

Page 1

Intel® Pentium® P6000 and U5000 Mobile Processor Series
Datasheet
This is volume 1 of 2. Refer to Document 322813 for Volume 2
June 2010
Document Number: 323873-002
Page 2

Legal Lines and Disclaimers
INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED,
BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS
PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER,
AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING
LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY
PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT.
UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY
APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH
MAY OCCUR.
Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the
absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future
definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The
information here is subject to change without notice. Do not finalize a design with this information.
Δ Intel processor numbers are not a measure of performance. Processor numbers differentiate features within each processor
family, not across different processor families. See http://www.intel.com/products/processor_number
Intel, Intel SpeedStep, Pentium, Intel vPro and the Intel logo are trademarks of Intel Corporation in the U.S. and other countries.
*Other names and brands may be claimed as the property of others.
Copyright © 2010, Intel Corporation. All rights reserved.
2 Datasheet
for details.
Page 3

Contents
1 Features Summary ....................................................................................................8
1.1 Introduction .......................................................................................................8
1.2 Processor Feature Details ...................................................................................10
1.2.1 Supported Technologies ..........................................................................10
1.3 Interfaces......................................................................................................... 10
1.3.1 System Memory Support ......................................................................... 10
1.3.2 PCI Express* .........................................................................................11
1.3.3 Direct Media Interface (DMI).................................................................... 12
1.3.4 Platform Environment Control Interface (PECI)...........................................13
1.3.5 Intel® HD Graphics Controller.................................................................. 13
1.3.6 Embedded DisplayPort* (eDP*) ................................................................ 14
1.3.7 Intel® Flexible Display Interface (Intel® FDI) ............................................ 14
1.4 Power Management Support ............................................................................... 14
1.4.1 Processor Core.......................................................................................14
1.4.2 System ................................................................................................. 14
1.4.3 Memory Controller.................................................................................. 15
1.4.4 PCI Express* .........................................................................................15
1.4.5 DMI...................................................................................................... 15
1.4.6 Integrated Graphics Controller .................................................................15
1.5 Thermal Management Support ............................................................................15
1.6 Package ........................................................................................................... 15
1.7 Terminology ..................................................................................................... 16
1.8 Related Documents............................................................................................18
2Interfaces................................................................................................................ 19
2.1 System Memory Interface................................................................................... 19
2.1.1 System Memory Technology Supported ..................................................... 19
2.1.2 System Memory Timing Support...............................................................20
2.1.3 System Memory Organization Modes ......................................................... 20
2.1.4 Rules for Populating Memory Slots............................................................22
2.1.5 Technology Enhancements of Intel
2.1.6 DRAM Clock Generation........................................................................... 23
2.1.7 System Memory Pre-Charge Power Down Support Details ............................ 23
2.2 PCI Express Interface.........................................................................................24
2.2.1 PCI Express Architecture .........................................................................24
2.2.2 PCI Express Configuration Mechanism ....................................................... 26
2.2.3 PCI Express Ports and Bifurcation ............................................................. 26
2.3 DMI.................................................................................................................27
2.3.1 DMI Error Flow.......................................................................................27
2.3.2 Processor/PCH Compatibility Assumptions.................................................. 27
2.3.3 DMI Link Down ...................................................................................... 27
2.4 Intel® HD Graphics Controller.............................................................................28
2.4.1 3D and Video Engines for Graphics Processing............................................ 28
2.4.2 Integrated Graphics Display Pipes.............................................................31
2.4.3 Intel Flexible Display Interface ................................................................. 33
2.5 Platform Environment Control Interface (PECI)...................................................... 33
2.6 Interface Clocking ............................................................................................. 34
2.6.1 Internal Clocking Requirements................................................................ 34
®
Fast Memory Access (Intel® FMA).......... 23
Datasheet 3
Page 4

3 Technologies............................................................................................................35
3.1 Intel Graphics Dynamic Frequency .......................................................................35
4 Power Management .................................................................................................36
4.1 ACPI States Supported .......................................................................................36
4.1.1 System States........................................................................................36
4.1.2 Processor Core/Package Idle States...........................................................36
4.1.3 Integrated Memory Controller States.........................................................37
4.1.4 PCIe Link States .....................................................................................37
4.1.5 DMI States ............................................................................................37
4.1.6 Integrated Graphics Controller States ........................................................37
4.1.7 Interface State Combinations ...................................................................38
4.2 Processor Core Power Management......................................................................38
4.2.1 Enhanced Intel SpeedStep® Technology....................................................39
4.2.2 Low-Power Idle States.............................................................................39
4.2.3 Requesting Low-Power Idle States ............................................................41
4.2.4 Core C-states .........................................................................................42
4.2.5 Package C-States ...................................................................................43
4.3 IMC Power Management .....................................................................................46
4.3.1 Disabling Unused System Memory Outputs.................................................47
4.3.2 DRAM Power Management and Initialization ...............................................47
4.4 PCIe Power Management ....................................................................................48
4.5 DMI Power Management .....................................................................................49
4.6 Integrated Graphics Power Management ...............................................................49
4.6.1 Intel
®
Display Power Saving Technology 5.0 (Intel®DPST 5.0).....................49
4.6.2 Graphics Render C-State .........................................................................49
4.6.3 Graphics Performance Modulation Technology.............................................49
4.6.4 Intel
®
Smart 2D Display Technology (Intel® S2DDT)...................................49
4.7 Thermal Power Management ...............................................................................50
5 Thermal Management ..............................................................................................51
5.1 Thermal Design Power and Junction Temperature...................................................51
5.1.1 Intel Graphics Dynamic Frequency ............................................................51
5.1.2 Intel Graphics Dynamic Frequency Thermal Design Considerations and
Specifications.........................................................................................52
5.1.3 Idle Power Specifications .........................................................................54
5.1.4 Intelligent Power Sharing Control Overview ................................................54
5.1.5 Component Power Measurement/Estimation Error .......................................55
5.2 Thermal Management Features............................................................................56
5.2.1 Processor Core Thermal Features..............................................................56
5.2.2 Integrated Graphics and Memory Controller Thermal Features ......................62
5.2.3 Platform Environment Control Interface (PECI) ...........................................66
6 Signal Description....................................................................................................68
6.1 System Memory Interface ...................................................................................69
6.2 Memory Reference and Compensation ..................................................................71
6.3 Reset and Miscellaneous Signals ..........................................................................72
6.4 PCI Express Graphics Interface Signals .................................................................73
6.5 Embedded DisplayPort (eDP)...............................................................................74
6.6 Intel Flexible Display Interface Signals..................................................................74
6.7 DMI .................................................................................................................75
6.8 PLL Signals .......................................................................................................75
6.9 TAP Signals.......................................................................................................76
4 Datasheet
Page 5

6.10 Error and Thermal Protection ..............................................................................77
6.11 Power Sequencing .............................................................................................78
6.12 Processor Power Signals..................................................................................... 79
6.13 Ground and NCTF ..............................................................................................81
6.14 Processor Internal Pull Up/Pull Down.................................................................... 81
7 Electrical Specifications........................................................................................... 83
7.1 Power and Ground Pins ...................................................................................... 83
7.2 Decoupling Guidelines........................................................................................ 83
7.2.1 Voltage Rail Decoupling........................................................................... 83
7.3 Processor Clocking (BCLK, BCLK#) ...................................................................... 83
7.3.1 PLL Power Supply ................................................................................... 84
7.4 Voltage Identification (VID) ................................................................................84
7.5 Reserved or Unused Signals................................................................................88
7.6 Signal Groups ................................................................................................... 88
7.7 Test Access Port (TAP) Connection....................................................................... 91
7.8 Absolute Maximum and Minimum Ratings ............................................................. 92
7.9 Storage Conditions Specifications ........................................................................92
7.10 DC Specifications...............................................................................................93
7.10.1 Voltage and Current Specifications............................................................94
7.11 Platform Environmental Control Interface (PECI) DC Specifications......................... 101
7.11.1 DC Characteristics ................................................................................ 101
7.11.2 Input Device Hysteresis......................................................................... 102
8 Processor Pin and Signal Information.................................................................... 103
8.1 Processor Pin Assignments................................................................................ 103
8.2 Package Mechanical Information........................................................................ 177
Figures
Figure 1-1 Intel® Pentium® P6000 and U5000 Mobile Processor Series on the Calpella
Platform..................................................................................................9
Figure 2-2 Intel Flex Memory Technology Operation ................................................... 21
Figure 2-3 Dual-Channel Symmetric (Interleaved) and Dual-Channel
Asymmetric Modes ................................................................................. 22
Figure 2-4 PCI Express Layering Diagram ................................................................. 24
Figure 2-5 Packet Flow through the Layers................................................................ 25
Figure 2-6 PCI Express Related Register Structures in the Processor ............................. 26
Figure 2-7 Integrated Graphics Controller Unit Block Diagram......................................28
Figure 2-8 Processor Display Block Diagram ..............................................................31
Figure 4-9 Idle Power Management Breakdown of the Processor Cores..........................40
Figure 4-10 Thread and Core C-State Entry and Exit ....................................................40
Figure 4-11 Package C-State Entry and Exit ................................................................45
Figure 5-12 Frequency and Voltage Ordering............................................................... 57
Figure 7-13 Active V
Figure 7-14 Active V
Figure 7-15 VAXG/IAXG Static and Ripple Voltage Regulation ........................................ 97
Figure 7-16 Input Device Hysteresis......................................................................... 102
Figure 8-17 Socket-G (rPGA988A) Pinmap (Top View, Upper-Left Quadrant).................. 104
Figure 8-18 Socket-G (rPGA988A) Pinmap (Top View, Upper-Right Quadrant)................ 105
Figure 8-19 Socket-G (rPGA988A) Pinmap (Top View, Lower-Left Quadrant).................. 106
Figure 8-20 Socket-G (rPGA988A) Pinmap (Top View, Lower-Right Quadrant)................ 107
and ICC Loadline (PSI# Asserted) ..............................................95
CC
and ICC Loadline (PSI# Not Asserted) ........................................ 95
CC
Datasheet 5
Page 6

Figure 8-21 BGA1288 Ballmap (Top View, Upper-Left Quadrant) ..................................136
Figure 8-22 BGA1288 Ballmap (Top View, Upper-Right Quadrant) ................................137
Figure 8-23 BGA1288 Ballmap (Top View, Lower-Left Quadrant) ..................................138
Figure 8-24 BGA1288 Ballmap (Top View, Lower-Right Quadrant) ................................139
Figure 8-25 rPGA Mechanical Package (Sheet 1 of 2) ................................................. 177
Figure 8-26 rPGA Mechanical Package (Sheet 2 of 2) ..................................................178
Figure 8-27 BGA Mechanical Package (Sheet 1 of 2)...................................................179
Figure 8-28 BGA Mechanical Package (Sheet 2 of 2)...................................................180
Tables
Table 2-1 Supported SO-DIMM Module Configurations1..............................................19
Table 2-2 DDR3 System Memory Timing Support ......................................................20
Table 2-3 eDP/PEG Ball Mapping .............................................................................32
Table 2-4 Processor Reference Clocks ......................................................................34
Table 4-5 System States........................................................................................36
Table 4-6 Processor Core/Package State Support ......................................................36
Table 4-7 Integrated Memory Controller States.........................................................37
Table 4-8 PCIe Link States .....................................................................................37
Table 4-9 DMI States ............................................................................................37
Table 4-10 Integrated Graphics Controller States ........................................................37
Table 4-11 G, S and C State Combinations.................................................................38
Table 4-12 D, S, and C State Combination .................................................................38
Table 4-13 Coordination of Thread Power States at the Core Level ................................41
Table 4-14 P_LVLx to MWAIT Conversion ...................................................................41
Table 4-15 Coordination of Core Power States at the Package Level...............................44
Table 4-16 Targeted Memory State Conditions............................................................48
Table 5-17 Intel Pentium U5000 mobile processor series Dual-Core ULV Thermal Power
Table 5-18 Intel Pentium P6000 mobile processor series Dual-Core SV Thermal Power
Table 5-19 18 W Ultra Low Voltage (ULV) Processor Idle Power ....................................54
Table 5-20 35 W Standard Voltage (SV) Processor Idle Power.......................................54
Table 6-21 Signal Description Buffer Types ................................................................68
Table 6-22 Memory Channel A..................................................................................69
Table 6-23 Memory Channel B..................................................................................70
Table 6-24 Memory Reference and Compensation .......................................................71
Table 6-25 Reset and Miscellaneous Signals ...............................................................72
Table 6-26 PCI Express Graphics Interface Signals ......................................................73
Table 6-27 Intel® Flexible Display Interface...............................................................74
Table 6-28 DMI - Processor to PCH Serial Interface .....................................................75
Table 6-29 PLL Signals ............................................................................................75
Table 6-30 TAP Signals............................................................................................76
Table 6-31 Error and Thermal Protection....................................................................77
Table 6-32 Power Sequencing ..................................................................................78
Table 6-33 Processor Power Signals ..........................................................................79
Table 6-34 Ground and NCTF ...................................................................................81
Table 6-35 Processor Internal Pull Up/Pull Down .........................................................81
Table 7-36 Voltage Identification Definition ................................................................84
Table 7-37 Market Segment Selection Truth Table for MSID[2:0] ..................................87
Table 7-38 Signal Groups1.......................................................................................88
Table 7-39 Processor Absolute Minimum and Maximum Ratings ....................................92
Specifications.........................................................................................53
Specifications.........................................................................................54
6 Datasheet
Page 7

Table 7-40 Storage Condition Ratings .......................................................................93
Table 7-41 Processor Core (VCC) Active and Idle Mode DC Voltage and Current
Specifications.........................................................................................94
Table 7-42 Processor Uncore I/O Buffer Supply DC Voltage and Current Specifications..... 96
Table 7-43 Processor Graphics VID based (VAXG) Supply DC Voltage and Current
Specifications.........................................................................................97
Table 7-44 DDR3 Signal Group DC Specifications ........................................................98
Table 7-45 Control Sideband and TAP Signal Group DC Specifications............................99
Table 7-46 PCI Express DC Specifications ................................................................ 100
Table 7-47 eDP DC Specifications ........................................................................... 101
Table 7-48 PECI DC Electrical Limits ....................................................................... 102
Table 8-49 rPGA988A Processor Pin List by Pin Number ............................................. 108
Table 8-50 rPGA988A Processor Pin List by Pin Name................................................ 122
Table 8-51 BGA1288 Processor Ball List by Ball Name ............................................... 140
Table 8-52 BGA1288 Processor Ball List by Ball Number ............................................ 158
Datasheet 7
Page 8

Revision History
Revision
Number
001 • Initial release May 2010
002 • Added Pentium P6000 sku information June 2010
Description
Revision
Date
§
8 Datasheet
Page 9

Features Summary
1 Features Summary
1.1 Introduction
Intel® Pentium® P6000 and U5000 Mobile Processor Series is the next generation of
64-bit, multi-core mobile processor built on 32-nanometer process technology. Based
on the low-power/high-performance Nehalem micro-architecture, the processor is
designed for a two-chip platform as opposed to the traditional three-chip platforms
(processor, GMCH, and ICH). The two-chip platform consists of a processor and the
Platform Controller Hub (PCH) and enables higher performance, lower cost, easier
validation, and improved x-y footprint. The PCH may also be referred to as Mobile
Intel® 5 Series Chipset (formerly Ibex Peak-M). Intel® Pentium® P6000 and U5000
Mobile Processor Series is designed for the Calpella platform and is offered in rPGA988A
and BGA1288 package respectively.
Included in this family of processors is Intel® HD graphics and memory controller die
on the same package as the processor core die. This two-chip solution of a processor
core die with an integrated graphics and memory controller die is known as a multi-chip
package (MCP) processor.
Note:
1. Throughout this document, Intel® Pentium® P6000 and U5000 Mobile Processor
Series is referred to as processor.
2. Throughout this document, Intel® HD graphics is referred as integrated graphics.
3. Integrated graphics and memory controller die is built on 45-nanometer process
technology
4. Intel® Pentium® P6000 and U5000 Mobile Processor Series is not Intel® vPro™
eligible
Datasheet 9
Page 10
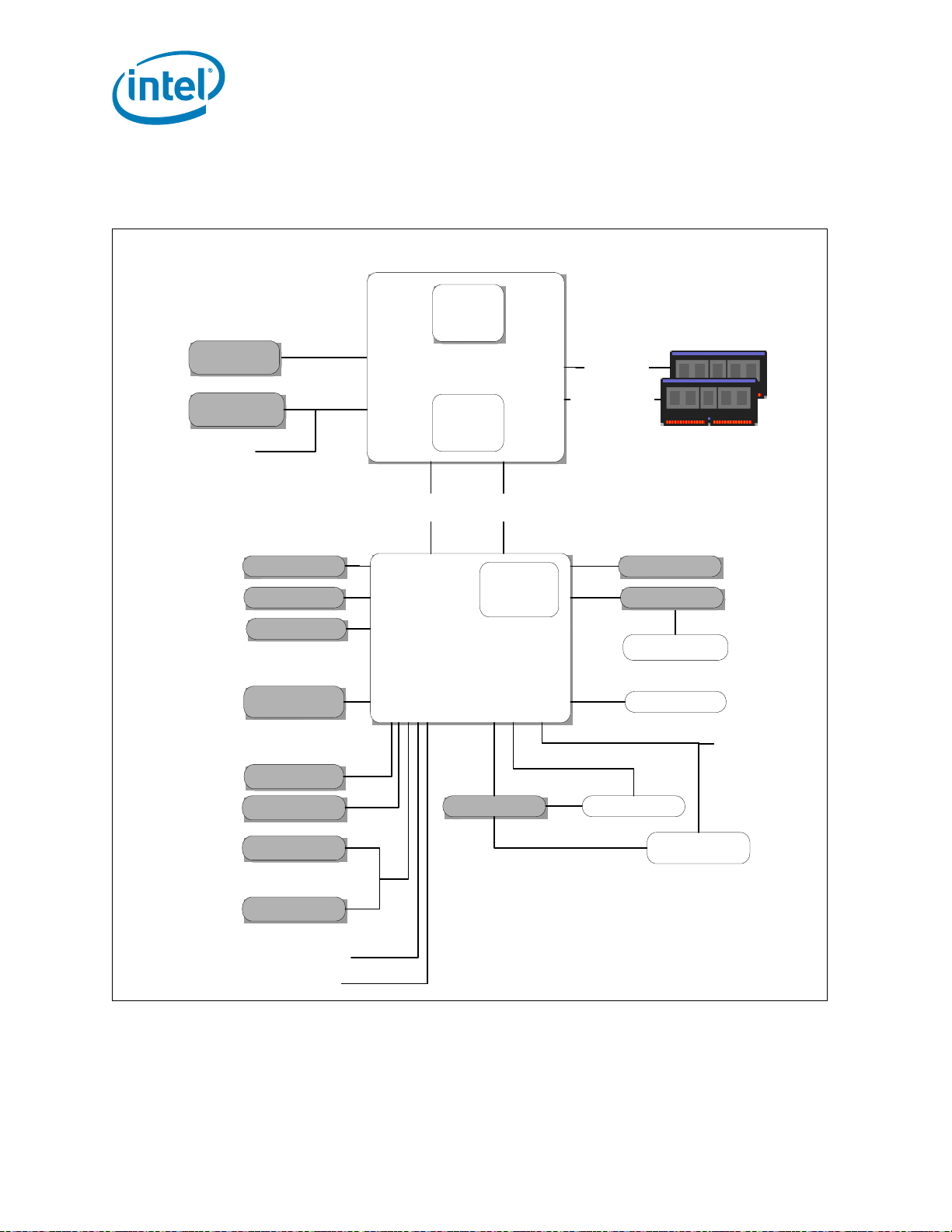
Features Summary
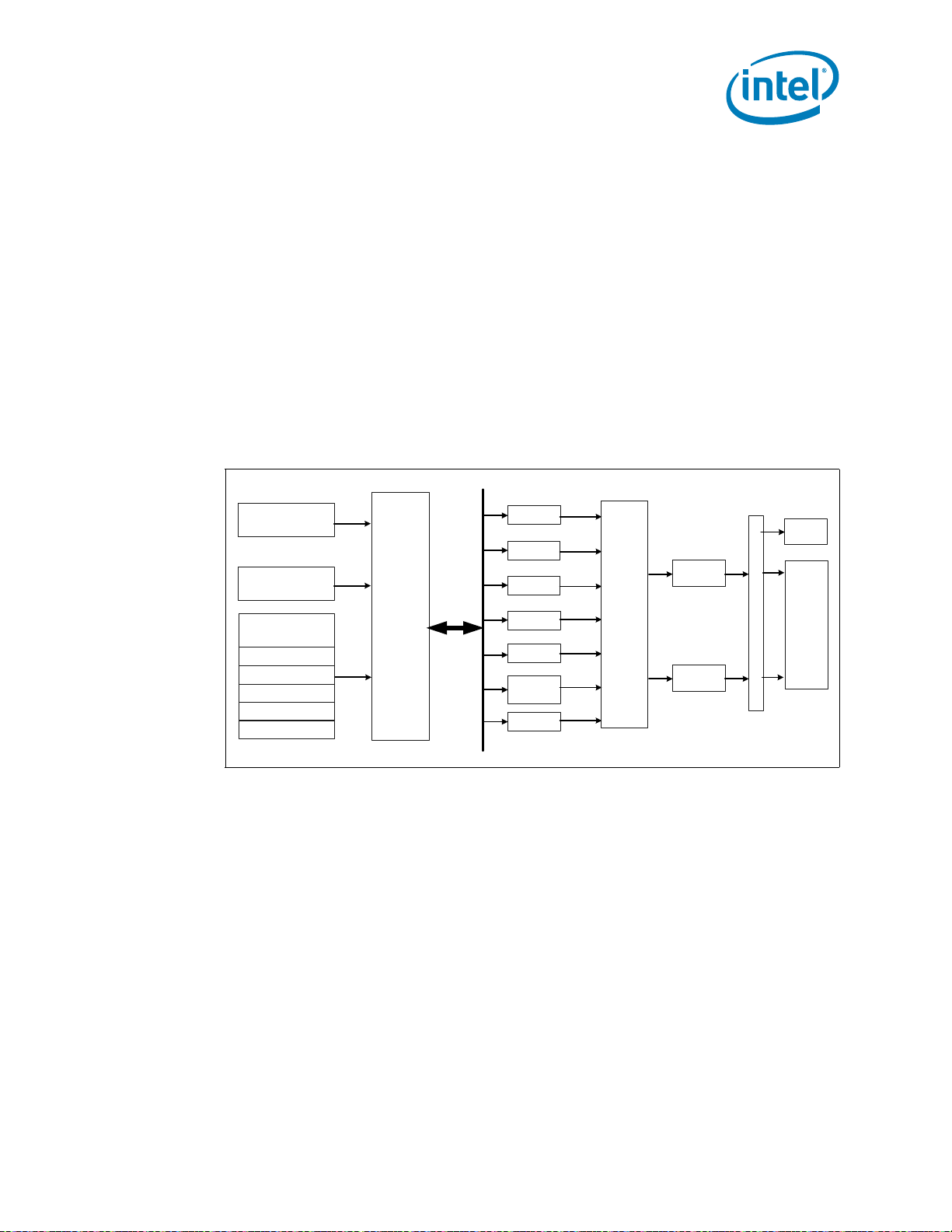
Processor
Discrete Graphics
(PEG)
Analog CRT
Gigabit
Network Connection
USB 2.0
Intel® HD Audio
FWH
Super I/O
PCI
Serial ATA
Mobile Intel® 5 Series Chipset
PCH
DDR3 SO-DIMMs
PCI Express* x16
8 PCI Express* x1
Ports
(2.5 GT/s)
14 Ports
PCI
6 Ports
3 Gb/s
SPI
Digital Display x 3
Intel® Flexible
Display Interface
PCI Express*
WiMax
SPI Flash
LPC
SMBUS 2.0
PECI
GPIO
OR
GPU, Memory
Controller
Dual Core
Processor
800/1066 MT/s
2 Channels
1 SO-DIMM / Channel
DMI2
(x4)
Dual Channel NAND
Interface
LVDS Flat Panel
Intel®
Management
Engine
WiFi
Controller Link 1
Embedded
DisplayPort* (eDP)
PCI Express x 1
Figure 1-1. Intel® Pentium® P6000 and U5000 Mobile Processor Series on the Calpella
Platform
10 Datasheet
Page 11

Features Summary
1.2 Processor Feature Details
• Two execution cores
• A 32-KB instruction and 32-KB data first-level cache (L1) for each core
• A 512-KB shared instruction/data second-level cache (L2), 256-KB for each core
• Up to 3-MB shared instruction/data third-level cache (L3), shared among all cores
1.2.1 Supported Technologies
• Intel® 64 architecture
• Execute Disable Bit
• Processor Context Identifier (PCID) (U5400 processor only)
Note: Please refer to the Intel® Pentium® P6000 and U5000 Mobile Processor Series
Specification Update for feature support details
1.3 Interfaces
1.3.1 System Memory Support
• One or two channels of DDR3 memory with a maximum of one SO-DIMM per
channel
• Single- and dual-channel memory organization modes
• Data burst length of eight for all memory organization modes
• Memory DDR3 data transfer rates of 800 MT/s (SV/ULV) and 1066 MT/s (SV)
• 64-bit wide channels
• DDR3 I/O Voltage of 1.5 V
• Non-ECC, unbuffered DDR3 SO-DIMMs only
• Theoretical maximum memory bandwidth of:
— 12.8 GB/s in dual-channel mode assuming DDR3 800 MT/s
• 1-Gb, and 2-Gb DDR3 DRAM technologies are supported for x8 and x16 devices.
• Using 2-Gb device technologies, the largest memory capacity possible is 8 GB,
assuming dual-channel mode with two x8, double-sided, un-buffered, non-ECC,
SO-DIMM memory configuration.
• Up to 32 simultaneous open pages, 16 per channel (assuming 4 Ranks of 8 Bank
Devices)
• Memory organizations:
— Single-channel modes
— Dual-channel modes - Intel® Flex Memory Technology:
Datasheet 11
Page 12

Dual-channel symmetric (Interleaved)
Dual-channel asymmetric
• Command launch modes of 1n/2n
• Partial Writes to memory using Data Mask (DM) signals
• On-Die Termination (ODT)
• Intel® Fast Memory Access (Intel® FMA):
— Just-in-Time Command Scheduling
— Command Overlap
— Out-of-Order Scheduling
1.3.2 PCI Express*
• The Processor PCI Express ports are fully compliant to the PCI Express Base
Specification Revision 2.0.
— One 16-lane PCI Express* port intended for graphics attach.
• Gen1 (2.5 GT/s) PCI Express* frequency is supported.
Features Summary
• Gen1 Raw bit-rate on the data pins of 2.5 Gb/s, resulting in a real bandwidth per
pair of 250 MB/s given the 8b/10b encoding used to transmit data across this
interface. This also does not account for packet overhead and link maintenance.
• Maximum theoretical bandwidth on interface of 4 GB/s in each direction
simultaneously, for an aggregate of 8 GB/s when x16 Gen 1.
• Hierarchical PCI-compliant configuration mechanism for downstream devices.
• Traditional PCI style traffic (asynchronous snooped, PCI ordering).
• PCI Express extended configuration space. The first 256 bytes of configuration
space aliases directly to the PCI compatibility configuration space. The remaining
portion of the fixed 4-KB block of memory-mapped space above that (starting at
100h) is known as “extended configuration space”.
• PCI Express Enhanced Access Mechanism. Accessing the device configuration space
in a flat memory mapped fashion.
• Automatic discovery, negotiation, and training of link out of reset.
• Traditional AGP style traffic (asynchronous non-snooped, PCI-X Relaxed ordering).
• Peer segment destination posted write traffic (no peer-to-peer read traffic) in
Virtual Channel 0:
— DMI -> PCI Express Port 0
• 64-bit downstream address format, but the processor never generates an address
above 64 GB (Bits 63:36 will always be zeros).
• 64-bit upstream address format, but the processor responds to upstream read
transactions to addresses above 64 GB (addresses where any of Bits 63:36 are
12 Datasheet
Page 13

Features Summary
• Re-issues configuration cycles that have been previously completed with the
• PCI Express reference clock is 100-MHz differential clock buffered out of system
• Power Management Event (PME) functions.
• Static lane numbering reversal
• Supports Half Swing “low-power/low-voltage” mode.
• Message Signaled Interrupt (MSI and MSI-X) messages
• PEG Lanes shared with Embedded DisplayPort* (see eDP, Section 1.3.6).
• Polarity inversion
non-zero) with an Unsupported Request response. Upstream write transactions to
addresses above 64 GB will be dropped.
Configuration Retry status.
clock generator.
— Does not support dynamic lane reversal, as defined (optional) by the PCI
Express Base Specification.
— PCI Express 1x16 configuration
Normal (1x16): PEG_RX[15:0]; PEG_TX[15:0]
Reversal (1x16): PEG_RX[0:15]; PEG_TX[0:15]
1.3.3 Direct Media Interface (DMI)
• Compliant to Direct Media Interface second generation (DMI2).
• Four lanes in each direction.
• 2.5 GT/s point-to-point DMI interface to PCH is supported.
• Raw bit-rate on the data pins of 2.5 Gb/s, resulting in a real bandwidth per pair of
250 MB/s given the 8b/10b encoding used to transmit data across this interface.
Does not account for packet overhead and link maintenance.
• Maximum theoretical bandwidth on interface of 1 GB/s in each direction
simultaneously, for an aggregate of 2 GB/s when DMI x4.
• Shares 100-MHz PCI Express reference clock.
• 64-bit downstream address format, but the processor never generates an address
above 64 GB (Bits 63:36 will always be zeros).
• 64-bit upstream address format, but the processor responds to upstream read
transactions to addresses above 64 GB (addresses where any of Bits 63:36 are
nonzero) with an Unsupported Request response. Upstream write transactions to
addresses above 64 GB will be dropped.
• Supports the following traffic types to or from the PCH:
— DMI -> PCI Express Port 0 write traffic
—DMI -> DRAM
— DMI -> processor core (Virtual Legacy Wires (VLWs), Resetwarn, or MSIs only)
Datasheet 13
Page 14

— Processor core -> DMI
• APIC and MSI interrupt messaging support:
— Message Signaled Interrupt (MSI and MSI-X) messages
• Downstream SMI, SCI and SERR error indication.
• Legacy support for ISA regime protocol (PHOLD/PHOLDA) required for parallel port
DMA, floppy drive, and LPC bus masters.
• DC coupling – no capacitors between the processor and the PCH.
• Polarity inversion.
• PCH end-to-end lane reversal across the link.
• Supports Half Swing “low-power/low-voltage.”
1.3.4 Platform Environment Control Interface (PECI)
The PECI is a one-wire interface that provides a communication channel between a
PECI client (the processor) and a PECI master (the PCH).
Features Summary
1.3.5 Intel® HD Graphics Controller
• The integrated graphics controller contains a refresh of the fifth generation graphics
core
• Intel® Dynamic Video Memory Technology (Intel® DVMT) support
• Intel® Graphics Performance Modulation Technology (Intel® GPMT)
• Intel® Smart 2D Display Technology (Intel® S2DDT)
• Intel® Clear Video Technology
— MPEG2 Hardware Acceleration
— WMV9/VC1 Hardware Acceleration
— AVC Hardware Acceleration
—ProcAmp
— Advanced Pixel Adaptive De-interlacing
— Sharpness Enhancement
— De-noise Filter
— High Quality Scaling
— Film Mode Detection (3:2 pull-down) and Correction
—Intel® TV Wizard
• 12 EUs
• Dedicated analog and digital display ports are supported through the Intel 5 Series
Chipset PCH
14 Datasheet
Page 15

Features Summary
1.3.6 Embedded DisplayPort* (eDP*)
• Shared with PCI Express Graphics port
• Shared on upper four logical lanes, after any lane reversal
• eDP[3:0] map to PEG[12:15] (non-reversed)
• eDP[3:0] map to PEG[3:0] (reversed)
• Concurrent eDP and PEG x1 supported
1.3.7 Intel® Flexible Display Interface (Intel® FDI)
• Carries display traffic from the integrated graphics controller in the processor to the
legacy display connectors in the PCH.
• Based on DisplayPort standard.
• Two independent links - one for each display pipe.
• Four unidirectional downstream differential transmitter pairs:
— Scalable down to 3X, 2X, or 1X based on actual display bandwidth requirements
— Fixed frequency 2.7 GT/s data rate
• Two sideband signals for Display synchronization:
— FDI_FSYNC and FDI_LSYNC (Frame and Line Synchronization)
• One Interrupt signal used for various interrupts from the PCH:
— FDI_INT signal shared by both Intel FDI Links
• PCH supports end-to-end lane reversal across both links.
1.4 Power Management Support
1.4.1 Processor Core
• Full support of ACPI C-states as implemented by the following processor C-states:
— Ultra low voltage supports C0, C1, C1E, C3, Deep Power Down Technology (code
named C6)
— Standard voltage supports C0, C1, C1E, C3
• Enhanced Intel SpeedStep® Technology
1.4.2 System
• S0, S3, S4, S5
Datasheet 15
Page 16

1.4.3 Memory Controller
• Conditional self-refresh (Intel® Rapid Memory Power Management (Intel® RMPM))
• Dynamic power-down
1.4.4 PCI Express*
• L0s and L1 ASPM power management capability
1.4.5 DMI
• L0s and L1 ASPM power management capability
1.4.6 Integrated Graphics Controller
• Intel Smart 2D Display Technology (Intel S2DDT)
• Intel® Display Power Saving Technology (Intel® DPST)
• Graphics Render C-State (RC6)
Features Summary
1.5 Thermal Management Support
• Digital Thermal Sensor
• Adaptive Thermal Monitor
• THERMTRIP# and PROCHOT# support
• On-Demand Mode
• Open and Closed Loop Throttling
• Memory Thermal Throttling
• External Thermal Sensor (TS-on-DIMM and TS-on-Board)
• Render Thermal Throttling
• Fan speed control with DTS
1.6 Package
• The Intel® Pentium® P6000 and U5000 Mobile Processor Series is available is
available on:
— A 37.5 x 37.5 mm rPGA package (rPGA988A) (Standard Voltage only)
— A 34 x 28 mm BGA package (BGA1288) (Ultra Low voltage only)
16 Datasheet
Page 17

Features Summary
1.7 Terminology
Term Description
BLT Block Level Transfer
CRT Cathode Ray Tube
DDR3 Third-generation Double Data Rate SDRAM memory technology
DP DisplayPort*
DMA Direct Memory Access
DMI Direct Media Interface
DTS Digital Thermal Sensor
ECC Error Correction Code
eDP* Embedded DisplayPort*
Intel® DPST Intel
Enhanced Intel
SpeedStep®
Tech no logy
Execute Disable Bit The Execute Disable bit allows memory to be marked as executable or
(G)MCH Legacy component - Graphics Memory Controller Hub
GPU Graphics Processing Unit
ICH The legacy I/O Controller Hub component that contains the main PCI
IMC Integrated Memory Controller
Intel® 64 Technology 64-bit memory extensions to the IA-32 architecture
ITPM Integrated Trusted Platform Module
IOV I/O Virtualization
LCD Liquid Crystal Display
LVDS Low Voltage Differential Signaling. A high speed, low power data
MCP Multi-Chip Package.
NCTF Non-Critical to Function. NCTF locations are typically redundant
Nehalem Intel’s 45-nm processor design, follow-on to the 45-nm Penryn design.
®
Display Power Saving Technology
Technology that provides power management capabilities to laptops.
non-executable, when combined with a supporting operating system.
If code attempts to run in non-executable memory the processor
raises an error to the operating system. This feature can prevent some
classes of viruses or worms that exploit buffer overrun vulnerabilities
and can thus help improve the overall security of the system. See the
Intel® 64 and IA-32 Architectures Software Developer's Manuals for
more detailed information.
interface, LPC interface, USB2, Serial ATA, and other I/O functions. It
communicates with the legacy (G)MCH over a proprietary interconnect
called DMI.
transmission standard used for display connections to LCD panels.
ground or non-critical reserved, so the loss of the solder joint
continuity at end of life conditions will not affect the overall product
functionality.
Datasheet 17
Page 18

Features Summary
Term Description
PCH Platform Controller Hub. The new, 2009 chipset with centralized
platform capabilities including the main I/O interfaces along with
display connectivity, audio features, power management,
manageability, security and storage features. The PCH may also be
referred to using the name (Mobile) Intel® 5 Series Chipset
PECI Platform Environment Control Interface.
PEG PCI Express* Graphics. External Graphics using PCI Express
Architecture. A high-speed serial interface whose configuration is
software compatible with the existing PCI specifications.
Processor The 64-bit, single-core or multi-core component (package).
Processor Core The term “processor core” refers to Si die itself which can contain
multiple execution cores. Each execution core has an instruction
cache, data cache, and 256-KB L2 cache. All execution cores share the
L3 cache.
Rank A unit of DRAM corresponding four to eight devices in parallel, ignoring
ECC. These devices are usually, but not always, mounted on a single
side of a SO-DIMM.
SCI System Control Interrupt. Used in ACPI protocol.
Storage Conditions A non-operational state. The processor may be installed in a platform,
in a tray, or loose. Processors may be sealed in packaging or exposed
to free air. Under these conditions, processor landings should not be
connected to any supply voltages, have any I/Os biased or receive any
clocks. Upon exposure to “free air” (i.e., unsealed packaging or a
device removed from packaging material) the processor must be
handled in accordance with moisture sensitivity labeling (MSL) as
indicated on the packaging material.
TAC Thermal Averaging Constant.
TDP Thermal Design Power.
V
V
V
V
V
CC
SS
AXG
TT
DDQ
Processor core power supply.
Processor ground.
Graphics core power supply.
L3 shared cache, memory controller, and processor I/O power rail.
DDR3 power rail.
VLD Variable Length Decoding.
x1 Refers to a Link or Port with one Physical Lane.
x4 Refers to a Link or Port with four Physical Lanes.
x8 Refers to a Link or Port with eight Physical Lanes.
x16 Refers to a Link or Port with sixteen Physical Lanes.
18 Datasheet
Page 19

Features Summary
1.8 Related Documents
Document
Public Specifications
Advanced Configuration and Power Interface Specification 3.0 http://www.acpi.info/
PCI Local Bus Specification 3.0 http://www.pcisig.com/
PCI Express Base Specification 2.0 http://www.pcisig.com
DDR3 SDRAM Specification http://www.jedec.org
DisplayPort Specification http://www.vesa.org
Intel® 64 and IA-32 Architectures Software Developer's Manuals http://www.intel.com/
Volume 1: Basic Architecture 253665
Volume 2A: Instruction Set Reference, A-M 253666
Volume 2B: Instruction Set Reference, N-Z 253667
Volume 3A: System Programming Guide 253668
Volume 3B: System Programming Guide 253669
Document Number/
Location
specifications
products/processor/
manuals/index.htm
§
Datasheet 19
Page 20

2 Interfaces
This chapter describes the interfaces supported by the processor.
2.1 System Memory Interface
2.1.1 System Memory Technology Supported
The Integrated Memory Controller (IMC) supports DDR3 protocols with two,
independent, 64-bit wide channels each accessing one SO-DIMM. It supports a
maximum of one, unbuffered non-ECC DDR3 SO-DIMM per-channel thus allowing up to
two device ranks per-channel.
DDR3 Data Transfer Rates:
— 800 MT/s (PC3-6400) and 1066 MT/s (PC3-8500)
Interfaces
• DDR3 SO-DIMM Modules:
— Raw Card A – double-sided x16 unbuffered non-ECC
— Raw Card B – single-sided x8 unbuffered non-ECC
— Raw Card C – single-sided x16 unbuffered non-ECC
— Raw Card D – double-sided x8 (stacked) unbuffered non-ECC
— Raw Card F – double-sided x8 (planar) unbuffered non-ECC
• DDR3 DRAM Device Technology:
— Standard 1-Gb, and 2-Gb technologies and addressing are supported for x16
and x8 devices. There is no support for memory modules with different
technologies or capacities on opposite sides of the same memory module. If one
side of a memory module is populated, the other side is either identical or
empty.
Table 2-1. Supported SO-DIMM Module Configurations
Raw
Card
Version
A 1 GB 1 Gb 64 M x 16 8 2 13/10 8 8K
A 2 GB 2 Gb 128 M x 16 8 2 14/10 8 8K
B 1 GB 1 Gb 128 M x 8 8 1 14/10 8 8K
B 2 GB 2 Gb 256 M x 8 8 1 15/10 8 8K
C 512 MB 1 Gb 64 M x 16 4 1 13/10 8 8K
C 1 GB 2 Gb 128 M x 16 4 1 14/10 8 8K
DIMM
Capacity
DRAM
Device
Technology
DRAM
Organization
# of
DRAM
Devices
1
# of
Physical
Device
Ranks
# of Row/
Col
Address
Bits
# of
Banks
Inside
DRAM
Page
Size
20 Datasheet
Page 21

Interfaces
Table 2-1. Supported SO-DIMM Module Configurations
Raw
Card
Version
2
D
F 2 GB 1 Gb 128 M x 8 16 2 14/10 8 8K
F 4 GB 2 Gb 256 M x 8 16 2 15/10 8 8K
NOTES:
1. System memory configurations are based on availability and are subject to change.
DIMM
Capacity
4 GB 2 Gb 256 M x 8 16 2 15/10 8 8K
2. Only Raw Card D SO-DIMMs at 1066 MT/s are supported.
DRAM
Device
Technology
DRAM
Organization
# of
DRAM
Devices
1
# of
Physical
Device
Ranks
# of Row/
Col
Address
Bits
# of
Banks
Inside
DRAM
2.1.2 System Memory Timing Support
The IMC supports the following DDR3 Speed Bin, CAS Write Latency (CWL), and
command signal mode timings on the main memory interface:
• tCL = CAS Latency
• tRCD = Activate Command to READ or WRITE Command delay
• tRP = PRECHARGE Command Period
• CWL = CAS Write Latency
• Command Signal modes = 1n indicates a new command may be issued every clock
and 2n indicates a new command may be issued every 2 clocks. Command launch
mode programming depends on the transfer rate and memory configuration.
Page
Size
Table 2-2. DDR3 System Mem ory Timing Support
Transfer
Rate
(MT/s)
800 6 6 6 5 1n 1
1066 7 7 7 6 1n 1
NOTES:
1. System memory timing support is based on availability and is subject to change.
tCL
(tCK)
888
tRCD
(tCK)
tRP
(tCK)
CWL
(tCK)
CMD Mode Notes
2.1.3 System Memory Organization Modes
The IMC supports two memory organization modes, single-channel and dual-channel.
Depending upon how the SO-DIMM Modules are populated in each memory channel, a
number of different configurations can exist.
Datasheet 21
Page 22

2.1.3.1 Single-Channel Mode
CH BCH A
CH BCH A
B B
C
BB
C
B
B
C
Non interleaved
access
Dual channel
interleaved access
TOM
B – The largest physical mem ory amount of the smaller size mem ory module
C – The remaining physical mem ory amount of the larger size mem ory module
In this mode, all memory cycles are directed to a single-channel. Single-channel mode
is used when either Channel A or Channel B SO-DIMM connectors are populated in any
order, but not both.
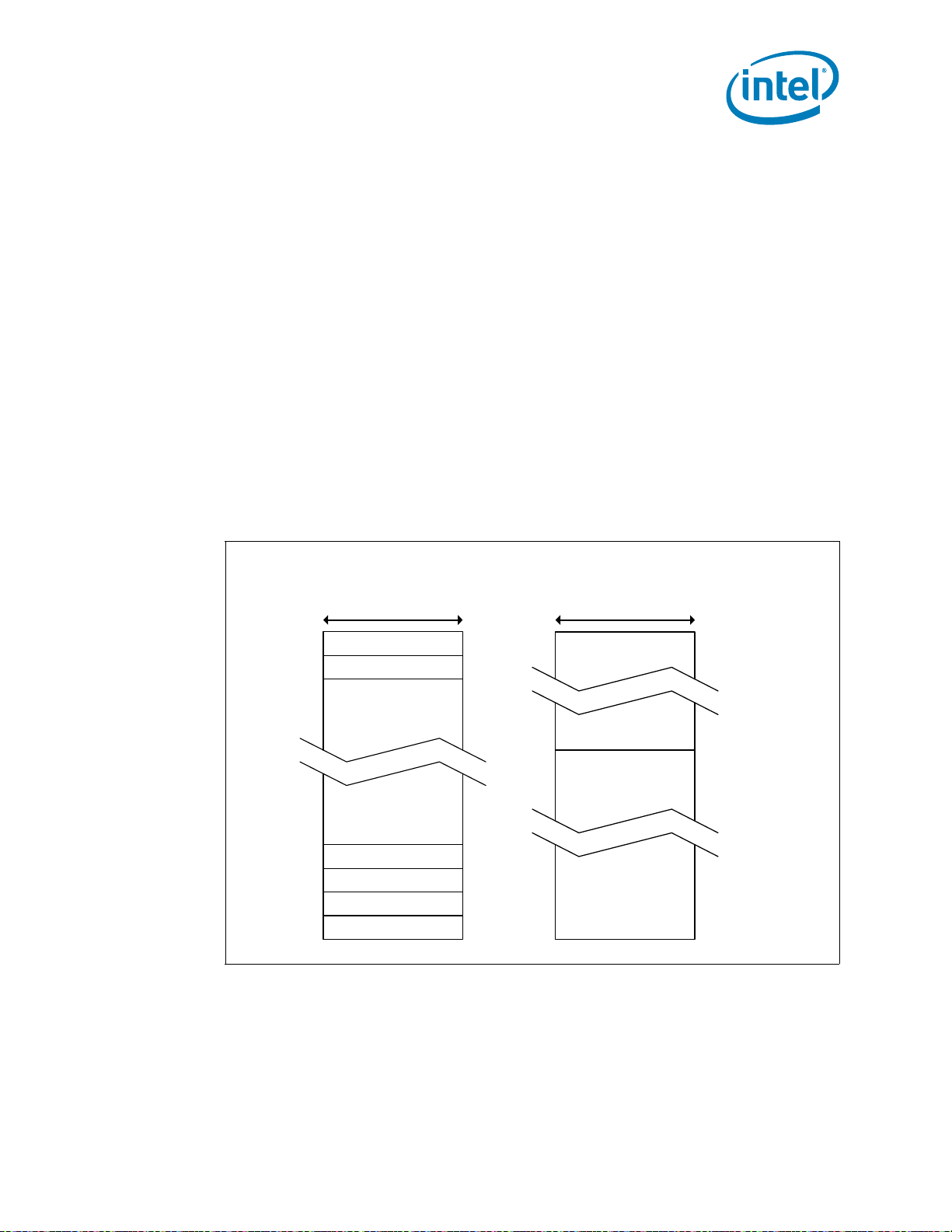
2.1.3.2 Dual-Channel Mode - Intel® Flex Memory Technology Mode
The IMC supports Intel Flex Memory Technology Mode. This mode combines the
advantages of the Dual-Channel Symmetric (Interleaved) and Dual-Channel
Asymmetric Modes. Memory is divided into a symmetric and a asymmetric zone. The
symmetric zone starts at the lowest address in each channel and is contiguous until the
asymmetric zone begins or until the top address of the channel with the smaller
capacity is reached. In this mode, the system runs with one zone of dual-channel mode
and one zone of single-channel mode, simultaneously, across the whole memory array.
Figure 2-2.Intel Flex Memory Technology Operation
Interfaces
2.1.3.2.1 Dual-Channel Symmetric Mode
Dual-Channel Symmetric mode, also known as interleaved mode, provides maximum
performance on real world applications. Addresses are ping-ponged between the
channels after each cache line (64-byte boundary). If there are two requests, and the
second request is to an address on the opposite channel from the first, that request can
be sent before data from the first request has returned. If two consecutive cache lines
are requested, both may be retrieved simultaneously, since they are ensured to be on
opposite channels. Use Dual-Channel Symmetric mode when both Channel A and
22 Datasheet
Channel B SO-DIMM connectors are populated in any order, with the total amount of
memory in each channel being the same.
Page 23
Interfaces
CH. B
CH. A
CH. B
CH. A
CH. B
CH. A
CL
0
Top of
Memory
CL
0
CH. B
CH. A
CH.A-top
DRB
Dual Channel Interleaved
(memory sizes must match)
Dual Channel Asymmetric
(memory sizes can differ)
Top of
Memory
When both channels are populated with the same memory capacity and the boundary
between the dual channel zone and the single channel zone is the top of memory, IMC
operates completely in Dual-Channel Symmetric mode.
Note: The DRAM device technology and width may vary from one channel to the other.
2.1.3.2.2 Dual-Channel Asymmetric Mode
This mode trades performance for system design flexibility. Unlike the previous mode,
addresses start at the bottom of Channel A and stay there until the end of the highest
rank in Channel A, and then addresses continue from the bottom of Channel B to the
top. Real world applications are unlikely to make requests that alternate between
addresses that sit on opposite channels with this memory organization, so in most
cases, bandwidth is limited to a single channel.
This mode is used when Intel Flex Memory Technology is disabled and both Channel A
and Channel B SO-DIMM connectors are populated in any order with the total amount
of memory in each channel being different.
Figure 2-3.Dual-Channel Symmetric (Interleaved) and Dual-Channel Asymmetric Modes
2.1.4 Rules for Populating Memory Slots
Datasheet 23
In all modes, the frequency of system memory is the lowest frequency of all memory
modules placed in the system, as determined through the SPD registers on the
memory modules. The system memory controller supports only one SO-DIMM
Page 24

Interfaces
connector per channel. For dual-channel modes both channels must have an SO-DIMM
connector populated. For single-channel mode, only a single-channel can have an
SO-DIMM connector populated.
2.1.5 Technology Enhancements of Intel® Fast Memory Access (Intel® FMA)
The following sections describe the Just-in-Time Scheduling, Command Overlap, and
Out-of-Order Scheduling Intel FMA technology enhancements.
2.1.5.1 Just-in-Time Command Scheduling
The memory controller has an advanced command scheduler where all pending
requests are examined simultaneously to determine the most efficient request to be
issued next. The most efficient request is picked from all pending requests and issued
to system memory Just-in-Time to make optimal use of Command Overlapping. Thus,
instead of having all memory access requests go individually through an arbitration
mechanism forcing requests to be executed one at a time, they can be started without
interfering with the current request allowing for concurrent issuing of requests. This
allows for optimized bandwidth and reduced latency while maintaining appropriate
command spacing to meet system memory protocol.
2.1.5.2 Command Overlap
Command Overlap allows the insertion of the DRAM commands between the Activate,
Precharge, and Read/Write commands normally used, as long as the inserted
commands do not affect the currently executing command. Multiple commands can be
issued in an overlapping manner, increasing the efficiency of system memory protocol.
2.1.5.3 Out-of-Order Scheduling
While leveraging the Just-in-Time Scheduling and Command Overlap enhancements,
the IMC continuously monitors pending requests to system memory for the best use of
bandwidth and reduction of latency. If there are multiple requests to the same open
page, these requests would be launched in a back to back manner to make optimum
use of the open memory page. This ability to reorder requests on the fly allows the IMC
to further reduce latency and increase bandwidth efficiency.
2.1.6 DRAM Clock Generation
Every supported SO-DIMM has two differential clock pairs. There are total of four clock
pairs driven directly by the processor to two SO-DIMMs.
2.1.7 System Memory Pre-Charge Power Down Support Details
The IMC supports and enables slow exit DDR3 DRAM Device pre-charge power down
DLL control. During a pre-charge power down, a slow exit is where the DRAM device
DLL is disabled after entering pre-charge power down for potential power savings.
24 Datasheet
Page 25
Interfaces
2.2 PCI Express Interface
This section describes the PCI Express interface capabilities of the processor. See the
PCI Express Base Specification for details of PCI Express.
The processor has one PCI Express controller that can support one external x16 PCI
Express Graphics Device or two external x8 PCI Express Graphics Devices. The primary
PCI Express Graphics port is referred to as PEG 0 and the secondary PCI Express
Graphics port is referred to as PEG 1.
2.2.1 PCI Express Architecture
Compatibility with the PCI addressing model is maintained to ensure that all existing
applications and drivers operate unchanged.
The PCI Express configuration uses standard mechanisms as defined in the PCI
Plug-and-Play specification. The initial recovered clock speed of 1.25 GHz results in
2.5 Gb/s/direction which provides a 250 MB/s communications channel in each
direction (500 MB/s total). That is close to twice the data rate of classic PCI. The fact
that 8b/10b encoding is used accounts for the 250 MB/s where quick calculations would
imply 300 MB/s.
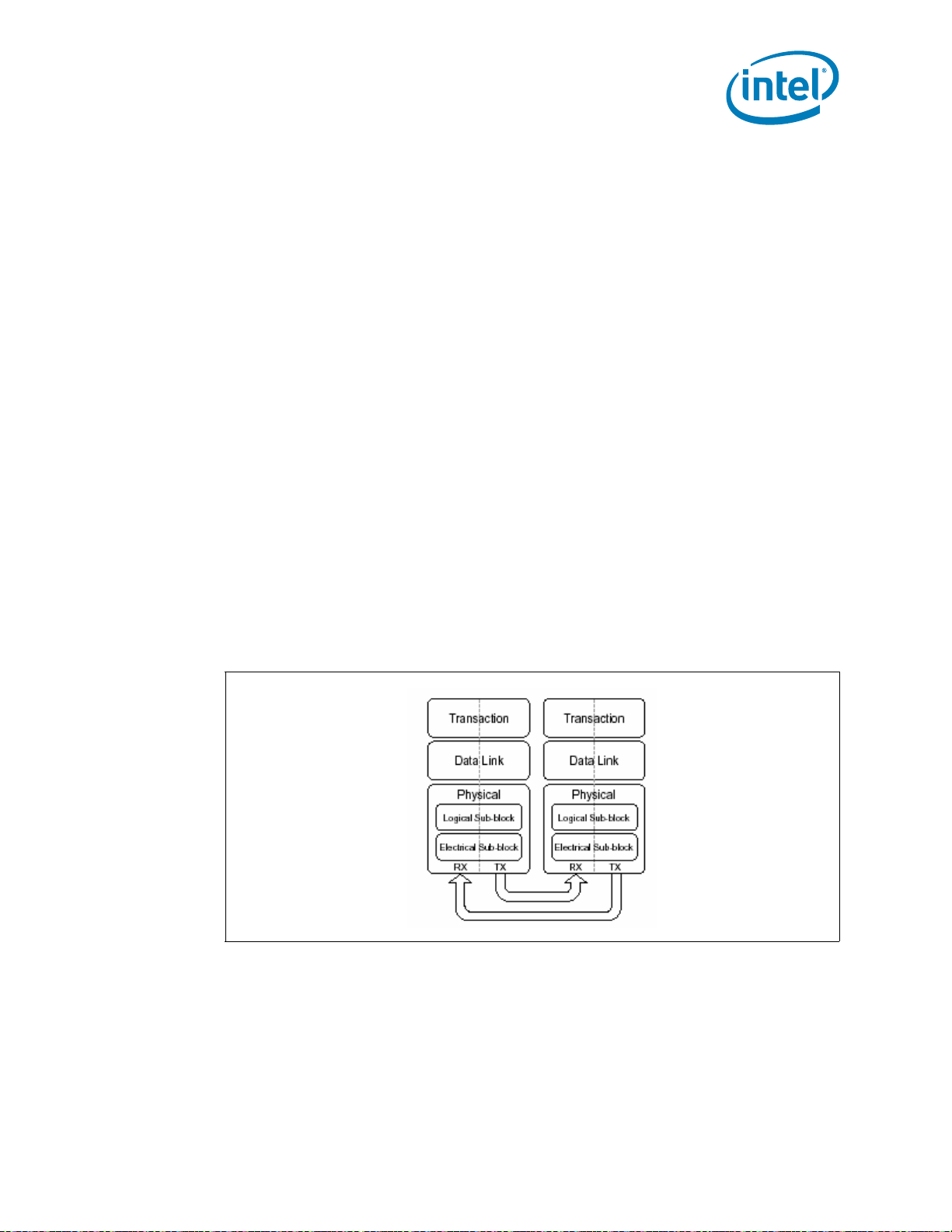
The PCI Express architecture is specified in three layers: Transaction Layer, Data Link
Layer, and Physical Layer. The partitioning in the component is not necessarily along
these same boundaries. Refer to Figure 2-4 for the PCI Express Layering Diagram.
Figure 2-4.PCI Express Layering Diagram
PCI Express uses packets to communicate information between components. Packets
are formed in the Transaction and Data Link Layers to carry the information from the
transmitting component to the receiving component. As the transmitted packets flow
through the other layers, they are extended with additional information necessary to
handle packets at those layers. At the receiving side, the reverse process occurs and
Datasheet 25
Page 26

packets get transformed from their Physical Layer representation to the Data Link
Layer representation and finally (for Transaction Layer Packets) to the form that can be
processed by the Transaction Layer of the receiving device.
Figure 2-5.Packet Flow through the Layers
2.2.1.1 Transaction Layer
The upper layer of the PCI Express architecture is the Transaction Layer. The
Transaction Layer's primary responsibility is the assembly and disassembly of
Transaction Layer Packets (TLPs). TLPs are used to communicate transactions, such as
read and write, as well as certain types of events. The Transaction Layer also manages
flow control of TLPs.
Interfaces
2.2.1.2 Data Link Layer
The middle layer in the PCI Express stack, the Data Link Layer, serves as an
intermediate stage between the Transaction Layer and the Physical Layer.
Responsibilities of Data Link Layer include link management, error detection, and error
correction.
The transmission side of the Data Link Layer accepts TLPs assembled by the
Transaction Layer, calculates and applies data protection code and TLP sequence
number, and submits them to Physical Layer for transmission across the Link. The
receiving Data Link Layer is responsible for checking the integrity of received TLPs and
for submitting them to the Transaction Layer for further processing. On detection of TLP
error(s), this layer is responsible for requesting retransmission of TLPs until information
is correctly received, or the Link is determined to have failed. The Data Link Layer also
generates and consumes packets which are used for Link management functions.
2.2.1.3 Physical Layer
The Physical Layer includes all circuitry for interface operation, including driver and
input buffers, parallel-to-serial and serial-to-parallel conversion, PLL(s), and impedance
matching circuitry. It also includes logical functions related to interface initialization and
maintenance. The Physical Layer exchanges data with the Data Link Layer in an
implementation-specific format, and is responsible for converting this to an appropriate
serialized format and transmitting it across the PCI Express Link at a frequency and
width compatible with the remote device.
26 Datasheet
Page 27
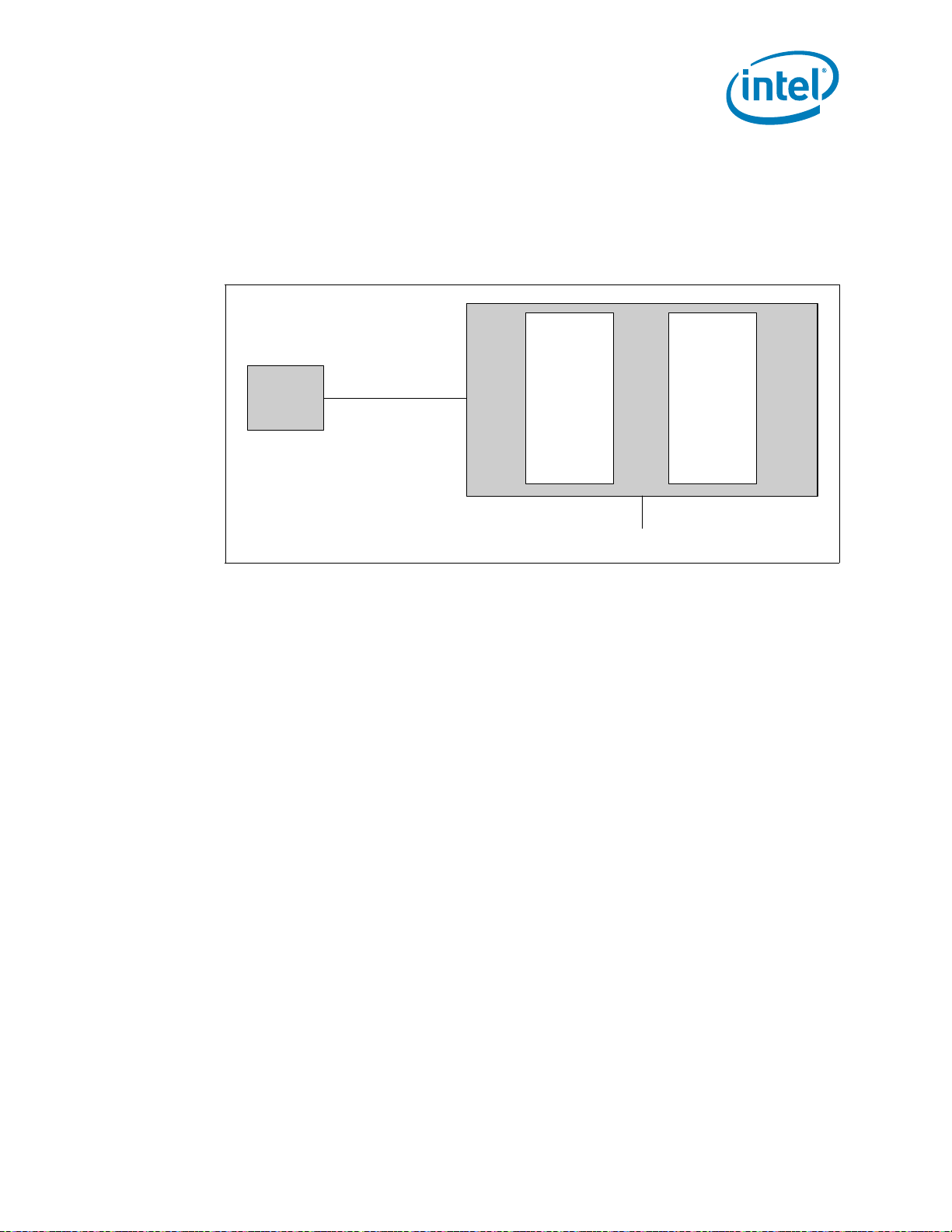
Interfaces
PCI-PCI
Bridge
representing
root PCI
Express port
(Device 1)
PCI
Compatible
Host Bridge
Device
(Device 0)
PCI
Express
Device
PEG0
DMI
2.2.2 PCI Express Configuration Mechanism
The PCI Express (external graphics) link is mapped through a PCI-to-PCI bridge
structure.
Figure 2-6.PCI Express Related Register Structures in the Processor
PCI Express extends the configuration space to 4096 bytes per-device/function, as
compared to 256 bytes allowed by the Conventional PCI Specification. PCI Express
configuration space is divided into a PCI-compatible region (which consists of the first
256 bytes of a logical device's configuration space) and an extended PCI Express region
(which consists of the remaining configuration space). The PCI-compatible region can
be accessed using either the mechanisms defined in the PCI specification or using the
enhanced PCI Express configuration access mechanism described in the PCI Express
Enhanced Configuration Mechanism section.
The PCI Express Host Bridge is required to translate the memory-mapped PCI Express
configuration space accesses from the host processor to PCI Express configuration
cycles. To maintain compatibility with PCI configuration addressing mechanisms, it is
recommended that system software access the enhanced configuration space using
32-bit operations (32-bit aligned) only. See the PCI Express Base Specification for
details of both the PCI-compatible and PCI Express Enhanced configuration
mechanisms and transaction rules.
2.2.3 PCI Express Ports and Bifurcation
The external graphics attach (PEG) on the processor is a single, 16-lane (x16) port that
can be:
• configured at narrower widths
• bifurcated into two x8 PCI Express ports that may train to narrower widths
The PEG port is being designed to be compliant with the PCI Express Base
Datasheet 27
Specification, Revision 2.0.
Page 28

2.2.3.1 PCI Express Bifurcated Mode
When bifurcated, the signals which had previously been assigned to Lanes 15:8 of the
single x16 Primary port are reassigned to lanes 7:0 of the x8 Secondary Port. This
assignment applies whether the lane numbering is reversed or not. PCI Express Port 0
is mapped to PCI Device 1 and PCI Express Port 1 is mapped to PCI Device 6.
2.2.3.2 Static Lane Numbering Reversal
Does not support dynamic lane reversal, as defined (optional) by the PCI Express Base
Specification.
PCI Express 1x16 configuration:
• Normal (1x16): PEG_RX[15:0]; PEG_TX[15:0]
• Reversal (1x16): PEG_RX[0:15]; PEG_TX[0:15]
2.3 DMI
Interfaces
DMI connects the processor and the PCH chip-to-chip. DMI2 is supported. The DMI is
similar to a four-lane PCI Express supporting up to 1 GB/s of bandwidth in each
direction.
Note: Only DMI x4 configuration is supported.
2.3.1 DMI Error Flow
DMI can only generate SERR in response to errors, never SCI, SMI, MSI, PCI INT, or
GPE. Any DMI related SERR activity is associated with Device 0.
2.3.2 Processor/PCH Compatibility Assumptions
The processor is compatible with the PCH and is not compatible with any previous
(G)MCH or ICH products.
2.3.3 DMI Link Down
The DMI link going down is a fatal, unrecoverable error. If the DMI data link goes to
data link down, after the link was up, then the DMI link hangs the system by not
allowing the link to retrain to prevent data corruption. This is controlled by the PCH.
Downstream transactions that had been successfully transmitted across the link prior
to the link going down may be processed as normal. No completions from downstream,
non-posted transactions are returned upstream over the DMI link after a link down
event.
28 Datasheet
Page 29
Interfaces
Plane A
Cursor B
Sprite B
Plane B
Cursor A
Sprite A
Pipe B
Pipe A
Memory
M
U
X
VGA
Video Engine
2D Engine
3D Engine
Clipper
Strip & Fan/Setup
Alpha
Blend/
Gamma
/Panel
Fitter
Geometry Shader
Vertex Fetch/Vertex
Shader
Windower/IZ
Intel®
FDI
eDP
2.4 Intel® HD Graphics Controller
This section details the 2D, 3D and video pipeline and their respective capabilities.
The integrated graphics is powered by a refresh of the fifth generation graphics core
and supports twelve, fully-programmable execution cores. Full-precision, floating-point
operations are supported to enhance the visual experience of compute-intensive
applications.The integrated graphics controller contains several types of components;
the graphics engines, planes, pipes, port and the Intel FDI. The integrated graphics has
a 3D/2D Instruction Processing unit to control the 3D and 2D engines respectively. The
integrated graphics controller’s 3D and 2D engines are fed with data through the IMC.
The outputs of the graphics engine are surfaces sent to memory, which are then
retrieved and processed by the planes. The surfaces are then blended in the pipes and
the display timings are transitioned from display core clock to the pixel (dot) clock.
Figure 2-7.Integrated Graphics Controller Unit Block Diagram
2.4.1 3D and Video Engines for Graphics Processing
The 3D graphics pipeline architecture simultaneously operates on different primitives or
on different portions of the same primitive. All the cores are fully programmable,
increasing the versatility of the 3D Engine. The Gen 5.75 3D engine provides the
following performance and power-management enhancements:
• Execution units (EUs) increased to 12 from the previous 10 EUsin Gen 5.0.
• Includes Hierarchal-Z
• Includes video quality enhancements
2.4.1.1 3D Engine Execution Units
• Support 12 EUs. The EUs perform 128-bit wide execution per clock.
Datasheet 29
Page 30

• Support SIMD8 instructions for vertex processing and SIMD16 instructions for pixel
processing.
2.4.1.2 3D Pipeline
2.4.1.2.1 Vertex Fetch (VF) Stage
The VF stage executes 3DPRIMITIVE commands. Some enhancements have been
included to better support legacy D3D APIs as well as SGI OpenGL*.
2.4.1.2.2 Vertex Shader (VS) Stage
The VS stage performs shading of vertices output by the VF function. The VS unit
produces an output vertex reference for every input vertex reference received from the
VF unit, in the order received.
2.4.1.2.3 Geometry Shader (GS) Stage
The GS stage receives inputs from the VS stage. Compiled application-provided GS
programs, specifying an algorithm to convert the vertices of an input object into some
output primitives. For example, a GS shader may convert lines of a line strip into
polygons representing a corresponding segment of a blade of grass centered on the
line. Or it could use adjacency information to detect silhouette edges of triangles and
output polygons extruding out from the edges.
Interfaces
2.4.1.2.4 Clip Stage
The Clip stage performs general processing on incoming 3D objects. However, it also
includes specialized logic to perform a Clip Test function on incoming objects. The Clip
Test optimizes generalized 3D Clipping. The Clip unit examines the position of incoming
vertices, and accepts/rejects 3D objects based on its Clip algorithm.
2.4.1.2.5 Strips and Fans (SF) Stage
The SF stage performs setup operations required to rasterize 3D objects. The outputs
from the SF stage to the Windower stage contain implementation-specific information
required for the rasterization of objects and also supports clipping of primitives to some
extent.
2.4.1.2.6 Windower/IZ (WIZ) Stage
The WIZ unit performs an early depth test, which removes failing pixels and eliminates
unnecessary processing overhead.
The Windower uses the parameters provided by the SF unit in the object-specific
rasterization algorithms. The WIZ unit rasterizes objects into the corresponding set of
pixels. The Windower is also capable of performing dithering, whereby the illusion of a
higher resolution when using low-bpp channels in color buffers is possible. Color
dithering diffuses the sharp color bands seen on smooth-shaded objects.
30 Datasheet
Page 31

Interfaces
2.4.1.3 Video Engine
The Video Engine handles the non-3D (media/video) applications. It includes support
for VLD and MPEG2 decode in hardware.
2.4.1.4 2D Engine
The 2D Engine contains BLT (Block Level Transfer) functionality and an extensive set of
2D instructions. To take advantage of the 3D during engine’s functionality, some BLT
functions make use of the 3D renderer.
2.4.1.4.1 Integrated Graphics VGA Registers
The 2D registers consists of original VGA registers and others to support graphics
modes that have color depths, resolutions, and hardware acceleration features that go
beyond the original VGA standard.
2.4.1.4.2 Logical 128-Bit Fixed BLT and 256 Fill Engine
This BLT engine accelerates the GUI of Microsoft Windows* operating systems. The
128-bit BLT engine provides hardware acceleration of block transfers of pixel data for
many common Windows operations. The BLT engine can be used for the following:
• Move rectangular blocks of data between memory locations
• Data alignment
• To perform logical operations (raster ops)
The rectangular block of data does not change, as it is transferred between memory
locations. The allowable memory transfers are between: cacheable system memory
and frame buffer memory, frame buffer memory and frame buffer memory, and within
system memory. Data to be transferred can consist of regions of memory, patterns, or
solid color fills. A pattern is always 8 x 8 pixels wide and may be 8, 16, or 32 bits per
pixel.
The BLT engine expands monochrome data into a color depth of 8, 16, or 32 bits. BLTs
can be either opaque or transparent. Opaque transfers move the data specified to the
destination. Transparent transfers compare destination color to source color and write
according to the mode of transparency selected.
Data is horizontally and vertically aligned at the destination. If the destination for the
BLT overlaps with the source memory location, the BLT engine specifies which area in
memory to begin the BLT transfer. Hardware is included for all 256 raster operations
(source, pattern, and destination) defined by Microsoft, including transparent BLT.
The BLT engine has instructions to invoke BLT and stretch BLT operations, permitting
software to set up instruction buffers and use batch processing. The BLT engine can
perform hardware clipping during BLTs.
Datasheet 31
Page 32

2.4.2 Integrated Graphics Display Pipes
Plane A
Cursor B
Sprite B
Plane B
Cursor A
Sprite A
Pipe B
Pipe A
Alpha
Blend/
Gamma/
Panel
Fitter
M
U
X
eDP
Intel®
FDI
VGA
The integrated graphics controller display pipe can be broken down into three
components:
• Display Planes
• Display Pipes
• Embedded DisplayPort and Intel FDI
Figure 2-8.Processor Display Block Diagram
Interfaces
2.4.2.1 Display Planes
A display plane is a single displayed surface in memory and contains one image
(desktop, cursor, overlay). It is the portion of the display HW logic that defines the
format and location of a rectangular region of memory that can be displayed on display
output device and delivers that data to a display pipe. This is clocked by the Core
Display Clock.
2.4.2.1.1 Planes A and B
Planes A and B are the main display planes and are associated with Pipes A and B
respectively. The two display pipes are independent, allowing for support of two
independent display streams. They are both double-buffered, which minimizes latency
and improves visual quality.
2.4.2.1.2 Sprite A and B
Sprite A and Sprite B are planes optimized for video decode, and are associated with
Planes A and B respectively. Sprite A and B are also double-buffered.
32 Datasheet
Page 33

Interfaces
2.4.2.1.3 Cursors A and B
Cursors A and B are small, fixed-sized planes dedicated for mouse cursor acceleration,
and are associated with Planes A and B respectively. These planes support resolutions
up to 256 x 256 each.
2.4.2.1.4 VGA
Used for boot, safe mode, legacy games, etc. Can be changed by an application without
OS/driver notification, due to legacy requirements.
2.4.2.2 Display Pipes
The display pipe blends and synchronizes pixel data received from one or more display
planes and adds the timing of the display output device upon which the image is
displayed. This is clocked by the Display Reference clock inputs.
The display pipes A and B operate independently of each other at the rate of 1 pixel per
clock. They can attach to any of the display ports. Each pipe sends display data to the
PCH over the Intel Flexible Display Interface (Intel FDI).
2.4.2.3 Display Ports
The display ports consist of output logic and pins that transmit the display data to the
associated encoding logic and send the data to the display device (i.e., LVDS, HDMI,
DVI, SDVO, etc.). All display interfaces connecting external displays are now
repartitioned and driven from the PCH with the exception of the eDP DisplayPort.
2.4.2.4 Embedded DisplayPort (eDP)
The DisplayPort abbreviated as DP (different than the generic term display port)
specification is a VESA standard. DisplayPort consolidates internal and external
connection methods to reduce device complexity, support cross industry applications,
and provide performance scalability. The integrated graphics supports an embedded
DisplayPort (eDP) interface for display devices that are integrated into the system
(e.g., laptop LCD panel). All other display interfaces connecting to the LVDS or external
panels are driven from the PCH.
The eDP interface is physically shared with a subset of the PCIe interface. Specifically,
eDP[3:0] map to Logical Lanes PEG[12:15] of the PCIe interface. Mapping for reversed
case is: eDP[3:0] maps to PEG[3:0], ex: eDP[0]=PEG[15] in non reversed case. In
reversed case: eDP[0] = PEG[0].
Table 2-3. eDP/PEG Ball Mapping
eDP Signal PEG Signal Lane Reversal
eDP_AUX PEG_RX[13] PEG_RX[2]
eDP_AUX# PEG_RX#[13] PEG_RX#[2]
eDP_HPD# PEG_RX[12] PEG_RX[3]
Datasheet 33
Page 34

Table 2-3. eDP/PEG Ball Mapping
eDP Signal PEG Signal Lane Reversal
eDP_TX[0] PEG_TX[15] PEG_TX[0]
eDP_TX#[0] PEG_TX#[15] PEG_TX#[0]
eDP_TX[1] PEG_TX[14] PEG_TX[1]
eDP_TX#[1] PEG_TX#[14] PEG_TX#[1]
eDP_TX[2] PEG_TX[13] PEG_TX[2]
eDP_TX#[2] PEG_TX#[13] PEG_TX#[2]
eDP_TX[3] PEG_TX[12] PEG_TX[3]
eDP_TX#[3] PEG_TX#[12] PEG_TX#[3]
When eDP is enabled, the lower logical lanes are still available for standard PCIe
devices, using the PEG 0 controller. PEG 0 is limited to x1. The board manufacture
chooses whether to use eDP and whether to use lane numbering reversal.
The eDP interface supports link-speeds of 1.62 Gbps and 2.7 Gbps on 1, 2 or 4 data
lanes. The eDP and PCI Express x1 may be supported concurrently. eDP interface may
support -0.5% SSC and non-SSC clock settings.
Interfaces
2.4.3 Intel Flexible Display Interface
The Intel Flexible Display Interface (Intel FDI) is a proprietary link for carrying display
traffic from the integrated graphics controller to the PCH display I/O’s. Intel FDI
supports two independent channels; one for pipe A and one for pipe B.
• Each channel has four transmit (Tx) differential pairs used for transporting pixel
and framing data from the display engine.
• Each channel has one single-ended LineSync and one FrameSync input (1-V CMOS
signaling).
• One display interrupt line input (1-V CMOS signaling).
• Intel FDI may dynamically scalable down to 2X or 1X based on actual display
bandwidth requirements.
• Common 100-MHz reference clock is sent to both processor and PCH.
• Each channel transports at a rate of 2.7 Gbps.
• PCH supports end-to-end lane reversal across both channels (no reversal support
required)
2.5 Platform Environment Control Interface (PECI)
The PECI is a one-wire interface that provides a communication channel between a
PECI client (processor) and a PECI master, usually the PCH. The processor implements
a PECI interface to:
34 Datasheet
Page 35

Interfaces
• Allow communication of processor thermal and other information to the PECI
master.
• Read averaged Digital Thermal Sensor (DTS) values for fan speed control.
2.6 Interface Clocking
2.6.1 Internal Clocking Requirements
Table 2-4. Processor Reference Clocks
Reference Input Clocks Input Frequency Associated PLL
BCLK/BCLK# 133 MHz Processor/Memory/Graphics
PEG_CLK/PEG_CLK# 100 MHz PCI Express*/DMI/Intel® FDI
DPLL_REF_SSCLK/DPLL_REF_SSCLK# 120 MHz Embedded DisplayPort* (eDP)
§
Datasheet 35
Page 36

3 Technologies
3.1 Intel Graphics Dynamic Frequency
Graphics render frequency are selected by the Intel graphics driver dynamically based
on graphics workload demand as permitted by Intel Turbo Boost Technology Driver. The
processor core die and the integrated graphics and memory controller core die have an
individual TDP limit. If one component is not consuming enough thermal power to
reach its TDP, the other component can increase its TDP limit and take advantage of the
unused thermal power headroom. For the integrated graphics, this could mean an
increase in the render core frequency (above its rated frequency) and increased
graphics performance.
Note: Please note that processor Turbo is not supported on Pentium processor skus.
Processor Utilization of Intel Graphics Dynamic Frequency require the following
• Graphics driver
• Intel Turbo Boost Technology Driver
Technologies
Enabling Intel Turbo Boost Technology and Intel Graphics Dynamic Frequency will
maximize the performance of the GPU within its specified power levels. Compared with
previous generation products, Intel Turbo Boost Technology and Intel Graphics
Dynamic Frequency will increase the ratio of application power to TDP. Thus, thermal
solutions and platform cooling that are designed to less than thermal design guidance
might experience thermal and performance issues since more applications will tend to
run at the maximum power limit for significant periods of time. For more details, refer
to Chapter 5, “Thermal Management”.
§
36 Datasheet
Page 37

Power Management
4 Power Management
This chapter provides information on the following power management topics:
• ACPI States
• Processor Core
• Integrated Memory Controller (IMC)
• PCI Express
• Direct Media Interface (DMI)
• Integrated Graphics Controller
4.1 ACPI States Supported
The ACPI states supported by the processor are described in this section.
4.1.1 System States
Table 4-5. System States
State Description
G0/S0 Full On
G1/S3-Cold Suspend-to-RAM (STR). Context saved to memory (S3-Hot is not
supported by the processor).
G1/S4 Suspend-to-Disk (STD). All power lost (except wakeup on PCH).
G2/S5 Soft off. All power lost (except wakeup on PCH). Total reboot.
G3 Mechanical off. All power (AC and battery) removed from system.
4.1.2 Processor Core/Package Idle States
Table 4-6. Processor Core/Package State Support
State Description
C0 Active mode, processor executing code.
C1 AutoHALT state.
C1E AutoHALT state with lowest frequency and voltage operating point.
C3 Execution cores in C3 flush their L1 instruction cache, L1 data cache,
and L2 cache to the L3 shared cache. Clocks are shut off to each core.
C6 Execution cores in this state save their architectural state before
removing core voltage.
Datasheet 37
Page 38

4.1.3 Integrated Memory Controller States
Table 4-7. Integrated Memory Controller States
State Description
Power up CKE asserted. Active mode.
Pre-charge Power down CKE deasserted (not self-refresh) with all banks closed.
Active Power down CKE deasserted (not self-refresh) with minimum one bank active.
Self-Refresh CKE deasserted using device self-refresh.
4.1.4 PCIe Link States
Table 4-8. PCIe Link States
State Description
L0 Full on – Active transfer state.
L0s First Active Power Management low power state – Low exit latency.
L1 Lowest Active Power Management - Longer exit latency.
L3 Lowest power state (power-off) – Longest exit latency.
Power Management
4.1.5 DMI States
Table 4-9. DMI States
State Description
L0 Full on – Active transfer state.
L0s First Active Power Management low power state – Low exit latency.
L1 Lowest Active Power Management - Longer exit latency.
L3 Lowest power state (power-off) – Longest exit latency.
4.1.6 Integrated Graphics Controller States
Table 4-10.Integrated Graphics Controller States
State Description
D0 Full on, display active.
D3 Cold Power-off.
38 Datasheet
Page 39

Power Management
4.1.7 Interface Stat e Combinations
Table 4-11.G, S and C State Combinations
Global
(G) State
G0 S0 C0 Full On On Full On
G0 S0 C1/C1E Auto-Halt On Auto-Halt
G0 S0 C3 Deep Sleep On Deep Sleep
G0 S0 C6 Deep Power
G1 S3 Power off Off, except RTC Suspend to RAM
G1 S4 Power off Off, except RTC Suspend to Disk
G2 S5 Power off Off, except RTC Soft Off
G3 NA Power off Power off Hard off
Sleep
(S) State
Processor
Core
(C) State
Table 4-12.D, S, and C State Combination
Graphics Adapter
(D) State
D0 S0 C0 Full On, Displaying
D0 S0 C1/C1E Auto-Halt, Displaying
D0 S0 C3 Deep sleep, Displaying
D0 S0 C6 Deep Power Down,
D3 S0 Any Not displaying
D3 S3 N/A Not displaying, Graphics
D3 S4 N/A Not displaying, suspend to
Sleep (S) State Package (C) State Description
Processor
State
Down
System Clocks Description
On Deep Power Down
Displaying
Core is powered off
disk
4.2 Processor Core Power Management
While executing code, Enhanced Intel SpeedStep Technology optimizes the processor’s
frequency and core voltage based on workload. Each frequency and voltage operating
point is defined by ACPI as a P-state. When the processor is not executing code, it is
idle. A low-power idle state is defined by ACPI as a C-state. In general, lower power
C-states have longer entry and exit latencies.
Datasheet 39
Page 40

4.2.1 Enhanced Intel SpeedStep® Technology
The following are the key features of Enhanced Intel SpeedStep Technology:
• Multiple frequency and voltage points for optimal performance and power
efficiency. These operating points are known as P-states.
• Frequency selection is software controlled by writing to processor MSRs. The
voltage is optimized based on the selected frequency and the number of active
processor cores.
— If the target frequency is higher than the current frequency, V
steps to an optimized voltage. This voltage is signaled by the VID[6:0] pins to
the voltage regulator. Once the voltage is established, the PLL locks on to the
target frequency.
— If the target frequency is lower than the current frequency, the PLL locks to the
target frequency, then transitions to a lower voltage by signaling the target
voltage on the VID[6:0] pins.
— All active processor cores share the same frequency and voltage. In a multi-core
processor, the highest frequency P-state requested amongst all active cores is
selected.
— Software-requested transitions are accepted at any time. If a previous transition
is in progress, the new transition is deferred until the previous transition is
completed.
• The processor controls voltage ramp rates internally to ensure glitch-free
transitions.
Power Management
is ramped up in
CC
• Because there is low transition latency between P-states, a significant number of
transitions per-second are possible.
4.2.2 Low-Power Idle States
When the processor is idle, low-power idle states (C-states) are used to save power.
More power savings actions are taken for numerically higher C-states. However, higher
C-states have longer exit and entry latencies. Resolution of C-states occur at the
thread, processor core, and processor package level. Thread-level C-states are
available if Intel Hyper-Threading Technology is enabled.
40 Datasheet
Page 41

Power Management
Processor Package State
Core 1 State
Thread 0
Core 0 State
Thread 0
C1 C1E C6C3
C0
MWAIT(C1), HLT
C0
MWAIT(C6),
P_LVL3 I/O Read
MWAIT(C3),
P_LV2 I/O Read
MWAIT(C1), HLT
(C1E Enabled)
Figure 4-9.Idle Power Management Breakdown of the Processor Cores
Entry and exit of the C-States at the thread and core level are shown in below figure.
Figure 4-10.Thread and Core C-State Entry and Exit
While individual threads can request low power C-states, power saving actions only
take place once the core C-state is resolved. Core C-states are automatically resolved
by the processor. For thread and core C-states, a transition to and from C0 is required
before entering any other C-state.
Datasheet 41
Page 42

Table 4-13.Coordination of Thread Power States at the Core Level
Power Management
Processor Core
C-State
C0
C1
C3
Thread 0
C6
C0 C1 C3 C6
C0 C0 C0 C0
C0 C1
C0 C1
C0 C1
1
1
1
NOTE:If enabled, the core C-state will be C1E if all actives cores have also resolved a
core C1 state or higher
4.2.3 Requesting Low-Power Idle States
The primary software interfaces for requesting low power idle states are through the
MWAIT instruction with sub-state hints and the HLT instruction (for C1 and C1E).
However, software may make C-state requests using the legacy method of I/O reads
from the ACPI-defined processor clock control registers, referred to as P_LVLx. This
method of requesting C-states provides legacy support for operating systems that
initiate C-state transitions via I/O reads.
For legacy operating systems, P_LVLx I/O reads are converted within the processor to
the equivalent MWAIT C-state request. Therefore, P_LVLx reads do not directly result in
I/O reads to the system. The feature, known as I/O MWAIT redirection, must be
enabled in the BIOS.
Thread 1
1
C1
C3 C3
C3 C6
C1
1
Note: The P_LVLx I/O Monitor address needs to be set up before using the P_LVLx I/O read
interface. Each P-LVLx is mapped to the supported MWAIT(Cx) instruction as follows.
Table 4-14.P_LVLx to MWAIT Conversion
P_LVLx MWAIT(Cx) Notes
P_LVL2 MWAIT(C3) The P_LVL2 base address is defined in the PMG_IO_CAPTURE
MSR, described in the RS - Nehalem Processor Family BWG.
P_LVL3 MWAIT(C6) C6. No sub-states allowed.
The BIOS can write to the C-state range field of the PMG_IO_CAPTURE MSR to restrict
the range of I/O addresses that are trapped and emulate MWAIT like functionality. Any
P_LVLx reads outside of this range does not cause an I/O redirection to MWAIT(Cx) like
request. They fall through like a normal I/O instruction.
Note: When P_LVLx I/O instructions are used, MWAIT substates cannot be defined. The
MWAIT substate is always zero if I/O MWAIT redirection is used. By default, P_LVLx I/O
redirections enable the MWAIT 'break on EFLAGS.IF’ feature which triggers a wakeup
on an interrupt even if interrupts are masked by EFLAGS.IF.
42 Datasheet
Page 43

Power Management
4.2.4 Core C-states
The following are general rules for all core C-states, unless specified otherwise:
• A core C-State is determined by the lowest numerical thread state (e.g., Thread 0
requests C1E while Thread 1 requests C3, resulting in a core C1E state). See
Ta b l e 4-11.
• A core transitions to C0 state when:
— An interrupt occurs
— There is an access to the monitored address if the state was entered via an
MWAIT instruction
• For core C1/C1E, and core C3, an interrupt directed toward a single thread wakes
only that thread. However, since both threads are no longer at the same core
C-state, the core resolves to C0.
• For core C6, an interrupt coming into either thread wakes both threads into C0
state.
• Any interrupt coming into the processor package may wake any core.
4.2.4.1 Core C0 State
The normal operating state of a core where code is being executed.
4.2.4.2 Core C1/C1E State
C1/C1E is a low power state entered when all threads within a core execute a HLT or
MWAIT(C1/C1E) instruction.
A System Management Interrupt (SMI) handler returns execution to either Normal
state or the C1/C1E state. See the Intel
Developer’s Manual, Volume 3A/3B: System Programmer’s Guide for more information.
While a core is in C1/C1E state, it processes bus snoops and snoops from other
threads. For more information on C1E, see “Package C1/C1E”.
4.2.4.3 Core C3 State
Individual threads of a core can enter the C3 state by initiating a P_LVL2 I/O read to
the P_BLK or an MWAIT(C3) instruction. A core in C3 state flushes the contents of its
L1 instruction cache, L1 data cache, and L2 cache to the shared L3 cache, while
maintaining its architectural state. All core clocks are stopped at this point. Because the
core’s caches are flushed, the processor does not wake any core that is in the C3 state
when either a snoop is detected or when another core accesses cacheable memory.
®
64 and IA-32 Architecture Software
Datasheet 43
Page 44

4.2.4.4 Core C6 State
Individual threads of a core can enter the C6 state by initiating a P_LVL3 I/O read or an
MWAIT(C6) instruction. Before entering core C6, the core will save its architectural
state to a dedicated SRAM. Once complete, a core will have its voltage reduced to zero
volts. During exit, the core is powered on and its architectural state is restored.
4.2.4.5 C-State Auto-Demotion
In general, deeper C-states such as Deep Power Down Technology (code named C6
state) have long latencies and have higher energy entry/exit costs. The resulting
performance and energy penalties become significant when the entry/exit frequency of
a deeper C-state is high. Therefore incorrect or inefficient usage of deeper C-states
have a negative impact on battery life. In order to increase residency and improve
battery life in deeper C-states, the processor supports C-state auto-demotion.
There are two C-State auto-demotion options:
• Deep Power Down Technology (code named C6 state) to C3
• Deep Power Down Technology (code named C6 state)/C3 To C1
Power Management
The decision to demote a core from Deep Power Down Technology (code named C6
state) to C3 or C3/Deep Power Down Technology (code named C6 state) to C1 is based
on each core’s immediate residency history. Upon each core Deep Power Down
Technology (code named C6 state) request, the core C-state is demoted to C3 or C1
until a sufficient amount of residency has been established. At that point, a core is
allowed to go into C3/Deep Power Down Technology (code named C6 state). Each
option can be run concurrently or individually.
This feature is disabled by default.
4.2.5 Package C-States
The processor supports C0, C1/C1E, C3, and Deep Power Down Technology (code
named C6 state) package idle power states. The following is a summary of the general
rules for package C-state entry. These apply to all package C-states unless specified
otherwise:
• A package C-state request is determined by the lowest numerical core C-state
amongst all cores.
• A package C-state is automatically resolved by the processor depending on the
core idle power states and the status of the platform components.
— Each core can be at a lower idle power state than the package if the platform
does not grant the processor permission to enter a requested package C-state.
— The platform may allow additional power savings to be realized in the processor.
Refer to Section 4.3.2.2
• For package C-states, the processor is not required to enter C0 before entering any
other C-state.
44 Datasheet
Page 45

Power Management
The processor exits a package C-state when a break event is detected. Depending on
the type of break event, the processor does the following:
• If a core break event is received, the target core is activated and the break event
• If the break event was due to a memory access or snoop request.
Ta b l e 4-15 shows package C-state resolution for a dual-core processor. Figure 4-11
summarizes package C-state transitions.
message is forwarded to the target core.
— If the break event is not masked, the target core enters the core C0 state and
the processor enters package C0.
— If the break event is masked, the processor attempts to re-enter its previous
package state.
— But the platform did not request to keep the processor in a higher package C-
state, the package returns to its previous C-state.
— And the platform requests a higher power C-state, the memory access or snoop
request is serviced and the package remains in the higher power C-state.
Table 4-15.Coordination of Core Power States at the Package Level
Core 1
Package C-State
C0
C1
Core 0
NOTE:
1. If enabled, the package C-state will be C1E if all actives cores have resolved a core C1
state or higher.
C3
C6
C0 C1 C3
C0 C0 C0 C0
C0 C1
C0 C1
C0 C1
1
1
1
Deep Power
Down
Technology
(code named
C6 state)
1
C1
C3 C3
C3 C6
C1
1
Datasheet 45
Page 46

Figure 4-11.Package C-State Entry and Exit
C0
C1
C6
C3
Power Management
4.2.5.1 Package C0
The normal operating state for the processor. The processor remains in the normal
state when at least one of its cores is in the C0 or C1 state or when the platform has
not granted permission to the processor to go into a low power state. Individual cores
may be in lower power idle states while the package is in C0.
4.2.5.2 Package C1/C1E
No additional power reduction actions are taken in the package C1 state. However, if
the C1E sub-state is enabled, the processor automatically transitions to the lowest
supported core clock frequency, followed by a reduction in voltage.
The package enters the C1 low power state when:
• At least one core is in the C1 state.
• The other cores are in a C1 or lower power state.
The package enters the C1E state when:
• All cores have directly requested C1E via MWAIT(C1) with a C1E sub-state hint.
• All cores are in a power state lower that C1/C1E but the package low power state is
limited to C1/C1E via the PMG_CST_CONFIG_CONTROL MSR.
• All cores have requested C1 using HLT or MWAIT(C1) and C1E auto-promotion is
enabled in IA32_MISC_ENABLES.
46 Datasheet
Page 47

Power Management
No notification to the system occurs upon entry to C1/C1E.
4.2.5.3 Package C3 State
A processor enters the package C3 low power state when:
• At least one core is in the C3 state.
• The other cores are in a C3 or lower power state, and the processor has been
granted permission by the platform.
• The platform has not granted a request to a package C6 state but has allowed a
package C6 state.
In package C3-state, the L3 shared cache is snoopable.
4.2.5.4 Package C6 State
A processor enters the package C6 low power state when:
• At least one core is in the C6 state.
• The other cores are in a C6 or lower power state, and the processor has been
granted permission by the platform.
In package C6 state, all cores have saved their architectural state and have had their
core voltages reduced to zero volts. The L3 shared cache is still powered and snoopable
in this state. The processor remains in package C6 state as long as any part of the L3
cache is active.
4.2.5.5 Power Status Indicator (PSI#) and DPRSLPVR#
PSI# and DPRSLPVR# are signals used to optimize VR efficiency over a wide power
range depending on amount of activity within the processor core. The PSI# signal is
utilized by the processor core to:
• Improve intermediate and light load efficiency of the voltage regulator when the
processor is active (P-states).
• Optimize voltage regulator efficiency in very low power states. Assertion of
DPRSLPVR# indicates that the processor core is in a C6 low power state.
The VR efficiency gains result in overall platform power savings and extended battery
life.
4.3 IMC Power Management
The main memory is power managed during normal operation and in low-power ACPI
Cx states.
Datasheet 47
Page 48

4.3.1 Disabling Unused System Memory Outputs
Any system memory (SM) interface signal that goes to a memory module connector in
which it is not connected to any actual memory devices (such as SO-DIMM connector is
unpopulated, or is single-sided) is tri-stated. The benefits of disabling unused SM
signals are:
• Reduced power consumption.
• Reduced possible overshoot/undershoot signal quality issues seen by the processor
I/O buffer receivers caused by reflections from potentially un-terminated
transmission lines.
When a given rank is not populated, the corresponding chip select and CKE signals are
not driven.
At reset, all rows must be assumed to be populated, until it can be proven that they are
not populated. This is due to the fact that when CKE is tristated with an SO-DIMM
present, the SO-DIMM is not guaranteed to maintain data integrity.
Power Management
4.3.2 DRAM Power Management and Initialization
The processor implements extensive support for power management on the SDRAM
interface. There are four SDRAM operations associated with the Clock Enable (CKE)
signals, which the SDRAM controller supports. The processor drives four CKE pins to
perform these operations.
4.3.2.1 Initialization Role of CKE
During power-up, CKE is the only input to the SDRAM that has its level is recognized
(other than the DDR3 reset pin) once power is applied. It must be driven LOW by the
DDR controller to make sure the SDRAM components float DQ and DQS during powerup. CKE signals remain LOW (while any reset is active) until the BIOS writes to a
configuration register. Using this method, CKE is guaranteed to remain inactive for
much longer than the specified 200 micro-seconds after power and clocks to SDRAM
devices are stable.
4.3.2.2 Conditional Self-Refresh
The processor conditionally places memory into self-refresh in the package C3 and C6
low-power states.
When entering the Suspend-to-RAM (STR) state, the processor core flushes pending
cycles and then enters all SDRAM ranks into self refresh. In STR, the CKE signals
remain LOW so the SDRAM devices perform self-refresh.
The target behavior is to enter self-refresh for the package C3 and C6 states as long as
there are no memory requests to service. The target usage is shown in Table 4-16.
48 Datasheet
Page 49

Power Management
Table 4-16.Targeted Memory State Conditions
Mode Memory State with Internal Graphics Memory State with External Graphics
C0, C1, C1E Dynamic memory rank power down based on
idle conditions.
C3, C6 If the internal graphics engine is idle and there
are no pending display requests when in single
display mode, then enter self-refresh.
Otherwise use dynamic memory rank power
down based on idle conditions.
S3 Self-Refresh Mode. Self-Refresh Mode.
S4 Memory power down (contents lost). Memory power down (contents lost)
Dynamic memory rank power down based on
idle conditions.
If there are no memory requests, then enter
self-refresh. Otherwise use dynamic memory
rank power down based on idle conditions.
4.3.2.3 Dynamic Power Down Operation
Dynamic power-down of memory is employed during normal operation. Based on idle
conditions, a given memory rank may be powered down. The IMC implements
aggressive CKE control to dynamically put the DRAM devices in a power down state.
The processor core controller can be configured to put the devices in active power down
(CKE deassertion with open pages) or precharge power down (CKE deassertion with all
pages closed). Precharge power down provides greater power savings but has a bigger
performance impact, since all pages will first be closed before putting the devices in
power down mode.
If dynamic power-down is enabled, all ranks are powered up before doing a refresh
cycle and all ranks are powered down at the end of refresh.
4.3.2.4 DRAM I/O Power Management
Unused signals should be disabled to save power and reduce electromagnetic
interference. This includes all signals associated with an unused memory channel.
Clocks can be controlled on a per SO-DIMM basis. Exceptions are made for per SODIMM control signals such as CS#, CKE, and ODT for unpopulated SO-DIMM slots.
The I/O buffer for an unused signal should be tri-stated (output driver disabled), the
input receiver (differential sense-amp) should be disabled, and any DLL circuitry
related ONLY to unused signals should be disabled. The input path must be gated to
prevent spurious results due to noise on the unused signals (typically handled
automatically when input receiver is disabled).
4.4 PCIe Power Management
• Active power management support using L0s, and L1 states.
• All inputs and outputs disabled in L2/L3 Ready state.
Datasheet 49
Page 50

Power Management
4.5 DMI Power Management
Active power management support using L0s/L1 state.
4.6 Integrated Graphics Power Management
4.6.1 Intel® Display Power Saving Technology 5.0 (Intel®DPST 5.0)
Intel DPST maintains visual experience by managing display image brightness and
contrast while adaptively dimming the backlight. As a result, the display backlight
power can be reduced by up to 25% depending on Intel DPST settings and system use.
Intel DPST 5.0 provides enhanced image quality over the previous version of Intel
DPST.
4.6.2 Graphics Render C-State
Render C-State (RC6) is a technique designed to optimize the average power to the
graphics render engine during times of idleness of the render engine. RC6 is entered
when the graphics render engine, blitter engine and the video engine have no workload
being currently worked on and no outstanding graphics memory transactions. When
the render engine idleness condition is met: The graphics VR will lower the graphics
voltage rail (V
shut down.
) into a lower voltage state (0.3 V).The render frequency clock will
AXG
4.6.3 Graphics Performance Modulation Technology
Graphics Performance Modulation Technology (GPMT) is a method for optimizing the
power efficiency in the graphics render engine while continuing to render 3D objects
during battery operation. The GPMT feature will dynamically switch the render
frequency based on the render workload, on power policy, skew, and environmental
conditions.
4.6.4 Intel® Smart 2D Display Technology (Intel® S2DDT)
Intel S2DDT reduces display refresh memory traffic by reducing memory reads
required for display refresh. Power consumption is reduced by less accesses to the IMC.
Intel S2DDT is most effective with:
• Display images well suited to compression, such as text windows, slide shows, etc.
Poor examples are 3D games.
• Static screens such as screens with significant portions of the background showing
2D applications, CPU benchmarks, etc., or conditions when the CPU is idle. Poor
examples are full-screen 3D games and benchmarks that flip the display image at
or near display refresh rates.
50 Datasheet
Page 51

Power Management
4.7 Thermal Power Management
• See Section 5, “Thermal Management” on page 52 for all graphics thermal power
management-related features.
§
Datasheet 51
Page 52

Thermal Management
5 Thermal Management
A multi-chip package (MCP) processor requires a thermal solution to maintain
temperatures of the processor core and graphics/memory core within operating limits.
A complete thermal solution provides both the component-level and the system-level
thermal management. To allow for the optimal operation and long-term reliability of
Intel processor-based systems, the system/processor thermal solution should be
designed so that the processor:
• Remains below the maximum junction temperature (T
maximum thermal design power (TDP).
• Conforms to system constraints, such as system acoustics, system skin-
temperatures, and exhaust-temperature requirements.
Caution: Thermal specifications given in this chapter are on the component and package level
and apply specifically to the processor. Operating the processor outside the specified
limits may result in permanent damage to the processor and potentially other
components in the system.
) specification at the
j,Max
5.1 Thermal Design Power and Junction Temperature
The TDP of an MCP processor is the expected maximum power from each of its
components (processor core and integrated graphics and memory controller) while
running realistic, worst case applications (TDP applications).TDP is not the absolute
worst case power of each component. It could, for example, be exceeded under a
synthetic worst case condition or under short power spikes. In production, a range of
power is to be expected from the components due to the natural variation in the
manufacturing process. The thermal solution, at a minimum, needs to ensure that the
junction temperatures of both components do not exceed the maximum junction
temperature (T
5.1.1 Intel Graphics Dynamic Frequency
Typical workloads are not intensive enough to push both the processor core and the
integrated graphics and memory controller towards their TDP limit simultaneously. As
such, the opportunity exists to share thermal power between the components and
boost the performance of either the processor core or integrated graphics and memory
controller on demand. This intelligent power sharing capability is implemented by Intel
Turbo Boost Technology Driver on these processors. When enabled, the integrated
graphics and memory controller can increase its thermal power consumption above its
own component TDP limit. However, the sum of component thermal powers adhere to
the specified MCP thermal power limit.
On this processor, Intel Graphics Dynamic Frequency is implemented via a combination
of Intel silicon capabilities, graphics driver and the Intel Turbo Boost Technology driver.
If Intel provides Intel Graphics Dynamic Frequency support for the target operating
) limit while running TDP applications.
j,max
52 Datasheet
Page 53

Thermal Management
system that is shipped with the customer’s platform and Intel Graphics Dynamic
Frequency is enabled, the Intel Turbo Boost Technology driver and graphics driver must
be installed and operating to keep the product operating within specification limits.
Caution: The TURBO_POWER_CURRENT_LIMIT MSR is exclusively reserved for Intel Turbo
Technology Driver use. Under no circumstances should this value be altered from the
default register value after reset of the processor. Altering this MSR value may result in
unpredictable behavior.
5.1.2 Intel Graphics Dynamic Frequency Thermal Design Considerations and Specifications
When designing a thermal solution for Intel Graphics Dynamic frequency enabled
processor:
• Both component TDPs as well as extreme thermal power levels for the processor
core and integrated graphics and memory controller must be considered.
• Note that the processor can consume close to its maximum thermal power limit
more frequently, and for prolonged periods of time.
• One must ensure that the component T
component is operating at its extreme thermal power limit.
limits are not exceeded when either
j,max
There are two “extreme” design points:
• The processor core operating at maximum thermal power level (which is greater
than its component TDP) and the integrated graphics and memory controller
operating at its minimum thermal power.
• The integrated graphics operates at its maximum thermal power level, while the
processor core consumes the remaining thermal power budget.
In both cases, the combined component thermal power will not exceed the total MCP
package power limit. The design approach accommodating two extreme power levels is
referred to as a “two-point” design.
The following notes apply to Table 5- 17 and Ta b l e 5-19.
Note Definition
1 The component TDPs given are not the maximum power the components can generate. Analysis
2 A range of power is to be expected among the components due to the natural variation in the
3 Concurrent package power refers to the actual power consumed by the package while TDP
4 The thermal solution needs to ensure that the temperatures of both components do not exceed the
indicates that real applications are unlikely to cause the processor to consume the theoretical
maximum power dissipation for sustained periods of time.
manufacturing process. Nevertheless, the individual component powers are not to exceed the
component TDPs specified.
applications are running simultaneously by the processor core and the integrated graphics
controller. An example of this could be the processor core running a Prime95* application, and the
integrated graphics core running a Star Wars: Jedi Knight* menu simultaneously.
maximum junction temperature (T
bit. Please refer to processor Specification Update for Tjmax value per sku.
) limit, as measured by the DTS and the critical temperature
j,max
Datasheet 53
Page 54

Thermal Management
Note Definition
5 Processor core and integrated graphics and memory controller junction temperatures are monitored
by their respective DTS. A DTS outputs a temperature relative to the maximum supported junction
temperature. The error associated with DTS measurements will not exceed ±5°C within the
operating range.
6 The power supply to the processor core and the integrated graphics /Memory core should be
designed as per Intel’s guidelines.
7 Processor core currents is monitored by IMON VR feedback (ISENSE) and calculated using a moving
average method. Error associated with power monitoring will depend upon individual VR design.
8 A thermal solution for an power sharing enabled system needs to ensure that the Tj limit is not
exceeded while operating under the two extreme power conditions between the processor core and
the integrated graphics and memory controller components.
9 Projected range in advance of the measured product data. Measured values will be available after
silicon characterization.
10 For power sharing designs it is recommended to establish the full cooling capability within 10°C of
the T
processor Specification Update for details.
specifications. Some processors may have a different Tj max value, please refer to the
j,max
11 In rare occasions the specified maximum power limits may be violated when the package is not at a
thermally constrained environment
12 Tj, min =0 deg
13 While running intensive graphical and computational workloads simultaneously the concurrent
package power may exceed specified limits in exceptional occasions. Nevertheless, the individual
component powers are not to exceed the component TDPs specified.
Table 5-17.Intel Pentium U5000 mobile processor serie s Dual-Core ULV Thermal Power
Specifications
1,2,6,7
State
number
Processor
CPU Core (W)
TDP
Int. Gfx & Memory
3,13
Controller (w)
Pkg Concurrent
Power (w)
Frequency
CPU Core (GHz)
Int. Gfx (MHz)
166
HFM 10.5 8.5 18 1.20
up to
500
U5400
LFM 9 8.5 17.5 667 MHz N/A N/A N/A N/A
Power Sharing Design
Points
6,7
CPU Core
Extreme (W)
Proc: 10.5
Int. Gfx:
Proc: 7
Int Gfx:
7.5
8
6,7
Int. Gfx
Extreme (W)
11
MCP Thermal
18
Power Limit (W)
4,5,10,12
T
j,max
CPU Core (ºC)
105 100
Int. Gfx & Memory
Controller (ºC)
54 Datasheet
Page 55

Thermal Management
Table 5-18.Intel Pentium P6000 mobile processor series Dual-Core SV Thermal Power
Specifications
1,2,6,7
TDP
3,13
State
number
Processor
HFM 25 12.5 35 1.86
P6000
LFM 20 12.5 32.5 933 MHz N/A
CPU Core (W)
Controller (w)
Int. Gfx & Memory
Power (w)
Pkg Concurrent
Frequency
CPU Core (GHz)
500
up to
667
5.1.3 Idle Power Specificatio ns
The idle power specifications in Table 5- 17 and Tab le 5 - 1 9 are not 100% tested. These
power specifications are determined by the characterization of the processor currents
at higher temperatures and extrapolating the values for the junction temperature
indicated.
Power Sharing
Design Points
6,7
CPU Core
Int. Gfx (MHz)
Extreme (W)
Proc: 25
Int. Gfx: 10
N/A
8
6,7
Int. Gfx
MCP Thermal
Extreme (W)
35
Proc: 15
Int Gfx:20
N/A
N/A
Power Limit (W)
4,5,10,12
T
j,max
CPU Core (ºC)
90 85
Controller (ºC)
Int. Gfx & Memory
Table 5-19.18 W Ultra Low Voltage (ULV) Processor Idle Power
Symbol Parameter Min Typ Max T
P
C1E
P
C3
P
C6
Idle power in the Package C1e state - - 12 W 50ºC
Idle power in the Package C3 state - - 5.0 W 35ºC
Idle power in the Package C6 state - - 2.6 W 35ºC
j
Table 5-20.35 W Standard Voltage (SV) Processor Idle Power
Symbol Parameter Min Typ Max T
P
C1E
P
C3
Idle power in the Package C1e state - - 16 W 50 ºC
Idle power in the Package C3 state - - 7.5 W 35 ºC
j
5.1.4 Intelligent Power Sharing Control Overview
Based upon knowledge of the processor core and integrated graphics and memory
controller thermal power, performance state, and temperature, power sharing control
does the following:
• Utilizes internal graphics controller dynamic frequency performance states to
achieve their highest performance within the rated thermal power envelope. Intel
Datasheet 55
Page 56

Thermal Management
Dynamic Frequency enabled processors will offer a range of upside performance
capability beyond their rated or guaranteed frequency.
• Controls the processor core and internal graphics controller Intel Turbo Boost
performance states to ensure that overall MCP thermal power consumption does
not exceed the specified MCP thermal power limit.
• Limits MCP component usage to ensure that each of the components' T
not exceeded.
It is possible that the thermal influence between the MCP components could potentially
cause a component to reach its T
throttling. It is expected that when running the TDP workload, power sharing control
may limit the entire range of component Intel Turbo Boost capabilities (effectively,
disabling them).
The principal component of the power sharing control architecture is the policy
manager within the Intel Turbo Boost Technology driver which:
, invoking undesirable component hardware auto-
j,max
j,max
value is
• Communicates with the graphics software driver to limit, or increase, internal
graphics thermal power.
• Communicates with the processor core via the PCH to processor core PECI interface
to limit, or increase, processor core thermal power.
The Intel Turbo Boost Technology policy manager will set a thermal power limit to
which the graphics driver and processor core will adjust their Intel Turbo Boost
Technology performance dynamically, to stay within the limit.
Note: The processor PECI pin must be connected to the PCH PECI pin in order for Intel Turbo
Boost Technology to properly function.
5.1.5 Component Power Measurement/Estimation Error
The processor input pin (ISENSE) informs the processor core of how much amperage
the processor core is consuming. This information is provided by the processor core VR.
The process will calculate its current power based upon the ISENSE input information
and current voltage state. The internal graphics and memory controller power is
estimated by the GFX driver using PMON.
Any error in power estimation or measurement may limit or completely eliminate the
performance benefit of Intel Turbo Boost Technology. When a power limit is reached,
Power sharing control will adaptively remove Intel Turbo Boost Technology states to
remain with the MCP thermal power limit. Power sharing control assumes the power
error is always accurate so if the ISENSE input reports power greater than the actual
power, control mechanisms will lower performance before the actual TDP power limit is
reached. Intelligent Power sharing will provide better overall Intel Turbo Boost
Technology performance with increasing VR current sense accuracy. Designers and
system manufacturers should study trade-offs on VR component accuracy
characteristics, such as inductors, to find the best balance of cost vs. performance for
their system price and performance targets.
56 Datasheet
Page 57

Thermal Management
5.2 Thermal Management Features
This section will cover thermal management features for the processor.
5.2.1 Processor Core Thermal Features
Occasionally the processor core will operate in conditions that exceed its maximum
allowable operating temperature. This can be due to internal overheating or due to
overheating in the entire system. In order to protect itself and the system from thermal
failure, the processor core is capable of reducing its power consumption and thereby its
temperature until it is back within normal operating limits via the Adaptive Thermal
Monitor.
The Adaptive Thermal Monitor can be activated when any core temperature, monitored
by a digital thermal sensor (DTS), exceeds its maximum junction temperature (T
and asserts PROCHOT#. The assertion of PROCHOT# activates the thermal control
circuit (TCC). The TCC will remain active as long as any core exceeds its temperature
limit. Therefore, the Adaptive Thermal Monitor will continue to reduce the processor
core power consumption until the TCC is de-activated.
j,Max
)
Caution: The Adaptive Thermal Monitor must be enabled for the processor to remain within
specification.
5.2.1.1 Adaptive Thermal Monitor
The purpose of the Adaptive Thermal Monitor is to reduce processor core power
consumption and temperature until it operates at or below its maximum operating
temperature. Processor core power reduction is achieved by:
• Adjusting the operating frequency (via the core ratio multiplier) and input voltage
(via the VID signals).
• Modulating (starting and stopping) the internal processor core clocks (duty cycle).
The Adaptive Thermal Monitor dynamically selects the appropriate method. BIOS is not
required to select a specific method as with previous-generation processors supporting
Intel® Thermal Monitor 1 (TM1) or Intel® Thermal Monitor 2 (TM2). The temperature
at which the Adaptive Thermal Monitor activates the Thermal Control Circuit is not user
configurable but is software visible in the IA32_TEMPERATURE_TARGET (0x1A2) MSR,
Bits 23:16. The Adaptive Thermal Monitor does not require any additional hardware,
software drivers, or interrupt handling routines. Note that the Adaptive Thermal
Monitor is not intended as a mechanism to maintain processor TDP. The system design
should provide a thermal solution that can maintain TDP within its intended usage
range.
Datasheet 57
Page 58

5.2.1.1.1 Frequency/VID Control
Upon TCC activation, the processor core attempts to dynamically reduce processor core
power by lowering the frequency and voltage operating point. The operating points are
automatically calculated by the processor core itself and do not require the BIOS to
program them as with previous generations of Intel processors. The processor core will
scale the operating points such that:
• The voltage will be optimized according to the temperature, the core bus ratio, and
number of cores in deep C-states.
• The core power and temperature are reduced while minimizing performance
degradation.
A small amount of hysteresis has been included to prevent an excessive amount of
operating point transitions when the processor temperature is near its maximum
operating temperature. Once the temperature has dropped below the maximum
operating temperature and the hysteresis timer has expired, the operating frequency
and voltage transition back to the normal system operating point. This is illustrated in
Figure 5-12.
Thermal Management
Figure 5-12.Frequency and Voltage Ordering
Once a target frequency/bus ratio is resolved, the processor core will transition to the
new target automatically.
• On an upward operating point transition, the voltage transition precedes the
frequency transition.
58 Datasheet
Page 59

Thermal Management
• On a downward transition, the frequency transition precedes the voltage transition.
When transitioning to a target core operating voltage, a new VID code to the voltage
regulator is issued. The voltage regulator must support dynamic VID steps to support
this method.
During the voltage change:
• It will be necessary to transition through multiple VID steps to reach the target
operating voltage.
• Each step is 12.5 mV for Intel MVP-6.5 compliant VRs.
• The processor continues to execute instructions. However, the processor will halt
instruction execution for frequency transitions.
If a processor load-based Enhanced Intel SpeedStep Technology/P-state transition
(through MSR write) is initiated while the Adaptive Thermal Monitor is active, there are
two possible outcomes:
• If the P-state target frequency is higher than the processor core optimized target
frequency, the p-state transition will be deferred until the thermal event has been
completed.
• If the P-state target frequency is lower than the processor core optimized target
frequency, the processor will transition to the P-state operating point.
5.2.1.1.2 Clock Modulation
If the frequency/voltage changes are unable to end an Adaptive Thermal Monitor
event, the Adaptive Thermal Monitor will utilize clock modulation. Clock modulation is
done by alternately turning the clocks off and on at a duty cycle (ratio between clock
“on” time and total time) specific to the processor. The duty cycle is factory configured
to 37.5% on and 62.5% off and cannot be modified. The period of the duty cycle is
configured to 32 microseconds when the TCC is active. Cycle times are independent of
processor frequency. A small amount of hysteresis has been included to prevent
excessive clock modulation when the processor temperature is near its maximum
operating temperature. Once the temperature has dropped below the maximum
operating temperature, and the hysteresis timer has expired, the TCC goes inactive and
clock modulation ceases. Clock modulation is automatically engaged as part of the TCC
activation when the frequency/VID targets are at their minimum settings. Processor
performance will be decreased by the same amount as the duty cycle when clock
modulation is active. Snooping and interrupt processing are performed in the normal
manner while the TCC is active.
5.2.1.2 Digital Thermal Sensor
Each processor execution core has an on-die Digital Thermal Sensor (DTS) which
detects the core’s instantaneous temperature. The DTS is the preferred method of
monitoring processor die temperature because
• It is located near the hottest portions of the die.
Datasheet 59
Page 60

Thermal Management
• It can accurately track the die temperature and ensure that the Adaptive Thermal
Monitor is not excessively activated.
Temperature values from the DTS can be retrieved through
• A software interface via processor Model Specific Register (MSR).
• A processor hardware interface as described in “Platform Environment Control
Interface (PECI)” on page 67.
Note: When temperature is retrieved by processor MSR, it is the instantaneous temperature
of the given core. When temperature is retrieved via PECI, it is the average
temperature of each execution core’s DTS over a programmable window (default
window of 256 ms.) Intel recommends using the PECI output reading for fan speed or
other platform thermal control.
Code execution is halted in C1-C6. Therefore temperature cannot be read via the
processor MSR without bringing a core back into C0. However, temperature can still be
monitored through PECI in lower C-states.
Unlike traditional thermal devices, the DTS outputs a temperature relative to the
maximum supported operating temperature of the processor (T
responsibility of software to convert the relative temperature to an absolute
temperature. The absolute reference temperature is readable in an MSR. The
temperature returned by the DTS is an implied negative integer indicating the relative
offset from T
. The DTS does not report temperatures greater than T
j,max
j,max
). It is the
.
j,max
The DTS-relative temperature readout directly impacts the Adaptive Thermal Monitor
trigger point. When a DTS indicates that the maximum processor core temperature has
been reached (a reading of 0x0 on any core), the TCC will activate and indicate a
Adaptive Thermal Monitor event.
Changes to the temperature can be detected via two programmable thresholds located
in the processor thermal MSRs. These thresholds have the capability of generating
interrupts via the core's local APIC. Refer to the Intel® 64 and IA-32 Architectures
Software Developer's Manuals for specific register and programming details.
5.2.1.3 PROCHOT# Signal
PROCHOT# (processor hot) is asserted when the processor core temperature has
reached its maximum operating temperature (T
signal a thermal event which is then resolved by the Adaptive Thermal Monitor. See
Figure 5-12 (above) for a timing diagram of the PROCHOT# signal assertion relative to
the Adaptive Thermal Response. Only a single PROCHOT# pin exists at a package level
of the processor. When any core arrives at the TCC activation point, the PROCHOT#
signal will be driven by the processor core. PROCHOT# assertion policies are
independent of Adaptive Thermal Monitor enabling.
Note: Bus snooping and interrupt latching are active while the TCC is active.
). This will activate the TCC and
j,max
60 Datasheet
Page 61

Thermal Management
5.2.1.3.1 Bi-Directional PROCHOT#
By default, the PROCHOT# signal is defined as an output only. However, the signal may
be configured as bi-directional. When configured as a bi-directional signal, PROCHOT#
can be used for thermally protecting other platform components should they overheat
as well. When PROCHOT# is signaled externally:
• The processor core will immediately reduce processor power to the minimum
voltage and frequency supported. This is contrary to the internally-generated
Adaptive Thermal Monitor response.
• Clock modulation is not activated.
The TCC will remain active until the system deasserts PROCHOT#. The processor can
be configured to generate an interrupt upon assertion and deassertion of the
PROCHOT# signal.
5.2.1.3.2 Voltage Regulator Protection
PROCHOT# may be used for thermal protection of voltage regulators (VR). System
designers can create a circuit to monitor the VR temperature and activate the TCC
when the temperature limit of the VR is reached. By asserting PROCHOT# (pulled-low)
and activating the TCC, the VR will cool down as a result of reduced processor power
consumption. Bi-directional PROCHOT# can allow VR thermal designs to target thermal
design current (I
cooling for the VR and rely on bi-directional PROCHOT# only as a backup in case of
system cooling failure. Overall, the system thermal design should allow the power
delivery circuitry to operate within its temperature specification even while the
processor is operating at its TDP.
) instead of maximum current. Systems should still provide proper
TDC
5.2.1.3.3 Thermal Solution Design and PROCHOT# Behavior
With a properly designed and characterized thermal solution, it is anticipated that
PROCHOT# will only be asserted for very short periods of time when running the most
power intensive applications. The processor performance impact due to these brief
periods of TCC activation is expected to be so minor that it would be immeasurable.
However, an under-designed thermal solution that is not able to prevent excessive
assertion of PROCHOT# in the anticipated ambient environment may:
• Cause a noticeable performance loss
• Result in prolonged operation at or above the specified maximum junction
temperature and affect the long-term reliability of the processor
• May be incapable of cooling the processor even when the TCC is active continuously
(in extreme situations)
Datasheet 61
Page 62

5.2.1.3.4 Low-Power States and PROCHOT# Behavior
If the processor enters a low-power package idle state such as C3 or C6 with
PROCHOT# asserted, PROCHOT# will remain asserted until:
• The processor exits the low-power state
• The processor junction temperature drops below the thermal trip point
Note that the PECI interface is fully operational during all C-states and it is expected
that the platform continues to manage processor core thermals even during idle states
by regularly polling for thermal data over PECI.
5.2.1.4 On-Demand Mode
The processor provides an auxiliary mechanism that allows system software to force
the processor to reduce its power consumption via clock modulation. This mechanism is
referred to as “On-Demand” mode and is distinct from Adaptive Thermal Monitor and
bi-directional PROCHOT#. Platforms must not rely on software usage of this
mechanism to limit the processor temperature. On-Demand Mode can be done via
processor MSR or chipset I/O emulation.
Thermal Management
On-Demand Mode may be used in conjunction with the Adaptive Thermal Monitor.
However, if the system software tries to enable On-Demand mode at the same time the
TCC is engaged, the factory configured duty cycle of the TCC will override the duty
cycle selected by the On-Demand mode. If the I/O based and MSR-based On-Demand
modes are in conflict, the duty cycle selected by the I/O emulation-based On-Demand
mode will take precedence over the MSR-based On-Demand Mode.
5.2.1.4.1 MSR Based On-Demand Mode
If Bit 4 of the IA32_CLOCK_MODULATION MSR is set to a 1, the processor will
immediately reduce its power consumption via modulation of the internal core clock,
independent of the processor temperature. The duty cycle of the clock modulation is
programmable via Bits 3:1 of the same IA32_CLOCK_MODULATION MSR. In this mode,
the duty cycle can be programmed from 12.5% on/87.5% off to 87.5% on/12.5% off in
12.5% increments. Thermal throttling using this method will modulate each processor
core’s clock independently.
5.2.1.4.2 I/O Emulation-Based On-Demand Mode
I/O emulation-based clock modulation provides legacy support for operating system
software that initiates clock modulation through I/O writes to ACPI defined processor
clock control registers on the chipset (PROC_CNT). Thermal throttling using this
method will modulate all processor cores simultaneously.
62 Datasheet
Page 63

Thermal Management
5.2.1.5 THERMTRIP# Signal
Regardless of enabling the automatic or on-demand modes, in the event of a
catastrophic cooling failure, the processor will automatically shut down when the silicon
has reached an elevated temperature that risks physical damage to the processor. At
this point the THERMTRIP# signal will go active. THERMTRIP# activation is independent
of processor activity and does not generate any bus cycles.
5.2.1.6 Critical Temperature Detection
Critical Temperature detection is performed by monitoring the processor temperature
and temperature gradient. This feature is intended for graceful shutdown before the
THERMTRIP# is activated. If the processor's Adaptive Thermal Monitor is triggered and
the temperature remains high, a critical temperature status and sticky bit are latched in
the thermal status MSR register and also generates a thermal interrupt if enabled. The
assertion of critical temperature bit indicates that processor can no longer be assumed
to be working reliably.For more details on the interrupt mechanism, refer to the Intel®
64 and IA-32 Architectures Software Developer's Manuals.
5.2.2 Integrated Graphics and Memory Controller Thermal Features
The integrated graphics and memory controller provides the following features for
monitoring the integrated graphics and memory controller temperature and triggering
thermal management:
• One internal digital thermal sensor
• Hooks for an external thermal sensor mechanism which can either be TS-on-DIMM
or TS-on-Board
The integrated graphics and memory controller has implemented several silicon level
thermal management features that can lower both integrated graphics and memory
controller and DDR3 power during periods of high activity. As a result, these features
can help control temperature and help prevent thermally induced component failures.
These features include:
• Bandwidth throttling triggered by memory loading
• Bandwidth throttling triggered by integrated graphics and memory controller
heating
• THERMTRIP# support
• Render Thermal Throttling
5.2.2.1 Internal Digital Thermal Sensor
The integrated graphics and memory controller incorporates one on-die digital thermal
sensor for thermal management. The thermal sensor may be programmed to cause
hardware throttling and/or software interrupts. Hardware throttling includes render
thermal throttling and main memory programmable throttling thresholds. Sensor trip
Datasheet 63
Page 64

points may also be programmed to generate various interrupts including SCI, SMI,
INTR, and SERR. The internal thermal sensor reports six trip points: Aux0, Aux1, Aux2,
Aux3, Hot, and Catastrophic trip points in order of increasing temperature.
5.2.2.1.1 Aux0, Aux1, Aux2, Aux3 Temperature Trip Points
These trip points may be set dynamically if desired and provides a configurable
interrupt mechanism to allow software to respond when a trip is crossed in either
direction. These auxiliary temperature trip points do not automatically cause any
hardware throttling but may be used by software to trigger interrupts.
5.2.2.1.2 Hot Temperature Trip Point
This trip point is set at the temperature at which the integrated graphics and memory
controller must start throttling. It may optionally enable integrated graphics and
memory controller throttling when the temperature is exceeded. This trip point may
provide an interrupt to ACPI (or other software) when it is crossed in either direction.
Software could optionally set this as an interrupt when the temperature exceeds this
level setting.
Thermal Management
5.2.2.1.3 Catastrophic Trip Point
This trip point is set at the temperature at which the integrated graphics and memory
controller must be shut down immediately without any software support. This trip point
may be programmed to generate an interrupt, enable throttling, or immediately shut
down the system (via Halt or via THERMTRIP# assertion). Crossing a trip point in either
direction may generate several types of interrupts.
5.2.2.1.4 Recommended Programming for Available Trip Points
See the integrated graphics and memory controller BIOS Specification for
recommended Trip Point programming. Aux Trip Points (0, 1, 2, 3) should be
programmed for software and firmware control via interrupts. HOT Trip Point should be
set to throttle integrated graphics and memory controller to avoid T
of 100°C.
j,max
Catastrophic Trip Point should be set to halt operation to avoid maximum Tj of 130°C.
Note: Crossing a trip point in either direction may generate several types of interrupts. Each
trip point has a register that can be programmed to select the type of interrupt to be
generated. Crossing a trip point is implemented as edge detection on each trip point to
generate the interrupts. Either edge (i.e., crossing the trip point in either direction)
generates the interrupt.
5.2.2.1.5 Thermal Sensor Accuracy (T
accuracy
)
The error associated with DTS measurement will not exceed ±5°C within the operating
range. Integrated graphics and memory controller may not operate above T
j,max
spec.
This value is based on product characterization and is not guaranteed by manufacturing
test.
64 Datasheet
Page 65

Thermal Management
Software has the ability to program the T
cat
points should be selected with consideration for the thermal sensor accuracy and the
quality of the platform thermal solution. Overly conservative (unnecessarily low)
temperature settings may unnecessarily degrade performance due to frequent
throttling, while overly aggressive (dangerously high) temperature settings may fail to
protect the part against permanent thermal damage.
5.2.2.1.6 Hysteresis Operation
Hysteresis provides a small amount of positive feedback to the thermal sensor circuit to
prevent a trip point from flipping back and forth rapidly when the temperature is right
at the trip point. The digital hysteresis offset is programmable via processor registers.
5.2.2.2 Memory Thermal Throttling Options
The integrated graphics and memory controller has two, independent mechanisms that
cause system memory throttling:
TDP Controller: The TDP Controller is the main mechanism for limiting MCH power by
limiting memory bandwidth. Utilized as a thermal throttling mechanism, this feature is
triggered by the Hot temperature trip point of the Graphics and Memory Controller
digital thermal sensor (DTS) and initiates duty cycle throttling to delay memory
transactions and thereby reducing MCH power. Power reduction is memory
configuration and application dependant but duty cycle throttling intervals can be
customized for maximum throttling efficiency. The TDP Controller can also be used as a
bandwidth limiter using programmable memory read/write bandwidth thresholds. Intel
sets the default thresholds that will not restrict bandwidth and performance for most
applications but these thresholds can be modified to reduce MCH power regardless of
DTS temperature.
, T
hot
, and T
trip points, but these trip
aux
Note: The TDP controller can be used as a closed loop thermal throttling (CLTT) mechanism or
an open loop thermal throttling (OLTT) mechanism, although CLTT is recommended.
• DRAM Thermal Management: Ensures that the DRAM chips are operating within
thermal limits. The integrated graphics and memory controller can control the
amount of integrated graphics and memory controller-initiated bandwidth per rank
to a programmable limit via a weighted input averaging filter.
5.2.2.3 External Thermal Sensor Interface Overview
The integrated graphics and memory controller supports two inputs for external
thermal sensor notifications, based on which it can regulate memory accesses.
Note: The thermal sensors should be capable of measuring the ambient temperature only and
should be able to assert PM_EXT_TS#[0] and/or PM_EXT_TS#[1] if the preprogrammed thermal limits/conditions are met or exceeded.
Datasheet 65
Page 66

An external thermal sensor with a serial interface may be placed next to a SO-DIMM (or
any other appropriate platform location), or a remote Thermal Diode may be placed
next to the SO-DIMM (or any other appropriate platform location) and connected to the
external Thermal Sensor.
Additional external thermal sensor's outputs, for multiple sensors, can be wire-OR'd
together allow signaling from multiple sensors that are physically located separately.
Software can, if necessary, distinguish which SO-DIMM(s) is the source of the overtemp
through the serial interface. However, since the SO-DIMM's is located on the same
Memory Bus Data lines, any integrated graphics and memory controller-based read
throttle will apply equally.
Thermal sensors can either be directly routed to the integrated graphics and memory
controller PM_EXT_TS#[0] and PM_EXT_TS#[1] pins or indirectly routed to integrated
graphics and memory controller by invoking an Embedded Controller (EC) connected in
between the thermal sensor and integrated graphics and memory controller pins. Both
routing methods are applicable for both thermal sensors placed on the motherboard
(TS-on-Board) and/or thermal sensors located on the memory modules (TS-on-DIMM).
5.2.2.4 THERMTRIP# Operation
Thermal Management
The integrated graphics and memory controller can assert THERMTRIP# (Thermal Trip)
to indicates that its junction temperature has reached a level beyond which damage
may occur. Upon assertion of THERMTRIP#, the integrated graphics and memory
controller will shut off its internal clocks (thus halting program execution) in an attempt
to reduce the core junction temperature. Once activated, THERMTRIP# remains latched
until RSTIN# is asserted.
5.2.2.5 Render Thermal Throttling
Render Thermal Throttling of the integrated graphics and memory controller allows for
the reduction the render core engine frequency and voltage, thus reducing internal
graphics controller power and integrated graphics and memory controller thermals.
Performance is degraded, but the platform thermal burden is relieved.
Render Thermal Throttling using several frequency/voltage operating points that can be
used to throttle the render core. If the temperature of the integrated graphics and
memory controller internal DTS exceeds the Hot-trip point, the integrated graphics will
switch to a lower frequency/voltage operating point. After a timeout, the DTS is
rechecked, and if the DTS temperature is still greater than the designed hysteresis, the
integrated graphics will continue to switch to lower frequency/voltage operating points.
Once the DTS reports a temperature below the hysteresis value, the render clock
frequency and voltage will be restored to its pre-thermal event state.
Caution: The Render Thermal Throttling must be enabled for the product to remain within
specification.
66 Datasheet
Page 67

Thermal Management
5.2.3 Platform Environment Control Interface (PECI)
The Platform Environment Control Interface (PECI) is a one-wire interface that provides
a communication channel between Intel processor and chipset components to external
monitoring devices. The processor implements a PECI interface to allow communication
of processor thermal information to other devices on the platform. The processor
provides a digital thermal sensor (DTS) for fan speed control. The DTS is calibrated at
the factory to provide a digital representation of relative processor temperature.
Averaged DTS values are read via the PECI interface.
The PECI physical layer is a self-clocked one-wire bus that begins each bit with a
driven, rising edge from an idle level near zero volts. The duration of the signal driven
high depends on whether the bit value is a Logic 0 or Logic 1. PECI also includes
variable data transfer rate established with every message. The single wire interface
provides low board routing overhead for the multiple load connections in the congested
routing area near the processor and chipset components. Bus speed, error checking,
and low protocol overhead provides adequate link bandwidth and reliability to transfer
critical device operating conditions and configuration information.
5.2.3.1 Fan Speed Control with Digital Thermal Sensor
Digital Thermal Sensor based fan speed control (T
achieve optimal thermal performance. At the T
cooling capability well before the DTS reading reaches T
be T
FAN
= T
j,max
- 10ºC.
) is a recommended feature to
FAN
temperature, Intel recommends full
FAN
. An example of this would
j,max
5.2.3.2 Processor Thermal Data Sample Rate and Filtering
The processor digital thermal sensor (DTS) provides an improved capability to monitor
device hot spots, which inherently leads to more varying temperature readings over
short time intervals. To reduce the sample rate requirements on PECI and improve
thermal data stability vs. time the processor DTS implements an averaging algorithm
that filters the incoming data. This filter is expressed mathematically as:
PECI(t) = PECI(t-1)+1/(2^^X)*[Temp - PECI(t-1)]
where:
• PECI(t) is the new averaged temperature
• PECI(t-1) is the previous averaged temperature
• Temp is the raw temperature data from the DTS
• X is the Thermal Averaging Constant (TAC)
The Thermal Averaging Constant is a BIOS configurable value that determines the time
in milliseconds over which the DTS temperature values are averaged (the default time
is 256 ms). Short averaging times will make the averaged temperature values respond
more quickly to DTS changes. Long averaging times will result in better overall thermal
smoothing but also incur a larger time lag between fast DTS temperature changes and
the value read via PECI.
Datasheet 67
Page 68

Thermal Management
Within the processor, the DTS converts an analog signal into a digital value
representing the temperature relative to PROCHOT# circuit activation. The conversions
are in integers with each single number change corresponding to approximately 1°C.
DTS values reported via the internal processor MSR will be in whole integers.
As a result of the PECI averaging function described above, DTS values reported over
PECI will include a 6-bit fractional value. Under typical operating conditions, where the
temperature is close to PROCHOT#, the fractional values may not be of interest. But
when the temperature approaches zero, the fractional values can be used to detect the
activation of the PROCHOT# circuit. An averaged temperature value between 0 and 1
can only occur if the PROCHOT# circuit has been activated during the averaging
window. As PROCHOT# circuit activation time increases, the fractional value will
approach zero. Fan control circuits can detect this situation and take appropriate action
as determined by the system designers. Of course, fan control chips can also monitor
the PROCHOT# pin to detect PROCHOT# circuit activation via a dedicated input pin on
the package.
§
68 Datasheet
Page 69

Signal Description
6 Signal Description
This chapter describes the processor signals. They are arranged in functional groups
according to their associated interface or category. The following notations are used to
describe the signal type:
Notations Signal Type
IInput Pin
OOutput Pin
I/O Bi-directional Input/Output Pin
The signal description also includes the type of buffer used for the particular signal:
Table 6-21.Signal Description Buffer Types
Signal Description
PCI Express* PCI Express interface signals. These signals are compatible with PCI
Express 2.0 Signalling Environment AC Specifications and are AC coupled.
The buffers are not 3.3-V tolerant. Refer to the PCIe specification.
FDI Intel Flexible Display interface signals. These signals are compatible with
PCI Express 2.0 Signaling Environment AC Specifications, but are DC
coupled. The buffers are not 3.3-V tolerant.
DMI Direct Media Interface signals. These signals are compatible with PCI
CMOS CMOS buffers. 1.1-V tolerant
DDR3 DDR3 buffers: 1.5-V tolerant
A Analog reference or output. May be used as a threshold voltage or for
GTL Gunning Transceiver Logic signaling technology
Ref Voltage reference signal
Asynchronous
Express 2.0 Signaling Environment AC Specifications, but are DC coupled.
The buffers are not 3.3-V tolerant.
buffer compensation
1
Signal has no timing relationship with any reference clock.
NOTES:
1. Qualifier for a buffer type.
Datasheet 69
Page 70

6.1 System Memory Interface
Table 6-22.Memory Channel A (Sheet 1 of 2)
Signal Description
Signal Name Description
SA_BS[2:0] Bank Select: These signals define which
banks are selected within each SDRAM rank.
SA_WE# Write Enable Control Signal: Used with
SA_RAS# and SA_CAS# (along with
SA_CS#) to define the SDRAM Commands.
SA_RAS# RAS Control Signal: Used with SA_CAS#
and SA_WE# (along with SA_CS#) to define
the SRAM Commands.
SA_CAS# CAS Control Signal: Used with SA_RAS#
and SA_WE# (along with SA_CS#) to define
the SRAM Commands.
SA_DM[7:0] Data Mask: These signals are used to mask
individual bytes of data in the case of a
partial write and to interrupt burst writes.
When activated during writes, the
corresponding data groups in the SDRAM are
masked. There is one SA_DM[7:0] for every
data byte lane.
SA_DQS[7:0] Data Strobes: SA_DQS[7:0] and its
complement signal group make up a
differential strobe pair. The data is captured
at the crossing point of SA_DQS[7:0] and its
SA_DQS#[7:0] during read and write
transactions
SA_DQS#[7:0] Data Strobe Complements: These are the
complementary strobe signals.
SA_DQ[63:0] Data Bus: Channel A data signal interface to
the SDRAM data bus.
SA_MA[15:0] Memory Address: These signals are used to
provide the multiplexed row and column
address to the SDRAM.
SA_CK[1:0] SDRAM Differential Clock: Channel A
SDRAM Differential clock signal pair. The
crossing of the positive edge of SA_CK and
the negative edge of its complement
SA_CK# are used to sample the command
and control signals on the SDRAM.
SA_CK#[1:0] SDRAM Inverted Differential Clock:
Channel A SDRAM Differential clock signalpair complement.
Direction/Buffer
Type
O
DDR3
O
DDR3
O
DDR3
O
DDR3
O
DDR3
I/O
DDR3
I/O
DDR3
I/O
DDR3
O
DDR3
O
DDR3
O
DDR3
70 Datasheet
Page 71

Signal Description
Table 6-22.Memory Channel A (Sheet 2 of 2)
Signal Name Description
SA_CKE[1:0] Clock Enable: (1 per rank) Used to:
- Initialize the SDRAMs during power-up
- Power-down SDRAM ranks
- Place all SDRAM ranks into and out of selfrefresh during STR
SA_CS#[1:0] Chip Select: (1 per rank) Used to select
particular SDRAM components during the
active state. There is one Chip Select for
each SDRAM rank.
SA_ODT[1:0] On Die Termin at ion: Active Termination
Control.
Table 6-23.Memory Channel B (Sheet 1 of 2)
Signal Name Description
SB_BS[2:0] Bank Select: These signals define which
banks are selected within each SDRAM rank.
SB_WE# Write Enable Control Signal: Used with
SB_RAS# and SB_CAS# (along with
SB_CS#) to define the SDRAM Commands.
SB_RAS# RAS Co ntrol Signal: Used with SB_CAS#
and SB_WE# (along with SB_CS#) to define
the SRAM Commands.
SB_CAS# CAS Contro l Si gn al: Used with SB_RAS#
and SB_WE# (along with SB_CS#) to define
the SRAM Commands.
SB_DM[7:0] Data Mask: These signals are used to mask
individual bytes of data in the case of a
partial write and to interrupt burst writes.
When activated during writes, the
corresponding data groups in the SDRAM are
masked. There is one SB_DM[7:0] for every
data byte lane.
SB_DQS[7:0] Data Strobes: SB_DQS[7:0] and its
complement signal group make up a
differential strobe pair. The data is captured
at the crossing point of SB_DQS[7:0] and its
SB_DQS#[7:0] during read and write
transactions.
SB_DQS#[7:0] Data Strobe Complements: These are the
complementary strobe signals.
SB_DQ[63:0] Data Bus: Channel B data signal interface to
the SDRAM data bus.
Direction/Buffer
Type
O
DDR3
O
DDR3
O
DDR3
Direction/
Buffer Type
O
DDR3
O
DDR3
O
DDR3
O
DDR3
O
DDR3
I/O
DDR3
I/O
DDR3
I/O
DDR3
Datasheet 71
Page 72

Table 6-23.Memory Channel B (Sheet 2 of 2)
Signal Description
Signal Name Description
SB_MA[15:0] Memory Address: These signals are used to
provide the multiplexed row and column
address to the SDRAM.
SB_CK[1:0] SDRAM Differential Clock: Channel B
SDRAM Differential clock signal pair. The
crossing of the positive edge of SB_CK and
the negative edge of its complement
SB_CK# are used to sample the command
and control signals on the SDRAM.
SB_CK#[1:0] SDRAM Inverted Differential Clock:
Channel B SDRAM Differential clock signalpair complement.
SB_CKE[1:0] Clock Enable: (1 per rank) Used to:
- Initialize the SDRAMs during power-up.
- Power-down SDRAM ranks.
- Place all SDRAM ranks into and out of selfrefresh during STR.
SB_CS#[1:0] Chip Select: (1 per rank) Used to select
particular SDRAM components during the
active state. There is one Chip Select for
each SDRAM rank.
SB_ODT[1:0] On Die Termination: Active Termination
Control.
Direction/
Buffer Type
O
DDR3
O
DDR3
O
DDR3
O
DDR3
O
DDR3
O
DDR3
6.2 Memory Reference and Compensation
Table 6-24.Memory Reference and Compensation
Signal Name Description
SM_RCOMP[2:0] System Memory Impedance
SA_DIMM_VREFDQ
SB_DIMM_VREFDQ
72 Datasheet
Compensation:.
Memory Channel A/B DIMM Voltage.O
Direction/Buffer
Type
I
A
A
Page 73

Signal Description
6.3 Reset and Miscellaneous Signals
Table 6-25.Reset and Miscellaneous Signals (Sheet 1 of 2)
Signal Name Description
SM_DRAMRST# DDR3 DRAM Reset: Reset signal from
PM_EXT_TS#[0]
PM_EXT_TS#[1]
COMP0 Impedance compensation must be
COMP1 Impedance compensation must be
COMP2 Impedance compensation must be
COMP3 Impedance compensation must be
PM_SYNC Power Management Sync: A sideband
RESET_OBS# This signal is an indication of the processor
RSTIN# Reset In: When asserted this signal will
BPM#[7:0] Breakpoint and Performance Monitor
DBR# Debug Reset: Used only in systems where
processor to DRAM devices. One for all
channels or SO-DIMMs.
External Thermal Sensor Input: If the
system temperature reaches a dangerously
high value then this signal can be used to
trigger the start of system memory
throttling.
terminated on the system board using a
precision resistor.
terminated on the system board using a
precision resistor.
terminated on the system board using a
precision resistor.
terminated on the system board using a
precision resistor.
signal to communicate power management
status from the platform to the processor.
being reset.
asynchronously reset the processor logic.
This signal is connected to the PLTRST#
output of the PCH.
Signals: Outputs from the processor that
indicate the status of breakpoints and
programmable counters used for monitoring
processor performance.
no debug port is implemented on the system
board. DBR# is used by a debug port
interposer so that an in-target probe can
drive system reset. This signal only routes
through the package and does not connect to
the the processor silicon itself.
Direction/Buffer
Type
O
DDR3
I
CMOS
I
A
I
A
I
A
I
A
I
CMOS
O
Asynchronous CMOS
I
CMOS
I/O
GTL
O
Datasheet 73
Page 74

Table 6-25.Reset and Miscellaneous Signals (Sheet 2 of 2)
Signal Description
Signal Name Description
PRDY# PRDY#: A processor output used by debug
PREQ# PREQ#: Used by debug tools to request
RSVD
RSVD_TP
RSVD_NCTF
tools to determine processor debug
readiness.
debug operation of the processor.
RESERVED. All signals that are RSVD and
RSVD_NCTF must be left unconnected on the
board. However, Intel recommends that all
RSVD_TP signals have via test points.
6.4 PCI Express Graphics Interface Signals
Table 6-26.PCI Express Graphics Interface Signals
Signal Name Description
PEG_RX[15:0]
PEG_RX#[15:0]
PEG_TX[15:0]
PEG_TX#[15:0]
PEG_ICOMPI PCI Express Graphics Input Current
PEG_ICOMPO PCI Express Graphics Output Current
PEG_RCOMPO PCI Express Graphics Resistance
PEG_RBIAS PCI Express Resistor Bias Control I
PCI Express Graphics Receive
Differential Pair
PCI Express Graphics Transmit
Differential Pair
Compensation
Compensation
Compensation
Direction/Buffer
Type
O
Asynchronous GTL
I
Asynchronous GTL
No Connect
Test P oin t
Non-Critical to
Function
Direction/Buffer
Type
I
PCI Express
O
PCI Express
I
A
I
A
I
A
A
74 Datasheet
Page 75

Signal Description
6.5 Embedded DisplayPort (eDP)
Embedded Display Port Signals
Signal Name Description
eDP_TX[3:0]
eDP_TX#[3:0]
eDP_AUX
eDP_AUX#
eDP_HPD# Embedded DisplayPort Hot Plug Detect:
eDP_ICOMPI Embedded DisplayPort Input Current
eDP_ICOMPO Embedded DisplayPort Output Current and
eDP_RCOMPO Embedded DisplayPort Resistance
Embedded DisplayPort Transmit Differential
Pair: Nominally, eDP_TX[3:0] is multiplexed
with PEG_TX[12:15] and eDP_TX#[3:0] is
multiplexed with PEG_TX#[12:15]. When
reversed, eDP_TX[3:0] is multiplexed with
PEG_TX[3:0] and eDP_TX#[3:0] is multiplexed
with PEG_TX#[3:0]
Embedded DisplayPort Auxiliary Differential
Pair: Nominally, eDP_AUX is multiplexed with
PEG_RX[13] and eDP_AUX# is multiplexed
with PEG_RX#[13]. When reversed, eDP_AUX
is multiplexed with PEG_RX[2] and eDP_AUX#
is multiplexed with PEG_RX#[2]
Nominally, eDP_HPD# is multiplexed with
PEG_RX[12]. When reversed, eDP_HPD# is
multiplexed with PEG_RX[3]
Compensation: Multiplexed with PEG_ICOMPI
Resistance Compensation: Multiplexed with
PEG_ICOMPO
Compensation: Multiplexed with PEG_RCOMPO
Direction/Buffer
Type
O
PCI Express
I/O
PCI Express
I
PCI Express
I
A
I
A
I
A
eDP_RBIAS Embedded DisplayPort Resistor Bias Control:
Multiplexed with PEG_RBIAS
I
A
6.6 Intel Flexible Display Interface Signals
Table 6-27.Intel® Flexible Display Interface (Sheet 1 of 2)
Signal Name Description
FDI_TX[3:0]
FDI_TX#[3:0]
FDI_FSYNC[0] Intel® Flexible Display Interface Frame
FDI_LSYNC[0] Intel® Flexible Display Interface Line Sync
Datasheet 75
Intel® Flexible Display Interface
Transmit Differential Pair - Pipe A
Sync - Pipe A
- Pipe A
Direction/Buffer
Type
O
FDI
I
CMOS
I
CMOS
Page 76

Table 6-27.Intel® Flexible Display Interface (Sheet 2 of 2)
Signal Description
Signal Name Description
FDI_TX[7:4]
FDI_TX#[7:4]
FDI_FSYNC[1] Intel® Flexible Display Interface Frame
FDI_LSYNC[1] Intel® Flexible Display Interface Line Sync
FDI_INT Intel® Flexible Display Interface Hot Plug
Intel® Flexible Display Interface
Transmit Differential Pair - Pipe B
Sync - Pipe B
- Pipe B
Interrupt
6.7 DMI
Table 6-28.DMI - Processor to PCH Serial Interface
Signal Name Description
DMI_RX[3:0]
DMI_RX#[3:0]
DMI_TX[3:0]
DMI_TX#[3:0]
DMI Input from PCH: Direct Media
Interface receive differential pair.
DMI Output to PCH: Direct Media
Interface transmit differential pair.
Direction/Buffer
Type
O
FDI
I
CMOS
I
CMOS
I
CMOS
Direction/Buffer
Type
I
DMI
O
DMI
6.8 PLL Signals
Table 6-29.PLL Signals
Signal Name Description
BCLK
BCLK#
BCLK_ITP
BCLK_ITP#
PEG_CLK
PEG_CLK#
DPLL_REF_SSCLK
DPLL_REF_SSCLK#
76 Datasheet
Differential bus clock input to the processor I
Buffered differential bus clock pair to ITP O
Differential PCI Express Based
Graphics/DMI Clock In: These pins receive
a 100-MHz Serial Reference clock from the
external clock synthesizer. This clock is used
to generate the clocks necessary for the
support of PCI Express. This also is the
reference clock for Intel® FDI.
Embedded Display Port PLL Differential
Clock In: With or without SSC -120 MHz.
Direction/Buffer
Type
Diff Clk
Diff Clk
I
Diff Clk
I
Diff Clk
Page 77

Signal Description
6.9 TAP Signals
Table 6-30.TAP Signals
Signal Name Description
TCK TCK (Test Clock): Provides the clock input
for the processor Test Bus (also known as
the Test Access Port).
TDI TDI (Test Data In): Transfers serial test
data into the processor. TDI provides the
serial input needed for JTAG specification
support.
TDO Test Data Output O
TDI_M Test Data In for the GPU/Memory core:
Tie TDI_M and TDO_M together on the
motherboard
TDO_M Test Data Output from the processor
core: Tie TDO_M and TDI_M together on the
motherboard.
TMS TMS (Test Mode Select): A JTAG
specification support signal used by debug
tools.
TRST# TRST# (Test Reset) Boundary-Scan test
reset pin
TAPPWRGOOD Power good for ITP O
Direction/Buffer
Type
CMOS
CMOS
CMOS
CMOS
CMOS
CMOS
CMOS
Asynchronous CMOS
I
I
I
O
I
I
Datasheet 77
Page 78

6.10 Error and Thermal Protection
Table 6-31.Error and Thermal Protection
Signal Description
Signal Name Description
CATERR# Catastrophic Error: This signal indicates that
the system has experienced a catastrophic error
and cannot continue to operate. The processor
will set this for non-recoverable machine check
errors or other unrecoverable internal errors.
External agents are allowed to assert this pin
which will cause the processor to take a machine
check exception.
PECI PECI (Platform Environment Control
Interface): A serial sideband interface to the
processor, it is used primarily for thermal, power,
and error management. Details regarding the
PECI electrical specifications, protocols, and
functions can be found in the RS - Platform
Environment Control Interface (PECI)
Specification, Revision 2.0.
PROCHOT# Processor Hot: PROCHOT# goes active when
the processor temperature monitoring sensor(s)
detects that the processor has reached its
maximum safe operating temperature. This
indicates that the processor Thermal Control
Circuit (TCC) has been activated, if enabled. This
signal can also be driven to the processor to
activate the TCC.
THERMTRIP# Thermal Trip: The processor protects itself from
catastrophic overheating by use of an internal
thermal sensor. This sensor is set well above the
normal operating temperature to ensure that
there are no false trips. The processor will stop
all execution when the junction temperature
exceeds approximately 130°C. This is signaled to
the system by the THERMTRIP# pin.
Direction/Buffer
Type
I/O
GTL
I/O
Asynchronous
I/O
Asynchronous GTL
O
Asynchronous GTL
78 Datasheet
Page 79

Signal Description
6.11 Power Sequencing
Table 6-32.Power Sequencing
Signal Name Description
VCCPWRGOOD_0
VCCPWRGOOD_1
SM_DRAMPWROK SM_DRAMPWROK Processor Input:
VTTPWRGOOD VTTPWRGOOD Processor Input: The
SKTOCC#(rPGA988A only)
PROC_DETECT (BGA only)
VCCPWRGOOD_0 and VCCPWRGOOD_1
(Power Good) Processor Input: The
processor requires these signals to be a
clean indication that:
-VCC, VCCPLL, and VTT supplies are stable
and within their specifications
-BCLK is stable and has been running for a
minimum number of cycles.
Both signals must then transition
monotonically to a high state.
VCCPWRGOOD_0 and VCCPWRGOOD_1 can
be driven inactive at any time, but BCLK and
power must again be stable before a
subsequent rising edge of these signals.
VCCPWRGOOD_0 and VCCPWRGOOD_1
should be tied together and connected to the
PROCPWRGD output signal of the PCH.
Connects to PCH DRAMPWROK.
processor requires this input signal to be a
clean indication that the VTT power supply is
stable and within specifications. Clean
implies that the signal will remain low
(capable of sinking leakage current), without
glitches, from the time that the power
supplies are turned on until they come within
specification. The signal must then transition
monotonically to a high state. Note it is not
valid for VTTPWRGOOD to be deasserted
while VCCPWRGOOD_0 and
VCCPWRGOOD_1 is asserted.
SKTOCC# (Socket Occupied)/
PROC_DETECT (Processor Detect): pulled
to ground on the processor package. There is
no connection to the processor silicon for this
signal. System board designers may use this
signal to determine if the processor is
present.
Direction/Buffer
Type
I
Asynchronous CMOS
I
Asynchronous CMOS
I
Asynchronous CMOS
Datasheet 79
Page 80

6.12 Processor Power Signals
Table 6-33.Processor Power Signals (Sheet 1 of 3)
Signal Description
Signal Name Description
VCC Processor core power rail. Ref
VTT
(VTT0 and VTT1)
VDDQ DDR3 power rail (1.5 V) Ref
VCCPLL Power rail for filters and PLLs (1.8 V) Ref
ISENSE Current Sense from an Intel® MVP6.5
PROC_DPRSLPVR Processor output signal to Intel MVP-6.5
PSI# Processor Power Status Indicator: This
Processor I/O power rail (1.05 V). VTT0 and
VTT1 should share the same VR
Compliant Regulator to the processor core.
controller to indicate that the processor is in
the package C6 state.
signal is asserted when the processor core
current consumption is less than 15 A.
Assertion of this signal is an indication that
the VR controller does not currently need to
provide ICC above 15 A. The VR controller
can use this information to move to a more
efficient operating point. This signal will deassert at least 3.3 µs before the current
consumption will exceed 15 A. The minimum
PSI# assertion and de-assertion time is 1
BCLK.
Asynchronous CMOS
Direction/Buffer
Type
Ref
I
A
O
CMOS
O
80 Datasheet
Page 81

Signal Description
Table 6-33.Processor Power Signals (Sheet 2 of 3)
Signal Name Description
VID[6]
VID[5:3]/CSC[2:0]
VID[2:0]/MSID[2:0]
VTT_SELECT The VTT_SELECT signal is used to select the
VCC_SENSE
VSS_SENSE
VTT_SENSE
VSS_SENSE_VTT
VAXG Graphics core power rail. Ref
VAXG_SENSE
VSSAXG_SENSE
GFX_VID[6:0] GFX_VID[6:0] (Voltage ID) pins are used to
GFX_VR_EN GPU output signal to Intel MVP6.5 compliant
VID[6:0] (Voltage ID) Pins: Used to
support automatic selection of power supply
voltages (VCC). These are CMOS signals that
are driven by the processor.
CSC[2:0]/VID[5:3] - Current Sense
Configuration bits, for ISENSE gain setting.
This value is latched on the rising edge of
VTTPWRGOOD.
MSID[2:0]/VID[2:0]- Market Segment
Identification is used to indicate the
maximum platform capability to the
processor. A processor will only boot if the
MSID[2:0] pins are strapped to the
appropriate setting (or higher) on the
platform (see Table 7-37 for MSID
encodings). MSID is used to help protect the
platform by preventing a higher power
processor from booting in a platform
designed for lower power processors.
MSID[2:0] are latched on the rising edge of
VTTPWRGOOD.
NOTE: VID[5:3] and VID[2:0] are bidirectional. As an input, they are CSC[2:0]
and MSID[2:0] respectively.
correct VTT voltage level for the processor.
Voltage Feedback Signals to an Intel MVP-6.5
Compliant VR: Use VCC_SENSE to sense
voltage and VSS_SENSE to sense ground
near the silicon with little noise.
Isolated low impedance connection to the
processor VTT voltage and ground. They can
be used to sense or measure voltage near
the silicon.
VAXG_SENSE and VSSAXG_SENSE provide
an isolated, low impedance connection to the
VAXG voltage and ground. They can be used
to sense or measure voltage near the silicon.
support automatic selection of nominal
voltages (VAXG). These are CMOS signals
that are driven by the processor.
VR. Th is signal is used as an on/off control to
enable/disable the GPU VR.
Direction/Buffer
Type
O
CMOS
O
CMOS
O
A
O
A
O
A
O
CMOS
O
CMOS
Datasheet 81
Page 82

Table 6-33.Processor Power Signals (Sheet 3 of 3)
Signal Description
Signal Name Description
GFX_DPRSLPVR GPU output signal to Intel MVP6.5 compliant
GFX_IMON Current Sense from an Intel MVP6.5
VDDQ_CK Filtered power for VDDQ (BGA Only) Ref
VTT0_DDR Filtered power for VTT0 (BGA Only) Ref
VCAP0
VCAP1
VCAP2
VR. When asserted this signal indicates that
the GPU is in render suspend mode. This
signal is also used to control render suspend
state exit slew rate.
Compliant Regulator to the GPU.
Processor Connection to On-board
decoupling capacitors (BGA only)
6.13 Ground and NCTF
Table 6-34.Ground and NCTF
Signal Name Description
VSS Processor ground node GND
VSS_NCTF Non-Critical to Function: The pins are for
package mechanical reliability.
DC_TEST_xx# Daisy Chain Test - These pins are for solder
joint reliability and are non-critical to
function (BGA only).
Direction/Buffer
Type
O
CMOS
I
A
PWR
Direction/Buffer
Type
NC
6.14 Processor Internal Pull Up/Pull Down
Table 6-35.Processor Internal Pull Up/Pull Down
Signal Name Pull Up/Pull Down Rail Value
SM_DRAMPWROK Pull Down VSS 10 - 20 kΩ
VCCPWRGOOD_0
VCCPWRGOOD_1
VTTPWRGOOD Pull Down VSS 10 - 20 kΩ
BPM#[7:0] Pull Up VTT 44 - 55 kΩ
TCK Pull Up VTT 44 - 55 kΩ
TDI Pull Up VTT 44 - 55 kΩ
TMS Pull Up VTT 44 - 55 kΩ
TRST# Pull Up VTT 1 - 5 kΩ
82 Datasheet
Pull Down VSS 10 - 20 kΩ
Page 83

Signal Description
Table 6-35.Processor Internal Pull Up/Pull Down
Signal Name Pull Up/Pull Down Rail Value
TDI_M Pull Up VTT 44 - 55 kΩ
PREQ# Pull Up VTT 44 - 55 kΩ
CFG[17:0] Pull Up VTT 5 - 14 kΩ
§
Datasheet 83
Page 84

7 Electrical Specifications
7.1 Power and Ground Pins
Electrical Specifications
The processor has VCC, VTT, V
power distribution. All power pins must be connected to their respective processor
power planes, while all V
multiple power and ground planes is recommended to reduce I*R drop. The V
must be supplied with the voltage determined by the processor Voltage IDentification
(VID) signals. Likewise, the V
determined by the GFX_VID signals. Ta bl e 7- 3 6 specifies the voltage level for the
various VIDs. The voltage levels are the same for both the processor VIDs and
GFX_VIDs.
DDQ, VCCPLL, VAXG
pins must be connected to the system ground plane. Use of
SS
pins must also be supplied with the voltage
AXG
and V
(ground) inputs for on-chip
SS
CC
pins
7.2 Decoupling Guidelines
Due to its large number of transistors and high internal clock speeds, the processor is
capable of generating large current swings between low- and full-power states. To keep
voltages within specification, output decoupling must be properly designed.
Caution: Design the board to ensure that the voltage provided to the processor remains within
the specifications listed in Ta b l e 7 -3 6. Failure to do so can result in timing violations or
reduced lifetime of the processor.
7.2.1 Voltage Rail Decoupling
The voltage regulator solution must:
• provide sufficient decoupling to compensate for large current swings generated
during different power mode transitions.
• provide low parasitic resistance from the regulator to the socket.
• meet voltage and current specifications as defined in Table 7 - 3 6 .
7.3 Processor Clocking (BCLK, BCLK#)
The processor utilizes a differential clock to generate the processor core(s) operating
frequency, memory controller frequency, and other internal clocks. The processor core
frequency is determined by multiplying the processor core ratio by 133 MHz. Clock
multiplying within the processor is provided by an internal phase locked loop (PLL),
which requires a constant frequency input, with exceptions for Spread Spectrum
Clocking (SSC).
The processor’s maximum core frequency is configured during power-on reset by using
its manufacturing default value. This value is the highest core multiplier at which the
processor can operate.
84 Datasheet
Page 85

Electrical Specifications
7.3.1 PLL Power Supply
An on-die PLL filter solution is implemented on the processor. Refer to Tabl e 7-36 for
DC specifications
7.4 Voltage Identification (VID)
The processor uses seven voltage identification pins, VID[6:0], to support automatic
selection of the processor power supply voltages. VID pins for the processor are CMOS
outputs driven by the processor VID circuitry. A dedicated graphics voltage regulator is
required to deliver voltage to the integrated graphics controller. Like the processor
core, the integrated graphics controller will use seven voltage identification pins,
GFX_VID[6:0], to set the nominal operating voltage GFX_VID pins for the graphics core
are CMOS outputs driven by the graphics core VID circuitry. Ta b l e 7 -3 6 specifies the
voltage level for VID[6:0] and GFX_VID[6:0]; 0 refers to a low-voltage level
VID signals are CMOS push/pull drivers. Refer to Table 7 - 4 5 for the DC specifications
for these signals. The VID codes will change due to temperature, frequency, and/or
power mode load changes in order to minimize the power of the part. A voltage range
is provided in Table 7 - 3 6 . The specifications are set so that one voltage regulator can
operate with all supported frequencies.
Individual processor VID values may be set during manufacturing so that two devices
at the same core frequency may have different default VID settings. This is shown in
the VID range values in Table 7 -3 6. The processor
transitioning to an adjacent VID and its associated processor core voltage (V
provides the ability to operate while
). This
CC
will represent a DC shift in the loadline.
Note: A low-to-high or high-to-low voltage state change will result in as many VID transitions
as necessary to reach the target core voltage. Transitions above the maximum or below
the minimum specified VID are not permitted. One VID transition occurs in 2.5 µs.
The VR utilized must be capable of regulating its output to the value defined by the new
VID values issued. DC specifications for dynamic VID transitions are included in
Ta b l e 7 -36..
Several of the VID signals (VID[5:3]/CSC[2:0] and VID[2:0]/MSID[2:0]) serve a dual
purpose and are sampled during reset. Refer to the signal description table in
Chapter 6 for more information.
Table 7-36.Voltage Identification Definition (Sheet 1 of 4)
VID6 VID5 VID4 VID3 VID2 VID1 VID0 VCC (V)
00 0 0 0 0 01.5000
00 0 0 0 0 11.4875
00 0 0 0 1 01.4750
00 0 0 0 1 11.4625
00 0 0 1 0 01.4500
00 0 0 1 0 11.4375
00 0 0 1 1 01.4250
Datasheet 85
Page 86

Table 7-36.Voltage Identification Definition (Sheet 2 of 4)
VID6 VID5 VID4 VID3 VID2 VID1 VID0 VCC (V)
0 0 0 0 1 1 1 1.4125
0 0 0 1 0 0 0 1.4000
0 0 0 1 0 0 1 1.3875
0 0 0 1 0 1 0 1.3750
0 0 0 1 0 1 1 1.3625
0 0 0 1 1 0 0 1.3500
0 0 0 1 1 0 1 1.3375
0 0 0 1 1 1 0 1.3250
0 0 0 1 1 1 1 1.3125
0 0 1 0 0 0 0 1.3000
0 0 1 0 0 0 1 1.2875
0 0 1 0 0 1 0 1.2750
0 0 1 0 0 1 1 1.2625
0 0 1 0 1 0 0 1.2500
0 0 1 0 1 0 1 1.2375
0 0 1 0 1 1 0 1.2250
0 0 1 0 1 1 1 1.2125
0 0 1 1 0 0 0 1.2000
0 0 1 1 0 0 1 1.1875
0 0 1 1 0 1 0 1.1750
0 0 1 1 0 1 1 1.1625
0 0 1 1 1 0 0 1.1500
0 0 1 1 1 0 1 1.1375
0 0 1 1 1 1 0 1.1250
0 0 1 1 1 1 1 1.1125
0 1 0 0 0 0 0 1.1000
0 1 0 0 0 0 1 1.0875
0 1 0 0 0 1 0 1.0750
0 1 0 0 0 1 1 1.0625
0 1 0 0 1 0 0 1.0500
0 1 0 0 1 0 1 1.0375
0 1 0 0 1 1 0 1.0250
0 1 0 0 1 1 1 1.0125
0 1 0 1 0 0 0 1.0000
0 1 0 1 0 0 1 0.9875
0 1 0 1 0 1 0 0.9750
0 1 0 1 0 1 1 0.9625
0 1 0 1 1 0 0 0.9500
0 1 0 1 1 0 1 0.9375
0 1 0 1 1 1 0 0.9250
0 1 0 1 1 1 1 0.9125
0 1 1 0 0 0 0 0.9000
0 1 1 0 0 0 1 0.8875
0 1 1 0 0 1 0 0.8750
0 1 1 0 0 1 1 0.8625
0 1 1 0 1 0 0 0.8500
Electrical Specifications
86 Datasheet
Page 87

Electrical Specifications
Table 7-36.Voltage Identification Definition (Sheet 3 of 4)
VID6 VID5 VID4 VID3 VID2 VID1 VID0 VCC (V)
01 1 0 1 0 10.8375
01 1 0 1 1 00.8250
01 1 0 1 1 10.8125
01 1 1 0 0 00.8000
01 1 1 0 0 10.7875
01 1 1 0 1 00.7750
01 1 1 0 1 10.7625
01 1 1 1 0 00.7500
01 1 1 1 0 10.7375
01 1 1 1 1 00.7250
01 1 1 1 1 10.7125
10 0 0 0 0 00.7000
10 0 0 0 0 10.6875
10 0 0 0 1 00.6750
10 0 0 0 1 10.6625
10 0 0 1 0 00.6500
10 0 0 1 0 10.6375
10 0 0 1 1 00.6250
10 0 0 1 1 10.6125
10 0 1 0 0 00.6000
10 0 1 0 0 10.5875
10 0 1 0 1 00.5750
10 0 1 0 1 10.5625
10 0 1 1 0 00.5500
10 0 1 1 0 10.5375
10 0 1 1 1 00.5250
10 0 1 1 1 10.5125
10 1 0 0 0 00.5000
10 1 0 0 0 10.4875
10 1 0 0 1 00.4750
10 1 0 0 1 10.4625
10 1 0 1 0 00.4500
10 1 0 1 0 10.4375
10 1 0 1 1 00.4250
10 1 0 1 1 10.4125
10 1 1 0 0 00.4000
10 1 1 0 0 10.3875
10 1 1 0 1 00.3750
10 1 1 0 1 10.3625
10 1 1 1 0 00.3500
10 1 1 1 0 10.3375
10 1 1 1 1 00.3250
10 1 1 1 1 10.3125
11 0 0 0 0 00.3000
11 0 0 0 0 10.2875
11 0 0 0 1 00.2750
Datasheet 87
Page 88

Table 7-36.Voltage Identification Definition (Sheet 4 of 4)
VID6 VID5 VID4 VID3 VID2 VID1 VID0 VCC (V)
1 1 0 0 0 1 1 0.2625
1 1 0 0 1 0 0 0.2500
1 1 0 0 1 0 1 0.2375
1 1 0 0 1 1 0 0.2250
1 1 0 0 1 1 1 0.2125
1 1 0 1 0 0 0 0.2000
1 1 0 1 0 0 1 0.1875
1 1 0 1 0 1 0 0.1750
1 1 0 1 0 1 1 0.1625
1 1 0 1 1 0 0 0.1500
1 1 0 1 1 0 1 0.1375
1 1 0 1 1 1 0 0.1250
1 1 0 1 1 1 1 0.1125
1 1 1 0 0 0 0 0.1000
1 1 1 0 0 0 1 0.0875
1 1 1 0 0 1 0 0.0750
1 1 1 0 0 1 1 0.0625
1 1 1 0 1 0 0 0.0500
1 1 1 0 1 0 1 0.0375
1 1 1 0 1 1 0 0.0250
1 1 1 0 1 1 1 0.0125
1 1 1 1 0 0 0 0.0000
1 1 1 1 0 0 1 0.0000
1 1 1 1 0 1 0 0.0000
1 1 1 1 0 1 1 0.0000
1 1 1 1 1 0 0 0.0000
1 1 1 1 1 0 1 0.0000
1 1 1 1 1 1 0 0.0000
1 1 1 1 1 1 1 0.0000
Electrical Specifications
88 Datasheet
Page 89

Electrical Specifications
Table 7-37.Market Segment Selection Truth Table for MSID[2:0]
MSID[2] MSID[1] MSID[0] Description
0 0 0 Reserved
0 0 1 Reserved
0 1 0 Reserved
0 1 1 Reserved
1 0 0 Standard Voltage (SV) 35-W Supported 3
1 0 1 Reserved
1 1 0 Reserved
1 1 1 Reserved
1,2
Notes
1. MSID[2:0] signals are provided to indicate the maximum platform capability to the processor.
2. MSID is used on rPGA988A platforms only.
NOTES:
3. Processors specified for use with a -1.9 mΩ
7.5 Reserved or Unused Signals
The following are the general types of reserved (RSVD) signals and connection
guidelines:
• RSVD - these signals should not be connected
• RSVD_TP - these signals should be routed to a test point
• RSVD_NCTF - these signals are non-critical to function and may be left un-
connected
Arbitrary connection of these signals to V
other signal (including each other) may result in component malfunction or
incompatibility with future processors. See Chapter 8 for a pin listing of the processor
and the location of all reserved signals.
For reliable operation, always connect unused inputs or bi-directional signals to an
appropriate signal level. Unused active high inputs should be connected through a
resistor to ground (V
). Unused outputs maybe left unconnected; however, this may
SS
interfere with some Test Access Port (TAP) functions, complicate debug probing, and
prevent boundary scan testing. A resistor must be used when tying bi-directional
signals to power or ground. When tying any signal to power or ground, a resistor will
also allow for system testability. Resistor values should be within ±20% of the
impedance of the baseboard trace, unless otherwise noted in the appropriate platform
design guidelines. For details see Tabl e 7-45.
, VTT, V
CC
DDQ
, V
CCPLL
, V
, VSS, or to any
AXG
Datasheet 89
Page 90

7.6 Signal Groups
Signals are grouped by buffer type and similar characteristics as listed in Table 7 -3 8.
The buffer type indicates which signaling technology and specifications apply to the
signals. All the differential signals, and selected DDR3 and Control Sideband signals
have On-Die Termination (ODT) resistors. There are some signals that do not have ODT
and need to be terminated on the board.
Electrical Specifications
Table 7-38.Signal Groups
Signal Group
System Reference Clock
Differential (a) CMOS Input BCLK, BCLK#
Differential (b) CMOS Output BCLK_ITP, BCLK_ITP#
DDR3 Reference Clocks
Differential (c) DDR3 Output SA_CK[1:0], SA_CK#[1:0]
DDR3 Command Signals
Single Ended (d) DDR3 Output SA_RAS#, SB_RAS#, SA_CAS#, SB_CAS#
DDR3 Data Signals
Single ended (e) DDR3 Bi-directional SA_DQ[63:0], SB_DQ[63:0]
Differential (f) DDR3 Bi-directional SA_DQS[7:0], SA_DQS#[7:0]
TAP (ITP/XDP)
Single Ended (g) CMOS Input TCK, TMS, TRST#
Single Ended (ga) CMOS Input TDI,TDI_M
Single Ended (h) CMOS Open-Drain
Single Ended (i) Asynchronous
2
1
(Sheet 1 of 3)
Alpha
Group
2
2
Type Signals
PEG_CLK, PEG_CLK#
DPLL_REF_SSCLK, DPLL_REF_SSCLK#
SB_CK[1:0], SB_CK#[1:0]
SA_WE#, SB_WE#
SA_MA[15:0], SB_MA[15:0]
SA_BS[2:0], SB_BS[2:0]
SA_DM[7:0], SB_DM[7:0]
SM_DRAMRST#
SA_CS#[1:0], SB_CS#[1:0]
SA_ODT[1:0], SB_ODT[1:0]
SA_CKE[1:0], SB_CKE[1:0]
SB_DQS[7:0], SB_DQS#[7:0]
TDO, TDO_M
Output
TAPPWRGOOD
CMOS Output
90 Datasheet
Page 91

Electrical Specifications
Table 7-38.Signal Groups1 (Sheet 2 of 3)
Signal Group
Alpha
Group
Type Signals
Control Sideband
Single Ended (ja) Asynchronous
CMOS Input
Single Ended (jb) Asynchronous
V
CCPWRGOOD_0
, V
SM_DRAMPWROK
CCPWRGOOD_1
, V
TTPWR GOOD
CMOS Input
Single Ended (k) Asynchronous
RESET_OBS#
CMOS Output
Single Ended (l) Asynchronous GTL
PRDY#, THERMTRIP#
Output
Single Ended (m) Asynchronous GTL
PREQ#
Input
Single Ended (n) GTL Bi-directional CATERR#, BPM#[7:0]
Single Ended (o) Asynchronous Bi-
PECI
directional
Single Ended (p) Asynchronous GTL
PROCHOT#
Bi-directional
Single Ended (qa) CMOS Input PM_SYNC, PM_EXT_TS#[0], PM_EXT_TS#[1],
CFG[17:0]
Single Ended (qb) CMOS Input RSTIN#
Single Ended (r) CMOS Output PROC_DPRSLPVR
VID[6]
V
TT_SELECT
Single Ended (s) CMOS
Bi-directional
VID[5:3]/CSC[2:0]
VID[2:0]/MSID[2:0]
Single Ended (t) Analog Input COMP0, COMP1, COMP2, COMP3,
SM_RCOMP[2:0], I
Single Ended (ta) Analog Output SA_DIMM_VREFDQ5, SB_DIMM_VREFDQ
SENSE
5
Power/Ground/Other
Single Ended (u) Power V
(v) Ground VSS, V
(w) No Connect /Test
, V
, V
CC
V
DDQ_CK
TT0
3
SS_NCTF
TT1
, V
, DC_TEST_xx#
CCPLL
, V
DDQ
RSVD, RSVD_TP, RSVD_NCTF
, V
3
AXG
, V
TT0_DDR
Point
(x) Asynchronous
PSI#
CMOS Output
(y) Sense Points V
CC_SENSE
V
AXG_SENSE
(z) Other SKTOCC#, DBR#, PROC_DETECT3, VCAP03,
VCAP
, V
3
, VCAP2
SS_SENSE
, V
SSAXG_SENSE
3
, V
TT_SE NSE
, V
SS_SENSE_VTT
3
,
,
Datasheet 91
Page 92
Table 7-38.Signal Groups1 (Sheet 3 of 3)
Electrical Specifications
Signal Group
Integrated Graphics
Single Ended (aa) Analog Input GFX_IMON
Single Ended (ab) CMOS Output GFX_VID[6:0], GFX_VR_EN, GFX_DPRSLPVR
PCI Express* Graphics
Differential (ac) PCI Express Input PEG_RX[15:0], PEG_RX#[15:0]
Differential (ad) PCI Express Output PEG_TX[15:0], PEG_TX#[15:0]
Single Ended (ae) Analog Input PEG_ICOMP0, PEG_ICOMPI, PEG_RCOMP0,
DMI
Differential (af) DMI Input DMI_RX[3:0], DMI_RX#[3:0]
Differential (ag) DMI Output DMI_TX[3:0], DMI_TX#[3:0]
Intel® FDI
Single Ended (ah) CMOS Input FDI_FSYNC[1:0], FDI_LSYNC[1:0], FDI_INT
Differential (ai) Analog Output FDI_TX[7:0], FDI_TX#[7:0]
NOTES:
1. Refer to Chapter 6 for signal description details.
2. SA and SB refer to DDR3 Channel A and DDR3 Channel B.
3. These signals are only applicable for the BGA package
4. These signals are only applicable for the rPGA988A package.
Alpha
Group
Type Signals
PEG_RBIAS
All Control Sideband Asynchronous signals are required to be asserted/deasserted for
at least eight BCLKs in order for the processor to recognize the proper signal state. See
Section 7.10 for the DC specifications.
7.7 Test Access Port (TAP) Connection
Due to the voltage levels supported by other components in the Test Access Port (TAP)
logic, Intel recommends the processor be first in the TAP chain, followed by any other
components within the system. A translation buffer should be used to connect to the
rest of the chain unless one of the other components is capable of accepting an input of
the appropriate voltage. Two copies of each signal may be required with each driving a
different voltage level.
92 Datasheet
Page 93

Electrical Specifications
7.8 Absolute Maximum and Minimum Ratings
Ta b l e 7 -39 specifies absolute maximum and minimum ratings. At conditions outside
functional operation condition limits, but within absolute maximum and minimum
ratings, neither functionality nor long-term reliability can be expected. If a device is
returned to conditions within functional operation limits after having been subjected to
conditions outside these limits (but within the absolute maximum and minimum
ratings) the device may be functional, but with its lifetime degraded depending on
exposure to conditions exceeding the functional operation condition limits.
At conditions exceeding absolute maximum and minimum ratings, neither functionality
nor long-term reliability can be expected. Moreover, if a device is subjected to these
conditions for any length of time it will either not function or its reliability will be
severely degraded when returned to conditions within the functional operating
condition limits.
Although the processor contains protective circuitry to resist damage from ElectroStatic Discharge (ESD), precautions should always be taken to avoid high static
voltages or electric fields.
Table 7-39.Processor Absolute Minimum and Maximum Ratings
Symbol Parameter Min Max Unit Notes
V
CC
V
TT
V
DDQ
V
CCPLL
V
AXG
NOTES:
1. For functional operation, all processor electrical, signal quality, mechanical and thermal specifications must
2. V
Processor Core voltage with respect to V
Voltage for the memory controller and Shared Cache
with respect to V
Processor I/O supply voltage for DDR3 with respect to
V
SS
Processor PLL voltage with respect to V
Graphics voltage with respect to V
SV
ULV
be satisfied.
CC
and V
are VID based rails.
AXG
SS
SS
SS
SS
-0.3 1.40 V 1, 2
-0.3 1.40 V
-0.3 1.80 V
-0.3 1.98 V
V
-0.3
-0.3
1.55
1.55
7.9 Storage Conditions Specifications
Environmental storage condition limits define the temperature and relative humidity to
which the device is exposed to while being stored in a moisture barrier bag. The
specified storage conditions are for component level prior to board attach.
Ta b l e 7 -40 specifies absolute maximum and minimum storage temperature limits which
represent the maximum or minimum device condition beyond which damage, latent or
otherwise, may occur. The table also specifies sustained storage temperature, relative
humidity, and time-duration limits. these limits specify the maximum or minimum
Datasheet 93
Page 94

Electrical Specifications
device storage conditions for a sustained period of time. At conditions outside sustained
limits, but within absolute maximum and minimum ratings, quality and reliability may
be affected.
Table 7-40.Storage Condition Ratings
Symbol Parameter Min Max Notes
T
absolute storage
T
sustained storage
RH
sustained storage
Time
sustained storage
NOTES:
1. Refers to a component device that is not assembled in a board or socket and is not electrically connected to
a voltage reference or I/O signal.
2. Specified temperatures are not to exceed values based on data collected. Exceptions for surface mount
reflow are specified by the applicable JEDEC standard. Non-adherence may affect processor reliability.
3. T
4. Component product device storage temperature qualification methods may follow JESD22-A119 (low
5. Intel® branded products are specified and certified to meet the following temperature and humidity limits
6. The JEDEC J-JSTD-020 moisture level rating and associated handling practices apply to all moisture
7. Nominal temperature and humidity conditions and durations are given and tested within the constraints
absolute storage
moisture barrier bags, or desiccant.
temp) and JESD22-A103 (high temp) standards when applicable for volatile memory.
that are given as an example only (Non-Operating Temperature Limit: -40°C to 70°C and Humidity: 50%
to 90%, non-condensing with a maximum wet bulb of 28°C.) Post board attach storage temperature limits
are not specified for non-Intel branded boards.
sensitive devices removed from the moisture barrier bag.
imposed by T
The non-operating device storage temperature.
Damage (latent or otherwise) may occur when
exceeded for any length of time.
The ambient storage temperature (in shipping
media) for a sustained period of time)
The maximum device storage relative humidity
for a sustained period of time.
A prolonged or extended period of time; typically
associated with customer shelf life.
applies to the unassembled component only and does not apply to the shipping media,
sustained storage
and customer shelf life in applicable Intel boxes and bags.
-25°C 125°C 1, 2, 3, 4
-5°C 40°C 5, 6
60% @ 24°C 6, 7
0 Months 6 Months 7
7.10 DC Specifications
The processor DC specifications in this section are defined at the processor
pins, unless noted otherwise. See Chapter 8 for the processor pin listings and
Chapter 6 for signal definitions.
The DC specifications for the DDR3 signals are listed in Tab l e 7 -4 4 Control Sideband
and Test Access Port (TAP) are listed in Ta b l e 7 -4 5.
Table 7 - 4 1 lists the DC specifications for the processor and are valid only while meeting
specifications for junction temperature, clock frequency, and input voltages. Care
should be taken to read all notes associated with each parameter.
94 Datasheet
Page 95

Electrical Specifications
7.10.1 Voltage and Current Specifications
Table 7-41.Processor Core (VCC) Active and Idle Mode DC Voltage and Current
Specifications
Symbol Parameter Segment Min Typ Max Unit Note
HFM_VID VID Range for Highest
Frequency Mode
LFM_VID VID Range for Lowest
Frequency Mode
V
CC
I
CCMAX
I
CC_TDC
I
CC_LFM
I
C6
TOL
VID
VCC for processor core See Figure 7-13 and Figure 7-14 V2, 3, 4
Maximum Processor
Core I
CC
Thermal Design ICC SV
ICC at LFM SV
ICC at C6 Idle-state ULV 0.3 A
VID Tolerance See Figure 7-13 and Figure 7-14
VR Step VID resolution 12.5 mV
SLOPE
LL
Non-VR LL
contribution
Processor Loadline SV
Non-VR Loadline
Contribution for V
CC
NOTES:
1. Unless otherwise noted, all specifications in this table are based on pre-silicon estimates and simulations or
empirical data. These specifications will be updated with characterized data from silicon measurements at
a later date.
2. Each processor is programmed with a maximum valid voltage identification value (VID), which is set at
manufacturing and cannot be altered. Individual maximum VID values are calibrated during manufacturing
such that two processors at the same frequency may have different settings within the VID range. Please
note this differs from the VID employed by the processor during a power or thermal management event
(Intel Adaptive Thermal Monitor, Enhanced Intel SpeedStep Technology, or Low Power States).
3. The voltage specification requirements are defined across VCC_SENSE and VSS_SENSE pins on the bottom
side of the baseboard.
4. Refer to Figure 7-13 and Figure 7-14 for the minimum, typical, and maximum V
current. The processor should not be subjected to any V
V
5. Processor core VR to be designed to electrically support this current
for a given current.
CC_MAX
6. Processor core VR to be designed to thermally support this current indefinitely.
7. This specification assumes that Intel Turbo Boost Technology with Intelligent Power Sharing is enabled.
SV
ULV
SV
ULV
SV
ULV
ULV
ULV
ULV
0.800
0.750
0.775
0.725
1.4
V1,2,7
1.4
1.0
V1,2
1.0
48
A5,7
27
32
A6,7
16
18
A6
8
-1.9
mΩ
-3.0
-0.9 mΩ
allowed for a given
and ICC combination wherein VCC exceeds
CC
CC
Datasheet 95
Page 96

Figure 7-13.Active VCC and ICC Loadline (PSI# Asserted)
ICCmax
V
CC
V
]
VCCnom
± V
CC
Tolerance
= VR St. Pt. Error
V
CC, DC
min
V
CC, DC
max
V
CC
max
V
CC
min
13mV= RIPPLE
ICC[A]
0
Slope = SLOPE
LL
VCC_SENSE, VSS_SENSE pins.
D iffere nt ial R em o te S en se req uire d .
VCCS et P oin t E rro r T ole ra nc e is pe r b elo w :
Tolerance V
CC-CORE
VID Voltage Range
--------------- --------------------- ----------------------------------
± [V ID*1.5 %-3 mV ] V
CC
> 0.7500V
± [11.5mV-3m V] 0.5000V<V
CC
= 0.7500V
ICCmax
V
CC
VCCnom
± V
CC
Tolerance
= VR St. Pt. Error
V
CC, DC
min
V
CC, DC
max
V
CC
max
V
CC
min
10mV= RIPPLE
ICC[A]
0
Slope = SLOPE
LL
VCC_SENSE, VSS_SENSE pins.
Differential Remote Sense required.
VCCSet Point Error Tolerance is per below:
Tolerance V
CC-CORE
VID Voltage Range
--------------- -------------------------------------------------------
± [VID*1.5%] V
CC
> 0.7500V
± [11.5mV] 0.5000V < V
CC
=0.7500V
[
Electrical Specifications
Figure 7-14.Active VCC and ICC Loadline (PSI# Not Asserted)
[V]
96 Datasheet
Page 97

Electrical Specifications
Table 7-42.Processor Uncore I/O Buffer Supply DC Voltage and Current Specifications
Symbol Parameter Min Typ Max Unit Note
V
TT
V
(DC+AC) Processor I/O supply voltage for DDR3
DDQ
V
CCPLL
TOL
TT
TOL
DDQ
TOL
CCPLL
I
CCMAX_VTT
I
CCMAX_VDDQ
I
CCMAX_VDDQ_CK
I
CCMAX_VTT0_DDR
I
CCMAX_VCCPLL
I
CCTDC_VTT
I
CCAVG_VDDQ
(Standby)
Voltage for the memory controller and
shared cache defined at the
0.9975 1.05 1.1025 V 1
motherboard Vtt pinfield via
Voltage for the memory controller and
shared cache defined across
0.9765 1.05 1.1235 V 2
VTT_SENSE and VSS_SENSE_VTT
(DC + AC specification)
PLL supply voltage (DC + AC
specification)
VTT Tolerance defined at the socket
motherboard VTT pinfield via
Tolerance defined across
V
TT
VTT_SENSE and VSS_SENSE_VTT
1.425 1.5 1.575 V
1.710 1.8 1.890 V
DC: ±2%
AC: ±3% including ripple
DC: ±2%
AC: ±5% including ripple
%1
VDDQ Tolerance DC= ±3%
AC= ±2%
%
AC+DC= ±5%
VCCPLL Tolerance AC+DC= ±5% %
Max Current for VTT Rail
SV
ULV
Max Current for V
Rail - 3 A
DDQ
18
16
0.2 A 4
2.6 A 4
Max Current for V
Thermal Design Current
(TDC) for V
TT
Rail
SV
ULV
Average Current for V
Standby
Rail - 1.35 A
CCPLL
-
18
16
Rail during
DDQ
-0.33A 5
A3
A3
2
NOTES:
1. The voltage specification requirements are defined across at the socket motherboard pinfield vias on the
bottom side of the baseboard.
2. The voltage specification requirements are defined across VTT_SENSE and VSS_SENSE_VTT pins on the
bottom side of the baseboard.
3. Defined at nominal VTT voltage
4. These are pre-silicon estimates and are subject to change.
5. Based on junction temperature of 50°C.
Datasheet 97
Page 98

Electrical Specifications
I
CCMAX_VAXG
V
AXG
[V]
V
AXG_NOM
= GFX_VID
V
AXG
Total tolerance window (GFX_DPRSLPVR de-asserted)
DC (set poin t +LL tolerance)+ AC (ripple)
for Standard and Enhanced Performance Frequency Modes
V
AXG_MAX
=
V
AXG_NOM
+2.2%*GFX_VID
I
AXG
[A]
0
Slope = LL
AXG
at package VAXG_SENSE, and VSSAXG_SENSE pins
Differential Remote Sense required.
+/-VID*2.2%
V
AXG_MIN
=
V
AXG_NOM
-LL
AXG*ICCMAX_VAXG
-2.2%*GFX_VID
Table 7-43.Processor Graphics VID based (V
Specifications
) Supply DC Voltage and Current
AXG
Symbol Parameter Min Typ Max Unit Note
GFX_VID
V
AXG
TOL
AXG
Non-VR LL
contribution
LL
AXG
I
CCMAX_VAXG
I
CCTDC_VAXG
VID Range for V
SV
ULV
AXG
0
0
Graphics core voltage See Figure 7-15
V
Tole r anc e See Figure 7-15
AXG
Non-VR Load Line Contribution for
V
AXG
rPGA
BGA
V
Loadline -7 mΩ
AXG
Max Current for Integrated
Graphics Rail
SV
ULV
Thermal Design Current
(TDC) for Integrated Graphics Rail
SV
ULV
4
4.25
1.4
V2,3,4
1.35
mΩ
-
22
A4
12
-
12
A4
6
NOTES:
1. These are pre-silicon estimates and are subject to change.
2. Minimum values assume Graphics Render C-state (RC6) is enabled.
3. V
4. This specification assumes Intel Turbo Boost Technology with Intelligent Power Sharing is enabled.
is a VID-Based rail driven by an Intel MVP6.5 compliant voltage regulator.
AXG
1
Figure 7-15.V
AXG/IAXG
98 Datasheet
Static and Ripple Voltage Regulation
Page 99

Electrical Specifications
Table 7-44.DDR3 Signal Group DC Specifications
Symbol Parameter
V
IL
V
IH
V
OL
V
OH
R
ON
Input Low Voltage (e,f) 0.43*V
Input High Voltage (e,f) 0.57*V
Output Low Voltage (c,d,e,f) (V
Output High Voltage (c,d,e,f ) V
DDR3 Clock Buffer On
Resistance
R
ON
R
ON
R
ON
R
ON
DDR3 Clock Buffer On
Resistance
DDR3 Command Buffer
On Resistance
DDR3 Command Buffer
On Resistance
DDR3 Control Buffer On
Resistance
R
ON
R
ON
R
ON
DDR3 Control Buffer On
Resistance
DDR3 Data Buffer On
Resistance
DDR3 Data Buffer On
Resistance
Data ODT On-Die Termination for
Data Signals
I
LI
SM_RCOMP0
SM_RCOMP1
SM_RCOMP2
Input Leakage Current ±500 μA
COMP Resistance (t) 99 100 101 Ω 8
COMP Resistance (t) 24.7 24.9 25.1 Ω 8
COMP Resistance (t) 128.7 130 131.3 Ω 8
Alpha
Group
(d) 102
Min Typ Max Units Notes
V2,4
V3
6
V4,6
DDQ
/ 2)* (R
DDQ
(R
ON+RVTT_TERM
- ((V
DDQ
2)* (R
(R
ON+RVTT_TERM
ON
DDQ
/
ON
DDQ
/
))
/
))
21 31 Ω 5
21 36 Ω 5
16 24 Ω 5
20 31 Ω 5
21 31 Ω 5
20 31 Ω 5
21 31 Ω 5
21 36 Ω 5
51
138
69
Ω 7
1
NOTES:
1. Unless otherwise noted, all specifications in this table apply to all processor frequencies.
2. V
is defined as the maximum voltage level at a receiving agent that will be interpreted as a logical low
IL
value.
3. V
4. V
is defined as the minimum voltage level at a receiving agent that will be interpreted as a logical high
IH
value.
and VOH may experience excursions above V
IH
signal quality specifications.
. However, input signal drivers must comply with the
DDQ
5. This is the pull down driver resistance. Refer to processor I/O Buffer Models for I/V characteristics.
6. R
7. The minimum and maximum values for these signals are programmable by BIOS to one of the two sets.
VTT_TERM
8. COMP resistance must be provided on the system board with 1% resistors. COMP resistors are to V
is the termination on the DIMM and in not controlled by the Processor.
SS
.
Datasheet 99
Page 100

Electrical Specifications
Table 7-45.Control Sideband and TAP Signal Group DC Specifications
Symbol Alpha Group Parameter Min Typ Max Units Notes
V
V
V
V
V
V
V
V
V
V
V
V
V
V
R
(m),(n),(p),(s) Input Low Voltage 0.64
IL
(m),(n),(p),(s) Input High Voltage 0.76
IH
(g) Input Low Voltage 0.25
IL
(g) Input High Voltage 0.80
IH
(ga) Input Low Voltage 0.4
IL
(ga) Input High Voltage 0.75
IH
(qa) Input Low Voltage 0.38
IL
(qa) Input High Voltage 0.70
IH
(ja),(qb) Input Low Voltage 0.25
IL
(ja),(qb) Input High Voltage 0.75
IH
(jb) Input Low Voltage 0.29 2,3
IL
(jb) Input High Voltage 0.87 V 2,3,5
IH
(k),(l),(n),(p),
OL
(r),(s),(ab),(h),(i)
(k),(l),(n),(p),(r),(s),(
OH
Output Low Voltage VTT * RON /
Output High Voltage V
* VTT
* VTT
* VTT
* VTT
* VTT
TT
* VTT
* VTT
* VTT
* VTT
* VTT
(R
ON
R
SYS_TERM
+
)
ab),(i)
(k),(l),(n),(p),(r),(s),(i)Buffer on Resistance 10 18 Ω
ON
V2,3
V 2,3,5
V2,3
V 2,3,5
V2,3
V 2,3,5
V2,3
V 2,3,5
V2,3
V 2,3,5
V2,7
V2,5
1,8
R
I
I
(ab) Buffer on Resistance 20-30 27-45 Ω
ON
(ja),(jb),(m),(n),(p),(
LI
qa),(s),(t),(aa),(g)
(qb) Input Leakage Current ±150 μA4
LI
Input Leakage Current ±200 μA4
COMP0 (t) COMP Resistance 49.4 49.9 50.4 Ω 6
COMP1 (t) COMP Resistance 49.4 49.9 50.4 Ω 6
COMP2 (t) COMP Resistance 19.8 20 20.2 Ω 6
COMP3 (t) COMP Resistance 19.8 20 20.2 Ω 6
NOTES:
1. Unless otherwise noted, all specifications in this table apply to all processor frequencies.
2. The V
3. Refer to the processor I/O Buffer Models for I/V characteristics.
4. For V
5. V
signal quality specifications.
referred to in these specifications refers to instantaneous VTT.
TT
between “0” V and VTT. Measured when the driver is tristated.
IN
and VOH may experience excursions above V
IH
. However, input signal drivers must comply with the
TT
6. COMP resistance must be provided on the system board with 1% resistors. COMP resistors are to V
7. R
SYS_TERM
is the system termination on the signal.
SS
.
100 Datasheet
 Loading...
Loading...