

Page 1

Data Sheet
June 1999
Features
High-performance, cost-effective, low-power
■
0.35 µm CMOS technology (OR2CxxA), 0.3 µm CMOS
technology (OR2TxxA), and 0.25 µm CMOS technology
(OR2TxxB), (four-input look-up table (LUT) delay less
than 1.0 ns with -8 speed grade)
High density (up to 43,200 usable, logic-only gates; or
■
99,400 gates including RAM )
Up to 480 user I/Os (OR2TxxA and OR2TxxB I/Os are
■
5 V tolerant to allow interconnection to both 3.3 V and
5 V devices, selectable on a per-pin basis)
Four 16-bit look-up tables and four latches/flip-flops per
■
PFU, nib ble-oriented f or im ple me nti ng 4 -, 8-, 16 -, and /or
32-bit (or wider) bus structures
Eight 3-state buffers per PFU for on-chip bus structures
■
Fast, on-chip user SRAM has features to simplify RAM
■
design and increase RAM speed:
— Asynchronous single port: 64 bits/PFU
— Synchronous single port: 64 bits/PFU
— Synchronous dual port: 32 bits/PFU
Improved ability to combine PFUs to create larger RAM
■
structures using write-port enable and 3-state buffers
Fas t, den se multipliers c an be cre ated with the mul tip lie r
■
mode (4 x 1 multiplier/PFU):
— 8 x 8 multiplier requires only 16 PFUs
— 30% increase in speed
Flip-flop /latch opti ons to allow programmable priority of
■
synchronous set/reset vs. clock enable
Enhanced cascadable nibble-wide data path
■
capabilities for adders, subtr acto rs, co unters , m ulti pliers ,
and comparators inc lu ding internal fast-carry operation
®
ORCA
Series 2
Field-Programmable Gate Arrays
Innovative, abundant, and hierarchical nibble-
■
oriented routing resources that allow automatic use of
internal gates for all device densities without sacrificing
performance
Upward bit stream compatible with the
■
ATT2Txx series of devices
Pinout-compatible with new
■
TTL or CMOS input levels programmable per pin for the
■
Series 3 FPGAs
ORCA
OR2CxxA (5 V) devices
Individually programmable drive capability:
■
12 mA sink/6 mA source or 6 mA sink/3 mA source
Built-in boundary scan (
■
*1149.1 JTAG) and
IEEE
3-state all I/O pins, (TS_ALL) testability functions
Multiple configuration options, including simple, low pin-
■
count serial ROMs , an d peripheral or JTAG modes for insystem programming (ISP)
Full PCI bus compliance for all devices
■
Supported by industry-standard CAE tools for design
■
entry, synthesis, and simulation with
ORCA
Development System support (for back-end implementation)
New, added features (OR2TxxB) have:
■
— More I/O per package than the OR2TxxA family
— No dedicated 5 V supply (V
DD
5)
— Faster configuration speed (40 MHz)
— Pin selectab le I /O clam ping di odes pr ovide 5V or 3.3V
PCI compliance and 5V tolerance
— Full PCI bus complia nce in both 5V and 3.3V PCI sys-
tems
*
is a registered trademark of The Institute of Electrical and
IEEE
Electronics Engineers, Inc.
ORCA
Foundry
ATT2Cxx/
Table 1
. ORCA
Device
Series 2 FPGAs
Usable
Gates*
# LUTs Registers
Max User
RAM Bits
User
I/Os
Array Size
OR2C04A/OR2T04A 4,800—11,000 400 400 6,400 160 10 x 10
OR2C06A/OR2T06A 6,900—15,900 576 576 9,216 192 12 x 12
OR2C08A/OR2T08A 9,400—21,600 784 724 12,544 224 14 x 14
OR2C10A/OR2T10A 12,300—28,300 1024 1024 16,384 256 16 x 16
OR2C12A/OR2T12A 15,600—35,800 1296 1296 20,736 288 18 x 18
OR2C15A/OR2T15A/OR2T15B 19,200—44,200 1600 1600 25,600 320 20 x 20
OR2C26A/OR2T26A 27,600—63,600 2304 2304 36,864 384 24 x 24
OR2C40A/OR2T40A/OR2T40B 43,200—99,400 3600 3600 57,600 480 30 x 30
* The first number in the usable gates column assumes 48 gates per PFU (12 gates per four-input LUT/FF pair) for logic-only designs . The
second number assumes 30% of a design is RAM. PFUs used as RAM are counted at four gates per bit, with each PFU capable of
implementing a 16 x 4 RAM (or 256 gates) per PFU.
Page 2

Data Sheet
ORCA
Series 2 FPGAs June 1999
Table of Contents
Contents Page Contents Page
Features ......................................................................1
Description...................................................................3
ORCA
Foundry Development System Overview.........5
Architecture .................................................................5
Programmable Logic Cells ..........................................5
Programmable Function Unit...................................5
Look-Up Table Operating Modes ............................7
Latches/Flip-Flops .................................................15
PLC Routing Resources ........................................17
PLC Architectural Description................................22
Programmable Input/Output Cells.............................25
Inputs.....................................................................25
Outputs..................................................................26
5 V Tolerant I/O (OR2TxxB) ..................................27
PCI Compliant I/O..................................................27
PIC Routing Resources .........................................28
PIC Architectural Description.................................29
PLC-PIC Routing Resources.................................30
Interquad Routing......................................................32
Subquad Routing (OR2C40A/OR2T40A Only)......34
PIC Interquad (MID) Routing .................................36
Programmable Corner Cells......................................37
Programmable Routing..........................................37
Special-Purpose Functions....................................37
Clock Distribution Network ........................................37
Primary Clock ........................................................37
Secondary Clock ...................................................38
Selecting Clock Input Pins.....................................39
FPGA States of Operation.........................................40
Initialization............................................................40
Configuration .........................................................41
Start-Up .................................................................42
Reconfiguration .....................................................42
Partial Reconfiguration ..........................................43
Other Configuration Options..................................43
Configuration Data Format ........................................43
Using
ORCA
Foundry to Generate
Configuration RAM Data.....................................44
Configuration Data Frame .....................................44
Bit Stream Error Checking.........................................47
FPGA Configuration Modes.......................................47
Master Parallel Mode.............................................47
Master Serial Mode ...............................................48
Asynchronous Periphera l Mode ..................... .......49
Synchronous Peripheral Mode..............................49
Slave Serial Mode .................................................50
Slave Parallel Mode...............................................50
Daisy Chain ...........................................................51
Special Function Blocks ............................................52
Single Function Blocks ..........................................52
Boundary Scan......................................................54
Boundary-Scan Instructions...................................55
ORCA
Boundary-Scan Circuitry ............................56
ORCA
Timing Characteristics....................................60
Estimating Power Dissipation....................................61
OR2CxxA...............................................................61
OR2TxxA ...............................................................63
OR2T15B and OR2T40B.......................................65
Pin Information ......................................... ....... ...... ....66
Pin Descriptions................. ...... ..............................66
Package Compatibility ...........................................68
Compatibility with Series 3 FPGAs........................70
Package Thermal Characteristics............................126
QJA......................................................................126
yJC.......................................................................126
QJC......................................................................126
QJB......................................................................126
Package Coplanarity ...............................................127
Package Parasitics..................................................127
Absolute Maximum Ratings.....................................129
Recommended Operating Conditions......................129
Electrical Characteristics .........................................130
Timing Characteristics .............................................132
Series 2................................................................160
Measurement Conditions.........................................169
Output Buffer Characteristics...................................170
OR2CxxA.............................................................170
OR2TxxA .............................................................171
OR2TxxB .............................................................172
Package Outline Drawings ......................................173
Terms and Definitions..........................................173
84-Pin PLCC........................................................174
100-Pin TQFP......................................................175
144-Pin TQFP......................................................176
160-Pin QFP........................................................177
208-Pin SQFP......................................................178
208-Pin SQFP2....................................................179
240-Pin SQFP......................................................180
240-Pin SQFP2....................................................181
256-Pin PBGA .....................................................182
304-Pin SQFP......................................................183
304-Pin SQFP2....................................................184
352-Pin PBGA .....................................................185
432-Pin EBGA .....................................................186
Ordering Information................................................187
Index........................................................................189
2 Lucent Technologies Inc.
Page 3
Data Sheet
June 1999
ORCA
Series 2 FPGAs
Description
mable input/output cells (PICs). An array of PLCs is
surrounded by PICs as shown in Figure 1. Each PLC
The
ORCA
Series 2 series of SRAM -bas ed FPGAs are
an enhanced version of the ATT2C/2T architecture.
The latest
ORCA
series includes patented architectural
enhancements that make functions faster and easier to
design while conserving the use of PLCs and routing
resources.
The Series 2 devices can be used as drop-in replacements for the ATT2Cxx/ATT2Txx series, respectively,
and they are also bit stream compatible with each
other. The usable gate counts associated with each
series are provided in Table 1. Both series are offered
in a variety of packages, speed grades, and temperature ranges.
The
ORCA
series FPGA consists of two basic ele-
ments: programmable logic cells (PLCs) and program-
Table 2
. ORCA
Series 2 System Performance
Function
16-bit loadable up/down
#
PFUs
-2A -3A -4A -5A -6A -7A -7B -8B
4 51.0 66.7 87.0 104.2
contains a programmable function unit (PFU). The
PLCs and PICs also contain routing resources and
configuration RAM. All logic is done in the PFU. Each
PFU contains four 16-bit look-up tables (LUTs) and four
latches/flip-flops (FFs).
The PLC architecture provides a balanced mix of logic
and routing that allows a higher utilized gate/PFU than
alternative architectures. The routing resources carry
logic signals between PFUs and I/O pads. The routing
in the PLC is symmetrical about the horizontal and vertical axes. This improves routability by allowing a bus of
signals to be routed into the PLC from any direction.
Some examples of the resources required and the performance t hat can be ach ie v ed us ing th ese devices are
represented in Table 2.
Speed Grade
counter
16-bit accumulator 4 51.0 66.7 87.0 104.2
8 x 8 parallel multiplier:
— Multiplier mode, unpipelined
— ROM mode, unpipelined
— Multiplier mode, pipelined
1
2
22
3
44
14.2
9
41.5
50.5
19.3
55.6
69.0
25.1
71.9
82.0
31.0
87.7
103.1
32 x 16 RAM:
— Single port (read and write/
4
cycle)
— Single port
— Dual port
5
6
9
9
16
21.8
38.2
38.2
28.6
52.6
52.6
36.2
69.0
83.3
53.8
92.6
92.6
36-bit parity check (internal) 4 13.9 11.0 9.1 7.4
32-bit address decode
3.25 12.3 9.5 7.5 6.1
(internal)
129.9 144.9 131.6 149.3
129.9 144.9 131.6 149.3
36.0
107.5
125.0
53.8
92.6
92.6
5.6 5.2 6.1 5.1
4.6 4.3 4.8 4.0
40.3
122.0
142.9
62.5
96.2
96.2
37.7
103.1
123.5
57.5
97.7
97.7
44.8
120.5
142.9
69.4
112.4
112.4
Unit
MHz
MHz
MHz
MHz
MHz
MHz
MHz
MHz
ns
ns
1. Implemented using 4 x 1 multiplier mode (unpipelined), register-to-register, two 8-bit inputs, one 16-bit output.
2. Implemented using two 16 x 12 ROMs and one 12-bit adder, one 8-bit input, one fixed operand, one 16-bit output.
3. Implemented using 4 x 1 multiplier mode (fully pipelined), two 8-bit inputs, one 16-bit output (28 of 44 PFUs contain only pipelining registers).
4. Implemented using 16 x 4 synchronous single-port RAM mode allowing both read and write per clock cycle, including write/read address
multiplexer.
5. Implemented using 16 x 4 synchronous single-port RAM mode allowing either read or write per clock cycle, including write/read address multiplex er.
6. Implemented using 16 x 2 synchronous dual-port RAM mode.
7. OR2TxxB available only in -7 and -8 speeds only.
8. Speed grades of -5, -6, and -7 are for OR2TxxA devices only.
Lucent Technologies Inc. 3
Page 4

ORCA
Data Sheet
Series 2 FPGAs June 1999
Description
(continued)
The FPGA’s functionality is determined by internal configuration RAM. The FPGA’s internal initialization/configuration circuitry loads the configuration data at powerup or under system control. The RAM is loaded by using one of
several configuration modes. The configuration data resides externally in an EEPROM, EPROM, or ROM on the
circuit board, or any other storage media. Serial ROMs provide a simple, low pin count method for configuring
FPGAs, while the peripheral and JTAG configuration modes allow for easy, in-system programming (ISP).
PT1 PT2 PT3 PT4 PT5 PT6 PT7 PT8 PT9 PT11 PT12
R1C1 R1C2 R1C3 R1C4 R1C5 R1C6 R1C7 R1C8 R1C9 R1C10
R2C1 R2C2 R2C3 R2C4 R2C5 R2C6 R2C7 R2C8 R2C9 R2C10
R3C1 R3C2 R3C3 R3C4 R3C5 R3C6 R3C7 R3C8 R3C9 R3C10
R4C1 R4C2 R4C3 R4C4 R4C5 R4C6 R4C7 R4C8 R4C9 R4C10
R5C1 R5C2 R5C3 R5C4 R5C5 R5C6 R5C7 R5C8 R5C9 R5C10
R6C1 R6C2 R6C3 R6C4 R6C5 R6C6 R6C7 R6C8 R6C9 R6C10
R7C1 R7C2 R7C3 R7C4 R7C5 R7C6 R7C7 R7C8 R7C9 R7C10
TMID
vIQ
PT10
PT13 PT14 PT15 PT16 PT17 PT18
R1C18R1C17R1C16R1C15R1C14R1C13R1C12R1C11
R2C18R2C17R2C16R2C15R2C14R2C13R2C12R2C11
R3C18R3C17R13C16R3C15R3C14R3C13R3C12R3C11
R4C18R4C17R4C16R4C15R4C14R4C13R4C12R4C11
R5C18R5C17R5C16R5C15R5C14R5C13R5C12R5C11
R6C18R6C17R6C16R6C15R6C14R6C13R6C12R6C11
R7C18R7C17R7C16R7C15R7C14R7C13R7C12R7C11
R8C1 R8C2 R8C3 R8C4 R8C5 R8C6 R8C7 R8C8 R8C9 R8C10
R9C1 R9C2 R9C3 R9C4 R9C5 R9C6 R9C7 R9C8 R9C9 R9C10
PL9 PL8 PL7 PL6 PL5 PL4 PL3 PL2 PL1PL13 PL12 PL11
LMID
PL10
PL18 PL17 PL16 PL15 PL14
hIQ
R10C1 R10C2 R10C3 R10C4 R10C5 R10C6 R10C7 R10C8 R10C9 R10C10
R11C10R11C9R11C8R11C7R11C6R11C5R11C4R11C3R11C2R11C1
R12C10R12C9R12C8R12C7R12C6R12C5R12C4R12C3R12C2R12C1
R13C10R13C9R13C8R13C7R13C6R13C5R13C4R13C3R13C2R13C1
R14C10R14C9R14C8R14C7R14C6R14C5R14C4R14C3R14C2R14C1
R15C10R15C9R15C8R15C7R15C6R15C5R15C4R15C3R15C2R15C1
R16C10R16C9R16C8R16C7R16C6R16C5R16C4R16C3R16C2R16C1
R17C10R17C9R17C8R17C7R17C6R17C5R17C4R17C3R17C2R17C1
R18C10R18C9R18C8R18C7R18C6R18C5R18C4R18C3R18C2R18C1
PB1 PB2 PB3 PB4 PB5 PB6 PB7 PB8 PB9 PB10 PB11 PB12
BMID
R8C18R8C17R8C16R8C15R8C14R8C13R8C12R8C11
R9C18R9C17R9C16R9C15R9C14R9C13R9C12R9C11
R10C18R10C17R10C16R10C15R10C14R10C13R10C12R10C11
R11C18R11C17R11C16R11C15R11C14R11C13R11C12R11C11
PR12PR11PR9PR8PR7PR6PR5PR4PR3PR2PR1 PR13 PR18PR17PR16PR15PR14RMIDPR10
R12C18R12C17R12C16R12C15R12C14R12C13R12C12R12C11
R13C18R13C17R13C16R13C15R13C14R13C13R13C12R13C11
R14C18R14C17R14C16R14C15R14C14R14C13R14C12R14C11
R15C18R15C17R15C16R15C15R15C14R15C13R15C12R15C11
R16C18R16C17R16C16R16C15R16C14R16C13R16C12R16C11
R17C18R17C17R17C16R17C15R17C14R17C13R17C12R17C11
R18C18R18C17R18C16R18C15R18C14R18C13R18C12R18C11
PB13 PB14 PB15 PB16 PB17 PB18
5-6779(F)
Figure 1. Series 2 Array
4 Lucent Technologies Inc.
Page 5

Data Sheet
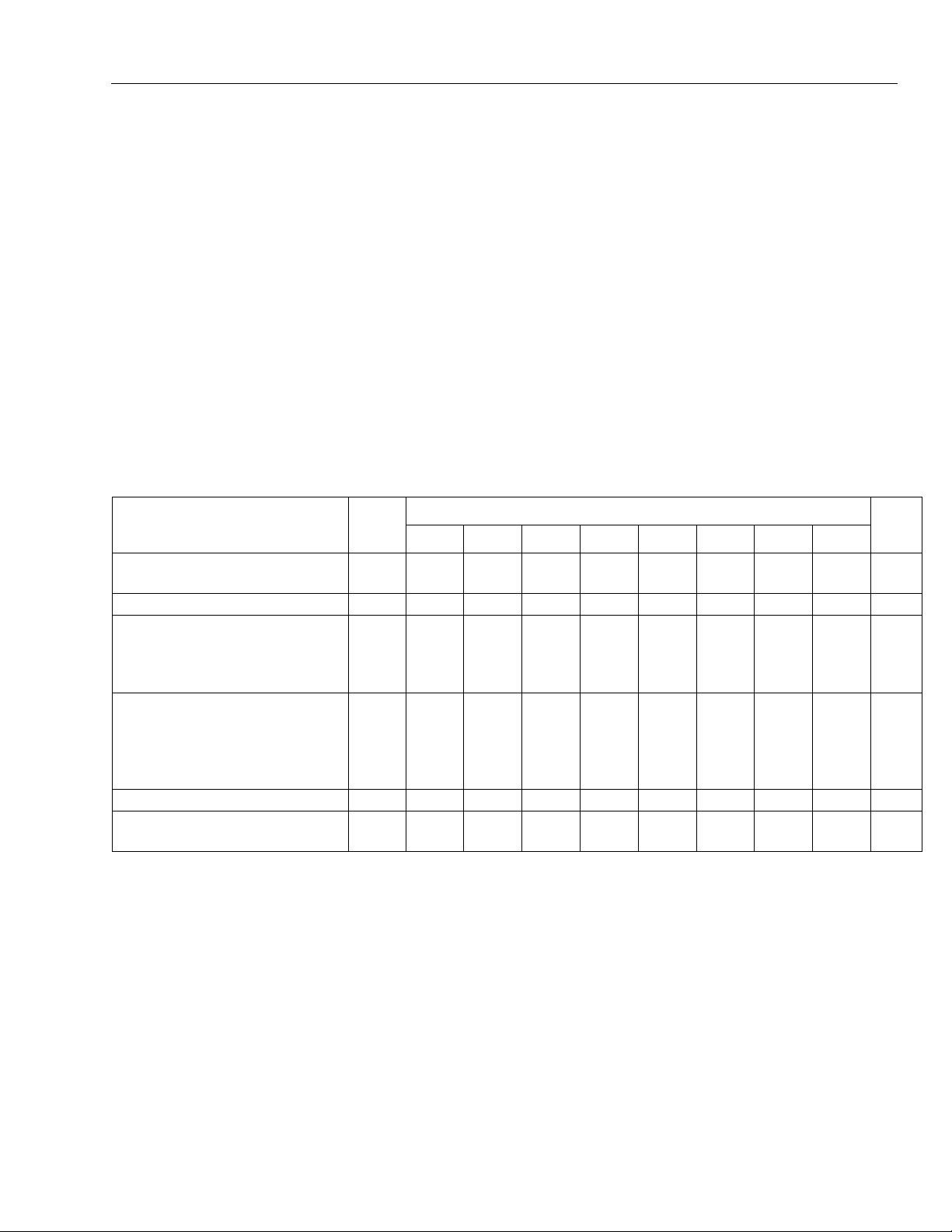
PROGRAMMABLE LOGIC CELL (PLC)
WD3
WD2
WD1
WD0
A4
A3
A2
A1
A0
B4
B3
B2
B1
B0
O4
O3
O2
O1
O0
PROGRAMMABLE
FUNCTION UNIT
CE LSRC0 CK
(ROUTING RESOURCES, CONFIGURATION RAM)
CIN
(PFU)
COUT
June 1999
ORCA
Series 2 FPGAs
ORCA
Foundry
Development System
Overview
The
ORCA
Foundry Development System interfaces to
front-end design entry tools and provides the tools to
produce a configured FPGA. In the design flow, the
user defines the functionality of the FPGA at two
points: at design entry and at the bit stream generation
stage.
Following design entry, the dev elopment system’s map ,
place, and route tools translate the netlist into a routed
FPGA. Its bit stream generator is then used to generate
the configuration data which is loaded into the FPGA’s
internal configuration RAM. When using the bit stream
generator, the user selects options that affect the functionality of the FPGA. Combined with the front-end
tools,
ORCA
Foundry produces configuration data that
implements the various logic and routing options discussed in this data sheet.
Architecture
The
ORCA
Series FPGA is comprised of two basic
elements: PLCs and PICs. Figure 1 shows an array of
programmable logic cells (PLCs) surrounded by programmable input/output cells (PICs). The Series 2 has
PLCs arranged in an array of 20 rows and 20 columns.
PICs are located on all four sides of the FPGA between
the PLCs and the IC edge.
binatorial mode, the LUTs can realize any four-, five-,
or six-input logic functions. In ripple mode, the highspeed carry logic is used for arithmetic functions, the
new multiplier function, or the enhanced data path
functions. In memory mode, the LUTs can be used as a
16 x 4 read/write or read-only memory (asynchronous
mode or the new synchronous mode) or a new 16 x 2
dual-por t memory.
Programmable Logic Cells
The programmable logic cell (PLC) consists of a programmable function unit (PFU) and routing resources.
All PLCs in the array are identical. The PFU, which contains four LUTs and four latches/FFs for logic implementation, is discussed in the next section.
Programmable Functio n Unit
The PFUs are used for logic. Each PFU has 19 external inputs and six outputs and can operate in several
modes. The functionality of the inputs and outputs
depends on the operating mode.
The PFU uses three input data buses (A[4:0], B[4:0],
WD[3:0]), four control inputs (C0, CK, CE, LSR), and a
carry input (CIN); the last is used for fast arithmetic
functions. There is a 5-bit output bus (O[4:0]) and a
carry-out (COUT).
The location of a PLC is indicated by its row and column so that a PLC in the second row and third column
is R2C3. PICs are indicated similarly, with PT (top) and
PB (bottom) designating rows and PL (left) and PR
(right) designating columns, followed by a number. The
routing resources and configuration RAM are not
shown, but the interquad routing blocks (hIQ, vIQ)
present in the Series 2 series are shown.
Each PIC contains the necessary I/O buffers to interface to bond pads. The PICs also contain the routing
resources needed to connect signals from the bond
pads to/from PLCs. The PICs do not contain any useraccessible logic elements, such as flip-flops.
Combinatorial logic is done in look-up tables (LUTs)
located in the PFU. The PFU can be used in different
modes to meet different logic requirements. The LUT’s
configurable medium-/large-grain architecture can be
used to implement from one to four combinatorial logic
functions. The flexibility of the LUT to handle wide input
functions, as well as multiple smaller input functions,
maximizes the gate count/PFU.
The LUTs can be programmed to operate in one of
three modes: combinatorial, ripple, or memory. In com-
Figure 2. PFU Ports
Lucent Technologies Inc. 5
5-2750(F).r3
Page 6
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Logic Cells
CARRY
A4
A3
A2
A1
A0
B4
B3
B2
B1
B0
CIN
C0
LSR
GSR
WD[3:0]
CK
CKEN
TRI
Key: C = controlled by configuration RAM.
A4
A3
A2
A1
A3
A2
A1
A0
B4
B3
B2
B1
B3
B2
B1
B0
QLUT3
CARRY
QLUT2
A4
CARRY
QLUT1
CARRY
QLUT0
B4
(continued))
PFU_NAND
PFU_MUX
PFU_XOR
C C
COUT
F3
C
WD3
F2
C
WD2
F1
C
WD1
F0
C
WD0
D3
SR EN
D2
SR EN
D1
SR EN
D0
SR EN
C
REG3
REG2
REG1
REG0
Q3
O4
Q2
C
Q1
Q0
C
O3
O2
O1
O0
T
T
T
T
C
T
T
T
T
C
5-4573(F)
Figure 3. Simplified PFU Diagram
Figure 2 and Figure 3 show high-level and detailed
views of the ports in the PFU, respectively. The ports
are referenced with a two- to four-character suffix to a
PFU’s location. As mentioned, there are two 5-bit input
data buses (A[4:0] and B[4:0]) to the LUT, one 4-bit
input data bus (WD[3:0]) to the latches/FFs, and an
output data bus (O[4:0]).
Figure 3 shows the four latches/FFs (REG[3:0]) and the
64-bit look-up table (QLUT[3:0]) in the PFU. The PFU
does combinatorial logic in the LUT and sequential
logic in the latches/FFs. The LUT is static random
access memory (SRAM) and can be used for read/
found in each PLC are also shown, although they actually reside external to the PFU.
Each latch/FF can accept data from the LUT. Alternatively, the latches/FFs can accept direct data from
WD[3:0], eliminating the LUT delay if no combinatorial
function is needed. The LUT outputs can bypass the
latches/FFs, which reduces the delay out of the PFU. It
is possible to use the LUT and latches/FFs more or
less independently. For example, the latches/FFs can
be used as a 4-bit shift register, and the LUT can be
used to detect when a register has a particular pattern
in it.
write or read-only memory. The eight 3-state buffers
6 Lucent Technologies Inc.
Page 7

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Programmable Logic Cells
Table 3 lists the basic operating modes of the LUT. The
operating mode affects the functionality of the PFU
input and output ports and internal PFU routing. For
example, in some operating modes, the WD[3:0] inputs
are direct data inputs to the PFU latches/FFs. In the
dual 16 x 2 memory mode, the same WD[3:0] inputs
are used as a 4-bit data input bus into LUT memory.
The PFU is used in a variety of modes, as illustrated in
Figures 4 through 11, and it is these specific modes
that are most relevant to PFU functionality.
PFU Control Inputs
The four control inputs to the PFU are clock (CK), local
set/reset (LSR), clock enable (CE), and C0. The CK,
CE, and LSR inputs control the operation of all four
latches in the PFU. An active-low global set/reset
(GSRN) signal is also available to the latches/FFs in
every PFU. Their operation is discussed briefly here,
and in more detail in the Latches/Flip-Flops section.
The polarity of the control inputs can be inverted.
The CK input is distributed to each PFU from a vertical
or horizontal net. The CE input inhibits the latches/FFs
from responding to data inputs. The CE input can be
disabled, always enabling the clock. Each latch/FF can
be independently programmed to be set or reset by the
LSR and the global set/reset (GSRN) signals. Each
PFU’s LSR input can be configured as synchronous or
asynchronous. The GSRN signal is always asynchr o nous. The LSR signal applies to all four latches/FFs in
a PFU. The LSR input can be disabled (the default).
The asynchronous set/reset is dominant over clocked
inputs.
The C0 input is used as an input into the special PFU
gates for wide functions in combinatorial logic mode.
In the memory modes, this input is also used as the
write-port enable input. The C0 input can be disabled
(the default).
(continued)
used as LUT inputs. The use of these ports changes
based on the PFU operating mode.
The functionality of the LUT is determined by its operating mode. The entries in T ab le 3 show the basic modes
of operation for combinatorial logic, ripple, and memory
functions in the LUT. Depending on the operating
mode, the LUT can be divided into sub-LUTs. The LUT
is comprised of two 32-bit half look-up tables, HLUTA
and HLUTB. Each half look-up table (HLUT) is comprised of two quarter look-up tables (QLUTs). HLUTA
consists of QLUT2 and QLUT3, while HLUTB consists
of QLUT0 and QLUT1. The outputs of QLUT0, QLUT1,
QLUT2, and QLUT3 are F0, F1, F2, and F3, respectively.
Table 3. Look-Up Table Operating Modes
Mode Function
F4A Two functions of four inputs, some inputs
shared (QLUT2/QLUT3)
F4B Two functions of four inputs, some inputs
shared (QLUT0/QLUT1)
F5A One function of five inputs (HLUTA)
F5B One function of five inputs (HLUTB)
R 4-bit ripple (LUT)
MA 16 x 2 asynchronous memory (HLUTA)
MB 16 x 2 asynchronous memory (HLUTB)
SSPM 16 x 4 synchronous single-port memory
SDPM 16 x 2 synchronous dual-port memory
For combinatorial logic, the LUT can be used to do any
single function of six inputs, any two functions of five
inputs, or four functions of four inputs (with some inputs
shared), and three special functions based on the two
five-input functions and C0.
Look-Up Table Operating Modes
The look-up table (LUT) can be configured to operate
in one of three general modes:
■
Combinatorial logic mode
■
Ripple mode
■
Memory mode
The combinatorial logic mode uses a 64-bit look-up
table to implement Boolean functions. The two 5-bit
logic inputs, A[4:0] and B[4:0], and the C0 input are
Lucent Technologies Inc. 7
Page 8
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Logic Cells
(continued)
The LUT ripple mode operation offers standard arithmetic functions, such as 4-bit adders, subtractors,
adder/subtractors, and counters. In the
ORCA
Series 2, there are two new ripple modes available.
The first new mode is a 4 x 1 multiplier, and the second
is a 4-bit comparator. These new modes offer the
advantages of faster speeds as well as denser logic
capabilities.
When the LUT is configured to operate in the memory
mode, a 16 x 2 asynchronous memory fits into an
HLUT. Both the MA and MB modes were available in
previous
ORCA
architectures, and each mode can be
configured in an HLUT separately. In the Series 2,
there are two new memory modes available. The first is
a 16 x 4 synchronous single-port memory (SSPM), and
the second is a 16 x 2 synchronous dual-port memory
(SDPM). These new modes offer easier implementation, faster speeds, denser RAMs, and a dual-port
capability that wasn’t previously offered as an option in
the ATT2Cxx/ATT2Txx families.
If the LUT is configured to operate in the ripple mode, it
cannot be used for basic combinatorial logic or memory
functions. In modes other than the ripple, SSPM, and
SDPM modes, combinations of operating modes are
possible. For example, the LUT can be configured as a
16 x 2 RAM in one HLUT and a five-input combinatorial
logic function in the second HLUT. This can be done by
configuring HLUT A in the MA mode and HLUTB in the
F5B mode (or vice ve rsa).
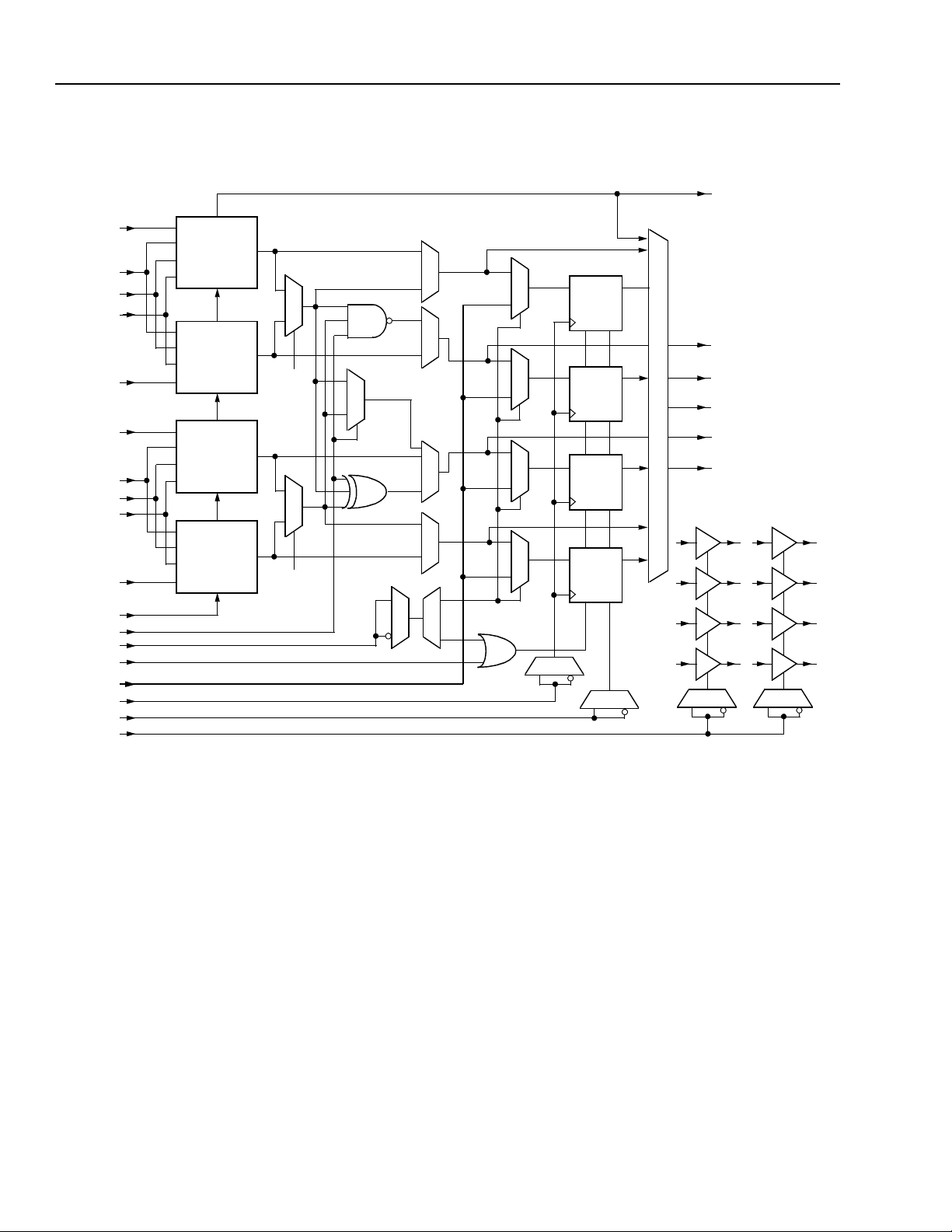
F4A/F4B Mode—Two Four-Input Functions
Each HLUT can be used to implement two four-input
combinatorial functions, but the total number of inputs
into each HLUT cannot exceed five. The two QLUTs
within each HLUT share three inputs. In HLUTA, the
A1, A2, and A3 inputs are shared by QLUT2 and
QLUT3. Similarly, in HLUTB, the B1, B2, and B3 inputs
are shared by QLUT0 and QLUT1. The four outputs
are F0, F1, F2, and F3. The results can be routed to
the D0, D1, D2, and D3 latch/FF inputs or as an output
of the PFU. The use of the LUT for four functions of up
to four inputs each is given in Figure 4.
F5A/F5B Mode—One Five-Input Variable Function
independent functions of up to five inputs is shown in
Figure 5. In this case, the LUT is configured in the F5A
and F5B modes. As a variation, the LUT can do one
function of up to five input variables and two four-input
functions using F5A and F4B modes or F4A and F5B
modes.
A4
A3
A2
A1
A3
A2
A1
A0
B4
B3
B2
B1
B3
B2
B1
B0
A4
A3
A2
A1
A3
A2
A1
A0
B4
B3
B2
B1
B3
B2
B1
B0
QLUT3
QLUT2
QLUT1
QLUT0
HLUTA
F3
F2
HLUTB
F1
F0
5-2753(F).r2
Figure 4. F4 Mode—Four Functions of Four-
Input Variables
HLUTA
WEA
A3
A2
A1
A0
WD3
WD2
WPE
B4
B3
B2
B1
B0
A4
A3
A2
A1
A0
WD3
WD2
B4
B3
B2
B1
B0
QLUT3
QLUT2
c0
QLUT1
QLUT0
F3
F2
HLUTB
F0
Each HLUT can be used to implement any five-input
combinatorial function. The input ports are A[4:0] and
B[4:0], and the output ports are F0 and F3. One five or
less input function is input into A[4:0], and the second
five or less input function is input into B[4:0]. The
results are routed to the latch/FF D0 and latch/FF D3
Figure 5. F5 Mode—Two Functions of Five-Input
Variables
5-2845(F).r2
inputs, or as a PFU output. The use of the LUT for two
8 Lucent Technologies Inc.
Page 9
Data Sheet
QLUT3
QLUT2
A4
A4
A3
A2
A1
A0
A3
A2
A1
A0
QLUT1
QLUT0
B4
B4
B3
B2
B1
B0
B3
B2
B1
B0
C0
F3
F0
F1
F0
F2
F3
A4 A4
A3
A2
A1
A0
A3
A2
A1
A0
B4 B4
B3
B2
B1
B0
B3
B2
B1
B0
C0
F3
F0
F1
F0
F2
F3
HLUTA
HLUTB
June 1999
ORCA
Series 2 FPGAs
Programmable Logic Cells
(continued)
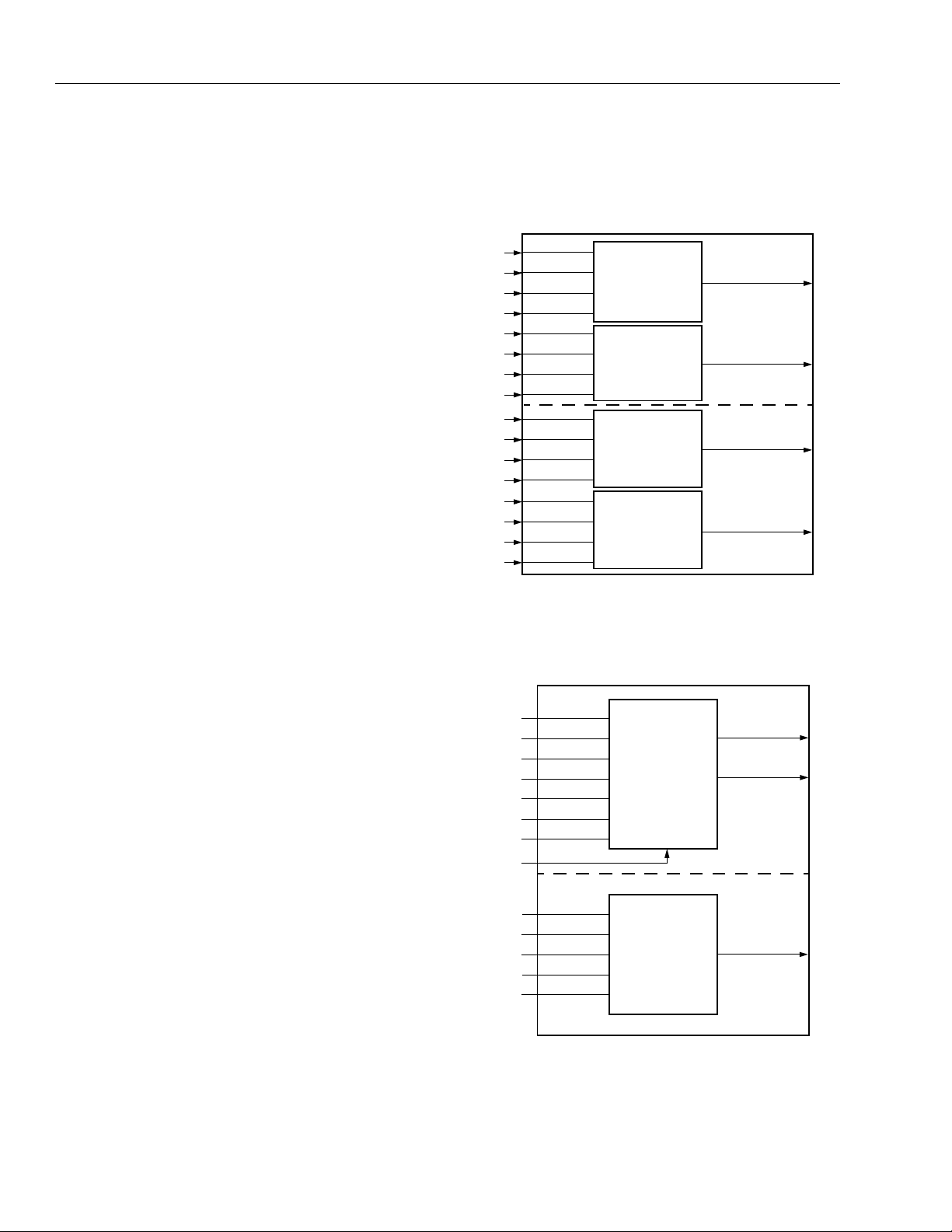
F5M and F5X Modes—Special Function Modes
The PFU contains logic to implement two special function modes which are variations on the F5 mode. As
with the F5 mode, the LUT implements two independent five-input functions. Figure 6 and Figure 7 show
the schematics for F5M and F5X modes, respectively.
The F5X and F5M functions differ from the basic F5A/
F5B functions in that there are three logic gates which
have inputs from the two 5-input LUT outputs. In some
cases, this can be used for faster and/or wider logic
functions.
As can be seen, two of the three inputs into the NAND,
XOR, and MUX gates, F0 and F3, are from the LUT.
The third input is from the C0 input into PFU. Since the
C0 input bypasses the LUTs, it has a much smaller
delay through the PFU than for all other inputs into the
special PFU gates. This allows multiple PFUs to be
cascaded together while reducing the delay of the critical path through the PFUs. The output of the first special function (either XOR or MUX) is F1. Since the XOR
and MUX share the F1 output, the F5X and F5M
modes are mutually exclusive. The output of the NAND
PFU gate is F2 and is always available in either mode.
5-2754(F).r3
Figure 6. F5M Mode—Multiplexed Function of Two
Independent Five-Input Variable
Functions
To use either the F5M or F5X functions, the LUT must
be in the F5A/F5B mode; i.e., only 5-input LUTs
allowed. In both the F5X and F5M functions, the outputs of the five-input combinatorial functions, F0 and
F3, are also usable simultaneously with the special
PFU gate outputs.
The output of the MUX is:
F1 = (HLUTA & C0) + (HLUTB &
F1 = (F3 & C0) + (F0 &
C0
C0
)
)
The output of the exclusive OR is:
F1 = HLUTA ⊕ HLUTB ⊕ C0
F1 = F3 ⊕ F0 ⊕ C0
The output of the NAND is:
HLUTA & HLUTB & C0
F2 =
F2 = F3 & F0 & C0
5-2755(F).r2
Figure 7. F5X Mode—Exclusive OR Function of T wo
Independent Five-Input Variable
Functions
Lucent Technologies Inc. 9
Page 10
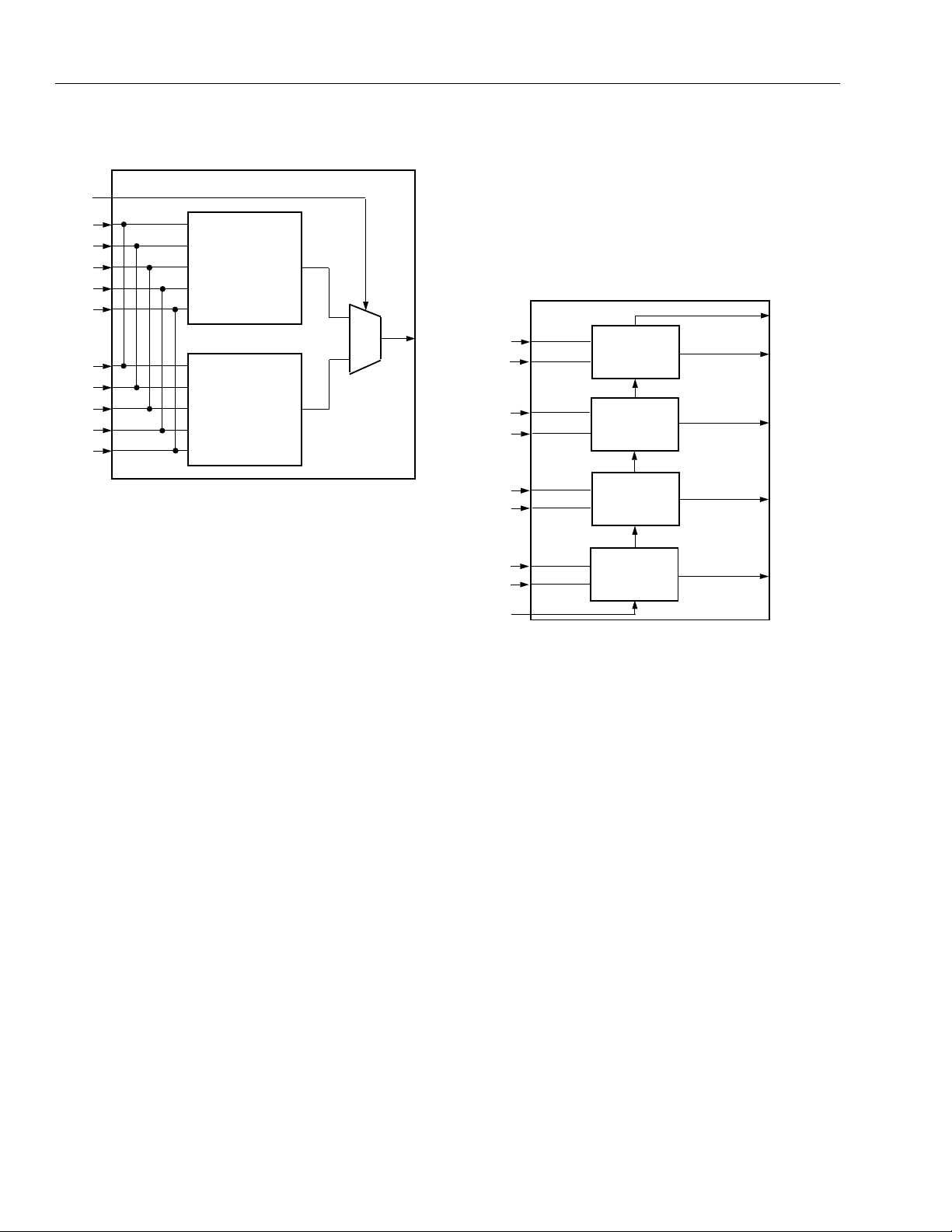
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Logic Cells
C0
A4
A3
A2
A1
A0
B4
B3
B2
B1
B0
A4
A3
A2
A1
A0
B4
B3
B2
B1
B0
QLUT3
QLUT2
QLUT1
QLUT0
(continued)
F3
F1
F0
5-2751(F).r3
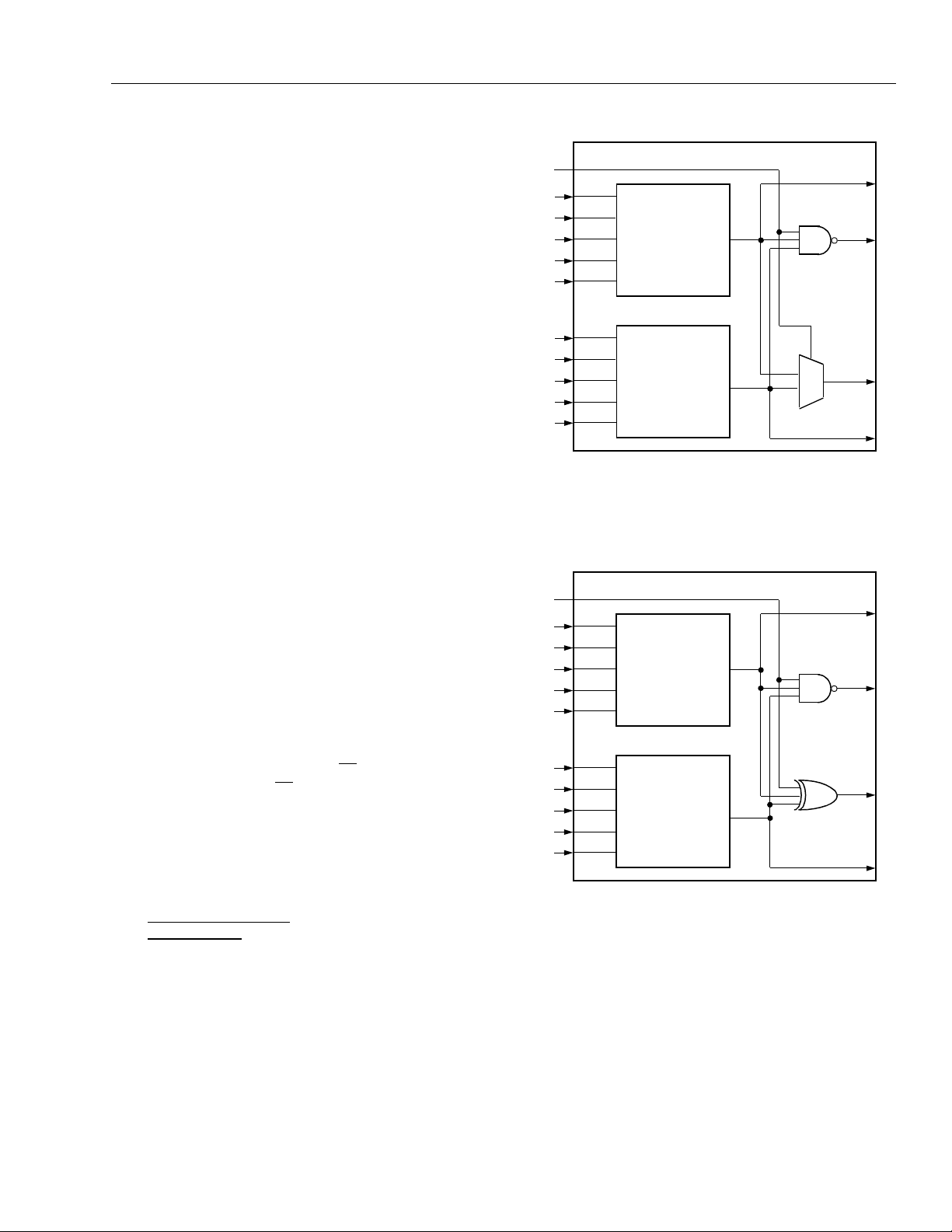
Figure 8. F5M Mode—One Six-Input Variable
Function
F5M Mode—One Six-Input Variab le Function
The LUT can be used to implement any function of sixinput variables. As shown in Figure 8, five input signals
(A[4:0]) are routed into both the A[4:0] and B[4:0] ports,
and the C0 port is used for the sixth input. The output
port is F1.
two operands are input into A[3:0] and B[3:0]. The four
result bits, one per QLUT, are F[3:0] (see Figure 9).
The ripple output from QLUT3 can be routed to dedicated carry-out circuitry into any of four adjacent PLCs,
or it can be placed on the O4 PFU output, or both. This
allows the PLCs to be cascaded in the ripple mode so
that nibble-wide ripple functions can be expanded easily to any length.
COUT
COUT
B3
A3
B2
A2
B1
A1
B0
A0
CIN
B3
A3
B2
A2
B1
A1
B0
A0
QLUT3
QLUT2
QLUT1
QLUT0
CIN
F3
F2
F1
F0
5-2756(F).r32
Figure 9. Ripple Mode
Ripple Mode
The LUT can do nibble-wide ripple functions with highspeed carry logic. Each QLUT has a dedicated carryout net to route the carry to/from the adjacent QLUT.
Using the internal carry circuits, fast arithmetic and
counter functions can be implemented in one PFU.
Similarly , each PFU has carry-in (CIN) and carry-out
(COUT) ports for fast-carry routing between adjacent
PFUs.
The ripple mode is generally used in operations on two
4-bit buses. Each QLUT has two operands and a ripple
(generally carry) input, and provides a result and ripple
(generally carry) output. A single bit is rippled from the
previous QLUT and is used as input into the current
QLUT. For QLUT0, the ripple input is from the PFU CIN
The ripple mode can be used in one of four submodes.
The first of these is
adder/subtractor mode
. In this
mode, each QLUT generates two separate outputs.
One of the two outputs selects whether the carry-in is
to be propagated to the carry-out of the current QLUT
or if the carry-out needs to be generated. The result of
this selection is placed on the carry-out signal, which is
connected to the next QLUT or the COUT signal, if it is
the last QLUT (QLUT3).
The other QLUT output creates the result bit for each
QLUT that is connected to F[3:0]. If an adder/subtractor
is needed, the control signal to select addition or subtraction is input on A4. The result bit is created in onehalf of the QLUT from a single bit from each input bus,
along with the ripple input bit. These inputs are also
used to create the programmable propagate.
port. The CIN data can come from either the fast-carry
routing or the PFU input B4, or it can be tied to logic 1
or logic 0.
The resulting output and ripple output are calculated by
using generate/propagate circuitry. In ripple mode, the
10 Lucent Technologies Inc.
Page 11
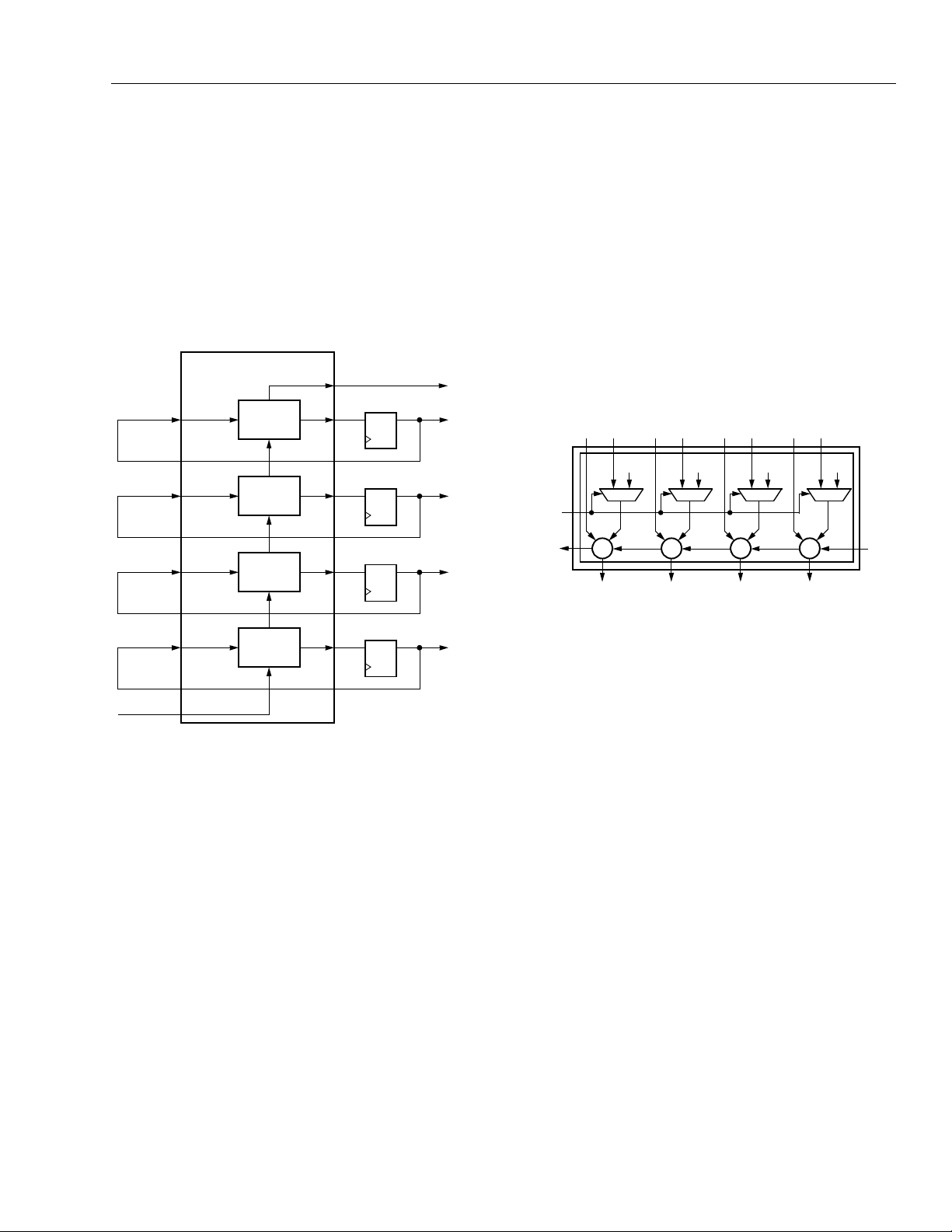
Data Sheet
+
10
A3 B3
0
A4
COUT
F3
+
A2 B2
F2
+
A1 B1
F1
+
A0 B0
F0
CIN
10
0
10
0
10
0
5-4620(F)
June 1999
ORCA
Series 2 FPGAs
Programmable Logic Cells
The second submode is the
counter submode
(continued)
(see
Figure 10). The present count is supplied to input
A[3:0], and then output F[3:0] will either be incremented by one for an up counter or decremented by
one for a down counter. If an up counter or down
counter is needed, the control signal to select the direction (up or down) is input on A4. Generally, the latches/
FFs in the same PFU are used to hold the present
count value.
LUT
COUT
A3
A2
A1
COUT
QLUT3
QLUT2
QLUT1
F3
F2
F1
DQ
DQ
DQ
Q3
Q2
Q1
In the third submode,
multiplier submode
, a single
PFU can affect a 4 x 1-bit multiply and sum with a partial product (see Figure 11). The multiplier bit is input at
A4, and the multiplicand bits are input at B[3:0], where
B3 is the most sign ifi cant bi t (M SB) . A [3:0 ] c ont ain s th e
partial product (or other input to be summed) from a
previous stage. If A4 is logical 1, the multiplicand is
added to the partial product. If A4 is logical zero, zero is
added to the partial product, which is the same as
passing the partial product. CIN can hold the carry-in
from the less significant PFUs if the multiplicand is
wider than 4 bits, and COUT holds any carry-out from
the addition, which may then be used as part of the
product or routed to another PFU in multiplier mode for
multiplicand width expansion.
A0
CIN
QLUT0
CIN
F0
DQ
Figure 10. Counter Submode with Flip-Flops
Q0
5-4643(F).r1
Figure 11. Multiplier Submode
Ripple mode’s fourth submode features
comparators
, where one 4-bit bus is input on B[3:0],
equality
another 4-bit bus is input on B[3:0], and the carry-in is
tied to 0 inside the PFU. The carry-out (¦) signal will be
0 if A = B or will be 1 if A ¦ B. If larger than 4 bits, the
carry-out (¦) signal can be cascaded using fast-carry
logic to the carry-in of any adjacent PFU. Comparators
for greater than or equal or less than (>, =, <) continue
to be supported using the ripple mode subtractor. The
use of this submode could be shown using Figure 9
with CIN tied to 0.
Lucent Technologies Inc. 11
Page 12
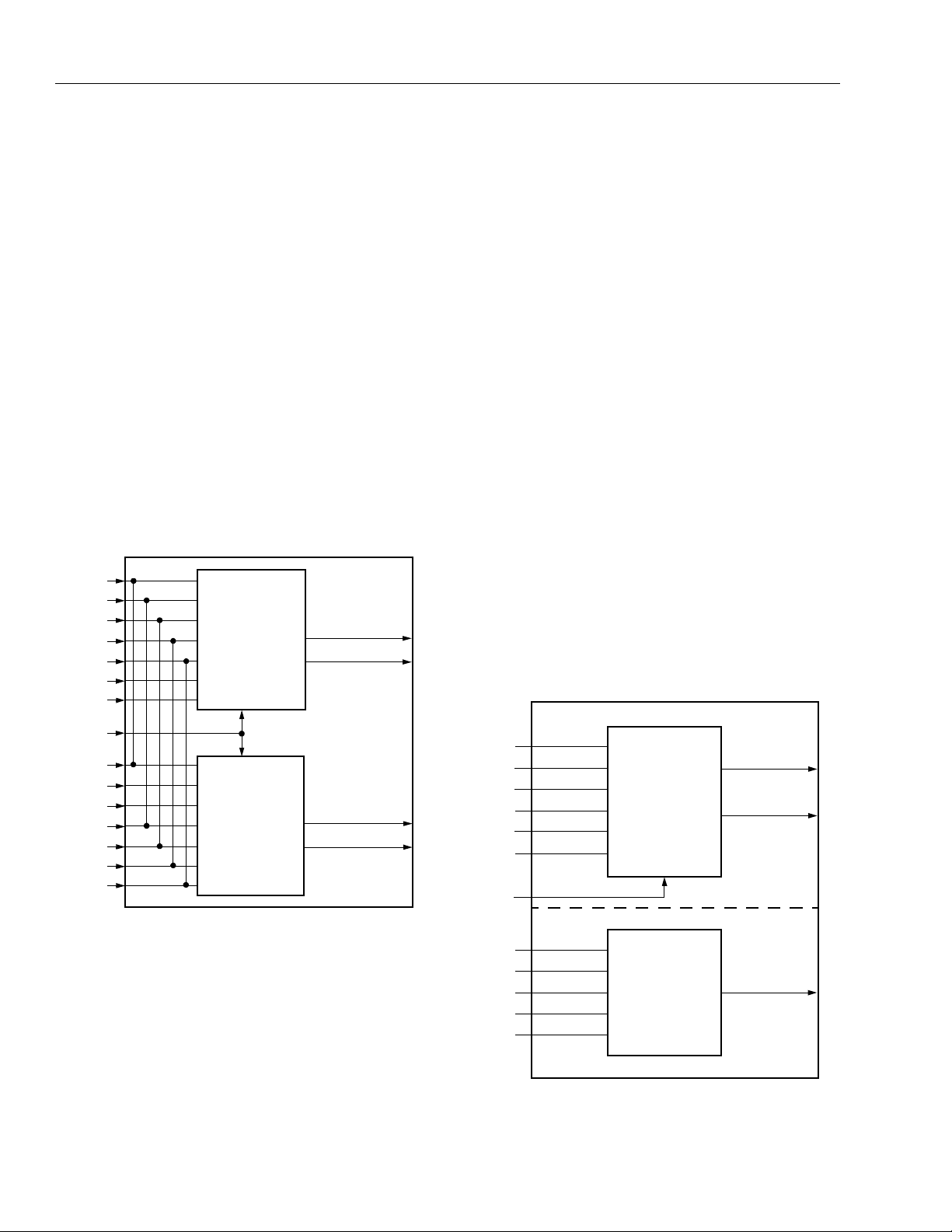
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Logic Cells
(continued)
enable 4 bits of data from a PLC onto the read data
bus.
Asynchronous Memory Modes—MA and MB
The LUT in the PFU can be configured as either read/
write or read-only memory. A read/write address
(A[3:0], B[3:0]), write data (WD[1:0], WD[3:2]), and two
write-enable (WE) ports are used for memory. In asynchronous memory mode, each HLUT can be used as a
16 x 2 memory. Each HLUT is configured independently, allowing functions such as a 16 x 2 memory in
one HLUT and a logic function of five input variables or
less in the other HLUT.
Figure 12 illustrates the use of the LUT for a 16 x 4
memory. When the LUTs are used as memory, there
are independent address, input data, and output data
buses. If the LUT is used as a 16 x 4 read/write memory, the A[3:0] and B[3:0] ports are address inputs
(A[3:0]). The A4 and B4 ports are write-enable (WE)
signals. The WD[3:0] inputs are the data inputs. The
F[3:0] data outputs can be routed out on the O[4:0]
PFU outputs or to the latch/FF D[3:0] inputs.
The
ORCA
Series 2 series also has a new AND function available for each PFU in RAM mode. The inputs to
this function are the write-enable (WE) signal and the
write-port enable (WPE) signal. The write-enable signal is A4 for HLUTA and B4 for HLUTB, while the other
input into the AND gates for both HLUTs is the writeport enable, input on C0 or CIN. Generally, the WPE
input is driven by the same RAM bank-enable signal
that controls the BIDIs in each PFU.
The selection of which RAM bank to write data into
does not require the use of LUTs from other PFUs, as
in previ ous
ORCA
architectures. This reduces the number of PFUs required for RAMs larger than 16 words in
depth. Note that if either HLUT is in MA/MB mode, then
the same WPE is active for both HLUTs.
To increase the memory’s word size (e.g., 16 x 8), two
or more PLCs are used again. The address, writeenable, and write-port enable of the PLCs are tied
together (bit by bit), and the data is different for each
PLC. Increasing both the address locations and word
size is done by using a combination of these two tech-
WEA
A3 A3
A2
A1
A0
WD3
WPE
WEB
WD1
WD0
B3
B2
B1
Figure 12. MA/MB Mode—16 x 4 RAM
To increase memory word depth above 16 (e.g., 32 x
4), two or more PLCs can be used. The address and
write data inputs for the two or more PLCs are tied
together (bit by bit), and the data outputs are routed
A4
A2
A1
A0
WD3
WD2WD2
B4
WD1
WD0
B3
B2
B1
B0B0
C0
C0
HLUTA
HLUTB
F3
F2
F1
F0
5-2757(F).r3
niques.
The LUT can be used simultaneously for both memory
and a combinatorial logic function. Figure 13 shows the
use of a LUT implementing a 16 x 2 RAM (HLUTA) and
any function of up to five input variables (HLUTB).
HLUTA
WEA
A3
A2
A1
A0
WD3
WPE
B4
B3
B2
B1
B0
A4
A3
A2
A1
A0
WD3
B4
B3
B2
B1
B0
QLUT3
QLUT2
C0
QLUT1
QLUT0
F3
F2
HLUTB
F0
through the four 3-statable BIDIs available in each PFU
and are then tied together (bit by bit).
The control signal of the 3-statable BIDIs, called a RAM
bank-enable, is created from a decode of upper
address bits. The RAM bank-enable is then used to
Figure 13. MA/F5 Mode—16 x 2 Memory and One
Function of Five Input Variables
5-2845(F).a.r1
12 Lucent Technologies Inc.
Page 13
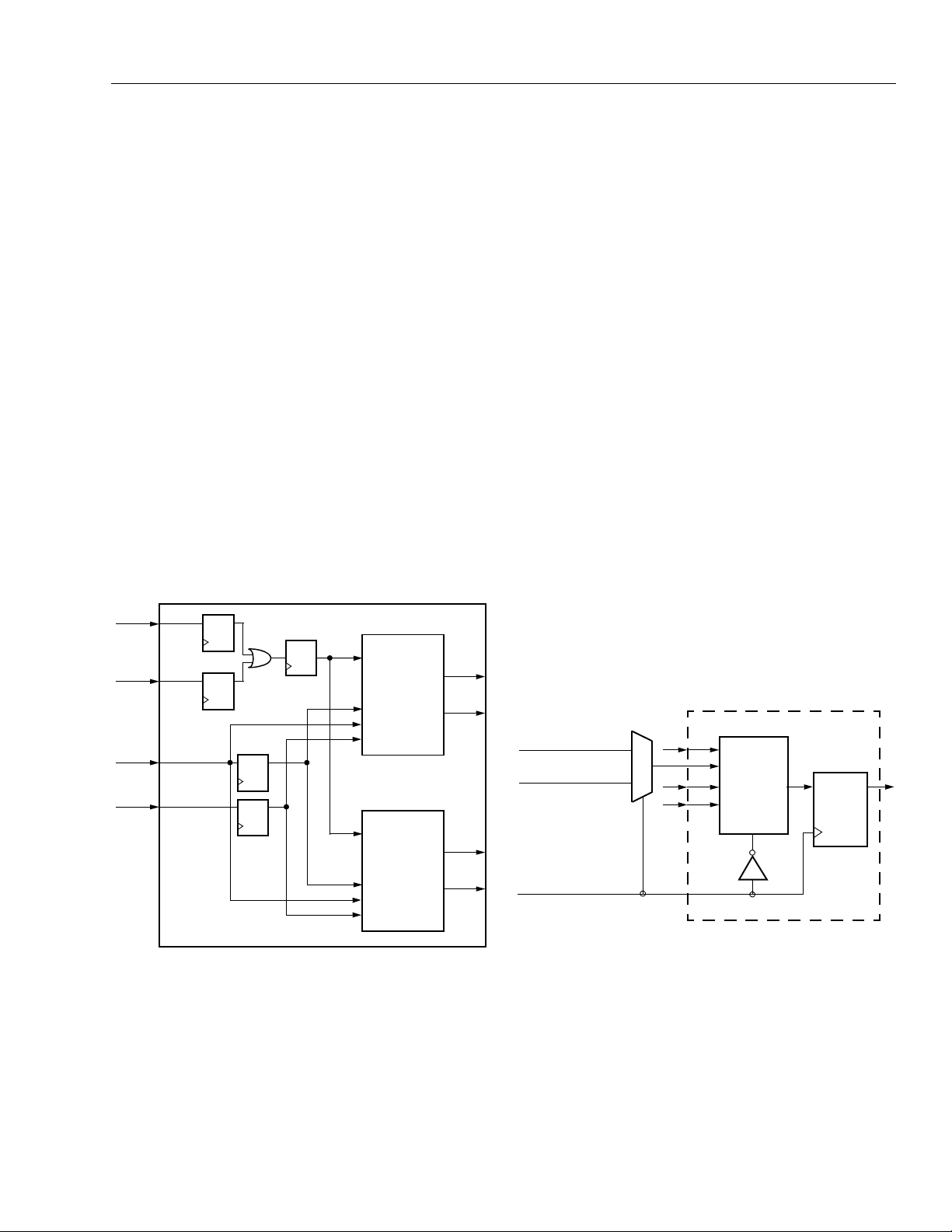
Data Sheet
WE
A
WD
RAM CLK
WRITE ADDRESS
READ ADDRESS
0
1
WPE
SSPM
CLOCK
DQ
PFU
June 1999
ORCA
Series 2 FPGAs
Programmable Logic Cells
(continued)
Synchronous Memory Modes—SSPM and SDPM
The MA/MB asynchronous memory modes described
previously allow the PFU to perform as a 16 x 4
(64 bits) single-port RAM. Synchronously writing to this
RAM requires the write-enable control signal to be
gated with the clock in another PFU to create a write
pulse. To simplify this functionality, the Series 2 devices
contain a
synchronous single-port memory
(SSPM)
mode, where the generation of the write pulse is done
in each PFU.
With SSPM mode, the entire LUT becomes a 16 x 4
RAM, as shown in Figure 14. In this mode, the input
ports are write enable (WE), write-port enable (WPE),
read/write address (A[3:0]), and write data (WD[3:0]).
To synchronously write the RAM, WE (input into a4)
and WPE (input into either C0 or CIN) are latched and
ANDed together. The result of this AND function is sent
to a pulse generator in the LUT, which writes the RAM
synchronous to the RAM clock. This RAM clock is the
same one sent to the PFU latches/FFs; however , if necessary, it can be programmably inverted.
A4
WE
WPE
A[3:0]
DQ
CIN, C0
DQ
A[3:0], B[3:0]
WRITE PULSE
GENERATOR
DQ
WR
WA[3:0]
RA[3:0]
WD[3:2]
HLUTA
F3
F2
The write address (WA[3:0]) and write data (WD[3:0])
are also latched by the RAM clock in order to simplify
the timing. Reading data from the RAM is done asynchronously; thus, the read address (RA[3:0]) is not
latched. The result from the read operation is placed on
the LUT outputs (F[3:0]). The F[3:0] data outputs can
be routed out of the PFU or sent to the latch/FF D[3:0]
inputs.
There are two ways to use the latches/FFs in conjunction with the SSPM. If the phase of the latch/FF clock
and the RAM clock are the same, only a read address
or write address can be supplied to the RAM that
meets the synchronous timing requirements of both
the RAM clock and latch/FF clock. Therefore, either a
write to the RAM or a read from the RAM can be done
in each clock cycle, but not both. If the RAM clock is
inverted from the latch/FF clock, then both a write to
the RAM and a read from the RAM can occur in each
clock cycle. This is done by adding an external write
address/read address multiplexer as shown in
Figure 15.
The write address is supplied on the phase of the clock
that allows for setup to the RAM clock, and the read
address is supplied on the phase of the clock that
allows the read data to be set up to the latch/FF clock.
If a higher-speed RAM is required that allows both a
read and write in each clock cycle, the synchronous
dual-port memory mode (SDPM) can be used, since it
does not require the use of an external multiplexer.
WD[3:0]
WD[3:0]
DQ
WR
WA[3:0]
RA[3:0]
WD[1:0]
HLUTB
F1
F0
5-4642(F).r1
5-4644(F).r1
Figure 15. SSPM with Read/Write per Clock Cycle
Figure 14. SSPM Mode—16 x 4 Synchronous
Single-Port Memory
Lucent Technologies Inc. 13
Page 14
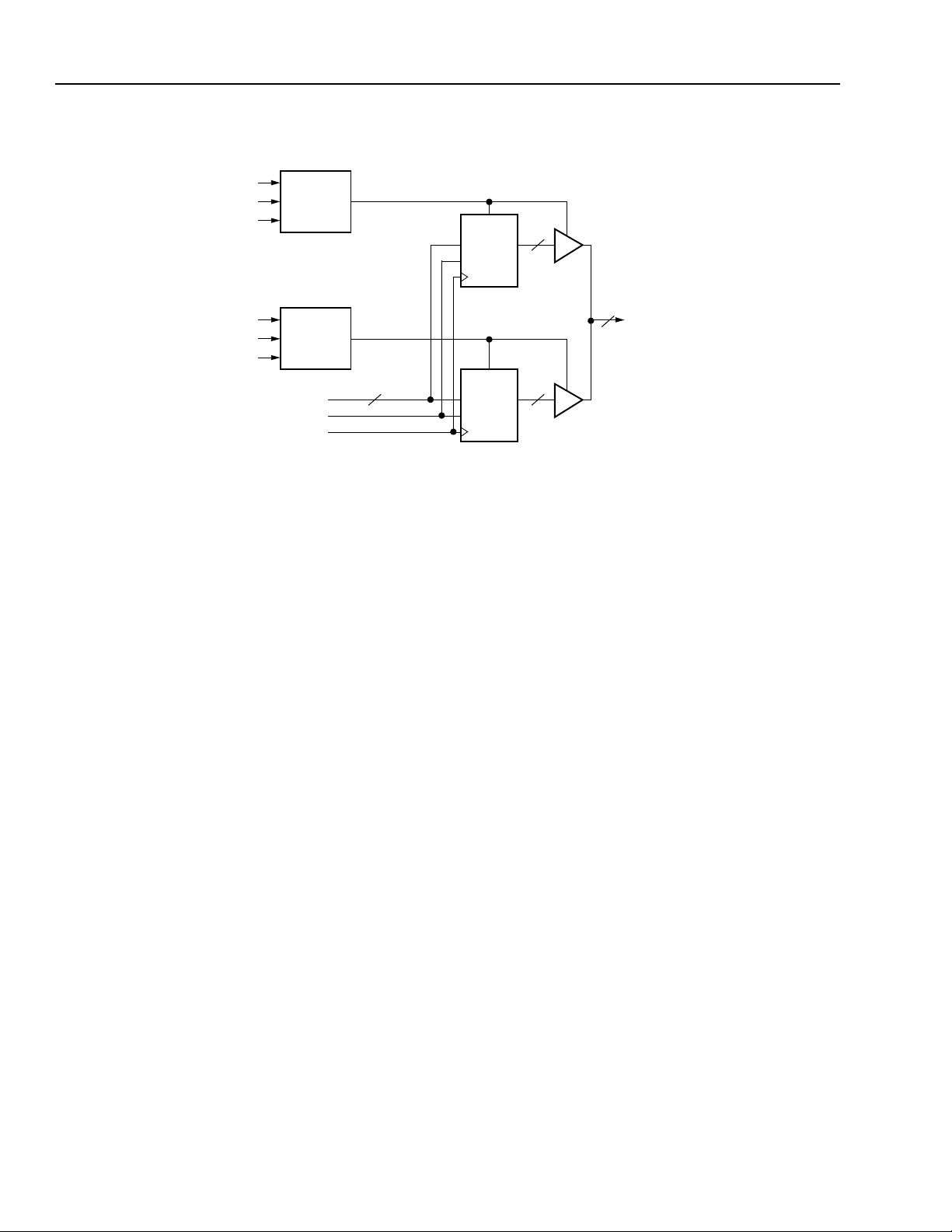
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Logic Cells
UPPER
ADDRESS
BITS
UPPER
ADDRESS
BITS
Note: The lower address bits are not shown.
Figure 16. Synchronous RAM with Write-Port Enable (WPE)
ADDRESS
DECODE
LUT1
ADDRESS
DECODE
LUT2
CLK
(continued)
DIN
WR
BANK_EN1
BANK_EN2
4
WPE
DI
DO
WR
16 x 4 RAM +
4 BUFFERS/P FU
WPE
DI
DO
WR
16 x 4 RAM +
4 BUFFERS/P FU
4
BIDI
4
DOUT
4
BIDI
5-4640(F)
To increase memory word depth above 16 (e.g., 32 x
4), two or more PLCs can be used. The address and
write data inputs for the two or more PLCs are tied
together (bit by bit), and the data outputs are routed
through the four 3-statable BIDIs available in each
PFU. The BIDI outputs are then tied together (bit by
bit), as seen in Figure 16.
The control signals of the 3-statable BIDIs, called RAM
bank-enable (BANK_EN1 and BANK_EN2), are created from a decode of upper address bits. The RAM
bank-enable is then used to enable 4 bits of data from
a PLC onto the read data (DOUT) bus.
The Series 2 series now has a new AND function available for each PFU in RAM mode. The inputs to this
function are the write-enable (WE) signal and the writeport enable (WPE) signal. The write-enable signal is
input on A4, while the write-port enable is input on C0
or CIN. Generally, the WPE input is driven by the same
RAM bank-enable signal that controls the BIDIs in each
PFU.
The selection as to which RAM bank to write data into
does not require the use of LUTs from other PFUs, as
in previ ous
ORCA
architectures. This reduces the number of PFUs required for RAMs larger than 16 words in
depth.
A special use of this method can be to increase word
depth to 32 words. Since both the WPE input into the
RAM and the 3-state input into the BIDI can be
inverted, a decode of the one upper address bit is not
required. Instead, the bank-enable signal for both
banks is tied to the upper address bit, with the WPE
and 3-state inputs active-high for one bank and activelow for the other.
To increase the memory’s word size (e.g., 16 x 8), two
or more PLCs are used again. The address, writeenable, and write-port enable of the PLCs are tied
together (bit by bit), and the data is different for each
PLC. Increasing both the address locations and word
size is accomplished by using a combination of these
two techniques.
14 Lucent Technologies Inc.
Page 15
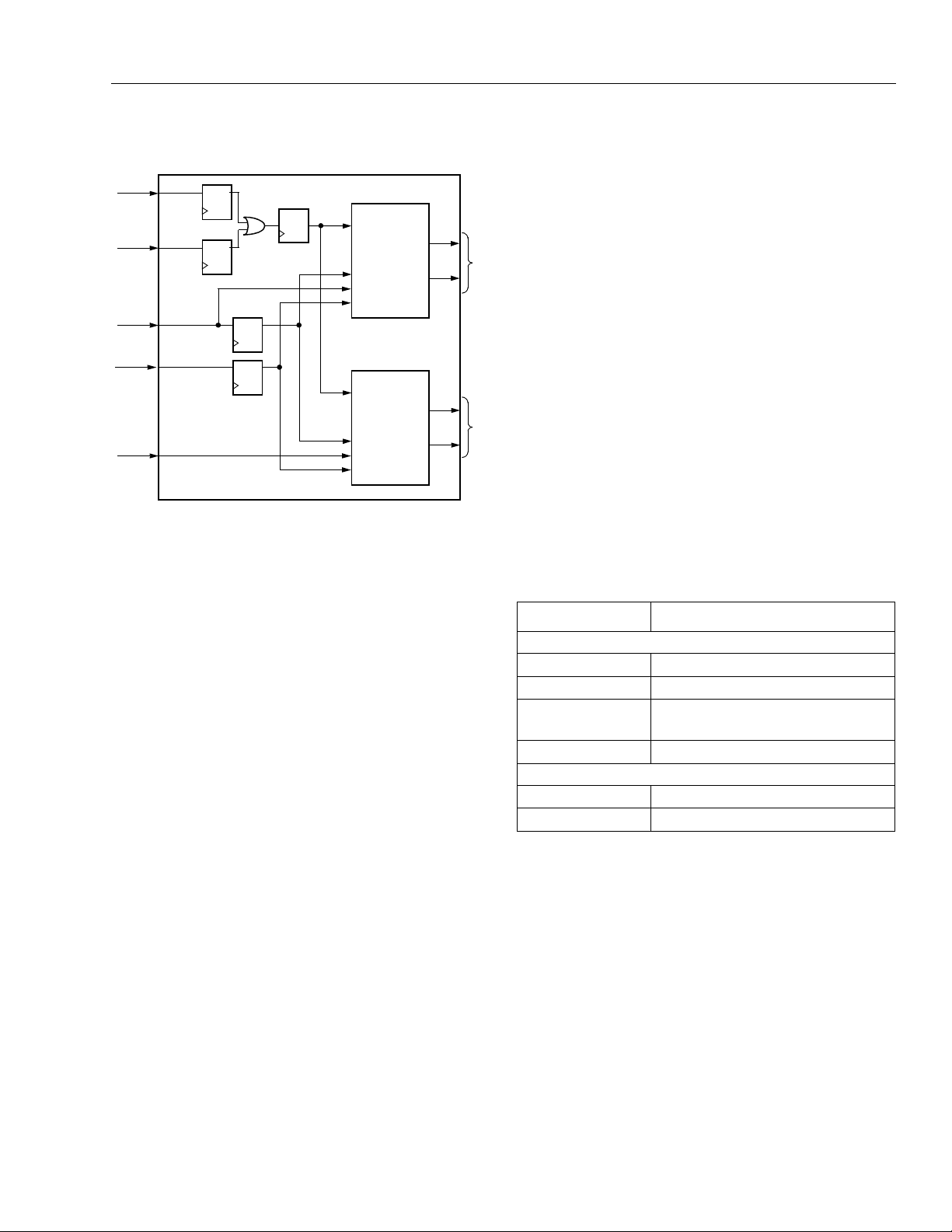
Data Sheet
June 1999
ORCA
Series 2 FPGAs
Programmable Logic Cells
A4
WE
WPE
WA[3:0]
WD[1:0]
RA[3:0]
CIN, C0
A[3:0]
WD[1:0]
B[3:0]
DQ
DQ
WRITE PULSE
GENERATOR
DQ
DQ
(continued)
HLUTA
WR
WA[3:0]
RA[3:0]
WD[1:0]
HLUTB
WR
WA[3:0]
RA[3:0]
WD[1:0]
Figure 17. SDPM Mode—16 x 2 Synchronous
Dual-Port Memory
F3
F2
F1
F0
5-4641(F).r1
Latches/Flip-Flops
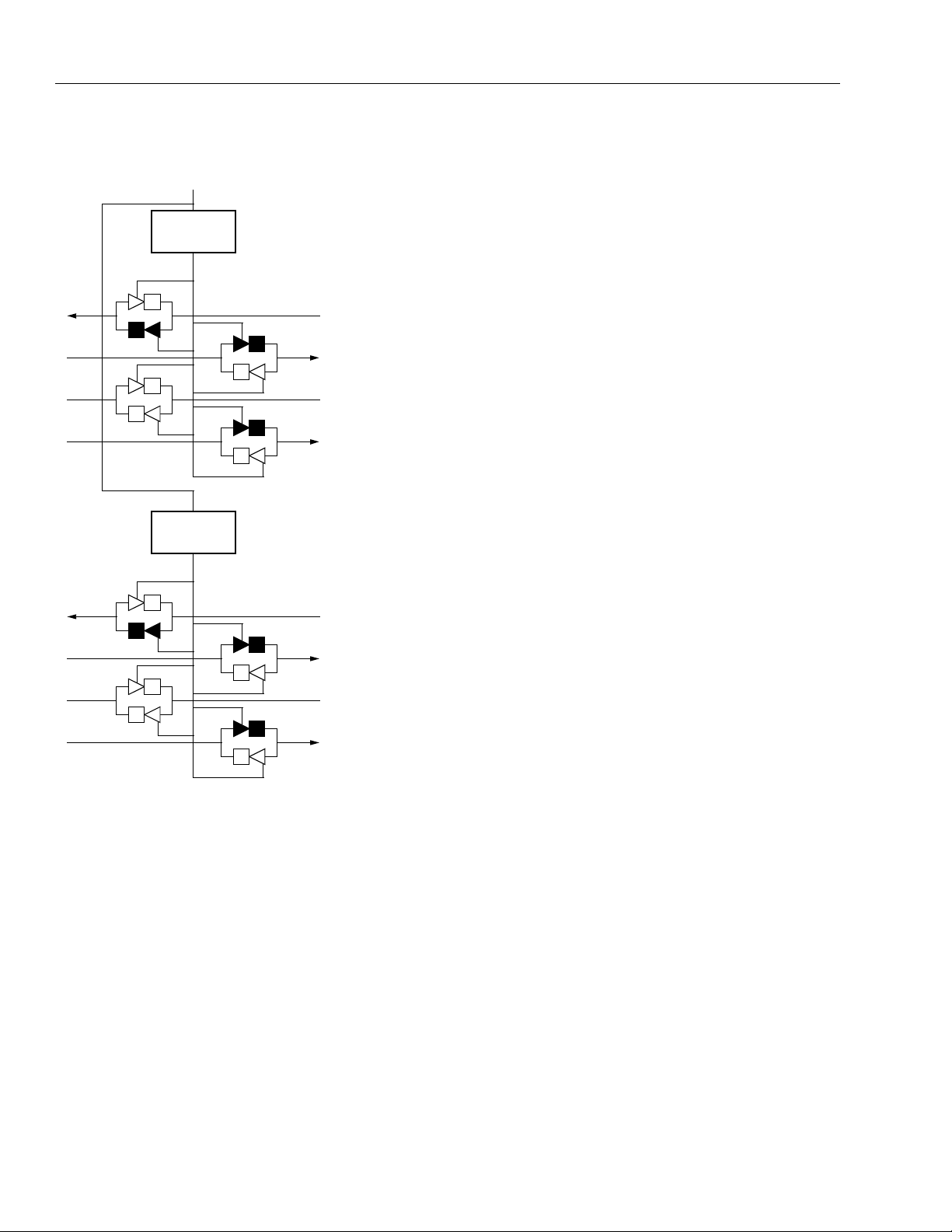
The four latches/FFs in the PFU can be used in a variety of configurations. In some cases, the configuration
options apply to all four latches/FFs in the PFU. For
other options, each latch/FF is independently program-
SSPM OUTPUT SDPM OUTPUT
mable.
Table 4 summarizes these latch/FF options. The
latches/FFs can be configured as either positive or
negative level-sensitive latches, or positive or negative
edge-triggered flip-flops. All latches/FFs in a given PFU
share the same clock, and the clock to these latches/
FFs can be inverted. The input into each latch/FF is
from either the corresponding QLUT output (F[3:0]) or
the direct data input (WD[3:0]). For latches/FFs located
in the two outer rings of PLCs, additional inputs are
possible. These additional inputs are fast paths from
I/O pads located in PICs in the same row or column as
the PLCs. If the latch/FF is not located in the two outer
rings of the PLCs, the latch/FF input can also be tied to
logic 0, which is the default. The four latch/FF outputs,
Q[3:0], can be placed on the five PFU outputs, O[4:0].
Table 4. Configuration RAM Controlled Latch/
Flip-Flop Operation
The Series 2 devices have added a second synchronous memory mode known as the
port memory
(SDPM) mode. This mode writes data
synchronous dual-
into the memory synchronously in the same manner
described previously for SSPM mode. The SDPM
mode differs in that two separate 16 x 2 memories are
created in each PFU that have the same WE, WPE,
write data (WD[1:0]), and write address (WA[3:0])
inputs, as shown in Figure 17.
The outputs of HLUTA (F[3:2]) operate the same way
they do in SSPM mode—the read address comes
directly from the A[3:0] inputs used to create the
latched write address. The outputs of HLUTB (F[1:0])
operate in a dual-port mode where the write address
comes from the latched version of A[3:0], and the read
address comes directly from RA[3:0], which is input on
B[3:0].
Since external multiplexing of the write address and
read address is not required, extremely fast RAMs can
be created. New system applications that require an
interface between two different asynchronous clocks
can also be implemented using the SDPM mode. An
example of this is accomplished by creating FIFOs
where one clock controls the synchronous write of data
into the FIFO, and the other clock controls the read
address to allow reading of data at any time from the
FIFO.
Function Options
Functionality Common to All Latch/FFs in PFU
LSR Operation Asyn ch ronous or synchronous
Clock Polar ity Noninverted or inverted
Front-End Select Direct (WD[3:0]) or fro m LU T
(F[3:0])
LSR Priorit y Either LSR or CE has prio rity
Functionality Set Individually in Each Latch/FF in PFU
Latch/FF Mode Latch or flip-flop
Set/Reset Mode Set or Reset
The four latches/FFs in a PFU share the clock (CK),
clock enable (CE), and local set/reset (LSR) inputs.
When CE is disabled, each latch/FF retains its previous
value when clocked. Both the clock enable and LSR
inputs can be inverted to be active-low.
Lucent Technologies Inc. 15
Page 16
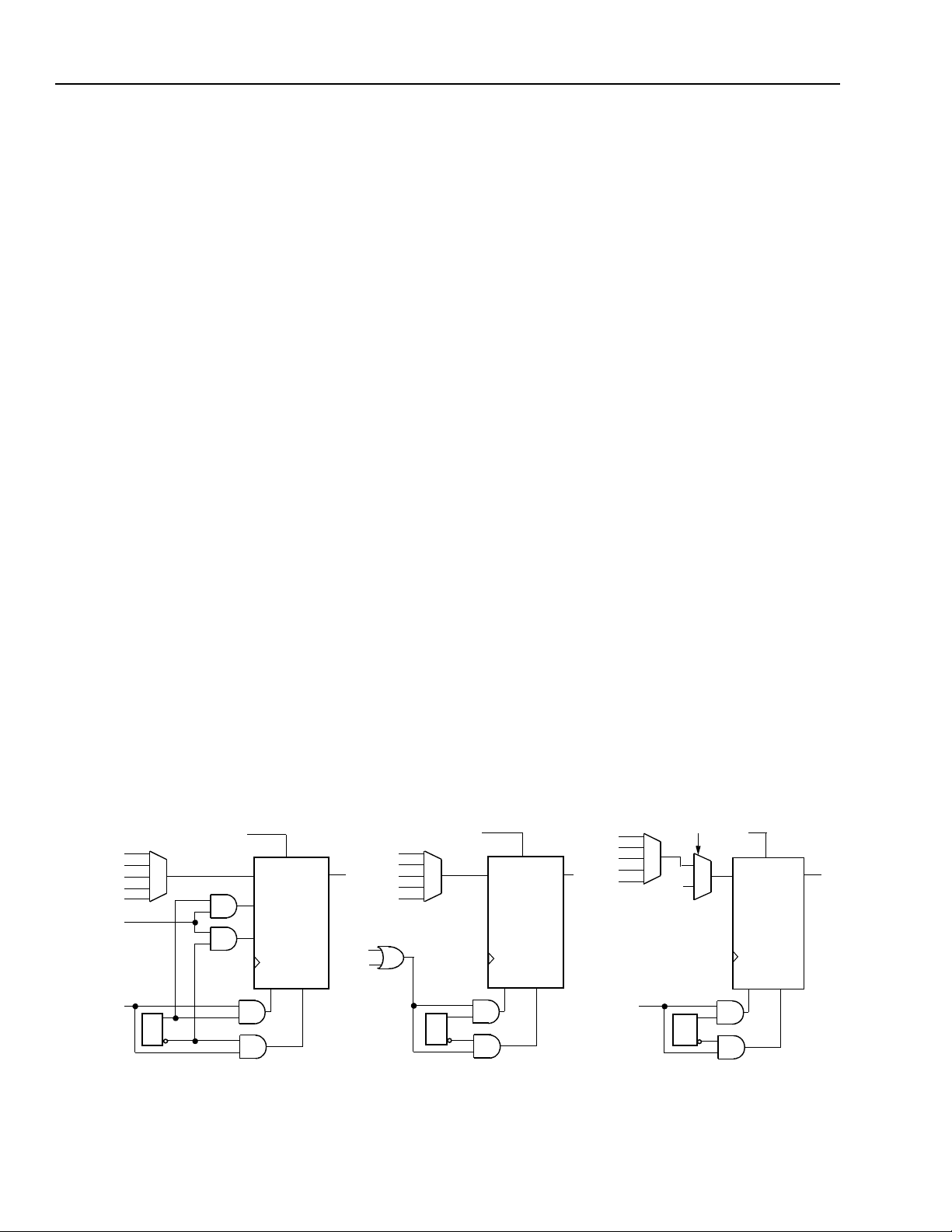
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Logic Cells
(continued)
The set/reset operation of the latch/FF is controlled by
two parameters: reset mode and set/reset value. When
the global set/reset (GSRN) or local set/reset (LSR) are
inactive, the storage element operates normally as a
latch or FF. The reset mode is used to select a synchronous or asynchronous LSR operation. If synchronous,
LSR is enabled only if clock enable (CE) is active. For
the Series 2 series, a new option called the LSR priority allows the synchronous LSR to have priority over the
CE input, thereby setting or resetting the FF independent of the state of CE. The clock enable is supported
on FFs, not latches. The clock enable function is implemented by using a two-input multiplexer on the FF
input, with one input being the previous state of the FF
and the other input being the new data applied to the
FF. The select of this two-input multiplexer is clock
enable (CE), which selects either the new data or the
previous state. When CE is inactive, the FF output
does not change when the clock edge arrives.
The GSRN signal is only asynchronous, and it sets/
resets all latches/FFs in the FPGA based upon the set/
reset configuration bit for each latch/FF. The set/reset
value determines whether GSRN and LSR are set or
reset inputs. The set/reset value is independent for
each latch/FF.
If the local set/reset is not needed, the latch/FF can be
configured to have a data front-end select. Two data
inputs are possible in the front-end select mode, with
the LSR signal used to select which data input is used.
The data input into each latch/FF is from the output of
its associated QLUT F[3:0] or direct from WD[3:0],
bypassing the LUT. In the front-end data select mode,
both signals are available to the latches/FFs.
For PLCs that are in the two outside rows or columns of
the array, the latch/FFs can have two inputs in addition
to the F and WD inputs mentioned above. One input is
from an I/O pad located at the PIC closest to either the
left or right of the given PLC (if the PLC is in the left two
columns or right two columns of the array). The other
input is from an I/O pad located at the closest PIC
either above or below the given PLC (if the PLC is in
the top or the bottom two rows). It should be noted that
both inputs are available for a 2 x 2 array of PLCs in
each corner of the array. For the entire array of PLCs, if
either or both of these inputs is unavailable, the latch/
FF data input can be tied to a logic 0 instead (the
default).
To speed up the interface between signals external to
the FPGA and the latches/FFs, there are direct paths
from latch/FF outputs to the I/O pads. This is done for
each PLC that is adjacent to a PIC.
The latches/FFs can be configured in three modes:
1. Local synchronous set/reset: the input into the PFU’s
LSR port is used to synchronously set or reset each
latch/FF.
2. Local asynchronous set/reset: the input into LSR
asynchronously sets or resets each latch/FF.
3. Latch/FF with front-end select: the data select signal
(actually LSR) selects the input into the latches/FFs
between the LUT output and direct data in.
For all three modes, each latch/FF can be independently programmed as either set or reset. Each latch/
FF in the PFU is independently configured to operate
as either a latch or flip-flop. Figure 18 provides the logic
functionality of the front-end select, global set/reset,
and local set/reset operations.
WD
CD
LSR
CE
CE
D
CLK
SET RESET
5-2839(F).a
PDINTB
PDINLR
F
WD
LOGIC 0
LSR
GSRN
CD
Note: CD = configuration data.
CE
CE
D
S_SET
S_RESET
CLK
SET RESET
Q
PDINTB
PDINLR
LOGIC 0
GSRN
LSR
WD
CE
CE
F
CD
D
CLK
SET RESET
PDINTB
PDINLR
F
Q Q
WD
LOGIC 0
GSRN
Figure 18. Latch/FF Set/Reset Configurations
16 Lucent Technologies Inc.
Page 17
Data Sheet
2
INDEPENDENT CIP
CD
A
B
AB
=
MULTIPLEXED CIP
A
B
C
A
B
C
O
O
CD
June 1999
ORCA
Series 2 FPGAs
Programmable Logic Cells
(continued)
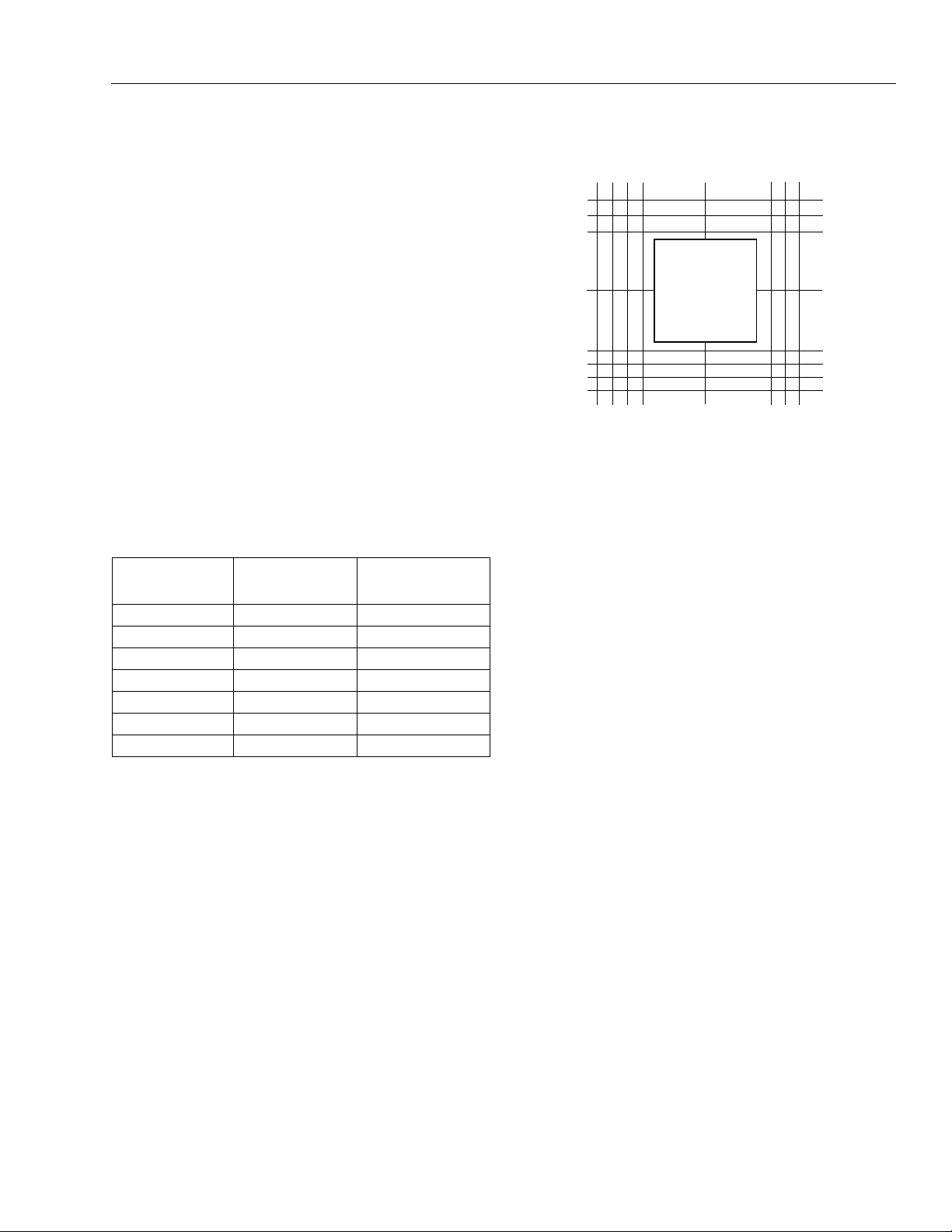
PLC Routing Resources
Generally, the
used to automatically route interconnections. Interactive routing with the
(EPIC) is also available for design optimization. To use
EPIC for interactive layout, an understanding of the
routing resources is needed and is provided in this section.
The routing resources consist of switching circuitry and
metal interconnect segments. Generally , the metal lines
which carry the signals are designated as routing
nodes (lines). The switching circuitry connects the routing nodes, providing one or more of three basic functions: signal switching, amplification, and isolation. A
net running from a PFU or PIC output (source) to a
PLC or PIC input (destination) consists of one or more
lines, connected by switching circuitry designated as
configurable interconnect points (CIPs).
The following sections discuss PLC, PIC, and interquad
routing resources. This section dis c us se s the PLC
switching circuitry, intra-PLC routing, inter-PLC routing,
and clock distribution.
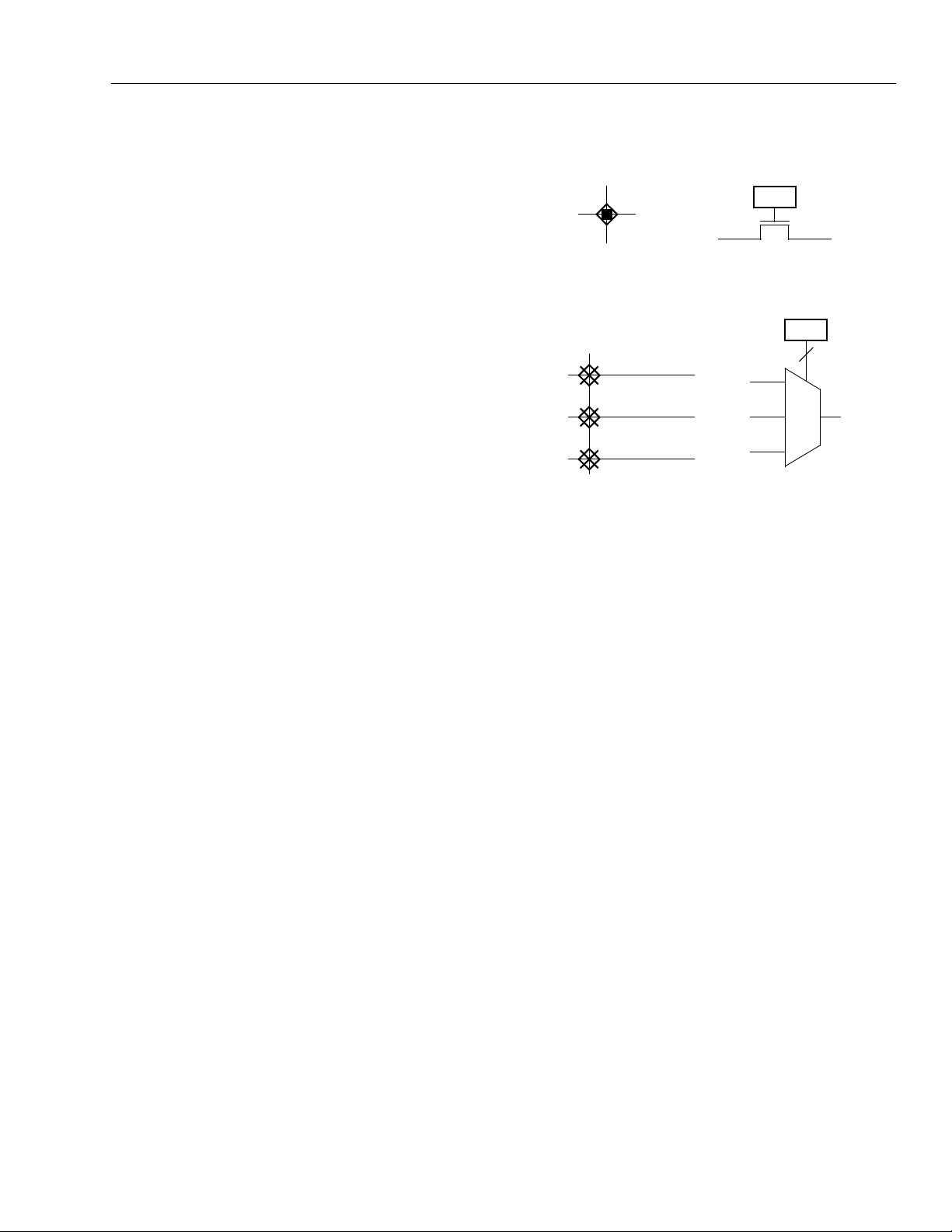
Configurable Interconnect Points
The process of connecting lines uses three basic types
of switching circuits: two types of configurable interconnect points (CIPs) and bidirectional buffers (BIDIs). The
basic element in CIPs is one or more pass transistors,
each controlled by a configuration RAM bit. The two
types of CIPs are the mutually exclusive (or multiplexed) CIP and the independent CIP.
A mutually exclusive set of CIPs contains two or more
CIPs, only one of which can be on at a time. An independent CIP has no such restrictions and can be on
independent of the state of other CIPs. Figure 19
shows an example of both types of CIPs.
ORCA
Foundry Development System is
ORCA
Foundry design editor
f.13(F)
Figure 19. Configurable Interconnect Point
3-Statable Bidirectional Buffers
Bidirectional buffers provide isolation as well as amplification for signals routed a long distance. Bidirectional
buffers are also used to drive signals directly onto
either vertical or horizontal XL and XH lines (to be
described later in the inter-PLC routing section). BIDIs
are also used to indirectly route signals through the
switching lines. Any number from zero to eight BIDIs
can be used in a given PLC.
The BIDIs in a PLC are divided into two nibble-wide
sets of four (BIDI and BIDIH). Each of these sets has a
separate BIDI controller that can have an application
net connected to its TRI input, which is used to 3-state
enable the BIDIs. Although only one application net can
be connected to both BIDI controllers, the sense of this
signal (active-high, active-low, or ignored) can be configured independently. Therefore, one set can be used
for driving signals, the other set can be used to create
3-state buses, both sets can be used for 3-state buses,
and so forth.
Lucent Technologies Inc. 17
Page 18
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Logic Cells
TRI
BIDI
CONTROLLER
BIDIH
CONTROLLER
(continued)
RIGHT-LEFT BIDI
LEFT-RIGHT BIDI
UNUSED BIDI
LEFT-RIGHT BIDI
RIGHT-LEFT BIDIH
LEFT-RIGHT BIDIH
UNUSED BIDIH
LEFT-RIGHT BIDIH
Switchin g Lin es.
There are four sets of switching lines
in each PLC, one in each corner. Each set consists of
five switching elements, labeled SUL[4:0], SUR[4:0],
SLL[4:0], and SLR[4:0], for the upper-left, upper-right,
lower-left, and lower-right sections of the PFUs,
respectively. The switching lines connect to the PFU
inputs and outputs as well as the BIDI and BIDIH lines,
to be described later. They also connect to both the
horizontal and vertical X1 and X4 lines (inter-PLC routing resources, described below) in their specific corner.
One of the four sets of switching lines can be connected to a set of switching lines in each of the four
adjacent PLCs or PICs. This allows direct routing of up
to five signals without using inter-PLC routing.
BIDI/BIDIH Lines.
There are two sets of bidirectional
lines in the PLC, each set consisting of four bidirectional buffers. They are designated BIDI and BIDIH and
have similar functionality. The BIDI lines are used in
conjunction with the XL lines, and the BIDIH lines are
used in conjunction with the XH lines. Each side of the
four BIDIs in the PLC is connected to a BIDI line on the
left (BL[3:0]) and on the right (BR[3:0]). These lines can
be connected to the XL lines through CIPs, with BL[3:0]
connected to the vertical XL lines and BR[3:0] connected to the horizontal XL lines. Both BL[3:0] and
BR[3:0] have CIPs which connect to the switching lines.
Similarly , each side of the four BIDIHs is connected to a
BIDIH line: BLH[3:0] on the left and BRH[3:0] on the
right. These lines can also be connected to the XH
lines through CIPs, with BLH[3:0] connected to the vertical XH lines and BRH[3:0] connected to the horizontal
XH lines. Both BLH[3:0] and BRH[3:0] have CIPs which
connect to the switching lines.
5-4479p2(F)
Figure 20. 3-Statable Bidirectional Buffers
lines together on each side of the BIDIs. For example,
BLH3 can connect to BL3, while BRH3 can connect to
BR3.
Intra-PLC Routing
The function of the intra-PLC routing resources is to
connect the PFU’s input and output ports to the routing
resources used for entry to and exit from the PLC.
These are nets for providing PFU feedback, turning
corners, or switching from one type of routing resource
to another.
CIPs are also provided to connect the BIDIH and BIDIL
PFU Input and Output P orts.
There are 19 input ports
to each PFU. The PFU input ports are labeled A[4:0],
B[4:0], WD[3:0], C0, CK, LSR, CIN, and CE. The six
output ports are O[4:0] and COUT. These ports correspond to those described in the PFU section.
18 Lucent Technologies Inc.
Page 19
Data Sheet
PROGRAMMABLE
FUNCTION UNIT
DIRECT[4:0]
HX4[7:4]
HX1[7:4]
DIRECT[4:0]
HXH[3:0]
HX1[3:0]
DIRECT[4:0]
DIRECT[4:0]
HX4[3:0]
VX4[7:4]
VX1[7:4]
VXL[3:0]
VX1[3:0]
VX4[3:0]
VXH[3:0]
CKB, CKT
HXL[3:0]
CKL, CKR
June 1999
ORCA
Series 2 FPGAs
Programmable Logic Cells
(continued)
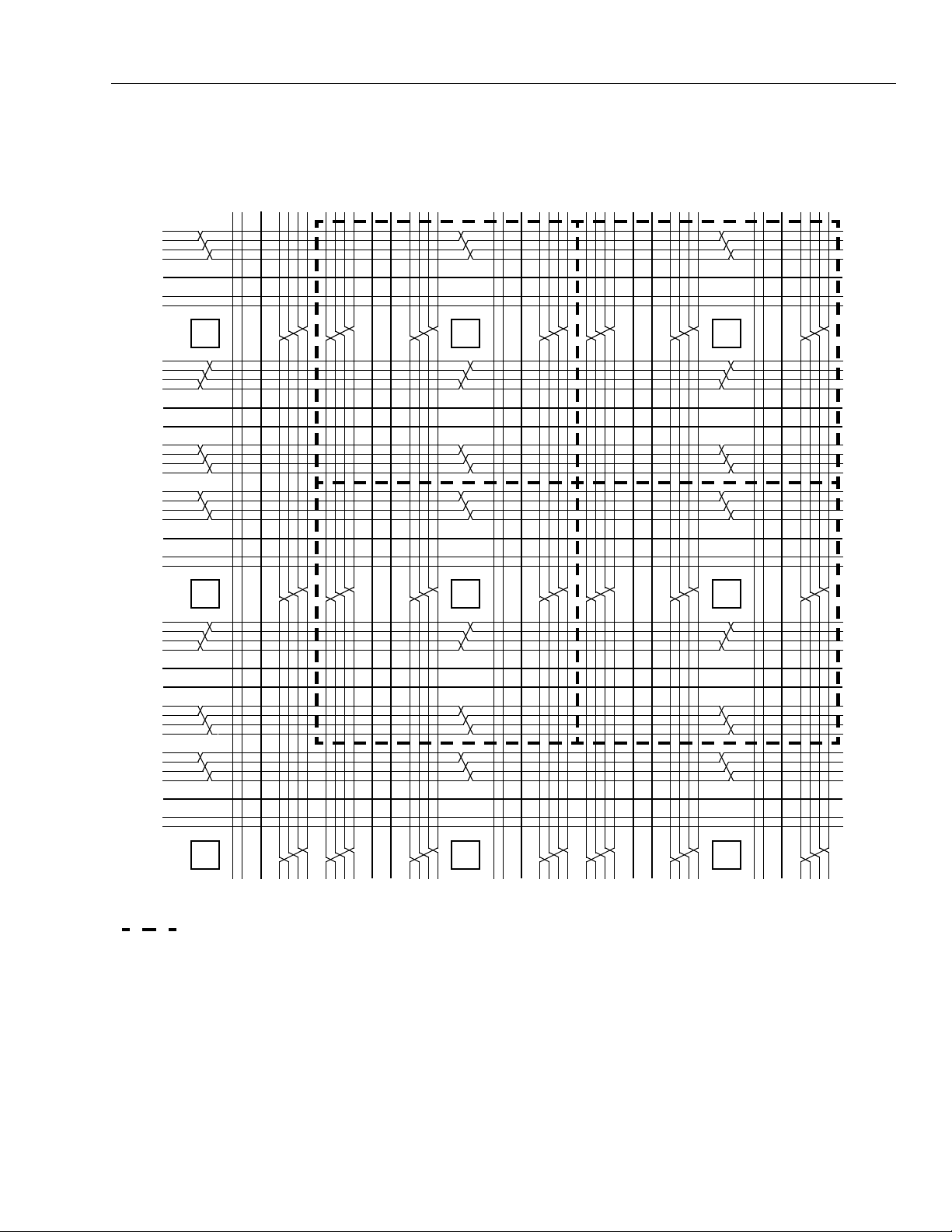
Inter-PLC Routing Resources
The inter-PLC routing is used to route signals between
PLCs. The lines occur in groups of four, and differ in the
numbers of PLCs spanned. The X1 lines span one
PLC, the X4 lines span four PLCs, the XH lines span
one-half the width (height) of the PLC array, and the XL
lines span the width (height) of the PLC array. All types
of lines run in both horizontal and vertical directions.
Table 5 shows the groups of inter-PLC lines in each
PLC. In the table, there are two rows/columns each for
X1 and X4 lines. In the design editor, the horizontal X1
and X4 lines are located above and below the PFU.
Similarly, the vertical segments are located on each
side. The XL and XH lines only run below and to the left
of the PFU. The indexes specify individual lines within a
group. For example, the VX4[2] line runs vertically to
the left of the PFU, spans four PLCs, and is the third
line in the 4-bit wide bus.
Table 5. Inter-PLC Routing Resources
Horizontal
Lines
Vertical
Lines
Distance
Spanned
HX1[3:0] VX1[3:0] One PLC
HX1[7:4] VX1[7:4] One PLC
HX4[3:0] VX4[3:0] Four PLCs
HX4[7:4] VX4[7:4] Four PLCs
HXL[3:0] VXL[3:0] PLC Array
HXH[3:0] VXH[3:0] 1/2 PLC Array
CKL, CKR CKT, CKB PLC Array
Figure 21 shows the inter-PLC routing within one PLC.
Figure 22 provides a global view of inter-PLC routing
resources across multiple PLCs.
5-4528(F)
Figure 21. Single PLC View of Inter-PLC Lines
X1 Lines.
There are a total of 16 X1 lines per PLC:
eight vertical and eight horizontal. Each of these is subdivided into nibble-wide buses: HX1[3:0], HX1[7:4],
VX1[3:0], and VX1[7:4]. An X1 line is one PLC long.
If a net is longer than one PLC, an X1 line can be
lengthened to n times its length by turning on n – 1
CIPs. A signal is routed onto an X1 line via the switching lines.
X4 Lines.
There are four sets of four X4 lines, for a
total of 16 X4 lines per PLC. They are HX4[3:0],
HX4[7:4], VX4[3:0], and VX4[7:4]. Each set of X4 lines
is twisted each time it passes through a PLC, and one
of the four is broken with a CIP. This allows a signal to
be routed for a length of four cells in any direction on a
single line without additional CIPs. The X4 lines can be
used to route any nets that require minimum delay. A
longer net is routed by connecting two X4 lines
together by a CIP. The X4 lines are accessed via the
switching lines.
Lucent Technologies Inc. 19
Page 20

ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Logic Cells
XL Lines.
tally the height and width of the array, respectively.
There are a total of eight XL lines per PLC: four horizontal (HXL[3:0]) and four vertical (VXL[3:0]). Each
PLC column has four XL lines, and each PLC row has
four XL lines. Each of the XL lines connects to the two
PICs at either end. The Series 2, which consists of a
18 x 18 array of PLCs, contains 72 VXL and 72 HXL
lines. They are intended primarily for global signals
which must travel long distances and require minimum
delay and/or skew, such as clocks.
There are three methods for routing signals onto the XL
lines. In each PLC, there are two long-line drivers: one
for a horizontal XL line, and one for a vertical XL line.
Using the long-line drivers produces the least delay.
The XL lines can also be driven directly by PFU outputs
using the BIDI lines. In the third method, the XL lines
are accessed by the bidirectional buffers, again using
the BIDI lines.
XH Lines
four XH lines run vertically in each row and column in
the array. These lines travel a distance of one-half the
PLC array before being broken in the middle of the
array, where they connect to the interquad block (discussed later). They also connect at the periphery of the
FPGA to the PICs, like the XL lines. The XH lines do
not twist like XL lines, allowing nibble-wide buses to be
routed easily.
Two of the three methods of routing signals onto the
XL lines can also be used for the XH lines. A special
XH line driver is not supplied for the XH lines.
The long XL lines run vertically and horizon-
. Four by half (XH) lines run horizontally and
(continued)
The clock lines are designed to be a clock spine. In
each PLC, there is a fast connection available from the
clock line to the long-line driver (described earlier).
With this connection, one of the clock lines in each PLC
can be used to drive one of the four XL lines perpendicular to it, which, in turn, creates a clock tree.
This feature is discussed in detail in the Clock Distribution Network section.
Minimizing Routing Delay
The CIP is an active element used to connect two lines.
As an active element, it adds significantly to the resistance and capacitance of a net, thus increasing the
net’s dela y. The advantage of the X1 line over a X4 line
is routing fl e x ibil ity. A net f rom PLC db to PL C cb is eas ily routed by using X1 lines. As more CIPs are added to
a net, the delay increases. To increase speed, routes
that are greater than two PLCs away are routed on the
X4 lines because a CIP is located only in every fourth
PLC. A net that spans eight PLCs requires seven X1
lines and six CIPs. Using X4 lines, the same net uses
two lines and one CIP.
All routing resources in the PLC can carry 4-bit buses.
In order for data to be used at a destination PLC that is
in data path mode, the data must arrive unscrambled.
For example, in data path operation, the least significant bit 0 must arrive at either A[0] or B[0]. If the bus is
to be routed by using either X4 or XL lines (both of
which twist as they propagate), the bus must be placed
on the appropriate lines at the source PLC so that the
data arrives at the destination unscrambled. The
switching lines provide the most efficient means of connecting adjacent PLCs. Signals routed with these lines
have minimum propagation delay.
Clock Lines.
other global signal tree), clock lines run the entire
height and width of the PLC array. There are two horizontal clock lines per PLC row (CKL, CKR) and two
vertical clock lines per PLC column (CKT, CKB). The
source for these clock lines can be any of the four I/O
buffers in the PIC. The horizontal clock lines in a row
(CKL, CKR) are driven by the left and right PICs,
respectively. The vertical clock lines in a column (CKT,
CKB) are driven by the top and bottom PICs, respectively.
20 Lucent Technologies Inc.
For a very fast and low-skew clock (or
Page 21
Data Sheet
June 1999
ORCA
Series 2 FPGAs
Programmable Logic Cells
VX4[1]
VX4[2]
VX4[3]
HX4[7]
HX4[6]
HX4[5]
HX4[4]
HX1[7:4]
CKL
CKR
HXL[3]
HXL[2]
HXL[1]
HXL[0]
HXH[3:0]
HX1[3:0]
HX4[3]
HX4[2]
HX4[1]
HX4[0]
HX4[7]
HX4[6]
HX4[5]
HX4[4]
HX1[7:4]
CKL
CKR
PFU
VX4[0]
VX1[3:0]
CKT
CKB
VX4[6]
VX4[7]
VX4[4]
(continued)
VX4[5]
VXL[2]
VXH[3:0]
VX1[7:4]
VX4[1]
VX4[2]
VX4[3]
VXL[3]
VXL[0]
VXL[1]
VX4[0]
VX1[3:0]
CKT
CKB
VX4[5]
VX4[6]
VX4[7]
VX4[4]
VX1[7:4]
VXL[1]
VXL[2]
VXL[3]
VXL[0]
VXH[3:0]
PFUPFU
VX1[3:0]
CKT
CKB
VX4[1]
VX4[2]
VX4[3]
VX4[0]
HX4[4]
HX4[7]
HX4[6]
HX4[5]
HX1[7:4]
CKL
CKR
HXL[2]
HXL[1]
HXL[0]
HXL[3]
HXH[3:0]
HX1[3:0]
HX4[0]
HX4[3]
HX4[2]
HX4[1]
HX4[4]
HX4[7]
HX4[6]
HX4[5]
HX1[7:4]
CKL
CKR
HXL[3]
HXL[2]
HXL[1]
HXL[0]
HXH[3:0]
HX1[3:0]
HX4[3]
HX4[2]
HX4[1]
HX4[0]
HX4[7]
HX4[6]
HX4[5]
HX4[4]
HX1[7:4]
CKL
CKR
PFU
PFU PFU
CKT
CKB
VX1[3:0]
SHOWS PLCs
VX4[0]
VX4[1]
VX4[2]
VX4[3]
VX4[4]
VX4[5]
VX4[6]
VX4[7]
VX1[7:4]
VXL[0]
VXL[1]
VXL[2]
VXL[3]
VXH[3:0]
Figure 22. Multiple PLC View of Inter-PLC Routing
PFUPFU
HXL[2]
HXL[1]
HXL[0]
HXL[3]
HXH[3:0]
HX1[3:0]
HX4[0]
HX4[3]
HX4[2]
HX4[1]
HX4[4]
HX4[7]
HX4[6]
HX4[5]
HX1[7:4]
CKL
CKR
PFU
CKT
CKB
VX4[0]
VX4[1]
VX4[2]
VX4[3]
VX1[3:0]
VX4[4]
VX4[5]
VX4[6]
VX4[7]
VX1[7:4]
VXL[0]
VXL[1]
VXL[2]
VXL[3]
VXH[3:0]
CKT
CKB
VX1[3:0]
VX4[1]
VX4[2]
VX4[3]
VX4[0]
5-2841(F)2C.r9
Lucent Technologies Inc. 21
Page 22

ORCA
Programmable Logic Cells
Series 2 FPGAs June 1999
(continued)
PLC Architectural Description
Figure 23 is an architectural drawing of the PLC which
reflects the PFU, the lines, and the CIPs. A discussion
of each of the letters in the drawing follows.
A
. These are switching lines which give the router flexi-
bility. In general switching theory, the more levels of
indirection there are in the routing, the more routable
the network is. The switching lines can also connect
to adjacent PLCs.
The switching lines provide direct connections to
PLCs directly to the top, bottom, left, and right, without using other routing resources. The ability to disable this connection between PLCs is provided so
that each side of these connections can be used
exclusively as switching lines in their respective
PLC.
B
. These CIPs connect the X1 routing. These are
located in the middle of the PLC to allow the block to
connect to either the left end of the horizontal X1 line
from the right or the right end of the horizontal X1
line from the left, or both. By symmetry, the same
principle is used in the vertical direction. The X1
lines are not twisted, making them suitable for data
paths.
C
. This set of CIPs is used to connect the X1 and X4
nets to the switching lines or to other X1 and X4
nets. The CIPs on the major diagonal allow data to
be transmitted from X1 nets to the switching lines
without being scrambled. The CIPs on the major
diagonal also allow unscrambled data to be passed
between the X1 and X4 nets.
In addition to the major diagonal CIPs for the X1
lines, other CIPs provide an alternative entry path
into the PLC in case the first one is already used.
The other CIPs are arrayed in two patterns, as
shown. Both of these patterns start with the main
diagonal, but the extra CIPs are arrayed on either a
parallel diagonal shifted by one or shifted by two
(modulo the size of the vertical bus (5)). This allows
any four application nets incident to the PLC corner
to be transferred to the five switching lines in that
corner. Many patterns of five nets can also be transferred.
Data Sheet
D
. The X4 lines are twisted at each PLC. One of the
four X4 lines is broken with a CIP, which allows a signal to be route d a dist anc e of four PLCs in any dir ection on a single line without an intermediate CIP. The
X4 lines are less populated with CIPs than the X1
lines to increase their speed. A CIP can be enabled
to extend an X4 line four more PLCs, and so on.
For example, if an application signal is routed onto
HX4[4] in a PLC, it appears on HX4[5] in the PLC to
the right. This signal step-up continues until it
reaches HX4[7], two PLCs later. At this point, the
user can break the connection or continue the signal
for another four PLCs.
E
. These symbols are bidirectional buffers (BIDIs).
There are four BIDIs per PLC, and they provide signal amplification as nee ded to dec re ase signal
delay. The BIDIs are also used to transmit signals on
XL lines.
F
. These are the BIDI and BIDIH controllers. The 3-
state control signal can be disabled. They can be
configured as active-high or active-low independently of each other.
G
.This set of CIPs allows a BIDI to get or put a signal
from one set of switching lines on each side. The
BIDIs can be accessed by the s witch ing lines . These
CIPs allow a nibble of data to be routed though the
BIDIs and continue to a subsequent block. They also
provide an alternative routing resource to improve
routability.
H
.These CIPs are used to take data from/to the BIDIs
to/from the XL lines. These CIPs have been optimized to allow the BIDI buffers to drive the large load
usually seen when using XL lines.
I
. Each latch/FF can accept data: from an LUT output;
from a direct data input signal from general routing;
or, as in the case of PLCs located in the two rows
(columns) adjacent to PICs, directly from the pad. In
addition, the LUT outputs can bypass the latches/
FFs completely and output data on the general routing resources. The four inputs shown are used as
the direct input to the latches/FFs from general routing resources. If the LUT is in memory mode, the
four inputs WD[3:0] are the data input to the memory.
22 Lucent Technologies Inc.
Page 23
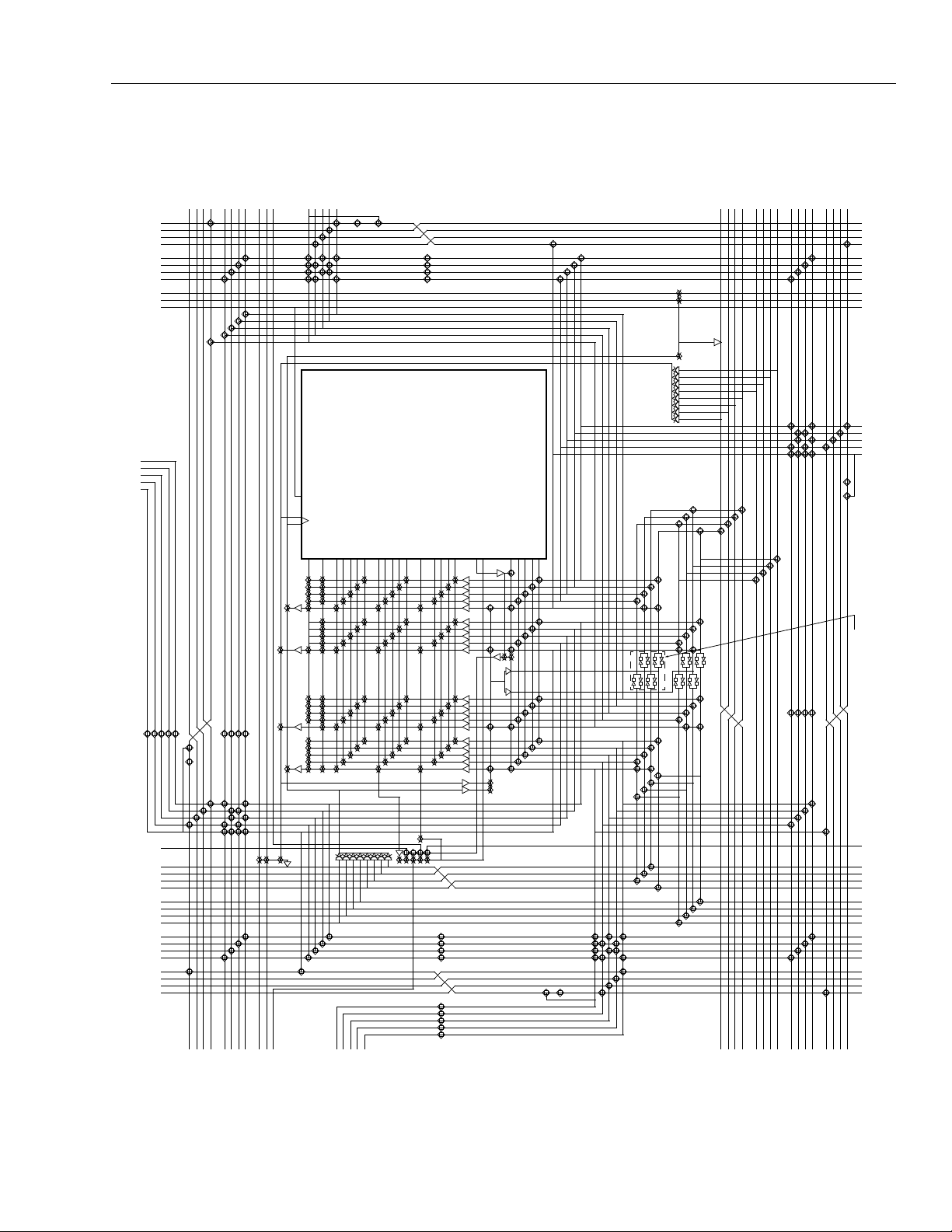
Data Sheet
June 1999
ORCA
Series 2 FPGAs
Programmable Logic Cells
HX4[6]
HX4[5]
HX4[4]
HX4[7]
HX1[7]
HX1[6]
HX1[5]
HX1[4]
CKL
VX4[0]
VX4[1]
VX4[2]
VX4[3]
VX1[0]
VX1[1]
VX1[2]
VX1[3]
CKT
CKB
GSRN
A
INT[0]
INT[1]
INT[2]
INT[3]
INT[4]
TT
C
CKR
INR[4]
INR[3]
INR[2]
INR[1]
CARRY_R
HCK
VCK
INR[0]
C
GSRN
CK
A[4]
A[3]
A[2]
LSR
CE
(continued)
D
U
B
N
A[1]
A[0]
B[4]
B[3]
B[2]
B[1]
B[0]C0WD[3]
PFU:R1C2
HXL[0]
HXL[3]
HXL[2]
HXL[1]
HXH[3]
HXH[2]
HXH[1]
HXH[0]
C
S
L
L
R
J
WD[2]
WD[1]
WD[0]
COUT
M
O[2]
O[0]
O[4]IO[3]
CIN
O[1]
G
H
Q
HX4[2]
HX4[1]
HX4[0]
HX1[3]
HX1[2]
O
HX4[3]
HX1[1]
HX1[0]
VX4[1]
VX4[2]
VX4[3]
VX4[0]
VX1[0]
VX1[1]
VX1[2]
VX1[3]
CKT
CKB
GSRN
A
C
INB[0]
INB[1]
INB[2]
INB[3]
INB[4]
U
K
U
CARRY_T
VXL[0]
VXL[1]
VXL[2]
VXL[3]
VXH[0]
VXH[1]
VXH[2]
VXH[3]
VX1[4]
VX1[5]
VX1[6]
VX1[7]
VX4[4]
VX4[5]
VX4[6]
VX4[7]
HX4[7]
HX4[6]
HX4[5]
B
D
C
L
S
C
CKL
HX4[4]
CKR
HX1[7]
HX1[6]
HX1[5]
HX1[4]
CARRY_L
INL[4]
INL[3]
INL[2]
INL[1]
INL[0]
A
N
M
W
L
DB
A
F
V
AA A A
O
U
E
P
Q
G
R
H
C
HXL[3]
HXL[2]
HXL[1]
HXL[0]
HX1[3]
HX1[2]
HXH[3]
HX1[1]
HXH[2]
HXH[1]
HXH[0]
SEE FIGURE 14
D
CB
CARRY_B
VXL[1]
VXL[2]
VXL[3]
VXL[0]
VXH[0]
VXH[1]
VXH[2]
VXH[3]
VX1[4]
VX1[5]
VX1[6]
T T
HX4[3]
HX1[0]
VX1[7]
VX4[5]
VX4[6]
VX4[7]
VX4[4]
HX4[2]
HX4[1]
HX4[0]
5-4479(F).r2
Figure 23. PLC Architecture
Lucent Technologies Inc. 23
Page 24

ORCA
Programmable Logic Cells
J
. Any five of the eight output signals can be routed out
K
. These lines deliver the auxiliary signals’ clock
L
. This is the clock input to the latches/FFs. Any of the
M
.These lines are used to route the fast carry signal to/
Series 2 FPGAs June 1999
(continued)
of the PLC. The eight signals are the four LUT outputs (F0, F1, F2, and F3) and the four latch/FF outputs (Q0, Q1, Q2, and Q3). This allows the user to
access all four latch/FF outputs, read the present
state and next state of a latch/FF, build a 4-bit shift
register, etc. Each of the outputs can drive any number of the five PFU outputs. The speed of a signal
can be increased by dividing its load among multiple
PFU output drivers.
enable and set/reset to the latches/FFs. All four of
the latches/FFs share these signals.
horizontal and vertical XH or XL lines can drive the
clock of the PLC latches/FFs. Long-line drivers are
provided so that a PLC can drive one XL line in the
horizontal directi on and one XL li ne in the ver tical
direction. The XL lines in each direction exhibit the
same properties as X4 lines, except there are no
CIPs. The clock lines (CKL, CKR, CKT, and CKB)
and multiplexers/drivers are used to connect to the
XL lines for low-skew, low-delay global signals.
The long lines run the length or width of the PLC
array. They rotate to allow four PLCs in one row or
column to generate four independent global signals.
These lines d o not ha v e to be used f or cloc k rout ing.
Any highly used application net can use this
resource, especially one requiring low skew.
from the neighboring four PLCs. The carry-out
(COUT) of the PFU can also be routed out of the
PFU onto the fifth output (O4). The carry-in (CIN)
signal can also be supplied by the B4 input to the
PFU.
Data Sheet
N
. These are the 11 logic inputs to the LUT. The A[4:0]
inputs are provided into HLUTA, and the B[4:0]
inputs are provided into HLUTB. The C0 input
bypasses the main LUT and is used in the pfumux,
pfuxor, and pfunand functions (F5M, F5X modes).
Since this input bypasses the LUT, it can be used as
a fast path around the LUT, allowing the implementation of fast, wide combinatorial functions. The C0
input can be disabled or inverted.
O
. The XH lines run one-half the length (width) of the
array before being broken by a CIP.
P
. The BIDIHs are used to access the XH lines.
Q
.The BIDIH lines are used to connect the BIDIHs to
the XSW lines, the XH lines, or the BIDI lines.
R
. These CIPs connect the BIDI lines and the BIDIH
lines.
S
. These are clock lines (CKT, CKB, CKL, and CKR)
with the multiplexers and drivers to connect to the
XL lines.
T
. These CIPs connect X1 lines which cross in each
corner to allow turns on the X1 lines without using
the XSW lines.
U
. These CIPs connect X4 lines and xsw lines, allowing
nets that run a distance that is not divisible by four to
be routed more efficiently.
V
. This routing structure allows any PFU output, includ-
ing LUT and latch/FF outputs, to be placed on O4
and be routed onto the fast carry routing.
W
.This routing structure allows the fast carry routing to
be routed onto the C0 PFU input.
24 Lucent Technologies Inc.
Page 25

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Programmable Input/Output Cells
The programmable input/output cells (PICs) are
located along the perimeter of the device. Each PIC
interfaces to four bond pads and contains the necessary routing resources to provide an interface between
I/O pads and the PLCs. Each PIC is composed of input
buffers, output buffers, and routing resources as
described below. Table 6 provides an overview of the
programmable functions in an I/O cell. A is a simplified
diagram of the functionality of the OR2CxxA
cells, while B is a simplified functional diagram of the
OR2TxxA and OR2TxxB series I/O cells.
Table 6. Input/Output Cell Options
Input Option
Input Levels TTL/CMOS (OR2CxxA only)
5 V PCI compliant (OR2CxxA only)
3.3 V PCI compliant (OR2TxxA only)
3.3 V and 5 V PCI compliant
(OR2TxxB only)
Input Speed Fast/Delayed
Float Value Pull-up/Pull-down/None
Direct-in to FF Fast/Delayed
Output Option
Output Drive 12 mA/6 mA or 6 mA/3 mA
Output Speed Fast/Slewlim/Sinklim
Output Source FF Direct-out/General Routing
Output Sense Active-high/-low
3-State Sense Active-high/-low (3-state)
series I/O
Inputs
Each I/O can be configured to be either an input, an
output, or bidirectional I/O. Inputs for the OR2CxxA can
be configured as either TTL or CMOS compatible. The
I/O for the OR2TxxA and OR2TxxB series devices are
5 V tolerant, and will be described in a later section of
this data sheet. Pull-up or pull-down resistors are available on inputs to minimize power consumption.
To allow zero hold time to PLC latches/FFs, the input
signal can be delayed. When enabled, this delay affects
the input signal driven to general routing, but does not
affect the clock input or the input lines that drive the
TRIDI buffers (used to drive onto XL, XH, BIDI, and
BIDIH lines).
A fast path from the input buffer to the clock lines is
also provided. Any one of the four I/O pads on any PIC
can be used to drive the clock line generated in that
PIC. This path cannot be delayed.
To reduce the time required to input a signal into the
FPGA, a dedicated path (PDIN) from the I/O pads to
the PFU flip-flops is provided. Like general input signals, this signal can be configured as normal or
delayed. The delayed direct input can be selected independently from the delayed general input.
Inputs should have transition times of less than 500 ns
and should not be left floating. If an input can float, a
pull-up or pul l-down should be enabl ed. F loa tin g inp uts
increase power consumption, produce oscillations, and
increase system noise. The OR2CxxA inputs have a
typical hysteresis of approximately 280 mV (200 mV for
the OR2TxxA and OR2TxxB) to reduce sensitivity to
input noise. The PIC contains input circuitry which provides protection against latch-up and electrostatic discharge.
Lucent Technologies Inc. 25
Page 26
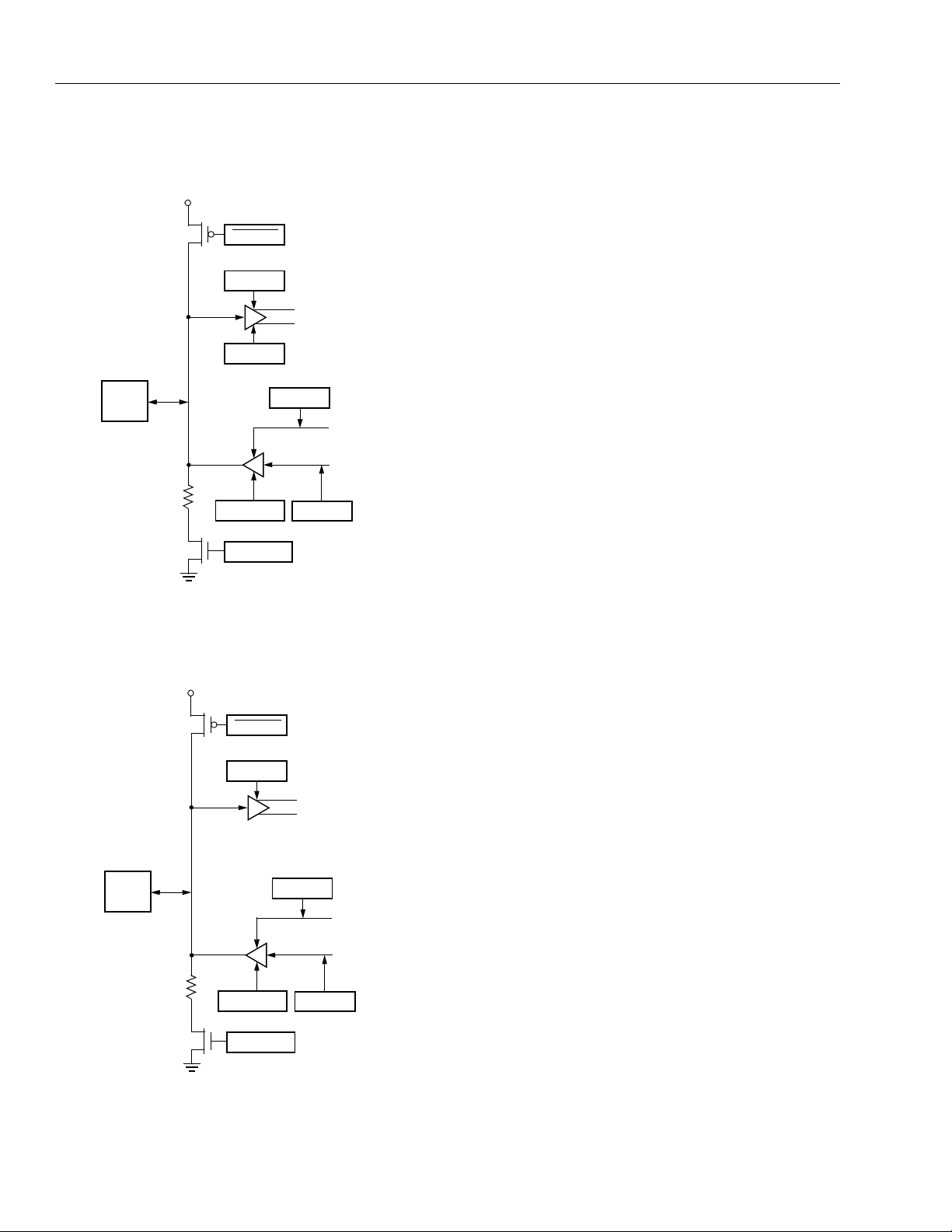
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Input/Output Cells
(continued)
DD
V
PULL-UP
DELAY
dintb, dinlr
in
TTL/CMOS
PAD
SLEW RATE
POLARITY
TRI
DOUT/OUT
POLARITY
PULL-DOWN
5-4591(F)
A. Simplified Diagram of OR2CxxA Programmable
I/O Cell (PIC)
DD
V
PULL-UP
Outputs
The PIC’s output drivers have programmable drive
capability and slew rates. Three propagation delays
(fast, slewlim, sinklim) are available on output drivers.
The sinklim mode has the longest propagation delay
and is used to minimize system noise and minimize
power consumption. The fast and slewlim modes allow
critical timing to be met.
The drive current is 12 mA sink/6 mA source for the
slewlim and fast output speed selections and
6 mA sink/3 mA source for the sinklim output. Two adjacent outputs can be interconnected to increase the output sink current to 24 mA.
All outputs that are not speed critical should be configured as sinklim to minimize power and noise. The number of outputs that switch simultaneously in the same
direction should be limited to minimize ground bounce.
To minimize ground bounce problems, locate heavily
loaded output buffers near the ground pads. Ground
bounce is generally a function of the driving circuits,
traces on the PCB, and loads and is best determined
with a circuit simulation.
Outputs can be inverted, and 3-state control signals
can be active-high or active-low. An open-drain output
may be obtained by using the same signal for driving
the output and 3-state signal nets so that the buffer output is enabled only by a low. At powerup, the output
drivers are in slewlim mode, and the input buffers are
configured as TTL-level compatible with a pull-up. If an
output is not to be driven in the selected configuration
mode, it is 3-stated.
DELAY
dintb, dinlr
in
5 V Tolerant I/O (OR2TxxA)
The I/O on the OR2TxxA series devices allow interconnection to both 3.3 V and 5 V device (selectable on a
per-pin basis) by way of special V
5 pins that have
DD
been added to the OR2TxxA devices. If any I/O on the
OR2TxxA device interfaces to a 5 V input, then all of
PAD
POLARITY
TRI
DOUT/OUT
the V
5 pins must be connected to the 5 V supply. If
DD
no pins on the device interface to a 5 V signal, then the
V
5 pins must be connected to the 3.3 V supply.
DD
If the V
5 pins are disconnected (i.e., they are float-
DD
ing), the device will not be damaged; however, the
SLEW RATE
PULL-DOWN
POLARITY
5-4591.T(F)
device may not operate properly until V
to a proper voltage level. If the V
DD
shorted to ground, a large current flow will develop, and
the device may be damaged.
5 is returned
DD
5 pins are then
B. Simplified Diagram of OR2TxxA/OR2TxxB
Programmable I/O Cell (PIC)
Figure 24. Simplified Diagrams
26 Lucent Technologies Inc.
Page 27

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Programmable Input/Output Cells
(continued)
Regardless of the power supply that the VDD5 pins are
connected to (5 V or 3.3 V), the OR2TxxA devices will
drive the pin to the 3.3 V levels when the output buffer
is enabled. If the other device being driven by the
OR2TxxA device has TTL-compatible inputs, then the
device will not dissipate much input buffer power. This
is because the OR2TxxA output is being driven to a
higher level than the TTL level required. If the other
device has a CMOS-compatible input, the amount of
input buffer power will also be small. Both of these
power values are dependent upon the input buffer characteristics of the other device when driven at the
OR2TxxA output buffer voltage levels.
The 2TxxA device has internal programmable pull-ups
on the I/O buffers. These pull-up voltages are always
referenced to V
has no effect on the value of the pull-up voltage at the
pad. This voltage level is always sufficient to pull the
input buffer of the 2TxxA device to a high state. The pin
on the 2TxxA device will be at a level 1.0 V below V
(minimum of 2.0 V with a minimum V
voltage is sufficient to pull the external pin up to a 3.3 V
CMOS high-input level (1.8 V min) or a TTL high-input
level (2.0 V min) in a 5 V tolerant system, but it will
never pull the pad up to the V
5 V tolerant system using 5 V CMOS parts, care must
be taken to evaluate the use of these pull-ups to pull
the pin of the 2TxxA device to a typical 5 V CMOS
high-input level (2.2 V min).
For more information on 5 V tolerant I/Os, please see
ORCA
(AP99-027FPGA), May 1999.
5 V Tolerant I/O (OR2TxxB)
The I/O on the OR2TxxB Series devices allow interconnection to both 3.3 V and 5 V device (selectable on a
per-pin basis). Unlike the OR2TxxA family, when interfaceing into a 5 V signal, it no longer requires a V
supply.
. This means that the VDD5 voltage
DD
®
Series 5 V Tolerant I/Os
of 3.0 V). This
DD
5 rail. Therefore, in a
DD
Application Note
DD
DD
5
the input buffer characteristics of the other device when
driven at the OR2TxxB output buffer voltage levels.
The OR2TxxB device has internal programmable pullups on the I/O buffers. These pull-up voltages are
always referenced to V
and are always sufficient to
DD
pull the input buffer of the OR2TxxB device to a high
state. The pin on the OR2TxxB device will be at a level
1.0 V below V
V
of 3.0 V). This voltage is sufficient to pull the exter-
DD
(minimum of 2.0 V with a minimum
DD
nal pin up to a 3.3 V CMOS high-input level (1.8 V, min)
or a TTL high input level (2.0 V, min) in a 5 V tolerant
system. Therefore, in a 5 V tolerant system using 5 V
CMOS parts, care must be taken to evaluate the use of
these pull-ups to pull the pin of the OR2TxxB device to
a typical 5 V CMOS high-input level (2.2 V, min).
PCI Compliant I/O
The I/O on the OR2TxxB Series devices allows compliance with PCI local bus (Rev. 2.1) 5 V and 3.3 V signaling environments. The signaling environment used for
each input buffer can be selected on a per-pin basis.
The selection provides the appropriate I/O clamping
diodes for PCI compliance.
OR2TxxB devices have 5 V tolerant I/Os as previously
explained, but can optionally be selected on a pin-bypin basis to be PCI bus 3.3 V signaling compliant (PCI
bus 5 V signaling compliance occurs in 5 V tolerant
operation mode). Inputs may have a pull-up or pulldown resistor selected on an input for signal stabilization and power management. Input signals in a PIO
can be passed to PIC routing on any of three paths,
two general signal paths into PIC routing, and/or a fast
route into the clock routing system.
OR2TxxA series devices are only compliant in 3.3 V
PCI Local Bus (Rev 2.1) signalling environments.
OR2CxxA devices are only compliant in 5 V PCI Local
Bus (Rev 2.1) signalling environments.
The OR2TxxB devices will drive the pin to the 3.3 V levels when the output buffer is enabled. If the other
device being driven by the OR2TxxB device has TTLcompatible inputs, then the device will not dissipate
much input buffer power. This is because the OR2TxxB
output is being driven to a higher level than the TTL
level required. If the other device has a CMOS-com patible input, the amount of input buffer power will also be
small. Both of these power values are dependent upon
Lucent Technologies Inc. 27
Page 28
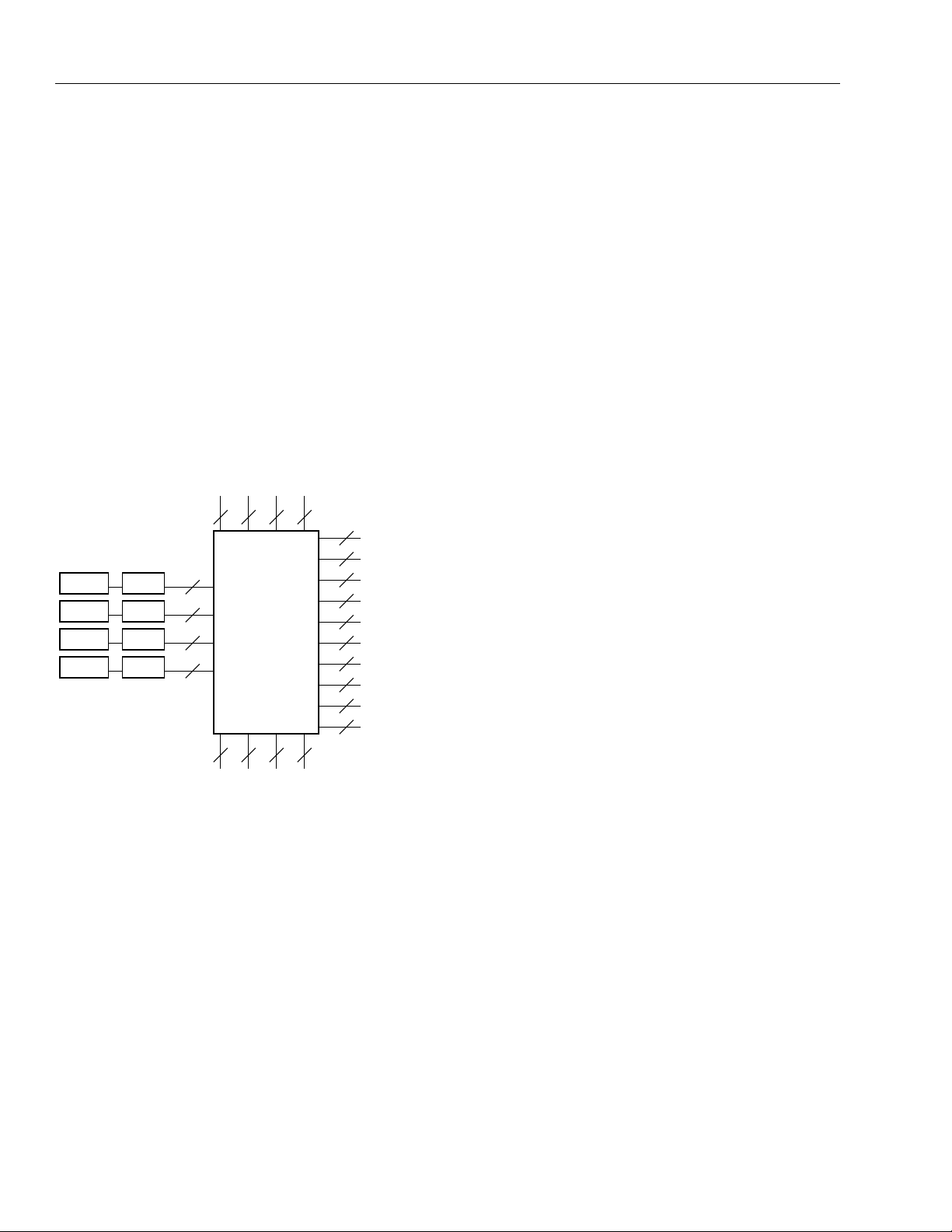
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Input/Output Cells
(continued)
PIC Routing Resources
The PIC routing is designed to route 4-bit wide buses
efficiently. For example, any four consecutive I/O pads
can have both their input and output signals routed into
one PLC. Using only PIC routing, either the input or
output data can be routed to/from a single PLC from/to
any eight pads in a row, as in Figure 25.
The connections between PLCs and the I/O pad are
provided by two basic types of routing resources.
These are routing resources internal to the PIC and
routing resources used for PIC-PLC connection.
Figure 26 and Figure 27 show a high-level and detailed
view of these routing resources, respectively.
PAD D I/O3
PAD C I/O2
PAD B I/O1
PAD A I/O0
PXH4PX24PX1
PXL
PIC
4
2
CK
4
PLC X4
4
PLC X1
5
PLC PSW
4
PLC DOUT
4
PLC XL
4
PLC XH
4
PLC X1
4
PLC X4
4
PLC DIN
4
4
4
4
4
2
SWITCHING
MATRIX
sides are left (L), right (R), top (T), and bottom (B). The
individual I/O pad is indicated by a single letter (either
A, B, C, or D) placed at the end of the PIC name. As an
example, PL10A indicates a pad located on the left
side of the array in the tenth row.
Each PIC has four pads and each pad can be configured as an input, an output (3-statable), a direct output,
or a bidirectional I/O. When the pads are used as
inputs, the external signals are provided to the internal
circuitry at IN[3:0]. When the pads are used to provide
direct inputs to the latches/FFs, they are connected
through DIN[3:0]. When the pads are used as outputs,
the internal signals connect to the pads through
OUT[3:0]. When the pads are used as direct outputs,
the output from the latches/flip-flops in the PLCs to the
PIC is designated DOUT[3:0]. When the outputs are
3-statable, the 3-state enable signals are TS[3:0].
Routing Resources Internal to the PIC
For i nt er -P I C ro ut i ng, t h e PI C co n t ai ns 1 4 li nes used to
route signals around the perimeter of the FPGA. Figure
25 shows these lines running vertically for a PIC
located on the left side. Figure 26 shows the lines running horizontally for a PIC located at the top of the
FPGA.
PXL Lines.
Each PIC has two PXL lines, labeled
PXL[1:0]. Like the XL lines of the PLC, the PXL lines
span the entire edge of the FPGA.
PXH Lines.
Each PIC has four PXH lines, labeled
PXH[3:0]. Like the XH lines of the PLC, the PXH lines
span half the edge of the FPGA.
PXL2PXH4PX24PX1
5-4504(F)
Figure 25. Simplified PIC Routing Diagram
PX2 Lines.
There are four PX2 lines in each PIC,
labeled PX2[3:0]. The PX2 lines pass through two adjacent PICs before being broken. These are used to
route nets around the perimeter equally a distance of
two or more PICs.
The PIC’s name is represented by a two-letter designation to indicate on which side of the device it is located
followed by a number to indicate in which row or column it is located. The first letter, P, designates that the
PX1 Lines.
PX1[3:0]. The PX1 lines are one PIC long and are
extended to adjacent PICs by enabling CIPs.
Each PIC has four PX1 lines, labeled
cell is a PIC and not a PLC. The second letter indicates
the side of the array where the PIC is located. The four
28 Lucent Technologies Inc.
Page 29

Data Sheet
June 1999
Programmable Input/Output Cells
(continued)
PIC Architectural Description
The PIC architecture given in Figure 26 is described
using the following letter references. The figure depicts
a PIC at the top of the array, so inter-PIC routing is horizontal and the indirect PIC-PLC routing is horizontal to
vertical. In some cases, letters are provided in more
than one location to indicate the path of a line.
A
.As in the PLCs, the PIC contains a set of lines which
run the length (width) of the array. The PXL lines
connect in the corners of the array to other PXL
lines. The PXL lines also connect to the PIC BIDI,
PIC BIDIH, and LLDRV lines. As in the PLC XL lines,
the PXH lines twist as they propagate through the
PICs.
B
. As in the PLCs, the PIC contains a set of lines which
run one-half the length (width) of the array. The PXH
lines connect in the corners and in the middle of the
array perimeter to other PXH lines. The PXH lines
also connect to the PIC BIDI, PIC BIDIH, and
LLDRV lines. As in the PLC XH lines, the PXH lines
do not twist as they propagate through the PICs.
C
. The PX2[3:0] lines span a length of two PICs before
intersecting with a CIP. The CIP allows the length of
a path using PX2 lines to be extended two PICs.
D
. The PX1[3:0] lines span a single PIC before inter-
secting with a CIP. The CIP allows the length of a
path using PX1 lines to be extended by one PIC.
E
. These are four dedicated direct output lines con-
nected to the output buffers. The DOUT[3:0] signals
go directly from a PLC latch/FF to an output buffer,
minimizing the latch/FF to pad propagation delay.
F
. This is a direct path from the input pad to the PLC
latch/flip-flops in the two rows (columns) adjacent to
PICs. This input allows a reduced setup time. Direct
inputs from the top and bottom PIC rows are
PDINTB[3:0]. Direct inputs from the left and right
PIC columns are PDINLR[3:0].
G
.The OUT[3:0], TS[3:0], and IN[3:0] signals for each
I/O pad can be routed directly to the adjacent PLC’s
switching lines.
H
.The four TRIDI buffers allow connections from the
pads to the PLC XL lines. The TRIDIs also allow
connections between the PLC XL lines and the
PBIDI lines, which are described in J below.
ORCA
I
. The four TRIDIH buffers allow connections from the
pads to the PLC XH lines. The TRIDIHs also allow
connections between the PLC XH lines and the
pBIDIH lines, which are described in K below.
J
. The PBIDI lines (bidi[3:0]) connect the PXL lines,
PXH lines, and the PX1 lines. These are bidirectional in that the path can be from the PXL, PXH, or
PX1 lines to the XL lines, or from the XL lines to the
PXL, PXH, or PX1 lines.
K
.The pBIDIH lines (BIDIH[3:0]) connect the PXL
lines, PXH lines, and the PX1 lines. These are bidirectional in that the path can be from the PXL, PXH,
or PX1 lines to the XH lines, or from the XH lines to
the PXL, PXH, or PX1 lines.
L
. The LLIN[3:0] lines provide a fast connection from
the I/O pads to the XL and XH lines.
M
.This set of CIPs allows the eight X1 lines (four on
each side) of the PLC perpendicular to the PIC to be
connected to either the PX1 or PX2 lines in the PIC.
N
.This set of CIPs allows the eight X4 lines (four on
each side) of the PLC perpendicular to the PIC to be
connected to the PX1 lines. This allows fast access
to/from the I/O pads from/to the PLCs.
O
.All four of the PLC X4 lines in a group connect to all
four of the PLC X4 lines in the adjacent PLC through
a CIP. (This differs from the
which two of the X4 lines in adjacent PLCs are
directly connected without any CIPs.)
P
. The long-line driver (LLDRV) line can be driven by
the XSW4 switching line of the adjacent PLC. To provide connectivity to the pads, the LLDRV line can
also connect to any of the four PXH or to one of the
PXL lines. The 3-state enable (TS[i]) for all four I/O
pads can be driven by XSW4, PXH, or PXL lines.
Q
.For fast clock routing, one of the four I/O pads in
each PIC can be selected to be driven onto a dedicated clock line. The clock line spans the length
(width) of the PLC array. This dedicated clock line is
typically used as a clock spine. In the PLCs, the
spine is connected to an XL line to provide a clock
branch in the perpendicular direction. Since there is
another clock line in the PIC on the opposite side of
the array, only one of the I/O pads in a given row
(column) can be used to generate a global signal in
this manner, if all PLCs are driven by the signal.
Series 2 FPGAs
ORCA 1C
Series in
Lucent Technologies Inc. 29
Page 30
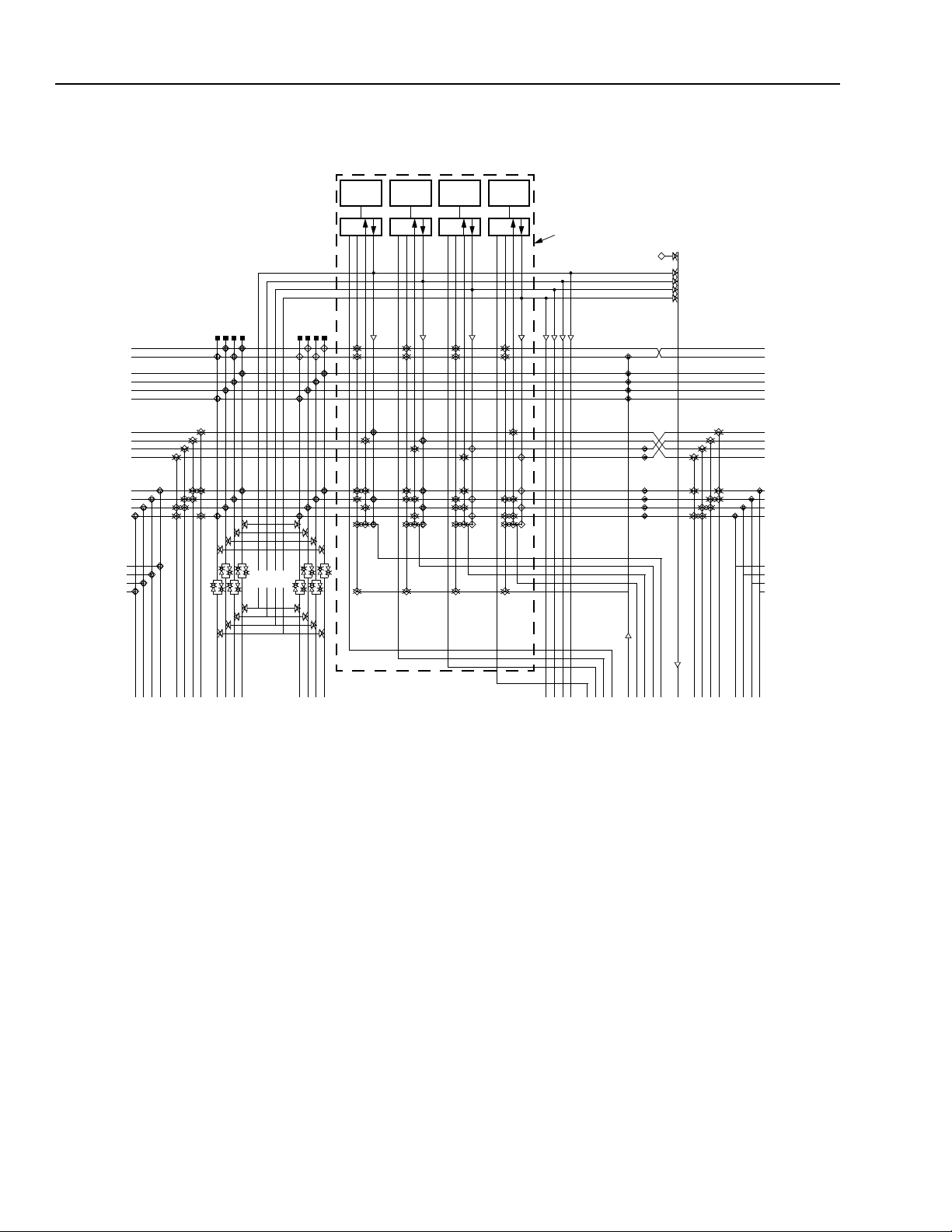
ORCA
Data Sheet
Series 2 FPGAs June 1999
Programmable Input/Output Cells
PA PB PC PD
DT DT DT DT
TS0
OUT0
DOUT0
BIDI3
BIDI2
BIDI1
BIDI0
JK
A
B
C
D
PXL[1]
PXL[0]
PXH[0]
PXH[1]
PXH[2]
PXH[3]
PX2[2]
PX2[3]
PX2[0]
PX2[1]
PX1[0]
PX1[1]
PX1[2]
PX1[3]
BIDIH3
BIDIH2
BIDIH1
BIDIH0
M
N
(continued)
IN0
TS1
OUT1
IN1
DOUT1
PIC DETAIL
TS3
OUT3
IN3
DOUT3
TS2
OUT2
IN2
DOUT2
F
P
Q
PXL[0]
A
PXL[1]
PXH[0]
PXH[1]
B
PXH[2]
PXH[3]
PX2[0]
PX2[1]
C
PX2[2]
PX2[3]
C
D
M
PX1[0]
PX1[1]
D
PX1[2]
PX1[3]
N
O
I
VX1[7]
VX1[6]
VX1[5]
VX4[7]
VX4[6]
VX4[5]
VX1[4]
VX4[4]
LLIN3
LLIN2
LLIN1
LLIN0
L
VXL[3]
VXL[2]
VXL[1]
VXH[3]
VXH[2]
VXH[1]
VXH[0]
VXL[0]
Figure 26. PIC Architecture
PLC-PIC Routing Resources
There is no direct connection between the inter-PIC
lines and the PLC lines. All connections to/from the
PLC must be done through the connecting lines which
are perpendicular to the lines in the PIC. The use of
perpendicular and parallel lines will be clearer if the
PLC and PIC architectures (Figure 23 and Figure 26)
are placed side by side. Twenty-nine lines in the PLC
can be connected to the 15 lines in the PIC.
Multiple connections between the PIC PX1 lines and
the PLC X1 l ines are available. These allow buses
placed in any arbitrary order on the I/O pads to be
unscrambled when placed on the PLC X1 lines. Con-
O
P
LLDRV
P
XSW[3]
XSW[2]
XSW[4]
DOUT[3]
DOUT[2]
DOUT[1]
PDINTB[3]
PDINTB[2]
PDINTB[1]
FE G
DOUT[0]
PDINTB[0]
Q
CKT
VX1[3]
VX1[2]
VX1[1]
VX1[0]
VX4[3]
VX4[2]
VX4[1]
XSW[1]
XSW[0]
VX4[0]
5-2843(F).r8
nections are also availab le between the PIC PX2 lines
and the PLC X1 lines.
There are eight tridirectional (four TRIDI/four TRIDIH)
buffers in each PIC; they can do the following:
■
Drive a signal from an I/O pad onto one of the adjacent PLC’s XL or XH lines
■
Drive a signal from an I/O pad onto one of the two
PXL or four PXH lines in the PIC
■
Drive a signal from the PLC XL or XH lines onto one
of the two PXL or four PXH lines in the PIC
■
Drive a signal from the PIC PXL or PXH lines onto
one of the PLC XL or XH lines
30 Lucent Technologies Inc.
Page 31

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Programmable Input/Output Cells
(continued)
Figure 27 shows paths to and from pads and the use of MUX CIPs to connect lines. Detail A shows six MUX CIPs
for the pad P0 used to construct the net for the 3-state signal. In the MUX CIP, one of six lines is connected to a line
to form the net. In this case, the ts0 signal can be driven by either of the two PXLs, PX1[0], PX1[1], XSW[0], or the
LLDRV lines. Detail B shows the four MUX CIPs used to drive the P1 output. The source line for OUT1 is either
XSW[1], PX1[1], PX1[3], or PX2[2].
PA PB PC PD
DT DT DT DT
TS0
OUT0
IN0
DOUT0
TS1
OUT1
DOUT1
IN1
TS2
OUT2
DOUT2
IN2
TS3
OUT3
DOUT3
IN3
PXL[1]
PXL[0]
PXH[0]
PXH[1]
PXH[2]
PXH[3]
PX2[2]
PX2[3]
PX2[0]
PX2[1]
PX1[0]
PX1[1]
PX1[2]
PX1[3]
A
B
DOUT[0] DOUT[1] DOUT[2] DOUT[3]
PXL[1]
PXL[0]
PXH[0]
PXH[1]
PXH[2]
PXH[3]
PX2[2]
PX2[3]
PX2[0]
PX2[1]
PX1[0]
PX1[1]
PX1[2]
PX1[3]
XSW[0]
XSW[1]
XSW[2]
XSW[3]
LLDRV
5-2843.BL(F).2C.r3
Figure 27. PIC Detail
Lucent Technologies Inc. 31
Page 32

ORCA
Data Sheet
Series 2 FPGAs June 1999
Interquad Routing
In all the
into four equal quadrants. In between these quadrants,
routing has been added to route signals between the
quadrants, especially to the quadrant in the opposite
corner. The two types of interquad blocks, vertical and
horizontal, are pitch matched to PICs. Vertical interquad blocks (vIQ) run between quadrants on the left
and right, while horizontal interquad blocks (hIQ) run
ORCA
SEE
DETAIL IN
FIGURE 29
Series 2 devi ces , the PL C array is split
between top and bottom quadrants. Since hIQ and vIQ
blocks have the same logic, only the hIQ block is
described below.
The interquad routing connects XL and XH lines. It
does not affect local routing (XSW, X1, X4, fast carry),
so local routing is the same, whether PLC-PLC connections cross quadrants or not. There are no connections to the local lines in the interquad blocks. Figure 28
presents a (not to scale) view of interquad routing.
TMID
5555
vIQ0[4:0]
vIQ3[4:0]
vIQ2[4:0]
vIQ1[4:0]
LMID
5
5
5
5
hIQ3[4:0]
hIQ2[4:0]
hIQ1[4:0]
hIQ0[4:0]
RMID
BMID
5-4538(F)
Figure 28. Interquad Routing
32 Lucent Technologies Inc.
Page 33

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Interquad Routing
(continued)
In the hIQ block in Figure 29, the XH lines from one
quadrant connect through a CIP to its counterpart in
the opposite quadrant, creating a path that spans the
PLC array. Since a passive CIP is used to connect the
two XH lines, a 3-state signal can be routed on the two
XH lines in the opposite quadrants, and then they can
be connected through this CIP.
In the hIQ block, the 20 hIQ lines span the array in a
horizontal direction. The 20 hIQ lines consist of four
VX4[7]
VX4[6]
VX4[5]
VX4[4]
VX1[7]
VX1[6]
VX1[5]
VX1[4]
VXH[3]
VXH[2]
VXH[1]
VXH[0]
VXL[3]
VXL[2]
VXL[1]
VXL[0]
CARRY
hIQ3[4]
hIQ3[3]
hIQ3[2]
hIQ3[1]
hIQ3[0]
hIQ2[4]
hIQ2[3]
hIQ2[2]
hIQ2[1]
hIQ2[0]
groups of five lines each. To effectively route nibblewide buses, each of these sets of five lines can connect
to only one of the bits of the nibble for both the XH and
XL. For example, hIQ0 lines can only connect to the
XH0 and XL0 lines, and the hIQ1 lines can connect
only to the XH1 and XL1 lines, etc. Buffers are provided
for routing signals from the XH and XL lines onto the
hIQ lines and from the hIQ lines onto the XH and XL
lines. Therefore, a connection from one quadrant to
another can be made using only two XH lines (one in
each quadrant) and one interquad line.
VX1[3]
VX1[2]
VX1[1]
VX1[0]
VX4[3]
VX4[2]
VX4[1]
INB[4]
INB[3]
INB[2]
INB[1]
INB[0]
GSRN
CKB
CKT
VX4[0]
hIQ3[4]
hIQ3[3]
hIQ3[2]
hIQ3[1]
hIQ3[0]
hIQ2[4]
hIQ2[3]
hIQ2[2]
hIQ2[1]
hIQ2[0]
hIQ1[4]
hIQ1[3]
hIQ1[2]
hIQ1[1]
hIQ1[0]
hIQ0[4]
hIQ0[3]
hIQ0[2]
hIQ0[1]
hIQ0[0]
CKT
INT[4]
INT[3]
VX4[7]
VX4[6]
VX4[5]
VX4[4]
VX1[7]
VX1[6]
VX1[5]
VX1[4]
VXH[3]
VXL[3]
VXL[2]
VXL[1]
VXH[2]
VXH[1]
VXH[0]
VXL[0]
CARRY
INT[2]
CKB
INT[1]
INT[0]
GSRN
VX1[3]
VX1[2]
VX1[1]
VX1[0]
hIQ1[4]
hIQ1[3]
hIQ1[2]
hIQ1[1]
hIQ1[0]
hIQ0[4]
hIQ0[3]
hIQ0[2]
hIQ0[1]
hIQ0[0]
VX4[3]
VX4[2]
VX4[1]
VX4[0]
5-4537(F).r3
Figure 29. hIQ Block Detail
Lucent Technologies Inc. 33
Page 34

ORCA
Data Sheet
Series 2 FPGAs June 1999
Interquad Routing
(continued)
Subquad Routing (OR2C40A/OR2T40A Only)
In the
ORCA
OR2C40A/OR2T40A/OR2T40B, each
quadrant of the device is split into smaller arrays of
PLCs called subquads. Each of these subquads is
made of a 4 x 4 array of PLCs (for a total of 16 per subquadrant), except at the outer edges of array, which
have less than 16 PLCs per subquad. New routing
resources, called subquad lines, have been added
between each adjacent pair of subquads to enhance
the routability of the device. A portion of the center of
the OR2C40A and OR2T40A array is shown in Figure
30, including the subquad blocks containing a 4 x 4
array of PLCs, the interquad routing lines, and the subquad routing lines.
All of the inter-PLC routing resources discussed previously continue to be routed between a PLC and its
adjacent PLC, even if the two adjacent PLCs are in different subquad blocks. Since the PLC routing has not
been modified for the OR2C40A/OR2T40A architectures, this means that all of the same routing connections are possible for these devices as for any other
ORCA
2C series device. In this way, both the
OR2C40A and OR2T40A/OR2T40B are upwardly compatible when compared with the ATT2Cxx series
devices. As the inter-PLC routing runs between subquad blocks, it crosses the new subquad lines. When
this happens, CIPs are used to connect the subquad
lines to the X4 and/or the XH lines which lie along the
other axis of the PLC array.
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
VERTICAL
SUBQUAD
ROUTING
(VSUB)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
VERTICAL
INTERQUAD
ROUTING
(vIQ)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SUBQUAD
(4 x 4 PLCs)
SEE DETAIL
IN FIGURES 25
AND 26
HORIZONTAL
INTERQUAD
ROUTING
(hIQ)
HORIZONTAL
SUBQUAD
ROUTING
(HSUB)
5-4200(F).r5
Figure 30. Subquad Blocks and Subquad Routing
34 Lucent Technologies Inc.
Page 35

Data Sheet
A
D
B
HSUB[11]
HSUB[10]
HSUB[9]
HSUB[8]
HSUB[15]
HSUB[14]
HSUB[13]
HSUB[12]
HSUB[3]
HSUB[2]
HSUB[1]
HSUB[0]
HSUB[11]
HSUB[10]
HSUB[9]
HSUB[8]
HSUB[15]
HSUB[14]
HSUB[13]
HSUB[12]
HSUB[3]
HSUB[2]
HSUB[1]
HSUB[0]
VX4[7]
VX4[6]
VX4[5]
VX4[4]
VX4[3]
VX4[2]
VX4[1]
VX4[0]
VX4[3]
VX4[2]
VX4[1]
VX4[0]
VX4[7]
VX4[6]
VX4[5]
VX4[4]
VX4[3]
VX4[2]
VX4[1]
VX4[0]
VX4[3]
VX4[2]
VX4[1]
VX4[0]
C
HSUB[7]
HSUB[6]
HSUB[5]
HSUB[4]
HSUB[7]
HSUB[6]
HSUB[5]
HSUB[4]
June 1999
ORCA
Series 2 FPGAs
Interquad Routing
VX4[7]
VX4[6]
VX4[5]
VX4[4]
HSUB[11]
HSUB[10]
HSUB[9]
HSUB[8]
HSUB[7]
HSUB[6]
HSUB[5]
HSUB[4]
HSUB[3]
HSUB[2]
HSUB[1]
HSUB[0]
VX4[7]
VX4[6]
VX4[5]
VX4[4]
(continued)
VX4[3]
VX4[2]
VX4[1]
VX4[0]
VX4[3]
VX4[2]
VX4[1]
VX4[0]
VX4[3]
VX4[2]
VX4[3]
VX4[2]
VX4[1]
VX4[0]
VX4[1]
VX4[0]
HSUB[11]
HSUB[10]
HSUB[9]
HSUB[8]
HSUB[7]
HSUB[6]
HSUB[5]
HSUB[4]
HSUB[3]
HSUB[2]
HSUB[1]
HSUB[0]
5-4201(F).r4
C
B
Figure 31. Horizontal Subquad Routing
Connectivity
The X4 and XH lines make the only connections to the
subquad lines; therefore, the array remains symmetrical and homogeneous. Since each subquad is made
from a 4 x 4 array of PLCs, the distance between sets
of subquad lines is four PLCs, which is also the distance between the breaks of the X4 lines. Therefore,
each X4 line will cross exactly one set of subquad lines.
Since all X4 lines make the same connections to the
subquad lines that they cross, all X4 lines in the array
have the same connectivity, and the symmetry of the
routing is preserved. Since all XH lines cross the same
number of subquad blocks, the symmetry is maintained
for the XH lines as well.
subquad blocks, four of the blocks shown in Figure 31
are used, one for each pair of vertical PLCs.
The first two groups, depicted as A and B, have connectivity to only one of the two sets of X4 lines between
pairs of PLCs. Since they are very lightly loaded, they
are very fast. The third group, C, connects to both
A
groups of X4 lines between pairs of PLCs, as well as all
of the XH lines between pairs of PLCs, providing high
flexibility. The connectivity for the vertical subquad routing (Vsub) is the same as described above for the horizontal subquad routing, when rotated onto the other
axis.
At the center row and column of each quadrant, a
fourth group of subquad lines has been added. These
subquad lines only have connectivity to the XH lines.
The XH lines are also broken at this point, which
means that each XH line travels one-half of the quadrant (i.e., one-quarter of the device) before it is broken
by a CIP. Since the XH lines can be connected end-toend, the resulting line can be either one-quarter, onehalf, three-quarters, or the entire length of the array.
The connectivity of the XH lines and this fourth group of
subquad lines, indicated as D, are detailed in Figure
32. Again, the connectivity for the vertical subquad
routing (VSUB) is the same as the horizontal subquad
routing, when rotated onto the other axis.
The new subquad lines travel a length of eight PLCs
(seven PLCs on the outside edge) before they are broken. Unlike other inter-PLC lines, they cannot be connected end-to-end. As shown in Figure 30, some of the
horizontal (vertical) subquad lines have connectivity to
the subquad to the left of (above) the current subquad,
while others have connectivity to the subquad to the
right (below). This allows connections to/from the current subquad from/to the PLCs in all subquads that surround it.
Between all subquads, including in the center of the
array, there are three groups of subquad lines where
each group contains four lines. Figure 31 shows the
connectivity of these three groups of subquad lines
(HSUB) to the VX4 and VXH lines running between a
vertical pair of PLCs. Between each vertical pair of
Lucent Technologies Inc. 35
Figure 32. Horizontal Subquad Routing
Connectivity (Half Quad)
5-4202(F).r3
Page 36

ORCA
Data Sheet
Series 2 FPGAs June 1999
Interquad Routing
(continued)
PIC Interquad (MID) Routing
Between the PICs in each quadrant, there is also connectivity between the PIC routing and the interquad
routing. These blocks are called LMID (left), TMID
(top), RMID (right), and BMID (bottom). The TMID routing is shown in Figure 33. As with the hIQ and vIQ
blocks, the only connectivity to the PIC routing is to the
global PXH and PXL lines.
PXL[1]
PXL[0]
PXH[3]
PXH[2]
PXH[1]
PXH[0]
PX4[3]
PX4[2]
PX4[1]
PX4[0]
PX1[3]
PX1[2]
PX1[1]
PX1[0]
The PXH lines from the one quadrant can be connected through a CIP to its counterpart in the opposite
quadrant, providing a path that spans the array of PICs.
Since a passive CIP is used to connect the two PXH
lines, a 3-state signal can be routed on the two PXH
lines in the opposite quadrants, and then connected
through this CIP. As with the hIQ and vIQ blocks, CIPs
and buffers allow nibble-wide connections between the
interquad lines, the XH lines, and the XL lines.
PXL[1]
PXL[0]
PXH[3]
PXH[2]
PXH[1]
PXH[0]
PX4[3]
PX4[2]
PX4[1]
PX4[0]
PX1[3]
PX1[2]
PX1[1]
PX1[0]
HX4[3]
HX4[2]
HX4[1]
HX4[0]
HX4[3]
HX4[2]
HX4[1]
HX4[0]
VIQ0[0]
VIQ1[0]
VIQ2[0]
VIQ3[0]
5-4201(F).r4
Figure 33. Top (TMID) Routing
36 Lucent Technologies Inc.
Page 37

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Programmable Corner Cells
Programmable Routing
The programmable corner cell (PCC) contains the circuitry to connect the routing of the two PICs in each
corner of the device. The PIC PX1 and PX2 lines are
directly connected together from one PIC to another.
The PIC PXL lines are connected from one block to
another through tridirectional buffers. Four CIPs in
each corner connect the four PXH lines from each side
of the device.
Special-Purpose Functi on s
In addition to routing functions, special-purpose functions are located in each FPGA corner. The upper-left
PCC contains connections to the boundary-scan logic.
The upper-right PCC contains connections to the readback logic and the connectivity to the global 3-state
signal (TS_ALL). The lower-left PCC contains connections to the internal oscillator.
The lower-right PCC contains connections to the startup and global reset logic. During configuration, the
RESET
input pad always initiates a configuration abort,
as described in the FPGA States of Operation section.
After configuration, the global set/reset signal (GSRN)
can either be disabled (the default), directly connected
RESET
to the
corner signal. If the
global reset after configuration, this pad can be used as
a normal input pad. During start-up, the release of the
global set/reset, the release of the I/Os, and the
release of the external DONE signal can each be timed
individually based upon the start-up clock. The start-up
clock can come from CCLK or it can be routed into the
start-up block using the lower-right corner routing
resources. More details on start-up can be found in the
FPGA States of Operation section.
input pad, or sourced by a lower-right
RESET
input pad is not used as a
Clock Distribution Network
The
ORCA
mary and secondary clocks. This provides the system
designer with additional flexibility in assigning clock
input pins.
One advantage is that board-level clock traces routed
to the FPGA are shorter. On a PC board, the added
length of high-speed clock traces routed to dedicated
clock input pins can significantly increase the parasitic
impedances. The primary advantage of the
clock distribution is the availability of a large number of
clocks, since all I/O pins are configurable as clocks.
Primary Clock
The primary clock distribution is shown in Figure 34. If
the clock signal is from an I/O pad, it can be driven onto
a clock line. The clock lines do not provide clock signals
directly to the PFU; they act as clock spines from which
clocks are branched to XL lines. The XL lines then feed
the clocks to PFUs. A multiplexer in each PLC is used
to transition from the clock spine to the branch.
For a clock spine in the horizontal direction, the inputs
into the multiplexer are the two lines from the left and
right PICs (CKL and CKR) and the local clock line from
the perpendicular direction (HCK). This signal is then
buffered and driven onto one of the vertical XL lines,
forming the branches. The same structure is used for a
clock spine in the vertical direction. In this case, the
multiplexer selects from lines from the top and bottom
PICs (CKT, CKB, and VCK) and drives the signal onto
one of the horizontal XL lines.
Figure 34 illustrates the distribution of the low-skew primary clock to a large number of loads using a main
spine and branches. Each row (column) has two dedicated clock lines originating from PICs on opposite
sides of the array. The clock is input from the pads to
the dedicated clock line CKT to form the clock spine
(see Figure 34, Detail A). From the clock spine, net
branches are routed using horizontal XL lines and then
PLC clock inputs are tapped from the XL lines, as
shown in Figure 34, Detail B.
Series 2 clock distribution schemes use pri-
ORCA
Lucent Technologies Inc. 37
Page 38

ORCA
Data Sheet
Series 2 FPGAs June 1999
Clock Distribution Network
CLK PIN
ABCD
DT DT DT DT
SEE DETAIL A
SEE DETAIL B
CLOCK SPINE
PIC PT8
PLC R1C8
(continued)
CLOCK
BRANCHES
Secondary Clock
There are times when a primary clock is either not
available or not desired, and a secondary clock is
needed. For example:
■
Only one input pad per PIC can be placed on the
clock routing. If a second input pad in a given PIC
requires global signal routing, a secondary clock
route must be used.
■
Since there is only one branch driver in each PLC for
either direction (vertical and horizontal), both clock
lines in a particular row or column (CKL and CKR, for
example) cannot drive a branch. Therefore, two
clocks should not be placed into I/O pads in PICs on
the opposite sides of the same row or column if global clocks are to be used.
■
Since the clock lines can only be driven from input
pads, internally generated clocks should use secondary clock routing.
Figure 35 illustrates the secondary clock distribution. If
the clock signal originates from either the left or right
side of the FPGA, it can be routed through the TRIDI
buffers in the PIC onto one of the adjacent PLC’s horizontal XL lines. If the clock signal originates from the
top or bottom of the FPGA, the vertical XL lines are
used for routing. In either case, an XL line is used as
the clock spine. In the same manner, if a clock is only
going to be used in one quadrant, the XH lines can be
used as a clock spine. The routing of the clock spine
from the input pads to the VXL (VXH) using the BIDIs
(BIDIHs) is shown in Figure 35, Detail A.
CLOCK SPINE
line driver can be used to connect a horizontal XL line
to a vertical XL line or vice versa. As shown in Figure
In each PLC, a low-skew connection through a long-
HCK
R7C7
PLC R18C8
DETAIL A
HCK
R7C8
CKT
35, Detail B, this is used to route the branches from the
clock spine. If the clock spine is a vertical XL line, then
the branches are horizontal XL lines and vice versa.
The clock is then routed into each PLC from the XL line
clock branches.
To minimize skew, the PLC clock input for all PLCs
must be connected to the branch XL lines, not the
spine XL line. Even in PLCs where the clock is routed
from the spine to the branches, the clock should be
routed back into the PLC from the clock branch.
HXL
HXL
If the clock is to drive only a limited number of loads,
CLOCK
BRANCH
DETAIL B
CLOCK
SPINES
CKTCKB
5-4480(F).r3
the PFUs can be connected directly to the clock spine.
In this case, all flip-flops driven by the clock must be
located in the same row or column.
Figure 34. Primary Clock Distribution
38 Lucent Technologies Inc.
Page 39

Data Sheet
DTDTDTDT
CLOCK
CLOCK SPINE
SEE DETAIL A
SEE DETAIL B
CLK PIN
BRANCHES
PFU
HCK
VCK
DETAIL B
PA PB
VXL[3]
VXL[2]
VXL[1]
VXL[0]
VXH[3]
VXH[2]
VXH[1]
VXH[0]
DETAIL A
PC PD
June 1999
ORCA
Series 2 FPGAs
Clock Distribution Network
(continued)
Alternatively, the clock can be routed from the spine to
the branches by using the BIDIs instead of the long-line
drivers. This results in added delay in the clock net, but
the clock skew is approximately equal to the clock
routed using the long-line drivers. This method can be
used to create a clock that is used in only one quadrant. The XH lines act as a clock spine, which is then
routed to perpendicular XH lines (the branches) using
the BIDIHs.
Clock signals, such as the output of a counter, can also
be generated in PLCs and routed onto an XL line,
which then acts as a clock spine. Although the clock
can be generated in any PLC, it is recommended that
the cloc k b e loca ted a s cl ose to t he cente r of the FPGA
as possible to minimize clock skew.
Selecting Clock Input Pins
Any user I/O pin on an
very fast, low-skew clock input. Choosing the first clock
pin is completely arbitrary, but using a pin that is near
the center of an edge of the device (as shown in Figures 34 and 35) will provide the lowest skew clock network. The pin-to-pin timing numbers in the Timing
Characteristics section of this data book assume that
the clock pin is in one of the four PICs at the center of
any side of the device.
Once the first clock pin has been chosen, there are
only two sets of pins (within the center four PICs on
each side of the device) that should not be chosen as
the second clock pin: a pin from the same PIC, and/or a
pin from the PIC on the exact opposite edge of the die
(i.e., if a pin from a PIC on the top edge is chosen for
the first clock, the same PIC on the bottom edge should
not be chosen for the second clock).
ORCA
FPGA can be used as a
The following equation can be used to determine pin
names:
Pad number = P[RL][TB]n ± (i x 4)[A – D]
Where i = 1—8, and n is the current PIC number.
For more information, please refer to
®
ORCA
OR2C/TxxA Clock Distribution Network
Utilizing the
Appli-
cation Note (AP97-055FPGA).
These rules should be followed iteratively until a total of
eight clocks (or other global signals) have been
selected: four from the left/right sides of the device, and
four from the top/bottom sides of the device. If more
than eight clocks are needed, then select another pin
outside the center four PICs to use primary-clock routing, use secondary clock routing for any pin, or use
local clock routing.
If it is desired to use a pin for one of the first eight
clocks that is not within the center four PICs of any side
of the device and primary clock routing is desired, the
pad names (see Pin Information) of the two clock pins
on the top or bottom of the device
plier of four PICs away. The same rule applies to clock
cannot
be a multi-
pins on the left or right side of the device.
Figure 35. Secondary Clock Distribution
Lucent Technologies Inc. 39
5-4481(F).r2
Page 40

ORCA
Data Sheet
Series 2 FPGAs June 1999
FPGA States of Operation
Prior to becoming operational, the FPGA goes through a
sequence of states, including initialization, configuration,
and start-up. Figure 36 outlines these three FPGA
states.
POWERUP
– POWER-ON TIME DELAY
INITIALIZATION
– CLEAR CONFIGURATION MEMORY
– INIT LOW, HDC HIGH, LDC LOW
RESET,
BIT
YES
ERROR
NO NO
– M[3:0] MODE IS SELECTED
– CONFIGURATION DATA FRAME WRITTEN
– INIT HIGH, HDC HIGH, LDC LOW
– DOUT ACTIVE
CONFIGURATION
START-UP
– ACTIVE I/O
– RELEASE INTERNAL RESET
– DONE GOES HIGH
INIT,
OR
PRGM
LOW
YES
RESET
OR
PRGM
LOW
PRGM
LOW
operating voltage (4.75 V for OR2CxxA commercial
devices and 3.0 V for OR2TxxA/B devices).
At the end of initialization, the default configuration
option is that the configuration RAM is written to a low
state. This prevents shorts prior to configuration. As a
configuration option, after the first configuration (i.e., at
reconfiguration), the user can reconfigure without
clearing the internal configuration RAM first.
The active-low, open-drain initialization signal INIT
is
released and must be pulled high by an external resistor when initialization is complete. To synchronize the
configuration of multiple FPGAs, one or more INIT
should be wire-ANDed. If INIT
is held low by one or
pins
more FPGAs or an external device, the FPGA remains
in the initialization state. INIT
the FPGAs are not yet initialized. After INIT
can be used to signal that
goes high
for two internal clock cycles, the mode lines (M[3:0])
are sampled and the FPGA enters the configuration
state.
The high during configuration (HDC), low during configuration (LDC
), and DONE signals are active outputs in
the FPGA’s initialization and configuration states. HDC,
LDC
, and DONE can be used to provide control of
external logic signals such as reset, bus enable, or
PROM enable during configuration. For parallel master
configuration modes, these signals provide PROM
enable control and allow the data pins to be shared
with user logic signals.
OPERATION
5-4529(F).r6
Figure 36. FPGA States of Operation
Initialization
Upon powerup, the device goes through an initialization
process. First, an internal power-on-reset circuit is triggered when power is applied. When V
voltage at which portions of the FPGA begin to operate
(2.5 V to 3 V for the OR2CxxA, 2.2 V to 2.7 V for the
OR2TxxA/OR2TxxB), the I/Os are configured based on
the configuration mode, as determined by the mode
select inputs M[2:0]. A time-out delay is initiated when
V
reaches between 3.0 V and 4.0 V (OR2CxxA) or
DD
2.7 V to 3.0 V (OR2TxxA/2TxxB) to allow the power
supply voltage to stabilize. The INIT
are low. At powerup, if V
V
in less than 25 ms, the user should delay configu-
DD
ration by inputting a low into INIT
until V
is greater than the recommended minimum
DD
does not rise from 2.0 V to
DD
, PRGM, or RESET
reaches the
DD
and DONE outputs
If configuration has begun, an assertion of RESET
PRGM
initiates an abort, returning the FPGA to the ini-
tialization state. The PRGM
and RESET pins must be
or
pulled back high before the FPGA will enter the configuration state. During the start-up and operating states,
only the assertion of PRGM
causes a reconfiguration.
In the master configuration modes, the FPGA is the
source of configuration clock (CCLK). In this mode, the
initialization state is extended to ensure that, in daisychain operation, all daisy-chained slave devices are
ready . Independent of differences in clock rates, master
mode devices remain in the initialization state an additional six internal clock cycles after INIT
goes high .
When configuration is initiated, a counter in the FPGA
is set to 0 and begins to count configuration clock
cycles applied to the FPGA. As each configuration data
frame is supplied to the FPGA, it is internally assembled into data words. Each data word is loaded into the
internal configuration memory. The configuration loading process is complete when the internal length count
equals the loaded length count in the length count field,
and the required end of configuration frame is written.
40 Lucent Technologies Inc.
Page 41

Data Sheet
June 1999
ORCA
Series 2 FPGAs
FPGA States of Operation
DD
V
RESET
PRGM
INIT
M[3:0]
CCLK
HDC
LDC
DONE
USER I/O
(continued)
INTERNAL
RESET
(gsm)
INITIALIZATION CONFIGURATION
Figure 37. Initialization/Configuration/Start-Up Waveforms
All OR2CxxA I/Os operate as TTL inputs during configuration (OR2TxxA/OR2TxxB I/Os are CMOS-only). All
I/Os that are not used during the configuration process
are 3-stated with internal pull-ups. During configuration, the PLC latch/FFs are held set/reset and the internal BIDI buffers are 3-stated. The TRIDIs in the PICs
are not 3-stated. The combinatorial logic begins to
function as the FPGA is configured. Figure 37 shows
the general waveform of the initialization, configuration,
and start-up states.
START-UP
OPERATION
5-4482(F)
Configuration
The
ORCA
the state of internal configuration RAM. This configuration RAM can be loaded in a number of different
modes. In these configuration modes, the FPGA can
act as a master or a slave of other devices in the system. The decision as to which configuration mode to
use is a system design issue. The next section discusses configuration in detail, including the configuration data format and the configuration modes used to
load the configuration data in the FPGA.
Series FPGA functionality is determined by
Lucent Technologies Inc. 41
Page 42

ORCA
Data Sheet
Series 2 FPGAs June 1999
FPGA States of Operation
(continued)
Start-Up
After configuration, the FPGA enters the start-up
phase. This phase is the transition between the configuration and operational states and begins when the
number of CCLKs received after
to the value of the length count field in the configuration
frame and when the end of configuration frame has
been written. The system design issue in the start-up
phase is to ensure the user I/Os become active without
inadvertently activating devices in the system or causing bus contention. A second system design concern is
the timing of the release of global set/reset of the PLC
latches/FFs.
There are configuration options that control the relative
timing of three events: DONE going high, release of the
set/reset of internal FFs, and user I/Os becoming
active. Figure 38 shows the start-up timing for both the
ORCA
designer determines the relative timing of the I/Os
becoming active, DONE going high, and the release of
the set/reset of internal FFs. In the
FPGA, the three events can occur in any arbitrary
sequence. This means that they can occur before or
after each other, or they can occur simultaneously.
There are four main start-up modes: CCLK_NOSYNC,
CCLK_SYNC, UCLK_NOSYNC, and UCLK_SYNC.
The only difference between the modes starting with
CCLK and those starting with UCLK is that for the
UCLK modes, a user clock must be supplied to the
start-up logic. The timing of start-up events is then
based upon this user clock, rather than CCLK. The difference between the SYNC and NOSYNC modes is
that, for SYNC mode, the timing of two of the start-up
events (release of the set/reset of internal FFs and the
I/Os becoming active) is triggered by the rise of the
external DONE pin followed by a variable number of rising clock edges (either CCLK or UCLK). For the
NOSYNC mode, the timing of these two events is
based only on either CCLK or UCLK.
DONE is an open-drain bidirectional pin that may
include an optional (enabled by default) pull-up resistor
to accommodate wired ANDing. The open-drain DONE
signals from multiple FPGAs can be tied together
(ANDed) with a pull-up (internal or external) and used
and ATT3000 Series FPGAs. The system
INIT
goes high is equal
ORCA
Series
as an active-high ready signal, an active-low PROM
enable, or a reset to other portions of the system.
When used in SYNC mode, these ANDed DONE pins
can be used to synchronize the other two start-up
events, since they can all be synchronized to the same
external signal. This signal will not rise until all FPGAs
release their DONE pins, allowing the signal to be
pulled high.
The default for
nized start-up mode where DONE is released on the
first CCLK rising edge , C1 (see Fi gure 38). Since thi s is
a synchronized start-up mode, the open-drain DONE
signal can be held low externally to stop the occurrence
of the other two start-up events. Once the DONE pin
has been released and pulled up to a high level, the
other two start-up events can be programmed individually to either happen immediately or after up to four rising edges of CCLK (Di, Di + 1, Di + 2, Di + 3, Di + 4).
The default is for both events to happen immediately
after DONE is released and pulled high.
A commonly used design technique is to release
DONE one or more clock cycles before allowing the I/O
to become active. This allows other configuration
devices, such as PROMs, to be disconnected using the
DONE signal so that there is no bus contention when
the I/Os become active. In addition to controlling the
FPGA during start-up, other start-up techniques that
avoid contention include using isolation devices
between the FPGA and other circuits in the system,
reassigning I/O locations and maintaining I/Os as
3-stated outputs until contentions are resolved.
Each of these start-up options can be selected during
bit stream generation in
Advanced Options. For more information, please see
the
ORCA
ORCA
is the CCLK_SYNC synchro-
ORCA
Foundry, using
Foundry documentation.
Reconfiguration
To reconfigure the FPGA when the device is operating
in the system, a low pulse is input into
figuration data in the FPGA is cleared, and the I/Os not
used for configuration are 3-stated. The FPGA then
samples the mode select inputs and begins reconfiguration. When reconfiguration is complete, DONE is
released, allowing it to be pulled high.
PRGM
. The con-
42 Lucent Technologies Inc.
Page 43

Data Sheet
June 1999
ORCA
Series 2 FPGAs
FPGA States of Operation
ATT3000
DONE
I/O
GLOBAL
RESET
DONE
I/O
GSRN
ACTIVE
DONE
C1, C2, C3, OR C4
I/O
GSRN
ACTIVE
UCLK
DONE
I/O
GSRN
ACTIVE
ORCA
CCLK_NOSYNC
C1 C2 C3 C4
C1 C2 C3 C4
C1 C2 C3 C4
ORCA
DONE IN
Di + 1Di Di + 2 Di + 3 Di + 4
Di + 1Di Di + 2 Di + 3 Di + 4
ORCA
UCLK_NOSYNC
U1 U2 U3 U4
C1
U1 U2 U3 U4
U1 U2 U3 U4
ORCA
F
CCLK_SYNC
UCLK_SYNC
(continued)
CCLK PERIOD
F
F
Partial Recon f iguration
All
ORCA
device families have been designed to allow
a partial reconfiguration of the FPGA at any time. This
is done by setting a bit stream option in the previous
configuration sequence that tells the FPGA to not reset
all of the configuration RAM during a reconfiguration.
Then only the configuration frames that are to be modified need to be rewritten, thereby reducing the configuration time.
Other bit stream options are also available that allow
one portion of the FPGA to remain in operation while a
partial reconfiguration is being done. If this is done, the
user must be careful to not cause contention between
the two configurations (the bit stream resident in the
FPGA and the partial reconfiguration bit stream) as the
second reconfiguration bit stre am is being loa ded .
Other Configuration Options
Configuration options used during device start-up were
previously discussed in the FPGA States of Operation
F
section of this data sheet. There are many other configuration options available to the user that can be set
during bit stream generation in
ORCA
Foundry. These
include options to enable boundary scan, readback
options, and options to control and use the internal
oscillator after configuration.
Other useful options that affect the next configuration
(not the current configuration process) include options
to disable the global set/reset during configuration, disable the 3-state of I/Os during configuration, and disable the reset of internal RAMs during configuration to
allow for partial configurations (see above). For more
information on how to set these and other configuration
options, please see the
ORCA
Foundry documenta-
tion.
DONE IN
DONE
I/O
GSRN
ACTIVE
F = finished, no more CLKs required.
C1 U1, U2, U3, OR U4
Di
UCLK PERIOD
SYNCHRONIZATION UNCERTAINTY
Figure 38. Start-Up Waveforms
F
Di + 1Di Di + 2 Di + 3 Di + 4
Di + 1 Di + 2 Di + 3
5-2761(F).r4
Configuration Data Format
The
ORCA
Foundry Development System interfaces
with front-end design entry tools and provides the tools
to produce a fully configured FPGA. This section discusses using the
to generate configuration RAM data and then provides
the details of the configuration frame format.
The
ORCA
versions of the
that provide upward bit stream compatibility for both
series of devices as well as with each other.
ORCA
Foundry Development System
Series 2 series of FPGAs are enhanced
ORCA
ATT2Cxx/ATT2Txx architectures
Lucent Technologies Inc. 43
Page 44

ORCA
Data Sheet
Series 2 FPGAs June 1999
Configuration Data Format
Using
ORCA
Foundry to Generate
(continued)
Configuration RAM Data
The configuration data defines the I/O functionality,
logic, and interconnections. The bit stream is generated by the development system. The bit stream created by the bit stream generation tool is a series of 1s
and 0s used to write the FPGA configuration RAM. The
bit stream can be loaded into the FPGA using one of
the configuration modes discussed later. In the bit
stream generator, the designer selects options which
affect the FPGA’s functionality. Using the output of the
bit stream generator, circuit.bit, the development system’s download tool can load the configuration data
into the
ORCA
series FPGA evaluation board from a
PC or workstation. Alternatively, a user can program a
PROM (such as the ATT1700A Series Serial ROM or a
standard EPROM) and load the FPGA from the PROM.
The development system’s PROM programming tool
produces a file in .mks or .exo format.
Configuration Data Frame
A detailed description of the frame format is shown in
Figure 39. The header frame begins with a series of 1s
and a preamble of 0010, followed by a 24-bit length
count field representing the total number of configuration clocks needed to complete the loading of the
FPGAs. Following the header frame is an optional ID
frame. This frame contains data used to determine if
the bit stream is being loaded to the correct type of
ORCA
FPGA (i.e., a bit stream generated for an
OR2C15A is being sent to an OR2C15A). Since the
OR2CxxA devices are bit stream compatible with the
ATT2Cxx, ATT2Txx, OR2TxxA, and OR2TxxB families,
a bit stream from any of these devices will not cause an
error when loaded into an OR2CxxA, OR2TxxA, or
OR2TxxB device. The ID frame has a secondary function of optionally enabling the parity checking logic for
the rest of the data frames.
The configuration data frames follow . Each frame starts
with a 0 start bit and ends with three or more 1 stop
bits. Following each start bit are four control bits: a program bit, set to 1 if this is a data frame; a compress bit,
set to 1 if this is a compressed frame; and the opar and
epar parity bits (see Bit Stream Error Checking). An
11-bit address field that determines in which column
the FPGA is to be written is followed by alignment and
write control bits. For uncompressed frames, the data
bits needed to write one column in the FPGA are next.
For compressed frames, the data bits from the previous
frame are sent to a different FPGA column, as specified by the new address bits; therefore, new data bits
are not required. When configuration of the current
FPGA is finished, an end-of-configuration frame (where
the program bit is set to 0) is sent to the FPGA. The
length and number of data frames and information on
the PROM size for the Series 3 FPGAs are given in
Table 7.
Table 7. Configuration Frame Size
Devices
# of Frames 480 568 656 744 832 920 1096 1378
Data Bits/Frame 110 130 150 170 190 210 250 316
Configuration Data
(# of frames x # of data bits/frame)
Maximum Total # Bits/Frame
(align bit s, 1 write bit, 8 stop bits)
Maximum Configuration Data
(# bits x # of frames)
Maximum PROM Size (bits)
(add 48-bit header, ID frame, and
40-bit end of configuration frame)
OR2C/
2T04A
52,800 73,840 98,400 126,480 158,080 193,200 274,000 435,448
136 160 176 200 216 240 280 344
65,280 90,880 115,456 148,800 179,712 220,800 306,880 474,032
65,504 91,128 115,720 149,088 180,016 221,128 307,248 474,464
OR2C/
2T06A
OR2C/
2T08A
OR2C/
2T10A
OR2C/
2T12A
OR2C/
2T15A/B
OR2C/
2T26A
OR2C/
2T40A/B
44 Lucent Technologies Inc.
Page 45

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Configuration Data Format
(continued)
The data frames for all the Series 2 series devices are given in Table 8. An alignment field is required in the slave
parallel mode for the uncompressed format. The alignment field (shown by [A]) is a series of 0s: five for the
OR2C06A/OR2T06A, OR2C10A/OR2T10A, OR2C15A/OR2T15A/OR2T15B, and OR2C26A/OR2T26A; three for
the OR2C40A/OR2T40A/OR2T40B; and one for the OR2C04A/OR2T04A, OR2C08A/OR2T08A, and OR2C12A/
OR2T12A. The alignment field is not required in any other mode.
Table 8. Configuration Data Frames
OR2C04A/OR2T04A
Uncompressed 010 opar epar [addr10:0] [A]1[Data109:0]111
Compressed 011 opar epar [addr10:0] 111
OR2C06A/OR2T06A
Uncompressed 010 opar epar [addr10:0] [A]1[Data129:0]111
Compressed 011 opar epar [addr10:0] 111
OR2C08A/OR2T08A
Uncompressed 010 opar epar [addr10:0] [A]1[Data149:0]111
Compressed 011 opar epar [addr10:0] 111
OR2C10A/OR2T10A
Uncompressed 010 opar epar [addr10:0] [A]1[Data169:0]111
Compressed 011 opar epar [addr10:0] 111
OR2C12A/OR2T12A
Uncompressed 010 opar epar [addr10:0] [A]1[Data189:0]111
Compressed 011 opar epar [addr10:0] 111
OR2C15A/OR2T15A/OR2T15B
Uncompressed 010 opar epar [addr10:0] [A]1[Data209:0]111
Compressed 011 opar epar [addr10:0] 111
OR2C26A/OR2T26A
Uncompressed 010 opar epar [addr10:0] [A]1[Data249:0]111
Compressed 011 opar epar [addr10:0] 111
OR2C40A/OR2T40A/OR2T40B
Uncompressed 010 opar epar [addr10:0] [A]1[Data315:0]111
Compressed 011 opar epar [addr10:0] 111
EIGHT 1s 0010
PREAMBLE
LEADING HEADER
24-bit
LENGTH
COUNT
DATA FRAMES
FPGA #1
END OF
CONFIGURATION
FRAME
FPGA #1
DATA FRAMES
FPGA #2
END OF
CONFIGURATION
FRAME
FPGA #2
POSTAMBLE
5-4530(F)
Figure 39. Serial Configuration Data Format
Lucent Technologies Inc. 45
Page 46

ORCA
Data Sheet
Series 2 FPGAs June 1999
Configuration Data Format
(continued)
Table 9. Configuration Frame Format and Contents
11111111 Leading header—4 bits minimum dummy bits
Header
24-Bit Length Count Configuration frame length
0010 Preamble
1111 Trailing header—4 bits minimum dummy bits
0 Frame start
P—1 Must be set to 1 to indicate data frame
C—0 Must be set to 0 to indicate uncompressed
Opar, Epar Frame parity bits
ID Frame
(Optional)
Addr[10:0] =
11111111111
ID frame address
Prty_En Set to 1 to enable parity
Reserved [42:0] Reserved bits set to 0
ID 20-bit part ID
111 Three or more stop bits (high) to separate frames
0 Frame start
P—1 or 0 1 indicates data frame; 0 indicates all frames are written
C—1 or 0 Uncompressed—0 indicates data and address are supplied;
Compressed—1 indicates only address is supplied
Configuration
Data
Frame
(repeated for
each data frame)
Opar, Epar Frame parity bits
Addr[10:0] Column address in FPGA to be written
A Alignment bit (different number of 0s needed for each part)
1 Write bit—used in uncompressed data frame
Data Bits Needed only in an uncompressed data frame
..
..
111 One or more stop bits (high) to separate frames
End of
0010011111111111 16 bits—00 indicates all frames are written
Configuration
Postamble
111111 . . . . . Additional 1s
Note: For slave parallel mode, the byte containing the preamble must be 11110010. The number of leading header dummy bits must
*
be (n
8) + 4, where n is any nonnegative integer and the number of trailing dummy bits must be (n * 8), where n is any positive
integer. The number of stop bits/frame for slave parallel mode must be (x
stream generator tool supplies a bit stream which is compatible with all configuration modes, including slave parallel mode.
*
8), where x is a positive integer. Note also that the bit
46 Lucent Technologies Inc.
Page 47

Data Sheet
TO DAISYCHAINED
DEVICES
DOUT
CCLK
HDC
LDC
RCLK
A[17:0]
D[7:0]
DONE
PRGM
M2
M1
M0
A[17:0]
D[7:0]
OE
CE
PROGRAM
V
DD
VDD OR GND
EPROM
ORCA
SERIES
FPGA
June 1999
ORCA
Series 2 FPGAs
Bit Stream Error Checking
There are three different types of bit stream error
checking performed in the
ID frame, frame alignment, and parity checking.
An optional ID data frame can be sent to a specified
address in the FPGA. This ID frame contains a unique
code for the part it was generated for which is compared within the FPGA. Any differences are flagged as
an ID error. This frame is automatically created by the
bit stream generation program in
Every data frame in the FPGA begins with a start bit
set to 0 and three or more stop bits set to 1. If any of
the three previous bits were a 0 when a start bit is
encountered, it is flagged as a frame alignment error.
Parity checking is also done on the FPGA for each
frame, if it has been enabled by setting the prty_en bit
to 1 in the ID frame. This is set by enabling the parity
check option in the bit stream generation program of
ORCA
Foundry. Two parity bits, opar and epar, are
used to check the parity of bits in alternating bit positions to even parity in each data frame. If an odd number of ones is found for either the even bits (starting
with the start bit) or the odd bits (starting with the program bit), then a parity error is flagged.
ORCA
Series 2 FPGAs:
ORCA
Foundry.
Table 10. Configuration Modes
M2 M1 M0 CCLK
0 0 0 Output Master Serial
0 0 1 Input Slave Parallel Parallel
010Reserved
0 1 1 Input Sync Peripheral Parallel
1 0 0 Output Master (up) Parallel
1 0 1 Output Async Peripheral Parallel
1 1 0 Output Master (down) Parallel
1 1 1 Input Slave Serial
Configuration
Mode
Data
Master Parallel Mode
The master parallel configuration mode is generally
used to interface to industry-standard byte-wide memory, such as the 2764 and larger EPROMs. Figure 40
provides the connections for master parallel mode. The
FPGA outputs an 18-bit address on A[17:0] to memory
and reads one byte of configuration data on the rising
edge of RCLK. The parallel bytes are internally serialized starting with the least significant bit, D0.
When any of the three possible errors occur, the FPGA
is forced into the INIT state, forcing
will remain in this state until either the
INIT
low . The FPGA
RESET
or
PRGM
pins are asserted.
FPGA Configuration Modes
There are eight methods for configuring the FPGA.
Seven of the configura tion modes are selected on the
M0, M1, and M2 inputs. The eighth configuration mode
is accessed through the boundary-scan interface. A
fourth input, M3, is used to select the frequency of the
internal oscillator, which is the source for CCLK in
some configuration modes. The nominal frequencies of
the internal oscillator are 1.25 MHz and 10 MHz. The
1.25 MHz frequency is selected when the M3 input is
unconnected or driven to a high state.
There are three basic FPGA configuration modes:
master, slave, and peripheral. The configuration data
can be transmitted to the FPGA serially or in parallel
bytes. As a master, the FPGA provides the control signals out to strobe data in. As a slave device, a clock is
generated externally and provided into CCLK. In the
peripheral mode, the FPGA acts as a microprocessor
peripheral. Table 10 lists the functions of the configuration mode pins.
5-4483(F)
Figure 40. Master Parallel Configuration Schematic
There are two parallel master modes: master up and
master down. In master up, the starting memory
address is 00000 Hex and the FPGA increments the
address for each byte loaded. In master down, the
starting memory address is 3FFFF Hex and the FPGA
decrements the address.
One master mode FPGA can interface to the memory
and provide configuration data on DOUT to additional
FPGAs in a daisy chain. The configuration data on
DOUT is provided synchronously with the falling edge
of CCLK. The frequency of the CCLK output is eight
times that of RCLK.
Lucent Technologies Inc. 47
Page 48

ORCA
Data Sheet
Series 2 FPGAs June 1999
FPGA Configuration Modes
(continued)
The FPGA DONE is routed to the
CE
pin. The low on
DONE enables the serial ROMs. At the completion of
Master Serial Mode
configuration, the high on the FPGA's DONE disables
the serial ROM.
In the master serial mode, the FPGA loads the configuration data from an external serial ROM. The configuration data is either loaded automatically at start-up or on
PRGM
a
command to reconfigure. The ATT1700 and
ATT1700A Series can be used to configure the FPGA
in the master serial mode. This provides a simple 4-pin
interface in an 8-pin package. The ATT1736, ATT1765,
and ATT17128 serial ROMs store 32K, 64K, and 128K
bits, respectively.
Configuration in the master serial mode can be done at
powerup and/or upon a configure command. The system or the FPGA must activate the serial ROM's
RESET
/OE and CE inputs. At powerup, the FPGA and
serial ROM each contain internal power-on reset circuitry that allows the FPGA to be configured without
the system providing an external signal. The power-on
reset circuitry causes the serial ROM's internal address
pointer to be reset. After powerup, the FPGA automatically enters its initialization phase.
The serial ROM/FPGA interface used depends on such
factors as the availability of a system reset pulse, availability of an intelligent host to generate a configure
command, whether a single serial ROM is used or multiple serial ROMs are cascaded, whether the serial
ROM contains a single or multiple configuration programs, etc. Because of differing system requirements
and capabilities, a single FPGA/serial ROM interface is
generally not appropriate for all applications.
Data is read in the FPGA sequentially from the serial
ROM. The DATA output from the serial ROM is connected directly into the DIN input of the FPGA. The
CCLK output from the FPGA is connected to the
CLOCK input of the serial ROM. During the configuration process, CCLK clocks one data bit on each rising
edge.
Since the data and clock are direct connects, the
FPGA/serial ROM design task is to use the system or
FPGA to enable the
RESET
/OE and CE of the serial
ROM(s). There are several methods for enabling the
RESET
RESET
/OE and CE inputs. The serial
/OE is programmable to function with
OE
active-low or
RESET
active-
serial ROM’s
ROM's
RESET active-high and
low and OE active-high.
In Figure 41, serial ROMs are cascaded to configure
multiple daisy-chained FPGAs. The host generates a
500 ns low pulse into the FPGA's
FPGA’s
RESET
function with
INIT
input is connected to the serial ROM’s
/OE input, which has been programmed to
RESET
active-low and OE active-high.
PRGM
input. The
Serial ROMs can also be cascaded to support the configuration of multiple FPGAs or to load a single FPGA
when configuration data requirements exceed the
capacity of a single serial ROM. After the last bit from
the first serial ROM is read, the serial ROM outputs
CEO
low and 3-states the DATA output. The next serial
ROM recognizes the low on
CE
input and outputs configuration data on the DATA output. After configuration
is complete, the FPGA’s DONE output into
CE
disables
the serial ROMs.
This FPGA/serial ROM interface is not used in applica-
tions in which a serial ROM stores multiple configuration programs. In these applications, the next
configuration program to be loaded is stored at the
ROM location that follows the last address for the previous configuration program. The reason the interface in
Figure 41 will not work in this application is that the low
output on the
INIT
signal would reset the serial RO M
address pointer, causing the first configuration to be
reloaded.
In some applications, there can be contention on the
FPGA's DIN pin. During configuration, DIN receives
configuration data, and after configuration, it is a user
I/O. If there is contention, an early DONE at start-up
(selected in
An alternative is to use
CE
pin. In order to reduce noise, it is generally better to
ORCA
Foundry) may correct the problem.
LDC
to drive the serial ROM's
run the master serial configuration at 1.25 MHz (M3 pin
tied high), rather than 10 MHz, if possible.
TO DAISYCHAINED
DATA
ATT1700A
RESET/OE
CEO
DA TA
ATT1700A
RESET
CEO
TO MORE
SERIAL ROMs
AS NEEDED
CLK
CE
CLK
CE
/OE
PROGRAM
DIN
CCLK
DONE
INIT
PRGM
M2
M1
M0
DOUT
ORCA
SERIES
FPGA
DEVICES
5-4456.1(F)
Figure 41. Master Serial Configuration Schematic
48 Lucent Technologies Inc.
Page 49

Data Sheet
TO DAISYCHAINED
DEVICES
DOUT
HDC
LDC
ORCA
SERIES
FPGA
MICRO-
PROCESSOR
PRGM
D[7:0]
M2
M1
M0
8
+5 V
CCLK
RDY/BUSY
INIT
June 1999
ORCA
Series 2 FPGAs
FPGA Configuration Modes
(continued)
Asynchronous Peripheral Mode
Figure 42 shows the connections needed for the asynchronous peripheral mode. In this mode, the FPGA
system interface is similar to that of a microprocessorperipheral interface. The microprocessor generates the
control signals to write an 8-bit byte into the FPGA. The
FPGA control inputs include active-low
high CS1 chip selects, a write
WR
input. The chip selects can be cycled or maintained at
a static level during the configuration cycle. Each byte
of data is written into the FPGA’s D[7:0] input pins.
The FPGA provides a RD Y status output to indicate
that another byte can be loaded. A low on RDY indicates that the double-buffered hold/shift registers are
not ready to receive data, and this pin must be monitored to go high before another byte of data can be
written. The shortest time RDY is low occurs when a
byte is loaded into the hold register and the shift register is empty, in which case the byte is immediately
transferred to the shift register. The longest time for
RDY to remain low occurs when a byte is loaded into
the holding register and the shift register has just
started shifting configuration data into configuration
RAM.
CS0
and active-
input, and a read RD
Synchronous Peripheral Mode
In the synchronous peripheral mode, byte-wide data is
input into D[7:0] on the rising edge of the CCLK input.
The first data byte is clocked in on the second CCLK
INIT
after
clocked in on every eighth rising edge of CCLK. The
RDY signal is an output which acts as an acknowledge.
RDY goes high one CCLK after data is clocked and,
after one CCLK cycle, returns low. The process repeats
until all of the data is loaded into the FPGA. The data
begins shifting on DOUT 1.5 cycles after it is loaded in
parallel. It requires additional CCLKs after the last byte
is loaded to complete the shifting. Figure 43 shows the
connections for synchronous peripheral mode.
As with master modes, the peripheral modes can be
used as the lead FPGA for a daisy chain of slave
FPGAs.
goes high. Subsequent data bytes are
The RDY status is also available on the D7 pin by
enabling the chip selects, setting
RD
ing
low, where the RD input is an output enable for
the D7 pin when
enabled to drive when
RD
is low. The D[6:0] pins are not
RD
is low and, thus, only act as
WR
high, and apply-
input pins in asynchronous peripheral mode.
8
MICRO-
PROCESSOR
Figure 42. Asynchronous Peripheral Configuration
ADDRESS
DECODE LOGIC
BUS
CONTROLLER
Schematic
V
DD
PRGM
D[7:0]
RDY/BUSY
INIT
DONE
CS0
CS1
RD
WR
M2
M1
M0
DOUT
CCLK
ORCA
SERIES
FPGA
HDC
LDC
TO DAISYCHAINED
DEVICES
5-4484(F)
5-4486(F)
Figure 43. Synchronous Peripheral Configuration
Schematic
Lucent Technologies Inc. 49
Page 50

ORCA
Data Sheet
Series 2 FPGAs June 1999
FPGA Configuration Modes
(continued)
Slave Serial Mode
The slave serial mode is primarily used when multiple
FPGAs are configured in a daisy chain. The serial
slave serial mode is also used on the FPGA evaluation
board which interfaces to the download cable. A device
in the slave serial mode can be used as the lead device
in a daisy chain. Figure 44 shows the connections for
the slave serial configuration mode.
The configuration data is provided into the FPGA’s DIN
input synchronous with the configuration clock CCLK
input. After the FPGA has loaded its configuration data,
it retransmits the incoming configuration data on
DOUT. CCLK is routed into all slave serial mode
devices in parallel.
Multiple slave FPGAs can be loaded with identical configurations simultaneously. This is done by loading the
configuration data into the DIN inputs in parallel.
TO DAISYCHAINED
DEVICES
5-4485(F)
MICRO-
PROCESSOR
OR
DOWNLOAD
CABLE
DOUT
INIT
PRGM
DONE
CCLK
DIN
V
DD
M2
M1
M0
ORCA
SERIES
FPGA
HDC
LDC
Slave Parallel Mode
The slave parallel mode is essentially the same as the
slave serial mode except that 8 bits of data are input on
pins D[7:0] for each CCLK cycle. Due to 8 bits of data
being input per CCLK cycle, the DOUT pin does not
contain a valid bit stream for slave parallel mode. As a
result, the lead device cannot be used in the slave
parallel mode in a daisy-chain configuration.
Figure 45 is a schematic of the connections for the
slave parallel configuration mode.
WR
active-low chip select signals, and CS1 is an activehigh chip select signal. These chip selects allow the
user to configure multiple FPGAs in slave parallel
mode using an 8-bit data bus common to all of the
FPGAs. These chip selects can then be used to select
the FPGA(s) to be configured with a given bit stream,
but once an FPGA has been selected, it cannot be
deselected until it has been completely programmed.
MICRO-
PROCESSOR
OR
SYSTEM
8
DD
V
D[7:0]
DONE
INIT
CCLK
PRGM
CS1
CS0
WR
M2
M1
M0
Figure 45. Slave Parallel Configuration Schematic
and
ORCA
SERIES
CS0
FPGA
HDC
LDC
are
5-4487(F)
Figure 44. Slave Serial Configuration Schematic
50 Lucent Technologies Inc.
Page 51

Data Sheet
June 1999
ORCA
Series 2 FPGAs
FPGA Configuration Modes
(continued)
Daisy Chain
Multiple FPGAs can be configured by using a daisy
chain of the FPGAs. Daisy chaining uses a lead FPGA
and one or more FPGAs configured in slave serial
mode. The lead FPGA can be configured in any mode
except slave parallel mode. (Daisy chaining is not available with the boundary-scan ram_w instruction, discussed later.)
All daisy-chained FPGAs are connected in series.
Each FPGA reads and shifts the preamble and length
count in on positive CCLK and out on negative CCLK
edges.
An upstream FPGA that has received the preamble
and length count outputs a high on DOUT until it has
received the appropriate number of data frames so that
downstream FPGAs do not receive frame start bits
(0s). After loading and retransmitting the preamble and
length count to a daisy chain of slave devices, the lead
device loads its configuration data frames. The loading
of configuration data continues after the lead device
has received its configuration data if its internal frame
bit counter has not reached the length count. When the
configuration RAM is full and the number of bits
received is less than the length count field, the FPGA
shifts any additional data out on DOUT.
The configuration data is read into DIN of slave devices
on the positive edge of CCLK, and shifted out DOUT
on the negative edge of CCLK. Figure 46 shows the
connections for loading multiple FPGAs in a daisychain configuration.
The generation of CCLK for the daisy-chained devices
which are in slave serial mode differs depending on the
configuration mode of the lead device. A master parallel mode device uses its internal timing generator to
produce an internal CCLK at eight times its memory
address rate (RCLK). The asynchronous peripheral
mode device outputs eight CCLKs for each write cycle.
If the lead device is configured in either synchronous
peripheral or a slave mode, CCLK is routed to the lead
device and to all of the daisy-chained devices.
The development system can create a composite
configuration bit stream for configuring daisy-chained
FPGAs. The frame format is a preamble, a length count
for the total bit stream, multiple concatenated data
frames, an end-of-configuration frame per device, a
postamble, and an additional fill bit per device in the
serial chain.
As seen in Figure 46, the
INIT
pins for all of the FPGAs
are connected together. This is required to guarantee
that powerup and initialization will work correctly. In
general, the DONE pins for all of the FPGAs are also
connected together as shown to guarantee that all of
the FPGAs enter the start-up state simultaneously. This
may not be required, depending upon the start-up
sequence desired.
CCLK
DOUT
ORCA
SERIES
FPGA
SLAVE #1
DONE
PRGM
V
DD
M2
M1
M0
HDC
LDC
RCLK
CCLK
DIN
ORCA
SERIES
FPGA
SLAVE #2
DONE
PRGM
V
DD
M2
M1
M0
DOUT
INIT
HDC
LDC
RCLK
V
DD
V
DD
5-4488(F)
A[17:0]
EPROM
D[7:0]
OE
CE
PROGRAM
V
VDD OR
GND
CCLK
A[17:0]
ORCA
SERIES
D[7:0]
DONE
PRGM
DD
M2
M1
M0
FPGA
MASTER
DOUT DIN
INIT INIT
HDC
LDC
RCLK
Figure 46. Daisy-Chain Configuration Schematic
Lucent Technologies Inc. 51
Page 52

ORCA
Data Sheet
Series 2 FPGAs June 1999
Special Function Blocks
Special function blocks in the Series 2 provide extra
capabilities beyond general FPGA operation. These
blocks reside in the corners of the FPGA array.
Single Function Blocks
Most of the special function blocks perform a specific
dedicated function. These functions are data/configuration readback control, global 3-state control (TS_ALL),
internal oscillator generation, global set/reset (GSRN),
and start-up logic.
Readback Logic
The readback logic is located in the upper rig ht corner
of the FPGA.
Readback is used to read back the configuration data
and, optionally, the state of the PFU outputs. A readback operation can be done while the FPGA is in normal system operation. The readback operation cannot
be daisy-chained. To use readback, the user selects
options in the bit stream generator in the
Foundry Development System.
Table 11 provides readback options selected in the bit
stream generator tool. The table provides the number
of times that the configuration data can be read back.
This is intended primarily to give the user control over
the security of the FPGA’s configuration program. The
user can prohibit readback (0), allow a single readback
(1), or allow unrestricted readback (U).
Table 11. Readback Options
Option Function
0 Prohibit Readback
1 Allow One Readback Only
U Allow Unrestricted Number of Readbacks
The pins used for readback are readback data
(RD_DATA), read configuration (
ration clock (CCLK). A readback operation is initiated
by a high-to-low transition on
input must remain low during the readback operation.
The readback operation can be restarted at frame 0 by
driving the
ing edges of CCLK, and then driving
RD_CFG
pin high, applying at least two ris-
RD_CFG
RD_CFG
ORCA
), and configu-
RD_CFG
. The
RD_CFG
low
again. One bit of data is shifted out on RD_DAT A at the
rising edge of CCLK. The first start bit of the readback
frame is transmitted out several cycles after the first rising edge of CCLK after
48, Readback Timing Characteristics in the Timing
Characteristics section).
It should be noted that the RD_DATA output pin is also
used as the dedicated boundary-scan output pin, TDO.
If this pin is being used as TDO, the RD_DATA output
from readback can be routed internally to any other pin
desired. The
the global 3-state (TS_ALL) function. Before and during
configuration, the TS_ALL signal is always driven by
RD_CFG
the
figuration, the selection as to whether this input drives
the readback or global 3-state function is determined
by a set of bit stream options. If used as the
input for readback, the internal TS_ALL input can be
routed internally to be driven by any input pin.
The readback frame contains the configuration data
and the state of the internal logic. During readback, the
value of all five PFU outputs can be captured. The following options are allowed when doing a capture of the
PFU outputs.
1. Do not capture data (the data written to the capture
RAMs, usually 0, will be read back).
2. Capture data upon entering readback.
3. Capture data based upon a configurable signal
internal to the FPGA. If this signal is tied to
logic 0, capture RAMs are written continuously.
4. Capture data on either options 2 or 3 above.
The readback frame has a similar, but not identical, format to the configuration frame. This eases a bitwise
comparison between the configuration and readback
data. The readback data is not inverted. Every data
frame has one low start bit and one high stop bit. The
preamble, including the length count field, is not part of
the readback frame. The readback frame contains
states in locations not used in the configuration. These
locations need to be masked out when comparing the
configuration and readback frames. The development
system optionally provides a readback bit stream to
compare to readback from the FPGA. Also note that if
any of the LUTs are used as RAM and new data is written to them, these bits will not have the same values as
the original configuration data frame either.
RD_CFG
input and readback is disabled. After con-
RD_CFG
input pin is also used to control
is input low (see Table
RD_CFG
52 Lucent Technologies Inc.
Page 53

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Special Function Blocks
Global 3-State Control (TS_ALL)
The TS_ALL block resides in the upper-right corner of
the FPGA array.
To increase the testability of the
the global 3-state function (TS_ALL) disables the
device. The TS_ALL signal is driven from either an
external pin or an internal signal. Before and during
configuration, the TS_ALL signal is driven by the input
RD_CFG
pad
can be disabled, driven from the
driven by a general routing signal in the upper-right corner. Before configuration, TS_ALL is active-low; after
configuration, the sense of TS_ALL can be inverted.
The following occur when TS_ALL is activated:
1. All of the user I/O output buffers are 3-stated, the
user I/O input buffers are pulled up (with the pulldown disabled), and the input buffers are configured
with TTL input thresholds (OR2CxxA only).
2. The TDO/RD_DATA output buffer is 3-stated.
3. The
active with a pull-up.
4. The DONE output buffer is 3-stated, and the input
buffer is pulled-up.
Internal Oscillator
The internal oscillator resides in the lower-left corner of
the FPGA array. It has output clock frequencies of
1.25 MHz and 10 MHz. The internal oscillator is the
source of the internal CCLK used for configuration. It
may also be used after configuration as a generalpurpose clock signal.
. After configuration, the TS_ALL signal
RD_CFG, RESET
, and
(continued)
ORCA
PRGM
Series FP G As,
RD_CFG
input buffers remain
input pad, or
Global Set/Reset (GSRN)
The GSRN logic resides in the lower-right corner of the
FPGA. GSRN is an invertible, default, active-low signal
that is used to reset all of the user-accessible latches/
FFs on the device. GSRN is automatically asserted at
powerup and during configuration of the device.
The timing of the release of GSRN at the end of configuration can be programmed in the start-up logic
described below. Following configuration, GSRN may
be connected to the
or it may be connected to any signal via normal routing.
Within each PFU, individual FFs and latches can be
programmed to either be set or reset when GSRN is
asserted.
RESET
The
GSRN. During configuration, the
always initiates a configuration abort, as described in
the FPGA States of Operation section. After configuration, the global set/reset signal (GSRN) can either be
disabled (the default), directly connected to the
input pad, or sourced by a lower-right corner signal. If
RESET
the
configuration, this pad can be used as a normal input
pad.
Start-Up Logic
The start-up logic block is located in the lower right corner of the FPGA. This block can be configured to coordinate the relative timing of the release of GSRN, the
activation of all user I/Os, and the assertion of the
DONE signal at the end of configuration. If a start-up
clock is used to time these events, the start-up clock
can come from CCLK, or it can be routed into the startup block using lower-right corner routing resources.
These signals are described in the Start-Up subsection
of the FPGA States of Operation section.
input pad has a special relationship to
input pad is not used as a global reset after
RESET
pin via dedicated routing,
RESET
input pad
RESET
Lucent Technologies Inc. 53
Page 54

ORCA
Data Sheet
Series 2 FPGAs June 1999
Special Function Blocks
(continued)
Boundary Scan
The increasing complexity of integrated circuits (ICs)
and IC packages has increased the difficulty of testing
printed-circuit boards (PCBs). To address this testing
problem, the
dard Test Access Port and Boundary-Scan Architecture) is implemented in the
allows users to efficiently test the interconnection
between integrated circuits on a PCB as well as test
the integrated circuit itself. The
is a well-defined protocol that ensures interoperability
among boundary-scan (BSCAN) equipped devices
from different vendors.
The
IEEE
(TAP) that consists of a 4-pin interface with an optional
reset pin for boundary-scan testing of integrated circuits in a system. The
four interface pins: test data in (TDI), test mode select
(TMS), test clock (TCK), and test data out (TDO). The
PRGM
pin used to reconfigure the device also resets
the boundary-scan logic.
The user test host serially loads test commands and
test data into the FPGA through these pins to drive outputs and examine inputs. In the configuration shown in
Figure 47, where boundary scan is used to test ICs,
test data is transmitted serially into TDI of the first
BSCAN device (U1), through TDO/TDI connections
between BSCAN devices (U2 and U3), and out TDO of
the last BSCAN device (U4). In this configuration, the
TMS and TCK signals are routed to all boundary-scan
ICs in parallel so that all boundary-scan components
operate in the same state. In other configurations, multiple scan paths are used instead of a single ring. When
multiple scan paths are used, each ring is independently controlled by its own TMS and TCK signals.
IEEE
standard 1149.1 - 1990 (
ORCA
series of FPGAs. It
IEEE
1149.1 standard
IEEE
Stan-
1149.1 standard defines a test access port
ORCA
series FPGA provides
net a
net b
net c
P_TS
ARRAY
P_OUT
BSC
DCC
SCAN
PLC
s
IN
BDC
PT[ij]
P_IN
PB[ij]
P_IN
TMS
TCK
TDO
TMS
TCK
TDO
BSC
BDC
TDI
TDI
P_OUT
P_IN
P_OUT
P_TS
SCAN
IN
U1
U4
DCC
P_TS
SCAN
OUT
SCAN
IN
BSC
BDC
DCC
SCAN
OUT
PR[ij]
Fig.34.a(F).1C
PL[ij]
TMS
TCK
TDO
TMS
TCK
TDO
TDI
U2
TDI
U3
TDO TCK TMS TDI
TAPC
BYPASS
REGISTER
INSTRUCTION
REGISTER
SCAN
OUT
P_TS
BSC
DCC
P_OUT
BDC
P_IN
SCAN
IN
SCAN
OUT
SEE ENLARGED VIEW BELOW
ENLARGED VIEW
Key: BSC = boundary-scan cell, BDC = bidirectional data cell,
and DCC = data control cell.
TDI
TMS
TCK
TDO
Figure 48 provides a system interface for components
used in the boundary-scan testing of PCBs. The three
major components shown are the test host, boundary-
Figure 47. Printed-Circuit Board with Boundary-
Scan Circuitry
scan support circuit, and the devices under test
(DUTs). The DUTs shown he re are
FPGAs with dedicated boundary-scan circuitry. The
test host is normally one of the following: automatic test
equipment (ATE), a workstation, a PC, or a microprocessor.
ORCA
Series
The boundary-scan support circuit shown in Figure 48
is the 497AA Boundary-Scan Master (BSM). The BSM
off-loads tasks from the test host to increase test
throughput. To interface between the test host and the
DUTs, the BSM has a general microprocessor interface
and provides parallel-to-serial/serial- to- pa rallel conversion, as well as three 8K data buffers.
54 Lucent Technologies Inc.
Page 55

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Special Function Blocks
CCLK
A[17:0]
EPROM
D[7:0]
OE
CE
PROGRAM
VDD OR
GND
A[17:0]
D[7:0]
DONE
PRGM
V
DD
M2
M1
M0
(continued)
ORCA
SERIES
FPGA
MASTER
DOUT DIN
INIT INIT
HDC
LDC
RCLK
V
DD
Figure 48. Boundary-Scan Interface
The BSM also increases test throughput with a dedicated automatic test-pattern generator and with compression of the test response with a signature analysis
register. The PC-based boundary-scan test card/software allows a user to quickly prototype a boundaryscan test setup.
Boundary-Scan Instructions
ORCA
The
three mandatory
PLE/PRELOAD, BYPASS) and four
instructions. The 3-bit wide instruction register supports the eight instructions listed in Table 12.
Series boundary-scan circuitry is used for
IEEE
1149.1 tests (EXTEST, SAM-
ORCA
-defined
CCLK
DONE
PRGM
M2
M1
M0
ORCA
SERIES
FPGA
SLAVE #1
DOUT
HDC
LDC
RCLK
CCLK
DIN
ORCA
SERIES
FPGA
SLAVE #2
DONE
PRGM
V
DD
M2
M1
M0
DOUT
INIT
HDC
LDC
RCLK
The external test (EXTEST) instruction allows the interconnections between ICs in a system to be tested for
opens and stuck-at faults. If an EXTEST instruction is
performed for the system shown in Figure 47, the connections between U1 and U2 (shown by nets a, b, and
c) can be tested by driving a value onto the given nets
from one device and then determining whether the
same value is seen at the other device. This is determined by shifting 2 bits of data for each pin (one for the
output value and one for the 3-state value) through the
BSR until each one aligns to the appropriate pin.
Then, based upon the value of the 3-state signal, either
the I/O pad is driven to the value given in the BSR, or
the BSR is updated with the input value from the I/O
pad, which allows it to be shifted out TDO.
V
DD
V
DD
5-4488(F)
Table 12. Boundary-Scan Instructions
Code Instruction
000 EXT ES T
001 PLC Scan Ring 1
010 RAM Write (RAM_W)
011 Reserved
100 SAMPLE/PRELOAD
The SAMPLE instruction is useful for system debugging and fault diagnosis by allowing the data at the
FPGA’s I/Os to be observed during normal operation.
The data for all of the I/Os is captured simultaneously
into the BSR, allowing them to be shifted-out TDO to
the test host. Since each I/O buffer in the PICs is bidirectional, two pieces of data are captured for each I/O
pad: the value at the I/O pad and the value of the
3-state control signal.
101 PLC Scan Ring 2
110 RAM Read (RAM_R)
111 BYPASS
Lucent Technologies Inc. 55
Page 56

ORCA
Data Sheet
Series 2 FPGAs June 1999
Special Function Blocks
ORCA
There are four
-defined instructions. The PLC
(continued)
scan rings 1 and 2 (PSR1, PSR2) allow user-defined
internal scan paths using the PLC latches/FFs. The
RAM_Write Enable (RAM_W) instruction allows the
user to serially configure the FPGA through TDI. The
RAM_Read Enable (RAM_R) allows the user to read
back RAM contents on TDO after configuration.
ORCA
The
Boundary-Scan Circuitry
ORCA
Series boundary-scan circuitry includes a
test access port controller (TAPC), instruction register
(IR), boundary-scan register (BSR), and bypass register. It also includes circuitry to support the four predefined instructions.
Figure 49 shows a functional diagram of the boundaryscan circuitry that is implemented in the
ORCA
series.
The input pins’ (TMS, TCK, and TDI) locations vary
depending on the part, and the output pin is the dedicated TDO/RD_DATA output pad. Test data in (TDI) is
the serial input data. Test mode select (TMS) controls
the boundary-scan test access port controller (TAPC).
Test clock (TCK) is the test clock on the board.
The BSR is a series connection of boundary-scan cells
(BSCs) around the periphery of the IC. Each I/O pad on
the FPGA, except for CCLK, DONE, and the boundaryscan pins (TCK, TDI, TMS, and TDO), is included in
the BSR. The first BSC in the BSR (connected to TDI)
is located in the first PIC I/O pad on the left of the top
side of the FPGA (PTA PIC). The BSR proceeds clockwise around the top, right, bottom, and left sides of the
array. The last BSC in the BSR (connected to TDO) is
located on the top of the left side of the array (PLA3).
The bypass instruction uses a single FF which resynchronizes test data that is not part of the current scan
operation. In a bypass instruction, test data received on
TDI is shifted out of the bypass register to TDO. Since
the BSR (which requires a two FF delay for each pad)
is bypassed, test throughput is increased when devices
that are not part of a test operation are bypassed.
The boundary-scan logic is enabled before and during
configuration. After configuration, a configuration
option determines whether or not boundary-scan logic
is used.
The 32-bit boundary-scan identification register contains the manufacturer’s ID number, unique part number, and version, but is not implemented in the
ORCA
series of FPGAs. If boundary scan is not used, TMS,
TDI, and TCK become user I/Os, and TDO is 3-stated
or used in the readback operation.
I/O BUFFERS
DATA REGISTERS
BOUNDARY-SCAN REGISTER
PSR1 REGISTER (PLCs)
DATA
MUX
SELECT
M
U
X
ENABLE
TDO
5-2840(C).r7
DD
V
TMS
V
DD
TCK
DD
V
PRGM
Figure 49.
DD
V
TDI
RESET
CLOCK-DR
SHIFT-DR
UPDATE-DR
TAP
CONTROLLER
ORCA
Series Boundary-Scan Circuitry Functional Diagram
PSR2 REGISTER (PLCs)
CONFIGURATION REGISTER
(RAM_R, RAM_W)
BYPASS REGISTER
INSTRUCTION DECODER
INSTRUCTION REGISTER
RESET
CLOCK-IR
SHIFT-IR
UPDATE-IR
PUR
56 Lucent Technologies Inc.
Page 57

Data Sheet
SELECT-
DR-SCAN
CAPTURE-DR
SHIFT-DR
EXIT1-DR
PAUSE-DR
EXIT2-DR
UPDATE-DR
1
1
0
0
10
RUN-TEST/
IDLE
1
TEST-LOGIC-
RESET
SELECT-
IR-SCAN
CAPTURE-IR
SHIFT-IR
EXIT1-IR
PAUSE-IR
EXIT2-IR
UPDATE-IR
1
1
0
10
00
0
0
1
0
1
1
1
0
1
1
0
0
0
0
1
11
0
June 1999
ORCA
Series 2 FPGAs
Special Function Blocks
ORCA
Series TAP Controller (TAPC)
The
ORCA
Series TAP controller (TAPC) is a 1149.1
(continued)
compatible test access port controller. The 16 JTAG
state assignments from the
IEEE
1149.1 specification
are used. The TAPC is controlled by TCK and TMS.
The TAPC states are used for loading the IR to allow
three basic functions in testing: providing test stimuli
(Update-DR), test execution (Run-Test/Idle), and
obtaining test responses (Capture-DR). The TAPC
allows the test host to shift in and out both instructions
and test data/results. The inputs and outputs of the
TAPC are provided in the table below. The outputs are
primarily the control signals to the instruction register
and the data register.
Table 13. TAP Controller Input/Outputs
Symbol I/O Function
TMS I Test Mode Select
TCK I Test Clock
PUR I Powerup Reset
PRGM
I BSCAN Reset
TRESET O Test Logic Reset
Select O Select IR (high); Select DR (low)
Enable O Test Data Out Enable
Capture-DR O Capture/Parallel Load DR
Capture-IR O Capture/Parallel Load IR
Shift-DR O Shift Data Register
Shift-DR O Shift Instruction Register
Update-DR O Update/Parallel Load DR
Update-IR O Update/Parallel Load IR
The TAPC generates control signals which allow capture, shift, and update operations on the instruction and
data registers. In the capture operation, data is loaded
into the register. In the shift operation, the captured
data is shifted out while new data is shifted in. In the
update operation, either the instruction register is
loaded for instruction decode, or the boundary-scan
register is updated for control of outputs.
The test host generates a test by providing input into
the
ORCA
Series TMS input synchronous with TCK.
This sequences the TAPC through states in order to
perform the desired function on the instruction register
or a data register. Figure 50 provides a diagram of the
state transitions for the TAPC. The next state is determined by the TMS input value.
5-5370(F)
Figure 50. TAP Controller State Tr ansition Diagram
Lucent Technologies Inc. 57
Page 58

ORCA
Data Sheet
Series 2 FPGAs June 1999
Special Function Blocks
(continued)
Boundary-Scan Cells
Figure 51 is a diagram of the boundary-scan cell (BSC)
in the
ORCA
series PICs. There are four BSCs in each
PIC: one for each pad, except as noted above. The
BSCs are connected serially to form the BSR. The
BSC controls the functionality of the in, out, and 3-state
signals for each pad.
The BSC allows the I/O to function in either the normal
or test mode. Normal mode is defined as when an output buffer receives input from the PLC array and provides output at the pad or when an input buffer
provides input from the pad to the PLC array. In the test
mode, the BSC executes a boundary-scan operation,
such as shifting in scan data from an upstream BSC in
the BSR, providing test stimuli to the pad, capturing
test data at the pad, etc.
The primary functions of the BSC are shifting scan data
serially in the BSR and observing input (P_IN), output
(P_OUT), and 3-state (P_TS) signals at the pads. The
BSC consists of two circuits: the bidirectional data cell
is used to access the input and output data, and the
direction control cell is used to access the 3-state
value. Both cells consist of a flip-flop used to shift scan
data which feeds a flip-flop to control the I/O buffer . The
bidirectional data cell is connected serially to the direction control cell to form a boundary-scan shift register.
The TAPC signals (capture, update, shiftn, treset, and
TCK) and the MODE signal control the operation of the
BSC. The bidirectional data cell is also controlled by
the high out/low in (HOLI) signal generated by the
direction control cell. When HOLI is low, the bidirectional data cell receives input buffer data into the BSC.
When HOLI is high, the BSC is loaded with functional
data from the PLC.
The MODE signal is generated from the decode of the
instruction register. When the MODE signal is high
(EXTEST), the scan data is propagated to the output
buffer. When the MODE signal is low (BYPASS or
SAMPLE), functional data from the FPGA’s internal
logic is propagated to the output buffer.
The boundary-scan description language (BSDL) is
provided for each device in the
ORCA
series of FPGAs.
The BSDL is generated from a device profile, pinout,
and other boundary-scan information.
P_IN
P_OUT
P_TS
HOLI
SCAN IN
0
1
I/O BUFFER
PAD_IN
BIDIRECTIONAL DATA CELL
0
1
0
1
Q
D
Q
D
DIRECTION CONTROL CELL
Q
D
Q
D
0
1
0
1
PAD_OUT
PAD_TS
MODEUPDATE/TCKSCAN OUTTCKSHIFTN/CAPTURE
5-2844(F).r4
Figure 51. Boundary-Scan Cell
58 Lucent Technologies Inc.
Page 59

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Special Function Blocks
TEST-LOGIC-RESET
RUN-TEST/IDLE
SELECT-DR-SCAN
SELECT-IR-SCAN
TCK
TMS
TDI
CAPTURE-IR
(continued)
SHIFT-IR
EXIT1-IR
PAUSE-IR
EXIT2-IR
SHIFT-IR
EXIT1-IR
UPDATE-IR
RUN-TEST/IDLE
Fig.5.3(F)
Figure 52. Instruction Register Scan Timing Diagram
Boundary-Scan Timing
To ensure race-free operation, data changes on specific clock edges. The TMS and TDI inputs are clocked in on
the rising edge of TCK, while changes on TDO occur on the falling edge of TCK. In the execution of an EXTEST
instruction, parallel data is output from the BSR to the FPGA pads on the falling edge of TCK. The maximum frequency allowed for TCK is 10 MHz.
Figure 52 shows timing waveforms for an instruction scan operation. The diagram shows the use of TMS to
sequence the TAPC through states. The test host (or BSM) changes data on the falling edge of TCK, and it is
clocked into the DUT on the rising edge.
Lucent Technologies Inc. 59
Page 60

ORCA
Data Sheet
Series 2 FPGAs June 1999
ORCA
To define speed grades, the
designation (see Table 54) uses a single-digit number
to designate a speed grade. This number is not related
to any single ac parameter. Higher numbers indicate a
faster set of timing parameters. The actual speed sorting is based on testing the delay in a path consisting of
an input buffer , combinatorial delay through all PLCs in
a row, and an output buffer. Other tests are then done
to verify other delay parameters, such as routing
delays, setup times to FFs, etc.
The most accurate timing characteristics are reported
by the timing analyzer in the
ment System. A timing report provided by the development system after layout divides path delays into logic
and routing delays. The timing analyzer can also provide logic delays prior to layout. While this allows routing budget estimates, there is wide variance in routing
delays associated with different layouts.
The logic timing parameters noted in the Electrical
Characteristics section of this data sheet are the same
as those in the design tools. In the PFU timing given in
Tables 31—79, symbol names are generally a concatenation of the PFU operating mode (as defined in
Table 3) and the parameter type. The wildcard character (*) is used in symbol names to indicate that the
parameter applies to any sub-LUT. The setup, hold,
and propagation delay parameters, defined below, are
designated in the symbol name by the SET, HLD, and
DEL characters, respectively.
The values given for the parameters are the same as
those used during production testing and speed binning of the devices. The junction temperature and supply voltage used to characterize the devices are listed
in the delay tables. Actual delays at nominal temperature and voltage for best-case processes can be much
better than the values given.
It should be noted that the junction temperature used in
the tables is generally 85 °C. The junction temperature
for the FPGA depends on the power dissipated by the
device, the package thermal characteristics (Θ
the ambient temperature, as calculated in the following
equation and as discussed further in the Package
Thermal Characteristics section:
Timing Characteristics
T
Jmax = TAmax
ORCA
+ (P • ΘJA) °C
Series part numb er
ORCA
Foundry Develop-
JA
), and
Table 14A and 14B and provide approximate power
supply and junction temperature derating for OR2CxxA
commercial and industrial devices. Table 15A and 15B
provides the same information for the OR2TxxA and
OR2TxxB devices (both commercial and industrial).
The delay values in this data sheet and reported by
ORCA
Foundry are shown as
method for determining the maximum junction temperature is defined in the Thermal Characteristics section.
Taken cumulatively, the range of parameter values for
best-case vs. worst-case processing, supply voltage,
and junction temperature can approach 3 to 1.
Table 14A. Derating for Commercial Devices
(OR2CxxA)
T
J
(°C)
0
25
85 1.00
100
125
Table 14B. Derating for Industrial Devices
(OR2CxxA)
T
J
(°C)
–40
0
25
85 1.00
100
125
Table 15A. Derating for Commercial/Industrial Devices (OR2TxxA)
T
(°C)
–40
0
25
85 1.00
100
125
4.5 V 4.75 V 5.0 V 5.25 V 5.5 V
0.71 0.70 0.68 0.66 0.65
0.80 0.78 0.76 0.74 0.73
0.84 0.82 0.80 0.78 0.77
1.05 1.01 0.99 0.97 0.95
1.12 1.09 1.06 1.04 1.02
J
Power Supply Voltage
4.75 V 5.0 V 5.25 V
0.81 0.79 0.77
0.85 0.83 0.81
1.05 1.02 1.00
1.12 1.09 1.07
Power Supply Voltage
0.97 0.94 0.93 0.91
Power Supply Voltage
3.0 V 3.3 V 3.6 V
0.73 0.66 0.61
0.82 0.73 0.68
0.87 0.78 0.72
1.04 0.94 0.87
1.10 1.00 0.92
1.00
in the tables. The
0.97 0.95
0.90 0.83
Note
: The user must determine this junction tempera-
ture to see if the delays from
should be derated based on the following derating tables.
60 Lucent Technologies Inc.
ORCA
Foundry
Page 61

Data Sheet
June 1999
ORCA
Series 2 FPGAs
ORCA
(continued)
Timing Characteristics
Table 15B. Derating for Commercial/Industrial
Devices (OR2TxxB)
T
J
(°C)
–40
3.0 V 3.15 V 3.3 V 3.45 V 3.6 V
0.81 0.78 0.76 0.74 0.73
0
0.86 0.83 0.80 0.77 0.76
25
0.9 0.87 0.83 0.8 0.78
85 1.0
100
125
Note:
1.02 0.98 0.95 0.91 0.88
1.06 1.03 0.98 0.95 0.92
The derating tables shown above are for a typical critical path
that contains 33% logic delay and 66% routing delay. Since the
routing delay derates at a higher rate than the logic delay, paths
with more than 66% routing delay will derate at a higher rate
than shown in the table. The approximate derating values vs.
temperature are 0.26% per °C for logic delay and 0.45% per °C
for routing delay. The approximate derating values vs. voltage
are 0.13% per mV for both logic and routing delays at 25 °C.
Power Supply Voltage
0.95 0.93 0.88 0.86
In addition to supply voltage, process variation, and
operating temperature, circuit and process improvements of the
ORCA
series FPGAs over time will result
in significant improvement of the actual performance
over those listed for a speed grade. Even though lower
speed grades may still be available, the distribution of
yield to timing parameters may be several speed bins
higher than that designated on a product brand. Design
practices need to consider best-case timing parameters (e.g., delays = 0), as well as worst-case timing.
The routing delays are a function of fan-out and the
capacitance associated with the CIPs and metal interconnect in the path. The number of logic elements that
can be driven (or fan-out) by PFUs is unlimited,
although the delay to reach a valid logic level can
exceed timing requirements. It is difficult to make accurate routing delay estimates prior to design compilation
based on fan-out. This is because the CAE software
may delete redundant logic inserted by the designer to
reduce fan-out, and/or it may also automatically reduce
fan-out by net splittin g.
The waveform test points are given in the Measurement Conditions section of this data sheet. The timing
parameters given in the electrical characteristics tables
in this data sheet follow industry practices, and the values they reflect are described below.
Propagation Delay
■
—the time between the specified
reference points. The delays provided are the worst
case of the tphh and tpll delays for noninverting functions, tplh and tphl for inverting functions, and tphz
and tplz for 3-state enable.
Setup Time
■
—the interval immediately preceding the
transition of a clock or latch enable signal, during
which the data must be stable to ensure it is recognized as the intended value.
Hold Time
■
—the interval immediately following the
transition of a clock or latch enable signal, during
which the data must be held stable to ensure it is recognized as the intended value.
3-state Enable
■
—the time from when a TS[3:0] signal
becomes active and the output pad reaches the highimpedance state.
Estimating Power Dissipation
OR2CxxA
The total operating power dissipated is estimated by
summing the standby (I
power dissipated. The internal and external power is
the power consumed in the PLCs and PICs, respectively. In general, the standby power is small and may
be neglected. The total operating power is as follows:
P
= Σ P
T
The internal operating power is made up of two parts:
clock generation and PFU output power. The PFU output power can be estimated based upon the number of
PFU outputs switching when driving an average fan-out
of two:
P
= 0.16 mW/MHz
PFU
For each PFU output that switches, 0.16 mW/MHz
needs to be multiplied times the frequency (in MHz)
that the output switches. Generally, this can be estimated by using one-half the clock rate, multiplied by
some activity factor; for example, 20%.
The power dissipated by the clock generation circuitry
is based upon four parts: the fixed clock power, the
power / clock branch row or colu mn , t he clock power dis sipated in each PFU that uses this particular clock, and
the power from the subset of those PFUs that is configured in either of the two synchronous modes (SSPM or
SDPM). Therefore, the clock power can be calculated
for the four parts using the following equations:
OR2C04A Clock Power
P = [0.62 mW/MHz
+ (0.22 mW/MHz – Branch) (# Branches)
+ (0.022 mW/MHz – PFU) (# PFUs)
+ (0.006 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2C04A clock power ≈ 3.9 mW/MHz.
), internal, and external
DDSB
+ Σ P
PLC
PIC
Lucent Technologies Inc. 61
Page 62

ORCA
Data Sheet
Series 2 FPGAs June 1999
Estimating Power Dissipation
(continued)
OR2C06A Clock Power
P = [0.63 mW/MHz
+ (0.25 mW/MHz – Branch) (# Branches)
+ (0.022 mW/MHz – PFU) (# PFUs)
+ (0.006 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2C06A clock power ≈ 5.3 mW/MHz.
OR2C08A Clock Power
P = [0.65 mW/MHz
+ (0.29 mW/MHz – Branch) (# Branches)
+ (0.022 mW/MHz – PFU) (# PFUs)
+ (0.006 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2C08A clock power ≈ 6.6 mW/MHz.
OR2C10A Clock Power
P = [0.66 mW/MHz
+ (0.32 mW/MHz – Branch) (# Branches)
+ (0.022 mW/MHz – PFU) (# PFUs)
+ (0.006 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2C10A clock power ≈ 8.6 mW/MHz.
OR2C12A Clock Power
P = [0.68 mW/MHz
+ (0.35 mW/MHz – Branch) (# Branches)
+ (0.022 mW/MHz – PFU) (# PFUs)
+ (0.006 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2C12A clock power ≈ 10.5 mW/MHz.
OR2C15A Clock Power
P = [0.69 mW/MHz
+ (0.38 mW/MHz – Branch) (# Branches)
+ (0.022 mW/MHz – PFU) (# PFUs)
+ (0.006 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2C15A clock power ≈ 12.7 mW/MHz.
OR2C26A Clock Power
P = [0.73 mW/MHz
+ (0.44 mW/MHz – Branch) (# Branches)
+ (0.022 mW/MHz – PFU) (# PFUs)
+ (0.006 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2C26A clock power ≈ 17.8 mW/MHz.
OR2C40A Clock Power
P = [0.77 mW/MHz
+ (0.53 mW/MHz – Branch) (# Branches)
+ (0.022 mW/MHz – PFU) (# PFUs)
+ (0.006 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2C40A clock power ≈ 26.6 mW/MHz.
The power dissipated in a PIC is the sum of the power
dissipated in the four I/Os in the PIC. This consists of
power dissipated by inputs and ac power dissipated by
outputs. The power dissipated in each I/O depends on
whether it is configured as an input, output, or input/
output. If an I/O is operating as an output, then there is
a power dissipation component for P
P
. This is because the output feeds back to the
OUT
, as well as
IN
input.
The pow er diss ipated b y a TTL input b uff er is estima ted
as:
P
= 2.2 mW + 0.17 mW/MHz
TTL
The power dissipated by an input buffer is estimated
as:
P
= 0.17 mW/MHz
CMOS
The ac power dissip ation from an output or bidirectional is estimated by the following:
P
= (CL + 8.8 pF) x V
OUT
where the unit for C
is farads, and the unit for F is Hz.
L
2
x F Watts
DD
As an example of estimating power dissipation,
suppose that a fully utilized OR2C15A has an average
of three outputs for each of the 400 PFUs, that all
20 clock branches are used, that 150 of the 400 PFUs
have FFs clock ed at 40 MHz (16 of which are operating
in a synchronous memory mode), and that the PFU
outputs have an average activity factor of 20%.
Twenty TTL-configured inputs, 20 CMOS-configured
inputs, 32 outputs driving 30 pF loads, and 16 bidirectional I/Os driving 50 pF loads are also generated from
the 40 MHz clock with an average activity factor of
20%. The worst-case (V
= 5.25 V) power dissipation
DD
is estimated as follows:
P
= 400 x 3 (0.16 mW/MHz x 20 MHz x 20%)
PFU
= 768 mW
62 Lucent Technologies Inc.
Page 63

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Estimating Power Dissipation
P
= [0.69 mW/MHz + (0.38 mW/MHz – Branch)
CLK
(continued)
(20 Branches)
+ (0.022 mW/MHz – PFU) (150 PFUs)
+ (0.006 mW/MHz – SMEM_PFU)
(16 SMEM_PFUs)] [40 MHz]
= 427 mW
P
= 20 x [2.2 mW + (0.17 mW/MHz x 20 MHz
TTL
x 20%)]
= 57 mW
P
= 20 x [0.17 mW x 20 MHz x 20%]
CMOS
= 13 mW
P
= 30 x [(30 pF + 8.8 pF) x (5.25)2 x 20 MHz
OUT
x 20%]
=128 mW
P
= 16 x [(50 pF + 8.8 pF) x (5.25)2 x 20 MHz
BID
x 20%]
= 104 mW
TOT AL
= 1.50 W
OR2TxxA
The total operating power dissipated is estimated by
summing the standby (I
power dissipated. The internal and external power is
the power consumed in the PLCs and PICs, respectively. In general, the standby power is small and may
be neglected. The total operating power is as follows:
P
= Σ P
T
The internal operating power is made up of two parts:
clock generation and PFU output power. The PFU output power can be estimated based upon the number of
PFU outputs switching when driving an average fan-out
of two:
P
= 0.08 mW/MHz
PFU
For each PFU output that switches, 0.08 mW/MHz
needs to be multiplied times the frequency (in MHz)
that the output switches. Generally, this can be estimated by using one-half the clock rate, multiplied by
some activity factor; for example, 20%.
The power dissipated by the clock generation circuitry
is based upon four parts: the fixed clock power, the
power/clock branch row or column, the clock power dissipated in each PFU that uses this particular clock, and
the power from the subset of those PFUs that is configured in either of the two synchronous modes (SSPM or
), internal, and external
DDSB
+ Σ P
PLC
PIC
SDPM). Therefore, the clock power can be calculated
for the four parts using the following equations:
OR2T04A Clock Power
P = [0.29 mW/MHz
+ (0.10 mW/MHz – Branch) (# Branches)
+ (0.01 mW/MHz – PFU) (# PFUs)
+ (0.003 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T04A clock power ≈ 1.8 mW/MHz.
OR2T06A Clock Power
P = [0.30 mW/MHz
+ (0.11 mW/MHz – Branch) (# Branches)
+ (0.01 mW/MHz – PFU) (# PFUs)
+ (0.003 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T06A clock power ≈ 2.4 mW/MHz.
OR2T08A Clock Power
P = [0.31 mW/MHz
+ (0.12 mW/MHz – Branch) (# Branches)
+ (0.01 mW/MHz – PFU) (# PFUs)
+ (0.003 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T08A clock power ≈ 3.2 mW/MHz.
OR2T10A Clock Power
P = [0.32 mW/MHz
+ (0.14 mW/MHz – Branch) (# Branches)
+ (0.01 mW/MHz – PFU) (# PFUs)
+ (0.003 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T10A clock power ≈ 4.0 mW/MHz.
OR2T12A Clock Power
P = [0.33 mW/MHz
+ (0.15 mW/MHz – Branch) (# Branches)
+ (0.01 mW/MHz – PFU) (# PFUs)
+ (0.003 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T12A clock power ≈ 4.9 mW/MHz.
Lucent Technologies Inc. 63
Page 64

ORCA
Data Sheet
Series 2 FPGAs June 1999
Estimating Power Dissipation
(continued)
OR2T15A Clock Power
P = [0.34 mW/MHz
+ (0.17 mW/MHz – Branch) (# Branches)
+ (0.01 mW/MHz – PFU) (# PFUs)
+ (0.003 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T15A clock power ≈ 5.9 mW/MHz.
OR2T26A Clock Power
P = [0.35 mW/MHz
+ (0.19 mW/MHz – Branch) (# Branches)
+ (0.01 mW/MHz – PFU) (# PFUs)
+ (0.003 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T26A clock power ≈ 8.3 mW/MHz.
OR2T40A Clock Power
P = [0.37 mW/MHz
+ (0.23 mW/MHz – Branch) (# Branches)
+ (0.01 mW/MHz – PFU) (# PFUs)
+ (0.003 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T40A clock power ≈ 12.4 mW/MHz.
The power dissipated in a PIC is the sum of the power
dissipated in the four I/Os in the PIC. This consists of
power dissipated by inputs and ac power dissipated by
outputs. The power dissipated in each I/O depends on
whether it is configured as an input, output, or input/
output. If an I/O is operating as an output, then there is
a power dissipation component for P
P
. This is because the output feeds back to the
OUT
, as well as
IN
input.
The power dissipated by an input buffer (V
= VDD –
IH
0.3 V or higher) is estimated as:
P
= 0.09 mW/MHz
IN
Table 16. dc Power for 5 V Tolerant I/Os for
OR2TxxA deviced
Device P
(VDD5 = 5.25 V)
TOL
2T04A 1.7 mW
2T06A 2.0 mW
2T08A 2.4 mW
2T10A 2.7 mW
2T12A 3.0 mW
2T15A 3.4 mW
2T26A 4.0 mW
2T40A 5.0 mW
The ac power dissip ation from an output or bidirectional is estimated by the following:
P
= (CL + 8.8 pF) x V
OUT
where the unit for C
is farads, and the unit for F is Hz.
L
2
x F Watts
DD
As an example of estimating power dissipation,
suppose that a fully utilized OR2T15A has an average
of three outputs for each of the 400 PFUs, that all
20 clock branches are used, that 150 of the 400 PFUs
have FFs clock ed at 40 MHz (16 of which are operating
in a synchronous memory mode), and that the PFU
outputs have an average activity factor of 20%.
Twenty inputs, 32 outputs driving 30 pF loads, and
16 bidirectional I/Os driving 50 pF loads are also generated from the 40 MHz clock with an average activity
factor of 20%. The worst-case (V
= 3.6 V) power dis-
DD
sipation is estimated as follows:
P
= 400 x 3 (0.08 mW/MHz x 20 MHz x 20%)
PFU
= 384 mW
= [0.34 mW/MHz + (0.17 mW/MHz – Branch)
P
CLK
(20 Branches)
+ (0.01 mW/MHz – PFU) (150 PFUs)
+ (0.003 mW/MHz – SMEM_PFU)
(16 SMEM_PFUs)] [40 MHz]
= 212 mW
P
= 20 x [0.09 mW/MHz x 20 MHz x 20%]
IN
= 7 mW
The 5 V tolerant input buffer feature dissipates additional dc power. The dc power, P
, is always dissi-
TOL
pated for the OR2TxxA, regardless of the number of
5 V tolerant input buffers used when the V
5 pins are
DD
connected to a 5 V supply as shown in Table 16. This
power is not dissipated when the V
5 pins are con-
DD
nected to the 3.3 V supply.
P
P
P
= 3.4 mW
TOL
= 30 x [(30 pF + 8.8 pF) x (3.6)2 x 20 MHz
OUT
x 20%]
= 60 mW
= 16 x [(50 pF + 8.8 pF) x (3.6)2 x 20 MHz
BID
x 20%]
= 49 mW
TOTAL
= 0.72 W
64 Lucent Technologies Inc.
Page 65

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Estimating Power Dissipation
(continued)
OR2T15B and OR2T40B
The total operating power dissipated is estimated by
summing the standby (I
power dissipated. The internal and external power is
the power consumed in the PLCs and PICs, respectively. In general, the standby power is small and may
be neglected. The total operating power is as follows:
P
= Σ P
T
The internal operating power is made up of two parts:
clock generation and PFU output power. The PFU output power can be estimated based upon the number of
PFU outputs switching when driving an average fan-out
of two:
P
= 0.08 mW/MHz
PFU
For each PFU output that switches, 0.08 mW/MHz
needs to be multiplied times the frequency (in MHz)
that the output switches. Generally, this can be estimated by using one-half the clock rate, multiplied by
some activity factor; for example, 20%.
The power dissipated by the clock generation circuitry
is based upon four parts: the fixed clock power, the
power/clock branch row or column, the clock power dissipated in each PFU that uses this particular clock, and
the power from the subset of those PFUs that is configured in either of the two synchronous modes (SSPM or
SDPM). Therefore, the clock power can be calculated
for the four parts using the following equations:
OR2T15B Clock Power
P = [0.30 mW/MHz
+ (0.85 mW/MHz – Branch) (# Branches)
+ (0.008 mW/MHz – PFU) (# PFUs)
+ (0.002 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T15B clock power ≈ 3.9 mW/MHz.
OR2T40B Clock Power
P = [0.42 mW/MHz
+ (0.118 mW/MHz – Branch) (# Branches)
+ (0.008 mW/MHz – PFU) (# PFUs)
+ (0.002 mW/MHz – SMEM_PFU)
(# SMEM_PFUs)] fCLK
For a quick estimate, the worst-case (typical circuit)
OR2T40B clock power ≈ 5.5 mW/MHz.
The power dissipated in a PIC is the sum of the power
dissipated in the four I/Os in the PIC. This consists of
), internal, and external
DDSB
+ Σ P
PLC
PIC
power dissipated by inputs and ac power dissipated by
outputs. The power dissipated in each I/O depends on
whether it is configured as an input, output, or input/
output. If an I/O is operating as an output, then there is
a power dissipation component for P
P
. This is because the output feeds back to the
OUT
, as well as
IN
input.
The power dissipated by an input buffer (V
= VDD –
IH
0.3 V or higher) is estimated as:
P
= 0.033 mW/MHz
IN
The OR2TxxB 5 V tolerant input buffer feature does not
dissipate additional dc power.
The ac power dissipation from an output or bidirectional is estimated by the following:
P
= (CL + 8.8 pF) x V
OUT
where the unit for C
is farads, and the unit for F is Hz.
L
2
x F Watts
DD
As an example of estimating power dissipation,
suppose that a fully utilized OR2T15B has an average
of three outputs for each of the 400 PFUs, that all
20 clock branches are used, that 150 of the 400 PFUs
have FFs clocked at 40 MHz (16 of which are operating
in a synchronous memory mode), and that the PFU
outputs have an average activity factor of 20%.
Twenty inputs, 32 outputs driving 30 pF loads, and
16 bidirectional I/Os driving 50 pF loads are also generated from the 40 MHz clock with an average activity
factor of 20%. The worst-case (V
= 3.6 V) power dis-
DD
sipation is estimated as follows:
P
= 400 x 3 (0.08 mW/MHz x 20 MHz x 20%)
PFU
= 384 mW
= [0.30 mW/MHz + (0.085 mW/MHz – Branch)
P
CLK
(20 Branch es)
+ (0.008 mW/MHz – PFU) (150 PFUs)
+ (0.002 mW/MHz – SMEM_PFU)
(16 SMEM_PFUs)] [40 MHz]
= 129 mW
P
= 20 x [0.033 mW/MHz x 20 MHz x 20%]
IN
= 3 mW
P
P
= 3.4 mW
TOL
= 30 x [(30 pF + 8.8 pF) x (3.6)2 x 20 MHz
OUT
x 20%]
= 60 mW
P
= 16 x [(50 pF + 8.8 pF) x (3.6)2 x 20 MHz
BID
x 20%]
= 49 mW
TOT AL
= 0.72 W
Lucent Technologies Inc. 65
Page 66

Data Sheet
ORCA
Series 2 FPGAs June 1999
Pin Information
Pin Descriptions
This section describes the pins found on the Series 2 FPGAs. Any pin not described in this table is a user-programmable I/O. During configuration, the user-programmable I/Os are 3-stated with an internal pull-up resistor enabled.
Table 17. Pin Descriptions
Symbol I/O Description
Dedicated Pins
DD
V
GND — Ground supply.
I/O-VDD5 — 5 V tolerant select. (For 2Txx A only.) All VDD5 pins mus t be tied to either the 5 V power
RESET I Durin g co nfi guration, RESET forces the restart of configuration and a pull-up is
CCLK I In the master and asynchronous peripheral modes, CCLK is an output which strobes
DONE I/O DONE is a bidirectional pin with an optional pull-up resistor. As an active-high, open-
PRGM IPRGM is an active-low input that forces the restart of configuration and resets the
RD_CFG I This pin must be held high during device initialization until the
— Positive power supply.
supply if 5 V tolerant I/O buffers are to be used, or to the 3.3 V power supply (VDD) if
they are not. For 2CxxA and 2TxxB devices, these pins are user-programmable I/Os.
enabled. After configuration, RESET can be used as a general FPGA input or as a
direct input, which causes all PLC latches/FFs to be asynchronously set/reset.
configuration data in. In the slave or synchronous peripheral mode, CCLK is input synchronous with the data on DIN or D[7:0].
drain outpu t, a high-le vel on this signal indicates that configuration is complete. As an
input, a low level on DONE delays FPGA start-up after configuration*.
boundary-scan circuitry. This pin always has an active pull-up.
INIT
pin goes high.
This pin always has an active pullup.
During configuration,
and 3-states all of the I/O.
After configuration,
TS_ALL function as described above, or, if readback is enabled via a bit stream option,
a high-to-low transition on
including PFU output states, starting with frame address 0.
RD_DATA/TDO O RD_DATA/TDO is a dual-function pin. If used for readback, RD_DATA provides configu-
ration data out. If used in boundary scan, TDO is test data out.
Special-Purpose Pins (Become User I/O After Configuration)
RDY/RCLK O During configuration in peripheral mode, RDY indicates another byte can be written to
the FPGA. If a read operation is done when the device is selected, the same status is
also available on D7 in asynchronous peripheral mode. After configuration, the pin is a
user-programmable I/O*.
During the master paralle l configur ation mo de RCLK, which is a read o utput s ignal to an
external mem ory. This output is n ot normally use d. A ft er co nfig ur a t ion, th is pi n is a use rprogrammable I/O pin*.
DIN I During slave serial or master serial configuration modes, DIN accepts serial configura-
tion data synchronous with CCLK. During paralle l configuration modes, DIN is the D0
input. During configuration, a pull-up is enabled, and after configuration, this pin is a
user-programmable I/O pin*.
* The FPGA States of Operation section contains more information on how to control these signals during start-up. The timing of DONE
release is controlled by one set of bit stream options, and the timing of the simultaneous release of all other configuration pins (and the activation of all user I/Os) is controlled by a second set of options.
RD_CFG
RD_CFG
is an active-low input that activates the TS_ALL function
can be selected (via a bit stream option) to activate the
RD_CFG
will initiate readba ck of the configuration data,
66 Lucent Technologies Inc.
Page 67

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
Table 17. Pin Descriptions
Symbol I/O Description
Special-Purpose Pins Special-Purpose Pins (Become User I/O After Config uration)
M0, M1, M2 I During powerup and initialization, M0—M2 are used to select the configuration mode
M3 I During powerup and initializa tion, M3 is used to select the speed of the internal oscilla-
TDI, TCK, TMS I If boundary scan is used, these pins are Test Data In, Test Clock, and T est Mode Select
HDC O High During Configuration is out put high until configuration is complete. It is used as a
LDC O Low During Configura t i on is output low until configuration is complete. It is used as a
INIT I/O INIT is a bidirect ional signal before and during configuration. During configur ation, a
CS0, CS1, WR, RD ICS0, CS1, WR, RD are used in the asynchronous peripheral configuration modes. The
(continued)
(continued)
with their values latched on the rising edge of INIT
modes. During configuration, a pull-up is enabled, and after configuration, the pins are
user-programmable I/O*.
tor during configuration, with it s value latched on the rising edge of INIT. When M3 is
low, the oscillator frequency is 10 MHz. When M3 is high, the oscillator is 1.25 MHz.
During configuration, a pull-up is enabled, and after configuration, this pin is a user-programmable I/O pin*.
inputs. If boundary scan is not selec ted, all boundary-scan functions are in hibited once
configuration is complete, and these pins are user-programmable I/O pins. Even if
boundary scan is not used, either TCK or TMS must be held at logic 1 du ring configuration. Each pin has a pull-up enabled during configuration*.
control output indicating that configuration is not complete. After configuration, this pin is
a user-programmabl e I/O pin*.
control output indicating that configuration is not complete. After configuration, this pin is
a user-programmabl e I/O pin*.
pull-up is enabled, but an external pul l -up resistor is re commended. As an ac tive-lo w
open-drain output, INIT is held low during power stabilization and internal clearing of
memory. As an active-l ow in put, INI T holds the FPGA in the wait-state before the start of
configuration. After configuration, the pin is a user-programmable I/O pin*.
FPGA is selected when CS0 is low and CS1 is high. When selected, a low on the write
strobe, WR, loads the data on D[7:0] inputs into an internal data buffer. WR, CS0, and
CS1 are also used as chip selects in the slave parallel m ode.
(continued)
. See Table 7 for the configuration
A low on RD changes D7 into a status output. As a status indication, a high indicates
ready and a lo w indicates busy. WR and RD should not be used simultaneously. If they
are, the write strobe overrides. During configuration, a pull-up is enabled, and after configuration, the pins are user-programmabl e I/O pins*.
A[17:0] O During master parallel configuration mode, A[17:0] address the configuration EPROM.
During configuration, a pull-up is enabled, and after configuration, the pins are userprogrammable I/O pins*.
D[7:0] I During master parallel, peripheral, and slave parallel configuration modes, D[7:0]
receive configuration data and each pi n has a pull-up enabled. After configuration, the
pins are user-programmable I/O pins*.
DOUT O During configuration, DOUT is the serial data output that can drive the DIN of daisy-
chained slave LCA devices. Data out on DOUT changes on the falling edge of CCLK.
After configuration, DOUT is a user-programmable I/O pin*.
* The FPGA States of Operation section contains more information on how to control these signals during start-up. The timing of DO NE
release is controlled by one set of bit stream options, and the timing of the simultaneous release of all other configuration pins (and the activation of all user I/Os) is controlled by a second set of options.
Lucent Technologies Inc. 67
Page 68

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Package Compatibility
The package pinouts are consistent across
Series FPGAs with the following exception:
I/O pins that do not have any special functions will
be converted to V
5 pins for the OR2TxxA series
DD
If the designer does not use these pins for the
OR2CxxA and OR2TxxB series, then pinout compatibility will be maintained between the
ORCA
OR2TxxA, and OR2TxxB series of FPGAs. Note that
they must be connected to a power supply for the
OR2TxxA series.
Package pinouts being consistent across all
Series FPGAs enables a designer to select a package
based on I/O requirements and change the FPGA without laying out the printed-circuit board again. The
change might be to a larger FPGA if additional functionality is needed, or it might be to a smaller FPGA to
decrease unit cost.
Table 18A provides the number of user I/Os available
for the
Table 18A.
ORCA
ORCA
OR2CxxA and OR2TxxB Series FPGAs
OR2CxxA and OR2TxxB Series FPGA I/Os Summary
ORCA
some user
OR2CxxA,
ORCA
for each available package, and Table 18B provides the
number of user I/Os available in the
ORCA
series. It should be noted that the number of user I/Os
available for the OR2TxxA series is reduced from the
equivalent OR2CxxA devices by the number of
required V
that are converted from user I/O to V
as I/O-V
.
through 28). Each package has six dedicated configu-
5 pins, as shown in Table 18B. The pins
DD
5 are denoted
DD
5 in the pin information tables (Table 19
DD
ration pins.
Table 19—Table 28. provide the package pin and pin
function for the
ORCA
Series 2 FPGAs and packages.
The bond pad name is identified in the PIC nomenclature used in the
ORCA
Foundry design editor.
When the number of FPGA bond pads exceeds the
number of package pins, bond pads are unused. When
the number of package pins exceeds the number of
bond pads, package pins are left unconnected (no
connects). When a package pin is to be left as a no
connect for a specific die, it is indicated as a note in the
device pad column for the FPGA. The tables provide no
information on unused pads.
OR2TxxA
Device
OR2C04A
User I/Os 64 77 114 130 160 — — — — —
V
DD/VSS
OR2C06A
User I/Os 64 77 114 130 171 192 192 — — —
VDD/V
SS
OR2C08A
User I/Os 64 — — 130 171 192 221 — — —
VDD/V
SS
OR2C10A
User I/Os 64 — — 130 171 192 221 — 256 —
VDD/V
SS
OR2C12A
User I/Os 64 — — — 171 192 223 252 288 —
VDD/V
SS
OR2C15A/OR2T15B
User I/Os 64 — — — 171 192 223 252 298 320*
VDD/V
SS
OR2C26A
User I/Os — — — — 171 192 — 252 298 342
VDD/V
SS
OR2C40A/OR2T40B
User I/Os — — — — 171 192 — 252 — 342
VDD/V
SS
* 432 EBGA not available for OR2T15B
84-Pin
PLCC
100-Pin
TQFP
14 17 24 24 31 — — — — —
14 17 24 24 31 42 26 — — —
14 — — 24 31 40 26 — — —
14 — — 24 31 40 26 — 48 —
14———3142264648—
14———314226464884
— — — — 31 42 — 46 48 84
— — — — 31 42 — 46 — 84
144-Pin
TQFP
160-Pin
QFP
208-Pin
SQFP/
SQFP2
240-Pin
SQFP/
SQFP2
256-Pin
PBGA
304-Pin
SQFP/
SQFP2
352-Pin
PBGA
432-Pin
EBGA
68 Lucent Technologies Inc.
Page 69

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
Table 18B.
Device
OR2T04A
User I/Os 62 74 110 126 152 — — — —
V
DD/VSS
V
DD
OR2T06A
User I/Os 62 74 110 126 163 184 182 — —
VDD/V
V
DD
OR2T08A
User I/Os 62 — — 126 163 184 209 — —
VDD/V
V
DD
OR2T10A
User I/Os 62 — — 126 163 184 209 244 —
VDD/V
V
DD
OR2T12A
User I/Os 62 — — — 163 184 211 276 —
VDD/V
V
DD
OR2T15A
User I/Os 62 — — — 163 184 211 286 307
VDD/V
V
DD
OR2T26A
User I/Os — — — — 163 184 — 286 326
VDD/V
V
DD
OR2T40A
User I/Os — — — — 163 184 — 286 326
VDD/V
V
DD
ORCA
523448————
SS
523448810——
SS
52——48812——
SS
52——4881212—
SS
52———881212—
SS
52———88121212
SS
5 — — — — 8 8 — 12 16
SS
5 — — — — 8 8 — 12 16
(continued)
OR2TxxA Series FPGA I/Os Summary
84-Pin
PLCC
100-Pin
TQFP
14 17 24 24 31 — — — —
14 17 24 24 31 42 26 — —
14 — — 24 31 40 26 — —
14 — — 24 31 40 26 48 —
14 — — — 31 42 26 48 —
14 — — — 31 42 26 48 84
— — — — 31 42 — 48 84
— — — — 31 42 — 48 84
144-Pin
TQFP
160-Pin
QFP
208-Pin
SQFP/
SQFP2
240-Pin
SQFP/
SQFP2
256-Pin
PBGA
352-Pin
PBGA
432-Pin
EBGA
Lucent Technologies Inc. 69
Page 70

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Compatibility with Series 3 FPGAs
Pinouts for the OR2CxxA, OR2TxxA, and OR2TxxB devices will be consistent with the Series 3 FPGAs for all
devices offered in the same packages. This includes the following pins: V
and all configuration pins. Identical to the OR2TxxB devices, Series 3 devices provide 5 V tolerant I/Os without a
dedicated V
The following restrictions apply:
1. There are two configuration modes supported in the OR2C/TxxA series that are
Series 3 FPGAs series: master parallel down and synchronous peripheral modes. The Series 3 FPGAs have two
new microprocessor interface (MPI) configuration modes that are unavailable in the Series 2.
2. There are 4 pins—one per each device side—that are user I/O in the OR2C/TxxA series which can only be used
as fast dedicated clocks or global inputs in the Series 3 series. These pins are also used to drive the ExpressCLK to the I/O FFs on their given side of the device. These four middle ExpressCLK pins should not be used to
connect to a programmable clock manager (PCM). A corner ExpressCLK input should be used instead (see note
below). See Table 18C for a list of these pins in each package.
3. There are two other pins that are user I/O in both the Series 2 and Series 3 series but also have optional added
functionality in the Series 3 series. Each of these pins drives the ExpressCLKs on two sides of the device. They
also have fast connectivity to the programmable clock manager (PCM). See Table 18C for a preliminary list of
these pins in each package.
Table 18C. Series 3 ExpressCLK Pins
DD
5 supply
, VSS, VDD5 (OR3C/Txxx series only),
DD
not
supported in the
Pin Name/
Package
ECKL 22 26 K3 N2 R29 U33
ECKB 80 91 W11 AE14 AH16 AM18
ECKR 131 152 K18 N23 T2 V2
ECKT 178 207 B11 B14 C15 C17
I/O—SECKLL 49 56 W1 AB4 AG29 AK34
I/O—SECKUR 159 184 A19 A25 D5 D5
Note: The ECKR, ECKL, ECKT, and ECKB pins drive the ExpressCLK on their given edge of the device, while I/O—SECKLL and
I/O—SECKUR drive an ExpressCLK on two edges of the device and provide connectivity to the programmable clock manager.
208-Pin
SQFP2
240-Pin
SQFP2
256-Pin
PBGA
352-Pin
PBGA
432-Pin
EBGA
600-Pin
EBGA
70 Lucent Technologies Inc.
Page 71

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 19. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, and OR2C/2T15A
84-Pin PLCC Pinout
Pin
2C/2T04A
Pad
1V
SS
2C/2T06A
Pad
V
SS
2C/2T08A
Pad
V
SS
2C/2T10A
Pad
V
SS
2C/2T12A
Pad
V
SS
2C/2T15A
Pad
V
SS
Function
V
SS
2 PT5A PT6A PT7A PT8A PT9A PT10A I/O-D2
3V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
4 PT4D PT5D PT6D PT7D PT8D PT9D I/O-D1
5 PT4A PT5A PT6A PT7A PT8A PT9A I/O-D0/DIN
6 PT3A PT4A PT5A PT6A PT7A PT8A I/O-DOUT
7 PT2D PT3D PT4D PT5D PT6D PT7D I/O-V
DD
8 PT2A PT3A PT4A PT4A PT5A PT6A I/O-TDI
9 PT1D PT2A PT3A PT3A PT3A PT4A I/O-TMS
10 PT1A PT1A PT1A PT1A PT1A PT1A I/O-TCK
RD_DATA/T D O RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO
11
12 V
13 V
DD
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
14 PL1C PL1A PL2D PL2D PL2D PL2D I/O-A0
15 PL1A PL2A PL3A PL3A PL4A PL5A I/O-A1
16 PL2D PL3D PL4D PL4A PL5A PL6A I/O-A2
17 PL2A PL3A PL4A PL5A PL6A PL7A I/O-A3
18 PL3A PL4A PL5A PL6A PL7A PL8A I/O-A4
19 PL4D PL5D PL6D PL7D PL8D PL9D I/O-A5
20 PL4A PL5A PL6A PL7A PL8A PL9A I/O-A6
21 PL5A PL6A PL7A PL8A PL9A PL10A I/O-A7
22 V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
23 PL6A PL7A PL8A PL9A PL10A PL11A I/O-A8
24 V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
25 PL7D PL8D PL9D PL10D PL11D PL12D I/O-A9
26 PL7A PL8A PL9A PL10A PL11A PL12A I/O-A10
27 PL8A PL9A PL10A PL11A PL12A PL13A I/O-A11
28 PL9D PL10D PL11D PL12D PL13D PL14D I/O-A12
29 PL9A PL10A PL11A PL13D PL14B PL15B I/O-A13
30 PL10D PL11A PL12A PL14C PL16D PL17D I/O-A14
31 PL10A PL12A PL14A PL16A PL18A PL20A I/O-A15
32 CCLK CCLK CCLK CCLK CCLK CCLK CCLK
33 V
34 V
DD
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
35 PB1A PB1A PB1A PB1A PB1A PB1A I/O-A16
36 PB1D PB2A PB3A PB3B PB3D PB4D I/O-A17
37 PB2A PB3A PB3D PB4D PB5B PB6B I/O
38 PB2D PB3D PB4D PB5D PB6D PB7D I/O
39 PB3A PB4A PB5A PB6A PB7A PB8A I/O
40 PB4A PB5A PB6A PB7A PB8A PB9A I/O
41 PB4D PB5D PB6D PB7D PB8D PB9D I/O
42 PB5A PB6A PB7A PB8A PB9A PB10A I/O
Note: The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
series.
5
Lucent Technologies Inc. 71
Page 72

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 19. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, and OR2C/2T15A
84-Pin PLCC Pinout
Pin
2C/2T04A
43 V
2C/2T06A
Pad
SS
(continued)
Pad
V
SS
2C/2T08A
Pad
V
SS
2C/2T10A
Pad
V
SS
2C/2T12A
Pad
V
SS
2C/2T15A
Pad
V
SS
Function
V
SS
44 PB6A PB7A PB8A PB9A PB10A PB11A I/O
45 V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
46 PB7A PB8A PB9A PB10A PB11A PB12A I/O-VDD5
47 PB7D PB8D PB9D PB10D PB11D PB12D I/O
48 PB8A PB9A PB10A PB11A PB12A PB13A I/O-HDC
49 PB9A PB10A PB11A PB12A PB13A PB14A I/O-
LDC
50 PB9D PB10D PB11D PB13A PB13D PB14D I/O
51 PB10A PB11A PB12C PB13D PB15A PB16A I/O-
INIT
52 PB10D PB12A PB13D PB15D PB18D PB20D I/O
53 DONE DONE DONE DONE DONE DONE DONE
54
55
RESET RESET RESET RESET
PRGM PRGM PRGM PRGM
RESET RESET
PRGM PRGM
RESET
PRGM
56 PR10A PR12A PR14A PR16A PR18A PR20A I/O-M0
57 PR10D PR11A PR12A PR14A PR16A PR17A I/O
58 PR9A PR10A PR11A PR13B PR15D PR16D I/O-M1
59 PR9D PR10D PR11D PR12B PR13A PR14A I/O
60 PR8A PR9A PR10A PR11A PR12A PR13A I/O-M2
61 PR7A PR8A PR9A PR10A PR11A PR12A I/O-M3
62 PR7D PR8D PR9D PR10D PR11D PR12D I/O
63 PR6A PR7A PR8D PR9D PR10A PR11A I/O
64 V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
65 PR5A PR6A PR7A PR8A PR9A PR10A I/O
66 V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
67 PR4A PR5A PR6A PR7A PR8A PR9A I/O
68 PR4D PR5D PR6D PR7D PR8D PR9D I/O
69 PR3A PR4A PR5A PR6A PR7A PR8A I/O-CS1
70 PR2A PR3A PR4A PR5A PR6A PR7A I/O-
CS0
71 PR2D PR3D PR4D PR4D PR5D PR6D I/O
72 PR1A PR2A PR3A PR3A PR4A PR5A I/O73 PR1D PR1A PR2A PR2A PR2A PR3A I/O74
RD_CFG RD_CFG RD_CFG RD_CFG
75 V
76 V
DD
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
RD_CFG RD_CFG
V
DD
V
SS
V
DD
V
SS
RD
WR
RD_CFG
V
DD
V
SS
77 PT10C PT12A PT13D PT15D PT17D PT19A I/O-RDY/RCLK
78 PT9D PT11A PT12C PT13D PT15D PT16D I/O-D7
79 PT9C PT10D PT11D PT13A PT14D PT15D I/O
80 PT9A PT10A PT11B PT12B PT13B PT14B I/O-D6
81 PT8A PT9A PT10A PT11A PT12A PT13A I/O-D5
82 PT7D PT8D PT9D PT10D PT11D PT12D I/O
83 PT7A PT8A PT9A PT10A PT11A PT12A I/O-D4
84 PT6A PT7A PT8A PT9A PT10A PT11A I/O-D3
Note: The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
series.
72 Lucent Technologies Inc.
Page 73

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 20. OR2C/2T04A and OR2C/2T06A 100-Pin TQFP Pinout
Pin
2C/2T04A
Pad
1V
2V
DD
SS
3 PL1C PL1A I/O-A0 45 PB9A PB10A I/O-
2C/2T06A
Pad
V
DD
V
SS
Function Pin
V
DD
V
SS
43 PB8C PB9C I/O
44 PB8D PB9D I/O
2C/2T04A
Pad
2C/2T06A
Pad
Function
LDC
4 PL1A PL2A I/O-A1 46 PB9D PB10D I/O
5 PL2D PL3D I/O-A2 47 PB10A PB11A I/O-
INIT
6 PL2A PL3A I/O-A3 48 PB10D PB12A I/O
7 PL3D PL4D I/O 49 DONE DONE DONE
8 PL3A PL4A I/O-A4 50 V
9 PL4D PL5D I/O-A5 51
10 PL4A PL5A I/O-A6 52
DD
RESET RESET RESET
PRGM PRGM PRGM
V
DD
V
DD
11 PL5D PL6D I/O 53 PR10A PR12A I/O-M0
12 PL5A PL6A I/O-A7 54 PR10D PR11A I/O
13 V
DD
V
DD
V
DD
55 PR9A PR10A I/O-M1
14 PL6A PL7A I/O-A8 56 PR9D PR10D I/O
15 V
SS
V
SS
V
SS
57 PR8A PR9A I/O-M2
16 PL7D PL8D I/O-A9 58 PR8D PR9D I/O
17 PL7A PL8A I/O-A10 59 PR7A PR8A I/O-M3
18 PL8A PL9A I/O-A11 60 PR7D PR8D I/O
19 PL9D PL10D I/O-A12 61 V
SS
V
SS
V
SS
20 PL9C PL10C I/O 62 PR6A PR7A I/O
21 PL9A PL10A I/O-A13 63 V
DD
V
DD
V
DD
22 PL10D PL11A I/O-A14 64 PR5A PR6A I/O
23 PL10A PL12A I/O-A15 65 V
24 V
SS
V
SS
V
SS
66 PR4A PR5A I/O-VDD5
SS
V
SS
V
SS
25 CCLK CCLK CCLK 67 PR4D PR5D I/O
26 V
27 V
DD
SS
V
DD
V
SS
28 PB1A PB1A I/O-A16 70 PR2A PR3A I/O-
V
DD
V
SS
68 PR3A PR4A I/O-CS1
69 PR3D PR4D I/O
CS0
29 PB1C PB1D I/O 71 PR2D PR3D I/O
30 PB1D PB2A I/O-A17 72 PR1A PR2A I/O-
RD
31 PB2A PB3A I/O 73 PR1C PR2D I/O
32 PB2D PB3D I/O 74 PR1D PR1A I/O33 PB3A PB4A I/O 75
34 PB4A PB5A I/O 76 V
35 PB4D PB5D I/O 77 V
RD_CFG RD_CFG RD_CFG
DD
SS
V
DD
V
SS
WR
V
DD
V
SS
36 PB5A PB6A I/O 78 PT10C PT12A I/O-RDY/RCLK
37 V
SS
V
SS
V
SS
79 PT9D PT11A I/O-D7
38 PB6A PB7A I/O 80 PT9C PT10D I/O
39 V
SS
40 PB7A PB8A I/O-V
V
SS
V
SS
582PT8D PT9D I/O
DD
81 PT9A PT10A I/O-D6
41 PB7D PB8D I/O 83 PT8A PT9A I/O-D5
42 PB8A PB9A I/O-HDC 84 PT7D PT8D I/O
Note: The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
series.
Lucent Technologies Inc. 73
Page 74

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
Table 20. OR2C/2T04A and OR2C/2T06A 100-Pin TQFP Pinout
Pin
2C/2T04A
Pad
(continued)
2C/2T06A
Pad
Function Pin
(continued)
2C/2T04A
Pad
2C/2T06A
Pad
Function
85 PT7A PT8A I/O-D4 93 PT3D PT4D I/O
86 PT6D PT7D I/O 94 PT3A PT4A I/O-DOUT
87 PT6A PT7A I/O-D3 95 PT2D PT3D I/O-V
88 V
SS
V
SS
V
SS
96 PT2A PT3A I/O-TDI
DD
89 PT5A PT6A I/O-D2 97 PT1D PT2A I/O-TMS
90 V
SS
V
SS
V
SS
98 PT1C PT1D I/O
91 PT4D PT5D I/O-D1 99 PT1A PT1A I/O-TCK
92 PT4A PT5A I/O-D0/DIN 100
Note: The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
series.
RD_DATA/
TDO
RD_DATA/TDO RD_DATA/TDO
5
74 Lucent Technologies Inc.
Page 75

Data Sheet
June 1999
Pin Information
(continued)
Table 21. OR2C/2T04A and OR2C/2T06A 144-Pin TQFP Pinout
ORCA
Series 2 FPGAs
Pin
1V
2V
2C/2T04A
Pad
DD
SS
3PL1C PL1A I/O-A0 45V
2C/2T06A
Pad
V
DD
V
SS
Function Pin
V
DD
V
SS
43 PB2B PB3B I/O
44 PB2D PB3D I/O
2C/2T04A
Pad
DD
2C/2T06A
Pad
V
DD
Function
V
DD
4 PL1B PL2D I/O 46 PB3A PB4A I/O
5 PL1A PL2A I/O-A1 47 PB3D PB4D I/O
6 PL2D PL3D I/O-A2 48 PB4A PB5A I/O
7 PL2A PL3A I/O-A3 49 PB4C PB5C I/O
8 PL3D PL4D I/O 50 PB4D PB5D I/O
9 PL3C PL4C I/O 51 PB5A PB6A I/O
10 PL3A PL4A I/O-A4 52 PB5C PB6C I/O
11 PL4D PL5D I/O-A5 53 PB5D PB6D I/O
12 PL4C PL5C I/O 54 V
SS
V
SS
V
SS
13 PL4A PL5A I/O-A6 55 PB6A PB7A I/O
14 V
SS
V
SS
V
SS
56 PB6C PB7C I/O
15 PL5D PL6D I/O 57 PB6D PB7D I/O
16 PL5C PL6C I/O 58 PB7A PB8A I/O-V
DD
17 PL5A PL6A I/O-A7 59 PB7D PB8D I/O
18 V
DD
V
DD
V
DD
60 PB8A PB9A I/O-HDC
19 PL6D PL7D I/O 61 PB8C PB9C I/O
20 PL6C PL7C I/O-V
21 PL6A PL7A I/O-A8 63 V
22 V
SS
V
SS
5 62 PB8D PB9D I/O
DD
DD
V
SS
64 PB9A PB10A I/O-
V
DD
V
DD
LDC
23 PL7D PL8D I/O-A9 65 PB9C PB10C I/O
24 PL7A PL8A I/O-A10 66 PB9D PB10D I/O
25 PL8D PL9D I/O 67 PB10A PB11A I/O-
INIT
26 PL8C PL9C I/O 68 PB10C PB11D I/O
27 PL8A PL9A I/O-A11 69 PB10D PB12A I/O
28 PL9D PL10D I/O-A12 70 V
SS
V
SS
V
SS
29 PL9C PL10C I/O 71 DONE DONE DONE
30 PL9A PL10A I/O-A13 72 V
31 PL10D PL11A I/O-A14 73 V
32 PL10C PL12D I/O 74
33 PL10B PL12B I/O 75
RESET RESET RESET
PRGM PRGM PRGM
DD
SS
V
DD
V
SS
V
DD
V
SS
34 PL10A PL12A I/O-A15 76 PR10A PR12A I/O-M0
35 V
SS
V
SS
V
SS
77 PR10B PR12D I/O
36 CCLK CCLK CCLK 78 PR10D PR11A I/O
37 V
38 V
DD
SS
V
DD
V
SS
V
DD
V
SS
79 PR9A PR10A I/O-M1
80 PR9C PR10C I/O
39 PB1A PB1A I/O-A16 81 PR9D PR10D I/O
40 PB1C PB1D I/O 82 PR8A PR9A I/O-M2
41 PB1D PB2A I/O-A17 83 PR8B PR9B I/O
42 PB2A PB3A I/O 84 PR8D PR9D I/O
Note: The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
series.
5
Lucent Technologies Inc. 75
Page 76

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 21. OR2C/2T04A and OR2C/2T06A 144-Pin TQFP Pinout
Pin
2C/2T04A
Pad
2C/2T06A
Pad
Function Pin
(continued)
2C/2T04A
Pad
2C/2T06A
Pad
Function
85 PR7A PR8A I/O-M3 115 PT9C PT10D I/O
86 PR7D PR8D I/O 116
87 V
SS
V
SS
V
SS
117 PT9A PT10A I/O-D6
88 PR6A PR7A I/O 118 V
PT9B PT10C I/O
DD
V
DD
V
DD
89 PR6C PR7C I/O 119 PT8D PT9D I/O
90 PR6D PR7D I/O 120 PT8A PT9A I/O-D5
91 V
DD
V
DD
V
DD
121 PT7D PT8D I/O
92 PR5A PR6A I/O 122 PT7B PT8B I/O
93 PR5C PR6C I/O 123 PT7A PT8A I/O-D4
94 PR5D PR6D I/O 124 PT6D PT7D I/O
95 V
SS
V
SS
96 PR4A PR5A I/O-V
97 PR4C PR5C I/O 127 V
V
SS
5 126 PT6A PT7A I/O-D3
DD
125 PT6C PT7C I/O
SS
V
SS
V
SS
98 PR4D PR5D I/O 128 PT5D PT6D I/O
99 PR3A PR4A I/O-CS1 129 PT5C PT6C I/O
100 PR3D PR4D I/O 130 PT5A PT6A I/O-D2
101 PR2A PR3A I/O-
CS0
131 PT4D PT5D I/O-D1
102 PR2D PR3D I/O 132 PT4C PT5C I/O
103 PR1A PR2A I/O-
RD
133 PT4A PT5A I/O-D0/DIN
104 PR1B PR2C I/O 134 PT3D PT4D I/O
105 PR1C PR2D I/O 135 PT3A PT4A I/O-DOUT
106 PR1D PR1A I/O107 V
108
RD_CFG RD_CFG RD_CFG
109 V
110 V
SS
DD
SS
V
SS
V
DD
V
SS
V
V
V
WR
SS
DD
SS
136 V
DD
V
DD
V
DD
137 PT2D PT3D I/O-VDD5
138 PT2C PT3C I/O
139 PT2A PT3A I/O-TDI
140 PT1D PT2A I/O-TMS
111 PT10D PT12D I/O 141 PT1C PT1D I/O
112 PT10C PT12A I/O-RDY/RCLK 142 PT1A PT1A I/O-TCK
113 PT10B PT11D I/O 143 V
114 PT9D PT11A I/O-D7 144
Note: The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
series.
SS
RD_DATA/
TDO
V
SS
RD_DATA/
TDO
V
SS
RD_DATA/TDO
76 Lucent Technologies Inc.
Page 77

Data Sheet
June 1999
Pin Information
(continued)
Table 22. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, and OR2C/2T10A 160-Pin QFP Pinout
Pin 2C/2T04A Pad 2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad Function
1V
2V
DD
SS
3 PL1D PL1D PL1D PL1D I/O
4 PL1C PL1A PL2D PL2D I/O-A0
5 PL1B PL2D PL3D PL3D I/O
6 PL1A PL2A PL3A PL3A I/O-A1
7 PL2D PL3D PL4D PL4A I/O-A2
8 PL2C PL3C PL4C PL5C I/O
9 PL2A PL3A PL4A PL5A I/O-A3
10 PL3D PL4D PL5D PL6D I/O
11 PL3C PL4C PL5C PL6C I/O
12 PL3A PL4A PL5A PL6A I/O-A4
13 PL4D PL5D PL6D PL7D I/O-A5
14 PL4C PL5C PL6C PL7C I/O
15 PL4A PL5A PL6A PL7A I/O-A6
16 V
SS
17 PL5D PL6D PL7D PL8D I/O
18 PL5C PL6C PL7C PL8C I/O
19 PL5A PL6A PL7A PL8A I/O-A7
20 V
DD
21 PL6D PL7D PL8D PL9D I/O
22 PL6C PL7C PL8C PL9C I/O-V
23 PL6A PL7A PL8A PL9A I/O-A8
24 V
SS
25 PL7D PL8D PL9D PL10D I/O-A9
26 PL7B PL8B PL9B PL10B I/O
27 PL7A PL8A PL9A PL10A I/O-A10
28 PL8D PL9D PL10D PL11D I/O
29 PL8C PL9C PL10C PL11C I/O
30 PL8A PL9A PL10A PL11A I/O-A11
31 PL9D PL10D PL11D PL12D I/O-A12
32 PL9C PL10C PL11C PL12C I/O
33 PL9B PL10B PL11B PL12B I/O
34 PL9A PL10A PL11A PL13D I/O-A13
35 PL10D PL11A PL12A PL14C I/O-A14
36 PL10C PL12D PL13D PL15D I/O
37 PL10B PL12B PL14D PL16D I/O
38 PL10A PL12A PL14A PL16A I/O-A15
39 CCLK CCLK CCLK CCLK CCLK
40 V
Note: The pins labeled I/O-V
series.
SS
DD
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
V
V
V
V
V
DD
SS
SS
DD
SS
SS
ORCA
Series 2 FPGAs
V
DD
V
SS
V
SS
V
DD
5
DD
V
SS
V
SS
Lucent Technologies Inc. 77
Page 78

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 22. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, and OR2C/2T10A 160-Pin QFP Pinout
(continued)
Pin 2C/2T04A Pad 2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad Function
41 V
42 V
DD
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
43 PB1A PB1A PB1A PB1A I/O-A16
44 PB1B PB1C PB2A PB2A I/O
45 PB1C PB1D PB2D PB2D I/O
46 PB1D PB2A PB3A PB3B I/O-A17
47 PB2A PB3A PB3D PB4D I/O
48 PB2B PB3B PB4A PB5A I/O
49 PB2C PB3C PB4C PB5C I/O
50 PB2D PB3D PB4D PB5D I/O
51 V
DD
V
DD
V
DD
V
DD
V
DD
52 PB3A PB4A PB5A PB6A I/O
53 PB3D PB4D PB5D PB6D I/O
54 PB4A PB5A PB6A PB7A I/O
55 PB4C PB5C PB6C PB7C I/O
56 PB4D PB5D PB6D PB7D I/O
57 PB5A PB6A PB7A PB8A I/O
58 PB5C PB6C PB7C PB8C I/O
59 PB5D PB6D PB7D PB8D I/O
60 V
SS
V
SS
V
SS
V
SS
V
SS
61 PB6A PB7A PB8A PB9A I/O
62 PB6C PB7C PB8C PB9C I/O
63 PB6D PB7D PB8D PB9D I/O
64 PB7A PB8A PB9A PB10A I/O-V
DD
5
65 PB7D PB8D PB9D PB10D I/O
66 PB8A PB9A PB10A PB11A I/O-HDC
67 PB8C PB9C PB10C PB11C I/O
68 PB8D PB9D PB10D PB11D I/O
69 V
DD
70 PB9A PB10A PB11A PB12A I/O-
V
DD
V
DD
V
DD
V
DD
LDC
71 PB9B PB10B PB11D PB13A I/O
72 PB9C PB10C PB12A PB13B I/O
73 PB9D PB10D PB12B PB13C I/O
74
75
PB10A PB11A PB12C PB13D
PB10B PB11C PB12D PB14A
I/O-
INIT
I/O
76 PB10C PB11D PB13D PB15D I/O
77 PB10D PB12A PB14D PB16D I/O
78 V
SS
V
SS
V
SS
V
SS
V
SS
79 DONE DONE DONE DONE DONE
80 V
81 V
Note: The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
series.
DD
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
78 Lucent Technologies Inc.
Page 79

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 22. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, and OR2C/2T10A 160-Pin QFP Pinout
(continued)
Pin 2C/2T04A Pad 2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad Function
82
83
RESET RESET RESET RESET RESET
PRGM PRGM PRGM PRGM PRGM
84 PR10A PR12A PR14A PR16A I/O-M0
85 PR10B PR12D PR13A PR15A I/O
86 PR10C PR11A PR13D PR15D I/O
87 PR10D PR11B PR12A PR14A I/O
88 PR9A PR10A PR11A PR13B I/O-M1
89 PR9B PR10B PR11B PR13C I/O
90 PR9C PR10C PR11C PR12A I/O
91 PR9D PR10D PR11D PR12B I/O
92 PR8A PR9A PR10A PR11A I/O-M2
93 PR8B PR9B PR10B PR11B I/O
94 PR8D PR9D PR10D PR11D I/O
95 PR7A PR8A PR9A PR10A I/O-M3
96 PR7D PR8D PR9D PR10D I/O
97 V
SS
V
SS
V
SS
V
SS
V
SS
98 PR6A PR7A PR8A PR9A I/O
99 PR6C PR7C PR8C PR9C I/O
100 PR6D PR7D PR8D PR9D I/O
101 V
DD
V
DD
V
DD
V
DD
V
DD
102 PR5A PR6A PR7A PR8A I/O
103 PR5C PR6C PR7C PR8C I/O
104 PR5D PR6D PR7D PR8D I/O
105 V
SS
V
SS
V
SS
V
SS
V
SS
106 PR4A PR5A PR6A PR7A I/O-VDD5
107 PR4C PR5C PR6C PR7C I/O
108
PR4D PR5D PR6D PR7D
I/O
109 PR3A PR4A PR5A PR6A I/O-CS1
110 PR3B PR4B PR5B PR6B I/O
111 PR3D PR4D PR5D PR6D I/O
112 PR2A PR3A PR4A PR5A I/O-
CS0
113 PR2C PR3C PR4B PR4B I/O
114 PR2D PR3D PR4D PR4D I/O
115 PR1A PR2A PR3A PR3A I/O-
RD
116 PR1B PR2C PR3C PR3C I/O
117 PR1C PR2D PR3D PR3D I/O
118 PR1D PR1A PR2A PR2A I/O119 V
120
121 V
122 V
Note: The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
series.
SS
RD_CFG RD_CFG RD_CFG RD_CFG RD_CFG
DD
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
WR
V
SS
V
DD
V
SS
Lucent Technologies Inc. 79
Page 80

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 22. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, and OR2C/2T10A 160-Pin QFP Pinout
(continued)
Pin 2C/2T04A Pad 2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad Function
123 PT10D PT12D PT14D PT16D I/O
124 PT10C PT12A PT13D PT15D I/O-RDY/RCLK
125 PT10B PT11D PT13A PT15A I/O
126 PT10A PT11C PT12D PT14D I/O
127 PT9D PT11A PT12C PT13D I/O-D7
128 PT9C PT10D PT12A PT13B I/O
129 PT9B PT10C PT11D PT13A I/O
130 PT9A PT10A PT11B PT12B I/O-D6
131 V
DD
V
DD
V
DD
V
DD
V
DD
132 PT8D PT9D PT10D PT11D I/O
133 PT8A PT9A PT10A PT11A I/O-D5
134 PT7D PT8D PT9D PT10D I/O
135 PT7B PT8B PT9B PT10B I/O
136 PT7A PT8A PT9A PT10A I/O-D4
137 PT6D PT7D PT8D PT9D I/O
138 PT6C PT7C PT8C PT9C I/O
139 PT6A PT7A PT8A PT9A I/O-D3
140 V
SS
V
SS
V
SS
V
SS
V
SS
141 PT5D PT6D PT7D PT8D I/O
142 PT5C PT6C PT7C PT8C I/O
143 PT5A PT6A PT7A PT8A I/O-D2
144 PT4D PT5D PT6D PT7D I/O-D1
145 PT4C PT5C PT6C PT7C I/O
146 PT4A PT5A PT6A PT7A I/O-D0/DIN
147 PT3D PT4D PT5D PT6D I/O
148 PT3C PT4C PT5C PT6C I/O
149 PT3A PT4A PT5A PT6A I/O-DOUT
150 V
DD
V
DD
V
DD
V
DD
V
DD
151 PT2D PT3D PT4D PT5D I/O-VDD5
152 PT2C PT3C PT4C PT5A I/O
153 PT2B PT3B PT4B PT4D I/O
154 PT2A PT3A PT4A PT4A I/O-TDI
155 PT1D PT2A PT3A PT3A I/O-TMS
156 PT1C PT1D PT2A PT2A I/O
157 PT1B PT1C PT1D PT1D I/O
158 PT1A PT1A PT1A PT1A I/O-TCK
159 V
SS
V
SS
V
SS
V
SS
V
SS
160 RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO
Note: The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA
series.
80 Lucent Technologies Inc.
Page 81

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 23. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B,
OR2C/2T26A, and OR2C/2T40A/B 208-Pin SQFP/SQFP2 Pinout
2C/2T04A
Pin
1 VSS VSS VSS VSS VSS VSS VSS VSS VSS
2 VSS VSS VSS VSS VSS VSS VSS VSS VSS
3 PL1D PL1D PL1D PL1D PL1D PL1D PL1D PL1D I/O
4 P L1C PL1A PL2D PL2D PL2D PL2D PL2D PL3D I/O-A0
5 PL1B PL2D PL3D PL3D PL3D PL4D PL4D PL5D I/O-VDD5
6 See Note PL2C PL3C PL3C PL3A PL4A PL4A PL6D I / O
7 PL1A PL2A PL3A PL3A PL4A PL5A PL5A PL8D I/O-A1
8 P L2D PL3D PL4D PL4A PL5A PL6A PL6A PL9A I/O-A2
9 PL2C PL3C PL4C PL5C PL6D PL7D PL7D PL10D I/O
10 PL2B PL3B PL4B PL5B PL6B PL7B PL7B PL10B I/O
11 PL2A PL3A PL4A PL5A PL6A PL7A PL7A PL10A I/O-A3
12 VDD VDD VDD VDD VDD VDD VDD VDD VDD
13 PL3D PL4D PL5D PL6D PL7D PL8D PL8D PL11D I/O
14 PL3C PL4C PL5C PL6C PL7C PL8C PL8A PL11A I/O
15 PL3B PL4B PL5B PL6B PL7B PL8B PL9D PL12D I/O
16 PL3A PL4A PL5A PL6A PL7A PL8A PL9A PL12A I/O-A4
17 P L4D PL5D PL6D PL7D PL8D PL9D PL10D PL13D I/O-A5
18 PL4C PL5C PL6C PL7C PL8C PL9C PL10A PL13A I / O
19 PL4B PL5B PL6B PL7B PL8B PL9B PL11D PL14D I/O
20 PL4A PL5A PL6A PL7A PL8A PL9A PL11A PL14A I/O-A6
21 VSS VSS VSS VSS VSS VSS VSS VSS VSS
22 PL5D PL6D PL7D PL8D PL9D PL10D PL12D PL15D I/O
23 PL5C PL6C PL7C PL8C PL9C PL10C PL12C PL15C I/O
24 PL5B PL6B PL7B PL8B PL9B PL10B PL12B PL15B I/O
25 PL5A PL6A PL7A PL8A PL9A PL10A PL12A PL15A I/O-A 7
26 VDD VDD VDD VDD VDD VDD VDD VDD VDD
27 PL6D PL7D PL8D PL9D PL10D PL11D PL13D PL16D I/O
28 P L6C PL7C PL8C PL9C PL10C PL11C PL13 C PL16C I/O-VDD5
29 PL6B PL7B PL8B PL9B PL10B PL11B PL13B PL16B I/O
30 PL6A PL7A PL8A PL9A PL10A PL11A PL13A PL16A I/O-A8
31 VSS VSS VSS VSS VSS VSS VSS VSS VSS
32 P L7D PL8D PL9D PL10D PL11D PL12D PL14D PL17D I/O-A9
33 PL7C PL8C PL9C PL10C PL11C PL12C PL14A PL17A I / O
34 PL7B PL8B PL9B PL10B PL11B PL12B PL15D PL18D I/O
35 PL7A PL8A PL9A PL10A PL11A PL12A PL15A PL18A I/O-A10
36 PL8D PL9D PL10D P L11D PL12D PL13D PL16D PL19D I/O
37 PL8C PL9C PL10C PL11 C PL12C PL13C PL16A PL19A I/ O
38 PL8B PL9B PL10B PL11B PL12B PL13B PL17D PL20D I/O
39 PL8A PL9A PL10A PL11A PL12A PL13A PL 17A PL20A I/O-A11
40 VDD VDD VDD VDD VDD VDD VDD VDD VDD
41 PL9D PL10D PL11D PL12 D PL13D PL14D PL18D PL21D I/O-A12
42 PL9C PL10C PL11C P L12C PL13B PL14 B PL18B PL21B I/O
43 PL9B PL 10B PL11B PL12B PL14D PL15D PL19D PL22D I/O
Notes:
The OR2C04A and OR2T04A do not have bond pads connected to 208-pin SQFP package pin numbers 6, 45, 47, 56, 60, 102, 153, 154, 166,
201, and 203.
The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
Pad
2C/2T06A
Pad
2C/2T08A
Pad
2C/2T10A
Pad
2C/2T12A
Pad
2C/2T15A/B
Pad
2C/2T26A
Pad
2C/2T40A/B
Pad
Function
Lucent Technologies Inc. 81
Page 82

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 23. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B,
OR2C/2T26A, and OR2C/2T40A/B 208-Pin SQFP/SQFP2 Pinout
2C/2T04A
Pin
44 PL9A PL10A PL11A PL13D PL14B PL15B PL19B PL22B I/O-A13
45 Se e N ote PL11D PL12D PL13B PL15D PL16D PL20D PL23D I/O
46 PL10D PL11A PL12A PL14C PL16D PL17D PL21D PL25A I/O-A14
47 Se e N ote PL12D PL13D PL15D PL17D PL18D PL22D PL27D I/O
48 PL10C PL12C PL13A PL15A PL17A PL19D PL23D PL28D I/O
49 PL10B PL12B PL14D PL16D PL18C PL19A PL23A PL28A I/O
50 PL10A PL12A PL14A PL16A PL18A PL20A PL24A PL30A I/O-A15
51 VSS VSS VSS VSS VSS VSS VSS VSS VSS
52 CCLK CCLK CCLK CCLK CCLK CCLK CCLK CCLK CCLK
53 VSS VSS VSS VSS VSS VSS VSS VSS VSS
54 VSS VSS VSS VSS VSS VSS VSS VSS VSS
55 PB1A PB1A PB1A PB 1A PB1A PB1A PB1A PB1A I/O-A16
56 See Note PB1B PB1D PB1D PB1D PB2A PB2A PB3A I/O
57 PB1B PB1C P B2A PB2A PB2A PB2D PB2D PB3D I/O-VDD5
58 PB1C PB1D PB2D PB2D PB2D PB3D PB3D PB4D I/O
59 PB1D PB2A PB3A PB3B PB3D PB4D PB4D PB5D I/O-A17
60 See Note PB2D PB3D PB4D PB4D PB5D PB5D PB6D I/O
61 PB2A PB3A PB4A PB 5A PB5B PB6B PB6B PB7D I/O
62 PB2B PB3B PB4B PB 5B PB5D PB6D PB6D PB8D I/O
63 PB2C PB3C PB4C PB5C PB6B PB7B PB7B PB9D I/O
64 PB2D PB3D PB4D PB5D PB6D PB7D PB7D PB10D I/O
65 VDD VDD VDD VDD VDD VDD VDD VDD VDD
66 PB3A PB4A PB5A PB 6A PB7A PB8A PB8A PB11A I/O
67 PB3B PB4B PB5B PB 6B PB7B PB8B PB8D PB11D I/O
68 PB3C PB4C PB5C PB6C PB7C PB8C PB9A PB12A I/O
69 PB3D PB4D PB5D PB6D PB7D PB8D PB9D PB12D I/O
70 PB4A PB5A PB6A PB7A PB8A PB9A PB10A PB13A I/O
71 PB4B PB5B PB6B PB7B PB8B PB9B PB10D PB13D I/O
72 PB4C PB5C PB6C PB7C PB8C PB9C PB11A PB14A I/O
73 PB4D PB5D PB6D PB7D PB8D PB9D PB11D PB14D I/O
74 VSS VSS VSS VSS VSS VSS VSS VSS VSS
75 PB5A PB6A PB7A PB 8A PB9A PB10A PB12A PB15A I/O
76 PB5B PB6B PB7B PB 8B PB9B PB10B PB12B PB15B I/O
77 PB5C PB6C PB7C PB8C PB9C PB10C PB12C PB1 5C I/O
78 PB5D PB6D PB7D PB8D PB9D PB10D PB12D PB1 5D I/O
79 VSS VSS VSS VSS VSS VSS VSS VSS VSS
80 PB6A PB7A PB8A PB9A PB10A PB11A PB13A PB16A I/O
81 PB6B PB7B PB8B PB9B PB10B PB11B PB13B PB16B I/O
82 PB6C PB7C PB8C PB9C P B10C PB11C PB13C PB16C I/O
83 PB6D PB7D PB8D PB9D P B10D PB11D PB13D PB16D I/O
84 VSS VSS VSS VSS VSS VSS VSS VSS VSS
85 PB7A PB8A PB9A PB10A PB1 1A PB12A PB14A PB17A I/O-VD D5
86 PB7B PB8B PB9B PB10B PB11B PB12B PB14D PB17D I/O
Notes:
The OR2C04A and OR2T04A do not have bond pads connected to 208-pin SQFP package pin numbers 6, 45, 47, 56, 60, 102, 153, 154, 166,
201, and 203.
The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
Pad
2C/2T06A
Pad
2C/2T08A
Pad
2C/2T10A
Pad
2C/2T12A
Pad
2C/2T15A/B
Pad
(continued)
2C/2T26A
Pad
2C/2T40A/B
Pad
Function
82 Lucent Technologies Inc.
Page 83

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 23. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B,
OR2C/2T26A, and OR2C/2T40A/B 208-Pin SQFP/SQFP2 Pinout
2C/2T04A
Pin
87 PB7C PB8C PB9C PB10C PB11C PB12C PB15A PB18A I/O
88 PB7D PB8D PB9D PB10D PB11D PB12D PB15D PB18D I/O
89 PB8A PB9A PB10A P B11A PB12A PB13A PB16A PB19A I/O-HDC
90 PB8B PB9B PB10B P B11B PB12B PB13B PB16D PB19D I/O
91 PB8C PB9C PB10C PB11C PB12C PB13C PB17A PB20A I/O
92 PB8D PB9D PB10D PB11D PB12D PB13D PB17D PB20D I/O
93 VDD VDD VDD VDD VDD VDD VDD VDD VDD
94 PB9A PB10A PB11A PB12A PB13A PB14A PB18A PB21A I/O-LDC
95 PB9B PB10B PB11D PB13A PB13D PB14D PB18D PB22D I/O
96 PB9C PB10C PB12A PB13B PB14A PB15A PB19A PB23A I/O
97 PB9D PB10D PB12B PB13C PB14D PB15D PB19D PB24D I/O
98 PB10A PB11A PB12C PB13D PB15A PB16A PB20A PB25A I/O-INIT
99 PB10B PB11C PB12D PB14A PB16A PB17A PB21A PB26A I/O
100 PB10C PB11D PB13A PB15A PB17A PB18A PB22A PB27A I/O
101 PB10D PB12A PB13D PB15D PB18A PB19D PB23D PB28D I/O
102 See Note PB12D PB14D PB16D PB18D PB20D PB24D PB30D I/O
103 VSS VSS VSS VSS VSS VSS VSS VSS VSS
104 DONE DONE DONE DONE DONE DONE DONE DONE DONE
105 VSS VSS VSS VSS VSS VSS VSS VSS VSS
106 RESET
107 PRGM PRGM PRGM PRGM PRGM PRGM PR GM PRGM PRGM
108 PR10A PR12A PR14A PR16A PR18A PR20A PR24A PR30A I/O-M 0
109 PR10B PR12D PR13A PR15A PR18D PR19A PR23A PR28A I/O
110 PR10C PR11A PR13D PR15D PR17B PR18A PR22A PR27A I/O
111 PR10D PR11B PR12A PR14A PR16A PR17A PR21A PR26A I/O
112 PR9A PR10A PR1 1A PR13B PR15D PR16D PR20D PR23D I/O-M1
113 PR9B PR10B PR1 1B PR13C PR14A PR15A PR 19A PR22A I/O
114 PR9C PR10C PR11C PR12A PR1 4D PR15D PR19D PR22D I/O-VD D5
115 PR9D P R 10D PR11D PR12B PR13A PR14A PR18A PR21A I/O
116 VDD VDD VDD VDD VDD VDD VDD VDD VDD
117 PR8A PR9A PR10A PR11A PR12A PR13A PR17A PR20A I/O-M2
118 PR8B PR9B PR10B PR11B PR12B PR13B PR17D PR20D I/O
119 PR8C PR9C PR10C PR11C PR12C PR13C PR16A PR19A I/O
120 PR8D PR9D PR10D PR11D PR12D PR13D PR16D PR19D I/O
121 PR7A PR 8A PR9A PR10A PR11A PR12A PR15A PR18A I/ O - M 3
122 PR7B PR 8B PR9B PR10B PR11B PR12B PR15D PR18D I/O
123 PR7C PR8C PR9C PR10C PR11C PR12C PR14A PR17A I/O
124 PR7D PR8D PR9D PR10D PR11D PR12D PR14D PR17D I/O
125 VSS VSS VSS VSS VSS VSS VSS VSS VSS
126 PR6A PR7A PR8A PR9A PR10A PR11A PR 13A PR 1 6A I/O
127 PR6B PR7B PR8B PR9B PR10B PR11B PR 13B PR 1 6B I/O
128 PR6C PR7C PR8C PR9C PR10C PR11C PR 13C PR16C I/O
129 PR6D PR7D PR8D PR9D PR10D PR11D PR 13D PR16D I/O
Notes:
The OR2C04A and OR2T04A do not have bond pads connected to 208-pin SQFP package pin numbers 6, 45, 47, 56, 60, 102, 153, 154, 166,
201, and 203.
The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
Pad
2C/2T06A
Pad
RESET RESET RESET RESET RESET RESET RESET RESET
2C/2T08A
Pad
2C/2T10A
Pad
2C/2T12A
Pad
2C/2T15A/B
Pad
(continued)
2C/2T26A
Pad
2C/2T40A/B
Pad
Function
Lucent Technologies Inc. 83
Page 84

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 23. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B,
OR2C/2T26A, and OR2C/2T40A/B 208-Pin SQFP/SQFP2 Pinout
2C/2T04A
Pin
130 VDD VDD VDD VDD VDD VDD VDD VDD VDD
131 PR5A PR6A PR7A PR8A PR9A PR10A PR12A PR1 5A I/O
132 PR5B PR6B PR7B PR8B PR9B PR10B PR12B PR1 5B I/O
133 PR5C PR6C PR7C PR8C PR9C PR10C PR12C PR15C I/O
134 PR5D PR6D PR7D PR8D PR9D PR10D PR12D PR15D I/O
135 VSS VSS VSS VSS VSS VSS VSS VSS VSS
136 P R4A PR5A PR6A PR7A PR8A PR 9A PR11A PR14A I/O-VDD5
137 PR4B PR5B PR6B PR7B PR8B PR9B PR11D PR14D I/O
138 PR4C PR5C PR6C PR7C PR8C PR9C PR10A PR1 3A I/O
139 PR4D PR5D PR6D PR7D PR8D PR9D PR10D PR13D I/O
140 PR3A PR4A PR5A PR6A PR7A PR 8A PR9A PR12A I/O-CS 1
141 PR3B PR4B PR5B PR6B PR7B PR 8B PR9D PR12D I/O
142 PR3C PR4C PR5C PR6C PR7C PR8C PR8 A PR11A I/O
143 PR3D PR4D PR5D PR6D PR7D PR8D PR8D PR11D I/O
144 VDD VDD VDD VDD VDD VDD VDD VDD VDD
145 PR2A PR3A PR4A PR5A PR6A PR 7A PR7A PR10A I/O-CS0
146 PR2B PR3B PR4B PR4B PR6B PR 7B PR7B PR10B I/O
147 PR2C PR3C PR4C PR4C PR5B P R6B PR6B PR9B I/O
148 PR2D PR3D PR4D PR4D PR5D PR6D PR6D PR9D I/O
149 P R1A PR2A PR3A PR3A PR4A PR 5A PR5A PR8A I/O-RD
150 PR1B PR2C PR3C PR3C PR4D PR5D PR5D PR6A I/O
151 PR1C PR2D PR3D PR3D PR3A PR4A PR4A PR5A I/O
152 PR1D PR1A PR2A PR2A PR2A PR3A PR3A PR4A I/O-WR
153 See Note PR1 C PR2D PR2D PR2C PR2A PR2A PR3A I/O
154 See Note PR 1 D PR1A PR1A PR1A PR1A PR1A PR2A I/O
155 VSS VSS VSS VSS VSS VSS VSS VSS VSS
156 RD_CFG
157 VSS VSS VSS VSS VSS VSS VSS VSS VSS
158 VSS VSS VSS VSS VSS VSS VSS VSS VSS
159 PT10D PT12 D PT14D P T16D PT18D PT20D PT24D PT30D I/O
160 PT10C PT12A PT13D PT15D PT17D PT19A PT23A PT28A I/O-RDY/RCLK
161 PT10B PT11D PT13A PT15A PT16D PT17 D PT21D PT26D I/O
162 PT10A PT11C PT12D PT14D PT16A PT17A PT21A PT26A I/O
163 PT9D PT11A PT12C PT13D PT 15D PT16D PT20D PT25D I/O-D 7
164 PT9C PT10D PT12A PT13B PT14D PT15D PT19D PT24D I/O-VDD5
165 PT9B PT10C PT11D PT13A PT14A PT15A P T19A PT23D I / O
166 See Note PT10B PT11C PT12D PT13D PT14D PT18D PT22D I/O
167 PT9A PT10A PT11B PT12B PT13B PT14B PT18B PT21D I/O-D6
168 VDD VDD VDD VDD VDD VDD VDD VDD VDD
169 PT8D PT9D PT10D PT11D PT12D PT13D PT17D PT20D I/O
170 PT8C PT9C PT10C PT11C PT12C PT13C PT17A PT20A I/O
171 PT8B PT9B PT10B PT11B PT12B PT13B PT16D PT19D I/O
172 PT8A PT9A PT10A PT11A PT12A PT13A PT16A PT19A I/O-D5
Notes:
The OR2C04A and OR2T04A do not have bond pads connected to 208-pin SQFP package pin numbers 6, 45, 47, 56, 60, 102, 153, 154, 166,
201, and 203.
The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
Pad
2C/2T06A
Pad
RD_CFG RD_CFG RD_CFG RD_CFG RD_CFG RD_C FG RD_CFG RD_CFG
2C/2T08A
Pad
2C/2T10A
Pad
2C/2T12A
Pad
2C/2T15A/B
Pad
(continued)
2C/2T26A
Pad
2C/2T40A/B
Pad
Function
84 Lucent Technologies Inc.
Page 85

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 23. OR2C/2T04A, OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B,
OR2C/2T26A, and OR2C/2T40A/B 208-Pin SQFP/SQFP2 Pinout
2C/2T04A
Pin
173 PT7D PT8D PT9D PT10D PT11D PT12D PT15D PT18D I/O
174 PT7C PT8C PT9C PT10C PT11C PT12C PT15A PT18A I/O
175 PT7B PT8B PT9B PT10B PT11B PT12B PT14D PT17D I/O
176 PT7A PT8A PT9A PT10A PT11A PT12A PT14A PT17A I/O-D4
177 VSS VSS VSS VSS VSS VSS VSS VSS VSS
178 PT6D PT7D PT8D PT9D PT10D PT11D PT13D PT16D I/O
179 PT6C PT7C PT8C PT9C PT10C PT11C PT13C PT16C I/O
180 PT6B PT7B PT8B PT9B PT10B PT11B PT13B PT16B I/O
181 PT6A PT7A PT8A PT9A PT10A PT11A PT13A PT16A I/O-D3
182 VSS VSS VSS VSS VSS VSS VSS VSS VSS
183 PT5D PT6D PT7D PT8D PT9D PT10D PT12D PT15D I/O
184 PT5C PT6C PT7C PT8C PT9C PT10C PT12C PT15C I/O
185 PT5B PT6B PT7B PT8B PT9B PT10B PT12B PT15B I/O-VDD5
186 PT5A PT6A PT7A PT8A PT9A PT10A PT12A PT15A I/O-D2
187 VSS VSS VSS VSS VSS VSS VSS VSS VSS
188 PT4D PT5D PT6D PT7D PT8D PT9D PT11D PT14D I/O-D1
189 PT4C PT5C PT6C PT7C PT8C PT9C PT11A PT14A I/O
190 PT4B PT5B PT6B PT7B PT8B PT9B PT10D PT13D I/O
191 PT4A PT5A PT6A PT7A PT8A PT9A PT10A PT13A I/O-D0/DIN
192 PT3D PT4D PT5D PT6D PT7D PT8D PT9D PT12D I/O
193 PT3C PT4C PT5C PT6C PT7C PT8C PT9A PT12A I/O
194 PT3B PT4B PT5B PT6B PT7B PT8B PT8D PT11D I/O
195 PT3A PT4A PT5A PT6A PT7A PT8A PT8A PT11A I/O-DOUT
196 VDD VDD VDD VDD VDD VDD VDD VDD VDD
197 PT2D PT3D PT4D PT5D PT6D PT7D PT7D PT10D I/O
198 PT2C PT3C PT4C PT5A PT6A PT7A PT7A PT9A I/O
199 PT2B PT3B PT4B PT4D PT5C PT6C PT6C PT8A I/O
200 PT2A PT3A PT4A PT4A PT5A PT6A PT6A PT7A I/O-TDI
201 See Note PT2D PT3D PT3D PT4A PT5A PT5A PT6A I/O
202 PT1D PT2A P T3A PT3A PT3A PT4A PT4A PT5A I/O-TMS
203 See Note PT1D PT2D PT2D PT2C PT3A PT3A PT4A I/ O
204 PT1C PT1C PT2A PT2A PT2A PT2A PT2A PT3A I/O
205 PT1B PT1B PT1D PT1D PT1D PT1D PT1D PT2D I/O
206 PT1A PT1A PT1A PT1A PT1A PT1A PT1A PT1A I/O-TC K
207 VSS VSS VSS VSS VSS VSS VSS VSS VSS
208 RD_DATA/
Notes:
The OR2C04A and OR2T04A do not have bond pads connected to 208-pin SQFP package pin numbers 6, 45, 47, 56, 60, 102, 153, 154, 166,
201, and 203.
The pins labeled I/O-VDD5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
Pad
TDO
2C/2T06A
Pad
RD_DATA/
TDO
2C/2T08A
Pad
RD_DATA/
TDO
2C/2T10A
Pad
RD_DATA/
TDO
2C/2T12A
Pad
RD_DATA/
TDO
2C/2T15A/B
Pad
RD_DATA/
TDO
(continued)
2C/2T26A
Pad
RD_DATA/
TDO
2C/2T40A/B
Pad
RD_DATA/
TDO
Function
RD_DATA/TDO
Lucent Technologies Inc. 85
Page 86

ORCA
Pin Information
Series 2 FPGAs June 1999
(continued)
Table 24. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B, OR2C/2T26A,
and OR2C/2T40A/B 240-Pin SQFP/SQFP2 Pinout
Data Sheet
2C/2T06A
Pin
1V
2V
Pad
SS
DD
2C/2T08A
Pad
V
SS
V
DD
2C/2T10A
Pad
V
SS
V
DD
2C/2T12A
Pad
V
SS
V
DD
2C/2T15A/B
Pad
V
SS
V
DD
2C/2T26A
Pad
V
SS
V
DD
2C/2T40A/B
Pad
V
SS
V
DD
Function
V
V
3 PL1D PL1D PL1D PL1D PL1D PL1D PL1D I/O
4 PL1C PL1B PL1B PL1C PL1C PL1C PL1A I/O
5 PL1B PL1A PL1A PL1B PL1B PL1B PL2D I/O
6 PL1A PL2D PL2D PL2D PL2D PL2D PL3D I/O-A0
7V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
8 PL2D PL3D PL3D PL3D PL4D PL4D PL5D I/O-VDD5
9 PL2C PL3C PL3C PL3A PL4A PL4A PL6D I/O
10 PL2B PL3B PL3B PL4D PL5D PL5D PL7D I/O
11 PL2A PL3A PL3A PL4A PL5A PL5A PL8D I/O-A1
12 PL3D PL4D PL4A PL5A PL6A PL6A PL9A I/O-A2
13 PL3C PL4C PL5C PL6D PL7D PL7D PL10D I/O
14 PL3B PL4B PL5B PL6B PL7B PL7B PL10B I/O
15 PL3A PL4A PL5A PL6A PL7A PL7A PL10A I/O-A3
16 V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
17 PL4D PL5D PL6D PL7D PL8D PL8D PL11D I/O
18 PL4C PL5C PL6C PL7C PL8C PL8A PL11A I/O
19 PL4B PL5B PL6B PL7B PL8B PL9D PL12D I/O
20 PL4A PL5A PL6A PL7A PL8A PL9A PL12A I/O-A4
21 PL5D PL6D PL7D PL8D PL9D PL10D PL13D I/O-A5
22 PL5C PL6C PL7C PL8C PL9C PL10A PL13A I/O
23 PL5B PL6B PL7B PL8B PL9B PL11D PL14D I/O
24 PL5A PL6A PL7A PL8A PL9A PL11A PL14A I/O-A6
25 V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
26 PL6D PL7D PL8D PL9D PL10D PL12D PL15D I/O
27 PL6C PL7C PL8C PL9C PL10C PL12C PL15C I/O
28 PL6B PL7B PL8B PL9B PL10B PL12B PL15B I/O
29 PL6A PL7A PL8A PL9A PL10A PL12A PL15A I/O-A7
30 V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
31 PL7D PL8D PL9D PL10D PL11D PL13D PL16D I/O
32 PL7C PL8C PL9C PL10C PL11C PL13C PL16C I/O-VDD5
33 PL7B PL8B PL9B PL10B PL11B PL13B PL16B I/O
34 PL7A PL8A PL9A PL10A PL11A PL13A PL16A I/O-A8
35 V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
36 PL8D PL9D PL10D PL11D PL12D PL14D PL17D I/O-A9
37 PL8C PL9C PL10C PL11C PL12C PL14A PL17A I/O
38 PL8B PL9B PL10B PL11B PL12B PL15D PL18D I/O
39 PL8A PL9A PL10A PL11A PL12A PL15A PL18A I/O-A10
40 PL9D PL10D PL11D PL12D PL13D PL16D PL19D I/O
41 PL9C PL10C PL11C PL12C PL13C PL16A PL19A I/O
42 PL9B PL10B PL11B PL12B PL13B PL17D PL20D I/O
Notes:
The OR2C/2T08A and OR2C/2T10A do not have bond pads connected to 240-pin SQFP package pin numbers 113 and 188.
The pins labeled I/O-V
DD
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
SS
DD
SS
DD
SS
DD
SS
86 Lucent Technologies Inc.
Page 87

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 24. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B, OR2C/2T26A,
and OR2C/2T40A/B 240-Pin SQFP/SQFP2 Pinout
2C/2T06A
Pin
Pad
43 PL9A PL10A PL11A PL12A PL13A PL17A PL20A I/O-A11
44 V
DD
45 PL10D PL11D PL12D PL13D PL14D PL18D PL21D I/O-A12
46 PL10C PL11C PL12C PL13B PL14B PL18B PL21B I/O
47 PL10B PL11B PL12B PL14D PL15D PL19D PL22D I/O
48 PL10A PL11A PL13D PL14B PL15B PL19B PL22B I/O-A13
49 PL11D PL12D PL13B PL14A PL15A PL19A PL22A I/O
50 PL11C PL12C PL13A PL15D PL16D PL20D PL23D I/O
51 PL11B PL12B PL14D PL15B PL16B PL20B PL24D I/O
52 PL11A PL12A PL14C PL16D PL17D PL21D PL25A I/O-A14
53 V
SS
54 PL12D PL13D PL15D PL17D PL18D PL22D PL27D I/O
55 PL12C PL13A PL15A PL17A PL19D PL23D PL28D I/O
56 PL12B PL14D PL16D PL18C PL19A PL23A PL28A I/O
57 PL12A PL14A PL16A PL18A PL20A PL24A PL30A I/O-A15
58 V
SS
59 CCLK CCLK CCLK CCLK CCLK CCLK CCLK CCLK
60 V
61 V
62 V
DD
SS
SS
63 PB1A PB1A PB1A PB1A PB1A PB1A PB1A I/O-A16
64 PB1B PB1D PB1D PB1D PB2A PB2A PB3A I/O
65 PB1C PB2A PB2A PB2A PB2D PB2D PB3D I/O-V
66 PB1D PB2D PB2D PB2D PB3D PB3D PB4D I/O
67 V
SS
68 PB2A PB3A PB3B PB3D PB4D PB4D PB5D I/O-A17
69 PB2B PB3B PB4B PB4D PB5D PB5D PB6D I/O
70 PB2C PB3C PB4C PB5A PB6A PB6A PB7A I/O
71 PB2D PB3D PB4D PB5B PB6B PB6B PB7D I/O
72 PB3A PB4A PB5A PB5D PB6D PB6D PB8D I/O
73 PB3B PB4B PB5B PB6A PB7A PB7A PB9A I/O
74 PB3C PB4C PB5C PB6B PB7B PB7B PB9D I/O
75 PB3D PB4D PB5D PB6D PB7D PB7D PB10D I/O
76 V
DD
77 PB4A PB5A PB6A PB7A PB8A PB8A PB11A I/O
78 PB4B PB5B PB6B PB7B PB8B PB8D PB11D I/O
79 PB4C PB5C PB6C PB7C PB8C PB9A PB12A I/O
80 PB4D PB5D PB6D PB7D PB8D PB9D PB12D I/O
81 PB5A PB6A PB7A PB8A PB9A PB10A PB13A I/O
82 PB5B PB6B PB7B PB8B PB9B PB10D PB13D I/O
83 PB5C PB6C PB7C PB8C PB9C PB11A PB14A I/O
84 PB5D PB6D PB7D PB8D PB9D PB11D PB14D I/O
Notes:
The OR2C/2T08A and OR2C/2T10A do not have bond pads connected to 240-pin SQFP package pin numbers 113 and 188.
The pins labeled I/O-V
2C/2T08A
Pad
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
SS
V
DD
DD
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
2C/2T10A
Pad
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
SS
V
DD
2C/2T12A
Pad
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
SS
V
DD
(continued)
2C/2T15A/B
Pad
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
SS
V
DD
2C/2T26A
Pad
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
SS
V
DD
2C/2T40A/B
Pad
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
SS
V
DD
Function
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
5
DD
V
SS
V
DD
Lucent Technologies Inc. 87
Page 88

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 24. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B, OR2C/2T26A,
and OR2C/2T40A/B 240-Pin SQFP/SQFP2 Pinout
2C/2T06A
Pin
85 V
Pad
SS
86 PB6A PB7A PB8A PB9A PB10A PB12A PB15A I/O
87 PB6B PB7B PB8B PB9B PB10B PB12B PB15B I/O
88 PB6C PB7C PB8C PB9C PB10C PB12C PB15C I/O
89 PB6D PB7D PB8D PB9D PB10D PB12D PB15D I/O
90 V
SS
91 PB7A PB8A PB9A PB10A PB11A PB13A PB16A I/O
92 PB7B PB8B PB9B PB10B PB11B PB13B PB16B I/O
93 PB7C PB8C PB9C PB10C PB11C PB13C PB16C I/O
94 PB7D PB8D PB9D PB10D PB11D PB13D PB16D I/O
95 V
SS
96 PB8A PB9A PB10A PB11A PB12A PB14A PB17A I/O-VDD5
97 PB8B PB9B PB10B PB11B PB12B PB14D PB17D I/O
98 PB8C PB9C PB10C PB11C PB12C PB15A PB18A I/O
99 PB8D PB9D PB10D PB11D PB12D PB15D PB18D I/O
100 PB9A PB10A PB11A PB12A PB13A PB16A PB19A I/O-HDC
101 PB9B PB10B PB11B PB12B PB13B PB16D PB19D I/O
102 PB9C PB10C PB11C PB12C PB13C PB17A PB20A I/O
103 PB9D PB10D PB11D PB12D PB13D PB17D PB20D I/O
104 V
DD
105 PB10A PB11A PB12A PB13A PB14A PB18A PB21A I/O-LDC
106 PB10B PB11D PB13A PB13D PB14D PB18D PB22D I/O
107 PB10C PB12A PB13B PB14A PB15A PB19A PB23A I/O
108 PB10D PB12B PB13C PB14D PB15D PB19D PB24D I/O
109 PB11A PB12C PB13D PB15A PB16A PB20A PB25A I/O-INIT
110 PB11B PB12D PB14A PB15D PB16D PB20D PB25D I/O
111 PB11C PB13A PB15A PB16A PB17A PB21A PB26A I/O
112 PB11D PB13B PB15B PB16D PB17D PB21D PB26D I/O
113 V
SS
114 PB12A PB13D PB15D PB17A PB18A PB22A PB27A I/O
115 PB12B PB14A PB16A PB17D PB19A PB23A PB28A I/O
116 PB12C PB14B PB16B PB18A PB19D PB23D PB28D I/O
117 PB12D PB14D PB16D PB18D PB20D PB24D PB30D I/O
118 V
SS
119 DONE DONE DONE DONE DONE DONE DONE DONE
120 V
121 V
DD
SS
122 RESET RESET RESET RESET RESET RESET RESET RESET
123 PRGM PRGM PRGM PRGM PRGM PRGM PRGM PRGM
124 PR12A PR14A PR16A PR18A PR20A PR24A PR30A I/O-M0
125 PR12B PR14D PR16D PR18C PR20D PR24D PR29D I/O
126 PR12C PR13A PR15A PR18D PR19A PR23A PR28A I/O
Notes:
The OR2C/2T08A and OR2C/2T10A do not have bond pads connected to 240-pin SQFP package pin numbers 113 and 188.
The pins labeled I/O-V
2C/2T08A
Pad
V
SS
V
SS
V
SS
V
DD
See Note See Note V
V
SS
V
DD
V
SS
DD
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
2C/2T10A
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
V
DD
V
SS
2C/2T12A
Pad
V
SS
V
SS
V
SS
V
DD
SS
V
SS
V
DD
V
SS
(continued)
2C/2T15A/B
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
2C/2T26A
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
2C/2T40A/B
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
Function
V
V
V
V
V
V
V
V
SS
SS
SS
DD
SS
SS
DD
SS
88 Lucent Technologies Inc.
Page 89

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 24. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B, OR2C/2T26A,
and OR2C/2T40A/B 240-Pin SQFP/SQFP2 Pinout
2C/2T06A
Pin
Pad
127 PR12D PR13D PR15D PR17B PR18A PR22A PR27A I/O
128 V
SS
129 PR11A PR12A PR14A PR16A PR17A PR21A PR26A I/O
130 PR11B PR12B PR14C PR16D PR17D PR21D PR25A I/O
131 PR11C PR12C PR14D PR15A PR16A PR20A PR24A I/O
132 PR11D PR12D PR13A PR15C PR16C PR20C PR24D I/O
133 PR10A PR11A PR13B PR15D PR16D PR20D PR23D I/O-M1
134 PR10B PR11B PR13C PR14A PR15A PR19A PR22A I/O
135 PR10C PR11C PR12A PR14D PR15D PR19D PR22D I/O-V
136 PR10D PR11D PR12B PR13A PR14A PR18A PR21A I/O
137 V
DD
138 PR9A PR10A PR11A PR12A PR13A PR17A PR20A I/O-M2
139 PR9B PR10B PR11B PR12B PR13B PR17D PR20D I/O
140 PR9C PR10C PR11C PR12C PR13C PR16A PR19A I/O
141 PR9D PR10D PR11D PR12D PR13D PR16D PR19D I/O
142 PR8A PR9A PR10A PR11A PR12A PR15A PR18A I/O-M3
143 PR8B PR9B PR10B PR11B PR12B PR15D PR18D I/O
144 PR8C PR9C PR10C PR11C PR12C PR14A PR17A I/O
145 PR8D PR9D PR10D PR11D PR12D PR14D PR17D I/O
146 V
SS
147 PR7A PR8A PR9A PR10A PR11A PR13A PR16A I/O
148 PR7B PR8B PR9B PR10B PR11B PR13B PR16B I/O
149 PR7C PR8C PR9C PR10C PR11C PR13C PR16C I/O
150 PR7D PR8D PR9D PR10D PR11D PR13D PR16D I/O
151 V
DD
152 PR6A PR7A PR8A PR9A PR10A PR12A PR15A I/O
153 PR6B PR7B PR8B PR9B PR10B PR12B PR15B I/O
154 PR6C PR7C PR8C PR9C PR10C PR12C PR15C I/O
155 PR6D PR7D PR8D PR9D PR10D PR12D PR15D I/O
156 V
SS
157 PR5A PR6A PR7A PR8A PR9A PR11A PR14A I/O-VDD5
158 PR5B PR6B PR7B PR8B PR9B PR11D PR14D I/O
159 PR5C PR6C PR7C PR8C PR9C PR10A PR13A I/O
160 PR5D PR6D PR7D PR8D PR9D PR10D PR13D I/O
161 PR4A PR5A PR6A PR7A PR8A PR9A PR12A I/O-CS1
162 PR4B PR5B PR6B PR7B PR8B PR9D PR12D I/O
163 PR4C PR5C PR6C PR7C PR8C PR8A PR11A I/O
164 PR4D PR5D PR6D PR7D PR8D PR8D PR11D I/O
165 V
DD
166 PR3A PR4A PR5A PR6A PR7A PR7A PR10A I/O-CS0
167 PR3B PR4B PR4B PR6B PR7B PR7B PR10B I/O
168 PR3C PR4C PR4C PR5B PR6B PR6B PR9B I/O
Notes:
The OR2C/2T08A and OR2C/2T10A do not have bond pads connected to 240-pin SQFP package pin numbers 113 and 188.
The pins labeled I/O-V
2C/2T08A
Pad
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
DD
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
2C/2T10A
Pad
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
2C/2T12A
Pad
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
(continued)
2C/2T15A/B
Pad
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
2C/2T26A
Pad
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
2C/2T40A/B
Pad
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
Function
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
DD
5
Lucent Technologies Inc. 89
Page 90

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 24. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B, OR2C/2T26A,
and OR2C/2T40A/B 240-Pin SQFP/SQFP2 Pinout
2C/2T06A
Pin
Pad
169 PR3D PR4D PR4D PR5D PR6D PR6D PR9D I/O
170 PR2A PR3A PR3A PR4A PR5A PR5A PR8A I/O-RD
171 PR2B PR3B PR3B PR4B PR5B PR5B PR7A I/O
172 PR2C PR3C PR3C PR4D PR5D PR5D PR6A I/O
173 PR2D PR3D PR3D PR3A PR4A PR4A PR5A I/O
174 V
SS
175 PR1A PR2A PR2A PR2A PR3A PR3A PR4A I/O-WR
176 PR1B PR2D PR2D PR2C PR2A PR2A PR3A I/O
177 PR1C PR1A PR1A PR1A PR1A PR1A PR2A I/O
178 PR1D PR1D PR1D PR1D PR1D PR1D PR1D I/O
179 V
SS
180 RD_CFGN RD_CFGN RD_CFGN RD_CFGN RD_CFGN RD_CFGN RD_CFGN RD_CFGN
181 V
182 V
183 V
SS
DD
SS
184 PT12D PT14D PT16D PT18D PT20D PT24D PT30D I/O
185 PT12C PT14C PT16C PT18B PT20A PT24A PT29A I/O
186 PT12B PT14A PT16A PT18A PT19D PT23D PT28D I/O
187 PT12A PT13D PT15D PT17D PT19A PT23A PT28A I/O-RDY/RCLK
188 V
SS
189 PT11D PT13B PT15B PT16D PT17D PT21D PT26D I/O
190 PT11C PT13A PT15A PT16C PT17C PT21C PT26C I/O
191 PT11B PT12D PT14D PT16A PT17A PT21A PT26A I/O
192 PT11A PT12C PT13D PT15D PT16D PT20D PT25D I/O-D7
193 PT10D PT12A PT13B PT14D PT15D PT19D PT24D I/O-V
194 PT10C PT11D PT13A PT14A PT15A PT19A PT23D I/O
195 PT10B PT11C PT12D PT13D PT14D PT18D PT22D I/O
196 PT10A PT11B PT12B PT13B PT14B PT18B PT21D I/O-D6
197 V
DD
198 PT9D PT10D PT11D PT12D PT13D PT17D PT20D I/O
199 PT9C PT10C PT11C PT12C PT13C PT17A PT20A I/O
200 PT9B PT10B PT11B PT12B PT13B PT16D PT19D I/O
201 PT9A PT10A PT11A PT12A PT13A PT16A PT19A I/O-D5
202 PT8D PT9D PT10D PT11D PT12D PT15D PT18D I/O
203 PT8C PT9C PT10C PT11C PT12C PT15A PT18A I/O
204 PT8B PT9B PT10B PT11B PT12B PT14D PT17D I/O
205 PT8A PT9A PT10A PT11A PT12A PT14A PT17A I/O-D4
206 V
SS
207 PT7D PT8D PT9D PT10D PT11D PT13D PT16D I/O
208 PT7C PT8C PT9C PT10C PT11C PT13C PT16C I/O
209 PT7B PT8B PT9B PT10B PT11B PT13B PT16B I/O
210 PT7A PT8A PT9A PT10A PT11A PT13A PT16A I/O-D3
Notes:
The OR2C/2T08A and OR2C/2T10A do not have bond pads connected to 240-pin SQFP package pin numbers 113 and 188.
The pins labeled I/O-V
2C/2T08A
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
See Note See Note V
V
DD
V
SS
DD
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
2C/2T10A
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
V
DD
V
SS
2C/2T12A
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
SS
V
DD
V
SS
(continued)
2C/2T15A/B
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
2C/2T26A
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
2C/2T40A/B
Pad
V
SS
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
Function
V
SS
V
SS
V
SS
V
DD
V
SS
V
SS
DD
V
DD
V
SS
5
90 Lucent Technologies Inc.
Page 91

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 24. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, OR2C/2T15A/B, OR2C/2T26A,
and OR2C/2T40A/B 240-Pin SQFP/SQFP2 Pinout
2C/2T06A
Pin
211 V
Pad
SS
212 PT6D PT7D PT8D PT9D PT10D PT12D PT15D I/O
213 PT6C PT7C PT8C PT9C PT10C PT12C PT15C I/O
214 PT6B PT7B PT8B PT9B PT10B PT12B PT15B I/O-V
215 PT6A PT7A PT8A PT9A PT10A PT12A PT15A I/O-D2
216 V
SS
217 PT5D PT6D PT7D PT8D PT9D PT11D PT14D I/O-D1
218 PT5C PT6C PT7C PT8C PT9C PT11A PT14A I/O
219 PT5B PT6B PT7B PT8B PT9B PT10D PT13D I/O
220 PT5A PT6A PT7A PT8A PT9A PT10A PT13A I/O-D0/DIN
221 PT4D PT5D PT6D PT7D PT8D PT9D PT12D I/O
222 PT4C PT5C PT6C PT7C PT8C PT9A PT12A I/O
223 PT4B PT5B PT6B PT7B PT8B PT8D PT11D I/O
224 PT4A PT5A PT6A PT7A PT8A PT8A PT11A I/O-DOUT
225 V
DD
226 PT3D PT4D PT5D PT6D PT7D PT7D PT10D I/O
227 PT3C PT4C PT5A PT6A PT7A PT7A PT9A I/O
228 PT3B PT4B PT4D PT5C PT6C PT6C PT8A I/O
229 PT3A PT4A PT4A PT5A PT6A PT6A PT7A I/O-TDI
230 PT2D PT3D PT3D PT4D PT5D PT5D PT6D I/O
231 PT2C PT3C PT3C PT4A PT5A PT5A PT6A I/O
232 PT2B PT3B PT3B PT3D PT4D PT4D PT5D I/O
233 PT2A PT3A PT3A PT3A PT4A PT4A PT5A I/O-TMS
234 V
SS
235 PT1D PT2D PT2D PT2C PT3A PT3A PT4A I/O
236 PT1C PT2A PT2A PT2A PT2A PT2A PT3A I/O
237 PT1B PT1D PT1D PT1D PT1D PT1D PT2D I/O
238 PT1A PT1A PT1A PT1A PT1A PT1A PT1A I/O-TCK
239 V
SS
240 RD_DATA/
TDO
Notes:
The OR2C/2T08A and OR2C/2T10A do not have bond pads connected to 240-pin SQFP package pin numbers 113 and 188.
The pins labeled I/O-V
2C/2T08A
Pad
V
SS
V
SS
V
DD
V
SS
V
SS
RD_DATA/
TDO
DD
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
2C/2T10A
Pad
V
SS
V
SS
V
DD
V
SS
V
SS
RD_DATA/
TDO
2C/2T12A
Pad
V
SS
V
SS
V
DD
V
SS
V
SS
RD_DATA/
TDO
(continued)
2C/2T15A/B
Pad
V
SS
V
SS
V
DD
V
SS
V
SS
RD_DATA/
TDO
2C/2T26A
Pad
V
SS
V
SS
V
DD
V
SS
V
SS
RD_DATA/
TDO
2C/2T40A/B
Pad
V
SS
V
SS
V
DD
V
SS
V
SS
RD_DATA/
TDO
Function
V
SS
V
SS
V
DD
V
SS
V
SS
RD_DATA/TDO
DD
5
Lucent Technologies Inc. 91
Page 92

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 25. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, and OR2C/2T15A/B
256-Pin PBGA Pinout
Pin
2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad 2C/2T12A Pad 2C/2T15A/B Pad
Function
C2 PL1D PL1D PL1D PL1D PL1D I/O
D2 PL1C PL1B PL1B PL1C PL1C I/O
D3 PL1B PL1A PL1A PL1B PL1B I/O
E4 PL1A PL2D PL2D PL2D PL2D I/O-A0
C1 — PL2C PL2C PL2C PL2A I/O
D1 — PL2B PL2B PL2B PL3D I/O
E3 — PL2A PL2A PL2A PL3A I/O
E2 PL2D PL3D PL3D PL3D PL4D I/O-V
E1 PL2C PL3C PL3C PL3A PL4A I/O
F3 PL2B PL3B PL3B PL4D PL5D I/O
G4 PL2A PL3A PL3A PL4A PL5A I/O-A1
F2 — — PL4D PL5D PL6D I/O
F1 PL3D PL4D PL4A PL5A PL6A I/O-A2
G3 PL3C PL4C PL5C PL6D PL7D I/O
G2 PL3B PL4B PL5B PL6B PL7B I/O
G1 PL3A PL4A PL5A PL6A PL7A I/O-A3
H3 PL4D PL5D PL6D PL7D PL8D I/O
H2 PL4C PL5C PL6C PL7C PL8C I/O
H1 PL4B PL5B PL6B PL7B PL8B I/O
J4 PL4A PL5A PL6A PL7A PL8A I/O-A4
J3 PL5D PL6D PL7D PL8D PL9D I/O-A5
J2 PL5C PL6C PL7C PL8C PL9C I/O
J1 PL5B PL6B PL7B PL8B PL9B I/O
K2 PL5A PL6A PL7A PL8A PL9A I/O-A6
K3 PL6D PL7D PL8D PL9D PL10D I/O
K1 PL6C PL7C PL8C PL9C PL10C I/O
L1 PL6B PL7B PL8B PL9B PL10B I/O
L2 PL6A PL7A PL8A PL9A PL10A I/O-A7
L3 PL7D PL8D PL9D PL10D PL11D I/O
L4 PL7C PL8C PL9C PL10C PL11C I/O-V
M1 PL7B PL8B PL9B PL10B PL11B I/O
M2 PL7A PL8A PL9A PL10A PL11A I/O-A8
M3 PL8D PL9D PL10D PL11D PL12D I/O-A9
M4 PL8C PL9C PL10C PL11C PL12C I/O
N1 PL8B PL9B PL10B PL11B PL12B I/O
N2 PL8A PL9A PL10A PL11A PL12A I/O-A10
N3 PL9D PL10D PL11D PL12D PL13D I/O
P1 PL9C PL10C PL11C PL12C PL13C I/O
P2 PL9B PL10B PL11B PL12B PL13B I/O
R1 PL9A PL10A PL11A PL12A PL13A I/O-A11
Notes:
The W3 pin on the 256-pin PBGA package is unconnected for all devices listed in this table .
The OR2C/2T08A do not have bond pads connected to the 256-pin PBGA package pins F2 and Y17.
DD
The pins labeled I/O-V
The pins labeled V
plane of the board for enhanced thermal capability (see Table 29), or they can be left unconnected.
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
SS
-ETC are the 4 x 4 array of thermal balls located at the center of the package. The balls can be attached to the ground
DD
DD
5
5
92 Lucent Technologies Inc.
Page 93

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 25. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, and OR2C/2T15A/B
Pin
256-Pin PBGA Pinout
2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad 2C/2T12A Pad 2C/2T15A/B Pad
(continued)
Function
P3 PL10D PL11D PL12D PL13D PL14D I/O-A12
R2 PL10C PL11C PL12C PL13B PL14B I/O
T1 PL10B PL11B PL12B PL14D PL15D I/O
P4 PL10A PL11A PL13D PL14B PL15B I/O-A13
R3 PL11D PL12D PL13B PL14A PL15A I/O
T2 PL11C PL12C PL13A PL15D PL16D I/O
U1 PL11B PL12B PL14D PL15B PL16B I/O
T3 PL11A PL12A PL14C PL16D PL17D I/O-A14
U2 — PL13D PL15D PL17D PL18D I/O-V
V1 PL12D PL13C PL15C PL17C PL18C I/O
T4 PL12C PL13B PL15B PL17B PL18A I/O
U3 PL12B PL13A PL15A PL17A PL19D I/O
V2 — PL14D PL16D PL18D PL19C I/O
W1 — PL14C PL16C PL18C PL19A I/O
V3 — PL14B PL16B PL18B PL20D I/O
W2 PL12A PL14A PL16A PL18A PL20A I/O-A15
Y1 CCLK CCLK CCLK CCLK CCLK CCLK
Y2 PB1A PB1A PB1A PB1A PB1A I/O-A16
W4 — PB1C PB1C PB1C PB1D I/O
V4 PB1B PB1D PB1D PB1D PB2A I/O
U5 PB1C PB2A PB2A PB2A PB2D I/O-V
Y3 PB1D PB2B PB2B PB2B PB3A I/O
Y4 — PB2C PB2C PB2C PB3C I/O
V5 — PB2D PB2D PB2D PB3D I/O
W5 PB2A PB3A PB3B PB3D PB4D I/O-A17
Y5 PB2B PB3B PB4B PB4D PB5D I/O
V6 PB2C PB3C PB4C PB5A PB6A I/O
U7 PB2D PB3D PB4D PB5B PB6B I/O
W6 PB3A PB4A PB5A PB5D PB6D I/O
Y6 PB3B PB4B PB5B PB6A PB7A I/O
V7 PB3C PB4C PB5C PB6B PB7B I/O
W7 PB3D PB4D PB5D PB6D PB7D I/O
Y7 PB4A PB5A PB6A PB7A PB8A I/O
V8 PB4B PB5B PB6B PB7B PB8B I/O
W8 PB4C PB5C PB6C PB7C PB8C I/O
Y8 PB4D PB5D PB6D PB7D PB8D I/O
U9 PB5A PB6A PB7A PB8A PB9A I/O
V9 PB5B PB6B PB7B PB8B PB9B I/O
W9 PB5C PB6C PB7C PB8C PB9C I/O
Y9 PB5D PB6D PB7D PB8D PB9D I/O
Notes:
The W3 pin on the 256-pin PBGA package is unconnected for all devices listed in this table.
The OR2C/2T08A do not have bond pads connected to the 256-pin PBGA package pins F2 and Y17.
DD
The pins labeled I/O-V
The pins labeled V
plane of the board for enhanced thermal capability (see Table 29), or they can be left unconnected.
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
SS
-ETC are the 4 x 4 array of thermal balls located at the center of the package. The balls can be attached to the ground
DD
DD
5
5
Lucent Technologies Inc. 93
Page 94

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 25. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, and OR2C/2T15A/B
Pin
256-Pin PBGA Pinout
2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad 2C/2T12A Pad 2C/2T15A/B Pad
(continued)
Function
W10 PB6A PB7A PB8A PB9A PB10A I/O
V10 PB6B PB7B PB8B PB9B PB10B I/O
Y10 PB6C PB7C PB8C PB9C PB10C I/O
Y11 PB6D PB7D PB8D PB9D PB10D I/O
W11 PB7A PB8A PB9A PB10A PB11A I/O
V11 PB7B PB8B PB9B PB10B PB11B I/O
U11 PB7C PB8C PB9C PB10C PB11C I/O
Y12 PB7D PB8D PB9D PB10D PB11D I/O
W12 PB8A PB9A PB10A PB11A PB12A I/O-V
V12 PB8B PB9B PB10B PB11B PB12B I/O
U12 PB8C PB9C PB10C PB11C PB12C I/O
Y13 PB8D PB9D PB10D PB11D PB12D I/O
W13 PB9A PB10A PB11A PB12A PB13A I/O-HDC
V13 PB9B PB10B PB11B PB12B PB13B I/O
Y14 PB9C PB10C PB11C PB12C PB13C I/O
W14 PB9D PB10D PB11D PB12D PB13D I/O
Y15 PB10A PB11A PB12A PB13A PB14A
I/O-
V14 PB10B PB11B PB12C PB13B PB14B I/O
W15 PB10C PB11C PB12D PB13C PB14C I/O
Y16 PB10D PB11D PB13A PB13D PB14D I/O
U14 — PB12A PB13B PB14A PB15A I/O
V15 — PB12B PB13C PB14D PB15D I/O
W16 PB11A PB12C PB13D PB15A PB16A
I/OY17 — — PB14A PB15D PB16D I/O
V16 — PB12D PB14B PB16A PB17A I/O-V
W17 PB11B PB13A PB15A PB16D PB17D I/O
Y18 PB11C PB13B PB15B PB17A PB18A I/O
U16 PB11D PB13C PB15C PB17C PB18D I/O
V17 PB12A PB13D PB15D PB17D PB19A I/O
W18 PB12B PB14A PB16A PB18A PB19D I/O
Y19 PB12C PB14B PB16B PB18B PB20A I/O
V18 PB12D PB14C PB16C PB18C PB20B I/O
W19 — PB14D PB16D PB18D PB20D I/O
Y20 DONE DONE DONE DONE DONE DONE
W20
V19
RESET RESET RESET RESET RESET RESET
PRGM PRGM PRGM PRGM PRGM PRGM
U19 PR12A PR14A PR16A PR18A PR20A I/O-M0
U18 — PR14C PR16C PR18C PR20D I/O
T17 — PR14D PR16D PR18D PR19A I/O
V20 — PR13A PR15A PR17A PR19D I/O
Notes:
The W3 pin on the 256-pin PBGA package is unconnected for all devices listed in this table .
The OR2C/2T08A do not have bond pads connected to the 256-pin PBGA package pins F2 and Y17.
DD
The pins labeled I/O-V
The pins labeled V
plane of the board for enhanced thermal capability (see Table 29), or they can be left unconnected.
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
SS
-ETC are the 4 x 4 array of thermal balls located at the center of the package. The balls can be attached to the ground
DD
LDC
INIT
DD
5
5
94 Lucent Technologies Inc.
Page 95

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 25. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, and OR2C/2T15A/B
Pin
256-Pin PBGA Pinout
2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad 2C/2T12A Pad 2C/2T15A/B Pad
(continued)
Function
U20 PR12B PR13B PR15B PR17B PR18A I/O
T18 PR12C PR13C PR15C PR17C PR18B I/O
T19 PR12D PR13D PR15D PR17D PR18D I/O
T20 PR11A PR12A PR14A PR16A PR17A I/O
R18 PR11B PR12B PR14C PR16D PR17D I/O
P17 PR11C PR12C PR14D PR15A PR16A I/O
R19 PR11D PR12D PR13A PR15C PR16C I/O
R20 PR10A PR11A PR13B PR15D PR16D I/O-M1
P18 PR10B PR11B PR13C PR14A PR15A I/O
P19 PR10C PR11C PR12A PR14D PR15D I/O-V
P20 PR10D PR11D PR12B PR13A PR14A I/O
N18 PR9A PR10A PR11A PR12A PR13A I/O-M2
N19 PR9B PR10B PR11B PR12B PR13B I/O
N20 PR9C PR10C PR11C PR12C PR13C I/O
M17 PR9D PR10D PR11D PR12D PR13D I/O
M18 PR8A PR9A PR10A PR11A PR12A I/O-M3
M19 PR8B PR9B PR10B PR11B PR12B I/O
M20 PR8C PR9C PR10C PR11C PR12C I/O
L19 PR8D PR9D PR10D PR11D PR12D I/O
L18 PR7A PR8A PR9A PR10A PR11A I/O
L20 PR7B PR8B PR9B PR10B PR11B I/O
K20 PR7C PR8C PR9C PR10C PR11C I/O
K19 PR7D PR8D PR9D PR10D PR11D I/O
K18 PR6A PR7A PR8A PR9A PR10A I/O
K17 PR6B PR7B PR8B PR9B PR10B I/O
J20 PR6C PR7C PR8C PR9C PR10C I/O
J19 PR6D PR7D PR8D PR9D PR10D I/O
J18 PR5A PR6A PR7A PR8A PR9A I/O-V
J17 PR5B PR6B PR7B PR8B PR9B I/O
H20 PR5C PR6C PR7C PR8C PR9C I/O
H19 PR5D PR6D PR7D PR8D PR9D I/O
H18 PR4A PR5A PR6A PR7A PR8A I/O-CS1
G20 PR4B PR5B PR6B PR7B PR8B I/O
G19 PR4C PR5C PR6C PR7C PR8C I/O
F20 PR4D PR5D PR6D PR7D PR8D I/O
G18 PR3A PR4A PR5A PR6A PR7A I/O-
F19 PR3B PR4B PR4B PR6B PR7B I/O
E20 PR3C PR4C PR4C PR5B PR6B I/O
G17 PR3D PR4D PR4D PR5D PR6D I/O
F18 PR2A PR3A PR3A PR4A PR5A I/O-
Notes:
The W3 pin on the 256-pin PBGA package is unconnected for all devices listed in this table.
The OR2C/2T08A do not have bond pads connected to the 256-pin PBGA package pins F2 and Y17.
DD
The pins labeled I/O-V
The pins labeled V
plane of the board for enhanced thermal capability (see Table 29), or they can be left unconnected.
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
SS
-ETC are the 4 x 4 array of thermal balls located at the center of the package. The balls can be attached to the ground
DD
DD
CS0
RD
5
5
Lucent Technologies Inc. 95
Page 96

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 25. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, and OR2C/2T15A/B
Pin
256-Pin PBGA Pinout
2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad 2C/2T12A Pad 2C/2T15A/B Pad
(continued)
Function
E19 PR2B PR3B PR3B PR4B PR5B I/O
D20 PR2C PR3C PR3C PR4D PR5D I/O
E18 PR2D PR3D PR3D P R3A PR4A I/O-V
D19 PR1A PR2A PR2A PR2A PR3A I/OC20 PR1B PR2B PR2B PR2B PR3B I/O
E17 PR1C PR2C PR2C PR2C PR2A I/O
D18 PR1D PR2D PR2D PR2D PR2D I/O
C19 — PR1A PR1A PR1A PR1A I/O
B20 — PR1B PR1B PR1B PR1B I/O
C18 — PR1C PR1C PR1C PR1C I/O
B19 — PR1D PR1D PR1D PR1D I/O
A20
RD_CFGN RD_CFGN RD_CFGN RD_CFGN RD_CFGN RD_CFGN
A19 — PT14D PT16D PT18D PT20D I/O
B18 PT12D PT14C PT16C PT18C PT20C I/O
B17 PT12C PT14B PT16B PT18B PT20A I/O
C17 PT12B PT14A PT16A PT18A PT19D I/O
D16 PT12A PT13D PT15D PT17D PT19A I/O-
RDY/RCLK
A18 — PT13C PT15C PT17A PT18A I/O
A17 PT11D PT13B PT15B PT16D PT17D I/O
C16 PT11C PT13A PT15A PT16C PT17C I/O
B16 PT11B PT12D PT14D PT16A PT17A I/O
A16 PT11A PT12C PT13D PT15D PT16D I/O-D7
C15 — PT12B PT13C PT15A PT16A I/O
D14 PT10D PT12A PT13B PT14D PT15D I/O-V
B15 PT10C PT11D PT13A PT14A PT15A I/O
A15 PT10B PT11C PT12D PT13D PT14D I/O
C14 PT10A PT11B PT12B PT13B PT14B I/O-D6
B14 PT9D PT11A PT12A PT13A PT14A I/O
A14 PT9C PT10D PT11D PT12D PT13D I/O
C13 — PT10C PT11C PT12C PT13C I/O
B13 PT9B PT10B PT11B PT12B PT13B I/O
A13 PT9A PT10A PT11A PT12A PT13A I/O-D5
D12 PT8D PT9D PT10D PT11D PT12D I/O
C12 PT8C PT9C PT10C PT11C PT12C I/O
B12 PT8B PT9B PT10B PT11B PT12B I/O
A12 PT8A PT9A PT10A PT11A PT12A I/O-D4
B11 PT7D PT8D PT9D PT10D PT11D I/O
C11 PT7C PT8C PT9C PT10C PT11C I/O
A11 PT7B PT8B PT9B PT10B PT11B I/O
A10 PT7A PT8A PT9A PT10A PT11A I/O-D3
Notes:
The W3 pin on the 256-pin PBGA package is unconnected for all devices listed in this table .
The OR2C/2T08A do not have bond pads connected to the 256-pin PBGA package pins F2 and Y17.
DD
The pins labeled I/O-V
The pins labeled V
plane of the board for enhanced thermal capability (see Table 29), or they can be left unconnected.
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
SS
-ETC are the 4 x 4 array of thermal balls located at the center of the package. The balls can be attached to the ground
DD
WR
DD
5
5
96 Lucent Technologies Inc.
Page 97

Data Sheet
June 1999
ORCA
Series 2 FPGAs
Pin Information
(continued)
Table 25. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, and OR2C/2T15A/B
Pin
256-Pin PBGA Pinout
2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad 2C/2T12A Pad 2C/2T15A/B Pad
(continued)
Function
B10 PT6D PT7D PT8D PT9D PT10D I/O
C10 PT6C PT7C PT8C PT9C PT10C I/O
D10 PT6B PT7B PT8B PT9B PT10B I/O-V
DD
A9 PT6A PT7A PT8A PT9A PT10A I/O-D2
B9 PT5D PT6D PT7D PT8D PT9D I/O-D1
C9 PT5C PT6C PT7C PT8C PT9C I/O
D9 PT5B PT6B PT7B PT8B PT9B I/O
A8 PT5A PT6A PT7A PT8A PT9A I/O-D0/DIN
B8 PT4D PT5D PT6D PT7D PT8D I/O
C8 PT4C PT5C PT6C PT7C PT8C I/O
A7 PT4B PT5B PT6B PT7B PT8B I/O
B7 PT4A PT5A PT6A PT7A PT8A I/O-DOUT
A6 PT3D PT4D PT5D PT6D PT7D I/O
C7 PT3C PT4C PT5A PT6A PT7A I/O
B6 PT3B PT4B PT4D PT5C PT6C I/O
A5 PT3A PT4A PT4A PT5A PT6A I/O-TDI
D7 PT2D PT3D PT3D PT4D PT5D I/O
C6 PT2C PT3C PT3C PT4A PT5A I/O-V
DD
B5 PT2B PT3B PT3B PT3D PT4D I/O
A4 PT2A PT3A PT3A PT3A PT4A I/O-TMS
C5 — PT2D PT2D PT2D PT3D I/O
B4 PT1D PT2C PT2C PT2C PT3A I/O
A3 PT1C PT2B PT2B PT2B PT2D I/O
D5 PT1B PT2A PT2A PT2A PT2A I/O
C4 — PT1D PT1D PT1D PT1D I/O
B3 — PT1C PT1C PT1C PT1C I/O
B2 — PT1B PT1B PT1B PT1B I/O
A2 PT1A PT1A PT1A PT1A PT1A I/O-TCK
C3 RD_ DATA/TDO RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO RD_DATA/TDO
A1 V
D4 V
D8 V
D13 V
D17 V
H4 V
H17 V
N4 V
N17 V
U4 V
Notes:
The W3 pin on the 256-pin PBGA package is unconnected for all devices listed in this table.
The OR2C/2T08A do not have bond pads connected to the 256-pin PBGA package pins F2 and Y17.
The pins labeled I/O-V
The pins labeled V
plane of the board for enhanced thermal capability (see Table 29), or they can be left unconnected.
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
DD
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
SS
-ETC are the 4 x 4 array of thermal balls located at the center of the package. The balls can be attached to the ground
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
5
5
Lucent Technologies Inc. 97
Page 98

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
(continued)
Table 25. OR2C/2T06A, OR2C/2T08A, OR2C/2T10A, OR2C/2T12A, and OR2C/2T15A/B
256-Pin PBGA Pinout
Pin
2C/2T06A Pad 2C/2T08A Pad 2C/2T10A Pad 2C/2T12A Pad 2C/2T15A/B Pad
U8 V
U13 V
U17 V
B1 V
D6 V
D11 V
D15 V
F4 V
F17 V
K4 V
L17 V
R4 V
R17 V
U6 V
U10 V
U15 V
SS
SS
SS
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
DD
(continued)
V
SS
V
SS
V
SS
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
Function
V
SS
V
SS
V
SS
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
SS
V
SS
V
SS
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
SS
V
SS
V
SS
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
SS
V
SS
V
SS
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
V
DD
W3 — — — — — No Connect
J10 V
J11 V
J12 V
J9 V
K10 V
K11 V
K12 V
K9 V
L10 V
L11 V
L12 V
L9 V
M10 V
M11 V
M12 V
M9 V
Notes:
The W3 pin on the 256-pin PBGA package is unconnected for all devices listed in this table .
The OR2C/2T08A do not have bond pads connected to the 256-pin PBGA package pins F2 and Y17.
The pins labeled I/O-V
The pins labeled V
plane of the board for enhanced thermal capability (see Table 29), or they can be left unconnected.
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
SS
DD
5 are user I/Os for the OR2CxxA and OR2TxxB series, but they are connected to VDD5 for the OR2TxxA series.
SS
-ETC are the 4 x 4 array of thermal balls located at the center of the package. The balls can be attached to the ground
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
V
SS
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
VSS—ETC
98 Lucent Technologies Inc.
Page 99

Data Sheet
June 1999
Pin Information
Table 26. OR2C12A, OR2C15A, OR2C26A, and OR2C40A 304-Pin SQFP/SQFP2 Pinout
Pin 2C12A Pad 2C15A Pad 2C26A Pad 2C40A Pad Function
1V
2V
3V
4 PL1D PL1D PL1D PL1D I/O
5 PL1C PL1C PL1C PL1A I/O
6 PL1B PL1B PL1B PL2D I/O
7 PL1A PL1A PL1A PL2A I/O
8 PL2D PL2D PL2D PL3D I/O-A0
9 PL2C PL2A PL2A PL3A I/O
10 PL2B PL3D PL3D PL4D I/O
11 PL2A PL3A PL3A PL4A I/O
12 V
13 PL3D PL4D PL4D PL5D I/O
14 PL3A PL4A PL4A PL6D I/O
15 PL4D PL5D PL5D PL7D I/O
16 PL4A PL5A PL5A PL8D I/O-A1
17 PL5D PL6D PL6D PL9D I/O
18 PL5C PL6C PL6C PL9C I/O
19 PL5B PL6B PL6B PL9B I/O
20 PL5A PL6A PL6A PL9A I/O-A2
21 PL6D PL7D PL7D PL10D I/O
22 PL6C PL7C PL7C PL10C I/O
23 PL6B PL7B PL7B PL10B I/O
24 PL6A PL7A PL7A PL10A I/O-A3
25 V
26 PL7D PL8D PL8D PL11D I/O
27 PL7C PL8C PL8A PL11A I/O
28 PL7B PL8B PL9D PL12D I/O
29 PL7A PL8A PL9A PL12A I/O-A4
30 PL8D PL9D PL10D PL13D I/O-A5
31 PL8C PL9C PL10A PL13A I/O
32 PL8B PL9B PL11D PL14D I/O
33 PL8A PL9A PL11A PL14A I/O-A6
34 V
35 PL9D PL10D PL12D PL15D I/O
36 PL9C PL10C PL12C PL15C I/O
37 PL9B PL10B PL12B PL15B I/O
38 PL9A PL10A PL12A PL15A I/O-A7
39 V
40 PL10D PL11D PL13D PL16D I/O
41 PL10C PL11C PL13C PL16C I/O
42 PL10B PL11B PL13B PL16B I/O
43 PL10A PL11A PL13A PL16A I/O-A8
44 V
Note: The OR2TxxA and OR2TxxB series are not offered in the 304-pin SQFP/SQFP2 packages.
(continued)
SS
DD
SS
SS
DD
SS
DD
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
V
DD
V
SS
V
V
V
V
V
V
V
V
SS
DD
SS
SS
DD
SS
DD
SS
ORCA
Series 2 FPGAs
V
SS
V
DD
V
SS
V
SS
V
DD
V
SS
V
DD
V
SS
Lucent Technologies Inc. 99
Page 100

ORCA
Data Sheet
Series 2 FPGAs June 1999
Pin Information
Table 26. OR2C12A, OR2C15A, OR2C26A, and OR2C40A 304-Pin SQFP/SQFP2 Pinout
(continued)
(continued)
Pin 2C12A Pad 2C15A Pad 2C26A Pad 2C40A Pad Function
45 PL11D PL12D PL14D PL17D I/O-A9
46 PL11C PL12C PL14A PL17A I/O
47 PL11B PL12B PL15D PL18D I/O
48 PL11A PL12A PL15A PL18A I/O-A10
49 PL12D PL13D PL16D PL19D I/O
50 PL12C PL13C PL16A PL19A I/O
51 PL12B PL13B PL17D PL20D I/O
52 PL12A PL13A PL17A PL20A I/O-A11
53 V
DD
V
DD
V
DD
V
DD
54 PL13D PL14D PL18D PL21D I/O-A12
55 PL13B PL14B PL18B PL21B I/O
56 PL13A PL14A PL18A PL21A I/O
57 PL14D PL15D PL19D PL22D I/O
58 PL14B PL15B PL19B PL22B I/O-A13
59 PL14A PL15A PL19A PL22A I/O
60 PL15D PL16D PL20D PL23D I/O
61 PL15B PL16B PL20B PL24D I/O
62 PL15A PL16A PL20A PL25D I/O
63 PL16D PL17D PL21D PL25A I/O-A14
64 PL16A PL17A PL21A PL26A I/O
65 V
SS
V
SS
V
SS
V
SS
66 PL17D PL18D PL22D PL27D I/O
67 PL17C PL18C PL22C PL27C I/O
68 PL17B PL18A PL22A PL27A I/O
69 PL17A PL19D PL23D PL28D I/O
70 PL18D PL19C PL23C PL28C I/O
71 PL18C PL19A PL23A PL28A I/O
72 PL18B PL20D PL24D PL29A I/O
73 PL18A PL20A PL24A PL30A I/O-A15
74 V
SS
V
SS
V
SS
V
SS
75 CCLK CCLK CCLK CCLK CCLK
76 V
77 V
78 V
79 V
DD
SS
DD
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
V
DD
V
SS
80 PB1A PB1A PB1A PB1A I/O-A16
81 PB1B PB1C PB1C PB2A I/O
82 PB1C PB1D PB1D PB2D I/O
83 PB1D PB2A PB2A PB3A I/O
84 PB2A PB2D PB2D PB3D I/O
85 PB2B PB3A PB3A PB4A I/O
86 PB2C PB3C PB3C PB4C I/O
87 PB2D PB3D PB3D PB4D I/O
88 V
SS
V
SS
V
SS
V
SS
89 PB3A PB4A PB4A PB5A I/O
Note: The OR2TxxA and OR2TxxB series are not offered in the 304-pin SQFP/SQFP2 packages.
V
DD
V
SS
V
SS
V
DD
V
SS
V
DD
V
SS
V
SS
100 Lucent Technologies Inc.
 Loading...
Loading...