................................236
Contents
5
Page 6

Chapter 13:
Constant Key ID........................................................................................ 253
Use Constant Key ID ...................................................................................254
Appendix A:
Match/Consolidate and Match programs................................................ 259
Product-line overview..................................................................................260
Appendix B:
Calculate the size of your work files......................................................... 263
Appendix C:
Analyze your matching strategies ............................................................ 267
Appendix D:
Match/Consolidate Wizard .......................................................................269
Index............................................................................................................ 277
6
Match/Consolidate User’s Guide
Page 7

Preface
Purpose and contents of this manual
Conventions
This guide explains how Match/Consolidate (MCD) programs perform record
matching. Beginning with an entry-level orientation on the basics of record
matching, this guide progresses through the common record matching
functions and an explanation of the features that comprise the current
technology of record matching.
Our examples and illustrations are based on actual MCD jobs set up and run
through the MCD Views program on a Windows NT platform. If you are not
using Views, look for similarly named parameters in the corresponding block
of your job file. We assume that you are familiar with your operating system
and have a general understanding of database management.
This document follows these conventions:
Convention Description
Bold We use bold type for file names, paths, emphasis, and text that you
should type exactly as shown. For example, “Type
Italics We use italics for emphasis and text for which you should substi-
tute your own data or values. For example, “Type a name for your
Menu
commands
file, and the
We indicate commands that you choose from menus in the following format: Menu Name > Command Name. For example, “Choose
File > New.”
.txt
extension (
testfile
.txt
).”
cd\dirs
.”
!
We use this symbol to alert you to important information and
potential problems.
We use this symbol to point out special cases that you should know
about.
We use this symbol to draw your attention to tips that may be useful
to you.
Preface
7
Page 8

Documentation
Documents related to this manual include the following:
Document Description
Access the latest
documentation
System Administrator’s Guide
Database Prep
Explains how to install your software.
Explains how to prepare input files for processing,
including how to create DEF, FMT, and DMT files.
Match/Consolidate Extended
Matching
Contains the operational how-to instructions for setting up extended matching.
Reference
Match Library Program-
This is a reference manual for the Match Library.
mer’s Reference
Match/Consolidate
Library Reference
Quick Reference
This is a reference for programmers working with
the Match/Consolidate Library.
Contains descriptions of the input and output fields,
and the command line for the MCD job file.
You can access documentation in several places:
On your computer. Release notes, manuals, and other documents for
each product that you’ve installed are available in the Documentation
folder. Choose Start > Programs > Business Objects Applications >
Documentation.
On the SAP Service Market Place. Go to http://help.sap.com, and then
click the Business Objects tab. Here, you can search for your products’
documentation.
8
Match/Consolidate User’s Guide
Page 9

Chapter 1:
Fundamentals of record matching
This chapter explains some of the fundamentals of record matching. It describes
how to use Match/Consolidate (MCD) to match your records.
Chapter 1: Fundamentals of record matching
9
Page 10

Terms
This guide references the following terms.
Term Definition
Consolidation
Group posting
Salvaging data
Dupe group
Match group
Match key Name, address, or other data that is broken down into components,
Raw Data Match Key
Name_Line1 = George F Hayes First_name for 8 characters = GEORGE
Address = 100 Main St #5 Mid_name for 3 characters = F
Last_line = Edna, MN 55424 Last_name for 10 characters = HAYES
Consolidation (or group posting) means copying or accumulating
data from one matched record to another. Often, it means merging
matched records to form a single best record. Some users migrate
information from one record to another, but do not specifically seek
to merge the records.
This is a follow-up process, which occurs after records are identified as members of match groups.
The terms dupe group and match group are used interchangeably in
this guide. This refers to two or more records that were found to
match each other.
standardized, and ready for comparison. For example:
Prim_range for 10 characters = 100
Prim_name for 15 characters = MAIN
Suffix for 6 characters = ST
Sec_range for 6 characters = 5
ZIP for 5 characters = 55424
Actual Key = GEORGE F HAYES 100 MAIN ST 5 55424
Match field Data that is part of the match key and is compared during the match-
ing process. The First_name data is one of the match fields in the
example above. Middle name (Mid_name) is another, and
Last_name, etc.
Break group Sorting keys into groups of records that are likely to match. Break
groups speed the duplicate detection process by eliminating comparisons of records that have no likelihood of matching. Only
records within the same break group are compared to one another.
10
Match/Consolidate User’s Guide
Page 11

Benefits of Match/Consolidate
The benefits of using MCD begins with record matching. That means comparing
name, address, and other customer data to find matching records, In other words,
deciding whether, within your rules, Record A and Record B represent the same
person, household, or company. We can help you get started with typical
matching rules; eventually you will probably want to adjust them or make new
rules.
Once you’ve identified pairs or groups of records that match, what do you want to
do? Eliminate redundant records? Migrate customer data from one file to
another? Consider the following possibilities listed in the following table.
Term Definition
Extended parsing Apply parsing and standardization capabilities of ACE and
Extended matching Highly tunable rule-based matching that lets you prioritize
Consolidation We offer two approaches to consolidation. With each, you create
TrueName, to prepare the cleanest, most complete data for
match keys.
match fields. You can prioritize your match fields and make
decisions for a match or non match on a per-field basis.
your own rules for comparing and consolidating records. You
can consolidate matched records into a best record, or migrate
data among your files.
Reference files When you repeatedly match against the same static database,
there’s no need to regenerate match keys each time. Some people call this feature durable or re-usable match keys.
Advanced matching Advanced matching lets you find up to three levels of matches
in one pass and find associated matches between separate data
sets. For example, you can find families and individuals as well
as separate residents all in one pass and give a unique number
for each level on output. Association is finding persons who live
at different residents at different times of the year by using a
common data field.
Constant key Constant key lets you create an ID that is unique to a record or
group of duplicate records. It is sequential, static, and it will not
change when records are updated or re-processed through
MCD.
When you append new records to the database, change when
records are updated or re-processed through MCD tags any that
belong to a group with an existing ID with that same ID.
Feature Options
Input purge or
create output file
Most users choose to send desirable records to an output database. Or, if disk space is a concern, you can drop undesirable
records from the input database(s).
Multi-buyer Let’s say you’re bringing together customer lists from several
other direct marketers or publishers. Your best prospects may
be the people whose names appear on two or more lists, indicating they may be most receptive to your offer.
Chapter 1: Fundamentals of record matching
11
Page 12

Feature Options
Custom sorting and
selection
You can perform Nth-select and/or limit your output to a certain number of records. Within your maximum-records limit,
you can select your best prospects using a variety of custom
sorting strategies.
Business-to-business MCD isn’t just for consumer marketing. For example, with the
proper setup and multiple passes, you can perform
N
-per-firm
selection—in other words, you can limit output so that only a
certain number of individuals in each company will receive
your offer. That helps you spend your advertising dollars most
effectively.
Group posting When you’re working with several lists, take advantage of the
best of each list. Use the MCD group posting feature to salvage
the best data—data that’s missing from your records—from
those duplicate records that won’t be included in your final
output.
Suppression lists You can work with suppression lists—for example, your own
bad-account file, or no-mail lists provided by the government
or direct-marketing association (DMA)—to prevent wasted
mailings and offending consumers.
12
Match/Consolidate User’s Guide
Page 13

Data, rules, and results
The keys to successful MCD use involves Data, Rules, and Results.
Data Clean, complete name and address data will make a big difference in your
success. If you have data from several sources or from outside your organization,
then there may be issues about format and consistency. We can help. Use ACE,
TrueName, DataRight, or DataRight IQ tools to break data down into
components, correct errors and inconsistencies, and fill in missing data.
Rules Rules refers to your matching rules—your criteria for when two records should
be called a match, and when they should not. You’ll need to think carefully about
which fields will be evaluated, how they will be compared, and any special or
exceptional circumstances that might override your
normal criteria.
For Views users within your match criteria, we provide five default sets of rules
to help you get started with individual, family, household, business, or businessindividual matching. We recommend that you start your learning and testing with
one of our rule sets, then adjust as necessary. That may mean a cyclical process in
which you run the search for matches, check your reports, make rule changes, and
run the search again.
Results Consider the results, or outputs, that you want at the end of the process. Do you
want to create an output database? If so, plan your criteria for the records to be
included in that file. If you want to consolidate records, write lists of fields to
consolidate and how to evaluate or combine each source. Finally, think about
what reports you will need for yourself and your clients.
Chapter 1: Fundamentals of record matching
13
Page 14

14
Match/Consolidate User’s Guide
Page 15

Chapter 2:
Record matching overview
This chapter summarizes the Match/Consolidate (MCD) process, and explains
how preparation, setup, and step-by-step execution of your job is vital to getting
the results you want from MCD.
Chapter 2: Record matching overview
15
Page 16

Summary of the record matching process
To help you understand the MCD process, consider
the five-step process shown at right.
You perform the first two steps and Match/
Consolidate performs steps 3, 4, and 5.
Here we concentrate on the basics, so we ignore
many of the features that you can include to tailor
your MCD job to your job requirements. The other
chapters of this guide further explain these features.
One step at a time This chapter describes the steps one at a time. As you better learn MCD and set
1. Prepare your files for
Match/Consolidate
2. Set up your Match/
Consolidate job
3. Read records and
create Match Sets
4. Find matching records
5. Process the match
results
up your MCD jobs, you can do all the processing steps at once.
Match/Consolidate is a batch process. That means you set up a MCD job (define
what records to use and what to do with them), and then start that job. Match/
Consolidate runs the job according to the job settings, in one batch.
Checking your results During the MCD batch process, your interaction is limited to reading progress
messages (if you so choose). However, once the process is complete, you can
check your results by checking MCD reports and/or output files.
Match/Consolidate can produce 16 different pre-formatted reports, containing
statistics about the process and actual record data for your analysis. In addition,
MCD can produce many statistics files in which you can find most any data
pertinent to your MCD job.
Disk space for generated files
Normally, you will create reports for every job (select the Create Reports option
at the Execution Options window). Carefully look at the appropriate reports. If
you don’t see the results you want, change your settings and re-process the job.
Do this at each step until you get the results you want.
As it runs, MCD generates work files. If you run out of disk space for those files,
the program will stop. Note that, depending on your operating system, you may
get a variety of errors. For details on estimating disk space requirements, refer to
“Calculate the size of your work files” on page 263.
16
Match/Consolidate User’s Guide
Page 17

C
Prepare your files for
A
Match/Consolidate
Input file
Input file
Input file
By guiding you through a job, this chapter provides
an overview of the three main Match/Consolidate
processes. For specific details about the processes,
refer to the remaining chapters of this guide.
Match/Consolidate reports are a most valuable
source of information about your job.
Study them carefully to see if you should
adjust your job settings and rerun the process.
Note that your MCD job can be run
in one execution; it need not be run in separate
phases as shown in this illustration.
Preparation
Execution Process:
Read Records and
Create Match Sets
JOHN CASILLO CONSOLIDAION BEVERAGE 12 SAINT MARK ST AUBURN
MA01501
ROBERT BRHDLEY WT. BRHDLEY & SONS ENTERPRISE 61 SUMMIT AVE SOUTH ADAMS
MA01247
JOSEPHINE LAMER NEC INFORMATIN SYSTEMS 1414 MASSACHUSETTS AVE BOXBORO
MA01719
MR BILL HANDRICH HELENA CHEMICAL CO PO BOX 220 HATFIELD
MA01038
MR GREG HAMMOND, MGR CUST REL LISTA INTERNATIONAL 106 LOWLAND ST HOLLISTON
MA01746
MARY PETERS UNIVERSAL PLASTICS CORP 165 FRONT ST CHICOPEE
MA01013
HECTOR R RODRIGUEZ IMPRESOS ALFA AVE DEGETAU A-7 SAN ALFONSO CAGUAS PR
CONSTANSA F FOSTER TRAULSEN & CO INC PO BOX 169 COLLEGE POINT
NY11356
TIM GLAZE SHEPHERD INTELLIGENCE SYSTEMS 358 BAKER AVE CONCORD
MA01742
CLAIRE MONAHAN ASTRA PHARM PRODUCTS 50 OTIS ST WESTBOROUGH
MA01581
ROBERT FINE AMERICAN BILTRITE INC PO BOX 6146 TRENTON
NJ08648
S DONGELO ACCO SWINGLINE 151 RADDIN RD GROTON
MA01450
MR MOE L CURLY, SLS SUPV ROBERTS DISTRIBUTING CORP 372 PASCO RD SPRINGFIELD
MA01119
LANCE R DUNHAM DIR ANGIOGRAPHIC DEVICES CORP 232 TAYLOR ST LITTLETON
MA01460
MR PETER BEYETTE BROOKFRONT MEDICAL SERVICES 1459 NIAGARA FALLS BLVD BUFFALO
NY14228
JAY SPUTNIK- MGR YANKEE AJOEIC ELEC CO 580 MAIN ST BOLTON
MA01740
JAN PAINTER LUCAS GRASON STADLER INC 537 GREAT RD LITTLETON
MA01460
BERNIE VITTI SANDOZ 59 ROUTE 10 EAST HANOVER
NJ07936
LUIS PABON MILES PUERTO RICO INC CALL BOX 11848 SAN JUAN PR
KAREN MCFADDEN VP ROCHE BIOMEDICAL LAB 17 WALDRON AVE GLEN ROCK
NJ07452
MAUREEN DABERNARDI BRADFORD FURNITURE 23 BRADFORD ST CONCORD
MA01742
JEANNE WEINTRAUB, MKTG COORD CHANNING L BETE CO 200 STAGE RD SOUTH DEERFIELD
MA01373
MR BRADFORD W PHOENIX H M SPENCER INC BOX 14030 HOLYOKE MA
MS SUZANNE MC KIERNAN THE HANOVER INSURANCE COMPA 100 SOUTH ST WORCESTER
MA01605
AL DIGREGORIONSON AAA WATER QUALITY SYSTEMS 154 CENTRAL ST SOUTHBRIDGE
MA01550
DENNIS R MILLS SCOTT CASTINGS CORP 461 TONAWANDA ST BUFFALO
ll input records
MSMI56MA55987
JCAS12SA01501
WSNI89LI56308
AMUT92KI56551
SWAL31SE44240
MZAS48FR44242
OLAR96SU06460
FDRA77MA14240
BJAD29HU80308
HEI11SA10158
key file
Execution Process:
Mary Jane Smith
Mary Smith
Set up your
Match/Consolidate job
Reports
Reports
Input File Summary
Input List Summary
Sorted Records report
Unparsed Records report
Find Matching
Records
M. Smi th
Maryjane Smith
Dupes, uniques…
Reports
Reports
Input file
Match/Consolidate
Multi-Occurrence
All Duplicates
Custom Match/Consolidate
Execution Process:
Process the Match
Results
Post records
Purge records
Post data
Chapter 2: Record matching overview
Resultant
record
matching
data
Reports
Reports
Output File report
Posted Dupe Groups report
Purge by List report
Statistics files
Duplicate Records report
List Duplicates report
List Match reports
Sorted Records report
…and more…
17
Page 18

About your first job
If you are new to MCD, we recommend that you make your first MCD job
simple, to familiarize yourself with the overall MCD job processes. As an
introductory job, and as a quick check to be sure your program is properly
installed, we supply a collection of files that are automatically copied to your
program's samples directory when you install MCD.
We provide the quik_mpg.dat file to serve as your database for the sample job.
We also provide the quik_mpg.def and quik_mpg.fmt support files for that
database. The database file contains 1000 records, each record having name and
address data. If you look through the file, you can find some blank fields, and you
may note that some of the records have addresses (or names, or both) similar to
those of other records.
Depending on your operating system, we provide a job file named quikunix.mpg
or quikwin.mpg. This job is preset to read the records of the quik_mpg.dat
database, process it to find duplicate records, and produce a MCD Output File.
If you have not used the standard directory structure prompted by the
installation program, then before you run the introductory job, you may have
to make some small changes to the Auxiliary Files settings, so your program
will be able to find the directories it needs for processing. Refer to your
System Administrator's Guide for additional details.
Subdirectories In addition, many users prefer to keep their
jobs' output and reports in separate
subdirectories, with a directory structure
similar to the one shown at right.
If you want to separate your output and reports
like this, you'll have to do two things:
First, create the additional directories
Then, in your job setup, (quikunix.mpg
or quikwin.mpg) modify the file paths
that are set in your reports and output file
blocks to correspond to those directories.
PW
MPG
Samples
Template
Work
Output
Reports
18
Match/Consolidate User’s Guide
Page 19

Prepare your files for Match/Consolidate
You need to have two types of files ready before
you run MCD:
Input files—the records you want in the job.
You can input up to 255 files for your MCD
job, and they can be of varying types, including
ASCII, dBASE3, EBCDIC, and delimited.
Supporting files — These files include the
1. Prepare your files for
Match/Consolidate
2. Set up your Match/
Consolidate job
3. Read records and
create Match Sets
4. Find matching records
5. Process the match
results
DEF file, which interprets your input data for
MCD, and format files such as FMT, DMT, or EBC.
For details about input files and support files, refer to Database Prep.
Input files The best way to prepare your input files for MCD is to standardize your input
data by using name and address correction software, like our DataRight,
TrueName, ACE, and IACE software. Standardized data increases the speed and
accuracy of the match process.
If your data is not standardized, MCD Job can perform extended parsing for name
and address data. Using extended parsing produces results equivalent to those
derived from using DataRight, TrueName, ACE, and IACE
(U.S. engine) software. However extended parsing is an extra cost option, and it
may increase overall processing time. Note that data is standardized in the key
data for the purpose of matching only.
If you are running our sample job (quikunix.mpg or quikwin.mpg) then your
input file, quik_mpg.dat, is in your program's samples directory.
Re-run the same job If you just changed settings and now want to re-run the same job, you may be able
to speed up the process by using reference files. For details, see “Re-use
processed input (key data) with reference files” on page 30.
Chapter 2: Record matching overview
19
Page 20

Set up your Match/Consolidate job
Once you have prepared your data for MCD, you
need to set up your job so that the MCD program
will know:
Which input file records to include
1. Prepare your files for
Match/Consolidate
2. Set up your Match/
Consolidate job
3. Read records and
How to parse data from the input record
What key data to store for each record
What makes a match or no-match
What result (output) to produce from this job
Which reports that you want to create
create Match Sets
4. Find matching records
5. Process the match
results
Three options If you are using MCD Views, you have the three options explained below for
setting up a MCD job. If you do not have Views, then you must use the third
alternative shown here.
1. Use the Views Wizard — The MCD Views job setup Wizard prompts you
through a setup for your job. The Wizard does not control all the features
available in MCD; however, it does get the job started with the input, output,
and processing options common for most MCD users.
Once you've initially set up your job through the Wizard, you can use Views
to add any additional sophistication needed to produce exactly the results you
want from MCD.
2. Design your job in Views — You can define and design your entire job setup
through Views. Use the Views windows to select the options and define the
setup parameters that produce the results you want.
Views currently includes standard, extended, and advanced matching
processes through Match Criteria and Match Options windows.
3. Copy and edit a job file — If you are already familiar with MCD or other
record matching programs, and like working in a text-only environment, you
may want to set up your job by directly editing the job file.
For the introductory sample job (quikunix.mpg or quikwin.mpg) your setup will
be minimal, to accommodate any differences from the standard MCD installation
(refer to page 18).
20
Match/Consolidate User’s Guide
Page 21

Read records and create Match Sets
As you learn to use MCD, you may want to
consider performing the first process, that of
reading the input records and creating match sets,
as a separate step. Once you have developed a
better understanding of MCD, you may be more
comfortable combining all of the processes of your
job in one execution.
To run our sample job (quikunix.mpg or
quikwin.mpg) issue the MCD start command from
1. Prepare your files for
Match/Consolidate
2. Set up your Match/
Consolidate job
3. Read records and
create Match Sets
4. Find matching records
5. Process the match
results
your command prompt, or, if using Views, open the sample job and run the job
from within Views. (Refer to our Quick Reference for command line options and
format requirements.)
The key file is a working file that MCD uses to hold the data that’s used in
placing, matching, and ranking (prioritizing) your records. You won’t read or use
this file; only the MCD process will.
The match process compares data from one record to corresponding data from
another record. However, comparing all the record data would take far too much
time for most purposes. Additionally, comparing some parts of the data might
actually be counterproductive.
Therefore, instead of using all the record data, your matching process uses key
data—data that you, the MCD user, identify as the significant parts of the record
to use for finding matches. That data is stored in the MCD key file.
Each key represents a record
The key file contains a string of data for each record to be processed. You identify
each field and the length of characters to use in the key. For example, you may
want to store 12 characters of the last name data, 30 characters of firm data, 10
characters of primary range data, and so on.
Raw Data Match Key
Name_Line1 = George F Hayes First_name for 8 characters = GEORGE
Address = 100 Main St #5 Mid_name for 3 characters = F
Last_line = Edna, MN 55424 Last_name for 10 characters = HAYES
Prim_range for 10 characters = 100
Prim_name for 15 characters = MAIN
Suffix for 6 characters = ST
Sec_range for 6 characters = 5
ZIP for 5 characters = 55424
Actual Key = GEORGE F HAYES 100 MAIN ST 5 55424
Chapter 2: Record matching overview
21
Page 22

Match sets represent a match strategy
When you set up your matching criteria, which determines whether two records
will match, you define your matching strategy. Match/Consolidate collects the
records that it compares using this match strategy into a match set.
Match Consolidate can evaluate more than one match set; however, this is an
advanced feature. For more information, refer to “Advanced matching” on
page 219. If you have defined only one match strategy in your Match Consolidate
job, then MCD automatically creates the match set. Once the key data is
assembled for MCD, it can move to the next process: finding matching records.
22
Match/Consolidate User’s Guide
Page 23

Find matching records
Summary of the matching process
Once MCD has read your input records and created
the key file, it performs the next main processing
step—finding matching records. For detailed
information about matching, refer to “Engineer
your match setup” on page 195.
1. Prepare your files for
Match/Consolidate
2. Set up your Match/
Consolidate job
3. Read records and
create Match Sets
4. Find matching records
5. Process the match
results
Normally, the match process step involves these three phases:
1. Match/Consolidate places records into small groups to avoid comparing
records that have no reasonable likelihood of matching. This process is often
referred to as forming break groups or sorting keys.
2. Next, MCD compares each key of a specific group to every other key in that
group. When two or more keys match, MCD identifies their records as
members of a dupe group—a duplicate record group. Note that the number of
records in a dupe group can vary widely, depending on the quality of your
data and your matching setup.
3. Then MCD sorts the keys of each group, to prioritize them and to categorize
each record as a unique record, or a master or subordinate “dupe.”
Raw Data Match Key
Name_Line1 = George F Hayes First_name for 8 characters = GEORGE
Address = 100 Main St #5 Mid_name for 3 characters = F
Last_line = Edna, MN 55424 Last_name for 10 characters = HAYES
Prim_range for 10 characters = 100
Prim_name for 15 characters = MAIN
Suffix for 6 characters = ST
Sec_range for 6 characters = 5
ZIP for 5 characters = 55424
Actual Key = GEORGE F HAYES 100 MAIN ST 5 55424
For the records of a break group, MCD assigns each to a group of records that it
has determined to match each other and then ranks each record within that dupe
group.
Chapter 2: Record matching overview
23
Page 24

Process the match results
After MCD has determined which records match,
you need to have MCD do something productive
with its conclusions. Normally, that something will
be one of the following:
Purge the input file.
Create a new output file.
Update existing records.
1. Prepare your files for
Match/Consolidate
2. Set up your Match/
Consolidate job
3. Read records and
create Match Sets
4. Find matching records
5. Process the match
results
Whichever outcome you want, MCD checks each record of the job, one after
another. Match/Consolidate acts on the record based on the results of the
matching process and your choice of processing options.
For details about input and output files, refer to “Purge input files or create output
files” on page 61.
Choose an output For detailed information about available options, refer to “Purge input files or
create output files” on page 61. For your jobs, your job process will likely make
obvious what you need from MCD.
The most common use of MCD is to use the results of your MCD job to produce
one of the following two output files. The introductory sample job that we
provide with MCD (quikunix.mpg or quikwin.mpg) is set up to produce the
MCD output file.
The MCD output file contains all the unique records as well as all master
records (master dupes). This type of output file could be used as a mailing
list.
The All Duplicates output file contains all the records that matched any
others. It will include all the records that were members of all the dupe
groups, but none of the unique records. This file might be used in further
database maintenance activities, or quality control functions. This type of
output file might have other uses, as well (refer to “Output file” on page 64).
24
Match/Consolidate User’s Guide
Page 25

Match/Consolidate features
When you're done with your first, introductory job, you’ll probably be ready to
learn more about some of the features that you can incorporate in your MCD jobs,
s u c h a s l i s t s a n d d a t a p o s t i n g . H e r e ' s w h e r e y o u ' l l f i n d t h e s e s u b j e c t s i n t h i s g u i d e :
Task MCD feature Page
number
Categorizing input records by source or
Lists 27
field value
Logically including or excluding
records, based on field data
Consolidating or copying data among
Filters
28
Functions
Group posting 147
matching (duplicate) records
Tracking what happens to (or with)
Super lists 41
records from various sources
Selecting the highest quality records
for output
Multi-Level matching
Match sets
Combined match set
Nth select
Custom sorting
224
228
236
224
72
You’ll probably also want to learn about these features.
Task MCD feature Page
number
Finding more matching records Key data 172
Speeding up the match process Break groups 188
Controlling the match process Standard matching
Extended matching
Advanced matching
Identifying the best of the matching
records
Ranking or prioritizing
records
Chapter 2: Record matching overview
165
171
170
48
25
Page 26

26
Match/Consolidate User’s Guide
Page 27

Chapter 3:
Define your input files and lists
This chapter describes how to define your input. In this chapter, we explain how
to define and limit files to be used as input, how to re-use already processed files,
as reference files, and how to characterize records through the use of input lists.
Match/Consolidate (MCD) uses the words file and list interchangeably. Even if
you do not set up lists, MCD considers each input file a list.
Chapter 3: Define your input files and lists
27
Page 28

Input files and lists
Terms The following table describes the various input files and lists.
Term Description
Input file Your records. The database you want MCD to process.
Reference file A re-usable file that results from MCD reading input records.
List A grouping of records based on a common data characteristic.
Normal list A list of records that MCD should consider to be eligible records.
Suppression list A list of records MCD uses to prevent matching records of other lists
from being sent to the output.
Special list A list of records that should be treated as transparent, like seed lists.
They are not counted in determining how to characterize a match
group—for example, multi-list or single-list.
Super list A group of lists. For example, a super list may be comprised of three
lists rented from one broker.
Set up your lists The following list summarizes how to set up lists using the MCD Job-File
and Views.
Input files and Reference files — Set up an input file block for each file you
want included in this job.
Lists — In your DEF file, define PW.List_ID. To manually set up lists, set up
one input list description block for each list. To automatically generate lists,
use the Input List Default block.
Select records based on a value in a field — In the DEF file, define
PW.List_ID as the field containing your list identification data. For example,
if you have a database field named List_Code that contains a useful value,
use PW.List_ID = List_Code.
Select records based on any criteria — In the Input List Description section of
your job, specify your selection criteria at the List Filter parameter.
28
Match/Consolidate User’s Guide
Page 29
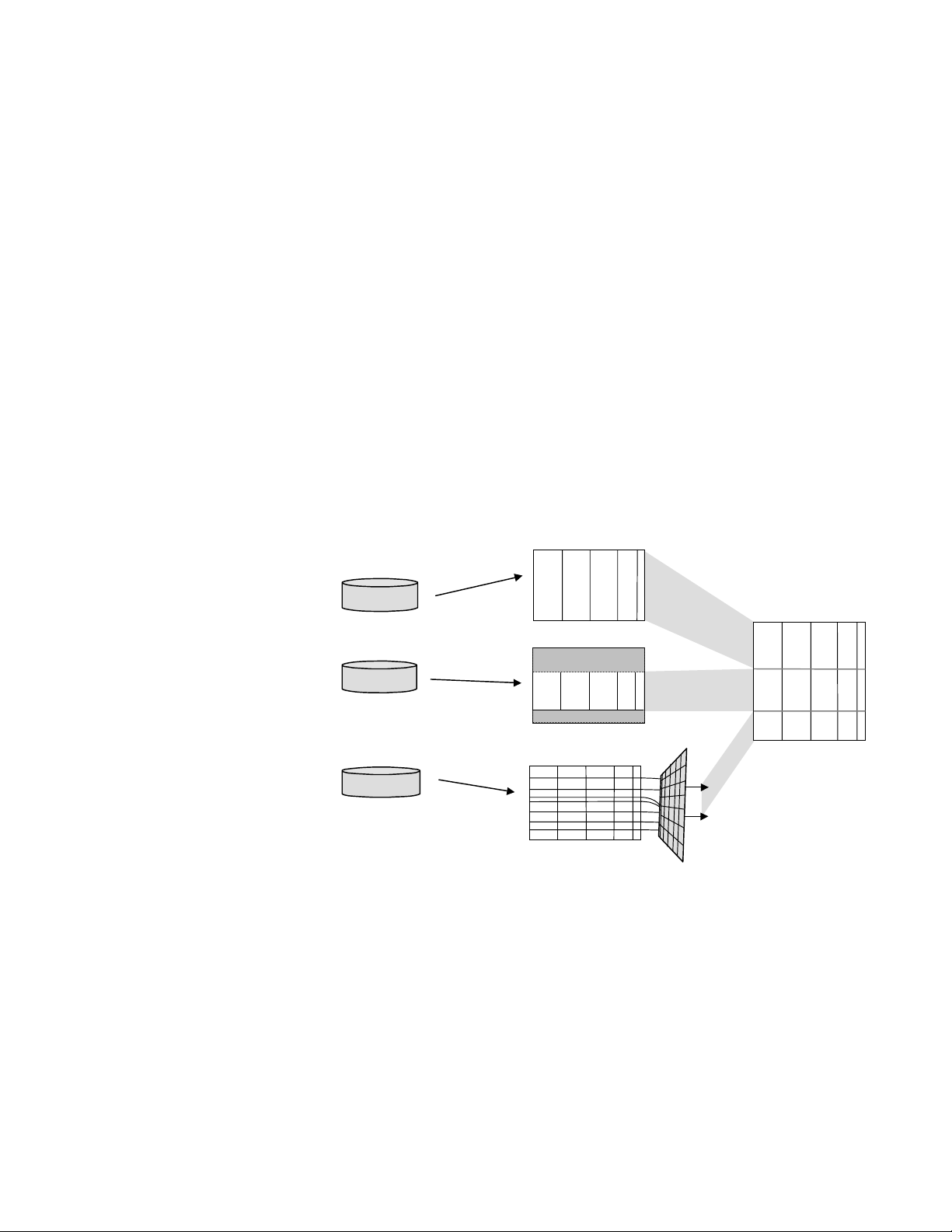
Input files
J
J
M
Before MCD can decide whether or not two records match, it must read those
records from your database file(s) and convert them into key data. Identify all
files that you want included in your MCD job.
Determine which input file records to include
Match/Consolidate processes records from your input files one at a time. First it
decides whether the record should be included in the job—perhaps the record has
been marked for deletion, for example. Or perhaps you want to limit the number
or type of records to use from an input file. You can set file by file limits on which
records should be used with these methods:
A starting record number.
A maximum number of records from the input file.
Filters that apply to records of this input file. Filters are formal, logical
statements that MCD can act on as it reads your input record. For example,
you might want to exclude or filter out any record that is not from a particular
state. Refer to filter information in the Quick Reference.
An input processing exit function.
OHN CASILLO CONSOLIDAION BEVERAGE 12 SAINT MARK ST AUBURN
MA0150 1
ROBERT BRHDLEY WT. BRHDLEY & SO NS ENTER PRISE 61 SUMMIT AV E SOUTH ADAMS
MA0124 7
JOSEPH INE LAME R NEC INFORM ATIN SYS TEMS 1414 MASSACH USETTS AVE BOXBOR O
MA0171 9
MR BILL HANDRICH HELENA CHEMICAL CO PO BOX 220 HATFIELD
MA0103 8
MR GREG HA MMOND, MGR CUST RE L LISTA IN TERNAT IONAL 106 LOWL AND ST HOLLIS TON
MA0174 6
MARY PET ERS UNIVERSAL PL ASTICS CORP 165 FRONT ST CHICOPEE
MA0101 3
HECTOR R RODRIGU EZ IMPRESOS ALF A AVE DEGETAU A- 7 SAN ALFO NSO CAGUAS PR
CONSTA NSA F FOST ER TRAULSEN & CO IN C PO BOX 169 COLLEGE PO INT
NY1135 6
TIM GLAZ E SHEPHERD INTELLI GENCE SY STEMS 35 8 BAKER AV E CONCORD
MA0174 2
CLAIRE MONAHAN ASTRA PHARM PR ODUCTS 50 OTIS ST WESTBO ROUGH
MA0158 1
ROBERT FINE AMERICAN BILTRITE INC PO BOX 6146 TRENTON
NJ0864 8
S DONGEL O ACCO SWING LINE 151 RADD IN RD GROTON
MA0145 0
MR MOE L CUR LY, SLS SU PV ROBERTS DIST RIBUTI NG CORP 372 PASC O RD SPRINGFIEL D
MA0111 9
input file
No limits; use al l records
input file
Start at #100
Maximum 3000
input file
Use records that pass the
filter; don’ t use the rest
LANCE R DU NHAM DIR ANGIOG RAPHIC DEVICES CORP 232 TAYLOR ST LITTLETON
MA0146 0
MR PETER BEYETTE BROOKFRONT MEDICAL SERVICES 1459 NIAGARA FALLS BLVD BUFFALO
NY1422 8
JAY SPUT NIK- MGR YANKEE AJO EIC ELEC CO 580 MAIN ST BOLTON
MA0174 0
JAN PAIN TER LUCAS GRASON STADLER INC 537 GREAT RD LITTLETO N
MA0146 0
BERNIE VITTI SANDOZ 59 ROUTE 10 EAST HANOVER
NJ0793 6
LUIS PABON MILES PUERTO RICO INC CALL BOX 11848 SAN JUAN PR
KAREN MC FADDEN VP ROCHE BI OMEDIC AL LAB 17 WALDR ON AVE GLEN ROC K
OHN CASILLO CONSOLIDAION BEVERAGE 12 SAINT MARK ST AUBURN
MA0150 1
ROBERT BRHDLEY WT. BRHDLEY & SONS ENTERPRISE 61 SUMMIT AVE SOUTH ADAMS
MA0124 7
JOSEPHINE LAMER NEC INFORMATIN SYSTEMS 1414 MASSACHUSETTS AVE BOXBORO
MA0171 9
MR BILL HANDRICH HELENA CHEMICAL CO PO BOX 220 HATFIELD
MA0103 8
MR GREG HA MMOND, MGR CUST RE L LISTA IN TERNAT IONAL 106 LOWL AND ST HOLLIS TON
MA0174 6
MARY PET ERS UNIVERSAL PL ASTICS CORP 165 FRONT ST CHICOPEE
MA0101 3
HECTOR R RODRIGU EZ IMPRESOS ALF A AVE DEGETAU A- 7 SAN ALFO NSO CAGUAS PR
CONSTA NSA F FOST ER TRAULSEN & CO IN C PO BOX 169 COLLEGE PO INT
NY1135 6
TIM GLAZ E SHEPHERD INTELLI GENCE SY STEMS 35 8 BAKER AV E CONCORD
MA0174 2
CLAIRE MONAHAN ASTRA PHARM PR ODUCTS 50 OTIS ST WESTBO ROUGH
MA0158 1
ROBERT FINE AMERICAN BILTRITE INC PO BOX 6146 TRENTON
NJ0864 8
S DONGELO ACCO SWINGLINE 151 RADDIN RD GROTON
MA0145 0
MR MOE L CUR LY, SLS SU PV ROBERTS DIST RIBUTI NG CORP 372 PASC O RD SPRINGFIEL D
MA0111 9
LANCE R DU NHAM DIR ANGIOG RAPHIC DEVICES CORP 232 TAYLOR ST LITTLETON
MA0146 0
MR PETER BEYETTE BROOKFRONT MEDICAL SERVICES 1459 NIAGARA FALLS BLVD BUFFALO
NY1422 8
JAY SPUT NIK- MGR YANKEE AJO EIC ELEC CO 580 MAIN ST BOLTON
MA0174 0
JAN PAIN TER LUCAS GRASON STADLER INC 537 GREAT RD LITTLETO N
MA0146 0
BERNIE VITTI SANDOZ 59 ROUTE 10 EAST HANOVER
NJ0793 6
LUIS PABON MILES PUERTO RICO INC CALL BOX 11848 SAN JUAN PR
KAREN MCFADDEN VP ROCHE BIOMEDICAL LAB 17 WALDRON AVE GLEN ROCK
NJ0745 2
MAUREEN DABERNARDI BRADFORD FURNITURE 23 BRADFORD ST CONCORD
MA0174 2
JOHN CASILLO CONSOLIDAION BEVERAGE 12 SAINT MARK ST AUBURN
MA0150 1
ROBERT BRHDLEY WT. BRHDLEY & SONS ENTERPRISE 61 SUMMIT AVE SOUTH ADAMS
MA0124 7
JOSEPHINE LAMER NEC INFORMATIN SYSTEMS 1414 MASSACHUSETTS AVE BOXBORO
MA0171 9
MR BILL HANDRICH HELENA CHEMICAL CO PO BOX 220 HATFIELD
MA0103 8
MR GREG HA MMOND, MGR CUST RE L LISTA IN TERNAT IONAL 106 LOWL AND ST HOLLIS TON
MA0174 6
MARY PET ERS UNIVERSAL PL ASTICS CORP 165 FRONT ST CHICOPEE
MA0101 3
HECTOR R RODRIGU EZ IMPRESOS ALF A AVE DEGETAU A- 7 SAN ALFO NSO CAGUAS PR
CONSTA NSA F FOST ER TRAULSEN & CO IN C PO BOX 169 COLLEGE PO INT
NY1135 6
TIM GLAZ E SHEPHERD INTELLI GENCE SY STEMS 35 8 BAKER AV E CONCORD
MA0174 2
CLAIRE MONAHAN ASTRA PHARM PR ODUCTS 50 OTIS ST WESTBO ROUGH
MA0158 1
ROBERT FINE AMERICAN BILTRITE INC PO BOX 6146 TRENTON
NJ0864 8
S DONGELO ACCO SWINGLINE 151 RADDIN RD GROTON
MA0145 0
R MOE L CURLY, SLS SUPV ROBERTS DI STRIBU TING COR P 372 PASCO RD SPRINGFI ELD
JOHN C ASIL LO CONS OLID AION BEV ERAG E 12 SAI NT M ARK ST AUBU RN
MA0150 1
ROBERT BRHDLEY WT. BRHDLEY & SO NS ENTER PRISE 61 SUMMIT AV E SOUTH ADAMS
MA0124 7
JOSEPH INE LAME R NEC INFORM ATIN SYS TEMS 1414 MASSACH USETTS AVE BOXBOR O
MA0171 9
MR BIL L HA NDRI CH HELE NA C HEMI CAL CO PO BOX 220 HATF IELD
MA0103 8
MR GREG HA MMOND, MGR CUST RE L LISTA IN TERNAT IONAL 106 LOWL AND ST HOLLIS TON
MA0174 6
MARY PET ERS UNIVERSAL PL ASTICS CORP 165 FRONT ST CHICOPEE
MA0101 3
HECTOR R RODRIGU EZ IMPRESOS ALF A AVE DEGETAU A- 7 SAN ALFO NSO CAGUAS PR
CONSTA NSA F FOST ER TRAULSEN & CO IN C PO BOX 169 COLLEGE PO INT
NY1135 6
TIM GLAZ E SHEPHERD INTELLI GENCE SY STEMS 35 8 BAKER AV E CONCORD
MA0174 2
CLAIRE MONAHAN ASTRA PHARM PR ODUCTS 50 OTIS ST WESTBO ROUGH
MA0158 1
ROBERT FIN E AMER ICAN BIL TRIT E IN C PO BOX 614 6 TREN TON
NJ0864 8
S DONGEL O ACCO SWING LINE 151 RADD IN RD GROTON
MA0145 0
MR MOE L CUR LY, SLS SU PV ROBERTS DIST RIBUTI NG CORP 372 PASC O RD SPRINGFIEL D
MA0111 9
LANCE R DU NHAM DIR ANGIOG RAPHIC DEVICES CORP 232 TAYLOR ST LITTLETON
MA0146 0
MR PETER BEYETTE BROOKFRONT MEDICAL SERVICES 1459 NIAGARA FALLS BLVD BUFFALO
NY1422 8
JAY SPUT NIK- MGR YANKEE AJO EIC ELEC CO 580 MAIN ST BOLTON
MA0174 0
JAN PAIN TER LUCAS GRASON STADLER INC 537 GREAT RD LITTLETO N
MA0146 0
BERNIE VIT TI SAND OZ 59 ROU TE 1 0 EAST HAN OVER
NJ0793 6
LUIS PAB ON MILES PU ERTO RIC O INC CALL BOX 11848 SAN JUAN PR
KAREN MC FADDEN VP ROCHE BI OMEDIC AL LAB 17 WALDR ON AVE GLEN ROC K
NJ0745 2
MAUREE N DA BERN ARDI BRAD FORD FUR NITU RE 23 BRA DFOR D ST CONC ORD
MA0174 2
JEANNE WEINTRA UB, MKTG COORD CHAN NING L BET E CO 200 STAGE RD SOUTH DEER FIELD
MA0137 3
MR BRADF ORD W PHOE NIX H M SPENCE R INC BOX 1403 0 HOLYOKE MA
MS SUZAN NE MC KIER NAN THE HANO VER INSU RANCE CO MPA 100 SOUT H ST WORCESTER
MA0160 5
AL DIGRE GORION SON AAA WATER QUAL ITY SYST EMS 154 CENTRA L ST SOUTHBRI DGE
MA0155 0
DENNIS R MILLS SCOTT CA STINGS CORP 461 TONAWA NDA ST BUFFALO
NY1420 7
All input records
Parse data from the input file
When it reads your input record, MCD identifies specific parts of your input
records, such as first name, last name, address, city, and so on. This is called
parsing. Later chapters explain the various parsing options.
The parsing process is only for internal program use, to improve the detection of
matching records. Match/Consolidate stores parsing results in working files that
MCD will use in creating the key file. Parsing does not actually change the data in
your input file, nor does it affect the data that will be in your output file (if you
choose to create one). For more information about matching records, refer to
“Find matching records” on page 23.
Chapter 3: Define your input files and lists
29
Page 30

Re-use processed input (key data) with reference files
A reference file is a specialized work file that contains all the key data for an
input file. Create the reference file during your first MCD process. For
subsequent passes, MCD uses that reference file as the input data instead of using
its associated input file.
Reference files are controlled by settings (parameters) of the Input File block of
your MCD job setup. Refer to the Job-File Reference manual for details about
how to create them or use them.
When you can use a reference file rather than an input file, you save the time that
would have been spent repetitively reading input data and creating key files. As
such, reference files can be a valuable substitute for large, frequently-used input
files, such as mailer suppression lists.
For example, many mailers use the DMA’s MPS file, which lists about 3 million
people who don't want to receive direct mail. Including this file as input
suppresses these people from appearing on any mailing list produced by the MCD
job.
When using reference files, you can change your matching and breaking setup in
subsequent MCD passes or jobs. However, you must stay within the bounds of
the key data that was captured when the reference file was created. The reference
file can’t accommodate changes in the key data, or changes in list or input filter
restrictions that apply to that file.
Lists and priorities Reference files inherit from their input file the settings that are used in their
corresponding input lists. (Lists are explained later in this chapter; priorities are
explained in the following chapter.) Therefore, a reference file would have to be
regenerated if your job includes the following:
List_ID — Changing to different List_ID field values. A reference file
inherits the List_ID of its input file, whether the List_ID is defined in the
DEF file as a constant or as a field. If the input file has no List_ID, then
neither will the reference file.
Priority field — Changing the priority field to a different field.
When you produce a reference file, generate the Job Summary report, for a record
of all the relevant job settings, and include any options that you may want to
include in jobs using this reference file.
Purge an input file When your MCD job includes input posting or group posting during an input file
purge, MCD will post to both the input file and its associated reference file. For
details about input file purging with reference files, refer to “Purge the input file”
on page 65.
30
Match/Consolidate User’s Guide
Page 31

Group your records with lists
A list is the grouping of records on the basis of some data characteristic that you
can identify. A list might be all records from one input file, or all records that
contain a particular value in a particular field.
Lists are abstract and arbitrary—there is no physical boundary line between lists.
List membership can cut across input files as well as distinguish among records
within a file, based on how you define the list.
Your MCD job can include up to 2,000 lists. However, if you are willing to treat
all your input records as normal, eligible records with equal priority, then you do
not need to include lists in your MCD job.
Typically, a MCD user expects some characteristic or combination of
characteristics to be significant, either for selecting the best matching record, or
for deciding which records to include or exclude from the job output. Lists enable
you to attach those characteristics to a record, by virtue of that record’s
membership in its particular list.
Before getting to the details about how to set up and use lists, here are some of the
many reasons you might want to include lists in your job:
To give one set of records priority over others. For example, you might want
to give the records of your master file priority over the records from an
update file. For more information, refer to “Prioritize or suppress records
based on list membership” on page 52.
To identify a set of records that MCD uses to exclude other records from the
output of your job. These are suppression-list records. For more information,
refer to “Prioritize or suppress records based on list membership” on page 52.
To set up a set of records that should not be counted toward multi-buyer
status. For example, some mailers use a seed list of potential buyers who
report back to the mailer when they receive a mail piece so that the mailer
can measure delivery. These are special-type records.
To save processing time, by canceling the dupe search within a set of records
that you know contains no matching records. In this case, you must know that
there are no matching records within the list, but there may be matches
among lists. To save processing time, you could set up lists and cancel
searching within each list.
To get separate report statistics for a set of records within an input file, or to
get report statistics for groups of lists. Refer to “Statistics files” on page 84
for details about report statistics and “Use super lists for report data” on
page 91 for details about super lists.
Chapter 3: Define your input files and lists
31
Page 32

Use lists to control the matching process
This chapter focuses on lists, rather than on the matching process. Because of
that, we’ll concentrate here on how to set up your lists, how to establish their list
properties (see the table below), and, in general, what those properties do. For
instruction about how to fine-tune your match setup with these and other controls,
Refer to Chapters 8, 9, 10, and 11 of this guide.
For each list, you can set the properties (or characteristics) shown in the table
below. Each record of the list then assumes those characteristics as they are set for
the list. When MCD deals with a record, its list settings affect the results as shown
below. The following pages provide details about each of these settings.
Setting Effect on matching
List Type MCD includes three types of lists; normal, suppress, and spe-
cial. In the matching process, a record is treated differently,
depending on its type (refer to page 33).
Dupe Search Within
This List
List Break Priority You can direct MCD to prefer records of certain lists to be the
List Match Priority You can direct MCD to prefer records of certain lists to
Suppress Apply Blank
Priority
Perform Data Salvage You can independently control data salvaging in comparisons
Use List to
Assign New ID
If you know a record has no matches within the records of its
list, you can direct MCD to exclude this record from the search
for duplicates within this list, but continue to search for duplicates among records from other lists. This can save processing
time (refer to page 35).
driver records for comparisons (refer to page 36).
become the master record from among matching records.
You can independently control whether MCD uses or ignores
blank priority for suppression-list records.
with any type of list (refer to “Fine-tune your matching pro-
cess” on page 218).
This lets you generate a value for AP.ID_INC_NO on a per-list
basis. You might want to enable/disable generating a value for
AP.ID_INC_NO if some incoming records already have a valid
ID and you do not want to assign them a new one.
32
Match/Consolidate User’s Guide
Page 33

List types
Match/Consolidate lets you identify each list as one of three different types:
Normal, Suppression, or Special. Match/Consolidate can process your records
differently depending on their list type.
List Description
Normal A list of records that MCD should consider to be good, eligible records.
Suppression A list of records that should not be used. A list of records MCD uses to
prevent matching records of other lists from being sent to the output.
Special A list of records that should be treated as transparent, such as seed lists.
They are not counted in determining how to characterize a match
group—for example, multi-list or single-list.
The reason for identifying the list type is to set that identity for each of the
records that are members of the list. List type plays an important role in how
MCD processes matching records (the members of dupe groups) and how MCD
produces output (that is; whether it includes or excludes a record from its output).
If Match/Consolidate sets the list type
If you elect to have MCD automatically generate lists from your PW.List_ID
fields, then you can also have MCD set the list type for each list. Here are your
alternatives:
If you’d like all the records of a file to have the same list type, you can add a
PW.List_Type entry to the file’s definition (DEF) file.
If types of records are mixed in your input file, and if the list type is stored in
one of the database fields, then you can use that field to identify each record’s
type to MCD. In the file’s definition file, set PW.List_Type to that database
field.
The first letter of the contents of that field must be N, P, or S (for Normal,
Suppress/Purge, and Special).
Chapter 3: Define your input files and lists
33
Page 34

If you set the list type If you elect to manually set up your list(s), assign the list type in your Setup Input
List block. Refer to “Prioritize and suppress records” on page 47 for information
about how the list type affects ranking and suppression of records.
Note that if MCD cannot assign a
list based on the PW.List_ID as
explained on the previous page, it
assigns the list according to the
undetermined list options setting in
the Input List Defaults.
Note also that if 2000 lists have
already been automatically
generated, any records that cannot
be assigned to one of those 2000
are also assigned from the Input
List Defaults.
34
Match/Consolidate User’s Guide
Page 35

Dupe search within this list
Your job may include some records that you are certain have no matching records
within their list. For example, you may have an input file that has already been
de-duped by processing it with MCD.
For these records, any time that MCD spends looking for matching records within
already de-duped records is wasted time. This list property enables you to avoid
wasting that time by directing MCD to not search for duplicate records within this
list.
If Match/Consolidate sets the list type
If you elect to have MCD automatically generate lists from your PW.List_ID
fields, then you can also have MCD set this dupe search value for each list. Here
are your alternatives:
If you’d like all the records of a file to be treated the same way in terms of the
dupe search, you can add a PW.List_Srch entry to the file’s definition (DEF)
file, either Y or N (for Yes or No).
If your input file contains a mix of records; some of which should be
included in the search for duplicates and others which should be excluded;
then you may be able to use a database field to identify each record’s dupe
search status to MCD. In the file’s definition file, set PW.List_Srch to that
database field.
The first letter of the contents of that field must be Y or N (for Yes or No).
When MCD performs the duplicate search process for a record whose
PW.List_Srch value is Y, it will compare that record to other records of its
list. However, for records with a PW.List_Srch value of N, the comparison
process will ignore the other records of its list.
If MCD cannot assign the value based on the PW.List_Srch as explained above, it
assigns the default value from the Input List Defaults.
If you set up the lists If you elect to manually set up your list(s), set list search in the Setup Input List
block of your MCD job.
Chapter 3: Define your input files and lists
35
Page 36

List Break Priority
By assigning a break priority value to a list, you can influence which record of a
break group is identified as the driver record for the record comparisons during
the duplicate detection process.
The driver record is the record to which others are compared during the duplicate
detection process. There are various reasons why you may want MCD to use the
records of a particular list (or lists) as driver records. For example, you may want
your best records driving the matching process.
The details of the matching process are complex, and the selection of the driver
record can affect the results. For details about the driver record and how the
comparisons are made, refer to “Comparisons start with the driver record” on
page 196.
If Match/Consolidate sets the list break priority
If you elect to have MCD automatically generate lists from your PW.List_ID
fields, then you can also have MCD set the break priority value for each list. Here
are your alternatives:
If you’d like all the records of a file to have the same break priority, you can
add a PW.Driv_Prior entry to the file’s definition (DEF) file.
If your input file contains a mix of records, which reflect differences in how
the records should be prioritized as drivers, then you may be able to use a
database field to identify each record’s break priority status to MCD. In the
file’s definition file, set PW.Driv_Prior to that database field.
The contents of that field must be a number from 0 to 255. When MCD
processes the records within the break group, it uses the value it finds in that
field for each record. Keep in mind that the lower the number, the higher the
priority.
If MCD cannot assign the value based on the PW.Driv_Prior as explained above,
it assigns the default value from the Input List Defaults.
If you set the list type If you elect to manually set up your list(s), set the break priority value in the
Setup Input List block of your MCD job.
36
Match/Consolidate User’s Guide
Page 37

Three approaches to defining lists
There are three different approaches to use in defining lists. You can use any or all
these approaches within your MCD job.
Treat an entire input file as a list
Link PW.List_ID to an input file
A common way of defining lists is to treat
each input file as a list. For example,
suppose your job includes a master file
Master file
Master List
and two update files.
In such a case, you may prefer to use the
records of your master file over any
Update file 1
Update 1
matching records from your updated files.
That is, if records from different files
match, you may want MCD to use your
house record instead of a updated record.
Update file 2
Update 2
To do this, define each input file as a list
and set each list’s priority so that MCD will prioritize your house records over
those of the updated lists.
First, you’ll need to establish a constant value in the input file’s definition (DEF)
file. For example, if you intend that all the records of input file acme.dbf be
considered members of a list, then in the acme.def file, set PW.List_ID to a
constant value, such as “house.” The quotation marks around “house” mark it as a
constant rather than a field in the output file.
DATABASE TYPE = DBASE3
NAME_LINE = NAME
FIRM = COMPANY
ADDRESS = ADDRESS
LAST_LINE = CITY&STATE&ZIP
list_id = “house”
Set your job for the PW.List_ID
For more information about DEF files, refer to your Database Prep manual.
Then, in addition, you’ll need to set your job to recognize and act on that List_ID.
You can set MCD to automatically generate lists from List_ID values, and you
can also manually control all or part of the list generation process.
To have MCD automatically generate lists from List_ID values, turn on the Auto
Generate… control of the Input List Defaults block. To manually control what
lists are generated, turn that control off and set up an Input List block for each list
you want to use.
Chapter 3: Define your input files and lists
37
Page 38

The result of this approach is that MCD generates a list for the records of each
L
L
L
input file, as shown below:
Select records based on a value in a field
Input file
Input file
Input file
ist_ID = “house”
ist_ID = “rentA”
ist_ID = “rentB”
List: house
List: rentA
List: rentB
But suppose you don’t want all the records of an input file to belong to the same
list. Instead, you have records of three different lists together in one file. In this
case, you can use the value in one of your database fields to identify the list to
which each record belongs.
For example, for an input file acme.dbf, with a List_Code database field that
contains a value of A, B, or C, that database field value can be used to identify the
list to which this record belongs.
This approach is not limited to just one input file. The same lists, or
additional ones, as well, can be set up for additional input files.
Link PW.List_ID to the field
Set your job for the PW.List_ID
First, identify the significant field in the input file’s definition (DEF) file. From
the example above, set PW.List_ID to the List_Code field.
DATABASE TYPE = DBASE3
NAME_LINE = NAME
FIRM = COMPANY
ADDRESS = ADDRESS
LAST_LINE = CITY&STATE&ZIP
list_id = lst_code
For complete information about DEF files, refer to Database Prep.
Set your job to recognize and act on the value of that List_ID. You can set MCD
to automatically generate lists from List_ID values, and you can also manually
control all or part of the list generation process.
To have MCD automatically generate lists from List_ID values, enable the Auto
Generate List from List_ID control of the Input List Defaults block. To manually
control what lists are generated, turn that control off and set up an Input List
block for each list you want to use. In this case, you’d need a list for each
predicted value that this List_ID might include.
38
Match/Consolidate User’s Guide
Page 39

As a result, MCD generates a list for each different value of the List_ID field, up
L
L
L
C
to the MCD limit of 2,000 lists:
Select records based on criteria
st_Code = A
st_Code = B
Input file
st_Code =
List: A
List: B
List: C
This approach is not limited to just one input file. The same lists, or additional
ones, as well, can be set up for additional input files.
A third approach to defining lists is to establish a record’s membership in a list
based on some database-derived criteria that you design. This approach uses the
MCD filter capability.
In this approach, you create lists—that is, you define list membership—based on
the result of filters that are identified for each list. Typically, the filter sets a range
of values that qualifies a record for membership in the list. In this approach, you
need not define PW.List_ID in your DEF files; instead, you define a filter
statement for each list. Note that you cannot define List ID and use a filter to
define a list in the same list block.
For example, if your database has a field that contains an annual income value—
we’ll call that field DB.Income—you could define lists for ranges of annual
income. You might want to set three lists:
List_1 for records with an annual income below $20,000
List_2 for records with an income between $20,000 and $30,000
List_3 for records with an annual income above $30,000
Link a filter to a list Define each of these three lists with Input List blocks, and include list filters such
as those shown below. (Refer to Database Prep for complete details about filters
and functions.)
For List_1: val(DB.Income) < 20000
For List_2: val(DB.Income) >= 20000 .and. val(DB.Income) <= 30000
For List_3: val(DB.Income) > 30000
The order of your lists when using filters to define the list is important. Once a
record is assigned to a list, it is not eligible to be assigned to any other list.
Match/Consolidate assigns lists in the order of the Input List blocks. The first
filter that evaluates to true puts the record into that list. In this example, if the
List_2 filter did not include val(DB.Income) <= 30000, then the records that you
would want in List_3 would be made members of List_2, instead.
Chapter 3: Define your input files and lists
39
Page 40

When a record doesn’t fit into any list
Regardless of which approach you use to assign list membership, you need to tell
MCD what to do with records that do not belong to any defined list. This can
happen for a variety of reasons, such as a defined PW.List_ID field being blank;
field data not properly entered, or inconsistent with the list definition; or filter
data not present or useable.
For those records that do not meet the criteria for any of your defined lists, you
have three choices:
Action Description
Ignore Leave the record out of the job.
Abort Halt processing and issue an error.
Assign Default Assign the record to a list that you set as the default list.
For example, you might
elect to assign all such
“undetermined” records to a
List_4 list. If so, you would
select the Assign Default
option at the Undetermined
List control of the Input List
Defaults block, and identify
List_4 as the Default List
Name, as shown at right.
Note that the default list
must be defined with an
Input List block, as well.
40
Match/Consolidate User’s Guide
Page 41

Create groups of lists (super lists)
The super list capability adds a higher level of list management. For example,
suppose you rented several files from two brokers. You define five lists to be used
in ranking the records. In addition, you would like to see your job’s statistics
broken down by broker as well as by file. To do this, you can define groups of
lists—super lists—for each broker.
Define each super list with a Super List Description block, such as those shown
below.
Broker A
Files
Super list for Broker A
List_1
List_2
List_3
Broker B
Files
Super list for Broker B
List_4
List_5
Super lists primarily affect reports. However, you can also use super lists to select
multi-buyers based on the number of super lists in which a name occurs. This
means that you can use super list membership to control output. For details, refer
to “Use super lists to find multi-buyers” on page 75.
Bear in mind, that you cannot use super lists in the same way you use lists. For
example, you cannot give one super list priority over another, nor can you cancel
matching within a super list.
Chapter 3: Define your input files and lists
41
Page 42

Reports on your lists
Match/Consolidate includes a wide range of reports that record what the program
has done in working with your lists. These reports provide your primary insight
into how your results compare to your expectations, and they provide the clues
for making any adjustments to further improve your results.
As with the other steps of the process, study the reports that show what MCD has
done. If your results show any trends that could be improved by adjustments to
your settings, then change those settings and re-process
the job.
What reports can tell you
Reports that show input record quality
These reports provide information that you can study to determine what—if
any—adjustments you should make to your list setup, or to other aspects of your
job setup, to optimize your results. Regarding input lists, here are the sorts of
questions that you can answer with the various MCD reports: Have the records of
my lists been read and has their data been appropriately included in the job?
The Input File Summary shows the number of records in each file and the number
of records that were input. That report can also show the number of records that
were not input because they could not be identified with a list (list drops). To
show list drops, set the the Undetermined List Action option in the Input List
Defaults block to Ignore.
Input File Summary Report Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
---------------------------------------------------------------------------------------Input Gross Delete Filter List Sample Net
File Input Drops Drops Drops Drops Input
house.txt 1000 0 0 0 0 1000
mail_sup.txt 100 0 0 0 0 100
house_fm.txt 1000 0 0 0 0 1000
update_1.txt 25 0 0 0 0 25
rent_mag.txt 250 0 0 0 0 250
Totals 2375 0 0 0 0 2375
42
The Input List Summary shows
the number of input records
from each of the job’s input
lists. There are two columns to
identify those assigned by
default versus those identified
through your list identification
controls.
By correlating the file
information with the list
information, you can see
whether your records have been read, and whether the records have been assigned
to lists as you expected.
Match/Consolidate User’s Guide
Input List Summary Report Match/Consolidate x.xx
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
----------------------------------------------------- Matched Id Default Net
List Records Records Input
house 1000 0 1000
firms 1000 0 1000
no_mail 100 0 100
select 250 0 250
update 25 0 25
Totals 2375 0 2375
Page 43

Reports that show input record quality
The List Quality report can show you how well your record data was parsed. It
shows the raw numbers and percentages that reflect the name, firm, and address
quality of your records, by list. It shows you whether each list’s records were read
and parsed successfully.
The Unparsed Records report goes beyond statistics to show the content of
records that could not be parsed and the reason the records were unparsed. This
report is especially useful to "trouble-shoot" records whose dupe detection
process was affected by certain unparsed data (refer to “Match with unparsed
addresses, last lines, names, and firms” on page 208). List membership is
identified for each record on this list, as well.
Among matching records,
which records have come
from which lists?
What matching records
have been found among
and
between the lists?
List identity is on the Duplicate Records report, the Sorted Records report, and
the Unparsed Records report. As shown below on the Duplicate Records report,
for each dupe group, you can see which lists its records came from.
Duplicate Records Report Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
--------------------------------------------------------------------------------------------------------------------------Code List File Record LIST_ID NAME_LINE ADDRESS CITY FIRM
M 1 1 421 house H. V. JACOBSEN P.O. BOX C-29100 SANTA ANA
M 1 1 667 house HAROLD JACOBSEN P O BOX C-29100 SANTA ANA
*M 2 3 421 firms H. V. JACOBSEN P.O. BOX C-29100 SANTA ANA CONCEPTS
M 2 3 667 firms H V JACOBSEN P O BOX C-29100 SANTA ANA CONCEPTS
M 1 1 683 house GERALD KRYWICKI PO BOX NO 2978 SPRINGFIELD
*M 2 3 683 firms GERALD KRYWICKI PO BOX NO 2978 SPRINGFIELD CORP.
M 1 1 324 house ANGEL J RODRIGUEZ URB TERRAZAS DE GUAYNABO GUAYNABO
*M 2 3 324 firms ANGEL J RODRIGUEZ URB TERRAZAS DE GUAYNABO GUAYNABO
M 1 1 60 house GRDN HLS PLZ/1353 CARR 19 203 GUAYNABO PR
*M 2 3 60 firms GRDN HLS PLZ/1353 CARR 19 203 GUAYNABO PR
To get a clear picture of the matching that was detected within and among your
lists, you can study several different reports that were designed for exactly that
purpose.
The List by List Match report, the List Match report, and the Multi-List report
show, for each input list, how many of its records were found to match records in
the lists of the job—inter-list and intra-list matches. Each report uses a different
format, so choose the one most useful for your purposes. The List Match report—
the Summary version—is shown on the following page.
You can see the number of matches that MCD found for records that are members
of each list. If you are surprised to find no intra-list matches, check your setting of
the Search for Dupes Within This List option.
List Match Report, Summary Information
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
-------------------------------------------------------- Net Intra List Inter List Total Percent of
List Input Matches Matches Matches Net Input
house 1000 157 1190 1347 134.70
firms 1000 157 1190 1347 134.70
no_mail 100 2 222 224 224.00
select 250 1 524 525 210.00
update 25 0 0 0 0.00
Totals 2375 317 3126 3443 144.97
Chapter 3: Define your input files and lists
43
Page 44

How have my lists
affected the results—the
output—of my job?
Because lists are so important in categorizing and ranking the members of match
groups, you can use list statistics and other report information to better assess the
results of your job.
List Duplicates Report, Summary Information Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
--------------------------------------------------------------------------------------------------- List List Total Pct of Total Pct of Net
List Name List_id Type Priority Dupes Net Non Dupes Net Input
house house NORM 10 255 25.50 745 74.50 1000
firms firms NORM 20 1000 100.00 0 0.00 1000
no_mail no_mail SUPP 0 0 0.00 0 0.00 100
select select NORM 10 250 100.00 0 0.00 250
update update NORM 5 0 0.00 25 100.00 25
The List Duplicates report (Summary version shown above) shows the numbers
of records, by list, that have been designated for each match status, and will
therefore be kept or dropped as your output.
The Multi-List report, shown below, can be a very useful report when creating
multi-occurrence files. For example, if you want to create a multi-buyer file, this
report shows the number of records from each list that were matched to records
from other lists. This report shows the number of inter-list matches. Refer to
“How Match/Consolidate counts intra-list and inter-list matches” on page 88 for a
detailed explanation of inter-list and intra-list matches.
Multi-List Report Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
-----------------------------------------------------------------------------------------List Multi List 2 List 3 List 4 List 5 List 8 List
house 745 522 223 0 0 0 0
firms 0 0 0 0 0 0 0
no_mail 0 0 0 0 0 0 0
select 0 0 0 0 0 0 0
update 0 0 0 0 0 0
Totals 745 522 223 0 0 0
The Output File report shows, on a list-by-list basis, the number of records that
were included in the job’s output file(s).
Output File Report,Summary Information: C:\pw\mpg\Work\output\Out_MPG.txt Match/Consolidate Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
---------------------------------------------------------------------------------------------------Output Results for no-fee
Net List List Filter Pct of Net Pct of
List Name Input List_id Type Priority Drops Net Input Output Net Input
house 1000 house NORM 10 0 0.00 745 74.50
firms 1000 firms NORM 20 0 0.00 0 0.00
Totals 2000 0 0.00 745 37.25
Totals 2000 0 0.00 745 37.25
(Including Suppression Records and After Filter)
44
If your job includes an input purge, the Purge by List report will show, on a listby-list basis, the number of records that were purged, or marked for deletion. The
following example shows a report generated for a job that predicted a purge,
rather than performing it. For more information, see “Predict a purge” on page 66.
Match/Consolidate User’s Guide
Page 45

Purge By List Report, Detail Information (PREDICTION) Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
--------------------------------------------------------------------------------------------------------------------------------- Single Multiple Single Multiple Suppress Suppress Suppress
Net Filter Suppress List List List List List List List
List Name Input Drops Dupes Dupes Dupes Uniques Masters Masters Uniques Masters Subord
house 1000 0 125 0 130 0 0 0 0 0 0
firms 1000 0 125 0 875 0 0 0 0 0 0
no_mail 100 0 0 0 0 0 0 0 0 0 0
select 250 0 27 0 223 0 0 0 0 0 0
update 25 0 0 0 0 0 0 0 0 0 0
Totals 2375 0 277 0 1228 0 0 0 0 0 0
Chapter 3: Define your input files and lists
45
Page 46

46
Match/Consolidate User’s Guide
Page 47

Chapter 4:
Prioritize and suppress records
This chapter explains how to control the ranking of records within groups of
matching records (dupe groups). Ranking of records affects which records will be
master records and which records will be grouped to other records.
Chapter 4: Prioritize and suppress records
47
Page 48

Record priorities and types
Terms This chapter focuses on the ranking of matching records. Match/Consolidate
(MCD) ranks records within a group after assigning matching records to a dupe
group. The following tables list general terms used throughout this chapter, and
the categories into which you can rank records.
Term Description
Priority The ranking of records within a match group. The record that has the highest priority in a match
group becomes the master duplicate. You can rank records according to list membership, completeness, the contents of a particular field, or randomly.
The ranking of record keys within a break group. The higher the ranking, the more likely that the
record key will become a driver record for match comparisons. Within break groups, records can be
ranked only by List Break Priority.
The score a record receives to determine its rank. Priority is scored on a penalty system. The fewer
penalty points a record receives, the higher its priority.
The lower the score, the higher the priority.
Record (match key) In this chapter, when we use the term
a record. The match key usually does not contain the entire data from a record.
Suppression list
(Suppress-type list)
Suppression record A record that came from a suppression list.
Master dupe The highest ranking member of a match (dupe) group.
Subordinate dupe Any member of a match (dupe) group which is not the highest ranking member.
Term Description
Suppression list dupe Subordinate member of a dupe group that includes a higher-priority record that came from a
Single list dupe Subordinate members of a dupe group whose members all came from the same list. These can be
Multiple list dupe Subordinate members of a dupe group whose members came from two or more lists. These can be
Unique record Records that are not members of any dupe group. No matching records were found. These can be
A list of records MCD uses to prevent matching records of other lists from being sent to the output.
For example, this might be delinquent accounts or consumers who have requested suppression of
advertising mail. For information about other list types (normal and special), refer to “List types” on
page 33.
Suppress -type list. Can be from normal- or special-type list.
from lists with a normal- or special-type list.
from lists with a normal or special-type list.
from lists with a normal- or special-type list.
record
, keep in mind that we are referring to the match key for
Single list master Highest ranking member of a dupe group whose members all came from the same list. Can be from
normal- or special-type lists.
Multiple list master Highest ranking member of a dupe group whose members came from two or more lists. Can be from
normal- or special-type lists.
Suppression list unique Records that came from a Suppress-type list, and for which no matching records were found.
Suppression list master A record that came from a Suppress-type list and is the highest ranking member of a dupe group.
Suppression list
subordinate
48
Match/Consolidate User’s Guide
A record that came from a Suppress-type list and is a subordinate member of a dupe group.
Page 49

Control priority The following table summarizes the steps that may be involved in setting up
priority and suppression in your MCD product.
Product Setting priority
MCD Job and
Views Standard Matching
MCD Job
Extended Matching
List Break Priority: If manually defining lists, in the Input List Description block or window,
set a break priority number from 0 to 255. If automatically generating lists with PW.List_ID,
use PW.Driv_Prior to set the break priority. Used to determine the driver record.
List Match Priority
: In the Input List Description section, set a list match priority number from
0 to 999. To create a suppression list, set the List Type parameter to Suppress. If you are automatically generating lists with PW.List_ID, use PW.List_Prior to set the list priority.
Blank-field priority
: In the Match Criteria section, set a number from –999 to 999 as the blank
priority for a key field. This is only valid when used with blank matching.
Field priority
: In the Match Options section, set the priority to ascending or descending. In
your DEF file(s), define the priority field as PW.Priority—for example, PW.Priority=
ExpireDate.
Random priority
List Break Priority
: In the Match Options section, set random sortation to Yes.
: In the Input List Description block or window, set a break priority number
from 0 to 255.
List match priority
: In addition to the job-file setup described above, in the Prioritize Matches
section of the extended matching file, set the Type to List, Fld, List_Fld, or Fld_List.
Blank-field priority
: In the Prioritize Matches section of the Extended Matching file, set up a
Blank Priority parameter with the field name and a number from –999 to 999.
Field priority
: In the Parsing and Key Options section of the Extended Matching file, set Store
Priority Field to Yes. In the Prioritize Matches section, specify ascending or descending order
at the Priority Field Order parameter. In your DEF file(s), define the priority field as
PW.Priority.
Random priority
: In the Prioritize Matches section of the extended matching file, set Break
Priority Ties Randomly to Yes.
MCD Library
with configuration files
MCD Library
without configuration files
List Break Priority
List match priority
Blank-field priority
Field priority
List Break Priority
List match priority
Blank-field priority
Field priority
: See MP_List_Config_File (
: See MP_List_Config_File (
: See MP_List_Config_File (
: See MP_Reference_Config_File (
mplist.cfg
mplist.cfg
mplist.cfg
mpref.cfg
).
).
).
).
: Call mp_list_set_list_attr(), with MP_LIST_ATTR_BREAK_PRIORITY.
: Call mp_list_set_list_priority() with MP_LIST_ATTR_PRIORITY.
: Call mp_misc_set_blank_field_priority().
: To create a priority field, call mp_refcreate_set_option() and set a value for
MP_REFCREATE_OPTION_PRIORITY_FLD_LEN. To set the priority order to ascending
or descending, call mp_misc_set_option_info(), with
MP_MISC_OPTION_PRIORITY_FIELD_ORDER.
Chapter 4: Prioritize and suppress records
49
Page 50

Record priority and suppression
Master
d
Priority within match groups
Different types of priorities
When two records match, they are assigned to a match group, along with any
other records that were found to match the same record. In this chapter, we will
not get into any detail on the match—or dupe detection—process. A complete
explanation about matching—how MCD determines whether two records are
matches—or dupes, begins in “Record matching” on page 163.
Our focus here is how does MCD rank records within a match group. How does
MCD identify the best record from among the matching records?
After MCD finishes the search for matches and all the match
groups are formed, MCD sorts the records within each
match group. The highest ranking record in each group is
the master record. All other members of the group are
subordinate records. For most purposes, you can consider
the master record to be the best record of the dupe group.
Subordinate #1
Subordinate #2
Subordinate #3
recor
You can control how MCD sorts records within a match
group. For example, you might want to prefer records from a file you own over
records from rented lists. Or, you may want to prefer newer records over older
records, or more complete records over those with blank fields. Whatever your
preference, the way to express it to MCD is through priorities.
There are four different types of priority you can use in MCD:
Priority Brief description
Priorities are assessed in sequence
List match priority Prefer records from one input list over another.
Blank-field priority Assign a lower priority to records in which a particular field
is blank.
Field priority Rank records in ascending or descending order based on the
contents of a particular field.
Random priority To break ties, assign a random number to each record and
assign priority based on that random number. If you do not use
random priority, ties are broken in favor of the driver record,
then by input file and record number.
With standard matching, List Match Priority has precedence over Field Priority.
With standard matching, priorities work in the following sequence, or hierarchy:
1. List match priority + blank-field priority
2. Field priority
3. Random priority
However, with Extended Matching, you can reverse this precedence. For more
information, refer to the Prioritize Matches section in Chapter 2 of the Extended
Matching Reference manual.
Field priority is used only as a tie-breaker if two records have the same score for
list and blank-field priority. Likewise, random priority is used only as a tiebreaker if two records are tied for list, blank-field, and field priority.
50
Match/Consolidate User’s Guide
Page 51

Random priority Random priority is an option that assigns a random number to each record and
sorts on that random number. This means that if you run the same job twice, you
may get a different set of surviving records each time.
If you do not elect random sortation (many users do not), ties are broken in favor
of the driver record, then by input file and record number.
Suppressing and priority
In addition to preferring certain kinds of records, you can actively suppress
certain records. That is, you can take steps to exclude records from the output of
your MCD job. The way to suppress records is by identifying those records as
members of a suppression list.
In this chapter, we explain how to prioritize records both for the purpose of
preference and for the purpose of suppressing them from your results.
When using more than one input file, the results of your duplicate records
search can be compromised by the order of your input files when you elect not
to dupe search within a list. If one of your input files is a suppress-type list,
that means your output could include records that you wanted (and expected)
to be suppressed.
In general, if you are using a suppress-type list, you should dupe search within
your other lists. That will ensure that all the dupes of those lists are suppressed
when any are found to duplicate a record on the suppress list, regardless of which
record is the driver record.
If you cannot dupe search within all your lists, you may find a work-around by reordering your input files. If you can, make the input file that includes your
suppress records come ahead of the other input files (as Input File blocks in your
job file or setup). Then, assuming you have not set up list break priorities, those
suppression records will be more likely to be driver records for your match
comparisons.
Chapter 4: Prioritize and suppress records
51
Page 52

Prioritize or suppress records based on list membership
Li
Priori
List match priority You can prioritize or suppress records based on list membership.
For example, suppose you are a charitable foundation mailing a solicitation to
your current donors and to names from two rented lists. If a name appears on your
house list and a rented list, you prefer to use the name from your
house list.
Penalty scoring system
For one of the rented lists, List B, suppose also
that you can negotiate a rebate for any records
you do not use. You want to use as few records
as possible from List B so that you can get the
largest possible rebate. Therefore, you want
records from List B to have the lowest
st
House List Highest
Rented List A Medium
Rented List B Lowest
ty
preference, or priority, from among the three
lists.
When you set up your lists, you can assign priority for each list. Think of priority
as a penalty-scoring system. You assign the most penalty points to the least
desirable list, and the least penalty points to the most desirable list.
For example, suppose we want to take records from our house list first, then
rented List A, then rented List B. To do this, we’ll assign the fewest penalty
points to our house list and the most penalty points to List B:
List List match priority (penalty points)
House List 100 Fewer penalty points means higher priority.
Rented List A 200
Rented List B 300
You can assign any score between -999 and 999, using any combination of
numbers—for example, 1/2/3, 10/20/30, or 100/200/300. Assess a higher penalty
to the least desirable list, and a lower penalty to the most desirable list.
Blank-field priority List match priority interacts with blank-field priority, but we’ll explain list match
priority first. Therefore, the examples explained on the following page ignore
blank field priority. For details about blank field priority, refer to “Penalize
records that contain blank fields” on page 54.
52
Match/Consolidate User’s Guide
Page 53

Suppression lists
Li
List
often have a high
priority
In most cases, you will want suppression list records to have a high priority—that
is, a low penalty score. This makes it likely that normal records that match a
suppress record will be subordinate duplicates, and will therefore be suppressed,
as well. Within each match group, any record with a lower priority than a
suppression list record is considered a suppress dupe.
For example, suppose you
are running your files against
the DMA Mail Preference
st
DMA Suppression List 0
match priority
(penalty points)
File (a list of people who do
not want to receive
advertising mailings). You
House List 100
Rented List A 200
would identify the DMA list
as a suppression list and
Rented List B 300
assign a list match priority of
zero.
Suppose MCD found four matching records among the input records, and
therefore established the following dupe group.
Matching record (name fields only) List List match priority
Maria Ramirez House 100
Ms. Ramirez List B 300
Ms. Maria A Ramirez List A 200
Ms. Maria A Ramirez DMA 0
Based on their list match priority, MCD would rank the records as shown below,
at the right of the table. As a result, the record from the suppression file (the
DMA file) would be the master record, and the others would be subordinate
suppress dupes, and thus suppressed, as well.
Matching record (name fields only) List List match priority
Maria Ramirez House 100
Ms. Ramirez List B 300
Ms. Maria A Ramirez List A 200
Ms. Maria A Ramirez DMA 0
Chapter 4: Prioritize and suppress records
List List match priority
DMA 0 Master
House 100
List A 200
List B 300
53
Page 54

Penalize records that contain blank fields
Field Blank-field priority
Blank-field priority Given two records, you may prefer to keep the record that contains the most
complete data. You can use blank-field priority to penalize records that contain
blank fields.
Use with blank matching
Penalty scoring system
Blank-field priority is appropriate if you feel that a blank in that field shouldn’t
disqualify one record from matching another. For example, suppose you are
willing to accept a record as a match even if the prename, first name, middle
name, street suffix, or secondary range is blank. Even though you accept these
records into your match groups, you can assign them a lower priority for each
blank field.
As with list match priority, blank-field priority is a penalty-scoring system. For
each blank field, you can assess a penalty of up to 999 points.
You can assess the same
penalty for each blank field,
or assess a higher penalty for
Prename 5
(penalty points)
fields you consider more
important. For example, if
you were targeting a mailing
First name 20
Middle name 5
to college students, who
primarily live in apartments
or dormitories, you might
Street suffix 5
Secondary range (apartment) 20
assess a higher penalty for a
blank first name or
ap ar tm ent nu mbe r.
As a result, the records below would be ranked in the order shown (assume they
are from the same list, so list match priority is not a factor). Even though the first
record has blank prename, middle name, and street suffix fields, we want it as the
master record because it does contain the data we consider more important: first
name and apartment.
Prename (5)* First (20)* Middle (5)* Last Range Street Suffix (5)* Apt (20)* Blank-field
Maria Ramirez 100 Main 6 5 + 5 + 5 =
Ms. Maria A Ramirez 100 Main St
Ms. Ramirez 100 Main St 6 20 + 5 =
54
Match/Consolidate User’s Guide
penalty
15
20
25
Page 55

Blank-field priority interacts with list match priority
When records are ranked, the list match priority and blank-field priority scores
are added together and considered as one score.
Therefore, you’ll need to consider how blank-field priority and list match priority
interact. For example, suppose you want records from your house list to have
high priority, but you also want records with blank fields to have low priority. Is
list membership more important, even if some fields are blank? Or is it more
important to have as complete a record as possible, even if it is not from the house
list?
Most users want their house records to have priority, and would not want blank
fields to override that priority. To make this happen, set a high penalty for
membership in a rented list, and lower penalties for blank fields:
List List match priority
(penalty points)
Suppression List 0 Prename 5
House List 100 First name 20
Rented List A 200 Middle name 5
Rented List B 300 Street suffix 5
Rented List C 400 Apartment 20
Field Blank-field priority
penalty points)
With this scoring system, a record from the house list will always receive priority
over a record from a rented list, even if the house record has blank fields. For
example, suppose the records below were in the same match group.
Even though the house record contains five blank fields, it receives only 155
penalty points (100 + 5 + 20 + 5 + 5 + 20), while the record from List A receives
200 penalty points. The house record, therefore, has the lower penalty and
therefore the higher priority.
Priorities
List Pre First Mid Last Range Street Suffix Apt ZIP List Blank Total
House Terranova 100 Bren 55343 100 55 155
List A Ms. Rita A Terranova 100 Bren Rd 12A 55343 200 0 200
List B Rita Terranova 100 Bren Rd 12 55343 300 10 310
You can manipulate the scores to set priority exactly as you’d like. In the example
above, suppose you prefer a rented record containing first-name data over a house
record without first-name data. You could set the first-name blank-field priority
score to 500 so that a blank first-name field would weigh more heavily than any
list membership.
Chapter 4: Prioritize and suppress records
55
Page 56

Prioritize records based on the contents of one field
Sometimes you may want to prioritize records based on data in a particular field.
For example, given two matching records, you might prefer the record with the
larger donation, the larger credit limit, or the later expiration date.
For example, suppose you are consolidating a file of recent subscribers into your
database. If two records match, you want to keep the record with the later
expiration date. You can sort records in descending order by date:
Prename First Middle Last Range Street Suffix Apt ZIP Expire Date
Craig R Andrews 1234 Main St 55987 04-01-2003
Mr Craig R Andrews 1234 Main St 55987 04-01-2002
In such a situation, there are two things you must do:
1. In your DEF file(s), define the PW field Priority, based on your amount or
date field. For example, if you have an Enroll_Date database field, your DEF
field should include a line like this:
PW.Priority = Enroll_Date
2. Set Field Priority to Ascend or Descend to set the prioritize direction.
Ascending or descending
Is field priority most important?
If you are using standard matching, this setting is in the job’s Match
Options block.
If you are using extended matching, your extended matching file should
include a Prioritize Matches block.
To determine priority, you can sort records in ascending order or descending
order. When you set Field Priority to ASCEND, the sort sequence is 0-9, A-Z, az. When you set it to DESCEND, the sequence is z-a, Z-A, 9-0.
If you set priority on an amount field, select ascending order to prefer the
record bearing the lesser amount. Select descending order to prefer the record
bearing the greater amount.
If you set priority on a date field, select ascending order to prefer the record
with the earlier date. Select descending order to prefer the later date.
To be sorted correctly, numbers may have to be right-justified or pre-padded with
zeroes. For example, when sorting in ascending order, “02” comes before “10,”
but “2,” (left-justified) comes after “10”.
In the MCD job-file product, the PW.Priority field is always a character-type
field, regardless of your database field type.
With standard matching, MCD uses field priority only as a tie-breaker when two
records have the same list match priority and blank-field priority.
56
Field priority may be more important to you than list match priority or blank-field
priority. For example, you might be willing to take the record with the later
expiration date no matter which list it comes from. If so, assign the same list
match priority to all lists, and do not use blank priority. Because all records will
Match/Consolidate User’s Guide
Page 57

tie on list match priority and blank-field priority, field priority will always be used
to break the tie.
Alternatively, with extended matching, you can set the priority type so that MCD
uses the list match priority or blank field priority as a tie breaker when two
records have the same field priority.
Chapter 4: Prioritize and suppress records
57
Page 58

Reports about record ranking and priorities
Match/Consolidate has two ways to show you how it has ranked your records. To
see the records themselves, produce the Duplicate Records report. Or, to see the
numbers about the various matching and ranking categories, produce the List
Duplicates report.
Study these reports to see what MCD has done. If your results show any trends
that could be improved by adjustments to your settings, then change those
settings and re-process the job. For example, if those records chosen as master
records are not as good as the subordinate dupes, check your priorities, and, if
necessary, change them.
Duplicate Records report
Produce the PW version of the Duplicate Records report to see matching
records—that is, the records themselves—as grouped in their dupe groups. You
may not want this report to include all the dupe groups, unless there aren’t many.
But you may want to include at least a reasonable sample, so you can see lists like
the one shown below.
The master record of each dupe group is listed first, with subordinate dupes
following the master. If, to your eyes, the order within each dupe group looks
right—that is, the first record appears to be the best record—then your setup is
right, and no priority adjustments are needed. Check the list identifiers, too, as
well as the field content, because that reflects your priority settings.
Duplicate Recor ds Report Match/Conso lidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publi cations
Sample Report
--------------- --------------- ----------------- -----------------------------------------------------------------------------------------------------------------Code List Fil e Record L IST_ID NAME_LINE ADDRESS C ITY ST ZIP FIRM
M 1 1 421 h ouse H. V. JACO BSEN P.O. BOX C-291 00 S ANTA ANA CA
M 1 1 667 h ouse HAROLD JAC OBSEN P O BOX C-2910 0 S ANTA ANA CA
*M 2 3 421 f irms H. V. JACO BSEN P.O. BOX C-291 00 S ANTA ANA CA PANEL C ONCEPTS
M 2 3 667 f irms H V JACOBS EN P O BOX C-2910 0 S ANTA ANA CA PANEL C ONCEPTS
M 1 1 683 h ouse GERALD KRY WICKI PO BOX NO 2978 S PRINGFIELD MA
*M 2 3 683 f irms GERALD KRY WICKI PO BOX NO 2978 S PRINGFIELD MA HEATBAT H CORP.
M 1 1 324 h ouse ANGEL J RO DRIGUEZ URB TERRAZAS D E GUAYNABO GUAYNABO PR
M 1 1 778 house DREW D HAM MOND VITRACO PAR K ST THOMAS VI
*M 2 3 324 f irms ANGEL J RO DRIGUEZ URB TERRAZAS D E GUAYNABO GUAYNABO PR
*M 2 3 778 fi rms DREW D HAMM OND VITRACO PARK S T THOMAS VI D J MANAGEMENT CORP
M 1 1 60 h ouse GRDN HLS PLZ/1 353 CARR 19 203 G UAYNABO PR
M 1 1 345 ho use MR WILLOUGH BY LEWIS PO BOX 5588 S T THOMAS VI 00803
*M 2 3 60 f irms GRDN HLS PLZ/1 353 CARR 19 203 G UAYNABO PR EXECUTI VE DYNAMICS
*M 2 3 345 fi rms MR WILLOUGH BY LEWIS PO BOX 5588 S T THOMAS VI 00803 VI EMPLO YEE BENEFIT CNSLT S INC
*P 3 2 70 no _mail MS DENISE C OSTELLO PO BOX 24439 C HRISTIANSTON VI 00824
P 1 1 687 ho use MS DENISE C OSTELLO PO BOX 24439 C HRISTIANSTON VI 00824
P 2 3 687 fi rms MS DENISE C OSTELLO PO BOX 24439 C HRISTIANSTON VI 00824 RAMCO IN C
M 1 1 922 ho use MARSTON ADA MS PO BOX 3003 K INGSHILL VI 00851
*M 2 3 922 fi rms MARSTON ADA MS PO BOX 3003 K INGSHILL VI 00851 TROPICAL SHIPPING CO
Code Definitions
M = Multi List
S = Single List
P = Purge Group
* = Driver
List Listname
1 house
2 firms
3 no_mail
4 select
5 update
File Filename
1 C:\pw\mpg \Work\house.txt
2 C:\pw\mpg \Work\mail_sup.txt
3 C:\pw\mpg \Work\house_fm.txt
4 C:\pw\mpg \Work\update_1.txt
5 C:\pw\mpg \Work\rent_mag.txt
Note: The bottom of the report shows the
names of the lists and files involved in the job,
as well as the code definitions.
Note: The asterisk (*) in the code indicates the
driver record. For details about how the driver
record affects matching, see page 204.
58
Match/Consolidate User’s Guide
Page 59

List Duplicates report If you want to see numbers—statistics—about the job, look at the List Duplicates
report. That report shows which list your master records came from. These
numbers can help confirm that your list priorities are right, or alert you to
potential problems.
For example, from the List Duplicates report, you can see how many of your
suppression-list records were identified as master records of dupe groups. You
can see which lists are supplying the records that are master records, and which
are supplying records that are subordinate dupes. You can also see how widely
dispersed are the matches among your lists’ records.
List Duplicates Report, Detail Information Match/Consolidate Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
----------------------------------------------------------------------------------------------------------------------------------- Single Multiple Single Multiple Total Suppress Suppress Suppress
Net Suppress List List Total List List Non List List List
List Name Input Dupes Dupes Dupes Dupes Uniques Masters Masters Dupes Uniques Masters Subord
house 1000 125 0 130 255 0 0 745 745 0 0 0
firms 1000 125 0 875 1000 0 0 0 0 0 0 0
no_mail 100 0 0 0 0 0 0 0 0 0 98 2
select 250 27 0 223 250 0 0 0 0 0 0 0
update 25 0 0 0 0 25 0 0 25 0 0 0
Totals 2275 277 0 1228 1505 25 0 745 770 0 0 0
Totals 2375 277 0 1228 1507 25 0 745 868 0 98 2
(Including Suppression Records)
Chapter 4: Prioritize and suppress records
59
Page 60

60
Match/Consolidate User’s Guide
Page 61

Chapter 5:
Purge input files or create output files
This chapter explains how to use the results of your record matching process to
produce your choice of four specialized output files or to refine your input file(s)
by purging unwanted records.
Chapter 5: Purge input files or create output files
61
Page 62

Match/Consolidate results
Terms This subsection explains how to control the results of your Match/Consolidate
(MCD) job, such as producing output files, purging input files, and making use of
MCD matching. This chapter uses the following terms.
Term Description
Input purge Marking for deletion the records of your input files that your
job has identified as subordinate dupes—that is, records which
have matching records that are better.
Input posting Adding MCD application fields or PW field data to the records
of your input files.
Output file The production of a new file that contains data as described in
your output file description. This can be one of four types.
Multi-buyer file
Multi-occurrence file
Master duplicate
Master record
Master
Subordinate duplicate
Subordinate dupe
Unique record A record that is not a member of any match group.
Single-list duplicate
Single-list dupe
Multiple-list duplicate
Multiple-list dupe
Suppression list A list of records MCD uses to prevent matching records of
N
per firm Include a limited number of records (N per firm). You can
Nth select Selecting eligible records at fixed or random intervals.
A file of names that occurred more than once. Typically, this is
shown by names that occur on more than one input list; they
are frequent or repetitive customers.
The highest ranked member of a match group. This is normally
considered the best record of the match group.
All members of a match group except the master.
A record from a match group whose members all came from
the same input list.
A record from a match group whose members came from multiple input lists.
other lists from being sent to the output.
select
whether the output includes N records per individual,
N records per department, or N records per firm.
62
Match/Consolidate User’s Guide
Page 63

This table shows the nine categories into which records can be placed.
Records to purge Description
Unique records Unique records are not members of any match group. This designation does not include
records that are members of suppression lists, which are categorized as suppression-list
uniques.
Single-list masters Master records from match groups whose members all came from the same input list.
(Does not include records from suppression lists.)
Single-list dupes Subordinate records from match groups whose members all came from the same input list.
(Does not include records from suppression lists.)
Multiple-list masters Master records from match groups whose members came from multiple input lists. (Does
not include records from suppression lists.)
Multiple-list dupes Subordinate records from match groups whose members came from multiple input lists.
(Does not include records from suppression lists.)
Suppression-list uniques Unique records from suppression lists.
Suppression-list masters Master records that came from a suppression list.
Suppress dupes Records that came from a normal list or special list, but matched a record from a suppres-
sion list and had a lower priority than that suppression-list record.
Suppression-list subordinates Subordinate records that came from a suppression list.
Producing results This table lists the ways you can set up your desired results according to
the product.
Product How to set up your desired results:
MCD Job
and Views
Input purge (Job): In the Execution block, set the Purge or Custom Purge parameter to
Y (Yes). Set the Protect Input File From Purge parameter to N (No).
Input purge (Views)
: In the Execution Options window, select either Purge or Custom Purge
from the Input File Options. To exempt an input file from the purge, set the Protect … from
Purge control at the Input File window.
Input posting (Job)
: In the Execution block, set the Post to Input File parameter to Y (yes).
Set up a Post to Input File block for each input file to which you want data posted.
Input posting (Views)
: In the Execution Options window, select Post to Input File from the
Input File Options. Set up a Post to Input File window for each input file to which you want
data posted.
Output file (Job)
: In the Execution block, set the appropriate output file parameter(s) to
Y (yes). For each desired output file, set up a Create File For Output block and the appropriate
…
Output File block.
Output file (Views)
For each, set up a Create File For Output window and the appropriate
: In the Execution Options window, select the appropriate output file(s).
…
Output File window.
MCD Library Your application controls how records are handled after matching. Use the mp_duperes_
functions to retrieve results about the matching process.
*
()
Chapter 5: Purge input files or create output files
63
Page 64

Purge bad records or post good records
After you have completed the search for matching records, you are ready to
separate the good records from the bad ones. Usually, good records refers to
unique records and the master record from each match group, and bad records
refers to subordinate records from match groups.
To keep the good records and discard the bad ones, you can either purge bad
records from the input file, or post good records to an output file.
Input purge You can delete bad records from your input file(s). This might involve removal of
the record data, or merely a non-destructive delete mark. You might elect this
method if disk space is limited. Non-destructive delete marking for a purge is
sometimes faster than output posting.
Output file You can copy good records from your input file(s) to another file. The output file
may be a new file, or you may append good records to an existing file.
Factors to consider Consider the following points if you’re not sure whether to purge bad records
from the input file, or post good records to an output file.
If disk space is limited, purge records from the input file. However, before
doing this, be sure to create a backup of the input file.
Each method’s processing time depends on your files, your machine, and on
the percentage of matches in your job. In most cases, a purge is faster.
If you use an input filter, you should probably create an output file. Records
that fail the filter are not processed at all, so they cannot be affected by an
input purge.
If you have strict criteria for what are good records, then good records may
be a small percentage of the input. For example, if you’re preparing a multibuyer list, good records might be just 10 percent of the total input.
In this case, consider creating an output file because it might be more
efficient for MCD to post the good 10 percent of records to an output file than
to review the input files and delete 90 percent of the records.
Contrast the purge controls with those of the custom output file. If you’re
purging input files, you specify which records to delete. If you’re creating an
output file, you specify which records to keep.
64
Match/Consolidate User’s Guide
Page 65

Purge the input file
Use input purging to delete unwanted records from your input files. The normal
purging process is based on the premise that the matching records of your match
groups represent unwanted duplicate records, and that you want to eliminate such
duplicate records from your file(s).
Conventional or custom purge
When you use conventional purging to purge an input file, MCD removes all
subordinate duplicates, whether from a normal list or suppression list. What
remains in your input file? Unique records and master duplicates.
With conventional purging, MCD does not consider whether a record came from
a list whose members are all from the same list or a list whose members are from
multiple lists. Match/Consolidate treats single-list and multiple-list records the
same.
Match/Consolidate also offers the custom-purge option. This lets you to design
your own purge, by selecting from the nine different categories of records, which
should be purged from your input file(s). The following Custom Purge Input
File(s) block shows those categories as you would set them for a conventional
purge.
You can also incorporate a filter. Records for which the filter evaluates to true are
deleted; those for which the filter evaluates to false are kept. A record may be
deleted either by falling into one of the purge categories or by passing the delete
filter.
Contrast the purge controls with those of the custom output file. If you’re
purging input files, you specify which records to delete. If you’re creating an
output file, you specify which records to keep.
If you elect to purge input files
If you elect to purge your input files, MCD includes three features to make the
process easier. Be sure to make a backup of the input file on tape or disk.
You can set your MCD job to predict the purge results before you actually
purge your input file.
You can protect any or all your input file(s) from the purge process.
You can have MCD create a backup of your input file(s).
Chapter 5: Purge input files or create output files
65
Page 66

Predict a purge You can choose to predict a purge before actually running the process and risking
any record losses. Predicting lets you generate reports and view the results of the
predicted purge to make sure they are satisfactory. The Purge by List report
(detail and summary versions) shows you how many records would be deleted
from the input file if you actually purge the file.
If, after studying the reports, you decide you need to adjust your settings, you can
do so and predict again to check the new results. Use the prediction feature as
often as you like to fine-tune your input file purge.
Non-destructive marking
When purging dBASE3 files, MCD uses non-destructive delete marking. A
“deleted” record is not literally removed. It is simply marked, and removing it
requires another operation. If you realize an error, you can use your database
program to remove the delete marks.
When you process ASCII files, you can mimic this feature. You will need a onecharacter field in your input file(s) to store the mark. Then, in your DEF file(s),
define a PW.Delete field. To mark a record for deletion, MCD places an asterisk
in this field.
After purging, MCD deletes all work files. If you want any reports, set them
up before you run the purge. If you change your mind after a purge, you must
restore the input file(s) from backup and re-run the job.
66
Match/Consolidate User’s Guide
Page 67

Create an output file or post data to the input file
Four kinds of output files
Output file structure You can create a new output file or append records to an existing file. If you
You can create four different kinds of output files:
Output file Contents of the output file
MCD output file Unique records and master duplicates. Suppression
records are not included.
All-duplicates output file All master and subordinate duplicates from all match
groups. Suppression records are included. Unique
records are not included.
Multi-occurrence
output file
Custom MCD output file You specify which types of records to keep.
All master duplicates—which, in essence, means one
record per dupe group (match group). Unique records,
subordinate duplicates, and suppression records are not
included.
You end up with a file of names that occurred more than
once—for example, frequent or repetitive customers or
donors.
create a new output file, you have three choices for the file structure.
You can clone, or copy, the structure of an existing file.
Post data back to the input file
Clone the structure of an existing file and append new fields.
Define all the fields yourself.
Note that MCD creates a DEF file to go with your new file, though that DEF file
contains only the Database Type parameter, no PW fields. You can elect to have
MCD not create that DEF file. For details about file structures and output DEF
files, refer to Database Prep.
You can use MCD to post data back to your input file. Your input file must
contain a field ready to receive the data that you post. You cannot append new
fields to input records—if you need to append new fields, you’ll need to create an
output file.
After input posting, MCD deletes all work files. If you want reports, be sure to set
them up before you run the job. If you want to perform both input posting and a
purge, make sure you perform them both in the same batch run. Because the work
files are deleted, you cannot post during one run and purge during another.
Chapter 5: Purge input files or create output files
67
Page 68

Data that you can post
You can post several kinds of data to your input or output file.
Input data: DB and PW fields
You can use database and PW fields to copy raw data from your input file(s) to an
output file. These fields are identified by the prefix DB or PW. For example:
DB.Soc_Sec_No, and PW.Name_Line.
Database or PW fields need not be common to all of your input files. When
posting a record that does not have the named source field, MCD simply places
blanks in the output field.
For example, suppose you post DB.Soc_Sec_No to the SSN field in your output
file. If one of the input files does not contain a Soc_Sec_No field, records from
that file will have a blank SSN field in the output file.
You can post DB or PW fields only to an output file. You cannot post DB or
PW fields to an input file. For a list of the PW fields, refer to the Quick
Reference.
MCD data: AP fields You can post data that was generated during MCD processing. These fields are
identified by the prefix AP: AP.Group_Cnt. For a complete list of MCD AP
fields, refer to the Quick Reference.
Constants A constant is a data string that does not change from one record to the next. For
example, you might post today’s date to a date field. When you post a constant,
enclose it in quotation marks. For example: “20020428”
Manipulate data before posting it
You can use functions to check or manipulate data before posting it to the output
field. For example, you could check the name field and, if it’s empty, post Current
Resident. Your function might look like this:
iif(empty(DB.Name), "Current Resident", DB.Name)
When posting to your input file, do not use DB or PW fields in filter or
function expressions. However, you can use DB and PW fields when posting
to output files.
68
Match/Consolidate User’s Guide
Page 69

Choose the best records for your output file
In some MCD jobs, especially jobs that prepare for a mailing, you must limit the
output to a certain number of records. For example, the mailing might be limited
by the client’s contract or by the number of pieces that the printer actually
produced.
After you eliminate duplicates and suppression records, you might still have more
eligible records than you need. In that case, you can pick the best records from the
pool of eligible records. To select the best records, first sort all eligible records in
order from best to worst. Then start at the top and take the best records for your
output file.
Sort all eligible records
To select the best records, first sort eligible records so that the best records can be
selected first. You decide what criteria should be used to sort the records. You can
sort records in either ascending order (0–9, A–Z), or descending order (9–0, Z–
A). The following table lists the available sort options.
Sort by Description
File Sort records in the same order they appear in the input file(s).
This is the fastest option.
Random order Sort randomly. This is useful for abbreviated jobs, like testing
output.
Match group Sort by match group. This makes it easier to relate members of
the same match group.
MCD field Sort by a field that you choose, such as an account number field
or affluence rating. You define the MCD field in your DEF
file(s).
Geographically Sort by state, city, ZIP Code, street name, street range, and so on.
Priority field Sort based on the total of list match priority plus blank-field pri-
ority. For more information about priority, see “Prioritize and
suppress records” on page 47.
List count Sort based on how many lists the record belongs to. Use this
option to sort multi-buyer lists.
MCD sorts based on key-field data
Dupe group size Sort based on how many records are in this record’s match group.
Use this option to sort multi-occurrence lists.
Custom Sort based on your own layered sortation.
Match/Consolidate sorts records based on the data in key fields, not the data in
your database fields. Therefore, key-data standardization settings can affect the
sorting results. For example, if you standardize data for firm keys, the original
firm data is not used for sorting—the standardized data is used.
Note that, when sorting by names, MCD uses input data rather than standardized
data. Your setting at the Standardize Name Keys parameter will not affect the
output sort.
Chapter 5: Purge input files or create output files
69
Page 70

Use reports for feedback
If you do not understand your sort results, generate a Sorted Records report,
Duplicate Records report, or Unparsed Records report in the Key version. These
reports should provide enough data to determine if adjustments should be made to
your sorting setup.
Use the best records After you sort eligible records in order from best to worst, use the best records for
your output file. For example, suppose you printed 50,000 copies of a catalog.
You could tell MCD to place a maximum of 50,000 records in the output file.
Match/Consolidate would select those records from your sorted list, starting with
the first (best) record.
As shown at right, regardless of
which type of output file you are
creating, the controls for selecting
the best records are at that output
file’s Output File block.
Example 1: Most affluent
Suppose your records include an INCOME field that contains an actual income
figure. You want to use this information to send your mailing to the 50,000 most
affluent people (after matching).
First, tell MCD which field to use for sorting. This is a two-step process:
1. First, define the Income field as PW.Merg_Purg1 in your DEF file:
PW.Merg_Purg1 = Income
2. Then, direct MCD to sort on the PW.Merg_Purg1 field. To do this, go to your
output file block (the Custom MCD Output File block is shown below) and
set the Sort By option to MP1.
To sort with the MP1 option, be sure the Merg_Purg1 field is included in the
match key. If you are using standard matching, that’s done at the Matching
Criteria block. For extended matching, it’s done with the Key Length
parameter of the Parsing and Key Options block.
70
Match/Consolidate User’s Guide
Page 71

3. Next, because you want higher incomes first, set the output sort order to
Descend. Finally, to select 50,000 records, set 50000 as the maximum
number of records to output.
This method works for actual income figures. If the field contains a
demographic code, you can use it if the codes are in logical sequence—for
example, A–K representing lowest to highest incomes. If codes are not
sequential, you will need to adjust them. You could create a sequential code
using the search-and-replace features of DataRight.
Example 2: Highest priority
Suppose you are processing your house database and three rented files. Given a
house record and a rented record, you prefer to select the house record. Express
this preference by setting up list match priority (see “Prioritize or suppress
records based on list membership” on page 52). Then, select output records based
on priority.For example, to select the 10,000 highest-priority records, you would
do the following.
1. First, direct MCD to sort on the records’ priority. To do this, go to your
output file block (the MCD Output File block is shown below) and set the
Sort By option to LB_Prior.
2. Next, because you want higher priorities first, set the output sort order to
Ascend. (Remember, a lower number indicates a higher priority.)
3. Finally, to select 10,000 records, set 10000 as the maximum number of
records to output.
When you select the sort option LB_Prior, you are sorting on a priority
number. If you want, you can post that same number to your output file by
using the application field AP.LB_Prior. For more details about setting
priorities, refer to “Prioritize and suppress records” on page 47.
Chapter 5: Purge input files or create output files
71
Page 72

Custom sort your output records
With MCD, you can also sort output records based on the contents of up to 16
fields. For example, assuming your database included these fields, you can sort
first by an INCOME field, then by an AGE field, then by a DONOR field.
You can sort in ascending or descending order for each sortation level. Consider
the following examples:
By INCOME in descending order.
By AGE in descending order.
By DONOR data in ascending order.
Be sure to define the fields in your DEF file(s). For the example described above,
your DEF file(s) would need the following entries.
PW.Merg_Purg1 = Income
PW.Merg_Purg2 = Age
PW.Merg_Purg3 = Donor
Be sure all three of the sorting fields (Merg_Purg1, Merg_Purg2, and
Merg_Purg3) are included in the match key. If you are using standard matching,
that’s done at the Matching Criteria block. For extended matching, it’s done with
the Key Length parameter of the Parsing and Key Options block.
Sort fields You can sort by any field defined in your match criteria or Parsing and Key
Options, or any of the following application fields. Refer to the following page
for information about setting up this custom sort process.
AP.File_No AP.Group_Cnt AP.Group_No AP.Group_Ord
AP.Parse AP.LB_Prior AP.List_Cnt AP.List_No
AP.Record_No AP.Super_Cnt AP.Unique_No
To set up your custom sortation, follow these two steps.
1. Tell MCD which fields to use for sorting. Use the Custom Output Sorting
block, as shown below. Be sure to use the right order for your sort levels;
MCD will sort in the order of your Custom Sort Fields as you set them here.
Note that this example (from the previous page), relates the database to the
Merg_Purg fields as follows.
PW.Merg_Purg1 = Income
PW.Merg_Purg2 = Age
PW.Merg_Purg3 = Donor
72
Match/Consolidate User’s Guide
Page 73

2. Direct MCD to sort on the
those fields. At your output
file block (the MCD Output
File block is shown below), set
the Sort By option to Custom.
Then, enter the Custom Sort
Name (from the Custom
Output Sorting block).
Chapter 5: Purge input files or create output files
73
Page 74

Create a multi-buyer file
In the direct-mail industry, a multi-buyer is someone whose name appears on two,
three, or more lists—someone who, by their appearance on several different lists,
demonstrates a pattern of consumption or affluence. To prepare a multi-buyer list,
you scan a large pool of input records for names that appear more than once. In
this situation, you hope for matches, because those are the names of frequent
buyers.
Target multi-buyers Suppose you are mailing catalogs of radio equipment. The printing, handling, and
postage cost is $4.75 per copy, so you have to be selective. You rent several
mailing lists:
List Number of records
Ham radio operators 458,087
Create a multi-buyer output file
Ham News
Proceedings
SIC Code 5731: Radio, TV, and Electronics Stores 53,976
subscribers 148,879
of the Amateur Radio Society 252,789
From the total input of 713,731 records, you want to select the best prospects.
Your assumption is that the more lists on which a name appears, the more active
that person is in amateur radio, and the more likely they will be to order from the
catalog. Therefore, you might want to include only those names which appear on
at least two lists.
To create a multi-buyer output file, set up your job to search all four input lists for
matches. Then, create a Custom MCD Output File, to output records for anyone
who appeared on at least three of the four lists. See the next page for details about
setting up this output file.
As output, select only the Output Multiple List Masters option.
Employ an output filter to select only those
records whose list count is 3 or more. You
can get list-count data from the MCD field
AP.List_Cnt. Your output filter will look
like this: val[AP.List_Cnt]>=3.
74
Match/Consolidate User’s Guide
Page 75

Select the best multi-buyers
Suppose you printed 10,000 catalogs, so you want to select the 10,000 best
prospects. It makes sense to choose those names that appeared on the largest
number of lists.
To select the 10,000 most frequent buyers, you would do the following:
1. Set 10000 as the maximum number of records to output.
2. Sort records by list count—the number of lists in which the record appears.
To do this, set the sort-by option to List_Cnt.
3. Sort records in descending order (highest to lowest) so that records with the
highest list count will be selected first.
Use super lists to find multi-buyers
Suppose you rented several lists from two different brokers, Able Direct and
Baker Marketing. In addition, you are using your house file.
To consider someone a multi-buyer, you want that person’s name to be found in at
least two of your three sources: your house file, Able Direct, and Baker
Marketing. If a name simply appears in two different Able Direct lists, you don’t
want to consider that person a multi-buyer.
This output can be produced in essentially the same way as in the prior example.
However, instead of using AP.List_Cnt, use AP.Super_Cnt.
1. Create a super list for each source (House, Able, and Baker).
House file
Rented from
Able Direct
Rented from
Baker Marketing
2. Create a Custom MCD Output File, to output records for anyone who
appeared on both of the super lists. To do this, base your output filter on
super-list count, which you can retrieve from the MCD field AP.Super_Cnt:
val(AP.Super_Cnt) = 2
Chapter 5: Purge input files or create output files
75
Page 76

Create a multi-occurrence file
Multi-occurrence vs. multi-buyer
Create a multioccurrence file
Select the best multioccurrences
A multi-occurrence file is similar to a multi-buyer file, because we look for a
buying pattern by searching for matches. The difference is this:
For a multi-buyer file, we count the number of input lists on which a name
appeared. In effect, we count the number of sources or companies from
which a person has purchased goods, services, or memberships.
For a multi-occurrence file, we count the total number of times a name
appears, without concern for the number of lists. This is appropriate if you
are willing to say that appearing twice on the same list is just as good as
appearing once each on two separate lists.
Suppose you rent a file of Porsche owners and a file of home owners. Mary
Smith’s name appears once on each list, because she owns a Porsche and a home.
John Doe’s name also appears twice because he bought two Porsches, but his
name doesn’t appear in the home-owners file because John rents.
Use the Multi-Occurrence Output File capability of MCD for this situation. In
that block, specify the minimum number of times a name must occur to be
included in the output file.
To select the names that occur most
frequently, look for the records that
have the most matching records. For
example, to select the 10,000 most
frequently matched names, type
10000 as the maximum number of
records to output.
Sort records by the number of records
in the match group (dupe group), by
setting the Sort By option to
Group_Cnt. Set the Sort Order to
Descend so records with the highest
group count will be selected first.
If you would like to post the group
count to a field in your output file,
post AP. Group_Cnt.
76
Match/Consolidate User’s Guide
Page 77

Select a sample of records
Would you like to post a limited number of records to your output file? Many
users do, for a number of reasons—for example, to set up test mailings or to split
output into multiple mail segments. One way to limit output is to set a Maximum
records to output number at your output file block.
In addition, MCD lets you output records at intervals—every third record, every
fifth record, or every tenth record, and so on. This approach to MCD output is
called Nth Select. All Nth Select settings are done at your selected output file
block.
MCD implements Nth Select downstream of sorting and of any filter. Records
that don’t pass a filter are not included. Of course, MCD also respects your
Maximum records to output setting.
In addition to the advantages for your actual job output, Nth Select helps you test
output, because your record sample can span a wider range of input files.
However, plan for extra processing time if you use the Auto or Random type of
Nth Select with an output filter. In that circumstance, MCD must count the
records that pass the output filter before it outputs the records.
Three types of Nth select
You can select from three types of Nth select:
Type Remarks
User MCD selects every “Nth” record. You set the value of N.
Auto You need not set a value for N; MCD calculates that increment based
on the Maximum records to output setting.
Random MCD selects at random which records to output, up to the Maximum
records to output setting.
Here’s a simplified example of all three types. Suppose there are 100 records
available for output. The output filter allows the following records to pass: 1, 2,
23, 29, 44, 78, 80, 82, 90, 97. The figure below shows how Nth selection would
act. In all three cases, Maximum records to output is set to 4.
User; N = 2
Auto
Random
2
1
1
29
23
2
29 44
23
44
78
78
82 90 97
80
80
82
90 97
1 2 23 29 44 78 80 82 90 97
Record #90 is the next
selection, but it won’t be
used, because four reco rds
have alre ady been
selected.
With Random output, any four of the records could be chosen.
Chapter 5: Purge input files or create output files
77
Page 78

Reports about your purging or output process
p
t
Input file purge report How do you know the results of your input purge? You should run your job, then
check the Purge by List report.
The Purge by List report shows the numbers of records that were deleted from the
job’s input file(s)—or marked for deletion, or predicted for deletion, depending
on your job setup. These numbers provide a clear picture of the results of an input
file purge.
This report is especially useful if you’ve included lists, because it shows results
on a list-by-list basis. For information about lists, see “Define your input files and
lists” on page 27.
What should you expect to see? That depends on the type of purge you set up.
Because a Custom Purge enables you to select any (or all) record categories,
you’ll have to check your Custom Purge setup to see what categories you were
trying to purge, and which you wanted to maintain.
Purge By List Report, Detail Information (PREDICTION) Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
---------------------------------------------------------------------------------------------------------------------------------- Single Multiple Single Multiple Suppress Suppress Suppress
Net Filter Suppress List List List List List List List
List Name Input Drops Dupes Dupes Dupes Uniques Masters Masters Uniques Masters Subord
house 1000 0 0 0 0 0 0 0 0 0 0
firms 1000 0 0 0 0 0 0 0 0 0 0
no_mail 100 0 0 0 0 0 0 0 0 0 0
select 250 0 0 0 0 0 0 0 0 0 0
update 25 0 0 0 0 0 0 0 0 0 0
Totals 2375 0 0 0 0 0 0 0 0 0 0
Purge By List Report, Summary Information (PREDICTION) Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
le Repor
Sam
The Output File report Your basic check about MCD output is to look at the output itself—the content of
the output file. In addition, though, MCD can produce the Output File report, to
see the numbers of output records that fit into the various matching and ranking
categories and that are therefore included in or excluded from your output.
Study your Output File report to see what MCD has done. If your results show
any trends that could be improved by adjustments to your settings, then change
those settings and re-run the job. For example, if your filter drops are higher than
you think is right, check your filter setup.
Keep in mind that you can sort the data in different ways. For example, you can
display the rows and pages of the report by State, by ZIP Code or other key field,
or by list, or super list. For details, see “Output File Reports (.ofr)” on page 119.
78
Match/Consolidate User’s Guide
Page 79

The different output files include different types of records. Your Output File
report should show the following, based on the type of output file:
Output File Contents of the output file Categories of records included
MCD
Output File
All-Duplicates
Output File
Multi-Occurrence
Output File
Custom
Output File
All unique records and master dupes are copied to the
output file (from Normal and Special input lists).
All master and subordinate dupes, representing names
that appear more than once (for example, frequent or
repetitive customers or donors are included), are copied
to the output file. Unique records are omitted.
All master dupes of all dupe groups are copied to the
output file. Unique records are omitted.
Any or all of the following types of records may be
included. Design the contents to suit your purpose.
Unique records
Single list masters
Single list dupes
Multiple list masters
Multiple list dupes
Suppress list uniques
Suppress list masters
Suppress list subordinates
Suppress list dupes
Unique records
Single-List Masters
Multiple-List Masters
Single-List Masters
Single-List Dupes
Multiple-List Masters
Multiple-List Dupes
Suppress List Masters
Suppress List Subordinates
Suppress Dupes
Single-List Masters
Multiple-List Masters
You specify the types of records to include.
The following figure shows the top of a Detail version of the Output File report,
sorted by State and list, for a MCD Output File. For this output file, you'd expect
to see numbers in the following categories:
Unique records
Single-list Masters
Multiple-list Masters
Output File Report, Detail Information: C:\pw\mpg\Work\output\Out_MPG.txt Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
----------------------------------------------------------------------------------------------------------------------------------Output Results for California
Single Multiple Single Multiple Suppress Suppress Suppres s
Net Filter Suppress List List List List List List List
List Name Input Drops Dupes Dupes Dupes Uniques Masters Masters Uniques Masters Subord
house 8 0 0 0 0 0 0 4 0 0 0
firms 8 0 0 0 0 0 0 0 0 0 0
Totals 16 0 0 0 0 0 0 4 0 0 0
Output File Report, Detail Information: C:\pw\mpg\Work\output\Out_MPG.txt Match/Consolidate x.xx Page 2
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
----------------------------------------------------------------------------------------------------------------------------------Output Results for Colorado
Single Multiple Single Multiple Suppress Suppress Suppres s
Net Filter Suppress List List List List List List List
List Name Input Drops Dupes Dupes Dupes Uniques Masters Masters Uniques Masters Subord
house 2 0 0 0 0 0 0 1 0 0 0
firms 2 0 0 0 0 0 0 0 0 0 0
Totals 4 0 0 0 0 0 0 1 0 0 0
Chapter 5: Purge input files or create output files
79
Page 80

80
Match/Consolidate User’s Guide
Page 81

Chapter 6:
Reports and statistics files
This chapter provides a sample of each available Match/Consolidate (MCD)
report, arranged alphabetically—first reports, then statistics files. These examples
show the content and format of the reports.
Chapter 6: Reports and statistics files
81
Page 82

Introduction to reports and report files
How do you know what’s happened in your MCD job? What records have been
input? Have any filters done what you expected? How many matches were found,
and what records were found to match?
If you batch process files with MCD Job or MCD Views, consider using their
report capabilities. As it processes your job, the program gathers the data needed
for your reports. Then, after processing is complete, it formats that data into your
choice of reports. Different types of data are collected during different job
processes, so some reports may not be available if you haven’t included their
associated process in your job setup.
The following table shows the report data that’s generated during each phase of
your MCD job.
Processing Step Reports Generated
Read records and create
match sets
Find duplicates Duplicate Records Report
Create output file(s) Output File Report and, if you perform Group Posting:
Purge or post to input file(s) Purge by List Report and, if you perform Group Posting
Updated at each step
throughout the job
Input File Summary Report
Input List Summary Report
List Quality Report
Unparsed Records Report
Sorted Records Report
List-by-List Match Report
Multi-List Report
List Duplicates Report
Match Results Report (if extended matching)
Posted Dupe Groups Report
Posted Dupe Groups Report
Job Summary Report
Executive Summary Report
You can send MCD reports directly to a printer. However, many users prefer to
save reports in files on disk to preview reports before committing them to paper.
One file or many You can direct the program to write each report to a separate file or send all the
reports to one file.
:
File names based on job name
82
Match/Consolidate User’s Guide
Many users write each report to a separate file. This approach gives you more
files to handle, but it’s easier to find a particular report. Also, the files are
smaller and you have more control over printing them.
Some users prefer to combine all the reports into one file. This file can be
quite large, but you can insert banner pages to help you organize it.
To save time and to keep files names manageable, name your report files $job.
Consider the following examples:
Page 83

Job-file name Report type Report file name as
for the job setup
my_job.mpg
Executive Summary
Job Summary
Duplicate Records
Unparsed Records
$job.exs my_job.exs
$job.mjs my_job.mjs
$job.dup my_job.dup
$job.unp my_job.unp
Report file
produced
Report defaults Another time-saver in setting up your reports is the use of defaults for many of
your report settings. Nearly all the report settings can be controlled with defaults,
including destinations, number of copies, and page format.
Three versions of record listings
The record listings are the Unparsed Records, Duplicate Records, and Sorted
Records reports. These reports provide information on how well your job setup
has performed, on a record-by-record basis.
When you create any of these record listings, you can choose the type of data that
you want from each record. You can elect to create the report with PW field data
or with key data, or you can design your own custom version for
the report.
Version Description
PW You can choose to use the PW fields on the record listing. This format,
which is the default, displays the raw data that was input to MCD with
PW fields in the DEF file(s).
Key Before searching for duplicates, MCD converts the raw input data
into keys. This includes parsing the address, standardizing names, and so
on. MCD uses that processed key data in its search for matching—duplicate—records. To report key data, choose the key format for your listings.
Custom This option gives you flexibility to choose which fields will be printed,
their sequence, and the title over each column of data. The Custom
option does require more setup, because you must identify each field that
you want included in the report.
As a source for your data, you can use application (AP), database (DB),
or PW fields.
You must also set the length of each column on the report. Most often
this will equal the length of the source field, but you may make the column wider or narrower. MCD will insert one blank space between columns. You can also place a title over each column.
Chapter 6: Reports and statistics files
83
Page 84

Statistics files
You can choose to generate up to seven statistics files to store data associated
with your job. The statistics files can be brought into a database, spreadsheet, or
word-processing program, so you can create your own reports. You can provide
your business or clients with reports, spreadsheets, and even graphs based on a
MCD job. The statistics files give you reporting flexibility, so you can present job
information in the format that will best suit the needs of your business or clients.
Create statistics files The data generated and stored in the statistics files depends on your processing
steps. For example, if you aren’t performing a purge, there is no need to set up the
Purge statistics file, because purge information will not be generated.
Individual statistics files may contain one or many records, depending on the
number of files or lists used in the job. As a result, the length of each statistics file
can vary according to the number of records it contains.
Each of the statistics files holds data available in a variety of MCD reports. In
some cases, the information in the file corresponds exactly with a specific report
(for example, all of the data in the Output Statistics file can be found in the
Output File report). In other cases, the information is borrowed from more than
one report.
Due primarily to field width limitations, any filters used are not shown in the
statistics files.
Valid file types The following are valid file types for statistics files:
ASCII
dBASE3
delimited
EBCDIC
If the statistics file is dBASE3 and there are more than 128 fields in the file,
you’ll receive a verification error. If this occurs, switch to a different file type.
If your file type is other than dBASE3, MCD will create a format file for each
statistics file that you are generating. The format file (FMT for ASCII files, DMT
for delimited files, EBC for EBCDIC files) will contain the field names, lengths,
and data types as shown in this chapter. For ASCII files, the new line character
(EOR or End-of-Record) will also be included.
84
Match/Consolidate User’s Guide
Page 85

Name statistics files Consider using the following names for statistics files.
Job Statistics File $jobj.sfj
List Statistics File $jobl.sfl
Input Statistics File $jobi.sfi
Output Statistics File $jobo.sfo
Purge Statistics File $jobp.sfp
List Match Statistics File $jobm.sfm
Super List Match Statistics File $jobs.sfs
These names are default entries in the master.mpg file and in the Statistics Files
window of the MCD Views program.
Note that the example base file names end with the same last character as the file
extension. If your file type is other than dBASE3, we recommend that you use the
seven statistics file names shown above to prevent the format files that MCD
creates (FMT, DMT, or EBC) from automatically overwriting each other.
For example, if you are creating ASCII statistics files, and if you name the Job
Statistics File promo.sfj and the List Statistics File promo.sfl (using the macro
$job), MCD names both of the FMT files it creates as promo.fmt. As MCD
creates each FMT, it overwrites the previous one.
Unsuccessful FMT file
creation
Successful FMT file creation
Job file name Statistics file name FMT file name
promo.mpg promo.sfj promo.fmt
promo.sfl promo.fmt
Job file name Statistics file name FMT file name
promo.mpg promoj.sfj promoj.fmt
promol.sfl promol.fmt
Chapter 6: Reports and statistics files
85
Page 86

How statistics files relate to Match/Consolidate reports
The following tables show how the data collected in MCD statistics files relates
to data shown on MCD reports. For details about the data, see the descriptions of
each MCD report and statistics file in this chapter.
MCD input questions MCD Report column title Statistics file field name
From this input file, how many records were/
will be input?
From this input file, how many records were not
input, because:
they were marked for deletion?
they did not pass an input filter?
their list was not determined?
they were outside the range?
From this input file, how many records were/
will be used?
Input list records questions MCD Report column title Statistics file field name
Of the input records, how many matched this
list’s list_id?
Of the input records, how many were assigned
to this list by default action?
Of this list’s records, from how many could
MCD
not
parse:
any data?
address data?
firm data?
title data?
last name data?
first name data?
Input File Summary Report
Gross Input
Input File Summary Report
Delete Drops
Filter Drops
List Drops
Sample Drops
Input File Summary Report
Net Input
Input List Summary Report
Matched Id Records
Input List Summary Report
Default Records
List Quality Report
No Parse Count
No Address Count
No Firm Count
No Title Count
No Last Name Count
No First Name Count
Input Statistics File
gross_in
Input Statistics File
del_drops
filt_drops
list_drops
samp_drops
Input Statistics File
net_in
List Statistics File
num_mtchid
List Statistics File
num_defaul
List Statistics File
num_nopars
num_noaddr
num_nofirm
num_notitl
num_nolnam
num_nofnam
Of this list’s input records, how many were:
suppress dupes?
single-list dupes?
multiple list dupes?
dupes of all types?
unique records?
single-list masters?
multiple-list masters?
suppress-list uniques?
suppress-list masters?
suppress-list subordinates?
uniques and masters of all types?
Of the input records, how many were assigned
to this list?
86
Match/Consolidate User’s Guide
List Duplicates Reports
Suppress Dupes
Single List Dupes
Multiple List Dupes
Total Dupes
Uniques
Single List Masters
Multiple List Masters
Suppress List Uniques
Suppress List Masters
Suppress List Subord
Total Non Dupes
List Quality Report
Input List Summary Report
List Duplicates Reports
Net Input
List Statistics File
suppr_dups
singl_dups
milti_dups
tot_dups
num_uniq
singl_mas
multi_mas
supprl_uni
supprl_mas
supprl_sub
num_nondup
List Statistics File
net_in
Page 87

Matching questions MCD Report column title Statistics file field name
How many records of this list were input to
this job?
How many records of this list matched other
records of this list?
How many records of this list matched records
of list2?
How many records of this list matched other
records of list
Questions about MCD results—
output or input file purging
N
?
List Match Reports
Net Input
List Match Reports
Matches (list1)
List Match Reports
Matches (list2)
List Match Reports
Matches (listN)
MCD Report column title Statistics file
How many records of this list were input to this job? Output File Reports
Purge by List Reports
Net Input
List Match Statistics File
net_in
List Match Statistics File
list1
Super List Match Statistics File
super1
List Match Statistics File
list2
Super List Match Statistics File
super2
List Match Statistics File
list
N
Super List Match Statistics File
super
N
field name
Output Statistics File
Purge Statistics File
net_in
Of this list’s output or purged records, how many were
categorized as the following:
suppress dupes?
single-list dupes?
multiple list dupes?
unique records?
single-list masters?
multiple-list masters?
suppress-list uniques?
suppress-list masters?
suppress-list subordinates?
filter drops
Output File Reports
Purge by List Reports
Suppress Dupes
Single List Dupes
Multiple List Dupes
Uniques
Single List Masters
Multiple List Masters
Suppress List Uniques
Suppress List Masters
Suppress List Subord
Filter Drops
Of this list, how many records were output or purged? Output File Reports
Net Output
Purge by List Reports
Total Deletes
Overall questions about your job MCD Report Statistics file
Executive Summary
Output Statistics File
Purge Statistics File
suppr_dups
singl_dups
milti_dups
num_uniq
singl_mas
multi_mas
supprl_uni
supprl_mas
supprl_sub
filt_drops
Output Statistics File
net_out
Purge Statistics File
total_del
Job Statistics File
Job Summary
Chapter 6: Reports and statistics files
87
Page 88

How Match/Consolidate counts intra-list and inter-list matches
For most multiple-list jobs, MCD users want to
know about record matches between and within
the lists. To facilitate that, MCD can track both
types of matches:
Intra-list matches are matches between
records of the same input list.
Inter-list matches are matches between
records of different lists.
List 1 List 2 List 3
John John John
John John
John
John Mary
Mary
Mary Mary
The table at right is a simplified job of three lists.
Consider that each first name represents a record,
and that the matching first names represent
matching records.
Intra-list matches When MCD counts intra-list matches, it looks at only one list at a time to find the
Sam
Sam
Sam
number of records in that list that matched another record within the same list.
The calculation is as follows: the number of matching records minus the number
of dupe groups. For every group of matching records within the list, count the
number of records within that group that matched the first record of the group.
From the List 1 example above, there are seven matching records. From those
matching records, there are three John records that matched the first John record
that MCD found, and two Sam records that matched the first Sam record that
MCD found. This calculates to five intra-list matches, or the number of matching
records (seven), minus the number of dupe groups (two).
The following list shows the results of the job represented by the above table.
List 1 contains seven matching records (the four John records, plus the three
Sam records). Subtract two dupe groups (the John group and the Sam group),
for a result of five intra-list matches.
List 2 contains five matching records (two John records plus, three Mary
records). There are two groups (the John group and the Mary group), which
results in three intra-list matches.
List 3 has no records that match any others in the list, so there are no intra-list
matches. (Remember, for intra-list matches, we just look inside the one list;
we do not look at any records from any other lists.)
Inter-list matches When MCD counts inter-list matches, it looks for dupe groups with records in
more than one list. First, the program drops those records that were already
counted as intra-list dupes. Then, for each list, it counts the number of times that a
record in that list matched a record in other lists. The tables on the following page
show the results for this job.
88
Match/Consolidate User’s Guide
Page 89

List 1
List 2
List 1 List 2 List 3
John John John
John John
John
John
Mary
Mary
Mary
Mary
Sam
Sam
Sam
List 1 List 2 List 3
John John John
John John
John
John
Mary
Mary
Mary
Mary
Sam
Sam
Sam
List 1 has
three interlist matches
List 2 has
three interlist matches
List 3
List 1 List 2 List 3
John John John
John John
John
John
Mary
Mary
Mary
Mary
Sam
Sam
Sam
Chapter 6: Reports and statistics files
List 3 has
two inter-list
matches
89
Page 90

Observations Counts of matches are not counts of records. As you can see from even this small
example, 14 records produced 16 matches (8 intra-list and 8 inter-list).
This match information shows relative duplication within and among lists. Do not
use this data to predict the results of a purge or output operation, because the data
does not in any way consider which records are masters and which are dupes.
90
Match/Consolidate User’s Guide
Page 91

Use super lists for report data
A super list is a way to prepare a second set of reports on matching, combining
the statistics for two or more regular lists. We see two situations in which you
might set up super lists:
Suppose you have four mailing lists stored in a single database, with a
database field identifying the list to which each record belongs. In this
situation, you may want to have two sets of reports—one containing separate
statistics for each list and a second set giving statistics for the file as a whole.
House file
Reports for Li st 1
Reports for Li st 2
Reports for Li st 3
Reports for Li st 4
Suppose, in addition, that you rent multiple lists from two different list
Super list
(Reports for the
entire file, as a
whole)
brokers (or other sources). You’ll want to see match statistics for each
individual list, of course. But you might also want a summary for each
broker. That’s a total of nine input lists, plus three super lists—one super list
for your house file (above), one for the two Able Direct files, and one for the
three Baker Marketing files.
Rented from
“Able Direct”
Rented from
“Baker Marketing”
When you use super lists, MCD will automatically append a second report to your
matching reports (List Match, List-by-List Match, and Multi-List). Keep these
details in mind when using super lists:
A super list might be related to an input file, or a list vendor, or any other
system of binding lists together.
Super lists affect only the way that match statistics are reported. They do not
affect matching or priorities at all.
Chapter 6: Reports and statistics files
91
Page 92

Print reports
″
Before printing reports, you’ll set up several options for their appearance. These
include page dimensions, margins, and header lines.
You can set these options once and make them apply to all reports through the
Report Defaults. Then, if you want a particular report to look a little different, you
can override your default settings when you set up that report.
Printer control Match/Consolidate Job does not use any printer-driver software. Reports are
formatted as ASCII text, with line break commands appropriate for your
operating system and form-feeds between the pages of the reports. For proper
alignment of report data, set your printer to use a non-proportional font such as
Courier.
Printable area Because of margins, report text cannot occupy the entire
sheet of paper. Remember to subtract your margins from the
height and width of your paper to determine the printable
area.
For example, if you are printing at 12 characters per inch,
and want .5-inch margins, the printable area of a normal
sheet is just 7.5 inches wide (90 characters)—not 8.5 inches
wide (102 characters).
Note that all of your MCD report settings are performed in
characters, (CPI) rather than in inches.
Some reports require a wide printable area, including the List Quality, List Match,
Multi-List, List Duplicates, Output File, Purge By List. In fact, the Duplicate
Records, Sorted Records, and Unparsed Records reports are formatted at 240
characters wide.
For the wide reports, you might have to set up your printer to use a condensed
font or landscape orientation. We recommend using a wide-carriage printer and
11-by-14-inch paper.
8.5″ by 11
Half-inch
margins reduce
the printable
area to
by 10
7.5
″
sheet
″
92
Match/Consolidate User’s Guide
Page 93

Duplicate Records Report (.dup)
This report lists each record of each dupe group—that is, groups of matching
records—separated by blank lines between the dupe groups. This listing can help
you decide if your match criteria are too loose. If you see records in a dupe group
which, based on what you see here, are not really duplicate records, then tighten
up your criteria to eliminate those matches.
The report data is generated during MCD’s duplicate detection (matching)
process.
Dupe groups are listed in the order in which they were found. For each group, the
master record is shown first, followed by the subordinate dupes, in the order of
their priority within their dupe group.
The driver record for each dupe group is coded with an asterisk in the first
column. If a record does not have data for a field/column, that space will be blank
on the report. This code data is not available for the Custom format report.
Options You can limit the size of this report by setting a maximum number of records to
print and by setting a starting record number. You can choose from three versions
of this report, based on the field types that you want to print.
You can elect to show the records’ PW data. The report will show a column
for each PW field of your job. The example on the following page is the PW
version of this report.
You can elect to show the records’ key data. The report will show a column
for each key field that you have set up in your job. The key version shows the
exact data that was used for comparing the records.
You can design your own Custom format. With the Custom format report,
you can select (from PW, database, and MCD application fields) the field
data for each column of your report. You pick the fields, the order, and the
heading for the column.
If your job includes lists, then the PW and key data versions show list data in the
first two columns of the report (see codes at the bottom of the report). We show
the names of the lists—as defined in the job setup—at the bottom of the report.
This saves some valuable space; look for the corresponding list number in the
second column of the report.
Use Simscore (see “Simscore” on page 199) to compare the driver record data to
the data for a record that shouldn’t have been in the dupe group. The Simscore
similarity score will help you determine how to change your match levels to
prevent a false dupe from appearing in a group.
Chapter 6: Reports and statistics files
93
Page 94

-
t
This part of the report is deleted from the picture so we can
show you the bottom of the repor
94
Duplicate Records Report
Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Code List File Record LIST_ID NAME_LINE ADDRESS CITY ST ZIP FIRM M 1 1 421 house H. V. JACOBSEN P.O. BOX C-29100 SANTA ANA CA
M 1 1 667 house HAROLD JACOBSEN P O BOX C-29100 SANTA ANA CA
*M 2 3 421 firms H. V. JACOBSEN P.O. BOX C-29100 SANTA ANA CA PANEL CONCEPTS
M 2 3 667 firms H V JACOBSEN P O BOX C-29100 SANTA ANA CA PANEL CONCEPTS
Match/Consolidate User’s Guide
M 1 1 683 house GERALD KRYWICKI PO BOX NO 2978 SPRINGFIELD MA
*M 2 3 683 firms GERALD KRYWICKI PO BOX NO 2978 SPRINGFIELD MA HEATBATH CORP.
M 1 1 324 house ANGEL J RODRIGUEZ URB TERRAZAS DE GUAYNABO GUAYNABO PR
*M 2 3 324 firms ANGEL J RODRIGUEZ URB TERRAZAS DE GUAYNABO GUAYNABO PR
M 1 1 140 house MR S L SMEAD 124 SWITZER AVE SPRINGFIELD MA 01109
M 1 1 764 house S. L. SMEAD 124 SWITZER AVE SPRINGFIELD MA 01109
*M 2 3 140 firms MR S L SMEAD 124 SWITZER AVE SPRINGFIELD MA 01109 MOTORACE
M 2 3 764 firms S. L. SMEAD 124 SWITZER AVE SPRINGFIELD MA 01109 MOTORACE
Code Definitions
M = Multi List
S = Single List
P = Purge Group
* = Driver
List Listname
1 house
2 firms
3 no_mail
4 select
5 update
File Filename
1 C:\pw\mpg\Work\house.txt
2 C:\pw\mpg\Work\mail_sup.txt
3 C:\pw\mpg\Work\house_fm.txt
4 C:\pw\mpg\Work\update_1.txt
5 C:\pw\mpg\Work\rent_mag.txt
Page 95

Executive Summary Report (.exs)
The Executive Summary is a concise listing of the most vital results of a MCD
job. The report summarizes facts that appear in more detail in other reports, such
as List Quality, List Duplicates, and Purge by List. Although you may use the
other reports as well, you will likely find that the Executive Summary is more
suitable for presentation to clients, and for your own records.
Data for the Executive Summary is generated through all the phases of your
MCD job, from input through output. The format of the report is the same for all
jobs. The “Input File Summary Report (.ifs)” on page 96 illustrates the six parts
of the report.
The Duplicate Detection and Non-Duplicate Records sections correspond with
data columns on the List Duplicates Report (detail version).
For ADV matching users, in the following example report, the Duplicate
Detection and Non Duplicate Records sections report on a match-level basis
only. The other sections report on an entire match-set basis.
Executive Summary Report Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
------------------------------------------------------------------------------- Pct of
Gross
Input
Number of Input Files: 5
Number of Reference Files: 0
Number of Input Lists: 5
Number of Suppression Lists: 1
Number of Suppression Records: 100
Gross Input Records: 2375
Records Dropped (Filtered, etc): 0 0.00%
Net Input Records: 2375 100.00%
Pct of
Net
List Quality
No Name Data Parsed: 26 1.09%
No Firm Data Parsed: 0 0.00%
No Address Data Parsed: 0 0.00%
Invalid Addresses: 32 1.35%
No Last Line Data Parsed: 0 0.00%
Invalid Last Lines: 0 0.00%
Foreign Last Lines: 0 0.00%
Total Unparsed Records: 58 2.44%
Duplicate Detection
Suppressed Duplicates: 277 11.66%
Single List Duplicates: 0 0.00%
Multiple List Duplicates: 1228 51.71%
Suppress List Subordinates: 2 0.08%
Total Duplicates: 1507 63.45%
Non Duplicate Records
Unique Records: 25 1.05%
Single List Masters: 0 0.00%
Multiple List Masters: 745 31.37%
Suppress List Uniques: 0 0.00%
Suppress List Masters: 98 4.13%
Total Non Dupes: 868 36.55%
Input Posting/Purging
Total Input Records Posted: 0
Total Input Records Purged: 0
Output
Number of Output Files: 1
Total Records Output: 770
Group Posted Records: 0
Chapter 6: Reports and statistics files
95
Page 96

Input File Summary Report (.ifs)
The Input File Summary shows input records per input file. Each line of the
report represents an input file. The entries show the gross number of records, the
number dropped for various reasons, and the resulting net number of records that
were in fact read as input. This report is valuable for verifying that your input
records have actually been read and will be processed. You can also use this
report to quickly gauge the effect of any input filters.
Data for this report is generated during the input phase of your MCD job, when
you have included the Read Records and Create Match Sets execution option.
The format of this report is always the same. The number of lines, of course,
depends upon the number of input files that you include in your MCD job. The
example below shows that five input files were included in this job.
Gross Input is the number of records physically present in the file.
Delete Drops is the number of records excluded because they had
been previously marked for deletion.
Filter Drops is the number of records excluded because they did not
pass an input filter.
List Drops is the number of records excluded because they could not
be assigned to any of the input lists. This can only happen when the
Undetermined List Action control is set to Ignore.
Sample Drops is the number of records excluded because they fell
outside the range of record numbers that you set for that input file
(see the Starting Record Number and Maximum # of Records to Input
controls).
Net Input is the actual number of records that will be processed.
Input File Summary Report Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
---------------------------------------------------------------------------------------Input Gross Delete Filter List Sample Net
File Input Drops Drops Drops Drops Input
house.txt 1000 0 0 0 0 1000
mail_sup.txt 100 0 0 0 0 100
house_fm.txt 1000 0 0 0 0 1000
update_1.txt 25 0 0 0 0 25
rent_mag.txt 250 0 0 0 0 250
Totals 2375 0 0 0 0 2375
96
Match/Consolidate User’s Guide
Page 97

Input List Summary Report (.ils)
lid
The Input List Summary shows input records per input list. Each line of the report
represents an input list. The entries show the total number of records assigned to
each list, and subdivides that total into two parts to identify those assigned by
default. This report is valuable for verifying that your input records’ list
membership has been identified, and that the lists will be reflected in your job
process.
Data for this report is generated during the input phase of your MCD job, when
you have included the Read Records and Create Match Sets execution option.
The format of this report is always the same. The number of lines, of course,
depends upon the number of input lists that you define in your MCD job. The
example below shows that five input lists were included in this job. A totals row
follows the lists.
Matched ID Records were assigned to each list based on the PW field
List_ID, or on passing the List Filter. Refer to the parameter value in
PW Field List_ID, or see the list filter setup in your Input List
Description block.
Default Records were assigned to the default list. Refer to the Unde-
termined List Action block in your job file.
Net Input is the number of records that will be processed from this list.
The Net Input total here should agree with the Net Input total from
your Input File Summary for this job.
Input List Summary Report Match/Conso
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
------------------------------------------------------------------------------- Matched Id Default Net
List Records Records Input
house 1000 0 1000
firms 1000 0 1000
no_mail 100 0 100
select 250 0 250
update 25 0 25
Totals 2375 0 2375
ate x.xx Page 1
Chapter 6: Reports and statistics files
97
Page 98

Job Summary Report (.mjs)
The Job Summary presents processing statistics, reflecting the process settings of
your MCD job. The report concisely summarizes your job setup, processing
performance, files used, and reports issued. Use this to verify and record all the
pertinent data about your job.
Data for this report is generated throughout all the phases of your MCD job. Data
will be shown only for those phases of a job that have been performed. For
example, if you have not elected to create output files, entries relating to that step
are blank in this report.
The format of this report is always the same. There are several pages, and many
sections to the report. We explain each section of the report in an example below,
looking at each section, one at a time.
Job Status The Job Status section of the report lists processing steps completed, with the date
and time of each. If a step is repeated, the date and time reflect the most recent
run. You can find each of the entries of this section as execution options in the
Execution block of your job setup.
Job Summary Report Match/Consolidate x.xx Page 1
tekpubs
Firstlogic, Inc
Technical Publications
Sample Report
-------------------------------------------------------------------------------------Job Description: TekPubs.mpg
Job Owner: TechPubs
Program Version: x.xx
Job Status
Read Records & Create Key File: Done Tue May 28 15:01:36 2002
Find Duplicates: Done Tue May 28 15:01:38 2002
Create Match/Consolidate Output File: Done Tue May 28 15:01:44 2002
Create Multi-Occurrence Output File:
Create All-Duplicates Output File:
Create Custom Match/Consolidate Output File:
Post to Input File(s):
Purge:
Custom Purge:
Create Reports: Done Tue May 28 15:01:44 2002
Create Report Statistics Files: No
Save Work Files: Yes
Process Statistics The Processing Statistics section breaks down performance statistics for the five
major processes involved in a MCD job:
1. Creating key files
2. Finding duplicates
3. Creating output files
4. Posting to input files
5. Purging input files
For each process, the following numbers are shown:
98
The elapsed time that was used in performing each major process.
The total number of records or comparisons processed.
Match/Consolidate User’s Guide
Page 99

The rate-per-hour that was achieved.
At the Find Duplicates entry, the total number of duplicates found.
The Elapsed Time of This Run is the time from the start of the run to its
completion. Because there is time between processes, don’t expect the sum of the
elapsed times for all the processes to equal the elapsed time of the run.
Processing Statistics
Create Key File
Elapsed Time (hrs:mins:secs): 00:00:06
Total Records Read: 2375
Records Read Per Hour: 1425000
Find Duplicates
Elapsed Time (hrs:mins:secs): 00:00:02
Total Comparisons: 4910
Comparisons Per Hour: 8838000
Total Duplicates Found: 1507
Create Output File(s)
Elapsed Time (hrs:mins:secs): 00:00:02
Total Records Output: 770
Records Output Per Hour: 2772000
Post to Input File(s)
Elapsed Time (hrs:mins:secs): 00:00:00
Total Records Posted: 0
Records Posted Per Hour: 0
Purge Input File(s)
Elapsed Time (hrs:mins:secs): 00:00:00
Total Records Purged: 0
Records Purged Per Hour: 0
Elapsed Time of This Run: 00:00:20
Elapsed Time of This Job: 00:00:20
Auxiliary Files This section of the Job Summary shows the directories and dictionaries used in
the process. These entries show all the files that have been included in your job
setup. It may be that some of these files are not actually used in the job.
For example, you may have identified extended name, title, and firm parsing
dictionaries (parsing.dct), but not included extended name, title, and firm
parsing in your job. If so, the files will be shown here, but they have no effect on
the job.
Auxiliary Files
Address Dictionary: C:\pw\mpg\addrln.dct
Last Line Dictionary: C:\pw\mpg\lastln.dct
City Directory: C:\pw\dirs\city07.dir
ZCF Directory: C:\pw\dirs\zcf07.dir
Zip+4 Directory 1: C:\pw\dirs\zip4us.dir
Zip+4 Directory 2:
Rev Zip+4 Directory: C:\pw\dirs\revzip4.dir
Firm Line Dictionary: C:\pw\mpg\firmln.dct
Capitalization Dictionary: C:\pw\mpg\pwcas.dct
Standard Pre-name Dictionary: C:\pw\mpg\prename.dct
Standard Name Dictionary: C:\pw\mpg\name.dct
Standard Pre-lastname Dictionary: C:\pw\mpg\prelname.dct
Standard Post-name Dictionary: C:\pw\mpg\postname.dct
Multi-line Rules: C:\pw\mpg\mlrules.gcf
Firm Rules: C:\pw\mpg\fprules.gcf
Parsing Dictionary: C:\pw\mpg\parsing.dct
Match Pct Dictionary: C:\pw\mpg\matchpct.dct
Ext Match Blocks:
Default ASCII FMT:
Default DEF:
Chapter 6: Reports and statistics files
99
Page 100

Input and Key File Information
The Input and Key File Information section includes the number of input files and
lists, gross and net input records, options related parsing and matching data of the
key file, and field IDs included in the key file. It also shows details about the
characteristics of the records, including gender, and the number of names in each
record.
The specific entries that you’ll see in this section of the report vary with the
choice of extended or standard matching for your MCD job.
If your job uses standard matching
If your job uses standard matching, you’ll see entries like the following in this
section of your Job Summary report.
Input and Key File Information
Number of Input Files: 5
Number of Input Lists: 5
Total Input Records (Gross): 2375
Records Dropped (Filtered, etc): 0
Net Input Records: 2375
Standardize Name Keys: No
Standardize Firm Keys: No
Standardize Lastline Keys: Yes
Include Second Name: No
Priority Field: off
Fields Included in Key File: Last_Name, 12
Street Range, 10
Street Pre-directional, 2
Street Primary Name, 22
Street Suffix, 4
Street Post-directional, 2
Street Secondary Range, 6
PO Box, 6
Rural Route Number, 2
Rural Route Box, 6
State, 2
ZIP, 5
Gender:
Unassigned 2375
Strong Male 0
Strong Female 0
Weak Male 0
Weak Female 0
Ambiguous 0
Multiple Names - Mixed 0
Multiple Names - Male 0
Multiple Names - Female 0
Multiple Names - Ambiguous 0
Parsed as:
Business 0
Residential 2375
Number of Parsed Names (per record):
One name 2348
Two names 1
Three names 0
Four names 0
Five names 0
Six names 0
100
Match/Consolidate User’s Guide
 Loading...
Loading...