

Page 1

Text Data Processing Language Reference Guide
■ SAP BusinessObjects Data Services XI 4.0 (14.0.0)
2010-12-02
Page 2

Copyright
© 2010 SAP AG. All rights reserved.SAP, R/3, SAP NetWeaver, Duet, PartnerEdge, ByDesign, SAP
Business ByDesign, and other SAP products and services mentioned herein as well as their respective
logos are trademarks or registered trademarks of SAP AG in Germany and other countries. Business
Objects and the Business Objects logo, BusinessObjects, Crystal Reports, Crystal Decisions, Web
Intelligence, Xcelsius, and other Business Objects products and services mentioned herein as well
as their respective logos are trademarks or registered trademarks of Business Objects S.A. in the
United States and in other countries. Business Objects is an SAP company.All other product and
service names mentioned are the trademarks of their respective companies. Data contained in this
document serves informational purposes only. National product specifications may vary.These materials
are subject to change without notice. These materials are provided by SAP AG and its affiliated
companies ("SAP Group") for informational purposes only, without representation or warranty of any
kind, and SAP Group shall not be liable for errors or omissions with respect to the materials. The
only warranties for SAP Group products and services are those that are set forth in the express
warranty statements accompanying such products and services, if any. Nothing herein should be
construed as constituting an additional warranty.
2010-12-02
Page 3

Contents
Introduction.............................................................................................................................7Chapter 1
1.1
1.1.1
1.1.2
1.1.3
1.1.4
1.2
1.2.1
1.2.2
2.1
2.2
2.2.1
2.3
2.4
3.1
3.2
3.3
3.3.1
3.4
3.5
3.5.1
3.5.2
3.5.3
3.5.4
3.5.5
3.5.6
3.5.7
3.6
Welcome to SAP BusinessObjects Data Services...................................................................7
Welcome.................................................................................................................................7
Documentation set for SAP BusinessObjects Data Services...................................................7
Accessing documentation......................................................................................................10
SAP BusinessObjects information resources.........................................................................11
Overview of This Guide..........................................................................................................12
About This Guide ..................................................................................................................13
Who Should Read This Guide................................................................................................13
Overview of Linguistic Analysis and Extraction....................................................................15Chapter 2
About Linguistic Analysis.......................................................................................................15
About Extraction.....................................................................................................................15
About Customizing Extraction................................................................................................16
Languages Modules Supported..............................................................................................17
Specialized Extraction Content...............................................................................................17
Linguistic Analysis Support...................................................................................................19Chapter 3
Linguistic Analysis Language Feature Matrix..........................................................................20
Segment Generation..............................................................................................................21
Word Segmentation...............................................................................................................21
White Space Languages........................................................................................................22
Case Normalization Rules......................................................................................................23
Stemming..............................................................................................................................24
Standard Inflectional Stemming..............................................................................................25
Expanded Inflectional Stemming.............................................................................................26
Inflectional Stemmer Guesser................................................................................................26
Compound Word Stemming...................................................................................................26
Non-Decompounding Stemming.............................................................................................26
Derivational Stemming...........................................................................................................27
Stemming Unknown Words....................................................................................................27
Part-of-Speech Support.........................................................................................................28
2010-12-023
Page 4

Contents
3.6.1
3.6.2
3.6.3
3.6.4
4.1
4.1.1
4.2
4.3
4.4
4.4.1
4.4.2
5.1
5.1.1
5.1.2
5.2
5.2.1
5.2.2
5.3
5.3.1
5.3.2
5.4
5.4.1
5.4.2
5.5
5.5.1
5.5.2
5.6
5.6.1
5.6.2
Tag Name Conventions..........................................................................................................28
Unfound Words......................................................................................................................29
Tagged Stemming..................................................................................................................29
Word Breaking.......................................................................................................................29
Extraction Support.................................................................................................................31Chapter 4
Entity and Fact Extraction.......................................................................................................31
Subentities and Subtypes......................................................................................................32
Extraction Resource Files.......................................................................................................32
Levels of Extraction Support for the Language Modules.........................................................33
Predefined Entity Type Support..............................................................................................34
Named Entities.......................................................................................................................35
Common Mentions................................................................................................................42
Language Modules Reference..............................................................................................45Chapter 5
Chinese (Simplified) Language Reference..............................................................................45
Linguistic Processing.............................................................................................................45
Extraction...............................................................................................................................50
English Language Reference..................................................................................................63
Linguistic Processing.............................................................................................................64
Extraction...............................................................................................................................73
French Language Reference.................................................................................................100
Linguistic Processing...........................................................................................................100
Extraction.............................................................................................................................108
German Language Reference...............................................................................................126
Linguistic Processing...........................................................................................................126
Extraction.............................................................................................................................139
Japanese Language Reference............................................................................................157
Linguistic Processing...........................................................................................................157
Extraction.............................................................................................................................167
Spanish Language Reference...............................................................................................167
Linguistic Processing...........................................................................................................168
Extraction.............................................................................................................................176
6.1
6.1.1
6.1.2
6.1.3
6.2
Voice of the Customer Content..........................................................................................193Chapter 6
Extracting Sentiments..........................................................................................................194
English: Sentiment Extraction Examples...............................................................................195
French: Sentiment Extraction Examples................................................................................196
Spanish: Sentiment Extraction Examples..............................................................................197
Extracting Requests.............................................................................................................198
2010-12-024
Page 5

Contents
6.2.1
6.2.2
6.2.3
7.1
7.2
7.3
7.4
7.5
8.1
8.1.1
8.1.2
8.1.3
8.1.4
8.1.5
8.1.6
8.1.7
8.1.8
8.1.9
8.1.10
8.1.11
8.2
8.2.1
English: Request Extraction Examples..................................................................................199
French: Request Extraction Examples...................................................................................200
Spanish: Request Extraction Examples.................................................................................200
Enterprise Content..............................................................................................................201Chapter 7
Extracting Membership Information......................................................................................202
Extracting Management Change Events...............................................................................204
Extracting Product Release Events.......................................................................................206
Extracting Merger Information..............................................................................................207
Extracting Organizational Information....................................................................................208
Public Sector Content.........................................................................................................211Chapter 8
English: Types of Information Extracted ...............................................................................211
Public Sector Content Rule Sets–English.............................................................................211
Public Sector Content Entities–English.................................................................................213
Extracting Action Events.......................................................................................................219
Extracting Travel Events.......................................................................................................227
Extracting Military Units........................................................................................................236
Extracting Organizational Information....................................................................................237
Extracting a Person's Aliases...............................................................................................240
Extracting Information About a Person's Appearance...........................................................243
Extracting Information About a Person's Attributes...............................................................244
Extracting Information About a Person's Relationships.........................................................249
Extracting Spatial References...............................................................................................250
Simplified Chinese: Types of Information Extracted..............................................................251
Public Sector Entities–Simplified Chinese.............................................................................251
Index 257
2010-12-025
Page 6

Contents
2010-12-026
Page 7

Introduction
Introduction
1.1 Welcome to SAP BusinessObjects Data Services
1.1.1 Welcome
SAP BusinessObjects Data Services delivers a single enterprise-class solution for data integration,
data quality, data profiling, and text data processing that allows you to integrate, transform, improve,
and deliver trusted data to critical business processes. It provides one development UI, metadata
repository, data connectivity layer, run-time environment, and management console—enabling IT
organizations to lower total cost of ownership and accelerate time to value. With SAP BusinessObjects
Data Services, IT organizations can maximize operational efficiency with a single solution to improve
data quality and gain access to heterogeneous sources and applications.
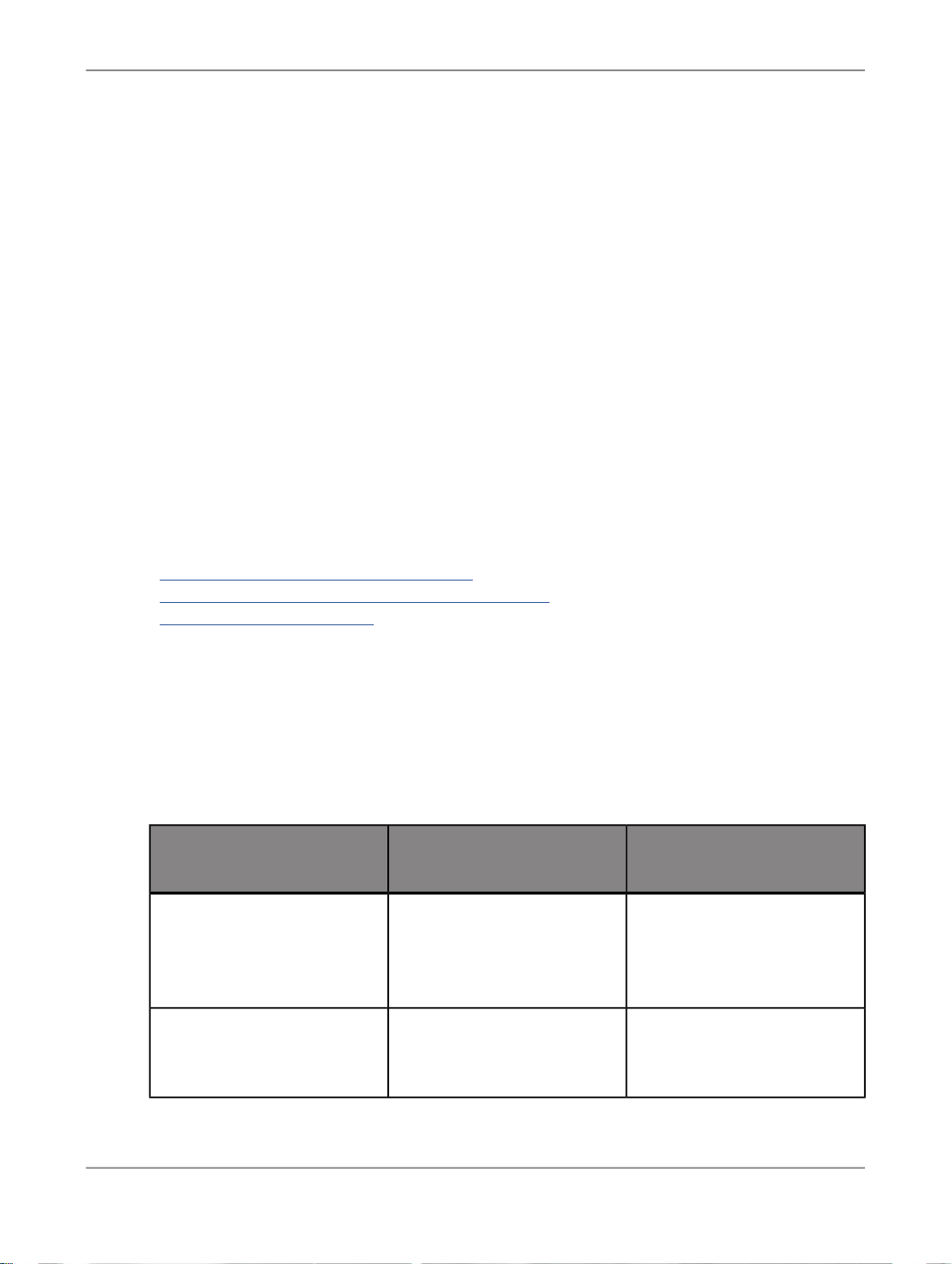
1.1.2 Documentation set for SAP BusinessObjects Data Services
You should become familiar with all the pieces of documentation that relate to your SAP BusinessObjects
Data Services product.
What this document providesDocument
Administrator's Guide
Customer Issues Fixed
Designer Guide
Information about administrative tasks such as monitoring,
lifecycle management, security, and so on.
Information about customer issues fixed in this release.
Information about how to use SAP BusinessObjects Data
Services Designer.
Documentation Map
Information about available SAP BusinessObjects Data Services books, languages, and locations.
2010-12-027
Page 8

Introduction
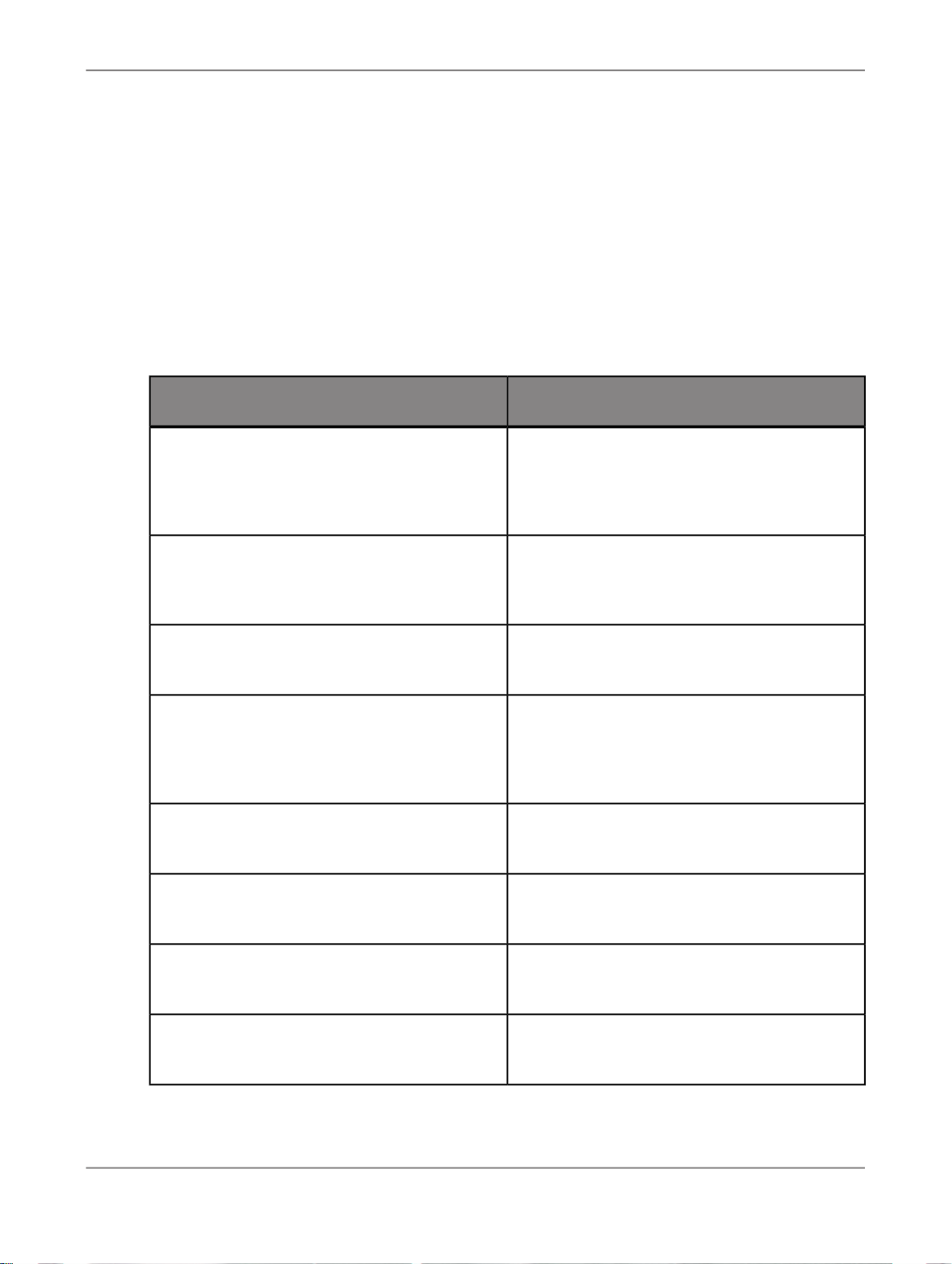
What this document providesDocument
Installation Guide for Windows
Installation Guide for UNIX
Integrator's Guide
Management Console Guide
Performance Optimization Guide
Reference Guide
Release Notes
Technical Manuals
Information about and procedures for installing SAP BusinessObjects Data Services in a Windows environment.
Information about and procedures for installing SAP BusinessObjects Data Services in a UNIX environment.
Information for third-party developers to access SAP BusinessObjects Data Services functionality using web services and
APIs.
Information about how to use SAP BusinessObjects Data
Services Administrator and SAP BusinessObjects Data Services Metadata Reports.
Information about how to improve the performance of SAP
BusinessObjects Data Services.
Detailed reference material for SAP BusinessObjects Data
Services Designer.
Important information you need before installing and deploying
this version of SAP BusinessObjects Data Services.
A compiled “master” PDF of core SAP BusinessObjects Data
Services books containing a searchable master table of contents and index:
•
Administrator's Guide
•
Designer Guide
•
Reference Guide
•
Management Console Guide
•
Performance Optimization Guide
•
Supplement for J.D. Edwards
•
Supplement for Oracle Applications
•
Supplement for PeopleSoft
•
Supplement for Salesforce.com
•
Supplement for Siebel
•
Supplement for SAP
Text Data Processing Extraction Customization Guide
Text Data Processing Language Reference
Guide
Information about building dictionaries and extraction rules to
create your own extraction patterns to use with Text Data
Processing transforms.
Information about the linguistic analysis and extraction processing features that the Text Data Processing component provides, as well as a reference section for each language supported.
2010-12-028
Page 9

Introduction
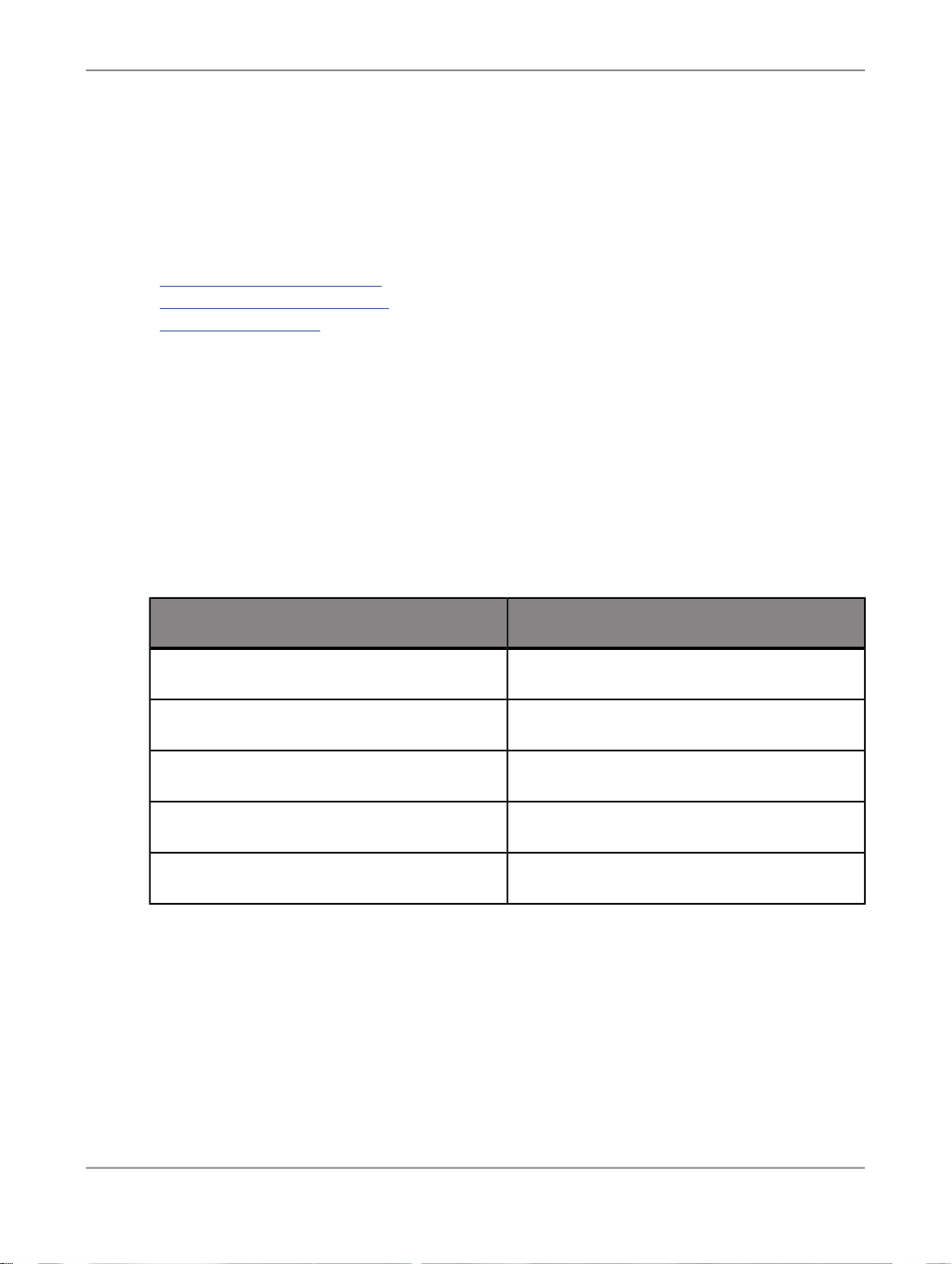
What this document providesDocument
Tutorial
Upgrade Guide
What's New
In addition, you may need to refer to several Adapter Guides and Supplemental Guides.
Supplement for J.D. Edwards
Supplement for Oracle Applications
Supplement for PeopleSoft
A step-by-step introduction to using SAP BusinessObjects
Data Services.
Release-specific product behavior changes from earlier versions of SAP BusinessObjects Data Services to the latest release. This manual also contains information about how to
migrate from SAP BusinessObjects Data Quality Management
to SAP BusinessObjects Data Services.
Highlights of new key features in this SAP BusinessObjects
Data Services release. This document is not updated for support package or patch releases.
What this document providesDocument
Information about interfaces between SAP BusinessObjects Data Services
and J.D. Edwards World and J.D. Edwards OneWorld.
Information about the interface between SAP BusinessObjects Data Services
and Oracle Applications.
Information about interfaces between SAP BusinessObjects Data Services
and PeopleSoft.
Supplement for Salesforce.com
Supplement for SAP
Supplement for Siebel
Information about how to install, configure, and use the SAP BusinessObjects
Data Services Salesforce.com Adapter Interface.
Information about interfaces between SAP BusinessObjects Data Services,
SAP Applications, and SAP NetWeaver BW.
Information about the interface between SAP BusinessObjects Data Services
and Siebel.
We also include these manuals for information about SAP BusinessObjects Information platform services.
Information platform services Administrator's Guide
Information platform services Installation Guide for
UNIX
What this document providesDocument
Information for administrators who are responsible for
configuring, managing, and maintaining an Information
platform services installation.
Installation procedures for SAP BusinessObjects Information platform services on a UNIX environment.
2010-12-029
Page 10

Introduction
What this document providesDocument
Information platform services Installation Guide for
Windows
1.1.3 Accessing documentation
You can access the complete documentation set for SAP BusinessObjects Data Services in several
places.
1.1.3.1 Accessing documentation on Windows
After you install SAP BusinessObjects Data Services, you can access the documentation from the Start
menu.
1.
Choose Start > Programs > SAP BusinessObjects Data Services XI 4.0 > Data Services
Documentation.
Installation procedures for SAP BusinessObjects Information platform services on a Windows environment.
Note:
Only a subset of the documentation is available from the Start menu. The documentation set for this
release is available in <LINK_DIR>\Doc\Books\en.
2.
Click the appropriate shortcut for the document that you want to view.
1.1.3.2 Accessing documentation on UNIX
After you install SAP BusinessObjects Data Services, you can access the online documentation by
going to the directory where the printable PDF files were installed.
1.
Go to <LINK_DIR>/doc/book/en/.
2.
Using Adobe Reader, open the PDF file of the document that you want to view.
1.1.3.3 Accessing documentation from the Web
2010-12-0210
Page 11

Introduction
You can access the complete documentation set for SAP BusinessObjects Data Services from the SAP
BusinessObjects Business Users Support site.
1.
Go to http://help.sap.com.
2.
Click SAP BusinessObjects at the top of the page.
3.
Click All Products in the navigation pane on the left.
You can view the PDFs online or save them to your computer.
1.1.4 SAP BusinessObjects information resources
A global network of SAP BusinessObjects technology experts provides customer support, education,
and consulting to ensure maximum information management benefit to your business.
Useful addresses at a glance:
2010-12-0211
Page 12

Introduction
ContentAddress
Customer Support, Consulting, and Education
services
http://service.sap.com/
SAP BusinessObjects Data Services Community
http://www.sdn.sap.com/irj/sdn/ds
Forums on SCN (SAP Community Network )
http://forums.sdn.sap.com/forum.jspa?foru
mID=305
Blueprints
http://www.sdn.sap.com/irj/boc/blueprints
Information about SAP Business User Support
programs, as well as links to technical articles,
downloads, and online forums. Consulting services
can provide you with information about how SAP
BusinessObjects can help maximize your information management investment. Education services
can provide information about training options and
modules. From traditional classroom learning to
targeted e-learning seminars, SAP BusinessObjects
can offer a training package to suit your learning
needs and preferred learning style.
Get online and timely information about SAP BusinessObjects Data Services, including tips and tricks,
additional downloads, samples, and much more.
All content is to and from the community, so feel
free to join in and contact us if you have a submission.
Search the SAP BusinessObjects forums on the
SAP Community Network to learn from other SAP
BusinessObjects Data Services users and start
posting questions or share your knowledge with the
community.
Blueprints for you to download and modify to fit your
needs. Each blueprint contains the necessary SAP
BusinessObjects Data Services project, jobs, data
flows, file formats, sample data, template tables,
and custom functions to run the data flows in your
environment with only a few modifications.
http://help.sap.com/businessobjects/
Supported Platforms (Product Availability Matrix)
https://service.sap.com/PAM
1.2 Overview of This Guide
SAP BusinessObjects product documentation.Product documentation
Get information about supported platforms for SAP
BusinessObjects Data Services.
Use the search function to search for Data Services.
Click the link for the version of Data Services you
are searching for.
2010-12-0212
Page 13

Introduction
Welcome to the
SAP BusinessObjects Data Services text data processing software enables you to perform linguistic
analysis of and extraction of content from unstructured text.
Linguistic analysis includes natural-language processing (NLP) capabilities, such as segmentation,
stemming, and tagging, among other things. Extraction analyzes unstructured text, in multiple languages
and from any text data source, and automatically identifies and extracts key entity types, including
people, dates, places, organizations, or other information, from the text.
Language Reference Guide
1.2.1 About This Guide
This guide contains two kinds of information:
• Overviews and conceptual information about the linguistic analysis and extraction features provided
by the software.
• A reference section for each language supported by the software. It describes the behavior of the
supported language modules during extraction and normalization.
.
1.2.2 Who Should Read This Guide
Users of this guide may need to enhance extraction in their text analytics application and should
understand text data processing extraction concepts. However, users of this guide are not expected to
understand or be familiar with the natural languages of the text being processed by the software.
Similarly, users are not required to be familiar with linguistic principles. This document assumes the
following:
• You are an application developer or consultant working on enhancing text data processing extraction.
• You understand your organization's text data processing extraction needs.
2010-12-0213
Page 14

Introduction
2010-12-0214
Page 15

Overview of Linguistic Analysis and Extraction
Overview of Linguistic Analysis and Extraction
The software includes language modules for the languages supported. Each language module consists
of a set of files that include system dictionaries containing words to support the language processing
operations for the given natural language. It is the language modules that enable linguistic analysis and
extraction of unstructured text in a given language. Language modules use the following language
processing technologies:
• Linguistic analysis to handle natural language processing
• Extraction to handle entity extraction
Related Topics
• Linguistic Analysis Support
• Extraction Support
2.1 About Linguistic Analysis
The software provides and uses sophisticated natural language processing capabilities for linguistic
analysis of unstructured data. Some of these capabilities include:
• Segmentation–the separation of input text into its elements
• Stemming–the identification of word stems, or dictionary forms
• Tagging–the labeling of words' parts of speech
Related Topics
• Linguistic Analysis Support
• Language Modules Reference
2.2 About Extraction
2010-12-0215
Page 16

Overview of Linguistic Analysis and Extraction
Extraction is the process of discovering and presenting specific entities and facts that occur in
unstructured text.
• Entities denote the names of people, places, things, dates, values, and so forth, that can be extracted
from text. An entity is defined as a pairing of a standard form and its type. For example, Winston
Churchill/PERSON is an entity in which Winston Churchill is the standard form and PERSON
is the type.
• Facts are entities and subentities, found during the extraction process, that represent relationships,
events, sentiments, or requests. Facts are extracted based on extraction rules consisting of patterns
that define the expressions to use to extract the information. The specialized voice of the customer
content, for example, provides the rules that let you extract facts that represent sentiments and
requests.
The language modules included with the software contain system dictionaries and provide an extensive
set of predefined entity types. The extraction process can extract entities using these lists of specific
entities. It can also discover new entities using linguistic models. Extraction classifies each extracted
entity by entity type and presents this metadata in a standardized format.
Related Topics
• Extraction Support
• Predefined Entity Type Support
• About Customizing Extraction
• Languages Modules Supported
• Language Modules Reference
• Specialized Extraction Content
2.2.1 About Customizing Extraction
You can enhance the extraction process by creating and using:
• Dictionaries that contain information about entities. You can customize information about the entities
your application must find.
• Extraction rules.
For details about enhancing extraction, refer to the
Data Processing Extraction Customization Guide
For certain language modules, you can also enhance extraction by using the specialized extraction
content included in them.
Related Topics
• Specialized Extraction Content
SAP BusinessObjects Data Services XI 4.0 Text
.
2010-12-0216
Page 17
Overview of Linguistic Analysis and Extraction
2.3 Languages Modules Supported
The software provides these language modules, which are supported by linguistic analysis and extraction:
• English
• French
• German
• Japanese
• Simplified Chinese
• Spanish
Note:
Not all linguistic analysis and extraction features are supported for all languages.
Related Topics
• Linguistic Analysis Language Feature Matrix
• Levels of Extraction Support for the Language Modules
• Language Modules Reference
2.4 Specialized Extraction Content
Certain language modules include specialized content that provides entity types and sets of rules that
address specific needs:
Specialized Extraction Content
Voice of the customer
Description
Extracts specific information
about your customers' needs
(requests) and perceptions and
problems (sentiments)
Included in These Language
Modules
English
French
Spanish
Enterprise
Extracts enterprise-specific information, such as management
changes and product releases
English
2010-12-0217
Page 18

Overview of Linguistic Analysis and Extraction
Specialized Extraction Content
Public Sector
Related Topics
• Voice of the Customer Content
• Enterprise Content
• Public Sector Content
Description
Extracts public-sector-specific
information, such as events and
relations
Included in These Language
Modules
English
Simplified Chinese
2010-12-0218
Page 19
Linguistic Analysis Support
Linguistic Analysis Support
The software provides and uses these linguistic analysis features for multilingual natural language
processing (NLP) of unstructured data:
Language and encoding identification
DescriptionFeature
The automatic recognition of the input language,
for example, French or Japanese, and of various
character encodings (such as Unicode UTF-8 and
Code Page 1252).
Segment generation
Word segmentation
Case normalization
Stemming
Tagging
Document analysis
The breaking of input text into segments of one
or more complete paragraphs for more efficient
processing.
The separation of input text into its elements, such
as words and punctuation.
The normalization of the initial letter of a word to
upper or lower case. Used to counteract case
changes related to document structure, such as
title and heading capitalization.
The identification of word stems, or dictionary
forms, for text or single words.
The labeling of words' parts of speech, for example, noun or verb.
The recognition of a document's major sections–paragraphs and sentences.
Tagged stemming
The identification of word stems for a word of a
given part-of-speech.
2010-12-0219
Page 20

Linguistic Analysis Support
Note:
Not all operations are supported for all languages.
Related Topics
• Linguistic Analysis Language Feature Matrix
• Segment Generation
• Word Segmentation
• Case Normalization Rules
• Stemming
• Part-of-Speech Support
• Tagged Stemming
• Language Modules Reference
3.1 Linguistic Analysis Language Feature Matrix
Linguistic analysis provides two levels of language support:
• Standard–Tagging is not supported
• Advanced–Tagging is supported
The following table shows the status of each supported feature for each natural language.
Inflectional Stemming
Tagging
Language
Multiword
Units
Word Segmentation
Compound
Words
Simplified
Chinese
Tagged
Stemming
XXX**X*X
XXX***XXEnglish
XXXXXFrench
XXXXXXGerman
XXXX*XJapanese
XXXXXSpanish
2010-12-0220
Page 21

Linguistic Analysis Support
• * Compound analysis is supported by the expanded language module for the language.
• ** Because Chinese words are not inflected, the stems of all Chinese words are identical to their
source forms. Therefore, stemming is not supported for Chinese.
• *** For English only, derivational stemming is also supported.
Related Topics
• Multiword Units
• Word Segmentation
• Stemming
• Compound Word Stemming
• Expanded Inflectional Stemming
• Derivational Stemming
• Part-of-Speech Support
• Tagged Stemming
• Language Modules Reference
3.2 Segment Generation
During the analysis of unstructured text, text processing objects operate on one segment of a data
stream at a time. Segments are small units of text, including one or more complete paragraphs. Linguistic
analysis operations break input streams into chunks. This chunking of the data stream is called segment
generation.
Segment generation involves two steps: reading in the input text as a byte stream and breaking it into
segments. The resulting segments contain associated metadata markup about the context text. These
segments are then passed on for further linguistic analysis from which words, sentences, and paragraphs
can then be extracted.
3.3 Word Segmentation
The word segmentation operation performs basic word breaking. It breaks text into the smallest,
meaningful syntactic units, such as words or punctuation. The word segmenter also identifies idiomatic
phrases, such as "case in point" or "out-of-the-box." These idiomatic phrases are processed as a single
unit or word. Hyphenated words are not broken, since they are syntactic units. However, contractions
(such as "don't") and elisions (such as "l'abri") are separated into their syntactic units.
2010-12-0221
Page 22

Linguistic Analysis Support
3.3.1 White Space Languages
White space languages mark word boundaries with white space and punctuation marks. This group
includes European, Balkan, and Middle Eastern languages, as well as Korean. Punctuation marks
sometimes end a sentence, in which case they are used in sentence detection.
Non-white space languages include the Chinese languages, Japanese, and Thai (CCJT for short).
Word segmentation in the CCJT languages occurs with a slightly different algorithm due to their structure.
Because complete morphological analysis is required to perform word segmentation in these languages,
the word segmentation, stemming, and part-of-speech tagging operations occur in a single step.
3.3.1.1 Multiword Units
By default, multiword units are segmented as a single unit, for example, "to and fro" and "Buenos Aires"
are each segmented as one unit. However, you can turn this behavior off. In this case, multiword units
are broken into their individual components. For example, "to and fro" is segmented into three units
instead of one.
3.3.1.2 Punctuation
Word segmentors generally split off punctuation marks as separate units. This includes periods and
commas, sentence-ending punctuation, and various quotation marks.
The following table summarizes punctuation-related segmentation conventions:
If a punctuation mark is followed by a character
No Whitespace
Abbreviations
and not by white space, it is not split off from its
surrounding word. For example: "filename.filetype"
is segmented as "filename.filetype".
Abbreviations ending in a period are important
exceptions to the general rule that splits punctuation from their terms; their periods remain with
them.
2010-12-0222
Page 23

Linguistic Analysis Support
Apostrophes
Hyphens
3.4 Case Normalization Rules
Contractions spelled with apostrophes (like can't,
don't, etc. in English) are handled via languagespecific rules.
Embedded and trailing hyphens are not split off
from their words. Leading hyphens are not split
off before a digit expression, for example, -1000
is segmented as one unit.
Case normalization provides case-normalized alternatives for words which, by their position in a sentence
or because they occur in a title, may or may not appear with their inherent, meaningful capitalization.
For instance, a proper noun like SAP is always capitalized, but a common noun like horse is only
capitalized if it begins a sentence or occurs in a title. Therefore, if Horse is encountered, the case
normalizer provides the lower-case alternative so that later processing will not mistake Horse for a
proper noun. The two resulting alternatives can then be passed on to the stemming or tagging operations.
Note:
Case normalization is not relevant to languages that do not distinguish between upper and lower case,
for example, the CCJT languages.
Case normalization depends on the type of sentence (normal sentence, title, or query) and the position
of the word to be normalized in each sentence type. The important position to consider is the
sentence-initial position, where special normalization rules may apply. Words directly following certain
punctuation marks are also treated as if they are in sentence-initial position.
• Title sentence
All capitalized words are normalized. For example, a newspaper heading would be normalized as:
• Cardinals Strike Out( Cardinals | cardinals ) ( Strike | strike ) (Out | out )
• Query sentence
Lowercase words are normalized to their upper case variants. Capitalized and all-caps words are
not normalized in query sentences.
• aaaa: aaaa, Aaaa, AAAA
• aaaA: aaaA, AaaA
• Normal sentence
2010-12-0223
Page 24

Linguistic Analysis Support
Capitalized words are normalized when they occur in sentence-initial position. All-caps words in
sentence-initial position are also normalized. In other positions of normal sentences, capitalized and
all-uppercase words are not normalized. For instance:
• Aaaa bbb Cccc:(Aaaa | aaaa) (bbb) (Cccc)
• AAAA bbb CCCC: (AAAA | Aaaa | aaaa) (bbb) (CCCC)
3.5 Stemming
Words like speaks or speaking have one stem– speak. Some words have more than one possible
stem: spoke, for instance, may turn out, in context, to be the past tense of the verb speak, but it could
also be the singular form of the noun spoke. A stem is a base form for one or more variant (source)
forms found in text; it is the form referenced in the dictionary.
Stemming a word means finding and returning its stem. For example, rather than redundantly deal with
grind, grinds, grinding, ground, and so on, all of these source forms can be recognized as variants
of the single verb grind. Ground can also be a noun whose meaning is completely unrelated to the
verb grind.
The example of indexing documents according to key words they contain can help to better understand
the advantages of working with more abstract forms. If indexing is done naïvely, grind, grinds, grinding,
ground will be handled as unrelated words, and a query containing one of these variants will not return
documents containing the other variants. With the use of a stemmer, however, all of the variants will
be indexed under the base form grind (verb).
The stemmer the software uses receives input of a series of syntactic units (for example, ground ) and
associates each unit with one or more base forms (for example, ground , grind ). The stemmer always
returns all possible alternative stems for each input term.
The software distinguishes between standard inflectional stemming and derivational stemming. The
stemmers are inflectional by default. Derived stemmers are indicated as such.
Inflectional stemming is provided for every supported language. At present, derivational stemming is
supported only for English.
For some languages, two different inflectional stemmers are included–the standard inflectional stemmer
and an expanded inflectional stemmer that is more permissive of variation in the input text.
The stemmers support several different variants of the stemming operation:
• The standard variant returns all possible normalized stems for the input. It also performs compound
analysis in languages like German, such that compound words are broken into their component
parts.
• The expanded variant covers the same normalization as the standard variant, but it is biased for
recall by allowing wider variation in capitalization, accentuation, and similar features, as found in
informal text.
2010-12-0224
Page 25
Linguistic Analysis Support
• In German, the no-split stemmer supports compound stemming without breaking the compound into
separate stems, which provides better browsability.
• In English, the derivational variant provides the root stem for morphologically derived words.
Related Topics
• Standard Inflectional Stemming
• Expanded Inflectional Stemming
• Derivational Stemming
3.5.1 Standard Inflectional Stemming
With inflectional stemming, words retain the part of speech (noun, verb, and so on) of the base forms.
For example, the verb forms speaks and speaking remain verbs like the base form speak, even while
incorporating changes related to person (first, second, third person), number (singular and plural), tense
(present, past, future), aspect (progressive) or other grammatical features.
Here are some additional examples:
Stems toExample
{aller, vais, vas, va, allons, allez, vont} [French]
{reach, reaches, reached, reaching}
{big, bigger, biggest}
{balloon, balloons}
{go, goes, going, gone, went}
aller
reach
big
balloon
go
The bold words are the stems (dictionary forms). The characters added to the stem (es in reaches, s
in balloons ) are called inflections or affixes.
To handle unknown words such as neologisms, the standard stemmer contains a set of morphological
rules that apply to words.
2010-12-0225
Page 26

Linguistic Analysis Support
3.5.2 Expanded Inflectional Stemming
The expanded inflectional stemming dictionaries provide all the same functionality as the standard
stemmers provided, and more. The expanded inflectional stemmer allows for certain non-standard word
forms–for example, capitalization errors–as well as standard forms. Thus it can be used to process
informal or imperfect text (such as email, online documents, or queries). The variation it handle includes
case variation, hyphenation and unaccented characters among others. The expanded variant of the
CCJT languages is designed for more granular stemming results suitable for index generation.
3.5.3 Inflectional Stemmer Guesser
The inflectional stemmer guesser contains morphological rules that can be applied to syntactic units
that are unknown to the standard or expanded inflectional stemmer and, therefore, cannot be stemmed.
The software provides inflectional stemmer guessers for English, French, German, and Spanish.
3.5.4 Compound Word Stemming
Compound words are those like bookmark or birdbath, formed by combining or concatenating several
words. German is especially famous for its compounds, for example, Bildungsroman from Bildung
"education" and Roman "novel", and Weltanschauung from Welt "world" and Anschauung "view".
The software performs compound analysis for German. In German, compounds are always separated
into their component stems.
3.5.5 Non-Decompounding Stemming
The German language module includes a variant no-split stemmer that does not perform de-compounding
in the stemmer. This stemmer stems the head of the compound, but does not split the compound into
separate stems. For example, the plural compound Bildungsromane is stemmed to Bildungsroman,
but is not split into component stems. The returned stem is always a single term; and since there is no
compound boundary marker, the term cannot be broken up.
If alternate stems are possible, more than one stem may be returned, as with the standard and expanded
stemmers.
2010-12-0226
Page 27

Linguistic Analysis Support
3.5.6 Derivational Stemming
Derivational stemming involves cases in which words and stems may or may not have the same part
of speech: a noun may be derived from a verb stem (as for participation and participate), or an
adjective may be derived from a noun (as for boyish and boy). Here are more derivational examples:
• {introduction, introductory, introducer} from introduce
• {subcategory, categorize, categorization} from category
• {useful, usable, unusable} from use
• {reenlist} from enlist
Derivational stemming is currently supported for English only.
3.5.7 Stemming Unknown Words
The stemmer identifies the stems of all the standard words of a language. However, an unknown word,
such as one not found in the system dictionary, will not have a stem. In general, the stemmer returns
the input term as the stem itself. A complicating factor is that, due to case-normalization, the input to
the stemmer may include more than one variant term for a given word. This means that one variant
might be found while another might not be. By default, the stemmer returns the stems of found terms
and removes unfound terms from the results.
For example, at the beginning of a sentence, the word Dogs would be normalized as the disjunction
(Dogs | dogs). In such cases, the stemmer considers both members of the disjunction–both Dogs and
dogs. Assume that lower-case dogs is in the stemmer dictionary, and that capitalized Dogs is absent.
Since Dogs is not in the dictionary (and considered an unfound word), it would stem to Dogs itself.
Since dogs is in the dictionary, it stems to dog. By default, the stemmer discards the unknown word
Dogs and returns dog as the stem of the found variant. This is the default behavior.
If none of the case-normalized variants is found, then the stemmer returns all the case-normalized
variants. For example, suppose the input sentence begins with the unknown word Fbzzz. The case
normalizer returns the disjunction (Fbzzz | fbzzz). The stemmer finds neither one in the dictionary
and returns both forms as stems.
Related Topics
• Case Normalization Rules
2010-12-0227
Page 28

Linguistic Analysis Support
3.6 Part-of-Speech Support
The part-of-speech tagger identifies and labels the part of speech for each word in context. A word's
part-of-speech is the grammatical category it falls into, such as noun or verb, along with subclass
attributes of each of these major categories, such as singular or plural for nouns, and present or past
tense for verbs.
For certain of its language modules, the software supports the use of two types of parts-of-speech tags.
You can also use these tags when creating extraction rules:
• Umbrella tags–These tags identify major parts-of-speech at a high level, without breaking down the
part of speech further than its overall function. For example, the Nn tag identifies all nouns, regardless
of whether they are singular or plural, feminine or masculine, and so on.
• Complete tags–These tags identify the exact part-of-speech, along with its attributes. For example,
the Nn-Pl tag identifies plural nouns, and V-Pres-3-sg identifies present tense, 3rd person singular
verbs.
For specific details about the tag sets in each supported language, refer to the chapter for that language
in the "
Language Module Reference
3.6.1 Tag Name Conventions
Tags consist of feature names separated by hyphens. The first feature name is called a category tag.
It usually specifies the high level part of speech of the word, for example, noun or verb, abbreviated as
Nn and V respectively. When the tag contains more than one part-of-speech, as in V/Adj or Det/Pron,
this indicates that the part-of-speech can be of either category.
Feature tags classify the word more precisely. They may indicate number (for example, plural and
singular), person (for example, first, second or third), or tense (for example, present and past). Thus,
the tag V-Pres-3-Sg indicates that the verb is present tense, third person singular.
When a feature appears in all lower case, as in the tag Prep-para from the Spanish tagger, it stands
for a word in that language (here, Spanish para), and means that the word's distribution differs enough
from that of other words of its category to rate its own feature. Such very specific features are listed in
the language-specific tables.
For specific details about the tag sets in each supported language, refer to the chapter for that language
in the "
Language Modules Reference
" part of this guide.
" part of this guide.
2010-12-0228
Page 29

Linguistic Analysis Support
3.6.2 Unfound Words
Words not found in the tagger dictionary are passed to the relevant guesser to be assigned the most
likely tag. The guesser assigns tags to unfound words based on a set of rules about the morphology
of the given language. Capitalization information may also be used as capitalized words are also proper
nouns in many languages. Combinations of alphabetic, numeric and optionally, punctuation characters
tend to be guessed as proper nouns as well. Ordinal numbers are tagged either as noun or adjective,
depending on the context. Internet and e-mail addresses are assigned the tag Nn-Net.
In the Asian languages, unfound words are assigned the tag Nn by default.
3.6.3 Tagged Stemming
The tagged stemming operation provides complete linguistic analysis of input text, including stemming
with respect to part-of-speech information. This operation segments text into words and punctuation,
performs document analysis, case normalization, and part-of-speech tagging. Then, given a term and
its part-of-speech tag, it performs stemming of the term. For example, for the input term-tag pair
children[Nn-Pl], the output is child.
3.6.4 Word Breaking
The word-breaking operation segments text into words and punctuation, performs document analysis,
case normalization, and part-of-speech tagging.
2010-12-0229
Page 30

Linguistic Analysis Support
2010-12-0230
Page 31

Extraction Support
Extraction Support
This section describes how extraction works when analyzing unstructured text.
4.1 Entity and Fact Extraction
Extracting entities from unstructured text tells us what the text is about–the people, organizations,
places, and other parties described in the document. The extraction process involves processing and
analyzing text, finding entities of interest, assigning them to the appropriate type, and presenting this
metadata in a standard format.
The extraction process can extract entities using lists of specific named entities. It can also discover
new entities using linguistic models.
Entities are often proper names, such as the names of specific and unique people, organizations, or
places. Other specified entity types include currency amounts and dates, among others.
Each entity is defined as a pairing of a name and its type. For example:
• Canada/COUNTRY
• Pope John Paul/PERSON
• General Motors Corporation/ORGANIZATION/COMMERCIAL
Entity types play a crucial role in the definition of an entity. Entity types are used to classify entities
extracted from documents and entities stored in a dictionary.
The extraction process presents this metadata in a standardized format, along with the entity's character
offset and length in the document, and other attributes.
The software contains an extensive set of predefined entity types. You can optionally enhance the
extraction process by using dictionaries and extraction rules.
For more details about creating dictionaries and extraction rules, refer to the
Data ServicesText Data Processing Extraction Customization Guide
.
SAP BusinessObjects
Related Topics
• Subentities and Subtypes
2010-12-0231
Page 32

Extraction Support
4.1.1 Subentities and Subtypes
Some languages support entities that can be further broken down into subentities and that can have a
subtype.
• A subentity is an embedded entity of the same semantic type as the containing entity and it has a
prefix that matches that of the larger, containing entity
For example, Mr. Joe Smith is an entity with the name "Mr. Joe Smith" and the type PERSON. For
this entity, there are three subentities:
• Mr. is associated with the subentity PERSON_PRE
• Joe is associated with the subentity PERSON_GIV
• Smith is associated with subentity PERSON_FAM
• A subtype indicates further classification of an entity type. It is a hierarchical specification that enables
the distinction between different semantic varieties of the same entity type, such as commercial and
educational organizations.
For example, SAP is an entity of type ORGANIZATION with a subtype COMMERCIAL, indicating a
subcategory within the main category.
For those languages that support these features, their respective subentities and subtypes are described
in the language's reference section in this guide.
Related Topics
• Entity and Fact Extraction
4.2 Extraction Resource Files
The extraction process uses several types of resource files: language modules, dictionaries, and
extraction rule files. Some of these files are user-configurable, but not all.
This table provides a brief description of the resources that the extraction process uses:
2010-12-0232
Page 33

Extraction Support
Language modules
Dictionaries
DescriptionResource
A language module is a set of prepackaged, language-specific files, including dictionaries and
other components that support a given operation
in a given natural language. The dictionaries
cover a large set of words for each supported
language and are not user-configurable. Extraction relies upon the language modules to analyze
text, extract entities and determine their type.
For more information about specific language
modules and their behavior, refer to their related
chapter in the "
Language Module Reference
"
section of this guide.
Dictionaries are repositories of information about
entities–their standard form and variant names,
their entity types, and so on. Dictionaries are
compiled into a proprietary format using the dictionary compiler tool.
Extraction rule files contain linguistic and patternbased rules that the software includes or that you
can write using regular expression patterns to
Extraction rules
help you create links between entities, thereby
extracting relation, event, and attributive-based
facts. These rules are compiled using the extraction rule compiler.
For more information about writing and using extraction rules, refer to the
Services XI 4.0 Text Data Processing Extraction Customization Guide
Related Topics
• Language Modules Reference
4.3 Levels of Extraction Support for the Language Modules
SAP BusinessObjects Data
.
2010-12-0233
Page 34

Extraction Support
The language modules contain system dictionaries and configuration files required to perform entity
extraction for several languages when analyzing text. All language modules include support for
dictionaries and extraction rules.
Language modules are classified according to the level of linguistic analysis and extraction they support.
They provide these levels of support:
• English–Of all the languages, English has the richest feature set. English supports a variety of
predefined entity types, which also include predefined subentities and entity subtypes. It also supports
parts-of-speech tags, the use of dictionaries and extraction rules, and the use of an advanced parsing
capability for grammatical relations and pronominal co-reference resolution when processing extraction
rules.
• Advanced–These languages support a variety of predefined entity types, dictionaries, and extraction
rules. The advanced languages support extraction rule writing using syntactic units, the standard
operators, the word stem and part-of-speech tag attributes to specify words, as well as a variety of
linguistic construct markers such as noun phrases and clauses. The advanced languages are:
• Chinese: Simplified
• French
• German
• Spanish
• Standard–These languages support noun phrase markers, dictionaries, and extraction rules. The
standard languages support extraction rule writing using tokens, the standard operators, as well as
the word stem and part-of-speech tag attributes to specify tokens.
Japanese is a standard language.
For more information about creating dictionaries and extraction rules, refer to the
Data Services XI 4.0 Text Data Processing Extraction Customization Guide
Related Topics
• Part-of-Speech Support
4.4 Predefined Entity Type Support
The entity type NOUN_GROUP is supported in all the language modules. A NOUN_GROUP is any common
noun sequence consisting of two or more related nouns and not identified as a name, measure, or
identifier.
SAP BusinessObjects
.
2010-12-0234
Page 35

Extraction Support
4.4.1 Named Entities
The following table lists the predefined entity types in alphabetical order and indicates which languages
support them.
Note:
For a list of additional public sector entities, see Public Sector Content.
In Language Module:
Entity
Type
ADDRESS
ADDRESS
subenti
ties
CITY
Descrip
tion
Components of
addresses
including
street
number,
street
name,
city, state,
zip code
and country
Simplified Chinese
SpanishJapaneseGermanFrenchEnglish
XXXXXAddress
XX
XXXXXCity name
CITY
subenti
ties
Components of
city
names
that include city
name and
state
name
X
2010-12-0235
Page 36

Extraction Support
In Language Module:
Entity
Type
CONTI
NENT
COUNTRY
CURREN
CY
DATE
DATE
subenti
ties
Descrip
tion
Any of the
continents
Country
name
Currency
and currency expressions
Date and
date expressions
Components of
date that
include
the day,
month,
and year
Simplified Chinese
SpanishJapaneseGermanFrenchEnglish
XXXX
XXXXX
XXXXX
XXXXX
X
DAY
DIS
TRICT
FACILI
TY
Day of the
week
Names of
counties,
prefectures, districts, and
so on
Manmade
structures
XXXXX
XXXXX
XX
2010-12-0236
Page 37

Extraction Support
In Language Module:
Entity
Type
FEDERA
TION
HOLIDAY
LAN
GUAGE
MEASURE
Descrip
tion
Geopolitical entities that
function
as political
entities
Holidays
and special days
Noun referring to
a language
Measurement and
measurement expressions
Simplified Chinese
SpanishJapaneseGermanFrenchEnglish
XXXXX
XXXXX
XX
XXXXX
MISC_NU
MERIC
MONTH
Number
sequence
followed
by measure
words
Month, includes abbreviations
X
XXXXX
2010-12-0237
Page 38

Extraction Support
In Language Module:
Entity
Type
NOUN_GROUP
ORGANI
ZATION
Descrip
tion
Any common noun
sequence
consisting
of two or
more related nouns
and not
identified
as a
name,
measure,
or identifier
Government, legal, or service agency including nonprofit associations
and institutions
Simplified Chinese
SpanishJapaneseGermanFrenchEnglish
XXXXXX
XXXXX
PEOPLE
PERCENT
Name referring to
a group of
people
based on
country,
ethnicity,
or region
XXXXX
XXXXXPercents
2010-12-0238
Page 39

Extraction Support
In Language Module:
Entity
Type
PERSON
PERSON
subenti
ties
PHONE
Descrip
tion
Person's
name
Components of
person
names including
given
name,
family
name, suffix and full
form
Phone
numbers
Simplified Chinese
SpanishJapaneseGermanFrenchEnglish
XXXXX
XX
XXXXX
PLACE_OTH
ER
PLACE_RE
GION
Geographical name
that does
not fit in
other
PLACE
types
Geographical area
that is
larger
than a city
and typically captures significant
geographical areas
XXXXX
XXXXX
2010-12-0239
Page 40

Extraction Support
In Language Module:
Entity
Type
POSI
TION
POSI
TION
subenti
ties
PRODUCT
PROP_MISC
Descrip
tion
Title that
is also
used to refer to a
person
Components of
position
including
affiliation
Product
name
Any proper noun
lacking an
unambiguous type
Simplified Chinese
SpanishJapaneseGermanFrenchEnglish
XXXXX
XX
XXXX
XXXXX
PUBLICA
TION
SPECIAL
Name of a
newspaper, magazine, journal, and
so on
Names of
geo-political entities for
which the
conventional labels do
not apply
X
XXXXX
2010-12-0240
Page 41

Extraction Support
In Language Module:
Entity
Type
SSN
STATE_PROVINCE
Descrip
tion
Social security
number,
including
Canadian
Social Insurance
Numbers
and
French INSEE Numbers
The major
administrative divisions of
countries
Simplified Chinese
SpanishJapaneseGermanFrenchEnglish
XX
XXXXX
TICKER
TIME
TIME_PE
RIOD
URI
Stock
market
ticker
symbol
Time and
time expressions
Measures
of time expressions
Email address,
URL, and
so on
XX
XXXXX
XXXXX
XXXXX
2010-12-0241
Page 42

Extraction Support
In Language Module:
Entity
Type
Descrip
tion
Year and
YEAR
year expressions
Related Topics
• Language Modules Reference
• Public Sector Content Entities–English
• Public Sector Entities–Simplified Chinese
4.4.2 Common Mentions
The following table lists the predefined common mentions in alphabetical order and indicates which
languages support them.
Simplified Chinese
SpanishJapaneseGermanFrenchEnglish
XXXXX
Note:
For a list of additional public sector entities, see Public Sector Content.
In Language Module:
DescriptionEntity Type
COMMON_ADDRESS
COMMON_CITY
COMMON_CONTINENT
Common names for
addresses
Common names for
cities
Common names for
continents
EnglishSimplified Chinese
X
XX
XX
2010-12-0242
Page 43

Extraction Support
In Language Module:
DescriptionEntity Type
EnglishSimplified Chinese
COMMON_COUNTRY
COMMON_DISTRICT
COMMON_FACILITY
COMMON_FEDERATION
COMMON_ORGANIZA
TION
COMMON_PEOPLE
COMMON_PERSON
Common names for
countries
Command names for
districts
Common names for
man-made structures
Common nouns for
geo-political entities
that can function as
political entities
Common names for organizations
Common names for
people
Common names for
persons
XX
XX
XX
X
XX
X
XX
COMMON_PLACE_OTH
ER
COMMON_PLACE_RE
GION
Common names for
places that are not geographical or political regions
Common names for
geographical regions
XX
XX
2010-12-0243
Page 44

Extraction Support
COMMON_SPECIAL
DescriptionEntity Type
Common nouns for
geo-political entities for
which the conventional
labels do not apply,
such as disputed territories or territories that
have not been internationally recognized
In Language Module:
EnglishSimplified Chinese
XX
COM
MON_STATE_PROVINCE
Common names for
states and provinces
Related Topics
• Language Modules Reference
• Public Sector Content Entities–English
• Public Sector Entities–Simplified Chinese
XX
2010-12-0244
Page 45

Language Modules Reference
Language Modules Reference
The Language Modules Reference provides a reference section for each language module supported
by the software, and it includes the following information:
• The expected behavior of the language modules for all linguistic operations
• The predefined entity types supported by each language, with examples
• The umbrella and complete part-of-speech tags supported by each language, with examples
5.1 Chinese (Simplified) Language Reference
This chapter describes the behavior of the Simplified Chinese language module.
5.1.1 Linguistic Processing
This section describes the language-specific information on the linguistic processing of Simplified
Chinese texts, including word segmentation, stemming, and tagging.
5.1.1.1 Character Encodings for Simplified Chinese
• euc_cn
• gb_18030, gb_2312_80
• utf_8, utf_16, ucs_4
2010-12-0245
Page 46

Language Modules Reference
5.1.1.2 Word Segmentation in Chinese
The Chinese segmenter follows all of the general segmentation rules in the non-white space languages.
See Word Segmentation and White Space Languages for details. It has the following language-specific
behavior.
Bound morphemes like affixes are attached to content words. Also, classifiers are attached to preceding
numbers. In the following Simplified Chinese example, 多 in 多媒体 is a prefix and 台 in 三台 is a
classifier.
SegmentedText
门市门市
经营经营
部门部门
购得购得
多媒体多媒体
电脑电脑
三台三台
Hyphenated words are segmented into their separate parts. For instance:
SegmentedText
北京
北京-东京 -
东京
5.1.1.3 Stemming in Chinese
This section describes the standard stemmer and the expanded stemmer used for stemming in Chinese.
2010-12-0246
Page 47

Language Modules Reference
5.1.1.3.1 Standard Stemmer
Since Chinese words are not inflected, the stems of all words are identical to their source forms. This
is true of the open class words listed in the following table as well as the closed class words.
ExampleBaseformCategory
政府 -> 政府, 学生 -> 学生Source formNoun
负责 -> 负责, 保留 -> 保留Source formVerb
小 -> 小, 必须 -> 必须Source formAdjective
非常 -> 非常Source formAdverb
5.1.1.3.2 Expanded Stemmer
The expanded Chinese language modules provide more fine-grained segmentation and stemming
results than the standard module. Its output is designed for optimized text indexing and search systems.
The expanded module output differs from the standard stemmer in that classifiers are separated from
numerals, prefixes and suffixes are separated from their head words, and compound analysis is
performed.
Examples are shown below.
Classifiers are separated from numerals:
OutputText
一
一本
本
Prefixes and suffixes are separated from their head words:
OutputText
女
女教师
教师
2010-12-0247
Page 48

Language Modules Reference
小张
发展部
Compounds are broken into their separate components:
布赖斯峡谷国家公园
OutputText
小
张
发展
部
OutputText
布赖斯
峡谷
国家
公园
彩色
彩色监定系统 监定
系统
The expanded variant supports all the same operations as the standard Chinese modules. However,
its fine-grained output provides less contextual information for each term, and this ambiguity can
compromise the accuracy of the tagging operations. For these operations, we recommend using the
standard Chinese modules. The expanded variant is recommended for stemming purposes only.
5.1.1.4 Part-of-Speech Tagging in Chinese
The following table shows the Chinese tag set, which is the same for both Traditional and Simplified
Chinese. The tag names are accompanied by a brief description and one or more examples. Simplified
Chinese examples are given in GB encoding.
DescriptionComplete TagUmbrella Tag
Simplified Chinese Examples (GB)
AdjAdj
一流,大型Adjective
2010-12-0248
Page 49

Language Modules Reference
Adv
Conj
Adv
Adv-BAN
Adv-Comp
Adv-DENG
Adv-Idiom
AspAsp
AuxAux
ClCl
Conj
Conj-Nn
DetDet
DescriptionComplete TagUmbrella Tag
Post-nominal abbreviation
Postverbal aspect
marker
Simplified Chinese Examples (GB)
仅仅,非常Adverb
般,似的Metaphor marker
最Comparative adverb
等
寸草春晖,游人止步Idiomatic expression
了,过,着
应当,能Auxiliary verb
张,副Classifier
不论,即使Clausal conjoiner
及,和Noun conjoiner
这,每,任何Determiner
Nn
InterjInterj
Nn
Nn-Ascii
Nn-Loc
Nn-Net
Nn-Prop
Nn-Time
NumNum
OrdOrd
PartPart
Nominal time expression
哇,喂Interjection
东西,菜单,椅子Common noun
a, BASCII character noun
上,以内,之中Iocative noun
www.inxight.comURL or email address
香港,叶尔钦Proper noun
今天, 周一, 上半年, 下
午
万,3,5Number
第Ordinal prefix
吧, 吗Sentence-final particle
2010-12-0249
Page 50

Language Modules Reference
Prep
Punct
Prep
Prep-Assoc
Prep-Assoc-ZHI
Prep-Assoc-DI
Prep-Assoc-DEI
PronPron
Punct
Punct-Comma
Punct-Open
Punct-Close
Punct-Sent
DescriptionComplete TagUmbrella Tag
Noun-modification
marker
Verb-modification
marker
Sentence-ending punctuation
Simplified Chinese Examples (GB)
根据,以,由Preposition
的Modification marker
之
地
得Modification marker
她,我,你Pronoun
..., –, ;, :Punctuation
,Comma
(, {, 【Opening punctuation
), }, 】Closing punctuation
。
QuantQuant
VerbVerb
5.1.2 Extraction
This section describes the extraction-specific information for Simplified Chinese.
5.1.2.1 Simplified Chinese Subtypes
Simplified Chinese supports subtypes in the types FACILITY, ORGANIZATION, PLACE_OTHER,
PLACE_REGION, URI, COMMON_FACILITY, COMMON_ORGANIZATION, COMMON_PEOPLE, COMMON_PER
SON, COMMON_PLACE_OTHER, and COMMON_PLACE_REGION.
整个,众多Quantifier
走,下雨,负责Verb
2010-12-0250
Page 51

Language Modules Reference
Related Topics
• Subentities and Subtypes
5.1.2.2 Predefined Entity Types
This section describes the predefined entity types supported by the Simplified Chinese language module
and examples of each. Click on the links to jump to that section: ADDRESS, CITY, CONTINENT,
COUNTRY, CURRENCY, DATE, DAY, DISTRICT, FACILITY, FEDERATION, HOLIDAY, MEASURE,
MISC_NUMERIC, MONTH, NOUN_GROUP, ORGANIZATION, PEOPLE, PERCENT, PERSON, PO
SITION, PHONE, PLACE_OTHER, PLACE_REGION, PROP_MISC, SPECIAL, STATE_PROVINCE,
TIME, TIME_PERIOD, URI, and YEAR.
Note:
The Simplified Chinese language module also extracts these public sector entities: VEHICLE, WEAPON,
COMMON_VEHICLE, COMMON_WEAPON.
For details about these public sector entities, refer to Public Sector Entities–Simplified Chinese.
5.1.2.2.1 ADDRESS
Postal addresses:
• 北京市朝阳区建国门外大街甲12号新华保险大厦7层701室(100022)
• 上海市静安区南京西路1266号恒隆广场23楼2302-2304室(200041)
• 北京市朝阳区工体北路甲二号
5.1.2.2.2 CITY
Name of a city:
• 北京
• 上海
• 苏州市
5.1.2.2.3 CONTINENT
Any of the continents, for example:
• 亚洲
• 欧洲
• 南美洲
2010-12-0251
Page 52

Language Modules Reference
5.1.2.2.4 COUNTRY
Names of countries:
• 中国
• 美国
• 英国
5.1.2.2.5 CURRENCY
Expressions denoting amounts of money:
• 33.8万元
• 港币五千万
• 一百四十四亿七千万美元
5.1.2.2.6 DATE
Dates are minimally composed of a number and month name:
• 7月2日
• 十月十七日
5.1.2.2.7 DAY
Names of the days of the week:
• 周一
• 周六
5.1.2.2.8 DISTRICT
Names of counties, prefectures, districts, or analogous geographical divisions or governmental units:
• 海淀区
• 陆家嘴
• 花莲县
5.1.2.2.9 FACILITY
Man-made structures, extracted as one of the following subtypes:
• AIRPORT–The names of primarily man-made or man-maintained structures whose primary use is
as transportation terminals. For example,
• 首都国际机场
2010-12-0252
Page 53

Language Modules Reference
• 浦东国际机场
• 中正机场
• BUILDGROUNDS–The names of architectural and civil engineering structures, and outdoor spaces
that are mainly man-made or man-maintained. There is no distinction with respect to their function,
they could be civil or military facilities, they could be used for work or entertainment, or they could
be monuments. For example,
• 人民公园
• 黄鹤楼
• 克林姆林宫
• PATH–The names of primarily man-made or man-maintained structures that allows fluids, energy,
persons, animals, or vehicles to pass from one location to another. For example,
• 卢沟桥
• 重庆南路
• 王府井大街
• PLANT–The names of facilities composed by one or more buildings used for industrial purposes.
For example,
• 三峡工程
• 切尔诺贝利核电站
• 小浪底水库
• SUBAREA–The names of portions of facilities, typically architectural ones, that are able to contain
people, animals, or objects. For Example,
• 大雄宝殿
• 椭圆形办公室
5.1.2.2.10 FEDERATION
Geopolitical entities that can function as political entities, for example:
• 欧盟
• 独联体
5.1.2.2.11 HOLIDAY
Holidays and special days:
• 元宵节
• 中秋
2010-12-0253
Page 54

Language Modules Reference
5.1.2.2.12 MEASURE
Measure expressions:
• 二百五十六公斤
• 5.5米
5.1.2.2.13 MISC_NUMERIC
Number sequence followed by measure words (not a major measure unit) or a noun:
• 八个
• 8000 多家
5.1.2.2.14 MONTH
Names of the months of the year:
• 6月份
• 八月
5.1.2.2.15 NOUN_GROUP
Noun groups can be simple or compound nouns with modifying adjectives:
• 新兴产业
• 高科技产品
5.1.2.2.16 ORGANIZATION
Government, legal, and service agencies, including non-profit organizations, fine arts groups, and other
associations and institutions, extracted as one of the following subtypes:
• COMMERCIAL–The name of commercial organizations, such as major companies or corporations.
For example:
• 美洲银行
• 花旗集团
• 首创股份
• 白云山制药股份有限公司
• EDUCATIONAL–The names of institutions focused primarily in education. For example:
• 交通大学
• 清华
• 浙大
2010-12-0254
Page 55

Language Modules Reference
• ENTERTAINMENT–The names of organizations focused primarily in entertainment. For examples:
• 中央芭蕾舞团
• 上海交响乐团
• 月之海合唱团
• GOVERNMENT–The names of organizations related to government, politics, or the state. For example:
• 国务院
• 海关总署
• 水利部
• MEDIA–The names of organizations focused on media, advertising, or publishing. For example,
• 新华社
• 时代周刊
• 人民日报
• MEDICALSCIENCE–The names of organizations focused on medical care or research. For example:
• 国家科学院
• 中国科协
• 中科院
• RELIGIOUS–the names of organizations focused on religion. For example:
• 佛教
• 基督教
• 天主教
• SPORTS–The names of organizations focused on sports. For example:
• 国家奥委会
• 足球总会
• 国际米兰俱乐部
• UNSPECIFIED–Any organization that does not fit into a more specific subtype.
• 中国共产党
• 联合国
• 全国总工会
5.1.2.2.17 PEOPLE
Names referring to identifiable groups of people based on country, ethnicity, region, or religion.
2010-12-0255
Page 56

Language Modules Reference
• 中国人
• 美国人民
5.1.2.2.18 PERCENT
Percent expressions:
• 百分之五十
• 55.3%
5.1.2.2.19 PERSON
Variations of person names:
• 胡锦涛
• 毛 泽东
• 温家宝
5.1.2.2.20 PHONE
Phone numbers based on the Chinese format:
• 68316616
5.1.2.2.21 PLACE_OTHER
A place name extracted as one of the following subtypes:
• BOUNDARY–The names of locations such as borders. For example:
• 南北回归线
• 赤道
• CELESTIAL–The names of locations that are outside of the boundaries of the Earth. For example:
• 地球
• 冥王星
• 北斗七星
• LAND–The names of locations that are goelogically or ecosystemically designed, non-artificial
locations. For example:
• 峨眉山
• 崇明岛
• 珠江三角洲
2010-12-0256
Page 57

Language Modules Reference
• WATER–The names of locations that are bodies of water. For example:
• 黄河
• 长江
• 西湖
• 日月潭
5.1.2.2.22 PLACE_REGION
A geographical area larger than a city that captures a significant land mass, such as a continent or a
group of countries, extracted as one of the following subtypes:
• DOMESTIC–The names of locations that do not cross national borders. For example:
• 华南
• 巴蜀
• 杭嘉湖
• INTL–The names of locations that cross national borders. For example:
• 大中华地区
• 加勒比地区
• 加沙地带
5.1.2.2.23 POSITION
Names of important positions in government, business, and other organizations:
• 主席
• 司法部长
• 总书记
5.1.2.2.24 PROP_MISC
Any proper noun phrase that does not belong to one of the entity types specified by the other entities:
• 抗日战争
• 八国集团首脑会议
• 文化大革命
5.1.2.2.25 SPECIAL
The names of geo-political entities for which the conventional labels do not apply. For example,
• 巴勒斯坦
2010-12-0257
Page 58

Language Modules Reference
• 台湾
5.1.2.2.26 STATE_PROVINCE
The major administrative divisions of countries, such as the provinces and territories of Canada, the
administrative regions of France, and the states of the United States:
• 江苏省
• 新疆维吾尔族自治区
• 加利福尼亚
5.1.2.2.27 TIME
Clock times and time expressions:
• 8时
• 3点零5分
5.1.2.2.28 TIME_PERIOD
Measures of time duration:
• 两个月
• 1小时
• 五天
5.1.2.2.29 URI
An address on the internet, extracted as one of the following subtypes:
• EMAIL–Email addresses, for example:
• johndoe@businessobjects.com
• support@inxight.com
• INTERNET_ADDRESS–Internet addresses, for example:
• www.businessobjects.com
• http://www.google.com
• IP–IP adresses, for example:
• 147.132.42.18
5.1.2.2.30 YEAR
A year identifier and expressions based on years:
2010-12-0258
Page 59

Language Modules Reference
• 2005年
• 一九九四年
5.1.2.3 Common Noun Mentions
Common noun mentions refer to the use of common nouns to refer to entities such as organizations,
persons, or facilities which would normally also be referred to by proper nouns.
This section describes the common mentions supported by the Simplified Chinese language module
and examples of each. Click on the links to jump to that section: COMMON_CITY, COMMON_CONTI
NENT, COMMON_COUNTRY, COMMON_DISTRICT, COMMON_FACILITY, COMMON_ORGANIZA
TION, COMMON_PEOPLE, COMMON_PERSON, COMMON_PLACE_OTHER, COMMON_PLACE_RE
GION, COMMON_SPECIAL, and COMMON_STATE_PROVINCE.
5.1.2.3.1 COMMON_CITY
Common nouns for cities:
• 全市
• 小镇
• 省会
5.1.2.3.2 COMMON_CONTINENT
Common nouns for the entirety of any continent:
• 大洲
5.1.2.3.3 COMMON_COUNTRY
Common nouns for countries:
• 王国
• 成员国
• 友邦
5.1.2.3.4 COMMON_DISTRICT
Common nouns for the entirety of district areas:
• 郡
• 县
2010-12-0259
Page 60

Language Modules Reference
• 区
5.1.2.3.5 COMMON_FACILITY
Common nouns for man-made structures, extracted as one of the following subtypes:
• AIRPORT–Common nouns of primarily man-made or man-maintained structures whose primary use
is as air transportation terminals. For example:
• 机场
• 空港
• 候机大楼
• BUILDGROUNDS–Common nouns for architectural and civil engineering structures, and outdoor
spaces that are mainly man-made or man-maintained. There is no distinction with respect to their
function, they could be civil or military facilities, they could be used for work or entertainment, or
they could be monuments. For example:
• 大杂院
• 建筑物
• 停车场
• PATH–Common nouns for primarily man-made or man-maintained structures that allows fluids,
energy, persons, animals, or vehicles to pass from one location to another. For example:
• 高速铁路
• 柏油路
• 天桥
• PLANT–Common nouns for facilities composed by one or more buildings used for industrial purposes.
For example:
• 水电站
• 厂矿
• 水利枢纽
• SUBAREA–Common nouns for portions of facilities, typically architectural ones, that are able to
contain people, animals, or objects. For Example:
• 盥洗室
• 卧房
• 育婴房
5.1.2.3.6 COMMON_ORGANIZATION
Common nouns for organizations, extracted as one of the following subtypes:
2010-12-0260
Page 61

Language Modules Reference
• COMMERCIAL–Common nouns for companies:
• 公司
• 集团
• 财团
• 银行
• EDUCATIONAL–Common nouns for institutions focused on education:
• 学院
• 高校
• 母校
• ENTERTAINMENT–Common nouns for institutions focused on entertainment:
• 弦乐队
• 马戏团
• 文工团
• GOVERNMENT–Common nouns for institutions related to government, politics, or the state:
• 军队
• 机关
• 法院
• MEDIA–Common nouns for institutions related to the media:
• 传媒
• 电视台
• 报社
• MEDICALSCIENCE–Common nouns for institutions related to medical science:
• 研究所
• 综合医院
• RELIGIOUS–Common nouns for institutions related to religion:
• 教宗
• 主教团
• 教会组织
• SPORTS–Common nouns for institutions related to sports:
• 蓝球队
• 羽毛球队
2010-12-0261
Page 62

Language Modules Reference
• 运动联合会
• UNSPECIFIED–Common nouns for organizations that do not fit into a more specific subtype:
• 协会
• 理事会
• 联合会
5.1.2.3.7 COMMON_PEOPLE
Common nouns for peoples, extracted as one of the following subtypes:
• NATIONALITY–Nationalities without modifiers:
• 人民
5.1.2.3.8 COMMON_PERSON
Common nouns for persons, extracted as one of the following subtypes:
• GROUP–Common nouns for groups of persons:
• 股民
• 小两口
• 中青年
• INDIVIDUAL–Common nouns for individual persons:
• 老大爷
• 师父
• 导演
5.1.2.3.9 COMMON_PLACE_OTHER
Common nouns for places that are not geographical or political regions, extracted as one of the following
subtypes:
• BOUNDARY–Common nouns for locations such as a border:
• 国界
• 边境线
• CELESTIAL–Common nouns for locations outside of Earth:
• 小行星
• 星系
• 星球
2010-12-0262
Page 63

Language Modules Reference
• LAND–Common nouns for geologically or ecosystemically designed non-artificial locations:
• 平原
• 群岛
• 戈壁
• WATER–Common nouns for bodies of water:
• 江
• 河
• 湖
• 海
5.1.2.3.10 COMMON_PLACE_REGION
Common nouns for geographical regions, extracted as one of the following subtypes:
• DOMESTIC–Common nouns for locations that do not cross national borders:
• 辖区
• 国内
• 非军事区
• INTL–Common nouns for locations that cross internatinal borders:
• 国际
• 国内外
5.1.2.3.11 COMMON_SPECIAL
Common nouns for political regions that do not fit into more specific common mentions:
• 两岸三地
5.1.2.3.12 COMMON_STATE_PROVINCE
Common nouns for major administrative divisions of countries:
• 省份
• 自治区
5.2 English Language Reference
2010-12-0263
Page 64

Language Modules Reference
This chapter describes the behavior of the English language module.
5.2.1 Linguistic Processing
This section describes the language-specific information on the linguistic processing of Engish texts,
including word segmentation, stemming, and tagging.
5.2.1.1 Character Encodings for English
• iso_8859_1
• cp_1252
• utf_8, utf_16, ucs_4
5.2.1.2 Word Segmentation in English
The English segmenter follows all of the general segmentation rules in the white space languages. See
Word Segmentation and White Space Languages for details. The English segmenter has the following
language-specific behavior.
In English, contractions like don't, can't and won't are separated into their constituent syntactic units.
Ain't is not separated, since there is no clearly correct way to break it. The possessive endings 's and
' are separated from the words they modify.
SegmentedText
can
can't
n't
won't
will
n't
2010-12-0264
Page 65

Language Modules Reference
it's
helper's
helpers'
SegmentedText
it
's
ain'tain't
helper
's
helpers
'
Abbreviations are not split from their punctuation, but do get split from following hyphens. Hyphens that
occur in between two abbreviations will not break the syntactic unit. Abbreviations are listed in a system
dictionary as well as in a set of rules allowing for uppercase and lowercase letters as well as periods
and optional hyphens.
Combinations of alphabetic, numeric, and optionally, punctuation characters are kept together. For
example:
SegmentedText
Apr.
Apr.-
-
D-Nebr.D-Nebr.
3a.m.3a.m.
11Jan.11Jan.
Mon.-Thurs.Mon.-Thurs.
2010-12-0265
Page 66

Language Modules Reference
5.2.1.3 Stemming in English
This section describes the standard stemmer and the expanded stemmer used for stemming in English.
5.2.1.3.1 Standard Stemmer
The English stemmer follows the general stemming rules, as described in Stemming. In brief, the major
word classes, also known as the open classes, stem to their baseforms. This is shown in the table
below.
SegmentedText
Bloomberg-U.S.Bloomberg-U.S.
ExamplesBaseformCategory
dog, dogs -> dogSingularNoun
runs, ran, run -> runInfinitiveVerb
Base formAdjective
happy, happier, happiest ->
happy
quickly -> quicklyBase form or source formAdverb
English pronouns are stemmed in the following way. All uninflecting forms stem to themselves. Plural-only
forms and all personal pronouns maintain their number and gender information. If applicable, these
pronouns are stemmed to the nominative form. All other forms stem to the singular form. This is shown
in the table below:
StemText
nonenone
2010-12-0266
Page 67

Language Modules Reference
The standard stemmer handles the spelling variation found in American and British English. Both variants
stem to the American spelling. These behaviors are shown in the following table:
StemText
thatthat
themselvesthemselves
sheher
thisthese
StemText
colorcolor
colorcolour
organizationorganization
organizationorganisation
5.2.1.3.2 Expanded Inflectional Stemmer
The expanded inflectional stemmer allows certain non-standard word forms–for example, capitalization
errors–as well as standard forms, and thus can be used to process informal or imperfect text (such as
email, online documents, or queries). See Expanded Inflectional Stemming for the general behavior.
Following is a list of the specifics for English.
Case Variants
The expanded version accepts lower case letters in addition to capital letters for words that are usually
capitalized. If both lower and upper case variants are included in the stemmer, both are returned as
stems. A lower case variant returns an uppercase stem if this is the only one included in the stemmer.
2010-12-0267
Page 68

Language Modules Reference
Hyphenation
To aid software that handles line-breaking hyphens by deleting them and concatenating the two parts
of the broken word, hyphens in non-numeric expressions are optional in the expanded version, so that
words that are truly hyphenated will still be recognized.
OutputExample
EricEric
Ericeric
OutputExample
square-dancesquare-dance
square-dancesquaredance
mother-in-lawmotherinlaw
5.2.1.3.3 Derivational Stemmer
The derivational stemmer is designed to produce the root word for an entry, crossing word categories
when necessary. For example, the noun connection is derived from the verb connect by adding the
suffix -ion.
Therefore, the derivational stemmer finds the root connect for the noun connection. Similarly, driver
is stemmed to drive and quickly to quick.
StemText
connectconnection
belongbelongings
drivedriver
quickquickly
2010-12-0268
Page 69

Language Modules Reference
5.2.1.3.4 Inflectional Stemmer Guesser
The inflectional stemmer guesser contains a set of morpological rules that can apply to words that are
unknown to the standard or expanded inflectional stemmer and therefore cannot be stemmed.
Linguistics processing first attempts to perform stemming using the standard or expanded inflectional
stemmer, and then applies the stemmer guesser only to words that cannot be conventionally stemmed.
5.2.1.4 Part-of-Speech Tagging in English
The following table shows the English tag set. The tag names are accompanied by a brief description
and one or more examples. If the example consists of more than one word, the word exemplifying the
current tag is in bold.
ExamplesDescriptionComplete TagUmbrella Tag
Adj
Adv
Conj
AbbrAbbr
Adj
Adj-Comp
Adj-Ord
Adj-Sup
Adv
Adv-Comp
Adv-Int/Rel
Adv-Sup
AuxAux
Conj-Coord
Conj-Sub
wh- adverb
Coordinating conjunction
Subordinating conjunction
i.e.Abbreviation
bigAdjective
biggerComparative adjective
thirdOrdinal adjective
biggestSuperlative adjective
quicklyAdverb
soonerComparative adverb
how
soonestSuperlative adverb
couldAuxiliary or modal
and
unless
2010-12-0269
Page 70

Language Modules Reference
ExamplesDescriptionComplete TagUmbrella Tag
Det
Det
Det-Def
Det-Indef
Det-Int
Det-Int/Rel
Det-Pl
Det-Poss
Det-Rel
Det-Sg
InterjInterj
Nn
Nn-Letter
Invariant determiner
(singular or plural)
Interrogative determiner
Interrogative or relative
determiner
Plural determiner
some food
theDefinite determiner
anIndefinite determiner
what time?
whose
those apples
myPossessive determiner
whatsoeverRelative determiner
everySingular determiner
oh, helloInterjection
sheepInvariant noun
b, NLetter
Nn
Part
Nn-Net
Nn-Pl
Nn-Sg
NumNum
Part-Inf
Part-Neg
Part-Poss
URL, e-mail address
Cardinal number or
other numeric expression
Cardinal number or
other numeric expression
Infinitive marker
Possessive marker
www.inxight.com,
info@inxight.com
computersPlural noun
farmer
40.5, 11/27/00, $12.55,
12%, xvii, 9:00
to be or not to be
notNegative particle
John's coat
2010-12-0270
Page 71

Language Modules Reference
ExamplesDescriptionComplete TagUmbrella Tag
Prep
Pron
Punct
Prep
Prep-at
Prep-of
Pron
Pron-Int
Pron-Int/Rel
Pron-Refl
Pron-Rel
PropProp
Punct
Punct-Close
Punct-Comma
Punct-Open
Preposition at
Preposition of
wh pronoun
Name of a person or
thing
belowPreposition
at
of
hePronoun
what do you want?wh pronoun
who
himselfReflexive pronoun
whoeverRelative pronoun
Graceland
- ; /%$Other punctuation
) ] }Closing punctuation
,Comma
( [ {Opening punctuation
Punct-Quote
Punct-Sent
Sentence-ending
punctuation
" ''Quote
. ! ?
2010-12-0271
Page 72

Language Modules Reference
ExamplesDescriptionComplete TagUmbrella Tag
V-Inf-be
V-PaPart
V-PaPart-be
V-PaPart-have
V-Past
V-Past-have
V-Past-Pl-be
V-Past-Sg-be
V
V-Pres
V-Pres-3-Sg
Infinitive to be
Verb, past participle,-ed verb form
Past participle of to
have
Past tense of have
Verb, past tense plural
of to be
Verb, past tense singular of to be
Verb, present tense or
infinitive
Verb, present tense,
3rd person singular
be
has walked
has beenPast participle of to be
he has had
ranVerb, past tense
we had
were
was
sit
sits
Present tense, 3rd
V-Pres-3-Sg-have
person singular of
has
have
V-Pres-have
V-Pres-Pl-be
V-Pres-Sg-be
V-PrPart
Present tense or infinitive of have
Verb, present tense
plural of to be
Verb, present tense
singular of to be
Verb, present participle, -ing verb form
have
are
is
is walking
5.2.1.4.1 Unfound Words
Words not found in the tagger dictionary are passed to the English tagger guesser to be assigned the
most likely tag. The English tagger guesser assigns tags to unfound words based on a set of rules
about English morphology, for example, a word ending in -ly is likely an adverb. Internet and e-mail
addresses are assigned the tag Nn-Net.
2010-12-0272
Page 73

Language Modules Reference
Capitalization information is also important; for instance, capitalized words tend to be guessed as proper
nouns. Combinations of alphabetic and numeric characters are guessed as proper nouns as well.
Ordinal numbers are tagged either as noun or adjective, depending on the context as determined by
the software.
5.2.2 Extraction
This section describes the extraction-specific information for English.
5.2.2.1 English Subentities
English supports subentities in the types ADDRESS, CITY, DATE, POSITION and PERSON.
Related Topics
• Subentities and Subtypes
5.2.2.2 English Subtypes
English supports subtypes in the types FACILITY, ORGANIZATION, PLACE_OTHER, PLACE_REGION,
URI, COMMON_FACILITY, COMMON_ORGANIZATION, COMMON_PERSON, COMMON_PLACE_OTHER, and
COMMON_PLACE_REGION.
Related Topics
• Subentities and Subtypes
5.2.2.3 Predefined Entity Types
This section describes the predefined entity types supported by the English language module and
examples of each.
2010-12-0273
Page 74

Language Modules Reference
Click each link to jump to that subsection: ADDRESS, ADDRESS Subentities, CITY, CITY Subentities,
CONTINENT, COUNTRY, CURRENCY, DATE, DATE Subentities, DAY, DISTRICT, FACILITY, FED
ERATION, HOLIDAY, MEASURE, MONTH, NOUN_GROUP, ORGANIZATION, PEOPLE, PERCENT,
PERSON, PERSON Subentities, PHONE, PLACE_OTHER, PLACE_REGION, POSITION, POSITION
Subentities, PRODUCT, PROP_MISC, SPECIAL, SSN, STATE_PROVINCE, TICKER, TIME,
TIME_PERIOD, URI, and YEAR.
Note:
The English language module also extracts these public sector entities:GEOCORD, GEORCORD subentities,
MGRS, MISC_NUMERIC, PHONEMTF, PRECURSOR, VEHICLE, VEHICLE (LAND) subentities, WEAPON,
COMMON_PRECURSOR, COMMON_VEHICLE, COMMON_WEAPON.
For details about these public sector entities, refer to Public Sector Content Entities–English.
5.2.2.3.1 ADDRESS
The format for ADDRESS is based on US address forms:
Street-Number &
Street
Zip-CodeStateCity
98765Hawai'iHonolulu1234 Mahana St.
Street number and street are required parts of the address, city, state, and zip code are optional. Post
office boxes and rural routes are also grouped as ADDRESS:
• 1234 Mahana St.
• PO Box 1010
• Rural Route 5
5.2.2.3.2 ADDRESS Subentities
Address subentities are identified for US and Canadian addresses, as shown in the table below, for the
following two examples:
• 123 Oak Street #205, San Francisco, CA 94205 USA
• 251 Rue Principale St-Sauveur, Montreal
Subentity TypeSubentity
123
251
ADDRESS_STR_NUM
2010-12-0274
Page 75

Language Modules Reference
Subentity TypeSubentity
Oak Street
Rue Principale St-Sauveur
# 205
San Francisco
Montreal
CA
94205
USA
5.2.2.3.3 CITY
Name of a city, including abbreviations for major cities:
• Cairo
ADDRESS_STR
ADDRESS_APT_NUM
ADDRESS_CITY
ADDRESS_STATE
ADDRESS_ZIP
ADDRESS_COUNTRY
• New Delhi
• Honolulu
• N.Y.
• Seville, Spain
• Paris, Texas
• Sunnyvale, CA, USA
5.2.2.3.4 CITY Subentities
City subentities are identified as shown in the table below, for the following example:
Amiens, Picardie, France
2010-12-0275
Page 76

Language Modules Reference
Subentity TypeSubentity
Amiens
Picardie
France
Dallas, Texas, USA
Dallas
Texas
USA
San Francisco, CA
CITY_CITY
CITY_PROVINCE
CITY_COUNTRY
Subentity TypeSubentity
CITY_CITY
CITY_STATE
CITY_COUNTRY
San Francisco
CA
5.2.2.3.5 CONTINENT
Any of the continents, for example:
• Asia
• Europe
Note:
America and Australia are extracted as COUNTRY only.
Subentity TypeSubentity
CITY_CITY
CITY_STATE
2010-12-0276
Page 77

Language Modules Reference
5.2.2.3.6 COUNTRY
Names of countries, and abbreviations:
• Italy
• U.K.
• USA
5.2.2.3.7 CURRENCY
Quantities of world currency, and ranges of amounts of currency:
• 35 cents
• 1.19 dlrs
• one dollar and twenty-five cents
• 785 to 995 dlrs
Currency Normalizer
The English currency normalizer converts currency expressions of the following types to the abbreviated
forms:
OutputInput
USD (United States of America)dollar
USD (United States of America)dollar sign
USD (United States of America)cents sign
EUReuro
PTE (Portugal)escudo
FRF (France)franc
SEK (Sweden)krona
GBP (United Kingdom)pence
2010-12-0277
Page 78

Language Modules Reference
OutputInput
ESP (Spain)peseta
GBP (United Kingdom)pound
RUR (Russia)ruble
INR (India)rupee
ATS (Austria)schilling
KRW (South Korea)won
The following currency expressions require country indication:
• dinar
• dirham
• koruna
• krone
• kwada
• lira
• manat
• peso
• colon
• shilling
• rial
The English currency normalizer accepts valid input and returns the normalized output:
OutputInput
100 USD$100
5 GBP£5 GBP
2010-12-0278
Page 79

Language Modules Reference
OutputInput
5.27 CADc$5.27
400 HKDHK$ 400
850 MXN850 MXN
3.32 MXNm$3.32
2749.57 CAD2,749.57 Canadian dollars
.99 OMR.99 Omani Rials
1.14 USD114 cents
.05 USDfive pennies
.25 USD25 cts
.375 USD37.5¢
.02 FRF2 centimes
101.125 USD$101 1/8
14200000000 JPY14.2 billion yen
157000000 USD$157M
100 TRLa hundred Turkish lira
87500000 USD$87 1/2m
77.45 NLGNLG 77.45
2010-12-0279
Page 80

Language Modules Reference
The English currency normalizer returns invalid input in its original untreated form.
ReasonInput
eighteen quadrillion rubles
Eighty-three Hong Kong dollars and forty-seven
cents
350 pesos
fifteen convertible yen
two new dollars
Romanian leus 445.99
Range for amount is from zero to a quadrillion
minus one.
Currently, cents and pence are assumed to refer
to USD and GBP, respectively.
Country information is required for pesos (there
are too many countries whose currency is the
peso that are of similar frequency of reference).
Extraction does not handle spelled-out fractions.one-half cent
Unknown currency, or unsure about assignment
of currency code.
Unknown currency, or unsure about assignment
of currency code.
Except for dollar and pound signs, currency information must follow the amount.
2 800 pounds
$957,000 salary
$9 14/17 Hong Kong dollars
Extraction does not handle currency ranges.80-85 cents
Extraction does not handle currency ranges.22.03-18 yen
Extraction does not handle a space being used
as a thousands-place marker.
Extraction ignores strings denoting non-currency
information.
Extraction only handles fractions where the denominator is 2, 3, 4, or 8.
2010-12-0280
Page 81

Language Modules Reference
5.2.2.3.8 DATE
Dates are minimally composed of a number and month:
• April 2
• 26 November 1998
• September tenth
• fourth of June
Date expressions:
• 2-4 May
• 3 June to 5 July
Date Normalizer
The English date normalizer accepts the following formats as valid input:
OutputInput
1885-04-2121/04/1885
2001-01-131/13/01
1911-01-1818-1-11
2009-02-1515.2.09
05-22the 22nd of May
11-06nov6
04-1515April
03-3131 March
1961-03-07March 7th, 1961
The date normalizer returns invalid input in its original untreated form.
2010-12-0281
Page 82

Language Modules Reference
ReasonInput
2/32/77
5/1/73
1/13
12 January 22
14 July 02
In NN/NN/Year format, neither of the first two
numbers may be greater than 31.
The first set of NN (in this example 5) is normalized to month. It appears that when English
speakers write dates in NN/NN/Year format, twothirds place the month first and one-third place
the day first. Faced with such an ambiguity, there
is no guarantee that the correct digit will be extracted as month.
No normalization is performed on the patterns
DIGIT-DIGIT or DIGIT/DIGIT , as they are not
unambiguously dates.
It is not possible to determine which number represents the date, and which the year.
It is not possible to determine which number represents the date, and which the year.
14/2/12055
October seventeenth, four hundred thousand and
two B.C.
Currently, the range of years is from 9999 BCE
to 9999 CE.
Currently, the range of years is from 9999 BCE
to 9999 CE.
5.2.2.3.9 DATE Subentities
Date subentities are identified for the parts of a date, as shown in the table below for the following
example:
March 10, 2005
Subentity TypeSubentity
March
DATE_MONTH
2010-12-0282
Page 83

Language Modules Reference
Subentity TypeSubentity
10
2005
DATE_DAY
DATE_YEAR
5.2.2.3.10 DAY
Days of the week, including abbreviations:
• Monday
• Mon.
• TUES
5.2.2.3.11 DISTRICT
Names of counties, prefectures, districts, or analogous geographical divisions or governmental units:
• District of Columbia
• Orange County
5.2.2.3.12 FACILITY
Man-made structures, extracted as one of the following subtypes:
• AIRPORT–The names of primarily man-made or man-maintained structures whose primary use is
as air transportation terminals. For example:
• Los Angeles International Airport
• South Capitol Street Heliport
• BUILDGROUNDS–The names of architectural and civil engineering structures, and outdoor spaces
that are mainly man-made or man-maintained. There is no distinction with respect to their function,
they could be civil or military facilities, they could be used for work or entertainment, or they could
be monuments. For example:
• Berlin Wall
• Disneyland
• Fort Knox
• Grand Central Station
• Statue of Liberty
2010-12-0283
Page 84

Language Modules Reference
• PATH–The names of primarily man-made or man-maintained structures that allows fluids, energy,
persons, animals, or vehicles to pass from one location to another. For example:
• Champs-Elysees
• Erie Canal
• London Bridge
• Times Square
• PLANT–The names of facilities composed of one or more buildings used for industrial purposes. For
example:
• San Onofre Nuclear Generating Station
• Shell Oil Refinery
• Three Mile Island
• SUBAREA–The names of portions of facilities, typically architectural ones, that are able to contain
people, animals, or objects. For Example:
• Air Canada Maple Leaf Lounge
5.2.2.3.13 FEDERATION
Groupings of geopolitical entities that can function as political entities, for example:
• European Community
• Benelux
5.2.2.3.14 HOLIDAY
Holidays and special days:
• New Year's Day
• 4th of July
• Martin Luther King Day
• Rosh Hashanah
5.2.2.3.15 MEASURE
Any measurement, such as weight, volume, or length, in English or metric units, including standard
abbreviations of measurement units:
• 25 cubic feet
• 20 grams
• 6m
2010-12-0284
Page 85

Language Modules Reference
Rates of change, and ratios and ranges of measurements:
• 65 mph
• 33 mpg
• five cts per share
• 20 dlrs per unit
5.2.2.3.16 MONTH
Months of the year, including abbreviations:
• January
• Feb.
• OCT
5.2.2.3.17 NOUN_GROUP
English noun groups are nouns with modifying adjectives. For example:
• biggest problem
• interest rate
• mortgage interest tax relief
5.2.2.3.18 ORGANIZATION
Commercial, governmental, educational, legal, and service agencies, including non-profit organizations,
fine arts groups, and other associations and institutions, extracted as one of the following subtypes:
• COMMERCIAL–The name of commercial organizations, such as major companies or corporations.
For example:
• Apple Corporation
• General Electric Co.
Also, variants and abbreviations for companies or corporations:
• Apple
• NBC
• IBM
• EDUCATIONAL–The names of institutions focused primarily on education. For example:
• Brown
• Cambridge University
• MIT
2010-12-0285
Page 86

Language Modules Reference
• Stanford University
• ENTERTAINMENT–The names of organizations focused primarily on entertainment. For examples:
• Cirque du Soleil
• Boston Symphony Orchestra
Note:
This excludes media conglomerates such as Time Warner or Disney, which are considered COM
MERCIAL.
• GOVERNMENT–The names of organizations related to government, politics, or the state. For example:
• Foreign Ministry
• Air National Guard
• MEDIA–The names of organizations focused on media, advertising, or publishing. For example:
• Associated Press
• PBS
• MEDICALSCIENCE–The names of organizations focused on medical care or research. For example:
• American Medical Association
• Dana-Farber Cancer Institute
• European Space Agency
• RELIGIOUS–The names of organizations focused on religion. For example:
• Church of Jesus Christ of Latter Day Saints
• Church of England
• SPORTS–The names of organizations focused on sports. For example:
• Red Sox
• New York Yankees
• UNSPECIFIED–Any organization that does not fit into a more specific subtype. For example:
• Greenpeace
• United Nations
5.2.2.3.19 PEOPLE
Names referring to identifiable groups of people based on country, ethnicity, region, or religion. For
example:
• Arabs
• Scots
2010-12-0286
Page 87

Language Modules Reference
5.2.2.3.20 PERCENT
A percentage:
• 220%
• 18 pc
• fifty percent
Percent expressions:
• from 10% to 20%
• between 5 and 10 percent
Percent Normalizer
The English percent normalizer returns a normalized form of percent expressions of the following
formats.
OutputInput
21%21%
14.5%14.5 %
157%157 PERCENT
0%Zero Percent
13%thirteen percentage points
17%seventeen pc.
1000%a thousand percent
The English percent normalizer returns invalid input in its original, untreated form.
eighteen quadrillion percent
ReasonInput
Range for amount is from negative a quadrillion
plus one to a quadrillion minus one.
2010-12-0287
Page 88

Language Modules Reference
0.1% payout
ReasonInput
Extraction does not handle percent ranges.forty-seven to forty-nine percent
Extraction does not handle percent ranges.2.5-7%
Extraction does normalize the percentage value,
however it ignores strings that denote non-percentage information, such as "payout" in this example.
56 212/256 %
Extraction only handles fractions where the denominator is 2, 3, 4, 5, 8, or 10.
5.2.2.3.21 PERSON
An individual specified by name. A variety of forms will be identified:
• Bill Clinton
• William J. Clinton
• W.J. Clinton III
• William Jefferson Clinton
• Mustafa Al-Jaziri `Abd Al-Rahaman Nudle
• Mary Beth Josephine Thomas
• Ms. Washington
• Mr. Copperfield
Note:
Given and family names that occur by themselves are extracted as PERSON as long as they are not
ambiguous with common names, with the exception of famous cases, such as Bush.
5.2.2.3.22 PERSON Subentities
Components of person names are identified as shown in the table below for the following examples:
Mr. John Smith Jr.
Mrs. Roberta Smith
2010-12-0288
Page 89

Language Modules Reference
Subentity TypeSubentity
Mr.
Mrs.
John
Roberta
Smith
Jr.
5.2.2.3.23 PHONE
Phone numbers based on US format:
• 1-408-738-6200
• 408-738-6200
PERSON_PRE (subentity for the PERSON entity,
extracts personal titles such as Mr. and Ms.)
PERSON_GIV
Note:
Middle names and middle initials are included in
the PERSON_GIV entity.
PERSON_FAM
PERSON_SUFF
• 738-6200
• (408) 738-6200
• 1-888-FLOWERS
• 408-738-6200 x111
International phone numbers based on French, German and Spanish formats:
• 11 11 22 22 22
• 11/22/33/44/55
• (01) 11 22 33 44 55
• (+49)-111-22-33333
• Telefon: 0111-22222
• T 030/11 22 333
2010-12-0289
Page 90

Language Modules Reference
5.2.2.3.24 PLACE_OTHER
A non-artificial geographical location, that does not constitute a political entity extracted as one of the
following subtypes:
• BOUNDARY–The names of locations such as borders. For example:
• Mason-Dixon
• Tropic of Cancer
• CELESTIAL–The names of astronomical locations that are outside of the boundaries of the Earth.
For example:
• Neptune
• Mars
• LAND–The names of locations that are geologically or ecosystemically designed, non-artificial
locations. For example:
• Grand Canyon
• Mount Fuji
• WATER–The names of locations that are bodies of water. For example:
• Pacific Ocean
• Lake Michigan
• Volga River
5.2.2.3.25 PLACE_REGION
A geographical area that captures a significant land mass, such as a group of countries, extracted as
one of the following subtypes:
• DOMESTIC–The names of locations that do not cross national borders. For example:
• Northern Chicago
• South Miami
• Midwest
• INTL–The names of locations that cross national borders. For example:
• Southeast Asia
• Western Europe
• European countries
• UNSPECIFIED–The names of locations that do not fit into a more specific subtype. For example:
• European region
2010-12-0290
Page 91

Language Modules Reference
5.2.2.3.26 POSITION
Titles, position, and affiliations:
• President
• Secretary of State
5.2.2.3.27 POSITION Subentities
Position types are identified as shown in the table below for the following examples:
• Director of Marketing
• United States Attorney
• Queen of England
• Microsoft CEO
Subentity TypeSubentity
Director of Marketing
Attorney
Queen
CEO
United States
England
Microsoft
POSITION_POS
POSITION_AFF
5.2.2.3.28 PRODUCT
A product name, including software and service-oriented products:
• Windows
• Cheerios
• Legos
5.2.2.3.29 PROP_MISC
A proper name that does not fall into any of the entity types specified by the other entities:
2010-12-0291
Page 92

Language Modules Reference
• Second World War in A book on the Second World War
• World Cup in It is called the World Cup
• North American Legal System in A working group on the "idea" of a North American Legal
System
5.2.2.3.30 SPECIAL
The names of geo-political entities for which the conventional labels do not apply, such as disputed
territories or territories that have not been internationally recognized:
• Palestinian National Authority
• Taiwan
5.2.2.3.31 SSN
Social security number, including Canadian Social Insurance Numbers and French INSEE Numbers:
• 012-44-5668
5.2.2.3.32 STATE_PROVINCE
One of the fifty states of the United States, including standard abbreviations and two-letter postal code:
• California
• Hawai'i
• Calif.
The major administrative divisions of countries, such as the provinces and territories of Canada, the
administrative regions of France, and so on. For example:
• British Columbia
• Puerto Rico
• Pays de la Loire
• Guam
• Bavaria
5.2.2.3.33 TICKER
Company stock ticker symbols used on the stock exchange. The TICKER entities are only extracted
when used within the context of the exchange, with one of the following patterns:
• An open "(" and on the right a ":" followed by an exchange. For example, (MSFT:NYSE
• An exchange followed by a ":". For example, NYSE:MSFT
• MSFT in "Microsoft Corporation (NASDAQ:MSFT)"
2010-12-0292
Page 93

Language Modules Reference
• HPQ in "Hewlett-Packard (HPQ:NASDAQ)"
5.2.2.3.34 TIME
Designations of hours, minutes, and seconds:
• 9:00
• 9:00 a.m.
• 9:15 pm PST
Time expressions:
• 8 a.m.-2 p.m.
• 2 to 5 p.m.
5.2.2.3.35 TIME_PERIOD
Measurements of time, and ranges of time measurements:
• 5 seconds
• 1 hour, 35 minutes
• 25 years
• 5-10 minutes
• 20-30 years
• 21st century
5.2.2.3.36 URI
An address on the internet, extracted as one of the following subtypes:
• EMAIL–Email addresses, for example:
• dot_com@sun.com
• INTERNET_ADDRESS–Internet addresses, for example:
• http://www.netscape.com
• www.netscape.com
• kcbs.com
• IP–IP adresses, for example:
• 8.22.200.3
2010-12-0293
Page 94

Language Modules Reference
5.2.2.3.37 YEAR
All years, including those with designators such as A.D., BC, BCE, or C.E.:
• 2001
• '63
• 1998 A.D.
• 200 BC
• 2525 C.E.
Decades, centuries, and year expressions:
• 1950s
• 50s
• 1999-2000
Year Normalizer
The English year normalizer returns the standard form of year expressions in the following formats.
OutputInput
19731973
17541754 A.D.
1999'99
2002'02
The English year normalizer returns invalid input in its original untreated form.
ReasonInput
Years cannot be negative.-1455
12055
Currently, the range of years is from 9999 BCE
to 9999 CE.
2010-12-0294
Page 95

Language Modules Reference
ReasonInput
1922-41
This gets extracted, but is not not normalized to
the 4-digit format.
5.2.2.4 Common Noun Mentions
Common noun mentions refer to the use of common nouns to refer to entities such as organizations,
persons, or facilities which would normally also be referred to by proper nouns. They are defined as
noun phrases headed by an appropriate noun. Both singular and plural forms are matched. Proper
nouns and modifiers are also included. Determiners are never included.
This section describes the common mentions supported by the Englishlanguagemoduleand examples
of each. Click each link to jump to that subsection: COMMON_ADDRESS, COMMON_CITY, COM
MON_CONTINENT, COMMON_COUNTRY, COMMON_DISTRICT, COMMON_FACILITY, COM
MON_FEDERATION, COMMON_ORGANIZATION, COMMON_PERSON,COMMON_PLACE_OTHER,
COMMON_PLACE_REGION, COMMON_SPECIAL, and COMMON_STATE_PROVINCE.
5.2.2.4.1 COMMON_ADDRESS
Common nouns for addresses:
• fictitious address
5.2.2.4.2 COMMON_CITY
Common nouns for cities:
• border town
• densely populated cities
5.2.2.4.3 COMMON_CONTINENT
Common nouns for the entirety of any continent:
• major continents
5.2.2.4.4 COMMON_COUNTRY
Common nouns for the entirety of any country:
• major countries
2010-12-0295
Page 96

Language Modules Reference
5.2.2.4.5 COMMON_DISTRICT
Common nouns for the entirety of district areas:
• millionaire counties
• development district
5.2.2.4.6 COMMON_FACILITY
Common nouns for man-made structures, extracted as one of the following subtypes:
• AIRPORTS–The names of primarily man-made or man-maintained structures whose primary use is
as air transportation terminals. For example,
• commercial airport
• busy air field
• public heliport
• BUILDGROUNDS–The names of architectural and civil engineering structures, and outdoor spaces
that are mainly man-made or man-maintained. There is no distinction with respect to their function,
they could be civil or military facilities, they could be used for work or entertainment, or they could
be monuments. For example,
• public library
• famous national archives
• national park
• training camp
• train station
• naval port
• PATH–The names of primarily man-made or man-maintained structures that allows fluids, energy,
persons, animals, or vehicles to pass from one location to another. For example,
• deserted street
• narrow canal
• heavily defended bridge
• PLANT–The names of facilities composed by one or more buildings used for industrial purposes.
For example,
• oil refinery
• copper smelter
• thermal power station
• steel foundry
2010-12-0296
Page 97

Language Modules Reference
• SUBAREA–The names of portions of facilities, typically architectural ones, that are able to contain
people, animals, or objects. For Example,
• small atrium
• cold cellar
• new kitchen
• top-floor apartment
5.2.2.4.7 COMMON_FEDERATION
Common nouns for groupings of geo-political entities that can function as political entities
• EU federation
5.2.2.4.8 COMMON_ORGANIZATION
Common nouns for organizations, extracted as one of the following subtypes:
• COMMERCIAL–Common nouns for companies:
• small robotics company
• pesticides manufacturers
• world's fourth-biggest airline
• EDUCATIONAL–Common nouns for institutions focused on education
• private university
• public colleges
• ENTERTAINMENT–Common nouns for institutions focused on entertainment
• contemporary circus
• theatre company
• GOVERNMENT–Common nouns for institutions related to government, politics, or the state
• Taliban regime
• Clinton administration
• MEDIA–Common nouns for institutions related to the media
• news service
• television station
• MEDICALSCIENCE–Common nouns for institutions related to medicine or research
• health group
• teaching hospital
2010-12-0297
Page 98

Language Modules Reference
• RELIGIOUS–Common nouns for institutions related to religion
• Catholic church
• powerful archdiocese
• SPORTS–Common nouns for institutions related to sports
• major league
• sport team
• UNSPECIFIED–Common nouns for organizations that do not fit into a more specific subtype
• Palestinian and Lebanese organizations
• largest opposition party
5.2.2.4.9 COMMON_PERSON
Common nouns for persons, extracted as one of the following subtypes:
• GROUP–Common nouns for groups of persons
• wedding ceremony ministers
• dead or injured members
• submarine crew
• INDIVIDUAL–Common nouns for individual persons
• 58-year-old man
• math teacher
5.2.2.4.10 COMMON_PLACE_OTHER
Common nouns for natural geographical or political regions, extracted as one of the following subtypes:
• BOUNDARY–Common nouns for locations such as a border
• northern border
• unaccessible frontiers
• CELESTIAL–Common nouns for locations outside of Earth
• largest planet
• night sky
• LAND–Common nouns for geologically or ecosystemically designed non-artificial locations
• mountain range
• French seaside
2010-12-0298
Page 99

Language Modules Reference
• WATER–Common nouns for bodies of water
• saltwater lake
• flooding rivers
5.2.2.4.11 COMMON_PLACE_REGION
Common nouns for geographical regions that are not political entities or natural locations, extracted as
one of the following subtypes:
• DOMESTIC–Common nouns for locations that do not cross national borders
• remote region
• open frontier area
• modest neighborhood
• INTL–Common nouns for locations that cross internatinal borders
• overseas
5.2.2.4.12 COMMON_SPECIAL
Common nouns for geo-political entities for which the conventional labels do not apply, such as disputed
territories or territories that have not been internationally recognized:
• Native American reservation
5.2.2.4.13 COMMON_STATE_PROVINCE
Common nouns for states and provinces
• historical provinces
• home state
5.2.2.5 Advanced Parsing
The extraction process performs linguistic processing by using tools that include semantic and syntactic
knowledge of words. In general, linguistic processing identifies paragraphs, sentences, and clauses,
and then identifies semantic and syntactic information within the text. Extraction provides two modes
for linguistic processing in English: standard and advanced. The default is standard.
Advanced parsing offers richer, better coordinated noun phrase extraction that includes syntactic function
attributes, as well as pronominal resolution and is available when processing extraction rules only.
2010-12-0299
Page 100

Language Modules Reference
5.3 French Language Reference
This chapter describes the behavior of the French language module.
5.3.1 Linguistic Processing
This section describes the language-specific information on the linguistic processing of French texts,
including word segmentation, stemming, and tagging.
5.3.1.1 Character Encodings for French
• iso_8859_1
• cp_1252
• utf_8, utf_16, ucs_4
5.3.1.2 Word Segmentation in French
The French segmenter follows all of the general segmentation rules in the white space languages. See
Word Segmentation and White Space Languages for details. The French segmenter has the following
language-specific behavior.
French clitics and elisions are separated from the words they modify. The segmenter leaves the hyphen
on the end of the verb and prefixes each clitic with a hyphen. When separating elisions, the apostrophe
is kept with the word whose letters were elided. Abbreviations are kept together with their punctuation.
2010-12-02100
 Loading...
Loading...