

Page 1

Freescale Semiconductor
Document Number: AN3636
Application Note
PowerQUICC III Performance
Monitors
Using the Core and System Performance Monitors
Rev. 2, 03/2014
This application note describes aspects of utilizing the core
and device-level performance monitors on PowerQUICC III
(PQ3). Included are example calculations to aid in
interpreting data collected.
1 Performance Monitors
PowerQUICC III processors are the first family of
PowerQUICC processors to include performance monitors
on-chip. These include both core performance monitors,
described in detail in the Power PC® e500 Core Family
Reference Manual, as well as device-level performance
monitors, described in detail in the product-specific
reference manual.
The e500 core level performance monitors enable the
counting of e500-specific events, for example, cache misses,
mispredicted branches, or the number of cycles an execution
unit stalls. These are configured by a set of special purpose
registers that can only be written through supervisor-level
accesses. The core-level event counters are also available
through a read-only set of user-level registers.
Contents
1. Performance Monitors . . . . . . . . . . . . . . . . . . . . . . . . 1
2. e500 Core Performance Monitors . . . . . . . . . . . . . . . . 2
3. Device Performance Monitors . . . . . . . . . . . . . . . . . . 2
4. Performance Metrics . . . . . . . . . . . . . . . . . . . . . . . . . . 3
5. Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
6. Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
7. Data Presentation . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
8. Revision History . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
The device-level performance monitors can be used to
monitor and record selected events on a device level. These
© 2008-2014 Freescale Semiconductor, Inc. All rights reserved.
Page 2

e500 Core Performance Monitors
performance monitors are similar in many respects to the performance monitors implemented on the e500
core. However, they are capable of counting events only outside the e500 core, for example, PCI, DDR,
and L2 cache events. Device-level performance monitors are memory-mapped, allowing user space
configuration accesses.
Together, these two sets of performance monitor registers can be used by the developer to improve system
performance, characterize and benchmark processors, and help debug their systems.
2 e500 Core Performance Monitors
The e500 core performance monitors are described in detail in Chapter 7 of the Power PC e500 Core
Family Reference Manual.
Performance monitor registers are grouped into supervisor-level registers, accessed with mtpmr and
mfpmr, and user-level performance monitor registers, which are read-only and accessed with the mfpmr
instruction. The supervisor-level registers consist of the four performance monitor counters
(PMC0-PMC3), each used to count up to 128 events; associated performance monitor local control
registers (PMLCa0-PMLCa3); and the performance monitor global control register. The user mode
registers are read-only copies of the supervisor-level registers. These consist of the same four counters
(UPMC0-UPMC3), associated local control registers (UPMLCa0-UPMLCa3), and global control register
(UPMGC0).
Additionally, the core performance monitor may use the external core input, pm_event, as well as the
performance monitor mark bit in the MSR (MSR[PMM]) to control which processes are monitored.
2.1 Counter Events
Counter events are listed in the Power PC e500 Core Family Reference Manual. These are subdivided into
three groups:
• Reference (Ref:#) - Possible to count these events on any of the four counters (PMC0-PMC3).
These events are applicable to most Power Architecture® microprocessors.
• Common (Com:#) - Possible to count these events on any of the four counters (PMC0-PMC3).
These events are specific to the e500 microarchitecture.
• Counter-Specific (C[0-3]:#) - Can only be counted on the specific counter noted. For example, an
event assigned to counter PMC2 is shown as C2:#
3 Device Performance Monitors
The device performance monitors are described in detail in the corresponding product reference manual.
These performance monitor counters operate separately from the core performance monitors and are
intended to monitor and record device-level events.
The device performance monitor consists of ten counters (PMC0-PMC9), capable of monitoring 576
events, as well as the associated local control registers (PMLCA0-PLMCA9) and the global control
register (PMGC0). These registers are all memory-mapped and can be accessed in supervisor or user
mode.
2 Freescale Semiconductor
PowerQUICC III Performance Monitors, Rev. 2
Page 3

Performance Metrics
3.1 Counter Events
PMC0 is a 64-bit counter specifically designed to count core complex bus (CCB) clock cycles. This
counter is started automatically out of reset and continually counts platform clock cycles. PMC1-PMC9
are 32-bit counters that can monitor up to 576 events.
Counter events are subdivided into two groups:
• Reference (Ref:#) - Possible to count these events on any of the nine counters PMC1-PMC9.
• Counter-Specific (C[0-3]:#) - Can only be counted on the specific counter noted. For example, an
event assigned to counter PMC2 is shown as C2:#
4 Performance Metrics
The use of the on-chip performance monitors to gather data is relatively straightforward. Using the data to
calculate meaningful performance metrics presents a much bigger challenge. Tab le 1 presents metrics
commonly used for performance analysis and characterization. These include:
• Instructions per cycle (IPC)
• Instructions per packet (IPP)
• Packets per second (PPS)
• Branch misses per total branches (%)
• Branches per 1000 instructions
• L1 instruction cache miss rate
• L1 data cache miss rate
• L2 cache core miss rate
• L2 cache non-core miss rate
• Memory system page hit ratio
Note that because these calculations make use of both the core events and the system events, we
differentiate between them by a two-letter prefix:
• CE - Core Event
• SE - System Event
To specify an event, this prefix is followed by the event number, as defined in the core and system manuals.
For example, CE:Ref:0 refers to Core Event, Reference 0, which according to the Power PC e500 Core
Family Reference Manual refers to processor cycles. SE:C0 would refer to System Event, Counter 0, which
according to the device-specific reference manuals corresponds to CCB (platform) clock cycles.
Note that for counter-specific events, an offset of 64 must be used when programming the field, because
counter-specific events occupy the bottom 4 values of the 7-bit event fields.
Freescale Semiconductor 3
PowerQUICC III Performance Monitors, Rev. 2
Page 4
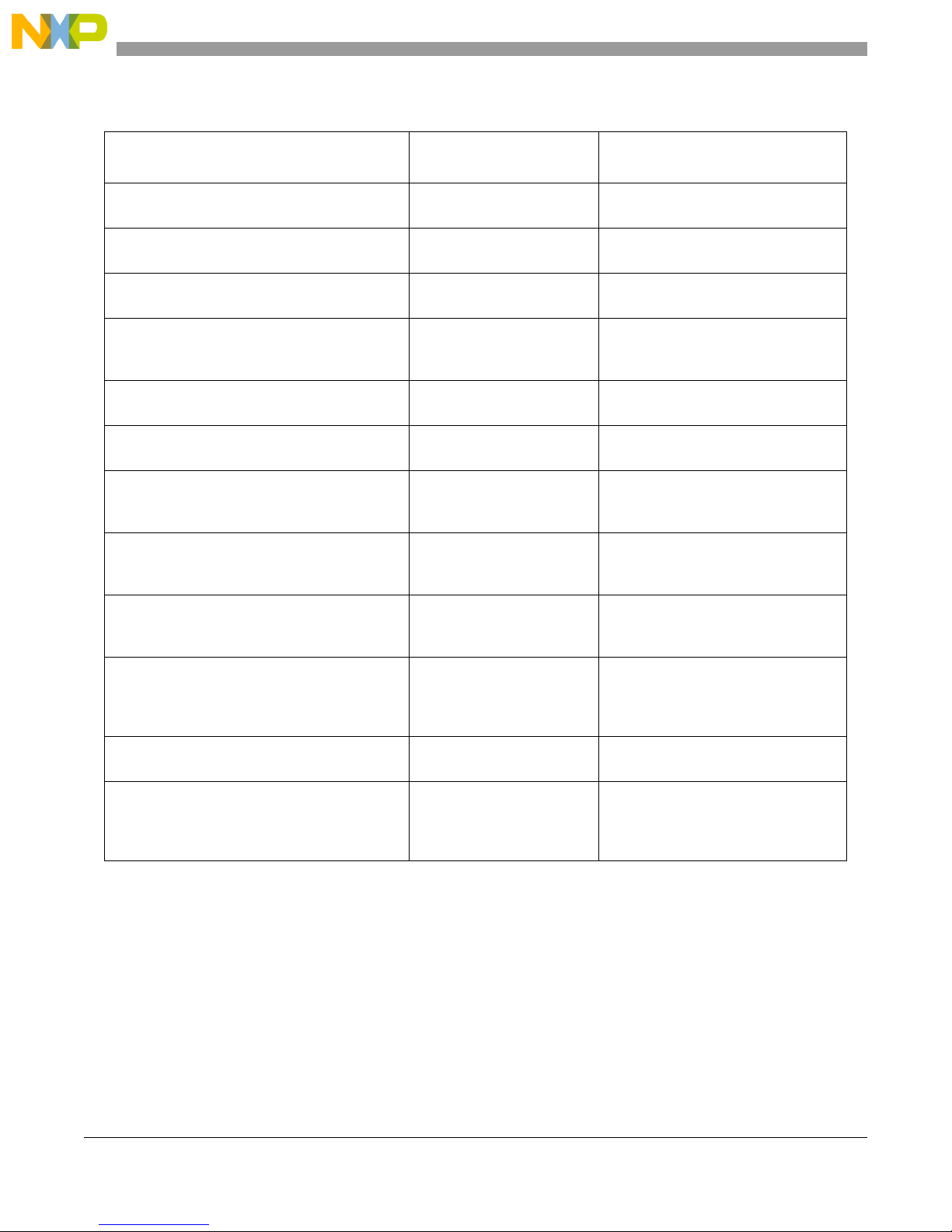
Performance Metrics
Table 1. Commonly Used Performance Metrics
Metric
Core cycles CE:Ref1, or SE:C0 CE:Ref:1 or
Time
[processor cycles/processor frequency]
Instructions cer cycle (IPC)
[instructions completed/processor cycles]
Instructions per packet (IPP)
instructions completed/accepted frames on
TSEC1
Packets per second (PPS)
accepted frames on TSEC1/Time
Branch miss ratio
branches mispredicted/branches finished
Branches per 1000 instructions
(1000*branches finished/kilo instructions
completed)
L1 I-cache miss rate
(I-cache fetch & pre-fetch miss)/instructions
completed
Performance Monitor
Event(s)
SE:C0 * Clock Ratio
CE:Ref:1 CE:Ref:1/Processor Frequency
CE:Ref:1
CE:Ref:2
SE:Ref:36
CE:Ref:2
SE:Ref:36
CE:Ref:1
CE:Com:12
CE:Com:17
CE:Com:12
CE:Ref:2
CE:Ref:2
CE:Com:60
CE:Ref:2/CE:Ref:1
CE:Ref:2/SE:Ref:36
SE:Ref:36/(CE:Ref:1/Processor
Frequency)
(CE:Com:12 - CE:Com17)/CE:Com:12
1000*CE:Com:12/CE:Ref:2
CE:Com:60/CE:Ref:2
Formula
L1 D-cache miss rate
D-cache miss/data micro-ops completed
L2 cache core miss rate
L2 D&I core miss/(L2 D&I core miss + L2 D&I
core hit)
L2 cache non-core miss rate
L2 non-core miss/(L2 non-core miss + hit)
DDR page row open table miss rate
DDR read & write miss/(DDR read & write miss +
hit)
CE:Com:41
CE:Com:9
CE:Com:10
SE:Ref:22
SE:C2:59
SE:Ref:23
SE:C4:57
SE:Ref:24
SE:C1:54
SE:C2
SE:C4
SE:C6
SE:C8
CE:Com:41/(CE:Com:9 + CE:Com:10)
(SE:C2L59 + SE:C4:57)/(SE:C2:59 +
SE:C4:57 + SE:Ref:22 + SE:Ref:23)
SE:C1:54/(SE:C1:54 + SE:Ref:24)
(SE:C2 + SE:C4)/(SE:C2 + SE:C4 +
SE:C6 + SE:C8)
Note that some of the events can be used in the calculation of multiple metrics. For example, CE:Ref:2
(instructions completed) is used to calculate IPC, IPP, Branches per 1k Instructions, and L1 I-cache miss
rate. This is advantageous, since only a limited number of events can be captured simultaneously in the
limited number of PMCs available.
4.1 Example Configuration
As an example, note the calculation of the L2 cache core miss rate. This metric requires the following
performance monitor events:
4 Freescale Semiconductor
PowerQUICC III Performance Monitors, Rev. 2
Page 5

Data Collection
• SE:Ref:22 - core instruction accesses to L2 that hit
• SE:C2:59 - core instruction accesses to L2 that miss
• SE:Ref:23 - core data accesses to L2 that hit
• SE:C4:57 - core data accesses to L2 that miss
Note that these are all device-level performance monitor events that can all be run simultaneously. This
example uses counters PMC2 - PMC5.
// Initialize Counters
*(unsigned int *) ((unsigned int) CCSB + 0xE1038) = 0x0 /*PMC2*/
*(unsigned int *) ((unsigned int) CCSB + 0xE1048) = 0x0 /*PMC3*/
*(unsigned int *) ((unsigned int) CCSB + 0xE1058) = 0x0 /*PMC4*/
*(unsigned int *) ((unsigned int) CCSB + 0xE1068) = 0x0 /*PMC5*/
// Initialize Global Control Register
*(unsigned int *) ((unsigned int) CCSB + 0xE1000) = 0x80000000 /*PMGC0*/
// Initialize Local Control Registers
*(unsigned int *) ((unsigned int) CCSB + 0xE1030) = 0x007B0000 /*PMLCa2*/
*(unsigned int *) ((unsigned int) CCSB + 0xE1040) = 0x00160000 /*PMLCa3*/
*(unsigned int *) ((unsigned int) CCSB + 0xE1050) = 0x00790000 /*PMLCa4*/
*(unsigned int *) ((unsigned int) CCSB + 0xE1060) = 0x00170000 /*PMLCa5*/
// Start Global Control Register
*(unsigned int *) ((unsigned int) CCSB + 0xE1000) = 0x00000000 /*PMGC0*/
The above code shows a sequence for initializing counters PMC2-PMC5 to zero, then setting up the local
control registers to count the events required for the metric previously mentioned. The global control
register is then set to 0x0, which will start the counting.
Note that because the events counted by C2 and C4 are counter-specific events, they are offset by 64.
When the software task is finished, the counters can be halted by the global control register, and results
may be read from the relevant counters.
5 Data Collection
The core performance monitor has four 32-bit PMCs for capturing core events. The system performance
monitor has eight 32-bit PMCs for capturing system events and one 64-bit PMC exclusively dedicated for
capturing the CCB clock cycles. Collectively, these counters allow the capture of four core events, eight
system events, and the CCB clock cycles simultaneously. Collecting data from various events
simultaneously makes the captured events almost perfectly correlated, as they are collected under the
Freescale Semiconductor 5
PowerQUICC III Performance Monitors, Rev. 2
Page 6

Data Collection
identical system parameters. However, it is sometimes desirable to capture more events than there are
PMCs. For example, Tab le 2 lists all the events necessary to calculate the full list of metrics from Table 1.
Table 2. Events Necessary for Data Collection of Common Metrics
Core Event System Event
CE:Ref:2 SE:C0
CE:Com:12 SE:Ref:36
CE:Com:17 SE:Ref:22
CE:Com:68 SE:Ref:23
CE:Com:9 SE:Ref:24
CE:Com:10 SE:C1:54
CE:Com:41 SE:C2:59
SE:C4:57
SE:C2
SE:C4
SE:C6
SE:C8
6 Freescale Semiconductor
PowerQUICC III Performance Monitors, Rev. 2
Page 7

Data Collection
CE:Ref:2 SE:Ref:36
CE:Ref:2 Chain SE:C2
CE:Com:12 SE:C4
CE:Com:68 SE:Ref:22
CE:Com:9 SE:Ref:23
CE:Com:10 SE:Ref:24
SE:C2:59
Run
#1
Run
#2
To capture all of these events, data collection must be broken up into two separate runs, which cover all of
the required core and system events. Figure 1 shows the multi-run coverage of data necessary for common
metrics.
Core Event System Event
SE:C0
CE:Com:17 SE:C6
SE:C8
Core Event System Event
SE:C0
To normalize the data collected over successive runs, one event should be chosen for inclusion in all runs.
The 64-bit PMC0, CCB clock cycle event is the best candidate for this baseline event. However, for results
to be comparable, and for the data correlation to be meaningful, the experiment needs to be repeatable in
a strict sense. The experiment may have strong dependencies on the application. It is important to
understand the system impact of turning on the performance counters to ensure that they do not have
adverse affects on the system.
5.1 Core Clock Cycles
There are two available methods for obtaining the core clock cycles. They may be measured directly, using
the core event CE:Ref:1, or calculated using the system event SE:C0, CCB clock cycles. Multiplying the
number of CCB clock cycles by the ratio between the CCB clock and the core clock results in the number
of core clock cycles. Although this measurement is not as exact as CE:Ref:1, it is within plus/minus
“Ratio” number of clocks. The deviation is minute in comparison to the number of clocks captured during
a typical experiment.
CE:Com:41 SE:C1:54
SE:C4:57
Figure 1. Multi-Run Coverage of Data Necessary for Common Metrics
Freescale Semiconductor 7
PowerQUICC III Performance Monitors, Rev. 2
Page 8

Data Collection
PMC0 322PMC1+× InstructionsCompleted=
5.1.1 Timestamping
SE:C0 starts running with board power-up. It is 64 bits wide and counts CCB clock cycles. Even if nothing
else is initialized in the PMON, SE:C0 can act as a system timer, which is one way for the performance
monitors to obtain a timestamp.
5.2 Chaining Counters
Some counters may need to be chained in order to avoid a wraparound, or exception. From the list of
counters used in Table 1, the only counters likely to go over the 32-bit limit are CE:Ref:1 and CE:Ref:2.
Counter-chaining is implemented in hardware and introduces no additional overhead other than the use of
an additional PMC for each chaining occurrence. Chaining is configured by specifying an event for one
PMC to be the chaining event corresponding to the counter which is expected to overflow. Events
CE:Com:82 through CE:Com:85 and SE:Ref:1 through SE:Ref:9 are used for counter-chaining.
In the example shown in Figure 1, the CE:Ref:2 chain is one of the core PMCs reserved for chaining of the
CE:Ref:2. In this example, the chaining is carried out by configuring
PMLCa0[EVENT]=83
PMLCa1[EVENT]=2
In this manner, a 64-bit counter for CE:Ref:2 is created. The total number of instructions completed can
be interpreted as:
Eqn. 1
5.3 Burstiness
The system performance monitor counters include a burstiness counting feature to aid in characterizing
events that occur in rapid succession followed by a relatively long pause. Event bursts are defined in the
corresponding counter’s PMLCAn register by size, granularity, and distance.
5.4 Inaccuracies
There are inherent inaccuracies in performance monitor measurements due to the time lag between
enabling/disabling the core and system counters. This time lag can be relatively closely approximated and
taken into account, if deemed to be significant. However, for the most part, the running length of the tests
is sufficient to make this overhead insignificant.
5.4.1 Cross Triggering
A system counter can be used to start and stop counting based on another counter's change. This feature
excludes core counters and is limited to systems counters only.
For example, SE:0 (CCB clock cycles) can be started by counter 1 (SE:1) and stopped by counter 2
(SE:2). It is possible to configure SE:1 to count an inbound packet accepted on SRIO and SE:2 to count
8 Freescale Semiconductor
PowerQUICC III Performance Monitors, Rev. 2
Page 9

Examples
an outbound packet sent to SRIO. Upon sending a read request over SRIO, the inbound packet starts
SE:0, and the outbound response stops SE:0. The result in SE:0 indicates the system’s SRIO read-completion latency.
This method is applicable to the cases where inaccuracies due to enabling and disabling performance
monitors are not tolerated and precise event counts are needed.
5.4.2 Sampling
Sampling of counters can be done periodically, at the start and stop of an application, based on a timer, or
even based on a system or core event.
To sample based on a core event, first initialize Counter A to a negative value (i.e. minus 10000). It can be
configured so that upon counting upwards to 0, it generates an interrupt to freeze all counters, collect them,
and reset Counter A to collect another set of statistics, at periodicity.
Any event may be assigned to the Counter A. Common choices include packet count, number of
instructions executed, or number of SRIO packets transmitted. The number of CCB cycles may be used as
a counter in order to periodically sample data every x CCB cycles (x*1/MHz seconds).
5.4.3 Debugger
The CCB platform counter, SE:C0, will continue to increment even if the core is halted by a debugger.
Carefully consider the implications of this when sampling counters during debugging.
6Examples
The metrics listed in Section 4, “Performance Metrics,” are generic, applying to a vast majority of
applications. However, some metrics are more applicable to certain applications than others. This section
lists a few sample design considerations, relative metrics, and performance evaluations. The data collection
for this section was performed on an MPC8560 ADS running a proprietary code segment that has both a
compute and data component to it. The code runs out of DDR memory and touches data in both DDR and
SDRAM on the local bus controller (LBC).
6.1 Example: Cache Performance
Utilizing the core and system performance monitors, it is possible to analyze cache performance and
compare cache hit ratios with system architectural predictions. On the PowerQUICC III it is possible to
tune the L2 cache to handle solely instructions or solely data, which has the potential to boost performance
on certain applications as well.
Freescale Semiconductor 9
PowerQUICC III Performance Monitors, Rev. 2
Page 10

Examples
Instructions Completed Ce:Ref:2 1473f03 1473f03 1473f03 1473f03
Core Cycles Ce:Ref:1 11e73d8 1425a5e 145d091 c236a2d
Instruction L1 cache reloads CE:Com:60 3f 4aa 4aa 0
Data L1 cache reloads CE:Com:41 351a 3523 3522 0
Loads Completed CE:Com:9 2f5588 2f5588 2f5588 0
Stores Completed CE:Com:10 17a750 17a750 17a750 0
Instr Accesses to L2 that hit
4 440 0 0
Instr to L2 th at m iss
3f 3d 0 0
Data Accesses to L2 that hit
2ed1 2ed3 0 0
Data to L2 that m iss
3732 372d 0 0
2.93756E-06 5.56737E-05 5.56737E-05 0
0.0029 0.0029 0.0029 #DIV/0!
0.542089985 0.520377095 #DIV/0! #DIV/0!
0.001584798 0.001536049 #DIV/0! #DIV/0!
99.8415% 99.8464% #DIV/0! #DIV/0!
18,772,952 21,125,726 21,352,593 203,647,533
1.1424E+00 1.0152E+00 1.0044E+00 1.0531E-01
Instructions Completed Ce:Ref:2 1473f09
Branches finished Ce:Com:12 73cd6
Branch Hits Ce:COM:17 73cbf
L2 & BPU enabled L2 enabled L2 Disabled Caches Disabled
SE:ref:22 (0x1
SE:2:59 (0x7b
SE:ref:23 (0x1
L1 Instruction Miss Ratio
L1 Data Miss Ratio
L2 Miss Ratio
Total Miss Ratio
Total Hit Ratio
Core Cycles (decimal)
IPC
SE:4:57 (0x79
Figure 2. Cache Example
The code used for this example is compiled with -O2 optimizations. As shown in Figure 2, it consists of a
constant number of instructions executed, 0x0147_3F03 instructions. Based on the total time it takes to
execute the application, a comparison can easily be made between caches disabled (at the far right), only
L1 caches enabled, L1 and L2 caches enabled, and L1, L2 caches, and Branch Prediction Unit (BPU)
enabled.
Due to the limited number of core performance counters, it is necessary to run through the application
twice (for each scenario, for a total of 8 times) to collect all data represented in Figure 2.
Through analysis such as this, it is possible to tune L2 cache usage as data-only cache, instruction-only
cache, or unified cache.
6.2 Example: Branch Prediction
As seen in Figure 2, enabling branch prediction can significantly increase performance. In this application,
it brought down the total number of cycles and increased IPC. It is possible to collect more information
about the BTB.
Branch Miss Rate 0.0048%
Figure 3. BPU Miss Rate
This example uses the same code as the example in Section 6.1, “Example: Cache Performance.” L1 and
L2 caches are enabled, as is the BPU. By collecting data on branches finished and branch hits, it is possible
to calculate a branch miss rate for this particular application.
6.3 Example: DDR Performance
It may be desirable to determine the performance of the DDR controller and possibly optimize parameters.
This example illustrates the impact of tweaking the BSTOPRE field.
PowerQUICC III Performance Monitors, Rev. 2
10 Freescale Semiconductor
Page 11

Examples
Platform Clock Cycles SE:R:0
ECM total dispatch SE:R:15
ECM dispatch from core SE:C1:16
ECM dispatch from TSEC1 SE:C3:19
ECM dispatch from TSEC2 SE:C4:21
ECM dispatch from RIO SE:C5:17
ECM dispatch from PCI SE:C6:17
ECM dispatch from DMA CSE:C7:14
Figure 4. DDR Page Hit Rate with Varying BSTOPRE
The code for this example is the same as the code run in the previous two examples. Branch prediction is
turned off and L2 Caches and BSTOPRE are varied. In this example, note that increasing BSTOPRE, or
keeping pages open longer, directly affects the overall DDR page hit rate, and in turn lowers the number
of clock cycles needed to run through this application. Also note that the core-to-CCB ratio is 4:1 in this
system, so even though the difference in platform clock cycles seems insignificant between
BSTOPRE=0xFF and BSTOPRE=0x3FF, the number of different core cycles is four times the number
shown in Figure 4, or 224 core clock cycles.
6.4 I/O and Compute-Bound Systems
Analysis of the performance monitors may be useful in determining if a system is I/O- or compute-bound.
I/O-bound may imply I/O to the core and force a stall while waiting for data. However, interfaces may also
become saturated without core involvement. The MPC8560, for example, may act as a RapidIO to PCI-X
bridge, without core intervention. In this case, the CCB or DDR, or high speed interfaces could become
system bottlenecks.
If the I/O port usage is unknown, it is possible to capture data about ECM transactions. This can be
accomplished in two passes, each utilizing all eight system counters.
Figure 5. Pass1 - ECM Dispatch Source
Freescale Semiconductor 11
PowerQUICC III Performance Monitors, Rev. 2
Page 12

Examples
Platform Clock Cycles SE:R:0
ECM total dispatch SE:R:15
ECM dispatch to DDR SE:C4:22
ECM dispatch to L2/SRAM SE:C5:18
ECM dispatch to LBC SE:C6:18
ECM dispatch to RIO SE:C7:15
ECM dispatch to PCI SE:C8:15
L2 Disabled L2 Disabled
LBC SDRAM CI All Cacheable
Platform Clock Cycles SE:R:0 27,279,655.000 10,679,745.000
ECM dispatch from core SE:C1:16 538,709.000 26,482.000
SE:R:11 104,798.000 105,650.000
Cycles read SDRAM SE:C3:57 17,404,947.000 4,307.000
ECM dispatch to DDR SE:C4:22 26,196.000 26,409.000
ECM total dispatch SE:R:15 538,709.000 26,482.000
ECM dispatch to LBC SE:C6:18 512,512.000 72.000
Figure 6. Pass2 - ECM Dispatch Destination
With the data collected from these two passes, it is possible to determine which interface is a potential
bottleneck.
The data collected in Figure 7 is based upon the same code execution as in the previous examples. I/O
interfaces such as TSEC, RIO, PCI are not used. Through use of the ECM performance monitor events, it
is possible to determine if a system is compute- or memory-bound.
Cycles Read or write transfers DDR
ECM dispatch to DDR 4.86% 99.72%
ECM dispatch to LBC 95.14% 0.27%
Cycles Reading LBC SDRAM 63.80% 0.04%
Cycles Read/Wr DDR 0.38% 0.99%
Figure 7. Platform Cycles Spent Reading/Writing
Figure 7 shows data collected in two successive program runs; the MMU in the first run has the LBC
marked as cache-inhibited whereas the second allows for cacheable accesses to the LBC.
The first run shows a very high percentage (95.14%) of dispatches to the LBC. These result in a very high
percentage of platform clock cycles spent reading SDRAM located on the local bus. In this scenario, the
system is bus-bound. In the second run, the LBC is cacheable and the number of ECM dispatches has
dropped dramatically. Because the percentage of cycles spent reading/writing DDR or the LBC is so low
(1.03%), the system in this scenario is compute-bound.
To ensure accuracy of these claims, cycles writing to LBC SDRAM (counter SE:C6:55) may be added to
the metrics sampled. However, this would require two samples per run, since both this metric and ECM
dispatches to LBC are counter-specific to C6. The code executed in these examples is previously known
to read only from LBC SDRAM, so this step is not necessary for the purposes of this example.
12 Freescale Semiconductor
PowerQUICC III Performance Monitors, Rev. 2
Page 13

Data Presentation
7 Data Presentation
The presentation of the data obtained is an important step in the performance evaluation of a system.
Graphical charts, such as Kiviat charts (known as radar plots in Excel) and Gantt charts, aid in the
understanding of performance evaluation results. Charts such as these enable readers to quickly grasp
details and compare the performance of one system over another.
Kiviat graphs are visual devices that allow for quick identification of performance problems. Typically, an
even number of metrics is used. Half of the metrics should be higher-bound metrics, meaning a higher
value of the metric is considered better and the other half should be lower-bound metrics, where a lower
value is considered better. These higher-bound and lower-bound metrics are plotted along alternate radial
lines in the Kiviat graph.
For example, the following might be plotted:
• CPU efficiency (higher bounds) Since the e500 is capable of completing 2 instructions per cycle
(plus one branch), this metric would be equivalent of 2 minus IPC.
• Cycles read/write to DDR (lower bounds)
• Cache hit ratio (higher bounds)
• Branch miss rate (lower bounds)
• Overall DDR page hit rate (higher bounds)
• Cycles reading LBC SDRAM (higher bounds)
• Packets per second TSEC1 (lower bounds)
• L2 non-core miss rate (higher bounds)
Freescale Semiconductor 13
PowerQUICC III Performance Monitors, Rev. 2
Page 14

Data Presentation
0.000%
20.000%
40.000%
60.000%
80.000%
100.000%
CPU Efficiency
Cycles Read/Wr DDR
Cache Hit Ratio
Branch Miss Rate
Overall DDR Page Hit Rate
Cycles Reading LBC SDRAM
Packets Per Second TSEC1
L2 Non-Core Miss Rate
Figure 8 shows a Kiviat graph for an unbalanced system.
Figure 8. Kiviat Graph for Unbalanced System
14 Freescale Semiconductor
PowerQUICC III Performance Monitors, Rev. 2
Page 15

Revision History
0.000%
20.000%
40.000%
60.000%
80.000%
100.000%
CPU E fficiency
Cycles Read/Wr DDR
Cache Hit Ratio
Branch Miss Rate
Overall DDR Page Hit Rate
Cycles Reading LBC SDRAM
Packets Per Second TSEC1
L2 Non-Core Miss Rate
A balanced system should be star-shaped. Figure 9 shows a Kiviat graph for a balanced system.
Figure 9. Kiviat Graph for Balanced System
It is easy to compare the operation of the two systems represented by Figure 8 and Figure 9. Figure 8 shows
an unbalanced system. It is apparent that a significant amount of time is being spent reading from the LBC.
This correlates to the data collected previously in Figure 7, in which the cache was disabled for the LBC,
making it easy to identify that problem.
Figure 9 is an example correlating to the corrected system, with cache enabled for the LBC. This system
appears balanced, as its plot looks more star-shaped.
8 Revision History
Table 3 provides a revision history for this application note.
Rev.
Number
2 03/2014 Added new Figure 4.
1 08/06/2008 In Ta bl e 1, corrected formula of the L1 I-cach miss rate from CE:Com:68/CE:Ref:2 to
Date Substantive Change(s)
Table 3. Document Revision History
CE:Com:60/CE:Ref:2. Fixed table formatting.
Freescale Semiconductor 15
PowerQUICC III Performance Monitors, Rev. 2
Page 16

How to Reach Us:
Home Page:
freescale.com
Web Support:
freescale.com/support
Information in this document is provided solely to enable system and software
implementers to use Freescale products. There are no express or implied copyright
licenses granted hereunder to design or fabricate any integrated circuits based on the
information in this document.
Freescale reserves the right to make changes without further notice to any products
herein. Freescale makes no warranty, representation, or guarantee regarding the
suitability of its products for any particular purpose, nor does Freescale assume any
liability arising out of the application or use of any product or circuit, and specifically
disclaims any and all liability, including without limitation consequential or incidental
damages. “Typical” parameters that may be provided in Freescale data sheets and/or
specifications can and do vary in different applications, and actual performance may vary
over time. All operating parameters, including “typicals,” must be validated for each
customer application by customer’s technical experts. Freescale does not convey any
license under its patent rights nor the rights of others. Freescale sells products pursuant
to standard terms and conditions of sale, which can be found at the following address:
freescale.com/SalesTermsandConditions.
Freescale, the Freescale logo, and PowerQUICC are trademarks of Freescale
Semiconductor, Inc., Reg. U.S. Pat. & Tm. Off. All other product or service names are
the property of their respective owners. The Power Architecture and Power.org word
marks and the Power and Power.org logos and related marks are trademarks and service
marks licensed by Power.org.
© 2008-2014 Freescale Semiconductor, Inc.
Document Number: AN3636
Rev. 2
03/2014
 Loading...
Loading...