

Page 1

Notepad ++ Podręcznik użytkownika
Dokumentacja jest jak seks, kiedy jest dobra, jest bardzo, bardzo dobra; kiedy
jest zła, jest lepsza niż nic.
Oczywiście nie jest naszym celem tworzenie złej dokumentacji, ale rozumiesz, co mamy
na myśli.
Notepad ++ Podręcznik użytkownika jest budowany wspólnie, a Twój wkład jest
bardzo mile widziany.
Pobierz offline Podręcznik użytkownika
Co to jest Notepad ++
Notepad ++ to edytor tekstu i edytor kodu źródłowego do użytku w systemie Microsoft
Windows. Obsługuje około 80 języków programowania z podświetlaniem składni i
składaniem kodu. Umożliwia pracę z wieloma otwartymi plikami w jednym oknie, dzięki
interfejsowi edycji z zakładkami. Notepad++ jest dostępny na licencji GPL i
rozpowszechniany jako wolne oprogramowanie.
Możesz odwiedzić stronę Notepad ++ pod adresemhttps://notepad-plus-plus.org/
Pobierz Notepad ++
Pobierz najnowszą wersję Notepad ++ z https://notepad-plus-plus.org/downloads/
Wybierz 32 lub 64-bitową kompilację Notepad ++ zgodnie z systemem operacyjnym, a
następnie wybierz pakiet, który chcesz pobrać. Większość użytkowników korzysta z
instalatora, ponieważ jest to najłatwiejsza trasa, jednak Notepad ++ jest również
dostępny w formatach 7z i zip.
Zainstaluj Notepad ++ za pomocą instalatora
1. Pobierz instalator
Page 2
2. Uruchom plik wykonywalny i postępuj zgodnie z instrukcjami instalacji
Język
ActionScript
Ada
ASN.1
ASP
Montaż
AutoIt
Skrypty
AviSynth
BaanC •
pliki
wsadowe
Blitz Basic
C
C #
C++
Kamila
CMake
Cobol
CoffeeScript
Dźwięk
CSS
D
Różn
Erlang
escript
Naprzód
Fortran
FreeBASIC
Gui4Cli
Haskell
Kod HTML
Pliki INI
Intel HEX
Skrypty Inno
Setup
Jawa
JavaScript
JSON
JSP
KiXtart
Lateks
SEPLENIENI
E
Lua
Jeśli wykonujesz instalację zarządzaną lub w inny sposób chcesz kontrolować instalator
z wiersza poleceń, instalator ma kilka opcji wiersza poleceń.
Zainstaluj Notepad ++ z 7z lub zip
1. Tworzenie nowego folderu
2. Rozpakuj zawartość do nowego folderu
3. Uruchom Notepad ++ z nowego folderu
Obsługiwane języki programowania
Prawie 80 języków programowania jest obsługiwanych przez Notepad ++:
Page 3
Makefile
Matlab
MMIX
Nim
nnCron
Skrypty NSIS
Cel-C
Skrypt
OScript
Paskal
Perl
Język PHP
Dopisek
Program
PowerShell
PureBasic
Pyton
R
Rebol
Skrypt
rejestru (reg)
Plik zasobów
Rubin
Rdza
Plan
Skrypt
powłoki
Smalltalk
PRZYPRAW
A
SQL
Szybki
S-Record
Tcl
Tektronix
HEX
Tex
txt2tags
Visual Basic
Prolog
wizualny
VHDL
Verilog
XML
YAML
Notepad ++ obsługuje ich podświetlanie składni (konfigurowalne), składanie
składni, automatyczne uzupełnianie (konfigurowalne), listę funkcji (konfigurowalne za
pomocą PCRE w pliku xml).
Jeśli Twojego ukochanego języka nie ma na powyższej liście, możesz go łatwo
zdefiniować za pomocą User Defined Languages System.
Co to są języki zdefiniowane przez użytkownika
Notepad ++ jest fabrycznie spakowany z wieloma lekserami językowymi, które stosują
podświetlanie składni do kodu źródłowego lub danych tekstowych. Jednak nie każdy
możliwy język lub styl formatowania jest dostępny. Wprowadź User Defined Languages
(lub w skrócie "UDL"): interfejs UDL pozwala użytkownikowi zdefiniować reguły
formatowania normalnego tekstu, słów kluczowych, komentarzy, liczb; zdefiniować
ograniczniki (takie jak cudzysłowy wokół ciągów lub nawiasy wokół list), które
spowodują sformatowanie tekstu między tymi ogranicznikami; oraz do definiowania
symboli lub słów kluczowych, które mogą być użyte do umożliwienia składania
(ukrywanie na żądanie i odkrywanie bloków kodu lub tekstu).
Page 4

Okno dialogowe lub okno UDL
Menu Języki na pasku menu zawiera listę języków wbudowanych, a poniżej znajduje
się separator, a następnie Zdefiniuj swój język... i lista wszystkich języków UDL, które
zostały już zdefiniowane.
Korzystanie z > Języki Definiowanie języka... spowoduje wyeksowanie okna
dialogowego (które można zadokować jako okienko w oknie Notatnik++ lub może być
ruchomym oknem dialogowym).
Główne menu rozwijane i przyciski są dostępne, niezależnie od aktywnej karty
konfiguracji:
Lista rozwijana Język użytkownika zawiera wszystkie istniejące UDL, które
pozwolą Ci wybrać UDL, który chcesz edytować lub zbadać. Istnieje specjalny
wpis dla domyślnego UDL, zwany tutaj Językiem zdefiniowanym przez
użytkownika (chociaż pojawia się w menu Języki Notepad ++ jako
Zdefiniowane przez użytkownika), który może być używany jako szablon dla
innych UDL.
Opcja Utwórz nowy skopiuje domyślne style i reguły języka zdefiniowanego
przez użytkownika do nowej nazwy.
Opcja Zapisz jako skopiuje aktualnie wybrany plik UDL ze wszystkimi jego
stylami i regułami do nowej nazwy.
Import... zaimportuje plik XML UDL do bieżącej instancji(patrz poniżej).
Eksport... zapisze plik XML UDL w wybranej lokalizacji; następnie możesz
udostępnić to innym, aby mogli zaimportować Twój UDL na własny użytek.
Dock lub Undock przełączy się, czy okno dialogowe UDL jest samodzielnym
oknem dialogowym, czy zadokowanym w oknie Notepad ++.
☐ Ignoruj przypadek spowoduje, że różne słowa kluczowe będą ignorować
litery podczas dopasowywania.
☐ przezroczystość (gdy nie jest zadokowana) sprawi, że okno dialogowe
będzie półprzezroczyste; suwak zmienia się z praktycznie niewidocznego (aż do
lewej) na przeważnie nieprzezroczysty (aż do prawej); jeśli chcesz, aby był
całkowicie nieprzezroczysty (bez przezroczystości), odznacz pole.
Gdy na menu rozwijanym zostanie wybrany język UDL inny niż domyślny język
zdefiniowany przez użytkownika, dostępne będą również następujące elementy:
Zmień nazwę aktualnie wybranego UDL.
Usuń spowoduje usunięcie aktualnie wybranego UDL.
Ext.: ____ zaakceptuje listę zerowych lub więcej rozszerzeń (bez kropki). Pliki
pasujące do tych rozszerzeń będą interpretowane jako należące do aktualnie
wybranego UDL i będą odpowiednio stylizowane. Rozszerzenia te zastępują
domyślne rozszerzenia dla wstępnie zdefiniowanych języków,więc jeśli
rozszerzenie UDL jest w konflikcie z rozszerzeniem innego języka, UDL będzie
mieć priorytet. Na przykład Ext.: md mkdn zostanie skojarzony lub z wybranym
Page 5

UDL.file.mkdnsomething.md
Karty konfiguracji UDL
Ivan Radić stworzył ostateczny przewodnik po nakrętkach i UDL w wersji 2.1, który jest
dostępny na https://ivan-radic.github.io/udl-documentation/. Wyjaśnia szczegóły
dotyczące tego, co zrobi każda z kart w oknie dialogowymJęzyk zdefiniowany przez
użytkownika i jak ich używać do stylizowania różnych słów kluczowych. Jednak te
opisy dają przegląd tego, do czego służy każda karta.
Karta Folder i domyślne umożliwia ustawienie domyślnego stylu,
skonfigurowanie słów kluczowych (lub znaków), które umożliwią składanie kodu,
oraz skonfigurowanie stylów dla tych słów kluczowych.
Pola Otwórz, Środeki Zamknij pod każdym typem składania definiują
wyzwalacze dla początku, środka i końca składania. Na przykład za pomocą , , i ,
zdefiniuje regiony składania, dzięki czemu można złożyć od do , od do , i
(zakładając, że nie ma klauzuli) od do . Składanie komentarzy umożliwia
komentarzom składanie; Składanie w stylu kodu 1 pozwala wyzwalaczom
dotykać czegoś innego (więc z wyzwalaczem , będzie pasować lub ), podczas
gdy składanie w stylu kodu 2 wymaga, aby wokół spustu była biała spacja
(więc nie pasowałaby do Otwórz-trigger
).ifelseendififelseelseendifelseifendif{if{if {if{{
Karta Lista słów kluczowych umożliwia zdefiniowanie ośmiu (8) różnych grup
słów kluczowych, dzięki czemu można inaczej stylizować różne grupy słów (np.
wbudowane funkcje i słowa kluczowe sterowania przepływem). Oddziel każde
słowo kluczowe spacją (a to oznacza, że spacje nie są dozwolone w słowach
kluczowych, chyba że umieścisz cudzysłowy wokół frazy). Jeśli ☐ tryb
prefiksu jest włączony dla danej grupy, oznacza to, że będzie pasować do
wszystkiego, co zaczyna się od twojego ciągu (więc słowo kluczowe będzie
pasować , i jeśli ta opcja jest włączona).forforforthformat
Jako punkt zainteresowania nie powinieneś mieć danego słowa kluczowego w
więcej niż jednej grupie słów kluczowych lub grupie folderów. Jeśli chcesz, aby //
powodował zwijanie bloków, nie umieszczaj ich również w jednej z grup słów
kluczowych.ifelseendif
Karta Komentarz i numer u możliwia ustawianie stylów komentarzy i liczb.
Pozycja komentarza wiersza pozwala zdecydować, czy "komentarze
liniowe" mogą zaczynać się w dowolnym miejscu w wierszu, muszą zaczynać
się na początku, czy mogą zaczynać się w dowolnym miejscu w wierszu, o ile
jest to tylko biała spacja przed komentarzem.
☐ Zezwalaj na zwijanie komentarzy umożliwi ich składanie.
Styl linii komentarza definiuje styl dla "komentarzy liniowych" – komentarzy,
Page 6

które przechodzą od wyzwalacza otwarcia do końca wiersza.
Styl komentarza definiuje styl komentarzy wieloliniowych.
Styl liczb definiuje styl liczb. Różne prefiksy, sufiksyi dodatkowes
umożliwiają definiowanie dodatkowych reprezentacji numerycznych
(przydatne dla reprezentacji szesnastkowych, binarnych, ósemki i podobnych,
a także do definiowania waluty jako liczby). Zakres umożliwia zdefiniowanie
składni zakresów, dzięki czemu dwie liczby z wymienionym tokenem
pomiędzy nimi będą nadal traktowane jako liczby. (Mogą jednak wystąpić
konflikty, jeśli ustawienie Zakres jest zgodne z ustawieniem Operatory i
ograniczniki
Zakładka Operatory i ograniczniki umożliwia ustawianie stylów dla operatorów i
par ograniczników
Operatory 1 i Operatory 2 definiują dwie grupy operatorów (zwykle
operatory matematyczne i matematyczno-podobne). Pierwszy definiuje
operatory, które będą dopasowywane, nawet jeśli dotykają innych znaków
(zezwalając ), podczas gdy drugi definiuje operatory, które muszą zawierać
spacje, które mają być rozpoznawane (jak ).1+21 + 2
Różne style ogranicznika to pary znaków Open i Close, gdzie te znaki i
wszystko, co się między nimi znajduje, będą stylizowane zgodnie z regułami
zdefiniowanymi dla tego wpisu. Jest to przydatne do nadawania stylu ciągom
znaków, listom parametrów w nawiasach, wyrażeniu w nawiasach i
wszystkim innym, gdzie może mieć plik . Wpis Escape pozwala zdefiniować
sposób "ucieczki" postaci tak, aby para ogranicznika nie została
przedwcześnie zamknięta (np. / / zezwalając )."\""this \" is an embedded
quote character inside a string, escaped by the backslash"
Importowanie UDL
Internet ma wiele plików xml Notepad ++ UDL. Po otrzymaniu kodu XML możesz
zaimportować go do Notepad ++, abyś mógł samodzielnie korzystać z tego UDL.
Można to zrobić na dwa główne sposoby:
1. Skopiuj kod XML do odpowiedniego podfolderu userDefineLangs. Zamknij
wszystkie wystąpienia Notepad ++ i załaduj ponownie, a następnie nowy UDL
będzie dostępny.
2. Użyj przycisku Importuj..., przejdź do źródłowego pliku XML, a UDL będzie
natychmiast dostępny.
Różnice między tymi dwiema metodami polegają na tym, kiedy UDL będzie dostępny
dla Notepad ++ i który plik konfiguracyjny będzie przechowywał ten UDL,
według lokalizacji plików UDL.
Lokalizacje plików UDL
Page 7

Poszczególne pliki UDL są przechowywane w jednym z dwóch podfolderów. Każdy plik
XML w tym folderze jest używany do definiowania jednego lub więcej
UDL.userDefineLangs
1. %AppData%\Notepad++\userDefineLangs: jest to domyślna lokalizacja dla
większości instalacji Notepad ++
2. <notepad++_directory>\userDefineLangs: jest to lokalizacja dla wersji
przenośnych lub jeśli podczas instalacji włączono "tryb konfiguracji lokalnej" (lub
wyłączony). odnosi się do dowolnego folderu, w jakim znajduje się plik
wykonywalny aplikacji.%AppData%<notepad++_directory>notepad++.exe
Jeśli UDL został utworzony lub zaimportowany za pomocą okna dialogowego Języki
zdefiniowane przez użytkownika w Notepad ++, będą one znajdować się w pliku. Ten
pojedynczy plik często zawiera wiele definicji UDL.userDefineLang.xml
1. %AppData%\Notepad++\userDefineLang.xml: jest to domyślna lokalizacja dla
większości instalacji Notepad ++
2. <notepad++_directory>\userDefineLang.xml: jest to lokalizacja dla wersji
przenośnych lub "trybu konfiguracji lokalnej", jak opisano powyżej
UDL i motywy
Aktywny motyw nie ma (w większości) wpływu na języki zdefiniowane
przez użytkownika. Oznacza to, że jeśli zmienisz motyw (w tym przejdziesz do trybu
ciemnego, który zmieni motyw na ), może być konieczne edytowanie kolorów UDL, aby
były czytelne. UDL nie zastępuje większości ustawień w ustawieniach "Style globalne"
konfiguratora stylów dla aktywnego motywu, więc niektóre ustawienia mogą sprawić, że
kolory UDL będą trudne do odczytania:DarkModeDefault
UDL zastępuje kolor pierwszego planu dla tekstu i kolor tła dla tekstu; jednak
UDL nie zastępuje koloru tła dla spacji ani pustego miejsca, które wypełnia
nieużywane części widoku edytora, więc jeśli domyślne tło UDL nie pasuje do
domyślnego tła motywu, dokument oparty na UDL może wyglądać dziwnie
UDL nie zastępuje wybranego koloru tekstu ani bieżącego tła linii, więc jeśli
kolory UDL nie zapewniają dobrego kontrastu z tymi ustawieniami z motywu,
wybrany tekst będzie trudny do odczytania
Ponieważ możesz ustawić kolory UDL na cokolwiek chcesz, możesz ręcznie
dopasować go do swojego motywu. Ogólnie rzecz biorąc, najlepiej jest ustawić folder
UDL i domyślny > domyślny styl, aby pasował do kolorów pierwszego planu i tła
aktywnego motywu, co powinno dobrze równoważyć się z innymi ustawieniami stylów
globalnych motywu. Ponadto ustawienie grup słów kluczowych i liczb oraz komentarzy i
operatorów w celu dopasowania ich do ustawień słów kluczowych, liczb i komentarzy
innych języków używanych w aktywnym motywie pomoże lepiej dopasować pliki UDL
do aktywnego motywu.
Page 8
Jeśli chcesz zdefiniować wiele UDL przy użyciu tego samego podstawowego schematu
Pole
wybor
u
Warto
ść
Pole
wybor
u
Warto
ść
Pole
wybor
u
Warto
ść
kolorów, co aktywny motyw, możesz zacząć od ustawienia kolorów domyślnego języka
zdefiniowanego przez użytkownika, a następnie Utwórz nowy dla każdego UDL,
który ma pasować do tego schematu, dostosowując reguły dla każdego nowego UDL.
(Jak tylko wyjdziesz z Notepad ++, zmiany w domyślnym UDL zostaną utracone, ale
wszystkie motywy, które utworzyłeś z tego, zachowają kolory, które odziedziczyły.)
Kolekcja języków zdefiniowanych przez użytkownika
W całej historii Notepad ++ wiele plików UDL zostało utworzonych przez użytkowników
Notepad ++ i udostępnionych publicznie. Po raz kolejny istnieje
scentralizowana kolekcja języków zdefiniowanych przez użytkownika.
https://github.com/notepad-plus-plus/userDefinedLanguages
Ta centralna kolekcja jest dogodną lokalizacją dla użytkowników UDL, aby znaleźć
nowe pliki UDL, a dla autorów UDL, aby udostępnić swoje pliki UDL całej społeczności
Notepad ++. Kolekcja zawiera instrukcje dotyczące korzystania z plików, a także
sposobu przesyłania nowego UDL do Kolekcji.
Zawartość pliku konfiguracyjnego UDL
Zaleca się, aby UDL był edytowany za pomocą okien dialogowych GUI. Jeśli jednak
jesteś typem użytkownika, który lubi konfigurować Notepad ++ za pomocą plików
konfiguracyjnych, jest to możliwe. Zapoznaj się ze szczegółami plików
konfiguracyjnych, aby uzyskać opis sekwencji poprawnej edycji dowolnego pliku
konfiguracyjnego, w tym plików definicji UDL.
Większość ustawień w plikach definicji UDL odpowiada bezpośrednio nazwom
widocznym w oknie dialogowym Języki zdefiniowane przez użytkownika lub w
podoknu dialogowym Styler. Sekcja definiuje słowa kluczowe lub symbole dla każdej
kategorii wyróżniania. Sekcja definiuje styl tekstu (kolor, czcionka, grubość i dekoracja)
dla każdej kategorii wyróżniania. Atrybut koduje ustawienie pól
wyboru Pogrubienie, Kursywai Podkreślenie w oknie dialogowym Styler przy
użyciu sumy Kursywa= 1, Pogrubienie= 2 i Podkreślenie= 4 (więc coś z ustawionymi
wszystkimi trzema polami wyboru miałoby ). Atrybut podobnie koduje różne pola wyboru
zagnieżdżania w oknie dialogowym Styler z sumą poniższych wartości i wskazuje,
które style będą prawidłowo zagnieżdżane wewnątrz aktywnego
stylu:<KeywordLists><Styles><WordsStyle>fontStylefontStyle="7"nesting
Page 9
Ograni
cznik
1
1
Słowo
kluczo
we 1
1024
Kome
ntarz
256
Ograni
cznik22
Słowo
kluczo
we 2
2048
Linia
komen
tarza
512
Ograni
cznik34
Słowo
kluczo
we 3
4096
Opera
torzy 1
16777
216
Ograni
cznik48
Słowo
kluczo
we 4
8192
Opera
torzy 2
33554
432
Ograni
cznik516
Słowo
kluczo
we 5
16384
Liczby
67108
864
Ograni
cznik632
Słowo
kluczo
we 6
32768
Ograni
cznik764
Słowo
kluczo
we 7
65536
Ograni
cznik8128
Słowo
kluczo
we 8
13107
2
Atrybut decyduje, czy użyć zdefiniowanych kolorów i atrybutów, czy użyć domyślnego
ustawienia koloru (z Ustawienia > Konfigurator stylu > Style globalne > Styl
domyślny, a nie z domyślnego stylu UDL). Atrybut powinien być ustawiony na jeden z
następujących:<WordsStyle>colorStylefgColorbgColor
Brak atrybutu: ten styl będzie używał zarówno atrybutów, jak i atrybutów z tego
elementu (zachowanie standardowe)colorStylefgColorbgColor<WordsStyle>
Ustaw: ten styl odziedziczy kolor pierwszego planu ze stylu domyślnego i użyje
Page 10
tej wartości jako koloru tła (odpowiednik kliknięcia prawym przyciskiem myszy
koloru pierwszego planu w oknie dialogowym Stylizator
UDL)colorStyle="2"bgColor
Ustaw: ten styl odziedziczy kolor tła ze stylu domyślnego i użyje tej wartości jako
koloru tła (odpowiednik kliknięcia prawym przyciskiem myszy koloru tła w oknie
dialogowym stylizatora UDL)colorStyle="1"fgColor
Ustaw: ten styl odziedziczy zarówno kolor pierwszego planu, jak i tła ze stylu
domyślnego (odpowiednik kliknięcia prawym przyciskiem myszy zarówno koloru
pierwszego planu, jak i koloru tła w oknie dialogowym Stylizator
UDL)colorStyle="0"
Tryb kolumnowy i edytor kolumn
Używanie lub przełączanie do trybu kolumnowego:Alt + Mouse draggingAlt + Shift +
Arrow keys
Okno dialogowe Edytor kolumn umożliwia wstawianie tekstu lub liczb w każdym wierszu
aktywnego wyboru trybu kolumnowego:
Page 11
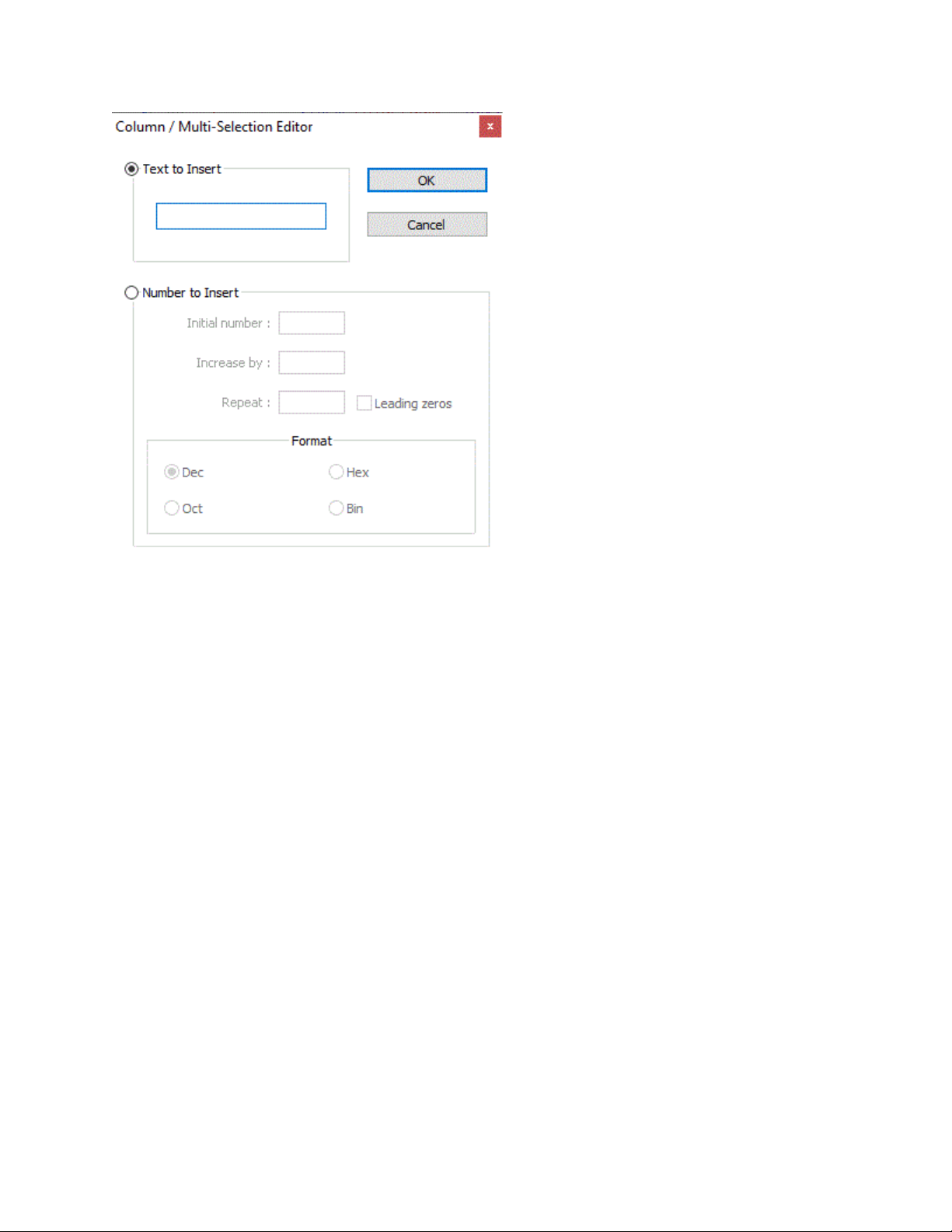
Będzie używany ten sam tekst w każdym wierszu.Text to Insert
Wstawia się coraz więcej liczb. Number to Insert
Initial number ustawia numer początkowy.
Increase by zmieni krok między liczbami. Z wartością (lub jeśli pozostanie
pusta), za każdym razem wstawia tę samą liczbę.0
Repeat powtórzy tę samą liczbę n razy. Wartość domyślna to 1, jeśli pole
pozostaje puste.
☐ Leading zeros spowoduje, że wszystkie liczby będą miały taką samą liczbę
cyfr, dodając zera wiodące dla mniejszych wartości
Format wybiera między Dec (0-9), Hex (0-9,A-F), Oct (0-7) lub Bin (0-1).
Uwaga: powyższe pola liczbowe są zawsze dziesiętne, nawet jeśli wybrano
inny format wyświetlania. (Przykład: aby uzyskać -, wybierz kolumnę 17
wierszy i ustaw początkową liczbę na - nie pozwoli .)F1F15F
Page 12
Wielokrotna edycja
Używanie, jeśli tryb edycji wielokrotnej jest włączony. Aby włączyć tryb edycji
wielokrotnej:CTRL + Mouse clicking
Page 13
Podwójny widok
Aby utworzyć podwójny widok, przeciągnij i upuść dowolną kartę, która ma znajdować
się w innym widoku (lub kliknij prawym przyciskiem myszy kartę), a następnie wybierz
polecenie "Przenieś do innego widoku" z wyskakującego menu kontekstowego. Po
wyświetleniu 2 możesz przenosić pliki między 2 widokami, przeciągając je i
upuszczając.
Klonuj dokument
Przeciągnij i upuść dowolną kartę, którą chcesz sklonować (lub kliknij prawym
przyciskiem myszy kartę), a następnie wybierz polecenie "Klonuj do innego widoku" z
wyskakującego menu kontekstowego. Sklonowany dokument jest tym samym
dokumentem, co jego oryginalny dokument, ale z oddzielnymi widokami.
Page 14
Edytuj menu
Oprócz zwykłych wpisów cofania / ponawiania / kopiowania / wklejania, istnieje wiele
podmenu do menu Edycja, które grupują różne kategorie poleceń związanych z edycją
i kilka innych poleceń edycji w głównym menu Edycja.
Copy to Clipboard > ⇒ podmenu z akcjami, które kopiują bieżącą nazwę pliku,
ścieżkę lub nazwę katalogu do schowka
Indent > ⇒ podmenu z akcjami zwiększającymi lub zmniejszającymi wcięcie
bieżącego wiersza na podstawie ustawień tabulacji/wcięcia języka składni
Convert Case to > ⇒ podmenu z akcjami, które zmieniają wielką literę
zaznaczonego tekstu (wszystkie WIELKIE LITERY, wszystkie małe litery i różne
ustawienia mieszane)
Line Operations > ⇒ podmenu z akcjami, które zazwyczaj działają na wierszach
Page 15

(nazywanych również "wierszami") dokumentu
Istnieje metoda powielania danych:
Duplicate Current Line : duplikuje bieżący wiersz, jeśli żadne
zaznaczenie nie jest aktywne, lub duplikuje zaznaczony tekst, jeśli
zaznaczenie jest aktywne
Istnieją dwie wersje funkcji Usuń duplikaty:
Remove Duplicate Lines: pozostawia tylko pierwsze wystąpienie
wszystkich pełnych wierszy, które mają więcej niż jedną kopię w
dowolnym miejscu aktywnego pliku; działa na zestawie wierszy rozpiętych
przez bieżące zaznaczenie lub na całym pliku, jeśli nie ma aktywnego
zaznaczenia
Remove Consecutive Duplicate Lines: usunie tylko duplikaty, które
znajdują się w wierszach bezpośrednio po pierwszym wystąpieniu (nadal
zachowując pierwsze wystąpienie); działa na zestawie wierszy rozpiętych
przez bieżące zaznaczenie lub na całym pliku, jeśli nie ma aktywnego
zaznaczenia
UWAGA: Usuwanie duplikatów odbywa się przy założeniu, że wszystkie
zakończenia wierszy w pliku są jednolite i pasują do bieżącego wyboru
edytowanego pliku - najszybszym sposobem sprawdzenia tego
zaznaczenia jest spojrzenie na pasek stanu, gdzie bieżący typ
zakończenia wiersza jest wyświetlany jako , lub . Może być pożądane
sprawdzenie typów kończących wiersze w pliku przed wykonaniem
operacji sortowania i użycie opcji lub kliknięcie prawym przyciskiem myszy
wskaźnika EOL stataus Bar, aby w razie potrzeby naprawić zakończenia
linii.Windows (CR LF)Unix (LF)Macintosh (CR)Edit > EOL Conversion >
Istnieją metody dzielenia linii i łączenia linii:
Split Lines: wstawi zakończenie linii do długiej linii: jeśli jest określona
jedna lub więcej wartości Vertical Edge (wymaga wersji 7.9.3 lub
nowszej), zostanie ona podzielona na najbardziej po prawej stronie
Page 16

Vertical Edge; w przeciwnym razie zostanie podzielony na bieżący rozmiar
okna edytora. Działa na liniach rozciągnętych przez bieżący wybór
strumienia lub pojedynczą linię opiekuna, jeśli wybór strumienia nie jest
obecnie aktywny.
Join Lines: połączy linie dotknięte aktywnym zaznaczeniem strumienia,
zastępując zakończenia linii pojedynczym znakiem spacji. Wymaga
aktywnego zaznaczenia strumienia, które obejmuje co najmniej dwie linie.
Istnieją polecenia usuwania linii
Remove empty lines: usunie wszystkie wiersze nie zawierające znaków z
całego dokumentu
Remove empty lines (Containing Blank characters): usunie wszystkie
wiersze nie zawierające żadnych znaków z całego dokumentu; jeśli wiersz
zawiera tylko spacje lub znaki tabulatora, ten wiersz również zostanie
usunięty
Istnieją polecenia do zmiany kolejności istniejących wierszy:
Move Up Current Line: zamieni bieżącą linię z linią nad nią, skutecznie
przesuwając linię wskaźnika w górę o jeden wiersz w dokumencie; jeśli
zaznaczenie obejmujące linie jest aktywne po wywołaniu, spowoduje to
przesunięcie linii dotkniętych zaznaczeniem w górę jako grupa
Move Down Current Line: zamieni bieżącą linię z linią pod nią, skutecznie
przesuwając linię wskaźnika w dół o jeden wiersz w dokumencie; jeśli
zaznaczenie obejmujące linie jest aktywne po wywołaniu, spowoduje to
przesunięcie linii dotkniętych zaznaczeniem w dół jako grupy
Reverse Line Order: weźmie zaznaczone wiersze (lub wszystkie wiersze
bieżącego dokumentu, jeśli nie ma aktywnego zaznaczenia) i uodwęzi je
odwrotnie (tj. odwrócone) z ich istniejącej kolejności (dodane w wersji
8.0.0)
Randomize Line Order: weźmie zaznaczone wiersze (lub wszystkie
wiersze bieżącego dokumentu, jeśli nie ma aktywnego zaznaczenia) i
Page 17

umieści je w nieprzewidywalnej kolejności (dodane w wersji 7.9 jako
"Sortuj wiersze losowo"; zmieniono nazwę w wersji 8.0.0)
Istnieje wiele algorytmów sortowania:
Ascending oznacza od najmniejszego do największego (A-Z)
Descending oznacza od największego do najmniejszego (Z-A)
Lexicographically (lub ) oznacza na podstawie punktu kodowego znaku,
porównującą jeden znak na raz: Lex.
Wszystkie wielkie litery będą sortowane przed jakąkolwiek małą literą,
więc wielkie litery będą sortowane przed małymi literami Za
Sekwencja zostanie posortowane przed , ponieważ sortuje znak po
znaku każdej kolekcji znaków, a znak pojawia się przed znakiem 10212
Ignoring case oznacza, że małe litery będą sortowane tak samo jak
wielkie litery , a oba będą przed albo aAZz
As Integers oznacza, że będzie sortowane jako większe niż 102
As Decimals (Comma) oznacza, że rozpozna i jako liczby dziesiętne i
posortuje je numerycznie10,2349,876
As Decimals (Dot) oznacza, że rozpozna i jako liczby dziesiętne i
posortuje je numerycznie10.2349.876
UWAGA: Sortowanie odbywa się przy założeniu, że wszystkie
zakończenia wierszy w pliku są jednolite i pasują do bieżącego wyboru
edytowanego pliku – najszybszym sposobem sprawdzenia tego
zaznaczenia jest spojrzenie na pasek stanu, gdzie bieżący typ kończący
wiersz jest wyświetlany jako , lub . Może być pożądane sprawdzenie
typów kończących wiersze w pliku przed wykonaniem operacji sortowania
i użycie opcji lub kliknięcie prawym przyciskiem myszy wskaźnika EOL
stataus Bar, aby w razie potrzeby naprawić zakończenia linii.Windows (CR
LF)Unix (LF)Macintosh (CR)Edit > EOL Conversion >
UWAGA: Jeśli zaznaczenie trybu kolumnowego jest aktywne, sortowanie
spowoduje ponowne uporządkowanie wszystkich wierszy zawartych w
Page 18

zaznaczeniach, ale klucz sortowania (tekst, który decyduje o kolejności
sortowania) będzie ograniczony do tego, co znajduje się wewnątrz
zaznaczenia kolumny. Jeśli klucze są identyczne w dwóch wierszach,
kolejność tych dwóch wierszy nie ulegnie zmianie (nawet jeśli tekst poza
zaznaczonymi kolumnami jest inny).
Comment/Uncomment > ⇒ podmenu z akcjami, które dodają lub usuwają składnię
komentarza na podstawie wyboru języka pliku
Auto-Completion > ⇒ podmenu z akcjami, które wyzwalają automatyczne
uzupełnianie nazwy funkcji, słowa, parametru funkcji i nazwy ścieżki, na które
mają wpływ ustawienia preferencji > automatycznego uzupełniania
EOL Conversion > ⇒ podmenu z akcjami konwertującymi zakończenia wierszy
między wartościami systemów Windows (), Unix () i starych macintosh (); te
operacje wpływają na wszystkie wiersze bieżącego pliku CRLFLFCR
Jeśli twój plik ma mieszane zakończenia linii (na przykład niektóre i niektóre),
możesz użyć tego menu, aby to naprawić: jeśli żądane zakończenie linii nie
jest wyszarzone, możesz po prostu je zaznaczyć, a wszelkie mieszane
zakończenia linii zostaną przekonwertowane na wybrane zakończenie linii;
Jeśli żądane zakończenie linii jest wyszarzone, zaznacz jedną z pozostałych
końców linii, a następnie przełącz się z powrotem na żądane zaznaczenie
kończące wiersz, a wszystkie mieszane zakończenia linii zostaną
przekonwertowane na ostateczny wybór zakończenia linii.CRLFLF
Blank Operations > ⇒ podmenu z akcjami, które przycinają lub konwertują
spacje i znaki tabulatorów we WSZYSTKICH wierszach bieżącego pliku
Trim Trailing Space: usuwa spacje lub znaki tabulatora występujące na
końcu wiersza, po znakach innych niż spacje
Trim Leading Space: usuwa spacje lub znaki tabulatora występujące na
początku wiersza, przed znakami niebędącymi spacjami
Trim Leading and Trailing Spaces: łączy funkcjonalności i w jedno
polecenieTrim Trailing SpaceTrim Leading Space
Page 19

EOL to Space: zastępuje znaki kończące wiersz pojedynczym znakiem spacji
(podobnym do funkcji, ale działa na cały plik, a nie na aktywne zaznaczenie);
Uwaga: "EOL" oznacza "Koniec wiersza" – innymi słowy, znaki kończące
wierszJoin Lines
Remove Unnecessary Blank and EOL : wykonuje operację łączone iTrim
Leading and Trailing SpacesEOL to Space
TAB to Space : zastępuje wszystkie znaki tabulatora równoważną liczbą spacji
Space to TAB (All) : konsoliduje znaki spacji w równoważną liczbę znaków
tabulatora, niezależnie od tego, gdzie występują spacje
Space to TAB (Leading) : konsoliduje znaki spacji w równoważną liczbę
znaków tabulatora, ale tylko wtedy, gdy występują przed pierwszym znakiem
bez spacji w wierszu
UWAGA dotycząca poleceń związanych z TAB: równoważna liczba spacji
(lub znaków tabulatora) jest oparta na ustawieniach > preferencjach > języku
> Ustawienia kart: Rozmiar karty dla aktywnego języka bieżącego pliku
Paste Special > ⇒ podmenu z akcjami wklejania HTML lub RTF oraz
specjalnymi wersjami kopiowania / wycinania / wklejania, które obsługują NULL i
inne znaki binarne
Uwaga: Akcje HTML i RTF wklejają kod źródłowy HTML i RTF z wpisów
HTML lub RTF w Schowku systemu Windows; nie stosuje formatowania
HTML ani RTF do tego, co wydaje się być zwykłym tekstem w oknie edytora
Notepad ++.
On Selection > ⇒ pod menu z akcjami, które używają aktualnie zaznaczonego
tekstu jako nazwy pliku lub folderu do otwarcia lub jako terminu do wyszukiwania
w Internecie. (Polecenia niestandardowe przy użyciu bieżącego zaznaczenia
można dodać do menu Uruchom za
pomocą <UserDefinedCommands>sekcja skrótów.xml).
Column Mode... ⇒ okno dialogowe wyjaśniające tryb kolumnowy
Column Editor ⇒ uruchamia opisane powyżej okno dialogowe Edytor kolumn
Page 20

Character Panel ⇒ mapuje 255 8-bitowych punktów kodu na ich znak dla
danego kodowania
Clipboard History ⇒ umożliwia ponowne uzyskiwanie dostępu do ostatnich
wartości kopiowania/wklejania (kliknij dwukrotnie wiersz, aby wkleić tę wartość)
Set Read-Only ⇒ przełącza flagę Notepad ++ tylko do odczytu w aktywnym
buforze plików.
Jeśli klikniesz ten wpis menu raz, doda znacznik wyboru do wpisu menu, aby
pokazać, że jest on obecnie tylko do odczytu dla Notepad ++. Jeśli klikniesz
ten wpis menu, gdy jest już znacznik wyboru , znacznik wyboru zostanie
wyczyszczony, a Notepad ++ nie będzie już traktować tego pliku jako tylko do
odczytu.✔✔
Stan tej flagi Notepad ++ tylko do odczytu jest zapisywany w pliku sesji, więc
zostanie zapamiętany przy następnym użycia sesji.
Uwaga:ten przełącznik nie wpływa na atrybut tylko do odczytu systemu
operacyjnego Windows w pliku; jeśli system Windows oznaczył ten plik jako
tylko do odczytu, ten wpis menu będzie wyszarzony i nie będzie można go
przełączyć, klikając go. Zobacz (poniżej), aby uzyskać więcej informacji na
temat flagi systemu operacyjnego.Clear Read-only Flag
Clear Read-Only Flag ⇒ czyści atrybut tylko do odczytu systemu operacyjnego
Windows dla pliku.
Po wyczyszczeniu flagi tylko do odczytu systemu operacyjnego ta opcja
menu zostanie wyszarzone, a kliknięcie jej nic nie da.
Nie można ustawić flagi tylko do odczytu systemu operacyjnego za pomocą
tego menu w Notepad ++; musi to być zrobione przez system operacyjny
(chociaż wtyczki skryptowe Notepad ++ są w stanie poprosić system
operacyjny o ustawienie flagi tylko do odczytu systemu operacyjnego w pliku,
jak w tym przykładziena forum społeczności ).
Page 21

Jeśli używasz systemu operacyjnego do ustawienia flagi na pliku otwartym w
Notepad ++, a Ustawienia > Preferencje > MISC > Automatyczne
wykrywanie stanu pliku zostało włączone, Notepad ++ zauważy, że jest to
teraz plik tylko do odczytu i nie pozwoli na edycję pliku.
Jeśli używasz systemu operacyjnego do ustawienia flagi na pliku otwartym w
Notepad ++, ale Ustawienia > Preferencje > MISC > Automatyczne
wykrywanie stanu pliku zostało wyłączone, Notepad ++ nie zauważy, że
został zmieniony na tylko do odczytu przez system operacyjny i ślepo pozwoli
ci kontynuować wprowadzanie zmian; jednak gdy spróbujesz zapisać i
zobaczysz, że plik jest tylko do odczytu zgodnie z systemem operacyjnym,
Notepad ++ powiadomi Cię, że nie możesz zapisać, i zapyta, czy chcesz
uruchomić Notepad ++ w trybie administratora, aby spróbować wprowadzić
zmiany (jeśli to zrobisz, wprowadzone zmiany mogą zostać utracone).
Karta bieżącego pliku będzie miała ikonę "zablokowany" (domyślnie
wyszarzoną ikonę dysku lub ikonę kłódki, jeśli Ustawienia > Preferencje >
Ogólne > ☑ Ikony alternatywne zostały zaznaczone), niezależnie od tego,
czy ustawiony jest atrybut tylko do odczytu systemu operacyjnego Windows,
czy ustawiono flagę Notepad ++ tylko do odczytu, lub oba. Ikona
"zablokowana" zmieni się w normalną ikonę, gdy nie zostanie ustawiony ani
atrybut tylko do odczytu systemu operacyjnego Windows, ani flaga Notepad
++ tylko do odczytu (lub równoważnie, gdy obie flagi zostaną wyczyszczone).
Wyszukiwanie
Istnieje wiele metod wyszukiwania (i zastępowania) tekstu w plikach. Możesz także
oznaczyć wyniki wyszukiwania zakładką w ich wierszach lub wyróżnić same wyniki
tekstowe. Możliwe jest również wygenerowanie liczby dopasowań.
Istnieją trzy główne wbudowane mechanizmy wyszukiwania: standardowy (oparty na
oknach dialogowych) Znajdź / Zamień / Znajdź w plikach / Oznacz, bez dialogów
Następna / Poprzednia nawigacja wyszukiwania i Wyszukiwanie przyrostowe.
Page 22

Wszystkie skróty klawiaturowe wymienione poniżej są wartościami domyślnymi, ale
można je skonfigurować w mapie skrótów. Aktywny skrót dla dowolnego elementu
menu można zobaczyć we wpisie menu lub w maperze skrótów.
Wyszukiwanie oparte na oknach dialogowych
Istnieje okno dialogowe "Znajdź". To okno dialogowe ma jedną kartę dla każdej z
następujących funkcji:
Karta Znajdź: daje dostęp do wyszukiwania i liczenia.
Można go wywołać bezpośrednio za pomocą funkcji Wyszukiwania >
Znajdź lub skrótu klawiaturowego Ctrl + F.
Karta Zamień: podobna do karty Znajdź, ale umożliwia zastąpienie
dopasowanego tekstu po jego znalezieniu.
Można go wywołać bezpośrednio za pomocą funkcji Wyszukiwania >
Zamień lub skrótu klawiaturowego Ctrl+H.
Znajdź na karcie Pliki: Umożliwia wyszukiwanie i zamienianie wielu plików jedną
operacją. Pliki używane do operacji są określane przez katalog.
Można go wywołać bezpośrednio za pomocą funkcji Wyszukiwania > Znajdź w
plikach lub skrótu klawiaturowego Ctrl + Shift + F.
Znajdź na karcie Projekty: Podobnie jak Znajdź w plikach, ale pliki panelu
projektu są używane zamiast plików z katalogu.
Można go wywołać w menu kontekstowym pierwszego wiersza panelu projektu.
Karta Oznacz: Umożliwia trwałe wyróżnienie wszystkich wystąpień celu
wyszukiwania w bieżącym dokumencie.
Można go wywołać bezpośrednio za pomocą funkcji Wyszukiwania > Mark lub
skrótu klawiaturowego Ctrl+M.
Uwaga: Chociaż polecenie klawiatury może otwierać i/lub przenosić fokus wejściowy na
jedną z kart okna "Znajdź", po osiągnięciu tego fokusu wejściowego nie ma możliwości
przełączenia się na inną kartę za pomocą klawiatury; należy użyć myszy lub zamknąć
okno (za pomocą klawisza Escape) i wywołać skrót klawiatury alternatywnej karty (lub
polecenie menu).
Uwaga: Korzystanie z niektórych funkcji rodziny "Znajdź" może spowodować
zamknięcie okna po pomyślnym wyszukiwaniu (jedno lub więcej "trafień"). Niektórzy
użytkownicy nie lubią tego i chcą, aby okno "Znajdź" zawsze pozostało otwarte. Można
to osiągnąć za pomocą opcjonalnego ustawienia: Preferencje > Wyszukiwanie >
Okno dialogowe Znajdź pozostaje otwarte po wyszukiwaniu, które wyświetla okno
wyników.
Uwaga: Opcje wyszukiwania dokonane przez użytkownika są zapamiętywane w
Page 23

wywołaniach Notepad ++.
Znajdowanie / zamienianie kart
Wszystkie okna dialogowe mają pewne wspólne cechy, chociaż niektóre są wyłączone
w pewnych okolicznościach.
Znajdź pole edycji z rozwijaną historią: jest to tekst, którego szukasz
Zamień na pole edycji z rozwijaną historią: jest to tekst, który zastąpi to, co
zostało dopasowane
☐ W zaznaczeniu:Jeśli zaznaczono region tekstu, a opcja W zaznaczeniu jest
włączona, będzie ona tylko zliczanie, zamienianie wszystkichlub zaznaczanie
wszystkie w obrębie tego zaznaczenia tekstu, a nie w całym dokumencie (inne
przyciski, takie jak Znajdź następny,będą nadal działać na całym dokumencie)
☐ Kierunek wsteczny:zwykle wyszukiwania idą do przodu (w dół strony); z tą
opcją przejdą wstecz (w górę strony)
☐ Dopasuj tylko całe słowo:jeśli jest włączona, wyszukiwania będą pasować
tylko wtedy, gdy wynik jest całym słowem (więc "to" nie zostanie znalezione w
"zaczepie")
☐ dopasuj przypadek:jeśli jest włączona, wyszukiwania muszą być zgodne w
przypadku (więc wyszukiwanie "to" nie znajdzie "To" lub "IT"). Flaga wyrażenia
regularnego zastąpi to pole wyboru, co spowoduje, że wyszukiwana wielkość liter
będzie niewrażliwa, i sprawi, że wyszukiwana wielkość liter będzie
wrażliwa.i(?i)(?-i)
☐ Zawij dookoła:jeśli ta opcja jest włączona, gdy wyszukiwanie dotrze do końca
dokumentu, zostanie zawijane do początku i będzie kontynuować wyszukiwanie
Tryb wyszukiwania:określa sposób traktowania tekstu w obszarze Znajdź
i Zamień na
☐ Normal: cały tekst jest traktowany dosłownie.
☐ Extended (\n, \r, \t, \0, \x...): użyj pewnych "symboli wieloznacznych",
zgodnie z opisem w rozszerzonym trybie wyszukiwania (poniżej)
☐ wyrażenie regularne:używa aparatu wyrażeń regularnych Boost do
wykonywania bardzo wydajnych akcji wyszukiwania i zastępowania, jak
wyjaśniono w sekcji Wyrażenia regularne (poniżej)
☐ . dopasowuje nowy wiersz: w wyrażeniach regularnych, przy
wyłączonym tym wyrażeniu, wyrażenie regularne dopasowuje dowolny
znak z wyjątkiem znaków kończących wiersz (powrót karetki i/lub wysuw
wiersza); po włączeniu tej opcji dopasowuje również znaki końcowe linii.
Page 24

Zamiast używać tego pola wyboru, zacznij tekst pola Znajdź, aby uzyskać
niezaznaczone zachowanie . pasuje do nowego wierszalub aby uzyskać
jego zaznaczone zachowanie...(?-s)(?s)
☐ Przezroczystość: te ustawienia mają wpływ na okno dialogowe. Zwykle okno
dialogowe jest nieprzezroczyste (nie widać tekstu poniżej), ale dzięki tym
ustawieniom można je uczynić półprzezroczystym (częściowo można zobaczyć
tekst poniżej)
☐ Po utracie fokusu: jeśli zostanie to wybrane, okno dialogowe będzie
nieprzezroczyste, gdy będziesz aktywnie w oknie dialogowym, ale jeśli
klikniesz w oknie Notepad ++, okno dialogowe stanie się półprzezroczyste
☐ Zawsze:jeśli ta opcja zostanie wybrana, okno dialogowe będzie
półprzezroczyste, nawet jeśli jesteś aktywnie w oknie dialogowym
Slider Bar: przesunięcie go w prawo sprawia, że okno dialogowe jest bardziej
nieprzezroczyste; przesuwanie go w lewo czyni go bardziej przezroczystym.
Zachowaj ostrożność podczas przesuwania go w lewo: okno dialogowe
może nie być już widać
Ustawiając go na Zawsze, możesz zobaczyć, jak przezroczyste będzie
okno dialogowe podczas przesuwania suwaka, co może pomóc w
zapobieganiu uczynieniu go zbyt przezroczystym, aby go zobaczyć.
Różne dostępne przyciski akcji obejmują:
Znajdź następny:Znajduje następny pasujący tekst
☐ To pole wyboru zmienia pojedynczy przycisk Znajdź
następny na przyciski << i >>, którymi są "Szukaj do tyłu" i "Szukaj do
przodu" (najechanie myszką na to pole wyboru spowoduje, po niewielkiej
przerwie w ruchu, wyskoczyli podpowiedź wskazująca "Tryb 2 znajdź
przyciski")
Licz:Zlicza, ile dopasowań znajduje się w całym dokumencie, w określonym
kierunku lub ewentualnie "W zaznaczeniu" i pokazuje tę liczbę w sekcji
wiadomości u dołu okna dialogowego.
Znajdź wszystko we wszystkich otwartych dokumentach:Wyświetla listę
wszystkich wyników wyszukiwania w nowym oknie wyników
wyszukiwania; przeszukuje wszystkie plików aktualnie otwarte w Notepad ++
Znajdź wszystko w bieżącym dokumencie:Wyświetla wszystkie wyniki
wyszukiwania w nowym oknie wyników wyszukiwania; przeszukuje tylko
aktywny bufor dokumentów
Zamknij:Zamyka okno dialogowe wyszukiwania
Zamień:Zastępuje aktualnie wybrane dopasowanie. (Jeśli aktualnie nie wybrano
żadnego dopasowania, zachowuje się ono jak Znajdź następny i po prostu
podświetla następny mecz w określonym kierunku)
Page 25

Zastąp wszystko:Po zaznaczeniu ☑ Wrap Around powoduje przejście przez
aktywny dokument, od samej góry do samego dołu, i zastępuje wszystkie
znalezione wystąpienia. Gdy ☐ Zawijanie wokół jest zaznaczone, wyszukuje od
karnaty do końca pliku (jeśli ☐ Kierunek wsteczny jest niezaznaczony) lub od
początku pliku do opiekunki (jeśli zaznaczona jest ☑ Kierunek wsteczny) i
zastępuje wszystkie wystąpienia znalezione w tym regionie.
UWAGA: w przypadku wyrażeń regularnych będzie to równoznaczne z
wielokrotnym uruchamianiem wyrażenia regularnego, co nie jest tym samym,
co uruchamianie z włączoną flagą globalną /g, która jest dostępna w
aparatach wyrażeń regularnych niektórych języków programowania.
Aby wyjaśnić wyniki Zastąp wszystkie, w zależności od stanu różnych
ustawień:
Poprzedni
wybór
Zawinięcia
Kierunek do tyłu
W wyborze
Zakres
NIE
OD
OD
OD
Od lokalizacji CARET do KOŃCA pliku
TAK
OD
Page 26

OD
OD
Od POCZĄTKU zaznaczenia do KOŃCA pliku
NIE
OD
NA
OD
Od POCZĄTKU pliku do lokalizacji CARET
TAK
OD
NA
OD
Od POCZĄTKU pliku do KOŃCA zaznaczenia
TAK
-/-
-/NA
Od POCZĄTKU wyboru do KOŃCA zaznaczenia
-/NA
-/-
Page 27

OD
Od POCZĄTKU pliku do KOŃCA pliku
Kolumna Poprzednie zaznaczenie wskazuje, że zakres tekstu został już
zaznaczony. Kolumny Zawijanie i Kierunek do tyłu oraz W
zaznaczaniu odnoszą się do ustawienia pól wyboru opisanych powyżej.
Kolumna Zakres opisuje zakres dokumentu, na który ma wpływ zastąp
wszystko. Wartość "-/-" oznacza, że ustawienie nie wpływa na wynik dla tej
kombinacji warunków.
Zamień wszystko we wszystkich otwartych dokumentach:tak samo
jak zamień wszystko, ale przechodzi przez wszystkie dokumenty otwarte w
Notepad ++, a nie tylko aktywny dokument.
Powyższe działania można zainicjować za pomocą myszy poprzez naciśnięcie
odpowiedniego przycisku lub za pomocą specjalnych kombinacji. Skoncentruj się na
jednym z okien dialogowych Znajdź, naciśnij i zwolnij. Spowoduje to, że Notepad ++
podkreśli pojedynczy znak w tekście większości przycisków. Naciśnięcie Alt i jednego z
podkreślonych znaków będzie takie samo jak naciśnięcie tego samego przycisku za
pomocą myszy, tj. wybrana akcja zostanie zainicjowana. Technika Alt działa również w
przypadku kontrolek innych niż przyciski, np. kontrolka pola wyboru może być
zaznaczona / odznaczona poprzez naciśnięcie polecenia Alt.AltAlt
Funkcja Znajdź następny ma specjalny sposób wywoływania przez sterowanie
klawiaturą. Naciśnięcie Enter, gdy w oknie dialogowym Znajdź ma fokus wejściowy,
spowoduje zainicjowanie polecenia Znajdź następny w kierunku wskazanym
przez kierunek wstecz. Naciśnięcie Shift+Enter, gdy w oknie dialogowym Znajdź ma
fokus wprowadzania, spowoduje uruchomienie przycisku Znajdź
następny w kierunku przeciwnym do wskazanego przez kierunek
wstecz. Najechanie myszą na przycisk Znajdź następny spowoduje, po niewielkim
opóźnieniu, pojawi się etykietka narzędzia wskazująca Użyj Shift + Enter, aby wyszukać
w przeciwnym kierunku jako przypomnienie o tej możliwości.
Gdy funkcja rodziny znajdowania jest wywoływana za pomocą menu Wyszukaj, paska
narzędzi lub kombinacji klawiatury, wyraz na karnecie (lub zaznaczony tekst, jeśli
istnieje) jest automatycznie kopiowany do pola edycji Znajdź. Tego zachowania nie
można wyłączyć; to się zawsze zdarza. Aby tego uniknąć w ograniczony sposób, użyj
myszy TYLKO do przeniesienia fokusu wejściowego z bufora karty edycji do już
otwartego okna dialogowego Znajdź lub upewnij się, że opiekun nie "dotyka" słowa i że
nie ma aktywnego zaznaczenia podczas wywoływania polecenia znajdź rodzinę. Na
marginesie: Ta funkcja automatycznego kopiowania może być wykorzystana do
uzyskania danych wielolijowych do pola edycji Znajdź, czego nie można zrobić tylko
poprzez wpisanie w polu. Po prostu zaznacz tekst wielowierszowy, który chcesz
wyszukać, a następnie wywołaj okno dialogowe Znajdź za pomocą jednej z jego funkcji.
Zaznaczony tekst pojawi się jak zwykle w polu Znajdź. Znaki kończące wiersze nie
Page 28

będą widoczne, ale będą tam i zostaną dopasowane po zainicjowaniu akcji
wyszukiwania/zamiany.
Prawidłowy wpis Znajdź pole edycji o długości od 1 do 2046 znaków. Prawidłowa
długość wpisu Zamień na pole edycji mieści się w zakresie od 0 do 2046 znaków.
Każdy tekst wprowadzony/wklejony do tych pól poza znakiem 2046 jest po prostu
ignorowany podczas wywoływania akcji. Należy zauważyć, że operacja zastępowania
wpisem pola zeruj długość jest w rzeczywistości usunięciem dopasowanego tekstu.
Wybranie opcji Tryb wyszukiwania wyrażenia regularnego spowoduje, że
opcja Dopasuj tylko całe słowo zostanie odznaczona i wyłączona. Możliwym
obejściem umożliwiam wykonywanie tego typu wyszukiwań jest dodanie do początku i
na końcu wyrażenia regularnego Znajdź tekst.\b
PolaZnajdź co i Zastąp edycją mają strzałkę listy rozwijanej, która umożliwia
użytkownikowi powtórzenie wcześniej przeprowadzonych wyszukiwań. Dla danego
uruchomienia Notepad ++ historia wyszukiwania może wzrosnąć dość dużo; po
zamknięciu Notepad ++ domyślnie zapisuje tylko ostatnie elementy 10 w historii; liczba
zachowanych wyszukiwanych/zastępowanych terminów może zostać zmieniona
poprzez edycję pliku konfiguracyjnego, zgodnie z Preferencjami dla zaawansowanych
użytkowników. Pola tekstowe Filtry i Katalog na karcie Znajdź w plikach również mają
tę funkcję "historii". Historię tę można aktywować, klikając strzałkę w dół za pomocą
myszy (lub, równoważnie, naciskając Alt + w dół), aby upuścić pole, lub bezpośrednio
(bez upuszczania) za pomocą w dół (i / lub w górę) - bądź jednak ostrożny, czasami
podczas edycji kontrolki z funkcją historii użytkownik przypadkowo naciśnie strzałki w
górę lub w dół, gdy naprawdę chce nacisnąć strzałkę w lewo lub w prawo; to niestety
usuwa wyrażenie wyszukiwania / zastępowania (ponieważ są one najczęściej
edytowane), nad którymi pracowano, i zastępuje je innym tekstem z bufora historii.
Niechciane elementy z historii można usunąć, upuszczając pole, podświetlając element
do usunięcia i naciskając Delete (wymaga wersji 7.9.3 lub nowszej).config.xml
Opcja W zaznaczeniu zostanie automatycznie wybrana przez Notepad ++, jeśli okno
dialogowe Znajdź zostanie otwarte, gdy w aktywnym zaznaczeniu wystąpi więcej niż
1024 znaki. Zaznaczony tekst zostanie również umieszczony w
polu Znajdź. Uruchomienie akcji Policz lub Zamień wszystko bez wprowadzania
innych zmian w parametrach wyszukiwania spowoduje odpowiednio Zliczanie: 1
dopasowanie lub Zastąp wszystko: 1 wystąpienie zostało zastąpione,co
prawdopodobnie nie jest zamierzone. Właściwym rozwiązaniem dla tej sytuacji jest
zmiana opcji Znajdź tekst, jeśli intencją jest wyszukiwanie w obrębie zaznaczenia, lub
usunięcie zaznaczenia opcji W zaznaczeniach, jeśli intencją jest wyszukanie dość
długiego bloku tekstu.
Obszar paska stanu okna dialogowego Znajdź informuje użytkownika o tym, co
wydarzyło się podczas akcji. Na przykład może być napisane Mark: 1 match lub Find:
Nieprawidłowe wyrażenie regularne. Kolory są używane na pasku stanu do
podkreślenia: czerwony dla jakiegoś błędu; zielony lub niebieski dla różnych sukcesów
lub ogólnych informacji.
Page 29

Ważna uwaga:Po wywołaniu trybu wyszukiwania wyrażeń regularnych czerwony
komunikat o błędzie alertu "Znajdź: Nieprawidłowe wyrażenie regularne" pojawia
się TYLKO po naciśnięciu przycisku Znajdź następny. Wszystkie inne możliwe
działania prowadzą po prostu do powiadomienia, że nie ma żadnego wyniku, podczas
gdy w rzeczywistości wyrażenie regularne wyszukiwania jest po prostu zniekształcone.
Dlatego zawsze najpierw wykonaj wyszukiwanie Znajdź następny, aby przetestować
poprawność wprowadzania wyrażeń regularnych.
Notepad ++ używa okna dialogowego Znajdź i głównego okna Notepad ++ (gdy okno
dialogowe Znajdź nie jest otwarte), aby wskazać, że wyszukiwany tekst nie został
znaleziony (lub ewentualnie, że wystąpiło zawijanie w wyszukiwaniu). Ogólnie rzecz
biorąc, jeśli wyszukiwanie nie spowoduje dopasowania, a okno dialogowe Znajdź jest
otwarte, okno to mignie na krótko jako wskaźnik niepowodzenia. Jeśli okno dialogowe
Znajdź NIE jest otwarte i zainicjowane zostanie nieudane wyszukiwanie (np. za
pomocą polecenia Znajdź następny w menu Szukaj), główne okno Notepad ++
ponownie mignie na krótko jako wskaźnik braku sukcesu. Po zamknięciu okna
dialogowego Znajdź, ale z wcześniej aktywnym zawijaniem wokół, wyszukiwanie, które
powoduje zawijanie na końcu pliku, spowoduje również flashowanie głównego okna
Notepad ++. Ponadto dźwiękowa informacja zwrotna zostanie dostarczona, jeśli
akcja Znajdź następny lub Zamień spowoduje, że tekst Nie zostanie napotkany;
dźwięk można wyciszyć za pomocą opcji Wycisz wszystkie dźwięki w Preferencjach
> MISC.
Jeśli akcja wyszukiwania zostanie wywołana przez polecenie klawiaturowe z otwartym
oknem dialogowym Znajdź i fokusem wprowadzania w oknie edycji, nieudane
wyszukiwanie spowoduje zmianę fokusu wprowadzania na okno Znajdź.
Przypuszczalnie użytkownik chciałby w tym momencie przeprowadzić inne
wyszukiwanie?
Zrzeczenie się odpowiedzialności: Intencją projektową Notepad ++ jest spełnienie
podstawowych możliwości wyszukiwania / zastępowania. W związku z tym
wyszukiwanie Notepad ++ nie jest nieskończenie elastyczne i może zaspokoić
wszystkie potrzeby. W przypadku takich potrzeb energetycznych należy zwrócić się do
zewnętrznych narzędzi, z których niektóre dobrze integrują się z Notepad ++. Dobra
integracja oznacza, że po uzyskaniu wyników takie narzędzia mogą powiedzieć
Notepad ++, które pliki otworzyć i do których linii i kolumn przenieść opiekunkę, aby
pracować z dopasowanymi wynikami. Przykładami takich narzędzi do wyszukiwania
plików / tekstu mogą być: "GrepWin", "PowerGREP", "FileSeek", "Everything" i wiele
innych.
Znajdź na karcie Pliki
Znajdź w plikach umożliwia zarówno znajdowanie, jak i zastępowanie. Możesz wybrać
filtr rozszerzenia (Filtry:), folder zawierający (Katalog:) oraz czy mają być
przetwarzane również ukryte pliki lub podfoldery.
Lista Filtry to rozdzielana spacjami lista wyrażeń wieloznacznych, które cmd.exe mogą
Page 30

zrozumieć, na przykład . Jeśli masz pusty filtr, sugeruje się, że jest to . Od Notepad ++
v7.8.2 można również wykluczyć niektóre wzorce plików, poprzedzając filtr ; na
przykład Filtry: !*.bin *.* wykluczy pasujące pliki z wyników wyszukiwania, ale
dołączy dowolną inną nazwę pliku. (W wersji 7.8.7, jeśli w filtrze było co najmniej jedno
wykluczenie, w filtrze musiało być co najmniej jedno włączenie, w przeciwnym razie
wykluczono pliki z 0 dopasowanych plików włączenia, co spowodowało, że pliki nie
zostały dopasowane, co prawdopodobnie nie jest tym, czego chciałeś. Zostało to
naprawione w wersji 7.8.7, więc teraz możesz mieć samotne wykluczenie i dopasować
je do dowolnego pliku, który nie kończy się na .) Należy również pamiętać, że interfejs
API systemu Windows PathMatchSpec() jest używany, ponieważ jego zachowanie
odbiega od cmd.exe czasami analizy symboli wieloznacznych.*.doc
foo.**.*!*.bin!*.bin.bin
Katalog jest folderem zawierającym miejsce wyszukiwania. Ma trzy opcje, które
wpływają na jego zachowanie:
☐ Obserwuj bieżący dokument ⇒ jeśli jest włączona, domyślnie będzie
przeszukiwać folder zawierający bieżący aktywny dokument (spowoduje to
ustawienie w ).fifFolderFollowsDocconfig.xml
☐ We wszystkich podfolderach ⇒ jeśli jest włączona, będzie rekurencyjnie
przeszukiwać podfoldery danego folderu.
☐ W ukrytych folderach ⇒ jeśli jest włączona, będzie przeszukiwać ukryte
podfoldery, a także normalnie widoczne podfoldery.
Znajdź na karcie Projekty
Znajdź w Projektach umożliwia zarówno znajdowanie, jak i zastępowanie. Pliki używane
do tych operacji są określane przez następujące znaczniki wyboru:
☐ Project Panel 1 ⇒ jeśli ta opcja jest włączona, wszystkie pliki wymienione w
Panelu projektu 1 zostaną uwzględnione w operacji wyszukiwania/zamiany
☐ Project Panel 2 ⇒ jeśli jest włączony, wszystkie pliki wymienione w Project
Panel 2 zostaną uwzględnione w operacji wyszukiwania/zamiany
☐ Project Panel 3 ⇒ jeśli jest włączony, wszystkie pliki wymienione w Project
Panel 3 zostaną uwzględnione w operacji wyszukiwania/zamiany.
Można przeszukiwać tylko panele projektowe, które są obecnie otwarte. Znaczniki
wyboru paneli projektu, które nie są obecnie otwarte, są wyszarzone.
Lista Filtry dzia ła w taki sam sposób, jak opisano w poprzedniej sekcji Znajdź w
plikach.
Karta Oznacz
Karta Oznacz w oknie dialogowym Znajdź/Zamień spowoduje wyszukiwanie podobne
do karty Znajdź w bieżącym dokumencie lub zaznaczenie:
Page 31

Gdy zaznaczona jest linia zakładki, zakładka jest upuszczana w każdym
*Które polecenie Znajdź wszystko w
... *
Karta Znajdź właściciela okna
wierszu, w którym występuje pojedyncze trafienie. W przypadku, gdy pojedyncze
trafienie obejmuje wiele linii, każda linia w zakresie otrzyma zakładkę.
W przeciwnym razie dopasowany wzór zostanie wyróżniony zgodnie z
konfiguratorem Ustawienia -> Styl -> Style globalne , Znajdź styl znacznika.
(Zobacz także Konfigurator stylów).
W obu przypadkach przycisk Oznacz wszystko wykona znakowanie. Podobnie jak w
przypadku funkcji Zamień wszystko, funkcja Zaznacz wszystko będzie wyszukiwać
od początku dokumentu do końca, jeśli zaznaczona jest opcję Zawijaj; jeśli pole
wyboru Zawijanie nie jest zaznaczone, zostanie zaznaczone od położenia karnaty do
końca pliku (jeśli kierunek wsteczny nie jest zaznaczony) lub od początku pliku do
pozycji opiekunki (jeśli zaznaczony jest kierunek wstecz).
Aby kontrolować, czy wyróżnienia lub zakładki mają się kumulować podczas kolejnych
wyszukiwań, użyj przycisku Wyczyść wszystkie znaczniki, aby usunąć znaczniki, lub
zaznacz opcję Wyczyść dla każdego wyszukiwania, aby ta akcja była wykonywana
automatycznie przy każdym wyszukiwaniu. Po naciśnięciu przycisku Wyczyść
wszystkie znaczniki kolor tła znaczników zostanie usunięty z zaznaczonego tekstu;
ponadto wszystkie wcześniej ustawione zakładki zostaną usunięte, jeśli zaznaczone
jest pole wyboru Linia zakładek.
Po zaznaczeniu tekstu w dokumencie można go skopiować do schowka, naciskając
przycisk Kopiuj zaznaczony tekst. Ta funkcja jest również wywoływalna z menu
Wyszukaj, a aby można było jej używać w makrze, należy użyć wersji tego polecenia
kopiowania w menu Wyszukaj.
Wyróżnianie jest również dostępne w wyszukiwaniu przyrostowym, a ustawienie stylu to
Ustawienia -> Konfigurator stylów -> Style globalne , Podświetlanie przyrostowe.
Okno wyników wyszukiwania
Po uruchomieniu jednego lub więcej poleceń Znajdź wszystko w... pojawia się nowe
okno wyników wyszukiwania, w którym znajduje się karta Wyniki
wyszukiwania. Okno Wyników wyszukiwania można otworzyć i/lub ustawić fokus na
wprowadzaniu za pomocą polecenia menu Wyszukaj > oknie wyników
wyszukiwania lub skrótu klawiaturowego F7. Uwaga: To polecenie menu wydaje się
nic nie robić, jeśli nie było żadnych poleceń Znajdź wszystko w ... uruchomiono od
czasu otwarcia Notepad ++ .
Definicja: Znajd ź wszystko w ... polecenia obejmują:
Page 32

Znajdź wszystko we wszystkich
otwartych dokumentach
Znaleźć
Znajdź wszystko w bieżącym
dokumencie
Znaleźć
Znajdź wszystko
Znajdź w plikach
Okno Wyników wyszukiwania do myślnie pojawia się zadokowane u dołu głównego
okna Notepad ++. Podobnie jak inne takie okna, można go przesuwać, a nawet być
swobodnie pływającym oknem.
Z poziomu wyszukiwania Znajdź wszystko w... do okna Wyniki
wyszukiwania dodawane są trzy typy sekcji. Pierwszy to wiersz opisujący, co zostało
wyszukane, ile łącznych dopasowań (znanych jako "trafienia") miało miejsce (jest to
również pokazane na pasku tytułu okna, dla ostatnio występującego wyszukiwania) i ile
plików miało dopasowania. Drugi to wiersz, który pokazuje nazwę pliku z
dopasowaniami i liczbę dopasowań dla tego pliku (ten typ zostanie powtórzony, jeśli
wyszukiwanie znajdzie wiele plików z dopasowaniami). Na koniec pojawiają się
szczegóły dotyczące znalezionych dopasowań, w tym numer wiersza i zawartość
wiersza z podkreślonym dopasowanym tekstem. Domyślnym wyróżnieniem jest
czerwony tekst na żółtym tle, ale można to zmienić w obszarze Język "Wynik
wyszukiwania" konfiguratora stylów.
Gdy Notepad ++ wypełnia okno wyników wyszukiwania, robi to za pomocą jednego
wiersza dla każdego dopasowania znalezionego przez wyszukiwanie. Zauważ, że może
to i często kończy się wielokrotnym powtarzaniem tej samej linii pliku źródłowego w
danych wyjściowych. Przykładem tego może być szukanie "the" w wierszu tekstu, który
brzmi "Teraz jest czas, aby wszyscy dobrzy ludzie przyszli z pomocą swojemu krajowi";
Okno wyników wyszukiwania wyświetliłoby wiersz dwa razy, raz ze słowem "the"
wywołanym czerwonym tekstem z żółtym tłem, a drugi raz z "the" w "ich" podobnie
podkreślonym.
Gdy okno Wyniki wyszukiwania ma fokus wejściowy, aktualnie aktywna linia ma inny
kolor tła, podobnie jak domyślnie główne okno edytora. W przeciwieństwie do głównego
okna edytora, w którym funkcja tła bieżącej linii może być wyłączona, okno wyników
wyszukiwania zawsze ma podświetlenie tła dla aktywnej linii.
Użyj strzałek w górę i w dół, aby poruszać się w oknie Wyników wyszukiwania, gdy
ma fokus wejściowy. Dwukrotne kliknięcie myszą lub naciśnięcie ENTER, gdy fokus
wejściowy znajduje się na określonym dopasowaniu, spowoduje przeniesienie okna
edytora do tego dopasowania i spowoduje zaznaczenie jego tekstu.
Inne sposoby powrotu do okna edytora za pomocą dopasowań okna wyników
Page 33

wyszukiwania obejmują pozycje menu Wyszukaj Następny wynik
*Naciśnięcie Delete, gdy aktywny
wiersz wyników
wyszukiwania zaczyna się od...*
Co jest usuwane
tekst: "Szukaj"
ta linia "Szukaj", wszystkie linie nazwy
ścieżki pod nią i wszystkie linie "Linia"
pod liniami nazwy ścieżki
nazwa ścieżki
ta linia nazwy ścieżki i wszystkie linie
"Linia" pod nią
tekst: "Linia"
tylko ta linia
wyszukiwania (klawiatura: F4) i Poprzedni wynik wyszukiwania (klawiatura: Shift+F4).
Można je wywołać niezależnie od tego, gdzie znajduje się fokus wejściowy w Notepad
++.
Delete może służyć do usuwania pojedynczych wyników, dopasowań plików lub całych
dopasowań wyszukiwania w oknie Wyniki wyszukiwania, w zależności od tego, który
typ linii jest aktywny po naciśnięciu. Ponieważ historia jest hierarchiczna, to znaczy
drzewia, naciśnięcie klawisza Delete, gdy w elemencie wyższego poziomu drzewa
usuwa całą tę gałąź. Więc:
Wiele wyszukiwań będzie wyświetlanych pod oddzielnymi nagłówkami, które są
"składane", dzięki czemu można ukryć lub odkryć wyniki poprzednich wyszukiwań. Po
uruchomieniu nowego wyszukiwania poprzednie wyszukiwania są składane.
Jeśli wiersze pliku źródłowego zostaną ocenione przez Notepad ++ jako zbyt długie,
gdy zostaną skopiowane, aby umieścić je w oknie Wyników wyszukiwania, zostaną
obcięte i ... zostaną dodane na końcu. W takim przypadku dopasowany tekst
występujący w wierszu po pozycji ... nie będzie podkreślany. Jednak zastosowanie
metody powrotu do okna edytora (np. naciśnięcie enter) spowoduje prawidłowy wybór
pasującego tam tekstu. Limit długości wynosi 1024 znaki; obejmuje to informacje o
numerze wiersza dopasowania i inne formatowanie.
Jeśli wyszukiwanie jest prowadzone w taki sposób, że występuje dopasowanie
obejmujące co najmniej dwa wiersze, tylko zawartość PIERWSZEGO wiersza tego
dopasowania zostanie skopiowana do okna Wyników wyszukiwania. Jednak
zastosowanie metody powrotu do okna edytora (np. naciśnięcie enter) spowoduje
prawidłowy wybór wielolijowego pasującego tam tekstu.
Polecenia RightClick w obszarze klienta karty okna wyników wyszukiwania
Page 34
Kopiowanie tekstu z okna Wyniki wyszukiwania
Prawy element
Co jest kopiowane po
uruchomieniu funkcji
RightClick > Copy Selected Line(s)
wiersz z linią # info
cały wiersz tekstu Prawego przycisku
Kliknij, ale bez tekstu numeru wiersza
wiersz nagłówka nazwy ścieżki
wszystkie wiersze dla tego
pojedynczego pliku bez tekstu nazwy
ścieżki lub numeru wiersza
wiersz nagłówka "szukaj"
wszystkie wiersze dla tego
wyszukiwania (1 lub więcej plików) bez
nagłówka wyszukiwania, nazwy ścieżki
lub tekstu numeru wiersza
Istnieją dwa sposoby kopiowania dokładnego tekstu z okna Wyniki
wyszukiwania: Upewnij się, że fokus wprowadzania znajduje się w oknie Wyniki
wyszukiwania, zaznaczając tekst i użyj klawiszy Ctrl+cna klawiaturze lub użyj prawego
przycisku myszy, aby wywołać menu kontekstowe i wybierz Kopiuj. Te dwa
mechanizmy kopiowania dają identyczne wyniki. Inną opcją jest użycie polecenia Kopiuj
wybrane wiersze menu kontekstowego; ten typ kopii można uznać za "Copy Special".
Kopiuje tekst CAŁYCH LINII z wyników, BEZ żadnych informacji o wyszukiwaniu
(zwanych "metadanymi") zawartych w tym, co jest kopiowane.
Oto bardziej szczegółowy opis tego, co dzieje się z RightClick > Kopiuj wybrane
wiersze:
Po pierwsze, jeśli użytkownik zaznacza tekst w oknie Wyniki wyszukiwania i kopiuje
go w ten sposób, tylko wiersze tekstu dotknięte (nawet częściowo) przez zaznaczenie
są częścią kopii. Cały inny tekst z informacjami o wyszukiwaniu (nazwa ścieżki, numer
wiersza itp.) nie jest kopiowany, nawet jeśli jest częścią zaznaczenia. Po drugie, jeśli
nie ma aktywnego wyboru, gdy wywoływane jest rightClick > Copy Selected
Line(s), wyniki zależą od tego, co dokładnie znajduje się pod kursorem
podczas rightClick:
Wskazówka:Możliwe jest wybranie i skopiowanie prostokątnego wyboru danych z
okna Wyniki wyszukiwania. Odbywa się to za pomocą zwykłych Shift + Alt + strzałek
lub przytrzymując Alt + LeftClick i przeciągając myszą. Jest to naprawdę praktyczne
tylko przy użyciu metody kopiowania Ctrl + c; Kliknij prawym przyciskiem myszy
> Kopiuj wybrane wiersze kopiuje tylko całe wiersze, a ta kopia skopiuje tylko
pojedynczy pełny wiersz u góry/u dołu bloku kolumny.
Page 35

Istnieje możliwość skopiowania listy plików, które zawierały działania z poprzednich
wyszukiwań (wersja 8.0.0 i nowsze). Polecenie menu kontekstowego Kopiuj nazwy
ścieżek skopiuje do schowka pełne nazwy ścieżek wszystkich plików pojawiających się
w wynikach wyszukiwania.
Inne polecenia
Istnieje kilka poleceń, które nie wymagają wielu wyjaśnień; są to:
Zwiń wszystko
Rozwiń wszystkie
Zaznacz wszystko
Wyczyść wszystko
Otwórz wszystko
Okno/karta Wyniki wyszukiwania gromadzi wyniki z każdego wyszukiwania Find All
in ... wyniki starych wyszukiwań pozostają, dopóki użytkownik ich nie usunie.
Poszczególne wyniki można usunąć za pomocą Delete lub wszystkie poprzednie wyniki
można usunąć, wywołując polecenie Wyczyść wszystko. Nieaktualne wyniki można
usunąć, aby zmniejszyć bałagan wizualny lub gdy pożądane jest, aby stare wyniki nie
miały wpływu na działanie następcze. Przykładem tego może być polecenie Otwórz
wszystko, które otwiera wszystkie pliki wymienione na karcie Wyniki
wyszukiwania, które wcześniej miały trafienia. Jeśli historia wyszukiwania w wynikach
wyszukiwania jest naprawdę długa, może nie być pożądane otwieranie wszystkich
wymienionych tam plików, więc użycie Wyczyść wszystko przed wykonaniem nowych
wyszukiwań (z zamiarem otwarcia wszystkich później) może być rzeczą do zrobienia.
Polecenie Zaznacz wszystko nie wymaga wyjaśnień: zostanie wybrany CAŁY tekst na
karcie Wyniki wyszukiwania
Zawartość karty Wyniki wyszukiwania ma postać drzewa. Gdy Notepad ++ dodaje do
historii wyników, robi to w niezwinięty sposób, to znaczy użytkownik może zobaczyć
wszystkie informacje z ostatnio dodanego wyszukiwania. Jednak przed dodaniem
nowych wyników Notepad ++ zwinie wszystkie poprzednie dane wyników; być może
decyduje, że najnowsze wyszukiwanie jest najważniejsze?
Użytkownik może zwijać/odwijać "gałęzie" tego drzewa. Aby zwinąć, kliknij myszą na
symbol małego pudełka z wnętrzem , znajdującym się po lewej stronie każdej linii. Po
wykonaniu tej czynności ta część drzewa zostanie zwinięta (usunięta z widoku), a
pierwsza linia gałęzi (pozostała widoczna) będzie następnie wyświetlać symbol w polu.
Aby rozwiknąć pojedynczy element, który został wcześniej zwinięty (przez użytkownika
lub przez automatyczny mechanizm Notepad ++), po prostu kliknij symbol pola z . Ta
gałąź zostanie następnie rozwinięta i ponownie wyświetlona.-++
Polecenia Zwiń wszystko i Rozwiń wszystkie wykonują odpowiednie akcje
na WSZYSTKICH elementach całej historii wyników w oknie Wyniki wyszukiwania
jednocześnie. Być może lepszą nazwą dla Uncollapse all byłoby bardziej
Page 36

konwencjonalne "Rozwiń wszystko"?
Wyszukiwanie we wcześniej znalezionych wynikach (wyszukiwanie dodatkowe)
Być może przeprowadziłeś wyszukiwanie, a wyniki znajdują się na karcie w
oknie Wyniki wyszukiwania. Tera z chcesz przeprowadzić wyszukiwanie, ale z
zakresem tylko tych plików, które mają poprzednie dopasowania. A może chcesz
szukać tylko w liniach dopasowanych do poprzednich wyszukiwań, a nie tylko
dopasowanych plików, jeszcze bardziej zaostrzając kryteria wyszukiwania. Czy możesz
przeprowadzić tego rodzaju wyszukiwanie drugiego poziomu za pomocą Notepad ++?
Tak, przez *RightClick*ing obszar klienta okna wyniki wyszukiwania i wybranie Opcji
Znajdź w tych wynikach wyszukiwania....
Wybranie opcji Znajdź w tych wynikach wyszukiwania... spowoduje, że pojawi się
okno, a to okno wygląda podobnie do standardowego okna Znajdź, ale jest nieco
okrojone. Po wprowadzeniu parametrów wyszukiwania i wybraniu opcji Znajdź
wszystkootworzy się nowa karta Wyniki wyszukiwania (w oknie Wyniki
wyszukiwania) z wynikami "zawężone" wyszukiwania.
Wyskakujące okienko ma parametr niedostępny w opisanych wcześniej
wyszukiwaniach: ☐ Szukaj tylko w znalezionych wierszach. Zaznaczenie tego pola
ogranicza wyszukiwanie do wierszy wyświetlanych w dopasowanych plikach w
nadrzędnym oknie wyników wyszukiwania. Odznaczenie tego pola spowoduje, że
nowe wyszukiwanie sprawdzi wcześniej dopasowane pliki w całości. Gdy wyszukiwanie
zostało ograniczone do wcześniej znalezionych linii, jego wyniki wskażą to, używając
tego typu danych wyjściowych: w przeciwieństwie do normalnie widzianych: Search
"___" (__ hits in __ files - Line Filter Mode: only display the filtered
results)Search "___" (__ hits in __ files)
Wskazówka: Użyj opcji RightClick Wyczyść wszystko, aby ograniczyć zakres tego
typu wyszukiwań (przed wywołaniem wyszukiwania wtórnego!) - pamiętaj: Znajdź w
tych wynikach wyszukiwania... wyszukiwanie będzie szukać w plikach dopasowanych
do WSZYSTKICH poprzednich wyszukiwań, których wyniki są nadal obecne na
nadrzędnej karcie Wyniki wyszukiwania.
Wskazówka: Ponieważ nowo otwarte okno wyników wyszukiwania ma również
menu RightClick, możesz wykonać kolejne Znajdź w tych wynikach wyszukiwania ...
w oparciu o nowe wyniki, koncentrując wyszukiwanie na niektórych danych jeszcze
bardziej. Ten rodzaj udoskonalenia może być powtarzany tak często, jak to pożądane.
[Zauważ, że pasek tytułu okna nie pokazuje liczby trafień aktualnie aktywnej karty, ale
raczej pokazuje liczbę trafień pierwszej karty Wyników wyszukiwania w oknie.]
Uwaga: Polecenia przełączające fokus wprowadzania na okno Wyniki
wyszukiwania zawsze aktywują pierwszą kartę Wyniki wyszukiwania, a nie
dodatkowe karty wyników wyszukiwania, które mogły zostać utworzone.
Uwaga: Zawartość okna Wyniki wyszukiwania jest odrzucana po zamknięciu Notepad
++. Jeśli są tam ważne dane, należy je skopiować, używając jednej z powyższych
Page 37

metod, i zapisać w bardziej trwałej lokalizacji.
Opcje konfiguracji wyników wyszukiwania
Obecnie istnieją dwa sposoby konfigurowania zachowania okna Wyników
wyszukiwania, oba znajdujące się w menu kontekstowym myszy RightClick:
Zawijanie długich wierszy wyrazów
Czyszczenie przy każdym wyszukiwaniu
Są to elementy menu z zaznaczanym znacznikami wyboru; wywołaj element menu raz,
aby włączyć funkcję (znacznik wyboru pojawi się w menu) i uruchom ją ponownie, aby
ją wyłączyć (znacznik wyboru już się nie pojawia). Te ustawienia konfiguracji są
zapamiętywane przez Notepad ++, dopóki ich stany nie zostaną ponownie zmienione
przez użytkownika.
Gdy opcja Zawijanie długich wierszy w programie Word jest włączona (włączona),
tekst okna Wyników wyszukiwania będzie zawijany przy prawej krawędzi i będzie
kontynuowany w następnym widocznym wierszu. Gdy funkcja jest wyłączona, okno
będzie miało poziomy pasek przewijania, dzięki czemu tekst po prawej stronie w długich
liniach może być przewijany do widoku użytkownika. Ta funkcja została wprowadzona w
Notepad++ w wersji 7.9 (.0).
Domyślnie okno Wyniki wyszukiwania gromadzi wszystkie wcześniejsze
wyszukiwania typu Znajdź wszystko w ... typie. Po wykonaniu nowego wyszukiwania
stare wyniki są zwijane, tak że tylko najnowsze wyniki są w pełni widoczne w górnej
części okna. Stare wyszukiwania pozostają u dołu okna, aby uzyskać możliwe przyszłe
odniesienia, rozwijając je. Jednym z zastosowań do zachowania wyników z poprzednich
wyszukiwań jest wykonanie kilku różnych wyszukiwań, a następnie wykonanie
polecenia Otwórz wszystko z menu kontekstowego prawym przyciskiem myszy okna spowoduje to otwarcie wszystkich plików trafionych przez poprzednią serię potencjalnie
odmiennych wyszukiwań.
Dla niektórych użytkowników te starsze wyniki kumulują się irytujące - ich dane mogą
szybko stać się nieaktualne wraz ze zmianami w plikach - więc Notepad ++ 7.9.6 i
wyższe obsługują ustawienie, które po włączeniu usuwa wszelkie stare dane
wyszukiwania z okna przed wypełnieniem go nowym. Ustawienie jest
ustawiane/czyszczone przez kliknięcie prawym przyciskiem myszy w dowolnym miejscu
okna Wyników wyszukiwania, co powoduje wyświetlenie menu kontekstowego; w tym
menu znajduje się sprawdzalna pozycja menu zatytułowana Wyczyść dla każdego
wyszukiwania. Po włączeniu funkcji, co spowoduje, że jej element menu będzie miał
znacznik wyboru, uruchomienie wyszukiwania spowoduje wyczyszczenie starych
wyników.
Operacje wyszukiwania/oznaczania bez okien dialogowych
Page 38

Wyszukiwanie
Następujące polecenia, dostępne za pośrednictwem menu Wyszukaj lub skrótów
klawiaturowych, wykonują wyszukiwanie bez wywoływania okna dialogowego,
ponieważ wyszukują poprzedni cel wyszukiwania lub słowo lub zaznaczenie w
bieżącym dokumencie:
Znajdź następny / Znajdź poprzedni Powtórz wyszukiwanie bieżącego celu
wyszukiwania, w dół lub w górę.
Następny wynik wyszukiwania / Poprzedni wynik wyszukiwania Przejdź do
następnego lub poprzedniego wyniku wyszukiwania zarejestrowanego w oknie
Wyników wyszukiwania. Okno wyników wyszukiwania jest tworzone w
odpowiedzi na dowolne polecenie Znajdź wszystko oparte na oknie dialogowym.
Jeśli istnieje, można użyć funkcji Wyszukiwanie -> okno wyników
wyszukiwania, aby uczynić ją widoczną i przełączyć fokus wejściowy między
oknem wyników wyszukiwania a bieżącym dokumentem.
Znajdź (ulotny) Następny / Znajdź (niestabilny) Poprzedni Spróbuj znaleźć
słowo, w które znajduje się zatyszka, lub zaznaczony tekst, w dół lub w górę.
Wyszukiwane słowo lub zaznaczenie nie jest zapamiętywać w historii
wyszukiwania, a wyszukiwanie nie będzie powtarzalne za pomocą funkcji
Znajdź następny / Znajdź poprzednią. Dlatego nazywa się to lotnym.
Wybierz i znajdź następny / Wybierz i znajdź poprzedni Spróbuj znaleźć
słowo, w które znajduje się zatyszka, lub zaznaczony tekst, w dół lub w górę.
Wyszukiwane słowo lub zaznaczenie jest zapamiętywać w historii wyszukiwania,
a wyszukiwanie można powtórzyć za pomocą Znajdź następny / Znajdź
poprzedni.
Wszystkie akcje wyszukiwania bez okien dialogowych zachowują bieżące opcje
wyszukiwania ustawione w oknie dialogowym Znajdź, takie jak Dopasuj sprawę lub
Zawiń.
Oznaczanie kolorem/stylem i wyróżnianie
Użyj podmenu Oznacz wszystko lub Odznacz wszystko w menu Szukaj, aby
zaznaczyć/odznaczyć wszystkie wystąpienia zaznaczonego tekstu lub słowa, w których
znajduje się ikona, jeśli nie ma aktywnego zaznaczenia. Masz do wyboru pięć różnych
kolorów/stylów (ponumerowanych od 1 do 5), w których można oznaczyć tekst w ten
sposób. Opcje podmenu Mark One (wersja 7.9.6 i nowsze) działają podobnie, ale tylko
na pojedynczym wystąpieniu zaznaczonego tekstu lub słowa opiekuna.
Ustawienia dla każdego z 5 dostępnych kolorów/stylów to Ustawienia -> Konfigurator
stylów -> Style globalne, Oznacz styl #.
Jeśli wyróżniłeś niektóre grupy tekstu w ten sposób i chcesz skopiować te sekcje,
Page 39

podmenu Kopiuj stylizowany tekst w menu Wyszukiwanie pozwoli Ci to zrobić. Szybkie
wyszukiwanie wcześniej oznaczonego tekstu jest możliwe za pomocą podmenu Jump
Up lub Jump Down.
Uwaga: Niestety nazwa podmenu Oznacz wszystko może powodować pewne
zamieszanie między przyciskiem akcji o identycznej nazwie na karcie Oznacz w oknie
dialogowym Znajdź rodzinę. Te dwa rodzaje "znakowania" są różne, ale mają pewne
wspólne cechy. Na przykład polecenia podmenu Kopiuj tekst stylizowany umożliwiają
kopiowanie tekstu, który został stylizowany za pomocą stylów od 1 do 5 LUB tekstu,
który został oznaczony za pomocą karty Oznacz w polu Znajdź.
Możesz również spowodować, że wszystkie wystąpienia słowa na ochocie będą
dynamicznie podświetlane, jeśli włączysz inteligentne wyróżnianie; styl znacznika to
Ustawienia -> Konfigurator stylu -> Style globalne, Inteligentne wyróżnianie. Możesz
tam wybrać, czy dopasowanie powinno być wrażliwe na wielkość liter.
Włączasz inteligentne wyróżnianie za pomocą Ustawień -> Preferencje -> MISC ->
Inteligentne podświetlanie, Włącz inteligentne wyróżnianie. Domyślnie w podświetlaniu
nie jest duża wartość liter, co czasami może stanowić problem. Następnie po prostu
przełącz Ustawienia -> Preferencje -> MISC -> Podświetlanie jest zależne od wielkości
liter. (Zobacz także Konfigurator stylów i preferencje).
Znajdowanie znaków w określonym zakresie
Chociaż wyrażenia regularne zapewniają określanie zakresu (lub wielu zakresów)
znaków za pomocą wzorca [początek...koniec], jest to czasami niezręczne, gdy znak
początkowy lub końcowy nie jest łatwo wpisany. Notepad ++ zapewnia określone okno
dialogowe, dostępne za pomocą Znajdź -> Znajdź znaki w zakresie....
Można poprosić o niestandardowy zakres znaków, a także połowę zakresu 0..255:
ASCII obejmuje dolną połowę, inne niż ASCII obejmuje górną część. Należy zauważyć,
że wpisy powinny być w notacji dziesiętnej i że wartości powyżej 255 nie są
obsługiwane w użyteczny sposób.
Wyszukiwanie może przebiegać w górę lub w dół i opcjonalnie zawija się. Naciśnij
Znajdź, aby to wykonać. Zamknij okno dialogowe za pomocą dedykowanego przycisku,
przycisku zamykania na pasku tytułu lub Esc.
Wyszukiwanie przyrostowe
Wyszukiwanie przyrostowe jest podobne do możliwości wyszukiwania w ulubionej
przeglądarce internetowej (takiej jak Firefox lub Chrome). Możesz go uruchomić z menu
Wyszukiwanie > wyszukiwanie przyrostowe lub skrótu klawiaturowego (Ctrl+Alt+I).
To polecenie pokaże mały region u dołu Notepad ++, który ma kilka prostych funkcji.
Page 40

✗ umożliwia zamknięcie wyszukiwania przyrostowego.
PoleZnajdź to miejsce, w którym wpisujesz dosłowny wyszukiwany termin.
Przyciski < i > przekiełują do tyłu i do przodu w wynikach wyszukiwania
(zawijając je dookoła, gdy dotrze do końca lub początku dokumentu).
Jeśli pole wyboru ☐ Wyróżnij wszystkie nie jest zaznaczone, zostanie
podświetlone tylko bieżące dopasowanie; jeśli jest zaznaczona, wszystkie
dopasowania zostaną podświetlone.
Jeśli pole wyboru ☐ dopasuj przypadek jest zaznaczone, wyniki będą zgodne
tylko wtedy, gdy przypadek jest dokładnie taki sam, w przeciwnym razie
przypadek nie ma znaczenia.
Po prawej stronie tych pól wyboru pojawi się komunikat o wynikach: liczba
dopasowań, komunikat wskazujący, że opakowanie znajduje się u góry lub u
dołu dokumentu, lub "Nie znaleziono frazy", jeśli nie ma dopasowań. Gdy nie ma
dopasowań, pole Znajdź również zmienia kolor.
Porównanie "Wybierz i znajdź następny" i "Znajdź następny (ulotny)"
Ta sekcja ma na celu wyjaśnienie zamieszania związanego z tymi 2 podobnymi
poleceniami.
Oba polecenia "Wybierz i znajdź następny" (Ctrl + F3) i "Znajdź następny (ulotny)" (Ctrl
+ Alt + F3) robią to samo (prawie): zaznacz bieżące słowo (na którym znajduje się
zaokita), a następnie przejdź do następnego wystąpienia.
Istnieje jednak niewielka różnica między tymi 2 poleceniami: "Wybierz i znajdź
następny" zapamiętuje wyszukiwane słowo, "Znajdź następny (lotny)" nie.
Oto przykład:
Jeśli wykonasz polecenie "Wybierz i znajdź następny" dla słowa word1, zawsze możesz
użyć polecenia "Znajdź następny" (F3) lub "Znajdź poprzedni" (Shift + F3), aby
wyszukać słowo1, nawet opiekun znajduje się na word2.
Jeśli twój opiekun znajduje się na słowie word2, "Znajdź następny (volatile)" przeszuka
następne słowo2. Teraz, jeśli przesuniesz swój opiekun na słowo word3 i zrobisz
"Znajdź następny (ulotny)", przeszuka następne słowo3, a słowo2 zostanie
zapomniane.
Rozszerzony tryb wyszukiwania
W trybie rozszerzonym te sekwencje ucieczki (ukośnik odwrotny, po którym następuje
pojedynczy znak i opcjonalny materiał) mają specjalne znaczenie i nie będą
interpretowane dosłownie.
Page 41

\n: znak sterujący podawania liniowego LF (ASCII 0x0A)
\r: Znak kontrolny powrotu karetki CR (ASCII 0x0D)
\t: znak sterujący TAB (ASCII 0x09)
\0: znak kontrolny NUL (ASCII 0x00)
\\: literał ukośnika odwrotnego (ASCII 0x5C)
\b: binarna reprezentacja bajtu, złożona z 8 cyfr, które są albo 1, albo 0. †
\o: ósemka bajtu, złożona z 3 cyfr w zakresie 0-7
\d: dziesiętna reprezentacja bajtu, złożona z 3 cyfr w zakresie 0-9
\x: szesnastkowa reprezentacja bajtu, złożona z 2 cyfr w zakresie 0-9, A-F/a-f.
\u: Szesnastkowe przedstawienie znaku dwuznakowego, składającego się z 4
cyfr w zakresie 0-9, A-F/a-f. W kompilacjach Unicode znajduje znak Unicode (na
przykład pasuje do znaku w pliku zakodowanym w UTF-8). W kompilacjach ANSI
znajduje znaki wymagające dwóch bajtów, jak w kodowaniu Shift-JIS. †\u2020†
†UWAGA: Chociaż niektóre z tych sekwencji ucieczki w trybie rozszerzonego
wyszukiwania wyglądają jak sekwencje ucieczki wyrażeń regularnych, nie są one
identyczne. Wyrażenia regularne są oznaczone † różnią się lub nie są dostępne w
wyrażeniach regularnych.
Wyrażenia regularne
Wyrażenia regularne Notepad ++ używają biblioteki wyrażeń regularnych Boost v1.70,
która jest oparta na składni PCRE (Perl Compatible Regular Expression), odchodząc od
niej tylko w bardzo drobny sposób. Kompletna dokumentacja dotycząca dokładnej
implementacji znajduje się na stronach Boost dla składni wyszukiwania i składni
zastępczej
Społeczność Notepad ++ ma FAQ na temat innych zasobów dla wyrażeń regularnych.
Uwaga: Począwszy od wersji 7.8.7, wyszukiwanie wsteczne regex jest niedozwolone z
powodu czasami zaskakujących wyników. Jeśli naprawdę potrzebujesz tej funkcji,
zobacz Zezwalaj na wyszukiwanie wsteczne regex, aby dowiedzieć się, jak włączyć
tę opcję.
Znaki specjalne Regex
W wyrażeniu regularnym (skróconym do regex w całym tekście) interpretowane znaki
specjalne to:
Dopasowania jednoznaki
. lub ⇒ dopasowuje dowolną postać. Jeśli zaznaczysz pole z napisem . pasuje
do nowego wiersza,kropka pasuje do dowolnego znaku, w tym sekwencji
nowych wierszy. Gdy opcja nie jest zaznaczona, będzie pasować tylko znaki w
Page 42

wierszu, a nie sekwencje nowego wiersza ( lub ).\C.\r\n
\X ⇒ Dopasowuje pojedynczy znak niekombinujący, po którym następuje
dowolna liczba znaków łączących. Jest to przydatne, jeśli masz tekst
zakodowany w Unicode z akcentami jako oddzielnymi, łączącymi znaki. Na
przykład litera , z czterema łączącymi się znakami po , można znaleźć albo z
regex, albo z krótszym regex
.o¯o(?-i)o\x{0304}\x{0328}\x{031a}\x{0333}\X
\☒ ⇒ Umożliwia to wyszukiwanie dosłownego znaku ☒, który w przeciwnym
razie miałby specjalne znaczenie jako meta-znak regex, zamiast traktować go
jako meta-znak regex. Na przykład byłby interpretowany jako dosłowny, a nie
jako początek zestawu znaków. Dodanie ukośnika odwrotnego (nazywa się
to ucieczką)może również działać w drugą stronę, ponieważ czyni znak
wyjątkowym, który w przeciwnym razie nie jest: na przykład oznacza "cyfrę",
podczas gdy jest to zwykła litera. (Uwaga: tutaj został wybrany jako symbol
zastępczy dla postaci, z którą chcesz uciec.)\[[\dd☒
Znaki inne niż ASCII
\xℕℕ ⇒ Określ pojedynczy znak z kodem NN, gdzie każde N jest cyfrą
szesnastkową. To, co to oznacza, zależy od kodowania tekstu. Na przykład
może pasować do lub w zależności od strony kodowej w dokumencie
zakodowanym w formacie ANSI.\xE9éθ
\x{ℕℕℕℕ} ⇒ Jak powyżej, ale pasuje do pełnego 16-bitowego znaku Unicode.
Jeśli dokument jest zakodowany w formacie ANSI, ta konstrukcja jest
nieprawidłowa.
\0ℕℕℕ ⇒ Znak jednojajtowy, którego kod w ósemce to NNN, gdzie każde N jest
cyfrą ósemką. (To jest liczba, a nie litera lub .) Na przykład szuka litery ,
ponieważ 101 w ósemce to 65 w decimal.0oO\0101A
[[.col ⇒ Postać, od która oznacza col "sekwencja zestawiania". Na przykład w
języku hiszpańskim jest pojedynczą literą, chociaż jest napisana przy użyciu
dwóch znaków. Pismo to byłoby reprezentowane jako . Ta sztuczka działa
również z symbolicznymi nazwami znaków kontrolnych, jak w przypadku znaku
kodu 0x07. Zobacz także dyskusję na temat zakresów
znaków..]]ch[[.ch.]][[.BEL.]]
Znaki kontrolne
\a ⇒ Znak kontrolny BEL 0x07 (alarm).
\b ⇒ Znak kontrolki BS 0x08 (backspace). Jest to dozwolone tylko wewnątrz
definicji klasy znaków. W przeciwnym razie oznacza to "granicę słowa".
\e ⇒ Znak kontrolny ESC 0x1B.
Page 43

\f ⇒ Znak kontrolny FF 0x0C (kanał formularza).
\n ⇒ Znak kontrolny LF 0x0A (podawanie linii). Jest to regularny koniec linii pod
systemami Unix.
\r ⇒ Znak kontrolny CR 0x0D (powrót karetki). Jest to część sekwencji wiersza
DOS / Windows CR-LF i był znakiem EOL na komputerach Mac 9 i
wcześniejszych. OSX i nowsze wersje używają .\n
\R ⇒ Dowolna sekwencja nowego wierszu. W szczególności grupa atomowa
.(?>\r\n|\n|\x0B|\f|\r|\x85|\x{2028}|\x{2029})
\t ⇒ Znak kontrolki TAB 0x09 (tabulator lub karta twarda, tabulator poziomy).
\c☒ ⇒ Znak kontrolny uzyskany z ☒ znaków przez usunięcie wszystkich bitów
najniższego rzędu oprócz 6. Na przykład , a wszystkie oznaczają znak kontrolny
SOH 0x01. Możesz myśleć o tym jako o "\c oznacza ctrl", podobnie jak znak,
który otrzymasz po naciśnięciu Ctrl + A w terminalu.\c1\cA\ca\cA
Zakresy lub rodzaje znaków
Klasy postaci
[set ⇒ Oznacza to, że zestaw znaków oznacza na przykład dowolny ze znaków
literału lub . Zakresów można również używać, wykonując łącznik między
znakami, na przykład dla dowolnego znaku od do . Możesz użyć sekwencji
sortowania w zakresach znaków, takich jak w (są to sekwencje sortowania w
języku hiszpańskim).][abc]abc[a-z]az[[.ch.]-[.ll.]]
[^zestaw ⇒ Dopełnienie postaci w zestawie. Na przykład oznacza dowolny znak
z wyjątkiem znaku alfabetycznego. Należy zachować ostrożność przy liście
dopełnień, ponieważ wyrażenia regularne są zawsze wieloliniowe, a zatem będą
pasować do pierwszego , lub (lub , lub , lub jeśli przypadek dopasowania jest
wyłączony), w tym wszelkie znaki nowego wiersza. Aby ograniczyć wyszukiwanie
do jednego wiersza, uwzględnij znaki nowego wiersza na liście wyjątków, np.
.][^A-Za-z][^ABC]*ABCabc[^ABC\r\n]
Należy pamiętać, że dopełnieniem zestawu znaków jest często o wiele więcej znaków
niż się spodziewasz: pasuje do 1 lub więcej wystąpień dowolnego znaku, w tym nowych
linii: modyfikator wyszukiwania wyłącza "kropka pasuje do nowych linii", ale nie jest
kropką , więc klasa nadal może pasować do nowych linii.(?-s)[^x]+x(?-s)[^x].
[[:nazwa lub ⇒ Cała klasa znaków o nazwie name. Dla wielu istnieje również
jednoliterowa "krótka" nazwa klasy, ☒. Uwaga: nazwa i musi znajdować się w
klasie postaci, aby mieć ich specjalne znaczenie.:]][[:☒:]][::][:☒:][...]
Page 44

krótki
imię i nazwisko
opis
równoważna klasa znaków
alnum
litery i cyfry
alfa
Litery
h
pusty
odstępy, które nie są terminatorem linii
[\t\x20\xA0]
cntrl
znaki kontrolne
[\x00-\x1F\x7F\x81\x8D\x8F\x90\x9D]
d
cyfra
Page 45

Cyfr
wykres
znak graficzny, więc w zasadzie dowolny znak z wyjątkiem znaków kontrolnych,
, \0x7F\x80
l
dolny
małe litery
drukować
znaki do druku
[\s[:graph:]]
punkt
znaki interpunkcyjne
[!"#$%&'()*+,\-./:;<=>?@\[\\\]^_{
s
przestrzeń
spacja (separator wyrazów lub linii)
Page 46

[\t\n\x0B\f\r\x20\x85\xA0\x{2028}\x{2029}]
u
górny
wielkie litery
Unicode
dowolny znak z punktem kodowym powyżej 255
[\x{0100}-\x{FFFF}]
w
słowo
znaki słowne
[_\d\l\u]
xdigit
cyfry szesnastkowe
[0-9A-Fa-f]
Zauważ, że litery zawierają dowolne litery Unicode (litery ASCII, litery
akcentowane i litery z różnych innych systemów pisania); cyfry obejmują cyfry
ASCII i wszystko inne w Unicode, które jest sklasyfikowane jako cyfra (jak liczby
indeksu górnego ¹²³...).
Należy zauważyć, że te nazwy klas znaków mogą być pisane wielkimi lub małymi
literami bez zmiany wyników. Tak samo jest z lub mieszanym przypadkiem
.[[:alnum:]][[:ALNUM:]][[:AlNuM:]]
Page 47

Jak wspomniano wcześniej, nazwa i (zwróć uwagę na pojedyncze nawiasy)
Opis]
Sekwencja
ucieczki
Klasa
pozytywna
Negatywna
sekwencja
ucieczki
Klasa
ujemna
Cyfr
\d
[[:digit:]]
\D
[^[:digit:]
]
muszą być częścią otaczającej klasy znaków. Można je jednak połączyć w jedną
klasę znaków, na przykład , która jest klasą znaków, która pasowałaby do
dowolnej cyfry, wielkich liter, małych liter oraz literałów i znaków. Te nazwane
klasy nie zawsze będą wyświetlane z podwójnymi nawiasami, ale zawsze będą
znajdować się wewnątrz klasy postaci.[::][:☒:][_[:d:]x[:upper:]=]x_=
Jeśli nazwa lub przypadkowo nie znajdują się w otaczającej klasie postaci, stracą
swoje specjalne znaczenie. Na przykład jest to klasa znaków pasująca , , , , i ;
podczas gdy jest podobny do (plus inne wielkie litery
Unicode)[::][:☒:][:upper:]:uper[[:upper:]][A-Z]
[^[:nazwa lub ⇒ Dopełnienie klasy znaków o nazwie nazwa lub ☒ (pasujące do
wszystkiego, co nie należy do tej nazwanej klasy). Używa tych samych długich
nazw, krótkich nazw i reguł, jak wspomniano w poprzednim opisie.:]][^[:☒:]]
Właściwości znaku
Właściwości te zachowują się podobnie do nazwanych klas znaków, ale nie mogą być
zawarte w klasie znaków.
\p☒ lub nazwa ⇒ Taka sama jak lub nazwa, gdzie ☒ oznacza jedną z krótkich
nazw z powyższej tabeli, a nazwa oznacza jedną z pełnych nazw z góry. Na
przykład i oba oznaczają cyfrę, podobnie jak sekwencja
ucieczki.\p{}[[:☒:]][[::]]\pd\p{digit}\d
\P☒ lub nazwa ⇒ Taka sama jak lub nazwa (nienależące
do nazwyklasy).\P{}[^[:☒:]][^[::]]
Sekwencje ucieczki znaków
\☒ ⇒ Gdzie ☒ jest jednym z , , , , , , , opisanych poniżej. Te jednoliterowe sekwencje
ucieczki są równoważne klasie z góry. Sekwencja ucieczki małymi literami oznacza, że
pasuje do tej klasy; sekwencja ucieczki wielkimi literami oznacza, że pasuje do
negatywu tej klasy. (W przeciwieństwie do właściwości, mogą one być używane
zarówno wewnątrz, jak i na zewnątrz klasy znaków).dlsuwhv
Page 48

Małe litery
\l
[[:lower:]]
\L
[^[:lower:]
]
znaki spacji
\s
[[:space:]]
\S
[^[:space:]
]
wielka litera
\u
[[:upper:]]
\U
[^[:upper:]
]
znaki
wyrazowe
\w
[[:word:]]
\W
[^[:word:]]
przestrzeń
pozioma
\h
[[:blank:]]
\H
[^[:blank:]
]
przestrzeń
pionowa
\v
patrz poniżej
\V
Przestrzeń pionowa: Obejmuje znaki kontrolne LF, VT, FF, CR, NEL oraz znaki formatu
LS i PS: 0x000A (podawanie linii), 0x000B (tabele pionowe), 0x000C (podawanie
formularzy), 0x000D (powrót karetki), 0x0085 (następny wiersz), 0x2028 (separator linii)
i 0x2029 (separator akapitów). Nie ma nazwanej klasy, która by pasowała.
Klasy równoważności
[[=znak ⇒ Wszystkie znaki, które różnią się od znaków tylko ze strony
przypadku, akcentu lub podobnej zmiany. Na przykład pasuje do dowolnego ze
znaków: , , , , , , , i .=]][[=a=]]aАБВГДЕAабвгде
Mnożenie operatorów
+ ⇒ Pasuje do 1 lub więcej wystąpień poprzedniego znaku, tak wielu, jak to
możliwe. Na przykład dopasowania , , , i tak dalej. dopasowuje kolejne ciągi
samogłosek.Sa+mSamSaamSaaam[aeiou]+
* ⇒ Pasuje do 0 lub więcej wystąpień poprzedniego znaku, czyli jak najwięcej.
Na przykład dopasowania , , , i tak dalej.Sa*mSmSamSaam
? ⇒ Zero lub jeden z ostatnich znaków. Tak więc pasuje i , ale nie
.Sa?mSmSamSaam
*? ⇒ Zero lub więcej z poprzedniej grupy, ale minimalnie: najkrótszy pasujący
ciąg, a nie najdłuższy ciąg, jak w przypadku operatora "chciwego". W ten sposób
zastosowany do tekstu będzie pasował , podczas gdy będzie pasował
Page 49

.m.*?omargin-bottom: 0;margin-bom.*omargin-botto
+? ⇒ Jedną lub więcej z poprzedniej grupy, ale minimalnie.
{ℕ} ⇒ dopasowuje N kopii elementu, którego dotyczy (gdzie N jest dowolną
liczbą dziesiętną).
{ℕ,} ⇒ pasuje do N lub więcej kopii elementu, do których się odnosi.
{ℕ,ℙ} ⇒ dopasowuje N do P kopie elementu, do którego się odnosi, w takim
stopniu, w jakim może (gdzie P ≥ N).
{ℕ,}? lub ⇒ Jak powyższe, ale minimalnie.{ℕ,ℙ}?
*+ lub lub lub lub ⇒ Te tak zwane "dzierżawcze" warianty chciwych
powtarzających się znaków nie cofają się. Pozwala to na zgłaszanie awarii
znacznie wcześniej, co może znacznie zwiększyć wydajność. Ale wyeliminują
mecze, które wymagałyby znalezienia backtrackingu. Na
przykład:?+++{ℕ,}+{ℕ,ℙ}+
Gdy regex jest uruchamiany przeciwko tekstowi:“.*”“abc”x
“ matches “
.* matches abc”x
” cannot match $ ( End of line ) => Backtracking
“ matches “
.* matches abc”
” cannot match letter x => Backtracking
“ matches “
.* matches abc
” matches ” => 1 overall match “abc”
Gdy regex , z dzierżawczym kwantyfikatorem, jest uruchamiany przeciwko
tekstowi:“.*+”“abc”x
“ matches “
.*+ matches abc”x ( catches all remaining characters )
” cannot match $ ( End of line )
Zauważ, że nie ma żadnego dopasowania dla wersji dzierżawczej, ponieważ
czynnik powtarzalny dzierżawcy uniemożliwia cofnięcie się do możliwego
rozwiązania
Page 50

Kotwice
Kotwice pasują do pozycji o zerowej długości w linii, a nie do określonego znaku.
^ ⇒ Pasuje do początku wiersza (z wyjątkiem sytuacji, gdy jest używany
wewnątrz zestawu, patrz wyżej).
$ ⇒ Odpowiada końcowi wiersza.
\< ⇒ Pasuje do początku słowa przy użyciu definicji słów Scintilli.
\> ⇒ Pasuje do końca słowa przy użyciu definicji słów Scintilli.
\b ⇒ Dopasowuje początek lub koniec wyrazu.
\B ⇒ Grani ca słowa. Reprezentuje dowolne miejsce między dwoma znakami
wyrazowymi lub między dwoma znakami niewyrazowymi.
\A lub ⇒ dopasowuje początek pliku.\`
\z lub ⇒ dopasowuje koniec pliku.\'
\Z ⇒ Dopasowania jak z opcjonalną sekwencją nowych linii przed nim. Jest to
odpowiednik , który odbiega od tradycyjnego znaczenia Perla dla tej
ucieczki.\z(?=\v*\z)
\G ⇒ Ta "Ucieczka kontynuacji" pasuje do końca poprzedniego meczu.
W przypadku sytuacji Znajdź wszystko lub Zastąp wszystkie umożliwi to
zakotwiczenie następnego meczu na końcu poprzedniego meczu. Jeśli jest to
pierwsze dopasowanie funkcji Znajdź wszystko lub Zamień wszystkoi za
każdym razem, gdy używasz pojedynczego znajdź następny lub Zamień,"koniec
poprzedniego dopasowania" jest definiowany jako początek obszaru
wyszukiwania - początek dokumentu, bieżąca pozycja kursora lub początek
wyróżnionego tekstu.
Przechwytywanie grup i odniesień wstecznych
(subset ⇒ Numbered Capture Group: Nawiasy oznaczają podzbiór wyrażenia
regularnego, znany również jako wyrażenie podzbioru lub grupa
przechwytywania. Ciąg dopasowany do zawartości nawiasów
(oznaczonych podzbiorem w tym przykładzie) może być ponownie użyty z
odniesieniem wstecznym lub jako część operacji zamiany; patrz Substytucje,
poniżej. Grupy mogą być zagnieżdżone.)
(?<name>podzbiór lub podzbiór lub podzbiór ⇒ Nazwana grupa
przechwytywania:Nadaje wartość dopasowaną przez podzbiór jako nazwę
grupy. Należy pamiętać, że w nazwach grup rozróżniana jest wielkość
liter.)(?'name')(?(name))
Page 51

\ℕ, , , , , , , lub ⇒ Numerowane odniesienia wsteczne: te składnie są zgodne z
N-tą grupą przechwytywania wcześniej w tym samym wyrażeniu. (Odniesienia
wsteczne są używane w odniesieniu do zawartości grupy przechwytywania tylko
w wyrażeniu wyszukiwania/dopasowania; zobacz Sekwencje ucieczki
zastępowania, aby zapoznać się z odniesieniem do grup przechwytywania w
podstawieniach/zastąpieniach).\gℕ\g{ℕ}\g<ℕ>\g'ℕ'\kℕ\k{ℕ}\k<ℕ>\k'ℕ'
Regex może mieć wiele podgrup, więc , , itp może być używany do
dopasowywania innych (liczby przesuwają się od lewej do prawej z nawiasem
otwierającym grupy). Możesz mieć tyle grup przechwytywania, ile potrzebujesz, i
nie są ograniczone tylko do 9 grup (chociaż niektóre warianty składni mogą
odwoływać się tylko do grup 1-9; zobacz uwagi poniżej i użyj składni, które
wyraźnie zezwalają na wielocyfrowe N, jeśli masz więcej niż 9 grup)\2\3
Przykład: pasuje do linii, takiej jak , ale nie .([Cc][Aa][Ss][Ee]).*\1Case
matches CaseCase doesn't match cASE
\gℕ, , , , , , lub ⇒ Te formularze mogą obsługiwać dowolne niezerowe
N.\g{ℕ}\g<ℕ>\g'ℕ'\kℕ\k{ℕ}\k<ℕ>\k'ℕ'
Dla dodatniego N pasuje do N-tej podgrupy, nawet jeśli N ma więcej niż
jedną cyfrę. dopasowuje zawartość z 10. grupy przechwytywania,
a nie zawartość z pierwszej grupy przechwytywania, po której następuje
literał .\g100
Jeśli chcesz dopasować literalną liczbę po zawartości N-tej grupy
przechwytywania, użyj jednego z formularzy, który ma nawiasy
klamrowe, nawiasy lub cudzysłowy, jak lub lub : Na przykład pasuje do
zawartości drugiej grupy przechwytywania, a następnie literał 3,
podczas gdy pasuje do zawartości dwudziestej trzeciej grupy
przechwytywania.\g{ℕ}\k'ℕ'\k<ℕ>\g{2}3\g23
Dla jasności zdecydowanie zaleca się, aby zawsze używać nawiasów
klamrowych lub nawiasów dla wielocyfrowego N
W przypadku ujemnego N grupy są liczone wstecz względem ostatniej
grupy, więc jest to ostatnia dopasowana grupa i przedostatnia
dopasowana grupa.\g{-1}\g{-2}
Proszę zwrócić uwagę na różnicę między bezwzględnymi i względnymi
odniesieniami wstecznymi. Na przykład dokładne czteroliterowe słowo
palindrom można dopasować do:
regex , przy użyciu współrzędnych bezwzględnych
(dodatnich)(?-i)\b(\w)(\w)\g{2}\g{1}\b
Page 52

regex , przy użyciu współrzędnych względnych
(ujemnych)(?-i)\b(\w)(\w)\g{-1}\g{-2}\b
\ℕ ⇒ Ten formularz może mieć tylko N jako cyfry 1-9, więc jeśli masz więcej
niż 9 grup przechwytywania, będziesz musiał użyć jednej z innych
numerowanych notacji wstecznych odniesień, wymienionych w następnym
podpunkcie.
Przykład: wyrażenie dopasowuje zawartość pierwszej grupy
przechwytywania, po której następuje literał ", a nie zawartość 10.
grupy.\10\10
\g{name}, , , lub ⇒ Named Backreference:Ciąg pasujący do podwyrażenia o
nazwie nazwa.\g<name>\g'name'\k{name}\k<name>\k'name'
Ulepszenia czytelności
(?:podzbiór ⇒ Konstrukcja grupowania dla wyrażenia podzbioru, która nie liczy
się jako podwyrażenie (nie jest numerowana ani nazywana), ale po prostu
grupuje rzeczy w celu łatwiejszego odczytania regex lub użycia ilości ilościowej
tej grupy, z kwantyfikatorem znajdującym się tuż za tą konstrukcją grupowania.)
(?#komentarz ⇒ komentarze. Cała grupa jest przeznaczona tylko dla ludzi i
będzie ignorowana w dopasowującym tekście.)
Użycie modyfikatora flagi x (patrz sekcja poniżej) jest również dobrym sposobem na
poprawę czytelności złożonych wyrażeń regularnych.
Modyfikatory wyszukiwania
Poniższe konstrukcje kontrolują sposób, w jaki dopasowania warunkują inne
dopasowania lub w inny sposób zmieniają sposób wyszukiwania.
\Q ⇒ Rozpoczyna tryb dosłowny (Perl nazywa go "cytowanym"). W tym trybie
wszystkie znaki są traktowane tak, jak są, jedynym wyjątkiem jest końcowa
dosłowna sekwencja trybu.\E
\E ⇒ Kończy tryb dosłowny. Tak więc mecze .\Q\*+\Ea+\*+aaaa
(?enable-disable) lub ⇒ Istnieją cztery flagi, opisane poniżej, które można
zastosować do regex lub podgrupy. Termin enable może składać się z 0-4 flag
opisanych poniżej; termin wyłączenia może składać się z 0-4 flag opisanych
poniżej. Wszystkie flagi w opcji włącz zostaną włączone (włączone); wszystkie
flagi w wyłączonym zostaną wyłączone (wyłączone). (Pamiętaj, że nie ma sensu
umieszczać tej samej flagi zarówno w terminach włączania, jak
i wyłączania). Jeśli nie ma flag wyłączania, nie jest to konieczne; jeśli nie ma
Page 53

flag włączania, pojawi się natychmiast po : . Jeśli istnieje podwzort, flagi dotyczą
tylko zawartości podwzorcy; bez podwzorcy nie ma separatora, a flagi mają
zastosowanie do pozostałej części bieżącego regexu lub do momentu ustawienia
kolejnych flag.(?enable-disable:subpattern)--?(?-...):
i ⇒ niewrażliwa na litery (domyślnie: ustawiana przez ☐ opcja okna
dialogowego Dopasuj sprawę)
m ⇒ ^ i $ pasują do osadzonych nowych linii (domyślnie: włączone)
s ⇒ kropka pasuje do nowego wiersza (domyślnie: zgodnie z ☐ . pasuje
do opcji okna dialogowego nowy wiersz)
x ⇒ Ignoruj spacje bez ucieczki w regex (domyślnie: wyłączone). Wszelkie
spacje, które chcesz dopasować, muszą zostać usunięte
Przykłady:
blah(?i-s)foobar ⇒ włącza niewrażliwość na litery i wyłącza
kropki-dopasowuje-nowy wiersz dla pozostałej części wyrażenia regularnego:
w ten sposób wyrażenie jest uruchamiane zgodnie z regułami domyślnymi
(ustawionymi przez okno dialogowe), podczas gdy wyrażenie nie będzie
miało potrzeby stosowania liter, a kropka nie będzie pasować do nowego
wyrazu.blahfoobar
(?i-s:subpattern) ⇒ włącza niewrażliwość na litery i wyłącza
kropki-dopasowania-nowy wiersz, ale tylko dla subpattern
(?-i)caseSensitive(?i)cAsE inSenSitive ⇒ wyłącza brak wrażliwości na
wielkość liter (sprawia, że rozróżniana jest wielkość liter) dla części regex
wskazanej przez , i ponownie włącza dopasowanie bez rozróżnialności
wielkości liter dla reszty regexcaseSensitive
(?m:justHere) ⇒ i będzie pasować do osadzonych nowych linii, ale tylko dla
zawartości tej podgrupy ^$justHere
(?x) ⇒ Zezwalaj na dodatkowe spacje w wyrażeniu dla pozostałej części
regex
Należy pamiętać, że wyłączenie "kropka pasuje do nowej linii" nie wpłynie na
klasy postaci: będzie pasować do 1 lub więcej wystąpień dowolnego znaku
niebędącego znakiem, w tym nowych linii, nawet jeśli modyfikator
wyszukiwania wyłącza "kropka pasuje do nowych linii" (kropka nie jest
kropką, więc nadal może dopasowywać nowe
linie).(?-s)(?-s)[^x]+x(?-s)[^x].
(?|expression) ⇒ Jeśli wyrażenie naprzemienne ma podwyrażenia w
nawiasach w niektórych alternatywach, można chcieć, aby licznik podwyrażenia
nie był zmieniany przez to, co znajduje się w innych gałęziach przemiany. Ta
konstrukcja po prostu to zrobi.
Na przykład można uzyskać następujące wartości liczników podwyrażenia:
Page 54

# before ---------------branch-reset----------- after
/ (?x) ( a ) (?| x ( y ) z | (p (q) r) | (t) u (v) ) ( z )
# 1 2 2 3 2 3 4
Bez resetowania gałęzi byłaby to grupa 3, byłaby to grupa 4 i grupa 5. Po
zresetowaniu gałęzi oba zgłaszają się jako grupa 2.(y)(p(q)r)(t)
Przepływ sterowania
Zwykle wyrażenie regularne jest analizowane liniowo od lewej do prawej. Ale może być
konieczna zmiana tego zachowania.
| ⇒ Operator przemienny, który umożliwia dopasowanie jednej z wielu opcji. Na
przykład będzie pasować do jednego z , lub . Mecze są podejmowane od lewej
do prawej. Użyj do dopasowania pustego ciągu w takiej
konstrukcji.one|two|threeonetwothree(?:)
(?ℕ) ⇒ Odnosi się do N-tej podwyrażenia. Jeśli N jest ujemne, użyje N-tej
podwyrażenia od końca.
Zwróć uwagę na różnicę między podwyrażami a odniesieniami wstecznymi. Na
przykład, używając podobnej struktury do tej, szukając czteroliterowego słowa
będącego palindromem, tym razem oba regeksy znajdują po prostu
czteroliterowe słowo, ponieważ każda podwyrażenie, podpisane lub nie, odnosi
się do samego regex, zamkniętego w każdej grupie, a NIE do obecnej wartości
każdej grupy!
regex znajduje czteroliterowe słowo, gdy używa współrzędnych
bezwzględnych(?-i)\b(\w)(\w)(?2)(?1)\b
regex znajduje czteroliterowe słowo, gdy używa współrzędnych
względnych(?-i)\b(\w)(\w)(?-1)(?-2)\b
W rzeczywistości te dwa regeksy można uprościć do , zakładając, że grupa 1
i 2 są nadal potrzebne w zamian(?-i)\b(\w)(\w)\w\w\b
(?0) lub ⇒ Backtrack do początku wzorca.(?R)
(?&name) lub ⇒ Wstecz do podwyrażenia o nazwie nazwa.(?P>name)
Jeśli niepodpisana podwyrażenie znajduje się POZA nawiasami grupy, do
której się odnosi, jest nazywane wywołaniem podprogramu
Jeśli niepodpisana podwyrażenie znajduje się WEWNĄTRZ nawiasów grupy,
Page 55

do której się odnosi, jest nazywane wywołaniem rekurencyjnym
(?(assertion)YesPattern|NoPattern) ⇒ Wyrażenia warunkowe
Jeśli potwierdzenie jest prawdziwe, to YesPattern zostanie użyty do
dopasowania tekstu; jeśli twierdzenie jest fałszywe, nopattern zostanie użyty do
dopasowania tekstu.
YesPattern i NoPattern są dowolnymi prawidłowymi wzorcami regex.
Twierdzenie zawsze będzie znajdować się w nawiasach; jest to podkreślone
przez umieszczenie nawiasów na liście obsługiwanych składni asercji, poniżej:
(ℕ) ⇒ prawda, jeśli N-ta nienazwana grupa została wcześniej zdefiniowana
(<name>) lub ⇒ true, jeśli nazwa grupy wywoływana została wcześniej
zdefiniowana('name')
(?=lookahead) ⇒ prawda, jeśli wyrażenie lookahead jest zgodne
(?!lookahead) ⇒ prawda, jeśli wyrażenie lookahead nie jest zgodne
(?<=lookbehind) ⇒ prawda, jeśli wyrażenie lookbehind jest zgodne
(?<!lookbehind) ⇒ prawda, jeśli wyrażenie lookbehind nie jest zgodne
(R) ⇒ prawda, jeśli wewnątrz rekurencji
(Rℕ) ⇒ prawda, jeśli w rekursji do podwyrażenia o numerze N
(R&name) ⇒ prawda, jeśli w rekursji do nazwanej nazwy podwyrażenia
Uwaga: Wszystkie one nadal znajdują się w wyrażeniu warunkowym.
Nie należy mylić asercji sterujących wyrażeniem warunkowym (tutaj) z
twierdzeniami, które są częścią dopasowania wzorca
(sekcja Asercje poni żej). Tutaj, jeśli twierdzenie jest używane do
decydowania, które wyrażenie jest używane; poniżej potwierdzenie decyduje,
czy wzorzec jest zgodny, czy nie.
Uwaga: PCRE nie traktuje wyrażeń rekurencyjnych tak jak Perl:
W PCRE (podobnie jak Python, ale w przeciwieństwie do Perla) rekurencyjne
wywołanie podwzorca jest zawsze traktowane jako grupa atomowa. Oznacza
to, że po dopasowaniu niektórych ciągów podmiotu nigdy nie jest ponownie
Page 56

wprowadzany, nawet jeśli zawiera niewypróbowane alternatywy i następuje
późniejszy błąd dopasowania.
(?>pattern) ⇒ Niezależne wyrażenie podrzędne
Dopasuj wzór niezależnie od otaczających wzorców. Wyszukiwanie nigdy nie
cofnie się do niezależnej podekspresji.
Niezależne wyrażenia podrzędne są zwykle używane w celu poprawy
wydajności, ponieważ brane będzie pod uwagę tylko najlepsze możliwe
dopasowanie do wzorca; jeśli nie pozwala to na dopasowanie wyrażenia jako
całości, nie można w ogóle znaleźć dopasowania.
Można go również użyć do zachowania poprawności logiki wyrażeń
warunkowych (powyżej), zapobiegając nieoczekiwanemu ścieżce do
niewłaściwej alternatywy. Na przykład, gdy używasz numeru grupy jako
potwierdzenia warunkowego, :(?(ℕ)YesPattern|NoPattern)
Regex nie używa niezależnego wyrażenia podrzędnego, więc znajdzie ,
nawet jeśli spodziewałeś się, że zostanie użyty po dopasowaniu. Dlaczego?
Jeśli się nie powiedzie, wyszukiwanie cofnie się do początku i wypróbuje
następną alternatywę, gdzie pasuje , ale oznacza to, że nie pasuje, więc
wyrażenie warunkowe używa .(?:(100)|\d{3}) apples
(?(1)YesPattern|NoPattern)100 apples
NoPatternYesPattern100YesPattern100\d{3}?(1)NoPattern
Zamiast tego można użyć niezależnego wyrażenia podrzędnego, aby
zapobiec cofaniu się, używając regex . Teraz, jeśli się nie powiedzie, nie
może cofnąć się do użycia , zapobiegając w ten sposób przypadkowemu
użyciu , więc z nim albo się dopasuje, albo całe wyrażenie nie powiedzie
się.(?>(100)|\d{3}) apples
(?(1)YesPattern|NoPattern)YesPattern\d{3}100 apples
NoPattern100100 apples YesPattern
\K ⇒ Resetuje dopasowany tekst w tym momencie. Na przykład dopasowanie
nie będzie pasować do . Będzie pasować , ale będzie udawać, że tylko pasuje.
Przydatne, gdy chcesz zastąpić tylko ogon dopasowanego tematu, a grupy są
niezdarne do sformułowania.foo\Kbarbarfoobarbar
Jest to również przydatne, jeśli potrzebujesz twierdzenia za tyłu, które
zawierałoby nieustały wzór długości (patrz dalej). Ponieważ wygląd o zmiennej
długości nie jest dozwolony w wyrażeniach regularnych funkcji Boost, można
zamiast tego użyć składni. Na przykład niedozwoloną składnię można zastąpić
poprawną składnią, która pasuje do dokładnego ciągu tylko wtedy, gdy
poprzedza ją co najmniej jedna cyfra.\K(?-i)(?<=\d+)abc(?-i)\d+\Kabcabc
Page 57

Potwierdzeń
Te specjalne grupy nie zużywają żadnych znaków. Ich udane dopasowanie liczy się, ale
kiedy są gotowe, dopasowywanie zaczyna się od miejsca, w którym pozostało.
(?=pattern) ⇒ pozytywnego wyglądu: Jeśli wzór jest zgodny, cofnij się do
początku wzorca. Pozwala to na użycie logicznego AND do łączenia regeksów.
Wyrażenie próbuje znaleźć małą literę w dowolnym miejscu. Po sukcesie
wycofuje się i szuka wielkiej litery. Przy kolejnym sukcesie sprawdza, czy
temat ma co najmniej 6
znaków.(?=.*[[:lower:]])(?=.*[[:upper:]]).{6,}
q(?=u)i nie pasuje , ponieważ assertion pasuje do , ale nie zużywa ,
ponieważ dopasowywanie zużywa zero znaków, więc próba dopasowania we
wzorcu kończy się niepowodzeniem, ponieważ nadal porównuje się z
wyszukiwanym tekstem.quit(?=u)uuuiu
(?!pattern) ⇒ negatywny lookahead: Pasuje, jeśli wzór lookahead nie pasował.
(?<=pattern) ⇒ pozytywny wygląd: To potwierdzenie jest zgodne,
jeśli wzorzec pasuje do bieżącego tokenu.
(?<!pattern) ⇒ negatywny wygląd: To potwierdzenie jest zgodne,
jeśli wzorzec ni e jest zgodny z bieżącym tokenem.
UWAGA: W twierdzeniach lookbehind wzór musi mieć stałą długość, aby
silnik regex wiedział, gdzie przetestować twierdzenie. Użyj (powyżej) dla
odpowiednika wyglądu o zmiennej długości.\K
Zastępstwa
Wyrażenia zastępcze (zawartość wpisu Zamień na) używają podobnej składni do
wyrażenia wyszukiwania, z dodatkowymi funkcjami opisanymi poniżej.
Wszystkie znaki są traktowane jako literały z wyjątkiem , , , , , i .$\()?:
Sekwencje ucieczki substytucji
W podstawieniach, oprócz zezwalania na znaki kontrolne, znaki inne niż
ASCIIi sekwencje ucieczki znaków z wyrażeń wyszukiwania, rozpoznawane są
następujące dodatkowe sekwencje ucieczki:
\l ⇒ Powoduje, że następny znak jest wyprowadzany małymi literami
\L ⇒ Powoduje, że następne znaki będą wyprowadzane małymi literami, dopóki
nie zostanie znaleziony znak.\E
Page 58

\u ⇒ Powoduje, że następny znak jest wyprowadzany wielkimi literami
\U ⇒ Powoduje, że kolejne znaki będą wyprowadzane wielkimi literami, dopóki
nie zostanie znalezione a.\E
\E ⇒ Kończy tryb wymuszonej sprawy zainicjowany przez lub .\L\U
$&, , , , ⇒ Cały dopasowany tekst.$MATCH${^MATCH}$0${0}
$` , , ⇒ Tekst między poprzednim i bieżącym dopasowaniem lub tekst przed
dopasowaniem, jeśli jest to pierwszy.$PREMATCH${^PREMATCH}
$', , ⇒ Wszystko, co następuje po bieżącym meczu.$POSTMATCH${^POSTMATCH}
$^N, , ⇒ Zwraca wartość ostatniego pasującego
podwyrażenia.$LAST_SUBMATCH_RESULT${^LAST_SUBMATCH_RESULT}
$+, , ⇒ Zwraca wartość, która pasowała do ostatniego podwyrażenia we wzorcu,
jeśli to podwyrażenie jest obecnie dopasowane przez aparat
regex.$LAST_PAREN_MATCH${^LAST_PAREN_MATCH}
$$ lub ⇒ Zwraca literał.\$$
$ℕ, , ⇒ Zwraca wartość zgodną z N-tym podwyrażeniem (numerowana grupa
przechwytywania), gdzie N jest dodatnią liczbą całkowitą (1 lub większą). Jeśli N
jest większe niż 9, użyj .${ℕ}\ℕ${ℕ}
Uwaga: składnia i backreference działają tylko w wyrażeniu wyszukiwania
i nie są zaprojektowane ani przeznaczone do działania w wyrażeniu
substytucji/zastąpienia.\g...\k...
$+{name} ⇒ Zwraca wartość zgodną z podwyrażeniem o
nazwie nazwa (nazwana grupa przechwytywania).
Jeśli nie opisano w tej sekcji, po którym następuje dowolny znak, wyemisz ten znak
literału.\
Grupowanie substytucyjne
Nawiasy i są używane do tworzenia grup leksykalnych i nie są częścią tekstu
wyjściowego. Aby wyprowadzić nawiasy literałowe, użyj i .()\(\)
Warunki substytucji
Jeśli chcesz podejmować decyzje podczas zastępowania (zastępowania
warunkowego), użyj jednego z poniższych wariantów składni warunkowej.
?ℕYesPattern:NoPattern: gdzie jest pojedynczą cyfrą dziesiętną (0-9) i są
Page 59

wyrażeniami zastępczymi. Jeśli N-ta ponumerowana grupa z wyrażenia
wyszukiwania została dopasowana, zostanie ona użyta jako dane wyjściowe;
jeśli nie, zostanie użyty zamiast
tego. ℕYesPatternNoPatternYesPatternNoPattern
Na przykład: ⇒ jeśli pierwsza grupa z wyszukiwania została dopasowana, a
następnie użyj tekstu literału , a następnie zawartości pierwszego
dopasowania w nawiasach literałów; jeśli pierwsza grupa nie jest zgodna,
użyj tekstu literału .?1george\($1\):graciegeorgegracie
?{ℕ}YesPattern:NoPattern: gdzie tutaj może być jedna lub więcej cyfr
dziesiętnych i są wyrażeniami zastępczymi, jak wyżej. Ten wariant składni będzie
działał dla każdej grupy numerowanej, a nie tylko dla grup z liczbami od 1 do
9. ℕYesPatternNoPattern
Na przykład: ⇒, czy trzynasta grupa z wyszukiwania została dopasowana,
użyj tekstu literału , a następnie zawartości trzynastego dopasowania w
nawiasach literału; jeśli trzynasta grupa nie pasuje, użyj tekstu literału
.?{13}george\(${13}\):graciegeorgegracie
?{name}YesPattern:NoPattern: gdzie nazwa jest nazwą grupy nazwanego
dopasowania i są wyrażeniami zastępczymi, jak wyżej. YesPatternNoPattern
Na przykład: ⇒, czy grupa o nazwie komik z wyszukiwania została
dopasowana, a następnie użyj dosłownego tekstu , a następnie zawartości
nazwanej grupy w dosłownych nawiasach; jeśli nazwana grupa nie jest
zgodna, użyj tekstu literału
.?{comedian}george\($+{comedian}\):graciegeorgegracie
Umieszczając wyrażenie w nawiasach, można oddzielić warunek od otaczającego
zastąpienia: wyprowadzi lub , podczas gdy pokazuje, kiedy kończy się warunek, więc
byłoby lub
.a=?1george:gracie=ba=georgea=gracie=ba=(?1george:gracie)=ba=george=ba=gra
cie=b
Pamiętaj, że aby w wyrażeniach warunkowego zastępowania uwzględnić nawiasy
literałowe, znaki zapytania lub dwukropki, pamiętaj, aby je uniknąć.
Dopasowania o zerowej długości
W trybie normalnym lub rozszerzonym nie byłoby sensu szukać tekstu o długości 0;
jednak w trybie wyrażenia regularnego często może się to zdarzyć. Na przykład, aby
dodać coś na początku wiersza, wyszukaj "^" i zastąp je tym, co ma zostać dodane.
Notepad ++ wybrałby dopasowanie, ale nie ma sensownego sposobu na wybranie
długiego znaku zerowego rozciągania. W takim przypadku wyświetlana jest etykietka
narzędzia bardzo podobna do porad wywołań funkcji, z zaopieką skierowaną w górę do
pustego dopasowania.
Przykłady
Page 60

Te przykłady mają pomóc lepiej pokazać, co osiągnie złożona składnia regex. Wiele z
tych przykładów, napisanych przez Georga Dembowskiego, od lat jest w poprzednich
wersjach dokumentacji; zostały one zaktualizowane w celu dopasowania do
nowoczesnej składni wyrażenia regularnego Notepad ++ v7.7.
WAŻNY
Musisz zaznaczyć pole "wyrażenie regularne" w oknie dialogowym wyszukiwania
i zamiany
Kopiując ciągi stąd, zwróć szczególną uwagę, aby nie mieć dodatkowych spacji
przed lub po nich! W przeciwnym razie testowany regex nie będzie pasował do
niczego!
Przykład 0
Jak zastąpić/usunąć pełne linie zgodnie ze wzorem regex? Załóżmy, że chcesz usunąć
wszystkie wiersze w pliku, które zawierają słowo "nieużywane", nie pozostawiając
zamiast nich pustych wierszy. Oznacza to, że musisz zlokalizować linię, usunąć ją całą,
a dodatkowo usunąć jej kończącą się nową linię.
Więc chciałbyś to zrobić:
Znaleźć: ^.*?unused.*?$\R
Zamień na: nic, nawet spację
Wyrażenie regularne wydaje się zawsze działać, należy je czytać w następujący
sposób:
potwierdzanie początku wiersza
dopasuj niektóre znaki, zatrzymując się tak wcześnie, jak to konieczne, aby
wyrażenie było zgodne
ciąg wyszukujący w pliku , "nieużywany"
więcej znaków, ponownie zatrzymując się najwcześniej, co jest konieczne, aby
wyrażenie pasowało
koniec wiersza assert
Znak lub sekwencja nowego wierszu
Pamiętaj, że pożera wszystko do końca linii, jeśli ☐ . pasuje do nowej linii jest
wyłączone, a wszystko do końca pliku, jeśli opcja jest włączona!.*
Cóż, dlaczego pojawia się powyżej pogrubionymi literami? Ponieważ to wyrażenie
Page 61

zakłada, że każdy wiersz kończy się końcem sekwencji wierszy. Jest to prawie zawsze
prawdą i może się nie powieść w ostatnim wierszu pliku. Nie będzie pasować i nie
zostanie usunięty.
Ale lekarstwo jest dość proste: tłumaczymy w żargonie regex, że nowa linia powinna
pasować, jeśli tam jest. Tak więc poprawne wyrażenie w rzeczywistości brzmi:
Znaleźć: ^.*?unused.*?$\R?
Dzieje się tak dlatego, że pasuje do 0 lub 1 .?\R
Przykład 1
Używasz MediaWiki (jak Wikipedia) i chcesz, aby wszystkie nagłówki były o jeden
poziom wyższe, więc H2 staje się H1 itp.
Szukać ^=(=)
Zamień na \1
KliknijZastąp wszystko
Robisz to, aby znaleźć wszystkie nagłówki2... 9 (wymagane są dwa znaki równości),
które zaczynają się od początku wiersza (^) i zastąpić dwa znaki równości tylko
ostatnim z dwóch, eliminując w ten sposób jeden i mając jeden pozostały.
Szukać =(=)$
Zamień na \1
KliknijZastąp wszystko
Robisz to, aby znaleźć wszystkie nagłówki2... 9 (wymagane są dwa znaki równości),
które kończą się na końcu wiersza ($) i zastąpić dwa znaki równości tylko ostatnim z
nich, eliminując w ten sposób jeden i mając jeden pozostały.
== title == Stał się = title =
Gotowe :-)
Przykład 2
Masz dokument z wieloma datami, które są w formacie daty i chcesz je przekształcić do
formatu sortowalnego. Nie bój się długości wyszukiwanego hasła – jest długie, ale
składa się z dość łatwych i krótkich części.dd.mm.yyyy-mm-dd
Wykonaj następujące czynności:
Page 62

Szukaj lub([^0-9.])([0123][0-9])\.([01][0-9])\.([0-9][0-9])([^0-9.])
Szukać (\s)([0123][0-9])\.([01][0-9])\.([0-9][0-9])(\s)
Zamień na \1\4-\3-\2\5
KliknijZastąp wszystko
Robisz to, aby pobrać:
dzień, którego pierwsza liczba może być tylko 0, 1, 2 lub 3
miesiąc, którego pierwsza liczba może być tylko 0 lub 1
ale tylko wtedy, gdy separator jest kropką literału, a nie żadnym standardowym
znakiem ( versus \.. )
ale tylko wtedy, gdy data nie zawiera żadnych liczb, ponieważ może to być adres
IP zamiast daty
i pisać to wszystko w odwrotnej kolejności, z wyjątkiem otoczenia. Zwróć uwagę:
Wszelkie dopasowania WYSZUKIWANIA zostaną usunięte i zastąpione tylko przez
rzeczy w polu ZASTĄP, dlatego obowiązkowe jest posiadanie otoczenia również w polu
ZASTĄP!
Wynik:
31.12.97 Stał się 97-12-31
14.08.05 Stał się 05-08-14
adres IP nie zmienił się14.13.14.14
Gotowe :-)
Przykład 3
Wydrukowano w systemie Windows listę plików używaną do listy plików.txt i chcesz
utworzyć z nich lokalne adresy URL.dir /a-d /b/s /-p > filelist.txt
Otwórz za pomocą Notepad ++filelist.txt
Szukać \\
Zamień na /
Kliknijprzycisk Zamień wszystko.
Page 63

Spowoduje to zmianę separatora ścieżki systemu Windows na znak separatora
ścieżki adresu URL \/
Szukać \x20
Zastąpić %20
Kliknij przycisk Zamień wszystko, aby zmienić dowolny znak spacji w
składnię%20
Zgodnie z Twoimi wymaganiami możesz podobnie zmienić dowolny możliwy
symbol z odpowiednim wyrażeniem! # $ % & ' ( ) + , - ; = @ [ ] ^ { } ~%ℕℕ
Szukać ^(?=.)
Zamień na file:///
KliknijZastąp wszystko
Dodaje to file:/// na początku wszystkich niepustych wierszy
Po tej sekwencji stał się .C:\!\Test A.csvfile:///C:/!/Test%20A.csv
Gotowe :-)
Przykład 4
Załóżmy, że potrzebujesz tabeli rozdzielanej przecinkami z poniższej tabeli:
[Data]
AS AF AFG 004 Afghanistan
EU AX ALA 248 Åland Islands
EU AL ALB 008 Albania, People's Socialist Republic of
AF DZ DZA 012 Algeria, People's Democratic Republic of
OC AS ASM 016 American Samoa
EU AD AND 020 Andorra, Principality of
AF AO AGO 024 Angola, Republic of
NA AI AIA 660 Anguilla
AN AQ ATA 010 Antarctica (the territory South of 60 deg S)
NA AG ATG 028 Antigua and Barbuda
SA AR ARG 032 Argentina, Argentine Republic
AS AM ARM 051 Armenia
NA AW ABW 533 Aruba
OC AU AUS 036 Australia, Commonwealth of
Page 64

Następnie użyj następującego regex S / R:
Szukać: (?-i)[\u\d]\K\x20(?=[\u\d])
Zamień na: ,
NaciśnijZastąp wszystko
[Final Data]
AS,AF,AFG,004,Afghanistan
EU,AX,ALA,248,Åland Islands
EU,AL,ALB,008,Albania, People's Socialist Republic of
AF,DZ,DZA,012,Algeria, People's Democratic Republic of
OC,AS,ASM,016,American Samoa
EU,AD,AND,020,Andorra, Principality of
AF,AO,AGO,024,Angola, Republic of
NA,AI,AIA,660,Anguilla
AN,AQ,ATA,010,Antarctica (the territory South of 60 deg S)
NA,AG,ATG,028,Antigua and Barbuda
SA,AR,ARG,032,Argentina, Argentine Republic
AS,AM,ARM,051,Armenia
NA,AW,ABW,533,Aruba
OC,AU,AUS,036,Australia, Commonwealth of
Gotowe :-)
Przykład 5
Jak rozpoznać zrównoważone wyrażenie, w matematyce lub programowaniu?
Najpierw podajmy kilka przykładowych danych:
[Sample Test Start]
((((ab(((cd((()))))ef))))))
0000 000 00100000 00000•
1234 567 89098765 43210
((ab((((cd(((ef(()))))gh))))ijkl))))
00 0000 000 1110000 0000 00••
12 3456 789 0109876 5432 10
((((((ab(cd(ef((()))))gh)ijkl)))mn)))))
000000 0 0 01110000 0 000 00•••
123456 7 8 90109876 5 432 10
Page 65

((01ab(cd(ef23gh(ij45kl)mn)op((qr67st)uv\wx)34)yz))128956)abc
12 3 4 5 4 3 45 4 3 2 10 •
[[@ab[cd{ef@gh{ij@kl}mn]op((qr@st}uv@x]34yz])12@56)[cdedf]
12 1 0
((12ab(cd{ef34gh{ij56kl}mn}123}op((qr78stu)v\wx34)yz)12905126]
12 3 45 4 3 2
••
[[@ab[cd{ef@gh{ij@kl}mn}123]op((qr@stu)v@x34)yz]12@5@6]
12 1 0
[Sample Test End]
Na przykład spróbujmy zbudować wyrażenie regularne, które znajduje największy
zakres tekstu z dobrze wyważonymi nawiasami!
Po pierwsze, kilka konwencji typograficznych:
Niech Sp będzie nawiasem początkowym. Tak więc jego składnia regex jest
formą ucieczki lub po prostu, jeśli wewnątrz klasy znaków\((
Niech Ep będzie nawiasem końcowym. Tak więc jego składnia regex jest formą
ucieczki lub po prostu, jeśli wewnątrz klasy znaków\))
Niech Ac będzie dowolnym dozwolonym znakiem, w tym znakiem EOF, innym
niż EP i SP. Tak więc jego składnia regex jest ujemnym znakiem klasy , tj.
Ujemnym znakiem klasy [^EpSp][^()]
Niech R0 będzie rekursją do całego dopasowanego wzorca. Zgodnie z
konwencją, w PCRE, jego składnia regex jest lub (?0)(?R)
Niech R1 będzie rekurezą do wzorca grupy 1. Zgodnie z konwencją, w PCRE,
jego składnia regex jest następująca: (?1)
Teraz, niech Bb będzie dobrze wyważonym blokiem, zawierającym konstrukcję
Ep....Sp, która sama w sobie może składać się zarówno ze znaków Ac, jak i
innych Bb, na dowolnym poziomie większym niż poziom 0
Ten blok Bb może być reprezentowany przez symboliczny regex, poniżej ( Puste
znaki są ignorowane, dla czytelności ):
Sp ( Ac+ | R0 )* Ep
Składnia ta może zostać poprawiona jako , używając zarówno :Bb = Sp (?: Ac++
Page 66

| R0 )* Ep
Grupa nieuchwytniania, otaczająca dwie alternatywy
Kwantyfikator dzierżawczy względem znaku Ac, podobny do atomowego stanu
rekurencji, w PCRE.
Ważne jest, aby podkreślić, że jeśli użyjesz chciwej formy , zamiast , ostatnim
dopasowaniem będzie, błędnie, cała zawartość pliku, nawet w przypadku bardzo
krótkiego tekstu! Ponownie, zaleta niezezwolenia na backtracking zmniejsza
kombinacje i pozwala uniknąć katastrofalnego procesu backtrackingu :-)Ac+Ac++
Teraz, dokładniej, między nawiasami Sp i Ep, możesz spotkać:
Nic, stąd kwantyfikator gwiazdy, po grupie nieuchwytającej
Niezerowy zakres dozwolonych znaków, a więc grupa atomowa Ac++
Kolejna dobrze wyważona konstrukcja Bb, którą można z kolei zweryfikować za
pomocą funkcji rekurencyjnej R0
Z drugiej strony, każdy zeskanowany tekst tematu można zdefiniować jako:
Kombinacja następujących po sobie składni Ac* Bb Ac* Bb Ac* Bb, zakończona
ostatnim Ac. Tak więc w symbolicznej składni regex można to zapisać jako (?:
Ac Bb)+ Ac*
Niezerowy zakres dozwolonych znaków, gdy tekst tematu NIE zawiera żadnych
nawiasów Ep i Sp, więc składnia symboliczna Ac+ jest tylko ( Przez
rozszerzenie, tekst bez nawiasów jest oczywiście dobrze wyważonym tekstem
nawiasów ... ponieważ nie zawiera nawiasów! )
Oznacza to, że ogólny regex symboliczny jest (?: Ac* Bb )+ Ac* | Ac+
Teraz, zastępując powyższą wartość dobrze wyważonej konstrukcji Bb, w naszym
końcowym wyrażeniu otrzymujemy nasze ostateczne symboliczne wyrażenie regex:
(?: Ac* ( Sp (?: Ac++ | R1 )* Ep ) )+ Ac* | Ac+
\ ---------------------- /
Group 1
Zauważ jednak, że musieliśmy dodać dwa nawiasy, aby zdefiniować nową grupę #1 ,
która osadza konstrukcję Bb. Rzeczywiście, podczas procesu rekurencji musi odnosić
się konkretnie do tej grupy, #1 i NIE powtarzać się do całego wzorca regex. Stąd
notacja R1, zamiast notacji R0!
Page 67

Wreszcie, możemy uzyskać coś bardziej czytelnego, jeśli użyjemy trybu swobodnych
odstępów, aby zidentyfikować składniki naszego regex i przepisać to wyrażenie z
poprawną składnią regex:
(?x) (?: [^()]* ( \( (?: [^()]++ | (?1) )* \) ) )+ [^()]* |
[^()]+
Zauważ, że w trybie swobodnych odstępów możesz również wstawiać komentarze i
dzielić regex na kilka wierszy, prowadząc na przykład do następującego tekstu:
(?x) # FREE-SPACING mode
(?: # Start of the FIRST NON-CAPTURING group
[^()]* # Any range, possibly NUL, of ALLOWED characters
( # Start of CAPTURING group #1
\( # STARTING parenthesis
(?: # Start of the SECOND NON-CAPTURING group
[^()]++ # Any NON-NULL ATOMIC range of ALLOWED
characters,
| # OR
(?1) # A RECURSION, using the regex pattern of
group #1
)* # End of the SECOND NON-CAPTURING group,
repeated 0 or MORE times
\) # ENDING parenthesis
) # End of the CAPTURING group 1
)+ # End of the FIRST NON-CAPTURING group, repeated 1 or
MORE times
[^()]* # Any range, possibly NUL, of ALLOWED characters
| # OR
[^()]+ # Any NON-NULL range of ALLOWED characters,
Jeśli zredukujemy składnię tego rekurencyjnego wyrażenia regularnego do minimum,
otrzymamy :
(?:[^()]*(\((?:[^()]++|(?1))*\)))+[^()]*|[^()]+
Ale jest tak samo trudny do odszyfrowania, jak źle wcięty fragment kodu bez
komentarza i z nieoszłymującymi, niejasnymi identyfikatorami.
Przykład 6
Ten przykład daje lepszy wgląd w używanie niezależnych wyrażeń podrzędnych, aby
zapobiec śledzeniu wstecznemu podczas korzystania z wyrażeń warunkowych.
Page 68

Biorąc pod uwagę plik:
5 apples in a box
100 apples in a box
200 apples in a barrel
250 apples in a box
500 apples in a barrel
Chcemy dopasować, gdy jest 250 lub mniej jabłek tylko wtedy, gdy są w pudełku; jeśli
jest więcej jabłek niż 250, powinno pasować tylko w beczce. Dlatego nie powinien
pasować.200 apples in a barrel
Najpierw musimy skonstruować kontener Wyrażenie warunkowe dla jabłek:
(?('LEQ250')in a box|in a barrel)
Odnosi się do jakiejś grupy chwytania, która złapie ilość jabłek w porównaniu z naszym
stanem:('LEQ250')
(?:(?'LEQ250'\d{1,2}|1\d\d|2[0-4]\d|250)|\d+)\D
Sztuczka polega na tym, że jeśli mamy alternatywy w tej grupie przechwytywania, nie
możemy pozwolić, aby wyszukiwanie się cofnij, aby wypróbować inną alternatywę niż
warunek, gdy warunek się nie powiedzie. Dlatego musimy użyć niezależnego wyrażenia
podrzędnego:
(?>(?:(?'LEQ250'\d{1,2}|1\d\d|2[0-4]\d|250)|\d+)\D)
Ale jeśli użyjemy niezależnego wyrażenia podrzędnego, mamy dwa inne problemy:
1. mamy możliwość pojawiania się spacji przed cyframi \h*
2. musimy sprawdzić, gdzie kończy się numer \D
Alternatywy i mnożenie Operatory wymagają backtrackingu, a więc muszą być
rozwiązane wewnątrz pod-wyrażenia Independent. W naszym przykładzie jest
definitywny - zawsze zatrzymuje się przed nie-spacją (a cyfra nie jest spacją), ale jeśli
chcesz uwzględnić pewne alternatywy lub mnożenie operatorów wewnątrz grupy
przechwytywania, dołącz je wszystkie, aby dać niezależnemu wyrażeniu podrzędnemu
możliwość cofnięcia się w sobie.\h*\d\h*\d
Page 69

Lepiej jest sprawdzić koniec w bardziej ogólnej formie, aby nie uwzględniać wzorców,
które nie są potrzebne do grupy przechwytywania wewnątrz podekspresji Independent;
w ten sposób użyjemy dodatniego lookahead (?=\D) Assertion.
W rezultacie mamy następujący regexp:
^\h*(?>(?:(?'LEQ250'\d{1,2}|1\d\d|2[0-4]\d|250)|\d+)(?=\D)) apples
(?('LEQ250')in a box|in a barrel)
W przypadku tego wyrażenia nasze wyniki wyszukiwania są
File1 (4 hits)
Line 1: 5 apples in a box
Line 2: 100 apples in a box
Line 4: 250 apples in a box
Line 5: 500 apples in a barrel
Gdybyśmy nie użyli pod-wyrażenia Independent, a zamiast tego użyli regex
^\h*(?:(?:(?'LEQ250'\d{1,2}|1\d\d|2[0-4]\d|250)|\d+)(?=\D)) apples
(?('LEQ250')in a box|in a barrel)
Nasze wyniki wyszukiwania będą niepoprawnie pasować do wiersza 3 ():200 apples in
a barrel
File1 (5 hits)
Line 1: 5 apples in a box
Line 2: 100 apples in a box
Line 3: 200 apples in a barrel
Line 4: 250 apples in a box
Line 5: 500 apples in a barrel
Wyszukiwanie akcji zarejestrowanych jako makra
Rodzinę akcji Znajdź można nagrać w makrze, aby ułatwić ich nazwanie, a następnie
odtworzenie za pomocą menu Makro lub przypisanego skrótu klawiaturowego. Nieco
niestety, Znajdź co i Zamień tekstem jest wbudowane w makro podczas jego
tworzenia i nie jest czymś, co użytkownik może zmienić po uruchomieniu makra, ale
często nie jest to znaczące ograniczenie.
Page 70

Zauważ jednak, że akcje związane z Find są rejestrowane nieco inaczej niż inne akcje
Notepad ++, więc omówimy je nieco bardziej szczegółowo tutaj. Zazwyczaj Notepad ++
rejestruje krok w makrze za każdym razem, gdy użytkownik robi coś w interfejsie
użytkownika Notepad ++. Rodzina akcji Znajdź jest bardziej "skoordynowana" w
przypadku nagrywania makr.
Rejestrator makr rejestruje tylko wtedy, gdy wystąpi rzeczywista akcja Znajdź rodzinę
(np. Zamień, Znajdź wszystko w bieżącym dokumencieitp.). W ten sposób możesz
dostosować parametry przyszłej akcji (np. Przypadek dopasowania, Zawiń
dookołaitp.) wszystko, co chcesz, a wszystkie te skrzypce nie są zapamiętywane. W
momencie wykonywania akcji pobierana jest migawka wszystkich parametrów i akcji,
która jest rejestrowana w pamięci makr jako właściwa sekwencja makr.
Podczas gdy użytkownik może po prostu nagrywać i używać makr rodziny Znajdź,
można również edytować te makra później, aby zmienić lub dodać do ich
funkcjonalności, dlatego warto znać szczegóły sekwencji makr, które zostały wcześniej
zarejestrowane. Podczas gdy szczegóły dotyczące ogólnego sposobu rejestrowania i
przechowywania makr w skrótach.xml omówiono w innym miejscu, oto szczegóły tego,
co się dzieje, gdy Notepad ++ zapisuje nagrane makro rodziny Find:
Najpierw pojawia się komunikat 1700, który przeprowadza inicjalizację silnika Find:
<Action type="3" message="1700" wParam="0" lParam="0" sParam="" />
Dalej znajduje się wiadomość 1601 z tekstem Znajdź w polu sParam; w tym
przykładzie wyszukujemy "to":
<Action type="3" message="1601" wParam="0" lParam="0" sParam="it" />
Następnie jest wiadomość 1625 z trybem wyszukiwania w lParam, z możliwymi
wartościami 0 =Normalny / 1 =Rozszerzony / 2 =Wyrażenie regularne;
pokażmy wyrażenie regularne w tym przykładzie:
<Action type="3" message="1625" wParam="0" lParam="2" sParam="" />
Następnie, jeśli wykonywana jest operacja wymiany typu, jest
komunikat 1602 z sParam przytrzymującego Zamień z tekstem; tutaj zrobimy to "IT":
<Action type="3" message="1602" wParam="0" lParam="0" sParam="IT" />
Przechodząc dalej, następnie, jeśli wykonujesz Znajdź wszystko (naprawdę Znajdź w
plikach) lub Zastąp w plikach, jest to komunikat 1653 zawierający katalog podstawowy
do wyszukiwania w sParam:
<Action type="3" message="1653" wParam="0" lParam="0" sParam="C:\Program
Files\Notepad++\" />
Również podczas wykonywania Znajdź wszystko lub Zamień w plikach, będzie
komunikat 1652 zawierający filtry do wyszukiwania w sParam:
Page 71

<Action type="3" message="1652" wParam="0" lParam="0" sParam="*.*" />
Waga 1702 bitów
Binarna waga bitowa
Znaczenie (zaznaczona
równoważna opcja)
1
0000000001
Dopasuj tylko całe słowo
2
0000000010
Etui meczowe
4
0000000100
Czyszczenie dla
każdego wyszukiwania
16
0000010000
Linia zakładki
32
0000100000
We wszystkich
podfolderach
64
0001000000
W ukrytych folderach
128
0010000000
W wyborze
256
0100000000
Zawinięcia
512
1000000000
Kierunek do tyłu (*)
Następny będzie komunikat 1702, który zawiera liczbę ważoną bitami w lParam, która
reprezentuje parametry opcji "checkbox" dla akcji (więcej na ten temat później, na razie
użyjemy tylko 515 w przykładzie i przedstawimy tabelę wagi bitów):
<Action type="3" message="1702" wParam="0" lParam="515" sParam="" />
*: Zaznaczony kierunek wsteczny oznacza, że 512 nie jest uwzględniony;
niezaznaczone oznacza, że 512 jest uwzględniony.
Zobaczmy, jak dekodowana jest przykładowa wartość 515 użyta powyżej:
lParam="515" (dziesiętny) = 203 (szesnastka) = 10 0000 0011 (binarny) = 512 + 2 + 1 =
(nie kierunek wsteczny + Przypadek dopasowania + Tylko dopasuj całe słowo). W
związku z tym stanowiłoby to wyszukiwanie od przodu od opiekuna do końca pliku z
określonym przypadkiem, z dodatkowym kwalifikatorem, że tekst dopasowania musi
Page 72

być w nawiasie przez znaki inne niż słowo.
1701-Wartość
Znaczenie (równoważne naciśnięcie
przycisku)
1
Znajdź następny
1608
Zastąpić
1609
Zastąp wszystko
1614
Hrabia
1615
Zaznacz wszystko
1633
Wyczyść wszystkie znaczniki
1635
Zastąp wszystko we wszystkich
otwartych dokumentach
1636
Znajdź wszystko we wszystkich
otwartych dokumentach
1641
Znajdź wszystko w bieżącym
dokumencie
1656
Znajdź wszystko (w plikach)
1660
Zastąp w plikach
Na koniec pojawia się komunikat 1701, który koduje akcję Znajdź rodzinę do wykonania
w lParam, która po wykonaniu przeprowadzi akcję przy użyciu wszystkich informacji
zakodowanych w poprzednich wiadomościach; zróbmy Zamień w plikach, który ma
wartość całkowitą 1660, dla celów przykładu:
<Action type="3" message="1701" wParam="0" lParam="1660" sParam="" />
Oto kompletny przykład (który może wystąpić w skrótach.xml) i jak jest interpretowany:
Page 73

<Macro name='Book Mark lines NOT containing ABC' Ctrl="no" Alt="no" Shift="no"
Key="0">
<Action type="3" message="1700" wParam="0" lParam="0" sParam="" />
<Action type="3" message="1601" wParam="0" lParam="0"
sParam="^(?-s)(?!.*ABC).*" />
<Action type="3" message="1625" wParam="0" lParam="2" sParam="" />
<Action type="3" message="1702" wParam="0" lParam="786" sParam="" />
<Action type="3" message="1701" wParam="0" lParam="1615" sParam="" />
</Macro>
Najpierw mamy naszą inicjującą wiadomość 1700.
Następnie w polu sParam wiadomości 1601 znajduje się wyrażenie regularne, które
będzie pasować do wierszy, które nie zawierają "ABC": ^(?-s)(?!.*ABC).*
Typ wyszukiwania "Wyrażenie regularne" pojawia się obok jako lParam="2" w
wiadomości z 1625 roku.
Pomijając na razie wiadomość 1702, wiadomość 1701 ma lParam="1615", co z tabeli
1701 oznacza "Zaznacz wszystko".
Na koniec rozważmy przesłanie z 1702 roku. Jego istotną częścią jest lParam="786".
Najlepszym sposobem na rozbicie tego na części składowe jest przekonwertowanie
liczby na binarną, a następnie określenie, w jaki sposób jedno-bity w pliku binarnym
przyczyniają się do znaczenia. 786 w binarnym jest 1100010010 (= 512 + 256 + 16 +
2), który dzieli się w następujący sposób, a następnie czytając tabelę 1702 z
wcześniejszych, otrzymujemy współtwórców funkcjonalności:
1000000000 = 512 - Kierunek do tyłu wyłączony (a więc kierunek do przodu od
opiekunki w kierunku dolnego końca pliku)
0100000000 = 256 - Zawiń wokół
0000010000 = 16 - Linia zakładki
0000000010 = 2 - Przypadek dopasowania
Zauważ, że w tym przykładzie wydaje się, że mamy sprzeczne parametry
wyszukiwania: Mamy zakodowany kierunek, a także Zawijanie, które niweluje potrzebę
kierunku. Nie stanowi to problemu, ponieważ opcja Zawijaj będzie mieć pierwszeństwo,
podobnie jak w interaktywnej operacji wyszukiwania bez makr.
Sesje, obszary robocze
Page 74

i projekty
Istnieją trzy wbudowane systemy "zarządzania wieloma plikami" dostępne natywnie w
Notepad ++.
Sesje = zestaw plików, które można otworzyć za pomocą jednej akcji.
Folder jako obszar roboczy = interfejs oparty na drzewie, aby łatwo uzyskać
dostęp do plików w danym katalogu systemu Windows.
Panele projektu = interfejs oparty na drzewie, umożliwiający dostęp do
powiązanych plików, które niekoniecznie są zgrupowane w tej samej strukturze
katalogów systemu Windows.
Dostępne są również różne wtyczki, które mogą pomóc w zarządzaniu sesjami lub
obszarami roboczymi lub służyć podobnym celom, ale z innym zestawem funkcji w
porównaniu z tymi wbudowanymi funkcjami.
Sesji
Sesje to zestaw plików do otwarcia w Notepad ++. Korzystając z sesji, można otworzyć
zestaw plików za pomocą jednej akcji. Nie muszą znajdować się w tym samym katalogu
ani nawet na tym samym dysku.
Plik sesji przechowuje ścieżki otwartych plików, aktywny plik (i który widok, patrz sekcja
o Multi-View), bieżące zaznaczenie i położenie w pliku, bieżące zakładki (patrz
Zakładki) i bieżący język (patrz sekcja o językach). Po załadowaniu sesji wszystkie te
informacje są ładowane z powrotem do Notepad ++.
Sesja ładowania > plików... może być używany do ładowania istniejącej sesji.
Zapisz sesję > plików... może służyć do zapisywania aktualnie otwartych plików
jako sesji.
Pliki sesji są XML i są identyczne pod względem formatu z plikiem
konfiguracyjnym sesji.xml . Preferencje MISC zawierają opcję ustawienia
rozszerzenia pliku, które będzie automatycznie otwierane równorzędnie z Load
Session, nawet jeśli używasz File > Open, aby uzyskać dostęp do tej sesji; to
rozszerzenie będzie również domyślne podczas zapisywania sesji¹.
Plik sesji można również załadować za pomocą argumentu wiersza
polecenia -openSession.
Folder jako obszar roboczy
Page 75

Ta funkcja umożliwia korzystanie z interfejsu opartego na drzewie w celu łatwego
dostępu do plików w danym katalogu. Po przeciągnięciu folderu z Eksploratora
Windows do Notepad ++ ta funkcja zostanie aktywowana (chyba że zostanie
zastąpiona przez "... opcja upuszczania folderów").
Folder można również załadować jako obszar roboczy za pomocą argumentu wiersza
polecenia -openFoldersAsWorkspace.
Jeśli klikniesz prawym przyciskiem myszy panel Folder jako przestrzeń robocza,
możesz dodać więcej katalogów do bieżącego obszaru roboczego.
Dwukrotne kliknięcie pliku z widoku drzewa otworzy go jako nową kartę w edytorze
Notepad ++ (lub aktywuje tę kartę, jeśli jest już otwarta). Zamknięcie karty pliku z
programu Project nie spowoduje usunięcia go z panelu Folder jako przestrzeń robocza,
dzięki czemu można go łatwo otworzyć ponownie.
Panele projektowe
Panele projektu są podobne do panelu Folder jako przestrzeń robocza, ale pozwalają
organizować widok drzewa według własnych upodobań, zamiast być zmuszonym do
przestrzegania hiearchii systemu plików Windows.
Dwukrotne kliknięcie pliku z widoku drzewa otworzy go jako nową kartę w edytorze
Notepad ++ (lub aktywuje tę kartę, jeśli jest już otwarta). Zamknięcie karty dla pliku z
programu Project nie spowoduje usunięcia go z panelu Projekt, więc ponowne otwarcie
tego pliku jest łatwe.
W podmenu Widok > projekt dostępne są trzy panele projektu. Trzy panele projektowe
mogą być indywidualnie zadokowane lub pływające.
W każdym panelu można otworzyć jeden plik Workspace. Za pomocą
przycisku Przestrzeń robocza w panelu Projektu lub klikając prawym przyciskiem
myszy nazwę obszaru roboczego w widoku drzewa, można wykonywać różne
czynności, wymienione poniżej. Preferencje MISC zawierają opcję ustawienia
rozszerzenia pliku, które będzie automatycznie otwierane równorzędnie z
poleceniem Otwórz obszar roboczy, nawet jeśli używasz file > Open, aby uzyskać
dostęp do tego pliku obszaru roboczego; to rozszerzenie będzie również domyślne
podczas zapisywania obszaru roboczego¹.
Każdy obszar roboczy może pomieścić jeden lub więcej projektów. Kliknięcie
przycisku Edytuj w panelu projektu lub kliknięcie prawym przyciskiem myszy nazwy
projektu spowoduje podanie opcji administracyjnych dla wybranego projektu,
wymienionego poniżej. W każdym projekcie można wybrać pojedyncze pliki lub
zawartość całych katalogów systemu Windows, które mają zostać dodane do projektu,
a także uchylić kolejność plików. Jeśli dodasz folder do projektu, nie tworzysz nigdzie
katalogu systemu Windows: tworzysz kontener wewnątrz elementu projektu Notepad
Page 76

++; pliki wymienione w folderze nie zostały przeniesione. Aby powtórzyć: Foldery
projektu są niezależne od systemu plików i są tylko hierarchicznymi kontenerami dla tej
funkcji Notepad ++.
Plik można przenieść z jednego miejsca w panelu Projekt do innego folderu lub
projektu, przeciągając plik w panelu Projektu i upuszczając go na nazwę projektu lub
folderu, do którego ma zostać przenieśny plik. Poza tym w panelu Projektu nie ma
innych funkcji przeciągania i upuszczania.
Pliki projektu zawsze zawierają ścieżki plików względem lokalizacji samego pliku
projektu. Tak więc, jeśli plik projektu jest przechowywany w folderze systemu plików,
który jest częścią projektu, bardzo łatwo jest przenieść ten folder do innej lokalizacji na
dysku twardym. Jeśli plik projektu zostanie załadowany z nowej lokalizacji, nadal będzie
działać.
Specyfika panelu projektu
Dla każdego wpisu w widoku drzewa Panel projektu kliknięcie prawym przyciskiem
myszy spowoduje wyświetlenie dostępnych akcji na tym konkretnym wpisie.
W obszarze roboczym:
Nowa przestrzeń robocza = zamknij istniejący obszar roboczy (jeśli jest
otwarty dla tego panelu Projektu) i utwórz pusty obszar roboczy dla tego
panelu projektu.
Otwórz przestrzeń roboczą = zamknij istniejącą przestrzeń roboczą (jeśli jest
otwarta dla tego panelu projektu) i otwórz wybrany plik przestrzeni roboczej.
Załaduj ponownie obszar roboczy = ponownie odczytaj plik XML dla
aktywnego obszaru roboczego (mógł być edytowany zewnętrznie).
Zapisz = zapisz wszelkie zmiany w projektach, plikach i folderach aktywnej
konfiguracji obszaru roboczego.
Zapisz jako = zapisz aktywny obszar roboczy w nowej lokalizacji systemu
plików systemu Windows.
Zapisz jako kopię = zapisz aktywny obszar roboczy w nowej lokalizacji
systemu plików systemu Windows, zachowując również stary plik obszaru
roboczego.
Dodaj nowy projekt = dodaj nowy kontener projektu do aktywnego obszaru
roboczego.
We wpisie projektu:
Przenieś w górę / Przenieś w dół = zmiana kolejności wybranego projektu
względem innych projektów w obszarze roboczym.
Zmień nazwę = zmień nazwę projektu.
Dodaj folder = utwórz nowy kontener, który ma przejść w tym projekcie.
Dodaj pliki = użyj okna dialogowego Otwórz systemu Windows, aby wybrać
jeden lub więcej plików do dodania do drzewa projektu.
Dodaj pliki z katalogu = dodaj wszystkie pliki z tego katalogu systemu
Windows do projektu.
Page 77

Uwaga: nie powoduje to utworzenia nowego wpisu folderu w projekcie.
We wpisie folderu:
Ma wszystkie te same akcje, co we wpisie Projekt, ale wszystko jest
względne dla tego folderu, a nie względem projektu.
We wpisie pliku:
Przenieś w górę / Przenieś w dół = zmień kolejność zaznaczonego pliku
względem innych plików lub folderów w zawierającym projekcie lub folderze.
Rename = zmienia nazwę pliku na liście.
Ta akcja nie powoduje zmiany pliku źródłowego.
Jeśli nowa nazwa nie istnieje jako plik, na ikonie pliku w drzewie pojawi
się mały symbol błędu.
Jeśli nowa nazwa istnieje jako plik, stary plik będzie nadal istniał, ale nie
będzie już częścią tego projektu.
Usuń = usuwa plik z projektu.
Ta akcja nie powoduje zmiany pliku źródłowego.
Modyfikuj ścieżkę pliku = podobnie jak zmiana nazwy, zmienia plik na liście,
ale także pozwala zmienić katalog systemu Windows, do którego się
odwołuje.
Ta akcja nie powoduje zmiany pliku źródłowego.
Jeśli nowa nazwa nie istnieje jako plik, na ikonie pliku w drzewie pojawi
się mały symbol błędu.
Jeśli nowa nazwa istnieje jako plik, stary plik będzie nadal istniał, ale nie
będzie już częścią tego projektu.
Różnice między projektami i folderem jako obszarem roboczym
W przeciwieństwie do funkcji Folder jako obszar roboczy projekty nie są powiązane z
zawartością określonego folderu na dysku twardym. Zamiast tego możliwe jest
połączenie plików i folderów z różnych lokalizacji na dysku twardym w jeden projekt.
Możliwe jest nawet tworzenie folderów w projekcie, które w rzeczywistości nie istnieją
na dysku twardym i dodawanie do nich plików z różnych lokalizacji. Dzięki projektom
możliwe jest łączenie plików i folderów w całkowicie wirtualną strukturę. Może to
przyspieszyć dostęp do plików, które są logicznie powiązane ze sobą, ale są szeroko
rozpowszechnione na dysku twardym.
Przypisy dolne
¹: jeśli ustawisz rozszerzenia sesji lub obszaru roboczego, trudno będzie edytować kod
XML dla danego pliku sesji lub obszaru roboczego w Notepad ++. Aby to zrobić,
możesz tymczasowo wyczyścić to ustawienie preferencji, edytować plik, a następnie
ponownie ustawić preferencje rozszerzenia.
Page 78

Automatyzacja zadań za pomocą makr
Notepad ++ jest w stanie nagrać niektóre z twoich działań podczas edycji dokumentu i
odtworzyć je później, aby uniknąć konieczności powtarzania tej sekwencji akcji. Nazywa
się to makrem i może zaoszczędzić dużo czasu. Makra można odtwarzać raz lub wiele
razy, nawet tak długo, jak jest to wymagane do uruchomienia całego dokumentu.
Można je zapisać do późniejszego użycia i przypisać do nich naciśnięcia w celu
szybkiego dostępu (patrz Maper skrótów). Makra są wrażliwe na bieżącą pozycję
kursora i będą (normalnie mówiąc) działać na nim względnie.
Rejestrowanie makra
Aby nagrać makro, wybierz opcję Makro > Rozpocznij nagrywanie lub naciśnij
przycisk na pasku narzędzi. Notepad ++ będzie teraz śledzić zmiany wprowadzone w
dokumencie lub niektóre działania wykonywane.
Aby zatrzymać nagrywanie, wybierz makro > Zatrzymaj nagrywanie lub wybierz
przycisk na pasku narzędzi. Jako wyjątek od większości poleceń można przełączać to
zachowanie za pomocą specjalnej kombinacji skrótów, która nie jest wymieniona w
menu, ale wyłącznie w maperze skrótów (patrz Ustawienia, Narzędzie do mapowania
skrótów). Domyślnie jest to kombinacja Ctrl-Shift-R.
Po zatrzymaniu nagrywania zostanie ono zapisane w tymczasowym buforze. Jeśli nie
wykonano żadnych czynności, ten bufor zostanie wyczyszczony. Jeśli rozpoczniesz
nagrywanie innego makra bez zapisywania wcześniejszej pracy, zostanie ono utracone.
Odtwarzanie przekodowanych makr
Aby odtworzyć makro w buforze, wybierz opcję Makro > Odtwarzanie lub naciśnij
przycisk. Spowoduje to wykonanie makra raz w bieżącej pozycji.
Zapisywanie zarejestrowanego makra
Aby zapisać makro w buforze, wybierz opcję Makro > Zapisz bieżące zarejestrowane
makro lub naciśnij przycisk. Pojawi się okno dialogowe z prośbą o nazwę makra i
domyślną kombinację. Można je później zmienić (i usunąć) za pomocą ustawień >
mapowania skrótów. Po zapisaniu makro będzie dostępne z menu Makro lub listy
odtwarzania Makro.
Wielokrotne odtwarzanie przekodowanych makr
Page 79

Aby odtworzyć bieżące makro w buforze lub dowolne zapisane makro raz lub wiele
razy, wybierz opcję Makro > Uruchom makro wiele razy... lub naciśnij przycisk. Pojawi
się okno dialogowe umożliwiające wybranie, które makro ma wykonać (makro buforowe
lub dowolne zapisane makro) i ile razy. Możesz także zdecydować się na wykonywanie
makra, dopóki kursor nie dotrze do końca bieżącego pliku (zaczynając od jego bieżącej
pozycji). Należy zauważyć, że jeśli żadne makra nie są dostępne, to okno dialogowe
jest niedostępne.
Edytowanie lub usuwanie istniejącego skrótu do makra
Aby edytować lub usunąć istniejący skrót do makr, można użyć mapera skrótów, który
wyświetla wszystkie skróty wszelkiego rodzaju i umożliwia zmianę lub usunięcie
powiązania. Interfejs jest również dostępny za pośrednictwem skrótu Macro > Modify /
Delete macro menu entry.
Zawartość definicji makra można edytować tylko w pliku: w Notepad ++ nie ma
wbudowanego interfejsu. Aby uzyskać więcej informacji na temat szczegółów
przechowywania makr i składni, zobacz sekcję Szczegóły plików
konfiguracyjnych: .shortcuts.xml
Co to jest automatyczne uzupełnianie
Notepad ++ oferuje automatyczne uzupełnianie różnych rodzajów tekstu
po wprowadzeniu początkowego podciągi (lub prefiksu), co może
zaoszczędzić konieczności wpisywania całego długiego słowa (i
potencjalnie zaoszczędzić błędnego wpisywania). Na przykład, jeśli
kodujesz w JavaScript i wpisujesz, Notepad ++ może przedstawić (słowo
kluczowe JavaScript) jako sugestię. Akceptujesz sugestię, wpisując
Enter lub Tab, a słowo zostanie ukończone w buforze, tak jakbyś wpisał
to wszystko. Jeśli sugerowane słowo nie jest tym, czego chcesz, pisz
dalej.synsynchronized
Jeśli więcej niż jedno słowo na liście słów kandydujących pasuje do
tego, co wpisałeś, Notepad ++ przedstawi listę zawierającą słowa;
wyróżnione słowo na liście to to, które zostanie wybrane w Enter,
ale możesz użyć strzałek w dół i w górę lub PageDown & PageUp, aby
poruszać się po liście; lub wpisz Esc, aby odrzucić listę.
Istnieją dwa zestawy słów kandydujących, których Notepad ++ używa
do tworzenia sugestii; są one określane jako "słowa" i "funkcje".
Zakończenie funkcji
"Funkcje" są wstępnie zdefiniowane i załadowane wraz z lekserem,
który odpowiada językowi komputerowemu pliku. (Lexer definiuje
Page 80

kolorowanie składni; plik autouzupększania określa nazwy funkcji).
Zazwyczaj te słowa funkcjowe zawierają słowa kluczowe języka (które
technicznie nie są funkcjami), takie jak C i podobne języki lub w
Pythonie, oraz pewien zestaw standardowych nazw funkcji biblioteki,
takich jak lub w C.switchlambdaassertfdopen
Te listy funkcji są przechowywane w plikach definicji
autouzupększań, z których każdy nosi nazwy zgodnie z językiem. (Słowa
w tych plikach niekoniecznie zawierają wszystkie słowa kluczowe
wymienione w definicjach lexerów). Pliki te mogą określać, które ze
słów są słowami kluczowymi, a które są funkcjami; funkcje obsługują
dodatkową funkcję uzupełniania, "wskazówkę do parametru".
Wskazówki dotyczące parametrów
Plik definicji autouzupamiętniania może określać, czy słowo kluczowe
jest funkcją. Po wpisaniu nazwy funkcji, po której następuje nawias
otwierający używany do zamknięcia argumentów funkcji, Notepad ++
automatycznie lub ręcznie wyświetli wskazówkę (a.k.a. "call tip"):
otwiera się małe pole w stylu etykietki narzędzia z tekstem
zawierającym opis funkcji. Podczas gdy rzeczywisty wyświetlany tekst
zależy od autora pliku definicji, zazwyczaj pokazuje to co najmniej
słowo kluczowe dla każdego z parametrów przyjmowanych przez
wywołanie funkcji. Może to zaoszczędzić Ci podróży do dokumentacji
funkcji, aby zapamiętać, jakie są te parametry.
Notepad ++ wyświetli wskazówkę automatycznie po wpisaniu otwartego
nawiasu, jeśli ta opcja jest zaznaczona w ustawieniach
autouzupamiękywania. Użytkownik może również wybrać Podpowiedź
parametrów funkcji z menu lub naciśnięciem (domyślnie: Ctrl + Shift
+ Spacja), gdy kursor znajduje się między nawiasami otwierającymi
i zamykającymi wywołanie funkcji. I znowu, wskazówkę można odrzucić
za pomocą Esc.
Uzupełnianie wyrazów
"Słowa" są pobierane z bieżącego pliku — wszędzie w bieżącym pliku,
komentarze i kod. Każde słowo o długości dwóch lub więcej znaków jest
dodawane do listy. Obejmuje to liczby, ale liczby z przecinkami
dziesiętnymi są podzielone na dwa różne "słowa".
Jak sprawić, by to działało
Automatyczne uzupełnianie
Page 81

Lista ukończenia może być wyzwalana automatycznie podczas pisania,
za pomocą ustawień w Ustawieniach > Preferencje > Automatyczne
uzupełnianie:Automatyczne uzupełnianie jest włączone przez pole
wyboru. Dodatkowo istnieje ustawienie Od X znaku, akceptujące
minimalną długość prefiksu potrzebną przed wyświetleniem listy
ukończenia (niektórzy ludzie lubią 2, niektórzy 3, niektórzy 4 ...);
i istnieje ustawienie określające, którzy kandydaci powinni być
używane: słowa, funkcje lub oba.
Po włączeniu automatycznego uzupełniania, po wpisaniu prefiksu o co
najmniej minimalnej długości, wyświetlana jest lista ze wszystkimi
dostępnymi słowami z wybranych list, które pasują do tego, co zostało
wpisane. (Jeśli żadna z nich nie jest zgodna, lista nie jest
wyświetlana). Lista może być długa na pojedynczy wpis lub może
zawierać wiele elementów, które wymagają nawigacji, ale tak czy
inaczej możesz wybrać dopasowanie i, mam nadzieję, zaoszczędzić
sobie trochę pisania.
Jeśli zamiast zaznaczać tekst, będziesz pisać dalej, elementy, które
nie są już zgodne, zostaną usunięte z listy i znikną całkowicie po
wpisaniu ciągu, który nie pasuje do żadnego z zaznaczeń. (Należy
zauważyć, że jeśli odrzucisz listę za pomocą Esc, a następnie
będziesz pisać dalej, a wpisywany tekst będzie nadal pasował do
wpisów listy słów, lista pojawi się ponownie).
Ręczne wypełnianie
Jeśli automatyczne uzupełnianie jest wyłączone, możesz ręcznie
wymusić ukończenie wpisanego tekstu, ograniczając wybór do listy
funkcji lub listy słów. Domyślnie funkcje te są powiązane z
Ctrl+Spacja (funkcje) lub Ctrl+Enter (słowa); są one również
dostępne w menu Edycja. Wpisanie jednego z tych naciśnięć następuje
natychmiastowego zakończenia: jeśli na liście słów znajduje się
jeden pasujący wpis, wpis ten jest używany bez wyświetlania listy.
Jeśli istnieje wiele pasujących wpisów, lista jest wyświetlana tak,
jakby automatyczne uzupełnianie zostało wyzwolone w tym samym
punkcie.
Uwaga: Ręczne "Uzupełnianie funkcji" (obecnie) pokazuje listę
wszystkich funkcji na liście słów, nawet jeśli nie pasują one do
bieżącego prefiksu - chyba że żadna funkcja nie pasuje do prefiksu,
w którym to przypadku lista nie jest wyświetlana. Ręczne
"Uzupełnianie słów" pokazuje tylko pasujące słowa.
Automatyczne wstawianie
Niektóre znaki tradycyjnie działają w parach, więc sensowne jest
Page 82

poproszenie edytora o wpisanie ich parami podczas wpisywania nawiasu
otwierającego - dodatkowy nawias zamykający jest jednorazowy.
W ustawieniach > preferencjach > opcje automatycznego
wstawianiaumożliwiają automatyczne dopasowunie dowolnego lub
wszystkich z pięciu wstępnie zdefiniowanych znaków — nawiasów,
nawiasów klamrowych, podwójnych cudzysłowów i pojedynczych
cudzysłowów (apostrof). Co więcej, można określić trzy
niestandardowe pary znaków. Na przykład możesz użyć podwójnych
cudzysłowów Unicode open- i close- double; dzięki tej funkcji można
wstawić oba znaki podczas wpisywania cudzysłowu otwierającego. (W
tych polach dozwolone są tylko pojedyncze znaki).
W każdym przypadku, po wpisaniu znaku otwierającego, znak zamykający
zostanie automatycznie wstawiony, a kursor zostanie umieszczony
między nimi.
Ponadto funkcja Auto-Insert obsługuje automatyczne zamykanie tagów
HTML i XML. Po włączeniu tej opcji podczas edycji plików HTML lub
XML, po wpisaniu znacznika otwierającego, takiego jak , program
automatycznie dopasuje go do zamknięcia , z kursorem umieszczonym
między dwoma znacznikami, aby można było dodać zawartość.
Dopasowywanie będzie działać nawet wtedy, gdy atrybuty zostaną
wprowadzone podczas wpisywania znacznika otwierającego. A jeśli
znacznik otwierający jest zakończony ukośnikiem () — na przykład —
wówczas nie zostanie wstawiony pasujący znacznik. (W przypadku
wprowadzenia bez ukośnika, pasujący znacznik close zostanie
wstawiony, nawet jeśli nie będzie to konieczne, zarówno do edycji
HTML, jak i XML. Potraktuj to jako dążenie do poprawności XML w kodzie
HTML.)<div></div>/<hr/><hr>
Ustawienia automatycznego uzupełniania
Główne ustawienia automatycznego uzupełniania znajdują się
w Ustawieniach > Preferencjach > Autouzupamiętnianie.
Skróty klawiaturowe do ręcznego uzupełniania można dostosować
w Ustawieniach > Mapowanie skrótów, w zakładce Menu
główne, w Kategoria = Edytuj; możesz filtrować, aby łatwo je
znaleźć.completion
Tworzenie plików definicji automatycznego
uzupełniania
Notepad ++ używa plików konfiguracyjnych XML do definiowania funkcji
Page 83

dla każdego języka i automatycznego uzupełniania parametrów. Te
pliki Autouzupełniania znajdują się w podkatalogu folderu
instalacyjnego Notepad ++. (W starszych wersjach, Notepad ++ v7.6.1
i wcześniejszych, znaleziono je w podkatalogu folderu
intstall.)autoCompletionplugins\APIs
Składnia plików Autouzupełniania jest prosta, ale ma kilka reguł,
przede wszystkim poprawną składnię i prawidłowe sortowanie. Jeśli
składnia jest niepoprawna, załadowanie pliku XML nie powiedzie się,
a autouzupełnianie zostanie wyłączone.
Nieprawidłowe sortowanie (patrz poniżej) może spowodować, że funkcja
Autouzupełnianie będzie zachowywać się nieprawidłowo, powodując
niepowodzenie niektórych słów.
Podstawowy zestaw znaków używany do rozpoznawania słów kluczowych
składa się z liter , , cyfr i podkreślenia . Interpunkcja może działać
w przypadku automatycznego uzupełniania; Jeśli jednak chcesz użyć
wskazówek dotyczących parametrów, nie powinieneś używać znaków
interpunkcyjnych w nazwie słowa kluczowego.a-zA-Z0-9_
Składnia:
<?xml version="1.0" encoding="Windows-1252" ?>
<NotepadPlus>
<AutoComplete language="C++">
<Environment ignoreCase="no" startFunc="(" stopFunc=")"
paramSeparator="," terminal=";" additionalWordChar = "."/>
<KeyWord name="abs" func="yes">
<Overload retVal="int" descr="Returns absolute value of given
integer">
<Param name="int number" />
</Overload>
</KeyWord>
</AutoComplete>
</NotepadPlus>
Mały przykład budowy pliku XML podano powyżej. , a elementy są
elementami singletonowymi: powinien być tylko jeden z nich, a
wszystkie z nich powinny być obecne dla poprawności, chociaż
dozwolone jest usunięcie elementu. Spowoduje to ustawienie domyślne
wszystkich wartości na podane w powyższym
przykładzie.<NotepadPlus><AutoComplete><Environment><Environment>
W przypadku słów kluczowych, które nie są funkcjami, tag jest
automatycznie zamknięty i ma tylko atrybut. Aby wskazać, że słowo
kluczowe może być wyświetlane w etykietce wywołania, dodaj atrybut
Page 84

. W tym przypadku znacznik jest węzłem i zawiera inne
znaczniki.<KeyWord>namefunc="yes"<KeyWord>
Następnie dla każdego przeciążenia funkcji należy dodać element,
który określa zachowanie i parametry funkcji. Funkcja musi mieć co
najmniej jedną, w przeciwnym razie nie będzie wyświetlana jako
etykietka wywołania. Wiele elementów pozwala na różne zestawy
parametrów dla danej funkcji. Atrybut musi być obecny i określa typ
zwracanej wartości, ale atrybut jest opcjonalny i opisuje zachowanie
funkcji, takie jak komentarz. Jeśli chcesz, możesz dodać nowe wiersze
w opisie. Dla każdego parametru, który przyjmuje funkcja, można dodać
element. Atrybut musi być obecny i określa typ parametrów i/lub
dowolną nazwę
parametru.<Overload><Overload><Overload>retValdescr<Param>name
W elemencie możesz dodać atrybut, ale nie jest on używany przez
Notepad ++; możesz dodać go dla kompletności, jeśli chcesz i możesz
wziąć dowolny ciąg, który chcesz.<AutoComplete>language
Automatyczne uzupełnianie formatu pliku
Pliki autouzupękowania znajdują się w podfolderze folderu
instalacyjnego Notepad ++ (w przeciwieństwie do niektórych plików
konfiguracyjnych, nie będą one działać w hierarchii). Te pliki są
opcjonalne: potrzebujesz tylko jednego dla każdego języka, dla
którego będziesz używać automatycznego uzupełniania lub etykietek
wywołań. Są one również obsługiwane w językach zdefiniowanych przez
użytkownika i noszą nazwę .autoCompletion\%AppData%\Notepad++\<Language
name>.xml
Uwaga: Utwórz plik autouzupełniania, aby dodać sugestie
niestandardowe do domyślnego języka, Tekst normalny [tj. Język
ustawiony na "Brak (normalny tekst)"].normal.xml
Pod zwykłym tagiem znajduje się tag. Posiada opcjonalny, nieużywany
atrybut, którego można użyć do dowolnego celu
opisowego.<NotepadPlus><AutoComplete>language
Zawartość zaczyna się od tagu automatycznego wykluczania z
następującymi atrybutami:<AutoComplete><Environment>
1. ignoreCase: jeśli w języku rozróżniana jest wielkość liter, else
(domyślnie)."no""yes"
2. startFunc: znak(-i) rozpoczynający listę parametrów. Wartość
domyślna to ."("
3. stopFunc: znak(-i) na końcu listy parametrów. Wartość domyślna
to .")"
4. paramSeparator: znak(-i), który(-e) oddziela parametry. Wartość
Page 85

domyślna to .","
5. terminal: znak(-i), który(-e) oznacza koniec prototypu, gdy
język pozwala na oddzielne prototypowanie w stylu C. Wartość
domyślna to . Pomiń to, jeśli język nie obsługuje oddzielnego
prototypowania lub ustaw go na jakiś nielegalny znak.";"
6. additionalWordChar: znak(-i), który(-e) może być częścią wyrazów
i który nie jest małą lub wielką literą, cyfrą lub
podkreśleniem. Wartość jest ciągiem ze wszystkimi tymi
dodatkowymi znakami, w dowolnej kolejności i bez separatorów.
Ciąg jest domyślnie pusty.
UWAGA: Spacji nie można używać jako znaków atrybutów.
Każdy atrybut można pominąć, a także znacznik. Praktyka ta nie jest
jednak zalecana.<Environment>
Poniżej znajduje się lista tagów. Są one albo automatycznie zamykane,
dla słów kluczowych, które nie są rutynowe, albo nie, gdy są. Każdy
taki tag ma obowiązkowy atrybut, słowo kluczowe/rutynową nazwę do
rozpoznania. Lista musi być posortowana według tego atrybutu i
wartości atrybutu <Environment>ignoreCase . Zobacz podsekcje poniżej,
aby uzyskać więcej informacji na temat nazw słów kluczowych i
sortowania.<KeyWord>name
Jeśli znacznik nie jest automatycznie zamykany, musi mieć drugi
atrybut, . Zawartość jest nieświeżą, nieposortowaną listą
znaczników, z których każdy opisuje możliwy podpis dla procedury.
ma atrybut, który ustawiłbyś na początkowy komentarz w wezwaniu. W
C/C++ tradycyjnie byłby to typ zwracany; jest wartością dozwoloną.
Ponadto znacznik ma opcjonalny atrybut, którego można użyć do dodania
opisu funkcji. Wskazówka: Możesz użyć do wstawienia podziałów
wierszy.<KeyWord>func="yes"<Overload><Overload>retVal""<Overload>descr&#x
0a;
Znacznik zawiera jeden lub więcej opisów parametrów, posortowanych
w kolejności występowania. Taki opis jest reprezentowany przez
automatycznie zamykający się tag z atrybutem "name". Może to zawierać
nazwę parametru lub inne przydatne komentarze.<Overload><Param>
Nazwy parametrów (właściwie dowolny tekst, który lubisz, może nawet
wymieniać nazwę parametru), zwracana wartość i opis muszą zmieścić
się w wewnętrznym buforze, obcinanie odbywa się w inny sposób. Dla
każdej danej funkcji cały tekst plus 2 bajty na parametr plus 24
bajty, jeśli 2 przeciążenia lub więcej, nie może rozlać się na 2 043
bajty. Pamiętaj, że bajt jest bajtem, więc formatowanie białych
znaków konkuruje z rzeczywistym tekstem.
Typowym przykładem wejścia może być:
Page 86

<KeyWord name="cos" func="yes" >
<Overload retVal="{double}" descr="Cosine of x" >
<Param name="x, radians" />
</Overload>
</KeyWord>
co skutkuje następującą wskazówką dotyczącą połączenia:
{double} cos (x, radians)
Cosine of x
Pamiętaj, że wskazówka dotycząca połączenia pojawia się po wpisaniu
nawiasu otwierającego po nazwie rutynowej. Domyślnie lub cokolwiek
innego ustawionego z startFunc w tagu."("<Environment>
Nazwy
Aby zarówno wskazówki dotyczące połączeń, jak i autouzupełnianie
działały, słowa kluczowe muszą być słowami, tj. Identyfikatorami,
które większość języków chętnie zaakceptowałaby. Oznacza to, że
tylko 26 liter alfabetu łacińskiego z małymi lub wielkimi literami
(bez znaków diakrytycznych), cyfr i podkreślenia są bezpieczne w
użyciu. Dodatkowe dozwolone znaki będą działać, jeśli nie są białymi
znakami. Autouzupełnianie może poradzić sobie ze spacjami lub
pustymi miejscami, wskazówki dotyczące połączeń nie. Jest to
ograniczenie Scintilla.
Sortowania
Lista znaczników musi być posortowana według kolejności
rosnącej. Niezastosowanie się do tego spowoduje niedziałanie pliku
bez ostrzeżenia.<KeyWord>name
Teraz które sortowanie, z rozróżnianiem wielkości liter lub
niewrażliwe? Zależy to od wartości atrybutu ignoreCase. Jeśli
ustawiono na , użyj sortowania niewrażliwego na litery, które
uwzględnia wszystkie litery jako wielkie litery. W przeciwnym razie
użyj sortowania z rozróżnianiem wielkości liter.<Environment>"yes"
Najprostszym sposobem utworzenia nowego pliku może być:
1. w nowym dokumencie wymień wszystkie słowa kluczowe, które mają
zostać rozpoznane;
2. posortuj listę z odpowiednią kolejnością;
Page 87

3. Korzystając z Edytora kolumn, dodaj przed każdym
wierszem.<KeyWord name="
4. Korzystając z funkcji wyszukiwania i zastępowania w trybie
rozszerzonym, dodaj na końcu wszystkich wierszy."/>
5. Dodaj fantazyjny znak (jest dobrym kandydatem) na końcu wierszy
reprezentujących funkcje;+
6. Korzystając z trybu rozszerzonego, zamień
na />+\r\n>\r\n\t<Overload
retVal="">\r\n\t</Overload>\r\n</KeyWord>\r\n
7. Teraz ręcznie dodaj tekst i dodatkowe przeciążenia. W
stosownych przypadkach ponownie wciąć;
8. Zapisz i przetestuj swój plik;
9. Niechlujna praca, ponownie przetestuj (rekurencyjny, uważaj na
nieskończone pętle).
Do sortowania z rozróżnianiem wielkości liter można użyć Operacji
edycji > wierszy Notepad ++ > Sortuj leksykograficznie rosnącolub
dowolnego ogólnego sortownika ASCII / ANSI, który sortuje według
wartości bajtowej znaków. Mówiąc najprościej, oznacza to, że znak
podkreślenia znajduje się między wielkimi i małymi literami.
W przypadku sortowania niewrażliwego na litery traktuj małe litery
jako wielkie litery, to znaczy odejmij 32 od każdej wartości bajtu
małych liter; Oznacza to, że podkreślenie musi znajdować się zarówno
po wielkich, jak i małych literach. Niestety, Notepad ++ Edytuj >
operacje liniowe > Sortuj leksykograficznie rosnąco, sortuje z
rozróżnianiem wielkości liter i nie będzie działać w tym celu.
Co to jest lista funkcji
Panel lista funkcji to strefa do wyświetlania wszystkich funkcji (lub
metod) znalezionych w bieżącym pliku. Użytkownik może użyć panelu
lista funkcji, aby szybko uzyskać dostęp do definicji funkcji,
klikając dwukrotnie element funkcji na liście. Listę funkcji można
dostosować, aby wyświetlić listę funkcji dla języka. Aby dostosować
listę funkcji do rozpoznawania ulubionego języka, sprawdź poniżej.
Lista funkcji zawiera wyszukiwarkę (przy użyciu wyrażenia
regularnego) i panel do wyświetlania wyników wyszukiwania (lista
funkcji). Został zaprojektowany tak, aby był jak najbardziej ogólny
i pozwala użytkownikowi modyfikować sposób wyszukiwania lub dodawać
nowy parser dla dowolnego języka programowania. Aby lista funkcji
działała dla Twojego języka (jeśli nie jest obsługiwana), należy
zmodyfikować (lub dodać) plik xml języka. Pliki xml dla różnych
języków można znaleźć w folderze zlokalizowanym w katalogu
zainstalowanym Notepad ++, jeśli używasz pakietu
Page 88

zip.%APPDATA%\notepad++\functionListfunctionList
Jak dostosować listę funkcji
W węźle parsera zawiera:
id: uniq ID dla tego parsera
displayName: zarezerwowane do wykorzystania w przyszłości.
comment: Opcjonalnie. w tym atrycycie można wykonać wyrażenie
regularne w celu zidentyfikowania stref komentarzy.
Zidentyfikowane strefy zostaną zignorowane przez wyszukiwanie.
Istnieją 3 rodzaje parserów: parser funkcji, parser klas i parser
mix. Zdefiniuj parser funkcji, jeśli język ma tylko funkcje do
przeanalizowania (na przykład C). Zdefiniuj parser klasy, jeśli
język ma funkcje "zdefiniowane" w klasie, ale nie ma funkcji
zdefiniowanej poza klasą (na przykład Java). Zdefiniuj parser
miksowania, jeśli funkcja jest "zdefiniowana" zarówno wewnątrz, jak
i obok klasy w pliku (na przykład C++).
Parser funkcji zawiera tylko węzeł funkcji. Parser klasy zawiera
tylko węzeł classRange. Parser mix zawiera zarówno węzły function,
jak i classRange.
Zauważ, że operacje RegEx look behind nie działają z parserem.
Parser funkcji
W węźle funkcyjnym zawiera:
mainExpr: jest to regex, aby uzyskać cały ciąg, który zawiera
wszystkie potrzebne informacje.
displayMode: zarezerwowane do wykorzystania w przyszłości.
functionName: zdefiniuj wyrażenie regularne lub kilka wyrażeń
regularnych, aby uzyskać nazwę funkcji z wyniku atrybutu
"mainExpr" węzła "function".
nameExpr: 1..N
expr: tutaj definiujesz wyrażenie regularne, aby znaleźć
nazwę funkcji.
className: zdefiniuj wyrażenie regularne lub kilka, aby uzyskać
nazwę klasy z wyniku "mainExpr".
nameExpr: 1..N
Page 89

expr: tutaj definiujesz wyrażenie regularne, aby znaleźć
nazwę funkcji.
Oba i węzły są opcjonalne. Jeśli i są nieobecne, znaleziony ciąg
według wyrażenia regularnego zostanie przetworzony jako nazwa
funkcji, a nazwa klasy nie będzie
używana.functionNameclassNamefunctionNameclassNamemainExpr
Węzły i mają tę samą strukturę i mają takie samo zachowanie
parsowania. Na przykład w węźle otrzymaliśmy 2 węzły: Jeśli parser
funkcji znajdzie pierwszy wynik według atrybutu, użyje pierwszego
do wyszukiwania w pierwszym wyniku, jeśli zostanie znaleziony (2.
wynik), a następnie użyje 2. do wyszukiwania w 2. wyniku. Jeśli
zostanie znaleziony, nazwa funkcji zostanie
rozwiązana.functionNameclassNamefunctionNamenameExprmainExprnameExprname
Expr
Parser klas
W węźle classRange zawiera:
mainExr: główny cały ciąg do wyszukania
displayMode: zarezerwowane do wykorzystania w przyszłości.
openSymbole & closeSymbole: są opcjonalne. jeśli zostanie
zdefiniowany, parser określi strefę tej klasy. Znajduje się
najpierw od pierwszego znaku znalezionego ciągu według atrybutu
mainExpr. następnie określa koniec klasy przez znalezione.
Algorytm zajmuje się kilkoma poziomami nietrzeźwości. na
przykład: openSymbolecloseSymbole\{\{\{\}\{\}\}\{\}\}
className: 1 (lub więcej) węzła do określania nazwy klasy (na
podstawie wyniku wyszukiwania).nameExprmainExpr
function: wyszukiwanie w strefie klasy przy użyciu atrybutu i
węzłów.mainExprfunctionName
Parser miksu
Mix Parser zawiera parser class (węzeł) i function parser (węzeł).
Parser klasy zostanie zastosowany najpierw do znalezienia stref
klas, a następnie parser funkcji zostanie zastosowany do stref innych
niż klasy.classRangefunction
Testowanie parsera
Po zakończeniu definiowania parsera zapisz i nazwij plik jako nazwę
języka z rozszerzeniem pliku w folderze, aby działał z żądanym
językiem. Sprawdź overrideMap.xml, aby uzyskać listę nazw
Page 90

wszystkich obsługiwanych języków programowania.xmlfunctionList
Jeśli nie jesteś zadowolony z istniejącej reguły parsera, możesz
napisać regułę parsera, a następnie zapisać pod inną dowolną nazwą.
Reguła parsera nie zostanie usunięta przez domyślny plik przy
następnej aktualizacji. Użyj overrideMap.xmlaby zastąpić domyślne
pliki reguł analizowania functionList, a także w celu dodania plików
reguł analizowania UDL.
Współtworzenie nowej lub ulepszonej reguły
parsera
Zapraszamy do wniesienia nowego lub ulepszonego parsera, tworząc PR
na stronie Notepad ++ GitHub. Poniższe sekcje opisują, jak
przygotować swój PR w zależności od różnych sytuacji.
Testy jednostkowe
Aby uniknąć regresji, ważne jest uruchomienie testów jednostkowych
przed przesłaniem modyfikacji. Oto kroki, aby uruchomić testy
jednostkowe:
1. Upewnij się, że skopiować zmodyfikowaną regułę parsera (plik
xml)
do [YOUR_SOURCES_DIR]\notepad-plus-plus\PowerEditor\bin\functionList
\
2. Otwórz powerShell, przejdź do uruchom
.[YOUR_SOURCES_DIR]\notepad-plus-plus\PowerEditor\Test\FunctionList\
.\unitTestLauncher.ps1
3. Gdy zobaczysz "Wszystkie testy zostały zaliczyne.", możesz
przesłać swój PR.
Plik testu jednostkowego jest nieobecny
Może się okazać, że tworzysz nowy parser języka dla listy funkcji
lub ulepszasz istniejący parser języka, ale plik nie istnieje. W obu
przypadkach należy:unitTest
1. Dodaj katalog z nazwą języka pisaną małymi literami do
.[YOUR_SOURCES_DIR]\notepad-plus-plus\PowerEditor\Test\FunctionList\
2. Dodaj nowy plik testowy jako do nowego dodanego
katalogu.unitTest
3. Otwórz przejdź do , uruchom
polecenie cmd[YOUR_SOURCES_DIR]\notepad-plus-plus\PowerEditor\Test\
FunctionList\..\..\bin\notepad++.exe -export=functionList
-l[langName] .\[langName]\unitTest
Page 91

4. Zostanie wygenerowany plik o nazwie. Zmień jego nazwę na
.unitTest.result.jsonunitTest.expected.result
5. Uruchom testy jednostkowe (sprawdź powyżej sekcji Testy
jednostkowe), aby upewnić się, że reguła parsera (plik xml) nie
spowoduje regresji.
Plik testu jednostkowego jest obecny
Jeśli ulepszasz istniejący parser i jest obecny,
powinieneś zmodyfikować istniejący plik unitTest lub dodać nowy
plik unitTest. Jeśli modyfikacja parsera ma na celu pokrycie kilku
dodatkowych przypadków, możesz dodać te przypadki do istniejącego
pliku unitTest. W przeciwnym razie, jeśli modyfikacja ma na celu
pokrycie innych kategorii i musisz dodać wiele funkcji do
przetestowania, możesz po prostu pozostawić bieżący plik unitTest
takim, jaki jest, i dodać nowy plik unitTest.unitTest
- Zmodyfikuj istniejący plik unitTest
1. Uruchom testy jednostkowe (sprawdź powyżej sekcji Testy
jednostkowe), aby upewnić się, że reguła parsera (plik xml) nie
spowoduje regresji.
2. Zmodyfikuj plik zgodnie z ulepszeniem. Ogólnie rzecz biorąc,
nie usuwasz zawartości, ale dodajesz zawartość do tego
pliku.[YOUR_SOURCES_DIR]\notepad-plus-plus\PowerEditor\Test\Functio
nList\[langName]\unitTest
3. Otwórz przejdź do , uruchom
polecenie cmd[YOUR_SOURCES_DIR]\notepad-plus-plus\PowerEditor\Test\
FunctionList\..\..\bin\notepad++.exe -export=functionList
-l[langName] .\[langName]\unitTest
4. Zostanie wygenerowany plik o nazwie. Usuń i zmień nazwę na
.unitTest.result.jsonunitTest.expected.resultunitTest.result.jsonuni
tTest.expected.result
- Dodaj nowy plik unitTest
1. Uruchom testy jednostkowe (sprawdź powyżej sekcji Testy
jednostkowe), aby upewnić się, że reguła parsera (plik xml) nie
spowoduje regresji.
2. Dodaj katalog do programu , nazwa katalogu jest dowolna, ale
powinna być odpowiednia dla kategorii testu. Nazwij plik testu
jednostkowego jako i skopiuj go do właśnie utworzonego
katalogu.[YOUR_SOURCES_DIR]\notepad-plus-plus\PowerEditor\Test\Func
tionList\[langName]\unitTest
3. Otwórz przejdź do , uruchom
polecenie cmd[YOUR_SOURCES_DIR]\notepad-plus-plus\PowerEditor\Test\
FunctionList\..\..\bin\notepad++.exe -export=functionList
-l[langName] .\[langName]\[yourTestDir2]\unitTest
Page 92

4. Plik o nazwie zostanie wygenerowany w utworzonym katalogu .
Zmień nazwę w utworzonym katalogu na
.unitTest.result.json[YOUR_SOURCES_DIR]\notepad-plus-plus\PowerEdito
r\Test\FunctionList\[langName]\[yourTestDir2]\unitTest.result.jsonun
itTest.expected.result
Rozszerz funkcjonalność dzięki wtyczkom
Notepad ++ jest bardzo rozszerzalny za pomocą tak zwanych wtyczek.
Wtyczki są małymi lub dużymi dodatkami do Notepad ++ w celu
zwiększenia jego funkcjonalności. Notepad ++ jest dostarczany w
pakiecie z kilkoma wtyczkami (podczas korzystania z instalatora
możesz wybrać, które z nich dodać), ale zawsze możesz dodać własne
lub usunąć niektóre. Wtyczki znajdują się w katalogu Plugins w
głównym katalogu instalacyjnym Notepad ++. Są to pliki DLL i
wystarczy je po prostu usunąć lub dodać.
Jak zainstalować wtyczkę
Zainstaluj za pomocą Plugins Admin
Plugins Admin pozwala łatwo zainstalować wtyczki, które znajdują się
na liście wtyczek. Aby to zrobić, umieść znacznik wyboru obok
wtyczek, które chcesz zainstalować, a następnie wybierz Zainstaluj.
Page 93

Zainstaluj wtyczkę ręcznie
Jeśli wtyczka, która chcesz zainstalować, nie jest wymieniona w
Plugins Admin, nadal możesz zainstalować ją ręcznie. Wtyczka (w
formie DLL) powinna być umieszczona w podfolderze plugins folderu
Notepad ++ Install, pod podfolderem o tej samej nazwie nazwy binarnej
wtyczki bez rozszerzenia pliku. Na przykład, jeśli wtyczka, którą
chcesz zainstalować, nazywa się , powinieneś zainstalować ją w
następującej
ścieżce: myAwesomePlugin.dll%PROGRAMFILES(x86)%\Notepad++\plugins\myAwes
omePlugin\myAwesomePlugin.dll
Po zainstalowaniu wtyczki możesz jej używać (i możesz konfigurować)
za pomocą menu "Wtyczki".
Jak opracować wtyczkę
Wprowadzenie
Oto instrukcje, aby wykonać pierwszą wtyczkę Notepad ++ w mniej niż
10 minut, wykonując następujące kroki 6:
Page 94

1. Pobierz i rozpakuj najnowszą wersję Notepad ++ Plugin Template.
2. Otwórz w programie Visual Studio.NppPluginTemplate.vcproj
3. Zdefiniuj nazwę wtyczki w PluginDefinition.h
4. Zdefiniuj numer poleceń wtyczki w PluginDefinition.h
5. Dostosuj nazwy poleceń wtyczek i powiązane nazwy funkcji (i inne
rzeczy, opcjonalne) w programie .PluginDefinition.cpp
6. Zdefiniuj skojarzone funkcje.
Kierujesz się następującymi komentarzami zarówno w plikach
PluginDefinition.h, jak i PluginDefinition.cpp:
//-- STEP 1. DEFINE YOUR PLUGIN NAME --//
//-- STEP 2. DEFINE YOUR PLUGIN COMMAND NUMBER --//
//-- STEP 3. CUSTOMIZE YOUR PLUGIN COMMANDS --//
//-- STEP 4. DEFINE YOUR ASSOCIATED FUNCTIONS --//
Dobra próbka lepiej ilustruje cały obraz niż szczegółowa
dokumentacja. Możesz sprawdzić Notepad ++ Plugin Demo, aby
dowiedzieć się, jak uczynić niektóre polecenia bardziej złożonymi.
Jednak znajomość systemu wtyczek Notepad ++ jest wymagana, jeśli
chcesz wykonać kilka wyrafinowanych poleceń wtyczek.
Możesz użyć forum rozwoju wtyczek dla wszelkich pytań technicznych
/ odpowiedzi i ogłoszenia nowej wtyczki.
W innych językach
Ada
C #
D
Delphi
Budowanie wtyczki lexer
Wtyczka lexer jest rodzajem rozszerzenia w
porównaniu do zwykłej wtyczki, tj. oprócz wszystkich wymienionych
już funkcji, należy wyeksportować dodatkowe, a także wygenerować
plik XML definiujący style.
Notepad ++ (Npp) obecnie obsługuje tylko interfejs ILexer4.
Lexer powinien definiować wszystkie metody tego interfejsu, aby
zapewnić płynną interakcję.
Dodatkowe funkcje lexer do wyeksportowania przez
Page 95

wtyczkę to
- GetLexerCount - GetLexerName
- GetLexerStatusText
- GetLexerFactory
W przeciwieństwie do poprzednich funkcji, muszą one być eksportowane
jako konwencja wywoływania stdcall.
1. GetLexerCount
(typedef int (EXT_LEXER_DECL *GetLexerCountFn)();)
Args: none
Return: 32bit signed integer
Description:
A Lexer_Plugin can contain multiple lexers, so GetLexerCount returns
the
number of defined lexers in this plugin. Mostly this will be 1.
2. GetLexerName
(typedef void (EXT_LEXER_DECL *GetLexerNameFn)(unsigned int index, char
*name, int buflength);)
Args:
- Index
- name
- buflength
Return: none
Description:
This function should return the name which should be displayed in the
LanguageMenu.
If more than one lexer is contained in a plugin, this function will be
called accordingly often
and the respective lexer is queried via index.
Name is a pointer to the memory area allocated by Npp.
This name should be encoded as an 8bit string using the current Windows
codepage.
The size is given by buflength.
3. GetLexerStatusText
(typedef void (EXT_LEXER_DECL *GetLexerStatusTextFn)(unsigned int
Index, TCHAR *desc, int buflength);)
Args:
- Index
- name
- buflength
Return: none
Page 96

Description:
This function should return the description to be displayed in the first
field of the status line.
The parameters are to be treated in the same way as in the GetLexerName
function, except for
the name parameter, which requires a string encoded with UTF-16.
4. GetLexerFactory
(typedef LexerFactoryFunction(EXT_LEXER_DECL
*GetLexerFactoryFunction)(unsigned int Index);)
Args:
- Index
Return: function pointer
Description:
This function returns a function pointer that returns a pointer to an
implementation of the ILexer4 interface.
If the lexer is written in Cpp, this means you create a class with all
virtual methods of the ILexer4 interface.
If another programming language is used to create the Lexer_Plugin this
means that you create a fixed array with voidptr, pointing to the methods
to be implemented, and assign this to a variable from which you return
the pointer.
Przykład implementacji ILexer4 w
Pseudocode: (Uwaga: Komentarze w stylu C są tutaj tylko w celach
informacyjnych)
Function GetLexerFactory(index)
return LexerFactoryImplementation
Function LexerFactoryImplementation()
ILexer4[0] = voidptr(version) // virtual int SCI_METHOD Version() const
= 0;
ILexer4[1] = voidptr(release) // virtual void SCI_METHOD Release() = 0;
ILexer4[2] = voidptr(property_names) // virtual const char * SCI_METHOD
PropertyNames() = 0;
ILexer4[3] = voidptr(property_type) // virtual int SCI_METHOD
PropertyType(const char *name) = 0;
ILexer4[4] = voidptr(describe_property) // virtual const char * SCI_METHOD
DescribeProperty(const char *name) = 0;
ILexer4[5] = voidptr(property_set) // virtual Sci_Position SCI_METHOD
PropertySet(const char *key, const char *val) = 0;
ILexer4[6] = voidptr(describe_word_list_sets) // virtual const char *
SCI_METHOD DescribeWordListSets() = 0;
ILexer4[7] = voidptr(word_list_set) // virtual Sci_Position SCI_METHOD
WordListSet(int n, const char *wl) = 0;
ILexer4[8] = voidptr(lex) // virtual void SCI_METHOD Lex(Sci_PositionU
startPos, Sci_Position lengthDoc, int initStyle, IDocument *pAccess) = 0;
Page 97

ILexer4[9] = voidptr(fold) // virtual void SCI_METHOD Fold(Sci_PositionU
startPos, Sci_Position lengthDoc, int initStyle, IDocument *pAccess) = 0;
ILexer4[10] = voidptr(private_call) // virtual void * SCI_METHOD
PrivateCall(int operation, void *pointer) = 0;
ILexer4[11] = voidptr(line_end_types_supported) // virtual int SCI_METHOD
LineEndTypesSupported() = 0;
ILexer4[12] = voidptr(allocate_sub_styles) // virtual int SCI_METHOD
AllocateSubStyles(int styleBase, int numberStyles) = 0;
ILexer4[13] = voidptr(sub_styles_start) // virtual int SCI_METHOD
SubStylesStart(int styleBase) = 0;
ILexer4[14] = voidptr(sub_styles_length) // virtual int SCI_METHOD
SubStylesLength(int styleBase) = 0;
ILexer4[15] = voidptr(style_from_sub_style) // virtual int SCI_METHOD
StyleFromSubStyle(int subStyle) = 0;
ILexer4[16] = voidptr(primary_style_from_style) // virtual int SCI_METHOD
PrimaryStyleFromStyle(int style) = 0;
ILexer4[17] = voidptr(free_sub_styles) // virtual void SCI_METHOD
FreeSubStyles() = 0;
ILexer4[18] = voidptr(set_identifiers) // virtual void SCI_METHOD
SetIdentifiers(int style, const char *identifiers) = 0;
ILexer4[19] = voidptr(distance_to_secondary_styles) // virtual int
SCI_METHOD DistanceToSecondaryStyles() = 0;
ILexer4[20] = voidptr(get_sub_style_bases) // virtual const char *
SCI_METHOD GetSubStyleBases() = 0;
ILexer4[21] = voidptr(named_styles) // virtual int SCI_METHOD
NamedStyles() = 0;
ILexer4[22] = voidptr(name_of_style) // virtual const char * SCI_METHOD
NameOfStyle(int style) = 0;
ILexer4[23] = voidptr(tags_of_style) // virtual const char * SCI_METHOD
TagsOfStyle(int style) = 0;
ILexer4[24] = voidptr(description_of_style) // virtual const char *
SCI_METHOD DescriptionOfStyle(int style) = 0;
ilexer = Pointer(ILexer4)
return Pointer(ilexer)
Function version()
...
Function release()
...
Function property_names()
...
Najważniejsze funkcje, które lexer musi zapewnić, to Lex, Fold i
WordListSet.
Jak sugerują nazwy, Lex jest wywoływany przez Npp (właściwie
Scintilla), aby pokolorować bieżący bufor, a następnie Fold, aby
zdefiniować dowolne punkty składania.
WordListSet jest wywoływany w zależności od tego, ile grup słów
Page 98

kluczowych zostało zdefiniowanych w pliku XML stylów i za każdym
razem, gdy zmiany są wprowadzane za pośrednictwem Npp StyleDialog.
Więcej informacji na temat tych i wszystkich innych metod można
uzyskać
od https://www.scintilla.org/ScintillaDoc.html#SCI_LOADLEXERLIBR
ARY.
Tworzenie pliku LEXER Styles XML.
Aby Npp wiedział, jak kolorować styl, oprócz oryginalnego pliku dll
lexer należy utworzyć plik XML o tej samej nazwie co lexer.
Na przykład, jeśli wtyczka Lexer nazywa się MyNewLexer.dll, plik XML
musi nazywać się MyNewLexer.xml i musi być obecny w katalogu
konfiguracyjnym wtyczki.
Plik XML musi mieć następujący układ.
<?xml version="1.0" encoding="UTF-8" ?>
<NotepadPlus>
<Languages>
<Language name="NAME_OF_THE_LEXER"
ext="EXTENSIONS_USED_TO_IDENTIFY_THE_LEXER" commentLine="//"
commentStart="/*" commentEnd="*/">
<Keywords name="instre1">if then else ...</Keywords>
<Keywords name="instre2">...</Keywords>
<Keywords name="type1">...</Keywords>
<Keywords name="type2">...</Keywords>
<Keywords name="type3">...</Keywords>
<Keywords name="type4">...</Keywords>
<Keywords name="type5" />
<Keywords name="type6" />
</Language>
</Languages>
<LexerStyles>
<LexerType name="NAME_OF_THE_LEXER"
desc="DESCRIPTION_OF_THE_LEXER_SHOWN_IN_STATUSBAR" ext="" excluded="no">
<WordsStyle styleID="0" name="Default" fgColor="000000"
bgColor="FFFFFF" colorStyle="0" fontName="" fontStyle="0" fontSize="" />
<WordsStyle styleID="1" name="WHATEVER" fgColor="FF0000"
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0" fontSize="" />
<WordsStyle styleID="2" name="SOMETHING_DIFFERENT"
fgColor="00FF00" bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0"
fontSize="" />
<WordsStyle styleID="3" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0" fontSize="" />
<WordsStyle styleID="4" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0" fontSize="" />
<WordsStyle styleID="5" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0" fontSize="" />
<WordsStyle styleID="6" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0"
Page 99

keywordClass="instre1" fontSize="" />
<WordsStyle styleID="7" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0"
keywordClass="instre2" fontSize="" />
<WordsStyle styleID="8" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0"
keywordClass="type1" fontSize="" />
<WordsStyle styleID="9" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0"
keywordClass="type2" />
<WordsStyle styleID="10" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0"
keywordClass="type3" />
<WordsStyle styleID="11" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0"
keywordClass="type4" />
<WordsStyle styleID="12" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0"
keywordClass="type5" />
<WordsStyle styleID="13" name="..." fgColor="..."
bgColor="FFFFFF" colorStyle="1" fontName="" fontStyle="0"
keywordClass="type6" />
</LexerType>
</LexerStyles>
</NotepadPlus>
Obecnie w programie .
Następnie należy się do nich odwołać za pomocą odpowiedniego atrybutu
keywordClass w znaczniku WordsStyle węzła.
O zaletach i wyczuciu colorStyle można przeczytać tutaj.
Atrybut ext in jest domyślnym rozszerzeniem oraz w dodatkowych
zdefiniowanych przez użytkownika.
Dzięki temu wszystko jest zrobione. Właściwie to całkiem proste.
Ale, jak zwykle w tworzeniu oprogramowania, istnieją również pewne
nie tak oczywiste pułapki.
Porady i wskazówki
1. Npp używa 2 widoków z różnymi instancjami scyntyli.
Aby określić, które wystąpienie powinno być obsługiwane
z którym dokumentem w danej chwili, pAccess może być używany
w Lex i Fold.
Wskazówka: Możliwe jest przewijanie nieaktywnej instancji, a
tym samym wyzwalanie wywołań zwrotnych Lex i Fold.
2. Pliki API XML, które są używane do autouzupełniania przez Npp,
a także pliki XML funtionlist mogą
Page 100

obecnie nie być używane przez lexery wtyczek.
Dlatego sensowne jest wdrożenie również tych funkcji.
3. GetLexerName i GetLexerCount są wywoływane dwukrotnie.
Raz z Npp bezpośrednio i raz ze Scintilla.
Każdy z inną długością bufora.
4. Gdy Npp ładuje wtyczkę Lexer, oczekuje
się, że odpowiedni plik XML stylów jest również obecny w
katalogu konfiguracji wtyczki.
Ponieważ z jakiegokolwiek powodu ten plik może nie być obecny,
dobrze jest sprawdzić to w wywołaniu zwrotnym setInfo i
odpowiednio zareagować.
Pluginy Admin
Wbudowany Plugins Admin pokazuje listę dostępnych wtyczek, pozwala
użytkownikom instalować nowe wtyczki i aktualizować/usuwać
zainstalowane wtyczki. Potrzebuje listy wtyczek (patrz następna
sekcja) do działania.
Lista wtyczek
Lista w formacie JSON opakowana w dll zawiera najbardziej poplular
Notepad ++ plugins. Ta lista, która jest utrzymywana przez zespół,
jest również projektem open source hostowanym w
GitHub: https://github.com/notepad-plus-plus/nppPluginList/.
Każda wtyczka jest mile widziana, aby dołączyć do listy.
Przetestuj swoje wtyczki lokalnie
Do testowania wtyczki do wyświetlania, instalacji, usuwania i
aktualizacji w plugin admin, potrzebujesz pliku binarnego Notepad
++ w trybie debugowania 32-bitowego lub 64-bitowego, najnowszej
wersji wingup 32-bit lub 64-bit i nppPluginList.json (powinieneś
zmienić jego nazwę z lub , zgodnie z architekturą wtyczki). Zastąp
i swoją instalację Notepad ++ przez pobrane, skopiuj lub do , wtedy
wszystko jest ustawione - pozycja menu Plugins Admin będzie w
menu Wtyczki twojego trybu debugowania notepad ++.exe. Uruchom to
polecenie, aby uruchomić okno dialogowe Plugins Admin, a reszta
powinna być
intuicyjna.pl.x64.jsonpl.x86.jsonnotepad++.exeGUP.exepl.x64.jsonpl.x86.j
son<NPP_INST_DIR>\plugins\Config\nppPluginList.json
Zasady dodawania wtyczek do listy
 Loading...
Loading...