

Page 1
IBM Certification Study Guide
AIX HACMP
David Thiessen, Achim Rehor, Reinhard Zettler
International Technical Support Organization
http://www.redbooks.ibm.com
SG24-5131-00
Page 2

Page 3

International Technical Support Organization
IBM Certification Study Guide
AIX HACMP
May 1999
SG24-5131-00
Page 4
Take Note!
Before using this information and t he product it suppor ts, be sure t o re ad th e gen eral infor mation in
Appendix A, “Special Notices” on page 205.
First Edition (May 1 999)
This edition applies to HACMP f or AIX and HACMP/En hanced Scalab ility (H ACMP/E S), P rogram
Number 5765-D28, for use with t he A IX Operat ing System Version 4.3.2 and lat er.
Comments may be addressed to:
IBM Corporation, Internation al Technical Support Organization
Dept. JN9B Building 003 Interna l Zip 2834
11400 Burnet Road
Austin, Texas 78758-3493
When you send information to IBM, you gra nt I BM a non-exclusive right to use or di strib ute t he
information in any way it belie ves appropr iate without incur ring any ob ligati on to you.
© Copyright International Business Machines Corpora tion 1999. All rights reserved.
Note to U.S Government Users – Do cum entation r elated to r estric ted righ ts – Us e, duplication or dis closu re is
subject to restrictions set forth in GSA ADP Sc hedule Contra ct with IBM Co rp .
Page 5

Contents
Figures. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .ix
Tables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .xi
Preface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .xiii
The Team That Wrote This Redbook. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .xiv
Comments Welcome . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xv
Chapter 1. Certification Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1
1.1 IBM Certified Specialist - AIX HACMP . . . . . . . . . . . . . . . . . . . . . . . . .1
1.2 Certification Exam Objectives. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2
1.3 Certification Education Courses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4
Chapter 2. Cluster Planning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7
2.1 Cluster Nodes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7
2.1.1 CPU Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7
2.1.2 Cluster Node Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . .8
2.2 Cluster Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11
2.2.1 TCP/IP Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11
2.2.2 Non-TCPIP Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .14
2.3 Cluster Disks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .16
2.3.1 SSA Disks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .16
2.3.2 SCSI Disks. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .26
2.4 Resource Planning. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .28
2.4.1 Resource Group Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .28
2.4.2 Shared LVM Components. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .30
2.4.3 IP Address Takeover . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .34
2.4.4 NFS Exports and NFS Mounts . . . . . . . . . . . . . . . . . . . . . . . . . .41
2.5 Application Planning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .41
2.5.1 Performance Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . .42
2.5.2 Application Startup and Shutdown Routines. . . . . . . . . . . . . . . .42
2.5.3 Licensing Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .43
2.5.4 Coexistence with other Applications . . . . . . . . . . . . . . . . . . . . . .43
2.5.5 Critical/Non-Critical Prioritizations . . . . . . . . . . . . . . . . . . . . . . .43
2.6 Customization Planning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .44
2.6.1 Event Customization. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .44
2.6.2 Error Notification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .45
2.7 User ID Planning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .48
2.7.1 Cluster User and Group IDs . . . . . . . . . . . . . . . . . . . . . . . . . . . .48
2.7.2 Cluster Passwords . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .49
2.7.3 User Home Directory Planning . . . . . . . . . . . . . . . . . . . . . . . . . .49
© Copyright IBM Corp. 1999 iii
Page 6

Chapter 3. Cluster Hardware and Software Preparation . . . . . . . . . . .51
3.1 Cluster Node Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .51
3.1.1 Adapter Slot Placement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .51
3.1.2 Rootvg Mirroring. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .51
3.1.3 AIX Prerequisite LPPs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .55
3.1.4 AIX Parameter Settings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .56
3.2 Network Connection and Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . .60
3.2.1 TCP/IP Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .60
3.2.2 Non TCP/IP Networks. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .63
3.3 Cluster Disk Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .66
3.3.1 SSA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .66
3.3.2 SCSI. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .72
3.4 Shared LVM Component Configuration . . . . . . . . . . . . . . . . . . . . . . .81
3.4.1 Creating Shared VGs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .82
3.4.2 Creating Shared LVs and File Systems . . . . . . . . . . . . . . . . . . .84
3.4.3 Mirroring Strategies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .86
3.4.4 Importing to Other Nodes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .86
3.4.5 Quorum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .88
3.4.6 Alternate Method - TaskGuide . . . . . . . . . . . . . . . . . . . . . . . . . .90
Chapter 4. HACMP Installation and Cluster Definition. . . . . . . . . . . . .93
4.1 Installing HACMP. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .93
4.1.1 First Time Installs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .93
4.1.2 Upgrading From a Previous Version. . . . . . . . . . . . . . . . . . . . . .96
4.2 Defining Cluster Topology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .100
4.2.1 Defining the Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
4.2.2 Defining Nodes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .101
4.2.3 Defining Adapters. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
4.2.4 Configuring Network Modules. . . . . . . . . . . . . . . . . . . . . . . . . .105
4.2.5 Synchronizing the Cluster Definition Across Nodes . . . . . . . . .106
4.3 Defining Resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .108
4.3.1 Configuring Resource Groups . . . . . . . . . . . . . . . . . . . . . . . . .108
4.4 Initial Testing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .111
4.4.1 Clverify. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
4.4.2 Initial Startup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .112
4.4.3 Takeover and Reintegration . . . . . . . . . . . . . . . . . . . . . . . . . . .112
4.5 Cluster Snapshot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .113
4.5.1 Applying a Cluster Snapshot. . . . . . . . . . . . . . . . . . . . . . . . . . .114
Chapter 5. Cluster Customization. . . . . . . . . . . . . . . . . . . . . . . . . . . .117
5.1 Event Customization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .117
5.1.1 Predefined Cluster Events . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
5.1.2 Pre- and Post-Event Processing. . . . . . . . . . . . . . . . . . . . . . . .122
iv IBM Certification Study Guide A IX HAC MP
Page 7

5.1.3 Event Notification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
5.1.4 Event Recovery and Retry . . . . . . . . . . . . . . . . . . . . . . . . . . . .122
5.1.5 Notes on Customizing Event Processing . . . . . . . . . . . . . . . . . 123
5.1.6 Event Emulator. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .123
5.2 Error Notification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
5.3 Network Modules/Topology Services and Group Services . . . . . . . . 124
5.4 NFS considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .125
5.4.1 Creating Shared Volume Groups . . . . . . . . . . . . . . . . . . . . . . .125
5.4.2 Exporting NFS File Systems. . . . . . . . . . . . . . . . . . . . . . . . . . .126
5.4.3 NFS Mounting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .126
5.4.4 Cascading Takeover with Cross Mounted NFS File Systems . . 126
5.4.5 Cross Mounted NFS File Systems and the Network Lock Manager.
128
Chapter 6. Cluster Testing. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .131
6.1 Node Verification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .131
6.1.1 Device State. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .131
6.1.2 System Parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .132
6.1.3 Process State. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
6.1.4 Network State. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .132
6.1.5 LVM State . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .133
6.1.6 Cluster State . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .133
6.2 Simulate Errors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .134
6.2.1 Adapter Failure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .134
6.2.2 Node Failure / Reintegration . . . . . . . . . . . . . . . . . . . . . . . . . . .137
6.2.3 Network Failure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .138
6.2.4 Disk Failure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .139
6.2.5 Application Failure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .141
Chapter 7. Cluster Troubleshootin g . . . . . . . . . . . . . . . . . . . . . . . . . .143
7.1 Cluster Log Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .143
7.2 config_too_long . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .144
7.3 Deadman Switch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .145
7.3.1 Tuning the System Using I/O Pacing . . . . . . . . . . . . . . . . . . . .146
7.3.2 Extending the syncd Frequency . . . . . . . . . . . . . . . . . . . . . . . .146
7.3.3 Increase Amount of Memory for Communications Subsystem. . 146
7.3.4 Changing the Failure Detection Rate . . . . . . . . . . . . . . . . . . . .147
7.4 Node Isolation and Partitioned Clusters . . . . . . . . . . . . . . . . . . . . . .147
7.5 The DGSP Message. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .148
7.6 User ID Problems. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
7.7 Troubleshooting Strategy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .149
Chapter 8. Cluster Management and Administration. . . . . . . . . . . . . 151
8.1 Monitoring the Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
v
Page 8

8.1.1 The clstat Command. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .152
8.1.2 Monitoring Clusters using HAView . . . . . . . . . . . . . . . . . . . . . .152
8.1.3 Cluster Log Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .153
8.2 Starting and Stopping HACMP on a Node or a Client. . . . . . . . . . . .154
8.2.1 HACMP Daemons . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .155
8.2.2 Starting Cluster Services on a Node. . . . . . . . . . . . . . . . . . . . . 156
8.2.3 Stopping Cluster Services on a Node . . . . . . . . . . . . . . . . . . . .157
8.2.4 Starting and Stopping Cluster Services on Clients . . . . . . . . . .159
8.3 Replacing Failed Components . . . . . . . . . . . . . . . . . . . . . . . . . . . . .160
8.3.1 Nodes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .160
8.3.2 Adapters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .160
8.3.3 Disks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .161
8.4 Changing Shared LVM Components. . . . . . . . . . . . . . . . . . . . . . . . .163
8.4.1 Manual Update. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .163
8.4.2 Lazy Update. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .164
8.4.3 C-SPOC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
8.4.4 TaskGuide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .167
8.5 Changing Cluster Resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
8.5.1 Add/Change/Remove Cluster Resources . . . . . . . . . . . . . . . . . 168
8.5.2 Synchronize Cluster Resources . . . . . . . . . . . . . . . . . . . . . . . .168
8.5.3 DARE Resource Migration Utility . . . . . . . . . . . . . . . . . . . . . . .169
8.6 Applying Software Maintenance to an HACMP Cluster. . . . . . . . . . . 174
8.7 Backup Strategies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .176
8.7.1 Split-Mirror Backups. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .176
8.7.2 Using Events to Schedule a Backup. . . . . . . . . . . . . . . . . . . . .178
8.8 User Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .178
8.8.1 Listing Users On All Cluster Nodes. . . . . . . . . . . . . . . . . . . . . .179
8.8.2 Adding User Accounts on all Cluster Nodes . . . . . . . . . . . . . . .179
8.8.3 Changing Attributes of Users in a Cluster. . . . . . . . . . . . . . . . . 180
8.8.4 Removing Users from a Cluster . . . . . . . . . . . . . . . . . . . . . . . . 180
8.8.5 Managing Group Accounts . . . . . . . . . . . . . . . . . . . . . . . . . . . .181
8.8.6 C-SPOC Log . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .181
Chapter 9. Special RS/6000 SP Topics . . . . . . . . . . . . . . . . . . . . . . . . 183
9.1 High Availability Control Workstation (HACWS) . . . . . . . . . . . . . . . . 183
9.1.1 Hardware Requirements. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .183
9.1.2 Software Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .184
9.1.3 Configuring the Backup CWS . . . . . . . . . . . . . . . . . . . . . . . . . .184
9.1.4 Install High Availability Software. . . . . . . . . . . . . . . . . . . . . . . . 185
9.1.5 HACWS Configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
9.1.6 Setup and Test HACWS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .186
9.2 Kerberos Security. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .187
9.2.1 Configuring Kerberos Security with HACMP Version 4.3. . . . . . 189
vi IBM Certification Study Guide A IX HAC MP
Page 9

9.3 VSDs - RVSDs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .190
9.3.1 Virtual Shared Disk (VSDs) . . . . . . . . . . . . . . . . . . . . . . . . . . .190
9.3.2 Recoverable Virtual Shared Disk . . . . . . . . . . . . . . . . . . . . . . .193
9.4 SP Switch as an HACMP Network . . . . . . . . . . . . . . . . . . . . . . . . . .195
9.4.1 Switch Basics Within HACMP. . . . . . . . . . . . . . . . . . . . . . . . . . 195
9.4.2 Eprimary Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
9.4.3 Switch Failures. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .196
Chapter 10. HACMP Classic vs. HACMP/ES vs. HANFS. . . . . . . . . . .199
10.1 HACMP for AIX Classic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
10.2 HACMP for AIX / Enhanced Scalability. . . . . . . . . . . . . . . . . . . . . . 199
10.2.1 IBM RISC System Cluster Technology (RSCT). . . . . . . . . . . .200
10.2.2 Enhanced Cluster Security . . . . . . . . . . . . . . . . . . . . . . . . . . .201
10.3 High Availability for Network File System for AIX . . . . . . . . . . . . . .201
10.4 Similarities and Differences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .202
10.5 Decision Criteria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .202
Appendix A. Special Notices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
Appendix B. Related Publications. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
B.1 International Technical Support Organization Publications . . . . . . . . . . 209
B.2 Redbooks on CD-ROMs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
B.3 Other Publications. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
How to Get ITSO Redb ook s . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .211
How IBM Employees Can Get ITSO Redbooks. . . . . . . . . . . . . . . . . . . . . . . 211
How Customers Can Get ITSO Redbooks. . . . . . . . . . . . . . . . . . . . . . . . . . . 212
IBM Redbook Order Form . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213
List of Abbreviations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .215
Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .217
ITSO Redbook Evaluation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .221
vii
Page 10

viii IBM Certification Stud y Gu ide AIX HACMP
Page 11

Figures
1. Basic SSA Configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2. Hot-Standby Configuration. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3. Mutual Takeover Configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4. Third-Party Takeover Configuration. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5. Single-Network Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
6. Dual-Network Setup. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
7. A Point-to-Point Connection. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
8. Sample Screen for Add a Notification Method. . . . . . . . . . . . . . . . . . . . . . 46
9. Connecting Networks to a Hub . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
10. 7135-110 RAIDiant Arrays Connected on Two Shared 8-Bit SCSI Buses 74
11. 7135-110 RAIDiant Arrays Connected on Two Shared 16-Bit SCSI Buses77
12. Termination on the SCSI-2 Differential Controller . . . . . . . . . . . . . . . . . . . 78
13. Termination on the SCSI-2 Differential Fast/Wide Adapters . . . . . . . . . . . 78
14. NFS Cross Mounts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
15. Applying a PTF to a Cluster Node. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
16. A Simple HACWS Environment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
17. VSD Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
18. VSD State Transitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
19. RVSD Function . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
20. RVSD Subsystem and HA Infrastructure. . . . . . . . . . . . . . . . . . . . . . . . . 194
© Copyright IBM Corp. 1999 ix
Page 12

x IBM Certification Study Guide A IX HA CMP
Page 13

Tables
1. AIX Version 4 HACMP Installation and Implementation . . . . . . . . . . . . . . . 4
2. AIX Version 4 HACMP System Administration . . . . . . . . . . . . . . . . . . . . . . 5
3. Hardware Requirements for the Different HACMP Versions . . . . . . . . . . . . 8
4. Number of Adapter Slots in Each Model . . . . . . . . . . . . . . . . . . . . . . . . . . 10
5. Number of Available Serial Ports in Each Model. . . . . . . . . . . . . . . . . . .15
6. 7131-Model 405 SSA Multi-Storage Tower Specifications . . . . . . . . . . . . 18
7. 7133 Models 010, 020, 500, 600, D40, T40 Specifications. . . . . . . . . . . . 18
8. SSA Disks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
9. SSA Adapters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
10. The Advantages and Disadvantages of the Different RAID Levels . . . . . 24
11. Necessary APAR Fixes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
12. AIX Prerequisite LPPs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
13. smit mkvg Options (Non-Concurrent) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
14. smit mkvg Options (Concurrent, Non-RAID) . . . . . . . . . . . . . . . . . . . . . . . 83
15. smit mkvg Options (Concurrent, RAID) . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
16. smit crjfs Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
17. smit importvg Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
18. smit crjfs Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
19. Options for Synchronization of the Cluster Topology. . . . . . . . . . . . . . . . 107
20. Options Configuring Resources for a Resource Group . . . . . . . . . . . . . . 109
21. HACMP Log Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
© Copyright IBM Corp. 1999 xi
Page 14

xii IBM Certification Study Gu ide AIX HACMP
Page 15

Preface
The AIX and RS/6000 Certifications offered through the Professional
Certification Program from IBM are designed to validate the skills required of
technical professionals who work in the powerful and often complex
environments of AIX and RS/6000. A complete set of professional
certifications is available. It includes:
• IBM Certified AIX User
• IBM Certified Specialist - RS/6000 Solution Sales
• IBM Certified Specialist - AIX V4.3 System Administration
• IBM Certified Specialist - AIX V4.3 System Support
• IBM Certified Specialist - RS/6000 SP
• IBM Certified Specialist - AIX H ACMP
• IBM Certified Specialist - Domino for RS/6000
• IBM Certified Specialist - Web Server for RS/6000
• IBM Certified Specialist - Business Intelligence for RS/6000
• IBM Certified Advanced Technical Expert - RS/6000 AIX
Each certification is developed by following a thorough and rigorous process
to ensure the exam is applicable to the job role and is a meaningful and
appropriate assessment of skill. Subject Matter Experts who successfully
perform the job participate throughout the entire development process. These
job incumbents bring a wealth of experience into the development process,
thus making the exams much more meaningful than the typical test, which
only captures classroom knowledge. These Subject Matter experts ensure
the exams are relevant to the
useful and valid. The result is a certification of value that appropriately
measures the skill required to perform the job role.
real world
and that the test content is both
This redbook is designed as a study guide for professionals wishing to
prepare for the certification exam to achieve IBM Certified Specialist - AIX
HACMP.
The AIX HACMP certification validates the skills required to successfully
plan, install, configure, and support an AIX HACMP cluster installation. The
requirements for this include a working knowledge of the following:
• Hardware options supported for use in a cluster, along with the
considerations that affect the choices made
xiii
Page 16

• AIX parameters that are affected by an HACMP installation, and their
correct settings
• The cluster and resource configuration process, including how to choose
the best resource configuration for a customer requirement
• Customization of the standard HACMP facilities to satisfy special
customer requirements
• Diagnosis and troubleshooting knowledge and skills
This redbook helps AIX professionals seeking a comprehensive and
task-oriented guide for developing the knowledge and skills required for the
certification. It is designed to provide a combination of theory and practical
experience. It also provides sample questions that will help in the evaluation
of personal progress and provide familiarity with the types of questions that
will be encountered in the exam.
This redbook will not replace the practical experience you should have, but,
when combined with educational activities and experience, should prove to
be a very useful preparation guide for the exam. Due to the practical nature of
the certification content, this publication can also be used as a desk-side
reference. So, whether you are planning to take the AIX HACMP certification
exam, or just want to validate your HACMP skills, this book is for you.
For additional information about certification and instructions on How to
Register for an exam, call IBM at 1-800-426-8322 or visit our Web site at:
http://www.ibm.com/certify
The Team That Wrote This Redbook
This redbook was produced by a team of specialists from around the world
working at the International Technical Support Organization Austin Center.
David Thiessen is an Advisory Software Engineer at the International
Techni cal Support Organization, Austin Center. He writes extensively and
teaches IBM classes worldwide on all areas of high availability and clustering.
Before joining the ITSO six years ago, David worked in Vancouver, Canada
as an AIX Systems Engineer.
Achim Rehor is a Software Service Specialist in Mainz/Germany. He is Team
Leader of the HACMP/SP Software Support Group in the European Central
Region (Germany, Austria and Switzerland). Achim started working with AIX
in 1990, just as AIX Version 3 and the RISC System/6000 were first being
introduced. Since 1993, he has specialized in the 9076 RS/6000 Scalable
xiv IBM Certification Study Guide AIX HACM P
Page 17

POWERparallel Systems area, known as the SP1 at that time. In 1997 he
began working on HACMP as the Service Groups for HACMP and RS/6000
SP merged into one. He holds a diploma in Computer Science from the
University of Frankfurt in Germany. This is his first redbook.
Reinhard Zettler is an AIX Software Engineer in Munich, Germany. He has
two years of experience working with AIX and HACMP. He has worked at IBM
for two years. He holds a degree in Telecommunication Technology. This is
his first redbook.
Thanks to the following people for their invaluable contributions to this
project:
Marcus Brewer
International Technic al Support Organization, Austin Center
Rebecca Gonzalez
IBM AIX Certification Project Manager, Austin
Milos Radosavljevic
International Technic al Support Organization, Austin Center
Comments Welcome
Your comments are important to us!
We want our redbooks to be as helpful as possible. Please send us your
comments about this or other redbooks in one of the following ways:
• Fax the evaluation form found in “ITSO Redbook Evaluation” on page 221
to the fax number shown on the form.
• Use the electronic evaluation form found on the Redbooks Web sites:
For Internet users
http://www.redbook s.ibm.com
For IBM Intranet users http://w3.itso.ibm .com
• Send us a note at the following address:
redbook@us.ibm.com
xv
Page 18

xvi IBM Certification Study Guide AIX HACM P
Page 19

Chapter 1. Certification Overview
This chapter provides an overview of the skill requirements for obtaining an
IBM Certified Specialist - AIX HACMP certification. The following chapters
are designed to provide a comprehensive review of specific topics that are
essential for obtaining the certification.
1.1 IBM Certified Specialist - AIX HACMP
This certification demonstrates a proficiency in the implementation skills
required to plan, install, and configure AIX High Availability Cluster
Multi-Processing (HACMP) systems, and to perform the diagnostic activities
needed to support Highly Available Clusters.
Certification Requirement (two Tests):
To attain the IBM Certified Specialist - AIX HACMP certification, candidates
must first obtain the AIX System Administration or the AIX System Support
certification. In order to obtain one of these prerequisite certifications, the
candidate must pass one of the following two exams:
Test 181: AIX V4.3 System Administration
or
Test 189: AIX V4.3 System Support.
Following this, the candidate must pass the following exam:
Test 167: HACMP for AIX V 4.2.
Recommended Prerequisites
A minimum of six to twelve months implementation experience installing,
configuring, and testing/supporting HACMP for AIX.
Registration for the Certification Exam
For information about how to register for the certification exam, please visit
the following Web site:
http://www.ibm.com/c ertify
© Copyright IBM Corp. 1999 1
Page 20

1.2 Certification Exam Objective s
The following objectives were used as a basis for what is required when the
certification exam was developed. Some of these topics have been
regrouped to provide better organization when discussed in this publication.
Section 1 - Preinstallation
The following items should be considered as part of the preinstallation plan:
• Conduct a Planning Session.
• Set customer expectations at the beginning of the planning session.
• Gather customer's availability requirements.
• Articulate trade-offs of different HA configurations.
• Assist customers in identifying HA applications.
• Evaluate the Customer Environment and Tailorable Components.
• Evaluate the configuration and identify Single Points of Failure (SPOF).
• Define and analyze NFS requirements.
• Identify components affecting HACMP.
• Identify HACMP event logic customizations.
• Plan for Installation.
• Develop a disk management modification plan.
• Understand issues regarding single adapter solutions.
• Produce a Test Plan.
Section 2 - HACMP Implementation
The following items should be considered for proper implementation:
• Configure HACMP Solutions.
• Install HACMP Code.
• Configure an IP Address Takeover (IPAT).
• Configure non-IP heartbeat paths.
• Configure a network adapter.
• Customize/tailor AIX.
• Set up a shared disk (SSA).
• Set up a shared disk (SCSI).
• Verify a cluster configuration.
2 IBM Certification Study Guide A IX HA CMP
Page 21

• Create an application server.
• Set up Event Notification.
• Set up event notification and pre/post event scripts.
• Set up error notification.
• Post Configuration Activities.
• Configure a client notification and ARP update.
• Implement a test plan.
• Create a snapshot.
• Create a customization document.
• Perform Testing and Troubleshooting.
• Troubleshoot a failed IPAT failover.
• Troubleshoot failed shared volume groups.
• Troubleshoot a failed network configuration.
• Troubleshoot failed shared disk tests.
• Troubleshoot a failed application.
• Troubleshoot failed Pre/Post event scripts.
• Troubleshoot failed error notifications.
• Troubleshoot errors reported by cluster verification.
Section 3 - System Management
The following items should be considered for System Management:
• Communicate with the Customer.
• Conduct a turnover session.
• Provide hands-on customer education.
• Set customer expectations of their HACMP solution's capabilities.
• Perform Systems Maintenance.
• Perform HACMP maintenance tasks (PTFs, adding products, replacing
disks, adapters).
• Perform AIX maintenance tasks.
• Dynamically update the cluster configuration.
• Perform testing and troubleshooting as a result of changes.
Certification Overview 3
Page 22

1.3 Certification Educ ation Courses
Courses and publications are offered to help you prepare for the certification
tests. These courses are recommended, but not required, before taking a
certification test. At the printing of this guide, the following courses are
available. For a current list, please visit the following Web site:
http://www.ibm.com/certify
Table 1. AIX Version 4 HACMP Installation and Impl emen tation
Course Number Q1054 (USA) AU54 (Worldwide)
Course Duration Five days
Course Abstract This course provides a detailed understanding of the
High Availability Clustered Multi-Processing for AIX.
The course is supplemented with a series of laboratory
exercises to configure the hardware and software
environments for HACMP. Additionally, the labs provide
the opportunity to:
• Install the product.
• Define networks.
• Create file systems.
• Complete several modes of HACMP installations.
4 IBM Certification Study Guide A IX HA CMP
Page 23

The following table outlines information about the next course.
Table 2. AIX Version 4 HACMP System A dmin istration
Course Number
Q1150 (USA); AU50 (Worldwide)
Course Duration
Course Abstract
Five days
This course teaches the student the skills required to
administer an HACMP cluster on an ongoing basis
after it is installed. The skills that are developed in this
course include:
• Integrating the cluster with existing network
services (DNS, NIS, etc.)
• Monitoring tools for the cluster, including HAView
for Netview
• Maintaining user IDs and passwords across the
cluster
• Recovering from script failures
• Making configuration or resource changes in the
cluster
• Repairing failed hardware
• Maintaining required cluster documentation
The course involves a significant number of hands-on
exercises to reinforce the concepts. Students are
expected to have completed the course AU54
(Q1054) HACMP Installation and Implementation
before attending this course.
Certification Overview 5
Page 24

6 IBM Certification Study Guide A IX HA CMP
Page 25

Chapter 2. Cluster Planning
The area of cluster planning is a large one. Not only does it include planning
for the types of hardware (CPUs, networks, disks) to be used in the cluster,
but it also includes other aspects. These include resource planning, that is,
planning the desired behavior of the cluster in failure situations. Resource
planning must take into account application loads and characteristics, as well
as priorities. This chapter will cover all of these areas, as well as planning for
event customizations and user id planning issues.
2.1 Cluster Nodes
One of HACMP’s key design strengths is its ability to provide support across
the entire range of RISC System/6000 products. Because of this built-in
flexibility and the facility to mix and match RISC System/6000 products, the
effort required to design a highly available cluster is significantly reduced.
In this chapter, we shall outline the various hardware options supported by
HACMP for AIX and HACMP/ES. We realize that the rapid pace of change in
products will almost certainly render any snapshot of the options out of date
by the time it is published. This is true of almost all technical writing, though
to yield to the spoils of obsolescence would probably mean nothing would
ever make it to the printing press.
The following sections will deal with the various:
• CPU Options
• Cluster Node Considerations
available to you when you are planning your HACMP cluster.
2.1.1 CPU Options
HACMP is designed to execute with RISC System/6000 uniprocessors,
Symmetric Multi-Processor (SMP) servers and the RS/6000 Scalable
POWERparallel Systems (RS/6000 SP) in a
configuration. The minimum configuration and sizing of each system CPU is
highly dependent on the user's application and data requirements.
Nevertheless, systems with 32 MB of main storage and 1 GB of disk storage
would be practical, minimum configurations.
Almost any model of the RISC System/6000 POWERserver family can be
included in an HACMP environment and new models continue to be added to
the list. The following table gives you an overview of the currently supported
© Copyright IBM Corp. 1999 7
no single point of failure
server
Page 26
RISC System/6000 models as nodes in an HACMP 4.1 for AIX, HACMP 4.2
for AIX, or HACMP 4.3 for AIX cluster.
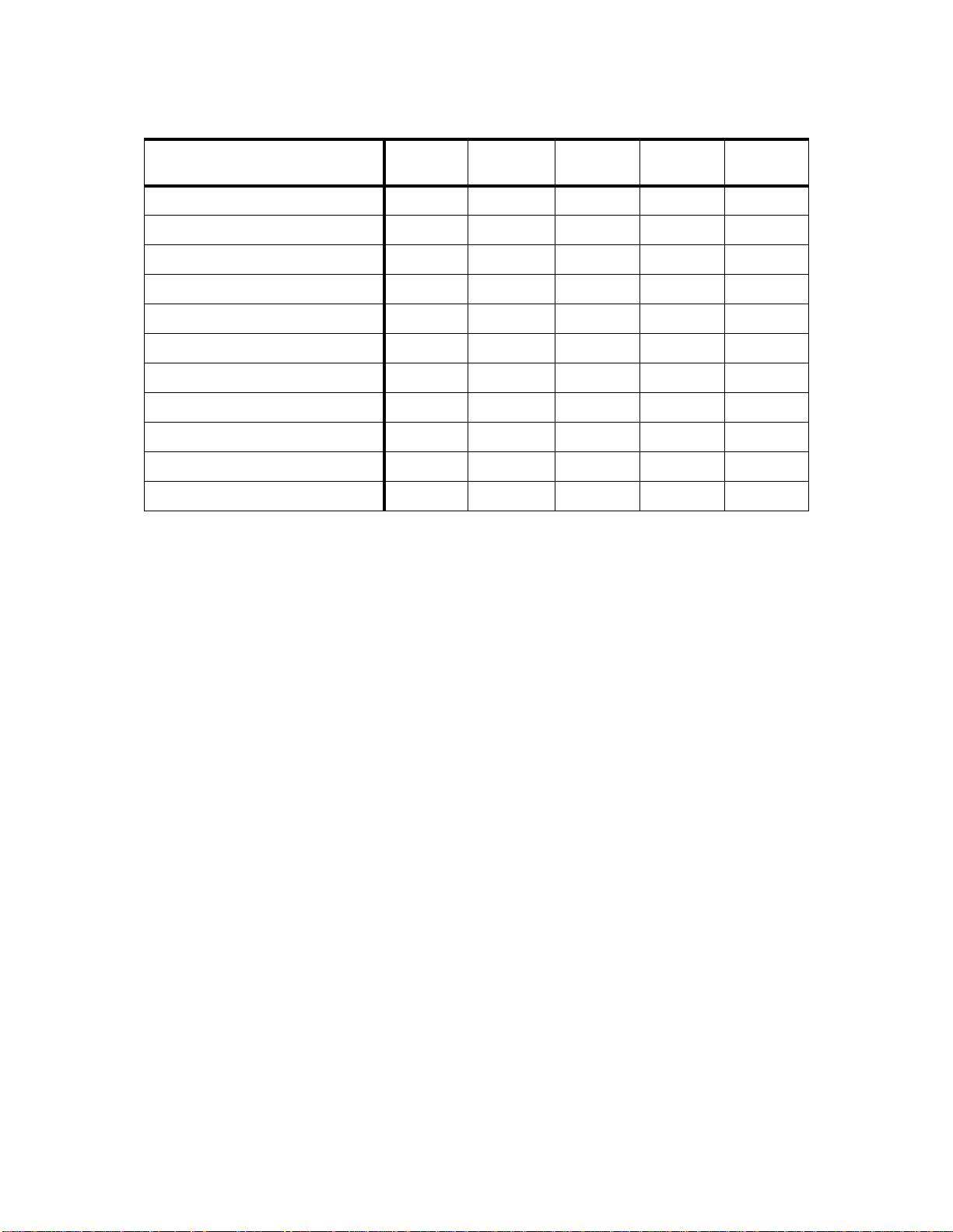
Table 3. Hardware Requ irements for the Differ ent HA CMP Versions
HACMP Version 4.1 4.2 4.3 4.2/ES 4.3/ES
7009 Mod. CXX yes yes yes no yes
7011 Mod. 2XX yes yes yes no yes
7012 Mod. 3XX and GXX yes yes yes no yes
7013 Mod. 5XX and JXX yes yes yes no yes
7015 Mod. 9XX and RXX yes yes yes no yes
7017 Mod. S7X yes yes yes no yes
7024 Mod. EXX yes yes yes no yes
7025 Mod. FXX yes yes yes no yes
7026 Mod. HXX yes yes yes no yes
7043 Mod. 43P, 260 yes yes yes no yes
9076 RS/6000 SP yes yes yes yes yes
1
AIX 4.3.2 required
For a detailed description of system models supported by HACMP/6000 and
HACMP/ES, you should refer to the current Announcement Letters for
HACMP/6000 and HACMP/ES.
1
1
1
1
1
1
1
1
1
1
1
HACMP/ES 4.3 further enhances cluster design flexibility even further by
including support for the RISC System/6000 family of machines and the
Compact Server C20. Since the introduction of HACMP 4.1 for AIX, you have
been able to mix uniprocessor and multiprocessor machines in a single
cluster. Even a mixture of “normal” RS/6000 machines and RS/6000 SP
nodes is possible.
2.1.2 Cluster Node Con siderations
It is important to understand that selecting the system components for a
cluster requires careful consideration of factors and information that may not
be considered in the selection of equipment for a single-system environment.
In this section, we will offer some guidelines to assist you in choosing and
sizing appropriate machine models to build your clusters.
8 IBM Certification Study Guide A IX HA CMP
Page 27

Much of the decision centers around the following areas:
• Processor capacity
• Application requirements
• Anticipated growth requirements
• I/O slot requirements
These paradigms are certainly not new ones, and are also important
considerations when choosing a processor for a single-system environment.
However, when designing a cluster, you must car efully consider the
requirements of the cluster as a total entity. This includes understanding
system capacity requirements of other nodes in the cluster beyond the
requirements of each system's prescribed normal load. You must consider
the required performance of the solution during and after failover, when a
surviving node has to add the workload of a failed node to its own workload.
For example, in a two node cluster, where applications running on both nodes
are critical to the business, each of the two nodes functions as a backup for
the other, in a mutual takeover configuration. If a node is required to provide
failover support for all the applications on the other node, then its capacity
calculation needs to take that into account. Essentially, the choice of a model
depends on the requirements of highly available applications, not only in
terms of CPU cycles, but also of memory and possibly disk space.
Approximately 50 MB of disk storage is required for full installation of the
HACMP software.
A major consideration in the selection of models will be the number of I/O
expansion slots they provide. The model selected must have enough slots to
house the components required to remove single points of failure (SPOFs)
and provide the desired level of availability. A single point of failure is defined
as any single component in a cluster whose failure would cause a service to
become unavailable to end users. The more single points of failure you can
eliminate, the higher your level of availability will be. Typically, you need to
consider the number of slots required to support network adapters and disk
I/O adapters. Your slot configuration must provide for at least two network
adapters to provide adapter redundancy for one service network. If your
system needs to be able to take over an IP address for more than one other
system in the cluster at a time, you will want to configure more standby
network adapters. A node can have up to seven standby adapters for each
network it connects to. Again, if that is your requirement, you will need to
select models as nodes where the number of slots will accomodate the
requirement.
Cluster Planning 9
Page 28

Your slot configuration must also allow for the disk I/O adapters you need to
support the cluster’s shared disk (volume group) configuration. If you intend
to use disk mirroring for shared volume groups, whic h i s strongly
recommended, then you will need to use slots for additional disk I/O
adapters, providing I/O adapter redundancy across separate buses.
The following table tells you the number of additional adapters you can put
into the different RS/6000 models. Ethernet environments can sometimes
make use of the integrated ethernet port provided by some models. No such
feature is available for token-ring, FDDI or ATM; you must use an I/O slot to
provide token-ring adapter redundancy.
Table 4. Number of Adap ter Slo ts in Eac h Mod el
RS/6000 Model Number of Slots Integrated Ethernet Port
7006 4 x MCA yes
7009 C10, C20 4x PCI no
7012 Mod. 3XX and GXX 4 x MCA yes
7013 Mod. 5XX 7 x MCA no
7013 Mod. JXX 6 x MCA, 14 x MCA
with expansion unit J01
7015 Mod. R10, R20, R21 8 x MCA no
7015 Mod. R30, R40, R50 16 x MCA no
7017 Mod. S7X 52 x PCI no
7024 EXX 5 x PCI, 1 x PCI/ISA 2 x
ISA
7025 F50 6 x PCI, 2 x ISA/PCI yes
7026 Mod. H50 6 x PCI, 2 x ISA/PCI yes
7043Mod. 3 x PCI, 2 x ISA/PCI yes
9076 thin node 4 x MCA yes
9076 wide node 7 x MCA no
9076 high node 15 x MCA no
9076 thin node (silver) 2 x PCI yes
9076 wide node (silver) 10 x PCI yes
1
The switch adapter is onboard and does not need an extra slot.
no
no
1
1
10 IBM Certification Study Gu ide AIX HACMP
Page 29

2.2 Cluster Networks
HACMP differentiates between two major types of networks: TCP/IP networks
and non-TCP/IP networks. HACMP utilizes both of them for exchanging
heartbeats. HACMP uses these heartbeats to diagnose failures in the cluster.
Non-TCP/IP networks are used to distinguish an actual hardware failure from
the failure of the TCP/IP software. If there were only TCP/IP networks being
used, and the TCP/IP software failed, causing heartbeats to stop, HACMP
could falsely diagnose a node failure when the node was really still
functioning. Since a non-TCP/IP network would continue working in this
event, the correct diagnosis could be made by HACMP. In general, all
networks are also used for verification, synchronization, communication and
triggering events between nodes. Of course, TCP/IP networks are used for
communication with client machines as well.
At the time of publication, the HACMP/ES Version 4.3 product does not use
non-TCP/IP networks for node-to-node communications in triggering,
synchronizing, and executing event reactions. This can be an issue if you are
configuring a cluster with only one TCP/IP network. This limitation of
HACMP/ES is planned to be removed in a future release. You would be
advised to check on the status of this issue if you are planning a new
installation, and to plan your cluster networks accordingly.
2.2.1 TCP/IP Networks
The following sections describe supported TCP/IP network types and network
considerations.
2.2.1.1 Supported TCP/IP Network Types
Basically every adapter that is capable of running the TCP/IP protocol is a
supported HACMP network type. There are some special considerations for
certain types of adapters however . The following gives a brief overview on the
supported adapters and their special considerations.
Below is a list of TCP/IP network types as you will find them at the
configuration time of an adapter for HACMP. You will find the non-TCP/IP
network types in 2.2.2.1, “Supported Non-TCP/IP Network Types” on page
14.
• Generic IP
•ATM
• Ethernet
•FCS
Cluster Planning 11
Page 30

• FDDI
• SP Switch
•SLIP
•SOCC
• Token-Ring
As an independent, layered component of AIX, the HACMP for AIX software
works with most TCP/IP-based networks. HACMP for AIX has been tested
with standard Ethernet interfaces (en*) but not with IEEE 802.3 Ethernet
interfaces (et*), where * reflects the interface number. HACMP for AIX also
has been tested with Token-Ring and Fiber Distributed Data Interchange
(FDDI) networks, with IBM Serial Optical Channel Converter (SOCC), Serial
Line Internet Protocol (SLIP), and Asynchronous Transfer Mode (ATM)
point-to-point connections.
Note
ATM and SP Switch networks are special cases of point-to-point, private
networks that can connect clients
The HACMP for AIX software supports a maximum of 32 networks per cluster
and 24 TCP/IP network adapters on each node. These numbers provide a
great deal of flexibility in designing a network configuration. The network
design affects the degree of system availability in that the more
communication paths that connect clustered nodes and clients, the greater
the degree of network availability.
2.2.1.2 Specia l Network Considerat ions
Each type of interface has different characteristics concerning speed, MAC
addresses, ARP, and so on. In case there is a limitation you will have to work
around, you need to be aware of the characteristics of the adapters you plan
to use. In the next paragraphs, we summarize some of the considerations
that are known.
Hardware Address Swapping is one issue. If you enable HACMP to put one
address on another adapter, it would need something like a boot and a
service address for IPAT, but on the hardware layer. So, in addition to the
manufacturers burnt-in address, there has to be an alternate address
configured.
The speed of the network can be another issue. Your application may have
special network throughput requirements that must be taken into account.
12 IBM Certification Study Gu ide AIX HACMP
Page 31

Network types also differentiate themselves in the maximum distance they
allow between adapters, and in the maximum number of adapters allowed on
a physical network.
• Ethernet supports 10 and 100 Mbps currently, and supports hardware
address swapping. Alternate hardware addresses should be in the form
xxxxxxxxxxyy , where xx xxxxxxxx is replaced with the first five pairs of digits
of the original burned-in MAC address and
yy can be chosen freely. There
is a limit of 29 adapters on one physical network, unless a network
repeater is used.
• Token-Ring supports 4 or 16 Mbps, but 4 Mbps is very rarely used now. It
also supports hardware address swapping, but here the convention is to
use 42 as the first two characters of the alternate address, since this
indicates that it is a locally set address.
• FDDI is a 100 Mbps optical LAN interface, that supports hardware address
takeover as well. For FDDI adapters you should leave the last six digits of
the burned-in address as they are, and use a 4, 5, 6, or 7 as the first digit
of the rest. FDDI can connect as many as 500 stations with a maximum
link-to-link distance of two kilometers and a total LAN circumference of
100 kilometers.
•ATM is a point-to-point connection network. It currently supports the OC3
and the OC12 standard, which is 155 Mbps or 625 Mbps. You cannot use
hardware address swapping with ATM. ATM doesn’t support broadcasts,
so it must be configured as a private network to HACMP. However, if you
are using LAN Emulation on an existing ATM network, you can use the
emulated ethernet or Token-Ring interfaces just as if they were real ones,
except that you cannot use hardware address swapping.
• FCS is a fiber channel network, currently available as two adapters for
either MCA or PCI technology. The Fibre Channel Adapter /1063-MCA,
runs up to 1063 Mb/second, and the Gigabit Fibre Channel Adapter for
PCI Bus (#6227), announced on October 5th 1998, will run with 100 MBps.
Both of them support TCP/IP, but not hardware address swapping.
•SLIP runs at up to 38400 bps. Since it is a point-to-point connection and
very slow, it is rarely used as an HACMP network. An HACMP cluster is
much more likely to use the serial port as a non-TCP/IP connection. See
below for details.
• SOCC is a fast optical connection, again point-to-point. This is an optical
line with a serial protocol running on it. However, the SOCC Adapter
(Feature 2860) has been withdrawn from marketing for some years now.
Some models, like 7013 5xx, offer SOCC as an option onboard, but these
are rarely used today.
Cluster Planning 13
Page 32

• SP Switch is a high-speed packet switching network, running on the
RS/6000 SP system only. It runs bidirectionally up to 80 MBps, which adds
up to 160 MBps of capacity per adapter. This is node-to-node
communication and can be done in parallel between every pair of nodes
inside an SP. The SP Switch network has to be defined as a private
Network, and ARP must be enabled. This network is restricted to one
adapter per node, thus, it has to be considered as a Single Point Of
Failure. Therefore, it is strongly recommended to use AIX Error
Notification to propagate a switch failure into a node failure when
appropriate. As there is only one adapter per node, HACMP uses the
ifconfig alias addresses for IPAT on the switch; so, a standby address is
not necessary and, therefore, not used on the switch network. Hardware
address swapping also is not supported on the SP Switch.
For IP Address Takeover (IPAT), in general, there are two adapters per
cluster node and network recommended in order to eliminate single points of
failure. The only exception to this rule is the SP Switch because of hardware
limitations.
2.2.2 Non-TCPIP Ne tworks
Non-TCP/IP networks in HACMP are used as an independent path for
exchanging messages or heartbeats between cluster nodes. In case of an IP
subsystem failure, HACMP can still differentiate between a network failure
and a node failure when an independent path is available and functional.
Below is a short description of the three currently available non-TCP/IP
network types and their characteristics. Even though HACMP works without
one, it is strongly recommended that you use at least one non-TCP/IP
connection between the cluster nodes.
2.2.2.1 Supported Non-TCP/IP Network Types
Currently HACMP supports the following types of networks for non-TCP/IP
heartbeat exchange between cluster nodes:
• Serial (RS232)
• Target-mode SCSI
• Target-mode SSA
All of them must be configured as Network Type: serial in the HACMP
definitions.
14 IBM Certification Study Gu ide AIX HACMP
Page 33

2.2.2.2 Specia l Consider ations
As for TCP/IP networks, there are a number of restrictions on non-TCP/IP
networks. These are explained for the three different types in more detail
below.
Serial (RS232)
A serial (RS232) network needs at least one available serial port per cluster
node. In case of a cluster consisting of more than two nodes, a ring of nodes
is established through serial connections, which r equires two seri al ports per
node. Table 3 shows a list of possible cluster nodes and the number of native
serial ports for each:
Table 5. Number of Available Se rial P orts in Each M odel
RS/6000 Model Number of Serial Ports Available
7006 1
7009 C10, C20 1
1
1
7012 Mod. 3XX and GXX 2
7013 Mod. 5XX 2
7013 Mod. JXX 3
7015 Mod. R1 0, R20, R21 3
7015 Mod. R3 0, R40, R50 3
7013,7015,7017 Mod. S7X 0
7024 EXX 1
2
1
.
7025 F50 2
7026 Mod. H50 3
7043Mod. 2
9076 thin node 2
9076 wide node 2
9076 high node 3
9076 thin node (silver) 2
9076 wide node (silver) 2
1
serial port can be multiplexed through a dual-port cable, thus offering two
3
3
3
3
3
ports
Cluster Planning 15
Page 34

2
a PCI Multiport Async Card is required in an S7X model, no native ports
3
only one serial port available for customer use, i.e. HACMP
In case the number of native serial ports doesn’t match your HACMP cluster
configuration needs, you can extend it by adding an eight-port asynchronous
adapter, thus reducing the number of available MCA slots, or the
corresponding PCI Multiport Async Card for PCI Machines, like the S7X
model.
Target-mode SCSI
Another possibility for a non-TCP/IP network is a target mode SCSI
connection. Whenever you make use of a shared SCSI device, you can also
use the SCSI bus for exchanging heartbeats.
Target Mode SCSI is only supported with SCSI-2 Differential or SCSI-2
Differential Fast/Wide devices. SCSI/SE or SCSI-2/SE are not supported for
HACMP serial networks.
The recommendation is to not use more than 4 target mode SCSI networks in
a cluster.
Target-mode SSA
If you are using shared SSA devices, target mode SSA is the third possibility
for a serial network within HACMP. In order to use target-mode SSA, you
must use the Enhanced RAID-5 Adapter (#6215 or #6219), since these are
the only current adapters that support the Multi-Initiator Feature. The
microcode level of the adapter must be 1801 or higher.
2.3 Cluster Disks
This section describes the various choices you have in selecting the type of
shared disks to use in your cluster.
2.3.1 SSA Disks
The following is a brief description of SSA and the basic rules to follow when
designing SSA networks. For a full description of SSA and its functionality,
please read
SG24-5251.
SSA is a high-performance, serial interconnect technology used to connect
disk devices and host adapters. SSA is an open standard, and SSA
specifications have been approved by the SSA Industry Association and also
as an ANSI standard through the ANSI X3T10.1 subcommittee.
16 IBM Certification Study Gu ide AIX HACMP
Monitoring and Managing IBM SSA Disk Subsystems,
Page 35

SSA subsystems are built up from loops of adapters and disks. A simple
example is shown in Figure 1.
SSA Architecture
B
p
M
0
2
s
M
0
B
2
p
s
HOST
M
B
0
p
2
l
High performance 80 MB/s interface
l
Loop architecture with up to 127 nodes per loop
l
Up to 25 m (82 ft) between SSA devices with copper cables
l
Up to 2.4 km (1.5 mi) between SSA devices with optical extender
l
Spatial reuse (multiple simultaneous transmissions)
s
2
0
M
B
p
s
Figure 1. Basic SSA Co nfigur ation
Here, a single adapter controls one SSA loop of eight disks. Data can be
transferred around the loop, in either direction, at 20 MBps. Consequently,
the peak transfer rate of the adapter is 80 MBps. The adapter contains two
SSA nodes and can support two SSA loops. Each disk drive also contains a
single SSA node. A node can be either an initiator or a target. An
issues commands, while a
The SSA nodes in the adapter are therefore initiators, while the SSA nodes in
the disk drives are targets.
There are two types of SSA Disk Subsystems for RISC System/6000
available:
• 7131 SSA Multi-Storage Tower Model 405
target
responds with data and status information.
Cluster Planning 17
initiator
Page 36

• 7133 Serial Storage Architecture (SSA) Disk Subsystem Models 010, 500,
020, 600, D40 and T40.
The 7133 models 010 and 500 were the first SSA products announced in
1995 with the revolutionary new Serial Storage Architecture. Some IBM
customers still use the Models 010 and 500, but these have been replaced by
7133 Model 020, and 7133 Model 600 respectively. More recently, in
November 1998, the models D40 and T40 were announced.
All 7133 Models have redundant power and cooling, which is hot-swappable.
The following tables give you more configuration information about the
different models:
Table 6. 7131-Model 405 S SA Multi- Storage Tower Specifications
Item Specification
Transfer rate SSA
interface
Configuration 2 to 5 disk drives (2.2 GB, 4.5 GB or 9.1 GB) per subsystem
Configuration range 4.4 to 1 1 GB (with 2.2 GB disk drives )
Supported RAID
levels
Supported adapters 6214, 6216, 6217, 6218
Hot-swap disks Yes
Table 7. 7133 Models 010, 020, 500 , 600, D40, T4 0 Spec ifications
Item Specification
Transfer rate SSA
interface
Configuration 4 to 16 disks
Configuration range 8.8 to 17.6 GB (with 1.1 GB disks)
80 MB
9.0 to 22.5 GB (With 4.5 GB disk drives)
18.2 to 45.5 GB (With 9.1 GB disk drives)
5
80 MB/s
- 1.1 GB, 2.2 GB, 4.5 GB, for Models 10, 20, 500, and 600
- 9.1 GB for Models 20, 600, D40 and T40
- With 1.1 GB disk drives you must have 8 to 16 disks)
8.8 to 35.2 GB (with 2.2 GB disks)
18 to 72 GB (with 4.5 GB disks)
36.4 to 145.6 GB (with 9.1 GB disks)
72.8 to 291.2 GB (with 18.2 GB disks)
18 IBM Certification Study Gu ide AIX HACMP
Page 37

Item Specification
Supported RAID level 5
Supported adapters all
Hot-swappable disk Yes (and hot-swappable, redundant power and cooling)
2.3.1.1 Disk C apaciti es
Table 8 lists the different SSA disks, and provides an overview of their
characteristics.
Table 8. SSA Disks
Name Capacities (GB) Buffer size (KB) Maximum Transfer rate
(MBps)
Starfire 1100 1.1 0 20
Starfire 2200 2.2 0 20
Starfire 4320 4.5 512 20
Scorpion 4500 4.5 512 80
Scorpion 9100 9.1 512 160
Sailfin 9100 9.1 1024 160
Thresher 9100 9.1 1024 160
Ultrastar 9.1, 18.2 4096 160
2.3.1.2 Supported and Non-Supported Adapters
Table 9 lists the different SSA adapters and presents an overview of their
characteristics.
Table 9. SSA Adapters
Feature Code Adapter
Label
6214 4-D MCA Classic 2 n/a
6215 4-N PCI Enhanced RAID-5 8
6216 4-G MCA Enhanced 8 n/a
6217 4-I MCA RAID-5 1 5
6218 4-J PCI RAID-5 1 5
Bus Adapter Description Number of
Adapters per
Loop
1
Cluster Planning 19
Hardware
Raid Types
5
Page 38

Feature Code Adapter
Label
6219 4-M MCA Enhanced RAID-5 8
1
See 2.3.1.3, “Rules for SSA Loops” on page 20 for more information.
Bus Adapter Description Number of
The following rules apply to SSA Adapters:
• You cannot have more than four adapters in a single system.
• The MCA SSA 4-Port RAID Adapter (FC 6217) and PCI SSA 4-Port RAID
Adapter (FC 6218) are not useful for HACMP, because only one can be in
a loop.
• Only the PCI Multi Initiator/RAID Adapter (FC 6215) and the MCA Multi
Initiator/RAID EL Adapter (FC 6219) support target mode SSA (for more
information about target mode SSA see 3.2.2, “Non TCP/IP Networks” on
page 63).
2.3.1.3 Rules for SSA Loops
The following rules must be followed when configuring and connecting SSA
loops:
• Each SSA loop must be connected to a valid pair of connectors on the
SSA adapter (that is, either Connectors A1 and A2, or Connectors B1 and
B2).
Adapters per
Loop
1
Hardware
Raid Types
5
• Only one of the two pairs of connectors on an adapter card can be
connected in a single SSA loop.
• A maximum of 48 devices can be connected in a single SSA loop.
• A maximum of two adapters can be connected in a particular loop if one
adapter is an SSA 4-Port adapter, Feature 6214.
• A maximum of eight adapters can be connected in a particular loop if all
the adapters are Enhanced SSA 4-Port Adapters, Feature 6216.
• A maximum of two SSA adapters, both connected in the same SSA loop,
can be installed in the same system.
For SSA loops that include an SSA Four-Port RAID adapter (Feature 6217) or
a PCI SSA Four-Port RAID adapter (Feature 6218), the following rules apply:
• Each SSA loop must be connected to a valid pair of connectors on the
SSA adapter (that is, either Connectors A1 and A2, or Connectors B1 and
B2).
20 IBM Certification Study Gu ide AIX HACMP
Page 39

• A maximum of 48 devices can be connected in a particular SSA loop.
• Only one pair of adapter connectors can be connected in a particular SSA
loop.
• Member disk drives of an array can be on either SSA loop.
For SSA loops that include a Micro Channel Enhanced SSA
Multi-initiator/RAID EL adapter, Feature 6215 or a PCI SSA
Multi-initiator/RAID EL adapter, Feature 6219, the following rules apply:
• Each SSA loop must be connected to a valid pair of connectors on the
SSA adapter (that is, either Connectors A1 and A2, or Connectors B1 and
B2).
• A maximum of eight adapters can be connected in a particular loop if none
of the disk drives in the loops are array disk drives and none of them is
configured for fast-write operations. The adapters can be up to eight
Micro Channel Enhanced SSA Multi-initiator/RAID EL Adapters, up to
eight PCI Multi-initiator/RAID EL Adapters, or a mixture of the two types.
• A maximum of two adapters can be connected in a particular loop if one or
more of the disk drives in the loop are array disk drives that are not
configured for fast-write operations. The adapters can be two Micro
Channel Enhanced SSA Multi-initiator/RAID EL Adapters, two PCI
Multi-initiator/RAID EL Adapters, or one adapter of each type.
• Only one Micro Channel Enhanced SSA Multi-initiator/RAID EL Adapter or
PCI SSA Multi-initiator/RAID EL Adapter can be connected in a particular
loop if any disk drives in the loops are members of a RAID-5 array, and are
configured for fast-write operations.
• All member disk drives of an array must be on the same SSA loop.
• A maximum of 48 devices can be connected in a particular SSA loop.
• Only one pair of adapter connectors can be connected in a particular loop.
• When an SSA adapter is connected to two SSA loops, and each loop is
connected to a second adapter, both adapters must be connected to both
loops.
For the IBM 7190-100 SCSI to SSA converter, the following rules apply:
• There can be up to 48 disk drives per loop.
• There can be up to four IBM 7190-100 attached to any one SSA loop.
Cluster Planning 21
Page 40

2.3.1.4 RAID vs . Non-RAI D
RAID Technology
RAID is an acronym for Redundant Array of Independent Disks. Disk arrays
are groups of disk drives that work together to achieve higher data-transfer
and I/O rates than those provided by single large drives.
Arrays can also provide data redundancy so that no data is lost if a single
drive (physical disk) in the array should fail. Depending on the RAID level,
data is either mirrored or striped. The following gives you more information
about the different RAID levels.
RAID Level 0
RAID 0 is also known as data striping. Conventionally, a file is written out
sequentially to a single disk. With striping, the information is split into chunks
(fixed amounts of data usually called blocks) and the chunks are written to (or
read from) a series of disks in parallel. There are two main performance
advantages to this:
1. Data transfer rates are higher for sequential operations due to the
overlapping of multiple I/O streams.
2. Random access throughput is higher because access pattern skew is
eliminated due to the distribution of the data. This means that with data
distributed evenly across a number of disks, random accesses will most
likely find the required information spread across multiple disks and thus
benefit from the increased throughput of more than one drive.
RAID 0 is only designed to increase performance. There is no redundancy; so
any disk failures will require reloading from backups.
RAID Level 1
RAID 1 is also known as disk mirroring. In this implementation, identical
copies of each chunk of data are kept on separate disks, or more commonly,
each disk has a twin that contains an exact replica (or mirror image) of the
information. If any disk in the array fails, then the mirrored twin can take over.
Read performance can be enhanced because the disk with its actuator
closest to the required data is always used, thereby minimizing seek times.
The response time for writes can be somewhat slower than for a single disk,
depending on the write policy; the writes can either be executed in parallel for
speed or serially for safety.
RAID Level 1 has data redundancy, but data should be regularly backed up
on the array. This is the only way to recover data in the event that a file or
directory is accidentally deleted.
22 IBM Certification Study Gu ide AIX HACMP
Page 41

RAID Levels 2 and 3
RAID 2 and RAID 3 are parallel process array mechanisms, where all drives
in the array operate in unison. Similar to data striping, information to be
written to disk is split into chunks (a fixed amount of data), and each chunk is
written out to the same physical position on separate disks (in parallel). When
a read occurs, simultaneous requests for the data can be sent to each disk.
This architecture requires parity information to be written for each stripe of
data; the difference between RAID 2 and RAID 3 is that RAID 2 can utilize
multiple disk drives for parity, while RAID 3 can use only one. If a drive should
fail, the system can reconstruct the missing data from the parity and
remaining drives.
Performance is very good for large amounts of data but poor for small
requests since every drive is always involved, and there can be no
overlapped or independent operation.
RAID Level 4
RAID 4 addresses some of the disadvantages of RAID 3 by using larger
chunks of data and striping the data across all of the drives except the one
reserved for parity. Using disk striping means that I/O requests need only
reference the drive that the required data is actually on. This means that
simultaneous, as well as independent reads, are possible. Write requests,
however, require a read/modify/update cycle that creates a bottleneck at the
single parity drive. Each stripe must be read, the new data inserted and the
new parity then calculated before writing the stripe back to the disk. The
parity disk is then updated with the new parity, but cannot be used for other
writes until this has completed. This bottleneck means that RAID 4 is not
used as often as RAID 5, which implements the same process but without the
bottleneck. RAID 5 is discussed in the next section.
RAID Level 5
RAID 5, as has been mentioned, is very similar to RAID 4. The difference is
that the parity information is distributed across the same disks used for the
data, thereby eliminating the bottleneck. Parity data is never stored on the
same drive as the chunks that it protects. This means that concurrent read
and write operations can now be performed, and there are performance
increases due to the availability of an extra disk (the disk previously used for
parity). There are other enhancements possible to further increase data
transfer rates, such as caching simultaneous reads from the disks and
transferring that information while reading the next blocks. This can generate
data transfer rates that approach the adapter speed.
Cluster Planning 23
Page 42

As with RAID 3, in the event of disk failure, the information can be r ebuilt from
the remaining drives. RAID level 5 array also uses parity information, though
it is still important to make regular backups of the data in the array . RAID level
5 stripes data across all of the drives in the array, one segment at a time (a
segment can contain multiple blocks). In an array with n drives, a stripe
consists of data segments written to n-1 of the drives and a parity segment
written to the nth drive. This mechanism also means that not all of the disk
space is available for data. For example, in an array with five 2 GB disks,
although the total storage is 10 GB, only 8 GB are available for data.
The advantages and disadvantages of the various RAID levels are
summarized in the following table:
Table 10. The Advantages and Dis advanta ges of the Different RAID Levels
RAID Level Availability
Mechanism
0 none 100% high medium
1 mirroring 50% medium/high high
3 parity 80% medium medium
5 parity 80% medium medium
Capacity Performance Cost
RAID on the 7133 Disk Subsys tem
The only RAID level supported by the 7133 SSA disk subsystem is RAID 5.
RAID 0 and RAID 1 can be achieved with the striping and mirroring facility of
the Logical Volume Manager (LVM).
RAID 0 does not provide data redundancy, so it is not recommended for use
with HACMP, because the shared disks would be a single point of failure. The
possible configurations to use with the 7133 SSA disk subsystem are RAID 1
(mirroring) or RAID 5. Consider the following points before you make your
decision:
• Mirroring is more expensive than RAID, but it provides higher data
redundancy. Even if more than one disk fails, you may still have access to
all of your data. In a RAID, more than one broken disk means that the data
are lost.
• The SSA loop can include a maximum of two SSA adapters if you use
RAID. So, if you want to connect more than two nodes into the loop,
mirroring is the way to go.
• A RAID array can consist of three to 16 disks.
24 IBM Certification Study Gu ide AIX HACMP
Page 43

• Array member drives and spares must be on same loop (cannot span A
and B loops) on the adapter.
• You cannot boot (ipl) from a RAID.
2.3.1.5 Adva ntages
Because SSA allows SCSI-2 mapping, all functions associated with initiators,
targets, and logical units are translatable. Therefore, SSA can use the same
command descriptor blocks, status codes, command queuing, and all other
aspects of current SCSI systems. The effect of this is to make the type of disk
subsystem transparent to the application. No porting of applications is
required to move from traditional SCSI I/O subsystems to high-performance
SSA. SSA and SCSI I/O systems can coexist on the same host running the
same applications.
The advantages of SSA are summarized as follows:
• Dual paths to devices.
• Simplified cabling - cheaper, smaller cables and connectors, no separate
terminators.
• Faster interconnect technology.
• Not an arbitrated system.
• Full duplex, frame multiplexed serial links.
• 40 MBps total per port, resulting in 80 MBps total per node, and 160 MBps
total per adapter.
• Concurrent access to disks.
• Hot-pluggable cables and disks.
• Very high capacity per adapter - up to 127 devices per loop, although most
adapter implementations limit this. For example, current IBM SSA
adapters provide 96 disks per Micro Channel or PCI slot.
• Distance between devices of up to 25 meters with copper cables, 10km
with optical links.
• Auto-configuring - no manual address allocation.
• SSA is an open standard.
• SSA switches can be introduced to produce even greater fan-out and
more complex topologies.
Cluster Planning 25
Page 44

2.3.2 SCSI Disks
After the announcement of the 7133 SSA Disk Subsystems, the SCSI Disk
subsystems became less common in HACMP clusters. However, the 7135
RAIDiant Array (Model 110 and 210) and other SCSI Subsystems are still in
use at many customer sites. We will not describe other SCSI Subsystems
such as 9334 External SCSI Disk Storage. See the appropriate
documentation if you need information about these SCSI Subsystems.
The 7135 RAIDiant Array is offered with a range of features, with a maximum
capacity of 135 GB (RAID 0) or 108 GB (RAID-5) in a single unit, and uses
the 4.5 GB disk drive modules. The array enclosure can be integrated into a
RISC System/6000 system rack, or into a deskside mini-rack. It can attach to
multiple systems through a SCSI-2 Differential 8-bit or 16-bit bus.
2.3.2.1 Capa cities
Disks
There are four disk sizes available for the 7135 RAIDiant Array Models 110
and 210:
• 1.3 GB
• 2.0 GB
• 2.2 GB (only supported by Dual Active Software)
• 4.5 GB (only supported by Dual Active Software)
Subsystems
The 7135-110/210 can contain 15 Disks (max. 67.5 GB) in the base
configuration and 30 Disks (max. 135 GB) in an extended configuration.You
can for example only use the full 135 GB storage space for data if you
configure the 7135 with RAID level 0. When using RAID level 5, only 108 GB
of the 135 GB are available for data storage.
2.3.2.2 How M any in a St ring?
HACMP supports a maximum of two 7135s on a shared SCSI bus. This is
because of cable length restrictions.
2.3.2.3 Supported SCSI Adapters
The SCSI adapters that can be used to connect RAID subsystems on a
shared SCSI bus in an HACMP cluster are:
• SCSI-2 Differential Controller (MCA, FC: 2420, Adapter Label: 4-2)
• SCSI-2 Differential Fast/Wide Adapter/A (MCA, FC: 2416, Adapter Label:
4-6)
26 IBM Certification Study Gu ide AIX HACMP
Page 45

• Enhanced SCSI-2 Differential Fast/Wide Adapter/A (MCA, FC: 2412,
Adapter Label: 4-C); not usable with 7135-110
• SCSI-2 Fast/Wide Differential Adapter (PCI, FC: 6209, Adapter Label:
4-B)
• DE Ultra SCSI Adapter (PCI, FC: 6207, Adapter Label: 4-L); not usable
with 7135-110
2.3.2.4 Advan tages - Dis advantag es
The 7135 RAIDiant Array incorporates the following high availability features:
• Support for RAID-1, RAID-3 (Model 110 only) and RAID-5
You can run any combination of RAID levels in a single 7135 subsystem.
Each LUN can run its own RAID level.
• Multiple Logical Unit (LUN) support
The RAID controller takes up only one SCSI ID on the external bus. The
internal disks are grouped into logical units (LUNs). The array will support
up to six LUNs, each of which appears to AIX as a single hdisk device.
Since each of these LUNs can be configured into separate volume groups,
different parts of the subsystem can be logically attached to different
systems at any one time.
• Redundant Power Supply
Redundant power supplies provide alternative sources of power. If one
supply fails, power is automatically supplied by the other.
• Redundant Cooling
Extra cooling fans are built into the RAIDiant Array to safeguard against
fan failure.
• Concurrent Maintenance
Power supplies, cooling fans, and failed disk drives can be replaced
without the need to take the array offline or to power it down.
• Optional Second Array Controller
This allows the array subsystem to be configured with no single point of
failure. Under the control of the system software, the machine can be
configured in
Dual Active
mode, so that each controller controls the
operation of specific sets of drives. In the event of failure of either
controller, all I/O activity is switched to the remaining active controller.
In the last few years, the 7133 SSA Subsystems have become more popular
than 7135 RAIDiant Systems due to better technology. IBM decided to
Cluster Planning 27
Page 46

withdraw the 7135 RAIDiant Systems from marketing because it is equally
possible to configure RAID on the SSA Subsystems.
2.4 Resource Planning
HACMP provides a highly available environment by identifying a set of
cluster-wide resources essential to uninterrupted processing, and then
defining relationships among nodes that ensure these resources are
available to client processes.
When a cluster node fails or detaches from the cluster for a scheduled
outage, the Cluster Manager redistributes its resources among any number of
the surviving nodes.
HACMP considers the following as resourc e types:
• Volume Groups
• Disks
• File Systems
• File Systems to be NFS mounted
• File Systems to be NFS exported
• Service IP addresses
• Applications
The following paragraphs will tell you what to consider when configuring
resources to accomplish the following:
• IP Address Takeover
• Shared LVM Components
• NFS Exports
and the options you have when combining these resources to a resource
group.
2.4.1 Resource Group Options
Each resource in a cluster is defined as part of a resource group. This allows
you to combine related resources that need to be together to provide a
particular service. A resource group also includes the list of nodes that can
acquire those resources and serve them to clients.
A resource group is defined as one of three types:
28 IBM Certification Study Gu ide AIX HACMP
Page 47

• Cascading
• Rotating
• Concurrent
Each of these types describes a different set of relationships between nodes
in the cluster, and a different set of behaviors upon nodes entering and
leaving the cluster.
Cascading Resource Groups: All nodes in a cascading resource group are
assigned priorities for that resource group. These nodes are said to be part of
that group's resource chain. In a cascading resource group, the set of
resources cascades up or down to the highest priority node active in the
cluster. When a node that is serving the resources fails, the surviving node
with the highest priority takes over the resources.
A parameter called
Inactive Takeover
decides which node takes the
cascading resources when the nodes join the cluster for the first time. If this
true
parameter is set to
, the first node in a group's resource chain to join the
cluster acquires all the resources in the resource group. As successive nodes
join the resource group, the resources cascade up to any node with a higher
false
priority that joins the cluster. If this parameter is set to
, the first node in a
group's resource chain to join the cluster acquires all the resources in the
resource group only if it is the node with the highest priority for that group. If
the first node to join does not acquire the resource group, the second node in
the group's resource chain to join acquires the resource group, if it has a
higher priority than the node already active. As successive nodes join, the
resource group cascades to the active node with the highest priority for the
false
group. The default is
.
Member nodes of a cascading resource chain always release a resource
group to a reintegrating node with a higher priority.
Rotating Resource Groups: A rotating resource group is associated with a
group of nodes, rather than a particular node. A node can be in possession of
a maximum of one rotating resource group per network.
As participating nodes join the cluster for the first time, they acquire the first
available rotating resource group per network until all the groups are
acquired. The remaining nodes maintain a standby role.
When a node holding a rotating resource group leaves the cluster, either
because of a failure or gracefully while specifying the takeover option, the
node with the highest priority and available connectivity takes over. Upon
Cluster Planning 29
Page 48

reintegration, a node remains as a standby and does not take back any of the
resources that it had initially served.
Concurrent Resource Groups: A concurrent resource group may be shared
simultaneously by multiple nodes. The resources that can be part of a
concurrent resource group are limited to volume groups with raw logical
volumes, raw disks, and application servers.
When a node fails, there is no takeover involved for concurrent resources.
Upon reintegration, a node again accesses the resources simultaneously with
the other nodes.
The Cluster Manager makes the following assumptions about the acquisition
of resource groups:
Cascading The active node with the highest priority controls the
resource group.
Concurrent All activ e nodes have access to the resource group.
Rotating The node with the rotating resource group’s associated
service IP address controls the resource group.
2.4.2 Shared LVM Components
The first distinction that you need to make while designing a cluster is
whether you need a non-concurrent or a concurrent shared disk access
environment.
2.4.2.1 Non-Concurrent Disk Access Configurations
The possible non-concurrent disk access configurations are:
• Hot-Standby
• Rotating Standby
• Mutual Takeover
• Third-Party Takeover
Hot-Standby Configuration
Figure 2 illustrates a two node cluster in a hot-standby configuration.
30 IBM Certification Study Gu ide AIX HACMP
Page 49

Figure 2. Hot-Standb y Con figur ation
In this configuration, there is one cascading resource group cons isting of the
four disks, hdisk1 to hdisk4, and their constituent volume groups and file
systems. Node 1 has a priority of 1 for this resource group while node 2 has a
priority of 2. During normal operations, node 1 provides all critical services to
end users. Node 2 may be idle or may be providing non-critical services, and
hence is referred to as a hot-standby node. When node 1 fails or has to leave
the cluster for a scheduled outage, node 2 acquires the resource group and
starts providing the critical services.
The advantage of this type of a configuration is that you can shift from a
single-system environment to an HACMP cluster at a low cost by adding a
less powerful processor. Of course, this assumes that you are willing to
accept a lower level of performance in a failover situation. This is a trade-off
that you will have to make between availability, performance, and cost.
Rotating Standby Configuration
This configuration is the same as the previous configuration except that the
resource groups used are rotating resource groups.
In the hot-standby configuration, when node 1 reintegrates into the cluster, it
takes back the resource group since it has the highest priority for it. This
implies a break in service to the end users during reintegration.
If the cluster is using rotating resource groups, reintegrating nodes do not
reacquire any of the resource groups. A failed node that recovers and rejoins
Cluster Planning 31
Page 50

the cluster becomes a standby node. You must choose a rotating standby
configuration if you do not want a break in service during reintegration.
Since takeover nodes continue providing services until they have to leave the
cluster, you should configure your cluster with nodes of equal power. While
more expensive in terms of CPU hardware, a rotating standby configuration
gives you better availability and performance than a hot-standby
configuration.
Mutual Takeover Configuration
Figure 3 illustrates a two node cluster in a mutual takeover configuration.
Figure 3. Mutual Takeover Configuration
In this configuration, there are two cascading resource groups: A and B.
Resource group A consists of two disks, hdisk1 and hdisk3, and one volume
group, sharedvg. Resource group B consists of two disks, hdisk2 and hdisk4,
and one volume group, databasevg. Node 1 has priorities of 1 and 2 for
resource groups A and B respectively, while Node 2 has priorities of 1 and 2
for resource groups B and A respectively.
During normal operations, nodes 1 and 2 have control of resource groups A
and B respectively, and both provide critical services to end users. If either
node 1 or node 2 fails, or has to leave the cluster for a scheduled outage, the
surviving node acquires the failed node’s resource groups and continues to
provide the failed node’s critical services.
32 IBM Certification Study Gu ide AIX HACMP
Page 51

When a failed node reintegrates into the cluster, it takes back the resource
group for which it has the highest priority. Therefore, even in this
configuration, there is a break in service during reintegration. Of course, if
you look at it from the point of view of performance, this is the best thing to
do, since you have one node doing the work of two when any one of the
nodes is down.
Third-Party Takeover Configuration
Figure 4 illustrates a three node cluster in a third-party takeover
configuration.
Figure 4. Third-Party Takeover Configuration
This configuration can avoid the performance degradation that results from a
failover in the mutual takeover configuration.
Cluster Planning 33
Page 52

Here the resource groups are the same as the ones in the mutual takeover
configuration. Also, similar to the previous configuration, nodes 1 and 2 each
have priorities of 1 for one of the resource groups, A or B. The only thing
different in this configuration is that there is a third node which has a priority
of 2 for both the resource groups.
During normal operations, node 3 is either idle or is providing non-critical
services. In the case of either node 1 or node 2 failing, node 3 takes over the
failed node’s resource groups and starts providing its services. When a failed
node rejoins the cluster, it reacquires the resource group for which it has the
highest priority.
So, in this configuration, you are protected against the failure of two nodes
and there is no performance degradation after the failure of one node.
2.4.2.2 Concurrent Disk Access Configurations
A concurrent disk access configuration usually has all its disk storage defined
as part of one concurrent resource group. The nodes associated with a
concurrent resource group have no priorities assigned to them.
If a 7135 RAIDiant Array Subsystem is used for storage, you can have a
maximum of four nodes concurrently accessing a set of storage resources. If
you are using the 7133 SSA Disk Subsystem, you can have up to eight nodes
concurrently accessing it.This is because of the physical characteristics of
SCSI versus SSA.
In the case of a node failure, a concurrent resource group is not explicitly
taken over by any other node, since it is already active on the other nodes.
However, in order to somewhat mask a node failure from the end users, you
should also have cascading resource groups, each containing the service IP
address for each node in the cluster. When a node fails, its service IP
address will be taken over by another node and users can continue to access
critical services at the same IP address that they were using before the node
failed.
2.4.3 IP Address Takeover
The goal of IP Address Takeover is to make the server’s service address
highly available and to give clients the poss ibility of alway s c onnecting to the
same IP address. In order to achieve this, you must do the following:
• Decide which types of networks and point-to-point connections to use in
the cluster (see 2.2, “Cluster Networks” on page 11 for supported network
types)
34 IBM Certification Study Gu ide AIX HACMP
Page 53

• Design the network topology
• Define a network mask for your site
• Define IP addresses (adapter identifiers) for each node’s service and
standby adapters.
• Define a boot address for each service adapter that can be taken over, if
you are using IP address takeover or rotating resources.
• Define an alternate hardware address for each service adapter that can
have its IP address taken over, if you are using hardware address
swapping.
2.4.3.1 Network Topology
The following sections cover topics of network topology.
Single Network
In a single-network setup, each node in the cluster is connected to only one
network and has only
one service adapter available to clients. In this setup, a
service adapter on any of the nodes may fail, and a standby adapter will
acquire its IP address. The network itself, however, is a single point of failure.
The following figure shows a single-network configuration:
Client
Network
In the single-network setup, each node is connected to one network.
Each node has one service adapter and can have none, one, or more
standby adapters per public network.
Figure 5. Single-N etwork Setup
Cluster Planning 35
Page 54

Dual Network
A dual-network setup has two separate networks for communication. Nodes
are connected to two networks, and each node has two service adapters
available to clients. If one network fails, the remaining network can still
function, connecting nodes and providing resource access to clients.
In some recovery situations, a node connected to two networks may route
network packets from one network to another. In normal cluster activity,
however, each network is separate—both logically and physically.
Keep in mind that a client, unless it is connected to more than one network, is
susceptible to network failure.
The following figure shows a dual-network setup:
Figure 6. Dual-Netwo rk S etup
Point-to-Point Connection
A point-to-point connection links two (neighboring) cluster nodes directly.
SOCC, SLIP, and ATM are point-to-point connection types. In HACMP
clusters of four or more nodes, however, use an SOCC line
network between neighboring nodes because it cannot guarantee cluster
communications with nodes other than its neighbors.
36 IBM Certification Study Gu ide AIX HACMP
only
as a private
Page 55

The following diagram shows a cluster consisting of two nodes and a client. A
single public network connects the nodes and the client, and the nodes are
linked point-to-point by a private high-speed SOCC connection that provides
an alternate path for cluster and lock traffic should the public network fail.
Figure 7. A Point-to-Poin t Conn ection
2.4.3.2 Netw orks
Networks in an HACMP cluster are identified by name and attribute.
Network Name
The network name is a symbolic value that identifies a network in an HACMP
for AIX environment. Cluster processes use this information to determine
which adapters are connected to the same physical network. In most cases,
the network name is arbitrary, and it must be used consistently. If several
adapters share the same physical network, make sure that you use the same
network name when defining these adapters.
Network Attribute
A TCP/IP network’s attribute is either public or private.
Public A public network connects from two to 32 nodes and allows clients to
monitor or access cluster nodes. Ethernet, Token-Ring, FDDI, and
Cluster Planning 37
Page 56

SLIP are considered public networks. Note that a SLIP line, however,
does not provide client access.
Private A private network provides communication between nodes only; it
typically does not allow client access. An SOCC line or an ATM
network are also private networks; however, an ATM network does
allow client connections and may contain standby adapters. If an
SP node is used as a client, the SP Switch network, although
private, can allow client access.
Serial This network attribute is used for non TCP/IP netw orks (see 2.2.2,
“Non-TCPIP Networks” on page 14.)
2.4.3.3 Network Adapters
A network adapter (interface) connects a node to a network. A node typically
is configured with at least two network interfaces for each network to which it
connects: a service interface that handles cluster traffic, and one or more
standby interfaces. A service adapter must also have a boot address defined
for it if IP address takeover is enabled.
Adapters in an HACMP cluster have a label and a function (service, standby,
or boot). The maximum number of network interfaces per node is 24.
Adapter Label
A network adapter is identified by an adapter label. For TCP/IP networks, the
adapter label
address. Thus, a single node can have several adapter labels and IP
addresses assigned to it. The adapter labels, however, should not be
confused with the “hostname”, of which there is only one per node.
is the name in the /etc/hosts file associated with a specific IP
Adapter Function
In the HACMP for AIX environment, each adapter has a specific function that
indicates the role it performs in the cluster. An adapter’s function can be
service, standby, or boot.
Service Adapter The service adapter is the primary connection between
the node and the network. A node has one service adapter
for each physical network to which it connects. The
service adapter is used for general TCP/IP traffic and is
the address the Cluster Information Program (Clinfo)
makes known to application programs that want to monitor
or use cluster services.
In configurations using rotating resources, the service
adapter on the standby node remains on its boot address
38 IBM Certification Study Gu ide AIX HACMP
Page 57

until it assumes the shared IP address. Consequently,
Clinfo makes known the boot address for this adapter.
In an HACMP for AIX environment on the RS/6000 SP, the
SP Ethernet adapters can be configured as service
adapters but
should not
be configured for IP address
takeover. For the SP switch network, service addresses
used for IP address takeover are ifconfig alias addresses
used on the css0 network.
Standby Adapter A standby adapter backs up a service adapter . If a service
adapter fails, the Cluster Manager swaps the standby
adapter’s address with the service adapter’s address.
Using a standby adapter eliminates a network adapter as
a single point of failure. A node can have no standby
adapter, or it can have from one to seven standby
adapters for each network to which it connects. Your
software configuration and hardware slot constraints
determine the actual number of standby adapters that a
node can support.
The standby adapter is configured on a different subnet
from any service adapters on the same system, and its
use should be reserved for HACMP only.
In an HACMP for AIX environment on the RS/6000 SP, for
an IP address takeover configuration using the SP switch,
standby adapters are not required.
Boot Adapter IP address takeover is an AIX facility that allows one node
to acquire the network address of another node in the
cluster. To enable IP address takeover, a boot adapter
label (address) must be assigned to the service adapter
on each cluster node. Nodes use the boot label after a
system reboot and before the HACMP for AIX software is
started.
In an HACMP for AIX environment on the RS/6000 SP,
boot addresses used in the IP address for the switch
network takeover are ifconfig alias addresses used on
that css0 network.
When the HACMP for AIX software is started on a node,
the node’s service adapter is reconfigured to use the
Cluster Planning 39
Page 58

service label (address) instead of the boot label. If the
node should fail, a takeover node acquires the failed
node’s service address on its standby adapter, thus
making the failure transparent to clients using that specific
service address.
During the reintegration of the failed node, which comes
up on its boot address, the takeover node will release the
service address it acquired from the failed node.
Afterwards, the reintegrating node will reconfigure its
adapter from the boot address to its reacquired service
address.
Consider the following scenario: Suppose that Node A
fails. Node B acquires Node A’s service address and
services client requests directed to that address. Later,
when Node A is restarted, it comes up on its boot address
and attempts to reintegrate into the cluster on its service
address by requesting that Node B release Node A’s
service address. When Node B releases the requested
address, Node A reclaims the address and reintegrates it
into the cluster. Reintegration, however, fails if Node A has
not been configured to boot using its boot address.
The boot address does not use a separate physical
adapter, but instead is a second name and IP address
associated with a service adapter. It must be on the same
subnetwork as the service adapter. All cluster nodes must
have this entry in the local /etc/hosts
applicable, in the nameserver configuration.
2.4.3.4 Defining Hardware Addresses
The hardware address swapping facility works in tandem with IP address
takeover. Hardware address swapping maintains the binding between an IP
address and a hardware address, which eliminates the need to flush the ARP
cache of clients after an IP address takeover. This facility, however, is
supported only for Ethernet, Token-Ring, and FDDI adapters. It does not work
with the SP Switch or ATM LAN emulation networks.
Note that hardware address swapping takes about 60 seconds on a
Token- Ring network, and up to 120 seconds on an FDDI network. These
periods are longer than the usual time it takes for the Cluster Manager to
detect a failure and take action.
40 IBM Certification Study Gu ide AIX HACMP
file and, if
Page 59

If you do not use Hardware Address Takeover, the ARP cache of clients can
be updated by adding the clients’ IP addresses to the
variable in the /usr/sbin/cluster/etc/clinfo.rc file.
2.4.4 NFS Exports and NFS Mounts
There are two items concerning NFS when doing the configuration of a
Resource Group:
Filesystems to Export File systems listed her e will be NFS ex ported,
PING_CLIENT_LIST
so they can be mounted by NFS client
systems or other nodes in the clus ter.
Filesystems to NFS mount Filling in this field sets up what we call an
2.5 Application Planning
The central purpose for combining nodes in a cluster is to provide a highly
available environment for mission-critical applications. These applications
must remain available at all times in many organizations. For example, an
HACMP cluster could run a database server program that services client
applications. The clients send queries to the server program that responds to
their requests by accessing a database that is stored on a shared external
disk.
Planning for these applications requires that you be aware of their location
within the cluster, and that you provide a solution that enables them to be
handled correctly, in case a node should fail. In an HACMP for AIX cluster,
these critical applications can be a single point of failure. To ensure the
availability of these applications, the node configured to take over the
resources of the node leaving the cluster should also restart these
applications so that they remain available to client processes.
NFS
cross mount
. Any file system defined in this
field will be NFS mounted by all the
participating nodes, other than the node that is
currently holding the resource group. If the
node holding the resource group fails, the next
node to take over breaks its NFS mount for
this file system, and mounts the file system
itself as part of its takeover processing.
To put the application under HACMP control, you create an application server
cluster resource that associates a user-defined name with the names of
specially written scripts to start and stop the application. By defining an
application server, HACMP for AIX can start another instance of the
Cluster Planning 41
Page 60

application on the takeover node when a fallover occurs. For more
information about creating application server resources, see the
AIX, Version 4.3: Installation Guide
2.5.1 Performan ce Requirement s
In order to plan your application’s needs, you must have a thorough
understanding of it. One part of that is to have The Application Planning
Worksheets, found in Appendix A of the
SC23-4277, filled out.
Your applications have to be served correctly in an HACMP cluster
environment. Therefore, you need to know not only how they run on a single
uni- or multiprocessor machine, but also which resources are required by
them. How much disk space is required, what is the usual and critical load the
application puts on a server, and how users access the application are some
critical factors that will influence your decisions on how to plan the cluster.
Within an HACMP environment there are always a number of possible states
in which the cluster could be. Under normal conditions, the load is serviced
by a cluster node that was designed for this application’s needs. In case of a
failover, another node has to handle its own work plus the application it is
going to take over from a failing node. You can even plan one cluster node to
be the takeover node for multiple nodes; so, when any one of its primary
nodes fail, it has to take over its application and its load. Therefore, the
performance requirements of any cluster application have to be understood in
order to have the computing power available for mission-critical applications
in all possible cluster states.
, SC23-4278.
HACMP for AIX Planning Guide
HACMP for
,
2.5.2 Application Sta rtup and Shutdow n Routines
Highly available applications do not only have to come up at boot time, or
when someone is starting them up, but also when a critical resource fails and
has to be taken over by another cluster node. In this case, there have to be
robust scripts to both start up and shut down the application on the cluster
nodes. The startup script especially must be able to recover the application
from an abnormal termination, such as a power failure. You should verify that
it runs properly in a uniprocessor environment before including the HACMP
for AIX software.
42 IBM Certification Study Gu ide AIX HACMP
Page 61

Note
Application start and stop scripts have to be available on the primary as
well as the takeover node. They are not tr ansferred d uring synchronization;
so, the administrator of a cluster has to ensure that they are found in the
same path location, with the same permissions and in the same state, i.e.
changes have to be transferred manually.
2.5.3 Licensing Methods
Some vendors require a unique license for each processor that runs an
application, which means that you must license-protect the application by
incorporating processor-specific information into the application when it is
installed. As a result, it is possible that even though the HACMP for AIX
software processes a node failure correctly, it is unable to restart the
application on the failover node because of a restriction on the number of
licenses available within the cluster for that application. To avoid this
problem, make sure that you have a license for each system unit in the
cluster that may potentially run an application.
This can be done by “floating licenses”, where a license server is asked to
grant the permission to run an application on request, as well as “node-locked
licenses”, where each processor possibly running an application must have
the licensing files installed and configured.
2.5.4 Coexistence w ith other Applicatio ns
In case of a failover, a node might have to handle several applications
concurrently. This means the applications data or resources
with each other. Again, the Application Worksheets can help in deciding
whether certain resources might conflict with others.
2.5.5 Critical/Non-Critical Prio ritizations
Building a highly available environment for mission-critical applications also
forces the need to differentiate between the priorities of a number of
applications. Should a server node fail, it might be appropriate to shut down
another application, which is not as highly prioritized, in favor of the takeover
of the server node’s application. The applications running in a cluster have to
be clearly ordered and prioritized in order to decide what to do under these
circumstances.
must not
Cluster Planning 43
conflict
Page 62

2.6 Customization Plan ning
The Cluster Manager’s ability to recognize a specific series of events and
subevents permits a very flexible customization scheme. The HACMP for AIX
software provides an event customization facility that allows you to tailor
cluster event processing to your site.
2.6.1 Event Customiza tion
As part of the planning process, you need to decide whether to customize
event processing. If the actions taken by the default scripts are sufficient for
your purposes, you do not need to do anything further to configure events
during the installation process.
If you decide to tailor event processing to your environment, it is strongly
recommended that you use the HACMP for A IX event c ustomization facili ty
described in this chapter. If you tailor event processing, you must register
user-defined scripts with HACMP during the installation process. The
for AIX, Version 4.3: Installation Guide
configure event processing for a cluster.
You cannot define additional cluster events.
HACMP
, SC23-4278 describes how to
You can, however, define
defined in the HACMPevent ODM class.
The event customization facility includes the following features:
• Event notification
• Pre- and post-event processing
• Event recovery and retry
2.6.1.1 Special Application Requirements
Some applications may have some special requirements that have to be
checked and ensured before or after a cluster event happens. In case of a
failover you can customize events through the definition of pre- and postevents, to act according to your application’s needs. For example, an
application might want to reset a counter or unlock a user before it can be
started correctly on the failover node.
2.6.1.2 Event Notification
You can specify a
about to happen (or has just occurred), and that an event script succeeded or
failed. For example, a site may want to use a network_down notification
44 IBM Certification Study Gu ide AIX HACMP
notify command that sends mail to indicate that an event is
multiple
pre- and post-events for each of the events
Page 63

event to inform system administrators that traffic may have to be rerouted.
Afterwards, you can use a network_up notification event to inform system
administrators that traffic can again be serviced through the restored network.
2.6.1.3 Predic tive Ev ent Error Correc tion
You can specify a command that attempts to recover from an event script
failure. If the recovery command succeeds and the retry count for the event
script is greater than zero, the event script is rerun. You can also specify the
number of times to attempt to execute the recovery command.
For example, a recovery command can include the retry of unmounting a file
system after logging a user off and making sure no one was currently
accessing the file system.
If a condition that affects the processing of a given event on a cluster is
identified, such as a timing issue, you can insert a recovery command with a
retry count high enough to be sure to cover for the problem.
2.6.2 Error Notification
The AIX Error Notification facility detects errors that are logged to the AIX
error log, such as network and disk adapter failures, and triggers a predefined
response to the failure. It can even act on application failures, as long as they
are logged in the error log.
To implement error notification, you have to add an object to the Error
Notification object class in the ODM. This object clearly identifies what sort of
errors you are going to react to, and how.
By specifying the following in a file:
errnotify:
en_name = "Failuresample "
en_persistenceflg = 0
en_class = "H"
en_type = "PERM"
en_rclass = "disk"
en_method = "errpt -a -l $1 | mail -s ’Disk Error’ ro ot"
and adding this to the errnotify class through the odmadd <filename>
command, the specified
en_method is executed every time the error notification
daemon finds a matching entry in the error report. In the example above, the
root user will get e-mail identifying the exact error report entry.
Cluster Planning 45
Page 64

2.6.2.1 Single Point-of-Failure Hardware Component Recovery
As described in 2.2.1.2, “Special Network Considerations” on page 12, the
HPS Switch network is one resource that has to be considered as a single
point of failure. Since a node can support only one switch adapter, its failure
will disable the switch network for this node. It is strongly recommended to
promote a failure like this into a node failure, if the switch network is critical to
your operations.
Critical failures of the switch adapter would cause an entry in the AIX error
log. Error labels like
HPS_FAULT9_ER or HPS_FAULT3 _ER are considered critical,
and can be specified to AIX Error Notification in order to be able to act upon
them.
With HACMP, there is a SMIT screen to make it easier to set up an error
notification object. This is much easier than the traditional AIX way of adding
a template file to the ODM class. Under
Notification > Add a Notify Method ,
smit hacmp > RAS Su pport > Error
you will find the menu allowing you to
add these objects to the ODM. An example of the SMIT panel is shown
below:
Add a Notify Method
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
* Notification Object Name [HPS_ER9]
* Persist across system restart? Yes +
Process ID for use by Notify Method [] +#
Select Error Class All +
Select Error Type PERM +
Match Alertable errors? All +
Select Error Label [HPS_FAULT9_ER] +
Resource Name [All] +
Resource Class [All] +
Resource Type [All] +
* Notify Method [/usr/sbin/cluster/utilities/clstop -grsy]
F1=Help F2=Refresh F3=Cancel F4=List
F5=Reset F6=Command F7=Edit F8=Image
F9=Shell F10=Exit Enter=Do
Figure 8. Sample Screen for Add a Notification Method
46 IBM Certification Study Gu ide AIX HACMP
[Entry Fields]
Page 65

The above example screen will add a Notification Method to the ODM, so that
upon appearance of the HPS_FAULT9_ER entry in the error log, the error
notification daemon will trigger the execution of the
/usr/sbin/cluster/utilities/clstop -grsy command, which shuts HACMP down
gracefully with takeover. In this way, the switch failure is acted upon as a
node failure.
2.6.2.2 Notification
The method that is triggered upon the appearance of a specified error log
entry will be run by the error notification daemon with the command
<en_method>
. Because this a regular shell, any shell script can act as a
sh -c
method.
So, if you want a specific notification, such as e-mail from this event, you can
define a script that sends e-mail and then issues the appropriate commands.
Note
Because the Notification Method is an object in the node’s ODM, it has to
be added to each and every node potentially facing a situation where it
would be wise to act upon the appearance of an error log entry.
This is NOT handled by the HACMP synchronization facility. You have to
take care of this manually.
Alternatively, you can always customize any cluster event to enable a Notify
Command whenever this event is triggered through the SMIT screen for
customizing events.
2.6.2.3 Application Failure
Even application failures can cause an event to happen, if you have
configured this correctly. To do so, you have to find some method to decide
whether an application has failed. This can be as easy as looking for a
specific process, or much more complex, depending on the application. If you
issue an Operator Message through the
errlogger <message >
command, you can act on that as you would on an error notification as
described in 2.6.2.1, “Single Point-of-Failure Hardware Component
Recovery” on page 46.
Cluster Planning 47
Page 66

2.7 User ID Planning
The following sections describe various aspects of User ID Planning.
2.7.1 Cluster User and Group IDs
One of the basic tasks any system administrator must perform is setting up
user accounts and groups. All users require accounts to gain access to the
system. Every user account must belong to a group. Groups provide an
additional level of security and allow system administrators to manipulate a
group of users as a single entity.
For users of an HACMP for AIX cluster, system administrators must create
duplicate accounts on each cluster node. The user account information
stored in the /etc/passwd file, and in other files stored in the /etc/security
directory, should be consistent on all cluster nodes. For example, if a cluster
node fails, users should be able to log on to the surviving nodes without
experiencing problems caused by mismatches in the user or group IDs.
System administrators typically keep user acc ounts s ynchronized acr oss
cluster nodes by copying the key system account and security files to all
cluster nodes whenever a new account is created or an existing account is
changed.Typically
supper are widely used. For C-SPOC clusters, the C-SPOC utility simplifies
or
the cluster-wide synchronization of user accounts by propagating the new
account or changes to an existing account across all cluster nodes
automatically.
rdist or rcp is used, for that. On RS/6000 SP systems pcp
The following are some common user and group management tasks, and are
briefly explained in 8.8, “User Management” on page 178:
• Listing all user accounts on all cluster nodes
• Adding users to all cluster nodes
• Changing characteristics of a user account on all cluster nodes
• Removing a user account from all cluster nodes.
• Listing all groups on all cluster nodes
• Adding groups to all cluster nodes
• Changing characteristics of a group on all cluster nodes
• Removing a group from all cluster nodes
48 IBM Certification Study Gu ide AIX HACMP
Page 67

2.7.2 Cluster Passwords
While user and group management is very much facilitated with C-SPOC, the
password information still has to be distributed by some other means. If the
system is not configured to use NIS or DCE, the system administrator still has
to distribute the password information, meaning that found in the
/etc/security/password file, to all cluster nodes.
As before, this can be done through
there are tools like
pcp or supper to distribute information or better files.
2.7.3 User Home D irectory Plan ning
As for user IDs, the system administrator has to ensure that users have their
home directories available and in the same position at all times. That is, they
don’t care whether a takeover has taken place or everything is normal. They
simply want to access their files, wherever they may reside physically, under
the same directory path with the same permissions, as they would on a single
machine.
There are different approaches to that. You could either put them on a shared
volume and handle them within a resource group, or you could use NFS
mounts.
2.7.3.1 Home Directories on Shared Volumes
Within an HACMP cluster, this approach is quite obvious, however, it restricts
you to only one machine where a home directory can be active at any given
time. If you have only one application that the user needs to access, or all of
the applications are running on one machine, where the second node serves
as a standby machine only, this would be sufficient.
2.7.3.2 NFS-Mounted Home Directorie s
The NFS mounted home directory approach is much more flexible. Because
the directory can be mounted on several machines at the same time, a user
can work with it in several applications on several nodes at the same time.
rdist or rcp. On RS/6000 SP systems,
However, if one cluster node provides NFS service of home directories to
other nodes, in case of a failure of the NFS server node, the access to the
home directories is barred. Placing them onto a machine outside the cluster
doesn’t help either, since this again introduces a single point of failure, and
machines outside the cluster are not any less likely to fail than machines
within.
Cluster Planning 49
Page 68

2.7.3.3 NFS-Mounted Home Directories on Shared Volumes
So, a combined approach is used in most cases. In order to make home
directories a highly available resource, they have to be part of a resource
group and placed on a shared volume. That way, all cluster nodes can access
them in case they need to.
To make the home directories accessible on nodes that currently do not own
the resource where they are physically residing, they have to be NFS
exported from the resource group and imported on all the other nodes in case
any application is running there, needing access to the users files.
In order to make the directory available to users again, when a failover
happens, the takeover node that previously had the directory NFS mounted
from the failed node has to break locks on NFS files, if there are any. Next, it
must unmount the NFS directory, acquire the shared volume (varyon the
shared volume group) and mount the shared file system. Only after that can
users access the application on the takeover node again.
50 IBM Certification Study Gu ide AIX HACMP
Page 69

Chapter 3. Cluster Hardware and Software Preparation
This chapter covers the steps that are required to prepare the RS/6000
hardware and AIX software for the installation of HACMP and the
configuration of the cluster. This includes configuring adapters for TCP/IP,
setting up shared volume groups, and mirroring and editing AIX configuration
files.
3.1 Cluster Node Se tup
The following sections describe important details of cluster node setup.
3.1.1 Adapter Slot Placement
For information regarding proper adapter placement, see the following
documentation:
PCI Adapter Placement Reference Guide,
•
Adapters, Devices, and Cable Information for Micro Channel Bus
•
Systems
Adapters, Devices, and Cable Information for Multiple Bus Systems
•
SA38-0516
3.1.2 Rootvg Mirrorin g
Of all the components used to build a computer system, physical disk devices
are usually the most susceptible to failure. Because of this, disk mirroring is a
frequently used technique for increasing system availability.
File system mirroring and disk mirroring are easily configured using the AIX
Logical Volume Manager. However, conventional file system and disk
mirroring offer no protection against operating system failure or against a
failure of the disk from which the operating system normally boots.
Operating system failure does not always occur instantaneously, as
demonstrated by a system that gradually loses access to operating system
services. This happens as code and data that were previously being
accessed from memory gradually disappear in response to normal paging.
Normally, in an HACMP environment, it is not necessary to think about
mirroring the root volume group, because the node failure facilities of HACMP
can cover for the loss of any of the rootvg physical volumes. However, it is
possible that a customer with business-critical applications will justify
SA38-0538
, SA38-0533
,
© Copyright IBM Corp. 1999 51
Page 70

mirroring rootvg in order to avoid the impact of the failover time involved in a
node failure. In terms of maximizing availability, this technique is just as valid
for increasing the availability of a cluster as it is for increasing single-system
availability.
The following procedure contains information that will enable you to mirror
the root volume group (rootvg), using the advanced functions of the Logical
Volume Manager (LVM). It contains the steps required to:
• Mirror all the file sys tems in rootvg.
• Create an additional boot logical volume (blv).
• Modify the bootlist to contain all boot devices.
You may mirror logical volumes in the rootvg in the same way as any AIX
logical volume may be mirrored, either once (two copies), or twice (three
copies). The following procedure is designed for mirroring rootvg to a second
disk only . Upon completion of these steps, your system will remain available if
one of the disks in rootvg fails, and will even automatically boot from an
alternate disk drive, if necessary.
If the dump device is mirrored, you may not be able to capture the dump
image from a crash or the dump image may be corrupted. The design of LVM
prevents mirrored writes of the dump device. Only one of the mirrors will
receive the dump image. Depending on the boot sequence and disk
availability after a crash, the dump will be in one of the following three states:
1. Not available
2. Available and not corrupted
3. Available and corrupted
State (1) will always be a possibility. If the user prefers to prevent the risk of
encountering State (3), then the user must create a non-mirrored logical
volume (that is not hd6) and set the dump device to this non-mirrored logical
volume.
In AIX 4.2.1, two new LVM commands were introduced:
unmirrorvg. These two commands where introduced to simplify mirroring or
unmirroring of the entire contents of a volume group. The commands will
detect if the entity to be mirrored or unmirrored is rootvg, and will give slightly
different completion messages based on the type of volume group.The
mirrorvg command does the equivalent of Procedure steps (2), (3), and (4).
mirrorvg command takes dump devices and paging devices into account.
The
If the dump devices are also the paging device, the logical volume will be
52 IBM Certification Study Gu ide AIX HACMP
mirrorvg and
Page 71

mirrored. If the dump devices are NOT the paging device, that dump logical
volume will not be mirrored.
3.1.2.1 Procedure
The following steps assume the user has rootvg contained on hdisk0 and is
attempting to mirror the rootvg to a new disk: hdisk1.
1. Extend rootvg to hdisk1 by executing the following:
extendvg rootvg h disk1
2. Disable QUORUM, by executing the following:
chvg -Qn rootvg
3. Mirror the logical volumes that make up the AIX operating system by
executing the following:
mklvcopy hd1 2 hd isk1 # /home fil e system
mklvcopy hd2 2 hd isk1 # /usr file system
mklvcopy hd3 2 hd isk1 # /tmp file system
mklvcopy hd4 2 hd isk1 # / (root) file system
mklvcopy hd5 2 hd isk1 # blv, boot logical volume
mklvcopy hd6 2 hd isk1 # paging sp ace
mklvcopy hd8 2 hd isk1 # file syst em log
mklvcopy hd9var 2 hdisk1 # /var f ile system
If you have other paging devices, rootvg and non-rootvg, it is
recommended that you also mirror those logical volumes in addition to
hd6.
If hd5 consists of more than one logical partition, then, after mirroring hd5
you must verify that the mirrored copy of hd5 resides on contiguous
physical partitions. This can be verified with the following command:
lslv -m hd5
If the mirrored hd5 partitions are not contiguous, you must delete the
mirror copy of hd5 (on hdisk1) and rerun the
Cluster Hardware and Software Preparation 53
mklvcopy for hd5, using the
Page 72

“-m” option. You should consult documentation on the usage of the “-m”
option for
mklvcopy .
4. Synchronize the newly created mirrors with the following command:
syncvg -v rootvg
5. Bosboot to initialize all boot records and devices by executing the
following command:
bosboot -a -d /de v/hdisk?
where
command
hdisk? is the first hdisk listed under the “PV” heading after the
lslv -l hd5 has executed.
6. Initialize the boot list by executing the following:
bootlist -m norma l hdisk0 hdisk1
Note
Even though this command identifies the list of possible boot disks, it
does not guarantee that the system will boot from the alternate disk in all
cases involving failures of the first disk. In such situations, it may be
necessary for the user to boot from the installation/maintenance media.
Select maintenance, reissue the
bootlist command leaving out the
failing disk, and then reboot. On some models, firmware provides a
utility for selecting the boot device at boot time. This may also be used
to force the system to boot from the alternate disk.
7. Shutdown and reboot the system by executing the following command:
shutdown -Fr
This is so that the “Quorum OFF” functionality takes effect.
54 IBM Certification Study Gu ide AIX HACMP
Page 73

3.1.2.2 Necessary APAR Fixes
Table 11. Necessary APAR Fixes
AIX Version APARs needed
4.1 IX56564
4.2 IX62417
4.3 IX72550
To determine if either fix is installed on a machine, execute the following:
instfix -i -k <ap ar number>
3.1.3 AIX Prerequisite LPPs
In order to install HACMP and HACMP/ES the AIX setup must be in a proper
state. The following table gives you the prerequisite AIX levels for the
different HACMP versions:
Table 12. AIX Prerequisite LP Ps
HACMP Version Prerequisite AIX and PSSP Version
IX61184
IX60521
IX68483
IX70884
IX72058
HACMP 4.1 for AIX AIX 4.1.5
PSSP 2.2, if installed on an SP
HACMP 4.2 for AIX AIX 4.1.5
PSSP 2.2, if installed on an SP
HACMP 4.3 for AIX AIX 4.3.2
PSSP 2.2, if installed on an SP
HACMP/ES 4.2 for AIX AIX 4.2.1
PSSP 2.2, if installed on an SP
HACMP/ES 4.3 for AIX AIX 4.3.2
PSSP 3.1, if installed on an SP
The Prerequisites for the HACMP component HAView 4.2 are
• xlC.rte 3.1.3.0
• nv6000.base.obj 4.1.0.0
Cluster Hardware and Software Preparation 55
Page 74

• nv6000.database.obj 4.1.0.0
• nv6000.Features.obj 4.1.2.0
• nv6000.client.obj 4.1.0.0
and for HAView 4.3
• xlC.rte 3.1.4.0
• nv6000.base.obj 4.1.2.0
• nv6000.database.obj 4.1.2.0
• nv6000.Features.obj 4.1.2.0
• nv6000.client.obj 4.1.2.0
3.1.4 AIX Parameter S ettings
This section discusses several general tasks necessary to ensure that your
HACMP for AIX cluster environment works as planned. Consider or check the
following issues to ensure that AIX works as expected in an HACMP cluster.
• I/O pacing
• User and group IDs (see Chapter 2.7, “User ID Planning” on page 48)
• Network option settings
• /etc/hosts file and nameserver edits
• /.rhosts file edits
3.1.4.1 I/O Pacing
AIX users have occasionally seen poor interactive performance from some
applications when another application on the system is doing heavy
input/output. Under certain conditions, I/O can take several seconds to
complete. While the heavy I/O is occurring, an interactive process can be
severely affected if its I/O is blocked, or, if it needs resources held by a
blocked process.
Under these conditions, the HACMP for AIX software may be unable to send
keepalive packets from the affected node. The Cluster Managers on other
cluster nodes interpret the lack of keepalives as node failure, and the
I/O-bound node is “failed” by the other nodes. When the I/O finishes, the node
resumes sending keepalives. Its packets, however, are now out of sync with
the other nodes, which then kill the I/O-bound node with a RESET packet.
You can use I/O pacing to tune the system so that system resources are
distributed more equitably during high disk I/O. You do this by setting high-
56 IBM Certification Study Gu ide AIX HACMP
Page 75

and low-water marks. If a process tries to write to a file at the high-water
mark, it must wait until enough I/O operations have finished to make the
low-water mark.
Use the
smit chgsys fastpath to set high- and low-water marks on the
Change/Show Characteristics of the Operating System screen.
By default, AIX is installed with high- and low-water marks set to zero, which
disables I/O pacing.
While enabling I/O pacing may have a slight performance effect on very
I/O-intensive processes, it is required for an HACMP cluster to behave
correctly during large disk writes. If you anticipate heavy I/O on your HACMP
cluster, you should enable I/O pacing.
Although the most efficient high- and low-water marks vary from system to
system, an initial high-water mark of 33 and a low-water mark of 24 provides
a good starting point. These settings only slightly reduce write times and
consistently generate correct fallover behavior from the HACMP for AIX
software.
See the
AIX Performance Monitoring & Tuning Guide
, SC23-2365, for more
information on I/O pacing.
3.1.4.2 Checking Network Option Settings
To ensur e that HACMP for AIX requests for memory are handled correctly,
you can set (on every cluster node)
thewall network option to be higher than
its default value. The suggested value for this option is shown below:
thewall = 5120
To change this default value, add the following line to the end of the
/etc/rc.net
no -o thewall=5120
file:
After making this change, monitor mbuf usage using the netstat -m command
and increase or decrease “thewall” option as needed.
To list the values of other network options (not configurable) that are currently
set on a node, enter:
no -a
Cluster Hardware and Software Preparation 57
Page 76

3.1.4.3 Editing the /etc/hosts File and Nameserver Config uration
Make sure all nodes can resolve all cluster addresses. See the chapter on
planning TCP/IP networks (the section Using HACMP with NIS and DNS) in
HACMP for AIX, Version 4.3: Planning Guide, SC23-4277
the
for more
information on name serving and HACMP.
Edit the /etc/hosts file (and the /etc/resolv.conf file, if using the nameserver
configuration) on each node in the cluster to make sure the IP addresses of
all clustered interfaces are listed.
For each boot address, make an entry similar to the following:
100.100.50.200 cra b_boot
Also, make sure that the /etc/hosts file on each node has the following entry:
127.0.0.1 loopba ck localhost
3.1.4.4 cron and NIS Considerations
If your HACMP cluster nodes use NIS services, which include the mapping of
the /etc/passwd file, and IPAT is enabled, users that are known only in the
NIS-managed version of the /etc/passwd file will not be able to create
crontabs. This is because cron is started with the /etc/inittab file with run level
2 (for example, when the system is booted), but ypbind is started in the
course of starting HACMP with the
enabled in HACMP, the run level of the
with the
telinit -a command by HACMP.
rcnfs entry in /etc/init tab. When IPAT is
rcnfs entry is changed to -a and run
In order to let those NIS-managed users create crontabs, you can do one of
the following:
• Change the run level of the
it is positioned after the
recommended if it is acceptable to start cron after HACMP has started.
• Add an entry to the /etc/inittab file like the following script with run level
Make sure it is positioned after the
thing is to kill the cron process, which will respawn and know about all of
the NIS-managed users. Whether or not you log the fact that cron has
been refreshed is optional.
58 IBM Certification Study Gu ide AIX HACMP
cron entry in /etc/inittab to -a and make sure
rcnfs entry in /etc/ini ttab. This solution is
-a.
rcnfs entry in /etc/inittab. The important
Page 77

#! /bin/sh
# This script che cks for a ypbind and a cron process . If both
# exist and cron was started befo re ypbind, cron is killed so
# it will respawn and know about any new users that are found
# in the passwd f ile managed as a n NIS map.
echo "Entering $0 at ‘date‘" >> / tmp/refr_cron.out
cronPid=‘ps -ef | grep "/etc/cron" |grep -v grep |awk \
’{ print $2 }’‘
ypbindPid=‘ps -ef | grep "/usr/et c/ypbind" | grep -v grep | \
if [ ! -z "${ypbi ndPid}" ]
then
if [ ! -z "${cronPi d}" ]
then
echo "ypbind pid i s ${ypbindPid}" > > /tmp/refr_cron.ou t
echo "cron pid is ${cronPid}" >> /t mp/refr_cron.out
echo "Killing cron (pid ${cronPid}) to refresh user \
list" >> /tmp/refr_cron.o ut
kill -9 ${cronPid}
if [ $? -ne 0 ]
then
echo "$PROGNAME: Unable to refr esh cron." \
>>/tmp/refr_cron.o ut
exit 1
fi
fi
fi
echo "Exiting $0 at ‘date‘" >> /tmp/ refr_cron.out
exit 0
3.1.4.5 Editing th e /.rhosts File
Make sure that each node’s service adapters and boot addresses are listed in
the /.rhosts
/usr/sbin/cluster/ utilities/clrunc md command and the
file on each cluster node. Doing so allows the
/usr/sbin/cluster/godm daemon to run. The /usr/sbin/cluster/godm daemon is
used when nodes are configured from a central location.
For security reasons, IP label entries that you add to the /.rhosts file to
identify cluster nodes should be deleted when you no longer need to log on to
a remote node from these nodes. The cluster synchronization and verification
functions use
rcmd and rsh and thus require these /.rhosts entries. These
entries are also required to use C-SPOC commands in a cluster environment.
The /usr/sbin/cluster/clstrmgr daemon, however, does not depend on /.rhosts
file entries.
The /.rhosts file is not required on SP systems running the HACMP Enhanced
Security . This feature removes the requirement of TCP/IP access control lists
(for example, the /.rhosts file) on remote nodes during HACMP configuration.
Cluster Hardware and Software Preparation 59
Page 78

3.2 Network Connecti on and Testing
The following sections describe important aspects of network connection and
testing.
3.2.1 TCP/IP Networks
Since there are several types of TCP/IP Networks available within HACMP,
there are several different characteristics and some restrictions on them.
Characteristics like maximum distance between nodes have to be
considered. Y ou don’t want to put two cluster nodes running a mission-critical
application in the same room for example.
3.2.1.1 Cabling Considerations
Characteristics of the different types of cable, their maximum length, and the
like are beyond the scope of this book. However, for actual planning of your
clusters, you have to check whether your network cabling allows you to put
two cluster nodes away from each other, or even in different buildings.
There’s one additional point with cabling, that should be taken care of.
Cabling of networks often involves hubs or switches. If not carefully planned,
this sometimes introduces another single point of failure into your cluster. To
eliminate this you should have at least two hubs.
As shown in Figure 9, failure of a hub would not result in one machine being
disconnected from the network. In that case, a hub failure would cause either
both service adapters to fail, which would cause a
the standby adapters would take over the network, or both standby adapters
would fail, which would cause
method for these events can alert the network administrator to check and fix
the broken hub.
fail_standby
swap_adapter
events. Configuring a notify
event, and
60 IBM Certification Study Gu ide AIX HACMP
Page 79

.
Figure 9. Connecting Netw orks to a Hub
3.2.1.2 IP Addresses and Subnets
The design of the HACMP for AIX software specifies that:
• All client traffic be carried over the service adapter
• Standby adapters be hidden from client applications and carry only
internal Cluster Manager traffic
Cluster Hardware and Software Preparation 61
Page 80

To comply with these rules, pay careful attention to the IP addresses you
must
assign to standby adapters. Standby adapters
be on a separate subnet
from the service adapters, even though they are on the same physical
network. Placing standby adapters on a different subnet from the service
adapter allows HACMP for AIX to determine which adapter TCP/IP will use to
send a packet to a network.
If there is more than one adapter with the same network address, there is no
way to guarantee which of these adapters will be chosen by IP as the
transmission route. All choices will be correct, since each choice will deliver
the packet to the correct network. To guarantee that only the service adapter
handles critical traffic, you must limit IP’s choice of a transmission route to
one adapter. This keeps all traffic off the standby adapter so that it is
available for adapter swapping and IP address takeover (IPAT). Limiting the
IP’s choice of a transmission route also facilitates identifying an adapter
failure.
Note
The netmask for all adapters in an HACMP network must be the same even
though the service and standby adapters are on different logical subnets.
See the
HACMP for AIX, Version 4.3: Concepts and Facilities, SC23-4276
guide for more information about using the same netmask for all adapters.
See Chapter 2.4.3, “IP Address Takeover” on page 34 for more detailed
information.
3.2.1.3 Testing
After setting up all adapters with AIX, you can do several things to check
whether TCP/IP is working correctly. Note, that without HACMP being started,
the service adapters defined to HACMP will remain on their boot address.
After startup these adapters change to their service addresses.
Use the following AIX commands to investigate the TCP/IP subsystem:
• Use the
netstat command to make sure that the adapters are initialized
and that a communication path exists between the local node and the
target node.
• Use the
ping command to check the point-to-point connectivity between
nodes.
• Use the
ifconfig command on all adapters to detect bad IP addresses,
incorrect subnet masks, and improper broadcast addresses.
62 IBM Certification Study Gu ide AIX HACMP
Page 81

• Scan the /tmp/hacmp.out file to confirm that the /etc/rc.net script has run
successfully. Look for a zero exit status.
• If IP address takeover is enabled, confirm that the /etc/rc.net script has
run and that the service adapter is on its service address and not on its
boot address.
• Use the
lssrc -g tcpip command to make sure that the inetd daemon is
running.
• Use the
lssrc -g portmap command to make sure that the portmapper
daemon is running.
• Use the
arp command to make sure that the cluster nodes are not using
the same IP or hardware address.
3.2.2 Non TCP/IP Netw orks
Currently three types of non-TCP/IP networks are supported:
• Serial (RS232)
• Target-mode SCSI
• Target-mode SSA
While we use the word serial here to refer to RS232 only, in HACM P
definitions, a “serial” network means a non-TCP/IP network of any kind.
Therefore, when we are talking about HACMP network definitions, a serial
network could also be a target-mode SCSI or target-mode SSA network.
The following describes some cabling issues on each type of non-TCP/IP
network, how they are to be configured, and how you can test if they are
operational.
3.2.2.1 Cabling Considerations
RS232 Cabling a serial connection requires a null-modem cable. As often
cluster nodes are further apart than 60 m (181 ft.), sometimes
modem eliminators or converters to fiber channel are used.
TMSCSI If your cluster uses SCSI disks as shared devices, you can use
that line for TMSCSI as well. TMSCSI requires Differential SCSI
adapters (see Chapter 2.3.2.3, “Supported SCSI Adapters” on
page 26). Because the SCSI bus has to be terminated on both
ends, and not anywhere else in between, resistors on the
adapters should be removed, and cabling should be done as
shown in Figure 11 on page 77, that is, with Y-cables that are
terminated at one end connected to the adapters where the other
end connects to the shared disk device.
Cluster Hardware and Software Preparation 63
Page 82

TMSSA Target-mode SSA is only supported with the SSA Multi-Initiator
RAID Adapters (Feature #6215 and #6219), Microcode Level
1801 or later. You need at least HACMP Version 4.2.2 with APAR
IX75718.
3.2.2.2 Configuring RS232
Use the
smit tty fastpath to create a tty device on the nodes. On the resulting
panel, you can add an RS232 tty by selecting a native serial port, or a port on
an asynchronous adapter. Make sure that the Enable Login field is set to
disable. You do not want a getty process being spawned on this interface.
3.2.2.3 Configuring Target Mode SCSI
To configur e a target-mode SCSI network on the Differential SCSI adapters,
you have to enable the SCSI adapter’s feature TARGET MODE by setting the
enabled characteristics to yes. Since disks on the SCSI bus are normally
configured at boot time, and the characteristics of the parent device cannot
be changed as long as there are child devices present and active, you have
to set all the disks on that bus to
rmdev -l hdiskx
Defined with the
command, before you can enable that feature. Alternatively you can make
these changes to the database (ODM) only, and they will be activated at the
time of the next reboot.
If you choose not to reboot, instead setting all the child devices to
you have to run cfgmgr, to get the tmscsi device created, as well as all the
child devices of the adapter back to the available state.
Note
The target mode device created is a logical new device on the bus.
Because it is created by scanning the bus for possible initiator devices, a
tmscsix device is created on a node for each SCSI adapter on the same
bus that has the target mode flag enabled, therefore representing this
adapter’s unique SCSI ID. In that way, the initiator can address packets to
exactly one target device.
This procedure has to be done for all the cluster nodes that are going to use a
serial network of type tmscsi as defined in your planning sheets.
64 IBM Certification Study Gu ide AIX HACMP
Defined,
Page 83

3.2.2.4 Configuring Target Mode SSA
The node number on each system needs to be changed from the default of
zero to a number. All systems on the SSA loop must have a unique node
number.
To change the node number use the following command:
chdev -l ssar -a n ode_number=#
To show the system’s node number use the following command:
lsattr -El ssar
Having the node numbers set to non-zero values enables the target mode
devices to be configured. Run the
cfgmgr command to configure the tmssa#
devices on each system. Check that the tmssa devices are available on each
system using the following command:
lsdev -C | grep tm ssa
The Target Mode SCSI or SSA serial network can now be configured into an
HACMP cluster.
3.2.2.5 Testing RS232 and Target Mode Networ ks
Testing of the serial networks functionality is similar. Basically you just write
to one side’s device and read from the other.
Serial (RS323): After configuring the serial adapter and cabling it correctly,
you can check the functionality of the connection by entering the command
cat < /dev/ttyx
on one node for reading from that device and
cat /etc/environme nt > /dev/ttyy
on the corresponding node for writing. You should see the first command
hanging until the second command is issued, and then showing the output of
it.
Target Mode SSA: After configuration of Target Mode SSA, you can check
the functionality of the connection by entering the command:
cat < /dev/tmssax. tm
on one node for reading from that device and:
Cluster Hardware and Software Preparation 65
Page 84

cat /etc/environme nt > /dev/tmssay .im
on the corresponding node for writing. x and y correspond to the appropriate
opposite nodenumber. You should see the first command hanging until the
second command is issued, and then showing its output.
Target Mode SCSI: After configuration of Target Mode SCSI, you can check
the functionality of the connection by entering the command:
cat < /dev/tmscsix .tm
on one node for reading from that device and:
cat /etc/environme nt > /dev/tmscsi y.im
on the corresponding node for writing. You should see the first command
hanging until the second command is issued, and then showing the output of
that second command.
3.3 Cluster Disk Setup
The following sections relate important information about cluster disk setup.
3.3.1 SSA
The following sections describe cabling, AIX configuration, microcode
loading, and configuring a RAID on SSA disks.
3.3.1.1 Cabli ng
The following rules must be followed when connecting a 7133 SSA
Subsystem:
• Each SSA loop must be connected to a valid pair of connectors on the
SSA adapter card (A1 and A2 to form one loop, or B1 and B2 to form one
loop).
• Only one pair of connectors of an SSA adapter can be connected in a
particular SSA loop (A1 or A2, with B1 or B2 cannot be in the same SSA
loop).
• A maximum of 48 disks can be connected in an SSA loop.
• A maximum of three dummy disk drive modules can be connected next to
each other.
• The maximum length of an SSA cable is 25 m. With Fiber-Optic
Extenders, the connection length can be up to 2.4 km.
66 IBM Certification Study Gu ide AIX HACMP
Page 85

For more information regarding adapters and cabling rules see 2.3.1, “SSA
Disks” on page 16 or the following documents:
• 7133 SSA Disk Subsystems: Se rvice Guide, SY33-0185-02
• 7133 SSA Disk Subsystem: Operator Guide, GA 33-3259-01
• 7133 Models 010 and 020 SSA Disk Subsystems: Installation Guide,
GA33-3260-02
• 7133 Models 500 and 600 SSA Disk Subsystems: Installation Guide,
GA33-3263-02
• 7133 SSA Disk Subsystems for Open Attachment: Servic e Guide,
SY33-0191-00
• 7133 SSA Disk Subsystems for Open Attachment: Installation and User's
Guide, SA33-3273-00
3.3.1.2 AIX Configuration
During boot time, the configuration manager of AIX configures all the device
drivers needed to have the SSA disks available for usage. The configuration
manager can’t do this configuration if the SSA Subsystem is not properly
connected or if the SSA Software is not installed. If the SSA Software is not
already installed, the configuration manager will tell you the missing filesets.
You can either install the missing filesets with
smit, or call the configuration
manager with the -i flag.
The configuration manager configures the following devices:
• SSA Adapter Router
• SSA Adapter
• SSA Disks
Adapter Router
The adapter Router (ssar) is only a conceptual configuration aid and is
always in a “Defined” state. It cannot be made “Available.” You can list the
ssar with the following command:
#lsdev -C | grep ssar
ssar Defined SSA Adapter Router
Cluster Hardware and Software Preparation 67
Page 86

Adapter Definitions
By issuing the following command, you can check the correct adapter
configuration. In order to work correctly, the adapter must be in the
“Available” state:
#lsdev -C | grep ssa
ssa0 Available 00-07 SSA Enhanced Adapter
ssar Defined SSA Adapter Router
The third column in the adapter device line shows the location of the adapter.
Disk Definitions
SSA disk drives are represented in AIX as SSA logical disks (hdisk0,
hdisk1,...,hdiskN) and SSA physical disks (pdisk0, pdisk1,...,pdiskN). SSA
RAID arrays are represented as SSA logical disks (hdisk0, hdisk1,...,hdiskN).
SSA logical disks represent the logical properties of the disk drive or array,
and can have volume groups and file systems mounted on them. SSA
physical disks represent the physical properties of the disk drive. By default,
one pdisk is always configured for each physical disk drive. One hdisk is
configured for each disk drive that is connected to the using system, or for
each array. By default, all disk drives are configured as system (AIX) disk
drives. The array management software can be used to change the disks
from hdisks to array candidate disks or hot spares.
SSA logical disks:
• Are configured as hdisk0, hdisk1,...,hdiskN.
• Support a character special file (/dev/rhdisk0,
/dev/rhdisk1,...,/dev/rhdiskN).
• Support a block special file (/dev/hdisk0, /dev/hdisk1,...,/dev/hdiskN).
• Support the I/O Control (IOCTL) subroutine call for non service and
diagnostic functions only.
• Accept the read and write subroutine calls to the special files.
• Can be members of volume groups and have file systems mounted on
them.
In order to list the logical disk definitions, use the following command:
68 IBM Certification Study Gu ide AIX HACMP
Page 87

#lsdev -Cc disk| grep SSA
hdisk3 Available 00-07-L SSA Logical Disk Drive
hdisk4 Available 00-07-L SSA Logical Disk Drive
hdisk5 Available 00-07-L SSA Logical Disk Drive
hdisk6 Available 00-07-L SSA Logical Disk Drive
hdisk7 Available 00-07-L SSA Logical Disk Drive
hdisk8 Available 00-07-L SSA Logical Disk Drive
SSA physical disks:
• Are configured as pdisk0, pdisk1,...,pdiskN.
• Have errors logged against them in the system error log.
• Support a character special file (/dev/pdisk0, /dev/pdisk1,...,/dev/p.diskN).
• Support the IOCTLl subroutine for servicing and diagnostic functions.
• Do not accept read or write subroutine calls for the character special file.
In order to list the physical disk definitions use the following command:
#lsdev -Cc pdisk| grep SSA
pdisk0 Available 00-07-P 1GB SSA C Physical Disk Dri ve
pdisk1 Available 00-07-P 1GB SSA C Physical Disk Dri ve
pdisk2 Available 00-07-P 1GB SSA C Physical Disk Dri ve
pdisk3 Available 00-07-P 1GB SSA C Physical Disk Dri ve
pdisk4 Available 00-07-P 1GB SSA C Physical Disk Dri ve
pdisk5 Available 00-07-P 1GB SSA C Physical Disk Dri ve
Diagnostics
A good tool to get rid of SSA problems are the SSA service aids in the AIX
diagnostic program
A Practical Guide to SSA for AIX
in
diag. The SSA diagnostic routines are fully documented
, SG24-4599. The following is a brief
overview:
The SSA service aids are accessed from the main menu of the
diag program.
Select Task Selection -> SSA Service Aids. This will give you the following
options:
Set Service Mode T his option enables you to determine the location
of a specific SSA disk drive within a loop and to
remove the drive from the configuration, if
required.
Link Verification This option enables you to determine the
operational status of a link
Cluster Hardware and Software Preparation 69
Page 88

Configuration Verification This option enables you to display the
relationships between physical (pdisk) and logical
(hdisk) disks.
Format Disk This option enables you to format SSA disk drives.
Certify Disk This option enables you to test whether data on an
SSA disk drive can be read correctly.
Display/Download... This option enables you to display the microcode
level of the SSA disk drives and to download new
microcode to individual or all SSA disk drives
connected to the system.
Note
When an SSA loop is attached to multiple host systems, do not invoke the
diagnostic routines from more than one host simultaneously, to avoid
unpredictable results that may result in data corruption.
3.3.1.3 Microcode Loading
To ensur e that everything works correctly, install the latest filesets, fixes and
microcode for your SSA disk subsystem. The latest information and
downloadable files can be found under
http://www.hursley. ibm.com/~ssa.
Upgrade Instructions
Follow these steps to perform an upgrade:
1. Login as root
2. Download the appropriate microcode file for your AIX version from the
web-site mentioned above
3. Save the file upgrade.tar in your /tmp
4. Type tar -xvf upgrade.tar
5. Run
smitty install
6. Select install & update software
7. Select install & update from ALL available software
8. Use the directory /usr/sys/inst.images as the install device
9. Select all filesets in this directory for install
10.Execute the command
11 .Exi t S mit
70 IBM Certification Study Gu ide AIX HACMP
directory
Page 89

Note
You must ensure that:
• You do not attempt to perform this adapter microcode download
concurrently on systems that are in the same SSA loop. This may cause
a portion of the loop to be isolated and could prevent access to these
disks from elsewhere in the loop.
• You do not run advanced diagnostics while downloads are in progress.
Advanced diagnostics causes the SSA adapter to be reset temporarily,
thereby introducing a break in the loop, portions of the loop may
become temporarily isolated and inaccessible.
• You have complete SSA loops. Check this by using diagnostics in
System Verification mode. If you have incomplete loops (such as
strings) action must be taken to resolve this before you can continue.
• All of your loops are valid, in this case with one or two adapters in each
loop. This is also done by using Diagnostics in System Verification
mode.
12.Run
cfgmgr to install the microcode to adapters.
13.To complete the device driver upgrade, you must now reboot your system.
14.T o confirm that the upgrade was a success, type
lscfg -vl ssaX where X is
0,1... for all SSA adapters. Check the ROS Level line to see that each
adapter has the appropriate microcode level (for the correct microcode
level, see the above mentioned web-site).
15.Run
lslpp -l|grep SSA and check that the fileset levels you have match, or
are above the levels shown in the list on the above mentioned web-site. If
any of the SSA filesets are at a lower level than those shown in the above
link, please repeat the whole upgrade procedure again. If, after repeating
the procedure, the code levels do not match the latest ones, place a call
with your local IBM Service Center.
16.If the adapters are in SSA loops which contain other adapters in other
systems, please repeat this procedure on all systems as soon as possible.
17.In order to install the disk microcode, run
ssadload -u from each system in
turn.
Note
Allow ssadload to complete on one system before running it on another.
Cluster Hardware and Software Preparation 71
Page 90

18.To confirm that the upgrade was a success, type lscfg -vl pdiskX where X
is 0,1... for all SSA disks. Check the ROS Level line to see that each disk
has the appropriate microcode level (for the correct microcode level see
the above mentioned web-site).
3.3.1.4 Configuring a RAID on SSA Disks
Disk arrays are groups of disk drives that act like one disk as far as the
operating system is concerned, and which provide better availability or
performance characteristics than the individual drives operating alone.
Depending on the particular type of array that is used, it is possible to
optimize availability or performance, or to select a compromise between both.
The SSA Enhanced Raid adapters only support RAID level 5 (RAID5). RAID0
(Striping) and RAID1 (Mirroring) is not directly supported by the SSA
Enhanced Raid adapters, but with the Logical V olume Manager ( LVM), RAID0
and RAID1 can be configured on non-RAID disks.
3.3.2 SCSI
In order to create a RAID5 on SSA Disks, use the command
smitty ssaraid.
This will show you the following menu:
SSA RAID Arrays
Move cursor to desired item and press Enter.
List All Defined SSA RAID Arrays
List All Supported SSA RAID Arrays
List All SSA RAID Arrays Connected to a RAID Manager
List Status Of All Defined SSA RAID Arrays
List/Identify SSA Physical Disks
List/Delete Old RAID Arrays Recorded in an SSA RAID Manager
Add an SSA RAID Array
Delete an SSA RAID Array
Change/Show Attributes of an SSA RAID Array
Change Member Disks in an SSA RAID Array
Change/Show Use of an SSA Physical Disk
Change Use of Multiple SSA Physical Disks
F1=Help F2=Refresh F3=Cancel F8=Image
F9=Shell F10=Exit Enter=Do
Select Add an SSA RAID Array to do the definitions.
The following sections contain important information about SCSI: cabling,
connecting RAID subsystems, and adapter SCSI ID and termination change.
72 IBM Certification Study Gu ide AIX HACMP
Page 91

3.3.2.1 Cabli ng
The following sections describe important information about cabling.
SCSI Adapters
A overview of SCSI adapters that can be used on a shared SCSI bus is given
in 2.3.2.3, “Supported SCSI Adapters” on page 26. For the necessary adapter
changes, see 3.3.2.3, “Adapter SCSI ID and Termination change” on page 77.
RAID Enclosures
The 7135 RAIDiant Array can hold a maximum of 30 single-ended disks in
two units (one base and one expansion). It has one controller by default, and
another controller can be added for improved performance and availability.
Each controller takes up one SCSI ID. The disks sit on internal single-ended
buses and hence do not take up IDs on the external bus. In an HACMP
cluster, each 7135 should have two controllers, each of which is connected to
a separate shared SCSI bus. This configuration protects you against any
failure (SCSI adapter, cables, or RAID controller) on either SCSI bus.
Because of cable length restrictions, a maximum of two 7135s on a shared
SCSI bus are supported by HACMP.
3.3.2.2 Connecting RAID Subsystems
In this section, we will list the different components required to connect RAID
subsystems on a shared bus. We will also show you how to connect these
components together.
The 7135-110 RAIDiant Array can be connected to multiple systems on either
an 8-bit or a 16-bit SCSI-2 differential bus. The Model 210 can only be
connected to a 16-bit SCSI-2 Fast/Wide differential bus, using the Enhanced
SCSI-2 Differential Fast/Wide Adapter/A.
To connect a set of 7135-110s to SCSI-2 Differential Controllers on a shared
8-bit SCSI bus, you need the following:
• SCSI-2 Differential Y-Cable
FC: 2422 (0.765m), PN: 52G7348
• SCSI-2 Differential System-to-System Cable
FC: 2423 (2.5m), PN: 52G7349
This cable is used only if there are more than two nodes attached to the
same shared bus.
• Differential SCSI Cable (RAID Cable)
FC: 2901 or 9201 (0.6m), PN: 67G1259 - OR -
Cluster Hardware and Software Preparation 73
Page 92

FC: 2902 or 9202 (2.4m), PN: 67G1260 - OR FC: 2905 or 9205 (4.5m), PN: 67G1261 - OR FC: 2912 or 9212 (12m), PN: 67G1262 - OR FC: 2914 or 9214 (14m), PN: 67G1263 - OR FC: 2918 or 9218 (18m), PN: 67G1264
• Terminator (T)
Included in FC 2422 (Y-Cable), PN: 52G7350
• Cable Interposer (I)
FC: 2919, PN: 61G8323
One of these is required for each connection between an SCSI-2
Differential Y-Cable and a Differential SCSI Cable going to the 7135
unit, as shown in Figure 10.
Figure 10 shows four RS/6000s, each represented by two SCSI-2 Differential
Controllers, connected on two 8-bit buses to two 7135-110s , each with two
controllers.
Figure 10. 7135-110 RAIDiant Arrays Connected on Two Shared 8-Bit SCSI B uses
To connect a set of 7135s to SCSI-2 Differential Fast/Wide Adapter/As or
Enhanced SCSI-2 Differential Fast/Wide Adapter/As on a shared 16-bit SCSI
bus, you need the following:
• 16-Bit SCSI-2 Differential Y-Cable
74 IBM Certification Study Gu ide AIX HACMP
Page 93

FC: 2426 (0.94m), PN: 52G4234
• 16-Bit SCSI-2 Differential System-to-System Cable
FC: 2424 (0.6m), PN: 52G4291 - OR FC: 2425 (2.5m), PN: 52G4233
This cable is used only if there are more than two nodes attached to the
same shared bus.
• 16-Bit Differential SCSI Cable (RAID Cable)
FC: 2901 or 9201 (0.6m), PN: 67G1259 - OR FC: 2902 or 9202 (2.4m), PN: 67G1260 - OR FC: 2905 or 9205 (4.5m), PN: 67G1261 - OR FC: 2912 or 9212 (12m), PN: 67G1262 - OR FC: 2914 or 9214 (14m), PN: 67G1263 - OR FC: 2918 or 9218 (18m), PN: 67G1264
• 16-Bit Terminator (T)
Included in FC 2426 (Y-Cable), PN: 61G8324
Figure 11 shows four RS/6000s, each represented by two SCSI-2 Differential
Fast/Wide Adapter/As connected on two 16-bit buses to two 7135-110s, each
with two controllers.
The 7135-210 requires the Enhanced SCSI-2 Differential Fast/Wide
Adapter/A adapter for connection. Other than that, the cabling is exactly the
same as shown in Figure 11, if you just substitute the Enhanced SCSI-2
Differential Fast/Wide Adapter/A (FC: 2412) for the SCSI-2 Differential
Fast/Wide Adapter/A (FC: 2416) in the picture.
Cluster Hardware and Software Preparation 75
Page 94

6 bit)
(16-bit)
-
b
#2416 (16
#2424
6-bit)
(16-bit )
#2426
#2426
T
T
Maximum total cable length: 25m
T
T
#2416 (16-
#2416 (16-bit)
76 IBM Certification Study Gu ide AIX HACMP
Page 95

#2416 (16-bit)
#2416 (16-bit)
#2426
#2902
#2902
7135-110
Controller 1
Controller 2
#2902
RAID
cable
#2902
RAID
cable
#2424
7135-110
Controller 1
Controller 2
#2902
#2902
#2426
#2416 (16-bit)
#2416 (16-bit)
#2426
#2416 (16-bit)
#2416 (16-bit )
Figure 11. 7135-110 RAIDiant Arrays Connected on Two Shared 16-Bit SCS I Buses
T
T
Maximum total cable length: 25m
3.3.2.3 Adapter SCSI ID and Termination change
The SCSI-2 Differential Controller is used to connect to 8-bit disk devices on
a shared bus. The SCSI-2 Differential Fast/Wide Adapter/A or Enhanced
SCSI-2 Differential Fast/Wide Adapter/A is usually used to connect to 16-bit
devices but can also be used with 8-bit devices.
In a dual head-of-chain configuration of shared disks, there should be no
termination anywhere on the bus except at the extremities. Therefore, you
should remove the termination resistor blocks from the SCSI-2 Differential
Controller and the SCSI-2 Differential Fast/Wide Adapter/A or Enhanced
SCSI-2 Differential Fast/Wide Adapter/A. The positions of these blocks (U8
and U26 on the SCSI-2 Differential Controller, and RN1, RN2 and RN3 on the
#2426
T
T
#2416 (16-bit)
#2416 (16-bit)
Cluster Hardware and Software Preparation 77
Page 96

SCSI-2 Differential Fast/Wide Adapter/A and Enhanced SCSI-2 Differential
Fast/Wide Adapter/A) are shown in Figure 12 and Figure 13 respectively.
Termination
Resistor
P/N 43G0176
Blocks
4-2
Figure 12. Termination on the SCSI-2 Differential Controller
P/N 56G7315
Figure 13. Termination on the SCSI-2 Differential Fast/Wide Ada pters
78 IBM Certification Study Gu ide AIX HACMP
Termination
Resistor
Internal 8-bit SEInternal 16-bit SE
Blocks
4-6
Page 97

The ID of an SCSI adapter, by default, is 7. Since each device on an SCSI
bus must have a unique ID, the ID of at least one of the adapters on a shared
SCSI bus has to be changed.
The procedure to change the ID of an SCSI-2 Differential Controller is:
1. At the command prompt, enter
smit chgscsi.
2. Select the adapter whose ID you want to change from the list presented to
you.
SCSI Adapter
Move cursor to de sired item and p ress Enter.
scsi0 Available 00 -02 SCSI I/O Con troller
scsi1 Available 06 -02 SCSI I/O Con troller
scsi2 Available 08 -02 SCSI I/O Con troller
scsi3 Available 07 -02 SCSI I/O Con troller
F1=Help F2=Refresh F3=Cancel
F8=Image F10=Exit Enter=Do
/=Find n=F ind Next
3. Enter the new ID (any integer from 0 to 7) for this adapter in the Adapter
card SCSI ID field. Since the device with the highest SCSI ID on a bus
gets control of the bus, set the adapter’s ID to the highest available ID. Set
the Apply change to DATABASE only field to yes.
Cluster Hardware and Software Preparation 79
Page 98

Change / Show Characteristics of a SCSI Adapter
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
SCSI Adapter scsi0
Description SCSI I/O Controller
Status Available
Location 00-08
Adapter card SCSI ID [6] +#
BATTERY backed adapter no +
DMA bus memory LENGTH [0x202000] +
Enable TARGET MODE interface no +
Target Mode interface enabled no
PERCENTAGE of bus memory DMA area
for target mode [50] +#
Name of adapter code download file /etc/microcode/8d>
Apply change to DATABASE only yes +
F1=Help F2=Refresh F3=Cancel F4=List
F5=Reset F6=Command F7=Edit F8=Image
F9=Shell F10=Exit Enter=Do
[Entry Fields]
4. Reboot the machine to bring the change into effect.
The same task can be executed from the command line by entering:
# chdev -l scsi1 -a id=6 -P
Also with this method, a reboot is required to bring the change into effect.
The procedure to change the ID of an SCSI-2 Differential Fast/Wide
Adapter/A or Enhanced SCSI-2 Differential Fast/Wide Adapter/A is almost the
same as the one described above. Here, the adapter that you choose from
the list you get after executing the
smit chgsys command should be an ascsi
device. Also, as shown below, you need to change the external SCSI ID only.
80 IBM Certification Study Gu ide AIX HACMP
Page 99

Change/Show Characteristics of a SCSI Adapter
SCSI adapter ascsi1
Description Wide SCSI I/O Control>
Status Available
Location 00-06
Internal SCSI ID 7 +#
External SCSI ID [6] +#
WIDE bus enabled yes +
...
Apply change to DATABASE only yes
The command line version of this is:
# chdev -l ascsi1 -a id=6 -P
As in the case of the SCSI-2 Differential Controller, a system reboot is
required to bring the change into effect.
The maximum length of the bus, including any internal cabling in disk
subsystems, is limited to 19 meters for buses connected to the SCSI-2
Differential Controller, and 25 meters for those connected to the SCSI-2
Differential Fast/Wide Adapter/A or Enhanced SCSI-2 Differential Fast/Wide
Adapter/A.
3.4 Shared LVM Component Configuration
This section describes how to define the LVM components shared by cluster
nodes in an HACMP for AIX cluster environment.
Creating the volume groups, logical volumes, and file systems shared by the
nodes in an HACMP cluster requires that you perform steps on all nodes in
the cluster. In general, you define t he components on one node (refer red to in
the text as the source node) and then import the volume group on the other
nodes in the cluster (referred to as destination nodes). This ensures that the
ODM definitions of the shared components are the same on all nodes in the
cluster.
Non-concurrent access environments typically use journaled file systems to
manage data, while concurrent access environments use raw logical
volumes. This chapter provides different instructions for defining shared LVM
components in non-concurrent access and concurrent access environments.
Cluster Hardware and Software Preparation 81
Page 100

3.4.1 Creating Share d VGs
The following sections contain information about creating non-concurrent
VGs and VGs for concurrent access.
3.4.1.1 Creating Non-Concurrent VGs
This section covers how to create a shared volume group on the source node
using the SMIT interface. Use the
volume group. Use the default field values unless your site has other
requirements, or unless you are specifically instructed otherwise here.
Table 13. smit mkvg Options (Non- Conc urre nt)
Options Description
VOLUME GROUP name The name of the shared volume group should be
smit mkvg fastpath to create a shared
unique within the cluster.
Activate volume group
AUTOMATICALLY at system
restart?
ACTIVATE volume group after it
is created?
Volume Group MAJOR
NUMBER
Set to no so that the volume group can be
activated as appropriate by the cluster event
scripts.
Set to yes
If you are not using NFS, you can use the default
(which is the next available number in the valid
range). If you are using NFS, you must make sure
to use the same major number on all no des. Use
the lvlstmajor command on each node to
determine a free major number common to all
nodes.
.
3.4.1.2 Creating VGs for Concurrent Access
The procedure used to create a concurrent access volume group varies
depending on which type of device you are using: serial disk subsystem
(7133) or RAID disk subsystem (7135).
Note
If you are creating (or plan to create) concurrent volume groups on SSA
devices, be sure to assign unique non-zero node numbers through the
SSAR on each cluster node. If you plan to specify SSA disk fencing in your
concurrent resource group, the node numbers are assigned when you
synchronize resources. If you do not specify SSA disk fencing, assign node
numbers using the following command:
chdev -l ssar -a n ode_number=x,
where x is the number to assign to that node. You must reboot the system
to effect the change.
82 IBM Certification Study Gu ide AIX HACMP
 Loading...
Loading...