

Data Services Reference Guide
BusinessObjects Data Services XI 3.1 (12.1.1)

Copyright
© 2008 Business Objects, an SAP company. All rights reserved. Business Objects
owns the following U.S. patents, which may cover products that are offered and
licensed by Business Objects: 5,295,243; 5,339,390; 5,555,403; 5,590,250;
5,619,632; 5,632,009; 5,857,205; 5,880,742; 5,883,635; 6,085,202; 6,108,698;
6,247,008; 6,289,352; 6,300,957; 6,377,259; 6,490,593; 6,578,027; 6,581,068;
6,628,312; 6,654,761; 6,768,986; 6,772,409; 6,831,668; 6,882,998; 6,892,189;
6,901,555; 7,089,238; 7,107,266; 7,139,766; 7,178,099; 7,181,435; 7,181,440;
7,194,465; 7,222,130; 7,299,419; 7,320,122 and 7,356,779. Business Objects and
its logos, BusinessObjects, Business Objects Crystal Vision, Business Process
On Demand, BusinessQuery, Cartesis, Crystal Analysis, Crystal Applications,
Crystal Decisions, Crystal Enterprise, Crystal Insider, Crystal Reports, Crystal
Vision, Desktop Intelligence, Inxight and its logos , LinguistX, Star Tree, Table
Lens, ThingFinder, Timewall, Let There Be Light, Metify, NSite, Rapid Marts,
RapidMarts, the Spectrum Design, Web Intelligence, Workmail and Xcelsius are
trademarks or registered trademarks in the United States and/or other countries
of Business Objects and/or affiliated companies. SAP is the trademark or registered
trademark of SAP AG in Germany and in several other countries. All other names
mentioned herein may be trademarks of their respective owners.
Third-party
Contributors
Business Objects products in this release may contain redistributions of software
licensed from third-party contributors. Some of these individual components may
also be available under alternative licenses. A partial listing of third-party
contributors that have requested or permitted acknowledgments, as well as required
notices, can be found at: http://www.businessobjects.com/thirdparty
2008-11-28

Contents
Introduction 17Chapter 1
Welcome to Data Services........................................................................18
Overview of this guide...............................................................................24
Data Services Objects 27Chapter 2
Characteristics of objects...........................................................................28
Descriptions of objects ..............................................................................31
Welcome..............................................................................................18
Documentation set for Data Services...................................................18
Accessing documentation....................................................................21
Business Objects information resources..............................................22
About this guide....................................................................................24
Who should read this guide..................................................................25
Object classes .....................................................................................28
Object options, properties, and attributes............................................30
Annotation............................................................................................35
Batch Job.............................................................................................36
Catch ...................................................................................................49
COBOL copybook file format ...............................................................53
Conditional ..........................................................................................63
Data flow .............................................................................................65
Datastore..............................................................................................68
Document...........................................................................................146
DTD....................................................................................................146
Excel workbook format ......................................................................161
File format..........................................................................................170
Data Services Reference Guide 3

Contents
Function..............................................................................................186
Log.....................................................................................................187
Message function...............................................................................197
Outbound message............................................................................198
Project................................................................................................198
Query transform.................................................................................199
Real-time job......................................................................................200
Script..................................................................................................205
Source................................................................................................206
Table...................................................................................................214
Target.................................................................................................220
Target Writer migrated from Data Quality ..........................................269
Template table....................................................................................269
Transform...........................................................................................273
Try......................................................................................................274
While loop...........................................................................................275
Work flow............................................................................................276
XML file..............................................................................................279
XML message....................................................................................284
XML schema......................................................................................286
XML template.....................................................................................306
Smart editor 309Chapter 3
Accessing the smart editor......................................................................310
Smart editor options.................................................................................312
Smart editor toolbar............................................................................312
Editor Library pane.............................................................................312
Editor pane.........................................................................................314
To browse for a function...........................................................................318
To search for a function...........................................................................318
4 Data Services Reference Guide

Contents
Data types 321Chapter 4
Descriptions of data types.......................................................................322
date....................................................................................................323
datetime..............................................................................................325
decimal...............................................................................................326
double ................................................................................................327
int........................................................................................................327
interval................................................................................................328
Large object data types......................................................................328
numeric...............................................................................................335
real.....................................................................................................336
time.....................................................................................................336
timestamp...........................................................................................338
varchar...............................................................................................339
Data type processing...............................................................................341
Date arithmetic...................................................................................341
Type conversion.................................................................................343
Transforms 373Chapter 5
Operation codes......................................................................................374
Descriptions of transforms.......................................................................375
Data Integrator transforms.................................................................379
Data Quality transforms......................................................................464
Platform transforms............................................................................665
Functions and Procedures 719Chapter 6
About functions........................................................................................720
Functions compared with transforms.................................................720
Operation of a function.......................................................................720
Data Services Reference Guide 5

Contents
Arithmetic in date functions................................................................721
Including functions in expressions.....................................................721
Kinds of functions you can use in Data Services...............................725
Descriptions of built-in functions..............................................................730
abs......................................................................................................743
add_months........................................................................................744
ascii....................................................................................................745
avg......................................................................................................746
cast.....................................................................................................747
ceil......................................................................................................750
chr......................................................................................................751
base64_decode..................................................................................752
base64_encode..................................................................................753
concat_date_time ..............................................................................754
count ..................................................................................................754
count_distinct.....................................................................................755
current_configuration .........................................................................757
current_system_configuration............................................................758
dataflow_name ..................................................................................758
datastore_field_value.........................................................................759
date_diff..............................................................................................760
date_part ...........................................................................................761
day_in_month.....................................................................................763
day_in_week......................................................................................764
day_in_year........................................................................................765
db_type...............................................................................................766
db_version..........................................................................................768
db_database_name............................................................................770
db_owner............................................................................................771
decode................................................................................................772
double_metaphone.............................................................................775
6 Data Services Reference Guide

Contents
exec....................................................................................................777
extract_from_xml................................................................................784
file_exists ...........................................................................................787
fiscal_day...........................................................................................788
floor....................................................................................................789
gen_row_num_by_group....................................................................790
gen_row_num ....................................................................................793
get_domain_description.....................................................................794
get_env...............................................................................................795
get_error_filename ............................................................................796
get_file_attribute.................................................................................797
get_monitor_filename ........................................................................798
get_trace_filename ............................................................................799
greatest..............................................................................................800
host_name .........................................................................................802
ifthenelse............................................................................................802
index...................................................................................................804
init_cap...............................................................................................805
interval_to_char..................................................................................807
is_group_changed..............................................................................808
is_set_env..........................................................................................809
is_valid_date......................................................................................810
is_valid_datetime................................................................................812
is_valid_decimal.................................................................................813
is_valid_double...................................................................................815
is_valid_int..........................................................................................816
is_valid_real.......................................................................................817
is_valid_time.......................................................................................819
isempty ..............................................................................................820
isweekend .........................................................................................822
job_name ...........................................................................................823
Data Services Reference Guide 7

Contents
julian...................................................................................................823
julian_to_date.....................................................................................824
key_generation...................................................................................825
last_date ............................................................................................826
least....................................................................................................827
length .................................................................................................829
literal...................................................................................................830
ln.........................................................................................................832
load_to_xml........................................................................................833
log.......................................................................................................838
long_to_varchar..................................................................................839
lookup ................................................................................................840
lookup_ext..........................................................................................846
lookup_seq.........................................................................................857
lower ..................................................................................................863
lpad ....................................................................................................864
lpad_ext..............................................................................................865
ltrim ....................................................................................................868
ltrim_blanks .......................................................................................869
ltrim_blanks_ext ................................................................................870
mail_to................................................................................................871
match_pattern....................................................................................875
match_regex ......................................................................................879
match_simple.....................................................................................891
max.....................................................................................................893
min......................................................................................................894
mod....................................................................................................895
month.................................................................................................896
num_to_interval..................................................................................897
nvl.......................................................................................................899
power..................................................................................................900
8 Data Services Reference Guide

Contents
previous_row_value...........................................................................901
print ...................................................................................................902
pushdown_sql ...................................................................................904
quarter................................................................................................906
raise_exception .................................................................................907
raise_exception_ext ..........................................................................908
rand....................................................................................................909
rand_ext.............................................................................................910
replace_substr ...................................................................................911
replace_substr_ext.............................................................................912
repository_name ................................................................................916
round..................................................................................................917
rpad....................................................................................................918
rpad_ext.............................................................................................919
rtrim ...................................................................................................922
rtrim_blanks .......................................................................................923
rtrim_blanks_ext ................................................................................924
search_replace...................................................................................925
set_env ..............................................................................................934
sleep ..................................................................................................935
soundex..............................................................................................936
sql ......................................................................................................937
sqrt.....................................................................................................941
smtp_to...............................................................................................941
substr..................................................................................................946
sum.....................................................................................................948
sysdate...............................................................................................949
system_user_name ...........................................................................950
systime...............................................................................................951
table_attribute ....................................................................................952
to_char...............................................................................................953
Data Services Reference Guide 9

Contents
to_date...............................................................................................957
to_decimal .........................................................................................958
to_decimal_ext ..................................................................................960
total_rows...........................................................................................961
trunc...................................................................................................963
truncate_table.....................................................................................964
upper..................................................................................................966
varchar_to_long..................................................................................967
wait_for_file........................................................................................968
week_in_month..................................................................................970
week_in_year.....................................................................................971
WL_GetKeyValue ..............................................................................973
word....................................................................................................974
word_ext ............................................................................................976
workflow_name .................................................................................978
year....................................................................................................979
About procedures....................................................................................980
Overview............................................................................................980
Requirements.....................................................................................981
Creating stored procedures in a database.........................................982
Importing metadata for stored procedures ........................................986
Structure of a stored procedure..........................................................987
Calling stored procedures..................................................................989
Checking execution status ................................................................995
Data Services Scripting Language 997Chapter 7
To use Data Services scripting language................................................998
Language syntax.....................................................................................998
Syntax for statements in scripts.........................................................998
Syntax for column and table references in expressions.....................999
Strings..............................................................................................1000
10 Data Services Reference Guide

Contents
Variables...........................................................................................1001
Variable interpolation........................................................................1002
Functions and stored procedures.....................................................1003
Operators.........................................................................................1003
NULL values.....................................................................................1007
Debugging and Validation................................................................1011
Keywords..........................................................................................1013
Sample scripts.......................................................................................1015
Square function................................................................................1016
RepeatString function.......................................................................1016
Metadata in Repository Tables and Views 1019Chapter 8
Auditing metadata..................................................................................1020
AL_AUDIT........................................................................................1020
AL_AUDIT_INFO..............................................................................1022
Imported metadata.................................................................................1024
AL_INDEX........................................................................................1024
AL_PCOLUMN.................................................................................1025
AL_PKEY.........................................................................................1026
ALVW_COLUMNATTR.....................................................................1027
ALVW_COLUMNINFO.....................................................................1028
ALVW_FKREL..................................................................................1030
ALVW_MAPPING.............................................................................1031
ALVW_TABLEATTR.........................................................................1042
ALVW_TABLEINFO..........................................................................1044
Internal metadata...................................................................................1044
AL_LANG.........................................................................................1045
AL_LANGXMLTEXT.........................................................................1046
AL_ATTR..........................................................................................1047
AL_SETOPTIONS............................................................................1048
AL_USAGE......................................................................................1049
Data Services Reference Guide 11

Contents
ALVW_FUNCINFO...........................................................................1053
ALVW_PARENT_CHILD..................................................................1054
Metadata Integrator tables.....................................................................1056
AL_CMS_BV....................................................................................1056
AL_CMS_BV_FIELDS......................................................................1058
AL_CMS_REPORTS........................................................................1059
AL_CMS_REPORTUSAGE.............................................................1060
AL_CMS_FOLDER..........................................................................1062
AL_CMS_UNV.................................................................................1063
AL_CMS_UNV_OBJ........................................................................1064
Operational metadata............................................................................1065
AL_HISTORY...................................................................................1065
ALVW_FLOW_STAT........................................................................1067
Locales and Multi-byte Functionality 1069Chapter 9
Locale support.......................................................................................1070
Locale selection................................................................................1072
Code page support...........................................................................1075
Guidelines for setting locales...........................................................1078
Multi-byte support..................................................................................1084
Multi-byte string functions.................................................................1084
Numeric data types: assigning constant values...............................1084
Byte Order Mark characters.............................................................1086
Round-trip conversion......................................................................1086
Column sizing...................................................................................1087
Limitations of multi-byte support............................................................1087
Definitions..............................................................................................1088
Supported locales and encodings.........................................................1090
Supported languages.......................................................................1091
Supported territories.........................................................................1091
Supported code pages.....................................................................1093
12 Data Services Reference Guide

Contents
Data Quality Fields 1097Chapter 10
Data Quality fields..................................................................................1098
Content types...................................................................................1098
Associate output fields...........................................................................1100
Country ID fields....................................................................................1101
Input Fields.......................................................................................1101
Output fields.....................................................................................1102
Data Cleanse fields................................................................................1103
Input fields........................................................................................1103
Output fields.....................................................................................1105
Geocoder fields......................................................................................1111
Input fields........................................................................................1112
Output fields.....................................................................................1113
Global Address Cleanse fields..............................................................1115
Field category columns in Output tab...............................................1115
Input fields........................................................................................1120
Output Fields....................................................................................1123
Global Suggestion Lists fields...............................................................1141
Input fields........................................................................................1141
Output fields.....................................................................................1143
Match fields............................................................................................1148
Match transform output fields...........................................................1148
Prioritization fields............................................................................1152
USA Regulatory Address Cleanse fields...............................................1152
Field category columns in Output tab...............................................1153
Input fields........................................................................................1157
Output fields.....................................................................................1160
Data Services Reference Guide 13

Contents
Python 1191Chapter 11
Python in Data Services........................................................................1192
About Python in Data Services ........................................................1192
Create an expression with the Python Expression editor.................1196
Built-in objects..................................................................................1200
Data Services-defined classes and methods...................................1202
FlDataCollection class......................................................................1203
FlDataManager class.......................................................................1208
FlDataRecord class..........................................................................1210
FlProperties class.............................................................................1213
FlPythonString class.........................................................................1214
Data Services Python examples......................................................1217
Reserved Words 1227Chapter 12
About Reserved Words..........................................................................1228
Data Quality Appendix 1233Chapter 13
Address Cleanse reference...................................................................1234
Country ISO codes and assignment engines...................................1234
Information codes (Global Address Cleanse)..................................1260
Status codes (Global Address Cleanse)..........................................1263
Quality codes (Global Address Cleanse).........................................1269
Status Codes (USA Regulatory Address Cleanse)..........................1271
USA Regulatory Address Cleanse transform fault codes................1275
About ShowA and ShowL (USA and Canada).................................1278
Data Cleanse reference.........................................................................1289
Data parsing details..........................................................................1289
User-defined pattern matching (UDPM)...........................................1297
Overview of UDPM...........................................................................1298
14 Data Services Reference Guide

Contents
Working with the pattern file.............................................................1299
Regular expressions.........................................................................1301
Creating regular expressions...........................................................1306
Define a pattern................................................................................1308
Alternate expressions.......................................................................1311
Modify the rule file............................................................................1312
What is the rule file?.........................................................................1312
Rule file organization........................................................................1313
Rule example...................................................................................1315
Definition section of a parsing rule...................................................1316
Action section of a parsing rule........................................................1320
Data Cleanse migration tools...........................................................1326
Index 1335
Data Services Reference Guide 15

Contents
16 Data Services Reference Guide

Introduction
1
Introduction
1
Welcome to Data Services
Welcome to Data Services
Welcome
Data Services XI Release 3 provides data integration and data quality
processes in one runtime environment, delivering enterprise performance
and scalability.
The data integration processes of Data Services allow organizations to easily
explore, extract, transform, and deliver any type of data anywhere across
the enterprise.
The data quality processes of Data Services allow organizations to easily
standardize, cleanse, and consolidate data anywhere, ensuring that end-users
are always working with information that's readily available, accurate, and
trusted.
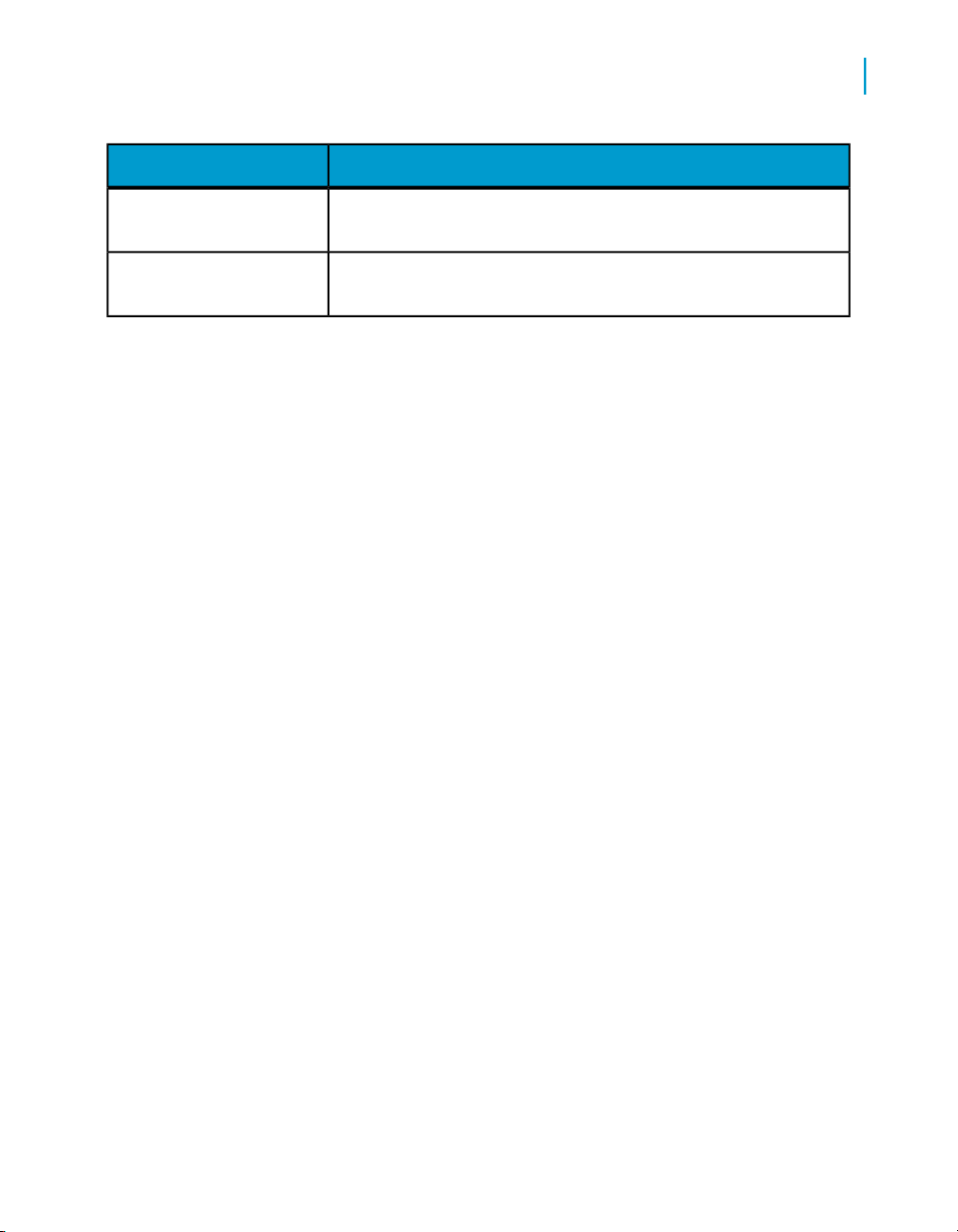
Documentation set for Data Services
You should become familiar with all the pieces of documentation that relate
to your Data Services product.
What this document providesDocument
Documentation Map
Release Summary
Release Notes
Getting Started Guide
Installation Guide for Windows
18 Data Services Reference Guide
Information about available Data Services books,
languages, and locations
Highlights of key features in this Data Services release
Important information you need before installing and
deploying this version of Data Services
An introduction to Data Services
Information about and procedures for installing Data
Services in a Windows environment.
Introduction
Welcome to Data Services
What this document providesDocument
1
Installation Guide for UNIX
Advanced Development Guide
Designer Guide
Integrator's Guide
Management Console: Administrator
Guide
Management Console: Metadata Reports Guide
Migration Considerations Guide
Information about and procedures for installing Data
Services in a UNIX environment.
Guidelines and options for migrating applications including information on multi-user functionality and
the use of the central repository for version control
Information about how to use Data Services Designer
Information for third-party developers to access Data
Services functionality. Also provides information about
how to install, configure, and use the Data Services
Adapter for JMS.
Information about how to use Data Services Administrator
Information about how to use Data Services Metadata
Reports
Information about:
• Release-specific product behavior changes from
earlier versions of Data Services to the latest release
• How to migrate from Data Quality to Data Services
Performance Optimization Guide
Reference Guide
Information about how to improve the performance
of Data Services
Detailed reference material for Data Services Designer
Data Services Reference Guide 19
Introduction
1
Welcome to Data Services
Technical Manuals
What this document providesDocument
A compiled “master” PDF of core Data Services books
containing a searchable master table of contents and
index:
•
Getting Started Guide
•
Installation Guide for Windows
•
Installation Guide for UNIX
•
Designer Guide
•
Reference Guide
•
Management Console: Metadata Reports Guide
•
Management Console: Administrator Guide
•
Performance Optimization Guide
•
Advanced Development Guide
•
Supplement for J.D. Edwards
•
Supplement for Oracle Applications
•
Supplement for PeopleSoft
•
Supplement for Siebel
•
Supplement for SAP
Tutorial
In addition, you may need to refer to several Adapter Guides and
Supplemental Guides.
What this document providesDocument
Salesforce.com Adapter
Interface
Supplement for J.D. Edwards
Supplement for Oracle Applications
Supplement for PeopleSoft
20 Data Services Reference Guide
Information about how to install, configure, and use the Data
Services Salesforce.com Adapter Interface
Information about license-controlled interfaces between Data
Services and J.D. Edwards World and J.D. Edwards OneWorld
Information about the license-controlled interface between Data
Services and Oracle Applications
Information about license-controlled interfaces between Data
Services and PeopleSoft
A step-by-step introduction to using Data Services
Introduction
Welcome to Data Services
What this document providesDocument
1
Supplement for SAP
Supplement for Siebel
Information about license-controlled interfaces between Data
Services, SAP ERP, and SAP BI/BW
Information about the license-controlled interface between Data
Services and Siebel
Accessing documentation
You can access the complete documentation set for Data Services in several
places.
Accessing documentation on Windows
After you install Data Services, you can access the documentation from the
Start menu.
1. Choose Start > Programs > BusinessObjects XI 3.1 >
BusinessObjects Data Services > Data Services Documentation.
Note:
Only a subset of the documentation is available from the Start menu. The
documentation set for this release is available in LINK_DIR\Doc\Books\en.
2. Click the appropriate shortcut for the document that you want to view.
Accessing documentation on UNIX
After you install Data Services, you can access the online documentation by
going to the directory where the printable PDF files were installed.
1. Go to LINK_DIR/doc/book/en/.
2. Using Adobe Reader, open the PDF file of the document that you want
to view.
Data Services Reference Guide 21

Introduction
1
Welcome to Data Services
Accessing documentation from the Web
You can access the complete documentation set for Data Services from the
Business Objects Customer Support site.
1.
Go to http://help.sap.com.
2. Cick Business Objects at the top of the page.
You can view the PDFs online or save them to your computer.
Business Objects information resources
A global network of Business Objects technology experts provides customer
support, education, and consulting to ensure maximum business intelligence
benefit to your business.
Useful addresses at a glance:
ContentAddress
22 Data Services Reference Guide
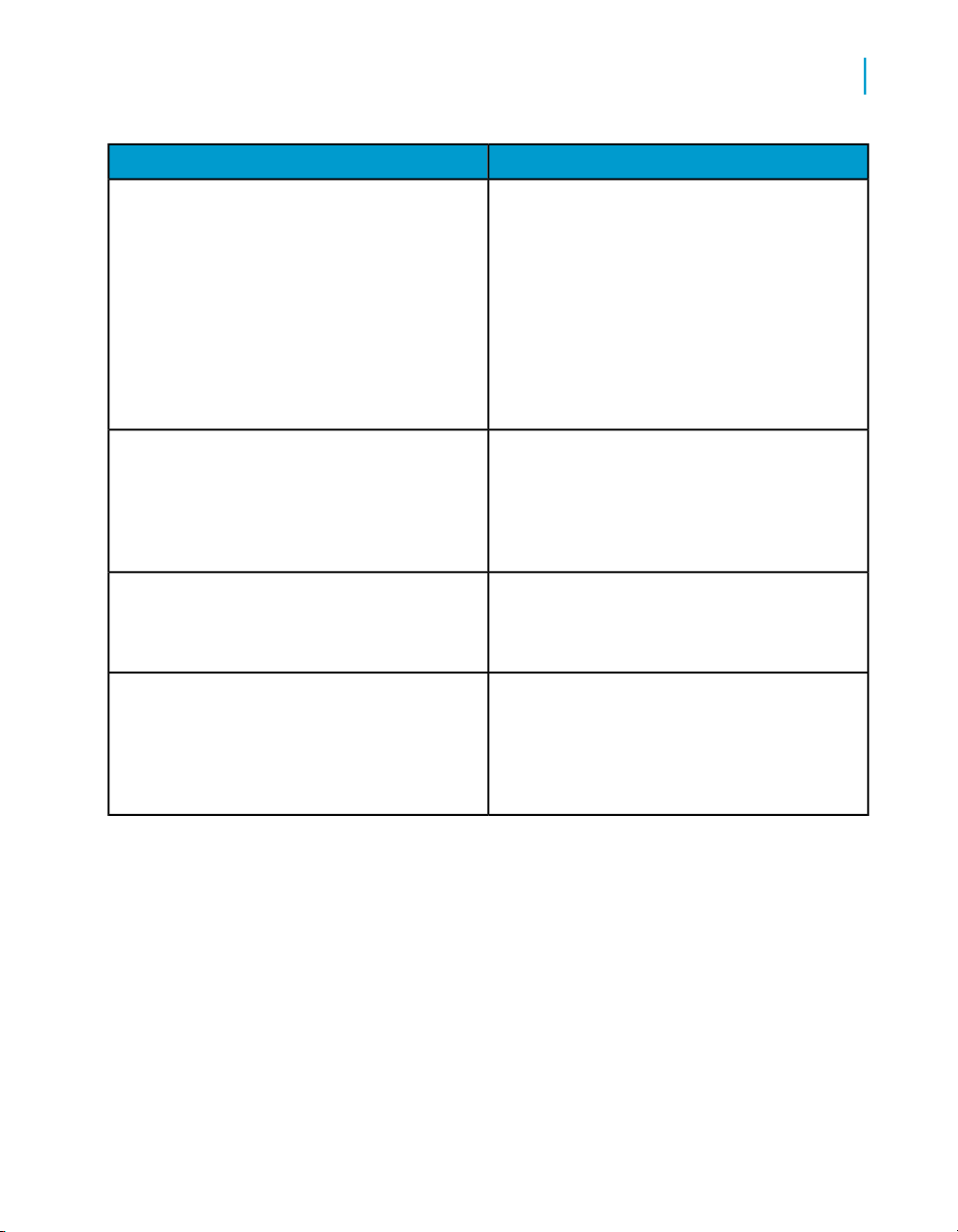
Introduction
Welcome to Data Services
ContentAddress
1
Customer Support, Consulting, and Education
services
http://service.sap.com/
Data Services Community
https://www.sdn.sap.com/irj/sdn/businessob
jects-ds
Forums on SCN (SAP Community Network)
https://www.sdn.sap.com/irj/sdn/businessob
jects-forums
Blueprints
http://www.sdn.sap.com/irj/boc/blueprints
Information about Customer Support programs,
as well as links to technical articles, downloads,
and online forums. Consulting services can
provide you with information about how Business Objects can help maximize your business
intelligence investment. Education services can
provide information about training options and
modules. From traditional classroom learning
to targeted e-learning seminars, Business Objects can offer a training package to suit your
learning needs and preferred learning style.
Get online and timely information about Data
Services, including tips and tricks, additional
downloads, samples, and much more. All content is to and from the community, so feel free
to join in and contact us if you have a submission.
Search the Business Objects forums on the
SAP Community Network to learn from other
Data Services users and start posting questions
or share your knowledge with the community.
Blueprints for you to download and modify to fit
your needs.Each blueprint contains the necessary Data Services project, jobs, data flows, file
formats, sample data, template tables, and
custom functions to run the data flows in your
environment with only a few modifications.
Data Services Reference Guide 23
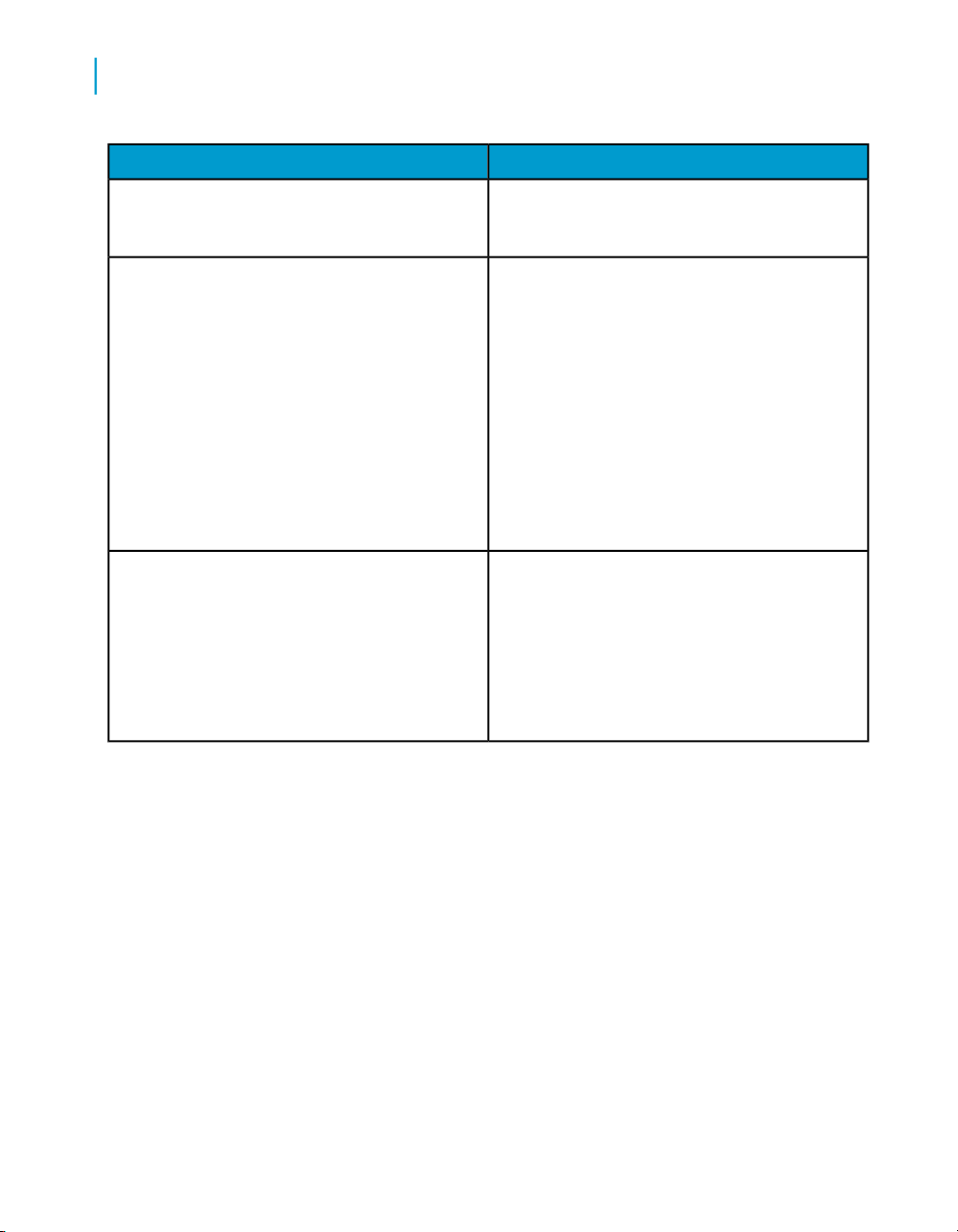
Introduction
1
Overview of this guide
http://help.sap.com/
ContentAddress
Business Objects product documentation.Product documentation
Documentation mailbox
documentation@businessobjects.com
Supported platforms documentation
https://service.sap.com/bosap-support
Send us feedback or questions about your
Business Objects documentation. Do you have
a suggestion on how we can improve our documentation? Is there something that you particularly like or have found useful? Let us know,
and we will do our best to ensure that your
suggestion is considered for the next release
of our documentation.
Note:
If your issue concerns a Business Objects
product and not the documentation, please
contact our Customer Support experts.
Get information about supported platforms for
Data Services.
In the left panel of the window, navigate to
Documentation > Supported Platforms >
BusinessObjects XI 3.1. Click the BusinessObjects Data Services link in the main window.
Overview of this guide
About this guide
The Data Services Reference Guide provides a detailed information about
the objects, data types, transforms, and functions in the Data Services
Designer.
For source-specific information, such as information pertaining to a particular
back-office application, refer to the supplement for that application.
24 Data Services Reference Guide

Who should read this guide
This and other Data Services product documentation assume the following:
• You are an application developer, consultant, or database administrator
working on data extraction, data warehousing, data integration, or data
quality.
• You understand your source and target data systems, DBMS, legacy
systems, business intelligence, and messaging concepts.
• You understand your organization's data needs.
• You are familiar with SQL (Structured Query Language).
• If you are interested in using this product to design real-time processing,
you are familiar with:
• DTD and XML Schema formats for XML files
• Publishing Web Services (WSDL, HTTP/S and SOAP protocols, and
so on.)
Introduction
Overview of this guide
1
• You are familiar with Data Services installation environments: Microsoft
Windows or UNIX.
Data Services Reference Guide 25

Introduction
Overview of this guide
1
26 Data Services Reference Guide

Data Services Objects
2

Data Services Objects
2
Characteristics of objects
This section provides a reference of detailed information about the objects,
data types, transforms, and functions in the Data Services Designer.
Note:
For information about source-specific objects, consult the reference chapter
of the Data Services supplement document for that source.
Related Topics
• Characteristics of objects on page 28
• Descriptions of objects on page 31
Characteristics of objects
This section discusses common characteristics of all Data Services objects.
Related Topics
• Object classes on page 28
• Object options, properties, and attributes on page 30
Object classes
An object's class determines how you create and retrieve the object. There
are two classes of objects:
• Reusable objects
• Single-use objects
Related Topics
• Reusable objects on page 28
• Single-use objects on page 30
Reusable objects
After you define and save a reusable object, Data Services stores the
definition in the repository. You can then reuse the definition as often as
necessary by creating calls to the definition.
28 Data Services Reference Guide

Data Services Objects
Characteristics of objects
Most objects created in Data Services are available for reuse. You access
reusable objects through the object library.
A reusable object has a single definition; all calls to the object refer to that
definition. If you change the definition of the object in one place, and then
save the object, the change is reflected to all other calls to the object.
A data flow, for example, is a reusable object. Multiple jobs, such as a weekly
load job and a daily load job, can call the same data flow. If the data flow is
changed, both jobs call the new version of the data flow.
When you drag and drop an object from the object library, you are creating
a new reference (or call) to the existing object definition.
You can edit reusable objects at any time independent of the current open
project. For example, if you open a new project, you can go to the object
library, open a data flow, and edit it. The object will remain "dirty" (that is,
your edited changes will not be saved) until you explicitly save it.
Functions are reusable objects that are not available in the object library.
Data Services provides access to these objects through the function wizard
wherever they can be used.
2
Some objects in the object library are not reusable in all instances:
• Datastores are in the object library because they are a method for
categorizing and accessing external metadata.
• Built-in transforms are "reusable" in that every time you drop a transform,
a new instance of the transform is created.
"Saving" a reusable object in Data Services means storing the language that
describes the object to the repository. The description of a reusable object
includes these components:
• Properties of the object
• Options for the object
• Calls this object makes to other objects
• Definition of single-use objects called by this object
If an object contains a call to another reusable object, only the call to the
second object is saved, not changes to that object's definition.
Data Services stores the description even if the object does not validate.
Data Services Reference Guide 29

Data Services Objects
2
Characteristics of objects
Data Services saves objects without prompting you:
• When you import an object into the repository.
• When you finish editing:
You can explicitly save the reusable object currently open in the workspace
by choosing Save from the Project menu. If a single-use object is open in
the workspace, the Save command is not available.
To save all objects in the repository that have changes, choose Save All
from the Project menu.
Data Services also prompts you to save all objects that have changes when
you execute a job and when you exit the Designer.
Single-use objects
• Datastores
• Flat file formats
• XML Schema or DTD formats
Single-use objects appear only as components of other objects. They operate
only in the context in which they were created.
"Saving" a single-use object in Data Services means storing the language
that describes the object to the repository. The description of a single-use
object can only be saved as part of the reusable object that calls the
single-use object.
Data Services stores the description even if the object does not validate.
Object options, properties, and attributes
Each object is associated with a set of options, properties, and attributes:
• Options control the operation of an object. For example, in a datastore,
an option is the name of the database to which the datastore connects.
• Properties document an object. For example, properties include the
name, description of an object, and the date on which it was created.
30 Data Services Reference Guide

Properties merely describe an object; they do not affect an object's
operation.
To view properties, right-click an object and select Properties.
• Attributes provide additional information about an object. Attribute
values may also affect an object's behavior.
To view attributes, double-click an object from an editor and click the
Attributes tab.
Descriptions of objects
This section describes each Data Services object and tells you how to access
that object.
The following table lists the names and descriptions of objects available in
Data Services:
DescriptionClassObject
Data Services Objects
Descriptions of objects
2
COBOL copybook
file format
Single-useAnnotation
Single-useCatch
Reusable
Single-useConditional
Describes a flow, part of a flow, or a diagram in the
workspace.
Specifies the steps to execute if anerror occurs in a
given exception group while a job is running.
Defines the format for a COBOL copybook file
source.
Specifies the steps to execute based on the result
of a condition.
Data Services Reference Guide 31

Data Services Objects
2
Descriptions of objects
DescriptionClassObject
Defines activities that Data Services executes at a
given time including error, monitor and trace messages.
ReusableBatch Job
Jobs can be dropped only in the project tree. The
object created is a direct reference to the object in
the object library. Only one reference to a job can
exist in the project tree at one time.
Excel workbook
format
ReusableData flow
Single-useDatastore
ReusableDocument
ReusableDTD
ReusableFile format
Specifies the requirements for extracting, transforming, and loading data from sources to targets.
Specifies the connection information Data Services
needs to access a database or other data source.
Cannot be dropped.
Available in certain adapter datastores, documents
are data structures that can support complicated
nested schemas.
A description of an XML file or message. Indicates
the format an XML document reads or writes.
Defines the format for an Excel workbook source.Reusable
Indicates how flat file data is arranged in a source
or target file.
32 Data Services Reference Guide
Returns a value.ReusableFunction

Data Services Objects
Descriptions of objects
DescriptionClassObject
2
Outbound message
Single-useLog
ReusableMessage function
Reusable
Single-useQuery transform
ReusableReal-time job
Records information about a particular execution of
a single job.
Available in certain adapter datastores, message
functions can accommodate XML messages when
properly configured.
Available in certain adapter datastores, outbound
messages are XML-based, hierarchical communications that real-time jobs can publish to adapters.
Groups jobs for convenient access.Single-useProject
Retrieves a data set that satisfies conditions that you
specify.
Defines activities that Data Services executes ondemand.
Real-time jobs are created in the Designer, then
configured and run as services associated with an
Access Server in the Administrator. Real-time jobs
are designed according to data flow model rules and
run as a request-response system.
Source
Single-useScript
Single-use
Evaluates expressions, calls functions, and assigns
values to variables.
An object from which Data Services reads data in a
data flow.
Data Services Reference Guide 33

Data Services Objects
2
Descriptions of objects
DescriptionClassObject
Indicates an external DBMS table for which metadata
has been imported into Data Services, or the target
table into which data is or has been placed.
ReusableTable
A table is associated with its datastore; it does not
exist independently of a datastore connection. A table retrieves or stores data based on the schema of
the table definition from which it was created.
Single-useTarget
ReusableTemplate table
ReusableTransform
Single-useWhile loop
An object in which Data Services loads extracted
and transformed data in a data flow.
A new table you want added to a database.
All datastores except SAP ERP or R/3 datastores
have a default template that you can use to create
any number of tables in the datastore.
Data Services creates the schema for each instance
of a template table at runtime. The created schema
is based on the data loaded into the template table.
Performs operations on data sets.
Requires zero or more data sets; produces zero or
one data set (which may be split).
Introduces a try/catch block.Single-useTry
Repeats a sequence of steps as long as a condition
is true.
ReusableWork flow
34 Data Services Reference Guide
Orders data flows and operations supporting data
flows.

Data Services Objects
Descriptions of objects
DescriptionClassObject
A batch or real-time source or target. As a source,
an XML file translates incoming XML-formatted data
Single-useXML file
Single-useXML message
into data that Data Services can process. As a target,
an XML file translates the data produced by a data
flow, including nested data, into an XML-formatted
file.
A real-time source or target. As sources, XML messages translate incoming XML-formatted requests
into data that a real-time job can process. As targets,
XML messages translate the result of the real-time
job, including hierarchical data, into an XML-formatted response and sends the messages to the Access
Server.
2
Annotation
Class
Single-use
ReusableXML Schema
Single-useXML template
A description of an XML file or message. Indicates
the format an XML document reads or writes.
A target that creates an XML file that matches a
particular input schema. No DTD or XML Schema
is required.
Data Services Reference Guide 35

Data Services Objects
2
Descriptions of objects
Batch Job
Access
Click the annotation icon in the tool palette, then click in the workspace.
Description
Annotations describe a flow, part of a flow, or a diagram in a workspace. An
annotation is associated with the job., work flow, or data flow where it appears.
When you import or export that job, work flow, or data flow, you import or
export associated annotations.
Note:
An annotation has no options or properties.
Related Topics
• Designer Guide: Creating annotations
Class
Reusable
Access
• In the object library, click the Jobs tab.
• In the project area, select a project and right-click Batch Job.
Description
A batch job is a set of objects that you can schedule and execute together.
For Data Services to execute the steps of any object, the object must be part
of a job.
A batch job can contain the following objects:
• Data flows
• Sources
36 Data Services Reference Guide

Data Services Objects
Descriptions of objects
• Transforms
• Targets
• Work flows
• Scripts
• Conditionals
• Try/catch blocks
• While Loops
You can run batch jobs such that you can automatically recover from jobs
that do not execute successfully. During automatic recovery, Data Services
retrieves the results from steps that were successfully completed in the
previous run and executes all other steps. Specifically, Data Services retrieves
results from the following types of steps:
• Work flows
• Data flows
• Script statements
2
• Custom functions (stateless type only)
• SQL function
• EXEC function
• get_env function
• rand function
• sysdate function
• systime function
Batch jobs have the following built-in attributes:
DescriptionAttribute
Name
The name of the object. This name appears on the object
in the object library and in the calls to the object.
Data Services Reference Guide 37

Data Services Objects
2
Descriptions of objects
DescriptionAttribute
Your description of the job.Description
The date when the object was created.Date created
Batch and real-time jobs have properties that determine what information
Data Services collects and logs when running the job. You can set the default
properties that apply each time you run the job or you can set execution
(run-time) properties that apply for a particular run. Execution properties
override default properties.
To set default properties, select the job in the project area or the object library,
right-click, and choose Properties to open the Properties window.
Execution properties are set as you run a job. To set execution properties,
right-click the job in the project area and choose Execute. The Designer
validates the job and opens the Execution Properties window.
You can set three types of execution properties:
• Parameters
• Trace properties
• Global variables
Related Topics
• Designer Guide: Setting global variable values
Parameters
Use parameter options to help capture and diagnose errors using log,
auditing, statistics collection, or recovery options.
Data Services writes log information to one of three files (in the
$LINK_DIR\log\ Job Server name\repository name directory):
• Monitor log file
38 Data Services Reference Guide

• Trace log file
• Error log file
You can also select a system configuration and a Job Server or server group
from the Parameters tab of the Execution Properties window.
Select the Parameters tab to set the following options.
Monitor sample
rate
(# of rows)
Data Services Objects
Descriptions of objects
DescriptionOptions
Enter the number of rows processed before Data Services writes information to the monitor log file and updates job events. Data Services
writes information about the status of each source, target, or transform.
For example, if you enter 1000, Data Services updates the logs after
processing 1,000 rows.
The default is 1000. When setting the value, you must evaluate performance improvements gained by making fewer calls to the operating
system against your ability to find errors quickly. With a higher monitor
sample rate, Data Services collects more data before calling the operating system to open the file: performance improves. However, with
a higher monitor rate, more time passes before you are able to see
any errors.
2
Print all trace
messages
Note:
If you use a virus scanner on your files, exclude the Data Services log
from the virus scan. Otherwise, the virus scan analyzes the Data Services
log repeated during the job execution, which causes a performance
degradation.
Select this check box to print all trace messages to the trace log file
for the current Job Server.
Selecting this option overrides the trace properties set on the Trace
tab.
Data Services Reference Guide 39

Data Services Objects
2
Descriptions of objects
DescriptionOptions
Select this check box if you do not want to collect data validation
statistics for any validation transforms in this job. (The default is
cleared.)
Disable data validation statistics
collection
Enable auditing
Enable recovery
For more information about data validation statistics, see Data Validation dashboards Settings control panel" in the Data Services Manage-
ment Console: Metadata Reports Guide.
For more information about data validation statistics, see the Data
Validation Dashboard Reports chapter in the Data Services Manage-
ment Console: Metadata Reports Guide.
Clear this check box if you do not want to collect audit statistics for
this specific job execution. (The default is selected.)
For more information about auditing, see Using Auditing in the Data
Services Designer Guide.
For more information about auditing, see the Data Assessment
chapter in the Data Services Designer Guide.
(Batch jobs only) Select this check box to enable the automatic recovery feature. When enabled, Data Services saves the results from
completed steps and allows you to resume failed jobs. You cannot
enable the automatic recovery feature when executing a job in data
scan mode.
See Automatically recovering jobs in the Data Services Designer
Guide for information about the recovery options.
See the Recovery Mechanisms chapter in the Data Services Designer
Guide for information about the recovery options.
This property is only available as a run-time property. It is not available
as a default property.
40 Data Services Reference Guide

Recover from last
failed execution
Collect statistics
for optimization
Data Services Objects
Descriptions of objects
DescriptionOptions
(Batch Job only) Select this check box to resume a failed job. Data
Services retrieves the results from any steps that were previously
executed successfully and re-executes any other steps.
This option is a run-time property. This option is not available when
a job has not yet been executed or when recovery mode was disabled
during the previous run.
Select this check box if you want to collect statistics that the Data
Services optimizer will use to choose an optimal cache type (inmemory or pageable). This option is not selected by default.
For more information, see Caching sources in the Data Services
Performance Optimization Guide.
For more information, see the Using Caches chapter in the Data
Services Performance Optimization Guide.
2
Collect statistics
for monitoring
Select this check box if you want to display cache statistics in the
Performance Monitor in the Administrator. (The default is cleared.)
Note:
Use this option only if you want to look at the cache size.
For more information, see Monitoring and tuning caches in the Data
Services Performance Optimization Guide.
For more information, see the Using Caches chapter in the Data
Services Performance Optimization Guide.
Data Services Reference Guide 41

Data Services Objects
2
Descriptions of objects
Use collected
statistics
DescriptionOptions
Select this check box if you want the Data Services optimizer to use
the cache statistics collected on a previous execution of the job. (The
default is selected.)
For more information, see Monitoring and tuning caches in the Data
Services Performance Optimization Guide.
For more information, see Chapter 6: Using Caches in the Data Ser-
vices Performance Optimization Guide.
Select the level within a job that you want to distribute to multiple job
servers for processing:
•
Job - The whole job will execute on an available Job Server.
•
Data flow - Each data flow within the job can execute on an available Job Server.
•
Sub data flow - Each sub data flow (can be a separate transform
Distribution level
42 Data Services Reference Guide
or function) within a data flow can execute on an available Job
Server.
For more information, see Using grid computing to distribute data
flows execution in the Data Services Performance Optimization
Guide.
For more information, see the Distributing Data Flow Execution
chapter in the Data Services Performance Optimization Guide.

System configuration
Data Services Objects
Descriptions of objects
DescriptionOptions
Select the system configuration to use when executing this job. A
system configuration defines a set of datastore configurations, which
define the datastore connections.
For more information, see Creating and managing multiple datastore
configurations Data Services Designer Guide.
For more information, see the Datastores chapter in the Data Services
Designer Guide.
If a system configuration is not specified, Data Services uses the default datastore configuration for each datastore.
This option is a run-time property. This option is only available if there
are system configurations defined in the repository.
Select the Job Server or server group to execute this job. A Job
Server is defined by a host name and port while a server group is
defined by its name. The list contains Job Servers and server groups
linked to the job's repository.
2
Job Server or
server group
For an introduction to server groups, see Server group architecture
in the Data Services Management Console: Administrator Guide.
For an introduction to server groups, see the Using Server Groups
chapter in the Data Services Management Console: Administrator
Guide.
When selecting a Job Server or server group, remember that many
objects in the Designer have options set relative to the Job Server's
location. For example:
•
Directory and file names for source and target files
•
Bulk load directories
Data Services Reference Guide 43

Data Services Objects
2
Descriptions of objects
Trace properties
Use trace properties to select the information that Data Services monitors
and writes to the trace log file during a job. Data Services writes trace
messages to the trace log associated with the current Job Server and writes
error messages to the error log associated with the current Job Server.
To set trace properties, click the Trace tab. To turn a trace on, select the
trace, click Yes in the Value list, and click OK. To turn a trace off, select the
trace, click No in the Value list, and click OK.
You can turn several traces on and off.
DescriptionTrace
Writes a message when a transform imports or exports a row.Row
Session
Work Flow
Data Flow
Trace ABAP
Writes a message when the job description is read from the repository, when the job is optimized, and when the job runs.
Writes a message when the work flow description is read from the
repository, when the work flow is optimized, when the work flow runs,
and when the work flow ends.
Writes a message when the data flow starts, when the data flow
successfully finishes, or when the data flow terminates due to error.
This trace also reports when the bulk loader starts, any bulk loader
warnings occur, and when the bulk loader successfully completes.
Writes a message when a transform starts, completes, or terminates.Transform
Writes a message when an ABAP dataflow starts or stops, and to
report the ABAP job status.
44 Data Services Reference Guide

SQL Functions
SQL Transforms
Data Services Objects
Descriptions of objects
DescriptionTrace
Writes data retrieved before SQL functions:
•
Every row retrieved by the named query before the SQL is submitted in the key_generation function
•
Every row retrieved by the named query before the SQL is submitted in the lookup function (but only if PRE_LOAD_CACHE is
not specified).
•
When mail is sent using the mail_to function.
Writes a message (using the Table_Comparison transform) about
whether a row exists in the target table that corresponds to an input
row from the source table.
The trace message occurs before submitting the query against the
target and for every row retrieved when the named query is submitted
(but only if caching is not turned on).
2
SQL Readers
Writes the SQL query block that a script, query transform, or SQL
function submits to the system. Also writes the SQL results.
Data Services Reference Guide 45

Data Services Objects
2
Descriptions of objects
DescriptionTrace
Writes a message when the bulk loader:
•
Starts
•
Submits a warning message
•
Completes successfully
•
Completes unsuccessfully, if the Clean up bulk loader directory
after load option is selected
Additionally, for Microsoft SQL Server and Sybase ASE, writes
when the SQL Server bulk loader:
•
Completes a successful row submission
•
Encounters an error
SQL Loaders
This instance reports all SQL that Data Services submits to the
target database, including:
•
When a truncate table command executes if the Delete data
from table before loading option is selected.
•
Any parameters included in PRE-LOAD SQL commands
•
Before a batch of SQL statements is submitted
•
When a template table is created (and also dropped, if the
Drop/Create option is turned on)
•
When a delete from table command executes if auto correct
is turned on (Informix environment only).
This trace also writes all rows that Data Services loads into the
target.
Writes a message for every row retrieved from the memory table.Memory Source
Writes a message for every row inserted into the memory table.Memory Target
46 Data Services Reference Guide

SQL Only
Tables
Scripts and Script
Functions
Data Services Objects
Descriptions of objects
DescriptionTrace
Use in conjunction with Trace the SQL Transforms option, the Trace
SQL Readers option, or the Trace SQL Loaders option to stop the writing
of trace messages for data sent and received from the database.
For Business Objects consulting and technical support use.Optimized Dataflow
Writes a message when a table is created or dropped. The message
indicates the datastore to which the created table belongs and the
SQL statement used to create the table.
Writes a message when Data Services runs a script or invokes a
script function. Specifically, this trace links a message when:
•
The script is called. Scripts can be started any level from the job
level down to the data flow level. Additional (and separate) notation is made when a script is called from within another script.
•
A function is called by the script.
2
Trace Parallel Execution
Access Server
Communication
•
The script successfully completes.
Writes messages describing how data in a data flow is parallel processed.
Writes messages exchanged between the Access Server and a
service provider, including:
•
The registration message, which tells the Access Server that the
service provider is ready
•
The request the Access Server sends to the service to execute
•
The response from the service to the Access Server
•
Any request from the Access Server to shut down
Data Services Reference Guide 47

Data Services Objects
2
Descriptions of objects
RFC Function
Stored Procedure
DescriptionTrace
Writes a message related to RFC calls including:
• start of RFC call
• end of RFC call
• a message for each record received from Data Services for the RFC
call
Writes a message when Data Services invokes a stored procedure.
This trace reports:
•
When the stored procedure starts
•
The SQL query submitted for the stored procedure call
•
The value (or values) of the input parameter (or parameters)
•
The value (or values) of the output parameter (or parameters)
•
The return value (if the stored procedure is a stored function)
•
When the stored procedure finishes
Writes messages from readers of SAP and R/3 system tables including:
SAP Table Reader
IDoc file reader
48 Data Services Reference Guide
• start reading from table
• stop reading from table
• start of connection to SAP system where table is present
• end of connection to SAP system
Writes a message when reading IDoc files including:
• start reading the IDoc file
• stop reading the IDoc file
• result of the IDoc file validation

Audit Data
Assemblers
Data Services Objects
Descriptions of objects
DescriptionTrace
Writes a message when auditing:
•
Collects a statistic at an audit point
•
Determines if an audit rule passes or fails
Writes messages for Substitution Parameter and SDK Transforms:
• Substitution parameters - Writes trace messages such as substitution
configuration used and the actual value substituted for each substitution parameter.
• SDK transforms - Writes transform-specific information specified in
the form of XML. This information can be hierarchical. At runtime
this XML information is extracted or assembled. The trace messages
write the assembled XML.
2
Catch
Class
Single-use
Access
With a work flow in the workspace, click the catch icon in the tool palette.
Description
A catch object is part of a serial sequence called a try/catch block. The
try/catch block allows you to specify alternative work flows if one or more
errors occur while Data Services is executing a job. Try/catch blocks "catch"
Data Services Reference Guide 49

Data Services Objects
2
Descriptions of objects
exception groups of errors, apply solutions that you provide, and continue
execution.
For each catch object in the try/catch block, specify the following:
• One or more groups of exceptions that the catch object handles.
If you want to assign different actions to different exception groups, add
a catch for each set of actions.
• The actions to execute if an exception in the indicated exception groups
occurs.
It is recommended that you define, test, and save the actions as a
separate object rather than constructing them inside the catch editor. The
actions can be a single script object, a data flow, a workflow, or a
combination of these objects.
• Optional error functions inside the catch block to identify details of the
error.
If an exception is thrown during the execution of a try/catch block, and if no
catch object is looking for that exception group, then the exception is handled
by normal error logic.
For batch jobs only, do not reference output variables from a try/catch block
in any subsequent steps if you are using the automatic recovery feature.
Referencing such variables could alter the results during automatic recovery.
Also, try/catch blocks can be used within any real-time job component.
However, try/catch blocks cannot straddle a real-time processing loop and
the initialization or cleanup component of a real-time job.
Catch objects have the following attribute:
DescriptionAttribute
Name
The following table describes exception groups that you can catch in a
try/catch block:
50 Data Services Reference Guide
The name of the object. This name appears on the object
in the diagram.

Data Services Objects
Descriptions of objects
2
Exception group
Group
number
1002Database access errors
Description
All errorsAllCatch All Exceptions
Errors in Data Services job server1001Execution errors
Errors from the database server while reading data,
writing data, or bulk loading to tables
Errors connecting to database servers1003Database connection errors
Errors processing flat files1004Flat file processing errors
Errors accessing local and FTP files1005File access errors
Errors accessing the Data Services repository1006Repository access errors
Errors from the SAP R/3 System1007R/3 Execution errors
Errors accessing operating system resources1008System resource exception
Errors from the SAP BW system1009SAP BW execution errors
Errors processing XML files and messages1010XML processing errors
Catch error functions
The following table describes error functions that you can use in the script
that your catch work flow executes.
Errors processing COBOL copybook files1011COBOL copybook errors
Errors processing Excel books1012Excel book errors
Errors processing Data Quality transforms1013Data Quality transform errors
Data Services Reference Guide 51

Data Services Objects
2
Descriptions of objects
Note:
You can only invoke these error functions inside a catch script, a user
function, or in an audit script for a data flow. If you call these error functions
in any other place, a validation error occurs.
Catch error function
Related Topics
• Designer Guide: Work flows, Example: Catching details
Catch scripts
of an error
Return data type
and size
timestamperror_timestamp()
varchar 512error_context()
varchar 512error_message()
interror_number()
Description
Returns the timestamp of the caught
exception.
Returns the context ofthe caught exception. For example, "|Session datapreview_job|Dataflow debug_DataFlow|Transform Debug"
Returns the error message of the caught
exception.
Returns the error number of the caught
exception.
A script is the most common action that a catch executes for a thrown
exception. The catch script can contain the following:
• Catch error functions and other function calls
• Nested try/catch blocks
• if statements to perform different actions for different exceptions
The syntax for a try/catch block within a script is as follows:
try
begin
steps
end
52 Data Services Reference Guide

catch(integer_constants)
begin
steps
end
Where:
steps
integer_constants
Data Services Objects
Descriptions of objects
Catch error functions, other function
calls, if statements, or other statements
you want to perform for an error in the
specified exception group number.
One or more exception group numbers that you want to catch.
Use a comma to separate exception
group numbers. For example,
catch(1002,1003)
Specify ALL to catch all exceptions:
2
Related Topics
• Designer Guide: Work flows, Example: Catching details
of an error
COBOL copybook file format
Class
Reusable
catch(ALL)
Data Services Reference Guide 53

Data Services Objects
2
Descriptions of objects
Access
In the object library, click the Formats tab.
Description
A COBOL copybook file format describes the structure defined in a COBOL
copybook file (usually denoted with a .cpy extension). You store templates
for file formats in the object library. You use the templates to define the file
format of a particular source in a data flow.
The following tables describe the Import, Edit, and Source COBOL
copybook options.
Import or Edit COBOL copybook format options
The "ImportCOBOL Copybook" and "Edit COBOL Copybook" format windows
include options on the following tabs:
• Format
• Data File
• Data Access
The "Edit COBOL Copybook" format window includes options on the following
tabs:
• Field ID
• Record Length Field
Format tab
The Format tab defines the parameters of the COBOL copybook format.
Format tab options are not editable in the "Edit COBOL Copybook" window.
DescriptionFormat option
File name
54 Data Services Reference Guide
Type or browse to the COBOL copybook file name (usually has a .cpy
extension). This file contains the schema definition.
For added flexibility, you can enter a variable for this option.

Data Services Objects
Descriptions of objects
DescriptionFormat option
2
Expand OCCURS
Source format
Specifies the way to handle OCCURS groups. These groups can be
imported with each field in an OCCURS group in one of the following
ways:
• Getting a sequential suffix for each repetition: fieldname_1, field-
name_2, etc. (expanded view)
• Appearing only once in the copybook's schema (collapsed view).
For a collapsed view, the output schema matches the OCCURS
group definition, and for each input record there will be several output
records.
If a copybook contains more than one OCCURS group, you must
select this box. The default is selected.
Determines whether or not to ignore REDEFINES clauses.Ignore redefines
The format of the copybook source code. Options include:
• Free—All characters on the line can contain COBOL source code.
• Smart mode—Data Services will try to determine whether the source
code is in Standard or Free format; if this does not produce the desired result, choose the appropriate source format (Standard or Free)
manually for reimporting.
• Standard—The traditional (IBM mainframe) COBOL source format,
where each line of code is divided into the following five areas: sequence number (1-6), indicator area (7), area A (8-11), area B (12-
72) and comments (73-80).
Source codes [start]
Source codes [end]
Generate record
number field
Defines the start column of the copybook source file to use during the
import. Typical value is 7 for IBM mainframe copybooks (standard source
format) and 0 for free format.
Defines the end column of the copybook source file to use during the
import. Typical value is 72 for IBM mainframe copybooks (standard
source format) and 9999 for free format.
If selected, creates a new field at the beginning of the schema that Data
Services populates at run time with the record number.
Data Services Reference Guide 55

Data Services Objects
2
Descriptions of objects
Data File tab
The Data File tab defines the parameters of the data file.
DescriptionData file option
Directory
File name
Type
Has record length
Specifies the directory that contains the COBOL copybook data file to
import. For added flexibility, you can enter a variable for this option. If
you include a directory path here, then enter only the file name in the
Name field. During design, you can specify a file in one of the following
ways:
• For a file located on the computer where the Designer runs, you can
use the Browse button.
• For a file located on the computer where the Job Server runs, you
must type the path to the file. You can type an absolute path or a
relative path, but the Job Server must be able to access it.
Type the name or browse to the COBOL copybook data file. You can
use variables or wild cards (* or ?).
If you leave Directory blank, then type the full path and file name
here.
Specifies the record format—fixed or variable:
• Fixed(F)
• Variable(V)
Specifies whether variable-length records of the data file contain information about the length of each record. The possible values are:
• 2-byte integer
• 2-byte followed by 0x0000 (integer followed by two zero bytes)
• 4-byte integer
• None—No length information at the beginning of each record
Record size
Record trailer
length
56 Data Services Reference Guide
Defines fixed record length in bytes. All records in the file have this length
(padded, if necessary).
Specifies the length of extra character padding in bytes at the end of
each record.

Data Services Objects
Descriptions of objects
DescriptionData file option
2
Has record mark
Integer format
Skip first
Read total
Low Value and High
Value
Defines whether there is an extra byte in the beginning of each record's
data.
Describes how the existing data file stores binary data:
• Big endian—the most significant byte comes first
• Little endian—the least significant byte comes first
Specifies the character encoding of character data in the data file.Code page
Defines the number of data records to skip before starting to process
the file. For added flexibility, you can enter a variable for this option.
Defines the number of records to read and process. For added flexibility,
you can enter a variable for this option.
Identifies a valid hexadecimal value for a low value, high value, or both
from the copybook and applies the associated Action. You can also use
a variable to define a different value at run time. The Low Value default
is 0x40 and the High Value default is 0xFF.
For example, if the source field is binary 0x40, enter a Low Value of
0x40 and select the action Convert to NULL. The result would be
as follows for these data types:
• Char—Character represented by 0x40
• Packed decimal—NULL
• Binary—0x40
Action
For a Low or High Value, applies one of the following actions:
• No conversion—Reads the value as an ASCII character (default).
• Convert to NULL—Converts the given value to NULL.
• Convert to 0—Converts the given value to 0.
Data Access tab
The Data Access tab specifies how Data Services accesses the data file. If
both check boxes are cleared, Data Services assumes the data file is on the
same computer as the Job Server.
Data Services Reference Guide 57

Data Services Objects
2
Descriptions of objects
option
DescriptionData access
Select to use FTP to access the data file.FTP
Host
Directory
File name
Type the computer (host) name, fully qualified domain name, or IP address
of the computer where the data file resides.
Type the FTP user name.User
Type the FTP user password.Password
Type or browse to the directory that contains the COBOL copybook data file
to import. If you include a directory path here, then enter only the file name
in the Name field.
Type or browse to the COBOL copybook data file Name. You can use variables or wild cards (* or ?).
If you leave Directory blank, then type a full path and file name here.
Select to use a custom executable to access the data file.Custom
Type the name of the program to read data file.Executable
Type the user name.User
Type the password.Password
Include any custom program arguments.Arguments
Field ID tab
If the imported copybook contains multiple schemas, the Field ID tab is visible
on the "Edit COBOL Copybook" window. These options allow you to create
rules for identifying which records represent which schemas.
58 Data Services Reference Guide

tion
Data Services Objects
Descriptions of objects
DescriptionField ID op-
2
Use field
<FIELD
NAME> as ID
Insert above
Insert below
Record Length Field tab
Select to set a value for the field selected in the top pane. Clear
to not set a value for that field.
Changes the selected value in the Values pane to editable text.Edit
Deletes the selected value in the Values pane.Delete
Inserts a new value in the Values pane above the selected
value.
Inserts a new value in the Values pane below the selected
value.
After you import a copybook, the Record Length Field tab is visible on the
"Edit COBOL Copybook" window. It lets you identify the field that contains
the length of the schema's record.
DescriptionRecord Length
Field column
The data schemas in the copybook.Schema
Record length
field
Offset
Click to enable a drop-down menu where you select a field
(one per schema) that contains the record's length.
The value that results in the total record length when added
to the value in the Record length field. The default value for
offset is 4; however, you can change it to any other numeric
value.
Data Services Reference Guide 59

Data Services Objects
2
Descriptions of objects
COBOL copybook source options
The source editor includes the following COBOL copybook options on the
following tabs:
• Source
• Field clauses
• Data File
• Data Access
Source tab
DescriptionSource option
Makes the source table an embedded data flow port.
For more information, see Creating embedded data flows in the
Make port
Data Services Designer Guide.
For more information, see the Embedded Data Flows chapter in
the Data Services Designer Guide.
Performance
Indicates the rank of the source relative to other tables and files
in the data flow when creating a join. Data Services joins sources
with higher join ranks before joining sources with lower join ranks.
For more information, see Join ordering in the Data Services
Join rank
60 Data Services Reference Guide
Performance Optimization Guide. and the Other Tuning Techniques
chapter in the Data Services Performance Optimization Guide .
Note:
Must be a non-negative integer. When set to its default value (zero),
Data Services determines join order.

Data Services Objects
Descriptions of objects
DescriptionSource option
2
Cache
Error handling
Log data conversion
warnings
Maximum warnings
to log
Include file name column
Include file name column
Indicates whether Data Services should read the required data
from the source and load it into memory or pageable cache. .
Determines whether to include data-type conversion warnings in
the Data Services error log. Defaults to Yes.
If Log data conversion warnings is enabled, you can limit how
many warnings Data Services logs. Defaults to {no limit}.
Determines whether to add a column that contains the source file
name in the source output. Defaults to No.
Change the value to Yes when you want to identify the source file
in situations such as the following:
•
You specified a wildcard character to read multiple source
COBOL copybooks at one time
Modify
File name column
•
You load from different source copybooks on different runs
If the file name is included, this button enables you to modify File
name column and Column size.
If the file name is included, the name of the column that holds the
source file name. Defaults to DI_FILENAME.
Data Services Reference Guide 61

Data Services Objects
2
Descriptions of objects
Column size
DescriptionSource option
If the file name is included, the size (in characters) of the column
that holds the source file name.
Defaults to 100. If the size of the file name column is not large
enough to store the file name, truncation occurs from the left.
Include path
Field clauses tab
The Field clauses tab displays the attributes for a selected column.
Possible values
Level
If the file name is included, determines whether to include the full
path name of the source file. Defaults to No.
DescriptionField clauses option
Enter values here to force Data Services to only process rows
that contain the specified value(s). Separate multiple values with
the pipe character (|). You can click the ellipses button to open
the smart editor; for details on how to use the smart editor, see
the Smart Editor chapter in the Data Services Reference Guide.
The level number (01-50) assigned to the field in the source record
definition.
The name of the field in the copybook.Original name
The PICTURE clause of the field in the copybook.Original picture
The USAGE clause of the field in the copybook.Original usage
62 Data Services Reference Guide

Data Services Objects
Descriptions of objects
DescriptionField clauses option
2
Min occurs
Max occurs
Occurs depending on
Sign separate
Multiply by
Minimum number of occurrences for this field (if this field is a part
of an OCCURS group).
Maximum number of occurrences for this field (if this field is a
part of an OCCURS group).
Specifies the repetition counter field name for the ODO (OCCURS
DEPENDING ON).
Specifies the name of another field that this one REDEFINES.Redefines
Specifies whether the sign is stored separately from the field's
value.
Specifies whether the sign is LEADING or TRAILING.Sign position
Specifies whether the field needs to be scaled (multiplied or divided by a certain number). For example, if the field's PICTURE
clause is 9(5)P(3), the value of the field from the data file will be
multiplied by 1000.
Related Topics
• Import or Edit COBOL copybook format options on page 54
Conditional
Data Services Reference Guide 63

Data Services Objects
2
Descriptions of objects
Class
Single-use
Access
With a work flow diagram in the workspace, click the conditional icon in the
tool palette.
Description
A conditional implements if/then/else logic in a work flow.
For each conditional, specify the following:
• If: A Boolean expression defining the condition to evaluate.
The expression evaluates to TRUE or FALSE. You can use constants,
functions, variables, parameters, and standard operators to construct the
expression. For information about expressions, see Chapter 3: Smart
Editor.
Note:
Do not put a semicolon (;) at the end of your expression in the If box.
• Then: A work flow to execute if the condition is TRUE.
• Else: A work flow to execute if the condition is FALSE.
This branch is optional.
The Then and Else branches of the conditional can be any steps valid in a
work flow, including a call to an existing work flow.
Conditionals have the following attribute:
64 Data Services Reference Guide

Data Services Objects
Descriptions of objects
DescriptionAttribute
2
Data flow
Name
Class
Reusable
Access
• In the object library, click the Data Flows tab.
• With a work flow diagram in the workspace, click the data flow icon in the
tool palette.
Description
The name of the object. This name appears on the object
in the diagram.
A data flow extracts, transforms, and loads data.
You can define parameters to pass values into the data flow. You can also
define variables for use inside the data flow.
When Data Services executes data flows, it optimizes the extract, transform,
and load requirements into commands to the DBMS and commands executed
internally. Where it can, Data Services runs these operations in parallel.
By definition, a data flow can contain the following objects:
Sources Files, tables, XMl files, XML messages (real-time jobs only),
documents, or pre-defined template tables
Data Services Reference Guide 65

Data Services Objects
2
Descriptions of objects
Targets Files, tables, XML files, XML messages (real-time jobs only),
outbound messages, documents, XML template, or template tables
Transforms Query is the most commonly used transform
You can view the SQL code Data Services generates for table sources in
data flows and improve your data flow design accordingly.
Data flows have several built-in properties.
DescriptionAttribute
Name
If you delete a data flow from the object library, calls to the object are replaced
with an icon indicating that the calls are no longer valid in the workspace.
Related Topics
• Performance Optimization Guide: Viewing SQL
The name of the object. This name appears on the object
in the object library and in the calls to the object.
Your description of the data flow.Description
Executing jobs only once
You can ensure that a job executes a data flow only one time by selecting
the Execute only once check box on the data flow Properties window. When
you select this check box, Data Services executes only the first occurrence
of the data flow and skips subsequent occurrences of it in the job. You might
use this feature when developing complex jobs with multiple paths, such as
those containing try/catch blocks or conditionals, and you want to ensure
that Data Services executes a particular data flow only once. Before selecting
the Execute only once, note that:
66 Data Services Reference Guide

• If you design a job to execute the same Execute only once data flow in
parallel flows, Data Services only executes the first occurrence of that
data flow and you cannot control which one Data Services executes first.
Subsequent flows wait until Data Services processes the first one. The
engine provides a wait message for each subsequent data flow. Since
only one Execute only once data flow can execute in a single job, the
engine skips subsequent data flows and generates a second trace
message for each, "Data flow n did not run more than one time. It is an
execute only once flow."
• The Execute only once data flow option does not override the Recover
as a unit work flow option and the Enable recovery job option.
Parallel processing
You can run certain transforms and functions in parallel by entering a number
in the Degree of parallelism box on your data flow Properties window. When
you drop a transform into the data flow and a function into each transform,
the number you enter in the Degree of parallelism box is the maximum
number of instances that can be generated for each transform or function in
the data flow.
Data Services Objects
Descriptions of objects
2
Related Topics
• Performance Optimization Guide: Degree of parallelism
Caching data
You can cache data to improve performance of operations such as joins,
groups, sorts, lookups, and table comparisons. You can select one of the
following values for the Cache type option on your data flow Properties
window:
• In-Memory: Choose this value if your data flow processes a small amount
• Pageable: This value is the default.
of data that can fit in the available memory.
Data Services Reference Guide 67

Data Services Objects
2
Descriptions of objects
Datastore
Note:
For data flows that you created prior to version 11.7, the default cache
type is in-memory. If the data retrieved does not fit into available memory,
change the cache type to pageable in the data flow Properties window.
Note:
You cannot use pageable cache with nested data or LONG data types.
Related Topics
• Performance Optimization Guide: Caching sources
Class
Reusable
Access
In the object library, click the Datastores tab.
Description
A datastore provides a connection to a data source such as a database.
Through the datastore connection, Data Services can import descriptions of
the data source such as its metadata. When you specify tables as sources
or targets in a data flow, Data Services uses the datastore to determine how
to read data from or load data to those tables. In addition, some transforms
and functions require a datastore name to qualify the tables they access.
Datastores have the following properties:
68 Data Services Reference Guide

Data Services Objects
Descriptions of objects
DescriptionProperty
2
Name
Date_created
Note:
If you delete a datastore from the object library, you must remove references
to the datastore from the following locations:
• Source or target tables using this datastore in your diagrams
• The lookup and key_generation functions and Key_Generation,
History_Preserving, Table_Comparison, and SQL transform references
Datastore editor
To open the datastore editor, go to the Datastores tab in the object library,
right-click the white space, and select New to open the Create New Datastore
window.
The name of the object. This name appears on the object
in the object library and in the calls to the object. You cannot change the name of a datastore after creation.
Text that you enter to describe and document the datastore.Description
The date that you created the datastore. You cannot
change this value.
Alternatively, right-click the name of an existing datastore and select Edit to
open the Edit Datastore DatastoreName window. Depending on the
datastore, some options cannot be changed on the Edit Datastore editor.
Basic datastore options
When you create a new datastore, complete the top part of the Create New
Datastore window to provide the minimum required information. Initially, only
three options appear on this resizable window: Datastore name, Datastore
type, and Database type. When you select a datastore type, the window
automatically updates to display other options relevant to that type. The
combination of Datastore type and Database type determine the rest of
the available options for that datastore.
There are four general categories of datastores:
Data Services Reference Guide 69

Data Services Objects
2
Descriptions of objects
• Database datastores let you connect to supported databases.
• Adapter datastores let you connect to adapters.
• Application datastores such as PeopleSoft and JDE One World let you
connect to applications that run on databases. You can select these
applications by name from the Datastore type list.
• Web service datastores let you connect to external Web-service-based
data sources.
For example, if for Datastore type you select Database and for Database
type you select Oracle, the following options appear:
Data Services supports changed-data capture (CDC) and transfer tables
with Oracle databases. So in this case, the Designer displays the Enable
CDC and Enable automatic data transfer check boxes.
• The Enable CDC option is available only when you create a new
datastore. After you save a datastore, or when editing a datastore, Data
Services disables the Enable CDC check box. Note that although a
database datastore may have multiple configurations of different database
types, if you enable CDC for a datastore then all configurations must use
the same database type.
• The Enable automatic data transfer check box is selected by default
when you create a new datastore and you chose Database for Datastore
type. This option is available when you edit an existing datastore. This
option displays for all databases except Attunity Connector, Memory, and
Persistent Cache. Keep Enable automatic data transfer selected to
enable transfer tables in this datastore that the Data_Transfer transform
can use to push down subsequent database operations.
70 Data Services Reference Guide

Note:
The Enable automatic data transfer check box is not available for
application datastores such as SAP and Oracle Applications.
Related Topics
• Advanced datastore options on page 71
• Database datastores on page 83
• Designer Guide: Datastores, Adapter datastores
• Application datastores on page 133
• Designer Guide: Datastores, Web service datastores
• Designer Guide: Techniques for Capturing Changed Data, Understanding
changed-data capture
• Performance Optimization Guide: Maximizing Push-Down Operations,
Data_Transfer transform for push-down operations
Advanced datastore options
Click Advanced to expand the datastore editor. The expanded window
displays a grid of additional datastore options.
Data Services Objects
Descriptions of objects
2
Data Services Reference Guide 71

Data Services Objects
2
Descriptions of objects
You can toggle the Advanced button to hide and show the grid of additional
datastore editor options.
The grid displays datastore configurations as column headings and lists
datastore options in the left column. Each row represents a configuration
option. Different options appear depending upon datastore type and (if
applicable) database type and version. Specific options appear under group
headings such as Connection, General, and Locale.
To improve readability, you can expand and collapse the datastore option
groups. Each cell in the grid represents the value for a configuration option.
If the value for a cell comes from a closed set, the cell becomes a drop-down
list when you click it. If Data Services requires you to manually enter the
value for an option, the cell becomes an text box when you click it.
72 Data Services Reference Guide

If the Database type supports multiple configurations, the window also
enables the Edit… button.
Related Topics
• Basic datastore options on page 69
Datastore configurations editor
Use the configurations editor to add, edit, and remove datastore
configurations. The configurations editor is a subset of datastore editor
functionality.
Using multiple configurations with database datastores can minimize your
efforts to port existing jobs from one database type and version to another.
The datastore editor supports quick creation of multiple configurations by
allowing you to duplicate and rename configurations. Duplicating a
configuration copies its options to create another configuration.
To open the configurations editor, in the datastore editor, display the
Advanced options. Click the Edit button.
The configurations editor contains a grid of options and an editing toolbar.
It always contains at least one configuration (initially that configuration reflects
the first values set for the datastore). This first configuration is the default.
When a datastore contains only one configuration (the default), you cannot
remove it from the datastore. All subsequent configurations appear as
additional columns in the grid.
Data Services Objects
Descriptions of objects
2
Data Services Reference Guide 73

Data Services Objects
2
Descriptions of objects
The configurations editor provides a tool bar that includes commands to add,
edit, and remove configurations. From left to right, the toolbar buttons are:
Create NewConfiguration
74 Data Services Reference Guide
DescriptionButton nameButton
Adds a new configuration with no values.

Duplicate Configuration
Data Services Objects
Descriptions of objects
DescriptionButton nameButton
Creates a new configuration with identical
settings as the selected configuration. The
new configuration name must be unique,
so Data Services uses the following naming convention: OldConfigurationName
_Copy_CopyNumber.
For example, if you duplicate a configuration called TestConfiguration, Data
Services would name the duplicate
TestConfiguration_Copy_1. If you do
not rename the original or duplicate
configuration and duplicate the original
configuration again, the copy number
appends by 1. So, Data Services would
name the second duplicate TestConfiguration_Copy_2, and so forth.
2
Rename Configuration
Delete Configuration
Sort Configurations
(Ascending)
Sort Configurations
(Descending)
Highlights shifts input focus to the name
of the selected configuration so you can
edit it.
Removes the configuration from the datastore and its column from the grid.
Arranges the configurations by their
names in ascending order. The arrangement is sensitive to the computer's system
locale.
Arranges the configurations by their
names in descending order. The arrangement is sensitive to the computer's system
locale.
Data Services Reference Guide 75

Data Services Objects
2
Descriptions of objects
DescriptionButton nameButton
Move Default to
First
Create New Alias
Delete Alias
Expand All Categories
Collapse All Categories
Show/Hide Details
Navigation box
Moves the default configuration to the first
column in the list. Does not change the
order of other columns.
Adds a new alias name for the datastore.
To map individual configurations to an
alias, enter the real owner name of the
configuration in the grid.
Removes the selected alias name for the
datastore.
Opens all the nodes so that every configuration property is visible.
Closes all the nodes so that every configuration property is hidden.
This is a toggle to show additional datastore options on the dialog box: Database
type, Number of Configurations, and CDC
status.
This list contains the names of all configurations. Selecting a name from this list will
(if necessary) scroll the configuration into
view and highlight the configuration name
in the grid.
These commands (except for the Navigation box) also appear on a shortcut
menu when you right-click any active cell on the grid. The right-click menu
also contains the following commands:
• Add Linked Datastore
• Delete Linked Datastore
• Create New Alias
• Delete Alias
To save a newly defined configuration and keep working in the configurations
editor, click Apply. To save configuration changes and exit the configurations
76 Data Services Reference Guide

Data Services Objects
Descriptions of objects
editor, click OK. Data Services saves your configurations in the same
sequence shown in the configurations editor. To exit the configurations editor
without saving changes, click Cancel.
You can also manage configurations by directly manipulating the grid.
• When a datastore contains more than one configuration, you can
rearrange the order of configuration columns by clicking a configuration
name and dragging it left or right.
• Double-click a configuration name to edit it.
• Right-click a configuration name or any active cell on the grid to select
an option from the shortcut menu.
Because Data Services requires that each datastore have only one default
configuration (used to browse, search, and import metadata), when you
select Yes as the default for any one configuration, the grid automatically
sets the Default configuration value for the others to No.
Note:
While you can change the Default configuration value from No to Yes, you
cannot change the value from Yes to No. If you attempt to do so, the Designer
displays an error message instructing you to select Yes for another
configuration instead.
2
Related Topics
• Importing database links on page 81
• Working with aliases on page 81
Adding a datastore configuration
To add a configuration, in the configurations editor click the Create New
Configuration icon, or right-click a configuration name or any active cell on
the grid and select Create New Configuration.
When you add a new configuration, Data Services modifies the language of
data flows in the datastore if the data flows contain any of the following
objects:
• Table targets
• Table transfer type used in Data_Transfer transform as a target
• SQL transforms
Data Services adds the target options and SQL transform text to additional
datastore configurations based their definitions in an existing configuration.
Data Services Reference Guide 77

Data Services Objects
2
Descriptions of objects
This functionality operates in the following ways:
• If a new configuration has the same database type and the same or newer
version as an old configuration, then Data Services automatically uses
the existing SQL transform, target table editor, and Data_Transfer
transform editor values (including bulk loader options).
• If the database type and version are not already associated with (or if the
version is older than) any existing configuration, you can use the values
from an existing database type and version by selecting that option from
the Use values from list.
The Use values from list always contains the following options:
• Default values
• Database type and version for each configuration currently associated
with the datastore
So if your datastore contains two configurations, for example one for
Oracle 9i and one for Microsoft SQL Server 2000, when you create a third
configuration, (in this example, for DB2) in the Use values from list, you
will see the options Default values, Oracle 9i, and Microsoft SQL Server
2000.
Default values are the same defaults that appear for all database targets,
Data_Transfer target tables, and SQL transforms. Default SQL text is
always blank. Some target option default values are:
Row commit size = 1000
Column comparison = Compare by name
78 Data Services Reference Guide

Data Services Objects
Descriptions of objects
Delete data from table before loading = No
Drop and re-create table = No for regular tables (Yes for template tables)
• If you select the Restore values if they already exist check box
(pre-selected as default), Data Services creates the new configuration
then determines whether SQL transform, target table editor, or
Data_Transfer transform editor values already exist for the new database.
If the database values already exist, Data Services restores the bulk load
option. However, if no values exist for the database, Data Services sets
the bulk load option to None, the default value.
Also, if you clear Restore values if they already exist, Data Services
sets the bulk load option to None, the default value.
For example, suppose you are working in a multiuser environment and have
a local datastore with configurations for Oracle 9i and SQL Server 2000. You
also have existing data flows that use target tables, Data_Transfer target
tables, or SQL transforms from this datastore. You then delete Oracle 9i
(perhaps because you checked out a different version of the datastore from
the central repository). Later, you want to add an Oracle 9i configuration to
this datastore.
2
Deleting a version causes Data Services to remove the configuration, but
not the target table, Data_Transfer target table, and SQL transform values.
If you select Restore values if they already exist when you create a new
configuration, Data Services determines whether values already exist for the
database. If Data Services cannot find these values, the Designer uses
values specified in the Use values from box.
After you click Apply to save a new configuration, Data Services:
• Copies any existing SQL transform, target table editor, and Data_Transfer
target table editor values, and
• Displays a report of the modified objects in a pop-up window as well as
in the Designer "Output" window.
Data Services Reference Guide 79

Data Services Objects
2
Descriptions of objects
The report shows the following information:
• Names of the data flows where language was modified
• Objects in the data flows that were affected
• Types of the objects affected (table target or SQL transform)
• Usage of the objects (source or target)
• Whether the objects have a bulk loader
• Whether the bulk loader option was copied
• Whether there were previous values
• Whether the previous values were restored
You can use this report as a guide to manually change the values for options
of targets, Data_Transfer target tables, and SQL transforms, as needed. In
the pop-up window, you can sort results by clicking on column headers. You
can also save the output to a file. The pop-up appears after each newly
added configuration.
Data Services also clears and displays the results in the Output window after
each newly added configuration. Because the datastore editor windows are
modal, you cannot see the entire Output window or manipulate it. However,
you can double-click one of the objects on the report and to view the data
flow.
When a datastore contains multiple configurations of different database
types, the rows show the options for all configurations.
When an option does not apply to a configuration, the cell displays N/A in
gray and does not accept input. Cells that correspond to a group header
such as Connection and Locale display hashed gray lines and also do not
accept input.
80 Data Services Reference Guide

Working with aliases
Use this option to define aliases for your datastore. After you create an alias
(for example, ALIAS1, ALIAS2), navigate horizontally to each configuration
and define the owner name to which that alias name maps.
Note that Data Services does not label alias owner names in the
configurations grid.
When you delete an alias name, the delete operation applies to the entire
datastore (all configurations). Data Services removes the selected row which
includes the alias and all assigned owner names.
Importing database links
Use this datastore option to import and configure a database link in the
Designer. To link a target datastore to a source datastore using a database
link:
1. From the Datastores tab in the object library, right-click a target datastore
and select Edit.
Data Services Objects
Descriptions of objects
2
If the database type supports database links, the list of configuration
options includes the Linked Datastores option in the Advanced options
and in the configurations options.
Note:
The datastore editor allows you to edit database links on target datastores
for the default configuration only. So, if your target datastore contains
multiple configurations (for example: Config1, Config2, and Config3),
change your default configuration before you attempt to import or edit
links that apply to it (for example, make Config2 the default if you want
to edit it).
2. Click the Linked Datastores label.
The Add Linked Datastore window opens.
3. From the Add Linked Datastore window, select a datastore that your
target datastore will be linked to based on the settings in the database
link you want to import.
Data Services Reference Guide 81

Data Services Objects
2
Descriptions of objects
For example, if your target datastore is DS_Emp (employee information)
and the database link you want to import will associate employee
information with sales information, select DS_Sales (sales information).
The datastores in the list box have database types that Data Services
supports for linked datastores.
Note:
The datastore editor allows only one database link between a target
datastore and a source datastore pair. Therefore, if target datastore B
already has a link to source datastore A, you cannot import another
database link that associates datastore B with datastore A.
4. Click OK.
The Datastore Editor window displays the datastore that you selected.
5. Select the list button to the right of Not Linked or double-click the cell.
The Database Link window opens.
6. To link to a datastore or to change the existing link, select Use the
database link.
Note:
To remove an existing link, select Do not link.
7. Select a database link from the list that Data Services reads from the
default configuration connection of the target datastore you are editing.
This list box contains links that you previously defined on the DBMS.
8. Select the source datastore configuration that you want to use with this
database link.
9. (Optional) Select Details to view additional information about the links or
to test them.
82 Data Services Reference Guide

Data Services Objects
Descriptions of objects
The check mark indicates the link to use. If you use the Details window,
click OK when you are finished.
10. From the Database Link dialog, click OK.
Related Topics
• Designer Guide: Datastores, Linked datastores
2
Database datastores
You can define datastores so that Data Services can read from and write to
the following types of databases:
• Attunity Connector (use for mainframe systems)
• Data Federator (read only)
• DB2
•
HP Neoview (see ODBC on page 96)
• Informix
• Memory
• Microsoft SQL Server
•
MySQL (see ODBC on page 96)
•
Netezza (see ODBC on page 96)
• ODBC
• Oracle
• Persistent Cache
• Sybase ASE
Data Services Reference Guide 83

Data Services Objects
2
Descriptions of objects
Attunity
• Sybase IQ
• Teradata
Each database requires its own connection information in the datastore
definition.
For a description of the datastore connection information and options specific
to each database, see the tables in this section.
Note:
The Enable CDC option is available with a subset of the databases. When
the Enable CDC option is checked, the options in the following group
headings do not display because a CDC datastore is read-only and you can
only use it as a source: General, Bulk Loader, and FTP.
Related Topics
• Designer Guide: Datastores, What are datastores?
• Performance Optimization Guide: Using Bulk Loading
DescriptionPossible valuesAttunity option
Main window
Data source
Host location
84 Data Services Reference Guide
Refer to the requirements of
your database
Computer name, fully qualified domain name, or IP address
Positive integerPort
Type the Attunity data source
name(s) as defined in Attunity Studio. Separate multiple
data source names with
semicolons.
Type the name of the Attunity server computer (host).
Type the port number for the
Attunity server.

Attunity workspace
User name
Password
Refer to the requirements of
your database
Alphanumeric characters
and underscores
Alphanumeric characters,
underscores, and punctuation
Data Services Objects
Descriptions of objects
DescriptionPossible valuesAttunity option
Type the workspace name
under which the data
sources are defined in Attunity Studio.
Type the user name of the
account through which Data
Services accesses the
database.
Type the user's password.
2
Enable CDC
General (these options do not appear for CDC datastores)
Positive integerRows per commit
Overflow file directory
Directory path or click Browse
Select to enable changed data
capture for this datastore.
Enter the maximum number
of rows loaded to a target table before saving the data.
This value is the default
commit size for target tables
in this datastore. You can
overwrite this value for individual target tables.
Enter the location of overflow
files written by target tables
in this datastore. A variable
can also be used.
Data Services Reference Guide 85

Data Services Objects
2
Descriptions of objects
Locale
DescriptionPossible valuesAttunity option
Language
Code page
Server code page
Session
Additional session parameters
Aliases (Click here to create)
Aliases
A valid SQL statement or
multiple SQL statements delimited by semicolon
See the section "Locales and
Multi-Byte Functionality."
See the section "Locales and
Multi-Byte Functionality."
See the section "Locales and
Multi-Byte Functionality."
Additional session parameters specified as valid SQL
statement(s)
Enter the alias name and the
owner name to which the
alias name maps.
Data Federator
Any decimal column imported to Data Services from a Business Objects
Data Federator data source is converted to the decimal precision and
scale(28,6).
Any varchar column imported to Data Services from a Business Objects Data
Federator data source is varchar(1024).
86 Data Services Reference Guide

DB2
Main window
Database version
Data Services Objects
Descriptions of objects
You may change the decimal precision or scale and varchar size within Data
Services after importing form the Business Objects Data Federator data
source.
DescriptionPossible valuesDB2 option
DB2 UDB 6.1
DB2 UDB 7.1
DB2 UDB 7.2
Select the version of your DB2
client. This is the version of
DB2 that this datastore accesses.
DB2 UDB 8.x
Type the data source name
defined in DB2 for connecting
to your database.
2
Data source
User name
Password
General
Refer to the requirements of
your database
Alphanumeric characters and
underscores
Alphanumeric characters, underscores, and punctuation
Data Services Reference Guide 87
If you are going to use the
Auto correct load feature for
DB2 targets, be sure that
your data source allows your
user name to create or replace stored procedures.
Enter the user name of the
account through which Data
Services accesses the
database.
Enter the user's password.

Data Services Objects
2
Descriptions of objects
Bulk loader directory
Positive integerRows per commit
Directory path or click
Browse
DescriptionPossible valuesDB2 option
Enter the maximum number
of rows loaded to a target table before saving the data.
This value is the default
commit size for target tables
in this datastore. You can
overwrite this value for individual target tables.
Enter the location where
command and data files are
written for bulk loading. For
Solaris systems, the path
name must be less than 80
characters.
You can enter a variable for
this option.
Overflow file directory
Locale
Language
Code page
88 Data Services Reference Guide
Directory path or click
Browse
Enter the location of overflow
files written by target tables
in this datastore. A variable
can also be used.
See the section "Locales and
Multi-Byte Functionality."
See the section "Locales and
Multi-Byte Functionality."

Data Services Objects
Descriptions of objects
DescriptionPossible valuesDB2 option
2
Server code page
Bulk loader
Bulk loader user name
Bulk loader password
DB2 server working directory
Alphanumeric characters
and underscores or blank
Alphanumeric characters,
underscores, and punctuation, or blank
Directory path or click
Browse
See the section "Locales and
Multi-Byte Functionality."
The user name Data Services uses when loading data with the bulk loader option.
For bulk loading, you might
specify a different user
name. For example, specify
a user who has import and
load permissions.
The password Data Services
uses when loading with the
bulk loader option.
The working directory for the
load utility on the computer
that runs the DB2 server.
You must complete this field
whenever the DB2 server
and the Data Services Job
Server run on separate machines.
FTP
Data Services Reference Guide 89

Data Services Objects
2
Descriptions of objects
FTP host name
Computer name, fully qualified domain name, or IP address
DescriptionPossible valuesDB2 option
If this field is left blank or
contains the name of the
computer (host) where the
Data Services Job Server
resides, Data Services assumes that DB2 and Data
Services share the same
computer and that FTP is
unnecessary. When FTP is
unnecessary, all other FTPrelated fields can remain
blank.
FTP login user name
FTP login password
Session
Additional session parameters
Aliases (Click here to create)
Aliases
Linked Datastores (Click here to create)
Alphanumeric characters
and underscores, or blank
Alphanumeric characters,
underscores, and punctuation, or blank
A valid SQL statement or
multiple SQL statements delimited by semicolon.
Must be defined to use FTP.
Must be defined to use FTP.
Additional session parameters specified as valid SQL
statement(s)
Enter the alias name and the
owner name to which thealias
name maps.
90 Data Services Reference Guide

Datastore name
Informix datastore options
Main window
Alphanumeric characters
and underscores or blank
DescriptionPossible valuesInformix option
Data Services Objects
Descriptions of objects
DescriptionPossible valuesDB2 option
The name of a datastore to
which you linked the current
datastore configuration in
preparation to import a
database link
2
Database version
Data source
User name
Password
General
Informix IDS 7.3
Informix IDS 9.2
Refer to the requirements
of your database
Alphanumeric characters
and underscores
Alphanumeric characters,
underscores, and punctuation
Positive integerRows per commit
Select the version of your Informix
client. This is the version of Informix
that this datastore accesses.
Type the Data Source Name defined in
the ODBC.
Enter the user name of the account
through which Data Services accesses
the database.
Enter the user's password.
Enter the maximum number of rows
loaded to a target table before saving
the data. This value is the default commit size for target tables in this datastore. You can overwrite this value for
individual target tables.
Data Services Reference Guide 91

Data Services Objects
2
Descriptions of objects
Bulk loader directory
Directory path or click
Browse
DescriptionPossible valuesInformix option
Enter the directory where Data Services
writes sql, control, command, and data
files for bulk loading. For Solaris systems, the path name must be less than
80 characters.
You can enter a variable for this option.
Overflow file directory
Locale
Language
Code page
Server code page
Session
Additional session parameters
Directory path or click
Browse
A valid SQL statement
or multiple SQL statements delimited by
semicolon.
Enter the location of overflow files written by target tables in this datastore.
See the section "Locales and MultiByte Functionality."
See the section "Locales and MultiByte Functionality."
See the section "Locales and MultiByte Functionality."
Additional session parameters specified as valid SQL statement(s).
Aliases (Click here to create)
Aliases
92 Data Services Reference Guide
Enter the alias name and the owner
name to which the alias name maps.

Memory
Bulk Loader
JS andDB on same machine
Related Topics
• Locales and Multi-byte Functionality on page 1069
Microsoft SQL Server
Yes, No
Data Services Objects
Descriptions of objects
DescriptionPossible valuesMemory option
Indicate whether the Job
Server and database are on
the same computer.
2
Microsoft SQL Server option
Main window
Database version
Database server name
Database name
Microsoft SQL Server 7.0
Microsoft SQL Server 2000
Microsoft SQL Server 2005
Computer name, fully qualified domain name, or IP address
Refer to the requirements of
your database
DescriptionPossible values
Select the version of your
SQL Server client. This is the
version of SQL Server that
this datastore accesses.
Enter the name of machine
where the SQL Server instance is located.
Enter the name of the
database to which the datastore connects.
Data Services Reference Guide 93

Data Services Objects
2
Descriptions of objects
Microsoft SQL Server option
User name
Password
Enable CDC
Connection
Alphanumeric characters
and underscores
Alphanumeric characters,
underscores, and punctuation
No, YesUse Windows Authentication
DescriptionPossible values
Enter the user name of the
account through which Data
Services accesses the
database.
Enter the user's password.
Select to enable changed data
capture for this datastore.
Select whether to use Windows authentication or Microsoft SQL Server authentication to connect to this
datastore. Defaults to No.
For more information on how
to use Windows authentication with Microsoft SQL
Server, refer to the Microsoft
SQL Server documentation.
General
94 Data Services Reference Guide

Data Services Objects
Descriptions of objects
2
Microsoft SQL Server option
Overflow file directory
Locale
Language
Positive integerRows per commit
Directory path or click
Browse
DescriptionPossible values
Enter the maximum number
of rows loaded to a target table before saving the data.
This value is the default
commit size for target tables
in this datastore. You can
overwrite this value for individual target tables.
Enter the location of overflow
files written by target tables
in this datastore. You can
enter a variable for this option.
See the section "Locales and
Multi-Byte Functionality."
Code page
Server code page
Session
See the section "Locales and
Multi-Byte Functionality."
See the section "Locales and
Multi-Byte Functionality."
Data Services Reference Guide 95

Data Services Objects
2
Descriptions of objects
Microsoft SQL Server option
Additional session parameters
Aliases (Click here to create)
Aliases
Linked Datastores (Click here to create)
Datastore Name
A valid SQL statement or
multiple SQL statements delimited by semicolon
Alphanumeric characters
and underscores or blank
DescriptionPossible values
Additional session parameters specified as valid SQL
statement(s)
Enter the alias name and the
owner name to which the
alias name maps.
The name of a datastore to
which you linked the current
datastore configuration in
preparation to import a
database link
ODBC
Use an ODBC datastore to define the following databases:
• MySQL
• Netezza
• HP Neoview
To define an ODBC datastore connection, you need to define a data source,
a user name, a password if applicable, and optionally a set of advanced
options.
96 Data Services Reference Guide

Data Services Objects
Descriptions of objects
Selecting an ODBC data source
You can select a data source in one of the following ways. In the Data source
field of the ODBC datastore editor:
• From the drop-down list, click an existing data source
• Type the name of a data source
• Click ODBC Admin to launch the Windows ODBC Data Source
Administrator where you create or configure data sources. After closing
the ODBC Data Source Administrator, you can select a newly created
data source from the datastore editor's drop-down list.
Defining ODBC datastore options
To define options for an ODBC datastore, click Advanced. For each option
to configure, you can select a value from its drop-down list, or many options
allow you to type a custom value.
Most ODBC datastore options include the following values.
2
Automatic
When you create a new ODBC datastore, most options default to Automatic.
With this setting, if you do not know if the ODBC driver supports an option,
Data Services queries the driver to determine its capabilities. If the driver
supports that option, Data Services pushes down the operation to the ODBC
database. If the ODBC driver does not support that option, Data Services
executes the operation internally.
To circumvent possible inconsistencies with the ODBC driver, you might
need to specify an option other than Automatic. If you select anything other
than Automatic, Data Services does not query the driver for that particular
capability. Most options in the ODBC datastore editor provide some or all of
the following choices.
ODBC syntax
Data Services assumes the ODBC driver supports the function/capability
and uses ODBC syntax.
Data Services Reference Guide 97

Data Services Objects
2
Descriptions of objects
For example, for the ABSOLUTE function, the syntax is:
{fn abs (TAB1.COL1)}
SQL-92
Data Services assumes the ODBC driver supports the function/capability
and uses SQL-92 syntax.
For example, when Data Services generates an explicit CONVERT function,
the syntax is:
CAST (TAB1.VC_COL AS SQL_INTEGER)
No
Data Services assumes the ODBC driver does not support the
function/capability and executes it internally.
Custom
Many functions allow you to type in the specific function call to use for that
option. Data Services assumes the ODBC driver supports the
function/capability.
Note:
You cannot specify the signature of the function; it will be the same as in the
ODBC signature.
For example, for the string function Upper case, instead of using {fn
ucase(...)}, you can type in the Upper case option field upper. Data
Services generates:
upper(TAB1.VC_COL)
The following table describes all of the fields and options in the ODBC
datastore editor.
Main window
98 Data Services Reference Guide
DescriptionPossible valuesODBC option

Data source
Refer to the requirements of
your database.
Data Services Objects
Descriptions of objects
DescriptionPossible valuesODBC option
Select or type the Data Source
Name defined in the ODBC
Administrator for connecting
to your database.
Enter the user name of the
account through which Data
Services accesses the
database.
2
User name
Password
ODBC Admin button
Alphanumeric characters and
underscores
Alphanumeric characters, underscores, and punctuation
Note:
If you use the Neoview utility
Nvtencrsrv for storing the encrypted words in the security
file when using Neoview
Transporter, enter the encrypted user name
Enter the user's password.
Note:
If you use the Neoview utility
Nvtencrsrv for storing the encrypted words in the security
file when using Neoview
Transporter, enter the encrypted password.
Click to launch the Windows
ODBC Data Source Administrator where you create or
configure data sources. After
closing the ODBC Data
Source Administrator, you can
select a newly created data
source from the datastore editor's drop-down list.
Connection
Data Services Reference Guide 99

Data Services Objects
2
Descriptions of objects
Additional connection information
General
Alphanumeric characters and
underscores, or blank
Positive integerRows per commit
DescriptionPossible valuesODBC option
Enter information for any additional parameters that the data
source supports (parameters
that the data source's ODBC
driver and database support).
Use the format:
<parameter1=value1; pa
rameter2=value2>
Enter the maximum number of
rows loaded to a target table
before saving the data. This
value is the default commit
size for target tables in this
datastore. You can overwrite
this value for individual target
tables.
Directory path or click BrowseBulk loader directory
Directory path or click BrowseOverflow file directory
100 Data Services Reference Guide
Enter the directory where Data
Services writes sql, control,
command, and data files for
bulk loading. For Solaris systems, the path name must be
less than 80 characters.
You can enter a variable for
this option.
Enter the location of overflow
files written by target tables in
this datastore. You can enter
a variable for this option.
 Loading...
Loading...