

Page 1

CICS Transaction Server fo r z/OS
Version 4 Release 1
Recovery and Restart Guide
SC34-7012-01
Page 2

Page 3

CICS Transaction Server fo r z/OS
Version 4 Release 1
Recovery and Restart Guide
SC34-7012-01
Page 4
Note
Before using this information and the product it supports, read the information in “Notices” on page 243.
This edition applies to Version 4 Release 1 of CICS Transaction Server for z/OS (product number 5655-S97) and to
all subsequent releases and modifications until otherwise indicated in new editions.
© Copyright IBM Corporation 1982, 2010.
US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract
with IBM Corp.
Page 5

Contents
Preface ..............vii
What this book is about ..........vii
Who should read this book .........vii
What you need to know to understand this book vii
How to use this book ...........vii
Changes in CICS Transaction Server for
z/OS, Version 4 Release 1 .......ix
Part 1. CICS recovery and restart
concepts ..............1
Chapter 1. Recovery and restart facilities 3
Maintaining the integrity of data .......3
Minimizing the effect of failures ........4
The role of CICS .............4
Recoverable resources ...........5
CICS backward recovery (backout) .......5
Dynamic transaction backout ........6
Emergency restart backout .........6
CICS forward recovery ...........7
Forward recovery of CICS data sets......7
Failures that require CICS recovery processing . . . 8
CICS recovery processing following a
communication failure ..........8
CICS recovery processing following a transaction
failure ...............10
CICS recovery processing following a system
failure ...............10
Chapter 2. Resource recovery in CICS 13
Units of work .............13
Shunted units of work ..........13
Locks ...............14
Synchronization points .........15
CICS recovery manager ..........17
Managing the state of each unit of work....18
Coordinating updates to local resources ....19
Coordinating updates in distributed units of
work ...............20
Resynchronization after system or connection
failure ...............21
CICS system log .............21
Information recorded on the system log ....21
System activity keypoints.........22
Forward recovery logs ...........22
User journals and automatic journaling .....22
Chapter 3. Shutdown and restart
recovery ..............25
Normal shutdown processing ........25
First quiesce stage ...........25
Second quiesce stage ..........26
Third quiesce stage ...........26
Warm keypoints ............27
Shunted units of work at shutdown .....27
Flushing journal buffers .........28
Immediate shutdown processing (PERFORM
SHUTDOWN IMMEDIATE) .........28
Shutdown requested by the operating system . . . 29
Uncontrolled termination ..........30
The shutdown assist transaction .......30
Cataloging CICS resources .........31
Global catalog ............31
Local catalog .............32
Shutdown initiated by CICS log manager ....33
Effect of problems with the system log ....33
How the state of the CICS region is reconstructed 34
Overriding the type of start indicator .....35
Warm restart .............35
Emergency restart ...........35
Cold start ..............36
Dynamic RLS restart ..........37
Recovery with VTAM persistent sessions ....38
Running with persistent sessions support . . . 38
Running without persistent sessions support . . 40
||
Part 2. Recovery and restart
processes.............43
Chapter 4. CICS cold start ......45
Starting CICS with the START=COLD parameter . . 45
Files ................46
Temporary storage ...........47
Transient data ............47
Transactions .............48
Journal names and journal models......48
LIBRARY resources...........48
Programs ..............48
Start requests (with and without a terminal) . . 48
Resource definitions dynamically installed . . . 48
Monitoring and statistics .........49
Terminal control resources ........49
Distributed transaction resources ......50
Dump table .............50
Starting CICS with the START=INITIAL parameter 50
Chapter 5. CICS warm restart .....53
Rebuilding the CICS state after a normal shutdown 53
Files ................54
Temporary storage ...........55
Transient data ............55
Transactions .............56
LIBRARY resources...........56
Programs ..............56
Start requests .............57
Monitoring and statistics .........57
© Copyright IBM Corp. 1982, 2010 iii
Page 6

Journal names and journal models......58
Terminal control resources ........58
Distributed transaction resources ......59
URIMAP definitions and virtual hosts ....59
Chapter 6. CICS emergency restart . . 61
Recovering after a CICS failure ........61
Recovering information from the system log . . 61
Driving backout processing for in-flight units of
work ...............61
Concurrent processing of new work and backout 61
Other backout processing.........62
Rebuilding the CICS state after an abnormal
termination ..............62
Files ................62
Temporary storage ...........63
Transient data ............63
Start requests .............64
Terminal control resources ........64
Distributed transaction resources ......65
Chapter 7. Automatic restart
management ............67
CICS ARM processing ...........67
Registering with ARM ..........68
Waiting for predecessor subsystems .....68
De-registering from ARM.........68
Failing to register ...........69
ARM couple data sets ..........69
CICS restart JCL and parameters .......69
Workload policies ............70
Connecting to VTAM ...........70
The COVR transaction..........71
Messages associated with automatic restart . . . 71
Automatic restart of CICS data-sharing servers . . 71
Server ARM processing .........71
Chapter 8. Unit of work recovery and
abend processing ..........73
Unit of work recovery ...........73
Transaction backout ..........74
Backout-failed recovery .........79
Commit-failed recovery .........83
Indoubt failure recovery .........84
Investigating an indoubt failure .......85
Recovery from failures associated with the coupling
facility ................88
Cache failure support ..........88
Lost locks recovery ...........89
Connection failure to a coupling facility cache
structure ..............91
Connection failure to a coupling facility lock
structure ..............91
MVS system recovery and sysplex recovery . . 91
Transaction abend processing ........92
Exit code ..............92
Abnormal termination of a task.......93
Actions taken at transaction failure ......94
Processing operating system abends and program
checks ................94
Chapter 9. Communication error
processing .............97
Terminal error processing..........97
Node error program (DFHZNEP) ......97
Terminal error program (DFHTEP) .....97
Intersystem communication failures ......98
Part 3. Implementing recovery and
restart ..............99
Chapter 10. Planning aspects of
recovery .............101
Application design considerations ......101
Questions relating to recovery requirements . . 101
Validate the recovery requirements statement 102
Designing the end user ’s restart procedure . . 103
End user’s standby procedures ......103
Communications between application and user 103
Security ..............104
System definitions for recovery-related functions 104
Documentation and test plans ........105
Chapter 11. Defining system and
general log streams ........107
Defining log streams to MVS ........108
Defining system log streams ........108
Specifying a JOURNALMODEL resource
definition..............109
Model log streams for CICS system logs . . . 110
Activity keypointing ..........112
Defining forward recovery log streams .....116
Model log streams for CICS general logs . . . 117
Merging data on shared general log streams . . 118
Defining the log of logs ..........118
Log of logs failure ...........119
Reading log streams offline ........119
Effect of daylight saving time changes .....120
Adjusting local time ..........120
Time stamping log and journal records ....120
Chapter 12. Defining recoverability for
CICS-managed resources ......123
Recovery for transactions .........123
Defining transaction recovery attributes . . . 123
Recovery for files ............125
VSAM files .............125
Basic direct access method (BDAM) .....126
Defining files as recoverable resources ....126
File recovery attribute consistency checking
(non-RLS) .............129
Implementing forward recovery with
user-written utilities ..........131
Implementing forward recovery with CICS
VSAM Recovery MVS/ESA .......131
Recovery for intrapartition transient data ....131
Backward recovery ..........131
Forward recovery ...........133
Recovery for extrapartition transient data ....134
iv CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 7

Input extrapartition data sets .......134
Output extrapartition data sets ......135
Using post-initialization (PLTPI) programs . . 135
Recovery for temporary storage .......135
Backward recovery ..........135
Forward recovery ...........136
Recovery for Web services .........136
Configuring CICS to support persistent
messages ..............136
Defining local queues in a service provider . . 137
Persistent message processing .......138
Chapter 13. Programming for recovery 141
Designing applications for recovery ......141
Splitting the application into transactions . . . 141
SAA-compatible applications .......143
Program design ............143
Dividing transactions into units of work . . . 143
Processing dialogs with users .......144
Mechanisms for passing data between
transactions .............145
Designing to avoid transaction deadlocks . . . 146
Implications of interval control START requests 147
Implications of automatic task initiation (TD
trigger level) ............148
Implications of presenting large amounts of data
to the user .............148
Managing transaction and system failures ....149
Transaction failures ..........149
System failures ............151
Handling abends and program level abend exits 151
Processing the IOERR condition ......152
START TRANSID commands .......153
PL/I programs and error handling .....153
Locking (enqueuing on) resources in application
programs...............153
Implicit locking for files .........154
Implicit enqueuing on logically recoverable TD
destinations .............157
Implicit enqueuing on recoverable temporary
storage queues ............157
Implicit enqueuing on DL/I databases with
DBCTL ..............158
Explicit enqueuing (by the application
programmer) ............158
Possibility of transaction deadlock .....159
User exits for transaction backout ......160
Where you can add your own code .....160
XRCINIT exit ............161
XRCINPT exit ............161
XFCBFAIL global user exit ........161
XFCLDEL global user exit ........162
XFCBOVER global user exit .......162
XFCBOUT global user exit ........162
Coding transaction backout exits ......162
Chapter 14. Using a program error
program (PEP) ...........163
The CICS-supplied PEP ..........163
YourownPEP.............164
Omitting the PEP ............165
Chapter 15. Resolving retained locks
on recoverable resources ......167
Quiescing RLS data sets ..........167
The RLS quiesce and unquiesce functions . . . 168
Switching from RLS to non-RLS access mode. . . 172
Exception for read-only operations .....172
What can prevent a switch to non-RLS access
mode?...............173
Resolving retained locks before opening data
sets in non-RLS mode .........174
Resolving retained locks and preserving data
integrity ..............176
Choosing data availability over data integrity 177
The batch-enabling sample programs ....178
CEMT command examples ........178
A special case: lost locks.........180
Overriding retained locks ........180
Coupling facility data table retained locks ....182
Chapter 16. Moving recoverable data
sets that have retained locks ....183
Procedure for moving a data set with retained
locks ................183
Using the REPRO method ........183
Using the EXPORT and IMPORT functions . . 185
Rebuilding alternate indexes .......186
Chapter 17. Forward recovery
procedures ............187
Forward recovery of data sets accessed in RLS
mode ................187
Recovery of data set with volume still available 188
Recovery of data set with loss of volume . . . 189
Forward recovery of data sets accessed in non-RLS
mode ................198
Procedure for failed RLS mode forward recovery
operation ...............198
Procedure for failed non-RLS mode forward
recovery operation ...........201
Chapter 18. Backup-while-open (BWO) 203
BWO and concurrent copy .........203
BWO and backups ..........203
BWO requirements ...........204
Hardware requirements .........205
Which data sets are eligible for BWO .....205
How you request BWO ..........206
Specifying BWO using access method services 206
Specifying BWO on CICS file resource
definitions .............207
Removing BWO attributes .........208
Systems administration ..........208
BWO processing ............209
File opening .............210
File closing (non-RLS mode) .......212
Shutdown and restart .........213
Data set backup and restore .......213
Contents v
Page 8

Forward recovery logging ........215
Forward recovery ...........216
Recovering VSAM spheres with AIXs ....217
An assembler program that calls DFSMS callable
services ...............218
Chapter 19. Disaster recovery ....223
Why have a disaster recovery plan? ......223
Disaster recovery testing .........224
Six tiers of solutions for off-site recovery ....225
Tier 0: no off-site data .........225
Tier 1 - physical removal ........225
Tier 2 - physical removal with hot site ....227
Tier 3 - electronic vaulting ........227
Tier 0–3 solutions ...........228
Tier 4 - active secondary site .......229
Tier 5 - two-site, two-phase commit .....231
Tier 6 - minimal to zero data loss......231
Tier 4–6 solutions ...........233
Disaster recovery and high availability .....234
Peer-to-peer remote copy (PPRC) and extended
remote copy (XRC) ..........234
Remote Recovery Data Facility ......236
Choosing between RRDF and 3990-6 solutions 237
Disaster recovery personnel considerations . . 237
Returning to your primary site ......238
Disaster recovery facilities .........238
MVS system logger recovery support ....238
CICS VSAM Recovery QSAM copy .....239
Remote Recovery Data Facility support....239
CICS VR shadowing ..........239
CICS emergency restart considerations .....239
Indoubt and backout failure support ....239
Remote site recovery for RLS-mode data sets 239
Final summary .............240
Part 4. Appendixes ........241
Notices ..............243
Trademarks ..............244
Bibliography............245
CICS books for CICS Transaction Server for z/OS 245
CICSPlex SM books for CICS Transaction Server
for z/OS ...............246
Other CICS publications ..........246
Accessibility............247
Index ...............249
vi
CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 9

Preface
What this book is about
This book contains guidance about determining your CICS®recovery and restart
needs, deciding which CICS facilities are most appropriate, and implementing your
design in a CICS region.
The information in this book is generally restricted to a single CICS region. For
information about interconnected CICS regions, see the CICS Intercommunication
Guide.
This manual does not describe recovery and restart for the CICS front end
programming interface. For information on this topic, see the CICS Front End
Programming Interface User's Guide.
Who should read this book
This book is for those responsible for restart and recovery planning, design, and
implementation—either for a complete system, or for a particular function or
component.
What you need to know to understand this book
To understand this book, you should have experience of installing CICS and the
products with which it is to work, or of writing CICS application programs, or of
writing exit programs.
You should also understand your application requirements well enough to be able
to make decisions about realistic recovery and restart needs, and the trade-offs
between those needs and the performance overhead they incur.
How to use this book
This book deals with a wide variety of topics, all of which contribute to the
recovery and restart characteristics of your system.
It’s unlikely that any one reader would have to implement all the possible
techniques discussed in this book. By using the table of contents, you can find the
sections relevant to your work. Readers new to recovery and restart should find
the first section helpful, because it introduces the concepts of recovery and restart.
© Copyright IBM Corp. 1982, 2010 vii
Page 10

viii CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 11

Changes in CICS Transaction Server for z/OS, Version 4
Release 1
For information about changes that have been made in this release, please refer to
What's New in the information center, or the following publications:
v CICS Transaction Server for z/OS What's New
v CICS Transaction Server for z/OS Upgrading from CICS TS Version 3.2
v CICS Transaction Server for z/OS Upgrading from CICS TS Version 3.1
v CICS Transaction Server for z/OS Upgrading from CICS TS Version 2.3
Any technical changes that are made to the text after release are indicated by a
vertical bar (|) to the left of each new or changed line of information.
© Copyright IBM Corp. 1982, 2010 ix
Page 12

x CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 13

Part 1. CICS recovery and restart concepts
It is very important that a transaction processing system such as CICS can restart
and recover following a failure. This section describes some of the basic concepts
of the recovery and restart facilities provided by CICS.
© Copyright IBM Corp. 1982, 2010 1
Page 14

2 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 15

Chapter 1. Recovery and restart facilities
Problems that occur in a data processing system could be failures with
communication protocols, data sets, programs, or hardware. These problems are
potentially more severe in online systems than in batch systems, because the data
is processed in an unpredictable sequence from many different sources.
Online applications therefore require a system with special mechanisms for
recovery and restart that batch systems do not require. These mechanisms ensure
that each resource associated with an interrupted online application returns to a
known state so that processing can restart safely. Together with suitable operating
procedures, these mechanisms should provide automatic recovery from failures
and allow the system to restart with the minimum of disruption.
The two main recovery requirements of an online system are:
v To maintain the integrity and consistency of data
v To minimize the effect of failures
CICS provides a facility to meet these two requirements called the recovery
manager. The CICS recovery manager provides the recovery and restart functions
that are needed in an online system.
Maintaining the integrity of data
Data integrity means that the data is in the form you expect and has not been
corrupted. The objective of recovery operations on files, databases, and similar data
resources is to maintain and restore the integrity of the information.
Recovery must also ensure consistency of related changes, whereby they are made
as a whole or not at all. (The term resources used in this book, unless stated
otherwise, refers to data resources.)
Logging changes
One way of maintaining the integrity of a resource is to keep a record, or log, of all
the changes made to a resource while the system is executing normally. If a failure
occurs, the logged information can help recover the data.
An online system can use the logged information in two ways:
1. It can be used to back out incomplete or invalid changes to one or more
resources. This is called backward recovery, or backout. For backout, it is
necessary to record the contents of a data element before it is changed. These
records are called before-images. In general, backout is applicable to processing
failures that prevent one or more transactions (or a batch program) from
completing.
2. It can be used to reconstruct changes to a resource, starting with a backup copy
of the resource taken earlier. This is called forward recovery. For forward
recovery, it is necessary to record the contents of a data element after it is
changed. These records are called after-images.
© Copyright IBM Corp. 1982, 2010 3
Page 16
In general, forward recovery is applicable to data set failures, or failures in
similar data resources, which cause data to become unusable because it has
been corrupted or because the physical storage medium has been damaged.
Minimizing the effect of failures
An online system should limit the effect of any failure. Where possible, a failure
that affects only one user, one application, or one data set should not halt the
entire system.
Furthermore, if processing for one user is forced to stop prematurely, it should be
possible to back out any changes made to any data sets as if the processing had
not started.
If processing for the entire system stops, there may be many users whose updating
work is interrupted. On a subsequent startup of the system, only those data set
updates in process (in-flight) at the time of failure should be backed out. Backing
out only the in-flight updates makes restart quicker, and reduces the amount of
data to reenter.
Ideally, it should be possible to restore the data to a consistent, known state
following any type of failure, with minimal loss of valid updating activity.
The role of CICS
The CICS recovery manager and the log manager perform the logging functions
necessary to support automatic backout. Automatic backout is provided for most
CICS resources, such as databases, files, and auxiliary temporary storage queues,
either following a transaction failure or during an emergency restart of CICS.
If the backout of a VSAM file fails, CICS backout failure processing ensures that all
locks on the backout-failed records are retained, and the backout-failed parts of the
unit of work (UOW) are shunted to await retry. The VSAM file remains open for
use. For an explanation of shunted units of work and retained locks, see “Shunted
units of work” on page 13.
If the cause of the backout failure is a physically damaged data set, and provided
the damage affects only a localized section of the data set, you can choose a time
when it is convenient to take the data set offline for recovery. You can then use the
forward recovery log with a forward recovery utility, such as CICS VSAM
Recovery, to restore the data set and re-enable it for CICS use.
Note: In many cases, a data set failure also causes a processing failure. In this
event, forward recovery must be followed by backward recovery.
You don't need to shut CICS down to perform these recovery operations. For data
sets accessed by CICS in VSAM record-level sharing (RLS) mode, you can quiesce
the data set to allow you to perform the forward recovery offline. On completion
of forward recovery, setting the data set to unquiesced causes CICS to perform the
backward recovery automatically.
For files accessed in non-RLS mode, you can issue a SET DSNAME RETRY command
after the forward recovery, which causes CICS to perform the backward recovery
online.
4 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 17
Another way is to shut down CICS with an immediate shutdown and perform the
forward recovery, after which a CICS emergency restart performs the backward
recovery.
Recoverable resources
In CICS, a recoverable resource is any resource with recorded recovery information
that can be recovered by backout.
The following resources can be made recoverable:
v CICS files that relate to:
– VSAM data sets
– BDAM data sets
v Data tables (but user-maintained data tables are not recovered after a CICS
failure, only after a transaction failure)
v Coupling facility data tables
v The CICS system definition (CSD) file
v Intrapartition transient data destinations
v Auxiliary temporary storage queues
v Resource definitions dynamically installed using resource definition online
(RDO)
In some environments, a VSAM file managed by CICS file control might need to
remain online and open for update for extended periods. You can use a backup
manager, such as DFSMSdss, in a separate job under MVS
file at regular intervals while it is open for update by CICS applications. This
operation is known as backup-while-open (BWO). Even changes made to the
VSAM file while the backup is in progress are recorded.
DFSMSdss is a functional component of DFSMS/MVS, and is the primary data
mover. When used with supporting hardware, DFSMSdss also provides a
concurrent copy capability. This capability enables you to copy or back up data
while that data is being used.
If a data set failure occurs, you can use a backup of the data set and a forward
recovery utility, such as CICS VSAM Recovery (CICSVR), to recover the VSAM file.
CICS backward recovery (backout)
Backward recovery, or backout, is a way of undoing changes made to resources
such as files or databases.
Backout is one of the fundamental recovery mechanisms of CICS. It relies on
recovery information recorded while CICS and its transactions are running
normally.
Before a change is made to a resource, the recovery information for backout, in the
form of a before-image, is recorded on the CICS system log. A before-image is a
record of what the resource was like before the change. These before-images are
used by CICS to perform backout in two situations:
v In the event of failure of an individual in-flight transaction, which CICS backs
out dynamically at the time of failure (dynamic transaction backout)
™
, to back up a VSAM
Chapter 1. Recovery and restart facilities 5
Page 18

v In the event of an emergency restart, when CICS backs out all those transactions
that were in-flight at the time of the CICS failure (emergency restart backout).
Although these occur in different situations, CICS uses the same backout process in
each case. CICS does not distinguish between dynamic backout and emergency
restart backout. See Chapter 6, “CICS emergency restart,” on page 61 for an
explanation of how CICS reattaches failed in-flight units of work in order to
perform transaction backout following an emergency restart.
Each CICS region has only one system log, which cannot be shared with any other
CICS region. The system log is written to a unique MVS system logger log stream.
The CICS system log is intended for use only for recovery purposes, for example
during dynamic transaction backout, or during emergency restart. It is not meant
to be used for any other purpose.
CICS supports two physical log streams - a primary and a secondary log stream.
CICS uses the secondary log stream for storing log records of failed units of work,
and also some long running tasks that have not caused any data to be written to
the log for two complete activity key points. Failed units of work are moved from
the primary to the secondary log stream at the next activity keypoint. Logically,
both the primary and secondary log stream form one log, and as a general rule are
referred to as the system log.
Dynamic transaction backout
In the event of a transaction failure, or if an application explicitly requests a
syncpoint rollback, the CICS recovery manager uses the system log data to drive
the resource managers to back out any updates made by the current unit of work.
This process, known as dynamic transaction backout, takes place while the rest of
CICS continues normally.
For example, when any updates made to a recoverable data set are to be backed
out, file control uses the system log records to reverse the updates. When all the
updates made in the unit of work have been backed out, the unit of work is
completed. The locks held on the updated records are freed if the backout is
successful.
For data sets open in RLS mode, CICS requests VSAM RLS to release the locks; for
data sets open in non-RLS mode, the CICS enqueue domain releases the locks
automatically.
See “Units of work” on page 13 for a description of units of work.
Emergency restart backout
If a CICS region fails, you restart CICS with an emergency restart to back out any
transactions that were in-flight at the time of failure.
During emergency restart, the recovery manager uses the system log data to drive
backout processing for any units of work that were in-flight at the time of the
failure. The backout of units of work during emergency restart is the same as a
dynamic backout; there is no distinction between the backout that takes place at
emergency restart and that which takes place at any other time. At this point,
while recovery processing continues, CICS is ready to accept new work for normal
processing.
6 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 19

The recovery manager also drives:
v The backout processing for any units of work that were in a backout-failed state
at the time of the CICS failure
v The commit processing for any units of work that had not finished commit
processing at the time of failure (for example, for resource definitions that were
being installed when CICS failed)
v The commit processing for any units of work that were in a commit-failed state
at the time of the CICS failure
See “Unit of work recovery” on page 73 for an explanation of the terms
commit-failed and backout-failed.
The recovery manager drives these backout and commit processes because the
condition that caused them to fail might be resolved by the time CICS restarts. If
the condition that caused a failure has not been resolved, the unit of work remains
in backout- or commit-failed state. See “Backout-failed recovery” on page 79 and
“Commit-failed recovery” on page 83 for more information.
CICS forward recovery
Some types of data set failure cannot be corrected by backward recovery; for
example, failures that cause physical damage to a database or data set.
Recovery from failures of this type is usually based on the following actions:
1. Take a backup copy of the data set at regular intervals.
2. Record an after-image of every change to the data set on the forward recovery
log (a general log stream managed by the MVS system logger).
3. After the failure, restore the most recent backup copy of the failed data set, and
use the information recorded on the forward recovery log to update the data
set with all the changes that have occurred since the backup copy was taken.
These operations are known as forward recovery. On completion of the forward
recovery, as a fourth step, CICS also performs backout of units of work that failed
in-flight as a result of the data set failure.
Forward recovery of CICS data sets
CICS supports forward recovery of VSAM data sets updated by CICS file control
(that is, by files or CICS-maintained data tables defined by a CICS file definition).
CICS writes the after-images of changes made to a data set to a forward recovery
log, which is a general log stream managed by the MVS system logger.
CICS obtains the log stream name of a VSAM forward recovery log in one of two
ways:
1. For files opened in VSAM record level sharing (RLS) mode, the explicit log
stream name is obtained directly from the VSAM ICF catalog entry for the data
set.
2. For files in non-RLS mode, the log stream name is derived from:
v The VSAM ICF catalog entry for the data set if it is defined there, and if
RLS=YES is specified as a system initialization parameter. In this case, CICS
file control manages writes to the log stream directly.
v A journal model definition referenced by a forward recovery journal name
specified in the file resource definition.
Chapter 1. Recovery and restart facilities 7
Page 20

Forward recovery journal names are of the form DFHJnn where nn is a
number in the range 1–99 and is obtained from the forward recovery log id
(FWDRECOVLOG) in the FILE resource definition.
In this case, CICS creates a journal entry for the forward recovery log, which
can be mapped by a JOURNALMODEL resource definition. Although this
method enables user application programs to reference the log, and write
user journal records to it, you are recommended not to do so. You should
ensure that forward recovery log streams are reserved for forward recovery
data only.
Note: You cannot use a CICS system log stream as a forward recovery log.
The VSAM recovery options or the CICS file control recovery options that you
require to implement forward recovery are explained further in “Defining files as
recoverable resources” on page 126.
For details of procedures for performing forward recovery, see Chapter 17,
“Forward recovery procedures,” on page 187.
Forward recovery for non-VSAM resources
CICS does not provide forward recovery logging for non-VSAM resources, such as
BDAM files. However, you can provide this support yourself by ensuring that the
necessary information is logged to a suitable log stream. In the case of BDAM files,
you can use the CICS autojournaling facility to write the necessary after-images to
a log stream.
Failures that require CICS recovery processing
The following section briefly describes CICS recovery processing after a
communication failure, transaction failure, and system failure.
Whenever possible, CICS attempts to contain the effects of a failure, typically by
terminating only the offending task while all other tasks continue normally. The
updates performed by a prematurely terminated task can be backed out
automatically.
CICS recovery processing following a communication failure
Causes of communication failure include:
v Terminal failure
v Printer terminal running out of paper
v Power failure at a terminal
v Invalid SNA status
v Network path failure
v Loss of an MVS image that is a member of a sysplex
There are two aspects to processing following a communications failure:
1. If the failure occurs during a conversation that is not engaged in syncpoint
protocol, CICS must terminate the conversation and allow customized handling
of the error, if required. An example of when such customization is helpful is
for 3270 device types. This is described below.
8 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 21

2. If the failure occurs during the execution of a CICS syncpoint, where the
conversation is with another resource manager (perhaps in another CICS
region), CICS handles the resynchronization. This is described in the CICS
Intercommunication Guide.
If the link fails and is later reestablished, CICS and its partners use the SNA
set-and-test-sequence-numbers (STSN) command to find out what they were doing
(backout or commit) at the time of link failure. For more information on link
failure, see the CICS Intercommunication Guide.
When communication fails, the communication system access method either retries
the transmission or notifies CICS. If a retry is successful, CICS is not informed.
Information about the error can be recorded by the operating system. If the retries
are not successful, CICS is notified.
When CICS detects a communication failure, it gives control to one of two
programs:
®
v The node error program (NEP) for VTAM
logical units
v The terminal error program (TEP) for non-VTAM terminals
Both dummy and sample versions of these programs are provided by CICS. The
dummy versions do nothing; they allow the default actions selected by CICS to
proceed. The sample versions show how to write your own NEP or TEP to change
the default actions.
The types of processing that might be in a user-written NEP or TEP are:
v Logging additional error information. CICS provides some error information
when an error occurs.
v Retrying the transmission. This is not recommended because the access method
will already have made several attempts.
v Leaving the terminal out of service. This means that it is unavailable to the
terminal operator until the problem is fixed and the terminal is put back into
service by means of a master terminal transaction.
v Abending the task if it is still active (see “CICS recovery processing following a
transaction failure” on page 10).
v Reducing the amount of error information printed.
For more information about NEPs and TEPs, see Chapter 9, “Communication error
processing,” on page 97.
XCF/MRO partner failures
Loss of communication between CICS regions can be caused by the loss of an MVS
image in which CICS regions are running.
If the regions are communicating over XCF/MRO links, the loss of connectivity
may not be immediately apparent because XCF waits for a reply to a message it
issues.
The loss of an MVS image in a sysplex is detected by XCF in another MVS, and
XCF issues message IXC402D. If the failed MVS is running CICS regions connected
through XCF/MRO to CICS regions in another MVS, tasks running in the active
regions are initially suspended in an IRLINK WAIT state.
XCF/MRO-connected regions do not detect the loss of an MVS image and its
resident CICS regions until an operator replies to the XCF IXC402D message.
Chapter 1. Recovery and restart facilities 9
Page 22

When the operator replies to IXC402D, the CICS interregion communication
program, DFHIRP, is notified and the suspended tasks are abended, and MRO
connections closed. Until the reply is issued to IXC402D, an INQUIRE
CONNECTION command continues to show connections to regions in the failed
MVS as in service and normal.
When the failed MVS image and its CICS regions are restarted, the interregion
communication links are reopened automatically.
CICS recovery processing following a transaction failure
Transactions can fail for a variety of reasons, including a program check in an
application program, an invalid request from an application that causes an abend,
a task issuing an ABEND request, or I/O errors on a data set that is being accessed
by a transaction.
During normal execution of a transaction working with recoverable resources,
CICS stores recovery information in the system log. If the transaction fails, CICS
uses the information from the system log to back out the changes made by the
interrupted unit of work. Recoverable resources are thus not left in a partially
updated or inconsistent state. Backing out an individual transaction is called
dynamic transaction backout.
After dynamic transaction backout has completed, the transaction can restart
automatically without the operator being aware of it happening. This function is
especially useful in those cases where the cause of transaction failure is temporary
and an attempt to rerun the transaction is likely to succeed (for example, DL/I
program isolation deadlock). The conditions when a transaction can be
automatically restarted are described under “Abnormal termination of a task” on
page 93.
If dynamic transaction backout fails, perhaps because of an I/O error on a VSAM
data set, CICS backout failure processing shunts the unit of work and converts the
locks that are held on the backout-failed records into retained locks. The data set
remains open for use, allowing the shunted unit of work to be retried. If backout
keeps failing because the data set is damaged, you can create a new data set using
a backup copy and then perform forward recovery, using a utility such as CICSVR.
When the data set is recovered, retry the shunted unit of work to complete the
failed backout and release the locks.
Chapter 8, “Unit of work recovery and abend processing,” on page 73 gives more
details about CICS processing of a transaction failure.
CICS recovery processing following a system failure
Causes of a system failure include a processor failure, the loss of a electrical power
supply, an operating system failure, or a CICS failure.
During normal execution, CICS stores recovery information on its system log
stream, which is managed by the MVS system logger. If you specify
START=AUTO, CICS automatically performs an emergency restart when it restarts
after a system failure.
During an emergency restart, the CICS log manager reads the system log backward
and passes information to the CICS recovery manager.
10 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 23

The CICS recovery manager then uses the information retrieved from the system
log to:
v Back out recoverable resources.
v Recover changes to terminal resource definitions. (All resource definitions
installed at the time of the CICS failure are initially restored from the CICS
global catalog.)
A special case of CICS processing following a system failure is covered in
Chapter 6, “CICS emergency restart,” on page 61.
Chapter 1. Recovery and restart facilities 11
Page 24

12 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 25

Chapter 2. Resource recovery in CICS
Before you begin to plan and implement resource recovery in CICS, you should
understand the concepts involved, including units of work, logging and journaling.
Units of work
When resources are being changed, there comes a point when the changes are
complete and do not need backout if a failure occurs later. The period between the
start of a particular set of changes and the point at which they are complete is
called a unit of work (UOW). The unit of work is a fundamental concept of all CICS
backout mechanisms.
From the application designer's point of view, a UOW is a sequence of actions that
needs to be complete before any of the individual actions can be regarded as
complete. To ensure data integrity, a unit of work must be atomic, consistent,
isolated, and durable.
The CICS recovery manager operates with units of work. If a transaction that
consists of multiple UOWs fails, or the CICS region fails, committed UOWs are not
backed out.
A unit of work can be in one of the following states:
v Active (in-flight)
v Shunted following a failure of some kind
v Indoubt pending the decision of the unit of work coordinator.
v Completed and no longer of interest to the recovery manager
Shunted units of work
A shunted unit of work is one awaiting resolution of an indoubt failure, a commit
failure, or a backout failure. The CICS recovery manager attempts to complete a
shunted unit of work when the failure that caused it to be shunted has been
resolved.
A unit of work can be unshunted and then shunted again (in theory, any number
of times). For example, a unit of work could go through the following stages:
1. A unit of work fails indoubt and is shunted.
2. After resynchronization, CICS finds that the decision is to back out the indoubt
unit of work.
3. Recovery manager unshunts the unit of work to perform backout.
4. If backout fails, it is shunted again.
5. Recovery manager unshunts the unit of work to retry the backout.
6. Steps 4 and 5 can occur several times until the backout succeeds.
These situations can persist for some time, depending on how long it takes to
resolve the cause of the failure. Because it is undesirable for transaction resources
to be held up for too long, CICS attempts to release as many resources as possible
while a unit of work is shunted. This is generally achieved by abending the user
task to which the unit of work belongs, resulting in the release of the following:
v Terminals
v User programs
© Copyright IBM Corp. 1982, 2010 13
Page 26

v Working storage
v Any LU6.2 sessions
v Any LU6.1 links
v Any MRO links
The resources CICS retains include:
v Locks on recoverable data. If the unit of work is shunted indoubt, all locks are
retained. If it is shunted because of a commit- or backout-failure, only the locks
on the failed resources are retained.
v System log records, which include:
– Records written by the resource managers, which they need to perform
recovery in the event of transaction or CICS failures. Generally, these records
are used to support transaction backout, but the RDO resource manager also
writes records for rebuilding the CICS state in the event of a CICS failure.
– CICS recovery manager records, which include identifiers relating to the
original transaction such as:
- The transaction ID
- The task ID
- The CICS terminal ID
- The VTAM LUNAME
- The user ID
- The operator ID.
Locks
For files opened in RLS mode, VSAM maintains a single central lock structure
using the lock-assist mechanism of the MVS coupling facility. This central lock
structure provides sysplex-wide locking at a record level. Control interval (CI)
locking is not used.
The locks for files accessed in non-RLS mode, the scope of which is limited to a
single CICS region, are file-control managed locks. Initially, when CICS processes a
read-for-update request, CICS obtains a CI lock. File control then issues an ENQ
request to the enqueue domain to acquire a CICS lock on the specific record. This
enables file control to notify VSAM to release the CI lock before returning control
to the application program. Releasing the CI lock minimizes the potential for
deadlocks to occur.
For coupling facility data tables updated under the locking model, the coupling
facility data table server stores the lock with its record in the CFDT. As in the case
of RLS locks, storing the lock with its record in the coupling facility list structure
that holds the coupling facility data table ensures sysplex-wide locking at record
level.
For both RLS and non-RLS recoverable files, CICS releases all locks on completion
of a unit of work. For recoverable coupling facility data tables, the locks are
released on completion of a unit of work by the CFDT server.
Active and retained states for locks
CICS supports active and retained states for locks.
14 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 27

When a lock is first acquired, it is an active lock. It remains an active lock until
successful completion of the unit of work, when it is released, or is converted into
a retained lock if the unit of work fails, or for a CICS or SMSVSAM failure:
v If a unit of work fails, RLS VSAM or the CICS enqueue domain continues to
hold the record locks that were owned by the failed unit of work for recoverable
data sets, but converted into retained locks. Retaining locks ensures that data
integrity for those records is maintained until the unit of work is completed.
v If a CICS region fails, locks are converted into retained locks to ensure that data
integrity is maintained while CICS is being restarted.
v If an SMSVSAM server fails, locks are converted into retained locks (with the
conversion being carried out by the other servers in the sysplex, or by the first
server to restart if all servers have failed). This means that a UOW that held
active RLS locks will hold retained RLS locks following the failure of an
SMSVSAM server.
Converting active locks into retained locks not only protects data integrity. It also
ensures that new requests for locks owned by the failed unit of work do not wait,
but instead are rejected with the LOCKED response.
Synchronization points
The end of a UOW is indicated to CICS by a synchronization point, usually
abbreviated to syncpoint.
A syncpoint arises in the following ways:
v Implicitly at the end of a transaction as a result of an EXEC CICS RETURN
command at the highest logical level. This means that a UOW cannot span tasks.
v Explicitly by EXEC CICS SYNCPOINT commands issued by an application program
at appropriate points in the transaction.
v Implicitly through a DL/I program specification block (PSB) termination (TERM)
call or command. This means that only one DL/I PSB can be scheduled within a
UOW.
Note that an explicit EXEC CICS SYNCPOINT command, or an implicit syncpoint at
the end of a task, implies a DL/I PSB termination call.
v Implicitly through one of the following CICS commands:
– EXEC CICS CREATE TERMINAL
– EXEC CICS CREATE CONNECTION COMPLETE
– EXEC CICS DISCARD CONNECTION
– EXEC CICS DISCARD TERMINAL
v Implicitly by a program called by a distributed program link (DPL) command if
the SYNCONRETURN option is specified. When the DPL program terminates
with an EXEC CICS RETURN command, the CICS mirror transaction takes a
syncpoint.
It follows from this that a unit of work starts:
v At the beginning of a transaction
v Whenever an explicit syncpoint is issued and the transaction does not end
v Whenever a DL/I PSB termination call causes an implicit syncpoint and the
transaction does not end
v Whenever one of the following CICS commands causes an implicit syncpoint
and the transaction does not end:
– EXEC CICS CREATE TERMINAL
Chapter 2. Resource recovery in CICS 15
Page 28
– EXEC CICS CREATE CONNECTION COMPLETE
– EXEC CICS DISCARD CONNECTION
– EXEC CICS DISCARD TERMINAL
A UOW that does not change a recoverable resource has no meaningful effect for
the CICS recovery mechanisms. Nonrecoverable resources are never backed out.
A unit of work can also be ended by backout, which causes a syncpoint in one of
the following ways:
v Implicitly when a transaction terminates abnormally, and CICS performs
dynamic transaction backout
v Explicitly by EXEC CICS SYNCPOINT ROLLBACK commands issued by an application
program to backout changes made by the UOW.
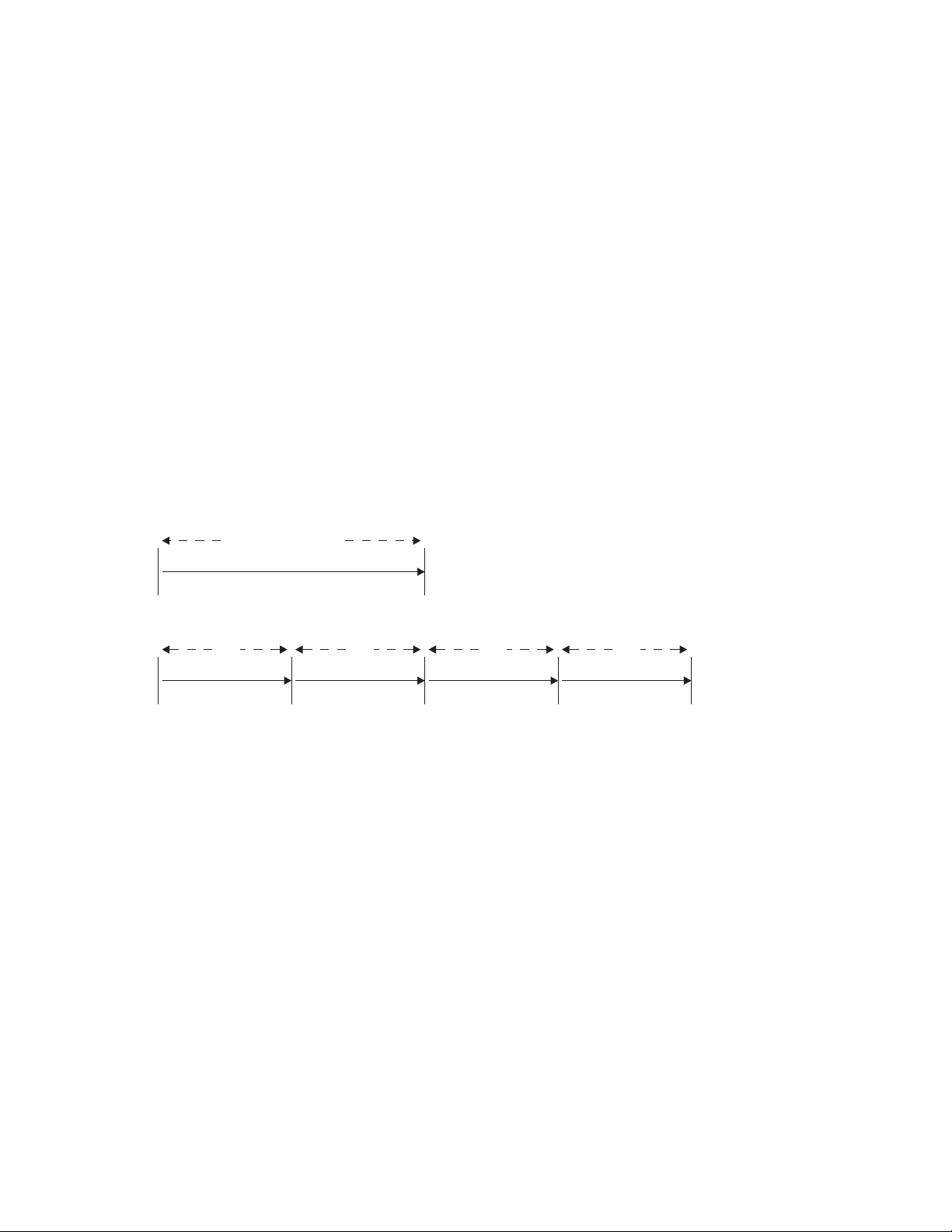
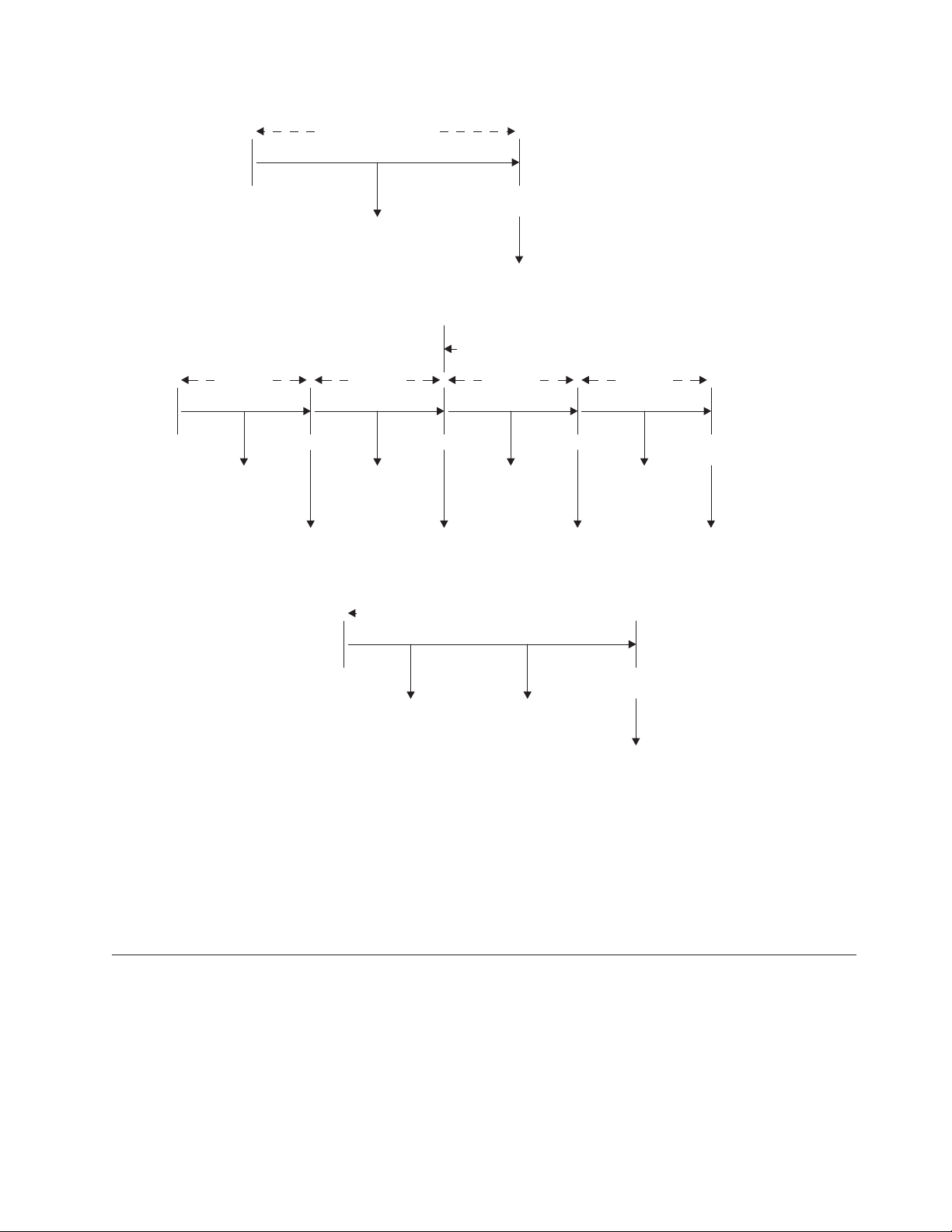
Examples of synchronization points
In Figure 1, task A is a nonconversational (or pseudoconversational) task with one
UOW, and task B is a multiple UOW task (typically a conversational task in which
each UOW accepts new data from the user). The figure shows how UOWs end at
syncpoints. During the task, the application program can issue syncpoints
explicitly, and, at the end, CICS issues a syncpoint.
Unit of work
Task A
SOT EOT
UOW UOW UOW UOW
Task B
SOT SP SP SP EOT
Abbreviations:
EOT: End of task SOT: Start of task
UOW: Unit of work SP: Syncpoint
Figure 1. Units of work and syncpoints
Figure 2 on page 17 shows that database changes made by a task are not
committed until a syncpoint is executed. If task processing is interrupted because
of a failure of any kind, changes made within the abending UOW are
automatically backed out.
If there is a system failure at time X:
v The change(s) made in task A have been committed and are therefore not backed
out.
v In task B, the changes shown as Mod 1 and Mod 2 have been committed, but
the change shown as Mod 3 is not committed and is backed out.
v All the changes made in task C are backed out.
(SP)
(SP)
16 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 29
Task B
X
Unit of work .
.
Task A .
.
SOT EOT .
(SP).
Mod .
.
.
Commit.
Mod .
.
.
Backout .
===========.
.
UOW 1 UOW 2 UOW 3 . UOW 4
.
.
SOT SP SP . SP EOT
. (SP)
Mod Mod Mod . Mod
123.4
.
.
Commit Commit .Commit Commit
Mod 1 Mod 2 .Mod 3 Mod 4
.
.
Backout .
=======================.
.
Task C
.
SOT . EOT
. (SP)
Mod Mod .
.
.
. Commit
Abbreviations: . Mods
EOT: End of task .
UOW: Unit of work X
Mod: Modification to database
SOT: Start of task
SP: Syncpoint
X: Moment of system failure
Figure 2. Backout of units of work
CICS recovery manager
The recovery manager ensures the integrity and consistency of resources (such as
files and databases) both within a single CICS region and distributed over
interconnected systems in a network.
Figure 3 on page 18 shows the resource managers and their resources with which
the CICS recovery manager works.
The main functions of the CICS recovery manager are:
Chapter 2. Resource recovery in CICS 17
Page 30

c
o
L
RDO
v Managing the state, and controlling the execution, of each UOW
v Coordinating UOW-related changes during syncpoint processing for recoverable
resources
v Coordinating UOW-related changes during restart processing for recoverable
resources
v Coordinating recoverable conversations to remote nodes
v Temporarily suspending completion (shunting), and later resuming completion
(unshunting), of UOWs that cannot immediately complete commit or backout
processing because the required resources are unavailable, because of system,
communication, or media failure
r
c
e
u
a
o
s
e
R
l
TS
M
a
n
a
g
e
r
s
TD
FC
Recovery
LOG
C
o
m
Figure 3. CICS recovery manager and resources it works with
m
u
LU6.2
n
i
c
a
Manager
DBCTL
t
LU6.1
i
o
n
s
M
a
n
a
g
Managing the state of each unit of work
The CICS recovery manager maintains, for each UOW in a CICS region, a record of
the changes of state that occur during its lifetime.
Typical events that cause state changes include:
v Creation of the UOW, with a unique identifier
v Premature termination of the UOW because of transaction failure
v Receipt of a syncpoint request
v Entry into the indoubt period during two-phase commit processing (see the
MRO
e
r
s
CICS Transaction Server for z/OS Glossary for a definition of two-phase commit)
MQM
R
M
o
f
I
FC/RLS
DB2
t
o
m
e
R
r
e
R
e
e
c
r
u
o
s
18 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 31

v Notification that the resource is not available, requiring temporary suspension
(shunting) of the UOW
v Notification that the resource is available, enabling retry of shunted UOWs
v Notification that a connection is reestablished, and can deliver a commit or
rollback (backout) decision
v Syncpoint rollback
v Normal termination of the UOW
The identity of a UOW and its state are owned by the CICS recovery manager, and
are recorded in storage and on the system log. The system log records are used by
the CICS recovery manager during emergency restart to reconstruct the state of the
UOWs in progress at the time of the earlier system failure.
The execution of a UOW can be distributed over more than one CICS system in a
network of communicating systems.
The CICS recovery manager supports SPI commands that provide information
about UOWs.
Coordinating updates to local resources
The recoverable local resources managed by a CICS region are files, temporary
storage, and transient data, plus resource definitions for terminals, typeterms,
connections, and sessions.
Each local resource manager can write UOW-related log records to the local system
log, which the CICS recovery manager may subsequently be required to re-present
to the resource manager during recovery from failure.
To enable the CICS recovery manager to deliver log records to each resource
manager as required, the CICS recovery manager adds additional information
when the log records are created. Therefore, all logging by resource managers to
the system log is performed through the CICS recovery manager.
During syncpoint processing, the CICS recovery manager invokes each local
resource manager that has updated recoverable resources within the UOW. The
local resource managers then perform the required action. This provides the means
of coordinating the actions performed by individual resource managers.
If the commit or backout of a file resource fails (for example, because of an I/O
error or the inability of a resource manager to free a lock), the CICS recovery
manager takes appropriate action with regard to the failed resource:
v If the failure occurs during commit processing, the UOW is marked as
commit-failed and is shunted awaiting resolution of whatever caused the
commit failure.
v If the failure occurs during backout processing, the UOW is marked as
backout-failed, and is shunted awaiting resolution of whatever caused the
backout to fail.
Note that a commit failure can occur during the commit phase of a completed
UOW, or the commit phase that takes place after successfully completing backout.
(These two phases (or ‘directions’) of commit processing—commit after normal
completion and commit after backout—are sometimes referred to as ‘forward
commit’ and ‘backward commit’ respectively.) Note also that a UOW can be
backout-failed with respect to some resources and commit-failed with respect to
Chapter 2. Resource recovery in CICS 19
Page 32

others. This can happen, for example, if two data sets are updated and the UOW
has to be backed out, and the following happens:
v One resource backs out successfully
v While committing this successful backout, the commit fails
v The other resource fails to back out
These events leave one data set commit-failed, and the other backout-failed. In this
situation, the overall status of the UOW is logged as backout-failed.
During emergency restart following a CICS failure, each UOW and its state is
reconstructed from the system log. If any UOW is in the backout-failed or
commit-failed state, CICS automatically retries the UOW to complete the backout
or commit.
Coordinating updates in distributed units of work
If the execution of a UOW is distributed across more than one system, the CICS
recovery manager (or their non-CICS equivalents) in each pair of connected
systems ensure that the effects of the distributed UOW are atomic.
Each CICS recovery manager (or its non-CICS equivalent) issues the requests
necessary to effect two-phase syncpoint processing to each of the connected
systems with which a UOW may be in conversation.
Note: In this context, the non-CICS equivalent of a CICS recovery manager could
be the recovery component of a database manager, such as DBCTL or DB2
equivalent function where one of a pair of connected systems is not CICS.
|
|
|
|
|
In each connected system in a network, the CICS recovery manager uses interfaces
to its local recovery manager connectors (RMCs) to communicate with partner
recovery managers. The RMCs are the communication resource managers (IPIC,
LU6.2, LU6.1, MRO, and RMI) which have the function of understanding the
transport protocols and constructing the flows between the connected systems.
As remote resources are accessed during UOW execution, the CICS recovery
manager keeps track of data describing the status of its end of the conversation
with that RMC. The CICS recovery manager also assumes responsibility for the
coordination of two-phase syncpoint processing for the RMC.
®
,orany
Managing indoubt units of work
During the syncpoint phases, for each RMC, the CICS recovery manager records
the changes in the status of the conversation, and also writes, on behalf of the
RMC, equivalent information to the system log.
If a session fails at any time during the running of a UOW, it is the RMC
responsibility to notify the CICS recovery manager, which takes appropriate action
with regard to the unit of work as a whole. If the failure occurs during syncpoint
processing, the CICS recovery manager may be in doubt and unable to determine
immediately how to complete the UOW. In this case, the CICS recovery manager
causes the UOW to be shunted awaiting UOW resolution, which follows
notification from its RMC of successful resynchronization on the failed session.
During emergency restart following a CICS failure, each UOW and its state is
reconstructed from the system log. If any UOW is in the indoubt state, it remains
shunted awaiting resolution.
20 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 33

Resynchronization after system or connection failure
Units of work that fail while in an indoubt state remain shunted until the indoubt
state can be resolved following successful resynchronization with the coordinator.
Resynchronization takes place automatically when communications are next
established between subordinate and coordinator. Any decisions held by the
coordinator are passed to the subordinate, and indoubt units of work complete
normally. If a subordinate has meanwhile taken a unilateral decision following the
loss of communication, this decision is compared with that taken by the
coordinator, and messages report any discrepancy.
For an explanation and illustration of the roles played by subordinate and
coordinator CICS regions, and for information about recovery and
resynchronization of distributed units of work generally, see the CICS
Intercommunication Guide.
CICS system log
CICS system log data is written to two MVS system logger log streams, the
primary log stream and secondary log stream, which together form a single logical
log stream.
The system log is the only place where CICS records information for use when
backing out transactions, either dynamically or during emergency restart
processing. CICS automatically connects to its system log stream during
initialization, unless you have specified a journal model definition that defines the
system log as DUMMY (in which case CICS can perform only an initial start).
The integrity of the system log is critical in enabling CICS to perform recovery. If
any of the components involved with the system log—the CICS recovery manager,
the CICS log manager, or the MVS system logger—experience problems with the
system log, it might be impossible for CICS to perform successfully recovery
processing. For more information about errors affecting the system log, see “Effect
of problems with the system log” on page 33.
The CICS System Definition Guide tells you more about CICS system log streams,
and how you can use journal model definitions to map the CICS journal names for
the primary system log stream (DFHLOG) and the secondary system log stream
(DFHSHUNT) to specific log stream names. If you don't specify journal model
definitions, CICS uses default log stream names.
Information recorded on the system log
The information recorded on the system log is sufficient to allow backout of
changes made to recoverable resources by transactions that were running at the
time of failure, and to restore the recoverable part of CICS system tables.
Typically, this includes before-images of database records and after-images of
recoverable parts of CICS tables—for example, transient data cursors or TCTTE
sequence numbers. You cannot use the system log for forward recovery
information, or for terminal control or file control autojournaling.
Your application programs can write user-defined recovery records to the system
log using EXEC CICS WRITE JOURNALNAME commands. Any user-written log
records to support your own recovery processes are made available to global user
exit programs enabled at the XRCINPT exit point.
Chapter 2. Resource recovery in CICS 21
Page 34

CICS also writes “backout-failed” records to the system log if a failure occurs in
backout processing of a VSAM data set during dynamic backout or emergency
restart backout.
Records on the system log are used for cold, warm, and emergency restarts of a
CICS region. The only type of start for which the system log records are not used is
an initial start.
System activity keypoints
The recovery manager controls the recording of keypoint information, and the
delivery of the information to the various resource managers at emergency restart.
The recovery manager provides the support that enables activity keypoint
information to be recorded at frequent intervals on the system log. You specify the
activity keypoint frequency on the AKPFREQ system initialization parameter. See the
CICS System Definition Guide for details. Activity keypoint information is of two
types:
1. A list of all the UOWs currently active in the system
2. Image-copy type information allowing the current contents of a particular
resource to be rebuilt
During an initial phase of CICS restart, recovery manager uses this information,
together with UOW-related log records, to restore the CICS system to its state at
the time of the previous shutdown. This is done on a single backward scan of the
system log.
Frequency of taking activity keypoints: You are strongly recommended to specify a
nonzero activity keypoint frequency. Choose an activity keypoint frequency that is
suitable for the size of your system log stream. Note that writing activity keypoints
at short intervals improves restart times, but at the expense of extra processing
during normal running.
The following additional actions are taken for files accessed in non-RLS mode that
use backup while open (BWO):
v Tie-up records are recorded on the forward recovery log stream. A tie-up record
associates a CICS file name with a VSAM data set name.
v Recovery points are recorded in the integrated catalog facility (ICF) catalog.
These define the starting time for forward recovery. Data recorded on the
forward recovery log before that time does not need to be used.
Forward recovery logs
CICS writes VSAM forward recovery logs to a general log stream defined to the
MVS system logger. You can merge forward recovery log data for more than one
VSAM data set to the same log stream, or you can dedicate a forward recovery log
stream to a single data set.
See “Defining forward recovery log streams” on page 116 for information about the
use of forward recovery log streams.
User journals and automatic journaling
User journals and autojournals are written to a general log stream defined to the
MVS system logger.
22 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 35

v User journaling is entirely under your application programs’ control. You write
records for your own purpose using EXEC CICS WRITE JOURNALNAME
commands. See “Flushing journal buffers” on page 28 for information about
CICS shutdown considerations.
v Automatic journaling means that CICS automatically writes records to a log
stream, referenced by the journal name specified in a journal model definition,
as a result of:
– Records read from or written to files. These records represent data that has
been read, or data that has been read for update, or data that has been
written, or records to indicate the completion of a write, and so on,
depending on what types of request you selected for autojournaling.
You specify that you want autojournaling for VSAM files using the
autojournaling options on the file resource definition in the CSD. For BDAM
files, you specify the options on a file entry in the file control table.
– Input or output messages from terminals accessed through VTAM.
You specify that you want terminal control autojournaling on the JOURNAL
option of the profile resource definition referenced by your transaction
definitions. These messages could be used to create audit trails.
Automatic journaling is used for user-defined purposes; for example, for an
audit trail. Automatic journaling is not used for CICS recovery purposes.
Chapter 2. Resource recovery in CICS 23
Page 36

24 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 37

Chapter 3. Shutdown and restart recovery
CICS can shut down normally or abnormally and this affects the way that CICS
restarts after it shuts down.
CICS can stop executing as a result of:
v A normal (warm) shutdown initiated by a CEMT, or EXEC CICS, PERFORM
SHUT command
v An immediate shutdown initiated by a CEMT, or EXEC CICS, PERFORM SHUT
IMMEDIATE command
v An abnormal shutdown caused by a CICS system module encountering an
irrecoverable error
v An abnormal shutdown initiated by a request from the operating system
(arising, for example, from a program check or system abend)
v A machine check or power failure
Normal shutdown processing
Normal shutdown is initiated by issuing a CEMT PERFORM SHUTDOWN
command, or by an application program issuing an EXEC CICS PERFORM
SHUTDOWN command. It takes place in three quiesce stages, as follows:
First quiesce stage
During the first quiesce stage of shutdown, all terminals are active, all CICS
facilities are available, and the a number of activities are performed concurrently
The following activities are performed:
v CICS invokes the shutdown assist transaction specified on the SDTRAN system
initialization parameter or on the shutdown command.
Because all user tasks must terminate during the first quiesce stage, it is possible
that shutdown could be unacceptably delayed by long-running tasks (such as
conversational transactions). The purpose of the shutdown assist transaction is to
allow as many tasks as possible to commit or back out cleanly, while ensuring
that shutdown completes within a reasonable time.
CICS obtains the name of the shutdown assist transaction as follows:
1. If SDTRAN(tranid) is specified on the PERFORM SHUTDOWN command, or
as a system initialization parameter, CICS invokes that tranid.
2. If NOSDTRAN is specified on the PERFORM SHUTDOWN command, or as
a system initialization parameter, CICS does not start a shutdown
transaction. Without a shutdown assist transaction, all tasks that are already
running are allowed to complete.
3. If the SDTRAN (or NOSDTRAN) options are omitted from the PERFORM
SHUTDOWN command, and omitted from the system initialization
parameters, CICS invokes the default shutdown assist transaction, CESD,
which runs the CICS-supplied program DFHCESD.
The SDTRAN option specified on the PERFORM SHUT command overrides any
SDTRAN option specified as a system initialization parameter.
© Copyright IBM Corp. 1982, 2010 25
Page 38

v The DFHCESD program started by the CICS-supplied transaction, CESD,
attempts to purge and back out long-running tasks using increasingly stronger
methods (see “The shutdown assist transaction” on page 30).
v Tasks that are automatically initiated are run—if they start before the second
quiesce stage.
v Any programs listed in the first part of the shutdown program list table (PLT)
are run sequentially. (The shutdown PLT suffix is specified in the PLTSD system
initialization parameter, which can be overridden by the PLT option of the
CEMT or EXEC CICS PERFORM SHUTDOWN command.)
v A new task started as a result of terminal input is allowed to start only if its
transaction code is listed in the current transaction list table (XLT) or has been
defined as SHUTDOWN(ENABLED) in the transaction resource definition. The
XLT list of transactions restricts the tasks that can be started by terminals and
allows the system to shut down in a controlled manner. The current XLT is the
one specified by the XLT=xx system initialization parameter, which can be
overridden by the XLT option of the CEMT or EXEC CICS PERFORM
SHUTDOWN command.
Certain CICS-supplied transactions are, however, allowed to start whether their
code is listed in the XLT or not. These transactions are CEMT, CESF, CLR1,
CLR2, CLQ2, CLS1, CLS2, CSAC, CSTE, and CSNE.
v Finally, at the end of this stage and before the second stage of shutdown, CICS
unbinds all the VTAM terminals and devices.
The first quiesce stage is complete when the last of the programs listed in the first
part of the shutdown PLT has executed and all user tasks are complete. If the
CICS-supplied shutdown transaction CESD is used, this stage does not wait
indefinitely for all user tasks to complete.
Second quiesce stage
During the second quiesce stage of shutdown:
v Terminals are not active.
v No new tasks are allowed to start.
v Programs listed in the second part of the shutdown PLT (if any) run
sequentially. These programs cannot communicate with terminals, or make any
request that would cause a new task to start.
The second quiesce stage ends when the last of the programs listed in the PLT has
completed executing.
Third quiesce stage
During the third quiesce stage of shutdown:
v CICS closes all files that are defined to CICS file control. However, CICS does
not catalog the files as UNENABLED; they can then be opened implicitly by the
first reference after a subsequent CICS restart.
Files that are eligible for BWO support have the BWO attributes in the ICF
catalog set to indicate that BWO is not supported. This prevents BWO backups
being taken in the subsequent batch window.
v All extrapartition TD queues are closed.
v CICS writes statistics to the system management facility (SMF) data set.
v CICS recovery manager sets the type-of-restart indicator in its domain state
record in the global catalog to “warm-start-possible”. If you specify
START=AUTO when you next initialize the CICS region, CICS uses the status of
26 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 39

this indicator to determine the type of startup it is to perform. See “How the
state of the CICS region is reconstructed” on page 34.
v CICS writes warm keypoint records to:
– The global catalog for terminal control and profiles
– The CICS system log for all other resources.
See “Warm keypoints.”
v CICS deletes all completed units of work (log tail deletion), leaving only shunted
units of work and the warm keypoint.
Note: Specifying no activity keypointing (AKPFREQ=0) only suppresses log tail
deletion while CICS is running, not at shutdown. CICS always performs log
cleanup at shutdown unless you specify RETPD=dddd on the MVS definition of
the system log. See “Activity keypointing” on page 112 for more information.
v CICS stops executing.
Warm keypoints
The CICS-provided warm keypoint program (DFHWKP) writes a warm keypoint
to the global catalog, for terminal control and profile resources only, during the
third quiesce stage of shutdown processing when all system activity is quiesced.
The remainder of the warm keypoint information, for all other resources, is written
to the CICS system log stream, under the control of the CICS recovery manager.
This system log warm keypoint is written by the activity keypoint program as a
special form of activity keypoint that contains information relating to shutdown.
The warm keypoints contain information needed to restore the CICS environment
during a subsequent warm or emergency restart. Thus CICS needs both the global
catalog and the system log to perform a restart. If you run CICS with a system log
that is defined by a journal model specifying TYPE(DUMMY), you cannot restart
CICS with START=AUTO following a normal shutdown, or with START=COLD.
Shunted units of work at shutdown
If there are shunted units of work of any kind at shutdown, CICS issues message
DFHRM0203.
This message displays the numbers of indoubt, backout-failed, and commit-failed
units of work held in the CICS region's system log at the time of the normal
shutdown. It is issued only if there is at least one such UOW. If there are no
shunted units of work, CICS issues message DFHRM0204.
DFHRM0203 is an important message that should be logged, and should be taken
note of when you next restart the CICS region. For example, if you receive
DFHRM0203 indicating that there is outstanding work waiting to be completed,
you should not perform a cold or initial start of the CICS region. You are
recommended to always restart CICS with START=AUTO, and especially after
message DFHRM0203, otherwise recovery data is lost.
See Chapter 4, “CICS cold start,” on page 45 for information about a cold start if
CICS has issued message DFHRM0203 at the previous shutdown.
Chapter 3. Shutdown and restart recovery 27
Page 40

Flushing journal buffers
During a successful normal shutdown, CICS calls the log manager domain to flush
all journal buffers, ensuring that all journal records are written to their
corresponding MVS system logger log streams.
During an immediate shutdown, the call to the log manager domain is bypassed
and journal records are not flushed. This also applies to an immediate shutdown
that is initiated by the shutdown-assist transaction because a normal shutdown has
stalled. Therefore, any user journal records in a log manager buffer at the time of
an immediate shutdown are lost. This does not affect CICS system data integrity.
The system log and forward recovery logs are always synchronized with regard to
I/O and unit of work activity. If user journal data is important, you should take
appropriate steps to ensure that journal buffers are flushed at shutdown.
These situations and possible solutions are summarized as follows:
v In a controlled shutdown that completes normally, CICS ensures that user
journals are flushed.
v In a controlled shutdown that is forced into an immediate shutdown by a
shutdown-assist transaction, CICS does not flush buffers. To avoid the potential
loss of journal records in this case, you can provide a PLTSD program that issues
a SET JOURNAL FLUSH command to ensure that log manager buffers are written to
the corresponding log streams. PLTSD programs are invoked before an
immediate shutdown is initiated by the shutdown-assist transaction.
v In an uncontrolled shutdown explicitly requested with the SHUT IMMEDIATE
command, CICS does not flush buffers. To avoid the potential loss of journal
records in this case, you can issue an EXEC CICS WAIT JOURNALNAME command at
appropriate points in the application program, or immediately before returning
control to CICS. (Alternatively, you could specify the WAIT option on the WRITE
JOURNALNAME command.) See the description of the command in the CICS
Application Programming Reference for information about the journaling WAIT
option.
Immediate shutdown processing (PERFORM SHUTDOWN IMMEDIATE)
As a general rule when terminating CICS, you are recommended to use a normal
shutdown with a shutdown assist transaction, specifying either your own or the
CICS-supplied default, CESD.
PERFORM IMMEDIATE not recommended
You should resort to using an immediate shutdown only if you have a special
reason for doing so. For instance, you might need to stop and restart CICS during
a particularly busy period, when the slightly faster immediate shutdown may be of
benefit. Also, you can use VTAM persistent sessions support with an immediate
shutdown.
You initiate an immediate shutdown by a CEMT, or EXEC CICS, PERFORM
SHUTDOWN IMMEDIATE command. Immediate shutdown is different from a
normal shutdown in a number of important ways:
1. If the shutdown assist transaction is not run (that is, the SDTRAN system
initialization parameter specifies NO, or the PERFORM SHUTDOWN command
specifies NOSDTRAN), user tasks are not guaranteed to complete. This can
lead to an unacceptable number of units of work being shunted, with locks
being retained.
28 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 41

2. If the default shutdown assist transaction CESD is run, it allows as many tasks
as possible to commit or back out cleanly, but within a shorter time than that
allowed on a normal shutdown. See “The shutdown assist transaction” on page
30 for more information about CESD, which runs the CICS-supplied program
DFHCESD.
3. None of the programs listed in the shutdown PLT is executed.
4. CICS does not write a warm keypoint or a warm-start-possible indicator to the
global catalog.
5. CICS does not close files managed by file control. It is left to VSAM to close the
files when VSAM is notified by MVS that the address space is terminating. This
form of closing files means that a VSAM VERIFY is needed on the next open of
the files closed in this way, but this is done automatically.
6. VTAM sessions wait for the restarted region to initialize or until the expiry of
the interval specified in the PSDINT system initialization parameter, whichever
is earlier.
The next initialization of CICS must be an emergency restart, in order to preserve
data integrity. An emergency restart is ensured if the next initialization of CICS
specifies START=AUTO. This is because the recovery manager’s type-of-restart
indicator is set to “emergency-restart-needed” during initialization and is not reset
in the event of an immediate or uncontrolled shutdown. See “How the state of the
CICS region is reconstructed” on page 34.
Note: A PERFORM SHUTDOWN IMMEDIATE command can be issued, by the
operator or by the shutdown assist transaction, while a normal or immediate
shutdown is already in progress. If this happens, the shutdown assist transaction is
not restarted; the effect is to force an immediate shutdown with no shutdown
assist transaction.
If the original PERFORM SHUTDOWN request specified a normal shutdown, and
the restart manager (ARM) was active, CICS is restarted (because CICS will not
de-register from the automatic restart manager until the second quiesce stage of
shutdown has completed).
Shutdown requested by the operating system
This type of shutdown can be initiated by the operating system as a result of a
program check or an operating system abend.
A program check or system abend can cause either an individual transaction to
abend or CICS to terminate. (For further details, see “Processing operating system
abends and program checks” on page 94.)
A CICS termination caused by an operating system request:
v Does not guarantee that user tasks will complete.
v Does not allow shutdown PLT programs to execute.
v Does not write a warm keypoint or a warm-start-possible indicator to the global
catalog.
v Takes a system dump (unless system dumps are suppressed by the DUMP=NO
system initialization parameter).
v Does not close any open files. It is left to VSAM to close the files when VSAM is
notified by MVS that the address space is terminating. This form of closing files
means that a VSAM VERIFY is needed on the next open of the files closed in
this way, but this is done automatically.
Chapter 3. Shutdown and restart recovery 29
Page 42

The next initialization of CICS must be an emergency restart, in order to preserve
data integrity. An emergency restart is ensured if the next initialization of CICS
specifies START=AUTO. This is because the recovery manager’s type-of-restart
indicator is set to “emergency-restart-needed” during initialization, and is not reset
in the event of an immediate or uncontrolled shutdown.
Uncontrolled termination
An uncontrolled shutdown of CICS can be caused by a power failure, machine
check, or operating system failure.
In each case, CICS cannot perform any shutdown processing. In particular, CICS
does not write a warm keypoint or a warm-start-possible indicator to the global
catalog.
The next initialization of CICS must be an emergency restart, in order to preserve
data integrity. An emergency restart is ensured if the next initialization of CICS
specifies START=AUTO. This is because the recovery manager’s type-of-restart
indicator is set to “emergency-restart-needed” during initialization, and is not reset
in the event of an immediate or uncontrolled shutdown.
The shutdown assist transaction
On an immediate shutdown, CICS does not allow running tasks to finish. A
backout is not performed until an emergency restart.
This can cause an unacceptable number of units of work to be shunted, with locks
being retained. On the other hand, on a normal shutdown, CICS waits indefinitely
for running transactions to finish, which can delay shutdown to a degree that is
unacceptable. The CICS shutdown assist transaction improves both these forms of
shutdown and, to a large degree, removes the need for an immediate shutdown.
The operation of CESD, for both normal and immediate shutdowns, takes place
over a number of stages. CESD controls these stages by sampling the number of
tasks present in the system, and proceeds to the next stage if the number of
in-flight tasks is not reducing quickly enough.
The stages of a normal shutdown CESD are as follows:
v In the initial stage of assisted shutdown, CESD attempts to complete a normal
shutdown in a reasonable time.
v After a time allowed for transactions to finish normally (that is, after the number
of tasks has not reduced over a period of eight samples), CESD proceeds to issue
a normal purge for each remaining task. The transaction dump data set is closed
in this stage.
v If there are still transactions running after a further eight samples (except when
persistent sessions support is being used), VTAM is force-closed and IRC is
closed immediately.
v Finally, if there are still transactions running, CICS shuts down abnormally,
leaving details of the remaining in-flight transactions on the system log to be
dealt with during an emergency restart.
The operation of CESD is quicker for an immediate shutdown, with the number of
tasks in the system being sampled only four times instead of eight.
30 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 43

You are recommended always to use the CESD shutdown-assist transaction when
shutting down your CICS regions. You can use the DFHCESD program “as is”, or
use the supplied source code as the basis for your own customized version (CICS
supplies versions in assembler, COBOL, and PL/I). For more information about the
operation of the CICS-supplied shutdown assist program, see the CICS Operations
and Utilities Guide.
Cataloging CICS resources
CICS uses a global catalog data set (DFHGCD) and a local catalog data set
(DFHLCD) to store information that is passed from one execution of CICS, through
a shutdown, to the next execution of CICS.
This information is used for warm and emergency restarts, and to a lesser extent
for cold starts. If the global catalog fails (for reasons other than filling the available
space), the recovery manager control record is lost. Without this, it is impossible to
perform a warm, emergency, or cold start, and the only possibility is then an initial
start. For example, if the failure is due to an I/O error, you cannot restart CICS.
Usually, if the global catalog fills, CICS abnormally terminates, in which case you
could define more space and attempt an emergency restart.
Consider putting the catalog data sets on the most reliable storage
available—RAID or dual-copy devices—to ensure maximum protection of the data.
Taking ordinary copies is not recommended because of the risk of getting out of
step with the system log.
From a restart point of view, the system log and the CICS catalog (both data sets)
form one logical set of data, and all of them are required for a restart.
The CICS System Definition Guide tells you how to create and initialize these CICS
catalog data sets.
Global catalog
The global catalog contains information that CICS requires on a restart.
CICS uses the global catalog to store the following information:
v The names of the system log streams.
v Copies of tables of installed resource definitions, and related information, for the
following:
– Transactions and transaction classes
– DB2 resource definitions
– Programs, mapsets, and partitionsets (including autoinstalled programs,
subject to the operand you specify on the PGAICTLG system initialization
parameter)
– Terminals and typeterms (for predefined and autoinstalled resources)
– Autoinstall terminal models
– Profiles
– Connections, sessions, and partners
– BDAM and VSAM files (including data tables) and
- VSAM LSR pool share control blocks
- Data set names and data set name blocks
Chapter 3. Shutdown and restart recovery 31
Page 44

- File control recovery blocks (only if a SHCDS
NONRLSUPDATEPERMITTED command has been used).
– Transient data queue definitions
– Dump table information
– Interval control elements and automatic initiate descriptors at shutdown
– APPC connection information so that relevant values can be restored during a
persistent sessions restart
– Logname information used for communications resynchronization
– Monitoring options in force at shutdown
– Statistics interval collection options in force at shutdown
– Journal model and journal name definitions
– Enqueue model definitions
– Temporary storage model definitions
– URIMAP definitions and virtual hosts for CICS Web support.
Most resource managers update the catalog whenever they make a change to
their table entries. Terminal and profile resource definitions are exceptions (see
the next list item about the catalog warm keypoint). Because of the typical
volume of changes, terminal control does not update the catalog, except when:
– Running a VTAM query against a terminal
– A generic connection has bound to a remote system
– Installing a terminal
– Deleting a terminal.
v A partial warm keypoint at normal shutdown. This keypoint contains an image
copy of the TCT and profile resource definitions at shutdown for use during a
warm restart.
Note: The image copy of the TCT includes all the permanent devices installed
by explicit resource definitions. Except for some autoinstalled APPC connections,
it does not include autoinstalled devices. Autoinstalled terminal resources are
cataloged initially, in case they need to be recovered during an emergency
restart, but only if the AIRDELAY system initialization parameter specifies a
nonzero value. Therefore, apart from the APPC exceptions mentioned above,
autoinstalled devices are excluded from the warm keypoint, and are thus not
recovered on a warm start.
v Statistics options.
v Monitoring options.
v The recovery manager ’s control record, which includes the type-of-restart
indicator (see “How the state of the CICS region is reconstructed” on page 34).
All this information is essential for a successful restart following any kind of
shutdown.
Local catalog
The CICS local catalog data set represents just one part of the CICS catalog, which
is implemented as two physical data sets.
The two data sets are logically one set of cataloged data managed by the CICS
catalog domain. Although minor in terms of the volume of information recorded
on it, the local catalog is of equal importance with the global catalog, and the data
should be equally protected when restarts are performed.
32 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 45

If you ever need to redefine and reinitialize the CICS local catalog, you should also
reinitialize the global catalog. After reinitializing both catalog data sets, you must
perform an initial start.
Shutdown initiated by CICS log manager
The CICS log manager initiates a shutdown of the region if it encounters an error
in the system log that indicates previously logged data has been lost.
In addition to initiating the shutdown, the log manager informs the recovery
manager of the failure, which causes the recovery manager to set the
type-of-restart indicator to “no-restart-possible” and to issue message DFHRM0144.
The result is that recovery during a subsequent restart is not possible and you can
perform only an initial start of the region. To do this you are recommended to run
the recovery manager utility program (DFHRMUTL) to force an initial start, using
the SET_AUTO_START=AUTOINIT option.
During shutdown processing, existing transactions are given the chance to
complete their processing. However, no further data is written to the system log.
This strategy ensures that the minimum number of units of work are impacted by
the failure of the system log. This is because:
v If a unit of work does not attempt to backout its resource updates, and
completes successfully, it is unaffected by the failure.
v If a unit of work does attempt to backout, it cannot rely on the necessary log
records being available, and therefore it is permanently suspended.
Therefore, when the system has completed the log manager-initiated shutdown all
(or most) units of work will have completed normally during this period and if
there are no backout attempts, data integrity is not compromised.
Effect of problems with the system log
A key value of CICS is its ability to implement its transactional recovery
commitments and thus safeguard the integrity of recoverable data updated by
CICS applications.
This ability relies upon logging before-images and other information to the system
log. However, the system log itself might suffer software or hardware related
problems, including failures in the CICS recovery manager, the CICS logger
domain, or the MVS system logger. Although problems with these components are
unlikely, you must understand the actions to take to minimize the impact of such
problems.
If the CICS log manager detects an error in the system log that indicates
previously logged data has been lost, it initiates a shutdown of the region. This
action minimizes the number of transactions that fail after a problem with the log
is detected and therefore minimizes the data integrity exposure.
Any problem with the system log that indicates that it might not be able to access
all the data previously logged invalidates the log. In this case, you can perform
only a diagnostic run or an initial start of the region to which the system log
belongs.
The reason that a system log is completely invalidated by these kinds of error is
that CICS can no longer rely on the data it previously logged being available for
recovery processing. For example, the last records logged might be unavailable,
Chapter 3. Shutdown and restart recovery 33
Page 46

and therefore recovery of the most recent units of work cannot be carried out.
However, data might be missing from any part of the system log and CICS cannot
identify what is missing. CICS cannot examine the log and determine exactly what
data is missing, because the log data might appear consistent in itself even when
CICS has detected that some data is missing.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
These are the messages that CICS issues as it reads the log during a warm or
emergency start and that can help you identify which units of work were
recovered:
DFHRM0402
This message is issued for each unit of work when it is first encountered
on the log.
DFHRM0403 and DFHRM0404
One of these messages is issued for each unit of work when its context is
found. The message reports the state of the unit of work.
DFHRM0405
This message is issued when a complete keypoint has been recovered from
the log.
If you see that message DFHRM0402 is issued for a unit of work, and it is matched
by message DFHRM0403 or DFHRM0404, you can be sure of the state of the unit
of work. If you see message DFHRM0405, you can use the preceding messages to
determine which units of work are incomplete, and you can also be sure that none
of the units of work is completely missing.
Another class of problem with the system log is one that does not indicate any loss
of previously logged data; for example, access to the logstream was lost due to
termination of the MVS system logger address space. This class of problem causes
an immediate termination of CICS because a subsequent emergency restart will
probably succeed when the cause of the problem has been resolved.
For information about how to deal with system log problems, see the CICS Problem
Determination Guide.
How the state of the CICS region is reconstructed
CICS recovery manager uses the type-of-restart indicator in its domain state record
from the global catalog to determine which type of restart it is to perform.
This indicator operates as follows:
v Before the end of initialization, on all types of startup, CICS sets the indicator in
the control record to “emergency restart needed”.
v If CICS terminates normally, this indicator is changed to “warm start possible”.
v If CICS terminates abnormally because the system log has been corrupted and is
no longer usable, this indicator is changed to “no restart”. After fixing the
system log, perform an initial start of the failed CICS region.
v For an automatic start (START=AUTO):
– If the indicator says “warm start possible”, CICS performs a warm start.
– If the indicator says “emergency restart needed”, CICS performs an
emergency restart.
34 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 47

Overriding the type of start indicator
The operation of the recovery manager's control record can be modified by
running the recovery manager utility program, DFHRMUTL.
About this task
This can set an autostart record that determines the type of start CICS is to
perform, effectively overriding the type of start indicator in the control record. See
the CICS Operations and Utilities Guide for information about using DFHRMUTL to
modify the type of start performed by START=AUTO.
Warm restart
If you shut down a CICS region normally, CICS restarts with a warm restart if you
specify START=AUTO. For a warm start to succeed, CICS needs the information
stored in the CICS catalogs at the previous shutdown, and the information stored
in the system log.
In a warm restart, CICS:
1. Restores the state of the CICS region to the state it was in at completion of the
normal shutdown. All CICS resource definitions are restored from the global
catalog, and the GRPLIST, FCT, and CSD system initialization parameters are
ignored.
CICS also uses information from the warm keypoint in the system log.
2. Reconnects to the system log.
3. Retries any backout-failed and commit-failed units of work.
4. Rebuilds indoubt-failed units of work.
For more information about the warm restart process, see Chapter 5, “CICS warm
restart,” on page 53.
Emergency restart
If a CICS region fails, CICS restarts with an emergency restart if you specify
START=AUTO. An emergency restart is similar to a warm start but with additional
recovery processing for example, to back out any transactions that were in-flight at
the time of failure, and thus free any locks protecting resources.
If the failed CICS region was running with VSAM record-level sharing, SMSVSAM
converts into retained locks any active exclusive locks held by the failed system,
pending the CICS restart. This means that the records are protected from being
updated by any other CICS region in the sysplex. Retained locks also ensure that
other regions trying to access the protected records do not wait on the locks until
the failed region restarts. See the CICS Application Programming Guide for
information about active and retained locks.
For non-RLS data sets (including BDAM data sets), any locks (ENQUEUES) that
were held before the CICS failure are reacquired.
Initialization during emergency restart
Most of CICS initialization following an emergency restart is the same as for a
warm restart, and CICS uses the catalogs and the system log to restore the state of
the CICS region. Then, after the normal initialization process, emergency restart
Chapter 3. Shutdown and restart recovery 35
Page 48

performs the recovery process for work that was in-flight when the previous run of
CICS was abnormally terminated.
Recovery of data during an emergency restart
During the final stage of emergency restart, the recovery manager uses the system
log data to drive backout processing for any units of work that were in-flight at
the time of the failure. The backout of units of work during emergency restart is
the same as a dynamic backout; there is no distinction between the backout that
takes place at emergency restart and that which takes place at any other time.
The recovery manager also drives:
v The backout processing for any units of work that were in a backout-failed state
at the time of the CICS failure.
v The commit processing for any units of work that were in a commit-failed state
at the time of the CICS failure.
v The commit processing for units of work that had not completed commit at the
time of failure (resource definition recovery, for example).
The recovery manager drives these backout and commit processes because the
condition that caused them to fail may be resolved by the time CICS restarts. If the
condition that caused a failure has not been resolved, the unit of work remains in
backout- or commit-failed state. See “Backout-failed recovery” on page 79 and
“Commit-failed recovery” on page 83 for more information.
For more information about the emergency restart process, see Chapter 6, “CICS
emergency restart,” on page 61.
Cold start
On a cold start, CICS reconstructs the state of the region from the previous run for
remote resources only. For all resources, the region is built from resource
definitions specified on the GRPLIST system initialization parameter and those
resources defined in control tables.
The following is a summary of how CICS uses information stored in the global
catalog and the system log on a cold start:
v CICS preserves, in both the global catalog and the system log, all the
information relating to distributed units of work for partners linked by:
– APPC
– MRO connections to regions running under CICS Transaction Server
– The resource manager interface (RMI); for example, to DB2 and DBCTL.
v CICS does not preserve any information in the global catalog or the system log
that relates to local units of work.
Generally, to perform a cold start you specify START=COLD, but CICS can also
force a cold start in some circumstances when START=AUTO is specified. See the
CICS System Definition Guide for details of the effect of the START parameter in
conjunction with various states of the global catalog and the system log.
An initial start of CICS
If you want to initialize a CICS region without reference to the global catalog from
a previous run, perform an initial start.
36 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 49

You can do this by specifying START=INITIAL as a system initialization parameter,
or by running the recovery manager's utility program (DFHRMUTL) to override
the type of start indicator to force an initial start.
See the CICS Operations and Utilities Guide for information about the DFHRMUTL
utility program.
Dynamic RLS restart
If a CICS region is connected to an SMSVSAM server when the server fails, CICS
continues running, and recovers using a process known as dynamic RLS restart.
An SMSVSAM server failure does not cause CICS to fail, and does not affect any
resource other than data sets opened in RLS mode.
When an SMSVSAM server fails, any locks for which it was responsible are
converted to retained locks by another SMSVSAM server within the sysplex, thus
preventing access to the records until the situation has been recovered. CICS
detects that the SMSVSAM server has failed the next time it tries to perform an
RLS access after the failure, and issues message DFHFC0153. The CICS regions that
were using the failed SMSVSAM server defer in-flight transactions by abending
units of work that attempt to access RLS, and shunt them when the backouts fail
with “RLS is disabled” responses. If a unit of work is attempting to commit its
changes and release RLS locks, commit failure processing is invoked when CICS
first detects that the SMSVSAM server is not available (see “Commit-failed
recovery” on page 83).
RLS mode open requests and RLS mode record access requests issued by new
units of work receive error responses from VSAM when the server has failed. The
SMSVSAM server normally restarts itself without any manual intervention. After
the SMSVSAM server has restarted, it uses the MVS event notification facility
(ENF) to notify all the CICS regions within its MVS image that the SMSVSAM
server is available again.
CICS performs a dynamic equivalent of emergency restart for the RLS component,
and drives backout of the deferred work.
Recovery after the failure of an SMSVSAM server is usually performed
automatically by CICS. CICS retries any backout-failed and commit-failed units of
work. In addition to retrying those failed as a result of the SMSVSAM server
failure, this also provides an opportunity to retry any backout failures for which
the cause has now been resolved. Manual intervention is required only if there are
units of work which, due to the timing of their failure, were not retried when CICS
received the ENF signal. This situation is extremely unlikely, and such units of
work can be detected using the INQUIRE UOWDSNFAIL command.
Note that an SMSVSAM server failure causes commit-failed or backout-failed units
of work only in the CICS regions registered with the server in the same MVS
image. Transactions running in CICS regions in other MVS images within the
sysplex are affected only to the extent that they receive LOCKED responses if they
try to access records protected by retained locks owned by any CICS regions that
were using the failed SMSVSAM server.
Chapter 3. Shutdown and restart recovery 37
Page 50

Recovery with VTAM persistent sessions
With VTAM persistent sessions support, if CICS fails or undergoes immediate
shutdown (by means of a PERFORM SHUTDOWN IMMEDIATE command), VTAM holds
the CICS LU-LU sessions in recovery-pending state, and they can be recovered
during startup by a newly starting CICS region. With multinode persistent sessions
support, sessions can also be recovered if VTAM or z/OS
The CICS system initialization parameter PSTYPE specifies the type of persistent
sessions support for a CICS region:
SNPS, single-node persistent sessions
Persistent sessions support is available, so that VTAM sessions can be
recovered after a CICS failure and restart. This setting is the default.
MNPS, multinode persistent sessions
In addition to the SNPS support, VTAM sessions can also be recovered
after a VTAM or z/OS failure in a sysplex.
®
fails in a sysplex.
|
|
|
|
NOPS, no persistent sessions
Persistent sessions support is not required for the CICS region. For
example, a CICS region that is used only for development or testing might
not require persistent sessions.
For single-node persistent sessions support, you require VTAM V3.4.1 or later,
which supports persistent LU-LU sessions. CICS Transaction Server for z/OS,
Version 4 Release 1 functions with releases of VTAM earlier than V3.4.1, but in the
earlier releases sessions are not retained in a bound state if CICS fails. For
multinode persistent sessions support, you require VTAM V4.R4 or later, and
VTAM must be in a Parallel Sysplex
Implementation Guide explains the exact VTAM configuration requirements for
multinode persistent sessions support.
CICS support of persistent sessions includes the support of all LU-LU sessions,
except LU0 pipeline and LU6.1 sessions. With multinode persistent sessions
support, if VTAM or z/OS fails, LU62 synclevel 1 sessions are restored, but LU62
synclevel 2 sessions are not restored.
®
with a coupling facility. The VTAM Network
Running with persistent sessions support
When you specify SNPS or MNPS for the PSTYPE system initialization parameter so
that VTAM persistent sessions support is in use for a CICS region, the time
specified by the PSDINT system initialization parameter for the region determines
how long the sessions are retained.
If a CICS, VTAM, or z/OS failure occurs, if a connection to VTAM is reestablished
within this time, CICS can use the retained sessions immediately; there is no need
for network flows to rebind them.
Make sure that you set a nonzero value for the persistent sessions delay interval,
so that sessions are retained. The default is zero, which means that persistent
sessions support is available if you have specified SNPS or MNPS for PSTYPE, but it
is not being exploited.
You can change the persistent sessions delay interval using the CEMT SET VTAM
command, or the EXEC CICS SET VTAM command. The changed interval is not
stored in the CICS global catalog, and therefore is not restored in an emergency
restart.
38 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 51

During an emergency restart of CICS, CICS restores those sessions pending
recovery from the CICS global catalog and the CICS system log to an in-session
state. This process of persistent sessions recovery takes place when CICS opens its
VTAM ACB. With multinode persistent sessions support, if VTAM or z/OS fails,
sessions are restored when CICS reopens its VTAM ACB, either automatically by
the COVR transaction, or by a CEMT or EXEC CICS SET VTAM OPEN command.
Although sessions are recovered, any transactions inflight at the time of the failure
are abended and not recovered.
When a terminal user enters data during persistent sessions recovery, CICS appears
to hang. The screen that was displayed at the time of the failure remains on
display until persistent sessions recovery is complete. You can use options on the
TYPETERM and SESSIONS resource definitions for the CICS region to customize
CICS so that either a successful recovery can be transparent to terminal users, or
terminal users can be notified of the recovery, allowing them to take the
appropriate actions.
If APPC sessions are active at the time of the CICS, VTAM or z/OS failure,
persistent sessions recovery appears to APPC partners as CICS hanging. VTAM
saves requests issued by the APPC partner, and passes them to CICS when
recovery is complete. When CICS reestablishes a connection with VTAM, recovery
of terminal sessions is determined by the settings for the PSRECOVERY option of
the CONNECTION resource definition and the RECOVOPTION option of the
SESSIONS resource definition. You must set the PSRECOVERY option of the
CONNECTION resource definition to the default value SYSDEFAULT for sessions
to be recovered. The alternative, NONE, means that no sessions are recovered. If
you have selected the appropriate recovery options and the APPC sessions are in
the correct state, CICS performs an ISSUE ABEND to inform the partner that the
current conversation has been abnormally ended.
If CICS has persistent verification defined, the sign-on is not active under
persistent sessions until the first input is received by CICS from the terminal.
The CICS Resource Definition Guide describes the steps required to define persistent
sessions support for a CICS region.
Situations in which sessions are not reestablished
When VTAM persistent sessions support is in use for a CICS region, CICS does not
always reestablish sessions that are being held by VTAM in a recovery pending
state. In the situations listed here, CICS or VTAM unbinds and does not rebind
recovery pending sessions.
v If CICS does not restart within the persistent sessions delay interval, as specified
by the PSDINT system initialization parameter.
v If you perform a COLD start after a CICS failure.
v If CICS restarts with XRF=YES, when the failed CICS was running with
XRF=NO.
v If CICS cannot find a terminal control table terminal entry (TCTTE) for a session;
for example, because the terminal was autoinstalled with AIRDELAY=0
specified.
v If a terminal or session is defined with the recovery option (RECOVOPTION) of
the TYPETERM or SESSIONS resource definition set to RELEASESESS,
UNCONDREL or NONE.
v If a connection is defined with the persistent sessions recovery option
(PSRECOVERY) of the CONNECTION resource definition set to NONE.
Chapter 3. Shutdown and restart recovery 39
Page 52

v If CICS determines that it cannot recover the session without unbinding and
rebinding it.
The result in each case is as if CICS has restarted following a failure without
VTAM persistent sessions support.
In some other situations APPC sessions are unbound. For example, if a bind was in
progress at the time of the failure, sessions are unbound.
With multinode persistent sessions support, if a VTAM or z/OS failure occurs and
the TPEND failure exit is driven, the autoinstalled terminals that are normally
deleted at this point are retained by CICS. If the session is not reestablished and
the terminal is not reused within the AIRDELAY interval, CICS deletes the TCTTE
when the AIRDELAY interval expires after the ACB is reopened successfully.
Situations in which VTAM does not retain sessions
When VTAM persistent sessions support is in use for a CICS region, in some
circumstances VTAM does not retain LU-LU sessions.
v If you close VTAM with any of the following CICS commands:
– SET VTAM FORCECLOSE
– SET VTAM IMMCLOSE
– SET VTAM CLOSED
v If you close the CICS node with the VTAM command VARY NET INACT ID=applid.
v If your CICS system performs a normal shutdown, with a PERFORM SHUTDOWN
command.
If single-node persistent sessions support (SNPS), which is the default, is specified
for a CICS region, sessions are not retained after a VTAM or z/OS failure. If
multinode persistent sessions support (MNPS) is specified, sessions are retained
after a VTAM or z/OS failure.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Running without persistent sessions support
VTAM persistent sessions support is the default for a CICS region, but you might
choose to run a CICS region without this support if it is used only for
development or testing. Specify NOPS for the PSTYPE system initialization
parameter to start a CICS region without persistent sessions support. Running
without persistent sessions support can enable you to increase the number of CICS
regions in an LPAR.
If you have a large number of CICS regions in the same LPAR (around 500), with
persistent sessions support available for all the regions, you might reach a z/OS
limit on the maximum number of data spaces and be unable to add any more
CICS regions. In this situation, when you attempt to start further CICS regions,
you see messages IST967I and DFHSI1572, stating that the ALESERV ADD request
has failed and the VTAM ACB cannot be opened. However, a region without
persistent sessions support does not use a data space and so does not count
towards the limit. To obtain a greater number of CICS regions in the LPAR:
1. Identify existing regions that can run without persistent sessions support.
2. Change the PSTYPE system initialization parameter for those regions to specify
NOPS, and specify a zero value for the PSDINT system initialization parameter.
3. Cold start the regions to implement the change.
40 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 53

|
|
|
You can then start further CICS regions with or without persistent sessions support
as appropriate, provided that you do not exceed the limit for the number of
regions that do have persistent sessions support.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
If you specify NOPS (no persistent session support) for the PSTYPE system
initialization parameter, a zero value is required for the PSDINT (persistent session
delay interval) system initialization parameter.
When persistent sessions support is not in use, all sessions existing on a CICS
system are lost if that CICS system, VTAM, or z/OS fails. In any subsequent restart
of CICS, the rebinding of sessions that existed before the failure depends on the
AUTOCONNECT option for the terminal. If AUTOCONNECT is specified for a
terminal, the user of that terminal waits until the GMTRAN transaction has run
before being able to continue working. The user sees the VTAM logon panel
followed by the “good morning” message. If AUTOCONNECT is not specified for
a terminal, the user of that terminal has no way of knowing (unless told by
support staff) when CICS is operational again unless the user tries to log on. In
either case, users are disconnected from CICS and need to reestablish a session, or
sessions, to regain their working environment.
Chapter 3. Shutdown and restart recovery 41
Page 54

42 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 55

Part 2. Recovery and restart processes
You can add your own processing to the CICS recovery and restart processes.
This part contains the following sections:
v Chapter 4, “CICS cold start,” on page 45
v Chapter 5, “CICS warm restart,” on page 53
v Chapter 6, “CICS emergency restart,” on page 61
v Chapter 7, “Automatic restart management,” on page 67
v Chapter 8, “Unit of work recovery and abend processing,” on page 73
v Chapter 9, “Communication error processing,” on page 97
© Copyright IBM Corp. 1982, 2010 43
Page 56

44 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 57

Chapter 4. CICS cold start
This section describes the CICS startup processing specific to a cold start.
It covers the two forms of cold start:
v “Starting CICS with the START=COLD parameter”
v “Starting CICS with the START=INITIAL parameter” on page 50
Starting CICS with the START=COLD parameter
START=COLD performs a dual type of startup, performing a cold start for all local
resources while preserving recovery information that relates to remote systems or
resource managers connected through the resource manager interface (RMI).
About this task
This ensures the integrity of the CICS region with its partners in a network that
manages a distributed workload. You can use a cold start to install resource
definitions from the CSD (and from macro control tables). It is normally safe to
cold start a CICS region that does not own any local resources (such as a
terminal-owning region that performs only transaction routing). For more
information about performing a cold start, and when it is safe to do so, see the
CICS Intercommunication Guide.
If you specify START=COLD, CICS either discards or preserves information in the
system log and global catalog data set, as follows:
v CICS deletes all cataloged resource definitions in the CICS catalogs and installs
definitions either from the CSD or from macro control tables. CICS writes a
record of each definition in the global catalog data set as each resource definition
is installed.
v Any program LIBRARY definitions that had been dynamically defined will be
lost. Only the static DFHRPL concatenation will remain, together with any
LIBRARY definitions in the grouplist specified at startup or installed via BAS at
startup.
v CICS preserves the recovery manager control record, which contains the CICS
logname token used in the previous run. CICS also preserves the log stream
name of the system log.
v CICS discards any information from the system log that relates to local resources,
and resets the system log to begin writing at the start of the primary log stream.
Note: If CICS detects that there were shunted units of work at the previous
shutdown (that is, it had issued message DFHRM0203) CICS issues a warning
message, DFHRM0154, to let you know that local recovery data has been lost,
and initialization continues. The only way to avoid this loss of data from the
system log is not to perform a cold start after CICS has issued DFHRM0203.
If the cold start is being performed following a shutdown that issued message
DFHRM0204, CICS issues message DFHRM0156 to confirm that the cold start
has not caused any loss of local recovery data.
v CICS releases all retained locks:
© Copyright IBM Corp. 1982, 2010 45
Page 58

– CICS requests the SMSVSAM server, if connected, to release all RLS retained
locks.
– CICS does not rebuild the non-RLS retained locks.
v CICS requests the SMSVSAM server to clear the RLS sharing control status for
the region.
v CICS does not restore the dump table, which may contain entries controlling
system and transaction dumps.
v CICS preserves resynchronization information about distributed units of
work—information regarding unit of work obligations to remote systems, or to
non-CICS resource managers (such as DB2) connected through the RMI. For
example, the preserved information includes data about the outcome of
distributed UOWs that is needed to allow remote systems (or RMI resource
managers) to resynchronize their resources.
Note: The system log information preserved does not include before-images of
any file control data updated by a distributed unit of work. Any changes made
to local file resources are not backed out, and by freeing all locks they are
effectively committed. To preserve data integrity, perform a warm or emergency
restart using START=AUTO.
v CICS retrieves its logname token from the recovery manager control record for
use in the “exchange lognames” process during reconnection to partner systems.
Thus, by using the logname token from the previous execution, CICS ensures a
warm start of those connections for which there is outstanding resynchronization
work.
Files
To perform these actions on a cold start, CICS needs the contents of the catalog
data sets and the system log from a previous run.
See the CICS System Definition Guide for details of the actions that CICS takes for
START=COLD in conjunction with various states of the global catalog and the
system log.
The DFHRMUTL utility returns information about the type of previous CICS
shutdown which is of use in determining whether a cold restart is possible or not.
For further details, see the CICS Operations and Utilities Guide.
All previous file control state data, including file resource definitions, is lost.
If RLS support is specified, CICS connects to the SMSVSAM, and when connected
requests the server to:
v Release all RLS retained locks
v Clear any “lost locks” status
v Clear any data sets in “non-RLS update permitted” status
For non-RLS files, the CICS enqueue domain does not rebuild the retained locks
relating to shunted units of work.
File resource definitions are installed as follows:
VSAM
Except for the CSD itself, all VSAM file definitions are installed from the
CSD. You specify these in groups named in the CSD group list, which you
46 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 59

specify on the GRPLIST system initialization parameter. The CSD file
definition is built and installed from the CSDxxxx system initialization
parameters.
Data tables
As for VSAM file definitions.
BDAM
File definitions are installed from file control table entries, specified by the
FCT system initialization parameter.
Attention: If you use the SHCDS REMOVESUBSYS command for a CICS region that
uses RLS access mode, ensure that you perform a cold start the next time you start
the CICS region. The SHCDS REMOVESUBSYS command causes SMSVSAM to release
all locks held for the region that is the subject of the command, allowing other
CICS regions and batch jobs to update records released in this way. If you restart a
CICS region with either a warm or emergency restart, after specifying it on a
REMOVESUBSYS command, you risk losing data integrity.
You are recommended to use the REMOVESUBSYS command only for those CICS
regions that you do not intend to run again, and therefore you need to free any
retained locks that SMSVSAM might be holding.
Temporary storage
All temporary storage queues from a previous run are lost, including
CICS-generated queues (for example, for data passed on START requests).
If the auxiliary temporary storage data set was used on a previous run, CICS
opens the data set for update. If CICS finds that the data set is newly initialized,
CICS closes it, reopens it in output mode, and formats all the control intervals
(CIs) in the primary extent. When formatting is complete, CICS closes the data set
and reopens it in update mode. The time taken for this formatting operation
depends on the size of the primary extent, but it can add significantly to the time
taken to perform a cold start.
Temporary storage data sharing server
Any queues written to a shared temporary storage pool normally persist across a
cold start.
Shared TS pools are managed by a temporary storage server, and stored in the
coupling facility. Stopping and restarting a TS data sharing server does not affect
the contents of the TS pool, unless you clear the coupling facility structure in
which the pool resides.
If you want to cause a server to reinitialize its pool, use the MVS SETXCF FORCE
command to clean up the structure:
SETXCF FORCE,STRUCTURE,STRNAME(DFHXQLS_poolname)
The next time you start up the TS server following a SETXCF FORCE command,
the server initializes its TS pool in the structure using the server startup
parameters specified in the DFHXQMN job.
Transient data
All transient data queues from a previous run are lost.
Chapter 4. CICS cold start 47
Page 60

Transient data resource definitions are installed from Resource groups defined in
the CSD, as specified in the CSD group list (named on the GRPLIST system
initialization parameter). Any extrapartition TD queues that require opening are
opened; that is, any that specify OPEN(INITIAL). All the newly-installed TD queue
definitions are written to the global catalog. All TD queues are installed as
enabled.CSD definitions are installed later than the macro-defined entries because
of the position of CSD group list processing in the initialization process. Any
extrapartition TD queues that need to be opened are opened; that is, any that
specify OPEN=INITIAL. The TDINTRA system initialization parameter has no
effect in a cold start.
Note: If, during the period when CICS is installing the TD queues, an attempt is
made to write a record to a CICS-defined queue that has not yet been installed (for
example, CSSL), CICS writes the record to the CICS-defined queue CXRF.
Transactions
All transaction and transaction class resource definitions are installed from the
CSD, and are cataloged in the global catalog.
Journal names and journal models
All journal model definitions are installed from the CSD, and are cataloged in the
global catalog. Journal name definitions (including the system logs DFHLOG and
DFHSHUNT) are created using the installed journal models and cataloged in the
global catalog.
Note: The CICS log manager retrieves the system log stream name from the global
catalog, ensuring that, even on a cold start, CICS uses the same log stream as on a
previous run.
LIBRARY resources
All LIBRARY resources from a previous run are lost.
LIBRARY resource definitions are installed from resource groups defined in the
CSD, as specified in the CSD group list (named on the GRPLIST system
initialization parameter).
Programs
All programs, mapsets, and partitionsets are installed from the CSD, and are
cataloged in the global catalog.
Start requests (with and without a terminal)
All forms of start request recorded in a warm keypoint (if the previous shutdown
was normal) are lost. This applies both to START requests issued by a user
application program and to START commands issued internally by CICS in
support of basic mapping support (BMS) paging.
Any data associated with START requests is also lost, even if it was stored in a
recoverable TS queue.
Resource definitions dynamically installed
Any resource definitions dynamically added to a previous run of CICS are lost in a
cold start, unless they are included in the group list specified on the GRPLIST
system initialization parameter.
48 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 61

If you define new resource definitions and install them dynamically, ensure the
group containing the resources is added to the appropriate group list.
Monitoring and statistics
The initial status of CICS monitoring is determined by the monitoring system
initialization parameters (MN and MNxxxx).
The initial recording status for CICS statistics is determined by the statistics system
initialization parameter (STATRCD). If STATRCD=ON is specified, interval
statistics are recorded at the default interval of every three hours.
Terminal control resources
All previous terminal control information stored in the global catalog warm
keypoint is lost.
Terminal control resource definitions are installed as follows:
VTAM devices
All VTAM terminal resource definitions are installed from the CSD. The
definitions to be installed are specified in groups named in the CSD group
list, which is specified by the GRPLIST system initialization parameter. The
resource definitions, of type TERMINAL and TYPETERM, include
autoinstall model definitions as well as explicitly defined devices.
Connection, sessions, and profiles
All connection and sessions definitions are installed from the CSD. The
definitions to be installed are specified in groups named in the CSD group
list, which is specified by the GRPLIST system initialization parameter. The
connections and sessions resource definitions include those used for APPC
autoinstall of parallel and single sessions, as well as explicitly defined
connections.
TCAM and sequential devices
All TCAM and sequential (BSAM) device terminal resource definitions are
installed from the terminal control table specified by the TCT system
initialization parameter. CICS loads the table from the load library defined
in the DFHRPL library concatenation. CICS TS for z/OS, Version 4.1
Note: supports only remote TCAM terminals—that is, the only TCAM
terminals you can define are those attached to a remote, pre-CICS TS 3.1,
terminal-owning region by TCAM/DCB.
Resource definitions for TCAM and BSAM terminals are not cataloged at
install time. They are cataloged only in the terminal control warm keypoint
during a normal shutdown.
Committing and cataloging resources installed from the CSD
CICS has two ways of installing and committing terminal resource definitions.
Some resource definitions can be installed in groups or individually and are
committed at the individual resource level, whereas some VTAM terminal control
resource definitions must be installed in groups and are committed in “installable
sets”.
Single resource install
All except the resources that are installed in installable sets are committed
individually. CICS writes each single resource definition to the global
catalog as the resource is installed. If a definition fails, it is not written to
the catalog (and therefore is not recovered at a restart).
Chapter 4. CICS cold start 49
Page 62

Installable set install
The following VTAM terminal control resources are committed in
installable sets:
v Connections and their associated sessions
v Pipeline terminals—all the terminal definitions sharing the same POOL
name
If one definition in an installable set fails, the set fails. However, each
installable set is treated independently within its CSD group. If an
installable set fails as CICS installs the CSD group, it is removed from the
set of successful installs. Logical sets that are not successfully installed do
not have catalog records written and are not recovered.
If the install of a resource or of an installable set is successful, CICS writes the
resource definitions to the global catalog during commit processing.
Distributed transaction resources
Unlike all other resources in a cold start, CICS preserves any information (units of
work) about distributed transactions.
This has no effect on units of work that relate only to the local CICS - it applies
only to distributed units of work. The CICS recovery manager deals with these
preserved units of work when resynchronization with the partner system takes
place, just as in a warm or emergency restart.
This is effective only if both the system log stream and the global catalog from the
previous run of CICS are available at restart.
See the CICS Transaction Server for z/OS Installation Guide for information about
recovery of distributed units of work.
Dump table
The dump table that you use for controlling system and transaction dumps is not
preserved in a cold start.
If you have built up over a period of time a number of entries in a dump table,
which is recorded in the CICS catalog, you have to re-create these entries following
a cold start.
Starting CICS with the START=INITIAL parameter
If you specify START=INITIAL, CICS performs an initial start as if you are starting
a new region for the first time.
About this task
This initial start of a CICS region is different from a CICS region that initializes
with a START=COLD parameter, as follows:
v The state of the global catalog is ignored. It can contain either data from a
previous run of CICS, or it can be newly initialized. Any previous data is
purged.
v The state of the system log is ignored. It can contain either data from a previous
run of CICS, or it can reference new log streams. CICS does not keep any
50 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 63

information saved in the system log from a previous run. The primary and
secondary system log streams are purged and CICS begins writing a new system
log.
v Because CICS is starting a new catalog, it uses a new logname token in the
“exchange lognames” process when connecting to partner systems. Thus, remote
systems are notified that CICS has performed a cold start and cannot
resynchronize.
v User journals are not affected by starting CICS with the START=INITIAL
parameter.
Note: An initial start can also result from a START=COLD parameter if the global
catalog is newly initialized and does not contain a recovery manager control
record. If the recovery manager finds that there is no control record on the catalog,
it issues a message to the console prompting the operator to reply with a GO or
CANCEL response. If the response is GO, CICS performs an initial start as if
START=INITIAL was specified.
For more information about the effect of the state of the global catalog and the
system log on the type of start CICS performs, see the CICS System Definition
Guide.
Chapter 4. CICS cold start 51
Page 64

52 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 65

Chapter 5. CICS warm restart
This section describes the CICS startup processing specific to a warm restart.
If you specify START=AUTO, which is the recommended method, CICS
determines which type of start to perform using information retrieved from the
recovery manager's control record in the global catalog. If the type-of-restart
indicator in the control record indicates “warm start possible”, CICS performs a
warm restart.
You should not attempt to compress a library after a warm start, without
subsequently performing a CEMT SET PROGRAM(PRGMID) NEWCOPY for each
program in the library. This is because on a warm start, CICS obtains the directory
information for all programs which were installed on the previous execution.
Compressing a library could alter its contents and subsequently invalidate the
directory information known to CICS.
See Chapter 6, “CICS emergency restart,” on page 61 for the restart processing
performed if the type-of-restart indicates “emergency restart needed”.
Rebuilding the CICS state after a normal shutdown
During a warm restart, CICS initializes using information from the catalogs and
system log to restore the region to its state at the previous normal shutdown.
Note: CICS needs both the catalogs and the system log from the previous run of
CICS to perform a warm restart—the catalogs alone are not sufficient. If you run
CICS with the system log defined as TYPE(DUMMY), CICS appears to shut down
normally, but only the global catalog portion of the warm keypoint is written.
Therefore, without the warm keypoint information from the system log, CICS
cannot perform a warm restart. CICS startup fails unless you specify an initial start
with START=INITIAL.
Recovering their own state is the responsibility of the individual resource
managers (such as file control) and the CICS domains. This topic discusses the
process of rebuilding their state from the catalogs and system log, in terms of the
following resources:
v Files
v Temporary storage queues
v Transient data queues
v Transactions
v LIBRARY resources
v Programs, including mapsets and partitionsets
v Start requests
v Monitoring and statistics
v Journals and journal models
v Terminal control resources
v Distributed transaction resources
v URIMAP definitions and virtual hosts
© Copyright IBM Corp. 1982, 2010 53
Page 66

Files
File control information from the previous run is recovered from information
recorded in the CICS catalog only.
File resource definitions for VSAM and BDAM files, data tables, and LSR pools are
installed from the global catalog, including any definitions that were added
dynamically during the previous run. The information recovered and reinstalled in
this way reflects the state of all file resources at the previous shutdown. For
example:
v If you manually set a file closed (which changes its status to UNENABLED) and
perform a normal shutdown, it remains UNENABLED after the warm restart.
v Similarly, if you set a file DISABLED, it remains DISABLED after the warm
restart.
Note: An exception to the above rule occurs when there are updates to a file to be
backed out during restarts, in which case the file is opened regardless of the
OPENTIME option. At a warm start, there cannot be any in-flight units of work to
back out, so this backout can only occur when retrying backout-failed units of
work against the file.
CICS closes all files at shutdown, and, as a general rule, you should expect your
files to be re-installed on restart as either:
v OPEN and ENABLED if the OPENTIME option is STARTUP
v CLOSED and ENABLED if the OPENTIME option is FIRSTREF.
The FCT and the CSDxxxx system initialization parameters are ignored.
File control uses the system log to reconstruct the internal structures, which it uses
for recovery.
Data set name blocks
Data set name blocks (DSNBs), one for each data set opened by CICS file control,
are recovered during a warm restart.
If you have an application that creates many temporary data sets, with a different
name for every data set created, it is important that your application removes these
after use. If applications fail to get rid of unwanted name blocks they can, over
time, use up a considerable amount of CICS dynamic storage. See the CICS System
Programming Reference for information about using the SET DSNAME REMOVE
command to remove unwanted data set name blocks.
Reconnecting to SMSVSAM for RLS access
CICS connects to the SMSVSAM server, if present, and exchanges RLS recovery
information.
In this exchange, CICS finds out whether SMSVSAM has lost any retained locks
while CICS has been shut down. This could happen, for example, if SMSVSAM
could not recover from a coupling facility failure that caused the loss of the lock
structure. If this has happened, CICS is notified by SMSVSAM to perform lost
locks recovery. See “Lost locks recovery” on page 89 for information about this
process.
Recreating non-RLS retained locks
For non-RLS files, the CICS enqueue domain rebuilds the retained locks relating to
shunted units of work.
54 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 67

Temporary storage
Auxiliary temporary storage queue information (for both recoverable and
non-recoverable queues) is retrieved from the warm keypoint. Note that TS READ
pointers are recovered on a warm restart (which is not the case on an emergency
restart).
CICS opens the auxiliary temporary storage data set for update.
Temporary storage data sharing server
Any queues written to a shared temporary storage pool, even though
non-recoverable, persist across a warm restart.
Transient data
Transient data initialization on a warm restart depends on the TDINTRA system
initialization parameter, which specifies whether or not TD is to initialize with
empty intrapartition queues. The different options are discussed as follows:
TDINTRA=NOEMPTY (the default)
All transient data resource definitions are installed from the global catalog,
including any definitions that were added dynamically during the previous run.
TD queues are always installed as enabled.
CICS opens any extrapartition TD queues that need to be opened—that is, any that
specify OPEN=INITIAL.
Note: If, during the period when CICS is installing the TD queues, an attempt is
made to write a record to a CICS-defined queue that has not yet been installed (for
example, CSSL), CICS writes the record to the CICS-defined queue CXRF.
The recovery manager returns log records and keypoint data associated with TD
queues. CICS applies this data to the installed queue definitions to return the TD
queues to the state they were in at normal shutdown. Logically recoverable,
physically recoverable, and non-recoverable intrapartition TD queues are recovered
from the warm keypoint data.
Trigger levels (for TERMINAL and SYSTEM only):
After the queues have been recovered, CICS checks the trigger level status of each
intrapartition TD queue that is defined with FACILITY(TERMINAL|SYSTEM) to
determine whether a start request needs to be rescheduled for the trigger
transaction.
If a trigger transaction failed to complete during the previous run (that is, did not
reach the empty queue (QZERO) condition) or the number of items on the queue is
greater than the trigger level, CICS schedules a start request for the trigger
transaction.
This does not apply to trigger transactions defined for queues that are associated
with files (FACILITY(FILE)).
TDINTRA=EMPTY
If you specify this option, the transient data queues are cold started, but the
resource definitions are warm started.
The following processing takes place:
Chapter 5. CICS warm restart 55
Page 68

v All intrapartition TD queues are initialized empty.
v The queue resource definitions are installed from the global catalog, but they are
not updated by any log records or keypoint data. They are always installed
enabled.
This option is intended for use when initiating remote site recovery (see Chapter 6,
“CICS emergency restart,” on page 61), but you can also use it for a normal warm
restart. For example, you might want to 'cold start' the intrapartition queues when
switching to a new data set if the old one is corrupted, while preserving all the
resource definitions from the catalog.
You cannot specify a general cold start of transient data while the rest of CICS
performs a warm restart, as you can for temporary storage.
Transactions
All transaction and transaction class resource definitions are installed from the
CSD, and updated with information from the warm keypoint in the system log.
The resource definitions installed from the catalog include any that were added
dynamically during the previous run.
LIBRARY resources
On WARM or EMERGENCY start, all LIBRARY definitions will be restored from
the catalog, and the actual search order through the list of LIBRARY resources that
was active at the time of the preceding shutdown will be preserved.
The latter will ensure that the search order of two LIBRARY resources of equal
RANKING will remain the same. An equal RANKING implies that the relative
search order of the LIBRARY resources is unimportant, but unexpected behavior
might result if this order changed after a warm or emergency restart.
If a LIBRARY with an option of CRITICAL(YES) is restored from the catalog, and
one of the data sets in its concatenation is no longer available, a message will be
issued to allow the operator to choose whether to continue the CICS startup, or to
cancel it. This Go or Cancel message will be preceded by a set of messages
providing information on any data sets which are not available. For LIBRARY
resources, with an option of CRITICAL(NO), this condition will not cause CICS
startup to fail, but a warning message will be issued and the LIBRARY will not be
reinstalled. This warning message will be preceded by a set of messages providing
information on any data sets which are not available
Programs
The recovery of program, mapset, and partitionset resource definitions depends on
whether you are using program autoinstall and, if you are, whether you have
requested autoinstall cataloging (specified by the system initialization parameter
PGAICTLG=ALL|MODIFY).
No autoinstall for programs
If program autoinstall is disabled (PGAIPGM=INACTIVE), all program, mapset,
and partitionset resource definitions are installed from the CSD, and updated with
information from the warm keypoint in the system log.
The resource definitions installed from the catalog include any that were added
dynamically during the previous run.
56 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 69

Autoinstall for programs
If program autoinstall is enabled (PGAIPGM=ACTIVE), program, mapset, and
partitionset resource definitions are installed from the CSD only if they were
cataloged; otherwise they are installed at first reference by the autoinstall process.
All definitions installed from the CSD are updated with information from the
warm keypoint in the system log.
CICS catalogs program, mapset, and partitionset resource definitions as follows:
v If they are installed from predefined definitions in the CSD, either during a cold
start or by an explicit INSTALL command, CICS catalogs the definitions.
v If the PGAICTLG system initialization parameter specifies ALL, CICS catalogs
all the autoinstalled program-type definitions, and these are reinstalled during
the warm restart.
v If the PGAICTLG system initialization parameter specifies MODIFY, CICS
catalogs only those autoinstalled program-type definitions that are modified by a
SET PROGRAM command, and these are reinstalled during the warm restart.
Start requests
In general, start requests are recovered together with any associated start data.
Recovery can, however, be suppressed by specifying explicit cold start system
initialization parameters for temporary storage, interval control, or basic mapping
support (on the TS, ICP, and BMS system initialization parameters respectively).
Any data associated with suppressed starts is discarded.
The rules governing the operation of the explicit cold requests on system
initialization parameters are:
v ICP=COLD suppresses all starts that do not have both data and a terminal
associated with them. It also suppresses any starts that had not expired at
shutdown. This includes BMS starts.
v TS=COLD (or TS main only) suppresses all starts that had data associated with
them.
v BMS=COLD suppresses all starts relating to BMS paging.
Start requests that have not been suppressed for any of the above reasons either
continue to wait if their start time or interval has not yet expired, or they are
processed immediately. For start requests with terminals, consider the effects of the
CICS restart on the set of installed terminal definitions. For example, if the
terminal specified on a start request is no longer installed after the CICS restart,
CICS invokes an XALTENF global user exit program (if enabled), but not the
XICTENF exit.
Monitoring and statistics
The CICS monitoring and statistics domains retrieve their status from their control
records stored in the global catalog at the previous shutdown.
This is modified by any runtime system initialization parameters.
Chapter 5. CICS warm restart 57
Page 70

Journal names and journal models
The CICS log manager restores the journal name and journal model definitions
from the global catalog. Journal name entries contain the names of the log streams
used in the previous run, and the log manager reconnects to these during the
warm restart.
Terminal control resources
Terminal control information is installed from the warm keypoint in the global
catalog, or installed from the terminal control table (TCT), depending on whether
the resources are CSD-defined or TCT-defined.
CSD-defined resource definitions
When resources are defined in the CICS System Definition data set (CSD), terminal
control information is installed from the warm keypoint in the global catalog.
CICS installs the following terminal control resource definitions from the global
catalog:
v All permanent terminal devices, originally installed from explicit resource
definitions, and profiles.
v The following autoinstalled APPC connections:
– Synclevel-2-capable connections (for example, CICS-to-CICS connections)
– Synclevel-1-capable, limited resource connections installed on a CICS that is a
member of a VTAM generic resource.
Other autoinstalled terminals are not recovered, because they are removed from
the warm keypoint during normal shutdown. This ensures that their definitions
are installed only when terminal users next log on after a CICS restart that
follows a normal shutdown.
When a multiregion operation (MRO) connection is restored, it has the same status
that was defined in the CSD. Any changes of status, for example the service status,
are not saved on the global catalog, so are not recovered during a warm or
emergency restart.
Only the global catalog is referenced for terminals defined in the CSD.
To add a terminal after initialization, use the CEDA INSTALL or EXEC CICS
CREATE command, or the autoinstall facility. To delete a terminal definition, use
the DISCARD command or, if autoinstalled, allow it to be deleted by the
autoinstall facility after the interval specified by the AILDELAY system
initialization parameter.
TCAM and sequential (BSAM) devices
Terminal control information for TCAM and sequential terminal devices is installed
from the terminal control table (TCT).
CICS installs TCAM and sequential terminal resource definitions as follows:
v Same TCT as last run. CICS installs the TCT and then modifies the terminal
entries in the table by applying the cataloged data from the terminal control
warm keypoint from the previous shutdown. This means that, if you reassemble
the TCT and keep the same suffix, any changes you make could be undone by
the warm keypoint taken from the catalog.
58 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 71

v Different TCT from last run. CICS installs the TCT only, and does not apply the
warm keypoint information, effectively making this a cold start for these
devices.
Note: CICS TS for z/OS, Version 4.1 supports only remote TCAM terminals—that
is, the only TCAM terminals you can define are those attached to a remote,
pre-CICS TS 3.1, terminal-owning region by TCAM/DCB.
Distributed transaction resources
CICS retrieves its logname from the recovery manager control record in the global
catalog for use in the “exchange lognames” process with remote systems.
Resynchronization of indoubt units of work takes place after CICS completes
reconnection to remote systems.
See the CICS Recovery and Restart Guide for information about recovery of
distributed units of work.
URIMAP definitions and virtual hosts
Installed URIMAP definitions for CICS Web support are restored from the global
catalog, including their enable status. Virtual hosts, which are created by CICS
using the host names specified in installed URIMAP definitions, are also restored
to their former enabled or disabled state.
Chapter 5. CICS warm restart 59
Page 72

60 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 73

Chapter 6. CICS emergency restart
This section describes the CICS startup processing specific to an emergency restart.
If you specify START=AUTO, CICS determines what type of start to perform using
information retrieved from the recovery manager’s control record in the global
catalog. If the type-of-restart indicator in the control record indicates “emergency
restart needed”, CICS performs an emergency restart.
See Chapter 5, “CICS warm restart,” on page 53 for the restart processing
performed if the type-of-restart indicates “warm start possible”.
Recovering after a CICS failure
CICS initialization for an emergency restart after a CICS failure is the same as
initialization for a warm restart, with some additional processing.
The additional processing performed for an emergency restart is mainly related to
the recovery of in-flight transactions. There are two aspects to the recovery
operation:
1. Recovering information from the system log
2. Driving backout processing for in-flight units of work
Recovering information from the system log
At some point during initialization (and before CICS performs program list table
post-initialization (PLTPI) processing), the recovery manager scans the system log
backwards. CICS uses the information retrieved to restore the region to its state at
the time of the abnormal termination.
For non-RLS data sets and other recoverable resources, any locks (ENQUEUES)
that were held before the CICS failure are re-acquired during this initial phase.
For data sets accessed in RLS mode, the locks that were held by SMSVSAM for
in-flight tasks are converted into retained locks at the point of abnormal
termination.
Driving backout processing for in-flight units of work
When initialization is almost complete, and after the completion of PLTPI
processing, the recovery manager starts backout processing for any units of work
that were in-flight at the time of the failure of the previous run.
Starting recovery processing at the end of initialization means that it occurs
concurrently with new work.
Concurrent processing of new work and backout
The backout of units of work that occurs after an emergency restart is the same
process as dynamic backout of a failed transaction. Backing out in-flight
transactions continues after “control is given to CICS”, which means that the
process takes place concurrently with new work arriving in the region.
© Copyright IBM Corp. 1982, 2010 61
Page 74

Any non-RLS locks associated with in-flight (and other failed) transactions are
acquired as active locks for the tasks attached to perform the backouts. This means
that, if any new transaction attempts to access non-RLS data that is locked by a
backout task, it waits normally rather than receiving the LOCKED condition.
Retained RLS locks are held by SMSVSAM, and these do not change while backout
is being performed. Any new transactions that attempt to access RLS resources
locked by a backout task receive a LOCKED condition.
For both RLS and non-RLS resources, the backout of in-flight transactions after an
emergency restart is indistinguishable from dynamic transaction backout.
Effect of delayed recovery on PLTPI processing
Because recovery processing does not take place until PLTPI processing is
complete, PLT programs may fail during an emergency restart if they attempt to
access resources protected by retained locks. If PLT programs are not written to
handle the LOCKED exception condition they abend with an AEX8 abend code.
If successful completion of PLTPI processing is essential before your CICS
applications are allowed to start, consider alternative methods of completing
necessary PLT processing. You may have to allow emergency restart recovery
processing to finish, and then complete the failed PLTPI processing when the locks
have been released.
Other backout processing
The recovery manager also drives the backout processing for any units of work
that were in a backout-failed state at the time of a CICS failure and the commit
processing for any units of work that were in a commit-failed state at the time of a
CICS failure.
The recovery manager drives these backout and commit processes because the
condition that caused them to fail may be resolved by the time CICS restarts. If the
condition that caused a failure has not been resolved, the unit of work remains in
backout- or commit-failed state. See “Backout-failed recovery” on page 79 and
“Commit-failed recovery” on page 83 for more information.
Rebuilding the CICS state after an abnormal termination
The individual resource managers, such as file control, and the CICS domains are
responsible for recovering their state as it was at an abnormal termination.
The process of rebuilding the state for the following resources is the same as for a
warm restart:
v Transactions
v Programs
v Monitoring and statistics
v Journal names and journal models
v URIMAP definitions and virtual hosts
The processing for other resources is different from a warm restart.
Files
All file control state data and resource definitions are recovered in the same way as
on a warm start.
62 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 75

Reconnecting to SMSVSAM for RLS access
As on a warm restart, CICS connects to the SMSVSAM server. In addition
to notifying CICS about lost locks, VSAM also informs CICS of the units of
work belonging to the CICS region for which it holds retained locks. See
“Lost locks recovery” on page 89 for information about the lost locks
recovery process for CICS.
CICS uses the information it receives from SMSVSAM to eliminate orphan
locks.
RLS restart processing and orphan locks
CICS emergency restart performs CICS-RLS restart processing during
which orphan locks are eliminated. An orphan lock is one that is held by
VSAM RLS on behalf of a specific CICS but unknown to the CICS region,
and a VSAM interface enables CICS to detect units of work that are
associated with such locks.
Orphan locks can occur if a CICS region acquires an RLS lock, but then
fails before logging it. Records associated with orphan locks that have not
been logged cannot have been updated, and CICS can safely release them.
Note: Locks that fail to be released during UOW commit processing cause
the UOW to become a commit-failed UOW. CICS automatically retries
commit processing for these UOWs, but if the locks are still not released
before the CICS region terminates, these also are treated as orphan locks
during the next restart.
Recreating non-RLS retained locks
Recovery is the same as for a warm restart. See “Recreating non-RLS
retained locks” on page 54 for details.
Temporary storage
Auxiliary temporary storage queue information for recoverable queues only is
retrieved from the warm keypoint. The TS READ pointers are not recovered and
are set to zero.
If a nonzero TSAGE parameter is specified in the temporary storage table (TST), all
queues that have not been referenced for this interval are deleted.
Transient data
Recovery of transient data is the same as for a warm start, with the following
exceptions:
v Non-recoverable queues are not recovered.
v Physically recoverable queues are recovered, using log records and keypoint
data. Generally, backing out units of work that were in-flight at the time of the
CICS failure does not affect a physically recoverable TD intrapartition data set.
Changes to physically recoverable TD queues are committed immediately, with
the result that backing out a unit of work does not affect the physical data set.
An exception to this is the last read request from a TD queue by a unit of work
that fails in-flight because of a CICS failure. In this case, CICS backs out the last
read, ensuring that the queue item is not deleted by the read. A further
exception occurs when the read is followed by a “delete queue” command. In
this case, the read is not backed out, because the whole queue is deleted.
Chapter 6. CICS emergency restart 63
Page 76

Start requests
In general, start requests are recovered only when they are associated with
recoverable data or are protected and the issuing unit of work is indoubt.
However, recovery can be further limited by the use of the specific COLD option
on the system initialization parameter for TS, ICP, or BMS. If you suppress start
requests by means of the COLD option on the appropriate system initialization
parameter, any data associated with the suppressed starts is discarded. The rules
are:
v ICP=COLD suppresses all starts including BMS starts.
v TS=COLD (or TS main only) suppresses all starts that had data associated with
them.
v BMS=COLD suppresses all starts relating to BMS paging.
Start requests that have not been suppressed for any of the above reasons either
continue to wait if their start time or interval has not yet expired, or are processed
immediately.
For start requests with terminals, consider the effects of the CICS restart on the set
of installed terminal definitions. For example, if the terminal specified on a start
request is no longer installed after the CICS restart, CICS invokes an XALTENF
global user exit program (if enabled), but not the XICTENF exit.
Terminal control resources
Terminal control information is installed from the warm keypoint in the global
catalog, or installed from the TCT, depending on whether the definitions are
CSD-defined or TCT-defined.
CSD-defined resource definitions
CICS retrieves the state of the CSD-eligible terminal control resources from the
catalog entries that were written:
v During a previous cold start
v When resources were added with EXEC CICS CREATE or CEDA INSTALL
v When resources were added with autoinstall (subject to the AIRDELAY system
initialization parameter)
v Rewritten to the catalog at an intervening warm shutdown
The state of the catalog may have been modified for some of the above resources
by their removal with a CEMT, or an EXEC CICS DISCARD, command.
CICS uses records from the system log, written when any terminal resources were
being updated, to perform any necessary recovery on the cataloged data. This may
be needed if terminal resources are installed or deleted while CICS is running, and
CICS fails before the operation is completed.
Some terminal control resources are installed or deleted in “installable sets” as
described under “Committing and cataloging resources installed from the CSD” on
page 49. If modifications are made to terminal resource definitions while CICS is
running, CICS writes the changes in the form of forward recovery records to the
system log. If the installation or deletion of installable sets or individual resources
64 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 77

is successful, but CICS abnormally terminates before the catalog can be updated,
CICS recovers the information from the forward recovery records on the system
log.
If the installation or deletion of installable sets or individual resources is
unsuccessful, or has not reached commit point when CICS abnormally terminates,
CICS does not recover the changes.
In this way, CICS ensures that the terminal entries recovered at emergency restart
consist of complete logical sets of resources (for connections, sessions, and
pipelines), and complete terminal resources and autoinstall models, and that the
catalog reflects the real state of the system accurately.
TCAM and sequential (BSAM) devices
CICS installs TCAM and sequential terminal resource definitions from the TCT.
Because there is no warm keypoint if the previous run terminated abnormally, the
TCT cannot be modified as on a warm start. Whatever is defined in the TCT is
installed, and the effect is the same whether or not it is a different TCT from the
last run.
Note: CICS TS for z/OS, Version 4.1 supports only remote TCAM terminals. That
is, the only TCAM terminals you can define are those attached to a remote,
pre-CICS TS 3.1, terminal-owning region by TCAM/DCB.
Distributed transaction resources
CICS retrieves its logname from the recovery manager control record in the global
catalog for use in the “exchange lognames” process with remote systems.
Resynchronization of indoubt units of work takes place when CICS completes
reconnection to remote systems.
See the CICS Installation Guide for information about recovery of distributed units
of work.
Chapter 6. CICS emergency restart 65
Page 78

66 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 79

Chapter 7. Automatic restart management
CICS uses the automatic restart manager (ARM) component of MVS to increase the
availability of your systems.
MVS automatic restart management is a sysplex-wide integrated automatic restart
mechanism that performs the following tasks:
v Restarts an MVS subsystem in place if it abends (or if a monitor program
notifies ARM of a stall condition)
v Restarts all the elements of a workload (for example, CICS TORs, AORs, FORs,
DB2, and so on) on another MVS image after an MVS failure
v Restarts CICS data sharing servers in the event of a server failure.
v Restarts a failed MVS image
CICS reconnects to DBCTL and VTAM automatically if either of these subsystems
restart after a failure. CICS is not dependent on using ARM to reconnect in the
event of failure.
The MVS automatic restart manager provides the following benefits:
v Enables CICS to preserve data integrity automatically in the event of any system
failure.
v Eliminates the need for operator-initiated restarts, or restarts by other automatic
packages, thereby:
– Improving emergency restart times
– Reducing errors
– Reducing complexity.
v Provides cross-system restart capability. It ensures that the workload is restarted
on MVS images with spare capacity, by working with the MVS workload
manager.
v Allows all elements within a restart group to be restarted in parallel. Restart
levels (using the ARM WAITPRED protocol) ensure the correct starting sequence
of dependent or related subsystems.
Restrictions
You cannot use MVS automatic restart for CICS regions running with XRF. If you
specify XRF=YES, CICS deregisters from ARM and continues initialization with
XRF support.
MVS automatic restart management is available only to those MVS subsystems that
register with ARM. CICS regions register with ARM automatically as part of CICS
system initialization. If a CICS region fails before it has registered for the first time
with ARM, it will not be restarted. After a CICS region has registered, it is
restarted by ARM according to a predefined policy for the workload.
CICS ARM processing
A prime objective of CICS support for the MVS automatic restart manager (ARM)
is to preserve data integrity automatically in the event of any system failure.
© Copyright IBM Corp. 1982, 2010 67
Page 80

If CICS is restarted by ARM with the same persistent JCL, CICS forces
START=AUTO to ensure data integrity.
Registering with ARM
To register with ARM, you must implement automatic restart management on the
MVS images that the CICS workload is to run on. You must also ensure that the
CICS startup JCL used to restart a CICS region is suitable for ARM.
Before you begin
The implementation of ARM is part of setting up your MVS environment to
support CICS. See the CICS Transaction Server for z/OS Installation Guide for details.
About this task
During initialization CICS registers with ARM automatically.
CICS always registers with ARM because CICS needs to know whether it is being
restarted by ARM and, if it is, whether or not the restart is with persistent JCL.
(The ARM registration response to CICS indicates whether or not the same JCL
that started the failed region is being used for the ARM restart.) You indicate
whether MVS is to use the same JCL or command text that previously started CICS
by specifying PERSIST as the restart_type operand on the RESTART_METHOD
parameter in your automatic restart management policy.
When it registers with ARM, CICS passes the value ‘SYSCICS' as the element type,
and the string ‘SYSCICS_aaaaaaaa' as the element name, where aaaaaaaa is the CICS
applid. Using the applid in the element name means that only one CICS region can
successfully register with ARM for a given applid. If two CICS regions try to
register with the same applid, the second region is rejected by ARM.
Waiting for predecessor subsystems
During initialization CICS issues an ARM WAITPRED (wait predecessor) request
to wait, if necessary, for predecessor subsystems (such as DB2 and DBCTL) to
become available.
This is indicated by message DFHKE0406. One reason for this wait is to ensure
that CICS can resynchronize with its partner resource managers for recovery
purposes before accepting new work from the network.
De-registering from ARM
During normal shutdown, CICS de-registers from ARM to ensure that it is not
automatically restarted. Also, if you want to perform an immediate shutdown and
do not want ARM to cause an automatic restart, you can specify the NORESTART
option on the PERFORM SHUT IMMEDIATE command.
About this task
CICS also de-registers during initialization if it detects XRF=YES is specified as a
system initialization parameter—XRF takes precedence over ARM.
Some error situations that occur during CICS initialization cause CICS to issue a
message, with an operator prompt to reply GO or CANCEL. If you reply
68 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 81

CANCEL, CICS de-registers from ARM before terminating, because if CICS
remained registered, an automatic restart would probably encounter the same error
condition.
For other error situations, CICS does not de-register, and automatic restarts follow.
To control the number of restarts, specify in your ARM policy the number of times
ARM is to restart a failed CICS region.
Failing to register
If ARM support is present but the register fails, CICS issues message DFHKE0401.
In this case, CICS does not know if it is being restarted by ARM, and therefore it
doesn’t know whether to override the START parameter to force an emergency
restart to preserve data integrity.
If START=COLD or START=INITIAL is specified as a system initialization
parameter and CICS fails to register, CICS also issues message DFHKE0408. When
CICS is restarting with START=COLD or START=INITIAL, CICS relies on ARM to
determine whether to override the start type and change it to AUTO. Because the
REGISTER has failed, CICS cannot determine whether the region is being restarted
by ARM, and so does not know whether to override the start type. Message
DFHKE0408 prompts the operator to reply ASIS or AUTO, to indicate the type of
start CICS is to perform:
v A reply of ASIS means that CICS is to perform the start specified on the START
parameter.
v A reply of AUTO means that CICS is being restarted by ARM, and the type of
start is to be resolved by CICS. If the previous run terminated abnormally, CICS
will perform an emergency restart.
Note: A CICS restart can have been initiated by ARM, even though CICS
registration with ARM has failed in the restarted CICS.
ARM couple data sets
You must ensure that you define the couple data sets required for ARM and that
they are online and active before you start any CICS region for which you want
ARM support.
v CICS automatic ARM registration fails if the couple data sets are not active at
CICS startup. When CICS is notified by ARM that registration has failed for this
reason, CICS assumes this means that you do not want ARM support, and CICS
initialization continues.
v If ARM loses access to the couple data sets, the CICS registration is lost. In this
event, ARM cannot restart a CICS region that fails.
See z/OS MVS Setting Up a Sysplex for information about ARM couple data sets
and ARM policies.
CICS restart JCL and parameters
Each CICS restart can use the previous startup JCL and system initialization
parameters, or can use a new job and parameters.
You cannot specify XRF=YES if you want to use ARM support. If the XRF system
initialization parameter is changed to XRF=YES for a CICS region being restarted
by ARM, CICS issues message DFHKE0407 to the console, then terminates.
Chapter 7. Automatic restart management 69
Page 82

CICS START options
You are recommended to specify START=AUTO, which causes a warm start after a
normal shutdown and an emergency restart after failure.
You are also recommended always to use the same JCL, even if it specifies
START=COLD or START=INITIAL, to ensure that CICS restarts correctly when
restarted by the MVS automatic restart manager after a failure.
If you specify START=COLD (or INITIAL) and your ARM policy specifies that the
automatic restart manager is to use the same JCL for a restart following a CICS
failure, CICS overrides the start parameter when restarted by ARM and enforces
START=AUTO. CICS issues message DFHPA1934 and ensures the resultant
emergency restart handles recoverable data correctly.
If the ARM policy specifies different JCL for an automatic restart and that JCL
specifies START=COLD, CICS uses this parameter value but risks losing data
integrity. Therefore, if you need to specify different JCL to ARM, specify
START=AUTO to ensure data integrity.
Workload policies
Workloads are started initially by scheduling or automation products.
The components of the workload, and the MVS images capable of running them,
are specified as part of the policies for MVS workload manager and ARM. The
MVS images must have access to the databases, logs, and program libraries
required for the workload.
Administrative policies provide ARM with the necessary information to perform
appropriate restart processing. You can define one or more administrative policies,
but can have only one active policy for all MVS images in a sysplex. You can
modify administrative policies by using an MVS-supplied utility, and can activate a
policy with the MVS SETXCF command.
Connecting to VTAM
VTAM is at restart level 1, the same as DB2 and DBCTL.
However, VTAM is not restarted when failed subsystems are being restarted on
another MVS, because ARM expects VTAM to be running on all MVS images in
the sysplex. For this reason, CICS and VTAM are not generally part of the same
restart group.
In a VTAM network, the session between CICS and VTAM is started automatically
if VTAM is started before CICS. If VTAM is not active when you start (or restart)
CICS, you receive the following messages:
+DFHSI1589D ’applid’ VTAM is not currently active.
+DFHSI1572 ’applid’ Unable to OPEN VTAM ACB - RC=xxxxxxxx, ACB CODE=yy.
CICS provides a new transaction, COVR, to open the VTAM ACB automatically
when VTAM becomes available. See “The COVR transaction” on page 71 for more
information about this.
70 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 83

The COVR transaction
To ensure that CICS reconnects to VTAM in the event of a VTAM abend, CICS
keeps retrying the OPEN VTAM ACB using a time-delay mechanism via the
non-terminal transaction COVR.
After CICS has completed clean-up following the VTAM failure, it invokes the
CICS open VTAM retry (COVR) transaction. The COVR transaction invokes the
terminal control open VTAM retry program, DFHZCOVR, which performs an
OPEN VTAM retry loop with a 5-second wait. CICS issues a DFHZC0200 message
every minute, while the open is unsuccessful, and each attempt is recorded on the
CSNE transient data queue. After ten minutes, CICS issues a DFHZC0201 message
and terminates the transaction. If CICS shutdown is initiated while the transaction
is running, CICS issues a DFHZC0201 message and terminates the transaction.
You cannot run the COVR transaction from a terminal. If you invoke COVR from a
terminal, it abends with an AZCU transaction abend.
Messages associated with automatic restart
There are some CICS messages for ARM support, which CICS can issue during
startup if problems are encountered when CICS tries to connect to ARM.
The message numbers are:
DFHKE0401 DFHKE0407
DFHKE0402 DFHKE0408
DFHKE0403 DFHKE0410
DFHKE0404 DFHKE0411
DFHKE0405 DFHZC0200
DFHKE0406 DFHZC0201
For the text of these messages, see CICS Messages and Codes.
Automatic restart of CICS data-sharing servers
All three types of CICS data-sharing server—temporary storage, coupling facility
data tables, and named counters—support automatic restart using the services of
automatic restart manager.
The servers also have the ability to wait during start-up, using an event
notification facility (ENF) exit, for the coupling facility structure to become
available if the initial connection attempt fails.
Server ARM processing
During initialization, a data-sharing server unconditionally registers with ARM,
except when starting up for unload or reload. A server does not start if registration
fails, with return code 8 or above.
If a server encounters an unrecoverable problem with the coupling facility
connection, consisting either of lost connectivity or a structure failure, it cancels
itself using the server command CANCEL RESTART=YES. This terminates the existing
connection, closes the server and its old job, and starts a new instance of the server
job.
Chapter 7. Automatic restart management 71
Page 84

You can also restart a server explicitly using either the server command CANCEL
RESTART=YES, or the MVS command CANCEL jobname,ARMRESTART
By default, the server uses an ARM element type of SYSCICSS, and an ARM
element identifier of the form DFHxxnn_poolname where xx is the server type (XQ,
CF or NC) and nn is the one- or two-character &SYSCLONE identifier of the MVS
image. You can use these parameters to identify the servers for the purpose of
overriding automatic restart options in the ARM policy.
Waiting on events during initialization
If a server is unable to connect to its coupling facility structure during server
initialization because of an environmental error, the server uses an ENF event exit
to wait for cross-system extended services (XES) to indicate that it is worth trying
again.
The event exit listens for either:
v A specific XES event indicating that the structure has become available, or
v A general XES event indicating that some change has occurred in the status of
coupling facility resources (for example, when a new CFRM policy has been
activated).
When a relevant event occurs, the server retries the original connection request,
and continues to wait and retry until the connection succeeds. A server can be
canceled at this stage using an MVS CANCEL command if necessary.
Server initialization parameters for ARM support
The server startup parameters for ARM support are:
ARMELEMENTNAME=elementname
specifies the automatic restart manager element name, up to 16 characters, to
identify the server to ARM for automatic restart purposes.
ARMELEMENTTYPE=elementtype
specifies the automatic restart manager element type, up to 8 characters for use
in ARM policies as a means of classifying similar elements.
These parameters are the same for all the data sharing servers. For more details,
see the automatic restart manager (ARM) parameters in the CICS System Definition
Guide .
Server commands for ARM support
The following are the ARM options you can use on server commands:
CANCEL RESTART={NO|YES}
terminates the server immediately, specifying whether or not automatic restart
should be requested. The default is RESTART=NO.
You can also enter RESTART on its own for RESTART=YES, NORESTART for
RESTART=NO.
ARMREGISTERED
shows whether ARM registration was successful (YES or NO).
ARM
This keyword, in the category of display keywords that represent combined
options, can be used to display all ARM-related parameter values. It can also
be coded as ARMSTATUS.
These commands are the same for all the data sharing servers.
72 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 85

Chapter 8. Unit of work recovery and abend processing
A number of different events can cause the abnormal termination of transactions in
CICS.
These events include:
v A transaction ABEND request issued by a CICS management module.
v A program check or operating system abend (this is trapped by CICS and
converted into an ASRA or ASRB transaction abend).
v An ABEND request issued by a user application program.
v A CEMT, or EXEC CICS, command such as SET TASK PURGE or FORCEPURGE.
Note: Unlike the EXEC CICS ABEND command above, these EXEC CICS
commands cause other tasks to abend, not the one issuing the command.
v A transaction abend request issued by DFHZNEP or DFHTEP following a
communication error. This includes the abnormal termination of a remote CICS
during processing of in-flight distributed UOWs on the local CICS.
v An abnormal termination of CICS, in which all in-flight transactions are
effectively abended as a result of the CICS region failing.
In-flight transactions are recovered during a subsequent emergency restart to
enable CICS to complete the necessary backout of recoverable resources, which
is performed in the same way as if the task abended while CICS was running.
Unit of work recovery
A unit of work in CICS is also the unit of recovery - that is, it is the atomic
component of the transaction in which any changes made either must all be
committed, or must all be backed out.
A transaction can be composed of a single unit of work or multiple units of work.
In CICS, recovery is managed at the unit of work level.
For recovery purposes, CICS recovery manager is concerned only with the units of
work that have not yet completed a syncpoint because of some failure. This topic
discusses how CICS handles these failed units of work.
The CICS recovery manager has to manage the recovery of the following types of
unit of work failure:
In-flight-failed
Commit-failed
The transaction fails before the current unit of work reaches a syncpoint, as
a result either of a task abend, or the abnormal termination of CICS. The
transaction is abnormally terminated, and recovery manager initiates
backout of any changes made by the unit of work.
See “Transaction backout” on page 74.
A unit of work fails during commit processing while taking a syncpoint. A
partial copy of the unit of work is shunted to await retry of the commit
process when the problem is resolved.
This does not cause the transaction to terminate abnormally.
© Copyright IBM Corp. 1982, 2010 73
Page 86

See “Commit-failed recovery” on page 83.
Backout-failed
A unit of work fails while backing out updates to file control recoverable
resources. (The concept of backout-failed applies in principle to any
resource that performs backout recovery, but CICS file control is the only
resource manager to provide backout failure support.) A partial copy of the
unit of work is shunted to await retry of the backout process when the
problem is resolved.
Note: Although the failed backout may have been attempted as a result of
the abnormal termination of a transaction, the backout failure itself does
not cause the transaction to terminate abnormally.
For example, if a transaction initiates backout through an EXEC CICS
SYNCPOINT ROLLBACK command, CICS returns a normal response (not
an exception condition) and the transaction continues executing. It is up to
recovery manager to ensure that locks are preserved until backout is
eventually completed.
If some resources involved in a unit of work are backout-failed, while
others are commit-failed, the UOW as a whole is flagged as backout-failed.
See “Backout-failed recovery” on page 79.
Indoubt-failed
A distributed unit of work fails while in the indoubt state of the two-phase
commit process. The transaction is abnormally terminated. If there are
normally more units of work that follow the one that failed indoubt, these
will not be executed as a result of the abend.
A partial copy of the unit of work is shunted to await resynchronization
when CICS re-establishes communication with its coordinator. This action
happens only when the transaction resource definition specifies that units
of work are to wait in the event of failure while indoubt. If they are
defined with WAIT(NO), CICS takes the action specified on the ACTION
parameter, and the unit of work cannot become failed indoubt.
See “Indoubt failure recovery” on page 84.
Transaction backout
If the resources updated by a failed unit of work are defined as recoverable, CICS
automatically performs transaction backout of all uncommitted changes to the
recoverable resources.
Transaction backout is mandatory and automatic - there is not an option on the
transaction resource definition allowing you to control this. You can, however,
control backout of the resources on which your transactions operate by defining
whether or not they are recoverable.
In transaction backout, CICS restores the resources specified as recoverable to the
state they were in at the beginning of the interrupted unit of work (that is, at start
of task or completion of the most recent synchronization point). The resources are
thus restored to a consistent state.
In general, the same process of transaction backout is used for individual units of
work that abend while CICS is running and for in-flight tasks recovered during
emergency restart. One difference is that dynamic backout of a single abnormally
74 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 87

terminating transaction takes place immediately. Therefore, it does not cause any
active locks to be converted into retained locks. In the case of a CICS region abend,
in-flight tasks have to wait to be backed out when CICS is restarted, during which
time the locks are retained to protect uncommitted resources.
To restore the resources to the state they were in at the beginning of the unit of
work, CICS preserves a description of their state at that time:
v For tables maintained by CICS, information is held in the tables themselves.
v For recoverable auxiliary temporary storage, CICS maintains information on the
system log about all new items written to TS queues. CICS maintains
information about TS queues for backout purposes in main storage.
v For transient data, CICS maintains cursors that indicate how much has been
read and written to the queue, and these cursors are logged. CICS does not log
before- or after-images for transient data.
v For CICS files, the before-images of deleted or changed records are recorded in
the system log. Although they are not strictly “before-images”, CICS also logs
newly added records, because CICS needs information about them if they have
to be removed during backout.
Files
CICS file control is presented with the log records of all the recoverable files that
have to be backed out.
File control performs the following processing:
v Restores the before-images of updated records
v Restores deleted records
v Removes new records added by the unit of work
If backout fails for any file-control-managed resources, file control invokes backout
failure support before the unit of work is marked as backout-failed. See
“Backout-failed recovery” on page 79.
BDAM files and VSAM ESDS files:
In the special case of the file access methods that do not support delete requests
(VSAM ESDS and BDAM) CICS cannot remove new records added by the unit of
work.
In this case, CICS invokes the global user exit program enabled at the XFCLDEL
exit point whenever a WRITE to a VSAM ESDS, or to a BDAM data set, is being
backed out. This enables your exit program to perform a logical delete by
amending the record in some way that flags it as deleted.
If you do not have an XFCLDEL exit program, CICS handles the unit of work as
backout-failed, and shunts the unit of work to be retried later (see “Backout-failed
recovery” on page 79). For information about resolving backout failures, see
Logical delete not performed.
Such flagged records can be physically deleted when you subsequently reorganize
the data set offline with a utility program.
CICS data tables:
For CICS-maintained data tables, the updates made to the source VSAM data set
are backed out. For user-maintained data tables, the in-storage data is backed out.
Chapter 8. Unit of work recovery and abend processing 75
Page 88

Intrapartition transient data
Intrapartition destinations specified as logically recoverable are restored by
transaction backout. Read and write pointers are restored to what they were before
the transaction failure occurred.
Physically recoverable queues are recovered on warm and emergency restarts.
Transient data does not provide any support for the concept of transaction
backout, which means that:
v Any records retrieved by the abending unit of work are not available to be read
by another task, and are therefore lost.
v Any records written by the abending unit of work are not backed out. This
means that these records are available to be read by other tasks, although they
might be invalid.
CICS does not support recovery of extrapartition queues.
Auxiliary temporary storage
CICS transaction backout backs out updates to auxiliary temporary storage queues
if they are defined as recoverable in a temporary storage table. Read and write
pointers are restored to what they were before the transaction failure occurred.
CICS does not back out changes to temporary storage queues held in main storage
or in a TS server temporary storage pool.
START requests
Recovery of EXEC CICS START requests during transaction backout depends on
some of the options specified on the request. The options that affect recoverability
are:
PROTECT
This option effectively causes the start request to be treated like any other
recoverable resource, and the request is committed only when the task issuing
the START takes a syncpoint. It ensures that the new task cannot be attached
for execution until the START request is committed.
FROM, QUEUE, RTERMID, RTRANSID
These options pass data to the started task using temporary storage.
When designing your applications, consider the recoverability of data that is being
passed to a started transaction.
Recovery of START requests during transaction backout is described below for
different combinations of these options.
START with no data (no PROTECT)
Transaction backout does not affect the START request. The new task will start
at its specified time (and could already be executing when the task issuing the
START command is backed out). Abending the task that issued the START
does not abend the started task.
START with no data (PROTECT)
Transaction backout of the task issuing the START command causes the START
request also to be backed out (canceled). If the abended transaction is restarted,
it can safely reissue the START command without risk of duplication.
START with recoverable data (no PROTECT)
Transaction backout of the task issuing the START also backs out the data
76 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 89

intended for the started task, but does not back out the START request itself.
Thus the new task will start at its specified time, but the data will not be
available to the started task, to which CICS will return a NOTFND condition
in response to the RETRIEVE command.
START with recoverable data (PROTECT)
Transaction backout of the task issuing the START command causes the START
request and the associated data to be backed out. If the abended transaction is
restarted, it can safely reissue the START command without risk of duplication.
START with nonrecoverable data (no PROTECT)
Transaction backout of the task issuing the START does not back out either the
START request or the data intended for the (canceled) started task. Thus the
new task will start at its specified time, and the data will be available,
regardless of the abend of the issuing task.
START with nonrecoverable data (PROTECT)
Transaction backout of the task issuing the START command causes the START
request to be canceled, but not the associated data, which is left stranded in
temporary storage.
Note: Recovery of temporary storage (whether or not PROTECT is specified) does
not cause the new task to start immediately. (It may qualify for restart like any
other task, if RESTART(YES) is specified on the transaction resource definition.) On
emergency restart, a started task is restarted only if it was started with data
written to a recoverable temporary storage queue.
Restart of started transactions:
Non-terminal START transactions that are defined with RESTART(YES) are eligible
for restart in certain circumstances only.
The effect of RESTART(NO) and RESTART(YES) on started transactions is shown
in Table 1.
Table 1. Effect of RESTART option on started transactions
Description of
non-terminal START
command
Specifies either
recoverable or
nonrecoverable data
Specifies recoverable data Started task
Specifies recoverable data Started task
Specifies nonrecoverable
data
Events Effect of
RESTART(YES)
Started task ends
normally, but does
not retrieve data.
abends after
retrieving its data
abends without
retrieving its data
Started task
abends after
retrieving its data
START request and its
data (TS queue) are
discarded at normal
end.
START request and its
data are recovered and
restarted, up to n¹
times.
START request and its
data are recovered and
restarted, up to n¹
times.
START request is
discarded and not
restarted.
Effect of
RESTART(NO)
START request
and its data (TS
queue) are
discarded at
normal end.
START request
and its data are
discarded.
START request
and its data are
discarded.
Not restarted.
Chapter 8. Unit of work recovery and abend processing 77
Page 90

Table 1. Effect of RESTART option on started transactions (continued)
Description of
non-terminal START
command
Specifies nonrecoverable
data
Without data Started task
Events Effect of
RESTART(YES)
Started task
abends without
retrieving its data
abends
Transaction is restarted
with its data still
available, up to n¹
times.
Transaction is restarted
up to n¹ times.
Effect of
RESTART(NO)
START request
and its data are
discarded.
—
¹ n is defined in the transaction restart program, DFHREST, where the
CICS-supplied default is 20.
EXEC CICS CANCEL requests
Recovery from CANCEL requests during transaction backout depends on whether
the data is being passed to the started task and if the temporary storage queue
used to pass the data is defined as recoverable.
During transaction backout of a failed task that has canceled a START request that
has recoverable data associated with it, CICS recovers both the temporary storage
queue and the start request. Thus the effect of the recovery is as if the CANCEL
command had never been issued.
If there is no data associated with the START command, or if the temporary
storage queue is not recoverable, neither the canceled started task nor its data is
recovered, and it stays canceled.
Basic mapping support (BMS) messages
Recovery of BMS messages affects those BMS operations that store data on
temporary storage.
They are:
v BMS commands that specify the PAGING operand
v The BMS ROUTE command
v The message switching transaction (CMSG)
Backout of these BMS operations is based on backing out START requests because,
internally, BMS uses the START mechanism to implement the operations listed
above. You request backout of these operations by making the BMS temporary
storage queues recoverable, by defining their DATAIDs in the temporary storage
table. For more information about the temporary storage table, see the CICS
Resource Definition Guide.
Application programmers can override the default temporary storage DATAIDs by
specifying the following operands:
v REQID operand in the SEND MAP command
v REQID operand in the SEND TEXT command
v REQID operand in the ROUTE command
v PROTECT operand in the CMSG transaction
Note: If backout fails, CICS does not try to restart regardless of the setting of the
restart program.
78 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 91

Backout-failed recovery
Backout failure support is currently provided only by CICS file control.
If backout to a VSAM data set fails for any reason, CICS performs the following
processing:
v Invokes the backout failure global user exit program at XFCBFAIL, if this exit is
enabled. If the user exit program chooses to bypass backout failure processing,
the remaining actions below are not taken.
v Issues message DFHFC4701, giving details of the update that has failed backout,
and the type of backout failure that has occurred.
v Converts the active exclusive locks into retained locks. This ensures that no
other task in any CICS region (including the region that owns the locks) waits
for a lock that cannot be granted until the failure is resolved. (In this situation,
CICS returns the LOCKED condition to other tasks that request a lock.)
Preserving locks in this way also prevents other tasks from updating the records
until the failure is resolved.
– For data sets open in RLS mode, CICS requests SMSVSAM to retain the locks.
– For VSAM data sets open in non-RLS mode, the CICS enqueue domain
provides an equivalent function.
Creating retained locks also ensures that other requests do not have to wait on
the locks until the backout completes successfully.
v Keeps the log records that failed to be backed out (by shunting the unit of work)
so that the failed records can be presented to file control again when backout is
retried. (See “Shunted units of work” on page 13 for more information about
shunted units of work.
If a unit of work updates more than one data set, the backout might fail for only
one, or some, of the data sets. When this occurs, CICS converts to retained locks
only those locks held by the unit of work for the data sets for which backout has
failed. When the unit of work is shunted, CICS releases the locks for records in
data sets that are backed out successfully. The log records for the updates made to
the data sets that fail backout are kept for the subsequent backout retry. CICS does
not keep the log records that are successfully backed out.
For a given data set, it is not possible for some of the records updated by a unit of
work to fail backout and for other records not to fail. For example, if a unit of
work updates several records in the same data set, and backout of one record fails,
they are all deemed to have failed backout. The backout failure exit is invoked
once only within a unit of work, and the backout failure message is issued once
only, for each data set that fails backout. However, if the backout is retried and
fails again, the exit is reinvoked and the message is issued again.
For BDAM data sets, there is only limited backout failure support: the backout
failure exit, XFCBFAIL, is invoked (if enabled) to take installation-defined action,
and message DFHFC4702 is issued.
Auxiliary temporary storage
All updates to recoverable auxiliary temporary storage queues are managed in
main storage until syncpoint. TS always commits forwards; therefore TS can never
suffer a backout failure.
Chapter 8. Unit of work recovery and abend processing 79
Page 92

Transient data
All updates to logically recoverable intrapartition queues are managed in main
storage until syncpoint, or until a buffer must be flushed because all buffers are in
use. TD always commits forwards; therefore, TD can never suffer a backout failure
on DFHINTRA.
Retrying backout-failed units of work
Backout retry for a backout-failed data set either can be driven manually (using the
SET DSNAME RETRY command) or in many situations occurs automatically when the
cause of the failure has been resolved.
When CICS performs backout retry for a data set, any backout-failed units of work
that are shunted because of backout failures on that data set are unshunted, and
the recovery manager passes the log records for that data set to file control. File
control attempts to back out the updates represented by the log records and, if the
original cause of the backout failure is now resolved, the backout retry succeeds. If
the cause of a backout failure is not resolved, the backout fails again, and backout
failure support is reinvoked.
Disposition of data sets after backout failures
Because individual records are locked when a backout failure occurs, CICS need
not set the entire data set into a backout-failed condition.
CICS may be able to continue using the data set, with only the locked records
being unavailable. Some kinds of backout failure can be corrected without any
need to take the data set offline (that is, without needing to stop all current use of
the data set and prevent further access). Even for those failures that cannot be
corrected with the data set online, it may still be preferable to schedule the repair
at some future time and to continue to use the data set in the meantime, if this is
possible.
Possible reasons for VSAM backout failure
There are many reasons why back out can fail, and these are described in this
topic. In general, each of these descriptions corresponds with a REASON returned
on an INQUIRE UOWDSNFAIL command.
I/O error
You must take the data set offline to repair it, but there may be occasions when
the problem is localized and use of the data set can continue until it is
convenient to carry out the repair.
Message DFHFC4701 with a failure code of X'24' indicates that an I/O error (a
physical media error) has occurred while backing out a VSAM data set. This
indicates that there is some problem with the data set, but it may be that the
problem is localized. A better indication of the state of a data set is given by
message DFHFC0157 (followed by DFHFC0158), which CICS issues whenever
an I/O error occurs (not just during backout). Depending on the data set
concerned, and other factors, your policy may be to repair the data set:
v After a few I/O errors
v After the first backout failure
v After a number of I/O errors that you consider to be significant
v After a significant number of backout failures
v Not at all
80 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 93

It might be worth initially deciding to leave a data set online for some time
after a backout failure, to evaluate the level of impact the failures have on
users.
To recover from a media failure, re-create the data set by applying forward
recovery logs to the latest backup. The steps you take depend on whether the
data set is opened in RLS or non-RLS mode:
v For data sets opened in non-RLS mode, set the data set offline to all CICS
applications by closing all open files against the data set.
Perform forward recovery using a forward recovery utility.
When the new data set is ready, use the CEMT (or EXEC CICS) SET
DSNAME RETRY command to drive backout retry against the data set for
all the units of work in backout-failed state.
v For data sets opened in RLS mode, use the CEMT (or EXEC CICS) SET
DSNAME QUIESCED command to quiesce the data set.
Perform forward recovery using CICSVR as your forward recovery utility.
CICS regions are notified through the quiesce protocols when CICSVR has
completed the forward recovery. This causes backout to be automatically
retried. The backout retry fails at this attempt because the data set is still
quiesced, and the UOWs are again shunted as backout-failed.
Unquiesce the data set as soon as you know that forward recovery is
complete. Completion of the unquiesce is notified to the CICS regions, which
causes backout to be automatically retried again, and this time it should
succeed.
This mechanism, in which the backout retry is performed within CICS,
supersedes the batch backout facility supported by releases of CICSVR
earlier than CICSVR 2.3. You do not need a batch backout utility.
Logical delete not performed
This error occurs if, during backout of a write to an ESDS, the XFCLDEL
logical delete exit was either not enabled, or requested that the backout be
handled as a backout failure.
You can correct this by enabling a suitable exit program and manually retrying
the backout. There is no need to take the data set offline.
Open error
Investigate the cause of any error that occurs in a file open operation. A data
set is normally already open during dynamic backout, so an open error should
occur only during backout processing if the backout is being retried, or is
being carried out following an emergency restart. Some possible causes are:
v The data set has been quiesced, in which case the backout is automatically
retried when the data set is unquiesced.
v It is not possible to open the data set in RLS mode because the SMSVSAM
server is not available, in which case the backout is automatically retried
when the SMSVSAM server becomes available.
For other cases, manually retry the backout after the cause of the problem has
been resolved. There is no need to take the data set offline.
SMSVSAM server failure
This error can occur only for VSAM data sets opened in RLS access mode. The
failure of the SMSVSAM server might be detected by the backout request, in
which case CICS file control starts to close the failed SMSVSAM control ACB
Chapter 8. Unit of work recovery and abend processing 81
Page 94

and issues a console message. If the failure has already been detected by some
other (earlier) request, CICS has already started to close the SMSVSAM control
ACB when the backout request fails.
The backout is normally retried automatically when the SMSVSAM server
becomes available. (See “Dynamic RLS restart” on page 37.) There is no need
to take the data set offline.
SMSVSAM server recycle during backout
This error can occur only for VSAM data sets opened in RLS access mode.
This is an extremely unlikely cause of a backout failure. CICS issues message
DFHFC4701 with failure code X'C2'. Retry the backout manually: there is no
need to take the data set offline.
Coupling facility cache structure failure
This error can occur only for VSAM data sets opened in RLS access mode. The
cache structure to which the data set is bound has failed, and VSAM has been
unable to rebuild the cache, or to re-bind the data set to an alternative cache.
The backout is retried automatically when a cache becomes available again.
(See “Cache failure support” on page 88.) There is no need to take the data set
offline.
DFSMSdss non-BWO backup in progress
This error can occur only for VSAM data sets opened in RLS access mode.
DFSMSdss makes use of the VSAM quiesce protocols when taking non-BWO
backups of data sets that are open in RLS mode. While a non-BWO backup is
in progress, the data set does not need to be closed, but updates to the data set
are not allowed. This error means that the backout request was rejected
because it was issued while a non-BWO backup was in progress.
The backout is retried automatically when the non-BWO backup completes.
Data set full
The data set ran out of storage during backout processing.
Take the data set offline to reallocate it with more space. (See Chapter 16,
“Moving recoverable data sets that have retained locks,” on page 183 for
information about preserving retained locks in this situation.) You can then
retry the backout manually, using the CEMT, or EXEC CICS, SET DSNAME(...)
RETRY command.
Non-unique alternate index full
Take the data set offline to rebuild the data set with a larger record size for the
alternate index. (See Chapter 16, “Moving recoverable data sets that have
retained locks,” on page 183 for information about preserving retained locks in
this situation.) You can then retry the backout manually, using the CEMT, or
EXEC CICS, SET DSNAME(...) RETRY command.
Deadlock detected
This error can occur only for VSAM data sets opened in non-RLS access mode.
This is a transient condition, and a manual retry should enable backout to
complete successfully. There is no need to take the data set offline.
Duplicate key error
The backout involved adding a duplicate key value to a unique alternate
index. This error can occur only for VSAM data sets opened in non-RLS access
mode.
82 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 95

This situation can be resolved only by deleting the rival record with the
duplicate key value.
Lock structure full error
The backout required VSAM to acquire a lock for internal processing, but it
was unable to do so because the RLS lock structure was full. This error can
occur only for VSAM data sets opened in RLS access mode.
To resolve the situation, you must allocate a larger lock structure in an
available coupling facility, and rebuild the existing lock structure into the new
one. The failed backout can then be retried using SET DSNAME RETRY.
None of the above
If any other error occurs, it indicates a possible error in CICS or VSAM code,
or a storage overwrite in the CICS region. Diagnostic information is given in
message DFHFC4700, and a system dump is provided.
If the problem is only transient, a manual retry of the backout should succeed.
Commit-failed recovery
Commit failure support is provided only by CICS file control, because it is the only
CICS component that needs this support.
A commit failure is one that occurs during the commit stage of a unit of work
(either following the prepare phase of two-phase commit, or following backout of
the unit of work). It means that the unit of work has not yet completed, and the
commit must be retried successfully before the recovery manager can forget about
the unit of work.
When a failure occurs during file control’s commit processing, CICS ensures that
all the unit of work log records for updates made to data sets that have suffered
the commit failure are kept by the recovery manager. Preserving the log records
ensures that the commit processing for the unit of work can be retried later when
conditions are favorable.
The most likely cause of a file control commit failure, from which a unit of work
can recover, is that the SMSVSAM server is not available when file control is
attempting to release the RLS locks. When other SMSVSAM servers in the sysplex
detect that a server has failed, they retain all the active exclusive locks held by the
failed server on its behalf. Therefore, CICS does not need to retain locks explicitly
when a commit failure occurs. When the SMSVSAM server becomes available
again, the commit is automatically retried.
However, it is also possible for a file control commit failure to occur as a result of
some other error when CICS is attempting to release RLS locks during commit
processing, or is attempting to convert some of the locks into retained locks during
the commit processing that follows a backout failure. In this case it may be
necessary to retry the commit explicitly using the SET DSNAME RETRY command.
Such failures should be rare, and may be indicative of a more serious problem.
It is possible for a unit of work that has not performed any recoverable work, but
which has performed repeatable reads, to suffer a commit failure. If the SMSVSAM
server fails while holding locks for repeatable read requests, it is possible to access
the records when the server recovers, because all repeatable read locks are released
at the point of failure. If the commit failure is not due to a server failure, the locks
are held as active shared locks. The INQUIRE UOWDSNFAIL command
Chapter 8. Unit of work recovery and abend processing 83
Page 96

distinguishes between a commit failure where recoverable work was performed,
and one for which only repeatable read locks were held.
Indoubt failure recovery
The CICS recovery manager is responsible for maintaining the state of each unit of
work in a CICS region.
For example, typical events that cause a change in the state of a unit of work are
temporary suspension and resumption, receipt of syncpoint requests, and entry
into the indoubt period during two-phase commit processing.
The CICS recovery manager shunts a unit of work if all the following conditions
apply:
v The unit of work has entered the indoubt period.
v The recovery manager detects loss of connectivity to its coordinator for the unit
of work.
v The indoubt attribute on the transaction resource definition under which the
unit of work is running specifies WAIT(YES).
v The conditions exist that allow shunting. See ../dfht1/topics/dfht12z.dita for a
complete list of conditions.
Files
When file control shunts its resources for the unit of work, it detects that the shunt
is being issued during the first phase of two-phase commit, indicating an indoubt
failure.
Any active exclusive lock held against a data set updated by the unit of work is
converted into a retained lock. The result of this action is as follows:
v No CICS region, including the CICS region that obtained the locks, can update
the records that are awaiting indoubt resolution because the locks have not been
freed.
v Other units of work do not wait on these locked records, because the locks are
not active locks but retained locks, requests for which cause CICS to return the
LOCKED response.
For information about types of locks, see “Locks” on page 14.
For data sets opened in RLS mode, interfaces to VSAM RLS are used to retain the
locks. For VSAM data sets opened in non-RLS mode, and for BDAM data sets, the
CICS enqueue domain provides an equivalent function. It is not possible for some
of the data sets updated in a particular unit of work to be failed indoubt and for
the others not to be.
It is possible for a unit of work that has not performed any recoverable work, but
which has performed repeatable reads, to be shunted when an indoubt failure
occurs. In this event, repeatable read locks are released. Therefore, for any data set
against which only repeatable reads were issued, it is possible to access the
records, and to open the data set in non-RLS mode for batch processing, despite
the existence of the indoubt failure. The INQUIRE UOWDSNFAIL command
distinguishes between an indoubt failure where recoverable work has been
performed, and one for which only repeatable read locks were held. If you want to
open the data set in non-RLS mode in CICS, you need to resolve the indoubt
failure before you can define the file as having RLSACCESS(NO). If the unit of
work has updated any other data sets, or any other resources, you should try to
resolve the indoubt correctly, but if the unit of work has only performed repeatable
84 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 97

reads against VSAM data sets and has made no updates to other resources, it is
safe to force the unit of work using the SET DSNAME or SET UOW commands.
CICS saves enough information about the unit of work to allow it to be either
committed or backed out when the indoubt unit of work is unshunted when the
coordinator provides the resolution (or when the transaction wait time expires).
This information includes the log records written by the unit of work.
When CICS has re-established communication with the coordinator for the unit of
work, it can resynchronize all indoubt units of work. This involves CICS first
unshunting the units of work, and then proceeding with the commit or backout.
All CICS enqueues and VSAM RLS record locks are released, unless a commit
failure or backout failure occurs.
For information about the resynchronization process for units of work that fail
indoubt, see the CICS Installation Guide.
Intrapartition transient data
When a UOW that has updated a logically recoverable intrapartition transient data
queue fails indoubt, CICS converts the locks held against the TD queue to retained
locks.
Until the UOW is unshunted, the default action is to reject with the LOCKED
condition further requests of the following types:
v READQ, if the indoubt UOW had issued READQ or DELETEQ requests
v WRITEQ, if the indoubt UOW had issued WRITEQ or DELETEQ requests
v DELETEQ, if the indoubt UOW had issued READQ, WRITEQ, or DELETEQ
requests
You can use the WAITACTION option on the TD queue resource definition to
control the action that CICS takes when an update request is made against a
shunted indoubt UOW that has updated the queue. In addition to the default
option, which is WAITACTION(REJECT), you can specify WAITACTION(QUEUE)
to queue further requests while the queue is locked by the failed-indoubt UOW.
After resynchronization, the shunted updates to the TD queue are either
committed or backed out, and the retained locks are released.
Auxiliary temporary storage
When a UOW that has updated a recoverable temporary storage queue fails
indoubt, the locks held against the queue are converted to retained locks. Until the
UOW is unshunted, further update requests against the locked queue items are
rejected with the LOCKED condition.
After resynchronization, the shunted updates to the TS queue are either committed
or backed out, and the retained locks are released.
Investigating an indoubt failure
This example shows how to investigate a unit of work (UOW) that has failed
indoubt. For the purposes of the example, the CICS-supplied transaction CIND has
been used to create the failure - one of the FILEA sample application transactions,
UPDT, has been made to fail indoubt.
For more information about CIND, see the CICS Supplied Transactions.
Chapter 8. Unit of work recovery and abend processing 85
Page 98

To retrieve information about a unit of work (UOW), you can use either the CEMT,
or EXEC CICS, INQUIRE UOW command. For the purposes of this illustration, the
CEMT method is used. You can filter the command to show only UOWs that are
associated with a particular transaction. For example, Figure 4 shows one UOW
(AC0CD65E5D990800) associated with transaction UPDT.
INQUIRE UOW TRANS(UPDT)
STATUS: RESULTS - OVERTYPE TO MODIFY
Uow(AC0CD65E5D990800) Ind Shu Tra(UPDT) Tas(0003155)
Age(00000680) Ter(S233) Netn(IGBS233 ) Use(CICSUSER) Con Lin(DFHINDSP)
Figure 4. The CEMT INQUIRE UOW command showing UOWs associated with a transaction
Each UOW identifier is unique within the local CICS system. To see more
information about the UOW, move the cursor to the UOW row and press ENTER.
This display the following screen:
INQUIRE UOW TRA(UPDT)
RESULT - OVERTYPE TO MODIFY
Uow(AC0CD65E5D990800)
Uowstate( Indoubt )
Waitstate(Shunted)
Transid(UPDT)
Taskid(0003155)
Age(00000826)
Termid(S233)
Netname(IGBS233)
Userid(CICSUSER)
Waitcause(Connection)
Link(DFHINDSP)
Sysid()
Netuowid(..GBIBMIYA.IGBS233 .O;)r...)
Figure 5. CEMT INQUIRE UOW - details of UOW AC0CD65E5D990800
The UOWSTATE for this UOW is Indoubt. The TRANSACTION definition
attribute WAIT(YES|NO) controls the action that CICS takes when a UOW fails
indoubt. CICS does one of two things:
v Makes the UOW wait, pending recovery from the failure. (In other words, the
UOW is shunted.) Updates to recoverable resources are suspended,
v Takes an immediate decision to commit or backout the recoverable resource
updates.
The WAITSTATE of Shunted shows that this UOW has been suspended.
Figure 5 reveals other information about the UOW:
v The original transaction was UPDT, the taskid was 3155, and the termid was
S233. Any of these can be used to tie this particular failure with messages
written to CSMT.
v The UOW has been indoubt for 826 seconds (AGE).
v The cause of the indoubt failure was a Connection failure. (The connection is the
dummy connection used by CIND DFHINDSP.)
86 CICS TS for z/OS 4.1: Recovery and Restart Guide
Page 99

When a UOW has been shunted indoubt, CICS retains locks on the recoverable
resources that the UOW has updated. This prevents further tasks from changing
the resource updates while they are indoubt. To display CICS locks held by a
UOW that has been shunted indoubt, use the CEMT INQUIRE UOWENQ
command. You can filter the command to show only locks that are associated with
a particular UOW. (Note that the INQUIRE UOWENQ command operates only on
non-RLS resources on which CICS has enqueued, and for RLS-accessed resources
you should use the INQUIRE UOWDSNFAIL command.) For example:
INQUIRE UOWENQ UOW(*0800)
STATUS: RESULTS
Uow(AC0CD65E5D990800) Tra(UPDT) Tas(0003155) Ret Dat Own
Res(DCXISCG.IYLX.FILEA ) Rle(018) Enq(00000003)
Figure 6. CEMT INQUIRE UOWENQ—used to display locks associated with a UOW
To see more information about this UOWENQ, put the cursor alongside it and
press ENTER:
INQUIRE UOWENQ UOW(*0800)
RESULT
Uowenq
Uow(AC0CD65E5D990800)
Transid(UPDT)
Taskid(0003155)
State(Retained)
Type(Dataset)
Relation(Owner)
Resource(DCXISCG.IYLX.FILEA)
Rlen(018)
Enqfails(00000003)
Netuowid(..GBIBMIYA.IGBS233 .O;)r...)
Qualifier(000001)
Qlen(006)
Figure 7. CEMT INQUIRE UOWENQ—details of a lock associated with a UOW
We can now see that:
v This UOW is the Owner of a Retained lock on a Dataset. Retained locks differ
from active locks in that a further task requiring this lock is not suspended;
instead, the transaction receives the LOCKED condition—if the condition is not
handled by the application, this results in an AEX8 abend.
v The data set is DCXISCG.IYLX.FILEA, and the Qualifier (in this case, the key
of the record which is indoubt) is 000001.
v Three other tasks have attempted to update the indoubt record (ENQFAILS).
Because CIND was used to create this indoubt failure, it can also be used to
resolve the indoubt UOW. For an example of how to resolve a real indoubt failure,
see the CICS Intercommunication Guide.
Chapter 8. Unit of work recovery and abend processing 87
Page 100

Recovery from failures associated with the coupling facility
This topic deals with recovery from failures arising from the use of the coupling
facility, and which affect CICS units of work.
It covers:
v SMSVSAM cache structure failures
v SMSVSAM lock structure failures (lost locks)
v Connection failure to a coupling facility cache structure
v Connection failure to a coupling facility lock structure
v MVS system recovery and sysplex recovery
Cache failure support
This type of failure affects only data sets opened in RLS mode.
SMSVSAM supports cache set definitions that allow you to define multiple cache
structures within a cache set across one or more coupling facilities. To ensure
against a cache structure failure, use at least two coupling facilities and define each
cache structure, within the cache set, on a different coupling facility.
In the event of a cache structure failure, SMSVSAM attempts to rebuild the
structure. If the rebuild fails, SMSVSAM switches data sets that were using the
failed structure to use another cache structure in the cache set. If SMSVSAM is
successful in either rebuilding or switching to another cache structure, processing
continues normally, and the failure is transparent to CICS regions. Because the
cache is used as a store-through cache, no committed data has been lost.
The support for rebuilding cache structures enables coupling facility storage to be
used effectively. It is not necessary to reserve space for a rebuild to recover from a
cache structure failure—SMSVSAM uses any available space.
If RLS is unable to recover from the cache failure for any reason, the error is
reported to CICS when it tries to access a data set that is bound to the failed cache,
and CICS issues message DFHFC0162 followed by DFHFC0158. CICS defers any
activity on data sets bound to the failed cache by abending units of work that
attempt to access the data sets. When “cache failed” responses are encountered
during dynamic backout of the abended units of work, CICS invokes backout
failure support (see “Backout-failed recovery” on page 79). RLS open requests for
data sets that must bind to the failed cache, and RLS record access requests for
open data sets that are already bound to the failed cache, receive error responses
from SMSVSAM.
When either the failed cache becomes available again, or SMSVSAM is able to
connect to another cache in a data set’s cache set, CICS is notified by the
SMSVSAM quiesce protocols. CICS then retries all backouts that were deferred
because of cache failures.
Whenever CICS is notified that a cache is available, it also drives backout retries
for other types of backout failure, because this notification provides an opportunity
to complete backouts that may have failed for some transient condition.
1. Cache structure. One of three types of coupling facility data structure supported by MVS. SMSVSAM uses its cache structure to
perform buffer pool management across the sysplex. This enables SMSVSAM to ensure that the data in the VSAM buffer pools in
each MVS image remains valid.
88 CICS TS for z/OS 4.1: Recovery and Restart Guide
 Loading...
Loading...