

Page 1

i
IBM SPSS St
atistics 19 Core
System 用户指
南
Page 2

Note: Before using this information and the product it supports, read the general
information under Notices第 384 页码.
This document contains proprietary information of SPSS Inc, an IBM Company. It
is provided under a license agreement and is protected by copyright law. The
information contained in this publication does not include any product warranties,
and any statements provided in this manual should not be interpreted as such.
When you send information to IBM or SPSS, you grant IBM and SPSS a nonexclusive
right to use or distribute the information in any way it believes appropriate
without incurring any obligation to you.
© Copyright SPSS Inc. 1989, 2010.
Page 3

IBM SPSS Statistics
IBM® SPSS® Statistics 是一种用于分析数据的综合系统。SPSS Statistics可以从几
乎任何类型的文件中获取数据,然后使用这些数据生成分布和趋势、描述统计以及复
杂统计分析的表格式报告、图表和图。
本手册《IBM SPSS Statistics 19 Core System 用户指南》记录了 SPSS Statistics 的图
形用户界面。随软件安装的帮助系统中提供了使用附加选项中所包含统计过程的示例。
此外,在菜单和对话框之下,SPSS Statistics 使用命令语言。该系统的一些扩展
功能只能通过命令语法来访问。(这些功能在 Student Version 中不提供。)命令语
法的详细参考信息,以两种方式提供:集成在完整的“帮助”系统中,在“帮助”菜
单的命令语法参考中,也以单独的 PDF 格式文档提供。
IBM SPSS Statistics 选项
前言
以下选项作为完整(非 Student Version)IBM® SPSS® Statistics Core 系统的附加增
强功能提供:
Statistics Base 为您提供广泛的统计过程以执行基本分析和报告,其中包括计数、交叉
表和描述统计、OLAP 立方和码本报告。它还提供了多种降维、分类和细分方法,例如因
子分析、聚类分析、最近邻元素分析和判别函数分析。此外,SPSS Statistics Base 还提
供了广泛的平均值比较算法和预测方法,例如 t 检验、方差分析、线性回归和序数回归。
Advanced Statistics 主要提供一些复杂试验和生物医学研究中常用的技术。它包括一些
用于一般线性
保险精算寿命表、Kaplan-Meier 生存分析以及基础和扩展 Cox 回归的过程。
Bootstrap 方法可以导出稳健的标准误估计值,并能为诸如均值、中位数、比例、几率
比、相关系数或回归系数等估计值导出置信区间。
Categories 执行最优尺度过程,包括对应分析。
Complex Samples 使得调查、市场、卫生和民意研究者以及使用抽样调查方法的社会学家
能够将他们复杂的样本设计并入数据分析中。
Conjoint 提供度量单个产品属性如何影响消费者和市民偏好的现实的方式。使用
Conjoint,您可以轻松地在一组产品属性的环境中度量每个产品属性的折衷效应—如同
消费者在进行采购决策时所做的一样。
Custom Tables 可创建各种具有演示质量的表格式报表,包括复杂的行列表和多重响应
数据的显示。
模型 (GLM)、线性混合模型、方差成分分析、对数线性分析、序数回归、
© Copyright SPSS Inc. 1989, 2010
iii
Page 4

Data Preparation 提供数据的快捷可视快照。使用它可以应用标识无效数据值的验证
规则。您可以创建标记超出范围的值、缺失值或空值的规则。还可以保存记录个别规
则的违反和每个个案的规则违反总数的变量。还提供了可以复制或修改的一组有限的
预定义规则。
Decision Trees 创建基于树的分类模型。它将个案分为若干组,或根据自变量(预测
变量)的值预测因变量(目标变量)的值。此过程为探索性和证实性分类分析提供验
证工具。
Direct Marketing 使组织能够通过专为直销设计的方法确保其营销计划尽可能地发
挥效力。
Exact Tests 可在小样本或分布非常不均匀的样本可能导致常规检验不准确的情况下计算
统计检验的精确的 p 值。此选项只在 Windows 操作系统中可用。
Forecasting 通过使用多种曲线拟合模型、平滑模型和用于估计自回归函数的方法,执行
综合的预测和时间序列分析。
Missing Values 描述了缺失数据的模式、估计均值和其他统计量,并为缺失观察值
归因值。
Neural Networks可以通过将产品需求预测为价格函数以及其他变量的函数或根据购买习
惯和人口统计特征分类客户来制定经营决策。神经网络是非线性数据建模工具。它们可
以用来建立输入与输出之间的复杂关系模型,也可用来查找数据中的模式。
Regression 提供了用于分析那些不能拟合传统线性统计模型的数据的方法。它包括一
些用于 probit 分析、logistic 回归、权重估计、两阶段最小平方回归和常规非线性
回归的过程。
Amos(矩™结构的™分析™)使用结构化方程建模以确认和解释涉及态度、观念和其他
驱动行为的因素的概念模型。
关于 SPSS Inc.,IBM 下属公司
SPSS Inc. 是一家 IBM 下属公司,它也是全球领先的预测分析软件和解决方案提供商。
该公司拥有全面的产品系列,涵盖数据收集、统计量、建模和部署,通过在业务流程
中嵌入分析技术,收集人们的态度与看法,预测未来客户交互结果,然后针对这些深
入见解采取相应行动。SPSS Inc. 解决方案着眼于整合分析技术、IT 基础设施和业务
流程,以帮助达成整个企业内相互关联的业务目标。全球各地的众多企业、政府和学
术机构客户依靠 SPSS Inc. 技术在吸引、留住和发展客户方面取得竞争优势,同时减
少欺诈并缓解风险。SPSS Inc. 在 2009 年 10 月被 IBM 并购。有关更多信息,请访问
http://www.spss.com。
技术支持
我们提供有“技术支持”以维护客户。客户可就 SPSS Inc. 产品使
用或某一受支持硬件环境的安装帮助寻求技术支持。要获得“技术支
持”,请访问 SPSS Inc. 网站 http://support.spss.com,或通过网站
http://support.spss.com/default.asp?refpage=contactus.asp 找到当地办事处。在请
求协助时,请准备好您和您组织的 ID 以及支持协议。
iv
Page 5

客户服务
如果对发货或帐户存在任何问题,请联系您当地的办事处,联系方式列在 Web 站点中,
网址为 http://www.spss.com/worldwide。请先准备好您的序列号以供识别。
培训讲座
SPSS Inc. 提供公开的以及现场的培训讲座。所有讲座都是以实践小组为特色的。讲座
将定期在各大城市开展。关于这些讲座的更多信息,请联系您本地的办事处,联系方式
列在 Web 站点上,网址为 http://www.spss.com/worldwide。
附加出版物
SPSS Statistics:数据分析指南、SPSS Statistics:Statistical Procedures Companion
和 SPSS Statistics:Advanced Statistical Procedures Companion(由 Marija Norušis
编写,并已由 Prentice Hall 出版)作为建议的补充材料提供。这些出版物涵盖 SPSS
Statistics Base 模块、Advanced Statistics 模块和 回归模块中的统计过程。无论您是
刚开始从事数据分析工作,还是已准备好使用高级应用程序,这些书籍都将帮助您最有
效地利用在 IBM® SPSS® Statistics 产品中找到的功能。有关其他信息,包括出版物的
内容和示例章节,请参阅作者的网站: http://www.norusis.com
v
Page 6

1
概述 1
19 版本中的新增功能. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
Windows..................................... 2
指定的窗口和活动窗口 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
状态栏 ..................................... 4
对话框 ..................................... 4
对话框列表中的变量名和变量标签 . . . . . . . . . . . . . . . . . . . . . . . . 4
“调整大小”对话框 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
对话框控件 ................................... 5
选择变量 .................................... 5
数据类型、测量级别和变量列表图标 . . . . . . . . . . . . . . . . . . . . . . . 6
获得关于对话框中的变量的信息 . . . . . . . . . . . . . . . . . . . . . . . . . 6
数据分析中的基本步骤 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
统计辅导 .................................... 7
了解更多信息 .................................. 7
内容
2
获得帮助 8
获得输出项帮助 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3
数据文件 10
打开数据文件 ................................. 10
打开数据文件 ............................... 10
数据文件类型 ............................... 11
打开文件选项 ............................... 11
读取 Excel 95 或更高版本的文件 . . . . . . . . . . . . . . . . . . . . . . 11
读取旧 Excel 文件和其他电子表格 . . . . . . . . . . . . . . . . . . . . . 12
读取dBASE文件.............................. 12
读取Stata文件.............................. 12
读取数据库文件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
文本向导 ................................. 27
读取IBMSPSSDataCollection数据..................... 36
vi
Page 7

文件信息 ................................... 37
保存数据文件 ................................. 38
保存已修改的数据文件 . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
以外部格式保存数据文件 . . . . . . . . . . . . . . . . . . . . . . . . . . 38
以 Excel 格式保存数据文件. . . . . . . . . . . . . . . . . . . . . . . . . 41
以 SAS 格式保存数据文件 . . . . . . . . . . . . . . . . . . . . . . . . . . 41
以 Stata 格式保存数据文件. . . . . . . . . . . . . . . . . . . . . . . . . 42
保存变量子集 ............................... 43
导出到数据库 ............................... 44
导出到 IBM SPSS Data Collection . . . . . . . . . . . . . . . . . . . . . . 55
保护原始数据 ................................. 56
虚拟活动文件 ................................. 57
创建数据高速缓存 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4
分布式分析模式 60
服务器登录 .................................. 60
添加或编辑服务器登录设置 . . . . . . . . . . . . . . . . . . . . . . . . . 61
选择、切换或添加服务器 . . . . . . . . . . . . . . . . . . . . . . . . . . 62
搜索可用服务器 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
从远程服务器打开数据文件. . . . . . . . . . . . . . . . . . . . . . . . . . . 63
本地和分布式分析模式下的文件访问 . . . . . . . . . . . . . . . . . . . . . . 63
分布式分析模式下过程的可用性 . . . . . . . . . . . . . . . . . . . . . . . . 64
绝对和相对路径指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5
数据编辑器 66
数据视图 ................................... 66
变量视图 ................................... 67
显示或定义变量属性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
变量名 .................................. 68
变量测量级别 ............................... 69
变量类型 ................................. 70
变量标签 ................................. 71
值标签 .................................. 72
在标签中插入换行符 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
缺失值 .................................. 73
角色.................................... 73
列宽.................................... 74
变量对齐 ................................. 74
vii
Page 8

将变量定义属性应用于多个变量 . . . . . . . . . . . . . . . . . . . . . . 74
定制变量属性 ............................... 75
自定义变量视图 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
拼写检查 ................................. 79
输入数据 ................................... 80
输入数值数据 ............................... 80
输入非数值数据 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
使用值标签进行数据输入 . . . . . . . . . . . . . . . . . . . . . . . . . . 81
数据编辑器中的数据值限制 . . . . . . . . . . . . . . . . . . . . . . . . . 81
编辑数据 ................................... 81
替换或修改数据值 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
剪切、复制并粘贴数据值 . . . . . . . . . . . . . . . . . . . . . . . . . . 82
插入新个案 ................................ 82
插入新变量 ................................ 83
更改数据类型 ............................... 83
查找个案、变量或插补 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
查找并替换数据和属性值 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
数据编辑器中的个案选择状态 . . . . . . . . . . . . . . . . . . . . . . . . . 86
数据编辑器显示选项 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
数据编辑器打印 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
打印数据编辑器目录 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
6
使用多数据源 88
多数据源的基本处理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
使用命令语法中的多个数据集 . . . . . . . . . . . . . . . . . . . . . . . . . 90
在数据集之间复制和粘贴信息 . . . . . . . . . . . . . . . . . . . . . . . . . 91
重命名数据集 ................................. 91
不显示多个数据集 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
7
数据准备 93
变量属性 ................................... 93
定义变量属性 ................................. 93
定义变量属性 ............................... 94
定义值标签和其他变量属性 . . . . . . . . . . . . . . . . . . . . . . . . . 9
指定测量级别 ............................... 96
设定变量属性 ............................... 97
复制变量属性 ............................... 98
5
viii
Page 9

为测量级别未知的变量设置测量级别 . . . . . . . . . . . . . . . . . . . . . . 99
多重响应集 .................................. 100
定义多重响应集 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
复制数据属性 ................................. 103
复制数据属性 ............................... 103
选择源变量和目标变量 . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
选择要复制的变量属性 . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
复制数据集(文件)属性 . . . . . . . . . . . . . . . . . . . . . . . . . . 107
结果.................................... 109
标识重复个案 ................................. 109
可视离散化 .................................. 111
离散化变量 ................................ 112
离散化变量 ................................ 113
自动生成离散化类别 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
复制离散化类别 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
可视离散化中的用户缺失值 . . . . . . . . . . . . . . . . . . . . . . . . . 117
8
数据转换 119
计算变量 ................................... 119
计算变量:If个案............................. 121
计算变量:类型和标签 . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
函数 ..................................... 122
函数中的缺失值 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
随机数字生成器 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
计算个案内值的出现次数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
计算个案内的值:要计数的值. . . . . . . . . . . . . . . . . . . . . . . . 124
统计出现次数:If 个案. . . . . . . . . . . . . . . . . . . . . . . . . . . 125
转换值 .................................... 126
对值重新编码 ................................. 127
重新编码到相同的变量中 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
重新编码为相同变量:旧值和新值 . . . . . . . . . . . . . . . . . . . . . 128
重新编码为其他变量 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
重新编码为不同变量:旧值和新值 . . . . . . . . . . . . . . . . . . . . . 130
自动重新编码 ................................. 132
个案排秩 ................................... 134
个案排秩:类型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
个案排秩:结 ............................... 135
日期和时间向导 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
IBM SPSS Statistics 中的日期和时间 . . . . . . . . . . . . . . . . . . . . 138
ix
Page 10

从字符串中创建一个日期/时间变量 . . . . . . . . . . . . . . . . . . . . . 138
从变量组中创建一个日期/时间变量 . . . . . . . . . . . . . . . . . . . . . 140
从日期/时间变量中加减值 . . . . . . . . . . . . . . . . . . . . . . . . . 142
提取部分日期/时间变量 . . . . . . . . . . . . . . . . . . . . . . . . . . 149
时间序列数据转换 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
定义日期 ................................. 152
创建时间序列 ............................... 153
替换缺失值 ................................ 155
9
文件处理和文件转换 157
排序个案 ................................... 157
排列变量 ................................... 158
转置 ..................................... 159
合并数据文件 ................................. 160
添加个案 ................................... 160
添加个案:重命名 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
添加个案:字典信息 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
合并两个以上的数据源 . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
添加变量 ................................... 163
添加变量:重命名 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
合并两个以上的数据源 . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
分类汇总数据 ................................. 165
分类汇总数据:分类汇总函数. . . . . . . . . . . . . . . . . . . . . . . . 167
分类汇总数据:变量名称和标签 . . . . . . . . . . . . . . . . . . . . . . 168
分割文件 ................................... 168
选择个案 ................................... 169
选择个案:如果............................... 171
选择个案:随机样本 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
选择个案:范围............................... 172
加权个案 ................................... 173
重组数据 ................................... 174
重组数据 ................................. 174
重组数据向导:选择类型 . . . . . . . . . . . . . . . . . . . . . . . . . . 174
重组数据向导(变量到个案):变量组的数目 . . . . . . . . . . . . . . . . 177
重组数据向导(变量到个案):选择变量 . . . . . . . . . . . . . . . . . . 178
重组数据向导(变量到个案):创建索引变量 . . . . . . . . . . . . . . . . 180
重组数据向导(变量到个案):创建一个索引变量 . . . . . . . . . . . . . . 182
重组数据向导(变量到个案):创建多个索引变量 . . . . . . . . . . . . . . 183
重组数据向导(变量到个案):选项 . . . . . . . . . . . . . . . . . . . . 183
x
Page 11

重组数据向导(个案到变量):选择变量 . . . . . . . . . . . . . . . . . . 184
重组数据向导(个案到变量):排序数据 . . . . . . . . . . . . . . . . . . 185
重组数据向导(个案到变量):选项 . . . . . . . . . . . . . . . . . . . . 186
重组数据向导:完成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
10
使用输出 190
查看器 .................................... 190
显示和隐藏结果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
移动、删除和复制输出 . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
更改初始对齐方式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
更改各输出项的对齐方式 . . . . . . . . . . . . . . . . . . . . . . . . . . 192
查看器概要 ................................ 192
将项添加到查看器 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
查找和替换查看器中的信息 . . . . . . . . . . . . . . . . . . . . . . . . . 194
将输出复制到其他应用程序. . . . . . . . . . . . . . . . . . . . . . . . . . . 196
将输出项复制并粘贴到其他应用程序 . . . . . . . . . . . . . . . . . . . . 196
导出输出 ................................... 197
HTML选项 ................................. 198
Word/RTF选项............................... 199
Excel选项................................. 200
PowerPoint选项.............................. 201
PDF选项.................................. 203
文本选项 ................................. 204
只有图形选项 ............................... 205
图形格式选项 ............................... 206
查看器打印 .................................. 207
打印输出和图表 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207
打印预览 ................................. 207
页面属性:页眉和页脚 . . . . . . . . . . . . . . . . . . . . . . . . . . . 208
页面属性:选项............................... 210
保存输出 ................................... 211
保存查看器文档 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211
11
枢轴表 212
操作枢轴表 .................................. 212
激活枢轴表 ................................ 212
透视表 .................................. 212
更改元素在维度内的显示顺序. . . . . . . . . . . . . . . . . . . . . . . . 213
xi
Page 12

在维度元素中移动行和列 . . . . . . . . . . . . . . . . . . . . . . . . . . 213
交换行和列 ................................ 213
对行或列分组 ............................... 214
对行或列取消分组 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
旋转行标签或列标签 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
使用层 .................................... 215
创建并显示层 ............................... 215
转至层类别 ................................ 217
显示和隐藏项目 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217
隐藏表中的行和列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
显示表中的隐藏行和列 . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
隐藏和显示维度标签 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
隐藏和显示表标题 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
表格外观 ................................... 219
应用或保存表格外观 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219
编辑或创建表格外观 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219
表格属性 ................................... 220
更改枢轴表属性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220
表格属性:一般 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220
表格属性:脚注 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223
表格属性:单元格格式 . . . . . . . . . . . . . . . . . . . . . . . . . . . 223
表格属性:边框 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226
表格属性:打印 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226
单元格属性 .................................. 227
字体及背景 ................................ 228
格式值 .................................. 228
对齐与边缘 ................................ 229
脚注和题注 .................................. 230
添加脚注和题注 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
隐藏或显示题注 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
隐藏或显示表中的脚注 . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
脚注标记符 ................................ 231
对脚注重新编号 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
数据单元格宽度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232
更改列宽 ................................... 232
显示枢轴表中的隐藏边框 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232
在枢轴表中选择行和列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233
打印枢轴表 .................................. 234
控制宽表和长表的表分隔符 . . . . . . . . . . . . . . . . . . . . . . . . . 234
从枢轴表创建图表 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234
轻量表 .................................... 235
xii
Page 13

12
模型 236
与模型进行交互作用 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236
使用模型查看器 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236
打印模型 ................................... 237
探索模型 ................................... 238
将模型中使用的字段保存到新的数据集 . . . . . . . . . . . . . . . . . . . . . 238
根据重要性将预测变量保存到新的数据集 . . . . . . . . . . . . . . . . . . . . 238
整体模型 ................................... 239
模型摘要 ................................. 241
预测变量重要性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242
预测变量频率 ............................... 243
组件模型精确性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244
组件模型详细信息 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246
自动数据准备 ............................... 247
拆分模型查看器 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 247
13
使用命令语法 249
语法规则 ................................... 249
从对话框粘贴语法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250
从对话框粘贴语法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250
从输出日志复制语法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251
从输出日志复制语法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
使用语法编辑器 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253
语法编辑器窗口 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253
术语.................................... 255
自动完成 ................................. 255
颜色编码 ................................. 255
分界点 .................................. 256
书签.................................... 257
注释或取消注释文本 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 258
设置语法格式 ............................... 259
运行命令语法 ............................... 260
Unicode语法文件 ............................... 261
多条执行命令 ................................. 261
xiii
Page 14

14
图表工具的概述 262
生成和编辑图表 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
生成图表 ................................. 262
编辑图表 ................................. 266
图表定义选项 ................................. 269
添加和编辑标题和脚注 . . . . . . . . . . . . . . . . . . . . . . . . . . . 269
设置一般选项 ............................... 269
15
使用预测模型对数据评分 272
评分向导 ................................... 273
匹配模型字段到数据集字段 . . . . . . . . . . . . . . . . . . . . . . . . . 274
选择评分函数 ............................... 277
对活动数据集进行评分 . . . . . . . . . . . . . . . . . . . . . . . . . . . 278
合并模型和转换 XML 文件. . . . . . . . . . . . . . . . . . . . . . . . . . . . 279
16
实用程序 280
变量信息 ................................... 280
数据文件注释 ................................. 281
变量集 .................................... 281
定义变量集 .................................. 281
使用变量集合显示和隐藏变量 . . . . . . . . . . . . . . . . . . . . . . . . . 282
重新排序目标变量列表 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284
使用扩展束 .................................. 284
创建扩展束 ................................ 284
安装扩展束 ................................ 285
查看已安装的扩展束 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 288
17
选项 289
一般选项 ................................... 290
查看器选项 .................................. 292
数据选项 ................................... 294
更改默认变量视图 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
6
xiv
Page 15

货币选项 ................................... 296
创建自定义货币格式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297
输出标签选项 ................................. 298
图表选项 ................................... 299
数据元素颜色 ............................... 300
数据元素线 ................................ 300
数据元素标记 ............................... 301
数据元素填充 ............................... 301
枢轴表选项 .................................. 302
文件位置选项 ................................. 304
脚本选项 ................................... 305
语法编辑器选项 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 308
多重插补选项 ................................. 310
18
定制菜单和工具栏 312
菜单编辑器 .................................. 312
定制工具栏 .................................. 313
显示工具栏 .................................. 313
定制工具栏 .................................. 314
工具栏属性 ................................ 314
编辑工具栏 ................................ 315
创建新工具 ................................ 316
19
创建和管理定制对话框 318
定制对话框生成器布局 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319
构建定制对话框 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319
对话框属性 .................................. 320
为定制对话框指定菜单位置. . . . . . . . . . . . . . . . . . . . . . . . . . . 321
在画布上布置控件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322
构建语法模板 ................................. 322
预览定制对话框 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325
管理定制对话框 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325
控件类型 ................................... 327
源列表 .................................. 328
目标列表 ................................. 328
过滤变量列表 ............................... 329
xv
Page 16

复选框 .................................. 329
组合框和列表框控件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 330
文本控件 ................................. 331
数字控件 ................................. 331
静态文本控件 ............................... 332
项目组 .................................. 332
单选组 .................................. 333
复选框组 ................................. 334
文件浏览器 ................................ 334
子对话框按钮 ............................... 336
扩展命令的自定义对话框 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 336
创建定制对话框的本地化版本 . . . . . . . . . . . . . . . . . . . . . . . . . 338
20
生产作业 340
HTML选项 ................................... 342
PowerPoint选项................................ 342
PDF选项.................................... 342
文本选项 ................................... 343
运行时间值 .................................. 343
用户提示 ................................... 344
从命令行运行生产作业 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345
转换生产工具文件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 346
21
输出管理系统 347
输出对象类型 ................................. 349
命令标识符和表子类型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 350
标签 ..................................... 351
OMS:选项................................... 352
日志记录 ................................... 356
从查看器排除输出显示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357
将输出转到IBMSPSSStatistics数据文件 ................... 357
示例:单个二维表. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357
示例:带有层的表. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 358
从多个表创建的数据文件 . . . . . . . . . . . . . . . . . . . . . . . . . . 359
控制列元素转换为数据文件中的控制变量 . . . . . . . . . . . . . . . . . . 362
OMS 生成的数据文件中的变量名 . . . . . . . . . . . . . . . . . . . . . . . 364
OXML表结构.................................. 365
xvi
Page 17

OMS标识符 .................................. 368
从查看器概要复制 OMS 标识符 . . . . . . . . . . . . . . . . . . . . . . . 370
22
脚本编写工具 371
自动脚本 ................................... 372
创建自动脚本 ............................... 372
关联已有脚本与查看器对象 . . . . . . . . . . . . . . . . . . . . . . . . . 373
以 Python 编程语言编写脚本 . . . . . . . . . . . . . . . . . . . . . . . . . . 374
运行Python脚本与Python程序 ...................... 375
“Python 编程语言”的“脚本编辑器” . . . . . . . . . . . . . . . . . . . 376
Basic 语言中的脚本编写 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 377
与 16.0 之前版本的兼容性 . . . . . . . . . . . . . . . . . . . . . . . . . 377
脚本上下文对象 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 379
启动脚本 ................................... 380
附录
A
TABLES 和 IGRAPH 命令语法转换器 381
B Notices 384
索引 387
xvii
Page 18

Page 19

概述
19 版本中的新增功能
线性模型。 线性模型根据目标与一个或多个预测变量间的线性关系来预测连续目标。线
性模型相对简单,用于评分的数学公式也易于解释。这些模型的属性比较好理解,与同
一数据集上的其他模型类型(如神经网络或决策树)相比能够非常快速构建。此功能
在 Statistics Base 附加模块中可用。
广义线性混合模型。 广义线性混合模型扩展了线性模型,使得:目标通过指定的关联函
数与因子和协变量线性相关;目标可以有非正态分布;观测可能相关。广义线性混合模
型涵盖了从简单线性回归到复杂的非正态纵向数据多变量模型的各种模型。此功能在
Advanced Statistics 附加模块中可用。
章
1
轻量表。 轻量表可以比全功能枢轴表更快呈现。尽管缺乏枢轴表的编辑功能,但它们很
容易转换为所有编辑功能可用的枢轴表。
评分向导。 新的评分向导使您可以轻松应用预测模型对数据评分,并且评分不再需要
IBM® SPSS® Statistics 服务器。
改进的默认测量级别。 对于从外部来源读取的数据以及在会话中创建的新变量,确定默
认测量级别的方法已有所改进,以评估多个条件而不仅仅是唯一值的数量。由于测量级
别会影响许多过程的结果,因此正确的测量级别指派通常是非常重要的。
“智能”输出。 直销附加模块的过程现在提供“智能”输出:帮助您评估结果的
简单、非技术性说明。
语法编辑器增强。 您现在可以将编辑器窗格拆分为上下两个窗格。您可以增加或减少
语法块的缩进,或者采用与所粘贴语法类似的格式自动缩进选定
钮允许您取消注释先前被注释的文本,并且新的选项设置允许您将语法粘贴在光标位
置。您现在还可以导航到下一个或上一个语法错误(例如,不匹配的引号),这样
很容易在运行语法之前找到这些错误。
salesforce.com 的数据库驱动程序。 salesforce.com 的数据库驱动程序允许分析人员访
问 salesforce.com 中的数据,就像您在访问 SQL 数据库中的数据一样。分析人员现在
可以连接到 salesforce.com,提取相关数据并执行分析。
内容。新的工具栏按
编译转换。 在您使用编译转换时,转换命令(如 COMPUTE 和 RECODE)在运行期间被编
译成机器代码,以提升那些包含大量个案的数据集的转换性能。此功能需要 SPSS
Statistics 服务器。
© Copyright SPSS Inc. 1989, 2010
1
Page 20

2
章1
Windows
Statistics portal。Statistics portal 是一个基于 Web 的 IBM® SPSS® Collaboration
and Deployment Services 用户界面,允许这些用户使用 SPSS Statistics 引擎的强大
功能来分析他们的数据。用户从在 SPSS Statistics 中编写的自定义用户界面(使用
自定义对话框生成器)上运行分析,并存储在他们的 IBM SPSS Collaboration and
Deployment Services Repository 中。有关 Statistics portal 的自定义用户界面的作者
的功能增强包括:在相邻分析之间接受为活动数据集指定的过滤器;在
OLAP CUBES 和 CTABLES 生成的表中隐藏较小计数;并在 CROSSTABS 交叉表中将一组行
CROSSTABS、
和列维度显示为表层。
IBM® SPSS® Statistics 中有一些不同类型的窗口:
数据编辑器。数据编辑器显示数据文件的内容。您可以用数据编辑器创建新的数据文
件或修改现有的数据文件。如果打开了多个数据文件,则每个数据文件都有一个单
独的数据编辑器窗口。
查看器。所有的统计结果、表格和图表都显示在“查看器”中。您可以编辑输出并进行
保存,便于以后使用。“查看器”窗口在您第一次运行生成输出的过程时自动打开。
枢轴表编辑器。使用枢轴表编辑器可以通过多种方法修改显示在枢轴表中的输出。您可以
编辑文本,交换行中和列中的数据,添加颜色,创建多维表,以及选择隐藏和显示结果。
图表编辑器。您可以修改图表窗口中的高分辨率图表以及绘图。您可以更改颜色,选择
不同类型的字体或大小,切换水平轴和垂直轴,旋转三维散点图,甚至更改图表类型。
文本输出编辑器。没有显示在枢轴表中的文本输出可以用文本输出编辑器进行修改。可
以编辑输出并更改字体特征(类型、样式、颜色、大小)。
语法编辑器。可以将对话框中的选择内容粘贴到语法窗口,在语法窗口中您的选择显示
为命令语法格式。然后可以编辑命令语法,以使用不能通过对话框使用的特殊功能。您
可以将这些命令保存在文件中,便于在以后的会话中使用。
Page 21
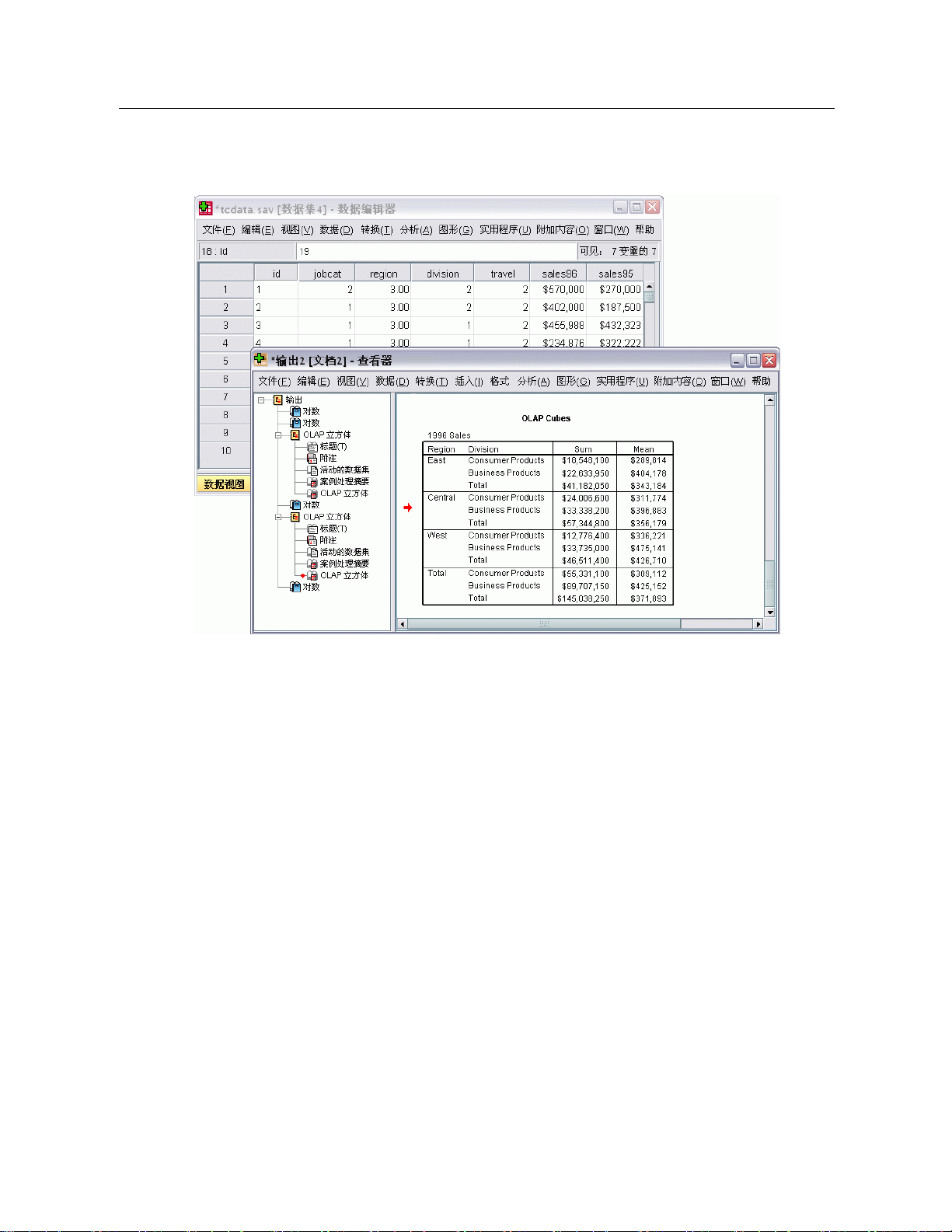
图片 1-1
数据编辑器和查看器
3
概述
指定的窗口和活动窗口
如果您打开了多个“查看器”窗口,输出会转到指定的“查看器”窗口。如果打开了
多个语法编辑器窗口,命令语法会粘贴到指定的语法编辑器窗口中。指定的窗口在标
题栏中用加号图标表示。您可以随时更改指定的窗口。
指定的窗口不应与活动窗口相混淆,活动窗口是当前选中的窗口。如果您有重叠
的窗口,则活动窗口显示在最前面。如果您打开一个窗口,该窗口就自动成为活动窗
口和指定的窗口。
更改指定的窗口
E 使您要指定的窗口成为活动窗口(单击窗口中的任意位置)。
E 单击工具栏上的“指定窗口”按钮(加号图标)。
或
E 从菜单中选择:
实用程序 > 指定窗口
注意:对于数据编辑器窗口,活动的数据编辑器窗口确定在后续计算或分析中使用的数
据集。没有“指定的”数据编辑器窗口。
Page 22

4
章1
状态栏
对话框
每个 IBM® SPSS® Statistics 窗口底部的状态栏提供以下信息:
命令状态。对于您运行的每个过程或命令,都会有一个个案计数器指示到目前为止已经
处理的个案数。对于需要迭代处理的统计过程,将显示迭代的次数。
过滤状态。如果您已选择了要分析的随机样本或个案子集,过滤范围消息表明当前正在进
行某种类型的个案过滤,并且不是数据文件中的所有个案都包括在分析中。
权重状态。加权范围消息表明正在使用权重变量对要分析的个案进行加权。
拆分文件状态。分割文件范围消息表明数据文件已按照一个或多个分组变量的值分割
成单个组以进行分析。
大多数菜单选择都会打开对话框。可以使用对话框选择要分析的变量和分析选项。
统计过程和图表的对话框一般有两个基本组件:
源变量列表。活动数据集中的变量的列表。只有选中的过程所允许的变量类型才会显示
在源列表中。短字符串和长字符串变量的使用在许多过程中受到限制。
目标变量列表。指示您已选择用于分析的变量的一个或多个列表,如因变量和自变
量列表。
对话框列表中的变量名和变量标签
可以在对话框列表中显示变量名或变量标签,并且可以控制变量列表中的变量排序顺
序。要控制源列表中变量的默认显示属性,请从“编辑”菜单中选择
您也可以在对话框中更改变量列表显示属性。更改显示属性的方法因对话框而异:
如果对话框在源变量列表上方提供有排序和显示控件,则使用这些控件更改显
示属性。
如果对话框在源变量列表上方未包含排序控件,请右键单击源列表中的任何变量,
然后从上下文菜单中选择显示属性。
可以显示变量名或变量标签(对于未定义标签的变量,显示变量名),并且可以按文
件顺序、字母顺序或测量级别对源列表进行排序。(在源变量列表上方具有排序控件
将按文件顺序对列表排序。)
的对话框中,默认选择
无
选项。
“调整大小”对话框
您可以像窗口那样,单击并拖动外部边框或角落来调整对话框大小。例如,如果使
对话框变宽,变量列表也将变得更宽。
Page 23
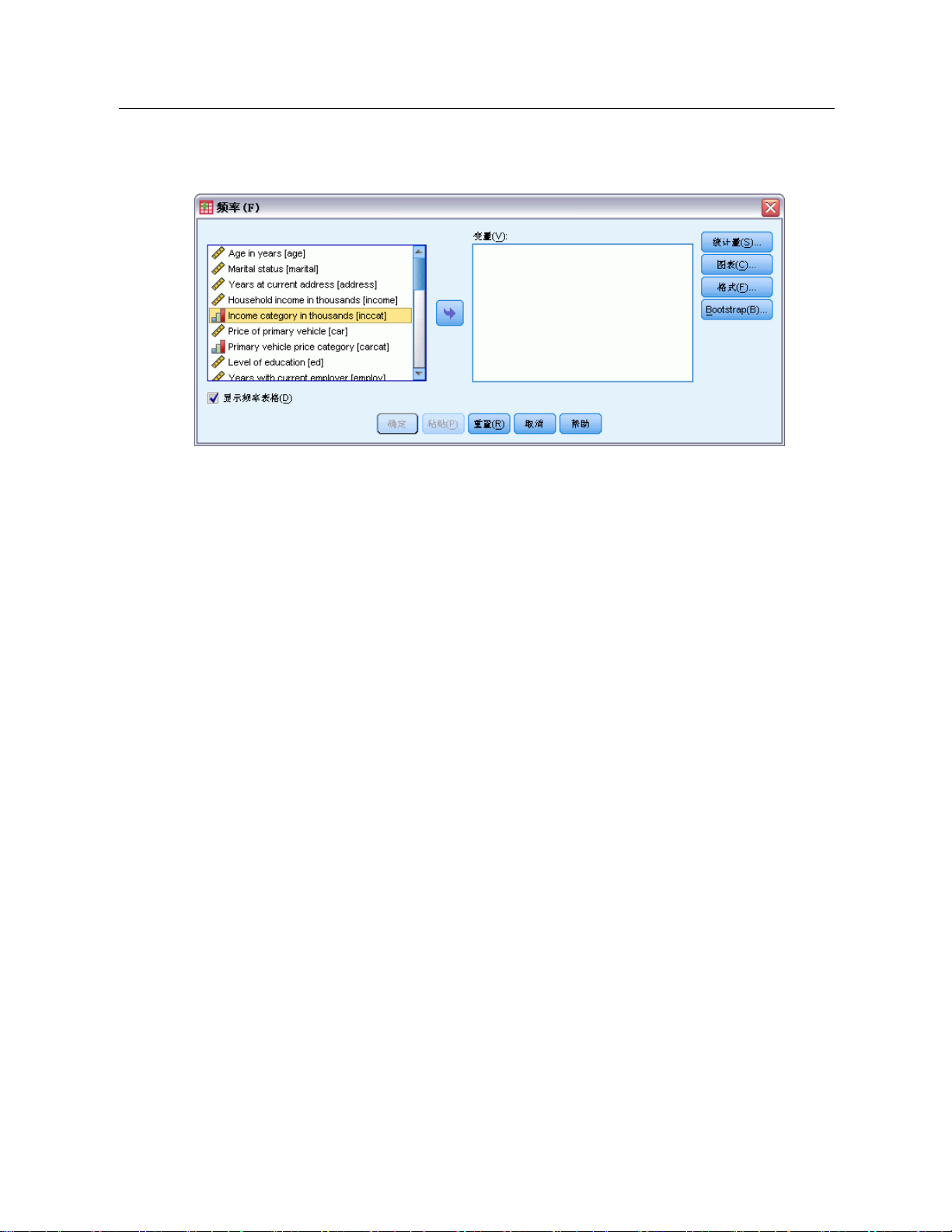
图片 1-2
“调整大小”对话框
对话框控件
5
概述
大多数对话框中都有 5 个标准控件:
确定或运行。运行过程。选择变量并选择任何其他指定后,请单击确定运行过程并关闭
对话框。某些对话框包含运行按钮,而不是“确定”按钮。
粘贴。从对话框选择生成命令语法,并将语法粘贴到语法窗口中。然后可以使用对话框
中没有的其他功能定制命令。
重置。取消选择选中的变量列表中的任何变量,将对话框和所有子对话框中的所有
指定重置为默认状态。
取消。取消对话框设置中自上次打开对话框以来所做的任何更改,并关闭对话框。在一
次会话中,对话框设置是不变的。对话框将保留上次的指定信息,直到覆盖它们。
帮助。提供上下文相关的帮助。该控件将打开一个“帮助”窗口,其中包含关于当
前对话框的信息。
选择变量
要选择单个变量,只需在源变量列表中选择该变量,然后将其拖放到目标变量列表。
还可以使用箭头按钮将变量从源列表移动到目标列表。如果只有一个目标变量列表,
则可以双击单个变量,将其从源列表移动到目标列表。
也可以选择多个变量:
要选择变量列表中分在一组中的多个变量,请单击第一个变量,然后按住 Shift
再单击组中的最后一个变量。
要选择变量列表上没有分在一组中的多个变量,请单击第一个变量,然后按住 Ctrl
再单击下一个变量,依此类推(Macintosh:Command-click)。
Page 24
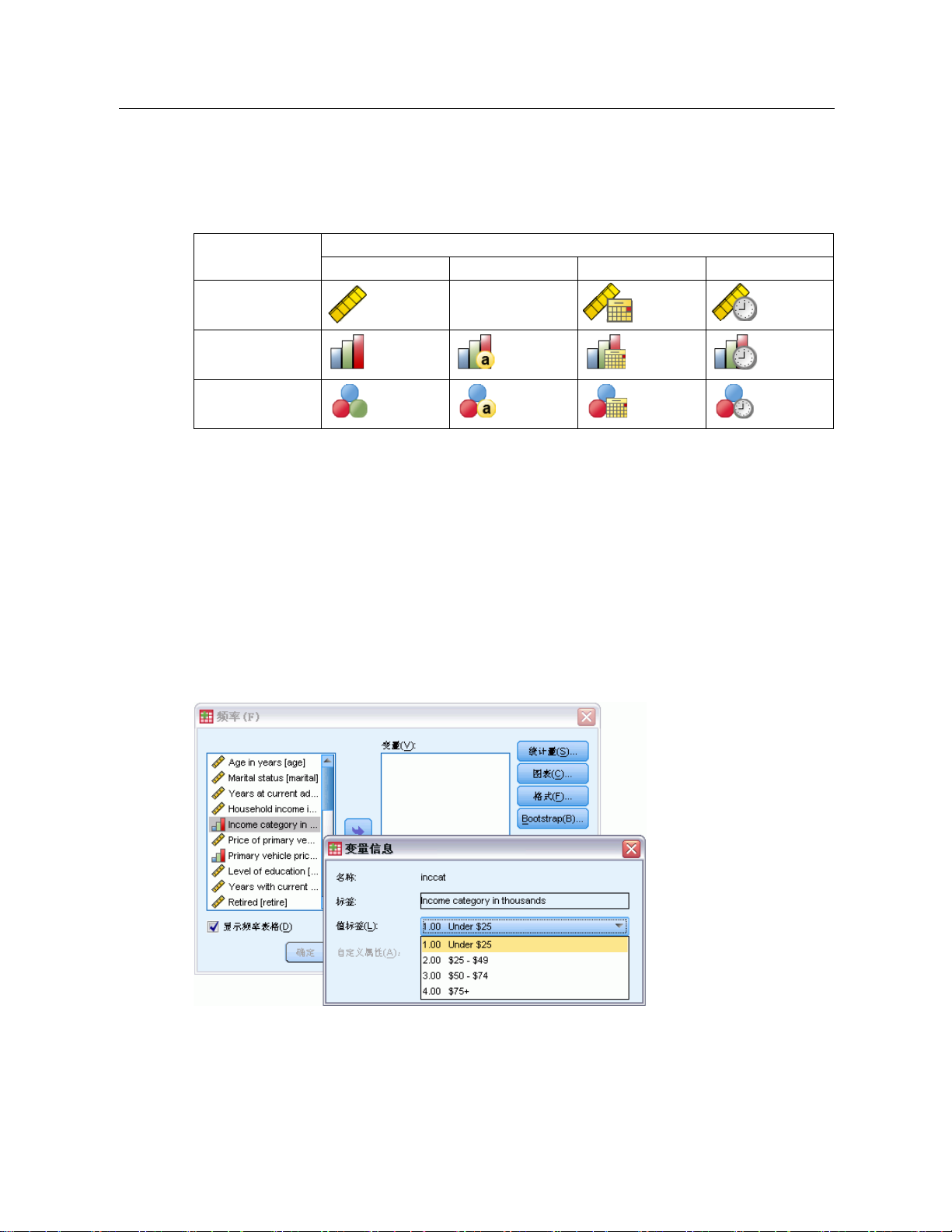
6
章1
数据类型、测量级别和变量列表图标
显示在对话框列表中的变量旁边的图标提供有关变量类型和测量级别的信息。
测量级别
数值 字符串
尺度(连续)
有序
名义
有关测量级别的更多信息,请参见变量测量级别第 69 页码。
有关数值、字符串、日期和时间数据类型的更多信息,请参见变量类型第 70 页码。
n/a
获得关于对话框中的变量的信息
许多对话框提供有查看有关在变量列表 所显示变量的更多信息的功能。
E 右键单击源变量列表或目标变量列表中的变量。
E 选择变量信息。
图片 1-3
变量信息
数据类型
日期 时间
数据分析中的基本步骤
用 IBM® SPSS® Statistics 分析数据非常简单。您需要做的只是:
Page 25

将数据输入 SPSS Statistics。您可以打开先前保存的 SPSS Statistics 数据文件;读取
电子表格、数据库或文本数据文件;或者将数据直接输入数据编辑器。
选择一个过程。从菜单中选择一个过程来计算统计量或创建图表。
选择要分析的变量。数据文件中的变量显示在该过程的对话框中。
运行过程并查看结果。结果显示在查看器中。
统计辅导
如果您不熟悉 IBM® SPSS® Statistics 或其中可用的统计过程,“统计指导”可以帮助
您入门。它用简单的问题、非技术性的语言和可视的示例提示您,帮助您选择最适合您
的数据的基本统计功能和图表绘制功能。
要使用“统计指导”,请从任意 SPSS Statistics 窗口的菜单中选择:
帮助 > 统计辅导
“统计指导”仅涵盖选定的过程子集。它旨在对许多基本的、常用的统计技巧提供帮助。
7
概述
了解更多信息
要获得基础知识的综合概述,请参见联机教程。从任意 IBM® SPSS® Statistics 菜单
中选择:
帮助 > 教程
Page 26

获得帮助
帮助以多种不同形式提供:
“帮助”菜单。大多数窗口中的“帮助”菜单可以访问主帮助系统、教程和技术参
考材料。
主题。 可以访问“目录”、“索引”和“搜索”选项卡,使用这些选项卡可以查
找特定帮助主题。
教程。有关如何使用众多基本功能的分步图解说明。不必通读整个教程。可以选择要
查看的主题,以任何顺序跳过和查看主题,使用索引或目录查找特定主题。
个案研究。如何创建各种类型的统计分析以及如何解释结果的实践示例。同时还提供
示例所使用的样本数据文件,使您能够通过对示例的研究,实际了解结果是如何生
成的。可以从目录选择要了解的特定过程,或在索引中搜索相关主题。
统计指导。类似于向导的方法,指导您完成查找要使用的过程。进行一系列选择后,
“统计指导”将打开用于符合所选标准的统计、报告或绘图过程的对话框。
命令语法参考。 命令语法的详细参考信息,以两种方式提供:集成在完整的“帮
助”系统中,在“帮助”菜单的命令语法参考中,以单独的 PDF 格式文档提供。
统计算法。 以两种形式提供用于大多数统计过程的算法:与整个帮助系统集成,或
以单独的 PDF 文档,可以从手册 CD 中获得。有关指向帮助系统中的特定算法的链
接,请在“帮助”菜单中选择
章
2
“算法”。
上下文相关的帮助。在用户界面中的许多地方都可以获得上下文相关的帮助。
对话框“帮助”按钮。大多数对话框都有“帮助”按钮,点击该按钮可直接进入该对
话框的“帮助”主题。“帮助”主题提供一般信息和相关主题的链接。
枢轴表上下文菜单帮助。右键单击浏览器中已激活的枢轴表里的项,并在上下文菜单
中选择
命令语法。在命令语法窗口中,将光标放在命令的语法块中的任意位置,然后按键盘
上的 F1。此时将显示该命令的完整命令语法图表。可从相关主题列表中的链接中以
及“帮助目录”选项卡中获得完整的命令语法文档。
其他资源
技术支持网站。
(技术支持网站需要登录 ID 和密码。上面列出的 URL 提供了有关如何获得 ID 和密
码的信息。)
Developer Central。Developer Central 拥有适合所有级别用户和应用程序开发人员的资
源。下载实用程序、图形示例、新统计模块和文章。请访问 Developer Central,网
址为http://www.spss.com/devcentral。
© Copyright SPSS Inc. 1989, 2010
这是什么?以显示这些项的定义。
在以下网站可以找到许多常见问题的解答:http://support.spss.com。
8
Page 27
获得输出项帮助
要在浏览器的枢轴表输出中查看某项的定义:
E 双击激活枢轴表。
E 右键单击想要得到解释的项。
E 从上下文菜单中,选择这是什么?。
在弹出窗口中将显示该项的定义。
图片 2-1
单击鼠标右键可出现已激活的枢轴表词汇表帮助
9
获得帮助
Page 28

数据文件
数据文件有多种格式,而本软件被设计为可以处理其中的许多格式,包括:
用 Excel 和 Lotus 创建的电子表格
来自许多数据库源(包括 Oracle、SQLServer、Access、dBASE 和其他)的数据库表
以 Tab 分隔的和其他类型的简单文本文件
在其他操作系统上创建的 IBM® SPSS® Statistics 格式的数据文件
SYSTAT 数据文件
SAS 数据文件
Stata 数据文件
章
3
打开数据文件
除了以 IBM® SPSS® Statistics 格式保存的文件以外,还可以打开 Excel、SAS、Stata、
制表符分隔文件和其他文件,而无需将文件转换为中间格式或输入数据定义信息。
打开数据文件会使其成为活动数据集。如果已经打开了一个或多个数据文件,则它
们将保持打开状态,并可在以后的会话中使用。单击“数据编辑器”窗口中的任意
位置会使打开的数据文件成为活动数据集。
在分布式分析中,使用远程服务器处理命令和运行过程的模式、可用的数据文件、
文件夹和驱动器取决于远程服务器上可用的内容。当前服务器名称在对话框的顶部
指明。除非将驱动器指定为共享设备,或者将包含数据文件的文件夹指定为共享
文件夹,否则将不能访问本地计算机上的数据文件。
打开数据文件
E 从菜单中选择:
文件 > 打开 > 数据...
E
在“打开数据”对话框中,选择要打开的文件。
E 单击打开。
根据需要,您可以:
根据观察值,最小化字符串宽度将每个字符串变量宽度自动设置为该变量的最长观察
值。在 Unicode 模式中读取代码页数据文件时特别有用。
从电子表格文件的第一行读取变量名。
© Copyright SPSS Inc. 1989, 2010
10
Page 29

指定电子表格文件中要读取的单元范围。
指定 Excel 文件中要读取的工作表(Excel 95 或更高版本)。
有关从数据库中读取数据的信息,请参见读取数据库文件第 13 页码。有关从文本数据
文件中读取数据的信息,请参见文本向导第 27 页码。
数据文件类型
SPSS Statistics。 打开以 IBM® SPSS® Statistics 格式保存的数据文件以及 DOS 产
品 SPSS/PC+。
SPSS/PC+。 打开 SPSS/PC+ 数据文件。此选项只在 Windows 操作系统上可用。
SYSTAT。 打开 SYSTAT 数据文件。
SPSS Statistics 便携。 打开以可移植格式保存的数据文件。以便携格式保存文件比以
SPSS Statistics 格式保存文件所耗费的时间要长得多。
Excel。 打开 Excel 文件。
Lotus 1-2-3。 打开以 1-2-3 格式(Lotus R3.0、2.0 或 1A)保存的数据文件。
11
数据文件
SYLK。 打开以 SYLK(符号链接)格式保存的数据文件,这是某些电子表格应用程序
使用的格式。
dBASE。 打开 dBASE 格式文件(dBASE IV、dBASE III 或 III PLUS 或者 dBASE II)。
每个个案均是一条记录。当您以这种格式保存文件时,变量和值标签以及缺失值的
指定会丢失。
SAS。 SAS 版本 6–9 和 SAS 传输文件。使用命令语法,您还可以从 SAS 格式目录文
件中读取值标签。
Stata。 Stata 版 4–8。
打开文件选项
读取变量名称。 对于电子表格,您可以从文件的第一行或定义范围的第一行读取变量
名。按需要转换值,以创建有效的变量名,例如将空格转换为下划线。
工作表。 Excel 95 或更高版本的文件可以包含多个工作表。缺省情况下,数据编辑器读
取第一张工作表。要读取其它工作表,请从下拉列表中选择工作表。
范围。 对于电子表格数据文件,您还可以读取某个单元范围。请使用与在电子表格
应用程序中相同的方法指定单元范围。
读取 Excel 95 或更高版本的文件
以下规则适用于读取 Excel 95 或更高版本的文件:
数据类型和宽度。每一列都是一个变量。每个变量的数据类型和宽度都由 Excel 文件中
的数据类型和宽度决定。如果该列包含多个数据类型(例如:日期和数字),数据类型
就设置为字符串,所有的值都读取为有效的字符串值。
Page 30

12
章3
空白单元格。对于数值变量,空白单元格会转换为系统缺失的值,用句点表示。对于字
符串变量,空格是有效的字符串值,空白单元格被视为有效的字符串值。
变量名称。如果将 Excel 文件的第一行(或者指定范围的第一行)读取为变量名称,则
不符合变量命名规则的值会转换为有效的变量名称,原始名称用作变量标签。如果不从
Excel 文件读取变量名称,则会指定缺省的变量名称。
读取旧 Excel 文件和其他电子表格
以下规则适用于读取早于 Excel 95 的 Excel 文件以及其他电子表格数据:
数据类型和宽度。 每个变量的数据类型和宽度由列中第一个数据单元的列宽和数据类型
确定。其他类型的值会转换为系统缺失值。如果列中的第一个数据单元是空白的,则
使用该电子表格的全局缺省数据类型(通常为数值)。
空白单元格。对于数值变量,空白单元格会转换为系统缺失的值,用句点表示。对于字
符串变量,空格是有效的字符串值,空白单元格被视为有效的字符串值。
变量名称。 如果不从电子表格读取变量名,则列字母(A、B、C...)用于 Excel 和
Lotus 文件的变量名。对于以 R1C1 显示
用以字母 C 开头的列号作为变量名(C1、C2、C3 等)。
格式保存的 SYLK 文件和 Excel 文件,本软件使
读取 dBASE 文件
数据库文件在逻辑上与 IBM® SPSS® Statistics 数据文件非常相似。以下一般规则适
用于 dBASE 文件:
字段名称会转换为有效的变量名。
用于 dBASE 字段名称的冒号会转换为下划线。
包含标记为要删除但未实际清除的记录。本软件创建一个新的字符串变量 D_R,该变
量对标记为要删除的个案包含一个星号。
读取 Stata 文件
以下一般规则适用于 Stata 数据文件:
变量名称。Stata 变量名以区分大小写的形式转换为 IBM® SPSS® Statistics 变量
名。通过附加下划线和顺序字母(_A、_B、_C、...、_Z、_AA、_AB、...等等),
将只有大小写不同的 Stata 变量名转换为有效的变量名。
变量标签。Stata 变量标签转换为 SPSS Statistics 变量标签。
值标签。Stata 值标签转换为 SPSS Statistics 值标签,但归为“扩展”缺失值
的 Stata 值标签除外。
缺失值。Stata“扩展”缺失值转换为系统缺失值。
日期转换。 Stata 日期格式值转换为 SPSS Statistics DATE 格式 (d-m-y) 值。Stata“
时间序列”日期格式值(周数、月数、季度数等)转换为简单数值 (F) 格式,同时
保留原始内部整数值,即从 1960 年开始算起的周数、月数、季度数等等。
Page 31

读取数据库文件
只要有某种数据库格式的数据库驱动程序,就可以读取该数据库格式的数据。用本地分
析模式时,本地计算机上必须装有所需的驱动程序。用分布式分析模式时(IBM® SPSS®
Statistics Server 提供),远程服务器上必须安装这些驱动程序。
注意:如果您正在运行 SPSS Statistics 的 Windows 64 位版本,则无法读取 Excel、
Access 或 dBASE 数据库源,即使它们出现在可用数据库源列表中。这些产品的 32 位
ODBC 驱动程序不兼容。
读取数据库文件
E 从菜单中选择:
文件 > 打开数据库(B) > 新建查询...
E
选择数据源。
E 如果需要(取决于数据源),可选择数据库文件和/或输入登录名、密码和其他信息。
E 选择表和字段。对于 OLE DB 数据源(仅在 Windows 操作系统上可用)只能选择一个表。
13
数据文件
E 指定表之间的关系。
E 或者:
为数据指定任何选择条件。
添加一个提示,供用户输入信息以创建参数查询。
运行构建的查询之前请先保存。
编辑已保存的数据库查询
E 从菜单中选择:
文件 > 打开数据库(B) > 编辑查询...
E
选择要编辑的查询文件 (*.spq)。
E 请按照创建新查询的说明操作。
使用已保存的查询读取数据库文件
E 从菜单中选择:
文件 > 打开数据库(B) > 运行查询...
E
选择要运行的查询文件 (*.spq)。
E 如果需要(取决于数据库文件),输入登录名和密码。
E 如果查询包含嵌入的提示,则根据需要输入其他信息(例如,要检索销售数据的季度)。
选择数据源
使用“数据库向导”的第一个屏幕选择要读取的数据源类型。
Page 32

14
章3
ODBC 数据源(O)
如果没有配置任何 ODBC 数据源,或者要添加新的数据源,请单击添加 ODBC 数据源。
在 Linux 操作系统中,该按钮不可用。在 odbc.ini 中指定 ODBC 数据源,并且
ODBCINI 环境变量必须设定为该文件的位置。有关更多信息,请参见数据库驱
动程序文档。
用分布式分析模式时(IBM® SPSS® Statistics Server 提供),该按钮不可用。要
用分布式分析模式添加数据源,请咨询系统管理员。
ODBC 数据源由两条基本信息组成:要用来访问数据的驱动程序和要访问的数据库的位
置。要指定数据源,必须装有适当的驱动程序。针对不同数据库格式的驱动程序可以
从 http://www.spss.com/drivers 获得。
图片 3-1
数据库向导
Page 33

15
数据文件
OLEDB数据源
要访问 OLE DB 数据源(在 Microsoft Windows 操作系统上可用),必须安装有以下内容:
.NET Framework。要获得最新版本的 .NET Framework,请转至
http://www.microsoft.com/net。
IBM® SPSS® Data Collection Survey Reporter Developer Kit。可以从安装介质上安
装与此发行版本兼容的某个版本。如果您在使用 IBM® SPSS® Statistics Developer,
则可以从 www.spss.com/statistics (http://www.spss.com/statistics/) 的“下
载”选项卡上下载兼容的版本。
以下限制适用于 OLE DB 数据源:
OLE DB 数据源不支持表连接。一次只能读取一个表。
您只能以本地分析模式添加 OLE DB 数据源。要在 Windows 服务器上以分布式分析模
式添加 OLE DB 数据源,请咨询系统管理员。
使用分布式分析模式时(SPSS Statistics Server 提供),OLE DB 数据源只能在
Windows 服务器上使用,并且该服务器上必须安装有 .NET 和 SPSS Survey Reporter
Developer Kit。
Page 34

16
章3
图片 3-2
使用数据库向导访问 OLE DB 数据源
添加 OLE DB 数据源:
E 单击添加 OLE DB 数据源。
E 在“数据链接属性”对话框中,单击提供程序选项卡,然后选择 OLE DB 提
E 单击下一步,或单击连接选项卡。
E 可通过输入目录位置和数据库名称,或者单击按钮浏览到数据库来选择数据库。(还可
供程序。
能需要用户名和密码。)
E 输入所有必需信息后,单击确定。(您可通过单击测试连接按钮来确保指定的数据库
可用。)
E 为数据库连接信息输入名称。(该名称将显示在可用的 OLE DB 数据源列表中。)
Page 35

图片 3-3
“将 OLE DB 连接信息另存为”对话框
E 单击确定。
此操作将返回到“数据库向导”的第一个屏幕,您可以在该屏幕上从 OLE DB 数据源列
表中选择已保存的名称,然后继续执行向导的下一步。
删除 OLE DB 数据源
要从 OLE DB 数据源列表中删除数据源名称,可在下列位置删除包含该数据源名称
的UDL文件:
17
数据文件
[驱动器]:\Doc
uments and Settings\[user login]\Local Settings\Application
Data\SPSS\UDL
选择数据字段
“选择数据”步骤控
制将读取哪些表和字段。数据库字段(列)读取为变量。
如果在表中选择了任何字段,则在以下“数据库向导”窗口中所有的字段都可见,
但只有在这一步中选中的字段才作为变量导入。这使您可以创建表连接,并使用未
导入的字段指定条件
。
Page 36
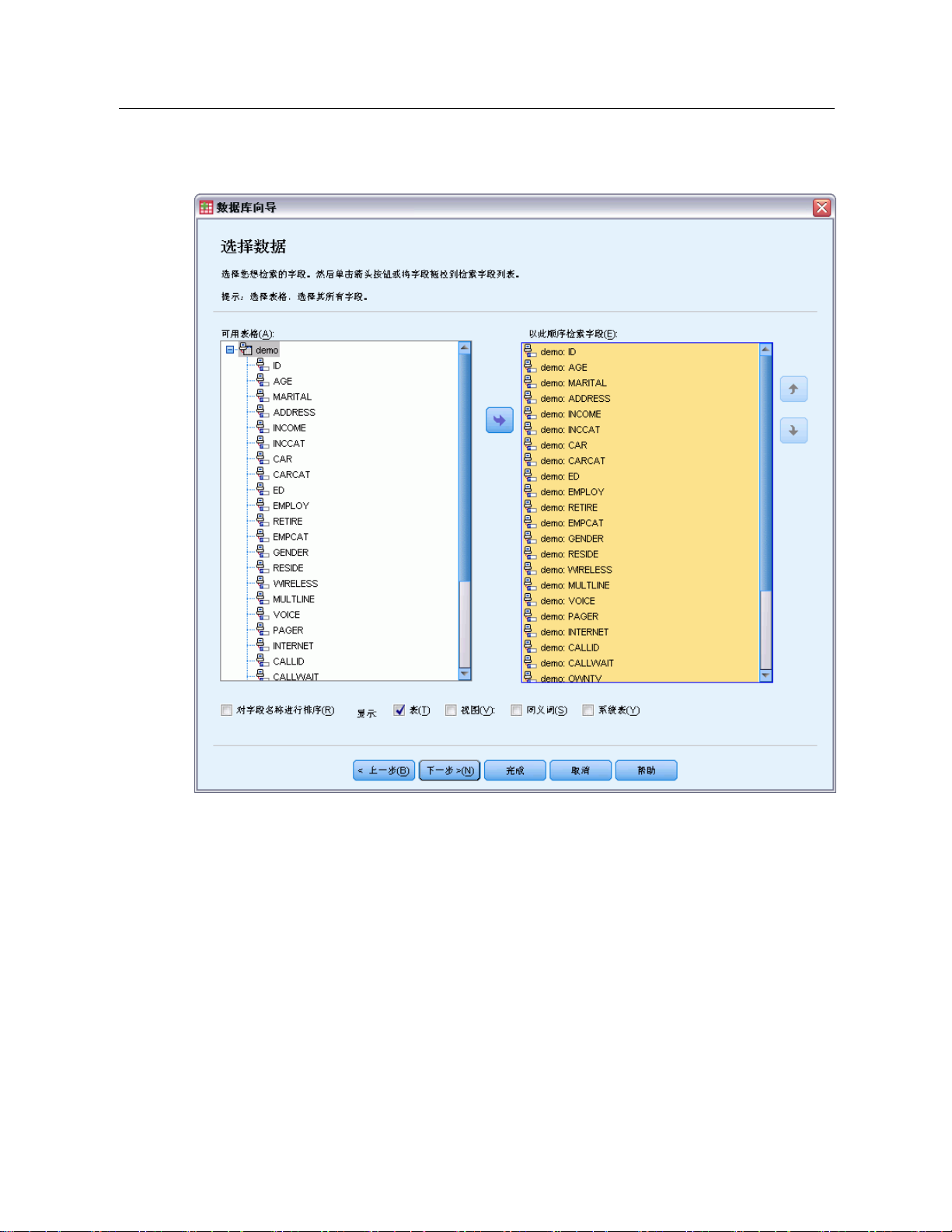
18
章3
图片 3-4
数据库向导,选择数据
显示字段名称。要列出表中的字段,请单击表名称左边的加号 (+)。要隐藏字段,请
单击表名称左边的减号 (–)。
要添加字段。双击“可用的表”列表中的任何字段,或者将其拖到“按此顺序检索字
段”列表中。在字段列表中拖放字段可以对其重新排序。
删除字段。双击“按此顺序检索字段”列表中的任何字段,或者将其拖到“可用
的表”列表。
将字段名称排序。如果选中该复选框,“数据库向导”就会按照字母顺序显示可用
的字段。
默认情况下,可用表的列表只显示标准数据库表。可以控制列表中显示的项的类型:
表。标准数据库表。
Page 37

视图。视图是由查询定义的虚拟的或动态的“表”。视图中可以包含基于其他字段值
计算得出的多个表和/或字段的连接。
同义词。同义词是表或视图的别名,通常在查询中定义。
系统表。系统表定义数据库的属性。在某些情况下,标准数据库表可能会被分类
成系统表,并且仅在选择了该选项后才会显示。通常只有数据库管理员才有访问
真正的系统表的权限。
注意:对于 OLE DB 数据源(仅在 Windows 操作系统上可用),只能从单个表中选择字
段。OLE DB 数据源不支持多个表连接。
创建表之间的关系
“指定关系”步骤使您可以定义 ODBC 数据源的表之间的关系。如果选择的字段来自一
个以上的表,则必须定义至少一个连接。
19
数据文件
Page 38
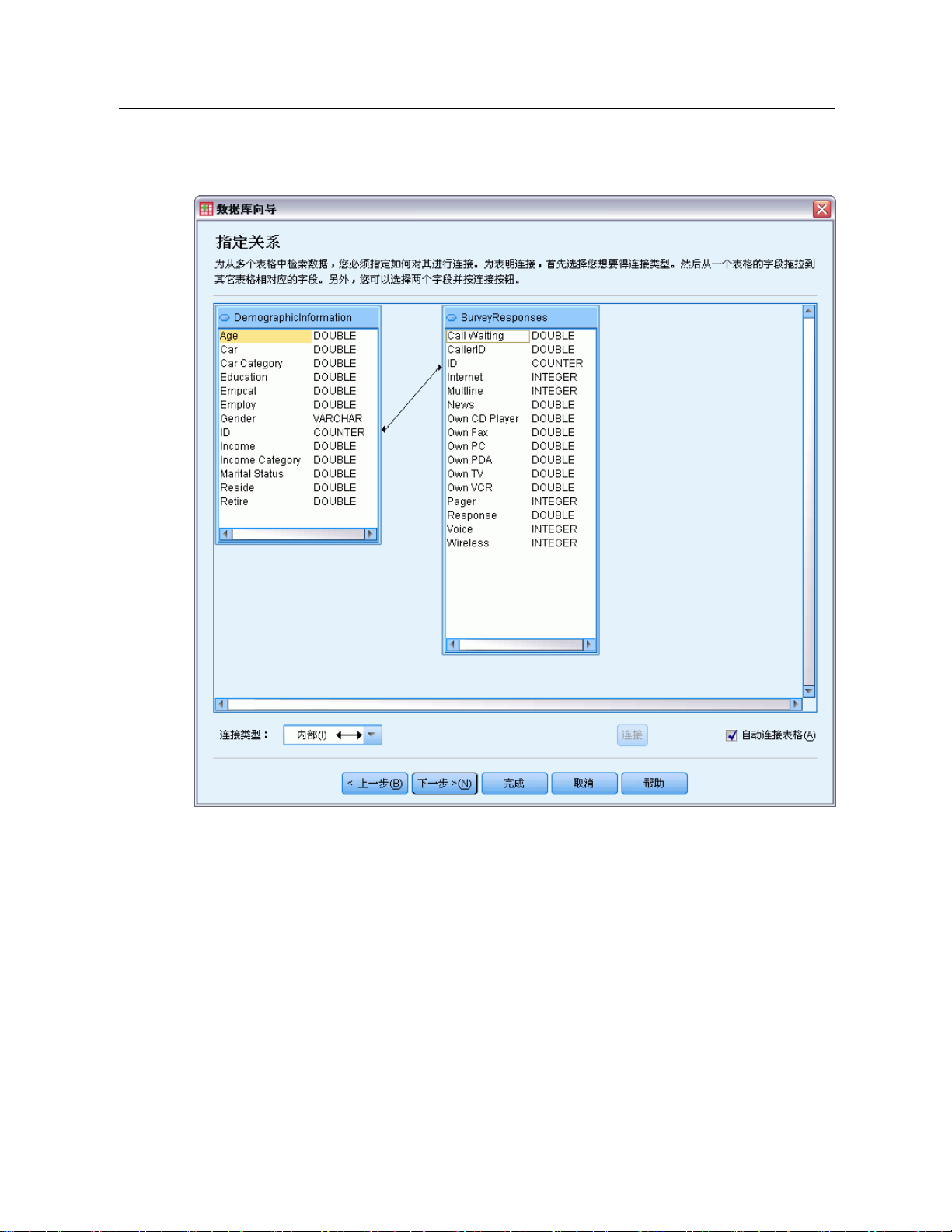
20
章3
图片 3-5
数据库向导,指定关系
建立关系。要创建关系,请将任意表上的字段拖到要连接的字段上。“数据库向导”将
在两个字段之间画一条连接线,表明它们的关系。这些字段的数据类型必须相同。
自动连接表。可尝试按照主/外键或匹配的字段名和数据类型来自动连接表。
连接类型。如果驱动程序支持外部连接,则可以指定内部连接、左边外连接或右边
外连接。
Inner joins.内部连接仅包括相关字段相等的行。在此示例中,将包括两个表中
具有匹配的 ID 值的所有行。
外部连接。除了内部连接的一对一匹配外,还可以使用外部连接通过一对多匹配方案
来合并表。例如,您可以将其中只包含少量代表数据值和关联描述性标签的记录的
表,和包含上百个或上千个代表调查响应者的记录的表中的值相匹配。左边外连接包
括左边的表中的所有记录,而仅包括右边的表中相关字段相等的记录。在右边外连
接中,连接从右边的表导入所有记录,而仅从左边的表导入相关字段相等的记录。
Page 39

限制检索的个案
“限制检索的个案”步骤使您可以指定选择个案(行)的子集的条件。限制个案通常包
括用条件填充条件网格。条件由两个表达式以及它们之间的某种关系组成。该表达式返
回每个个案的 true、false 或 missing 值。
如果结果是 true,则选中该个案。
如果结果是 false 或 missing,则不选中该个案。
大多数条件使用六个关系运算符中的一个或多个(<、>、<=、>=、= 和 <>)。
表达式可以包括字段名、常数、算术运算符、数字和其他函数以及逻辑变量。
可以将不打算导入的字段用作变量。
图片 3-6
数据库向导,限制检索的个案
21
数据文件
要建立条件,至少需要两个表达式和一种连接表达式的关系。
E 要建立表达式,请选择下列一种方法:
Page 40

22
章3
在“表达式”单元格中,键入字段名、常数、算术运算符、数字和其他函数或逻
辑变量。
双击“字段”列表中的一个字段。
将字段从“字段”列表中拖到“表达式”单元格。
从任何活动的“表达式”单元格的下拉菜单中选择一个字段。
E 要选择关系运算符(如 = 或 >),请将光标放在“关系”单元格上,然后键入运算
符或从下拉菜单中进行选择。
如果 SQL 包含具有个案选择表达式的
WHERE 子句,则表达式中的日期和时间需要以特殊
方式指定(包括示例中显示的花括号):
应使用一般形式 {d 'yyyy-mm-dd'} 来指定日期文本。
应使用一般格式 {t 'hh:mm:ss'} 来指定时间文本。
应使用一般格式 {ts 'yyyy-mm-dd hh:mm:ss'} 来指定日期/时间文本(时间戳)。
整个日期和/或时间值都必须用单引号括起。年份必须以四位数的形式表示;日期
和时间的值的每个部分都必须包含两位数。例如,2005 年 1 月 1 日上午 1:05 应
表示为以下形式:
{ts '2005-01-01 01:05:00'}
函数。可选择内置算术、逻辑、字符串、日期和时间 SQL 函数。可将函数从列表中拖到
表达式中,或者输入任何有效的 SQL 函数。关于有效的 SQL 函数,请参阅您的数据库文
档。可从以下位置获得标准函数的列表:
http://msdn2.microsoft.com/en-us/library/ms711813.aspx
使用随机抽样。该选项从数据源选择个案的随机样本。对于大数据源,您可能需要将个
案数限制为小的、具有代表性的样本,这可以显著减少其运行程序所需的时间。本机随
机抽样(如果对该数据源可用)速度比 IBM® SPSS® Statistics 随机抽样要快,因为
SPSS Statistics 随机抽样必须读取整个数据源才能抽取随机样本。
近似. 生成近似于指定个案百分比的随机样本。由于此例程为每个个案作出独立的
伪随机决策,因此选定个案的百分比只能近似于指定的百分比。数据文件中的个
案越多,选定个案的百分比与指定百分比就越接近。
准确. 从指定的个案总数中选择指定数目的个案作为随机样本。如果指定的个案总数
超过数据文件中的个案总数,则样本将按比例包含比请求数目少的个案。
注意:如果使用随机抽样,则分类汇总(SPSS Statistics Server 中的分布式模式提
供)不可用。
输入值提示。可以在查询中嵌入一个提示来创建参数查询。当用户运行查询时,系统将
要求用户输入信息(根据此处指定的信息)。如果要查看同一数据的不同视图,则可能
要进行这一操作。例如,您可能想要运行相同的查询来查看不同财政季度的销售数据。
E 将光标放在任何“表达式”单元格中,然后单击输入值提示来创建提示。
Page 41

创建参数查询
使用“输入值提示”步骤来创建一个对话框,在每次有人运行查询时请求用户提供信
息。如果要用不同的条件查询相同的数据源,则该功能将很有用。
图片 3-7
值的提示
23
数据文件
要建立提示,请输入提示字符串和默认值。每次用户运行查询时,该提示字符串都会显
示。该字符串应指定要输入的信息类型。如果用户不从列表中进行选择,那么该字符串
应给出有关如何设置输入格式的提示。示例如下:
允许用户从列表中选择值。如果选中该复选框,您可以限制用户选择您放在此处的值。
输入季度(Q1、Q2、Q3...)。
确保使用回车分隔值。
数据类型。在此处选择数据类型(数字、字符串或日期)。
最后的结果看起来如下所示:
图片 3-8
用户定义提醒
分类汇总数据
如果处于分布式模式中,并已连接到远程服务器(IBM® SPSS® Statistics Server 提
供),那么可以先对数据进行分类汇总,然后再将其读入 IBM® SPSS® Statistics 中。
Page 42

24
章3
图片 3-9
数据库向导,汇总数据
还可以在将数据读到 SPSS Statistics 中之后再对其进行分类汇总,但对于大数据源来
说,预先进行分类汇总可以节省时间。
E 要创建分类汇总数据,请选择一个或多个定义如何分组个案的分隔变量。
E 选择一个或多个分类汇总变量。
E 为每个分类汇总变量选择一个分类汇总函数。
E 或者,创建包含每个分类组中
的个案数的变量。
注意:如果使用 SPSS Statistics 随机抽样,分类汇总将不可用。
定义变量
变量名和标签。完整的数据库字段(列)名用作变量标签。除非您修改变量名,否则
“数据库向导”将按照以下两种方法中的一种将变量名指定给数据库的每一列:
Page 43

数据文件
如果数据库字段的名称是有效的、唯一的变量名,则该名称将用作变量名。
如果数据库字段的名称不是有效的、唯一的变量名,那么将自动生成一个新的唯
一名称。
单击任何单元格来编辑变量名。
将字符串转换为数字值。如果要自动将字符串变量转换为数值型变量,请针对该字符
串变量选择重新编码为数值型框。字符串值按照原始值的字母顺序转换为连续的整数
值。原始值保留为新的变量的值标签。
变量宽度字符串字段的宽度。该选项控制变量宽度字符串值的宽度。默认情况下,宽度
为 255 个字节,并且只读取前 255 个字节(通常指单字节语言中的 255 个字符)。
宽度至多可以为 32,767 个字节。尽管您可能不需要截断字符串值,但也不要指定不
必要的长值,这会导致处理效率很低。
根据观察值,最小化字符串宽度。自动将每个字符串变量的宽度设置为最长观察值。
图片 3-10
数据库向导,定义变量
25
Page 44

26
章3
排序个案
如果处于分布式模式中,并已连接到远程服务器(IBM® SPSS® Statistics Server 提
供),那么可以先对数据进行分类,然后再将其读入 IBM® SPSS® Statistics 中。
图片 3-11
数据库向导,对个案进行排序
还可以在将数据读到 SPSS Statistics 中之后再对其进行排序,但对于大数据源来说,
预先进行排序可以节省时间。
结果
“结果”步骤显示查询的 SQL Select 语句。
可以在运行查询前编辑该 SQL Select 语句,但是如果单击上一步按钮在前面的步骤
中进行更改,那么对 Select 语句所做的更改将丢失。
要保存查询以供将来使用,可使用将查询保存到文件区段。
要将完整的 GET DATA 语法粘贴到语法窗口,请选择将其粘贴到语法编辑器以供将来修改。
从“结果”窗口复制和粘贴 Select 语句将不会粘贴所需的命令语法。
注意:粘贴的语法在由向导生成的每一行 SQL 中的结束引号之前包含一个空格。这些空
格不是多余的。在处理命令时,SQL 语句的所有行将以一种文本形式合并在一起。如果
没有空格,在一行的最后一个字符和下一行的第一个字符之间就不会存在空格。
Page 45

图片 3-12
数据库向导,结果面板
27
数据文件
文本向导
文本向导可以读取多种格式的文本数据文件:
制表符分隔文件
空格分隔文件
逗号分隔文件
固定字段格式的文件
对于分隔的文件,也可以将其他字符指定为值之间的分隔符,并且可以指定多个分隔符。
Page 46

28
章3
读取文本数据文件
E 从菜单中选择:
文件 > 读取文本数据...
在“打开数据”对话框中选择文本文件。
E
E 按照文本向导中的步骤来定义如何读取数据文件。
文本向导:第 1 步
图片 3-13
文本向导:第 1 步
文本文件显示在一个预览窗口中。可以应用预定义的格式(以前在文本向导中保存
的),或者按照文本向导中的步骤来指定如何读取数据。
Page 47

文本向导:第 2 步
图片 3-14
文本向导:第 2 步
29
数据文件
此步骤提供变量的信息。变量类似于数据库中的字段。例如,问卷中的每一项都是一
个变量。
变量是如何排列的?要正确读取您的数据,文本向导需要知道如何确定一个变量的数据
值结束且下一个变量的数据值开始的位置。变量的安排定义用于将一个变量与另一个
变量区分开来的方法。
分隔。使用空格、逗号、制表符和其他字符分隔变量。变量为每个个案按照同样的顺
序进行记录,但不一定在相同的列位置。
固定宽度。对于数据文件中的每个个案,每个变量都记录在同一个记录(行)上的相
同列位置。变量之间不需要分隔符。实际上,在许多由计算机程序生成的文本数
据文件中,数据值可能显示为连在一起,互相之间甚至没有用空格分隔开。列位
置确定要读取的是哪个变量。
变量名称是否包括在文件的顶部?如果数据文件的第一行包含每个变量的描述性标签,则
可以将这些标签用作变量名。不符合变量命名规则的值会转换为有效的变量名。
Page 48

30
章3
文本向导:第 3 步(分隔的文件)
图片 3-15
文本向导:第 3 步(对于分隔的文件)
这一步提供有关个案的信息。个案类似于数据库中的记录。例如,问卷的每个回答
者都是一个个案。
第一个数据个案从哪个行号开始?(F)表示包含数据值的数据文件的第一行。如果数据文
件的顶行包含描述性标签或者包含不代表数据值的其他文本,这就不是第 1 行。
如何表示个案?控制文本向导如何确定每个个案结束、下一个个案开始的位置。
每一行表示一个个案。每一行仅包含一个个案。每个个案通常包含在一个单行中,即
使这一行对于有大量变量的数据文件会很长。如果不是所有的行都包含相同数量的
数据值,则每个个案的变量数由数据值的个数最多的行决定。对于数据值较少的
个案,多出来的变量指定为缺失值。
变量的特定编号表示一个个案。每个实例的指定变量数告诉文本向导在哪里停止读取
某个个案,并开始读取下一个个案。同一行可以包含多个个案,个案可以在一行的
中间开始,并在下一行继续。文本向导按照读取的值的数量确定每个个案的结束,
不管有多少行。每个个案必须包含所有变量的数据值(或者由分隔符表示的缺失
值),否则数据文件将无法正确读取。
Page 49
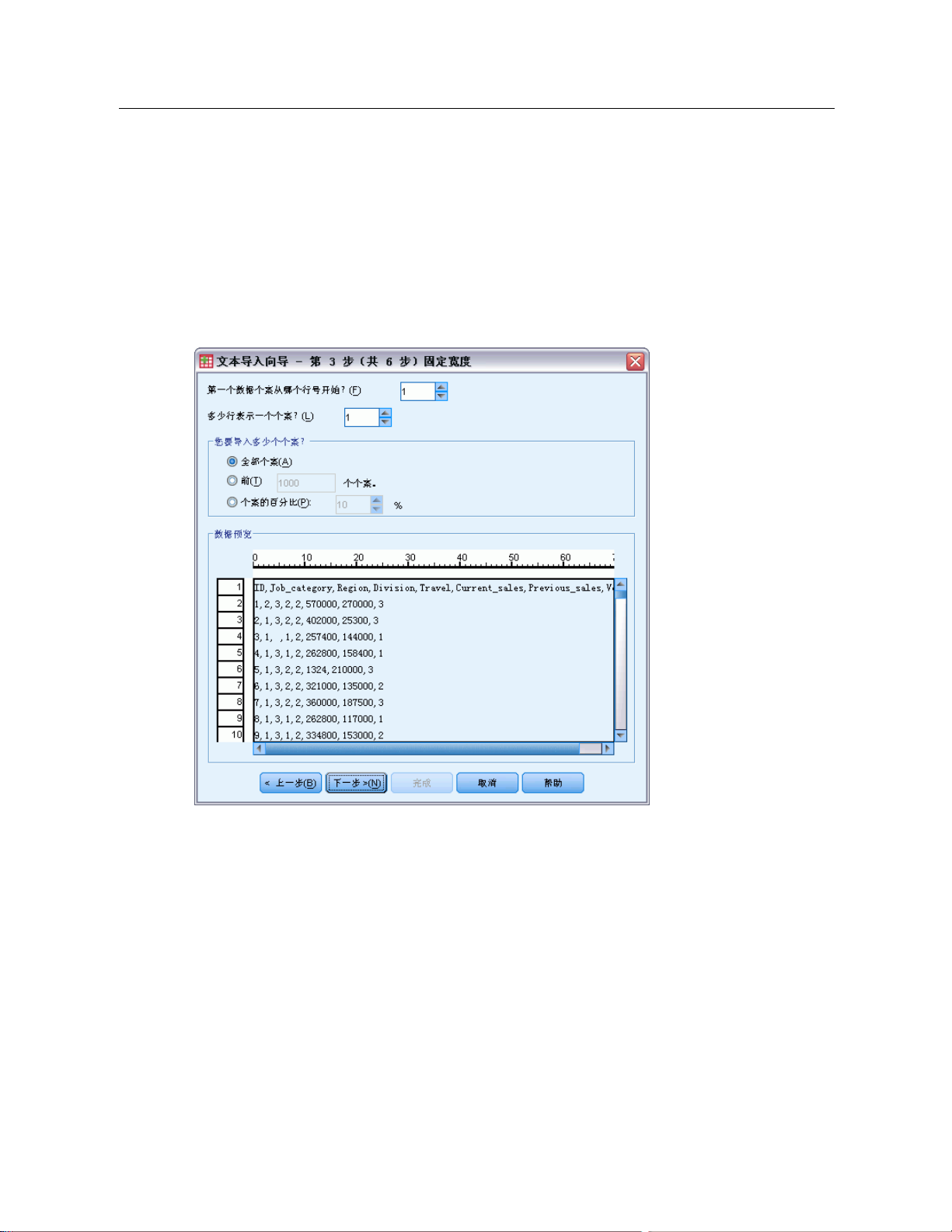
您要导入多少个个案?您可以导入数据文件中的所有个案,可以导入前 n 个个案(n 是您
指定的数字),也可以随机导入指定百分比的样本。因为随机抽样程序对每个个案都作
出独立的假随机决策,所以选定的个案的百分比可能只与指定的百分比相近。数据文件
中的个案越多,选定个案的百分比与指定百分比就越接近。
文本向导:第 3 步(固定宽度的文件)
图片 3-16
文本向导:第 3 步(对于固定宽度的文件)
31
数据文件
这一步提供有关个案的信息。个案类似于数据库中的记录。例如,问卷中的每个回答
者都是一个个案。
第一个数据个案从哪个行号开始?(F)表示包含数据值的数据文件的第一行。如果数据文
件的顶行包含描述性标签或者包含不代表数据值的其他文本,这就不是第 1 行。
多少行表示一个个案?(L)控制文本向导如何确定每个个案结束、下一个个案开始的位
置。每个变量由其个案内的行数及其列位置定义。需要指定每个个案的行数,才能正
确读取数据。
您要导入多少个个案?您可以导入数据文件中的所有个案,可以导入前 n 个个案(n 是您
指定的数字),也可以随机导入指定百分比的样本。因为随机抽样程序对每个个案都作
出独立的假随机决策,所以选定的个案的百分比可能只与指定的百分比相近。数据文件
中的个案越多,选定个案的百分比与指定百分比就越接近。
Page 50

32
章3
文本向导:第 4 步(分隔的文件)
图片 3-17
文本向导:第 4 步(对于分隔的文件)
此步骤显示文本向导对于如何读取数据文件的最佳猜测,并使您可以修改文本向导
从数据文件读取变量的方式。
变量之间有哪些分隔符?表示隔开数据的值的字符或符号。可以选择空格、逗号、分号、
制表符或其他字符的任意组合。中间没有插入数据值的多个连续的分隔符被视为缺失值。
文本限定符是什么?用于包括包含分隔符字符的值的字符。例如,如果逗号是分隔符,
包含逗号的值将读取错误,除非有文本限定符封装了该值,使值中的逗号不会被当作值
之间的分隔符。从 Excel 导出的 CSV 格式的数据文件使用双引号 (“) 用作文本限定
符。文本限定符出现在值的开头和结尾,封装了整个值。
Page 51
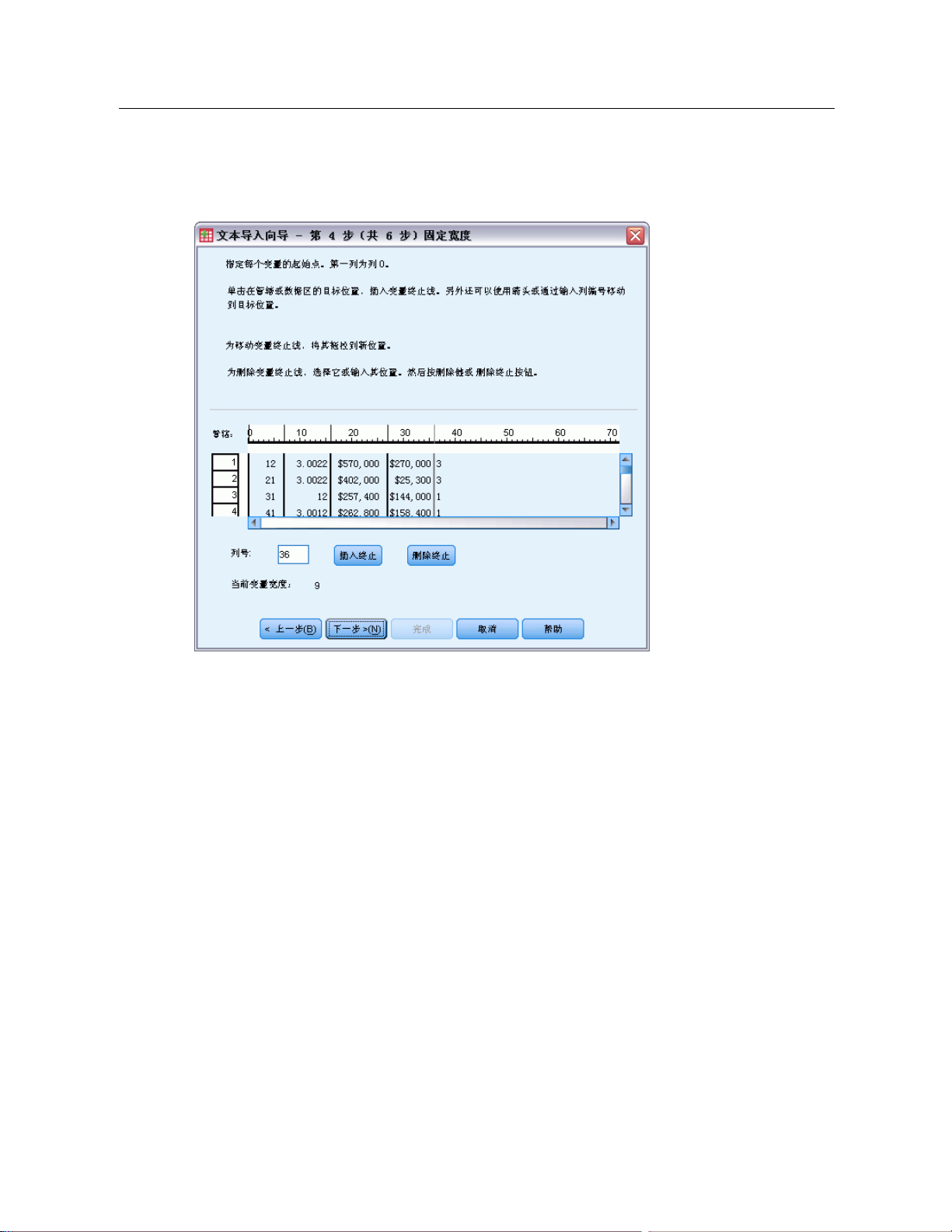
文本向导:第 4 步(固定宽度的文件)
图片 3-18
文本向导:第 4 步(对于固定宽度的文件)
33
数据文件
此步骤显示文本向导对于如何读取数据文件的最佳猜测,并使您可以修改文本向导从
数据文件读取变量的方式。预览窗口中的垂直线表示文本向导当前认为每个变量在文
件中开始的位置
。
必要时插入、移动和删除变量换行符以分隔变量。如果每个个案使用多行,则数据将
按每个个案一行的方式显示,后续行附加在行的末尾。
注意:
对于计算机生成
的数据文件,其所生成的一连串连续的数据值没有插入空格或其他明显
特征,这样就很难确定每个变量开始的位置。这样的数据文件通常依赖于数据定义文
件或其他一些指定每个变量的行和列位置的书面说明。
Page 52

34
章3
文本向导:第 5 步
图片 3-19
文本向导:第 5 步
此步骤控制文本向导用于读取每个变量的变量名和数据格式,并制最终数据文件中
将包括哪些变量。
变量名称。可以用自己的变量名覆盖缺省的变量名。如果从数据文件读取变量名,文
本向导将自动修改不符合变量命名规则的变量名。在预览窗口中选择一个变量,然后
输入变量名。
数据格式。在预览窗口选择一个变量,然后从下拉列表选择一种格式。按住 Shift 单击
可以选择多个相邻的变量,或者按住 Ctrl 单击可以选择多个不相邻的变量。
缺省格式由前 250 行中的数据值确定。如果在前 250 行中有多种格式(例如,数值、日
期、字符串等),则缺省格式设置为字符串。
文本向导格式选项
用文本向导读取变量的格式选项包括:
不导入。省略在导入的数据文件中选择的变量。
数值。有效值包括数字、前导加号或减号以及小数指示符。
Page 53
字符串。有效值包括几乎任何键盘字符和嵌入的空格。对于分隔文件,可以指定值的字
符数量,最多可以指定为 32,767 个。缺省情况下,文本向导将字符数量设置为选定
的变量在文件前 250 行中遇到过的最长的字符串值。对于固定宽度的文件,字符串
值的字符的数量由步骤 4 中的变量换行符的位置定义。
日期/时间。有效值包括常用的日期格式 dd-mm-yyyy、mm/dd/yyyy、dd.mm.yyyy、
yyyy/mm/dd、hh:mm:ss 以及其他各种日期和时间格式。月份可以用数字、罗马数字或三
个字母的缩写形式表示,也可以使用全拼的格式。从列表中选择一个日期格式。
美元。有效值为数字,前导美元符号是可选的,作为千位分隔符的逗号也是可选的。
逗号。有效值包括将句点用作小数指示符和将逗号用作千位分隔符的数字。
点。有效值包括将逗号用作小数指示符和将句点用作千位分隔符的数字。
注意:包含对选定的格式无效的字符的值将视为缺失值。包含任何指定分隔符的值将
视为多个值。
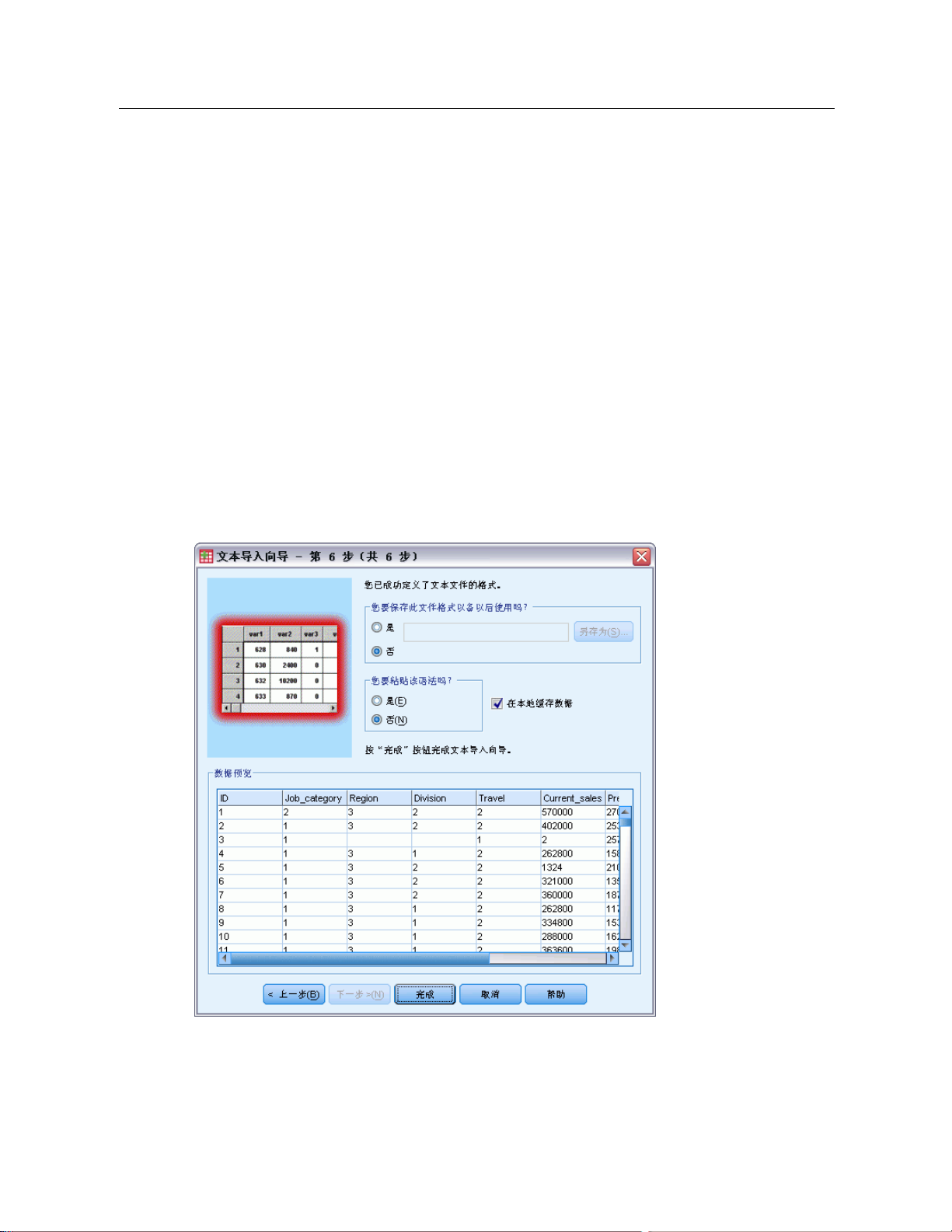
文本向导:第 6 步
图片 3-20
文本向导:第 6 步
35
数据文件
这是文本向导的最后一步。可以将您的规格保存在文件中,以便在导入类似的文本数据
文件时使用。也可以将文本向导生成的语法粘贴到语法窗口。然后就可以定制和/或保
存语法,以便用于其他对话或生产作业中。
Page 54

36
章3
在本地缓存数据. 数据高速缓存是数据文件的完整副本,它存储在临时磁盘空间中。高
速缓存数据文件可以改进性能。
读取 IBM SPSS Data Collection 数据
在 Microsoft Windows 操作系统上,您可以从 IBM® SPSS® Data Collection 产品读
取数据。(注意:此功能只在安装在 Microsoft Windows 操作系统上的 IBM® SPSS®
Statistics 中可用。
要读取 Data Collection 数据源,必须安装以下项目:
.NET Framework。要获得最新版本的 .NET Framework,请转至
http://www.microsoft.com/net。
IBM® SPSS® Data Collection Survey Reporter Developer Kit。有关获取 SPSS
Survey Reporter Developer Kit 兼容版本的信息,请转至 support.spss.com
(http://support.spss.com)。
只能以本地分析模式读取 Data Collection 数据源。此功能不能用于使用 SPSS
Statistics Server 的分布式分析模式。
从 Data Collection 数据源读取数据:
E 从打开的任意 SPSS Statistics 窗口中的菜单选择:
文件 > 打开 Data Collection 数据
在“数据链接属性”的“连接”选项卡上,指定元数据文件、个案数据类型和个案数
E
据文件。
E 单击确定。
E 在“Data Collection 数据导入”对话框中,选择要包括的变量并选择个案选择标准。
E 单击确定以读取数据。
“数据链接属性”:“连接”选项卡
要读取 IBM® SPSS® Data Collection 数据源,需要指定:
元数据位置。 包含问卷定义信息的元数据文档文件 (.mdd)。
个案数据类型。 个案数据文件的格式。可用格式包括:
Quancept 数据文件 (DRS)。Quancept .drs、.drz 或 .dru 文件中的个案数据。
Quanvert 数据库。Quanvert 数据库中的个案数据。
Data Collection 数据库 (MS SQL Server)。SQL Server 中关系数据库中的个案数据。
Data Collection XML 数据文件。XML 文件中的个案数据。
个案数据位置。包含个案数据的文件。此文件的格式必须与所选个案数据类型一致。
Page 55

注意:“连接”选项卡上的其他设置或其他“数据链接属性”选项卡上的任何设置对
将 Data Collection 数据读取到 IBM® SPSS® Statistics 中的影响程度尚未知,因此
建议不要更改其中任何设置。
“选择变量”选项卡
可以选择要读取的变量的子集。缺省情况下,将显示并选中数据源中的所有标准变量。
显示系统变量。 显示任何“系统”变量,包括指示访问状态(进行中、已完成、
完成日期等)的变量。随后可以选择要包含的任何系统变量。缺省情况下将排
除所有系统变量。
显示代码变量。显示任何表示代码(用于对分类变量未确定的“其他”响应)的变
量。随后可以选择要包含的任何代码变量。缺省情况下将排除所有代码变量。
显示 SourceFile 变量。 显示任何包含已扫描响应的映像文件名的变量。随后可以选
择要包含的任何 SourceFile 变量。缺省情况下将排除所有 SourceFile 变量。
“个案选择”选项卡
对于包含系统变量的 IBM® SPSS® Data Collection 数据源,可以基于一定数目的系统变
量标准选择个案。您不必在要读取的变量的列表中包括相应的系统变量,但是在源数
据中必须存在必要的系统变量才能应用选择标准。如果源数据中不存在必要的系统变
量,则忽略相应的选择标准。
37
数据文件
数据收集状态。可以选择响应者数据、测试数据或两者都选择。还可以基于以下访问状
态参数的任意组合来选择个案:
成功完成
活动/进行中
超时
被脚本中止
被响应中止
访问系统关闭
信号(已由脚本中的信号语句终止)
数据收集结束日期。 可以基于完成数据收集的日期选择个案。
起始日期。包括其数据收集在指定日期或该日期之后完成的个案。
结束日期。 包括其数据收集在指定的日期之前完成的个案。这不包括其数据收集在
如果同时指定起始日期和结束日期,则这会定义从起始日期到(但不包括)结束
文件信息
数据文件包含的内容远不止是原始数据。它还包含所有变量定义信息,包括:
变量名
结束日期完成的个案。
日期的完成日期范围。
Page 56

38
章3
变量格式
描述性的变量标签和值标签
这些信息存储在数据文件的字典部分。数据编辑器提供一种查看变量定义信息的方法。
还可以显示活动数据集或任何其他数据文件的完整字典信息。
显示数据文件信息
E 从数据编辑器窗口的菜单中选择:
文件 > 显示数据文件信息
对于当前打开的数据文件,请选择工作文件。
E
E 对于其他数据文件,选择外部文件,然后选择数据文件。
浏览器中会显示数据文件信息。
保存数据文件
除了以 IBM® SPSS® Statistics 格式保存数据文件之外,还可以用多种外部格式保存
数据,这些格式包括:
Excel 和其他电子表格格式
Tab 分隔和 CSV 文本文件
SAS
Stata
数据库表
保存已修改的数据文件
E 使数据编辑器成为活动窗口(单击窗口的任何部位即可使其成为活动窗口)。
E 从菜单中选择:
文件 > 保存
已修改的数据文件被保存,并覆盖文件的上一版本。
注意:16.0 版之前的 IBM® SPSS® Statistics 版本无法读取以 Unicode 格式保存的数
据文件。要保存早期发行版可以读取的 Unicode 数据文件,在代码页中打开文件并将
其重新保存。将根据当前区域编码格式保存该文件。如果包含当前区域无法识别的字
符,可能会丢失一些数据。有关切换 Unicode 模式和代码页模式的信息,请参见一般
选项第290页码。
以外部格式保存数据文件
E 使数据编辑器成为活动窗口(单击窗口的任何部位即可使其成为活动窗口)。
E 从菜单中选择:
文件 > 另存为 ...
Page 57

E
从下拉列表中选择文件类型。
E 为新数据文件输入文件名。
要将变量名写入电子表格或 tab 分隔数据文件的第一行,请执行以下操作:
E 单击“将数据保存为”对话框中的将变量名称写入电子表格。
要以 Excel 文件保存值标签而非数据值,请执行以下操作:
E 单击“将数据保存为”对话框中的在已定义值标签时保存值标签而不是保存数据值。
要将值标签保存到 SAS 语法文件(仅当选择了 SAS 文件类型时是活动的),请执行以下操作:
E 单击“将数据保存为”对话框中的将值标签保存到 .sas 文件。
有关将数据导出到数据库表的信息,请参见 导出到数据库第 44 页码。
有关导出数据以用于 IBM® SPSS® Data Collection 应用程序的信息,请参见 导出到
IBM SPSS Data Collection第 55 页码。
39
数据文件
保存数据:数据文件类型
您可以用以下格式保存数据:
SPSS Statistics (*.sav)。IBM® SPSS® Statistics 格式。
7.5 版之前的软件无法读取以 SPSS Statistics 格式保存的数据文件。16.0 版之前的
SPSS Statistics 版本无法读取以 Unicode 格式保存的数据文件
在版本 10.x 或 11.x 中使用有变量名称长于八字节的数据文件时,将使用变量名称
的唯一的八字节版本,—但是在发行版 12.0 或更高版本中将保留原变量名称。在
10.0 之前的发行版中,在您保存数据文件时原来的长变量名会丢失。
在 13.0 版之前使用字符串变量长于 255 字节的数据文件时,会将这些字符串变量
分解为多个 255 字节的字符串变量。
7.0 版 (*.sav)。 7.0 版格式。7.0 版和较早版本的 Windows 版可以读取以 7.0 版格式保
存的数据文件,但是不包括已定义的多重响应集或 Data Entry for Windows 信息。
SPSS/PC+ (*.sys)。 SPSS/PC+ 格式。如果数据文件包含的变量多于 500 个,将仅保存前
500 个。对于具有多个已定义用户缺失值的变量,将把其他的用户缺失值记录到第一个
已定义用户缺失值中。此格式只在 Windows 操作系统上可用。
SPSS Statistics 便携 (*.por)。 可移植格式,其他版本的SPSS Statistics以及其他操
作系统上的版本都可以读取此格式。变量名限制为八字节,并自动转换成唯一的八字
节名称(如果必要)。在多数情况下,不再需要以便携格式保存数据,因为 SPSS
Statistics 数据文件应该独立于平台/操作系统。您无法在 Unicode 模式中以可移植
文件来保存数据文件。
制表符分隔格式 (*.dat)。 用制表符分隔值的文本文件。(注意:嵌入字符串值中的 Tab
字符在制表符分隔文件中将保留为 Tab 字符。不对嵌入值中的 Tab 字符和分隔值的
Tab 字符进行区分。)
Page 58

40
章3
逗号分隔 (*.csv)。 用逗号或分号分隔值的文本文件。如果当前 SPSS Statistics 小数指
示符为句点,则用逗号分隔各值。如果当前小数指示符为逗号,则用分号分隔各值。
固定 ASCII 格式 (*.dat)。 固定格式的文本文件,对所有变量使用缺省的书写格式。在
变量字段之间没有 tab 或空格。
Excel 2007 (*.xlsx)。 Microsoft Excel 2007 XLSX 格式工作表。最大变量数为 16,000;删
除超过 16,000 的任何其他变量。如果数据集包含一百万个个案,在工作表中创建多页。
Excel 97 至 2003 (*.xls)。 Microsoft Excel 97 工作表。最大变量数为 256;删除超过
256 的任何其他变量。如果数据集包含 65,356 个个案,在工作表中创建多页。
Excel 2.1 (*.xls)。 Microsoft Excel 2.1 电子表格文件。最大变量数为 256,最大行
数为 16,384。
1-2-3 R3.0 (*.wk3)。 Lotus 1-2-3 电子表格文件,版本 3.0。可以保存的最大变量数
为256。
1-2-3 R2.0 (*.wk1)。 Lotus 1-2-3 电子表格文件,版本 2.0。可以保存的最大变量数
为256。
1-2-3 R1.0 (*.wks)。 Lotus 1-2-3 电子表格文件,版本 1A。可以保存的最大变量数
为256。
SYLK (*.slk)。 Microsoft Excel 和 Multiplan 电子表格文件的符号链接格式。可以保存
的最大变量数为 256。
dBASE IV (*.dbf)。 dBASE IV 格式。
dBASE III (*.dbf)。 dBASE III 格式。
dBASE II (*.dbf)。 dBASE II 格式。
SAS v9+ Windows (*.sas7bdat)。 SAS v9 Windows 版。
SAS v9+ UNIX (*.sas7bdat)。 SASv9UNIX版。
SAS v7-8 Windows 短扩展名 (*.sd7)。 SAS V7–8 for Windows 短文件名格式。
SAS v7-8 Windows 长扩展名 (*.sas7bdat)。 SAS v7–8 for Windows 长文件名格式。
SAS v7-8 UNIX 版 (*.sas7bdat)。 SASv8UNIX版。
SAS v6 Windows
SAS v6 UNIX 版 (*.ssd01)。 用于 UNIX(Sun、HP、IBM)的 SAS V6 文件格式。
SAS v6 Alpha/OSF 版 (*.ssd04)。 用于 Alpha/OSF (DEC UNIX) 的 SAS V6 文件格式。
SAS 传输格式 (*.xpt)。 SAS 传输格式文件。
Stata V8 Intercooled (*.dta)。
Stata V8 SE (*.dta)。
Stata V7 Intercooled (*.dta)。
版 (*.sd2)。
用于 Windows/OS2 的 SAS V6 文件格式。
Stata V7 SE (*.dta)。
Stata V6 (*.dta)。
Stata V4–5 (*.dta)。
Page 59

保存文件选项
对于电子表格、Tab 分隔文件和逗号分隔文件,您可以将变量名写入文件的第一行。
以 Excel 格式保存数据文件
您可以用三种 Microsoft Excel 文件格式之一来保存数据。Excel 2.1、Excel 97 和
Excel 2007。
Excel 2.1 和 Excel 97 限于 256 个列;所以只能包括前 256 个变量。
Excel 2007 限于 16,000 个列;所以只能包括前 16,000 个变量。
Excel 2.1 限于 16,384 个行;所以只能包括前 16,384 个个案。
Excel 97 和 Excel 2007 每页有行数的限制,但是工作表可以有多页,如果已经超过
单页最大数,可以创建多页。
变量类型
41
数据文件
下表显示 IBM® SPSS® Statistics 中的原始数据与 Excel 中的导出数据之间的变量类
型匹配情况。
SPSS Statistics变量类型 Excel 数据格式
数值
逗号
美元
日期
时间
字符串
以 SAS 格式保存数据文件
当将您的数据保存为 SAS 文件时,将对数据的各个方面进行特殊处理。这些情况包括:
某些在 IBM® SPSS® Statistics 变量名中允许的字符在 SAS 中是无效的,如 @、# 和
$。这些非法字符将在数据导出时用下划线来代替。
包含多字节字符(例如,日语或中文字符)的 SPSS Statistics 变量名将转换为
一般形式的变量名,即 Vnnn,其中 nnn 是整数值。
包含多于 40 个字符的 SPSS Statistics 变量标签在导出至 SAS v6 文件时会被截断。
只要存在,SPSS Statistics 变量标签,就将它们映射为 SAS 变量标签。如果在 SPSS
Statistics 数据中不存在任何变量标签,则将变量名映射为 SAS 变量标签。
SAS 仅允许一个值为系统缺失值,而 SPSS Statistics 除系统缺失值外还允许有许
多用户缺失值。因此,SPSS Statistics 中的所有用户缺失值均映射为 SAS 文件
中的单个系统缺失值。
0.00; #,##0.00; ...
0.00; #,##0.00; ...
$#,##0_); ...
d-mmm-yyyy
hh:mm:ss
常规
Page 60

42
章3
SAS 6-8 数据文件以当前 SPSS Statistics 本地编码保存,不考虑当前模式(Unicode
或代码页)。在 Unicode 模式下,SAS 9 文件以 UTF-8 格式保存。在代码页模式
下,SAS 9 文件以当前本地编码保存。
最多可以保存 32,767 个变量到 SAS 6-8。
保存值标签
您可以选择将与 数据文件相关联的值和值标签保存到 SAS 语法文件。该语法文件包含可
在 SAS 中运行以创建 SAS 格式目录文件的 proc format 和 proc datasets 命令。
SAS 传输格式文件不支持此功能。
变量类型
下表显示 SPSS Statistics 中的原始数据与 SAS 中的导出数据之间的变量类型匹配情况。
SPSS Statist
数值 数值
逗号
点
科学计数法 数值
日期
日期(时间)
美元 数值
定制货币 数值
字符串 字符
ics变量类型
以 Stata 格式保存数据文件
可以用 Stata 5–8 格式,也可以同时用 Intercooled 和 SE 格式(仅限版本 7 和
8)写入数据。
以 Stata 5 格式保存的数据文件可以由 Stata 4 读取。
变量标签的前 80 个字节保存为 Stata 变量标签。
对于数值变量,值标签的前 80 个字节保存为 Stata 值标签。对于字符串变量、非整
数值和绝对值大于 2,147,483,647 的数值,将去除值标签。
对于版本 7 和 8,区分大小写形式的变量名的前 32 个字节保存为 Stata 变量名。
对于早期版本,变量名的前 8 个字节保存为 Stata 变量名。字母、数字和下划
线以外的任何字符都转换为下划线。
包含多字节字符(例如,日语或中文字符)的 IBM® SPSS® Statistics 变量名将转换
为一般形式的变量名,即 Vnnn,其中 nnn 是整数值。
SAS 变量类型 SAS 数据格式
12
数值
数值
数值
数值
12
12
12
(日期)例如:MMDDYY10 ...
Time18
12
12
$8
Page 61

数据文件
对于版本 5–6 和 Intercooled 版本 7–8,保存字符串值的前 80 个字节。对于
Stata SE 7–8,保存字符串值的前 244 个字节。
对于版本 5–6 和 Intercooled 版本 7–8,仅保存前 2,047 个变量。对于 Stata
SE 7–8,仅保存前 32,767 个变量。
43
SPSS Statisti
类型
数值 数值
逗号
点
科学计数法 数值
Date*、Datetime
Time、DTime
Wkday
月份
美元 数值
定制货币 数值
字符串 字符串
*Date、Adate、Edate、SDate、Jdate、Qyr、Moyr、Wkyr
保存变量子集
图片 3-21
“将数据保存为变量”对话框
cs变量
Stata 变量类型 Stata 数据格式
g
数值
数值
数值
数值 g(秒数)
数值
数值
g
g
g
D_m_Y
g(1–7)
g (1–12)
g
g
s
使用“将数据保存为变量”对话框可以选择要在新数据文件中保存的变量。缺省情况下将
保存所有变量。取消选择您不想保存的变量,或单击全部丢弃然后选择想要保存的变量。
仅可视。仅选择当前使用的变量集中的变量。
Page 62

44
章3
保存变量子集
E 使数据编辑器成为活动窗口(单击窗口的任何部位即可使其成为活动窗口)。
E 从菜单中选择:
文件 > 另存为 ...
E
单击变量。
E 选择想要保存的变量。
导出到数据库
可使用导出到数据库向导完成以下任务:
替换现有数据库表字段(列)中的值或为表添加新字段。
将新记录(行)追加到数据库表。
完全替换数据库表或创建新表。
要将数据导出到数据库,请执行下列操作:
E 在包含要导出数据的数据集的“数据编辑器”窗口中,从菜单中选择:
文件 > 导出到数据库
E
选择数据库源。
E 按照导出向导中的说明操作以导出数据。
从 IBM SPSS Statistics 变量创建数据库字段
创建新字段(向现有数据库表添加字段、创建新表或替换表)时,可以指定字段名、数
据类型和宽度(适用的情况下)。
字段名称。缺省字段名称与 IBM® SPSS® Statistics 变量名相同。可以将字段名称更
改为数据库格式允许的任何名称。例如,很多数据库允许字段名称中包含 变量名中
不允许的字符,包括空格。因此,类似于 CallWaiting 的 变量名可以更改为字段名
称 Call Waiting。
类型。导出向导基于标准 ODBC 数据类型或选定的数据库格式允许的与定义的 SPSS
Statistics 数据格式最匹配的数据类型进行首次数据类型指定,但是数据库可对在
SPSS Statistics 中没有直接对应类型的类型进行区分。例如,SPSS Statistics 中的很
多数值都以双精度浮点值保存,而数据库数值类型包含浮点(双精度)、整数、实数等
等。此外,很多数据库没有与 SPSS Statistics 对应的时间格式类型。可以将数据类
型更改为下拉列表中可用的任何类型。
作为一个通常的规则,变量的基本数据类型(字符串或数值)应与数据库字段的基本
数据类型相匹配。如果出现了数据库无法解决的数据类型不匹配,则会出现错误结果,
并且不会将任何数据导出到数据库中。例如,如果将 字符串变量导出到数值数据类型的
数据库字段,则当字符串变量的任何值包含非数字字符时,结果将出错。
宽度。可以对 string (char, varchar) 字段类型的已定义宽度进行更改。数字字段
宽度由数据类型决定。
Page 63

数据文件
缺省情况下,SPSS Statistics 变量格式根据下列总体原则映射到数据库字段类型。实
际数据库字段类型可能取决于数据库。
45
SPSS Statisti
数值 浮点数或双精度数
逗号
点
科学计数法 浮点数或双精度数
日期
日期时间
Time、 DTime
Wkday
月份
美元 浮点数或双精度数
定制货币 浮点数或双精度数
字符串
cs 变量格式
数据库字段类型
浮点数或双精度数
浮点数或双精度数
日期、日期时间或时间
日期时间或时间戳
浮点数或双精度数(秒
整数 (1–7)
整数 (1–12)
Char 或 Varchar
戳
数)
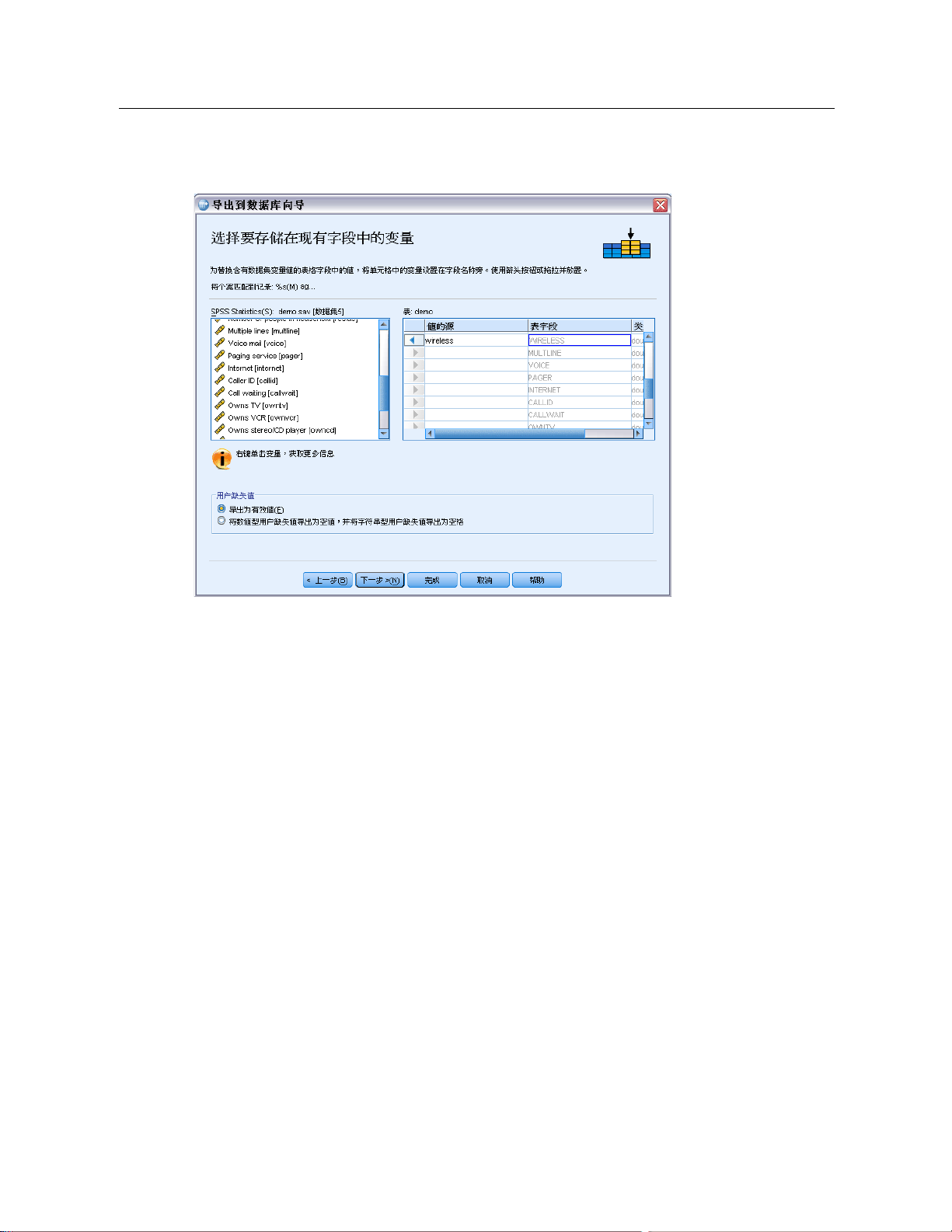
用户缺失值
将来自变量的数据导出到数据库字段时,有两个选项可用于处理用户缺失值:
导出为有效值。用户缺失值当作常规的、有效的非缺失值处理。
将数值型的用户缺失值作为 Null 导出,并将字符串类型的用户缺失值作为空格导出。数
值型的用户缺失值被视为与系统缺失值相同。字符串类型的用户缺失值被转换为
空格(字符串不能是系统缺失的)。
选择数据源
在导出到数据库向导的第一个面板中,选择要向其导出数据的数据源。
Page 64

46
章3
图片 3-22
导出到数据库向导,选择数据源
可以将数据导出到具有相应 ODBC 驱动程序的任何数据库源。(注意:不支持将数据导
出到 OLE DB 数据源。)
如果没有配置任何 ODBC 数据源,或者要添加新的数据源,请单击
在 Linux 操作系统中,该按钮不可用。在 odbc.ini 中指定 ODBC 数据源,并且
添加 ODBC 数据源。
ODBCINI 环境变量必须设定为该文件的位置。有关更多信息,请参见数据库驱
动程序文档。
用分布式分析模式时(IBM® SPSS® Statistics Server 提供),该按钮不可用。要
用分布式分析模式添加数据源,请咨询系统管理员。
ODBC 数据源由两条基本信息组成:要用来访问数据的驱动程序和要访问的数据库的位
置。要指定数据源,必须装有适当的驱动程序。针对不同数据库格式的驱动程序可以
从 http://www.spss.com/drivers 获得。
有些数据源可能要求登录 ID 和密码才能进行到下一步。
选择如何导出数据
选择了数据源后,需要指明导出数据所采用的方式。
Page 65
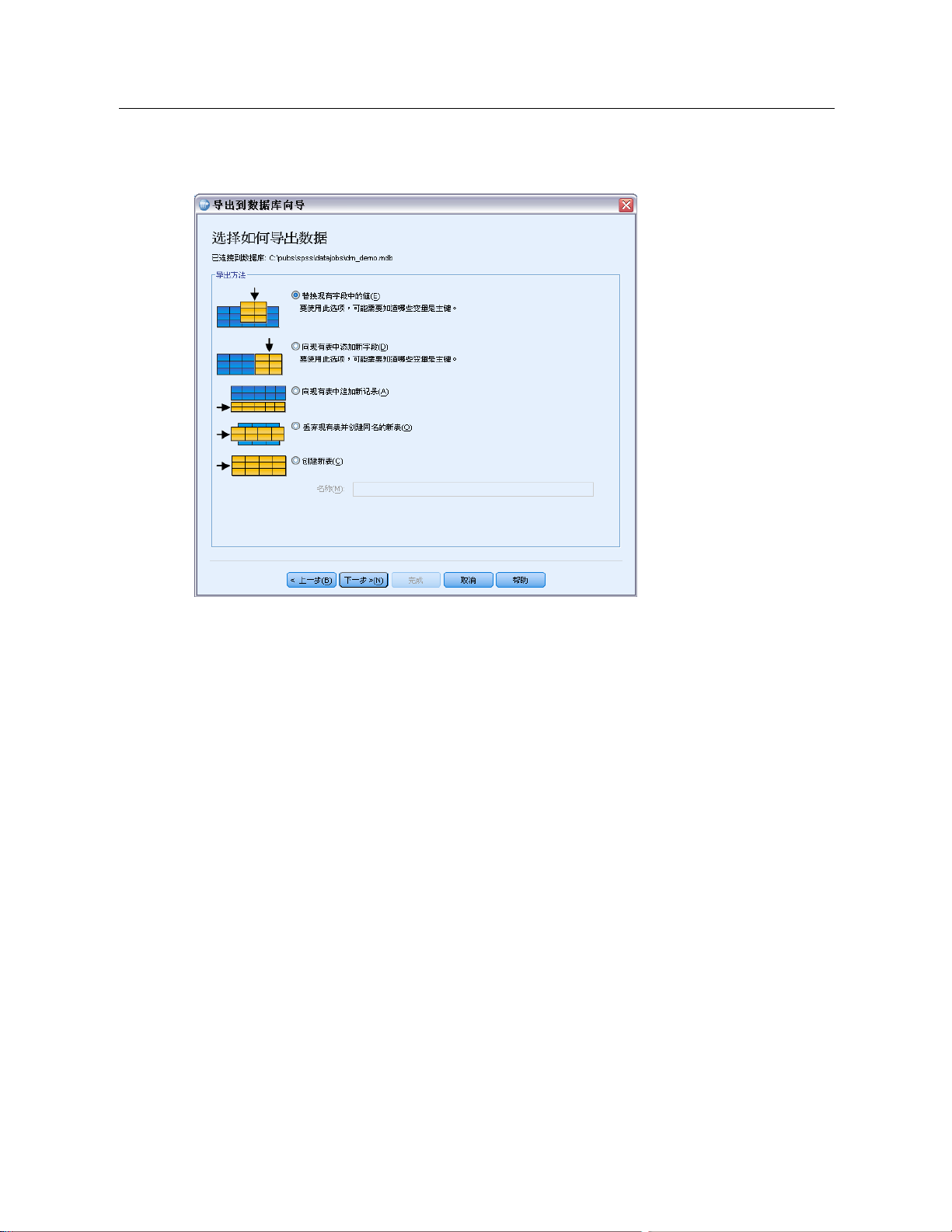
图片 3-23
导出到数据库向导,选择导出方式
47
数据文件
以下选择可供将数据导出到数据库:
替换现有字段中的值。将现有表中选定字段的值用活动数据集中选定变量的值替换。
向现有表中添加新字段。在现有表中创建新字段,这些字段将包含活动数据集中选定
变量的值。此选项不支持 Excel 文件。
向现有表中追加新记录。向现有表添加新记录(行),这些记录将包含活动数据
集中的个案的值。
丢弃现有表并创建同名的新表。删除指定的表并创建同名的新表,新表中将包含活动
数据集中的选定变量。原始表中包括字段属性定义(例如主键和数据类型)在内
的所有信息都将丢失。
创建新表。在数据库中创建新表,其中包含来自活动数据集中的选定变量的数
据。名称可以是数据源允许作为表名的任何值。此名称不能与数据库中现有表
或视图名称重复。
选择表
修改或替换数据库中的表时,需要选择要修改或替换的表。导出到数据库向导中的此面
板显示了一个列表,其中列出选定数据库中的表和视图。
Page 66

48
章3
图片 3-24
导出到数据库向导,选择表或视图
默认情况下,此列表仅显示标准数据库表。可以控制列表中显示的项的类型:
表。标准数据库表。
视图。视图是由查询定义的虚拟的或动态的“表”。视图中可以包含基于其他字段
值计算得出的多个表和/或字段的连接。虽然可以对视图追加记录,或替换其现
有字段的值,但是您能够修改的字段是受限制的,这取决于视图的结构。例如,
不能修改派生的字段、为视图添加字段或替换视图。
同义词。同义词是表或视图的别名,通常在查询中定义。
系统表。系统表定义数据库的属性。在某些情况下,标准数据库表可能会被归类
为系统表,并且仅在选择了该选项后才会显示。通常只有数据库管理员才有访问
真正的系统表的权限。
选择要导出的个案
导出到数据库向导中对个案的选择仅限于所有个案以及使用先前定义的过滤条件选择的个
案。如果没有有效的个案过滤,此面板将不显示,并将导出活动数据集中的所有个案。
Page 67

图片 3-25
导出到数据库向导,选择要导出的个案
49
数据文件
有关定义用于个案选择的过滤器条件的信息,请参见选择个案第 169 页码。
将个案匹配到记录
在向现有表添加字段(列)或替换现有字段中的值时,需确保活动数据集中的每个个案
(行)与数据库中相应的记录能够正确匹配。
在数据库中,唯一标识每个记录的字段或字段组通常被指定为主键。
需要确定与主键字段或其他能唯一标识每个记录的字段组对应的变量。
字段不一定必须是数据库中的主键,但是字段值或字段值的组合对于每个个案必
须是唯一的。
要使变量与数据库中唯一标识每个记录的字段匹配,请执行下列操作:
E 将变量拖放至相应的数据库字段上。
或
E 从变量列表中选择变量,再选择数据库表中相应的字段,然后单击连接。
要删除连接线,请执行下列操作:
E 选择连接线并按 Delete 键。
Page 68

50
章3
图片 3-26
导出到数据库向导,将个案匹配到记录
注意:变量名和数据库字段名不一定相同(因为数据库字段名可能包含 IBM® SPSS®
Statistics 变量名所不允许的字符),但是如果活动数据集是从所修改的数据库表创建
的,那么变量名或变量标签两者之一通常将至少与数据库字段名相似。
替换现有字段中的值
要替换数据库中现有字段的值,请执行下列操作:
E 在导出到数据库向导的选择如何导出数据面板中,选择替换现有字段中的值。
E 在选择表或视图面板中,选择数据库表。
E 在将个案匹配到记录面板中,将唯一标识每个个案的变量与相应的数据库字段名称相匹配。
E 对于要替换其值的每个字段,将包含新值的变量拖放到相应数据库字段名旁的值的源列。
Page 69
图片 3-27
导出到数据库向导,替换现有字段中的值
51
数据文件
作为一个通常的规则,变量的基本数据类型(字符串或数值)应与数据库字段的基本
数据类型相匹配。如果出现了数据库无法解决的数据类型不匹配,则会出现错误结
果,并且不会将任何数据导出到数据库中。例如,如果将字符串变量导出到数值数据
类型(例如双精度数、实数或整数)的数据库字段,则当字符串变量的任何值包含
非数字字符时,结果将出错。变量旁的图标中的字母 a 指示该变量为字符串变量。
不能修改字段名、类型或宽度。原始数据库字段属性将被保留,只有值被替换。
添加新字段
要向现有数据库表添加新字段,请执行下列操作:
E 在导出到数据库向导的选择如何导出数据面板中,选择向现有表中添加新字段。
E 在选择表或视图面板中,选择数据库表。
E 在将个案匹配到记录面板中,将唯一标识每个个案的变量与相应的数据库字段名称相匹配。
E 将要作为新字段添加的变量拖放到值的源列。
Page 70

52
章3
图片 3-28
导出到数据库向导,向现有表中添加新字段
有关字段名称和数据类型的信息,请参见导出到数据库第 44 页码中有关从 IBM® SPSS®
Statistics 变量创建数据库字段的章节。
显示现有的字段。选择此选项以显示现有字段的列表。不能使用导出到数据库向导中的
此面板替换现有字段,但是了解表中已有的字段会有帮助。如果要替换现有字段中的
值,请参见替换现有字段中的值第 50 页码。
追加新记录(个案)
要将新记录(个案)追加到数据库表,请执行下列操作:
E 在导出到数据库向导的选择如何导出数据面板中,选择向现有表中追加新记录。
E 在选择表或视图面板中,选择数据库表。
E 将活动数据集中的变量与表字段匹配,方法是将变量拖放到值的源列。
Page 71

图片 3-29
导出到数据库向导,向表添加记录(个案)
53
数据文件
导出到数据库向导将根据存储在活动数据集(如可用)中的原始数据库表和/或与字段
名同名的变量名的信息,自动选择与现有字段匹配的所有变量。此初始自动匹配功能的
目的仅是提供一个指导,并不妨碍您更改变量与数据库字段匹配的方式。
向现有表中添加新字段时,将应用以下基本规则/限制:
活动数据集中的所有个案(或所有选定个案)都将添加到表中。如果这些个案中任
何一个与数据库中的现有记录重复,则当遇到重复键值时,会发生错误。有关仅导
出选定个案的信息,请参见选择要导出的个案第 48 页码。
可以使用会话中创建的新变量的值作为现有字段的值,但是不能添加新字段或更改
现有字段的名称。要向数据库表添加新字段,请参见添加新字段第 51 页码。
对于任何排除的数据库字段或未匹配到变量的字段,数据库表中的新增记录将没有
相应的值。(如果
值的源单元格为空,则没有任何变量匹配到字段。)
创建新表或替换表
要创建新的数据库表,或替换
E 在导出向导的选择如何导出数据面板中,选择丢弃现有表并创建同名的新表或选择创建新表
现有的数据库表,请执行下列步骤:
并为新表输入一个名称。如果表名称包含除字母、数字或下划线以外的任何其他字
符,名称必须用双引号括起。
E 如果要替换现有的表,则在选择表或视图面板中选择数据库表。
E 将变量拖放到要保存的变量列。
Page 72

54
章3
E
(可选)您可以指定定义主键的变量/字段,更改字段名以及更改数据类型。
图片 3-30
导出到数据库向导,为新表选择变量
主键。要将变量指定为数据库表中的主键,请选择由键图标标识的列中的框。
主键的所有值必须是唯一的,否则将发生错误。
如果选择了单个变量作为主键,则每个记录(个案)对于该变量必须具有唯一值。
如果选择了多个变量作为主键,这定义了组合主键,则选定变量的值的组合对
每个个案来说必须是唯一的。
有关字段名称和数据类型的信息,请参见导出到数据库第 44 页码中有关从 IBM® SPSS®
Statistics 变量创建数据库字段的章节。
完成数据库导出向导
“数据库导出向导”的最后一个面板提供了摘要,其中指明要导出的数据和导出方式。
此面板还提供了是将数据导出还是将底层命令语法粘贴到语法窗口的选项。
Page 73
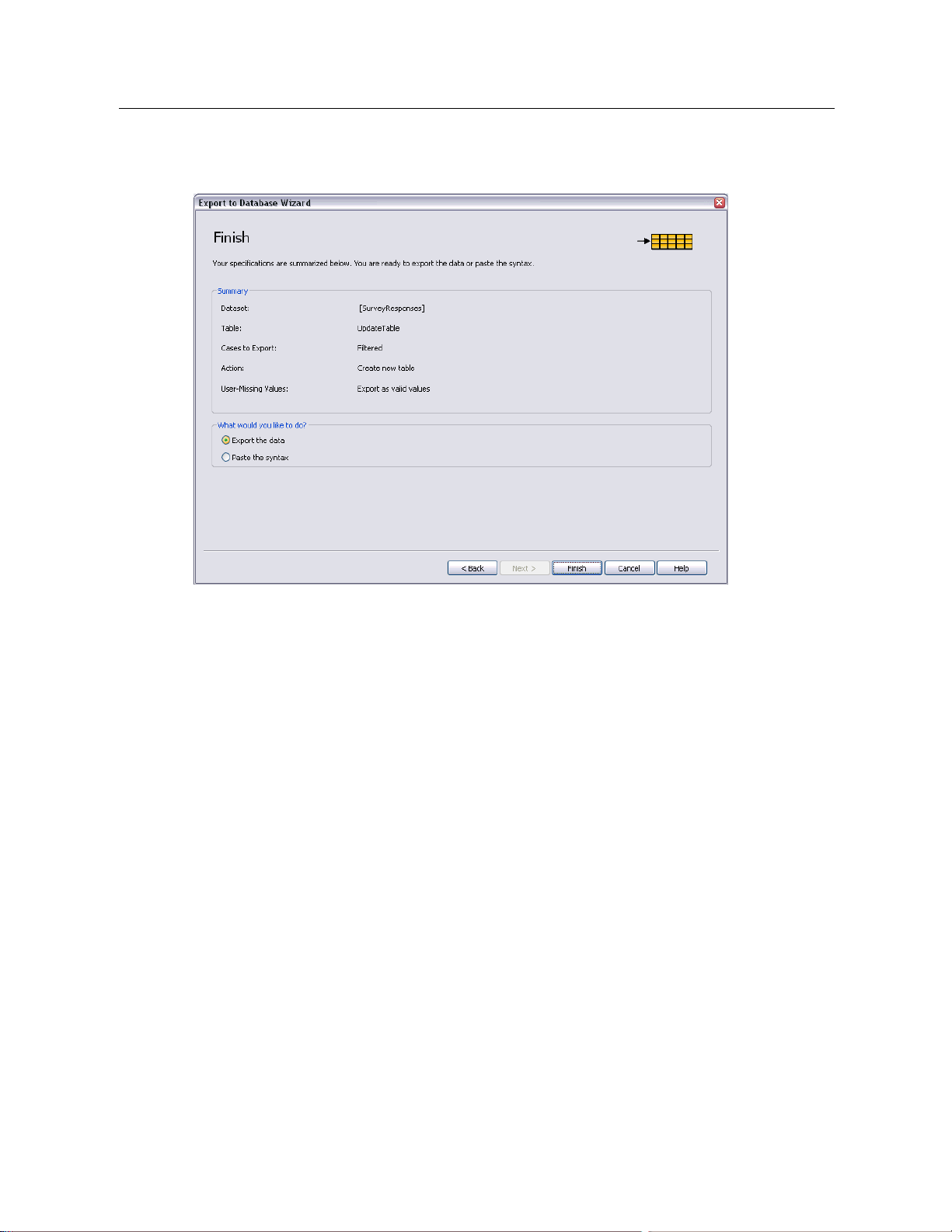
图片 3-31
导出到数据库向导,“完成”面板
55
数据文件
摘要信息
数据集。将用于导出数据的数据集的 IBM® SPSS® Statistics 会话名。如果有多个打
开的数据源,此信息将非常有用。对于通过图形用户界面(如数据库向导)打开的
数据源,将自动指定诸如 DataSet1、DataSet2 等的名称。通过命令语法打开的数
据源将只有数据集名(如果明确指定了一个名称)。
表要修改或创建的表的名称。
要导出的个案。导出所有个案,或导出由先前定义的过滤器条件选定的所有个案。
操作。表示对数据库的修改方式(例如,创建新表或者向现有表添加字段或记录)。
用户缺失值。用户缺失值可作为有效值导出;或者,对于数值变量与系统缺失值同等
对待,对于字符串变量转换为空格。此设置在选择要导出的变量的面板中控制。
导出到 IBM SPSS Data Collection
“导出到 IBM® SPSS® Data Collection”对话框可以创建 IBM® SPSS® Statistics 数据文
件和 Data Collectio
应用程序中。在 SPSS Statistics 和 Data Collection 应用程序之间“穿插”使用数据
时,该操作非常有用。
要将数据导出以供 Data Collection 应用程序使用,请执行下列操作:
E 在包含要导出的数据的“数据编辑器”窗口中,从菜单中选择:
文件 > 导出到 Data Collection
n 元数据文件,您可以使用这些文件将数据读取到 Data Collection
Page 74

56
章3
E
单击数据文件以指定 SPSS Statistics 数据文件的名称和位置。
E 单击元数据文件以指定 Data Collection 元数据文件的名称和位置。
对于不是从 Data Collection 数据源创建的新变量和数据集,则根据 IBM® SPSS® Data
Collection Developer Library 中的 SAV DSC 文档中描述的方法,SPSS Statistics 变量
特性将映射到元数据文件中的 Data Collection 元数据特性。
如果活动数据集是从 Data Collection 数据源创建的:
新的元数据文件是通过将原始元数据库特性与任何新变量的元数据特性合并而来的,
再加上可能影响其元数据特性(例如添加或更改值标签)的对原始变量的任何更改。
对于从 Data Collection 数据源读取的原始变量,SPSS Statistics 不识别的任何元
数据特性都将保留其原始状态。例如,SPSS Statistics 将网格变量转换为常规 SPSS
Statistics 变量,但定义这些网格变量的元数据将在您保存新元数据文件时保留。
如果任何 Data Collection 变量自动重命名以符合 SPSS Statistics 变量命名规则,
则元数据文件会将已转换的名称映射到原始 Data Collection 变量名。
值标签是否存在会影响变量的元数据特性,并因此影响 Data Collection 应用程序读取
这些变量的方式。如果已为变量的任何非缺失值定义了值标签,则应为该变量的所有非
缺失值定义值标签;否则,当 Data Collection 读取数据文件时,未加标签的值将丢失。
此功能仅在安装了 SPSS Statistics 的 Microsoft Windows 操作系统上可用,且仅在本
地分析模式中可用。此功能不能用于使用 SPSS Statistics Server 的分布式分析模式。
要写入 Data Collection 元数据文件,必须安装以下项目:
.NET Framework。要获得最新版本的 .NET Framework,请转至
http://www.microsoft.com/net。
IBM® SPSS® Data Collection Survey Reporter Developer Kit。有关获取 SPSS
Survey Reporter Developer Kit 兼容版本的信息,请转至 support.spss.com
(http://support.spss.com)。
保护原始数据
为了防止原始数据被意外修改或删除,您可以将该文件标记为只读。
E 从“数据编辑器”菜单中选择:
文件 > 将文件标记为只读
如果随后对数据进行修改,然后尝试保存数据文件,则只能用其他文件名保存数据;
这样原始数据就不会受影响。
通过从“文件”菜单中选择
将文件标记为读写您可以将文件权限改回为读写。
Page 75

虚拟活动文件
虚拟活动文件使您能够处理大型数据文件,而无需足够大(或更大)的临时磁盘空间。
对于大多数分析和绘图过程,会在每次您运行不同的过程时重新读取初始数据源。修改
数据的过程需要确定的临时磁盘空间量来记录更改,而且一些操作始终需要足够的磁盘
空间容纳数据文件的至少一个完整副本。
图片 3-32
临时磁盘空间要求
57
数据文件
不需要任何临时磁盘空间的操作包括:
读取 IBM® SPSS® Statistics 数据文件
合并两个或更多 SPSS Statistics 数据文件
使用数据库向导读取数据库表
将 SPSS Statistics 数据文件与数据库表合并
运行读取数据的过程(例如“频率”、“交叉表”和“探索”)
在临时磁盘空间中创建一列或多列数据的操作包括:
计算新变量
对现有变量重新编码
运行创建或修改变量的过程(例如在“线性回归”中保存预测值)
在临时磁盘空间中创建数据文件的整个副本的操作包括:
读取 Excel 文件
运行对数据排序的过程(例如“对个案进行排序”和“拆分文件”)
使用 GET TRANSLATE 或 DATA LIST 命令读取数据
使用“高速缓存数据”工具或 CACHE 命令
从 SPSS Statistics 启动其他读取数据文件的应用程序(例如 AnswerTree 和
DecisionTime)
Page 76

58
章3
注意:GET DATA 命令提供类似于 DATA LIST 的功能,但不在临时磁盘空间中创建数据文件
的完整副本。命令语法中的
件的副本。但是此命令需要已排序的数据才能正确运行,此过程的对话框接口将自动对
数据文件进行排序,生成数据文件的完整副本。(命令语法在学生版中不可用。)
缺省情况下创建数据文件的完整副本的操作:
使用数据库向导读取数据库
使用文本向导读取文本文件
文本向导提供了可选的设置以自动高速缓存数据。缺省情况下,此选项是选中的。您可
以通过取消选择
命令语法并删除
创建数据高速缓存
尽管虚拟活动文件可以显著地减少所需的临时磁盘空间量,但是缺少“活动”文件的临
时副本意味着必须为每个过程均重复读取初始数据源。对于从外部源读取的大型数据文
件,创建数据的临时副本可以改善性能。例如,对于从数据库源读取的数据表,必须为
需要读取数据的任何命令或过程重复执行从数据库读取信息的 SQL 查询。由于实际上所
有统计分析过程和图表绘制过程均需要读取数据,因此会为您运行的每个过程重复执行
SQL 查询,如果您运行大量过程,这会导致处理时间的显著增加。
如果您在执行分析的计算机(本地计算机或远程计算机)上有足够的磁盘空间,则
可以通过创建活动文件的数据高速缓存来消除多次 SQL 查询,并减少处理时间。此
数据高速缓存是完整数据的临时副本。
SPLIT FILE 命令不对数据文件进行排序,因此不创建数据文
在本地高速缓存数据关闭此选项。对于数据库向导,您可以粘贴生成的
CACHE 命令。
注意:缺省情况下,数据库向导自动创建数据高速缓存,但是如果您在命令语法中使
GET DATA 命令读取数据库,则不会自动创建数据高速缓存。(命令语法在学生版
用
中不可用。)
创建数据高速缓存
E 从菜单中选择:
文件 > 高速缓存数据...
单击确定或立即高速缓存。
E
确定会在程序下次读取数据(例如,下次您运行统计程序)时创建数据高速缓存,
单击
这通常是您想要的,因为它不要求额外的数据传输。
存,这在大多数情况下是不必要的。
数据源被“锁定”,在您结束会话、打开不同的数据源或高速缓存数据之前,
立即高速缓存主要用于以下两种情况:
立即高速缓存会立即创建数据高速缓
任何人都无法更新该数据源。
对于大型数据源,如果您高速缓存了数据,则在数据编辑器的“数据视图”选项卡
的内容中进行滚动会快得多。
Page 77

自动高速缓存数据
可以使用 SET 命令,在活动数据文件中发生指定数量的更改之后自动创建数据高速缓存。
缺省情况下,在活动数据文件发生 20 个更改之后,会自动高速缓存该活动数据文件。
E 从菜单中选择:
文件 > 新建 > 语句
在语法窗口中键入 SET CACHE n(其中 n 表示数据文件高速缓冲前活动数据文件中更
E
改的数量)。
E 从语法窗口中的菜单选择:
运行 > 全部
注意:高速缓存设置并不是在各个会话之间持续存在。每次启动新会话时,该值均
重置为缺省值 20。
59
数据文件
Page 78

分布式分析模式
分布式分析模式允许您使用本地(或桌面)计算机以外的计算机以进行内存密集型工
作。由于用于分布式分析的远程服务器通常比本地计算机性能更强,速度更快,因此使
用分布式分析模式可以显著地缩短计算机处理时间。如果工作涉及到以下内容,则通过
远程服务器进行分布式分析可能会有用:
大型数据文件,尤其是从数据库源中读取的数据。
内存密集型任务。任何在本地分析模式下耗时很长的任务均是适合于进行分布式
分析的对象。
分布式分析仅影响与数据相关的任务,例如读取数据、转换数据、计算新变量和计算统
计量。分布式分析对与编辑输出相关的任务没有影响,例如操作枢轴表或修改图表。
注意:只有在既有该软件的本地版本,又能访问安装在远程服务器上的该软件的许可服
务器版本的情况下,才能使用分布式分析。
章
4
服务器登录
“服务器登录”对话框允许您选择处理命令和运行过程的计算机。您可以选择本地计算
机,也可以选择远程服务器。
图片 4-1
“服务器登录”对话框
© Copyright SPSS Inc. 1989, 2010
60
Page 79

您可以在列表中添加、修改或删除远程服务器。远程服务器通常需要用户标识和密码,
可能还需要域名。请联系系统管理员以获取关于可用服务器、用户标识和密码、域
名的信息以及其他连接信息。
您可以选择缺省服务器并保存与任何服务器相关联的用户标识、域名和密码。启动
新会话时,会自动连接到缺省服务器。
如果您被许可使用 Statistics Adapter,且站点正在运行 IBM® SPSS® Collaboration
and Deployment Services 3.5 或更新版本,则可单击
服务器列表。如果尚未登录到 IBM® SPSS® Collaboration and Deployment Services
Repository,则您将被提示输入连接信息,然后才能查看服务器列表。
添加或编辑服务器登录设置
使用“服务器登录设置”对话框可以添加或编辑远程服务器的连接信息,以便在分
布式分析模式下使用。
图片 4-2
“服务器登录设置”对话框
61
分布式分析模式
搜索...以查看网络上可用的
请联系系统管理员获取可用服务器列表、服务器端口号以及其他连接信息。除非有管理
员指示,否则请勿使用“安全套接字层”。
服务器名称。服务器?名称?可以是分配给计算机的字母数字名称(例如
NetworkServer),也可以是分配给计算机的 IP 地址(例如 202.123.456.78)。
端口号。端口号是服务器软件用于通信的端口。
描述。可以输入可选的描述以显示在服务器列表中。
使用安全套接字层连接。安全套接字层 (SSL) 在分布式分析请求发送到远程服务器
时加密请求。使用 SSL 之前,请与管理员协商。要启用此选项,必须在桌面计算机
和服务器上配置 SSL。
Page 80

62
章4
选择、切换或添加服务器
E 从菜单中选择:
文件 > 切换服务器...
选择缺省服务器:
E 在服务器列表中,选择要使用的服务器旁边的框。
E 输入管理员提供的用户标识、域名和密码。
注意:启动新会话时,会自动连接到缺省服务器。
切换到其他服务器:
E 从列表中选择服务器。
E 输入用户标识、域名和密码(如果需要)。
注意:在会话期间切换服务器时,所有打开的窗口均会关闭。在窗口关闭之前会提示
您保存更改。
添加服务器:
E 从管理员处获取服务器连接信息。
E 单击添加打开?服务器登录设置?对话框。
E 输入连接信息和可选设置,然后单击确定。
编辑服务器:
E 从管理员处获取修订的连接信息。
E 单击编辑打开?服务器登录设置?对话框。
E 输入更改并单击确定。
选择缺省服务器:
注意:仅当您被许可使用 Statistics Adapter,且站点正在运行 IBM® SPSS®
Collaboration and Deployment Services 3.5 或更新版本时,才可使用搜索可用服务
器功能。
E 单击搜索...以打开?搜索服务器?对话框。如果您尚未登录到 IBM® SPSS® Collaboration
and Deployment Services Repository,将提示您连接信息。
E 选择一个或多个服务器,并单击确定。服务器现在将出现在“服务器登录”对话框中。
要连接到其中一个服务器,请按照“切换到其他服务器”的说明进行操作。
E
搜索可用服务器
使用?搜索服务器?对话框,选择网络上可用的一个或多个服务器。在您从?服务器登录?
对话框中单击
搜索...时,该对话框出现。
Page 81

图片 4-3
“搜索服务器”对话框
选择一个或多个服务器,单击确定以将其添加到?服务器登录?对话框中。尽管您可在
“服务器登录”对话框中手动添加服务器,但搜索可用服务器功能允许您无需知道正
确的服务器名称和端口号,就能连接到服务器。这信息会自动提供。不过,您仍然需
要提供正确的登录信息,例如用户名、域名和密码等。
从远程服务器打开数据文件
63
分布式分析模式
在分布式分析模式下,“打开远程文件”对话框替换了标准的“打开文件”对话框。
可用文件、文件夹和驱动器的列表内容取决于远程服务器上可用的,或可从该服务
器访问的文件、文件夹和驱动器。当前服务器名称在对话框的顶部指明。
在分布式分析模式下,除非将驱动器指定为共享设备,或者将包含数据文件的文件
夹指定为共享文件夹,否则将不能访问本地计算机上的数据文件。有关如何与服务
器网络“共享”本地计算机上的文件夹的信息,请参见操作系统文档。
如果服务器在运行不同的操作系统(例如您在运行 Windows 而服务器在运行
UNIX),那么即使本地数据文件位于共享文件夹中,您在分布式分析模式下也可
能无法访问它们。
本地和分布式分析模式下的文件访问
本地计算机和网络的数据文件、文件夹(目录)和驱动器视图基于您正用来处理命令和
运行过程的计算机,该计算机不一定是您面前的计算机。
本地分析模式。如果使用本地计算机作为您的?服务器?,则您在文件访问对话框中看到
的数据文件、文件夹和驱动器视图(对于打开数据文件)类似于在其他应用程序或在
Windows 资源管理器中看到的视图。您可以看到您的计算机上的所有数据文件和文件
夹,以及所安装的网络驱动器上的所有文件和文件夹。
分布式分析模式。如果使用另外一台计算机作为运行命令和过程的?远程服务器?,则数
据文件、文件夹和驱动器的视图代表从远程服务器计算机看到的视图。尽管您可以看到
熟悉的文件夹名称(例如 Program Files)和驱动器名称(例如 C),但这些不是 您的
计算机上的文件夹或驱动器;它们是远程服务器上的文件夹和驱动器。
Page 82

64
章4
图片 4-4
本地和远程视图
在分布式分析模式下,除非将驱动器指定为共享设备,或者将包含数据文件的文件夹指
定为共享文件夹,否则将不能访问本地计算机上的数据文件。如果服务器在运行不同的
操作系统(例如您在运行 Windows 而服务器在运行 UNIX),那么即使本地数据文件位于
共享文件夹中,您在分布式分析模式下也可能无法访问它们。
分布式分析模式不同于访问驻留在网络上另一台计算机上的数据文件。在本地分析模
式或分布式分析模式下您都可以访问其他网络设备上的数据文件。在本地模式下,您是从
本地计算机访问其他设备。而在分布式模式下,您是从远程服务器访问其他网络设备。
如果对于是在使用本地分析模式还是分布式分析模式没有把握,可查看用于访问数据
文件的对话框中的标题栏。如果对话框的标题包含词远程(例如
果文本
注意:此情况只对访问数据文件的对话框(例如“打开数据”、“保存数据”、“打开
数据库”和“应用数据字典”)有影响。对于所有其他文件类型(例如查看器文件、语
法文件和脚本文件),始终使用本地视图。
远程服务器:[服务器名称] 显示在对话框顶部,则说明您在使用分布式分析模式。
分布式分析模式下过程的可用性
在分布式分析模式下,只有同时安装在本地版本和远程服务器上的版本中的过程才可用。
如果在本地安装远程服务器上未安装的可选组件,并从本地计算机切换到远程服务
器,则受影响的程序将从菜单中移去,相应的命令语法将导致出现错误。切换回本地方
式可恢复所有受影响的过程。
打开远程文件),或者如
绝对和相对路径指定
在分布式分析模式下,数据文件和命令语法文件的相对路径指定是相对于当前服务器
的,而不是相对于本地计算机。相对路径指定(如 /mydocs/mydata.sav)并不指向您的
本地驱动器上的目录和文件;它指向远程服务器的硬盘上的目录和文件。
Page 83

65
分布式分析模式
Windows UNC 路径指定
如果在使用 Windows 服务器版本的程序,则在使用命令语法访问数据和语法文件时,可
以使用通用命名约定 (UNC) 指定。UNC 指定的一般形式为:
\\servername\sharename\path\filename
Servername 是包含数据文件的计算机的名称。
Sharename 是该计算机上指定为共享文件夹的文件夹(目录)。
Path 是共享文件夹下的任何其他文件夹(子目录)路径。
Filename 是数据文件的名称。
示例如下:
GET FILE='\\hqdev001\public\july\sales.sav'。
如果计算机没有为其指定的名称,则可以使用其 IP 地址,例如:
GET FILE='\\204.125.125.53\public\july\sales.sav'。
即使是通过 UNC 路径指定,您也只能访问指定为共享的驱动器和文件夹中的数据与语法
文件。使用分布式分析模式时,此情况包括本地计算机上的数据与语法文件。
UNIX 绝对路径指定
在 UNIX 服务器版本中,不存在与 UNC 路径等同的路径指定法,所有目录路径必须是以服
务器根目录开始的绝对路径,不允许使用相对路径。例如,如果数据文件位于 /bin/data
且当前目录也是 /bin/data,则
GET FILE='/bin/sales.sav'.
INSERT FILE='/bin/salesjob.sps'.
GET FILE='sales.sav' 无效;必须指定整个路径,例如:
Page 84
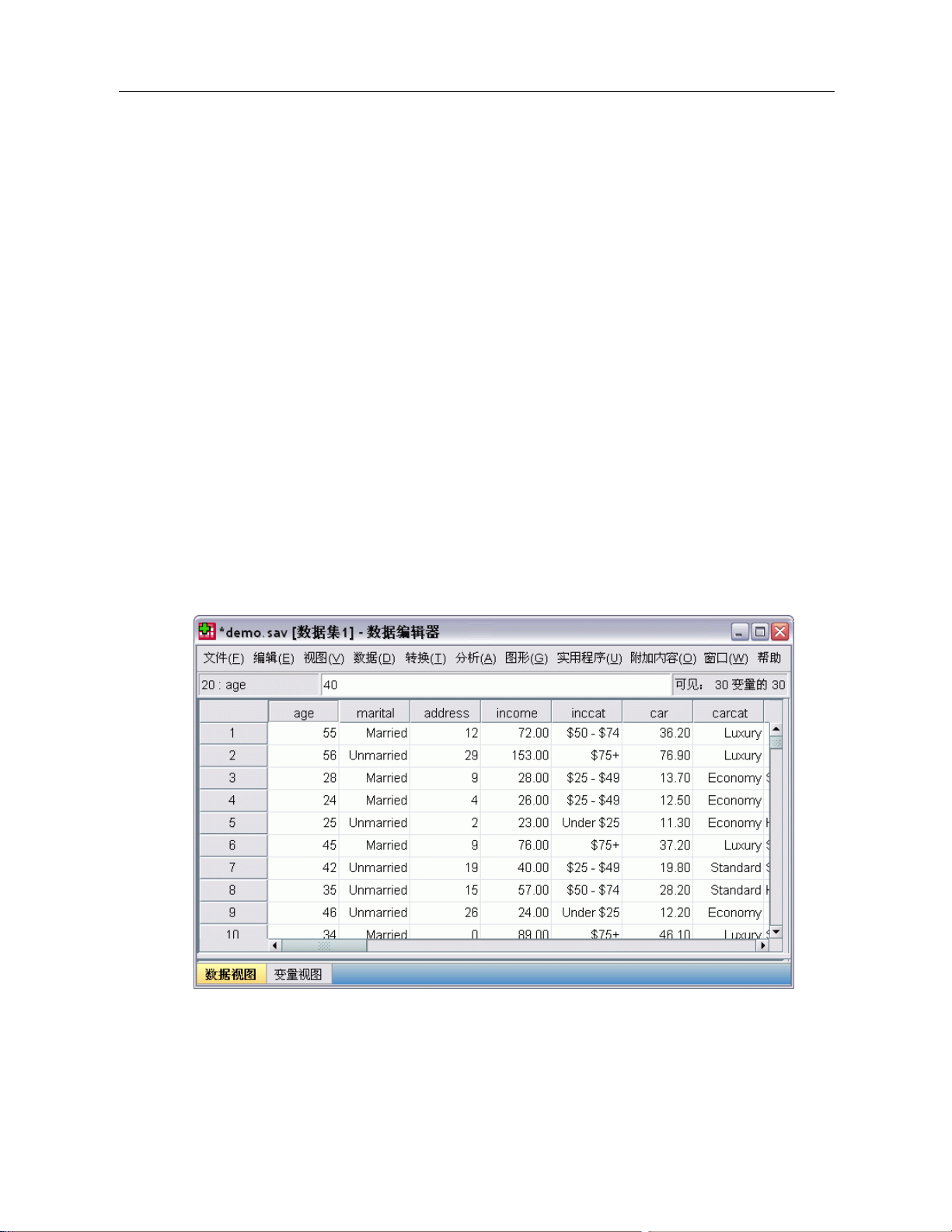
数据编辑器
数据编辑器提供一种类似电子表格的便利方法来创建和编辑数据文件。当您启动会
话时,“数据编辑器”窗口自动打开。
数据编辑器提供数据的两种视图:
数据视图。显示实际的数据值或定义的值标签。
变量视图。显示变量定义信息,包括定义的变量标签和值标签、数据类型(例如,字
符串、日期或数值)、测量级别(名义、序数或刻度)及用户定义的缺失值。
在两种视图中,您都可以添加、更改和删除包含在数据文件中的信息。
数据视图
章
5
图片 5-1
数据视图
数据视图的许多功能类似于电子表格应用程序中提供的功能。不过,有一些重要的不
同之处:
行为个案。每一行代表一个个案或一个观察值。例如,问卷的每个回答者都是一
个个案。
© Copyright SPSS Inc. 1989, 2010
66
Page 85
单元包含值。每个单元均包含某个个案的某个变量的单个值。单元是个案和变量
数据文件是矩形的。数据文件的尺寸由个案和变量的个数确定。您可以在任何单
变量视图
图片 5-2
变量视图
67
数据编辑器
列为变量。每一列代表一个要度量的变量或特征。例如,问卷中的每一项都是一
个变量。
相交的位置。单元仅包含数据值。与电子表格程序不同,数据编辑器中的单元不
能包含公式。
元中输入数据。如果在定义的数据文件的界限以外的单元中输入数据,则数据矩
形将扩展以包含该单元与文件界限之间的任何行和/或列。数据文件的界限内没
有“空”单元。对于数值变量,空白单元会转换成系统缺失值。对于字符串变
量,则将空白单元视为有效值。
“变量视图”包含对数据文件中每个变量的属性的描述。在“变量视图”中:
行为变量。
列为变量属性。
您可以添加或删除变量,以及修改变量属性,包括:
变量名
数据类型
数字位数或字符个数
小数位数
描述性的变量标签和值标签
Page 86

68
章5
用户定义的缺失值
列宽
测量级别
当您保存数据文件时,将保存所有这些属性。
除了在“变量视图”中定义变量属性以外,另外还有两种方法可用于定义变量属性:
“复制数据属性向导”使您能够使用外部 IBM® SPSS® Statistics 数据文件或当前
会话中的另一数据集作为模板,用于定义活动数据集中的文件和变量的属性。您
也可以将活动数据集中的变量用作活动数据集中其他变量的模板。“复制数据属
性”可以在数据编辑器窗口的“数据”菜单上找到。
“定义变量属性”(也在数据编辑器窗口的“数据”菜单上提供)扫描您的数据并
列出任何选定变量的所有唯一数据值、标识未标注的值以及提供自动标注功能。这
对于使用数值代码表示类别(例如,0 = Male,1 = Female)的分类变量特别有用。
显示或定义变量属性
E 使数据编辑器成为活动窗口。
E 双击位于“数据视图”中列顶端的变量名,或单击变量视图选项卡。
E 要定义新变量,请在任意空白行中输入一个变量名。
E 选择您想要定义或修改的属性。
变量名
以下规则适用于变量名:
每个变量名必须是唯一的;不允许重复。
变量名最多可包含 64 个字节,并且第一个字符必须是字母或字符 @、# 或 $ 之一。
后续字符可以是字母、数字、非标点字符和句点 (.) 的任意组合。在代码页模式
中,64 个字节在单字节语言(例如英语、法语、德语、西班牙语、意大利语、希
伯来语、俄语、希腊语、阿拉伯语和泰语)中通常意味着 64 个字符,在双字节
语言(例如日语、中文和韩语)中则为 32 个字符。许多在代码页模式中只占一
个字节的字符串在 Unicode 模式中则会占到两个或更多字节。例如,é 以代
码页
格式是一个字节,但是以 Unicode 格式就是两个字节;因此 résumé 在代码页文
件中是六个字节,但在 Unicode 模式中是八个字节。
注意:(请注意:字母包括书写日常文字所用的任何非标点字符,这些文字要属
于
平台字符集所支持的语言。)
变量名不能包含空格。
变量名第一个位置中的 # 字符将变量定义为临时变量。只能使用命令语法创建临时
变量。不能在创建新变量的对话框中将变量的第一个字符指定为 #。
第一个位置中的 $ 符号表示变量为系统变量。$ 符号不能作为用户定义的变量
的
第一个字符。
可在变量名中使用句点、下划线和字符 $、# 以及 @。例如,A._$@#1 是一个有
效的变量名。
Page 87

应避免用句点结束变量名,因为句点可能被解释为命令终止符。只能使用命令语法
创建以句点结束的变量。不能在创建新变量的对话框中创建以句点结束的变量。
应避免使用下划线结束变量名,因为这样的名称可能与命令和过程自动创建的
变量名冲突。
不能将保留关键字用作变量名。保留关键字有:ALL、AND、BY、EQ、GE、GT、
LE、LT、NE、NOT、OR、TO 和 WITH。
可以用任意混合的大小写字符来定义变量名,大小写将为显示目的而保留。
当长变量名需要在输出中换行为多行时,会在下划线、句点和内容从小写变为
大写的位置进行换行。
变量测量级别
您可以将测量级别指定为刻度(定距或者定比刻度上的数值数据)、有序或名义。名
义数据和有序数据可以是字符串(字母数字)或数值。
标定. 当变量值表示不具有内在等级的类别时,该变量可以作为名义变量;例如,雇
员任职的公司部门。名义变量的示例包括地区、邮政编码和宗教信仰。
有序. 当变量值表示带有某种内在等级的类别时,该变量可以作为有序变量;例如,
从十分不满意到十分满意的服务满意度水平。有序变量的示例包括表示满意度或
可信度的态度分数和优先选择评分。
刻度. 当变量值表示带有有意义的度规的已排序类别时,该变量可以作为刻度(连
续)变量对待,以便在值之间进行合适的距离比较。刻度变量的示例包括以年为单
位的年龄和以千美元为单位的收入。
69
数据编辑器
注意:对于有序字符串变量,将假定字符串值的字母顺序反映了类别的真实顺序。例
如,对于具有 low、medium、high 值的字符串变量,类别的顺序将解释为 high、low、
medium,这个顺序是错误的。通常,使用数值代码代表有序数据更为可靠。
对于通过转换创建的新数值变量、来自外部源的数据以及在版本 8 之前创建的 IBM®
SPSS® Statistics 数据文件,默认测量级别由以下表格中的条件决定。将以条件在表格
中的排列顺序对其进行评估。将应用与数据匹配的第一个条件的测量级别。
条件
变量的所有值均缺失
格式为美元或定制货币 连续
格式为日期或时间(不包括月份和星期) 连续
变量包含至少一个非整数值 连续
变量包含至少一个负值 连续
变量不包含少于 10,000 的有效值 连续
变量具有 N 个或更多唯一有效值* 连续
变量不包含少于 10 的有效值 连续
变量具有少于 N 个唯一有效值*
测量级别
名义
名义
* N 是用户指定的临界值。默认值为 24。
Page 88
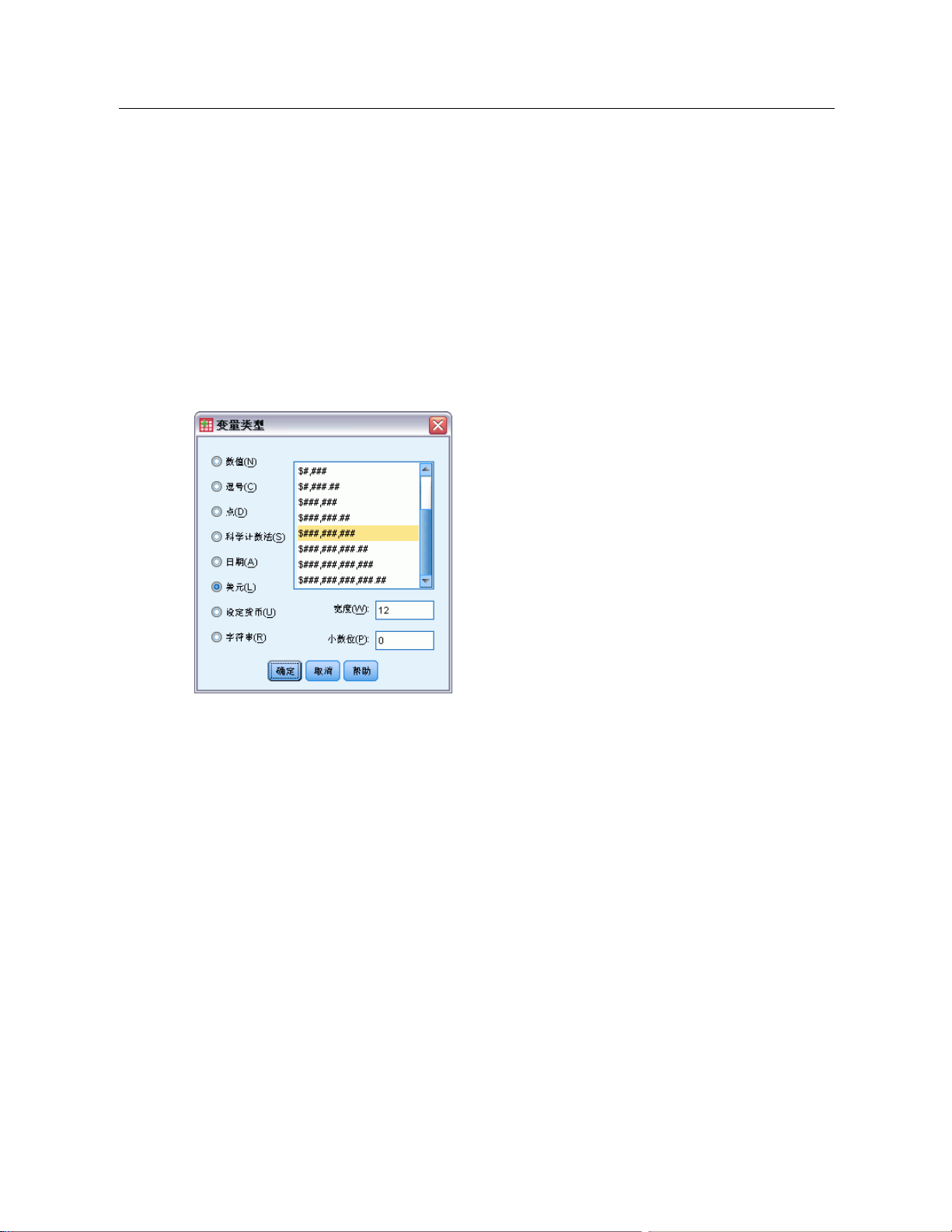
70
章5
变量类型
您可以在“选项”对话框中更改临界值。
“数据”菜单中的“定义变量属性”对话框可帮助您指派正确的测量级别。
“变量类型”指定每个变量的数据类型。默认情况下,假定所有新变量都为数值变量。
您可以使用“变量类型”来更改数据类型。“变量类型”对话框的内容取决于选定的数
据类型。对于某些数据类型,存在有关宽度和小数位数的文本框;对于其他数据类型,
只需从可滚动的示例列表中选择一种格式即可。
图片 5-3
“变量类型”对话框
可用的数据类型如下:
数值。值为数字的变量。值以标准数值格式显示。数据编辑器接受以标准格式或科
学计数法表示的数值。
逗号。变量值显示为每三位用逗号分隔,并用句点作为小数分隔符的数值变量。数据
编辑器为逗号变量接受带或不带逗号的数值,或以科学计数法表示的数值。值的小
数指示符右侧不能包含逗号。
点。变量值显示为每三位用句点分隔,并带有逗号作为小数分隔符的数值变量。数据
编辑器为点变量接受带或不带点的数值,或以科学计数法表示的数值。值的小数指示
符右侧不能包含句点。
科学计数法。一个数值变量,它的值以嵌入的 E
以及带符号的 10 次幂指数形式显示。数
据编辑器为此类变量接受带或不带指数的数值。指数前面可以加上带符号(可选)的 E
或 D,或只加上符号 — 例如,123、1.23E2、1.23D2、1.23E+2 以及 1.23+2。
日期。一种数值变量,其值以若干种日历-日期或时钟-时间格式中的一种显示。从列表
中选择一种格式。输入日期时可以用斜杠、连字符、句号、逗号或空格作为分隔符。
两位数年份值的世纪范围由您的“选项”设置确定(从“编辑”菜单中,选择
后单击
数据选项卡)。
选项然
Page 89

美元。数值变量,显示时前面带美元符号 ($),每三位用逗号分隔,并用句点作为小数
分隔符。可以输入带有或不带有前导美元符号的数据值。
定制货币。一种数值变量,其值以定制货币格式中的一种显示,定制货币格式是在“选
项”对话框的“货币”选项卡中定义的。定义的定制货币字符不能用于数据输入,但
显示在数据编辑器中。
字符串。字符串变量的值不是数值,因此不用在计算中。字符串值可以包含任何字
符,可包含的最大字符数不超过定义的长度。字符串变量区分大小写字母。此类型
又称为字母数值变量。
定义变量类型
E 单击您想要定义的变量的类型单元中的按钮。
E 在“变量类型”对话框中选择数据类型。
E 单击确定。
输入格式与显示格式
71
数据编辑器
变量标签
根据格式,值在“数据视图”中的显示可能与输入的及内部存储的实际值不同。以下
是一些通用准则:
对于数值、逗号和点格式,您可以输入具有任意小数位数(最多 16 位)的值,整个
值会存储在内部。“数据视图”仅显示定义的小数位数,并且对具有更多小数位的
值进行舍入。不过,在所有的计算中都使用完整的值。
对于字符串变量,所有值都向右填充到最大宽度。对于最大宽度为三的字符串变
量,No 值在内部存储为
对于日期格式,您可以使用斜杠、短划线、空格、逗号或句点作为日、月、年值
“No”,并不等于“No”。
之间的分隔符,并且可以为月值输入数字、三字母缩写或完整名称。以通用格式
dd-mmm-yy 显示日期,其中以短划线作为分隔符并对月份使用三字母缩写。以通用格
式 dd/mm/yy 和 mm/dd/yy 显示日期,其中以斜杠作为分隔符并对月份使用数字。日
期在内部存储为自 1582 年 10 月 14 日以来的累计秒数。两位数年份的日期世纪范围
由您的“选项”设置确定(从“编辑”菜单中,选择
在时间格式中,您可以使用冒号、句号或空格作为小时、分钟和秒数间的分隔符。
选项,然后单击数据选项卡)。
时间以冒号分隔显示。时间被内部储存为表示时间间隔的秒数。例如,10:00:00 被
内部储存为 36000,即 60(秒每分钟)x 60(分钟每小时)x 10(小时)。
您可以为描述性变量标签分配最多可达 256 个的字符(在双字节语言中则为 128 个字
符)。变量标签可以包含空格和变量名称中所不允许的保留字符。
指定变量标签
E 使数据编辑器成为活动窗口。
E 双击位于“数据视图”中列顶端的变量名,或单击变量视图选项卡。
Page 90

72
章5
E
值标签
在变量的标签单元格中,输入描述性变量标签。
您可以为每个变量值分配描述值标签。当您的数据文件使用数值代码表示非数值类别时
(例如:代码 1 和 2 代表 male 和 female),此过程特别有用。
值标签最多可达 120 个字节。
图片 5-4
“值标签”对话框
指定值标签
E 单击您想要定义的变量的值单元中的按钮。
E 在每个值中,输入值和标签。
E 单击添加输入值标签。
E 单击确定。
在标签中插入换行符
若单元格或区域没有足够宽度在一行内显示整个标签,则枢轴表和图表中的变量标签和
值标签会自动换行至多行,而如果您想将标签换行至不同点,可以编辑结果,插入手动
换行符。您还可以创建变量标签和值标签,这将一直换行至指定点并以多行显示。
E 对于变量标签,在数据编辑器的变量视图中选择标签变量单元格。
E 对于值标签,在数据编辑器的变量视图中选择值变量单元格,单击单元格中的按钮,选
择您想在“值标签”对话框中修改的标签。
E 在标签中您想让标签换行的地方,输入\n。
\n 不在枢轴表或图表中显示;它被翻译为换行字符。
Page 91

缺失值
73
数据编辑器
缺失值将指定数据值定义为用户缺失值。例如,您想要区分因对象拒绝回答问题造成的
数据缺失与由于问题不适于该对象而未回答所引起的数据缺失。将指定为用户缺失值的
数据值标记为进行特殊处理,并将其从大多数计算中排除。
图片 5-5
“缺失值”对话框
您最多可以输入三个离散(单个)缺失值、一个缺失值范围或一个范围加一个
离散值。
只有数值变量能被指定范围。
除非您将其明显定义为缺失,否则所有字符串值包括“零”或空白值都被视为有效。
字符串变量的缺失值不得超过八个字节。(字符串变量的宽度定义没有限制,但
定义的缺失值不得超过八个字节。)
若想将“零”或空白值定义为字符串变量的缺失,则在离散缺失值选项下的字段
之一输入一个单空格。
定义缺失值
角色
E 单击您想要定义的变量的缺失单元中的按钮。
E 输入表示缺失数据的值或值范围。
某些对话框支持可用于预先选择分析变量的预定义角色。当打开其中一个对话框时,满
足角色要求的变量将自动显示在目标列表中。可用角色包括:
输入。变量将用作输入(例如,预测变量、自变量)。
目标。变量将用作输出或目标(例如,因变量)。
两者。变量将同时用作输入和输出。
无。变量没有角色分配。
分区。变量将用于将数据划分为单独的训练、检验和验证样本。
Page 92

74
章5
列宽
拆分。包括以便与 IBM® SPSS® Modeler 相互兼容。具有此角色的变量不会在 IBM®
SPSS® Statistics 中用作拆分文件变量。
默认情况下,为所有变量分配输入角色。这包括外部文件格式的数据和 SPSS
Statistics 18 之前版本的数据文件。
角色分配只影响支持角色分配的对话框。它对命令语法没有影响。
指定角色
E 从变量的角色单元格的列表中选择角色。
您可以为列宽指定一些字符。也可以通过单击并拖拽列边框来更改数据视图中的列宽。
比例字体的列宽是基于平均字符宽度。根据值中使用的字符,在指定宽度内可以显
示较多或较少的字符。
列宽度只影响数据编辑器中的值显示。更改列宽不会改变变量的已定义宽度。
变量对齐
对齐控制着数据视图中数据值和/或值标签的显示。默认对齐方式为数值变量在右边,
字符串变量在左边。此设置只影响数据编辑器中的显示。
将变量定义属性应用于多个变量
在定义了变量的变量定义属性之后,可以复制一个或多个属性并将其应用到一个或多
个变量。
基础复制粘贴操作被用于变量定义属性的应用。您可以:
复制一个单一属性(例如,值标签)并将其粘贴至一个或多个变量的相同属性
单元中。
从一个变量中复制所有属性并将其粘贴至一个或多个其他变量。
通过一个已复制变量的所有属性创建多个新变量。
将变量定义属性应用于其他变量
从已定义变量中应用单个属性
E 在变量视图中,选择您想应用于其他变量的属性单元格。
E 从菜单中选择:
编辑 > 粘贴
选择您想应用其属性的属性单元格。(您可以选择多个目标变量。)
E
Page 93

E
从菜单中选择:
编辑 > 粘贴
如果您将属性粘贴至空白行,则新变量就与所有属性中除选定属性以外的默认属性
一同被创建。
应用已定义变量中的全部属性
E 在变量视图中,与您想使用的属性一同选择变量行号。(突出显示整行。)
E 从菜单中选择:
编辑 > 粘贴
与您想使用的属性一同选择变量行号。(您可以选择多个目标变量。)
E
E 从菜单中选择:
编辑 > 粘贴
通过相同属性生成多个新变量
E 在变量视图中,单击具有您想用于新变量属性的变量。(突出显示整行。)
75
数据编辑器
E 从菜单中选择:
编辑 > 粘贴
在数据文件中单击最后一个已定义变量下面的空行号码
E
E 从菜单中选择:
编辑 > 粘贴变量...
在“粘贴变量”对话框中,输入您想创建的变量数。
E
E 输入新变量的前缀和起始数字。
E 单击确定。
新变量名将包括指定前缀和由指定数字开始的序列数。
定制变量属性
除了标准变量属性(如值标签、缺失值、测量级别)之外,还可以自己创建定制的变
量属性。与标准变量属性一样,这些定制变量属性也随 IBM® SPSS® Statistics 数据
文件一同保存。因此,您可以创建识别调查问题响应类型的变量属性(例如,单选、
多选、填空)或计算变量使用的公式。
创建定制变量属性
。
创建新的定制属性:
E 在“变量视图”中,从菜单中选择:
数据 > 新建定制属性...
Page 94

76
章5
E
将要向其分配新属性的变量拖放到“选定的变量”列表中。
E 为新属性输入名称。属性名必须遵循与变量名相同的规则。
E 为新属性输入一个可选值。如果选择多个变量,则将该值指定给所有选定的变量。可以
将此字段保留为空,然后在“变量视图”中输入各变量的值。
图片 5-6
“新建定制属性”对话框
在数据编辑器中显示属性。在数据编辑器的“变量视图”中显示属性。有关控制定制属性
显示的信息,请参见下面的显示和编辑定制变量属性。
显示定义的列表属性。显示已为数据集定义的定制属性列表。以美元符号 ($) 开头的属
性名称是不能修改的保留属性。
显示和编辑定制变量属性
可以在数据编辑器的“变量视图”中显示和编辑定制变量属性。
Page 95

数据编辑器
图片 5-7
“变量视图”中显示的定制变量属性
定制变量属性的名称用方括号括起。
以美元符号开头的属性名是保留名称,不能修改这些名称。
空单元格表示该变量没有属性;单元格中显示为 Empty 的文本表示该变量具有属
性,但还没有为该变量的属性赋值。在单元格中输入文本后,该变量即拥有了具有
您所输入的值的属性
在单元格中显示的
。
数组... 表示此属性是属性数组,即包含多个值的属性。单击单
元格中的按钮以显示值列表。
77
显示和编辑定制变量属性
E 在“变量视图”中,从菜单中选择:
视图 > 自定义变量视图...
选择(选中)要显示的定制变量属性。(定制变量属性用方括号括起。)
E
Page 96
78
章5
图片 5-8
自定义变量视图
一旦在“变量视图”中显示属性,您即可直接在数据编辑器中对其进行编辑。
变量属性数组
在“变量视图”的定制变量属性单元格中或者在“定义变量属性”的“定制变量属性”
对话框中显示的文本数组...表示:该属性是一个属性数组,即一个包含多个值的属
性。例如,可以有一个属性数组,它标识用于计算派生变量的所有源变量。单击单
元格中的按钮可以显示和编辑值列表。
图片 5-9
“定制属性数组”对话框
Page 97
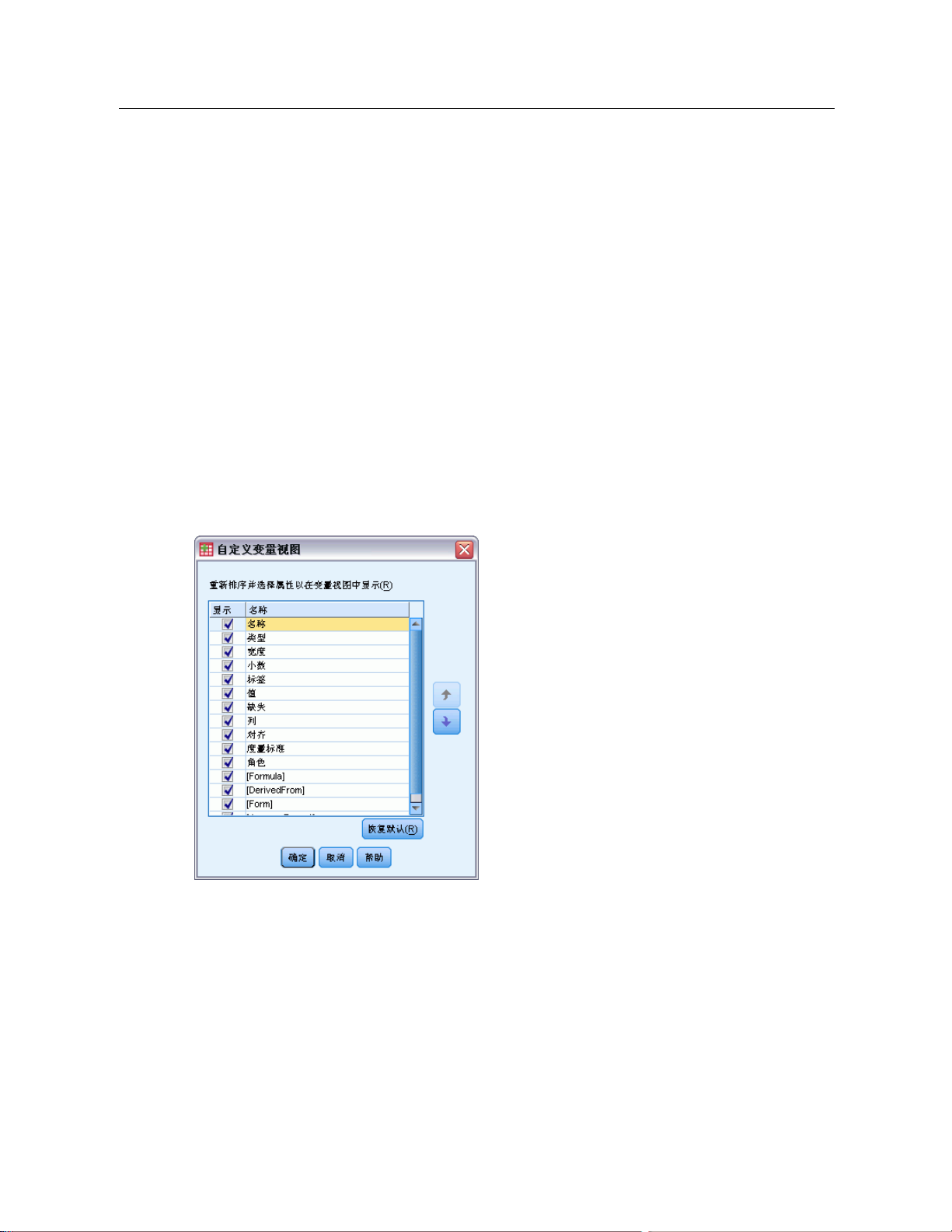
自定义变量视图
您可以使用自定义变量视图控制变量视图中显示的属性(例如,名称、类型、标签)及
其显示顺序。
任何与数据库有关的定制变量属性都以方括号括起。
自定义显示设置保存在 IBM® SPSS® Statistics 数据文件中。
您还可以控制变量视图中的默认显示和属性顺序。
自定义变量视图
E 在“变量视图”中,从菜单中选择:
视图 > 自定义变量视图...
选择(选中)要显示的变量属性。
E
E 使用向上和向下箭头按钮更改属性的显示顺序。
图片 5-10
“自定义变量视图”对话框
79
数据编辑器
拼写检查
E 在“数据编辑器”窗口中,选择“变量视图”选项卡。
恢复默认。应用默认显示与顺序设置。
变量和值标签
检查变量标签与值标签的拼写:
Page 98

80
章5
E
右键单击标签或值列,并从上下文菜单中选择:
拼写
或
E 在“变量视图”中,从菜单中选择:
实用程序 > 拼写
或
E 在对话框中单击拼写。(这将值标签的拼写检查限制为特定变量。)
拼写检查仅限于数据编辑器的变量视图中的变量标签和值标签。
字符串数据值
检查字符串数据值的拼写:
E 在“数据编辑器”窗口中,选择“
E (可选)选择一个或多个待检查的变量(列)。要选择变量,请单击列顶部的变量名。
E 从菜单中选择:
实用程序 > 拼写
如果数据集不包含字符串变量,或选定变量均非字符串变量,则“实用程序”上的
输入数据
在数据视图中,您可以在数据编辑器里直接输入数据。您可以以任何顺序输入数据。您
可以在选定区域或个别单元格中,按个案或按变量输入数据。
突出显示活动单元格。
在数据编辑器左上角显示变量名称和活动单元格的行号。
当您选择一个单元格输入数据值时,该值显示在数据编辑器顶端的单元格编辑器中。
当按下回车键或选择另一个单元格时,数据值方被保存。
欲输入除简单数值数据外的任何其他数据时,您必须先定义变量类型。
如果在空列中输入一个值,数据编辑器将自动创建一个新变量并赋予一个变量名。
数据视图”选项卡。
如果在“数据视图”中没有选定的变量,则会选中所有字符串变量。
“拼写”选项被禁用。
输入数值数据
E 在数据视图中选择一个单元格。
E 输入数据值。(值被显示在数据编辑器顶端的单元格编辑器中。)
E 按回车键或选择另一个单元格,即可保存值。
Page 99

输入非数值数据
E 双击位于“数据视图”中列顶端的变量名,或单击变量视图选项卡。
E 单击变量的类型单元格。
E 在“变量类型”对话框中选择数据类型。
E 单击确定。
E 双击行号或单击数据视图选项卡。
E 在新近定义的变量列中输入数据。
使用值标签进行数据输入
E 若值标签没有显示在当前数据视图中,就从菜单中选择:
视图 > 值标签
单击您想输入值的单元格。
E
81
数据编辑器
E 从下拉列表中选择值标签。
值被输入后,值标签就显示在单元格里。
注意:此过程仅当您已对变量的值标签定义时才会运行。
数据编辑器中的数据值限制
既定变量类型和宽度决定了在数据视图单元格中可以输入的值类型。
如果输入了一个既定变量类型不允许的字符,则该字符无法输入。
对于字符串变量,不允许字符超出既定宽度。
对于数值变量,可以输入超出既定宽度的整数值,但数据编辑器既显示科学计数
法又显示一部分值,其后用省略号(...)指明该值已超出既定宽度。更改变量的
既定宽度即可在单元格中显示该值。
注意:更改列宽不会影响变量宽度。
编辑数据
通过数据编辑器,您可以在数据视图中以多种方法修改数据值。您可以:
更改数据值
剪切、复制并粘贴数据值
添加删除个案
添加删除变量
更改变量顺序
Page 100

82
章5
替换或修改数据值
删除原有值,输入新值
E 在数据视图中双击单元格。(单元格值显示在单元格编辑器中。)
E 在单元格或单元格编辑器中直接编辑值。
E 按回车键或选择另一个单元格保存新值。
剪切、复制并粘贴数据值
在数据编辑器中您可以对单个单元格值或组值进行剪切、复制和粘贴。您可以:
将一个单一单元格值移动或复制到另一个单元格
将一个单一单元格值移动或复制到一组单元格
将单个个案(行)的值移动或复制到多个个案
将单个变量(列)的值移动或复制到多个变量
将一组单元格值移动或复制到另一组单元格
数据编辑器中已粘贴值的数据转换
若源单元格与目标单元格的既定变量类型不同,数
法转换,将在目标单元格中插入系统缺失值。
将数值或日期转换为字符串。数值(例如,数值、美元符号、点或逗号)和日期格式
若被粘贴至字符串变量单元格,则将被转换为字符串。在单元格中显示时,字符串值
为数值型值。例如,对于一个美元符号格式的变量,显示的美元符号图标则变成字符
串值的一部分。超出既定字符串值宽度的值将被截去。
将字符串转换为数值或日期。包含被目标单元格的数值或日期格式所接受字符的字符串值
将被转换为同等的数值或日期值。例如,如果目标单元格的格式类型为日-月-年格式中
的一种,则字符串 25/12/91 将被转换为有效日期,但如果目标单元格的格式类型为月日-年格式中的一种,则该值将被转换为系统缺失值。
将日期转换为数值。如果目标单元格为数值格式中的一种,则日期和时间值将被转换
为秒数(例如,数值、美元符号、点或逗号)。因为日期从 1582 年 10 月 14 日开始
被内部储存为秒数,且将日期转换为数值可以产生一些非常大的数字。例如,日期
10/29/91 被转换为数值 12,908,073,600。
将数值转换为日期或时间。如果该值表示能产生有效日期或时间的秒数,则该数值将被转
换为日期或时间。对于日期,小于 86,400 的数值将被转换为系统缺失值。
插入新个案
据编辑器会试图将该值转换。如果无
在空行的单元格值输入数据会自动创建一个新个案。数据编辑器将为所有个案中的所有
其他变量插入系统缺失值。若在新个案和已有个案间存在任何空行,则该空行将成为具
有用于所有变量的系统缺失值的新个案。您也可以在已有个案之间插入新个案。
 Loading...
Loading...