

Page 1
Data Services Performance
Optimization Guide
BusinessObjects Data Services XI 3.1 (12.1.1)
Page 2

Copyright
© 2008 Business Objects, an SAP company. All rights reserved. Business Objects
owns the following U.S. patents, which may cover products that are offered and
licensed by Business Objects: 5,295,243; 5,339,390; 5,555,403; 5,590,250;
5,619,632; 5,632,009; 5,857,205; 5,880,742; 5,883,635; 6,085,202; 6,108,698;
6,247,008; 6,289,352; 6,300,957; 6,377,259; 6,490,593; 6,578,027; 6,581,068;
6,628,312; 6,654,761; 6,768,986; 6,772,409; 6,831,668; 6,882,998; 6,892,189;
6,901,555; 7,089,238; 7,107,266; 7,139,766; 7,178,099; 7,181,435; 7,181,440;
7,194,465; 7,222,130; 7,299,419; 7,320,122 and 7,356,779. Business Objects and
its logos, BusinessObjects, Business Objects Crystal Vision, Business Process
On Demand, BusinessQuery, Cartesis, Crystal Analysis, Crystal Applications,
Crystal Decisions, Crystal Enterprise, Crystal Insider, Crystal Reports, Crystal
Vision, Desktop Intelligence, Inxight and its logos , LinguistX, Star Tree, Table
Lens, ThingFinder, Timewall, Let There Be Light, Metify, NSite, Rapid Marts,
RapidMarts, the Spectrum Design, Web Intelligence, Workmail and Xcelsius are
trademarks or registered trademarks in the United States and/or other countries
of Business Objects and/or affiliated companies. SAP is the trademark or registered
trademark of SAP AG in Germany and in several other countries. All other names
mentioned herein may be trademarks of their respective owners.
Third-party
Contributors
Business Objects products in this release may contain redistributions of software
licensed from third-party contributors. Some of these individual components may
also be available under alternative licenses. A partial listing of third-party
contributors that have requested or permitted acknowledgments, as well as required
notices, can be found at: http://www.businessobjects.com/thirdparty
2008-11-28
Page 3

Contents
Welcome to Data Services 9Chapter 1
Welcome....................................................................................................10
Documentation set for Data Services........................................................10
Accessing documentation..........................................................................13
Business Objects information resources...................................................14
Environment Test Strategy 17Chapter 2
The source OS and database server.........................................................18
The target OS and database server..........................................................19
The network...............................................................................................20
Data Services Job Server OS and job options..........................................20
Accessing documentation on Windows................................................13
Accessing documentation on UNIX......................................................13
Accessing documentation from the Web..............................................14
Operating system.................................................................................18
Database..............................................................................................18
Operating system.................................................................................19
Database..............................................................................................19
Operating system.................................................................................20
Data Services jobs...............................................................................21
Measuring Data Services Performance 23Chapter 3
Data Services processes and threads.......................................................24
Data Services processes .....................................................................24
Data Services threads..........................................................................25
Measuring performance of Data Services jobs..........................................25
Data Services Performance Optimization Guide 3
Page 4

Contents
Checking system utilization..................................................................26
Analyzing log files for task duration......................................................30
Reading the Monitor Log for execution statistics ................................31
Reading the Performance Monitor for execution statistics...................32
To view the Performance Monitor.........................................................33
Reading Operational Dashboards for execution statistics...................34
To compare execution times for the same job over time......................34
Tuning Overview 37Chapter 4
Strategies to execute Data Services jobs..................................................38
Maximizing push-down operations to the database server..................38
Improving Data Services throughput....................................................39
Using advanced Data Services tuning options.....................................40
Maximizing Push-Down Operations 41Chapter 5
Push-down operations...............................................................................42
Full push-down operations...................................................................42
Partial push-down operations...............................................................43
Operations that cannot be pushed down.............................................44
Push-down examples................................................................................45
Scenario 1: Combine transforms to push down ..................................45
Scenario 2: Full push down from the source to the target....................46
Scenario 3: Full push down for auto correct load to the target ............46
Scenario 4: Partial push down to the source .......................................47
To view SQL...............................................................................................47
Data_Transfer transform for push-down operations..................................50
Scenario 1: Push down an operation after a blocking operation..........50
Scenario 2: Using Data_Transfer tables to speed up auto correct
loads.....................................................................................................53
Database link support for push-down operations across datastores.........57
4 Data Services Performance Optimization Guide
Page 5

Contents
Software support..................................................................................58
To take advantage of linked datastores................................................58
Example of push-down with linked datastores.....................................59
Generated SQL statements..................................................................60
Tuning performance at the data flow or Job Server level.....................61
Using Caches 63Chapter 6
Caching data..............................................................................................64
Caching sources...................................................................................65
Caching joins........................................................................................66
To change the cache type for a data flow.............................................66
Caching lookups...................................................................................67
Caching table comparisons..................................................................68
Specifying a pageable cache directory................................................69
Using persistent cache..............................................................................70
Using persistent cache tables as sources ...........................................70
Monitoring and tuning caches....................................................................71
Using statistics for cache self-tuning ...................................................71
To have Data Services automatically choose the cache type..............71
To monitor and tune in-memory and pageable caches........................71
Using parallel Execution 77Chapter 7
Parallel data flows and work flows.............................................................78
Parallel execution in data flows.................................................................79
Table partitioning..................................................................................79
Degree of parallelism ..........................................................................85
Combining table partitioning and a degree of parallelism....................93
File multi-threading...............................................................................96
Data Services Performance Optimization Guide 5
Page 6

Contents
Distributing Data Flow Execution 101Chapter 8
Splitting a data flow into sub data flows...................................................102
Run as a separate process option ....................................................103
Examples of multiple processes for a data flow.................................103
Data_Transfer transform....................................................................110
Examples of multiple processes with Data_Transfer.........................110
Using grid computing to distribute data flow execution...........................116
Server Group......................................................................................116
Distribution levels for data flow execution..........................................116
Using Bulk Loading 123Chapter 9
Bulk loading in Oracle..............................................................................124
Bulk-loading methods.........................................................................124
Bulk-loading modes............................................................................125
Bulk-loading parallel-execution options..............................................125
Bulk-loading scenarios.......................................................................126
Using bulk-loading options.................................................................127
Bulk loading in Microsoft SQL Server......................................................129
To use the SQL Server ODBC bulk copy API....................................130
Network packet size option................................................................130
Maximum rejects option.....................................................................131
Bulk loading in HP Neoview.....................................................................131
Using the UPSERT bulk operation.....................................................132
Bulk loading in Informix............................................................................132
To set Informix server variables..........................................................133
Bulk loading in DB2 Universal Database.................................................133
When to use each DB2 bulk-loading method.....................................133
Using the DB2 CLI load method.........................................................136
To configure your system to use the CLI load method.......................136
6 Data Services Performance Optimization Guide
Page 7

Contents
To use the CLI load method in a Data Services job...........................136
Using the DB2 bulk load utility............................................................137
To configure your system to use the load utility.................................137
To use the load utility in a Data Services job......................................140
Using the import utility .......................................................................142
Bulk loading in Netezza...........................................................................142
Netezza bulk-loading process............................................................142
Options overview................................................................................143
Netezza log files.................................................................................144
Configuring bulk loading for Netezza ................................................144
To configure the target table...............................................................145
Bulk loading in Sybase ASE....................................................................146
Bulk loading in Sybase IQ........................................................................146
Bulk loading in Teradata..........................................................................147
When to use each Teradata bulk load method...................................147
How Data Services and Teradata use the file options to load............154
Using the UPSERT bulk operation.....................................................156
Parallel Transporter method...............................................................157
Teradata standalone utilities ..............................................................161
Other Tuning Techniques 179Chapter 10
Source-based performance options........................................................181
Join ordering.......................................................................................181
Minimizing extracted data...................................................................184
Using array fetch size.........................................................................185
Target-based performance options..........................................................186
Loading method .................................................................................186
Rows per commit................................................................................187
Job design performance options.............................................................188
Loading only changed data ...............................................................188
Minimizing data type conversion........................................................189
Data Services Performance Optimization Guide 7
Page 8

Contents
Minimizing locale conversion..............................................................189
Precision in operations ......................................................................189
Index 191
8 Data Services Performance Optimization Guide
Page 9

Welcome to Data Services
1
Page 10
Welcome to Data Services
1
Welcome
Welcome
Data Services XI Release 3 provides data integration and data quality
processes in one runtime environment, delivering enterprise performance
and scalability.
The data integration processes of Data Services allow organizations to easily
explore, extract, transform, and deliver any type of data anywhere across
the enterprise.
The data quality processes of Data Services allow organizations to easily
standardize, cleanse, and consolidate data anywhere, ensuring that end-users
are always working with information that's readily available, accurate, and
trusted.
Documentation set for Data Services
You should become familiar with all the pieces of documentation that relate
to your Data Services product.
What this document providesDocument
Documentation Map
Release Summary
Release Notes
Getting Started Guide
Installation Guide for Windows
Installation Guide for UNIX
10 Data Services Performance Optimization Guide
Information about available Data Services books,
languages, and locations
Highlights of key features in this Data Services release
Important information you need before installing and
deploying this version of Data Services
An introduction to Data Services
Information about and procedures for installing Data
Services in a Windows environment.
Information about and procedures for installing Data
Services in a UNIX environment.
Page 11
Advanced Development Guide
Welcome to Data Services
Documentation set for Data Services
What this document providesDocument
Guidelines and options for migrating applications including information on multi-user functionality and
the use of the central repository for version control
1
Designer Guide
Integrator's Guide
Management Console: Administrator
Guide
Management Console: Metadata Reports Guide
Migration Considerations Guide
Performance Optimization Guide
Reference Guide
Information about how to use Data Services Designer
Information for third-party developers to access Data
Services functionality. Also provides information about
how to install, configure, and use the Data Services
Adapter for JMS.
Information about how to use Data Services Administrator
Information about how to use Data Services Metadata
Reports
Information about:
• Release-specific product behavior changes from
earlier versions of Data Services to the latest release
• How to migrate from Data Quality to Data Services
Information about how to improve the performance
of Data Services
Detailed reference material for Data Services Designer
Data Services Performance Optimization Guide 11
Page 12
Welcome to Data Services
1
Documentation set for Data Services
Technical Manuals
What this document providesDocument
A compiled “master” PDF of core Data Services books
containing a searchable master table of contents and
index:
•
Getting Started Guide
•
Installation Guide for Windows
•
Installation Guide for UNIX
•
Designer Guide
•
Reference Guide
•
Management Console: Metadata Reports Guide
•
Management Console: Administrator Guide
•
Performance Optimization Guide
•
Advanced Development Guide
•
Supplement for J.D. Edwards
•
Supplement for Oracle Applications
•
Supplement for PeopleSoft
•
Supplement for Siebel
•
Supplement for SAP
Tutorial
A step-by-step introduction to using Data Services
In addition, you may need to refer to several Adapter Guides and
Supplemental Guides.
What this document providesDocument
Salesforce.com Adapter
Interface
Supplement for J.D. Edwards
Supplement for Oracle Applications
Supplement for PeopleSoft
12 Data Services Performance Optimization Guide
Information about how to install, configure, and use the Data
Services Salesforce.com Adapter Interface
Information about license-controlled interfaces between Data
Services and J.D. Edwards World and J.D. Edwards OneWorld
Information about the license-controlled interface between Data
Services and Oracle Applications
Information about license-controlled interfaces between Data
Services and PeopleSoft
Page 13
Welcome to Data Services
Accessing documentation
What this document providesDocument
1
Supplement for SAP
Supplement for Siebel
Information about license-controlled interfaces between Data
Services, SAP ERP, and SAP BI/BW
Information about the license-controlled interface between Data
Services and Siebel
Accessing documentation
You can access the complete documentation set for Data Services in several
places.
Accessing documentation on Windows
After you install Data Services, you can access the documentation from the
Start menu.
1. Choose Start > Programs > BusinessObjects XI 3.1 >
BusinessObjects Data Services > Data Services Documentation.
Note:
Only a subset of the documentation is available from the Start menu. The
documentation set for this release is available in LINK_DIR\Doc\Books\en.
2. Click the appropriate shortcut for the document that you want to view.
Accessing documentation on UNIX
After you install Data Services, you can access the online documentation by
going to the directory where the printable PDF files were installed.
1. Go to LINK_DIR/doc/book/en/.
2. Using Adobe Reader, open the PDF file of the document that you want
to view.
Data Services Performance Optimization Guide 13
Page 14

Welcome to Data Services
1
Business Objects information resources
Accessing documentation from the Web
You can access the complete documentation set for Data Services from the
Business Objects Customer Support site.
1.
Go to http://help.sap.com.
2. Cick Business Objects at the top of the page.
You can view the PDFs online or save them to your computer.
Business Objects information resources
A global network of Business Objects technology experts provides customer
support, education, and consulting to ensure maximum business intelligence
benefit to your business.
Useful addresses at a glance:
ContentAddress
14 Data Services Performance Optimization Guide
Page 15
Welcome to Data Services
Business Objects information resources
ContentAddress
1
Customer Support, Consulting, and Education
services
http://service.sap.com/
Data Services Community
https://www.sdn.sap.com/irj/sdn/businessob
jects-ds
Forums on SCN (SAP Community Network)
https://www.sdn.sap.com/irj/sdn/businessob
jects-forums
Blueprints
http://www.sdn.sap.com/irj/boc/blueprints
Information about Customer Support programs,
as well as links to technical articles, downloads,
and online forums. Consulting services can
provide you with information about how Business Objects can help maximize your business
intelligence investment. Education services can
provide information about training options and
modules. From traditional classroom learning
to targeted e-learning seminars, Business Objects can offer a training package to suit your
learning needs and preferred learning style.
Get online and timely information about Data
Services, including tips and tricks, additional
downloads, samples, and much more. All content is to and from the community, so feel free
to join in and contact us if you have a submission.
Search the Business Objects forums on the
SAP Community Network to learn from other
Data Services users and start posting questions
or share your knowledge with the community.
Blueprints for you to download and modify to fit
your needs. Each blueprint contains the necessary Data Services project, jobs, data flows, file
formats, sample data, template tables, and
custom functions to run the data flows in your
environment with only a few modifications.
Data Services Performance Optimization Guide 15
Page 16
Welcome to Data Services
1
Business Objects information resources
http://help.sap.com/
ContentAddress
Business Objects product documentation.Product documentation
Documentation mailbox
documentation@businessobjects.com
Supported platforms documentation
https://service.sap.com/bosap-support
Send us feedback or questions about your
Business Objects documentation. Do you have
a suggestion on how we can improve our documentation? Is there something that you particularly like or have found useful? Let us know,
and we will do our best to ensure that your
suggestion is considered for the next release
of our documentation.
Note:
If your issue concerns a Business Objects
product and not the documentation, please
contact our Customer Support experts.
Get information about supported platforms for
Data Services.
In the left panel of the window, navigate to
Documentation > Supported Platforms >
BusinessObjects XI 3.1. Click the BusinessObjects Data Services link in the main window.
16 Data Services Performance Optimization Guide
Page 17

Environment Test Strategy
2
Page 18

Environment Test Strategy
2
The source OS and database server
This section covers suggested methods of tuning source and target database
applications, their operating systems, and the network used by your Data
Services environment. It also introduces key Data Services job execution
options.
This section contains the following topics:
•
The source OS and database server on page 18
•
The target OS and database server on page 19
•
The network on page 20
•
Data Services Job Server OS and job options on page 20
To test and tune Data Services jobs, work with all four of these components
in the order shown above.
In addition to the information in this section, you can use your UNIX or
Windows operating system and database server documentation for specific
techniques, commands, and utilities that can help you measure and tune the
Data Services environment.
The source OS and database server
Tune the source operating system and database to quickly read data from
disks.
Operating system
Make the input and output (I/O) operations as fast as possible. The
read-ahead protocol, offered by most operating systems, can greatly improve
performance. This protocol allows you to set the size of each I/O operation.
Usually its default value is 4 to 8 kilobytes which is too small. Set it to at least
64K on most platforms.
Database
Tune your database on the source side to perform SELECTs as quickly as
possible.
18 Data Services Performance Optimization Guide
Page 19

Environment Test Strategy
The target OS and database server
In the database layer, you can improve the performance of SELECTs in
several ways, such as the following:
• Create indexes on appropriate columns, based on your Data Services
data flows.
• Increase the size of each I/O from the database server to match the OS
read-ahead I/O size.
• Increase the size of the shared buffer to allow more data to be cached in
the database server.
• Cache tables that are small enough to fit in the shared buffer. For example,
if jobs access the same piece of data on a database server, then cache
that data. Caching data on database servers will reduce the number of
I/O operations and speed up access to database tables.
See your database server documentation for more information about
techniques, commands, and utilities that can help you measure and tune the
the source databases in your Data Services jobs.
The target OS and database server
2
Tune the target operating system and database to quickly write data to disks.
Operating system
Make the input and output operations as fast as possible. For example, the
asynchronous I/O, offered by most operating systems, can greatly improve
performance. Turn on the asynchronous I/O.
Database
Tune your database on the target side to perform INSERTs and UPDATES
as quickly as possible.
In the database layer, there are several ways to improve the performance
of these operations.
Here are some examples from Oracle:
Data Services Performance Optimization Guide 19
Page 20

Environment Test Strategy
2
The network
• Turn off archive logging
• Turn off redo logging for all tables
• Tune rollback segments for better performance
• Place redo log files and data files on a raw device if possible
• Increase the size of the shared buffer
See your database server documentation for more information about
techniques, commands, and utilities that can help you measure and tune the
the target databases in your Data Services jobs.
The network
When reading and writing data involves going through your network, its ability
to efficiently move large amounts of data with minimal overhead is very
important. Do not underestimate the importance of network tuning (even if
you have a very fast network with lots of bandwidth).
Set network buffers to reduce the number of round trips to the database
servers across the network. For example, adjust the size of the network
buffer in the database client so that each client request completely fills a
small number of network packets.
Data Services Job Server OS and job options
Tune the Job Server operating system and set job execution options to
improve performance and take advantage of self-tuning features of Data
Services.
Operating system
Data Services jobs are multi-threaded applications. Typically a single data
flow in a job initiates one al_engine process that in turn initiates at least 4
threads.
For maximum performance benefits:
20 Data Services Performance Optimization Guide
Page 21

• Consider a design that will run one al_engine process per CPU at a
time.
• Tune the Job Server OS so that Data Services threads spread to all
available CPUs.
For more information, see Checking system utilization on page 26.
Data Services jobs
You can tune Data Services job execution options after:
• Tuning the database and operating system on the source and the target
computers
• Adjusting the size of the network buffer
• Your data flow design seems optimal
You can tune the following execution options to improve the performance of
Data Services jobs:
• Monitor sample rate
Environment Test Strategy
Data Services Job Server OS and job options
2
• Collect statistics for optimization and Use collected statistics
Setting Monitor sample rate
During job execution, Data Services writes information to the monitor log file
and updates job events after processing the number of rows specified in
Monitor sample rate. Default value is 1000. Increase Monitor sample rate
to reduce the number of calls to the operating system to write to the log file.
When setting Monitor sample rate, you must evaluate performance
improvements gained by making fewer calls to the operating system against
your ability to view more detailed statistics during job execution. With a higher
Monitor sample rate, Data Services collects more data before calling the
operating system to open the file, and performance improves. However, with
a higher monitor rate, more time passes before you can view statistics during
job execution.
Data Services Performance Optimization Guide 21
Page 22

Environment Test Strategy
2
Data Services Job Server OS and job options
In production environments when your jobs transfer large volumes of data,
Business Objects recommends that you increase Monitor sample rate to
50,000.
Note:
If you use a virus scanner on your files, exclude the Data Services log from
the virus scan. Otherwise, the virus scan analyzes the Data Services log
repeated during the job execution, which causes a performance degradation.
Collecting statistics for self-tuning
Data Services provides a self-tuning feature to determine the optimal cache
type (in-memory or pageable) to use for a data flow.
To take advantage of this self-tuning feature
1. When you first execute a job, select the option Collect statistics for
optimization to collect statistics which include number of rows and width
of each row. Ensure that you collect statistics with data volumes that
represent your production environment. This option is not selected by
default.
2. The next time you execute the job, this option is selected by default.
3. When changes occur in data volumes, re-run your job with Collect
statistics for optimization to ensure that Data Services has the most
current statistics to optimize cache types.
For more information about these caches, see .
Related Topics
• Using Caches on page 63
22 Data Services Performance Optimization Guide
Page 23

Measuring Data Services Performance
3
Page 24

Measuring Data Services Performance
3
Data Services processes and threads
This section contains the following topics:
•
Data Services processes and threads on page 24
•
Measuring performance of Data Services jobs on page 25
Data Services processes and threads
Data Services uses processes and threads to execute jobs that extract data
from sources, transform the data, and load data into a data warehouse. The
number of concurrently executing processes and threads affects the
performance of Data Services jobs.
Data Services processes
The processes Data Services uses to run jobs are:
• al_jobserver
The al_jobserver initiates one process for each Job Server configured on
a computer. This process does not use much CPU power because it is
only responsible for launching each job and monitoring the job's execution.
• al_engine
For batch jobs, an al_engine process runs when a job starts and for each
of its data flows. Real-time jobs run as a single process.
The number of processes a batch job initiates also depends upon the
number of:
• parallel work flows
• parallel data flows
• sub data flows
For an example of the Data Services monitor log that displays the processes,
see Analyzing log files for task duration on page 30.
24 Data Services Performance Optimization Guide
Page 25

Data Services threads
A data flow typically initiates one al_engine process, which creates one
thread per data flow object. A data flow object can be a source, transform,
or target. For example, two sources, a query, and a target could initiate four
threads.
If you are using parallel objects in data flows, the thread count will increase
to approximately one thread for each source or target table partition. If you
set the Degree of parallelism (DOP) option for your data flow to a value
greater than one, the thread count per transform will increase. For example,
a DOP of 5 allows five concurrent threads for a Query transform. To run
objects within data flows in parallel, use the following Data Services features:
• Table partitioning
• File multithreading
• Degree of parallelism for data flows
Measuring Data Services Performance
Measuring performance of Data Services jobs
3
Related Topics
• Using parallel Execution on page 77
Measuring performance of Data Services
jobs
You can use several techniques to measure performance of Data Services
jobs:
•
Checking system utilization on page 26
•
Analyzing log files for task duration on page 30
•
Reading the Monitor Log for execution statistics on page 31
•
Reading the Performance Monitor for execution statistics on page 32
•
Reading Operational Dashboards for execution statistics on page 34
Data Services Performance Optimization Guide 25
Page 26

Measuring Data Services Performance
3
Measuring performance of Data Services jobs
Checking system utilization
The number of Data Services processes and threads concurrently executing
affects the utilization of system resources (see Data Services processes and
threads on page 24).
Check the utilization of the following system resources:
• CPU
• Memory
• Disk
• Network
To monitor these system resources, use the following tools:
For UNIX:
• top or a third party utility (such as glance for HPUX)
For Windows:
• Performance tab on the Task Manager
Depending on the performance of your jobs and the utilization of system
resources, you might want to adjust the number of Data Services processes
and threads. The following sections describe different situations and suggests
Data Services features to adjust the number of processes and threads for
each situation.
CPU utilization
Data Services is designed to maximize the use of CPUs and memory
available to run the job.
The total number of concurrent threads a job can run depends upon job
design and environment. Test your job while watching multi-threaded Data
Services processes to see how much CPU and memory the job requires.
Make needed adjustments to your job design and environment and test again
to confirm improvements.
26 Data Services Performance Optimization Guide
Page 27

Measuring Data Services Performance
Measuring performance of Data Services jobs
For example, if you run a job and see that the CPU utilization is very high,
you might decrease the DOP value or run less parallel jobs or data flows.
Otherwise, CPU thrashing might occur.
For another example, if you run a job and see that only half a CPU is being
used, or if you run eight jobs on an eight-way computer and CPU usage is
only 50%, you can be interpret this CPU utilization in several ways:
• One interpretation might be that Data Services is able to push most of
the processing down to source and/or target databases.
• Another interpretation might be that there are bottlenecks in the database
server or the network connection. Bottlenecks on database servers do
not allow readers or loaders in jobs to use Job Server CPUs efficiently.
To determine bottlenecks, examine:
• Disk service time on database server computers
Disk service time typically should be below 15 milliseconds. Consult
your server documentation for methods of improving performance.
For example, having a fast disk controller, moving database server
log files to a raw device, and increasing log size could improve disk
service time.
3
• Number of threads per process allowed on each database server
operating system. For example:
• On HPUX, the number of kernel threads per process is configurable.
The CPU to thread ratio defaults to one-to-one. Business Objects
recommends setting the number of kernel threads per CPU to
between 512 and 1024.
• On Solaris and AIX, the number of threads per process is not
configurable. The number of threads per process depends on
system resources. If a process terminates with a message like
"Cannot create threads," you should consider tuning the job.
For example, use the Run as a separate process option to split
a data flow or use the Data_Transfer transform to create two sub
data flows to execute sequentially. Since each sub data flow is
executed by a different Data Services al_engine process, the
number of threads needed for each will be 50% less than in your
previous job design.
Data Services Performance Optimization Guide 27
Page 28

Measuring Data Services Performance
3
Measuring performance of Data Services jobs
If you are using the Degree of parallelism option in your data flow,
reduce the number for this option in the data flow Properties
window.
• Network connection speed
Determine the rate that your data is being transferred across your
network.
• If the network is a bottle neck, you might change your job execution
distribution level from sub data flow to data flow or job to execute
the entire data flow on the local Job Server.
• If the capacity of your network is much larger, you might retrieve
multiple rows from source databases using fewer requests.
• Yet another interpretation might be that the system is under-utilized. In
this case, you might increase the value for the Degree of parallelism
option and increase the number of parallel jobs and data flows.
Related Topics
• Using parallel Execution on page 77
• Using grid computing to distribute data flow execution on page 116
• Using array fetch size on page 185
Data Services memory
For memory utilization, you might have one of the following different cases:
• Low amount of physical memory.
In this case, you might take one of the following actions:
• Add more memory to the Job Server.
• Redesign your data flow to run memory-consuming operations in
separate sub data flows that each use a smaller amount of memory,
and distribute the sub data flows over different Job Servers to access
memory on multiple machines. For more information, see Splitting a
data flow into sub data flows on page 102.
• Redesign your data flow to push down memory-consuming operations
to the database. For more information, see Push-down operations on
page 42.
28 Data Services Performance Optimization Guide
Page 29

Measuring Data Services Performance
Measuring performance of Data Services jobs
For example, if your data flow reads data from a table, joins it to a file,
and then groups it to calculate an average, the group by operation might
be occurring in memory. If you stage the data after the join and before
the group by into a database on a different computer, then when a sub
data flow reads the staged data and continues with the group processing,
it can utilize memory from the database server on a different computer.
This situation optimizes your system as a whole.
For information about how to stage your data, see Data_Transfer transform
on page 110. For more information about distributing sub data flows to
different computers, see Using grid computing to distribute data flow
execution on page 116.
• Large amount of memory but it is under-utilized.
In this case, you might cache more data. Caching data can improve the
performance of data transformations because it reduces the number of
times the system must access the database.
Data Services provides two types of caches: in-memory and pageable.
For more information, see Caching data on page 64.
3
• Paging occurs.
Pageable cache is the default cache type for data flows. On Windows
and Linux, the virtual memory available to the al_engine process is 1.5
gigabytes (500 megabytes of virtual memory is reserved for other engine
operations, totaling 2GB). On UNIX, Data Services limits the virtual
memory for the al_engine process to 3.5 gigabytes (500MB is reserved
for other engine operations, totaling 4GB). If more memory is needed
than these virtual memory limits, Data Services starts paging to continue
executing the data flow.
If your job or data flow requires more memory than these limits, you can
take advantage of one of the following Data Services features to avoid
paging:
• Split the data flow into sub data flows that can each use the amount
of memory set by the virtual memory limits.
Each data flow or each memory-intensive operation within a data flow
can run as a separate process that uses separate memory from each
other to improve performance and throughput. For more information,
see Splitting a data flow into sub data flows on page 102.
Data Services Performance Optimization Guide 29
Page 30
Measuring Data Services Performance
3
Measuring performance of Data Services jobs
• Push-down memory-intensive operations to the database server so
that less memory is used on the Job Server computer. For more
information, see Push-down operations on page 42.
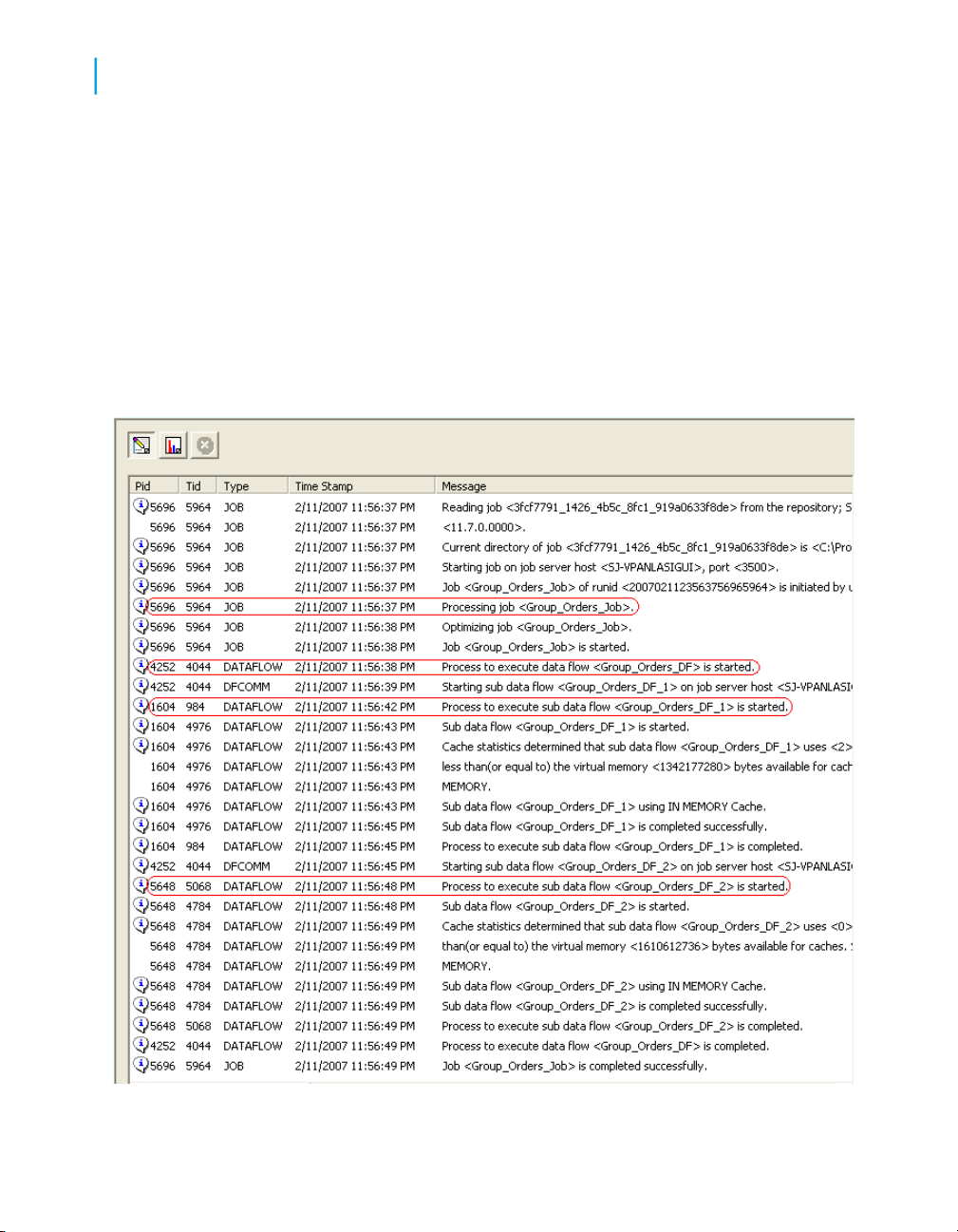
Analyzing log files for task duration
The trace log shows the progress of an execution through each component
(object) of a job. The following sample Trace log shows a separate Process
ID (Pid) for the Job, data flow, and each of the two sub data flows.
30 Data Services Performance Optimization Guide
Page 31

Measuring Data Services Performance
Measuring performance of Data Services jobs
This sample log contains messages about sub data flows, caches, and
statistics.
Related Topics
• Splitting a data flow into sub data flows on page 102
• Caching data on page 64
• Reference Guide: Data Services Objects, Log
Reading the Monitor Log for execution statistics
The Monitor log file indicates how many rows Data Services produces or
loads for a job. By viewing this log during job execution, you can observe
the progress of row-counts to determine the location of bottlenecks. You can
use the Monitor log to answer questions such as the following:
• What transform is running at any moment?
• How many rows have been processed so far?
The frequency that the Monitor log refreshes the statistics is based on
Monitor sample rate.
3
• How long does it take to build the cache for a lookup or comparison table?
How long does it take to process the cache?
If take long time to build the cache, use persistent cache.
• How long does it take to sort?
If take long time to sort, you can redesign your data flow to push down
the sort operation to the database.
• How much time elapses before a blocking operation sends out the first
row?
If your data flow contains resource-intensive operations after the blocking
operation, you can add Data_Transfer transforms to push-down the
resource-intensive operations.
You can view the Monitor log from the following tools:
• The Designer, as the job executes, when you click the Monitor icon.
• The Administrator of the Management Console, when you click the Monitor
link for a job from the Batch Job Status page.
Data Services Performance Optimization Guide 31
Page 32

Measuring Data Services Performance
3
Measuring performance of Data Services jobs
The following sample Monitor log in the Designer shows the path for each
object in the job, the number of rows processed and the elapsed time for
each object. The Absolute time is the total time from the start of the job to
when Data Services completes the execution of the data flow object.
Related Topics
• Setting Monitor sample rate on page 21
• Using persistent cache on page 70
• Push-down operations on page 42
• Data_Transfer transform for push-down operations on page 50
• Reference Guide: Data Services Objects, Log
Reading the Performance Monitor for execution statistics
The Performance Monitor displays execution information for each work flow,
data flow, and sub data flow within a job. You can display the execution times
in a graph or a table format. You can use the Performance Monitor to answer
questions such as the following:
• Which data flows might be bottlenecks?
• How much time did a a data flow or sub data flow take to execute?
• How many rows did the data flow or sub data flow process?
• How much memory did a specific data flow use?
32 Data Services Performance Optimization Guide
Page 33

Measuring Data Services Performance
Measuring performance of Data Services jobs
Note:
Memory statistics (Cache Size column) display in the Performance Monitor
only if you select the Collect statistics for monitoring option when you
execute the job.
The following sample Performance Monitor shows the following information:
• The Query_Lookup transform used 110 kilobytes of memory.
• The first sub data flow processed 830 rows, and the second sub data
flow processed 35 rows.
3
To view the Performance Monitor
1. Access the Management Console with one of the following methods:
• In the Designer top menu bar, click Tools and select Data Services
Management Console.
• Click Start > Programs > BusinessObjects Data Services >
Management Console.
2. On the launch page, click Administrator.
3. Select Batch > repository
4. On the Batch Job Statuspage, find a job execution instance.
5. Under Job Information for an instance, click Performance > Monitor.
Data Services Performance Optimization Guide 33
Page 34

Measuring Data Services Performance
3
Measuring performance of Data Services jobs
Related Topics
• To monitor and tune in-memory and pageable caches on page 71
Reading Operational Dashboards for execution statistics
Operational dashboard reports contain job and data flow execution information
for one or more repositories over a given time period (for example the last
day or week). You can use operational statistics reports to answer some of
the following questions:
• Are jobs executing within the allotted time frames?
• How many jobs succeeded or failed over a given execution period?
• How is the execution time for a job evolving over time?
• How many rows did the data flow process?
To compare execution times for the same job over time
1. Access the metadata reporting tool with one of the following methods:
• In the Designer top menu bar, click Tools and select Data Services
Management Console.
• In the Windows Start menu, click Programs > BusinessObjectsData
Services> Data Services Management Console.
2. On the launch page, click Dashboards.
3. Look at the graphs in Job Execution Statistic History or Job Execution
Duration History to see if performance is increasing or decreasing.
4. On the Job Execution Duration History, if there is a specific day that looks
high or low compared to the other execution times, click that point on the
graph to view the Job Execution Duration graph for all jobs that ran that
day.
34 Data Services Performance Optimization Guide
Page 35

Measuring Data Services Performance
Measuring performance of Data Services jobs
5. Click View all history to compare different executions of a specific job
or data flow.
6. On the Job Execution History tab, you can select a specific job and number
of days.
3
7. On the Data Flow Execution History tab, you can select a specific job and
number of days, as well as search for a specific data flow.
Data Services Performance Optimization Guide 35
Page 36

Measuring Data Services Performance
3
Measuring performance of Data Services jobs
Related Topics
• Management Console Metadata Reports Guide: Operational Dashboard
Reports
36 Data Services Performance Optimization Guide
Page 37

Tuning Overview
4
Page 38

Tuning Overview
4
Strategies to execute Data Services jobs
This section presents an overview of the different Data Services tuning
options, with cross-references to subsequent chapters for more details.
Strategies to execute Data Services jobs
To maximize performance of your Data Services jobs, Business Objects
recommends that you use the following tuning strategies:
•
Maximizing push-down operations to the database server on page 38
•
Improving Data Services throughput on page 39
•
Using advanced Data Services tuning options on page 40
Maximizing push-down operations to the database server
Data Services generates SQL SELECT statements to retrieve the data from
source databases. Data Services automatically distributes the processing
workload by pushing down as much as possible to the source database
server.
Pushing down operations provides the following advantages:
• Use the power of the database server to execute SELECT operations
(such as joins, Group By, and common functions such as decode and
string functions). Often the database is optimized for these operations.
• Minimize the amount of data sent over the network. Less rows can be
retrieved when the SQL statements include filters or aggregations.
You can also do a full push down from the source to the target, which means
Data Services sends SQL INSERT INTO... SELECT statements to the target
database. The following features enable a full push down:
• Data_Transfer transform
• Database links and linked datastores
Related Topics
• Maximizing Push-Down Operations on page 41
38 Data Services Performance Optimization Guide
Page 39

Strategies to execute Data Services jobs
Improving Data Services throughput
Use the following Data Services features to improve throughput:
• Using caches for faster access to data
You can improve the performance of data transformations by caching as
much data as possible. By caching data in memory, you limit the number
of times the system must access the database.
• Bulk loading to the target
Data Services supports database bulk loading engines including the
Oracle bulk load API. You can have multiple bulk load processes running
in parallel.
• Other tuning techniques
• Source-based performance options
• Join ordering
• Minimizing extracted data
Tuning Overview
4
• Using array fetch size
• Target-based performance options
• Loading method
• Rows per commit
• Job design performance options
• Loading only changed data
• Minimizing data type conversion
• Minimizing locale conversion
• Precision in operations
Related Topics
• Using Caches on page 63
• Using Bulk Loading on page 123
• Other Tuning Techniques on page 179
Data Services Performance Optimization Guide 39
Page 40

Tuning Overview
4
Strategies to execute Data Services jobs
• Join ordering on page 181
• Minimizing extracted data on page 184
• Using array fetch size on page 185
• Loading method on page 186
• Rows per commit on page 187
• Loading only changed data on page 188
• Minimizing data type conversion on page 189
• Minimizing locale conversion on page 189
• Precision in operations on page 189
Using advanced Data Services tuning options
If your jobs have CPU-intensive and memory-intensive operations, you can
use the following advanced tuning features to improve performance:
• Parallel processes - Individual work flows and data flows can execute in
parallel if you do not connect them in the Designer workspace.
• Parallel threads - Data Services supports partitioned source tables,
partitioned target tables, and degree of parallelism. These options allow
you to control the number of instances for a source, target, and transform
that can run in parallel within a data flow. Each instance runs as a separate
thread and can run on a separate CPU.
• Server groups and distribution levels - You can group Job Servers on
different computers into a logical Data Services component called a server
group. A server group automatically measures resource availability on
each Job Server in the group and distributes scheduled batch jobs to the
computer with the lightest load at runtime. This functionality also provides
a hot backup method. If one Job Server in a server group is down, another
Job Server in the group processes the job.
You can distribute the execution of data flows or sub data flows within a
batch job across multiple Job Servers within a Server Group to better
balance resource-intensive operations.
Related Topics
• Using parallel Execution on page 77
• Management Console Administrator Guide: Server Groups
• Using grid computing to distribute data flow execution on page 116
40 Data Services Performance Optimization Guide
Page 41

Maximizing Push-Down Operations
5
Page 42

Maximizing Push-Down Operations
5
Push-down operations
For SQL sources and targets, Data Services creates database-specific SQL
statements based on the data flow diagrams in a job. Data Services generates
SQL SELECT statements to retrieve the data from source databases. To
optimize performance, Data Services pushes down as many SELECT
operations as possible to the source database and combines as many
operations as possible into one request to the database. Data Services can
push down SELECT operations such as joins, Group By, and common
functions such as decode and string functions.
Data flow design influences the number of operations that Data Services
can push to the database. Before running a job, you can view the SQL that
Data Services generates and adjust your design to maximize the SQL that
is pushed down to improve performance.
You can use database links and the Data_Transfer transform to pushdown
more operations.
This section discusses:
• Push-down operations
• Push-down examples
• Viewing SQL
• Data_Transfer transform for push-down operations
• Database link support for push-down operations across datastores
Push-down operations
By pushing down operations to the source database, Data Services reduces
the number of rows and operations that the engine must retrieve and process,
which improves performance. When determining which operations to push
to the database, Data Services examines the database and its environment.
Full push-down operations
The Data Services optimizer always first tries to do a full push-down operation.
A full push-down operation is when all Data Services transform operations
can be pushed down to the databases and the data streams directly from
the source database to the target database. Data Services sends SQL
42 Data Services Performance Optimization Guide
Page 43

Maximizing Push-Down Operations
Push-down operations
INSERT INTO... SELECT statements to the target database where the
SELECT retrieves data from the source.
Data Services does a full push-down operation to the source and target
databases when the following conditions are met:
• All of the operations between the source table and target table can be
pushed down
• The source and target tables are from the same datastore or they are in
datastores that have a database link defined between them.
You can also use the following features to enable a full push-down from the
source to the target:
• Data_Transfer transform
• Database links
When all other operations in the data flow can be pushed down to the source
database, the auto-correct loading operation is also pushed down for a full
push-down operation to the target. Data Services sends an SQL MERGE
INTO target statement that implements the Ignore columns with value
and Ignore columns with null options.
5
Partial push-down operations
When a full push-down operation is not possible, Data Services still pushes
down the SELECT statement to the source database. Operations within the
SELECT statement that Data Services can push to the database include:
• Aggregations — Aggregate functions, typically used with a Group by
statement, always produce a data set smaller than or the same size as
the original data set.
• Distinct rows — When you select Distinct rows from the Select tab in
the query editor, Data Services will only output unique rows.
• Filtering — Filtering can produce a data set smaller than or equal to the
original data set.
• Joins — Joins typically produce a data set smaller than or similar in size
to the original tables. Data Services can push down joins when either of
the following conditions exist:
Data Services Performance Optimization Guide 43
Page 44

Maximizing Push-Down Operations
5
Push-down operations
• The source tables are in the same datastore
• The source tables are in datastores that have a database link defined
between them
• Ordering — Ordering does not affect data-set size. Data Services can
efficiently sort data sets that fit in memory. Business Objects recommends
that you push down the Order By for very large data sets.
• Projection — Projection is the subset of columns that you map on the
Mapping tab in the query editor. Projection normally produces a smaller
data set because it only returns columns needed by subsequent operations
in a data flow.
• Functions — Most Data Services functions that have equivalents in the
underlying database are appropriately translated. These functions include
decode, aggregation, and string functions.
Operations that cannot be pushed down
Data Services cannot push some transform operations to the database. For
example:
• Expressions that include Data Services functions that do not have
database correspondents
• Load operations that contain triggers
• Transforms other than Query
• Joins between sources that are on different database servers that do not
have database links defined between them.
Similarly, Data Services cannot always combine operations into single
requests. For example, when a stored procedure contains a COMMIT
statement or does not return a value, Data Services cannot combine the
stored procedure SQL with the SQL for other operations in a query.
Data Services can only push operations supported by the DBMS down to
that DBMS. Therefore, for best performance, try not to intersperse Data
Services transforms among operations that can be pushed down to the
database.
44 Data Services Performance Optimization Guide
Page 45

Maximizing Push-Down Operations
Push-down examples
Push-down examples
The following are typical push-down scenarios.
Scenario 1: Combine transforms to push down
When determining how to push operations to the database, Data Services
first collapses all the transforms into the minimum set of transformations
expressed in terms of the source table columns. Next, Data Services pushes
all possible operations on tables of the same database down to that DBMS.
For example, the following data flow extracts rows from a single source table.
5
The first query selects only the rows in the source where column A contains
a value greater than 100. The second query refines the extraction further,
reducing the number of columns returned and further reducing the qualifying
rows.
Data Services collapses the two queries into a single command for the DBMS
to execute. The following command uses AND to combine the WHERE
clauses from the two queries:
SELECT A, MAX(B), C
Data Services can push down all the operations in this SELECT statement
to the source DBMS.
FROM source
WHERE A > 100 AND B = C
GROUP BY A, C
Data Services Performance Optimization Guide 45
Page 46

Maximizing Push-Down Operations
5
Push-down examples
Scenario 2: Full push down from the source to the target
If the source and target are in the same datastore, Data Services can do a
full push-down operation where the INSERT into the target uses a SELECT
from the source. In the sample data flow in scenario 1, a full push down
passes the following statement to the database:
INSERT INTO target (A, B, C)
SELECT A, MAX(B), C
FROM source
WHERE A > 100 AND B = C
GROUP BY A, C
If the source and target are not in the same datastore, Data Services can
also do a full push-down operation if you use one of the following features:
• Add a Data _Transfer transform before the target.
• Define a database link between the two datastores.
Scenario 3: Full push down for auto correct load to the target
For an Oracle target, if you specify the Auto correct load option, Data
Services can do a full push-down operation where the SQL statement is a
MERGE into the target with a SELECT from the source. In the sample data
flow in scenario 1, a full push down passes the following statement to the
database when the source and target are in the same datastore:
MERGE INTO target s
USING
(SELECT A, MAX(B), C
ON ((s.A = n.A))
WHEN MATCHED THEN
UPDATE SET s.A = n.A,
WHEN NOT MATCHED THEN
46 Data Services Performance Optimization Guide
FROM source) n
s.MAX(B) = n.MAX(B)
s.C = n.C
Page 47

Maximizing Push-Down Operations
INSERT (s.A, s.Max(B), s.C)
VALUES (n.A, n.MAX(B), n.C)
Scenario 4: Partial push down to the source
If the data flow contains operations that cannot be passed to the DBMS,
Data Services optimizes the transformation differently than the previous two
scenarios. For example, if Query1 called func(A) > 100, where func is a
Data Services custom function, then Data Services generates two commands:
• The first query becomes the following command which the source DBMS
executes:
SELECT A, B, C
FROM source
WHERE B = C
• The second query becomes the following command which Data Services
executes because func cannot be pushed to the database:
To view SQL
5
SELECT A, MAX(B), C
FROM Query1
WHERE func(A) > 100
GROUP BY A, C
To view SQL
Before running a job, you can view the SQL code that Data Services
generates for table sources in data flows. By examining the SQL code, you
can verify that Data Services generates the commands you expect. If
necessary, you can alter your design to improve the data flow.
Note:
This option is not available for R/3 data flows.
1. Validate and save data flows.
2. Open a data flow in the workspace.
3. Select Display Optimized SQL from the Validation menu.
Alternately, you can right-click a data flow in the object library and select
Display Optimized SQL.
Data Services Performance Optimization Guide 47
Page 48

Maximizing Push-Down Operations
5
To view SQL
The Optimize SQL window opens and shows a list of datastores and the
optimized SQL code for the selected datastore. By default, the Optimize
SQL window selects the first datastore, as the following example shows:
Data Services only shows the SELECT generated for table sources and
INSERT INTO... SELECT for targets. Data Services does not show the
SQL generated for SQL sources that are not table sources, such as:
• Lookup function
• Key_generation function
• Key_Generation transform
• Table_Comparison transform
4. Select a name from the list of datastores on the left to view the SQL that
this data flow applies against the corresponding database or application.
The following example shows the optimized SQL for the second datastore
which illustrates a full push-down operation (INSERT INTO... SELECT).
This data flows uses a Data_Transfer transform to create a transfer table
that Data Services loads directly into the target. For more information,
see "Data_Transfer transform for push-down operations" on page 1667
48 Data Services Performance Optimization Guide
Page 49

Maximizing Push-Down Operations
To view SQL
In the Optimized SQL window you can:
• Use the Find button to perform a search on the SQL displayed.
• Use the Save As button to save the text as a .sql file.
5
If you try to use the Display Optimized SQL command when there are no
SQL sources in your data flow, Data Services alerts you. Examples of
non-SQL sources include:
• R/3 data flows
• Message sources
• File sources
• IDoc sources
If a data flow is not valid when you click the Display Optimized SQL option,
Data Services alerts you.
Note:
The Optimized SQL window displays the existing SQL statement in the
repository. If you changed your data flow, save it so that the Optimized SQL
window displays your current SQL statement.
Data Services Performance Optimization Guide 49
Page 50

Maximizing Push-Down Operations
5
Data_Transfer transform for push-down operations
Data_Transfer transform for push-down
operations
Use the Data_Transfer transform to move data from a source or from another
transform into the target datastore and enable a full push-down operation
(INSERT INTO... SELECT) to the target. You can use the Data_Transfer
transform to pushdown resource-intensive operations that occur anywhere
within a data flow to the database. Resource-intensive operations include
joins, GROUP BY, ORDER BY, and DISTINCT.
Scenario 1: Push down an operation after a blocking operation
You can place a Data_Transfer transform after a blocking operation to enable
Data Services to push down a subsequent operation. A blocking operation
is an operation that Data Services cannot push down to the database, and
prevents ("blocks") operations after it from being pushed down.
For example, you might have a data flow that groups sales order records by
country and region, and sums the sales amounts to find which regions are
generating the most revenue. The following diagram shows that the data
flow contains a Pivot transform to obtain orders by Customer ID, a Query
transform that contains a lookup_ext function to obtain sales subtotals, and
another Query transform to group the results by country and region.
Because the Pivot transform and the lookup_ext function are before the
query with the GROUP BY clause, Data Services cannot push down the
GROUP BY operation. The following Optimize SQL window shows the
SELECT statement that Data Services pushes down to the source database:
50 Data Services Performance Optimization Guide
Page 51

Maximizing Push-Down Operations
Data_Transfer transform for push-down operations
However, if you add a Data_Transfer transform before the second Query
transform and specify a transfer table in the same datastore as the target
table, Data Services can push down the GROUP BY operation.
5
The following Data_Transfer Editor window shows that the transfer type is
table and the transfer table is in the same datastore as the target table.
Data Services Performance Optimization Guide 51
Page 52

Maximizing Push-Down Operations
5
Data_Transfer transform for push-down operations
The following Optimize SQL window shows that Data Services pushed down
the GROUP BY to the transfer table TRANS2.
52 Data Services Performance Optimization Guide
Page 53

Maximizing Push-Down Operations
Data_Transfer transform for push-down operations
Related Topics
• Operations that cannot be pushed down on page 44
• Reference Guide: Transforms, Data_Transfer
5
Scenario 2: Using Data_Transfer tables to speed up auto correct loads
Auto correct loading ensures that the same row is not duplicated in a target
table, which is useful for data recovery operations. However, an auto correct
load prevents a full push-down operation from the source to the target when
the source and target are in different datastores.
For large loads where auto-correct is required, you can put a Data_Transfer
transform before the target to enable a full push down from the source to the
target. Data Services generates an SQL MERGE INTO target statement
that implements the Ignore columns with value and Ignore columns with
null options if they are selected on the target editor.
For example, the following data flow loads sales orders into a target table
which is in a different datastore from the source.
Data Services Performance Optimization Guide 53
Page 54

Maximizing Push-Down Operations
5
Data_Transfer transform for push-down operations
The following target editor shows that the Auto correct load option is
selected. The Ignore columns with null and Use merge options are also
selected in this example.
The following Optimize SQL window shows the SELECT statement that Data
Services pushes down to the source database.
54 Data Services Performance Optimization Guide
Page 55

Maximizing Push-Down Operations
Data_Transfer transform for push-down operations
When you add a Data_Transfer transform before the target and specify a
transfer table in the same datastore as the target, Data Services can push
down the auto correct operation.
5
Data Services Performance Optimization Guide 55
Page 56

Maximizing Push-Down Operations
5
Data_Transfer transform for push-down operations
The following Optimize SQL window shows the MERGE statement that Data
Services will push down to the target.
56 Data Services Performance Optimization Guide
Page 57

Maximizing Push-Down Operations
Database link support for push-down operations across datastores
Database link support for push-down
operations across datastores
5
Various database vendors support one-way communication paths from one
database server to another. Data Services refers to communication paths
between databases as database links. The datastores in a database link
relationship are called linked datastores.
Data Services uses linked datastores to enhance its performance by pushing
down operations to a target database using a target datastore. Pushing down
operations to a database not only reduces the amount of information that
needs to be transferred between the databases and Data Services but also
allows Data Services to take advantage of the various DMBS capabilities,
such as various join algorithms.
With support for database links, Data Services pushes processing down from
different datastores, which can also refer to the same or different database
type. Linked datastores allow a one-way path for data. For example, if you
import a database link from target database B and link datastore B to
datastore A, Data Services pushes the load operation down to database B,
not to database A.
This section contains the following topics:
• Software support
Data Services Performance Optimization Guide 57
Page 58

Maximizing Push-Down Operations
5
Database link support for push-down operations across datastores
• Example of push-down with linked datastores
• Generated SQL statements
• Tuning performance at the data flow or Job Server level
Related Topics
• Designer Guide: Datastores, Linked datastores
Software support
Data Services supports push-down operations using linked datastores on
all Windows and Unix platforms. It supports DB2, Oracle, and MS SQL server
databases.
To take advantage of linked datastores
1. Create a database link on a database server that you intend to use as a
target in a Data Services job.
The following database software is required. See the Supported Platforms
document for specific version numbers.
• For DB2, use the DB2 Information Services (previously known as
Relational Connect) software and make sure that the database user
has privileges to create and drop a nickname.
To end users and client applications, data sources appear as a single
collective database in DB2. Users and applications interface with the
database managed by the information server. Therefore, configure an
information server and then add the external data sources. DB2 uses
nicknames to identify remote tables and views.
See the DB2 database manuals for more information about how to
create links for DB2 and non-DB2 servers.
• For Oracle, use the Transparent Gateway for DB2 and MS SQL Server.
See the Oracle database manuals for more information about how to
create database links for Oracle and non-Oracle servers.
• For MS SQL Server, no special software is required.
58 Data Services Performance Optimization Guide
Page 59

Maximizing Push-Down Operations
Database link support for push-down operations across datastores
Microsoft SQL Server supports access to distributed data stored in
multiple instances of SQL Server and heterogeneous data stored in
various relational and non-relational data sources using an OLE
database provider. SQL Server supports access to distributed or
heterogeneous database sources in Transact-SQL statements by
qualifying the data sources with the names of the linked server where
the data sources exist.
See the MS SQL Server database manuals for more information.
2. Create a database datastore connection to your target database.
Example of push-down with linked datastores
Linked datastores enable a full push-down operation (INSERT INTO...
SELECT) to the target if all the sources are linked with the target. The sources
and target can be in datastores that use the same database type or different
database types.
The following diagram shows an example of a data flow that will take
advantage of linked datastores:
5
The dataflow joins three source tables from different database types:
• ora_source.HRUSER1.EMPLOYEE on \\oracle_server1
• ora_source_2.HRUSER2.PERSONNEL on \\oracle_server2
• mssql_source.DBO.DEPARTMENT on \\mssql_server3.
Data Services Performance Optimization Guide 59
Page 60

Maximizing Push-Down Operations
5
Database link support for push-down operations across datastores
Data Services loads the join result into the target table
ora_target.HRUSER3.EMP_JOIN on \\oracle_server1.
In this data flow, the user (HRUSER3) created the following database links
in the Oracle database oracle_server1.
Database Link
Name
To enable a full push-down operation, database links must exist from the
target database to all source databases and links must exist between the
following datastores:
• ora_target and ora_source
• ora_target and ora_source2
• ora_target and mssql_source
Data Services executes this data flow query as one SQL statement in
oracle_server1:
INSERT INTO HR_USER3.EMP_JOIN (FNAME, ENAME, DEPTNO, SAL, COMM)
Local (to
database link location) Connection Name
Remote (to
database link location) Connection Name
Remote User
HRUSER2oracle_server2oracle_server1orasvr2
DBOmssql_serveroracle_server1tg4msql
SELECT psnl.FNAME, emp.ENAME, dept.DEPTNO, emp.SAL, emp.COMM
FROM HR_USER1.EMPLOYEE emp, HR_USER2.PERSONNEL@orasvr2 psnl,
oracle_server1.mssql_server.DBO.DEPARTMENT@tg4msql dept;
Generated SQL statements
To see how Data Services optimizes SQL statements, use Display Optimized
SQL from the Validation menu when a data flow is open in the workspace.
60 Data Services Performance Optimization Guide
Page 61

Maximizing Push-Down Operations
Database link support for push-down operations across datastores
• For DB2, Data Services uses nicknames to refer to remote table
references in the SQL display.
• For Oracle, Data Services uses the following syntax to refer to remote
table references: <remote_table>@<dblink_name>.
• For SQL Server, Data Services uses the following syntax to refer to remote
table references: <liked_server >.<remote_database >.<remote_user
>.<remote_table>.
Tuning performance at the data flow or Job Server level
You might want to turn off linked-datastore push downs in cases where you
do not notice performance improvements.
For example, the underlying database might not process operations from
different data sources well. Data Services pushes down Oracle stored
procedures and external functions. If these are in a job that uses database
links, it will not impact expected performance gains. However, Data Services
does not push down functions imported from other databases (such as DB2).
In this case, although you may be using database links, Data Services cannot
push the processing down.
5
Test your assumptions about individual job designs before committing to a
large development effort using database links.
For a data flow
On the data flow properties dialog, Data Services enables the Use datastore
links option by default to allow push downs using linked datastores. If you
do not want Data Services to use linked datastores in a data flow to push
down processing, deselect the check box.
For a Job Server
You can also disable linked datastores at the Job Server level. However, the
Use database links option, at the data flow level, takes precedence.
Data Services Performance Optimization Guide 61
Page 62

Maximizing Push-Down Operations
5
Database link support for push-down operations across datastores
Related Topics
• Designer Guide: Executing Jobs, Changing Job Server options
62 Data Services Performance Optimization Guide
Page 63

Using Caches
6
Page 64

Using Caches
6
Caching data
This section contains the following topics:
•
Caching data on page 64
•
Using persistent cache on page 70
•
Monitoring and tuning caches on page 71
Caching data
You can improve the performance of data transformations that occur in
memory by caching as much data as possible. By caching data, you limit
the number of times the system must access the database.
Data Services provides the following types of caches that your data flow can
use for all of the operations it contains:
• In-memory
Use in-memory cache when your data flow processes a small amount of
data that fits in memory.
• Pageable cache
Use pageable cache when your data flow processes a very large amount
of data that does not fit in memory. When memory-intensive operations
(such as Group By and Order By) exceed available memory, Data Services
uses pageable cache to complete the operation.
Pageable cache is the default cache type. To change the cache type, use
the Cache type option on the data flow Properties window.
Note:
If your data fits in memory, Business Objects recommends that you use
in-memory cache because pageable cache incurs an overhead cost.
This section includes the following topics:
• Caching sources
•
Caching sources on page 65
•
Caching joins on page 66
• Caching intermediate data
•
Caching lookups on page 67
64 Data Services Performance Optimization Guide
Page 65

•
Caching table comparisons on page 68
•
Specifying a pageable cache directory on page 69 for memory-intensive
operations
Caching sources
By default, the Cache option is set to Yes in a source table or file editor to
specify that data from the source is cached using memory on the Job Server
computer. The default value for Cache type for data flows is Pageable.
Business Objects recommends that you cache small tables in memory.
Calculate the approximate size of a table with the following formula to
determine if you should use a cache type of Pageable or In-memory.
table size = (in bytes)
# of rows *
# of columns *
20 bytes (average column
size) *
1.3 (30% overhead)
Using Caches
Caching data
6
Compute row count and table size on a regular basis, especially when:
• You are aware that a table has significantly changed in size.
• You experience decreased system performance.
If the table fits in memory, change the value of Cache type to In-memory in
the Properties window of the data flow.
Data Services Performance Optimization Guide 65
Page 66

Using Caches
6
Caching data
Caching joins
Cache a source only if it is being used as an inner source (or "inner loop").
(Inner sources or loops have a lower join rank than outer sources or loops).
Caching does not affect the order in which tables are joined. If optimization
conditions are such that Data Services is pushing down operations to the
underlaying database, it ignores your cache setting.
If a table becomes too large to fit in the cache, ensure that the cache type
is pageable.
To change the cache type for a data flow
1. In the object library, select the data flow name.
2. Right-click and choose Properties.
66 Data Services Performance Optimization Guide
Page 67

3. On the General tab of the Properties window, select Pageable in the
drop-down list for the Cache type option.
Caching lookups
You can also improve performance by caching data when looking up
individual values from tables and files.
There are two methods of looking up data:
•
Using a Lookup function in a query on page 67
•
Using a source table and setting it as the outer join on page 68
Using a Lookup function in a query
Data Services has three Lookup functions: lookup, lookup_seq, and
lookup_ext. The lookup and lookup_ext functions have cache options.
Caching lookup sources improves performance because Data Services
avoids the expensive task of creating a database query or full file scan on
each row.
Using Caches
Caching data
6
You can set cache options when you specify a lookup function. There are
three caching options:
• NO_CACHE — Does not cache any values.
• PRE_LOAD_CACHE — Preloads the result column and compare column
into memory (it loads the values before executing the lookup).
• DEMAND_LOAD_CACHE — Loads the result column and compare
column into memory as the function executes.
Use this option when looking up highly repetitive values that are a small
subset of the data and when missing values are unlikely.
Demand-load caching of lookup values is helpful when the lookup result
is the same value multiple times. Each time Data Services cannot find
the value in the cache, it must make a new request to the database for
that value. Even if the value is invalid, Data Services has no way of
knowing if it is missing or just has not been cached yet.
Data Services Performance Optimization Guide 67
Page 68

Using Caches
6
Caching data
When there are many values and some values might be missing,
demand-load caching is significantly less efficient than caching the entire
source.
Using a source table and setting it as the outer join
Although you can use lookup functions inside Data Services queries, an
alternative is to expose the translate (lookup) table as a source table in the
data flow diagram, and use an outer join (if necessary) in the query to look
up the required data. This technique has some advantages:
• You can graphically see the table the job will search on the diagram,
making the data flow easier to maintain
• Data Services can push the execution of the join down to the underlying
RDBMS (even if you need an outer join)
This technique also has some disadvantages:
• You cannot specify default values in an outer join (default is always null),
but you can specify a default value in lookup_ext.
• If an outer join returns multiple rows, you cannot specify what to return,
(you can specify MIN or MAX in lookup_ext).
• The workspace can become cluttered if there are too many objects in the
data flow.
• There is no option to use DEMAND_LOAD caching, which is useful when
looking up only a few repetitive values in a very large table.
Tip:
If you use the lookup table in multiple jobs, you can create a persistent cache
that multiple data flows can access. For more information, see Using
persistent cache on page 70.
Caching table comparisons
You can improve the performance of a Table_Comparison transform by
caching the comparison table. There are three modes of comparisons:
• Row-by-row select
68 Data Services Performance Optimization Guide
Page 69

• Cached comparison table
• Sorted input
Of the three, Row-by-rowselect will likely be the slowest and Sorted input
the fastest.
Tip:
• If you want to sort the input to the table comparison transform, then choose
the Sorted input option for comparison.
• If the input is not sorted, then choose the Cached comparisontable
option.
Specifying a pageable cache directory
If the memory-consuming operations in your data flow exceed the available
memory, Data Services uses pageable cache to complete the operation.
Memory-intensive operations include the following operations:
• Distinct
Using Caches
Caching data
6
• Functions such as count_distinct and lookup_ext
• Group By
• Hierarchy_Flattening
• Order By
Note:
The default pageable cache directory is %LINKDIR\Log\PCache. If your data
flows contain memory-consuming operations, change this value to a pageable
cache directory that:
• Contains enough disk space for the amount of data you plan to profile.
• Is on a separate disk or file system from the Data Services system.
Change the directory in the Specify a directory with enough disk space
for pageable cache option in the Server Manager, under Runtime resources
configured for this computer.
Data Services Performance Optimization Guide 69
Page 70

Using Caches
6
Using persistent cache
Using persistent cache
Persistent cache datastores provide the following benefits for data flows that
process large volumes of data.
• You can store a large amount of data in persistent cache which Data
Services quickly pages into memory each time the job executes. For
example, you can access a lookup table or comparison table locally
(instead of reading from a remote database).
• You can create cache tables that multiple data flows can share (unlike a
memory table which cannot be shared between different real-time jobs).
For example, if a large lookup table used in a lookup_ext function rarely
changes, you can create a cache once and subsequent jobs can use this
cache instead of creating it each time.
Persistent cache tables can cache data from relational database tables and
files.
Note:
You cannot cache data from hierarchical data files such as XML messages
and SAP IDocs (both of which contain nested schemas). You cannot perform
incremental inserts, deletes, or updates on a persistent cache table.
You create a persistent cache table by loading data into the persistent cache
target table using one data flow. You can then subsequently read from the
cache table in another data flow. When you load data into a persistent cache
table, Data Services always truncates and recreates the table.
Using persistent cache tables as sources
After you create a persistent cache table as a target in one data flow, you
can use the persistent cache table as a source in any data flow. You can
also use it as a lookup table or comparison table.
Related Topics
• Reference Guide: Data Services Objects, Persistent cache source
70 Data Services Performance Optimization Guide
Page 71

Monitoring and tuning caches
This section describes the following topics:
Related Topics
• Using statistics for cache self-tuning on page 71
• To monitor and tune in-memory and pageable caches on page 71
Using statistics for cache self-tuning
Data Services uses cache statistics collected from previous job runs to
automatically determine which cache type to use for a data flow. Cache
statistics include the number of rows processed.
The default cache type is pageable. Data Services can switch to in-memory
cache when it determines that your data flow processes a small amount of
data that fits in memory.
Using Caches
Monitoring and tuning caches
6
To have Data Services automatically choose the cache type
1. Run your job with options Collect statistics for optimization.
2. Run your job again with option Use collected statistics (this option is
selected by default).
To monitor and tune in-memory and pageable caches
You can also monitor and choose the cache type to use for the data flow.
1. Test run your job with options Collect statistics for optimization and
Collect statistics for monitoring.
Note:
The option Collect statistics for monitoring is very costly to run because
it determines the cache size for each row processed.
Data Services Performance Optimization Guide 71
Page 72

Using Caches
6
Monitoring and tuning caches
2. Run your job again with option Use collected statistics (this option is
3. Look in the Trace Log to determine which cache type was used.
selected by default).
• The first time you run the job or if you have not previously collected
statistics, the following messages indicate that cache statistics are not
available and the sub data flows use the default cache type, pageable.
Cache statistics for sub data flow <GroupBy_DF_1_1> are
not available to be used for optimization and need to be
collected before they can be used.
Sub data flow <GroupBy_DF_1_1> using PAGEABLE Cache with
<1280 MB> buffer pool.
• You might see the following message that indicates that Data Services
is switching to In-memory cache:
Cache statistics determined that sub data flow <Group
By_DOP2_DF_1_4> uses <1> caches with a total size of
<1920> bytes. This is less than (or equal to) the virtual
memory <1342177280> bytes available for caches. Statis
tics is switching the cache type to IN MEMORY.
Sub data flow <GroupBy_DOP2_DF_1_4> using IN MEMORY Cache.
Because pageable cache is the default cache type for a data flow, you
might want to permanently change Cache type to In-Memory in the
data flow Properties window.
72 Data Services Performance Optimization Guide
Page 73

Using Caches
Monitoring and tuning caches
6
• You might see the following messages that indicate on sub data flow
uses IN MEMORY cache and the other sub data flow uses PAGEABLE
cache:
Sub data flow <Orders_Group_DF_1> using IN MEMORY Cache.
...
Sub data flow <Orders_Group_DF_2> using PAGEABLE Cache
with <1536 MB> buffer pool.
4. Look in the Administrator Performance Monitor to view data flow statistics
and see the cache size.
a. On the Administrator, select Batch > repository
b. On the Batch Job Statuspage, find a job execution instance.
Data Services Performance Optimization Guide 73
Page 74

Using Caches
6
Monitoring and tuning caches
c. Under Job Information for an instance, click Performance > Moni
tor.
The Administrator opens the Graph tab of the Performance Monitor
page. This tab shows a graphical view of the start time, stop time, and
execution time for each work flow, data flow, and sub data flow within
the job.
d. To display the data flow times in a tabular format, click the Table
tab.
e. To display statistics for each object within a data flow or sub data flow,
click either the corresponding execution bar on the Graph tab, or one
of the data flow names on the Table tab. The Transform tab displays
the following statistics.
Name
74 Data Services Performance Optimization Guide
DescriptionStatistic
Name that you gave the object
(source, transform, or target) in
the Designer.
Page 75

Type
Using Caches
Monitoring and tuning caches
DescriptionStatistic
Type of object within the data
flow. Possible values include
Source, Mapping, Target.
6
Start time
End time
Execution time (sec)
Row Count
Cache Size (KB)
Date and time this object instance
started execution.
Date and time this object instance
stopped execution.
Time (in seconds) the object took
to complete execution.
Number of rows that this object
processed.
Size (in kilobytes) of the cache
that Data Services used to process this object.
Note:
This statistics displays only if you
selected Collect statistics for
monitoring for the job execution.
For example, click the top execution bar or the name Group_Orders_DF
to display the following statistics for both sub data flows.
Data Services Performance Optimization Guide 75
Page 76

Using Caches
6
Monitoring and tuning caches
5. If the value in Cache Size is approaching the physical memory limit on
the job server, consider changing the Cache type of a data flow from
In-memory to Pageable.
76 Data Services Performance Optimization Guide
Page 77

Using parallel Execution
7
Page 78

Using parallel Execution
7
Parallel data flows and work flows
You can set Data Services to perform data extraction, transformation, and
loads in parallel by setting parallel options for sources, transforms, and
targets. In addition, you can set individual data flows and work flows to run
in parallel by simply not connecting them in the workspace. If the Data
Services Job Server is running on a multi-processor computer, it takes full
advantage of available CPUs.
This section contains the following topics:
•
Parallel data flows and work flows on page 78
•
Parallel execution in data flows on page 79
Parallel data flows and work flows
You can explicitly execute different data flows and work flows in parallel by
not connecting them in a work flow or job. Data Services coordinates the
parallel steps, then waits for all steps to complete before starting the next
sequential step.
For example, use parallel processing to load dimension tables by calling
work flows in parallel. Then specify that your job creates dimension tables
before the fact table by moving it to the left of a second (parent) work flow
and connecting the flows.
Parallel Data Services engine processes execute the parallel data flow
processes. Note that if you have more than eight CPUs on your Job Server
computer, you can increase Maximum number of engine processes to
improve performance. To change the maximum number of parallel Data
78 Data Services Performance Optimization Guide
Page 79

Parallel execution in data flows
Services engine processes, use the Job Server options (Tools > Options>
Job Server > Environment).
Parallel execution in data flows
For batch jobs, Data Services allows you to execute parallel threads in data
flows.
This section contains the following:
•
Table partitioning on page 79
•
Degree of parallelism on page 85
•
Combining table partitioning and a degree of parallelism on page 93
•
File multi-threading on page 96
Table partitioning
Using parallel Execution
7
Data Services processes data flows with partitioned tables based on the
amount of partitioning defined. There are three basic scenarios:
•
Data flow with source partitions only on page 79
•
Data flow with target partitions only on page 80
•
Dataflow with source and target partitions on page 80
Data flow with source partitions only
If you have a data flow with a source that has two partitions connected to a
query and a target, it appears in the workspace as shown in the following
diagram:
At runtime, Data Services translates this data flow to:
Data Services Performance Optimization Guide 79
Page 80

Using parallel Execution
7
Parallel execution in data flows
Data Services instantiates a source thread for each partition, and these
threads run in parallel. The data from these threads later merges into a single
stream by an internal merge transform before processing the query.
Data flow with target partitions only
If you have a data flow with a target that has two partitions connected to a
query and a source, it appears in the workspace as shown in the following
diagram:
At runtime, Data Services translates this data flow to:
Data Services inserts an internal Round Robin Split (RRS) transform after
the Query transform, which routes incoming rows in a round-robin fashion
to internal Case transforms. The Case transforms evaluate the rows to
determine the partition ranges. Finally, an internal Merge transform collects
the incoming rows from different Case transforms and outputs a single stream
of rows to the target threads. The Case, Merge, and the target threads
execute in parallel.
Dataflow with source and target partitions
If you have a data flow with a source that has two partitions connected to a
query and a target that has two partitions, it appears in the workspace as
shown in the following diagram:
80 Data Services Performance Optimization Guide
Page 81

At runtime, Data Services translates this data flow to:
The source threads execute in parallel and the Case, Merge, and targets
execute in parallel.
Viewing, creating, and enabling table partitions
Oracle databases support range, list, and hash partitioning. You can import
this information as table metadata and use it to extract data in parallel. You
can use range and list partitions to load data to Oracle targets. You can also
specify logical range and list partitions using Data Services metadata for
Oracle tables.
Using parallel Execution
Parallel execution in data flows
7
In addition, Data Services provides the ability to specify logical range
partitions for DB2, Microsoft SQL Server, Sybase ASE, and Sybase IQ tables
by modifying imported table metadata.
Data Services uses partition information by instantiating a thread at runtime
for each partition. These threads execute in parallel. To maximize
performance benefits, use a multi-processor environment.
To view partition information
1. Import a table into Data Services.
2. In the Datastores tab of the object library, right-click the table name and
select Properties.
3. Click the Partitions tab.
When you import partitioned tables from your database, you will find these
partitions displayed on the Partitions tab of the table's Properties window.
The partition name appears in the first column. The columns that are used
for partitioning appear as column headings in the second row.
Data Services Performance Optimization Guide 81
Page 82

Using parallel Execution
7
Parallel execution in data flows
If you import a table that does not have partitions, you can create logical
partitions using the Partitions tab of the table's Properties window.
To create or edit table partition information
1. In the Datastores tab of the object library, right-click the table name and
select Properties.
2. In the Properties window, click the Partitions tab.
3. Select a partition type.
DescriptionPartition Type
This table is not partitioned.None
Range
List
Note:
If you imported an Oracle table with hash partitions, you cannot edit the
hash settings in Data Services. The Partitions tab displays the hash
82 Data Services Performance Optimization Guide
Each partition contains a set of
rows with column values less than
those specified.
For example, if the value of column
one is 100,000, then the data set
for partition one will include rows
with values less than 100,000 in
column one.
Each partition contains a set of
rows that contain the specified column values.
Page 83

Using parallel Execution
Parallel execution in data flows
partition name and ID as read-only information. However, you can change
the partition type to Range or List to create logical range or list partitions
for an Oracle table imported with hash partitions.
4. Add, insert, or remove partitions and columns using the tool bar. (See
table at the end of this procedure.)
5. Select the name of a column from each column list box.
6. Enter column values for each partition.
7
Data Services validates the column values entered for each partition
according to the following rules:
• Values can be literal numbers and strings or datetime types.
• Column values must match column data types.
• Literal strings must include single quotes: 'Director'.
• For range partitions, the values for a partition must be greater than
the values for the previous partition.
• For the last partition, you can enter the value MAXVALUE to include all
values.
7. Click OK.
Data Services Performance Optimization Guide 83
Page 84

Using parallel Execution
7
Parallel execution in data flows
If the validation rules described in the previous step are not met, you will
see an error message.
DescriptionIcon
Add Partition
Insert Partition
Remove Partition
Add Column
Insert Column
Remove Column
The number of partitions in a table equals the maximum number of parallel
instances that Data Services can process for a source or target created from
this table.
In addition to importing partitions or creating and editing partition metadata,
enable the partition settings when you configure sources and targets.
To enable partition settings in a source or target table
1. Drop a table into a data flow and select Make Source or Make Target.
2. Click the name of the table to open the source or target table editor.
3. Enable partitioning for the source or target:
a. For a source table, click the Enable Partitioning check box.
b. For a target table, click the Options tab, then click the Enable
Partitioning check box.
4. Click OK.
84 Data Services Performance Optimization Guide
Page 85

Tip
Using parallel Execution
Parallel execution in data flows
When the job executes, Data Services generates parallel instances based
on the partition information.
Note:
If you are loading to partitioned tables, a job will execute the load in parallel
according to the number of partitions in the table. If you select both Enable
Partitioning and Include in transaction, the Include in transaction setting
overrides the Enable Partitioning option. For example, if your job is
designed to load to a partitioned table but you select Include in transaction
and enter a value for Transaction order, when the job executes, Data
Services will include the table in a transaction load and does not parallel
load to the partitioned table.
If the underlying database does not support range partitioning and if you are
aware of a natural distribution of ranges, for example using an Employee
Key column in an Employee table, then you can edit the imported table
metadata and define table ranges. Data Services would then instantiate
multiple reader threads, one for each defined range, and execute them in
parallel to extract the data.
7
Note:
Table metadata editing for partitioning is designed for source tables. If you
use a partitioned table as a target, the physical table partitions in the database
must match the metadata table partitions in Data Services. If there is a
mismatch, Data Services will not use the partition name to load partitions.
Consequently, the whole table updates.
Degree of parallelism
Degree Of Parallelism (DOP) is a property of a data flow that defines how
many times each transform defined in the data flow replicates for use on a
parallel subset of data. If there are multiple transforms in a data flow, Data
Services chains them together until it reaches a merge point.
You can run transforms in parallel by entering a number in the Degree of
Parallelism box on a data flow's Properties window. The number is used to
replicate transforms in the data flow which run as separate threads when
the Job Server processes the data flow.
Data Services Performance Optimization Guide 85
Page 86

Using parallel Execution
7
Parallel execution in data flows
This section describes the following parallel operations:
•
Degree of parallelism and transforms on page 86
•
Degree of parallelism and joins on page 89
•
Degree of parallelism and functions on page 91
Degree of parallelism and transforms
The Query transform always replicates when you set DOP to a value greater
than one. Data Services also replicates query operations such as Order By,
Group By, join, and functions such as lookup_ext.
The Table Comparison replicates when you use the Row-by-row select and
Cached comparison table comparison methods."
• Map_Operation
• History_Preserving
• Pivot
There are two basic scenarios:
• DOP and a data flow with a single transform
• DOP and a data flow with multiple transforms
DOP and a data flow with a single transform
The following figures show runtime instances of a data flow with a DOP of
1, and the same data flow with a DOP of 2.
Figure 7-1: Runtime instance of a data flow where DOP =1
86 Data Services Performance Optimization Guide
Page 87

Using parallel Execution
Parallel execution in data flows
Figure 7-2: Runtime instance of a data flow where DOP = 2
With a DOP greater than one, Data Services inserts an internal Round Robin
Split (RRS) that transfers data to each of the replicated queries. The replicated
queries execute in parallel, and the results merge into a single stream by an
internal Merge transform.
DOP and a data flow with multiple transforms
The following figures show runtime instances of a data flow with a DOP of
1, and the same data flow with a DOP of 2. Notice multiple transforms in a
data flow replicate and chain when the DOP is greater than 1.
7
Figure 7-3: Runtime instance of a data flow where DOP =1
Figure 7-4: Runtime instance of a data flow where DOP = 2
When there are multiple transforms in a data flow and the DOP is greater
than 1, Data Services carries the replicated stream as far as possible, then
merges the data into a single stream.
To set the degree of parallelism for a data flow
The degree of parallelism (DOP) is a data flow property that acts on
transforms added to the data flow.
Data Services Performance Optimization Guide 87
Page 88

Using parallel Execution
7
Parallel execution in data flows
1. In the object library, go to the data flow tab.
2. Right-click the data flow icon and select Properties.
3. Enter a number for Degree of parallelism.
The default value for degree of parallelism is 0. If you set an individual
data flow's degree of parallelism to this default value, then you can control
it using a Global_DOP value which affects all data flows run by a given
Job Server. If you use any other value for a data flow's degree of
parallelism, it overrides the Global_DOP value.
You can use the local and global DOP options in different ways. For
example:
• If you want to globally set all data flow DOP values to 4, but one data
flow is too complex and you do not want it to run in parallel, you can
set the Degree of parallelism for this data flow locally. From the data
flow's Properties window, set this data flow's Degree of parallelism
to 1. All other data flows will replicate and run transforms in parallel
88 Data Services Performance Optimization Guide
Page 89

after you set the Global_DOP value to 4. The default for the
Global_DOP value is 1.
• If you want to set the DOP on a case-by-case basis for each data flow,
set the value for each data flow's Degree of parallelism to any value
except zero.
You set the Global_DOP value in the Job Server options.
4. Click OK.
Related Topics
• Designer Guide: Executing Jobs, Changing Job Server options
Degree of parallelism and joins
If your Query transform joins sources, DOP determines the number of times
the join replicates to process a parallel subset of data.
This section describes two scenarios:
• DOP and executing a join as a single process
Using parallel Execution
Parallel execution in data flows
7
• DOP and executing a join as multiple processes
DOP and executing a join as a single process
The following figures show runtime instances of a data flow that contains a
join with a DOP of 1 and the same data flow with a DOP of 2. You use join
ranks to define the outer source and inner source (see Join ordering on
page 181). In both data flows, the inner source is cached in memory (see
Caching joins on page 66).
Figure 7-5: Runtime instance of a join where DOP =1
Data Services Performance Optimization Guide 89
Page 90

Using parallel Execution
7
Parallel execution in data flows
Figure 7-6: Runtime instance of a join where DOP = 2
With a DOP greater than one, Data Services inserts an internal Round Robin
Split (RRS) that transfers data to each of the replicated joins. The inner
source is cached once, and each half of the outer source joins with the cached
data in the replicated joins. The replicated joins execute in parallel, and the
results merge into a single stream by an internal Merge transform.
DOP and executing a join as multiple processes
When you select the Run JOIN as a separate process in the Query
transform, you can split the execution of a join among multiple processes.
Data Services creates a sub data flow for each separate process.
The following figure shows a runtime instance of a data flow that contains a
join with a DOP of 2 and the Run JOIN as a separate process option
selected.
Figure 7-7: Runtime instance of a join that runs as multiple processes and DOP = 2
The data flow becomes four sub data flows (indicated by the blue dotted and
dashed line in the figure):
• The first sub data flow uses an internal hash algorithm to split the data.
90 Data Services Performance Optimization Guide
Page 91

• The next two sub data flows are the replicated joins that run as separate
processes.
• The last sub data flow merges the data and loads the target.
Tip:
If DOP is greater than one, select either job or data flow for the
Distribution level option when you execute the job. If you execute the job
with the value sub data flow for Distribution level, the Hash Split sends
data to the replicated queries that might be executing on different job servers.
Because the data is sent on the network between different job servers, the
entire data flow might be slower. For more information about job distribution
levels, see Using grid computing to distribute data flow execution on page 116.
Degree of parallelism and functions
In Data Services, you can set stored procedures and custom functions to
replicate with the transforms in which they are used. To specify this option,
select the Enable parallel execution check box on the function's Properties
window. If this option is not selected and you add the function to a transform,
the transform will not replicate and run in parallel even if its parent data flow
has a value greater than 1 set for Degree of parallelism.
Using parallel Execution
Parallel execution in data flows
7
When enabling functions to run in parallel, verify that:
• Your database will allow a stored procedure to run in parallel
• A custom function set to run in parallel will improve performance
All built-in functions, except the following, replicate if the transform they are
used in replicates due to the DOP value:
•
avg()
•
count()
•
count_distinct()
•
double_metaphone()
Data Services Performance Optimization Guide 91
•
min()
•
previous_row_value()
•
print()
•
raise_exception()
Page 92

Using parallel Execution
7
Parallel execution in data flows
•
exec()
•
get_domain_description()
•
gen_row_num()
•
gen_row_num_by_group()
•
is_group_changed()
•
key_generation()
•
mail_to()
•
max()
•
raise_exception_ext()
•
set_env()
•
sleep()
•
smtp_to()
•
soundex()
•
sql()
•
sum()
•
total_rows()
To enable stored procedures to run in parallel
Use the Enable parallel execution option to set functions to run in parallel
when the transforms in which they are used execute in parallel.
1. In the Datastores tab of the object library, expand a Datastore node.
2. Expand its Function node.
3. Right-click a function and select Properties.
4. In the Properties window, click the Function tab.
5. Click the Enable Parallel Execution check box.
6. Click OK.
To enable custom functions to run in parallel
1. In the Custom Functions tab of the object library, right-click a function
name and select Properties.
92 Data Services Performance Optimization Guide
Page 93

Tips
Using parallel Execution
Parallel execution in data flows
2. In the Properties window, click the Function tab.
3. Click the Enable Parallel Execution check box.
4. Click OK.
DOP can degrade performance if you do not use it judiciously. The best
value to choose depends on the complexity of the flow and number of CPUs
available. For example, on a computer with four CPUs, setting a DOP greater
than two for the following data flow will not improve performance but can
potentially degrade it due to thread contention.
If your data flow contains an Order By or a Group By that is not pushed down
to the database, put them at the end of a data flow. A sort node (Order By,
Group By) is always a merge point, after which the engine proceeds as if
the DOP value is 1. For information on viewing the SQL statements pushed
down to the database, see To view SQL on page 47.
7
Combining table partitioning and a degree of parallelism
Different settings for source and target partitions and the degree of parallelism
result in different behaviors in the Data Services engine. The sections that
follow show some examples. For all the following scenarios, the data flow
appears as follows:
Data Services Performance Optimization Guide 93
Page 94

Using parallel Execution
7
Parallel execution in data flows
Two source partitions and a DOP of three
When a source has two partitions, it replicates twice. The input feeds into a
merge-round-robin splitter (MRRS) that merges the input streams and splits
them into a number equal to the value for DOP (in this case, three outputs
to the query transform). The stream then merges and feeds into the target.
Tip:
If the target is not partitioned, set the Number of loaders option equal to
the DOP value. Depending on the number of CPUs available, set the DOP
value equal to the number of source partitions as a general rule. This
produces a data flow without the Merge Round Robin Split and each partition
pipes the data directly into the consuming transform.
Two source partitions and a DOP of two
When the number of source partitions is the same as the value for DOP, the
engine merges before the target (or before any operation that requires a
merge, such as aggregation operations) and proceeds in a single stream to
complete the flow.
94 Data Services Performance Optimization Guide
Page 95

Using parallel Execution
Parallel execution in data flows
Two source partitions, DOP of three, two target partitions
When the number of source partitions is less then the value for DOP, the
input feeds into a merge-round-robin splitter (MRRS) that merges the input
streams and splits them into a number equal to the value for DOP. The engine
then merges the data before the target to equal the number of target
partitions, then proceeds to complete the flow.
Tip:
If the number of target partitions is not equal to the number of source
partitions, set the Number of loaders option equal to the DOP value and
do not enable partitioning for the target. Depending on the number of CPUs
available, set the DOP value equal to the number of source partitions as a
general rule. This produces a data flow without the Merge Round Robin Split
and each partition pipes the data directly into the consuming transform.
7
Two source partitions, DOP of two, and two target partitions
The best case situation is when the following conditions exist:
• The source and target are partitioned the same way.
• The source and target have the same number of partitions.
• DOP is equal to the same number of partitions.
When a source has two partitions, it replicates twice. Because the DOP value
is two, the query transform replicates twice. When a target has two partitions,
it replicates twice. The following figure shows that each source partition feeds
directly into a replicated query transform, and the output from each query
feeds directly into a replicated target.
Data Services Performance Optimization Guide 95
Page 96

Using parallel Execution
7
Parallel execution in data flows
File multi-threading
You can set the number of threads Data Services uses to process flat file
sources and targets. The Parallel process threads option is available on
the:
• File format editor
• Source file editor
• Target file editor
• Properties window of an SAP ERP or R/3 data flow.
Without multi-threading:
• With delimited file reading, Data Services reads a block of data from the
file system and then scans each character to determine if it is a column
delimiter, a row delimiter, or a text delimiter. Then it builds a row using
an internal format.
• For positional file reading, Data Services does not scan character by
character, but it still builds a row using an internal format.
• For file loading, processing involves building a character-based row from
the Data Services internal row format.
You can set these time-consuming operations to run in parallel. You can use
the Parallel process threads option to specify how many threads to execute
in parallel to process the I/O blocks.
Note:
Enabling CPU hyperthreading can negatively affect the performance of Data
Services servers and is therefore not supported.
Related Topics
• Designer Guide: File Formats
• Reference Guide: Data Services Objects, Source
• Reference Guide: Data Services Objects, Target
96 Data Services Performance Optimization Guide
Page 97

Flat file sources
To use the Parallel process threads option, the following conditions must
be met:
• In the file format editor:
• For delimited files, no text delimiters are defined.
• An end-of-file (EOF) marker for the file's input/output style is not
• The value of the row delimiter is not set to {none}. A row delimiter
• If the file has a multi-byte locale and you want to take advantage of
Using parallel Execution
Parallel execution in data flows
For fixed-width files, having a text delimiter defined does not prevent
the file from being read by parallel process threads.
You can set Data Services to read flat file data in parallel in most cases
because the majority of Data Services jobs use fixed-width or
column-delimited source files that do not have text delimiters specified.
specified.
can be {none} only if the file is a fixed-width file.
parallel process threads, set the row delimiter as follows:
• The length of the row delimiter must be 1. If the codepage of the
file is UTF-16, the length of the row delimiter can be 2.
• The row delimiter hex value must be less than 0x40.
7
• In the Source File Editor, no number has been entered for Rows to read.
The Rows to read option indicates the maximum number of rows that
Data Services reads. It is normally used for debugging. Its default value
is none.
• The maximum row size does not exceed 128 KB.
If a file source needs to read more than one file, for example, *.txt is specified
for the File(s) option in the file format editor, Data Services processes the
data in the first file before the data in the next file. It performs file
multi-threading one file at a time.
Data Services Performance Optimization Guide 97
Page 98

Using parallel Execution
7
Parallel execution in data flows
Flat file targets
If you enter a positive value for Parallel process threads, Data Services
parallel processes flat file targets when the maximum row size does not
exceed 128KB.
Tuning performance
The Parallel process threads option is a performance enhancement for flat
file sources and targets. Performance is defined as the total elapsed time
used to read a file source.
A multi-threaded file source or target achieves high performance for reads
and loads by maximizing the utilization of the CPUs on your Job Server
computer. You will notice higher CPU usage when you use this feature. You
might also notice higher memory usage because the number of process
threads you set (each consisting of blocks of rows that use 128 kilobytes)
reside in memory at the same time.
To tune performance, adjust the value for Parallel process threads. Ideally,
have at least as many CPUs as process threads. For example, if you enter
the value 4 for Parallel process threads, have at least four CPUs on your
Job Server computer.
However, increasing the value for process threads does not necessarily
improve performance. The file reads and loads achieve their best performance
when the work load is distributed evenly among all the CPUs and the speed
of the file's input/output (I/O) thread is comparable with the speed of the
process threads
The I/O thread for a file source reads data from a file and feeds it to process
threads. The I/O thread for a file target takes data from process threads and
loads it to a file. Therefore, if a source file's I/O thread is too slow to keep
the process threads busy, there is no need to increase the number of process
threads.
If there is more than one process thread on one CPU, that CPU will need to
switch between the threads. There is an overhead incurred in creating these
threads and switching the CPU between them.
98 Data Services Performance Optimization Guide
Page 99

Tips
Using parallel Execution
Parallel execution in data flows
The best value for Parallel process threads depends on the complexity of
your data flow and the number of available processes. If your Job Server is
on a computer with multiple CPUs, the values for file sources and targets
should be set to at least two.
After that, experiment with different values to determine the best value for
your environment.
Here are some additional guidelines:
• If Parallel process threads is set to none, then flat file reads and loads
are not processed in parallel.
• If Parallel process threads is set to 1, (meaning that one process thread
will spawn) and your Job Server computer has one CPU, then reads and
loads can occur faster than single-threaded file reads and loads because
Data Services reads the I/O thread separately and concurrently with the
process thread.
7
• If Parallel process threads is set to 4, four process threads will spawn.
You can run these threads on a single CPU. However, using four CPUs
would more likely maximize the performance of flat file reads and loads.
Data Services Performance Optimization Guide 99
Page 100

Using parallel Execution
Parallel execution in data flows
7
100 Data Services Performance Optimization Guide
 Loading...
Loading...