

Novell SUSE Linux Enterprise 10 Heartbeat

SUSE Linux Enterprise
www.novell.com10 SP2
May08,2008 Heartbeat
Server

Heartbeat
All content is copyright © Novell, Inc.
Legal Notice
This manual is protected under Novell intellectual property rights. By reproducing, duplicating or
distributing this manual you explicitly agree to conform to the terms and conditions of this license
agreement.
This manual may be freely reproduced, duplicated and distributed either as such or as part of a bundled
package in electronic and/or printed format, provided however that the following conditions are fullled:
That this copyright notice and the names of authors and contributors appear clearly and distinctively
on all reproduced, duplicated and distributed copies. That this manual, specically for the printed
format, is reproduced and/or distributed for noncommercial use only. The express authorization of
Novell, Inc must be obtained prior to any other use of any manual or part thereof.
For Novell trademarks, see the Novell Trademark and Service Mark list http://www.novell
.com/company/legal/trademarks/tmlist.html. * Linux is a registered trademark of
Linus Torvalds. All other third party trademarks are the property of their respective owners. A trademark
symbol (®, ™ etc.) denotes a Novell trademark; an asterisk (*) denotes a third party trademark.
All information found in this book has been compiled with utmost attention to detail. However, this
does not guarantee complete accuracy. Neither Novell, Inc., SUSE LINUX Products GmbH, the authors,
nor the translators shall be held liable for possible errors or the consequences thereof.

Contents
About This Guide v
1 Overview 1
1.1 Product Features . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Product Benets . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Cluster Congurations . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Heartbeat Cluster Components . . . . . . . . . . . . . . . . . . . . 8
1.5 Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Installation and Setup 13
2.1 Hardware Requirements . . . . . . . . . . . . . . . . . . . . . . 14
2.2 Software Requirements . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Shared Disk System Requirements . . . . . . . . . . . . . . . . . . 14
2.4 Preparations . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.5 Installing Heartbeat . . . . . . . . . . . . . . . . . . . . . . . . 17
2.6 Conguring STONITH . . . . . . . . . . . . . . . . . . . . . . . 21
3 Setting Up a Simple Resource 25
3.1 Conguring a Resource with the Heartbeat GUI . . . . . . . . . . . . 25
3.2 Manual Conguration of a Resource . . . . . . . . . . . . . . . . . 27
4 Conguring and Managing Cluster Resources 29
4.1 Graphical HA Management Client . . . . . . . . . . . . . . . . . . 29
4.2 Creating Cluster Resources . . . . . . . . . . . . . . . . . . . . . 31
4.3 Conguring Resource Constraints . . . . . . . . . . . . . . . . . . 33
4.4 Specifying Resource Failover Nodes . . . . . . . . . . . . . . . . . 33

4.5 Specifying Resource Failback Nodes (Resource Stickiness) . . . . . . . . 34
4.6 Conguring Resource Monitoring . . . . . . . . . . . . . . . . . . 35
4.7 Starting a New Cluster Resource . . . . . . . . . . . . . . . . . . . 36
4.8 Removing a Cluster Resource . . . . . . . . . . . . . . . . . . . . 36
4.9 Conguring a Heartbeat Cluster Resource Group . . . . . . . . . . . . 37
4.10 Conguring a Heartbeat Clone Resource . . . . . . . . . . . . . . . 40
4.11 Migrating a Cluster Resource . . . . . . . . . . . . . . . . . . . . 41
5 Manual Conguration of a Cluster 43
5.1 Conguration Basics . . . . . . . . . . . . . . . . . . . . . . . . 44
5.2 Conguring Resources . . . . . . . . . . . . . . . . . . . . . . . 47
5.3 Conguring Constraints . . . . . . . . . . . . . . . . . . . . . . 52
5.4 Conguring CRM Options . . . . . . . . . . . . . . . . . . . . . 55
5.5 For More Information . . . . . . . . . . . . . . . . . . . . . . . 59
6 Managing a Cluster 61
7 Creating Resources 103
7.1 STONITH Agents . . . . . . . . . . . . . . . . . . . . . . . . . 103
7.2 Resource Agents . . . . . . . . . . . . . . . . . . . . . . . . . 104
7.3 Writing OCF Resource Agents . . . . . . . . . . . . . . . . . . . 104
8 Troubleshooting 107
A HB OCF Agents 109
Terminology 173

About This Guide
Heartbeat is an open source clustering software for Linux. Heartbeat ensures high
availability and manageability of critical network resources including data, applications,
and services. It is a multinode clustering product that supports failover, failback, and
migration (load balancing) of individually managed cluster resources.
This guide is intended for administrators given the task of building Linux clusters. Basic
background information is provided to build up an understanding of the Heartbeat architecture. Setup, conguration, and maintenance of a Heartbeat cluster are covered in
detail. Heartbeat offers a graphical user interface as well as many command line tools.
Both approaches are covered in detail to help the administrators choose the appropriate
tool matching their particular needs.
NOTE
This manual covers Heartbeat version 2 and higher. Whenever the authors use
the term “Heartbeat”, they refer to Heartbeat 2, even when no explicit version
number is given.
This guide contains the following:
Overview
Before starting to install and congure your cluster, learn about the features
Heartbeat offers. Familiarize yourself with the Heartbeat terminology and its basic
concepts.
Installation and Setup
Learn about hardware and software requirements that must be met before you can
consider installing and running your own cluster. Perform a basic installation and
conguration using the Heartbeat graphical user interface.
Setting Up a Simple Resource
After you have completed the basic cluster conguration, check out a quick stepby-step instruction of how to congure an example resource. Choose from a GUIbased approach or a command line-driven one.

Conguring and Managing Cluster Resources
Managing resources encompasses much more than just the initial conguration.
Learn how to use the Heartbeat graphical user interface to congure and manage
resources.
Manual Conguration of a Cluster
Managing resources encompasses much more than just the initial conguration.
Learn how to use the Heartbeat command line tools to congure and manage resources.
Managing a Cluster
Heartbeat provides a comprehensive set of command line tools to assist you in
managing your own cluster. Get to know the most important ones for your daily
cluster management tasks.
Creating Resources
In case you consider writing your own resource agents for Heartbeat or modifying
existing ones, get some detailed background information about the different types
of resource agents and how to create them.
Troubleshooting
Managing your own cluster requires you to perform a certain amount of troubleshooting. Learn about the most common problems with Heartbeat and how to x them.
Terminology
1 Feedback
We want to hear your comments and suggestions about this manual and the other documentation included with this product. Please use the User Comments feature at the
bottom of each page of the online documentation and enter your comments there.
vi Heartbeat
Refer to this chapter for some basic Heartbeat terminology that helps you understand
the Heartbeat fundamentals.

2 Documentation Updates
Expect updates to this documentation in the near future while it is extended to match
the capabilities of the software itself and to address more and more use cases. By using
the User Comments feature described in Section 1, “Feedback” (page vi), let us know
on which aspects of Heartbeat this guide should elaborate.
For the latest version of this documentation, see the SLES 10 SP2 documentation Web
site at http://www.novell.com/documentation/sles10.
3 Documentation Conventions
The following typographical conventions are used in this manual:
• /etc/passwd: lenames and directory names
• placeholder: replace placeholder with the actual value
• PATH: the environment variable PATH
• ls, --help: commands, options, and parameters
• user: users or groups
•
Alt, Alt + F1: a key to press or a key combination; keys are shown in uppercase as
on a keyboard
•
File, File > Save As: menu items, buttons
• ►amd64 ipf: This paragraph is only relevant for the specied architectures. The
arrows mark the beginning and the end of the text block.◄
►ipseries s390 zseries: This paragraph is only relevant for the specied architectures. The arrows mark the beginning and the end of the text block.◄
•
Dancing Penguins (Chapter Penguins, ↑Another Manual): This is a reference to a
chapter in another manual.
About This Guide vii


Overview
Heartbeat is an open source server clustering system that ensures high availability and
manageability of critical network resources including data, applications, and services.
It is a multinode clustering product for Linux that supports failover, failback, and migration (load balancing) of individually managed cluster resources. Heartbeat is shipped
with SUSE Linux Enterprise Server 10 and provides you with the means to make virtual
machines (containing services) highly available.
This chapter introduces the main product features and benets of Heartbeat. Find several exemplary scenarios for conguring clusters and learn about the components
making up a Heartbeat version 2 cluster. The last section provides an overview of the
Heartbeat architecture, describing the individual architecture layers and processes
within the cluster.
1.1 Product Features
Heartbeat includes several important features to help you ensure and manage the
availability of your network resources. These include:
• Support for Fibre Channel or iSCSI storage area networks
1
• Multi-node active cluster, containing up to 16 Linux servers. Any server in the
cluster can restart resources (applications, services, IP addresses, and le systems)
from a failed server in the cluster.
Overview 1

• A single point of administration through either a graphical Heartbeat tool or a
command line tool. Both tools let you congure and monitor your Heartbeat cluster.
• The ability to tailor a cluster to the specic applications and hardware infrastructure
that t your organization.
• Dynamic assignment and reassignment of server storage on an as-needed basis.
• Time-dependent conguration enables resources to fail back to repaired nodes at
specied times.
• Support for shared disk systems. Although shared disk systems are supported, they
are not required.
• Support for cluster le systems like OCFS 2.
• Support for cluster-aware logical volume managers like EVMS.
1.2 Product Benets
Heartbeat allows you to congure up to 16 Linux servers into a high-availability cluster,
where resources can be dynamically switched or moved to any server in the cluster.
Resources can be congured to automatically switch or be moved in the event of a resource server failure, or they can be moved manually to troubleshoot hardware or balance
the workload.
Heartbeat provides high availability from commodity components. Lower costs are
obtained through the consolidation of applications and operations onto a cluster.
Heartbeat also allows you to centrally manage the complete cluster and to adjust resources to meet changing workload requirements (thus, manually “load balance” the
cluster).
An equally important benet is the potential reduction of unplanned service outages as
well as planned outages for software and hardware maintenance and upgrades.
Reasons that you would want to implement a Heartbeat cluster include:
2 Heartbeat
• Increased availability
• Improved performance
• Low cost of operation
• Scalability
• Disaster recovery
• Data protection
• Server consolidation
• Storage consolidation
Shared disk fault tolerance can be obtained by implementing RAID on the shared disk
subsystem.
The following scenario illustrates some of the benets Heartbeat can provide.
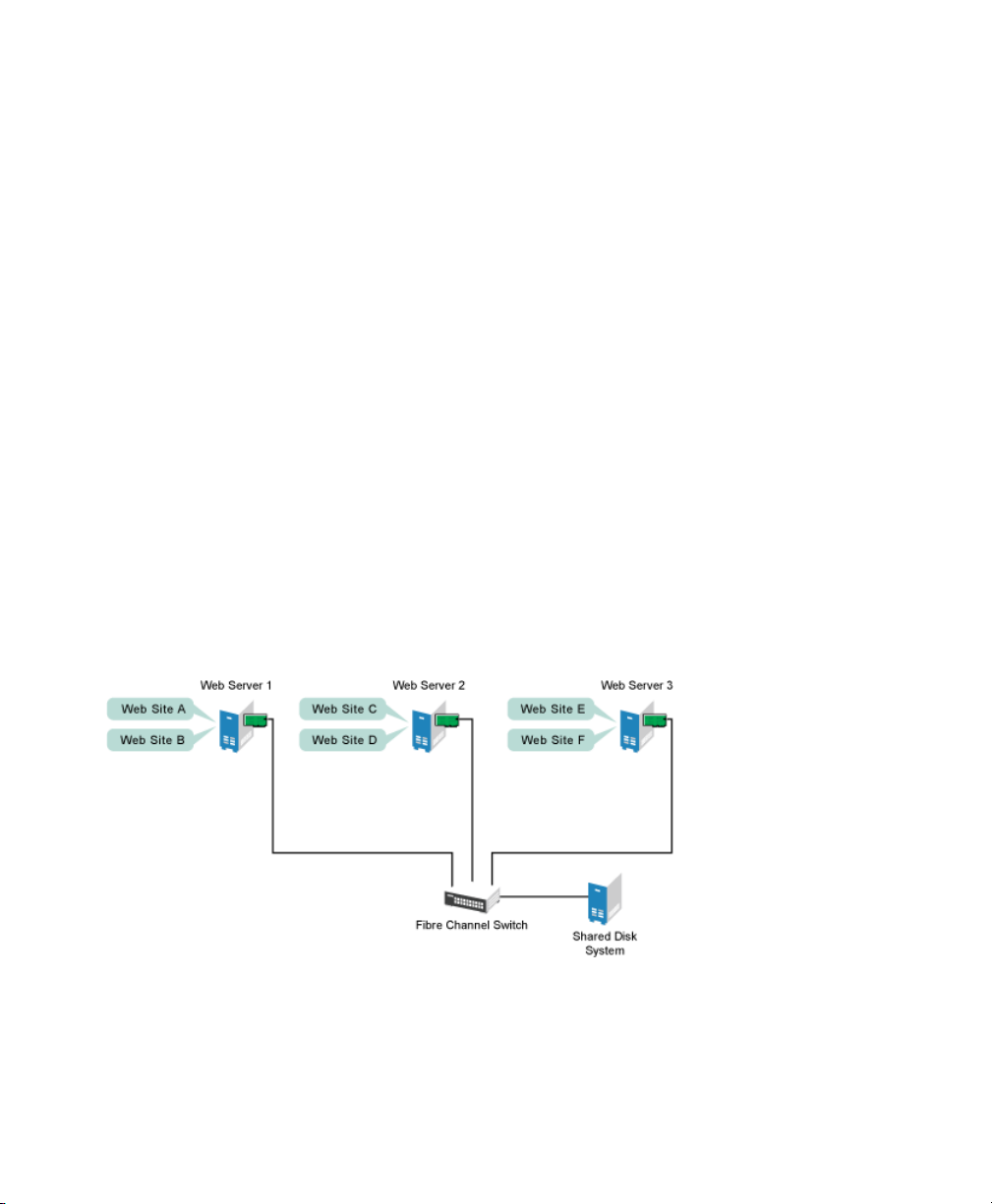
Suppose you have congured a three-server cluster, with a Web server installed on
each of the three servers in the cluster. Each of the servers in the cluster hosts two Web
sites. All the data, graphics, and Web page content for each Web site are stored on a
shared disk subsystem connected to each of the servers in the cluster. The following
gure depicts how this setup might look.
Figure 1.1
During normal cluster operation, each server is in constant communication with the
other servers in the cluster and performs periodic polling of all registered resources to
detect failure.
Three-Server Cluster
Overview 3
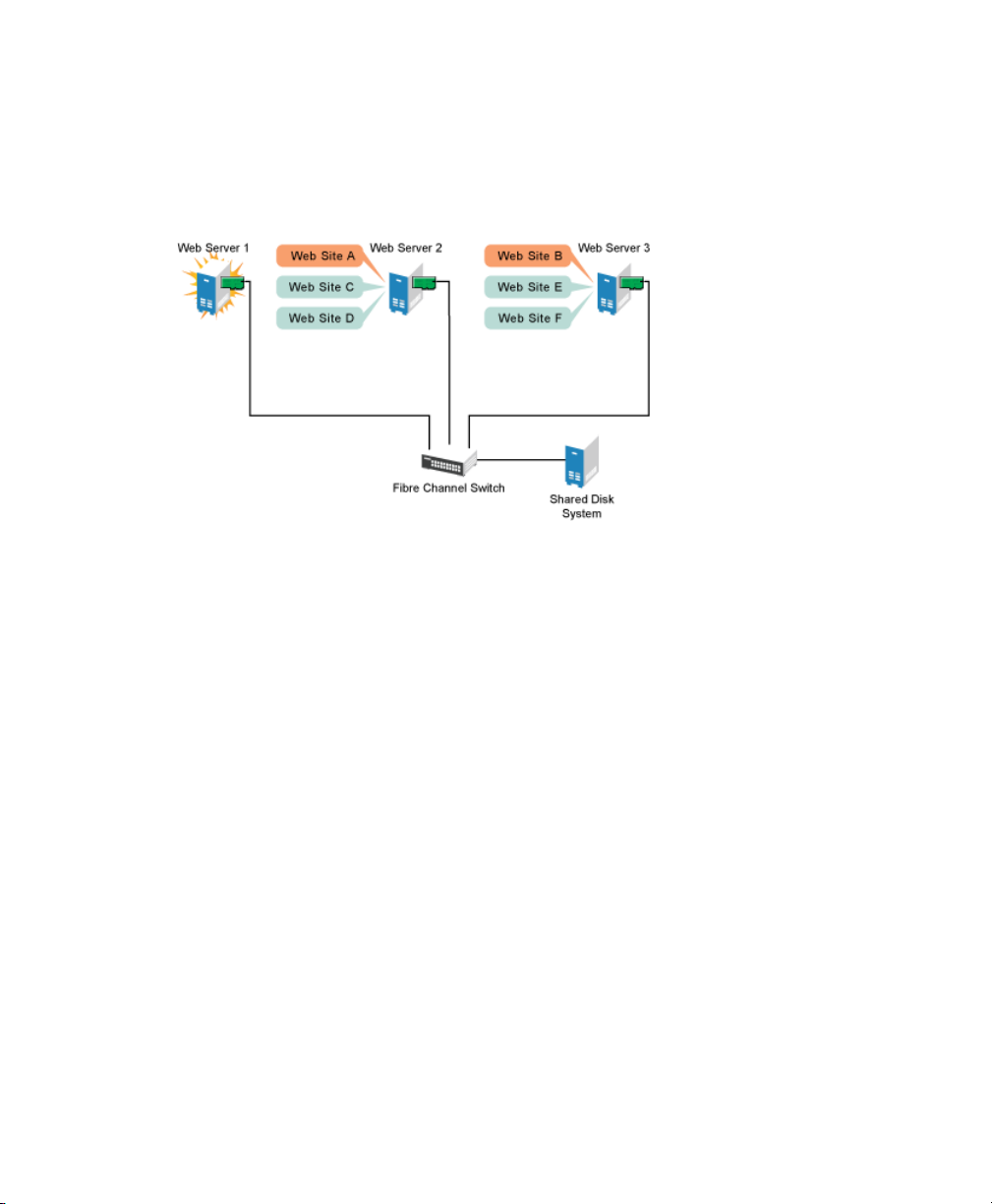
Suppose Web Server 1 experiences hardware or software problems and the users depending on Web Server 1 for Internet access, e-mail, and information lose their connections. The following gure shows how resources are moved when Web Server 1 fails.
Figure 1.2
Web Site A moves to Web Server 2 and Web Site B moves to Web Server 3. IP addresses
and certicates also move to Web Server 2 and Web Server 3.
When you congured the cluster, you decided where the Web sites hosted on each Web
server would go should a failure occur. In the previous example, you congured Web
Site A to move to Web Server 2 and Web Site B to move to Web Server 3. This way,
the workload once handled by Web Server 1 continues to be available and is evenly
distributed between any surviving cluster members.
When Web Server 1 failed, Heartbeat software
Three-Server Cluster after One Server Fails
In this example, the failover process happened quickly and users regained access to
Web site information within seconds, and in most cases, without needing to log in again.
4 Heartbeat
• Detected a failure
• Remounted the shared data directories that were formerly mounted on Web server
1 on Web Server 2 and Web Server 3.
• Restarted applications that were running on Web Server 1 on Web Server 2 and
Web Server 3
• Transferred IP addresses to Web Server 2 and Web Server 3

Now suppose the problems with Web Server 1 are resolved, and Web Server 1 is returned
to a normal operating state. Web Site A and Web Site B can either automatically fail
back (move back) to Web Server 1, or they can stay where they are. This is dependent
on how you congured the resources for them. There are advantages and disadvantages
to both alternatives. Migrating the services back to Web Server 1 will incur some downtime. Heartbeat also allows you to defer the migration until a period when it will cause
little or no service interruption.
Heartbeat also provides resource migration capabilities. You can move applications,
Web sites, etc. to other servers in your cluster without waiting for a server to fail.
For example, you could have manually moved Web Site A or Web Site B from Web
Server 1 to either of the other servers in the cluster. You might want to do this to upgrade
or perform scheduled maintenance on Web Server 1, or just to increase performance
or accessibility of the Web sites.
1.3 Cluster Congurations
Heartbeat cluster congurations might or might not include a shared disk subsystem.
The shared disk subsystem can be connected via high-speed Fibre Channel cards, cables,
and switches, or it can be congured to use iSCSI. If a server fails, another designated
server in the cluster automatically mounts the shared disk directories previously
mounted on the failed server. This gives network users continuous access to the directories on the shared disk subsystem.
IMPORTANT: Shared Disk Subsystem with EVMS
When using a shared disk subsystem with EVMS, that subsystem must be connected to all servers in the cluster.
Typical Heartbeat resources might include data, applications, and services. The following
gure shows how a typical Fibre Channel cluster conguration might look.
Overview 5
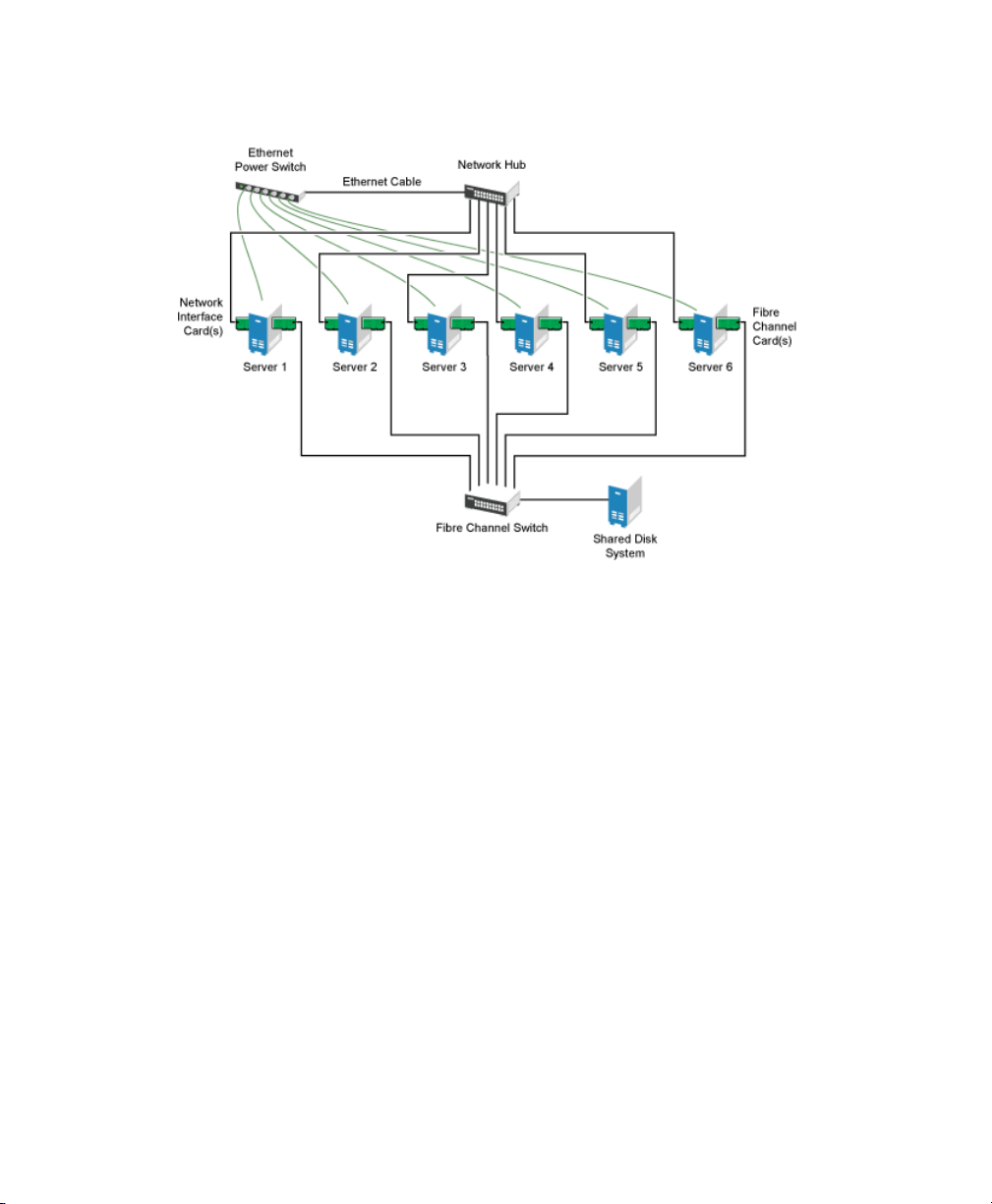
Figure 1.3
Although Fibre Channel provides the best performance, you can also congure your
cluster to use iSCSI. iSCSI is an alternative to Fibre Channel that can be used to create
a low-cost SAN. The following gure shows how a typical iSCSI cluster conguration
might look.
Typical Fibre Channel Cluster Conguration
6 Heartbeat
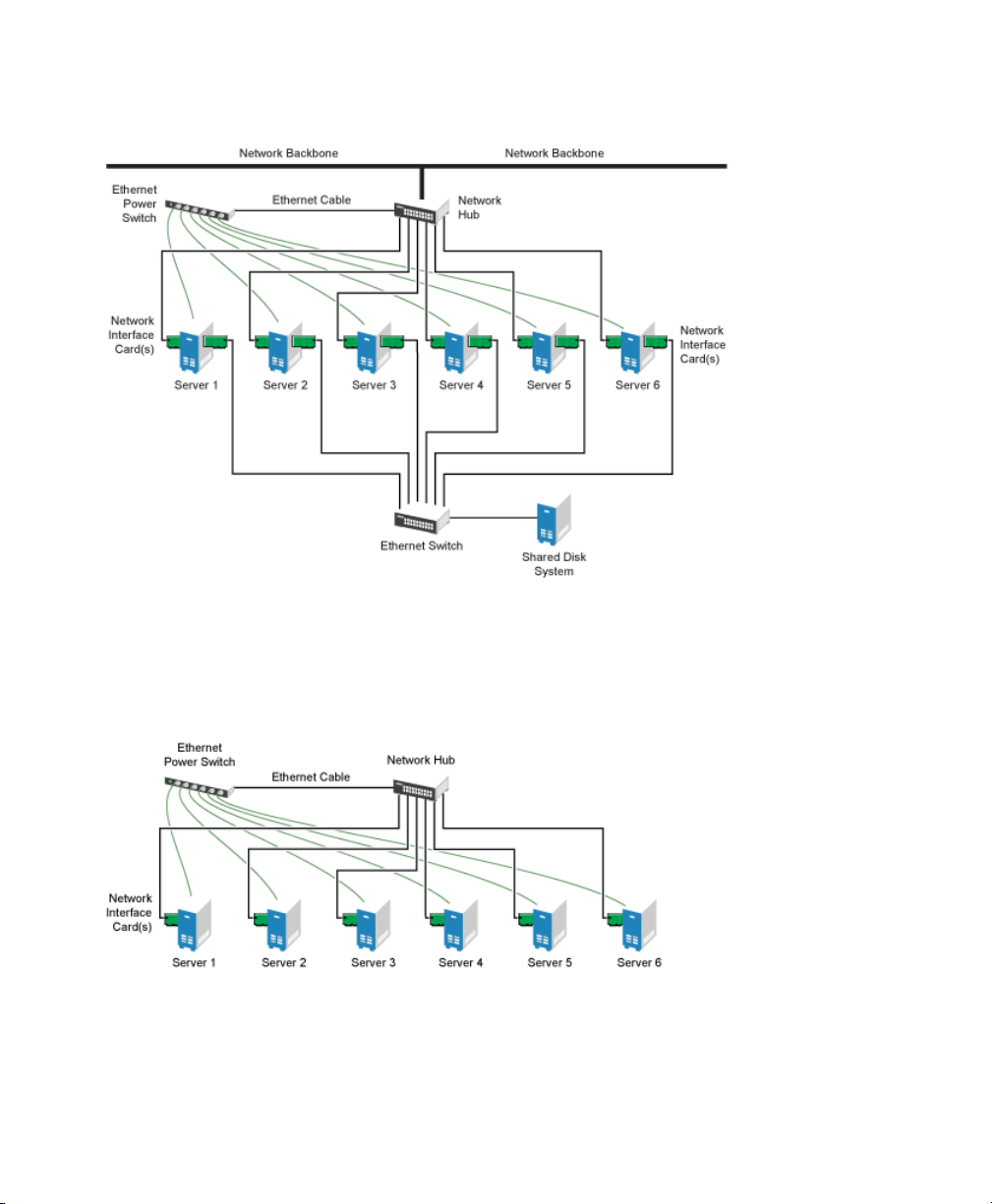
Figure 1.4
Although most clusters include a shared disk subsystem, it is also possible to create a
Heartbeat cluster without a share disk subsystem. The following gure shows how a
Heartbeat cluster without a shared disk subsystem might look.
Typical iSCSI Cluster Conguration
Figure 1.5
Typical Cluster Conguration Without Shared Storage
Overview 7

1.4 Heartbeat Cluster Components
The following components make up a Heartbeat version 2 cluster:
• From 2 to 16 Linux servers, each containing at least one local disk device.
• Heartbeat software running on each Linux server in the cluster.
• Optional: A shared disk subsystem connected to all servers in the cluster.
• Optional: High-speed Fibre Channel cards, cables, and switch used to connect the
servers to the shared disk subsystem.
• At least two communications mediums over which Heartbeat servers can communicate. These currently include Ethernet (mcast, ucast, or bcast) or Serial.
• A STONITH device. A STONITH device is a power switch which the cluster uses
to reset nodes that are considered dead. Resetting non-heartbeating nodes is the
only reliable way to ensure that no data corruption is performed by nodes that hang
and only appear to be dead.
See The High-Availability Linux Project [http://www.linux-ha.org/
STONITH] for more information on STONITH.
1.5 Architecture
This section provides a brief overview of the Heartbeat architecture. It identies and
provides information on the Heartbeat architectural components, and describes how
those components interoperate.
1.5.1 Architecture Layers
Heartbeat has a layered architecture. Figure 1.6, “Heartbeat Architecture” (page 9)
illustrates the different layers and their associated components.
8 Heartbeat
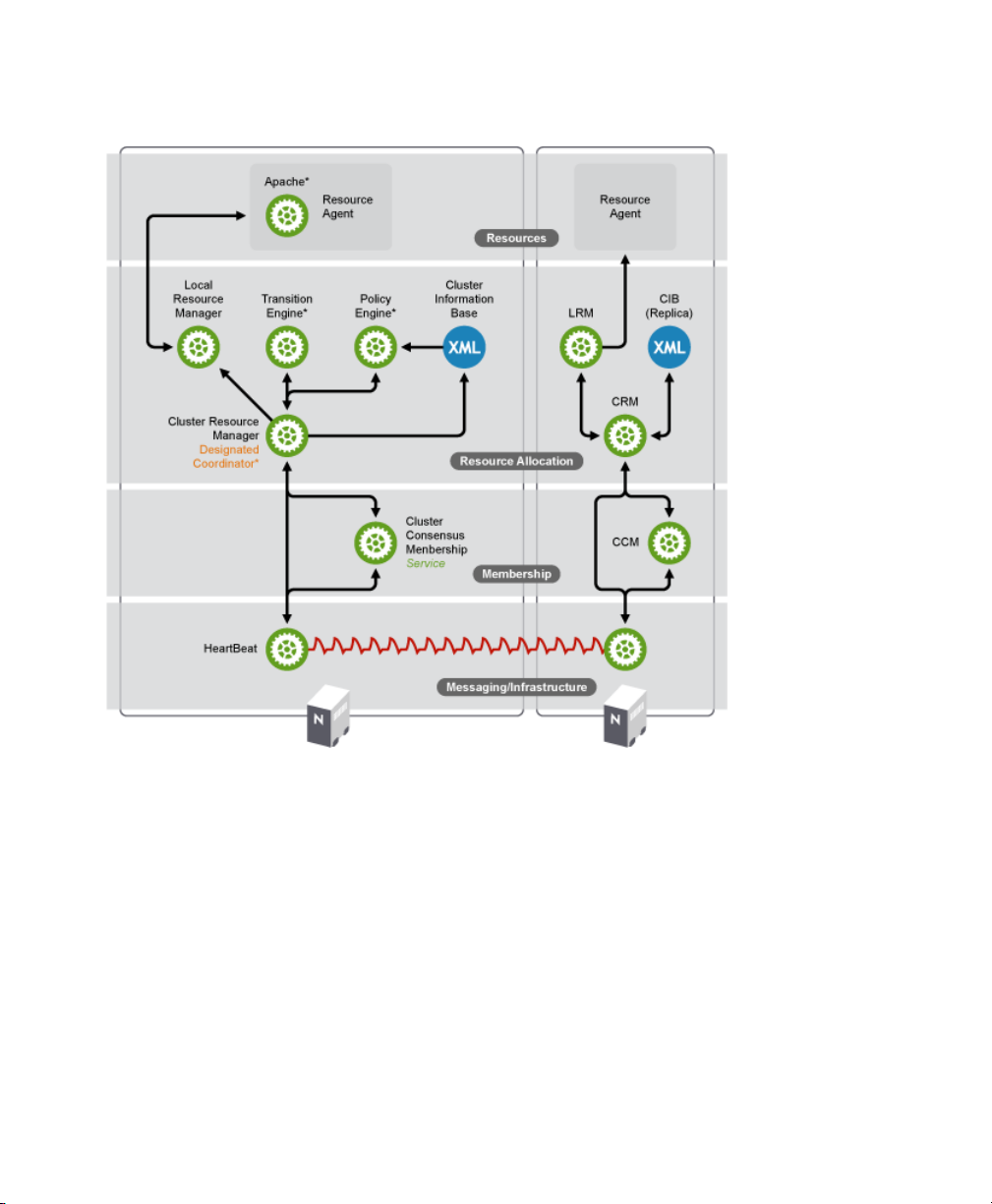
Figure 1.6
Heartbeat Architecture
Messaging and Infrastructure Layer
The primary or rst layer is the messaging/infrastructure layer, also known as the
Heartbeat layer. This layer contains components that send out the Heartbeat messages
containing “I'm alive” signals, as well as other information. The Heartbeat program
resides in the messaging/infrastructure layer.
Membership Layer
The second layer is the membership layer. The membership layer is responsible for
calculating the largest fully connected set of cluster nodes and synchronizing this view
Overview 9

to all of its members. It performs this task based on the information it gets from the
Heartbeat layer. The logic that takes care of this task is contained in the Cluster Consensus Membership service, which provides an organized cluster topology overview
(node-wise) to cluster components that are the higher layers.
Resource Allocation Layer
The third layer is the resource allocation layer. This layer is the most complex, and
consists of the following components:
Cluster Resource Manager
Every action taken in the resource allocation layer passes through the Cluster Resource Manager. If any other components of the resource allocation layer, or other
components which are in a higher layer need to communicate, they do so through
the local Cluster Resource Manager.
On every node, the Cluster Resource Manager maintains the Cluster Information
Base, or CIB (see Cluster Information Base (page 10) below). One Cluster Resource
Manager in the cluster is elected as the Designated Coordinator (DC), meaning that
it has the master CIB. All other CIBs in the cluster are a replicas of the master CIB.
Normal read and write operations on the CIB are serialized through the master CIB.
The DC is the only entity in the cluster that can decide that a cluster-wide change
needs to be performed, such as fencing a node or moving resources around.
Cluster Information Base
10 Heartbeat
The Cluster Information Base or CIB is an in-memory XML representation of the
entire cluster conguration and status, including node membership, resources,
constraints, etc. There is one master CIB in the cluster, maintained by the DC. All
the other nodes contain a CIB replica. If an administrator wants to manipulate the
cluster's behavior, he can use either the cibadmin command line tool or the
Heartbeat GUI tool.
NOTE: Usage of Heartbeat GUI Tool and cibadmin
The Heartbeat GUI tool can be used from any machine with a connection
to the cluster. The cibadmin command must be used on a cluster node,
and is not restricted to only the DC node.

Policy Engine (PE) and Transition Engine (TE)
Whenever the Designated Coordinator needs to make a cluster-wide change (react
to a new CIB), the Policy Engine is used to calculate the next state of the cluster
and the list of (resource) actions required to achieve it. The commands computed
by the Policy Engine are then executed by the Transition Engine. The DC will send
out messages to the relevant Cluster Resource Managers in the cluster, who then
use their Local Resource Managers (see Local Resource Manager (LRM) (page 11)
below) to perform the necessary resource manipulations. The PE/TE pair only runs
on the DC node.
Local Resource Manager (LRM)
The Local Resource Manager calls the local Resource Agents (see Section “Resource
Layer” (page 11) below) on behalf of the CRM. It can thus perform start / stop /
monitor operations and report the result to the CRM. The LRM is the authoritative
source for all resource related information on its local node.
Resource Layer
The fourth and highest layer is the Resource Layer. The Resource Layer includes one
or more Resource Agents (RA). A Resource Agent is a program, usually a shell script,
that has been written to start, stop, and monitor a certain kind of service (a resource).
The most common Resource Agents are LSB init scripts. However, Heartbeat also
supports the more exible and powerful Open Clustering Framework Resource Agent
API. The agents supplied with Heartbeat are written to OCF specications. Resource
Agents are called only by the Local Resource Manager. Third parties can include their
own agents in a dened location in the le system and thus provide out-of-the-box
cluster integration for their own software.
1.5.2 Process Flow
Many actions performed in the cluster will cause a cluster-wide change. These actions
can include things like adding or removing a cluster resource or changing resource
constraints. It is important to understand what happens in the cluster when you perform
such an action.
For example, suppose you want to add a cluster IP address resource. To do this, you
use either the cibadmin command line tool or the Heartbeat GUI tool to modify the
master CIB. It is not required to use the cibadmin command or the GUI tool on the
Overview 11

Designated Coordinator. You can use either tool on any node in the cluster, and the
local CIB will relay the requested changes to the Designated Coordinator. The Designated Coordinator will then replicate the CIB change to all cluster nodes and will start
the transition procedure.
With help of the Policy Engine and the Transition Engine, the Designated Coordinator
obtains a series of steps that need to be performed in the cluster, possibly on several
nodes. The Designated Coordinator sends commands out via the messaging/infrastructure
layer which are received by the other Cluster Resource Managers.
If necessary, the other Cluster Resource Managers use their Local Resource Manager
to perform resource modications and report back to the Designated Coordinator about
the result. Once the Transition Engine on the Designated Coordinator concludes that
all necessary operations are successfully performed in the cluster, the cluster will go
back to the idle state and wait for further events.
If any operation was not carried out as planned, the Policy Engine is invoked again
with the new information recorded in the CIB.
When a service or a node dies, the same thing happens. The Designated Coordinator
is informed by the Cluster Consensus Membership service (in case of a node death) or
by a Local Resource Manager (in case of a failed monitor operation). The Designated
Coordinator determines that actions need to be taken in order to come to a new cluster
state. The new cluster state will be represented by a new CIB.
12 Heartbeat

Installation and Setup
A Heartbeat cluster can be installed and congured using YaST. During the Heartbeat
installation, you are prompted for information that is necessary for Heartbeat to function
properly. This chapter contains information to help you install, set up, and congure a
Heartbeat cluster. Learn about the hardware and software requirements and which
preparations to take before installing Heartbeat. Find detailed information about the
installation process and the conguration of a STONITH device.
NOTE: Installing Heartbeat Software Packages on Cluster Nodes
This Heartbeat installation program does not copy the Heartbeat software
package to cluster nodes. Prior to running the installation program, the Heartbeat software package must be installed on all nodes that will be part of your
cluster. This can be done during the SUSE Linux Enterprise Server 10 installation,
or after.
The Heartbeat installation program lets you create a new cluster or add nodes to an
existing cluster. To add new nodes to an existing cluster, you must run the installation
program from a node that is already in the cluster, not on a node that you want to add
to the cluster.
After installing Heartbeat, you need to create and congure cluster resources. You
might also need to create le systems on a shared disk (Storage Area Network, SAN)
if they do not already exist and, if necessary, congure those le systems as Heartbeat
cluster resources.
2
Both cluster-aware (OCFS 2) and non-cluster-aware le systems can be congured
with Heartbeat. See the Oracle Cluster File System 2 Administration Guide [http://
Installation and Setup 13

www.novell.com/documentation/sles10/sles_admin/data/ocfs2
.html] for more information.
2.1 Hardware Requirements
The following list species hardware requirements for a Heartbeat cluster. These requirements represent the minimum hardware conguration. Additional hardware might
be necessary, depending on how you intend to use your Heartbeat cluster.
• A minimum of two Linux servers. The servers do not require identical hardware
(memory, disk space, etc.).
• At least two communication media (Ethernet, etc.) that allow cluster nodes to
communicate with each other. The communication media should support a data
rate of 100 Mbit/s or higher.
• A STONITH device.
2.2 Software Requirements
Ensure that the following software requirements are met:
• SLES 10 with all available online updates installed on all nodes that will be part
• The Heartbeat software package including all available online updates installed to
2.3 Shared Disk System Requirements
A shared disk system (Storage Area Network, or SAN) is recommended for your cluster
if you want data to be highly available. If a shared disk subsystem is used, ensure the
following:
• The shared disk system is properly set up and functional according to the manufac-
14 Heartbeat
of the Heartbeat cluster.
all nodes that will be part of the Heartbeat cluster.
turer’s instructions.

• The disks contained in the shared disk system should be congured to use mirroring
or RAID to add fault tolerance to the shared disk system. Hardware-based RAID
is recommended. Software-based RAID1 is not supported for all congurations.
• If you are using iSCSI for shared disk system access, ensure that you have properly
congured iSCSI initiators and targets.
2.4 Preparations
Prior to installation, execute the following preparatory steps:
• Congure hostname resolution by either setting up a DNS server or by editing the
/etc/hosts le on each server in the cluster as described in Modifying /etc/
hosts with YaST (page 15). It is essential that members of the cluster are able
to nd each other by name. If the names are not available, internal cluster communication will fail.
• Congure time synchronization by making Heartbeat nodes synchronize to a time
server outside the cluster as described in Conguring the Heartbeat Servers for
Time Synchronization (page 16). The cluster nodes will use the time server as their
time synchronization source.
Heartbeat does not require that time is synchronized for each of the nodes in the
cluster, however, it is highly recommended if you ever plan to look at logles.
Procedure 2.1
On one SLES 10 server, open YaST, and in left column, select Network Services
1
> Hostnames.
In the Host Conguration window, click Add and ll in the necessary information
2
in the pop-up window for one other server in the cluster.
This information includes the IP address, hostname (for example node2.novell.com), and host alias (for example node2) of the other server.
Use node names for host aliases. You can nd node names by executing uname
-n at a command prompt on each server.
Modifying /etc/hosts with YaST
Installation and Setup 15

Click OK, and then repeat Step 2 (page 15) to add the other nodes in the cluster
3
to the /etc/hosts le on this server.
Repeat Step 1 (page 15) through Step 3 (page 16) on each server in your
4
Heartbeat cluster.
To check if hostname resolution is functioning properly, ping the node name
5
(host alias) you specied in Step 2 (page 15) .
Procedure 2.2
Time synchronization will not start unless the date and time on the cluster servers is
already close. To manually set the date and time on cluster servers, use the date
command at the command line of each cluster server to view, and if necessary change,
the date and time for that server.
To congure the nodes in the cluster to use the time server as their time source proceed
as follows:
On a cluster server, start YaST, click Network Services, then click NTP Client.
1
Choose to have the NTP daemon start during boot and then enter the IP address
2
of the time server you congured.
Click Finish and reboot this server to ensure the service starts correctly.
3
Repeat Step 1 (page 16) through Step 3 (page 16) on the other non-time server
4
nodes in the cluster.
Reboot all cluster nodes. After rebooting the nodes, time should be synchronized
5
properly.
To check if time synchronization is functioning properly, run the ntpq -p
6
command on each cluster node. Running the ntpq -p command on a non-time
server node will display the server that is being used as the time source.
Conguring the Heartbeat Servers for Time Synchronization
16 Heartbeat
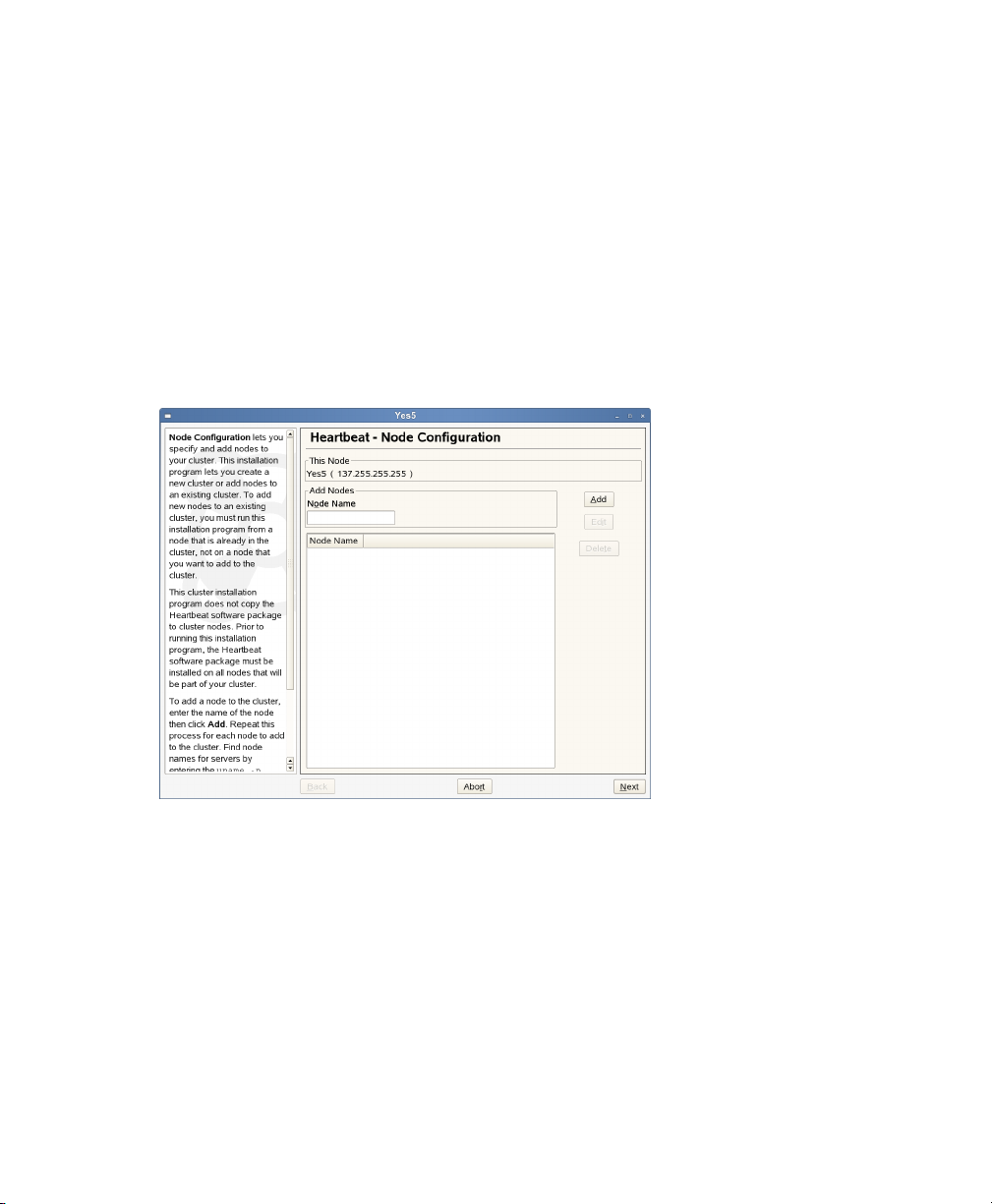
2.5 Installing Heartbeat
Start YaST and select Miscellaneous > High Availability or enter yast2
1
heartbeat to start the YaST Heartbeat module. It lets you create a new cluster
or add new nodes to an existing cluster.
On the Node Conguration screen, add a node to the cluster by specifying the
2
node name of the node you want to add, then click Add. Repeat this process for
each node you want to add to the cluster, then click Next.
Figure 2.1
You can nd node names for servers by entering uname -n on each node.
The installation program will not let you add this node, because the node name
of this server is already automatically added to the cluster.
Node Conguration
If after adding a node to the cluster, you need to specify a different node name
for that node, double-click the node you want to edit, change the node name,
then click Edit.
Installation and Setup 17
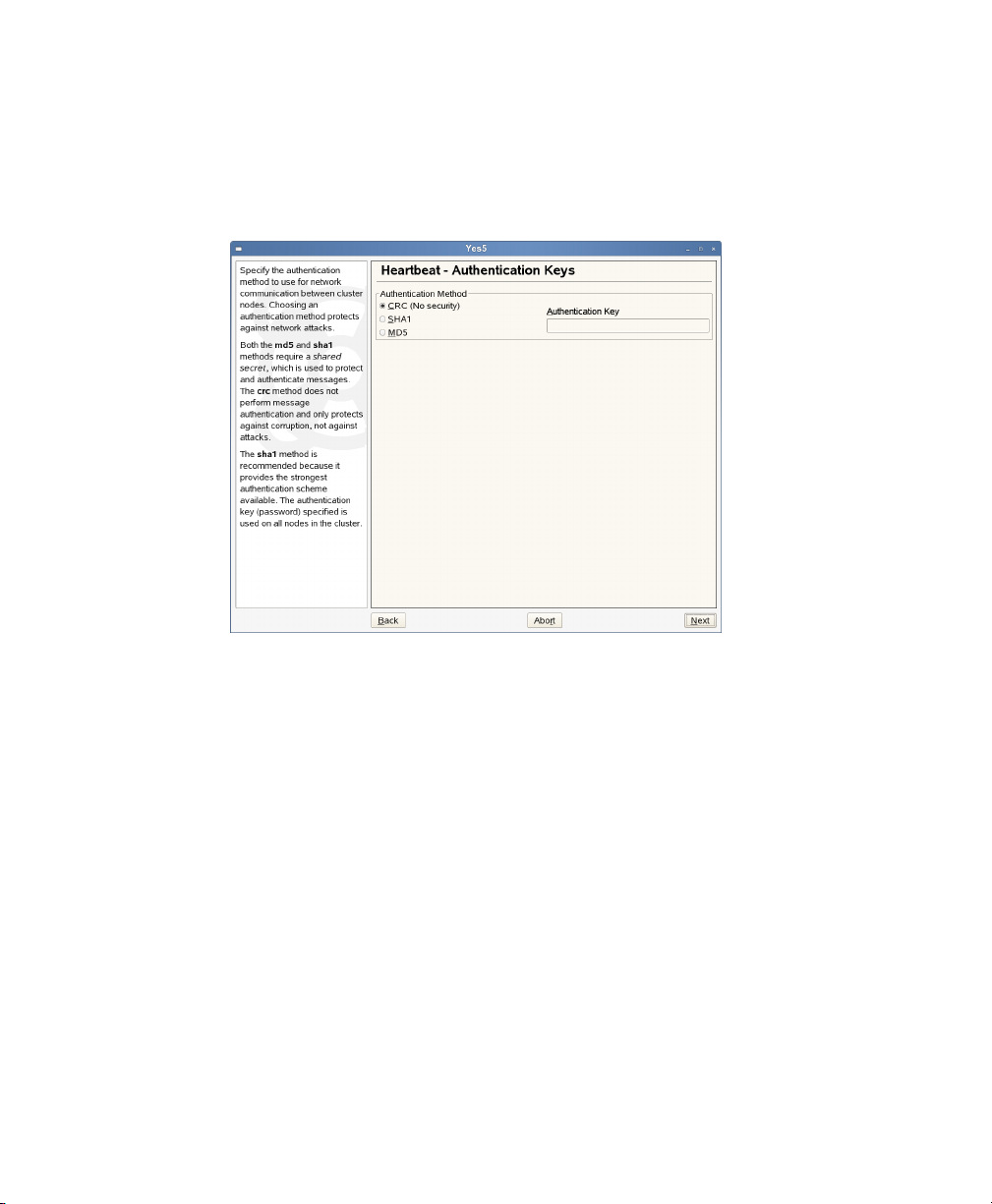
On the Authentication Keys screen, specify the authentication method the cluster
3
will use for communication between cluster nodes, and if necessary an Authentication Key (password). Then click Next.
Figure 2.2
Both the MD5 and SHA1 methods require a shared secret, which is used to protect
and authenticate messages. The CRC method does not perform message authentication, and only protects against corruption, not against attacks.
The SHA1 method is recommended, because it provides the strongest authentication scheme available. The authentication key (password) you specify will be
used on all nodes in the cluster.
Authentication Keys
18 Heartbeat
When running this installation program on the other cluster nodes, you should
choose the same authentication method for all nodes.
On the Media Conguration screen, specify the method Heartbeat will use for
4
internal communication between cluster nodes. This conguration is written to
/etc/ha.d/ha.cf.
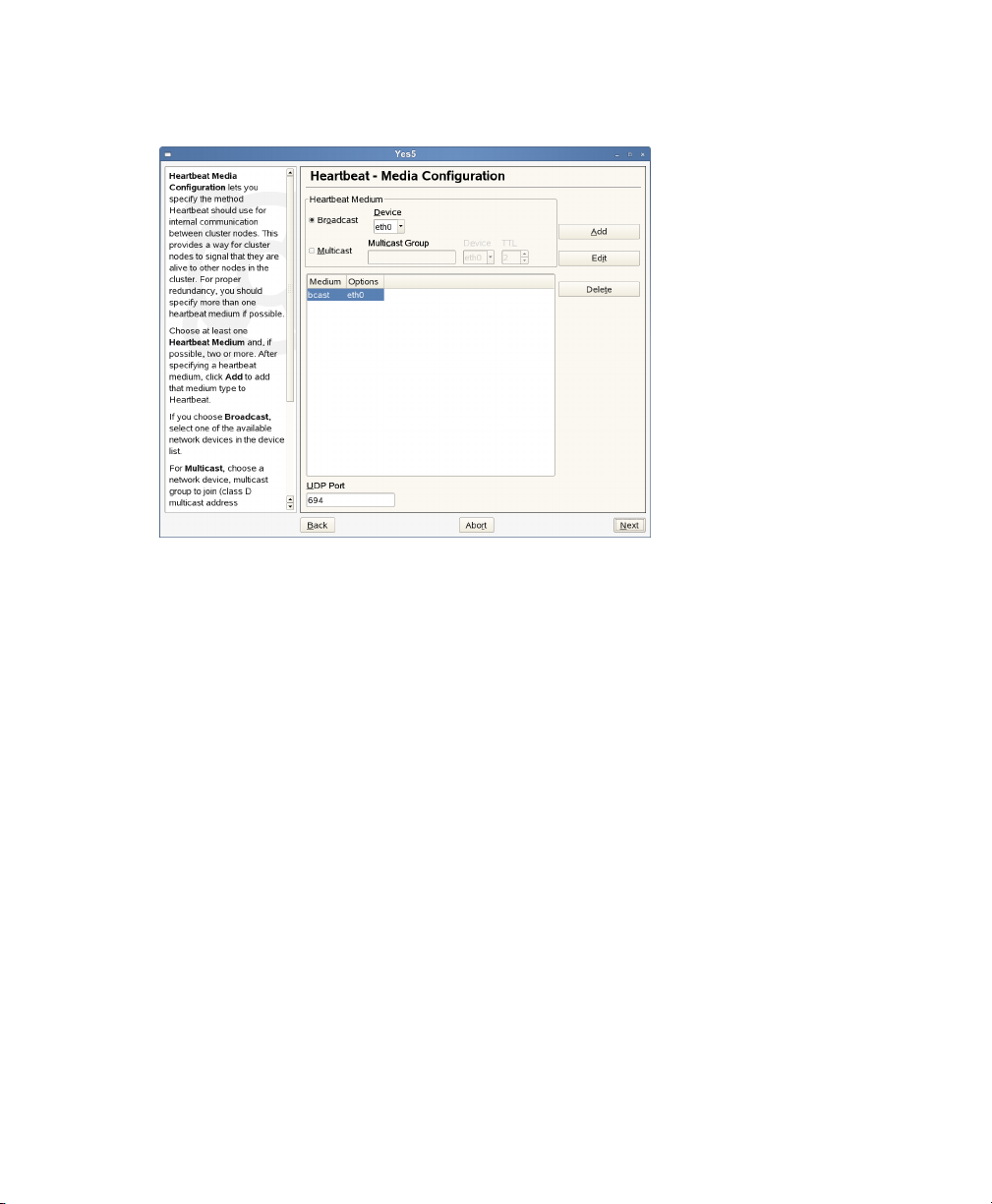
Figure 2.3
This provides a way for cluster nodes to signal that they are alive to other nodes
in the cluster. For proper redundancy, you should specify at least two Heartbeat
media if possible. Choose at least one Heartbeat medium, and if possible, more
than one:
Media Conguration
•
If you choose Broadcast, select one of the available network devices in the
Device list.
•
For Multicast, choose a network Device, Multicast Group to join (class D
multicast address 224.0.0.0 - 239.255.255.255) and the TTL value (1-255).
UDP Port sets the UDP port that is used for the broadcast media. Leave this set
to the default value (694) unless you are running multiple Heartbeat clusters on
the same network segment, in which case you need to run each cluster on a different port number.
Installation and Setup 19
NOTE: UDP Port Settings
Note that the UDP port setting only apply to broadcast media, not to
the other media you may use. When editing UDP ports manually in /etc/
ha.d/ha.cf, the udpport entry must precede the bcast entry it
belongs to, otherwise Heartbeat will ignore the port setting.
After specifying a Heartbeat medium, click Add to add that medium type to
Heartbeat and proceed with Next.
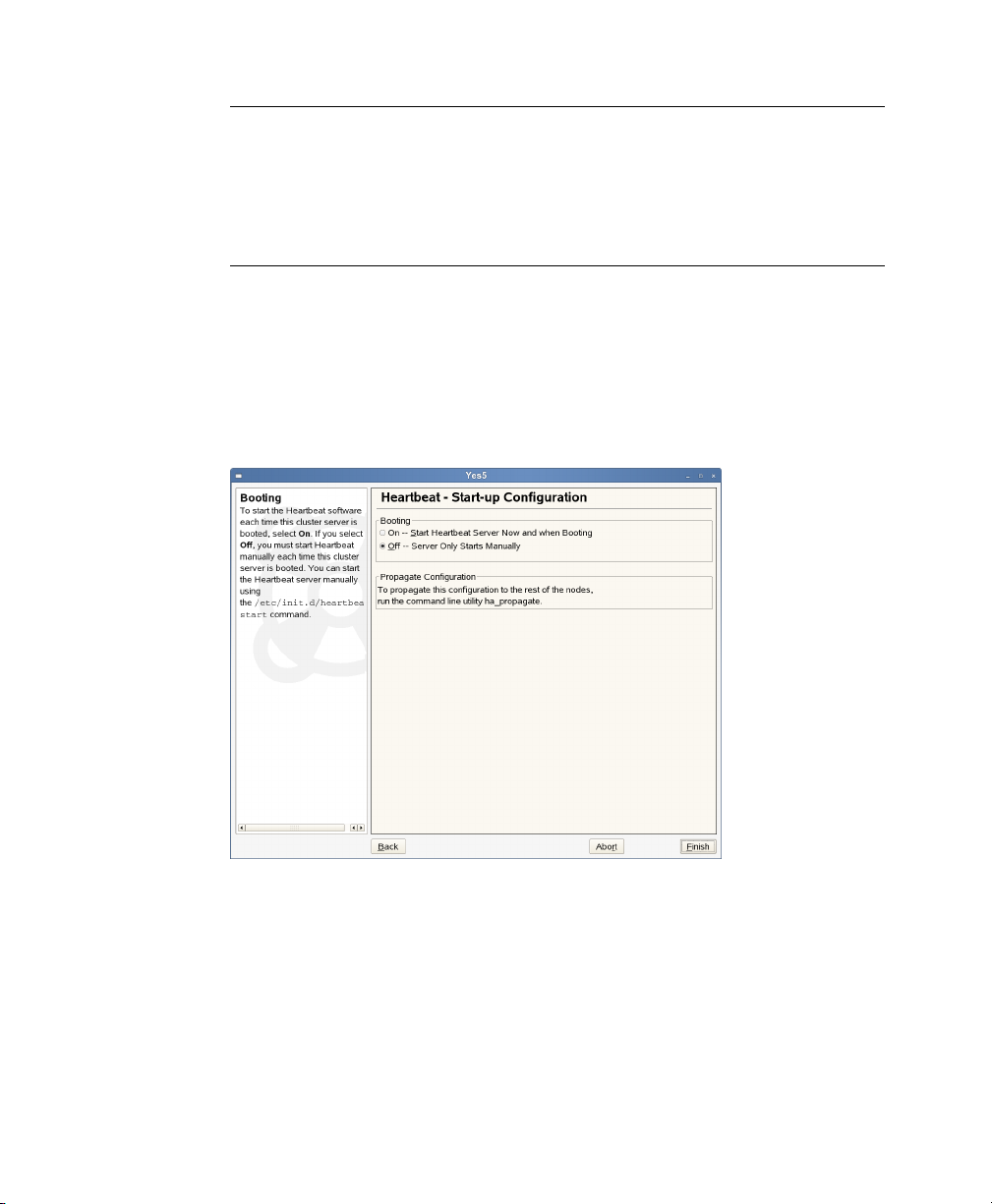
On the Start-up Conguration screen, choose whether you want to start the
5
Heartbeat software on this cluster server each time it is booted.
Figure 2.4
If you select Off, you must start Heartbeat manually each time this cluster server
is booted. You can start the Heartbeat server manually using the rcheartbeat
start command.
To start the Heartbeat server immediately, select On - Start Heartbeat Server
Now and when Booting.
Startup Conguration
20 Heartbeat

To start Heartbeat on the other servers in the cluster when they are booted, enter
chkconfig heartbeat on at the server console of each of those servers.
You can also enter chkconfig heartbeat off at the server console to
have Heartbeat not start automatically when the server is rebooted.
To congure Heartbeat on the other nodes in the cluster run
6
/usr/lib/heartbeat/ha_propagate on the heartbeat node you just
congured. On 64-bit systems, the command ha_propagate is located below
/usr/lib64/heartbeat/.
This will copy the Heartbeat conguration to the other nodes in the cluster. You
will be prompted to enter the root user password for each cluster node.
Run rcheartbeat start to start heartbeat on each of the nodes where the
7
conguration has been copied.
2.6 Conguring STONITH
STONITH is the service used by Heartbeat to protect shared data. Heartbeat is capable
of controlling a number of network power switches, and can prevent a potentially faulty
node from corrupting shared data by using STONITH to cut the power to that node.
With the STONITH service congured properly, Heartbeat does the following if a node
fails:
• Notices that the node is not sending “I'm alive” packets out to the cluster.
• Sends out pre-stop notications to the other cluster nodes.
These notications include messages that the failed node will be powered off.
• Instructs the STONITH service to power off the failed node.
• Sends post-stop notications to other cluster nodes after successfully powering off
the failed node.
These notications include messages that the failed node will be powered off.
Installation and Setup 21

For Heartbeat, STONITH must be congured as a cluster resource. After reviewing
Chapter 4, Conguring and Managing Cluster Resources (page 29), continue with
Conguring STONITH as a Cluster Resource (page 22).
Procedure 2.3
Start the HA Management Client and log in to the cluster as described in
1
Section 4.1, “Graphical HA Management Client” (page 29).
To generally enable the use of STONITH, select the linux-ha entry in the left
2
pane and click the Congurations tab on the right.
Activate the STONITH Enabled check box.
3
From the menu, select Resources > Add New Item or click the + button.
4
Choose Native as the item type.
5
Specify the Resource ID (name) for the STONITH resource.
6
In the Type section of the window, scroll down and select the type of STONITH
7
device that corresponds to your network power switch.
(Conditional) After selecting a STONITH resource type, a line for that resource
8
type might be added to the Parameters section of the screen. If a line is added,
click the line once and then click the line again under the Value heading to
open a eld where you can add the needed value.
Conguring STONITH as a Cluster Resource
22 Heartbeat
Some STONITH options require you to add parameter values in the parameters
section of the page. For example, you may be required to add host names
(server names) for each cluster node in your cluster. You can nd the hostname
for each server using the uname -n command on the server. You can add
multiple hostnames in the provided eld using a comma or a space to separate
the names.
Select the Clone check box. This allows the resource to simultaneously run
9
on multiple cluster nodes.
In the clone_node_max eld, enter the number of instances of STONITH that
10
will run on a given node. This value should normally be set to 1.
 Loading...
Loading...